This is to help you learn, gdb, bash, ssh, and git. Our goal is to download this repository and run everything in it.
You will want Bash on Windows. Then follow the steps for Linux. Link to Horid Resource
Please replace <csid> with you utcs id.
ssh-keygen -t rsa -f ~/.ssh/utlab
data=`cat ~/.ssh/utlab.pub` && ssh <csid>@atlas-moth.cs.utexas.edu " echo $data >> ~/.ssh/authorized_keys"
ssh -i ~/.ssh/utlab <csid>@linux.cs.utexas.eduThis is the same as Linux for SSH.
On a lab machine, there is no need to do that!!!! YAY.
Git is a version control system. GitHub is an online place to store repositories, which fosters a community of people (That Microsoft might destroy, stay tuned.)
git clone https://github.com/AdityaAtulTewari/CS429HPrep.git
cd CS429HPrepYou have now cloned the directory and should be inside it.
Learning how to write your own scripts will make you a much better programmer. It will also help you get familiar with bash.
First let us create a directory for our scripts In your terminal (if on windows in WSL):
mkdir -p ~/scripts
echo 'export PATH="$PATH:$HOME/scripts"' >> ~/.bash_profileWhenever you open a new terminal the bash profile is run in order to set up your terminal environment. So it will now add the scripts directory to our PATH, which will allow us to execute those files.
Make sure to replace <csid> with your csid.
echo '#!/bin/bash' > ~/scripts/sshut
echo "ssh -i ~/.ssh/utlab <csid>@linux.cs.utexas.edu" >> ~/scripts/sshut
chmod u+x ~/scripts/sshut
source ~/.bash_profilechmod is a command that allows us to change the execution privileges of the file, so we can execute the new script we have created. source is similar to reloading the terminal, for the particular file specified.
Now just use
sshutTo always be able to reliably login from anywhere on this same machine.
Eventually you will want to edit text on the lab machine. My personal preference is vim. On a lab machine we can use vimtutor in order to learn this. To start the tutor just type.
vimtutorIn the Information age it is sufficient to know something up to Google Searching (or knowing the right reference) the exact thing we are looking for. So suddenly knowing what the type of thing we want to do is called is far more important than knowing exactly how to do that thing itself. Thus definitions become far more important than methods. This might seem rather obvious, but all of the best Researchers and Software Engineers use Google to efficiently find what they need. Being able to do that is an invaluable skill that comes through practice. But often times you will not want to have to look everything up. So we also want to know things we use every day, so we learn that but just doing it (this is called knowledge by usage).
Version control systems are used in order to ensure we can capture the state of our code and rollback to it. They have thousands of other features, but this is the main goal. They are a useful tool that any person who wants a CS degree should have a mastery up to Google.
Version control systems keep track of patches in a tree structure in order to have a full history of whatever files you would like. In this context we view files as a series of patches that are applied one after another to reveal the content of a file. We can view an individual patch to a file as the insertions and deletions to that file. Then a patch to the repository is the list of all of the individual file patches to all the files changed between the last state of the repo and the current one. To understand patches more in depth, there is some interesting mathematics involved: you can view a simple introduction here. This resource also details why I git is not my favorite version control system. To be very clear you do not need to understand patch theory, just have an operating knowledge of what I have detailed above.
This is what makes version control powerful, it allows for distributed changes to be made in order to ensure that multiple people can edit files at the same time.
Git was one of the first to do this efficiently and well making it the most popular version control software to this date.
But if we make these branches we want to reconcile these changes in a process called merging.
The process to figure this out is hard.
This is essentially the biggest use for branching.
Here is a clean visualization courtesy of Atlassian.
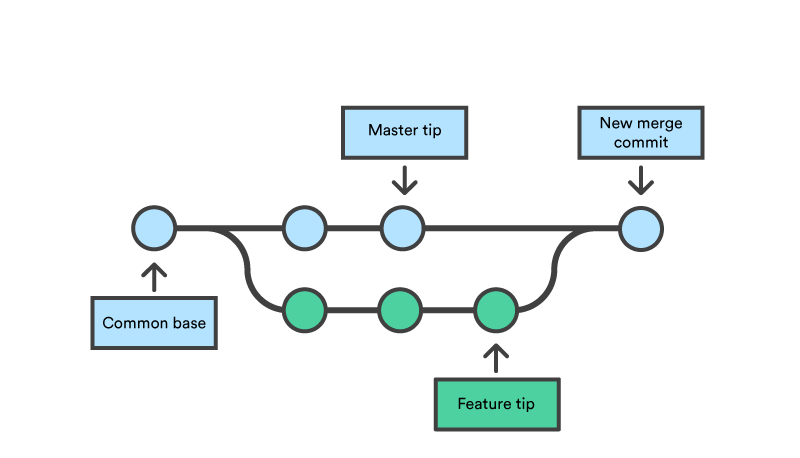
In the above image you may be wondering what a commit is. It is git's version of a patch. Git keeps track of changes to binary objects instead of files. This allows it a way to track things like file name changes, in a clean manner, but also increases the complexity of git's algorithms. Now that you have cloned this repository (gotten a copy of it on your own computer) we are going to make some changes,
There is a file called mult.c in the mult branch. A checkout is a method to grab some repositories object from somewhere and move it into a working environment. So let's checkout the mult branch and take a look.
git checkout multI've made a number of horrible mistakes in the mult.c file. See if you can find them and use vim to fix them. After you have fixed that, continue on to the next part. The next command will do what is called add that file to staging, meaning it will be committed on the next commit.
git add mult.c
git statusThe status command will allow us to view the current state of the branch.
git commit -m "Fixed mult"This forms a commit with the message in quotes. What this does is add a commit to the tree. This helpful visual describes the staging to commit process courtesy of Microsoft.

Test the code by running the below command, if it fails be sure to keep making edits until you succeed.
make mult
./multOnce you are finished make sure to commit that file to the mult branch.
Then we are going to discuss several different ways of moving the changes over to the master branch. In order to do this we first want to be on the master branch. This command should move you to the master branch:
git checkout masterTo show you the different ways of doing this we will also explore ways to undo changes as well. These are techniques that you always, always look up the exact command before you execute. They are dangerous and you want to make sure you execute exactly what you want.
The first method is checking out the file. It is a simple way of moving one file over. This is recommend for very small changes, as it does not create an actual commit and gives you flexibility to throw changes away.
git checkout mult -- mult.cThe more general version of this command is:
git checkout <branch> -- <paths>Omitting the paths has the side effect of switching branches. Now it is just like you have edited the mult.c file to change it to what you want manually and you can commit it to the master branch like before. This method however does not track where the changes have come from. In order to undo this change before you have committed it do:
git checkout mult.cIf you already committed this change then we want to delete the last commit.
git reset --hard HEAD~1Again do not use that command unless you are absolutely sure you typed it correctly. Small changes can do sad things. Reset commands in general set the state of your branch to some previous state and thus should be well researched before use.
For larger changes where we would like to combine the HEAD (the topmost commit) of two branches, we use a merge commit. They can be formulated in various ways. The best practice is to merge to the target branch" into the "working branch" and then merge the new "working branch" into the target branch. This allows you to incorporate changes that have been made to the target without disturbing changes other people could be making. This method also has the benefit of creating essentially a copy of the intended on the "working branch". Which can be further modified and then later re-merged to the target seamlessly. Merging has so many options and can become complicated very quickly if we loose sight of the basic tree structure of a repository. Let us remind ourselves of the earlier diagram:
In our example the common branch is master and the feature branch is mult. The above diagram is about what we want at the end result. But we will also create a merge commit on the mult branch. So checkout the mult branch. Then run the following.
git merge masterIn some circumstances you will have a merge conflict, here is a good resource for managing those. You should not have one here. Now we want to view this commit by running:
git logYou should see some auto generated commit that specifies this is a merge commit.
Whenever you want to quit just type the letter q.
Reading through the git log is a very important skill, this resource should help.
Before we continue, ensure everything is in proper working order, and
Now if we want to move that commit to the master branch, checkout the master branch and run.
git merge multNotice this is the mirror of the above merge command, because we are merging the "working branch" into the "target branch" now. So make sure that everything works and we can continue to the most interesting method to fix the changes. Obviously we should on both branches delete the commit with the reset command. Make sure you check the git log before running the command. This time however use the git log to find the last commit you want to reset to.
git reset --hard <commit-id>Also to check the branch you are on run:
git branchThus it is reasonable to understand that HEAD~1 must represent some commit id, this commit id is the one before the current HEAD commit id. The obvious question here of course is: What is a commit id? It is a unique representation of the commit in that place as a number.
The true power of patches is I can apply them in any order I want if I am sufficiently motivated (bored).
This allows me to recognize parts of things that I would like transfered from branch to branch.
In order to use this tool effectively one must have at least one commit per major repository change.
That metric can be expounded upon by your own exploration.
But to continue we want to apply the set of commits writing and fixing the mult.c file.
In this case, a merge is most useful, so I have created another two branches for practicing this technique.
One called pow and the other called weirdstuff.
When on the pow branch you should see at the top of the file the imports are missing.
They are included in some commit in the weirdstuff branch.
Make sure to use:
git log -pWhen viewing the log for weirdstuff in order to see the content of the commits.
We want to cherry-pick this commit onto the master branch.
We can do this by switching to the pow branch and running:
git cherry-pick <commit-id>This will try and merge the changes from that commit in weirdstuff to pow.
Make sure that you deal with the merge conflict.
Then follow the directions in the git status command.
If you got this far and were able to do everything congratulations you now know a little bit more about git. I suggest you start using it to manage all of your different projects, both cs related and not.