+
+
+
+
+NLTK Setup
+Hello there! 🌟 Welcome to your first step into the fascinating world of Natural Language Processing (NLP) with the Natural Language Toolkit (NLTK). This guide is designed to be super beginner-friendly. We’ll cover everything from installation to basic operations with lots of explanations along the way. Let's get started!
+What is NLTK?
+The Natural Language Toolkit (NLTK) is a comprehensive Python library for working with human language data (text). It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning. It also includes wrappers for industrial-strength NLP libraries.
+Key Features of NLTK:
+1.Corpora and Lexical Resources: NLTK includes access to a variety of text corpora and lexical resources, such as WordNet, the Brown Corpus, the Gutenberg Corpus, and many more.
+2.Text Processing Libraries: It provides tools for a wide range of text processing tasks:
+Tokenization (splitting text into words, sentences, etc.)
+Part-of-Speech (POS) tagging
+Named Entity Recognition (NER)
+Stemming and Lemmatization
+Parsing (syntax analysis)
+Semantic reasoning
+3.Classification and Machine Learning: NLTK includes various classifiers and machine learning algorithms that can be used for text classification tasks.
+4.Visualization and Demonstrations: It offers visualization tools for trees, graphs, and other linguistic structures. It also includes a number of interactive demonstrations and sample data.
+Installation
+First, we need to install NLTK. Make sure you have Python installed on your system. If not, you can download it from python.org. Once you have Python, open your command prompt (or terminal) and type the following command:
+
+To verify that NLTK is installed correctly, open a Python shell and import the library:
+import nltk
+If no errors occur, NLTK is successfully installed.
+NLTK requires additional data packages for various functionalities. To download all the data packages, open a python shell and run :
+
import nltk
+nltk.download ('all')
+
nltk.download ('punkt') # Tokenizer for splitting sentences into words
+nltk.download ('averaged_perceptron_tagger') # Part-of-speech tagger for tagging words with their parts of speech
+nltk.download ('maxent_ne_chunker') # Named entity chunker for recognizing named entities in text
+nltk.download ('words') # Corpus of English words required for many NLTK functions
+Now that we have everything set up, let’s dive into some basic NLP operations with NLTK.
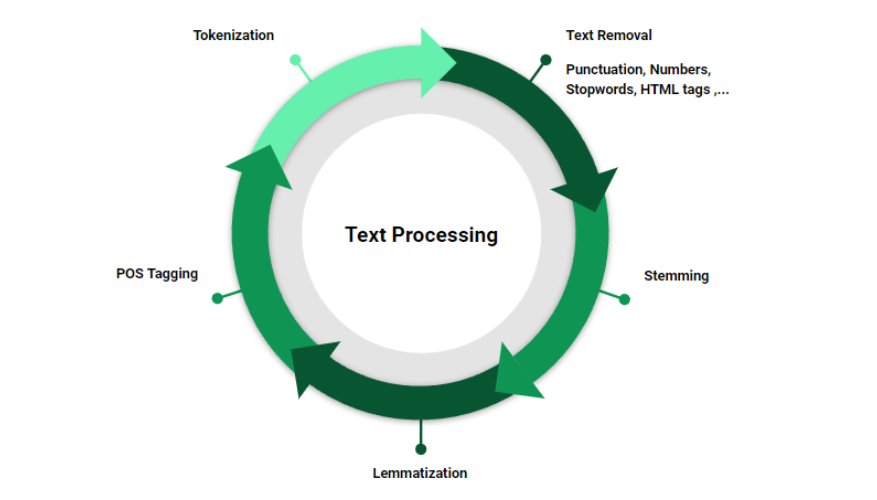
+Tokenization
+Tokenization is the process of breaking down text into smaller pieces, like words or sentences. It's like cutting a big cake into smaller slices.
+
from nltk.tokenize import word_tokenize, sent_tokenize
+
+#Sample text to work with
+text = "Natural Language Processing with NLTK is fun and educational."
+
+#Tokenize into words
+words = word_tokenize(text)
+print("Word Tokenization:", words)
+
+#Tokenize into sentences
+sentences = sent_tokenize(text)
+print("Sentence Tokenization:", sentences)
+
Sentence Tokenization: ['Natural Language Processing with NLTK is fun and educational.']
+Stopwords Removal
+Stopwords are common words that don’t carry much meaning on their own. In many NLP tasks, we remove these words to focus on the important ones.
+
from nltk.corpus import stopwords
+
+# Get the list of stopwords in English
+stop_words = set(stopwords.words('english'))
+
+# Remove stopwords from our list of words
+filtered_words = [word for word in words if word.lower() not in stop_words]
+
+print("Filtered Words:", filtered_words)
+
Explanation:
+stopwords.words('english'): This gives us a list of common English stopwords.
+[word for word in words if word.lower() not in stop_words]: This is a list comprehension that filters out the stopwords from our list of words.
+Stemming
+Stemming is the process of reducing words to their root form. It’s like finding the 'stem' of a word.
+
from nltk.stem import PorterStemmer
+
+# Create a PorterStemmer object
+ps = PorterStemmer()
+
+# Stem each word in our list of words
+stemmed_words = [ps.stem(word) for word in words]
+
+print("Stemmed Words:", stemmed_words)
+
Explanation:
+PorterStemmer(): This creates a PorterStemmer object, which is a popular stemming algorithm.
+[ps.stem(word) for word in words]: This applies the stemming algorithm to each word in our list.
+Lemmatization
+Lemmatization is similar to stemming but it uses a dictionary to find the base form of a word. It’s more accurate than stemming.
+
from nltk.stem import WordNetLemmatizer
+
+# Create a WordNetLemmatizer object
+lemmatizer = WordNetLemmatizer()
+
+# Lemmatize each word in our list of words
+lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
+
+print("Lemmatized Words:", lemmatized_words)
+
Explanation:
+WordNetLemmatizer(): This creates a lemmatizer object.
+[lemmatizer.lemmatize(word) for word in words]: This applies the lemmatization process to each word in our list.
+Part-of-speech tagging
+Part-of-speech tagging is the process of labeling each word in a sentence with its corresponding part of speech, such as noun, verb, adjective, etc. NLTK provides functionality to perform POS tagging easily.
+
# Import the word_tokenize function from nltk.tokenize module
+# Import the pos_tag function from nltk module
+from nltk.tokenize import word_tokenize
+from nltk import pos_tag
+
+# Sample text to work with
+text = "NLTK is a powerful tool for natural language processing."
+
+# Tokenize the text into individual words
+# The word_tokenize function splits the text into a list of words
+words = word_tokenize(text)
+
+# Perform Part-of-Speech (POS) tagging
+# The pos_tag function takes a list of words and assigns a part-of-speech tag to each word
+pos_tags = pos_tag(words)
+
+# Print the part-of-speech tags
+print("Part-of-speech tags:")
+print(pos_tags)
+
Explanation:
+pos_tags = pos_tag(words): The pos_tag function takes the list of words and assigns a part-of-speech tag to each word. For example, it might tag 'NLTK' as a proper noun (NNP), 'is' as a verb (VBZ), and so on.
+Here is a list of common POS tags used in the Penn Treebank tag set, along with explanations and examples:
+
+CC: Coordinating conjunction (e.g., and, but, or)
+CD: Cardinal number (e.g., one, two)
+DT: Determiner (e.g., the, a, an)
+EX: Existential there (e.g., there is)
+FW: Foreign word (e.g., en route)
+IN: Preposition or subordinating conjunction (e.g., in, of, like)
+JJ: Adjective (e.g., big, blue, fast)
+JJR: Adjective, comparative (e.g., bigger, faster)
+JJS: Adjective, superlative (e.g., biggest, fastest)
+LS: List item marker (e.g., 1, 2, One)
+MD: Modal (e.g., can, will, must)
+NN: Noun, singular or mass (e.g., dog, city, music)
+NNS: Noun, plural (e.g., dogs, cities)
+NNP: Proper noun, singular (e.g., John, London)
+NNPS: Proper noun, plural (e.g., Americans, Sundays)
+PDT: Predeterminer (e.g., all, both, half)
+POS: Possessive ending (e.g., 's, s')
+PRP: Personal pronoun (e.g., I, you, he)
+PRP$: Possessive pronoun (e.g., my, your, his)
+RB: Adverb (e.g., quickly, softly)
+RBR: Adverb, comparative (e.g., faster, harder)
+RBS: Adverb, superlative (e.g., fastest, hardest)
+RP: Particle (e.g., up, off)
+SYM: Symbol (e.g., $, %, &)
+TO: to (e.g., to go, to read)
+UH: Interjection (e.g., uh, well, wow)
+VB: Verb, base form (e.g., run, eat)
+VBD: Verb, past tense (e.g., ran, ate)
+VBG: Verb, gerund or present participle (e.g., running, eating)
+VBN: Verb, past participle (e.g., run, eaten)
+VBP: Verb, non-3rd person singular present (e.g., run, eat)
+VBZ: Verb, 3rd person singular present (e.g., runs, eats)
+WDT: Wh-determiner (e.g., which, that)
+WP: Wh-pronoun (e.g., who, what)
+WP$: Possessive wh-pronoun (e.g., whose)
+WRB: Wh-adverb (e.g., where, when)
+
+
+
+
+
+
+
+
+
+
+
+
+
+  +
+ +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+.jpg) +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+ .webp) +
+  +
+  +
+  +
+  +
+  +
+  +
+ 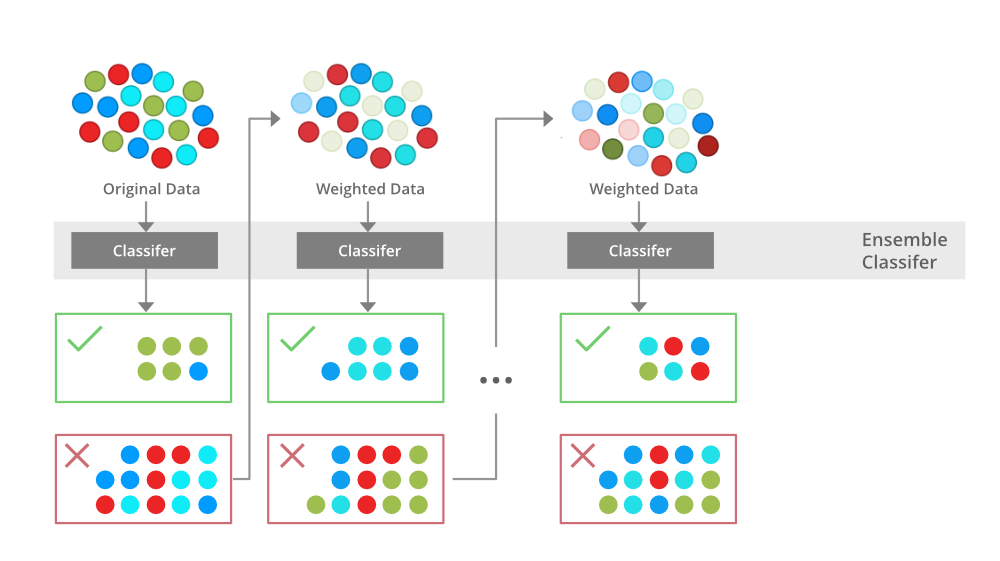 +
+  +
+  +
+  +
+  +
+  +
+ 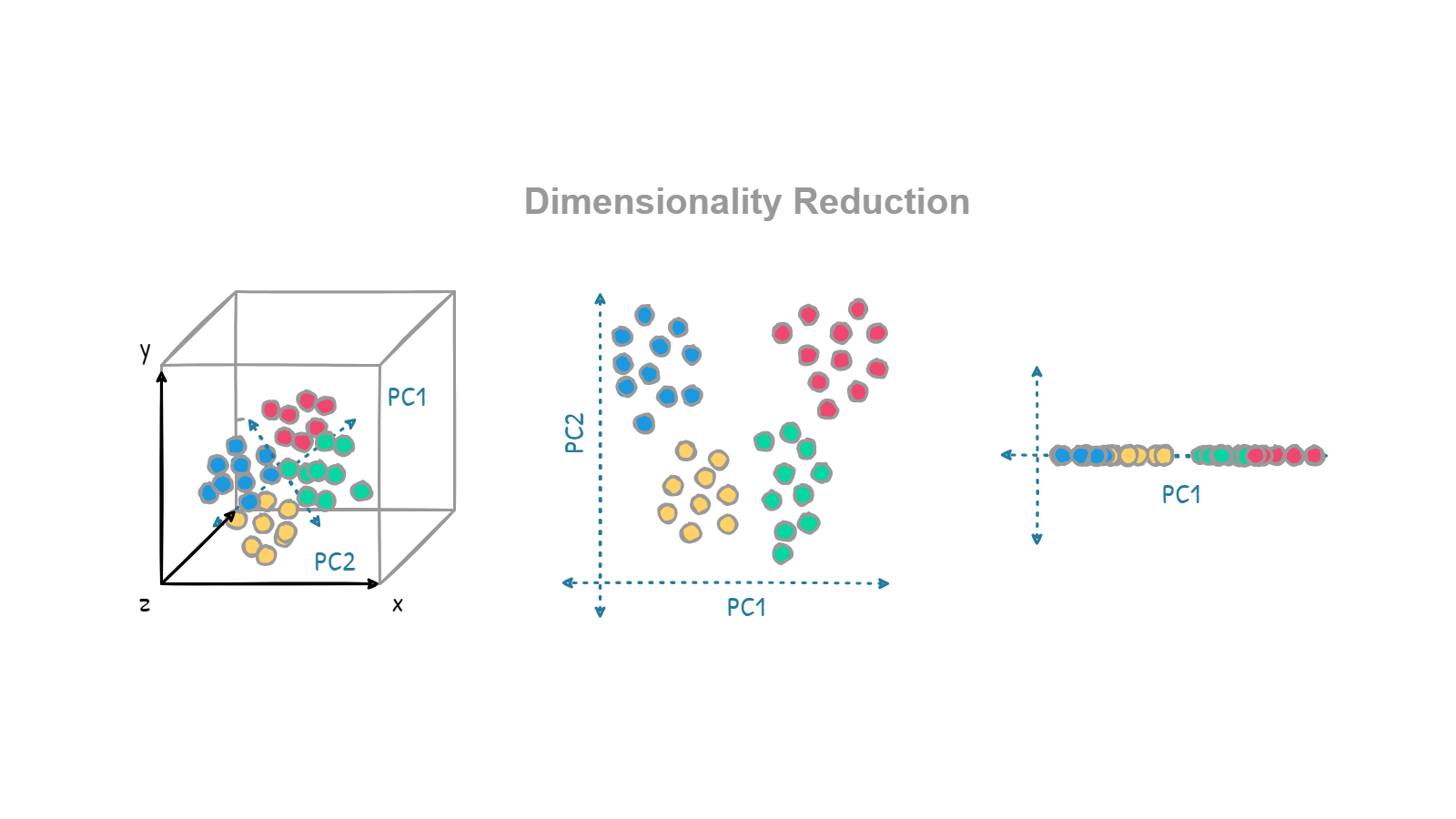 +
+ 
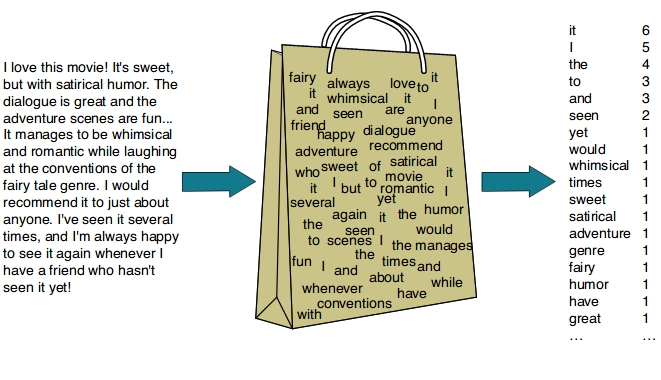 +
+  +
+ 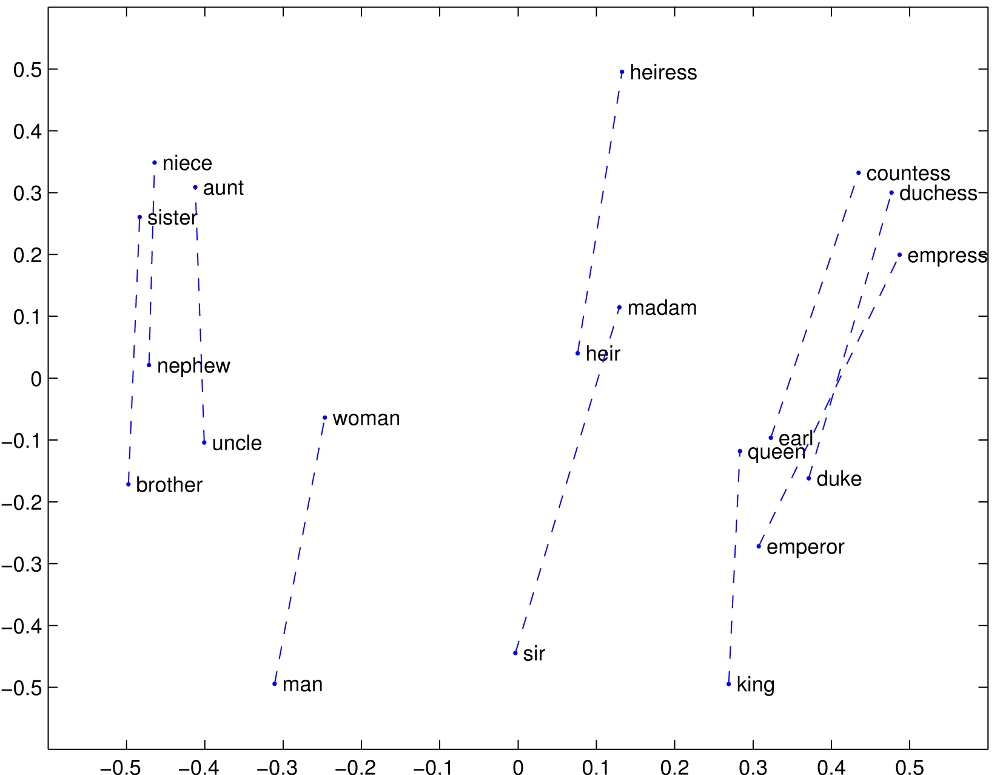 +
+  +
+  +
+  +
+  +
+  +
+  +
+ :max_bytes(150000):strip_icc()/Descriptive_statistics-5c8c9cf1d14d4900a0b2c55028c15452.png) +
+  +
+  +
+  +
+