Data Set: Kaggle Spotify Dataset 1912-2020, 160k Tracks
Model Type: K-nearest neighbors
Target: Song ID’s
- DS_16 Machine Learning
- DS_17 Data Engineering
Content:
- Product Vision
- Tech Stack
- Project Goals
- Audio Features
- Getting started
- File Structure
- More Instructions
- Deploying to Heroku
- Example: Data Visualization
- Example: Machine Learning
- Color Scheme
To build a functioning application programming interface and machine learning model to be used in a full-stack enviroment capable of recieving front-end GET requests and outputting POST requests to back-end.
- FastAPI: Web framework. Like Flask, but faster, with automatic interactive docs.
- Flake8: Linter, enforces PEP8 style guide.
- Heroku: Platform as a service, hosts your API.
- Pipenv: Reproducible virtual environment, manages dependencies.
- Plotly: Visualization library, for Python & JavaScript.
- Pytest: Testing framework, runs your unit tests.
- Uvicorn: Uvicorn is a lightning-fast ASGI server, built on uvloop and httptools.
- SQLAlchemy: SQLAlchemy is the Python SQL toolkit and Object Relational Mapper that gives application developers the full power and flexibility of SQL.
- Spotipy: (Not designed in structure of project) Spotipy is a lightweight Python library for the Spotify Web API. With Spotipy you get full access to all of the music data provided by the Spotify platform.
- SciKit-Learn: Simple and efficient tools for predictive data analysis.
- Pandas: Pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
Describe the established data source with at least rough data able to be provided on day one.
A: List of songs, basic info about songs, song name, artist, album, length of song, genre, general classification/categorization, number of plays, indicator of how much you might like song
Write a description for what the data science problem is. Discover an uncertainty and/or a prediction. Use the data to find a solution to this problem.
A: The Data Science team aims to solve the problem of inadequate or inaccurate predictions of songs that the user might enjoy. Current models do not seem to be super effective -- a large portion of our team does not enjoy ~30% of their Discovery Weekly playlist, and we aim to minimize that number (aiming for ~20%)
Create a good song suggestion. Determine how we know the suggestion was good. Determine whether the user would like it or add it to playlist of any kind.
A: From our team's personal experience, listening to a song all the way through without skipping is generally the best indication of whether a song was a good prediction or not. Adding a song to a playlist or liking a song can give an indication about a particularly good suggestion, but we've discovered that most users are not likely to do this on "good suggestions" only "really good suggestions".
Determine the targeted output to deliver to the Web/UX/iOS teams. Ensure JSON format or requested output format is used.
A: The Spotify API already outputs search requests as JSON, which our Data Engineer plans to flatten for ease of data analysis. We plan to change this back to Python via a Flask app when we return it to the backend team.
-
Acoustics (Confidence levels ranging from 0.0 to 1.0. 1.0 represents high confidence the track is acoustic.)
-
Artist Popularity (A value between 0 and 100, with 100 being the most popular. The popularity is calculated by algorithm and is based, in the most part, on the total number of plays the track has had and how recent those plays are.)
-
Danceability (Confidence levels ranging from 0.0 to 1.0. 1.0 represents track is most danceable based on tempo, rhythm stability, beat strength, and overall regularity.)
-
Duration_MS (The duration of the track in milliseconds.)
-
Energy (Confidence levels ranging from 0.0 to 1.0 representing a measure of intensity and activity. For example, acid screamo has high energy whereas trance scores low on the scale.)
-
Instrumentalness (Confidence levels ranging from 0.0 to 1.0. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. - Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0. “Ooh” and “aah” sounds are treated as instrumental in this context.)
-
Genre (* A conventional category that identifies some pieces of music as belonging to a shared tradition or set of conventions. It is to be distinguished from musical form and musical style.)
-
ID (A string to uniquely identify the Spotify ID for a track. For example, '1kKLWkqyZEnrOd5tBYYCUn',)
-
Liveness (Confidence levels ranging from 0.0 to 1.0. A value above 0.8 provides confidence the track is live.)
-
Loudness (Amplitude level ranging from -60 to 0 decibels (dB).)
-
Mode (Mode indicates the modality (major or minor) of a track, the type of scale from which its melodic content is derived. Major is represented by 1 and minor is 0.)
-
Speechiness (Confidence levels ranging from 0.0 to 1.0 to detect the presence of spoken words in a track. The more exclusively speech-like the recording (e.g. podcast, audio book, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks.)
-
Tempo (The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration.)
-
URI (A string to uniquely identify the Spotify URI (Uniform Resource Identifier) for a track. For example, 'spotify:track:7lEptt4wbM0yJTvSG5EBof': https://itknowledgeexchange.techtarget.com/overheard/files/2016/11/URI.png.)
-
Year (Production year of a track.)
Reason for using K-nearest neighbors: We chose to work with nearest neighbors because of its ability to cluster observations around common features. Since we were working a tabular dataset it seemed best to avoid any type of neural networks. There was also no need to apply any NLP techniques because there was justifiable reason to use it on any of the columns that contained text. Instead we dummy encoded the genres because most songs had multiple genres/sub genres.
Results: We were able to pull an array of similar song suggestions when we would input a single song ID.
Further research: We have begun working on applying text classification to the lyrics of the songs to see if we can get a different type of recommendation that is still useful and appreciated by the user.
- Spotify Kaggle Dataset: https://www.kaggle.com/yamaerenay/spotify-dataset-19212020-160k-tracks
- Spotify Audio Features: https://developer.spotify.com/documentation/web-api/reference/tracks/get-audio-features/
- Genre definition: https://en.wikipedia.org/wiki/Music_genre
Here's a template with starter code to deploy an API for your machine learning model and data visualizations.
You can deploy on Heroku in 10 minutes. Here's the template deployed as-is: https://ds-bw-test.herokuapp.com/
This diagram shows two different ways to use frameworks like Flask.

Instead of Flask, use FastAPI. It's similar, but faster, with automatic interactive docs. For more comparison, see FastAPI for Flask Users.
Build and deploy a Data Science API. May need to work cross-functionally with a Web teammate to connect the API to a full-stack web app!

Create a new repository from this template.
Clone the repo
git clone https://github.com/YOUR-GITHUB-USERNAME/YOUR-REPO-NAME.git
cd YOUR-REPO-NAME
Install dependencies
pipenv install --dev
Activate the virtual environment
pipenv shell
Launch the app
uvicorn app.main:app --reload
Go to localhost:8000 in the browser.

You'll see the API documentation:
- Your app's title, "DS API"
- Your description, "Lorem ipsum"
- An endpoint for POST requests,
/predict - An endpoint for GET requests,
/vis/{statecode}
Click the /predict endpoint's green button.

You'll see the endpoint's documentation, including:
- Your function's docstring, """Make random baseline predictions for classification problem."""
- Request body example, as JSON (like a Python dictionary)
- A button, "Try it out"
Click the "Try it out" button.

The request body becomes editable.
Click the "Execute" button. Then scroll down.

You'll see the server response, including:
- Code 200, which means the request was successful.
- The response body, as JSON, with random baseline predictions for a classification problem.
Your job is to replace these random predictions with real predictions from your model. Use this starter code and documentation to deploy your model as an API!
.
└── app
├── __init__.py
├── main.py
├── api
│ ├── __init__.py
│ ├── predict.py
│ └── viz.py
└── tests
├── __init__.py
├── test_main.py
├── test_predict.py
└── test_viz.py
app/main.py is where you edit the app's title and description, which are displayed at the top of the automatically generated documentation. This file also configures "Cross-Origin Resource Sharing", which you shouldn't need to edit.
app/api/predict.py defines the Machine Learning endpoint. /predict accepts POST requests and responds with random predictions. In a notebook, train your model and pickle it. Then in this source code file, unpickle your model and edit the predict function to return real predictions.
When the API receives a POST request, FastAPI automatically parses and validates the request body JSON, using the Item class attributes and functions. Edit this class so it's consistent with the column names and types from the training dataframe.
- FastAPI docs - Request Body
- FastAPI docs - Field additional arguments
- calmcode.io video - FastAPI - Json
- calmcode.io video - FastAPI - Type Validation
- pydantic docs - Validators
app/api/viz.py defines the Visualization endpoint. Currently /viz/{statecode} accepts GET requests where {statecode} is a 2 character US state postal code, and responds with a Plotly figure of the state's unemployment rate, as a JSON string. Create your own Plotly visualizations in notebooks. Then add your code to this source code file. Your web developer teammates can use react-plotly.js to show the visualizations.
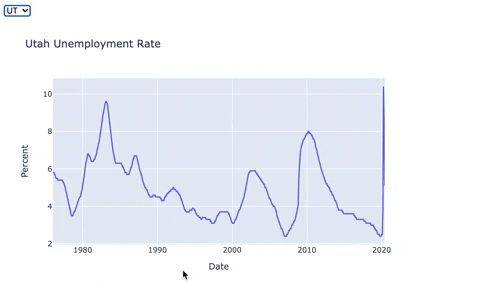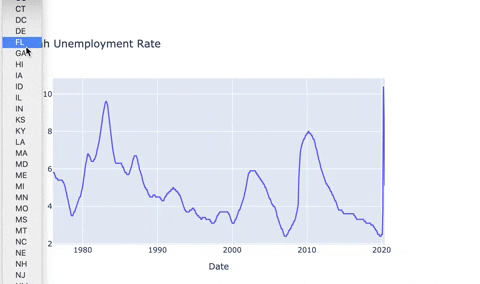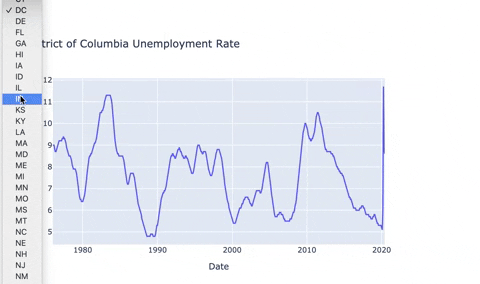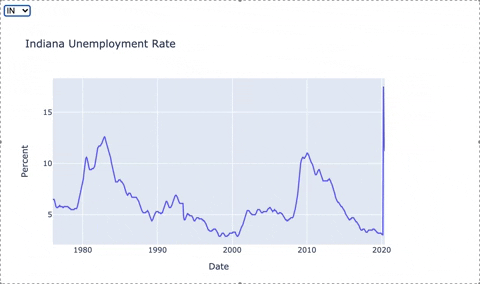
{kind=link}
- Lambda School docs - Data visualization with React & Plotly. This is the code for the example above. Your web teammate(s) can reuse this as-is.
- Plotly docs
app/tests/test_*.py is where you edit the pytest unit tests.
Activate the virtual environment
pipenv shell
Install additional packages
pipenv install PYPI-PACKAGE-NAME
Launch a Jupyter notebook
jupyter notebook
Run tests
pytest
Run linter
flake8
Prepare Heroku
heroku login
heroku create YOUR-APP-NAME-GOES-HERE
heroku git:remote -a YOUR-APP-NAME-GOES-HERE
Deploy to Heroku
git add --all
git add --force Pipfile.lock
git commit -m "Deploy to Heroku"
git push heroku main:master
heroku open
(If you get a Locking failed! error when deploying to Heroku or running pipenv install then delete Pipfile.lock and try again, without git add --force Pipfile.lock)
Deactivate the virtual environment
exit
Recommended: Use Plotly, a popular visualization library for both Python & JavaScript.
Follow the getting started instructions.
Edit app/main.py to add your API title and description.
app = FastAPI(
title='World Metrics DS API',
description='Visualize world metrics from Gapminder data',
version='0.1',
docs_url='/',
)Prototype the visualization in a notebook.
import plotly.express as px
dataframe = px.data.gapminder().rename(columns={
'year': 'Year',
'lifeExp': 'Life Expectancy',
'pop': 'Population',
'gdpPercap': 'GDP Per Capita'
})
country = 'United States'
metric = 'Population'
subset = dataframe[dataframe.country == country]
fig = px.line(subset, x='Year', y=metric, title=f'{metric} in {country}')
fig.show()Define a function for the visualization. End with return fig.to_json()
Then edit app/api/viz.py to add the code.
import plotly.express as px
dataframe = px.data.gapminder().rename(columns={
'year': 'Year',
'lifeExp': 'Life Expectancy',
'pop': 'Population',
'gdpPercap': 'GDP Per Capita'
})
@router.get('/worldviz')
async def worldviz(metric, country):
"""
Visualize world metrics from Gapminder data
### Query Parameters
- `metric`: 'Life Expectancy', 'Population', or 'GDP Per Capita'
- `country`: [country name](https://www.gapminder.org/data/geo/), case sensitive
### Response
JSON string to render with react-plotly.js
"""
subset = dataframe[dataframe.country == country]
fig = px.line(subset, x='Year', y=metric, title=f'{metric} in {country}')
return fig.to_json()Test locally, then deploy to Heroku.
Your web teammates can re-use the data viz code & docs in our labs-spa-starter repo. The web app will call the DS API to get the data, then use react-plotly.js to render the visualization.
- Example gallery
- Setting Graph Size
- Styling Plotly Express Figures
- Text and font styling
- Theming and templates
Follow the getting started instructions.
Edit app/main.py to add your API title and description.
app = FastAPI(
title='House Price DS API',
description='Predict house prices in California',
version='0.1',
docs_url='/',
)Edit app/api/predict.py to add a docstring for the predict function and return a naive baseline.
@router.post('/predict')
async def predict(item: Item):
"""Predict house prices in California."""
y_pred = 200000
return {'predicted_price': y_pred}In a notebook, explore the data. Make an educated guess of what features you could use.
import pandas as pd
from sklearn.datasets import fetch_california_housing
# Load data
california = fetch_california_housing()
print(california.DESCR)
X = pd.DataFrame(california.data, columns=california.feature_names)
y = california.target
# Rename columns
X.columns = X.columns.str.lower()
X = X.rename(columns={'avebedrms': 'bedrooms', 'averooms': 'total_rooms'})
# Explore descriptive stats
X.describe()# Use these 3 features
features = ['bedrooms', 'total_rooms', 'house_age']Edit the class in app/api/predict.py to use the features.
class House(BaseModel):
"""Use this data model to parse the request body JSON."""
bedrooms: int
total_rooms: float
house_age: float
def to_df(self):
"""Convert pydantic object to pandas dataframe with 1 row."""
return pd.DataFrame([dict(self)])
@router.post('/predict')
async def predict(house: House):
"""Predict house prices in California."""
X_new = house.to_df()
y_pred = 200000
return {'predicted_price': y_pred}Test locally, then deploy to Heroku with the work-in-progress. Now your web teammates can make POST requests to the API endpoint.
In a notebook, train the pipeline and pickle it. See these docs:
Get version numbers for every package you used in the pipeline. Install the exact versions of these packages in your virtual environment.
Edit app/api/predict.py to unpickle the model and use it in your predict function.
Now you are ready to re-deploy! 🚀
Background color: #D4F779
Text-color: Black
Footer and Header Text Color: #F22FA5
Font: Circular --- be sure to import and specify in font-family, can be found here or here. Alternatively, the path is CircularStd-Bold.otf
Logo: can be found here. The path is assets/vinyl-logo-512-pink.png/