Sorry, we've misplaced that URL or it's pointing to something that doesn't exist.
404: Page not found
Recently Updated
Sorry, we've misplaced that URL or it's pointing to something that doesn't exist.
(。・∀・)ノ゙Hi. My name is Linze. We can make a friend, I suppose. I hope you can enjoy my blogs.
My research interests are …
In this role I was doing the job with crawling the commodity information of foreign e-commerce websites, such as size or color, etc.
YYYY: Name et al. Article title. Journal name. Link/DOI
To be continued…
YYYY: Description of award, certificate, supporting info etc.
To be continued…
Email: zee_lin@foxmail.com
QQ/Wechat: 493103671
本篇博客不阐述原理,只是记录一些知识点以及常用的C++函数代码。
这两个符号都是C++成员运算符1,主要用于确定类对象和成员之间的关系,用于引用类、结构和共用体的成员。
箭头运算符->与一个指针对象的指针一起使用。如果是指针访问数据成员或成员函数,用->;
点运算符.与实际的对象一起使用。如果是某个数据类型的对象,访问自己的数据成员和成员函数用.;
举个例子:
1
+2
+3
+4
+
string s1 = "a string",*p = &s1;
+int n = s1.size(); //运行string对象s1的size()成员
+n = (*p).size(); //运行p所指对象的size成员
+n = p->size(;) //等价于(*p).size
+
左移乘,右移除
bitset.count()函数用于统计二进制数中1的数量。
__builtin_popcount()函数也可以统计二进制中1的数量。
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+
#include<bits/stdc++.h>
+using namespace std;
+int main() {
+ unsigned short short1 = 4;
+ bitset<16> bitset1(short1); // the bitset representation of 4
+ cout << bitset1 << endl; // 0b00000000'00000100
+
+ unsigned short short2 = short1 << 1; // 4 left-shifted by 1 = 8
+ bitset<16> bitset2(short2);
+ cout << bitset2 << endl; // 0b00000000'00001000
+
+ unsigned short short3 = short1 >> 2; // 4 right-shifted by 2 = 1
+ bitset<16> bitset3(short3);
+ cout << bitset3 << endl; // 0b00000000'00000001
+
+ int int1 = 5;
+ bitset<4> bitset4(int1); // 0b1001
+ cout << bitset4.count() << endl; // number of set bits in bitset4 = 2
+ cout << __builtin_popcount(5) << endl; // same as above
+}
+
前序(preorder): 根结点 -> 遍历左子树 -> 遍历右子树 (首先访问根结点)
中序(inorder): 遍历左子树 -> 根结点 -> 遍历右子树
后序(postorder): 遍历左子树 -> 遍历右子树 -> 根结点 (最后访问根结点)
简介:n 个人围成一个圈,每次数 k 个数,被数到的那个人出局。
数学解法:
1
+2
+3
+4
+5
+6
+7
+
int findTheWinner(int n, int k) {
+ int p = 0;
+ for (int i = 2; i <= n; i++) {
+ p = (p + k) % i;
+ }
+ return p + 1;
+}
+
队列:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+
int findTheWinner(int n, int k) {
+ queue<int> q;
+ for(int i = 0; i < n; i++) q.push(i + 1);
+ while(q.size() != 1){
+ for(int i = 0; i < k - 1; i++){
+ q.push(q.front());
+ q.pop();
+ }
+ q.pop();
+ }
+ return q.front();
+}
+
STL: Standard Template Library
emplace可以代替insert. emplace_back可以代替push_back. emplace_front可以代替push_front.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+
mylist.front()
+mylist.back()
+mylist.begin()
+mylist.end()
+mylist.empty()
+
+mylist.erase()
+mylist.remove()
+
+mylist.insert()
+
+mylist.pop_back()
+mylist.pop_front()
+mylist.push_back()
+mylist.push_front()
+
+mylist.reverse()
+mylist.sort()
+
+mylist.unique()
+
emplace可以代替insert. emplace_back可以代替push_back. emplace_front可以代替push_front.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+
myvector.front()
+myvector.back()
+myvector.size()
+
+myvector.begin()
+myvector.end()
+
+for(vector<int>::iterator it = myvector.begin();it!=myvector.end();it++){
+ cout<<*it<<endl;
+}
+
+myvector.clear()
+
+myvector.pop_back()
+myvector.push_back()
+
+myvector.empty()
+myvector.insert()
+
emplace可以代替push
1
+2
+3
+4
+5
+6
+
myqueue.push()
+myqueue.pop()
+myqueue.empty()
+myqueue.size()
+myqueue.front()
+myqueue.back()
+
emplace可以代替push
1
+2
+3
+4
+5
+
mystack.empty()
+mystack.pop()
+mystack.push()
+mystack.size()
+mystack.top() //栈顶,即出入口
+
emplace可以代替insert
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+
// 不需要对key进行排列或数据量不小于10000的时候,用unordered_map.
+
+unordered_map<char,int> mymap;
+mymap['a'] = 100;
+mymap['b'] = 200;
+
+for(map<char,int>::iterator it = mymap.begin();it != mymap.end(); it++){
+ cout<<it->first<<" => " <<it->second<<endl;
+}
+
+mymap.size()
+
+mymap.clear()
+
+mymap.count(k) //return 1 if found or 0 otherwise
+
+mymap.erase(key)
+mymap.erase(iterator first,iterator last)
+
+it = mymap.find('b')
+mymap.insert()
+
emplace可以代替insert
1
+2
+3
+
unordered_set<int> myset;
+
+unordered_set<pair<int, string>> myset;
+
优先队列与堆类似。默认大顶堆。
和队列基本操作相同:
top()访问队头元素empty()队列是否为空size()返回队列内元素个数push()插入元素到队尾 (并排序)emplace()原地构造一个元素并插入队列pop()弹出队头元素
1
+2
+3
+4
+5
+
//大顶堆,即降序队列
+priority_queue<int> big_heap;
+priority_queue<int, vector<int>, less<int> > big_heap2;
+//小顶堆,即升序队列
+priority_queue<int, vector<int>, greater<int> > small_heap;
+
pair的比较,先比较第一个元素,第一个相等比较第二个
1
+2
+3
+4
+
//大顶堆,即降序队列
+priority_queue<pair<int, int> > big_pair_heap;
+//小顶堆,即升序队列
+priority_queue<pair<int, int>, vector<pair<int, int>>, greater<>> small_pair_heap;
+
lower_bound()和upper_bound()是利用二分查找的方法在一个排好序的容器中进行查找,比如set,vector,map容器。具体用法如下所示:
lower_bound(value): 第一个大于等于(可以是字典序,也可以是值)value的下标或者指针upper_bound(value): 第一个大于(可以是字典序,也可以是值)value的下标或者指针map:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+
map<char,int> mymap;
+mymap['a']=20;
+mymap['b']=40;
+mymap['c']=60;
+mymap['d']=80;
+mymap['f']=100;
+map<char,int>::iterator itlow=mymap.lower_bound ('b'); // itlow points to b
+map<char,int>::iterator temp=mymap.upper_bound ('d'); // temp points to f (not d!)
+map<char,int>::iterator itup=mymap.upper_bound ('e'); // there's no e, so itup points to f
+mymap.erase(itlow,itup); // erases [itlow,itup)
+
set:
1
+2
+3
+4
+5
+6
+7
+
set<int> myset;
+for (int i=1; i<10; i++) myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90
+set<int>::iterator temp1=myset.lower_bound (25); // 30 >= 25,so temp1 points to 30
+set<int>::iterator temp2=myset.lower_bound (60); // 70 > 60,so temp2 points to 70
+set<int>::iterator itlow=myset.lower_bound (30); // itlow points to 30
+set<int>::iterator itup=myset.upper_bound (65); // itup points to 70
+myset.erase(itlow,itup); // erases [itlow,itup)
+
int index = mystring.find(s, pos);
其中 s 可以是字符也可以是字符串,pos 是寻找字符或字符串的起始位置。
1
+2
+3
+
string str = "abcdefgabc";
+int index = str.find("abc"); // index = 0
+int index = str.find("abc", 3); // index = 7
+
string str = mystring.substr(pos, len);2
Example
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+
// string::substr
+#include <iostream>
+#include <string>
+
+int main ()
+{
+ std::string str="We think in generalities, but we live in details."; // (quoting Alfred N. Whitehead)
+
+ std::string str2 = str.substr (3,5); // "think"
+
+ std::size_t pos = str.find("live"); // position of "live" in str
+
+ std::string str3 = str.substr (pos); // get from "live" to the end
+
+ std::cout << str2 << ' ' << str3 << '\n';
+
+ return 0;
+}
+
Output:
think live in details.
string str = to_string(a); 3
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+
include<bits/stdc++.h>
+
+struct person{ // structure
+ double a;
+ double b;
+}temp[100];
+
+getline(cin,s);
+
+int a; // int to string
+string str = to_string(a);
+
+string b; // string to int
+int int1 = atoi(b.c_str()); //遇到字母会自动停下,如果没有数字,则定义为0 。b为string类型的情况下还需要使用c_str()函数
+int int2 = stoi(b); //遇到字母会自动停下,如果没有数字,运行会出错
+
+string str; // length(string)
+int res = str.length();
+
+char *test; // length(char)
+int res = strlen(test);
+
+int num = 3;
+temp = string(num, 'a'); // "aaa"
+
+int i = 1, j = 4;
+int res = (i + j)/2; // 向下取整,res = 2;
+cout<<res<<endl;
+
动态分配与释放内存。与vector相比,使用malloc的效率更高。
分配一维与二维数组代码如下所示:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+
#include<bits/stdc++.h>
+using namespace std;
+
+int main(){
+ // 1-dimensional
+ int len = 10;
+ int *p;
+ p = (int *)malloc(len * sizeof(int));
+ free(p);
+ // 2-dimensional
+ int **a;
+ int row = 3; int col = 3;
+ a = (int **)malloc(row * sizeof(int*));
+ for(int i = 0; i < row; i++)
+ {
+ a[i] = (int *)malloc(col * sizeof(int));
+ }
+
+ for(int i = 0; i < row; i++)
+ {
+ free(a[i]);
+ }
+ free(a);
+}
+
1
+2
+3
+4
+5
+6
+
bool is_prime(int s){
+ if(s <= 3) return s > 1;
+ int sqt = sqrt(s);
+ for(int i = 2; i <= sqt; i++) if(s % i == 0) return false;
+ return true;
+}
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+
bool cmp(string a, string b){
+ if(a.length() != b.length()) return a.length() < b.length(); // 按长度升序:a的长度小于b的长度,所以从左到右长度变大。
+ return a > b; // 按字典序降序:a的字典序大于b的字典序,所以从左到右字典序降低。
+}
+
+int main(){
+ sort(temp1, temp1 + 4, cmp); // temp1为数组
+ sort(temp2.begin(), temp2.end(), cmp); // temp2为向量
+}
+
与sort()函数类似,可对数组、向量的任意区间求最大或最小值。
1
+2
+3
+4
+5
+6
+7
+8
+
#include<bits/stdc++.h>
+using namespace std;
+int main(){
+ int temp_myv[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
+ vector<int> myv(temp_myv, temp_myv + 10);
+ cout<<*min_element(temp_myv, temp_myv + 10)<<endl;
+ cout<<*max_element(myv.begin(), myv.end())<<endl;
+}
+
1
+2
+3
+4
+
int a[5] = {1, 2, 3, 4, 5};
+vector<int> v(a);
+int sum = accumulate(a, a + 5, 0);
+int sum2 = accumulate(v.begin(), v.end(), 0);
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+
cout<<fixed<<setprecision(1)<<a<<endl; // accurate to 1 decimal place
+
+cout<<setw(3)<<setfill('0')<<a<<endl; // filled with '0'
+printf("%03d",a); // if a=1; 输出001
+
+
+cout<<hex<<12<<endl; // 十六进制输出
+cout<<oct<<12<<endl; // 八进制输出
+
+cout<<left<<setw(5)<<10<<endl; // 左对齐
+cout<<right<<setw(5)<<10<<endl; // 右对齐
+
+string a;
+int b,c;
+scanf("%s : %d :%d", &a[0], &b, &c); //可以隔着冒号取值,记得引用符号&
+printf("%s\n",a);
+
用于判断字符串s中的任意子串是否回文。
动态规划法:
judge[start][end]表示字符串s中[start, end]的子串是否为回文串。
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
int n = s.length();
+vector<vector<bool> > judge(n, vector<bool>(n, true));
+// 从后往前去遍历
+for (int i = n - 1; i >= 0; --i)
+{
+ for (int j = i + 1; j < n; ++j)
+ {
+ // 判断i和j是否相等,相等则扩展
+ judge[i][j] = (s[i] == s[j]) && judge[i + 1][j - 1];
+ }
+}
+
双指针遍历法:
描述同动态规划法,适用于单次简单判断。若要判断字符串s的每个子串是否为回文串,复杂度则为O(n^3)。
1
+2
+3
+4
+5
+6
+
bool judge(string s, int start, int end){ // 双指针遍历
+ for(int i = start; i <= (start + end) / 2; i++){
+ if(s[i] != s[end + start - i]) return false;
+ }
+ return true;
+}
+
详细的二分查找分析见此。
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+
int nums[5] = {10, 20, 30, 40, 50};
+int flag = -1, target = 16;
+int i = 0, j = n - 1; // 前闭后闭
+while(i <= j){ // 因此i > j(即i == j + 1)时退出循环
+ int mid = i + (j - i)/2;
+ if(target == nums[mid]){
+ flag = mid;
+ break;
+ }
+ else if(target > nums[mid]) i = mid + 1; // mid已经遍历,所以新的区间为[i, mid - 1]或[mid + 1, j]
+ else j = mid - 1;
+}
+
排列(permutation):
\[A_{n}^{m} = \frac{n!}{(n - m)!} = (n - m + 1) * \cdots * (n - 1) * n\]1
+2
+3
+4
+5
+6
+7
+
int A(int n, int m) {
+ int res = 1;
+ for(int i = n - m + 1; i <= n; i++){
+ res *= i;
+ }
+ return res;
+}
+
组合(combination):
\[C_{n}^{m} = \frac{ A_{n}^{m} }{m!} = \frac{n!}{(n - m)!m!} = C_{n}^{n-m}\]1
+2
+3
+4
+5
+6
+
int C(int n, int m) {
+ m = min(m, n - m);
+ int numerator = A(n, m); //分子
+ int denominator = A(m, m); //分母
+ return numerator / denominator;
+}
+
大小写判断:
1
+2
+
for (int i = 0; i < str.size(); i++) if(islower(str[i])) return false; // bool islower(int c);
+for (int i = 0; i < str.size(); i++) if(isupper(str[i])) return false; // bool isupper(int c);
+
大小写转换:
1
+2
+
for (int i = 0; i < str.size(); i++) str[i] = tolower(str[i]); // int tolower(int c);
+for (int i = 0; i < str.size(); i++) str[i] = toupper(str[i]); // int toupper(int c);
+
max()、min()函数中只有两个参数,意味着只能在两个数中取最大或者最小值。
当需要对三个及以上的数字取最大或最小值时,可用以下方法。
1
+2
+3
+4
+5
+6
+7
+8
+9
+
int x = 6, y = 2, z = 10;
+int m1 = max({x,y,z});
+int m2 = max<int>({x,y,z});
+int m3 = max({(int)x,y,z});
+
+double a = 9.2, b = 2.4, c = 5.5555;
+double n1 = min({a,b,c});
+double n2 = min<double>({a,b,c});
+double n3 = min({(double)a,b,c});
+
或者:
1
+2
+3
+
int maxn(int x, int y, int z){
+ return max(max(x, y), z);
+}
+
伪随机数:
rand() / double(RAND_MAX) 产生随机数的范围是 [0, 1]
rand() / double(RAND_MAX) * 2 * r 产生随机数范围为 [0, 2r]
rand() / double(RAND_MAX) * 2 * r - r + x 产生随机数范围为 [x - r, x + r]
真随机数:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+
#include <random>
+#include <iostream>
+
+int main()
+{
+ std::random_device rd; // random_device 是一个“真随机数”发生器,它的缺点就是耗能太大,所以尽量别奢侈地一直用它
+ std::mt19937 gen(rd()); // 用 random_device产生一个真随机数,用作“伪随机数发生器”的种子,此后就雪藏之
+ std::uniform_int_distribution<> dis(1, 6); // 一个正态“分布器”,高斯分布器是 std::normal_distribution
+
+ for (int n=0; n<10; ++n)
+ // 用 dis 变换 gen 所生成的随机 unsigned int 到 [1, 6] 中的 int
+ std::cout << dis(gen) << ' ';
+ std::cout << '\n';
+}
+
1
+2
+
//初始化一个size为0的vector
+vector<int> abc;
+
1
+2
+3
+4
+
//初始化size,但每个元素值为默认值
+vector<int> abc(10); //初始化了10个默认值为0的元素
+//初始化size,并且设置初始值
+vector<int> cde(10, 1); //初始化了10个值为1的元素
+
1
+2
+3
+
int a[5] = {1, 2, 3, 4, 5};
+//通过数组a的地址初始化,注意地址是从0到5(左闭右开区间)
+vector<int> b(a, a + 5);
+
1
+2
+3
+
vector<int> a(5, 1);
+//通过a初始化
+vector<int> b(a);
+
1
+2
+3
+4
+5
+
//insert初始化方式将同类型的迭代器对应的始末区间(左闭右开区间)内的值插入到vector中
+vector<int> a(6, 6);
+vecot<int> b;
+//将a[0]~a[2]插入到b中,b.size()由0变为3
+b.insert(b.begin(), a.begin(), a.begin() + 3);
+
insert也可通过数组地址区间实现插入
1
+2
+3
+4
+
int a[6] = {6, 6, 6, 6, 6, 6};
+vector<int> b;
+//将a的所有元素插入到b中
+b.insert(b.begin(), a, a + 6);
+
此外,insert还可以插入m个值为n的元素
1
+2
+
//在b开始位置处插入3个6
+b.insert(b.begin(), 3, 6);
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+
vector<int> a(5, 1);
+int a1[5] = {2, 2, 2, 2, 2};
+vector<int> b(10);
+
+/*将a中元素全部拷贝到b开始的位置中,注意拷贝的区间为a.begin() ~ a.end()的左闭右开的区间*/
+copy(a.begin(), a.end(), b.begin());
+
+//拷贝区间也可以是数组地址构成的区间
+copy(a1, a1 + 5, b.begin() + 5);
+
vector<vector<int> > myv(row, vector<int>(column,0));
1
+2
+3
+4
+5
+
vector<vector<int> > myv(5, vector<int>(10,0)); // 两个维度都是向量
+cout<<myv.size()<<endl; // 正确,因为向量有size()函数
+
+vector<int> temp(2);
+myv.push_back(temp); // 正确,可以将向量插入到向量中
+
或者:
1
+2
+3
+
vector<vector<int> > myv(5); // 两个维度都是向量,只是第二个维度的向量长度为0
+cout<<myv.size()<<endl; // 5
+cout<<myv[0].size()<<endl; // 0
+
vector<vector<int>> v(5) 大于号之间没有空格的初始化方式在C++11之后也是正确的,即C++11以后允许两个大于号之间没有空格。C++11是一种标准。
1
+2
+3
+4
+5
+
vector<int> myv[n]; // 此时第一维是数组,第二维才是向量。
+// cout<<myv.size()<<endl; // 错误,因为数组没有size()函数
+
+vector<int> temp(2);
+myv.push_back(temp); // 错误,无法将向量插入到数组中
+
Click Tools and Complier Options
Add -std=c++11

Elasticsearch是基于 Lucene 架构实现的分布式、海量数据的存储分析引擎,其中 Lucene 最主要的倒排索引结构,赋予了ES全文检索、模糊匹配、联合索引查询等等快速检索文档数据的能力,使得ES在这些查询的应用场景下优于数据库。适合用于搜索,不适合复杂的关系查询
倒排索引:被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。
本质上都是写操作!磁盘上的每个段都有一个相应的 .del 文件。
.del 文件中被标记为删除的文档将不会被写入新段。大概分为三个步骤:write -> refresh -> flush
1、write:文档数据到内存缓存,并存到 translog
2、refresh:内存缓存中的文档数据,到文件缓存中的 segment 。此时可以被搜到。
3、flush: 缓存中的 segment 文档数据写入到磁盘
当数据添加到索引后并不能马上被查询到,等到索引刷新后才会被查询到。refresh_interval 参数设置为正数之后,需要等一段时间后才可以在es索引中搜索到,因为已经从内存缓存刷新到文件缓存中了。详见数据写入与查询存在时间差问题

Term Index: 倒排的树状结构,存在内存里,是Term dictionary的索引。
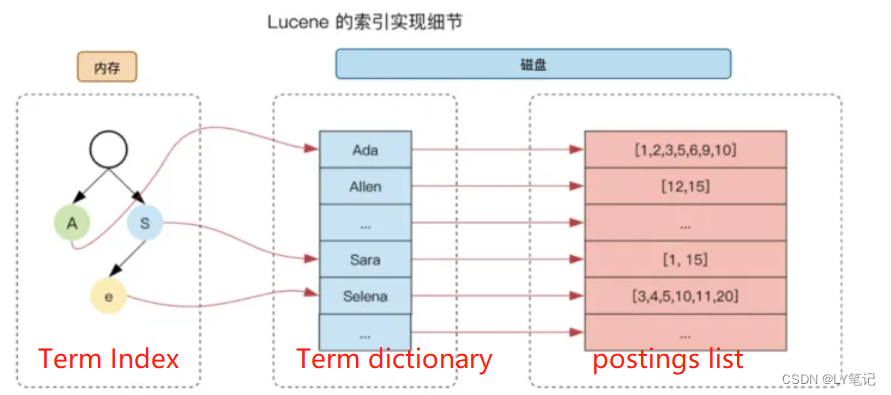
基本概念:
分片与副本的区别在于:
尽可能使用过滤器上下文(Filter)替代查询上下文(Query)
Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一样计算相关性分数,同时Filter结果可以缓存。
Scroll Query + Bulk
Ingest pipeline 可以在数据存入ES之前对数据进行转换,例如转小写,增加字段等。
性能优化:
背景:每五分钟就有6.5M条数据,直接reindex需要1000s(15分钟)
text类型: text类型是指可分词的文本,适用于长文本或短语查询。当文本被索引时,会被分成一些个别单词或词组,并且会去除停用词(如“a”、“the”、“and”等)和标点符号。这些单词或词组将被标准化并存储在倒排索引中,使得搜索时可以更快地匹配文档。适合全文搜索。
keyword类型: keyword类型是指未经过分词处理的文本,适用于精确匹配和排序。当文本被索引时,会被作为一个整体进行索引。它们通常用于搜索和排序非文本字段,例如数字或日期。适合过滤、排序、聚合。
ElasticSearch 默认为text类型,但是text类型总会有keyword的类型的字段,等价于 .keyword
垂直扩容(纵向扩容):替换旧的设备
水平扩容(横向扩容):直接新增设备到集群中,会触发relocation

针对写入和更新时可能出现的并发问题,ES是通过文档版本号来解决的。当用户对文档进行操作时,并不需要对文档加锁和解锁操作,只需要带着版本号。当版本号冲突的时候,ES会提示冲突并抛出异常,并进行重试

查询时,会把所有的segment查询结果汇总归并为最终的分片查询结果返回。
为了实现高索引速度,故使用了segment 分段架构存储。
一批写入数据保存在一个段中,其中每个段是磁盘中的单个文件。
由于两次写入之间的文件操作非常繁重,因此将一个段设为不可变的,以便所有后续写入都转到New段。
可以是内存里的段,也可以是在磁盘里的段进行段合并
.del 文件里标记为删除)。在合并过程中ES会进行数据的排序和去重,并重新生成倒排索引由于自动刷新流程每秒会创建一个新的段(由动态配置参数:refresh_interval 决定),这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦,导致:
后台进程定期检查,可能进行 merge 操作
单击图片即可得到HSV或BGR的值,代码如下:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+
import cv2
+
+def getposHsv(event, x, y, flags, param):
+ if event == cv2.EVENT_LBUTTONDOWN:
+ print("HSV is", HSV[y, x])
+
+def getposBgr(event, x, y, flags, param):
+ if event == cv2.EVENT_LBUTTONDOWN:
+ print("BGR is", image[y, x])
+
+image = cv2.imread('frame_B.jpg')
+HSV = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
+cv2.imshow("imageHSV", HSV)
+cv2.imshow('image', image)
+cv2.setMouseCallback("imageHSV", getposHsv)
+cv2.setMouseCallback("image", getposBgr)
+cv2.waitKey(0)
+
1
+2
+3
+
var s string = "string"
+var s = "string"
+s := "string"
+
1
+2
+3
+4
+
slice1 := make([][]bool, m)
+for i := range slice1 {
+ slice1[i] = make([]bool, n)
+}
+
只有后缀自增或自减,并且必须单独一行(除了在range语句中)。
条件判断语句中的初始变量可以在布尔表达式里,并且不能使用0/1作为判断条件。
1
+2
+3
+
if cond := true; cond {
+ fmt.Println()
+}
+
生成 [0, 99] 的随机数
1
+2
+3
+
rand.Seed(time.Now().UnixNano())
+r := rand.Intn(100)
+fmt.Println(r)
+
Go 语言中的栈和队列都是基于切片实现的。
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
stack := make([]int, 0) //创建切片
+stack = append(stack, 10) //push压入栈
+value := stack[len(stack)-1] // 取栈顶的值
+stack = stack[:len(stack)-1] //pop弹出
+len(stack) == 0 //检查栈空
+
+queue := make([]int, 0) //创建切片
+queue = append(queue, 10) //enqueue入队
+v := queue[0] // 取队首的值
+queue = queue[1:] //dequeue出队
+len(queue) == 0 //检查队列为空
+
1
+2
+3
+4
+
slice1 := []string{"Moe", "Larry", "Curly"}
+slice2 := []string{"php", "golang", "java"}
+slice3 = append(slice1, slice2...)
+fmt.Println(slice3)//[Moe Larry Curly php golang java]
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
// string to int, "99" -> 99
+int, err := strconv.Atoi(str)
+
+// asscii to string, 97 -> "a"
+str := string(asscii) // asscii to string
+
+// int to string, 10 -> "10"
+str := fmt.Sprintf("%d", int)
+str := strconv.Itoa(int)
+str := strconv.FormatInt(int, 10)
+
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+
// 数组
+var pow = []int{1, 2, 4, 8, 16, 32, 64, 128}
+for i, v := range pow {
+ fmt.Printf("2**%d = %d\n", i, v)
+}
+// Map
+for key, value := range oldMap {
+ newMap[key] = value
+}
+for key := range oldMap {
+ fmt.Println(oldMap[key])
+}
+for _, value := range oldMap {
+ fmt.Println(value)
+}
+
+// 字符串。第一个参数是字符的索引,第二个是字符(Unicode的值)本身。
+for i, c := range "go" {
+ fmt.Println(i, c, string(c)) //0 103 g \n 1 111 o
+}
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
fmt.Printf("int min - max: %d - %d\n", math.MinInt, math.MaxInt) // int
+fmt.Printf("int8 min - max: %d - %d\n", math.MinInt8, math.MaxInt8) // int8
+fmt.Printf("int16 min - max: %d - %d\n", math.MinInt16, math.MaxInt16) // int16
+fmt.Printf("int32 min - max: %d - %d\n", math.MinInt32, math.MaxInt32) // int32
+fmt.Printf("int64 min - max: %d - %d\n", math.MinInt64, math.MaxInt64) // int64
+// unsigned
+fmt.Printf("uint min - max: %d - %d\n", uint(0), uint(math.MaxUint)) // uint
+fmt.Printf("uint8 min - max: %d - %d\n", 0, math.MaxUint8) // uint8
+fmt.Printf("uint16 min - max: %d - %d\n", 0, math.MaxUint16) // uint16
+fmt.Printf("uint32 min - max: %d - %d\n", 0, math.MaxUint32) // uint32
+fmt.Printf("uint64 min - max: %d - %d\n", 0, uint64(math.MaxUint64)) // uint64
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+
// int
+array := []int{3, 1, 34, 25, 14, 5}
+sort.Ints(array) // 升序
+fmt.Println(array)
+sort.Sort(sort.Reverse(sort.IntSlice(array))) // 降序
+fmt.Println(array)
+// string
+array1 := []string{"ss", "sa", "avs", "vs"}
+sort.Strings(array1)
+fmt.Println(array1)
+sort.Sort(sort.Reverse(sort.StringSlice(array1)))
+fmt.Println(array1)
+
1
+2
+3
+4
+5
+6
+7
+8
+
array := []int{3, 17, 1, 34, 25, 14, 5}
+sort.Slice(array, func(i, j int) bool {
+ if abs(array[i]-9) != abs(array[j]-9) {
+ return abs(array[i]-9) < abs(array[j]-9)
+ }
+ return array[i] < array[j]
+})
+fmt.Printf("%+v", array)
+
1
+2
+3
+4
+
doubleLinkedList := list.New()
+doubleLinkedList.PushBack(3)
+var doubleLinkedListElement *list.Element
+doubleLinkedListElement = doubleLinkedList.Back()
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+
m := make(map[string]int) // 初始化
+
+m := map[string]int{ // 使用组合字面量初始化
+ "apple": 1,
+ "banana": 2,
+ "orange": 3,
+}
+
+v1 := m["apple"] // 获取键值对
+v2, ok := m["pear"] // 如果键不存在,ok 的值为 false,v2 的值为该类型的零值
+
+for k, v := range m { // 遍历Map,无序的
+ fmt.Printf("key=%s, value=%d\n", k, v)
+}
+delete(m, "banana") // 删除元素
+m := make(map[string]int) // 清空元素的方法就是重新make一个map
+
+// 基于 Map 实现 Set
+set := make(map[string]bool)
+set["Foo"] = true
+for k := range set {
+ fmt.Println(k)
+}
+delete(set, "Foo")
+size := len(set)
+exists := set["Foo"]
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+43
+
package main
+
+import (
+ "container/heap"
+ "fmt"
+ "sort"
+)
+
+type heap2 struct {
+ sort.IntSlice
+}
+
+func (h heap2) Less(i, j int) bool { // 最小堆:h.IntSlice[i] < h.IntSlice[j];最大堆:h.IntSlice[i] > h.IntSlice[j];
+ return h.IntSlice[i] > h.IntSlice[j]
+}
+
+func (h *heap2) Push(v interface{}) {
+ h.IntSlice = append(h.IntSlice, v.(int))
+}
+
+func (h *heap2) Pop() interface{} {
+ temp := h.IntSlice
+ v := temp[len(temp)-1]
+ h.IntSlice = temp[:len(temp)-1]
+ return v
+}
+
+func (h *heap2) push(v int) {
+ heap.Push(h, v)
+}
+
+func (h *heap2) pop() int {
+ return heap.Pop(h).(int)
+}
+
+func main() {
+ q := &heap2{[]int{3, 4, 1, 2, 4, 3}}
+ heap.Init(q)
+ q.pop()
+ fmt.Println(len(q.IntSlice))
+ fmt.Println(q)
+}
+
+
s[x: y] 表示 s 中第 x 位到第 y - 1 位元素截取。进程:是具有一定独立功能的程序,是系统资源分配和调度的最小单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
线程:是进程的一个实体,是内核态,而且是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程:是一种用户态的轻量级线程,调度完全是由用户来控制的拥有自己的寄存器上下文和栈。调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。一个线程可以有多个协程,线程、进程都是同步机制,但协程是异步
在Windows上使用RubyInstaller安装比较方便,在Ruby官网下载最新版本的RubyInstaller WITH DEVKIT。注意32位和64位版本的区分。

安装:使用默认路径即可,避免出错;勾选添加到PATH,就不用手动添加环境变量了

安装完成如图:

这里需要勾选Run 'ridk install',在弹出来的安装界面中选择3,安装MSYS2 and MINGW development toolchain:


在RubyGems官网下载ZIP格式的安装包,下载后解压到任意路径。进入解压目录,在终端输入命令:ruby setup.rb 或者直接双击setup.rb文件即可。
打开cmd输入以下命令并等待安装完成即可。
1
+2
+3
+
gem install jekyll
+gem install jekyll-paginate
+gem install bundler
+
1
+2
+
jekyll -v
+bundle -v
+
输出版本信息则代表安装没问题。
安装完成,我们可以用jekyll命令创建一个博客模板,进入一个目录,打开命令行执行:
1
+2
+3
+
jekyll new testblog
+cd testblog
+bundle exec jekyll serve
+
大功告成!
问题描述:执行 bundle exec jekyll serve 时出现 cannot load such file -- webrick (LoadError) 错误,如下图所示

解决方法:终端输入bundle add webrick.See here.
This post is to show Markdown syntax rendering on Chirpy, you can also use it as an example of writing. Now, let’s start looking at text and typography.
I wandered lonely as a cloud
That floats on high o’er vales and hills,
When all at once I saw a crowd,
A host, of golden daffodils;
Beside the lake, beneath the trees,
Fluttering and dancing in the breeze.
Nested and mixed lists are an interesting beast1. It’s a corner case to make sure that
Only one thing is impossible for God: To find any sense in any copyright law on the planet.
An example showing the
tiptype prompt.
An example showing the
infotype prompt.
An example showing the
warningtype prompt.
An example showing the
dangertype prompt.
🎨 Finally got around to adding all my @procreateapp creations with time lapse videos https://t.co/1nNbkefC3L pic.twitter.com/gcNLJoJ0Gn
— Michael Rose (@mmistakes) November 6, 2015
This post tests Twitter Embeds.
YouTube video embedded below.
Here is the code:
1
+
<iframe width="640" height="360" src="https://www.youtube.com/embed/fBnAMUkNM2k" frameborder="0" allowfullscreen></iframe>
+
| Header1 | Header2 | Header3 |
|---|---|---|
| left | center | right |
| left | center | right |
| left | center | right |
| left | center | right |
Welcome to image alignment! The best way to demonstrate the ebb and flow of the various image positioning options is to nestle them snuggly among an ocean of words. Grab a paddle and let’s get started.
 ]
]
The image above happens to be centered.
 The rest of this paragraph is filler for the sake of seeing the text wrap around the 150×150 image, which is left aligned.
The rest of this paragraph is filler for the sake of seeing the text wrap around the 150×150 image, which is left aligned.
As you can see there should be some space above, below, and to the right of the image. The text should not be creeping on the image. Creeping is just not right. Images need breathing room too. Let them speak like you words. Let them do their jobs without any hassle from the text. In about one more sentence here, we’ll see that the text moves from the right of the image down below the image in seamless transition. Again, letting the do it’s thing. Mission accomplished!
And now for a massively large image. It also has no alignment.

The image above, though 1200px wide, should not overflow the content area. It should remain contained with no visible disruption to the flow of content.

And now we’re going to shift things to the right align. Again, there should be plenty of room above, below, and to the left of the image. Just look at him there — Hey guy! Way to rock that right side. I don’t care what the left aligned image says, you look great. Don’t let anyone else tell you differently.
In just a bit here, you should see the text start to wrap below the right aligned image and settle in nicely. There should still be plenty of room and everything should be sitting pretty. Yeah — Just like that. It never felt so good to be right.
And just when you thought we were done, we’re going to do them all over again with captions!
Once the position is specified, the image caption should not be added.
 Full screen width and center alignment
Full screen width and center alignment
 shadow effect (visible in light mode)
shadow effect (visible in light mode)
Float to left
“A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space.”
Float to right
“A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space. A repetitive and meaningless text is used to fill the space.”
gantt
+ title Adding GANTT diagram functionality to mermaid
+ apple :a, 2017-07-20, 1w
+ banana :crit, b, 2017-07-23, 1d
+ cherry :active, c, after b a, 1d
+The mathematics powered by MathJax:
\[\sum_{n=1}^\infty 1/n^2 = \frac{\pi^2}{6}\]When $a \ne 0$, there are two solutions to $ax^2 + bx + c = 0$ and they are
\[x = {-b \pm \sqrt{b^2-4ac} \over 2a}\]Here is the /path/to/the/file.extend.
1
+
This is a common code snippet, without syntax highlight and line number.
+
Using ```{language} you will get a code block with syntax highlight:
1
+2
+3
+
```yaml
+key: value
+```
+
1
+2
+3
+
$ env |grep SHELL
+SHELL=/usr/local/bin/bash
+PYENV_SHELL=bash
+
1
+2
+3
+4
+
if [ $? -ne 0 ]; then
+ echo "The command was not successful.";
+ #do the needful / exit
+fi;
+
1
+2
+3
+
@import
+ "colors/light-typography",
+ "colors/dark-typography"
+
By default, all languages except plaintext, console, and terminal will display line numbers. When you want to hide the line number of a code block, add the class nolineno to it:
1
+2
+3
+4
+
```shell
+echo 'No more line numbers!'
+```
+{: .nolineno }
+
For more knowledge about Jekyll posts, visit the Jekyll Docs: Posts.
This post has been updated and show a modified date.
| 优先级 | 运算符 |
|---|---|
| 1 | ( ) [ ] . |
| 2 | ! ~ ++ – |
| 3 | * / % |
| 4 | + - |
| 5 | « » «< »> |
| 6 | < <= > >= instanceof |
| 7 | == != |
| 8 | & |
| 9 | ^ |
| 10 | | |
| 11 | && |
| 12 | || |
| 13 | ? : |
| 14 | = += -= *= /= %= &= |= ^= ~= «= »= »>= |
| 15 | , |
总结:括号级别最高,逗号级别最低,单目 > 算术 > 位移 > 关系 > 逻辑 > 三目 > 赋值。

1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+
+Deque<Integer> stack = new ArrayDeque<>(); // stack
+
+Deque<String> queue = new ArrayDeque<>(); // queue
+
+PriorityQueue<Integer> queue = new PriorityQueue<>(); // priority queue
+
+// Set
+
+HashSet<String> unordered_set = new HashSet<>(); // 乱序,底层使用散列函数
+
+LinkedHashSet<String> set = new LinkedHashSet<>(); // 以插入顺序排序
+
+TreeSet<String> set = new TreeSet<>(); // 以字典序排序,底层使用红黑树
+
+// Map
+
+HashMap<String, Object> unordered_map = new HashMap<>(); // 乱序
+
+LinkedHashMap<Integer, Integer> map = new LinkedHashMap<>(); // 以插入顺序排序
+
+TreeMap<Integer, Integer> map = new TreeMap<>(); // 以字典序排序
+
+TreeMap<Integer, Integer> map = new TreeMap<Integer, Integer>(); // 手动加泛型,多一些约束少一些出错。在运行期没有任何区别, java的泛型只在编译期有效。
+
+
ArrayList:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+
public static void main(String[] args) {
+ ArrayList<String> sites = new ArrayList<String>();
+ sites.add("Google");
+ sites.add("Runoob");
+ sites.add("Taobao");
+ sites.add("Weibo");
+ System.out.println(sites.get(1)); // 访问第二个元素
+ sites.set(2, "Wiki"); // 第一个参数为索引位置,第二个为要修改的值
+ sites.remove(3); // 删除第四个元素
+ Collections.sort(sites); // 字母排序
+ System.out.println(sites.isEmpty()); // 空判断
+ System.out.println(sites);
+ String[] arr = new String[sites.size()]; // 创建一个新的 String 类型的数组
+ sites.toArray(arr); // 将ArrayList对象转换成数组
+}
+
LinkedList:
1
+
+
HashSet:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
public static void main(String[] args) {
+ HashSet<Integer> set = new HashSet<Integer>();
+ set.add(1);
+ set.add(2);
+ set.add(3);
+ set.remove(2);
+ System.out.println(set.contains(4));
+ for(int item: set){
+ System.out.println(item);
+ }
+}
+
HashMap:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+
public static void main(String[] args) {
+ Map<String, Integer> numbers = new HashMap<>();
+ numbers.put("One", 1);
+ numbers.put("Two", 2);
+ numbers.put("Three", 3);
+ numbers.put("Four", 4);
+ System.out.println(numbers.getOrDefault("Five", 0));
+ numbers.remove("Two");
+ numbers.replace("One",111);
+ System.out.println(numbers.containsKey("Four"));
+ System.out.println(numbers.containsValue(111));
+
+ // Method A(Recommended!)
+ numbers.forEach((k,v) -> System.out.println("Item: " + k + " Count: " + v));
+ numbers.forEach((k,v) -> {
+ System.out.println("Item: " + k + " Count: " + v);
+ if("Four".equals(k)){
+ System.out.println("Hello Four");
+ }
+ });
+ // Method B(Recommended!)
+ for (Map.Entry<String, Integer> entry : numbers.entrySet()) {
+ System.out.println("key:" + entry.getKey() + ".value:" + entry.getValue());
+ }
+ // Method C(NOT Recommended!)
+ for (String string : numbers.keySet()) {
+ System.out.println("key:" + string + ".value:" + numbers.get(string));
+ }
+ // Method D(Recommended When Deleting)
+ Iterator<String> iterators = numbers.keySet().iterator();
+ while (iterators.hasNext()) {
+ String key = iterators.next();
+ System.out.println("key:" + key + ".value:" + numbers.get(key));
+ }
+}
+
ArrayDeque:
在堆栈中,元素从栈顶插入,从栈顶弹出
在队列中,元素从队尾插入,从队首弹出
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+
public static void main(String[] args) {
+ ArrayDeque<String> animals= new ArrayDeque<>();
+ /*
+ *****Stack*****
+ */
+ animals.push("Pig");
+ System.out.println("返回栈顶元素: " + animals.peek());
+ System.out.println("返回栈顶元素并弹出: " + animals.pop());
+
+ /*
+ *****Queue*****
+ */
+ animals.offer("Horse");
+ System.out.println("返回队首元素: " + animals.peek());
+ System.out.println("返回队首元素并弹出: " + animals.poll());
+
+ /*
+ *****Deque*****
+ */
+ animals.push("Bird"); // 队首
+ animals.offer("Dog"); // 队尾
+ System.out.println("返回队首元素: " + animals.peek());
+ System.out.println("返回队首元素并弹出: " + animals.poll());
+ System.out.println("返回队尾元素: " + animals.peekLast());
+ System.out.println("返回队尾元素并弹出: " + animals.pollLast());
+
+ /*
+ *****Common*****
+ */
+ System.out.println("判断是否包含Dog: " + (animals.contains("Dog") ? "是" : "否"));
+ System.out.println("转换成数组输出: " + Arrays.toString(animals.toArray()));
+}
+
赋值是创建常量,在编译期时就被确定了;new创建的对象不是常量,无法在编译期中确定。

1
+2
+3
+4
+5
+6
+7
+8
+
+String s0 = "aaa" + "bbb"; // 常量,同"aaabbb",放入常量池中。创建了1个对象
+String s1 = "aaa" + new String("bbb"); // 非常量,因为new出来的字符串无法在编译期中确定。创建了4个对象
+String s2 = new String("aaabbb"); // 同上。由于常量池中已经存在"aaabbb",因此只创建了1个对象
+System.out.println(s1.intern() == s0); // true,intern()函数会在常量池里找是否相同的字符串,有则返回常量池的引用
+System.out.println(s2.intern() == s0); // true,同上
+System.out.println(s0 == s1); // false,虽然内容一样,但是new出来的地址肯定不一样
+System.out.println(s1 == s2); // false,同上
+
SEE HERE
赋值是给变量绑定一个新对象,而不是改变对象。
举例:
1
+2
+3
+4
+5
+6
+7
+8
+9
+
public static void main(String[] args) {
+ String x = new String("沉默王二");
+ change(x);
+ System.out.println(x); // "沉默王二"
+}
+
+public static void change(String x) {
+ x = "沉默王三";
+}
+
直接改变对象内容。
举例:
1
+2
+3
+4
+5
+6
+7
+8
+9
+
public static void change(A a) {
+ a.name = "bbb";
+}
+public static void main(String[] args) {
+ A a = new A();
+ a.name = "aaa";
+ change(a);
+ System.out.println(a.name); // "bbb"
+}
+
一棵含有n个节点的红黑树的高度至多为2log(n+1).See Here.
同步容器主要包括2类:
Vector、Stack、HashTable
Collections类中提供的静态工厂方法创建的类
同步容器的所有操作并不都是线程安全的。HERE
所谓“线程安全”,并不包括多个操作之间的“原子性”支持。
100%的情况下不要用 StringBuffer
99% 的情况下不要用 Vector
那么那剩下的 1% 用 Vector 的情况在哪呢?
熟悉Swing的都知道: 现有的一些 model 的类里面用了 Vector,假如你去定制它们,有时不可避免要用到 Vector。
与StringBuffer相比,StringBuilder不是线程安全,所以单线程情况下效率更高。两者除线程安全方面之外无差别。
1
+2
+
StringBuilder sb = new StringBuilder();
+sb.append("a".repeat(100)); // repeat方法用于构造重复String
+
三大特点:封装继承多态。
语法糖:switch支持String、泛型、自动拆装箱、变长参数、枚举、内部类、条件编译、断言、数值下划线、for-each、try-with-resources、Lambda表达式
装箱:Integer i = Integer.valueOf(10), 拆箱:int n = i.intValue()
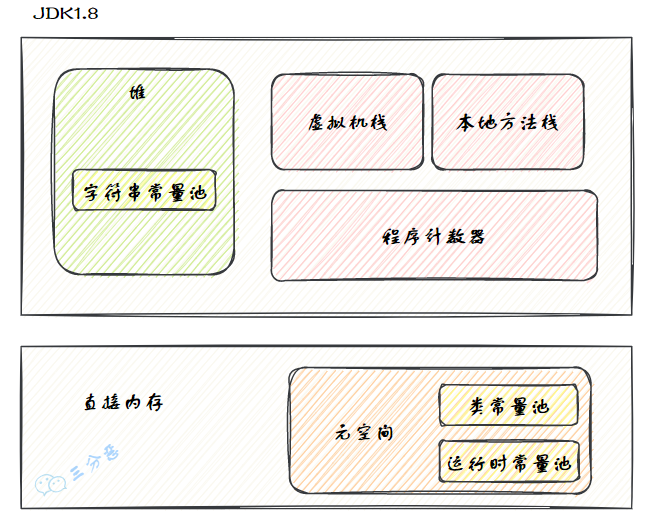
运行时数据区域包含线程私有的程序计数器、虚拟机栈、本地方法栈,线程共享的堆(包含字符串常量池)和非运行时数据区的元空间(包含类常量池和运行时常量池)、直接内存。
OutOfMemoryError 的内存区域。String#intern 的用法。JMM 旨在提供一个统一的可参考的规范,屏蔽平台内存访问差异性。这个规范为读写共享变量时如何与内存交互提供了规则和保证。并发编程中,程序会因为 CPU 多级缓存或指令重排序等出现问题,因此需要一些规范要保证并发编程的可靠性。
关键概念包括:
JMM 为处理共享变量定义了三个特征(多线程中的概念):
通过内存屏障来保证可见性的
happens-before原则定义如下:
As-if-serial的意思是所有的语句都可以为了优化而被重排序,但是必须保证它们重排序后的结果和程序代码本身的应有结果是一致的。为保证as-if-serial语义,Java异常处理机制也会为重排序做一些特殊处理。
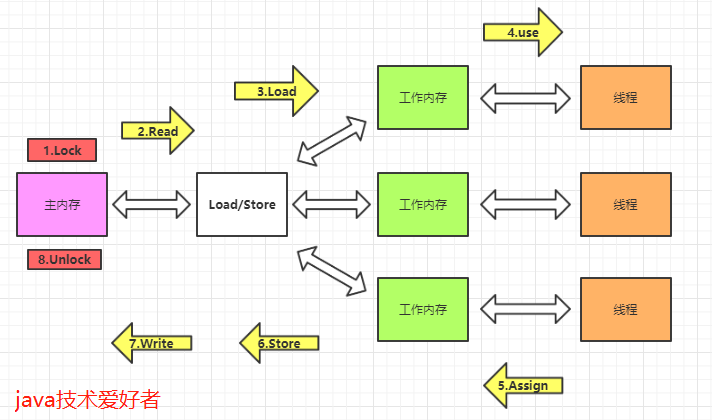
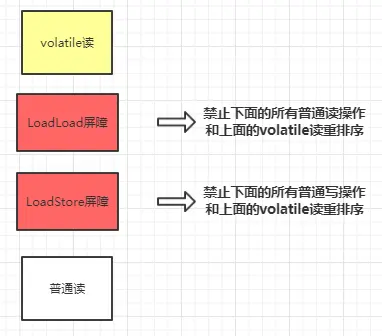
在每个volatile读操作后插入LoadLoad屏障,在读操作后插入LoadStore屏障。
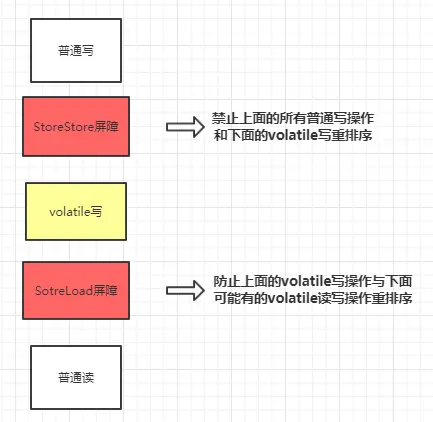
在每个volatile写操作的前面插入一个StoreStore屏障,后面插入一个SotreLoad屏障。
 |  |
线程上下文类加载器:破坏了“双亲委派模型”,可以在执行线程中抛弃双亲委派加载链模式,使程序可以逆向使用类加载器,例如SPI (Service Provider Interface)。SPI接口中的代码经常需要加载具体的实现类。SPI接口是Java核心库的一部分,由 启动类加载器(Bootstrap Classloader) 来加载,而实现类由 系统类加载器(AppClassLoader) 来加载。
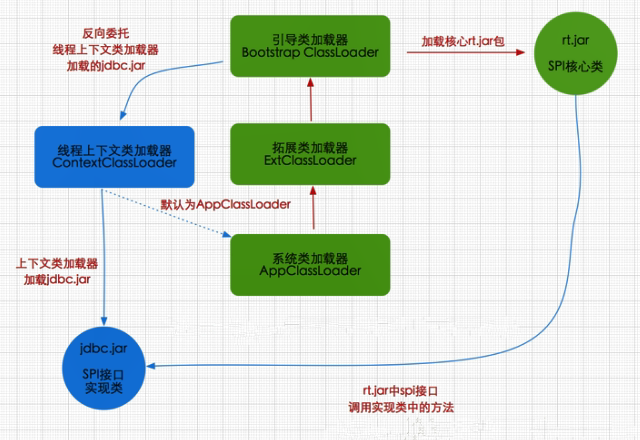
双亲委派机制概念:双亲委派机制是指当一个类加载器收到某个类加载请求时,该类加载器首先会把请求委派给父类加载器。每个类加载器都是如此,它会先委托父类加载器在自己的搜索范围内找不到对应的类时,该类加载器才会尝试自己去加载。
Tomcat中的类加载器:
Java的SPI:SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。当服务的提供者提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。
1.6 -> 1.7 -> 1.8:
JVM触发GC时,首先会让所有的用户线程到达安全点SafePoint时阻塞,也就是STW,然后枚举根节点,即找到所有的GC Roots,通过可达性算法向下搜寻活跃对象,可达的对象就保留,不可达的对象就回收。
空间担保策略是 JVM 的一种机制,发生 Minor GC 之前,虚拟机会检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。如果小于,则虚拟机会查看HandlePromotionFailure设置值是否允许担保失败。如果HandlePromotionFailure=true,那么会继续检查老年代最大可用连续空间是否大于历次晋升到老年代的对象的平均大小,如果大于,则尝试进行一次Minor GC,但这次Minor GC依然是有风险的;如果小于或者HandlePromotionFailure=false,则改为进行一次Full GC。
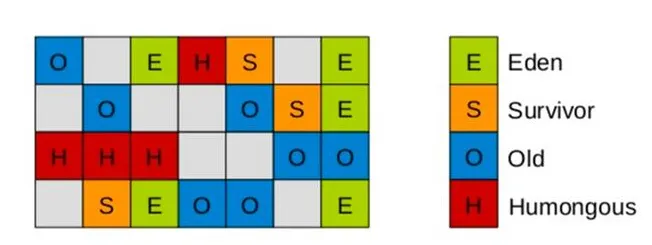 G1收集器内存模型
G1收集器内存模型
垃圾收集器发展历程:
CMS(Concurrent Mark Sweep)收集器: 基于标记-清除算法,在Minor GC时会暂停所有的应用线程,并以多线程的方式进行垃圾回收。在Full GC时不再暂停应用线程,而是使用若干个后台线程定期的对老年代空间进行扫描。
Garbage First(G1)收集器:
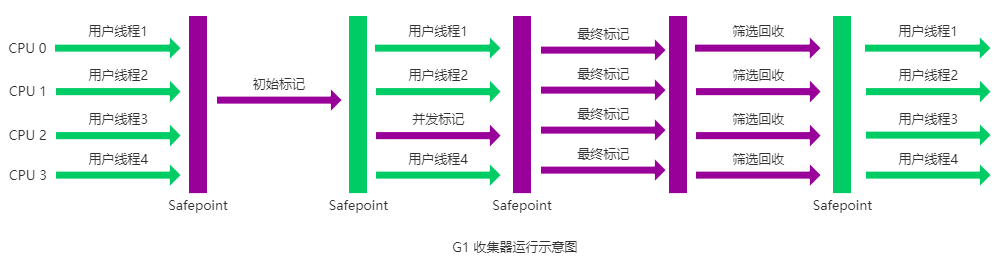
-XX:MaxGCPauseMillis-XX:SurvivorRatio=6, -XX:NewRatio=4-XX:InitialTenuringThreshol=7-XX:PretenureSizeThreshold=1000000//新生代可容纳的最大对象,大于则直接会分配到老年代,0代表没有限制。调优的一条经验总结:
将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
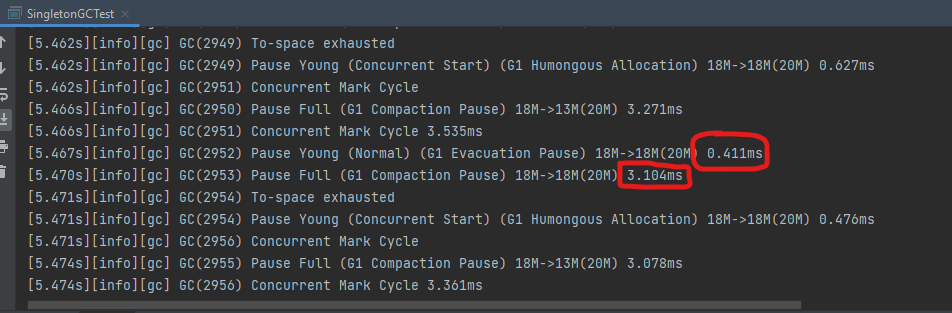
NIO vs IO:
IO多路复用(事件驱动):一个线程不断轮询多个socket的状态,只有当socket真正有读写状态时,借用当前线程或者使用线程池额外启动线程,调用实际的IO读写操作。
Java NIO:
一个 Java 程序的运行是 main 线程和多个其他线程同时运行。
底层都是通过对象头里 Mark Word 指向的对象监听器(Monitor)实现的,再底层是操作系统的互斥量(mutex)实现的
同一时刻只能有一个线程运行 synchronized(lock) 内的代码块,其他线程会否则阻塞。PS:获取锁(运行代码块),释放锁(阻塞代码块)
wait())的线程wait())的线程,注意:notify() 或 notifyAll() 必须等到退出 synchronized() 或 wait() 后才释放锁!
1
+2
+3
+4
+5
+6
+7
+8
+
synchronized (obj) {
+ // 条件不满足
+ while (condition does not hold) {
+ obj.wait();
+ }
+ // 执行满足条件的代码
+ obj.notifyAll();
+}
+
or
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
synchronized (obj) {
+ while (true){
+ // 条件满足
+ if (condition holds){
+ // 执行满足条件的代码
+ obj.notifyAll();
+ }
+ obj.wait();
+ }
+}
+
+
synchronized 可以用来修饰非静态方法(普通方法)、静态方法、代码块,锁住的是 class 对象的对象头!
run() 和 start() 的区别:
Synchronized 和 Lock 的区别:
RenentantLock:
Java 中的线程分为两种:
集合框架:
线程安全的list:
为什么计算哈希值采用低十六位和高十六位异或操作:
计算数组下标是与操作,只有低 n 位进行与操作,高位不参与任何操作 -> 为了增大散列程度减小哈希碰撞,因此将高十六位参与进哈希值的计算。
put() 的流程:
扩容的过程:
Set:
NULL key AND NULL value:
为什么ConcureentHashMap的key和value都不能为null:
containsKey() 解决,但是多线程下无法使用同样的方法,因为可能会有其他线程进行其他操作影响返回值。ConcurrentHashMap JDK7 vs JDK8
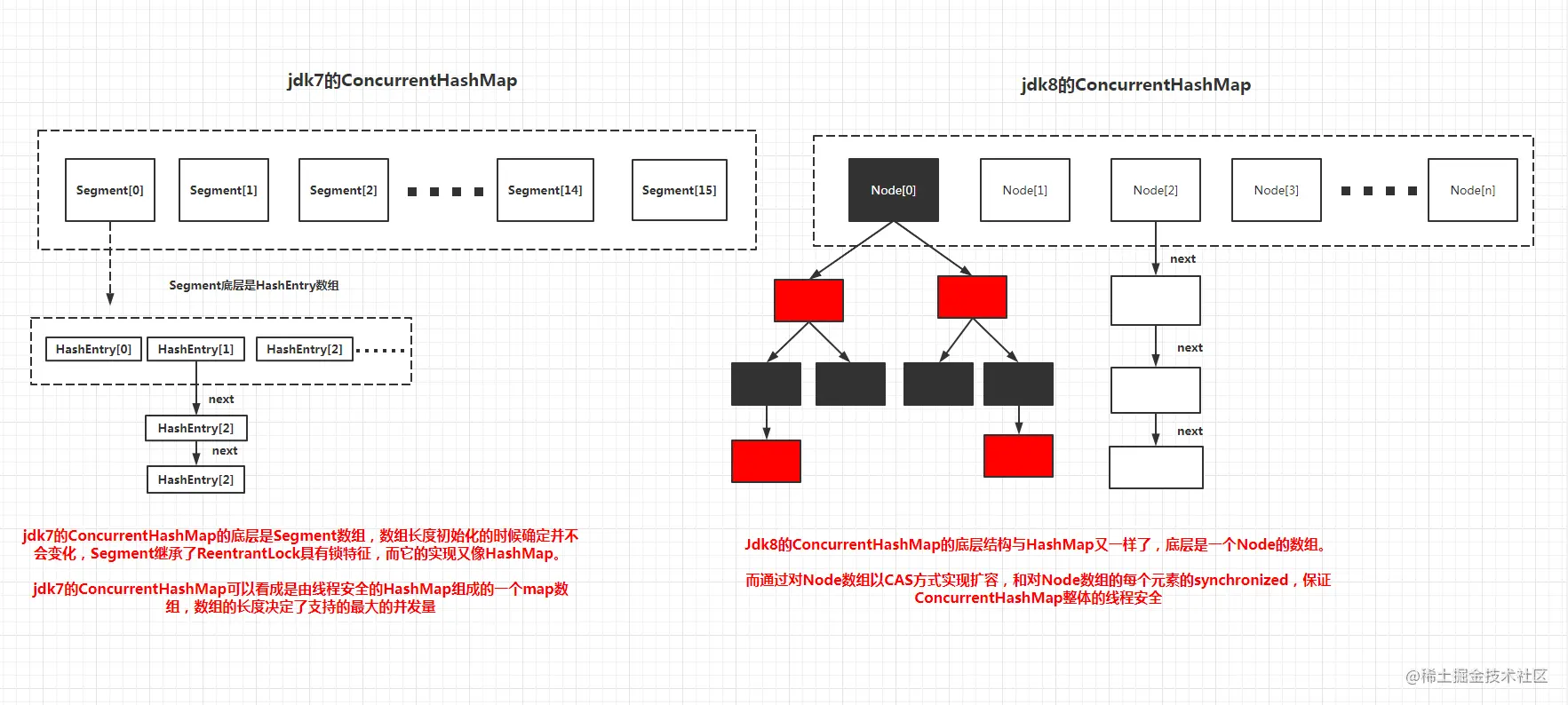
HashTable速度慢:使用synchronized对整个对象加锁。
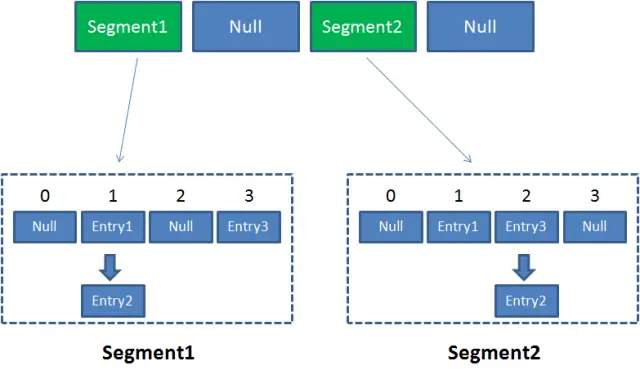
JDK7:对整个数组进行分段(每段都是由若干个 hashEntry 对象组成的链表),每个分段都有一个 Segment 分段锁(继承 ReentrantLock 分段锁)。与hashtable相比,加锁粒度更细,但是初始化Segment数组长度后就无法扩容。ConcurrentHashMap 是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
JDK8:对table数组的头节点加锁(哈希桶为空时,使用CAS将新的Node写入哈希桶的首节点;哈希桶不为空时,使用synchronized对首节点加锁接着添加节点)
ThreadLocal: 提供线程内的局部变量,在多线程的环境中保证各个线程内的变量不同。将数据封闭在线程中而避免使用同步,即线程封闭。一个ThreadLocal对象即是一个线程局部变量。jdbc连接池就是用ThreadLocal,典型例子。以下使四种方法:
底层是 ThreadLocalMap 内部静态类,由数组实现,解决 hash 冲突的方式采用的是线性探测法
存在内存泄漏的原因:由于 ThreadLocalMap 的生命周期跟 Thread 一样长,如果没有手动删除对应 key 就会导致该 key 的value 永远无法被访问,造成内存泄漏
正确使用方法:
线程池的七个参数:
核心线程数(corePoolSize): 核心线程数是线程池中保持活动状态的线程数。即使没有任务需要执行,核心线程也不会被回收。当有新任务提交时,如果核心线程都在忙碌,则会创建新的线程来处理任务。
最大线程数(maximumPoolSize): 最大线程数是线程池中允许的最大线程数。当工作队列满了并且活动线程数达到最大线程数时,如果还有新任务提交,线程池将创建新的线程来处理任务。但是,超过最大线程数的线程可能会导致资源消耗过大。
空闲线程存活时间(keepAliveTime): 空闲线程存活时间指的是非核心线程在没有任务执行时的最长存活时间。当线程池中的线程数超过核心线程数且空闲时间达到设定值时,多余的线程将被终止,直到线程池中的线程数不超过核心线程数。
时间单位(unit): 时间单位是用于表示核心线程数和空闲线程存活时间的单位。常见的时间单位包括秒、毫秒、分钟等。
工作队列(workQueue): 工作队列用于存储待执行的任务。当线程池中的线程都在忙碌时,新提交的任务将被添加到工作队列中等待执行。常见的工作队列类型有有界队列(如 ArrayBlockingQueue)和无界队列(如 LinkedBlockingQueue)等。
线程工厂(threadFactory): 线程工厂用于创建新线程。线程工厂提供了创建线程的方法,可以自定义线程的名称、优先级等属性。
JDK四种线程池:
线程池执行顺序:
简而言之:corePool->workQueue->maxPool
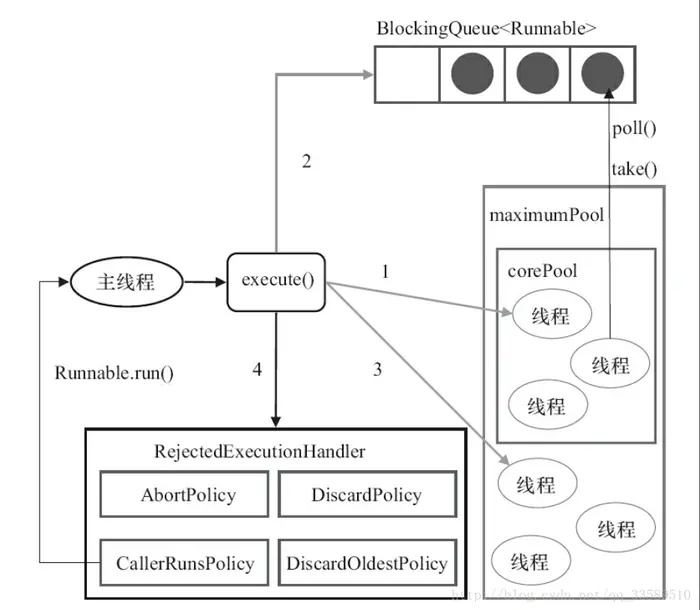
线程池被回收:线程池也是在堆中也是一个对象,一定要调用shutdown
线程池何时回收线程:getTask()的返回值为null时
核心线程数设置:
锁升级的过程:当有线程访问同步块时,无锁升级为偏向锁;当有锁竞争时,升级为轻量级锁;当自旋十次失败,升级为重量级锁。
Synchronized(同步锁):属于独占锁、悲观锁、可重入锁、非公平锁。
ReentrantLock:继承了Lock类,两者都是可重入锁、悲观锁、独占锁、默认非公平锁。
该类是一个抽象类,采用模板方法的设计模式,规定了独占和共享模式需要实现的方法。
简单解释:CAS修改volatile修饰的int值state(该值代表竞争资源标识) + 一个存放等待锁的线程队列。其定义了两种资源共享模式:
独占式。ReentrantLock 是独占式的锁资源。初始化 state = 0,表示资源未被锁定,调用 lock() 方法时state的值加一,并且当 state = 0 才表明其他线程有机会获取锁。
共享式。ReentrantWriteLock 和 CountDownLatch 是共享锁模式。CountDownLatch 会将任务分成 N 个子任务,初始化 state = N,每个子线程完成任务后会减一,直到为零。
Contract接口模式,结合feign实现
接口和抽象类的区别:
java中静态属性和静态方法可以被继承,但是不能被重写,因此不能实现多态。
静态常量/静态变量/静态方法是用static修饰的常量/变量/方法,其从属于类。另外,static是不允许用来修饰局部变量的。
静态方法可以调用静态变量,但不能调用非静态变量,因为静态方法在类加载时就分配了内存,而非静态变量是在对象实例化时才分配内存。
非静态方法可以调用静态变量,也可以调用非静态变量。
执行顺序:静态初始化块 > 初始化块 > 构造方法
非静态初始化块(构造代码块):
作用:给对象进行初始化。对象一建立就运行,且优先于构造函数的运行。
与构造函数的区别:
非静态初始化块给所有对象进行统一初始化,构造函数只给对应对象初始化。
应用:将所有构造函数共性的东西定义在构造代码块中。
静态初始化块:
作用:给类进行初始化。随着类的加载而执行,且只执行一次
与构造代码块的区别:
泛型:参数化类型,指在定义一个类、接口或者方法时可以指定类型参数。
泛型擦除:是指Java中的泛型只在编译期有效,在运行期间会被删除。也就是说所有泛型参数在编译后都会被清除掉。
在编译器编译后,泛型的转换规则如下:
java.lang.reflect.Proxy 中的动态代理java.util.Iterator 使用迭代器遍历集合容器acquire 和 release 方法被独占式和共享式所重写Topic 是逻辑概念,队列(Kafka 中叫分区)是物理概念。每个主题包含多个消息,每条消息只属于一个主题。一个 Producer 可以同时发送多种 Topic 的消息,而一个 Consumer 只能订阅一个 Topic 的消息。Tag 类似于子主题。
MessageQueue用于存储消息的物理地址,每个Topic中的消息地址存储于多个MessageQueue,是消息的最小存储单元。
整体区别是 Kafka 的设计初衷是用于日志传输,而 RocketMQ 是用于解决各类应用可靠的消息传输,适用于业务需求。
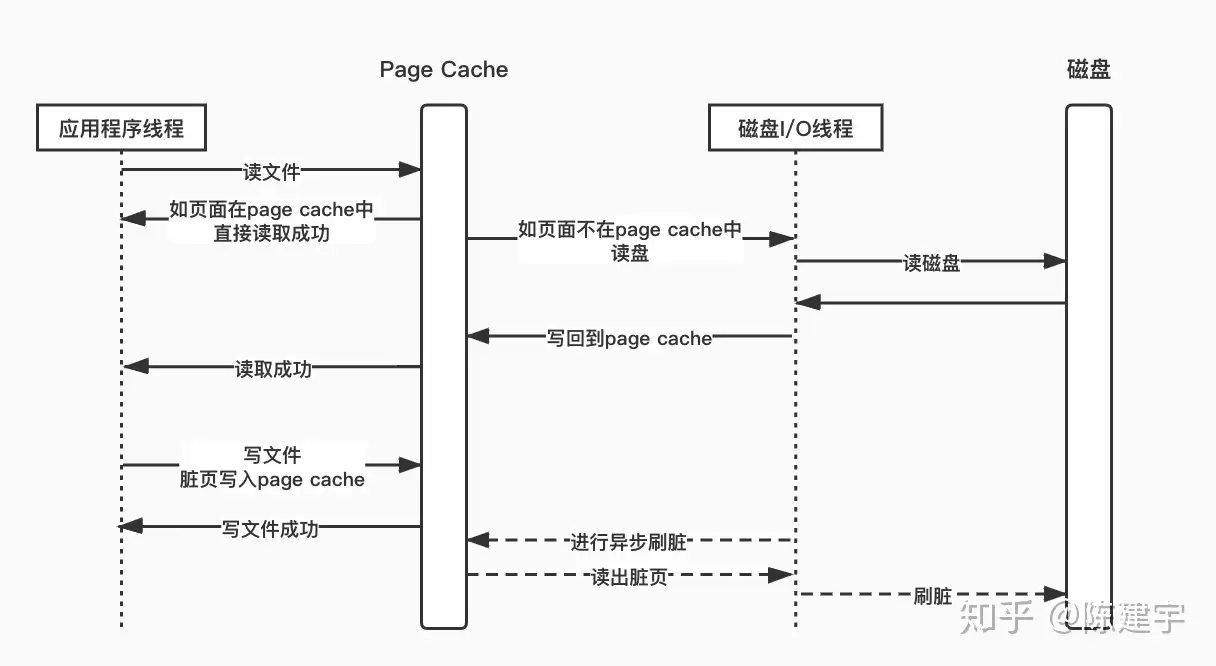
Kafka 采用partition,每个topic的每个partition对应一个文件。顺序写入,定时刷盘。但一旦单个broker的partition过多,则顺序写将退化为随机写,Page Cache脏页过多,频繁触发缺页中断,性能大幅下降。
RocketMQ 采用CommitLog + ConsumeQueue,物理存储文件是CommitLog,ConsumeQueue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每个Topic下的每个MessageQueue都有一个对应的ConsumeQueue文件,单个broker所有topic在CommitLog中顺序写。每个CommitLog大小固定为1G。
生产消息:Producer 先向 CommitLog 顺序写,持久化后将数据 Dispatch 到 ConsumeQueue 中。 消费消息:Consumer 从 ConsumeQueue 中拉取数据,但拉取到数据是指向 CommitLog 的地址,此时是随机读,但又因为 PageCache 的存在,还是整体有序的。
Page Cache(页面缓存)从内存中划出一块区域缓存文件页,如果要访问外部磁盘上的文件页,首先将这些页面拷贝到内存中,再进行读写。
RocketMQ新增同步刷盘和同步复制机制,保证可靠性。而 Kafka 倾向于牺牲部分可靠性换取更高的性能(因为 Kafka 中的 producer 将信息堆起来一起发送,以减少网络IO,但是这个时候如果 producer 宕机了,会导致信息丢失的)。
异步刷盘:返回写成功状态时,消息可能只是被写进内存,吞吐量大,当内存大消息积累到一定程度时,统一触发写磁盘操作,快速写入。
同步刷盘:返回写成功状态时,消息已经被写入磁盘。流程是消息写入内存后,立刻通知刷盘线程刷盘,等待刷盘完成后再唤醒等待的线程返回消息写成功的状态。
异步复制:只要写就返回写成功状态。较低的延迟和较高的吞吐量。
同步复制:写成功后返回写成功状态。容易恢复故障的数据。
两者类似,都是从 Producer -> Broker -> Consumer 三个阶段逐一判断,只不过设置的参数不同。
Producer: 同步发送消息;超时重试发送;消息补偿机制(Kafka,超时仍失败的情况下,会继续投递到本地消息表,定时轮询并推送到Kafka);ACKs(Kafka中,该参数表示多少个副本收到消息,认为消息写入成功)
Broker: 同步刷盘;设置主从模式,配置副本
Consumer: At least Once 的消费机制;消费重试;ACK机制;手动提交位移(Kafka)
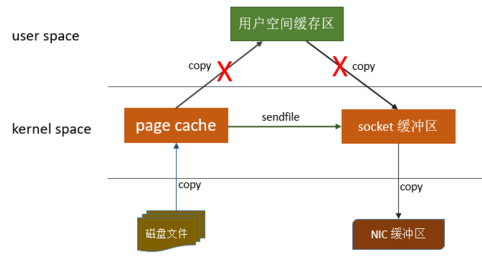
传统的数据传输过程通常需要经历多次内存拷贝。
首先,从磁盘读取数据,然后将数据从内核空间拷贝到用户空间,再从用户空间拷贝到应用程序的内存中。这些额外的拷贝会消耗大量的CPU资源和内存带宽,降低数据传输的效率。零拷贝就是为了避免这些不必要的数据拷贝,能够将数据直接传输到目标内存区域,以提高数据传输的效率。
实现方式
零拷贝技术减少了用户进程地址空间和内核地址空间之间由于上下文切换而带来的开销。DMA (Direct Memory Access) 是零拷贝技术的基石。并不是不需要拷贝,而是减少冗余不必要的拷贝。
为什么 Kafka 这么快?
答:六个要点,顺序读写、零拷贝、消息压缩、分批读写/发送、基于操作系统内存PageCache的读写、分区分段 + 索引。
为什么 RocketMQ 这么快?
答:顺序写,零拷贝,异步刷盘(先写入操作系统的PageCache再异步刷盘到磁盘)
RocketMQ 的消费重试是基于延迟消息实现的,在消息消费失败的情况下,重新当作延迟消息投递到 Broker 中,并且延迟等级逐渐增加,消息重试会有 16 个级别,恰好是延迟消息的 18 个级别的后 16 个级别。
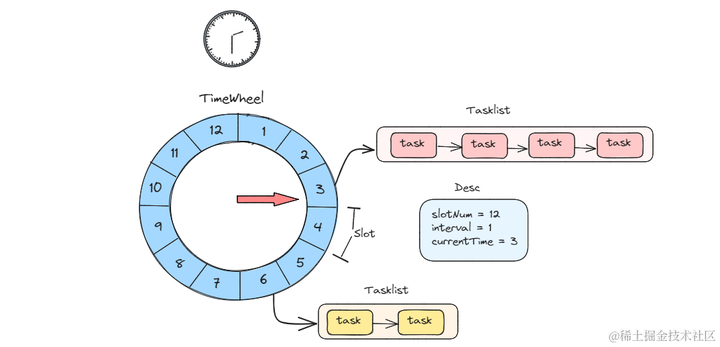
主要分为以下几步,类似于流转:
基于 时间轮 算法(类似于钟表):存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表。每隔一个时间跨度,下标移动一次。
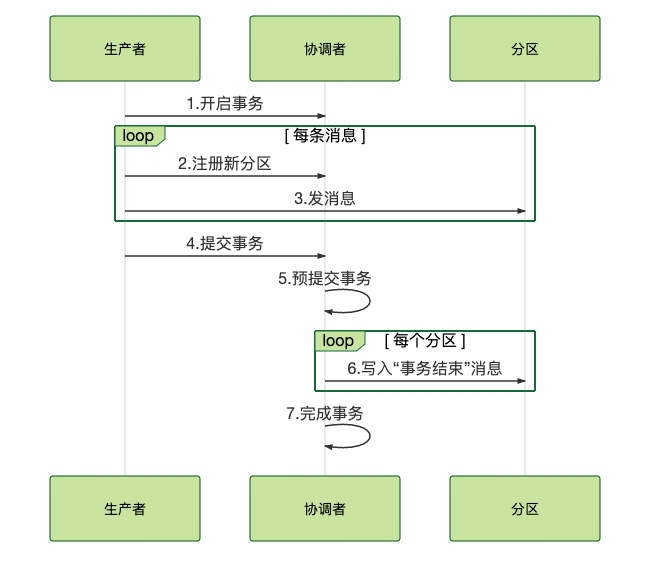
![]()
二阶段:第一阶段发送 prepared 消息,接着执行本地事务,第二阶段发送 commit 或 rollback 的消息。
定时回查:定时遍历 commitlog 中的半事务消息
如果事务正常执行,则 commit 该消息,如果抛出异常,则 rollback。对于消费消息失败,RocketMQ 会尝试重新消费,直到被加入死信队列中为止。在重试的过程中有可能产生重复的消息,所以对于消费端来说要确保消费幂等!
原因可能是以下三种:
处理堆积的消息:建立临时的 topic(扩容),转发堆积的消息
RocketMQ:topic 可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic
Kafka:topic 从几十到几百个时候,吞吐量会大幅度下降。原理:Kafka 利用操作系统的 PageCache 先将消息持久化到内存中,并不是直接写入磁盘。Topic 增加,也就是 Partition 数量会增加,使用的 PageCache 也会大量增加,大量增加后需要使用 LRU 淘汰算法对 Page 内容刷新到磁盘中,导致性能会下降。
分为两步:生产者有序存储,消费者有序消费。
针对消息有序的业务需求,还分为全局有序和局部有序。已知,每个partition的消费是顺序性的,但每个topic可以有若干个partition。
全局有序:一个Topic下的所有消息都需要按照生产顺序消费。
解决方法:1个Topic只能对应1个Partition。
局部有序:一个Topic下的消息,只需要满足同一业务字段的要按照生产顺序消费。例如:Topic消息是订单的流水表,包含订单orderId,业务要求同一个orderId的消息需要按照生产顺序进行消费。
解决方法:要满足局部有序,只需要在发消息的时候指定Partition Key,Partition Key相同的消息会放在同一个Partition。
全局有序:对于指定的一个 Topic,设置读写队列的数量为一。(与Kafka设置一个partition类似) 局部有序:对于指定的一个 Topic,生产者根据 hashKey 将消息发送到同一个MessageQueue。 同一个分区内的消息按照严格的 FIFO 顺序进行发布和消费。
实现消息有序性从三个方面:
主写主读,不支持读写分离
当 key 不存在时,会从当前存活的分区中轮询;当 key 存在时,发送给哈希后的指定分区。
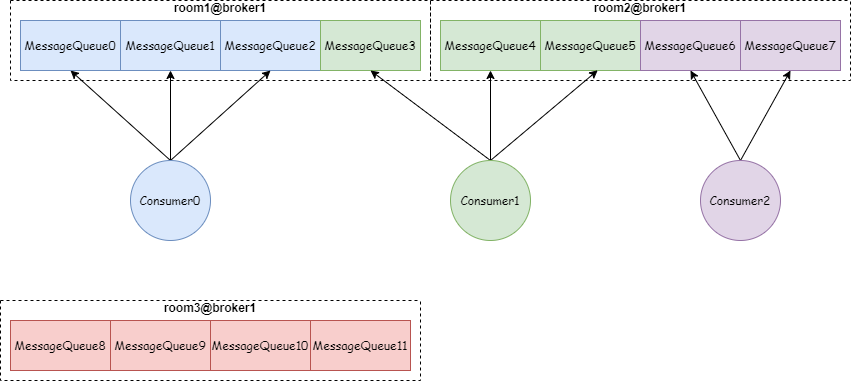
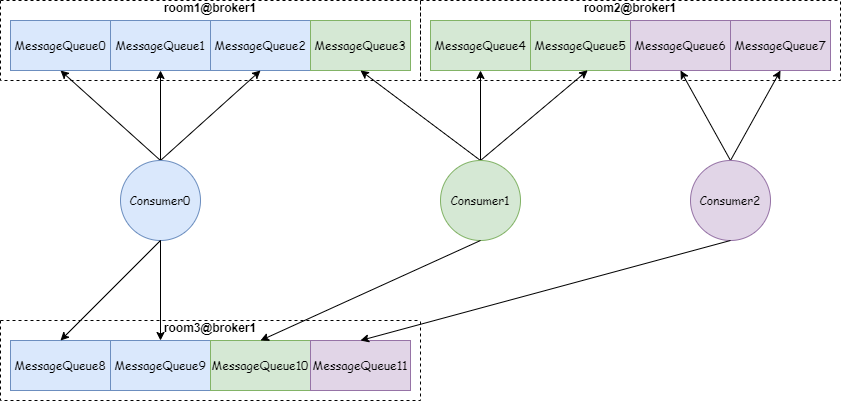
Kafka 中主题订阅者的基本单位是消费者组,每个分区只能由消费者组中的一个消费者进行消费,多个消费者组之间对于分区的消费互不影响。共有三个分区分配器:
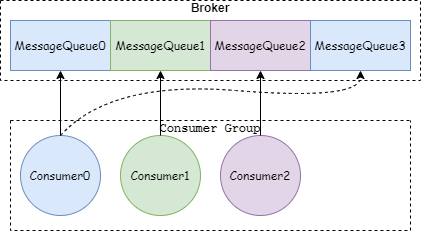
Producer 默认采用轮询的方法,按顺序将消息发送到 MessageQueue 里。
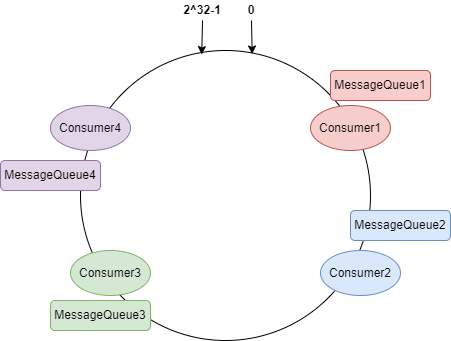
Kafka:适用于日志收集与分析、实时流处理、大数据集成(例如 Apache Storm 或 Flink)、用户行为追踪等场景。 RocketMQ:更适合金融交易、订单处理、秒杀活动、库存同步、跨系统间的服务解耦和异步调用等场景,尤其是那些对消息顺序、事务完整性和实时性要求极高的业务。
消费者组是一组共享 group.id 的消费者实例,一个消费者组可以消费多个 Topic 的消息,组内的消费者只能订阅相同的 Topic 和相同的 Tag 且 Tag 顺序相同。详见订阅关系一致。
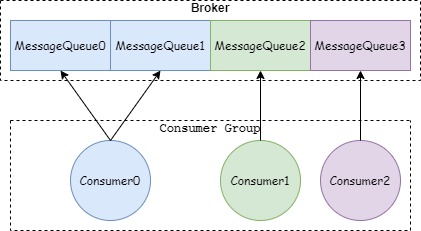
集群模式(默认):相同消费者群组的消费者平摊消息,便于负载均衡 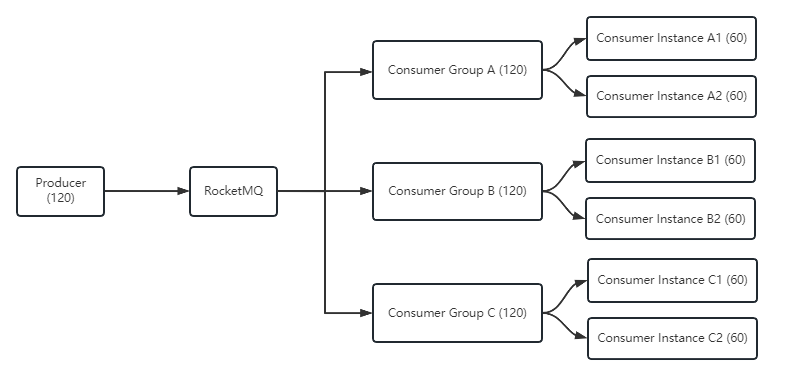
广播模式:相同消费者群组的每个消费者接收全量的消息,适合并行处理的场景。在该模式下,消费者组的概念在消息划分方面并没有意义。 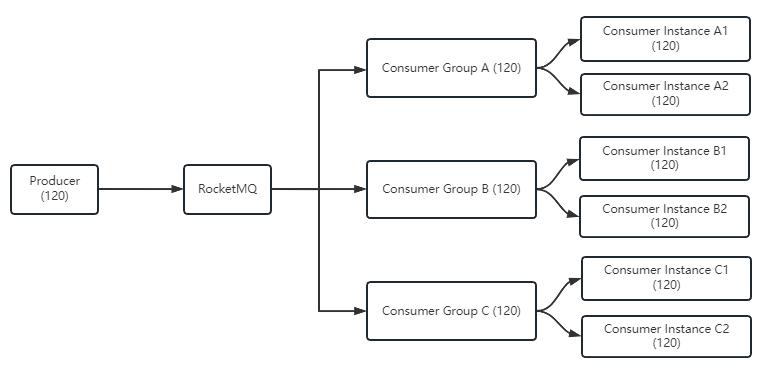
RocketMQ/Kafka 使用 Consumer Group 机制,实现了传统两大消息引擎。如果所有实例属于同一个Group,那么它实现的就是消息队列模型;如果所有实例分别属于不同的Group,且订阅了相同的主题,那么它就实现了发布/订阅模型;
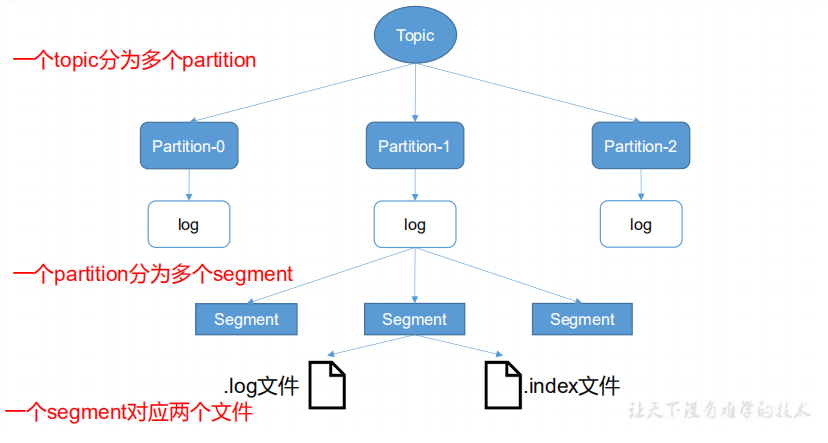
一个Topic分为多个Partition,一个Partition分为多个Segment。每个Segment对应三个文件:偏移量索引文件、时间戳索引文件、消息存储文件
在消息发送的过程中,涉及到两个线程,main线程和sender线程,其中main线程是消息的生产线程,而sender线程是jvm单例的线程,专门用于消息的发送。在jvm的内存中开辟了一块缓存空间叫RecordAccumulator(消息累加器),用于将多条消息合并成一个批次,然后由sender线程发送给kafka集群。
Kafka 采用 Pull 的方式,每个 Consumer 维护一个 HW 水位信息
Thread per consumer model:即每个线程都有自己的consumer实例,然后在一个线程里面完成数据的获取(pull)、处理(process)、offset提交。
Producer 发送压缩消息到 Broker 后,Broker 会保存压缩数据,由Consumer 解压数据。
Controller 用于在 ZK 的帮助下管理和协调整个 Kafka 集群。集群内任意一台 Broker 都能充当 Controller 的角色,但在运行过程中,只有一个 Controller。
利用labelme制作coco格式的实例分割数据集,该数据集适用于mmdetection2.0中的mask部分。
在mmdetection2.0框架下,利用coco格式的数据集进行实例分割默认只需要train2017和val2017两部分(当然也可以将test中的目录修改成test2017,但没必要)。

mmdetection2.0框架下coco格式数据集文件如下图放置:(运行完本文的.py文件后即可生成以下文件夹)

数据集标注方式:
当一张图片里没有多个同类别的物体,使用car,computer,bottle等标签直接进行标注;当一张图片里同个类别有多个物体时,标签采用sofa-1,sofa-2,desk-1,desk-2等标签-数字的格式进行标注;如果同一物体在遮挡情况下被分为多个部分,则不同部分都用同一个标签(具体如下图所示,牙膏的三个部分标签均为toothpaste)。

最后得到的json文件里的segmentation是分为三部分,bbox只存在一个(在笔者找的其他资料里,都是分为三个独立的牙膏部分,得到三个segmentation以及三个相应的bbox,显然不符合实际情况)。

建议在使用labelme进行对数据集标注时,将生成的.json文件放置在与数据集相同的路径下以避免一些不必要的麻烦。即下图:

否则,生成的json文件里的imagePath可能出现下图所示的情况:

如果实在是没办法,没有在同一路径下,imagePath会比较复杂(可能是windows系统用\分隔号,ubuntu系统则会是/分隔号,这一点是笔者的猜测),根据不同的情况修改后文代码。
各文件夹布局如下所示:

所有的.jpg文件放在images文件夹下,所有的.json文件(labelme标注完成后生成的文件)放在labelme/total2017文件夹下。
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+
# !/usr/bin/python
+# -*- coding: utf-8 -*-
+import os
+import random
+
+trainval_percent = 1 # No test sample
+train_percent = 0.9
+jsonfilepath = 'labelme/total2017'
+txtsavepath = './'
+total_xml = os.listdir(jsonfilepath)
+
+num = len(total_xml)
+list = range(num)
+tv = int(num * trainval_percent)
+tr = int(tv * train_percent)
+trainval = random.sample(list, tv)
+train = random.sample(trainval, tr)
+
+ftrainval = open('./trainval2017.txt', 'w')
+ftrain = open('./train2017.txt', 'w')
+fval = open('./val2017.txt', 'w')
+ftest = open('./test2017.txt', 'w') #Still create test2017.txt
+
+for i in list:
+ name = total_xml[i][:-5] + '\n'
+ if i in trainval:
+ ftrainval.write(name)
+ if i in train:
+ ftrain.write(name)
+ else:
+ fval.write(name)
+ else:
+ ftest.write(name)
+ftrainval.close()
+ftrain.close()
+fval.close()
+ftest.close()
+print('Create_txt Done')
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+
import shutil
+import os
+import os.path as osp
+
+sets=['train2017', 'val2017', 'test2017']
+for image_set in sets:
+ if osp.exists(image_set):
+ shutil.rmtree(image_set)
+ print('Deleted previous %s file and created a new one'%(image_set))
+ os.makedirs(image_set)
+ json_path = 'labelme/%s'%(image_set)
+ if osp.exists(json_path):
+ shutil.rmtree(json_path)
+ print('Deleted previous %s file and created a new one' % (json_path))
+ os.makedirs(json_path)
+ image_ids = open('./%s.txt'%(image_set)).read().strip().split()
+ for image_id in image_ids:
+ img = 'images/%s.jpg' % (image_id)
+ json = 'labelme/total2017/%s.json'% (image_id)
+ shutil.copy(img,image_set)
+ shutil.copy(json,'labelme/%s/'% (image_set))
+print("Done")
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+43
+44
+45
+46
+47
+48
+49
+50
+51
+52
+53
+54
+55
+56
+57
+58
+59
+60
+61
+62
+63
+64
+65
+66
+67
+68
+69
+70
+71
+72
+73
+74
+75
+76
+77
+78
+79
+80
+81
+82
+83
+84
+85
+86
+87
+88
+89
+90
+91
+92
+93
+94
+95
+96
+97
+98
+99
+100
+101
+102
+103
+104
+105
+106
+107
+108
+109
+110
+111
+112
+113
+114
+115
+116
+117
+118
+119
+120
+121
+122
+123
+124
+125
+126
+127
+128
+129
+130
+
#!/usr/bin/env python
+import collections
+import datetime
+import glob
+import json
+import os
+import os.path as osp
+import sys
+import numpy as np
+import PIL.Image
+import labelme
+import shutil
+
+try:
+ import pycocotools.mask
+except ImportError:
+ print('Please install pycocotools:\n\n pip install pycocotools\n')
+ sys.exit(1)
+
+
+def main():
+ sets = ['train2017','val2017','test2017']
+ output_dir = './annotations'
+ if osp.exists(output_dir):
+ print('Output directory already exists:', output_dir)
+ shutil.rmtree(output_dir)
+ os.makedirs(output_dir)
+ print('Creating dataset:', output_dir)
+ for set in sets:
+ input_dir = './labelme/%s'%(set)
+ filename = 'instances_%s'%(set)
+ now = datetime.datetime.now()
+ data = dict(
+ info=dict(
+ description=None,
+ version=None,
+ contributor=None,
+ date_created=now.strftime('%Y-%m-%d %H:%M:%S.%f'),
+ ),
+ licenses=[dict(
+ id=0,
+ name=None,
+ )],
+ images=[
+ # license, url, file_name, height, width, date_captured, id
+ ],
+ type='instances',
+ annotations=[
+ # segmentation, area, iscrowd, image_id, bbox, category_id, id
+ ],
+ categories=[
+ # supercategory, id, name
+ ],
+ )
+
+ class_name_to_id = {}
+ for i, line in enumerate(open('labels.txt').readlines()):
+ class_id = i - 1 # starts with -1
+ class_name = line.strip()
+ if class_id == -1:
+ assert class_name == '__ignore__'
+ continue
+ class_name_to_id[class_name] = class_id
+ data['categories'].append(dict(
+ supercategory=None,
+ id=class_id,
+ name=class_name,
+ ))
+ out_ann_file = osp.join(output_dir, filename+'.json')
+ label_files = glob.glob(osp.join(input_dir, '*.json'))
+ for image_id, label_file in enumerate(label_files):
+ with open(label_file) as f:
+ label_data = json.load(f)
+ path=label_data['imagePath'].split("\\") # 可能因为windows或ubuntu不同的系统用\\或/划分,详见前言三
+ img_file = './%s/'%(set) + path[-1]
+ img = np.asarray(PIL.Image.open(img_file))
+ data['images'].append(dict(
+ license=0,
+ url=None,
+ file_name=label_file.split('/')[-1].split('.')[0] + '.jpg',
+ height=img.shape[0],
+ width=img.shape[1],
+ date_captured=None,
+ id=image_id,
+ ))
+ masks = {} # for area
+ segmentations = collections.defaultdict(list) # for segmentation
+ for shape in label_data['shapes']:
+ points = shape['points']
+ label = shape['label']
+ shape_type = shape.get('shape_type', None)
+ mask = labelme.utils.shape_to_mask(
+ img.shape[:2], points, shape_type
+ )
+
+ if label in masks:
+ masks[label] = masks[label] | mask
+ else:
+ masks[label] = mask
+
+ points = np.asarray(points).flatten().tolist()
+ segmentations[label].append(points)
+
+ for label, mask in masks.items():
+ cls_name = label.split('-')[0]
+ if cls_name not in class_name_to_id:
+ continue
+ cls_id = class_name_to_id[cls_name]
+
+ mask = np.asfortranarray(mask.astype(np.uint8))
+ mask = pycocotools.mask.encode(mask)
+ area = float(pycocotools.mask.area(mask))
+ bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
+
+ data['annotations'].append(dict(
+ id=len(data['annotations']),
+ image_id=image_id,
+ category_id=cls_id,
+ segmentation=segmentations[label],
+ area=area,
+ bbox=bbox,
+ iscrowd=0,
+ ))
+
+ with open(out_ann_file, 'w') as f:
+ json.dump(data, f,indent=4)
+ print(set + ' is done')
+
+if __name__ == '__main__':
+ main()
+
上述三个文件按顺序执行即可。
最后所有的文件夹如下图所示,如前文所提到的,在mmdetection中被利用到的只有annotations,train2017,val2017三个文件夹。

本文的代码可以反复运行,因为代码中包含一些旧文件夹的删除以及新建,不会报错。
MathJax中的公式排版有两种方式,inline和displayed。
inline表示公式嵌入到文本段中,也称为行模式。$ f(x) = 3 \times x $这是一个inline公式
displayed表示公式独自成为一个段落,也成为块模式。下面则是一个displayed公式。
| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\pm$ | \pm | $\mp$ | \mp | $\times$ | \times |
| $\div$ | \div | $\cdot$ | \cdot | $\ast$ | \ast |
| $\star$ | \star | $\dagger$ | \dagger | $\ddagger$ | \ddagger |
| $\amalg$ | \amalg | $\cap$ | \cap | $\cup$ | \cup |
| $\uplus$ | \uplus | $\sqcap$ | \sqcap | $\sqcup$ | \sqcup |
| $\vee$ | \vee | $\wedge$ | \wedge | $\oplus$ | \oplus |
| $\ominus$ | \ominus | $\otimes$ | \otimes | $\circ$ | \circ |
| $\bullet$ | \bullet | $\diamond$ | \diamond | $\lhd$ | \lhd |
| $\rhd$ | \rhd | $\unlhd$ | \unlhd | $\unrhd$ | \unrhd |
| $\oslash$ | \oslash | $\odot$ | \odot | $\bigcirc$ | \bigcirc |
| $\triangleleft$ | \triangleleft | $\Diamond$ | \Diamond | $\bigtriangleup$ | \bigtriangleup |
| $\bigtriangledown$ | \bigtriangledown | $\Box$ | \Box | $\triangleright$ | \triangleright |
| $\setminus$ | \setminus | $\wr$ | \wr | $\sqrt{x}$ | \sqrt{x} |
| $x^{\circ}$ | x^{\circ} | $\triangledown$ | \triangledown | $\sqrt[n]{x}$ | \sqrt[n]{x} |
| $a^x$ | a^x | $a^{xyz}$ | a^{xyz} | $\frac{x}{y}$ | \frac{x}{y} |
| $\sin{x}$ | \sin{x} | $\cos{x}$ | \cos{x} | $\tan{x}$ | \tan{x} |
| $\log_xy$ | \log_xy | $\ln{x}$ | \ln{x} | $\max(x,y,z)$ | \max(x,y,z) |
\sum\limits_{i=0}^n{a_i} 显示为$\sum\limits_{i=0}^n{a_i}$\prod\limits_{i=0}^n{\frac{1}{i^2}} 显示为$\prod\limits_{i=0}^n{\frac{1}{i^2}}$\int_0^xf(x)dx显示为$\int_0^xf(x)dx$\lim\limits_{x\to 0}{x} 显示为$\lim\limits_{x\to 0}{x}$\mathop{SUPER}\limits_{i=0}^n{i^2} 显示为$\mathop{SUPER}\limits_{i=0}^n{i^2}$| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\le $ | \le | $\ge $ | \ge | $\neq $ | \neq |
| $\sim $ | \sim | $\ll $ | \ll | $\gg $ | \gg |
| $\doteq $ | \doteq | $\simeq $ | \simeq | $\subset $ | \subset |
| $\supset $ | \supset | $\approx $ | \approx | $\asymp $ | \asymp |
| $\subseteq $ | \subseteq | $\supseteq $ | \supseteq | $\cong $ | \cong |
| $\smile $ | \smile | $\sqsubset $ | \sqsubset | $\sqsupset $ | \sqsupset |
| $\equiv $ | \equiv | $\frown $ | \frown | $\sqsubseteq $ | \sqsubseteq |
| $\sqsupseteq$ | \sqsupseteq | $\propto $ | \propto | $\bowtie $ | \bowtie |
| $\in $ | \in | $\ni $ | \ni | $\prec $ | \prec |
| $\succ $ | \succ | $\vdash $ | \vdash | $\dashv $ | \dashv |
| $\preceq $ | \preceq | $\succeq $ | \succeq | $\models $ | \models |
| $\perp $ | \perp | $\parallel $ | \parallel | ||
| $\mid $ | \mid | $\bumpeq $ | \bumpeq |
上面这些关系符号的否定(反义)形式可以通过在原符号前添加 \not 来进行实现,或者在 \ 和符号单词之间添加 n 来实现。
下面列出几个常用的否定形式,其他符号的否定形式规则基本类似。
| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\nmid $ | \nmid | $\nleq $ | \nleq | $\ngeq $ | \ngeq |
| $\nsim $ | \nsim | $\ncong $ | \ncong | $\nparallel $ | \nparallel |
| $\not< $ | \not< | $\not> $ | \not> | $\not= $ | \not= |
| $\not\le $ | \not\le | $\not\ge $ | \not\ge | $\not\sim $ | \not\sim |
| $\not\approx $ | \not\approx | $\not\cong $ | \not\cong | $\not\equiv $ | \not\equiv |
| $\not\parallel $ | \not\parallel | $\nless $ | \nless | $\ngtr $ | \ngtr |
| $\lneq $ | \lneq | $\gneq $ | \gneq | $\lnsim $ | \lnsim |
| $\lneqq $ | \lneqq | $\gneqq $ | \gneqq |
像 =, >, 和 < 并没有列在上面的符号,可以直接字面输入,并不需要命令进行触发。
小写:
| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\alpha $ | \alpha | $ \beta $ | \beta | $\gamma $ | \gamma |
| $\epsilon $ | \epsilon | $ \varepsilon $ | \varepsilon | $\zeta $ | \zeta |
| $\theta $ | \theta | $ \vartheta $ | \vartheta | $\iota $ | \iota |
| $\lambda $ | \lambda | $ \mu $ | \mu | $\nu $ | \nu |
| $\pi $ | \pi | $ \varpi $ | \varpi | $\rho $ | \rho |
| $\sigma $ | \sigma | $ \varsigma $ | \varsigma | $\tau $ | \tau |
| $\phi $ | \phi | $ \varphi $ | \varphi | $\chi $ | \chi |
| $\omega $ | \omega | $ \varrho $ | \varrho | $\kappa $ | \kappa |
| $\delta $ | \delta | $ \upsilon $ | \upsilon | $\xi $ | \xi |
| $\eta $ | \eta | $ \psi $ | \psi |
大写:
| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\Gamma $ | \Gamma | $\Delta $ | \Delta | $ \Theta $ | \Theta |
| $\Xi $ | \Xi | $\Pi $ | \Pi | $ \Sigma $ | \Sigma |
| $\Phi $ | \Phi | $\Psi $ | \Psi | $ \Omega $ | \Omega |
| $\Lambda $ | \Lambda | $\Upsilon $ | \Upsilon |
斜体大写:
| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\varGamma $ | \varGamma | $\varDelta $ | \varDelta | $ \varTheta $ | \varTheta |
| $\varXi $ | \varXi | $\varPi $ | \varPi | $ \varSigma $ | \varSigma |
| $\varPhi $ | \varPhi | $\varPsi $ | \varPsi | $ \varOmega $ | \varOmega |
| $\varLambda $ | \varLambda | $\varUpsilon $ | \varUpsilon |
| Symbol | Command | Symbol | Command |
|---|---|---|---|
| $\gets $ | \gets | $\to $ | \to |
| $\leftarrow $ | \leftarrow | $\Leftarrow $ | \Leftarrow |
| $\rightarrow $ | \rightarrow | $\Rightarrow $ | \Rightarrow |
| $\leftrightarrow $ | \leftrightarrow | $\Leftrightarrow $ | \Leftrightarrow |
| $\mapsto $ | \mapsto | $\hookleftarrow $ | \hookleftarrow |
| $\leftharpoonup $ | \leftharpoonup | $\leftharpoondown $ | \leftharpoondown |
| $\rightleftharpoons $ | \rightleftharpoons | $\longleftarrow $ | \longleftarrow |
| $\Longleftarrow $ | \Longleftarrow | $\longrightarrow $ | \longrightarrow |
| $\Longrightarrow $ | \Longrightarrow | $\longleftrightarrow$ | \longleftrightarrow |
| $\Longleftrightarrow $ | \Longleftrightarrow | $\longmapsto $ | \longmapsto |
| $\hookrightarrow $ | \hookrightarrow | $\rightharpoonup $ | \rightharpoonup |
| $\rightharpoondown $ | \rightharpoondown | $\leadsto $ | \leadsto |
| $\uparrow $ | \uparrow | $\Uparrow $ | \Uparrow |
| $\downarrow $ | \downarrow | $\Downarrow $ | \Downarrow |
| $\updownarrow $ | \updownarrow | $\Updownarrow $ | \Updownarrow |
| $\nearrow $ | \nearrow | $\searrow $ | \searrow |
| $\swarrow $ | \swarrow | $\nwarrow $ | \nwarrow |
有些箭头指令, mathjax 提供了缩写指令, $\iff$(\iff) 和 $\implies$(\implies) 可以分别表示为 $\Longleftrightarrow$(\Longleftrightarrow) 和 $\Longrightarrow$(\Longrightarrow)
| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\hat{x} $ | \hat{x} | $\check{x} $ | \check{x} | $\dot{x} $ | \dot{x} |
| $\breve{x}$ | \breve{x} | $\acute{x} $ | \acute{x} | $\ddot{x} $ | \ddot{x} |
| $\grave{x}$ | \grave{x} | $\tilde{x} $ | \tilde{x} | $\mathring{x} $ | \mathring{x} |
| $\bar{x} $ | \bar{x} | $\vec{x} $ | \vec{x} | $\overline{x} $ | \overline{x} |
| $\widehat{7+x}$ | \widehat{7+x} | $\widetilde{abc}$ | \widetilde{abc} |
\tilde 和 \hat 两个指令有宽符号的版本。
上述表格最后一行,\widetilde 和 \widehat,通过这两个指令可以生成长版本的表达式结构的符号。
1
+2
+3
+4
+5
+6
+7
+
$$
+f(n) = \tag{1}
+\begin{cases}
+\frac{a_n^3}{2}, & \text{if $n$ is even} \\
+3a_n^2+1, & \text{if $n$ is odd}
+\end{cases}
+$$
+
\mathtt{R} 显示为$\mathtt{R}$\mathbb{R} 显示为$\mathbb{R}$。表示实数集的意思。\mathsf{R} 显示为$\mathsf{R}$\mathscr{R} 显示为$\mathscr{R}$\mathrm{R} 显示为$\mathrm{R}$| Symbol | Command | Symbol | Command |
|---|---|---|---|
| $\cdot $ | \cdot | $\vdots $ | \vdots |
| $\dots $ | \dots | $\ddots $ | \ddots |
| $\cdots$ | \cdots | $\ldots $ | \ldots |
\ldots 和 \cdots 是低位置省略号和中心位置省略号的 latex 命令, \dots 是 amsmath 命令用来试图帮你在 \ldots 和 \cdots 中自动做决断的。
通常来讲中心省略 \cdots 一般用在数学模式的中心线上的符号后面,例如加号 + 或者右箭头 -> , 而 \ldots 一般用在标点符号的后面,例如句号“ . ” or逗号“ , ”。
例如,
$ a + b + \cdots + z \quad a_1, \ldots, a_n $ 显示为$ a + b + \cdots + z \quad a_1, \ldots, a_n $
改为\dots便可以根据实际情况自动地改变省略号的位置
$ a + b + \dots + z \quad a_1, \dots, a_n $ 显示为$ a + b + \dots + z \quad a_1, \dots, a_n $
使用\dots基本可以满足要求。但是,\dots 并不是每次都能正确自动改变省略号的位置,所以还是需要根据自己的实际情况选择不同的dots。
1
+2
+3
+4
+5
+6
+7
+8
+
$$
+\begin{bmatrix}
+{a_{11}}&{a_{12}}&{\cdots}&{a_{1n}}\\
+{a_{21}}&{a_{22}}&{\cdots}&{a_{2n}}\\
+{\vdots}&{\vdots}&{\ddots}&{\vdots}\\
+{a_{m1}}&{a_{m2}}&{\cdots}&{a_{mn}}\\
+\end{bmatrix}
+$$
+
在数学公式里,有时我们会通过括号( (), [], {} )进行界线控制。这些符号有些是可以直接输入,比如 (), [], | 等,而有些符号是要经过转义的,下面列出了这些比较特殊的符号。
| Symbol | Command | Symbol | Command |
|---|---|---|---|
| $\lfloor $ | \lfloor | $\rfloor $ | \rfloor |
| $\lceil $ | \lceil | $\rceil $ | \rceil |
| $\langle $ | \langle | $\rangle $ | \rangle |
上括号$ \overbrace{a_0+a_1+a_2+\cdots+a_n}^{x} $,显示为$ \overbrace{a_0+a_1+a_2+\cdots+a_n}^{x} $
下括号$ \underbrace{a_0+a_1+a_2+\cdots+a_n}_{x} $,显示为$ \underbrace{a_0+a_1+a_2+\cdots+a_n}_{x} $
但是有时候界限符号不够高,所以需要一些自适应括号,比如$ (\frac{a}{x} )^2 $,显示为
使用自适应括号的代码为$ \left(\frac{a}{x} \right)^2 $,显示为
但是也只有在块模式的时候会比较明显。
| Symbol | Command | Symbol | Command | Symbol | Command |
|---|---|---|---|---|---|
| $\infty $ | \infty | $ \triangle $ | \triangle | $\angle $ | \angle |
| $\aleph $ | \aleph | $ \hbar $ | \hbar | $\imath $ | \imath |
| $\jmath $ | \jmath | $ \ell $ | \ell | $\wp $ | \wp |
| $\Re $ | \Re | $ \Im $ | \Im | $\mho $ | \mho |
| $\prime $ | \prime | $ \emptyset $ | \emptyset | $\nabla $ | \nabla |
| $\surd $ | \surd | $ \partial $ | \partial | $\top $ | \top |
| $\bot $ | \bot | $ \vdash $ | \vdash | $\dashv $ | \dashv |
| $\forall $ | \forall | $ \exists $ | \exists | $\neg $ | \neg |
| $\flat $ | \flat | $ \natural $ | \natural | $\sharp $ | \sharp |
| $\backslash$ | \backslash | $ \Box $ | \Box | $\Diamond $ | \Diamond |
| $\clubsuit $ | \clubsuit | $ \diamondsuit $ | \diamondsuit | $\heartsuit $ | \heartsuit |
| $\spadesuit$ | \spadesuit | $ \Join $ | \Join | $\blacksquare$ | \blacksquare |
| $\bigstar $ | \bigstar | $ \in $ | \in | $\cup $ | \cup |
| $\square $ | \square | $ \S $ | \S | $\checkmark $ | \checkmark |
| $\because $ | \because | $ \therefore $ | \therefore |
两个独立的仓库A、B,将仓库B合并至仓库A的分支,并保留A、B的所有commits
例如:将dumped-CompetitiveLin.github.io中的所有提交内容合并至CompetitiveLin.github.io的another分支。
1
+
git clone git@github.com:CompetitiveLin/CompetitiveLin.github.io
+
1
+
git remote add base git@github.com:CompetitiveLin/dumped-CompetitiveLin.github.io
+
此时查看remote: git remote -v,如下图所示:

如果需要删除remote: git remote rm base
1
+
git fetch base
+
1
+
git checkout -b another base/dumped
+
查看branch分支:git branch
1
+
git checkout main
+
1
+
git merge another
+
此时可能出现类似下图fatal: refusing to merge unrelated histories的报错信息。

解决方法:
1
+
git merge another --allow-unrelated-histories
+
在合并时有可能两个分支对同一个文件都做了修改,这时需要解决冲突1,在windows下可以使用Github Desktop解决冲突问题。
1
+
git push origin another
+
原因:没有配置ssh-key,没有权限2
解决方法:
1
+2
+
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
+ clip < ~/.ssh/id_rsa.pub
+
See here.
单机 QPS 为 4k 左右。
* 拓展为表上的所有列。组成:段(默认256MB) -> 区(默认1MB) -> 页(默认16KB) -> 行
页:InnoDB的数据按页为单位读写,默认每个页大小为16KB,意味着一次最少从磁盘读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。表中的记录存储在数据页中。B+树的每个节点都是一个数据页。
区:数据量大的时候,索引分配空间则是按区为单位分配,每个区的大小为1MB,对于16KB的页来说,连续(物理连续)64个页会被划分到一个区,这样,B+树中节点所构成的链表中相邻页的物理位置也相邻,便能顺序IO。
段:段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。在段中不要求区与区之间是相邻的。
数据页都是以双向链表的形式存在,如果以页分配存储空间,双向链表相邻的两个页之间的物理位置可能距离非常远,会产生随机 IO,影响性能
对于范围查询,本质是对B+树叶子节点中的记录进行顺序扫描,但如果不区分叶子节点和非叶子节点,把节点代表的页都申请到区中,范围查找效率大打折扣。一个索引会产生两个段,一个叶子节点段(数据段)和一个非叶子节点段(索引段)。
MySQL 规定除了 TEXT、BLOBs 这种大对象类型之外,其他所有的列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过 65535 个字节。注意,是一行数据的最大字节数 65535,其实是包含「变长字段长度列表」和 「NULL 值列表」所占用的字节数的。
行格式溢出后,数据存放到溢出页。
数据的检索效率是:char>varchar>text
char: 定长,会用空格补齐 varchar:变长
与红黑树的比较,B+树的优势:
为什么不使用 B 树:B+ 树的非叶子节点只存储索引,单个节点可以存储更多的索引,计算机一次性加载更多的索引数据到内存中。并且B树不适合范围查找。
为什么不使用跳表:MySQL 一次数据页加载都需要一次磁盘IO。并且磁盘IO的次数和树高有关系,又因为跳表的高度一般比B+树高,所以查询速度会大大降低,因此不适合。
为什么 Redis 使用了跳表:因为 Redis 不存在磁盘IO。重点在于磁盘IO次数。
给表添加索引时,是会对表加锁,因此在生产环境中不能直接添加索引。InnoDB 存储引擎默认会创建一个主键索引,也就是聚簇索引,其它索引都属于二级索引。当没有显式定义主键索引时,MySQL 会选择第一个唯一索引,并自动设置非空约束,当作聚簇索引。
一定失效:
可能失效:
最左缀原则可以通过跳跃扫描的方式打破,当第一列索引的唯一值较少时,即使where条件没有第一列索引,查询的时候也可以用到联合索引。
指查询列被所建的索引覆盖,覆盖索引是 select 的数据列只需要从索引中就能取到,不必回表。例如对于联合索引(col1,col2,col3),查询语句SELECT col1,col2,col3 FROM test WHERE col2=2
指将部分上层(服务层)负责index filter的事情,交给了下层(引擎层)去处理。它能减少二级索引再查询时的回表查询次数,提高查询效率。只适用于二级索引。
EXPLAIN 命令的extra一栏中有Using index condition,表明使用了索引下推
举例:select * from table1 where b like '3%' and c = 3
5.6 之前:
5.6 之后:
有分页需求时,一般会用limit实现,但是当偏移量特别大的时候,查询效率就变得低下。
select * from table limit 10 和 select * from table limit 10000, 10 的查询时间是不一样的,后者是查询出 10010 条,再取最后 10 条记录。
本质原因就是:偏移量(offset)越大,mysql就会扫描越多的行,然后再抛弃掉。这样就导致查询性能的下降。
解决方案:
select * from table where id > 10000 limit 10,select * from table where id between 100000 and 100010 order by id desc;select * from table where id >= (select a.id from table a where a.update_time >= xxx limit 100000, 1) limit 10MVCC 用于解决脏读和不可重复读的问题,在读已提交和可重复读两种隔离级别生效。读已提交是每次 select 都会重新生成一次 Read View,而可重复读是一次事务只会创建一次且在第一次查询时创建 Read View。
MVCC: Read view + undo log + 两个隐藏字段,基于乐观锁的理论为了解决读写冲突,可以在读已提交和可重复读的隔离级别下使用。
MVCC(Multiversion Concurrency Control) + 间隙锁在RR的隔离级别下能解决大部分幻读情况
若要尽可能避免幻读现象的发生,尽量在开启时候后马上执行当前读。
三种问题:
SQL的四种隔离级别:
WAL(Write-ahead logging)指 MySQL 在执行写操作时先记录在日志中,后更新到磁盘中。
WAL 核心:将随机写(磁盘的写操作是随机IO,耗性能)转变成顺序写和组提交机制,降低客户端延迟,提高吞吐量。
如果对数据一致性和可靠性要求较高,可以考虑使用半同步复制;如果对延迟和主服务器性能要求较高,可以继续使用异步复制,根据实际需求调整复制模式。
主服务器将数据修改操作记录到二进制日志,并等待至少一个slave服务器确认已接收到并应用了这些日志后才继续执行后续操作。
Binlog 有三种格式:
Binlog 写入到磁盘的操作:
Binlog 的持久化:
刷盘时机:事务进行中
前提:innodb_flush_log_at_trx_commit 设置为1,sync_binlog 设置大于0
如果发生崩溃,先检查 redo log 记录的事务操作是否为 commit 状态。
为什么需要两阶段提交?
每一步执行时都会产生一个虚拟表,都会被用作下一个步骤的输入。
select lock in share modeselect for update常见的数据同步方案主要有以下三种:
但也有异步调用和binlog监听结合在一起的例子,用canal作slave节点。
分为 水平切分(又称为 Sharding) 和 垂直切分。
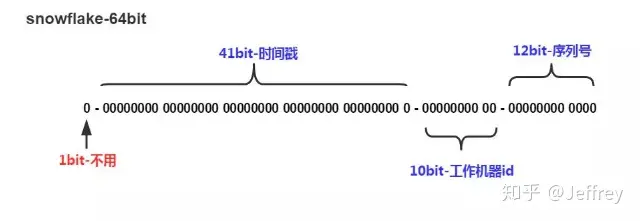
建议使用雪花算法,其中序列号一直保持递增,不会因为时间戳的不同而归零,防止被猜测上下文ID。
通过客户端向应用程序输入数据来插入或注入一个 SQL 查询/操作。
# 和 $ 的区别# 将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。很大程度防止sql注入$ 将传入的数据直接显示生成在sql中。无法防止Sql注入。new/delete是C++关键字,需要编译器支持。
malloc/free是库函数,需要头文件支持。
new操作符申请内存分配时无须指定内存块的大小,编译器会根据类型信息自行计算。
而malloc则需要显式地指出所需内存的尺寸。
new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无须进行类型转换,故new是符合类型安全性的操作符。
而malloc内存分配成功则是返回void * ,需要通过强制类型转换将void*指针转换成我们需要的类型。
new内存分配失败时,会抛出bac_alloc异常。
malloc分配内存失败时返回NULL。
new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。
malloc/free是库函数,只能动态的申请和释放内存,无法强制要求其做自定义类型对象构造和析构工作。
C++允许重载new/delete操作符,特别的,布局new的就不需要为对象分配内存,而是指定了一个地址作为内存起始区域,new在这段内存上为对象调用构造函数完成初始化工作,并返回此地址。
而malloc不允许重载。
new操作符从自由存储区(free store)上为对象动态分配内存空间。自由存储区是C++基于new操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。
而malloc函数从堆上动态分配内存。堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于程序的内存动态分配,C语言使用malloc从堆上分配内存,使用free释放已分配的对应内存。自由存储区不等于堆,如上所述,布局new就可以不位于堆中。
new没有扩张内存的机制。
而malloc分配内存后,如果发现内存不够用,可以通过realloc函数来扩张内存大小,realloc会先判断当前申请的内存后面是否还有足够的内存空间进行扩张,如果有足够的空间,那么就会往后面继续申请空间,并返回原来的地址指针;否则realloc会在另外有足够大小的内存申请一块空间,并将当前内存空间里的内容拷贝到新的内存空间里,最后返回新的地址指针。
以下是 vector, vector with reserve, array, malloc, new 这几种不同创建并销毁数据的方法的运行时间对比代码。
根据运行结果可以大致得到:$T_{array} \approx T_{malloc} \approx T_{new} < T_{vector-with-reserve} < T_{vector}$
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+43
+44
+45
+46
+47
+48
+49
+50
+51
+52
+53
+54
+55
+56
+57
+58
+59
+60
+61
+62
+63
+64
+65
+66
+67
+68
+69
+70
+71
+72
+
#include<bits/stdc++.h>
+#include <windows.h>
+using namespace std;
+
+int main(){
+ cout<<"=====Runing time of program=====" <<endl;
+ // vector
+ DWORD start = GetTickCount();
+ int t = 100;
+ int n = 200000;
+ while (t)
+ {
+ vector<int> a;
+ for(int i=0;i<n;i++) a.push_back(i);
+ t--;
+ }
+ cout<<"Vector: "<<GetTickCount() - start<<endl;
+
+ // vector with reserve
+ start = GetTickCount();
+ t = 100;
+ n = 200000;
+ while (t)
+ {
+ vector<int> b;
+ b.reserve(n);
+ for(int i=0;i<n;i++) b.push_back(i);
+ t--;
+ }
+ cout<<"Vector with reserve: "<<GetTickCount() - start<<endl;
+
+ // array
+ start = GetTickCount();
+ t = 100;
+ n = 200000;
+ while (t)
+ {
+ int a[200000];
+ for(int i=0;i<n;i++) a[i]=i;
+ t--;
+ }
+ cout<<"Array: "<<GetTickCount() - start<<endl;
+
+
+ // malloc
+ start = GetTickCount();
+ t = 100;
+ n = 200000;
+ while (t)
+ {
+ int *p = (int *)malloc((n+1) * sizeof(int));
+ for(int i=0;i<n;i++) p[i]=i;
+ free(p);
+ t--;
+ }
+ cout<<"Malloc: "<<GetTickCount()-start<<endl;
+
+
+ // new
+ start = GetTickCount();
+ t = 100;
+ n = 200000;
+ while (t)
+ {
+ int *p=new int[n+1];
+ for(int i=0;i<n;i++) p[i]=i;
+ delete []p;
+ t--;
+ }
+ cout<<"New: "<<GetTickCount() - start<<endl;
+
+}
+

Grafana 的数据显示会五分钟自动补全。当向 Prometheus 中插入某个时间戳的值时,其值会延续五分钟。
K8S 中的 Sidecar 模式:通常情况下一个 Pod 只包含一个容器,但是 Sidecar 模式是指为主容器提供额外功能(例如监控) 从而将其他容器加入到同一个 Pod 中。再例如 Istio 实现 Sidecar 自动注入。
Federated cluster,联邦集群
限流算法:漏桶和令牌桶算法,漏桶算法处理请求的速度固定,突发请求过多时会丢弃;令牌桶算法除了限制数据的平均传输速率外,还要求允许某种程度的突发传输。
常见 HTTP 状态码:2XX,成功响应;3XX,重定向消息;4XX,客户端错误响应;5XX,服务端错误响应。
请求分为四部分:请求行,请求头,空行,请求正文(不一定有)。
.gitignore 是在文件从工作区被 add 到暂存区时判断是否要被忽略,对于已经在暂存区的文件,不作判断。
Clickhouse:
https://juejin.cn/post/6844903621495095309
https://juejin.cn/post/6844903621495111688
在网络可靠,存在节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性算法。对于允许节点失效情况下,纯粹异步系统无法确保一致性在有限时间内完成。
举例:三个人在不同房间,进行投票(投票结果是 0 或者 1)。三个人彼此可以通过电话进行沟通,但经常会有人时不时地睡着。比如某个时候,A 投票 0,B 投票 1,C 收到了两人的投票,然后 C 睡着了。A 和 B 则永远无法在有限时间内获知最终的结果。
分布式系统只能交付以下三个所需特性中的两个特性:一致性、可用性和分区容错性。
一般来说,在分布式系统中不可避免会出现分区,因此认为 P 总是成立。因此若要实现一致性(CP),那么当出现分区问题时,就需要舍弃不一致的节点,即牺牲可用性。同理,若要实现可用性(AP),那么当出现分区问题时,就无法保证一致性。
Nacos集群默认支持 AP 原则(即不支持数据一致性,支持服务注册的临时实例),但也可切换至基于 Raft的 CP 原则(支持服务注册的永久实例)。
临时实例和持久化实例的区别:
MongoDB 是一种 CP 数据存储——它通过牺牲可用性、保持一致性来解决网络分区问题。
核心思想是:即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
三种角色:
记时器:
由于某种原因(网络不稳定)使得主从集群一分为二,导致master或者leader节点的数量不为1(0或2)。
master 机器突然脱离网络,使得 sentinel 集群无法感知到 master 的存在,会重新选举一个 master 节点。网络恢复后则会存在两个 master 节点。
脑裂可能出现平票的情况,从而无法选举出 leader。因此,zk 中建议节点数是奇数。
Kubernetes主要由以下几个核心组件组成:
除了核心组件,还有一些推荐的add-ons(扩展):
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+
public class Singleton {
+
+ private static volatile Singleton singleton = null; // volatile 必不可少,防止jvm指令重排优化
+
+ private Singleton() {
+ }
+
+ public static Singleton getInstance(){
+ //第一次校验singleton是否为空,为了提高代码执行效率,由于单例模式只要一次创建实例即可,所以当创建了一个实例之后,再次调用getInstance方法就不必要进入同步代码块,不用竞争锁。直接返回前面创建的实例即可。
+ if(singleton==null){
+ synchronized (Singleton.class){
+ //第二次校验singleton是否为空,防止二次创建实例
+ if(singleton==null){
+ singleton = new Singleton();
+ }
+ }
+ }
+ return singleton;
+ }
+
+ public static void main(String[] args) {
+ for (int i = 0; i < 100; i++) {
+ new Thread(new Runnable() {
+ public void run() {
+ System.out.println(Thread.currentThread().getName()+" : "+Singleton.getInstance().hashCode());
+ }
+ }).start();
+ }
+ }
+}
+
Cloneable 接口是立即可用的原型模式。分两阶段提交
执行流程:
四大模式:
其他分布式事务解决方案:
使用 ZAB 协议,包括两种运行模式:
消息广播(Leader 正常运行),所有事务请求由单一主进程处理,Leader 转换为事务 Proposal 并广播分发给 Follower,Leader 等待 Follower 的反馈,超过半数的 Follower 反馈消息后,Leader 再发送 Commit 消息提交事务 Proposal。
崩溃恢复(Leader 不可用时),新选举产生的 Leader 与过半的 Follower 进行同步,使数据一致,同步后进入消息广播模式。
主要服务于分布式系统,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理,用来解决分布式集群中应用系统的一致性问题,构建 ZooKeeper 集群时使用的服务器最好是奇数台。其设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
数据结构:Znode节点,与Unix文件系统类似,通过路径来标识,例如 /home/app,Znode节点又分为两种类型:临时节点、持久节点、临时顺序节点、持久顺序节点。客户端和服务端断开连接后,临时节点会自动删除但持久节点不会。分布式锁使用的是临时节点。
Watcher 监听器:节点的数据发生变化后会通知到节点的监听器。
基本命令:
实现分布式锁原理:判断能否创建临时节点,如果不能则监听父节点(非公平锁)或上一个节点(公平锁),任务执行完成后释放该节点并通知所有监听的节点。
实现注册中心原理:初始化时 Provider 先向目录写入 URL 地址,Consumer 订阅相同目录的 URL 地址和自己的 URL 地址,监控中心订阅 Provider 和 Consumer 的 URL 地址;Consumer 在第一次调用服务时,会通过注册中心找到相应的服务的IP地址列表,并缓存到本地,以供后续使用;当 Provider 下线时,会在列表中移除 URL 并将新的 URL 地址发送给 Consumer 并缓存至本地,服务上线也是一样的。
与 Nacos 的区别:
Nacos 是 AP 的,保证可用性,每个节点都是平等的,若干个节点 crash 后不会影响正常节点,但查到的信息不一定是最新的。ZK 在 crash 后进行 leader 选举,期间是不可用的。
底层基于 Netty 的 NIO 框架,基于 TCP 协议传输
支持服务端服务级别、服务端方法级别、客户端服务级别、客户端方法级别的负载均衡配置。还可以拓展负载均衡算法。
TLS 协议:
TLS 的 rsa 握手过程,存在什么安全隐患,怎么解决的?
SSL 加密是绝对安全的,但是 HTTPS 并不是绝对安全的,可以通过中间人攻击的方式,即所有请求先发送给第三方(中间人),返回中间人的证书,后续的请求/响应都通过中间人进行转发。
默认浏览器对同一域名的并发请求限制为 6 - 8 个。
基于谷歌的QUIC,底层使用udp代码tcp协议,解决了队头阻塞问题,同样无需握手,性能大大地提升,默认使用tls加密。
区别:
进程间通信方式:
线程间通信方式:
为什么要有这两个状态?保护机制,防止用户误操作或恶意破坏系统
如果自己实现服务注册与发现,需要考虑以下三点:
实现方案:
Paxos 和 Raft 算法都属于一致性算法,所以是保证 CP
实际上,作为一个注册中心来说,保证 AP 更加重要,即可用性。
与 HTTP 的对比,RPC 使用二进制传输,传输效率高(HTTP额外空间开销大,包含大量元数据,头字段等),但通用性不如 HTTP 协议
可以。传输层有两个传输协议分别是 TCP 和 UDP,在内核中是两个完全独立的软件模块。可以在 IP 包头的协议号字段判断出 TCP 还是 UDP
因为三次握手才能保证双方具有接收和发送的能力,并且防止重复建立历史连接。
本质原因是 TCP 是全双工通信,客户端确认没有数据发送后,发出结束报文,此时服务端返回确认后,服务端也不会接收客户端数据。但是此时服务端可能还有数据没有传输完,客户端还是可以接收数据。
如果挥手过程中「没有数据要发送」并且「开启了 TCP 延迟确认机制」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手。
DNS 在进行区域传输的时候使用 TCP,其他情况使用 UDP。
区域传输:是指DNS主从服务器之间的数据同步,保证数据的一致性,传送会利用DNS域,所以就称为DNS区域传送。
在高并发环境下,服务之间的依赖关系导致调用失败,解决的方式通常是: 限流->熔断->隔离->降级, 其目的是防止雪崩效应。
四个条件:
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环(固定大小)上。数据存储在哈希值通过顺时针找到的第一个节点。
一致性哈希算法是对 2^32 取模,是一个固定的值;而普通哈希表的长度是由节点数决定的。
一致性哈希算法并不保证节点能够在哈希环上分布均匀,因此引入均匀分布的虚拟节点,建立真实节点和虚拟节点的映射关系。
虚拟内存是一种计算机技术,它允许系统将一部分硬盘空间当作RAM(随机存取存储器)使用。当物理内存不足以支持正在运行的应用程序时,系统会将不常用的数据移动至磁盘中。虚拟内存为每个进程提供了一个一致的、私有的地址空间
32位/64位表示CPU可以处理最大位数,一次性的运算量不一样,寻址能力也不同。
CPU 占用排查:使用 top 和 top -Hp xxx 命令定位占用率最高的进程和该进程的线程 内存占用排查:jstack, jmap 打印出堆栈信息, jstat 查看垃圾回收的情况
使用 pprof 工具,可以查看 CPU 占用、排查内存泄漏、协程泄漏等。
型号:NUC11PAHi5
硬盘:Samsung 970Pro 1TB
内存:Samsung 3200MHz 8GB * 2
操作系统:Windows10 Pro
锁屏黑屏后有一定几率无法唤醒,右侧蓝色的电源灯常亮(非呼吸灯),左侧橙色的硬盘灯不亮(正常情况下会闪),只能通过长按电源键十秒左右才能关机。
显卡驱动回滚至27版本。
 27版本的驱动
27版本的驱动
单机 QPS 能力参考范围为 8 - 10 万。
Redis 的数据并不是完全在内存中,当 Redis 的数据量大于物理内存容量时,会通过虚拟内存的手段,将不经常使用的数据(冷数据)存储到硬盘上,以释放物理内存空间。
在虚拟内存中,数据被分为多个页面,每个页面大小默认 32 字节。显然,虚拟内存可以节省内存,但也带来一定的性能损失。
采用写后日志的方式,先执行命令,再将操作日志以文本形式追加到文件中。
为什么采用写后日志?(Mysql是采用写前日志)
当 AOF文件太大时,Redis fork出一个子进程调用 bgrewriteaof 方法重写一个新的文件,比如increase(1)和increase(1),会被合并成set(2)。也用到了 写时复制。
将某一时刻的内存数据以二进制的形式写入磁盘。
RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
save 和 bgsave 两条命令触发 RDB 持久化操作。save 命令在主线程中执行,会导致阻塞。而 bgsave 创建一个子线程,避免阻塞,是默认的 RDB 的默认配置。并且 bgsave 允许执行快照命令期间修改数据,因为子线程会创建一个修改后的副本再写入(写时复制)。
原理:fork() 后的子进程与父进程共享内存空间,如果是读取数据,相安无事;如果是写数据,会检测到内存页是只读然后触发中断最后复制一份数据再做修改。
好处:减少不必要的资源分配;减少分配和复制大量资源时带来的瞬间延时。
缺点:如果父子进程都在进行大量的写操作,会产生大量的分页错误。
结合 AOF 和 RDB 两种持久化方式。混合持久化只发生于 AOF 重写过程。 重写后的新 AOF 文件前半段是 RDB 格式的全量数据,后半段是 AOF 格式的增量数据。
缺点:不再是 AOF 格式的文件,可读性差。
Redis 7之后使用 Listpack(紧凑列表) 数据结构代替 Ziplist。
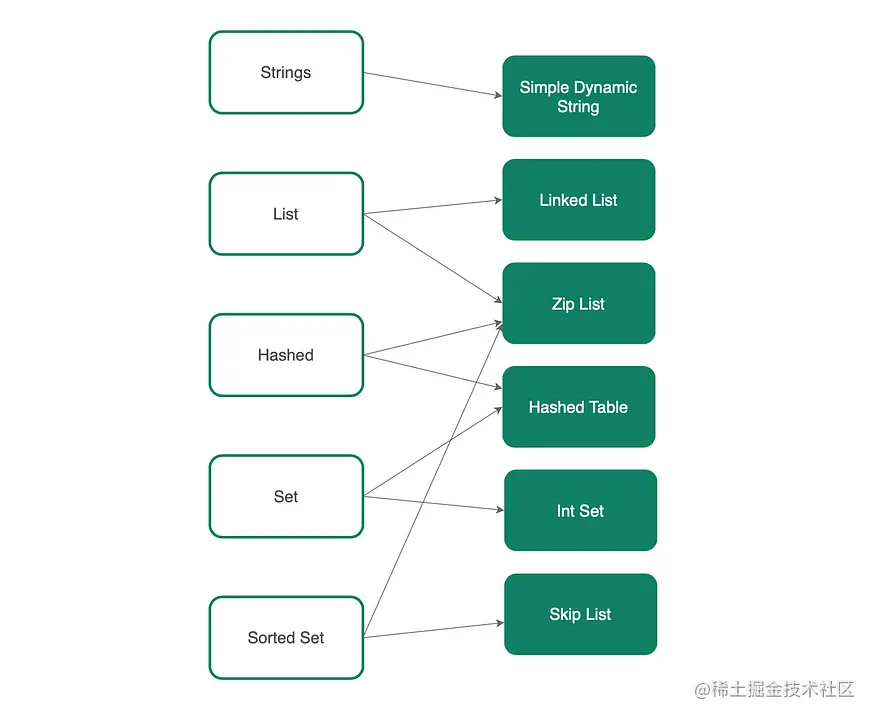
消息通信模式:pub/sub,不支持消息持久化
注意事项:
好处:将一次性的大批量拷贝分摊到多个请求中。
共有三个缓冲区:
为了解决客户端和服务器端的请求发送和处理速度不匹配所设置的。
输入缓冲区会先暂存客户端发送过来的命令,Redis 主线程从输入缓冲区中读取命令,进行处理。当 Redis 主线程处理完数据后,会把结果写入到输出缓冲区,再从输出缓冲区返回给客户端。
缓冲区溢出的可能情况:BigKey,缓冲区大小不合理。
用于Redis主从节点之间复制时使用的。由于主从节点间的数据复制包括全量复制和增量复制两种。因此也分为复制缓冲区和复制积压缓冲区两种。
复制缓冲区是 Redis 在全量复制过程中,主节点在向从节点传输 RDB 文件的同时,会继续接收客户端发送的写命令请求。这些写命令就会先保存在复制缓冲区中,等 RDB 文件传输完成后,再发送给从节点去执行。主节点上会为每个从节点都维护一个复制缓冲区,来保证主从节点间的数据同步。
复制积压缓冲区是一个大小有限的环形缓冲区。当服务器断线重连后,复制积压缓冲区的内容会被发送到从节点,当主节点把复制积压缓冲区写满后,会覆盖缓冲区中的旧命令数据,会造成主从节点的数据不一致。在命令传播阶段出现断网的情况,或者网络抖动时会导致连接断开,此时主节点会向复制积压缓冲区写数据。
AOF 缓冲区:Redis在AOF持久化的时候,会先把命令写入到AOF缓冲区,然后通过回写策略(always、everysec、no)来写入硬盘AOF文件。
AOF 重写缓冲区:当需要进行AOF重写时,主进程会fork一个子进程进行AOF重写,此时主进程还要继续接收客户端传来的指令,此时这些指令就会存放在AOF重写缓冲区中;当AOF重写完成后,将AOF重写缓冲区中的指令追加到aof文件中,并将原来的aof文件替换,来保证数据的一致性。(与主从复制中的复制缓冲区类似)
redis 4.0 后部分命令开始使用多线程。
为什么使用单线程?
什么是多路IO复用:一个服务端进程可以同时处理多个客户端连接。用于AOF持久化任务和处理客户端请求。其实现函数有:
为什么 Redis 又支持多线程了?
主节点可以读、写,从节点只能读
主从模式下,服务端并不做转发处理。而要实现读写分离的功能,需要客户端自行处理了。比如要自行定位master节点,然后将写请求发送过去,读请求则可以做负载均衡处理。
哨兵模式基于主从复制模式,只是引入了哨兵来监控与自动处理故障。
哨兵每2秒向pubsub频道接收和发送hello信息,实现哨兵之间的通信。
哨兵每1秒向所有主从节点和其他哨兵发送PING命令来判断其是否正常运行。
哨兵每10秒向主从节点发送INFO命令来获取节点信息(被标记为客观下线后每1秒一次)。
如果主节点或者从节点没有在规定的时间内响应哨兵的 PING 命令,哨兵就会将它们标记为「主观下线」。其他哨兵会尝试与节点建立连接,如果大于配置文件中设定的值,则认定节点「客观下线」。
Redis 集群无法保证强一致性,选择了高可用和分区容忍,即AP。
将不同的数据分布在不同的节点中,分布的规则采用一致性哈希算法。指将数据映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。共有16384个哈希槽。
一致性哈希算法存在节点分布不均匀的问题。解决方法:引入虚拟节点,将数据映射至虚拟节点而不是真实节点,虚拟节点和真实节点又存在一层映射关系。
在集群模式下,对于读/写请求,并非是服务端转发请求,而是服务端返回转移指令,通知客户端数据所在节点,并让客户端重新发起请求
Redis 有事务但没有回滚,因为Redis认为事务的失败都是使用者造成的。
不存在实时一致性,只能保证最终一致性。
首选
如果对缓存命中率有要求,可以采用先更新数据库再更新缓存 + 分布式锁的方案。分布式锁保证同一时间只运行一个请求更新缓存。
最终一致性方案:
主要考虑以下两点:
如果采用先删除缓存,再更新数据库如何避免出现脏数据?
延迟双删:先删除缓存,更新数据库,睡眠,再次删除缓存。睡眠的时间一般是一次查询的耗时 + 几百毫秒。第二次的删除可以清除掉因并发导致的缓存脏数据。
1
+2
+3
+4
+5
+6
+7
+8
+
#删除缓存
+redis.delKey(X)
+#更新数据库
+db.update(X)
+#睡眠
+Thread.sleep(N)
+#再删除缓存
+redis.delKey(X)
+
缓存删除重试:为了保证缓存删除成功,需要在缓存失败时增加重试机制。可以借助消息队列,将删除失败的数据进行异步重试。
BinLog缓存删除方案:BinLog存储了对数据库的更改操作日志记录,通过订阅该日志(如:canal),获取需要更新缓存的key和数据。
Redis的删除策略是惰性删除+定期删除。定期删除如果检查到过期key的数据超过一定百分比,循环再次检查并删除。
不进行数据淘汰(默认的内存淘汰策略),写入时禁止写入并报错。
进行数据淘汰
出于节省内存的考虑,Redis 的 LRU 算法并非完整的实现,是一个基于哈希表的近似 LRU 算法,通过对少量键进行取样,然后回收其中的最久未被访问的键。通过调整每次回收时的采样数量 maxmemory-samples,可以实现调整算法的精度。
红锁是一种分布式锁。在 Redis 单独节点的基础上,RedLock 使用了多个独立的 Redis 的 Master 实例(通常建议是奇数个,比如 5 个),共同协作来提供更强健的分布式锁服务。
RedLock 是对集群的每个节点进行加锁,如果大多数节点(N/2+1)加锁成功,则才会认为加锁成功。
这样即使集群中有某个节点挂掉了,因为大部分集群节点都加锁成功了,所以分布式锁还是可以继续使用的。
答:设置看门狗(定时器)
指 Redis 的 Key 对应的 Value 过大,并不是指 Key 过大。
redis-cli --bigkeys 命令,不建议scan 命令del 命令(会造成线程阻塞)scan 命令(会造成线程阻塞)unlink 异步删除指短时间内被频繁访问的数据
monitor 命令redis-cli --hotkeys 命令,不建议New Markdown File:1
+2
+3
+4
+5
+6
+7
+
Windows Registry Editor Version 5.00
+[HKEY_CLASSES_ROOT\.md]
+@="Typora.md"
+"Content Type"="text/markdown"
+"PerceivedType"="text"
+[HKEY_CLASSES_ROOT\.md\ShellNew]
+"NullFile"=""
+
Open with Code,需要根据实际情况修改路径:1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+
Windows Registry Editor Version 5.00
+; Open files
+[HKEY_CLASSES_ROOT\*\shell\Open with VS Code]
+@="Open with Code"
+"Icon"="C:\\Program Files\\Microsoft VS Code\\Code.exe,0"
+[HKEY_CLASSES_ROOT\*\shell\Open with VS Code\command]
+@="\"C:\\Program Files\\Microsoft VS Code\\Code.exe\" \"%1\""
+; This will make it appear when you right click ON a folder
+; The "Icon" line can be removed if you don't want the icon to appear
+[HKEY_CLASSES_ROOT\Directory\shell\vscode]
+@="Open with Code"
+"Icon"="\"C:\\Program Files\\Microsoft VS Code\\Code.exe\",0"
+[HKEY_CLASSES_ROOT\Directory\shell\vscode\command]
+@="\"C:\\Program Files\\Microsoft VS Code\\Code.exe\" \"%1\""
+; This will make it appear when you right click INSIDE a folder
+; The "Icon" line can be removed if you don't want the icon to appear
+[HKEY_CLASSES_ROOT\Directory\Background\shell\vscode]
+@="Open with Code"
+"Icon"="\"C:\\Program Files\\Microsoft VS Code\\Code.exe\",0"
+[HKEY_CLASSES_ROOT\Directory\Background\shell\vscode\command]
+@="\"C:\\Program Files\\Microsoft VS Code\\Code.exe\" \"%V\""
+
线段树
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+43
+
class NumArray {
+ int[] segmentTree;
+ int n;
+
+
+ public NumArray(int[] nums) {
+ n = nums.length;
+ segmentTree = new int [2 * n];
+ System.arraycopy(nums, 0, segmentTree, n, n);
+ for(int i = n - 1; i > 0; i--){
+ segmentTree[i] = segmentTree[2 * i] + segmentTree[2 * i + 1];
+ }
+ }
+
+ public void update(int index, int val) {
+ index += n;
+ segmentTree[index] = val;
+ index /= 2;
+ while(index != 0){
+ segmentTree[index] = segmentTree[2 * index] + segmentTree[2 * index + 1];
+ index /= 2;
+ }
+ }
+
+ public int sumRange(int left, int right) {
+ left += n;
+ right += n;
+ int sum = 0;
+ while(left <= right){
+ if(left % 2 == 1){
+ sum += segmentTree[left];
+ left ++;
+ }
+ if(right % 2 == 0){
+ sum += segmentTree[right];
+ right--;
+ }
+ left /= 2;
+ right /= 2;
+ }
+ return sum;
+ }
+}
+
使用 win + r 打开运行,再输入 regedit
在打开的注册表中定位至HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Advanced
新建 DWORD(32位)值,命名为ShowSecondsInSystemClock,将其数值置为 1 并保存。
打开任务管理器重新启动Windows资源管理器即可。
版权中心官网链接:https://www.ccopyright.com.cn/。
在没有加急的情况下,申请一篇软著的总体周期大概需要三四个月左右。如果时间紧迫,可以去某宝找机构加急办理(不建议)。
另外,申请软著可能用到的模板材料放到文末的附件中,有需要自取。
2020-07-24:填写并提交两篇软著申请电子稿
2020-07-28:EMS邮寄所需材料
2020-07-29:北京登记部签收
2020-09-03:一篇受理登记,邮箱收到受理通知书。同天,另一篇软著材料提交不规范,收到补正通知书。
2020-09-04:再次EMS邮寄材料不规范的替代材料。
2020-09-05:北京登记部签收
2020-09-17:补正软著成功受理
2020-10-29:收到第一件软著登记证书的挂号信(寄信日期为10月26日)
2020-11-13:收到第二件软著登记证书的挂号信(寄信日期为11月9日)
 第一篇软著时间线
第一篇软著时间线
 第二篇软著时间线
第二篇软著时间线
第三篇软件著作初次邮寄材料的时间点是2020年12月17日左右,其余时间点见下。从受理到邮寄发放间隔了一个半月,可见效率之低下!
 第三篇软著时间线
第三篇软著时间线
身份证复印件复印到同一张A4纸上。
使用说明书里的图片要清晰。
在合作开发的情况下,合作开发合同的落款一定要早于开发完成时间。
副本不收费
Spring, SpringBoot, Spring MVC 区别:
运行 SpringApplication 又分为: 1、获取并启动监听器 2、根据监听器和参数来创建运行环境 3、准备 Banner 打印器 4、创建 Spring 容器 5、Spring 容器前置处理(将前几步生成的监听器,Banner打印器和环境等配置到容器中) 6、刷新容器 7、Spring 容器后置处理(空方法) 8、发出结束执行的事件通知 9、返回容器
Spring核心之控制反转(IOC)和依赖注入(DI):
refresh() 的作用:在创建IoC容器前,如果已经有容器存在,则需要把已有的容器销毁和关闭,以保证在refresh之后使用的是新建立起来的IoC容器。refresh的作用类似于对IoC容器的重启,在新建立好的容器中对容器进行初始化,对Bean定义资源进行载入。
AbstractAutowireCapableBeanFactory 的 createBeanInstance 方法AbstractAutowireCapableBeanFactory 的 populateBean 方法AbstractAutowireCapableBeanFactory 的 initializeBean 方法Spring启动时先扫描所有Bean信息,BeanDefinition存储日常给Spring Bean定义的元数据。然后存储BeanDefinition的BeanDefinitionMap,是根据字典序依次创建Bean对象。
IOC的实现原理是工厂模式加反射机制。
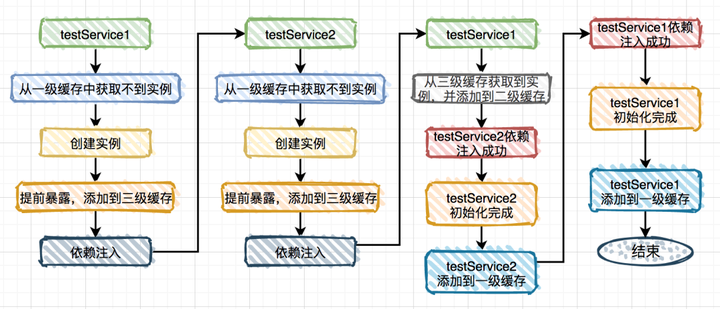
为什么需要二级缓存: 如果出现循环依赖+aop时,多个地方注入这个动态代理对象需要保证都是同一个对象。如果只使用这两层缓存,在使用三级缓存中的工厂对象生成的动态代理对象都是新创建的,循环依赖的时候,注入到别的bean里面去的那个动态代理对象和最终这个bean在初始化后自己创建的bean地址值不一样。如果 Spring 选择二级缓存来解决循环依赖的话,那么就意味着所有 Bean 都需要在实例化完成之后就立马为其创建代理,而 Spring 的设计原则是在 Bean 初始化完成之后才为其创建代理。所以,Spring 选择了三级缓存。但是因为循环依赖的出现,导致了 Spring 不得不提前去创建代理,因为如果不提前创建代理对象,那么注入的就是原始对象,这样就会产生错误。
Prototype(原型)对象和单例对象的区别:
为什么Springboot默认创建单例Bean:
面向切面编程(AOP)也是一种设计思想,本质是为了解耦。其实现方式是动态织入,在运行时动态将要增强的代码织入到目标类中,借助动态代理技术完成的。并且接口与非接口的动态代理机制并不相同,如下所示:
执行顺序:
注解:
@Component修饰的类为组件类并为这个对象创建Bean,@Bean修饰的方法会生成一个对象Bean。
@SpringBootApplication 包含三个注解:
AutoConfigurationImportSelector.java 中可以看到所有自动配置类的名称。自动配置类原理事务的几个参数:rollbackFor,propagation,isolation
PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的区别:
前提:a方法调用b方法
| a | b | 报错情况 | 同类调用的现象 | 不同类调用的现象 |
|---|---|---|---|---|
| transactional注解 | 无注解 | a方法报错,b方法不报错 | 均回滚 | 均回滚 |
| transactional注解 | 无注解 | a方法不报错,b方法报错 | 均回滚 | 均回滚 |
| 无注解 | transactional注解 | a方法报错,b方法不报错 | 均不回滚 | 均不回滚 |
| 无注解 | transactional注解 | a方法不报错,b方法报错 | 均不回滚 | a不回滚,b回滚 |
结论:
局部静态变量用于函数体内部修饰变量,这种变量的生存期长于该函数。
用法:局部变量前加static,修饰局部变量为静态局部变量。
作用:改变局部变量的销毁时期。
作用域:局部作用域,当定义它的函数或语句块结束的时候,作用域结束。
与局部变量的区别:
与全局变量的区别:
同样是初始化一次,连续调用fun()的结果是一样的,但是,使用全局变量的话,变量就不属于函数本身了,不再仅受函数的控制,给程序的维护带来不便。
静态局部变量正好可以解决这个问题。静态局部变量保存在全局数据区,而不是保存在栈中,每次的值保持到下一次调用,直到下次赋新值。
Code:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
#include<stdio.h>
+int fun(void){
+ static int count = 20; // 只能在该函数内修改静态局部变量的值
+ return count--;
+}
+
+int main() {
+ printf("global\t\tlocal static\n");
+ int count = 1;
+ for(; count <= 10; ++count) printf("%d\t\t%d\n", count, fun());
+}
+
 运行结果图
运行结果图
全局静态变量定义在函数体外,该变量只在本文件可见。
用法:全局变量前加static,修饰全局变量为静态全局变量。
作用:改变全局变量的可见性。静态全局变量的存储位置在静态存储区,未被初始化的静态全局变量会被自动初始化为0。
作用域:全局静态变量在声明他的文件之外是不可见的,仅在从定义该变量的开始位置到文件结尾可见。
特点:
Code:
以下两个文件要放到项目工程里才有效果。
1
+2
+3
+4
+
//file a.cpp
+
+//static int n = 15; // ERROR!因为static隔离了文件。
+int n = 15;
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+
//file main.cpp
+
+#include <iostream>
+//#include"a.cpp" //不管有没有static,加include都不会报错
+using namespace std;
+
+extern int n;
+
+void fn(){
+ n++;
+}
+
+int main() {
+ cout<<"Before:" <<n<<endl;
+ fn();
+ cout<<"After:" <<n<<endl;
+ return 0;
+}
+
 运行结果图
运行结果图
静态函数的作用与2. 静态全局变量类似。特点也类似:不能被其他文件所用;其它文件中可以定义相同名字的变量,不会发生冲突。
用法:函数返回类型前加static,修饰函数为静态函数。
作用:改变函数的可见性。函数的定义和声明在默认情况下都是extern的,但静态函数只在声明它的文件中可见,不能被其他文件使用。
用法:类成员前加static,修饰类的成员为类的静态成员。
作用:实现多个对象之间的数据共享,并且使用静态成员不会破坏封装性,也保证了安全性。
Code:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+
#include<iostream>
+using namespace std;
+
+class Rectangle
+{
+private:
+ int m_w,m_h;
+ static int s_sum;
+
+public:
+ Rectangle(int w,int h)
+ {
+ this->m_w = w;
+ this->m_h = h;
+ s_sum += (this->m_w * this->m_h);
+ }
+
+ void GetSum()
+ {
+ cout<<"sum = "<<s_sum<<endl;
+ }
+};
+
+int Rectangle::s_sum = 0; //静态成员类外初始化,因为其属于类,不属于类对象
+
+int main()
+{
+ cout<<"sizeof(Rectangle)="<<sizeof(Rectangle)<<endl;
+ Rectangle *rect1 = new Rectangle(3,4);
+ rect1->GetSum();
+ cout<<"sizeof(rect1)="<<sizeof(*rect1)<<endl;
+ Rectangle rect2(2,3);
+ rect2.GetSum();
+ cout<<"sizeof(rect2)="<<sizeof(rect2)<<endl;
+}
+
1
+2
+3
+4
+5
+
sizeof(Rectangle)=8
+sum = 12
+sizeof(rect1)=8
+sum = 12
+sizeof(rect1)=8
+
由此可知:sizeof(Rectangle) = 8bytes = sizeof(m_w) + sizeof(m_h)。也就是说静态数据成员并不占用Rectangle的内存空间。因为静态数据成员在全局数据区(静态区)分配内存。再看看GetSum(),第一次12 = 3 * 4,第二次18 = 12 + 2 * 3。因此,静态数据成员只会被初始化一次,与对象无关。
结论:
静态数据成员被当作是类的成员,由该类型的所有对象共享访问,对该类的多个对象来说,静态数据成员只分配一次内存。静态数据成员存储在全局数据区。静态数据成员定义时要分配空间,所以不能在类声明中定义。从某种程度上来说,静态数据成员与静态变量相类似。
用法:类函数前加static,修饰类的函数为静态函数。
作用:减少资源消耗,不需要实例化就可以使用
Code:
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+
#include<iostream>
+using namespace std;
+
+class Rectangle
+{
+private:
+ int m_w,m_h;
+ static int s_sum;
+
+public:
+ Rectangle(int w,int h)
+ {
+ this->m_w = w;
+ this->m_h = h;
+ s_sum += (this->m_w * this->m_h);
+ }
+
+ static void GetSum() // 此处为静态成员函数
+ {
+ cout<<"sum = "<<s_sum<<endl;
+ }
+};
+
+int Rectangle::s_sum = 0; //静态成员类外初始化,因为其属于类,不属于类对象
+
+int main()
+{
+ cout<<"sizeof(Rectangle)="<<sizeof(Rectangle)<<endl;
+ Rectangle *rect1 = new Rectangle(3,4);
+ rect1->GetSum();
+ cout<<"sizeof(rect1)="<<sizeof(*rect1)<<endl;
+ Rectangle rect2(2,3);
+ rect2.GetSum(); //可以用对象名.函数名访问
+ cout<<"sizeof(rect2)="<<sizeof(rect2)<<endl;
+ Rectangle::GetSum(); //也可以可以用类名::函数名访问
+}
+
结论:
非静态成员函数可访问静态成员函数/成员;
静态成员函数不能访问非静态成员函数/成员,只能访问静态成员函数/变量;
调用静态成员函数,可以用成员访问操作符(.)和(->)为一个类的对象或指向类对象的指针调用静态成员函数,也可以用类名::函数名调用。
另外,既然是在类里操作,对类成员的访问还是要遵从public,protected,private访问规则。
全局变量、文件域的静态变量和类的静态成员变量在main执行之前的静态初始化过程中分配内存并初始化;局部静态变量(一般为函数内的静态变量)在第一次使用时分配内存并初始化。这里的变量包含内置数据类型和自定义类型的对象。
在编程中,难免会用到全局变量,全局变量的作用域是整个源程序,当一个源程序由多个源文件组成时,全局变量在所有的源文件中都是有效的。如果希望全局变量仅限于在本源文件中使用,在其他源文件中不能引用,也就是说限制其作用域只在定义该变量的源文件内有效,而在同一源程序的其他源文件中不能使用,这时,就可以通过在全局变量上加static来实现,使全局变量被定义成一个静态全局变量。这样就可以避免其他源文件使用该变量、避免其他源文件因为该变量引起的错误。起到了对其他源文件隐藏该变量和隔离错误的作用,有利于模块化程序。
有时候,我们希望函数中局部变量的值在函数调用结束之后不会消失,仍然保留函数调用结束的值。即它所在的存储单元不释放。这时,应该将该局部变量用关关键字static声明为静态局部变量。当局部变量被声明为静态局部变量的时候,也就改变了局部变量的存储位置,从原来的栈中存放改为静态存储区存放,全局变量也存放在静态存储区,静态局部变量与全局变量的主要区别就在于可见性,静态局部变量只在其被声明的代码块中是可见的。
通过Python代码关闭杰锐微通摄像头的自动曝光功能。
查阅相关资料,有网友提出使用以下代码:
1
+
capture.set(cv2.CAP_PROP_AUTO_EXPOSURE, 0.25)
+
失败。
先通过在终端输入v4l2-ctl --list-devices得到摄像头列表。

接着输入v4l2-ctl -d /dev/video2 --all查看单个摄像头的参数。

发现最后几行中的exposure_auto的默认值为3,正好代表着光圈优先。将其设置为1,代表手动模式
因此在代码修改为
1
+2
+
capture.set(cv2.CAP_PROP_AUTO_EXPOSURE, 1)
+capture.set(cv2.CAP_PROP_EXPOSURE, 50)
+
即可。
曝光值参数可根据环境自主调节。
众所周知,已经Push到Github的Commits是不能撤销的。但是,我们可以通过创建分支并修改默认分支的方法让Repo回退至某个版本并删除该版本后的所有Commits记录。
删除已Push的Commits并回退至旧版本。如下图所示,删除红框中的Commits记录并回退至箭头所指的版本。

Revert Commits也能回退版本。但是其不同之处在于,Revert Commits会保留所有的Commits。
本方法是在Windows的Github Desktop中操作的。但不管在哪个操作系统,解决该问题的思路是类似的。
首先选择要回退到的Commit并Create branch, Name branch, Publish branch. 如下三图所示:



接着,在Github上设置默认分支1,删除原分支,修改新建的分支名即可,如下三图所示:



但是这样有个缺点:因为在Github主页上修改分支名并不会实时同步到Github Desktop,因此GitHub Desktop中会出现“混乱”,此时建议删除本地代码并重新Clone至本地。
Zookeeper 是一个分布式的协调服务,可以实现
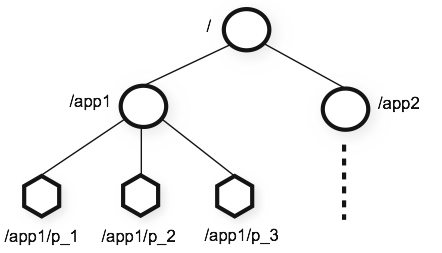
文件系统类似的,整体上可以看成一棵树,每个节点称作一个 ZNode,每个 ZNode 都可以通过其路径得到唯一标识。默认只能最多存储 1MB 的数据
但与文件系统不同,每一个 ZNode 节点都可以存储数据,但文件系统的目录不可以存储数据。
三大类:
四种形式:
每次的变化都会产生一个集群全局的唯一的事务id, Zxid(ZooKeeper Transaction Id),由Zookeeper的 Leader 实例维护。变化包括
具体是基于观察者模式实现的。在ZooKeeper中,客户端是观察者,服务端是被观察者。 客户端通过注册Watch来监听服务端节点的数据变化。
ZooKeeper 的观察机制允许用户在指定节点上针对感兴趣的事件注册监听,当事件发生时,监听器会被触发,并将事件信息推送到客户端。
监听两方面的内容:
一主多从的结构

client与ZooKeeper集群中的某一台server保持连接,发送读/写请求,读请求直接由当前连接的server处理,写请求由于是事务请求,由当前server转发给leader进行处理。同时,client还能接收来自server端的watcher通知。所有的这些交互,都是基于client和ZooKeeper的server之间的TCP长连接,也称之为Session会话。有了会话之后,后续的请求发送,回应,心跳检测等机制都是基于会话来实现的。
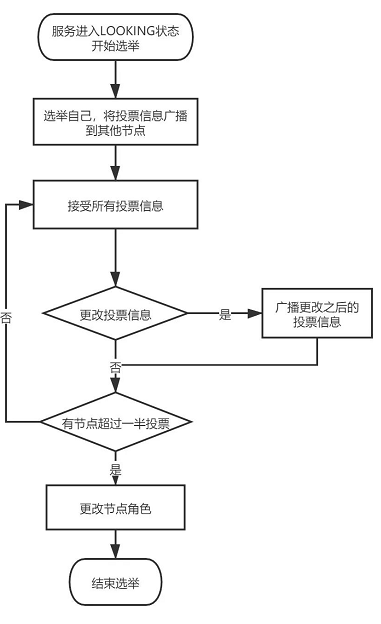
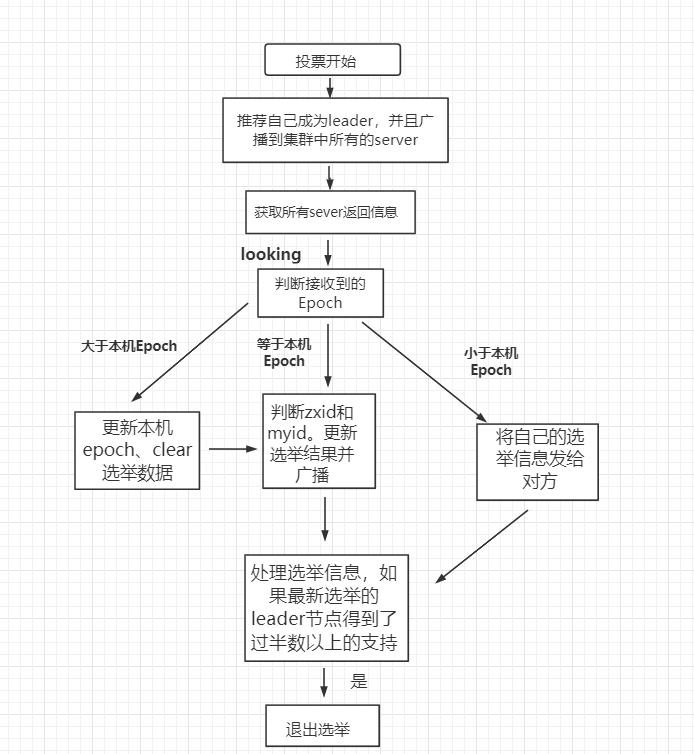
每个节点都有一个定时器,最先结束倒计时的节点最先发送选举的信号(基本也会是被选举为 leader)