Computer vision, machine vision and image processing are to process image in computer for different visual tasks from diverse perspectives. Computer vision focus on the visual representation includes images, graphics, animation and videos rather than the sounds, speech or text.
Visual recognition tasks, such as image classification, localization, and detection, are the core building blocks of many of these applications, and recent developments in Convolutional Neural Networks (CNNs) have led to outstanding performance in these state-of-the-art visual recognition tasks and systems. As a result, CNNs now form the crux of deep learning algorithms in computer vision. The Ancient Secret of Computer Vision covers standard techniques in image processing like filtering, edge detection, stereo, flow, etc. (old-school vision), as well as newer, machine-learning based computer vision, which is more comprehensive.

In this section, we will focus on more technological details of CNN architecures, training and the motivation.
See CV, NLP for the state-of-the-art methods.
- https://www.openml.org/
- https://www.jiqizhixin.com/sota
- https://www.pyimagesearch.com/start-here/
- https://deepai.org/
- https://www.mlhub123.com/
- https://sites.google.com/visipedia.org/index
- https://github.com/Ewenwan/MVision/tree/master/CNN
- Computational Vision at Caltech
- SE(3) COMPUTER VISION GROUP AT CORNELL TECH
- https://vcla.stat.ucla.edu/index.html
- 香港中文大学多媒体实验室
- 计算机视觉与遥感实验室 Computer Vision & Remote Sensing (CVRS) Lab@WHU
- Center for Research in Computer Vision
- Vision and Content Engineering Lab@ETZH
- Computer Vision and Geometry Group
- https://github.com/jbhuang0604/awesome-computer-vision
- CS231n: Convolutional Neural Networks for Visual Recognition
- Spring 2019 CS 543/ECE 549: Computer Vision
- Elements of Geometric Computer Vision. by Andrea Fusiello
- CVonline: The Evolving, Distributed, Non-Proprietary, On-Line Compendium of Computer Vision
- An Introduction to Projective Geometry (for computer vision) by Stan Birchfield
- Photogrammetric Computer Vision -- Statistics, Geometry, and Reconstruction
- http://slazebni.cs.illinois.edu/spring17/lec01_cnn_architectures.pdf
- https://blog.algorithmia.com/introduction-to-computer-vision/
- https://hayo.io/computer-vision/
- http://www.robots.ox.ac.uk/~vgg/research/text/
- https://ieeexplore.ieee.org/document/8295029
- http://www.vlfeat.org/matconvnet/
- http://cvcl.mit.edu/aude.htm

| Image acquisition | Image processing | Image analysis |
|---|---|---|
| Webcams & embedded cameras | Edge detection | 3D scene mapping |
| Digital compact cameras & DSLR | Segmentation | Object recognition |
| Consumer 3D cameras | Classification | Object tracking |
| Laser range finders | Feature detection and matching | --- |
- 9 Applications of Deep Learning for Computer Vision
- Deep Learning for Computer Vision Image Classification, Object Detection, and Face Recognition in Python
- http://modelnet.cs.princeton.edu/
Like other classification tasks, the feature engineering is the core and kernel of preprocessing. The predicted labels is always supposed to be attached to some specific features. As the fingerprint can be an biological identifier of its owner, the desired features are supposed to be sufficient to identify the differences between the ones with the same label.
- https://cv-tricks.com/cnn/understand-resnet-alexnet-vgg-inception/
- https://www.jeremyjordan.me/convnet-architectures/
- http://www.tamaraberg.com/teaching/Spring_16/
LeNet learns the parameters using error back-propagation. In another word, the optimization procedure of CNNs are based on gradient methods. This CNN
model was successfully applied to recognize handwritten digits.

As shown in the above figure, it consists of convolution, subsampling, full connection and Gaussian connections. It is a typical historical architecture.
AlexNet was the winning entry in ILSVRC 2012. It solves the problem of image classification where the input is an image of one of 1000 different classes (e.g. cats, dogs etc.) and the output is a vector of 1000 numbers.


AlexNet consists of 5 Convolutional Layers and 3 Fully Connected Layers.
Overlapping Max Pool layers are similar to the Max Pool layers, except the adjacent windows over which the max is computed overlap each other.
An important feature of the AlexNet is the use of ReLU(Rectified Linear Unit) Nonlinearity.
- https://engmrk.com/alexnet-implementation-using-keras/
- http://gyxie.github.io/2016/09/21/%E6%B7%B1%E5%85%A5AlexNet/
- Understanding AlexNet
- ImageNet Classification with Deep Convolutional Neural Networks

- http://www.robots.ox.ac.uk/~vgg/practicals/cnn/index.html
- http://www.robots.ox.ac.uk/~vgg/research/very_deep/
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION

- Deep Learning in the Trenches: Understanding Inception Network from Scratch
- http://www.csc.kth.se/~roelof/deepdream/bvlc_googlenet.html
- https://zh.d2l.ai/chapter_convolutional-neural-networks/googlenet.html
ResNet is to solve the degeneration of deep neural network when the depth of layers of deep neural network increase.
It is guessed that the nonlinearity of activation function makes it tough to learn (linear) identity transformation (Id(x)=x).

- https://neurohive.io/en/popular-networks/resnet/
- http://teleported.in/posts/decoding-resnet-architecture/
- https://zh.d2l.ai/chapter_convolutional-neural-networks/resnet.html
- Layer-Parallel Training of Deep Residual Neural Networks
- Fast deep parallel residual network for accurate super resolution image processing
- What Can ResNet Learn Efficiently, Going Beyond Kernels?
- https://github.com/tomgoldstein/loss-landscape
- CNN meets PDEs
- Deep Neural Network motivated by PDEs
- https://www.semanticscholar.org/author/Lars-Ruthotto/2557699
- https://www.robots.ox.ac.uk/~vedaldi//research/visualization/visualization.html
- https://www.graphcore.ai/posts/what-does-machine-learning-look-like
- https://srdas.github.io/DLBook/ConvNets.html#visualizing-convnets
| graphcore.ai |
|---|
 |
DenseNet

HRNet
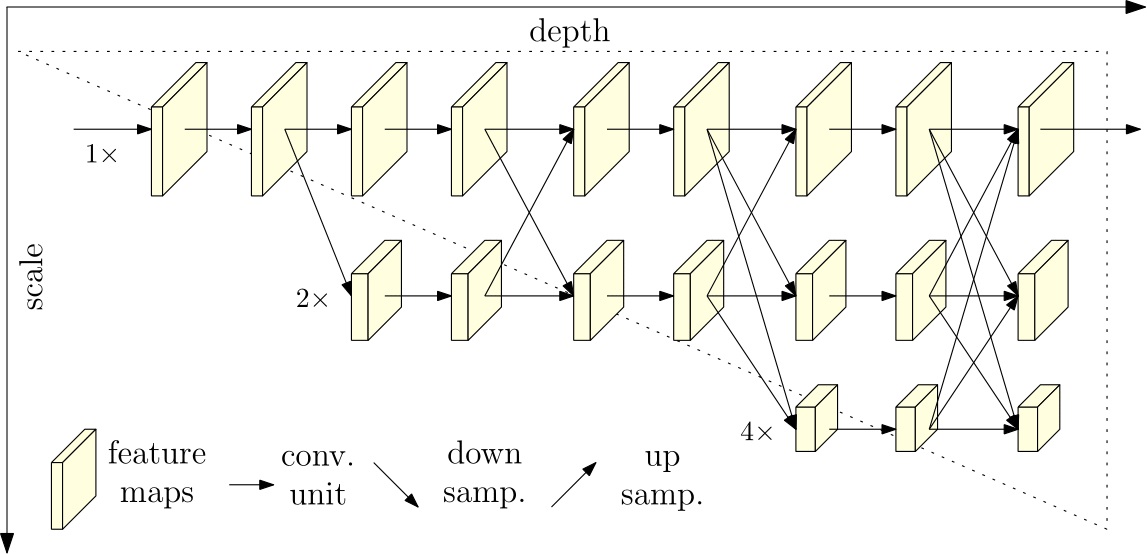
The high-resolution network (HRNet) maintains high-resolution representations by connecting high-to-low resolution convolutions in parallel and strengthens high-resolution representations by repeatedly performing multi-scale fusions across parallel convolutions. We demonstrate the effectives on pixel-level classification, region-level classification, and image-level classification.
The HRNet turns out to be a strong repalcement of classification networks (e.g., ResNets, VGGNets) for visual recognition. We believe that the HRNet will become the new standard backbone.
- http://cvlab.postech.ac.kr/research/deconvnet/
- https://deeplearninganalytics.org/semantic-segmentation/
- http://www.cs.toronto.edu/~tingwuwang/semantic_segmentation.pdf
- http://wp.doc.ic.ac.uk/bglocker/project/semantic-imaging/
- A 2017 Guide to Semantic Segmentation with Deep Learning
- Semantic Image Segmentation Live Demo
- Awesome Semantic Segmentation
- https://arxiv.org/pdf/1711.05847.pdf

only look once (YOLO) is a state-of-the-art, real-time object detection system.
- YOLO 1 到 YOLO 3
- https://github.com/jwchoi384/Gaussian_YOLOv3
- https://pjreddie.com/darknet/yolo/
- https://pjreddie.com/darknet/
- https://github.com/qqwweee/keras-yolo3
- https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
- https://www.jeremyjordan.me/object-detection-one-stage/
- https://github.com/amusi/awesome-object-detection
- Object Detection 2015
- https://blog.csdn.net/v_JULY_v/article/details/80170182
- https://www.fritz.ai/features/pose-estimation.html
- https://github.com/xinghaochen/awesome-hand-pose-estimation
- https://github.com/cbsudux/awesome-human-pose-estimation
- https://cv-tricks.com/pose-estimation/using-deep-learning-in-opencv/
- https://cs.stanford.edu/people/karpathy/sfmltalk.pdf
- https://www.ripublication.com/ijaer18/ijaerv13n9_102.pdf
- Deep Visual-Semantic Alignments for Generating Image Descriptions
- Automatic Image Captioning using Deep Learning (CNN and LSTM) in PyTorch
- How to Develop a Deep Learning Photo Caption Generator from Scratch
- Deep Learning Image Caption Generator
- Conceptual Captions: A New Dataset and Challenge for Image Captioning Wednesday, September 5, 2018
- Towards Total Scene Understanding: Classification, Annotation and Segmentation in an Automatic Framewor
- 6.870 Object Recognition and Scene Understanding Fall 2008
- http://vladlen.info/projects/scene-understanding/
- Holistic Scene Understanding
- http://www.kalisteo.eu/en/thematic_vs.htm
- https://ps.is.tue.mpg.de/research_fields/semantic-scene-understanding
- ScanNet Indoor Scene Understanding Challenge CVPR 2019 Workshop, Long Beach, CA
- Human-Centric Scene Understanding from Single View 360 Video
- HoloVis - 3D Holistic Scene Understanding
- Scene Recognition and Understanding
- BlitzNet: A Real-Time Deep Network for Scene Understanding
- L3ViSU: Lifelong Learning of Visual Scene Understanding

- https://indic-ocr.github.io/
- https://github.com/kba/awesome-ocr
- https://github.com/pannous/tensorflow-ocr
- https://zhuanlan.zhihu.com/p/65707543
- https://github.com/tesseract-ocr/tesseract
- https://github.com/Swift-AI/Swift-AI
- https://github.com/wanghaisheng/awesome-ocr
- https://github.com/chineseocr
- http://tesseract-ocr.github.io/4.0.0/index.html
- https://anyline.com/
- https://github.com/vinayakkailas/Deeplearning-OCR
- https://github.com/hs105/Deep-Learning-for-OCR
- http://cs231n.stanford.edu/reports/2017/pdfs/810.pdf
- https://handong1587.github.io/deep_learning/2015/10/09/ocr.html
- STN-OCR: A single Neural Network for Text Detection and Text Recognition
- https://github.com/titu1994/Neural-Style-Transfer
- https://pjreddie.com/darknet/nightmare/
- https://deepdreamgenerator.com/
- https://www.pyimagesearch.com/2018/08/27/neural-style-transfer-with-opencv/
- https://reiinakano.github.io/2019/01/27/world-painters.html
- https://www.andrewszot.com/blog/machine_learning/deep_learning/style_transfer
- Convolutional Neural Network – Exploring the Effect of Hyperparameters and Structural Settings for Neural Style Transfe
It has shown that
ImageNet trained CNNs are strongly biased towards recognising
texturesrather thanshapes, which is in stark contrast to human behavioural evidence and reveals fundamentally different classification strategies.
- Deep Visualization
- Interpretable Representation Learning for Visual Intelligence
- IMAGENET-TRAINED CNNS ARE BIASED TOWARDS TEXTURE; INCREASING SHAPE BIAS IMPROVES ACCURACY AND ROBUSTNESS
- 2017 Workshop on Visualization for Deep Learning
- Understanding Neural Networks Through Deep Visualization
- vadl2017: Visual Analysis of Deep Learning
- Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks
- Interactive Visualizations for Deep Learning
- https://www.zybuluo.com/lutingting/note/459569
- https://cs.nyu.edu/~fergus/papers/zeilerECCV2014.pdf
- 卷积网络的可视化与可解释性(资料整理) - 陈博的文章 - 知乎
- https://zhuanlan.zhihu.com/p/24833574
- https://zhuanlan.zhihu.com/p/30403766
- https://zhuanlan.zhihu.com/p/28054589
- https://blog.keras.io/how-convolutional-neural-networks-see-the-world.html
- http://people.csail.mit.edu/bzhou/ppt/presentation_ICML_workshop.pdf
- https://www.robots.ox.ac.uk/~vedaldi//research/visualization/visualization.html
- https://www.graphcore.ai/posts/what-does-machine-learning-look-like
- https://srdas.github.io/DLBook/ConvNets.html#visualizing-convnets
- CNN meets PDEs
- Deep Neural Network motivated by PDEs
- https://www.semanticscholar.org/author/Lars-Ruthotto/2557699
| graphcore.ai |
|---|
|
- https://github.com/alecjacobson/computer-graphics-csc418
- http://graphics.cs.cmu.edu/courses/15-463/
- https://github.com/ivansafrin/CS6533s
- https://github.com/ericjang/awesome-graphics
- CreativeAI: Deep Learning for Computer Graphics
- https://github.com/smartgeometry-ucl/dl4g
- https://graphics.stanford.edu/
- https://github.com/arrayfire/arrayfire-python
- https://ge.in.tum.de/research/
- An extensible framework for fluid simulation
- https://people.csail.mit.edu/tzumao/
| Deep Dream |
|---|
 |