UPDATED this tutorial has been changed to use Postgres as a data store instead of a MongoDB (which is obsoleted as of LDES Server version 3.x). You can find the previous version here.
This quick start guide will show you how to create a more advanced processing pipeline in the LDIO Workbench for converting our example model to a standard open vocabulary and to publish that as a Linked Data Event Stream (LDES).
Please see the introduction for the example data set and pre-requisites, as well as an overview of all examples.
To kickstart this tutorial we can use the basic setup tutorial.
For the server we only will need to change the actual model. Everything else can stay the same: we will still need to volume mount the server configuration file and provide the database connection string (which we have changed to reflect our tutorial).
The workbench is where we need to change a few things: we'll need to transform our custom model to the standard vocabulary. To make it a bit more interesting we'll start from an actual real-time message which contains more than one state object. In fact, we'll be checking for changes on a regular basis. Now we have a real linked data event stream!
As mentioned above, we'll be using an open vocabulary standard to describe our model. This allows us to attach real semantic meaning to it and create interoperability with other Data Publishers that use the same vocabulary.
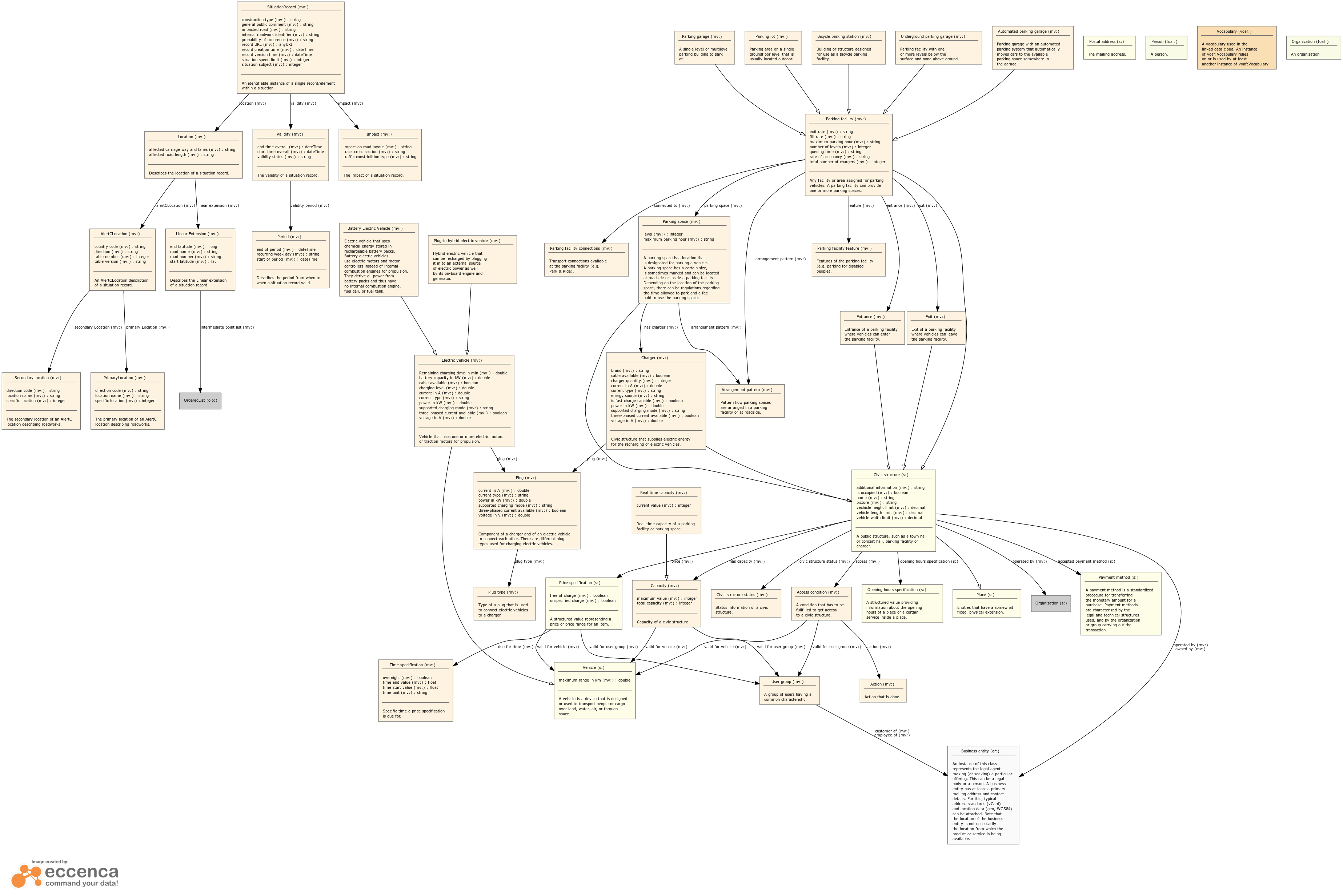
Understanding and mapping our source model (check out the dataset schema) to the target model is the hard part, in particular if we are missing descriptions for the model structure and its properties. Lucky for us, most of the property names are more-or-less self-explanatory.
{kind=link}
| source property | meaning |
|---|---|
| name | descriptive name |
| lastupdate | timestamp when last updated |
| type | type of parking facility, always offStreetParkingGround |
| openingtimesdescription | description of opening times |
| isopennow | is parking currently open? specified as boolean: yes = 1, no = 0 |
| temporaryclosed | is parking temporary closed? (boolean) |
| operatorinformation | description of company operating the parking |
| freeparking | is parking freely accessable? (boolean) |
| urllinkaddress | webpage URL of the parking offering more information |
| numberofspaces | total number of spaces (capacity) |
| availablespaces | available number of spaces |
| occupancytrend | ? |
| occupation | amount of occupied spaces expressed as a rounded percentage of the capacity |
| latitude | north-south position of the parking |
| longitude | east-west position of the parking |
| location.lon | same as longitude but expressed as a number |
| location.lat | same as latitude but expressed as a number |
| gentse_feesten | ? |
As you can see, except for a few, we have a pretty good idea of the meaning of the properties. Obviously we should double-check our assumptions with the publisher of this data. For this tutorial, we'll assume that the meaning is correct and that we can ignore the few unclear properties. So, let's continue by looking into how these properties map onto the Mobivoc model.
Looking at the Mobivoc model we notice a central entity named parking facility. It derives from a civic structure inheriting its properties. We can also see that there is an entity parking lot derived from a parking facility and is essentially the same as our offstreet parking ground. Following the civic structure relations we see that it can have a capacity and a real time capacity (derived from capacity). Exactly what we need! Furthermore, a capacity is valid for a vehicle type, a civic structure has an opening hours specification and is operated by an organization. Let's create a mapping from our source model to the target model based on this knowledge.
Note that for readability we use well-known abbreviations for the namespaces used in the properties and values.
| source | target |
|---|---|
| name value | rdfs:label value |
| lastupdate value | dct:modified value |
| type offStreetParkingGround | rdf:type mv:ParkingLot |
| openingtimesdescription value | schema:openingHoursSpecification [rdf:type schema:OpeningHoursSpecification; rdfs:label value] |
| isopennow value | N/A |
| temporaryclosed value | N/A |
| operatorinformation value | mv:operatedBy [rdf:type schema:Organization, dct:Agent; rdfs:label value] |
| freeparking value | mv:price [rdf:type schema:PriceSpecification; mv:freeOfCharge value] |
| urllinkaddress value | mv:url value |
| numberofspaces value | mv:capacity [rdf:type mv:Capacity; mv:totalCapacity value] |
| availablespaces value | mv:capacity [rdf:type mv:RealTimeCapacity; mv:currentValue value] |
| occupancytrend value | N/A |
| occupation value | mv:rateOfOccupancy value |
| latitude value | geo:lat value |
| longitude value | geo:long value |
| location.lon | N/A |
| location.lat | N/A |
| gentse_feesten value | N/A |
Note that we mark some mappings as not applicable (N/A) because we cannot map a property, we do not known the exact meaning of the property or we do not need it (e.g. duplicates).
Great! We have determined what will be mapped and how. We're done. Well, not quite. There is one more thing we need: an identity for our entity. It has to be an URI and obviously it needs to be unique. In addition, for every update of the available spaces the identity should remain the same (duh!). So, what do we use for the identity? One possible option is to take the urllinkaddress value. It would work as long as the Data Owner does not decide to relocate it. Best option is to check with the Data Owner but for this tutorial we'll continue on the assumption that the urllinkaddress will not change.
As mention above, to make it more interesting we will be retrieving the number of available spaces in our parking lots on a regular interval. To do so we can use a component that can poll one or more URLs using HTTP. To do so, we need to replace the LdioHttpIn component (push model) that listens for incoming HTTP requests by a LdioHttpInPoller component (pull model).
For example, to poll our source URL every two minutes we need to configure our pipeline input as:
input:
name: Ldio:HttpInPoller
config:
url: https://data.stad.gent/api/explore/v2.1/catalog/datasets/real-time-bezetting-pr-gent/exports/csv?lang=en&timezone=Europe%2FBrussels
cron: 0 */2 * * * *This will ensure we receive the actual state of our parking lots at regular time intervals (e.g. every minute), which may or may not have changed since the last time we checked. We still need to configure an adapter to convert the received CSV message to linked data. We'll do that next.
Now that we can get the actual state of our parking lots, we need to convert the source message in semicolon (;) separated CSV format to the linked data models we defined in the mapping. For this we can use a technology called RDF Mapping Language (RML). There are various ways to produce the mapping that we need: directly using linked data which defines the RML mapping rules or indirectly using a more human readable way named Yarrrml. Personally I prefer the real thing but using Matey may be more your thing.
Explaining the RML technology is beyond the scope of this tutorial. The technology allows us to convert formats such as CSV, XML and JSON into complex RDF models. However, using it to create these complex models can be quite challenging. The solution is to do a straight forward mapping and create the structure we need in a second phase. Basically we map the properties of our source model one-to-one into an intermediate linked data model and then transform this intermediate model into our final model using another RDF technology (SPARQL construct), which is way easier to use for creating complex structures. We'll do this in the next section.
We start by creating a simple intermediate model where we already set the correct identity and entity type but map everything else as-is onto an intermediate vocabulary (temp: or https://temp.org/ns/advanced-compose# in full).
| source | intermediate |
|---|---|
| name value | temp:name value |
| lastupdate value | temp:lastupdate value |
| type offStreetParkingGround | rdf:type mv:ParkingLot |
| openingtimesdescription value | temp:openingtimesdescription value |
| operatorinformation value | temp:operatorinformation value |
| freeparking value | temp:freeparking value |
| urllinkaddress id | id |
| numberofspaces value | temp:numberofspaces value |
| availablespaces value | temp:availablespaces value |
| occupation value | temp:occupation value |
| latitude value | temp:latitude value |
| longitude value | temp:longitude value |
To create a RML mapping file we need to write the RML rules in Turtle. All the Turtle prefixes should go at the start of the file but for simplicity we'll add the prefixes as we go. Let's start with the most common ones:
@prefix rml: <http://semweb.mmlab.be/ns/rml#> .
@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix ql: <http://semweb.mmlab.be/ns/ql#> .
@prefix carml: <http://carml.taxonic.com/carml/> .
Note that the last one is always needed for our RML adapter component (
RmlAdaptor).
Now, we start by defining the map which will contain our mapping rules. We define a prefix for our map and rules (:) and tell the RML component that we will be mapping CSV messages. Do not forget that all prefixes go at the start before our mapping and rules.
@prefix temp: <https://temp.org/ns/advanced-compose#> .
temp:TriplesMap a rr:TriplesMap;
rml:logicalSource [
a rml:LogicalSource;
rml:source [ a carml:Stream ];
rml:referenceFormulation ql:CSV
].
Let's continue now with defining the identity and type of our parking lots. Remember that for the identity we use the URL value and for the type we use parking lot. At the same time we'll also add each parking lot in its own graph. Say what? We'll learn about triples and graphs a bit later. For now, just remember that we want to handle each parking lot separately so we instruct the RML component to generate a stream of mv:ParkingLot entities, one for each row in the CSV.
@prefix mv: <http://schema.mobivoc.org/#> .
temp:TriplesMap rr:subjectMap [
rr:graphMap [ rr:template "{urllinkaddress}" ];
rml:reference "urllinkaddress";
rr:class mv:ParkingLot
].
Easy enough. No? Let's continue with one property. We define a rule saying that the entity will have a property (predicate) named temp:name whose value (object) comes from the source property name.
temp:TriplesMap rr:predicateObjectMap [
rr:predicate temp:name;
rr:objectMap [ rml:reference "name" ]
].
Again, no rocket-science once you get used to the Turtle and RML syntax.
Let's do the other properties as well. We define a rule to map each source property value onto the intermediate property. However, to make our life a bit easier in the next step, where we convert the intermediate to the target model, we can already add the correct value types.
temp:TriplesMap rr:predicateObjectMap [
rr:predicate temp:lastupdate;
rr:objectMap [ rml:reference "lastupdate"; rr:datatype xsd:dateTime ]
], [
rr:predicate temp:openingtimesdescription;
rr:objectMap [ rml:reference "openingtimesdescription" ]
], [
rr:predicate temp:operatorinformation;
rr:objectMap [ rml:reference "operatorinformation" ]
], [
rr:predicate temp:freeparking;
rr:objectMap [ rml:reference "freeparking"; rr:datatype xsd:integer ]
], [
rr:predicate temp:numberofspaces;
rr:objectMap [ rml:reference "numberofspaces"; rr:datatype xsd:integer ]
], [
rr:predicate temp:availablespaces;
rr:objectMap [ rml:reference "availablespaces"; rr:datatype xsd:integer ]
], [
rr:predicate temp:occupation;
rr:objectMap [ rml:reference "occupation"; rr:datatype xsd:integer ]
], [
rr:predicate temp:latitude;
rr:objectMap [ rml:reference "latitude"; rr:datatype xsd:double ]
], [
rr:predicate temp:longitude;
rr:objectMap [ rml:reference "longitude"; rr:datatype xsd:double ]
].
All of the above results in a mapping which we simply embed in our pipeline. So, we change our workbench pipeline to use a RML mapping component (RmlAdapter) and specify the above RML mapping as its configuration. Our CSV pipeline is now complete and looks like this (polls every 2 minutes):
name: csv-pipeline
description: "Polls for park-and-ride data in CSV format, converts to linked data & sends to our P&R pipeline."
input:
name: Ldio:HttpInPoller
config:
url: https://data.stad.gent/api/explore/v2.1/catalog/datasets/real-time-bezetting-pr-gent/exports/csv?lang=en&timezone=Europe%2FBrussels
cron: 0 */2 * * * *
adapter:
name: Ldio:RmlAdapter
config:
mapping: |
@prefix rml: <http://semweb.mmlab.be/ns/rml#> .
@prefix rr: <http://www.w3.org/ns/r2rml#> .
@prefix ql: <http://semweb.mmlab.be/ns/ql#> .
@prefix carml: <http://carml.taxonic.com/carml/> .
@prefix mv: <http://schema.mobivoc.org/#> .
@prefix temp: <https://temp.org/ns/advanced-compose#> .
temp:TriplesMap a rr:TriplesMap;
...Note that we have actually split the workbench pipeline in two parts: a first pipeline that polls for the park & ride data, converts it to linked data (temporary format) using RML and send it to a second pipeline which then converts it to the standard model, creates a version object (see later) and sends that to the LDES Server. The reason we have split the pipeline is to show you polling for alternative data formats and handle these.
We could have also requested the data as JSON or GeoJSON. It is as simple as using a different URL. Of course, the mapping in RML is a bit different for these as the formats and model structures are different. You can verify later that these data formats can also be used.
The JSON mapping is slightly different as we need to tell the RML component to use JSON instead of CSV and how to iterate the JSON objects (for CSV it simply iterates over the non-header lines). So, now our map for JSON looks as this:
temp:TriplesMap a rr:TriplesMap;
rml:logicalSource [
a rml:LogicalSource;
rml:source [ a carml:Stream ];
rml:referenceFormulation ql:JSONPath;
rml:iterator "$.*";
];
Note that our
rml:referenceFormulationnow usesql:JSONPathand that we addedrml:iterator "$.*"to tell it to iterate over the array elements.
The GeoJSON mapping is very similar to the JSON mapping. Allthough the GeoJSON structure is centered around features which contain a geometry and properties we can get away with ignoring the geometry as the properties also contain the latitude and longitude values. Basically we can iterate the elements in the features array and select the properties:
temp:TriplesMap a rr:TriplesMap;
rml:logicalSource [
a rml:LogicalSource;
rml:source [ a carml:Stream ];
rml:referenceFormulation ql:JSONPath;
rml:iterator "$.features.*.properties";
];
Note that our
rml:referenceFormulationalso usesql:JSONPathand that now we userml:iterator "$.features.*.properties"to iterate.
Now that we have an intermediate model as linked data we can use a SPARQL component which allows us to query the values in our intermediate model and construct a target model.
If we look at our intermediate model and the target model we see that we need to keep the identity and type of our parking lot, convert the other properties to a different namespace and for some properties introduce the required structure:
| intermediate | target |
|---|---|
| temp:name value | rdfs:label value |
| temp:lastupdate value | dct:modified value |
| rdf:type mv:ParkingLot | as-is |
| temp:openingtimesdescription value | schema:openingHoursSpecification [rdf:type schema:OpeningHoursSpecification; rdfs:label value] |
| temp:operatorinformation value | mv:operatedBy [rdf:type schema:Organization, dct:Agent; rdfs:label value] |
| temp:freeparking value | mv:price [rdf:type schema:PriceSpecification; mv:freeOfCharge value ] |
| id | mv:url id |
| temp:numberofspaces value | mv:capacity [rdf:type mv:Capacity; mv:totalCapacity value] |
| temp:availablespaces value | mv:capacity [rdf:type mv:RealTimeCapacity; mv:currentValue value] |
| temp:occupation value | mv:rateOfOccupancy value |
| temp:latitude value | geo:lat value |
| temp:longitude value | geo:long value |
So, let's start with the an empty SPARQL construct query (which is similar to a SPARQL query but the result is a new RDF model not just some values). Again, we use Turtle to do this:
# TODO: add our prefixes here
CONSTRUCT {
# TODO: add our target model here
} WHERE {
# TODO: select the intermediate model values here
}
Not too difficult to understand: in, the where part we select values from the intermediate model and put them in variables. We then use those variables to create the target model in the constructpart.
Note that the casing of the words
constructandwhereis not important.
Let's take a brief moment and look at the intermediate model. It is now linked data so we can look at this model as being a collection of id-property-value triples, where the id is the id of eack parking lot, the properties being the names in our temp: namespace and the values being values, obviously. In linked data we call this a triple. The S stands for subject (the identity of a thing), the P stands for predicate (a property identified by its unique full name, including the namespace) and the O stands for object (the value which can be literal or a reference to some other subject, with or without an actual identity). Conceptually, a triple is a way to represent a unidirectional, named relation between a subject and an object.
In linked data we also define the concept of a graph, which is just a tag for a triple and as such basically a way of grouping a bunch of triples together. It has no implicit meaning. A graph can be named by having an URI which identifies it. There's also one special unnamed graph (has no URI) which we call the default graph. When we add a graph part to a triple (SPO) we get a quad (SPOG). In fact, triples are just a special case of quads where the 4th component is the default graph. We can use graphs for many purposes, e.g. to identify the source of the triples, to group together all related entities, etc. But, we use graphs in our pipelines to split data containing multiple entities into a stream of entities that are processed one-by-one in the pipeline.
Wow, let's think about this for a moment: in linked data we model everything as a collection of (subject-predicate-object) triples. It allows us to look at SPARQL queries as being filters that select a subset of the triple collection. For example, if we need to select all the identities of our parking lots we can simply state that we look for all the triples for which the predicate is rdf:type and the object is mv:ParkingLot. The subjects of these triples are in fact what we search for: the identities. To express this in a SPARQL query we specify this as follows:
?id <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.mobivoc.org/#ParkingLot>
The interesting part is the variable ?id. It represents each result in our query.
To make it more readable and in order to not repeat the namespace in every subject, predicate and object, we can again use prefixes:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX mv: <http://schema.mobivoc.org/#>
?id rdf:type mv:ParkingLot
Note that the syntax for our prefix definitions is slightly different than for the Turtle files: we use
PREFIXinstead of@prefixand there is no dot (.) at the end of the line.
The full SPARQL query would be:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX mv: <http://schema.mobivoc.org/#>
SELECT ?id WHERE { ?id rdf:type mv:ParkingLot }
But we do not need the identities only. Instead we want to create a new collection of triples for each parking lot with the predicates changed to those needed by our target model. Let's start with simply copying the triple that defines our parking lots and their update timestamp:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX mv: <http://schema.mobivoc.org/#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX temp: <https://temp.org/ns/advanced-compose#>
CONSTRUCT {
?id a mv:ParkingLot .
?id dct:modified ?lastupdate .
} WHERE {
?id rdf:type mv:ParkingLot .
?id temp:lastupdate ?lastupdate .
}
Note that
ais a short-hand notation ofrdf:type.
In the where part we look for each ?id which is a mv:ParkingLot and then we retrieve its value of temp:lastupdate as variable ?lastupdate. Now that we have found these we can use the variables to create a new set of triples listed under the construct part. Not too difficult, is it?
Our target model is a bit more structured that our intermediate model, so at times we need to introduce an intermediate relation to some structure. Take for example the capacity. In the model diagram, we see that a civic structure has a relation has capacity to a Capacity object that has a property total capacity. In linked data we model this as triples in this way:
<civic-structure-id> rdf:type schema:CivicStructure .
<civic-structure-id> mv:capacity <a-capacity> .
<a-capacity> rdf:type mv:Capacity .
<a-capacity> mv:totalCapacity "some-numeric-value"^^xsd:integer .
We see a very interesting difference between the civic structure and its capacity: a civic-structure has some unique identifier such as "https://example.org/id/civic-structure/parking-lot-1" but a capacity is something that does not exist on its own, it is part of the civic structure and does not have an identity of its own. In linked data we call this a blank node because we can represent a triple as two nodes connected by a directed arrow, where the start node is a subject, the arrow is the predicate and the end node is the object. A blank node is a node without an identity and can be both the source and the destination of one or more arrows, representing its relations aka. properties aka. predicates.
Because a blank node has no identity, we can write the above a bit more condensed by dropping the meaningless <a-capacity> and separating the predicates of the same subject by a semi-colon (;) - formatted for clarity:
<civic-structure-id>
rdf:type schema:CivicStructure ;
mv:capacity [
rdf:type mv:Capacity ;
mv:totalCapacity "some-numeric-value"^^xsd:integer
].
Note that
[ ... ]now represents our capacity.
Now that we have learned how to introduce structure in our target model we can create the complete mapping using SPARQL construct and we need to embed this transformation step in the workbench pipeline:
transformers:
- name: Ldio:SparqlConstructTransformer
config:
query: |
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX schema: <http://schema.org/>
PREFIX mv: <http://schema.mobivoc.org/#>
PREFIX temp: <https://temp.org/ns/advanced-compose#>
PREFIX wgs84: <http://www.w3.org/2003/01/geo/wgs84_pos#>
CONSTRUCT {
...Note that in the complete mapping when we query the properties from our source model that almost all of these query lines are wrapped by an
optional { ... }construct. The reason for this is that any of these triples may be missing. Remember that theWHEREclause is in essence a filter on the collection of source triples, where each query line refines the subset of results from the previous query line. Therefore, if we do not useoptionalthen the query returns no results and hence no target entity is constructed.
If you looked closely at the Park & Ride pipeline you may have noticed that we also added a component to create version objects ourselves:
- name: Ldio:VersionObjectCreator
config:
member-type: http://schema.mobivoc.org/#ParkingLot
delimiter: "#"
date-observed-property: <http://purl.org/dc/terms/modified>
generatedAt-property: http://purl.org/dc/terms/modified
versionOf-property: http://purl.org/dc/terms/isVersionOfIn the previous examples (Setting up a minimal LDES Server, Setting up a minimal LDIO Workbench and Publishing a simple data set with a basic setup) we let the LDES Server handle this for us by providing a flag (ldes:createVersions true ;) in the LDES definition. So, why did we now add this component? And why did we not need to do that in the previous examples? Well, it turns out that there are pros and cons to both approaches and sometimes we have to choose one or the other by necessity. But first, a bit of theory!
If you look at the state of a software system, you will see that it consists of data modelled in a particular way dependant on its domain. This state changes over time when humans or other systems interact with it. Many times we only care about the latest state of such a system but sometimes we need to know the subsequent changes of the models in a system. We use this in order to be able to take decisions or calculate values based on the history of the individual model changes, e.g. your bank account balance, the level of water in a river, etc. Systems that need to keep the history of changes will typically store the event that lead to a model change as well as the (partial or full) model state in a append-only way (Event Streaming).
A Linked Data Event Stream (LDES) is actually very similar: it allows us to store all the model states changes that happen in a (source) system as linked data using a LDES Server and offers a way to duplicate (replicate) them using a LDES Client to another (destination) system downstream, ensuring that the latter is aware of all new changes (synchronize) in a continuous way (streaming). While nothing keeps us from having the event that triggered the state change in the LDES member, typically it will only contain the (full!) model state. So, a state object is the actual state of a model, while a version object is that state object at some point in time. Basically, all version objects for a particular state object define the changes over time of the model for which the state changed. You need to wrap your head around these concepts, but once you do, it is very simple.
Actually, when you define a LDES you provide two properties: a ldes:timestampPath and a ldes:versionOfPath, e.g.:
</occupancy> a ldes:EventStream ;
...
ldes:timestampPath prov:generatedAtTime ;
ldes:versionOfPath dcterms:isVersionOf .
The ldes:versionOfPath provides the property that is used to refer from the version object (i.e. historical object, point-in-time object) to the state object it is derived from and the ldes:timestampPath defines the property holding the date/time value for the point-in-time. Typically we respectively use dcterms:isVersionOf and prov:generatedAtTime but you can use something else as long as the semantics (meaning) is similar or equivalent (e.g. dcterms:modified). In fact, if you think about it, these two properties allow us to group together version objects about some model and order them so we get the changes over time.
Enough theory! Let's look at when to create these versions yourself versus having the LDES Server do it for you. But before we do that, let me tell you about how the LDES Server does this.
When you push one or more state objects to the LDES Server, it will look at the linked data and validate that there are no dangling nor shared blank nodes. Why is that? Well, as you know by now, a named node identifies something (a model!) that is identifiable while a blank nodes is something which is part of such a model and cannot exist on its own as a LDES member. The LDES Server can create a version object for some (identifiable!) model state but clearly that is not possible for a blank node. Therefore any dangling blank node (i.e. a blank node that does not belong to a named node) would not be versioned and data would be lost. A shared blank node is one that is used by two or more named nodes (state objects) and would have to be duplicated for each named node that uses it because the version objects created for these named nodes could be split across different LDES fragments on retrieval. Clearly that would be a problem because a state object would not be complete it the shared (sub)-state was not de-duplicated. However, in our opinion, this de-duplication is not a functionality that belongs to a LDES Server but rather a task for the source system. Any message containing a dangling or shared blank node results in the message being refused. After this validation, the LDES Server creates a new version for each named node (i.e. state object) after grouping together all RDF statements (triples) that directly or indirectly (blank nodes) belong to that model (i.e. it recusively follows are referenced blank nodes).
Note that we emphasized that you can ingest state objects in bulk and that the LDES Server creates a version each time!
But what if the model did not change its state? Obviously, we do not want to create a version if the state did not change. So, either we do not send those state objects to the LDES Server or we create versions ourselves and send those to the LDES Server. Moreover, if we have a pipeline where we request for data (i.e. we poll a source system API) we typically will get the current state of a system, that is, we get all changed and unchanged models. Unless we want the LDES Server to create unneeded version objects, we need to do our own state change detection and create versions ourselves.
Note that the LDES Server will verify for a version object if it has already received one with the same ID. As a version object is considered immutable (should not change!) it will not store it again, but instead the LDES Server will log a warning and ignore the duplicate member (version object).
So, how can we detect changes? Well, clearly as the model can be large we do not want to do a full comparison to verify that a model has been altered but rather we want to rely on some modification or update timestamp. Therefore, we can use such a timestamp to create the versions and count on the LDES Server to ignore duplicate version objects. When we use polling we typically will create versions ourselves based on some timestamp property.
Now, in case we have a pipeline accepting data (i.e. the source system pushes messages) there are two options. If the source system only pushes changes, we can leave the version object creating to the LDES Server or we create versions in the workbench pipeline (typically right before outputting to the LDES Server) based on some date/time property or the current time. However, if the source system pushes the current state of its models and not the changes, then we use a update or modification timestamp in the model to create our version objects in the pipeline and send those to the LDES Server.
OK, time for a summary! The rules are really simple:
- If your source system pushes changes to your workbench pipeline, simply convert your models to linked data (state objects) and let the LDES Server worry about versioning.
- If your source system pushes complete state and the model contains a changed timestamp, create version objects in the pipeline based on this timestamp and send these versions to the LDES Server.
- If your source system pushes complete state but there is no timestamp you can use, let the LDES Server create a new version each time. Not ideal because too many version will exist negatively impacting storage. You can control the number of versions by using retention but their will still be many identical version object for a model. In addition, downstream (destination) systems will receive too many updates and have to cope with that.
- If your workbench pipeline polls for object model changes (API allow some sort of change subscription) and the source system provides a timestamp, create version based on that timestamp.
- If your workbench pipeline polls for object model changes but there is no timestamp (very unlikely), let the LDES Server create a new version each time. This is not really a problem as the LDES Server does not create too many versions.
- If your workbench pipeline polls for a full state model and that model contains a changed timestamp, create version based on that timestamp and send versions to the LDES Server.
- If your workbench pipeline polls for a full state model but there is no timestamp in the model, let the LDES Server worry about versioning. Again, the latter results in a new version on each poll cycle, negatively impacting storage and destination systems.
Now that we have set everything up, we can launch our systems and wait for them to be available:
clear
# start for all systems and wait for them to be available
docker compose up -d --wait
# define the LDES and the view
curl -X POST -H "content-type: text/turtle" "http://localhost:9003/ldes/admin/api/v1/eventstreams" -d "@./definitions/occupancy.ttl"
curl -X POST -H "content-type: text/turtle" "http://localhost:9003/ldes/admin/api/v1/eventstreams/occupancy/views" -d "@./definitions/occupancy.by-page.ttl"
# define our pipelines and start polling for CSV data
curl -X POST -H "content-type: application/yaml" http://localhost:9004/admin/api/v1/pipeline --data-binary @./definitions/park-n-ride-pipeline.yml
curl -X POST -H "content-type: application/yaml" http://localhost:9004/admin/api/v1/pipeline --data-binary @./definitions/csv-pipeline.ymlPlease verify that both pipelines are running:
curl http://localhost:9004/admin/api/v1/pipeline/statuswhich should return:
{"csv-pipeline":"RUNNING","park-n-ride-pipeline":"RUNNING"}After a bit of time, you will see something similar to this in the workbench docker log:
2024-04-18T14:18:00.881Z INFO 1 --- [p-nio-80-exec-1] b.v.i.ldes.ldi.VersionObjectCreator : Created version: https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-bourgoyen#2024-04-18T16:15:27+02:00
2024-04-18T14:18:00.881Z INFO 1 --- [-nio-80-exec-10] b.v.i.ldes.ldi.VersionObjectCreator : Created version: https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-bourgoyen#2024-04-18T16:15:27+02:00
2024-04-18T14:18:00.938Z INFO 1 --- [p-nio-80-exec-2] b.v.i.ldes.ldi.VersionObjectCreator : Created version: https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-bourgoyen#2024-04-18T16:15:27+02:00
2024-04-18T14:18:00.942Z INFO 1 --- [p-nio-80-exec-3] b.v.i.ldes.ldi.VersionObjectCreator : Created version: https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-wondelgem-industrieweg#2024-04-18T16:15:10+02:00
2024-04-18T14:18:00.977Z INFO 1 --- [p-nio-80-exec-4] b.v.i.ldes.ldi.VersionObjectCreator : Created version: https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-bourgoyen#2024-04-18T16:15:27+02:00
To display and keep following the workbench log for updates you can execute the following:
docker logs -f $(docker compose ps -q ldio-workbench)Press CTRL-C to stop following the logs.
To verify the LDES, view and data:
clear
curl "http://localhost:9003/ldes/occupancy"
curl "http://localhost:9003/ldes/occupancy/by-page"
curl "http://localhost:9003/ldes/occupancy/by-page?pageNumber=1"The last URL will contain our members, looking something like this (limited to one member):
PREFIX by-page: <http://localhost:9003/ldes/occupancy/by-page/>
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dct: <http://purl.org/dc/terms/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX geo: <http://www.opengis.net/ont/geosparql#>
PREFIX ldes: <https://w3id.org/ldes#>
PREFIX m8g: <http://data.europa.eu/m8g/>
PREFIX mobility: <https://example.org/ns/mobility#>
PREFIX mobivoc: <http://schema.mobivoc.org/#>
PREFIX occupancy: <http://localhost:9003/ldes/occupancy/>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX prov: <http://www.w3.org/ns/prov#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX schema: <http://schema.org/>
PREFIX sh: <http://www.w3.org/ns/shacl#>
PREFIX shsh: <http://www.w3.org/ns/shacl-shacl#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX tree: <https://w3id.org/tree#>
PREFIX wgs84_pos: <http://www.w3.org/2003/01/geo/wgs84_pos#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
<http://localhost:9003/ldes/occupancy/by-page?pageNumber=1>
rdf:type tree:Node;
dct:isPartOf <http://localhost:9003/ldes/occupancy> .
<https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-gentbrugge-arsenaal#2024-12-18T15:54:10+01:00>
rdf:type mobivoc:ParkingLot;
rdfs:label "P+R Gentbrugge Arsenaal";
dct:isVersionOf <https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-gentbrugge-arsenaal>;
dct:modified "2024-12-18T15:54:10+01:00"^^xsd:dateTime;
mobivoc:capacity [ rdf:type mobivoc:RealTimeCapacity;
mobivoc:currentValue 0
];
mobivoc:capacity [ rdf:type mobivoc:Capacity;
mobivoc:totalCapacity 280
];
mobivoc:operatedBy [ rdf:type dct:Agent , schema:Organization;
rdfs:label "Mobiliteitsbedrijf Gent"
];
mobivoc:price [ rdf:type schema:PriceSpecification;
mobivoc:freeOfCharge 1
];
mobivoc:rateOfOccupancy 100;
mobivoc:url <https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-gentbrugge-arsenaal>;
schema:openingHoursSpecification
[ rdf:type schema:OpeningHoursSpecification;
rdfs:label "24/7"
];
wgs84_pos:lat "51.0325480691"^^xsd:double;
wgs84_pos:long "3.7583663653"^^xsd:double .
...
<http://localhost:9003/ldes/occupancy>
rdf:type ldes:EventStream;
tree:member <https://stad.gent/nl/mobiliteit-openbare-werken/parkeren/park-and-ride-pr/pr-gentbrugge-arsenaal#2024-12-18T15:54:10+01:00> , ...
...
Note that every two minutes the pipeline will request the latest state of our parking lots and will create additional version objects. The identity of a member depends only on the
lastupdateproperty of our parking lot. If that did not change for a parking lot then the pipeline will create a version object with an identical identity as before. Any such version object will be refused by the LDES server and a warning will be logged in the LDES server log. The new version objects are added to the LDES and become new members.
Above we have assumed that the input is CSV. We have seen previously that JSON and GeoJSON can also be converted to Linked Data using RML. In order to verify this, you need to stop or remove the CSV pipeline and start the JSON pipeline or the GeoJSON pipeline.
To stop the a pipeline use, e.g. the CSV pipeline:
curl -X POST http://localhost:9004/admin/api/v1/pipeline/csv-pipeline/haltThe CSV pipeline is now stopped/halted.
Now you can run the JSON pipeline:
curl -X POST -H "content-type: application/yaml" http://localhost:9004/admin/api/v1/pipeline --data-binary @./definitions/json-pipeline.ymlYou can follow the workbench log again to see new version objects being created every poll cycle.
To stop the JSON pipeline use:
curl -X POST http://localhost:9004/admin/api/v1/pipeline/json-pipeline/haltTo run the GeoJSON pipeline use:
curl -X POST -H "content-type: application/yaml" http://localhost:9004/admin/api/v1/pipeline --data-binary @./definitions/geojson-pipeline.ymlTo stop the GeoJSON pipeline use:
curl -X POST http://localhost:9004/admin/api/v1/pipeline/geojson-pipeline/haltFinally, to resume the CSV pipeline again:
curl -X POST http://localhost:9004/admin/api/v1/pipeline/csv-pipeline/resumeTo verify the LDES, view and data:
clear
curl "http://localhost:9003/ldes/occupancy"
curl "http://localhost:9003/ldes/occupancy/by-page"
curl "http://localhost:9003/ldes/occupancy/by-page?pageNumber=1"You can also simply look at the workbench docker logs file to verify that the members have been created and send to the LDES server:
docker logs -f $(docker compose ps -q ldio-workbench)Note use
CTRL-Cto stop following the logs.
You should now know some basics about linked data. You learned how to define a mapping from non-linked data to linked data using RML as well as how to transform a linked data model into a different linked data model. In addition, you learned that you can periodically pull data into a workbench pipeline to create a continuous stream of versions of the state of some system. You can now stop all the systems.
To bring the containers down and remove the private network:
docker compose down