In the paper Prefrontal cortex as a meta-reinforcement learning system, Deep Mind introduces a new Meta Reinforcement Learning (RL) based theory of reward-based learning in the human brain. Different from other theories that considered a single form of reinforcement learning where phasic dopamine release is interpreted as a reward prediction error signal similar to temporal-difference RL algorithms, this theory suggests that the prefrontal cortex performs a form of Model-based RL and is trained (similar to current Meta RL) by a Model-free RL model implemented by the dopaminergic pathways in the brain. The model conceptualizes the prefrontal cortex, the basal ganglia, and thalamic nuclei as forming a recurrent neural network (RNN), which accepts perceptual data that is accompanied or contains information of executed actions and received rewards as input and outputs actions and estimates of state values. The synaptic weights of this RNN are then adjusted by the dopamine-based model-free RL procedure.
Inspired by this theory I decided to explore practical applications of biologically inspired versions of Meta-RL algorithms. My initial idea was to select a common Meta Learning algorithm and modify it to fit Deep Mind’s model. One algorithm that stood out was Model Agnostic Meta Learning (MAML). This algorithm is compatible with any model trained on gradient descent and therefore can be used for reinforcement learning. For this project I focused on the RL species of MAML. The model itself is implemented by a Linear Neural Network (Linear-NN) and it is explicitly trained by performing gradient descent on its parameters. I decided that the approach I would take to modifying this would be to make the model network more similar to the prefrontal-cortex, basal ganglia, and thalamic nuclei model presented in the Deep Mind paper. This can be though of as a biologically-inspired MAML where the RNN component is attempting to represent the prefrontal-cortex, basal ganglia, and thalamic nuclei and the MAML algorithm is replacing the dopaminergic pathways as describted by Deep Mind.
My initial idea was to implement a form of memory-augmented neural network as the NN component of MAML. I had decided on Geometric Recurrent Neural Networks, which utilize attention mechanisms to stably store values in long-term memory when operating in the RNN. Unfortunately, the computational requirements exceeded my available resources and so the idea had to be abandoned. Instead I decided to implement a regular RNN as the NN component of MAML. The substitution of the Linear NN with an RNN is essential to properly modeling the Meta-RL based learning system. The capacity to have short-term task related memory is essential to the prefrontal cortex in order to assess the reward of actions in previous contexts.
Since my intentions are to assess the practical applications of this biologically inspired MAML I decided to test it in a particularly pertinent task. Being involved in research with Tony Dear and Jack Shi on Deep-RL in swimmer robots, I was recently exposed to the necessity of efficient and practical learning algorithms in robotics. Part of my intention with this project is that, if the model is a significant improvement on MAML, the algorithm could be tested on swimmer robot simulations and eventually on swimmer robots on land and in the water. I therefore decided to test the algorithm on MuJoCo robotics simulations.
My approach to the problem was to find a MAML implementation built on PyTorch and check how it performs on MuJoCo tasks relative to a modified implementation that has the RNN component. I selected pytorch-maml-rl by Tristan Deleu.
The model was already built for two useful MuJoCo environments, half-cheetah (a 2-legged cheetah) and ant (a 4-legged insect), both of which tasked with learning walking. I decided to collect data on 2-legged cheetah because, due to training times, I could only train one of the models. I have written code for the other models as well. I decided to compare the original MAML and the biologically inspired MAML by statistically comparing the mean total reward in every batch. Unfortunately, the task was less straight forward than I expected. Much of the simulation infrastructure was nonexistent for this task and, due to how MAML is structured, I had to make judgement calls as to how to modify the training of the algorithm to account for the structure of RNNs.

- MuJoCo Half Cheetah trained on MAML and with a random policy (from pytorch-maml-rl)
I decided that the best way to create similar algorithms would be to substitute every Linear “cell” with an RNN “cell” and to only train the parameters related to the input and output and not train the parameters related to the in “cell” recursion. In order to implement this, I performed gradient descent in all network parameters except for the inner recursion weights and biases.
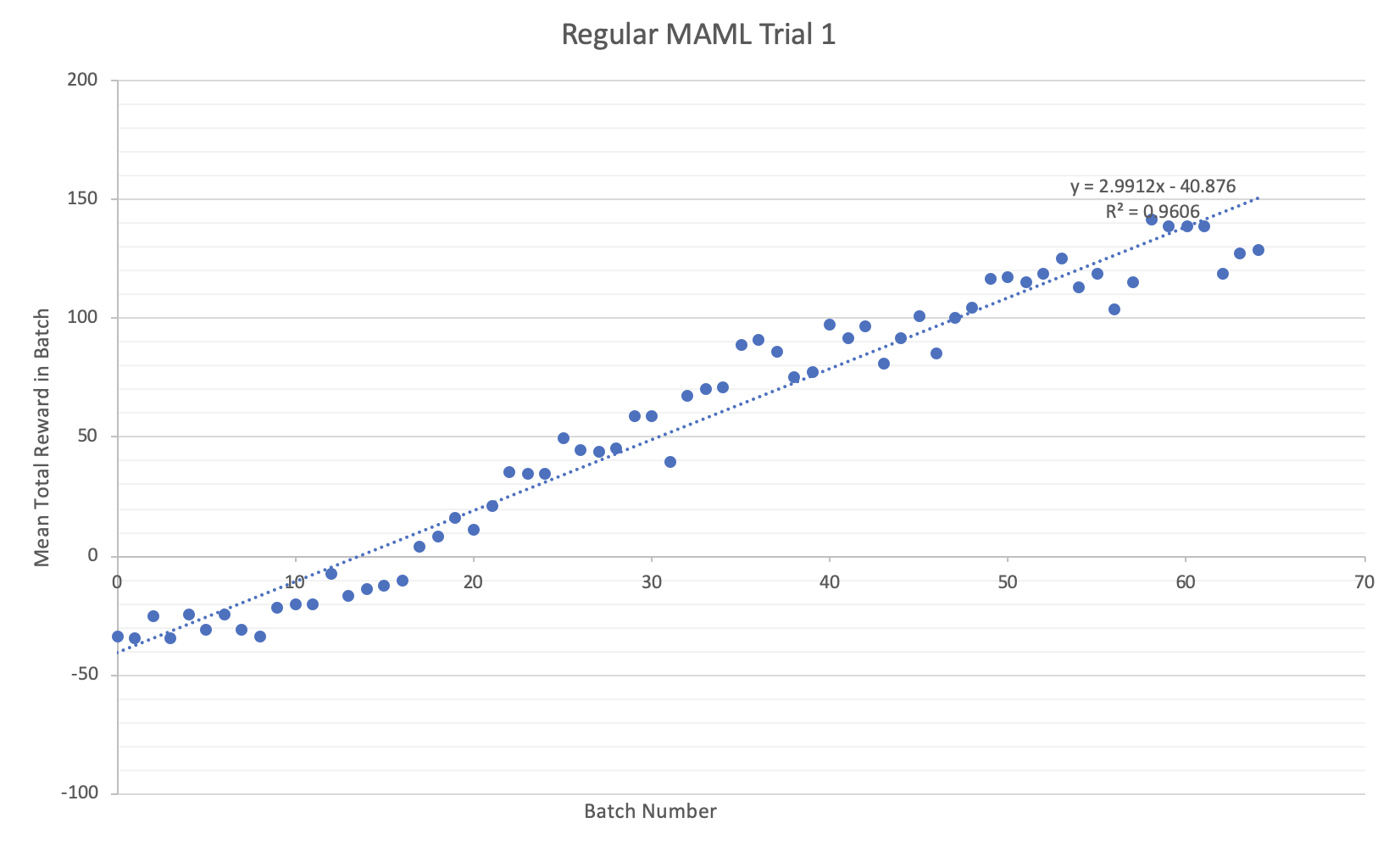
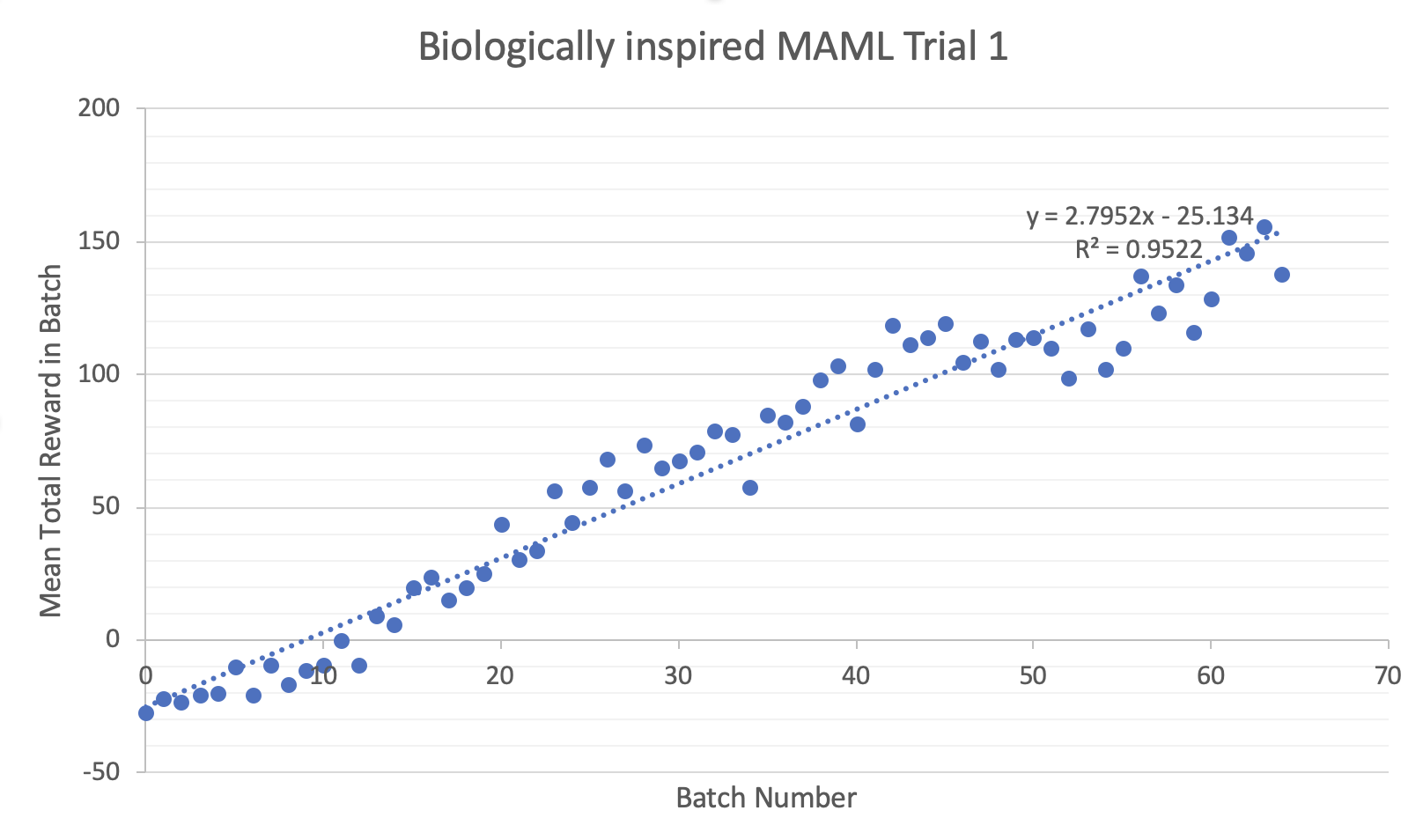
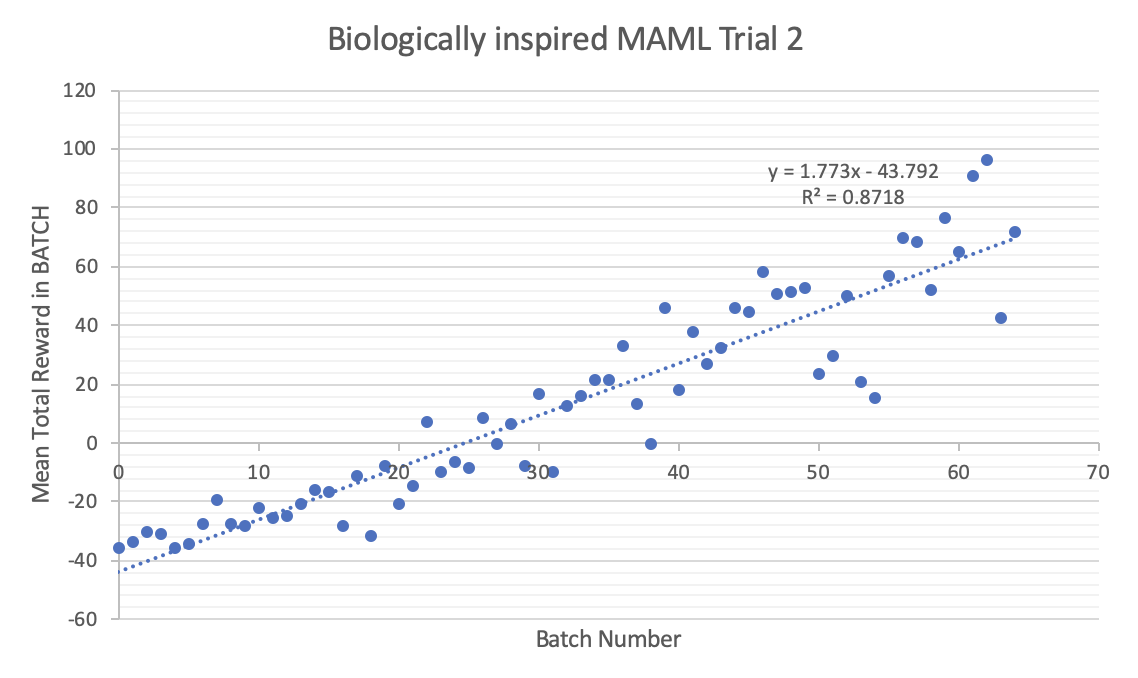
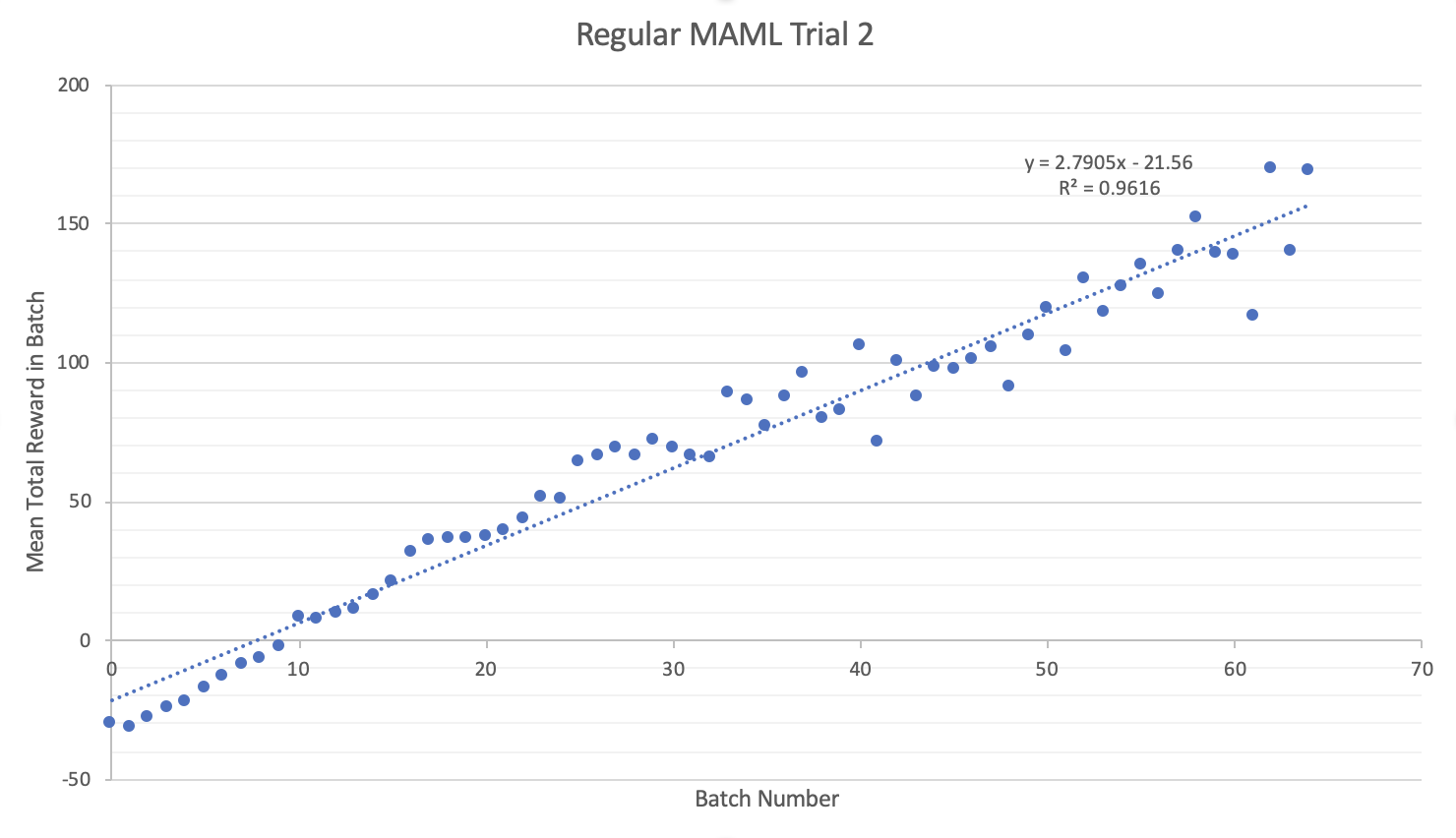
It seems that there is little statistical improvement, at least for RL on the Half-Cheetah model, between the RNN-Policy MAML and the regular NN-Policy MAML. If anything, it seems that sometimes it is worse (as evidenced in trial 2). In general, the behaviour of the Biologically inspired MAML are less predictable, with large variance and often difficultly learning. I believe an improvement could be possible with some form of long term memory component (such as an LSTM or a memory-augmented NN) because at that point the policy would be learning with information on previous policies.
I noticed in trials with smaller NNs and smaller batches the Biologically inspired NN learned faster but with larger variance meaning that, although on average the rate of learning was larger, often the policy would regress back to a lower total reward. I hypothesise that this is due to the memory component not being trained with the other parameters and keeping information from before the parameter update.
I succeeded in creating this new MAML but failed at making a general improvement in learning in small tasks. If I had more computational resources I would implement an LSTM test and a memory-based NN. I think this supports the assertion that the algorithms currently being used for Meta-RL do resemble (at least in behaviour) our current understanding of learning in the prefrontal cortex and that neuroscience inspired algorithms can in fact be helpful when applied to practical tasks such as robot locomotion.
To check raw data and how to use both the regular MAML and the biologically inspired MAML check Testing_Notebook.ipynb
Notes on organization:
- The RNN based MAML is in the regular MAML folder whereas the standard MAML is in the memory_based_maml folder but there are way too many dependencies for me to change it and I plan on implementing an LSTM based system in the memory_based_maml folder.
- The program saves logs, policies, and data (for debugging)
- Simulation is implemented but turned off due to bugs