-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy pathblog.sql
192 lines (157 loc) · 58.4 KB
/
blog.sql
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
/*
SQLyog Ultimate v13.1.1 (64 bit)
MySQL - 5.7.34 : Database - blog
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`blog` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `blog`;
/*Table structure for table `t_blog` */
DROP TABLE IF EXISTS `t_blog`;
CREATE TABLE `t_blog` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
`content` text,
`first_picture` varchar(255) DEFAULT NULL,
`flag` varchar(255) DEFAULT NULL,
`views` int(11) DEFAULT NULL,
`appreciation` int(11) NOT NULL DEFAULT '0',
`share_statement` int(11) NOT NULL DEFAULT '0',
`commentabled` int(11) NOT NULL DEFAULT '0',
`published` int(11) NOT NULL DEFAULT '0',
`recommend` int(11) NOT NULL DEFAULT '0',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`type_id` bigint(20) DEFAULT NULL,
`user_id` bigint(20) DEFAULT NULL,
`description` text,
`tag_ids` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=18 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
/*Data for the table `t_blog` */
insert into `t_blog`(`id`,`title`,`content`,`first_picture`,`flag`,`views`,`appreciation`,`share_statement`,`commentabled`,`published`,`recommend`,`create_time`,`update_time`,`type_id`,`user_id`,`description`,`tag_ids`) values
(14,'Java多线程整理,面试相关','# Java多线程\r\n\r\n## 多线程的实现方式\r\n\r\n1. 继承Thread类,重写run方法,执行start\r\n\r\n2. 实现Runnable接口里面的run方法,并把实现对象作为参数给Thread\r\n\r\n ```java\r\n new Thread(()->{\r\n System.out.println(\"通过Runnable实现多线程:\"+Thread.currentThread().getName());\r\n }).start();\r\n ```\r\n\r\n3. 通过Callable和FutureTask方式\r\n\r\n4. 通过线程池,不用使用start\r\n\r\n## 线程的常见状态\r\n\r\nNEW,\r\n\r\nRUNNABLE,\r\n\r\nRUNNING,\r\n\r\nBLOCKED,\r\n\r\n WATTING,\r\n\r\n TIMEDWATTING,\r\n\r\nTERMINATED,\r\n\r\n## 线程常用API\r\n\r\nThread方法:\r\n\r\n* sleep:交出使用权不释放锁,进入TIMEWATTING,睡眠结束后RUNNABLE\r\n* yield:交出使用权不释放锁,进入RUNNABLE\r\n* join:先执行join的线程\r\n\r\nobject方法:\r\n\r\n* wait:交出使用权并**释放锁(和sleep最大的区别)**\r\n* notify:唤醒等待的线程,唤醒是任意的\r\n\r\n## 线程的几种状态\r\n\r\n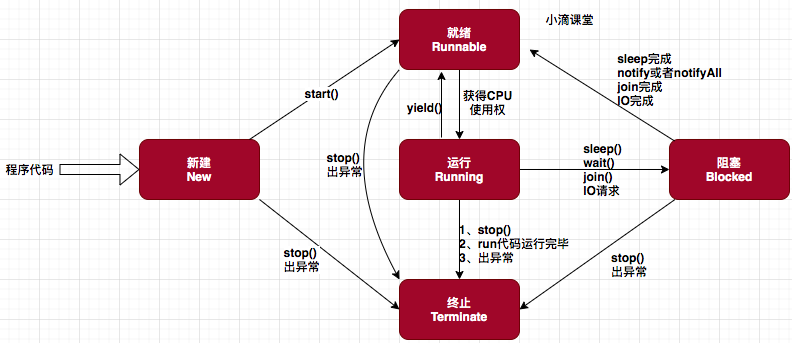\r\n\r\n\r\n\r\n## 保证线程安全的方法\r\n\r\n1. 加锁,synchronize/ReentrantLock\r\n2. volatile,轻量级同步不保证原子性,保证可见性和有序性\r\n3. 线程安全类(原子类,线程安全容器,信号量)\r\n\r\n## **volatile**和synchronized以及ReentrantLock\r\n\r\n```\r\nvolatile:保证可见性,但是不能保证原子性\r\nsynchronized:保证可见性,也保证原子性\r\n```\r\n\r\n### volatile:\r\n\r\nJMM模型,volatile声明变量必须到主内存去读取,每次写入必须写到主内存,可以通过避免指令重排解决有序性\r\n\r\n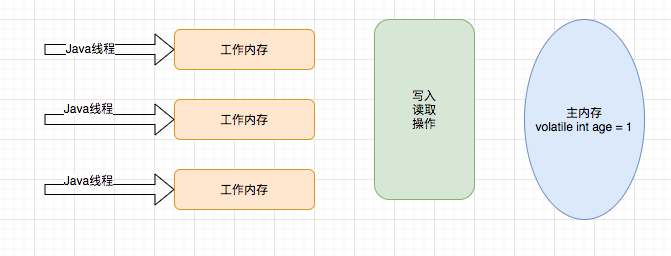\r\n\r\n### synchronized:\r\n\r\nsynchronized是解决线程安全的问题,常用在 同步普通方法、静态方法、代码块中,非公平、可重入\r\n\r\n```\r\n两种形式:\r\n方法:生成的字节码文件中会多一个 ACC_SYNCHRONIZED 标志位,当一个线程访问方法时,会去检查是否存在ACC_SYNCHRONIZED标识,如果存在,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象,也叫隐式同步\r\n\r\n代码块:加了 synchronized 关键字的代码段,生成的字节码文件会多出 monitorenter 和 monitorexit 两条指令,每个monitor维护着一个记录着拥有次数的计数器, 未被拥有的monitor的该计数器为0,当一个线程获执行monitorenter后,该计数器自增1;当同一个线程执行monitorexit指令的时候,计数器再自减1。当计数器为0的时候,monitor将被释放.也叫显式同步\r\n\r\n两种本质上没有区别,底层都是通过monitor来实现同步, 只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成\r\n```\r\n\r\n1.6以后的优化:\r\n\r\n阻塞状态涉及到用户态和内核态的转换代价比较高,1.6后进行偏向锁->轻量级锁(自旋锁)->重量级锁(阻塞状态)的转换\r\n\r\n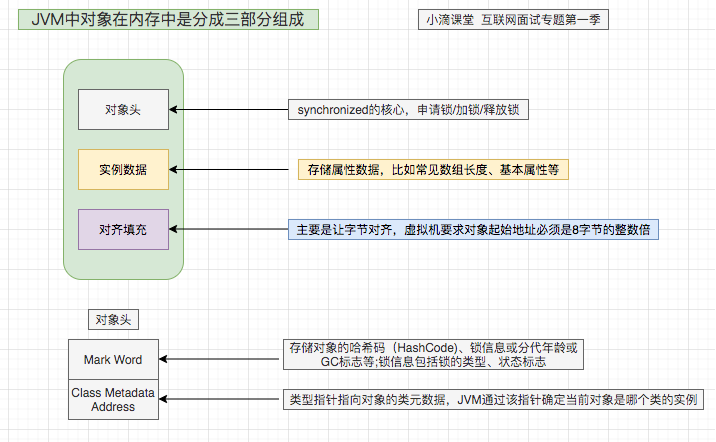\r\n\r\n### ReentrantLock\r\n\r\n* ReentrantLock是接口AQS实现类,通过state和FIFO队列控制加锁,synchronized控制的是对象头\r\n* 可重入,可判断,可选择是否公平;synchronized只能不公平\r\n* synchronized自动加锁解锁,ReentrantLock要手动有时候不方便\r\n* synchronized和ReentrantLock都是可重入锁,悲观锁,独占锁\r\n\r\n## Java中的锁分类\r\n\r\n* 悲观锁和乐观锁(CAS)\r\n* 公平锁和非公平锁,非公平锁效率一般高于公平锁,ReentrantLock可选择是否公平,synchronized非公平\r\n* 可重入锁(synchronized、ReentrantLock)和不可重入锁\r\n* 自旋锁\r\n* 读锁和写锁\r\n\r\n## CAS相关\r\n\r\ncompare and swap\r\n\r\n通过unsafe类实现原子操作,地址不一样时使用自旋操作,原子类由CAS实现\r\n\r\nCAS会产生ABA问题,可以通过标志位解决问题\r\n\r\n### AQS相关\r\n\r\n全称AbstractQueuedSynchronizer,java底层同步的工具类\r\n\r\n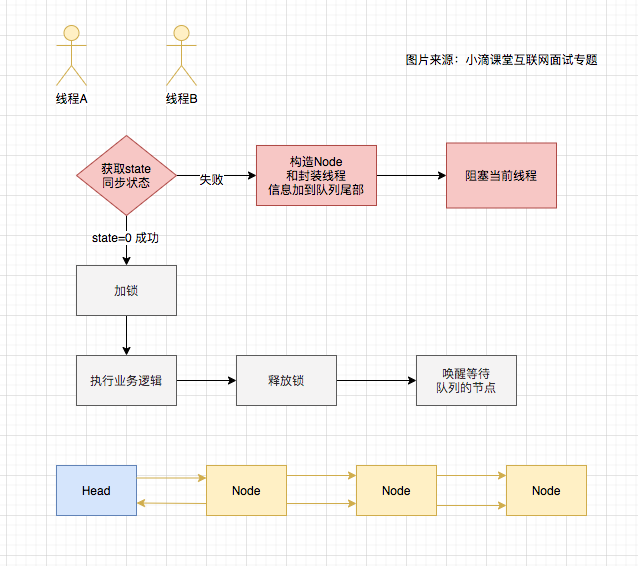\r\n\r\n```\r\n实现支持独占锁的同步器应该实现tryAcquire、 tryRelease、isHeldExclusively\r\n实现支持共享获取的同步器应该实现tryAcquireShared、tryReleaseShared、isHeldExclusively\r\n```\r\n\r\n## ReentrantReadWriteLock和ReentrantLock?\r\n\r\n读写分离以及读写不分离区别\r\n\r\n* 都是AQS的实现类\r\n* 读锁可以共享,写锁独占;ReentrantLock全部独占\r\n* 读写允许降级不允许升级,只有读锁之间不互斥\r\n\r\n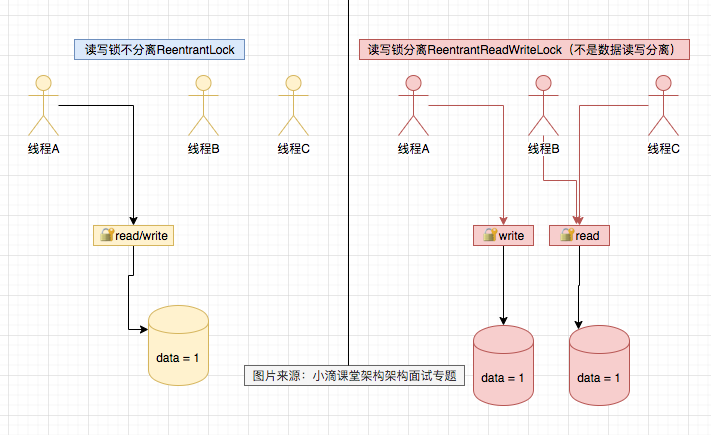\r\n\r\n## 阻塞队列和非阻塞队列\r\n\r\n\r\n\r\n### 阻塞队列\r\n\r\nArrayBlockingQueue:基于数组实现,先进先出,有界队列,必须指定容量,基于ReentraitLock,可指定是否公平\r\n\r\nLinkedBlokingQueue:基于链表实现,不指定容量大小的话默认max,先进先出,使用两个独占锁控制并发,优先使用\r\n\r\nPriorityBlockingQueue:优先级队列\r\n\r\nDelayQueue:\r\n\r\nSynchronousQueue:CAS实现,一个没有容量的队列 ,不会存储数据,每执行一次put就要执行一次take,否则就会阻塞。未使用锁。通过cas实现,吞吐量异常高。\r\n\r\n| | 抛出异常 | 特殊值 | 阻塞 | *超时* |\r\n| -------- | ----------- | ---------- | -------- | ---------------------- |\r\n| **插入** | `add(e)` | `offer(e)` | `put(e)` | `offer(e, time, unit)` |\r\n| **移除** | `remove()` | `poll()` | `take()` | `poll(time, unit)` |\r\n| **检查** | `element()` | `peek()` | *不可用* | *不可用* |\r\n\r\n总结:阻塞队列多基于AQS实现,属于悲观锁。当一个线程无法使用时很容易造成所有线程无法使用。当队列中没有元素时取元素会被阻塞\r\n\r\n### 非阻塞队列\r\n\r\nConcurrentLinkedQueue:无界线程安全队列,先进先出,通过add方法加在队尾,通过pool方法移除并返回队首元素。\r\n\r\nLinkedTransferQueue\r\n\r\n总结:非阻塞队列多基于CAS实现,属于乐观锁,队列中没有元素时取元素直接返回null,想要阻塞只能主动使用wait()和notify()\r\n\r\n## 线程池相关\r\n\r\n线程池的一些优点\r\n\r\n* 重用线程,简绍对象创建以及销毁的开销\r\n* 控制最大并发线程数,一定程度上避免阻塞\r\n* 定时定期执行,有一些拒绝策略\r\n\r\n常见的一些线程池:\r\n\r\n1. newFixedThreadPool,定长线程池可控制线程最大并发,允许请求的队列长度为Interger.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。\r\n2. newCachedThreadPool,可缓存线程池,允许的创建线程数量为:Interger.MAX_VALUE,可能会创建大量的线程,从而导致OOM。\r\n3. newSingleThreadExecutor,单线程化的线程池,允许请求的队列长度为Interger.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。\r\n4. newScheduledThreadPool,定长线程池,定时周期任务\r\n\r\n线程池创建线程过程\r\n\r\n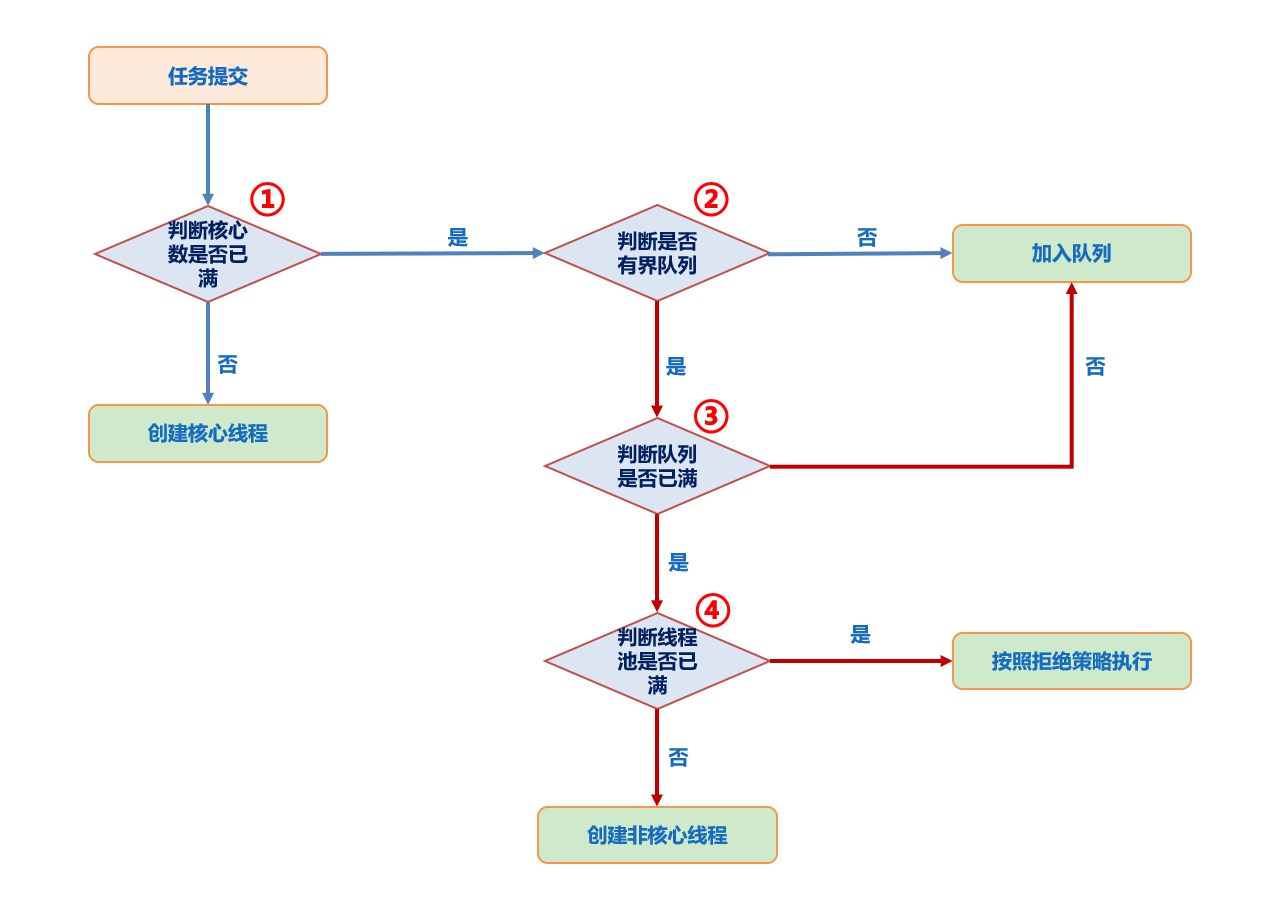\r\n\r\n线程满足corePoolSize,之后满足BlokingQueue,再满足maxiumPoolSize,超过总数时抛出异常\r\n\r\n## 线程同时执行,依次执行和交错执行\r\n\r\nCountDownLatch\r\n\r\n底层原理为AQS,全程维护一个Volatile修饰的state变量,state为0时通知等待的进程执行,await调用Unsafe中的park方法进行自旋,countDown通过CAS操作使state减一\r\n\r\n```java\r\nCountDownLatch latch = new CountDownLatch(1);\r\n//核心方法:\r\nlatch.await();//等待信号量为0时开始\r\nlatch.countDown();//信号数目减一 \r\n//业务逻辑\r\nCountDownLatch latch = new CountDownLatch(1);\r\nA线程(latch.await(),task.....,start());\r\nB线程(latch.await(),task.....,start());\r\nlatch.countDown();\r\n//此时所有线程开始执行\r\n主线程;\r\n\r\n也可以满足任务要求:\r\n 一个线程等待多个线程执行完毕才可以进行执行,只需要调整countDown和await的位置\r\n```\r\n\r\nCylicBarrier\r\n\r\n和CountDownLatch区别\r\n\r\n* 前者阻塞子线程,要求所有线程调用await后才可以执行;后者阻塞主线程,当countDown为0的时候子线程才可以执行\r\n* 调用await后都进入阻塞状态,前者是所有线程await后开始执行,后者是countDown为0时所有线程开始执行\r\n\r\n```java\r\n//核心方法\r\n//await\r\n//使用方法\r\n//主线程main\r\npublic static void main(String[] args) {\r\n \r\n CyclicBarrier barrier = new CyclicBarrier(3);\r\n \r\n for(int i = 0; i < barrier.getParties(); i++){\r\n \r\n new Thread(new MyRunnable(barrier), \"队友\"+i).start();\r\n \r\n }\r\n \r\n private static MyRunnable implements Runnable{\r\n \r\n private final CyclicBarrier barrier;\r\n //构造方法\r\n public MyRunnable(CyclicBarrier barrier){\r\n this.barrier = barrier;\r\n }\r\n @Override\r\n public void run(){\r\n //此处为执行的任务\r\n task....;\r\n //核心方法\r\n this.barrier.await();\r\n } \r\n \r\n \r\n }\r\n```\r\n\r\n\r\n\r\nSemaphore\r\n\r\n保证并发的线程数不大于设置的信号数目\r\n\r\n```java\r\nSemaphore semaphore = new Semaphore(num);\r\n//核心方法\r\nsemaphore.acquire();\r\nsemaphore.release();\r\n```\r\n\r\n','https://pic4.zhimg.com/v2-0f922e2f43da24e4deb943938b056881_b.jpg','原创',3,1,1,1,1,1,'2021-07-25 10:09:26','2021-07-25 11:01:47',1,1,'对于多线程常见概念的整理和简单使用。','10'),
(15,'Java数据结构整理,面试','# Java集合相关\r\n\r\njava的集合\r\n\r\n1. Collection接口\r\n\r\n * List实现类:元素有序,可以包含重复元素\r\n\r\n - ArrayList\r\n\r\n 1. 底层结构为数组,查询快增删慢,线程不安全\r\n\r\n 2. 如何实现线程安全的ArrayList?\r\n 1. 自己写包装类加锁\r\n\r\n 2. Collection.synchronedList(new ArrayList<>())\r\n\r\n 3. CopyOnWriteArrayList<>(),通过ReentrantLock加锁\r\n\r\n 2和3的区别是什么?\r\n\r\n * CopyOnWriteArrayList会拷贝新的数据,通过可重入锁保证多个线程不会拷贝一个数组,读性能很高,写性能相对较差,读不需要加锁\r\n * Collection.synchronedList(new ArrayList<>())完全使用synchroned进行加锁\r\n\r\n 3. List的扩容机制\r\n\r\n 1. 1.7前默认是10,1.7后默认是0\r\n 2. 未指定容量时是0,第一个元素进去后是10,大于其容量后扩容大小 = 原始大小+原始大小/2 \r\n\r\n - LinkList\r\n\r\n 底层为链表,查询慢,增删快,线程不安全\r\n\r\n - Vector\r\n\r\n 底层为数组,只不过线程安全\r\n\r\n * Set实现类:不能包含重复元素,最多一个null值\r\n\r\n - HashSet\r\n\r\n 底层由Hash表实现,元素无序且唯一\r\n\r\n 线程不安全,效率高\r\n\r\n 唯一性靠重写HashCode()和Equal()方法来保证\r\n\r\n + LinkHashSet\r\n\r\n 底层数据结构采用链表+哈希表\r\n\r\n 链表保证元素的添加顺序\r\n\r\n 哈希表保证元素的唯一性。\r\n\r\n - TreeSet\r\n\r\n 底层数据结构为红黑树\r\n\r\n 元素唯一且已经排序,同样需要重写HashCode()和Equal()方法\r\n\r\n - 面试相关:HashSet是如何保证元素的唯一性?\r\n\r\n 当调用add()方法向集合中存入对象的时候,首先会使用 hash() 函数生成一个 int 类型的 hashCode 散列值,然后与已经存储的元素的 hashCode 值作比较,如果 hashCode 值不相等,则所存储的两个对象一定不相等,此时把这个新元素存储在它的 hashCode 位置上;如果 hashCode 相等,存储元素的对象还是不一定相等,此时会调用 equals() 方法判断两个对象的内容是否相等,如果 equals() 返回true,则是同一个对象,无需存储;如果 equals() 返回 false,那么就是不同的对象,就需要存储,不过由于 hashCode 相同,HashSet会以链式结构将两个对象保存在同一位置,这将导致性能下降,因此在编码时应避免出现这种情况。\r\n\r\n2. Map接口\r\n\r\n - HashMap\r\n\r\n HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的\r\n HashMap是无序的散列映射表;*\r\n HashMap通过Hash 算法来决定存储位置\r\n 底层实现是**数组+链表+红黑树**(泊松分布),初始容量是16,初始加载因子0.75,\r\n\r\n 1. 如何实现HashMap的线程安全?\r\n\r\n 多线程环境下可以使用ConcurrentHashMap,或者使用Collections.synchronizedMap()\r\n\r\n 2. 为什么2的n次方为数组\r\n\r\n 再进行tab[i = (n - 1) & hash]与运算的过程中,如果不是2的n次方,对应的二进制位肯定有一位为0永远用不上\r\n\r\n 3. 扩容\r\n\r\n 当元素个数超过负载因子的时候会进行扩容,直接扩大一倍,之后会重新计算元素的位置非常耗性能,尽量设置hashmap的初始容量\r\n\r\n 4. hashcode计算方法\r\n\r\n ```java\r\n (h = key.hashCode()) ^ (h >>> 16)\r\n ```\r\n\r\n 5. ConcurrentHashMap\r\n\r\n 在读操作的时候使用大量的unsafe类\r\n\r\n ```\r\n 比如\r\n tabAt中的getObjectVolatile\r\n casTabAt中的compareAndSwapObject\r\n setTabAt中的putObjectVolatile\r\n ```\r\n \r\n \r\n \r\n 在写操作的时候使用synchronize锁操作\r\n \r\n ```java\r\n 对key进行重哈希;\r\n 初始化bitcount等于0;\r\n 对当前table无限循环;\r\n 如果没有table初始化table;\r\n 如果已经存在table;\r\n 如果没有hash冲突采用cas的方式插入;\r\n 如果当前为数据迁移模式进行数据迁移;\r\n 如果存在哈希冲突:\r\n 记录旧值,并开始加synchronize锁;\r\n 如果为链表结构:\r\n 记录bitcount为1\r\n 遍历链表:\r\n 有相同的key修改旧值;\r\n 没有相同的key插入新节点\r\n 如果为树节点结构:\r\n 记录bitcount为2\r\n 插入新节点\r\n 查看bitcount的值,如果大于8开始转换为红黑树 bitcount的值加一 \r\n ```\r\n \r\n \r\n \r\n - LinkedHashMap\r\n \r\n LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,\r\n \r\n 在遍历的时候会比HashMap慢,有HashMap的全部特性\r\n \r\n - TreeMap\r\n \r\n TreeMap实现SortMap接口,能够把它保存的记录根据键排序\r\n \r\n 默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的\r\n \r\n 不允许key值为空,非同步\r\n 适用于按自然顺序或自定义顺序遍历键(key)。\r\n 底层是二叉树\r\n 提供compareTo,可以定义排序方法\r\n \r\n - HashTable\r\n \r\n Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步\r\n \r\n 即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢\r\n \r\n 它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低\r\n \r\n HashMap 需要重新计算 hash 值,而 HashTable 直接使用对象的 hashCode','https://www.freesion.com/images/629/caf046f64783cc96ab2f3377b0c57fed.png','原创',2,1,1,1,1,1,'2021-07-25 10:12:00','2021-07-25 10:12:00',1,1,'对Java常见数据结构进行整理,包含并发数据结构相关知识概念。','10'),
(16,'Redis底层分析整理,面试备用','-\r\n\r\n## Redis为什么速度快\r\n\r\n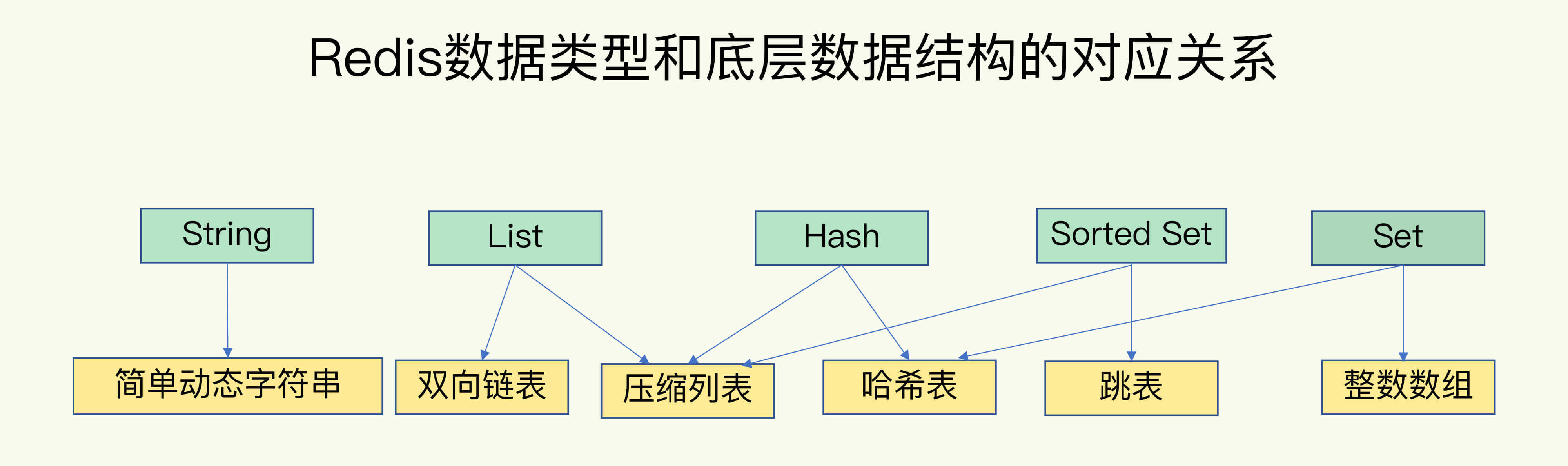\r\n\r\n1. 使用内存作为存储\r\n2. 数据结构\r\n\r\n### 什么时候变慢\r\n\r\nRedis使用哈希表保存所有的键值对,但是哈希表冲突问题和rehash可能带来操作阻塞。\r\n\r\n当数据过多时会采用rehash操纵增加哈希通的数量。\r\n\r\n一开始有两个全局hash表,当快满的时候采用rehash\r\n\r\n* 给表2更大的空间\r\n* 表1的数据映射拷贝过去\r\n* 释放表1的空间\r\n* 大量拷贝开销很大,一般渐进式操作,找到索引位置的entry一并拷贝到第二张表。\r\n\r\n#### 集合操作效率\r\n\r\n哈希表:O(1)\r\n\r\n整数数组:O(n)\r\n\r\n双向链表:O(n)\r\n\r\n压缩表:第一个和最后一个元素复杂度O(1),其他为O(n)\r\n\r\n跳表:有序链表为基础O(logN)\r\n\r\n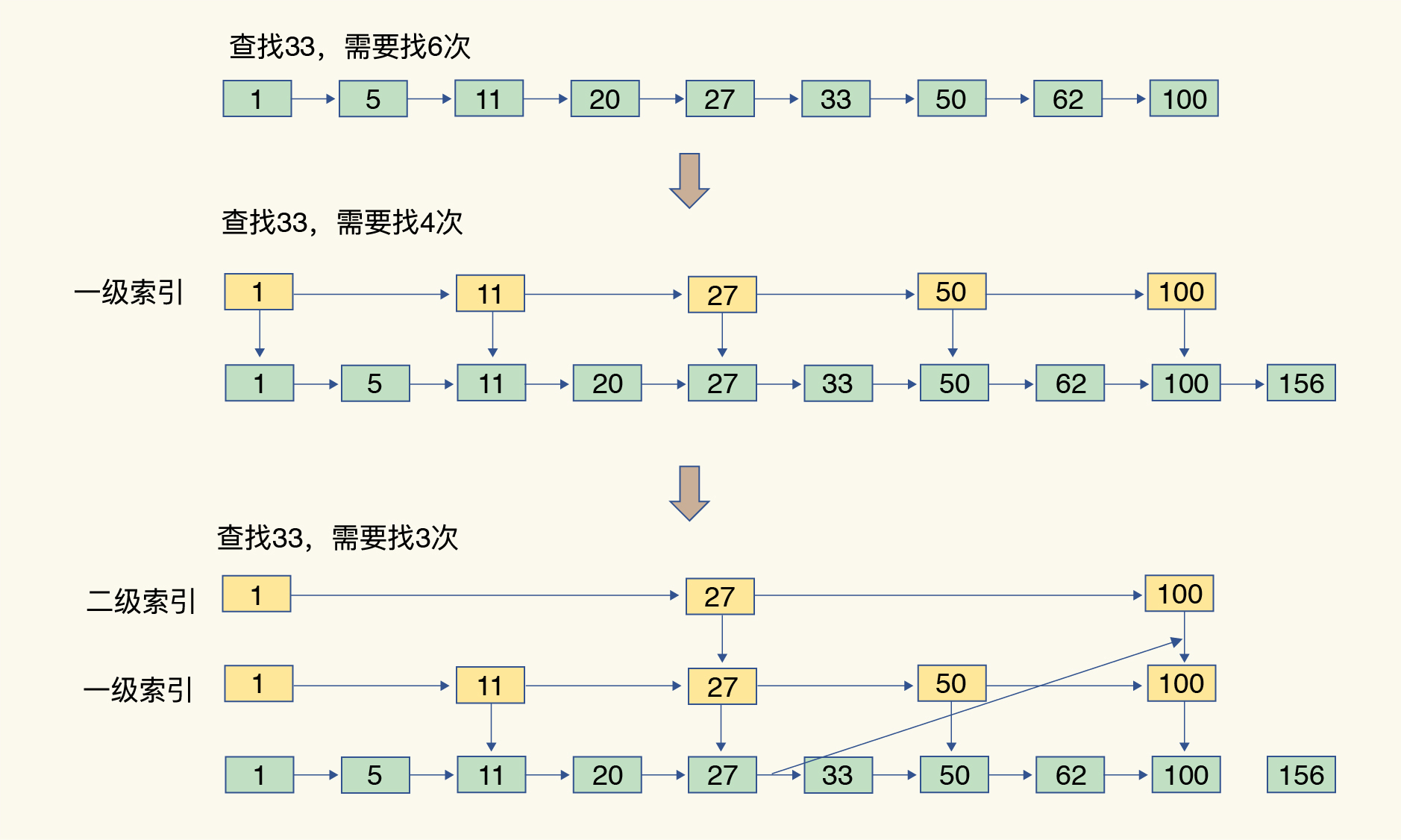\r\n\r\n尽量避免全局遍历,复杂度过高。\r\n\r\n## 为什么单线程的Redis这么快\r\n\r\nRedis网络IO和键值对读写是一个线程\r\n\r\n多线程容易产生并发以及互斥问题\r\n\r\n### 为什么Redis快\r\n\r\n1. 内存数据库\r\n2. 高效数据结构\r\n3. 多路复用机制\r\n\r\n### scoket网络模型\r\n\r\n\r\n\r\n### 基于多路复用的高性能IO模型\r\n\r\n允许内核中存在多个监听嵌套字和已连接嵌套字\r\n\r\n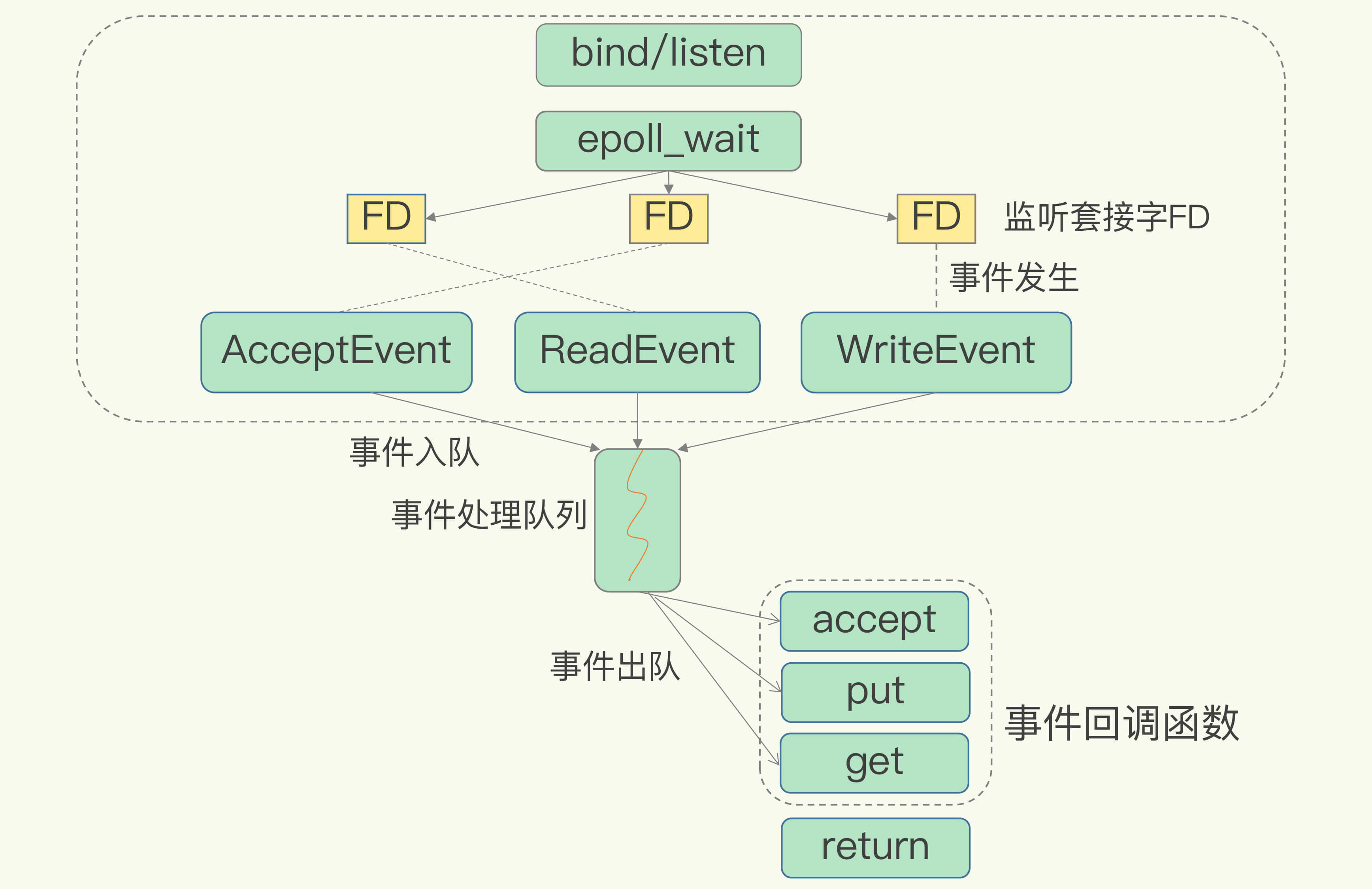\r\n\r\n## 如何避免数据丢失\r\n\r\n### AOF(Append Only File)日志\r\n\r\n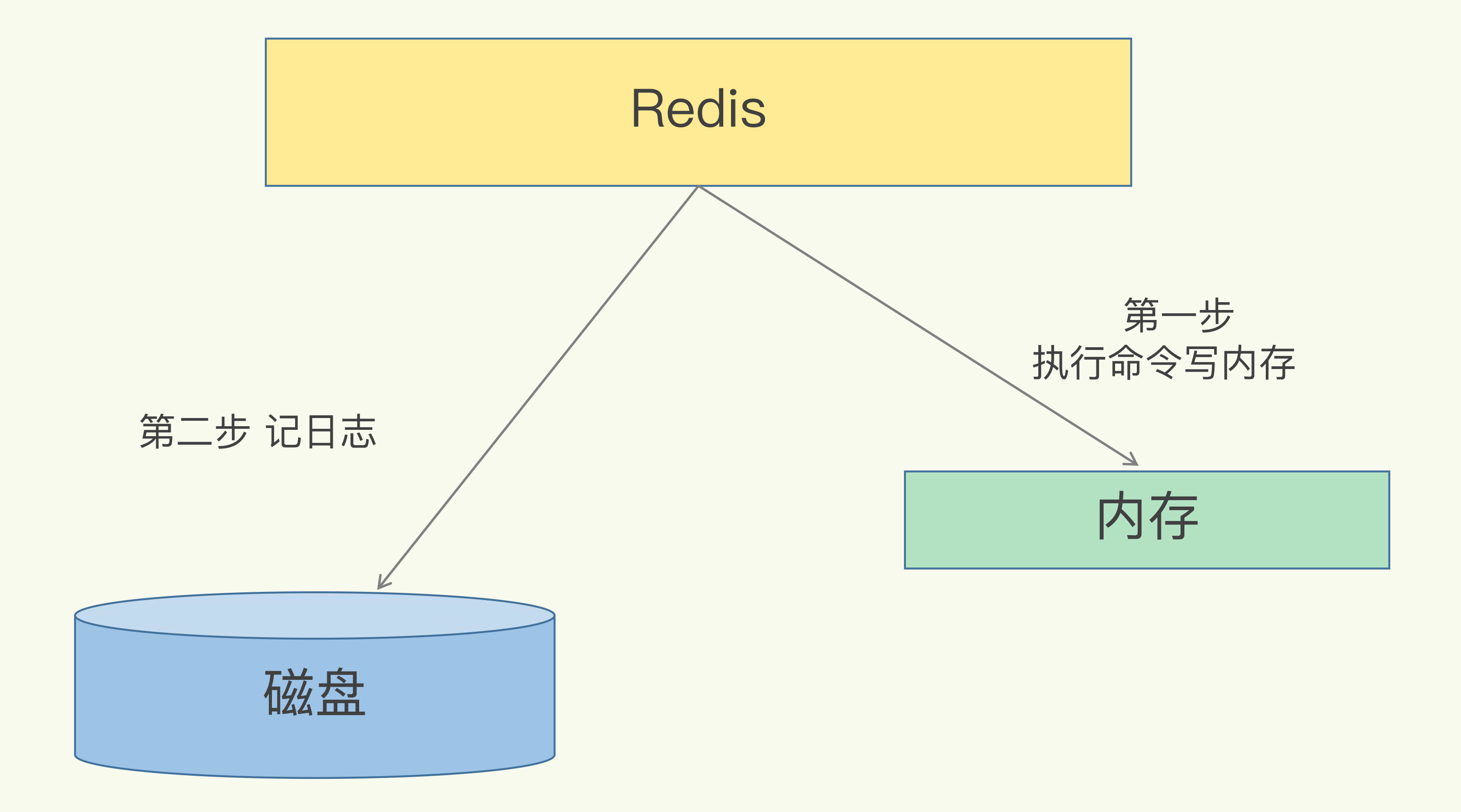\r\n\r\nredo log记录的是修改后的数据\r\n\r\nAOF记录的是每一条命令,先执行命令后修改,不会阻塞当前的写操作。\r\n\r\n潜在风险\r\n\r\n* 没来得及保存就丢失\r\n* 阻塞下一次写\r\n\r\n#### 写回策略\r\n\r\n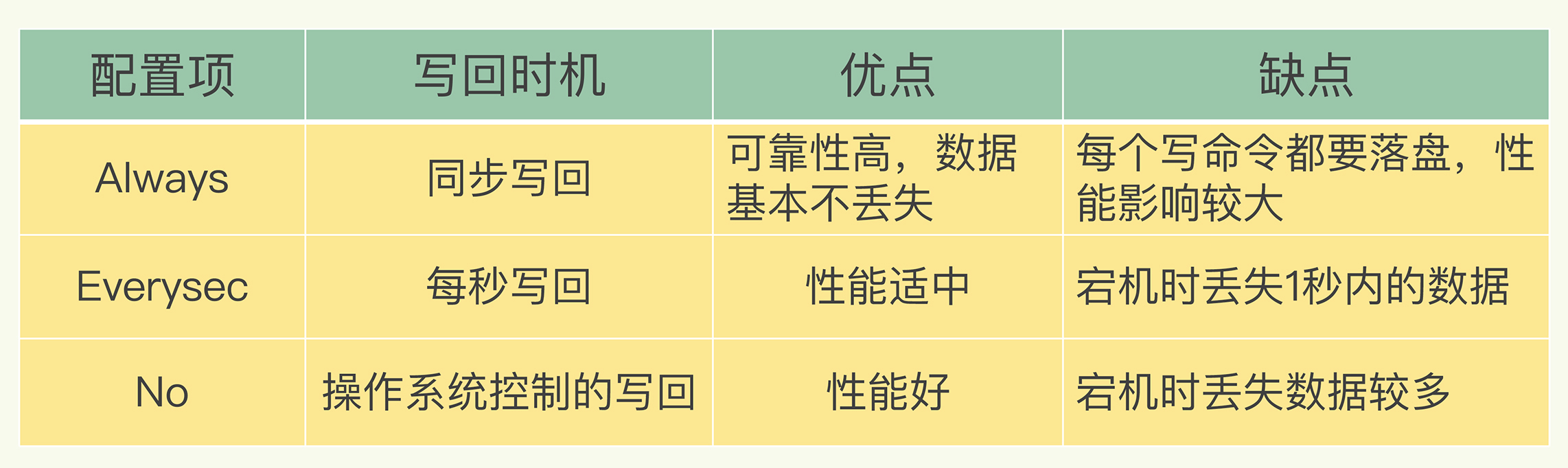\r\n\r\n#### AOF重写机制\r\n\r\n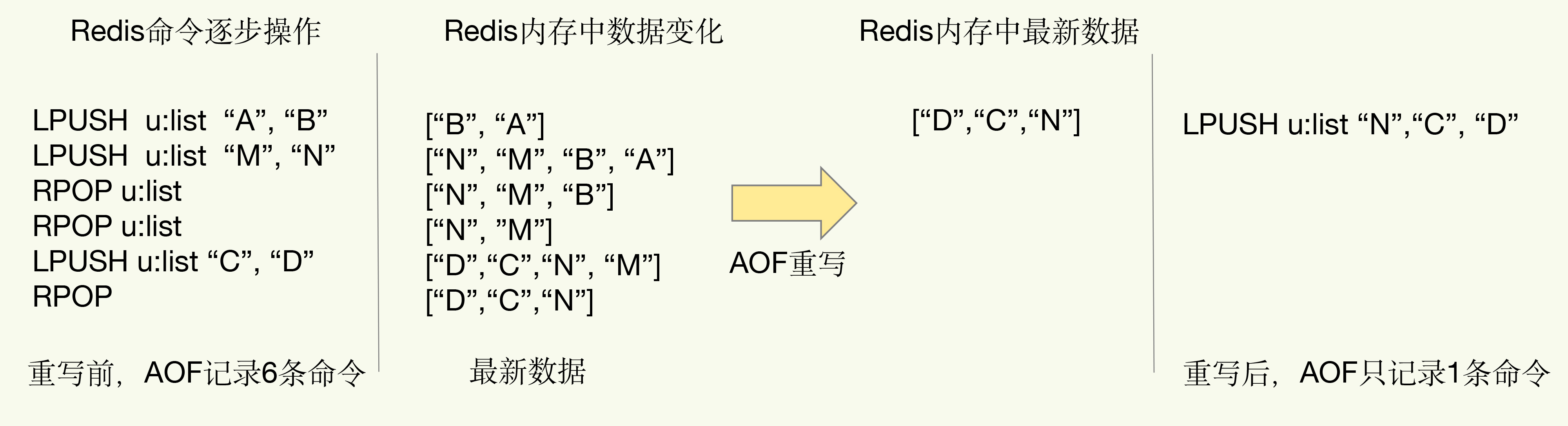\r\n\r\n对同一个键值对多次处理后可以只使用最新的数据\r\n\r\n#### 重写是否造成线程阻塞\r\n\r\n重写的过程由子线程完成,写会数据由主线程完成\r\n\r\n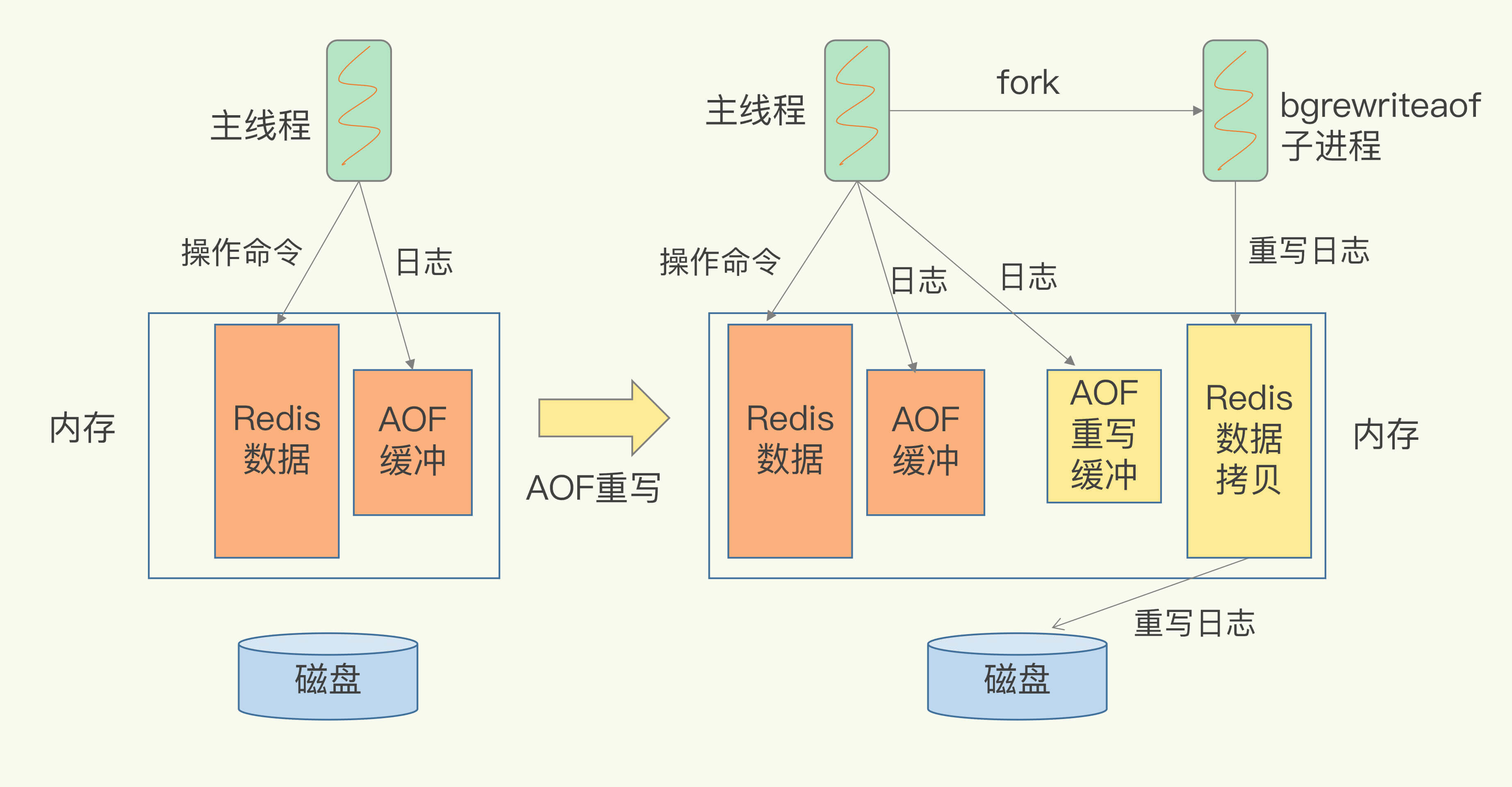\r\n\r\n### RDB (REedis DataBase)快照\r\n\r\n#### 给哪些内存数据做快照?\r\n\r\n全量快照,默认使用 bgsave,创建一个子进程专门处理存储\r\n\r\n#### 快照时数据是否可以修改?\r\n\r\n使用写时复制技术(Copy-On-Write, COW)技术,执行快照的同时正常处理写操作\r\n\r\n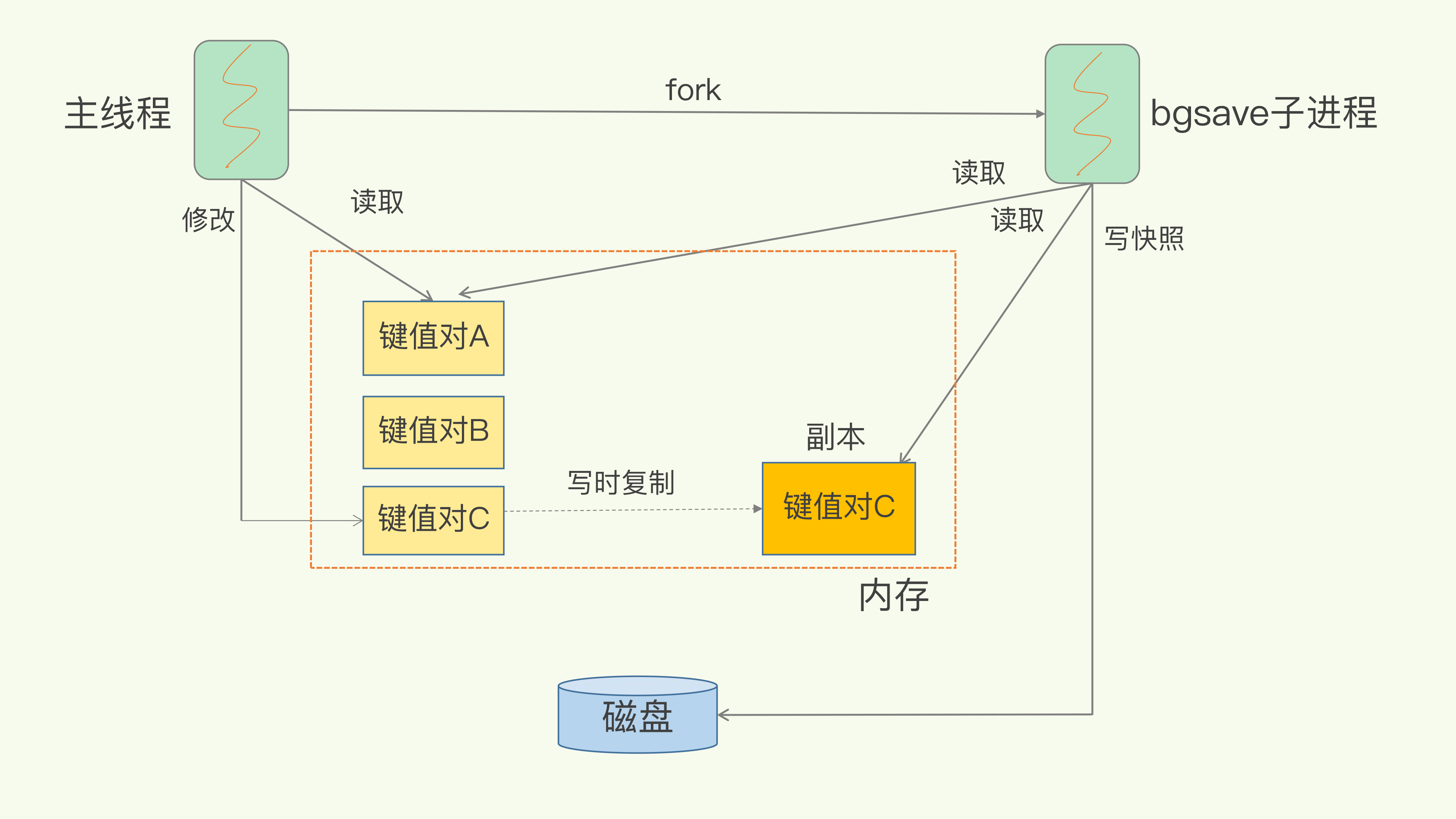\r\n\r\n#### 多久做一次快照\r\n\r\nRedis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。\r\n\r\n## 主从库如何实现数据移植\r\n\r\n### 如何进行第一次同步\r\n\r\n\r\n\r\n第一次复制是全量复制\r\n\r\n### 主从级联模式分担全量复制时的主库压力\r\n\r\n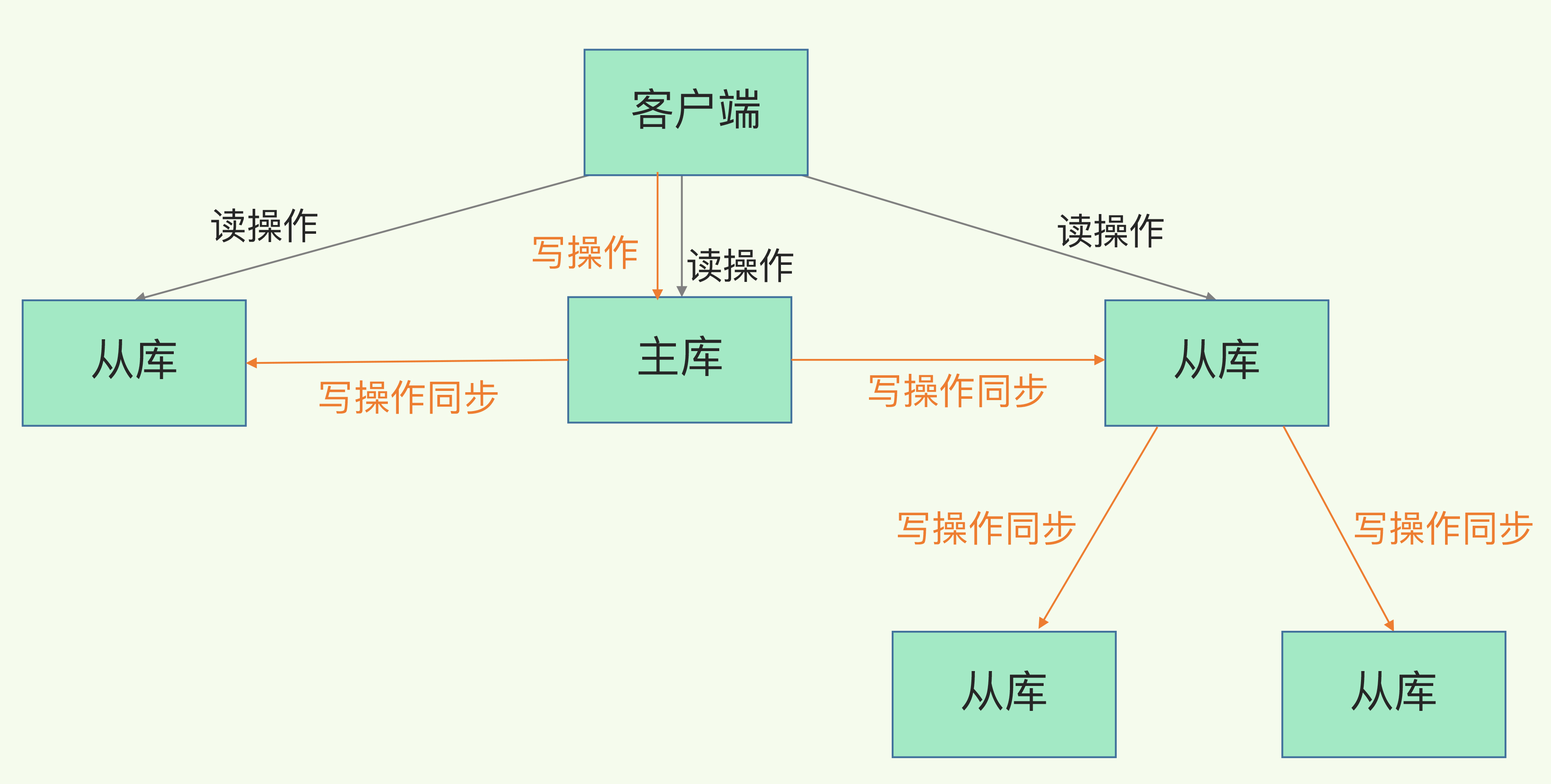\r\n\r\n### 主从库网络断了怎么办?\r\n\r\n采用缓冲区环形增量复制\r\n\r\nmaster_repl_offset\r\n\r\nslave_repl_offset\r\n\r\n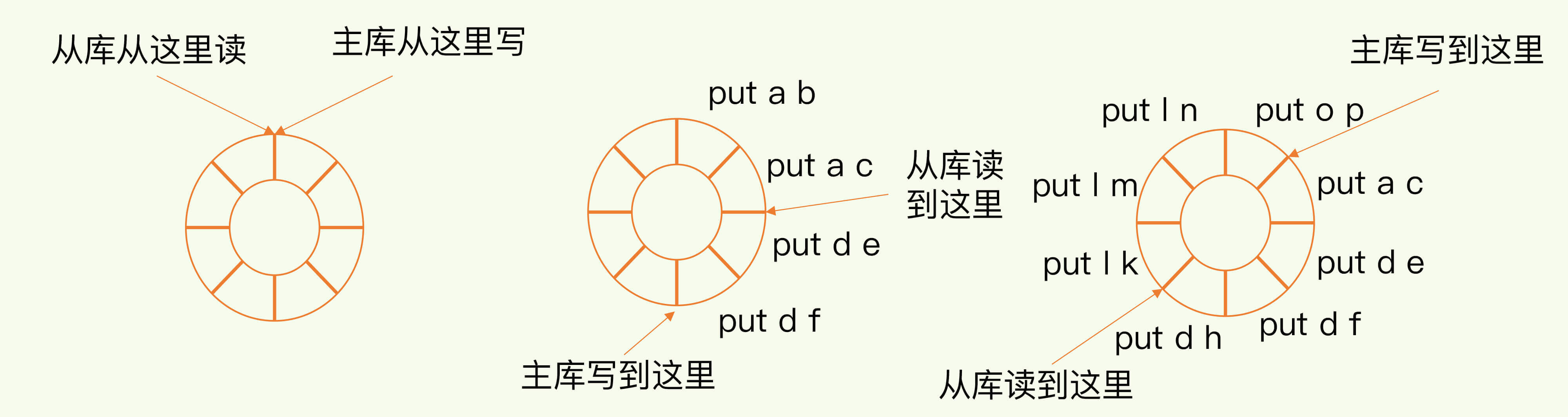\r\n\r\n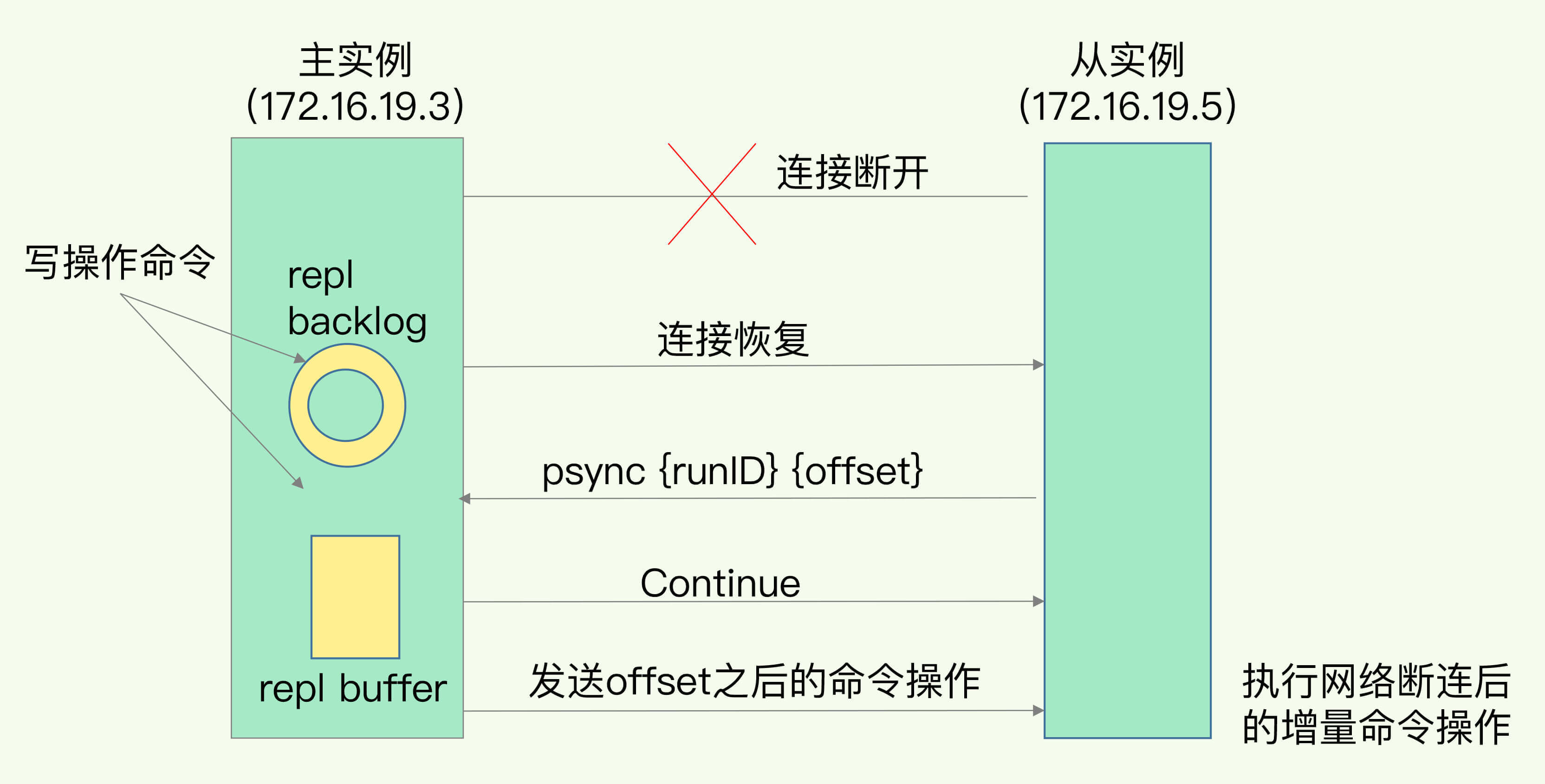\r\n\r\n由于环形写的问题存在写满的情况\r\n\r\nrepl_backlog_size设置\r\n\r\n## 主库挂了怎么办\r\n\r\n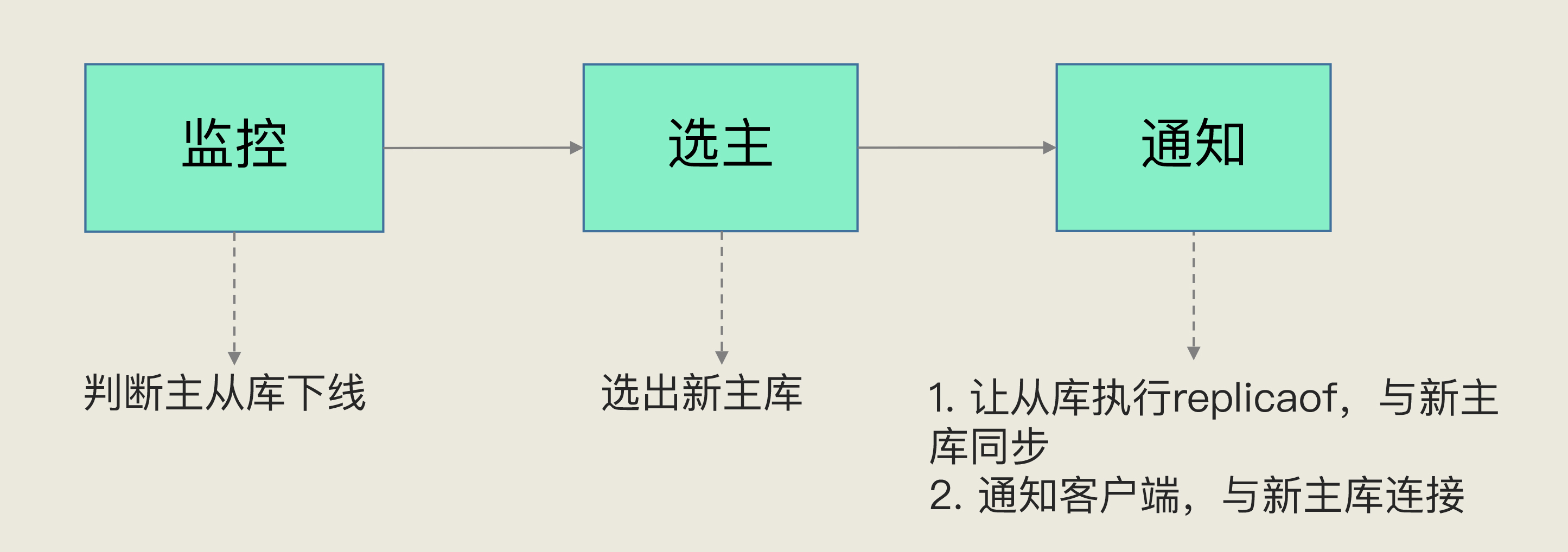\r\n\r\n* 在监控任务中,哨兵需要判断主库是否处于下线状态;\r\n * 主观下线\r\n * 客观下线\r\n * 误判一般会发生在集群网络压力较大、网络拥塞,或者是主库本身压力较大的情况下。\r\n * 通常会采用多实例组成的集群模式进行部署,这也被称为哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。\r\n* 在选主任务中,哨兵也要决定选择哪个从库实例作为主库。\r\n * 除了要检查从库的当前在线状态,还要判断它之前的网络连接状态\r\n * 第一轮:优先级最高的从库得分高。\r\n * 第二轮:和旧主库同步程度最接近的从库得分高。\r\n * slave_repl_offset 需要最接近 master_repl_offset\r\n * 第三轮:ID 号小的从库得分高。\r\n\r\n## 哨兵挂了主从库如何切换\r\n\r\n### 基于 pub/sub 机制的哨兵集群组成\r\n\r\n哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是发布 / 订阅机制。\r\n\r\n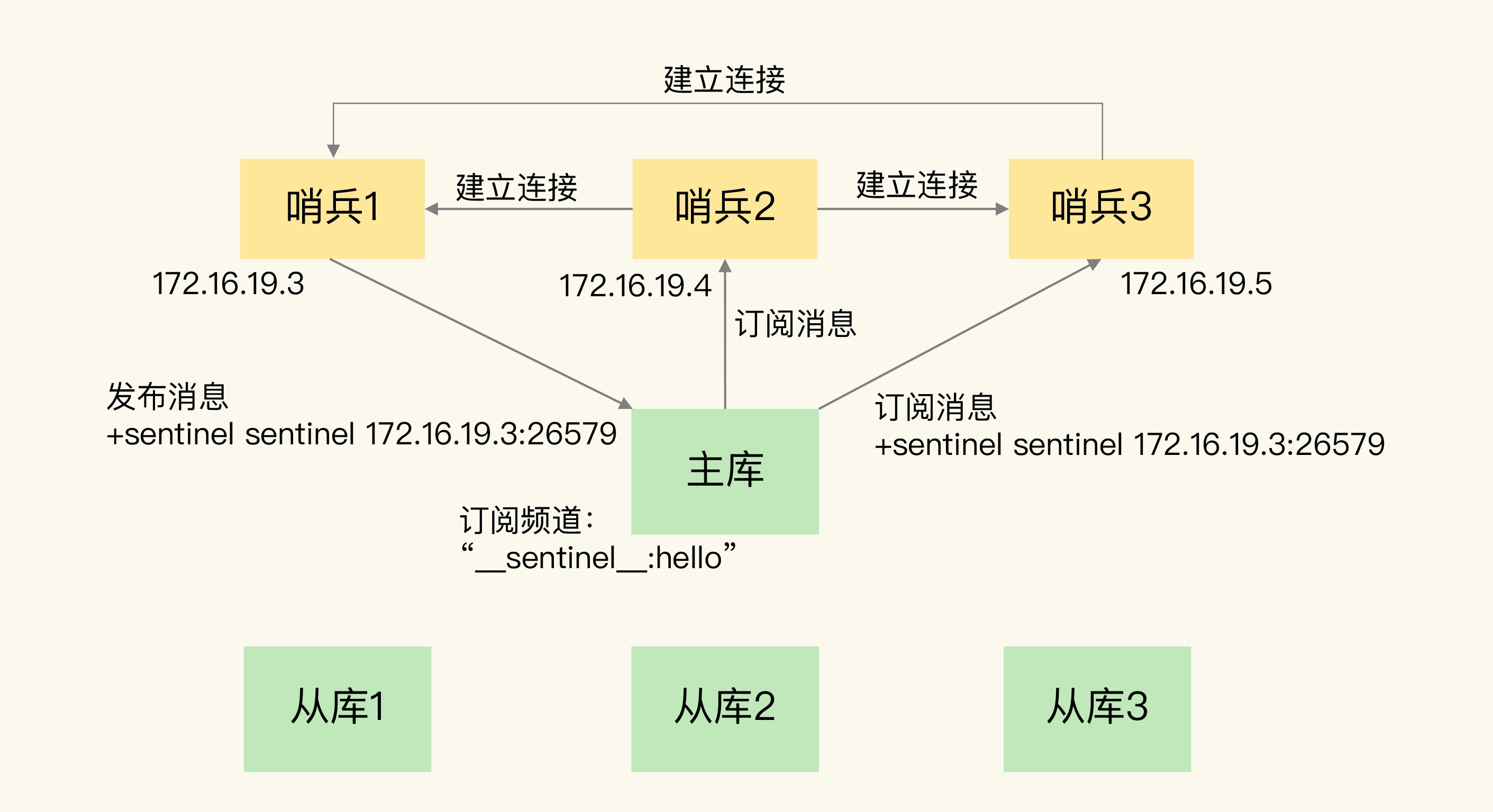\r\n\r\n哨兵通过INFO命令和主库链接得到从库的地址\r\n\r\n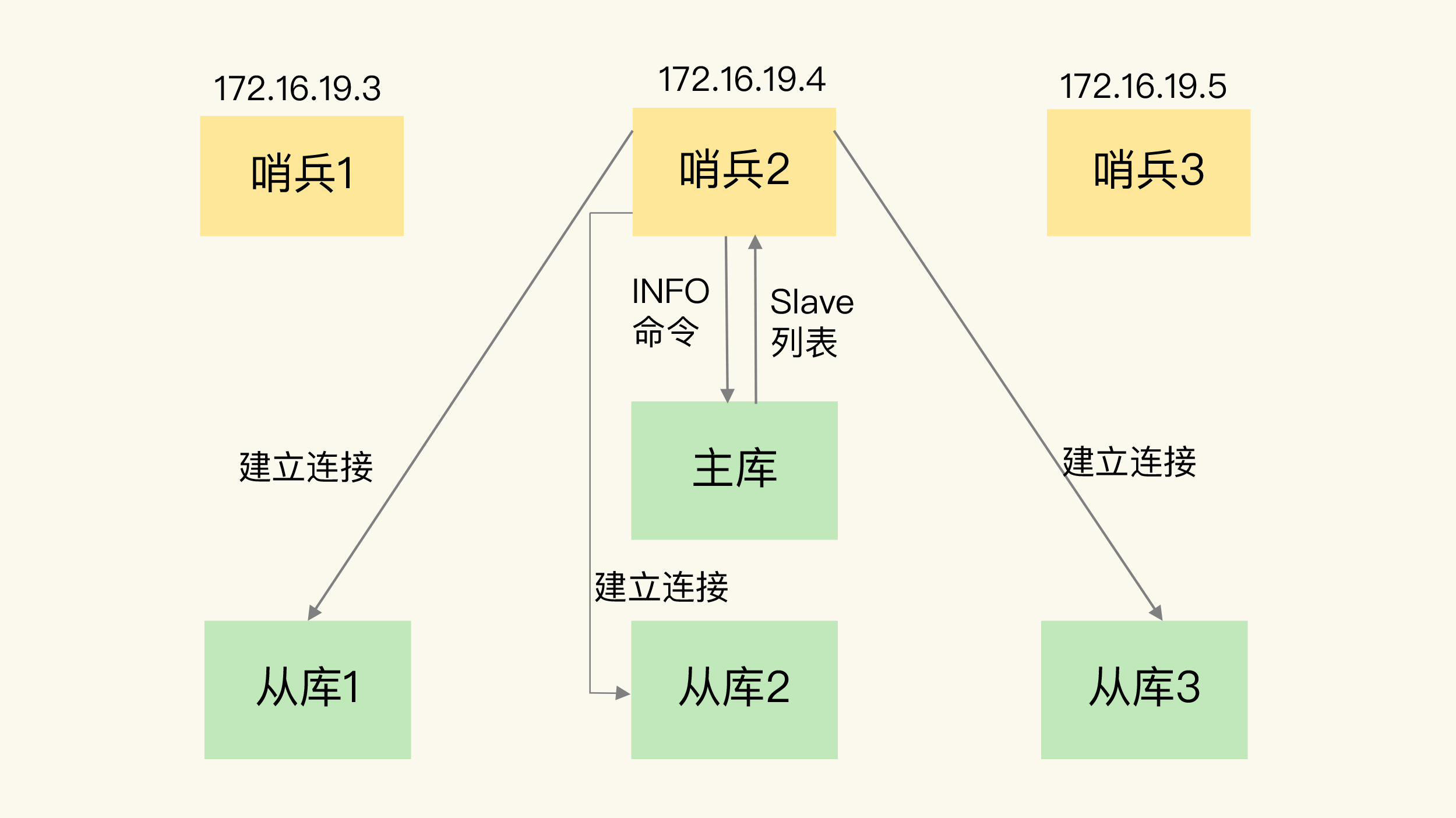\r\n\r\n### 基于 pub/sub 机制的客户端事件通知\r\n\r\n从本质上说,哨兵就是一个运行在特定模式下的 Redis 实例,只不过它并不服务请求操作,只是完成监控、选主和通知的任务。所以,每个哨兵实例也提供 pub/sub 机制,客户端可以从哨兵订阅消息。哨兵提供的消息订阅频道有很多,不同频道包含了主从库切换过程中的不同关键事件。\r\n\r\n### 由哪个哨兵执行主从切换?\r\n\r\n任何一个实例只要自身判断主库“主观下线”后,就会给其他实例发送 is-master-down-by-addr 命令。\r\n\r\n一个哨兵获得了仲裁所需的赞成票数后,就可以标记主库为“客观下线”。这个所需的赞成票数是通过哨兵配置文件中的 quorum 配置项设定的。\r\n\r\n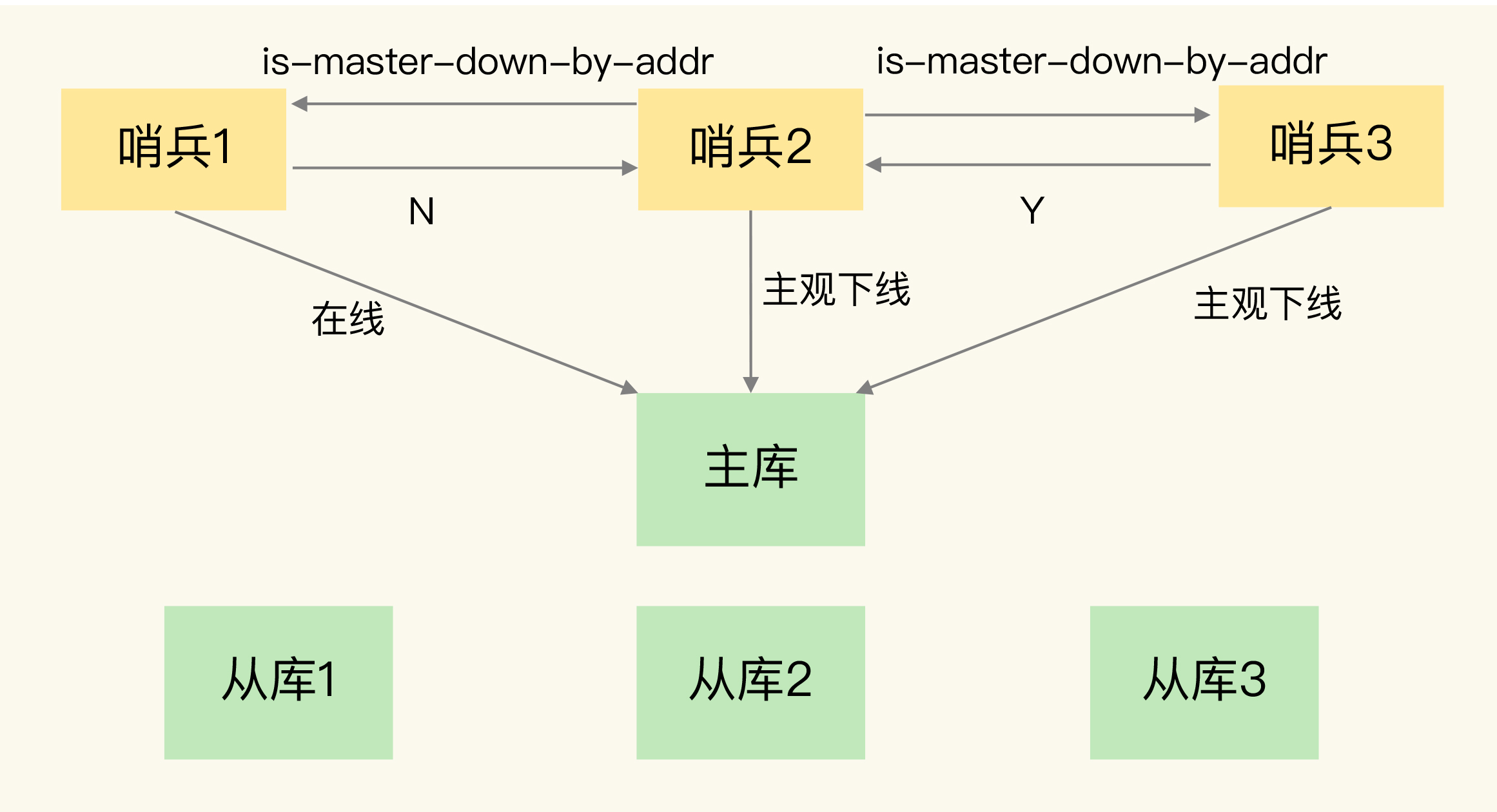\r\n\r\n在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:第一,拿到半数以上的赞成票;第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。\r\n\r\n## 切片集群:数据增多了,是该加内存还是加实例?\r\n\r\n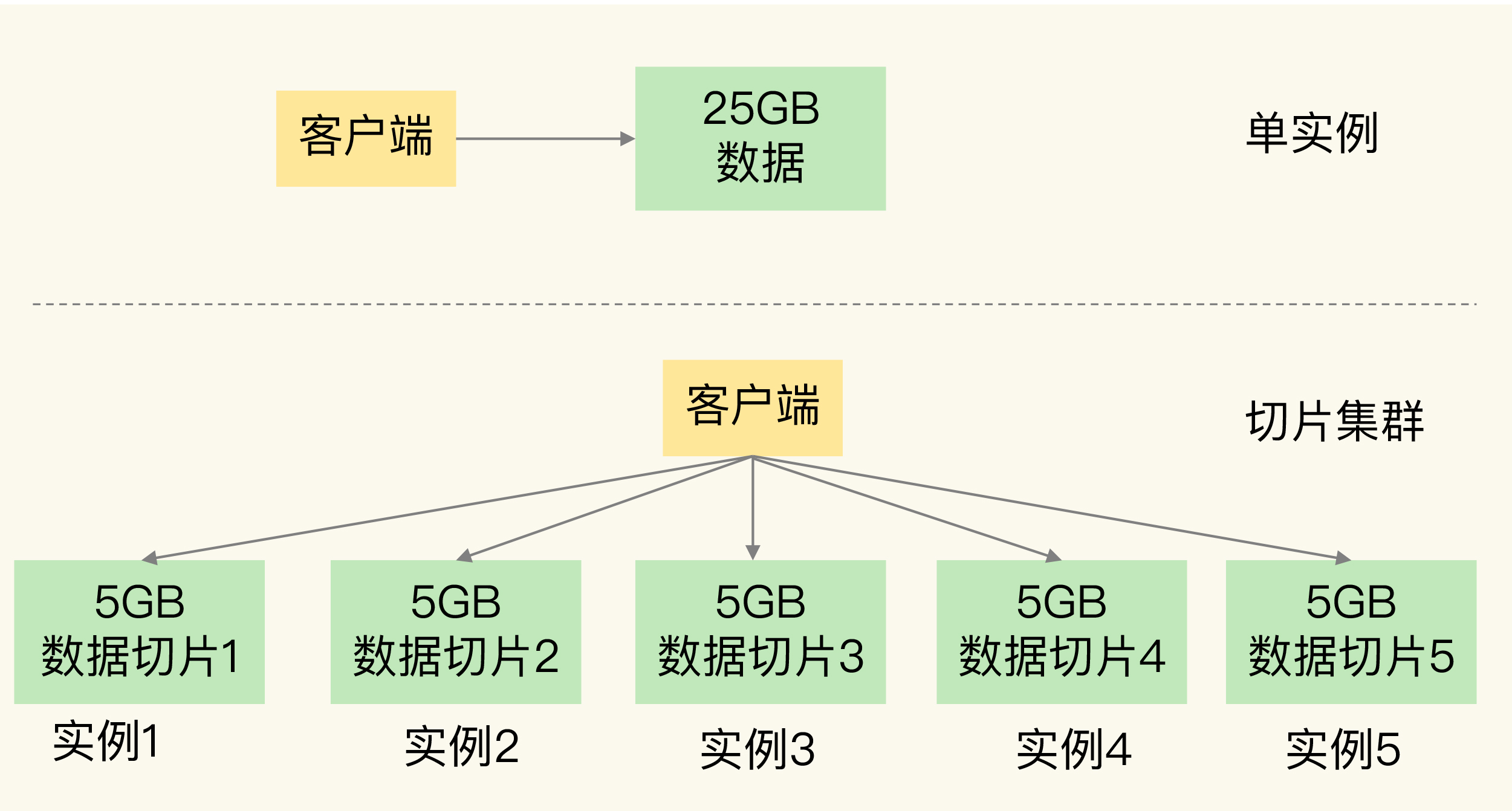\r\n\r\n### 如何保存更多数据?\r\n\r\n* 纵向扩展:升级单个 Redis 实例的资源配置,包括增加内存容量、增加磁盘容量、使用更高配置的 CPU。就像下图中,原来的实例内存是 8GB,硬盘是 50GB,纵向扩展后,内存增加到 24GB,磁盘增加到 150GB。\r\n* 横向扩展:横向增加当前 Redis 实例的个数,就像下图中,原来使用 1 个 8GB 内存、50GB 磁盘的实例,现在使用三个相同配置的实例。\r\n\r\n\r\n\r\n### 数据切片和实例的对应分布关系\r\n\r\n一个实例可以有很多哈希槽,一共16384个槽\r\n\r\n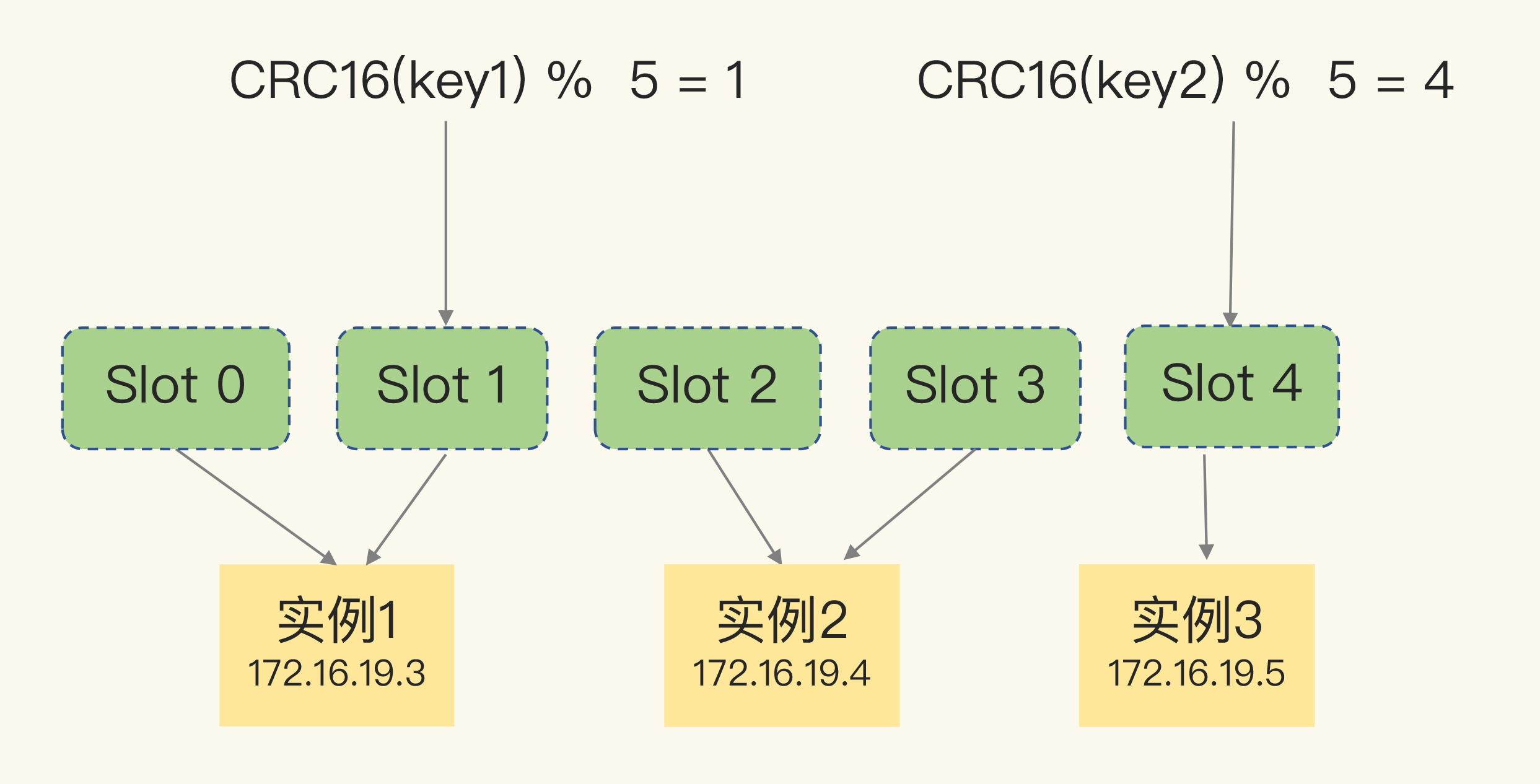\r\n\r\n### 客户端如何定位数据?\r\n\r\n一般来说,客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端。Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。\r\n\r\n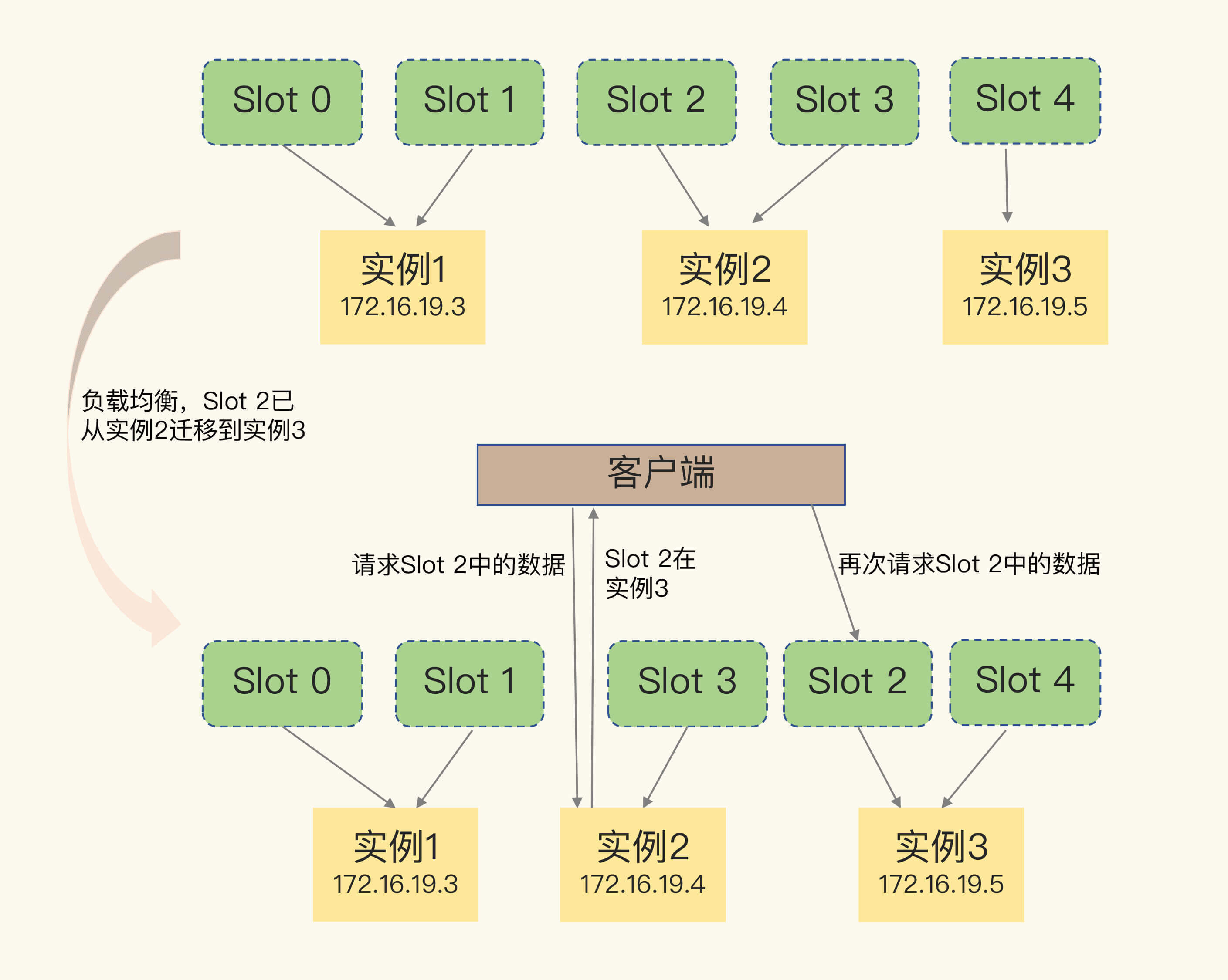\r\n\r\n## 为什么String的内存开销大\r\n\r\nString 类型并不是适用于所有场合的,它有一个明显的短板,就是它保存数据时所消耗的内存空间较多。\r\n\r\n当保存的数据包含字符时,String类型使用简单动态字符串\r\n\r\n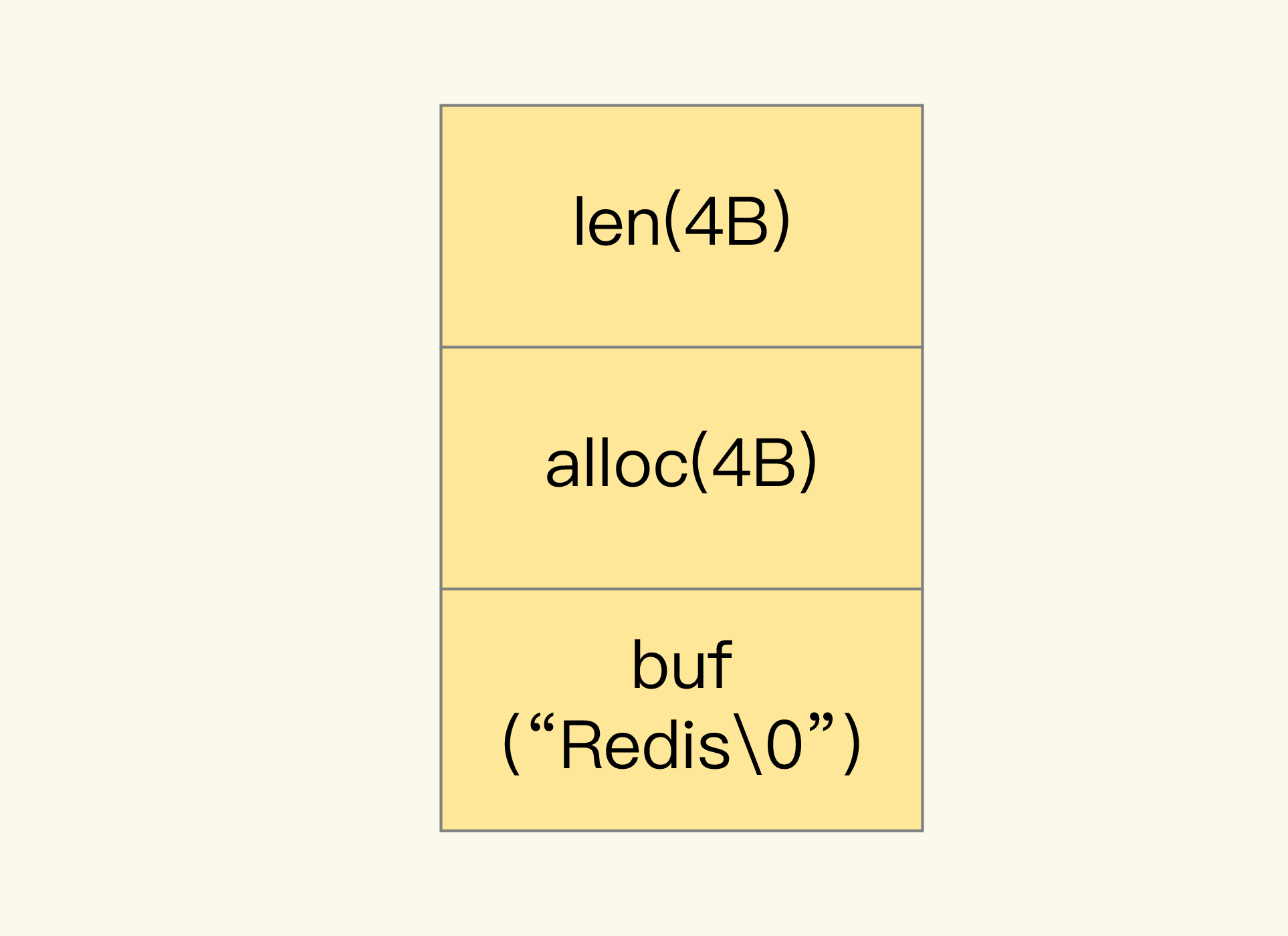\r\n\r\nlen:已用长度\r\n\r\nalloc:全部长度\r\n\r\nbuf:实际内容\r\n\r\n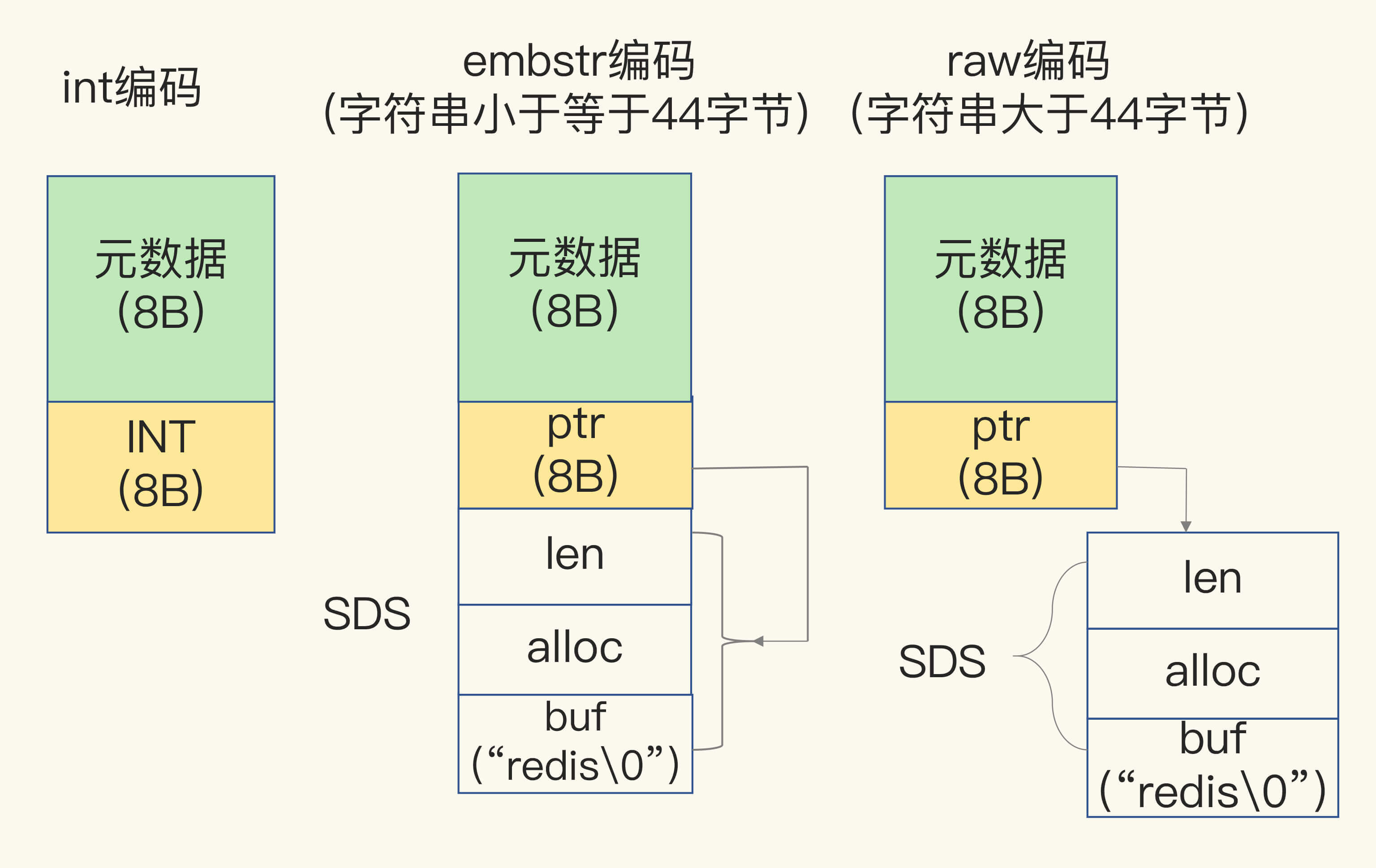\r\n\r\njemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。\r\n\r\n### 节省内存的数据结构\r\n\r\n压缩列表ziplist\r\n\r\n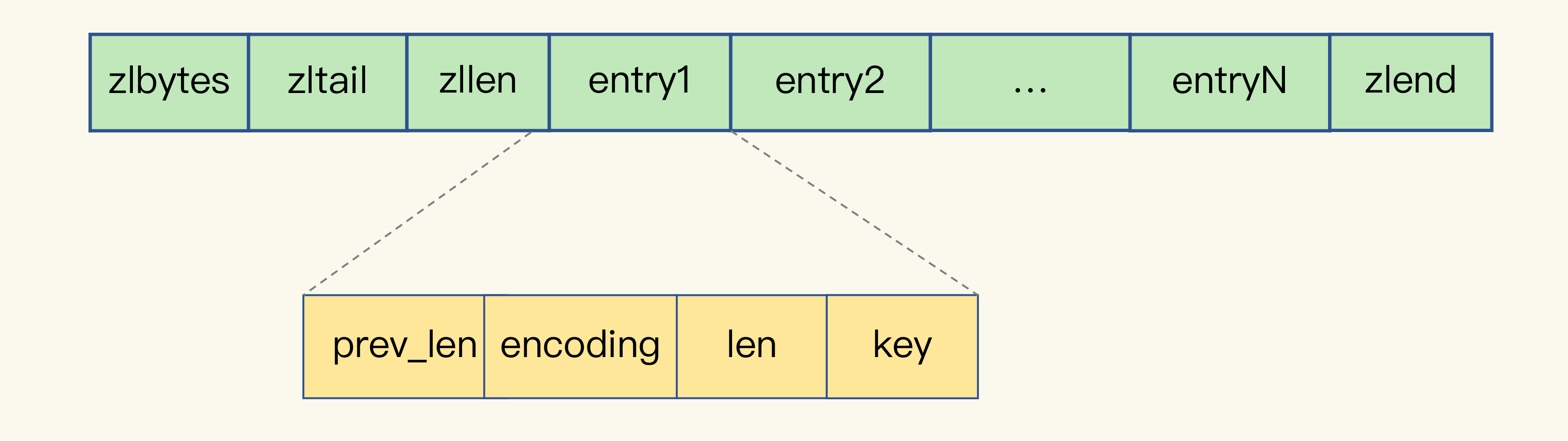\r\n\r\n表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量,以及列表中的 entry 个数。压缩列表尾还有一个 zlend,表示列表结束。\r\n\r\n### 如何用集合类型保存单值的键值对?\r\n\r\n在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。这里说的二级编码,就是把一个单值的数据拆分成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value,这样一来,我们就可以把单值数据保存到 Hash 集合中了。\r\n\r\n### Hash 类型底层结构什么时候使用压缩列表,什么时候使用哈希表呢?\r\n\r\nHash 类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。\r\n\r\n* hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。hash-max\r\n* ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。\r\n\r\n## 统计大量的key如何解决?\r\n\r\n集合类型常见的四种统计模式,包括聚合统计、排序统计、二值状态统计和基数统计\r\n\r\n### 聚合统计\r\n\r\nSet 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。所以,我给你分享一个小建议:你可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计,这样就可以规避阻塞主库实例和其他从库实例的风险了。\r\n\r\n### 排序统计\r\n\r\n在 Redis 常用的 4 个集合类型中(List、Hash、Set、Sorted Set),List 和 Sorted Set 就属于有序集合。\r\n\r\nList 是按照元素进入 List 的顺序进行排序的,而 Sorted Set 可以根据元素的权重来排序\r\n\r\n### 二值状态\r\n\r\nBitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态。你可以把 Bitmap 看作是一个 bit 数组。\r\n\r\n### 基数统计\r\n\r\n基数统计。基数统计就是指统计一个集合中不重复的元素个数。对应到我们刚才介绍的场景中,就是统计网页的 UV。\r\n\r\n## 消息队列\r\n\r\n### 对于消息队列的存取需求\r\n\r\n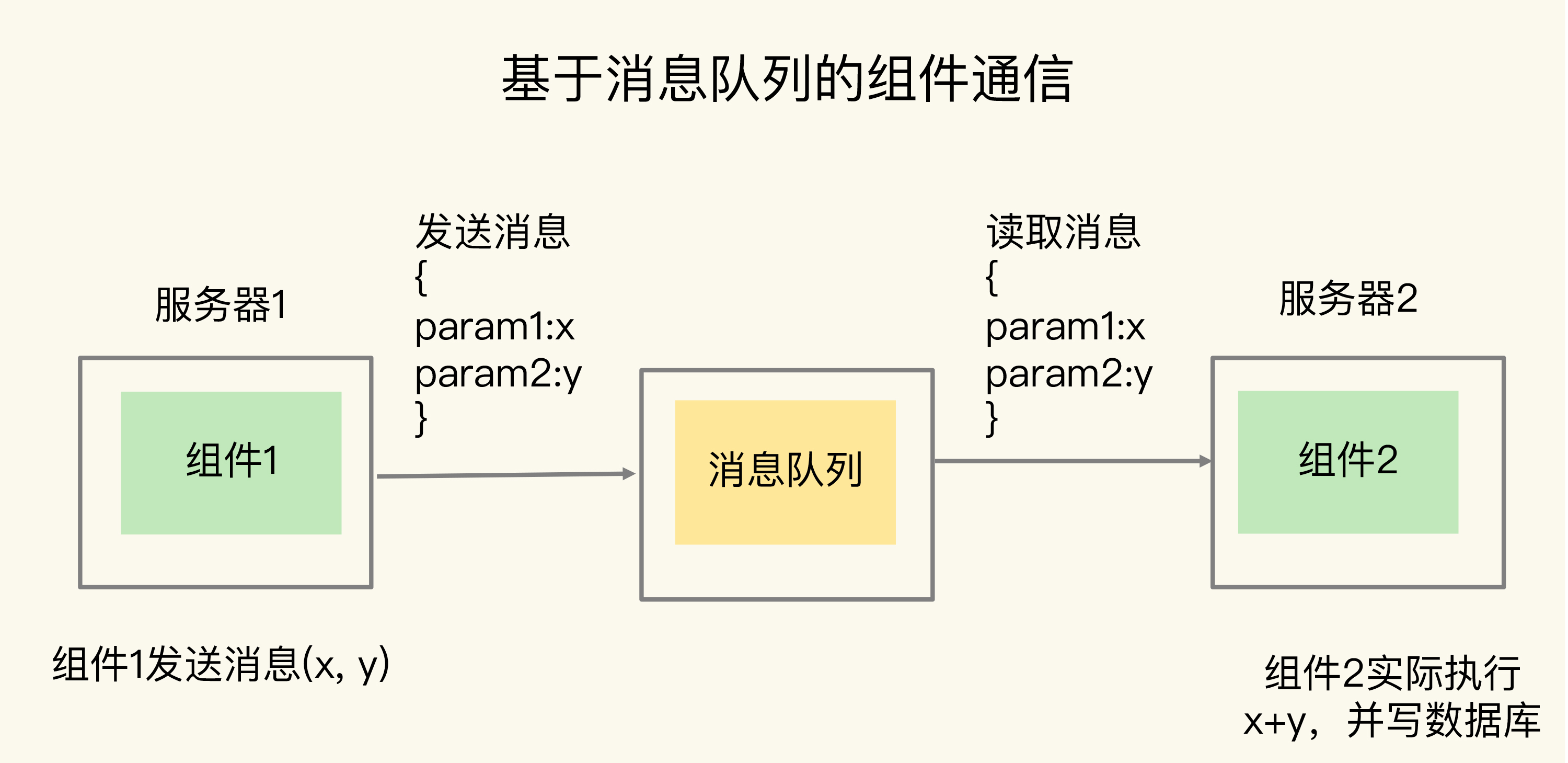\r\n\r\n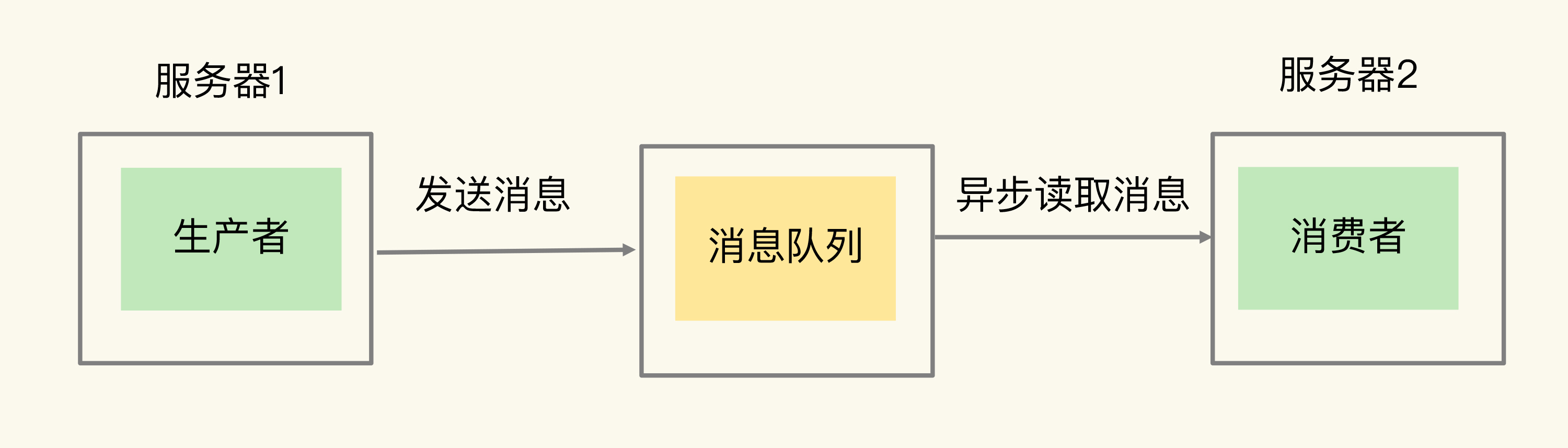\r\n\r\n\r\n\r\n三个要求\r\n\r\n* 消息保存\r\n* 处理重复消息\r\n* 消息可靠性\r\n\r\n### 基于 List 的消息队列解决方案\r\n\r\n* 消息保存:BRPOP 命令也称为阻塞式读取,客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据\r\n* 重复消息:一方面,消息队列要能给每一个消息提供全局唯一的 ID 号;另一方面,消费者程序要把已经处理过的消息的 ID 号记录下来。\r\n* 消息可靠性:List 类型提供了 BRPOPLPUSH 命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存。\r\n\r\n### 基于 Streams 的消息队列解决方案\r\n\r\n* XADD:插入消息,保证有序,可以自动生成全局唯一 ID;\r\n* XREAD:用于读取消息,可以按 ID 读取数据;\r\n* XREADGROUP:按消费组形式读取消息;\r\n* XPENDING 和 XACK:XPENDING 命令可以用来查询每个消费组内所有消费者已读取但尚未确认的消息,而 XACK 命令用于向消息队列确认消息处理已完成。\r\n\r\n使用消费组的目的是让组内的多个消费者共同分担读取消息,所以,我们通常会让每个消费者读取部分消息,从而实现消息读取负载在多个消费者间是均衡分布的。\r\n\r\n## 如何避免单线程的阻塞\r\n\r\n### Redis 实例有哪些阻塞点?\r\n\r\n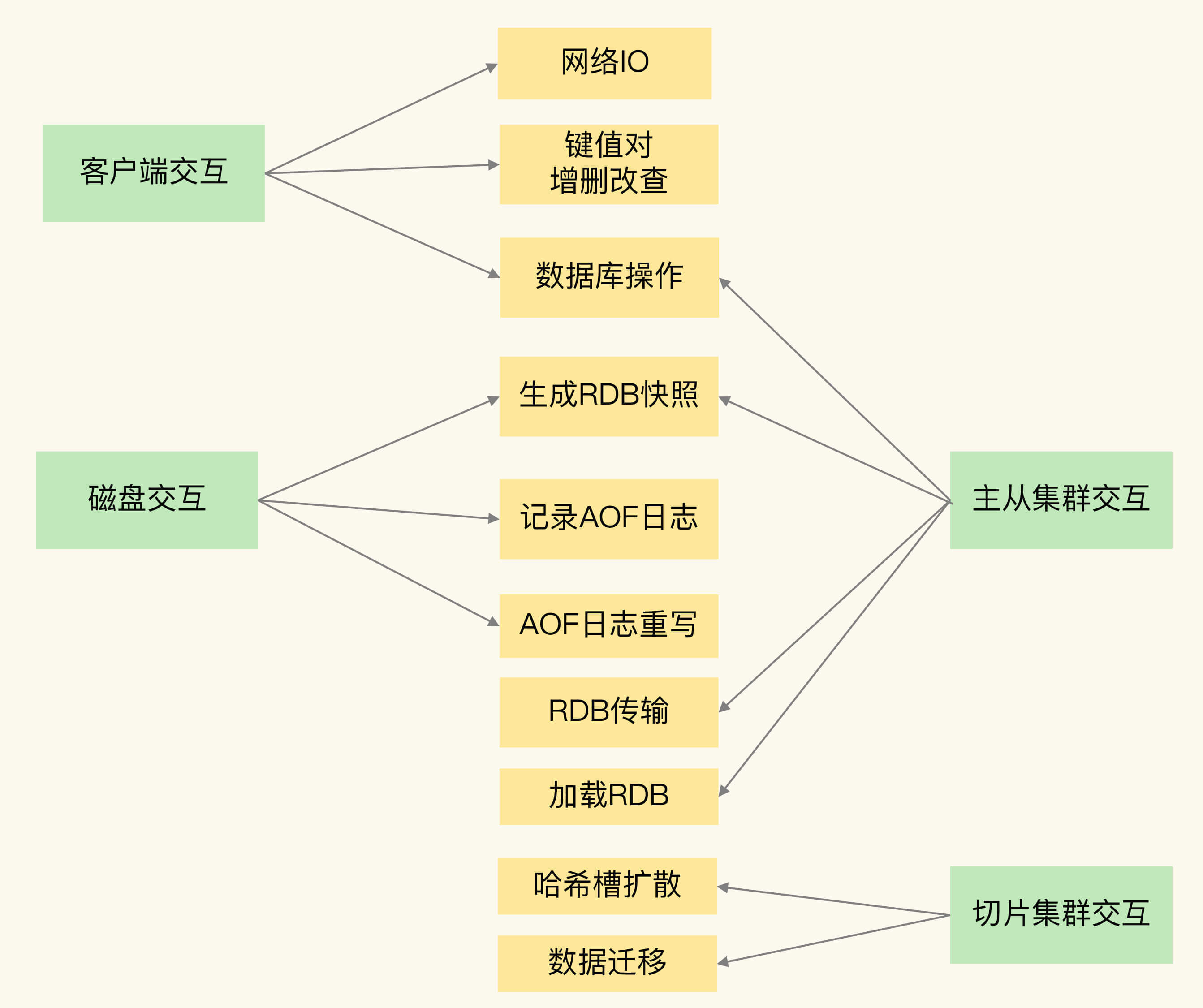\r\n\r\n### 1. 和客户端交互时的阻塞点\r\n\r\n* 多路复用机制IO多路复用不是主要的点\r\n* 当高于O(N)会被判断为高复杂度,第一个阻塞点:集合全量查询和聚合操作\r\n* 大量删除操作,bigkey和清空数据库\r\n\r\n### 2. 和磁盘交互时的阻塞点\r\n\r\nRedis 进一步设计为采用子进程的方式生成 RDB 快照文件,以及执行 AOF 日志重写操作。不会导致阻塞。\r\n\r\n第四个阻塞点了:AOF 日志同步写。\r\n\r\n### 3. 主从节点交互时的阻塞点\r\n\r\n从库FLUSHDB以及从库加载RDB文件\r\n\r\n### 4. 切片集群实例交互时的阻塞点\r\n\r\n当没有 bigkey 时,切片集群的各实例在进行交互时不会阻塞主线程,就可以了。\r\n\r\n### 总结\r\n\r\n集合全量查询和聚合操作;bigkey 删除;清空数据库;AOF 日志同步写;从库加载 RDB 文件。\r\n\r\n## 为什么CPU的结构会影响Redis速度\r\n\r\n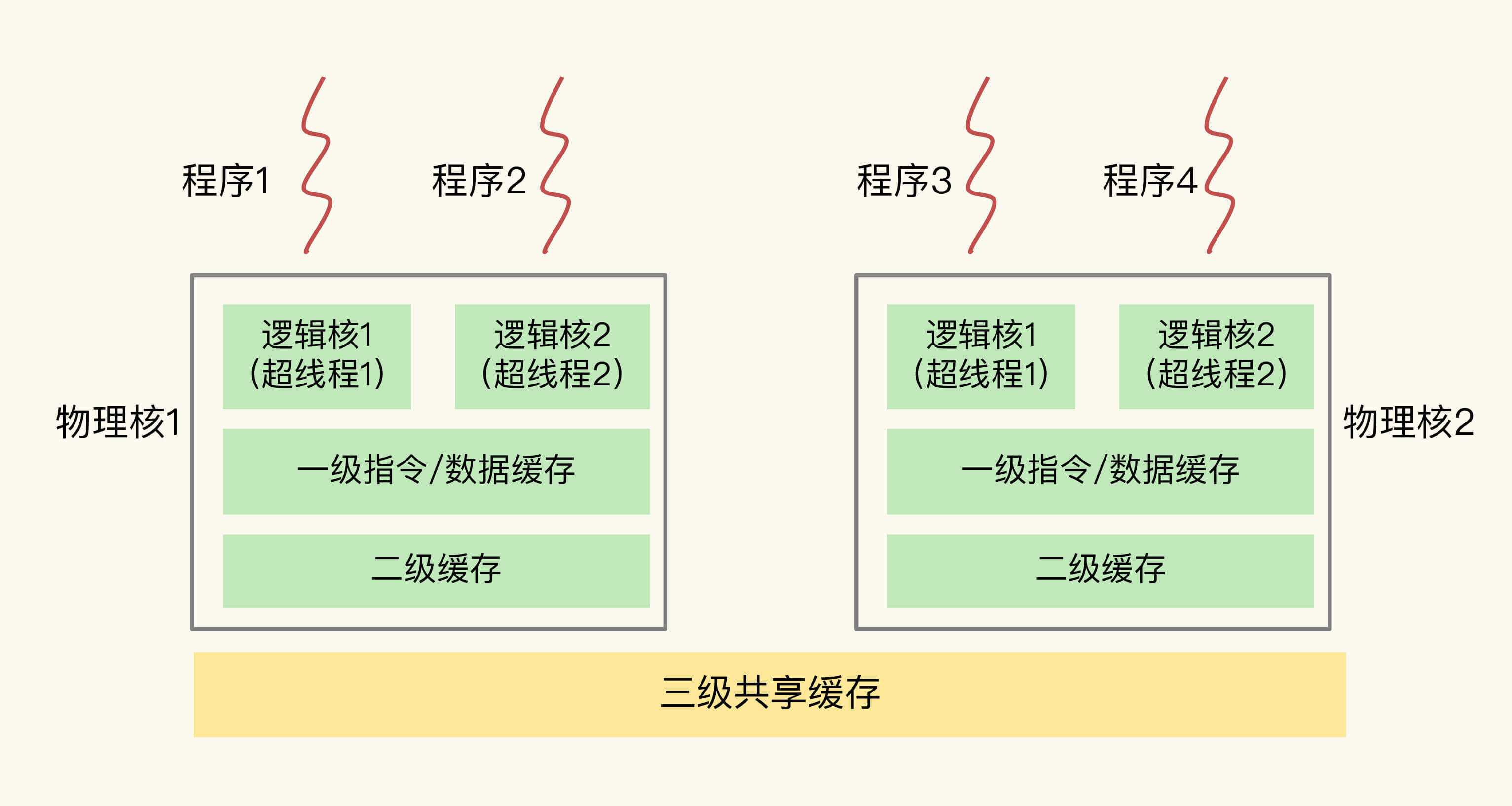\r\n\r\ncontext switch 是指线程的上下文切换,这里的上下文就是线程的运行时信息。在 CPU 多核的环境中,一个线程先在一个 CPU 核上运行,之后又切换到另一个 CPU 核上运行,这时就会发生 context switch。\r\n\r\n通过\r\n\r\n```\r\ntaskset -c 0 ./redis-server\r\n```\r\n\r\n命令绑定核减少多核切换带来的损耗\r\n\r\n对于网络中断程序:\r\n\r\n我们最好把网络中断程序和 Redis 实例绑在同一个 CPU Socket 上,这样一来,Redis 实例就可以直接从本地内存读取网络数据了,如下图所示:\r\n\r\n\r\n\r\n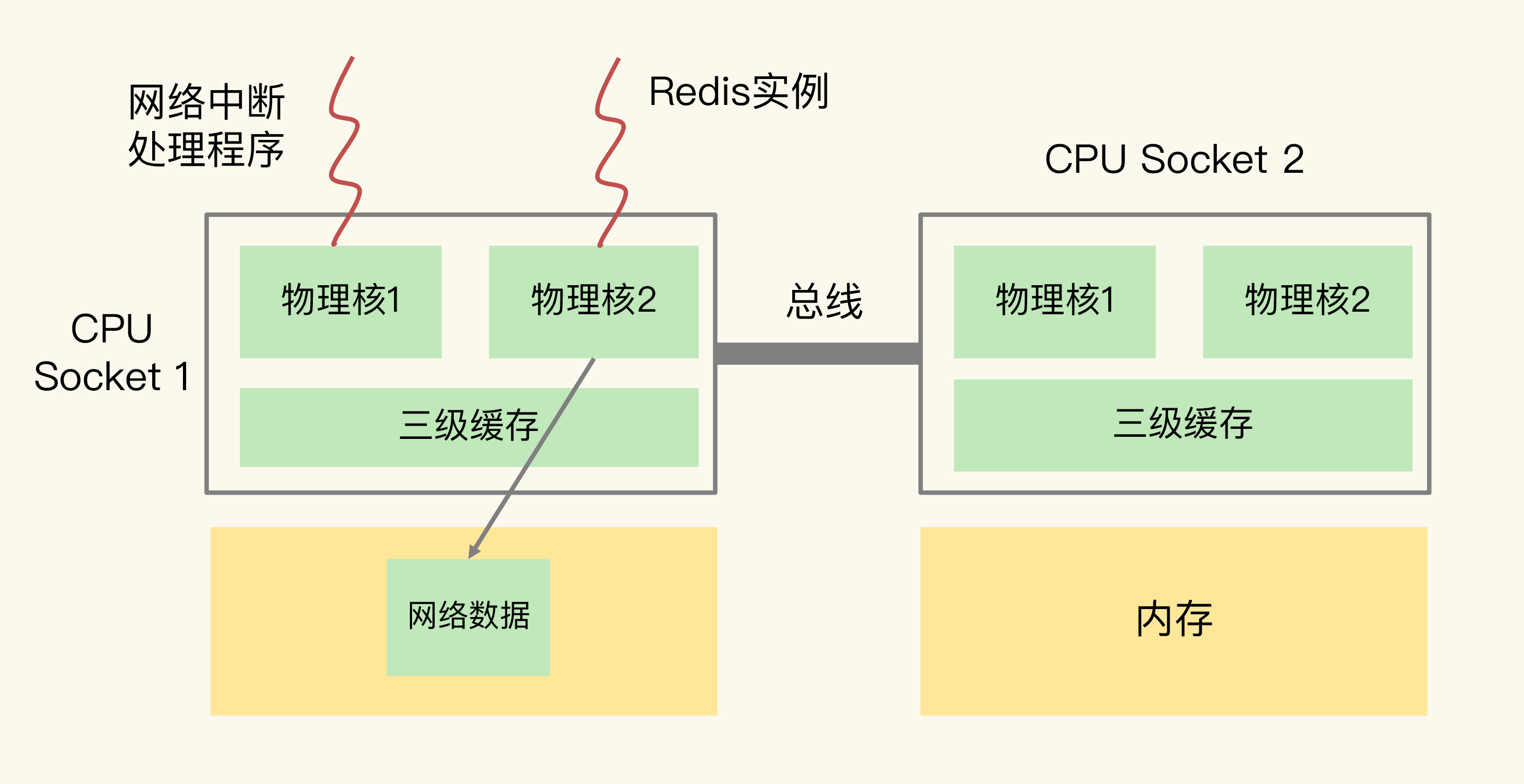\r\n\r\n绑定核心数带来的风险:\r\n\r\n* 一个 Redis 实例对应绑一个物理核,物理核有多个逻辑核\r\n* 修改源码,把子进程和后台进程绑定到不同的核上\r\n\r\n## Redis的慢操作\r\n\r\n### Redis自身操作特性影响\r\n\r\n1. 慢查询命令\r\n 1. 高效命令代替:SCCAN代替SMEMBERS\r\n 2. 排序,交集,并集操作交给客户端\r\n 3. keys命令\r\n2. 过期key操作\r\n 1. 删除操作是阻塞的,4.0后用异步线程减少带来的影响\r\n 2. 大量的key同时过期\r\n3. 文件系统压力比较大\r\n\r\n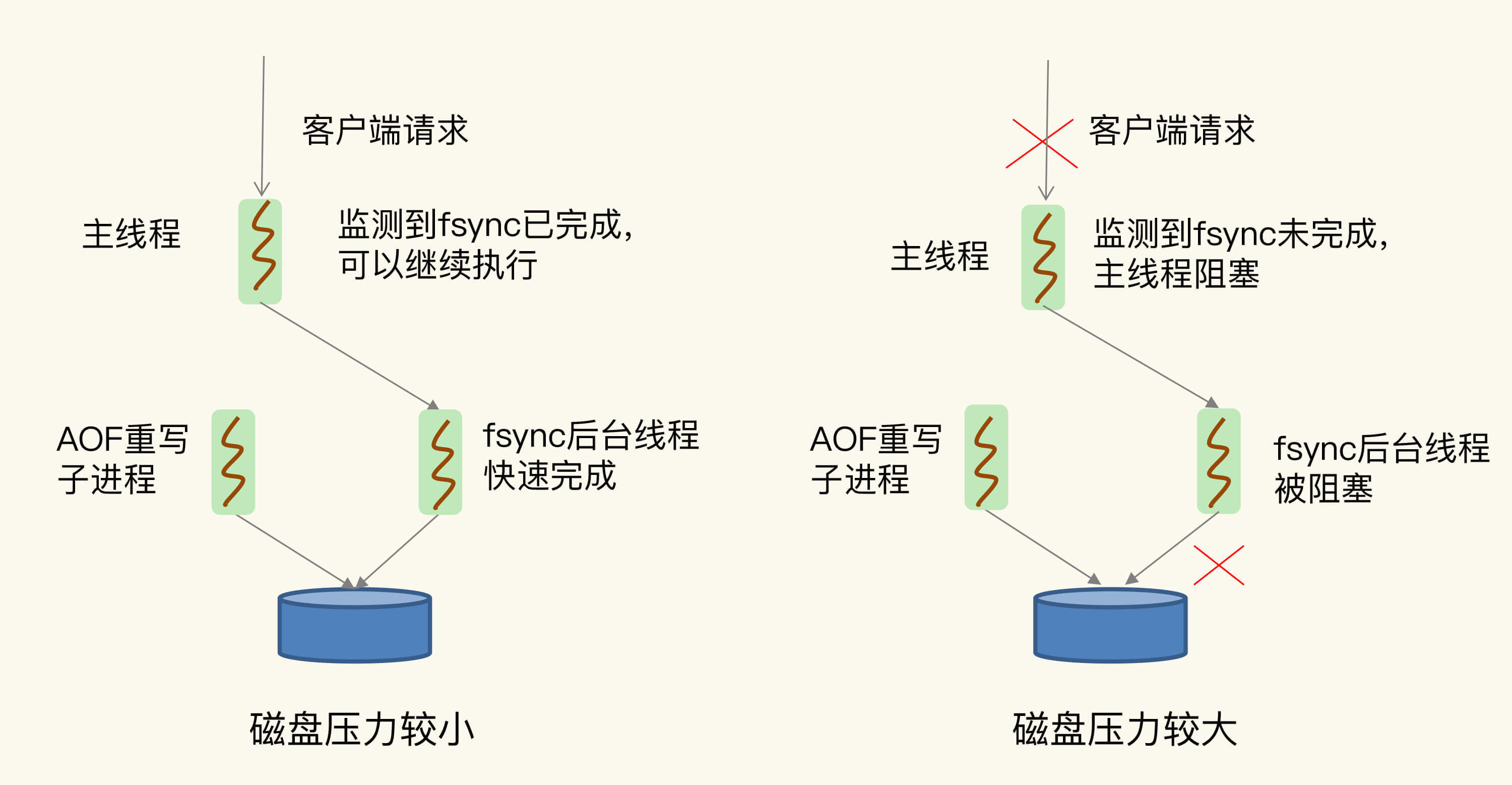\r\n\r\n由于 fsync 后台子线程和 AOF 重写子进程的存在,主 IO 线程一般不会被阻塞。但是,如果在重写日志时,AOF 重写子进程的写入量比较大,fsync 线程也会被阻塞,进而阻塞主线程,导致延迟增加。\r\n\r\n4. 操作系统的swap\r\n 1. swap 的原因主要是物理机器内存不足\r\n 1. Redis 实例自身使用了大量的内存,导致物理机器的可用内存不足;\r\n 2. 和 Redis 实例在同一台机器上运行的其他进程,在进行大量的文件读写操作。文件读写本身会占用系统内存,这会导致分配给 Redis 实例的内存量变少,进而触发 Redis 发生 swap。\r\n 2. 增加机器的内存或者使用 Redis 集群。\r\n 3. 内存大页机制,很少的数据却要拷贝较大的内存页\r\n\r\n### 总结\r\n\r\n获取 Redis 实例在当前环境下的基线性能。是否用了慢查询命令?如果是的话,就使用其他命令替代慢查询命令,或者把聚合计算命令放在客户端做。\r\n\r\n是否对过期 key 设置了相同的过期时间?对于批量删除的 key,可以在每个 key 的过期时间上加一个随机数,避免同时删除。\r\n\r\n是否存在 bigkey? 对于 bigkey 的删除操作,如果你的 Redis 是 4.0 及以上的版本,可以直接利用异步线程机制减少主线程阻塞;如果是 Redis 4.0 以前的版本,可以使用 SCAN 命令迭代删除;对于 bigkey 的集合查询和聚合操作,可以使用 SCAN 命令在客户端完成。\r\n\r\nRedis AOF 配置级别是什么?业务层面是否的确需要这一可靠性级别?如果我们需要高性能,同时也允许数据丢失,可以将配置项 no-appendfsync-on-rewrite 设置为 yes,避免 AOF 重写和 fsync 竞争磁盘 IO 资源,导致 Redis 延迟增加。当然, 如果既需要高性能又需要高可靠性,最好使用高速固态盘作为 AOF 日志的写入盘。\r\n\r\nRedis 实例的内存使用是否过大?发生 swap 了吗?如果是的话,就增加机器内存,或者是使用 Redis 集群,分摊单机 Redis 的键值对数量和内存压力。同时,要避免出现 Redis 和其他内存需求大的应用共享机器的情况。\r\n\r\n在 Redis 实例的运行环境中,是否启用了透明大页机制?如果是的话,直接关闭内存大页机制就行了。\r\n\r\n是否运行了 Redis 主从集群?如果是的话,把主库实例的数据量大小控制在 2~4GB,以免主从复制时,从库因加载大的 RDB 文件而阻塞。\r\n\r\n是否使用了多核 CPU 或 NUMA 架构的机器运行 Redis 实例?使用多核 CPU 时,可以给 Redis 实例绑定物理核;使用 NUMA 架构时,注意把 Redis 实例和网络中断处理程序运行在同一个 CPU Socket 上。\r\n\r\n## 数据删除后Redis内存占用依然过高\r\n\r\n### 内存碎片如何产生\r\n\r\n1. 内存分配器的分配策略:jemalloc 的分配策略之一,是按照一系列固定的大小划分内存空间,例如 8 字节、16 字节、32 字节、48 字节,…, 2KB、4KB、8KB 等。\r\n2. 外因:键值对大小不一样和删改操作,通过查看碎片率自动清理,会带来额外的时间消耗','https://th.bing.com/th/id/OIP.fbhEiN3rkB1mjIxGDlrUKAHaHa?pid=ImgDet&rs=1','原创',1,0,1,1,1,1,'2021-07-25 10:16:53','2021-07-25 10:16:53',1,1,'Redis底层数据结构解析。','10,11'),
(17,'MySQL底层分析,面试相关','# Mysql\r\n\r\n## sql语句是如何执行的\r\n\r\n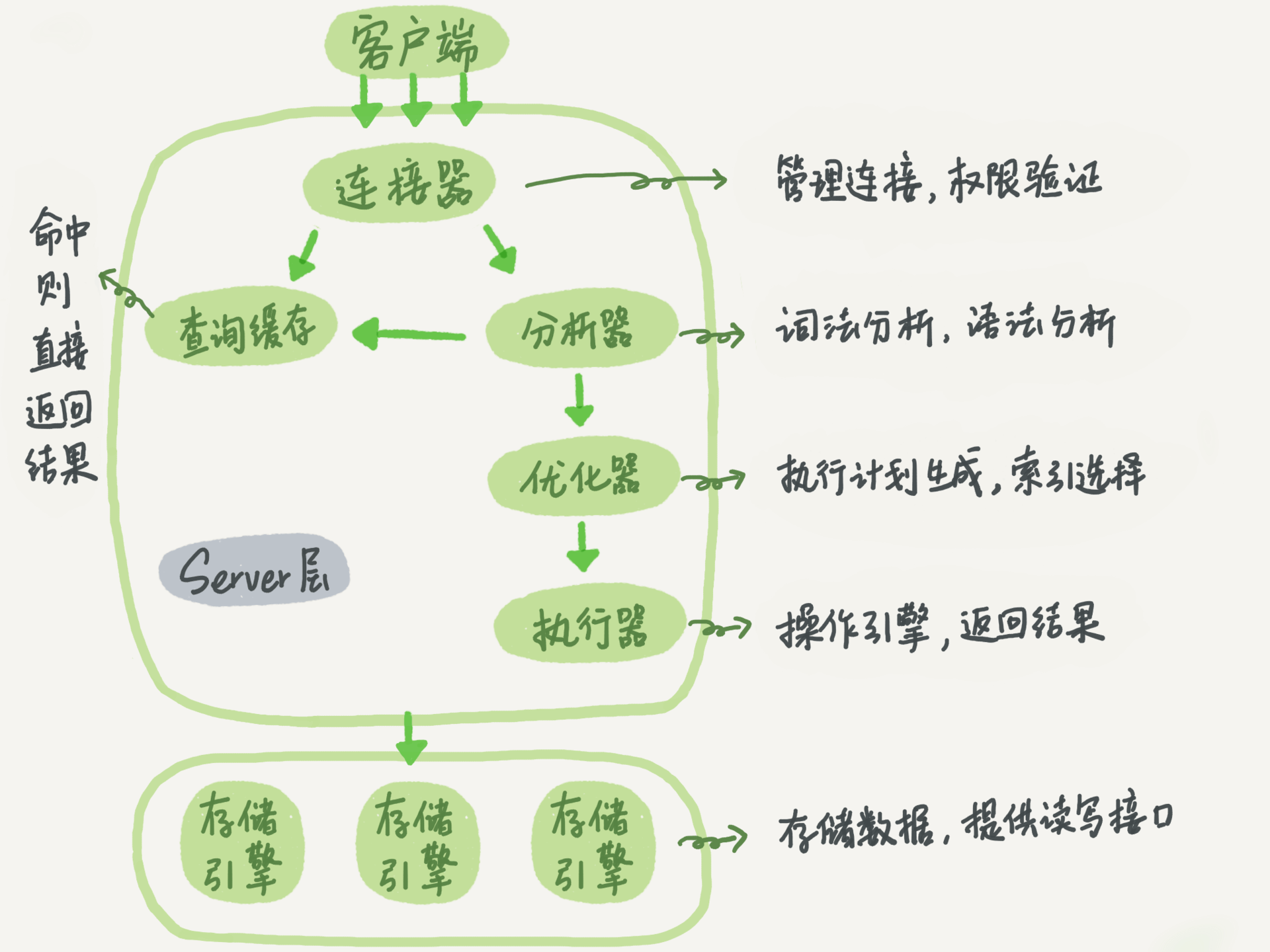\r\n\r\n1. 连接器\r\n\r\n 长连接和短连接\r\n\r\n 长连接指连接成功后持续请求使用一个,短连接为执行很少的查询就断开\r\n\r\n 建立连接比较复杂建议使用长连接\r\n\r\n - 长连接带来内存满问题两种解决方案\r\n\r\n 定期断开长连接\r\n\r\n 5.7以上执行完大的操作后mysq_reset_connection初始化链接\r\n\r\n2. 查询缓存\r\n\r\n 命中后就返回,不建议使用因为频繁更新的表缓存命中率十分低,8.0以后的版本删除。\r\n\r\n3. 分析器\r\n\r\n 先进性词法分析后进行语法分析。\r\n\r\n4. 优化器\r\n\r\n 多个索引时哪个索引\r\n\r\n 多表关联时连接表的顺序\r\n\r\n5. 执行器\r\n\r\n## SQL更新语句是如何执行的\r\n\r\n\r\n\r\n### redo log\r\n\r\n记账方法:直接记账,粉笔记账\r\n\r\n粉笔记账:WAL(wtrite-ahead-logging)先写日志再写磁盘\r\n\r\n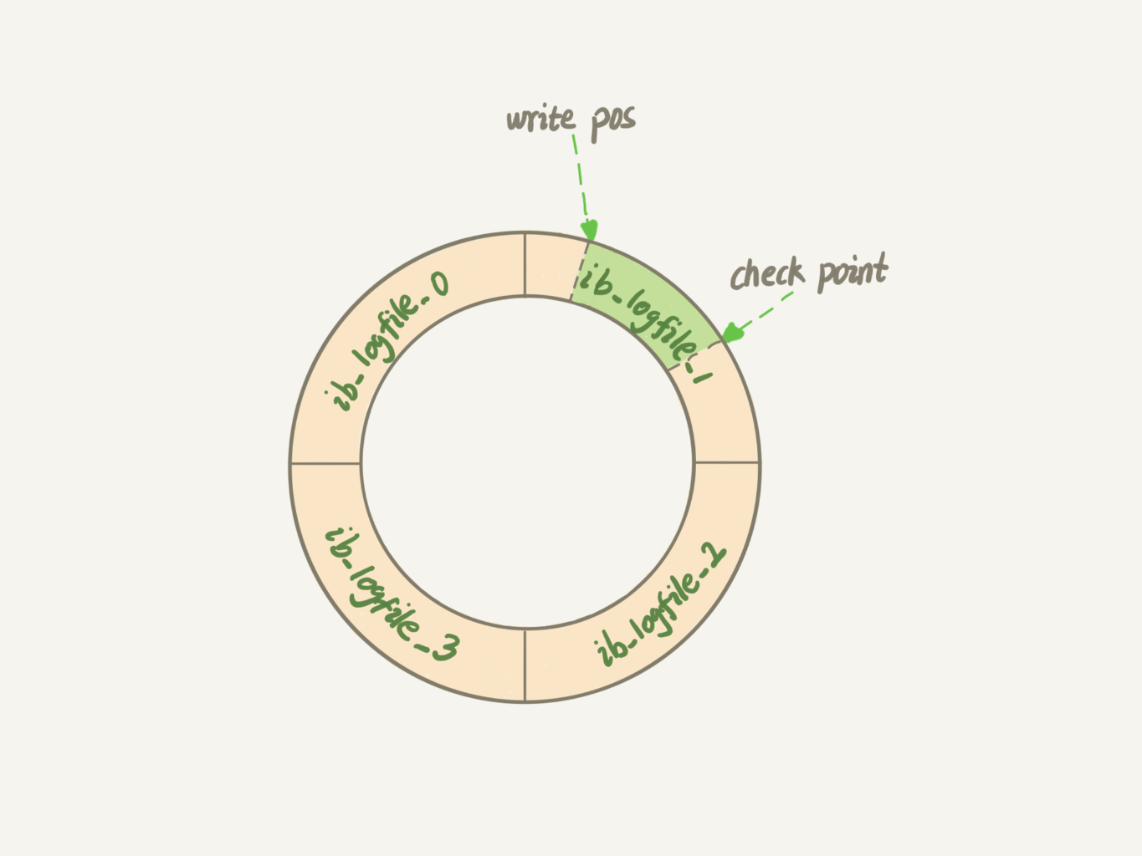\r\n\r\nInnoDB的redolog大小为4GB,系统空闲的时候进行io操作,分为write pos和check pos\r\n\r\n保证异常重启后记录不会丢失,crash-safe\r\n\r\n### binlog\r\n\r\n1. 两者区别\r\n\r\n redo log只有InnoDB拥有,binlog都拥有,属于SQL的service层\r\n\r\n redo log是物理日志,binlog是逻辑日志\r\n\r\n redo log循环写,binlog追加写\r\n\r\n2. 执行流程先写入redolog后写入binlog\r\n\r\n 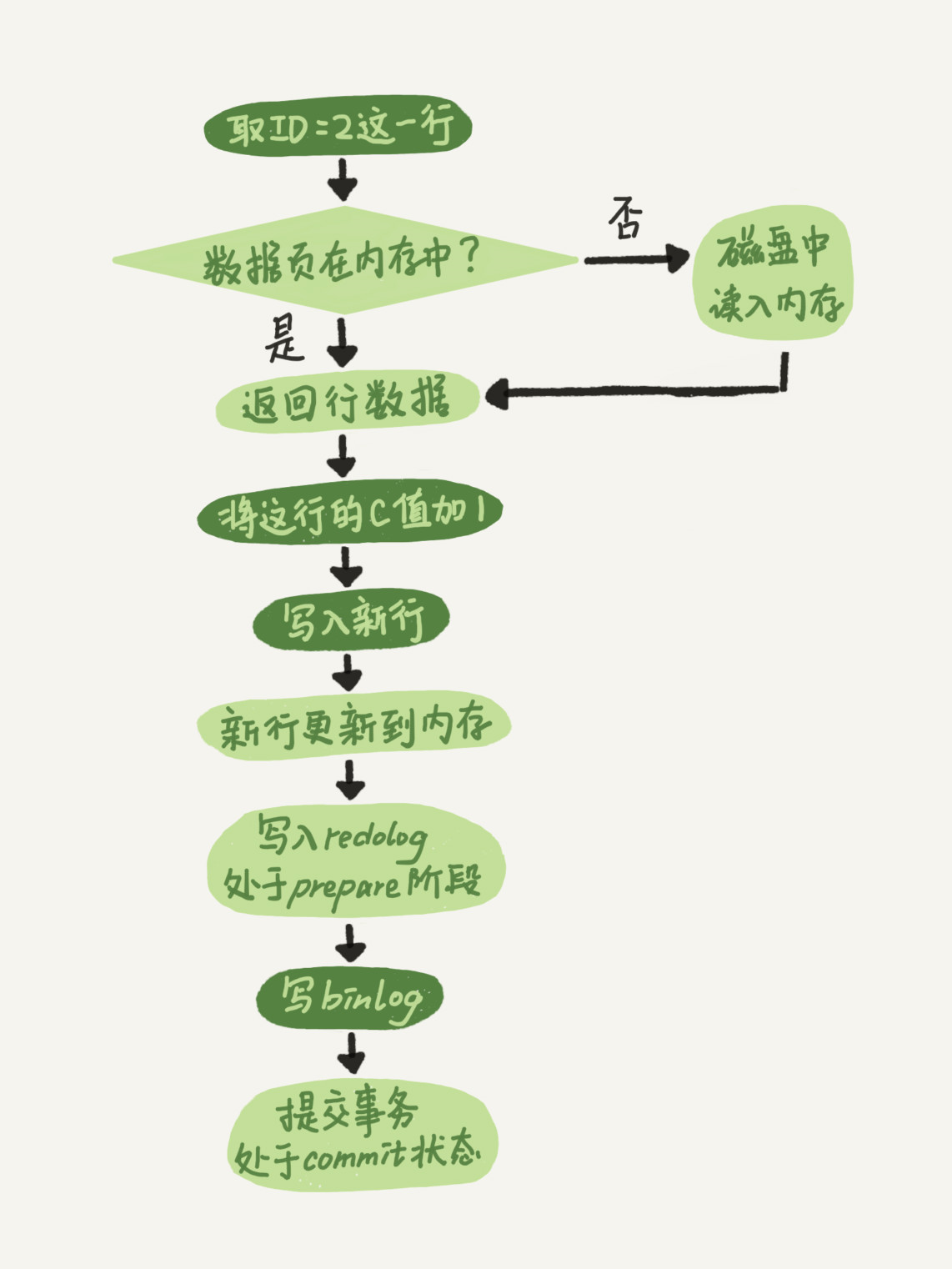\r\n\r\n3. 两阶段提交\r\n\r\n 为了两份日志的逻辑一致\r\n\r\n## 事务隔离\r\n\r\n原子性,一致性,隔离性,永久性\r\n\r\n四种隔离级别\r\n\r\n* 读未提交:事务提交前能被别的事务看到\r\n* 读提交:事务提交后才能被别的事务看到\r\n* 可重复读: 执行时看到的数据总是和在启动时是一致的\r\n* 串行化:同一行记录会增加读锁和写锁\r\n\r\n## SQL的索引\r\n\r\n### 索引的常见模型\r\n\r\n1. 哈希表\r\n\r\n 优点:增加新的值速度很快\r\n\r\n 缺点:不是有序的,区间索引非常慢\r\n\r\n 适用于等值查询\r\n\r\n2. 有序数组\r\n\r\n 优点:等值查询以及区间查询速度非常快\r\n\r\n 缺点:数据更新慢\r\n\r\n 适用于静态存储引擎\r\n\r\n3. 搜索树\r\n\r\n 一般是多叉树\r\n\r\n### InnoDB的索引模型\r\n\r\n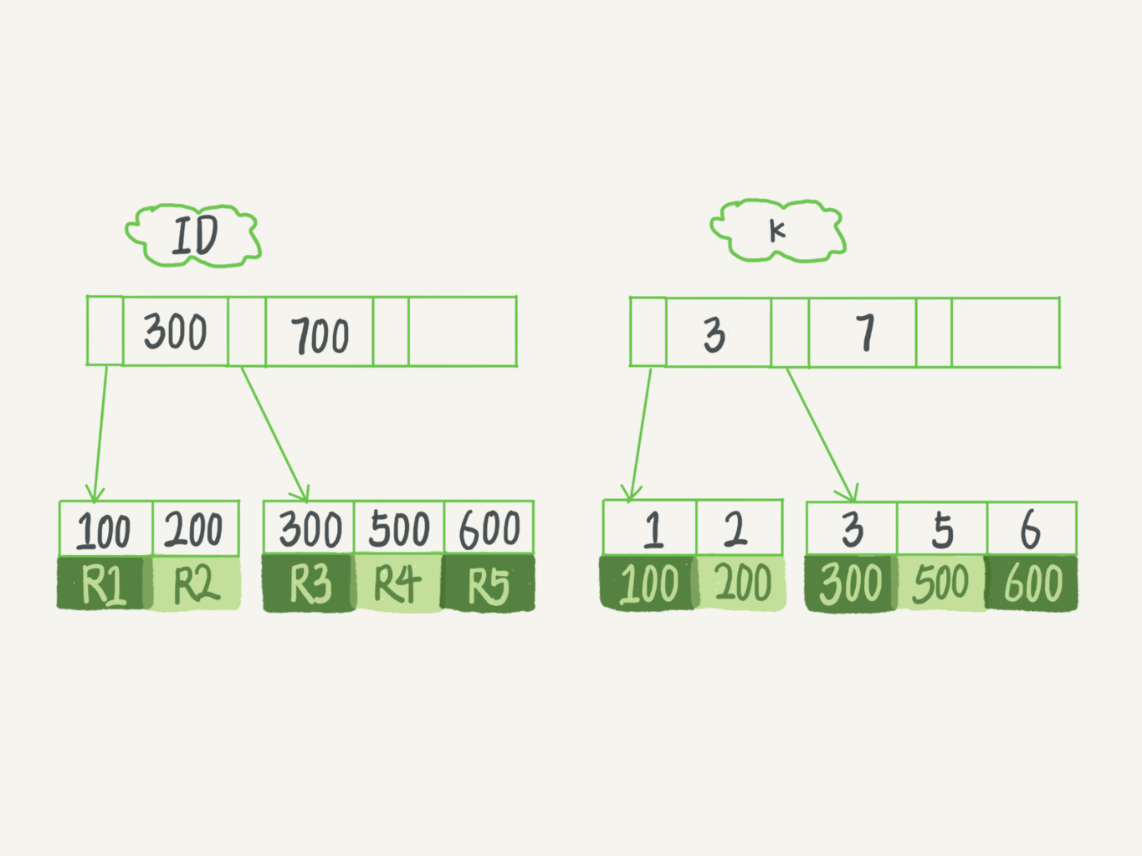\r\n\r\n根据叶子结点的内容分为主键索引和非主键索引\r\n\r\n主键索引的叶子节点是所有数据,也成为聚簇索引\r\n\r\n非主键索引叶子节点为主键的值也称为二级索引\r\n\r\n尽量使用主键索引节约时间\r\n\r\n### 索引维护\r\n\r\n自增主键不涉及页分裂以及页的合并效率较高,推荐使用自增主键作为主键。\r\n\r\n业务字段作为主键:\r\n\r\n 只有一个索引\r\n\r\n 必须是唯一索引\r\n\r\n### 覆盖索引\r\n\r\n考虑一个市民表定义\r\n\r\n```mysql\r\nCREATE TABLE `tuser` (\r\n `id` int(11) NOT NULL,\r\n `id_card` varchar(32) DEFAULT NULL,\r\n `name` varchar(32) DEFAULT NULL,\r\n `age` int(11) DEFAULT NULL,\r\n `ismale` tinyint(1) DEFAULT NULL,\r\n PRIMARY KEY (`id`),\r\n KEY `id_card` (`id_card`),\r\n KEY `name_age` (`name`,`age`)\r\n) ENGINE=InnoDB\r\n```\r\n\r\n如果高频请求:根据身份证查询姓名存在,是否建立姓名对身份证号的索引?\r\n\r\n应该,避免回表,当然额外索引浪费空间。\r\n\r\n### 最左前缀原则\r\n\r\n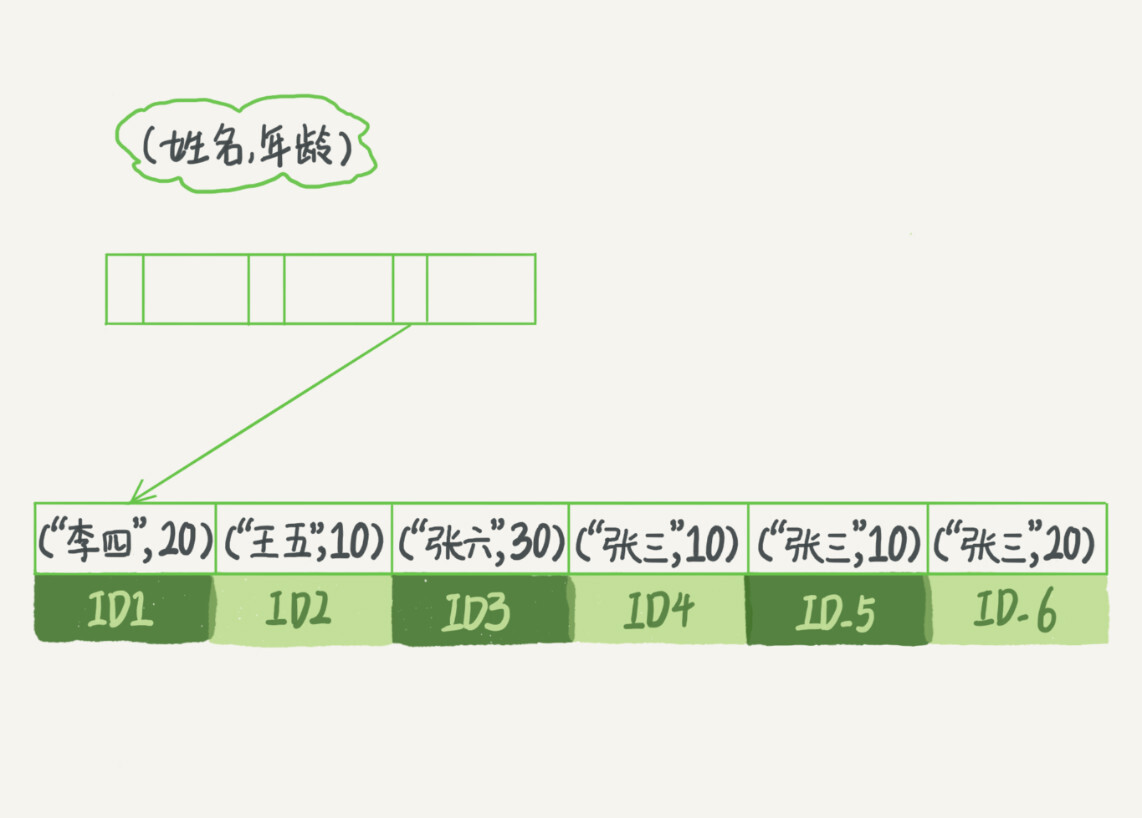\r\n\r\n\r\n\r\n联合索引时如何安排字段顺序?\r\n\r\n1. 如果调整顺序可以少维护一个索引,优先考虑\r\n2. 不得已的情况考虑空间原则\r\n\r\n### 索引下推\r\n\r\nMySQL5.6以后在索引的时候就进行一次判断,减少回表次数\r\n\r\n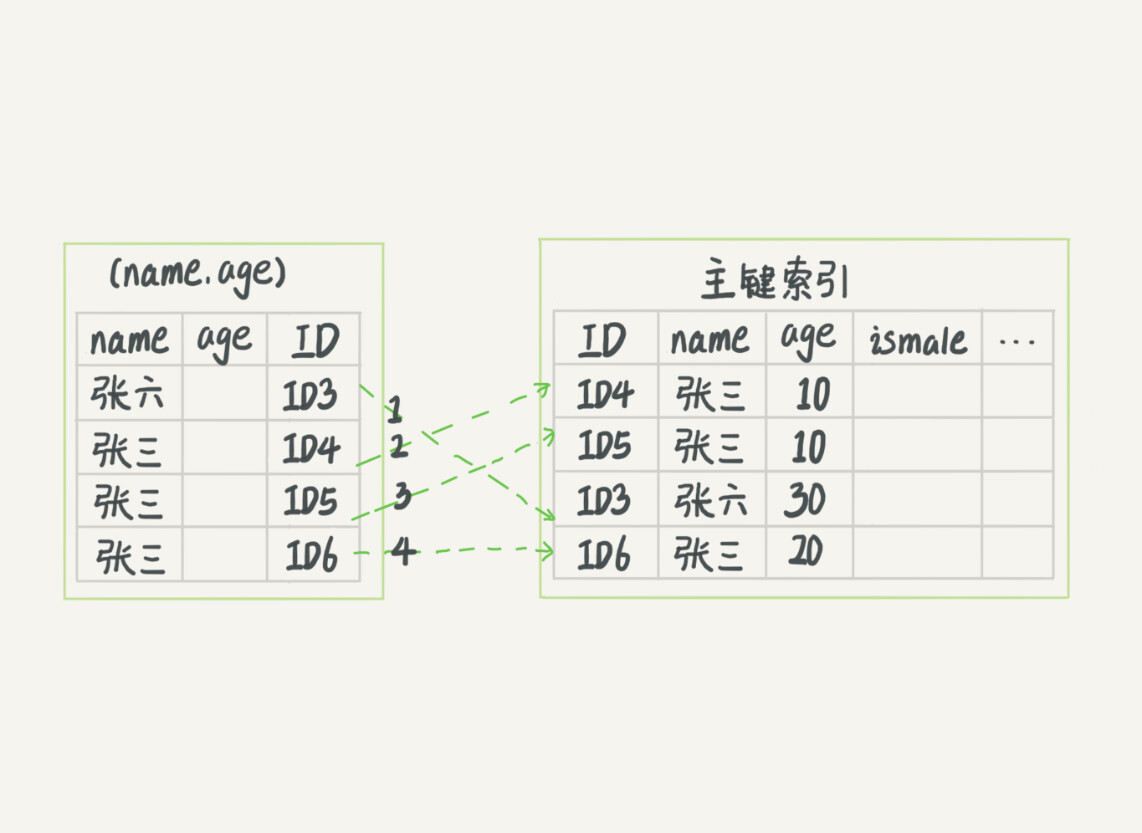\r\n\r\n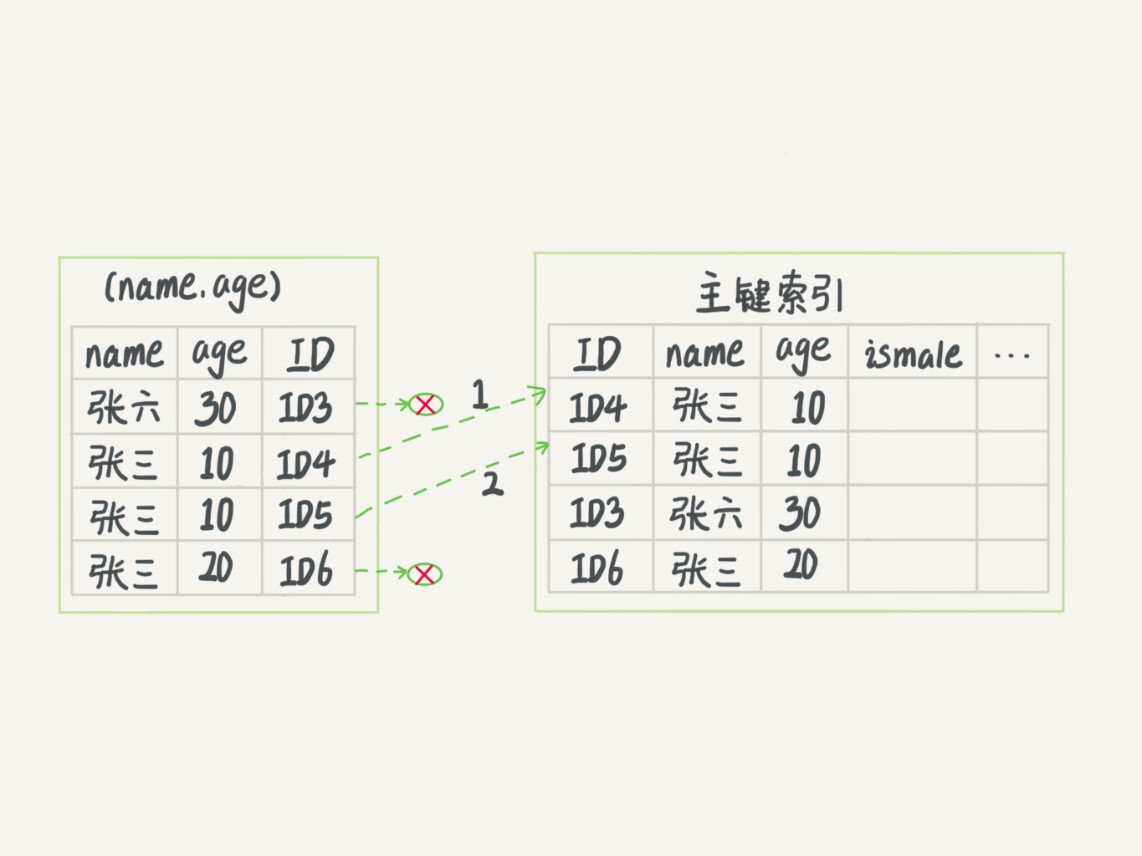\r\n\r\n## 全局锁和表锁\r\n\r\n### 全局锁\r\n\r\nFlush tables with read lock(FTWRL)\r\n\r\n数据库变为只读状态,典型的使用场景:做全库逻辑备份\r\n\r\n为什么全库只读使用全局锁的方法而不是用set global readonly=true的方式?\r\n\r\n* 有些系统readonly的值会被用于其他逻辑,修改global变量影像方式太大\r\n* FTWARL命令在客户端异常断开后MySQL会自动释放全局锁,而readongly在客户端异常后一直保持readonly状态\r\n\r\n### 表级锁\r\n\r\n表锁以及元数据锁\r\n\r\n表锁:加上读锁不会限制读会限制写,加上写锁限制读写。同时本线程依然被限制。\r\n\r\n元数据锁:访问时自动加上,保证读写的正确性。\r\n\r\n* MySQL5.5版本后加上,增删改查加读锁,表结构变更加写锁\r\n* 读锁之间不互斥\r\n* 读写锁之间,写锁之间互斥,两个线程3同时加字段一个要等另一个结束。\r\n\r\n## 行锁\r\n\r\n对数据表中行记录的锁\r\n\r\n### 两阶段锁\r\n\r\n在InoDB事务中,行锁在需要的时候才加上,事务结束后才释放。\r\n\r\n如果在事务中需要锁多个行,把最可能造成锁冲突,最可能影响并发度的锁往后放\r\n\r\n 电影票例子,先扣余额还是先扣电影票\r\n\r\n### 死锁和死锁检测\r\n\r\n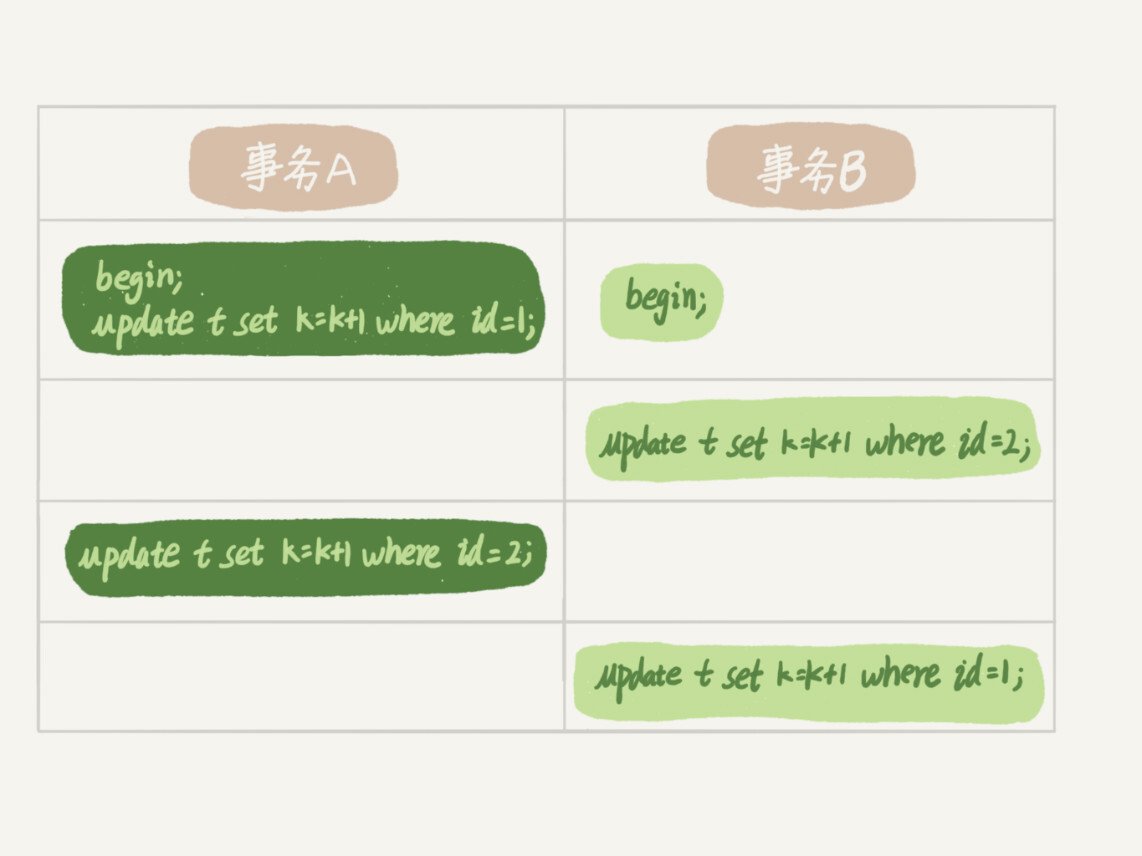\r\n\r\nA需要B的id=2行锁,B需要A的id=1行锁\r\n\r\n解决方法\r\n\r\n* 直接等待直到超时innodb_lock_wait_timeout默认50s\r\n* 发起死锁检测,发现死锁之后主动回滚到某一个事务innodb_deadlocked_detect设置为on\r\n\r\n热点更新导致的性能问题:所有事务更新同一行(死锁检测消耗大量的cpu资源)\r\n\r\n* 临时关掉死锁检测\r\n* 控制并发度\r\n* 修改源码,相同行的更新,进入引擎前排队\r\n* 将一行改为逻辑上的多行\r\n\r\n## 普通索引还是唯一索引\r\n\r\n### 查询过程\r\n\r\n区别微乎其微,因为InnoDb数据以数据页为单位进行读写,普通索引多做一次查找和判断下一条操作\r\n\r\n### 更新过程\r\n\r\nchange buffer\r\n\r\n* 如果更新时数据在内存直接更新数据\r\n* 如果更新时数据不在内存将数据页的逻辑操作存储在changeb buffer,下一次读这个数据页执行相关操作\r\n* merge操作定期进行\r\n\r\n唯一索引不使用change buffer因为要将数据页读取到内存才能判断\r\n\r\n普通索引能大幅度减少磁盘访问时间\r\n\r\n### change buffer的使用场景\r\n\r\n适用于写多读少,且写完后马上被访问的几率比较小的操作\r\n\r\n### redo log和change buffer\r\n\r\nredo log节省随机写磁盘的消耗,转为顺序写\r\n\r\nchange buffer节省随机读磁盘的操作\r\n\r\n## MySQL为什么会选错索引\r\n\r\n### 优化器的逻辑\r\n\r\n语句在执行前根据统计信息估算记录数,统计信息就是索引的区分度,索引的不同的值越多区分度越大,不同值的个数称之为基数。\r\n\r\n采样统计的过程中,InnoDB会选择N个数据页,统计页面不同的值得到平均值,乘以索引的页面数得到索引的基数,并且持续更新。\r\n\r\n## 字符串索引问题\r\n\r\n通过区分度设置合适的前置索引可以降低空间的实用以及扫描的时间。\r\n\r\n```mysql\r\nmysql> select count(distinct email) as L from SUser;\r\n\r\nmysql> select \r\n count(distinct left(email,4))as L4,\r\n count(distinct left(email,5))as L5,\r\n count(distinct left(email,6))as L6,\r\n count(distinct left(email,7))as L7,\r\nfrom SUser;\r\n```\r\n\r\n### 前缀索引对覆盖索引的影响\r\n\r\n当需要的字段都在完整字符\r\n\r\n索引中时不需要回表,前缀索引需要回表使用前缀索引用不上覆盖索引对查询性能的优化\r\n\r\n### 其他方式\r\n\r\n当前缀区分度不够好的时候(身份证)\r\n\r\n* 倒序索引\r\n* 使用hash字段的方式,两边判断因为hash字段可能相同\r\n\r\n相同点:\r\n\r\n* 都不支持范围查找\r\n\r\n不同点\r\n\r\n* 空间消耗问题\r\n* cpu消耗方面:reverse消耗比crc32()要小\r\n* hash效率相对稳定,倒序还是前缀索引方法\r\n\r\n## 数据为什么会抖一下\r\n\r\n有时候SQL语句会突然慢一下\r\n\r\n### SQL语句为什么变慢了\r\n\r\n将内存数据写入磁盘的操作flush\r\n\r\n当内存数据页与磁盘数据页不一致的时候,称之为脏页\r\n\r\n什么时候引发flush?\r\n\r\n* InnoDB的redo log写满了\r\n* 系统内存不足,淘汰一些数据页,如果淘汰的是脏页就要保存到磁盘,而且只要有脏页就必须写盘,为了方便下一次阅读不是直接写脏页\r\n* MySQL认为系统空闲的时候刷一下\r\n* MySQL正常关闭的时候\r\n\r\n第三种和第四种无所谓,第一种尽量要避免,因为此时系统不能更新。\r\n\r\n缓存池buffer pool状态\r\n\r\n* 没使用\r\n* 实用并且干净\r\n* 使用了但是不干净(脏页)\r\n\r\n影响性能的情况\r\n\r\n* 一个查询淘汰的脏页太多了\r\n* 日志写满了,写性能跌为零\r\n\r\n### InnoDB刷脏页的机制\r\n\r\n告诉主机的IO能力一般是磁盘的IOPS参数\r\n\r\n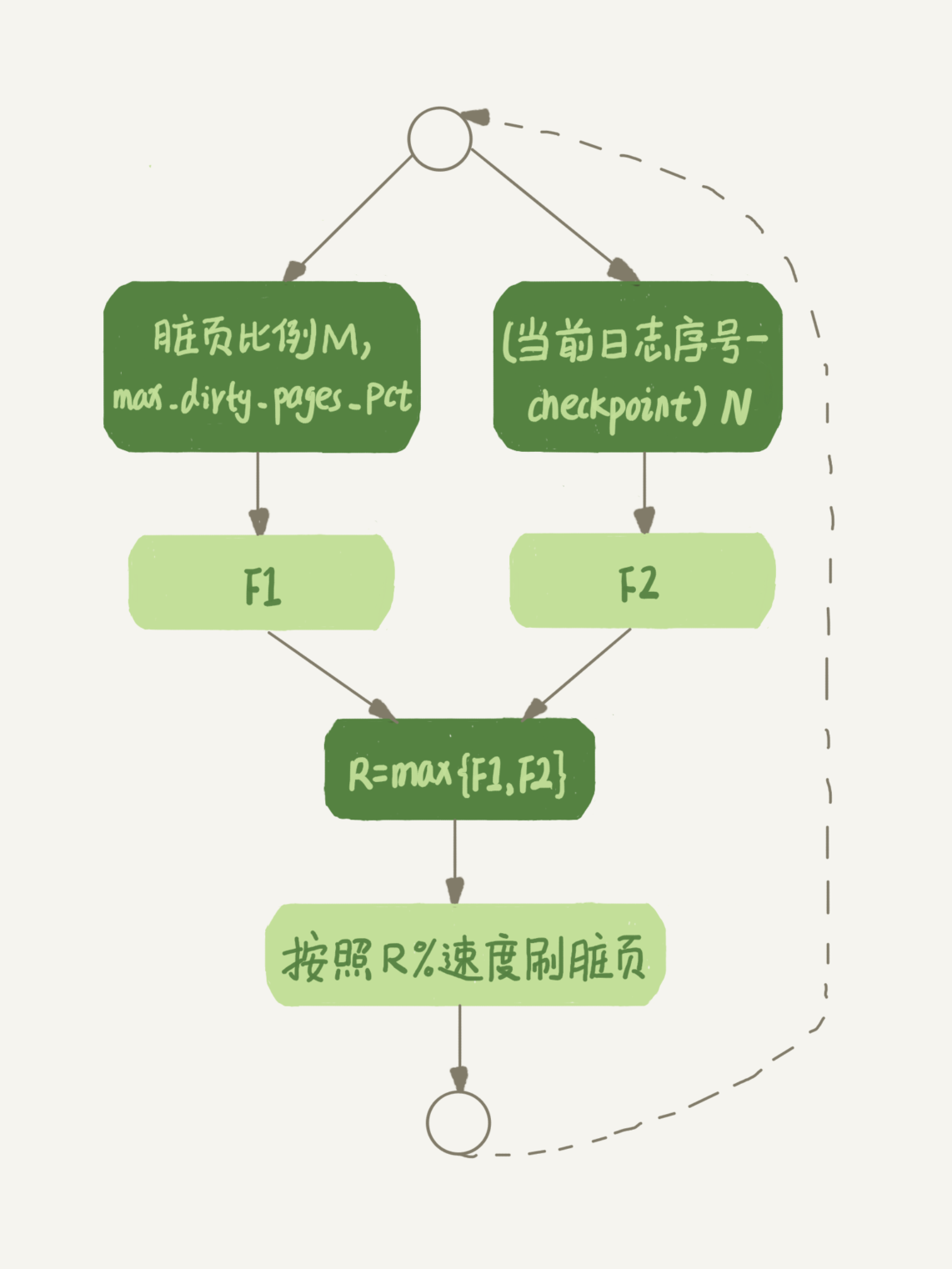\r\n\r\ninnodb_max_dirty_pages_pct为脏页比例上限\r\n\r\ninnodb_flush_neighbors决定是否采用连坐机制,在8的版本中默认是0\r\n\r\n## 表数据删掉一半,表文件大小不变\r\n\r\n### 参数 innodb_file_per_table\r\n\r\non表示,表数据储存在以.ibd为后缀的文件\r\n\r\noff表示表数据放在系统共享表空间,和数据字典放到一起\r\n\r\n### 数据删除流程\r\n\r\n删除记录后将此位置记录为可复用,数据页同理\r\n\r\n当delete将表删除后,数据页标记为可复用,但是文件不会变小\r\n\r\n大量的增删改查的表都会存在空洞\r\n\r\n### 重建表\r\n\r\n5.6后出现onlineDDL\r\n\r\n重建表命令\r\n\r\n```mysql\r\nalter table A engine=InnoDB\r\noptimize table t = recreate+analyze\r\n```\r\n\r\n\r\n\r\n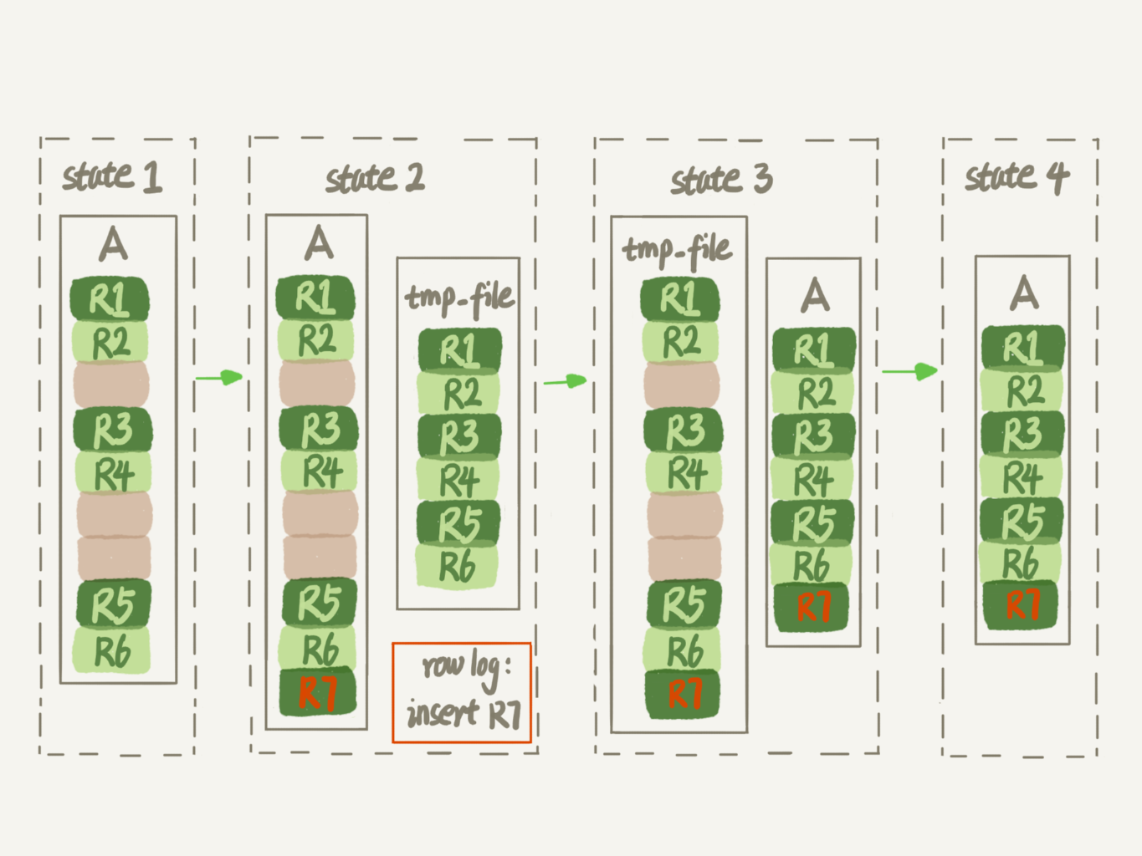\r\n\r\n* 建立一个临时文件,扫描表 A 主键的所有数据页;\r\n* 用数据页中表 A 的记录生成 B+ 树,存储到临时文件中;\r\n* 生成临时文件的过程中,将所有对 A 的操作记录在一个日志文件(row log)中,对应的是图中 state2 的状态;\r\n* 临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表 A 相同的数据文件,对应的就是图中 state3 的状态;\r\n* 用临时文件替换表 A 的数据文件。\r\n\r\nalter 语句在启动的时候需要获取 MDL 写锁,但是这个写锁在真正拷贝数据之前就退化成读锁了,保证不会阻塞增删改操作\r\n\r\n注意生成的表并不是最紧凑的,每个页预留了1/16的空间\r\n\r\n## count(*)这么慢,我该怎么办\r\n\r\n### count(*) 的实现方式\r\n\r\n* MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高;\r\n* MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高;\r\n\r\n这和 InnoDB 的事务设计有关系,可重复读是它默认的隔离级别,在代码上就是通过多版本并发控制,也就是 MVCC 来实现的。每一行记录都要判断自己是否对这个会话可见,因此对于 count(*) 请求来说,InnoDB 只好把数据一行一行地读出依次判断,可见的行才能够用于计算“基于这个查询”的表的总行数。\r\n\r\n分析性能差别的原则\r\n\r\n* server 层要什么就给什么;\r\n* nnoDB 只给必要的值;\r\n* 现在的优化器只优化了 count(*) 的语义为“取行数”,其他“显而易见”的优化并没有做。\r\n\r\n按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(*),所以我建议你,尽量使用 count(**)\r\n\r\n## 日志索引相关问题\r\n\r\n### 日至相关问题\r\n\r\n#### MySQL两阶段不同的瞬间异常重启数据如何完整?\r\n\r\n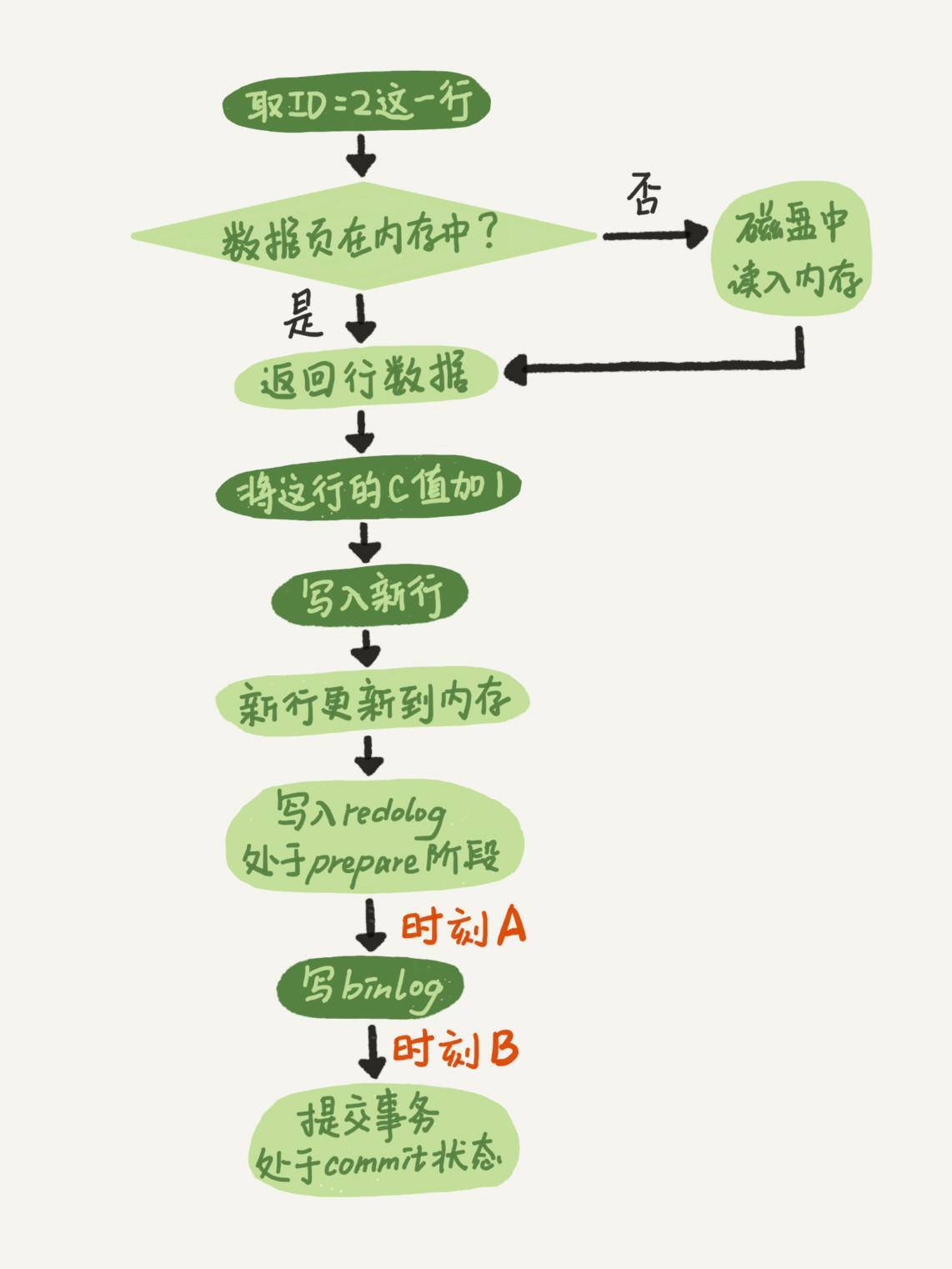\r\n\r\n## order by如何工作\r\n\r\n### 全字段排序\r\n\r\n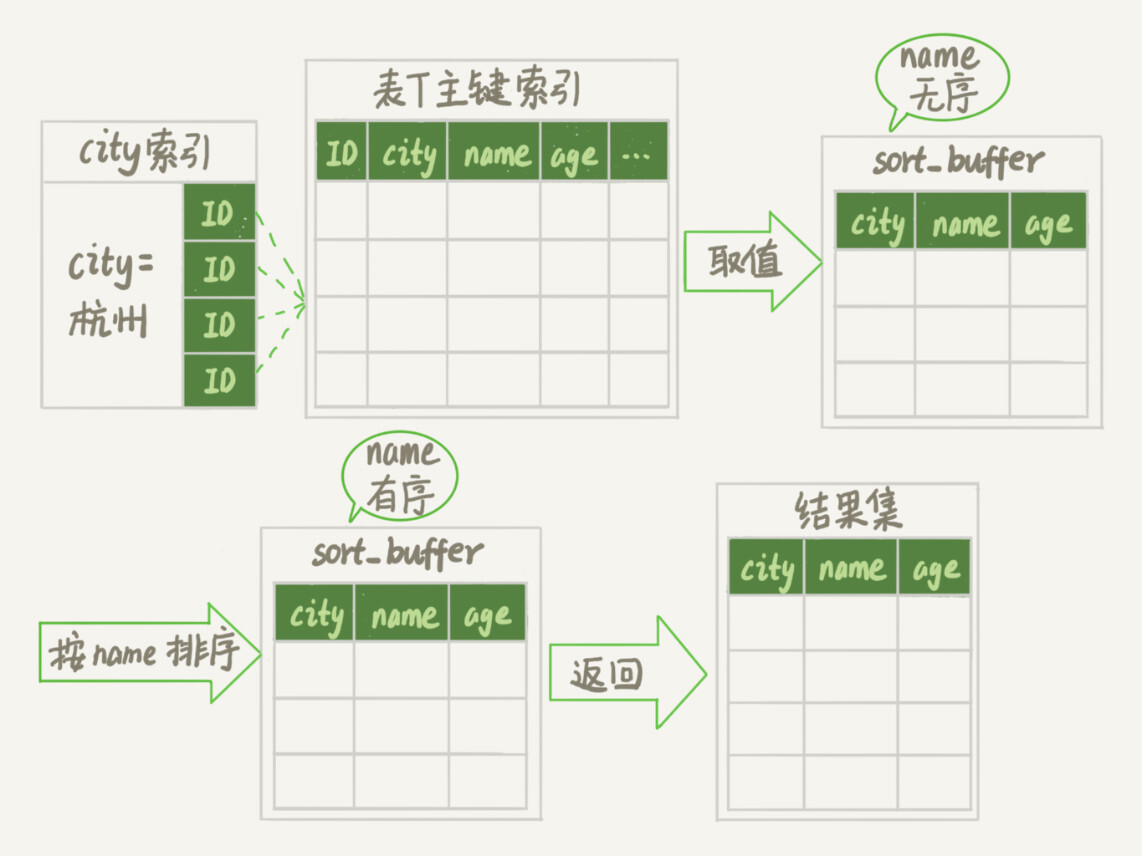\r\n\r\n根据sort_buffer_size判断是否要使用外部排序\r\n\r\n### rowid排序\r\n\r\n根据max_length_for_sort_data判断单行长度是否超过要求\r\n\r\n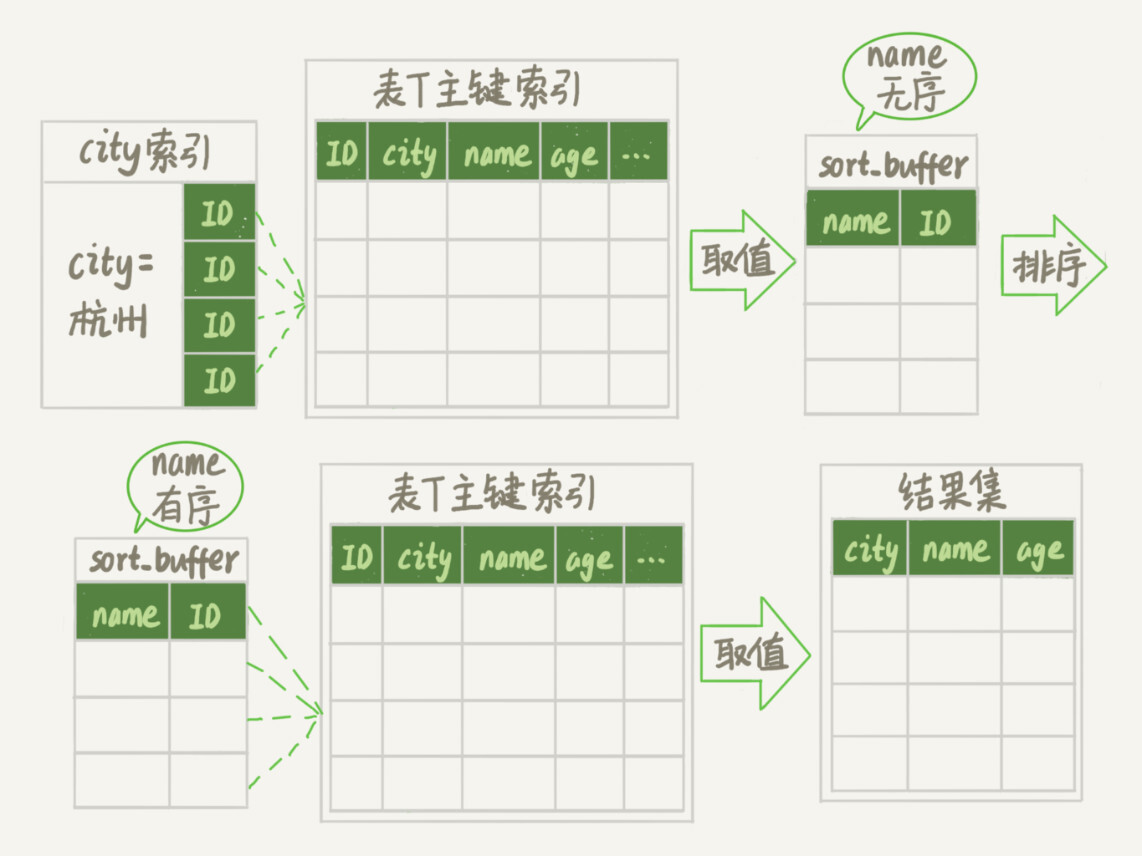\r\n\r\n* rowid需要两次IO浪费大量的时间,如果空间足够优先使用全字段排序\r\n\r\n* 全字段排序同样需要时间,如果建立新的联合索引天然有序加上覆盖排序可以减少更多的时间\r\n\r\n## 如何正确选择随机值消息\r\n\r\n### 内存临时表\r\n\r\n```mysql\r\nmysql> select word from words order by rand() limit 3;\r\n```\r\n\r\n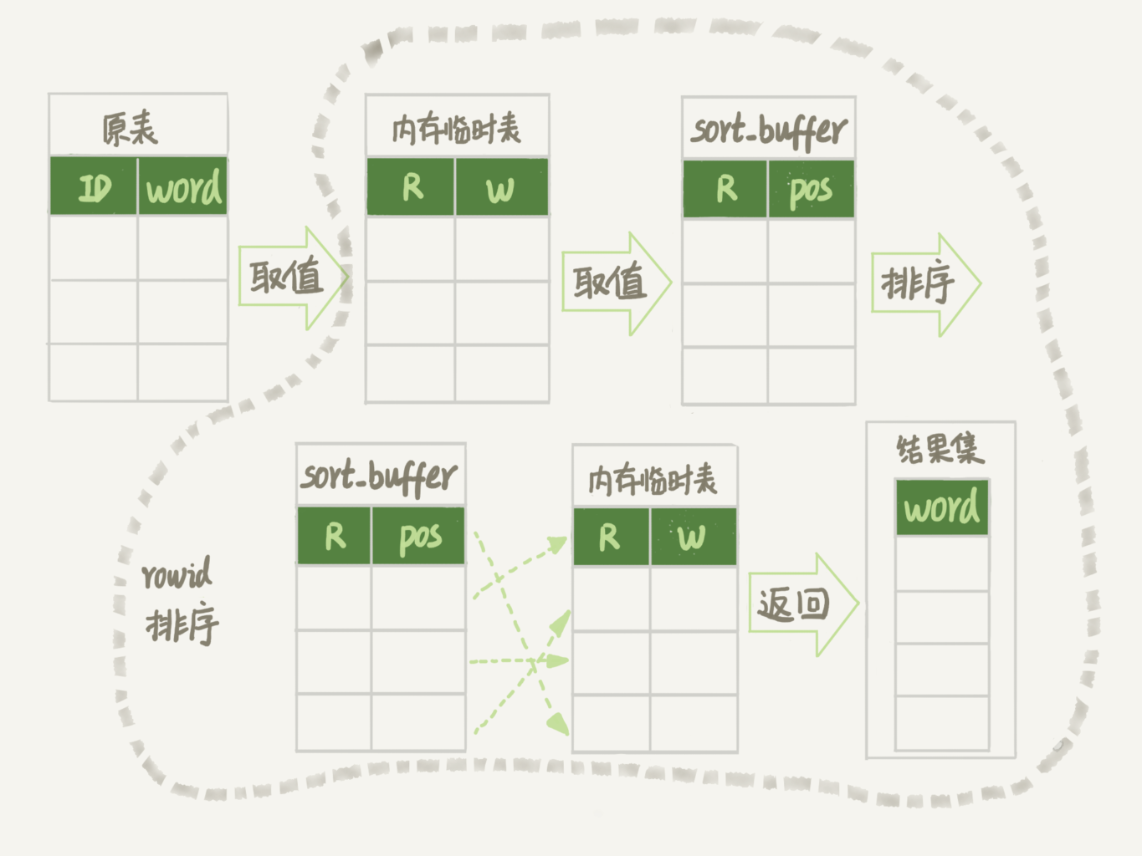\r\n\r\n随机选取书籍的逻辑顺序\r\n\r\norder by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法\r\n\r\n当删除逐渐的时候MySQL会自动生成一个新的六个字节rowid主键\r\n\r\n### 磁盘临时表\r\n\r\n有时采用优先队列算法,通过堆实现\r\n\r\n1. 对于这 10000 个准备排序的 (R,rowid),先取前三行,构造成一个堆;\r\n\r\n2. 取下一个行 (R’,rowid’),跟当前堆里面最大的 R 比较,如果 R’小于 R,把这个 (R,rowid) 从堆中去掉,换成 (R’,rowid’);\r\n\r\n3. 重复第 2 步,直到第 10000 个 (R’,rowid’) 完成比较。\r\n\r\n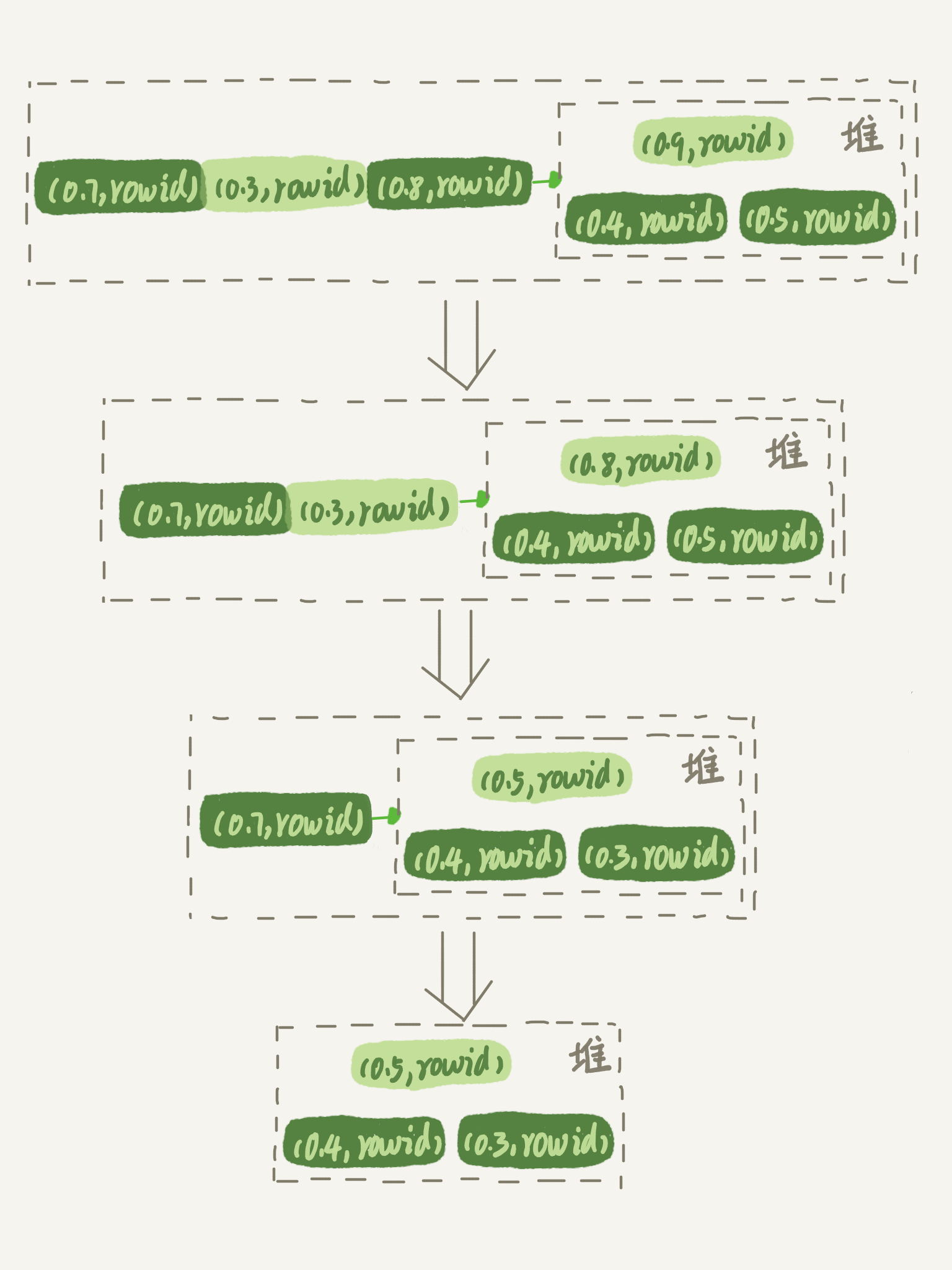\r\n\r\n如果数据过大依然使用归并排序\r\n\r\n### 随机算法\r\n\r\n## 为什么有的SQL语句逻辑相同速度却差距很大\r\n\r\n### 条件字段的函数操作\r\n\r\n```mysql\r\nmysql> CREATE TABLE `tradelog` (\r\n `id` int(11) NOT NULL,\r\n `tradeid` varchar(32) DEFAULT NULL,\r\n `operator` int(11) DEFAULT NULL,\r\n `t_modified` datetime DEFAULT NULL,\r\n PRIMARY KEY (`id`),\r\n KEY `tradeid` (`tradeid`),\r\n KEY `t_modified` (`t_modified`)\r\n) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;\r\n\r\n\r\nmysql> select count(*) from tradelog where month(t_modified)=7;\r\n```\r\n\r\n\r\n\r\n目的是统计所有年份7月的数据\r\n\r\n如果对字段进行了函数计算就无法使用索引\r\n\r\n尽量使用这种格式\r\n\r\n```mysql\r\nmysql> select count(*) from tradelog where\r\n -> (t_modified >= \'2016-7-1\' and t_modified<\'2016-8-1\') or\r\n -> (t_modified >= \'2017-7-1\' and t_modified<\'2017-8-1\') or \r\n -> (t_modified >= \'2018-7-1\' and t_modified<\'2018-8-1\');\r\n```\r\n\r\n### 隐式类型转换\r\n\r\n```mysql\r\nmysql> select * from tradelog where tradeid=110717;\r\n```\r\n\r\n输入类型和表的字段要对应不然会进行转换\r\n\r\n字符串和数字进行比较的话,字符串会转换为数字\r\n\r\n如果这种情况会直接触发全表扫描而不是索引扫描减缓速度\r\n\r\n同理主键是整数而字符串作为条件的时候不会影响速度\r\n\r\n## 为什么查询一行的速度都很慢\r\n\r\n### 查询长时间不返回\r\n\r\n```mysql\r\nmysql> select * from t where id=1;\r\nshow processlist\r\n查询语句出于什么状态\r\n```\r\n\r\n1. 等MDL锁\r\n2. 等flush\r\n3. 等行锁\r\n4. 查询没有索引的值只能使用主键查询\r\n5. 一致性读的问题\r\n\r\n','https://th.bing.com/th/id/OIP.Wjt0K12apjwJFCkCbkWj_wHaCx?pid=ImgDet&rs=1','原创',1,0,1,1,1,1,'2021-07-25 10:54:24','2021-07-25 10:54:24',1,1,'MySQL底层原理分析以及面试相关问题整理。','10,13,12');
/*Table structure for table `t_blog_tags` */
DROP TABLE IF EXISTS `t_blog_tags`;
CREATE TABLE `t_blog_tags` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`tag_id` bigint(20) DEFAULT NULL,
`blog_id` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=102 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
/*Data for the table `t_blog_tags` */
insert into `t_blog_tags`(`id`,`tag_id`,`blog_id`) values
(1,3,'4'),
(2,4,'1'),
(3,4,'3'),
(4,5,'3'),
(5,5,'4'),
(6,7,'2'),
(7,6,'5'),
(64,5,'3'),
(65,4,'3'),
(66,4,'6'),
(74,7,'10'),
(75,8,'11'),
(76,8,'12'),
(77,8,'13'),
(78,8,'12'),
(79,9,'12'),
(80,8,'12'),
(81,9,'12'),
(82,9,'13'),
(83,10,'13'),
(84,9,'13'),
(85,10,'13'),
(86,8,'12'),
(87,9,'12'),
(88,9,'13'),
(89,10,'13'),
(90,9,'13'),
(91,10,'13'),
(92,10,'14'),
(93,11,'14'),
(94,10,'15'),
(95,10,'16'),
(96,11,'16'),
(97,10,'14'),
(98,10,'17'),
(99,13,'17'),
(100,12,'17'),
(101,10,'14');
/*Table structure for table `t_comment` */
DROP TABLE IF EXISTS `t_comment`;
CREATE TABLE `t_comment` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`nickname` varchar(255) DEFAULT NULL,
`email` varchar(255) DEFAULT NULL,
`content` varchar(255) DEFAULT NULL,
`avatar` varchar(255) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`blog_id` bigint(20) DEFAULT NULL,
`parent_comment_id` bigint(20) DEFAULT NULL,
`admincomment` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
/*Data for the table `t_comment` */
insert into `t_comment`(`id`,`nickname`,`email`,`content`,`avatar`,`create_time`,`blog_id`,`parent_comment_id`,`admincomment`) values
(1,'小白','bai@qq.com','小白的评论','/images/avatar.jpg','2020-03-15 21:28:13',4,-1,NULL),
(2,'小红','hong@qq.com','小红的评论','/images/avatar.jpg','2020-03-15 21:35:02',4,-1,NULL),
(5,'小蓝','lan@qq.com','小蓝的评论','/images/avatar.jpg','2020-03-16 15:04:24',4,-1,NULL),
(7,'朱一鸣','691639910@qq.com','博主的评论','http://5b0988e595225.cdn.sohucs.com/images/20181103/feaa7d14883047fb81bbaa16f681f583.jpeg','2020-03-16 15:11:07',2,-1,1),
(8,'安东尼','2333@qq.com','不论是我的世界车水马龙繁华盛世 还是它们都瞬间消失化为须臾 我都会坚定地走向你 不慌张 不犹豫','/images/avatar.jpg','2020-03-24 17:41:17',11,-1,0);
/*Table structure for table `t_tag` */
DROP TABLE IF EXISTS `t_tag`;
CREATE TABLE `t_tag` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
/*Data for the table `t_tag` */
insert into `t_tag`(`id`,`name`) values
(8,'杂谈'),
(9,'大数据'),
(10,'Java'),
(11,'Hadoop'),
(12,'Spark'),
(13,'面试');
/*Table structure for table `t_type` */
DROP TABLE IF EXISTS `t_type`;
CREATE TABLE `t_type` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
/*Data for the table `t_type` */
insert into `t_type`(`id`,`name`) values
(1,'学习方法'),
(3,'娱乐方法'),
(6,'动漫方法');
/*Table structure for table `t_user` */
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`nickname` varchar(255) DEFAULT NULL,
`username` varchar(255) NOT NULL DEFAULT '',
`password` varchar(255) NOT NULL DEFAULT '',
`email` varchar(255) DEFAULT NULL,
`avatar` varchar(255) DEFAULT NULL,
`type` int(10) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT;
/*Data for the table `t_user` */
insert into `t_user`(`id`,`nickname`,`username`,`password`,`email`,`avatar`,`type`,`create_time`,`update_time`) values
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;