Releases: JohnSnowLabs/spark-nlp
Spark NLP 5.2.0: Introducing a Zero-Shot Image Classification by CLIP, ONNX support for T5, Marian, and CamemBERT, a new Text Splitter annotator, Over 8000 state-of-the-art Transformer Models in ONNX, bug fixes, and more!
🎉 Celebrating 80 Million Downloads on PyPI - A Spark NLP Milestone! 🚀

We are thrilled to announce that Spark NLP has reached a remarkable milestone of 80 million downloads on PyPI! This achievement is a testament to the strength and dedication of our community.
A heartfelt thank you to each and every one of you who has contributed, used, and supported Spark NLP. Your invaluable feedback, contributions, and enthusiasm have played a crucial role in evolving Spark NLP into an award-winning, production-ready, and scalable open-source NLP library.
As we celebrate this milestone, we're also excited to announce the release of Spark NLP 5.2.0! This new version marks another step forward in our journey, new features, improved performance, bug fixes, and extending our Models Hub to 30,000 open-source and forever free models with 8000 new state-of-the-art language models in 5.2.0 release.
Here's to many more milestones, breakthroughs, and advancements! 🌟
🔥 New Features & Enhancements
- NEW: Introducing the
CLIPForZeroShotClassificationfor Zero-Shot Image Classification using OpenAI's CLIP models. CLIP is a state-of-the-art computer vision designed to recognize a specific, pre-defined group of object categories. CLIP is a multi-modal vision and language model. It can be used for Zero-Shot image classification. To achieve this, CLIP utilizes a Vision Transformer (ViT) to extract visual attributes and a causal language model to process text features. These features from both text and images are then mapped to a common latent space having the same dimensions. The similarity score is calculated using the dot product of the projected image and text features in this space.

CLIP (Contrastive Language–Image Pre-training) builds on a large body of work on zero-shot transfer, natural language supervision, and multimodal learning. The idea of zero-data learning dates back over a decade but until recently was mostly studied in computer vision as a way of generalizing to unseen object categories. A critical insight was to leverage natural language as a flexible prediction space to enable generalization and transfer. In 2013, Richer Socher and co-authors at Stanford developed a proof of concept by training a model on CIFAR-10 to make predictions in a word vector embedding space and showed this model could predict two unseen classes. The same year DeVISE scaled this approach and demonstrated that it was possible to fine-tune an ImageNet model so that it could generalize to correctly predicting objects outside the original 1000 training set. - CLIP: Connecting text and images
As always, we made this feature super easy and scalable:
image_assembler = ImageAssembler() \
.setInputCol("image") \
.setOutputCol("image_assembler")
labels = [
"a photo of a bird",
"a photo of a cat",
"a photo of a dog",
"a photo of a hen",
"a photo of a hippo",
"a photo of a room",
"a photo of a tractor",
"a photo of an ostrich",
"a photo of an ox",
]
image_captioning = CLIPForZeroShotClassification \
.pretrained() \
.setInputCols(["image_assembler"]) \
.setOutputCol("label") \
.setCandidateLabels(labels)- NEW: Introducing the
DocumentTokenSplitterwhich allows users to split large documents into smaller chunks to be used in RAG with LLM models - NEW: Introducing support for ONNX Runtime in T5Transformer annotator
- NEW: Introducing support for ONNX Runtime in MarianTransformer annotator
- NEW: Introducing support for ONNX Runtime in BertSentenceEmbeddings annotator
- NEW: Introducing support for ONNX Runtime in XlmRoBertaSentenceEmbeddings annotator
- NEW: Introducing support for ONNX Runtime in CamemBertForQuestionAnswering, CamemBertForTokenClassification, and CamemBertForSequenceClassification annotators
- Adding a caching support for newly imported T5 models in TF format to improve the performance to be competitive to ONNX version
- Refactor ZIP utility and add new tests for both ZipArchiveUtil and OnnxWrapper thanks to @anqini
- Refactor ONNX and add OnnxSession to broadcast to improve stability in some cluster setups
- Update ONNX Runtime to 1.16.3 to enjoy the following features in upcoming releases:
- Support for serialization of models >=2GB
- Support for fp16 and bf16 tensors as inputs and outputs
- Improve LLM quantization accuracy with smoothquant
- Support 4-bit quantization on CPU
- Optimize BeamScore to improve BeamSearch performance
- Add FlashAttention v2 support for Attention, MultiHeadAttention and PackedMultiHeadAttention ops
🐛 Bug Fixes
- Fix random dimension mismatch in E5Embeddings and MPNetEmbeddings due to a missing average_pool after last_hidden_state in the output
- Fix batching exception in E5 and MPNet embeddings annotators failing when sentence is used instead of document
- Fix chunk construction when an entity is found
- Fix a bug in library's version in Scala where it was pointing to 5.1.2 wrongly
- Fix Whisper models not downloading due to wrong library's version
- Fix and refactor saving best model based on given metrics during NerDL training
ℹ️ Known Issues
- Some annotators are not yet compatible with Apache Spark and PySpark 3.5.x release. Due to this, we have changed the support matrix for Spark/PySpark 3.5.x to
Partiallyuntil we are 100% compatible.
💾 Models
Spark NLP 5.2.0 comes with more than 8000+ new state-of-the-art pretrained transformer models in multi-languages.
The complete list of all 30000+ models & pipelines in 230+ languages is available on Models Hub
📓 New Notebooks
- You can visit Import Transformers in Spark NLP
- You can visit Spark NLP Examples for 100+ examples
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas,
and show off how you use Spark NLP! - Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.2.0Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.2.0GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.0
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.2.0Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12...Contributors
Assets 2
Spark NLP 5.1.4: Introducing the new Text Splitter annotator, ONNX support for RoBERTa Token and Sequence Classifications, and Question Answering task, Over 1,200 state-of-the-art Transformer Models in ONNX, new Databricks and EMR support, along with various bug fixes!
88ad2d4📢 Overview
Spark NLP 5.1.4 🚀 comes with new ONNX support for RoBertaForTokenClassification, RoBertaForSequenceClassification, and RoBertaForQuestionAnswering annotators. Additionally, we've added over 1,200 state-of-the-art transformer models in ONNX format to ensure rapid inference for OpenAI Whisper and BERT for multi-class/multi-label classification models.
We're pleased to announce that our Models Hub now boasts 22,000+ free and truly open-source models & pipelines 🎉. Our deepest gratitude goes out to our community for their invaluable feedback, feature suggestions, and contributions.
🔥 New Features & Enhancements
- NEW: Introducing the
DocumentCharacterTextSplitter, which allows users to split large documents into smaller chunks. This splitter accepts a list of separators in sequence and divides subtexts if they exceed the chunk length, while optionally overlapping chunks. Our inspiration came from theCharacterTextSplitterandRecursiveCharacterTextSplitterimplementations within theLangChainlibrary. As always, we've ensured that it's optimized, ready for production, and scalable:
textDF = spark.read.text(
"/home/ducha/Workspace/scala/spark-nlp/src/test/resources/spell/sherlockholmes.txt",
wholetext=True
).toDF("text")
documentAssembler = DocumentAssembler().setInputCol("text")
textSplitter = DocumentCharacterTextSplitter() \
.setInputCols(["document"]) \
.setOutputCol("splits") \
.setChunkSize(1000) \
.setChunkOverlap(100) \
.setExplodeSplits(True)- NEW: Introducing support for ONNX Runtime in
RoBertaForTokenClassificationannotator - NEW: Introducing support for ONNX Runtime in
RoBertaForSequenceClassificationannotator - NEW: Introducing support for ONNX Runtime in
RoBertaForQuestionAnsweringannotator - Introducing first support for Apache Spark and PySpark 3.5 that comes with lots of improvements for Spark Connect: https://spark.apache.org/releases/spark-release-3-5-0.html#highlights
- Welcoming 6 new Databricks runtimes with support for new Spark 3.5:
- Databricks 14.0 LTS
- Databricks 14.0 LTS ML
- Databricks 14.0 LTS ML GPU
- Databricks 14.1 LTS
- Databricks 14.1 LTS ML
- Databricks 14.1 LTS ML GPU
- Welcoming AWS 3 new EMR versions to our Spark NLP family:
- emr-6.12.0
- emr-6.13.0
- emr-6.14.0
- Adding an example to load a model directly from Azure using .load() method. This example helps users to understand how to set Spark NLP to load models from Azure
PS: Please remember to read the migration and breaking changes for new Databricks 14.x https://docs.databricks.com/en/release-notes/runtime/14.0.html#breaking-changes
🐛 Bug Fixes
- Fix a bug with in
Whisperannotator, that would not allow every model to be imported - Fix BPE Tokenizer to include a flag whether or not to always prepend a space before words (previous behavior for embeddings)
- Fix BPE Tokenizer to correctly convert and tokenize non-latin and other special characters/words
- Fix
RobertaForQuestionAnsweringto produce the same logits and indexes as the implementation in Transformer library - Fix the return order of logits in
BertForQuestionAnsweringandDistilBertForQuestionAnsweringannotators
📓 New Notebooks
| Notebooks | Colab |
|---|---|
| HuggingFace ONNX in Spark NLP RoBertaForQuestionAnswering | |
| HuggingFace ONNX in Spark NLP RoBertaForSequenceClassification | |
| HuggingFace ONNX in Spark NLP BertForTokenClassification |
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.1.4Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x: (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.4GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.4Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.4AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.4Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, 3.4.x, and 3.5.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.1.4</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.1.4</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.1.4</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.1.4</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.1.4.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.1.4.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.1.4.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x/3.5.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.1.4.jar
What's Changed
- Models hub by @maziyarpanahi @ahmedlone127 in #14042
- SPARKNLP-921: Bug Fix for BPE and RobertaForQA by @DevinTDHa in #14022
- Adding ONNX support for RobertaClassification by @danilojsl in #14024
- WhisperForCTC: Fix for dyn...
Contributors
Assets 2
Spark NLP 5.1.3: New ONNX Configs, ONNX support for BERT Token and Sequence Classifications, DistilBERT token and sequence classifications, BERT and DistilBERT Question Answering, and bug fixes!
📢 Overview
Spark NLP 5.1.3 🚀 comes with new ONNX support for BertForTokenClassification, BertForSequenceClassification, BertForQuestionAnswering, DistilBertForTokenClassification, DistilBertForSequenceClassification, and DistilBertForQuestionAnswering annotators, a new way to configure ONNX Runtime via Spark NLP Config, and bug fixes!
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 21,000+ free and truly open-source models & pipelines. 🎉
🔥 New Features & Enhancements
- NEW: Introducing support for ONNX Runtime in BertForTokenClassification annotator
- NEW: Introducing support for ONNX Runtime in BertForSequenceClassification annotator
- NEW: Introducing support for ONNX Runtime in BertForQuestionAnswering annotator
- NEW: Introducing support for ONNX Runtime in DistilBertForTokenClassification annotator
- NEW: Introducing support for ONNX Runtime in DistilBertForSequenceClassification annotator
- NEW: Introducing support for ONNX Runtime in DistilBertForQuestionAnswering annotator
- NEW: Setting ONNX configuration such as GPU device id, execution mode, etc. via Spark NLP configs
onnx_params = {
"spark.jsl.settings.onnx.gpuDeviceId": "0",
"spark.jsl.settings.onnx.intraOpNumThreads": "5",
"spark.jsl.settings.onnx.optimizationLevel": "BASIC_OPT",
"spark.jsl.settings.onnx.executionMode": "SEQUENTIAL"
}
import sparknlp
# let's start Spark with Spark NLP
spark = sparknlp.start(params=onnx_params)- Update Whisper documentation with minimum required version of Spark/PySpark (3.4)
🐛 Bug Fixes
- Fix
module 'sparknlp.annotator' has no attribute 'Token2Chunk'error in Python when usingToken2Chunkannotator inside loaded PipelineModel
📓 New Notebooks
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.1.3Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.3GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.3Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.3AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.3
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.3Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.1.3</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.1.3</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.1.3</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.1.3</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.1.3.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.1.3.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.1.3.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.1.3.jar
What's Changed
- Fixing some 404 errors by @agsfer in #14012
- SPARKNLP-907 Allows setting up ONNX configs through spark session by @danilojsl in #14009
- Adding ONNX support for BertClassific...
Contributors
Assets 2
Spark NLP 5.1.2: Unveiling the First Image-to-Text VisionEncoderDecoder, Over 3,000 ONNX state-of-the-art Transformer Models, Overhaul update in documentation, and bug fixes!
📢 Overview
For the first time, Spark NLP 5.1.2 🚀 proudly presents a new image-to-text annotator designed for captioning images. Additionally, we've added over 3,000 state-of-the-art transformer models in ONNX format to ensure rapid inference in your RAG when you are using LLMs.
We're pleased to announce that our Models Hub now boasts 21,000+ free and truly open-source models & pipelines 🎉. Our deepest gratitude goes out to our community for their invaluable feedback, feature suggestions, and contributions.
🔥 New Features & Enhancements
- NEW: We're excited to introduce the
VisionEncoderDecoderForImageCaptioningannotator, designed specifically for image-to-text captioning. We used VisionEncoderDecoderModel to import models fine-tuned for auto image captioning
The VisionEncoderDecoder can be employed to set up an image-to-text model. The encoding part can utilize any pretrained Transformer-based vision model, such as ViT, BEiT, DeiT, or Swin. Meanwhile, for the decoding part, it can make use of any pretrained language model like RoBERTa, GPT2, BERT, or DistilBERT.
The efficacy of using pretrained checkpoints to initialize image-to-text-sequence models is evident in the study titled TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models by Minghao Li, Tengchao Lv, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei.
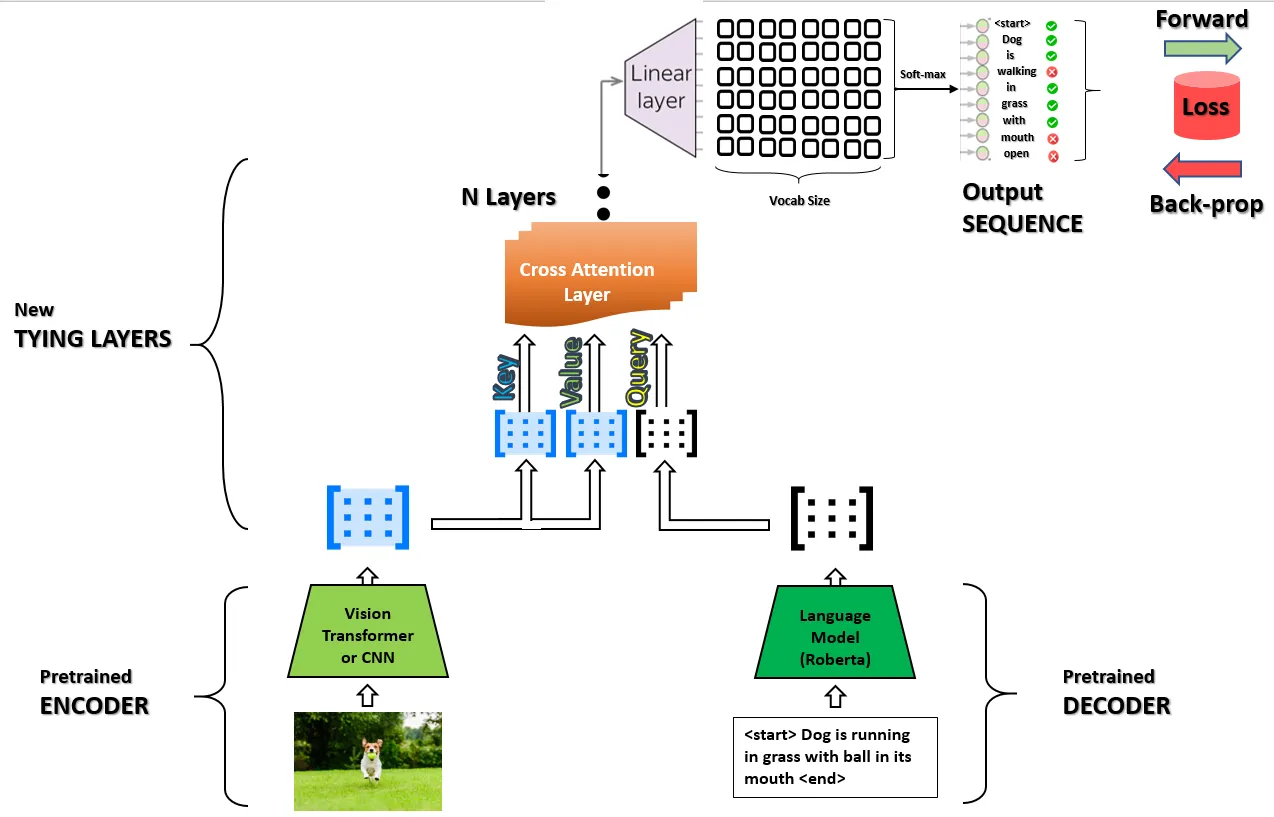
Image Captioning Using Hugging Face Vision Encoder Decoder — Step2Step Guide (Part 2)
-
NEW: We've added cutting-edge transformer models in ONNX format for seamless integration. Our annotators will automatically recognize and utilize these models, streamlining your LLM pipelines without any additional setup.
-
We have added all the missing features from our documentation and added examples to Python and Scala APIs:
- E5Embeddings
- InstructorEmbeddings
- MPNetEmbeddings
- OpenAICompletion
- VisionEncoderDecoderForImageCaptioning
- DocumentSimilarityRanker
- BartForZeroShotClassification
- XlmRoBertaForZeroShotClassification
- CamemBertForQuestionAnswering
- DeBertaForSequenceClassification
- DeBertaForTokenClassification
- Date2Chunk
🐛 Bug Fixes
- We've made a minor adjustment to the beam search algorithm, enhancing the quality of the BART Transformer results.
📓 New Notebooks
| Notebooks | Colab |
|---|---|
| Vision Encoder Decoder: Image Captioning at Scale in Spark NLP | |
| Import Whisper models (ONNX) |
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.1.2Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.2GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.2Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.2AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.2Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.1.2</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.1.2</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.1.2</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.1.2</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.1.2.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.1.2.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.1.2.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.1.2.jar
What's Changed
- FAQ fix by @agsfer in #13985
- faq fix by @agsfer in #13986
- Models hub by @maziyarpanahi in #14006 @ahmedlone127
- Release/512 release candidate by @maziyarpanahi in #14007 @DevinTDHa
Full Changelog: 5.1.1...5.1.2
Contributors
Assets 2
Spark NLP 5.1.1: Introducing ONNX Support for MPNet, AlbertForTokenClassification, AlbertForSequenceClassification, AlbertForQuestionAnswering transformers, access to full vectors in Word2VecModel, Doc2VecModel, WordEmbeddingsModel annotators, 460+ new ONNX models, and bug fixes!
📢 Overview
Spark NLP 5.1.1 🚀 comes with new ONNX support for MPNet, AlbertForTokenClassification, AlbertForSequenceClassification, and AlbertForQuestionAnswering annotators, a new getVectors feature in Word2VecModel, Doc2VecModel, and WordEmbeddingsModel annotators, 460+ new ONNX models for MPNet and BERT transformers, and bug fixes!
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 18,800+ free and truly open-source models & pipelines. 🎉
🔥 New Features & Enhancements
- NEW: Introducing support for ONNX Runtime in
MPNetembedding annotator - NEW: Introducing support for ONNX Runtime in
AlbertForTokenClassificationannotator - NEW: Introducing support for ONNX Runtime in
AlbertForSequenceClassificationannotator - NEW: Introducing support for ONNX Runtime in
AlbertForQuestionAnsweringannotator - Implement
getVectorsfeature inWord2VecModel,Doc2VecModel, andWordEmbeddingsModelannotators. This new feature allows access to the entire tokens and their vectors from the loaded models.
🐛 Bug Fixes
- Fix how to save and load
Whispermodels - Fix saving ONNX model on Windows operating system
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.1.1Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.1.1GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.1.1Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.1.1AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.1.1Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.1.1</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.1.1</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.1.1</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.1.1</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.1.1.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.1.1.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.1.1.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.1.1.jar
What's Changed
- fixed e5 modelhub card code sections by @ahmedlone127 in #13950
- fixing modelhub cards by @ahmedlone127 in #13952
- Models hub by @maziyarpanahi in #13943
- [SPARKNLP-906] Fix reading suffix by @DevinTDHa in #13945
- Sparknlp 888 Add ONNX support to MPNet embeddings by @ahmedlone127 in #13955
- Adding ONNX Support to ALBERT Token and Sequence Classification and Question Answering annotators by @danilojsl in #13956
- SPARKNLP-884 Enabling getVectors method by @danilojsl in #13957
- [SPARKNLP-890] ONNX E5 MPnet example by @DevinTDHa in #13958
- Models hub by @maziyarpanahi in #13972
- Fixing onnx saving path bug by @ahmedlone127 in #13959
- release/511-release-candidate by @maziyarpanahi in #13961
Full Changelog: 5.1.0...5.1.1
Contributors
Assets 2
Spark NLP 5.1.0: Introducing state-of-the-art OpenAI Whisper speech-to-text, OpenAI Embeddings and Completion transformers, MPNet text embeddings, ONNX support for E5 text embeddings, new multi-lingual BART Zero-Shot text classification, and much more!
438d9e6📢 And RAG whispered to Spark NLP, you complete me!
It's a well-established principle: any LLM, whether open-source or proprietary, isn't dependable without a RAG. And truly, there can't be an effective RAG without an NLP library that is production-ready, natively distributed, state-of-the-art, and user-friendly. This holds true in our 5.1.0 release!
Release Summary:
We're excited to unveil Spark NLP 🚀 5.1.0 with:
- New OpenAI Whisper, Embeddings and Completions!
- Extended ONNX support for highly-rated E5 embeddings. Anticipate swifter inferences, seamless optimizations, and quantization for exporting LLM models.
- MPNet, a cherished sentence-embedding LLM boasting 140+ ready-to-use models!
- Cutting-edge BGE and GTE text embedding models lead the MTEB leaderboard, surpassing even the renowned OpenAI text-embedding-ada-002. We employ these models for text vectorization, pairing them with LLM models to ensure accuracy and prevent misinterpretations.
- Unified Support for All Major Cloud Storage (Azure, GCP, and S3)
- BART multi-lingual Zero-Shot multi-class/multi-label text classification
- and more!
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 18,000+ free and truly open-source models & pipelines. 🎉
Don't miss our free Webinar: From GPT-4 to Llama-2: Supercharging State-of-the-Art Embeddings for Vector Databases
🔥 New Features
Spark NLP ❤️ ONNX (toujours)

In Spark NLP 5.1.0, we're persisting with our commitment to ONNX Runtime support. Following our introduction of ONNX Runtime in Spark NLP 5.0.0—which has notably augmented the performance of models like BERT—we're further integrating features to bolster model efficiency. Our endeavors include optimizing existing models and expanding our ONNX-compatible offerings. For a detailed overview of ONNX compatibility in Spark NLP, refer to this issue.
NEW: In the 5.1.0 release, we've extended ONNX support to the E5 embedding annotator and introduced 15 new E5 models in ONNX format. This includes both optimized and quantized versions. Impressively, the enhanced ONNX support and these new models showcase a performance boost ranging from 2.3x to 3.4x when compared to the TensorFlow versions released in the 5.0.0 update.

OpenAI Whisper: Robust Speech Recognition via Large-Scale Weak Supervision
NEW: Introducing WhisperForCTC annotator in Spark NLP 🚀. WhisperForCTC can load all state-of-the-art Whisper models inherited from OpenAI Whisper for Robust Speech Recognition. Whisper was trained and open-sourced that approaches human level robustness and accuracy on English speech recognition.

We study the capabilities of speech processing systems trained simply to predict large amounts of transcripts of audio on the internet. When scaled to 680,000 hours of multilingual and multitask supervision, the resulting models generalize well to standard benchmarks and are often competitive with prior fully supervised results but in a zeroshot transfer setting without the need for any finetuning. When compared to humans, the models approach their accuracy and robustness. We are releasing models and inference code to serve as a foundation for further work on robust speech processing.
For more details, check out the official paper
audio_assembler = AudioAssembler() \
.setInputCol("audio_content") \
.setOutputCol("audio_assembler")
speech_to_text = WhisperForCTC \
.pretrained()\
.setInputCols("audio_assembler") \
.setOutputCol("text")
pipeline = Pipeline(stages=[
audio_assembler,
speech_to_text,
])
MPNet: Masked and Permuted Pre-training for Language Understanding
NEW: Introducing MPNetEmbeddings annotator in Spark NLP 🚀. MPNetEmbeddings can load all state-of-the-art MPNet Models for Text Embeddings.

We propose MPNet, a novel pre-training method that inherits the advantages of BERT and XLNet and avoids their limitations. MPNet leverages the dependency among predicted tokens through permuted language modeling (vs. MLM in BERT), and takes auxiliary position information as input to make the model see a full sentence and thus reducing the position discrepancy (vs. PLM in XLNet). We pre-train MPNet on a large-scale dataset (over 160GB text corpora) and fine-tune on a variety of down-streaming tasks (GLUE, SQuAD, etc). Experimental results show that MPNet outperforms MLM and PLM by a large margin, and achieves better results on these tasks compared with previous state-of-the-art pre-trained methods (e.g., BERT, XLNet, RoBERTa) under the same model setting.
MPNet: Masked and Permuted Pre-training for Language Understanding by
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, Tie-Yan Liu
Available new state-of-the-art BGE, TGE, E5, and INSTRUCTOR models for Text Embeddings are currently dominating the top of the MTEB leaderboard positioning themselves way above OpenAI text-embedding-ada-002

Massive Text Embedding Benchmark (MTEB) Leaderboard. To submit, refer to the MTEB GitHub repository 🤗
New OpenAI Embeddings and Completions
NEW: In Spark NLP 5.1.0, we're thrilled to introduce the integration of OpenAI Embeddings and Completions transformers. By merging the prowess of OpenAI's language model with the robust NLP processing capabilities of Spark NLP, we've created a powerful synergy. Specifically, with the newly introduced OpenAIEmbeddings and OpenAICompletion transformers, users can now make direct API calls to OpenAI's Embeddings and Completion endpoints right from an Apache Spark DataFrame. This enhancement promises to elevate the efficiency and versatility of data processing workflows within Spark NLP pipelines.
# to use OpenAI completions endpoint
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
openai_completion = OpenAICompletion() \
.setInputCols("document") \
.setOutputCol("completion") \
.setModel("text-davinci-003") \
.setMaxTokens(50)
# to use OpenAI embeddings endpoint
document_assembler = DocumentAssembler() \
.setInputCol("text") \
.setOutputCol("document")
openai_embeddings = OpenAIEmbeddings() \
.setInputCols("document") \
.setOutputCol("embeddings") \
.setModel("text-embedding-ada-002")
# Define the pipeline
pipeline = Pipeline(stages=[
document_assembler, openai_embeddings
])
Unified Support for All Major Cloud Storage
In Spark NLP 5.1.0, we're thrilled to announce a holistic integration of all major cloud and distributed file storage systems. Building on our existing support for AWS, DBFS, and HDFS, we've now introduced seamless operations with Google Cloud Platform (GCP) and Azure. Here's a brief overview of what's been added and improved:
- Comprehensive Integration: We've successfully unified all externally supported file systems and cloud access, ensuring a consistent experience across platforms.
- Enhanced Cloud Access: Undergoing refactoring, the
cache_pretrainedproperty now offers unified cloud access, making it easier to cache models from any supported platform. - New Azure Storage Support: We've integrated Azure dependencies, allowing for Azure support in all cloud operations, ensuring users of Microsoft's cloud platform have a first-class experience.
- New GCP Storage support: Users can now effortlessly export NER log files directly to GCP Storage. Additionally, importing HF models from GCP has been made straightforward.
- Refinements and Fixes: We've relocated the Credentials component to the AWS package for better organization and addressed issues related to HDFS log and NER Graph loading.
- Documentation: To help users get started and transition smoothly, comprehensive documentation has been added detailing the support for Azure, GCP, and S3 operations.
We're confident these updates will provide a smoother, more unified experience for users across all cloud platforms for the following features:
- Define a custom path for
cache_pretraineddirectory - Store logs during training
- Load TF graphs for NerDL annotator
- Importing any HF model into Spark NLP
BART: New multi-lingual Zero-Shot Text Classification
- NEW: Introducing BartForZeroShotClassification annotator for Zero-Shot Text Classification in Spark NLP 🚀. You can use the
BartForZeroShotClassificationannotator for text classification with your labels! 💯
Zero-Shot Learning (ZSL): Traditionally, ZSL most often referred to a fairly specific type of task: learning a classifier on one set of labels and then evaluating on a different set of labels that the classifier has never seen before. ...
Contributors
Assets 2
Spark NLP 5.0.2: Introducing ONNX Support for ALBERT, CmameBERT, and XLM-RoBERTa, a new Zero-Short Classifier for XLM-RoBERTa transformer, 200+ new ONNX models, and bug fixes!
📢 Overview
Spark NLP 5.0.2 🚀 comes with new ONNX support for ALBERT, CmameBERT, and XLM-RoBERTa annotators, a new Zero-Short Classifier for XLM-RoBERTa transformer, 200+ new ONNX models, and bug fixes! We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 18,000+ free and truly open-source models & pipelines. 🎉
🔥 New Features
- NEW: Introducing support for ONNX Runtime in
ALBERT,CamemBERT, andXLM-RoBERTaannotators. We have already converted 200+ models to ONNX format for these annotators for our community - NEW: Implement
XlmRoBertaForZeroShotClassificationannotator for Zero-Shot multi-class & multi-label text classification based onXLM-RoBERTatransformer
🐛 Bug Fixes & Enhancements
- Fix MarianTransformers annotator breaking with
java.lang.ClassCastExceptionin Python - Fix out of 0.0/1.0 accuracy in SentenceDetectorDL and MultiClassifierDL annotators
- Fix BART issue with a low-temperature value that only occurred when there are no non-infinite logits satisfying the low temperature and top_k values
- Add missing
E5EmbeddingsandInstructorEmbeddingsannotators toannotatorsin Scala for easy all-in-one import
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas, and show off how you use Spark NLP!
- Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.0.2Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.0.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.0.2GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.0.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.0.2Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.0.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.0.2AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.0.2
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.0.2Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.0.2</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.0.2</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.0.2</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.0.2</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.0.2.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.0.2.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.0.2.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.0.2.jar
What's Changed
- SPARKNLP-738 Enforcing accuracy to 0 and 1 in classifiers by @danilojsl in #13901
- Introducing a new Zero-Short Classifier for XLM-RoBERTa transformer by @ahmedlone127 in #13902
- Add support for ONNX to ALBERT, CamemBERT, and XLM-RoBERTa by @maziyarpanahi in #13907
- SPARKNLP-873 Issue with MarianTransformers models by @danilojsl in #13908
- BART Bug fix #13898 by @prabod in #13911
- Models hub by @maziyarpanahi in #13913
- release/502-release-candidate by @maziyarpanahi in #13912
Full Changelog: 5.0.1...5.0.2
Contributors
Assets 2
Spark NLP 5.0.1: Patch release
2b2f93c📢 Overview
Spark NLP 5.0.1 🚀 is a patch release with bug fixes and other improvements. We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 18,000+ free and truly open-source models & pipelines. 🎉
🐛 Bug Fixes & Enhancements
- Fix
multiLabelparam issue inXXXForSequenceClassiticationandXXXForZeroShotClassificationannotators - Add the missing
thresholdparam to allXXXForSequenceClassiticationin Python - Fix issue with passing
spark.driver.coresconfig as a param into start() function in Python and Scala - Fix 600+ models' cards on Models Hub with duplicated code snippets
- Add new notebooks to export
BERT,DistilBERT,RoBERTa, andDeBERTamodels toONNXformat
📓 New Notebooks
| Spark NLP | Notebooks | Colab |
|---|---|---|
| BertEmbeddings | HuggingFace in Spark NLP - BERT | BERT |
| DistilBertEmbeddings | HuggingFace in Spark NLP - DistilBERT | DistilBERT |
| RoBertaEmbeddings | HuggingFace in Spark NLP - RoBERTa | RoBERTa |
| DeBertaEmbeddings | HuggingFace in Spark NLP - DeBERTa | DeBERTa |
- You can visit Import Transformers in Spark NLP
- You can visit Spark NLP Examples for 100+ examples
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas,
and show off how you use Spark NLP! - Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==5.0.1Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.0.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:5.0.1GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.0.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:5.0.1Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.0.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:5.0.1AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.0.1
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:5.0.1Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>5.0.1</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>5.0.1</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>5.0.1</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>5.0.1</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-5.0.1.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-5.0.1.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-5.0.1.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-5.0.1.jar
What's Changed
- Edited notebook for doc sim ranker with E5 by @wolliq in #13878
- update SEO titles by @agsfer in #13887
- SPARKNLP-867 Solves multiLabel param issue in ZeroShot annotators by @danilojsl in #13888
- Sparknlp 868 make spark driver cores override local in start functions by @maziyarpanahi in #13894
- [SPARKNLP-863 SPARKNLP-864 SPARKNLP-865 SPARKNLP-866] ONNX Export Notebooks by @DevinTDHa in #13889
- SPARKNLP-869 Adding threshold to properties for python module by @danilojsl in #13890
- Models hub by @maziyarpanahi in #13896
- Release/501 release candidate by @maziyarpanahi in #13895
Full Changelog: 5.0.0...5.0.1
Contributors
Assets 2
Spark NLP 5.0.0: Introducing ONNX Support, State-of-the-Art Instructor Embeddings, E5 Text Embeddings, Document Similarity Ranker, and Much More!
📢 It's All About That Search!
We are delighted to announce the release of Spark NLP 🚀 5.0.0, featuring the highly anticipated support for ONNX! From the start of 2023, we have been working tirelessly to ensure that the integration of ONNX is not just possible but also seamless for all our users. With this support, you can look forward to faster inference, automatic optimization, and quantization when exporting your LLM models. Additionally, we are also set to release an array of new LLM models fine-tuned specifically for chat and instruction, now that we have successfully integrated ONNX Runtime into Spark NLP 🚀.
We have introduced two state-of-the-art models for text embedding, INSTRUCTOR and E5 embeddings. Currently, these models are leading the way on the MTEB leaderboard, even outperforming the widely recognized OpenAI text-embedding-ada-002. These cutting-edge models are now being utilized in production environments to populate Vector Databases. In addition, they are being paired with LLM models like Falcon, serving to augment their existing knowledge base and reduce the chances of hallucinations.
We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 18,000+ free and truly open-source models & pipelines. 🎉
🔥 New Features
Spark NLP ❤️ ONNX
NEW: Introducing support for ONNX Runtime in Spark NLP🚀. Serving as a high-performance inference engine, ONNX Runtime can handle machine learning models in the ONNX format and has been proven to significantly boost inference performance across a multitude of models.
Our integration of ONNX Runtime has already led to substantial improvements when serving our LLM models, including BERT. Furthermore, this integration empowers Spark NLP users to optimize their model performance. As users export their models to ONNX, they can utilize the built-in features provided by libraries such as onnx-runtime, transformers, optimum, and PyTorch. Notably, these libraries offer out-of-the-box capabilities for optimization and quantization, enhancing model efficiency and performance.

In the realm of Vector Databases, the quest for faster and more efficient Embeddings models has become an imperative pursuit. Models like BERT, DistilBERT, and DeBERTa have revolutionized natural language processing tasks by capturing intricate semantic relationships between words. However, their computational demands and slow inference times pose significant challenges in the game of Vector Databases.
In Vector Databases, the speed at which queries are processed and embeddings are retrieved directly impacts the overall performance and responsiveness of the system. As these databases store vast amounts of vectorized data, such as documents, sentences, or entities, swiftly retrieving relevant embeddings becomes paramount. It enables real-time applications like search engines, recommendation systems, sentiment analysis, and chat/instruct-like products similar to ChatGPT to deliver timely and accurate results, ensuring a seamless user experience.
Keeping this in mind, we've initiated ONNX support for the following annotators:
- We've introduced ONNX support for the
BertEmbeddingsannotator. Approximately 180 models of the same name have already been converted to the ONNX format to automatically benefit from the associated performance enhancements. - We've added ONNX support for the
RoBertaEmbeddingsannotator. Roughly 55 models of the same name have been imported in the ONNX format, thus allowing for automatic speed improvements. - ONNX support has been initiated for the
DistilBertEmbeddingsannotator. Around 25 models with the same name have been converted to the ONNX format, facilitating automatic speed enhancements. - We've incorporated ONNX support into the
DeBertaEmbeddingsannotator. About 12 models bearing the same name have been imported in the ONNX format, enabling them to automatically reap the benefits of speed improvements.
We have successfully identified all existing models for these annotators on our Models Hub, converted them into the ONNX format, and re-uploaded them under the same names. This process was carried out to ensure a seamless transition for our community starting with Spark NLP 5.0.0. We will continue to import additional models in the ONNX format in the days ahead. To keep track of the ONNX compatibility with Spark NLP, follow this issue: #13866.
INSTRUCTOR: Instruction-Finetuned Text Embeddings
NEW: Introducing InstructorEmbeddings annotator in Spark NLP 🚀. InstructorEmbeddings can load new state-of-the-art INSTRUCTOR Models inherited from Google T5 for Text embedding.
This annotator is compatible with all the models trained/fine-tuned by using T5EncoderModel for PyTorch or TFT5EncoderModel for TensorFlow models in HuggingFace 🤗

Instructor👨🏫, an instruction-finetuned text embedding model that can generate text embeddings tailored to any task (e.g., classification, retrieval, clustering, text evaluation, etc.) and domains (e.g., science, finance, etc.) by simply providing the task instruction, without any finetuning. Instructor👨 achieves sota on 70 diverse embedding tasks!
For more details, check out the official paper and the project page!
E5: Text Embeddings by Weakly-Supervised Contrastive Pre-training
NEW: Introducing E5Embeddings annotator in Spark NLP 🚀. E5Embeddings can load new state-of-the-art E5 Models based on BERT for Text Embeddings.

Text Embeddings by Weakly-Supervised Contrastive Pre-training.
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
Our new state-of-the-art annotators for Text Embeddings are currently dominating the top of the MTEB leaderboard positioning themselves above OpenAI text-embedding-ada-002

Massive Text Embedding Benchmark (MTEB) Leaderboard. To submit, refer to the MTEB GitHub repository 🤗
Document Similarity Ranker by LSH techniques
NEW: Introducing DocumentSimilarityRanker annotator in Spark NLP 🚀. DocumentSimilarityRanker is a new annotator that uses LSH techniques present in Spark ML lib to execute approximate nearest neighbors search on top of sentence embeddings, It aims to capture the semantic meaning of a document in a dense, continuous vector space and return it to the ranker search.
- Welcoming 6 new Databricks runtimes to our Spark NLP family:
- Databricks 13.1 LTS
- Databricks 13.1 LTS ML
- Databricks 13.1 LTS ML GPU
- Databricks 13.2 LTS
- Databricks 13.2 LTS ML
- Databricks 13.2 LTS ML GPU
- Welcome AWS EMR 6.11 version to our Spark NLP family
- Fix BART issue with input longer than the
maxInputLength
💾 Models
Spark NLP 5.0.0 comes with more than 400+ new Large Language Models (LLMs) in ONNX format. We are also providing optimized and quantized versions of popular models that can be used immediately in any Spark NLP pipelines:
Featured Models
| Model | Name | Lang |
|---|---|---|
| BertEmbeddings | bert_base_cased | en |
| BertEmbeddings | bert_base_cased_opt | en |
| BertEmbeddings | bert_base_cased_quantized | en |
| BertEmbeddings | small_bert_L2_768 | en |
| BertEmbeddings | small_bert_L2_768_opt | en |
| BertEmbeddings | small_bert_L2_768_quantized | en |
| DeBertaEmbeddings | roberta_base | en |
| DeBertaEmbeddings | roberta_base_opt | en |
| DeBertaEmbeddings | roberta_base_quantized | en |
| DistilBertEmbeddings | [distilbert_b... |
Contributors
Assets 2
Spark NLP 4.4.4: Patch release
📢 Overview
Spark NLP 4.4.4 🚀 is a patch release with bug fixes and other improvements. We want to thank our community for their valuable feedback, feature requests, and contributions. Our Models Hub now contains over 17,000+ free and truly open-source models & pipelines. 🎉
Spark NLP has a new home! https://sparknlp.org is where you can find all the documentation, models, and demos for Spark NLP. It aims to provide valuable resources to anyone interested in 100% open-source NLP solutions by using Spark NLP 🚀.
⭐ New Features & Enhancements
- Add
Warmupstage to loading all Transformers for word embeddings: ALBERT, BERT, CamemBERT, DistilBERT, RoBERTa, XLM-RoBERTa, and XLNet. This helps to reduce the first inference time and also validate importing external models from HuggingFace #13851 - Add new notebooks to import ZeroShot Classifiers for Bert, DistilBERT, and RoBERTa fine-tuned based on NLI datasets #13845
🐛 Bug Fixes
- Fix not being able to save models from XXXForSequenceClassitication and XXXForZeroShotClassification annotators #13842
- Fix pretrained pipelines that stopped working since the 4.4.2 release on PySpark 3.2 and 3.3 versions (adding 121 new pipelines were added) #13836
📓 New Notebooks
| Notebooks | Colab | Colab |
|---|---|---|
| BertForZeroShotClassification | HuggingFace in Spark NLP - BertForZeroShotClassification | |
| DistilBertForZeroShotClassification | HuggingFace in Spark NLP - DistilBertForZeroShotClassification | |
| RoBertaForZeroShotClassification | HuggingFace in Spark NLP - RoBertaForZeroShotClassification |
- You can visit Import Transformers in Spark NLP
- You can visit Spark NLP Examples for 100+ examples
📖 Documentation
- Import models from TF Hub & HuggingFace
- Spark NLP Notebooks
- Models Hub with new models
- Spark NLP Articles
- Spark NLP in Action
- Spark NLP Documentation
- Spark NLP Scala APIs
- Spark NLP Python APIs
❤️ Community support
- Slack For live discussion with the Spark NLP community and the team
- GitHub Bug reports, feature requests, and contributions
- Discussions Engage with other community members, share ideas,
and show off how you use Spark NLP! - Medium Spark NLP articles
- JohnSnowLabs official Medium
- YouTube Spark NLP video tutorials
Installation
Python
#PyPI
pip install spark-nlp==4.4.4Spark Packages
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x (Scala 2.12):
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_2.12:4.4.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_2.12:4.4.4GPU
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.4.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-gpu_2.12:4.4.4Apple Silicon (M1 & M2)
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:4.4.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-silicon_2.12:4.4.4AArch64
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:4.4.4
pyspark --packages com.johnsnowlabs.nlp:spark-nlp-aarch64_2.12:4.4.4Maven
spark-nlp on Apache Spark 3.0.x, 3.1.x, 3.2.x, 3.3.x, and 3.4.x:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp_2.12</artifactId>
<version>4.4.4</version>
</dependency>spark-nlp-gpu:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-gpu_2.12</artifactId>
<version>4.4.4</version>
</dependency>spark-nlp-silicon:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-silicon_2.12</artifactId>
<version>4.4.4</version>
</dependency>spark-nlp-aarch64:
<dependency>
<groupId>com.johnsnowlabs.nlp</groupId>
<artifactId>spark-nlp-aarch64_2.12</artifactId>
<version>4.4.4</version>
</dependency>FAT JARs
-
CPU on Apache Spark 3.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-assembly-4.4.4.jar
-
GPU on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-gpu-assembly-4.4.4.jar
-
M1 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-silicon-assembly-4.4.4.jar
-
AArch64 on Apache Spark 3.0.x/3.1.x/3.2.x/3.3.x/3.4.x: https://s3.amazonaws.com/auxdata.johnsnowlabs.com/public/jars/spark-nlp-aarch64-assembly-4.4.4.jar
What's Changed
- Models hub by @maziyarpanahi in #13837
- FEATURE NMH-175: Add Copy to s3 on open source models [skip-test] by @KshitizGIT in #13844
- FEATURE NMH-175: Remove models with missing s3 [skip-test] by @KshitizGIT in #13847
- Resolve saving bug with multilabel parameter by @DevinTDHa in #13842
- SPARKNLP-815: Add examples for ZeroShotClassifiers by @DevinTDHa in #13845
- SPARKNLP 801 set up warmup for all embeddings by @maziyarpanahi in #13851
- Sparknlp 801 set up warmup for all embeddings classifiers by @maziyarpanahi in #13852
Full Changelog: 4.4.3...4.4.4