[TOC]
树顾名思义,就是来源于我们生活中的树,一支分多支,无限延展下去的结构。在数据结构中,树结构主要是和真实的树反着的。类似于这种。

树结构在我们生活中最常见的就是文件存储、家谱结构和公司职能分布等等都是采用的树这种结构。
上面那种结构就是二叉树,一个节点连接着两个节点。具体的程序实现如下:
private class Node{ //内部类
public E e;
public Node left, right; //左右节点
}可以看出这种结构和链表结构很像,只不过链表节点只存储一个一个节点信息。当然我们依然可以定义三叉树,四叉树等等。
我们定义最顶层的节点尾根节点,对于左右孩子都会空的称之为叶子节点。
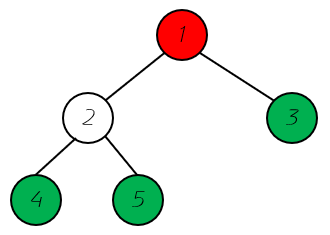
注: 红色为跟节点,绿色为叶子节点,根据结构我们可以看出来二叉树既有天然的递归性。孩子节点依然是一个新的二叉树。这就体现了递归性。
我们从上面可以看出来二叉树不一定是满的,而且一个节点也是二叉树,NULL也是二叉树。
二分搜索树也是一种二叉树,只不过相对于二叉树增加了一些规则。二分搜索树要求。
规则:一个节点的元素值必须大于它的左子树所有节点的值小于它的右子树所有节点的值。
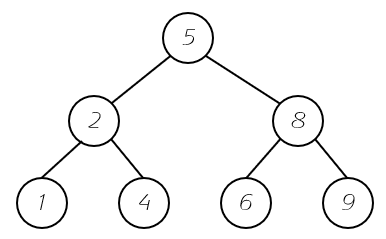
这也就正好验证了搜索这个概念。如果我们想要查找的元素大于该节点,我们就去它的右子树去找,小于就与左子树就找。但是我们需要注意,这里我们只是以数字作为例子,其实这种结构要求我们的节点具有可比较性,也就是自己实现的类对象必须继承Comparable这个类,并重写compareto这个函数。也就是存储的元素必须有可比性。
作为一种高级数据结构,它依然避免不了进行增删改查四个操作,下面我们就逐一进行实现。
我们知道二分搜索树的基本规则是一个节点的元素值必须大于它的左子树所有节点的值小于它的右子树所有节点的值。我们就是用这条规则进行添加元素。从根节点出发,如果添加的元素大于我们跟节点元素值,我们就去跟节点的右子树继续添加元素,直到待插入节点为NULL,我们就把节点插入该位置。

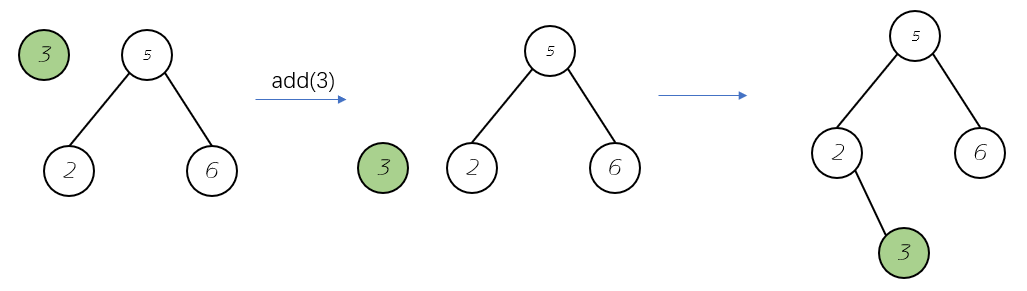
注: 我们可以看出,我们的二分搜索树不包含重复的元素,如果我们希望包含的重复的元素,我们只需要重新定义规则:一个节点的元素值必须大于它的左子树所有节点的值小于==等于==它的右子树所有节点的值。
对于二分搜索树来说,具有天然的递归性,所以我们就哪递归来实现增加这个操作。 由于我们递归的思想就是把一个问题分成一节一节去处理,所以我们实现递归的时候需要返回我们处理完的头结点。所以我们引入私有函数,返回添加后的根节点。 程序实现:
public void add(E e) {
root = add(root, e);
}
private Node add(Node node, E e) {
// 终止条件
if (node == null){
size++;
return new Node(e);
}
// 开始递归
if (e.compareTo(node.e) < 0) //去左子树添加元素
node.left = add(node.left, e);
else if (e.compareTo(node.e) > 0) //去右子树添加元素
node.right = add(node.right, e);
return node;
}我们并不先介绍删除操作,因为删除操作最为复杂,我们先介绍查询操作,最后再说删除操作。
contains函数,返回bool判断树结构中是否包含我们待查元素。同添加元素相同,我们需要采用递归的形式查询元素。那么我们就需要新建私有函数来传入我们要查询的节点。
程序实现:
public boolean contains(E e) {
return contains(root, e);
}
private boolean contains(Node node, E e) {
if (node == null) //递归到底
return false;
if (e.compareTo(node.e) < 0)
return contains(node.left, e);
else if (e.compareTo(node.e) > 0)
return contains(node.right, e);
else //相同
return true;
}我们根据二叉树的定义我们知道,大树值的元素都是向右子树去添加,同理小数值的元素都是向左子树去添加。所以最大值存在于树的最右边,最小值存在于树的最左边。
最小值程序实现:
public void minimum() {
if (size == 0)
throw new IllegalArgumentException("BST is empty");
System.out.println(minimum(root).e);
}
private Node minimum(Node node) {
if (node.left == null)
return node;
return minimum(node.left);
}最大值程序实现:
public void maximum() {
if (size == 0)
throw new IllegalArgumentException("BST is empty");
System.out.println(maximum(root).e);
}
private Node maximum(Node node) {
if (node.right == null)
return node;
return minimum(node.right);
}改变元素同查询元素相同,找到元素后修改后即可。仿照查询元素的程序就可以实现改变元素的函数
程序实现:
public void set(E e) {
set(root, e);
}
private void set(Node node, E e) {
if (node == null) //递归到底
return;
if (e.compareTo(node.e) < 0)
set(node.left, e);
else if (e.compareTo(node.e) > 0)
set(node.right, e);
else //相同
node.e = e;
}树的遍历操作同线性结构的遍历不同,线性结构需要从头遍历到尾,对于树结构来说遍历分为很多种情况。
- 前序遍历
- 中序遍历
- 后续遍历
- 层序遍历
1-3 遍历为深度优先的算法,而层序遍历为广度优先的算法,下面我们逐个进行说明。所谓的前中后指的就是啥时候访问节点信息。在左子树前面,在左子树和右子树中间,还是在右子树后面。
前序遍历的主要思想就是先访问这个元素,然后再对它的左右子树分别进行前序遍历操作。
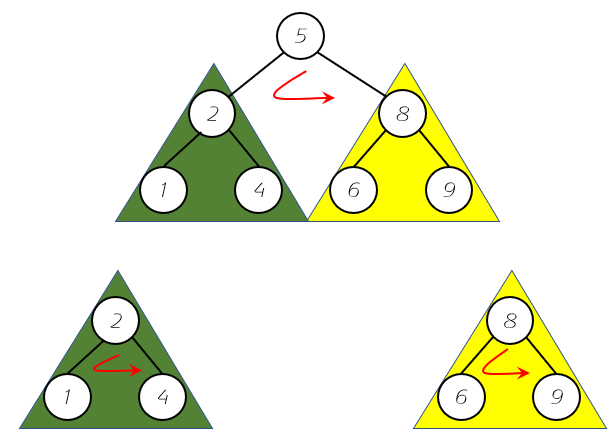
根据图我们可以得出前序遍历的顺序如下:
- 访问元素5,然后按照红色箭头,对左子树(绿色)进行前序遍历;
- 访问元素2,然后按照红色箭头遍历左右子树,由于左右子树均为叶子节点,所以遍历结果为2-1-4;
- 返回去遍历根节点的右子树(黄色),按照红色箭头,顺序为8-6-9;
- 最终遍历的结果是:5-2-1-4-8-6-9;
程序实现:
/** 前序遍历 **/
public void preOrder(){
preOrder(root);
}
private void preOrder(Node node) {
if (node == null)
return;
System.out.println(node.e); // 先访问节点信息
preOrder(node.left); //前序遍历左子树
preOrder(node.right); //前序遍历右子树
}中序遍历和前序遍历类似,中序遍历就是将访问元素的环节放在了中间,先遍历其左子树,然后访问其节点元素,最后遍历其右子树。
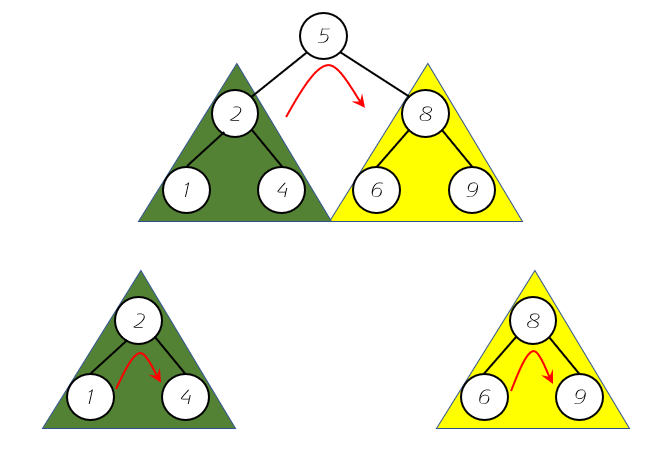
根据图我们可以得出中序遍历的顺序如下:
- 先前序遍历根节点的左子树,按照红色箭头的方向,结果为1-2-4;
- 访问该元素,结果为 5;
- 最后遍历右子树,结果为6-8-9;
- 最后的结果为1-2-4-5-6-8-9;
我们不难发现中序遍历的特点就是具有顺序性,本次中序遍历是从小到大,如果先遍历右子树,最后遍历左子树,结果就为从大到小排列。
程序实现:
public void inOrder() {
inOrder(root);
}
private void inOrder(Node node) {
if (node == null)
return;
inOrder(node.left);
System.out.println(node.e); // 在中间访问节点信息
inOrder(node.right);
}有了前面两个基础,后序遍历就比较简单了,就是最后再访问元素,先遍历左子树,后遍历右子树,最后访问该节点信息。
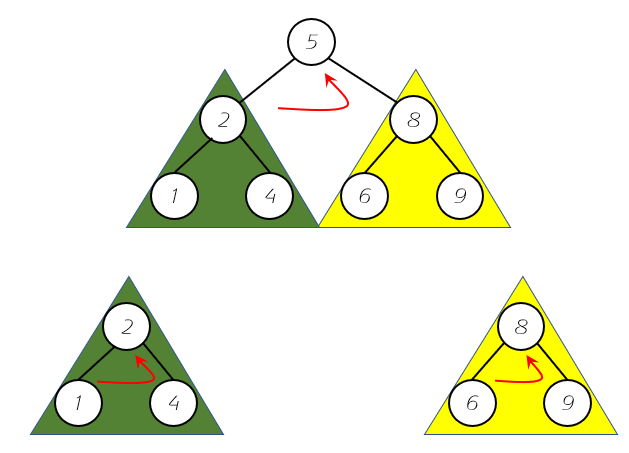
根据图我们可以得出后序遍历的顺序如下:
- 先后序遍历左子树,结果为:1-4-2;
- 再后序遍历右子树,结果为:6-9-8;
- 最后访问节点信息,结果为5;
- 最终结果为1-4-2-6-9-8-5;
程序实现:
public void lastOrder() {
lastOrder(root);
}
private void lastOrder(Node node) {
if (node == null)
return;
lastOrder(node.left);
lastOrder(node.right);
System.out.println(node.e); //最后访问节点信息
}层序遍历和前面的不同,层序遍历是广度优先的算法。也就是一层一层的访问。将某一个深度的信息全部访问完,在访问下一深度节点信息。这里就会用到我们之前讲的队列的数据结构。
核心思想就是:入队的元素是将要出队的左右节点的元素
针对前面所展示的二分搜索树,层序遍历我们用图来表示就是:

步骤:
- 先放入根节点;
- 出队队首的元素,同时入队根节点的左右节点;
- 开始循环,没出队一个元素,就要将他的孩子节点入队,如果没有则不入,直到队列中的元素为空;
- 最后我们输出的就是:5-2-8-1-4-6-9。
程序实现:
public void levelOrder() {
Queue<Node> q = new LinkedList<>();
q.add(root); //先放入根节点
while (!q.isEmpty()) { //循环知道队列元素为空
Node cur = q.remove(); //出队队首元素
System.out.println(cur.e);
if (cur.left != null) //同时入队刚出队元素的左右节点
q.add(cur.left);
if (cur.right != null)
q.add(cur.right);
}
}删除元素是最难的一个操作,我们不从删除任意元素开始,我们先从删除最大值和最小值入手,一步步深入了解删除操作
我们在查询元素那一节中提到,最小值存在于BST的最左边。这里又得分情况。最左边的元素存在的状态分为两种。
- 若是叶子节点,直接删除该元素即可;
- 若无左孩子节点,右孩子节点顶替待删除节点。
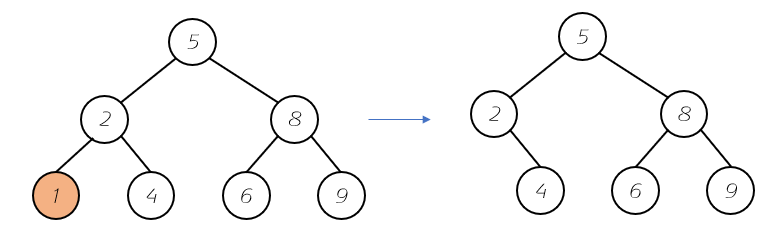
删除元素-叶子节点:
删除元素-无左孩子:
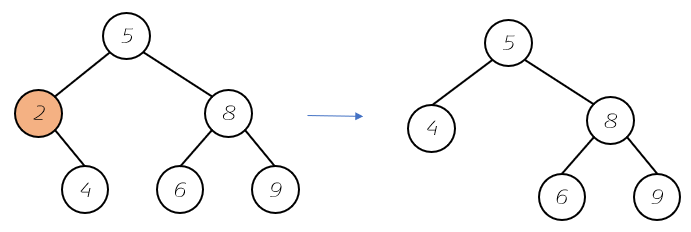
程序实现中,主要就是对两种情况进行分析。实际上,我们发现两者情况均是无左孩子节点(必然),所以最底的情况就是到达了最靠左的位置(左孩子为null),然后返回删除节点的全部右子树。第一种情况返回null,也就删除最小值。第二中情况也就是代替原来的位置。
程序实现:
public void removeMinimum() {
if (size == 0)
throw new IllegalArgumentException("BST is empty");
removeMinimum(root);
}
private Node removeMinimum(Node node) {
if (node.left == null) { // 到达最小值的节点
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}
node.left = removeMinimum(node.left);
return node;
}有了前面的删除最小值元素的概念,删除最大值就是向右走到底,删除最大值元素也分为两种,只不过方向相反而已。根据上面的程序我们就可以仿制删除最大值元素。
程序实现:
public void removeMaximum() {
if (size == 0)
throw new IllegalArgumentException("BST is empty");
removeMaximum(root);
}
private Node removeMaximum(Node node) {
if (node.right == null) { //到达最大值的节点
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
}
node.right = removeMaximum(node.right);
return node;
}删除元素就没有像其他操作那么简单了。这里呢我们引入一个方法,这是方法是在1962年 Hibbard 提出来的。下面我们用实例进行演示。
对于这个树结构,我们以最难的节点进行删除,也就是根节点进行删除,删除的步骤如下:
- 找到一个节点来代替根节点,这里我们选择待删除节点5的后继。后继:就是该节点右子树中离节点大小最近的节点,也就是右子树中的最小值节点。这里指的就是节点6。
- 找到了该节点6,就需要将原树中的节点6删除。这样6就从树结构中脱离出来。
- 将节点6的右子树指向节点8,节点6的左子树指向节点2。 这样就将节点5的后继节点6代替了节点5。完成了删除操作
程序实现:
public void remove(E e) {
root = remove(root, e);
}
private Node remove(Node node, E e) {
if (node == null)
return null;
if (e.compareTo(node.e) < 0) { //找到待删除的节点
node.left = remove(node.left, e);
return node;
} else if (e.compareTo(node.e) > 0) {
node.right = remove(node.right, e);
return node;
} else { //找到了待删除节点
if (node.left == null) { //单方向形式的和删除最大值和最小值类似
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}
if (node.right == null) {
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
} // 最复杂的情况,利用到后继
Node successor = minimum(node.right); //找到后继的节点
successor.right = removeMinimum(node.right); // 已经队size进行了自减操作
successor.left = node.left;
node.left = node.right = null;
return successor;
}
}这里并没有做时间复杂度分析,是因为这个树结构并不完美,有可能退化成链表这种数据结构。大家可以想一想,add(1),add(2),add(4),add(5)。当我以顺序的方式增加元素的时候,会发现树结构退化成了链表。
对于一般性的树结构,我们可以发现,我们查找一个元素并不需要遍历整个树结构,时间只取决于树的高度,树的高度越低速度越快。
对于一个满的二叉树来说,假设树的高度为M,那么整个树结构的元素个数为2^M - 1;也就是 .gif)
.gif)
假设N = 1000000 ;M = log(N) = 20,也就是提升了50000倍,随着数据量的提升,效果会更加明显.这也就体现了在大数据的情况下,树结构的优势。
更多精彩内容,大家可以转到我的主页:曲怪曲怪的主页
或者关注我的微信公众号:TeaUrn
或者扫描下方二维码进行关注。里面有惊喜等你哦。
源码地址:可在公众号内回复 数据结构与算法源码 即可获得。
