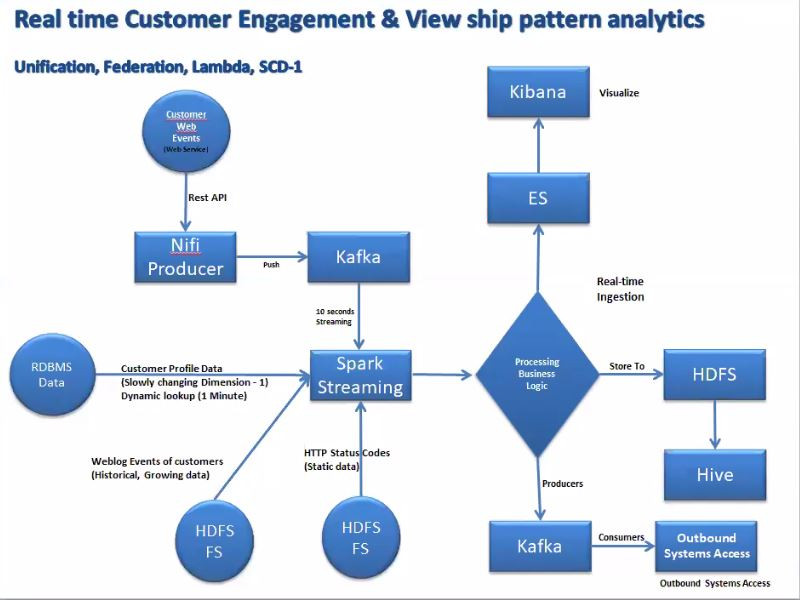
In this project, i have created data pipeline using the lambda architecture (Batch and screaming flow). Project cleanup and optimization in progress.
I have acquired following types of data from different sources:
1.Customer Profile Data: This a dimension data of SCD1 type stored in Oracle DB. Type of data is structured. Dynamic lookup is performed on this data every minute and cached in memory.
2.Weblog Events of Customers: This data is loaded by some other system into the linux landing pad. It is a growing, historical data of CSV type. This data is loaded once in a day.
3.HTTP Status Codes: This is a static data of XML type which is loaded only once.
4.Customer Web Events: This data represents what customers doing right now. It is a json data which is pulled from web service via NIFI and pushed to Kafka topic which is then consumed every 10 sec.
Current Code Flow (will Optimize later):
- Imported necessary libraries in POM.xml and imported in project.
- Initialized spark Session, spark Context and logger level.
- Loaded the static XML data and converted to Data Frame using databricks library.
- Created StructType Schema for weblog data.
- Loaded the weblog csv file as rdd using sc.textFile and converted to row rdd and then created dataframe using createDataFrame method to enforce null type validation.
- Method is created to load customer profile data from DB using spark jdbc option.
- Created a new ConstantInputDStream which always returns the same mandatory input RDD at every batch time. This is used to pull data from RDMS in a streaming fashion. In this stream we are doing the dynamic lookup by calling method to load data from DB every one minute and caching the result in memory.
- Performed joining of all the 3 dataframes in a final DF to aggregate the results and store it in ElasticSearch index.
- Visualization is created in Kibana from the ES index.
- Final DF is streamed to output Kafka Topic.
Functionality Achieved:
- Unification
- Federation
- Lambda
- SCD-1