Small INSERTs #89
Comments
|
Question: Would this mean the scan will load the both tables in memory / RAM? Or is this something duckdb can separate? I think depending on the insert rate a buffer table / async inserts that batch every x seconds would be a great feature. See the following diagram: |
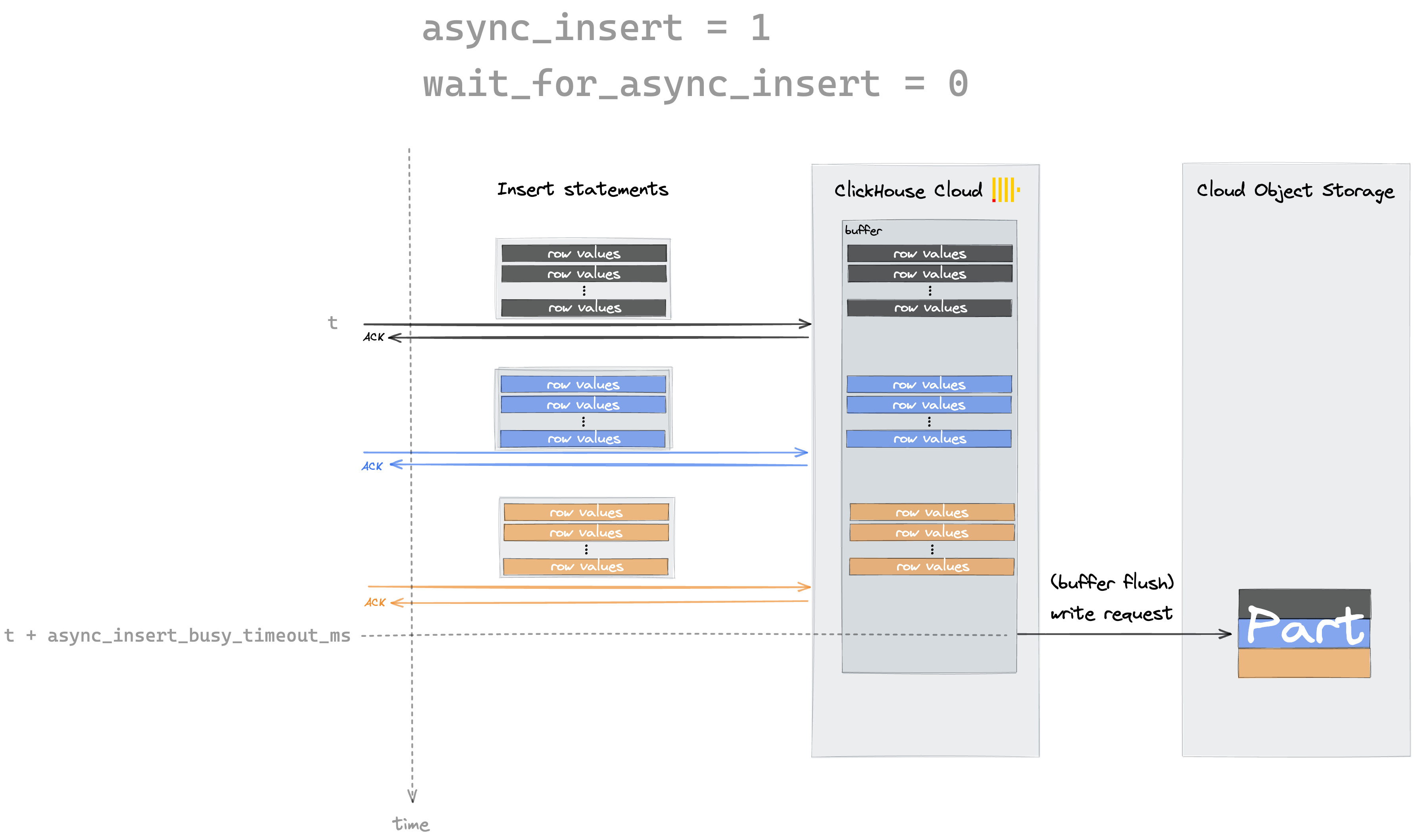
|
No The main difference between our design and ClickHouse's is that our table scan will scan not only the parts stored in cloud object storage but also the rows in the buffer. The way we scan the parts stored in cloud object storage is not much different In ClickHouse, data only becomes visible after a delay following the transaction commit, which is undesirable. With our design, queries access the most up-to-date data immediately. This added functionality comes at minimal cost, as scanning the buffer is negligible compared to scanning the parts You can learn more at https://dl.acm.org/doi/pdf/10.1145/3514221.3526055. The design presented here is a simplified version for workloads that are mostly append-only |
|
wow, thanks for linking that paper. makes sense. in terms of coding effort the delay seemed easier. looking forward for the progress. |
|
Looking forward to this. Seeing insert performance roughly the same for 1k records vs 1m today |
|
I can take this one! |
|
What is the state of this feature? Really looking forward to use it asap it's implemented. |
|
We are actively working on this and other v0.2 features. Stay tuned! |
|
Hello, I'm working on a project that requires tracking user interactions (widget impressions, orders, etc.) which will involve numerous small writes to a database followed by analytics queries. While the queries won't be complex, I'm expecting to accumulate a large volume of data over time. I'm considering using Neon.tech's serverless Postgres along with the pg_mooncake columnar extension, but I've noticed that pg_mooncake is still in early development (v0.1.2) and has performance issues with small writes (per GitHub issue #89). As a primarily frontend/app developer without extensive database experience, I'm wondering: Would it be advisable to start with a standard Neon Postgres database for now, and later migrate to a new Neon instance with pg_mooncake when it becomes more stable? How complicated would this migration process be? Are there any alternative approaches you'd recommend for my use case? Neon's serverless features like autoscaling and scale-to-zero seem particularly appealing for my variable workload, but I want to ensure I'm making the right architectural decision from the start. Thank you for your guidance! |
If you have really small inserts (concurrent single inserts), the recommended way is to have a regular postgres table as buffer for writes and use pg_cron to batch insert them into columnstore, and this should work good enough on existing version of pg_mooncake& neon. If you prefer not to do the manual workaround, I would suggest wait until v0.2. In v0.2 we will enable remove the restriction and allow small inserts directly to columnstore table without any perf penalty. |
|
I'm using it now and can't wait for the new version. I want to know how small an insert is considered a small insert. My use case is between 10 and 2000 rows per insert. |
|
@zhang-wenchao As a workaround, I would recommend using a Postgres heap table as a staging area to accumulate smaller inserts. You can then periodically flush this data into the columnstore table in batches. Also, you can run a no-op UPDATE like v0.2 is coming very soon and will support small INSERT/UPDATE/DELETE |
|
Is there a rough release plan for v2.0? Thanks for your work. |
|
The current plan is to have a preview version available in mid-late May, with a release in June |
What feature are you requesting?
Make columnstore tables good for small INSERTs
Why are you requesting this feature?
Small INSERTs into columnstore tables are currently very inefficient:
What is your proposed implementation for this feature?
ColumnstoreScanwill scan the union of the rowstore table and Parquet filesmooncake.flush_table(), to flush the rowstore table to a new Parquet fileThe text was updated successfully, but these errors were encountered: