前言:p项目,e员工,s薪水
数据应该尽可能少地冗余,这意味着重复数据应该减少到最少。比如说,一个部门雇员的电话不应该被存储在不同的表中, 因为这里的电话号码是雇员的一个属性。如果存在过多的冗余数据,这就意味着要占用了更多的物理空间,同时也对数据的维护和一致性检查带来了问题,当这个员工的电话号码变化时,冗余数据会导致对多个表的更新动作,如果有一个表不幸被忽略了,那么就可能导致数据的不一致性。
表 1-1
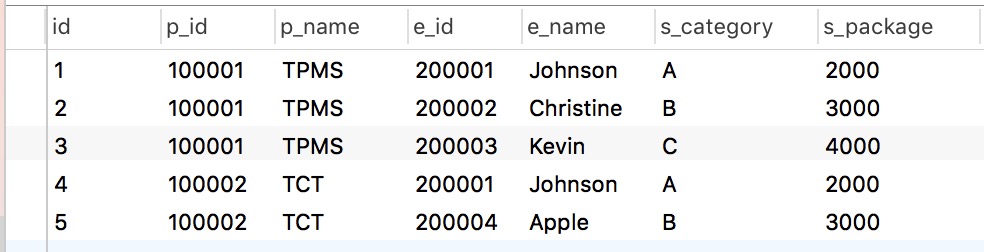
我们可以看到,这张表一共有六个字段,分析每个字段都有重复的值出现,也就是说,存在数据冗余问题。这将潜在地造成数据操作(比如删除、更新等操作)时的异常情况,因此,需要进行规范化。
参照范式的定义,考察上表,我们发现,这张表已经满足了第一范式的要求。
1、因为这张表中字段都是单一属性的,不可再分
2、而且每一行的记录都是没有重复的
3、存在主属性,而且所有的属性都是依赖于主属性
4、所有的主属性都已经定义
可以看到,属性对<p_id, e_id>是主键,其他所有的属性都依赖于该主键。
根据第二范式的定义,转化为二范式就是消除部分依赖。
1、数据冗余:每一个字段都有值重复
2、更新异常:比如对p_name值"TPMS"做了修改,那么就要一次更新该字段的多个值
3、插入异常:如果新建了一个p,名字为"TPT", 但是还没有e加入,那么e_id将会空缺,而该字段是主键的一部分,因此将无法插入记录
4、删除异常:如果一个员工 200003, Kevin 离职了,要将该员工的记录从表中删除,而此时相关的s_category C 也将丢失, 因为再没有别的行纪录下 ``s_category`C的信息
因此,我们需要将存在部分依赖关系的主属性和非主属性从满足第一范式的表中分离出来,形成一张新的表,而新表和旧表之间是一对多的关系。由此,我们得到:
表 1-2
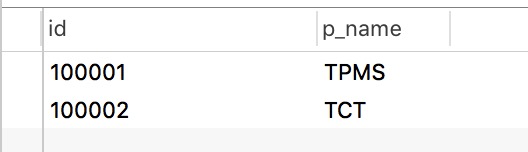
表 1-3
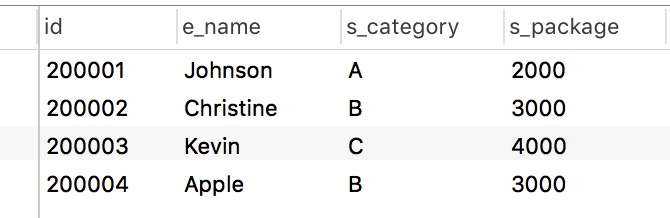
表 1-4
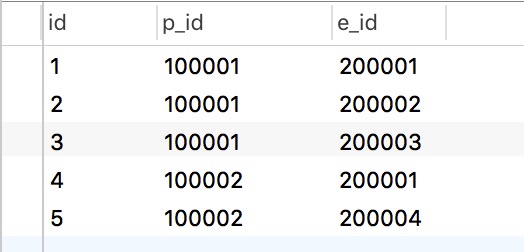
这时候我们仔细观察一下表1-2, 1-3, 1-4, 我们发现插入异常已经不存在了,当我们引入一个新的p"TPT" 的时候,我们只需要向表1-2 中插入一条数据就可以了, 当有新人加入p"TPT" 的时候,我们需要向表1-3, 1-4 中各插入一条数据就可以了。虽然我们解决了一个大问题,但是仔细观察我们还是发现有问题存在。
考察表前面生成的三张表,我们发现,表1-3存在传递依赖关系。而这是不满足三范式的规则的,存在以下的不足:
1、数据冗余:s_category和s_package的值有重复
2、更新异常:有重复的冗余信息,修改时需要同时修改多条记录,否则会出现数据不一致的情况
3、删除异常:同样的,如果员工 200003 Kevin 离开了公司,会直接导致 s_category C 的信息的丢失
因此,我们需要继续进行规范化的过程,把表1-3拆开,我们得到:
表 1-5
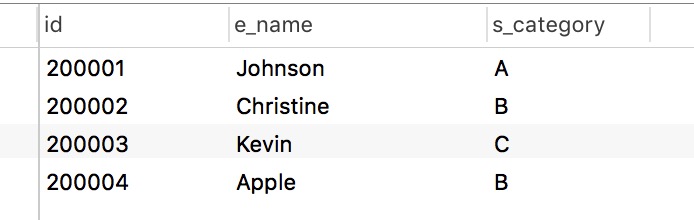
表 1-6
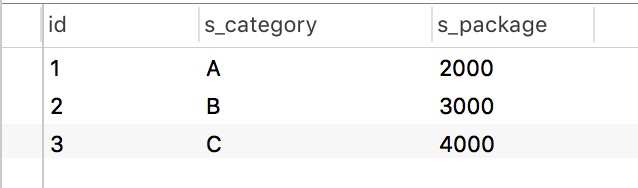
这时候如果 200003 Kevin 离开公司,我们只需要从表 1-5 中删除他就可以了, 存在于表1-6中的 s_category C 信息并不会丢失。但是我们要注意到除了表 1-5 中存在 Kevin 的信息之外, 表1-4中也存在 Kevin 的信息, 这很容易理解, 因为 Kevin 参与了项目 100001, TPMS, 所以当然也要从中删除。
至此,我们将表1-1经过规范化步骤,得到四张表,满足了三范式的约束要求,数据冗余、更新异常、插入异常和删除异常。
在三范式之上,还存在着更为严格约束的BC范式和四范式,但是这两种形式在商业应用中很少用到,在绝大多数情况下,三范式已经满足了数据库表规范化的要求,有效地解决了数据冗余和维护操作的异常问题。
在本文描述的过程中,我们通过结合实例的方法,通俗地演绎了数据表规范化的过程,并展示了在此过程中数据冗余、数据库操作异常等问题是如何得到解决的。
在具体的工程应用中,运用数据库规范化的方法来设计数据库表,将是具有现实意义的。