Measure twice, cut once
Resist the urge to just start writing code
- Read the problem completely twice.
- Solve the problem manually with 3 sets of sample data.
- Optimize the manual steps.
- Write the manual steps as comments or pseudo-code.
- Replace the comments or pseudo-code with real code.
- Optimize the real code.
- 70% of your time should be spent on steps 1-3
You need to completely understand the problem before you can try to solve it.
- work through exmaples if they are given
Break it down manually first (Solve the problem using cake baking steps)
- do optimization of the manual process
Psudeo-code for reversing a string.
// NewWord = “”
// Loop backwards through word to reverse
// NewWord += CurrentLetter
// Return NewWord
String newWord =""
for(int index = oldWord.Length – 1; index <= 0; index—)
newWord += oldWord[index];
return newWord;If you are having trouble here, you have not broken the problem down small enough yet.
“Pretend your time is worth $1,000/hr. Would you spend five of them doing extra work for free? Would you waste one on being angry?” -Niklas Göke
“Being busy is a form of mental laziness.” -Tim Ferriss
Are you busy or are you focused?
YOu teach people how to treat you. If you let people know your time is free and low valued, people will treat it as such.
Value your time at what it deserves to be. The higher the value, the more important and productive work you’ll do — and the less trivial and mindless tasks you’ll get caught in.
Have a framework and practice it!
- Understand
- Know exactly what is being asked
- doodle a diagram, write it down etc
- Plan
- Plan your solution
- 'Given input (x), what are the steps to return (y)?'
- Plan your solution
- Divide
- Break it down into sub problems, then solve each sub problem one by one
- Stuck?
- Debug your code step by step
- Reassess your plan
- Research your problem
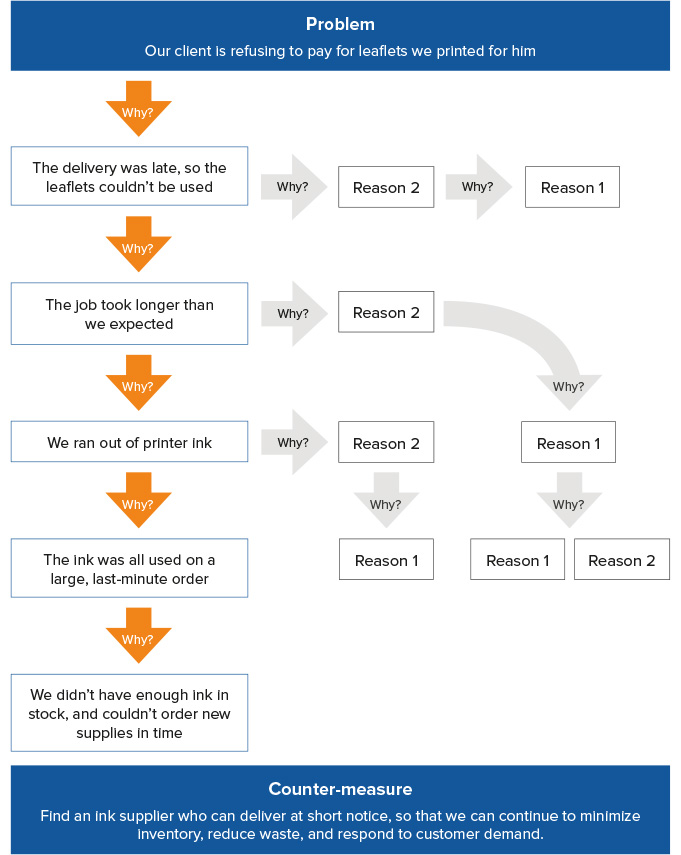
Developed by SAkichi Toyoda (founder of Toyota) in the 30s 'Go and See' Philosophy
- Assemble the team
- people familair with the specifics of the problem
- Define the problem
- Observe the problem in action
- Discuss with the team and write a brief, clear problem statement
- Ask the first WHY?
- Why is the problem occuring?
-
Ask 4 more WHYs to delve deeper into the problem 5 whys diagram 5 whys with multiple lanes
-
Know when to stop
-
Address the Root Cause(s)
-
Monitor your measures
- Why would you want to run JavaScript code outside of a browser?
- So that you can run applications on a local machine or without a web connection.
- What is the difference between a module and a package?
- A module is a group of packages. Packages are small aspects that make up a larger module, they are used to add on or seperate functions for cleaner code.
- What does the node package manager do?
- It manages which modules are installed and used. It allows you to bring in other modules and publish your own to the node ecosystem.
- Provide code snippets showing 3 different ways to export a function from a node module
module.exports = {
getName: () => {
return 'Jim';
},
getLocation: () => {
return 'Munich';
},
dob: '12.01.1982',
};const foo = require('./lib/foo');exports.getFoo = () => {
return 'foo';
}| Term | Definition |
|---|---|
| ecosystem | a collaboartive community of developers creating modules for the environment |
| Node.js | a Javascript runtime environment |
| V8 Engine | Google Chrome's JS environment |
| module | a JS library created to do a function really well |
| package | all the files that are needed for a module |
| node package manager (npm) | manages the node modules that are installed |
| server | a program that manages access to a centralized database |
| environment | the variables and space that the framework is running in |
| interpreter | a program that directly executes instructions in a written language |
| compiler | translates human-readable code into computer executable code |
- Name 3 advantages to Test Driven Development
- Fast and Consistent Feedback!
- Reduces time spent on reworking code
- Makes you really think about the codebase
- In what case would you need to use beforeEach() or afterEach() in a test suite?
- It can help prep and clear test environments after or before each test.
- What is one downside of Test Driven Development
- Lots of up-front work
- Not a silver bullet, there can still be bugs
- Its difficult to write good tests
- What’s the primary difference between ES6 Classes and Constructor/Prototype Classes?
- Classes create a unique object and also make the variables implicitly 'this.'
- Name a use case for a static method
- providing a class specific method
- Write an example of a Higher Order function and describe the use case it solves function foo(value, callback) { return callback(greeting) { console.log(greetin + value) } }
foo(7, callback)(hello)
A higher order function that utilizes a function as an argument or returns a function as an output.
| Term | Definition |
|---|---|
| functional programming | Process of buoilding software by composing pure functions |
| pure function | a program that does not change any attributes not contained within the fucntion |
| higher-order function | A higher order function that utilizes a function as an argument or returns a function as an output. |
| immutable state | a state that cannot be changed |
| object | a group of key values and protoype functions |
| object-oriented programming (OOP) | programming oriented around creating objects and passing them around |
| class | ES6 replacement for ES5 constructor functions |
| prototype | a method attached to the instance of a constructed object |
| super | used inside of a subclass to call a method in the parent class |
| inheritance | basing an object on another object |
| constructor | a special subroutine to create an object |
| instance | a concrete occurence of an object |
| context | all relevant information from different sources and programmers to interpret the same information based on the progaramming goal |
| this | the current instance of an object |
| Test Driven Development (TDD) | developing using user built test to test functions. |
| Jest | an NPM module to create an execute tests |
| Continuous Integration (CI) | the continuous updating of server or point based on updates to the repository |
| unit test | a level of software development where individual units or componenets are tested to validate each unit |
- Why would a developer choose to make data models?
- so that they can better create schema files and better visualize the data flow on the backend
- What purpose do CRUD operations serve?
- to create entries, read entries, update entries, and delete entries in a database. To modify or retrieve data from a database
- What kind of database is Postgres? What kind of database is MongoDB?
- Postgres is a SQL database whereas mongoDB is a noSQL database
- What is Mongoose and why do we need it?
- An object data modeling lobrary from mongoDB and Node,js. It manages relationships between data, provides schema validation and is used to translate objects in code to objects in a mongoDB database
- Define three related pieces of data in a possible application. An example for a store application might be Product, Category and Department. Describe the constraints and rules on each piece of data and how you would relate these pieces to each other. For example, each Product has a Category and belongs in a Department.
- If you were creating a food order, You might have a User, Orders and Menu Items. A user would have a profile that would create and order from the menu items database.
| Term | Definition |
|---|---|
| database | A place where data is stored |
| data model | an abstract model that represents a database structure or schema |
| CRUD | CREATE READ UPDATE DELETE |
| schema | How data is formatted in a database |
| sanitize | removal of malicious data from user input |
| Structured Query Language (SQL) | A language to query and maneuver through tables |
| Non SQL (NoSQL) | a collection of JSON-like documents that store data |
| MongoDB | |
| Mongoose | |
| record | A row of data |
| document | a JSON-like structured database |
| Object Relation Mapping (ORM) | A programming technique for converting data between incompatible type systems using object-oriented programming. This create a virtual object database that can be used from withing the programming language |
- Why would a developer choose to make data models?
- Making a data model can help you better plan and organize your data structures as well as help you develop the different data points needed. It can also help inform a decision over whether or not to use SQL or NoSQL.
- What purpose do CRUD operations serve?
- To Create Data objects, to Read data objects, To Update data objects and to Delete data objects
- What kind of database is Postgres? What kind of database is MongoDB?
- Postrgres is an SQL and table based databse system. MongoDB is a NoSQL and JSON-like document based database system.
- What is Mongoose and why do we need it?
- Mongoose is an Object Data Modeling library which provides schema validation and provides object translation between code and mongoDB.
- Describe how NoSQL Databases scale horizontally
- They can handle increased traffic by simply adding more servers.
- Give one strong argument for and against NoSQL Databases
- Because data is not relational, it is less safe from accidental mutation or deletion. Also, it is more prone to having data holes.
- Define three related pieces of data in a possible application. An example for a store application might be Product, Category and Department. Describe the constraints and rules on each piece of data and how you would relate these pieces to each other. For example, each Product has a Category and belongs in a Department.
- On a pizza order, you would have a User, a pizza and toppings. The user would have user profile data and hold an object that would be the pizza. The pizza would have a list of pre-made pizzas or a custom made pizza object. The toppings would have an interior list and price as well as be added to the pizza based on the pizza object.
- Name 3 cloud based NoSQL Databases
- MongoAtlas
- DynamoDB
- BigTable
| Term | Definition |
|---|---|
| database | A database is a repository of packages that contain data and is modeled ona schema |
| data model | An abstract visualization of data and how it is related to eachother |
| CRUD | CREATE, READ, UPDATE, DELETE! |
| schema | a file that places data into a certain format in a database |
| sanitize | cleaning inputs to make sure there is no malicious code |
| Structured Query Language (SQL) | A language and database structure based on tables and foreign IDs |
| Non SQL (NoSQL) | a Language and structure based on JSON-like documents that contain data |
| MongoDB | a NoSQL database repository much like postgresql |
| Mongoose | a node module to send and recieve data from the mongoDB client |
| record | an instance of database data |
| document | a file that contains data that conforms to a schema |
| Object Relation Mapping (ORM) | a technique to allow for converting data between systems using object oriented programming |
What is a linked list?
- A sequence of Nodes that are connected to eachother. Each Node references the next Node in the link.
What types of linked lists are there?
- Singly: Only one reference is linked into the next node
- Doubly: A reference to both the next and previous linked nodes
A Node contains the data for each linked list
- these should be as specific and compact as possible
Next: A reference to the next node Head: A reference to the first node Current: The current node being looked at

CANNOT USE FOR LOOPS OR FOREACH METHODS
- replaced with the Next value
- traverse linked lists using while loops
- allows you to check to see if the next node is not null (avoids errors)
ALGORTIHM Includes (value)
// INPUT <-- integer value
// OUTPUT <-- boolean
Current <-- Head
WHILE Current is not NULL
IF Current.Value is equal to value
return TRUE
Current <-- Current.Next
return FALSE
- Set the Current to the Head
- guarantees we are starting from the beginning
- create a while loop to check if the Current node is not null
- Check the value of the current node to the node we are looking for
- returns true
- Step 2-3 repeats until the end of the list is found
- while loop breaks
- If we hit the end, the value is not included and returns false
The Big O
- time for INCLUDES would be O(n)
- Space for INCLUDES would be O(1)
Add method for linked list - O(1)
ALGORITHM Add(newNode)
// INPUT <-- Node to add
// OUTPUT<-- No output
Current <-- Head
newNode.Next <-- Head
Head <-- newNode
Current <-- Head
Add method for linked list O(n)
ALGORITHM AddBefore(newNode, existingNode)
// INPUT <-- New Node, Existing Node
// OUTPUT <-- No Output
Current <-- Head
while Current.Next is not equal to NULL
if Current.Next.Value is equal to existingNode.Value
newNode.Next <-- existingNode
Current.Next <-- newNode
Current <-- Current.Next;
Print out Nodes
ALGORITHM Print()
// INPUT <-- None
// OUTPUT <-- string to console
Current <-- Head
while Current.Next is not equal to NULL
OUTPUT <-- "Current.Value --> "
Current <-- Current.Next
OUTPUT <-- "Current.Value --> NULL"
-
Tip: When making your Node class, consider requiring a value to be passed in to require that each node has a value.
-
Tip: When making a Linked List, you may want to require that at least one node gets passed in upon instantiation. This first node is what your Head and Current will point too.
Hyper-Text Transfer Protocol
- A stateless request-response application layer.
- Build distributed, collaborative, hypermedia information systems.
- typically serves .html, .json, .xml and binary executables
| HTTP | Method | Request Has Body | Response Has Body | Safe | Idempotent | Cacheable | Function |
|---|---|---|---|---|---|---|---|
| GET | No | Yes | Yes | Yes | Yes | Retrieve a resource | |
| HEAD | No | No | Yes | Yes | Yes | Like GET but headers only | |
| POST | Yes | Yes | No | No | Yes | Create a resource | |
| PUT | Yes | Yes | No | Yes | No | Update a resource | |
| DELETE | No | Yes | No | Yes | No | Delete a resource | |
| CONNECT | Yes | Yes | No | No | No | Create TCP/IP tunnel | |
| OPTIONS | Optional | Yes | Yes | Yes | No | Returns supported methods for a URL | |
| TRACE | No | Yes | Yes | Yes | No | Echos retrieved request | |
| PATCH | Yes | Yes | No | No | No | Partial modification of resource |
HTTP/1.1 200 OK
Date: Tue, 22 Aug 2017 06:34:16 GMT
Content-Type: application/json; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 82
Last-Modified: Mon, 21 Aug 2017 12:10:38 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Connection: close
{"id":"1234123412341324","title":"kata","content":"get 100 points on hacker rank"}-
REpresentational State Transfer
-
RESTful Endpoint: http://api.server.com/api/v1/people
- http:// - Protocol/Scheme
- api.server.com - Domain or Server
- /api/v1 - API Endpoint
- /people - The resource (This identifies a collection: all people)
- /people/12345 - A more specific resource: The person with id 1234
| REST Method | CRUD Operation | Function |
|---|---|---|
| GET | READ | Retrieve 1 or More Records |
| POST | CREATE | Create a new record |
| PUT | UPDATE | Update a record through replacement (Put it back) |
| PATCH | UPDATE | Update a record (just the parts that changed) |
| DESTROY | DELETE | Remove a record |
RESTful servers return JSON formatted Data <<<<<<< HEAD
Express is a route driven system
- it sends a request and recieves a response
app.get('/thing', (req,res) => {})When you request an object you will recieve a:
- req.params
- req.body
Query parameter api/:thing Query String api/route?item=thing
Responses will either:
- send()
- status()
Express Middleware
- a series of functions the request goes through
- each recieves a request, response and next
- Error Handling
- Bringing in other routes
- Applies Defaults
- JSON, Body and Form Parsing
- Runs on every request
- Dealing with specific things for a route
- Generally, things many routes would participate in
- Are you logged in?
- What is your IP?
- Have we seen you here before?
We can take advantage of this by
- logging
- Dynamic Model Loading
- Browser, Location and User specific data
- Consistent Data Tansitions(Pre-rendering)
CREATE
app.post('/resource')READ
app.get('/resource')UPDATE
app.put('/resource/:id')DESTROY
app.get('/resource/:id')TEST YOUR SERVER!
- Export Servers as a module
- use
Supertestto run your tests
Route Handlers
Single Callback Function
app.get('/example/a', function (req, res) {
res.send('Hello from A!')
})Array of Callback Functions
var cb0 = function (req, res, next) {
console.log('CB0')
next()
}
var cb1 = function (req, res, next) {
console.log('CB1')
next()
}
var cb2 = function (req, res) {
res.send('Hello from C!')
}
app.get('/example/c', [cb0, cb1, cb2])Routes can be put through route handlers as if they were middleware
Chainable Route Handlers
app.route('/book')
.get(function (req, res) {
res.send('Get a random book')
})
.post(function (req, res) {
res.send('Add a book')
})
.put(function (req, res) {
res.send('Update the book')
})Express Router
- This will handle both /birds and /birds/about routes
birds.js
var express = require('express')
var router = express.Router()
// middleware that is specific to this router
router.use(function timeLog (req, res, next) {
console.log('Time: ', Date.now())
next()
})
// define the home page route
router.get('/', function (req, res) {
res.send('Birds home page')
})
// define the about route
router.get('/about', function (req, res) {
res.send('About birds')
})
module.exports = routerrouter.js
var birds = require('./birds')
// ...
app.use('/birds', birds)Parameters on routes can be read /places/:city -> req.params.city
We can run middleware on any route or every route
We can run middleware only when certain parameters are present and expected
Mongoose is a schema driven ORM
- this gives us the ability to provide structure to our Mongo documents
ex. an online store likely has a collection of products. They probably also have a list of customers, each of which has placed orders which contain one or more products. When modeling the users collection, it would be nice to add orders as an array, and within the orders, and array of items … if you’ve previously modeled an item, you can re-use that schema within the orders section of a customer to keep the shape of that data the same.
var childSchema = new Schema({ name: 'string' });
var house = new Schema({ address: 'string', city: 'string', state: 'string' });
var adult = new Schema({
// Array of subdocuments
children: [childSchema],
// Single nested subdocuments.
address: house
});Sub Documents are a great way for data like comments on a blog post.
populate()
- method to connect 2 connections
method 1: physically joining using reference to another collection
method 2:
- create a virtual field in a document pointed to a field in another one
- in pre('find), do a collection on the fly
Pre and Post hooks (middleware)
Direct Join
const personSchema = Schema({
_id: Schema.Types.ObjectId,
name: String,
age: Number,
stories: [{ type: Schema.Types.ObjectId, ref: 'Story' }]
});
const storySchema = Schema({
author: { type: Schema.Types.ObjectId, ref: 'Person' },
title: String,
fans: [{ type: Schema.Types.ObjectId, ref: 'Person' }]
});Virtual Join
const teams = mongoose.Schema({
name: { type:String, required:true },
}, { toObject:{virtuals:true}, toJSON:{virtuals:true} });
teams.virtual('players', {
ref: 'players',
localField: 'name',
foreignField: 'team',
justOne:false,
});
teams.pre('find', function() {
this.populate('players');
});A stack is a data structure thtt consists of nodes
- nodes reference the next node in the stack but not the previous
- Push - Nodes or items that are put into the stack are pushed
- Pop - Nodes or items that are removed from the stack are popped. When you attempt to pop an empty stack an exception will be raised.
- Top - This is the top of the stack.
- Peek - When you peek you will view the value of the top Node in the stack. When you attempt to peek an empty stack an exception will be raised.
- IsEmpty - returns true when stack is empty otherwise returns false. First In Last Out
- first item added in the stack will be the last one popped out
Last IN First Out
- The last item added to the stack will be the first one popped out
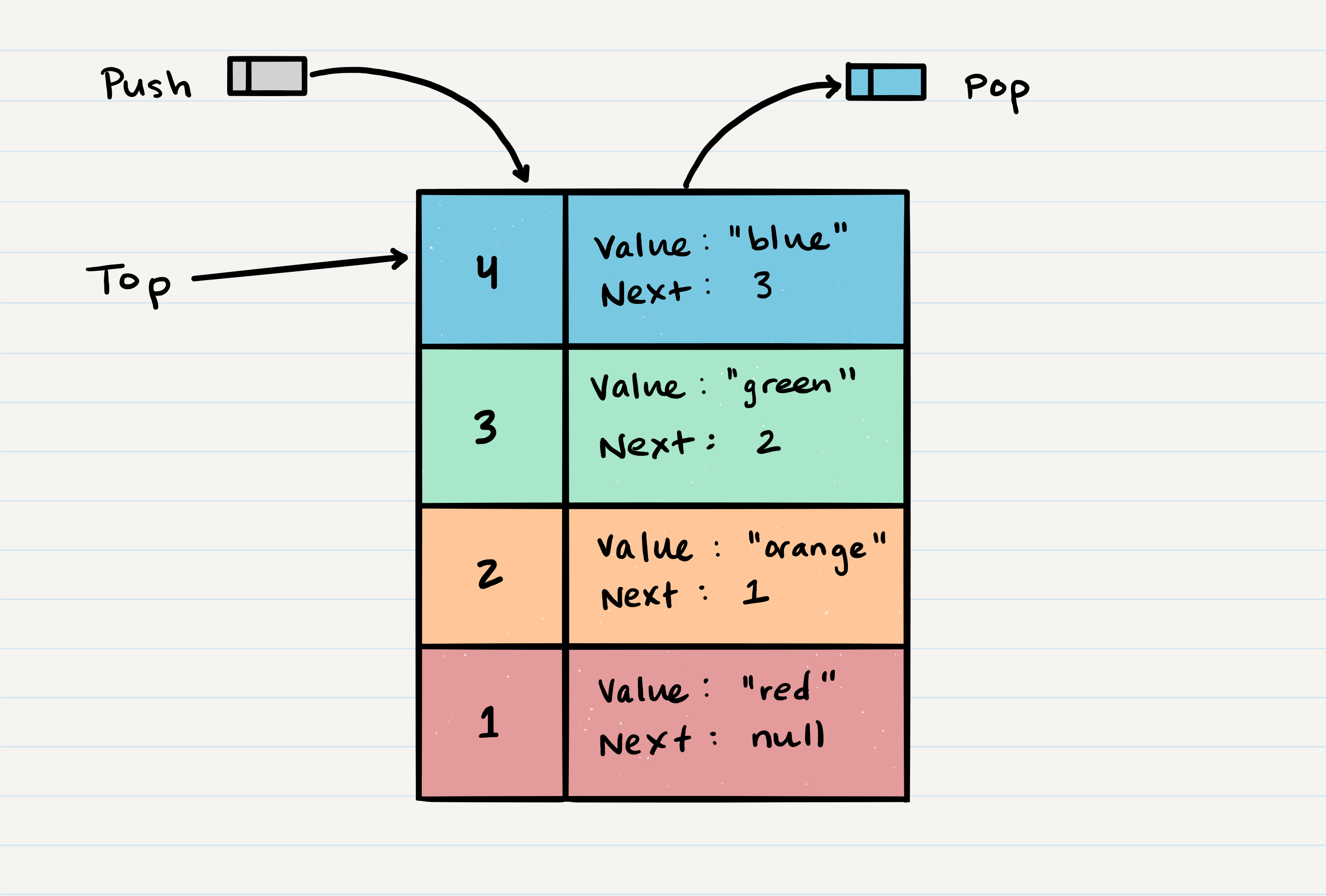
Pushing a Node onto a stack will always be an O(1) operations
- Identify the node to add
- assign the next property of the new node to reference the same node as the top
- Re-assign top to the new node
ALOGORITHM push(value)
// INPUT <-- value to add, wrapped in Node internally
// OUTPUT <-- none
node = new Node(value)
node.next <-- Top
top <-- Node
Popping a node off a stack is an O(1) operation
- make a reference of temp that points to the top of the node
- reassign top to the value of next
- remove the old node by redefining next as null
ALGORITHM pop()
// INPUT <-- No input
// OUTPUT <-- value of top Node in stack
// EXCEPTION if stack is empty
Node temp <-- top
top <-- top.next
temp.next <-- null
return temp.value
Peek
ALGORITHM peek()
// INPUT <-- none
// OUTPUT <-- value of top Node in stack
// EXCEPTION if stack is empty
return top.value
isEmpty
ALGORITHM isEmpty()
// INPUT <-- none
// OUTPUT <-- boolean
return top = NULL
- Enqueue - Nodes or items that are added to the queue.
- Dequeue - Nodes or items that are removed from the queue. If called when the queue is empty an exception will be raised.
- Front - This is the front/first Node of the queue.
- Rear - This is the rear/last Node of the queue.
- Peek - When you peek you will view the value of the front Node in the queue. If called when the queue is empty an exception will be raised.
- IsEmpty - returns true when queue is empty otherwise returns false.
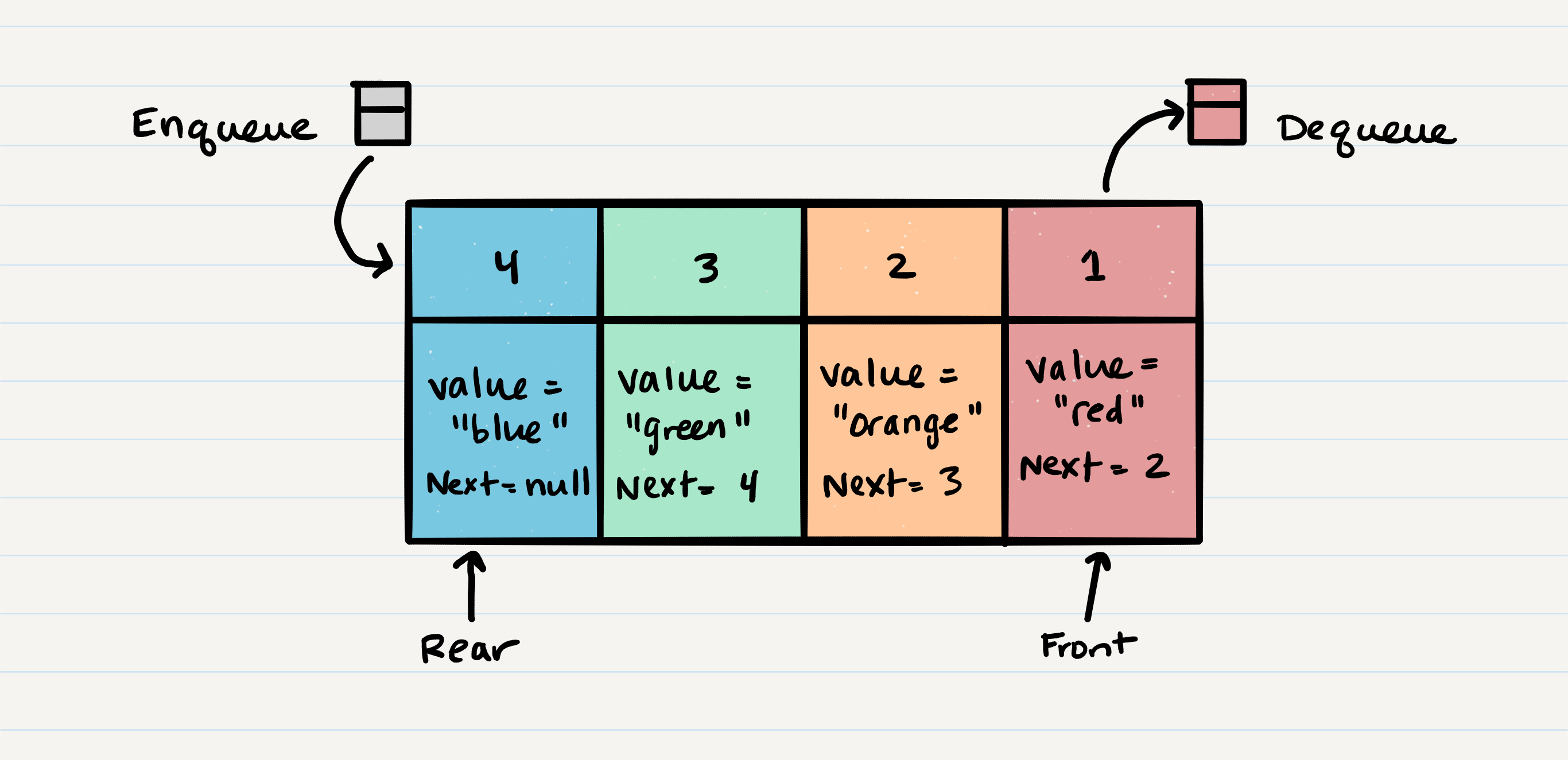
ENQUEUE
- change next of the top node to the node we are adding
- reassign rear to the new node
ALGORITHM enqueue(value)
// INPUT <-- value to add to queue (will be wrapped in Node internally)
// OUTPUT <-- none
node = new Node(value)
rear.next <-- node
rear <-- node
DEQUEUE
- assign the front node to a temp value
- reassign front to the next node
- reassign the previous front next to null
- return temp
ALGORITHM dequeue()
// INPUT <-- none
// OUTPUT <-- value of the removed Node
// EXCEPTION if queue is empty
Node temp <-- front
front <-- front.next
temp.next <-- null
return temp.value
Peek
ALGORITHM peek()
// INPUT <-- none
// OUTPUT <-- value of the front Node in Queue
// EXCEPTION if Queue is empty
return front.value
isEmpty
ALGORITHM isEmpty()
// INPUT <-- none
// OUTPUT <-- boolean
return front = NULL
It is our responsibility to store user information responsibly!
Passwords should be encrypted!
- if you must show sensitive data, make a second model profile and strictly limit access to the new return profile
Cryptography is a the study of encoding messages, this is important in encryption
- User tokens can be created by associateding random unique strings to a user account
- Send the encrypted token to the client.
- When the client makes a future request, send back the token
- The server reverses the token back into the tokenSeed by decrypting it with a secret key.
Base64 Encoding
let encoded = window.btoa('someusername:P@55w0rD!')
// c29tZXVzZXJuYW1lOlBANTV3MHJEIQ==
let decoded = window.atob('c29tZXVzZXJuYW1lOlBANTV3MHJEIQ==');
// someusername:P@55w0rD!
request({
method: 'GET',
url: 'https://api.example.com/login',
headers: {
Authorization: `Basic ${encoded}`,
},
})
.then(handleLogin)
.catch(handleLoginError)as a Node Module
let base64 = require('base-64');
let string = 'someusername:P@55w0rD!';
let encoded = base64.encode(string); // c29tZXVzZXJuYW1lOlBANTV3MHJEIQ==
let decoded = base64.decode(encoded); // someusername:P@55w0rD!JSON Web Tokens - JWT
structure - header.payload.signature
Header
{
"algorithm": "HS256",
"type": "JWT"
}Payload
Registered Claims
Public Claims
Private Claims
{
"sub":"123456",
"name": "john Doe",
"admin": true
}Signature - verifies the message was not changed along the way
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)The output looks like this

Auth0 Server
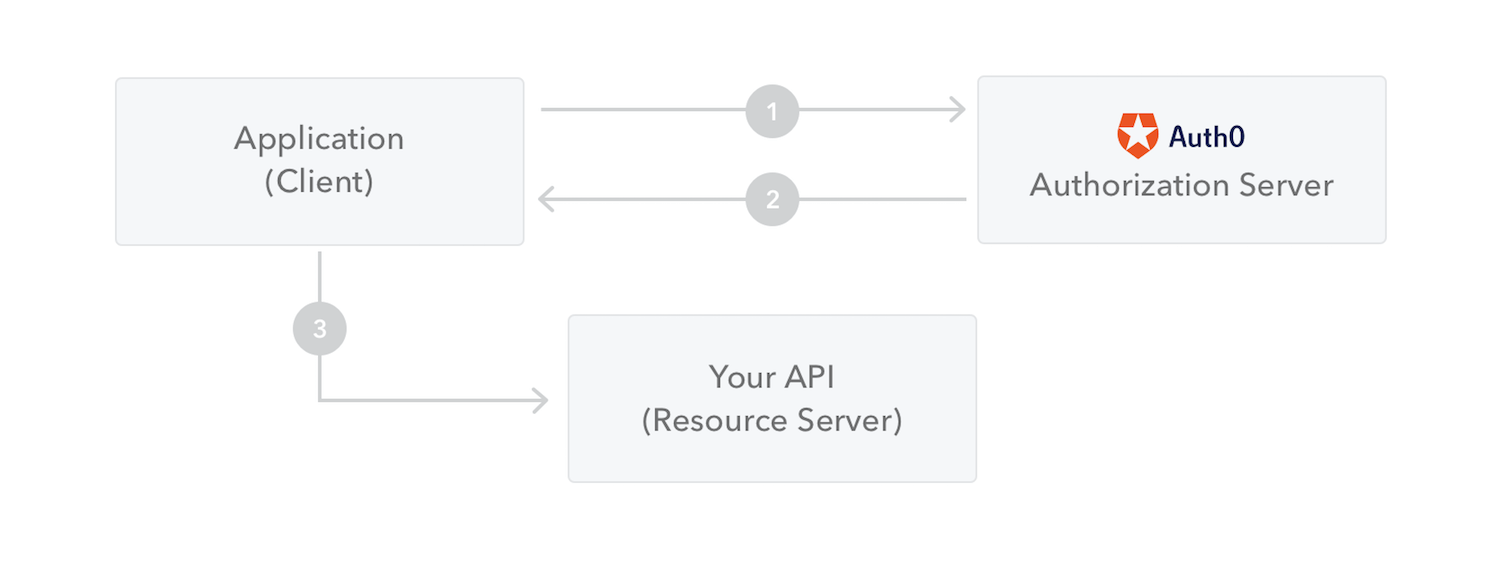
- The application or client requests authorization to the authorization server. This is performed through one of the different authorization flows. For example, a typical OpenID Connect compliant web application will go through the
/oauth/authorizeendpoint using the authorization code flow. - When the authorization is granted, the authorization server returns an access token to the application.
- The application uses the access token to access a protected resource (like an API).
login with google/facebook/other site, this is OAuth.
Oauth is a client that is an open standard for access delegation.
- gives a way to grant apllication access without giving a password
Through a series of “handshakes”, an application such as an Express Web Server asks the user if it’s ok to login as them at some remote service, and then begins the process of authentication and access.
1. Application spawns the “Login Using xxx” window, asking for specific permissions
2. User Agrees to allow this to happen
3. Remote service (i.e. Google) contacts the application with a one-time-use `Code`
4. The application calls back to a special address on the remote service to exchange that `Code` for a `Token`
5. Once the token has been granted, the application will then be able to contact the remote service, using that Token to access information on behalf of the user
The `token` is the userYou must grant application permission by sending an tag
response_type=code- indicates that your server wants to recieved authorizationclient_id=<your client id>- tellsthe authorization server which app the user is granting access toredirect_uri=<YOUR_REDIRECT_URI>- tells the auth server which app the user is granting access toscope=<list-of-scopes>- tells the auth server what you want the user to give access tostate=<anything-you-want>- a place where you can store infor to pass to your server (optional)
Access Token
If the users grants access to the application, the authorization server will redirect to a provided redirect URI callback with a “code”. Once you have this code, you can exchange it for an access token by making a POST request to the authorization server and providing the following information:
grant_type=authorization_codecode=<the code your receivedredirect_uri=REDIRECT_URImust be same as the redirect URI your client providedclient_id=<your client id>tells the authorization server which application is making the requestsclient_secret=<your client secret>authenticates that the application making the request is the application registered with theclient_id- Once you get an access token, you can use it to make API calls to the service on behalf of that user
Following a signin attempt your service will make a boolean decision on the success of the handshake
Instead of continously sending authorization requests with the password we can use a secondary authentication method called Bearer Token
A JSON object that contains enough information for a server to assert to any client that it is an authentic connection
Bearer Tokens are sent after the signin
- every request after must contain:
Authorization: Bearer encoded.jsonwebtoken.hereas the header
Express middleware to create a Bearer token
app.get('/somethingsecret', bearerToken, (req,res) => {
res.status(200).send('secret sauce');
});
function bearerToken( req, res, next ) {
let token = req.headers.authorization.split(' ').pop();
try {
if ( tokenIsValid(token) ) { next(); }
}
catch(e) { next("Invalid Token") }
}
function tokenIsValid(token) {
let parsedToken = jwt.verify(token, SECRETKEY);
return Users.find(parsedToken.id);
}Contrlols the selective restriction of resources
A user can be a token and signup and login and that token can be passed back to the server requests to access certain routes
A Client Service might:
- Allow admin users to create categories, content, manage user accounts, and run reports
- Allow editor users to create, edit and delete existing content, but not see or manage user accounts
- Allow guest users to access (read) content
- Allow user users (logged in users) to access (read) content and apply a thumbs-up/down to content, but not change the actual content
Back End layer:
- Manage the login cycle with the front-end application
- Maintain the User’s database
- Maintain roles for each user
- Authenticate users (basic and bearer)
- Create, manage, and apply Role Based Access Controls
- Maintain and reference their capabilities, based on their role
- Restrict access to features (like routes) based on capabilities
- Express Middleware could be used to restrict access to routes
- Mongoose Middleware/Hooks could be use to restrict access to business logic
Front End Layer:
- Initiate the login process
- Store login tokens as cookies
- Manage login state, capabilities
- Control physical & visual access (hide/show/alter) to components based on RBAC rules
- Alter behaviors based on RBAC rules
What is RBAC?
- The idea of assigning a system of access to users based on their roles in the organization.
-
Access control lists (ACL) — An ACL is a means of defining access rights by a given user or user group, to a specific object, such as a document. As a simple example, an ACL could be used to allow users from one department to make changes to a document, while only allowing users from other departments to read the document.
-
Attribute-based access control (ABAC) — ABAC, sometimes known as policy-based access control, can use a variety of attributes, including user department, time of day, location of access, type of access required, etc. to determine whether a user’s access request should be granted.
RBAC:
- Inventory your system
- what resources do you have that needs control?
- Analyze your workflow and create roles
- Define roles and determine access levels
- Assign people to roles
- Never make one-off changes
- Routinely audit your roles
This is a tree
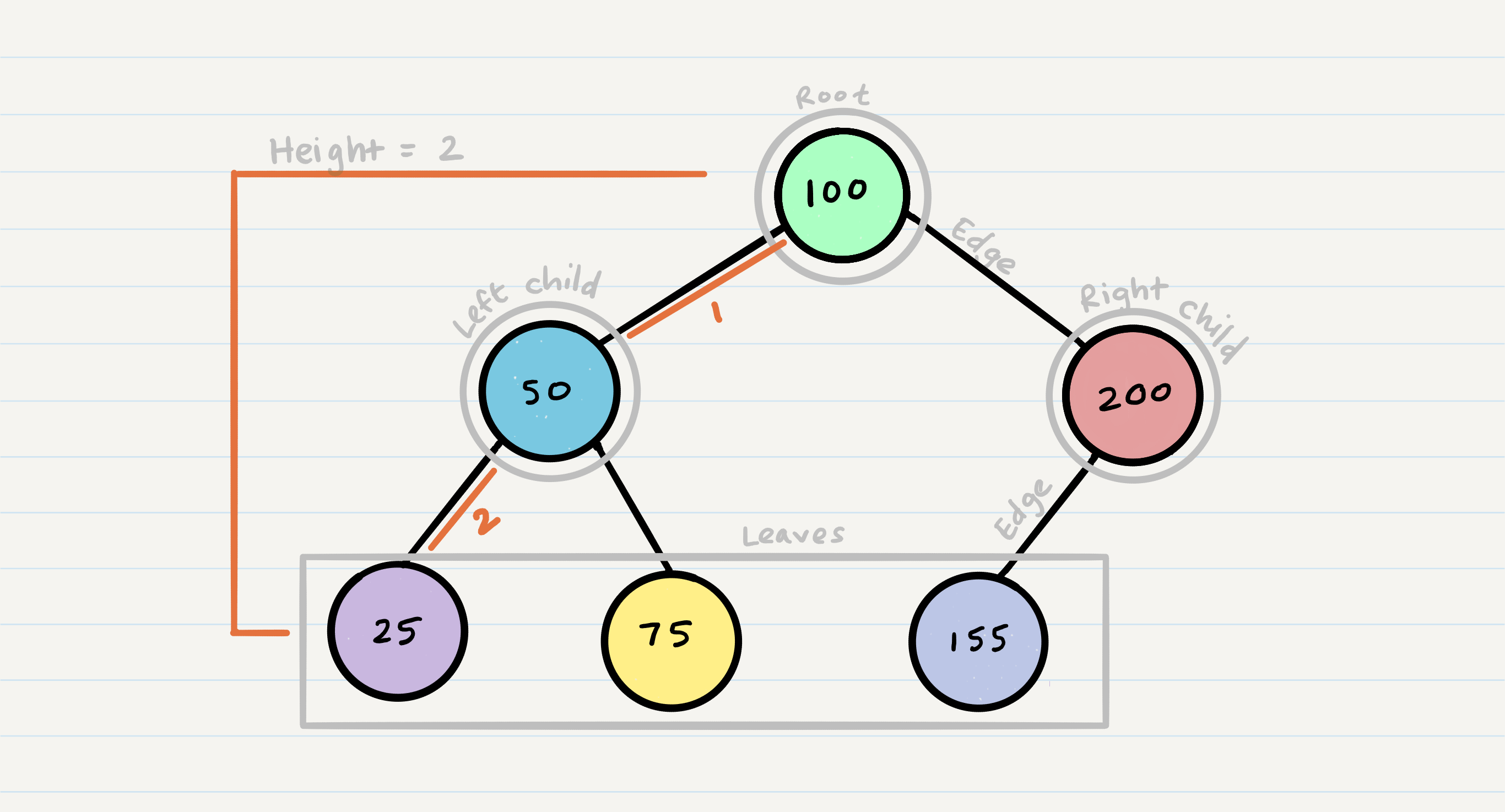
Traversing trees is the most important part
- Depth First
- Breadth First
Depth traverals prioritize going down a tree first
Pre-Order
ALGORITHM preOrder(root)
OUTPUT <-- root.value
if root.left is not NULL
preOrder(root.left)
if root.right is not NULL
preOrder(root.right)Root value is looked at first
- Root is added to call stack
output Root.value and check left
- if left is true, send left
Process continues until we hit the last node (leaf node)
The leaf node is popped off the call stack and the root is reset to the previous node.value
- if left is false, go right
Goes back to root
- if left and right are false, go back to previous root
In Order
ALGORITHM inOrder(root)
// INPUT <-- root node
// OUTPUT <-- in-order output of tree node's values
if root.left is not NULL
inOrder(root.left)
OUTPUT <-- root.value
if root.right is not NULL
inOrder(root.right)Post Order
ALGORITHM postOrder(root)
// INPUT <-- root node
// OUTPUT <-- post-order output of tree node's values
if root.left is not NULL
postOrder(root.left)
if root.right is not NULL
postOrder(root.right)
OUTPUT <-- root.valueBREADTH uses queues instead of stacks
ALGORITHM breadthFirst(root)
// INPUT <-- root node
// OUTPUT <-- front node of queue to console
Queue breadth <-- new Queue()
breadth.enqueue(root)
while breadth.peek()
node front = breadth.dequeue()
OUTPUT <-- front.value
if front.left is not NULL
breadth.enqueue(front.left)
if front.right is not NULL
breadth.enqueue(front.right)Everything in the world is 'event' driven
How can we leverage this in a software application?
- Everything in JS is an object
- Most actions in JS are event driven
- UI Events
- Express Routes
- (soon) Model Lifecycle Hooks
- (later) React … everything
we can harness that power!
express-server.js
let SQL = "DELETE FROM sometable WHERE id = $1"
let values = [request.query.id];
client.query(SQL, values)
.then( results => {
emit('delete', request.query.id);
res.send('Record Deleted')
});another-module.js
// Whenever the "delete" event has been emitted anywhere in my code base
// Run this function
events.on('delete', (data) => {
sendEmail({
to: 'admin@here.com',
subject: 'Someone deleted part of the database',
body: `Record id: ${data} was removed`
});
});set up event emitter
const EventEmitter = require('events').EventEmitter;
const chatRoomEvents = new EventEmitter;
function userJoined(username){
// Assuming we already have a function to alert all users.
alertAllUsers('User ' + username + ' has joined the chat.');
}
// Run the userJoined function when a 'userJoined' event is triggered.
chatRoomEvents.on('userJoined', userJoined);call the event to emit
function login(username){
chatRoomEvents.emit('userJoined', username);
}we can remove events as well
chatRoomEvents.removeListener('message', displayMessage);emitting with Class Objects
const EventEmitter = require('events').EventEmitter;
const myGatorEvents = new EventEmitter;
class Food {
constructor(name) {
this.name = name;
// Become eaten when gator emits 'gatorEat'
myGatorEvents.on('gatorEat', this.becomeEaten);
}
becomeEaten(){
return 'I have been eaten.';
}
}
var bacon = new Food('bacon');
const gator = {
eat() {
myGatorEvents.emit('gatorEat');
}
}OSI Model - Open Systems Interconnections Reference Model
OSI Layer model | # | Layer | Protocol | Data | Unit | Function Examples| |---|---|---|---|---|---| | 7 | Application | Data| Height| Level | APIs HTTP, IMAP, POP, SSH| 6 | Presentation| Data | Data | translating, including encryption, character encoding, and compression Strings encoded with null terminated strings vs Strings defined by an Integer Length| 5| Session | Data| Manages a session though passing data back and fourth NetBios and Remote Procedure Protocol (RPC)| 4| Transport | Segment / Datagram| Reliable transmission of data between points on a network TCP and UDP| 3 | Network | Packet| Managing the network through addressing, routing, and traffic control IP and ICMP| 2 | Data | Link | Frame | Reliable transmission of frames between to physical layer nodes Ethernet and IEEE 802.11 wireless LAN| 1 | Physical | bit | transmission and reception of raw data streams over a physical medium USB, Bluetooth, Ethernet physical layer, SMB, Telephone network modem
Internet Protocol Suite | Layer | Function| Examples| |---|---|---| | Application | Provides high level data exchange for use in user application development| HTTP, SMTP, FTP, DHCP | Transport| Provides process to process data exchange | TCP, UDP, µTP | Internet| Maintains computer addressing and identification and manages packet routing | IPv4, IPv6, ICMP | Link layer| Used to move packets between two different hosts| MAC, ARP, DSL, Ethernet|
TCP Transmission Control Protocol
- A TCP segment is made up of header and data sections
TCP Header
Byte 0: Source port
Byte 3: Destination port
Byte 4: Sequence number
Byte 8: Acknowledgement number
Byte 12: Data Offset, NS flag, and 3 undefined bits
Byte 13: CWR, ECE, URG, ACK, PSH, RST, SYN, and FYN flags
Byte 14: Window size
Byte 16: Checksum
Byte 18: Urgent pointer
Byte 20: Options- a 16 bit source port
- a 16 bit destination port
- a 32 bit sequence number that sets the initial sequence number and manages the accumulated sequence number
- if ACK is set it contains a 32 bit acknowledgement number that is the next sequence number that the sender is expecting. It is used for acknowledging the bytes it has so far received
- a 4 bit data offset specifies the size of the tcp header in 32 bit words.
- 9 flag bits
- NS - an experimental feature for a nonce sum - a nonce is a random cryptographic number used to prevent people from lying about who they are (authentication)
- CWR - used to acknowledge that a TCP segment with the ECE flag has been received, and the Window has been reduced to alleviate congestion
- ECE - if SYN is 1 it indicates that the peer is * ECN capable, other otherwise its used to indicate that there is network congestion.
- URG - indicates that the Urgent pointer filed is significant
- ACK - indicates that the ACK field is significant - all packets after the initial SYN should have this flag set
- PSH - used to ask to push the buffered data to the receiving application.
- RST - used to reset the connection
- SYN - sent only on the first packet sent from each end to synchronize the sequence numbers
- FIN - indicates the last package from a sender, and is used in closing a connection
- a 16 bit window size
- a 16 bit checksum used for error checking the header
- if URG is set it contains a 16 bit urgent Pointer
- a variable 0 to 320 bit (divisible by 32) options section
Connection Establishment
The client sends a SYN packet with an random initial sequence number. The server sends a SYN-ACK packet with the acknowledgment number set to one more than the initial sequence number. The client responds with an ACK and an acknowledgment number incremented by one.
Connection Termination
One end sends a FIN Segment and the other sends an ACK segment followed by a FIN segment. The termination initiation will then respond with an ACK segment.
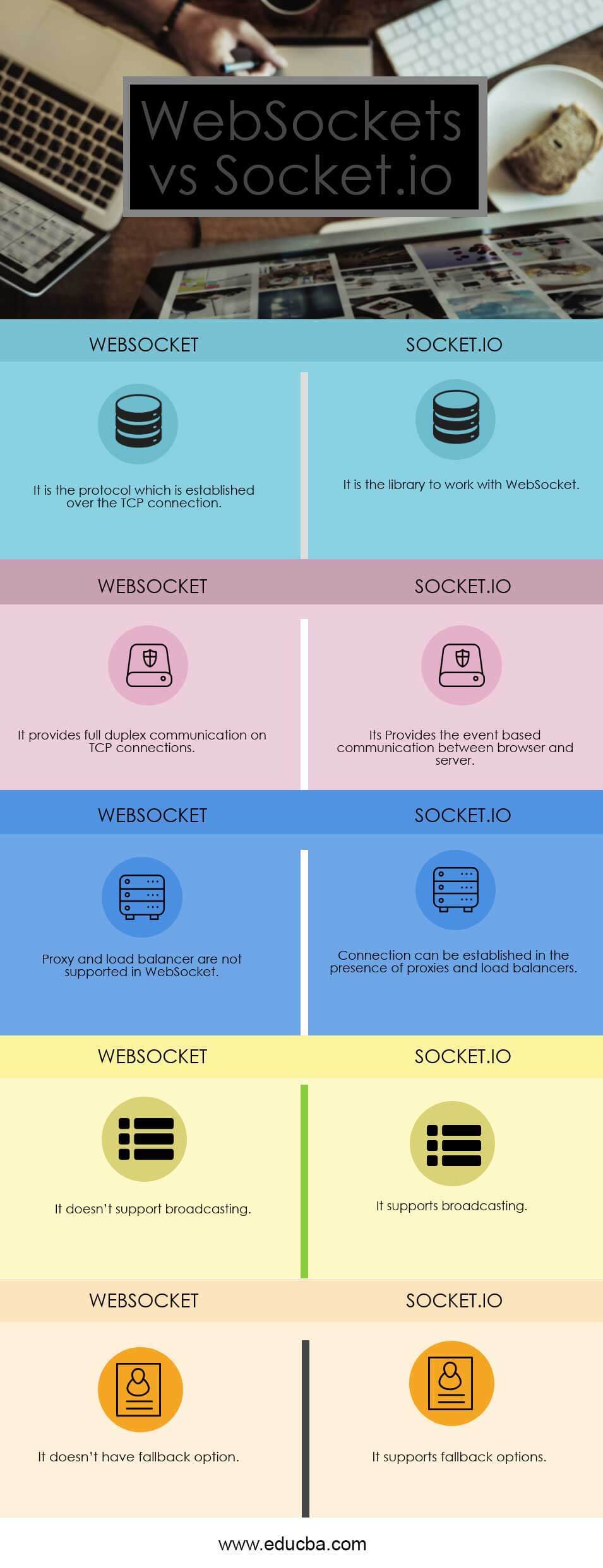
Web sockets are a communication protocol between Client and Server over a TCP connection
- WebSocket stays open the whole time allowing 'realtime' data transfer
Socket.io is a library real-time and full duplex communication between the client and the web servers
- Client Side: it is the library that runs inside the browser
- Server Side: It is the library for Node.js
Connections
-
With TCP, you connect directly to a server with a keep-alive type of connection.
-
With Socket.io, you connect to a server over HTTP. The session is “kept alive” through it’s internal use of the WebSocket Protocol, with session information being preserved.
{kind=link}
A queue server runs independently and is tasked with 'routing' events and messaging in between clients
- any client can publish to the server
- any client can subscribe to recieve messages by type
- A message is a package of information, categorized by queue and event
queue- Which general bucket does this message belong- i.e. “Database Events”, “Filesystem Events”, “Network Events”, etc
event- What event has happened- i.e. “delete, add, update, connection lost, error”, etc.
payload- data associated with the event- i.e. “record id, record information, error text”, etc.
Use Case
An API server responds to a POST request
User’s access rights are confirmed
The data is analyzed and normalized
The data is sent to the database for saving
The database “publishes” a message into the queue
Queue: DB
Event: CREATE
Payload: JSON Object containing the created record
The API server sends information back to it’s client as normal
Elsewhere …
A logging application is connected to the queue
It has subscribed to the “DB” Queue and is listening for CREATE events
When the above transaction happens, the logger “hears” the CREATE event and logs some details to it’s logging database and updates some summary data.
A web based ‘dashboard’ application is running and is connected to the queue
It also subscribes to DB/CREATE
When this event happens, it updates a counter in the browser for the operator to see that a new record was created.
A monitor application is running and is connected to the queue
It also subscribes to DB/CREATE
When this event happens, it sends a text to all sales people alerting them that a new customer account was created.
… and so on.io.on('connect', onConnect);
function onConnect(socket){
// sending to the client
socket.emit('hello', 'can you hear me?', 1, 2, 'abc');
// sending to all clients except sender
socket.broadcast.emit('broadcast', 'hello friends!');
// sending to all clients in 'game' room except sender
socket.to('game').emit('nice game', "let's play a game");
// sending to all clients in 'game1' and/or in 'game2' room, except sender
socket.to('game1').to('game2').emit('nice game', "let's play a game (too)");
// sending to all clients in 'game' room, including sender
io.in('game').emit('big-announcement', 'the game will start soon');
// sending to all clients in namespace 'myNamespace', including sender
io.of('myNamespace').emit('bigger-announcement', 'the tournament will start soon');
// sending to a specific room in a specific namespace, including sender
io.of('myNamespace').to('room').emit('event', 'message');
// sending to individual socketid (private message)
io.to(socketId).emit('hey', 'I just met you');
// WARNING: `socket.to(socket.id).emit()` will NOT work, as it will send to everyone in the room
// named `socket.id` but the sender. Please use the classic `socket.emit()` instead.
// sending with acknowledgement
socket.emit('question', 'do you think so?', function (answer) {});
// sending without compression
socket.compress(false).emit('uncompressed', "that's rough");
// sending a message that might be dropped if the client is not ready to receive messages
socket.volatile.emit('maybe', 'do you really need it?');
// specifying whether the data to send has binary data
socket.binary(false).emit('what', 'I have no binaries!');
// sending to all clients on this node (when using multiple nodes)
io.local.emit('hi', 'my lovely babies');
// sending to all connected clients
io.emit('an event sent to all connected clients');
};Systems like React, Angular and Vue
Rather than a large interconnected database, these are compositions of components that work together to make the app work.
The Two main components are Classes and functions which make up the components and state of the application
JSX looks like markup but is actuaklly javascript REACT automatically escapes user inputs before rendering
JSX
const element = () => {
return {
<h1 className="greeting">
Hello, world!
</h1>
}
);JS behind the scenes
const element = () => {
return {
<h1 className="greeting">
Hello, world!
</h1>
}
);Basic JSX in React
const name = 'Josh Perez';
const element = <h1>Hello, {name}</h1>;
ReactDOM.render(
element,
document.getElementById('root')
);JSX with Dynamic variables
function formatName(user) {
return user.firstName + ' ' + user.lastName;
}
const user = {
firstName: 'Harper',
lastName: 'Perez'
};
const element = (
<h1>
Hello, {formatName(user)}!
</h1>
);
ReactDOM.render(
element,
document.getElementById('root')
);Setting up an element
// Note: this structure is simplified
const element = {
type: 'h1',
props: {
className: 'greeting',
children: 'Hello, world!'
}
};(React Cheat Sheet)[https://reactcheatsheet.com/]
- Snapshots - make assersion on the exact rendered markup (w/ content) at any state of the app
- Render Testing - allows for JQuery-like inspection of virtual DOM tree
- Shallow testing - executes and renders the called components but does not compose children
- Mounting - executes the full component and children. Allows for inspection of redered virtual DOM
SAMPLE TEST
import React from 'react';
import renderer from 'react-test-renderer';
import Counter from '../../../../src/components/counter/counter.js';
describe('<Counter/> (Enzyme Test)', () => {
it('is alive at application start', () => {
let app = mount(<Counter />);
expect(app.find('.count').text()).toBe('0');
});
it('can count up', () => {
let app = mount(<Counter />);
app.find('.up').simulate('click');
expect(app.state('count')).toEqual(1);
app.find('.up').simulate('click');
expect(app.state('count')).toEqual(2);
});
it('can count down', () => {
let app = mount(<Counter />);
app.find('.down').simulate('click');
expect(app.state('count')).toEqual(-1);
app.find('.down').simulate('click');
expect(app.state('count')).toEqual(-2);
});
it('visually displays proper polarity and value on the count element', () => {
let app = mount(<Counter />);
expect(app.find('.count.negative').exists()).toBeFalsy();
expect(app.find('.count.positive').exists()).toBeFalsy();
// Go to 1
app.find('.up').simulate('click');
expect(app.find('.count.positive').exists()).toBeTruthy();
expect(app.find('.count').text()).toBe('1');
// Down to zero
app.find('.down').simulate('click');
expect(app.find('.count').text()).toBe('0');
expect(app.find('.count.negative').exists()).toBeFalsy();
expect(app.find('.count.positive').exists()).toBeFalsy();
// Down to -1
app.find('.down').simulate('click');
expect(app.find('.count.negative').exists()).toBeTruthy();
expect(app.find('.count').text()).toBe('-1');
});
});
describe('<Counter/> Core Component (Snapshot Test)', () => {
it('renders right', () => {
const component = renderer.create(<Counter />);
let tree = component.toJSON();
expect(tree).toMatchSnapshot();
});
});npm run build
if executed from the root folder, this outputs a 'static' website containing no more than the index.html, .js and .css files
- Enable GitHub Pages on your domain, using the
gh-pagesbranch - Create a Personal Access Token in your GitHub account
- Add this token as a “Secret” called
PERSONAL_TOKENin the repository housing your react app - Add the react workflow .yml file to your repository (in .github/workflows)
- This will initiate a GitHub Action whenever you push (or merge) code into your repository. This action will run the build command for you, create a new branch called gh-pages and deploy your React static files to that branch, which you can then view at the Github Pages link provided to you
- Create a new Bucket
- Storage containers for static assets
- Essentially, these are “folders”
- Objects
- These are the things in the buckets (your files)
- Upload the contents of your React application build folder to your bucket
- Set up to serve websites
- Properties Tab “Static Web Hosting” option
- Create a new Amplify Workflow
- Point the workflow at your GitHub repository (master branch)
- Merge your code to master on GitHub
- That’s it … Amplify will monitor your repository for changes, pull, build, and deploy your React app automatically
- Eventually, there’s a usage charge for the service, depending on your traffic level
- Create a netlify.com account
- Create a new application
- Point the application at your GitHub repository (master branch)
- Merge your code to master on GitHub
- That’s it … Netlify will monitor your repository for changes, pull, build, and deploy your React app automatically
- Create your account
- Open an FTP connection to your hosting company with a tool like Transmit or FileZilla
- Navigate to the web root folder
- Upload the contents of your react application’s build folder
React elements manintain an internal state.
- we must manage the state of unputs through our own stateful components and ONE-WAY data binding. The creation of a parent componenet manages the state for all child components and passes any necesasary state down into its inputs
propsonChange
After props is passed into the constructors super function, they are available on the context by using this.props
class Foo extends React.Component {
constructor(props){
super(props)
}
screamLoud() {
console.log("OUCH");
}
render(){
return (
<div>
<Bar handleClick={this.screamLoud} />
</div>
)
}
}
class Bar extends React.Component {
constructor(props) {
super(props);
}
render() {
<div>
<button onClick={this.props.handleClick}>Click</button>
</div>
}
}
// Render the element ...
<Foo /> import {Route} from 'react-router-dom'To use the Browser router properly, you eliminate the use of tags, instead use the built in
<Link to="/">Home</Link>
<Link to="/stuff">Stuff</Link>Defining Routes '''jsx <Route exact path="/stuff" render={() => {items}} />
Sending Child components the raw data for them to output
```jsx
// Dashboard Wrapper
// - feeds the SearchForm some methods
// - then feeds the results some data
<Dashboard>
<SearchForm handler={this.doTheSearch} />
<Results data={this.state.results} />
</Dashboard>
// .. Results Component
<ul>
{this.props.data.map( (item,i) =>
<li key={i}>{item}</li>
);
</ul>
With Logic-less children (pre-rendered JSX)
<Dashboard>
render() {
let listings = {this.state.results.map( (item,i) => <li key={i}>{item}</li> );
}
<SearchForm handler={this.doTheSearch} />
<Results>
{ listings.map( listing => listing ) }
</Results>
</Dashboard>
// Results Component
<ul>
{this.props.children}
</ul>- Hash: A hash is the result of some algorith taking an incoming string and converting into a value that can be used for either security of some other purpose. Used to determine the index of the array
- Buckets: A bucket is what is continaed in each index of the hashtable array. An index could potentailly containe multiple key/value pairs if a collision occurs
- Collisions: A collision is what occurs when one or more keys get hashed to the same location in the hashtable
Why do we use hashtables?
- Hold unique Values
- Dictionaries
- Libraries
Basically, the hash function takes a key and returns an integer. We use the integer to determine where the key/value pair should be placed in the array.
Output is only determined by their Input
Key = "Cat"
Value = "Josie"
// Add or multiply all the ASCII values together.
67 + 97 + 116 = 280
// Multiply it by a prime number such as 599.
280 * 599 = 69648
// Use modulo to get the remainder of the result, when divided by the total size of the array.
69648 % 1024 = 16
// Insert into the array at that index.
Key gets placed in index of 16. Collisions are solved by changing the initial state of the buckets. Instead of starting them all as null we can initialize a LinkedList in each one! Now if two keys resolve to the same index in the array then their key/value pairs can be stored as a node in a linked list. Each index in the array is called a “bucket” because it can store multiple key/value pairs.
- accept a key
- calculate the hash of the key
- use modulus to convert the hash into an array index
- store the key with the value by appending both to the end of a linked list
- accept a key
- calculate the hash of the key
- use modulus to convert the hash into an array index
- use the array index to access the short
LinkedListrepresenting a bucket - search through the bucket looking for a node with a key/value pair that matches the key you were given
Add()
- When adding a new key/value pair to a hashtable:
- send the key to the GetHash method.
- Once you determine the index of where it should be placed, go to that index
- Check if something exists at that index already, if it doesn’t, add it with the key/value pair.
- If something does exist, add the new key/value pair to the data structure within that bucket.
Find()
- The Find takes in a key, gets the Hash, and goes to the index location specified. Once at the index location is found in the array, it is then the responsibility of the algorithm the iterate through the bucket and see if the key exists and return the value.
Contains()
- The Contains method will accept a key, and return a bool on if that key exists inside the hashtable. The best way to do this is to have the contains call the GetHash and check the hashtable if the key exists in the table given the index returned.
GetHash()
- The GetHash will accept a key as a string, conduct the hash, and then return the index of the array where the key/value should be placed.
React hooks allow you to easily create and manage state in a functionl component.
- Hooks must hav a use pronoun - useFishingPole
- Do not call hooks inside of loops, conditions or nested functions
- Only call hooks from React components
import React from 'react';
import { useState } from 'react';
function Counter() {
const [clicks, setClicks] = useState(0);
return (
<div>
<h2>Button has been clicked {clicks} time(s)</h2>
<button type="button" onClick={() => setClicks(clicks + 1)}>
Update Count
</button>
</div>
);
}
export default Counter;Example:
-
clicksis the state variable, which will store the number of clicks -
setClicksis a function that is called to change the value of clicks -
We use
set+statevariable(camel cased) to name this function -
useState()takes a single param, which is the initial value to assign to the state variable -
You can call your setter function
setClicks(7)and the attribute value you call the function with is used as the new value for the state variable.
What is a custom Hook?
- Duplicated logic from other components
- share common functionality but not state
- take advantage of the useEffect lifestyle
Common use cases – make things DRY!
-
Handle forms easily
-
Pre-fetch API data
-
Connect to services (like socket.io, Q, etc)
- Unlike a React component, a custom Hook doesn’t need to have a specific signature. We can decide what it takes as arguments, and what, if anything, it should return. In other words, it’s just like a normal function. Its name should always start with use so that you can tell at a glance that the rules of Hooks apply to it.
// use-food-hook.js
export default function useFoodHook(hungry) {
let food = 'cookies';
return hungry ? food : null;
}
// Using a hook is a simple, then, as requiring it and calling it.
// my-component.js
import useFeedme from 'use-food-hook.js';
function myComponent() {
const food = useFeedMe(true);
return <div>{food}</div>
}A method of passing state down the component tree.
- A
providercan make it's state available for itsconsumerchildren
Creating a Context
import React from 'react';
export const SettingsContext = React.createContext();
class SettingsProvider extends React.Component {
constructor(props) {
super(props);
this.state = {
changeTitleTo: this.changeTitleTo,
title: 'My Amazing Website',
};
}
changeTitleTo = title => {
this.setState({ title });
};
render() {
return (
<SettingsContext.Provider value={this.state}>
{this.props.children}
</SettingsContext.Provider>
);
}
}App Level
<SettingsContext>
<Content />
</SettingsContext>Wrap the component with context function to provide this.state
<SettingsContext.Consumer>
{context => {
console.log(context);
return (
<div>
<h1>{context.title}</h1>
<button onClick={() => context.changeTitleTo('Your Website')}>
Change Title
</button>
</div>
);
}}
</SettingsContext.Consumer>OR
Statically Declare the context provider and use this.context to connect to the provider state
import {SettingsContext} from '../settings/context.js';
class MyComponent extends React.Component {
static contextType = SettingsContext;
render() {
return (
<div>
<h1>{this.context.title}</h1>
<button onClick={() => this.context.changeTitleTo('Your Website')}>
Change Title
</button>
</div>
);
)
}You can also hook into it
import React from 'react';
import faker from 'faker';
import { useContext } from 'react';
import { SettingsContext } from './settings/context';
function Counter() {
const context = useContext(SettingsContext);
return (
<div>
<h2>{context.title}</h2>
<button
type="button"
onClick={() => context.changeTitleTo(faker.company.companyName())}
>
Change Title
</button>
</div>
);
}
export default Counter;What are the problems we are solving for? Is this a valid user? What are they Authorized to do? Token? Role? Lets make this easy to use
<Auth />
based on permissions or login status, it either gives you access to a component or hides it Cannot use Redux
// The div only shows if you are logged in
<Auth>
<div />
</Auth>
// The div only shows if you are logged in AND have read permissions
<Auth capability="read">
<div />
</Auth>NPM react-cookies https://www.npmjs.com/package/react-cookies
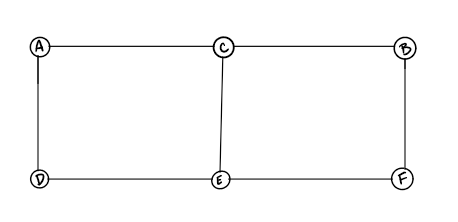
A graph is a non-linear data structure that can be looked at as a collection of vertices (nodes) potentially conected by line segments edges
An undirected graph is where each edge is bi-directional. - does not move in any direction
The undirected graph we are looking at has 6 vertices and 7 undirected edges.
Vertices/Nodes = {a,b,c,d,e,f}
Edges = {(a,c),(a,d),(b,c),(b,f),(c,e),(d,e),(e,f)}!(UndirectdGraph)[https://codefellows.github.io/common_curriculum/data_structures_and_algorithms/Code_401/class-35/resources/assets/UndirectedGraph.PNG]
{kind=link}
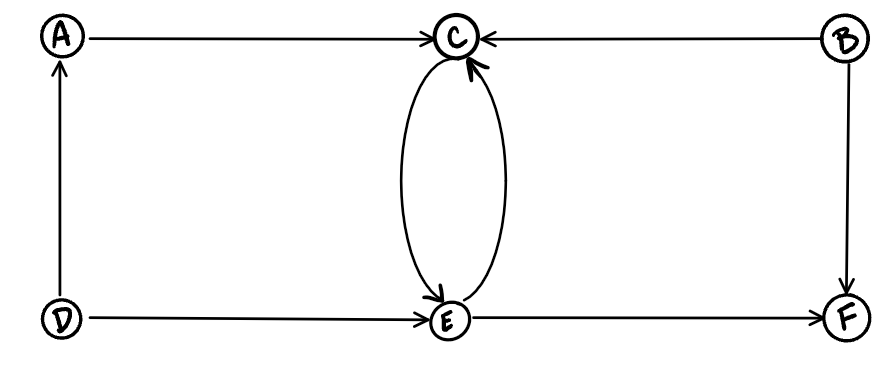
A graph where ever edge is directed.
The directed graph below has six vertices and eight directed edges
Vertices = {a,b,c,d,e,f}
Edges = {(a,c),(b,c),(b,f),(c,e),(d,a),(d,e)(e,c)(e,f)}!(DirectedGraph)[https://codefellows.github.io/common_curriculum/data_structures_and_algorithms/Code_401/class-35/resources/assets/DirectedGraph.PNG]
{kind=link}
The Three main types of graphs are completed, connected and disconnected.
COMPLETE GRAPH
- When all nodes are conected to all other nodes
CONNECTED
- All nodes have at least one edge
DISCONNECTED
- A graph where some vertices may not have edges
We also have Acyclic and Cyclic graphs
- An Acyclic graph is a directed graph without cycles.
- Cycle: A node that can be traversed and potentially end up back at itself.
!(AcyclicGraph)[https://codefellows.github.io/common_curriculum/data_structures_and_algorithms/Code_401/class-35/resources/assets/threeAcyclic.png]
{kind=link}
A Cyclic graph is a graph that has cycles
- A node that can be traversed and potentially end up back at itself.
An Adjacency Matrix
-
An Adjacency matrix is represented through a 2-dimensional array. If there are n vertices, then we are looking at an n x n Boolean matrix
-
Each Row and column represents each vertex of the data structure. The elements of both the column and the row must add up to 1 if there is an edge that connects the two, or zero if there isn’t a connection.
Adjacency List
-
An adjacency list is the most common way to represent graphs. An adjacency list is a collection of linked lists or array that lists all of the other vertices that are connected.
-
Adjacency lists make it easy to view if one vertices connects to another.
ALGORITHM BreadthFirst(vertex)
DECLARE nodes <-- new List()
DECLARE breadth <-- new Queue()
breadth.Enqueue(vertex)
while (breadth is not empty)
DECLARE front <-- breadth.Dequeue()
nodes.Add(front)
for each child in front.Children
if(child is not visited)
child.Visited <-- true
breadth.Enqueue(child)
return nodes;- We have declared that our starting
node(or root) is going to be Node A. - The first thing we want to do is
Enqueuetheroot - Next, we enter a
while loop. We want this loop to keep running until there are no more nodes in our queue. - Once we are in the while loop, we want to
Dequeuethe front node and then check to see if it has anychildren. - if there are
childrenof the node we are currently looking at, we want to mark each one as“visited”. By marking each child node as visited, this will help us know that we have already seen that node before, and won’t accidently push us into an infinite loop if the graph was cyclic. In addition to marking each child node as visited, we want to place any of its children that have not yet been visited into thequeue. - The process will complete until the queue is empty.
- Once the while loop breaks, we can then return the
order list. This order list will contain, in order, of all thenodesthat we traversed too.- DOES NOT TRAVERSE ISLANDS!
DEPTH FIRST ALGORITHM
Push the root node into the stack
Start a while loop while the stack is not empty
Peek at the top node in the stack
If the top node has unvisited children, mark the top node as visited, and then Push any unvisited children back into the stack.
If the top node does not have any unvisited children, Pop that node off the stack
Repeat until the stack is empty.Real World use of graphs
- GPS and Mapping
- Driving Directions
- Social Networks
- Airline Traffic
- Netflix uses graphs for suggestions of products
Redux rewuires a combination of 3 different aspects into a Store that all components can access
- State
- Reducers (strategies to alter state)
- Actions (mehotds that get run with associated triggers)
store - where the application state is stored
Shopping Cart
let initialState = { customerId: null, items: [] };
const myReducer = (state = initialState, action) => {
let { type, payload } = action;
switch (type) {
case 'INITIALIZE':
return {customerId: payload.id};
case 'ADD_ITEM':
return { items: [...items, payload.item] };
case 'CLEAR':
return initialState;
default:
return state;
}
};Redux applications dispatch actions with payloads
Bring in the methods
import React from 'react';
import { connect } from 'react-redux';
import * as actions from '../store/actions.js';
class App extends React.Component {
constructor(props) {
super(props);
}
render() {
return (
<button onClick={this.props.initializeTheCart}>
Start Shopping!
</button>
);
}
}
const mapStateToProps = state => ({
cart: state.cart,
});
const mapDispatchToProps = (dispatch, getState) => ({
initializeTheCart: () => dispatch(actions.newCart()),
});
export default connect(
mapStateToProps,
mapDispatchToProps,
)(App);Connect to State
import React from 'react';
import ReactDOM from 'react-dom';
import { Provider } from 'react-redux';
import './style.scss';
import App from './components/app';
import createStore from './store';
const store = createStore();
class Main extends React.Component {
render() {
return (
<Provider store={store}>
<React.Fragment>
<App />
</React.Fragment>
</Provider>
);
}
}
const rootElement = document.getElementById('root');
ReactDOM.render(<Main />, rootElement);Combining reducers is no more than pulling in more than one reducer and creating a keyed object from them
import todoReducer from './todo.store.js';
import itemReducer from './item.store.js';
let reducers = combineReducers({
todo: todoReducer,
item: itemReducer,
});Once combined, any component can reach into the store and get either one, both or all of the reducers
import * as actions from "../../store/todo.store.js";
import * as itemActions from "../../store/item.store.js";
const mapStateToProps = state => ({
todo: state.todo,
item: state.item,
});
const mapDispatchToProps = (dispatch, getState) => ({
deleteItem: id => dispatch(actions.deleteItem(id)),
hideDetails: id => dispatch(itemActions.hideDetails()),
});Why? Each reducer should really only have 1 part of the state to manage
- Is this more work/boilerplate? Yes.
- Does it allow you decouple logic? Yes.
This will RESET both reducers if a single response is sent
// counter.store.js
export default function reducer (state = initialState, action) {
switch (action.type) {
case 'INCREMENT':
return { value: state.value + 1 }
case 'RESET':
return {value:0};
default:
return state;
}
}
//history.store.js
export default function reducer (state = initialState, action) {
switch (action.type) {
case 'CLICK':
return { clicks: state.clicks + 1 }
case 'RESET':
return {clicks:0};
default:
return state;
}
}Reading
- Thunking!
This is what redux expects and requires when we get
let api = 'https://api.mockable.io/api/v1/stuff';
export const get = () => dispatch => {
return utils.fetchData(api).then(records => {
dispatch(getAction(records));
});
};
const getAction = payload => {
return {
type: 'GET',
payload: payload,
};
};Thunk inspects every action and then either lets it go through or it processes the function and then dispatches the return
Thunk Middleware
export default store => next => action =>
typeof action === 'function'
? action(store.dispatch, store.getState)
: next(action);In Redux, middleware is implemented as a curried function that ultimately evaluates the action and determines whether its a funcion or not.
- If it is, it gets inviked with the dispatch() and getState() methods
- If not, it runs the action.
Redux is great but it is a lot of boilerplate that just does 'magic'
- BUT every company has a different way to do Directory Names, reducer/action styles, and how you model data in the reducers
Redux Toolkit introduces and 'Batteries Included and Highly Opinionated' framework for making actions and reducers
const postsSlice = createSlice({
name: ‘posts’,
initialState: [],
reducers: { createPost(state, action) {},
updatePost(state, action) {},
deletePost(state, action) {}
}
})
// Extract the action creators object and the reducer
const { actions, reducer } = postsSlice
// Extract and export each action creator by name export
const { createPost, updatePost, deletePost } = actions
// Export the reducer, either as a default or named export export default reducer
// ————— Sample Use ————– //
console.log(createPost({ id: 123, title: ‘Hello World’ }))
// {type : “posts/createPost”, payload : {id : 123, title : “Hello World”}}
// Notice how createSlice transforms your definition?
console.log(postsSlice)
/* { name: ‘posts’, actions : { createPost, updatePost, deletePost, }, reducer } */Create-React-App
- generates html code needed to be rendered on the client side.
- pre rendered source code is a few lines of js and an empty div
- jsx injects the content in the div on the browser side.
Next.js is similar to CRA except that it injects the html server side.
- the browser recieves pre-rendered html code
Gatsby is a 'static site generator'
- injects html in the build process
-
Gatsby just generates pure HTML/CSS/JS. This means you can host it at S3, Netlify or other static hosting services. This makes it extremely scalable to high traffic loads.
-
Next creates HTML on runtime. So each time a new request comes in, it creates a new HTML page from the server.