-
Notifications
You must be signed in to change notification settings - Fork 2
/
1_DomainAdaptation.py
206 lines (147 loc) · 6.64 KB
/
1_DomainAdaptation.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
# coding: utf-8
# # Domain Adaptation between digits
#
# #### *Rémi Flamary, Nicolas Courty*
#
# In this practical session we will apply on digit classification the OT based domain adaptation method proposed in
#
# N. Courty, R. Flamary, D. Tuia, A. Rakotomamonjy, "[Optimal transport for domain adaptation](http://remi.flamary.com/biblio/courty2016optimal.pdf)", Pattern Analysis and Machine Intelligence, IEEE Transactions on , 2016.
#
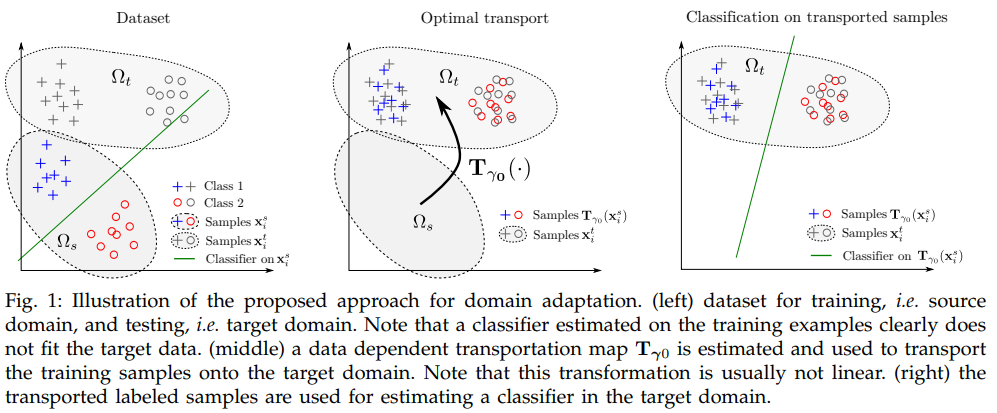
# 
#
# To this end we will try and adapt between the MNIST and USPS datasets. Since those datasets do not have the same resolution (28x28 and 16x16 for MNSIT and USPS) we perform a zeros padding of the USPS digits
#
#
#%% #### Import modules
#
# First we import the relevant modules. Note that you will need ```sklearn``` to learn the Support Vector Machine cleassifier and to projet the data with TSNE.
#
# In[1]:
import numpy as np # always need it
import pylab as pl # do the plots
from sklearn.svm import SVC
from sklearn.manifold import TSNE
import ot
#%% ### Loading data and normalization
#
# We load the data in memory and perform a normalization of the images so that they all sum to 1.
#
# Note that every line in the ```xs``` and ```xt``` is a 28x28 image.
# In[2]:
data=np.load('data/mnist_usps.npz')
xs,ys=data['xs'],data['ys']
xt,yt=data['xt'],data['yt']
# normalization
xs=xs/xs.sum(1,keepdims=True) # every l
xt=xt/xt.sum(1,keepdims=True)
ns=xs.shape[0]
nt=xt.shape[0]
#%% ### Vizualizing Source (MNIST) and Target (USPS) datasets
#
#
#
#
# In[3]:
# function for plotting images
def plot_image(x):
pl.imshow(x.reshape((28,28)),cmap='gray')
pl.xticks(())
pl.yticks(())
nb=10
# Fisrt we plot MNIST
pl.figure(1,(nb,nb))
for i in range(nb*nb):
pl.subplot(nb,nb,1+i)
c=i%nb
plot_image(xs[np.where(ys==c)[0][i//nb],:])
pl.gcf().suptitle("MNIST", fontsize=20);
pl.gcf().subplots_adjust(top=0.95)
# Then we plot USPS
pl.figure(2,(nb,nb))
for i in range(nb*nb):
pl.subplot(nb,nb,1+i)
c=i%nb
plot_image(xt[np.where(yt==c)[0][i//nb],:])
pl.gcf().suptitle("USPS", fontsize=20);
pl.gcf().subplots_adjust(top=0.95)
# Note that there is a large discrepancy especially between the 1,2 and 5 that have differnt shapes in both datasets.
#
# Also since we have performe zero padding on the USPS digits theyr are in average slightly smaller than NMSIT that can take the whole image.
#
#
#%% ### Classification without domain adaptation
#
# We learn a classifier on the MNIST dataset (we will not be state of the art on 1000 samples). We evaluate this claddifier on MNIST and on the USPS dataset.
# In[4]:
# Train SVM with reg parameter C=1 and RBF kernel parameter gamma=1e1
clf=SVC(C=1,gamma=1e2) # might take time
clf.fit(xs,ys)
# Compute accuracy
ACC_MNIST=clf.score(xs,ys) # beware of overfitting !
ACC_USPS=clf.score(xt,yt)
print('ACC_MNIST={:1.3f}'.format(ACC_MNIST))
print('ACC_USPS={:1.3f}'.format(ACC_USPS))
#%% There is a very large loss in performances. This can be better explained by performning a TSNE embedding on the data.
#
# ### TSNE of the Source/Target domains
#
# [t-distributed stochastic neighbor embedding (TSNE)](http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf) is a well knwn approch that allow projection of complex high dimensionnal data in a lower dimensionnal space while keeping its structure.
#
#
# In[5]:
xtot=np.concatenate((xs,xt),axis=0) # all data
xp=TSNE().fit_transform(xtot) # this maigh take a while (30 sec on my laptop)
# separate again but now in 2D
xps=xp[:ns,:]
xpt=xp[ns:,:]
# In[6]:
pl.figure(3,(12,10))
pl.scatter(xps[:,0],xps[:,1],c=ys,marker='o',cmap='tab10',label='Source data')
pl.scatter(xpt[:,0],xpt[:,1],c=yt,marker='+',cmap='tab10',label='Target data')
pl.legend()
pl.colorbar()
pl.title('TSNE Embedding of the Source/Target data');
# We can see that while the classes are relatively well clustured, the clusters from source and target dataset rarely overlapp. This is the main reason for the important loss in performance between Source and target.
#
#%% ### Optimal Transport Domain Adaptation (OTDA)
#
# Now we perform domain adaptation with the following 3 steps illustrated at the top of the notebook:
#
# 1. Compute the OT matrix betxeen source and target datasets
# 1. Perform OT mapping with barycentric mapping (```np.dot```).
# 1. Estimate classifier on the mapped source samples
#
# #### 1. OT between domain
#
# First we compute the Cost matrix and vizualize it. Note that the sampels are sorted by class in both source and target domains in order to better see the class based structure in the cost matrix and OT matrix.
#
#
#
# We can clearly see the (noisy) structure in the matrix. It is also interesting to note that the class 1 in usps (second column) is particularly different fromm all the other classes in MNIST data (even class 1).
#
#
#%% Next we compute the OT matrix using exact LP OT [ot.emd](http://pot.readthedocs.io/en/stable/all.html#ot.emd) or regularized OT with [ot.sinkhorn](http://pot.readthedocs.io/en/stable/all.html#ot.sinkhorn).
# We can see that most of the trasportation is done in the block-diagonal which means that in average samples from one class are affected to the proper classs in the target.
#
#%% #### 2/3 Mapping + Classification
#
# Now we perform the barycentric mapping of the samples and traing the classifier on the mapped samples. We recomend to use a smaller ```gamma=1e1``` here because some samples will be mislabeled and a smooth classifier will work better.
# We can see that the adaptation with EMD leads to a performance gain of nearly 10%. You can get even better performances using entropic regularized OT or group lasso regularization.
#
#%% #### TNSE vizualization for OTDA
#
# In order to see the effect of the adaptation we can perform a new TSNE embedding to see if the classes are betetr aligned.
#
#
# In[ ]:
# We can see that when using emd solver the OT matrix is a permutation wo the samples are exactly superimposed. In average the classes are also well transported but there exist a number of badly transported samples that have a class permutation.
#
#
#%% #### Transported sampels vizualization
#
# We can now also plot the transported samples.
# Those are the same MNIST samples that have been plotted above but after trasnportation. There are several samples that are transported on the wrong class but again in average the class information is preserved which explain the accuracy gain.
#
#%% ### OTDA with regularization
#
# We now recomend to try regularized OT and to redo classification/TSNE/Vizu to see the impact of the regularization in term of performances, TNSE and transported samples.