'
-api_key = encoder.request_api_key(username, email)
-
-# Index in 1 line of code
-items = ['dogs', 'toilet', 'paper', 'enjoy walking']
-encoder.add_documents(user, api_key, items)
-
-# Search in 1 line of code and get the most similar results.
-encoder.search('basin')
-```
-
-Add metadata to your search (information about your vectors)
-
-```
-# Add the number of letters of each word
-metadata = [7, 6, 5, 12]
-encoder.add_documents(user, api_key, items=items, metadata=metadata)
-```
-
-#### Using a document-orientated-approach instead:
-
-```
-from vectorhub.encoders.text import Transformer2Vec
-encoder = Transformer2Vec('bert-base-uncased')
-
-from vectorai import ViClient
-vi_client = ViClient(username, api_key)
-docs = vi_client.create_sample_documents(10)
-vi_client.insert_documents('collection_name_here', docs, models={'color': encoder.encode})
-
-# Now we can search through our collection
-vi_client.search('collection_name_here', field='color_vector_', vector=encoder.encode('purple'))
-```
-
----
-
-### Easily access information with your model!
-
-```
-# If you want to additional information about the model, you can access the information below:
-text_encoder.definition.repo
-text_encoder.definition.description
-# If you want all the information in a dictionary, you can call:
-text_encoder.definition.create_dict() # returns a dictionary with model id, description, paper, etc.
-```
-
----
-
-### Turn Off Error-Catching
-
-By default, if encoding errors, it returns a vector filled with 1e-7 so that if you are encoding and then inserting then it errors out.
-However, if you want to turn off automatic error-catching in VectorHub, simply run:
-
-```
-import vectorhub
-vectorhub.options.set_option('catch_vector_errors', False)
-```
-
-If you want to turn it back on again, run:
-```
-vectorhub.options.set_option('catch_vector_errors', True)
-```
-
----
-
-### Instantiate our auto_encoder class as such and use any of the models!
-
-```
-from vectorhub.auto_encoder import AutoEncoder
-encoder = AutoEncoder.from_model('text/bert')
-encoder.encode("Hello vectorhub!")
-[0.47, 0.83, 0.148, ...]
-```
-
-You can choose from our list of models:
-```
-['text/albert', 'text/bert', 'text/labse', 'text/use', 'text/use-multi', 'text/use-lite', 'text/legal-bert', 'audio/fairseq', 'audio/speech-embedding', 'audio/trill', 'audio/trill-distilled', 'audio/vggish', 'audio/yamnet', 'audio/wav2vec', 'image/bit', 'image/bit-medium', 'image/inception', 'image/inception-v2', 'image/inception-v3', 'image/inception-resnet', 'image/mobilenet', 'image/mobilenet-v2', 'image/resnet', 'image/resnet-v2', 'qa/use-multi-qa', 'qa/use-qa', 'qa/dpr', 'qa/lareqa-qa']
-```
-## What are Vectors?
-Common Terminologys when operating with Vectors:
-- Vectors (aka. Embeddings, Encodings, Neural Representation) ~ It is a list of numbers to represent a piece of data.
- E.g. the vector for the word "king" using a Word2Vec model is [0.47, 0.83, 0.148, ...]
-- ____2Vec (aka. Models, Encoders, Embedders) ~ Turns data into vectors e.g. Word2Vec turns words into vector
-
-
-
-
-
-### How can I use vectors?
-
-Vectors have a broad range of applications. The most common use case is to perform semantic vector search and analysing the topics/clusters using vector analytics.
-
-If you are interested in these applications, take a look at [Vector AI](https://github.com/vector-ai/vectorai).
-
-### How can I obtain vectors?
-- Taking the outputs of layers from deep learning models
-- Data cleaning, such as one hot encoding labels
-- Converting graph representations to vectors
-
-### How To Upload Your 2Vec Model
-
-[Read here if you would like to contribute your model!](https://vector-ai.github.io/vectorhub/how_to_add_a_model.html)
-
-## Philosophy
-
-The goal of VectorHub is to provide a flexible yet comprehensive framework that allows people to easily be able to turn their data into vectors in whatever form the data can be in. While our focus is largely on simplicity, customisation should always be an option and the level of abstraction is always up model-uploader as long as the reason is justified. For example - with text, we chose to keep the encoding at the text level as opposed to the token level because selection of text should not be applied at the token level so practitioners are aware of what texts go into the actual vectors (i.e. instead of ignoring a '[next][SEP][wo][##rd]', we are choosing to ignore 'next word' explicitly. We think this will allow practitioners to focus better on what should matter when it comes to encoding.
-
-Similarly, when we are turning data into vectors, we convert to native Python objects. The decision for this is to attempt to remove as many dependencies as possible once the vectors are created - specifically those of deep learning frameworks such as Tensorflow/PyTorch. This is to allow other frameworks to be built on top of it.
-
-## Team
-
-This library is maintained by the Relevance AI - your go-to solution for data science tooling with tvectors. If you are interested in using our API for vector search, visit https://relevance.ai or if you are interested in using API, check out https://relevance.ai its free for public research and open source.
-
-### Credit:
-
-This library wouldn't exist if it weren't for the following libraries and the incredible machine learning community that releases their state-of-the-art models:
+This repository was first set up by RelevanceAI - a platform to build and deploy AI apps and agents.
-1. https://github.com/huggingface/transformers
-2. https://github.com/tensorflow/hub
-3. https://github.com/pytorch/pytorch
-4. Word2Vec image - Alammar, Jay (2018). The Illustrated Transformer [Blog post]. Retrieved from https://jalammar.github.io/illustrated-transformer/
-5. https://github.com/UKPLab/sentence-transformers
+VectorHub is a free and open-source educational platform to learn how to build information retrieval and feature engineering powered by vector embeddings. VectorHub is community-led and maintained by Superlinked - an open-source compute framework , focused on turning complex data into vector embeddings.
diff --git a/assets/monthly_downloads.svg b/assets/monthly_downloads.svg
deleted file mode 100644
index 335c456f..00000000
--- a/assets/monthly_downloads.svg
+++ /dev/null
@@ -1 +0,0 @@
-Monthly Downloads Monthly Downloads 10965 10965 Total Downloads Total Downloads 98552 98552 Weekly Downloads Weekly Downloads 2661 2661
-
-Created by FontForge 20120731 at Mon Oct 24 17:37:40 2016
- By ,,,
-Copyright Dave Gandy 2016. All rights reserved.
-
-
-
-
-
diff --git a/docs/_static/css/fonts/fontawesome-webfont.ttf b/docs/_static/css/fonts/fontawesome-webfont.ttf
deleted file mode 100644
index 35acda2f..00000000
Binary files a/docs/_static/css/fonts/fontawesome-webfont.ttf and /dev/null differ
diff --git a/docs/_static/css/fonts/fontawesome-webfont.woff b/docs/_static/css/fonts/fontawesome-webfont.woff
deleted file mode 100644
index 400014a4..00000000
Binary files a/docs/_static/css/fonts/fontawesome-webfont.woff and /dev/null differ
diff --git a/docs/_static/css/fonts/fontawesome-webfont.woff2 b/docs/_static/css/fonts/fontawesome-webfont.woff2
deleted file mode 100644
index 4d13fc60..00000000
Binary files a/docs/_static/css/fonts/fontawesome-webfont.woff2 and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-bold-italic.woff b/docs/_static/css/fonts/lato-bold-italic.woff
deleted file mode 100644
index 88ad05b9..00000000
Binary files a/docs/_static/css/fonts/lato-bold-italic.woff and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-bold-italic.woff2 b/docs/_static/css/fonts/lato-bold-italic.woff2
deleted file mode 100644
index c4e3d804..00000000
Binary files a/docs/_static/css/fonts/lato-bold-italic.woff2 and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-bold.woff b/docs/_static/css/fonts/lato-bold.woff
deleted file mode 100644
index c6dff51f..00000000
Binary files a/docs/_static/css/fonts/lato-bold.woff and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-bold.woff2 b/docs/_static/css/fonts/lato-bold.woff2
deleted file mode 100644
index bb195043..00000000
Binary files a/docs/_static/css/fonts/lato-bold.woff2 and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-normal-italic.woff b/docs/_static/css/fonts/lato-normal-italic.woff
deleted file mode 100644
index 76114bc0..00000000
Binary files a/docs/_static/css/fonts/lato-normal-italic.woff and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-normal-italic.woff2 b/docs/_static/css/fonts/lato-normal-italic.woff2
deleted file mode 100644
index 3404f37e..00000000
Binary files a/docs/_static/css/fonts/lato-normal-italic.woff2 and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-normal.woff b/docs/_static/css/fonts/lato-normal.woff
deleted file mode 100644
index ae1307ff..00000000
Binary files a/docs/_static/css/fonts/lato-normal.woff and /dev/null differ
diff --git a/docs/_static/css/fonts/lato-normal.woff2 b/docs/_static/css/fonts/lato-normal.woff2
deleted file mode 100644
index 3bf98433..00000000
Binary files a/docs/_static/css/fonts/lato-normal.woff2 and /dev/null differ
diff --git a/docs/_static/css/theme.css b/docs/_static/css/theme.css
deleted file mode 100644
index 8cd4f101..00000000
--- a/docs/_static/css/theme.css
+++ /dev/null
@@ -1,4 +0,0 @@
-html{box-sizing:border-box}*,:after,:before{box-sizing:inherit}article,aside,details,figcaption,figure,footer,header,hgroup,nav,section{display:block}audio,canvas,video{display:inline-block;*display:inline;*zoom:1}[hidden],audio:not([controls]){display:none}*{-webkit-box-sizing:border-box;-moz-box-sizing:border-box;box-sizing:border-box}html{font-size:100%;-webkit-text-size-adjust:100%;-ms-text-size-adjust:100%}body{margin:0}a:active,a:hover{outline:0}abbr[title]{border-bottom:1px dotted}b,strong{font-weight:700}blockquote{margin:0}dfn{font-style:italic}ins{background:#ff9;text-decoration:none}ins,mark{color:#000}mark{background:#ff0;font-style:italic;font-weight:700}.rst-content code,.rst-content tt,code,kbd,pre,samp{font-family:monospace,serif;_font-family:courier new,monospace;font-size:1em}pre{white-space:pre}q{quotes:none}q:after,q:before{content:"";content:none}small{font-size:85%}sub,sup{font-size:75%;line-height:0;position:relative;vertical-align:baseline}sup{top:-.5em}sub{bottom:-.25em}dl,ol,ul{margin:0;padding:0;list-style:none;list-style-image:none}li{list-style:none}dd{margin:0}img{border:0;-ms-interpolation-mode:bicubic;vertical-align:middle;max-width:100%}svg:not(:root){overflow:hidden}figure,form{margin:0}label{cursor:pointer}button,input,select,textarea{font-size:100%;margin:0;vertical-align:baseline;*vertical-align:middle}button,input{line-height:normal}button,input[type=button],input[type=reset],input[type=submit]{cursor:pointer;-webkit-appearance:button;*overflow:visible}button[disabled],input[disabled]{cursor:default}input[type=search]{-webkit-appearance:textfield;-moz-box-sizing:content-box;-webkit-box-sizing:content-box;box-sizing:content-box}textarea{resize:vertical}table{border-collapse:collapse;border-spacing:0}td{vertical-align:top}.chromeframe{margin:.2em 0;background:#ccc;color:#000;padding:.2em 0}.ir{display:block;border:0;text-indent:-999em;overflow:hidden;background-color:transparent;background-repeat:no-repeat;text-align:left;direction:ltr;*line-height:0}.ir br{display:none}.hidden{display:none!important;visibility:hidden}.visuallyhidden{border:0;clip:rect(0 0 0 0);height:1px;margin:-1px;overflow:hidden;padding:0;position:absolute;width:1px}.visuallyhidden.focusable:active,.visuallyhidden.focusable:focus{clip:auto;height:auto;margin:0;overflow:visible;position:static;width:auto}.invisible{visibility:hidden}.relative{position:relative}big,small{font-size:100%}@media print{body,html,section{background:none!important}*{box-shadow:none!important;text-shadow:none!important;filter:none!important;-ms-filter:none!important}a,a:visited{text-decoration:underline}.ir a:after,a[href^="#"]:after,a[href^="javascript:"]:after{content:""}blockquote,pre{page-break-inside:avoid}thead{display:table-header-group}img,tr{page-break-inside:avoid}img{max-width:100%!important}@page{margin:.5cm}.rst-content .toctree-wrapper>p.caption,h2,h3,p{orphans:3;widows:3}.rst-content .toctree-wrapper>p.caption,h2,h3{page-break-after:avoid}}.btn,.fa:before,.icon:before,.rst-content .admonition,.rst-content .admonition-title:before,.rst-content .admonition-todo,.rst-content .attention,.rst-content .caution,.rst-content .code-block-caption .headerlink:before,.rst-content .danger,.rst-content .error,.rst-content .hint,.rst-content .important,.rst-content .note,.rst-content .seealso,.rst-content .tip,.rst-content .warning,.rst-content code.download span:first-child:before,.rst-content dl dt .headerlink:before,.rst-content h1 .headerlink:before,.rst-content h2 .headerlink:before,.rst-content h3 .headerlink:before,.rst-content h4 .headerlink:before,.rst-content h5 .headerlink:before,.rst-content h6 .headerlink:before,.rst-content p.caption .headerlink:before,.rst-content table>caption .headerlink:before,.rst-content tt.download span:first-child:before,.wy-alert,.wy-dropdown .caret:before,.wy-inline-validate.wy-inline-validate-danger .wy-input-context:before,.wy-inline-validate.wy-inline-validate-info .wy-input-context:before,.wy-inline-validate.wy-inline-validate-success .wy-input-context:before,.wy-inline-validate.wy-inline-validate-warning .wy-input-context:before,.wy-menu-vertical li.current>a,.wy-menu-vertical li.current>a span.toctree-expand:before,.wy-menu-vertical li.on a,.wy-menu-vertical li.on a span.toctree-expand:before,.wy-menu-vertical li span.toctree-expand:before,.wy-nav-top a,.wy-side-nav-search .wy-dropdown>a,.wy-side-nav-search>a,input[type=color],input[type=date],input[type=datetime-local],input[type=datetime],input[type=email],input[type=month],input[type=number],input[type=password],input[type=search],input[type=tel],input[type=text],input[type=time],input[type=url],input[type=week],select,textarea{-webkit-font-smoothing:antialiased}.clearfix{*zoom:1}.clearfix:after,.clearfix:before{display:table;content:""}.clearfix:after{clear:both}/*!
- * Font Awesome 4.7.0 by @davegandy - http://fontawesome.io - @fontawesome
- * License - http://fontawesome.io/license (Font: SIL OFL 1.1, CSS: MIT License)
- */@font-face{font-family:FontAwesome;src:url(fonts/fontawesome-webfont.eot?674f50d287a8c48dc19ba404d20fe713);src:url(fonts/fontawesome-webfont.eot?674f50d287a8c48dc19ba404d20fe713?#iefix&v=4.7.0) format("embedded-opentype"),url(fonts/fontawesome-webfont.woff2?af7ae505a9eed503f8b8e6982036873e) format("woff2"),url(fonts/fontawesome-webfont.woff?fee66e712a8a08eef5805a46892932ad) format("woff"),url(fonts/fontawesome-webfont.ttf?b06871f281fee6b241d60582ae9369b9) format("truetype"),url(fonts/fontawesome-webfont.svg?912ec66d7572ff821749319396470bde#fontawesomeregular) format("svg");font-weight:400;font-style:normal}.fa,.icon,.rst-content .admonition-title,.rst-content .code-block-caption .headerlink,.rst-content code.download span:first-child,.rst-content dl dt .headerlink,.rst-content h1 .headerlink,.rst-content h2 .headerlink,.rst-content h3 .headerlink,.rst-content h4 .headerlink,.rst-content h5 .headerlink,.rst-content h6 .headerlink,.rst-content p.caption .headerlink,.rst-content table>caption .headerlink,.rst-content tt.download span:first-child,.wy-menu-vertical li.current>a span.toctree-expand,.wy-menu-vertical li.on a span.toctree-expand,.wy-menu-vertical li span.toctree-expand{display:inline-block;font:normal normal normal 14px/1 FontAwesome;font-size:inherit;text-rendering:auto;-webkit-font-smoothing:antialiased;-moz-osx-font-smoothing:grayscale}.fa-lg{font-size:1.33333em;line-height:.75em;vertical-align:-15%}.fa-2x{font-size:2em}.fa-3x{font-size:3em}.fa-4x{font-size:4em}.fa-5x{font-size:5em}.fa-fw{width:1.28571em;text-align:center}.fa-ul{padding-left:0;margin-left:2.14286em;list-style-type:none}.fa-ul>li{position:relative}.fa-li{position:absolute;left:-2.14286em;width:2.14286em;top:.14286em;text-align:center}.fa-li.fa-lg{left:-1.85714em}.fa-border{padding:.2em .25em .15em;border:.08em solid #eee;border-radius:.1em}.fa-pull-left{float:left}.fa-pull-right{float:right}.fa-pull-left.icon,.fa.fa-pull-left,.rst-content .code-block-caption .fa-pull-left.headerlink,.rst-content .fa-pull-left.admonition-title,.rst-content code.download span.fa-pull-left:first-child,.rst-content dl dt .fa-pull-left.headerlink,.rst-content h1 .fa-pull-left.headerlink,.rst-content h2 .fa-pull-left.headerlink,.rst-content h3 .fa-pull-left.headerlink,.rst-content h4 .fa-pull-left.headerlink,.rst-content h5 .fa-pull-left.headerlink,.rst-content h6 .fa-pull-left.headerlink,.rst-content p.caption .fa-pull-left.headerlink,.rst-content table>caption .fa-pull-left.headerlink,.rst-content tt.download span.fa-pull-left:first-child,.wy-menu-vertical li.current>a span.fa-pull-left.toctree-expand,.wy-menu-vertical li.on a span.fa-pull-left.toctree-expand,.wy-menu-vertical li span.fa-pull-left.toctree-expand{margin-right:.3em}.fa-pull-right.icon,.fa.fa-pull-right,.rst-content .code-block-caption .fa-pull-right.headerlink,.rst-content .fa-pull-right.admonition-title,.rst-content code.download span.fa-pull-right:first-child,.rst-content dl dt .fa-pull-right.headerlink,.rst-content h1 .fa-pull-right.headerlink,.rst-content h2 .fa-pull-right.headerlink,.rst-content h3 .fa-pull-right.headerlink,.rst-content h4 .fa-pull-right.headerlink,.rst-content h5 .fa-pull-right.headerlink,.rst-content h6 .fa-pull-right.headerlink,.rst-content p.caption .fa-pull-right.headerlink,.rst-content table>caption .fa-pull-right.headerlink,.rst-content tt.download span.fa-pull-right:first-child,.wy-menu-vertical li.current>a span.fa-pull-right.toctree-expand,.wy-menu-vertical li.on a span.fa-pull-right.toctree-expand,.wy-menu-vertical li span.fa-pull-right.toctree-expand{margin-left:.3em}.pull-right{float:right}.pull-left{float:left}.fa.pull-left,.pull-left.icon,.rst-content .code-block-caption .pull-left.headerlink,.rst-content .pull-left.admonition-title,.rst-content code.download span.pull-left:first-child,.rst-content dl dt .pull-left.headerlink,.rst-content h1 .pull-left.headerlink,.rst-content h2 .pull-left.headerlink,.rst-content h3 .pull-left.headerlink,.rst-content h4 .pull-left.headerlink,.rst-content h5 .pull-left.headerlink,.rst-content h6 .pull-left.headerlink,.rst-content p.caption .pull-left.headerlink,.rst-content table>caption .pull-left.headerlink,.rst-content tt.download span.pull-left:first-child,.wy-menu-vertical li.current>a span.pull-left.toctree-expand,.wy-menu-vertical li.on a span.pull-left.toctree-expand,.wy-menu-vertical li span.pull-left.toctree-expand{margin-right:.3em}.fa.pull-right,.pull-right.icon,.rst-content .code-block-caption .pull-right.headerlink,.rst-content .pull-right.admonition-title,.rst-content code.download span.pull-right:first-child,.rst-content dl dt .pull-right.headerlink,.rst-content h1 .pull-right.headerlink,.rst-content h2 .pull-right.headerlink,.rst-content h3 .pull-right.headerlink,.rst-content h4 .pull-right.headerlink,.rst-content h5 .pull-right.headerlink,.rst-content h6 .pull-right.headerlink,.rst-content p.caption .pull-right.headerlink,.rst-content table>caption .pull-right.headerlink,.rst-content tt.download span.pull-right:first-child,.wy-menu-vertical li.current>a span.pull-right.toctree-expand,.wy-menu-vertical li.on a span.pull-right.toctree-expand,.wy-menu-vertical li span.pull-right.toctree-expand{margin-left:.3em}.fa-spin{-webkit-animation:fa-spin 2s linear infinite;animation:fa-spin 2s linear infinite}.fa-pulse{-webkit-animation:fa-spin 1s steps(8) infinite;animation:fa-spin 1s steps(8) infinite}@-webkit-keyframes fa-spin{0%{-webkit-transform:rotate(0deg);transform:rotate(0deg)}to{-webkit-transform:rotate(359deg);transform:rotate(359deg)}}@keyframes fa-spin{0%{-webkit-transform:rotate(0deg);transform:rotate(0deg)}to{-webkit-transform:rotate(359deg);transform:rotate(359deg)}}.fa-rotate-90{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=1)";-webkit-transform:rotate(90deg);-ms-transform:rotate(90deg);transform:rotate(90deg)}.fa-rotate-180{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=2)";-webkit-transform:rotate(180deg);-ms-transform:rotate(180deg);transform:rotate(180deg)}.fa-rotate-270{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=3)";-webkit-transform:rotate(270deg);-ms-transform:rotate(270deg);transform:rotate(270deg)}.fa-flip-horizontal{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=0, mirror=1)";-webkit-transform:scaleX(-1);-ms-transform:scaleX(-1);transform:scaleX(-1)}.fa-flip-vertical{-ms-filter:"progid:DXImageTransform.Microsoft.BasicImage(rotation=2, mirror=1)";-webkit-transform:scaleY(-1);-ms-transform:scaleY(-1);transform:scaleY(-1)}:root .fa-flip-horizontal,:root .fa-flip-vertical,:root .fa-rotate-90,:root .fa-rotate-180,:root .fa-rotate-270{filter:none}.fa-stack{position:relative;display:inline-block;width:2em;height:2em;line-height:2em;vertical-align:middle}.fa-stack-1x,.fa-stack-2x{position:absolute;left:0;width:100%;text-align:center}.fa-stack-1x{line-height:inherit}.fa-stack-2x{font-size:2em}.fa-inverse{color:#fff}.fa-glass:before{content:""}.fa-music:before{content:""}.fa-search:before,.icon-search:before{content:""}.fa-envelope-o:before{content:""}.fa-heart:before{content:""}.fa-star:before{content:""}.fa-star-o:before{content:""}.fa-user:before{content:""}.fa-film:before{content:""}.fa-th-large:before{content:""}.fa-th:before{content:""}.fa-th-list:before{content:""}.fa-check:before{content:""}.fa-close:before,.fa-remove:before,.fa-times:before{content:""}.fa-search-plus:before{content:""}.fa-search-minus:before{content:""}.fa-power-off:before{content:""}.fa-signal:before{content:""}.fa-cog:before,.fa-gear:before{content:""}.fa-trash-o:before{content:""}.fa-home:before,.icon-home:before{content:""}.fa-file-o:before{content:""}.fa-clock-o:before{content:""}.fa-road:before{content:""}.fa-download:before,.rst-content code.download span:first-child:before,.rst-content tt.download span:first-child:before{content:""}.fa-arrow-circle-o-down:before{content:""}.fa-arrow-circle-o-up:before{content:""}.fa-inbox:before{content:""}.fa-play-circle-o:before{content:""}.fa-repeat:before,.fa-rotate-right:before{content:""}.fa-refresh:before{content:""}.fa-list-alt:before{content:""}.fa-lock:before{content:""}.fa-flag:before{content:""}.fa-headphones:before{content:""}.fa-volume-off:before{content:""}.fa-volume-down:before{content:""}.fa-volume-up:before{content:""}.fa-qrcode:before{content:""}.fa-barcode:before{content:""}.fa-tag:before{content:""}.fa-tags:before{content:""}.fa-book:before,.icon-book:before{content:""}.fa-bookmark:before{content:""}.fa-print:before{content:""}.fa-camera:before{content:""}.fa-font:before{content:""}.fa-bold:before{content:""}.fa-italic:before{content:""}.fa-text-height:before{content:""}.fa-text-width:before{content:""}.fa-align-left:before{content:""}.fa-align-center:before{content:""}.fa-align-right:before{content:""}.fa-align-justify:before{content:""}.fa-list:before{content:""}.fa-dedent:before,.fa-outdent:before{content:""}.fa-indent:before{content:""}.fa-video-camera:before{content:""}.fa-image:before,.fa-photo:before,.fa-picture-o:before{content:""}.fa-pencil:before{content:""}.fa-map-marker:before{content:""}.fa-adjust:before{content:""}.fa-tint:before{content:""}.fa-edit:before,.fa-pencil-square-o:before{content:""}.fa-share-square-o:before{content:""}.fa-check-square-o:before{content:""}.fa-arrows:before{content:""}.fa-step-backward:before{content:""}.fa-fast-backward:before{content:""}.fa-backward:before{content:""}.fa-play:before{content:""}.fa-pause:before{content:""}.fa-stop:before{content:""}.fa-forward:before{content:""}.fa-fast-forward:before{content:""}.fa-step-forward:before{content:""}.fa-eject:before{content:""}.fa-chevron-left:before{content:""}.fa-chevron-right:before{content:""}.fa-plus-circle:before{content:""}.fa-minus-circle:before{content:""}.fa-times-circle:before,.wy-inline-validate.wy-inline-validate-danger .wy-input-context:before{content:""}.fa-check-circle:before,.wy-inline-validate.wy-inline-validate-success .wy-input-context:before{content:""}.fa-question-circle:before{content:""}.fa-info-circle:before{content:""}.fa-crosshairs:before{content:""}.fa-times-circle-o:before{content:""}.fa-check-circle-o:before{content:""}.fa-ban:before{content:""}.fa-arrow-left:before{content:""}.fa-arrow-right:before{content:""}.fa-arrow-up:before{content:""}.fa-arrow-down:before{content:""}.fa-mail-forward:before,.fa-share:before{content:""}.fa-expand:before{content:""}.fa-compress:before{content:""}.fa-plus:before{content:""}.fa-minus:before{content:""}.fa-asterisk:before{content:""}.fa-exclamation-circle:before,.rst-content .admonition-title:before,.wy-inline-validate.wy-inline-validate-info .wy-input-context:before,.wy-inline-validate.wy-inline-validate-warning .wy-input-context:before{content:""}.fa-gift:before{content:""}.fa-leaf:before{content:""}.fa-fire:before,.icon-fire:before{content:""}.fa-eye:before{content:""}.fa-eye-slash:before{content:""}.fa-exclamation-triangle:before,.fa-warning:before{content:""}.fa-plane:before{content:""}.fa-calendar:before{content:""}.fa-random:before{content:""}.fa-comment:before{content:""}.fa-magnet:before{content:""}.fa-chevron-up:before{content:""}.fa-chevron-down:before{content:""}.fa-retweet:before{content:""}.fa-shopping-cart:before{content:""}.fa-folder:before{content:""}.fa-folder-open:before{content:""}.fa-arrows-v:before{content:""}.fa-arrows-h:before{content:""}.fa-bar-chart-o:before,.fa-bar-chart:before{content:""}.fa-twitter-square:before{content:""}.fa-facebook-square:before{content:""}.fa-camera-retro:before{content:""}.fa-key:before{content:""}.fa-cogs:before,.fa-gears:before{content:""}.fa-comments:before{content:""}.fa-thumbs-o-up:before{content:""}.fa-thumbs-o-down:before{content:""}.fa-star-half:before{content:""}.fa-heart-o:before{content:""}.fa-sign-out:before{content:""}.fa-linkedin-square:before{content:""}.fa-thumb-tack:before{content:""}.fa-external-link:before{content:""}.fa-sign-in:before{content:""}.fa-trophy:before{content:""}.fa-github-square:before{content:""}.fa-upload:before{content:""}.fa-lemon-o:before{content:""}.fa-phone:before{content:""}.fa-square-o:before{content:""}.fa-bookmark-o:before{content:""}.fa-phone-square:before{content:""}.fa-twitter:before{content:""}.fa-facebook-f:before,.fa-facebook:before{content:""}.fa-github:before,.icon-github:before{content:""}.fa-unlock:before{content:""}.fa-credit-card:before{content:""}.fa-feed:before,.fa-rss:before{content:""}.fa-hdd-o:before{content:""}.fa-bullhorn:before{content:""}.fa-bell:before{content:""}.fa-certificate:before{content:""}.fa-hand-o-right:before{content:""}.fa-hand-o-left:before{content:""}.fa-hand-o-up:before{content:""}.fa-hand-o-down:before{content:""}.fa-arrow-circle-left:before,.icon-circle-arrow-left:before{content:""}.fa-arrow-circle-right:before,.icon-circle-arrow-right:before{content:""}.fa-arrow-circle-up:before{content:""}.fa-arrow-circle-down:before{content:""}.fa-globe:before{content:""}.fa-wrench:before{content:""}.fa-tasks:before{content:""}.fa-filter:before{content:""}.fa-briefcase:before{content:""}.fa-arrows-alt:before{content:""}.fa-group:before,.fa-users:before{content:""}.fa-chain:before,.fa-link:before,.icon-link:before{content:""}.fa-cloud:before{content:""}.fa-flask:before{content:""}.fa-cut:before,.fa-scissors:before{content:""}.fa-copy:before,.fa-files-o:before{content:""}.fa-paperclip:before{content:""}.fa-floppy-o:before,.fa-save:before{content:""}.fa-square:before{content:""}.fa-bars:before,.fa-navicon:before,.fa-reorder:before{content:""}.fa-list-ul:before{content:""}.fa-list-ol:before{content:""}.fa-strikethrough:before{content:""}.fa-underline:before{content:""}.fa-table:before{content:""}.fa-magic:before{content:""}.fa-truck:before{content:""}.fa-pinterest:before{content:""}.fa-pinterest-square:before{content:""}.fa-google-plus-square:before{content:""}.fa-google-plus:before{content:""}.fa-money:before{content:""}.fa-caret-down:before,.icon-caret-down:before,.wy-dropdown .caret:before{content:""}.fa-caret-up:before{content:""}.fa-caret-left:before{content:""}.fa-caret-right:before{content:""}.fa-columns:before{content:""}.fa-sort:before,.fa-unsorted:before{content:""}.fa-sort-desc:before,.fa-sort-down:before{content:""}.fa-sort-asc:before,.fa-sort-up:before{content:""}.fa-envelope:before{content:""}.fa-linkedin:before{content:""}.fa-rotate-left:before,.fa-undo:before{content:""}.fa-gavel:before,.fa-legal:before{content:""}.fa-dashboard:before,.fa-tachometer:before{content:""}.fa-comment-o:before{content:""}.fa-comments-o:before{content:""}.fa-bolt:before,.fa-flash:before{content:""}.fa-sitemap:before{content:""}.fa-umbrella:before{content:""}.fa-clipboard:before,.fa-paste:before{content:""}.fa-lightbulb-o:before{content:""}.fa-exchange:before{content:""}.fa-cloud-download:before{content:""}.fa-cloud-upload:before{content:""}.fa-user-md:before{content:""}.fa-stethoscope:before{content:""}.fa-suitcase:before{content:""}.fa-bell-o:before{content:""}.fa-coffee:before{content:""}.fa-cutlery:before{content:""}.fa-file-text-o:before{content:""}.fa-building-o:before{content:""}.fa-hospital-o:before{content:""}.fa-ambulance:before{content:""}.fa-medkit:before{content:""}.fa-fighter-jet:before{content:""}.fa-beer:before{content:""}.fa-h-square:before{content:""}.fa-plus-square:before{content:""}.fa-angle-double-left:before{content:""}.fa-angle-double-right:before{content:""}.fa-angle-double-up:before{content:""}.fa-angle-double-down:before{content:""}.fa-angle-left:before{content:""}.fa-angle-right:before{content:""}.fa-angle-up:before{content:""}.fa-angle-down:before{content:""}.fa-desktop:before{content:""}.fa-laptop:before{content:""}.fa-tablet:before{content:""}.fa-mobile-phone:before,.fa-mobile:before{content:""}.fa-circle-o:before{content:""}.fa-quote-left:before{content:""}.fa-quote-right:before{content:""}.fa-spinner:before{content:""}.fa-circle:before{content:""}.fa-mail-reply:before,.fa-reply:before{content:""}.fa-github-alt:before{content:""}.fa-folder-o:before{content:""}.fa-folder-open-o:before{content:""}.fa-smile-o:before{content:""}.fa-frown-o:before{content:""}.fa-meh-o:before{content:""}.fa-gamepad:before{content:""}.fa-keyboard-o:before{content:""}.fa-flag-o:before{content:""}.fa-flag-checkered:before{content:""}.fa-terminal:before{content:""}.fa-code:before{content:""}.fa-mail-reply-all:before,.fa-reply-all:before{content:""}.fa-star-half-empty:before,.fa-star-half-full:before,.fa-star-half-o:before{content:""}.fa-location-arrow:before{content:""}.fa-crop:before{content:""}.fa-code-fork:before{content:""}.fa-chain-broken:before,.fa-unlink:before{content:""}.fa-question:before{content:""}.fa-info:before{content:""}.fa-exclamation:before{content:""}.fa-superscript:before{content:""}.fa-subscript:before{content:""}.fa-eraser:before{content:""}.fa-puzzle-piece:before{content:""}.fa-microphone:before{content:""}.fa-microphone-slash:before{content:""}.fa-shield:before{content:""}.fa-calendar-o:before{content:""}.fa-fire-extinguisher:before{content:""}.fa-rocket:before{content:""}.fa-maxcdn:before{content:""}.fa-chevron-circle-left:before{content:""}.fa-chevron-circle-right:before{content:""}.fa-chevron-circle-up:before{content:""}.fa-chevron-circle-down:before{content:""}.fa-html5:before{content:""}.fa-css3:before{content:""}.fa-anchor:before{content:""}.fa-unlock-alt:before{content:""}.fa-bullseye:before{content:""}.fa-ellipsis-h:before{content:""}.fa-ellipsis-v:before{content:""}.fa-rss-square:before{content:""}.fa-play-circle:before{content:""}.fa-ticket:before{content:""}.fa-minus-square:before{content:""}.fa-minus-square-o:before,.wy-menu-vertical li.current>a span.toctree-expand:before,.wy-menu-vertical li.on a span.toctree-expand:before{content:""}.fa-level-up:before{content:""}.fa-level-down:before{content:""}.fa-check-square:before{content:""}.fa-pencil-square:before{content:""}.fa-external-link-square:before{content:""}.fa-share-square:before{content:""}.fa-compass:before{content:""}.fa-caret-square-o-down:before,.fa-toggle-down:before{content:""}.fa-caret-square-o-up:before,.fa-toggle-up:before{content:""}.fa-caret-square-o-right:before,.fa-toggle-right:before{content:""}.fa-eur:before,.fa-euro:before{content:""}.fa-gbp:before{content:""}.fa-dollar:before,.fa-usd:before{content:""}.fa-inr:before,.fa-rupee:before{content:""}.fa-cny:before,.fa-jpy:before,.fa-rmb:before,.fa-yen:before{content:""}.fa-rouble:before,.fa-rub:before,.fa-ruble:before{content:""}.fa-krw:before,.fa-won:before{content:""}.fa-bitcoin:before,.fa-btc:before{content:""}.fa-file:before{content:""}.fa-file-text:before{content:""}.fa-sort-alpha-asc:before{content:""}.fa-sort-alpha-desc:before{content:""}.fa-sort-amount-asc:before{content:""}.fa-sort-amount-desc:before{content:""}.fa-sort-numeric-asc:before{content:""}.fa-sort-numeric-desc:before{content:""}.fa-thumbs-up:before{content:""}.fa-thumbs-down:before{content:""}.fa-youtube-square:before{content:""}.fa-youtube:before{content:""}.fa-xing:before{content:""}.fa-xing-square:before{content:""}.fa-youtube-play:before{content:""}.fa-dropbox:before{content:""}.fa-stack-overflow:before{content:""}.fa-instagram:before{content:""}.fa-flickr:before{content:""}.fa-adn:before{content:""}.fa-bitbucket:before,.icon-bitbucket:before{content:""}.fa-bitbucket-square:before{content:""}.fa-tumblr:before{content:""}.fa-tumblr-square:before{content:""}.fa-long-arrow-down:before{content:""}.fa-long-arrow-up:before{content:""}.fa-long-arrow-left:before{content:""}.fa-long-arrow-right:before{content:""}.fa-apple:before{content:""}.fa-windows:before{content:""}.fa-android:before{content:""}.fa-linux:before{content:""}.fa-dribbble:before{content:""}.fa-skype:before{content:""}.fa-foursquare:before{content:""}.fa-trello:before{content:""}.fa-female:before{content:""}.fa-male:before{content:""}.fa-gittip:before,.fa-gratipay:before{content:""}.fa-sun-o:before{content:""}.fa-moon-o:before{content:""}.fa-archive:before{content:""}.fa-bug:before{content:""}.fa-vk:before{content:""}.fa-weibo:before{content:""}.fa-renren:before{content:""}.fa-pagelines:before{content:""}.fa-stack-exchange:before{content:""}.fa-arrow-circle-o-right:before{content:""}.fa-arrow-circle-o-left:before{content:""}.fa-caret-square-o-left:before,.fa-toggle-left:before{content:""}.fa-dot-circle-o:before{content:""}.fa-wheelchair:before{content:""}.fa-vimeo-square:before{content:""}.fa-try:before,.fa-turkish-lira:before{content:""}.fa-plus-square-o:before,.wy-menu-vertical li span.toctree-expand:before{content:""}.fa-space-shuttle:before{content:""}.fa-slack:before{content:""}.fa-envelope-square:before{content:""}.fa-wordpress:before{content:""}.fa-openid:before{content:""}.fa-bank:before,.fa-institution:before,.fa-university:before{content:""}.fa-graduation-cap:before,.fa-mortar-board:before{content:""}.fa-yahoo:before{content:""}.fa-google:before{content:""}.fa-reddit:before{content:""}.fa-reddit-square:before{content:""}.fa-stumbleupon-circle:before{content:""}.fa-stumbleupon:before{content:""}.fa-delicious:before{content:""}.fa-digg:before{content:""}.fa-pied-piper-pp:before{content:""}.fa-pied-piper-alt:before{content:""}.fa-drupal:before{content:""}.fa-joomla:before{content:""}.fa-language:before{content:""}.fa-fax:before{content:""}.fa-building:before{content:""}.fa-child:before{content:""}.fa-paw:before{content:""}.fa-spoon:before{content:""}.fa-cube:before{content:""}.fa-cubes:before{content:""}.fa-behance:before{content:""}.fa-behance-square:before{content:""}.fa-steam:before{content:""}.fa-steam-square:before{content:""}.fa-recycle:before{content:""}.fa-automobile:before,.fa-car:before{content:""}.fa-cab:before,.fa-taxi:before{content:""}.fa-tree:before{content:""}.fa-spotify:before{content:""}.fa-deviantart:before{content:""}.fa-soundcloud:before{content:""}.fa-database:before{content:""}.fa-file-pdf-o:before{content:""}.fa-file-word-o:before{content:""}.fa-file-excel-o:before{content:""}.fa-file-powerpoint-o:before{content:""}.fa-file-image-o:before,.fa-file-photo-o:before,.fa-file-picture-o:before{content:""}.fa-file-archive-o:before,.fa-file-zip-o:before{content:""}.fa-file-audio-o:before,.fa-file-sound-o:before{content:""}.fa-file-movie-o:before,.fa-file-video-o:before{content:""}.fa-file-code-o:before{content:""}.fa-vine:before{content:""}.fa-codepen:before{content:""}.fa-jsfiddle:before{content:""}.fa-life-bouy:before,.fa-life-buoy:before,.fa-life-ring:before,.fa-life-saver:before,.fa-support:before{content:""}.fa-circle-o-notch:before{content:""}.fa-ra:before,.fa-rebel:before,.fa-resistance:before{content:""}.fa-empire:before,.fa-ge:before{content:""}.fa-git-square:before{content:""}.fa-git:before{content:""}.fa-hacker-news:before,.fa-y-combinator-square:before,.fa-yc-square:before{content:""}.fa-tencent-weibo:before{content:""}.fa-qq:before{content:""}.fa-wechat:before,.fa-weixin:before{content:""}.fa-paper-plane:before,.fa-send:before{content:""}.fa-paper-plane-o:before,.fa-send-o:before{content:""}.fa-history:before{content:""}.fa-circle-thin:before{content:""}.fa-header:before{content:""}.fa-paragraph:before{content:""}.fa-sliders:before{content:""}.fa-share-alt:before{content:""}.fa-share-alt-square:before{content:""}.fa-bomb:before{content:""}.fa-futbol-o:before,.fa-soccer-ball-o:before{content:""}.fa-tty:before{content:""}.fa-binoculars:before{content:""}.fa-plug:before{content:""}.fa-slideshare:before{content:""}.fa-twitch:before{content:""}.fa-yelp:before{content:""}.fa-newspaper-o:before{content:""}.fa-wifi:before{content:""}.fa-calculator:before{content:""}.fa-paypal:before{content:""}.fa-google-wallet:before{content:""}.fa-cc-visa:before{content:""}.fa-cc-mastercard:before{content:""}.fa-cc-discover:before{content:""}.fa-cc-amex:before{content:""}.fa-cc-paypal:before{content:""}.fa-cc-stripe:before{content:""}.fa-bell-slash:before{content:""}.fa-bell-slash-o:before{content:""}.fa-trash:before{content:""}.fa-copyright:before{content:""}.fa-at:before{content:""}.fa-eyedropper:before{content:""}.fa-paint-brush:before{content:""}.fa-birthday-cake:before{content:""}.fa-area-chart:before{content:""}.fa-pie-chart:before{content:""}.fa-line-chart:before{content:""}.fa-lastfm:before{content:""}.fa-lastfm-square:before{content:""}.fa-toggle-off:before{content:""}.fa-toggle-on:before{content:""}.fa-bicycle:before{content:""}.fa-bus:before{content:""}.fa-ioxhost:before{content:""}.fa-angellist:before{content:""}.fa-cc:before{content:""}.fa-ils:before,.fa-shekel:before,.fa-sheqel:before{content:""}.fa-meanpath:before{content:""}.fa-buysellads:before{content:""}.fa-connectdevelop:before{content:""}.fa-dashcube:before{content:""}.fa-forumbee:before{content:""}.fa-leanpub:before{content:""}.fa-sellsy:before{content:""}.fa-shirtsinbulk:before{content:""}.fa-simplybuilt:before{content:""}.fa-skyatlas:before{content:""}.fa-cart-plus:before{content:""}.fa-cart-arrow-down:before{content:""}.fa-diamond:before{content:""}.fa-ship:before{content:""}.fa-user-secret:before{content:""}.fa-motorcycle:before{content:""}.fa-street-view:before{content:""}.fa-heartbeat:before{content:""}.fa-venus:before{content:""}.fa-mars:before{content:""}.fa-mercury:before{content:""}.fa-intersex:before,.fa-transgender:before{content:""}.fa-transgender-alt:before{content:""}.fa-venus-double:before{content:""}.fa-mars-double:before{content:""}.fa-venus-mars:before{content:""}.fa-mars-stroke:before{content:""}.fa-mars-stroke-v:before{content:""}.fa-mars-stroke-h:before{content:""}.fa-neuter:before{content:""}.fa-genderless:before{content:""}.fa-facebook-official:before{content:""}.fa-pinterest-p:before{content:""}.fa-whatsapp:before{content:""}.fa-server:before{content:""}.fa-user-plus:before{content:""}.fa-user-times:before{content:""}.fa-bed:before,.fa-hotel:before{content:""}.fa-viacoin:before{content:""}.fa-train:before{content:""}.fa-subway:before{content:""}.fa-medium:before{content:""}.fa-y-combinator:before,.fa-yc:before{content:""}.fa-optin-monster:before{content:""}.fa-opencart:before{content:""}.fa-expeditedssl:before{content:""}.fa-battery-4:before,.fa-battery-full:before,.fa-battery:before{content:""}.fa-battery-3:before,.fa-battery-three-quarters:before{content:""}.fa-battery-2:before,.fa-battery-half:before{content:""}.fa-battery-1:before,.fa-battery-quarter:before{content:""}.fa-battery-0:before,.fa-battery-empty:before{content:""}.fa-mouse-pointer:before{content:""}.fa-i-cursor:before{content:""}.fa-object-group:before{content:""}.fa-object-ungroup:before{content:""}.fa-sticky-note:before{content:""}.fa-sticky-note-o:before{content:""}.fa-cc-jcb:before{content:""}.fa-cc-diners-club:before{content:""}.fa-clone:before{content:""}.fa-balance-scale:before{content:""}.fa-hourglass-o:before{content:""}.fa-hourglass-1:before,.fa-hourglass-start:before{content:""}.fa-hourglass-2:before,.fa-hourglass-half:before{content:""}.fa-hourglass-3:before,.fa-hourglass-end:before{content:""}.fa-hourglass:before{content:""}.fa-hand-grab-o:before,.fa-hand-rock-o:before{content:""}.fa-hand-paper-o:before,.fa-hand-stop-o:before{content:""}.fa-hand-scissors-o:before{content:""}.fa-hand-lizard-o:before{content:""}.fa-hand-spock-o:before{content:""}.fa-hand-pointer-o:before{content:""}.fa-hand-peace-o:before{content:""}.fa-trademark:before{content:""}.fa-registered:before{content:""}.fa-creative-commons:before{content:""}.fa-gg:before{content:""}.fa-gg-circle:before{content:""}.fa-tripadvisor:before{content:""}.fa-odnoklassniki:before{content:""}.fa-odnoklassniki-square:before{content:""}.fa-get-pocket:before{content:""}.fa-wikipedia-w:before{content:""}.fa-safari:before{content:""}.fa-chrome:before{content:""}.fa-firefox:before{content:""}.fa-opera:before{content:""}.fa-internet-explorer:before{content:""}.fa-television:before,.fa-tv:before{content:""}.fa-contao:before{content:""}.fa-500px:before{content:""}.fa-amazon:before{content:""}.fa-calendar-plus-o:before{content:""}.fa-calendar-minus-o:before{content:""}.fa-calendar-times-o:before{content:""}.fa-calendar-check-o:before{content:""}.fa-industry:before{content:""}.fa-map-pin:before{content:""}.fa-map-signs:before{content:""}.fa-map-o:before{content:""}.fa-map:before{content:""}.fa-commenting:before{content:""}.fa-commenting-o:before{content:""}.fa-houzz:before{content:""}.fa-vimeo:before{content:""}.fa-black-tie:before{content:""}.fa-fonticons:before{content:""}.fa-reddit-alien:before{content:""}.fa-edge:before{content:""}.fa-credit-card-alt:before{content:""}.fa-codiepie:before{content:""}.fa-modx:before{content:""}.fa-fort-awesome:before{content:""}.fa-usb:before{content:""}.fa-product-hunt:before{content:""}.fa-mixcloud:before{content:""}.fa-scribd:before{content:""}.fa-pause-circle:before{content:""}.fa-pause-circle-o:before{content:""}.fa-stop-circle:before{content:""}.fa-stop-circle-o:before{content:""}.fa-shopping-bag:before{content:""}.fa-shopping-basket:before{content:""}.fa-hashtag:before{content:""}.fa-bluetooth:before{content:""}.fa-bluetooth-b:before{content:""}.fa-percent:before{content:""}.fa-gitlab:before,.icon-gitlab:before{content:""}.fa-wpbeginner:before{content:""}.fa-wpforms:before{content:""}.fa-envira:before{content:""}.fa-universal-access:before{content:""}.fa-wheelchair-alt:before{content:""}.fa-question-circle-o:before{content:""}.fa-blind:before{content:""}.fa-audio-description:before{content:""}.fa-volume-control-phone:before{content:""}.fa-braille:before{content:""}.fa-assistive-listening-systems:before{content:""}.fa-american-sign-language-interpreting:before,.fa-asl-interpreting:before{content:""}.fa-deaf:before,.fa-deafness:before,.fa-hard-of-hearing:before{content:""}.fa-glide:before{content:""}.fa-glide-g:before{content:""}.fa-sign-language:before,.fa-signing:before{content:""}.fa-low-vision:before{content:""}.fa-viadeo:before{content:""}.fa-viadeo-square:before{content:""}.fa-snapchat:before{content:""}.fa-snapchat-ghost:before{content:""}.fa-snapchat-square:before{content:""}.fa-pied-piper:before{content:""}.fa-first-order:before{content:""}.fa-yoast:before{content:""}.fa-themeisle:before{content:""}.fa-google-plus-circle:before,.fa-google-plus-official:before{content:""}.fa-fa:before,.fa-font-awesome:before{content:""}.fa-handshake-o:before{content:""}.fa-envelope-open:before{content:""}.fa-envelope-open-o:before{content:""}.fa-linode:before{content:""}.fa-address-book:before{content:""}.fa-address-book-o:before{content:""}.fa-address-card:before,.fa-vcard:before{content:""}.fa-address-card-o:before,.fa-vcard-o:before{content:""}.fa-user-circle:before{content:""}.fa-user-circle-o:before{content:""}.fa-user-o:before{content:""}.fa-id-badge:before{content:""}.fa-drivers-license:before,.fa-id-card:before{content:""}.fa-drivers-license-o:before,.fa-id-card-o:before{content:""}.fa-quora:before{content:""}.fa-free-code-camp:before{content:""}.fa-telegram:before{content:""}.fa-thermometer-4:before,.fa-thermometer-full:before,.fa-thermometer:before{content:""}.fa-thermometer-3:before,.fa-thermometer-three-quarters:before{content:""}.fa-thermometer-2:before,.fa-thermometer-half:before{content:""}.fa-thermometer-1:before,.fa-thermometer-quarter:before{content:""}.fa-thermometer-0:before,.fa-thermometer-empty:before{content:""}.fa-shower:before{content:""}.fa-bath:before,.fa-bathtub:before,.fa-s15:before{content:""}.fa-podcast:before{content:""}.fa-window-maximize:before{content:""}.fa-window-minimize:before{content:""}.fa-window-restore:before{content:""}.fa-times-rectangle:before,.fa-window-close:before{content:""}.fa-times-rectangle-o:before,.fa-window-close-o:before{content:""}.fa-bandcamp:before{content:""}.fa-grav:before{content:""}.fa-etsy:before{content:""}.fa-imdb:before{content:""}.fa-ravelry:before{content:""}.fa-eercast:before{content:""}.fa-microchip:before{content:""}.fa-snowflake-o:before{content:""}.fa-superpowers:before{content:""}.fa-wpexplorer:before{content:""}.fa-meetup:before{content:""}.sr-only{position:absolute;width:1px;height:1px;padding:0;margin:-1px;overflow:hidden;clip:rect(0,0,0,0);border:0}.sr-only-focusable:active,.sr-only-focusable:focus{position:static;width:auto;height:auto;margin:0;overflow:visible;clip:auto}.fa,.icon,.rst-content .admonition-title,.rst-content .code-block-caption .headerlink,.rst-content code.download span:first-child,.rst-content dl dt .headerlink,.rst-content h1 .headerlink,.rst-content h2 .headerlink,.rst-content h3 .headerlink,.rst-content h4 .headerlink,.rst-content h5 .headerlink,.rst-content h6 .headerlink,.rst-content p.caption .headerlink,.rst-content table>caption .headerlink,.rst-content tt.download span:first-child,.wy-dropdown .caret,.wy-inline-validate.wy-inline-validate-danger .wy-input-context,.wy-inline-validate.wy-inline-validate-info .wy-input-context,.wy-inline-validate.wy-inline-validate-success .wy-input-context,.wy-inline-validate.wy-inline-validate-warning .wy-input-context,.wy-menu-vertical li.current>a span.toctree-expand,.wy-menu-vertical li.on a span.toctree-expand,.wy-menu-vertical li span.toctree-expand{font-family:inherit}.fa:before,.icon:before,.rst-content .admonition-title:before,.rst-content .code-block-caption .headerlink:before,.rst-content code.download span:first-child:before,.rst-content dl dt .headerlink:before,.rst-content h1 .headerlink:before,.rst-content h2 .headerlink:before,.rst-content h3 .headerlink:before,.rst-content h4 .headerlink:before,.rst-content h5 .headerlink:before,.rst-content h6 .headerlink:before,.rst-content p.caption .headerlink:before,.rst-content table>caption .headerlink:before,.rst-content tt.download span:first-child:before,.wy-dropdown .caret:before,.wy-inline-validate.wy-inline-validate-danger .wy-input-context:before,.wy-inline-validate.wy-inline-validate-info .wy-input-context:before,.wy-inline-validate.wy-inline-validate-success .wy-input-context:before,.wy-inline-validate.wy-inline-validate-warning .wy-input-context:before,.wy-menu-vertical li.current>a span.toctree-expand:before,.wy-menu-vertical li.on a span.toctree-expand:before,.wy-menu-vertical li span.toctree-expand:before{font-family:FontAwesome;display:inline-block;font-style:normal;font-weight:400;line-height:1;text-decoration:inherit}.rst-content .code-block-caption a .headerlink,.rst-content a .admonition-title,.rst-content code.download a span:first-child,.rst-content dl dt a .headerlink,.rst-content h1 a .headerlink,.rst-content h2 a .headerlink,.rst-content h3 a .headerlink,.rst-content h4 a .headerlink,.rst-content h5 a .headerlink,.rst-content h6 a .headerlink,.rst-content p.caption a .headerlink,.rst-content table>caption a .headerlink,.rst-content tt.download a span:first-child,.wy-menu-vertical li.current>a span.toctree-expand,.wy-menu-vertical li.on a span.toctree-expand,.wy-menu-vertical li a span.toctree-expand,a .fa,a .icon,a .rst-content .admonition-title,a .rst-content .code-block-caption .headerlink,a .rst-content code.download span:first-child,a .rst-content dl dt .headerlink,a .rst-content h1 .headerlink,a .rst-content h2 .headerlink,a .rst-content h3 .headerlink,a .rst-content h4 .headerlink,a .rst-content h5 .headerlink,a .rst-content h6 .headerlink,a .rst-content p.caption .headerlink,a .rst-content table>caption .headerlink,a .rst-content tt.download span:first-child,a .wy-menu-vertical li span.toctree-expand{display:inline-block;text-decoration:inherit}.btn .fa,.btn .icon,.btn .rst-content .admonition-title,.btn .rst-content .code-block-caption .headerlink,.btn .rst-content code.download span:first-child,.btn .rst-content dl dt .headerlink,.btn .rst-content h1 .headerlink,.btn .rst-content h2 .headerlink,.btn .rst-content h3 .headerlink,.btn .rst-content h4 .headerlink,.btn .rst-content h5 .headerlink,.btn .rst-content h6 .headerlink,.btn .rst-content p.caption .headerlink,.btn .rst-content table>caption .headerlink,.btn .rst-content tt.download span:first-child,.btn .wy-menu-vertical li.current>a span.toctree-expand,.btn .wy-menu-vertical li.on a span.toctree-expand,.btn .wy-menu-vertical li span.toctree-expand,.nav .fa,.nav .icon,.nav .rst-content .admonition-title,.nav .rst-content .code-block-caption .headerlink,.nav .rst-content code.download span:first-child,.nav .rst-content dl dt .headerlink,.nav .rst-content h1 .headerlink,.nav .rst-content h2 .headerlink,.nav .rst-content h3 .headerlink,.nav .rst-content h4 .headerlink,.nav .rst-content h5 .headerlink,.nav .rst-content h6 .headerlink,.nav .rst-content p.caption .headerlink,.nav .rst-content table>caption .headerlink,.nav .rst-content tt.download span:first-child,.nav .wy-menu-vertical li.current>a span.toctree-expand,.nav .wy-menu-vertical li.on a span.toctree-expand,.nav .wy-menu-vertical li span.toctree-expand,.rst-content .btn .admonition-title,.rst-content .code-block-caption .btn .headerlink,.rst-content .code-block-caption .nav .headerlink,.rst-content .nav .admonition-title,.rst-content code.download .btn span:first-child,.rst-content code.download .nav span:first-child,.rst-content dl dt .btn .headerlink,.rst-content dl dt .nav .headerlink,.rst-content h1 .btn .headerlink,.rst-content h1 .nav .headerlink,.rst-content h2 .btn .headerlink,.rst-content h2 .nav .headerlink,.rst-content h3 .btn .headerlink,.rst-content h3 .nav .headerlink,.rst-content h4 .btn .headerlink,.rst-content h4 .nav .headerlink,.rst-content h5 .btn .headerlink,.rst-content h5 .nav .headerlink,.rst-content h6 .btn .headerlink,.rst-content h6 .nav .headerlink,.rst-content p.caption .btn .headerlink,.rst-content p.caption .nav .headerlink,.rst-content table>caption .btn .headerlink,.rst-content table>caption .nav .headerlink,.rst-content tt.download .btn span:first-child,.rst-content tt.download .nav span:first-child,.wy-menu-vertical li .btn span.toctree-expand,.wy-menu-vertical li.current>a .btn span.toctree-expand,.wy-menu-vertical li.current>a .nav span.toctree-expand,.wy-menu-vertical li .nav span.toctree-expand,.wy-menu-vertical li.on a .btn span.toctree-expand,.wy-menu-vertical li.on a .nav span.toctree-expand{display:inline}.btn .fa-large.icon,.btn .fa.fa-large,.btn .rst-content .code-block-caption .fa-large.headerlink,.btn .rst-content .fa-large.admonition-title,.btn .rst-content code.download span.fa-large:first-child,.btn .rst-content dl dt .fa-large.headerlink,.btn .rst-content h1 .fa-large.headerlink,.btn .rst-content h2 .fa-large.headerlink,.btn .rst-content h3 .fa-large.headerlink,.btn .rst-content h4 .fa-large.headerlink,.btn .rst-content h5 .fa-large.headerlink,.btn .rst-content h6 .fa-large.headerlink,.btn .rst-content p.caption .fa-large.headerlink,.btn .rst-content table>caption .fa-large.headerlink,.btn .rst-content tt.download span.fa-large:first-child,.btn .wy-menu-vertical li span.fa-large.toctree-expand,.nav .fa-large.icon,.nav .fa.fa-large,.nav .rst-content .code-block-caption .fa-large.headerlink,.nav .rst-content .fa-large.admonition-title,.nav .rst-content code.download span.fa-large:first-child,.nav .rst-content dl dt .fa-large.headerlink,.nav .rst-content h1 .fa-large.headerlink,.nav .rst-content h2 .fa-large.headerlink,.nav .rst-content h3 .fa-large.headerlink,.nav .rst-content h4 .fa-large.headerlink,.nav .rst-content h5 .fa-large.headerlink,.nav .rst-content h6 .fa-large.headerlink,.nav .rst-content p.caption .fa-large.headerlink,.nav .rst-content table>caption .fa-large.headerlink,.nav .rst-content tt.download span.fa-large:first-child,.nav .wy-menu-vertical li span.fa-large.toctree-expand,.rst-content .btn .fa-large.admonition-title,.rst-content .code-block-caption .btn .fa-large.headerlink,.rst-content .code-block-caption .nav .fa-large.headerlink,.rst-content .nav .fa-large.admonition-title,.rst-content code.download .btn span.fa-large:first-child,.rst-content code.download .nav span.fa-large:first-child,.rst-content dl dt .btn .fa-large.headerlink,.rst-content dl dt .nav .fa-large.headerlink,.rst-content h1 .btn .fa-large.headerlink,.rst-content h1 .nav .fa-large.headerlink,.rst-content h2 .btn .fa-large.headerlink,.rst-content h2 .nav .fa-large.headerlink,.rst-content h3 .btn .fa-large.headerlink,.rst-content h3 .nav .fa-large.headerlink,.rst-content h4 .btn .fa-large.headerlink,.rst-content h4 .nav .fa-large.headerlink,.rst-content h5 .btn .fa-large.headerlink,.rst-content h5 .nav .fa-large.headerlink,.rst-content h6 .btn .fa-large.headerlink,.rst-content h6 .nav .fa-large.headerlink,.rst-content p.caption .btn .fa-large.headerlink,.rst-content p.caption .nav .fa-large.headerlink,.rst-content table>caption .btn .fa-large.headerlink,.rst-content table>caption .nav .fa-large.headerlink,.rst-content tt.download .btn span.fa-large:first-child,.rst-content tt.download .nav span.fa-large:first-child,.wy-menu-vertical li .btn span.fa-large.toctree-expand,.wy-menu-vertical li .nav span.fa-large.toctree-expand{line-height:.9em}.btn .fa-spin.icon,.btn .fa.fa-spin,.btn .rst-content .code-block-caption .fa-spin.headerlink,.btn .rst-content .fa-spin.admonition-title,.btn .rst-content code.download span.fa-spin:first-child,.btn .rst-content dl dt .fa-spin.headerlink,.btn .rst-content h1 .fa-spin.headerlink,.btn .rst-content h2 .fa-spin.headerlink,.btn .rst-content h3 .fa-spin.headerlink,.btn .rst-content h4 .fa-spin.headerlink,.btn .rst-content h5 .fa-spin.headerlink,.btn .rst-content h6 .fa-spin.headerlink,.btn .rst-content p.caption .fa-spin.headerlink,.btn .rst-content table>caption .fa-spin.headerlink,.btn .rst-content tt.download span.fa-spin:first-child,.btn .wy-menu-vertical li span.fa-spin.toctree-expand,.nav .fa-spin.icon,.nav .fa.fa-spin,.nav .rst-content .code-block-caption .fa-spin.headerlink,.nav .rst-content .fa-spin.admonition-title,.nav .rst-content code.download span.fa-spin:first-child,.nav .rst-content dl dt .fa-spin.headerlink,.nav .rst-content h1 .fa-spin.headerlink,.nav .rst-content h2 .fa-spin.headerlink,.nav .rst-content h3 .fa-spin.headerlink,.nav .rst-content h4 .fa-spin.headerlink,.nav .rst-content h5 .fa-spin.headerlink,.nav .rst-content h6 .fa-spin.headerlink,.nav .rst-content p.caption .fa-spin.headerlink,.nav .rst-content table>caption .fa-spin.headerlink,.nav .rst-content tt.download span.fa-spin:first-child,.nav .wy-menu-vertical li span.fa-spin.toctree-expand,.rst-content .btn .fa-spin.admonition-title,.rst-content .code-block-caption .btn .fa-spin.headerlink,.rst-content .code-block-caption .nav .fa-spin.headerlink,.rst-content .nav .fa-spin.admonition-title,.rst-content code.download .btn span.fa-spin:first-child,.rst-content code.download .nav span.fa-spin:first-child,.rst-content dl dt .btn .fa-spin.headerlink,.rst-content dl dt .nav .fa-spin.headerlink,.rst-content h1 .btn .fa-spin.headerlink,.rst-content h1 .nav .fa-spin.headerlink,.rst-content h2 .btn .fa-spin.headerlink,.rst-content h2 .nav .fa-spin.headerlink,.rst-content h3 .btn .fa-spin.headerlink,.rst-content h3 .nav .fa-spin.headerlink,.rst-content h4 .btn .fa-spin.headerlink,.rst-content h4 .nav .fa-spin.headerlink,.rst-content h5 .btn .fa-spin.headerlink,.rst-content h5 .nav .fa-spin.headerlink,.rst-content h6 .btn .fa-spin.headerlink,.rst-content h6 .nav .fa-spin.headerlink,.rst-content p.caption .btn .fa-spin.headerlink,.rst-content p.caption .nav .fa-spin.headerlink,.rst-content table>caption .btn .fa-spin.headerlink,.rst-content table>caption .nav .fa-spin.headerlink,.rst-content tt.download .btn span.fa-spin:first-child,.rst-content tt.download .nav span.fa-spin:first-child,.wy-menu-vertical li .btn span.fa-spin.toctree-expand,.wy-menu-vertical li .nav span.fa-spin.toctree-expand{display:inline-block}.btn.fa:before,.btn.icon:before,.rst-content .btn.admonition-title:before,.rst-content .code-block-caption .btn.headerlink:before,.rst-content code.download span.btn:first-child:before,.rst-content dl dt .btn.headerlink:before,.rst-content h1 .btn.headerlink:before,.rst-content h2 .btn.headerlink:before,.rst-content h3 .btn.headerlink:before,.rst-content h4 .btn.headerlink:before,.rst-content h5 .btn.headerlink:before,.rst-content h6 .btn.headerlink:before,.rst-content p.caption .btn.headerlink:before,.rst-content table>caption .btn.headerlink:before,.rst-content tt.download span.btn:first-child:before,.wy-menu-vertical li span.btn.toctree-expand:before{opacity:.5;-webkit-transition:opacity .05s ease-in;-moz-transition:opacity .05s ease-in;transition:opacity .05s ease-in}.btn.fa:hover:before,.btn.icon:hover:before,.rst-content .btn.admonition-title:hover:before,.rst-content .code-block-caption .btn.headerlink:hover:before,.rst-content code.download span.btn:first-child:hover:before,.rst-content dl dt .btn.headerlink:hover:before,.rst-content h1 .btn.headerlink:hover:before,.rst-content h2 .btn.headerlink:hover:before,.rst-content h3 .btn.headerlink:hover:before,.rst-content h4 .btn.headerlink:hover:before,.rst-content h5 .btn.headerlink:hover:before,.rst-content h6 .btn.headerlink:hover:before,.rst-content p.caption .btn.headerlink:hover:before,.rst-content table>caption .btn.headerlink:hover:before,.rst-content tt.download span.btn:first-child:hover:before,.wy-menu-vertical li span.btn.toctree-expand:hover:before{opacity:1}.btn-mini .fa:before,.btn-mini .icon:before,.btn-mini .rst-content .admonition-title:before,.btn-mini .rst-content .code-block-caption .headerlink:before,.btn-mini .rst-content code.download span:first-child:before,.btn-mini .rst-content dl dt .headerlink:before,.btn-mini .rst-content h1 .headerlink:before,.btn-mini .rst-content h2 .headerlink:before,.btn-mini .rst-content h3 .headerlink:before,.btn-mini .rst-content h4 .headerlink:before,.btn-mini .rst-content h5 .headerlink:before,.btn-mini .rst-content h6 .headerlink:before,.btn-mini .rst-content p.caption .headerlink:before,.btn-mini .rst-content table>caption .headerlink:before,.btn-mini .rst-content tt.download span:first-child:before,.btn-mini .wy-menu-vertical li span.toctree-expand:before,.rst-content .btn-mini .admonition-title:before,.rst-content .code-block-caption .btn-mini .headerlink:before,.rst-content code.download .btn-mini span:first-child:before,.rst-content dl dt .btn-mini .headerlink:before,.rst-content h1 .btn-mini .headerlink:before,.rst-content h2 .btn-mini .headerlink:before,.rst-content h3 .btn-mini .headerlink:before,.rst-content h4 .btn-mini .headerlink:before,.rst-content h5 .btn-mini .headerlink:before,.rst-content h6 .btn-mini .headerlink:before,.rst-content p.caption .btn-mini .headerlink:before,.rst-content table>caption .btn-mini .headerlink:before,.rst-content tt.download .btn-mini span:first-child:before,.wy-menu-vertical li .btn-mini span.toctree-expand:before{font-size:14px;vertical-align:-15%}.rst-content .admonition,.rst-content .admonition-todo,.rst-content .attention,.rst-content .caution,.rst-content .danger,.rst-content .error,.rst-content .hint,.rst-content .important,.rst-content .note,.rst-content .seealso,.rst-content .tip,.rst-content .warning,.wy-alert{padding:12px;line-height:24px;margin-bottom:24px;background:#e7f2fa}.rst-content .admonition-title,.wy-alert-title{font-weight:700;display:block;color:#fff;background:#6ab0de;padding:6px 12px;margin:-12px -12px 12px}.rst-content .danger,.rst-content .error,.rst-content .wy-alert-danger.admonition,.rst-content .wy-alert-danger.admonition-todo,.rst-content .wy-alert-danger.attention,.rst-content .wy-alert-danger.caution,.rst-content .wy-alert-danger.hint,.rst-content .wy-alert-danger.important,.rst-content .wy-alert-danger.note,.rst-content .wy-alert-danger.seealso,.rst-content .wy-alert-danger.tip,.rst-content .wy-alert-danger.warning,.wy-alert.wy-alert-danger{background:#fdf3f2}.rst-content .danger .admonition-title,.rst-content .danger .wy-alert-title,.rst-content .error .admonition-title,.rst-content .error .wy-alert-title,.rst-content .wy-alert-danger.admonition-todo .admonition-title,.rst-content .wy-alert-danger.admonition-todo .wy-alert-title,.rst-content .wy-alert-danger.admonition .admonition-title,.rst-content .wy-alert-danger.admonition .wy-alert-title,.rst-content .wy-alert-danger.attention .admonition-title,.rst-content .wy-alert-danger.attention .wy-alert-title,.rst-content .wy-alert-danger.caution .admonition-title,.rst-content .wy-alert-danger.caution .wy-alert-title,.rst-content .wy-alert-danger.hint .admonition-title,.rst-content .wy-alert-danger.hint .wy-alert-title,.rst-content .wy-alert-danger.important .admonition-title,.rst-content .wy-alert-danger.important .wy-alert-title,.rst-content .wy-alert-danger.note .admonition-title,.rst-content .wy-alert-danger.note .wy-alert-title,.rst-content .wy-alert-danger.seealso .admonition-title,.rst-content .wy-alert-danger.seealso .wy-alert-title,.rst-content .wy-alert-danger.tip .admonition-title,.rst-content .wy-alert-danger.tip .wy-alert-title,.rst-content .wy-alert-danger.warning .admonition-title,.rst-content .wy-alert-danger.warning .wy-alert-title,.rst-content .wy-alert.wy-alert-danger .admonition-title,.wy-alert.wy-alert-danger .rst-content .admonition-title,.wy-alert.wy-alert-danger .wy-alert-title{background:#f29f97}.rst-content .admonition-todo,.rst-content .attention,.rst-content .caution,.rst-content .warning,.rst-content .wy-alert-warning.admonition,.rst-content .wy-alert-warning.danger,.rst-content .wy-alert-warning.error,.rst-content .wy-alert-warning.hint,.rst-content .wy-alert-warning.important,.rst-content .wy-alert-warning.note,.rst-content .wy-alert-warning.seealso,.rst-content .wy-alert-warning.tip,.wy-alert.wy-alert-warning{background:#ffedcc}.rst-content .admonition-todo .admonition-title,.rst-content .admonition-todo .wy-alert-title,.rst-content .attention .admonition-title,.rst-content .attention .wy-alert-title,.rst-content .caution .admonition-title,.rst-content .caution .wy-alert-title,.rst-content .warning .admonition-title,.rst-content .warning .wy-alert-title,.rst-content .wy-alert-warning.admonition .admonition-title,.rst-content .wy-alert-warning.admonition .wy-alert-title,.rst-content .wy-alert-warning.danger .admonition-title,.rst-content .wy-alert-warning.danger .wy-alert-title,.rst-content .wy-alert-warning.error .admonition-title,.rst-content .wy-alert-warning.error .wy-alert-title,.rst-content .wy-alert-warning.hint .admonition-title,.rst-content .wy-alert-warning.hint .wy-alert-title,.rst-content .wy-alert-warning.important .admonition-title,.rst-content .wy-alert-warning.important .wy-alert-title,.rst-content .wy-alert-warning.note .admonition-title,.rst-content .wy-alert-warning.note .wy-alert-title,.rst-content .wy-alert-warning.seealso .admonition-title,.rst-content .wy-alert-warning.seealso .wy-alert-title,.rst-content .wy-alert-warning.tip .admonition-title,.rst-content .wy-alert-warning.tip .wy-alert-title,.rst-content .wy-alert.wy-alert-warning .admonition-title,.wy-alert.wy-alert-warning .rst-content .admonition-title,.wy-alert.wy-alert-warning .wy-alert-title{background:#f0b37e}.rst-content .note,.rst-content .seealso,.rst-content .wy-alert-info.admonition,.rst-content .wy-alert-info.admonition-todo,.rst-content .wy-alert-info.attention,.rst-content .wy-alert-info.caution,.rst-content .wy-alert-info.danger,.rst-content .wy-alert-info.error,.rst-content .wy-alert-info.hint,.rst-content .wy-alert-info.important,.rst-content .wy-alert-info.tip,.rst-content .wy-alert-info.warning,.wy-alert.wy-alert-info{background:#e7f2fa}.rst-content .note .admonition-title,.rst-content .note .wy-alert-title,.rst-content .seealso .admonition-title,.rst-content .seealso .wy-alert-title,.rst-content .wy-alert-info.admonition-todo .admonition-title,.rst-content .wy-alert-info.admonition-todo .wy-alert-title,.rst-content .wy-alert-info.admonition .admonition-title,.rst-content .wy-alert-info.admonition .wy-alert-title,.rst-content .wy-alert-info.attention .admonition-title,.rst-content .wy-alert-info.attention .wy-alert-title,.rst-content .wy-alert-info.caution .admonition-title,.rst-content .wy-alert-info.caution .wy-alert-title,.rst-content .wy-alert-info.danger .admonition-title,.rst-content .wy-alert-info.danger .wy-alert-title,.rst-content .wy-alert-info.error .admonition-title,.rst-content .wy-alert-info.error .wy-alert-title,.rst-content .wy-alert-info.hint .admonition-title,.rst-content .wy-alert-info.hint .wy-alert-title,.rst-content .wy-alert-info.important .admonition-title,.rst-content .wy-alert-info.important .wy-alert-title,.rst-content .wy-alert-info.tip .admonition-title,.rst-content .wy-alert-info.tip .wy-alert-title,.rst-content .wy-alert-info.warning .admonition-title,.rst-content .wy-alert-info.warning .wy-alert-title,.rst-content .wy-alert.wy-alert-info .admonition-title,.wy-alert.wy-alert-info .rst-content .admonition-title,.wy-alert.wy-alert-info .wy-alert-title{background:#6ab0de}.rst-content .hint,.rst-content .important,.rst-content .tip,.rst-content .wy-alert-success.admonition,.rst-content .wy-alert-success.admonition-todo,.rst-content .wy-alert-success.attention,.rst-content .wy-alert-success.caution,.rst-content .wy-alert-success.danger,.rst-content .wy-alert-success.error,.rst-content .wy-alert-success.note,.rst-content .wy-alert-success.seealso,.rst-content .wy-alert-success.warning,.wy-alert.wy-alert-success{background:#dbfaf4}.rst-content .hint .admonition-title,.rst-content .hint .wy-alert-title,.rst-content .important .admonition-title,.rst-content .important .wy-alert-title,.rst-content .tip .admonition-title,.rst-content .tip .wy-alert-title,.rst-content .wy-alert-success.admonition-todo .admonition-title,.rst-content .wy-alert-success.admonition-todo .wy-alert-title,.rst-content .wy-alert-success.admonition .admonition-title,.rst-content .wy-alert-success.admonition .wy-alert-title,.rst-content .wy-alert-success.attention .admonition-title,.rst-content .wy-alert-success.attention .wy-alert-title,.rst-content .wy-alert-success.caution .admonition-title,.rst-content .wy-alert-success.caution .wy-alert-title,.rst-content .wy-alert-success.danger .admonition-title,.rst-content .wy-alert-success.danger .wy-alert-title,.rst-content .wy-alert-success.error .admonition-title,.rst-content .wy-alert-success.error .wy-alert-title,.rst-content .wy-alert-success.note .admonition-title,.rst-content .wy-alert-success.note .wy-alert-title,.rst-content .wy-alert-success.seealso .admonition-title,.rst-content .wy-alert-success.seealso .wy-alert-title,.rst-content .wy-alert-success.warning .admonition-title,.rst-content .wy-alert-success.warning .wy-alert-title,.rst-content .wy-alert.wy-alert-success .admonition-title,.wy-alert.wy-alert-success .rst-content .admonition-title,.wy-alert.wy-alert-success .wy-alert-title{background:#1abc9c}.rst-content .wy-alert-neutral.admonition,.rst-content .wy-alert-neutral.admonition-todo,.rst-content .wy-alert-neutral.attention,.rst-content .wy-alert-neutral.caution,.rst-content .wy-alert-neutral.danger,.rst-content .wy-alert-neutral.error,.rst-content .wy-alert-neutral.hint,.rst-content .wy-alert-neutral.important,.rst-content .wy-alert-neutral.note,.rst-content .wy-alert-neutral.seealso,.rst-content .wy-alert-neutral.tip,.rst-content .wy-alert-neutral.warning,.wy-alert.wy-alert-neutral{background:#f3f6f6}.rst-content .wy-alert-neutral.admonition-todo .admonition-title,.rst-content .wy-alert-neutral.admonition-todo .wy-alert-title,.rst-content .wy-alert-neutral.admonition .admonition-title,.rst-content .wy-alert-neutral.admonition .wy-alert-title,.rst-content .wy-alert-neutral.attention .admonition-title,.rst-content .wy-alert-neutral.attention .wy-alert-title,.rst-content .wy-alert-neutral.caution .admonition-title,.rst-content .wy-alert-neutral.caution .wy-alert-title,.rst-content .wy-alert-neutral.danger .admonition-title,.rst-content .wy-alert-neutral.danger .wy-alert-title,.rst-content .wy-alert-neutral.error .admonition-title,.rst-content .wy-alert-neutral.error .wy-alert-title,.rst-content .wy-alert-neutral.hint .admonition-title,.rst-content .wy-alert-neutral.hint .wy-alert-title,.rst-content .wy-alert-neutral.important .admonition-title,.rst-content .wy-alert-neutral.important .wy-alert-title,.rst-content .wy-alert-neutral.note .admonition-title,.rst-content .wy-alert-neutral.note .wy-alert-title,.rst-content .wy-alert-neutral.seealso .admonition-title,.rst-content .wy-alert-neutral.seealso .wy-alert-title,.rst-content .wy-alert-neutral.tip .admonition-title,.rst-content .wy-alert-neutral.tip .wy-alert-title,.rst-content .wy-alert-neutral.warning .admonition-title,.rst-content .wy-alert-neutral.warning .wy-alert-title,.rst-content .wy-alert.wy-alert-neutral .admonition-title,.wy-alert.wy-alert-neutral .rst-content .admonition-title,.wy-alert.wy-alert-neutral .wy-alert-title{color:#404040;background:#e1e4e5}.rst-content .wy-alert-neutral.admonition-todo a,.rst-content .wy-alert-neutral.admonition a,.rst-content .wy-alert-neutral.attention a,.rst-content .wy-alert-neutral.caution a,.rst-content .wy-alert-neutral.danger a,.rst-content .wy-alert-neutral.error a,.rst-content .wy-alert-neutral.hint a,.rst-content .wy-alert-neutral.important a,.rst-content .wy-alert-neutral.note a,.rst-content .wy-alert-neutral.seealso a,.rst-content .wy-alert-neutral.tip a,.rst-content .wy-alert-neutral.warning a,.wy-alert.wy-alert-neutral a{color:#2980b9}.rst-content .admonition-todo p:last-child,.rst-content .admonition p:last-child,.rst-content .attention p:last-child,.rst-content .caution p:last-child,.rst-content .danger p:last-child,.rst-content .error p:last-child,.rst-content .hint p:last-child,.rst-content .important p:last-child,.rst-content .note p:last-child,.rst-content .seealso p:last-child,.rst-content .tip p:last-child,.rst-content .warning p:last-child,.wy-alert p:last-child{margin-bottom:0}.wy-tray-container{position:fixed;bottom:0;left:0;z-index:600}.wy-tray-container li{display:block;width:300px;background:transparent;color:#fff;text-align:center;box-shadow:0 5px 5px 0 rgba(0,0,0,.1);padding:0 24px;min-width:20%;opacity:0;height:0;line-height:56px;overflow:hidden;-webkit-transition:all .3s ease-in;-moz-transition:all .3s ease-in;transition:all .3s ease-in}.wy-tray-container li.wy-tray-item-success{background:#27ae60}.wy-tray-container li.wy-tray-item-info{background:#2980b9}.wy-tray-container li.wy-tray-item-warning{background:#e67e22}.wy-tray-container li.wy-tray-item-danger{background:#e74c3c}.wy-tray-container li.on{opacity:1;height:56px}@media screen and (max-width:768px){.wy-tray-container{bottom:auto;top:0;width:100%}.wy-tray-container li{width:100%}}button{font-size:100%;margin:0;vertical-align:baseline;*vertical-align:middle;cursor:pointer;line-height:normal;-webkit-appearance:button;*overflow:visible}button::-moz-focus-inner,input::-moz-focus-inner{border:0;padding:0}button[disabled]{cursor:default}.btn{display:inline-block;border-radius:2px;line-height:normal;white-space:nowrap;text-align:center;cursor:pointer;font-size:100%;padding:6px 12px 8px;color:#fff;border:1px solid rgba(0,0,0,.1);background-color:#27ae60;text-decoration:none;font-weight:400;font-family:Lato,proxima-nova,Helvetica Neue,Arial,sans-serif;box-shadow:inset 0 1px 2px -1px hsla(0,0%,100%,.5),inset 0 -2px 0 0 rgba(0,0,0,.1);outline-none:false;vertical-align:middle;*display:inline;zoom:1;-webkit-user-drag:none;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none;-webkit-transition:all .1s linear;-moz-transition:all .1s linear;transition:all .1s linear}.btn-hover{background:#2e8ece;color:#fff}.btn:hover{background:#2cc36b;color:#fff}.btn:focus{background:#2cc36b;outline:0}.btn:active{box-shadow:inset 0 -1px 0 0 rgba(0,0,0,.05),inset 0 2px 0 0 rgba(0,0,0,.1);padding:8px 12px 6px}.btn:visited{color:#fff}.btn-disabled,.btn-disabled:active,.btn-disabled:focus,.btn-disabled:hover,.btn:disabled{background-image:none;filter:progid:DXImageTransform.Microsoft.gradient(enabled = false);filter:alpha(opacity=40);opacity:.4;cursor:not-allowed;box-shadow:none}.btn::-moz-focus-inner{padding:0;border:0}.btn-small{font-size:80%}.btn-info{background-color:#2980b9!important}.btn-info:hover{background-color:#2e8ece!important}.btn-neutral{background-color:#f3f6f6!important;color:#404040!important}.btn-neutral:hover{background-color:#e5ebeb!important;color:#404040}.btn-neutral:visited{color:#404040!important}.btn-success{background-color:#27ae60!important}.btn-success:hover{background-color:#295!important}.btn-danger{background-color:#e74c3c!important}.btn-danger:hover{background-color:#ea6153!important}.btn-warning{background-color:#e67e22!important}.btn-warning:hover{background-color:#e98b39!important}.btn-invert{background-color:#222}.btn-invert:hover{background-color:#2f2f2f!important}.btn-link{background-color:transparent!important;color:#2980b9;box-shadow:none;border-color:transparent!important}.btn-link:active,.btn-link:hover{background-color:transparent!important;color:#409ad5!important;box-shadow:none}.btn-link:visited{color:#9b59b6}.wy-btn-group .btn,.wy-control .btn{vertical-align:middle}.wy-btn-group{margin-bottom:24px;*zoom:1}.wy-btn-group:after,.wy-btn-group:before{display:table;content:""}.wy-btn-group:after{clear:both}.wy-dropdown{position:relative;display:inline-block}.wy-dropdown-active .wy-dropdown-menu{display:block}.wy-dropdown-menu{position:absolute;left:0;display:none;float:left;top:100%;min-width:100%;background:#fcfcfc;z-index:100;border:1px solid #cfd7dd;box-shadow:0 2px 2px 0 rgba(0,0,0,.1);padding:12px}.wy-dropdown-menu>dd>a{display:block;clear:both;color:#404040;white-space:nowrap;font-size:90%;padding:0 12px;cursor:pointer}.wy-dropdown-menu>dd>a:hover{background:#2980b9;color:#fff}.wy-dropdown-menu>dd.divider{border-top:1px solid #cfd7dd;margin:6px 0}.wy-dropdown-menu>dd.search{padding-bottom:12px}.wy-dropdown-menu>dd.search input[type=search]{width:100%}.wy-dropdown-menu>dd.call-to-action{background:#e3e3e3;text-transform:uppercase;font-weight:500;font-size:80%}.wy-dropdown-menu>dd.call-to-action:hover{background:#e3e3e3}.wy-dropdown-menu>dd.call-to-action .btn{color:#fff}.wy-dropdown.wy-dropdown-up .wy-dropdown-menu{bottom:100%;top:auto;left:auto;right:0}.wy-dropdown.wy-dropdown-bubble .wy-dropdown-menu{background:#fcfcfc;margin-top:2px}.wy-dropdown.wy-dropdown-bubble .wy-dropdown-menu a{padding:6px 12px}.wy-dropdown.wy-dropdown-bubble .wy-dropdown-menu a:hover{background:#2980b9;color:#fff}.wy-dropdown.wy-dropdown-left .wy-dropdown-menu{right:0;left:auto;text-align:right}.wy-dropdown-arrow:before{content:" ";border-bottom:5px solid #f5f5f5;border-left:5px solid transparent;border-right:5px solid transparent;position:absolute;display:block;top:-4px;left:50%;margin-left:-3px}.wy-dropdown-arrow.wy-dropdown-arrow-left:before{left:11px}.wy-form-stacked select{display:block}.wy-form-aligned .wy-help-inline,.wy-form-aligned input,.wy-form-aligned label,.wy-form-aligned select,.wy-form-aligned textarea{display:inline-block;*display:inline;*zoom:1;vertical-align:middle}.wy-form-aligned .wy-control-group>label{display:inline-block;vertical-align:middle;width:10em;margin:6px 12px 0 0;float:left}.wy-form-aligned .wy-control{float:left}.wy-form-aligned .wy-control label{display:block}.wy-form-aligned .wy-control select{margin-top:6px}fieldset{margin:0}fieldset,legend{border:0;padding:0}legend{width:100%;white-space:normal;margin-bottom:24px;font-size:150%;*margin-left:-7px}label,legend{display:block}label{margin:0 0 .3125em;color:#333;font-size:90%}input,select,textarea{font-size:100%;margin:0;vertical-align:baseline;*vertical-align:middle}.wy-control-group{margin-bottom:24px;max-width:1200px;margin-left:auto;margin-right:auto;*zoom:1}.wy-control-group:after,.wy-control-group:before{display:table;content:""}.wy-control-group:after{clear:both}.wy-control-group.wy-control-group-required>label:after{content:" *";color:#e74c3c}.wy-control-group .wy-form-full,.wy-control-group .wy-form-halves,.wy-control-group .wy-form-thirds{padding-bottom:12px}.wy-control-group .wy-form-full input[type=color],.wy-control-group .wy-form-full input[type=date],.wy-control-group .wy-form-full input[type=datetime-local],.wy-control-group .wy-form-full input[type=datetime],.wy-control-group .wy-form-full input[type=email],.wy-control-group .wy-form-full input[type=month],.wy-control-group .wy-form-full input[type=number],.wy-control-group .wy-form-full input[type=password],.wy-control-group .wy-form-full input[type=search],.wy-control-group .wy-form-full input[type=tel],.wy-control-group .wy-form-full input[type=text],.wy-control-group .wy-form-full input[type=time],.wy-control-group .wy-form-full input[type=url],.wy-control-group .wy-form-full input[type=week],.wy-control-group .wy-form-full select,.wy-control-group .wy-form-halves input[type=color],.wy-control-group .wy-form-halves input[type=date],.wy-control-group .wy-form-halves input[type=datetime-local],.wy-control-group .wy-form-halves input[type=datetime],.wy-control-group .wy-form-halves input[type=email],.wy-control-group .wy-form-halves input[type=month],.wy-control-group .wy-form-halves input[type=number],.wy-control-group .wy-form-halves input[type=password],.wy-control-group .wy-form-halves input[type=search],.wy-control-group .wy-form-halves input[type=tel],.wy-control-group .wy-form-halves input[type=text],.wy-control-group .wy-form-halves input[type=time],.wy-control-group .wy-form-halves input[type=url],.wy-control-group .wy-form-halves input[type=week],.wy-control-group .wy-form-halves select,.wy-control-group .wy-form-thirds input[type=color],.wy-control-group .wy-form-thirds input[type=date],.wy-control-group .wy-form-thirds input[type=datetime-local],.wy-control-group .wy-form-thirds input[type=datetime],.wy-control-group .wy-form-thirds input[type=email],.wy-control-group .wy-form-thirds input[type=month],.wy-control-group .wy-form-thirds input[type=number],.wy-control-group .wy-form-thirds input[type=password],.wy-control-group .wy-form-thirds input[type=search],.wy-control-group .wy-form-thirds input[type=tel],.wy-control-group .wy-form-thirds input[type=text],.wy-control-group .wy-form-thirds input[type=time],.wy-control-group .wy-form-thirds input[type=url],.wy-control-group .wy-form-thirds input[type=week],.wy-control-group .wy-form-thirds select{width:100%}.wy-control-group .wy-form-full{float:left;display:block;width:100%;margin-right:0}.wy-control-group .wy-form-full:last-child{margin-right:0}.wy-control-group .wy-form-halves{float:left;display:block;margin-right:2.35765%;width:48.82117%}.wy-control-group .wy-form-halves:last-child,.wy-control-group .wy-form-halves:nth-of-type(2n){margin-right:0}.wy-control-group .wy-form-halves:nth-of-type(odd){clear:left}.wy-control-group .wy-form-thirds{float:left;display:block;margin-right:2.35765%;width:31.76157%}.wy-control-group .wy-form-thirds:last-child,.wy-control-group .wy-form-thirds:nth-of-type(3n){margin-right:0}.wy-control-group .wy-form-thirds:nth-of-type(3n+1){clear:left}.wy-control-group.wy-control-group-no-input .wy-control,.wy-control-no-input{margin:6px 0 0;font-size:90%}.wy-control-no-input{display:inline-block}.wy-control-group.fluid-input input[type=color],.wy-control-group.fluid-input input[type=date],.wy-control-group.fluid-input input[type=datetime-local],.wy-control-group.fluid-input input[type=datetime],.wy-control-group.fluid-input input[type=email],.wy-control-group.fluid-input input[type=month],.wy-control-group.fluid-input input[type=number],.wy-control-group.fluid-input input[type=password],.wy-control-group.fluid-input input[type=search],.wy-control-group.fluid-input input[type=tel],.wy-control-group.fluid-input input[type=text],.wy-control-group.fluid-input input[type=time],.wy-control-group.fluid-input input[type=url],.wy-control-group.fluid-input input[type=week]{width:100%}.wy-form-message-inline{padding-left:.3em;color:#666;font-size:90%}.wy-form-message{display:block;color:#999;font-size:70%;margin-top:.3125em;font-style:italic}.wy-form-message p{font-size:inherit;font-style:italic;margin-bottom:6px}.wy-form-message p:last-child{margin-bottom:0}input{line-height:normal}input[type=button],input[type=reset],input[type=submit]{-webkit-appearance:button;cursor:pointer;font-family:Lato,proxima-nova,Helvetica Neue,Arial,sans-serif;*overflow:visible}input[type=color],input[type=date],input[type=datetime-local],input[type=datetime],input[type=email],input[type=month],input[type=number],input[type=password],input[type=search],input[type=tel],input[type=text],input[type=time],input[type=url],input[type=week]{-webkit-appearance:none;padding:6px;display:inline-block;border:1px solid #ccc;font-size:80%;font-family:Lato,proxima-nova,Helvetica Neue,Arial,sans-serif;box-shadow:inset 0 1px 3px #ddd;border-radius:0;-webkit-transition:border .3s linear;-moz-transition:border .3s linear;transition:border .3s linear}input[type=datetime-local]{padding:.34375em .625em}input[disabled]{cursor:default}input[type=checkbox],input[type=radio]{padding:0;margin-right:.3125em;*height:13px;*width:13px}input[type=checkbox],input[type=radio],input[type=search]{-webkit-box-sizing:border-box;-moz-box-sizing:border-box;box-sizing:border-box}input[type=search]::-webkit-search-cancel-button,input[type=search]::-webkit-search-decoration{-webkit-appearance:none}input[type=color]:focus,input[type=date]:focus,input[type=datetime-local]:focus,input[type=datetime]:focus,input[type=email]:focus,input[type=month]:focus,input[type=number]:focus,input[type=password]:focus,input[type=search]:focus,input[type=tel]:focus,input[type=text]:focus,input[type=time]:focus,input[type=url]:focus,input[type=week]:focus{outline:0;outline:thin dotted\9;border-color:#333}input.no-focus:focus{border-color:#ccc!important}input[type=checkbox]:focus,input[type=file]:focus,input[type=radio]:focus{outline:thin dotted #333;outline:1px auto #129fea}input[type=color][disabled],input[type=date][disabled],input[type=datetime-local][disabled],input[type=datetime][disabled],input[type=email][disabled],input[type=month][disabled],input[type=number][disabled],input[type=password][disabled],input[type=search][disabled],input[type=tel][disabled],input[type=text][disabled],input[type=time][disabled],input[type=url][disabled],input[type=week][disabled]{cursor:not-allowed;background-color:#fafafa}input:focus:invalid,select:focus:invalid,textarea:focus:invalid{color:#e74c3c;border:1px solid #e74c3c}input:focus:invalid:focus,select:focus:invalid:focus,textarea:focus:invalid:focus{border-color:#e74c3c}input[type=checkbox]:focus:invalid:focus,input[type=file]:focus:invalid:focus,input[type=radio]:focus:invalid:focus{outline-color:#e74c3c}input.wy-input-large{padding:12px;font-size:100%}textarea{overflow:auto;vertical-align:top;width:100%;font-family:Lato,proxima-nova,Helvetica Neue,Arial,sans-serif}select,textarea{padding:.5em .625em;display:inline-block;border:1px solid #ccc;font-size:80%;box-shadow:inset 0 1px 3px #ddd;-webkit-transition:border .3s linear;-moz-transition:border .3s linear;transition:border .3s linear}select{border:1px solid #ccc;background-color:#fff}select[multiple]{height:auto}select:focus,textarea:focus{outline:0}input[readonly],select[disabled],select[readonly],textarea[disabled],textarea[readonly]{cursor:not-allowed;background-color:#fafafa}input[type=checkbox][disabled],input[type=radio][disabled]{cursor:not-allowed}.wy-checkbox,.wy-radio{margin:6px 0;color:#404040;display:block}.wy-checkbox input,.wy-radio input{vertical-align:baseline}.wy-form-message-inline{display:inline-block;*display:inline;*zoom:1;vertical-align:middle}.wy-input-prefix,.wy-input-suffix{white-space:nowrap;padding:6px}.wy-input-prefix .wy-input-context,.wy-input-suffix .wy-input-context{line-height:27px;padding:0 8px;display:inline-block;font-size:80%;background-color:#f3f6f6;border:1px solid #ccc;color:#999}.wy-input-suffix .wy-input-context{border-left:0}.wy-input-prefix .wy-input-context{border-right:0}.wy-switch{position:relative;display:block;height:24px;margin-top:12px;cursor:pointer}.wy-switch:before{left:0;top:0;width:36px;height:12px;background:#ccc}.wy-switch:after,.wy-switch:before{position:absolute;content:"";display:block;border-radius:4px;-webkit-transition:all .2s ease-in-out;-moz-transition:all .2s ease-in-out;transition:all .2s ease-in-out}.wy-switch:after{width:18px;height:18px;background:#999;left:-3px;top:-3px}.wy-switch span{position:absolute;left:48px;display:block;font-size:12px;color:#ccc;line-height:1}.wy-switch.active:before{background:#1e8449}.wy-switch.active:after{left:24px;background:#27ae60}.wy-switch.disabled{cursor:not-allowed;opacity:.8}.wy-control-group.wy-control-group-error .wy-form-message,.wy-control-group.wy-control-group-error>label{color:#e74c3c}.wy-control-group.wy-control-group-error input[type=color],.wy-control-group.wy-control-group-error input[type=date],.wy-control-group.wy-control-group-error input[type=datetime-local],.wy-control-group.wy-control-group-error input[type=datetime],.wy-control-group.wy-control-group-error input[type=email],.wy-control-group.wy-control-group-error input[type=month],.wy-control-group.wy-control-group-error input[type=number],.wy-control-group.wy-control-group-error input[type=password],.wy-control-group.wy-control-group-error input[type=search],.wy-control-group.wy-control-group-error input[type=tel],.wy-control-group.wy-control-group-error input[type=text],.wy-control-group.wy-control-group-error input[type=time],.wy-control-group.wy-control-group-error input[type=url],.wy-control-group.wy-control-group-error input[type=week],.wy-control-group.wy-control-group-error textarea{border:1px solid #e74c3c}.wy-inline-validate{white-space:nowrap}.wy-inline-validate .wy-input-context{padding:.5em .625em;display:inline-block;font-size:80%}.wy-inline-validate.wy-inline-validate-success .wy-input-context{color:#27ae60}.wy-inline-validate.wy-inline-validate-danger .wy-input-context{color:#e74c3c}.wy-inline-validate.wy-inline-validate-warning .wy-input-context{color:#e67e22}.wy-inline-validate.wy-inline-validate-info .wy-input-context{color:#2980b9}.rotate-90{-webkit-transform:rotate(90deg);-moz-transform:rotate(90deg);-ms-transform:rotate(90deg);-o-transform:rotate(90deg);transform:rotate(90deg)}.rotate-180{-webkit-transform:rotate(180deg);-moz-transform:rotate(180deg);-ms-transform:rotate(180deg);-o-transform:rotate(180deg);transform:rotate(180deg)}.rotate-270{-webkit-transform:rotate(270deg);-moz-transform:rotate(270deg);-ms-transform:rotate(270deg);-o-transform:rotate(270deg);transform:rotate(270deg)}.mirror{-webkit-transform:scaleX(-1);-moz-transform:scaleX(-1);-ms-transform:scaleX(-1);-o-transform:scaleX(-1);transform:scaleX(-1)}.mirror.rotate-90{-webkit-transform:scaleX(-1) rotate(90deg);-moz-transform:scaleX(-1) rotate(90deg);-ms-transform:scaleX(-1) rotate(90deg);-o-transform:scaleX(-1) rotate(90deg);transform:scaleX(-1) rotate(90deg)}.mirror.rotate-180{-webkit-transform:scaleX(-1) rotate(180deg);-moz-transform:scaleX(-1) rotate(180deg);-ms-transform:scaleX(-1) rotate(180deg);-o-transform:scaleX(-1) rotate(180deg);transform:scaleX(-1) rotate(180deg)}.mirror.rotate-270{-webkit-transform:scaleX(-1) rotate(270deg);-moz-transform:scaleX(-1) rotate(270deg);-ms-transform:scaleX(-1) rotate(270deg);-o-transform:scaleX(-1) rotate(270deg);transform:scaleX(-1) rotate(270deg)}@media only screen and (max-width:480px){.wy-form button[type=submit]{margin:.7em 0 0}.wy-form input[type=color],.wy-form input[type=date],.wy-form input[type=datetime-local],.wy-form input[type=datetime],.wy-form input[type=email],.wy-form input[type=month],.wy-form input[type=number],.wy-form input[type=password],.wy-form input[type=search],.wy-form input[type=tel],.wy-form input[type=text],.wy-form input[type=time],.wy-form input[type=url],.wy-form input[type=week],.wy-form label{margin-bottom:.3em;display:block}.wy-form input[type=color],.wy-form input[type=date],.wy-form input[type=datetime-local],.wy-form input[type=datetime],.wy-form input[type=email],.wy-form input[type=month],.wy-form input[type=number],.wy-form input[type=password],.wy-form input[type=search],.wy-form input[type=tel],.wy-form input[type=time],.wy-form input[type=url],.wy-form input[type=week]{margin-bottom:0}.wy-form-aligned .wy-control-group label{margin-bottom:.3em;text-align:left;display:block;width:100%}.wy-form-aligned .wy-control{margin:1.5em 0 0}.wy-form-message,.wy-form-message-inline,.wy-form .wy-help-inline{display:block;font-size:80%;padding:6px 0}}@media screen and (max-width:768px){.tablet-hide{display:none}}@media screen and (max-width:480px){.mobile-hide{display:none}}.float-left{float:left}.float-right{float:right}.full-width{width:100%}.rst-content table.docutils,.rst-content table.field-list,.wy-table{border-collapse:collapse;border-spacing:0;empty-cells:show;margin-bottom:24px}.rst-content table.docutils caption,.rst-content table.field-list caption,.wy-table caption{color:#000;font:italic 85%/1 arial,sans-serif;padding:1em 0;text-align:center}.rst-content table.docutils td,.rst-content table.docutils th,.rst-content table.field-list td,.rst-content table.field-list th,.wy-table td,.wy-table th{font-size:90%;margin:0;overflow:visible;padding:8px 16px}.rst-content table.docutils td:first-child,.rst-content table.docutils th:first-child,.rst-content table.field-list td:first-child,.rst-content table.field-list th:first-child,.wy-table td:first-child,.wy-table th:first-child{border-left-width:0}.rst-content table.docutils thead,.rst-content table.field-list thead,.wy-table thead{color:#000;text-align:left;vertical-align:bottom;white-space:nowrap}.rst-content table.docutils thead th,.rst-content table.field-list thead th,.wy-table thead th{font-weight:700;border-bottom:2px solid #e1e4e5}.rst-content table.docutils td,.rst-content table.field-list td,.wy-table td{background-color:transparent;vertical-align:middle}.rst-content table.docutils td p,.rst-content table.field-list td p,.wy-table td p{line-height:18px}.rst-content table.docutils td p:last-child,.rst-content table.field-list td p:last-child,.wy-table td p:last-child{margin-bottom:0}.rst-content table.docutils .wy-table-cell-min,.rst-content table.field-list .wy-table-cell-min,.wy-table .wy-table-cell-min{width:1%;padding-right:0}.rst-content table.docutils .wy-table-cell-min input[type=checkbox],.rst-content table.field-list .wy-table-cell-min input[type=checkbox],.wy-table .wy-table-cell-min input[type=checkbox]{margin:0}.wy-table-secondary{color:grey;font-size:90%}.wy-table-tertiary{color:grey;font-size:80%}.rst-content table.docutils:not(.field-list) tr:nth-child(2n-1) td,.wy-table-backed,.wy-table-odd td,.wy-table-striped tr:nth-child(2n-1) td{background-color:#f3f6f6}.rst-content table.docutils,.wy-table-bordered-all{border:1px solid #e1e4e5}.rst-content table.docutils td,.wy-table-bordered-all td{border-bottom:1px solid #e1e4e5;border-left:1px solid #e1e4e5}.rst-content table.docutils tbody>tr:last-child td,.wy-table-bordered-all tbody>tr:last-child td{border-bottom-width:0}.wy-table-bordered{border:1px solid #e1e4e5}.wy-table-bordered-rows td{border-bottom:1px solid #e1e4e5}.wy-table-bordered-rows tbody>tr:last-child td{border-bottom-width:0}.wy-table-horizontal td,.wy-table-horizontal th{border-width:0 0 1px;border-bottom:1px solid #e1e4e5}.wy-table-horizontal tbody>tr:last-child td{border-bottom-width:0}.wy-table-responsive{margin-bottom:24px;max-width:100%;overflow:auto}.wy-table-responsive table{margin-bottom:0!important}.wy-table-responsive table td,.wy-table-responsive table th{white-space:nowrap}a{color:#2980b9;text-decoration:none;cursor:pointer}a:hover{color:#3091d1}a:visited{color:#9b59b6}html{height:100%}body,html{overflow-x:hidden}body{font-family:Lato,proxima-nova,Helvetica Neue,Arial,sans-serif;font-weight:400;color:#404040;min-height:100%;background:#edf0f2}.wy-text-left{text-align:left}.wy-text-center{text-align:center}.wy-text-right{text-align:right}.wy-text-large{font-size:120%}.wy-text-normal{font-size:100%}.wy-text-small,small{font-size:80%}.wy-text-strike{text-decoration:line-through}.wy-text-warning{color:#e67e22!important}a.wy-text-warning:hover{color:#eb9950!important}.wy-text-info{color:#2980b9!important}a.wy-text-info:hover{color:#409ad5!important}.wy-text-success{color:#27ae60!important}a.wy-text-success:hover{color:#36d278!important}.wy-text-danger{color:#e74c3c!important}a.wy-text-danger:hover{color:#ed7669!important}.wy-text-neutral{color:#404040!important}a.wy-text-neutral:hover{color:#595959!important}.rst-content .toctree-wrapper>p.caption,h1,h2,h3,h4,h5,h6,legend{margin-top:0;font-weight:700;font-family:Roboto Slab,ff-tisa-web-pro,Georgia,Arial,sans-serif}p{line-height:24px;font-size:16px;margin:0 0 24px}h1{font-size:175%}.rst-content .toctree-wrapper>p.caption,h2{font-size:150%}h3{font-size:125%}h4{font-size:115%}h5{font-size:110%}h6{font-size:100%}hr{display:block;height:1px;border:0;border-top:1px solid #e1e4e5;margin:24px 0;padding:0}.rst-content code,.rst-content tt,code{white-space:nowrap;max-width:100%;background:#fff;border:1px solid #e1e4e5;font-size:75%;padding:0 5px;font-family:SFMono-Regular,Menlo,Monaco,Consolas,Liberation Mono,Courier New,Courier,monospace;color:#e74c3c;overflow-x:auto}.rst-content tt.code-large,code.code-large{font-size:90%}.rst-content .section ul,.rst-content .toctree-wrapper ul,.wy-plain-list-disc,article ul{list-style:disc;line-height:24px;margin-bottom:24px}.rst-content .section ul li,.rst-content .toctree-wrapper ul li,.wy-plain-list-disc li,article ul li{list-style:disc;margin-left:24px}.rst-content .section ul li p:last-child,.rst-content .section ul li ul,.rst-content .toctree-wrapper ul li p:last-child,.rst-content .toctree-wrapper ul li ul,.wy-plain-list-disc li p:last-child,.wy-plain-list-disc li ul,article ul li p:last-child,article ul li ul{margin-bottom:0}.rst-content .section ul li li,.rst-content .toctree-wrapper ul li li,.wy-plain-list-disc li li,article ul li li{list-style:circle}.rst-content .section ul li li li,.rst-content .toctree-wrapper ul li li li,.wy-plain-list-disc li li li,article ul li li li{list-style:square}.rst-content .section ul li ol li,.rst-content .toctree-wrapper ul li ol li,.wy-plain-list-disc li ol li,article ul li ol li{list-style:decimal}.rst-content .section ol,.rst-content ol.arabic,.wy-plain-list-decimal,article ol{list-style:decimal;line-height:24px;margin-bottom:24px}.rst-content .section ol li,.rst-content ol.arabic li,.wy-plain-list-decimal li,article ol li{list-style:decimal;margin-left:24px}.rst-content .section ol li p:last-child,.rst-content .section ol li ul,.rst-content ol.arabic li p:last-child,.rst-content ol.arabic li ul,.wy-plain-list-decimal li p:last-child,.wy-plain-list-decimal li ul,article ol li p:last-child,article ol li ul{margin-bottom:0}.rst-content .section ol li ul li,.rst-content ol.arabic li ul li,.wy-plain-list-decimal li ul li,article ol li ul li{list-style:disc}.wy-breadcrumbs{*zoom:1}.wy-breadcrumbs:after,.wy-breadcrumbs:before{display:table;content:""}.wy-breadcrumbs:after{clear:both}.wy-breadcrumbs li{display:inline-block}.wy-breadcrumbs li.wy-breadcrumbs-aside{float:right}.wy-breadcrumbs li a{display:inline-block;padding:5px}.wy-breadcrumbs li a:first-child{padding-left:0}.rst-content .wy-breadcrumbs li tt,.wy-breadcrumbs li .rst-content tt,.wy-breadcrumbs li code{padding:5px;border:none;background:none}.rst-content .wy-breadcrumbs li tt.literal,.wy-breadcrumbs li .rst-content tt.literal,.wy-breadcrumbs li code.literal{color:#404040}.wy-breadcrumbs-extra{margin-bottom:0;color:#b3b3b3;font-size:80%;display:inline-block}@media screen and (max-width:480px){.wy-breadcrumbs-extra,.wy-breadcrumbs li.wy-breadcrumbs-aside{display:none}}@media print{.wy-breadcrumbs li.wy-breadcrumbs-aside{display:none}}html{font-size:16px}.wy-affix{position:fixed;top:1.618em}.wy-menu a:hover{text-decoration:none}.wy-menu-horiz{*zoom:1}.wy-menu-horiz:after,.wy-menu-horiz:before{display:table;content:""}.wy-menu-horiz:after{clear:both}.wy-menu-horiz li,.wy-menu-horiz ul{display:inline-block}.wy-menu-horiz li:hover{background:hsla(0,0%,100%,.1)}.wy-menu-horiz li.divide-left{border-left:1px solid #404040}.wy-menu-horiz li.divide-right{border-right:1px solid #404040}.wy-menu-horiz a{height:32px;display:inline-block;line-height:32px;padding:0 16px}.wy-menu-vertical{width:300px}.wy-menu-vertical header,.wy-menu-vertical p.caption{color:#55a5d9;height:32px;line-height:32px;padding:0 1.618em;margin:12px 0 0;display:block;font-weight:700;text-transform:uppercase;font-size:85%;white-space:nowrap}.wy-menu-vertical ul{margin-bottom:0}.wy-menu-vertical li.divide-top{border-top:1px solid #404040}.wy-menu-vertical li.divide-bottom{border-bottom:1px solid #404040}.wy-menu-vertical li.current{background:#e3e3e3}.wy-menu-vertical li.current a{color:grey;border-right:1px solid #c9c9c9;padding:.4045em 2.427em}.wy-menu-vertical li.current a:hover{background:#d6d6d6}.rst-content .wy-menu-vertical li tt,.wy-menu-vertical li .rst-content tt,.wy-menu-vertical li code{border:none;background:inherit;color:inherit;padding-left:0;padding-right:0}.wy-menu-vertical li span.toctree-expand{display:block;float:left;margin-left:-1.2em;font-size:.8em;line-height:1.6em;color:#4d4d4d}.wy-menu-vertical li.current>a,.wy-menu-vertical li.on a{color:#404040;font-weight:700;position:relative;background:#fcfcfc;border:none;padding:.4045em 1.618em}.wy-menu-vertical li.current>a:hover,.wy-menu-vertical li.on a:hover{background:#fcfcfc}.wy-menu-vertical li.current>a:hover span.toctree-expand,.wy-menu-vertical li.on a:hover span.toctree-expand{color:grey}.wy-menu-vertical li.current>a span.toctree-expand,.wy-menu-vertical li.on a span.toctree-expand{display:block;font-size:.8em;line-height:1.6em;color:#333}.wy-menu-vertical li.toctree-l1.current>a{border-bottom:1px solid #c9c9c9;border-top:1px solid #c9c9c9}.wy-menu-vertical .toctree-l1.current .toctree-l2>ul,.wy-menu-vertical .toctree-l2.current .toctree-l3>ul,.wy-menu-vertical .toctree-l3.current .toctree-l4>ul,.wy-menu-vertical .toctree-l4.current .toctree-l5>ul,.wy-menu-vertical .toctree-l5.current .toctree-l6>ul,.wy-menu-vertical .toctree-l6.current .toctree-l7>ul,.wy-menu-vertical .toctree-l7.current .toctree-l8>ul,.wy-menu-vertical .toctree-l8.current .toctree-l9>ul,.wy-menu-vertical .toctree-l9.current .toctree-l10>ul,.wy-menu-vertical .toctree-l10.current .toctree-l11>ul{display:none}.wy-menu-vertical .toctree-l1.current .current.toctree-l2>ul,.wy-menu-vertical .toctree-l2.current .current.toctree-l3>ul,.wy-menu-vertical .toctree-l3.current .current.toctree-l4>ul,.wy-menu-vertical .toctree-l4.current .current.toctree-l5>ul,.wy-menu-vertical .toctree-l5.current .current.toctree-l6>ul,.wy-menu-vertical .toctree-l6.current .current.toctree-l7>ul,.wy-menu-vertical .toctree-l7.current .current.toctree-l8>ul,.wy-menu-vertical .toctree-l8.current .current.toctree-l9>ul,.wy-menu-vertical .toctree-l9.current .current.toctree-l10>ul,.wy-menu-vertical .toctree-l10.current .current.toctree-l11>ul{display:block}.wy-menu-vertical li.toctree-l3,.wy-menu-vertical li.toctree-l4{font-size:.9em}.wy-menu-vertical li.toctree-l2 a,.wy-menu-vertical li.toctree-l3 a,.wy-menu-vertical li.toctree-l4 a,.wy-menu-vertical li.toctree-l5 a,.wy-menu-vertical li.toctree-l6 a,.wy-menu-vertical li.toctree-l7 a,.wy-menu-vertical li.toctree-l8 a,.wy-menu-vertical li.toctree-l9 a,.wy-menu-vertical li.toctree-l10 a{color:#404040}.wy-menu-vertical li.toctree-l2 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l3 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l4 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l5 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l6 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l7 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l8 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l9 a:hover span.toctree-expand,.wy-menu-vertical li.toctree-l10 a:hover span.toctree-expand{color:grey}.wy-menu-vertical li.toctree-l2.current li.toctree-l3>a,.wy-menu-vertical li.toctree-l3.current li.toctree-l4>a,.wy-menu-vertical li.toctree-l4.current li.toctree-l5>a,.wy-menu-vertical li.toctree-l5.current li.toctree-l6>a,.wy-menu-vertical li.toctree-l6.current li.toctree-l7>a,.wy-menu-vertical li.toctree-l7.current li.toctree-l8>a,.wy-menu-vertical li.toctree-l8.current li.toctree-l9>a,.wy-menu-vertical li.toctree-l9.current li.toctree-l10>a,.wy-menu-vertical li.toctree-l10.current li.toctree-l11>a{display:block}.wy-menu-vertical li.toctree-l2.current>a{padding:.4045em 2.427em}.wy-menu-vertical li.toctree-l2.current li.toctree-l3>a,.wy-menu-vertical li.toctree-l3.current>a{padding:.4045em 4.045em}.wy-menu-vertical li.toctree-l3.current li.toctree-l4>a,.wy-menu-vertical li.toctree-l4.current>a{padding:.4045em 5.663em}.wy-menu-vertical li.toctree-l4.current li.toctree-l5>a,.wy-menu-vertical li.toctree-l5.current>a{padding:.4045em 7.281em}.wy-menu-vertical li.toctree-l5.current li.toctree-l6>a,.wy-menu-vertical li.toctree-l6.current>a{padding:.4045em 8.899em}.wy-menu-vertical li.toctree-l6.current li.toctree-l7>a,.wy-menu-vertical li.toctree-l7.current>a{padding:.4045em 10.517em}.wy-menu-vertical li.toctree-l7.current li.toctree-l8>a,.wy-menu-vertical li.toctree-l8.current>a{padding:.4045em 12.135em}.wy-menu-vertical li.toctree-l8.current li.toctree-l9>a,.wy-menu-vertical li.toctree-l9.current>a{padding:.4045em 13.753em}.wy-menu-vertical li.toctree-l9.current li.toctree-l10>a,.wy-menu-vertical li.toctree-l10.current>a{padding:.4045em 15.371em}.wy-menu-vertical li.toctree-l10.current li.toctree-l11>a{padding:.4045em 16.989em}.wy-menu-vertical li.toctree-l2.current>a,.wy-menu-vertical li.toctree-l2.current li.toctree-l3>a{background:#c9c9c9}.wy-menu-vertical li.toctree-l2 span.toctree-expand{color:#a3a3a3}.wy-menu-vertical li.toctree-l3.current>a,.wy-menu-vertical li.toctree-l3.current li.toctree-l4>a{background:#bdbdbd}.wy-menu-vertical li.toctree-l3 span.toctree-expand{color:#969696}.wy-menu-vertical li.current ul{display:block}.wy-menu-vertical li ul{margin-bottom:0;display:none}.wy-menu-vertical li ul li a{margin-bottom:0;color:#d9d9d9;font-weight:400}.wy-menu-vertical a{line-height:18px;padding:.4045em 1.618em;display:block;position:relative;font-size:90%;color:#d9d9d9}.wy-menu-vertical a:hover{background-color:#4e4a4a;cursor:pointer}.wy-menu-vertical a:hover span.toctree-expand{color:#d9d9d9}.wy-menu-vertical a:active{background-color:#2980b9;cursor:pointer;color:#fff}.wy-menu-vertical a:active span.toctree-expand{color:#fff}.wy-side-nav-search{display:block;width:300px;padding:.809em;margin-bottom:.809em;z-index:200;background-color:#2980b9;text-align:center;color:#fcfcfc}.wy-side-nav-search input[type=text]{width:100%;border-radius:50px;padding:6px 12px;border-color:#2472a4}.wy-side-nav-search img{display:block;margin:auto auto .809em;height:45px;width:45px;background-color:#2980b9;padding:5px;border-radius:100%}.wy-side-nav-search .wy-dropdown>a,.wy-side-nav-search>a{color:#fcfcfc;font-size:100%;font-weight:700;display:inline-block;padding:4px 6px;margin-bottom:.809em}.wy-side-nav-search .wy-dropdown>a:hover,.wy-side-nav-search>a:hover{background:hsla(0,0%,100%,.1)}.wy-side-nav-search .wy-dropdown>a img.logo,.wy-side-nav-search>a img.logo{display:block;margin:0 auto;height:auto;width:auto;border-radius:0;max-width:100%;background:transparent}.wy-side-nav-search .wy-dropdown>a.icon img.logo,.wy-side-nav-search>a.icon img.logo{margin-top:.85em}.wy-side-nav-search>div.version{margin-top:-.4045em;margin-bottom:.809em;font-weight:400;color:hsla(0,0%,100%,.3)}.wy-nav .wy-menu-vertical header{color:#2980b9}.wy-nav .wy-menu-vertical a{color:#b3b3b3}.wy-nav .wy-menu-vertical a:hover{background-color:#2980b9;color:#fff}[data-menu-wrap]{-webkit-transition:all .2s ease-in;-moz-transition:all .2s ease-in;transition:all .2s ease-in;position:absolute;opacity:1;width:100%;opacity:0}[data-menu-wrap].move-center{left:0;right:auto;opacity:1}[data-menu-wrap].move-left{right:auto;left:-100%;opacity:0}[data-menu-wrap].move-right{right:-100%;left:auto;opacity:0}.wy-body-for-nav{background:#fcfcfc}.wy-grid-for-nav{position:absolute;width:100%;height:100%}.wy-nav-side{position:fixed;top:0;bottom:0;left:0;padding-bottom:2em;width:300px;overflow-x:hidden;overflow-y:hidden;min-height:100%;color:#9b9b9b;background:#343131;z-index:200}.wy-side-scroll{width:320px;position:relative;overflow-x:hidden;overflow-y:scroll;height:100%}.wy-nav-top{display:none;background:#2980b9;color:#fff;padding:.4045em .809em;position:relative;line-height:50px;text-align:center;font-size:100%;*zoom:1}.wy-nav-top:after,.wy-nav-top:before{display:table;content:""}.wy-nav-top:after{clear:both}.wy-nav-top a{color:#fff;font-weight:700}.wy-nav-top img{margin-right:12px;height:45px;width:45px;background-color:#2980b9;padding:5px;border-radius:100%}.wy-nav-top i{font-size:30px;float:left;cursor:pointer;padding-top:inherit}.wy-nav-content-wrap{margin-left:300px;background:#fcfcfc;min-height:100%}.wy-nav-content{padding:1.618em 3.236em;height:100%;max-width:800px;margin:auto}.wy-body-mask{position:fixed;width:100%;height:100%;background:rgba(0,0,0,.2);display:none;z-index:499}.wy-body-mask.on{display:block}footer{color:grey}footer p{margin-bottom:12px}.rst-content footer span.commit tt,footer span.commit .rst-content tt,footer span.commit code{padding:0;font-family:SFMono-Regular,Menlo,Monaco,Consolas,Liberation Mono,Courier New,Courier,monospace;font-size:1em;background:none;border:none;color:grey}.rst-footer-buttons{*zoom:1}.rst-footer-buttons:after,.rst-footer-buttons:before{width:100%;display:table;content:""}.rst-footer-buttons:after{clear:both}.rst-breadcrumbs-buttons{margin-top:12px;*zoom:1}.rst-breadcrumbs-buttons:after,.rst-breadcrumbs-buttons:before{display:table;content:""}.rst-breadcrumbs-buttons:after{clear:both}#search-results .search li{margin-bottom:24px;border-bottom:1px solid #e1e4e5;padding-bottom:24px}#search-results .search li:first-child{border-top:1px solid #e1e4e5;padding-top:24px}#search-results .search li a{font-size:120%;margin-bottom:12px;display:inline-block}#search-results .context{color:grey;font-size:90%}.genindextable li>ul{margin-left:24px}@media screen and (max-width:768px){.wy-body-for-nav{background:#fcfcfc}.wy-nav-top{display:block}.wy-nav-side{left:-300px}.wy-nav-side.shift{width:85%;left:0}.wy-menu.wy-menu-vertical,.wy-side-nav-search,.wy-side-scroll{width:auto}.wy-nav-content-wrap{margin-left:0}.wy-nav-content-wrap .wy-nav-content{padding:1.618em}.wy-nav-content-wrap.shift{position:fixed;min-width:100%;left:85%;top:0;height:100%;overflow:hidden}}@media screen and (min-width:1100px){.wy-nav-content-wrap{background:rgba(0,0,0,.05)}.wy-nav-content{margin:0;background:#fcfcfc}}@media print{.rst-versions,.wy-nav-side,footer{display:none}.wy-nav-content-wrap{margin-left:0}}.rst-versions{position:fixed;bottom:0;left:0;width:300px;color:#fcfcfc;background:#1f1d1d;font-family:Lato,proxima-nova,Helvetica Neue,Arial,sans-serif;z-index:400}.rst-versions a{color:#2980b9;text-decoration:none}.rst-versions .rst-badge-small{display:none}.rst-versions .rst-current-version{padding:12px;background-color:#272525;display:block;text-align:right;font-size:90%;cursor:pointer;color:#27ae60;*zoom:1}.rst-versions .rst-current-version:after,.rst-versions .rst-current-version:before{display:table;content:""}.rst-versions .rst-current-version:after{clear:both}.rst-content .code-block-caption .rst-versions .rst-current-version .headerlink,.rst-content .rst-versions .rst-current-version .admonition-title,.rst-content code.download .rst-versions .rst-current-version span:first-child,.rst-content dl dt .rst-versions .rst-current-version .headerlink,.rst-content h1 .rst-versions .rst-current-version .headerlink,.rst-content h2 .rst-versions .rst-current-version .headerlink,.rst-content h3 .rst-versions .rst-current-version .headerlink,.rst-content h4 .rst-versions .rst-current-version .headerlink,.rst-content h5 .rst-versions .rst-current-version .headerlink,.rst-content h6 .rst-versions .rst-current-version .headerlink,.rst-content p.caption .rst-versions .rst-current-version .headerlink,.rst-content table>caption .rst-versions .rst-current-version .headerlink,.rst-content tt.download .rst-versions .rst-current-version span:first-child,.rst-versions .rst-current-version .fa,.rst-versions .rst-current-version .icon,.rst-versions .rst-current-version .rst-content .admonition-title,.rst-versions .rst-current-version .rst-content .code-block-caption .headerlink,.rst-versions .rst-current-version .rst-content code.download span:first-child,.rst-versions .rst-current-version .rst-content dl dt .headerlink,.rst-versions .rst-current-version .rst-content h1 .headerlink,.rst-versions .rst-current-version .rst-content h2 .headerlink,.rst-versions .rst-current-version .rst-content h3 .headerlink,.rst-versions .rst-current-version .rst-content h4 .headerlink,.rst-versions .rst-current-version .rst-content h5 .headerlink,.rst-versions .rst-current-version .rst-content h6 .headerlink,.rst-versions .rst-current-version .rst-content p.caption .headerlink,.rst-versions .rst-current-version .rst-content table>caption .headerlink,.rst-versions .rst-current-version .rst-content tt.download span:first-child,.rst-versions .rst-current-version .wy-menu-vertical li span.toctree-expand,.wy-menu-vertical li .rst-versions .rst-current-version span.toctree-expand{color:#fcfcfc}.rst-versions .rst-current-version .fa-book,.rst-versions .rst-current-version .icon-book{float:left}.rst-versions .rst-current-version.rst-out-of-date{background-color:#e74c3c;color:#fff}.rst-versions .rst-current-version.rst-active-old-version{background-color:#f1c40f;color:#000}.rst-versions.shift-up{height:auto;max-height:100%;overflow-y:scroll}.rst-versions.shift-up .rst-other-versions{display:block}.rst-versions .rst-other-versions{font-size:90%;padding:12px;color:grey;display:none}.rst-versions .rst-other-versions hr{display:block;height:1px;border:0;margin:20px 0;padding:0;border-top:1px solid #413d3d}.rst-versions .rst-other-versions dd{display:inline-block;margin:0}.rst-versions .rst-other-versions dd a{display:inline-block;padding:6px;color:#fcfcfc}.rst-versions.rst-badge{width:auto;bottom:20px;right:20px;left:auto;border:none;max-width:300px;max-height:90%}.rst-versions.rst-badge .fa-book,.rst-versions.rst-badge .icon-book{float:none;line-height:30px}.rst-versions.rst-badge.shift-up .rst-current-version{text-align:right}.rst-versions.rst-badge.shift-up .rst-current-version .fa-book,.rst-versions.rst-badge.shift-up .rst-current-version .icon-book{float:left}.rst-versions.rst-badge>.rst-current-version{width:auto;height:30px;line-height:30px;padding:0 6px;display:block;text-align:center}@media screen and (max-width:768px){.rst-versions{width:85%;display:none}.rst-versions.shift{display:block}}.rst-content img{max-width:100%;height:auto}.rst-content div.figure{margin-bottom:24px}.rst-content div.figure p.caption{font-style:italic}.rst-content div.figure p:last-child.caption{margin-bottom:0}.rst-content div.figure.align-center{text-align:center}.rst-content .section>a>img,.rst-content .section>img{margin-bottom:24px}.rst-content abbr[title]{text-decoration:none}.rst-content.style-external-links a.reference.external:after{font-family:FontAwesome;content:"\f08e";color:#b3b3b3;vertical-align:super;font-size:60%;margin:0 .2em}.rst-content blockquote{margin-left:24px;line-height:24px;margin-bottom:24px}.rst-content pre.literal-block{white-space:pre;margin:0;padding:12px;font-family:SFMono-Regular,Menlo,Monaco,Consolas,Liberation Mono,Courier New,Courier,monospace;display:block;overflow:auto}.rst-content div[class^=highlight],.rst-content pre.literal-block{border:1px solid #e1e4e5;overflow-x:auto;margin:1px 0 24px}.rst-content div[class^=highlight] div[class^=highlight],.rst-content pre.literal-block div[class^=highlight]{padding:0;border:none;margin:0}.rst-content div[class^=highlight] td.code{width:100%}.rst-content .linenodiv pre{border-right:1px solid #e6e9ea;margin:0;padding:12px;font-family:SFMono-Regular,Menlo,Monaco,Consolas,Liberation Mono,Courier New,Courier,monospace;user-select:none;pointer-events:none}.rst-content div[class^=highlight] pre{white-space:pre;margin:0;padding:12px;display:block;overflow:auto}.rst-content div[class^=highlight] pre .hll{display:block;margin:0 -12px;padding:0 12px}.rst-content .linenodiv pre,.rst-content div[class^=highlight] pre,.rst-content pre.literal-block{font-family:SFMono-Regular,Menlo,Monaco,Consolas,Liberation Mono,Courier New,Courier,monospace;font-size:12px;line-height:1.4}.rst-content div.highlight .gp{user-select:none;pointer-events:none}.rst-content .code-block-caption{font-style:italic;font-size:85%;line-height:1;padding:1em 0;text-align:center}@media print{.rst-content .codeblock,.rst-content div[class^=highlight],.rst-content div[class^=highlight] pre{white-space:pre-wrap}}.rst-content .admonition,.rst-content .admonition-todo,.rst-content .attention,.rst-content .caution,.rst-content .danger,.rst-content .error,.rst-content .hint,.rst-content .important,.rst-content .note,.rst-content .seealso,.rst-content .tip,.rst-content .warning{clear:both}.rst-content .admonition-todo .last,.rst-content .admonition-todo>:last-child,.rst-content .admonition .last,.rst-content .admonition>:last-child,.rst-content .attention .last,.rst-content .attention>:last-child,.rst-content .caution .last,.rst-content .caution>:last-child,.rst-content .danger .last,.rst-content .danger>:last-child,.rst-content .error .last,.rst-content .error>:last-child,.rst-content .hint .last,.rst-content .hint>:last-child,.rst-content .important .last,.rst-content .important>:last-child,.rst-content .note .last,.rst-content .note>:last-child,.rst-content .seealso .last,.rst-content .seealso>:last-child,.rst-content .tip .last,.rst-content .tip>:last-child,.rst-content .warning .last,.rst-content .warning>:last-child{margin-bottom:0}.rst-content .admonition-title:before{margin-right:4px}.rst-content .admonition table{border-color:rgba(0,0,0,.1)}.rst-content .admonition table td,.rst-content .admonition table th{background:transparent!important;border-color:rgba(0,0,0,.1)!important}.rst-content .section ol.loweralpha,.rst-content .section ol.loweralpha>li{list-style:lower-alpha}.rst-content .section ol.upperalpha,.rst-content .section ol.upperalpha>li{list-style:upper-alpha}.rst-content .section ol li>*,.rst-content .section ul li>*{margin-top:12px;margin-bottom:12px}.rst-content .section ol li>:first-child,.rst-content .section ul li>:first-child{margin-top:0}.rst-content .section ol li>p,.rst-content .section ol li>p:last-child,.rst-content .section ul li>p,.rst-content .section ul li>p:last-child{margin-bottom:12px}.rst-content .section ol li>p:only-child,.rst-content .section ol li>p:only-child:last-child,.rst-content .section ul li>p:only-child,.rst-content .section ul li>p:only-child:last-child{margin-bottom:0}.rst-content .section ol li>ol,.rst-content .section ol li>ul,.rst-content .section ul li>ol,.rst-content .section ul li>ul{margin-bottom:12px}.rst-content .section ol.simple li>*,.rst-content .section ol.simple li ol,.rst-content .section ol.simple li ul,.rst-content .section ul.simple li>*,.rst-content .section ul.simple li ol,.rst-content .section ul.simple li ul{margin-top:0;margin-bottom:0}.rst-content .line-block{margin-left:0;margin-bottom:24px;line-height:24px}.rst-content .line-block .line-block{margin-left:24px;margin-bottom:0}.rst-content .topic-title{font-weight:700;margin-bottom:12px}.rst-content .toc-backref{color:#404040}.rst-content .align-right{float:right;margin:0 0 24px 24px}.rst-content .align-left{float:left;margin:0 24px 24px 0}.rst-content .align-center{margin:auto}.rst-content .align-center:not(table){display:block}.rst-content .code-block-caption .headerlink,.rst-content .toctree-wrapper>p.caption .headerlink,.rst-content dl dt .headerlink,.rst-content h1 .headerlink,.rst-content h2 .headerlink,.rst-content h3 .headerlink,.rst-content h4 .headerlink,.rst-content h5 .headerlink,.rst-content h6 .headerlink,.rst-content p.caption .headerlink,.rst-content table>caption .headerlink{visibility:hidden;font-size:14px}.rst-content .code-block-caption .headerlink:after,.rst-content .toctree-wrapper>p.caption .headerlink:after,.rst-content dl dt .headerlink:after,.rst-content h1 .headerlink:after,.rst-content h2 .headerlink:after,.rst-content h3 .headerlink:after,.rst-content h4 .headerlink:after,.rst-content h5 .headerlink:after,.rst-content h6 .headerlink:after,.rst-content p.caption .headerlink:after,.rst-content table>caption .headerlink:after{content:"\f0c1";font-family:FontAwesome}.rst-content .code-block-caption:hover .headerlink:after,.rst-content .toctree-wrapper>p.caption:hover .headerlink:after,.rst-content dl dt:hover .headerlink:after,.rst-content h1:hover .headerlink:after,.rst-content h2:hover .headerlink:after,.rst-content h3:hover .headerlink:after,.rst-content h4:hover .headerlink:after,.rst-content h5:hover .headerlink:after,.rst-content h6:hover .headerlink:after,.rst-content p.caption:hover .headerlink:after,.rst-content table>caption:hover .headerlink:after{visibility:visible}.rst-content table>caption .headerlink:after{font-size:12px}.rst-content .centered{text-align:center}.rst-content .sidebar{float:right;width:40%;display:block;margin:0 0 24px 24px;padding:24px;background:#f3f6f6;border:1px solid #e1e4e5}.rst-content .sidebar dl,.rst-content .sidebar p,.rst-content .sidebar ul{font-size:90%}.rst-content .sidebar .last,.rst-content .sidebar>:last-child{margin-bottom:0}.rst-content .sidebar .sidebar-title{display:block;font-family:Roboto Slab,ff-tisa-web-pro,Georgia,Arial,sans-serif;font-weight:700;background:#e1e4e5;padding:6px 12px;margin:-24px -24px 24px;font-size:100%}.rst-content .highlighted{background:#f1c40f;box-shadow:0 0 0 2px #f1c40f;display:inline;font-weight:700}.rst-content .citation-reference,.rst-content .footnote-reference{vertical-align:baseline;position:relative;top:-.4em;line-height:0;font-size:90%}.rst-content .hlist{width:100%}html.writer-html4 .rst-content table.docutils.citation,html.writer-html4 .rst-content table.docutils.footnote{background:none;border:none}html.writer-html4 .rst-content table.docutils.citation td,html.writer-html4 .rst-content table.docutils.citation tr,html.writer-html4 .rst-content table.docutils.footnote td,html.writer-html4 .rst-content table.docutils.footnote tr{border:none;background-color:transparent!important;white-space:normal}html.writer-html4 .rst-content table.docutils.citation td.label,html.writer-html4 .rst-content table.docutils.footnote td.label{padding-left:0;padding-right:0;vertical-align:top}html.writer-html5 .rst-content dl dt span.classifier:before{content:" : "}html.writer-html5 .rst-content dl.field-list,html.writer-html5 .rst-content dl.footnote{display:grid;grid-template-columns:max-content auto}html.writer-html5 .rst-content dl.field-list>dt,html.writer-html5 .rst-content dl.footnote>dt{padding-left:1rem}html.writer-html5 .rst-content dl.field-list>dt:after,html.writer-html5 .rst-content dl.footnote>dt:after{content:":"}html.writer-html5 .rst-content dl.field-list>dd,html.writer-html5 .rst-content dl.field-list>dt,html.writer-html5 .rst-content dl.footnote>dd,html.writer-html5 .rst-content dl.footnote>dt{margin-bottom:0}html.writer-html5 .rst-content dl.footnote{font-size:.9rem}html.writer-html5 .rst-content dl.footnote>dt{margin:0 .5rem .5rem 0;line-height:1.2rem;word-break:break-all;font-weight:400}html.writer-html5 .rst-content dl.footnote>dt>span.brackets{margin-right:.5rem}html.writer-html5 .rst-content dl.footnote>dt>span.brackets:before{content:"["}html.writer-html5 .rst-content dl.footnote>dt>span.brackets:after{content:"]"}html.writer-html5 .rst-content dl.footnote>dt>span.fn-backref{font-style:italic}html.writer-html5 .rst-content dl.footnote>dd{margin:0 0 .5rem;line-height:1.2rem}html.writer-html5 .rst-content dl.footnote>dd p,html.writer-html5 .rst-content dl.option-list kbd{font-size:.9rem}.rst-content table.docutils.footnote,html.writer-html4 .rst-content table.docutils.citation,html.writer-html5 .rst-content dl.footnote{color:grey}.rst-content table.docutils.footnote code,.rst-content table.docutils.footnote tt,html.writer-html4 .rst-content table.docutils.citation code,html.writer-html4 .rst-content table.docutils.citation tt,html.writer-html5 .rst-content dl.footnote code,html.writer-html5 .rst-content dl.footnote tt{color:#555}.rst-content .wy-table-responsive.citation,.rst-content .wy-table-responsive.footnote{margin-bottom:0}.rst-content .wy-table-responsive.citation+:not(.citation),.rst-content .wy-table-responsive.footnote+:not(.footnote){margin-top:24px}.rst-content .wy-table-responsive.citation:last-child,.rst-content .wy-table-responsive.footnote:last-child{margin-bottom:24px}.rst-content table.docutils th{border-color:#e1e4e5}html.writer-html5 .rst-content table.docutils th{border:1px solid #e1e4e5}html.writer-html5 .rst-content table.docutils td>p,html.writer-html5 .rst-content table.docutils th>p{line-height:1rem;margin-bottom:0;font-size:.9rem}.rst-content table.docutils td .last,.rst-content table.docutils td .last>:last-child{margin-bottom:0}.rst-content table.field-list,.rst-content table.field-list td{border:none}.rst-content table.field-list td p{font-size:inherit;line-height:inherit}.rst-content table.field-list td>strong{display:inline-block}.rst-content table.field-list .field-name{padding-right:10px;text-align:left;white-space:nowrap}.rst-content table.field-list .field-body{text-align:left}.rst-content code,.rst-content tt{color:#000;font-family:SFMono-Regular,Menlo,Monaco,Consolas,Liberation Mono,Courier New,Courier,monospace;padding:2px 5px}.rst-content code big,.rst-content code em,.rst-content tt big,.rst-content tt em{font-size:100%!important;line-height:normal}.rst-content code.literal,.rst-content tt.literal{color:#e74c3c}.rst-content code.xref,.rst-content tt.xref,a .rst-content code,a .rst-content tt{font-weight:700;color:#404040}.rst-content kbd,.rst-content pre,.rst-content samp{font-family:SFMono-Regular,Menlo,Monaco,Consolas,Liberation Mono,Courier New,Courier,monospace}.rst-content a code,.rst-content a tt{color:#2980b9}.rst-content dl{margin-bottom:24px}.rst-content dl dt{font-weight:700;margin-bottom:12px}.rst-content dl ol,.rst-content dl p,.rst-content dl table,.rst-content dl ul{margin-bottom:12px}.rst-content dl dd{margin:0 0 12px 24px;line-height:24px}html.writer-html4 .rst-content dl:not(.docutils),html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple){margin-bottom:24px}html.writer-html4 .rst-content dl:not(.docutils)>dt,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple)>dt{display:table;margin:6px 0;font-size:90%;line-height:normal;background:#e7f2fa;color:#2980b9;border-top:3px solid #6ab0de;padding:6px;position:relative}html.writer-html4 .rst-content dl:not(.docutils)>dt:before,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple)>dt:before{color:#6ab0de}html.writer-html4 .rst-content dl:not(.docutils)>dt .headerlink,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple)>dt .headerlink{color:#404040;font-size:100%!important}html.writer-html4 .rst-content dl:not(.docutils) dl:not(.field-list)>dt,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) dl:not(.field-list)>dt{margin-bottom:6px;border:none;border-left:3px solid #ccc;background:#f0f0f0;color:#555}html.writer-html4 .rst-content dl:not(.docutils) dl:not(.field-list)>dt .headerlink,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) dl:not(.field-list)>dt .headerlink{color:#404040;font-size:100%!important}html.writer-html4 .rst-content dl:not(.docutils)>dt:first-child,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple)>dt:first-child{margin-top:0}html.writer-html4 .rst-content dl:not(.docutils) code,html.writer-html4 .rst-content dl:not(.docutils) tt,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) code,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) tt{font-weight:700}html.writer-html4 .rst-content dl:not(.docutils) code.descclassname,html.writer-html4 .rst-content dl:not(.docutils) code.descname,html.writer-html4 .rst-content dl:not(.docutils) tt.descclassname,html.writer-html4 .rst-content dl:not(.docutils) tt.descname,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) code.descclassname,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) code.descname,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) tt.descclassname,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) tt.descname{background-color:transparent;border:none;padding:0;font-size:100%!important}html.writer-html4 .rst-content dl:not(.docutils) code.descname,html.writer-html4 .rst-content dl:not(.docutils) tt.descname,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) code.descname,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) tt.descname{font-weight:700}html.writer-html4 .rst-content dl:not(.docutils) .optional,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) .optional{display:inline-block;padding:0 4px;color:#000;font-weight:700}html.writer-html4 .rst-content dl:not(.docutils) .property,html.writer-html5 .rst-content dl[class]:not(.option-list):not(.field-list):not(.footnote):not(.glossary):not(.simple) .property{display:inline-block;padding-right:8px}.rst-content .viewcode-back,.rst-content .viewcode-link{display:inline-block;color:#27ae60;font-size:80%;padding-left:24px}.rst-content .viewcode-back{display:block;float:right}.rst-content p.rubric{margin-bottom:12px;font-weight:700}.rst-content code.download,.rst-content tt.download{background:inherit;padding:inherit;font-weight:400;font-family:inherit;font-size:inherit;color:inherit;border:inherit;white-space:inherit}.rst-content code.download span:first-child,.rst-content tt.download span:first-child{-webkit-font-smoothing:subpixel-antialiased}.rst-content code.download span:first-child:before,.rst-content tt.download span:first-child:before{margin-right:4px}.rst-content .guilabel{border:1px solid #7fbbe3;background:#e7f2fa;font-size:80%;font-weight:700;border-radius:4px;padding:2.4px 6px;margin:auto 2px}.rst-content .versionmodified{font-style:italic}@media screen and (max-width:480px){.rst-content .sidebar{width:100%}}span[id*=MathJax-Span]{color:#404040}.math{text-align:center}@font-face{font-family:Lato;src:url(fonts/lato-normal.woff2?bd03a2cc277bbbc338d464e679fe9942) format("woff2"),url(fonts/lato-normal.woff?27bd77b9162d388cb8d4c4217c7c5e2a) format("woff");font-weight:400;font-style:normal;font-display:block}@font-face{font-family:Lato;src:url(fonts/lato-bold.woff2?cccb897485813c7c256901dbca54ecf2) format("woff2"),url(fonts/lato-bold.woff?d878b6c29b10beca227e9eef4246111b) format("woff");font-weight:700;font-style:normal;font-display:block}@font-face{font-family:Lato;src:url(fonts/lato-bold-italic.woff2?0b6bb6725576b072c5d0b02ecdd1900d) format("woff2"),url(fonts/lato-bold-italic.woff?9c7e4e9eb485b4a121c760e61bc3707c) format("woff");font-weight:700;font-style:italic;font-display:block}@font-face{font-family:Lato;src:url(fonts/lato-normal-italic.woff2?4eb103b4d12be57cb1d040ed5e162e9d) format("woff2"),url(fonts/lato-normal-italic.woff?f28f2d6482446544ef1ea1ccc6dd5892) format("woff");font-weight:400;font-style:italic;font-display:block}@font-face{font-family:Roboto Slab;font-style:normal;font-weight:400;src:url(fonts/Roboto-Slab-Regular.woff2?7abf5b8d04d26a2cafea937019bca958) format("woff2"),url(fonts/Roboto-Slab-Regular.woff?c1be9284088d487c5e3ff0a10a92e58c) format("woff");font-display:block}@font-face{font-family:Roboto Slab;font-style:normal;font-weight:700;src:url(fonts/Roboto-Slab-Bold.woff2?9984f4a9bda09be08e83f2506954adbe) format("woff2"),url(fonts/Roboto-Slab-Bold.woff?bed5564a116b05148e3b3bea6fb1162a) format("woff");font-display:block}
\ No newline at end of file
diff --git a/docs/_static/doctools.js b/docs/_static/doctools.js
deleted file mode 100644
index 61ac9d26..00000000
--- a/docs/_static/doctools.js
+++ /dev/null
@@ -1,321 +0,0 @@
-/*
- * doctools.js
- * ~~~~~~~~~~~
- *
- * Sphinx JavaScript utilities for all documentation.
- *
- * :copyright: Copyright 2007-2021 by the Sphinx team, see AUTHORS.
- * :license: BSD, see LICENSE for details.
- *
- */
-
-/**
- * select a different prefix for underscore
- */
-$u = _.noConflict();
-
-/**
- * make the code below compatible with browsers without
- * an installed firebug like debugger
-if (!window.console || !console.firebug) {
- var names = ["log", "debug", "info", "warn", "error", "assert", "dir",
- "dirxml", "group", "groupEnd", "time", "timeEnd", "count", "trace",
- "profile", "profileEnd"];
- window.console = {};
- for (var i = 0; i < names.length; ++i)
- window.console[names[i]] = function() {};
-}
- */
-
-/**
- * small helper function to urldecode strings
- *
- * See https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/decodeURIComponent#Decoding_query_parameters_from_a_URL
- */
-jQuery.urldecode = function(x) {
- if (!x) {
- return x
- }
- return decodeURIComponent(x.replace(/\+/g, ' '));
-};
-
-/**
- * small helper function to urlencode strings
- */
-jQuery.urlencode = encodeURIComponent;
-
-/**
- * This function returns the parsed url parameters of the
- * current request. Multiple values per key are supported,
- * it will always return arrays of strings for the value parts.
- */
-jQuery.getQueryParameters = function(s) {
- if (typeof s === 'undefined')
- s = document.location.search;
- var parts = s.substr(s.indexOf('?') + 1).split('&');
- var result = {};
- for (var i = 0; i < parts.length; i++) {
- var tmp = parts[i].split('=', 2);
- var key = jQuery.urldecode(tmp[0]);
- var value = jQuery.urldecode(tmp[1]);
- if (key in result)
- result[key].push(value);
- else
- result[key] = [value];
- }
- return result;
-};
-
-/**
- * highlight a given string on a jquery object by wrapping it in
- * span elements with the given class name.
- */
-jQuery.fn.highlightText = function(text, className) {
- function highlight(node, addItems) {
- if (node.nodeType === 3) {
- var val = node.nodeValue;
- var pos = val.toLowerCase().indexOf(text);
- if (pos >= 0 &&
- !jQuery(node.parentNode).hasClass(className) &&
- !jQuery(node.parentNode).hasClass("nohighlight")) {
- var span;
- var isInSVG = jQuery(node).closest("body, svg, foreignObject").is("svg");
- if (isInSVG) {
- span = document.createElementNS("http://www.w3.org/2000/svg", "tspan");
- } else {
- span = document.createElement("span");
- span.className = className;
- }
- span.appendChild(document.createTextNode(val.substr(pos, text.length)));
- node.parentNode.insertBefore(span, node.parentNode.insertBefore(
- document.createTextNode(val.substr(pos + text.length)),
- node.nextSibling));
- node.nodeValue = val.substr(0, pos);
- if (isInSVG) {
- var rect = document.createElementNS("http://www.w3.org/2000/svg", "rect");
- var bbox = node.parentElement.getBBox();
- rect.x.baseVal.value = bbox.x;
- rect.y.baseVal.value = bbox.y;
- rect.width.baseVal.value = bbox.width;
- rect.height.baseVal.value = bbox.height;
- rect.setAttribute('class', className);
- addItems.push({
- "parent": node.parentNode,
- "target": rect});
- }
- }
- }
- else if (!jQuery(node).is("button, select, textarea")) {
- jQuery.each(node.childNodes, function() {
- highlight(this, addItems);
- });
- }
- }
- var addItems = [];
- var result = this.each(function() {
- highlight(this, addItems);
- });
- for (var i = 0; i < addItems.length; ++i) {
- jQuery(addItems[i].parent).before(addItems[i].target);
- }
- return result;
-};
-
-/*
- * backward compatibility for jQuery.browser
- * This will be supported until firefox bug is fixed.
- */
-if (!jQuery.browser) {
- jQuery.uaMatch = function(ua) {
- ua = ua.toLowerCase();
-
- var match = /(chrome)[ \/]([\w.]+)/.exec(ua) ||
- /(webkit)[ \/]([\w.]+)/.exec(ua) ||
- /(opera)(?:.*version|)[ \/]([\w.]+)/.exec(ua) ||
- /(msie) ([\w.]+)/.exec(ua) ||
- ua.indexOf("compatible") < 0 && /(mozilla)(?:.*? rv:([\w.]+)|)/.exec(ua) ||
- [];
-
- return {
- browser: match[ 1 ] || "",
- version: match[ 2 ] || "0"
- };
- };
- jQuery.browser = {};
- jQuery.browser[jQuery.uaMatch(navigator.userAgent).browser] = true;
-}
-
-/**
- * Small JavaScript module for the documentation.
- */
-var Documentation = {
-
- init : function() {
- this.fixFirefoxAnchorBug();
- this.highlightSearchWords();
- this.initIndexTable();
- if (DOCUMENTATION_OPTIONS.NAVIGATION_WITH_KEYS) {
- this.initOnKeyListeners();
- }
- },
-
- /**
- * i18n support
- */
- TRANSLATIONS : {},
- PLURAL_EXPR : function(n) { return n === 1 ? 0 : 1; },
- LOCALE : 'unknown',
-
- // gettext and ngettext don't access this so that the functions
- // can safely bound to a different name (_ = Documentation.gettext)
- gettext : function(string) {
- var translated = Documentation.TRANSLATIONS[string];
- if (typeof translated === 'undefined')
- return string;
- return (typeof translated === 'string') ? translated : translated[0];
- },
-
- ngettext : function(singular, plural, n) {
- var translated = Documentation.TRANSLATIONS[singular];
- if (typeof translated === 'undefined')
- return (n == 1) ? singular : plural;
- return translated[Documentation.PLURALEXPR(n)];
- },
-
- addTranslations : function(catalog) {
- for (var key in catalog.messages)
- this.TRANSLATIONS[key] = catalog.messages[key];
- this.PLURAL_EXPR = new Function('n', 'return +(' + catalog.plural_expr + ')');
- this.LOCALE = catalog.locale;
- },
-
- /**
- * add context elements like header anchor links
- */
- addContextElements : function() {
- $('div[id] > :header:first').each(function() {
- $('').
- attr('href', '#' + this.id).
- attr('title', _('Permalink to this headline')).
- appendTo(this);
- });
- $('dt[id]').each(function() {
- $('').
- attr('href', '#' + this.id).
- attr('title', _('Permalink to this definition')).
- appendTo(this);
- });
- },
-
- /**
- * workaround a firefox stupidity
- * see: https://bugzilla.mozilla.org/show_bug.cgi?id=645075
- */
- fixFirefoxAnchorBug : function() {
- if (document.location.hash && $.browser.mozilla)
- window.setTimeout(function() {
- document.location.href += '';
- }, 10);
- },
-
- /**
- * highlight the search words provided in the url in the text
- */
- highlightSearchWords : function() {
- var params = $.getQueryParameters();
- var terms = (params.highlight) ? params.highlight[0].split(/\s+/) : [];
- if (terms.length) {
- var body = $('div.body');
- if (!body.length) {
- body = $('body');
- }
- window.setTimeout(function() {
- $.each(terms, function() {
- body.highlightText(this.toLowerCase(), 'highlighted');
- });
- }, 10);
- $('
' + _('Hide Search Matches') + '
')
- .appendTo($('#searchbox'));
- }
- },
-
- /**
- * init the domain index toggle buttons
- */
- initIndexTable : function() {
- var togglers = $('img.toggler').click(function() {
- var src = $(this).attr('src');
- var idnum = $(this).attr('id').substr(7);
- $('tr.cg-' + idnum).toggle();
- if (src.substr(-9) === 'minus.png')
- $(this).attr('src', src.substr(0, src.length-9) + 'plus.png');
- else
- $(this).attr('src', src.substr(0, src.length-8) + 'minus.png');
- }).css('display', '');
- if (DOCUMENTATION_OPTIONS.COLLAPSE_INDEX) {
- togglers.click();
- }
- },
-
- /**
- * helper function to hide the search marks again
- */
- hideSearchWords : function() {
- $('#searchbox .highlight-link').fadeOut(300);
- $('span.highlighted').removeClass('highlighted');
- },
-
- /**
- * make the url absolute
- */
- makeURL : function(relativeURL) {
- return DOCUMENTATION_OPTIONS.URL_ROOT + '/' + relativeURL;
- },
-
- /**
- * get the current relative url
- */
- getCurrentURL : function() {
- var path = document.location.pathname;
- var parts = path.split(/\//);
- $.each(DOCUMENTATION_OPTIONS.URL_ROOT.split(/\//), function() {
- if (this === '..')
- parts.pop();
- });
- var url = parts.join('/');
- return path.substring(url.lastIndexOf('/') + 1, path.length - 1);
- },
-
- initOnKeyListeners: function() {
- $(document).keydown(function(event) {
- var activeElementType = document.activeElement.tagName;
- // don't navigate when in search box, textarea, dropdown or button
- if (activeElementType !== 'TEXTAREA' && activeElementType !== 'INPUT' && activeElementType !== 'SELECT'
- && activeElementType !== 'BUTTON' && !event.altKey && !event.ctrlKey && !event.metaKey
- && !event.shiftKey) {
- switch (event.keyCode) {
- case 37: // left
- var prevHref = $('link[rel="prev"]').prop('href');
- if (prevHref) {
- window.location.href = prevHref;
- return false;
- }
- case 39: // right
- var nextHref = $('link[rel="next"]').prop('href');
- if (nextHref) {
- window.location.href = nextHref;
- return false;
- }
- }
- }
- });
- }
-};
-
-// quick alias for translations
-_ = Documentation.gettext;
-
-$(document).ready(function() {
- Documentation.init();
-});
diff --git a/docs/_static/documentation_options.js b/docs/_static/documentation_options.js
deleted file mode 100644
index 8839ac8c..00000000
--- a/docs/_static/documentation_options.js
+++ /dev/null
@@ -1,12 +0,0 @@
-var DOCUMENTATION_OPTIONS = {
- URL_ROOT: document.getElementById("documentation_options").getAttribute('data-url_root'),
- VERSION: '0.1',
- LANGUAGE: 'None',
- COLLAPSE_INDEX: false,
- BUILDER: 'html',
- FILE_SUFFIX: '.html',
- LINK_SUFFIX: '.html',
- HAS_SOURCE: true,
- SOURCELINK_SUFFIX: '.txt',
- NAVIGATION_WITH_KEYS: false
-};
\ No newline at end of file
diff --git a/docs/_static/file.png b/docs/_static/file.png
deleted file mode 100644
index a858a410..00000000
Binary files a/docs/_static/file.png and /dev/null differ
diff --git a/docs/_static/jquery-3.5.1.js b/docs/_static/jquery-3.5.1.js
deleted file mode 100644
index 50937333..00000000
--- a/docs/_static/jquery-3.5.1.js
+++ /dev/null
@@ -1,10872 +0,0 @@
-/*!
- * jQuery JavaScript Library v3.5.1
- * https://jquery.com/
- *
- * Includes Sizzle.js
- * https://sizzlejs.com/
- *
- * Copyright JS Foundation and other contributors
- * Released under the MIT license
- * https://jquery.org/license
- *
- * Date: 2020-05-04T22:49Z
- */
-( function( global, factory ) {
-
- "use strict";
-
- if ( typeof module === "object" && typeof module.exports === "object" ) {
-
- // For CommonJS and CommonJS-like environments where a proper `window`
- // is present, execute the factory and get jQuery.
- // For environments that do not have a `window` with a `document`
- // (such as Node.js), expose a factory as module.exports.
- // This accentuates the need for the creation of a real `window`.
- // e.g. var jQuery = require("jquery")(window);
- // See ticket #14549 for more info.
- module.exports = global.document ?
- factory( global, true ) :
- function( w ) {
- if ( !w.document ) {
- throw new Error( "jQuery requires a window with a document" );
- }
- return factory( w );
- };
- } else {
- factory( global );
- }
-
-// Pass this if window is not defined yet
-} )( typeof window !== "undefined" ? window : this, function( window, noGlobal ) {
-
-// Edge <= 12 - 13+, Firefox <=18 - 45+, IE 10 - 11, Safari 5.1 - 9+, iOS 6 - 9.1
-// throw exceptions when non-strict code (e.g., ASP.NET 4.5) accesses strict mode
-// arguments.callee.caller (trac-13335). But as of jQuery 3.0 (2016), strict mode should be common
-// enough that all such attempts are guarded in a try block.
-"use strict";
-
-var arr = [];
-
-var getProto = Object.getPrototypeOf;
-
-var slice = arr.slice;
-
-var flat = arr.flat ? function( array ) {
- return arr.flat.call( array );
-} : function( array ) {
- return arr.concat.apply( [], array );
-};
-
-
-var push = arr.push;
-
-var indexOf = arr.indexOf;
-
-var class2type = {};
-
-var toString = class2type.toString;
-
-var hasOwn = class2type.hasOwnProperty;
-
-var fnToString = hasOwn.toString;
-
-var ObjectFunctionString = fnToString.call( Object );
-
-var support = {};
-
-var isFunction = function isFunction( obj ) {
-
- // Support: Chrome <=57, Firefox <=52
- // In some browsers, typeof returns "function" for HTML elements
- // (i.e., `typeof document.createElement( "object" ) === "function"`).
- // We don't want to classify *any* DOM node as a function.
- return typeof obj === "function" && typeof obj.nodeType !== "number";
- };
-
-
-var isWindow = function isWindow( obj ) {
- return obj != null && obj === obj.window;
- };
-
-
-var document = window.document;
-
-
-
- var preservedScriptAttributes = {
- type: true,
- src: true,
- nonce: true,
- noModule: true
- };
-
- function DOMEval( code, node, doc ) {
- doc = doc || document;
-
- var i, val,
- script = doc.createElement( "script" );
-
- script.text = code;
- if ( node ) {
- for ( i in preservedScriptAttributes ) {
-
- // Support: Firefox 64+, Edge 18+
- // Some browsers don't support the "nonce" property on scripts.
- // On the other hand, just using `getAttribute` is not enough as
- // the `nonce` attribute is reset to an empty string whenever it
- // becomes browsing-context connected.
- // See https://github.com/whatwg/html/issues/2369
- // See https://html.spec.whatwg.org/#nonce-attributes
- // The `node.getAttribute` check was added for the sake of
- // `jQuery.globalEval` so that it can fake a nonce-containing node
- // via an object.
- val = node[ i ] || node.getAttribute && node.getAttribute( i );
- if ( val ) {
- script.setAttribute( i, val );
- }
- }
- }
- doc.head.appendChild( script ).parentNode.removeChild( script );
- }
-
-
-function toType( obj ) {
- if ( obj == null ) {
- return obj + "";
- }
-
- // Support: Android <=2.3 only (functionish RegExp)
- return typeof obj === "object" || typeof obj === "function" ?
- class2type[ toString.call( obj ) ] || "object" :
- typeof obj;
-}
-/* global Symbol */
-// Defining this global in .eslintrc.json would create a danger of using the global
-// unguarded in another place, it seems safer to define global only for this module
-
-
-
-var
- version = "3.5.1",
-
- // Define a local copy of jQuery
- jQuery = function( selector, context ) {
-
- // The jQuery object is actually just the init constructor 'enhanced'
- // Need init if jQuery is called (just allow error to be thrown if not included)
- return new jQuery.fn.init( selector, context );
- };
-
-jQuery.fn = jQuery.prototype = {
-
- // The current version of jQuery being used
- jquery: version,
-
- constructor: jQuery,
-
- // The default length of a jQuery object is 0
- length: 0,
-
- toArray: function() {
- return slice.call( this );
- },
-
- // Get the Nth element in the matched element set OR
- // Get the whole matched element set as a clean array
- get: function( num ) {
-
- // Return all the elements in a clean array
- if ( num == null ) {
- return slice.call( this );
- }
-
- // Return just the one element from the set
- return num < 0 ? this[ num + this.length ] : this[ num ];
- },
-
- // Take an array of elements and push it onto the stack
- // (returning the new matched element set)
- pushStack: function( elems ) {
-
- // Build a new jQuery matched element set
- var ret = jQuery.merge( this.constructor(), elems );
-
- // Add the old object onto the stack (as a reference)
- ret.prevObject = this;
-
- // Return the newly-formed element set
- return ret;
- },
-
- // Execute a callback for every element in the matched set.
- each: function( callback ) {
- return jQuery.each( this, callback );
- },
-
- map: function( callback ) {
- return this.pushStack( jQuery.map( this, function( elem, i ) {
- return callback.call( elem, i, elem );
- } ) );
- },
-
- slice: function() {
- return this.pushStack( slice.apply( this, arguments ) );
- },
-
- first: function() {
- return this.eq( 0 );
- },
-
- last: function() {
- return this.eq( -1 );
- },
-
- even: function() {
- return this.pushStack( jQuery.grep( this, function( _elem, i ) {
- return ( i + 1 ) % 2;
- } ) );
- },
-
- odd: function() {
- return this.pushStack( jQuery.grep( this, function( _elem, i ) {
- return i % 2;
- } ) );
- },
-
- eq: function( i ) {
- var len = this.length,
- j = +i + ( i < 0 ? len : 0 );
- return this.pushStack( j >= 0 && j < len ? [ this[ j ] ] : [] );
- },
-
- end: function() {
- return this.prevObject || this.constructor();
- },
-
- // For internal use only.
- // Behaves like an Array's method, not like a jQuery method.
- push: push,
- sort: arr.sort,
- splice: arr.splice
-};
-
-jQuery.extend = jQuery.fn.extend = function() {
- var options, name, src, copy, copyIsArray, clone,
- target = arguments[ 0 ] || {},
- i = 1,
- length = arguments.length,
- deep = false;
-
- // Handle a deep copy situation
- if ( typeof target === "boolean" ) {
- deep = target;
-
- // Skip the boolean and the target
- target = arguments[ i ] || {};
- i++;
- }
-
- // Handle case when target is a string or something (possible in deep copy)
- if ( typeof target !== "object" && !isFunction( target ) ) {
- target = {};
- }
-
- // Extend jQuery itself if only one argument is passed
- if ( i === length ) {
- target = this;
- i--;
- }
-
- for ( ; i < length; i++ ) {
-
- // Only deal with non-null/undefined values
- if ( ( options = arguments[ i ] ) != null ) {
-
- // Extend the base object
- for ( name in options ) {
- copy = options[ name ];
-
- // Prevent Object.prototype pollution
- // Prevent never-ending loop
- if ( name === "__proto__" || target === copy ) {
- continue;
- }
-
- // Recurse if we're merging plain objects or arrays
- if ( deep && copy && ( jQuery.isPlainObject( copy ) ||
- ( copyIsArray = Array.isArray( copy ) ) ) ) {
- src = target[ name ];
-
- // Ensure proper type for the source value
- if ( copyIsArray && !Array.isArray( src ) ) {
- clone = [];
- } else if ( !copyIsArray && !jQuery.isPlainObject( src ) ) {
- clone = {};
- } else {
- clone = src;
- }
- copyIsArray = false;
-
- // Never move original objects, clone them
- target[ name ] = jQuery.extend( deep, clone, copy );
-
- // Don't bring in undefined values
- } else if ( copy !== undefined ) {
- target[ name ] = copy;
- }
- }
- }
- }
-
- // Return the modified object
- return target;
-};
-
-jQuery.extend( {
-
- // Unique for each copy of jQuery on the page
- expando: "jQuery" + ( version + Math.random() ).replace( /\D/g, "" ),
-
- // Assume jQuery is ready without the ready module
- isReady: true,
-
- error: function( msg ) {
- throw new Error( msg );
- },
-
- noop: function() {},
-
- isPlainObject: function( obj ) {
- var proto, Ctor;
-
- // Detect obvious negatives
- // Use toString instead of jQuery.type to catch host objects
- if ( !obj || toString.call( obj ) !== "[object Object]" ) {
- return false;
- }
-
- proto = getProto( obj );
-
- // Objects with no prototype (e.g., `Object.create( null )`) are plain
- if ( !proto ) {
- return true;
- }
-
- // Objects with prototype are plain iff they were constructed by a global Object function
- Ctor = hasOwn.call( proto, "constructor" ) && proto.constructor;
- return typeof Ctor === "function" && fnToString.call( Ctor ) === ObjectFunctionString;
- },
-
- isEmptyObject: function( obj ) {
- var name;
-
- for ( name in obj ) {
- return false;
- }
- return true;
- },
-
- // Evaluates a script in a provided context; falls back to the global one
- // if not specified.
- globalEval: function( code, options, doc ) {
- DOMEval( code, { nonce: options && options.nonce }, doc );
- },
-
- each: function( obj, callback ) {
- var length, i = 0;
-
- if ( isArrayLike( obj ) ) {
- length = obj.length;
- for ( ; i < length; i++ ) {
- if ( callback.call( obj[ i ], i, obj[ i ] ) === false ) {
- break;
- }
- }
- } else {
- for ( i in obj ) {
- if ( callback.call( obj[ i ], i, obj[ i ] ) === false ) {
- break;
- }
- }
- }
-
- return obj;
- },
-
- // results is for internal usage only
- makeArray: function( arr, results ) {
- var ret = results || [];
-
- if ( arr != null ) {
- if ( isArrayLike( Object( arr ) ) ) {
- jQuery.merge( ret,
- typeof arr === "string" ?
- [ arr ] : arr
- );
- } else {
- push.call( ret, arr );
- }
- }
-
- return ret;
- },
-
- inArray: function( elem, arr, i ) {
- return arr == null ? -1 : indexOf.call( arr, elem, i );
- },
-
- // Support: Android <=4.0 only, PhantomJS 1 only
- // push.apply(_, arraylike) throws on ancient WebKit
- merge: function( first, second ) {
- var len = +second.length,
- j = 0,
- i = first.length;
-
- for ( ; j < len; j++ ) {
- first[ i++ ] = second[ j ];
- }
-
- first.length = i;
-
- return first;
- },
-
- grep: function( elems, callback, invert ) {
- var callbackInverse,
- matches = [],
- i = 0,
- length = elems.length,
- callbackExpect = !invert;
-
- // Go through the array, only saving the items
- // that pass the validator function
- for ( ; i < length; i++ ) {
- callbackInverse = !callback( elems[ i ], i );
- if ( callbackInverse !== callbackExpect ) {
- matches.push( elems[ i ] );
- }
- }
-
- return matches;
- },
-
- // arg is for internal usage only
- map: function( elems, callback, arg ) {
- var length, value,
- i = 0,
- ret = [];
-
- // Go through the array, translating each of the items to their new values
- if ( isArrayLike( elems ) ) {
- length = elems.length;
- for ( ; i < length; i++ ) {
- value = callback( elems[ i ], i, arg );
-
- if ( value != null ) {
- ret.push( value );
- }
- }
-
- // Go through every key on the object,
- } else {
- for ( i in elems ) {
- value = callback( elems[ i ], i, arg );
-
- if ( value != null ) {
- ret.push( value );
- }
- }
- }
-
- // Flatten any nested arrays
- return flat( ret );
- },
-
- // A global GUID counter for objects
- guid: 1,
-
- // jQuery.support is not used in Core but other projects attach their
- // properties to it so it needs to exist.
- support: support
-} );
-
-if ( typeof Symbol === "function" ) {
- jQuery.fn[ Symbol.iterator ] = arr[ Symbol.iterator ];
-}
-
-// Populate the class2type map
-jQuery.each( "Boolean Number String Function Array Date RegExp Object Error Symbol".split( " " ),
-function( _i, name ) {
- class2type[ "[object " + name + "]" ] = name.toLowerCase();
-} );
-
-function isArrayLike( obj ) {
-
- // Support: real iOS 8.2 only (not reproducible in simulator)
- // `in` check used to prevent JIT error (gh-2145)
- // hasOwn isn't used here due to false negatives
- // regarding Nodelist length in IE
- var length = !!obj && "length" in obj && obj.length,
- type = toType( obj );
-
- if ( isFunction( obj ) || isWindow( obj ) ) {
- return false;
- }
-
- return type === "array" || length === 0 ||
- typeof length === "number" && length > 0 && ( length - 1 ) in obj;
-}
-var Sizzle =
-/*!
- * Sizzle CSS Selector Engine v2.3.5
- * https://sizzlejs.com/
- *
- * Copyright JS Foundation and other contributors
- * Released under the MIT license
- * https://js.foundation/
- *
- * Date: 2020-03-14
- */
-( function( window ) {
-var i,
- support,
- Expr,
- getText,
- isXML,
- tokenize,
- compile,
- select,
- outermostContext,
- sortInput,
- hasDuplicate,
-
- // Local document vars
- setDocument,
- document,
- docElem,
- documentIsHTML,
- rbuggyQSA,
- rbuggyMatches,
- matches,
- contains,
-
- // Instance-specific data
- expando = "sizzle" + 1 * new Date(),
- preferredDoc = window.document,
- dirruns = 0,
- done = 0,
- classCache = createCache(),
- tokenCache = createCache(),
- compilerCache = createCache(),
- nonnativeSelectorCache = createCache(),
- sortOrder = function( a, b ) {
- if ( a === b ) {
- hasDuplicate = true;
- }
- return 0;
- },
-
- // Instance methods
- hasOwn = ( {} ).hasOwnProperty,
- arr = [],
- pop = arr.pop,
- pushNative = arr.push,
- push = arr.push,
- slice = arr.slice,
-
- // Use a stripped-down indexOf as it's faster than native
- // https://jsperf.com/thor-indexof-vs-for/5
- indexOf = function( list, elem ) {
- var i = 0,
- len = list.length;
- for ( ; i < len; i++ ) {
- if ( list[ i ] === elem ) {
- return i;
- }
- }
- return -1;
- },
-
- booleans = "checked|selected|async|autofocus|autoplay|controls|defer|disabled|hidden|" +
- "ismap|loop|multiple|open|readonly|required|scoped",
-
- // Regular expressions
-
- // http://www.w3.org/TR/css3-selectors/#whitespace
- whitespace = "[\\x20\\t\\r\\n\\f]",
-
- // https://www.w3.org/TR/css-syntax-3/#ident-token-diagram
- identifier = "(?:\\\\[\\da-fA-F]{1,6}" + whitespace +
- "?|\\\\[^\\r\\n\\f]|[\\w-]|[^\0-\\x7f])+",
-
- // Attribute selectors: http://www.w3.org/TR/selectors/#attribute-selectors
- attributes = "\\[" + whitespace + "*(" + identifier + ")(?:" + whitespace +
-
- // Operator (capture 2)
- "*([*^$|!~]?=)" + whitespace +
-
- // "Attribute values must be CSS identifiers [capture 5]
- // or strings [capture 3 or capture 4]"
- "*(?:'((?:\\\\.|[^\\\\'])*)'|\"((?:\\\\.|[^\\\\\"])*)\"|(" + identifier + "))|)" +
- whitespace + "*\\]",
-
- pseudos = ":(" + identifier + ")(?:\\((" +
-
- // To reduce the number of selectors needing tokenize in the preFilter, prefer arguments:
- // 1. quoted (capture 3; capture 4 or capture 5)
- "('((?:\\\\.|[^\\\\'])*)'|\"((?:\\\\.|[^\\\\\"])*)\")|" +
-
- // 2. simple (capture 6)
- "((?:\\\\.|[^\\\\()[\\]]|" + attributes + ")*)|" +
-
- // 3. anything else (capture 2)
- ".*" +
- ")\\)|)",
-
- // Leading and non-escaped trailing whitespace, capturing some non-whitespace characters preceding the latter
- rwhitespace = new RegExp( whitespace + "+", "g" ),
- rtrim = new RegExp( "^" + whitespace + "+|((?:^|[^\\\\])(?:\\\\.)*)" +
- whitespace + "+$", "g" ),
-
- rcomma = new RegExp( "^" + whitespace + "*," + whitespace + "*" ),
- rcombinators = new RegExp( "^" + whitespace + "*([>+~]|" + whitespace + ")" + whitespace +
- "*" ),
- rdescend = new RegExp( whitespace + "|>" ),
-
- rpseudo = new RegExp( pseudos ),
- ridentifier = new RegExp( "^" + identifier + "$" ),
-
- matchExpr = {
- "ID": new RegExp( "^#(" + identifier + ")" ),
- "CLASS": new RegExp( "^\\.(" + identifier + ")" ),
- "TAG": new RegExp( "^(" + identifier + "|[*])" ),
- "ATTR": new RegExp( "^" + attributes ),
- "PSEUDO": new RegExp( "^" + pseudos ),
- "CHILD": new RegExp( "^:(only|first|last|nth|nth-last)-(child|of-type)(?:\\(" +
- whitespace + "*(even|odd|(([+-]|)(\\d*)n|)" + whitespace + "*(?:([+-]|)" +
- whitespace + "*(\\d+)|))" + whitespace + "*\\)|)", "i" ),
- "bool": new RegExp( "^(?:" + booleans + ")$", "i" ),
-
- // For use in libraries implementing .is()
- // We use this for POS matching in `select`
- "needsContext": new RegExp( "^" + whitespace +
- "*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\\(" + whitespace +
- "*((?:-\\d)?\\d*)" + whitespace + "*\\)|)(?=[^-]|$)", "i" )
- },
-
- rhtml = /HTML$/i,
- rinputs = /^(?:input|select|textarea|button)$/i,
- rheader = /^h\d$/i,
-
- rnative = /^[^{]+\{\s*\[native \w/,
-
- // Easily-parseable/retrievable ID or TAG or CLASS selectors
- rquickExpr = /^(?:#([\w-]+)|(\w+)|\.([\w-]+))$/,
-
- rsibling = /[+~]/,
-
- // CSS escapes
- // http://www.w3.org/TR/CSS21/syndata.html#escaped-characters
- runescape = new RegExp( "\\\\[\\da-fA-F]{1,6}" + whitespace + "?|\\\\([^\\r\\n\\f])", "g" ),
- funescape = function( escape, nonHex ) {
- var high = "0x" + escape.slice( 1 ) - 0x10000;
-
- return nonHex ?
-
- // Strip the backslash prefix from a non-hex escape sequence
- nonHex :
-
- // Replace a hexadecimal escape sequence with the encoded Unicode code point
- // Support: IE <=11+
- // For values outside the Basic Multilingual Plane (BMP), manually construct a
- // surrogate pair
- high < 0 ?
- String.fromCharCode( high + 0x10000 ) :
- String.fromCharCode( high >> 10 | 0xD800, high & 0x3FF | 0xDC00 );
- },
-
- // CSS string/identifier serialization
- // https://drafts.csswg.org/cssom/#common-serializing-idioms
- rcssescape = /([\0-\x1f\x7f]|^-?\d)|^-$|[^\0-\x1f\x7f-\uFFFF\w-]/g,
- fcssescape = function( ch, asCodePoint ) {
- if ( asCodePoint ) {
-
- // U+0000 NULL becomes U+FFFD REPLACEMENT CHARACTER
- if ( ch === "\0" ) {
- return "\uFFFD";
- }
-
- // Control characters and (dependent upon position) numbers get escaped as code points
- return ch.slice( 0, -1 ) + "\\" +
- ch.charCodeAt( ch.length - 1 ).toString( 16 ) + " ";
- }
-
- // Other potentially-special ASCII characters get backslash-escaped
- return "\\" + ch;
- },
-
- // Used for iframes
- // See setDocument()
- // Removing the function wrapper causes a "Permission Denied"
- // error in IE
- unloadHandler = function() {
- setDocument();
- },
-
- inDisabledFieldset = addCombinator(
- function( elem ) {
- return elem.disabled === true && elem.nodeName.toLowerCase() === "fieldset";
- },
- { dir: "parentNode", next: "legend" }
- );
-
-// Optimize for push.apply( _, NodeList )
-try {
- push.apply(
- ( arr = slice.call( preferredDoc.childNodes ) ),
- preferredDoc.childNodes
- );
-
- // Support: Android<4.0
- // Detect silently failing push.apply
- // eslint-disable-next-line no-unused-expressions
- arr[ preferredDoc.childNodes.length ].nodeType;
-} catch ( e ) {
- push = { apply: arr.length ?
-
- // Leverage slice if possible
- function( target, els ) {
- pushNative.apply( target, slice.call( els ) );
- } :
-
- // Support: IE<9
- // Otherwise append directly
- function( target, els ) {
- var j = target.length,
- i = 0;
-
- // Can't trust NodeList.length
- while ( ( target[ j++ ] = els[ i++ ] ) ) {}
- target.length = j - 1;
- }
- };
-}
-
-function Sizzle( selector, context, results, seed ) {
- var m, i, elem, nid, match, groups, newSelector,
- newContext = context && context.ownerDocument,
-
- // nodeType defaults to 9, since context defaults to document
- nodeType = context ? context.nodeType : 9;
-
- results = results || [];
-
- // Return early from calls with invalid selector or context
- if ( typeof selector !== "string" || !selector ||
- nodeType !== 1 && nodeType !== 9 && nodeType !== 11 ) {
-
- return results;
- }
-
- // Try to shortcut find operations (as opposed to filters) in HTML documents
- if ( !seed ) {
- setDocument( context );
- context = context || document;
-
- if ( documentIsHTML ) {
-
- // If the selector is sufficiently simple, try using a "get*By*" DOM method
- // (excepting DocumentFragment context, where the methods don't exist)
- if ( nodeType !== 11 && ( match = rquickExpr.exec( selector ) ) ) {
-
- // ID selector
- if ( ( m = match[ 1 ] ) ) {
-
- // Document context
- if ( nodeType === 9 ) {
- if ( ( elem = context.getElementById( m ) ) ) {
-
- // Support: IE, Opera, Webkit
- // TODO: identify versions
- // getElementById can match elements by name instead of ID
- if ( elem.id === m ) {
- results.push( elem );
- return results;
- }
- } else {
- return results;
- }
-
- // Element context
- } else {
-
- // Support: IE, Opera, Webkit
- // TODO: identify versions
- // getElementById can match elements by name instead of ID
- if ( newContext && ( elem = newContext.getElementById( m ) ) &&
- contains( context, elem ) &&
- elem.id === m ) {
-
- results.push( elem );
- return results;
- }
- }
-
- // Type selector
- } else if ( match[ 2 ] ) {
- push.apply( results, context.getElementsByTagName( selector ) );
- return results;
-
- // Class selector
- } else if ( ( m = match[ 3 ] ) && support.getElementsByClassName &&
- context.getElementsByClassName ) {
-
- push.apply( results, context.getElementsByClassName( m ) );
- return results;
- }
- }
-
- // Take advantage of querySelectorAll
- if ( support.qsa &&
- !nonnativeSelectorCache[ selector + " " ] &&
- ( !rbuggyQSA || !rbuggyQSA.test( selector ) ) &&
-
- // Support: IE 8 only
- // Exclude object elements
- ( nodeType !== 1 || context.nodeName.toLowerCase() !== "object" ) ) {
-
- newSelector = selector;
- newContext = context;
-
- // qSA considers elements outside a scoping root when evaluating child or
- // descendant combinators, which is not what we want.
- // In such cases, we work around the behavior by prefixing every selector in the
- // list with an ID selector referencing the scope context.
- // The technique has to be used as well when a leading combinator is used
- // as such selectors are not recognized by querySelectorAll.
- // Thanks to Andrew Dupont for this technique.
- if ( nodeType === 1 &&
- ( rdescend.test( selector ) || rcombinators.test( selector ) ) ) {
-
- // Expand context for sibling selectors
- newContext = rsibling.test( selector ) && testContext( context.parentNode ) ||
- context;
-
- // We can use :scope instead of the ID hack if the browser
- // supports it & if we're not changing the context.
- if ( newContext !== context || !support.scope ) {
-
- // Capture the context ID, setting it first if necessary
- if ( ( nid = context.getAttribute( "id" ) ) ) {
- nid = nid.replace( rcssescape, fcssescape );
- } else {
- context.setAttribute( "id", ( nid = expando ) );
- }
- }
-
- // Prefix every selector in the list
- groups = tokenize( selector );
- i = groups.length;
- while ( i-- ) {
- groups[ i ] = ( nid ? "#" + nid : ":scope" ) + " " +
- toSelector( groups[ i ] );
- }
- newSelector = groups.join( "," );
- }
-
- try {
- push.apply( results,
- newContext.querySelectorAll( newSelector )
- );
- return results;
- } catch ( qsaError ) {
- nonnativeSelectorCache( selector, true );
- } finally {
- if ( nid === expando ) {
- context.removeAttribute( "id" );
- }
- }
- }
- }
- }
-
- // All others
- return select( selector.replace( rtrim, "$1" ), context, results, seed );
-}
-
-/**
- * Create key-value caches of limited size
- * @returns {function(string, object)} Returns the Object data after storing it on itself with
- * property name the (space-suffixed) string and (if the cache is larger than Expr.cacheLength)
- * deleting the oldest entry
- */
-function createCache() {
- var keys = [];
-
- function cache( key, value ) {
-
- // Use (key + " ") to avoid collision with native prototype properties (see Issue #157)
- if ( keys.push( key + " " ) > Expr.cacheLength ) {
-
- // Only keep the most recent entries
- delete cache[ keys.shift() ];
- }
- return ( cache[ key + " " ] = value );
- }
- return cache;
-}
-
-/**
- * Mark a function for special use by Sizzle
- * @param {Function} fn The function to mark
- */
-function markFunction( fn ) {
- fn[ expando ] = true;
- return fn;
-}
-
-/**
- * Support testing using an element
- * @param {Function} fn Passed the created element and returns a boolean result
- */
-function assert( fn ) {
- var el = document.createElement( "fieldset" );
-
- try {
- return !!fn( el );
- } catch ( e ) {
- return false;
- } finally {
-
- // Remove from its parent by default
- if ( el.parentNode ) {
- el.parentNode.removeChild( el );
- }
-
- // release memory in IE
- el = null;
- }
-}
-
-/**
- * Adds the same handler for all of the specified attrs
- * @param {String} attrs Pipe-separated list of attributes
- * @param {Function} handler The method that will be applied
- */
-function addHandle( attrs, handler ) {
- var arr = attrs.split( "|" ),
- i = arr.length;
-
- while ( i-- ) {
- Expr.attrHandle[ arr[ i ] ] = handler;
- }
-}
-
-/**
- * Checks document order of two siblings
- * @param {Element} a
- * @param {Element} b
- * @returns {Number} Returns less than 0 if a precedes b, greater than 0 if a follows b
- */
-function siblingCheck( a, b ) {
- var cur = b && a,
- diff = cur && a.nodeType === 1 && b.nodeType === 1 &&
- a.sourceIndex - b.sourceIndex;
-
- // Use IE sourceIndex if available on both nodes
- if ( diff ) {
- return diff;
- }
-
- // Check if b follows a
- if ( cur ) {
- while ( ( cur = cur.nextSibling ) ) {
- if ( cur === b ) {
- return -1;
- }
- }
- }
-
- return a ? 1 : -1;
-}
-
-/**
- * Returns a function to use in pseudos for input types
- * @param {String} type
- */
-function createInputPseudo( type ) {
- return function( elem ) {
- var name = elem.nodeName.toLowerCase();
- return name === "input" && elem.type === type;
- };
-}
-
-/**
- * Returns a function to use in pseudos for buttons
- * @param {String} type
- */
-function createButtonPseudo( type ) {
- return function( elem ) {
- var name = elem.nodeName.toLowerCase();
- return ( name === "input" || name === "button" ) && elem.type === type;
- };
-}
-
-/**
- * Returns a function to use in pseudos for :enabled/:disabled
- * @param {Boolean} disabled true for :disabled; false for :enabled
- */
-function createDisabledPseudo( disabled ) {
-
- // Known :disabled false positives: fieldset[disabled] > legend:nth-of-type(n+2) :can-disable
- return function( elem ) {
-
- // Only certain elements can match :enabled or :disabled
- // https://html.spec.whatwg.org/multipage/scripting.html#selector-enabled
- // https://html.spec.whatwg.org/multipage/scripting.html#selector-disabled
- if ( "form" in elem ) {
-
- // Check for inherited disabledness on relevant non-disabled elements:
- // * listed form-associated elements in a disabled fieldset
- // https://html.spec.whatwg.org/multipage/forms.html#category-listed
- // https://html.spec.whatwg.org/multipage/forms.html#concept-fe-disabled
- // * option elements in a disabled optgroup
- // https://html.spec.whatwg.org/multipage/forms.html#concept-option-disabled
- // All such elements have a "form" property.
- if ( elem.parentNode && elem.disabled === false ) {
-
- // Option elements defer to a parent optgroup if present
- if ( "label" in elem ) {
- if ( "label" in elem.parentNode ) {
- return elem.parentNode.disabled === disabled;
- } else {
- return elem.disabled === disabled;
- }
- }
-
- // Support: IE 6 - 11
- // Use the isDisabled shortcut property to check for disabled fieldset ancestors
- return elem.isDisabled === disabled ||
-
- // Where there is no isDisabled, check manually
- /* jshint -W018 */
- elem.isDisabled !== !disabled &&
- inDisabledFieldset( elem ) === disabled;
- }
-
- return elem.disabled === disabled;
-
- // Try to winnow out elements that can't be disabled before trusting the disabled property.
- // Some victims get caught in our net (label, legend, menu, track), but it shouldn't
- // even exist on them, let alone have a boolean value.
- } else if ( "label" in elem ) {
- return elem.disabled === disabled;
- }
-
- // Remaining elements are neither :enabled nor :disabled
- return false;
- };
-}
-
-/**
- * Returns a function to use in pseudos for positionals
- * @param {Function} fn
- */
-function createPositionalPseudo( fn ) {
- return markFunction( function( argument ) {
- argument = +argument;
- return markFunction( function( seed, matches ) {
- var j,
- matchIndexes = fn( [], seed.length, argument ),
- i = matchIndexes.length;
-
- // Match elements found at the specified indexes
- while ( i-- ) {
- if ( seed[ ( j = matchIndexes[ i ] ) ] ) {
- seed[ j ] = !( matches[ j ] = seed[ j ] );
- }
- }
- } );
- } );
-}
-
-/**
- * Checks a node for validity as a Sizzle context
- * @param {Element|Object=} context
- * @returns {Element|Object|Boolean} The input node if acceptable, otherwise a falsy value
- */
-function testContext( context ) {
- return context && typeof context.getElementsByTagName !== "undefined" && context;
-}
-
-// Expose support vars for convenience
-support = Sizzle.support = {};
-
-/**
- * Detects XML nodes
- * @param {Element|Object} elem An element or a document
- * @returns {Boolean} True iff elem is a non-HTML XML node
- */
-isXML = Sizzle.isXML = function( elem ) {
- var namespace = elem.namespaceURI,
- docElem = ( elem.ownerDocument || elem ).documentElement;
-
- // Support: IE <=8
- // Assume HTML when documentElement doesn't yet exist, such as inside loading iframes
- // https://bugs.jquery.com/ticket/4833
- return !rhtml.test( namespace || docElem && docElem.nodeName || "HTML" );
-};
-
-/**
- * Sets document-related variables once based on the current document
- * @param {Element|Object} [doc] An element or document object to use to set the document
- * @returns {Object} Returns the current document
- */
-setDocument = Sizzle.setDocument = function( node ) {
- var hasCompare, subWindow,
- doc = node ? node.ownerDocument || node : preferredDoc;
-
- // Return early if doc is invalid or already selected
- // Support: IE 11+, Edge 17 - 18+
- // IE/Edge sometimes throw a "Permission denied" error when strict-comparing
- // two documents; shallow comparisons work.
- // eslint-disable-next-line eqeqeq
- if ( doc == document || doc.nodeType !== 9 || !doc.documentElement ) {
- return document;
- }
-
- // Update global variables
- document = doc;
- docElem = document.documentElement;
- documentIsHTML = !isXML( document );
-
- // Support: IE 9 - 11+, Edge 12 - 18+
- // Accessing iframe documents after unload throws "permission denied" errors (jQuery #13936)
- // Support: IE 11+, Edge 17 - 18+
- // IE/Edge sometimes throw a "Permission denied" error when strict-comparing
- // two documents; shallow comparisons work.
- // eslint-disable-next-line eqeqeq
- if ( preferredDoc != document &&
- ( subWindow = document.defaultView ) && subWindow.top !== subWindow ) {
-
- // Support: IE 11, Edge
- if ( subWindow.addEventListener ) {
- subWindow.addEventListener( "unload", unloadHandler, false );
-
- // Support: IE 9 - 10 only
- } else if ( subWindow.attachEvent ) {
- subWindow.attachEvent( "onunload", unloadHandler );
- }
- }
-
- // Support: IE 8 - 11+, Edge 12 - 18+, Chrome <=16 - 25 only, Firefox <=3.6 - 31 only,
- // Safari 4 - 5 only, Opera <=11.6 - 12.x only
- // IE/Edge & older browsers don't support the :scope pseudo-class.
- // Support: Safari 6.0 only
- // Safari 6.0 supports :scope but it's an alias of :root there.
- support.scope = assert( function( el ) {
- docElem.appendChild( el ).appendChild( document.createElement( "div" ) );
- return typeof el.querySelectorAll !== "undefined" &&
- !el.querySelectorAll( ":scope fieldset div" ).length;
- } );
-
- /* Attributes
- ---------------------------------------------------------------------- */
-
- // Support: IE<8
- // Verify that getAttribute really returns attributes and not properties
- // (excepting IE8 booleans)
- support.attributes = assert( function( el ) {
- el.className = "i";
- return !el.getAttribute( "className" );
- } );
-
- /* getElement(s)By*
- ---------------------------------------------------------------------- */
-
- // Check if getElementsByTagName("*") returns only elements
- support.getElementsByTagName = assert( function( el ) {
- el.appendChild( document.createComment( "" ) );
- return !el.getElementsByTagName( "*" ).length;
- } );
-
- // Support: IE<9
- support.getElementsByClassName = rnative.test( document.getElementsByClassName );
-
- // Support: IE<10
- // Check if getElementById returns elements by name
- // The broken getElementById methods don't pick up programmatically-set names,
- // so use a roundabout getElementsByName test
- support.getById = assert( function( el ) {
- docElem.appendChild( el ).id = expando;
- return !document.getElementsByName || !document.getElementsByName( expando ).length;
- } );
-
- // ID filter and find
- if ( support.getById ) {
- Expr.filter[ "ID" ] = function( id ) {
- var attrId = id.replace( runescape, funescape );
- return function( elem ) {
- return elem.getAttribute( "id" ) === attrId;
- };
- };
- Expr.find[ "ID" ] = function( id, context ) {
- if ( typeof context.getElementById !== "undefined" && documentIsHTML ) {
- var elem = context.getElementById( id );
- return elem ? [ elem ] : [];
- }
- };
- } else {
- Expr.filter[ "ID" ] = function( id ) {
- var attrId = id.replace( runescape, funescape );
- return function( elem ) {
- var node = typeof elem.getAttributeNode !== "undefined" &&
- elem.getAttributeNode( "id" );
- return node && node.value === attrId;
- };
- };
-
- // Support: IE 6 - 7 only
- // getElementById is not reliable as a find shortcut
- Expr.find[ "ID" ] = function( id, context ) {
- if ( typeof context.getElementById !== "undefined" && documentIsHTML ) {
- var node, i, elems,
- elem = context.getElementById( id );
-
- if ( elem ) {
-
- // Verify the id attribute
- node = elem.getAttributeNode( "id" );
- if ( node && node.value === id ) {
- return [ elem ];
- }
-
- // Fall back on getElementsByName
- elems = context.getElementsByName( id );
- i = 0;
- while ( ( elem = elems[ i++ ] ) ) {
- node = elem.getAttributeNode( "id" );
- if ( node && node.value === id ) {
- return [ elem ];
- }
- }
- }
-
- return [];
- }
- };
- }
-
- // Tag
- Expr.find[ "TAG" ] = support.getElementsByTagName ?
- function( tag, context ) {
- if ( typeof context.getElementsByTagName !== "undefined" ) {
- return context.getElementsByTagName( tag );
-
- // DocumentFragment nodes don't have gEBTN
- } else if ( support.qsa ) {
- return context.querySelectorAll( tag );
- }
- } :
-
- function( tag, context ) {
- var elem,
- tmp = [],
- i = 0,
-
- // By happy coincidence, a (broken) gEBTN appears on DocumentFragment nodes too
- results = context.getElementsByTagName( tag );
-
- // Filter out possible comments
- if ( tag === "*" ) {
- while ( ( elem = results[ i++ ] ) ) {
- if ( elem.nodeType === 1 ) {
- tmp.push( elem );
- }
- }
-
- return tmp;
- }
- return results;
- };
-
- // Class
- Expr.find[ "CLASS" ] = support.getElementsByClassName && function( className, context ) {
- if ( typeof context.getElementsByClassName !== "undefined" && documentIsHTML ) {
- return context.getElementsByClassName( className );
- }
- };
-
- /* QSA/matchesSelector
- ---------------------------------------------------------------------- */
-
- // QSA and matchesSelector support
-
- // matchesSelector(:active) reports false when true (IE9/Opera 11.5)
- rbuggyMatches = [];
-
- // qSa(:focus) reports false when true (Chrome 21)
- // We allow this because of a bug in IE8/9 that throws an error
- // whenever `document.activeElement` is accessed on an iframe
- // So, we allow :focus to pass through QSA all the time to avoid the IE error
- // See https://bugs.jquery.com/ticket/13378
- rbuggyQSA = [];
-
- if ( ( support.qsa = rnative.test( document.querySelectorAll ) ) ) {
-
- // Build QSA regex
- // Regex strategy adopted from Diego Perini
- assert( function( el ) {
-
- var input;
-
- // Select is set to empty string on purpose
- // This is to test IE's treatment of not explicitly
- // setting a boolean content attribute,
- // since its presence should be enough
- // https://bugs.jquery.com/ticket/12359
- docElem.appendChild( el ).innerHTML = "" +
- " ";
-
- // Support: IE8, Opera 11-12.16
- // Nothing should be selected when empty strings follow ^= or $= or *=
- // The test attribute must be unknown in Opera but "safe" for WinRT
- // https://msdn.microsoft.com/en-us/library/ie/hh465388.aspx#attribute_section
- if ( el.querySelectorAll( "[msallowcapture^='']" ).length ) {
- rbuggyQSA.push( "[*^$]=" + whitespace + "*(?:''|\"\")" );
- }
-
- // Support: IE8
- // Boolean attributes and "value" are not treated correctly
- if ( !el.querySelectorAll( "[selected]" ).length ) {
- rbuggyQSA.push( "\\[" + whitespace + "*(?:value|" + booleans + ")" );
- }
-
- // Support: Chrome<29, Android<4.4, Safari<7.0+, iOS<7.0+, PhantomJS<1.9.8+
- if ( !el.querySelectorAll( "[id~=" + expando + "-]" ).length ) {
- rbuggyQSA.push( "~=" );
- }
-
- // Support: IE 11+, Edge 15 - 18+
- // IE 11/Edge don't find elements on a `[name='']` query in some cases.
- // Adding a temporary attribute to the document before the selection works
- // around the issue.
- // Interestingly, IE 10 & older don't seem to have the issue.
- input = document.createElement( "input" );
- input.setAttribute( "name", "" );
- el.appendChild( input );
- if ( !el.querySelectorAll( "[name='']" ).length ) {
- rbuggyQSA.push( "\\[" + whitespace + "*name" + whitespace + "*=" +
- whitespace + "*(?:''|\"\")" );
- }
-
- // Webkit/Opera - :checked should return selected option elements
- // http://www.w3.org/TR/2011/REC-css3-selectors-20110929/#checked
- // IE8 throws error here and will not see later tests
- if ( !el.querySelectorAll( ":checked" ).length ) {
- rbuggyQSA.push( ":checked" );
- }
-
- // Support: Safari 8+, iOS 8+
- // https://bugs.webkit.org/show_bug.cgi?id=136851
- // In-page `selector#id sibling-combinator selector` fails
- if ( !el.querySelectorAll( "a#" + expando + "+*" ).length ) {
- rbuggyQSA.push( ".#.+[+~]" );
- }
-
- // Support: Firefox <=3.6 - 5 only
- // Old Firefox doesn't throw on a badly-escaped identifier.
- el.querySelectorAll( "\\\f" );
- rbuggyQSA.push( "[\\r\\n\\f]" );
- } );
-
- assert( function( el ) {
- el.innerHTML = ") matching elements by id
- for ( ; i !== len && ( elem = elems[ i ] ) != null; i++ ) {
- if ( byElement && elem ) {
- j = 0;
-
- // Support: IE 11+, Edge 17 - 18+
- // IE/Edge sometimes throw a "Permission denied" error when strict-comparing
- // two documents; shallow comparisons work.
- // eslint-disable-next-line eqeqeq
- if ( !context && elem.ownerDocument != document ) {
- setDocument( elem );
- xml = !documentIsHTML;
- }
- while ( ( matcher = elementMatchers[ j++ ] ) ) {
- if ( matcher( elem, context || document, xml ) ) {
- results.push( elem );
- break;
- }
- }
- if ( outermost ) {
- dirruns = dirrunsUnique;
- }
- }
-
- // Track unmatched elements for set filters
- if ( bySet ) {
-
- // They will have gone through all possible matchers
- if ( ( elem = !matcher && elem ) ) {
- matchedCount--;
- }
-
- // Lengthen the array for every element, matched or not
- if ( seed ) {
- unmatched.push( elem );
- }
- }
- }
-
- // `i` is now the count of elements visited above, and adding it to `matchedCount`
- // makes the latter nonnegative.
- matchedCount += i;
-
- // Apply set filters to unmatched elements
- // NOTE: This can be skipped if there are no unmatched elements (i.e., `matchedCount`
- // equals `i`), unless we didn't visit _any_ elements in the above loop because we have
- // no element matchers and no seed.
- // Incrementing an initially-string "0" `i` allows `i` to remain a string only in that
- // case, which will result in a "00" `matchedCount` that differs from `i` but is also
- // numerically zero.
- if ( bySet && i !== matchedCount ) {
- j = 0;
- while ( ( matcher = setMatchers[ j++ ] ) ) {
- matcher( unmatched, setMatched, context, xml );
- }
-
- if ( seed ) {
-
- // Reintegrate element matches to eliminate the need for sorting
- if ( matchedCount > 0 ) {
- while ( i-- ) {
- if ( !( unmatched[ i ] || setMatched[ i ] ) ) {
- setMatched[ i ] = pop.call( results );
- }
- }
- }
-
- // Discard index placeholder values to get only actual matches
- setMatched = condense( setMatched );
- }
-
- // Add matches to results
- push.apply( results, setMatched );
-
- // Seedless set matches succeeding multiple successful matchers stipulate sorting
- if ( outermost && !seed && setMatched.length > 0 &&
- ( matchedCount + setMatchers.length ) > 1 ) {
-
- Sizzle.uniqueSort( results );
- }
- }
-
- // Override manipulation of globals by nested matchers
- if ( outermost ) {
- dirruns = dirrunsUnique;
- outermostContext = contextBackup;
- }
-
- return unmatched;
- };
-
- return bySet ?
- markFunction( superMatcher ) :
- superMatcher;
-}
-
-compile = Sizzle.compile = function( selector, match /* Internal Use Only */ ) {
- var i,
- setMatchers = [],
- elementMatchers = [],
- cached = compilerCache[ selector + " " ];
-
- if ( !cached ) {
-
- // Generate a function of recursive functions that can be used to check each element
- if ( !match ) {
- match = tokenize( selector );
- }
- i = match.length;
- while ( i-- ) {
- cached = matcherFromTokens( match[ i ] );
- if ( cached[ expando ] ) {
- setMatchers.push( cached );
- } else {
- elementMatchers.push( cached );
- }
- }
-
- // Cache the compiled function
- cached = compilerCache(
- selector,
- matcherFromGroupMatchers( elementMatchers, setMatchers )
- );
-
- // Save selector and tokenization
- cached.selector = selector;
- }
- return cached;
-};
-
-/**
- * A low-level selection function that works with Sizzle's compiled
- * selector functions
- * @param {String|Function} selector A selector or a pre-compiled
- * selector function built with Sizzle.compile
- * @param {Element} context
- * @param {Array} [results]
- * @param {Array} [seed] A set of elements to match against
- */
-select = Sizzle.select = function( selector, context, results, seed ) {
- var i, tokens, token, type, find,
- compiled = typeof selector === "function" && selector,
- match = !seed && tokenize( ( selector = compiled.selector || selector ) );
-
- results = results || [];
-
- // Try to minimize operations if there is only one selector in the list and no seed
- // (the latter of which guarantees us context)
- if ( match.length === 1 ) {
-
- // Reduce context if the leading compound selector is an ID
- tokens = match[ 0 ] = match[ 0 ].slice( 0 );
- if ( tokens.length > 2 && ( token = tokens[ 0 ] ).type === "ID" &&
- context.nodeType === 9 && documentIsHTML && Expr.relative[ tokens[ 1 ].type ] ) {
-
- context = ( Expr.find[ "ID" ]( token.matches[ 0 ]
- .replace( runescape, funescape ), context ) || [] )[ 0 ];
- if ( !context ) {
- return results;
-
- // Precompiled matchers will still verify ancestry, so step up a level
- } else if ( compiled ) {
- context = context.parentNode;
- }
-
- selector = selector.slice( tokens.shift().value.length );
- }
-
- // Fetch a seed set for right-to-left matching
- i = matchExpr[ "needsContext" ].test( selector ) ? 0 : tokens.length;
- while ( i-- ) {
- token = tokens[ i ];
-
- // Abort if we hit a combinator
- if ( Expr.relative[ ( type = token.type ) ] ) {
- break;
- }
- if ( ( find = Expr.find[ type ] ) ) {
-
- // Search, expanding context for leading sibling combinators
- if ( ( seed = find(
- token.matches[ 0 ].replace( runescape, funescape ),
- rsibling.test( tokens[ 0 ].type ) && testContext( context.parentNode ) ||
- context
- ) ) ) {
-
- // If seed is empty or no tokens remain, we can return early
- tokens.splice( i, 1 );
- selector = seed.length && toSelector( tokens );
- if ( !selector ) {
- push.apply( results, seed );
- return results;
- }
-
- break;
- }
- }
- }
- }
-
- // Compile and execute a filtering function if one is not provided
- // Provide `match` to avoid retokenization if we modified the selector above
- ( compiled || compile( selector, match ) )(
- seed,
- context,
- !documentIsHTML,
- results,
- !context || rsibling.test( selector ) && testContext( context.parentNode ) || context
- );
- return results;
-};
-
-// One-time assignments
-
-// Sort stability
-support.sortStable = expando.split( "" ).sort( sortOrder ).join( "" ) === expando;
-
-// Support: Chrome 14-35+
-// Always assume duplicates if they aren't passed to the comparison function
-support.detectDuplicates = !!hasDuplicate;
-
-// Initialize against the default document
-setDocument();
-
-// Support: Webkit<537.32 - Safari 6.0.3/Chrome 25 (fixed in Chrome 27)
-// Detached nodes confoundingly follow *each other*
-support.sortDetached = assert( function( el ) {
-
- // Should return 1, but returns 4 (following)
- return el.compareDocumentPosition( document.createElement( "fieldset" ) ) & 1;
-} );
-
-// Support: IE<8
-// Prevent attribute/property "interpolation"
-// https://msdn.microsoft.com/en-us/library/ms536429%28VS.85%29.aspx
-if ( !assert( function( el ) {
- el.innerHTML = " to avoid XSS via location.hash (#9521)
- // Strict HTML recognition (#11290: must start with <)
- // Shortcut simple #id case for speed
- rquickExpr = /^(?:\s*(<[\w\W]+>)[^>]*|#([\w-]+))$/,
-
- init = jQuery.fn.init = function( selector, context, root ) {
- var match, elem;
-
- // HANDLE: $(""), $(null), $(undefined), $(false)
- if ( !selector ) {
- return this;
- }
-
- // Method init() accepts an alternate rootjQuery
- // so migrate can support jQuery.sub (gh-2101)
- root = root || rootjQuery;
-
- // Handle HTML strings
- if ( typeof selector === "string" ) {
- if ( selector[ 0 ] === "<" &&
- selector[ selector.length - 1 ] === ">" &&
- selector.length >= 3 ) {
-
- // Assume that strings that start and end with <> are HTML and skip the regex check
- match = [ null, selector, null ];
-
- } else {
- match = rquickExpr.exec( selector );
- }
-
- // Match html or make sure no context is specified for #id
- if ( match && ( match[ 1 ] || !context ) ) {
-
- // HANDLE: $(html) -> $(array)
- if ( match[ 1 ] ) {
- context = context instanceof jQuery ? context[ 0 ] : context;
-
- // Option to run scripts is true for back-compat
- // Intentionally let the error be thrown if parseHTML is not present
- jQuery.merge( this, jQuery.parseHTML(
- match[ 1 ],
- context && context.nodeType ? context.ownerDocument || context : document,
- true
- ) );
-
- // HANDLE: $(html, props)
- if ( rsingleTag.test( match[ 1 ] ) && jQuery.isPlainObject( context ) ) {
- for ( match in context ) {
-
- // Properties of context are called as methods if possible
- if ( isFunction( this[ match ] ) ) {
- this[ match ]( context[ match ] );
-
- // ...and otherwise set as attributes
- } else {
- this.attr( match, context[ match ] );
- }
- }
- }
-
- return this;
-
- // HANDLE: $(#id)
- } else {
- elem = document.getElementById( match[ 2 ] );
-
- if ( elem ) {
-
- // Inject the element directly into the jQuery object
- this[ 0 ] = elem;
- this.length = 1;
- }
- return this;
- }
-
- // HANDLE: $(expr, $(...))
- } else if ( !context || context.jquery ) {
- return ( context || root ).find( selector );
-
- // HANDLE: $(expr, context)
- // (which is just equivalent to: $(context).find(expr)
- } else {
- return this.constructor( context ).find( selector );
- }
-
- // HANDLE: $(DOMElement)
- } else if ( selector.nodeType ) {
- this[ 0 ] = selector;
- this.length = 1;
- return this;
-
- // HANDLE: $(function)
- // Shortcut for document ready
- } else if ( isFunction( selector ) ) {
- return root.ready !== undefined ?
- root.ready( selector ) :
-
- // Execute immediately if ready is not present
- selector( jQuery );
- }
-
- return jQuery.makeArray( selector, this );
- };
-
-// Give the init function the jQuery prototype for later instantiation
-init.prototype = jQuery.fn;
-
-// Initialize central reference
-rootjQuery = jQuery( document );
-
-
-var rparentsprev = /^(?:parents|prev(?:Until|All))/,
-
- // Methods guaranteed to produce a unique set when starting from a unique set
- guaranteedUnique = {
- children: true,
- contents: true,
- next: true,
- prev: true
- };
-
-jQuery.fn.extend( {
- has: function( target ) {
- var targets = jQuery( target, this ),
- l = targets.length;
-
- return this.filter( function() {
- var i = 0;
- for ( ; i < l; i++ ) {
- if ( jQuery.contains( this, targets[ i ] ) ) {
- return true;
- }
- }
- } );
- },
-
- closest: function( selectors, context ) {
- var cur,
- i = 0,
- l = this.length,
- matched = [],
- targets = typeof selectors !== "string" && jQuery( selectors );
-
- // Positional selectors never match, since there's no _selection_ context
- if ( !rneedsContext.test( selectors ) ) {
- for ( ; i < l; i++ ) {
- for ( cur = this[ i ]; cur && cur !== context; cur = cur.parentNode ) {
-
- // Always skip document fragments
- if ( cur.nodeType < 11 && ( targets ?
- targets.index( cur ) > -1 :
-
- // Don't pass non-elements to Sizzle
- cur.nodeType === 1 &&
- jQuery.find.matchesSelector( cur, selectors ) ) ) {
-
- matched.push( cur );
- break;
- }
- }
- }
- }
-
- return this.pushStack( matched.length > 1 ? jQuery.uniqueSort( matched ) : matched );
- },
-
- // Determine the position of an element within the set
- index: function( elem ) {
-
- // No argument, return index in parent
- if ( !elem ) {
- return ( this[ 0 ] && this[ 0 ].parentNode ) ? this.first().prevAll().length : -1;
- }
-
- // Index in selector
- if ( typeof elem === "string" ) {
- return indexOf.call( jQuery( elem ), this[ 0 ] );
- }
-
- // Locate the position of the desired element
- return indexOf.call( this,
-
- // If it receives a jQuery object, the first element is used
- elem.jquery ? elem[ 0 ] : elem
- );
- },
-
- add: function( selector, context ) {
- return this.pushStack(
- jQuery.uniqueSort(
- jQuery.merge( this.get(), jQuery( selector, context ) )
- )
- );
- },
-
- addBack: function( selector ) {
- return this.add( selector == null ?
- this.prevObject : this.prevObject.filter( selector )
- );
- }
-} );
-
-function sibling( cur, dir ) {
- while ( ( cur = cur[ dir ] ) && cur.nodeType !== 1 ) {}
- return cur;
-}
-
-jQuery.each( {
- parent: function( elem ) {
- var parent = elem.parentNode;
- return parent && parent.nodeType !== 11 ? parent : null;
- },
- parents: function( elem ) {
- return dir( elem, "parentNode" );
- },
- parentsUntil: function( elem, _i, until ) {
- return dir( elem, "parentNode", until );
- },
- next: function( elem ) {
- return sibling( elem, "nextSibling" );
- },
- prev: function( elem ) {
- return sibling( elem, "previousSibling" );
- },
- nextAll: function( elem ) {
- return dir( elem, "nextSibling" );
- },
- prevAll: function( elem ) {
- return dir( elem, "previousSibling" );
- },
- nextUntil: function( elem, _i, until ) {
- return dir( elem, "nextSibling", until );
- },
- prevUntil: function( elem, _i, until ) {
- return dir( elem, "previousSibling", until );
- },
- siblings: function( elem ) {
- return siblings( ( elem.parentNode || {} ).firstChild, elem );
- },
- children: function( elem ) {
- return siblings( elem.firstChild );
- },
- contents: function( elem ) {
- if ( elem.contentDocument != null &&
-
- // Support: IE 11+
- // elements with no `data` attribute has an object
- // `contentDocument` with a `null` prototype.
- getProto( elem.contentDocument ) ) {
-
- return elem.contentDocument;
- }
-
- // Support: IE 9 - 11 only, iOS 7 only, Android Browser <=4.3 only
- // Treat the template element as a regular one in browsers that
- // don't support it.
- if ( nodeName( elem, "template" ) ) {
- elem = elem.content || elem;
- }
-
- return jQuery.merge( [], elem.childNodes );
- }
-}, function( name, fn ) {
- jQuery.fn[ name ] = function( until, selector ) {
- var matched = jQuery.map( this, fn, until );
-
- if ( name.slice( -5 ) !== "Until" ) {
- selector = until;
- }
-
- if ( selector && typeof selector === "string" ) {
- matched = jQuery.filter( selector, matched );
- }
-
- if ( this.length > 1 ) {
-
- // Remove duplicates
- if ( !guaranteedUnique[ name ] ) {
- jQuery.uniqueSort( matched );
- }
-
- // Reverse order for parents* and prev-derivatives
- if ( rparentsprev.test( name ) ) {
- matched.reverse();
- }
- }
-
- return this.pushStack( matched );
- };
-} );
-var rnothtmlwhite = ( /[^\x20\t\r\n\f]+/g );
-
-
-
-// Convert String-formatted options into Object-formatted ones
-function createOptions( options ) {
- var object = {};
- jQuery.each( options.match( rnothtmlwhite ) || [], function( _, flag ) {
- object[ flag ] = true;
- } );
- return object;
-}
-
-/*
- * Create a callback list using the following parameters:
- *
- * options: an optional list of space-separated options that will change how
- * the callback list behaves or a more traditional option object
- *
- * By default a callback list will act like an event callback list and can be
- * "fired" multiple times.
- *
- * Possible options:
- *
- * once: will ensure the callback list can only be fired once (like a Deferred)
- *
- * memory: will keep track of previous values and will call any callback added
- * after the list has been fired right away with the latest "memorized"
- * values (like a Deferred)
- *
- * unique: will ensure a callback can only be added once (no duplicate in the list)
- *
- * stopOnFalse: interrupt callings when a callback returns false
- *
- */
-jQuery.Callbacks = function( options ) {
-
- // Convert options from String-formatted to Object-formatted if needed
- // (we check in cache first)
- options = typeof options === "string" ?
- createOptions( options ) :
- jQuery.extend( {}, options );
-
- var // Flag to know if list is currently firing
- firing,
-
- // Last fire value for non-forgettable lists
- memory,
-
- // Flag to know if list was already fired
- fired,
-
- // Flag to prevent firing
- locked,
-
- // Actual callback list
- list = [],
-
- // Queue of execution data for repeatable lists
- queue = [],
-
- // Index of currently firing callback (modified by add/remove as needed)
- firingIndex = -1,
-
- // Fire callbacks
- fire = function() {
-
- // Enforce single-firing
- locked = locked || options.once;
-
- // Execute callbacks for all pending executions,
- // respecting firingIndex overrides and runtime changes
- fired = firing = true;
- for ( ; queue.length; firingIndex = -1 ) {
- memory = queue.shift();
- while ( ++firingIndex < list.length ) {
-
- // Run callback and check for early termination
- if ( list[ firingIndex ].apply( memory[ 0 ], memory[ 1 ] ) === false &&
- options.stopOnFalse ) {
-
- // Jump to end and forget the data so .add doesn't re-fire
- firingIndex = list.length;
- memory = false;
- }
- }
- }
-
- // Forget the data if we're done with it
- if ( !options.memory ) {
- memory = false;
- }
-
- firing = false;
-
- // Clean up if we're done firing for good
- if ( locked ) {
-
- // Keep an empty list if we have data for future add calls
- if ( memory ) {
- list = [];
-
- // Otherwise, this object is spent
- } else {
- list = "";
- }
- }
- },
-
- // Actual Callbacks object
- self = {
-
- // Add a callback or a collection of callbacks to the list
- add: function() {
- if ( list ) {
-
- // If we have memory from a past run, we should fire after adding
- if ( memory && !firing ) {
- firingIndex = list.length - 1;
- queue.push( memory );
- }
-
- ( function add( args ) {
- jQuery.each( args, function( _, arg ) {
- if ( isFunction( arg ) ) {
- if ( !options.unique || !self.has( arg ) ) {
- list.push( arg );
- }
- } else if ( arg && arg.length && toType( arg ) !== "string" ) {
-
- // Inspect recursively
- add( arg );
- }
- } );
- } )( arguments );
-
- if ( memory && !firing ) {
- fire();
- }
- }
- return this;
- },
-
- // Remove a callback from the list
- remove: function() {
- jQuery.each( arguments, function( _, arg ) {
- var index;
- while ( ( index = jQuery.inArray( arg, list, index ) ) > -1 ) {
- list.splice( index, 1 );
-
- // Handle firing indexes
- if ( index <= firingIndex ) {
- firingIndex--;
- }
- }
- } );
- return this;
- },
-
- // Check if a given callback is in the list.
- // If no argument is given, return whether or not list has callbacks attached.
- has: function( fn ) {
- return fn ?
- jQuery.inArray( fn, list ) > -1 :
- list.length > 0;
- },
-
- // Remove all callbacks from the list
- empty: function() {
- if ( list ) {
- list = [];
- }
- return this;
- },
-
- // Disable .fire and .add
- // Abort any current/pending executions
- // Clear all callbacks and values
- disable: function() {
- locked = queue = [];
- list = memory = "";
- return this;
- },
- disabled: function() {
- return !list;
- },
-
- // Disable .fire
- // Also disable .add unless we have memory (since it would have no effect)
- // Abort any pending executions
- lock: function() {
- locked = queue = [];
- if ( !memory && !firing ) {
- list = memory = "";
- }
- return this;
- },
- locked: function() {
- return !!locked;
- },
-
- // Call all callbacks with the given context and arguments
- fireWith: function( context, args ) {
- if ( !locked ) {
- args = args || [];
- args = [ context, args.slice ? args.slice() : args ];
- queue.push( args );
- if ( !firing ) {
- fire();
- }
- }
- return this;
- },
-
- // Call all the callbacks with the given arguments
- fire: function() {
- self.fireWith( this, arguments );
- return this;
- },
-
- // To know if the callbacks have already been called at least once
- fired: function() {
- return !!fired;
- }
- };
-
- return self;
-};
-
-
-function Identity( v ) {
- return v;
-}
-function Thrower( ex ) {
- throw ex;
-}
-
-function adoptValue( value, resolve, reject, noValue ) {
- var method;
-
- try {
-
- // Check for promise aspect first to privilege synchronous behavior
- if ( value && isFunction( ( method = value.promise ) ) ) {
- method.call( value ).done( resolve ).fail( reject );
-
- // Other thenables
- } else if ( value && isFunction( ( method = value.then ) ) ) {
- method.call( value, resolve, reject );
-
- // Other non-thenables
- } else {
-
- // Control `resolve` arguments by letting Array#slice cast boolean `noValue` to integer:
- // * false: [ value ].slice( 0 ) => resolve( value )
- // * true: [ value ].slice( 1 ) => resolve()
- resolve.apply( undefined, [ value ].slice( noValue ) );
- }
-
- // For Promises/A+, convert exceptions into rejections
- // Since jQuery.when doesn't unwrap thenables, we can skip the extra checks appearing in
- // Deferred#then to conditionally suppress rejection.
- } catch ( value ) {
-
- // Support: Android 4.0 only
- // Strict mode functions invoked without .call/.apply get global-object context
- reject.apply( undefined, [ value ] );
- }
-}
-
-jQuery.extend( {
-
- Deferred: function( func ) {
- var tuples = [
-
- // action, add listener, callbacks,
- // ... .then handlers, argument index, [final state]
- [ "notify", "progress", jQuery.Callbacks( "memory" ),
- jQuery.Callbacks( "memory" ), 2 ],
- [ "resolve", "done", jQuery.Callbacks( "once memory" ),
- jQuery.Callbacks( "once memory" ), 0, "resolved" ],
- [ "reject", "fail", jQuery.Callbacks( "once memory" ),
- jQuery.Callbacks( "once memory" ), 1, "rejected" ]
- ],
- state = "pending",
- promise = {
- state: function() {
- return state;
- },
- always: function() {
- deferred.done( arguments ).fail( arguments );
- return this;
- },
- "catch": function( fn ) {
- return promise.then( null, fn );
- },
-
- // Keep pipe for back-compat
- pipe: function( /* fnDone, fnFail, fnProgress */ ) {
- var fns = arguments;
-
- return jQuery.Deferred( function( newDefer ) {
- jQuery.each( tuples, function( _i, tuple ) {
-
- // Map tuples (progress, done, fail) to arguments (done, fail, progress)
- var fn = isFunction( fns[ tuple[ 4 ] ] ) && fns[ tuple[ 4 ] ];
-
- // deferred.progress(function() { bind to newDefer or newDefer.notify })
- // deferred.done(function() { bind to newDefer or newDefer.resolve })
- // deferred.fail(function() { bind to newDefer or newDefer.reject })
- deferred[ tuple[ 1 ] ]( function() {
- var returned = fn && fn.apply( this, arguments );
- if ( returned && isFunction( returned.promise ) ) {
- returned.promise()
- .progress( newDefer.notify )
- .done( newDefer.resolve )
- .fail( newDefer.reject );
- } else {
- newDefer[ tuple[ 0 ] + "With" ](
- this,
- fn ? [ returned ] : arguments
- );
- }
- } );
- } );
- fns = null;
- } ).promise();
- },
- then: function( onFulfilled, onRejected, onProgress ) {
- var maxDepth = 0;
- function resolve( depth, deferred, handler, special ) {
- return function() {
- var that = this,
- args = arguments,
- mightThrow = function() {
- var returned, then;
-
- // Support: Promises/A+ section 2.3.3.3.3
- // https://promisesaplus.com/#point-59
- // Ignore double-resolution attempts
- if ( depth < maxDepth ) {
- return;
- }
-
- returned = handler.apply( that, args );
-
- // Support: Promises/A+ section 2.3.1
- // https://promisesaplus.com/#point-48
- if ( returned === deferred.promise() ) {
- throw new TypeError( "Thenable self-resolution" );
- }
-
- // Support: Promises/A+ sections 2.3.3.1, 3.5
- // https://promisesaplus.com/#point-54
- // https://promisesaplus.com/#point-75
- // Retrieve `then` only once
- then = returned &&
-
- // Support: Promises/A+ section 2.3.4
- // https://promisesaplus.com/#point-64
- // Only check objects and functions for thenability
- ( typeof returned === "object" ||
- typeof returned === "function" ) &&
- returned.then;
-
- // Handle a returned thenable
- if ( isFunction( then ) ) {
-
- // Special processors (notify) just wait for resolution
- if ( special ) {
- then.call(
- returned,
- resolve( maxDepth, deferred, Identity, special ),
- resolve( maxDepth, deferred, Thrower, special )
- );
-
- // Normal processors (resolve) also hook into progress
- } else {
-
- // ...and disregard older resolution values
- maxDepth++;
-
- then.call(
- returned,
- resolve( maxDepth, deferred, Identity, special ),
- resolve( maxDepth, deferred, Thrower, special ),
- resolve( maxDepth, deferred, Identity,
- deferred.notifyWith )
- );
- }
-
- // Handle all other returned values
- } else {
-
- // Only substitute handlers pass on context
- // and multiple values (non-spec behavior)
- if ( handler !== Identity ) {
- that = undefined;
- args = [ returned ];
- }
-
- // Process the value(s)
- // Default process is resolve
- ( special || deferred.resolveWith )( that, args );
- }
- },
-
- // Only normal processors (resolve) catch and reject exceptions
- process = special ?
- mightThrow :
- function() {
- try {
- mightThrow();
- } catch ( e ) {
-
- if ( jQuery.Deferred.exceptionHook ) {
- jQuery.Deferred.exceptionHook( e,
- process.stackTrace );
- }
-
- // Support: Promises/A+ section 2.3.3.3.4.1
- // https://promisesaplus.com/#point-61
- // Ignore post-resolution exceptions
- if ( depth + 1 >= maxDepth ) {
-
- // Only substitute handlers pass on context
- // and multiple values (non-spec behavior)
- if ( handler !== Thrower ) {
- that = undefined;
- args = [ e ];
- }
-
- deferred.rejectWith( that, args );
- }
- }
- };
-
- // Support: Promises/A+ section 2.3.3.3.1
- // https://promisesaplus.com/#point-57
- // Re-resolve promises immediately to dodge false rejection from
- // subsequent errors
- if ( depth ) {
- process();
- } else {
-
- // Call an optional hook to record the stack, in case of exception
- // since it's otherwise lost when execution goes async
- if ( jQuery.Deferred.getStackHook ) {
- process.stackTrace = jQuery.Deferred.getStackHook();
- }
- window.setTimeout( process );
- }
- };
- }
-
- return jQuery.Deferred( function( newDefer ) {
-
- // progress_handlers.add( ... )
- tuples[ 0 ][ 3 ].add(
- resolve(
- 0,
- newDefer,
- isFunction( onProgress ) ?
- onProgress :
- Identity,
- newDefer.notifyWith
- )
- );
-
- // fulfilled_handlers.add( ... )
- tuples[ 1 ][ 3 ].add(
- resolve(
- 0,
- newDefer,
- isFunction( onFulfilled ) ?
- onFulfilled :
- Identity
- )
- );
-
- // rejected_handlers.add( ... )
- tuples[ 2 ][ 3 ].add(
- resolve(
- 0,
- newDefer,
- isFunction( onRejected ) ?
- onRejected :
- Thrower
- )
- );
- } ).promise();
- },
-
- // Get a promise for this deferred
- // If obj is provided, the promise aspect is added to the object
- promise: function( obj ) {
- return obj != null ? jQuery.extend( obj, promise ) : promise;
- }
- },
- deferred = {};
-
- // Add list-specific methods
- jQuery.each( tuples, function( i, tuple ) {
- var list = tuple[ 2 ],
- stateString = tuple[ 5 ];
-
- // promise.progress = list.add
- // promise.done = list.add
- // promise.fail = list.add
- promise[ tuple[ 1 ] ] = list.add;
-
- // Handle state
- if ( stateString ) {
- list.add(
- function() {
-
- // state = "resolved" (i.e., fulfilled)
- // state = "rejected"
- state = stateString;
- },
-
- // rejected_callbacks.disable
- // fulfilled_callbacks.disable
- tuples[ 3 - i ][ 2 ].disable,
-
- // rejected_handlers.disable
- // fulfilled_handlers.disable
- tuples[ 3 - i ][ 3 ].disable,
-
- // progress_callbacks.lock
- tuples[ 0 ][ 2 ].lock,
-
- // progress_handlers.lock
- tuples[ 0 ][ 3 ].lock
- );
- }
-
- // progress_handlers.fire
- // fulfilled_handlers.fire
- // rejected_handlers.fire
- list.add( tuple[ 3 ].fire );
-
- // deferred.notify = function() { deferred.notifyWith(...) }
- // deferred.resolve = function() { deferred.resolveWith(...) }
- // deferred.reject = function() { deferred.rejectWith(...) }
- deferred[ tuple[ 0 ] ] = function() {
- deferred[ tuple[ 0 ] + "With" ]( this === deferred ? undefined : this, arguments );
- return this;
- };
-
- // deferred.notifyWith = list.fireWith
- // deferred.resolveWith = list.fireWith
- // deferred.rejectWith = list.fireWith
- deferred[ tuple[ 0 ] + "With" ] = list.fireWith;
- } );
-
- // Make the deferred a promise
- promise.promise( deferred );
-
- // Call given func if any
- if ( func ) {
- func.call( deferred, deferred );
- }
-
- // All done!
- return deferred;
- },
-
- // Deferred helper
- when: function( singleValue ) {
- var
-
- // count of uncompleted subordinates
- remaining = arguments.length,
-
- // count of unprocessed arguments
- i = remaining,
-
- // subordinate fulfillment data
- resolveContexts = Array( i ),
- resolveValues = slice.call( arguments ),
-
- // the master Deferred
- master = jQuery.Deferred(),
-
- // subordinate callback factory
- updateFunc = function( i ) {
- return function( value ) {
- resolveContexts[ i ] = this;
- resolveValues[ i ] = arguments.length > 1 ? slice.call( arguments ) : value;
- if ( !( --remaining ) ) {
- master.resolveWith( resolveContexts, resolveValues );
- }
- };
- };
-
- // Single- and empty arguments are adopted like Promise.resolve
- if ( remaining <= 1 ) {
- adoptValue( singleValue, master.done( updateFunc( i ) ).resolve, master.reject,
- !remaining );
-
- // Use .then() to unwrap secondary thenables (cf. gh-3000)
- if ( master.state() === "pending" ||
- isFunction( resolveValues[ i ] && resolveValues[ i ].then ) ) {
-
- return master.then();
- }
- }
-
- // Multiple arguments are aggregated like Promise.all array elements
- while ( i-- ) {
- adoptValue( resolveValues[ i ], updateFunc( i ), master.reject );
- }
-
- return master.promise();
- }
-} );
-
-
-// These usually indicate a programmer mistake during development,
-// warn about them ASAP rather than swallowing them by default.
-var rerrorNames = /^(Eval|Internal|Range|Reference|Syntax|Type|URI)Error$/;
-
-jQuery.Deferred.exceptionHook = function( error, stack ) {
-
- // Support: IE 8 - 9 only
- // Console exists when dev tools are open, which can happen at any time
- if ( window.console && window.console.warn && error && rerrorNames.test( error.name ) ) {
- window.console.warn( "jQuery.Deferred exception: " + error.message, error.stack, stack );
- }
-};
-
-
-
-
-jQuery.readyException = function( error ) {
- window.setTimeout( function() {
- throw error;
- } );
-};
-
-
-
-
-// The deferred used on DOM ready
-var readyList = jQuery.Deferred();
-
-jQuery.fn.ready = function( fn ) {
-
- readyList
- .then( fn )
-
- // Wrap jQuery.readyException in a function so that the lookup
- // happens at the time of error handling instead of callback
- // registration.
- .catch( function( error ) {
- jQuery.readyException( error );
- } );
-
- return this;
-};
-
-jQuery.extend( {
-
- // Is the DOM ready to be used? Set to true once it occurs.
- isReady: false,
-
- // A counter to track how many items to wait for before
- // the ready event fires. See #6781
- readyWait: 1,
-
- // Handle when the DOM is ready
- ready: function( wait ) {
-
- // Abort if there are pending holds or we're already ready
- if ( wait === true ? --jQuery.readyWait : jQuery.isReady ) {
- return;
- }
-
- // Remember that the DOM is ready
- jQuery.isReady = true;
-
- // If a normal DOM Ready event fired, decrement, and wait if need be
- if ( wait !== true && --jQuery.readyWait > 0 ) {
- return;
- }
-
- // If there are functions bound, to execute
- readyList.resolveWith( document, [ jQuery ] );
- }
-} );
-
-jQuery.ready.then = readyList.then;
-
-// The ready event handler and self cleanup method
-function completed() {
- document.removeEventListener( "DOMContentLoaded", completed );
- window.removeEventListener( "load", completed );
- jQuery.ready();
-}
-
-// Catch cases where $(document).ready() is called
-// after the browser event has already occurred.
-// Support: IE <=9 - 10 only
-// Older IE sometimes signals "interactive" too soon
-if ( document.readyState === "complete" ||
- ( document.readyState !== "loading" && !document.documentElement.doScroll ) ) {
-
- // Handle it asynchronously to allow scripts the opportunity to delay ready
- window.setTimeout( jQuery.ready );
-
-} else {
-
- // Use the handy event callback
- document.addEventListener( "DOMContentLoaded", completed );
-
- // A fallback to window.onload, that will always work
- window.addEventListener( "load", completed );
-}
-
-
-
-
-// Multifunctional method to get and set values of a collection
-// The value/s can optionally be executed if it's a function
-var access = function( elems, fn, key, value, chainable, emptyGet, raw ) {
- var i = 0,
- len = elems.length,
- bulk = key == null;
-
- // Sets many values
- if ( toType( key ) === "object" ) {
- chainable = true;
- for ( i in key ) {
- access( elems, fn, i, key[ i ], true, emptyGet, raw );
- }
-
- // Sets one value
- } else if ( value !== undefined ) {
- chainable = true;
-
- if ( !isFunction( value ) ) {
- raw = true;
- }
-
- if ( bulk ) {
-
- // Bulk operations run against the entire set
- if ( raw ) {
- fn.call( elems, value );
- fn = null;
-
- // ...except when executing function values
- } else {
- bulk = fn;
- fn = function( elem, _key, value ) {
- return bulk.call( jQuery( elem ), value );
- };
- }
- }
-
- if ( fn ) {
- for ( ; i < len; i++ ) {
- fn(
- elems[ i ], key, raw ?
- value :
- value.call( elems[ i ], i, fn( elems[ i ], key ) )
- );
- }
- }
- }
-
- if ( chainable ) {
- return elems;
- }
-
- // Gets
- if ( bulk ) {
- return fn.call( elems );
- }
-
- return len ? fn( elems[ 0 ], key ) : emptyGet;
-};
-
-
-// Matches dashed string for camelizing
-var rmsPrefix = /^-ms-/,
- rdashAlpha = /-([a-z])/g;
-
-// Used by camelCase as callback to replace()
-function fcamelCase( _all, letter ) {
- return letter.toUpperCase();
-}
-
-// Convert dashed to camelCase; used by the css and data modules
-// Support: IE <=9 - 11, Edge 12 - 15
-// Microsoft forgot to hump their vendor prefix (#9572)
-function camelCase( string ) {
- return string.replace( rmsPrefix, "ms-" ).replace( rdashAlpha, fcamelCase );
-}
-var acceptData = function( owner ) {
-
- // Accepts only:
- // - Node
- // - Node.ELEMENT_NODE
- // - Node.DOCUMENT_NODE
- // - Object
- // - Any
- return owner.nodeType === 1 || owner.nodeType === 9 || !( +owner.nodeType );
-};
-
-
-
-
-function Data() {
- this.expando = jQuery.expando + Data.uid++;
-}
-
-Data.uid = 1;
-
-Data.prototype = {
-
- cache: function( owner ) {
-
- // Check if the owner object already has a cache
- var value = owner[ this.expando ];
-
- // If not, create one
- if ( !value ) {
- value = {};
-
- // We can accept data for non-element nodes in modern browsers,
- // but we should not, see #8335.
- // Always return an empty object.
- if ( acceptData( owner ) ) {
-
- // If it is a node unlikely to be stringify-ed or looped over
- // use plain assignment
- if ( owner.nodeType ) {
- owner[ this.expando ] = value;
-
- // Otherwise secure it in a non-enumerable property
- // configurable must be true to allow the property to be
- // deleted when data is removed
- } else {
- Object.defineProperty( owner, this.expando, {
- value: value,
- configurable: true
- } );
- }
- }
- }
-
- return value;
- },
- set: function( owner, data, value ) {
- var prop,
- cache = this.cache( owner );
-
- // Handle: [ owner, key, value ] args
- // Always use camelCase key (gh-2257)
- if ( typeof data === "string" ) {
- cache[ camelCase( data ) ] = value;
-
- // Handle: [ owner, { properties } ] args
- } else {
-
- // Copy the properties one-by-one to the cache object
- for ( prop in data ) {
- cache[ camelCase( prop ) ] = data[ prop ];
- }
- }
- return cache;
- },
- get: function( owner, key ) {
- return key === undefined ?
- this.cache( owner ) :
-
- // Always use camelCase key (gh-2257)
- owner[ this.expando ] && owner[ this.expando ][ camelCase( key ) ];
- },
- access: function( owner, key, value ) {
-
- // In cases where either:
- //
- // 1. No key was specified
- // 2. A string key was specified, but no value provided
- //
- // Take the "read" path and allow the get method to determine
- // which value to return, respectively either:
- //
- // 1. The entire cache object
- // 2. The data stored at the key
- //
- if ( key === undefined ||
- ( ( key && typeof key === "string" ) && value === undefined ) ) {
-
- return this.get( owner, key );
- }
-
- // When the key is not a string, or both a key and value
- // are specified, set or extend (existing objects) with either:
- //
- // 1. An object of properties
- // 2. A key and value
- //
- this.set( owner, key, value );
-
- // Since the "set" path can have two possible entry points
- // return the expected data based on which path was taken[*]
- return value !== undefined ? value : key;
- },
- remove: function( owner, key ) {
- var i,
- cache = owner[ this.expando ];
-
- if ( cache === undefined ) {
- return;
- }
-
- if ( key !== undefined ) {
-
- // Support array or space separated string of keys
- if ( Array.isArray( key ) ) {
-
- // If key is an array of keys...
- // We always set camelCase keys, so remove that.
- key = key.map( camelCase );
- } else {
- key = camelCase( key );
-
- // If a key with the spaces exists, use it.
- // Otherwise, create an array by matching non-whitespace
- key = key in cache ?
- [ key ] :
- ( key.match( rnothtmlwhite ) || [] );
- }
-
- i = key.length;
-
- while ( i-- ) {
- delete cache[ key[ i ] ];
- }
- }
-
- // Remove the expando if there's no more data
- if ( key === undefined || jQuery.isEmptyObject( cache ) ) {
-
- // Support: Chrome <=35 - 45
- // Webkit & Blink performance suffers when deleting properties
- // from DOM nodes, so set to undefined instead
- // https://bugs.chromium.org/p/chromium/issues/detail?id=378607 (bug restricted)
- if ( owner.nodeType ) {
- owner[ this.expando ] = undefined;
- } else {
- delete owner[ this.expando ];
- }
- }
- },
- hasData: function( owner ) {
- var cache = owner[ this.expando ];
- return cache !== undefined && !jQuery.isEmptyObject( cache );
- }
-};
-var dataPriv = new Data();
-
-var dataUser = new Data();
-
-
-
-// Implementation Summary
-//
-// 1. Enforce API surface and semantic compatibility with 1.9.x branch
-// 2. Improve the module's maintainability by reducing the storage
-// paths to a single mechanism.
-// 3. Use the same single mechanism to support "private" and "user" data.
-// 4. _Never_ expose "private" data to user code (TODO: Drop _data, _removeData)
-// 5. Avoid exposing implementation details on user objects (eg. expando properties)
-// 6. Provide a clear path for implementation upgrade to WeakMap in 2014
-
-var rbrace = /^(?:\{[\w\W]*\}|\[[\w\W]*\])$/,
- rmultiDash = /[A-Z]/g;
-
-function getData( data ) {
- if ( data === "true" ) {
- return true;
- }
-
- if ( data === "false" ) {
- return false;
- }
-
- if ( data === "null" ) {
- return null;
- }
-
- // Only convert to a number if it doesn't change the string
- if ( data === +data + "" ) {
- return +data;
- }
-
- if ( rbrace.test( data ) ) {
- return JSON.parse( data );
- }
-
- return data;
-}
-
-function dataAttr( elem, key, data ) {
- var name;
-
- // If nothing was found internally, try to fetch any
- // data from the HTML5 data-* attribute
- if ( data === undefined && elem.nodeType === 1 ) {
- name = "data-" + key.replace( rmultiDash, "-$&" ).toLowerCase();
- data = elem.getAttribute( name );
-
- if ( typeof data === "string" ) {
- try {
- data = getData( data );
- } catch ( e ) {}
-
- // Make sure we set the data so it isn't changed later
- dataUser.set( elem, key, data );
- } else {
- data = undefined;
- }
- }
- return data;
-}
-
-jQuery.extend( {
- hasData: function( elem ) {
- return dataUser.hasData( elem ) || dataPriv.hasData( elem );
- },
-
- data: function( elem, name, data ) {
- return dataUser.access( elem, name, data );
- },
-
- removeData: function( elem, name ) {
- dataUser.remove( elem, name );
- },
-
- // TODO: Now that all calls to _data and _removeData have been replaced
- // with direct calls to dataPriv methods, these can be deprecated.
- _data: function( elem, name, data ) {
- return dataPriv.access( elem, name, data );
- },
-
- _removeData: function( elem, name ) {
- dataPriv.remove( elem, name );
- }
-} );
-
-jQuery.fn.extend( {
- data: function( key, value ) {
- var i, name, data,
- elem = this[ 0 ],
- attrs = elem && elem.attributes;
-
- // Gets all values
- if ( key === undefined ) {
- if ( this.length ) {
- data = dataUser.get( elem );
-
- if ( elem.nodeType === 1 && !dataPriv.get( elem, "hasDataAttrs" ) ) {
- i = attrs.length;
- while ( i-- ) {
-
- // Support: IE 11 only
- // The attrs elements can be null (#14894)
- if ( attrs[ i ] ) {
- name = attrs[ i ].name;
- if ( name.indexOf( "data-" ) === 0 ) {
- name = camelCase( name.slice( 5 ) );
- dataAttr( elem, name, data[ name ] );
- }
- }
- }
- dataPriv.set( elem, "hasDataAttrs", true );
- }
- }
-
- return data;
- }
-
- // Sets multiple values
- if ( typeof key === "object" ) {
- return this.each( function() {
- dataUser.set( this, key );
- } );
- }
-
- return access( this, function( value ) {
- var data;
-
- // The calling jQuery object (element matches) is not empty
- // (and therefore has an element appears at this[ 0 ]) and the
- // `value` parameter was not undefined. An empty jQuery object
- // will result in `undefined` for elem = this[ 0 ] which will
- // throw an exception if an attempt to read a data cache is made.
- if ( elem && value === undefined ) {
-
- // Attempt to get data from the cache
- // The key will always be camelCased in Data
- data = dataUser.get( elem, key );
- if ( data !== undefined ) {
- return data;
- }
-
- // Attempt to "discover" the data in
- // HTML5 custom data-* attrs
- data = dataAttr( elem, key );
- if ( data !== undefined ) {
- return data;
- }
-
- // We tried really hard, but the data doesn't exist.
- return;
- }
-
- // Set the data...
- this.each( function() {
-
- // We always store the camelCased key
- dataUser.set( this, key, value );
- } );
- }, null, value, arguments.length > 1, null, true );
- },
-
- removeData: function( key ) {
- return this.each( function() {
- dataUser.remove( this, key );
- } );
- }
-} );
-
-
-jQuery.extend( {
- queue: function( elem, type, data ) {
- var queue;
-
- if ( elem ) {
- type = ( type || "fx" ) + "queue";
- queue = dataPriv.get( elem, type );
-
- // Speed up dequeue by getting out quickly if this is just a lookup
- if ( data ) {
- if ( !queue || Array.isArray( data ) ) {
- queue = dataPriv.access( elem, type, jQuery.makeArray( data ) );
- } else {
- queue.push( data );
- }
- }
- return queue || [];
- }
- },
-
- dequeue: function( elem, type ) {
- type = type || "fx";
-
- var queue = jQuery.queue( elem, type ),
- startLength = queue.length,
- fn = queue.shift(),
- hooks = jQuery._queueHooks( elem, type ),
- next = function() {
- jQuery.dequeue( elem, type );
- };
-
- // If the fx queue is dequeued, always remove the progress sentinel
- if ( fn === "inprogress" ) {
- fn = queue.shift();
- startLength--;
- }
-
- if ( fn ) {
-
- // Add a progress sentinel to prevent the fx queue from being
- // automatically dequeued
- if ( type === "fx" ) {
- queue.unshift( "inprogress" );
- }
-
- // Clear up the last queue stop function
- delete hooks.stop;
- fn.call( elem, next, hooks );
- }
-
- if ( !startLength && hooks ) {
- hooks.empty.fire();
- }
- },
-
- // Not public - generate a queueHooks object, or return the current one
- _queueHooks: function( elem, type ) {
- var key = type + "queueHooks";
- return dataPriv.get( elem, key ) || dataPriv.access( elem, key, {
- empty: jQuery.Callbacks( "once memory" ).add( function() {
- dataPriv.remove( elem, [ type + "queue", key ] );
- } )
- } );
- }
-} );
-
-jQuery.fn.extend( {
- queue: function( type, data ) {
- var setter = 2;
-
- if ( typeof type !== "string" ) {
- data = type;
- type = "fx";
- setter--;
- }
-
- if ( arguments.length < setter ) {
- return jQuery.queue( this[ 0 ], type );
- }
-
- return data === undefined ?
- this :
- this.each( function() {
- var queue = jQuery.queue( this, type, data );
-
- // Ensure a hooks for this queue
- jQuery._queueHooks( this, type );
-
- if ( type === "fx" && queue[ 0 ] !== "inprogress" ) {
- jQuery.dequeue( this, type );
- }
- } );
- },
- dequeue: function( type ) {
- return this.each( function() {
- jQuery.dequeue( this, type );
- } );
- },
- clearQueue: function( type ) {
- return this.queue( type || "fx", [] );
- },
-
- // Get a promise resolved when queues of a certain type
- // are emptied (fx is the type by default)
- promise: function( type, obj ) {
- var tmp,
- count = 1,
- defer = jQuery.Deferred(),
- elements = this,
- i = this.length,
- resolve = function() {
- if ( !( --count ) ) {
- defer.resolveWith( elements, [ elements ] );
- }
- };
-
- if ( typeof type !== "string" ) {
- obj = type;
- type = undefined;
- }
- type = type || "fx";
-
- while ( i-- ) {
- tmp = dataPriv.get( elements[ i ], type + "queueHooks" );
- if ( tmp && tmp.empty ) {
- count++;
- tmp.empty.add( resolve );
- }
- }
- resolve();
- return defer.promise( obj );
- }
-} );
-var pnum = ( /[+-]?(?:\d*\.|)\d+(?:[eE][+-]?\d+|)/ ).source;
-
-var rcssNum = new RegExp( "^(?:([+-])=|)(" + pnum + ")([a-z%]*)$", "i" );
-
-
-var cssExpand = [ "Top", "Right", "Bottom", "Left" ];
-
-var documentElement = document.documentElement;
-
-
-
- var isAttached = function( elem ) {
- return jQuery.contains( elem.ownerDocument, elem );
- },
- composed = { composed: true };
-
- // Support: IE 9 - 11+, Edge 12 - 18+, iOS 10.0 - 10.2 only
- // Check attachment across shadow DOM boundaries when possible (gh-3504)
- // Support: iOS 10.0-10.2 only
- // Early iOS 10 versions support `attachShadow` but not `getRootNode`,
- // leading to errors. We need to check for `getRootNode`.
- if ( documentElement.getRootNode ) {
- isAttached = function( elem ) {
- return jQuery.contains( elem.ownerDocument, elem ) ||
- elem.getRootNode( composed ) === elem.ownerDocument;
- };
- }
-var isHiddenWithinTree = function( elem, el ) {
-
- // isHiddenWithinTree might be called from jQuery#filter function;
- // in that case, element will be second argument
- elem = el || elem;
-
- // Inline style trumps all
- return elem.style.display === "none" ||
- elem.style.display === "" &&
-
- // Otherwise, check computed style
- // Support: Firefox <=43 - 45
- // Disconnected elements can have computed display: none, so first confirm that elem is
- // in the document.
- isAttached( elem ) &&
-
- jQuery.css( elem, "display" ) === "none";
- };
-
-
-
-function adjustCSS( elem, prop, valueParts, tween ) {
- var adjusted, scale,
- maxIterations = 20,
- currentValue = tween ?
- function() {
- return tween.cur();
- } :
- function() {
- return jQuery.css( elem, prop, "" );
- },
- initial = currentValue(),
- unit = valueParts && valueParts[ 3 ] || ( jQuery.cssNumber[ prop ] ? "" : "px" ),
-
- // Starting value computation is required for potential unit mismatches
- initialInUnit = elem.nodeType &&
- ( jQuery.cssNumber[ prop ] || unit !== "px" && +initial ) &&
- rcssNum.exec( jQuery.css( elem, prop ) );
-
- if ( initialInUnit && initialInUnit[ 3 ] !== unit ) {
-
- // Support: Firefox <=54
- // Halve the iteration target value to prevent interference from CSS upper bounds (gh-2144)
- initial = initial / 2;
-
- // Trust units reported by jQuery.css
- unit = unit || initialInUnit[ 3 ];
-
- // Iteratively approximate from a nonzero starting point
- initialInUnit = +initial || 1;
-
- while ( maxIterations-- ) {
-
- // Evaluate and update our best guess (doubling guesses that zero out).
- // Finish if the scale equals or crosses 1 (making the old*new product non-positive).
- jQuery.style( elem, prop, initialInUnit + unit );
- if ( ( 1 - scale ) * ( 1 - ( scale = currentValue() / initial || 0.5 ) ) <= 0 ) {
- maxIterations = 0;
- }
- initialInUnit = initialInUnit / scale;
-
- }
-
- initialInUnit = initialInUnit * 2;
- jQuery.style( elem, prop, initialInUnit + unit );
-
- // Make sure we update the tween properties later on
- valueParts = valueParts || [];
- }
-
- if ( valueParts ) {
- initialInUnit = +initialInUnit || +initial || 0;
-
- // Apply relative offset (+=/-=) if specified
- adjusted = valueParts[ 1 ] ?
- initialInUnit + ( valueParts[ 1 ] + 1 ) * valueParts[ 2 ] :
- +valueParts[ 2 ];
- if ( tween ) {
- tween.unit = unit;
- tween.start = initialInUnit;
- tween.end = adjusted;
- }
- }
- return adjusted;
-}
-
-
-var defaultDisplayMap = {};
-
-function getDefaultDisplay( elem ) {
- var temp,
- doc = elem.ownerDocument,
- nodeName = elem.nodeName,
- display = defaultDisplayMap[ nodeName ];
-
- if ( display ) {
- return display;
- }
-
- temp = doc.body.appendChild( doc.createElement( nodeName ) );
- display = jQuery.css( temp, "display" );
-
- temp.parentNode.removeChild( temp );
-
- if ( display === "none" ) {
- display = "block";
- }
- defaultDisplayMap[ nodeName ] = display;
-
- return display;
-}
-
-function showHide( elements, show ) {
- var display, elem,
- values = [],
- index = 0,
- length = elements.length;
-
- // Determine new display value for elements that need to change
- for ( ; index < length; index++ ) {
- elem = elements[ index ];
- if ( !elem.style ) {
- continue;
- }
-
- display = elem.style.display;
- if ( show ) {
-
- // Since we force visibility upon cascade-hidden elements, an immediate (and slow)
- // check is required in this first loop unless we have a nonempty display value (either
- // inline or about-to-be-restored)
- if ( display === "none" ) {
- values[ index ] = dataPriv.get( elem, "display" ) || null;
- if ( !values[ index ] ) {
- elem.style.display = "";
- }
- }
- if ( elem.style.display === "" && isHiddenWithinTree( elem ) ) {
- values[ index ] = getDefaultDisplay( elem );
- }
- } else {
- if ( display !== "none" ) {
- values[ index ] = "none";
-
- // Remember what we're overwriting
- dataPriv.set( elem, "display", display );
- }
- }
- }
-
- // Set the display of the elements in a second loop to avoid constant reflow
- for ( index = 0; index < length; index++ ) {
- if ( values[ index ] != null ) {
- elements[ index ].style.display = values[ index ];
- }
- }
-
- return elements;
-}
-
-jQuery.fn.extend( {
- show: function() {
- return showHide( this, true );
- },
- hide: function() {
- return showHide( this );
- },
- toggle: function( state ) {
- if ( typeof state === "boolean" ) {
- return state ? this.show() : this.hide();
- }
-
- return this.each( function() {
- if ( isHiddenWithinTree( this ) ) {
- jQuery( this ).show();
- } else {
- jQuery( this ).hide();
- }
- } );
- }
-} );
-var rcheckableType = ( /^(?:checkbox|radio)$/i );
-
-var rtagName = ( /<([a-z][^\/\0>\x20\t\r\n\f]*)/i );
-
-var rscriptType = ( /^$|^module$|\/(?:java|ecma)script/i );
-
-
-
-( function() {
- var fragment = document.createDocumentFragment(),
- div = fragment.appendChild( document.createElement( "div" ) ),
- input = document.createElement( "input" );
-
- // Support: Android 4.0 - 4.3 only
- // Check state lost if the name is set (#11217)
- // Support: Windows Web Apps (WWA)
- // `name` and `type` must use .setAttribute for WWA (#14901)
- input.setAttribute( "type", "radio" );
- input.setAttribute( "checked", "checked" );
- input.setAttribute( "name", "t" );
-
- div.appendChild( input );
-
- // Support: Android <=4.1 only
- // Older WebKit doesn't clone checked state correctly in fragments
- support.checkClone = div.cloneNode( true ).cloneNode( true ).lastChild.checked;
-
- // Support: IE <=11 only
- // Make sure textarea (and checkbox) defaultValue is properly cloned
- div.innerHTML = "";
- support.noCloneChecked = !!div.cloneNode( true ).lastChild.defaultValue;
-
- // Support: IE <=9 only
- // IE <=9 replaces tags with their contents when inserted outside of
- // the select element.
- div.innerHTML = " or other required elements.
- thead: [ 1, "" ],
- col: [ 2, "" ],
- tr: [ 2, "" ],
- td: [ 3, "" ],
-
- _default: [ 0, "", "" ]
-};
-
-wrapMap.tbody = wrapMap.tfoot = wrapMap.colgroup = wrapMap.caption = wrapMap.thead;
-wrapMap.th = wrapMap.td;
-
-// Support: IE <=9 only
-if ( !support.option ) {
- wrapMap.optgroup = wrapMap.option = [ 1, "", " " ];
-}
-
-
-function getAll( context, tag ) {
-
- // Support: IE <=9 - 11 only
- // Use typeof to avoid zero-argument method invocation on host objects (#15151)
- var ret;
-
- if ( typeof context.getElementsByTagName !== "undefined" ) {
- ret = context.getElementsByTagName( tag || "*" );
-
- } else if ( typeof context.querySelectorAll !== "undefined" ) {
- ret = context.querySelectorAll( tag || "*" );
-
- } else {
- ret = [];
- }
-
- if ( tag === undefined || tag && nodeName( context, tag ) ) {
- return jQuery.merge( [ context ], ret );
- }
-
- return ret;
-}
-
-
-// Mark scripts as having already been evaluated
-function setGlobalEval( elems, refElements ) {
- var i = 0,
- l = elems.length;
-
- for ( ; i < l; i++ ) {
- dataPriv.set(
- elems[ i ],
- "globalEval",
- !refElements || dataPriv.get( refElements[ i ], "globalEval" )
- );
- }
-}
-
-
-var rhtml = /<|&#?\w+;/;
-
-function buildFragment( elems, context, scripts, selection, ignored ) {
- var elem, tmp, tag, wrap, attached, j,
- fragment = context.createDocumentFragment(),
- nodes = [],
- i = 0,
- l = elems.length;
-
- for ( ; i < l; i++ ) {
- elem = elems[ i ];
-
- if ( elem || elem === 0 ) {
-
- // Add nodes directly
- if ( toType( elem ) === "object" ) {
-
- // Support: Android <=4.0 only, PhantomJS 1 only
- // push.apply(_, arraylike) throws on ancient WebKit
- jQuery.merge( nodes, elem.nodeType ? [ elem ] : elem );
-
- // Convert non-html into a text node
- } else if ( !rhtml.test( elem ) ) {
- nodes.push( context.createTextNode( elem ) );
-
- // Convert html into DOM nodes
- } else {
- tmp = tmp || fragment.appendChild( context.createElement( "div" ) );
-
- // Deserialize a standard representation
- tag = ( rtagName.exec( elem ) || [ "", "" ] )[ 1 ].toLowerCase();
- wrap = wrapMap[ tag ] || wrapMap._default;
- tmp.innerHTML = wrap[ 1 ] + jQuery.htmlPrefilter( elem ) + wrap[ 2 ];
-
- // Descend through wrappers to the right content
- j = wrap[ 0 ];
- while ( j-- ) {
- tmp = tmp.lastChild;
- }
-
- // Support: Android <=4.0 only, PhantomJS 1 only
- // push.apply(_, arraylike) throws on ancient WebKit
- jQuery.merge( nodes, tmp.childNodes );
-
- // Remember the top-level container
- tmp = fragment.firstChild;
-
- // Ensure the created nodes are orphaned (#12392)
- tmp.textContent = "";
- }
- }
- }
-
- // Remove wrapper from fragment
- fragment.textContent = "";
-
- i = 0;
- while ( ( elem = nodes[ i++ ] ) ) {
-
- // Skip elements already in the context collection (trac-4087)
- if ( selection && jQuery.inArray( elem, selection ) > -1 ) {
- if ( ignored ) {
- ignored.push( elem );
- }
- continue;
- }
-
- attached = isAttached( elem );
-
- // Append to fragment
- tmp = getAll( fragment.appendChild( elem ), "script" );
-
- // Preserve script evaluation history
- if ( attached ) {
- setGlobalEval( tmp );
- }
-
- // Capture executables
- if ( scripts ) {
- j = 0;
- while ( ( elem = tmp[ j++ ] ) ) {
- if ( rscriptType.test( elem.type || "" ) ) {
- scripts.push( elem );
- }
- }
- }
- }
-
- return fragment;
-}
-
-
-var
- rkeyEvent = /^key/,
- rmouseEvent = /^(?:mouse|pointer|contextmenu|drag|drop)|click/,
- rtypenamespace = /^([^.]*)(?:\.(.+)|)/;
-
-function returnTrue() {
- return true;
-}
-
-function returnFalse() {
- return false;
-}
-
-// Support: IE <=9 - 11+
-// focus() and blur() are asynchronous, except when they are no-op.
-// So expect focus to be synchronous when the element is already active,
-// and blur to be synchronous when the element is not already active.
-// (focus and blur are always synchronous in other supported browsers,
-// this just defines when we can count on it).
-function expectSync( elem, type ) {
- return ( elem === safeActiveElement() ) === ( type === "focus" );
-}
-
-// Support: IE <=9 only
-// Accessing document.activeElement can throw unexpectedly
-// https://bugs.jquery.com/ticket/13393
-function safeActiveElement() {
- try {
- return document.activeElement;
- } catch ( err ) { }
-}
-
-function on( elem, types, selector, data, fn, one ) {
- var origFn, type;
-
- // Types can be a map of types/handlers
- if ( typeof types === "object" ) {
-
- // ( types-Object, selector, data )
- if ( typeof selector !== "string" ) {
-
- // ( types-Object, data )
- data = data || selector;
- selector = undefined;
- }
- for ( type in types ) {
- on( elem, type, selector, data, types[ type ], one );
- }
- return elem;
- }
-
- if ( data == null && fn == null ) {
-
- // ( types, fn )
- fn = selector;
- data = selector = undefined;
- } else if ( fn == null ) {
- if ( typeof selector === "string" ) {
-
- // ( types, selector, fn )
- fn = data;
- data = undefined;
- } else {
-
- // ( types, data, fn )
- fn = data;
- data = selector;
- selector = undefined;
- }
- }
- if ( fn === false ) {
- fn = returnFalse;
- } else if ( !fn ) {
- return elem;
- }
-
- if ( one === 1 ) {
- origFn = fn;
- fn = function( event ) {
-
- // Can use an empty set, since event contains the info
- jQuery().off( event );
- return origFn.apply( this, arguments );
- };
-
- // Use same guid so caller can remove using origFn
- fn.guid = origFn.guid || ( origFn.guid = jQuery.guid++ );
- }
- return elem.each( function() {
- jQuery.event.add( this, types, fn, data, selector );
- } );
-}
-
-/*
- * Helper functions for managing events -- not part of the public interface.
- * Props to Dean Edwards' addEvent library for many of the ideas.
- */
-jQuery.event = {
-
- global: {},
-
- add: function( elem, types, handler, data, selector ) {
-
- var handleObjIn, eventHandle, tmp,
- events, t, handleObj,
- special, handlers, type, namespaces, origType,
- elemData = dataPriv.get( elem );
-
- // Only attach events to objects that accept data
- if ( !acceptData( elem ) ) {
- return;
- }
-
- // Caller can pass in an object of custom data in lieu of the handler
- if ( handler.handler ) {
- handleObjIn = handler;
- handler = handleObjIn.handler;
- selector = handleObjIn.selector;
- }
-
- // Ensure that invalid selectors throw exceptions at attach time
- // Evaluate against documentElement in case elem is a non-element node (e.g., document)
- if ( selector ) {
- jQuery.find.matchesSelector( documentElement, selector );
- }
-
- // Make sure that the handler has a unique ID, used to find/remove it later
- if ( !handler.guid ) {
- handler.guid = jQuery.guid++;
- }
-
- // Init the element's event structure and main handler, if this is the first
- if ( !( events = elemData.events ) ) {
- events = elemData.events = Object.create( null );
- }
- if ( !( eventHandle = elemData.handle ) ) {
- eventHandle = elemData.handle = function( e ) {
-
- // Discard the second event of a jQuery.event.trigger() and
- // when an event is called after a page has unloaded
- return typeof jQuery !== "undefined" && jQuery.event.triggered !== e.type ?
- jQuery.event.dispatch.apply( elem, arguments ) : undefined;
- };
- }
-
- // Handle multiple events separated by a space
- types = ( types || "" ).match( rnothtmlwhite ) || [ "" ];
- t = types.length;
- while ( t-- ) {
- tmp = rtypenamespace.exec( types[ t ] ) || [];
- type = origType = tmp[ 1 ];
- namespaces = ( tmp[ 2 ] || "" ).split( "." ).sort();
-
- // There *must* be a type, no attaching namespace-only handlers
- if ( !type ) {
- continue;
- }
-
- // If event changes its type, use the special event handlers for the changed type
- special = jQuery.event.special[ type ] || {};
-
- // If selector defined, determine special event api type, otherwise given type
- type = ( selector ? special.delegateType : special.bindType ) || type;
-
- // Update special based on newly reset type
- special = jQuery.event.special[ type ] || {};
-
- // handleObj is passed to all event handlers
- handleObj = jQuery.extend( {
- type: type,
- origType: origType,
- data: data,
- handler: handler,
- guid: handler.guid,
- selector: selector,
- needsContext: selector && jQuery.expr.match.needsContext.test( selector ),
- namespace: namespaces.join( "." )
- }, handleObjIn );
-
- // Init the event handler queue if we're the first
- if ( !( handlers = events[ type ] ) ) {
- handlers = events[ type ] = [];
- handlers.delegateCount = 0;
-
- // Only use addEventListener if the special events handler returns false
- if ( !special.setup ||
- special.setup.call( elem, data, namespaces, eventHandle ) === false ) {
-
- if ( elem.addEventListener ) {
- elem.addEventListener( type, eventHandle );
- }
- }
- }
-
- if ( special.add ) {
- special.add.call( elem, handleObj );
-
- if ( !handleObj.handler.guid ) {
- handleObj.handler.guid = handler.guid;
- }
- }
-
- // Add to the element's handler list, delegates in front
- if ( selector ) {
- handlers.splice( handlers.delegateCount++, 0, handleObj );
- } else {
- handlers.push( handleObj );
- }
-
- // Keep track of which events have ever been used, for event optimization
- jQuery.event.global[ type ] = true;
- }
-
- },
-
- // Detach an event or set of events from an element
- remove: function( elem, types, handler, selector, mappedTypes ) {
-
- var j, origCount, tmp,
- events, t, handleObj,
- special, handlers, type, namespaces, origType,
- elemData = dataPriv.hasData( elem ) && dataPriv.get( elem );
-
- if ( !elemData || !( events = elemData.events ) ) {
- return;
- }
-
- // Once for each type.namespace in types; type may be omitted
- types = ( types || "" ).match( rnothtmlwhite ) || [ "" ];
- t = types.length;
- while ( t-- ) {
- tmp = rtypenamespace.exec( types[ t ] ) || [];
- type = origType = tmp[ 1 ];
- namespaces = ( tmp[ 2 ] || "" ).split( "." ).sort();
-
- // Unbind all events (on this namespace, if provided) for the element
- if ( !type ) {
- for ( type in events ) {
- jQuery.event.remove( elem, type + types[ t ], handler, selector, true );
- }
- continue;
- }
-
- special = jQuery.event.special[ type ] || {};
- type = ( selector ? special.delegateType : special.bindType ) || type;
- handlers = events[ type ] || [];
- tmp = tmp[ 2 ] &&
- new RegExp( "(^|\\.)" + namespaces.join( "\\.(?:.*\\.|)" ) + "(\\.|$)" );
-
- // Remove matching events
- origCount = j = handlers.length;
- while ( j-- ) {
- handleObj = handlers[ j ];
-
- if ( ( mappedTypes || origType === handleObj.origType ) &&
- ( !handler || handler.guid === handleObj.guid ) &&
- ( !tmp || tmp.test( handleObj.namespace ) ) &&
- ( !selector || selector === handleObj.selector ||
- selector === "**" && handleObj.selector ) ) {
- handlers.splice( j, 1 );
-
- if ( handleObj.selector ) {
- handlers.delegateCount--;
- }
- if ( special.remove ) {
- special.remove.call( elem, handleObj );
- }
- }
- }
-
- // Remove generic event handler if we removed something and no more handlers exist
- // (avoids potential for endless recursion during removal of special event handlers)
- if ( origCount && !handlers.length ) {
- if ( !special.teardown ||
- special.teardown.call( elem, namespaces, elemData.handle ) === false ) {
-
- jQuery.removeEvent( elem, type, elemData.handle );
- }
-
- delete events[ type ];
- }
- }
-
- // Remove data and the expando if it's no longer used
- if ( jQuery.isEmptyObject( events ) ) {
- dataPriv.remove( elem, "handle events" );
- }
- },
-
- dispatch: function( nativeEvent ) {
-
- var i, j, ret, matched, handleObj, handlerQueue,
- args = new Array( arguments.length ),
-
- // Make a writable jQuery.Event from the native event object
- event = jQuery.event.fix( nativeEvent ),
-
- handlers = (
- dataPriv.get( this, "events" ) || Object.create( null )
- )[ event.type ] || [],
- special = jQuery.event.special[ event.type ] || {};
-
- // Use the fix-ed jQuery.Event rather than the (read-only) native event
- args[ 0 ] = event;
-
- for ( i = 1; i < arguments.length; i++ ) {
- args[ i ] = arguments[ i ];
- }
-
- event.delegateTarget = this;
-
- // Call the preDispatch hook for the mapped type, and let it bail if desired
- if ( special.preDispatch && special.preDispatch.call( this, event ) === false ) {
- return;
- }
-
- // Determine handlers
- handlerQueue = jQuery.event.handlers.call( this, event, handlers );
-
- // Run delegates first; they may want to stop propagation beneath us
- i = 0;
- while ( ( matched = handlerQueue[ i++ ] ) && !event.isPropagationStopped() ) {
- event.currentTarget = matched.elem;
-
- j = 0;
- while ( ( handleObj = matched.handlers[ j++ ] ) &&
- !event.isImmediatePropagationStopped() ) {
-
- // If the event is namespaced, then each handler is only invoked if it is
- // specially universal or its namespaces are a superset of the event's.
- if ( !event.rnamespace || handleObj.namespace === false ||
- event.rnamespace.test( handleObj.namespace ) ) {
-
- event.handleObj = handleObj;
- event.data = handleObj.data;
-
- ret = ( ( jQuery.event.special[ handleObj.origType ] || {} ).handle ||
- handleObj.handler ).apply( matched.elem, args );
-
- if ( ret !== undefined ) {
- if ( ( event.result = ret ) === false ) {
- event.preventDefault();
- event.stopPropagation();
- }
- }
- }
- }
- }
-
- // Call the postDispatch hook for the mapped type
- if ( special.postDispatch ) {
- special.postDispatch.call( this, event );
- }
-
- return event.result;
- },
-
- handlers: function( event, handlers ) {
- var i, handleObj, sel, matchedHandlers, matchedSelectors,
- handlerQueue = [],
- delegateCount = handlers.delegateCount,
- cur = event.target;
-
- // Find delegate handlers
- if ( delegateCount &&
-
- // Support: IE <=9
- // Black-hole SVG instance trees (trac-13180)
- cur.nodeType &&
-
- // Support: Firefox <=42
- // Suppress spec-violating clicks indicating a non-primary pointer button (trac-3861)
- // https://www.w3.org/TR/DOM-Level-3-Events/#event-type-click
- // Support: IE 11 only
- // ...but not arrow key "clicks" of radio inputs, which can have `button` -1 (gh-2343)
- !( event.type === "click" && event.button >= 1 ) ) {
-
- for ( ; cur !== this; cur = cur.parentNode || this ) {
-
- // Don't check non-elements (#13208)
- // Don't process clicks on disabled elements (#6911, #8165, #11382, #11764)
- if ( cur.nodeType === 1 && !( event.type === "click" && cur.disabled === true ) ) {
- matchedHandlers = [];
- matchedSelectors = {};
- for ( i = 0; i < delegateCount; i++ ) {
- handleObj = handlers[ i ];
-
- // Don't conflict with Object.prototype properties (#13203)
- sel = handleObj.selector + " ";
-
- if ( matchedSelectors[ sel ] === undefined ) {
- matchedSelectors[ sel ] = handleObj.needsContext ?
- jQuery( sel, this ).index( cur ) > -1 :
- jQuery.find( sel, this, null, [ cur ] ).length;
- }
- if ( matchedSelectors[ sel ] ) {
- matchedHandlers.push( handleObj );
- }
- }
- if ( matchedHandlers.length ) {
- handlerQueue.push( { elem: cur, handlers: matchedHandlers } );
- }
- }
- }
- }
-
- // Add the remaining (directly-bound) handlers
- cur = this;
- if ( delegateCount < handlers.length ) {
- handlerQueue.push( { elem: cur, handlers: handlers.slice( delegateCount ) } );
- }
-
- return handlerQueue;
- },
-
- addProp: function( name, hook ) {
- Object.defineProperty( jQuery.Event.prototype, name, {
- enumerable: true,
- configurable: true,
-
- get: isFunction( hook ) ?
- function() {
- if ( this.originalEvent ) {
- return hook( this.originalEvent );
- }
- } :
- function() {
- if ( this.originalEvent ) {
- return this.originalEvent[ name ];
- }
- },
-
- set: function( value ) {
- Object.defineProperty( this, name, {
- enumerable: true,
- configurable: true,
- writable: true,
- value: value
- } );
- }
- } );
- },
-
- fix: function( originalEvent ) {
- return originalEvent[ jQuery.expando ] ?
- originalEvent :
- new jQuery.Event( originalEvent );
- },
-
- special: {
- load: {
-
- // Prevent triggered image.load events from bubbling to window.load
- noBubble: true
- },
- click: {
-
- // Utilize native event to ensure correct state for checkable inputs
- setup: function( data ) {
-
- // For mutual compressibility with _default, replace `this` access with a local var.
- // `|| data` is dead code meant only to preserve the variable through minification.
- var el = this || data;
-
- // Claim the first handler
- if ( rcheckableType.test( el.type ) &&
- el.click && nodeName( el, "input" ) ) {
-
- // dataPriv.set( el, "click", ... )
- leverageNative( el, "click", returnTrue );
- }
-
- // Return false to allow normal processing in the caller
- return false;
- },
- trigger: function( data ) {
-
- // For mutual compressibility with _default, replace `this` access with a local var.
- // `|| data` is dead code meant only to preserve the variable through minification.
- var el = this || data;
-
- // Force setup before triggering a click
- if ( rcheckableType.test( el.type ) &&
- el.click && nodeName( el, "input" ) ) {
-
- leverageNative( el, "click" );
- }
-
- // Return non-false to allow normal event-path propagation
- return true;
- },
-
- // For cross-browser consistency, suppress native .click() on links
- // Also prevent it if we're currently inside a leveraged native-event stack
- _default: function( event ) {
- var target = event.target;
- return rcheckableType.test( target.type ) &&
- target.click && nodeName( target, "input" ) &&
- dataPriv.get( target, "click" ) ||
- nodeName( target, "a" );
- }
- },
-
- beforeunload: {
- postDispatch: function( event ) {
-
- // Support: Firefox 20+
- // Firefox doesn't alert if the returnValue field is not set.
- if ( event.result !== undefined && event.originalEvent ) {
- event.originalEvent.returnValue = event.result;
- }
- }
- }
- }
-};
-
-// Ensure the presence of an event listener that handles manually-triggered
-// synthetic events by interrupting progress until reinvoked in response to
-// *native* events that it fires directly, ensuring that state changes have
-// already occurred before other listeners are invoked.
-function leverageNative( el, type, expectSync ) {
-
- // Missing expectSync indicates a trigger call, which must force setup through jQuery.event.add
- if ( !expectSync ) {
- if ( dataPriv.get( el, type ) === undefined ) {
- jQuery.event.add( el, type, returnTrue );
- }
- return;
- }
-
- // Register the controller as a special universal handler for all event namespaces
- dataPriv.set( el, type, false );
- jQuery.event.add( el, type, {
- namespace: false,
- handler: function( event ) {
- var notAsync, result,
- saved = dataPriv.get( this, type );
-
- if ( ( event.isTrigger & 1 ) && this[ type ] ) {
-
- // Interrupt processing of the outer synthetic .trigger()ed event
- // Saved data should be false in such cases, but might be a leftover capture object
- // from an async native handler (gh-4350)
- if ( !saved.length ) {
-
- // Store arguments for use when handling the inner native event
- // There will always be at least one argument (an event object), so this array
- // will not be confused with a leftover capture object.
- saved = slice.call( arguments );
- dataPriv.set( this, type, saved );
-
- // Trigger the native event and capture its result
- // Support: IE <=9 - 11+
- // focus() and blur() are asynchronous
- notAsync = expectSync( this, type );
- this[ type ]();
- result = dataPriv.get( this, type );
- if ( saved !== result || notAsync ) {
- dataPriv.set( this, type, false );
- } else {
- result = {};
- }
- if ( saved !== result ) {
-
- // Cancel the outer synthetic event
- event.stopImmediatePropagation();
- event.preventDefault();
- return result.value;
- }
-
- // If this is an inner synthetic event for an event with a bubbling surrogate
- // (focus or blur), assume that the surrogate already propagated from triggering the
- // native event and prevent that from happening again here.
- // This technically gets the ordering wrong w.r.t. to `.trigger()` (in which the
- // bubbling surrogate propagates *after* the non-bubbling base), but that seems
- // less bad than duplication.
- } else if ( ( jQuery.event.special[ type ] || {} ).delegateType ) {
- event.stopPropagation();
- }
-
- // If this is a native event triggered above, everything is now in order
- // Fire an inner synthetic event with the original arguments
- } else if ( saved.length ) {
-
- // ...and capture the result
- dataPriv.set( this, type, {
- value: jQuery.event.trigger(
-
- // Support: IE <=9 - 11+
- // Extend with the prototype to reset the above stopImmediatePropagation()
- jQuery.extend( saved[ 0 ], jQuery.Event.prototype ),
- saved.slice( 1 ),
- this
- )
- } );
-
- // Abort handling of the native event
- event.stopImmediatePropagation();
- }
- }
- } );
-}
-
-jQuery.removeEvent = function( elem, type, handle ) {
-
- // This "if" is needed for plain objects
- if ( elem.removeEventListener ) {
- elem.removeEventListener( type, handle );
- }
-};
-
-jQuery.Event = function( src, props ) {
-
- // Allow instantiation without the 'new' keyword
- if ( !( this instanceof jQuery.Event ) ) {
- return new jQuery.Event( src, props );
- }
-
- // Event object
- if ( src && src.type ) {
- this.originalEvent = src;
- this.type = src.type;
-
- // Events bubbling up the document may have been marked as prevented
- // by a handler lower down the tree; reflect the correct value.
- this.isDefaultPrevented = src.defaultPrevented ||
- src.defaultPrevented === undefined &&
-
- // Support: Android <=2.3 only
- src.returnValue === false ?
- returnTrue :
- returnFalse;
-
- // Create target properties
- // Support: Safari <=6 - 7 only
- // Target should not be a text node (#504, #13143)
- this.target = ( src.target && src.target.nodeType === 3 ) ?
- src.target.parentNode :
- src.target;
-
- this.currentTarget = src.currentTarget;
- this.relatedTarget = src.relatedTarget;
-
- // Event type
- } else {
- this.type = src;
- }
-
- // Put explicitly provided properties onto the event object
- if ( props ) {
- jQuery.extend( this, props );
- }
-
- // Create a timestamp if incoming event doesn't have one
- this.timeStamp = src && src.timeStamp || Date.now();
-
- // Mark it as fixed
- this[ jQuery.expando ] = true;
-};
-
-// jQuery.Event is based on DOM3 Events as specified by the ECMAScript Language Binding
-// https://www.w3.org/TR/2003/WD-DOM-Level-3-Events-20030331/ecma-script-binding.html
-jQuery.Event.prototype = {
- constructor: jQuery.Event,
- isDefaultPrevented: returnFalse,
- isPropagationStopped: returnFalse,
- isImmediatePropagationStopped: returnFalse,
- isSimulated: false,
-
- preventDefault: function() {
- var e = this.originalEvent;
-
- this.isDefaultPrevented = returnTrue;
-
- if ( e && !this.isSimulated ) {
- e.preventDefault();
- }
- },
- stopPropagation: function() {
- var e = this.originalEvent;
-
- this.isPropagationStopped = returnTrue;
-
- if ( e && !this.isSimulated ) {
- e.stopPropagation();
- }
- },
- stopImmediatePropagation: function() {
- var e = this.originalEvent;
-
- this.isImmediatePropagationStopped = returnTrue;
-
- if ( e && !this.isSimulated ) {
- e.stopImmediatePropagation();
- }
-
- this.stopPropagation();
- }
-};
-
-// Includes all common event props including KeyEvent and MouseEvent specific props
-jQuery.each( {
- altKey: true,
- bubbles: true,
- cancelable: true,
- changedTouches: true,
- ctrlKey: true,
- detail: true,
- eventPhase: true,
- metaKey: true,
- pageX: true,
- pageY: true,
- shiftKey: true,
- view: true,
- "char": true,
- code: true,
- charCode: true,
- key: true,
- keyCode: true,
- button: true,
- buttons: true,
- clientX: true,
- clientY: true,
- offsetX: true,
- offsetY: true,
- pointerId: true,
- pointerType: true,
- screenX: true,
- screenY: true,
- targetTouches: true,
- toElement: true,
- touches: true,
-
- which: function( event ) {
- var button = event.button;
-
- // Add which for key events
- if ( event.which == null && rkeyEvent.test( event.type ) ) {
- return event.charCode != null ? event.charCode : event.keyCode;
- }
-
- // Add which for click: 1 === left; 2 === middle; 3 === right
- if ( !event.which && button !== undefined && rmouseEvent.test( event.type ) ) {
- if ( button & 1 ) {
- return 1;
- }
-
- if ( button & 2 ) {
- return 3;
- }
-
- if ( button & 4 ) {
- return 2;
- }
-
- return 0;
- }
-
- return event.which;
- }
-}, jQuery.event.addProp );
-
-jQuery.each( { focus: "focusin", blur: "focusout" }, function( type, delegateType ) {
- jQuery.event.special[ type ] = {
-
- // Utilize native event if possible so blur/focus sequence is correct
- setup: function() {
-
- // Claim the first handler
- // dataPriv.set( this, "focus", ... )
- // dataPriv.set( this, "blur", ... )
- leverageNative( this, type, expectSync );
-
- // Return false to allow normal processing in the caller
- return false;
- },
- trigger: function() {
-
- // Force setup before trigger
- leverageNative( this, type );
-
- // Return non-false to allow normal event-path propagation
- return true;
- },
-
- delegateType: delegateType
- };
-} );
-
-// Create mouseenter/leave events using mouseover/out and event-time checks
-// so that event delegation works in jQuery.
-// Do the same for pointerenter/pointerleave and pointerover/pointerout
-//
-// Support: Safari 7 only
-// Safari sends mouseenter too often; see:
-// https://bugs.chromium.org/p/chromium/issues/detail?id=470258
-// for the description of the bug (it existed in older Chrome versions as well).
-jQuery.each( {
- mouseenter: "mouseover",
- mouseleave: "mouseout",
- pointerenter: "pointerover",
- pointerleave: "pointerout"
-}, function( orig, fix ) {
- jQuery.event.special[ orig ] = {
- delegateType: fix,
- bindType: fix,
-
- handle: function( event ) {
- var ret,
- target = this,
- related = event.relatedTarget,
- handleObj = event.handleObj;
-
- // For mouseenter/leave call the handler if related is outside the target.
- // NB: No relatedTarget if the mouse left/entered the browser window
- if ( !related || ( related !== target && !jQuery.contains( target, related ) ) ) {
- event.type = handleObj.origType;
- ret = handleObj.handler.apply( this, arguments );
- event.type = fix;
- }
- return ret;
- }
- };
-} );
-
-jQuery.fn.extend( {
-
- on: function( types, selector, data, fn ) {
- return on( this, types, selector, data, fn );
- },
- one: function( types, selector, data, fn ) {
- return on( this, types, selector, data, fn, 1 );
- },
- off: function( types, selector, fn ) {
- var handleObj, type;
- if ( types && types.preventDefault && types.handleObj ) {
-
- // ( event ) dispatched jQuery.Event
- handleObj = types.handleObj;
- jQuery( types.delegateTarget ).off(
- handleObj.namespace ?
- handleObj.origType + "." + handleObj.namespace :
- handleObj.origType,
- handleObj.selector,
- handleObj.handler
- );
- return this;
- }
- if ( typeof types === "object" ) {
-
- // ( types-object [, selector] )
- for ( type in types ) {
- this.off( type, selector, types[ type ] );
- }
- return this;
- }
- if ( selector === false || typeof selector === "function" ) {
-
- // ( types [, fn] )
- fn = selector;
- selector = undefined;
- }
- if ( fn === false ) {
- fn = returnFalse;
- }
- return this.each( function() {
- jQuery.event.remove( this, types, fn, selector );
- } );
- }
-} );
-
-
-var
-
- // Support: IE <=10 - 11, Edge 12 - 13 only
- // In IE/Edge using regex groups here causes severe slowdowns.
- // See https://connect.microsoft.com/IE/feedback/details/1736512/
- rnoInnerhtml = /\s*$/g;
-
-// Prefer a tbody over its parent table for containing new rows
-function manipulationTarget( elem, content ) {
- if ( nodeName( elem, "table" ) &&
- nodeName( content.nodeType !== 11 ? content : content.firstChild, "tr" ) ) {
-
- return jQuery( elem ).children( "tbody" )[ 0 ] || elem;
- }
-
- return elem;
-}
-
-// Replace/restore the type attribute of script elements for safe DOM manipulation
-function disableScript( elem ) {
- elem.type = ( elem.getAttribute( "type" ) !== null ) + "/" + elem.type;
- return elem;
-}
-function restoreScript( elem ) {
- if ( ( elem.type || "" ).slice( 0, 5 ) === "true/" ) {
- elem.type = elem.type.slice( 5 );
- } else {
- elem.removeAttribute( "type" );
- }
-
- return elem;
-}
-
-function cloneCopyEvent( src, dest ) {
- var i, l, type, pdataOld, udataOld, udataCur, events;
-
- if ( dest.nodeType !== 1 ) {
- return;
- }
-
- // 1. Copy private data: events, handlers, etc.
- if ( dataPriv.hasData( src ) ) {
- pdataOld = dataPriv.get( src );
- events = pdataOld.events;
-
- if ( events ) {
- dataPriv.remove( dest, "handle events" );
-
- for ( type in events ) {
- for ( i = 0, l = events[ type ].length; i < l; i++ ) {
- jQuery.event.add( dest, type, events[ type ][ i ] );
- }
- }
- }
- }
-
- // 2. Copy user data
- if ( dataUser.hasData( src ) ) {
- udataOld = dataUser.access( src );
- udataCur = jQuery.extend( {}, udataOld );
-
- dataUser.set( dest, udataCur );
- }
-}
-
-// Fix IE bugs, see support tests
-function fixInput( src, dest ) {
- var nodeName = dest.nodeName.toLowerCase();
-
- // Fails to persist the checked state of a cloned checkbox or radio button.
- if ( nodeName === "input" && rcheckableType.test( src.type ) ) {
- dest.checked = src.checked;
-
- // Fails to return the selected option to the default selected state when cloning options
- } else if ( nodeName === "input" || nodeName === "textarea" ) {
- dest.defaultValue = src.defaultValue;
- }
-}
-
-function domManip( collection, args, callback, ignored ) {
-
- // Flatten any nested arrays
- args = flat( args );
-
- var fragment, first, scripts, hasScripts, node, doc,
- i = 0,
- l = collection.length,
- iNoClone = l - 1,
- value = args[ 0 ],
- valueIsFunction = isFunction( value );
-
- // We can't cloneNode fragments that contain checked, in WebKit
- if ( valueIsFunction ||
- ( l > 1 && typeof value === "string" &&
- !support.checkClone && rchecked.test( value ) ) ) {
- return collection.each( function( index ) {
- var self = collection.eq( index );
- if ( valueIsFunction ) {
- args[ 0 ] = value.call( this, index, self.html() );
- }
- domManip( self, args, callback, ignored );
- } );
- }
-
- if ( l ) {
- fragment = buildFragment( args, collection[ 0 ].ownerDocument, false, collection, ignored );
- first = fragment.firstChild;
-
- if ( fragment.childNodes.length === 1 ) {
- fragment = first;
- }
-
- // Require either new content or an interest in ignored elements to invoke the callback
- if ( first || ignored ) {
- scripts = jQuery.map( getAll( fragment, "script" ), disableScript );
- hasScripts = scripts.length;
-
- // Use the original fragment for the last item
- // instead of the first because it can end up
- // being emptied incorrectly in certain situations (#8070).
- for ( ; i < l; i++ ) {
- node = fragment;
-
- if ( i !== iNoClone ) {
- node = jQuery.clone( node, true, true );
-
- // Keep references to cloned scripts for later restoration
- if ( hasScripts ) {
-
- // Support: Android <=4.0 only, PhantomJS 1 only
- // push.apply(_, arraylike) throws on ancient WebKit
- jQuery.merge( scripts, getAll( node, "script" ) );
- }
- }
-
- callback.call( collection[ i ], node, i );
- }
-
- if ( hasScripts ) {
- doc = scripts[ scripts.length - 1 ].ownerDocument;
-
- // Reenable scripts
- jQuery.map( scripts, restoreScript );
-
- // Evaluate executable scripts on first document insertion
- for ( i = 0; i < hasScripts; i++ ) {
- node = scripts[ i ];
- if ( rscriptType.test( node.type || "" ) &&
- !dataPriv.access( node, "globalEval" ) &&
- jQuery.contains( doc, node ) ) {
-
- if ( node.src && ( node.type || "" ).toLowerCase() !== "module" ) {
-
- // Optional AJAX dependency, but won't run scripts if not present
- if ( jQuery._evalUrl && !node.noModule ) {
- jQuery._evalUrl( node.src, {
- nonce: node.nonce || node.getAttribute( "nonce" )
- }, doc );
- }
- } else {
- DOMEval( node.textContent.replace( rcleanScript, "" ), node, doc );
- }
- }
- }
- }
- }
- }
-
- return collection;
-}
-
-function remove( elem, selector, keepData ) {
- var node,
- nodes = selector ? jQuery.filter( selector, elem ) : elem,
- i = 0;
-
- for ( ; ( node = nodes[ i ] ) != null; i++ ) {
- if ( !keepData && node.nodeType === 1 ) {
- jQuery.cleanData( getAll( node ) );
- }
-
- if ( node.parentNode ) {
- if ( keepData && isAttached( node ) ) {
- setGlobalEval( getAll( node, "script" ) );
- }
- node.parentNode.removeChild( node );
- }
- }
-
- return elem;
-}
-
-jQuery.extend( {
- htmlPrefilter: function( html ) {
- return html;
- },
-
- clone: function( elem, dataAndEvents, deepDataAndEvents ) {
- var i, l, srcElements, destElements,
- clone = elem.cloneNode( true ),
- inPage = isAttached( elem );
-
- // Fix IE cloning issues
- if ( !support.noCloneChecked && ( elem.nodeType === 1 || elem.nodeType === 11 ) &&
- !jQuery.isXMLDoc( elem ) ) {
-
- // We eschew Sizzle here for performance reasons: https://jsperf.com/getall-vs-sizzle/2
- destElements = getAll( clone );
- srcElements = getAll( elem );
-
- for ( i = 0, l = srcElements.length; i < l; i++ ) {
- fixInput( srcElements[ i ], destElements[ i ] );
- }
- }
-
- // Copy the events from the original to the clone
- if ( dataAndEvents ) {
- if ( deepDataAndEvents ) {
- srcElements = srcElements || getAll( elem );
- destElements = destElements || getAll( clone );
-
- for ( i = 0, l = srcElements.length; i < l; i++ ) {
- cloneCopyEvent( srcElements[ i ], destElements[ i ] );
- }
- } else {
- cloneCopyEvent( elem, clone );
- }
- }
-
- // Preserve script evaluation history
- destElements = getAll( clone, "script" );
- if ( destElements.length > 0 ) {
- setGlobalEval( destElements, !inPage && getAll( elem, "script" ) );
- }
-
- // Return the cloned set
- return clone;
- },
-
- cleanData: function( elems ) {
- var data, elem, type,
- special = jQuery.event.special,
- i = 0;
-
- for ( ; ( elem = elems[ i ] ) !== undefined; i++ ) {
- if ( acceptData( elem ) ) {
- if ( ( data = elem[ dataPriv.expando ] ) ) {
- if ( data.events ) {
- for ( type in data.events ) {
- if ( special[ type ] ) {
- jQuery.event.remove( elem, type );
-
- // This is a shortcut to avoid jQuery.event.remove's overhead
- } else {
- jQuery.removeEvent( elem, type, data.handle );
- }
- }
- }
-
- // Support: Chrome <=35 - 45+
- // Assign undefined instead of using delete, see Data#remove
- elem[ dataPriv.expando ] = undefined;
- }
- if ( elem[ dataUser.expando ] ) {
-
- // Support: Chrome <=35 - 45+
- // Assign undefined instead of using delete, see Data#remove
- elem[ dataUser.expando ] = undefined;
- }
- }
- }
- }
-} );
-
-jQuery.fn.extend( {
- detach: function( selector ) {
- return remove( this, selector, true );
- },
-
- remove: function( selector ) {
- return remove( this, selector );
- },
-
- text: function( value ) {
- return access( this, function( value ) {
- return value === undefined ?
- jQuery.text( this ) :
- this.empty().each( function() {
- if ( this.nodeType === 1 || this.nodeType === 11 || this.nodeType === 9 ) {
- this.textContent = value;
- }
- } );
- }, null, value, arguments.length );
- },
-
- append: function() {
- return domManip( this, arguments, function( elem ) {
- if ( this.nodeType === 1 || this.nodeType === 11 || this.nodeType === 9 ) {
- var target = manipulationTarget( this, elem );
- target.appendChild( elem );
- }
- } );
- },
-
- prepend: function() {
- return domManip( this, arguments, function( elem ) {
- if ( this.nodeType === 1 || this.nodeType === 11 || this.nodeType === 9 ) {
- var target = manipulationTarget( this, elem );
- target.insertBefore( elem, target.firstChild );
- }
- } );
- },
-
- before: function() {
- return domManip( this, arguments, function( elem ) {
- if ( this.parentNode ) {
- this.parentNode.insertBefore( elem, this );
- }
- } );
- },
-
- after: function() {
- return domManip( this, arguments, function( elem ) {
- if ( this.parentNode ) {
- this.parentNode.insertBefore( elem, this.nextSibling );
- }
- } );
- },
-
- empty: function() {
- var elem,
- i = 0;
-
- for ( ; ( elem = this[ i ] ) != null; i++ ) {
- if ( elem.nodeType === 1 ) {
-
- // Prevent memory leaks
- jQuery.cleanData( getAll( elem, false ) );
-
- // Remove any remaining nodes
- elem.textContent = "";
- }
- }
-
- return this;
- },
-
- clone: function( dataAndEvents, deepDataAndEvents ) {
- dataAndEvents = dataAndEvents == null ? false : dataAndEvents;
- deepDataAndEvents = deepDataAndEvents == null ? dataAndEvents : deepDataAndEvents;
-
- return this.map( function() {
- return jQuery.clone( this, dataAndEvents, deepDataAndEvents );
- } );
- },
-
- html: function( value ) {
- return access( this, function( value ) {
- var elem = this[ 0 ] || {},
- i = 0,
- l = this.length;
-
- if ( value === undefined && elem.nodeType === 1 ) {
- return elem.innerHTML;
- }
-
- // See if we can take a shortcut and just use innerHTML
- if ( typeof value === "string" && !rnoInnerhtml.test( value ) &&
- !wrapMap[ ( rtagName.exec( value ) || [ "", "" ] )[ 1 ].toLowerCase() ] ) {
-
- value = jQuery.htmlPrefilter( value );
-
- try {
- for ( ; i < l; i++ ) {
- elem = this[ i ] || {};
-
- // Remove element nodes and prevent memory leaks
- if ( elem.nodeType === 1 ) {
- jQuery.cleanData( getAll( elem, false ) );
- elem.innerHTML = value;
- }
- }
-
- elem = 0;
-
- // If using innerHTML throws an exception, use the fallback method
- } catch ( e ) {}
- }
-
- if ( elem ) {
- this.empty().append( value );
- }
- }, null, value, arguments.length );
- },
-
- replaceWith: function() {
- var ignored = [];
-
- // Make the changes, replacing each non-ignored context element with the new content
- return domManip( this, arguments, function( elem ) {
- var parent = this.parentNode;
-
- if ( jQuery.inArray( this, ignored ) < 0 ) {
- jQuery.cleanData( getAll( this ) );
- if ( parent ) {
- parent.replaceChild( elem, this );
- }
- }
-
- // Force callback invocation
- }, ignored );
- }
-} );
-
-jQuery.each( {
- appendTo: "append",
- prependTo: "prepend",
- insertBefore: "before",
- insertAfter: "after",
- replaceAll: "replaceWith"
-}, function( name, original ) {
- jQuery.fn[ name ] = function( selector ) {
- var elems,
- ret = [],
- insert = jQuery( selector ),
- last = insert.length - 1,
- i = 0;
-
- for ( ; i <= last; i++ ) {
- elems = i === last ? this : this.clone( true );
- jQuery( insert[ i ] )[ original ]( elems );
-
- // Support: Android <=4.0 only, PhantomJS 1 only
- // .get() because push.apply(_, arraylike) throws on ancient WebKit
- push.apply( ret, elems.get() );
- }
-
- return this.pushStack( ret );
- };
-} );
-var rnumnonpx = new RegExp( "^(" + pnum + ")(?!px)[a-z%]+$", "i" );
-
-var getStyles = function( elem ) {
-
- // Support: IE <=11 only, Firefox <=30 (#15098, #14150)
- // IE throws on elements created in popups
- // FF meanwhile throws on frame elements through "defaultView.getComputedStyle"
- var view = elem.ownerDocument.defaultView;
-
- if ( !view || !view.opener ) {
- view = window;
- }
-
- return view.getComputedStyle( elem );
- };
-
-var swap = function( elem, options, callback ) {
- var ret, name,
- old = {};
-
- // Remember the old values, and insert the new ones
- for ( name in options ) {
- old[ name ] = elem.style[ name ];
- elem.style[ name ] = options[ name ];
- }
-
- ret = callback.call( elem );
-
- // Revert the old values
- for ( name in options ) {
- elem.style[ name ] = old[ name ];
- }
-
- return ret;
-};
-
-
-var rboxStyle = new RegExp( cssExpand.join( "|" ), "i" );
-
-
-
-( function() {
-
- // Executing both pixelPosition & boxSizingReliable tests require only one layout
- // so they're executed at the same time to save the second computation.
- function computeStyleTests() {
-
- // This is a singleton, we need to execute it only once
- if ( !div ) {
- return;
- }
-
- container.style.cssText = "position:absolute;left:-11111px;width:60px;" +
- "margin-top:1px;padding:0;border:0";
- div.style.cssText =
- "position:relative;display:block;box-sizing:border-box;overflow:scroll;" +
- "margin:auto;border:1px;padding:1px;" +
- "width:60%;top:1%";
- documentElement.appendChild( container ).appendChild( div );
-
- var divStyle = window.getComputedStyle( div );
- pixelPositionVal = divStyle.top !== "1%";
-
- // Support: Android 4.0 - 4.3 only, Firefox <=3 - 44
- reliableMarginLeftVal = roundPixelMeasures( divStyle.marginLeft ) === 12;
-
- // Support: Android 4.0 - 4.3 only, Safari <=9.1 - 10.1, iOS <=7.0 - 9.3
- // Some styles come back with percentage values, even though they shouldn't
- div.style.right = "60%";
- pixelBoxStylesVal = roundPixelMeasures( divStyle.right ) === 36;
-
- // Support: IE 9 - 11 only
- // Detect misreporting of content dimensions for box-sizing:border-box elements
- boxSizingReliableVal = roundPixelMeasures( divStyle.width ) === 36;
-
- // Support: IE 9 only
- // Detect overflow:scroll screwiness (gh-3699)
- // Support: Chrome <=64
- // Don't get tricked when zoom affects offsetWidth (gh-4029)
- div.style.position = "absolute";
- scrollboxSizeVal = roundPixelMeasures( div.offsetWidth / 3 ) === 12;
-
- documentElement.removeChild( container );
-
- // Nullify the div so it wouldn't be stored in the memory and
- // it will also be a sign that checks already performed
- div = null;
- }
-
- function roundPixelMeasures( measure ) {
- return Math.round( parseFloat( measure ) );
- }
-
- var pixelPositionVal, boxSizingReliableVal, scrollboxSizeVal, pixelBoxStylesVal,
- reliableTrDimensionsVal, reliableMarginLeftVal,
- container = document.createElement( "div" ),
- div = document.createElement( "div" );
-
- // Finish early in limited (non-browser) environments
- if ( !div.style ) {
- return;
- }
-
- // Support: IE <=9 - 11 only
- // Style of cloned element affects source element cloned (#8908)
- div.style.backgroundClip = "content-box";
- div.cloneNode( true ).style.backgroundClip = "";
- support.clearCloneStyle = div.style.backgroundClip === "content-box";
-
- jQuery.extend( support, {
- boxSizingReliable: function() {
- computeStyleTests();
- return boxSizingReliableVal;
- },
- pixelBoxStyles: function() {
- computeStyleTests();
- return pixelBoxStylesVal;
- },
- pixelPosition: function() {
- computeStyleTests();
- return pixelPositionVal;
- },
- reliableMarginLeft: function() {
- computeStyleTests();
- return reliableMarginLeftVal;
- },
- scrollboxSize: function() {
- computeStyleTests();
- return scrollboxSizeVal;
- },
-
- // Support: IE 9 - 11+, Edge 15 - 18+
- // IE/Edge misreport `getComputedStyle` of table rows with width/height
- // set in CSS while `offset*` properties report correct values.
- // Behavior in IE 9 is more subtle than in newer versions & it passes
- // some versions of this test; make sure not to make it pass there!
- reliableTrDimensions: function() {
- var table, tr, trChild, trStyle;
- if ( reliableTrDimensionsVal == null ) {
- table = document.createElement( "table" );
- tr = document.createElement( "tr" );
- trChild = document.createElement( "div" );
-
- table.style.cssText = "position:absolute;left:-11111px";
- tr.style.height = "1px";
- trChild.style.height = "9px";
-
- documentElement
- .appendChild( table )
- .appendChild( tr )
- .appendChild( trChild );
-
- trStyle = window.getComputedStyle( tr );
- reliableTrDimensionsVal = parseInt( trStyle.height ) > 3;
-
- documentElement.removeChild( table );
- }
- return reliableTrDimensionsVal;
- }
- } );
-} )();
-
-
-function curCSS( elem, name, computed ) {
- var width, minWidth, maxWidth, ret,
-
- // Support: Firefox 51+
- // Retrieving style before computed somehow
- // fixes an issue with getting wrong values
- // on detached elements
- style = elem.style;
-
- computed = computed || getStyles( elem );
-
- // getPropertyValue is needed for:
- // .css('filter') (IE 9 only, #12537)
- // .css('--customProperty) (#3144)
- if ( computed ) {
- ret = computed.getPropertyValue( name ) || computed[ name ];
-
- if ( ret === "" && !isAttached( elem ) ) {
- ret = jQuery.style( elem, name );
- }
-
- // A tribute to the "awesome hack by Dean Edwards"
- // Android Browser returns percentage for some values,
- // but width seems to be reliably pixels.
- // This is against the CSSOM draft spec:
- // https://drafts.csswg.org/cssom/#resolved-values
- if ( !support.pixelBoxStyles() && rnumnonpx.test( ret ) && rboxStyle.test( name ) ) {
-
- // Remember the original values
- width = style.width;
- minWidth = style.minWidth;
- maxWidth = style.maxWidth;
-
- // Put in the new values to get a computed value out
- style.minWidth = style.maxWidth = style.width = ret;
- ret = computed.width;
-
- // Revert the changed values
- style.width = width;
- style.minWidth = minWidth;
- style.maxWidth = maxWidth;
- }
- }
-
- return ret !== undefined ?
-
- // Support: IE <=9 - 11 only
- // IE returns zIndex value as an integer.
- ret + "" :
- ret;
-}
-
-
-function addGetHookIf( conditionFn, hookFn ) {
-
- // Define the hook, we'll check on the first run if it's really needed.
- return {
- get: function() {
- if ( conditionFn() ) {
-
- // Hook not needed (or it's not possible to use it due
- // to missing dependency), remove it.
- delete this.get;
- return;
- }
-
- // Hook needed; redefine it so that the support test is not executed again.
- return ( this.get = hookFn ).apply( this, arguments );
- }
- };
-}
-
-
-var cssPrefixes = [ "Webkit", "Moz", "ms" ],
- emptyStyle = document.createElement( "div" ).style,
- vendorProps = {};
-
-// Return a vendor-prefixed property or undefined
-function vendorPropName( name ) {
-
- // Check for vendor prefixed names
- var capName = name[ 0 ].toUpperCase() + name.slice( 1 ),
- i = cssPrefixes.length;
-
- while ( i-- ) {
- name = cssPrefixes[ i ] + capName;
- if ( name in emptyStyle ) {
- return name;
- }
- }
-}
-
-// Return a potentially-mapped jQuery.cssProps or vendor prefixed property
-function finalPropName( name ) {
- var final = jQuery.cssProps[ name ] || vendorProps[ name ];
-
- if ( final ) {
- return final;
- }
- if ( name in emptyStyle ) {
- return name;
- }
- return vendorProps[ name ] = vendorPropName( name ) || name;
-}
-
-
-var
-
- // Swappable if display is none or starts with table
- // except "table", "table-cell", or "table-caption"
- // See here for display values: https://developer.mozilla.org/en-US/docs/CSS/display
- rdisplayswap = /^(none|table(?!-c[ea]).+)/,
- rcustomProp = /^--/,
- cssShow = { position: "absolute", visibility: "hidden", display: "block" },
- cssNormalTransform = {
- letterSpacing: "0",
- fontWeight: "400"
- };
-
-function setPositiveNumber( _elem, value, subtract ) {
-
- // Any relative (+/-) values have already been
- // normalized at this point
- var matches = rcssNum.exec( value );
- return matches ?
-
- // Guard against undefined "subtract", e.g., when used as in cssHooks
- Math.max( 0, matches[ 2 ] - ( subtract || 0 ) ) + ( matches[ 3 ] || "px" ) :
- value;
-}
-
-function boxModelAdjustment( elem, dimension, box, isBorderBox, styles, computedVal ) {
- var i = dimension === "width" ? 1 : 0,
- extra = 0,
- delta = 0;
-
- // Adjustment may not be necessary
- if ( box === ( isBorderBox ? "border" : "content" ) ) {
- return 0;
- }
-
- for ( ; i < 4; i += 2 ) {
-
- // Both box models exclude margin
- if ( box === "margin" ) {
- delta += jQuery.css( elem, box + cssExpand[ i ], true, styles );
- }
-
- // If we get here with a content-box, we're seeking "padding" or "border" or "margin"
- if ( !isBorderBox ) {
-
- // Add padding
- delta += jQuery.css( elem, "padding" + cssExpand[ i ], true, styles );
-
- // For "border" or "margin", add border
- if ( box !== "padding" ) {
- delta += jQuery.css( elem, "border" + cssExpand[ i ] + "Width", true, styles );
-
- // But still keep track of it otherwise
- } else {
- extra += jQuery.css( elem, "border" + cssExpand[ i ] + "Width", true, styles );
- }
-
- // If we get here with a border-box (content + padding + border), we're seeking "content" or
- // "padding" or "margin"
- } else {
-
- // For "content", subtract padding
- if ( box === "content" ) {
- delta -= jQuery.css( elem, "padding" + cssExpand[ i ], true, styles );
- }
-
- // For "content" or "padding", subtract border
- if ( box !== "margin" ) {
- delta -= jQuery.css( elem, "border" + cssExpand[ i ] + "Width", true, styles );
- }
- }
- }
-
- // Account for positive content-box scroll gutter when requested by providing computedVal
- if ( !isBorderBox && computedVal >= 0 ) {
-
- // offsetWidth/offsetHeight is a rounded sum of content, padding, scroll gutter, and border
- // Assuming integer scroll gutter, subtract the rest and round down
- delta += Math.max( 0, Math.ceil(
- elem[ "offset" + dimension[ 0 ].toUpperCase() + dimension.slice( 1 ) ] -
- computedVal -
- delta -
- extra -
- 0.5
-
- // If offsetWidth/offsetHeight is unknown, then we can't determine content-box scroll gutter
- // Use an explicit zero to avoid NaN (gh-3964)
- ) ) || 0;
- }
-
- return delta;
-}
-
-function getWidthOrHeight( elem, dimension, extra ) {
-
- // Start with computed style
- var styles = getStyles( elem ),
-
- // To avoid forcing a reflow, only fetch boxSizing if we need it (gh-4322).
- // Fake content-box until we know it's needed to know the true value.
- boxSizingNeeded = !support.boxSizingReliable() || extra,
- isBorderBox = boxSizingNeeded &&
- jQuery.css( elem, "boxSizing", false, styles ) === "border-box",
- valueIsBorderBox = isBorderBox,
-
- val = curCSS( elem, dimension, styles ),
- offsetProp = "offset" + dimension[ 0 ].toUpperCase() + dimension.slice( 1 );
-
- // Support: Firefox <=54
- // Return a confounding non-pixel value or feign ignorance, as appropriate.
- if ( rnumnonpx.test( val ) ) {
- if ( !extra ) {
- return val;
- }
- val = "auto";
- }
-
-
- // Support: IE 9 - 11 only
- // Use offsetWidth/offsetHeight for when box sizing is unreliable.
- // In those cases, the computed value can be trusted to be border-box.
- if ( ( !support.boxSizingReliable() && isBorderBox ||
-
- // Support: IE 10 - 11+, Edge 15 - 18+
- // IE/Edge misreport `getComputedStyle` of table rows with width/height
- // set in CSS while `offset*` properties report correct values.
- // Interestingly, in some cases IE 9 doesn't suffer from this issue.
- !support.reliableTrDimensions() && nodeName( elem, "tr" ) ||
-
- // Fall back to offsetWidth/offsetHeight when value is "auto"
- // This happens for inline elements with no explicit setting (gh-3571)
- val === "auto" ||
-
- // Support: Android <=4.1 - 4.3 only
- // Also use offsetWidth/offsetHeight for misreported inline dimensions (gh-3602)
- !parseFloat( val ) && jQuery.css( elem, "display", false, styles ) === "inline" ) &&
-
- // Make sure the element is visible & connected
- elem.getClientRects().length ) {
-
- isBorderBox = jQuery.css( elem, "boxSizing", false, styles ) === "border-box";
-
- // Where available, offsetWidth/offsetHeight approximate border box dimensions.
- // Where not available (e.g., SVG), assume unreliable box-sizing and interpret the
- // retrieved value as a content box dimension.
- valueIsBorderBox = offsetProp in elem;
- if ( valueIsBorderBox ) {
- val = elem[ offsetProp ];
- }
- }
-
- // Normalize "" and auto
- val = parseFloat( val ) || 0;
-
- // Adjust for the element's box model
- return ( val +
- boxModelAdjustment(
- elem,
- dimension,
- extra || ( isBorderBox ? "border" : "content" ),
- valueIsBorderBox,
- styles,
-
- // Provide the current computed size to request scroll gutter calculation (gh-3589)
- val
- )
- ) + "px";
-}
-
-jQuery.extend( {
-
- // Add in style property hooks for overriding the default
- // behavior of getting and setting a style property
- cssHooks: {
- opacity: {
- get: function( elem, computed ) {
- if ( computed ) {
-
- // We should always get a number back from opacity
- var ret = curCSS( elem, "opacity" );
- return ret === "" ? "1" : ret;
- }
- }
- }
- },
-
- // Don't automatically add "px" to these possibly-unitless properties
- cssNumber: {
- "animationIterationCount": true,
- "columnCount": true,
- "fillOpacity": true,
- "flexGrow": true,
- "flexShrink": true,
- "fontWeight": true,
- "gridArea": true,
- "gridColumn": true,
- "gridColumnEnd": true,
- "gridColumnStart": true,
- "gridRow": true,
- "gridRowEnd": true,
- "gridRowStart": true,
- "lineHeight": true,
- "opacity": true,
- "order": true,
- "orphans": true,
- "widows": true,
- "zIndex": true,
- "zoom": true
- },
-
- // Add in properties whose names you wish to fix before
- // setting or getting the value
- cssProps: {},
-
- // Get and set the style property on a DOM Node
- style: function( elem, name, value, extra ) {
-
- // Don't set styles on text and comment nodes
- if ( !elem || elem.nodeType === 3 || elem.nodeType === 8 || !elem.style ) {
- return;
- }
-
- // Make sure that we're working with the right name
- var ret, type, hooks,
- origName = camelCase( name ),
- isCustomProp = rcustomProp.test( name ),
- style = elem.style;
-
- // Make sure that we're working with the right name. We don't
- // want to query the value if it is a CSS custom property
- // since they are user-defined.
- if ( !isCustomProp ) {
- name = finalPropName( origName );
- }
-
- // Gets hook for the prefixed version, then unprefixed version
- hooks = jQuery.cssHooks[ name ] || jQuery.cssHooks[ origName ];
-
- // Check if we're setting a value
- if ( value !== undefined ) {
- type = typeof value;
-
- // Convert "+=" or "-=" to relative numbers (#7345)
- if ( type === "string" && ( ret = rcssNum.exec( value ) ) && ret[ 1 ] ) {
- value = adjustCSS( elem, name, ret );
-
- // Fixes bug #9237
- type = "number";
- }
-
- // Make sure that null and NaN values aren't set (#7116)
- if ( value == null || value !== value ) {
- return;
- }
-
- // If a number was passed in, add the unit (except for certain CSS properties)
- // The isCustomProp check can be removed in jQuery 4.0 when we only auto-append
- // "px" to a few hardcoded values.
- if ( type === "number" && !isCustomProp ) {
- value += ret && ret[ 3 ] || ( jQuery.cssNumber[ origName ] ? "" : "px" );
- }
-
- // background-* props affect original clone's values
- if ( !support.clearCloneStyle && value === "" && name.indexOf( "background" ) === 0 ) {
- style[ name ] = "inherit";
- }
-
- // If a hook was provided, use that value, otherwise just set the specified value
- if ( !hooks || !( "set" in hooks ) ||
- ( value = hooks.set( elem, value, extra ) ) !== undefined ) {
-
- if ( isCustomProp ) {
- style.setProperty( name, value );
- } else {
- style[ name ] = value;
- }
- }
-
- } else {
-
- // If a hook was provided get the non-computed value from there
- if ( hooks && "get" in hooks &&
- ( ret = hooks.get( elem, false, extra ) ) !== undefined ) {
-
- return ret;
- }
-
- // Otherwise just get the value from the style object
- return style[ name ];
- }
- },
-
- css: function( elem, name, extra, styles ) {
- var val, num, hooks,
- origName = camelCase( name ),
- isCustomProp = rcustomProp.test( name );
-
- // Make sure that we're working with the right name. We don't
- // want to modify the value if it is a CSS custom property
- // since they are user-defined.
- if ( !isCustomProp ) {
- name = finalPropName( origName );
- }
-
- // Try prefixed name followed by the unprefixed name
- hooks = jQuery.cssHooks[ name ] || jQuery.cssHooks[ origName ];
-
- // If a hook was provided get the computed value from there
- if ( hooks && "get" in hooks ) {
- val = hooks.get( elem, true, extra );
- }
-
- // Otherwise, if a way to get the computed value exists, use that
- if ( val === undefined ) {
- val = curCSS( elem, name, styles );
- }
-
- // Convert "normal" to computed value
- if ( val === "normal" && name in cssNormalTransform ) {
- val = cssNormalTransform[ name ];
- }
-
- // Make numeric if forced or a qualifier was provided and val looks numeric
- if ( extra === "" || extra ) {
- num = parseFloat( val );
- return extra === true || isFinite( num ) ? num || 0 : val;
- }
-
- return val;
- }
-} );
-
-jQuery.each( [ "height", "width" ], function( _i, dimension ) {
- jQuery.cssHooks[ dimension ] = {
- get: function( elem, computed, extra ) {
- if ( computed ) {
-
- // Certain elements can have dimension info if we invisibly show them
- // but it must have a current display style that would benefit
- return rdisplayswap.test( jQuery.css( elem, "display" ) ) &&
-
- // Support: Safari 8+
- // Table columns in Safari have non-zero offsetWidth & zero
- // getBoundingClientRect().width unless display is changed.
- // Support: IE <=11 only
- // Running getBoundingClientRect on a disconnected node
- // in IE throws an error.
- ( !elem.getClientRects().length || !elem.getBoundingClientRect().width ) ?
- swap( elem, cssShow, function() {
- return getWidthOrHeight( elem, dimension, extra );
- } ) :
- getWidthOrHeight( elem, dimension, extra );
- }
- },
-
- set: function( elem, value, extra ) {
- var matches,
- styles = getStyles( elem ),
-
- // Only read styles.position if the test has a chance to fail
- // to avoid forcing a reflow.
- scrollboxSizeBuggy = !support.scrollboxSize() &&
- styles.position === "absolute",
-
- // To avoid forcing a reflow, only fetch boxSizing if we need it (gh-3991)
- boxSizingNeeded = scrollboxSizeBuggy || extra,
- isBorderBox = boxSizingNeeded &&
- jQuery.css( elem, "boxSizing", false, styles ) === "border-box",
- subtract = extra ?
- boxModelAdjustment(
- elem,
- dimension,
- extra,
- isBorderBox,
- styles
- ) :
- 0;
-
- // Account for unreliable border-box dimensions by comparing offset* to computed and
- // faking a content-box to get border and padding (gh-3699)
- if ( isBorderBox && scrollboxSizeBuggy ) {
- subtract -= Math.ceil(
- elem[ "offset" + dimension[ 0 ].toUpperCase() + dimension.slice( 1 ) ] -
- parseFloat( styles[ dimension ] ) -
- boxModelAdjustment( elem, dimension, "border", false, styles ) -
- 0.5
- );
- }
-
- // Convert to pixels if value adjustment is needed
- if ( subtract && ( matches = rcssNum.exec( value ) ) &&
- ( matches[ 3 ] || "px" ) !== "px" ) {
-
- elem.style[ dimension ] = value;
- value = jQuery.css( elem, dimension );
- }
-
- return setPositiveNumber( elem, value, subtract );
- }
- };
-} );
-
-jQuery.cssHooks.marginLeft = addGetHookIf( support.reliableMarginLeft,
- function( elem, computed ) {
- if ( computed ) {
- return ( parseFloat( curCSS( elem, "marginLeft" ) ) ||
- elem.getBoundingClientRect().left -
- swap( elem, { marginLeft: 0 }, function() {
- return elem.getBoundingClientRect().left;
- } )
- ) + "px";
- }
- }
-);
-
-// These hooks are used by animate to expand properties
-jQuery.each( {
- margin: "",
- padding: "",
- border: "Width"
-}, function( prefix, suffix ) {
- jQuery.cssHooks[ prefix + suffix ] = {
- expand: function( value ) {
- var i = 0,
- expanded = {},
-
- // Assumes a single number if not a string
- parts = typeof value === "string" ? value.split( " " ) : [ value ];
-
- for ( ; i < 4; i++ ) {
- expanded[ prefix + cssExpand[ i ] + suffix ] =
- parts[ i ] || parts[ i - 2 ] || parts[ 0 ];
- }
-
- return expanded;
- }
- };
-
- if ( prefix !== "margin" ) {
- jQuery.cssHooks[ prefix + suffix ].set = setPositiveNumber;
- }
-} );
-
-jQuery.fn.extend( {
- css: function( name, value ) {
- return access( this, function( elem, name, value ) {
- var styles, len,
- map = {},
- i = 0;
-
- if ( Array.isArray( name ) ) {
- styles = getStyles( elem );
- len = name.length;
-
- for ( ; i < len; i++ ) {
- map[ name[ i ] ] = jQuery.css( elem, name[ i ], false, styles );
- }
-
- return map;
- }
-
- return value !== undefined ?
- jQuery.style( elem, name, value ) :
- jQuery.css( elem, name );
- }, name, value, arguments.length > 1 );
- }
-} );
-
-
-function Tween( elem, options, prop, end, easing ) {
- return new Tween.prototype.init( elem, options, prop, end, easing );
-}
-jQuery.Tween = Tween;
-
-Tween.prototype = {
- constructor: Tween,
- init: function( elem, options, prop, end, easing, unit ) {
- this.elem = elem;
- this.prop = prop;
- this.easing = easing || jQuery.easing._default;
- this.options = options;
- this.start = this.now = this.cur();
- this.end = end;
- this.unit = unit || ( jQuery.cssNumber[ prop ] ? "" : "px" );
- },
- cur: function() {
- var hooks = Tween.propHooks[ this.prop ];
-
- return hooks && hooks.get ?
- hooks.get( this ) :
- Tween.propHooks._default.get( this );
- },
- run: function( percent ) {
- var eased,
- hooks = Tween.propHooks[ this.prop ];
-
- if ( this.options.duration ) {
- this.pos = eased = jQuery.easing[ this.easing ](
- percent, this.options.duration * percent, 0, 1, this.options.duration
- );
- } else {
- this.pos = eased = percent;
- }
- this.now = ( this.end - this.start ) * eased + this.start;
-
- if ( this.options.step ) {
- this.options.step.call( this.elem, this.now, this );
- }
-
- if ( hooks && hooks.set ) {
- hooks.set( this );
- } else {
- Tween.propHooks._default.set( this );
- }
- return this;
- }
-};
-
-Tween.prototype.init.prototype = Tween.prototype;
-
-Tween.propHooks = {
- _default: {
- get: function( tween ) {
- var result;
-
- // Use a property on the element directly when it is not a DOM element,
- // or when there is no matching style property that exists.
- if ( tween.elem.nodeType !== 1 ||
- tween.elem[ tween.prop ] != null && tween.elem.style[ tween.prop ] == null ) {
- return tween.elem[ tween.prop ];
- }
-
- // Passing an empty string as a 3rd parameter to .css will automatically
- // attempt a parseFloat and fallback to a string if the parse fails.
- // Simple values such as "10px" are parsed to Float;
- // complex values such as "rotate(1rad)" are returned as-is.
- result = jQuery.css( tween.elem, tween.prop, "" );
-
- // Empty strings, null, undefined and "auto" are converted to 0.
- return !result || result === "auto" ? 0 : result;
- },
- set: function( tween ) {
-
- // Use step hook for back compat.
- // Use cssHook if its there.
- // Use .style if available and use plain properties where available.
- if ( jQuery.fx.step[ tween.prop ] ) {
- jQuery.fx.step[ tween.prop ]( tween );
- } else if ( tween.elem.nodeType === 1 && (
- jQuery.cssHooks[ tween.prop ] ||
- tween.elem.style[ finalPropName( tween.prop ) ] != null ) ) {
- jQuery.style( tween.elem, tween.prop, tween.now + tween.unit );
- } else {
- tween.elem[ tween.prop ] = tween.now;
- }
- }
- }
-};
-
-// Support: IE <=9 only
-// Panic based approach to setting things on disconnected nodes
-Tween.propHooks.scrollTop = Tween.propHooks.scrollLeft = {
- set: function( tween ) {
- if ( tween.elem.nodeType && tween.elem.parentNode ) {
- tween.elem[ tween.prop ] = tween.now;
- }
- }
-};
-
-jQuery.easing = {
- linear: function( p ) {
- return p;
- },
- swing: function( p ) {
- return 0.5 - Math.cos( p * Math.PI ) / 2;
- },
- _default: "swing"
-};
-
-jQuery.fx = Tween.prototype.init;
-
-// Back compat <1.8 extension point
-jQuery.fx.step = {};
-
-
-
-
-var
- fxNow, inProgress,
- rfxtypes = /^(?:toggle|show|hide)$/,
- rrun = /queueHooks$/;
-
-function schedule() {
- if ( inProgress ) {
- if ( document.hidden === false && window.requestAnimationFrame ) {
- window.requestAnimationFrame( schedule );
- } else {
- window.setTimeout( schedule, jQuery.fx.interval );
- }
-
- jQuery.fx.tick();
- }
-}
-
-// Animations created synchronously will run synchronously
-function createFxNow() {
- window.setTimeout( function() {
- fxNow = undefined;
- } );
- return ( fxNow = Date.now() );
-}
-
-// Generate parameters to create a standard animation
-function genFx( type, includeWidth ) {
- var which,
- i = 0,
- attrs = { height: type };
-
- // If we include width, step value is 1 to do all cssExpand values,
- // otherwise step value is 2 to skip over Left and Right
- includeWidth = includeWidth ? 1 : 0;
- for ( ; i < 4; i += 2 - includeWidth ) {
- which = cssExpand[ i ];
- attrs[ "margin" + which ] = attrs[ "padding" + which ] = type;
- }
-
- if ( includeWidth ) {
- attrs.opacity = attrs.width = type;
- }
-
- return attrs;
-}
-
-function createTween( value, prop, animation ) {
- var tween,
- collection = ( Animation.tweeners[ prop ] || [] ).concat( Animation.tweeners[ "*" ] ),
- index = 0,
- length = collection.length;
- for ( ; index < length; index++ ) {
- if ( ( tween = collection[ index ].call( animation, prop, value ) ) ) {
-
- // We're done with this property
- return tween;
- }
- }
-}
-
-function defaultPrefilter( elem, props, opts ) {
- var prop, value, toggle, hooks, oldfire, propTween, restoreDisplay, display,
- isBox = "width" in props || "height" in props,
- anim = this,
- orig = {},
- style = elem.style,
- hidden = elem.nodeType && isHiddenWithinTree( elem ),
- dataShow = dataPriv.get( elem, "fxshow" );
-
- // Queue-skipping animations hijack the fx hooks
- if ( !opts.queue ) {
- hooks = jQuery._queueHooks( elem, "fx" );
- if ( hooks.unqueued == null ) {
- hooks.unqueued = 0;
- oldfire = hooks.empty.fire;
- hooks.empty.fire = function() {
- if ( !hooks.unqueued ) {
- oldfire();
- }
- };
- }
- hooks.unqueued++;
-
- anim.always( function() {
-
- // Ensure the complete handler is called before this completes
- anim.always( function() {
- hooks.unqueued--;
- if ( !jQuery.queue( elem, "fx" ).length ) {
- hooks.empty.fire();
- }
- } );
- } );
- }
-
- // Detect show/hide animations
- for ( prop in props ) {
- value = props[ prop ];
- if ( rfxtypes.test( value ) ) {
- delete props[ prop ];
- toggle = toggle || value === "toggle";
- if ( value === ( hidden ? "hide" : "show" ) ) {
-
- // Pretend to be hidden if this is a "show" and
- // there is still data from a stopped show/hide
- if ( value === "show" && dataShow && dataShow[ prop ] !== undefined ) {
- hidden = true;
-
- // Ignore all other no-op show/hide data
- } else {
- continue;
- }
- }
- orig[ prop ] = dataShow && dataShow[ prop ] || jQuery.style( elem, prop );
- }
- }
-
- // Bail out if this is a no-op like .hide().hide()
- propTween = !jQuery.isEmptyObject( props );
- if ( !propTween && jQuery.isEmptyObject( orig ) ) {
- return;
- }
-
- // Restrict "overflow" and "display" styles during box animations
- if ( isBox && elem.nodeType === 1 ) {
-
- // Support: IE <=9 - 11, Edge 12 - 15
- // Record all 3 overflow attributes because IE does not infer the shorthand
- // from identically-valued overflowX and overflowY and Edge just mirrors
- // the overflowX value there.
- opts.overflow = [ style.overflow, style.overflowX, style.overflowY ];
-
- // Identify a display type, preferring old show/hide data over the CSS cascade
- restoreDisplay = dataShow && dataShow.display;
- if ( restoreDisplay == null ) {
- restoreDisplay = dataPriv.get( elem, "display" );
- }
- display = jQuery.css( elem, "display" );
- if ( display === "none" ) {
- if ( restoreDisplay ) {
- display = restoreDisplay;
- } else {
-
- // Get nonempty value(s) by temporarily forcing visibility
- showHide( [ elem ], true );
- restoreDisplay = elem.style.display || restoreDisplay;
- display = jQuery.css( elem, "display" );
- showHide( [ elem ] );
- }
- }
-
- // Animate inline elements as inline-block
- if ( display === "inline" || display === "inline-block" && restoreDisplay != null ) {
- if ( jQuery.css( elem, "float" ) === "none" ) {
-
- // Restore the original display value at the end of pure show/hide animations
- if ( !propTween ) {
- anim.done( function() {
- style.display = restoreDisplay;
- } );
- if ( restoreDisplay == null ) {
- display = style.display;
- restoreDisplay = display === "none" ? "" : display;
- }
- }
- style.display = "inline-block";
- }
- }
- }
-
- if ( opts.overflow ) {
- style.overflow = "hidden";
- anim.always( function() {
- style.overflow = opts.overflow[ 0 ];
- style.overflowX = opts.overflow[ 1 ];
- style.overflowY = opts.overflow[ 2 ];
- } );
- }
-
- // Implement show/hide animations
- propTween = false;
- for ( prop in orig ) {
-
- // General show/hide setup for this element animation
- if ( !propTween ) {
- if ( dataShow ) {
- if ( "hidden" in dataShow ) {
- hidden = dataShow.hidden;
- }
- } else {
- dataShow = dataPriv.access( elem, "fxshow", { display: restoreDisplay } );
- }
-
- // Store hidden/visible for toggle so `.stop().toggle()` "reverses"
- if ( toggle ) {
- dataShow.hidden = !hidden;
- }
-
- // Show elements before animating them
- if ( hidden ) {
- showHide( [ elem ], true );
- }
-
- /* eslint-disable no-loop-func */
-
- anim.done( function() {
-
- /* eslint-enable no-loop-func */
-
- // The final step of a "hide" animation is actually hiding the element
- if ( !hidden ) {
- showHide( [ elem ] );
- }
- dataPriv.remove( elem, "fxshow" );
- for ( prop in orig ) {
- jQuery.style( elem, prop, orig[ prop ] );
- }
- } );
- }
-
- // Per-property setup
- propTween = createTween( hidden ? dataShow[ prop ] : 0, prop, anim );
- if ( !( prop in dataShow ) ) {
- dataShow[ prop ] = propTween.start;
- if ( hidden ) {
- propTween.end = propTween.start;
- propTween.start = 0;
- }
- }
- }
-}
-
-function propFilter( props, specialEasing ) {
- var index, name, easing, value, hooks;
-
- // camelCase, specialEasing and expand cssHook pass
- for ( index in props ) {
- name = camelCase( index );
- easing = specialEasing[ name ];
- value = props[ index ];
- if ( Array.isArray( value ) ) {
- easing = value[ 1 ];
- value = props[ index ] = value[ 0 ];
- }
-
- if ( index !== name ) {
- props[ name ] = value;
- delete props[ index ];
- }
-
- hooks = jQuery.cssHooks[ name ];
- if ( hooks && "expand" in hooks ) {
- value = hooks.expand( value );
- delete props[ name ];
-
- // Not quite $.extend, this won't overwrite existing keys.
- // Reusing 'index' because we have the correct "name"
- for ( index in value ) {
- if ( !( index in props ) ) {
- props[ index ] = value[ index ];
- specialEasing[ index ] = easing;
- }
- }
- } else {
- specialEasing[ name ] = easing;
- }
- }
-}
-
-function Animation( elem, properties, options ) {
- var result,
- stopped,
- index = 0,
- length = Animation.prefilters.length,
- deferred = jQuery.Deferred().always( function() {
-
- // Don't match elem in the :animated selector
- delete tick.elem;
- } ),
- tick = function() {
- if ( stopped ) {
- return false;
- }
- var currentTime = fxNow || createFxNow(),
- remaining = Math.max( 0, animation.startTime + animation.duration - currentTime ),
-
- // Support: Android 2.3 only
- // Archaic crash bug won't allow us to use `1 - ( 0.5 || 0 )` (#12497)
- temp = remaining / animation.duration || 0,
- percent = 1 - temp,
- index = 0,
- length = animation.tweens.length;
-
- for ( ; index < length; index++ ) {
- animation.tweens[ index ].run( percent );
- }
-
- deferred.notifyWith( elem, [ animation, percent, remaining ] );
-
- // If there's more to do, yield
- if ( percent < 1 && length ) {
- return remaining;
- }
-
- // If this was an empty animation, synthesize a final progress notification
- if ( !length ) {
- deferred.notifyWith( elem, [ animation, 1, 0 ] );
- }
-
- // Resolve the animation and report its conclusion
- deferred.resolveWith( elem, [ animation ] );
- return false;
- },
- animation = deferred.promise( {
- elem: elem,
- props: jQuery.extend( {}, properties ),
- opts: jQuery.extend( true, {
- specialEasing: {},
- easing: jQuery.easing._default
- }, options ),
- originalProperties: properties,
- originalOptions: options,
- startTime: fxNow || createFxNow(),
- duration: options.duration,
- tweens: [],
- createTween: function( prop, end ) {
- var tween = jQuery.Tween( elem, animation.opts, prop, end,
- animation.opts.specialEasing[ prop ] || animation.opts.easing );
- animation.tweens.push( tween );
- return tween;
- },
- stop: function( gotoEnd ) {
- var index = 0,
-
- // If we are going to the end, we want to run all the tweens
- // otherwise we skip this part
- length = gotoEnd ? animation.tweens.length : 0;
- if ( stopped ) {
- return this;
- }
- stopped = true;
- for ( ; index < length; index++ ) {
- animation.tweens[ index ].run( 1 );
- }
-
- // Resolve when we played the last frame; otherwise, reject
- if ( gotoEnd ) {
- deferred.notifyWith( elem, [ animation, 1, 0 ] );
- deferred.resolveWith( elem, [ animation, gotoEnd ] );
- } else {
- deferred.rejectWith( elem, [ animation, gotoEnd ] );
- }
- return this;
- }
- } ),
- props = animation.props;
-
- propFilter( props, animation.opts.specialEasing );
-
- for ( ; index < length; index++ ) {
- result = Animation.prefilters[ index ].call( animation, elem, props, animation.opts );
- if ( result ) {
- if ( isFunction( result.stop ) ) {
- jQuery._queueHooks( animation.elem, animation.opts.queue ).stop =
- result.stop.bind( result );
- }
- return result;
- }
- }
-
- jQuery.map( props, createTween, animation );
-
- if ( isFunction( animation.opts.start ) ) {
- animation.opts.start.call( elem, animation );
- }
-
- // Attach callbacks from options
- animation
- .progress( animation.opts.progress )
- .done( animation.opts.done, animation.opts.complete )
- .fail( animation.opts.fail )
- .always( animation.opts.always );
-
- jQuery.fx.timer(
- jQuery.extend( tick, {
- elem: elem,
- anim: animation,
- queue: animation.opts.queue
- } )
- );
-
- return animation;
-}
-
-jQuery.Animation = jQuery.extend( Animation, {
-
- tweeners: {
- "*": [ function( prop, value ) {
- var tween = this.createTween( prop, value );
- adjustCSS( tween.elem, prop, rcssNum.exec( value ), tween );
- return tween;
- } ]
- },
-
- tweener: function( props, callback ) {
- if ( isFunction( props ) ) {
- callback = props;
- props = [ "*" ];
- } else {
- props = props.match( rnothtmlwhite );
- }
-
- var prop,
- index = 0,
- length = props.length;
-
- for ( ; index < length; index++ ) {
- prop = props[ index ];
- Animation.tweeners[ prop ] = Animation.tweeners[ prop ] || [];
- Animation.tweeners[ prop ].unshift( callback );
- }
- },
-
- prefilters: [ defaultPrefilter ],
-
- prefilter: function( callback, prepend ) {
- if ( prepend ) {
- Animation.prefilters.unshift( callback );
- } else {
- Animation.prefilters.push( callback );
- }
- }
-} );
-
-jQuery.speed = function( speed, easing, fn ) {
- var opt = speed && typeof speed === "object" ? jQuery.extend( {}, speed ) : {
- complete: fn || !fn && easing ||
- isFunction( speed ) && speed,
- duration: speed,
- easing: fn && easing || easing && !isFunction( easing ) && easing
- };
-
- // Go to the end state if fx are off
- if ( jQuery.fx.off ) {
- opt.duration = 0;
-
- } else {
- if ( typeof opt.duration !== "number" ) {
- if ( opt.duration in jQuery.fx.speeds ) {
- opt.duration = jQuery.fx.speeds[ opt.duration ];
-
- } else {
- opt.duration = jQuery.fx.speeds._default;
- }
- }
- }
-
- // Normalize opt.queue - true/undefined/null -> "fx"
- if ( opt.queue == null || opt.queue === true ) {
- opt.queue = "fx";
- }
-
- // Queueing
- opt.old = opt.complete;
-
- opt.complete = function() {
- if ( isFunction( opt.old ) ) {
- opt.old.call( this );
- }
-
- if ( opt.queue ) {
- jQuery.dequeue( this, opt.queue );
- }
- };
-
- return opt;
-};
-
-jQuery.fn.extend( {
- fadeTo: function( speed, to, easing, callback ) {
-
- // Show any hidden elements after setting opacity to 0
- return this.filter( isHiddenWithinTree ).css( "opacity", 0 ).show()
-
- // Animate to the value specified
- .end().animate( { opacity: to }, speed, easing, callback );
- },
- animate: function( prop, speed, easing, callback ) {
- var empty = jQuery.isEmptyObject( prop ),
- optall = jQuery.speed( speed, easing, callback ),
- doAnimation = function() {
-
- // Operate on a copy of prop so per-property easing won't be lost
- var anim = Animation( this, jQuery.extend( {}, prop ), optall );
-
- // Empty animations, or finishing resolves immediately
- if ( empty || dataPriv.get( this, "finish" ) ) {
- anim.stop( true );
- }
- };
- doAnimation.finish = doAnimation;
-
- return empty || optall.queue === false ?
- this.each( doAnimation ) :
- this.queue( optall.queue, doAnimation );
- },
- stop: function( type, clearQueue, gotoEnd ) {
- var stopQueue = function( hooks ) {
- var stop = hooks.stop;
- delete hooks.stop;
- stop( gotoEnd );
- };
-
- if ( typeof type !== "string" ) {
- gotoEnd = clearQueue;
- clearQueue = type;
- type = undefined;
- }
- if ( clearQueue ) {
- this.queue( type || "fx", [] );
- }
-
- return this.each( function() {
- var dequeue = true,
- index = type != null && type + "queueHooks",
- timers = jQuery.timers,
- data = dataPriv.get( this );
-
- if ( index ) {
- if ( data[ index ] && data[ index ].stop ) {
- stopQueue( data[ index ] );
- }
- } else {
- for ( index in data ) {
- if ( data[ index ] && data[ index ].stop && rrun.test( index ) ) {
- stopQueue( data[ index ] );
- }
- }
- }
-
- for ( index = timers.length; index--; ) {
- if ( timers[ index ].elem === this &&
- ( type == null || timers[ index ].queue === type ) ) {
-
- timers[ index ].anim.stop( gotoEnd );
- dequeue = false;
- timers.splice( index, 1 );
- }
- }
-
- // Start the next in the queue if the last step wasn't forced.
- // Timers currently will call their complete callbacks, which
- // will dequeue but only if they were gotoEnd.
- if ( dequeue || !gotoEnd ) {
- jQuery.dequeue( this, type );
- }
- } );
- },
- finish: function( type ) {
- if ( type !== false ) {
- type = type || "fx";
- }
- return this.each( function() {
- var index,
- data = dataPriv.get( this ),
- queue = data[ type + "queue" ],
- hooks = data[ type + "queueHooks" ],
- timers = jQuery.timers,
- length = queue ? queue.length : 0;
-
- // Enable finishing flag on private data
- data.finish = true;
-
- // Empty the queue first
- jQuery.queue( this, type, [] );
-
- if ( hooks && hooks.stop ) {
- hooks.stop.call( this, true );
- }
-
- // Look for any active animations, and finish them
- for ( index = timers.length; index--; ) {
- if ( timers[ index ].elem === this && timers[ index ].queue === type ) {
- timers[ index ].anim.stop( true );
- timers.splice( index, 1 );
- }
- }
-
- // Look for any animations in the old queue and finish them
- for ( index = 0; index < length; index++ ) {
- if ( queue[ index ] && queue[ index ].finish ) {
- queue[ index ].finish.call( this );
- }
- }
-
- // Turn off finishing flag
- delete data.finish;
- } );
- }
-} );
-
-jQuery.each( [ "toggle", "show", "hide" ], function( _i, name ) {
- var cssFn = jQuery.fn[ name ];
- jQuery.fn[ name ] = function( speed, easing, callback ) {
- return speed == null || typeof speed === "boolean" ?
- cssFn.apply( this, arguments ) :
- this.animate( genFx( name, true ), speed, easing, callback );
- };
-} );
-
-// Generate shortcuts for custom animations
-jQuery.each( {
- slideDown: genFx( "show" ),
- slideUp: genFx( "hide" ),
- slideToggle: genFx( "toggle" ),
- fadeIn: { opacity: "show" },
- fadeOut: { opacity: "hide" },
- fadeToggle: { opacity: "toggle" }
-}, function( name, props ) {
- jQuery.fn[ name ] = function( speed, easing, callback ) {
- return this.animate( props, speed, easing, callback );
- };
-} );
-
-jQuery.timers = [];
-jQuery.fx.tick = function() {
- var timer,
- i = 0,
- timers = jQuery.timers;
-
- fxNow = Date.now();
-
- for ( ; i < timers.length; i++ ) {
- timer = timers[ i ];
-
- // Run the timer and safely remove it when done (allowing for external removal)
- if ( !timer() && timers[ i ] === timer ) {
- timers.splice( i--, 1 );
- }
- }
-
- if ( !timers.length ) {
- jQuery.fx.stop();
- }
- fxNow = undefined;
-};
-
-jQuery.fx.timer = function( timer ) {
- jQuery.timers.push( timer );
- jQuery.fx.start();
-};
-
-jQuery.fx.interval = 13;
-jQuery.fx.start = function() {
- if ( inProgress ) {
- return;
- }
-
- inProgress = true;
- schedule();
-};
-
-jQuery.fx.stop = function() {
- inProgress = null;
-};
-
-jQuery.fx.speeds = {
- slow: 600,
- fast: 200,
-
- // Default speed
- _default: 400
-};
-
-
-// Based off of the plugin by Clint Helfers, with permission.
-// https://web.archive.org/web/20100324014747/http://blindsignals.com/index.php/2009/07/jquery-delay/
-jQuery.fn.delay = function( time, type ) {
- time = jQuery.fx ? jQuery.fx.speeds[ time ] || time : time;
- type = type || "fx";
-
- return this.queue( type, function( next, hooks ) {
- var timeout = window.setTimeout( next, time );
- hooks.stop = function() {
- window.clearTimeout( timeout );
- };
- } );
-};
-
-
-( function() {
- var input = document.createElement( "input" ),
- select = document.createElement( "select" ),
- opt = select.appendChild( document.createElement( "option" ) );
-
- input.type = "checkbox";
-
- // Support: Android <=4.3 only
- // Default value for a checkbox should be "on"
- support.checkOn = input.value !== "";
-
- // Support: IE <=11 only
- // Must access selectedIndex to make default options select
- support.optSelected = opt.selected;
-
- // Support: IE <=11 only
- // An input loses its value after becoming a radio
- input = document.createElement( "input" );
- input.value = "t";
- input.type = "radio";
- support.radioValue = input.value === "t";
-} )();
-
-
-var boolHook,
- attrHandle = jQuery.expr.attrHandle;
-
-jQuery.fn.extend( {
- attr: function( name, value ) {
- return access( this, jQuery.attr, name, value, arguments.length > 1 );
- },
-
- removeAttr: function( name ) {
- return this.each( function() {
- jQuery.removeAttr( this, name );
- } );
- }
-} );
-
-jQuery.extend( {
- attr: function( elem, name, value ) {
- var ret, hooks,
- nType = elem.nodeType;
-
- // Don't get/set attributes on text, comment and attribute nodes
- if ( nType === 3 || nType === 8 || nType === 2 ) {
- return;
- }
-
- // Fallback to prop when attributes are not supported
- if ( typeof elem.getAttribute === "undefined" ) {
- return jQuery.prop( elem, name, value );
- }
-
- // Attribute hooks are determined by the lowercase version
- // Grab necessary hook if one is defined
- if ( nType !== 1 || !jQuery.isXMLDoc( elem ) ) {
- hooks = jQuery.attrHooks[ name.toLowerCase() ] ||
- ( jQuery.expr.match.bool.test( name ) ? boolHook : undefined );
- }
-
- if ( value !== undefined ) {
- if ( value === null ) {
- jQuery.removeAttr( elem, name );
- return;
- }
-
- if ( hooks && "set" in hooks &&
- ( ret = hooks.set( elem, value, name ) ) !== undefined ) {
- return ret;
- }
-
- elem.setAttribute( name, value + "" );
- return value;
- }
-
- if ( hooks && "get" in hooks && ( ret = hooks.get( elem, name ) ) !== null ) {
- return ret;
- }
-
- ret = jQuery.find.attr( elem, name );
-
- // Non-existent attributes return null, we normalize to undefined
- return ret == null ? undefined : ret;
- },
-
- attrHooks: {
- type: {
- set: function( elem, value ) {
- if ( !support.radioValue && value === "radio" &&
- nodeName( elem, "input" ) ) {
- var val = elem.value;
- elem.setAttribute( "type", value );
- if ( val ) {
- elem.value = val;
- }
- return value;
- }
- }
- }
- },
-
- removeAttr: function( elem, value ) {
- var name,
- i = 0,
-
- // Attribute names can contain non-HTML whitespace characters
- // https://html.spec.whatwg.org/multipage/syntax.html#attributes-2
- attrNames = value && value.match( rnothtmlwhite );
-
- if ( attrNames && elem.nodeType === 1 ) {
- while ( ( name = attrNames[ i++ ] ) ) {
- elem.removeAttribute( name );
- }
- }
- }
-} );
-
-// Hooks for boolean attributes
-boolHook = {
- set: function( elem, value, name ) {
- if ( value === false ) {
-
- // Remove boolean attributes when set to false
- jQuery.removeAttr( elem, name );
- } else {
- elem.setAttribute( name, name );
- }
- return name;
- }
-};
-
-jQuery.each( jQuery.expr.match.bool.source.match( /\w+/g ), function( _i, name ) {
- var getter = attrHandle[ name ] || jQuery.find.attr;
-
- attrHandle[ name ] = function( elem, name, isXML ) {
- var ret, handle,
- lowercaseName = name.toLowerCase();
-
- if ( !isXML ) {
-
- // Avoid an infinite loop by temporarily removing this function from the getter
- handle = attrHandle[ lowercaseName ];
- attrHandle[ lowercaseName ] = ret;
- ret = getter( elem, name, isXML ) != null ?
- lowercaseName :
- null;
- attrHandle[ lowercaseName ] = handle;
- }
- return ret;
- };
-} );
-
-
-
-
-var rfocusable = /^(?:input|select|textarea|button)$/i,
- rclickable = /^(?:a|area)$/i;
-
-jQuery.fn.extend( {
- prop: function( name, value ) {
- return access( this, jQuery.prop, name, value, arguments.length > 1 );
- },
-
- removeProp: function( name ) {
- return this.each( function() {
- delete this[ jQuery.propFix[ name ] || name ];
- } );
- }
-} );
-
-jQuery.extend( {
- prop: function( elem, name, value ) {
- var ret, hooks,
- nType = elem.nodeType;
-
- // Don't get/set properties on text, comment and attribute nodes
- if ( nType === 3 || nType === 8 || nType === 2 ) {
- return;
- }
-
- if ( nType !== 1 || !jQuery.isXMLDoc( elem ) ) {
-
- // Fix name and attach hooks
- name = jQuery.propFix[ name ] || name;
- hooks = jQuery.propHooks[ name ];
- }
-
- if ( value !== undefined ) {
- if ( hooks && "set" in hooks &&
- ( ret = hooks.set( elem, value, name ) ) !== undefined ) {
- return ret;
- }
-
- return ( elem[ name ] = value );
- }
-
- if ( hooks && "get" in hooks && ( ret = hooks.get( elem, name ) ) !== null ) {
- return ret;
- }
-
- return elem[ name ];
- },
-
- propHooks: {
- tabIndex: {
- get: function( elem ) {
-
- // Support: IE <=9 - 11 only
- // elem.tabIndex doesn't always return the
- // correct value when it hasn't been explicitly set
- // https://web.archive.org/web/20141116233347/http://fluidproject.org/blog/2008/01/09/getting-setting-and-removing-tabindex-values-with-javascript/
- // Use proper attribute retrieval(#12072)
- var tabindex = jQuery.find.attr( elem, "tabindex" );
-
- if ( tabindex ) {
- return parseInt( tabindex, 10 );
- }
-
- if (
- rfocusable.test( elem.nodeName ) ||
- rclickable.test( elem.nodeName ) &&
- elem.href
- ) {
- return 0;
- }
-
- return -1;
- }
- }
- },
-
- propFix: {
- "for": "htmlFor",
- "class": "className"
- }
-} );
-
-// Support: IE <=11 only
-// Accessing the selectedIndex property
-// forces the browser to respect setting selected
-// on the option
-// The getter ensures a default option is selected
-// when in an optgroup
-// eslint rule "no-unused-expressions" is disabled for this code
-// since it considers such accessions noop
-if ( !support.optSelected ) {
- jQuery.propHooks.selected = {
- get: function( elem ) {
-
- /* eslint no-unused-expressions: "off" */
-
- var parent = elem.parentNode;
- if ( parent && parent.parentNode ) {
- parent.parentNode.selectedIndex;
- }
- return null;
- },
- set: function( elem ) {
-
- /* eslint no-unused-expressions: "off" */
-
- var parent = elem.parentNode;
- if ( parent ) {
- parent.selectedIndex;
-
- if ( parent.parentNode ) {
- parent.parentNode.selectedIndex;
- }
- }
- }
- };
-}
-
-jQuery.each( [
- "tabIndex",
- "readOnly",
- "maxLength",
- "cellSpacing",
- "cellPadding",
- "rowSpan",
- "colSpan",
- "useMap",
- "frameBorder",
- "contentEditable"
-], function() {
- jQuery.propFix[ this.toLowerCase() ] = this;
-} );
-
-
-
-
- // Strip and collapse whitespace according to HTML spec
- // https://infra.spec.whatwg.org/#strip-and-collapse-ascii-whitespace
- function stripAndCollapse( value ) {
- var tokens = value.match( rnothtmlwhite ) || [];
- return tokens.join( " " );
- }
-
-
-function getClass( elem ) {
- return elem.getAttribute && elem.getAttribute( "class" ) || "";
-}
-
-function classesToArray( value ) {
- if ( Array.isArray( value ) ) {
- return value;
- }
- if ( typeof value === "string" ) {
- return value.match( rnothtmlwhite ) || [];
- }
- return [];
-}
-
-jQuery.fn.extend( {
- addClass: function( value ) {
- var classes, elem, cur, curValue, clazz, j, finalValue,
- i = 0;
-
- if ( isFunction( value ) ) {
- return this.each( function( j ) {
- jQuery( this ).addClass( value.call( this, j, getClass( this ) ) );
- } );
- }
-
- classes = classesToArray( value );
-
- if ( classes.length ) {
- while ( ( elem = this[ i++ ] ) ) {
- curValue = getClass( elem );
- cur = elem.nodeType === 1 && ( " " + stripAndCollapse( curValue ) + " " );
-
- if ( cur ) {
- j = 0;
- while ( ( clazz = classes[ j++ ] ) ) {
- if ( cur.indexOf( " " + clazz + " " ) < 0 ) {
- cur += clazz + " ";
- }
- }
-
- // Only assign if different to avoid unneeded rendering.
- finalValue = stripAndCollapse( cur );
- if ( curValue !== finalValue ) {
- elem.setAttribute( "class", finalValue );
- }
- }
- }
- }
-
- return this;
- },
-
- removeClass: function( value ) {
- var classes, elem, cur, curValue, clazz, j, finalValue,
- i = 0;
-
- if ( isFunction( value ) ) {
- return this.each( function( j ) {
- jQuery( this ).removeClass( value.call( this, j, getClass( this ) ) );
- } );
- }
-
- if ( !arguments.length ) {
- return this.attr( "class", "" );
- }
-
- classes = classesToArray( value );
-
- if ( classes.length ) {
- while ( ( elem = this[ i++ ] ) ) {
- curValue = getClass( elem );
-
- // This expression is here for better compressibility (see addClass)
- cur = elem.nodeType === 1 && ( " " + stripAndCollapse( curValue ) + " " );
-
- if ( cur ) {
- j = 0;
- while ( ( clazz = classes[ j++ ] ) ) {
-
- // Remove *all* instances
- while ( cur.indexOf( " " + clazz + " " ) > -1 ) {
- cur = cur.replace( " " + clazz + " ", " " );
- }
- }
-
- // Only assign if different to avoid unneeded rendering.
- finalValue = stripAndCollapse( cur );
- if ( curValue !== finalValue ) {
- elem.setAttribute( "class", finalValue );
- }
- }
- }
- }
-
- return this;
- },
-
- toggleClass: function( value, stateVal ) {
- var type = typeof value,
- isValidValue = type === "string" || Array.isArray( value );
-
- if ( typeof stateVal === "boolean" && isValidValue ) {
- return stateVal ? this.addClass( value ) : this.removeClass( value );
- }
-
- if ( isFunction( value ) ) {
- return this.each( function( i ) {
- jQuery( this ).toggleClass(
- value.call( this, i, getClass( this ), stateVal ),
- stateVal
- );
- } );
- }
-
- return this.each( function() {
- var className, i, self, classNames;
-
- if ( isValidValue ) {
-
- // Toggle individual class names
- i = 0;
- self = jQuery( this );
- classNames = classesToArray( value );
-
- while ( ( className = classNames[ i++ ] ) ) {
-
- // Check each className given, space separated list
- if ( self.hasClass( className ) ) {
- self.removeClass( className );
- } else {
- self.addClass( className );
- }
- }
-
- // Toggle whole class name
- } else if ( value === undefined || type === "boolean" ) {
- className = getClass( this );
- if ( className ) {
-
- // Store className if set
- dataPriv.set( this, "__className__", className );
- }
-
- // If the element has a class name or if we're passed `false`,
- // then remove the whole classname (if there was one, the above saved it).
- // Otherwise bring back whatever was previously saved (if anything),
- // falling back to the empty string if nothing was stored.
- if ( this.setAttribute ) {
- this.setAttribute( "class",
- className || value === false ?
- "" :
- dataPriv.get( this, "__className__" ) || ""
- );
- }
- }
- } );
- },
-
- hasClass: function( selector ) {
- var className, elem,
- i = 0;
-
- className = " " + selector + " ";
- while ( ( elem = this[ i++ ] ) ) {
- if ( elem.nodeType === 1 &&
- ( " " + stripAndCollapse( getClass( elem ) ) + " " ).indexOf( className ) > -1 ) {
- return true;
- }
- }
-
- return false;
- }
-} );
-
-
-
-
-var rreturn = /\r/g;
-
-jQuery.fn.extend( {
- val: function( value ) {
- var hooks, ret, valueIsFunction,
- elem = this[ 0 ];
-
- if ( !arguments.length ) {
- if ( elem ) {
- hooks = jQuery.valHooks[ elem.type ] ||
- jQuery.valHooks[ elem.nodeName.toLowerCase() ];
-
- if ( hooks &&
- "get" in hooks &&
- ( ret = hooks.get( elem, "value" ) ) !== undefined
- ) {
- return ret;
- }
-
- ret = elem.value;
-
- // Handle most common string cases
- if ( typeof ret === "string" ) {
- return ret.replace( rreturn, "" );
- }
-
- // Handle cases where value is null/undef or number
- return ret == null ? "" : ret;
- }
-
- return;
- }
-
- valueIsFunction = isFunction( value );
-
- return this.each( function( i ) {
- var val;
-
- if ( this.nodeType !== 1 ) {
- return;
- }
-
- if ( valueIsFunction ) {
- val = value.call( this, i, jQuery( this ).val() );
- } else {
- val = value;
- }
-
- // Treat null/undefined as ""; convert numbers to string
- if ( val == null ) {
- val = "";
-
- } else if ( typeof val === "number" ) {
- val += "";
-
- } else if ( Array.isArray( val ) ) {
- val = jQuery.map( val, function( value ) {
- return value == null ? "" : value + "";
- } );
- }
-
- hooks = jQuery.valHooks[ this.type ] || jQuery.valHooks[ this.nodeName.toLowerCase() ];
-
- // If set returns undefined, fall back to normal setting
- if ( !hooks || !( "set" in hooks ) || hooks.set( this, val, "value" ) === undefined ) {
- this.value = val;
- }
- } );
- }
-} );
-
-jQuery.extend( {
- valHooks: {
- option: {
- get: function( elem ) {
-
- var val = jQuery.find.attr( elem, "value" );
- return val != null ?
- val :
-
- // Support: IE <=10 - 11 only
- // option.text throws exceptions (#14686, #14858)
- // Strip and collapse whitespace
- // https://html.spec.whatwg.org/#strip-and-collapse-whitespace
- stripAndCollapse( jQuery.text( elem ) );
- }
- },
- select: {
- get: function( elem ) {
- var value, option, i,
- options = elem.options,
- index = elem.selectedIndex,
- one = elem.type === "select-one",
- values = one ? null : [],
- max = one ? index + 1 : options.length;
-
- if ( index < 0 ) {
- i = max;
-
- } else {
- i = one ? index : 0;
- }
-
- // Loop through all the selected options
- for ( ; i < max; i++ ) {
- option = options[ i ];
-
- // Support: IE <=9 only
- // IE8-9 doesn't update selected after form reset (#2551)
- if ( ( option.selected || i === index ) &&
-
- // Don't return options that are disabled or in a disabled optgroup
- !option.disabled &&
- ( !option.parentNode.disabled ||
- !nodeName( option.parentNode, "optgroup" ) ) ) {
-
- // Get the specific value for the option
- value = jQuery( option ).val();
-
- // We don't need an array for one selects
- if ( one ) {
- return value;
- }
-
- // Multi-Selects return an array
- values.push( value );
- }
- }
-
- return values;
- },
-
- set: function( elem, value ) {
- var optionSet, option,
- options = elem.options,
- values = jQuery.makeArray( value ),
- i = options.length;
-
- while ( i-- ) {
- option = options[ i ];
-
- /* eslint-disable no-cond-assign */
-
- if ( option.selected =
- jQuery.inArray( jQuery.valHooks.option.get( option ), values ) > -1
- ) {
- optionSet = true;
- }
-
- /* eslint-enable no-cond-assign */
- }
-
- // Force browsers to behave consistently when non-matching value is set
- if ( !optionSet ) {
- elem.selectedIndex = -1;
- }
- return values;
- }
- }
- }
-} );
-
-// Radios and checkboxes getter/setter
-jQuery.each( [ "radio", "checkbox" ], function() {
- jQuery.valHooks[ this ] = {
- set: function( elem, value ) {
- if ( Array.isArray( value ) ) {
- return ( elem.checked = jQuery.inArray( jQuery( elem ).val(), value ) > -1 );
- }
- }
- };
- if ( !support.checkOn ) {
- jQuery.valHooks[ this ].get = function( elem ) {
- return elem.getAttribute( "value" ) === null ? "on" : elem.value;
- };
- }
-} );
-
-
-
-
-// Return jQuery for attributes-only inclusion
-
-
-support.focusin = "onfocusin" in window;
-
-
-var rfocusMorph = /^(?:focusinfocus|focusoutblur)$/,
- stopPropagationCallback = function( e ) {
- e.stopPropagation();
- };
-
-jQuery.extend( jQuery.event, {
-
- trigger: function( event, data, elem, onlyHandlers ) {
-
- var i, cur, tmp, bubbleType, ontype, handle, special, lastElement,
- eventPath = [ elem || document ],
- type = hasOwn.call( event, "type" ) ? event.type : event,
- namespaces = hasOwn.call( event, "namespace" ) ? event.namespace.split( "." ) : [];
-
- cur = lastElement = tmp = elem = elem || document;
-
- // Don't do events on text and comment nodes
- if ( elem.nodeType === 3 || elem.nodeType === 8 ) {
- return;
- }
-
- // focus/blur morphs to focusin/out; ensure we're not firing them right now
- if ( rfocusMorph.test( type + jQuery.event.triggered ) ) {
- return;
- }
-
- if ( type.indexOf( "." ) > -1 ) {
-
- // Namespaced trigger; create a regexp to match event type in handle()
- namespaces = type.split( "." );
- type = namespaces.shift();
- namespaces.sort();
- }
- ontype = type.indexOf( ":" ) < 0 && "on" + type;
-
- // Caller can pass in a jQuery.Event object, Object, or just an event type string
- event = event[ jQuery.expando ] ?
- event :
- new jQuery.Event( type, typeof event === "object" && event );
-
- // Trigger bitmask: & 1 for native handlers; & 2 for jQuery (always true)
- event.isTrigger = onlyHandlers ? 2 : 3;
- event.namespace = namespaces.join( "." );
- event.rnamespace = event.namespace ?
- new RegExp( "(^|\\.)" + namespaces.join( "\\.(?:.*\\.|)" ) + "(\\.|$)" ) :
- null;
-
- // Clean up the event in case it is being reused
- event.result = undefined;
- if ( !event.target ) {
- event.target = elem;
- }
-
- // Clone any incoming data and prepend the event, creating the handler arg list
- data = data == null ?
- [ event ] :
- jQuery.makeArray( data, [ event ] );
-
- // Allow special events to draw outside the lines
- special = jQuery.event.special[ type ] || {};
- if ( !onlyHandlers && special.trigger && special.trigger.apply( elem, data ) === false ) {
- return;
- }
-
- // Determine event propagation path in advance, per W3C events spec (#9951)
- // Bubble up to document, then to window; watch for a global ownerDocument var (#9724)
- if ( !onlyHandlers && !special.noBubble && !isWindow( elem ) ) {
-
- bubbleType = special.delegateType || type;
- if ( !rfocusMorph.test( bubbleType + type ) ) {
- cur = cur.parentNode;
- }
- for ( ; cur; cur = cur.parentNode ) {
- eventPath.push( cur );
- tmp = cur;
- }
-
- // Only add window if we got to document (e.g., not plain obj or detached DOM)
- if ( tmp === ( elem.ownerDocument || document ) ) {
- eventPath.push( tmp.defaultView || tmp.parentWindow || window );
- }
- }
-
- // Fire handlers on the event path
- i = 0;
- while ( ( cur = eventPath[ i++ ] ) && !event.isPropagationStopped() ) {
- lastElement = cur;
- event.type = i > 1 ?
- bubbleType :
- special.bindType || type;
-
- // jQuery handler
- handle = (
- dataPriv.get( cur, "events" ) || Object.create( null )
- )[ event.type ] &&
- dataPriv.get( cur, "handle" );
- if ( handle ) {
- handle.apply( cur, data );
- }
-
- // Native handler
- handle = ontype && cur[ ontype ];
- if ( handle && handle.apply && acceptData( cur ) ) {
- event.result = handle.apply( cur, data );
- if ( event.result === false ) {
- event.preventDefault();
- }
- }
- }
- event.type = type;
-
- // If nobody prevented the default action, do it now
- if ( !onlyHandlers && !event.isDefaultPrevented() ) {
-
- if ( ( !special._default ||
- special._default.apply( eventPath.pop(), data ) === false ) &&
- acceptData( elem ) ) {
-
- // Call a native DOM method on the target with the same name as the event.
- // Don't do default actions on window, that's where global variables be (#6170)
- if ( ontype && isFunction( elem[ type ] ) && !isWindow( elem ) ) {
-
- // Don't re-trigger an onFOO event when we call its FOO() method
- tmp = elem[ ontype ];
-
- if ( tmp ) {
- elem[ ontype ] = null;
- }
-
- // Prevent re-triggering of the same event, since we already bubbled it above
- jQuery.event.triggered = type;
-
- if ( event.isPropagationStopped() ) {
- lastElement.addEventListener( type, stopPropagationCallback );
- }
-
- elem[ type ]();
-
- if ( event.isPropagationStopped() ) {
- lastElement.removeEventListener( type, stopPropagationCallback );
- }
-
- jQuery.event.triggered = undefined;
-
- if ( tmp ) {
- elem[ ontype ] = tmp;
- }
- }
- }
- }
-
- return event.result;
- },
-
- // Piggyback on a donor event to simulate a different one
- // Used only for `focus(in | out)` events
- simulate: function( type, elem, event ) {
- var e = jQuery.extend(
- new jQuery.Event(),
- event,
- {
- type: type,
- isSimulated: true
- }
- );
-
- jQuery.event.trigger( e, null, elem );
- }
-
-} );
-
-jQuery.fn.extend( {
-
- trigger: function( type, data ) {
- return this.each( function() {
- jQuery.event.trigger( type, data, this );
- } );
- },
- triggerHandler: function( type, data ) {
- var elem = this[ 0 ];
- if ( elem ) {
- return jQuery.event.trigger( type, data, elem, true );
- }
- }
-} );
-
-
-// Support: Firefox <=44
-// Firefox doesn't have focus(in | out) events
-// Related ticket - https://bugzilla.mozilla.org/show_bug.cgi?id=687787
-//
-// Support: Chrome <=48 - 49, Safari <=9.0 - 9.1
-// focus(in | out) events fire after focus & blur events,
-// which is spec violation - http://www.w3.org/TR/DOM-Level-3-Events/#events-focusevent-event-order
-// Related ticket - https://bugs.chromium.org/p/chromium/issues/detail?id=449857
-if ( !support.focusin ) {
- jQuery.each( { focus: "focusin", blur: "focusout" }, function( orig, fix ) {
-
- // Attach a single capturing handler on the document while someone wants focusin/focusout
- var handler = function( event ) {
- jQuery.event.simulate( fix, event.target, jQuery.event.fix( event ) );
- };
-
- jQuery.event.special[ fix ] = {
- setup: function() {
-
- // Handle: regular nodes (via `this.ownerDocument`), window
- // (via `this.document`) & document (via `this`).
- var doc = this.ownerDocument || this.document || this,
- attaches = dataPriv.access( doc, fix );
-
- if ( !attaches ) {
- doc.addEventListener( orig, handler, true );
- }
- dataPriv.access( doc, fix, ( attaches || 0 ) + 1 );
- },
- teardown: function() {
- var doc = this.ownerDocument || this.document || this,
- attaches = dataPriv.access( doc, fix ) - 1;
-
- if ( !attaches ) {
- doc.removeEventListener( orig, handler, true );
- dataPriv.remove( doc, fix );
-
- } else {
- dataPriv.access( doc, fix, attaches );
- }
- }
- };
- } );
-}
-var location = window.location;
-
-var nonce = { guid: Date.now() };
-
-var rquery = ( /\?/ );
-
-
-
-// Cross-browser xml parsing
-jQuery.parseXML = function( data ) {
- var xml;
- if ( !data || typeof data !== "string" ) {
- return null;
- }
-
- // Support: IE 9 - 11 only
- // IE throws on parseFromString with invalid input.
- try {
- xml = ( new window.DOMParser() ).parseFromString( data, "text/xml" );
- } catch ( e ) {
- xml = undefined;
- }
-
- if ( !xml || xml.getElementsByTagName( "parsererror" ).length ) {
- jQuery.error( "Invalid XML: " + data );
- }
- return xml;
-};
-
-
-var
- rbracket = /\[\]$/,
- rCRLF = /\r?\n/g,
- rsubmitterTypes = /^(?:submit|button|image|reset|file)$/i,
- rsubmittable = /^(?:input|select|textarea|keygen)/i;
-
-function buildParams( prefix, obj, traditional, add ) {
- var name;
-
- if ( Array.isArray( obj ) ) {
-
- // Serialize array item.
- jQuery.each( obj, function( i, v ) {
- if ( traditional || rbracket.test( prefix ) ) {
-
- // Treat each array item as a scalar.
- add( prefix, v );
-
- } else {
-
- // Item is non-scalar (array or object), encode its numeric index.
- buildParams(
- prefix + "[" + ( typeof v === "object" && v != null ? i : "" ) + "]",
- v,
- traditional,
- add
- );
- }
- } );
-
- } else if ( !traditional && toType( obj ) === "object" ) {
-
- // Serialize object item.
- for ( name in obj ) {
- buildParams( prefix + "[" + name + "]", obj[ name ], traditional, add );
- }
-
- } else {
-
- // Serialize scalar item.
- add( prefix, obj );
- }
-}
-
-// Serialize an array of form elements or a set of
-// key/values into a query string
-jQuery.param = function( a, traditional ) {
- var prefix,
- s = [],
- add = function( key, valueOrFunction ) {
-
- // If value is a function, invoke it and use its return value
- var value = isFunction( valueOrFunction ) ?
- valueOrFunction() :
- valueOrFunction;
-
- s[ s.length ] = encodeURIComponent( key ) + "=" +
- encodeURIComponent( value == null ? "" : value );
- };
-
- if ( a == null ) {
- return "";
- }
-
- // If an array was passed in, assume that it is an array of form elements.
- if ( Array.isArray( a ) || ( a.jquery && !jQuery.isPlainObject( a ) ) ) {
-
- // Serialize the form elements
- jQuery.each( a, function() {
- add( this.name, this.value );
- } );
-
- } else {
-
- // If traditional, encode the "old" way (the way 1.3.2 or older
- // did it), otherwise encode params recursively.
- for ( prefix in a ) {
- buildParams( prefix, a[ prefix ], traditional, add );
- }
- }
-
- // Return the resulting serialization
- return s.join( "&" );
-};
-
-jQuery.fn.extend( {
- serialize: function() {
- return jQuery.param( this.serializeArray() );
- },
- serializeArray: function() {
- return this.map( function() {
-
- // Can add propHook for "elements" to filter or add form elements
- var elements = jQuery.prop( this, "elements" );
- return elements ? jQuery.makeArray( elements ) : this;
- } )
- .filter( function() {
- var type = this.type;
-
- // Use .is( ":disabled" ) so that fieldset[disabled] works
- return this.name && !jQuery( this ).is( ":disabled" ) &&
- rsubmittable.test( this.nodeName ) && !rsubmitterTypes.test( type ) &&
- ( this.checked || !rcheckableType.test( type ) );
- } )
- .map( function( _i, elem ) {
- var val = jQuery( this ).val();
-
- if ( val == null ) {
- return null;
- }
-
- if ( Array.isArray( val ) ) {
- return jQuery.map( val, function( val ) {
- return { name: elem.name, value: val.replace( rCRLF, "\r\n" ) };
- } );
- }
-
- return { name: elem.name, value: val.replace( rCRLF, "\r\n" ) };
- } ).get();
- }
-} );
-
-
-var
- r20 = /%20/g,
- rhash = /#.*$/,
- rantiCache = /([?&])_=[^&]*/,
- rheaders = /^(.*?):[ \t]*([^\r\n]*)$/mg,
-
- // #7653, #8125, #8152: local protocol detection
- rlocalProtocol = /^(?:about|app|app-storage|.+-extension|file|res|widget):$/,
- rnoContent = /^(?:GET|HEAD)$/,
- rprotocol = /^\/\//,
-
- /* Prefilters
- * 1) They are useful to introduce custom dataTypes (see ajax/jsonp.js for an example)
- * 2) These are called:
- * - BEFORE asking for a transport
- * - AFTER param serialization (s.data is a string if s.processData is true)
- * 3) key is the dataType
- * 4) the catchall symbol "*" can be used
- * 5) execution will start with transport dataType and THEN continue down to "*" if needed
- */
- prefilters = {},
-
- /* Transports bindings
- * 1) key is the dataType
- * 2) the catchall symbol "*" can be used
- * 3) selection will start with transport dataType and THEN go to "*" if needed
- */
- transports = {},
-
- // Avoid comment-prolog char sequence (#10098); must appease lint and evade compression
- allTypes = "*/".concat( "*" ),
-
- // Anchor tag for parsing the document origin
- originAnchor = document.createElement( "a" );
- originAnchor.href = location.href;
-
-// Base "constructor" for jQuery.ajaxPrefilter and jQuery.ajaxTransport
-function addToPrefiltersOrTransports( structure ) {
-
- // dataTypeExpression is optional and defaults to "*"
- return function( dataTypeExpression, func ) {
-
- if ( typeof dataTypeExpression !== "string" ) {
- func = dataTypeExpression;
- dataTypeExpression = "*";
- }
-
- var dataType,
- i = 0,
- dataTypes = dataTypeExpression.toLowerCase().match( rnothtmlwhite ) || [];
-
- if ( isFunction( func ) ) {
-
- // For each dataType in the dataTypeExpression
- while ( ( dataType = dataTypes[ i++ ] ) ) {
-
- // Prepend if requested
- if ( dataType[ 0 ] === "+" ) {
- dataType = dataType.slice( 1 ) || "*";
- ( structure[ dataType ] = structure[ dataType ] || [] ).unshift( func );
-
- // Otherwise append
- } else {
- ( structure[ dataType ] = structure[ dataType ] || [] ).push( func );
- }
- }
- }
- };
-}
-
-// Base inspection function for prefilters and transports
-function inspectPrefiltersOrTransports( structure, options, originalOptions, jqXHR ) {
-
- var inspected = {},
- seekingTransport = ( structure === transports );
-
- function inspect( dataType ) {
- var selected;
- inspected[ dataType ] = true;
- jQuery.each( structure[ dataType ] || [], function( _, prefilterOrFactory ) {
- var dataTypeOrTransport = prefilterOrFactory( options, originalOptions, jqXHR );
- if ( typeof dataTypeOrTransport === "string" &&
- !seekingTransport && !inspected[ dataTypeOrTransport ] ) {
-
- options.dataTypes.unshift( dataTypeOrTransport );
- inspect( dataTypeOrTransport );
- return false;
- } else if ( seekingTransport ) {
- return !( selected = dataTypeOrTransport );
- }
- } );
- return selected;
- }
-
- return inspect( options.dataTypes[ 0 ] ) || !inspected[ "*" ] && inspect( "*" );
-}
-
-// A special extend for ajax options
-// that takes "flat" options (not to be deep extended)
-// Fixes #9887
-function ajaxExtend( target, src ) {
- var key, deep,
- flatOptions = jQuery.ajaxSettings.flatOptions || {};
-
- for ( key in src ) {
- if ( src[ key ] !== undefined ) {
- ( flatOptions[ key ] ? target : ( deep || ( deep = {} ) ) )[ key ] = src[ key ];
- }
- }
- if ( deep ) {
- jQuery.extend( true, target, deep );
- }
-
- return target;
-}
-
-/* Handles responses to an ajax request:
- * - finds the right dataType (mediates between content-type and expected dataType)
- * - returns the corresponding response
- */
-function ajaxHandleResponses( s, jqXHR, responses ) {
-
- var ct, type, finalDataType, firstDataType,
- contents = s.contents,
- dataTypes = s.dataTypes;
-
- // Remove auto dataType and get content-type in the process
- while ( dataTypes[ 0 ] === "*" ) {
- dataTypes.shift();
- if ( ct === undefined ) {
- ct = s.mimeType || jqXHR.getResponseHeader( "Content-Type" );
- }
- }
-
- // Check if we're dealing with a known content-type
- if ( ct ) {
- for ( type in contents ) {
- if ( contents[ type ] && contents[ type ].test( ct ) ) {
- dataTypes.unshift( type );
- break;
- }
- }
- }
-
- // Check to see if we have a response for the expected dataType
- if ( dataTypes[ 0 ] in responses ) {
- finalDataType = dataTypes[ 0 ];
- } else {
-
- // Try convertible dataTypes
- for ( type in responses ) {
- if ( !dataTypes[ 0 ] || s.converters[ type + " " + dataTypes[ 0 ] ] ) {
- finalDataType = type;
- break;
- }
- if ( !firstDataType ) {
- firstDataType = type;
- }
- }
-
- // Or just use first one
- finalDataType = finalDataType || firstDataType;
- }
-
- // If we found a dataType
- // We add the dataType to the list if needed
- // and return the corresponding response
- if ( finalDataType ) {
- if ( finalDataType !== dataTypes[ 0 ] ) {
- dataTypes.unshift( finalDataType );
- }
- return responses[ finalDataType ];
- }
-}
-
-/* Chain conversions given the request and the original response
- * Also sets the responseXXX fields on the jqXHR instance
- */
-function ajaxConvert( s, response, jqXHR, isSuccess ) {
- var conv2, current, conv, tmp, prev,
- converters = {},
-
- // Work with a copy of dataTypes in case we need to modify it for conversion
- dataTypes = s.dataTypes.slice();
-
- // Create converters map with lowercased keys
- if ( dataTypes[ 1 ] ) {
- for ( conv in s.converters ) {
- converters[ conv.toLowerCase() ] = s.converters[ conv ];
- }
- }
-
- current = dataTypes.shift();
-
- // Convert to each sequential dataType
- while ( current ) {
-
- if ( s.responseFields[ current ] ) {
- jqXHR[ s.responseFields[ current ] ] = response;
- }
-
- // Apply the dataFilter if provided
- if ( !prev && isSuccess && s.dataFilter ) {
- response = s.dataFilter( response, s.dataType );
- }
-
- prev = current;
- current = dataTypes.shift();
-
- if ( current ) {
-
- // There's only work to do if current dataType is non-auto
- if ( current === "*" ) {
-
- current = prev;
-
- // Convert response if prev dataType is non-auto and differs from current
- } else if ( prev !== "*" && prev !== current ) {
-
- // Seek a direct converter
- conv = converters[ prev + " " + current ] || converters[ "* " + current ];
-
- // If none found, seek a pair
- if ( !conv ) {
- for ( conv2 in converters ) {
-
- // If conv2 outputs current
- tmp = conv2.split( " " );
- if ( tmp[ 1 ] === current ) {
-
- // If prev can be converted to accepted input
- conv = converters[ prev + " " + tmp[ 0 ] ] ||
- converters[ "* " + tmp[ 0 ] ];
- if ( conv ) {
-
- // Condense equivalence converters
- if ( conv === true ) {
- conv = converters[ conv2 ];
-
- // Otherwise, insert the intermediate dataType
- } else if ( converters[ conv2 ] !== true ) {
- current = tmp[ 0 ];
- dataTypes.unshift( tmp[ 1 ] );
- }
- break;
- }
- }
- }
- }
-
- // Apply converter (if not an equivalence)
- if ( conv !== true ) {
-
- // Unless errors are allowed to bubble, catch and return them
- if ( conv && s.throws ) {
- response = conv( response );
- } else {
- try {
- response = conv( response );
- } catch ( e ) {
- return {
- state: "parsererror",
- error: conv ? e : "No conversion from " + prev + " to " + current
- };
- }
- }
- }
- }
- }
- }
-
- return { state: "success", data: response };
-}
-
-jQuery.extend( {
-
- // Counter for holding the number of active queries
- active: 0,
-
- // Last-Modified header cache for next request
- lastModified: {},
- etag: {},
-
- ajaxSettings: {
- url: location.href,
- type: "GET",
- isLocal: rlocalProtocol.test( location.protocol ),
- global: true,
- processData: true,
- async: true,
- contentType: "application/x-www-form-urlencoded; charset=UTF-8",
-
- /*
- timeout: 0,
- data: null,
- dataType: null,
- username: null,
- password: null,
- cache: null,
- throws: false,
- traditional: false,
- headers: {},
- */
-
- accepts: {
- "*": allTypes,
- text: "text/plain",
- html: "text/html",
- xml: "application/xml, text/xml",
- json: "application/json, text/javascript"
- },
-
- contents: {
- xml: /\bxml\b/,
- html: /\bhtml/,
- json: /\bjson\b/
- },
-
- responseFields: {
- xml: "responseXML",
- text: "responseText",
- json: "responseJSON"
- },
-
- // Data converters
- // Keys separate source (or catchall "*") and destination types with a single space
- converters: {
-
- // Convert anything to text
- "* text": String,
-
- // Text to html (true = no transformation)
- "text html": true,
-
- // Evaluate text as a json expression
- "text json": JSON.parse,
-
- // Parse text as xml
- "text xml": jQuery.parseXML
- },
-
- // For options that shouldn't be deep extended:
- // you can add your own custom options here if
- // and when you create one that shouldn't be
- // deep extended (see ajaxExtend)
- flatOptions: {
- url: true,
- context: true
- }
- },
-
- // Creates a full fledged settings object into target
- // with both ajaxSettings and settings fields.
- // If target is omitted, writes into ajaxSettings.
- ajaxSetup: function( target, settings ) {
- return settings ?
-
- // Building a settings object
- ajaxExtend( ajaxExtend( target, jQuery.ajaxSettings ), settings ) :
-
- // Extending ajaxSettings
- ajaxExtend( jQuery.ajaxSettings, target );
- },
-
- ajaxPrefilter: addToPrefiltersOrTransports( prefilters ),
- ajaxTransport: addToPrefiltersOrTransports( transports ),
-
- // Main method
- ajax: function( url, options ) {
-
- // If url is an object, simulate pre-1.5 signature
- if ( typeof url === "object" ) {
- options = url;
- url = undefined;
- }
-
- // Force options to be an object
- options = options || {};
-
- var transport,
-
- // URL without anti-cache param
- cacheURL,
-
- // Response headers
- responseHeadersString,
- responseHeaders,
-
- // timeout handle
- timeoutTimer,
-
- // Url cleanup var
- urlAnchor,
-
- // Request state (becomes false upon send and true upon completion)
- completed,
-
- // To know if global events are to be dispatched
- fireGlobals,
-
- // Loop variable
- i,
-
- // uncached part of the url
- uncached,
-
- // Create the final options object
- s = jQuery.ajaxSetup( {}, options ),
-
- // Callbacks context
- callbackContext = s.context || s,
-
- // Context for global events is callbackContext if it is a DOM node or jQuery collection
- globalEventContext = s.context &&
- ( callbackContext.nodeType || callbackContext.jquery ) ?
- jQuery( callbackContext ) :
- jQuery.event,
-
- // Deferreds
- deferred = jQuery.Deferred(),
- completeDeferred = jQuery.Callbacks( "once memory" ),
-
- // Status-dependent callbacks
- statusCode = s.statusCode || {},
-
- // Headers (they are sent all at once)
- requestHeaders = {},
- requestHeadersNames = {},
-
- // Default abort message
- strAbort = "canceled",
-
- // Fake xhr
- jqXHR = {
- readyState: 0,
-
- // Builds headers hashtable if needed
- getResponseHeader: function( key ) {
- var match;
- if ( completed ) {
- if ( !responseHeaders ) {
- responseHeaders = {};
- while ( ( match = rheaders.exec( responseHeadersString ) ) ) {
- responseHeaders[ match[ 1 ].toLowerCase() + " " ] =
- ( responseHeaders[ match[ 1 ].toLowerCase() + " " ] || [] )
- .concat( match[ 2 ] );
- }
- }
- match = responseHeaders[ key.toLowerCase() + " " ];
- }
- return match == null ? null : match.join( ", " );
- },
-
- // Raw string
- getAllResponseHeaders: function() {
- return completed ? responseHeadersString : null;
- },
-
- // Caches the header
- setRequestHeader: function( name, value ) {
- if ( completed == null ) {
- name = requestHeadersNames[ name.toLowerCase() ] =
- requestHeadersNames[ name.toLowerCase() ] || name;
- requestHeaders[ name ] = value;
- }
- return this;
- },
-
- // Overrides response content-type header
- overrideMimeType: function( type ) {
- if ( completed == null ) {
- s.mimeType = type;
- }
- return this;
- },
-
- // Status-dependent callbacks
- statusCode: function( map ) {
- var code;
- if ( map ) {
- if ( completed ) {
-
- // Execute the appropriate callbacks
- jqXHR.always( map[ jqXHR.status ] );
- } else {
-
- // Lazy-add the new callbacks in a way that preserves old ones
- for ( code in map ) {
- statusCode[ code ] = [ statusCode[ code ], map[ code ] ];
- }
- }
- }
- return this;
- },
-
- // Cancel the request
- abort: function( statusText ) {
- var finalText = statusText || strAbort;
- if ( transport ) {
- transport.abort( finalText );
- }
- done( 0, finalText );
- return this;
- }
- };
-
- // Attach deferreds
- deferred.promise( jqXHR );
-
- // Add protocol if not provided (prefilters might expect it)
- // Handle falsy url in the settings object (#10093: consistency with old signature)
- // We also use the url parameter if available
- s.url = ( ( url || s.url || location.href ) + "" )
- .replace( rprotocol, location.protocol + "//" );
-
- // Alias method option to type as per ticket #12004
- s.type = options.method || options.type || s.method || s.type;
-
- // Extract dataTypes list
- s.dataTypes = ( s.dataType || "*" ).toLowerCase().match( rnothtmlwhite ) || [ "" ];
-
- // A cross-domain request is in order when the origin doesn't match the current origin.
- if ( s.crossDomain == null ) {
- urlAnchor = document.createElement( "a" );
-
- // Support: IE <=8 - 11, Edge 12 - 15
- // IE throws exception on accessing the href property if url is malformed,
- // e.g. http://example.com:80x/
- try {
- urlAnchor.href = s.url;
-
- // Support: IE <=8 - 11 only
- // Anchor's host property isn't correctly set when s.url is relative
- urlAnchor.href = urlAnchor.href;
- s.crossDomain = originAnchor.protocol + "//" + originAnchor.host !==
- urlAnchor.protocol + "//" + urlAnchor.host;
- } catch ( e ) {
-
- // If there is an error parsing the URL, assume it is crossDomain,
- // it can be rejected by the transport if it is invalid
- s.crossDomain = true;
- }
- }
-
- // Convert data if not already a string
- if ( s.data && s.processData && typeof s.data !== "string" ) {
- s.data = jQuery.param( s.data, s.traditional );
- }
-
- // Apply prefilters
- inspectPrefiltersOrTransports( prefilters, s, options, jqXHR );
-
- // If request was aborted inside a prefilter, stop there
- if ( completed ) {
- return jqXHR;
- }
-
- // We can fire global events as of now if asked to
- // Don't fire events if jQuery.event is undefined in an AMD-usage scenario (#15118)
- fireGlobals = jQuery.event && s.global;
-
- // Watch for a new set of requests
- if ( fireGlobals && jQuery.active++ === 0 ) {
- jQuery.event.trigger( "ajaxStart" );
- }
-
- // Uppercase the type
- s.type = s.type.toUpperCase();
-
- // Determine if request has content
- s.hasContent = !rnoContent.test( s.type );
-
- // Save the URL in case we're toying with the If-Modified-Since
- // and/or If-None-Match header later on
- // Remove hash to simplify url manipulation
- cacheURL = s.url.replace( rhash, "" );
-
- // More options handling for requests with no content
- if ( !s.hasContent ) {
-
- // Remember the hash so we can put it back
- uncached = s.url.slice( cacheURL.length );
-
- // If data is available and should be processed, append data to url
- if ( s.data && ( s.processData || typeof s.data === "string" ) ) {
- cacheURL += ( rquery.test( cacheURL ) ? "&" : "?" ) + s.data;
-
- // #9682: remove data so that it's not used in an eventual retry
- delete s.data;
- }
-
- // Add or update anti-cache param if needed
- if ( s.cache === false ) {
- cacheURL = cacheURL.replace( rantiCache, "$1" );
- uncached = ( rquery.test( cacheURL ) ? "&" : "?" ) + "_=" + ( nonce.guid++ ) +
- uncached;
- }
-
- // Put hash and anti-cache on the URL that will be requested (gh-1732)
- s.url = cacheURL + uncached;
-
- // Change '%20' to '+' if this is encoded form body content (gh-2658)
- } else if ( s.data && s.processData &&
- ( s.contentType || "" ).indexOf( "application/x-www-form-urlencoded" ) === 0 ) {
- s.data = s.data.replace( r20, "+" );
- }
-
- // Set the If-Modified-Since and/or If-None-Match header, if in ifModified mode.
- if ( s.ifModified ) {
- if ( jQuery.lastModified[ cacheURL ] ) {
- jqXHR.setRequestHeader( "If-Modified-Since", jQuery.lastModified[ cacheURL ] );
- }
- if ( jQuery.etag[ cacheURL ] ) {
- jqXHR.setRequestHeader( "If-None-Match", jQuery.etag[ cacheURL ] );
- }
- }
-
- // Set the correct header, if data is being sent
- if ( s.data && s.hasContent && s.contentType !== false || options.contentType ) {
- jqXHR.setRequestHeader( "Content-Type", s.contentType );
- }
-
- // Set the Accepts header for the server, depending on the dataType
- jqXHR.setRequestHeader(
- "Accept",
- s.dataTypes[ 0 ] && s.accepts[ s.dataTypes[ 0 ] ] ?
- s.accepts[ s.dataTypes[ 0 ] ] +
- ( s.dataTypes[ 0 ] !== "*" ? ", " + allTypes + "; q=0.01" : "" ) :
- s.accepts[ "*" ]
- );
-
- // Check for headers option
- for ( i in s.headers ) {
- jqXHR.setRequestHeader( i, s.headers[ i ] );
- }
-
- // Allow custom headers/mimetypes and early abort
- if ( s.beforeSend &&
- ( s.beforeSend.call( callbackContext, jqXHR, s ) === false || completed ) ) {
-
- // Abort if not done already and return
- return jqXHR.abort();
- }
-
- // Aborting is no longer a cancellation
- strAbort = "abort";
-
- // Install callbacks on deferreds
- completeDeferred.add( s.complete );
- jqXHR.done( s.success );
- jqXHR.fail( s.error );
-
- // Get transport
- transport = inspectPrefiltersOrTransports( transports, s, options, jqXHR );
-
- // If no transport, we auto-abort
- if ( !transport ) {
- done( -1, "No Transport" );
- } else {
- jqXHR.readyState = 1;
-
- // Send global event
- if ( fireGlobals ) {
- globalEventContext.trigger( "ajaxSend", [ jqXHR, s ] );
- }
-
- // If request was aborted inside ajaxSend, stop there
- if ( completed ) {
- return jqXHR;
- }
-
- // Timeout
- if ( s.async && s.timeout > 0 ) {
- timeoutTimer = window.setTimeout( function() {
- jqXHR.abort( "timeout" );
- }, s.timeout );
- }
-
- try {
- completed = false;
- transport.send( requestHeaders, done );
- } catch ( e ) {
-
- // Rethrow post-completion exceptions
- if ( completed ) {
- throw e;
- }
-
- // Propagate others as results
- done( -1, e );
- }
- }
-
- // Callback for when everything is done
- function done( status, nativeStatusText, responses, headers ) {
- var isSuccess, success, error, response, modified,
- statusText = nativeStatusText;
-
- // Ignore repeat invocations
- if ( completed ) {
- return;
- }
-
- completed = true;
-
- // Clear timeout if it exists
- if ( timeoutTimer ) {
- window.clearTimeout( timeoutTimer );
- }
-
- // Dereference transport for early garbage collection
- // (no matter how long the jqXHR object will be used)
- transport = undefined;
-
- // Cache response headers
- responseHeadersString = headers || "";
-
- // Set readyState
- jqXHR.readyState = status > 0 ? 4 : 0;
-
- // Determine if successful
- isSuccess = status >= 200 && status < 300 || status === 304;
-
- // Get response data
- if ( responses ) {
- response = ajaxHandleResponses( s, jqXHR, responses );
- }
-
- // Use a noop converter for missing script
- if ( !isSuccess && jQuery.inArray( "script", s.dataTypes ) > -1 ) {
- s.converters[ "text script" ] = function() {};
- }
-
- // Convert no matter what (that way responseXXX fields are always set)
- response = ajaxConvert( s, response, jqXHR, isSuccess );
-
- // If successful, handle type chaining
- if ( isSuccess ) {
-
- // Set the If-Modified-Since and/or If-None-Match header, if in ifModified mode.
- if ( s.ifModified ) {
- modified = jqXHR.getResponseHeader( "Last-Modified" );
- if ( modified ) {
- jQuery.lastModified[ cacheURL ] = modified;
- }
- modified = jqXHR.getResponseHeader( "etag" );
- if ( modified ) {
- jQuery.etag[ cacheURL ] = modified;
- }
- }
-
- // if no content
- if ( status === 204 || s.type === "HEAD" ) {
- statusText = "nocontent";
-
- // if not modified
- } else if ( status === 304 ) {
- statusText = "notmodified";
-
- // If we have data, let's convert it
- } else {
- statusText = response.state;
- success = response.data;
- error = response.error;
- isSuccess = !error;
- }
- } else {
-
- // Extract error from statusText and normalize for non-aborts
- error = statusText;
- if ( status || !statusText ) {
- statusText = "error";
- if ( status < 0 ) {
- status = 0;
- }
- }
- }
-
- // Set data for the fake xhr object
- jqXHR.status = status;
- jqXHR.statusText = ( nativeStatusText || statusText ) + "";
-
- // Success/Error
- if ( isSuccess ) {
- deferred.resolveWith( callbackContext, [ success, statusText, jqXHR ] );
- } else {
- deferred.rejectWith( callbackContext, [ jqXHR, statusText, error ] );
- }
-
- // Status-dependent callbacks
- jqXHR.statusCode( statusCode );
- statusCode = undefined;
-
- if ( fireGlobals ) {
- globalEventContext.trigger( isSuccess ? "ajaxSuccess" : "ajaxError",
- [ jqXHR, s, isSuccess ? success : error ] );
- }
-
- // Complete
- completeDeferred.fireWith( callbackContext, [ jqXHR, statusText ] );
-
- if ( fireGlobals ) {
- globalEventContext.trigger( "ajaxComplete", [ jqXHR, s ] );
-
- // Handle the global AJAX counter
- if ( !( --jQuery.active ) ) {
- jQuery.event.trigger( "ajaxStop" );
- }
- }
- }
-
- return jqXHR;
- },
-
- getJSON: function( url, data, callback ) {
- return jQuery.get( url, data, callback, "json" );
- },
-
- getScript: function( url, callback ) {
- return jQuery.get( url, undefined, callback, "script" );
- }
-} );
-
-jQuery.each( [ "get", "post" ], function( _i, method ) {
- jQuery[ method ] = function( url, data, callback, type ) {
-
- // Shift arguments if data argument was omitted
- if ( isFunction( data ) ) {
- type = type || callback;
- callback = data;
- data = undefined;
- }
-
- // The url can be an options object (which then must have .url)
- return jQuery.ajax( jQuery.extend( {
- url: url,
- type: method,
- dataType: type,
- data: data,
- success: callback
- }, jQuery.isPlainObject( url ) && url ) );
- };
-} );
-
-jQuery.ajaxPrefilter( function( s ) {
- var i;
- for ( i in s.headers ) {
- if ( i.toLowerCase() === "content-type" ) {
- s.contentType = s.headers[ i ] || "";
- }
- }
-} );
-
-
-jQuery._evalUrl = function( url, options, doc ) {
- return jQuery.ajax( {
- url: url,
-
- // Make this explicit, since user can override this through ajaxSetup (#11264)
- type: "GET",
- dataType: "script",
- cache: true,
- async: false,
- global: false,
-
- // Only evaluate the response if it is successful (gh-4126)
- // dataFilter is not invoked for failure responses, so using it instead
- // of the default converter is kludgy but it works.
- converters: {
- "text script": function() {}
- },
- dataFilter: function( response ) {
- jQuery.globalEval( response, options, doc );
- }
- } );
-};
-
-
-jQuery.fn.extend( {
- wrapAll: function( html ) {
- var wrap;
-
- if ( this[ 0 ] ) {
- if ( isFunction( html ) ) {
- html = html.call( this[ 0 ] );
- }
-
- // The elements to wrap the target around
- wrap = jQuery( html, this[ 0 ].ownerDocument ).eq( 0 ).clone( true );
-
- if ( this[ 0 ].parentNode ) {
- wrap.insertBefore( this[ 0 ] );
- }
-
- wrap.map( function() {
- var elem = this;
-
- while ( elem.firstElementChild ) {
- elem = elem.firstElementChild;
- }
-
- return elem;
- } ).append( this );
- }
-
- return this;
- },
-
- wrapInner: function( html ) {
- if ( isFunction( html ) ) {
- return this.each( function( i ) {
- jQuery( this ).wrapInner( html.call( this, i ) );
- } );
- }
-
- return this.each( function() {
- var self = jQuery( this ),
- contents = self.contents();
-
- if ( contents.length ) {
- contents.wrapAll( html );
-
- } else {
- self.append( html );
- }
- } );
- },
-
- wrap: function( html ) {
- var htmlIsFunction = isFunction( html );
-
- return this.each( function( i ) {
- jQuery( this ).wrapAll( htmlIsFunction ? html.call( this, i ) : html );
- } );
- },
-
- unwrap: function( selector ) {
- this.parent( selector ).not( "body" ).each( function() {
- jQuery( this ).replaceWith( this.childNodes );
- } );
- return this;
- }
-} );
-
-
-jQuery.expr.pseudos.hidden = function( elem ) {
- return !jQuery.expr.pseudos.visible( elem );
-};
-jQuery.expr.pseudos.visible = function( elem ) {
- return !!( elem.offsetWidth || elem.offsetHeight || elem.getClientRects().length );
-};
-
-
-
-
-jQuery.ajaxSettings.xhr = function() {
- try {
- return new window.XMLHttpRequest();
- } catch ( e ) {}
-};
-
-var xhrSuccessStatus = {
-
- // File protocol always yields status code 0, assume 200
- 0: 200,
-
- // Support: IE <=9 only
- // #1450: sometimes IE returns 1223 when it should be 204
- 1223: 204
- },
- xhrSupported = jQuery.ajaxSettings.xhr();
-
-support.cors = !!xhrSupported && ( "withCredentials" in xhrSupported );
-support.ajax = xhrSupported = !!xhrSupported;
-
-jQuery.ajaxTransport( function( options ) {
- var callback, errorCallback;
-
- // Cross domain only allowed if supported through XMLHttpRequest
- if ( support.cors || xhrSupported && !options.crossDomain ) {
- return {
- send: function( headers, complete ) {
- var i,
- xhr = options.xhr();
-
- xhr.open(
- options.type,
- options.url,
- options.async,
- options.username,
- options.password
- );
-
- // Apply custom fields if provided
- if ( options.xhrFields ) {
- for ( i in options.xhrFields ) {
- xhr[ i ] = options.xhrFields[ i ];
- }
- }
-
- // Override mime type if needed
- if ( options.mimeType && xhr.overrideMimeType ) {
- xhr.overrideMimeType( options.mimeType );
- }
-
- // X-Requested-With header
- // For cross-domain requests, seeing as conditions for a preflight are
- // akin to a jigsaw puzzle, we simply never set it to be sure.
- // (it can always be set on a per-request basis or even using ajaxSetup)
- // For same-domain requests, won't change header if already provided.
- if ( !options.crossDomain && !headers[ "X-Requested-With" ] ) {
- headers[ "X-Requested-With" ] = "XMLHttpRequest";
- }
-
- // Set headers
- for ( i in headers ) {
- xhr.setRequestHeader( i, headers[ i ] );
- }
-
- // Callback
- callback = function( type ) {
- return function() {
- if ( callback ) {
- callback = errorCallback = xhr.onload =
- xhr.onerror = xhr.onabort = xhr.ontimeout =
- xhr.onreadystatechange = null;
-
- if ( type === "abort" ) {
- xhr.abort();
- } else if ( type === "error" ) {
-
- // Support: IE <=9 only
- // On a manual native abort, IE9 throws
- // errors on any property access that is not readyState
- if ( typeof xhr.status !== "number" ) {
- complete( 0, "error" );
- } else {
- complete(
-
- // File: protocol always yields status 0; see #8605, #14207
- xhr.status,
- xhr.statusText
- );
- }
- } else {
- complete(
- xhrSuccessStatus[ xhr.status ] || xhr.status,
- xhr.statusText,
-
- // Support: IE <=9 only
- // IE9 has no XHR2 but throws on binary (trac-11426)
- // For XHR2 non-text, let the caller handle it (gh-2498)
- ( xhr.responseType || "text" ) !== "text" ||
- typeof xhr.responseText !== "string" ?
- { binary: xhr.response } :
- { text: xhr.responseText },
- xhr.getAllResponseHeaders()
- );
- }
- }
- };
- };
-
- // Listen to events
- xhr.onload = callback();
- errorCallback = xhr.onerror = xhr.ontimeout = callback( "error" );
-
- // Support: IE 9 only
- // Use onreadystatechange to replace onabort
- // to handle uncaught aborts
- if ( xhr.onabort !== undefined ) {
- xhr.onabort = errorCallback;
- } else {
- xhr.onreadystatechange = function() {
-
- // Check readyState before timeout as it changes
- if ( xhr.readyState === 4 ) {
-
- // Allow onerror to be called first,
- // but that will not handle a native abort
- // Also, save errorCallback to a variable
- // as xhr.onerror cannot be accessed
- window.setTimeout( function() {
- if ( callback ) {
- errorCallback();
- }
- } );
- }
- };
- }
-
- // Create the abort callback
- callback = callback( "abort" );
-
- try {
-
- // Do send the request (this may raise an exception)
- xhr.send( options.hasContent && options.data || null );
- } catch ( e ) {
-
- // #14683: Only rethrow if this hasn't been notified as an error yet
- if ( callback ) {
- throw e;
- }
- }
- },
-
- abort: function() {
- if ( callback ) {
- callback();
- }
- }
- };
- }
-} );
-
-
-
-
-// Prevent auto-execution of scripts when no explicit dataType was provided (See gh-2432)
-jQuery.ajaxPrefilter( function( s ) {
- if ( s.crossDomain ) {
- s.contents.script = false;
- }
-} );
-
-// Install script dataType
-jQuery.ajaxSetup( {
- accepts: {
- script: "text/javascript, application/javascript, " +
- "application/ecmascript, application/x-ecmascript"
- },
- contents: {
- script: /\b(?:java|ecma)script\b/
- },
- converters: {
- "text script": function( text ) {
- jQuery.globalEval( text );
- return text;
- }
- }
-} );
-
-// Handle cache's special case and crossDomain
-jQuery.ajaxPrefilter( "script", function( s ) {
- if ( s.cache === undefined ) {
- s.cache = false;
- }
- if ( s.crossDomain ) {
- s.type = "GET";
- }
-} );
-
-// Bind script tag hack transport
-jQuery.ajaxTransport( "script", function( s ) {
-
- // This transport only deals with cross domain or forced-by-attrs requests
- if ( s.crossDomain || s.scriptAttrs ) {
- var script, callback;
- return {
- send: function( _, complete ) {
- script = jQuery( "
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
- VectorHub
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
Guide to using Auto-Encoder
-
Inspired by transformers’ adoption of the auto-models, we created an
-AutoEncoder class that allows you to easily get the relevant models. Not to be confused with the autoencoder architecture.
-
The relevant models can be found here:
-
from vectorhub import AutoEncoder
-encoder = AutoEncoder ( 'text/bert' )
-encoder . encode ( "Hi..." )
-
-
-
To view the list of available models, you can call:
-
import vectorhub as vh
-vh . list_available_auto_models ()
-
-
-
When you instantiate the autoencoder, you will need to pip install
-the relevant module. The requirements here can be given here.
-
The list of supported models are:
-
[ 'text/albert' , 'text/bert' , 'text/labse' , 'text/use' , 'text/use-multi' , 'text/use-lite' , 'text/legal-bert' , 'audio/fairseq' , 'audio/speech-embedding' , 'audio/trill' , 'audio/trill-distilled' , 'audio/vggish' , 'audio/yamnet' , 'audio/wav2vec' , 'image/bit' , 'image/bit-medium' , 'image/inception' , 'image/inception-v2' , 'image/inception-v3' , 'image/inception-resnet' , 'image/mobilenet' , 'image/mobilenet-v2' , 'image/resnet' , 'image/resnet-v2' , 'text_text/use-multi-qa' , 'text_text/use-qa' , 'text_text/dpr' , 'text_text/lareqa-qa]
-
-
-
-
-
-
-
-
-
-
-
-
-
 -
-
-
- -
-
-
-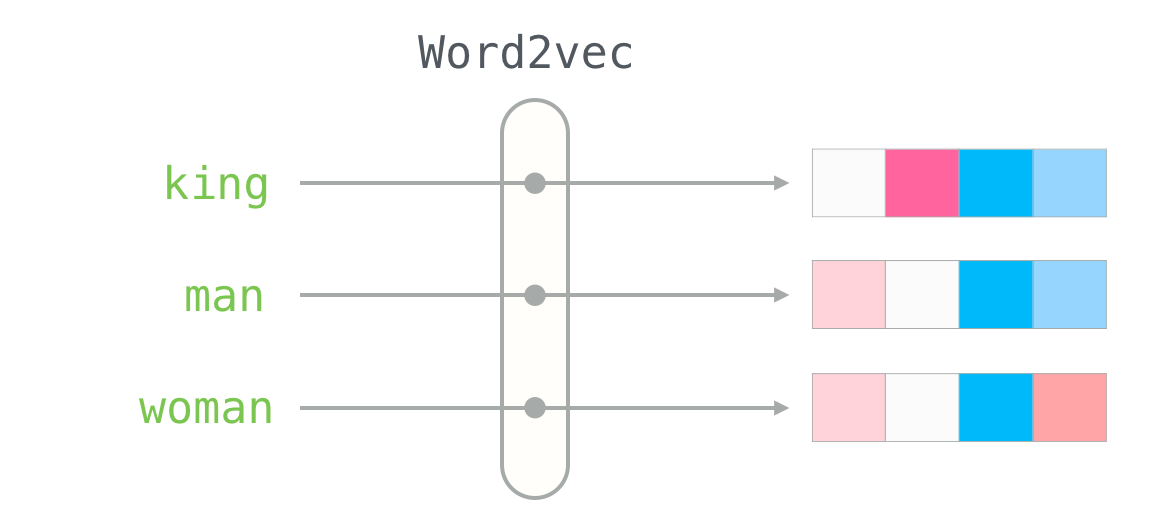 -
-  -
-  -
-  -
-