Profiling is an important aspect of software programming. Through profiling one can determine the parts in program code that are time consuming and need to be re-written. This helps make your program execution faster which is always desired.
In very large projects, profiling can save your day by not only determining the parts in your program which are slower in execution than expected but also can help you find many other statistics through which many potential bugs can be spotted and sorted out.
In this article, we will explore the GNU profiling tool ‘gprof’, Intel® VTune™ Profiler and NVIDIA Nsight™ Systems (prof is not included).
Important
This part is modified from GPROF Tutorial – How to use Linux GNU GCC Profiling Tool (thegeekstuff.com).
Using the gprof tool is not at all complex. You just need to do the following on a high-level:
- Have profiling enabled while compiling the code
- Execute the program code to produce the profiling data
- Run the gprof tool on the profiling data file (generated in the step above).
The last step above produces an analysis file which is in human readable form. This file contains a couple of tables (flat profile and call graph) in addition to some other information. While flat profile gives an overview of the timing information of the functions like time consumption for the execution of a particular function, how many times it was called etc. On the other hand, call graph focuses on each function like the functions through which a particular function was called, what all functions were called from within this particular function etc So this way one can get idea of the execution time spent in the sub-routines too.
Lets try and understand the three steps listed above through a practical example. Following test code will be used throughout the article :
//test_gprof.c
#include<stdio.h>
void new_func1(void);
void func1(void)
{
printf("\n Inside func1 \n");
int i = 0;
for(;i<0xffffffff;i++);
new_func1();
return;
}
static void func2(void)
{
printf("\n Inside func2 \n");
int i = 0;
for(;i<0xffffffaa;i++);
return;
}
int main(void)
{
printf("\n Inside main()\n");
int i = 0;
for(;i<0xffffff;i++);
func1();
func2();
return 0;
}
//test_gprof_new.c
#include<stdio.h>
void new_func1(void)
{
printf("\n Inside new_func1()\n");
int i = 0;
for(;i<0xffffffee;i++);
return;
}Note that the ‘for’ loops inside the functions are there to consume some execution time.
In this first step, we need to make sure that the profiling is enabled when the compilation of the code is done. This is made possible by adding the ‘-pg’ option in the compilation step.
From the man page of gcc :
-pg : Generate extra code to write profile information suitable for the analysis program gprof. You must use this option when compiling the source files you want data about, and you must also use it when linking.
So, lets compile our code with ‘-pg’ option :
$ gcc -Wall -pg test_gprof.c test_gprof_new.c -o test_gprof
$Please note : The option ‘-pg’ can be used with the gcc command that compiles (-c option), gcc command that links(-o option on object files) and with gcc command that does the both(as in example above).
In the second step, the binary file produced as a result of step-1 (above) is executed so that profiling information can be generated.
$ ls
test_gprof test_gprof.c test_gprof_new.c
$ ./test_gprof
Inside main()
Inside func1
Inside new_func1()
Inside func2
$ ls
gmon.out test_gprof test_gprof.c test_gprof_new.c
$So we see that when the binary was executed, a new file ‘gmon.out’ is generated in the current working directory.
Note that while execution if the program changes the current working directory (using chdir) then gmon.out will be produced in the new current working directory. Also, your program needs to have sufficient permissions for gmon.out to be created in current working directory.
In this step, the gprof tool is run with the executable name and the above generated ‘gmon.out’ as argument. This produces an analysis file which contains all the desired profiling information.
$ gprof test_gprof gmon.out > analysis.txtNote that one can explicitly specify the output file (like in example above) or the information is produced on stdout.
$ ls
analysis.txt gmon.out test_gprof test_gprof.c test_gprof_new.cSo we see that a file named ‘analysis.txt’ was generated.
On a related note, you should also understand how to debug your C program using gdb.
As produced above, all the profiling information is now present in ‘analysis.txt’. Lets have a look at this text file :
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
33.86 15.52 15.52 1 15.52 15.52 func2
33.82 31.02 15.50 1 15.50 15.50 new_func1
33.29 46.27 15.26 1 15.26 30.75 func1
0.07 46.30 0.03 main
% the percentage of the total running time of the
time program used by this function.
cumulative a running sum of the number of seconds accounted
seconds for by this function and those listed above it.
self the number of seconds accounted for by this
seconds function alone. This is the major sort for this
listing.
calls the number of times this function was invoked, if
this function is profiled, else blank.
self the average number of milliseconds spent in this
ms/call function per call, if this function is profiled,
else blank.
total the average number of milliseconds spent in this
ms/call function and its descendents per call, if this
function is profiled, else blank.
name the name of the function. This is the minor sort
for this listing. The index shows the location of
the function in the gprof listing. If the index is
in parenthesis it shows where it would appear in
the gprof listing if it were to be printed.
Call graph (explanation follows)
granularity: each sample hit covers 2 byte(s) for 0.02% of 46.30 seconds
index % time self children called name
[1] 100.0 0.03 46.27 main [1]
15.26 15.50 1/1 func1 [2]
15.52 0.00 1/1 func2 [3]
-----------------------------------------------
15.26 15.50 1/1 main [1]
[2] 66.4 15.26 15.50 1 func1 [2]
15.50 0.00 1/1 new_func1 [4]
-----------------------------------------------
15.52 0.00 1/1 main [1]
[3] 33.5 15.52 0.00 1 func2 [3]
-----------------------------------------------
15.50 0.00 1/1 func1 [2]
[4] 33.5 15.50 0.00 1 new_func1 [4]
-----------------------------------------------
This table describes the call tree of the program, and was sorted by
the total amount of time spent in each function and its children.
Each entry in this table consists of several lines. The line with the
index number at the left hand margin lists the current function.
The lines above it list the functions that called this function,
and the lines below it list the functions this one called.
This line lists:
index A unique number given to each element of the table.
Index numbers are sorted numerically.
The index number is printed next to every function name so
it is easier to look up where the function in the table.
% time This is the percentage of the `total' time that was spent
in this function and its children. Note that due to
different viewpoints, functions excluded by options, etc,
these numbers will NOT add up to 100%.
self This is the total amount of time spent in this function.
children This is the total amount of time propagated into this
function by its children.
called This is the number of times the function was called.
If the function called itself recursively, the number
only includes non-recursive calls, and is followed by
a `+' and the number of recursive calls.
name The name of the current function. The index number is
printed after it. If the function is a member of a
cycle, the cycle number is printed between the
function's name and the index number.
For the function's parents, the fields have the following meanings:
self This is the amount of time that was propagated directly
from the function into this parent.
children This is the amount of time that was propagated from
the function's children into this parent.
called This is the number of times this parent called the
function `/' the total number of times the function
was called. Recursive calls to the function are not
included in the number after the `/'.
name This is the name of the parent. The parent's index
number is printed after it. If the parent is a
member of a cycle, the cycle number is printed between
the name and the index number.
If the parents of the function cannot be determined, the word
`' is printed in the `name' field, and all the other
fields are blank.
For the function's children, the fields have the following meanings:
self This is the amount of time that was propagated directly
from the child into the function.
children This is the amount of time that was propagated from the
child's children to the function.
called This is the number of times the function called
this child `/' the total number of times the child
was called. Recursive calls by the child are not
listed in the number after the `/'.
name This is the name of the child. The child's index
number is printed after it. If the child is a
member of a cycle, the cycle number is printed
between the name and the index number.
If there are any cycles (circles) in the call graph, there is an
entry for the cycle-as-a-whole. This entry shows who called the
cycle (as parents) and the members of the cycle (as children.)
The `+' recursive calls entry shows the number of function calls that
were internal to the cycle, and the calls entry for each member shows,
for that member, how many times it was called from other members of
the cycle.
Index by function name
[2] func1 [1] main
[3] func2 [4] new_func1
So (as already discussed) we see that this file is broadly divided into two parts :
- Flat profile
- Call graph
The individual columns for the (flat profile as well as call graph) are very well explained in the output itself.
There are various flags available to customize the output of the gprof tool. Some of them are discussed below:
If there are some static functions whose profiling information you do not require then this can be achieved using -a option :
$ gprof -a test_gprof gmon.out > analysis.txtNow if we see that analysis file :
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
67.15 30.77 30.77 2 15.39 23.14 func1
33.82 46.27 15.50 1 15.50 15.50 new_func1
0.07 46.30 0.03 main
...
...
...
Call graph (explanation follows)
granularity: each sample hit covers 2 byte(s) for 0.02% of 46.30 seconds
index %time self children called name
[1] 100.0 0.03 46.27 main [1]
30.77 15.50 2/2 func1 [2]
-----------------------------------------------------
30.77 15.50 2/2 main [1]
[2] 99.9 30.77 15.50 2 func1 [2]
15.50 0.00 1/1 new_func1 [3]
----------------------------------------------------
15.50 0.00 1/1 func1 [2]
[3] 33.5 15.50 0.00 1 new_func1 [3]
-----------------------------------------------
...
...
...
So we see that there is no information related to func2 (which is defined static)
As you would have already seen that gprof produces output with lot of verbose information so in case this information is not required then this can be achieved using the -b flag.
$ gprof -b test_gprof gmon.out > analysis.txtNow if we see the analysis file :
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
33.86 15.52 15.52 1 15.52 15.52 func2
33.82 31.02 15.50 1 15.50 15.50 new_func1
33.29 46.27 15.26 1 15.26 30.75 func1
0.07 46.30 0.03 main
Call graph
granularity: each sample hit covers 2 byte(s) for 0.02% of 46.30 seconds
index % time self children called name
[1] 100.0 0.03 46.27 main [1]
15.26 15.50 1/1 func1 [2]
15.52 0.00 1/1 func2 [3]
-----------------------------------------------
15.26 15.50 1/1 main [1]
[2] 66.4 15.26 15.50 1 func1 [2]
15.50 0.00 1/1 new_func1 [4]
-----------------------------------------------
15.52 0.00 1/1 main [1]
[3] 33.5 15.52 0.00 1 func2 [3]
-----------------------------------------------
15.50 0.00 1/1 func1 [2]
[4] 33.5 15.50 0.00 1 new_func1 [4]
-----------------------------------------------
Index by function name
[2] func1 [1] main
[3] func2 [4] new_func1
So we see that all the verbose information is not present in the analysis file.
In case only flat profile is required then :
$ gprof -p -b test_gprof gmon.out > analysis.txt
Note that I have used(and will be using) -b option so as to avoid extra information in analysis output.
Now if we see that analysis output:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
33.86 15.52 15.52 1 15.52 15.52 func2
33.82 31.02 15.50 1 15.50 15.50 new_func1
33.29 46.27 15.26 1 15.26 30.75 func1
0.07 46.30 0.03 main
So we see that only flat profile was there in the output.
This can be achieved by providing the function name along with the -p option:
$ gprof -pfunc1 -b test_gprof gmon.out > analysis.txtNow if we see that analysis output :
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
103.20 15.26 15.26 1 15.26 15.26 func1
So we see that a flat profile containing information related to only function func1 is displayed.
If flat profile is not required then it can be suppressed using the -P option :
$ gprof -P -b test_gprof gmon.out > analysis.txtNow if we see the analysis output :
Call graph
granularity: each sample hit covers 2 byte(s) for 0.02% of 46.30 seconds
index % time self children called name
[1] 100.0 0.03 46.27 main [1]
15.26 15.50 1/1 func1 [2]
15.52 0.00 1/1 func2 [3]
-----------------------------------------------
15.26 15.50 1/1 main [1]
[2] 66.4 15.26 15.50 1 func1 [2]
15.50 0.00 1/1 new_func1 [4]
-----------------------------------------------
15.52 0.00 1/1 main [1]
[3] 33.5 15.52 0.00 1 func2 [3]
-----------------------------------------------
15.50 0.00 1/1 func1 [2]
[4] 33.5 15.50 0.00 1 new_func1 [4]
-----------------------------------------------
Index by function name
[2] func1 [1] main
[3] func2 [4] new_func1
So we see that flat profile was suppressed and only call graph was displayed in output.
Also, if there is a requirement to print flat profile but excluding a particular function then this is also possible using -P flag by passing the function name (to exclude) along with it.
$ gprof -Pfunc1 -b test_gprof gmon.out > analysis.txtIn the above example, we tried to exclude ‘func1’ by passing it along with the -P option to gprof. Now lets see the analysis output:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
50.76 15.52 15.52 1 15.52 15.52 func2
50.69 31.02 15.50 1 15.50 15.50 new_func1
0.10 31.05 0.03 main
So we see that flat profile was displayed but information on func1 was suppressed.
gprof -q -b test_gprof gmon.out > analysis.txtIn the example above, the option -q was used. Lets see what effect it casts on analysis output:
Call graph
granularity: each sample hit covers 2 byte(s) for 0.02% of 46.30 seconds
index % time self children called name
[1] 100.0 0.03 46.27 main [1]
15.26 15.50 1/1 func1 [2]
15.52 0.00 1/1 func2 [3]
-----------------------------------------------
15.26 15.50 1/1 main [1]
[2] 66.4 15.26 15.50 1 func1 [2]
15.50 0.00 1/1 new_func1 [4]
-----------------------------------------------
15.52 0.00 1/1 main [1]
[3] 33.5 15.52 0.00 1 func2 [3]
-----------------------------------------------
15.50 0.00 1/1 func1 [2]
[4] 33.5 15.50 0.00 1 new_func1 [4]
-----------------------------------------------
Index by function name
[2] func1 [1] main
[3] func2 [4] new_func1
So we see that only call graph was printed in the output.
This is possible by passing the function name along with the -q option.
$ gprof -qfunc1 -b test_gprof gmon.out > analysis.txt
Now if we see the analysis output:
Call graph
granularity: each sample hit covers 2 byte(s) for 0.02% of 46.30 seconds
index % time self children called name
15.26 15.50 1/1 main [1]
[2] 66.4 15.26 15.50 1 func1 [2]
15.50 0.00 1/1 new_func1 [4]
-----------------------------------------------
15.50 0.00 1/1 func1 [2]
[4] 33.5 15.50 0.00 1 new_func1 [4]
-----------------------------------------------
Index by function name
[2] func1 (1) main
(3) func2 [4] new_func1
So we see that information related to only func1 was displayed in call graph.
If the call graph information is not required in the analysis output then -Q option can be used.
$ gprof -Q -b test_gprof gmon.out > analysis.txtNow if we see the analysis output :
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
33.86 15.52 15.52 1 15.52 15.52 func2
33.82 31.02 15.50 1 15.50 15.50 new_func1
33.29 46.27 15.26 1 15.26 30.75 func1
0.07 46.30 0.03 main
So we see that only flat profile is there in the output. The whole call graph got suppressed.
Also, if it is desired to suppress a specific function from call graph then this can be achieved by passing the desired function name along with the -Q option to the gprof tool.
$ gprof -Qfunc1 -b test_gprof gmon.out > analysis.txtIn the above example, the function name func1 is passed to the -Q option.
Now if we see the analysis output:
Call graph
granularity: each sample hit covers 2 byte(s) for 0.02% of 46.30 seconds
index % time self children called name
[1] 100.0 0.03 46.27 main [1]
15.26 15.50 1/1 func1 [2]
15.52 0.00 1/1 func2 [3]
-----------------------------------------------
15.52 0.00 1/1 main [1]
[3] 33.5 15.52 0.00 1 func2 [3]
-----------------------------------------------
15.50 0.00 1/1 func1 [2]
[4] 33.5 15.50 0.00 1 new_func1 [4]
-----------------------------------------------
Index by function name
(2) func1 [1] main
[3] func2 [4] new_func1
So we see that call graph information related to func1 was suppressed.
Important
This part is modified from Intel® VTune™ Profiler User Guide. For the newest information about Intel VTune Profiler, please visit the official website. (FYI: The link's version is 2024-1)
Intel® VTune™ Profiler is a performance analysis tool for serial and multithreaded applications. Use VTune Profiler to analyze your choice of algorithm. Identify potential benefits for your application from available hardware resources.
You can use VTune Profiler to locate or determine:
- The most time-consuming (hot) functions in your application and/or on the whole system
- Sections of code that do not effectively utilize available processor time
- The best sections of code to optimize for sequential performance and for threaded performance
- Synchronization objects that affect the application performance
- Whether, where, and why your application spends time on input/output operations
- Whether your application is CPU or GPU bound and how effectively it offloads code to the GPU
- The performance impact of different synchronization methods, different numbers of threads, or different algorithms
- Thread activity and transitions
- Hardware-related issues in your code such as data sharing, cache misses, branch misprediction, and others
You can download Intel oneAPI Base Toolkit from this link: Download the Intel® oneAPI Base Toolkit.
On the webiste, different operating system versions and installation/package types are provided. However, I strongly suggest that you should use the offline installer and install everything by the following commands.
wget https://registrationcenter-download.intel.com/akdlm/IRC_NAS/fdc7a2bc-b7a8-47eb-8876-de6201297144/l_BaseKit_p_2024.1.0.596_offline.sh
# You should only choose one from the following two commands
# for root users
sudo sh ./l_BaseKit_p_2024.1.0.596_offline.sh -a --silent --cli --eula accept
# for non-root users
sh ./l_BaseKit_p_2024.1.0.596_offline.sh -a --silent --cli --eula acceptYou can download Intel HPC Toolkit from this link: Download the Intel® HPC Toolkit
On the webiste, different operating system versions and installation/package types are provided. However, I strongly suggest that you should use the offline installer and install everything by the following commands.
wget https://registrationcenter-download.intel.com/akdlm/IRC_NAS/7f096850-dc7b-4c35-90b5-36c12abd9eaa/l_HPCKit_p_2024.1.0.560_offline.sh
# You should only choose one from the following two commands
# for root users
sudo sh ./l_HPCKit_p_2024.1.0.560_offline.sh -a --silent --cli --eula accept
# for non-root users
sh ./l_HPCKit_p_2024.1.0.560_offline.sh -a --silent --cli --eula acceptOpen Intel® VTune™ Profiler with the graphical user interface (vtune-gui) or command-line interface (vtune).
Once you have downloaded Intel VTune Profiler follow these steps to run the application:
- Locate the installation directory.
- Set environment variables.
- Open Intel® VTune™ Profiler
Whether you downloaded Intel® VTune™ Profiler as a standalone component or with the Intel® oneAPI Base Toolkit, the default path for your is:
| Operating System | Path to |
|---|---|
| Windows* OS | C:\Program Files (x86)\Intel\oneAPI\ or C:\Program Files\Intel\oneAPI(in certain systems) |
| Linux* OS | /opt/intel/oneapi/ for root users or $HOME/intel/oneapi/ for non-root users |
To set up environment variables for VTune ProfilerVTune Profiler, you need to run the setvars script:
Linux OS:
source <install-dir>/setvars.sh
# For Example: for root users
source /opt/intel/oneapi/setvars.sh
# or : for non-root users
source /opt/intel/oneapi/setvars.shMeanwhile, it's a good idea to use alias to help the environment variables' quick setting.
# Add the Following Content to ~/.bashrc
alias Intel_oneAPI='source <install-dir>/setvars.sh'
source ~/.bashrc
# Set Environment Variables
Intel_oneAPIWindows OS:
<install-dir>\setvars.batWhen you run this script, it displays the product name and the build number. You can now use the vtune and vtune-gui commands.
On Windows OS, use the Search menu or locate VTune Profiler from the Start menu to run the standalone GUI client. When you start Intel® VTune™ Profiler, a Welcome page opens with several links to product news, resources, and directions for your next steps.
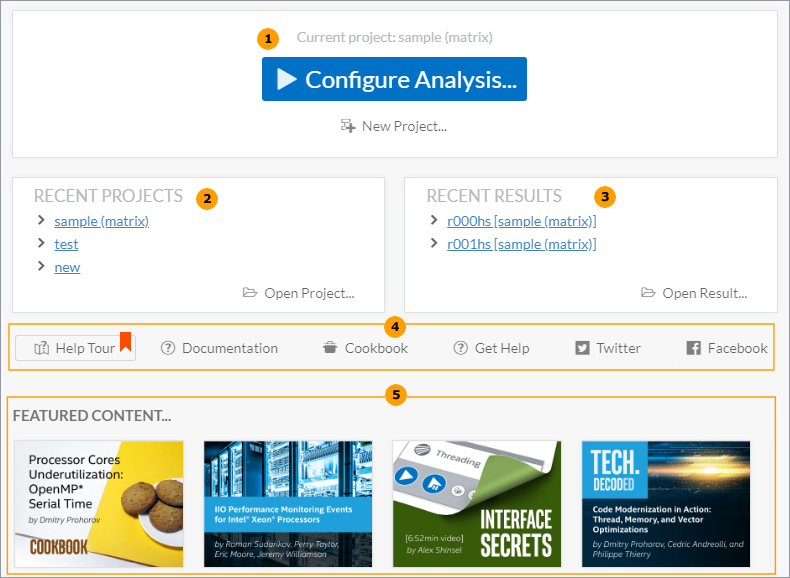
For the version of VTune Profiler that is integrated into Microsoft* Visual Studio* IDE on Windows OS, do one of the following:
- Select Intel VTune Profiler from the Tools menu of Visual Studio.
- Click the
Configure Analysis with VTune Profiler toolbar button.

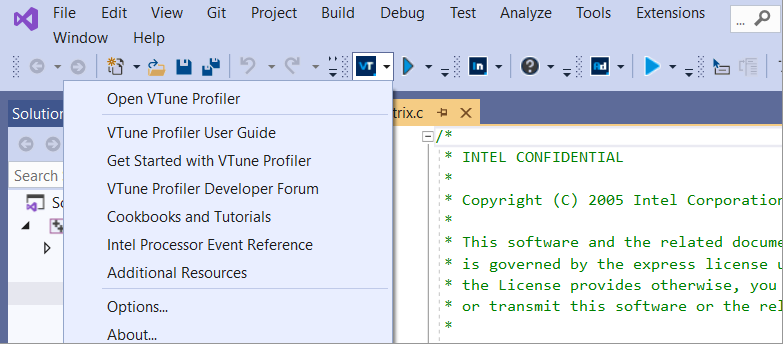
On a macOS* system, start Intel VTune Profiler *version* from the Launchpad.
To launch the VTune Profiler from the command line, run the following scripts from the <install-dir>/bin64 directory:
- vtune-gui for the standalone graphical interface
- vtune for the command line interface
To open a specific VTune Profiler project or a result file (mainly for Linux OS), enter:
vtune-gui <*path*>where <path> is one of the following:
- full path to a result file (*.vtune)
- full path to a project file (*.vtuneproj)
- full path to a project directory. If the project file does not exist in the directory, the New Project dialog box opens and prompts you to create a new project in the given directory.
For example, to open the matrix project in the VTune Profiler GUI on Linux, run:
vtune-gui /root/intel/vtune/projects/matrix/matrix.vtuneprojBefore you run an analysis with Intel® VTune™ Profiler, you must first create a project. This is a container for an analysis target, analysis type configuration, and data collection results. You use the VTune Profiler user interface to create a project. You cannot create one from the command line.
For Microsoft Visual Studio* IDE, VTune Profiler creates a project for an active startup project, inherits Visual Studio settings and uses the application generated for the selected project as your analysis target. The default project directory is My VTune Results-[project name] in the solution directory.
For the standalone graphical interface, create a project by specifying its name and path to an analysis target. The default project directory is %USERPROFILE%\My Documents\Amplifier XE\Projects on Windows* and $HOME/intel/vtune/projects on Linux*.
To create a VTune Profiler project for the standalone GUI:
-
Click New Project... in the Welcome screen.
-
In the Create a Project dialog box, configure these settings:
Use This To Do This Project Name field Enter the name of a new project. Location field and Browse button Choose or create a directory to contain the project.TIP:Store all your project directories in the same location. Create Project button Create a container *.vtuneproj file and open the Configure Analysis window. -
Click the Create Project button.
The Configure Analysis window opens.
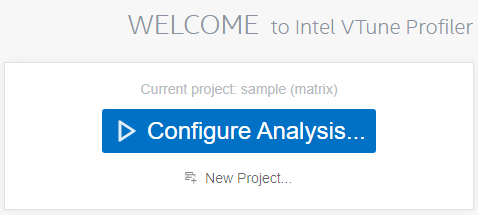
Your default project is pre-configured for the Performance Snapshot analysis. This presents an overview of issues that affect the performance of your application. Click the 
To select a different analysis type, click on the name of the analysis in the analysis header section. This opens an Analysis Tree with all available analysis types.
When you create a project for the Intel® VTune™ Profiler performance analysis, you have to specify what you want to profile - your analysis target, which could be an executable file, a process, or a whole system.
Before starting an analysis, make sure your target and system are compiled/configured properly for performance profiling.
VTune Profiler supports analysis targets that you can run in these environments:
| Development Environment Integration | Microsoft* Visual Studio*, Eclipse* |
|---|---|
| Target Platform | Linux* OS, Windows* OS, Android* OS, FreeBSD*, QNX*, Intel® Xeon Phi® processors (code name: Knights Landing) |
| Programming Language | C, C++, Fortran,C# (Windows Store applications), Java*, JavaScript, Python*, Go*, .NET*, .NET Core |
| Programming Model | Windows* API, OpenMP* API, Intel Cilk™ Plus, OpenCL™ API, Message Passing Interface (MPI), Intel Threading Building Blocks, Intel Media SDK API |
| Virtual Environment | VMWare*, Parallels*, KVM*, Hyper-V*, Xen* |
| Containers | LXC*, Docker*, Mesos* |
To specify your target for analysis:
-
Click the
New Project button on the toolbar to create a new project.
If you need to re-configure the target for an existing project, click the
Configure Analysis toolbar button.
The Configure Analysis window opens. By default, the project is pre-configured to run the Performance Snapshot analysis.
-
If you do not run an analysis on the local host, expand the WHERE pane and select an appropriate target system.
The target system can be the same as the host system, which is a system where the VTune Profiler GUI is installed. If you run an analysis on the same system where the VTune Profiler is installed (i.e. target system=host system), such a target system is called local. Target systems other than local are called remote systems. But both local and remote systems are accessible targets, which means you can access them either directly (local) or via a connection (for example, SSH connection to a remote target).
Local Host Run an analysis on the local host system.NOTE:This type of the target system is not available for macOS*. Remote Linux (SSH) Run an analysis on a remote regular or embedded Linux* system. VTune Profiler uses the SSH protocol to connect to your remote system. Make sure to fill in the SSH Destination field with the username, hostname, and port (if required) for your remote Linux target system as username@hostname[:port]. Android Device (ADB) Run an analysis on an Android device. VTune Profiler uses the Android Debug Bridge* (adb) to connect to your Android device. Make sure to specify an Android device targeted for analysis in the ADB Destination field. When the ADB connection is set up, the VTune Profiler automatically detects available devices and displays them in the menu. Arbitrary Host (not connected) Create a command line configuration for a platform NOT accessible from the current host, which is called an arbitrary target. -
From the WHAT pane, specify an application to launch or click the
Browse button to select a different target type:
Launch Application (pre-selected) Enable the Launch Application pane and choose and configure an application to analyze, which can be either a binary file or a script.NOTE:This target type is not supported for the Hotspots analysis of Android applications. Use the Attach to Process or Launch Android Package types instead. Attach to Process Enable the Attach to Process pane and choose and configure a process to analyze. Profile System Enable the Profile System pane and configure the system-wide analysis that monitors all the software executing on your system. Launch Android Package Enable the Launch Android Package pane to specify the name of the Android* package to analyze and configure target options.



Note
If you use VTune Profiler as a web server, the list of available targets and target systems differs.
Note
For driverless event-based sampling data collection, VTune Profiler supports local and remote Launch Application, Attach to Process and Profile System target types but their support fully depends on the Linux Perf profiling credentials specified in the /proc/sys/kernel/perf_event_paranoid file and managed by the administrator of your system using root credentials. For more information see the perf_event related configuration files topic at http://man7.org/linux/man-pages/man2/perf_event_open.2.html. By default, only user processes profiling at the both user and kernel spaces is permitted, so you need granting wider profiling credentials via the perf_event_paranoid file to employ the Profile System target type.
After you create a project and specify a target for analysis, you are ready to run your first analysis.
Click Configure Analysis on the Welcome page. By default, this action opens the Performance Snapshot analysis type. This is a good starting point to get an overview of potential performance issues that affect your application. The snapshot view includes recommendations for other analysis types you should consider next.
Click anywhere on the analysis header that contains the name of the analysis type. This opens the Analysis Tree, where you can see other analysis types grouped into several categories. See Analysis types to get an overview of these predefined options.
Advanced users can create custom analysis types which appear at the bottom of the analysis tree.
| Analysis Group | Analysis Types |
|---|---|
| Algorithm analysis | HotspotsAnomaly DetectionMemory Consumption |
| Microarchitecture analysis | Microarchitecture ExplorationMemory Access |
| Parallelism analysis | ThreadingHPC Performance Characterization |
| I/O analysis | Input and Output |
| Accelerators analysis | GPU OffloadGPU Compute/Media Hotspots (Preview)CPU/FPGA InteractionNPU Exploration Analysis (Preview) |
| Platform Analyses | System Overview |
Important
The most three important result is Bottom-up , Top-down Tree and Flame Graph. By analyzing the time used, you can know which function uses most of the time (NOT ALL TRUTH HOWEVER).

Important
Useful Guide:
- User Guide — nsight-systems 2024.4 documentation (nvidia.com)
- XiaoLi Zhi's Experiment Document
Waiting for updating...