Conversation
f5fbe61 to
83f2297
Compare
|
run-ci: all |
|
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
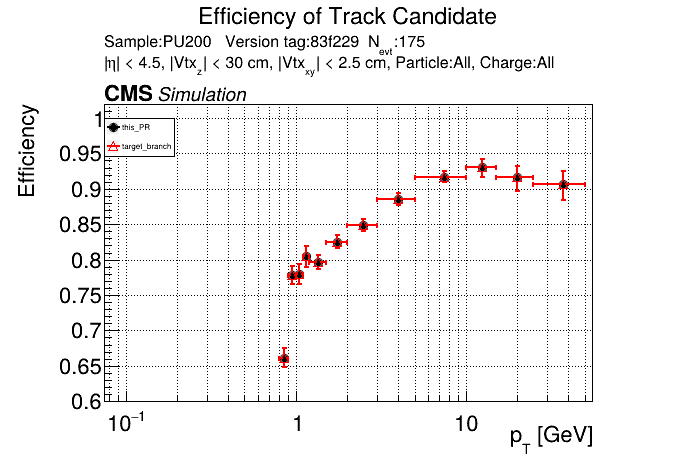
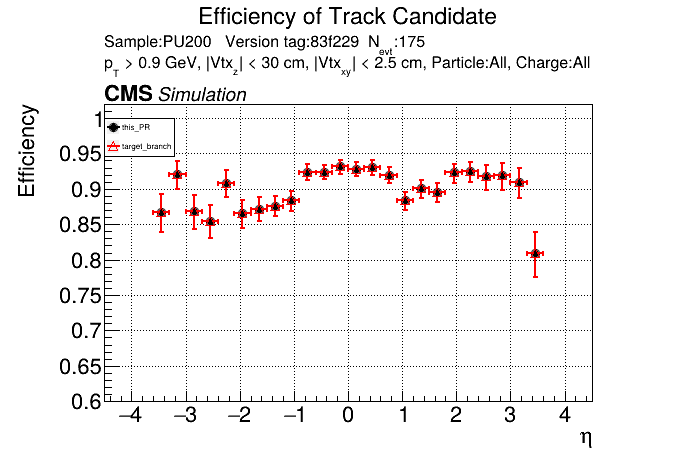
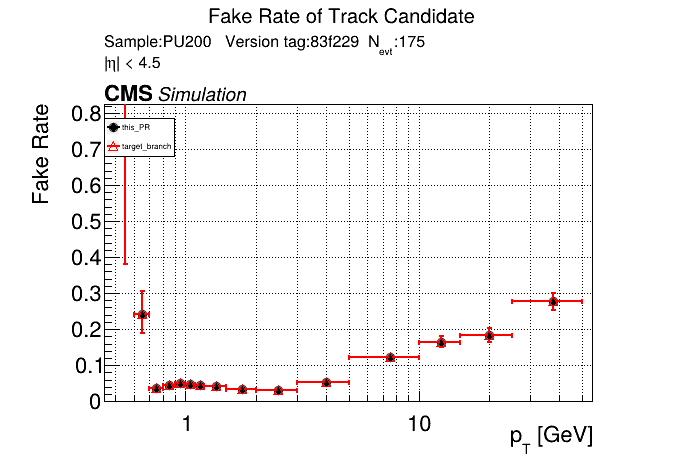
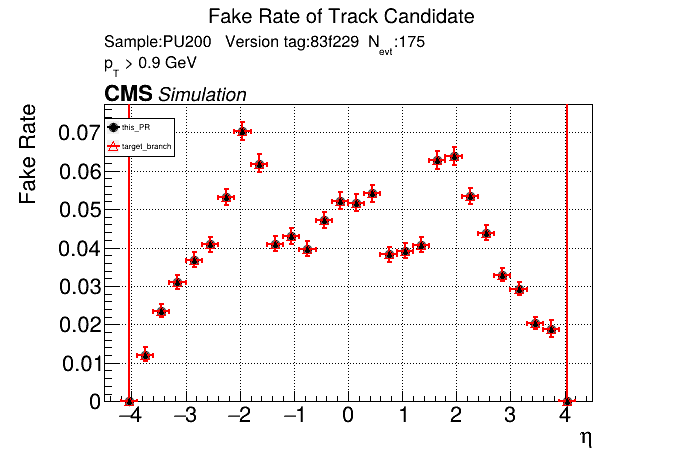
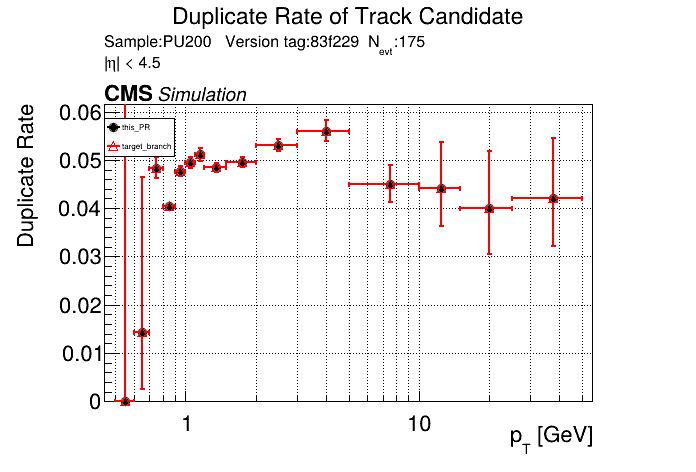
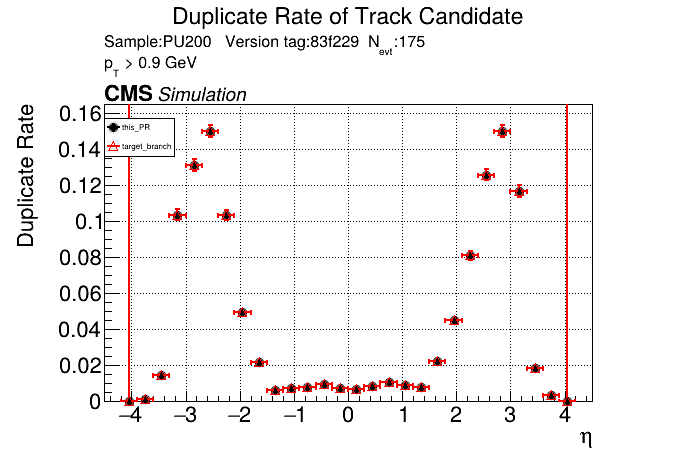
|
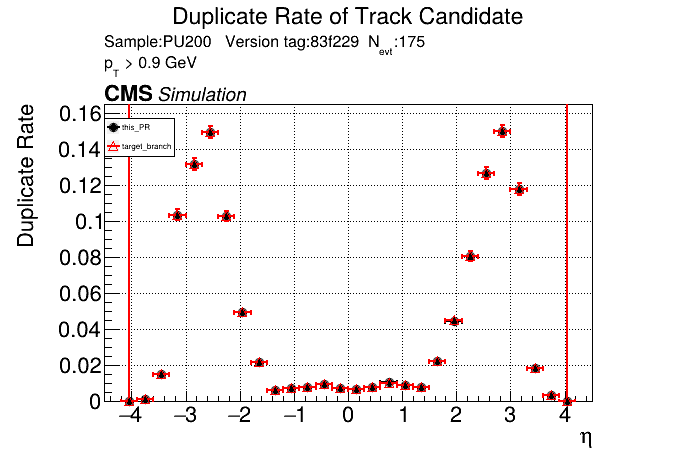
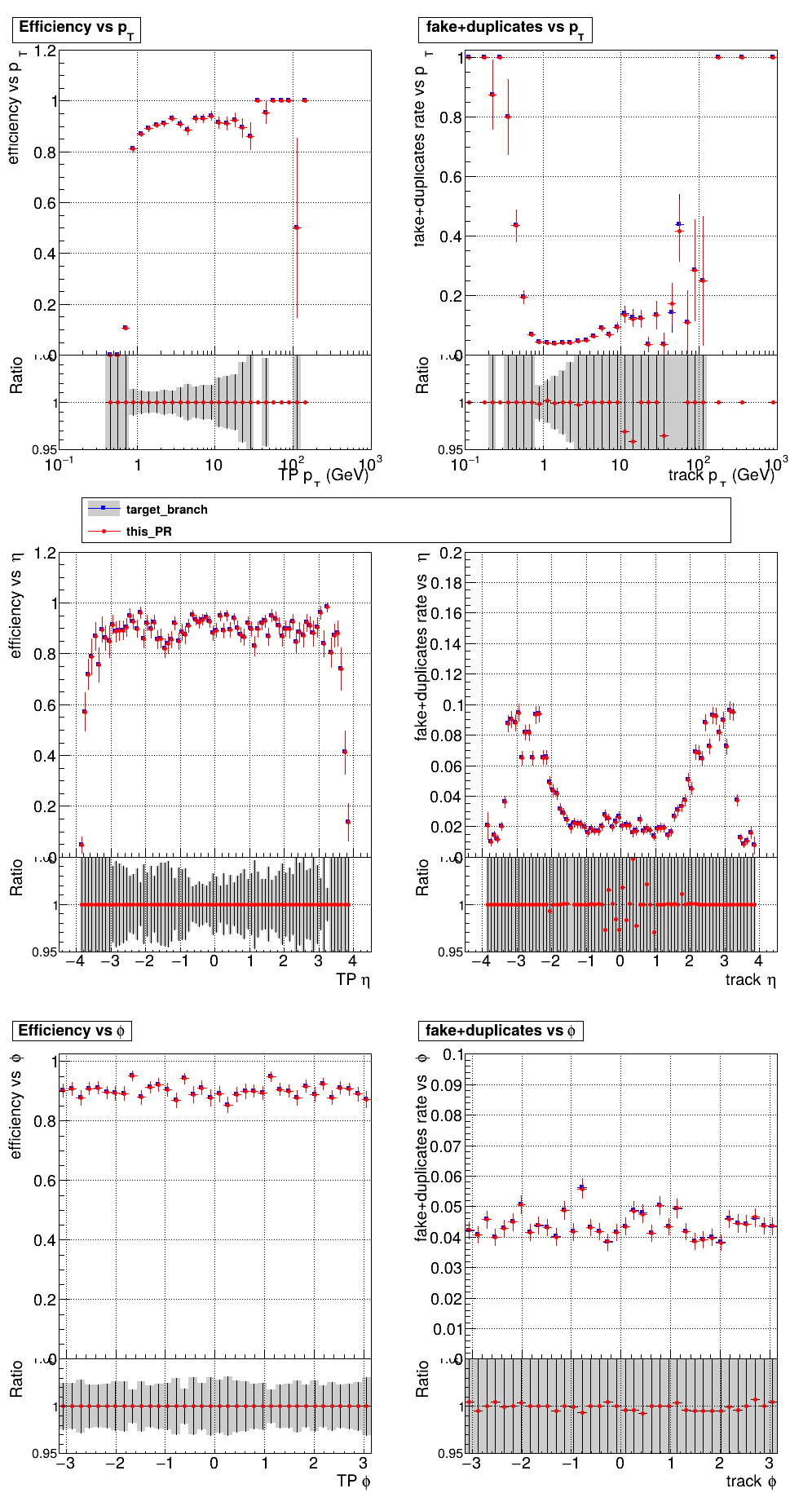
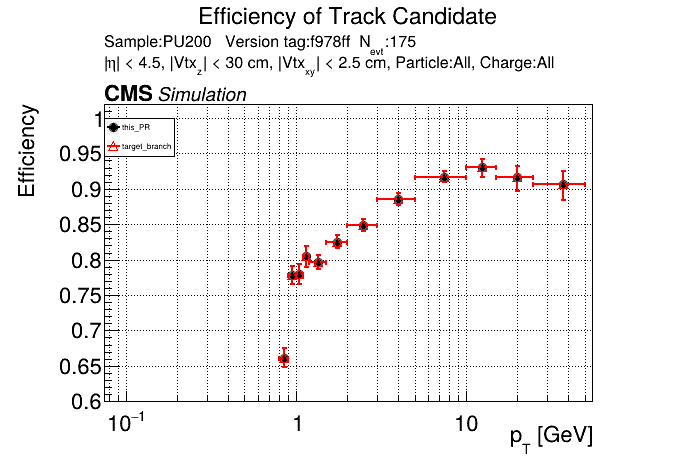
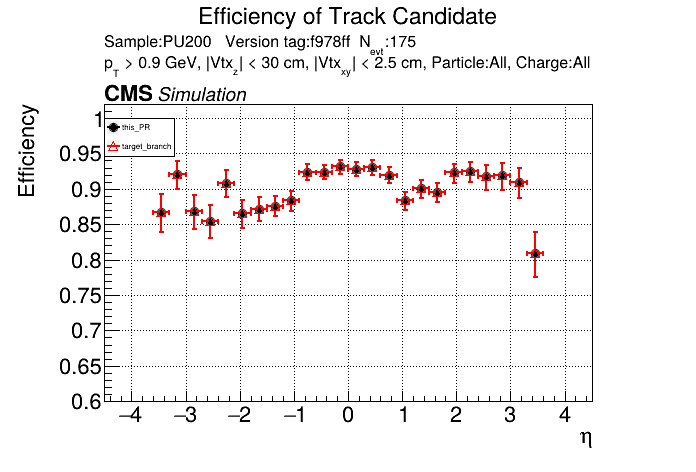
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
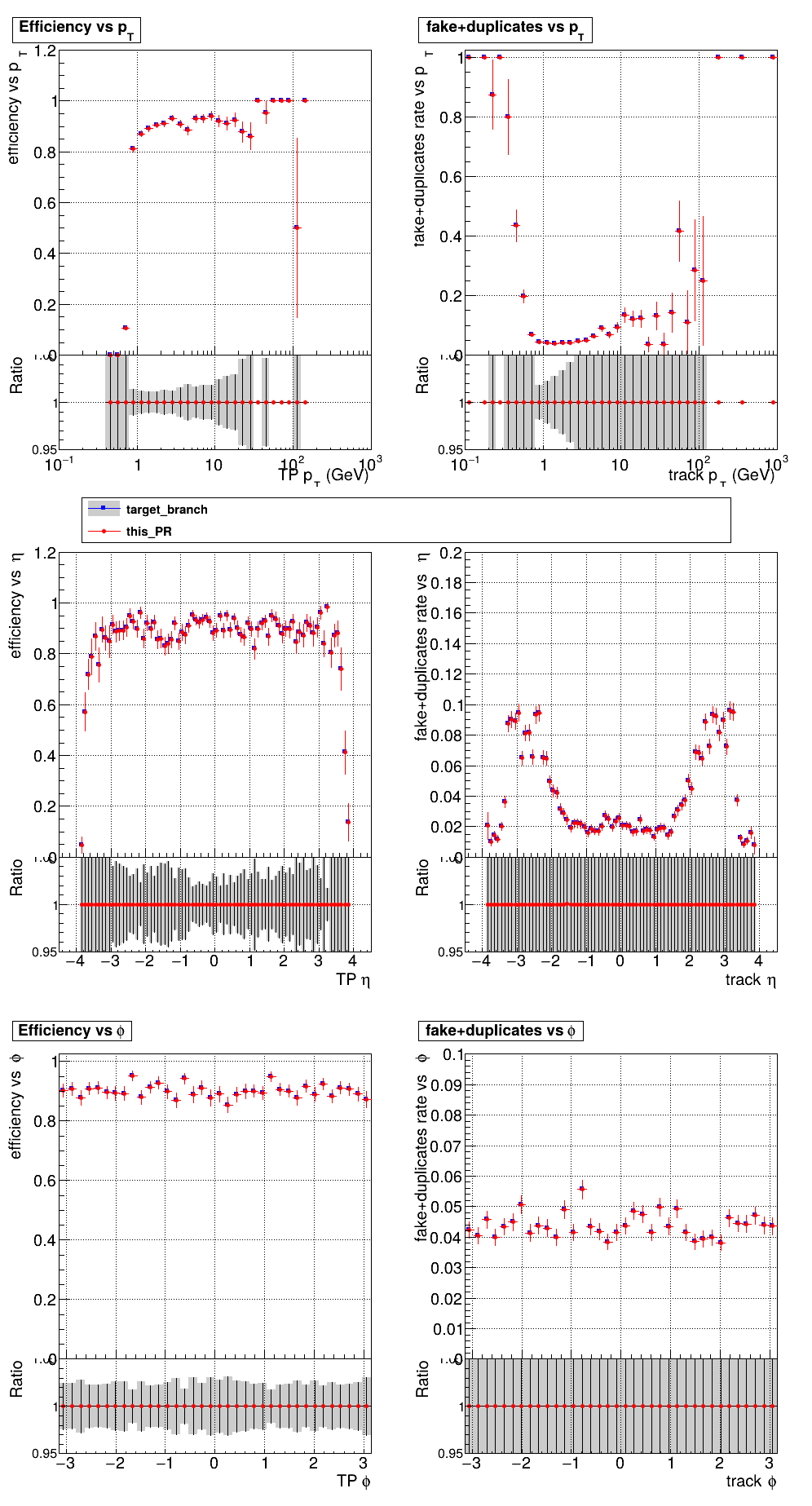
|
run-ci: all |
|
The PR was built and ran successfully in standalone mode running on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
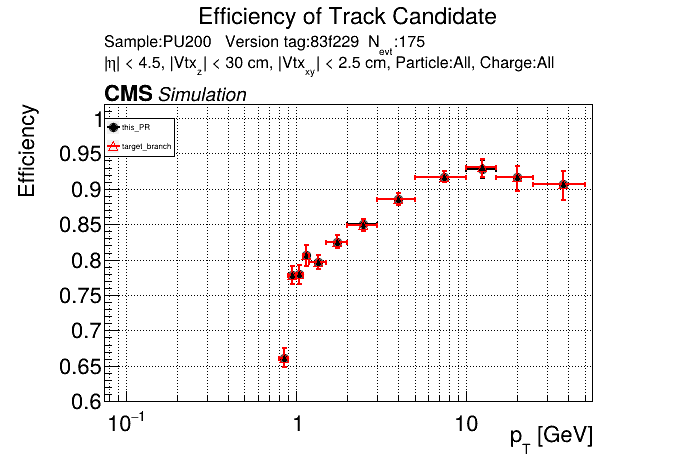
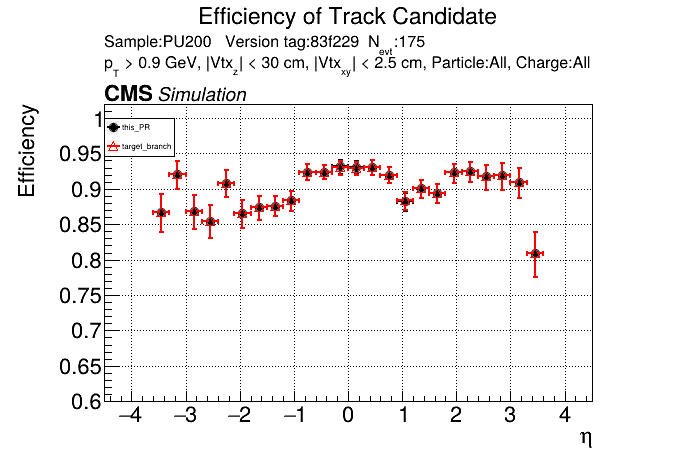
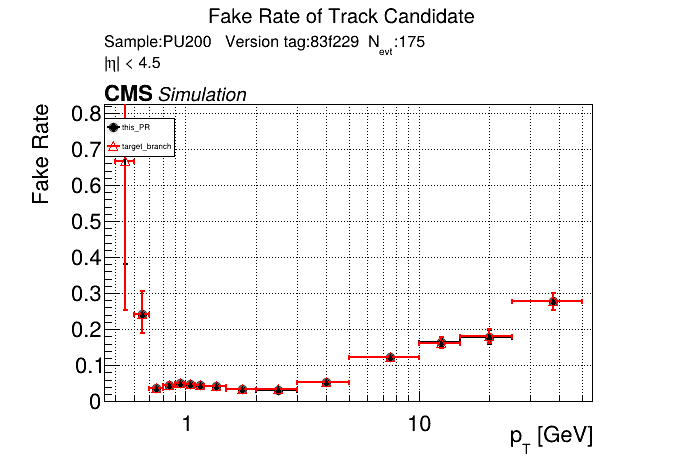
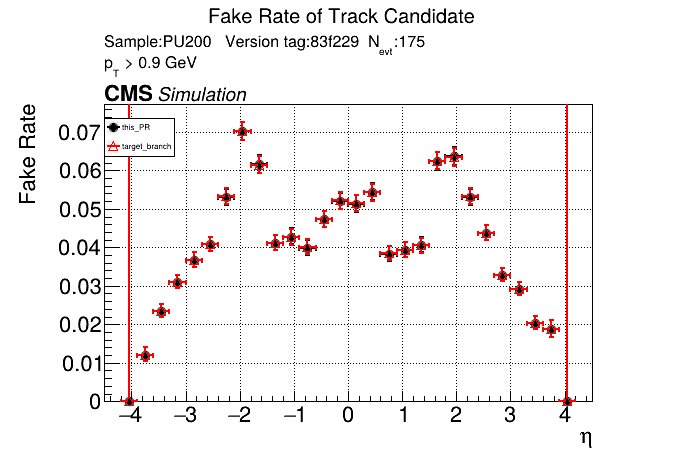
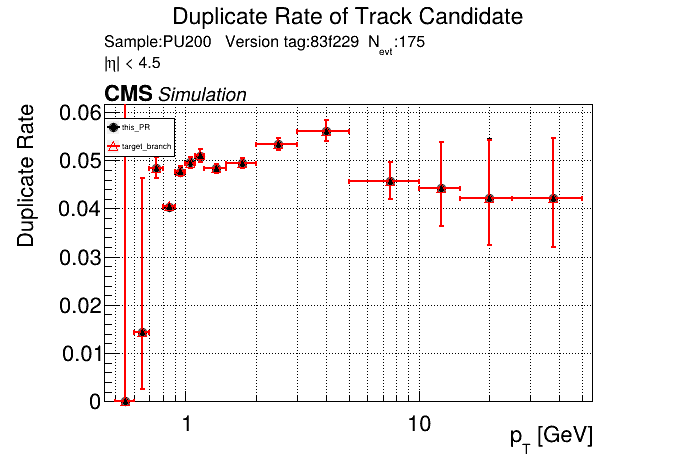
|
@slava77 I think this PR is good to go. Represents most of the boiler-plate changes of the CPU speedups PR. |
|
The PR was built and ran successfully with CMSSW running on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |

the GPU variant should have one more significant digit in the component columns (the total can be still with |
 slava77
left a comment
slava77
left a comment
There was a problem hiding this comment.
nice updates.
I think the comment cleanup in the MiniDoublet code is a bit too aggressive. While some removals may be clean for some tautological docs, quite a bit is going to lose clarity. Please recover
9aad224 to
727bac8
Compare
|
run-ci: all |
727bac8 to
2375562
Compare
|
run-ci: all |
|
run-ci: all |
|
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
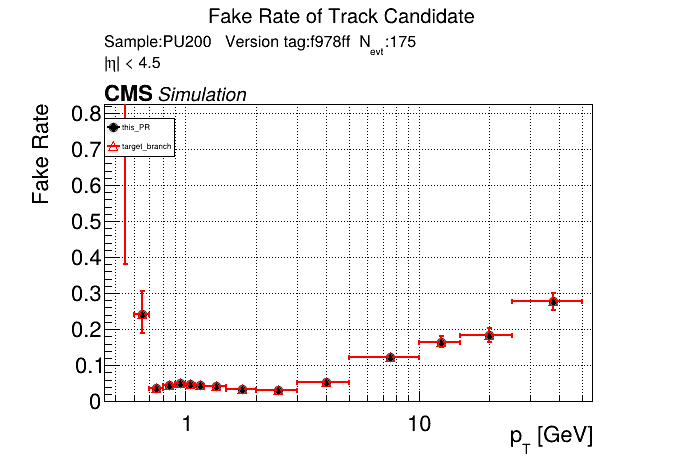
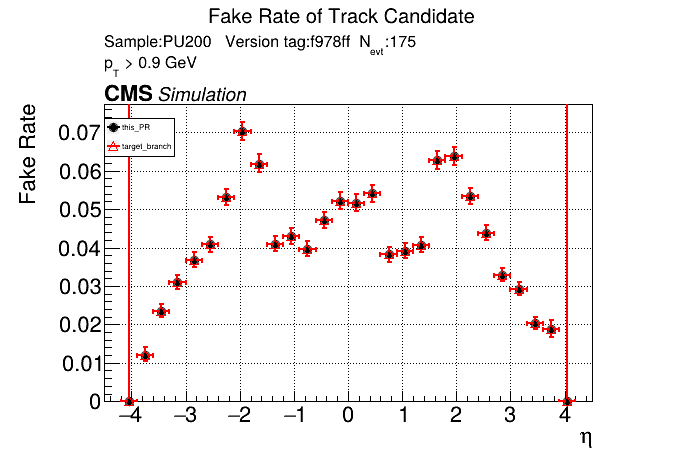
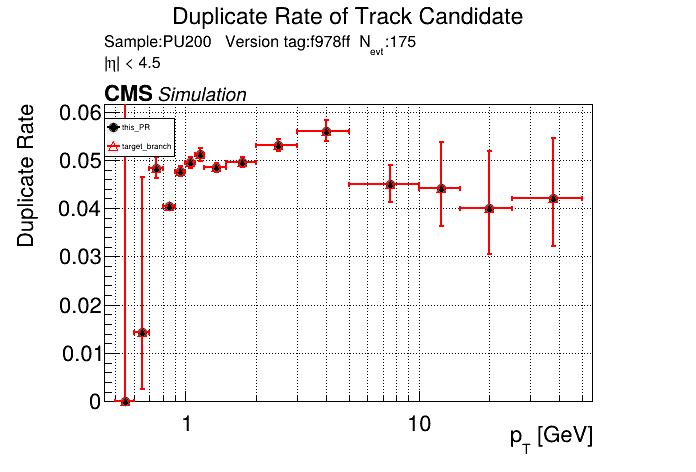
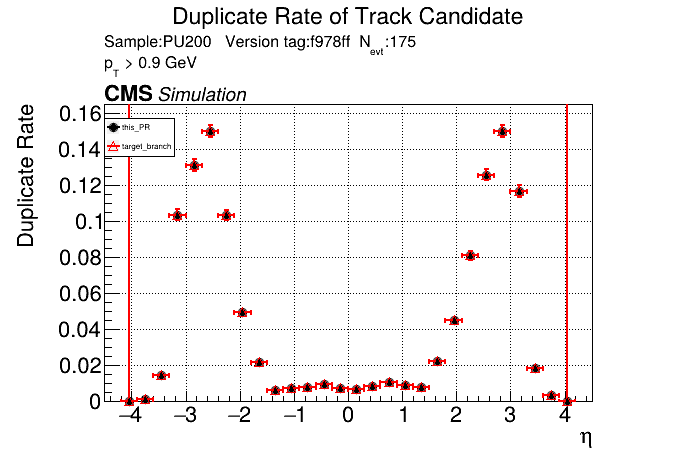
|
The PR was built and ran successfully with CMSSW running on GPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
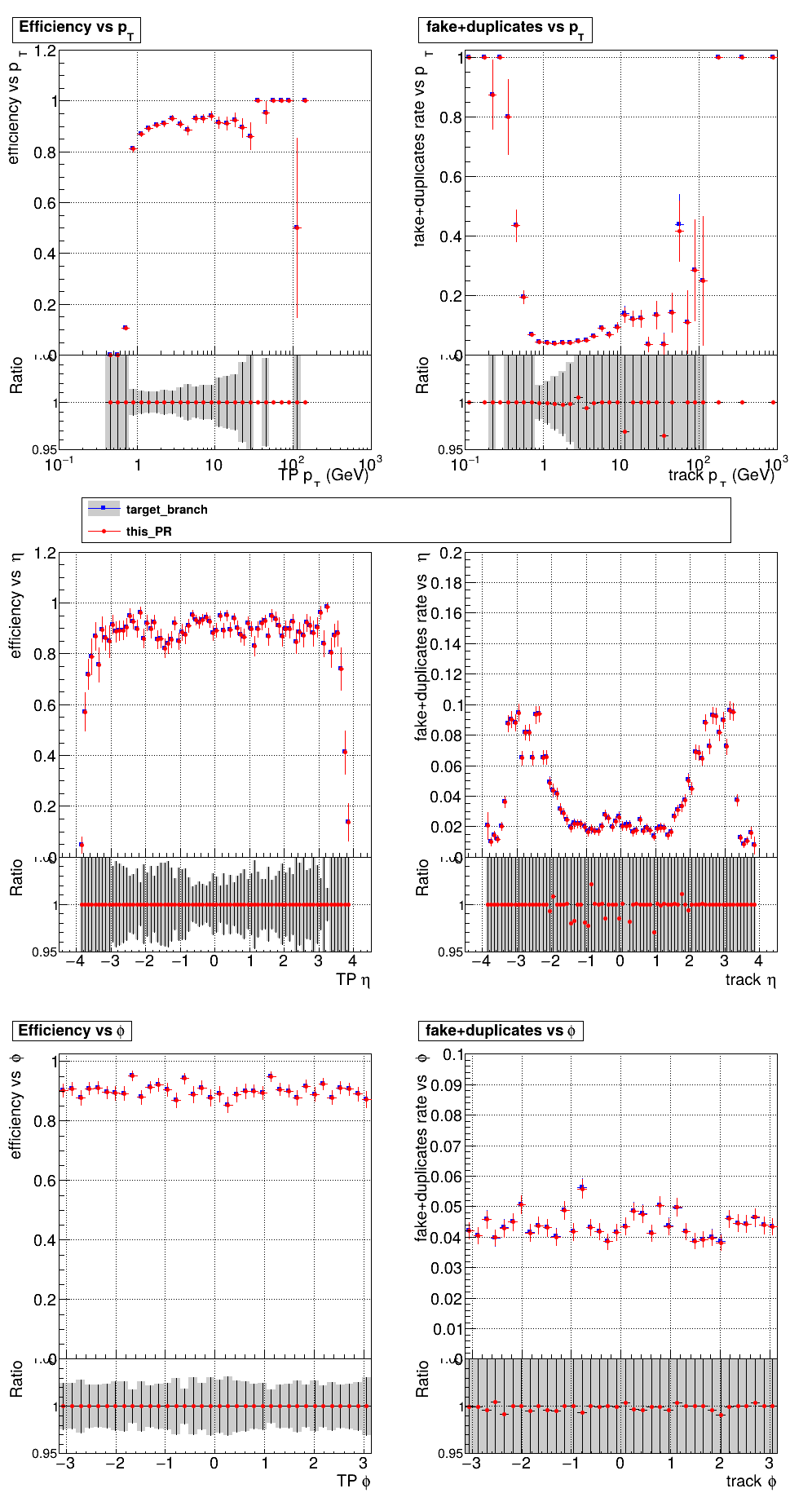
|
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
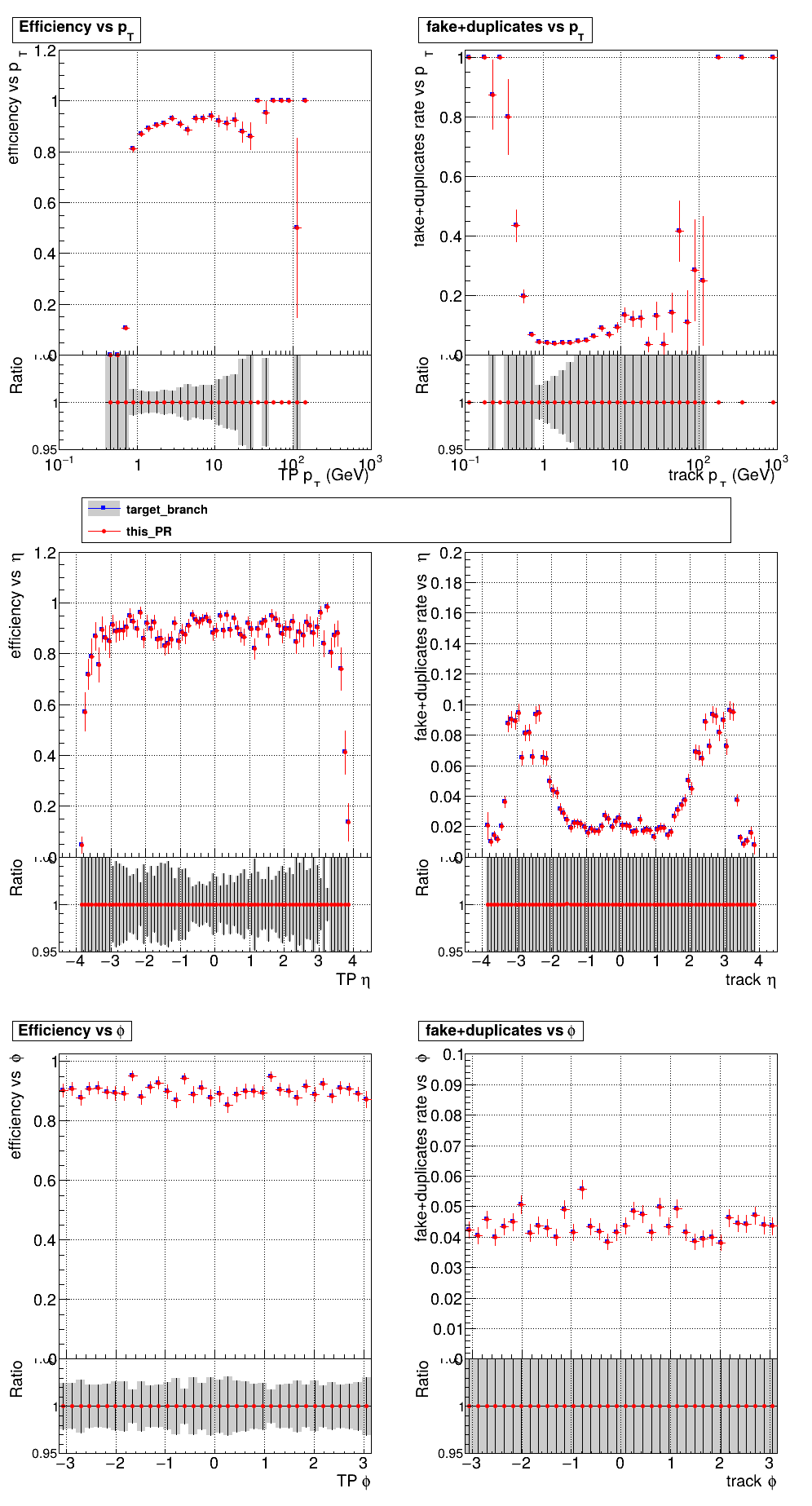
|
The PR was built and ran successfully in standalone mode running on GPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
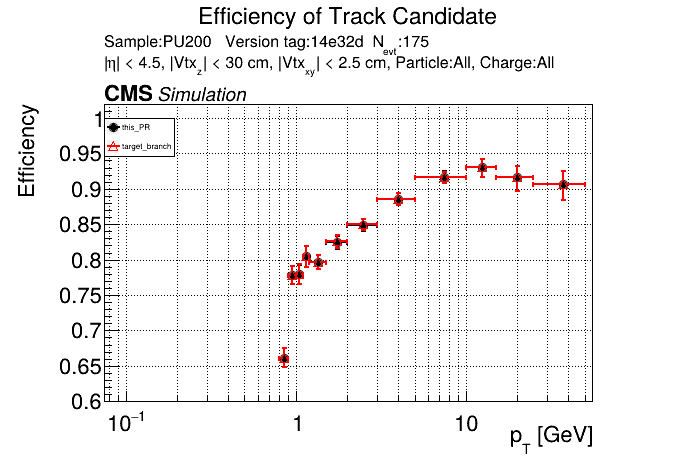
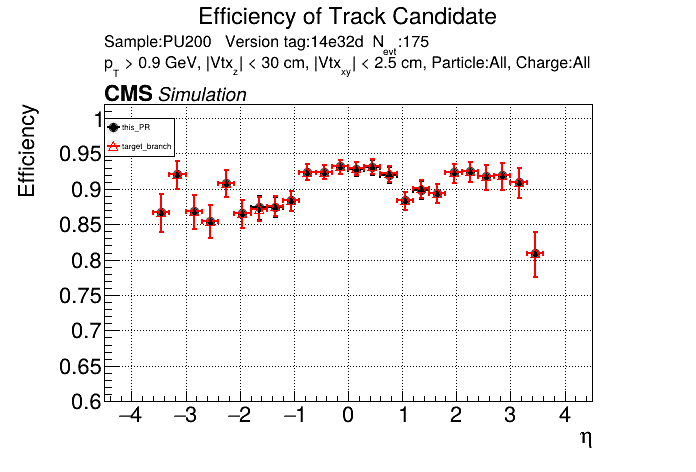
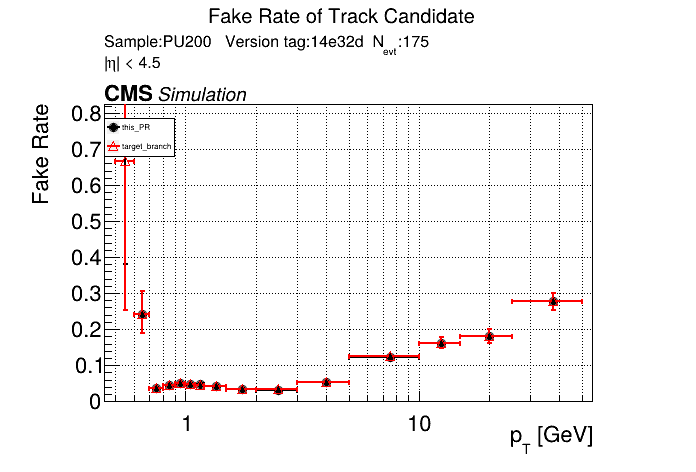
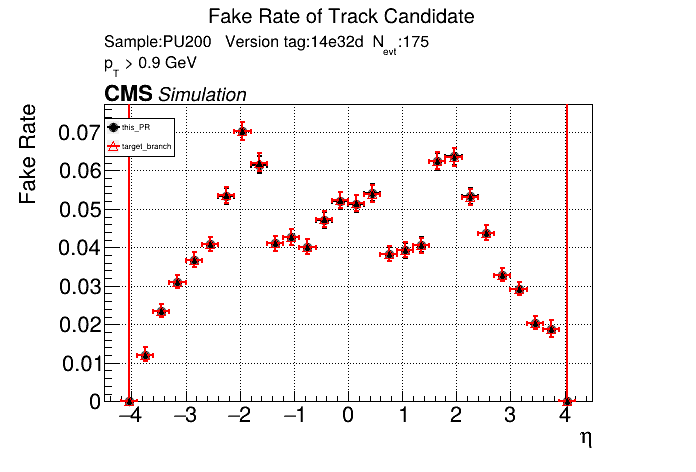
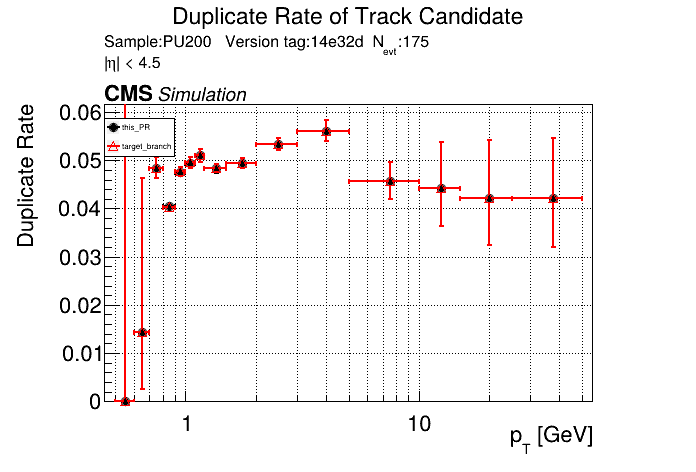
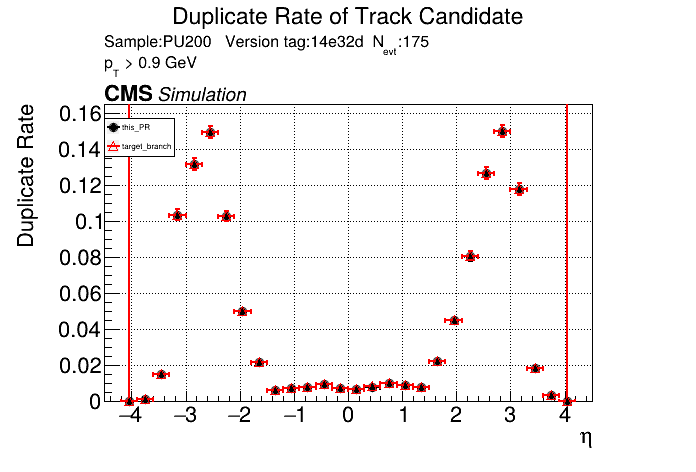
|
run-ci: all |
a2305fb to
df0990a
Compare
df0990a to
6ba26d8
Compare
6ba26d8 to
912b6d9
Compare
|
run-ci: all |
|
The PR was built and ran successfully in standalone mode running on CPU. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
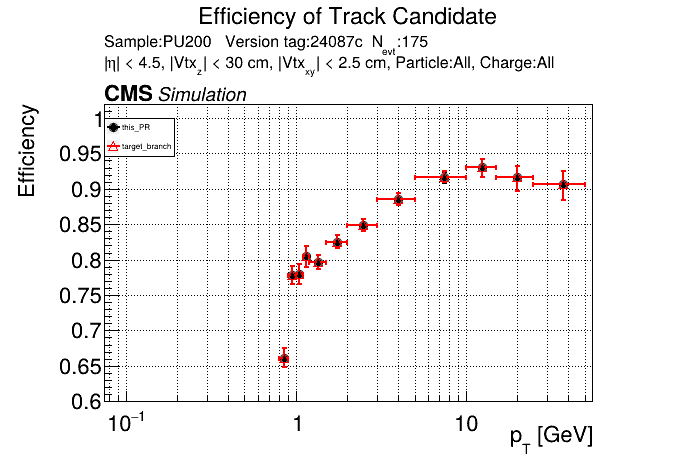
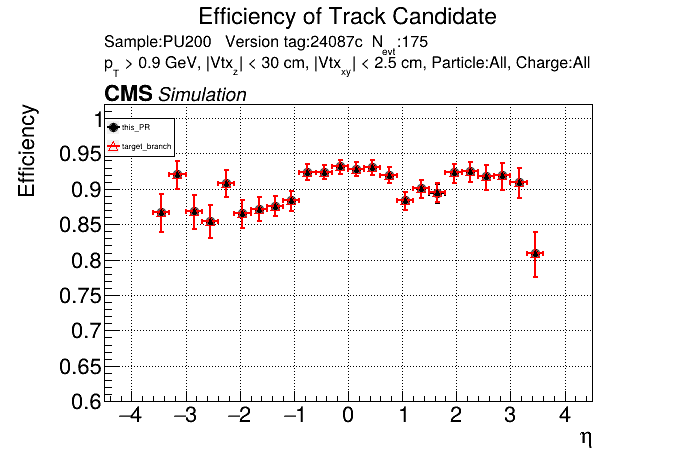
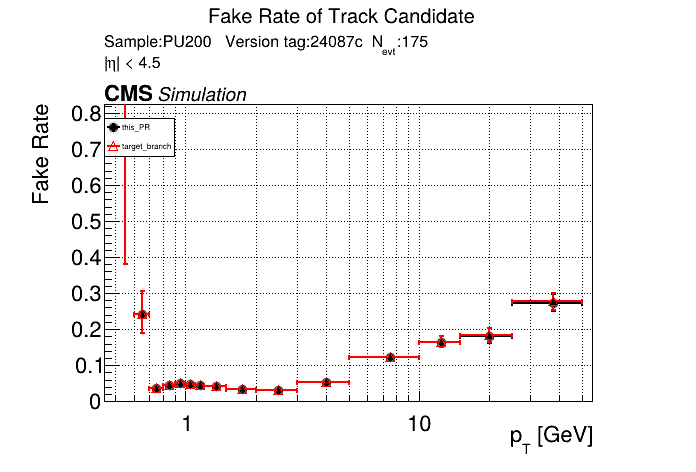
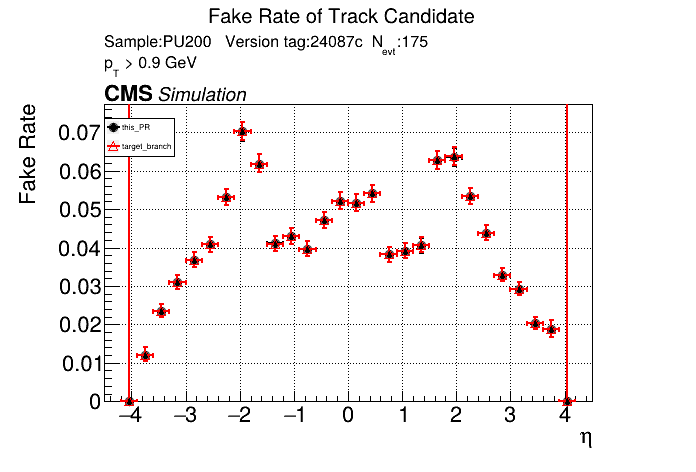
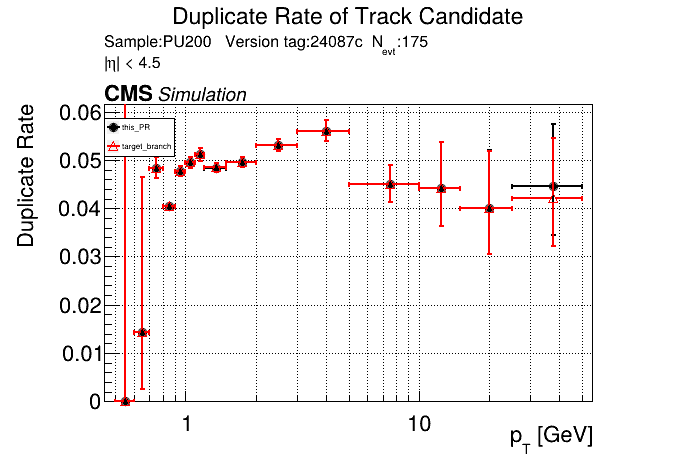
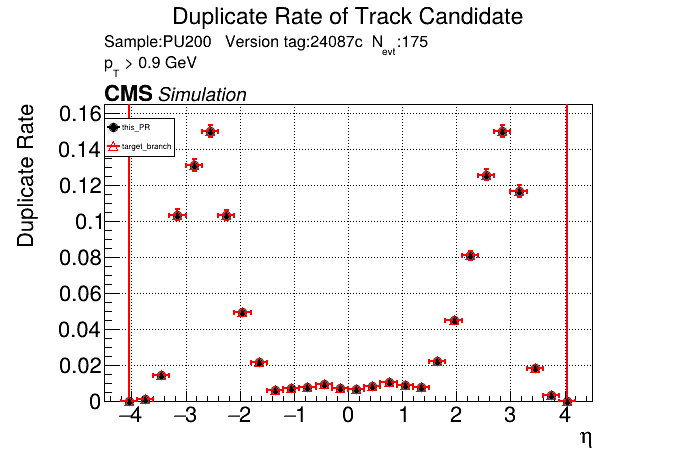
|
The PR was built and ran successfully with CMSSW running on CPU. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
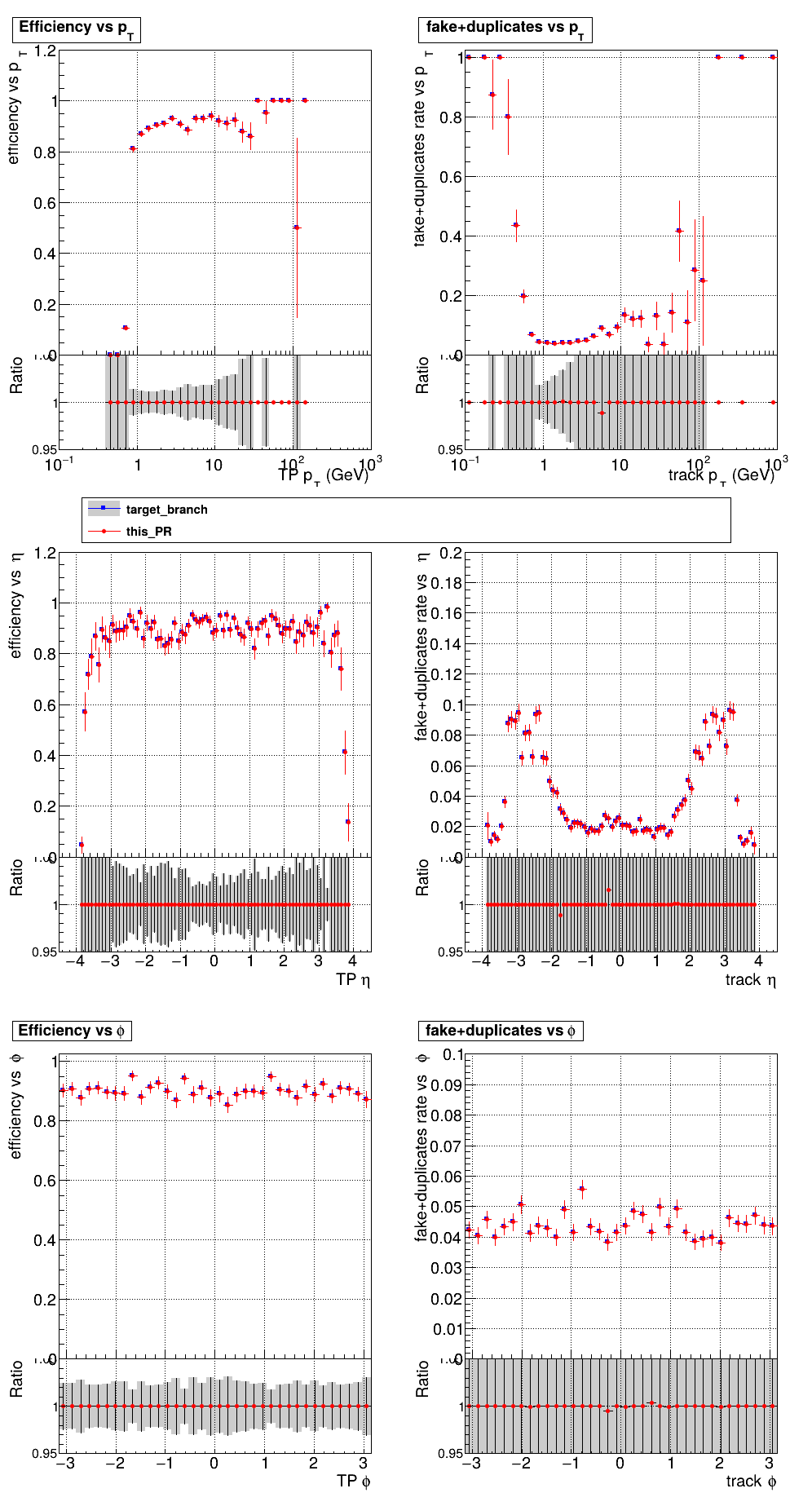
|
it would be good to get some rough accounting of the speedups bu the category/type of changes (from a rough look at the code: early loop exit, moving variables early in nested loops, moving compute closest to use after the cuts, dPhi xy1,2, module data and hit data pre-loading to structs) while some changes are rather clear expected speedups, some other are less so. |
|
|
||
| // Pre-computed module-constant data for MiniDoublet kernels. | ||
| // Populated once per module to avoid redundant SoA loads in the inner hit-pair loop. | ||
| struct ModuleMDData { |
There was a problem hiding this comment.
how large is the overlap in values between the MD-related and other module data?
It looks like this is a case for using AoS (plain old array): 1-2 cache line fetches will get the full MD data, compared to our current SoA mostly unused reads for modules
Also, consider to reorder by size at least partially to avoid padding
This PR Timing (CPU) - commit 2 (pre-checks, exact trig simplifications, and additional early exits)



This PR Timing (CPU) - commit 1 (reducing redundant memory loads)
Master Timing (CPU)