|
| 1 | +--- |
| 2 | +title: 一致性哈希算法详解 |
| 3 | +category: 分布式 |
| 4 | +tag: |
| 5 | + - 分布式协议&算法 |
| 6 | + - 哈希算法 |
| 7 | +--- |
| 8 | + |
| 9 | +开始之前,先说两个常见的场景: |
| 10 | + |
| 11 | +1. **负载均衡**:由于访问人数太多,我们的网站部署了多台服务器个共同提供相同的服务,但每台服务器上存储的数据不同。为了保证请求的正确响应,相同参数(key)的请求(比如同个 IP 的请求、同一个用户的请求)需要发到同一台服务器处理。 |
| 12 | +2. **分布式缓存**:由于缓存数据量太大,我们部署了多台缓存服务器共同提供缓存服务。缓存数据需要尽可能均匀地分布式在这些缓存服务器上,通过 key 可以找到对应的缓存服务器。 |
| 13 | + |
| 14 | +这两种场景的本质,都是需要建立一个**从 key 到服务器/节点的稳定映射关系**。 |
| 15 | + |
| 16 | +为了实现这个目标,你首先会想到什么方案呢? |
| 17 | + |
| 18 | +## 普通哈希算法 |
| 19 | + |
| 20 | +相信大家很快就能想到 **“哈希+取模”** 这个经典组合。通过哈希函数计算出 key 的哈希值,再对服务器数量取模,从而将 key 映射到固定的服务器上。 |
| 21 | + |
| 22 | +公式也很简单: |
| 23 | + |
| 24 | +```java |
| 25 | +node_number = hash(key) % N |
| 26 | +``` |
| 27 | + |
| 28 | +- `hash(key)`: 使用哈希函数(建议使用性能较好的非加密哈希函数,例如 SipHash、MurMurHash3、CRC32、DJB)对唯一键进行哈希。 |
| 29 | +- `% N`: 对哈希值取模,将哈希值映射到一个介于 0 到 N-1 之间的值,N 为节点数/服务器数。 |
| 30 | + |
| 31 | +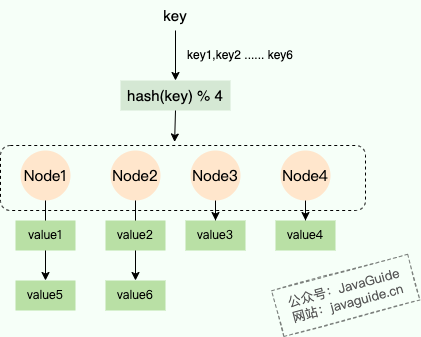 |
| 32 | + |
| 33 | +然而,传统的哈希取模算法有一个比较大的缺陷就是:**无法很好的解决机器/节点动态减少(比如某台机器宕机)或者增加的场景(比如又增加了一台机器)。** |
| 34 | + |
| 35 | +想象一下,服务器的初始数量为 4 台 (N = 4),如果其中一台服务器宕机,N 就变成了 3。此时,对于同一个 key,`hash(key) % 3` 的结果很可能与 `hash(key) % 4` 完全不同。 |
| 36 | + |
| 37 | +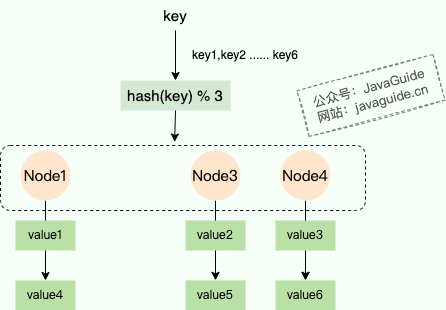 |
| 38 | + |
| 39 | +这意味着几乎所有的数据映射关系都会错乱。在分布式缓存场景下,这会导致**大规模的缓存失效和缓存穿透**,瞬间将压力全部打到后端的数据库上,引发系统雪崩。 |
| 40 | + |
| 41 | +据估算,当节点数量从 N 变为 N-1 时,平均有 (N-1)/N 比例的数据需要迁移,这个比例 **趋近于 100%** 。这种“牵一发而动全身”的效应,在生产环境中是完全不可接受的。 |
| 42 | + |
| 43 | +为了更好地解决这个问题,一致性哈希算法诞生了。 |
| 44 | + |
| 45 | +## 一致性哈希算法 |
| 46 | + |
| 47 | +一致性哈希算法在 1997 年由麻省理工学院提出(这篇论文的 PDF 在线阅读地址:<https://www.cs.princeton.edu/courses/archive/fall09/cos518/papers/chash.pdf>),是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了传统哈希算法在分布式[哈希表](https://baike.baidu.com/item/哈希表/5981869)(Distributed Hash Table,DHT)中存在的动态伸缩等问题 。 |
| 48 | + |
| 49 | +一致性哈希算法的底层原理也很简单,关键在于**哈希环**的引入。 |
| 50 | + |
| 51 | +### 哈希环 |
| 52 | + |
| 53 | +一致性哈希算法将哈希空间组织成一个环形结构,将数据和节点都映射到这个环上,然后根据顺时针的规则确定数据或请求应该分配到哪个节点上。通常情况下,哈希环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 **[0, 2^32-1]** 。 |
| 54 | + |
| 55 | +传统哈希算法是对服务器数量取模,一致性哈希算法是对哈希环的范围取模,固定值,通常为 2^32: |
| 56 | + |
| 57 | +```java |
| 58 | +node_number = hash(key) % 2^32 |
| 59 | +``` |
| 60 | + |
| 61 | +服务器/节点如何映射到哈希环上呢?也是哈希取模。例如,一般我们会根据服务器的 IP 或者主机名进行哈希,然后再取模。 |
| 62 | + |
| 63 | +```java |
| 64 | +hash(服务器ip)% 2^32 |
| 65 | +``` |
| 66 | + |
| 67 | +如下图所示: |
| 68 | + |
| 69 | +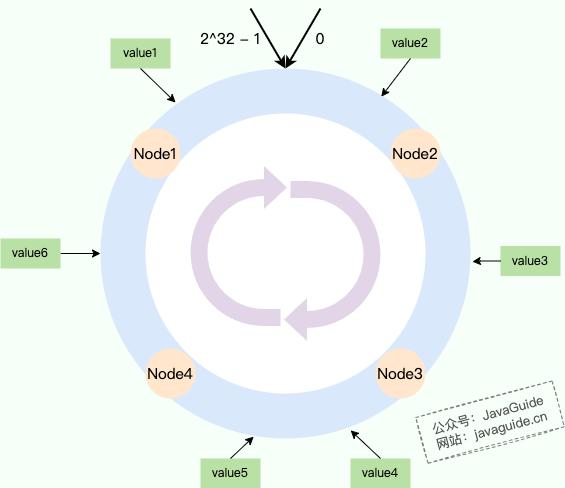 |
| 70 | + |
| 71 | +我们将数据和节点都映射到哈希环上,环上的每个节点都负责一个区间。对于上图来说,每个节点负责的数据情况如下: |
| 72 | + |
| 73 | +- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。 |
| 74 | +- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1, value2)。 |
| 75 | +- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value3)。 |
| 76 | +- **Node4:** 负责 Node3 到 Node4 之间的区域(包含 value4, value5)。 |
| 77 | + |
| 78 | +### 节点移除/增加 |
| 79 | + |
| 80 | +新增节点和移除节点的情况下,哈希环的引入可以避免影响范围太大,减少需要迁移的数据。 |
| 81 | + |
| 82 | +还是用上面分享的哈希环示意图为例,假设 Node2 节点被移除的话,那 Node3 就要负责 Node2 的数据,直接迁移 Node2 的数据到 Node3 即可,其他节点不受影响。 |
| 83 | + |
| 84 | +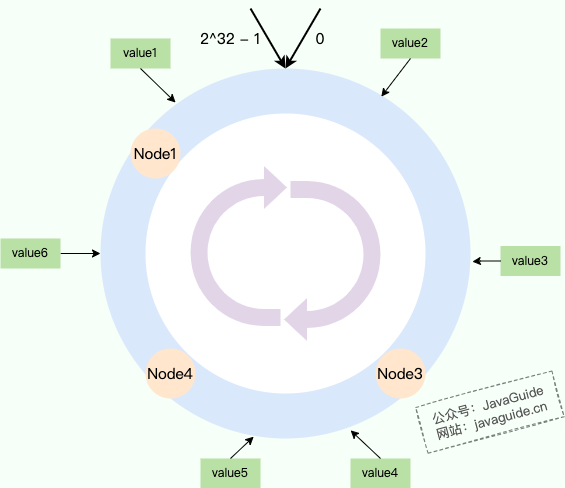 |
| 85 | + |
| 86 | +同样地,如果我们在 Node1 和 Node2 之间新增一个节点 Node5,那么原本应该由 Node2 负责的一部分数据(即哈希值落在 Node1 和 Node5 之间的数据,如图中的 value1)现在会由 Node5 负责。我们只需要将这部分数据从 Node2 迁移到 Node5 即可,同样只影响了相邻的节点,影响范围非常小。 |
| 87 | + |
| 88 | +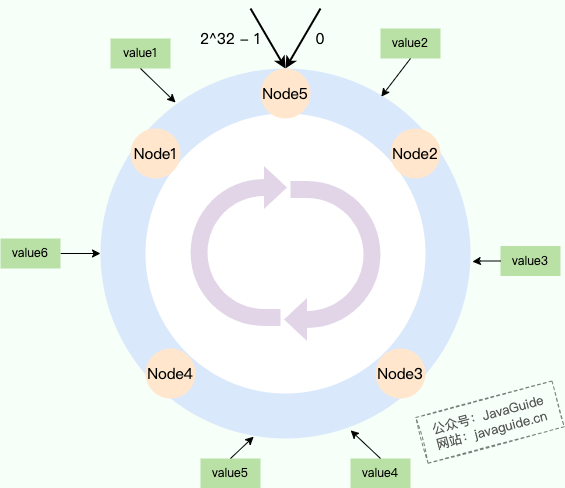 |
| 89 | + |
| 90 | +### 数据倾斜问题 |
| 91 | + |
| 92 | +理想情况下,节点在环上是均匀分布的。然而,现实可能并不是这样的,尤其是节点数量比较少的时候。节点可能被映射到附近的区域,这样的话,就会导致绝大部分数据都由其中一个节点负责。 |
| 93 | + |
| 94 | +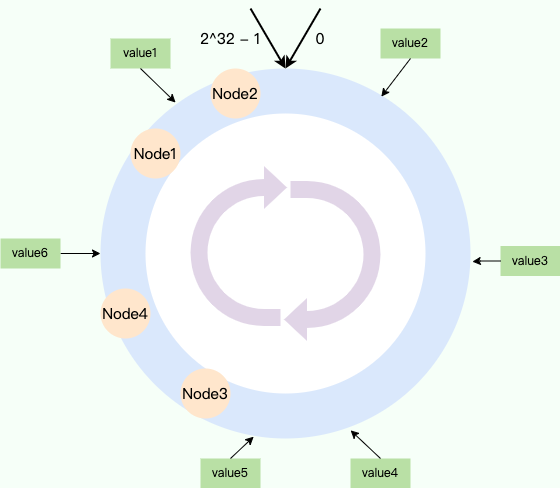 |
| 95 | + |
| 96 | +对于上图来说,每个节点负责的数据情况如下: |
| 97 | + |
| 98 | +- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。 |
| 99 | +- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1)。 |
| 100 | +- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value2,value3, value4, value5)。 |
| 101 | +- **Node4:** 负责 Node3 到 Node4 之间的区域。 |
| 102 | + |
| 103 | +除了数据倾斜问题,还有一个隐患。当新增或者删除节点的时候,数据分配不均衡。例如,Node3 被移除的话,Node3 负责的所有数据都要交给 Node4,随后所有的请求都要达到 Node4 上。假设 Node4 的服务器处理能力比较差的话,那可能直接就被干崩了。理想情况下,应该有更多节点来分担压力。 |
| 104 | + |
| 105 | +如何解决这些问题呢?答案是引入**虚拟节点**。 |
| 106 | + |
| 107 | +### 虚拟节点 |
| 108 | + |
| 109 | +虚拟节点就是对真实的物理节点在哈希环上虚拟出几个它的分身节点。数据落到分身节点上实际上就是落到真实的物理节点上,通过将虚拟节点均匀分散在哈希环的各个部分。 |
| 110 | + |
| 111 | +如下图所示,Node1、Node2、Node3、Node4 这 4 个节点都对应 3 个虚拟节点(下图只是为了演示,实际情况节点分布不会这么有规律)。 |
| 112 | + |
| 113 | +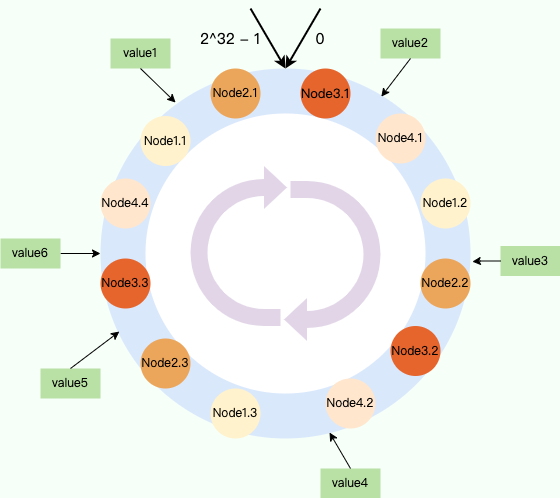 |
| 114 | + |
| 115 | +对于上图来说,每个节点最终负责的数据情况如下: |
| 116 | + |
| 117 | +- **Node1**:value4 |
| 118 | +- **Node2**:value1,value3 |
| 119 | +- **Node3**:value5 |
| 120 | +- **Node4**:value2,value6 |
| 121 | + |
| 122 | +**引入虚拟节点的好处是巨大的:** |
| 123 | + |
| 124 | +1. **数据均衡:** 虚拟节点越多,环上的“服务器点”就越密集,数据分布自然就越均匀,从根本上解决了数据倾斜问题。通常,每个真实节点对应的虚拟节点数在 100 到 200 之间,例如 Nginx 选择为每个权重分配 160 个虚拟节点。这里的权重的是为了区分服务器,例如处理能力更强的服务器权重越高,进而导致对应的虚拟节点越多,被命中的概率越大。 |
| 125 | +2. **容错性增强:** 这才是虚拟节点最精妙的地方。当一个物理节点宕机,它相当于在环上的多个虚拟节点同时下线。这些虚拟节点原本负责的数据和流量,会**自然地、均匀地分散**给环上其他**多个不同**的物理节点去接管,而不会将压力集中于某一个邻居节点。这极大地提升了系统的稳定性和容错能力。 |
| 126 | + |
| 127 | +## 参考 |
| 128 | + |
| 129 | +- 深入剖析 Nginx 负载均衡算法:<https://www.taohui.tech/2021/02/08/nginx/%E6%B7%B1%E5%85%A5%E5%89%96%E6%9E%90Nginx%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1%E7%AE%97%E6%B3%95/> |
| 130 | +- 读源码学架构系列:一致性哈希:<https://zhaoyang.me/posts/consistent-hash-algorithm/> |
| 131 | +- 一致性 Hash 算法原理总结:<https://mp.weixin.qq.com/s/WTz1KA9kOGrqFVTtALJzjQ> |
0 commit comments