` 三元组的形式存储。其中,TTL 为该映射关系的生存周期,典型值为 20 分钟,超过该时间,该条目将被丢弃。
+
+ARP 的工作原理将分两种场景讨论:
+
+1. **同一局域网内的 MAC 寻址**;
+2. **从一个局域网到另一个局域网中的网络设备的寻址**。
+
+### 同一局域网内的 MAC 寻址
+
+假设当前有如下场景:IP 地址为`137.196.7.23`的主机 A,想要给同一局域网内的 IP 地址为`137.196.7.14`主机 B,发送 IP 数据报文。
+
+> 再次强调,当主机发送 IP 数据报文时(网络层),仅知道目的地的 IP 地址,并不清楚目的地的 MAC 地址,而 ARP 协议就是解决这一问题的。
+
+为了达成这一目标,主机 A 将不得不通过 ARP 协议来获取主机 B 的 MAC 地址,并将 IP 报文封装成链路层帧,发送到下一跳上。在该局域网内,关于此将按照时间顺序,依次发生如下事件:
+
+1. 主机 A 检索自己的 ARP 表,发现 ARP 表中并无主机 B 的 IP 地址对应的映射条目,也就无从知道主机 B 的 MAC 地址。
+
+2. 主机 A 将构造一个 ARP 查询分组,并将其广播到所在的局域网中。
+
+ ARP 分组是一种特殊报文,ARP 分组有两类,一种是查询分组,另一种是响应分组,它们具有相同的格式,均包含了发送和接收的 IP 地址、发送和接收的 MAC 地址。当然了,查询分组中,发送的 IP 地址,即为主机 A 的 IP 地址,接收的 IP 地址即为主机 B 的 IP 地址,发送的 MAC 地址也是主机 A 的 MAC 地址,但接收的 MAC 地址绝不会是主机 B 的 MAC 地址(因为这正是我们要问询的!),而是一个特殊值——`FF-FF-FF-FF-FF-FF`,之前说过,该 MAC 地址是广播地址,也就是说,查询分组将广播给该局域网内的所有设备。
+
+3. 主机 A 构造的查询分组将在该局域网内广播,理论上,每一个设备都会收到该分组,并检查查询分组的接收 IP 地址是否为自己的 IP 地址,如果是,说明查询分组已经到达了主机 B,否则,该查询分组对当前设备无效,丢弃之。
+
+4. 主机 B 收到了查询分组之后,验证是对自己的问询,接着构造一个 ARP 响应分组,该分组的目的地只有一个——主机 A,发送给主机 A。同时,主机 B 提取查询分组中的 IP 地址和 MAC 地址信息,在自己的 ARP 表中构造一条主机 A 的 IP-MAC 映射记录。
+
+ ARP 响应分组具有和 ARP 查询分组相同的构造,不同的是,发送和接受的 IP 地址恰恰相反,发送的 MAC 地址为发送者本身,目标 MAC 地址为查询分组的发送者,也就是说,ARP 响应分组只有一个目的地,而非广播。
+
+5. 主机 A 终将收到主机 B 的响应分组,提取出该分组中的 IP 地址和 MAC 地址后,构造映射信息,加入到自己的 ARP 表中。
+
+
+
+在整个过程中,有几点需要补充说明的是:
+
+1. 主机 A 想要给主机 B 发送 IP 数据报,如果主机 B 的 IP-MAC 映射信息已经存在于主机 A 的 ARP 表中,那么主机 A 无需广播,只需提取 MAC 地址并构造链路层帧发送即可。
+2. ARP 表中的映射信息是有生存周期的,典型值为 20 分钟。
+3. 目标主机接收到了问询主机构造的问询报文后,将先把问询主机的 IP-MAC 映射存进自己的 ARP 表中,这样才能获取到响应的目标 MAC 地址,顺利的发送响应分组。
+
+总结来说,ARP 协议是一个**广播问询,单播响应**协议。
+
+### 不同局域网内的 MAC 寻址
+
+更复杂的情况是,发送主机 A 和接收主机 B 不在同一个子网中,假设一个一般场景,两台主机所在的子网由一台路由器联通。这里需要注意的是,一般情况下,我们说网络设备都有一个 IP 地址和一个 MAC 地址,这里说的网络设备,更严谨的说法应该是一个接口。路由器作为互联设备,具有多个接口,每个接口同样也应该具备不重复的 IP 地址和 MAC 地址。因此,在讨论 ARP 表时,路由器的多个接口都各自维护一个 ARP 表,而非一个路由器只维护一个 ARP 表。
+
+接下来,回顾同一子网内的 MAC 寻址,如果主机 A 发送一个广播问询分组,那么 A 所在的子网内所有设备(接口)都将会捕获该分组,因为该分组的目的 IP 与发送主机 A 的 IP 在同一个子网中。但是当目的 IP 与 A 不在同一子网时,A 所在子网内将不会有设备成功接收该分组。那么,主机 A 应该发送怎样的查询分组呢?整个过程按照时间顺序发生的事件如下:
+
+1. 主机 A 查询 ARP 表,期望寻找到目标路由器的本子网接口的 MAC 地址。
+
+The destination router refers to the router that can analyze the subnet where B is located based on the IP address of destination host B and can forward the packet to the subnet where B is located.
+
+2. Host A cannot find the MAC address of the subnet interface of the target router. It will use the ARP protocol to query the MAC address. Since the target interface and host A are in the same subnet, the process is the same as MAC addressing in the same LAN.
+
+3. Host A obtains the MAC address of the target interface, first constructs an IP datagram, where the source IP is A's IP address, and the destination IP address is B's IP address, and then constructs a link layer frame, where the source MAC address is A's MAC address, and the destination MAC address is the MAC address of the interface connected to the router in this subnet. Host A will send this link layer frame to the target interface in unicast mode.
+
+4. The target interface receives the link layer frame sent from host A, parses it, queries the forwarding table based on the destination IP address, and forwards the IP datagram to the interface connected to the subnet where host B is located.
+
+ At this point, the frame has been transferred from the subnet where host A is located to the subnet where host B is located.
+
+5. The router interface queries the ARP table, hoping to find the MAC address of host B.
+
+6. If the router interface fails to find the MAC address of host B, it will use the ARP protocol, broadcast inquiry, and unicast response to obtain the MAC address of host B.
+
+7. The router interface will re-encapsulate the IP datagram into a link layer frame, with the destination MAC address being the MAC address of host B, and send it in unicast until the destination.
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/computer-network-xiexiren-summary.en.md b/docs_en/cs-basics/network/computer-network-xiexiren-summary.en.md
new file mode 100644
index 00000000000..0d217320c4e
--- /dev/null
+++ b/docs_en/cs-basics/network/computer-network-xiexiren-summary.en.md
@@ -0,0 +1,328 @@
+---
+title: 《计算机网络》(谢希仁)内容总结
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络,谢希仁,术语,分层模型,链路,主机,教材总结
+ - - meta
+ - name: description
+ content: 基于《计算机网络》教材的学习笔记,梳理术语与分层模型等核心知识点,便于期末复习与面试巩固。
+---
+
+本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
+
+
+
+相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966) 。
+
+## 1. 计算机网络概述
+
+### 1.1. 基本术语
+
+1. **结点 (node)**:网络中的结点可以是计算机,集线器,交换机或路由器等。
+2. **链路(link )** : 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
+3. **主机(host)**:连接在因特网上的计算机。
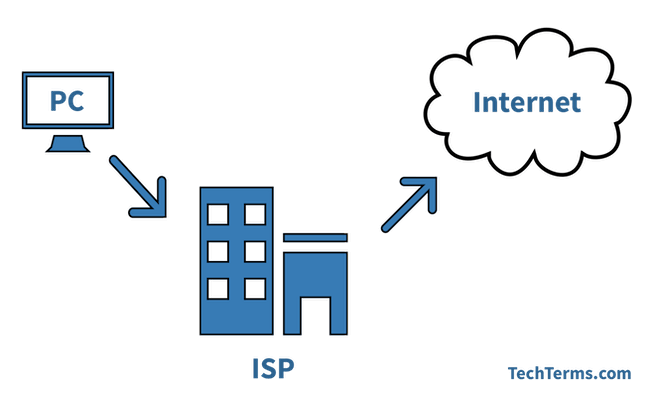
+4. **ISP(Internet Service Provider)**:因特网服务提供者(提供商)。
+
+ 
+
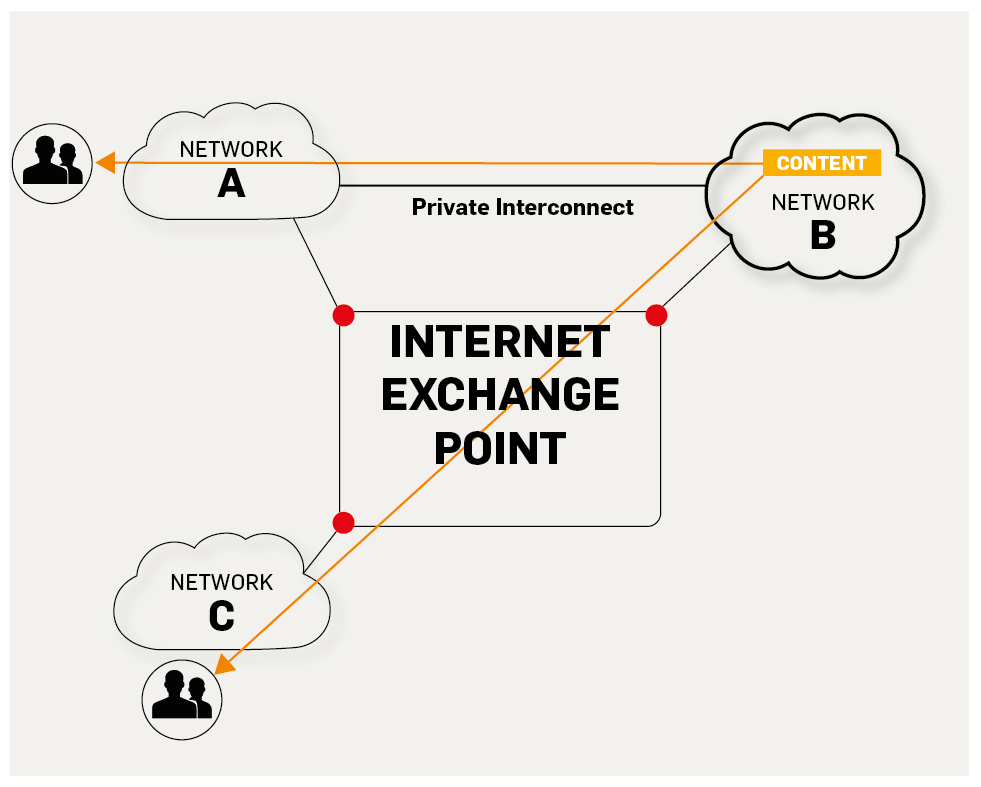
+5. **IXP(Internet eXchange Point)**:互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
+
+ 
+
+ https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
+
+6. **RFC(Request For Comments)**:意思是“请求评议”,包含了关于 Internet 几乎所有的重要的文字资料。
+7. **广域网 WAN(Wide Area Network)**:任务是通过长距离运送主机发送的数据。
+8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
+9. **局域网 LAN(Local Area Network)**:学校或企业大多拥有多个互连的局域网。
+
+ 
+
+ http://conexionesmanwman.blogspot.com/
+
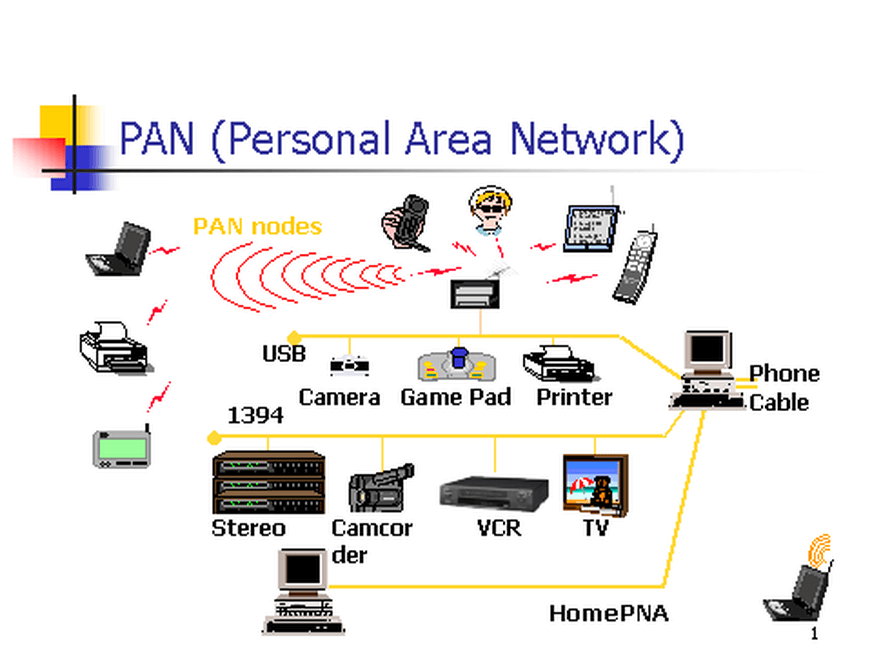
+10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
+
+ 
+
+ https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
+
+11. **分组(packet )**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
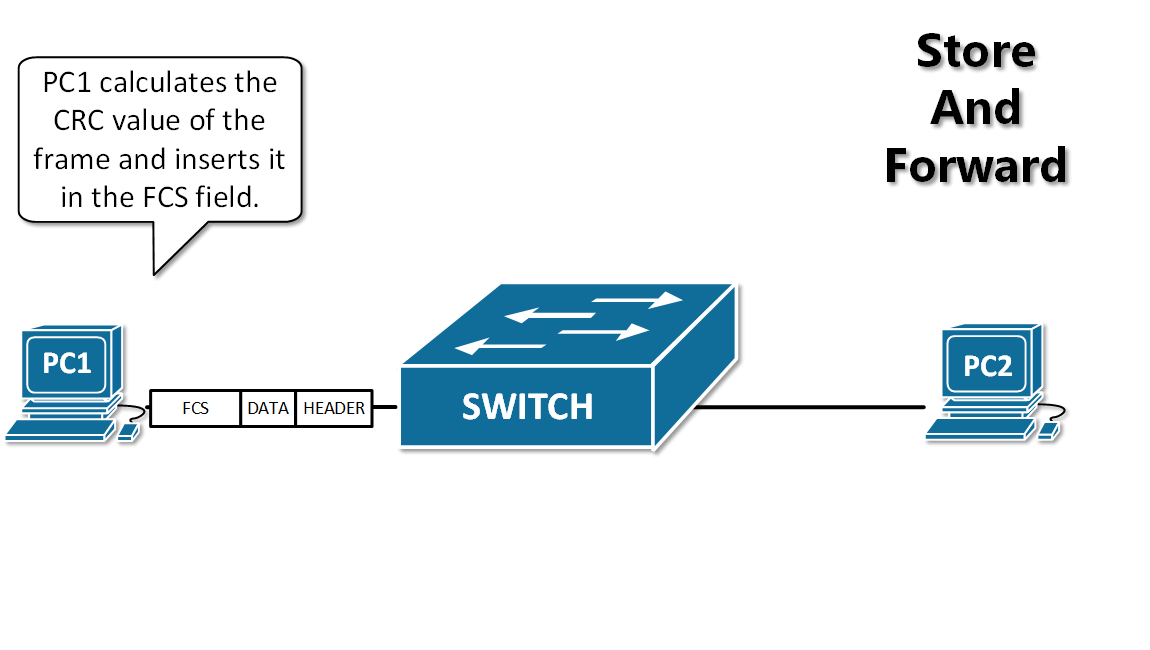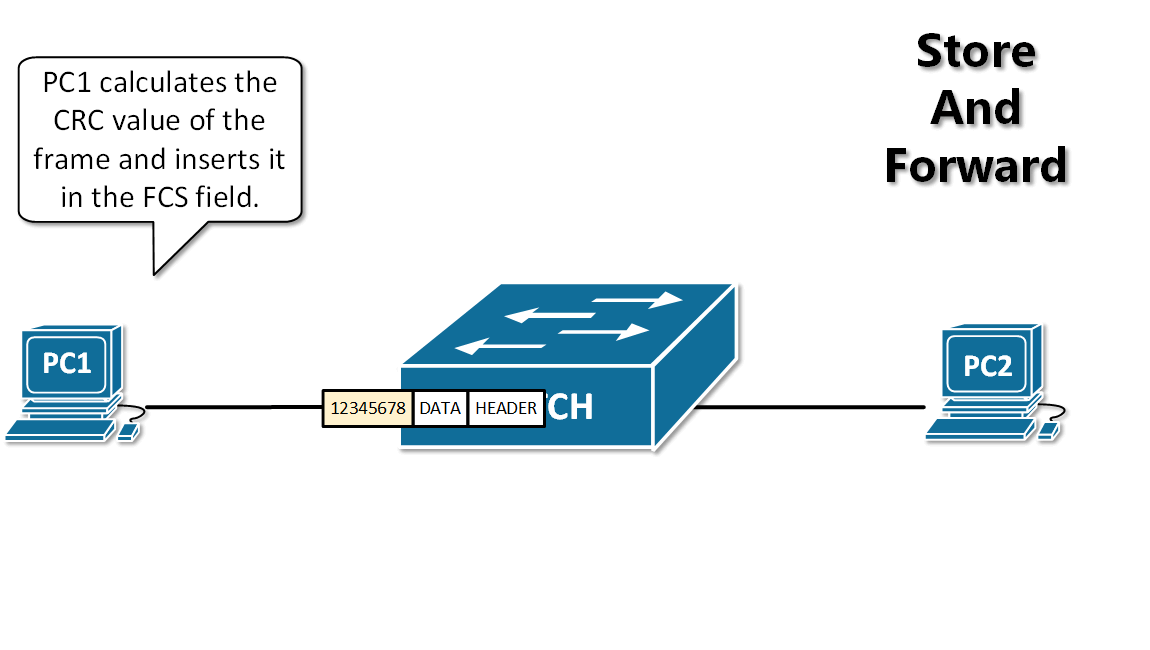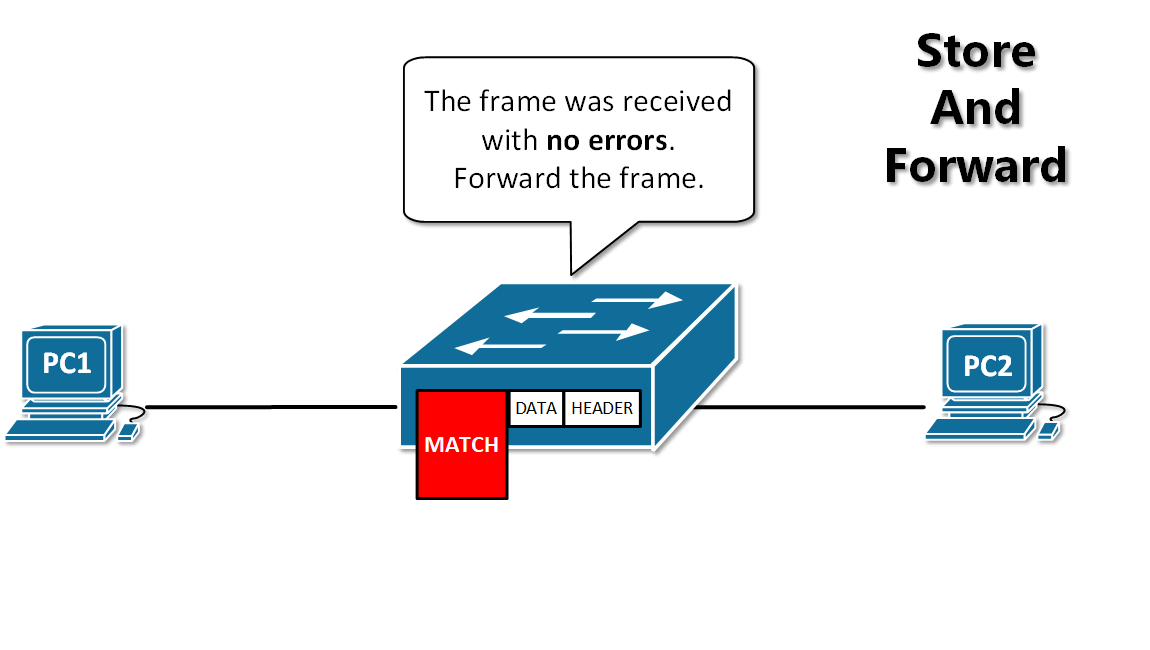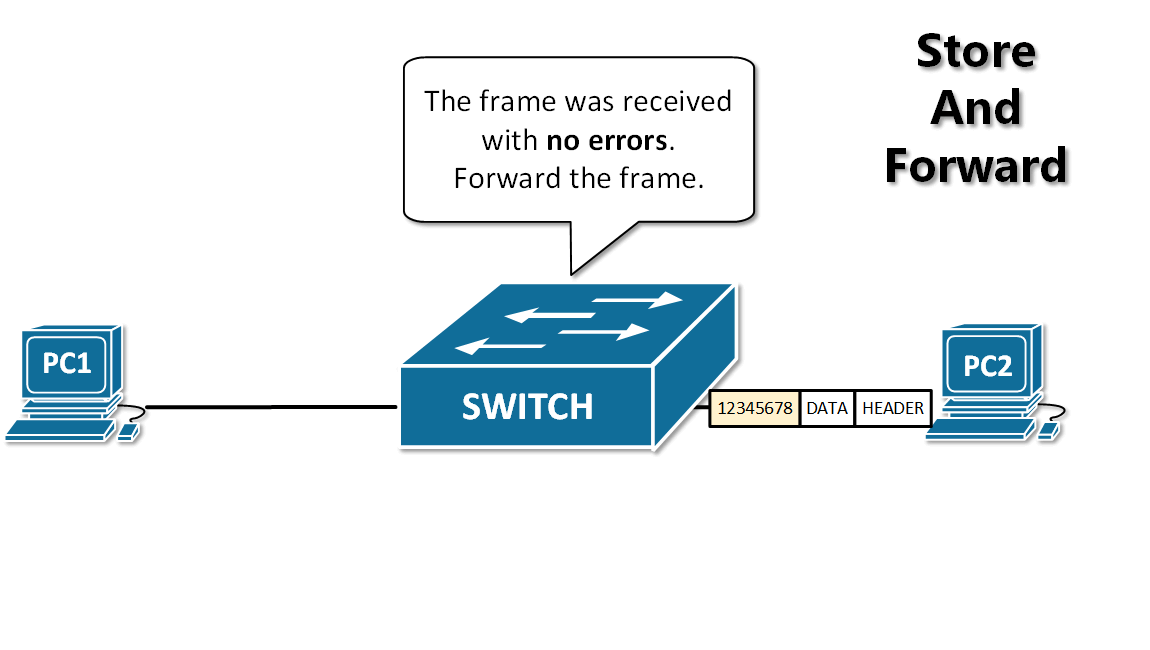
+12. **存储转发(store and forward )**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
+
+ 
+
+13. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
+14. **吞吐量(throughput )**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
+
+### 1.2. 重要知识点总结
+
+1. **计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。**
+2. 小写字母 i 开头的 internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。大写字母 I 开头的 Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用 TCP/IP 协议作为通信规则,其前身为 ARPANET。Internet 的推荐译名为因特网,现在一般流行称为互联网。
+3. 路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据段的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
+4. 互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
+5. 计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S 方式)和对等连接方式(P2P 方式)。
+6. 客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
+7. 按照作用范围的不同,计算机网络分为广域网 WAN,城域网 MAN,局域网 LAN,个人区域网 PAN。
+8. **计算机网络最常用的性能指标是:速率,带宽,吞吐量,时延(发送时延,处理时延,排队时延),时延带宽积,往返时间和信道利用率。**
+9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
+10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
+
+
+
+下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
+
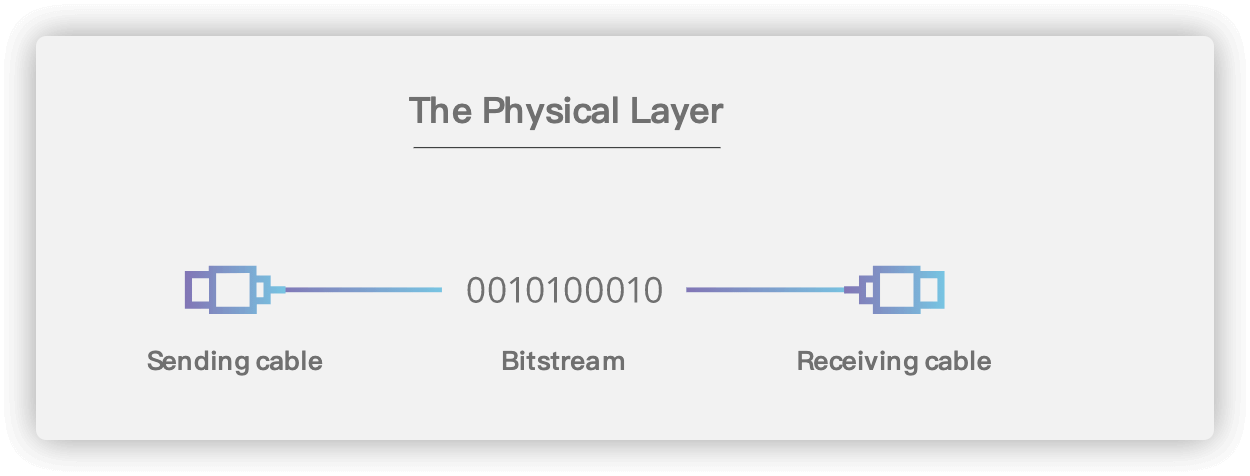
+## 2. 物理层(Physical Layer)
+
+
+
+### 2.1. 基本术语
+
+1. **数据(data)**:运送消息的实体。
+2. **信号(signal)**:数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
+3. **码元( code)**:在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
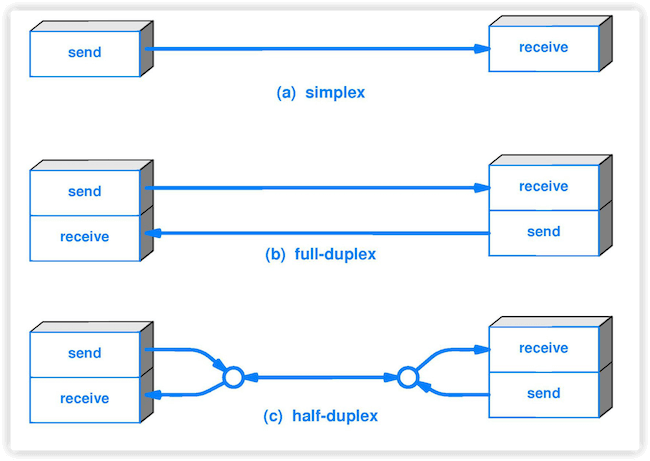
+4. **单工(simplex )**:只能有一个方向的通信而没有反方向的交互。
+5. **半双工(half duplex )**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
+6. **全双工(full duplex)**:通信的双方可以同时发送和接收信息。
+
+ 
+
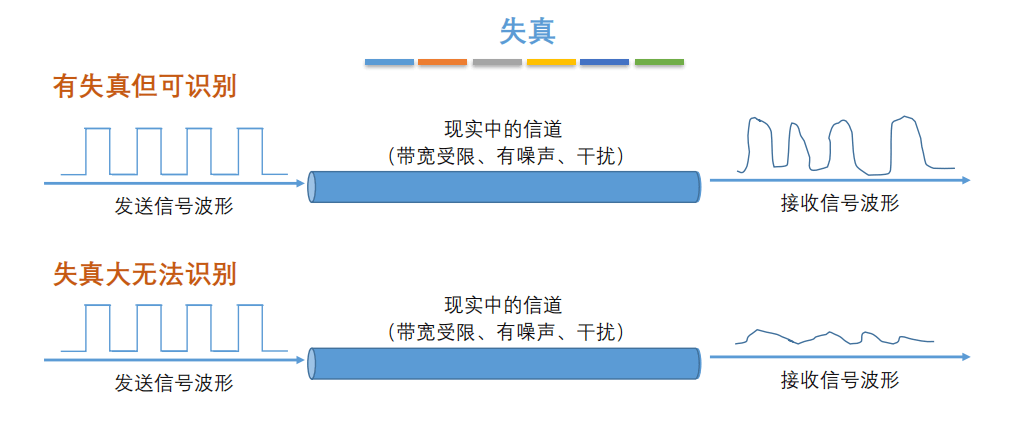
+7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
+
+ 
+
+8. **奈氏准则**:在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
+9. **香农定理**:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
+10. **基带信号(baseband signal)**:来自信源的信号。指没有经过调制的数字信号或模拟信号。
+11. **带通(频带)信号(bandpass signal)**:把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
+12. **调制(modulation )**:对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
+13. **信噪比(signal-to-noise ratio )**:指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
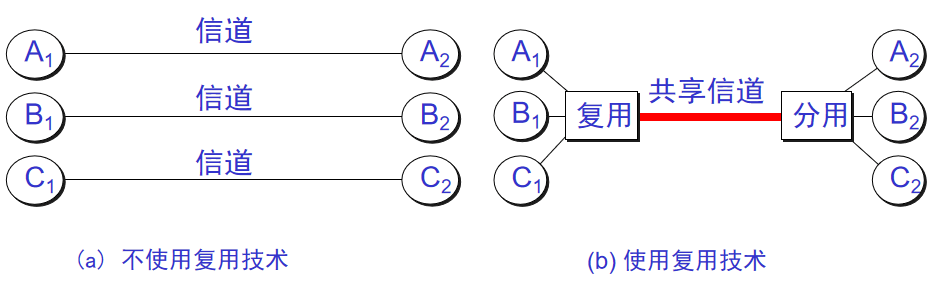
+14. **信道复用(channel multiplexing )**:指多个用户共享同一个信道。(并不一定是同时)。
+
+ 
+
+15. **比特率(bit rate )**:单位时间(每秒)内传送的比特数。
+16. **波特率(baud rate)**:单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
+17. **复用(multiplexing)**:共享信道的方法。
+18. **ADSL(Asymmetric Digital Subscriber Line )**:非对称数字用户线。
+19. **光纤同轴混合网(HFC 网)**:在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
+
+### 2.2. 重要知识点总结
+
+1. **物理层的主要任务就是确定与传输媒体接口有关的一些特性,如机械特性,电气特性,功能特性,过程特性。**
+2. 一个数据通信系统可划分为三大部分,即源系统,传输系统,目的系统。源系统包括源点(或源站,信源)和发送器,目的系统包括接收器和终点。
+3. **通信的目的是传送消息。如话音,文字,图像等都是消息,数据是运送消息的实体。信号则是数据的电气或电磁的表现。**
+4. 根据信号中代表消息的参数的取值方式不同,信号可分为模拟信号(或连续信号)和数字信号(或离散信号)。在使用时间域(简称时域)的波形表示数字信号时,代表不同离散数值的基本波形称为码元。
+5. 根据双方信息交互的方式,通信可划分为单向通信(或单工通信),双向交替通信(或半双工通信),双向同时通信(全双工通信)。
+6. 来自信源的信号称为基带信号。信号要在信道上传输就要经过调制。调制有基带调制和带通调制之分。最基本的带通调制方法有调幅,调频和调相。还有更复杂的调制方法,如正交振幅调制。
+7. 要提高数据在信道上的传递速率,可以使用更好的传输媒体,或使用先进的调制技术。但数据传输速率不可能任意被提高。
+8. 传输媒体可分为两大类,即导引型传输媒体(双绞线,同轴电缆,光纤)和非导引型传输媒体(无线,红外,大气激光)。
+9. 为了有效利用光纤资源,在光纤干线和用户之间广泛使用无源光网络 PON。无源光网络无需配备电源,其长期运营成本和管理成本都很低。最流行的无源光网络是以太网无源光网络 EPON 和吉比特无源光网络 GPON。
+
+### 2.3. 补充
+
+#### 2.3.1. 物理层主要做啥?
+
+物理层主要做的事情就是 **透明地传送比特流**。也可以将物理层的主要任务描述为确定与传输媒体的接口的一些特性,即:机械特性(接口所用接线器的一些物理属性如形状和尺寸),电气特性(接口电缆的各条线上出现的电压的范围),功能特性(某条线上出现的某一电平的电压的意义),过程特性(对于不同功能的各种可能事件的出现顺序)。
+
+**物理层考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。** 现有的计算机网络中的硬件设备和传输媒体的种类非常繁多,而且通信手段也有许多不同的方式。物理层的作用正是尽可能地屏蔽掉这些传输媒体和通信手段的差异,使物理层上面的数据链路层感觉不到这些差异,这样就可以使数据链路层只考虑完成本层的协议和服务,而不必考虑网络的具体传输媒体和通信手段是什么。
+
+#### 2.3.2. 几种常用的信道复用技术
+
+1. **频分复用(FDM)**:所有用户在同样的时间占用不同的带宽资源。
+2. **时分复用(TDM)**:所有用户在不同的时间占用同样的频带宽度(分时不分频)。
+3. **统计时分复用 (Statistic TDM)**:改进的时分复用,能够明显提高信道的利用率。
+4. **码分复用(CDM)**:用户使用经过特殊挑选的不同码型,因此各用户之间不会造成干扰。这种系统发送的信号有很强的抗干扰能力,其频谱类似于白噪声,不易被敌人发现。
+5. **波分复用( WDM)**:波分复用就是光的频分复用。
+
+#### 2.3.3. 几种常用的宽带接入技术,主要是 ADSL 和 FTTx
+
+用户到互联网的宽带接入方法有非对称数字用户线 ADSL(用数字技术对现有的模拟电话线进行改造,而不需要重新布线。ADSL 的快速版本是甚高速数字用户线 VDSL。),光纤同轴混合网 HFC(是在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网)和 FTTx(即光纤到······)。
+
+## 3. 数据链路层(Data Link Layer)
+
+
+
+### 3.1. 基本术语
+
+1. **链路(link)**:一个结点到相邻结点的一段物理链路。
+2. **数据链路(data link)**:把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路。
+3. **循环冗余检验 CRC(Cyclic Redundancy Check)**:为了保证数据传输的可靠性,CRC 是数据链路层广泛使用的一种检错技术。
+4. **帧(frame)**:一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
+5. **MTU(Maximum Transfer Uint )**:最大传送单元。帧的数据部分的的长度上限。
+6. **误码率 BER(Bit Error Rate )**:在一段时间内,传输错误的比特占所传输比特总数的比率。
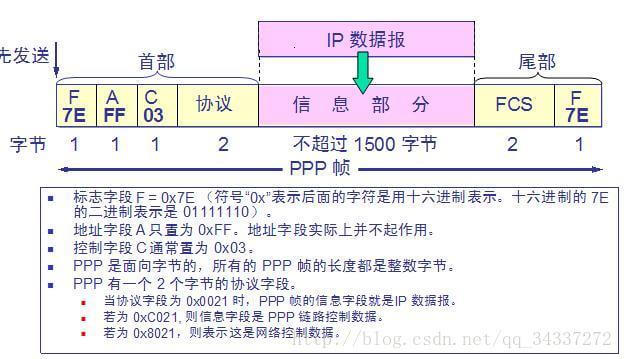
+7. **PPP(Point-to-Point Protocol )**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
+ 
+8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
+
+ 
+
+9. **网桥(bridge)**:一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
+10. **交换机(switch )**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
+
+### 3.2. 重要知识点总结
+
+1. 链路是从一个结点到相邻结点的一段物理链路,数据链路则在链路的基础上增加了一些必要的硬件(如网络适配器)和软件(如协议的实现)
+2. 数据链路层使用的主要是**点对点信道**和**广播信道**两种。
+3. 数据链路层传输的协议数据单元是帧。数据链路层的三个基本问题是:**封装成帧**,**透明传输**和**差错检测**
+4. **循环冗余检验 CRC** 是一种检错方法,而帧检验序列 FCS 是添加在数据后面的冗余码
+5. **点对点协议 PPP** 是数据链路层使用最多的一种协议,它的特点是:简单,只检测差错而不去纠正差错,不使用序号,也不进行流量控制,可同时支持多种网络层协议
+6. PPPoE 是为宽带上网的主机使用的链路层协议
+7. **局域网的优点是:具有广播功能,从一个站点可方便地访问全网;便于系统的扩展和逐渐演变;提高了系统的可靠性,可用性和生存性。**
+8. 计算机与外接局域网通信需要通过通信适配器(或网络适配器),它又称为网络接口卡或网卡。**计算器的硬件地址就在适配器的 ROM 中**。
+9. 以太网采用的无连接的工作方式,对发送的数据帧不进行编号,也不要求对方发回确认。目的站收到有差错帧就把它丢掉,其他什么也不做
+10. 以太网采用的协议是具有冲突检测的**载波监听多点接入 CSMA/CD**。协议的特点是:**发送前先监听,边发送边监听,一旦发现总线上出现了碰撞,就立即停止发送。然后按照退避算法等待一段随机时间后再次发送。** 因此,每一个站点在自己发送数据之后的一小段时间内,存在着遭遇碰撞的可能性。以太网上的各站点平等地争用以太网信道
+11. 以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。
+12. 使用集线器可以在物理层扩展以太网(扩展后的以太网仍然是一个网络)
+
+### 3.3. 补充
+
+1. 数据链路层的点对点信道和广播信道的特点,以及这两种信道所使用的协议(PPP 协议以及 CSMA/CD 协议)的特点
+2. 数据链路层的三个基本问题:**封装成帧**,**透明传输**,**差错检测**
+3. 以太网的 MAC 层硬件地址
+4. 适配器,转发器,集线器,网桥,以太网交换机的作用以及适用场合
+
+## 4. 网络层(Network Layer)
+
+
+
+### 4.1. 基本术语
+
+1. **虚电路(Virtual Circuit)** : 在两个终端设备的逻辑或物理端口之间,通过建立的双向的透明传输通道。虚电路表示这只是一条逻辑上的连接,分组都沿着这条逻辑连接按照存储转发方式传送,而并不是真正建立了一条物理连接。
+2. **IP(Internet Protocol )** : 网际协议 IP 是 TCP/IP 体系中两个最主要的协议之一,是 TCP/IP 体系结构网际层的核心。配套的有 ARP,RARP,ICMP,IGMP。
+3. **ARP(Address Resolution Protocol)** : 地址解析协议。地址解析协议 ARP 把 IP 地址解析为硬件地址。
+4. **ICMP(Internet Control Message Protocol )**:网际控制报文协议 (ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告)。
+5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
+6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
+7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
+8. **路由选择算法(Routing Algorithm)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
+
+### 4.2. 重要知识点总结
+
+1. **TCP/IP 协议中的网络层向上只提供简单灵活的,无连接的,尽最大努力交付的数据报服务。网络层不提供服务质量的承诺,不保证分组交付的时限,所传送的分组可能出错、丢失、重复和失序。进程之间通信的可靠性由运输层负责**
+2. 在互联网的交付有两种,一是在本网络直接交付不用经过路由器,另一种是和其他网络的间接交付,至少经过一个路由器,但最后一次一定是直接交付
+3. 分类的 IP 地址由网络号字段(指明网络)和主机号字段(指明主机)组成。网络号字段最前面的类别指明 IP 地址的类别。IP 地址是一种分等级的地址结构。IP 地址管理机构分配 IP 地址时只分配网络号,主机号由得到该网络号的单位自行分配。路由器根据目的主机所连接的网络号来转发分组。一个路由器至少连接到两个网络,所以一个路由器至少应当有两个不同的 IP 地址
+4. IP 数据报分为首部和数据两部分。首部的前一部分是固定长度,共 20 字节,是所有 IP 数据包必须具有的(源地址,目的地址,总长度等重要地段都固定在首部)。一些长度可变的可选字段固定在首部的后面。IP 首部中的生存时间给出了 IP 数据报在互联网中所能经过的最大路由器数。可防止 IP 数据报在互联网中无限制的兜圈子。
+5. **地址解析协议 ARP 把 IP 地址解析为硬件地址。ARP 的高速缓存可以大大减少网络上的通信量。因为这样可以使主机下次再与同样地址的主机通信时,可以直接从高速缓存中找到所需要的硬件地址而不需要再去以广播方式发送 ARP 请求分组**
+6. 无分类域间路由选择 CIDR 是解决目前 IP 地址紧缺的一个好办法。CIDR 记法在 IP 地址后面加上斜线“/”,然后写上前缀所占的位数。前缀(或网络前缀)用来指明网络,前缀后面的部分是后缀,用来指明主机。CIDR 把前缀都相同的连续的 IP 地址组成一个“CIDR 地址块”,IP 地址分配都以 CIDR 地址块为单位。
+7. 网际控制报文协议是 IP 层的协议。ICMP 报文作为 IP 数据报的数据,加上首部后组成 IP 数据报发送出去。使用 ICMP 数据报并不是为了实现可靠传输。ICMP 允许主机或路由器报告差错情况和提供有关异常情况的报告。ICMP 报文的种类有两种,即 ICMP 差错报告报文和 ICMP 询问报文。
+8. **要解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议-IPv6。** IPv6 所带来的变化有 ① 更大的地址空间(采用 128 位地址)② 灵活的首部格式 ③ 改进的选项 ④ 支持即插即用 ⑤ 支持资源的预分配 ⑥IPv6 的首部改为 8 字节对齐。
+9. **虚拟专用网络 VPN 利用公用的互联网作为本机构专用网之间的通信载体。VPN 内使用互联网的专用地址。一个 VPN 至少要有一个路由器具有合法的全球 IP 地址,这样才能和本系统的另一个 VPN 通过互联网进行通信。所有通过互联网传送的数据都需要加密。**
+10. MPLS 的特点是:① 支持面向连接的服务质量 ② 支持流量工程,平衡网络负载 ③ 有效的支持虚拟专用网 VPN。MPLS 在入口节点给每一个 IP 数据报打上固定长度的“标记”,然后根据标记在第二层(链路层)用硬件进行转发(在标记交换路由器中进行标记交换),因而转发速率大大加快。
+
+## 5. 传输层(Transport Layer)
+
+
+
+### 5.1. 基本术语
+
+1. **进程(process)**:指计算机中正在运行的程序实体。
+2. **应用进程互相通信**:一台主机的进程和另一台主机中的一个进程交换数据的过程(另外注意通信真正的端点不是主机而是主机中的进程,也就是说端到端的通信是应用进程之间的通信)。
+3. **传输层的复用与分用**:复用指发送方不同的进程都可以通过同一个运输层协议传送数据。分用指接收方的运输层在剥去报文的首部后能把这些数据正确的交付到目的应用进程。
+4. **TCP(Transmission Control Protocol)**:传输控制协议。
+5. **UDP(User Datagram Protocol)**:用户数据报协议。
+
+ 
+
+6. **端口(port)**:端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
+7. **停止等待协议(stop-and-wait)**:指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
+8. **流量控制** : 就是让发送方的发送速率不要太快,既要让接收方来得及接收,也不要使网络发生拥塞。
+9. **拥塞控制**:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。
+
+### 5.2. 重要知识点总结
+
+1. **运输层提供应用进程之间的逻辑通信,也就是说,运输层之间的通信并不是真正在两个运输层之间直接传输数据。运输层向应用层屏蔽了下面网络的细节(如网络拓补,所采用的路由选择协议等),它使应用进程之间看起来好像两个运输层实体之间有一条端到端的逻辑通信信道。**
+2. **网络层为主机提供逻辑通信,而运输层为应用进程之间提供端到端的逻辑通信。**
+3. 运输层的两个重要协议是用户数据报协议 UDP 和传输控制协议 TCP。按照 OSI 的术语,两个对等运输实体在通信时传送的数据单位叫做运输协议数据单元 TPDU(Transport Protocol Data Unit)。但在 TCP/IP 体系中,则根据所使用的协议是 TCP 或 UDP,分别称之为 TCP 报文段或 UDP 用户数据报。
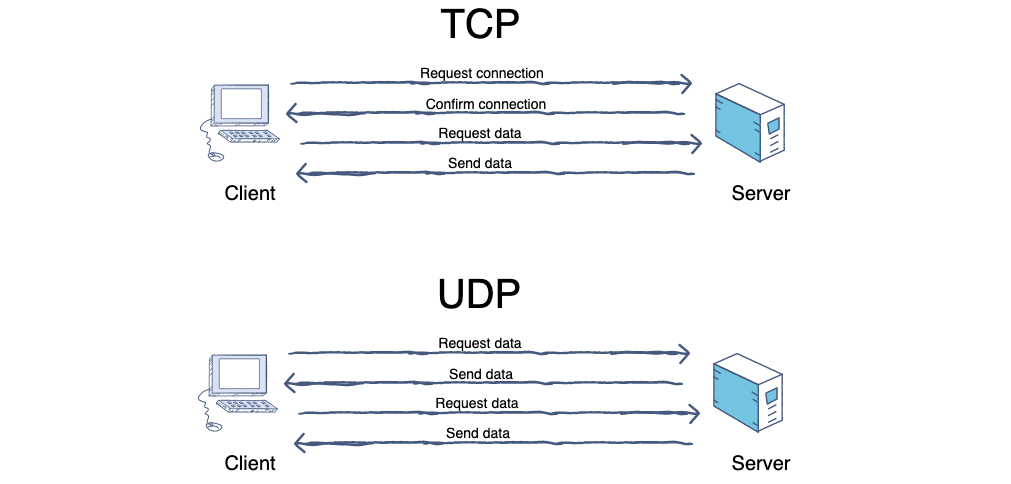
+4. **UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式。 TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务,难以避免地增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。**
+5. 硬件端口是不同硬件设备进行交互的接口,而软件端口是应用层各种协议进程与运输实体进行层间交互的一种地址。UDP 和 TCP 的首部格式中都有源端口和目的端口这两个重要字段。当运输层收到 IP 层交上来的运输层报文时,就能够根据其首部中的目的端口号把数据交付应用层的目的应用层。(两个进程之间进行通信不光要知道对方 IP 地址而且要知道对方的端口号(为了找到对方计算机中的应用进程))
+6. 运输层用一个 16 位端口号标志一个端口。端口号只有本地意义,它只是为了标志计算机应用层中的各个进程在和运输层交互时的层间接口。在互联网的不同计算机中,相同的端口号是没有关联的。协议端口号简称端口。虽然通信的终点是应用进程,但只要把所发送的报文交到目的主机的某个合适端口,剩下的工作(最后交付目的进程)就由 TCP 和 UDP 来完成。
+7. 运输层的端口号分为服务器端使用的端口号(0˜1023 指派给熟知端口,1024˜49151 是登记端口号)和客户端暂时使用的端口号(49152˜65535)
+8. **UDP 的主要特点是 ① 无连接 ② 尽最大努力交付 ③ 面向报文 ④ 无拥塞控制 ⑤ 支持一对一,一对多,多对一和多对多的交互通信 ⑥ 首部开销小(只有四个字段:源端口,目的端口,长度和检验和)**
+9. **TCP 的主要特点是 ① 面向连接 ② 每一条 TCP 连接只能是一对一的 ③ 提供可靠交付 ④ 提供全双工通信 ⑤ 面向字节流**
+10. **TCP 用主机的 IP 地址加上主机上的端口号作为 TCP 连接的端点。这样的端点就叫做套接字(socket)或插口。套接字用(IP 地址:端口号)来表示。每一条 TCP 连接唯一地被通信两端的两个端点所确定。**
+11. 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
+12. 为了提高传输效率,发送方可以不使用低效率的停止等待协议,而是采用流水线传输。流水线传输就是发送方可连续发送多个分组,不必每发完一个分组就停下来等待对方确认。这样可使信道上一直有数据不间断的在传送。这种传输方式可以明显提高信道利用率。
+13. 停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求 ARQ。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。连续 ARQ 协议可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
+14. TCP 报文段的前 20 个字节是固定的,其后有 40 字节长度的可选字段。如果加入可选字段后首部长度不是 4 的整数倍字节,需要在再在之后用 0 填充。因此,TCP 首部的长度取值为 20+4n 字节,最长为 60 字节。
+15. **TCP 使用滑动窗口机制。发送窗口里面的序号表示允许发送的序号。发送窗口后沿的后面部分表示已发送且已收到确认,而发送窗口前沿的前面部分表示不允许发送。发送窗口后沿的变化情况有两种可能,即不动(没有收到新的确认)和前移(收到了新的确认)。发送窗口的前沿通常是不断向前移动的。一般来说,我们总是希望数据传输更快一些。但如果发送方把数据发送的过快,接收方就可能来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。**
+16. 在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
+17. **为了进行拥塞控制,TCP 发送方要维持一个拥塞窗口 cwnd 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。**
+18. **TCP 的拥塞控制采用了四种算法,即慢开始,拥塞避免,快重传和快恢复。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。**
+19. 运输连接的三个阶段,即:连接建立,数据传送和连接释放。
+20. **主动发起 TCP 连接建立的应用进程叫做客户,而被动等待连接建立的应用进程叫做服务器。TCP 连接采用三报文握手机制。服务器要确认用户的连接请求,然后客户要对服务器的确认进行确认。**
+21. TCP 的连接释放采用四报文握手机制。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送时,则发送连接释放通知,对方确认后就完全关闭了 TCP 连接
+
+### 5.3. 补充(重要)
+
+以下知识点需要重点关注:
+
+1. 端口和套接字的意义
+2. UDP 和 TCP 的区别以及两者的应用场景
+3. 在不可靠的网络上实现可靠传输的工作原理,停止等待协议和 ARQ 协议
+4. TCP 的滑动窗口,流量控制,拥塞控制和连接管理
+5. TCP 的三次握手,四次挥手机制
+
+## 6. 应用层(Application Layer)
+
+
+
+### 6.1. 基本术语
+
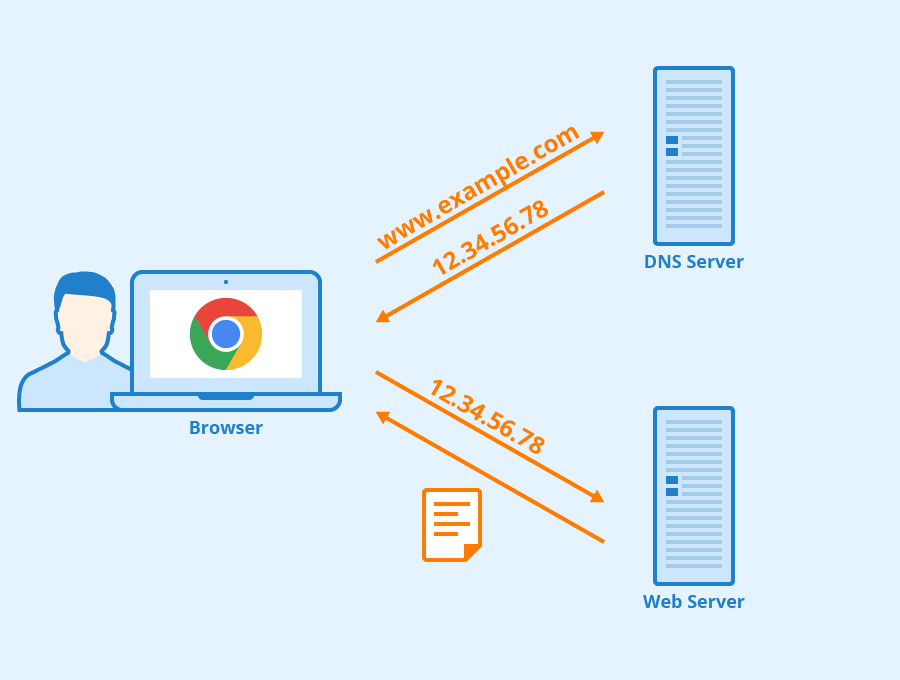
+1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
+
+ 
+
+ https://www.seobility.net/en/wiki/HTTP_headers
+
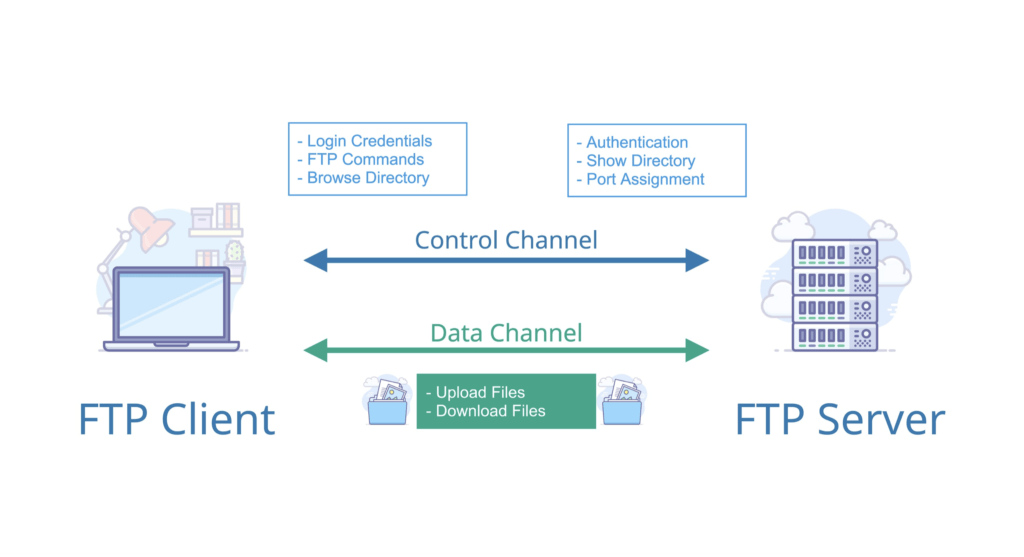
+2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
+
+ 
+
+3. **简单文件传输协议(TFTP)**:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
+4. **远程终端协议(TELNET)**:Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
+5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
+6. **万维网的大致工作工程:**
+
+ 
+
+7. **统一资源定位符(URL)**:统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
+8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
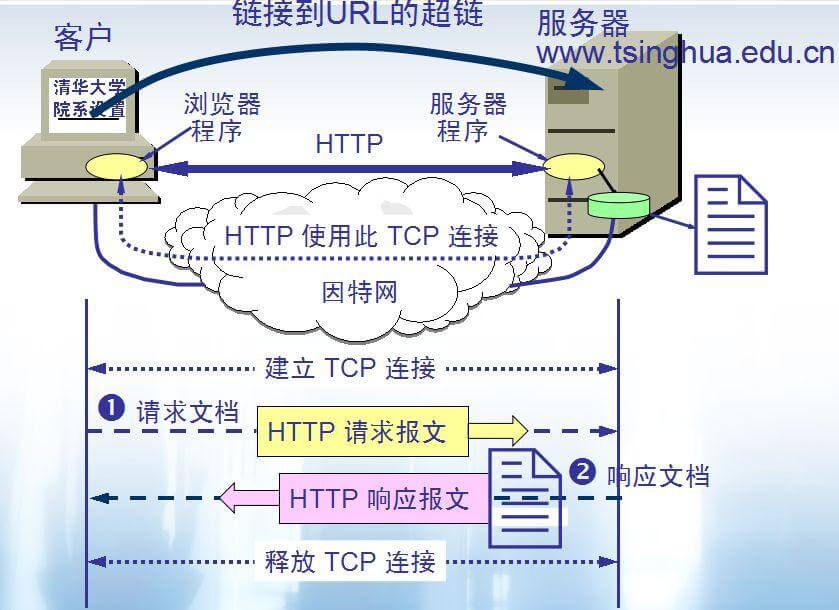
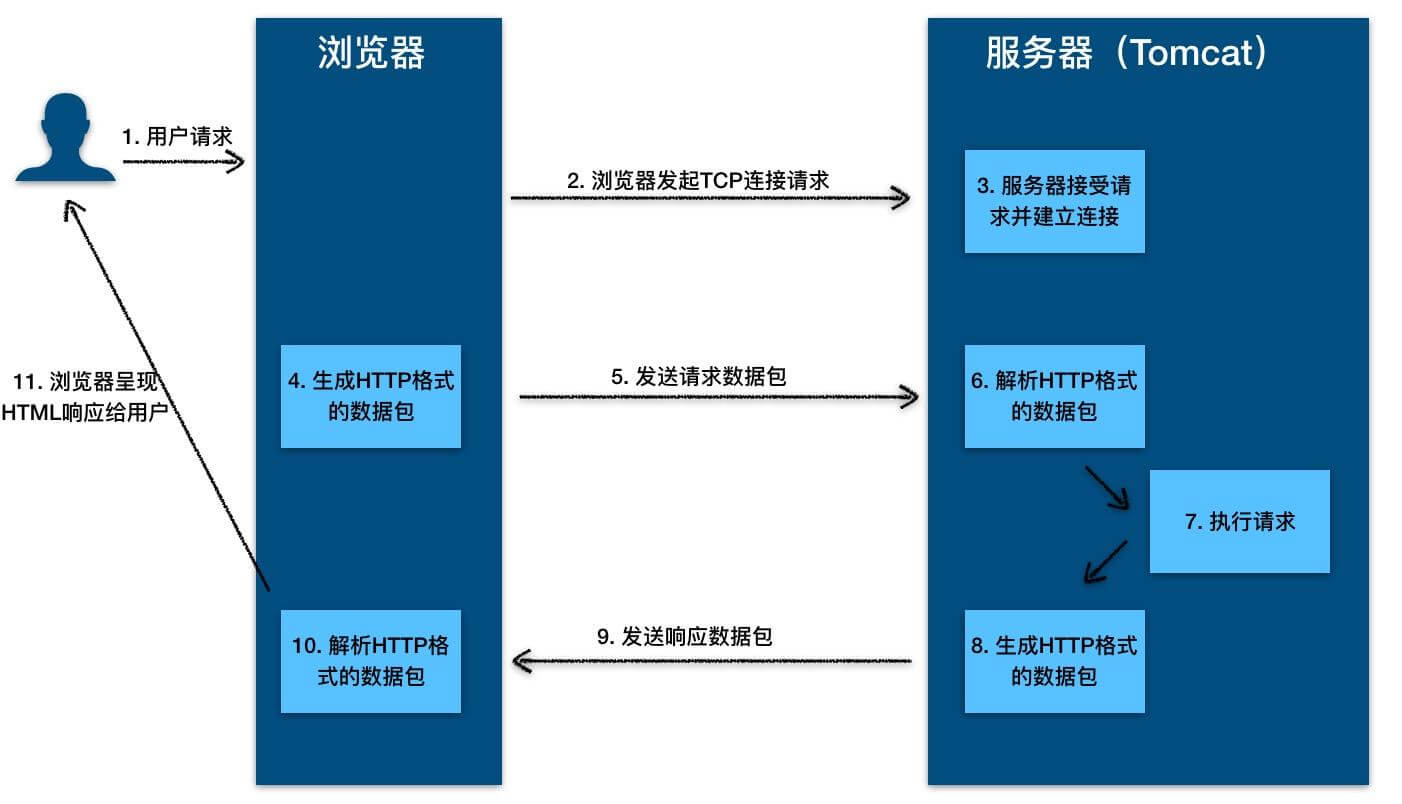
+
+ HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
+
+ 
+
+9. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
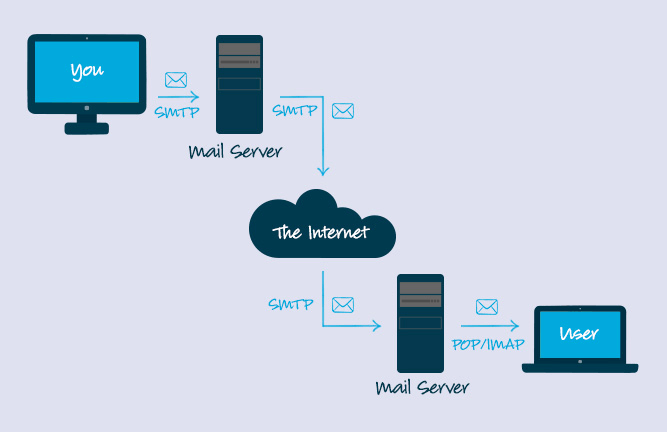
+10. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
+
+ 
+
+ https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/
+
+11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
+
+12. **垂直搜索引擎**:垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
+13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
+14. **目录索引**:目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
+
+### 6.2. 重要知识点总结
+
+1. 文件传输协议(FTP)使用 TCP 可靠的运输服务。FTP 使用客户服务器方式。一个 FTP 服务器进程可以同时为多个用户提供服务。在进行文件传输时,FTP 的客户和服务器之间要先建立两个并行的 TCP 连接:控制连接和数据连接。实际用于传输文件的是数据连接。
+2. 万维网客户程序与服务器之间进行交互使用的协议是超文本传输协议 HTTP。HTTP 使用 TCP 连接进行可靠传输。但 HTTP 本身是无连接、无状态的。HTTP/1.1 协议使用了持续连接(分为非流水线方式和流水线方式)
+3. 电子邮件把邮件发送到收件人使用的邮件服务器,并放在其中的收件人邮箱中,收件人可随时上网到自己使用的邮件服务器读取,相当于电子邮箱。
+4. An email system has three important components: user agent, mail server, and email protocol (including email sending protocols, such as SMTP, and email reading protocols, such as POP3 and IMAP). Both the user agent and the mail server must run these protocols.
+
+### 6.3. Supplement (Important)
+
+The following knowledge points need to be focused on:
+
+1. Common protocols at the application layer (focusing on the HTTP protocol)
+2. Domain name system-resolve IP address from domain name
+3. The general process of visiting a website
+4. System call and application programming interface concepts
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/dns.en.md b/docs_en/cs-basics/network/dns.en.md
new file mode 100644
index 00000000000..08af0ddb54d
--- /dev/null
+++ b/docs_en/cs-basics/network/dns.en.md
@@ -0,0 +1,115 @@
+---
+title: DNS 域名系统详解(应用层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: DNS,域名解析,递归查询,迭代查询,缓存,权威DNS,端口53,UDP
+ - - meta
+ - name: description
+ content: 详解 DNS 的层次结构与解析流程,覆盖递归/迭代、缓存与权威服务器,明确应用层端口与性能优化要点。
+---
+
+DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
+
+
+
+在实际使用中,有一种情况下,浏览器是可以不必动用 DNS 就可以获知域名和 IP 地址的映射的。浏览器在本地会维护一个`hosts`列表,一般来说浏览器要先查看要访问的域名是否在`hosts`列表中,如果有的话,直接提取对应的 IP 地址记录,就好了。如果本地`hosts`列表内没有域名-IP 对应记录的话,那么 DNS 就闪亮登场了。
+
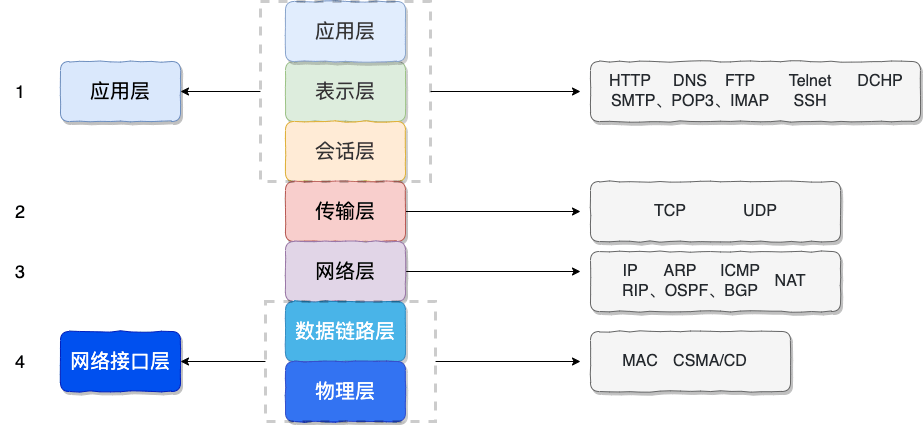
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,基于 UDP 协议之上,端口为 53** 。
+
+
+
+## DNS 服务器
+
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+
+- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如`com`、`org`、`net`和`edu`等。国家也有自己的顶级域,如`uk`、`fr`和`ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
+- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构。
+
+世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 600 多台,未来还会继续增加。
+
+## DNS 工作流程
+
+以下图为例,介绍 DNS 的查询解析过程。DNS 的查询解析过程分为两种模式:
+
+- **迭代**
+- **递归**
+
+下图是实践中常采用的方式,从请求主机到本地 DNS 服务器的查询是递归的,其余的查询时迭代的。
+
+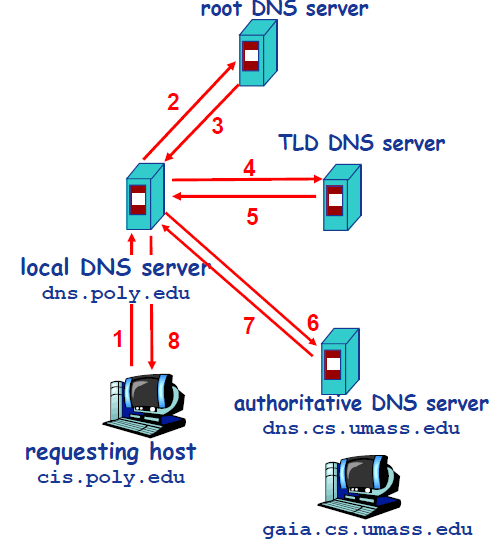
+
+现在,主机`cis.poly.edu`想知道`gaia.cs.umass.edu`的 IP 地址。假设主机`cis.poly.edu`的本地 DNS 服务器为`dns.poly.edu`,并且`gaia.cs.umass.edu`的权威 DNS 服务器为`dns.cs.umass.edu`。
+
+1. 首先,主机`cis.poly.edu`向本地 DNS 服务器`dns.poly.edu`发送一个 DNS 请求,该查询报文包含被转换的域名`gaia.cs.umass.edu`。
+2. 本地 DNS 服务器`dns.poly.edu`检查本机缓存,发现并无记录,也不知道`gaia.cs.umass.edu`的 IP 地址该在何处,不得不向根服务器发送请求。
+3. 根服务器注意到请求报文中含有`edu`顶级域,因此告诉本地 DNS,你可以向`edu`的 TLD DNS 发送请求,因为目标域名的 IP 地址很可能在那里。
+4. 本地 DNS 获取到了`edu`的 TLD DNS 服务器地址,向其发送请求,询问`gaia.cs.umass.edu`的 IP 地址。
+5. `edu`的 TLD DNS 服务器仍不清楚请求域名的 IP 地址,但是它注意到该域名有`umass.edu`前缀,因此返回告知本地 DNS,`umass.edu`的权威服务器可能记录了目标域名的 IP 地址。
+6. 这一次,本地 DNS 将请求发送给权威 DNS 服务器`dns.cs.umass.edu`。
+7. 终于,由于`gaia.cs.umass.edu`向权威 DNS 服务器备案过,在这里有它的 IP 地址记录,权威 DNS 成功地将 IP 地址返回给本地 DNS。
+8. 最后,本地 DNS 获取到了目标域名的 IP 地址,将其返回给请求主机。
+
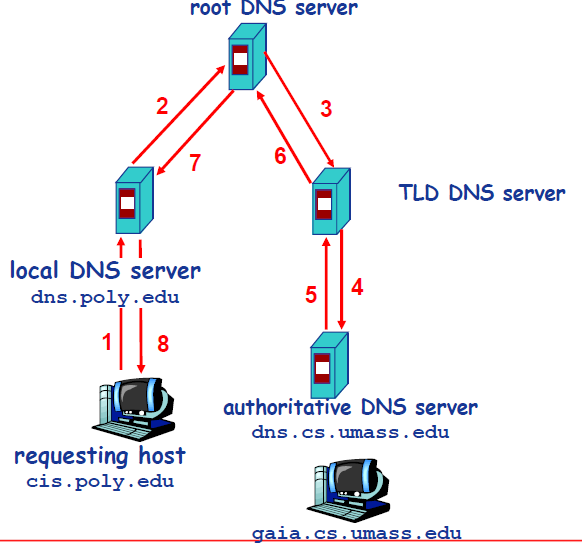
+除了迭代式查询,还有一种递归式查询如下图,具体过程和上述类似,只是顺序有所不同。
+
+
+
+另外,DNS 的缓存位于本地 DNS 服务器。由于全世界的根服务器甚少,只有 600 多台,分为 13 组,且顶级域的数量也在一个可数的范围内,因此本地 DNS 通常已经缓存了很多 TLD DNS 服务器,所以在实际查找过程中,无需访问根服务器。根服务器通常是被跳过的,不请求的。这样可以提高 DNS 查询的效率和速度,减少对根服务器和 TLD 服务器的负担。
+
+## DNS 报文格式
+
+DNS 的报文格式如下图所示:
+
+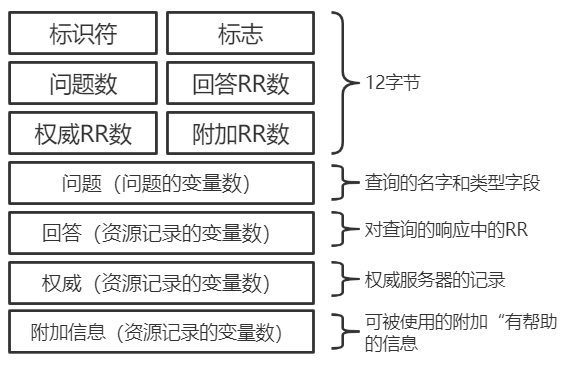
+
+DNS 报文分为查询和回答报文,两种形式的报文结构相同。
+
+- 标识符。16 比特,用于标识该查询。这个标识符会被复制到对查询的回答报文中,以便让客户用它来匹配发送的请求和接收到的回答。
+- 标志。1 比特的”查询/回答“标识位,`0`表示查询报文,`1`表示回答报文;1 比特的”权威的“标志位(当某 DNS 服务器是所请求名字的权威 DNS 服务器时,且是回答报文,使用”权威的“标志);1 比特的”希望递归“标志位,显式地要求执行递归查询;1 比特的”递归可用“标志位,用于回答报文中,表示 DNS 服务器支持递归查询。
+- 问题数、回答 RR 数、权威 RR 数、附加 RR 数。分别指示了后面 4 类数据区域出现的数量。
+- 问题区域。包含正在被查询的主机名字,以及正被询问的问题类型。
+- 回答区域。包含了对最初请求的名字的资源记录。**在回答报文的回答区域中可以包含多条 RR,因此一个主机名能够有多个 IP 地址。**
+- 权威区域。包含了其他权威服务器的记录。
+- 附加区域。包含了其他有帮助的记录。
+
+## DNS 记录
+
+DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为 **资源记录(Resource Record,RR)** 。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了`Name`, `Value`, `Type`, `TTL`四个字段的四元组。
+
+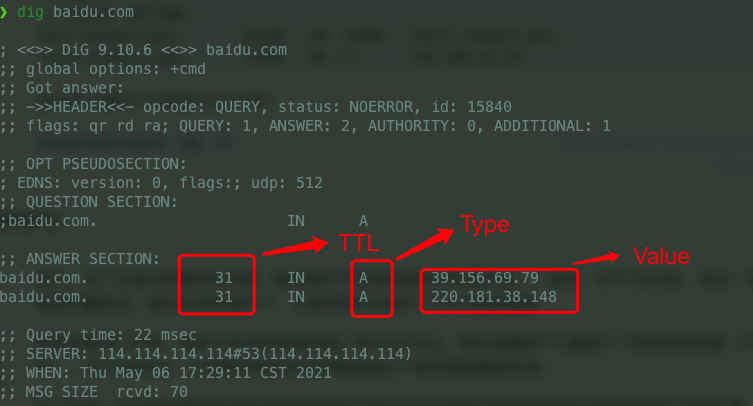
+
+`TTL`是该记录的生存时间,它决定了资源记录应当从缓存中删除的时间。
+
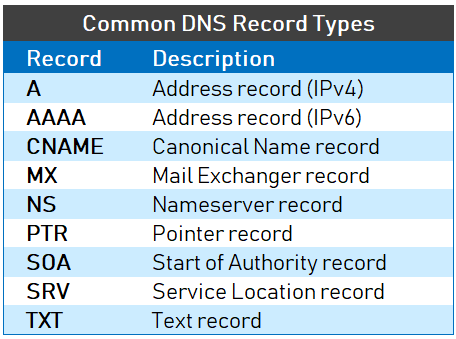
+`Name`和`Value`字段的取值取决于`Type`:
+
+
+
+- 如果`Type=A`,则`Name`是主机名信息,`Value` 是该主机名对应的 IP 地址。这样的 RR 记录了一条主机名到 IP 地址的映射。
+- 如果 `Type=AAAA` (与 `A` 记录非常相似),唯一的区别是 A 记录使用的是 IPv4,而 `AAAA` 记录使用的是 IPv6。
+- If `Type=CNAME` (Canonical Name Record, real name record), then `Value` is the canonical host name corresponding to the host with the alias `Name`. The `Value` value is the canonical host name. `CNAME` records map one hostname to another hostname. A `CNAME` record is used to create an alias for an existing `A` record. Examples below.
+- If `Type=NS`, then `Name` is a domain and `Value` is the hostname of an authoritative DNS server that knows how to obtain IP addresses for hosts in that domain. Typically such RRs are issued by the TLD server.
+- If `Type=MX`, then `Value` is the canonical hostname of the individual mail server named `Name`. Now that there are `MX` records, the mail server can use the same alias as other servers. To obtain the canonical hostname of a mail server, request an MX record; to obtain the canonical hostname of another server, request a CNAME record.
+
+`CNAME` records always point to another domain name, not an IP address. Assume the following DNS zone:
+
+```plain
+NAME TYPE VALUE
+--------------------------------------------------
+bar.example.com. CNAME foo.example.com.
+foo.example.com.A 192.0.2.23
+```
+
+When the user queries `bar.example.com`, the DNS Server actually returns the IP address of `foo.example.com`.
+
+## Reference
+
+- DNS server type:
+- DNS Message Resource Record Field Formats:
+- Understanding Different Types of Record in DNS Server:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/http-status-codes.en.md b/docs_en/cs-basics/network/http-status-codes.en.md
new file mode 100644
index 00000000000..09a0ddd7248
--- /dev/null
+++ b/docs_en/cs-basics/network/http-status-codes.en.md
@@ -0,0 +1,83 @@
+---
+title: Summary of common HTTP status codes (application layer)
+category: Computer Basics
+tag:
+ - computer network
+head:
+ - - meta
+ - name: keywords
+ content: HTTP status code, 2xx, 3xx, 4xx, 5xx, redirection, error code, 201 Created, 204 No Content
+ - - meta
+ - name: description
+ content: Summarizes the meanings and usage scenarios of common HTTP status codes, emphasizing confusion points such as 201/204 to improve interface design and debugging efficiency.
+---
+
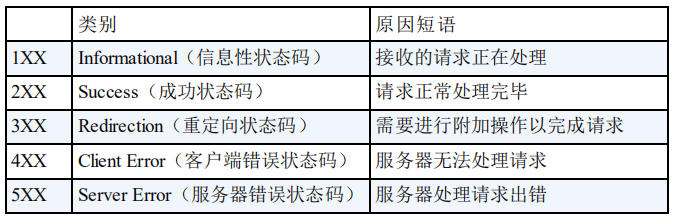
+HTTP status codes are used to describe the results of HTTP requests. For example, 2xx means that the request was successfully processed.
+
+
+
+### 1xx Informational (informational status code)
+
+Compared with other types of status codes, you will most likely not encounter 1xx, so you can skip it here.
+
+### 2xx Success (success status code)
+
+- **200 OK**: The request was successfully processed. For example, send an HTTP request to query user data to the server, and the server returns the user data correctly. This is the most common HTTP status code we usually have.
+- **201 Created**: The request was successfully processed and a new resource was created on the server. For example, create a new user via a POST request.
+- **202 Accepted**: The server has received the request, but has not yet processed it. For example, if you send a request that takes a long time to be processed by the server (such as report generation, Excel export), the server receives the request but has not yet completed the processing.
+- **204 No Content**: The server has successfully processed the request, but did not return any content. For example, a request is sent to delete a user, and the server successfully handles the deletion but returns nothing.
+
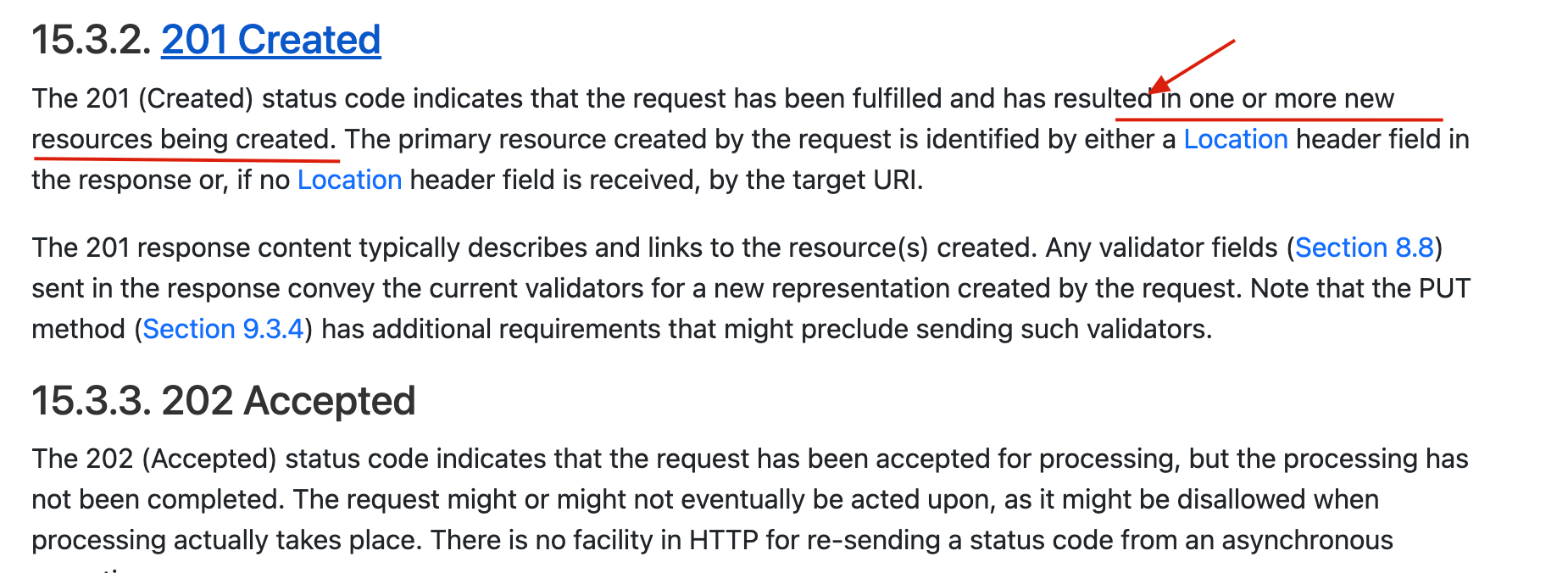
+🐛 Correction (see: [issue#2458](https://github.com/Snailclimb/JavaGuide/issues/2458)): The 201 Created status code is more precisely the creation of one or more new resources, please refer to: .
+
+
+
+Here is a special mention of the 204 status code, which is not seen many times in study/work.
+
+[HTTP RFC 2616 description of 204 status code](https://tools.ietf.org/html/rfc2616#section-10.2.5) is as follows:
+
+> The server has fulfilled the request but does not need to return an
+> entity-body, and might want to return updated metainformation. The
+> response MAY include new or updated metainformation in the form of
+> entity-headers, which if present SHOULD be associated with the
+> requested variant.
+>
+> If the client is a user agent, it SHOULD NOT change its document view
+> from that which caused the request to be sent. This response is
+> primarily intended to allow input for actions to take place without
+> causing a change to the user agent's active document view, although
+> any new or updated metainformation SHOULD be applied to the document
+> currently in the user agent's active view.
+>
+> The 204 response MUST NOT include a message-body, and thus is always
+> terminated by the first empty line after the header fields.
+
+Simply put, the 204 status code describes a scenario where after we send an HTTP request to the server, we only focus on whether the processing result is successful. In other words, what we need is a result: true/false.
+
+For example: you want to chase a girl, you ask the girl: "Can I chase you?", the girl replies: "Okay!". We can easily understand the 204 status code by treating this girl as a server.
+
+### 3xx Redirection (redirect status code)
+
+- **301 Moved Permanently**: The resource has been permanently redirected. For example, the URL of your website has been changed.
+- **302 Found**: The resource was temporarily redirected. For example, some resources on your website are temporarily transferred to another URL.
+
+### 4xx Client Error (client error status code)
+
+- **400 Bad Request**: There was a problem with the HTTP request sent. For example, the request parameters are illegal and the request method is wrong.
+- **401 Unauthorized**: Unauthenticated but requesting resources that require authentication before accessing.
+- **403 Forbidden**: Directly reject the HTTP request and do not process it. Generally used for illegal requests.
+- **404 Not Found**: The resource you requested was not found on the server. For example, if you request information about a certain user, the server does not find the specified user.
+- **409 Conflict**: Indicates that the requested resource conflicts with the current status of the server and the request cannot be processed.
+
+### 5xx Server Error (server error status code)
+
+- **500 Internal Server Error**: There is a problem on the server side (usually there is a bug on the server side). For example, your server suddenly throws an exception when processing a request, but the exception is not handled correctly on the server.
+- **502 Bad Gateway**: Our gateway forwards the request to the server, but the server returns an error response.
+
+### Reference
+
+-
+-
+-
+-
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/http-vs-https.en.md b/docs_en/cs-basics/network/http-vs-https.en.md
new file mode 100644
index 00000000000..65f7b24e05d
--- /dev/null
+++ b/docs_en/cs-basics/network/http-vs-https.en.md
@@ -0,0 +1,149 @@
+---
+title: HTTP vs HTTPS(应用层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP,HTTPS,SSL,TLS,加密,认证,端口,安全性,握手流程
+ - - meta
+ - name: description
+ content: 对比 HTTP 与 HTTPS 的协议与安全机制,解析 SSL/TLS 工作原理与握手流程,明确应用层安全落地细节。
+---
+
+## HTTP 协议
+
+### HTTP 协议介绍
+
+HTTP 协议,全称超文本传输协议(Hypertext Transfer Protocol)。顾名思义,HTTP 协议就是用来规范超文本的传输,超文本,也就是网络上的包括文本在内的各式各样的消息,具体来说,主要是来规范浏览器和服务器端的行为的。
+
+并且,HTTP 是一个无状态(stateless)协议,也就是说服务器不维护任何有关客户端过去所发请求的消息。这其实是一种懒政,有状态协议会更加复杂,需要维护状态(历史信息),而且如果客户或服务器失效,会产生状态的不一致,解决这种不一致的代价更高。
+
+### HTTP 协议通信过程
+
+HTTP 是应用层协议,它以 TCP(传输层)作为底层协议,默认端口为 80. 通信过程主要如下:
+
+1. 服务器在 80 端口等待客户的请求。
+2. 浏览器发起到服务器的 TCP 连接(创建套接字 Socket)。
+3. 服务器接收来自浏览器的 TCP 连接。
+4. 浏览器(HTTP 客户端)与 Web 服务器(HTTP 服务器)交换 HTTP 消息。
+5. 关闭 TCP 连接。
+
+### HTTP 协议优点
+
+扩展性强、速度快、跨平台支持性好。
+
+## HTTPS 协议
+
+### HTTPS 协议介绍
+
+HTTPS 协议(Hyper Text Transfer Protocol Secure),是 HTTP 的加强安全版本。HTTPS 是基于 HTTP 的,也是用 TCP 作为底层协议,并额外使用 SSL/TLS 协议用作加密和安全认证。默认端口号是 443.
+
+HTTPS 协议中,SSL 通道通常使用基于密钥的加密算法,密钥长度通常是 40 比特或 128 比特。
+
+### HTTPS 协议优点
+
+保密性好、信任度高。
+
+## HTTPS 的核心—SSL/TLS 协议
+
+HTTPS 之所以能达到较高的安全性要求,就是结合了 SSL/TLS 和 TCP 协议,对通信数据进行加密,解决了 HTTP 数据透明的问题。接下来重点介绍一下 SSL/TLS 的工作原理。
+
+### SSL 和 TLS 的区别?
+
+**SSL 和 TLS 没有太大的区别。**
+
+SSL 指安全套接字协议(Secure Sockets Layer),首次发布与 1996 年。SSL 的首次发布其实已经是他的 3.0 版本,SSL 1.0 从未面世,SSL 2.0 则具有较大的缺陷(DROWN 缺陷——Decrypting RSA with Obsolete and Weakened eNcryption)。很快,在 1999 年,SSL 3.0 进一步升级,**新版本被命名为 TLS 1.0**。因此,TLS 是基于 SSL 之上的,但由于习惯叫法,通常把 HTTPS 中的核心加密协议混称为 SSL/TLS。
+
+### SSL/TLS 的工作原理
+
+#### 非对称加密
+
+SSL/TLS 的核心要素是**非对称加密**。非对称加密采用两个密钥——一个公钥,一个私钥。在通信时,私钥仅由解密者保存,公钥由任何一个想与解密者通信的发送者(加密者)所知。可以设想一个场景,
+
+> 在某个自助邮局,每个通信信道都是一个邮箱,每一个邮箱所有者都在旁边立了一个牌子,上面挂着一把钥匙:这是我的公钥,发送者请将信件放入我的邮箱,并用公钥锁好。
+>
+> 但是公钥只能加锁,并不能解锁。解锁只能由邮箱的所有者——因为只有他保存着私钥。
+>
+> 这样,通信信息就不会被其他人截获了,这依赖于私钥的保密性。
+
+
+
+非对称加密的公钥和私钥需要采用一种复杂的数学机制生成(密码学认为,为了较高的安全性,尽量不要自己创造加密方案)。公私钥对的生成算法依赖于单向陷门函数。
+
+> 单向函数:已知单向函数 f,给定任意一个输入 x,易计算输出 y=f(x);而给定一个输出 y,假设存在 f(x)=y,很难根据 f 来计算出 x。
+>
+> 单向陷门函数:一个较弱的单向函数。已知单向陷门函数 f,陷门 h,给定任意一个输入 x,易计算出输出 y=f(x;h);而给定一个输出 y,假设存在 f(x;h)=y,很难根据 f 来计算出 x,但可以根据 f 和 h 来推导出 x。
+
+
+
+上图就是一个单向函数(不是单项陷门函数),假设有一个绝世秘籍,任何知道了这个秘籍的人都可以把苹果汁榨成苹果,那么这个秘籍就是“陷门”了吧。
+
+在这里,函数 f 的计算方法相当于公钥,陷门 h 相当于私钥。公钥 f 是公开的,任何人对已有输入,都可以用 f 加密,而要想根据加密信息还原出原信息,必须要有私钥才行。
+
+#### 对称加密
+
+使用 SSL/TLS 进行通信的双方需要使用非对称加密方案来通信,但是非对称加密设计了较为复杂的数学算法,在实际通信过程中,计算的代价较高,效率太低,因此,SSL/TLS 实际对消息的加密使用的是对称加密。
+
+> 对称加密:通信双方共享唯一密钥 k,加解密算法已知,加密方利用密钥 k 加密,解密方利用密钥 k 解密,保密性依赖于密钥 k 的保密性。
+
+
+
+对称加密的密钥生成代价比公私钥对的生成代价低得多,那么有的人会问了,为什么 SSL/TLS 还需要使用非对称加密呢?因为对称加密的保密性完全依赖于密钥的保密性。在双方通信之前,需要商量一个用于对称加密的密钥。我们知道网络通信的信道是不安全的,传输报文对任何人是可见的,密钥的交换肯定不能直接在网络信道中传输。因此,使用非对称加密,对对称加密的密钥进行加密,保护该密钥不在网络信道中被窃听。这样,通信双方只需要一次非对称加密,交换对称加密的密钥,在之后的信息通信中,使用绝对安全的密钥,对信息进行对称加密,即可保证传输消息的保密性。
+
+#### 公钥传输的信赖性
+
+SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐患,设想一个下面的场景:
+
+> 客户端 C 和服务器 S 想要使用 SSL/TLS 通信,由上述 SSL/TLS 通信原理,C 需要先知道 S 的公钥,而 S 公钥的唯一获取途径,就是把 S 公钥在网络信道中传输。要注意网络信道通信中有几个前提:
+>
+> 1. 任何人都可以捕获通信包
+> 2. 通信包的保密性由发送者设计
+> 3. 保密算法设计方案默认为公开,而(解密)密钥默认是安全的
+>
+> 因此,假设 S 公钥不做加密,在信道中传输,那么很有可能存在一个攻击者 A,发送给 C 一个诈包,假装是 S 公钥,其实是诱饵服务器 AS 的公钥。当 C 收获了 AS 的公钥(却以为是 S 的公钥),C 后续就会使用 AS 公钥对数据进行加密,并在公开信道传输,那么 A 将捕获这些加密包,用 AS 的私钥解密,就截获了 C 本要给 S 发送的内容,而 C 和 S 二人全然不知。
+>
+> 同样的,S 公钥即使做加密,也难以避免这种信任性问题,C 被 AS 拐跑了!
+
+
+
+为了公钥传输的信赖性问题,第三方机构应运而生——证书颁发机构(CA,Certificate Authority)。CA 默认是受信任的第三方。CA 会给各个服务器颁发证书,证书存储在服务器上,并附有 CA 的**电子签名**(见下节)。
+
+当客户端(浏览器)向服务器发送 HTTPS 请求时,一定要先获取目标服务器的证书,并根据证书上的信息,检验证书的合法性。一旦客户端检测到证书非法,就会发生错误。客户端获取了服务器的证书后,由于证书的信任性是由第三方信赖机构认证的,而证书上又包含着服务器的公钥信息,客户端就可以放心的信任证书上的公钥就是目标服务器的公钥。
+
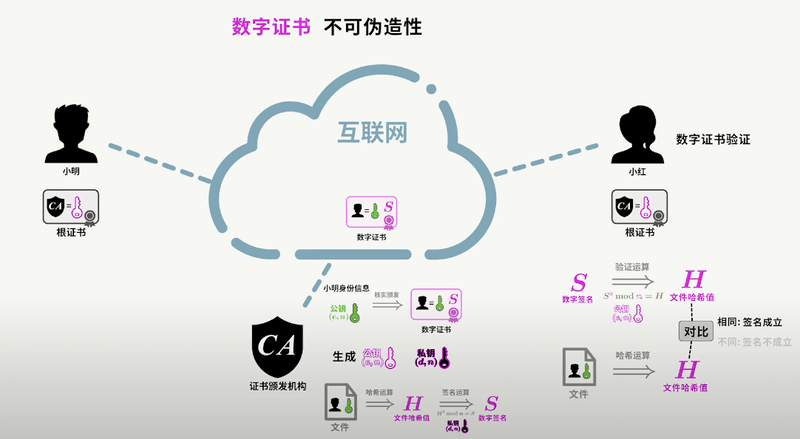
+#### 数字签名
+
+好,到这一小节,已经是 SSL/TLS 的尾声了。上一小节提到了数字签名,数字签名要解决的问题,是防止证书被伪造。第三方信赖机构 CA 之所以能被信赖,就是 **靠数字签名技术** 。
+
+数字签名,是 CA 在给服务器颁发证书时,使用散列+加密的组合技术,在证书上盖个章,以此来提供验伪的功能。具体行为如下:
+
+> CA 知道服务器的公钥,对证书采用散列技术生成一个摘要。CA 使用 CA 私钥对该摘要进行加密,并附在证书下方,发送给服务器。
+>
+> 现在服务器将该证书发送给客户端,客户端需要验证该证书的身份。客户端找到第三方机构 CA,获知 CA 的公钥,并用 CA 公钥对证书的签名进行解密,获得了 CA 生成的摘要。
+>
+> The client performs the same hashing process on the certificate data (including the server's public key) to obtain a digest, and compares the digest with the digest previously decoded from the signature. If they are the same, the authentication succeeds; otherwise, the verification fails.
+
+
+
+In summary, the public key transfer mechanism with certificates is as follows:
+
+1. There is a server S, a client C, and a third-party trust authority CA.
+2. S trusts the CA. The CA knows S’s public key, and the CA issues a certificate to S. And attach a cryptographic signature of the message digest with the CA's private key.
+3. S obtains a certificate issued by the CA and passes the certificate to C.
+4. C obtains S’s certificate, trusts the CA and knows the CA public key, uses the CA public key to decrypt the signature on S’s certificate, and hashes the message to obtain the digest. Compare summaries to verify the authenticity of the S-certificate.
+5. Trust S's public key (in S's certificate) if C verifies that S's certificate is authentic.
+
+
+
+For digital signatures, what I’m talking about here is relatively simple. If you don’t understand it, I strongly recommend you to watch the video [Principles of Digital Signatures and Digital Certificates] (https://www.bilibili.com/video/BV18N411X7ty/). This is the clearest explanation I have ever seen.
+
+
+
+## Summary
+
+- **Port number**: The default for HTTP is 80, and the default for HTTPS is 443.
+- **URL Prefix**: The URL prefix of HTTP is `http://`, and the URL prefix of HTTPS is `https://`.
+- **Security and Resource Consumption**: The HTTP protocol runs on top of TCP, all transmitted content is clear text, and neither the client nor the server can verify the identity of the other party. HTTPS is an HTTP protocol that runs on top of SSL/TLS, which runs on top of TCP. All transmitted content is encrypted using symmetric encryption, but the symmetric encryption key is asymmetrically encrypted using a server-side certificate. Therefore, HTTP is not as secure as HTTPS, but HTTPS consumes more server resources than HTTP.
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/http1.0-vs-http1.1.en.md b/docs_en/cs-basics/network/http1.0-vs-http1.1.en.md
new file mode 100644
index 00000000000..affb03ca907
--- /dev/null
+++ b/docs_en/cs-basics/network/http1.0-vs-http1.1.en.md
@@ -0,0 +1,175 @@
+---
+title: HTTP 1.0 vs HTTP 1.1(应用层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: HTTP/1.0,HTTP/1.1,长连接,管道化,缓存,状态码,Host,带宽优化
+ - - meta
+ - name: description
+ content: 细致对比 HTTP/1.0 与 HTTP/1.1 的协议差异,涵盖长连接、管道化、缓存与状态码增强等关键变更与实践影响。
+---
+
+这篇文章会从下面几个维度来对比 HTTP 1.0 和 HTTP 1.1:
+
+- 响应状态码
+- 缓存处理
+- 连接方式
+- Host 头处理
+- 带宽优化
+
+## 响应状态码
+
+HTTP/1.0 仅定义了 16 种状态码。HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+
+## 缓存处理
+
+缓存技术通过避免用户与源服务器的频繁交互,节约了大量的网络带宽,降低了用户接收信息的延迟。
+
+### HTTP/1.0
+
+HTTP/1.0 提供的缓存机制非常简单。服务器端使用`Expires`标签来标志(时间)一个响应体,在`Expires`标志时间内的请求,都会获得该响应体缓存。服务器端在初次返回给客户端的响应体中,有一个`Last-Modified`标签,该标签标记了被请求资源在服务器端的最后一次修改。在请求头中,使用`If-Modified-Since`标签,该标签标志一个时间,意为客户端向服务器进行问询:“该时间之后,我要请求的资源是否有被修改过?”通常情况下,请求头中的`If-Modified-Since`的值即为上一次获得该资源时,响应体中的`Last-Modified`的值。
+
+如果服务器接收到了请求头,并判断`If-Modified-Since`时间后,资源确实没有修改过,则返回给客户端一个`304 not modified`响应头,表示”缓冲可用,你从浏览器里拿吧!”。
+
+如果服务器判断`If-Modified-Since`时间后,资源被修改过,则返回给客户端一个`200 OK`的响应体,并附带全新的资源内容,表示”你要的我已经改过的,给你一份新的”。
+
+
+
+
+
+### HTTP/1.1
+
+HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和扩展性。基本工作原理和 HTTP/1.0 保持不变,而是增加了更多细致的特性。其中,请求头中最常见的特性就是`Cache-Control`,详见 MDN Web 文档 [Cache-Control](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control).
+
+## 连接方式
+
+**HTTP/1.0 默认使用短连接** ,也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 TCP 连接,这样就会导致有大量的“握手报文”和“挥手报文”占用了带宽。
+
+**为了解决 HTTP/1.0 存在的资源浪费的问题, HTTP/1.1 优化为默认长连接模式 。** 采用长连接模式的请求报文会通知服务端:“我向你请求连接,并且连接成功建立后,请不要关闭”。因此,该 TCP 连接将持续打开,为后续的客户端-服务端的数据交互服务。也就是说在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
+
+如果 TCP 连接一直保持的话也是对资源的浪费,因此,一些服务器软件(如 Apache)还会支持超时时间的时间。在超时时间之内没有新的请求达到,TCP 连接才会被关闭。
+
+有必要说明的是,HTTP/1.0 仍提供了长连接选项,即在请求头中加入`Connection: Keep-alive`。同样的,在 HTTP/1.1 中,如果不希望使用长连接选项,也可以在请求头中加入`Connection: close`,这样会通知服务器端:“我不需要长连接,连接成功后即可关闭”。
+
+**HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。**
+
+**实现长连接需要客户端和服务端都支持长连接。**
+
+## Host 头处理
+
+域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题,假设我们有一个资源 URL 是 的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
+
+因此,HTTP/1.1 在请求头中加入了`Host`字段。加入`Host`字段的报文头部将会是:
+
+```plain
+GET /home.html HTTP/1.1
+Host: example1.org
+```
+
+这样,服务器端就可以确定客户端想要请求的真正的网址了。
+
+## 带宽优化
+
+### 范围请求
+
+HTTP/1.1 引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1 可以在请求中加入`Range`头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略`Range`头部,也可以返回若干`Range`响应。
+
+`206 (Partial Content)` 状态码的主要作用是确保客户端和代理服务器能正确识别部分内容响应,避免将其误认为完整资源并错误地缓存。这对于正确处理范围请求和缓存管理非常重要。
+
+一个典型的 HTTP/1.1 范围请求示例:
+
+```bash
+# 获取一个文件的前 1024 个字节
+GET /z4d4kWk.jpg HTTP/1.1
+Host: i.imgur.com
+Range: bytes=0-1023
+```
+
+`206 Partial Content` 响应:
+
+```bash
+
+HTTP/1.1 206 Partial Content
+Content-Range: bytes 0-1023/146515
+Content-Length: 1024
+…
+(二进制内容)
+```
+
+简单解释一下 HTTP 范围响应头部中的字段:
+
+- **`Content-Range` 头部**:指示返回数据在整个资源中的位置,包括起始和结束字节以及资源的总长度。例如,`Content-Range: bytes 0-1023/146515` 表示服务器端返回了第 0 到 1023 字节的数据(共 1024 字节),而整个资源的总长度是 146,515 字节。
+- **`Content-Length` 头部**:指示此次响应中实际传输的字节数。例如,`Content-Length: 1024` 表示服务器端传输了 1024 字节的数据。
+
+`Range` 请求头不仅可以请求单个字节范围,还可以一次性请求多个范围。这种方式被称为“多重范围请求”(multiple range requests)。
+
+客户端想要获取资源的第 0 到 499 字节以及第 1000 到 1499 字节:
+
+```bash
+GET /path/to/resource HTTP/1.1
+Host: example.com
+Range: bytes=0-499,1000-1499
+```
+
+服务器端返回多个字节范围,每个范围的内容以分隔符分开:
+
+```bash
+HTTP/1.1 206 Partial Content
+Content-Type: multipart/byteranges; boundary=3d6b6a416f9b5
+Content-Length: 376
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 0-99/2000
+
+(第 0 到 99 字节的数据块)
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 500-599/2000
+
+(第 500 到 599 字节的数据块)
+
+--3d6b6a416f9b5
+Content-Type: application/octet-stream
+Content-Range: bytes 1000-1099/2000
+
+(第 1000 到 1099 字节的数据块)
+
+--3d6b6a416f9b5--
+```
+
+### Status code 100
+
+A new status code `100` was added to HTTP/1.1. The usage scenario of this status code is that there are some large file requests, and the server may not be willing to respond to such requests. At this time, the status code `100` can be used to indicate whether the request will be responded to normally. The process is as follows:
+
+
+
+
+
+However, in HTTP/1.0, there is no `100 (Continue)` status code. To trigger this mechanism, you can send an `Expect` header containing a `100-continue` value.
+
+### Compression
+
+Data in many formats are pre-compressed during transmission. Compression of data can significantly optimize bandwidth utilization. However, HTTP/1.0 does not provide many options for data compression, does not support the selection of compression details, and cannot distinguish between end-to-end compression or hop-by-hop compression.
+
+HTTP/1.1 makes a distinction between content-codings and transfer-codings. Content encoding is always end-to-end and transport encoding is always hop-by-hop.
+
+HTTP/1.0 includes the `Content-Encoding` header to encode messages end-to-end. HTTP/1.1 added the `Transfer-Encoding` header, which can perform hop-by-hop transfer encoding of messages. HTTP/1.1 also added the `Accept-Encoding` header, which is used by the client to indicate what kind of content encoding it can handle.
+
+## Summary
+
+1. **Connection method**: HTTP 1.0 is a short connection, and HTTP 1.1 supports long connections.
+1. **Status response codes**: A large number of new status codes have been added to HTTP/1.1, including 24 new error response status codes alone. For example, `100 (Continue)` - a warm-up request before requesting a large resource, `206 (Partial Content)` - the identification code of the range request, `409 (Conflict)` - the request conflicts with the specifications of the current resource, `410 (Gone)` - the resource has been permanently transferred and does not have any known forwarding address.
+1. **Cache processing**: In HTTP1.0, If-Modified-Since, Expires in the header are mainly used as the standard for cache judgment. HTTP1.1 introduces more cache control strategies such as Entity tag, If-Unmodified-Since, If-Match, If-None-Match and more optional cache headers to control the cache strategy.
+1. **Bandwidth optimization and use of network connections**: In HTTP1.0, there are some phenomena of wasting bandwidth. For example, the client only needs a part of an object, but the server sends the entire object, and does not support the resumption function. HTTP1.1 introduces the range header field in the request header, which allows only a certain part of the resource to be requested, that is, the return code is 206 (Partial Content). This facilitates developers to freely choose to make full use of bandwidth and connections.
+1. **Host header processing**: HTTP/1.1 adds the `Host` field to the request header.
+
+## References
+
+[Key differences between HTTP/1.0 and HTTP/1.1](http://www.ra.ethz.ch/cdstore/www8/data/2136/pdf/pd1.pdf)
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/nat.en.md b/docs_en/cs-basics/network/nat.en.md
new file mode 100644
index 00000000000..561386f91d1
--- /dev/null
+++ b/docs_en/cs-basics/network/nat.en.md
@@ -0,0 +1,68 @@
+---
+title: NAT 协议详解(网络层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: NAT,地址转换,端口映射,LAN,WAN,连接跟踪,DHCP
+ - - meta
+ - name: description
+ content: 解析 NAT 的地址转换与端口映射机制,结合 LAN/WAN 通信与转换表,理解家庭与企业网络的实践细节。
+---
+
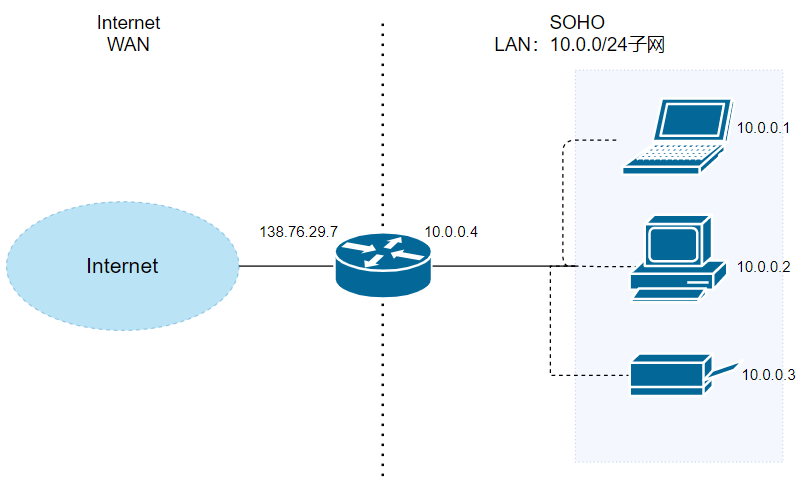
+## 应用场景
+
+**NAT 协议(Network Address Translation)** 的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,Local Area Network,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(Wide Area Network,WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
+
+这个场景其实不难理解。随着一个个小型办公室、家庭办公室(Small Office, Home Office, SOHO)的出现,为了管理这些 SOHO,一个个子网被设计出来,从而在整个 Internet 中的主机数量将非常庞大。如果每个主机都有一个“绝对唯一”的 IP 地址,那么 IPv4 地址的表达能力可能很快达到上限($2^{32}$)。因此,实际上,SOHO 子网中的 IP 地址是“相对的”,这在一定程度上也缓解了 IPv4 地址的分配压力。
+
+SOHO 子网的“代理人”,也就是和外界的窗口,通常由路由器扮演。路由器的 LAN 一侧管理着一个小子网,而它的 WAN 接口才是真正参与到 Internet 中的接口,也就有一个“绝对唯一的地址”。NAT 协议,正是在 LAN 中的主机在与 LAN 外界通信时,起到了地址转换的关键作用。
+
+## 细节
+
+
+
+假设当前场景如上图。中间是一个路由器,它的右侧组织了一个 LAN,网络号为`10.0.0/24`。LAN 侧接口的 IP 地址为`10.0.0.4`,并且该子网内有至少三台主机,分别是`10.0.0.1`,`10.0.0.2`和`10.0.0.3`。路由器的左侧连接的是 WAN,WAN 侧接口的 IP 地址为`138.76.29.7`。
+
+首先,针对以上信息,我们有如下事实需要说明:
+
+1. 路由器的右侧子网的网络号为`10.0.0/24`,主机号为`10.0.0/8`,三台主机地址,以及路由器的 LAN 侧接口地址,均由 DHCP 协议规定。而且,该 DHCP 运行在路由器内部(路由器自维护一个小 DHCP 服务器),从而为子网内提供 DHCP 服务。
+2. 路由器的 WAN 侧接口地址同样由 DHCP 协议规定,但该地址是路由器从 ISP(网络服务提供商)处获得,也就是该 DHCP 通常运行在路由器所在区域的 DHCP 服务器上。
+
+现在,路由器内部还运行着 NAT 协议,从而为 LAN-WAN 间通信提供地址转换服务。为此,一个很重要的结构是 **NAT 转换表**。为了说明 NAT 的运行细节,假设有以下请求发生:
+
+1. 主机`10.0.0.1`向 IP 地址为`128.119.40.186`的 Web 服务器(端口 80)发送了 HTTP 请求(如请求页面)。此时,主机`10.0.0.1`将随机指派一个端口,如`3345`,作为本次请求的源端口号,将该请求发送到路由器中(目的地址将是`128.119.40.186`,但会先到达`10.0.0.4`)。
+2. `10.0.0.4`即路由器的 LAN 接口收到`10.0.0.1`的请求。路由器将为该请求指派一个新的源端口号,如`5001`,并将请求报文发送给 WAN 接口`138.76.29.7`。同时,在 NAT 转换表中记录一条转换记录**138.76.29.7:5001——10.0.0.1:3345**。
+3. 请求报文到达 WAN 接口,继续向目的主机`128.119.40.186`发送。
+
+之后,将会有如下响应发生:
+
+1. 主机`128.119.40.186`收到请求,构造响应报文,并将其发送给目的地`138.76.29.7:5001`。
+2. 响应报文到达路由器的 WAN 接口。路由器查询 NAT 转换表,发现`138.76.29.7:5001`在转换表中有记录,从而将其目的地址和目的端口转换成为`10.0.0.1:3345`,再发送到`10.0.0.4`上。
+3. 被转换的响应报文到达路由器的 LAN 接口,继而被转发至目的地`10.0.0.1`。
+
+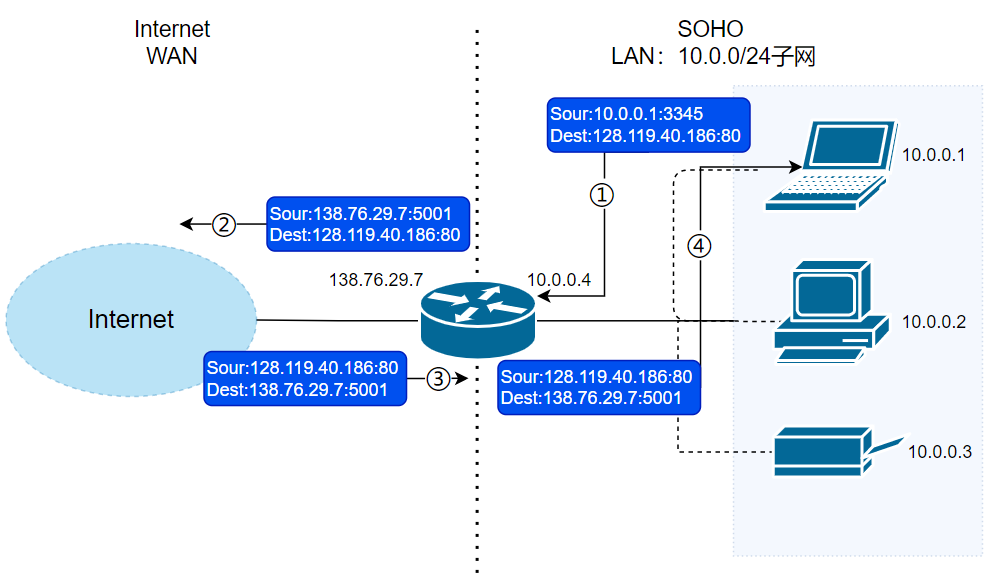
+
+🐛 修正(参见:[issue#2009](https://github.com/Snailclimb/JavaGuide/issues/2009)):上图第四步的 Dest 值应该为 `10.0.0.1:3345` 而不是~~`138.76.29.7:5001`~~,这里笔误了。
+
+## 划重点
+
+针对以上过程,有以下几个重点需要强调:
+
+1. 当请求报文到达路由器,并被指定了新端口号时,由于端口号有 16 位,因此,通常来说,一个路由器管理的 LAN 中的最大主机数 $≈65500$($2^{16}$ 的地址空间),但通常 SOHO 子网内不会有如此多的主机数量。
+2. 对于目的服务器来说,从来不知道“到底是哪个主机给我发送的请求”,它只知道是来自`138.76.29.7:5001`的路由器转发的请求。因此,可以说,**路由器在 WAN 和 LAN 之间起到了屏蔽作用**,所有内部主机发送到外部的报文,都具有同一个 IP 地址(不同的端口号),所有外部发送到内部的报文,也都只有一个目的地(不同端口号),是经过了 NAT 转换后,外部报文才得以正确地送达内部主机。
+3. 在报文穿过路由器,发生 NAT 转换时,如果 LAN 主机 IP 已经在 NAT 转换表中注册过了,则不需要路由器新指派端口,而是直接按照转换记录穿过路由器。同理,外部报文发送至内部时也如此。
+
+总结 NAT 协议的特点,有以下几点:
+
+1. NAT 协议通过对 WAN 屏蔽 LAN,有效地缓解了 IPv4 地址分配压力。
+2. LAN 主机 IP 地址的变更,无需通告 WAN。
+3. WAN 的 ISP 变更接口地址时,无需通告 LAN 内主机。
+4. LAN 主机对 WAN 不可见,不可直接寻址,可以保证一定程度的安全性。
+
+然而,NAT 协议由于其独特性,存在着一些争议。比如,可能你已经注意到了,**NAT 协议在 LAN 以外,标识一个内部主机时,使用的是端口号,因为 IP 地址都是相同的**。这种将端口号作为主机寻址的行为,可能会引发一些误会。此外,路由器作为网络层的设备,修改了传输层的分组内容(修改了源 IP 地址和端口号),同样是不规范的行为。但是,尽管如此,NAT 协议作为 IPv4 时代的产物,极大地方便了一些本来棘手的问题,一直被沿用至今。
+
+
+
diff --git a/docs_en/cs-basics/network/network-attack-means.en.md b/docs_en/cs-basics/network/network-attack-means.en.md
new file mode 100644
index 00000000000..917641e1496
--- /dev/null
+++ b/docs_en/cs-basics/network/network-attack-means.en.md
@@ -0,0 +1,478 @@
+---
+title: 网络攻击常见手段总结
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 网络攻击,DDoS,IP 欺骗,ARP 欺骗,中间人攻击,扫描,防护
+ - - meta
+ - name: description
+ content: 总结常见 TCP/IP 攻击与防护思路,覆盖 DDoS、IP/ARP 欺骗、中间人等手段,强调工程防护实践。
+---
+
+> 本文整理完善自[TCP/IP 常见攻击手段 - 暖蓝笔记 - 2021](https://mp.weixin.qq.com/s/AZwWrOlLxRSSi-ywBgZ0fA)这篇文章。
+
+这篇文章的内容主要是介绍 TCP/IP 常见攻击手段,尤其是 DDoS 攻击,也会补充一些其他的常见网络攻击手段。
+
+## IP 欺骗
+
+### IP 是什么?
+
+在网络中,所有的设备都会分配一个地址。这个地址就仿佛小蓝的家地址「**多少号多少室**」,这个号就是分配给整个子网的,「**室**」对应的号码即分配给子网中计算机的,这就是网络中的地址。「号」对应的号码为网络号,「**室**」对应的号码为主机号,这个地址的整体就是 **IP 地址**。
+
+### 通过 IP 地址我们能知道什么?
+
+通过 IP 地址,我们就可以知道判断访问对象服务器的位置,从而将消息发送到服务器。一般发送者发出的消息首先经过子网的集线器,转发到最近的路由器,然后根据路由位置访问下一个路由器的位置,直到终点
+
+**IP 头部格式** :
+
+
+
+### IP 欺骗技术是什么?
+
+骗呗,拐骗,诱骗!
+
+IP 欺骗技术就是**伪造**某台主机的 IP 地址的技术。通过 IP 地址的伪装使得某台主机能够**伪装**另外的一台主机,而这台主机往往具有某种特权或者被另外的主机所信任。
+
+假设现在有一个合法用户 **(1.1.1.1)** 已经同服务器建立正常的连接,攻击者构造攻击的 TCP 数据,伪装自己的 IP 为 **1.1.1.1**,并向服务器发送一个带有 RST 位的 TCP 数据段。服务器接收到这样的数据后,认为从 **1.1.1.1** 发送的连接有错误,就会清空缓冲区中建立好的连接。
+
+这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
+
+
+
+### 如何缓解 IP 欺骗?
+
+虽然无法预防 IP 欺骗,但可以采取措施来阻止伪造数据包渗透网络。**入口过滤** 是防范欺骗的一种极为常见的防御措施,如 BCP38(通用最佳实践文档)所示。入口过滤是一种数据包过滤形式,通常在[网络边缘](https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/)设备上实施,用于检查传入的 IP 数据包并确定其源标头。如果这些数据包的源标头与其来源不匹配或者看上去很可疑,则拒绝这些数据包。一些网络还实施出口过滤,检查退出网络的 IP 数据包,确保这些数据包具有合法源标头,以防止网络内部用户使用 IP 欺骗技术发起出站恶意攻击。
+
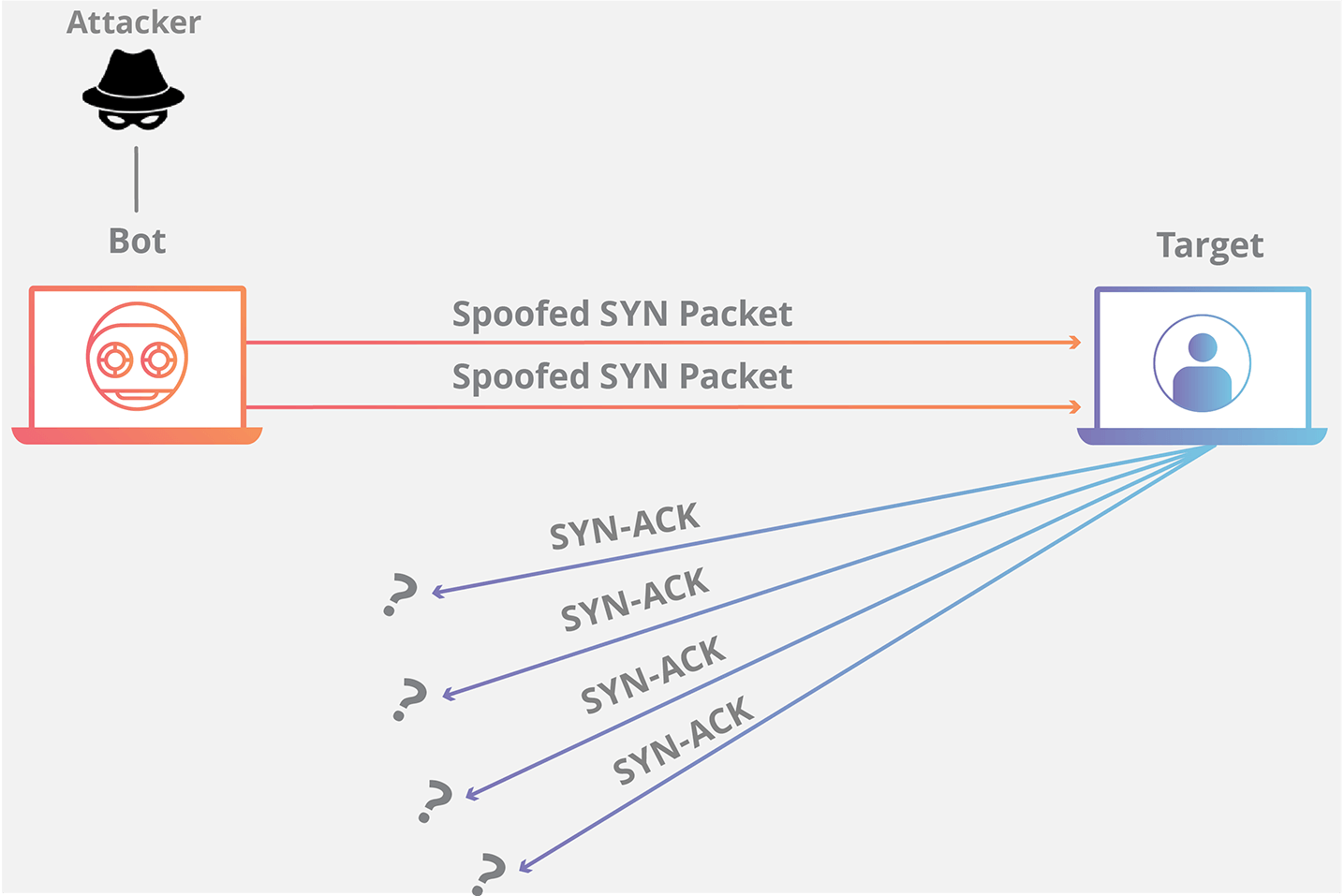
+## SYN Flood(洪水)
+
+### SYN Flood 是什么?
+
+SYN Flood 是互联网上最原始、最经典的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击之一,旨在耗尽可用服务器资源,致使服务器无法传输合法流量
+
+SYN Flood 利用了 TCP 协议的三次握手机制,攻击者通常利用工具或者控制僵尸主机向服务器发送海量的变源 IP 地址或变源端口的 TCP SYN 报文,服务器响应了这些报文后就会生成大量的半连接,当系统资源被耗尽后,服务器将无法提供正常的服务。
+增加服务器性能,提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪,防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
+
+
+
+### TCP SYN Flood 攻击原理是什么?
+
+**TCP SYN Flood** 攻击利用的是 **TCP** 的三次握手(**SYN -> SYN/ACK -> ACK**),假设连接发起方是 A,连接接受方是 B,即 B 在某个端口(**Port**)上监听 A 发出的连接请求,过程如下图所示,左边是 A,右边是 B。
+
+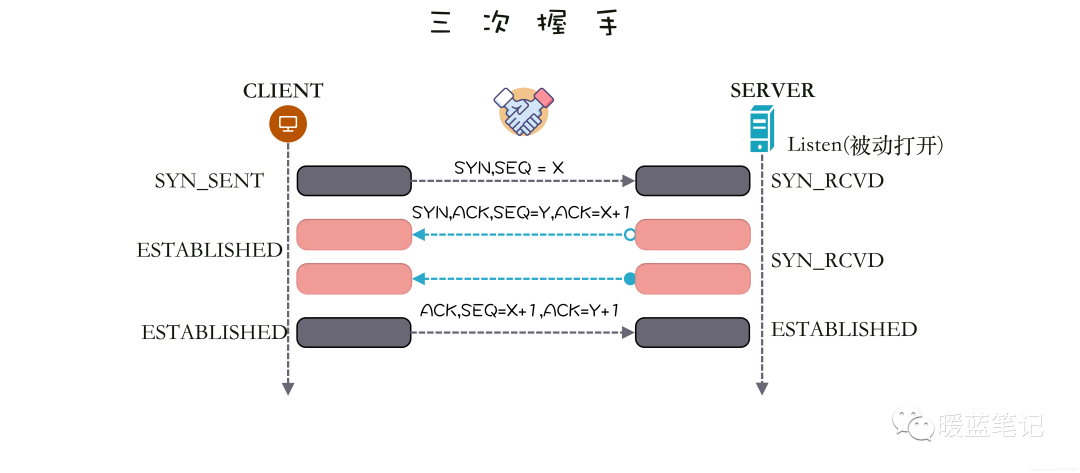
+
+A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement) 消息给 A,这个消息的目的有两个:
+
+- 向 A 确认已做好接收数据的准备,
+- 同时要求 A 也做好接收数据的准备,此时 B 已向 A 确认好接收状态,并等待 A 的确认,连接处于**半开状态(Half-Open)**,顾名思义只开了一半;A 收到后再次发送 **ACK** (Acknowledgement) 消息给 B,向 B 确认也做好了接收数据的准备,至此三次握手完成,「**连接**」就建立了,
+
+大家注意到没有,最关键的一点在于双方是否都按对方的要求进入了**可以接收消息**的状态。而这个状态的确认主要是双方将要使用的**消息序号(**SequenceNum),**TCP** 为保证消息按发送顺序抵达接收方的上层应用,需要用**消息序号**来标记消息的发送先后顺序的。
+
+**TCP**是「**双工**」(Duplex)连接,同时支持双向通信,也就是双方同时可向对方发送消息,其中 **SYN** 和 **SYN-ACK** 消息开启了 A→B 的单向通信通道(B 获知了 A 的消息序号);**SYN-ACK** 和 **ACK** 消息开启了 B→A 单向通信通道(A 获知了 B 的消息序号)。
+
+上面讨论的是双方在诚实守信,正常情况下的通信。
+
+但实际情况是,网络可能不稳定会丢包,使握手消息不能抵达对方,也可能是对方故意不按规矩来,故意延迟或不发送握手确认消息。
+
+假设 B 通过某 **TCP** 端口提供服务,B 在收到 A 的 **SYN** 消息时,积极的反馈了 **SYN-ACK** 消息,使连接进入**半开状态**,因为 B 不确定自己发给 A 的 **SYN-ACK** 消息或 A 反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接都设一个**Timer**,如果超过时间还没有收到 A 的 **ACK** 消息,则重新发送一次 **SYN-ACK** 消息给 A,直到重试超过一定次数时才会放弃。
+
+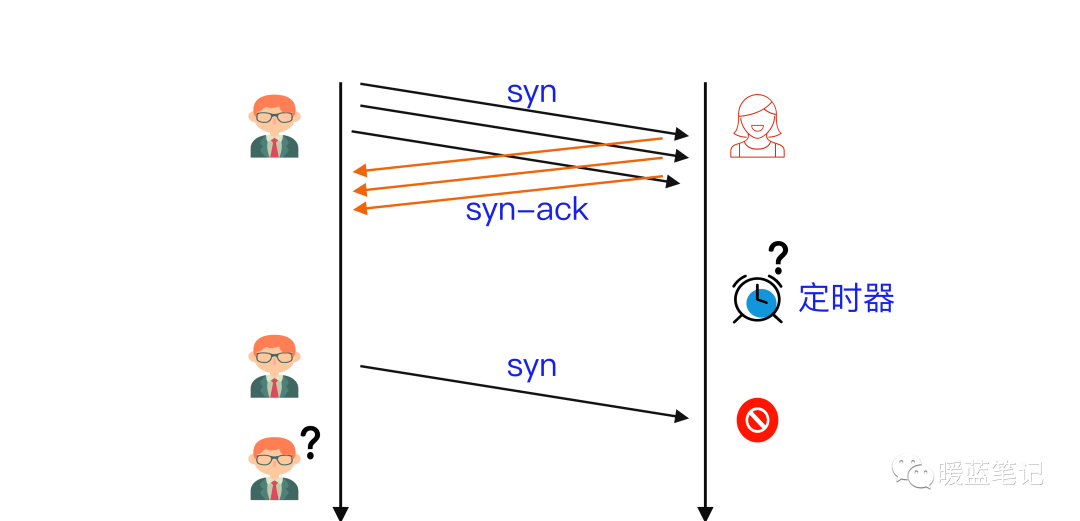
+
+B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接,那么当 B 面临海量的连接 A 时,如上图所示,**SYN Flood** 攻击就形成了。攻击方 A 可以控制肉鸡向 B 发送大量 SYN 消息但不响应 ACK 消息,或者干脆伪造 SYN 消息中的 **Source IP**,使 B 反馈的 **SYN-ACK** 消息石沉大海,导致 B 被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
+
+### SYN Flood 的常见形式有哪些?
+
+**恶意用户可通过三种不同方式发起 SYN Flood 攻击**:
+
+1. **直接攻击:** 不伪造 IP 地址的 SYN 洪水攻击称为直接攻击。在此类攻击中,攻击者完全不屏蔽其 IP 地址。由于攻击者使用具有真实 IP 地址的单一源设备发起攻击,因此很容易发现并清理攻击者。为使目标机器呈现半开状态,黑客将阻止个人机器对服务器的 SYN-ACK 数据包做出响应。为此,通常采用以下两种方式实现:部署防火墙规则,阻止除 SYN 数据包以外的各类传出数据包;或者,对传入的所有 SYN-ACK 数据包进行过滤,防止其到达恶意用户机器。实际上,这种方法很少使用(即便使用过也不多见),因为此类攻击相当容易缓解 – 只需阻止每个恶意系统的 IP 地址。哪怕攻击者使用僵尸网络(如 [Mirai 僵尸网络](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/)),通常也不会刻意屏蔽受感染设备的 IP。
+2. **欺骗攻击:** 恶意用户还可以伪造其发送的各个 SYN 数据包的 IP 地址,以便阻止缓解措施并加大身份暴露难度。虽然数据包可能经过伪装,但还是可以通过这些数据包追根溯源。此类检测工作很难开展,但并非不可实现;特别是,如果 Internet 服务提供商 (ISP) 愿意提供帮助,则更容易实现。
+3. **分布式攻击(DDoS):** 如果使用僵尸网络发起攻击,则追溯攻击源头的可能性很低。随着混淆级别的攀升,攻击者可能还会命令每台分布式设备伪造其发送数据包的 IP 地址。哪怕攻击者使用僵尸网络(如 Mirai 僵尸网络),通常也不会刻意屏蔽受感染设备的 IP。
+
+### 如何缓解 SYN Flood?
+
+#### 扩展积压工作队列
+
+目标设备安装的每个操作系统都允许具有一定数量的半开连接。若要响应大量 SYN 数据包,一种方法是增加操作系统允许的最大半开连接数目。为成功扩展最大积压工作,系统必须额外预留内存资源以处理各类新请求。如果系统没有足够的内存,无法应对增加的积压工作队列规模,将对系统性能产生负面影响,但仍然好过拒绝服务。
+
+#### 回收最先创建的 TCP 半开连接
+
+另一种缓解策略是在填充积压工作后覆盖最先创建的半开连接。这项策略要求完全建立合法连接的时间低于恶意 SYN 数据包填充积压工作的时间。当攻击量增加或积压工作规模小于实际需求时,这项特定的防御措施将不奏效。
+
+#### SYN Cookie
+
+此策略要求服务器创建 Cookie。为避免在填充积压工作时断开连接,服务器使用 SYN-ACK 数据包响应每一项连接请求,而后从积压工作中删除 SYN 请求,同时从内存中删除请求,保证端口保持打开状态并做好重新建立连接的准备。如果连接是合法请求并且已将最后一个 ACK 数据包从客户端机器发回服务器,服务器将重建(存在一些限制)SYN 积压工作队列条目。虽然这项缓解措施势必会丢失一些 TCP 连接信息,但好过因此导致对合法用户发起拒绝服务攻击。
+
+## UDP Flood(洪水)
+
+### UDP Flood 是什么?
+
+**UDP Flood** 也是一种拒绝服务攻击,将大量的用户数据报协议(**UDP**)数据包发送到目标服务器,目的是压倒该设备的处理和响应能力。防火墙保护目标服务器也可能因 **UDP** 泛滥而耗尽,从而导致对合法流量的拒绝服务。
+
+### UDP Flood 攻击原理是什么?
+
+**UDP Flood** 主要通过利用服务器响应发送到其中一个端口的 **UDP** 数据包所采取的步骤。在正常情况下,当服务器在特定端口接收到 **UDP** 数据包时,会经过两个步骤:
+
+- 服务器首先检查是否正在运行正在侦听指定端口的请求的程序。
+- 如果没有程序在该端口接收数据包,则服务器使用 **ICMP**(ping)数据包进行响应,以通知发送方目的地不可达。
+
+举个例子。假设今天要联系酒店的小蓝,酒店客服接到电话后先查看房间的列表来确保小蓝在客房内,随后转接给小蓝。
+
+首先,接待员接收到呼叫者要求连接到特定房间的电话。接待员然后需要查看所有房间的清单,以确保客人在房间中可用,并愿意接听电话。碰巧的是,此时如果突然间所有的电话线同时亮起来,那么他们就会很快就变得不堪重负了。
+
+当服务器接收到每个新的 **UDP** 数据包时,它将通过步骤来处理请求,并利用该过程中的服务器资源。发送 **UDP** 报文时,每个报文将包含源设备的 **IP** 地址。在这种类型的 **DDoS** 攻击期间,攻击者通常不会使用自己的真实 **IP** 地址,而是会欺骗 **UDP** 数据包的源 **IP** 地址,从而阻止攻击者的真实位置被暴露并潜在地饱和来自目标的响应数据包服务器。
+
+由于目标服务器利用资源检查并响应每个接收到的 **UDP** 数据包的结果,当接收到大量 **UDP** 数据包时,目标的资源可能会迅速耗尽,导致对正常流量的拒绝服务。
+
+
+
+### 如何缓解 UDP Flooding?
+
+大多数操作系统部分限制了 **ICMP** 报文的响应速率,以中断需要 ICMP 响应的 **DDoS** 攻击。这种缓解的一个缺点是在攻击过程中,合法的数据包也可能被过滤。如果 **UDP Flood** 的容量足够高以使目标服务器的防火墙的状态表饱和,则在服务器级别发生的任何缓解都将不足以应对目标设备上游的瓶颈。
+
+## HTTP Flood(洪水)
+
+### HTTP Flood 是什么?
+
+HTTP Flood 是一种大规模的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击,旨在利用 HTTP 请求使目标服务器不堪重负。目标因请求而达到饱和,且无法响应正常流量后,将出现拒绝服务,拒绝来自实际用户的其他请求。
+
+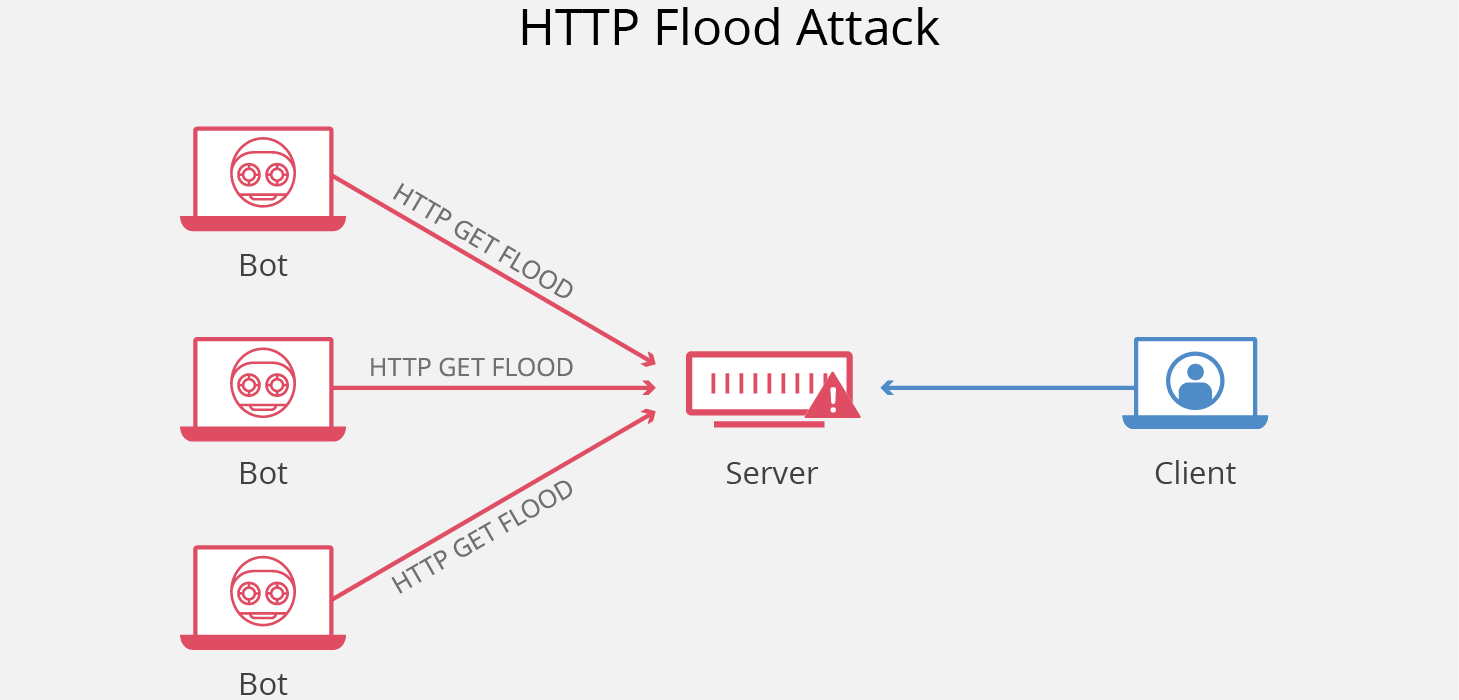
+
+### HTTP Flood 的攻击原理是什么?
+
+HTTP 洪水攻击是“第 7 层”DDoS 攻击的一种。第 7 层是 OSI 模型的应用程序层,指的是 HTTP 等互联网协议。HTTP 是基于浏览器的互联网请求的基础,通常用于加载网页或通过互联网发送表单内容。缓解应用程序层攻击特别复杂,因为恶意流量和正常流量很难区分。
+
+为了获得最大效率,恶意行为者通常会利用或创建僵尸网络,以最大程度地扩大攻击的影响。通过利用感染了恶意软件的多台设备,攻击者可以发起大量攻击流量来进行攻击。
+
+HTTP 洪水攻击有两种:
+
+- **HTTP GET 攻击**:在这种攻击形式下,多台计算机或其他设备相互协调,向目标服务器发送对图像、文件或其他资产的多个请求。当目标被传入的请求和响应所淹没时,来自正常流量源的其他请求将被拒绝服务。
+- **HTTP POST 攻击**:一般而言,在网站上提交表单时,服务器必须处理传入的请求并将数据推送到持久层(通常是数据库)。与发送 POST 请求所需的处理能力和带宽相比,处理表单数据和运行必要数据库命令的过程相对密集。这种攻击利用相对资源消耗的差异,直接向目标服务器发送许多 POST 请求,直到目标服务器的容量饱和并拒绝服务为止。
+
+### 如何防护 HTTP Flood?
+
+如前所述,缓解第 7 层攻击非常复杂,而且通常要从多方面进行。一种方法是对发出请求的设备实施质询,以测试它是否是机器人,这与在线创建帐户时常用的 CAPTCHA 测试非常相似。通过提出 JavaScript 计算挑战之类的要求,可以缓解许多攻击。
+
+其他阻止 HTTP 洪水攻击的途径包括使用 Web 应用程序防火墙 (WAF)、管理 IP 信誉数据库以跟踪和有选择地阻止恶意流量,以及由工程师进行动态分析。Cloudflare 具有超过 2000 万个互联网设备的规模优势,能够分析来自各种来源的流量并通过快速更新的 WAF 规则和其他防护策略来缓解潜在的攻击,从而消除应用程序层 DDoS 流量。
+
+## DNS Flood(洪水)
+
+### DNS Flood 是什么?
+
+域名系统(DNS)服务器是互联网的“电话簿“;互联网设备通过这些服务器来查找特定 Web 服务器以便访问互联网内容。DNS Flood 攻击是一种分布式拒绝服务(DDoS)攻击,攻击者用大量流量淹没某个域的 DNS 服务器,以尝试中断该域的 DNS 解析。如果用户无法找到电话簿,就无法查找到用于调用特定资源的地址。通过中断 DNS 解析,DNS Flood 攻击将破坏网站、API 或 Web 应用程序响应合法流量的能力。很难将 DNS Flood 攻击与正常的大流量区分开来,因为这些大规模流量往往来自多个唯一地址,查询该域的真实记录,模仿合法流量。
+
+### DNS Flood 的攻击原理是什么?
+
+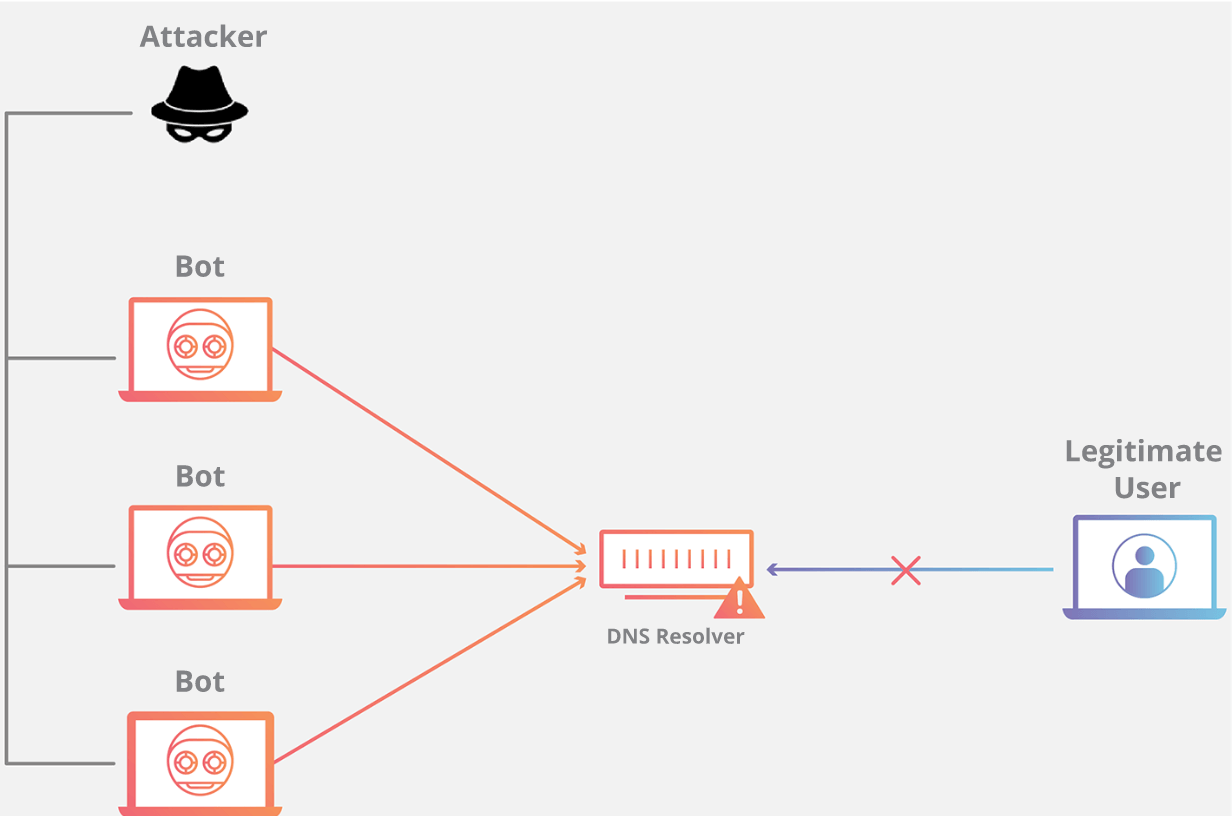
+
+域名系统的功能是将易于记忆的名称(例如 example.com)转换成难以记住的网站服务器地址(例如 192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood 攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood 攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
+
+DNS Flood 攻击不同于 [DNS 放大攻击](https://www.cloudflare.com/zh-cn/learning/ddos/dns-amplification-ddos-attack/)。与 DNS Flood 攻击不同,DNS 放大攻击反射并放大不安全 DNS 服务器的流量,以便隐藏攻击的源头并提高攻击的有效性。DNS 放大攻击使用连接带宽较小的设备向不安全的 DNS 服务器发送无数请求。这些设备对非常大的 DNS 记录发出小型请求,但在发出请求时,攻击者伪造返回地址为目标受害者。这种放大效果让攻击者能借助有限的攻击资源来破坏较大的目标。
+
+### 如何防护 DNS Flood?
+
+DNS Flood 对传统上基于放大的攻击方法做出了改变。借助轻易获得的高带宽僵尸网络,攻击者现能针对大型组织发动攻击。除非被破坏的 IoT 设备得以更新或替换,否则抵御这些攻击的唯一方法是使用一个超大型、高度分布式的 DNS 系统,以便实时监测、吸收和阻止攻击流量。
+
+## TCP 重置攻击
+
+在 **TCP** 重置攻击中,攻击者通过向通信的一方或双方发送伪造的消息,告诉它们立即断开连接,从而使通信双方连接中断。正常情况下,如果客户端收发现到达的报文段对于相关连接而言是不正确的,**TCP** 就会发送一个重置报文段,从而导致 **TCP** 连接的快速拆卸。
+
+**TCP** 重置攻击利用这一机制,通过向通信方发送伪造的重置报文段,欺骗通信双方提前关闭 TCP 连接。如果伪造的重置报文段完全逼真,接收者就会认为它有效,并关闭 **TCP** 连接,防止连接被用来进一步交换信息。服务端可以创建一个新的 **TCP** 连接来恢复通信,但仍然可能会被攻击者重置连接。万幸的是,攻击者需要一定的时间来组装和发送伪造的报文,所以一般情况下这种攻击只对长连接有杀伤力,对于短连接而言,你还没攻击呢,人家已经完成了信息交换。
+
+从某种意义上来说,伪造 **TCP** 报文段是很容易的,因为 **TCP/IP** 都没有任何内置的方法来验证服务端的身份。有些特殊的 IP 扩展协议(例如 `IPSec`)确实可以验证身份,但并没有被广泛使用。客户端只能接收报文段,并在可能的情况下使用更高级别的协议(如 `TLS`)来验证服务端的身份。但这个方法对 **TCP** 重置包并不适用,因为 **TCP** 重置包是 **TCP** 协议本身的一部分,无法使用更高级别的协议进行验证。
+
+## 模拟攻击
+
+> 以下实验是在 `OSX` 系统中完成的,其他系统请自行测试。
+
+现在来总结一下伪造一个 **TCP** 重置报文要做哪些事情:
+
+- 嗅探通信双方的交换信息。
+- 截获一个 `ACK` 标志位置位 1 的报文段,并读取其 `ACK` 号。
+- 伪造一个 TCP 重置报文段(`RST` 标志位置为 1),其序列号等于上面截获的报文的 `ACK` 号。这只是理想情况下的方案,假设信息交换的速度不是很快。大多数情况下为了增加成功率,可以连续发送序列号不同的重置报文。
+- 将伪造的重置报文发送给通信的一方或双方,时其中断连接。
+
+为了实验简单,我们可以使用本地计算机通过 `localhost` 与自己通信,然后对自己进行 TCP 重置攻击。需要以下几个步骤:
+
+- 在两个终端之间建立一个 TCP 连接。
+- 编写一个能嗅探通信双方数据的攻击程序。
+- 修改攻击程序,伪造并发送重置报文。
+
+下面正式开始实验。
+
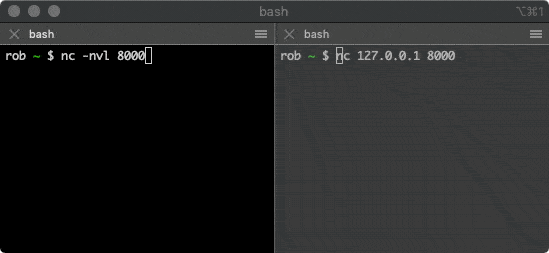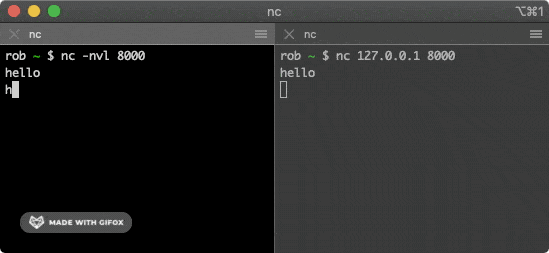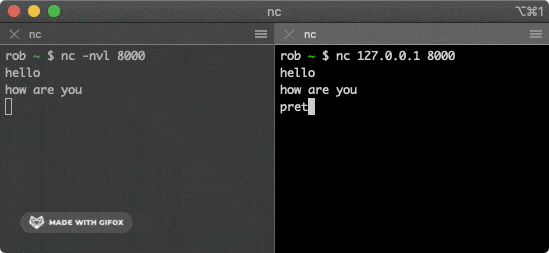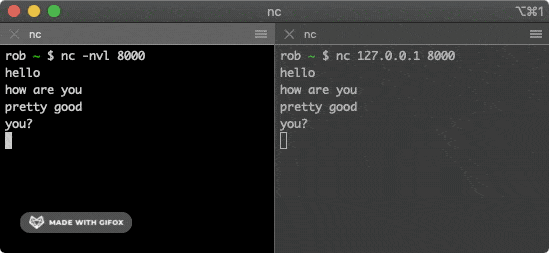
+> 建立 TCP 连接
+
+可以使用 netcat 工具来建立 TCP 连接,这个工具很多操作系统都预装了。打开第一个终端窗口,运行以下命令:
+
+```bash
+nc -nvl 8000
+```
+
+这个命令会启动一个 TCP 服务,监听端口为 `8000`。接着再打开第二个终端窗口,运行以下命令:
+
+```bash
+nc 127.0.0.1 8000
+```
+
+该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
+
+
+
+> 嗅探流量
+
+编写一个攻击程序,使用 Python 网络库 `scapy` 来读取两个终端窗口之间交换的数据,并将其打印到终端上。代码比较长,下面为一部份,完整代码后台回复 TCP 攻击,代码的核心是调用 `scapy` 的嗅探方法:
+
+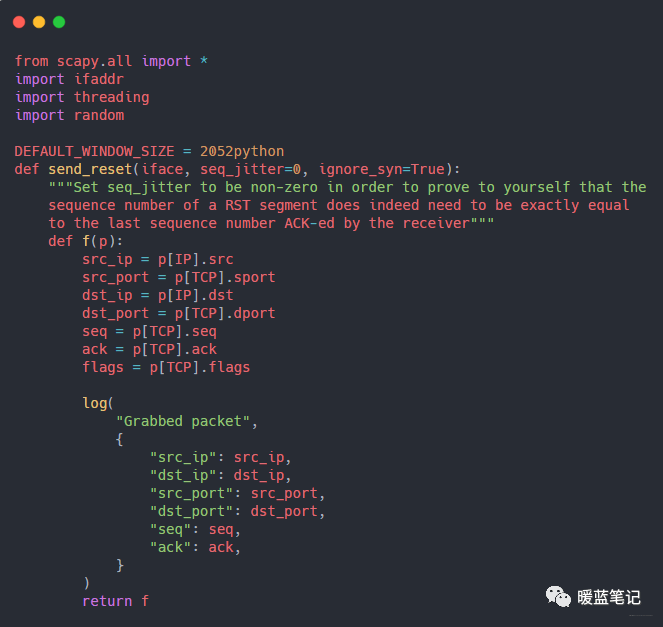
+
+这段代码告诉 `scapy` 在 `lo0` 网络接口上嗅探数据包,并记录所有 TCP 连接的详细信息。
+
+- **iface** : 告诉 scapy 在 `lo0`(localhost)网络接口上进行监听。
+- **lfilter** : 这是个过滤器,告诉 scapy 忽略所有不属于指定的 TCP 连接(通信双方皆为 `localhost`,且端口号为 `8000`)的数据包。
+- **prn** : scapy 通过这个函数来操作所有符合 `lfilter` 规则的数据包。上面的例子只是将数据包打印到终端,下文将会修改函数来伪造重置报文。
+- **count** : scapy 函数返回之前需要嗅探的数据包数量。
+
+> 发送伪造的重置报文
+
+下面开始修改程序,发送伪造的 TCP 重置报文来进行 TCP 重置攻击。根据上面的解读,只需要修改 prn 函数就行了,让其检查数据包,提取必要参数,并利用这些参数来伪造 TCP 重置报文并发送。
+
+例如,假设该程序截获了一个从(`src_ip`, `src_port`)发往 (`dst_ip`, `dst_port`)的报文段,该报文段的 ACK 标志位已置为 1,ACK 号为 `100,000`。攻击程序接下来要做的是:
+
+- 由于伪造的数据包是对截获的数据包的响应,所以伪造数据包的源 `IP/Port` 应该是截获数据包的目的 `IP/Port`,反之亦然。
+- 将伪造数据包的 `RST` 标志位置为 1,以表示这是一个重置报文。
+- 将伪造数据包的序列号设置为截获数据包的 ACK 号,因为这是发送方期望收到的下一个序列号。
+- 调用 `scapy` 的 `send` 方法,将伪造的数据包发送给截获数据包的发送方。
+
+对于我的程序而言,只需将这一行取消注释,并注释这一行的上面一行,就可以全面攻击了。按照步骤 1 的方法设置 TCP 连接,打开第三个窗口运行攻击程序,然后在 TCP 连接的其中一个终端输入一些字符串,你会发现 TCP 连接被中断了!
+
+> 进一步实验
+
+1. 可以继续使用攻击程序进行实验,将伪造数据包的序列号加减 1 看看会发生什么,是不是确实需要和截获数据包的 `ACK` 号完全相同。
+2. 打开 `Wireshark`,监听 lo0 网络接口,并使用过滤器 `ip.src == 127.0.0.1 && ip.dst == 127.0.0.1 && tcp.port == 8000` 来过滤无关数据。你可以看到 TCP 连接的所有细节。
+3. 在连接上更快速地发送数据流,使攻击更难执行。
+
+## 中间人攻击
+
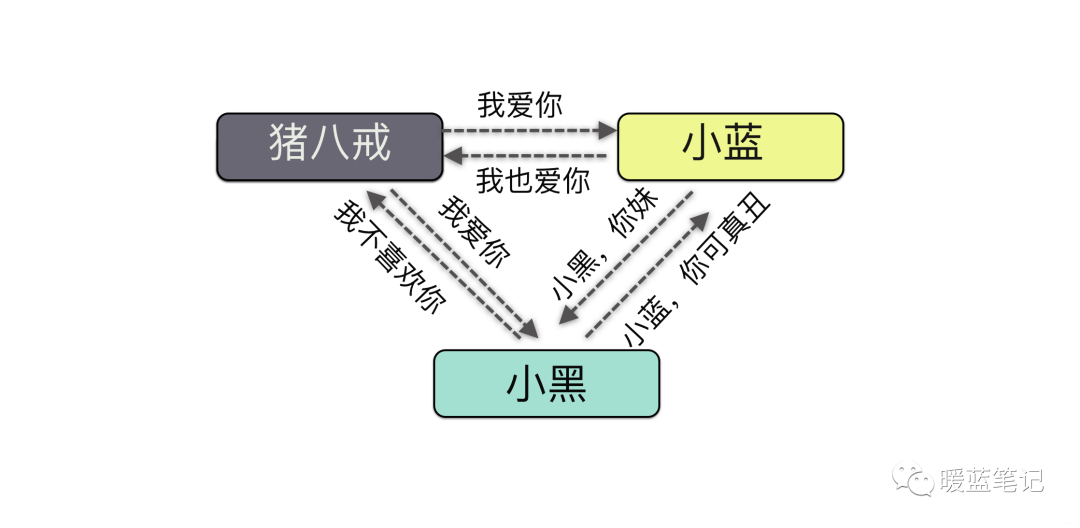
+猪八戒要向小蓝表白,于是写了一封信给小蓝,结果第三者小黑拦截到了这封信,把这封信进行了篡改,于是乎在他们之间进行搞破坏行动。这个马文才就是中间人,实施的就是中间人攻击。好我们继续聊聊什么是中间人攻击。
+
+### 什么是中间人?
+
+攻击中间人攻击英文名叫 Man-in-the-MiddleAttack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方 直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
+
+
+
+从这张图可以看到,中间人其实就是攻击者。通过这种原理,有很多实现的用途,比如说,你在手机上浏览不健康网站的时候,手机就会提示你,此网站可能含有病毒,是否继续访问还是做其他的操作等等。
+
+### 中间人攻击的原理是什么?
+
+举个例子,我和公司签了一个一份劳动合同,一人一份合同。不晓得哪个可能改了合同内容,不知道真假了,怎么搞?只好找专业的机构来鉴定,自然就要花钱。
+
+在安全领域有句话:**我们没有办法杜绝网络犯罪,只好想办法提高网络犯罪的成本**。既然没法杜绝这种情况,那我们就想办法提高作案的成本,今天我们就简单了解下基本的网络安全知识,也是面试中的高频面试题了。
+
+为了避免双方说活不算数的情况,双方引入第三家机构,将合同原文给可信任的第三方机构,只要这个机构不监守自盗,合同就相对安全。
+
+**如果第三方机构内部不严格或容易出现纰漏?**
+
+虽然我们将合同原文给第三方机构了,为了防止内部人员的更改,需要采取什么措施呢
+
+一种可行的办法是引入 **摘要算法** 。即合同和摘要一起,为了简单的理解摘要。大家可以想象这个摘要为一个函数,这个函数对原文进行了加密,会产生一个唯一的散列值,一旦原文发生一点点变化,那么这个散列值将会变化。
+
+#### 有哪些常用的摘要算法呢?
+
+目前比较常用的加密算法有消息摘要算法和安全散列算法(**SHA**)。**MD5** 是将任意长度的文章转化为一个 128 位的散列值,可是在 2004 年,**MD5** 被证实了容易发生碰撞,即两篇原文产生相同的摘要。这样的话相当于直接给黑客一个后门,轻松伪造摘要。
+
+所以在大部分的情况下都会选择 **SHA 算法** 。
+
+**出现内鬼了怎么办?**
+
+看似很安全的场面了,理论上来说杜绝了篡改合同的做法。主要某个员工同时具有修改合同和摘要的权利,那搞事儿就是时间的问题了,毕竟没哪个系统可以完全的杜绝员工接触敏感信息,除非敏感信息都不存在。所以能不能考虑将合同和摘要分开存储呢
+
+**那如何确保员工不会修改合同呢?**
+
+这确实蛮难的,不过办法总比困难多。我们将合同放在双方手中,摘要放在第三方机构,篡改难度进一步加大
+
+**那么员工万一和某个用户串通好了呢?**
+
+看来放在第三方的机构还是不好使,同样存在不小风险。所以还需要寻找新的方案,这就出现了 **数字签名和证书**。
+
+#### 数字证书和签名有什么用?
+
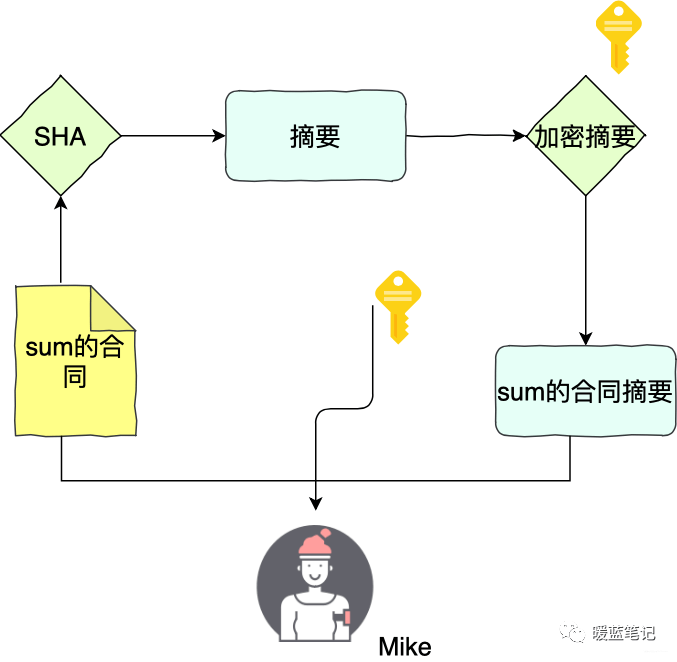
+同样的,举个例子。Sum 和 Mike 两个人签合同。Sum 首先用 **SHA** 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Sum 将合同原文、签名,以及公钥三者都交给 Mike
+
+
+
+如果 Sum 想要证明合同是 Mike 的,那么就要使用 Mike 的公钥,将这个签名解密得到摘要 x,然后 Mike 计算原文的 sha 摘要 Y,随后对比 x 和 y,如果两者相等,就认为数据没有被篡改
+
+在这样的过程中,Mike 是不能更改 Sum 的合同,因为要修改合同不仅仅要修改原文还要修改摘要,修改摘要需要提供 Mike 的私钥,私钥即 Sum 独有的密码,公钥即 Sum 公布给他人使用的密码
+
+总之,公钥加密的数据只能私钥可以解密。私钥加密的数据只有公钥可以解密,这就是 **非对称加密** 。
+
+隐私保护?不是吓唬大家,信息是透明的兄 die,不过尽量去维护个人的隐私吧,今天学习对称加密和非对称加密。
+
+大家先读读这个字"钥",是读"yao",我以前也是,其实读"yue"
+
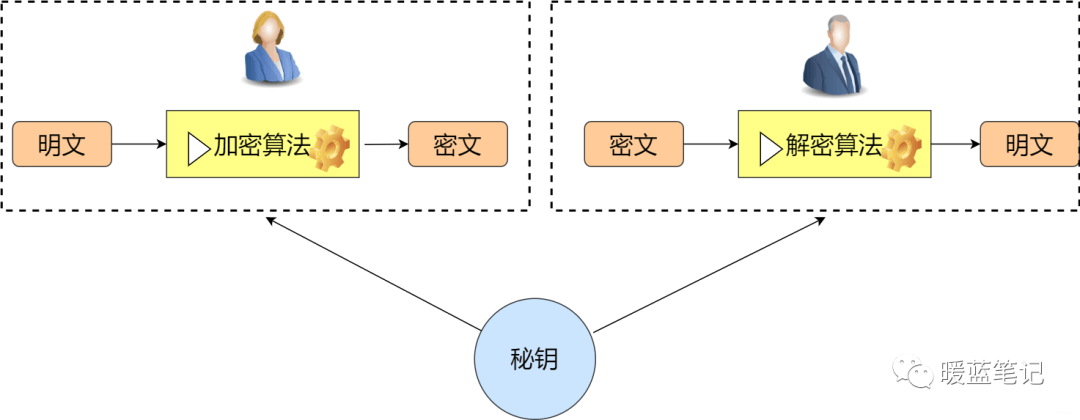
+#### 什么是对称加密?
+
+对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
+
+
+
+#### 常见的对称加密算法有哪些?
+
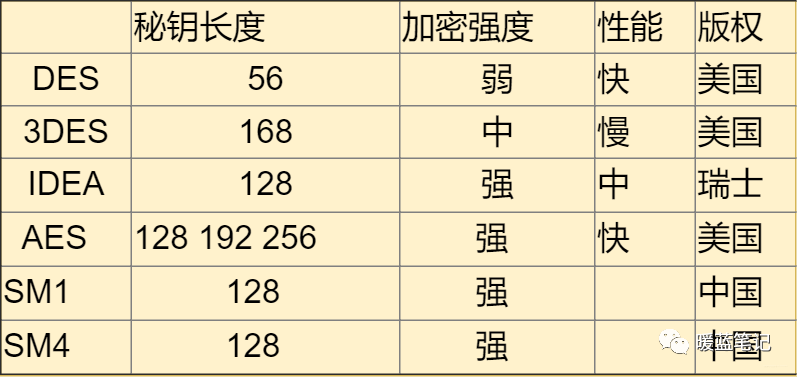
+**DES**
+
+DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实际用于算法,其余 8 位可以被用于奇偶校验,并在算法中被丢弃。因此,**DES** 的有效密钥长度为 56 位,通常称 **DES** 的密钥长度为 56 位。假设秘钥为 56 位,采用暴力破 Jie 的方式,其秘钥个数为 2 的 56 次方,那么每纳秒执行一次解密所需要的时间差不多 1 年的样子。当然,没人这么干。**DES** 现在已经不是一种安全的加密方法,主要因为它使用的 56 位密钥过短。
+
+
+
+**IDEA**
+
+国际数据加密算法(International Data Encryption Algorithm)。秘钥长度 128 位,优点没有专利的限制。
+
+**AES**
+
+当 DES 被破解以后,没过多久推出了 **AES** 算法,提供了三种长度供选择,128 位、192 位和 256,为了保证性能不受太大的影响,选择 128 即可。
+
+**SM1 和 SM4**
+
+之前几种都是国外的,我们国内自行研究了国密 **SM1**和 **SM4**。其中 S 都属于国家标准,算法公开。优点就是国家的大力支持和认可
+
+**总结**:
+
+
+
+#### 常见的非对称加密算法有哪些?
+
+在对称加密中,发送方与接收方使用相同的秘钥。那么在非对称加密中则是发送方与接收方使用的不同的秘钥。其主要解决的问题是防止在秘钥协商的过程中发生泄漏。比如在对称加密中,小蓝将需要发送的消息加密,然后告诉你密码是 123balala,ok,对于其他人而言,很容易就能劫持到密码是 123balala。那么在非对称的情况下,小蓝告诉所有人密码是 123balala,对于中间人而言,拿到也没用,因为没有私钥。所以,非对称密钥其实主要解决了密钥分发的难题。如下图
+
+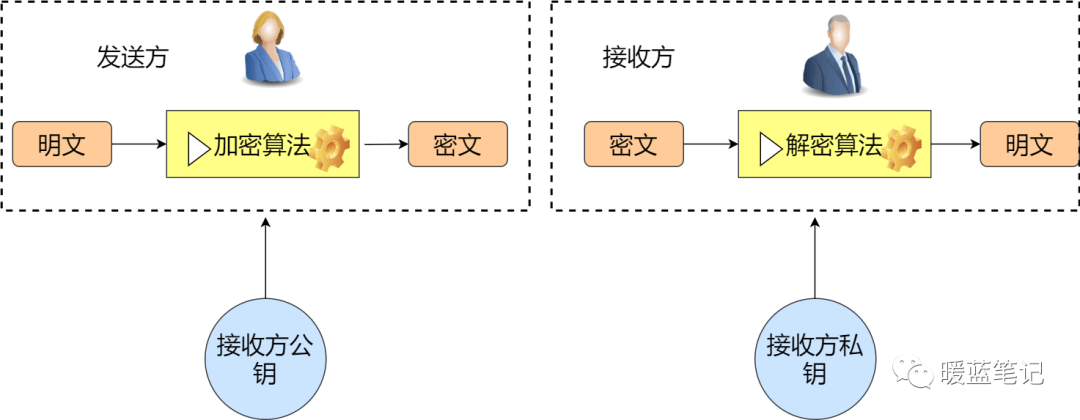
+
+其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 docker 集群也会使用相关非对称加密算法。
+
+常见的非对称加密算法:
+
+- RSA(RSA 加密算法,RSA Algorithm):优势是性能比较快,如果想要较高的加密难度,需要很长的秘钥。
+
+- ECC:基于椭圆曲线提出。是目前加密强度最高的非对称加密算法
+- SM2:同样基于椭圆曲线问题设计。最大优势就是国家认可和大力支持。
+
+总结:
+
+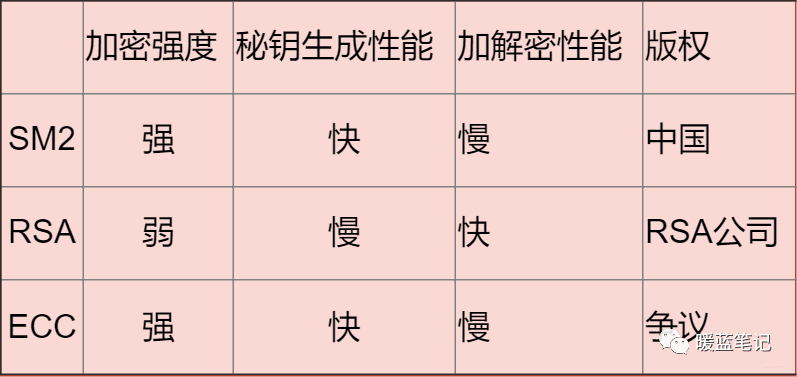
+
+#### 常见的散列算法有哪些?
+
+这个大家应该更加熟悉了,比如我们平常使用的 MD5 校验,在很多时候,我并不是拿来进行加密,而是用来获得唯一性 ID。在做系统的过程中,存储用户的各种密码信息,通常都会通过散列算法,最终存储其散列值。
+
+**MD5**(不推荐)
+
+MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较普遍的散列算法,具体的应用场景你可以自行 参阅。虽然,因为算法的缺陷,它的唯一性已经被破解了,但是大部分场景下,这并不会构成安全问题。但是,如果不是长度受限(32 个字符),我还是不推荐你继续使用 **MD5** 的。
+
+**SHA**
+
+安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA 将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1 已被证明不够安全,因此逐渐被 SHA-2 取代,而 SHA-3 则作为 SHA 系列的最新版本,采用不同的结构(Keccak 算法)提供更高的安全性和灵活性。
+
+**SM3**
+
+国密算法**SM3**。加密强度和 SHA-256 算法 相差不多。主要是受到了国家的支持。
+
+**总结**:
+
+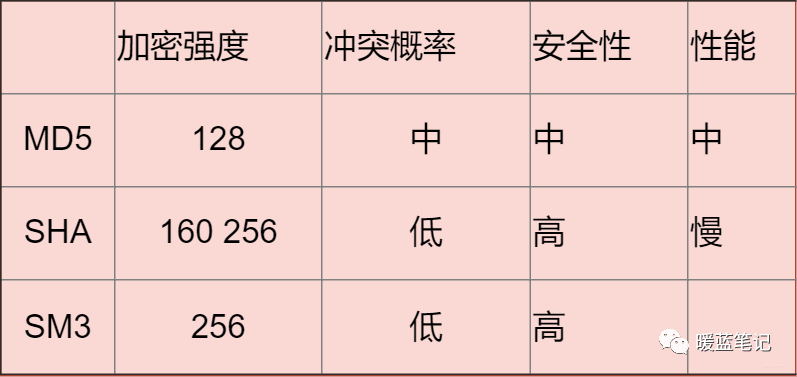
+
+**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则散列算法。** 因为这段时间有这方面需求,就看了一些这方面的资料,入坑信息安全,就怕以后洗发水都不用买。谢谢大家查看!
+
+#### 第三方机构和证书机制有什么用?
+
+问题还有,此时如果 Sum 否认给过 Mike 的公钥和合同,不久 gg 了
+
+所以需要 Sum 过的话做过的事儿需要足够的信誉,这就引入了 **第三方机构和证书机制** 。
+
+证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike ,而是提供由第三方机构,含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那 ik,信任关系成立
+
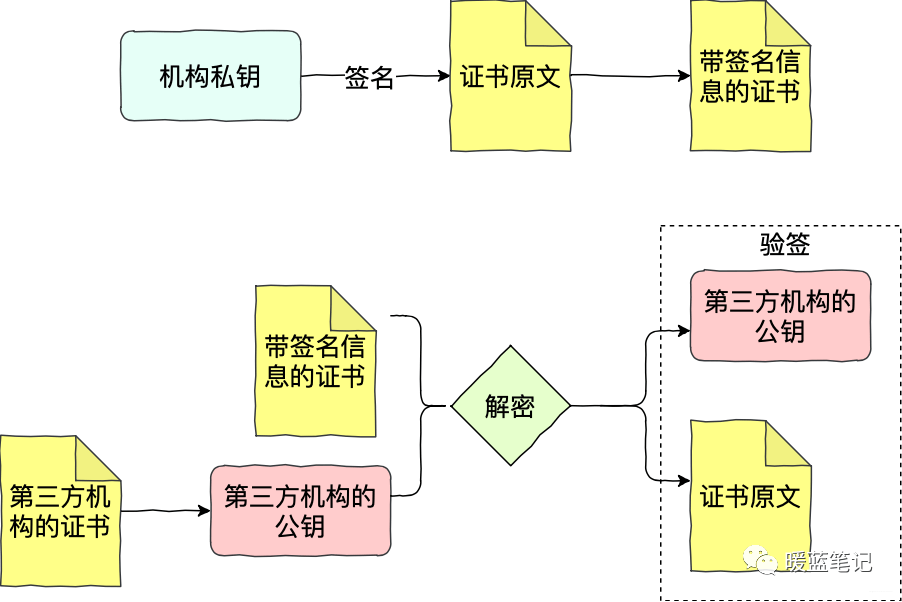
+
+
+如上图所示,Sum 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Sum 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Mike 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Sum 证书的摘要、证书的原文。有了 Sum 证书的摘要和原文,Mike 就可以进行验签。验签通过,Mike 就可以确认 Sum 的证书的确是第三方机构签发的。
+
+用上面这样一个机制,合同的双方都无法否认合同。这个解决方案的核心在于需要第三方信用服务机构提供信用背书。这里产生了一个最基础的信任链,如果第三方机构的信任崩溃,比如被黑客攻破,那整条信任链条也就断裂了
+
+为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险
+
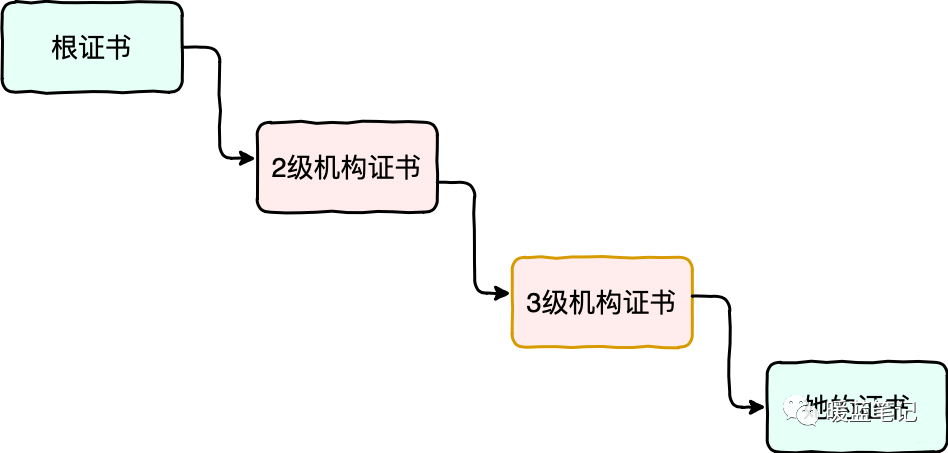
+
+
+上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Sum 证书。
+
+如果要验证 Sum 证书的合法性,就需要用三级机构证书中的公钥去解密 Sum 证书的数字签名。
+
+如果要验证三级机构证书的合法性,就需要用二级机构的证书去解密三级机构证书的数字签名。
+
+如果要验证二级结构证书的合法性,就需要用根证书去解密。
+
+以上,就构成了一个相对长一些的信任链。如果其中一方想要作弊是非常困难的,除非链条中的所有机构同时联合起来,进行欺诈。
+
+### 中间人攻击如何避免?
+
+既然知道了中间人攻击的原理也知道了他的危险,现在我们看看如何避免。相信我们都遇到过下面这种状况:
+
+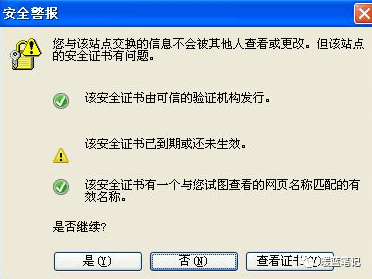
+
+出现这个界面的很多情况下,都是遇到了中间人攻击的现象,需要对安全证书进行及时地监测。而且大名鼎鼎的 github 网站,也曾遭遇过中间人攻击:
+
+想要避免中间人攻击的方法目前主要有两个:
+
+- 客户端不要轻易相信证书:因为这些证书极有可能是中间人。
+- App 可以提前预埋证书在本地:意思是我们本地提前有一些证书,这样其他证书就不能再起作用了。
+
+## DDOS
+
+通过上面的描述,总之即好多种攻击都是 **DDOS** 攻击,所以简单总结下这个攻击相关内容。
+
+其实,像全球互联网各大公司,均遭受过大量的 **DDoS**。
+
+2018 年,GitHub 在一瞬间遭到高达 1.35Tbps 的带宽攻击。这次 DDoS 攻击几乎可以堪称是互联网有史以来规模最大、威力最大的 DDoS 攻击了。在 GitHub 遭到攻击后,仅仅一周后,DDoS 攻击又开始对 Google、亚马逊甚至 Pornhub 等网站进行了 DDoS 攻击。后续的 DDoS 攻击带宽最高也达到了 1Tbps。
+
+### DDoS 攻击究竟是什么?
+
+DDos 全名 Distributed Denial of Service,翻译成中文就是**分布式拒绝服务**。指的是处于不同位置的多个攻击者同时向一个或数个目标发动攻击,是一种分布的、协同的大规模攻击方式。单一的 DoS 攻击一般是采用一对一方式的,它利用网络协议和操作系统的一些缺陷,采用**欺骗和伪装**的策略来进行网络攻击,使网站服务器充斥大量要求回复的信息,消耗网络带宽或系统资源,导致网络或系统不胜负荷以至于瘫痪而停止提供正常的网络服务。
+
+> 举个例子
+
+我开了一家有五十个座位的重庆火锅店,由于用料上等,童叟无欺。平时门庭若市,生意特别红火,而对面二狗家的火锅店却无人问津。二狗为了对付我,想了一个办法,叫了五十个人来我的火锅店坐着却不点菜,让别的客人无法吃饭。
+
+上面这个例子讲的就是典型的 DDoS 攻击,一般来说是指攻击者利用“肉鸡”对目标网站在较短的时间内发起大量请求,大规模消耗目标网站的主机资源,让它无法正常服务。在线游戏、互联网金融等领域是 DDoS 攻击的高发行业。
+
+攻击方式很多,比如 **ICMP Flood**、**UDP Flood**、**NTP Flood**、**SYN Flood**、**CC 攻击**、**DNS Query Flood**等等。
+
+### 如何应对 DDoS 攻击?
+
+#### 高防服务器
+
+还是拿开的重庆火锅店举例,高防服务器就是我给重庆火锅店增加了两名保安,这两名保安可以让保护店铺不受流氓骚扰,并且还会定期在店铺周围巡逻防止流氓骚扰。
+
+高防服务器主要是指能独立硬防御 50Gbps 以上的服务器,能够帮助网站拒绝服务攻击,定期扫描网络主节点等,这东西是不错,就是贵~
+
+#### 黑名单
+
+面对火锅店里面的流氓,我一怒之下将他们拍照入档,并禁止他们踏入店铺,但是有的时候遇到长得像的人也会禁止他进入店铺。这个就是设置黑名单,此方法秉承的就是“错杀一千,也不放一百”的原则,会封锁正常流量,影响到正常业务。
+
+#### DDoS 清洗
+
+**DDos** 清洗,就是我发现客人进店几分钟以后,但是一直不点餐,我就把他踢出店里。
+
+**DDoS** 清洗会对用户请求数据进行实时监控,及时发现 **DOS** 攻击等异常流量,在不影响正常业务开展的情况下清洗掉这些异常流量。
+
+#### CDN 加速
+
+CDN 加速,我们可以这么理解:为了减少流氓骚扰,我干脆将火锅店开到了线上,承接外卖服务,这样流氓找不到店在哪里,也耍不来流氓了。
+
+在现实中,CDN 服务将网站访问流量分配到了各个节点中,这样一方面隐藏网站的真实 IP,另一方面即使遭遇 **DDoS** 攻击,也可以将流量分散到各个节点中,防止源站崩溃。
+
+## 参考
+
+- HTTP 洪水攻击 - CloudFlare:
+- SYN 洪水攻击:
+- 什么是 IP 欺骗?:
+- 什么是 DNS 洪水?| DNS 洪水 DDoS 攻击:
+
+
+
diff --git a/docs_en/cs-basics/network/osi-and-tcp-ip-model.en.md b/docs_en/cs-basics/network/osi-and-tcp-ip-model.en.md
new file mode 100644
index 00000000000..aaf16393d80
--- /dev/null
+++ b/docs_en/cs-basics/network/osi-and-tcp-ip-model.en.md
@@ -0,0 +1,203 @@
+---
+title: OSI 和 TCP/IP 网络分层模型详解(基础)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: OSI 七层,TCP/IP 四层,分层模型,职责划分,协议栈,对比
+ - - meta
+ - name: description
+ content: 详解 OSI 与 TCP/IP 的分层模型与职责划分,结合历史与实践对比两者差异与工程取舍。
+---
+
+## OSI 七层模型
+
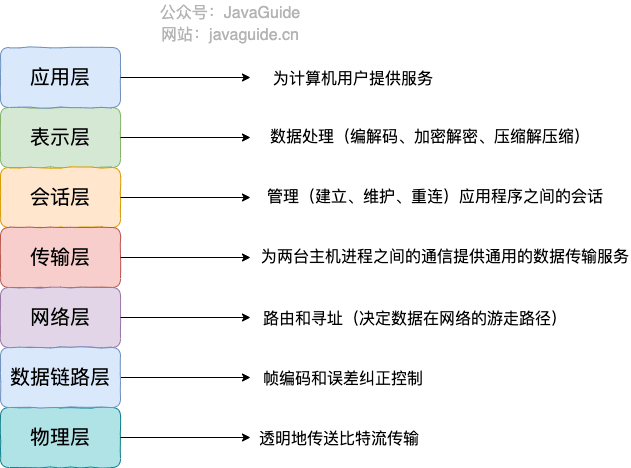
+**OSI 七层模型** 是国际标准化组织提出一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
+
+
+
+每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
+
+**OSI 的七层体系结构概念清楚,理论也很完整,但是它比较复杂而且不实用,而且有些功能在多个层中重复出现。**
+
+上面这种图可能比较抽象,再来一个比较生动的图片。下面这个图片是我在国外的一个网站上看到的,非常赞!
+
+
+
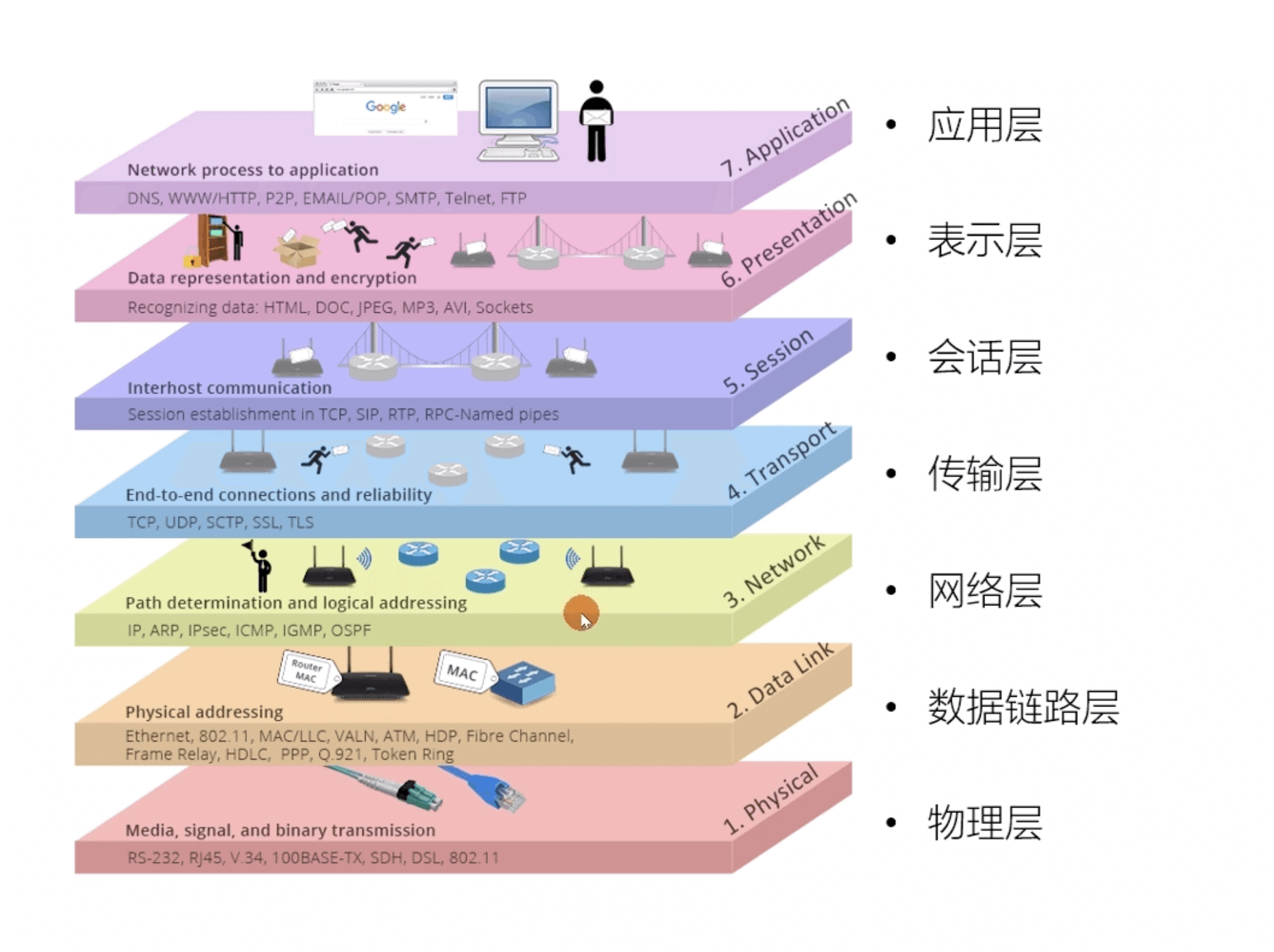
+**既然 OSI 七层模型这么厉害,为什么干不过 TCP/IP 四 层模型呢?**
+
+的确,OSI 七层模型当时一直被一些大公司甚至一些国家政府支持。这样的背景下,为什么会失败呢?我觉得主要有下面几方面原因:
+
+1. OSI 的专家缺乏实际经验,他们在完成 OSI 标准时缺乏商业驱动力
+2. OSI 的协议实现起来过分复杂,而且运行效率很低
+3. OSI 制定标准的周期太长,因而使得按 OSI 标准生产的设备无法及时进入市场(20 世纪 90 年代初期,虽然整套的 OSI 国际标准都已经制定出来,但基于 TCP/IP 的互联网已经抢先在全球相当大的范围成功运行了)
+4. OSI 的层次划分不太合理,有些功能在多个层次中重复出现。
+
+OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础。为了更好地去了解网络分层,OSI 七层模型还是非常有必要学习的。
+
+最后再分享一个关于 OSI 七层模型非常不错的总结图片!
+
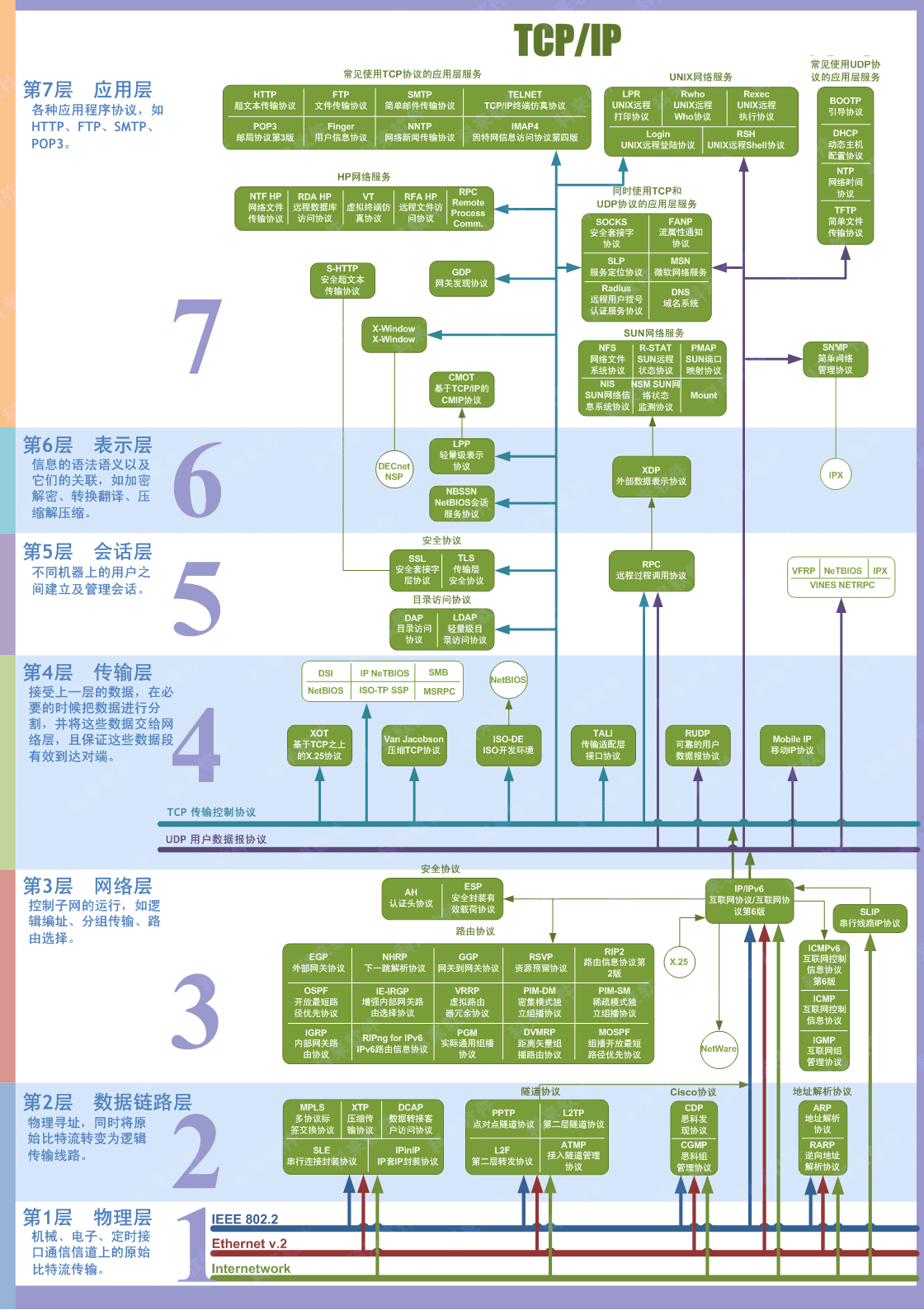
+
+
+## TCP/IP 四层模型
+
+**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
+
+1. 应用层
+2. 传输层
+3. 网络层
+4. 网络接口层
+
+需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:
+
+
+
+### 应用层(Application layer)
+
+**应用层位于传输层之上,主要提供两个终端设备上的应用程序之间信息交换的服务,它定义了信息交换的格式,消息会交给下一层传输层来传输。** 我们把应用层交互的数据单元称为报文。
+
+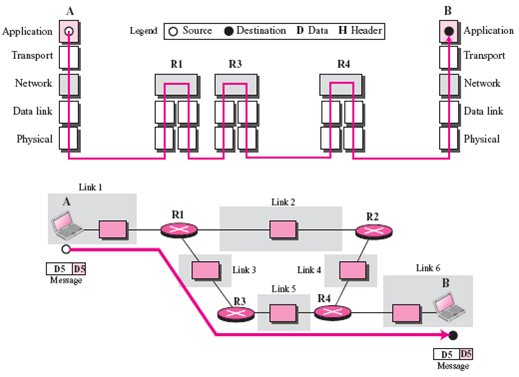
+
+应用层协议定义了网络通信规则,对于不同的网络应用需要不同的应用层协议。在互联网中应用层协议很多,如支持 Web 应用的 HTTP 协议,支持电子邮件的 SMTP 协议等等。
+
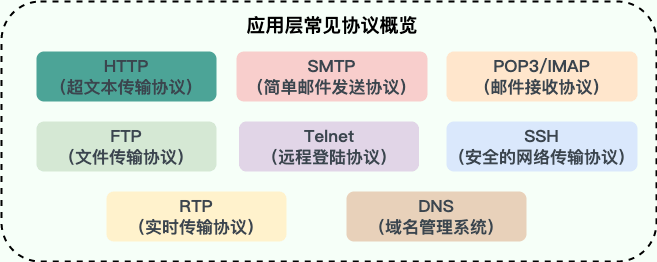
+**应用层常见协议**:
+
+
+
+- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
+- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
+- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
+- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
+- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
+- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
+- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
+- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
+
+关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
+
+### 传输层(Transport layer)
+
+**传输层的主要任务就是负责向两台终端设备进程之间的通信提供通用的数据传输服务。** 应用进程利用该服务传送应用层报文。“通用的”是指并不针对某一个特定的网络应用,而是多种应用可以使用同一个运输层服务。
+
+**传输层常见协议**:
+
+
+
+- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
+- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
+
+### 网络层(Network layer)
+
+**网络层负责为分组交换网上的不同主机提供通信服务。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 IP 协议,因此分组也叫 IP 数据报,简称数据报。
+
+⚠️ 注意:**不要把运输层的“用户数据报 UDP”和网络层的“IP 数据报”弄混**。
+
+**网络层的还有一个任务就是选择合适的路由,使源主机运输层所传下来的分组,能通过网络层中的路由器找到目的主机。**
+
+这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称。
+
+互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Protocol)和许多路由选择协议,因此互联网的网络层也叫做 **网际层** 或 **IP 层**。
+
+**网络层常见协议**:
+
+
+
+- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
+- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
+- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
+- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
+- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
+- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
+
+### 网络接口层(Network interface layer)
+
+我们可以把网络接口层看作是数据链路层和物理层的合体。
+
+1. 数据链路层(data link layer)通常简称为链路层( 两台主机之间的数据传输,总是在一段一段的链路上传送的)。**数据链路层的作用是将网络层交下来的 IP 数据报组装成帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。**
+2. **物理层的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异**
+
+网络接口层重要功能和协议如下图所示:
+
+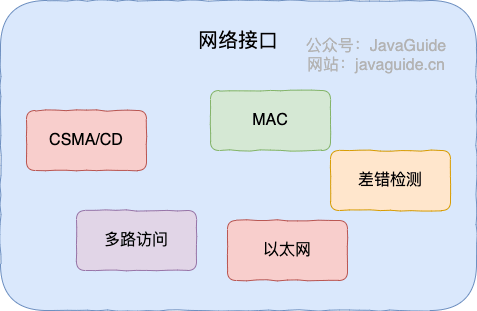
+
+### 总结
+
+简单总结一下每一层包含的协议和核心技术:
+
+
+
+**应用层协议** :
+
+- HTTP(Hypertext Transfer Protocol,超文本传输协议)
+- SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)
+- POP3/IMAP(邮件接收协议)
+- FTP(File Transfer Protocol,文件传输协议)
+- Telnet(远程登陆协议)
+- SSH(Secure Shell Protocol,安全的网络传输协议)
+- RTP(Real-time Transport Protocol,实时传输协议)
+- DNS(Domain Name System,域名管理系统)
+- ……
+
+**传输层协议** :
+
+- TCP 协议
+ - 报文段结构
+ - 可靠数据传输
+ - 流量控制
+ - 拥塞控制
+- UDP 协议
+ - 报文段结构
+ - RDT(可靠数据传输协议)
+
+**网络层协议** :
+
+- IP(Internet Protocol,网际协议)
+- ARP(Address Resolution Protocol,地址解析协议)
+- ICMP 协议(控制报文协议,用于发送控制消息)
+- NAT(Network Address Translation,网络地址转换协议)
+- OSPF(Open Shortest Path First,开放式最短路径优先)
+- RIP(Routing Information Protocol,路由信息协议)
+- BGP(Border Gateway Protocol,边界网关协议)
+- ……
+
+**网络接口层** :
+
+- 差错检测技术
+- 多路访问协议(信道复用技术)
+- CSMA/CD 协议
+- MAC 协议
+- 以太网技术
+- ……
+
+## 网络分层的原因
+
+在这篇文章的最后,我想聊聊:“为什么网络要分层?”。
+
+说到分层,我们先从我们平时使用框架开发一个后台程序来说,我们往往会按照每一层做不同的事情的原则将系统分为三层(复杂的系统分层会更多):
+
+1. Repository(数据库操作)
+2. Service(业务操作)
+3. Controller(前后端数据交互)
+
+**复杂的系统需要分层,因为每一层都需要专注于一类事情。网络分层的原因也是一样,每一层只专注于做一类事情。**
+
+好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
+
+1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
+2. **提高了整体灵活性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
+3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
+
+我想到了计算机世界非常非常有名的一句话,这里分享一下:
+
+> 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,计算机整个体系从上到下都是按照严格的层次结构设计的。
+
+## 参考
+
+- TCP/IP model vs OSI model:
+- Data Encapsulation and the TCP/IP Protocol Stack:
+
+
+
diff --git a/docs_en/cs-basics/network/other-network-questions.en.md b/docs_en/cs-basics/network/other-network-questions.en.md
new file mode 100644
index 00000000000..3db3be0802d
--- /dev/null
+++ b/docs_en/cs-basics/network/other-network-questions.en.md
@@ -0,0 +1,544 @@
+---
+title: 计算机网络常见面试题总结(上)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP/IP四层模型,HTTP面试,HTTPS vs HTTP,HTTP/1.1 vs HTTP/2,HTTP/3 QUIC,TCP三次握手,UDP区别,DNS解析,WebSocket vs SSE,GET vs POST,应用层协议,网络分层,队头阻塞,PING命令,ARP协议
+ - - meta
+ - name: description
+ content: 最新计算机网络高频面试题总结(上):TCP/IP四层模型、HTTP全版本对比、TCP三次握手、DNS解析、WebSocket/SSE实时推送等,附图解+⭐️重点标注,一文搞定应用层&传输层&网络层核心考点,快速备战后端面试!
+---
+
+
+
+上篇主要是计算机网络基础和应用层相关的内容。
+
+## 计算机网络基础
+
+### 网络分层模型
+
+#### OSI 七层模型是什么?每一层的作用是什么?
+
+**OSI 七层模型** 是国际标准化组织提出的一个网络分层模型,其大体结构以及每一层提供的功能如下图所示:
+
+
+
+每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
+
+**OSI 的七层体系结构概念清楚,理论也很完整,但是它比较复杂而且不实用,而且有些功能在多个层中重复出现。**
+
+上面这种图可能比较抽象,再来一个比较生动的图片。下面这个图片是我在国外的一个网站上看到的,非常赞!
+
+
+
+#### ⭐️TCP/IP 四层模型是什么?每一层的作用是什么?
+
+**TCP/IP 四层模型** 是目前被广泛采用的一种模型,我们可以将 TCP / IP 模型看作是 OSI 七层模型的精简版本,由以下 4 层组成:
+
+1. 应用层
+2. 传输层
+3. 网络层
+4. 网络接口层
+
+需要注意的是,我们并不能将 TCP/IP 四层模型 和 OSI 七层模型完全精确地匹配起来,不过可以简单将两者对应起来,如下图所示:
+
+
+
+关于每一层作用的详细介绍,请看 [OSI 和 TCP/IP 网络分层模型详解(基础)](https://javaguide.cn/cs-basics/network/osi-and-tcp-ip-model.html) 这篇文章。
+
+#### 为什么网络要分层?
+
+说到分层,我们先从我们平时使用框架开发一个后台程序来说,我们往往会按照每一层做不同的事情的原则将系统分为三层(复杂的系统分层会更多):
+
+1. Repository(数据库操作)
+2. Service(业务操作)
+3. Controller(前后端数据交互)
+
+**复杂的系统需要分层,因为每一层都需要专注于一类事情。网络分层的原因也是一样,每一层只专注于做一类事情。**
+
+好了,再来说回:“为什么网络要分层?”。我觉得主要有 3 方面的原因:
+
+1. **各层之间相互独立**:各层之间相互独立,各层之间不需要关心其他层是如何实现的,只需要知道自己如何调用下层提供好的功能就可以了(可以简单理解为接口调用)**。这个和我们对开发时系统进行分层是一个道理。**
+2. **提高了灵活性和可替换性**:每一层都可以使用最适合的技术来实现,你只需要保证你提供的功能以及暴露的接口的规则没有改变就行了。并且,每一层都可以根据需要进行修改或替换,而不会影响到整个网络的结构。**这个和我们平时开发系统的时候要求的高内聚、低耦合的原则也是可以对应上的。**
+3. **大问题化小**:分层可以将复杂的网络问题分解为许多比较小的、界线比较清晰简单的小问题来处理和解决。这样使得复杂的计算机网络系统变得易于设计,实现和标准化。 **这个和我们平时开发的时候,一般会将系统功能分解,然后将复杂的问题分解为容易理解的更小的问题是相对应的,这些较小的问题具有更好的边界(目标和接口)定义。**
+
+我想到了计算机世界非常非常有名的一句话,这里分享一下:
+
+> 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,计算机整个体系从上到下都是按照严格的层次结构设计的。
+
+### 常见网络协议
+
+#### ⭐️应用层有哪些常见的协议?
+
+
+
+- **HTTP(Hypertext Transfer Protocol,超文本传输协议)**:基于 TCP 协议,是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
+- **SMTP(Simple Mail Transfer Protocol,简单邮件发送协议)**:基于 TCP 协议,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
+- **POP3/IMAP(邮件接收协议)**:基于 TCP 协议,两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
+- **FTP(File Transfer Protocol,文件传输协议)** : 基于 TCP 协议,是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
+- **Telnet(远程登陆协议)**:基于 TCP 协议,用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
+- **SSH(Secure Shell Protocol,安全的网络传输协议)**:基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务
+- **RTP(Real-time Transport Protocol,实时传输协议)**:通常基于 UDP 协议,但也支持 TCP 协议。它提供了端到端的实时传输数据的功能,但不包含资源预留存、不保证实时传输质量,这些功能由 WebRTC 实现。
+- **DNS(Domain Name System,域名管理系统)**: 基于 UDP 协议,用于解决域名和 IP 地址的映射问题。
+
+关于这些协议的详细介绍请看 [应用层常见协议总结(应用层)](./application-layer-protocol.md) 这篇文章。
+
+#### 传输层有哪些常见的协议?
+
+
+
+- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
+- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
+
+#### 网络层有哪些常见的协议?
+
+
+
+- **IP(Internet Protocol,网际协议)**:TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+- **ARP (Address Resolution Protocol, Address Resolution Protocol)**: The ARP protocol solves the problem of conversion between network layer addresses and link layer addresses. Because during the physical transmission of an IP datagram, you always need to know where the next hop (physical next destination) should go, but the IP address is a logical address, and the MAC address is the physical address. The ARP protocol solves some problems of converting IP addresses to MAC addresses.
+- **ICMP (Internet Control Message Protocol)**: A protocol used to transmit network status and error messages, often used for network diagnosis and troubleshooting. For example, the Ping tool uses the ICMP protocol to test network connectivity.
+- **NAT (Network Address Translation, Network Address Translation Protocol)**: The application scenario of the NAT protocol is just like its name - Network Address Translation, which is used in the address translation process from the internal network to the external network. Specifically, within a small subnet (local area network, LAN), each host uses the IP address under the same LAN, but outside the LAN, in the wide area network (WAN), a unified IP address is needed to identify the location of the LAN on the entire Internet.
+- **OSPF (Open Shortest Path First, Open Shortest Path First)**: An Interior Gateway Protocol (IGP), which is also a widely used dynamic routing protocol. Based on the link state algorithm, it takes into account factors such as link bandwidth and delay to select the best path.
+- **RIP (Routing Information Protocol, Routing Information Protocol)**: An Interior Gateway Protocol (IGP), which is also a dynamic routing protocol. It is based on the distance vector algorithm, uses a fixed number of hops as a metric, and selects the path with the least number of hops as the best path.
+- **BGP (Border Gateway Protocol, Border Gateway Protocol)**: A routing protocol used to exchange Network Layer Reachability Information (NLRI) between routing domains, with a high degree of flexibility and scalability.
+
+## HTTP
+
+### ⭐️What exactly happens from entering the URL to page display? (very important)
+
+> Similar question: When opening a web page, what protocols will be used in the entire process?
+
+Let’s look at a picture first (from "Illustrating HTTP"):
+
+ +
+There is an error to note in the above picture: it is OSPF, not OPSF. OSPF (Open Shortest Path First, ospf) Open Shortest Path First Protocol is a routing protocol developed by the Internet Engineering Task Force
+
+Generally speaking, it is divided into the following steps:
+
+1. Enter the URL of the specified web page in the browser.
+2. The browser obtains the IP address corresponding to the domain name through the DNS protocol.
+3. The browser initiates a TCP connection request to the target server based on the IP address and port number.
+4. The browser sends an HTTP request message to the server on the TCP connection to request the content of the web page.
+5. After receiving the HTTP request message, the server processes the request and returns an HTTP response message to the browser.
+6. After the browser receives the HTTP response message, it parses the HTML code in the response body, renders the structure and style of the web page, and at the same time initiates an HTTP request again based on the URLs of other resources in the HTML (such as images, CSS, JS, etc.) to obtain the contents of these resources until the web page is fully loaded and displayed.
+7. When the browser does not need to communicate with the server, it can actively close the TCP connection, or wait for the server's closing request.
+
+For a detailed introduction, you can view this article: [The whole process of accessing web pages (knowledge connection)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html) (strongly recommended).
+
+### ⭐️What are the HTTP status codes?
+
+HTTP status codes are used to describe the results of HTTP requests. For example, 2xx means that the request was successfully processed.
+
+
+
+For a more detailed summary of HTTP status codes, you can read this article I wrote: [Summary of common HTTP status codes (application layer)](https://javaguide.cn/cs-basics/network/http-status-codes.html).
+
+### What are the common fields in HTTP Header?
+
+| Request header field name | Description | Example |
+| :---------------------------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-------------------------------------------------------------------------------------------------- |
+| Accept | Acceptable response content types (Content-Types). | Accept: text/plain |
+| Accept-Charset | Acceptable character set | Accept-Charset: utf-8 |
+| Accept-Datetime | Acceptable version expressed in time | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
+| Accept-Encoding | A list of acceptable encodings. See HTTP compression. | Accept-Encoding: gzip, deflate |
+| Accept-Language | A list of natural languages that are acceptable for response content. | Accept-Language: en-US || Authorization | Authentication information used for Hypertext Transfer Protocol authentication | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Cache-Control | Used to specify directives that all caching mechanisms in this request/response chain must comply with | Cache-Control: no-cache |
+| Connection | The type of connection this browser prefers to use | Connection: keep-alive |
+| Content-Length | The length of the request body as an octet array (8-bit bytes) | Content-Length: 348 |
+| Content-MD5 | The binary MD5 hash value of the request body's content, encoded in Base64 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
+| Content-Type | The multimedia type of the request body (used in POST and PUT requests) | Content-Type: application/x-www-form-urlencoded |
+| Cookie | A Hypertext Transfer Protocol Cookie previously sent by the server via Set-Cookie (described below) | Cookie: $Version=1; Skin=new; |
+| Date | The date and time the message was sent (sent in the "Hypertext Transfer Protocol Date" format defined in RFC 7231) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
+| Expect | Indicates that the client requires the server to perform specific behavior | Expect: 100-continue |
+| From | The email address of the user who initiated this request | From: `user@example.com` |
+| Host | The domain name of the server (used for virtual hosts), and the Transmission Control Protocol port number that the server listens on. The port number may be omitted if the requested port is the standard port of the corresponding service. | Host: en.wikipedia.org |
+| If-Match | The corresponding operation is performed only if the entity provided by the client matches the corresponding entity on the server. The main purpose is to be used in methods like PUT to update a resource only if the resource has not been modified since the user last updated the resource. | If-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Modified-Since | Allows the server to return a `304 Not Modified` status code if the requested resource has not been modified since the specified date | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| If-None-Match | Allows the server to return a `304 Not Modified` status code if the ETag of the requested resource has not changed | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Range | If the entity has not been modified, send me the part or parts I am missing; otherwise, send the entire new entity | If-Range: "737060cd8c284d8af7ad3082f209582d" || If-Unmodified-Since | Send a response only if the entity has not been modified since a certain time. | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| Max-Forwards | Limits the number of times this message can be forwarded by proxies and gateways. | Max-Forwards: 10 |
+| Origin | Initiates a request for cross-origin resource sharing. | `Origin: http://www.example-social-network.com` |
+| Pragma | Implementation dependent, these fields may have multiple effects at any time in the request/response chain. | Pragma: no-cache |
+| Proxy-Authorization | Authentication information used to authenticate to the proxy. | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Range | Requests only a portion of an entity. Byte offsets start with 0. See byte service. | Range: bytes=500-999 |
+| Referer | indicates the previous page visited by the browser. It is a link on that page that brings the browser to the currently requested page. | `Referer: http://en.wikipedia.org/wiki/Main_Page` |
+| TE | The transfer encoding that the browser expects to accept: you can use the value in the Transfer-Encoding field of the response protocol header; | TE: trailers, deflate |
+| Upgrade | Requests the server to be upgraded to another protocol. | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
+| User-Agent | The browser's browser identification string | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
+| Via | Informs the server which proxy this request was issued by. | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
+| Warning | A general warning that errors may exist in the entity content body. | Warning: 199 Miscellaneous warning |
+
+### ⭐️What is the difference between HTTP and HTTPS? (Important)
+
+
+
+- **Port number**: The default for HTTP is 80, and the default for HTTPS is 443.
+- **URL Prefix**: The URL prefix of HTTP is `http://`, and the URL prefix of HTTPS is `https://`.
+- **Security and Resource Consumption**: The HTTP protocol runs on top of TCP, all transmitted content is clear text, and neither the client nor the server can verify the identity of the other party. HTTPS is an HTTP protocol that runs on top of SSL/TLS, which runs on top of TCP. All transmitted content is encrypted using symmetric encryption, but the symmetric encryption key is asymmetrically encrypted using a server-side certificate. Therefore, HTTP is not as secure as HTTPS, but HTTPS consumes more server resources than HTTP.
+- **SEO (Search Engine Optimization)**: Search engines generally prefer websites that use the HTTPS protocol because HTTPS provides greater security and user privacy protection. Websites that use the HTTPS protocol may be prioritized in search results, impacting SEO.
+
+For a more detailed comparison summary of HTTP and HTTPS, you can read this article I wrote: [HTTP vs HTTPS (application layer)](https://javaguide.cn/cs-basics/network/http-vs-https.html).
+
+### What is the difference between HTTP/1.0 and HTTP/1.1?
+
+- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
+- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
+- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
+
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
+
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?
+
+
+
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
+- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
+- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
+
+HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://blog.cloudflare.com/http-2-for-web-developers/)):
+
+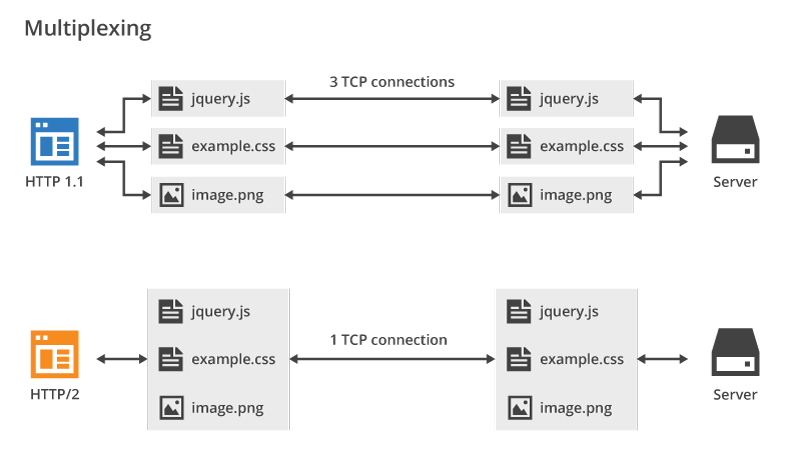
+
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
+
+### HTTP/2.0 和 HTTP/3.0 有什么区别?
+
+
+
+- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
+- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+- **头部压缩**:HTTP/2.0 使用 HPACK 算法进行头部压缩,而 HTTP/3.0 使用更高效的 QPACK 头压缩算法。
+- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
+- **连接迁移**:HTTP/3.0 支持连接迁移,因为 QUIC 使用 64 位 ID 标识连接,只要 ID 不变就不会中断,网络环境改变时(如从 Wi-Fi 切换到移动数据)也能保持连接。而 TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这个四元组中一旦有一项值发生改变,这个连接也就不能用了。
+- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
+- **安全性**:在 HTTP/2.0 中,TLS 用于加密和认证整个 HTTP 会话,包括所有的 HTTP 头部和数据负载。TLS 的工作是在 TCP 层之上,它加密的是在 TCP 连接中传输的应用层的数据,并不会对 TCP 头部以及 TLS 记录层头部进行加密,所以在传输的过程中 TCP 头部可能会被攻击者篡改来干扰通信。而 HTTP/3.0 的 QUIC 对整个数据包(包括报文头和报文体)进行了加密与认证处理,保障安全性。
+
+HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
+
+
+
+下图是一个更详细的 HTTP/2.0 和 HTTP/3.0 对比图:
+
+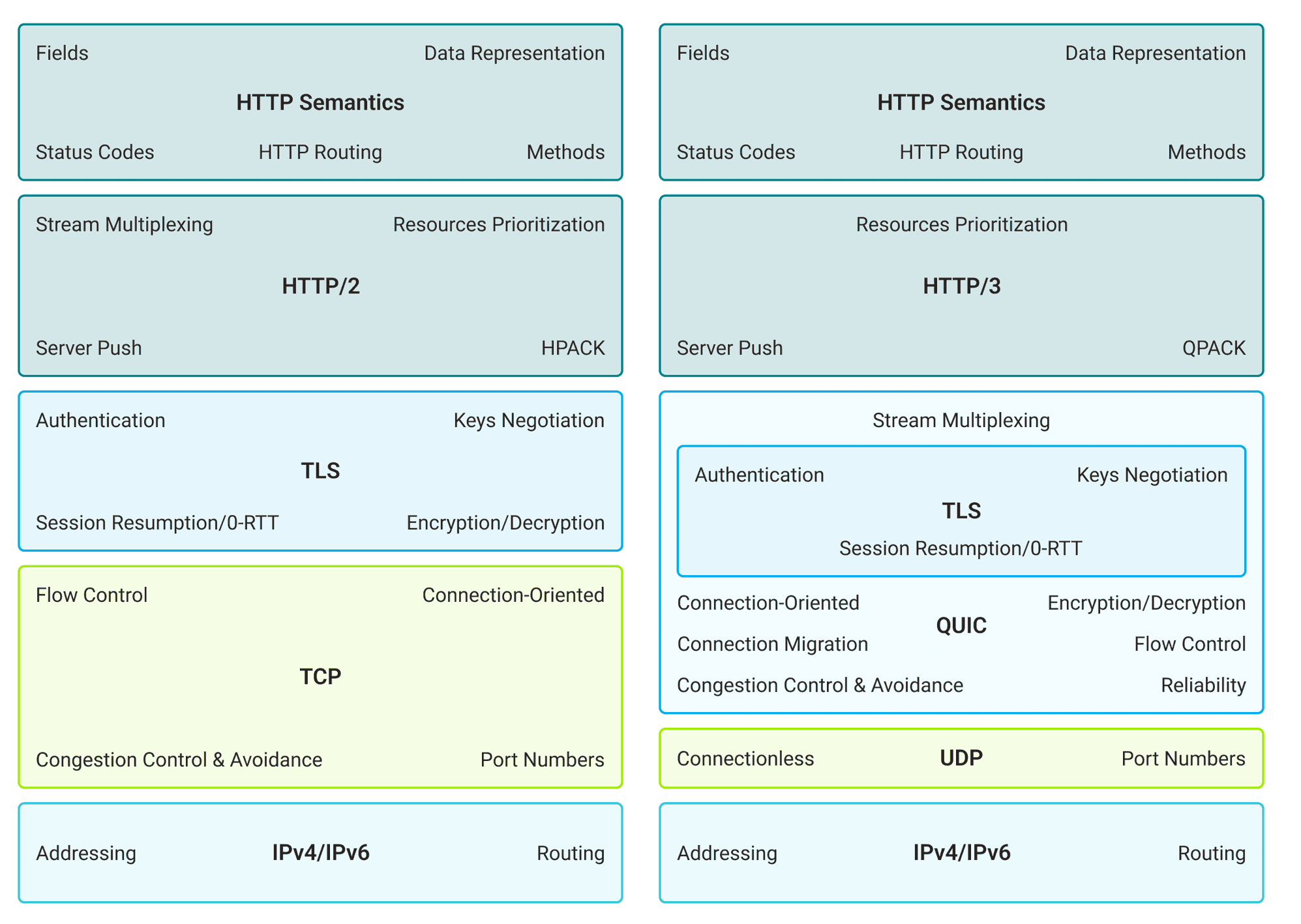
+
+从上图可以看出:
+
+- **HTTP/2.0**:使用 TCP 作为传输协议、使用 HPACK 进行头部压缩、依赖 TLS 进行加密。
+- **HTTP/3.0**:使用基于 UDP 的 QUIC 协议、使用更高效的 QPACK 进行头部压缩、在 QUIC 中直接集成了 TLS。QUIC 协议具备连接迁移、拥塞控制与避免、流量控制等特性。
+
+关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
+
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
+
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
+
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
+
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
+
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
+
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
+
+**方案一:Session (会话) 配合 Cookie (主流方式):**
+
+
+
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
+
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如:。服务器端会解析 URL 中的 `sessionid` 参数来获取 `SessionID`,进而找到对应的 Session 数据。
+
+这种方法一般不会使用,存在以下缺点:
+
+- URL 会变长且不美观;
+- `SessionID` 暴露在 URL 中,安全性较低(容易被复制、分享或记录在日志中);
+- 对搜索引擎优化 (SEO) 可能不友好。
+
+**方案三:Token-based 认证 (如 JWT - JSON Web Tokens)**
+
+这是一种越来越流行的无状态认证方式,尤其适用于前后端分离的架构和微服务。
+
+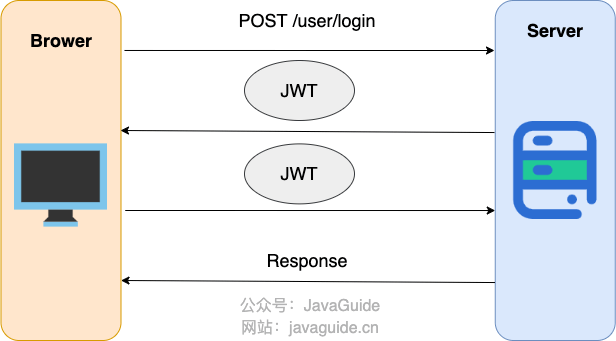
+
+以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下
+
+1. 用户向服务器发送用户名、密码以及验证码用于登陆系统;
+2. 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT;
+3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage` );
+4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT ;
+5. 服务端检查 JWT 并从中获取用户相关信息。
+
+JWT 详细介绍可以查看这两篇文章:
+
+- [JWT 基础概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)
+- [JWT 身份认证优缺点分析](https://javaguide.cn/system-design/security/advantages-and-disadvantages-of-jwt.html)
+
+总结来说,虽然 HTTP 本身是无状态的,但通过 Cookie + Session、URL 重写或 Token 等机制,我们能够有效地在 Web 应用中跟踪和管理用户状态。其中,**Cookie + Session 是最传统也最广泛使用的方式,而 Token-based 认证则在现代 Web 应用中越来越受欢迎。**
+
+### URI 和 URL 的区别是什么?
+
+- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
+- URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
+
+URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
+
+### Cookie 和 Session 有什么区别?
+
+准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
+
+### ⭐️GET 和 POST 的区别
+
+这个问题在知乎上被讨论的挺火热的,地址: 。
+
+
+
+GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
+
+- 语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
+- 幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
+- 格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
+- 缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
+- 安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
+
+再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
+
+## WebSocket
+
+### 什么是 WebSocket?
+
+WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
+
+WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
+
+WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
+
+
+
+下面是 WebSocket 的常见应用场景:
+
+- 视频弹幕
+- 实时消息推送,详见[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)这篇文章
+- 实时游戏对战
+- 多用户协同编辑
+- 社交聊天
+- ……
+
+### ⭐️WebSocket 和 HTTP 有什么区别?
+
+WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
+
+下面是二者的主要区别:
+
+- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
+- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
+- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
+- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
+
+### WebSocket 的工作过程是什么样的?
+
+WebSocket 的工作过程可以分为以下几个步骤:
+
+1. 客户端向服务器发送一个 HTTP 请求,请求头中包含 `Upgrade: websocket` 和 `Sec-WebSocket-Key` 等字段,表示要求升级协议为 WebSocket;
+2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 ,`Connection: Upgrade`和 `Sec-WebSocket-Accept: xxx` 等字段、表示成功升级到 WebSocket 协议。
+3. 客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
+4. 客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
+
+另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
+
+### ⭐️WebSocket 与短轮询、长轮询的区别
+
+这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
+
+**1.短轮询(Short Polling)**
+
+- **原理**:客户端每隔固定时间(如 5 秒)发起一次 HTTP 请求,询问服务器是否有新数据。服务器收到请求后立即响应。
+- **优点**:实现简单,兼容性好,直接用常规 HTTP 请求即可。
+- **缺点**:
+ - **实时性一般**:消息可能在两次轮询间到达,用户需等到下次请求才知晓。
+ - **资源浪费大**:反复建立/关闭连接,且大多数请求收到的都是“无新消息”,极大增加服务器和网络压力。
+
+**2.长轮询(Long Polling)**
+
+- **原理**:客户端发起请求后,若服务器暂时无新数据,则会保持连接,直到有新数据或超时才响应。客户端收到响应后立即发起下一次请求,实现“伪实时”。
+- **优点**:
+ - **实时性较好**:一旦有新数据可立即推送,无需等待下次定时请求。
+ - **空响应减少**:减少了无效的空响应,提升了效率。
+- **缺点**:
+ - **服务器资源占用高**:需长时间维护大量连接,消耗服务器线程/连接数。
+ - **资源浪费大**:每次响应后仍需重新建立连接,且依然基于 HTTP 单向请求-响应机制。
+
+**3. WebSocket**
+
+- **原理**:客户端与服务器通过一次 HTTP Upgrade 握手后,建立一条持久的 TCP 连接。之后,双方可以随时、主动地发送数据,实现真正的全双工、低延迟通信。
+- **优点**:
+ - **实时性强**:数据可即时双向收发,延迟极低。
+ - **资源效率高**:连接持续,无需反复建立/关闭,减少资源消耗。
+ - **功能强大**:支持服务端主动推送消息、客户端主动发起通信。
+- **缺点**:
+ - **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
+ - **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
+
+
+
+### ⭐️SSE 与 WebSocket 有什么区别?
+
+SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
+
+1. **通信方式:**
+ - **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
+ - **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
+2. **底层协议:**
+ - **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
+ - **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
+3. **实现复杂度和成本:**
+ - **SSE:** **实现相对简单**,主要在服务器端处理。浏览器端有标准的 EventSource API,使用方便。开发和维护成本较低。
+ - **WebSocket:** **稍微复杂一些**。需要服务器端专门处理 WebSocket 连接和协议,客户端也需要使用 WebSocket API。如果需要考虑兼容性、心跳、重连等,开发成本会更高。
+4. **断线重连:**
+ - **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
+ - **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
+5. **数据类型:**
+ - **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
+ - **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
+
+为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技术选择**。
+
+这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
+
+
+
+
+
+可以看到,响应头应里包含了 `text/event-stream`,说明使用的确实是 SSE。并且,响应数据也确实是持续分块传输。
+
+## PING
+
+### PING 命令的作用是什么?
+
+PING 命令是一种常用的网络诊断工具,经常用来测试网络中主机之间的连通性和网络延迟。
+
+这里简单举一个例子,我们来 PING 一下百度。
+
+```bash
+# 发送4个PING请求数据包到 www.baidu.com
+❯ ping -c 4 www.baidu.com
+
+PING www.a.shifen.com (14.119.104.189): 56 data bytes
+64 bytes from 14.119.104.189: icmp_seq=0 ttl=54 time=27.867 ms
+64 bytes from 14.119.104.189: icmp_seq=1 ttl=54 time=28.732 ms
+64 bytes from 14.119.104.189: icmp_seq=2 ttl=54 time=27.571 ms
+64 bytes from 14.119.104.189: icmp_seq=3 ttl=54 time=27.581 ms
+
+--- www.a.shifen.com ping statistics ---
+4 packets transmitted, 4 packets received, 0.0% packet loss
+round-trip min/avg/max/stddev = 27.571/27.938/28.732/0.474 ms
+```
+
+PING 命令的输出结果通常包括以下几部分信息:
+
+1. **ICMP Echo Request(请求报文)信息**:序列号、TTL(Time to Live)值。
+2. **目标主机的域名或 IP 地址**:输出结果的第一行。
+3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
+4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
+
+如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题(有些主机或网络管理员可能禁用了对 ICMP 请求的回复,这样也会导致无法得到正确的响应)。如果往返时间(RTT)过高,则表明网络延迟过高。
+
+### PING 命令的工作原理是什么?
+
+PING 基于网络层的 **ICMP(Internet Control Message Protocol,互联网控制报文协议)**,其主要原理就是通过在网络上发送和接收 ICMP 报文实现的。
+
+ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报文的类型有很多种,但大致可以分为两类:
+
+- **查询报文类型**:向目标主机发送请求并期望得到响应。
+- **差错报文类型**:向源主机发送错误信息,用于报告网络中的错误情况。
+
+PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
+
+- PING 命令会向目标主机发送 ICMP Echo Request。
+- 如果两个主机的连通性正常,目标主机会返回一个对应的 ICMP Echo Reply。
+
+## DNS
+
+### DNS 的作用是什么?
+
+DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
+
+
+
+在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
+
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
+
+### DNS 服务器有哪些?根服务器有多少个?
+
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+
+- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如`com`、`org`、`net`和`edu`等。国家也有自己的顶级域,如`uk`、`fr`和`ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
+- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
+
+世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 1700 多台,未来还会继续增加。
+
+### ⭐️DNS 解析的过程是什么样的?
+
+There are many steps in the whole process. I wrote a separate article to introduce it in detail: [DNS Domain Name System Detailed Explanation (Application Layer)](https://javaguide.cn/cs-basics/network/dns.html).
+
+### Do you know about DNS hijacking? How to deal with it?
+
+DNS hijacking is a network attack that modifies the resolution results of the DNS server so that the domain name visited by the user points to the wrong IP address, resulting in the user being unable to access normal websites or being directed to malicious websites. DNS hijacking is sometimes also called DNS redirection, DNS spoofing, or DNS pollution.
+
+## Reference
+
+- "HTTP Illustrated"
+- "Top-Down Method of Computer Networks" (Seventh Edition)
+- Detailed explanation of HTTP/2.0 and HTTPS protocols:
+- Complete list of HTTP request header fields | HTTP Request Headers:
+- HTTP1, HTTP2, HTTP3:
+- What do you think of HTTP/3? - Che Xiaopang's answer - Zhihu:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/other-network-questions2.en.md b/docs_en/cs-basics/network/other-network-questions2.en.md
new file mode 100644
index 00000000000..122a25ff93e
--- /dev/null
+++ b/docs_en/cs-basics/network/other-network-questions2.en.md
@@ -0,0 +1,273 @@
+---
+title: 计算机网络常见面试题总结(下)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP vs UDP,TCP三次握手,HTTP/3 QUIC,IPv4 vs IPv6,TCP可靠性,IP地址,NAT协议,ARP协议,传输层面试,网络层高频题,基于TCP协议,基于UDP协议,队头阻塞,四次挥手
+ - - meta
+ - name: description
+ content: 最新计算机网络高频面试题总结(下):TCP/UDP深度对比、三次握手四次挥手、HTTP/3 QUIC优化、IPv6优势、NAT/ARP详解,附表格+⭐️重点标注,一文掌握传输层&网络层核心考点,快速通关后端技术面试!
+---
+
+下篇主要是传输层和网络层相关的内容。
+
+## TCP 与 UDP
+
+### ⭐️TCP 与 UDP 的区别(重要)
+
+1. **是否面向连接**:
+ - TCP 是面向连接的。在传输数据之前,必须先通过“三次握手”建立连接;数据传输完成后,还需要通过“四次挥手”来释放连接。这保证了双方都准备好通信。
+ - UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
+2. **是否是可靠传输**:
+ - TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
+ - UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
+3. **是否有状态**:
+ - TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
+ - UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(**这很“渣男”!**)。
+4. **传输效率**:
+ - TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
+ - UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
+5. **传输形式**:
+ - TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
+ - UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
+6. **首部开销**:
+ - TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
+ - UDP 的头部非常简单,固定只有 8 字节。
+7. **是否提供广播或多播服务**:
+ - TCP 只支持点对点 (Point-to-Point) 的单播通信。
+ - UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
+8. ……
+
+为了更直观地对比,可以看下面这个表格:
+
+| 特性 | TCP | UDP |
+| ------------ | -------------------------- | ----------------------------------- |
+| **连接性** | 面向连接 | 无连接 |
+| **可靠性** | 可靠 | 不可靠 (尽力而为) |
+| **状态维护** | 有状态 | 无状态 |
+| **传输效率** | 较低 | 较高 |
+| **传输形式** | 面向字节流 | 面向数据报 (报文) |
+| **头部开销** | 20 - 60 字节 | 8 字节 |
+| **通信模式** | 点对点 (单播) | 单播、多播、广播 |
+| **常见应用** | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
+
+### ⭐️什么时候选择 TCP,什么时候选 UDP?
+
+选择 TCP 还是 UDP,主要取决于你的应用**对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高**。
+
+当**数据准确性和完整性至关重要,一点都不能出错**时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
+
+- **Web 浏览 (HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
+- **文件传输 (FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
+- **邮件收发 (SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
+- **远程登录 (SSH, Telnet):** 命令和响应需要准确传输。
+- ……
+
+当**实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序**时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
+
+- **实时音视频通信 (VoIP, 视频会议, 直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
+- **在线游戏:** 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
+- **DHCP (动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
+- **物联网 (IoT) 数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
+- ……
+
+### HTTP 基于 TCP 还是 UDP?
+
+~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
+
+🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
+
+HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
+
+- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
+- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
+
+
+
+**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
+
+1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
+2. 减少连接建立的延迟。
+
+下面我们来详细介绍这两大优化。
+
+在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
+
+In addition to solving the head-of-line blocking problem, HTTP/3.0 can also reduce the delay in the handshake process. In HTTP/2.0, if you want to establish a secure HTTPS connection, you need to go through the TCP three-way handshake and TLS handshake:
+
+1. TCP three-way handshake: The client and server exchange SYN and ACK packets to establish a TCP connection. This process requires 1.5 RTT (round-trip time), which is the time from sending to receiving a data packet.
+2. TLS handshake: The client and server exchange keys and certificates, establishing a TLS encryption layer. This process requires at least 1 RTT (TLS 1.3) or 2 RTT (TLS 1.2).
+
+Therefore, HTTP/2.0 connection establishment requires at least 2.5 RTT (TLS 1.3) or 3.5 RTT (TLS 1.2). In HTTP/3.0, the QUIC protocol used (TLS 1.3, TLS 1.3 not only supports 1 RTT handshake, but also supports 0 RTT handshake) connection establishment requires only 0-RTT or 1-RTT. This means that QUIC, in the best case scenario, does not require any additional round trip time to establish a new connection.
+
+For relevant proofs, please refer to the following two links:
+
+-
+-
+
+### What TCP/UDP based protocols do you know?
+
+TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are the two core protocols of the Internet transport layer. They provide basic communication services for various application layer protocols. Here are some common application layer protocols built on top of TCP and UDP:
+
+**Protocol running on top of TCP protocol (emphasis on reliable, orderly transmission):**
+
+| Full Chinese name (abbreviation) | Full English name | Main uses | Description and characteristics |
+| -------------------------- | ---------------------------------- | ------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- |
+| Hypertext Transfer Protocol (HTTP) | HyperText Transfer Protocol | Transfers web pages, hypertext, multimedia content | **HTTP/1.x and HTTP/2 are based on TCP**. Early versions were unencrypted and were the basis for web communications. |
+| HyperText Transfer Protocol Secure (HTTPS) | HyperText Transfer Protocol Secure | Encrypted web page transfer | Adds an SSL/TLS encryption layer between HTTP and TCP to ensure confidentiality and integrity of data transmission. |
+| File Transfer Protocol (FTP) | File Transfer Protocol | File transfer | Traditional FTP **clear text transfer**, unsafe. It is recommended to use its secure version **SFTP (SSH File Transfer Protocol)** or **FTPS (FTP over SSL/TLS)**. |
+| Simple Mail Transfer Protocol (SMTP) | Simple Mail Transfer Protocol | **Send** email | Responsible for sending emails from the client to the server, or between mail servers. Can be upgraded to encrypted transmission via **STARTTLS**. |
+| Post Office Protocol version 3 (POP3) | **Receive** email | Typically delete the server copy** after downloading the message from the server** to the local device** (configurable retention). **POP3S** is its SSL/TLS encrypted version. |
+| Internet Message Access Protocol (IMAP) | Internet Message Access Protocol | **Receive and manage** emails | Emails are retained on the server and support multi-device synchronization of email status, folder management, online search, etc. **IMAPS** is its SSL/TLS encrypted version. The modern email service of choice. |
+| Remote Terminal Protocol (Telnet) | Teletype Network | Remote Terminal Login | **Clear text transmission** All data (including passwords), security is extremely poor, and has basically been completely replaced by SSH. |
+| Secure Shell Protocol (SSH) | Secure Shell | Secure remote management, encrypted data transmission | Provides functions such as encrypted remote login and command execution, as well as secure file transfer (SFTP), and is a secure alternative to Telnet. |
+
+**Protocol running on top of UDP protocol (emphasis on fast, low-overhead transmission):**
+
+| Full Chinese name (abbreviation) | Full English name | Main uses | Description and characteristics |
+| ----------------------- | -------------------------------------------------- | ---------------------------- | --------------------------------------------------------------------------------------------------------------- |
+| Hypertext Transfer Protocol (HTTP/3) | HyperText Transfer Protocol version 3 | A new generation of web page transmission | Based on the **QUIC** protocol (QUIC itself is built on UDP), designed to reduce latency, solve the TCP head-of-queue blocking problem, and support 0-RTT connection establishment. |
+| Dynamic Host Configuration Protocol (DHCP) | Dynamic Host Configuration Protocol | Dynamic allocation of IP addresses and network configuration | The client automatically obtains IP address, subnet mask, gateway, DNS server and other information from the server. |
+| Domain Name System (DNS) | Domain Name System | Domain name to IP address resolution | **Usually UDP** is used for fast queries. When the response packet is too large or does a zone transfer (AXFR), **switches to TCP** to ensure data integrity. |
+| Real-time Transport Protocol (RTP) | Real-time Transport Protocol | Real-time audio and video data stream transmission | Commonly used in VoIP, video conferencing, live broadcast, etc. Pursue low latency and allow for a small amount of packet loss. Typically used with RTCP. |
+| RTP Control Protocol (RTCP) | RTP Control Protocol | Quality monitoring and control information of RTP streams | Works with RTP to provide statistical information such as packet loss, delay, jitter, etc. to assist flow control and congestion management. |
+| Trivial File Transfer Protocol (TFTP) | Trivial File Transfer Protocol | Simplified file transfer | Simple function, often used in small file transfer scenarios such as diskless workstation startup in LAN, network device firmware upgrade, etc. || 简单网络管理协议 (SNMP) | Simple Network Management Protocol | 网络设备的监控与管理 | 允许网络管理员查询和修改网络设备的状态信息。 |
+| 网络时间协议 (NTP) | Network Time Protocol | 同步计算机时钟 | 用于在网络中的计算机之间同步时间,确保时间的一致性。 |
+
+**总结一下:**
+
+- **TCP** 更适合那些对数据**可靠性、完整性和顺序性**要求高的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP/SFTP)、邮件收发 (SMTP/POP3/IMAP)。
+- **UDP** 则更适用于那些对**实时性要求高、能容忍少量数据丢失**的应用,如域名解析 (DNS)、实时音视频 (RTP)、在线游戏、网络管理 (SNMP) 等。
+
+### ⭐️TCP 三次握手和四次挥手(非常重要)
+
+**相关面试题**:
+
+- 为什么要三次握手?
+- 第 2 次握手传回了 ACK,为什么还要传回 SYN?
+- 为什么要四次挥手?
+- 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
+- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
+- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
+
+**参考答案**:[TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html) 。
+
+### ⭐️TCP 如何保证传输的可靠性?(重要)
+
+[TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
+
+## IP
+
+### IP 协议的作用是什么?
+
+**IP(Internet Protocol,网际协议)** 是 TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。
+
+目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+
+### 什么是 IP 地址?IP 寻址如何工作?
+
+每个连入互联网的设备或域(如计算机、服务器、路由器等)都被分配一个 **IP 地址(Internet Protocol address)**,作为唯一标识符。每个 IP 地址都是一个字符序列,如 192.168.1.1(IPv4)、2001:0db8:85a3:0000:0000:8a2e:0370:7334(IPv6) 。
+
+当网络设备发送 IP 数据包时,数据包中包含了 **源 IP 地址** 和 **目的 IP 地址** 。源 IP 地址用于标识数据包的发送方设备或域,而目的 IP 地址则用于标识数据包的接收方设备或域。这类似于一封邮件中同时包含了目的地地址和回邮地址。
+
+网络设备根据目的 IP 地址来判断数据包的目的地,并将数据包转发到正确的目的地网络或子网络,从而实现了设备间的通信。
+
+这种基于 IP 地址的寻址方式是互联网通信的基础,它允许数据包在不同的网络之间传递,从而实现了全球范围内的网络互联互通。IP 地址的唯一性和全局性保证了网络中的每个设备都可以通过其独特的 IP 地址进行标识和寻址。
+
+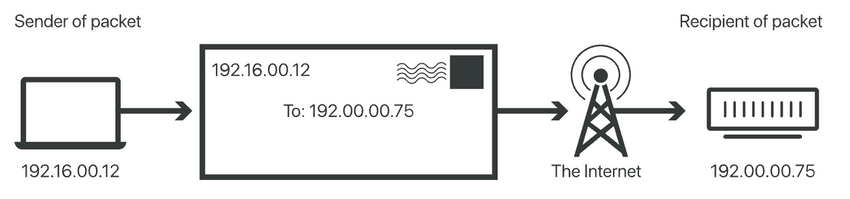
+
+### 什么是 IP 地址过滤?
+
+**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
+
+IP 地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP 地址过滤并不能完全保证网络的安全。
+
+### ⭐️IPv4 和 IPv6 有什么区别?
+
+**IPv4(Internet Protocol version 4)** 是目前广泛使用的 IP 地址版本,其格式是四组由点分隔的数字,例如:123.89.46.72。IPv4 使用 32 位地址作为其 Internet 地址,这意味着共有约 42 亿( 2^32)个可用 IP 地址。
+
+
+
+这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv6 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。
+
+
+
+除了更大的地址空间之外,IPv6 的优势还包括:
+
+- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)**:主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
+- **NAT(Network Address Translation,网络地址转换) 成为可选项**:IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
+- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
+- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
+- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
+- ……
+
+### 如何获取客户端真实 IP?
+
+获取客户端真实 IP 的方法有多种,主要分为应用层方法、传输层方法和网络层方法。
+
+**应用层方法** :
+
+通过 [X-Forwarded-For](https://en.wikipedia.org/wiki/X-Forwarded-For) 请求头获取,简单方便。不过,这种方法无法保证获取到的是真实 IP,这是因为 X-Forwarded-For 字段可能会被伪造。如果经过多个代理服务器,X-Forwarded-For 字段可能会有多个值(附带了整个请求链中的所有代理服务器 IP 地址)。并且,这种方法只适用于 HTTP 和 SMTP 协议。
+
+**传输层方法**:
+
+利用 TCP Options 字段承载真实源 IP 信息。这种方法适用于任何基于 TCP 的协议,不受应用层的限制。不过,这并非是 TCP 标准所支持的,所以需要通信双方都进行改造。也就是:对于发送方来说,需要有能力把真实源 IP 插入到 TCP Options 里面。对于接收方来说,需要有能力把 TCP Options 里面的 IP 地址读取出来。
+
+也可以通过 Proxy Protocol 协议来传递客户端 IP 和 Port 信息。这种方法可以利用 Nginx 或者其他支持该协议的反向代理服务器来获取真实 IP 或者在业务服务器解析真实 IP。
+
+**网络层方法**:
+
+隧道 +DSR 模式。这种方法可以适用于任何协议,就是实施起来会比较麻烦,也存在一定限制,实际应用中一般不会使用这种方法。
+
+### NAT 的作用是什么?
+
+**NAT (Network Address Translation)** is mainly used to translate IP addresses between different networks. It allows mapping of private IP addresses (such as the IP addresses used on the LAN) to public IP addresses (IP addresses used on the Internet) or vice versa, allowing multiple devices within the LAN to access the Internet through a single public IP address.
+
+NAT can not only alleviate the shortage of IPv4 address resources, but also hide the actual topology of the internal network, making it impossible for external networks to directly access devices in the internal network, thereby improving the security of the internal network.
+
+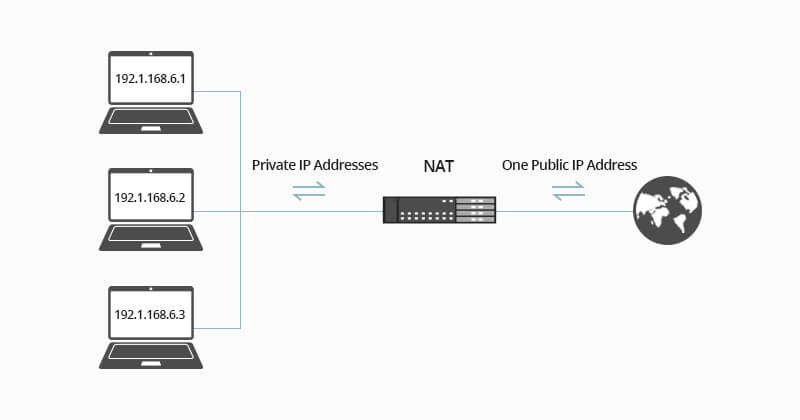
+
+Related reading: [Detailed explanation of NAT protocol (network layer)](https://javaguide.cn/cs-basics/network/nat.html).
+
+## ARP
+
+### What is a Mac address?
+
+The full name of MAC address is **Media Access Control Address**. If every resource on the Internet is uniquely identified by an IP address (IP protocol content), then all network devices are uniquely identified by a MAC address.
+
+
+
+It can be understood that the MAC address is the real ID number of a network device, and the IP address is just a non-duplicate positioning method (for example, for Zhang San who lives in a certain street in a certain city in a certain province, this logical positioning is the IP address, and his ID number is his MAC address). It can also be understood that the MAC address is the ID number and the IP address is the postal address. The MAC address also has some other names, such as LAN address, physical address, Ethernet address, etc.
+
+> Another thing to know is that not only network resources have IP addresses, but network devices also have IP addresses, such as routers. But structurally speaking, the role of network devices such as routers is to form a network, and it is usually an intranet, so the IP addresses they use are usually intranet IPs. When intranet devices communicate with devices outside the intranet, they need to use the NAT protocol.
+
+The length of the MAC address is 6 bytes (48 bits), and the address space size is as much as 280 trillion ($2^{48}$). The MAC address is managed and allocated by the IEEE. In theory, the MAC address on the network card in a network device is permanent. Different network card manufacturers purchase their own MAC address space (the first 24 bits of the MAC) from the IEEE, that is, the first 24 bits are managed uniformly by the IEEE to ensure no duplication. The next 24 bits are managed by each manufacturer themselves to ensure that the MAC addresses of the two network cards produced will not be repeated.
+
+The MAC address is portable and permanent, and the ID number permanently identifies a person's identity and will not change no matter where he goes. IP addresses do not have these properties. When a device changes networks, its IP address may change, which means its positioning on the Internet changes.
+
+Finally, remember that MAC addresses have a special address: FF-FF-FF-FF-FF-FF (all ones), which represents the broadcast address.
+
+### ⭐️What problems does the ARP protocol solve?
+
+ARP protocol, the full name is **Address Resolution Protocol**, which solves the problem of conversion between network layer addresses and link layer addresses. Because during the physical transmission of an IP datagram, you always need to know where the next hop (physical next destination) should go, but the IP address is a logical address, and the MAC address is the physical address. The ARP protocol solves some problems of converting IP addresses to MAC addresses.
+
+### How does the ARP protocol work?
+
+[Detailed explanation of ARP protocol (network layer)](https://javaguide.cn/cs-basics/network/arp.html)
+
+## Review suggestions
+
+I highly recommend everyone to read the book "HTTP Illustrated". This book does not have many pages, but the content is very substantial. It is very helpful whether it is used to systematically master some knowledge about the network or simply to cope with interviews. Some of the articles below are for reference only. When I was studying this course in my sophomore year, the textbook we used was "Computer Networks 7th Edition" (edited by Xie Xiren). I don't recommend everyone to read this textbook. The book is very thick and the knowledge is theoretical. I'm not sure if you can finish it calmly.
+
+## Reference
+
+- "HTTP Illustrated"
+- "Top-Down Method of Computer Networks" (Seventh Edition)
+- What is Internet Protocol (IP)? :
+- Various methods to transparently transmit the real source IP - Geek Time:
+- What Is NAT and What Are the Benefits of NAT Firewalls?:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/tcp-connection-and-disconnection.en.md b/docs_en/cs-basics/network/tcp-connection-and-disconnection.en.md
new file mode 100644
index 00000000000..65c705e5243
--- /dev/null
+++ b/docs_en/cs-basics/network/tcp-connection-and-disconnection.en.md
@@ -0,0 +1,134 @@
+---
+title: TCP 三次握手和四次挥手(传输层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,三次握手,四次挥手,状态机,SYN,ACK,FIN,半连接队列,全连接队列
+ - - meta
+ - name: description
+ content: 详解 TCP 建连与断连过程,结合状态迁移与队列机制解析可靠通信保障与高并发连接处理。
+---
+
+TCP 是一种面向连接的、可靠的传输层协议。为了在两个不可靠的端点之间建立一个可靠的连接,TCP 采用了三次握手(Three-way Handshake)的策略。
+
+## 建立连接-TCP 三次握手
+
+
+
+建立一个 TCP 连接需要“三次握手”,缺一不可:
+
+1. **第一次握手 (SYN)**: 客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含一个由客户端随机生成的初始序列号(Initial Sequence Number, ISN),例如 seq=x。发送后,客户端进入 **SYN_SEND** 状态,等待服务端的确认。
+2. **第二次握手 (SYN+ACK)**: 服务端收到 SYN 报文段后,如果同意建立连接,会向客户端回复一个确认报文段。该报文段包含两个关键信息:
+ - **SYN**:服务端也需要同步自己的初始序列号,因此报文段中也包含一个由服务端随机生成的初始序列号,例如 seq=y。
+ - **ACK** (Acknowledgement):用于确认收到了客户端的请求。其确认号被设置为客户端初始序列号加一,即 ack=x+1。
+ - 发送该报文段后,服务端进入 **SYN_RECV** 状态。
+3. **第三次握手 (ACK)**: 客户端收到服务端的 SYN+ACK 报文段后,会向服务端发送一个最终的确认报文段。该报文段包含确认号 ack=y+1。发送后,客户端进入 **ESTABLISHED** 状态。服务端收到这个 ACK 报文段后,也进入 **ESTABLISHED** 状态。
+
+至此,双方都确认了连接的建立,TCP 连接成功创建,可以开始进行双向数据传输。
+
+### 什么是半连接队列和全连接队列?
+
+在 TCP 三次握手过程中,服务端内核会使用两个队列来管理连接请求:
+
+1. **半连接队列**(也称 SYN Queue):当服务端收到客户端的 SYN 请求并回复 SYN+ACK 后,连接会处于 SYN_RECV 状态。此时,这个连接信息会被放入半连接队列。这个队列存储的是尚未完成三次握手的连接。
+2. **全连接队列**(也称 Accept Queue):当服务端收到客户端对 ACK 响应时,意味着三次握手成功完成,服务端会将该连接从半连接队列移动到全连接队列。如果未收到客户端的 ACK 响应,会进行重传,重传的等待时间通常是指数增长的。如果重传次数超过系统规定的最大重传次数,系统将从半连接队列中删除该连接信息。
+
+这两个队列的存在是为了处理并发连接请求,确保服务端能够有效地管理新的连接请求。
+
+如果全连接队列满了,新的已完成握手的连接可能会被丢弃,或者触发其他策略。这两个队列的大小都受系统参数控制,它们的容量限制是影响服务器处理高并发连接能力的重要因素,也是 SYN 泛洪攻击(SYN Flood)所针对的目标。
+
+### 为什么要三次握手?
+
+TCP 三次握手的核心目的是为了在客户端和服务器之间建立一个**可靠的**、**全双工的**通信信道。这需要实现两个主要目标:
+
+**1. 确认双方的收发能力,并同步初始序列号 (ISN)**
+
+TCP 通信依赖序列号来保证数据的有序和可靠。三次握手是双方交换和确认彼此初始序列号(ISN)的过程,通过这个过程,双方也间接验证了各自的收发能力。
+
+- **第一次握手 (客户端 → 服务器)** :客户端发送 SYN 包。
+ - 服务器:能确认客户端的发送能力正常,自己的接收能力正常。
+ - 客户端:无法确认任何事。
+- **第二次握手 (服务器 → 客户端)** :服务器回复 SYN+ACK 包。
+ - 客户端:能确认自己的发送和接收能力正常,服务器的接收和发送能力正常。
+ - 服务端:能确认对方发送能力正常,自己接收能力正常
+- **第三次握手 (客户端 → 服务器)** :客户端发送 ACK 包。
+ - 客户端:能确认双方发送和接收能力正常。
+ - 服务端:能确认双方发送和接收能力正常。
+
+经过这三次交互,双方都确认了彼此的收发功能完好,并完成了初始序列号的同步,为后续可靠的数据传输奠定了基础。
+
+**2. 防止已失效的连接请求被错误地建立**
+
+这是“为什么不能是两次握手”的关键原因。
+
+设想一个场景:客户端发送的第一个连接请求(SYN1)因网络延迟而滞留,于是客户端重发了第二个请求(SYN2)并成功建立了连接,数据传输完毕后连接被释放。此时,延迟的 SYN1 才到达服务端。
+
+- **如果是两次握手**:服务端收到这个失效的 SYN1 后,会误认为是一个新的连接请求,并立即分配资源、建立连接。但这将导致服务端单方面维持一个无效连接,白白浪费系统资源,因为客户端并不会有任何响应。
+- **有了第三次握手**:服务端收到失效的 SYN1 并回复 SYN+ACK 后,会等待客户端的最终确认(ACK)。由于客户端当前并没有发起连接的意图,它会忽略这个 SYN+ACK 或者发送一个 RST (Reset) 报文。这样,服务端就无法收到第三次握手的 ACK,最终会超时关闭这个错误的连接,从而避免了资源浪费。
+
+因此,三次握手是确保 TCP 连接可靠性的**最小且必需**的步骤。它不仅确认了双方的通信能力,更重要的是增加了一个最终确认环节,以防止网络中延迟、重复的历史请求对连接建立造成干扰。
+
+### 第 2 次握手传回了 ACK,为什么还要传回 SYN?
+
+服务端传回发送端所发送的 ACK 是为了告诉客户端:“我接收到的信息确实就是你所发送的信号了”,这表明从客户端到服务端的通信是正常的。回传 SYN 则是为了建立并确认从服务端到客户端的通信。
+
+> SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务端之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务端使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务端之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务端之间传递。
+
+### 三次握手过程中可以携带数据吗?
+
+在 TCP 三次握手过程中,第三次握手是可以携带数据的(客户端发送完 ACK 确认包之后就进入 ESTABLISHED 状态了),这一点在 RFC 793 文档中有提到。也就是说,一旦完成了前两次握手,TCP 协议允许数据在第三次握手时开始传输。
+
+如果第三次握手的 ACK 确认包丢失,但是客户端已经开始发送携带数据的包,那么服务端在收到这个携带数据的包时,如果该包中包含了 ACK 标记,服务端会将其视为有效的第三次握手确认。这样,连接就被认为是建立的,服务端会处理该数据包,并继续正常的数据传输流程。
+
+## 断开连接-TCP 四次挥手
+
+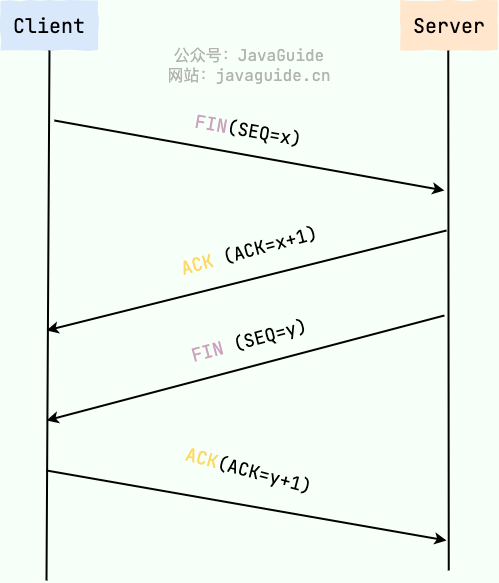
+
+断开一个 TCP 连接则需要“四次挥手”,缺一不可:
+
+1. **第一次挥手 (FIN)**:当客户端(或任何一方)决定关闭连接时,它会向服务端发送一个 **FIN**(Finish)标志的报文段,表示自己已经没有数据要发送了。该报文段包含一个序列号 seq=u。发送后,客户端进入 **FIN-WAIT-1** 状态。
+2. **第二次挥手 (ACK)**:服务端收到 FIN 报文段后,会立即回复一个 **ACK** 确认报文段。其确认号为 ack=u+1。发送后,服务端进入 **CLOSE-WAIT** 状态。客户端收到这个 ACK 后,进入 **FIN-WAIT-2** 状态。此时,TCP 连接处于**半关闭(Half-Close)**状态:客户端到服务端的发送通道已关闭,但服务端到客户端的发送通道仍然可以传输数据。
+3. **第三次挥手 (FIN)**:当服务端确认所有待发送的数据都已发送完毕后,它也会向客户端发送一个 **FIN** 报文段,表示自己也准备关闭连接。该报文段同样包含一个序列号 seq=y。发送后,服务端进入 **LAST-ACK** 状态,等待客户端的最终确认。
+4. **The fourth wave**: After receiving the FIN message segment from the server, the client will reply with a final **ACK** confirmation message segment, the confirmation number is ack=y+1. After sending, the client enters the **TIME-WAIT** state. After receiving this ACK, the server immediately enters the **CLOSED** state to complete the connection closure. The client will wait for **2MSL** (Maximum Segment Lifetime, the maximum survival time of the message segment) in the **TIME-WAIT** state before finally entering the **CLOSED** state.
+
+**As long as the four waves are not over, the client and server can continue to transmit data! **
+
+### Why wave four times?
+
+TCP is full-duplex communication and can transmit data in both directions. Either party can issue a connection release notification after the data transmission is completed, and enter a semi-closed state after the other party confirms. When the other party has no more data to send, a connection release notification is issued. After the other party confirms, the TCP connection is completely closed.
+
+For example: A and B are on the phone and the call is about to end.
+
+1. **First wave**: A said "I have nothing more to say"
+2. **Second wave**: B answers "I understand", but B may have something else to say, and A cannot ask B to end the call at his own pace.
+3. **Waving for the third time**: Then B may have talked for a while, and finally B said "I'm done"
+4. **The fourth wave**: Person A answers "I know", and the call ends.
+
+### Why can't the ACK and FIN sent by the server be combined into three waves?
+
+Because when the server receives the client's request to disconnect, there may still be some data that has not been sent. At this time, it responds with ACK first, indicating that it has received the disconnect request. Wait until the data is sent before sending FIN to disconnect the data transmission from the server to the client.
+
+### What will happen if the ACK from the server is not delivered to the client when waving for the second time?
+
+The client starts a retransmission timer after sending the FIN. If no ACK from the server is received before the timer expires, the client will consider the FIN message lost and resend the FIN message.
+
+### Why does the client need to wait for 2\*MSL (maximum segment life) time before entering the CLOSED state after the fourth wave?
+
+When waving for the fourth time, the ACK sent by the client to the server may be lost. If the server does not receive the ACK for some reason, the server will resend the FIN. If the client receives the FIN within 2\*MSL, it will resend the ACK and wait for 2MSL again to prevent the server from continuously resending FIN without receiving the ACK.
+
+> **MSL (Maximum Segment Lifetime)**: The maximum survival time of a segment in the network. 2MSL is the maximum time required for a send and a reply. If the Client does not receive the FIN again until 2MSL, the Client concludes that the ACK has been successfully received and ends the TCP connection.
+
+## Reference
+
+- "Computer Networks (7th Edition)"
+
+- "HTTP Illustrated"
+
+- TCP and UDP Tutorial:
+
+- Starting from an online problem, a detailed explanation of TCP semi-connection queue and full connection queue:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/tcp-reliability-guarantee.en.md b/docs_en/cs-basics/network/tcp-reliability-guarantee.en.md
new file mode 100644
index 00000000000..f1ef37bd3d3
--- /dev/null
+++ b/docs_en/cs-basics/network/tcp-reliability-guarantee.en.md
@@ -0,0 +1,135 @@
+---
+title: TCP 传输可靠性保障(传输层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,可靠性,重传,SACK,流量控制,拥塞控制,滑动窗口,校验和
+ - - meta
+ - name: description
+ content: 系统梳理 TCP 的可靠性保障机制,覆盖重传/选择确认、流量与拥塞控制,明确端到端可靠传输的实现要点。
+---
+
+## TCP 如何保证传输的可靠性?
+
+1. **基于数据块传输**:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
+2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
+3. **校验和** : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
+4. **重传机制** : 在数据包丢失或延迟的情况下,重新发送数据包,直到收到对方的确认应答(ACK)。TCP 重传机制主要有:基于计时器的重传(也就是超时重传)、快速重传(基于接收端的反馈信息来引发重传)、SACK(在快速重传的基础上,返回最近收到的报文段的序列号范围,这样客户端就知道,哪些数据包已经到达服务器了)、D-SACK(重复 SACK,在 SACK 的基础上,额外携带信息,告知发送方有哪些数据包自己重复接收了)。关于重传机制的详细介绍,可以查看[详解 TCP 超时与重传机制](https://zhuanlan.zhihu.com/p/101702312)这篇文章。
+5. **流量控制** : TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议(TCP 利用滑动窗口实现流量控制)。
+6. **拥塞控制** : 当网络拥塞时,减少数据的发送。TCP 在发送数据的时候,需要考虑两个因素:一是接收方的接收能力,二是网络的拥塞程度。接收方的接收能力由滑动窗口表示,表示接收方还有多少缓冲区可以用来接收数据。网络的拥塞程度由拥塞窗口表示,它是发送方根据网络状况自己维护的一个值,表示发送方认为可以在网络中传输的数据量。发送方发送数据的大小是滑动窗口和拥塞窗口的最小值,这样可以保证发送方既不会超过接收方的接收能力,也不会造成网络的过度拥塞。
+
+## TCP 如何实现流量控制?
+
+**TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。** 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+
+**为什么需要流量控制?** 这是因为双方在通信的时候,发送方的速率与接收方的速率是不一定相等,如果发送方的发送速率太快,会导致接收方处理不过来。如果接收方处理不过来的话,就只能把处理不过来的数据存在 **接收缓冲区(Receiving Buffers)** 里(失序的数据包也会被存放在缓存区里)。如果缓存区满了发送方还在狂发数据的话,接收方只能把收到的数据包丢掉。出现丢包问题的同时又疯狂浪费着珍贵的网络资源。因此,我们需要控制发送方的发送速率,让接收方与发送方处于一种动态平衡才好。
+
+这里需要注意的是(常见误区):
+
+- 发送端不等同于客户端
+- 接收端不等同于服务端
+
+TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客户端和服务端既可能是发送端又可能是服务端。因此,两端各有一个发送缓冲区与接收缓冲区,两端都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制(TCP 传输速率不能大于应用的数据处理速率)。通信双方的发送窗口和接收窗口的要求相同
+
+**TCP 发送窗口可以划分成四个部分**:
+
+1. 已经发送并且确认的 TCP 段(已经发送并确认);
+2. 已经发送但是没有确认的 TCP 段(已经发送未确认);
+3. 未发送但是接收方准备接收的 TCP 段(可以发送);
+4. 未发送并且接收方也并未准备接受的 TCP 段(不可发送)。
+
+**TCP 发送窗口结构图示**:
+
+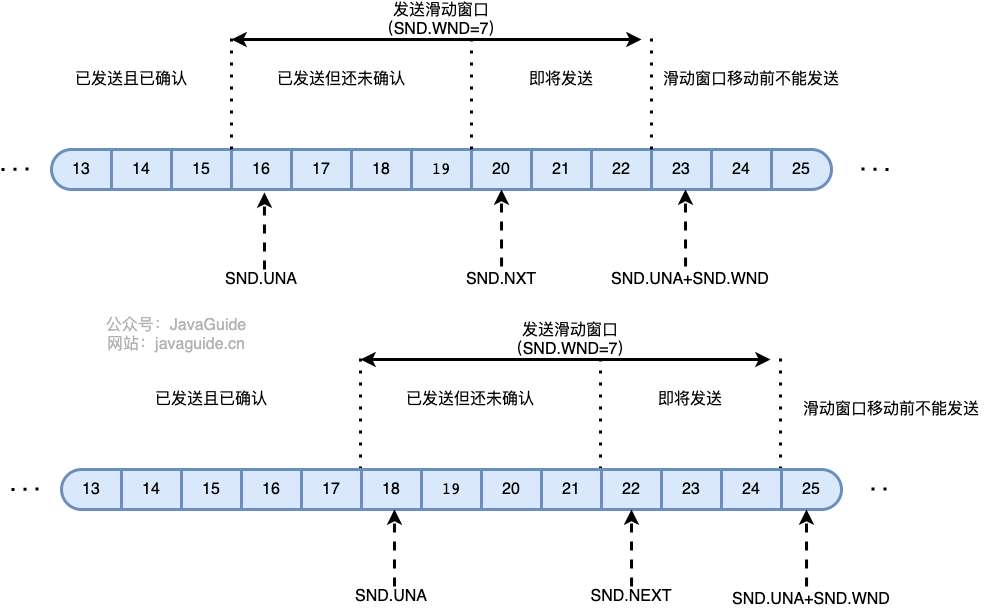
+
+- **SND.WND**:发送窗口。
+- **SND.UNA**:Send Unacknowledged 指针,指向发送窗口的第一个字节。
+- **SND.NXT**:Send Next 指针,指向可用窗口的第一个字节。
+
+**可用窗口大小** = `SND.UNA + SND.WND - SND.NXT` 。
+
+**TCP 接收窗口可以划分成三个部分**:
+
+1. 已经接收并且已经确认的 TCP 段(已经接收并确认);
+2. 等待接收且允许发送方发送 TCP 段(可以接收未确认);
+3. 不可接收且不允许发送方发送 TCP 段(不可接收)。
+
+**TCP 接收窗口结构图示**:
+
+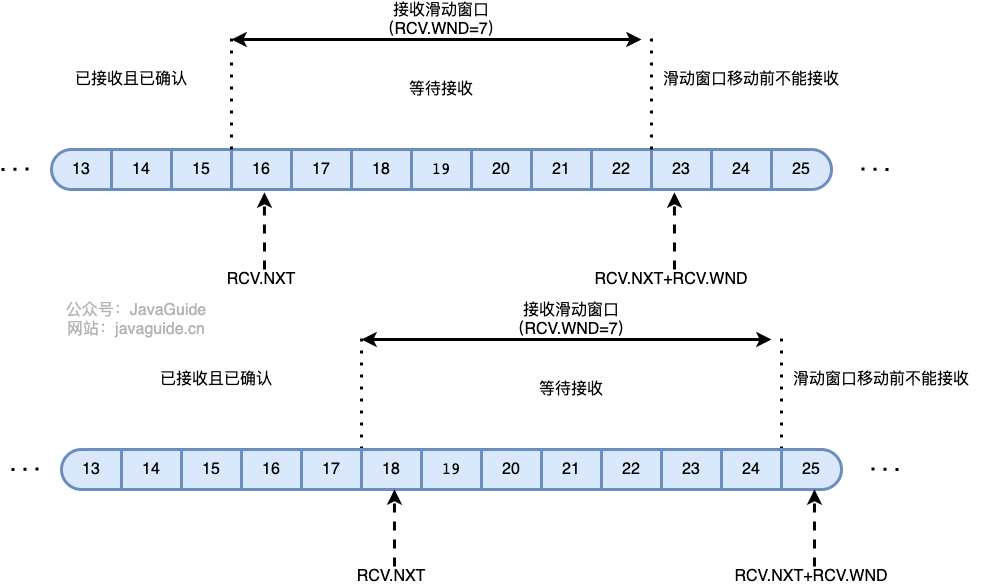
+
+**接收窗口的大小是根据接收端处理数据的速度动态调整的。** 如果接收端读取数据快,接收窗口可能会扩大。 否则,它可能会缩小。
+
+另外,这里的滑动窗口大小只是为了演示使用,实际窗口大小通常会远远大于这个值。
+
+## TCP 的拥塞控制是怎么实现的?
+
+在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
+
+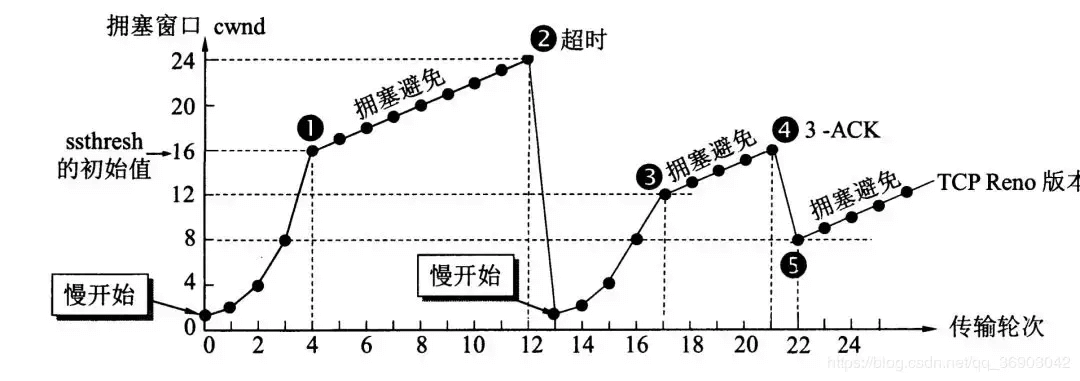
+
+为了进行拥塞控制,TCP 发送方要维持一个 **拥塞窗口(cwnd)** 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
+
+TCP 的拥塞控制采用了四种算法,即 **慢开始**、 **拥塞避免**、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
+
+- **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
+- **拥塞避免:** 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送方的 cwnd 加 1.
+- **快重传与快恢复:** 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
+
+## ARQ 协议了解吗?
+
+**自动重传请求**(Automatic Repeat-reQuest,ARQ)是 OSI 模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认信息(Acknowledgements,就是我们常说的 ACK),它通常会重新发送,直到收到确认或者重试超过一定的次数。
+
+ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
+
+### 停止等待 ARQ 协议
+
+The stop-and-wait protocol is to achieve reliable transmission. Its basic principle is to stop sending every time a packet is sent and wait for the other party to confirm (reply ACK). If after a period of time (after the timeout period), the ACK confirmation is still not received, it means that the transmission was not successful and needs to be resent until the confirmation is received before sending the next packet;
+
+In the stop-and-wait protocol, if the receiver receives a duplicate packet, it discards the packet, but also sends an acknowledgment at the same time.
+
+**1) No error situation:**
+
+The sender sends the packet, the receiver receives it within the specified time, and replies with confirmation. The sender sends again.
+
+**2) Error occurs (timeout retransmission):**
+
+Timeout retransmission in the stop-and-wait protocol means that as long as no confirmation is received after a period of time, the previously sent packet will be retransmitted (the packet just sent is considered to be lost). Therefore, a timeout timer needs to be set after each packet is sent, and its retransmission time should be longer than the average round-trip time of data in packet transmission. This automatic retransmission method is often called **Automatic Repeat Request ARQ**. In addition, in the stop-and-wait protocol, if a duplicate packet is received, the packet is discarded, but an acknowledgment is also sent at the same time.
+
+**3) Confirmation lost and confirmation late**
+
+- **Confirmation Lost**: The confirmation message is lost during transmission. When A sends an M1 message and B receives it, B sends an M1 confirmation message to A, but it is lost during transmission. However, A does not know that after the timeout, A retransmits the M1 message, and B takes the following two measures after receiving the message again: 1. Discard the duplicate M1 message and do not deliver it to the upper layer. 2. Send a confirmation message to A. (It will not be considered that it has been sent, so it will not be sent again. If A can retransmit, it proves that B's confirmation message is lost).
+- **ACKLATE**: The acknowledgment message was late during transmission. A sends M1 message, B receives and sends confirmation. If no acknowledgment message is received within the timeout period, A retransmits the M1 message, and B still receives and continues to send the acknowledgment message (B received 2 copies of M1). At this time, A receives the confirmation message sent by B for the second time. Then send other data. After a while, A received the first confirmation message for M1 sent by B (A also received 2 confirmation messages). The processing is as follows: 1. After A receives the duplicate confirmation, it discards it directly. 2. After B receives the duplicate M1, it also discards the duplicate M1 directly.
+
+### Continuous ARQ protocol
+
+The continuous ARQ protocol improves channel utilization. The sender maintains a sending window, and packets within the sending window can be sent continuously without waiting for confirmation from the other party. The receiver generally uses cumulative acknowledgment and sends an acknowledgment to the last packet that arrives in sequence, indicating that all packets up to this packet have been received correctly.
+
+- **Advantages:** The channel utilization rate is high and easy to implement. Even if the confirmation is lost, there is no need to retransmit.
+- **Disadvantage:** It cannot reflect to the sender the information of all packets that the receiver has correctly received. For example: the sender sends 5 messages, and the third one is lost (No. 3). At this time, the receiver can only send confirmations to the first two. The sender has no way of knowing the whereabouts of the last three packets, and has to retransmit them all once. This is also called Go-Back-N, which means that you need to go back and retransmit the N messages that have been sent.
+
+## How to implement timeout retransmission? How to determine the timeout and retransmission time?
+
+After the sender sends the data, it starts a timer and waits for the destination to confirm receipt of the segment. The receiving entity sends back a corresponding acknowledgment message (ACK) for the successfully received packet. If the sending entity does not receive the acknowledgment message within a reasonable round-trip delay (RTT), the corresponding data packet is assumed to be [lost](https://zh.wikipedia.org/wiki/PacketLost) and retransmitted.
+
+- RTT (Round Trip Time): round trip time, that is, the time from when a data packet is sent to when the corresponding ACK is received.
+- RTO (Retransmission Time Out): Retransmission timeout, which is calculated from the time when the data is sent. Retransmission will be performed after this time.
+
+The determination of RTO is a key issue because it directly affects the performance and efficiency of TCP. If the RTO is set too small, it will cause unnecessary retransmissions and increase network burden; if the RTO is set too large, it will cause delays in data transmission and reduce throughput. Therefore, RTO should be dynamically adjusted based on the actual network conditions.
+
+The value of RTT will change with network fluctuations, so TCP cannot directly use RTT as RTO. In order to dynamically adjust RTO, the TCP protocol uses some algorithms, such as the weighted moving average (EWMA) algorithm, Karn algorithm, Jacobson algorithm, etc. These algorithms all estimate the value of RTO based on the measurement and changes of the round-trip delay (RTT).
+
+## Reference
+
+1. "Computer Networks (7th Edition)"
+2. "HTTP Illustrated"
+3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial)
+4. [https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md](https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md)
+5. TCP Flow Control—[https://www.brianstorti.com/tcp-flow-control/](https://www.brianstorti.com/tcp-flow-control/)
+6. TCP flow control:
+7. TCP sliding window principle:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/the-whole-process-of-accessing-web-pages.en.md b/docs_en/cs-basics/network/the-whole-process-of-accessing-web-pages.en.md
new file mode 100644
index 00000000000..697228a32a9
--- /dev/null
+++ b/docs_en/cs-basics/network/the-whole-process-of-accessing-web-pages.en.md
@@ -0,0 +1,87 @@
+---
+title: 访问网页的全过程(知识串联)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 访问网页流程,DNS,TCP 建连,HTTP 请求,资源加载,渲染,关闭连接
+ - - meta
+ - name: description
+ content: 串联从输入 URL 到页面渲染的完整链路,涵盖 DNS、TCP、HTTP 与静态资源加载,助力面试与实践理解。
+---
+
+开发岗中总是会考很多计算机网络的知识点,但如果让面试官只考一道题,便涵盖最多的计网知识点,那可能就是 **网页浏览的全过程** 了。本篇文章将带大家从头到尾过一遍这道被考烂的面试题,必会!!!
+
+总的来说,网络通信模型可以用下图来表示,也就是大家只要熟记网络结构五层模型,按照这个体系,很多知识点都能顺出来了。访问网页的过程也是如此。
+
+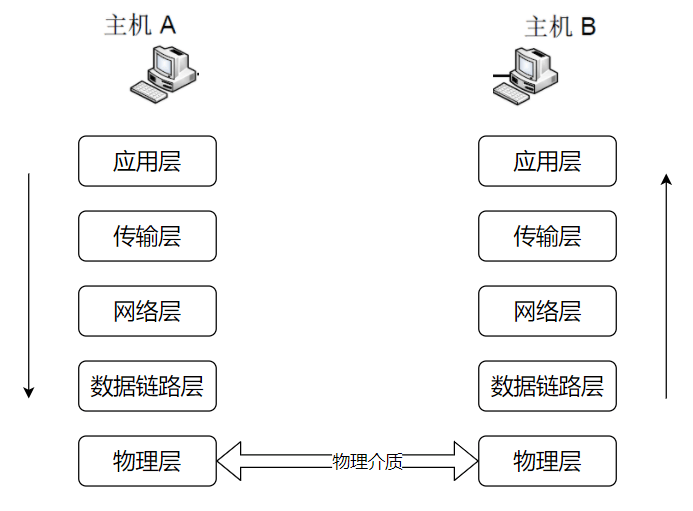
+
+开始之前,我们先简单过一遍完整流程:
+
+1. 在浏览器中输入指定网页的 URL。
+2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
+4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
+5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
+6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
+7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
+
+## 应用层
+
+一切的开始——打开浏览器,在地址栏输入 URL,回车确认。那么,什么是 URL?访问 URL 有什么用?
+
+### URL
+
+URL(Uniform Resource Locators),即统一资源定位器。网络上的所有资源都靠 URL 来定位,每一个文件就对应着一个 URL,就像是路径地址。理论上,文件资源和 URL 一一对应。实际上也有例外,比如某些 URL 指向的文件已经被重定位到另一个位置,这样就有多个 URL 指向同一个文件。
+
+### URL 的组成结构
+
+
+
+1. 协议。URL 的前缀通常表示了该网址采用了何种应用层协议,通常有两种——HTTP 和 HTTPS。当然也有一些不太常见的前缀头,比如文件传输时用到的`ftp:`。
+2. 域名。域名便是访问网址的通用名,这里也有可能是网址的 IP 地址,域名可以理解为 IP 地址的可读版本,毕竟绝大部分人都不会选择记住一个网址的 IP 地址。
+3. 端口。如果指明了访问网址的端口的话,端口会紧跟在域名后面,并用一个冒号隔开。
+4. 资源路径。域名(端口)后紧跟的就是资源路径,从第一个`/`开始,表示从服务器上根目录开始进行索引到的文件路径,上图中要访问的文件就是服务器根目录下`/path/to/myfile.html`。早先的设计是该文件通常物理存储于服务器主机上,但现在随着网络技术的进步,该文件不一定会物理存储在服务器主机上,有可能存放在云上,而文件路径也有可能是虚拟的(遵循某种规则)。
+5. 参数。参数是浏览器在向服务器提交请求时,在 URL 中附带的参数。服务器解析请求时,会提取这些参数。参数采用键值对的形式`key=value`,每一个键值对使用`&`隔开。参数的具体含义和请求操作的具体方法有关。
+6. 锚点。锚点顾名思义,是在要访问的页面上的一个锚。要访问的页面大部分都多于一页,如果指定了锚点,那么在客户端显示该网页是就会定位到锚点处,相当于一个小书签。值得一提的是,在 URL 中,锚点以`#`开头,并且**不会**作为请求的一部分发送给服务端。
+
+### DNS
+
+键入了 URL 之后,第一个重头戏登场——DNS 服务器解析。DNS(Domain Name System)域名系统,要解决的是 **域名和 IP 地址的映射问题** 。毕竟,域名只是一个网址便于记住的名字,而网址真正存在的地址其实是 IP 地址。
+
+传送门:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html)
+
+### HTTP/HTTPS
+
+利用 DNS 拿到了目标主机的 IP 地址之后,浏览器便可以向目标 IP 地址发送 HTTP 报文,请求需要的资源了。在这里,根据目标网站的不同,请求报文可能是 HTTP 协议或安全性增强的 HTTPS 协议。
+
+传送门:
+
+- [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)
+- [HTTP 1.0 vs HTTP 1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)
+- [HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)
+
+## 传输层
+
+由于 HTTP 协议是基于 TCP 协议的,在应用层的数据封装好以后,要交给传输层,经 TCP 协议继续封装。
+
+TCP 协议保证了数据传输的可靠性,是数据包传输的主力协议。
+
+传送门:
+
+- [TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html)
+- [TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
+
+## 网络层
+
+终于,来到网络层,此时我们的主机不再是和另一台主机进行交互了,而是在和中间系统进行交互。也就是说,应用层和传输层都是端到端的协议,而网络层及以下都是中间件的协议了。
+
+**网络层的的核心功能——转发与路由**,必会!!!如果面试官问到了网络层,而你恰好又什么都不会的话,最最起码要说出这五个字——**转发与路由**。
+
+- 转发:将分组从路由器的输入端口转移到合适的输出端口。
+- 路由:确定分组从源到目的经过的路径。
+
+所以到目前为止,我们的数据包经过了应用层、传输层的封装,来到了网络层,终于开始准备在物理层面传输了,第一个要解决的问题就是——**往哪里传输?或者说,要把数据包发到哪个路由器上?** 这便是 BGP 协议要解决的问题。
+
diff --git a/docs_en/cs-basics/operating-system/linux-intro.en.md b/docs_en/cs-basics/operating-system/linux-intro.en.md
new file mode 100644
index 00000000000..12d4dd29dd5
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/linux-intro.en.md
@@ -0,0 +1,437 @@
+---
+title: Linux 基础知识总结
+category: 计算机基础
+tag:
+ - 操作系统
+ - Linux
+head:
+ - - meta
+ - name: description
+ content: 简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
+ - - meta
+ - name: keywords
+ content: Linux,基础命令,发行版,文件系统,权限,进程,网络
+---
+
+
+
+简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
+
+## 初探 Linux
+
+### Linux 简介
+
+通过以下三点可以概括 Linux 到底是什么:
+
+- **类 Unix 系统**:Linux 是一种自由、开放源码的类似 Unix 的操作系统
+- **Linux 本质是指 Linux 内核**:严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
+- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)**:一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
+
+
+
+### Linux 诞生
+
+1989 年,Linus Torvalds 进入芬兰陆军新地区旅,服 11 个月的国家义务兵役,军衔为少尉,主要服务于计算机部门,任务是弹道计算。服役期间,购买了安德鲁·斯图尔特·塔能鲍姆所著的教科书及 minix 源代码,开始研究操作系统。1990 年,他退伍后回到大学,开始接触 Unix。
+
+> **Minix** 是一个迷你版本的类 Unix 操作系统,由塔能鲍姆教授为了教学之用而创作,采用微核心设计。它启发了 Linux 内核的创作。
+
+1991 年,Linus Torvalds 开源了 Linux 内核。Linux 以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
+
+
+
+### 常见的 Linux 发行版本
+
+
+
+Linus Torvalds 开源的只是 Linux 内核,我们上面也提到了操作系统内核的作用。一些组织或厂商将 Linux 内核与各种软件和文档包装起来,并提供系统安装界面和系统配置、设定与管理工具,就构成了 Linux 的发行版本。
+
+> 内核主要负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。
+
+Linux 的发行版本可以大体分为两类:
+
+- **商业公司维护的发行版本**:比如 Red Hat 公司维护支持的 Red Hat Enterprise Linux (RHEL)。
+- **社区组织维护的发行版本**:比如基于 Red Hat Enterprise Linux(RHEL)的 CentOS、基于 Debian 的 Ubuntu。
+
+对于初学者学习 Linux ,推荐选择 CentOS,原因如下:
+
+- CentOS 免费且开放源代码;
+- CentOS 基于 RHEL,功能与 RHEL 高度一致,安全稳定、性能优秀。
+
+## Linux 文件系统
+
+### Linux 文件系统简介
+
+在 Linux 操作系统中,一切被操作系统管理的资源,如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或目录等,都被视为文件。这是 Linux 系统中一个重要的概念,即"一切都是文件"。
+
+这种概念源自 UNIX 哲学,即将所有资源都抽象为文件的方式来进行管理和访问。Linux 的文件系统也借鉴了 UNIX 文件系统的设计理念。这种设计使得 Linux 系统可以通过统一的文件接口来管理和操作不同类型的资源,从而实现了一种统一的文件操作方式。例如,可以使用类似于读写文件的方式来对待网络接口、磁盘驱动器、设备文件等,使得操作和管理这些资源更加统一和简便。
+
+这种文件为中心的设计理念为 Linux 系统带来了灵活性和可扩展性,使得 Linux 成为一种强大的操作系统。同时,这也是 Linux 系统的一大特点,深受广大用户和开发者的喜欢和推崇。
+
+### inode 介绍
+
+inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作用呢?
+
+通过以下五点可以概括 inode 到底是什么:
+
+1. 硬盘以扇区 (Sector) 为最小物理存储单位,而操作系统和文件系统以块 (Block) 为单位进行读写,块由多个扇区组成。文件数据存储在这些块中。现代硬盘扇区通常为 4KB,与一些常见块大小相同,但操作系统也支持更大的块大小,以提升大文件读写性能。文件元信息(例如权限、大小、修改时间以及数据块位置)存储在 inode(索引节点)中。每个文件都有唯一的 inode。inode 本身不存储文件数据,而是存储指向数据块的指针,操作系统通过这些指针找到并读取文件数据。 固态硬盘 (SSD) 虽然没有物理扇区,但使用逻辑块,其概念与传统硬盘的块类似。
+2. inode 是一种固定大小的数据结构,其大小在文件系统创建时就确定了,并且在文件的生命周期内保持不变。
+3. inode 的访问速度非常快,因为系统可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
+4. inode 的数量是有限的,每个文件系统只能包含固定数量的 inode。这意味着当文件系统中的 inode 用完时,无法再创建新的文件或目录,即使磁盘上还有可用空间。因此,在创建文件系统时,需要根据文件和目录的预期数量来合理分配 inode 的数量。
+5. 可以使用 `stat` 命令可以查看文件的 inode 信息,包括文件的 inode 号、文件类型、权限、所有者、文件大小、修改时间。
+
+简单来说:inode 就是用来维护某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等信息。
+
+再总结一下 inode 和 block:
+
+- **inode**:记录文件的属性信息,可以使用 `stat` 命令查看 inode 信息。
+- **block**:实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
+
+
+
+可以看出,Linux/Unix 操作系统使用 inode 区分不同的文件。这样做的好处是,即使文件名被修改或删除,文件的 inode 号码不会改变,从而可以避免一些因文件重命名、移动或删除导致的错误。同时,inode 也可以提供更高的文件系统性能,因为 inode 的访问速度非常快,可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
+
+不过,使用 inode 号码也使得文件系统在用户和应用程序层面更加抽象和复杂,需要通过系统命令或文件系统接口来访问和管理文件的 inode 信息。
+
+### 硬链接和软链接
+
+在 Linux/类 Unix 系统上,文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。常见的文件链接类型有两种:
+
+**1、硬链接(Hard Link)**
+
+- 在 Linux/类 Unix 文件系统中,每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的(可以看作是互为硬链接,源头是同一份文件),删除其中任何一个对另外一个没有影响,可以通过给文件设置硬链接文件来防止重要文件被误删。
+- 只有删除了源文件和所有对应的硬链接文件,该文件才会被真正删除。
+- 硬链接具有一些限制,不能对目录以及不存在的文件创建硬链接,并且,硬链接也不能跨越文件系统。
+- `ln` 命令用于创建硬链接。
+
+**2、软链接(Symbolic Link 或 Symlink)**
+
+- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
+- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
+- 软连接类似于 Windows 系统中的快捷方式。
+- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
+- `ln -s` 命令用于创建软链接。
+
+**硬链接为什么不能跨文件系统?**
+
+我们之前提到过,硬链接是通过 inode 节点号建立连接的,而硬链接和源文件共享相同的 inode 节点号。
+
+然而,每个文件系统都有自己的独立 inode 表,且每个 inode 表只维护该文件系统内的 inode。如果在不同的文件系统之间创建硬链接,可能会导致 inode 节点号冲突的问题,即目标文件的 inode 节点号已经在该文件系统中被使用。
+
+### Linux 文件类型
+
+Linux 支持很多文件类型,其中非常重要的文件类型有: **普通文件**,**目录文件**,**链接文件**,**设备文件**,**管道文件**,**Socket 套接字文件** 等。
+
+- **普通文件(-)**:用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
+- **目录文件(d,directory file)**:目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
+- **符号链接文件(l,symbolic link)**:保留了指向文件的地址而不是文件本身。
+- **字符设备(c,char)**:用来访问字符设备比如键盘。
+- **设备文件(b,block)**:用来访问块设备比如硬盘、软盘。
+- **管道文件(p,pipe)** : 一种特殊类型的文件,用于进程之间的通信。
+- **套接字文件(s,socket)**:用于进程间的网络通信,也可以用于本机之间的非网络通信。
+
+每种文件类型都有不同的用途和属性,可以通过命令如`ls`、`file`等来查看文件的类型信息。
+
+```bash
+# 普通文件(-)
+-rw-r--r-- 1 user group 1024 Apr 14 10:00 file.txt
+
+# 目录文件(d,directory file)*
+drwxr-xr-x 2 user group 4096 Apr 14 10:00 directory/
+
+# 套接字文件(s,socket)
+srwxrwxrwx 1 user group 0 Apr 14 10:00 socket
+```
+
+### Linux 目录树
+
+Linux 使用一种称为目录树的层次结构来组织文件和目录。目录树由根目录(/)作为起始点,向下延伸,形成一系列的目录和子目录。每个目录可以包含文件和其他子目录。结构层次鲜明,就像一棵倒立的树。
+
+
+**常见目录说明:**
+
+- **/bin:** 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
+- **/etc:** 存放系统管理和配置文件;
+- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
+- **/usr:** 用于存放系统应用程序;
+- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
+- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
+- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
+- **/sbin:** 存放二进制可执行文件,只有 root 才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如 ifconfig 等;
+- **/dev:** 用于存放设备文件;
+- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
+- **/boot:** 存放用于系统引导时使用的各种文件;
+- **/lib 和/lib64:** 存放着和系统运行相关的库文件 ;
+- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
+- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
+- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
+
+## Linux 常用命令
+
+下面只是给出了一些比较常用的命令。
+
+推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。Linux 命令在线速查手册: 。
+
+
+
+另外,[shell.how](https://www.shell.how/) 这个网站可以用来解释常见命令的意思,对你学习 Linux 基本命令以及其他常用命令(如 Git、NPM)。
+
+
+
+### 目录切换
+
+- `cd usr`:切换到该目录下 usr 目录
+- `cd ..(或cd../)`:切换到上一层目录
+- `cd /`:切换到系统根目录
+- `cd ~`:切换到用户主目录
+- **`cd -`:** 切换到上一个操作所在目录
+
+### 目录操作
+
+- `ls`:显示目录中的文件和子目录的列表。例如:`ls /home`,显示 `/home` 目录下的文件和子目录列表。
+- `ll`:`ll` 是 `ls -l` 的别名,ll 命令可以看到该目录下的所有目录和文件的详细信息。
+- `mkdir [选项] 目录名`:创建新目录(增)。例如:`mkdir -m 755 my_directory`,创建一个名为 `my_directory` 的新目录,并将其权限设置为 755,其中所有者拥有读、写、执行权限,所属组和其他用户只有读、执行权限,无法修改目录内容(如创建或删除文件)。如果希望所有用户(包括所属组和其他用户)对目录都拥有读、写、执行权限,则应设置权限为 `777`,即:`mkdir -m 777 my_directory`。
+- `find [路径] [表达式]`:在指定目录及其子目录中搜索文件或目录(查),非常强大灵活。例如:① 列出当前目录及子目录下所有文件和文件夹: `find .`;② 在`/home`目录下查找以 `.txt` 结尾的文件名:`find /home -name "*.txt"` ,忽略大小写: `find /home -i name "*.txt"` ;③ 当前目录及子目录下查找所有以 `.txt` 和 `.pdf` 结尾的文件:`find . \( -name "*.txt" -o -name "*.pdf" \)`或`find . -name "*.txt" -o -name "*.pdf"`。
+- `pwd`:显示当前工作目录的路径。
+- `rmdir [选项] 目录名`:删除空目录(删)。例如:`rmdir -p my_directory`,删除名为 `my_directory` 的空目录,并且会递归删除`my_directory`的空父目录,直到遇到非空目录或根目录。
+- `rm [选项] 文件或目录名`:删除文件/目录(删)。例如:`rm -r my_directory`,删除名为 `my_directory` 的目录,`-r`(recursive,递归) 表示会递归删除指定目录及其所有子目录和文件。
+- `cp [选项] 源文件/目录 目标文件/目录`:复制文件或目录(移)。例如:`cp file.txt /home/file.txt`,将 `file.txt` 文件复制到 `/home` 目录下,并重命名为 `file.txt`。`cp -r source destination`,将 `source` 目录及其下的所有子目录和文件复制到 `destination` 目录下,并保留源文件的属性和目录结构。
+- `mv [选项] 源文件/目录 目标文件/目录`:移动文件或目录(移),也可以用于重命名文件或目录。例如:`mv file.txt /home/file.txt`,将 `file.txt` 文件移动到 `/home` 目录下,并重命名为 `file.txt`。`mv` 与 `cp` 的结果不同,`mv` 好像文件“搬家”,文件个数并未增加。而 `cp` 对文件进行复制,文件个数增加了。
+
+### 文件操作
+
+像 `mv`、`cp`、`rm` 等文件和目录都适用的命令,这里就不重复列举了。
+
+- `touch [选项] 文件名..`:创建新文件或更新已存在文件(增)。例如:`touch file1.txt file2.txt file3.txt` ,创建 3 个文件。
+- `ln [选项] <源文件> <硬链接/软链接文件>`:创建硬链接/软链接。例如:`ln -s file.txt file_link`,创建名为 `file_link` 的软链接,指向 `file.txt` 文件。`-s` 选项代表的就是创建软链接,s 即 symbolic(软链接又名符号链接) 。
+- `cat/more/less/tail 文件名`:文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 Tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
+- `vim 文件名`:修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤:`vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!` (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
+
+### 文件压缩
+
+**1)打包并压缩文件:**
+
+Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是以 `.gz` 结尾的。而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般 `.tar.gz`。
+
+命令:`tar -zcvf 打包压缩后的文件名 要打包压缩的文件` ,其中:
+
+- z:调用 gzip 压缩命令进行压缩
+- c:打包文件
+- v:显示运行过程
+- f:指定文件名
+
+比如:假如 test 目录下有三个文件分别是:`aaa.txt`、 `bbb.txt`、`ccc.txt`,如果我们要打包 `test` 目录并指定压缩后的压缩包名称为 `test.tar.gz` 可以使用命令:`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt` 或 `tar -zcvf test.tar.gz /test/` 。
+
+**2)解压压缩包:**
+
+命令:`tar [-xvf] 压缩文件`
+
+其中 x 代表解压
+
+示例:
+
+- 将 `/test` 下的 `test.tar.gz` 解压到当前目录下可以使用命令:`tar -xvf test.tar.gz`
+- 将 /test 下的 test.tar.gz 解压到根目录/usr 下:`tar -xvf test.tar.gz -C /usr`(`-C` 代表指定解压的位置)
+
+### 文件传输
+
+- `scp [选项] 源文件 远程文件` (scp 即 secure copy,安全复制):用于通过 SSH 协议进行安全的文件传输,可以实现从本地到远程主机的上传和从远程主机到本地的下载。例如:`scp -r my_directory user@remote:/home/user` ,将本地目录`my_directory`上传到远程服务器 `/home/user` 目录下。`scp -r user@remote:/home/user/my_directory` ,将远程服务器的 `/home/user` 目录下的`my_directory`目录下载到本地。需要注意的是,`scp` 命令需要在本地和远程系统之间建立 SSH 连接进行文件传输,因此需要确保远程服务器已经配置了 SSH 服务,并且具有正确的权限和认证方式。
+- `rsync [选项] 源文件 远程文件` : 可以在本地和远程系统之间高效地进行文件复制,并且能够智能地处理增量复制,节省带宽和时间。例如:`rsync -r my_directory user@remote:/home/user`,将本地目录`my_directory`上传到远程服务器 `/home/user` 目录下。
+- `ftp` (File Transfer Protocol):提供了一种简单的方式来连接到远程 FTP 服务器并进行文件上传、下载、删除等操作。使用之前需要先连接登录远程 FTP 服务器,进入 FTP 命令行界面后,可以使用 `put` 命令将本地文件上传到远程主机,可以使用`get`命令将远程主机的文件下载到本地,可以使用 `delete` 命令删除远程主机的文件。这里就不进行演示了。
+
+### 文件权限
+
+操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(executable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
+
+通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
+
+示例:在随意某个目录下`ls -l`
+
+
+
+第一列的内容的信息解释如下:
+
+
+
+> 下面将详细讲解文件的类型、Linux 中权限以及文件有所有者、所在组、其它组具体是什么?
+
+**文件的类型:**
+
+- d:代表目录
+- -:代表文件
+- l:代表软链接(可以认为是 window 中的快捷方式)
+
+**Linux 中权限分为以下几种:**
+
+- r:代表权限是可读,r 也可以用数字 4 表示
+- w:代表权限是可写,w 也可以用数字 2 表示
+- x:代表权限是可执行,x 也可以用数字 1 表示
+
+**文件和目录权限的区别:**
+
+对文件和目录而言,读写执行表示不同的意义。
+
+对于文件:
+
+| 权限名称 | 可执行操作 |
+| :------- | --------------------------: |
+| r | 可以使用 cat 查看文件的内容 |
+| w | 可以修改文件的内容 |
+| x | 可以将其运行为二进制文件 |
+
+对于目录:
+
+| 权限名称 | 可执行操作 |
+| :------- | -----------------------: |
+| r | 可以查看目录下列表 |
+| w | 可以创建和删除目录下文件 |
+| x | 可以使用 cd 进入目录 |
+
+需要注意的是:**超级用户可以无视普通用户的权限,即使文件目录权限是 000,依旧可以访问。**
+
+**在 Linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
+
+- **所有者(u)** :一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
+- **文件所在组(g)** :当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
+- **其它组(o)** :除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
+
+> 我们再来看看如何修改文件/目录的权限。
+
+**修改文件/目录的权限的命令:`chmod`**
+
+示例:修改/test 下的 aaa.txt 的权限为文件所有者有全部权限,文件所有者所在的组有读写权限,其他用户只有读的权限。
+
+**`chmod u=rwx,g=rw,o=r aaa.txt`** 或者 **`chmod 764 aaa.txt`**
+
+
+
+**补充一个比较常用的东西:**
+
+假如我们装了一个 zookeeper,我们每次开机到要求其自动启动该怎么办?
+
+1. 新建一个脚本 zookeeper
+2. 为新建的脚本 zookeeper 添加可执行权限,命令是:`chmod +x zookeeper`
+3. 把 zookeeper 这个脚本添加到开机启动项里面,命令是:`chkconfig --add zookeeper`
+4. 如果想看看是否添加成功,命令是:`chkconfig --list`
+
+### 用户管理
+
+Linux 系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
+
+用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
+
+**Linux 用户管理相关命令:**
+
+- `useradd [选项] 用户名`:创建用户账号。使用`useradd`指令所建立的帐号,实际上是保存在 `/etc/passwd`文本文件中。
+- `userdel [选项] 用户名`:删除用户帐号。
+- `usermod [选项] 用户名`:修改用户账号的属性和配置比如用户名、用户 ID、家目录。
+- `passwd [选项] 用户名`: 设置用户的认证信息,包括用户密码、密码过期时间等。。例如:`passwd -S 用户名` ,显示用户账号密码信息。`passwd -d 用户名`: 清除用户密码,会导致用户无法登录。`passwd 用户名`,修改用户密码,随后系统会提示输入新密码并确认密码。
+- `su [选项] 用户名`(su 即 Switch User,切换用户):在当前登录的用户和其他用户之间切换身份。
+
+### 用户组管理
+
+每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同 Linux 系统对用户组的规定有所不同,如 Linux 下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
+
+用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对`/etc/group`文件的更新。
+
+**Linux 系统用户组的管理相关命令:**
+
+- `groupadd [选项] 用户组` :增加一个新的用户组。
+- `groupdel 用户组`:要删除一个已有的用户组。
+- `groupmod [选项] 用户组` : 修改用户组的属性。
+
+### 系统状态
+
+- `top [选项]`:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。
+- `htop [选项]`:类似于 `top`,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
+- `uptime [选项]`:用于查看系统总共运行了多长时间、系统的平均负载等信息。
+- `vmstat [间隔时间] [重复次数]`:vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。
+- `free [选项]`:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。
+- `df [选项] [文件系统]`:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:`df -a`,查看全部文件系统。
+- `du [选项] [文件]`:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。
+- `sar [选项] [时间间隔] [重复次数]`:用于收集、报告和分析系统的性能统计信息,包括系统的 CPU 使用、内存使用、磁盘 I/O、网络活动等详细信息。它的特点是可以连续对系统取样,获得大量的取样数据。取样数据和分析的结果都可以存入文件,使用它时消耗的系统资源很小。
+- `ps [选项]`:用于查看系统中的进程信息,包括进程的 ID、状态、资源使用情况等。`ps -ef`/`ps -aux`:这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:`ps aux|grep redis` (查看包括 redis 字符串的进程),也可使用 `pgrep redis -a`。
+- `systemctl [命令] [服务名称]`:用于管理系统的服务和单元,可以查看系统服务的状态、启动、停止、重启等。
+
+### 网络通信
+
+- `ping [选项] 目标主机`:测试与目标主机的网络连接。
+- `ifconfig` 或 `ip`:用于查看系统的网络接口信息,包括网络接口的 IP 地址、MAC 地址、状态等。
+- `netstat [选项]`:用于查看系统的网络连接状态和网络统计信息,可以查看当前的网络连接情况、监听端口、网络协议等。
+- `ss [选项]`:比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
+- `nload`:`sar` 和 `nload` 都可以监控网络流量,但`sar` 的输出是文本形式的数据,不够直观。`nload` 则是一个专门用于实时监控网络流量的工具,提供图形化的终端界面,更加直观。不过,`nload` 不保存历史数据,所以它不适合用于长期趋势分析。并且,系统并没有默认安装它,需要手动安装。
+- `sudo hostnamectl set-hostname 新主机名`:更改主机名,并且重启后依然有效。`sudo hostname 新主机名`也可以更改主机名。不过需要注意的是,使用 `hostname` 命令直接更改主机名只是临时生效,系统重启后会恢复为原来的主机名。
+
+### 其他
+
+- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
+- `grep [选项] "搜索内容" 文件路径`:非常强大且常用的文本搜索命令,它可以根据指定的字符串或正则表达式,在文件或命令输出中进行匹配查找,适用于日志分析、文本过滤、快速定位等多种场景。示例:忽略大小写搜索 syslog 中所有包含 error 的行:`grep -i "error" /var/log/syslog`,查找所有与 java 相关的进程:`ps -ef | grep "java"`。
+- `kill -9 进程的pid`:杀死进程(-9 表示强制终止)先用 ps 查找进程,然后用 kill 杀掉。
+- `shutdown`:`shutdown -h now`:指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定 5 分钟后关机,同时送出警告信息给登入用户。
+- `reboot`:`reboot`:重开机。`reboot -w`:做个重开机的模拟(只有纪录并不会真的重开机)。
+
+## Linux 环境变量
+
+在 Linux 系统中,环境变量是用来定义系统运行环境的一些参数,比如每个用户不同的主目录(HOME)。
+
+### 环境变量分类
+
+按照作用域来分,环境变量可以简单的分成:
+
+- 用户级别环境变量 : `~/.bashrc`、`~/.bash_profile`。
+- 系统级别环境变量 : `/etc/bashrc`、`/etc/environment`、`/etc/profile`、`/etc/profile.d`。
+
+上述配置文件执行先后顺序为:`/etc/environment` –> `/etc/profile` –> `/etc/profile.d` –> `~/.bash_profile` –> `/etc/bashrc` –> `~/.bashrc`
+
+如果要修改系统级别环境变量文件,需要管理员具备对该文件的写入权限。
+
+建议用户级别环境变量在 `~/.bash_profile`中配置,系统级别环境变量在 `/etc/profile.d` 中配置。
+
+按照生命周期来分,环境变量可以简单的分成:
+
+- 永久的:需要用户修改相关的配置文件,变量永久生效。
+- 临时的:用户利用 `export` 命令,在当前终端下声明环境变量,关闭 shell 终端失效。
+
+### 读取环境变量
+
+通过 `export` 命令可以输出当前系统定义的所有环境变量。
+
+```bash
+# 列出当前的环境变量值
+export -p
+```
+
+除了 `export` 命令之外, `env` 命令也可以列出所有环境变量。
+
+`echo` 命令可以输出指定环境变量的值。
+
+```bash
+# 输出当前的PATH环境变量的值
+echo $PATH
+# 输出当前的HOME环境变量的值
+echo $HOME
+```
+
+### 环境变量修改
+
+通过 `export`命令可以修改指定的环境变量。不过,这种方式修改环境变量仅仅对当前 shell 终端生效,关闭 shell 终端就会失效。修改完成之后,立即生效。
+
+```bash
+export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
+```
+
+通过 `vim` 命令修改环境变量配置文件。这种方式修改环境变量永久有效。
+
+```bash
+vim ~/.bash_profile
+```
+
+如果修改的是系统级别环境变量则对所有用户生效,如果修改的是用户级别环境变量则仅对当前用户生效。
+
+修改完成之后,需要 `source` 命令让其生效或者关闭 shell 终端重新登录。
+
+```bash
+source /etc/profile
+```
+
+
+
diff --git a/docs_en/cs-basics/operating-system/operating-system-basic-questions-01.en.md b/docs_en/cs-basics/operating-system/operating-system-basic-questions-01.en.md
new file mode 100644
index 00000000000..4006ddfae2a
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/operating-system-basic-questions-01.en.md
@@ -0,0 +1,468 @@
+---
+title: 操作系统常见面试题总结(上)
+category: 计算机基础
+tag:
+ - 操作系统
+head:
+ - - meta
+ - name: keywords
+ content: 操作系统面试题,用户态 vs 内核态,进程 vs 线程,死锁必要条件,系统调用过程,进程调度算法,PCB进程控制块,进程间通信IPC,死锁预防避免,操作系统基础高频题,虚拟内存管理
+ - - meta
+ - name: description
+ content: 最新操作系统高频面试题总结(上):用户态/内核态切换、进程线程区别、死锁四条件、系统调用详解、调度算法对比,附图表+⭐️重点标注,一文掌握OS核心考点,快速通关后端技术面试!
+---
+
+
+
+很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如 **用户态和内核态、系统调用、进程和线程、死锁、内存管理、虚拟内存、文件系统**等等。
+
+这篇文章只是对一些操作系统比较重要概念的一个概览,深入学习的话,建议大家还是老老实实地去看书。另外, 这篇文章的很多内容参考了《现代操作系统》第三版这本书,非常感谢。
+
+开始本文的内容之前,我们先聊聊为什么要学习操作系统。
+
+- **从对个人能力方面提升来说**:操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
+- **从面试角度来说**:尤其是校招,对于操作系统方面知识的考察是非常非常多的。
+
+**简单来说,学习操作系统能够提高自己思考的深度以及对技术的理解力,并且,操作系统方面的知识也是面试必备。**
+
+## 操作系统基础
+
+
+
+### 什么是操作系统?
+
+通过以下四点可以概括操作系统到底是什么:
+
+1. 操作系统(Operating System,简称 OS)是管理计算机硬件与软件资源的程序,是计算机的基石。
+2. 操作系统本质上是一个运行在计算机上的软件程序 ,主要用于管理计算机硬件和软件资源。 举例:运行在你电脑上的所有应用程序都通过操作系统来调用系统内存以及磁盘等等硬件。
+3. 操作系统存在屏蔽了硬件层的复杂性。 操作系统就像是硬件使用的负责人,统筹着各种相关事项。
+4. 操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。 内核是连接应用程序和硬件的桥梁,决定着系统的性能和稳定性。
+
+很多人容易把操作系统的内核(Kernel)和中央处理器(CPU,Central Processing Unit)弄混。你可以简单从下面两点来区别:
+
+1. 操作系统的内核(Kernel)属于操作系统层面,而 CPU 属于硬件。
+2. CPU 主要提供运算,处理各种指令的能力。内核(Kernel)主要负责系统管理比如内存管理,它屏蔽了对硬件的操作。
+
+下图清晰说明了应用程序、内核、CPU 这三者的关系。
+
+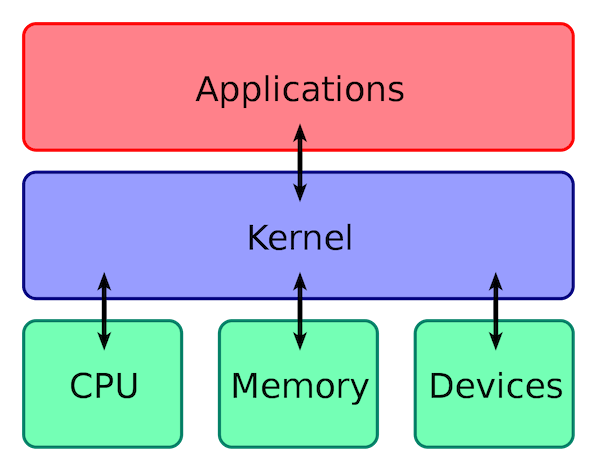
+
+### 操作系统主要有哪些功能?
+
+从资源管理的角度来看,操作系统有 6 大功能:
+
+1. **进程和线程的管理**:进程的创建、撤销、阻塞、唤醒,进程间的通信等。
+2. **存储管理**:内存的分配和管理、外存(磁盘等)的分配和管理等。
+3. **文件管理**:文件的读、写、创建及删除等。
+4. **设备管理**:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
+5. **网络管理**:操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
+6. **安全管理**:用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
+
+### 常见的操作系统有哪些?
+
+#### Windows
+
+目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。界面简单易操作,软件生态非常好。
+
+_玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Windows 用于玩游戏,一台 Mac 用于平时日常开发和学习使用。_
+
+
+
+#### Unix
+
+最早的多用户、多任务操作系统 。后面崛起的 Linux 在很多方面都参考了 Unix。
+
+目前这款操作系统已经逐渐逐渐退出操作系统的舞台。
+
+
+
+#### Linux
+
+**Linux 是一套免费使用、开源的类 Unix 操作系统。** Linux 存在着许多不同的发行版本,但它们都使用了 **Linux 内核** 。
+
+> 严格来讲,Linux 这个词本身只表示 Linux 内核,在 GNU/Linux 系统中,Linux 实际就是 Linux 内核,而该系统的其余部分主要是由 GNU 工程编写和提供的程序组成。单独的 Linux 内核并不能成为一个可以正常工作的操作系统。
+>
+> **很多人更倾向使用 “GNU/Linux” 一词来表达人们通常所说的 “Linux”。**
+
+
+
+#### Mac OS
+
+苹果自家的操作系统,编程体验和 Linux 相当,但是界面、软件生态以及用户体验各方面都要比 Linux 操作系统更好。
+
+
+
+### 用户态和内核态
+
+#### 什么是用户态和内核态?
+
+根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
+
+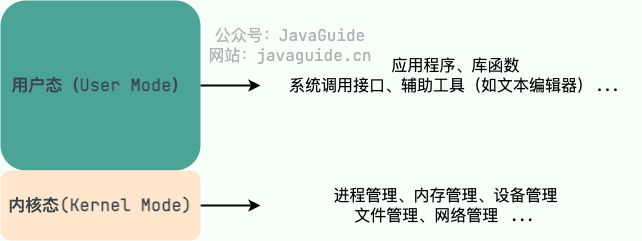
+
+- **用户态(User Mode)** : 用户态运行的进程可以直接读取用户程序的数据,拥有较低的权限。当应用程序需要执行某些需要特殊权限的操作,例如读写磁盘、网络通信等,就需要向操作系统发起系统调用请求,进入内核态。
+- **内核态(Kernel Mode)** :内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
+
+内核态相比用户态拥有更高的特权级别,因此能够执行更底层、更敏感的操作。不过,由于进入内核态需要付出较高的开销(需要进行一系列的上下文切换和权限检查),应该尽量减少进入内核态的次数,以提高系统的性能和稳定性。
+
+#### 为什么要有用户态和内核态?只有一个内核态不行么?
+
+这样设计主要是为了**安全**和**稳定**。
+
+- 在 CPU 的所有指令中,有一些指令是比较危险的比如内存分配、设置时钟、IO 处理等,如果所有的程序都能使用这些指令的话,会对系统的正常运行造成灾难性地影响。因此,我们需要限制这些危险指令只能内核态运行。这些只能由操作系统内核态执行的指令也被叫做 **特权指令** 。
+- 如果计算机系统中只有一个内核态,那么所有程序或进程都必须共享系统资源,例如内存、CPU、硬盘等,这将导致系统资源的竞争和冲突,从而影响系统性能和效率。并且,这样也会让系统的安全性降低,毕竟所有程序或进程都具有相同的特权级别和访问权限。
+
+因此,同时具有用户态和内核态主要是为了保证计算机系统的安全性、稳定性和性能。
+
+#### 用户态和内核态是如何切换的?
+
+
+
+用户态切换到内核态的 3 种方式:
+
+1. **系统调用(Trap)**:这是最主要的方式,是应用程序**主动**发起的。比如,当我们的程序需要读取一个文件或者发送网络数据时,它无法直接操作磁盘或网卡,就必须调用操作系统提供的接口(如 `read()`,`send()`), 这会触发一次从用户态到内核态的切换。
+2. **中断(Interrupt)**:这是**被动**的,由外部硬件设备触发。比如,当硬盘完成了数据读取,会向 CPU 发送一个中断信号,CPU 会暂停当前用户态的程序,切换到内核态去处理这个中断。
+3. **异常(Exception)**:这也是**被动**的,由程序自身错误引起。比如,我们的代码执行了一个除以零的操作,或者访问了一个非法的内存地址(缺页异常),CPU 会捕获这个异常,并切换到内核态去处理它。
+
+在系统的处理上,中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
+
+最后,需要强调的是,这种**状态切换是有性能开销的**。因为它涉及到保存用户态的上下文(寄存器等)、切换到内核态执行、再恢复用户态的上下文。因此,在高性能编程中,我们常常需要考虑如何减少这种切换次数,比如通过缓冲 I/O 来批量读写文件,就是一个典型的例子。
+
+### 系统调用
+
+#### 什么是系统调用?
+
+我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的内核态级别的子功能咋办呢?那就需要系统调用了!
+
+也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
+
+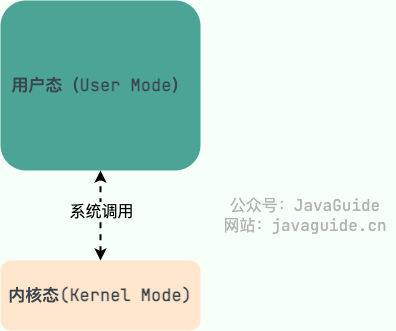
+
+这些系统调用按功能大致可分为如下几类:
+
+- 设备管理:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
+- 文件管理:完成文件的读、写、创建及删除等功能。
+- 进程管理:进程的创建、撤销、阻塞、唤醒,进程间的通信等功能。
+- 内存管理:完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
+
+系统调用和普通库函数调用非常相似,只是系统调用由操作系统内核提供,运行于内核态,而普通的库函数调用由函数库或用户自己提供,运行于用户态。
+
+总结:系统调用是应用程序与操作系统之间进行交互的一种方式,通过系统调用,应用程序可以访问操作系统底层资源例如文件、设备、网络等。
+
+#### 系统调用的过程了解吗?
+
+系统调用的过程可以简单分为以下几个步骤:
+
+1. 用户态的程序发起系统调用,因为系统调用中涉及一些特权指令(只能由操作系统内核态执行的指令),用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
+2. 发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序。内核程序开始执行,也就是开始处理系统调用。
+3. 当系统调用处理完成后,操作系统使用特权指令(如 `iret`、`sysret` 或 `eret`)切换回用户态,恢复用户态的上下文,继续执行用户程序。
+
+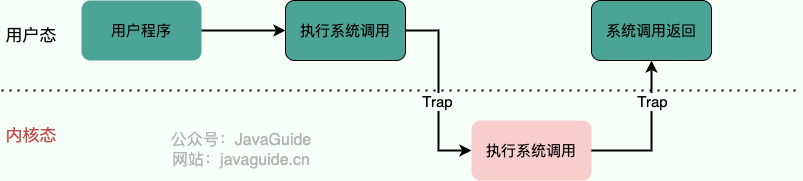
+
+## 进程和线程
+
+### 进程和线程的区别是什么?
+
+进程和线程是操作系统中并发执行的两个核心概念,它们的关系可以理解为 **工厂和工人** 的关系。
+
+**进程(Process)就像一个工厂**。操作系统在分配资源时,是以进程为基本单位的。比如,当我启动一个微信,操作系统就为它建立了一个独立的工厂,分配给它专属的内存空间、文件句柄等资源。这个工厂与其他工厂(比如我打开的浏览器进程)是严格隔离的。
+
+**线程(Thread)则像是工厂里的工人**。一个工厂里可以有很多工人,他们共享这个工厂的资源,但每个工人有自己的工具箱和任务清单,让他们可以独立地执行不同的任务。比如微信这个工厂里,可以有一个工人(线程)负责接收消息,一个工人负责渲染界面。
+
+这是我用 AI 绘制的一张图片,可以说是非常形象了:
+
+
+
+下图是 Java 内存区域,我们从 JVM 的角度来说一下线程和进程之间的关系吧!
+
+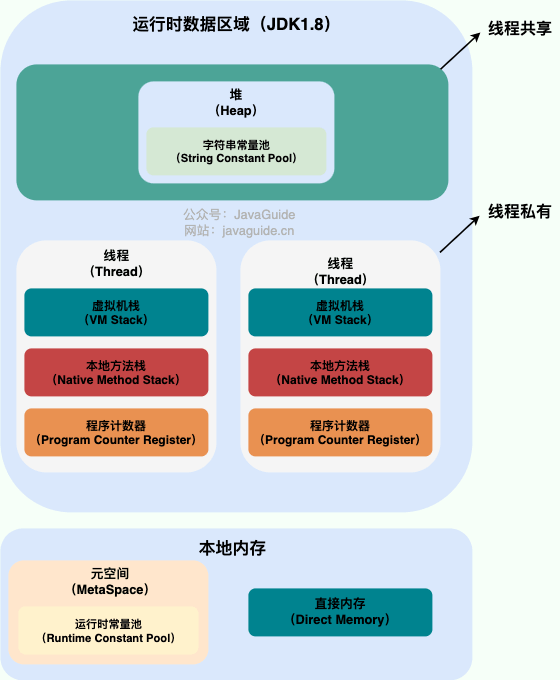
+
+从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
+
+这里从 3 个角度总结下线程和进程的核心区别:
+
+1. **资源所有权:** 进程是资源分配的基本单位,拥有独立的地址空间;而线程是 CPU 调度的基本单位,几乎不拥有系统资源,只保留少量私有数据(PC、栈、寄存器),主要共享其所属进程的资源。
+2. **开销:** 创建或销毁一个工厂(进程)的开销很大,需要分配独立的资源。而雇佣或解雇一个工人(线程)的开销就小得多。同理,进程间的上下文切换开销远大于线程间的切换。
+3. **健壮性:** 工厂之间是隔离的,一个工厂倒闭(进程崩溃)不会影响其他工厂。但一个工厂内的工人之间是共享资源的,一个工人操作失误(比如一个线程访问了非法内存)可能会导致整个工厂停工(整个进程崩溃)。
+
+### 有了进程为什么还需要线程?
+
+核心原因就是**为了在单个应用内实现低开销、高效率的并发**。如果我想让微信同时接收消息和发送文件,如果用两个进程来实现,不仅资源开销巨大,它们之间通信还非常麻烦(需要 IPC)。而使用两个线程,它们不仅切换成本低,还能直接通过共享内存高效通信,从而能更好地利用多核 CPU,提升应用的响应速度和吞吐量。
+
+再那我们上面举的工厂和工人为例:线程=同一屋檐下的轻量级工人,切换成本低、共享内存零拷贝;若换成两个独立进程,就得各建一座工厂(独立地址空间),既费砖又费电(资源与 IPC 开销)。
+
+### 为什么要使用多线程?
+
+先从总体上来说:
+
+- **从计算机底层来说:** 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
+- **从当代互联网发展趋势来说:** 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
+
+再深入到计算机底层来探讨:
+
+- **单核时代**:在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
+- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
+
+### 线程间的同步的方式有哪些?
+
+线程同步是两个或多个共享关键资源的线程的并发执行。应该同步线程以避免关键的资源使用冲突。
+
+下面是几种常见的线程同步的方式:
+
+1. **互斥锁(Mutex)** :采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
+2. **读写锁(Read-Write Lock)** :允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
+3. **信号量(Semaphore)** :它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
+4. **屏障(Barrier)** :屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
+5. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
+
+### PCB 是什么?包含哪些信息?
+
+**PCB(Process Control Block)** 即进程控制块,是操作系统中用来管理和跟踪进程的数据结构,每个进程都对应着一个独立的 PCB。你可以将 PCB 视为进程的大脑。
+
+当操作系统创建一个新进程时,会为该进程分配一个唯一的进程 ID,并且为该进程创建一个对应的进程控制块。当进程执行时,PCB 中的信息会不断变化,操作系统会根据这些信息来管理和调度进程。
+
+PCB 主要包含下面几部分的内容:
+
+- 进程的描述信息,包括进程的名称、标识符等等;
+- 进程的调度信息,包括进程阻塞原因、进程状态(就绪、运行、阻塞等)、进程优先级(标识进程的重要程度)等等;
+- 进程对资源的需求情况,包括 CPU 时间、内存空间、I/O 设备等等。
+- 进程打开的文件信息,包括文件描述符、文件类型、打开模式等等。
+- 处理机的状态信息(由处理机的各种寄存器中的内容组成的),包括通用寄存器、指令计数器、程序状态字 PSW、用户栈指针。
+- ……
+
+### 进程有哪几种状态?
+
+我们一般把进程大致分为 5 种状态,这一点和线程很像!
+
+- **创建状态(new)**:进程正在被创建,尚未到就绪状态。
+- **就绪状态(ready)**:进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
+- **运行状态(running)**:进程正在处理器上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
+- **阻塞状态(waiting)**:又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
+- **结束状态(terminated)**:进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
+
+
+
+### 进程间的通信方式有哪些?
+
+> 下面这部分总结参考了:[《进程间通信 IPC (InterProcess Communication)》](https://www.jianshu.com/p/c1015f5ffa74) 这篇文章,推荐阅读,总结的非常不错。
+
+1. **管道/匿名管道(Pipes)** :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
+2. **有名管道(Named Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 **先进先出(First In First Out)** 。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
+3. **信号(Signal)** :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
+4. **消息队列(Message Queuing)** :消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。
+5. **信号量(Semaphores)** :信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
+6. **共享内存(Shared memory)** :使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
+7. **套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
+
+### 进程的调度算法有哪些?
+
+
+
+进程调度算法的核心目标是决定就绪队列中的哪个进程应该获得 CPU 资源,其设计目标通常是在**吞吐量、周转时间、响应时间**和**公平性**之间做权衡。
+
+我习惯将这些算法分为两大类:**非抢占式**和**抢占式**。
+
+**第一类:非抢占式调度 (Non-Preemptive)**
+
+这种方式下,一旦 CPU 分配给一个进程,它就会一直运行下去,直到任务完成或主动放弃(比如等待 I/O)。
+
+1. **先到先服务调度算法(FCFS,First Come, First Served)** : 这是最简单的,就像排队,谁先来谁先用。优点是公平、实现简单。但缺点很明显,如果一个很长的任务先到了,后面无数个短任务都得等着,这会导致平均等待时间很长,我们称之为“护航效应”。
+2. **短作业优先的调度算法(SJF,Shortest Job First)** : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源。理论上,它的平均等待时间是最短的,吞吐量很高。但缺点是,它需要预测运行时间,这很难做到,而且可能会导致长作业“饿死”,永远得不到执行。
+
+**第二类:抢占式调度 (Preemptive)**
+
+操作系统可以强制剥夺当前进程的 CPU 使用权,分配给其他更重要的进程。现代操作系统基本都采用这种方式。
+
+- **时间片轮转调度算法(RR,Round-Robin)** : 这是最经典、最公平的抢占式算法。它给每个进程分配一个固定的时间片,用完了就把它放到队尾,切换到下一个进程。它非常适合分时系统,保证了每个进程都能得到响应,但时间片的设置很关键:太长了退化成 FCFS,太短了则会导致过于频繁的上下文切换,增加系统开销。
+- **优先级调度算法(Priority)**:每个进程都有一个优先级,进程调度器总是选择优先级最高的进程,具有相同优先级的进程以 FCFS 方式执行。这很灵活,可以根据内存要求,时间要求或任何其他资源要求来确定优先级,但同样可能导致低优先级进程“饿死”。
+
+前面介绍的几种进程调度的算法都有一定的局限性,如:**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。那有没有一种结合了上面这些进程调度算法优点的呢?
+
+**多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)** 是现实世界中最常用的一种算法,比如早期的 UNIX。它非常聪明,结合了 RR 和优先级调度。它设置了多个不同优先级的队列,每个队列使用 RR 调度,时间片大小也不同。新进程先进入最高优先级队列;如果在一个时间片内没执行完,就会被降级到下一个队列。这样既照顾了短作业(在高优先级队列中快速完成),也保证了长作业不会饿死(最终会在低优先级队列中得到执行),是一种非常均衡的方案。
+
+### 那究竟是谁来调度这个进程呢?
+
+负责进程调度的核心是操作系统内核中的两个紧密协作的组件:**调度程序(Scheduler)** 和 **分派程序(Dispatcher)**。我们可以把它们理解成一个团队:
+
+- **调度程序 (Scheduler):** 可以看作是决策者。当需要进行调度时,调度程序会被激活,它会根据预设的调度算法(比如我们前面聊到的多级反馈队列),从就绪队列中挑选出下一个应该占用 CPU 的进程。
+- **分派程序 (Dispatcher):** 可以看作是执行者。它负责完成具体的“交接”工作,也就是**上下文切换**。这个过程非常底层,主要包括:
+ - 保存当前进程的上下文(CPU 寄存器状态、程序计数器等)到其进程控制块(PCB)中。
+ - 加载下一个被选中进程的上下文,从其 PCB 中读取状态,恢复到 CPU 寄存器。
+ - 将 CPU 的控制权正式移交给新进程,让它开始运行。
+
+## 死锁
+
+### 什么是死锁?
+
+死锁(Deadlock)描述的是这样一种情况:多个进程/线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于进程/线程被无限期地阻塞,因此程序不可能正常终止。
+
+一个最经典的例子就是**“交叉持锁”**。想象有两个线程和两个锁:
+
+- 线程 1 先拿到了锁 A,然后尝试去获取锁 B。
+- 几乎同时,线程 2 拿到了锁 B,然后尝试去获取锁 A。
+
+这时,线程 1 等着线程 2 释放锁 B,而线程 2 等着线程 1 释放锁 A,双方都持有对方需要的资源,并等待对方释放,就形成了一个“死结”。
+
+
+
+There is an error to note in the above picture: it is OSPF, not OPSF. OSPF (Open Shortest Path First, ospf) Open Shortest Path First Protocol is a routing protocol developed by the Internet Engineering Task Force
+
+Generally speaking, it is divided into the following steps:
+
+1. Enter the URL of the specified web page in the browser.
+2. The browser obtains the IP address corresponding to the domain name through the DNS protocol.
+3. The browser initiates a TCP connection request to the target server based on the IP address and port number.
+4. The browser sends an HTTP request message to the server on the TCP connection to request the content of the web page.
+5. After receiving the HTTP request message, the server processes the request and returns an HTTP response message to the browser.
+6. After the browser receives the HTTP response message, it parses the HTML code in the response body, renders the structure and style of the web page, and at the same time initiates an HTTP request again based on the URLs of other resources in the HTML (such as images, CSS, JS, etc.) to obtain the contents of these resources until the web page is fully loaded and displayed.
+7. When the browser does not need to communicate with the server, it can actively close the TCP connection, or wait for the server's closing request.
+
+For a detailed introduction, you can view this article: [The whole process of accessing web pages (knowledge connection)](https://javaguide.cn/cs-basics/network/the-whole-process-of-accessing-web-pages.html) (strongly recommended).
+
+### ⭐️What are the HTTP status codes?
+
+HTTP status codes are used to describe the results of HTTP requests. For example, 2xx means that the request was successfully processed.
+
+
+
+For a more detailed summary of HTTP status codes, you can read this article I wrote: [Summary of common HTTP status codes (application layer)](https://javaguide.cn/cs-basics/network/http-status-codes.html).
+
+### What are the common fields in HTTP Header?
+
+| Request header field name | Description | Example |
+| :---------------------------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-------------------------------------------------------------------------------------------------- |
+| Accept | Acceptable response content types (Content-Types). | Accept: text/plain |
+| Accept-Charset | Acceptable character set | Accept-Charset: utf-8 |
+| Accept-Datetime | Acceptable version expressed in time | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
+| Accept-Encoding | A list of acceptable encodings. See HTTP compression. | Accept-Encoding: gzip, deflate |
+| Accept-Language | A list of natural languages that are acceptable for response content. | Accept-Language: en-US || Authorization | Authentication information used for Hypertext Transfer Protocol authentication | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Cache-Control | Used to specify directives that all caching mechanisms in this request/response chain must comply with | Cache-Control: no-cache |
+| Connection | The type of connection this browser prefers to use | Connection: keep-alive |
+| Content-Length | The length of the request body as an octet array (8-bit bytes) | Content-Length: 348 |
+| Content-MD5 | The binary MD5 hash value of the request body's content, encoded in Base64 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
+| Content-Type | The multimedia type of the request body (used in POST and PUT requests) | Content-Type: application/x-www-form-urlencoded |
+| Cookie | A Hypertext Transfer Protocol Cookie previously sent by the server via Set-Cookie (described below) | Cookie: $Version=1; Skin=new; |
+| Date | The date and time the message was sent (sent in the "Hypertext Transfer Protocol Date" format defined in RFC 7231) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
+| Expect | Indicates that the client requires the server to perform specific behavior | Expect: 100-continue |
+| From | The email address of the user who initiated this request | From: `user@example.com` |
+| Host | The domain name of the server (used for virtual hosts), and the Transmission Control Protocol port number that the server listens on. The port number may be omitted if the requested port is the standard port of the corresponding service. | Host: en.wikipedia.org |
+| If-Match | The corresponding operation is performed only if the entity provided by the client matches the corresponding entity on the server. The main purpose is to be used in methods like PUT to update a resource only if the resource has not been modified since the user last updated the resource. | If-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Modified-Since | Allows the server to return a `304 Not Modified` status code if the requested resource has not been modified since the specified date | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| If-None-Match | Allows the server to return a `304 Not Modified` status code if the ETag of the requested resource has not changed | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
+| If-Range | If the entity has not been modified, send me the part or parts I am missing; otherwise, send the entire new entity | If-Range: "737060cd8c284d8af7ad3082f209582d" || If-Unmodified-Since | Send a response only if the entity has not been modified since a certain time. | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
+| Max-Forwards | Limits the number of times this message can be forwarded by proxies and gateways. | Max-Forwards: 10 |
+| Origin | Initiates a request for cross-origin resource sharing. | `Origin: http://www.example-social-network.com` |
+| Pragma | Implementation dependent, these fields may have multiple effects at any time in the request/response chain. | Pragma: no-cache |
+| Proxy-Authorization | Authentication information used to authenticate to the proxy. | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
+| Range | Requests only a portion of an entity. Byte offsets start with 0. See byte service. | Range: bytes=500-999 |
+| Referer | indicates the previous page visited by the browser. It is a link on that page that brings the browser to the currently requested page. | `Referer: http://en.wikipedia.org/wiki/Main_Page` |
+| TE | The transfer encoding that the browser expects to accept: you can use the value in the Transfer-Encoding field of the response protocol header; | TE: trailers, deflate |
+| Upgrade | Requests the server to be upgraded to another protocol. | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
+| User-Agent | The browser's browser identification string | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
+| Via | Informs the server which proxy this request was issued by. | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
+| Warning | A general warning that errors may exist in the entity content body. | Warning: 199 Miscellaneous warning |
+
+### ⭐️What is the difference between HTTP and HTTPS? (Important)
+
+
+
+- **Port number**: The default for HTTP is 80, and the default for HTTPS is 443.
+- **URL Prefix**: The URL prefix of HTTP is `http://`, and the URL prefix of HTTPS is `https://`.
+- **Security and Resource Consumption**: The HTTP protocol runs on top of TCP, all transmitted content is clear text, and neither the client nor the server can verify the identity of the other party. HTTPS is an HTTP protocol that runs on top of SSL/TLS, which runs on top of TCP. All transmitted content is encrypted using symmetric encryption, but the symmetric encryption key is asymmetrically encrypted using a server-side certificate. Therefore, HTTP is not as secure as HTTPS, but HTTPS consumes more server resources than HTTP.
+- **SEO (Search Engine Optimization)**: Search engines generally prefer websites that use the HTTPS protocol because HTTPS provides greater security and user privacy protection. Websites that use the HTTPS protocol may be prioritized in search results, impacting SEO.
+
+For a more detailed comparison summary of HTTP and HTTPS, you can read this article I wrote: [HTTP vs HTTPS (application layer)](https://javaguide.cn/cs-basics/network/http-vs-https.html).
+
+### What is the difference between HTTP/1.0 and HTTP/1.1?
+
+- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
+- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
+- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
+- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
+- **Host 头(Host Header)处理** :HTTP/1.1 引入了 Host 头字段,允许在同一 IP 地址上托管多个域名,从而支持虚拟主机的功能。而 HTTP/1.0 没有 Host 头字段,无法实现虚拟主机。
+
+关于 HTTP/1.0 和 HTTP/1.1 更详细的对比总结,可以看我写的这篇文章:[HTTP/1.0 vs HTTP/1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html) 。
+
+### ⭐️HTTP/1.1 和 HTTP/2.0 有什么区别?
+
+
+
+- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接的限制。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
+- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
+- **队头阻塞**:HTTP/2 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 HTTP/1.1 应用层的队头阻塞问题,但 HTTP/2 依然受到 TCP 层队头阻塞 的影响。
+- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
+- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
+
+HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://blog.cloudflare.com/http-2-for-web-developers/)):
+
+
+
+可以看到,HTTP/2 的多路复用机制允许多个请求和响应共享一个 TCP 连接,从而避免了 HTTP/1.1 在应对并发请求时需要建立多个并行连接的情况,减少了重复连接建立和维护的额外开销。而在 HTTP/1.1 中,尽管支持持久连接,但为了缓解队头阻塞问题,浏览器通常会为同一域名建立多个并行连接。
+
+### HTTP/2.0 和 HTTP/3.0 有什么区别?
+
+
+
+- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
+- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
+- **头部压缩**:HTTP/2.0 使用 HPACK 算法进行头部压缩,而 HTTP/3.0 使用更高效的 QPACK 头压缩算法。
+- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
+- **连接迁移**:HTTP/3.0 支持连接迁移,因为 QUIC 使用 64 位 ID 标识连接,只要 ID 不变就不会中断,网络环境改变时(如从 Wi-Fi 切换到移动数据)也能保持连接。而 TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这个四元组中一旦有一项值发生改变,这个连接也就不能用了。
+- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
+- **安全性**:在 HTTP/2.0 中,TLS 用于加密和认证整个 HTTP 会话,包括所有的 HTTP 头部和数据负载。TLS 的工作是在 TCP 层之上,它加密的是在 TCP 连接中传输的应用层的数据,并不会对 TCP 头部以及 TLS 记录层头部进行加密,所以在传输的过程中 TCP 头部可能会被攻击者篡改来干扰通信。而 HTTP/3.0 的 QUIC 对整个数据包(包括报文头和报文体)进行了加密与认证处理,保障安全性。
+
+HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
+
+
+
+下图是一个更详细的 HTTP/2.0 和 HTTP/3.0 对比图:
+
+
+
+从上图可以看出:
+
+- **HTTP/2.0**:使用 TCP 作为传输协议、使用 HPACK 进行头部压缩、依赖 TLS 进行加密。
+- **HTTP/3.0**:使用基于 UDP 的 QUIC 协议、使用更高效的 QPACK 进行头部压缩、在 QUIC 中直接集成了 TLS。QUIC 协议具备连接迁移、拥塞控制与避免、流量控制等特性。
+
+关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
+
+### HTTP/1.1 和 HTTP/2.0 的队头阻塞有什么不同?
+
+HTTP/1.1 队头阻塞的主要原因是无法多路复用:
+
+- 在一个 TCP 连接中,资源的请求和响应是按顺序处理的。如果一个大的资源(如一个大文件)正在传输,后续的小资源(如较小的 CSS 文件)需要等待前面的资源传输完成后才能被发送。
+- 如果浏览器需要同时加载多个资源(如多个 CSS、JS 文件等),它通常会开启多个并行的 TCP 连接(一般限制为 6 个)。但每个连接仍然受限于顺序的请求-响应机制,因此仍然会发生 **应用层的队头阻塞**。
+
+虽然 HTTP/2.0 引入了多路复用技术,允许多个请求和响应在单个 TCP 连接上并行交错传输,解决了 **HTTP/1.1 应用层的队头阻塞问题**,但 HTTP/2.0 依然受到 **TCP 层队头阻塞** 的影响:
+
+- HTTP/2.0 通过帧(frame)机制将每个资源分割成小块,并为每个资源分配唯一的流 ID,这样多个资源的数据可以在同一 TCP 连接中交错传输。
+- TCP 作为传输层协议,要求数据按顺序交付。如果某个数据包在传输过程中丢失,即使后续的数据包已经到达,也必须等待丢失的数据包重传后才能继续处理。这种传输层的顺序性导致了 **TCP 层的队头阻塞**。
+- 举例来说,如果 HTTP/2 的一个 TCP 数据包中携带了多个资源的数据(例如 JS 和 CSS),而该数据包丢失了,那么后续数据包中的所有资源数据都需要等待丢失的数据包重传回来,导致所有流(streams)都被阻塞。
+
+最后,来一张表格总结补充一下:
+
+| **方面** | **HTTP/1.1 的队头阻塞** | **HTTP/2.0 的队头阻塞** |
+| -------------- | ---------------------------------------- | ---------------------------------------------------------------- |
+| **层级** | 应用层(HTTP 协议本身的限制) | 传输层(TCP 协议的限制) |
+| **根本原因** | 无法多路复用,请求和响应必须按顺序传输 | TCP 要求数据包按顺序交付,丢包时阻塞整个连接 |
+| **受影响范围** | 单个 HTTP 请求/响应会阻塞后续请求/响应。 | 单个 TCP 包丢失会影响所有 HTTP/2.0 流(依赖于同一个底层 TCP 连接) |
+| **缓解方法** | 开启多个并行的 TCP 连接 | 减少网络掉包或者使用基于 UDP 的 QUIC 协议 |
+| **影响场景** | 每次都会发生,尤其是大文件阻塞小文件时。 | 丢包率较高的网络环境下更容易发生。 |
+
+### ⭐️HTTP 是不保存状态的协议, 如何保存用户状态?
+
+HTTP 协议本身是 **无状态的 (stateless)** 。这意味着服务器默认情况下无法区分两个连续的请求是否来自同一个用户,或者同一个用户之前的操作是什么。这就像一个“健忘”的服务员,每次你跟他说话,他都不知道你是谁,也不知道你之前点过什么菜。
+
+但在实际的 Web 应用中,比如网上购物、用户登录等场景,我们显然需要记住用户的状态(例如购物车里的商品、用户的登录信息)。为了解决这个问题,主要有以下几种常用机制:
+
+**方案一:Session (会话) 配合 Cookie (主流方式):**
+
+
+
+这可以说是最经典也是最常用的方法了。基本流程是这样的:
+
+1. 用户向服务器发送用户名、密码、验证码用于登陆系统。
+2. 服务器验证通过后,会为这个用户创建一个专属的 Session 对象(可以理解为服务器上的一块内存,存放该用户的状态数据,如购物车、登录信息等)存储起来,并给这个 Session 分配一个唯一的 `SessionID`。
+3. 服务器通过 HTTP 响应头中的 `Set-Cookie` 指令,把这个 `SessionID` 发送给用户的浏览器。
+4. 浏览器接收到 `SessionID` 后,会将其以 Cookie 的形式保存在本地。当用户保持登录状态时,每次向该服务器发请求,浏览器都会自动带上这个存有 `SessionID` 的 Cookie。
+5. 服务器收到请求后,从 Cookie 中拿出 `SessionID`,就能找到之前保存的那个 Session 对象,从而知道这是哪个用户以及他之前的状态了。
+
+使用 Session 的时候需要注意下面几个点:
+
+- **客户端 Cookie 支持**:依赖 Session 的核心功能要确保用户浏览器开启了 Cookie。
+- **Session 过期管理**:合理设置 Session 的过期时间,平衡安全性和用户体验。
+- **Session ID 安全**:为包含 `SessionID` 的 Cookie 设置 `HttpOnly` 标志可以防止客户端脚本(如 JavaScript)窃取,设置 Secure 标志可以保证 `SessionID` 只在 HTTPS 连接下传输,增加安全性。
+
+Session 数据本身存储在服务器端。常见的存储方式有:
+
+- **服务器内存**:实现简单,访问速度快,但服务器重启数据会丢失,且不利于多服务器间的负载均衡。这种方式适合简单且用户量不大的业务场景。
+- **数据库 (如 MySQL, PostgreSQL)**:数据持久化,但读写性能相对较低,一般不会使用这种方式。
+- **分布式缓存 (如 Redis)**:性能高,支持分布式部署,是目前大规模应用中非常主流的方案。
+
+**方案二:当 Cookie 被禁用时:URL 重写 (URL Rewriting)**
+
+如果用户的浏览器禁用了 Cookie,或者某些情况下不便使用 Cookie,还有一种备选方案是 URL 重写。这种方式会将 `SessionID` 直接附加到 URL 的末尾,作为参数传递。例如:。服务器端会解析 URL 中的 `sessionid` 参数来获取 `SessionID`,进而找到对应的 Session 数据。
+
+这种方法一般不会使用,存在以下缺点:
+
+- URL 会变长且不美观;
+- `SessionID` 暴露在 URL 中,安全性较低(容易被复制、分享或记录在日志中);
+- 对搜索引擎优化 (SEO) 可能不友好。
+
+**方案三:Token-based 认证 (如 JWT - JSON Web Tokens)**
+
+这是一种越来越流行的无状态认证方式,尤其适用于前后端分离的架构和微服务。
+
+
+
+以 JWT 为例(普通 Token 方案也可以),简化后的步骤如下
+
+1. 用户向服务器发送用户名、密码以及验证码用于登陆系统;
+2. 如果用户用户名、密码以及验证码校验正确的话,服务端会返回已经签名的 Token,也就是 JWT;
+3. 客户端收到 Token 后自己保存起来(比如浏览器的 `localStorage` );
+4. 用户以后每次向后端发请求都在 Header 中带上这个 JWT ;
+5. 服务端检查 JWT 并从中获取用户相关信息。
+
+JWT 详细介绍可以查看这两篇文章:
+
+- [JWT 基础概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)
+- [JWT 身份认证优缺点分析](https://javaguide.cn/system-design/security/advantages-and-disadvantages-of-jwt.html)
+
+总结来说,虽然 HTTP 本身是无状态的,但通过 Cookie + Session、URL 重写或 Token 等机制,我们能够有效地在 Web 应用中跟踪和管理用户状态。其中,**Cookie + Session 是最传统也最广泛使用的方式,而 Token-based 认证则在现代 Web 应用中越来越受欢迎。**
+
+### URI 和 URL 的区别是什么?
+
+- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
+- URL(Uniform Resource Locator) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
+
+URI 的作用像身份证号一样,URL 的作用更像家庭住址一样。URL 是一种具体的 URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
+
+### Cookie 和 Session 有什么区别?
+
+准确点来说,这个问题属于认证授权的范畴,你可以在 [认证授权基础概念详解](https://javaguide.cn/system-design/security/basis-of-authority-certification.html) 这篇文章中找到详细的答案。
+
+### ⭐️GET 和 POST 的区别
+
+这个问题在知乎上被讨论的挺火热的,地址: 。
+
+
+
+GET 和 POST 是 HTTP 协议中两种常用的请求方法,它们在不同的场景和目的下有不同的特点和用法。一般来说,可以从以下几个方面来区分二者(重点搞清两者在语义上的区别即可):
+
+- 语义(主要区别):GET 通常用于获取或查询资源,而 POST 通常用于创建或修改资源。
+- 幂等:GET 请求是幂等的,即多次重复执行不会改变资源的状态,而 POST 请求是不幂等的,即每次执行可能会产生不同的结果或影响资源的状态。
+- 格式:GET 请求的参数通常放在 URL 中,形成查询字符串(querystring),而 POST 请求的参数通常放在请求体(body)中,可以有多种编码格式,如 application/x-www-form-urlencoded、multipart/form-data、application/json 等。GET 请求的 URL 长度受到浏览器和服务器的限制,而 POST 请求的 body 大小则没有明确的限制。不过,实际上 GET 请求也可以用 body 传输数据,只是并不推荐这样做,因为这样可能会导致一些兼容性或者语义上的问题。
+- 缓存:由于 GET 请求是幂等的,它可以被浏览器或其他中间节点(如代理、网关)缓存起来,以提高性能和效率。而 POST 请求则不适合被缓存,因为它可能有副作用,每次执行可能需要实时的响应。
+- 安全性:GET 请求和 POST 请求如果使用 HTTP 协议的话,那都不安全,因为 HTTP 协议本身是明文传输的,必须使用 HTTPS 协议来加密传输数据。另外,GET 请求相比 POST 请求更容易泄露敏感数据,因为 GET 请求的参数通常放在 URL 中。
+
+再次提示,重点搞清两者在语义上的区别即可,实际使用过程中,也是通过语义来区分使用 GET 还是 POST。不过,也有一些项目所有的请求都用 POST,这个并不是固定的,项目组达成共识即可。
+
+## WebSocket
+
+### 什么是 WebSocket?
+
+WebSocket 是一种基于 TCP 连接的全双工通信协议,即客户端和服务器可以同时发送和接收数据。
+
+WebSocket 协议在 2008 年诞生,2011 年成为国际标准,几乎所有主流较新版本的浏览器都支持该协议。不过,WebSocket 不只能在基于浏览器的应用程序中使用,很多编程语言、框架和服务器都提供了 WebSocket 支持。
+
+WebSocket 协议本质上是应用层的协议,用于弥补 HTTP 协议在持久通信能力上的不足。客户端和服务器仅需一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
+
+
+
+下面是 WebSocket 的常见应用场景:
+
+- 视频弹幕
+- 实时消息推送,详见[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)这篇文章
+- 实时游戏对战
+- 多用户协同编辑
+- 社交聊天
+- ……
+
+### ⭐️WebSocket 和 HTTP 有什么区别?
+
+WebSocket 和 HTTP 两者都是基于 TCP 的应用层协议,都可以在网络中传输数据。
+
+下面是二者的主要区别:
+
+- WebSocket 是一种双向实时通信协议,而 HTTP 是一种单向通信协议。并且,HTTP 协议下的通信只能由客户端发起,服务器无法主动通知客户端。
+- WebSocket 使用 ws:// 或 wss://(使用 SSL/TLS 加密后的协议,类似于 HTTP 和 HTTPS 的关系) 作为协议前缀,HTTP 使用 http:// 或 https:// 作为协议前缀。
+- WebSocket 可以支持扩展,用户可以扩展协议,实现部分自定义的子协议,如支持压缩、加密等。
+- WebSocket 通信数据格式比较轻量,用于协议控制的数据包头部相对较小,网络开销小,而 HTTP 通信每次都要携带完整的头部,网络开销较大(HTTP/2.0 使用二进制帧进行数据传输,还支持头部压缩,减少了网络开销)。
+
+### WebSocket 的工作过程是什么样的?
+
+WebSocket 的工作过程可以分为以下几个步骤:
+
+1. 客户端向服务器发送一个 HTTP 请求,请求头中包含 `Upgrade: websocket` 和 `Sec-WebSocket-Key` 等字段,表示要求升级协议为 WebSocket;
+2. 服务器收到这个请求后,会进行升级协议的操作,如果支持 WebSocket,它将回复一个 HTTP 101 状态码,响应头中包含 ,`Connection: Upgrade`和 `Sec-WebSocket-Accept: xxx` 等字段、表示成功升级到 WebSocket 协议。
+3. 客户端和服务器之间建立了一个 WebSocket 连接,可以进行双向的数据传输。数据以帧(frames)的形式进行传送,WebSocket 的每条消息可能会被切分成多个数据帧(最小单位)。发送端会将消息切割成多个帧发送给接收端,接收端接收消息帧,并将关联的帧重新组装成完整的消息。
+4. 客户端或服务器可以主动发送一个关闭帧,表示要断开连接。另一方收到后,也会回复一个关闭帧,然后双方关闭 TCP 连接。
+
+另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
+
+### ⭐️WebSocket 与短轮询、长轮询的区别
+
+这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
+
+**1.短轮询(Short Polling)**
+
+- **原理**:客户端每隔固定时间(如 5 秒)发起一次 HTTP 请求,询问服务器是否有新数据。服务器收到请求后立即响应。
+- **优点**:实现简单,兼容性好,直接用常规 HTTP 请求即可。
+- **缺点**:
+ - **实时性一般**:消息可能在两次轮询间到达,用户需等到下次请求才知晓。
+ - **资源浪费大**:反复建立/关闭连接,且大多数请求收到的都是“无新消息”,极大增加服务器和网络压力。
+
+**2.长轮询(Long Polling)**
+
+- **原理**:客户端发起请求后,若服务器暂时无新数据,则会保持连接,直到有新数据或超时才响应。客户端收到响应后立即发起下一次请求,实现“伪实时”。
+- **优点**:
+ - **实时性较好**:一旦有新数据可立即推送,无需等待下次定时请求。
+ - **空响应减少**:减少了无效的空响应,提升了效率。
+- **缺点**:
+ - **服务器资源占用高**:需长时间维护大量连接,消耗服务器线程/连接数。
+ - **资源浪费大**:每次响应后仍需重新建立连接,且依然基于 HTTP 单向请求-响应机制。
+
+**3. WebSocket**
+
+- **原理**:客户端与服务器通过一次 HTTP Upgrade 握手后,建立一条持久的 TCP 连接。之后,双方可以随时、主动地发送数据,实现真正的全双工、低延迟通信。
+- **优点**:
+ - **实时性强**:数据可即时双向收发,延迟极低。
+ - **资源效率高**:连接持续,无需反复建立/关闭,减少资源消耗。
+ - **功能强大**:支持服务端主动推送消息、客户端主动发起通信。
+- **缺点**:
+ - **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
+ - **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
+
+
+
+### ⭐️SSE 与 WebSocket 有什么区别?
+
+SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
+
+1. **通信方式:**
+ - **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
+ - **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
+2. **底层协议:**
+ - **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
+ - **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
+3. **实现复杂度和成本:**
+ - **SSE:** **实现相对简单**,主要在服务器端处理。浏览器端有标准的 EventSource API,使用方便。开发和维护成本较低。
+ - **WebSocket:** **稍微复杂一些**。需要服务器端专门处理 WebSocket 连接和协议,客户端也需要使用 WebSocket API。如果需要考虑兼容性、心跳、重连等,开发成本会更高。
+4. **断线重连:**
+ - **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
+ - **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
+5. **数据类型:**
+ - **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
+ - **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
+
+为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技术选择**。
+
+这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
+
+
+
+
+
+可以看到,响应头应里包含了 `text/event-stream`,说明使用的确实是 SSE。并且,响应数据也确实是持续分块传输。
+
+## PING
+
+### PING 命令的作用是什么?
+
+PING 命令是一种常用的网络诊断工具,经常用来测试网络中主机之间的连通性和网络延迟。
+
+这里简单举一个例子,我们来 PING 一下百度。
+
+```bash
+# 发送4个PING请求数据包到 www.baidu.com
+❯ ping -c 4 www.baidu.com
+
+PING www.a.shifen.com (14.119.104.189): 56 data bytes
+64 bytes from 14.119.104.189: icmp_seq=0 ttl=54 time=27.867 ms
+64 bytes from 14.119.104.189: icmp_seq=1 ttl=54 time=28.732 ms
+64 bytes from 14.119.104.189: icmp_seq=2 ttl=54 time=27.571 ms
+64 bytes from 14.119.104.189: icmp_seq=3 ttl=54 time=27.581 ms
+
+--- www.a.shifen.com ping statistics ---
+4 packets transmitted, 4 packets received, 0.0% packet loss
+round-trip min/avg/max/stddev = 27.571/27.938/28.732/0.474 ms
+```
+
+PING 命令的输出结果通常包括以下几部分信息:
+
+1. **ICMP Echo Request(请求报文)信息**:序列号、TTL(Time to Live)值。
+2. **目标主机的域名或 IP 地址**:输出结果的第一行。
+3. **往返时间(RTT,Round-Trip Time)**:从发送 ICMP Echo Request(请求报文)到接收到 ICMP Echo Reply(响应报文)的总时间,用来衡量网络连接的延迟。
+4. **统计结果(Statistics)**:包括发送的 ICMP 请求数据包数量、接收到的 ICMP 响应数据包数量、丢包率、往返时间(RTT)的最小、平均、最大和标准偏差值。
+
+如果 PING 对应的目标主机无法得到正确的响应,则表明这两个主机之间的连通性存在问题(有些主机或网络管理员可能禁用了对 ICMP 请求的回复,这样也会导致无法得到正确的响应)。如果往返时间(RTT)过高,则表明网络延迟过高。
+
+### PING 命令的工作原理是什么?
+
+PING 基于网络层的 **ICMP(Internet Control Message Protocol,互联网控制报文协议)**,其主要原理就是通过在网络上发送和接收 ICMP 报文实现的。
+
+ICMP 报文中包含了类型字段,用于标识 ICMP 报文类型。ICMP 报文的类型有很多种,但大致可以分为两类:
+
+- **查询报文类型**:向目标主机发送请求并期望得到响应。
+- **差错报文类型**:向源主机发送错误信息,用于报告网络中的错误情况。
+
+PING 用到的 ICMP Echo Request(类型为 8 ) 和 ICMP Echo Reply(类型为 0) 属于查询报文类型 。
+
+- PING 命令会向目标主机发送 ICMP Echo Request。
+- 如果两个主机的连通性正常,目标主机会返回一个对应的 ICMP Echo Reply。
+
+## DNS
+
+### DNS 的作用是什么?
+
+DNS(Domain Name System)域名管理系统,是当用户使用浏览器访问网址之后,使用的第一个重要协议。DNS 要解决的是**域名和 IP 地址的映射问题**。
+
+
+
+在一台电脑上,可能存在浏览器 DNS 缓存,操作系统 DNS 缓存,路由器 DNS 缓存。如果以上缓存都查询不到,那么 DNS 就闪亮登场了。
+
+目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
+
+### DNS 服务器有哪些?根服务器有多少个?
+
+DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
+
+- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
+- 顶级域 DNS 服务器(TLD 服务器)。顶级域是指域名的后缀,如`com`、`org`、`net`和`edu`等。国家也有自己的顶级域,如`uk`、`fr`和`ca`。TLD 服务器提供了权威 DNS 服务器的 IP 地址。
+- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
+- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
+
+世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 1700 多台,未来还会继续增加。
+
+### ⭐️DNS 解析的过程是什么样的?
+
+There are many steps in the whole process. I wrote a separate article to introduce it in detail: [DNS Domain Name System Detailed Explanation (Application Layer)](https://javaguide.cn/cs-basics/network/dns.html).
+
+### Do you know about DNS hijacking? How to deal with it?
+
+DNS hijacking is a network attack that modifies the resolution results of the DNS server so that the domain name visited by the user points to the wrong IP address, resulting in the user being unable to access normal websites or being directed to malicious websites. DNS hijacking is sometimes also called DNS redirection, DNS spoofing, or DNS pollution.
+
+## Reference
+
+- "HTTP Illustrated"
+- "Top-Down Method of Computer Networks" (Seventh Edition)
+- Detailed explanation of HTTP/2.0 and HTTPS protocols:
+- Complete list of HTTP request header fields | HTTP Request Headers:
+- HTTP1, HTTP2, HTTP3:
+- What do you think of HTTP/3? - Che Xiaopang's answer - Zhihu:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/other-network-questions2.en.md b/docs_en/cs-basics/network/other-network-questions2.en.md
new file mode 100644
index 00000000000..122a25ff93e
--- /dev/null
+++ b/docs_en/cs-basics/network/other-network-questions2.en.md
@@ -0,0 +1,273 @@
+---
+title: 计算机网络常见面试题总结(下)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 计算机网络面试题,TCP vs UDP,TCP三次握手,HTTP/3 QUIC,IPv4 vs IPv6,TCP可靠性,IP地址,NAT协议,ARP协议,传输层面试,网络层高频题,基于TCP协议,基于UDP协议,队头阻塞,四次挥手
+ - - meta
+ - name: description
+ content: 最新计算机网络高频面试题总结(下):TCP/UDP深度对比、三次握手四次挥手、HTTP/3 QUIC优化、IPv6优势、NAT/ARP详解,附表格+⭐️重点标注,一文掌握传输层&网络层核心考点,快速通关后端技术面试!
+---
+
+下篇主要是传输层和网络层相关的内容。
+
+## TCP 与 UDP
+
+### ⭐️TCP 与 UDP 的区别(重要)
+
+1. **是否面向连接**:
+ - TCP 是面向连接的。在传输数据之前,必须先通过“三次握手”建立连接;数据传输完成后,还需要通过“四次挥手”来释放连接。这保证了双方都准备好通信。
+ - UDP 是无连接的。发送数据前不需要建立任何连接,直接把数据包(数据报)扔出去。
+2. **是否是可靠传输**:
+ - TCP 提供可靠的数据传输服务。它通过序列号、确认应答 (ACK)、超时重传、流量控制、拥塞控制等一系列机制,来确保数据能够无差错、不丢失、不重复且按顺序地到达目的地。
+ - UDP 提供不可靠的传输。它尽最大努力交付 (best-effort delivery),但不保证数据一定能到达,也不保证到达的顺序,更不会自动重传。收到报文后,接收方也不会主动发确认。
+3. **是否有状态**:
+ - TCP 是有状态的。因为要保证可靠性,TCP 需要在连接的两端维护连接状态信息,比如序列号、窗口大小、哪些数据发出去了、哪些收到了确认等。
+ - UDP 是无状态的。它不维护连接状态,发送方发出数据后就不再关心它是否到达以及如何到达,因此开销更小(**这很“渣男”!**)。
+4. **传输效率**:
+ - TCP 因为需要建立连接、发送确认、处理重传等,其开销较大,传输效率相对较低。
+ - UDP 结构简单,没有复杂的控制机制,开销小,传输效率更高,速度更快。
+5. **传输形式**:
+ - TCP 是面向字节流 (Byte Stream) 的。它将应用程序交付的数据视为一连串无结构的字节流,可能会对数据进行拆分或合并。
+ - UDP 是面向报文 (Message Oriented) 的。应用程序交给 UDP 多大的数据块,UDP 就照样发送,既不拆分也不合并,保留了应用程序消息的边界。
+6. **首部开销**:
+ - TCP 的头部至少需要 20 字节,如果包含选项字段,最多可达 60 字节。
+ - UDP 的头部非常简单,固定只有 8 字节。
+7. **是否提供广播或多播服务**:
+ - TCP 只支持点对点 (Point-to-Point) 的单播通信。
+ - UDP 支持一对一 (单播)、一对多 (多播/Multicast) 和一对所有 (广播/Broadcast) 的通信方式。
+8. ……
+
+为了更直观地对比,可以看下面这个表格:
+
+| 特性 | TCP | UDP |
+| ------------ | -------------------------- | ----------------------------------- |
+| **连接性** | 面向连接 | 无连接 |
+| **可靠性** | 可靠 | 不可靠 (尽力而为) |
+| **状态维护** | 有状态 | 无状态 |
+| **传输效率** | 较低 | 较高 |
+| **传输形式** | 面向字节流 | 面向数据报 (报文) |
+| **头部开销** | 20 - 60 字节 | 8 字节 |
+| **通信模式** | 点对点 (单播) | 单播、多播、广播 |
+| **常见应用** | HTTP/HTTPS, FTP, SMTP, SSH | DNS, DHCP, SNMP, TFTP, VoIP, 视频流 |
+
+### ⭐️什么时候选择 TCP,什么时候选 UDP?
+
+选择 TCP 还是 UDP,主要取决于你的应用**对数据传输的可靠性要求有多高,以及对实时性和效率的要求有多高**。
+
+当**数据准确性和完整性至关重要,一点都不能出错**时,通常选择 TCP。因为 TCP 提供了一整套机制(三次握手、确认应答、重传、流量控制等)来保证数据能够可靠、有序地送达。典型应用场景如下:
+
+- **Web 浏览 (HTTP/HTTPS):** 网页内容、图片、脚本必须完整加载才能正确显示。
+- **文件传输 (FTP, SCP):** 文件内容不允许有任何字节丢失或错序。
+- **邮件收发 (SMTP, POP3, IMAP):** 邮件内容需要完整无误地送达。
+- **远程登录 (SSH, Telnet):** 命令和响应需要准确传输。
+- ……
+
+当**实时性、速度和效率优先,并且应用能容忍少量数据丢失或乱序**时,通常选择 UDP。UDP 开销小、传输快,没有建立连接和保证可靠性的复杂过程。典型应用场景如下:
+
+- **实时音视频通信 (VoIP, 视频会议, 直播):** 偶尔丢失一两个数据包(可能导致画面或声音短暂卡顿)通常比因为等待重传(TCP 机制)导致长时间延迟更可接受。应用层可能会有自己的补偿机制。
+- **在线游戏:** 需要快速传输玩家位置、状态等信息,对实时性要求极高,旧的数据很快就没用了,丢失少量数据影响通常不大。
+- **DHCP (动态主机配置协议):** 客户端在请求 IP 时自身没有 IP 地址,无法满足 TCP 建立连接的前提条件,并且 DHCP 有广播需求、交互模式简单以及自带可靠性机制。
+- **物联网 (IoT) 数据上报:** 某些场景下,传感器定期上报数据,丢失个别数据点可能不影响整体趋势分析。
+- ……
+
+### HTTP 基于 TCP 还是 UDP?
+
+~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
+
+🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
+
+HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
+
+- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
+- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
+
+
+
+**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
+
+1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
+2. 减少连接建立的延迟。
+
+下面我们来详细介绍这两大优化。
+
+在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
+
+In addition to solving the head-of-line blocking problem, HTTP/3.0 can also reduce the delay in the handshake process. In HTTP/2.0, if you want to establish a secure HTTPS connection, you need to go through the TCP three-way handshake and TLS handshake:
+
+1. TCP three-way handshake: The client and server exchange SYN and ACK packets to establish a TCP connection. This process requires 1.5 RTT (round-trip time), which is the time from sending to receiving a data packet.
+2. TLS handshake: The client and server exchange keys and certificates, establishing a TLS encryption layer. This process requires at least 1 RTT (TLS 1.3) or 2 RTT (TLS 1.2).
+
+Therefore, HTTP/2.0 connection establishment requires at least 2.5 RTT (TLS 1.3) or 3.5 RTT (TLS 1.2). In HTTP/3.0, the QUIC protocol used (TLS 1.3, TLS 1.3 not only supports 1 RTT handshake, but also supports 0 RTT handshake) connection establishment requires only 0-RTT or 1-RTT. This means that QUIC, in the best case scenario, does not require any additional round trip time to establish a new connection.
+
+For relevant proofs, please refer to the following two links:
+
+-
+-
+
+### What TCP/UDP based protocols do you know?
+
+TCP (Transmission Control Protocol) and UDP (User Datagram Protocol) are the two core protocols of the Internet transport layer. They provide basic communication services for various application layer protocols. Here are some common application layer protocols built on top of TCP and UDP:
+
+**Protocol running on top of TCP protocol (emphasis on reliable, orderly transmission):**
+
+| Full Chinese name (abbreviation) | Full English name | Main uses | Description and characteristics |
+| -------------------------- | ---------------------------------- | ------------------------------- | ------------------------------------------------------------------------------------------------------------------------------- |
+| Hypertext Transfer Protocol (HTTP) | HyperText Transfer Protocol | Transfers web pages, hypertext, multimedia content | **HTTP/1.x and HTTP/2 are based on TCP**. Early versions were unencrypted and were the basis for web communications. |
+| HyperText Transfer Protocol Secure (HTTPS) | HyperText Transfer Protocol Secure | Encrypted web page transfer | Adds an SSL/TLS encryption layer between HTTP and TCP to ensure confidentiality and integrity of data transmission. |
+| File Transfer Protocol (FTP) | File Transfer Protocol | File transfer | Traditional FTP **clear text transfer**, unsafe. It is recommended to use its secure version **SFTP (SSH File Transfer Protocol)** or **FTPS (FTP over SSL/TLS)**. |
+| Simple Mail Transfer Protocol (SMTP) | Simple Mail Transfer Protocol | **Send** email | Responsible for sending emails from the client to the server, or between mail servers. Can be upgraded to encrypted transmission via **STARTTLS**. |
+| Post Office Protocol version 3 (POP3) | **Receive** email | Typically delete the server copy** after downloading the message from the server** to the local device** (configurable retention). **POP3S** is its SSL/TLS encrypted version. |
+| Internet Message Access Protocol (IMAP) | Internet Message Access Protocol | **Receive and manage** emails | Emails are retained on the server and support multi-device synchronization of email status, folder management, online search, etc. **IMAPS** is its SSL/TLS encrypted version. The modern email service of choice. |
+| Remote Terminal Protocol (Telnet) | Teletype Network | Remote Terminal Login | **Clear text transmission** All data (including passwords), security is extremely poor, and has basically been completely replaced by SSH. |
+| Secure Shell Protocol (SSH) | Secure Shell | Secure remote management, encrypted data transmission | Provides functions such as encrypted remote login and command execution, as well as secure file transfer (SFTP), and is a secure alternative to Telnet. |
+
+**Protocol running on top of UDP protocol (emphasis on fast, low-overhead transmission):**
+
+| Full Chinese name (abbreviation) | Full English name | Main uses | Description and characteristics |
+| ----------------------- | -------------------------------------------------- | ---------------------------- | --------------------------------------------------------------------------------------------------------------- |
+| Hypertext Transfer Protocol (HTTP/3) | HyperText Transfer Protocol version 3 | A new generation of web page transmission | Based on the **QUIC** protocol (QUIC itself is built on UDP), designed to reduce latency, solve the TCP head-of-queue blocking problem, and support 0-RTT connection establishment. |
+| Dynamic Host Configuration Protocol (DHCP) | Dynamic Host Configuration Protocol | Dynamic allocation of IP addresses and network configuration | The client automatically obtains IP address, subnet mask, gateway, DNS server and other information from the server. |
+| Domain Name System (DNS) | Domain Name System | Domain name to IP address resolution | **Usually UDP** is used for fast queries. When the response packet is too large or does a zone transfer (AXFR), **switches to TCP** to ensure data integrity. |
+| Real-time Transport Protocol (RTP) | Real-time Transport Protocol | Real-time audio and video data stream transmission | Commonly used in VoIP, video conferencing, live broadcast, etc. Pursue low latency and allow for a small amount of packet loss. Typically used with RTCP. |
+| RTP Control Protocol (RTCP) | RTP Control Protocol | Quality monitoring and control information of RTP streams | Works with RTP to provide statistical information such as packet loss, delay, jitter, etc. to assist flow control and congestion management. |
+| Trivial File Transfer Protocol (TFTP) | Trivial File Transfer Protocol | Simplified file transfer | Simple function, often used in small file transfer scenarios such as diskless workstation startup in LAN, network device firmware upgrade, etc. || 简单网络管理协议 (SNMP) | Simple Network Management Protocol | 网络设备的监控与管理 | 允许网络管理员查询和修改网络设备的状态信息。 |
+| 网络时间协议 (NTP) | Network Time Protocol | 同步计算机时钟 | 用于在网络中的计算机之间同步时间,确保时间的一致性。 |
+
+**总结一下:**
+
+- **TCP** 更适合那些对数据**可靠性、完整性和顺序性**要求高的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP/SFTP)、邮件收发 (SMTP/POP3/IMAP)。
+- **UDP** 则更适用于那些对**实时性要求高、能容忍少量数据丢失**的应用,如域名解析 (DNS)、实时音视频 (RTP)、在线游戏、网络管理 (SNMP) 等。
+
+### ⭐️TCP 三次握手和四次挥手(非常重要)
+
+**相关面试题**:
+
+- 为什么要三次握手?
+- 第 2 次握手传回了 ACK,为什么还要传回 SYN?
+- 为什么要四次挥手?
+- 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
+- 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
+- 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
+
+**参考答案**:[TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html) 。
+
+### ⭐️TCP 如何保证传输的可靠性?(重要)
+
+[TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
+
+## IP
+
+### IP 协议的作用是什么?
+
+**IP(Internet Protocol,网际协议)** 是 TCP/IP 协议中最重要的协议之一,属于网络层的协议,主要作用是定义数据包的格式、对数据包进行路由和寻址,以便它们可以跨网络传播并到达正确的目的地。
+
+目前 IP 协议主要分为两种,一种是过去的 IPv4,另一种是较新的 IPv6,目前这两种协议都在使用,但后者已经被提议来取代前者。
+
+### 什么是 IP 地址?IP 寻址如何工作?
+
+每个连入互联网的设备或域(如计算机、服务器、路由器等)都被分配一个 **IP 地址(Internet Protocol address)**,作为唯一标识符。每个 IP 地址都是一个字符序列,如 192.168.1.1(IPv4)、2001:0db8:85a3:0000:0000:8a2e:0370:7334(IPv6) 。
+
+当网络设备发送 IP 数据包时,数据包中包含了 **源 IP 地址** 和 **目的 IP 地址** 。源 IP 地址用于标识数据包的发送方设备或域,而目的 IP 地址则用于标识数据包的接收方设备或域。这类似于一封邮件中同时包含了目的地地址和回邮地址。
+
+网络设备根据目的 IP 地址来判断数据包的目的地,并将数据包转发到正确的目的地网络或子网络,从而实现了设备间的通信。
+
+这种基于 IP 地址的寻址方式是互联网通信的基础,它允许数据包在不同的网络之间传递,从而实现了全球范围内的网络互联互通。IP 地址的唯一性和全局性保证了网络中的每个设备都可以通过其独特的 IP 地址进行标识和寻址。
+
+
+
+### 什么是 IP 地址过滤?
+
+**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
+
+IP 地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP 地址过滤并不能完全保证网络的安全。
+
+### ⭐️IPv4 和 IPv6 有什么区别?
+
+**IPv4(Internet Protocol version 4)** 是目前广泛使用的 IP 地址版本,其格式是四组由点分隔的数字,例如:123.89.46.72。IPv4 使用 32 位地址作为其 Internet 地址,这意味着共有约 42 亿( 2^32)个可用 IP 地址。
+
+
+
+这么少当然不够用啦!为了解决 IP 地址耗尽的问题,最根本的办法是采用具有更大地址空间的新版本 IP 协议 - **IPv6(Internet Protocol version 6)**。IPv6 地址使用更复杂的格式,该格式使用由单或双冒号分隔的一组数字和字母,例如:2001:0db8:85a3:0000:0000:8a2e:0370:7334 。IPv6 使用 128 位互联网地址,这意味着越有 2^128(3 开头的 39 位数字,恐怖如斯) 个可用 IP 地址。
+
+
+
+除了更大的地址空间之外,IPv6 的优势还包括:
+
+- **无状态地址自动配置(Stateless Address Autoconfiguration,简称 SLAAC)**:主机可以直接通过根据接口标识和网络前缀生成全局唯一的 IPv6 地址,而无需依赖 DHCP(Dynamic Host Configuration Protocol)服务器,简化了网络配置和管理。
+- **NAT(Network Address Translation,网络地址转换) 成为可选项**:IPv6 地址资源充足,可以给全球每个设备一个独立的地址。
+- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
+- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
+- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
+- ……
+
+### 如何获取客户端真实 IP?
+
+获取客户端真实 IP 的方法有多种,主要分为应用层方法、传输层方法和网络层方法。
+
+**应用层方法** :
+
+通过 [X-Forwarded-For](https://en.wikipedia.org/wiki/X-Forwarded-For) 请求头获取,简单方便。不过,这种方法无法保证获取到的是真实 IP,这是因为 X-Forwarded-For 字段可能会被伪造。如果经过多个代理服务器,X-Forwarded-For 字段可能会有多个值(附带了整个请求链中的所有代理服务器 IP 地址)。并且,这种方法只适用于 HTTP 和 SMTP 协议。
+
+**传输层方法**:
+
+利用 TCP Options 字段承载真实源 IP 信息。这种方法适用于任何基于 TCP 的协议,不受应用层的限制。不过,这并非是 TCP 标准所支持的,所以需要通信双方都进行改造。也就是:对于发送方来说,需要有能力把真实源 IP 插入到 TCP Options 里面。对于接收方来说,需要有能力把 TCP Options 里面的 IP 地址读取出来。
+
+也可以通过 Proxy Protocol 协议来传递客户端 IP 和 Port 信息。这种方法可以利用 Nginx 或者其他支持该协议的反向代理服务器来获取真实 IP 或者在业务服务器解析真实 IP。
+
+**网络层方法**:
+
+隧道 +DSR 模式。这种方法可以适用于任何协议,就是实施起来会比较麻烦,也存在一定限制,实际应用中一般不会使用这种方法。
+
+### NAT 的作用是什么?
+
+**NAT (Network Address Translation)** is mainly used to translate IP addresses between different networks. It allows mapping of private IP addresses (such as the IP addresses used on the LAN) to public IP addresses (IP addresses used on the Internet) or vice versa, allowing multiple devices within the LAN to access the Internet through a single public IP address.
+
+NAT can not only alleviate the shortage of IPv4 address resources, but also hide the actual topology of the internal network, making it impossible for external networks to directly access devices in the internal network, thereby improving the security of the internal network.
+
+
+
+Related reading: [Detailed explanation of NAT protocol (network layer)](https://javaguide.cn/cs-basics/network/nat.html).
+
+## ARP
+
+### What is a Mac address?
+
+The full name of MAC address is **Media Access Control Address**. If every resource on the Internet is uniquely identified by an IP address (IP protocol content), then all network devices are uniquely identified by a MAC address.
+
+
+
+It can be understood that the MAC address is the real ID number of a network device, and the IP address is just a non-duplicate positioning method (for example, for Zhang San who lives in a certain street in a certain city in a certain province, this logical positioning is the IP address, and his ID number is his MAC address). It can also be understood that the MAC address is the ID number and the IP address is the postal address. The MAC address also has some other names, such as LAN address, physical address, Ethernet address, etc.
+
+> Another thing to know is that not only network resources have IP addresses, but network devices also have IP addresses, such as routers. But structurally speaking, the role of network devices such as routers is to form a network, and it is usually an intranet, so the IP addresses they use are usually intranet IPs. When intranet devices communicate with devices outside the intranet, they need to use the NAT protocol.
+
+The length of the MAC address is 6 bytes (48 bits), and the address space size is as much as 280 trillion ($2^{48}$). The MAC address is managed and allocated by the IEEE. In theory, the MAC address on the network card in a network device is permanent. Different network card manufacturers purchase their own MAC address space (the first 24 bits of the MAC) from the IEEE, that is, the first 24 bits are managed uniformly by the IEEE to ensure no duplication. The next 24 bits are managed by each manufacturer themselves to ensure that the MAC addresses of the two network cards produced will not be repeated.
+
+The MAC address is portable and permanent, and the ID number permanently identifies a person's identity and will not change no matter where he goes. IP addresses do not have these properties. When a device changes networks, its IP address may change, which means its positioning on the Internet changes.
+
+Finally, remember that MAC addresses have a special address: FF-FF-FF-FF-FF-FF (all ones), which represents the broadcast address.
+
+### ⭐️What problems does the ARP protocol solve?
+
+ARP protocol, the full name is **Address Resolution Protocol**, which solves the problem of conversion between network layer addresses and link layer addresses. Because during the physical transmission of an IP datagram, you always need to know where the next hop (physical next destination) should go, but the IP address is a logical address, and the MAC address is the physical address. The ARP protocol solves some problems of converting IP addresses to MAC addresses.
+
+### How does the ARP protocol work?
+
+[Detailed explanation of ARP protocol (network layer)](https://javaguide.cn/cs-basics/network/arp.html)
+
+## Review suggestions
+
+I highly recommend everyone to read the book "HTTP Illustrated". This book does not have many pages, but the content is very substantial. It is very helpful whether it is used to systematically master some knowledge about the network or simply to cope with interviews. Some of the articles below are for reference only. When I was studying this course in my sophomore year, the textbook we used was "Computer Networks 7th Edition" (edited by Xie Xiren). I don't recommend everyone to read this textbook. The book is very thick and the knowledge is theoretical. I'm not sure if you can finish it calmly.
+
+## Reference
+
+- "HTTP Illustrated"
+- "Top-Down Method of Computer Networks" (Seventh Edition)
+- What is Internet Protocol (IP)? :
+- Various methods to transparently transmit the real source IP - Geek Time:
+- What Is NAT and What Are the Benefits of NAT Firewalls?:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/tcp-connection-and-disconnection.en.md b/docs_en/cs-basics/network/tcp-connection-and-disconnection.en.md
new file mode 100644
index 00000000000..65c705e5243
--- /dev/null
+++ b/docs_en/cs-basics/network/tcp-connection-and-disconnection.en.md
@@ -0,0 +1,134 @@
+---
+title: TCP 三次握手和四次挥手(传输层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,三次握手,四次挥手,状态机,SYN,ACK,FIN,半连接队列,全连接队列
+ - - meta
+ - name: description
+ content: 详解 TCP 建连与断连过程,结合状态迁移与队列机制解析可靠通信保障与高并发连接处理。
+---
+
+TCP 是一种面向连接的、可靠的传输层协议。为了在两个不可靠的端点之间建立一个可靠的连接,TCP 采用了三次握手(Three-way Handshake)的策略。
+
+## 建立连接-TCP 三次握手
+
+
+
+建立一个 TCP 连接需要“三次握手”,缺一不可:
+
+1. **第一次握手 (SYN)**: 客户端向服务端发送一个 SYN(Synchronize Sequence Numbers)报文段,其中包含一个由客户端随机生成的初始序列号(Initial Sequence Number, ISN),例如 seq=x。发送后,客户端进入 **SYN_SEND** 状态,等待服务端的确认。
+2. **第二次握手 (SYN+ACK)**: 服务端收到 SYN 报文段后,如果同意建立连接,会向客户端回复一个确认报文段。该报文段包含两个关键信息:
+ - **SYN**:服务端也需要同步自己的初始序列号,因此报文段中也包含一个由服务端随机生成的初始序列号,例如 seq=y。
+ - **ACK** (Acknowledgement):用于确认收到了客户端的请求。其确认号被设置为客户端初始序列号加一,即 ack=x+1。
+ - 发送该报文段后,服务端进入 **SYN_RECV** 状态。
+3. **第三次握手 (ACK)**: 客户端收到服务端的 SYN+ACK 报文段后,会向服务端发送一个最终的确认报文段。该报文段包含确认号 ack=y+1。发送后,客户端进入 **ESTABLISHED** 状态。服务端收到这个 ACK 报文段后,也进入 **ESTABLISHED** 状态。
+
+至此,双方都确认了连接的建立,TCP 连接成功创建,可以开始进行双向数据传输。
+
+### 什么是半连接队列和全连接队列?
+
+在 TCP 三次握手过程中,服务端内核会使用两个队列来管理连接请求:
+
+1. **半连接队列**(也称 SYN Queue):当服务端收到客户端的 SYN 请求并回复 SYN+ACK 后,连接会处于 SYN_RECV 状态。此时,这个连接信息会被放入半连接队列。这个队列存储的是尚未完成三次握手的连接。
+2. **全连接队列**(也称 Accept Queue):当服务端收到客户端对 ACK 响应时,意味着三次握手成功完成,服务端会将该连接从半连接队列移动到全连接队列。如果未收到客户端的 ACK 响应,会进行重传,重传的等待时间通常是指数增长的。如果重传次数超过系统规定的最大重传次数,系统将从半连接队列中删除该连接信息。
+
+这两个队列的存在是为了处理并发连接请求,确保服务端能够有效地管理新的连接请求。
+
+如果全连接队列满了,新的已完成握手的连接可能会被丢弃,或者触发其他策略。这两个队列的大小都受系统参数控制,它们的容量限制是影响服务器处理高并发连接能力的重要因素,也是 SYN 泛洪攻击(SYN Flood)所针对的目标。
+
+### 为什么要三次握手?
+
+TCP 三次握手的核心目的是为了在客户端和服务器之间建立一个**可靠的**、**全双工的**通信信道。这需要实现两个主要目标:
+
+**1. 确认双方的收发能力,并同步初始序列号 (ISN)**
+
+TCP 通信依赖序列号来保证数据的有序和可靠。三次握手是双方交换和确认彼此初始序列号(ISN)的过程,通过这个过程,双方也间接验证了各自的收发能力。
+
+- **第一次握手 (客户端 → 服务器)** :客户端发送 SYN 包。
+ - 服务器:能确认客户端的发送能力正常,自己的接收能力正常。
+ - 客户端:无法确认任何事。
+- **第二次握手 (服务器 → 客户端)** :服务器回复 SYN+ACK 包。
+ - 客户端:能确认自己的发送和接收能力正常,服务器的接收和发送能力正常。
+ - 服务端:能确认对方发送能力正常,自己接收能力正常
+- **第三次握手 (客户端 → 服务器)** :客户端发送 ACK 包。
+ - 客户端:能确认双方发送和接收能力正常。
+ - 服务端:能确认双方发送和接收能力正常。
+
+经过这三次交互,双方都确认了彼此的收发功能完好,并完成了初始序列号的同步,为后续可靠的数据传输奠定了基础。
+
+**2. 防止已失效的连接请求被错误地建立**
+
+这是“为什么不能是两次握手”的关键原因。
+
+设想一个场景:客户端发送的第一个连接请求(SYN1)因网络延迟而滞留,于是客户端重发了第二个请求(SYN2)并成功建立了连接,数据传输完毕后连接被释放。此时,延迟的 SYN1 才到达服务端。
+
+- **如果是两次握手**:服务端收到这个失效的 SYN1 后,会误认为是一个新的连接请求,并立即分配资源、建立连接。但这将导致服务端单方面维持一个无效连接,白白浪费系统资源,因为客户端并不会有任何响应。
+- **有了第三次握手**:服务端收到失效的 SYN1 并回复 SYN+ACK 后,会等待客户端的最终确认(ACK)。由于客户端当前并没有发起连接的意图,它会忽略这个 SYN+ACK 或者发送一个 RST (Reset) 报文。这样,服务端就无法收到第三次握手的 ACK,最终会超时关闭这个错误的连接,从而避免了资源浪费。
+
+因此,三次握手是确保 TCP 连接可靠性的**最小且必需**的步骤。它不仅确认了双方的通信能力,更重要的是增加了一个最终确认环节,以防止网络中延迟、重复的历史请求对连接建立造成干扰。
+
+### 第 2 次握手传回了 ACK,为什么还要传回 SYN?
+
+服务端传回发送端所发送的 ACK 是为了告诉客户端:“我接收到的信息确实就是你所发送的信号了”,这表明从客户端到服务端的通信是正常的。回传 SYN 则是为了建立并确认从服务端到客户端的通信。
+
+> SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务端之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务端使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务端之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务端之间传递。
+
+### 三次握手过程中可以携带数据吗?
+
+在 TCP 三次握手过程中,第三次握手是可以携带数据的(客户端发送完 ACK 确认包之后就进入 ESTABLISHED 状态了),这一点在 RFC 793 文档中有提到。也就是说,一旦完成了前两次握手,TCP 协议允许数据在第三次握手时开始传输。
+
+如果第三次握手的 ACK 确认包丢失,但是客户端已经开始发送携带数据的包,那么服务端在收到这个携带数据的包时,如果该包中包含了 ACK 标记,服务端会将其视为有效的第三次握手确认。这样,连接就被认为是建立的,服务端会处理该数据包,并继续正常的数据传输流程。
+
+## 断开连接-TCP 四次挥手
+
+
+
+断开一个 TCP 连接则需要“四次挥手”,缺一不可:
+
+1. **第一次挥手 (FIN)**:当客户端(或任何一方)决定关闭连接时,它会向服务端发送一个 **FIN**(Finish)标志的报文段,表示自己已经没有数据要发送了。该报文段包含一个序列号 seq=u。发送后,客户端进入 **FIN-WAIT-1** 状态。
+2. **第二次挥手 (ACK)**:服务端收到 FIN 报文段后,会立即回复一个 **ACK** 确认报文段。其确认号为 ack=u+1。发送后,服务端进入 **CLOSE-WAIT** 状态。客户端收到这个 ACK 后,进入 **FIN-WAIT-2** 状态。此时,TCP 连接处于**半关闭(Half-Close)**状态:客户端到服务端的发送通道已关闭,但服务端到客户端的发送通道仍然可以传输数据。
+3. **第三次挥手 (FIN)**:当服务端确认所有待发送的数据都已发送完毕后,它也会向客户端发送一个 **FIN** 报文段,表示自己也准备关闭连接。该报文段同样包含一个序列号 seq=y。发送后,服务端进入 **LAST-ACK** 状态,等待客户端的最终确认。
+4. **The fourth wave**: After receiving the FIN message segment from the server, the client will reply with a final **ACK** confirmation message segment, the confirmation number is ack=y+1. After sending, the client enters the **TIME-WAIT** state. After receiving this ACK, the server immediately enters the **CLOSED** state to complete the connection closure. The client will wait for **2MSL** (Maximum Segment Lifetime, the maximum survival time of the message segment) in the **TIME-WAIT** state before finally entering the **CLOSED** state.
+
+**As long as the four waves are not over, the client and server can continue to transmit data! **
+
+### Why wave four times?
+
+TCP is full-duplex communication and can transmit data in both directions. Either party can issue a connection release notification after the data transmission is completed, and enter a semi-closed state after the other party confirms. When the other party has no more data to send, a connection release notification is issued. After the other party confirms, the TCP connection is completely closed.
+
+For example: A and B are on the phone and the call is about to end.
+
+1. **First wave**: A said "I have nothing more to say"
+2. **Second wave**: B answers "I understand", but B may have something else to say, and A cannot ask B to end the call at his own pace.
+3. **Waving for the third time**: Then B may have talked for a while, and finally B said "I'm done"
+4. **The fourth wave**: Person A answers "I know", and the call ends.
+
+### Why can't the ACK and FIN sent by the server be combined into three waves?
+
+Because when the server receives the client's request to disconnect, there may still be some data that has not been sent. At this time, it responds with ACK first, indicating that it has received the disconnect request. Wait until the data is sent before sending FIN to disconnect the data transmission from the server to the client.
+
+### What will happen if the ACK from the server is not delivered to the client when waving for the second time?
+
+The client starts a retransmission timer after sending the FIN. If no ACK from the server is received before the timer expires, the client will consider the FIN message lost and resend the FIN message.
+
+### Why does the client need to wait for 2\*MSL (maximum segment life) time before entering the CLOSED state after the fourth wave?
+
+When waving for the fourth time, the ACK sent by the client to the server may be lost. If the server does not receive the ACK for some reason, the server will resend the FIN. If the client receives the FIN within 2\*MSL, it will resend the ACK and wait for 2MSL again to prevent the server from continuously resending FIN without receiving the ACK.
+
+> **MSL (Maximum Segment Lifetime)**: The maximum survival time of a segment in the network. 2MSL is the maximum time required for a send and a reply. If the Client does not receive the FIN again until 2MSL, the Client concludes that the ACK has been successfully received and ends the TCP connection.
+
+## Reference
+
+- "Computer Networks (7th Edition)"
+
+- "HTTP Illustrated"
+
+- TCP and UDP Tutorial:
+
+- Starting from an online problem, a detailed explanation of TCP semi-connection queue and full connection queue:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/tcp-reliability-guarantee.en.md b/docs_en/cs-basics/network/tcp-reliability-guarantee.en.md
new file mode 100644
index 00000000000..f1ef37bd3d3
--- /dev/null
+++ b/docs_en/cs-basics/network/tcp-reliability-guarantee.en.md
@@ -0,0 +1,135 @@
+---
+title: TCP 传输可靠性保障(传输层)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: TCP,可靠性,重传,SACK,流量控制,拥塞控制,滑动窗口,校验和
+ - - meta
+ - name: description
+ content: 系统梳理 TCP 的可靠性保障机制,覆盖重传/选择确认、流量与拥塞控制,明确端到端可靠传输的实现要点。
+---
+
+## TCP 如何保证传输的可靠性?
+
+1. **基于数据块传输**:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
+2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
+3. **校验和** : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
+4. **重传机制** : 在数据包丢失或延迟的情况下,重新发送数据包,直到收到对方的确认应答(ACK)。TCP 重传机制主要有:基于计时器的重传(也就是超时重传)、快速重传(基于接收端的反馈信息来引发重传)、SACK(在快速重传的基础上,返回最近收到的报文段的序列号范围,这样客户端就知道,哪些数据包已经到达服务器了)、D-SACK(重复 SACK,在 SACK 的基础上,额外携带信息,告知发送方有哪些数据包自己重复接收了)。关于重传机制的详细介绍,可以查看[详解 TCP 超时与重传机制](https://zhuanlan.zhihu.com/p/101702312)这篇文章。
+5. **流量控制** : TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议(TCP 利用滑动窗口实现流量控制)。
+6. **拥塞控制** : 当网络拥塞时,减少数据的发送。TCP 在发送数据的时候,需要考虑两个因素:一是接收方的接收能力,二是网络的拥塞程度。接收方的接收能力由滑动窗口表示,表示接收方还有多少缓冲区可以用来接收数据。网络的拥塞程度由拥塞窗口表示,它是发送方根据网络状况自己维护的一个值,表示发送方认为可以在网络中传输的数据量。发送方发送数据的大小是滑动窗口和拥塞窗口的最小值,这样可以保证发送方既不会超过接收方的接收能力,也不会造成网络的过度拥塞。
+
+## TCP 如何实现流量控制?
+
+**TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。** 接收方发送的确认报文中的窗口字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将窗口字段设置为 0,则发送方不能发送数据。
+
+**为什么需要流量控制?** 这是因为双方在通信的时候,发送方的速率与接收方的速率是不一定相等,如果发送方的发送速率太快,会导致接收方处理不过来。如果接收方处理不过来的话,就只能把处理不过来的数据存在 **接收缓冲区(Receiving Buffers)** 里(失序的数据包也会被存放在缓存区里)。如果缓存区满了发送方还在狂发数据的话,接收方只能把收到的数据包丢掉。出现丢包问题的同时又疯狂浪费着珍贵的网络资源。因此,我们需要控制发送方的发送速率,让接收方与发送方处于一种动态平衡才好。
+
+这里需要注意的是(常见误区):
+
+- 发送端不等同于客户端
+- 接收端不等同于服务端
+
+TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客户端和服务端既可能是发送端又可能是服务端。因此,两端各有一个发送缓冲区与接收缓冲区,两端都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制(TCP 传输速率不能大于应用的数据处理速率)。通信双方的发送窗口和接收窗口的要求相同
+
+**TCP 发送窗口可以划分成四个部分**:
+
+1. 已经发送并且确认的 TCP 段(已经发送并确认);
+2. 已经发送但是没有确认的 TCP 段(已经发送未确认);
+3. 未发送但是接收方准备接收的 TCP 段(可以发送);
+4. 未发送并且接收方也并未准备接受的 TCP 段(不可发送)。
+
+**TCP 发送窗口结构图示**:
+
+
+
+- **SND.WND**:发送窗口。
+- **SND.UNA**:Send Unacknowledged 指针,指向发送窗口的第一个字节。
+- **SND.NXT**:Send Next 指针,指向可用窗口的第一个字节。
+
+**可用窗口大小** = `SND.UNA + SND.WND - SND.NXT` 。
+
+**TCP 接收窗口可以划分成三个部分**:
+
+1. 已经接收并且已经确认的 TCP 段(已经接收并确认);
+2. 等待接收且允许发送方发送 TCP 段(可以接收未确认);
+3. 不可接收且不允许发送方发送 TCP 段(不可接收)。
+
+**TCP 接收窗口结构图示**:
+
+
+
+**接收窗口的大小是根据接收端处理数据的速度动态调整的。** 如果接收端读取数据快,接收窗口可能会扩大。 否则,它可能会缩小。
+
+另外,这里的滑动窗口大小只是为了演示使用,实际窗口大小通常会远远大于这个值。
+
+## TCP 的拥塞控制是怎么实现的?
+
+在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
+
+
+
+为了进行拥塞控制,TCP 发送方要维持一个 **拥塞窗口(cwnd)** 的状态变量。拥塞控制窗口的大小取决于网络的拥塞程度,并且动态变化。发送方让自己的发送窗口取为拥塞窗口和接收方的接受窗口中较小的一个。
+
+TCP 的拥塞控制采用了四种算法,即 **慢开始**、 **拥塞避免**、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
+
+- **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd 初始值为 1,每经过一个传播轮次,cwnd 加倍。
+- **拥塞避免:** 拥塞避免算法的思路是让拥塞窗口 cwnd 缓慢增大,即每经过一个往返时间 RTT 就把发送方的 cwnd 加 1.
+- **快重传与快恢复:** 在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
+
+## ARQ 协议了解吗?
+
+**自动重传请求**(Automatic Repeat-reQuest,ARQ)是 OSI 模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认信息(Acknowledgements,就是我们常说的 ACK),它通常会重新发送,直到收到确认或者重试超过一定的次数。
+
+ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
+
+### 停止等待 ARQ 协议
+
+The stop-and-wait protocol is to achieve reliable transmission. Its basic principle is to stop sending every time a packet is sent and wait for the other party to confirm (reply ACK). If after a period of time (after the timeout period), the ACK confirmation is still not received, it means that the transmission was not successful and needs to be resent until the confirmation is received before sending the next packet;
+
+In the stop-and-wait protocol, if the receiver receives a duplicate packet, it discards the packet, but also sends an acknowledgment at the same time.
+
+**1) No error situation:**
+
+The sender sends the packet, the receiver receives it within the specified time, and replies with confirmation. The sender sends again.
+
+**2) Error occurs (timeout retransmission):**
+
+Timeout retransmission in the stop-and-wait protocol means that as long as no confirmation is received after a period of time, the previously sent packet will be retransmitted (the packet just sent is considered to be lost). Therefore, a timeout timer needs to be set after each packet is sent, and its retransmission time should be longer than the average round-trip time of data in packet transmission. This automatic retransmission method is often called **Automatic Repeat Request ARQ**. In addition, in the stop-and-wait protocol, if a duplicate packet is received, the packet is discarded, but an acknowledgment is also sent at the same time.
+
+**3) Confirmation lost and confirmation late**
+
+- **Confirmation Lost**: The confirmation message is lost during transmission. When A sends an M1 message and B receives it, B sends an M1 confirmation message to A, but it is lost during transmission. However, A does not know that after the timeout, A retransmits the M1 message, and B takes the following two measures after receiving the message again: 1. Discard the duplicate M1 message and do not deliver it to the upper layer. 2. Send a confirmation message to A. (It will not be considered that it has been sent, so it will not be sent again. If A can retransmit, it proves that B's confirmation message is lost).
+- **ACKLATE**: The acknowledgment message was late during transmission. A sends M1 message, B receives and sends confirmation. If no acknowledgment message is received within the timeout period, A retransmits the M1 message, and B still receives and continues to send the acknowledgment message (B received 2 copies of M1). At this time, A receives the confirmation message sent by B for the second time. Then send other data. After a while, A received the first confirmation message for M1 sent by B (A also received 2 confirmation messages). The processing is as follows: 1. After A receives the duplicate confirmation, it discards it directly. 2. After B receives the duplicate M1, it also discards the duplicate M1 directly.
+
+### Continuous ARQ protocol
+
+The continuous ARQ protocol improves channel utilization. The sender maintains a sending window, and packets within the sending window can be sent continuously without waiting for confirmation from the other party. The receiver generally uses cumulative acknowledgment and sends an acknowledgment to the last packet that arrives in sequence, indicating that all packets up to this packet have been received correctly.
+
+- **Advantages:** The channel utilization rate is high and easy to implement. Even if the confirmation is lost, there is no need to retransmit.
+- **Disadvantage:** It cannot reflect to the sender the information of all packets that the receiver has correctly received. For example: the sender sends 5 messages, and the third one is lost (No. 3). At this time, the receiver can only send confirmations to the first two. The sender has no way of knowing the whereabouts of the last three packets, and has to retransmit them all once. This is also called Go-Back-N, which means that you need to go back and retransmit the N messages that have been sent.
+
+## How to implement timeout retransmission? How to determine the timeout and retransmission time?
+
+After the sender sends the data, it starts a timer and waits for the destination to confirm receipt of the segment. The receiving entity sends back a corresponding acknowledgment message (ACK) for the successfully received packet. If the sending entity does not receive the acknowledgment message within a reasonable round-trip delay (RTT), the corresponding data packet is assumed to be [lost](https://zh.wikipedia.org/wiki/PacketLost) and retransmitted.
+
+- RTT (Round Trip Time): round trip time, that is, the time from when a data packet is sent to when the corresponding ACK is received.
+- RTO (Retransmission Time Out): Retransmission timeout, which is calculated from the time when the data is sent. Retransmission will be performed after this time.
+
+The determination of RTO is a key issue because it directly affects the performance and efficiency of TCP. If the RTO is set too small, it will cause unnecessary retransmissions and increase network burden; if the RTO is set too large, it will cause delays in data transmission and reduce throughput. Therefore, RTO should be dynamically adjusted based on the actual network conditions.
+
+The value of RTT will change with network fluctuations, so TCP cannot directly use RTT as RTO. In order to dynamically adjust RTO, the TCP protocol uses some algorithms, such as the weighted moving average (EWMA) algorithm, Karn algorithm, Jacobson algorithm, etc. These algorithms all estimate the value of RTO based on the measurement and changes of the round-trip delay (RTT).
+
+## Reference
+
+1. "Computer Networks (7th Edition)"
+2. "HTTP Illustrated"
+3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial)
+4. [https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md](https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md)
+5. TCP Flow Control—[https://www.brianstorti.com/tcp-flow-control/](https://www.brianstorti.com/tcp-flow-control/)
+6. TCP flow control:
+7. TCP sliding window principle:
+
+
\ No newline at end of file
diff --git a/docs_en/cs-basics/network/the-whole-process-of-accessing-web-pages.en.md b/docs_en/cs-basics/network/the-whole-process-of-accessing-web-pages.en.md
new file mode 100644
index 00000000000..697228a32a9
--- /dev/null
+++ b/docs_en/cs-basics/network/the-whole-process-of-accessing-web-pages.en.md
@@ -0,0 +1,87 @@
+---
+title: 访问网页的全过程(知识串联)
+category: 计算机基础
+tag:
+ - 计算机网络
+head:
+ - - meta
+ - name: keywords
+ content: 访问网页流程,DNS,TCP 建连,HTTP 请求,资源加载,渲染,关闭连接
+ - - meta
+ - name: description
+ content: 串联从输入 URL 到页面渲染的完整链路,涵盖 DNS、TCP、HTTP 与静态资源加载,助力面试与实践理解。
+---
+
+开发岗中总是会考很多计算机网络的知识点,但如果让面试官只考一道题,便涵盖最多的计网知识点,那可能就是 **网页浏览的全过程** 了。本篇文章将带大家从头到尾过一遍这道被考烂的面试题,必会!!!
+
+总的来说,网络通信模型可以用下图来表示,也就是大家只要熟记网络结构五层模型,按照这个体系,很多知识点都能顺出来了。访问网页的过程也是如此。
+
+
+
+开始之前,我们先简单过一遍完整流程:
+
+1. 在浏览器中输入指定网页的 URL。
+2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
+3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
+4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
+5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
+6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
+7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
+
+## 应用层
+
+一切的开始——打开浏览器,在地址栏输入 URL,回车确认。那么,什么是 URL?访问 URL 有什么用?
+
+### URL
+
+URL(Uniform Resource Locators),即统一资源定位器。网络上的所有资源都靠 URL 来定位,每一个文件就对应着一个 URL,就像是路径地址。理论上,文件资源和 URL 一一对应。实际上也有例外,比如某些 URL 指向的文件已经被重定位到另一个位置,这样就有多个 URL 指向同一个文件。
+
+### URL 的组成结构
+
+
+
+1. 协议。URL 的前缀通常表示了该网址采用了何种应用层协议,通常有两种——HTTP 和 HTTPS。当然也有一些不太常见的前缀头,比如文件传输时用到的`ftp:`。
+2. 域名。域名便是访问网址的通用名,这里也有可能是网址的 IP 地址,域名可以理解为 IP 地址的可读版本,毕竟绝大部分人都不会选择记住一个网址的 IP 地址。
+3. 端口。如果指明了访问网址的端口的话,端口会紧跟在域名后面,并用一个冒号隔开。
+4. 资源路径。域名(端口)后紧跟的就是资源路径,从第一个`/`开始,表示从服务器上根目录开始进行索引到的文件路径,上图中要访问的文件就是服务器根目录下`/path/to/myfile.html`。早先的设计是该文件通常物理存储于服务器主机上,但现在随着网络技术的进步,该文件不一定会物理存储在服务器主机上,有可能存放在云上,而文件路径也有可能是虚拟的(遵循某种规则)。
+5. 参数。参数是浏览器在向服务器提交请求时,在 URL 中附带的参数。服务器解析请求时,会提取这些参数。参数采用键值对的形式`key=value`,每一个键值对使用`&`隔开。参数的具体含义和请求操作的具体方法有关。
+6. 锚点。锚点顾名思义,是在要访问的页面上的一个锚。要访问的页面大部分都多于一页,如果指定了锚点,那么在客户端显示该网页是就会定位到锚点处,相当于一个小书签。值得一提的是,在 URL 中,锚点以`#`开头,并且**不会**作为请求的一部分发送给服务端。
+
+### DNS
+
+键入了 URL 之后,第一个重头戏登场——DNS 服务器解析。DNS(Domain Name System)域名系统,要解决的是 **域名和 IP 地址的映射问题** 。毕竟,域名只是一个网址便于记住的名字,而网址真正存在的地址其实是 IP 地址。
+
+传送门:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html)
+
+### HTTP/HTTPS
+
+利用 DNS 拿到了目标主机的 IP 地址之后,浏览器便可以向目标 IP 地址发送 HTTP 报文,请求需要的资源了。在这里,根据目标网站的不同,请求报文可能是 HTTP 协议或安全性增强的 HTTPS 协议。
+
+传送门:
+
+- [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)
+- [HTTP 1.0 vs HTTP 1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)
+- [HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)
+
+## 传输层
+
+由于 HTTP 协议是基于 TCP 协议的,在应用层的数据封装好以后,要交给传输层,经 TCP 协议继续封装。
+
+TCP 协议保证了数据传输的可靠性,是数据包传输的主力协议。
+
+传送门:
+
+- [TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html)
+- [TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
+
+## 网络层
+
+终于,来到网络层,此时我们的主机不再是和另一台主机进行交互了,而是在和中间系统进行交互。也就是说,应用层和传输层都是端到端的协议,而网络层及以下都是中间件的协议了。
+
+**网络层的的核心功能——转发与路由**,必会!!!如果面试官问到了网络层,而你恰好又什么都不会的话,最最起码要说出这五个字——**转发与路由**。
+
+- 转发:将分组从路由器的输入端口转移到合适的输出端口。
+- 路由:确定分组从源到目的经过的路径。
+
+所以到目前为止,我们的数据包经过了应用层、传输层的封装,来到了网络层,终于开始准备在物理层面传输了,第一个要解决的问题就是——**往哪里传输?或者说,要把数据包发到哪个路由器上?** 这便是 BGP 协议要解决的问题。
+
diff --git a/docs_en/cs-basics/operating-system/linux-intro.en.md b/docs_en/cs-basics/operating-system/linux-intro.en.md
new file mode 100644
index 00000000000..12d4dd29dd5
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/linux-intro.en.md
@@ -0,0 +1,437 @@
+---
+title: Linux 基础知识总结
+category: 计算机基础
+tag:
+ - 操作系统
+ - Linux
+head:
+ - - meta
+ - name: description
+ content: 简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
+ - - meta
+ - name: keywords
+ content: Linux,基础命令,发行版,文件系统,权限,进程,网络
+---
+
+
+
+简单介绍一下 Java 程序员必知的 Linux 的一些概念以及常见命令。
+
+## 初探 Linux
+
+### Linux 简介
+
+通过以下三点可以概括 Linux 到底是什么:
+
+- **类 Unix 系统**:Linux 是一种自由、开放源码的类似 Unix 的操作系统
+- **Linux 本质是指 Linux 内核**:严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
+- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)**:一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
+
+
+
+### Linux 诞生
+
+1989 年,Linus Torvalds 进入芬兰陆军新地区旅,服 11 个月的国家义务兵役,军衔为少尉,主要服务于计算机部门,任务是弹道计算。服役期间,购买了安德鲁·斯图尔特·塔能鲍姆所著的教科书及 minix 源代码,开始研究操作系统。1990 年,他退伍后回到大学,开始接触 Unix。
+
+> **Minix** 是一个迷你版本的类 Unix 操作系统,由塔能鲍姆教授为了教学之用而创作,采用微核心设计。它启发了 Linux 内核的创作。
+
+1991 年,Linus Torvalds 开源了 Linux 内核。Linux 以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
+
+
+
+### 常见的 Linux 发行版本
+
+
+
+Linus Torvalds 开源的只是 Linux 内核,我们上面也提到了操作系统内核的作用。一些组织或厂商将 Linux 内核与各种软件和文档包装起来,并提供系统安装界面和系统配置、设定与管理工具,就构成了 Linux 的发行版本。
+
+> 内核主要负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。
+
+Linux 的发行版本可以大体分为两类:
+
+- **商业公司维护的发行版本**:比如 Red Hat 公司维护支持的 Red Hat Enterprise Linux (RHEL)。
+- **社区组织维护的发行版本**:比如基于 Red Hat Enterprise Linux(RHEL)的 CentOS、基于 Debian 的 Ubuntu。
+
+对于初学者学习 Linux ,推荐选择 CentOS,原因如下:
+
+- CentOS 免费且开放源代码;
+- CentOS 基于 RHEL,功能与 RHEL 高度一致,安全稳定、性能优秀。
+
+## Linux 文件系统
+
+### Linux 文件系统简介
+
+在 Linux 操作系统中,一切被操作系统管理的资源,如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或目录等,都被视为文件。这是 Linux 系统中一个重要的概念,即"一切都是文件"。
+
+这种概念源自 UNIX 哲学,即将所有资源都抽象为文件的方式来进行管理和访问。Linux 的文件系统也借鉴了 UNIX 文件系统的设计理念。这种设计使得 Linux 系统可以通过统一的文件接口来管理和操作不同类型的资源,从而实现了一种统一的文件操作方式。例如,可以使用类似于读写文件的方式来对待网络接口、磁盘驱动器、设备文件等,使得操作和管理这些资源更加统一和简便。
+
+这种文件为中心的设计理念为 Linux 系统带来了灵活性和可扩展性,使得 Linux 成为一种强大的操作系统。同时,这也是 Linux 系统的一大特点,深受广大用户和开发者的喜欢和推崇。
+
+### inode 介绍
+
+inode 是 Linux/Unix 文件系统的基础。那 inode 到是什么?有什么作用呢?
+
+通过以下五点可以概括 inode 到底是什么:
+
+1. 硬盘以扇区 (Sector) 为最小物理存储单位,而操作系统和文件系统以块 (Block) 为单位进行读写,块由多个扇区组成。文件数据存储在这些块中。现代硬盘扇区通常为 4KB,与一些常见块大小相同,但操作系统也支持更大的块大小,以提升大文件读写性能。文件元信息(例如权限、大小、修改时间以及数据块位置)存储在 inode(索引节点)中。每个文件都有唯一的 inode。inode 本身不存储文件数据,而是存储指向数据块的指针,操作系统通过这些指针找到并读取文件数据。 固态硬盘 (SSD) 虽然没有物理扇区,但使用逻辑块,其概念与传统硬盘的块类似。
+2. inode 是一种固定大小的数据结构,其大小在文件系统创建时就确定了,并且在文件的生命周期内保持不变。
+3. inode 的访问速度非常快,因为系统可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
+4. inode 的数量是有限的,每个文件系统只能包含固定数量的 inode。这意味着当文件系统中的 inode 用完时,无法再创建新的文件或目录,即使磁盘上还有可用空间。因此,在创建文件系统时,需要根据文件和目录的预期数量来合理分配 inode 的数量。
+5. 可以使用 `stat` 命令可以查看文件的 inode 信息,包括文件的 inode 号、文件类型、权限、所有者、文件大小、修改时间。
+
+简单来说:inode 就是用来维护某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等信息。
+
+再总结一下 inode 和 block:
+
+- **inode**:记录文件的属性信息,可以使用 `stat` 命令查看 inode 信息。
+- **block**:实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
+
+
+
+可以看出,Linux/Unix 操作系统使用 inode 区分不同的文件。这样做的好处是,即使文件名被修改或删除,文件的 inode 号码不会改变,从而可以避免一些因文件重命名、移动或删除导致的错误。同时,inode 也可以提供更高的文件系统性能,因为 inode 的访问速度非常快,可以直接通过 inode 号码定位到文件的元数据信息,无需遍历整个文件系统。
+
+不过,使用 inode 号码也使得文件系统在用户和应用程序层面更加抽象和复杂,需要通过系统命令或文件系统接口来访问和管理文件的 inode 信息。
+
+### 硬链接和软链接
+
+在 Linux/类 Unix 系统上,文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。常见的文件链接类型有两种:
+
+**1、硬链接(Hard Link)**
+
+- 在 Linux/类 Unix 文件系统中,每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的(可以看作是互为硬链接,源头是同一份文件),删除其中任何一个对另外一个没有影响,可以通过给文件设置硬链接文件来防止重要文件被误删。
+- 只有删除了源文件和所有对应的硬链接文件,该文件才会被真正删除。
+- 硬链接具有一些限制,不能对目录以及不存在的文件创建硬链接,并且,硬链接也不能跨越文件系统。
+- `ln` 命令用于创建硬链接。
+
+**2、软链接(Symbolic Link 或 Symlink)**
+
+- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
+- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
+- 软连接类似于 Windows 系统中的快捷方式。
+- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
+- `ln -s` 命令用于创建软链接。
+
+**硬链接为什么不能跨文件系统?**
+
+我们之前提到过,硬链接是通过 inode 节点号建立连接的,而硬链接和源文件共享相同的 inode 节点号。
+
+然而,每个文件系统都有自己的独立 inode 表,且每个 inode 表只维护该文件系统内的 inode。如果在不同的文件系统之间创建硬链接,可能会导致 inode 节点号冲突的问题,即目标文件的 inode 节点号已经在该文件系统中被使用。
+
+### Linux 文件类型
+
+Linux 支持很多文件类型,其中非常重要的文件类型有: **普通文件**,**目录文件**,**链接文件**,**设备文件**,**管道文件**,**Socket 套接字文件** 等。
+
+- **普通文件(-)**:用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
+- **目录文件(d,directory file)**:目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
+- **符号链接文件(l,symbolic link)**:保留了指向文件的地址而不是文件本身。
+- **字符设备(c,char)**:用来访问字符设备比如键盘。
+- **设备文件(b,block)**:用来访问块设备比如硬盘、软盘。
+- **管道文件(p,pipe)** : 一种特殊类型的文件,用于进程之间的通信。
+- **套接字文件(s,socket)**:用于进程间的网络通信,也可以用于本机之间的非网络通信。
+
+每种文件类型都有不同的用途和属性,可以通过命令如`ls`、`file`等来查看文件的类型信息。
+
+```bash
+# 普通文件(-)
+-rw-r--r-- 1 user group 1024 Apr 14 10:00 file.txt
+
+# 目录文件(d,directory file)*
+drwxr-xr-x 2 user group 4096 Apr 14 10:00 directory/
+
+# 套接字文件(s,socket)
+srwxrwxrwx 1 user group 0 Apr 14 10:00 socket
+```
+
+### Linux 目录树
+
+Linux 使用一种称为目录树的层次结构来组织文件和目录。目录树由根目录(/)作为起始点,向下延伸,形成一系列的目录和子目录。每个目录可以包含文件和其他子目录。结构层次鲜明,就像一棵倒立的树。
+
+
+**常见目录说明:**
+
+- **/bin:** 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
+- **/etc:** 存放系统管理和配置文件;
+- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
+- **/usr:** 用于存放系统应用程序;
+- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
+- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
+- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
+- **/sbin:** 存放二进制可执行文件,只有 root 才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如 ifconfig 等;
+- **/dev:** 用于存放设备文件;
+- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
+- **/boot:** 存放用于系统引导时使用的各种文件;
+- **/lib 和/lib64:** 存放着和系统运行相关的库文件 ;
+- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
+- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
+- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
+
+## Linux 常用命令
+
+下面只是给出了一些比较常用的命令。
+
+推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。Linux 命令在线速查手册: 。
+
+
+
+另外,[shell.how](https://www.shell.how/) 这个网站可以用来解释常见命令的意思,对你学习 Linux 基本命令以及其他常用命令(如 Git、NPM)。
+
+
+
+### 目录切换
+
+- `cd usr`:切换到该目录下 usr 目录
+- `cd ..(或cd../)`:切换到上一层目录
+- `cd /`:切换到系统根目录
+- `cd ~`:切换到用户主目录
+- **`cd -`:** 切换到上一个操作所在目录
+
+### 目录操作
+
+- `ls`:显示目录中的文件和子目录的列表。例如:`ls /home`,显示 `/home` 目录下的文件和子目录列表。
+- `ll`:`ll` 是 `ls -l` 的别名,ll 命令可以看到该目录下的所有目录和文件的详细信息。
+- `mkdir [选项] 目录名`:创建新目录(增)。例如:`mkdir -m 755 my_directory`,创建一个名为 `my_directory` 的新目录,并将其权限设置为 755,其中所有者拥有读、写、执行权限,所属组和其他用户只有读、执行权限,无法修改目录内容(如创建或删除文件)。如果希望所有用户(包括所属组和其他用户)对目录都拥有读、写、执行权限,则应设置权限为 `777`,即:`mkdir -m 777 my_directory`。
+- `find [路径] [表达式]`:在指定目录及其子目录中搜索文件或目录(查),非常强大灵活。例如:① 列出当前目录及子目录下所有文件和文件夹: `find .`;② 在`/home`目录下查找以 `.txt` 结尾的文件名:`find /home -name "*.txt"` ,忽略大小写: `find /home -i name "*.txt"` ;③ 当前目录及子目录下查找所有以 `.txt` 和 `.pdf` 结尾的文件:`find . \( -name "*.txt" -o -name "*.pdf" \)`或`find . -name "*.txt" -o -name "*.pdf"`。
+- `pwd`:显示当前工作目录的路径。
+- `rmdir [选项] 目录名`:删除空目录(删)。例如:`rmdir -p my_directory`,删除名为 `my_directory` 的空目录,并且会递归删除`my_directory`的空父目录,直到遇到非空目录或根目录。
+- `rm [选项] 文件或目录名`:删除文件/目录(删)。例如:`rm -r my_directory`,删除名为 `my_directory` 的目录,`-r`(recursive,递归) 表示会递归删除指定目录及其所有子目录和文件。
+- `cp [选项] 源文件/目录 目标文件/目录`:复制文件或目录(移)。例如:`cp file.txt /home/file.txt`,将 `file.txt` 文件复制到 `/home` 目录下,并重命名为 `file.txt`。`cp -r source destination`,将 `source` 目录及其下的所有子目录和文件复制到 `destination` 目录下,并保留源文件的属性和目录结构。
+- `mv [选项] 源文件/目录 目标文件/目录`:移动文件或目录(移),也可以用于重命名文件或目录。例如:`mv file.txt /home/file.txt`,将 `file.txt` 文件移动到 `/home` 目录下,并重命名为 `file.txt`。`mv` 与 `cp` 的结果不同,`mv` 好像文件“搬家”,文件个数并未增加。而 `cp` 对文件进行复制,文件个数增加了。
+
+### 文件操作
+
+像 `mv`、`cp`、`rm` 等文件和目录都适用的命令,这里就不重复列举了。
+
+- `touch [选项] 文件名..`:创建新文件或更新已存在文件(增)。例如:`touch file1.txt file2.txt file3.txt` ,创建 3 个文件。
+- `ln [选项] <源文件> <硬链接/软链接文件>`:创建硬链接/软链接。例如:`ln -s file.txt file_link`,创建名为 `file_link` 的软链接,指向 `file.txt` 文件。`-s` 选项代表的就是创建软链接,s 即 symbolic(软链接又名符号链接) 。
+- `cat/more/less/tail 文件名`:文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 Tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
+- `vim 文件名`:修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤:`vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!` (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
+
+### 文件压缩
+
+**1)打包并压缩文件:**
+
+Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是以 `.gz` 结尾的。而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般 `.tar.gz`。
+
+命令:`tar -zcvf 打包压缩后的文件名 要打包压缩的文件` ,其中:
+
+- z:调用 gzip 压缩命令进行压缩
+- c:打包文件
+- v:显示运行过程
+- f:指定文件名
+
+比如:假如 test 目录下有三个文件分别是:`aaa.txt`、 `bbb.txt`、`ccc.txt`,如果我们要打包 `test` 目录并指定压缩后的压缩包名称为 `test.tar.gz` 可以使用命令:`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt` 或 `tar -zcvf test.tar.gz /test/` 。
+
+**2)解压压缩包:**
+
+命令:`tar [-xvf] 压缩文件`
+
+其中 x 代表解压
+
+示例:
+
+- 将 `/test` 下的 `test.tar.gz` 解压到当前目录下可以使用命令:`tar -xvf test.tar.gz`
+- 将 /test 下的 test.tar.gz 解压到根目录/usr 下:`tar -xvf test.tar.gz -C /usr`(`-C` 代表指定解压的位置)
+
+### 文件传输
+
+- `scp [选项] 源文件 远程文件` (scp 即 secure copy,安全复制):用于通过 SSH 协议进行安全的文件传输,可以实现从本地到远程主机的上传和从远程主机到本地的下载。例如:`scp -r my_directory user@remote:/home/user` ,将本地目录`my_directory`上传到远程服务器 `/home/user` 目录下。`scp -r user@remote:/home/user/my_directory` ,将远程服务器的 `/home/user` 目录下的`my_directory`目录下载到本地。需要注意的是,`scp` 命令需要在本地和远程系统之间建立 SSH 连接进行文件传输,因此需要确保远程服务器已经配置了 SSH 服务,并且具有正确的权限和认证方式。
+- `rsync [选项] 源文件 远程文件` : 可以在本地和远程系统之间高效地进行文件复制,并且能够智能地处理增量复制,节省带宽和时间。例如:`rsync -r my_directory user@remote:/home/user`,将本地目录`my_directory`上传到远程服务器 `/home/user` 目录下。
+- `ftp` (File Transfer Protocol):提供了一种简单的方式来连接到远程 FTP 服务器并进行文件上传、下载、删除等操作。使用之前需要先连接登录远程 FTP 服务器,进入 FTP 命令行界面后,可以使用 `put` 命令将本地文件上传到远程主机,可以使用`get`命令将远程主机的文件下载到本地,可以使用 `delete` 命令删除远程主机的文件。这里就不进行演示了。
+
+### 文件权限
+
+操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(executable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
+
+通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
+
+示例:在随意某个目录下`ls -l`
+
+
+
+第一列的内容的信息解释如下:
+
+
+
+> 下面将详细讲解文件的类型、Linux 中权限以及文件有所有者、所在组、其它组具体是什么?
+
+**文件的类型:**
+
+- d:代表目录
+- -:代表文件
+- l:代表软链接(可以认为是 window 中的快捷方式)
+
+**Linux 中权限分为以下几种:**
+
+- r:代表权限是可读,r 也可以用数字 4 表示
+- w:代表权限是可写,w 也可以用数字 2 表示
+- x:代表权限是可执行,x 也可以用数字 1 表示
+
+**文件和目录权限的区别:**
+
+对文件和目录而言,读写执行表示不同的意义。
+
+对于文件:
+
+| 权限名称 | 可执行操作 |
+| :------- | --------------------------: |
+| r | 可以使用 cat 查看文件的内容 |
+| w | 可以修改文件的内容 |
+| x | 可以将其运行为二进制文件 |
+
+对于目录:
+
+| 权限名称 | 可执行操作 |
+| :------- | -----------------------: |
+| r | 可以查看目录下列表 |
+| w | 可以创建和删除目录下文件 |
+| x | 可以使用 cd 进入目录 |
+
+需要注意的是:**超级用户可以无视普通用户的权限,即使文件目录权限是 000,依旧可以访问。**
+
+**在 Linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
+
+- **所有者(u)** :一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
+- **文件所在组(g)** :当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
+- **其它组(o)** :除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
+
+> 我们再来看看如何修改文件/目录的权限。
+
+**修改文件/目录的权限的命令:`chmod`**
+
+示例:修改/test 下的 aaa.txt 的权限为文件所有者有全部权限,文件所有者所在的组有读写权限,其他用户只有读的权限。
+
+**`chmod u=rwx,g=rw,o=r aaa.txt`** 或者 **`chmod 764 aaa.txt`**
+
+
+
+**补充一个比较常用的东西:**
+
+假如我们装了一个 zookeeper,我们每次开机到要求其自动启动该怎么办?
+
+1. 新建一个脚本 zookeeper
+2. 为新建的脚本 zookeeper 添加可执行权限,命令是:`chmod +x zookeeper`
+3. 把 zookeeper 这个脚本添加到开机启动项里面,命令是:`chkconfig --add zookeeper`
+4. 如果想看看是否添加成功,命令是:`chkconfig --list`
+
+### 用户管理
+
+Linux 系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
+
+用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
+
+**Linux 用户管理相关命令:**
+
+- `useradd [选项] 用户名`:创建用户账号。使用`useradd`指令所建立的帐号,实际上是保存在 `/etc/passwd`文本文件中。
+- `userdel [选项] 用户名`:删除用户帐号。
+- `usermod [选项] 用户名`:修改用户账号的属性和配置比如用户名、用户 ID、家目录。
+- `passwd [选项] 用户名`: 设置用户的认证信息,包括用户密码、密码过期时间等。。例如:`passwd -S 用户名` ,显示用户账号密码信息。`passwd -d 用户名`: 清除用户密码,会导致用户无法登录。`passwd 用户名`,修改用户密码,随后系统会提示输入新密码并确认密码。
+- `su [选项] 用户名`(su 即 Switch User,切换用户):在当前登录的用户和其他用户之间切换身份。
+
+### 用户组管理
+
+每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同 Linux 系统对用户组的规定有所不同,如 Linux 下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
+
+用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对`/etc/group`文件的更新。
+
+**Linux 系统用户组的管理相关命令:**
+
+- `groupadd [选项] 用户组` :增加一个新的用户组。
+- `groupdel 用户组`:要删除一个已有的用户组。
+- `groupmod [选项] 用户组` : 修改用户组的属性。
+
+### 系统状态
+
+- `top [选项]`:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。
+- `htop [选项]`:类似于 `top`,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
+- `uptime [选项]`:用于查看系统总共运行了多长时间、系统的平均负载等信息。
+- `vmstat [间隔时间] [重复次数]`:vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。
+- `free [选项]`:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。
+- `df [选项] [文件系统]`:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:`df -a`,查看全部文件系统。
+- `du [选项] [文件]`:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。
+- `sar [选项] [时间间隔] [重复次数]`:用于收集、报告和分析系统的性能统计信息,包括系统的 CPU 使用、内存使用、磁盘 I/O、网络活动等详细信息。它的特点是可以连续对系统取样,获得大量的取样数据。取样数据和分析的结果都可以存入文件,使用它时消耗的系统资源很小。
+- `ps [选项]`:用于查看系统中的进程信息,包括进程的 ID、状态、资源使用情况等。`ps -ef`/`ps -aux`:这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:`ps aux|grep redis` (查看包括 redis 字符串的进程),也可使用 `pgrep redis -a`。
+- `systemctl [命令] [服务名称]`:用于管理系统的服务和单元,可以查看系统服务的状态、启动、停止、重启等。
+
+### 网络通信
+
+- `ping [选项] 目标主机`:测试与目标主机的网络连接。
+- `ifconfig` 或 `ip`:用于查看系统的网络接口信息,包括网络接口的 IP 地址、MAC 地址、状态等。
+- `netstat [选项]`:用于查看系统的网络连接状态和网络统计信息,可以查看当前的网络连接情况、监听端口、网络协议等。
+- `ss [选项]`:比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
+- `nload`:`sar` 和 `nload` 都可以监控网络流量,但`sar` 的输出是文本形式的数据,不够直观。`nload` 则是一个专门用于实时监控网络流量的工具,提供图形化的终端界面,更加直观。不过,`nload` 不保存历史数据,所以它不适合用于长期趋势分析。并且,系统并没有默认安装它,需要手动安装。
+- `sudo hostnamectl set-hostname 新主机名`:更改主机名,并且重启后依然有效。`sudo hostname 新主机名`也可以更改主机名。不过需要注意的是,使用 `hostname` 命令直接更改主机名只是临时生效,系统重启后会恢复为原来的主机名。
+
+### 其他
+
+- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
+- `grep [选项] "搜索内容" 文件路径`:非常强大且常用的文本搜索命令,它可以根据指定的字符串或正则表达式,在文件或命令输出中进行匹配查找,适用于日志分析、文本过滤、快速定位等多种场景。示例:忽略大小写搜索 syslog 中所有包含 error 的行:`grep -i "error" /var/log/syslog`,查找所有与 java 相关的进程:`ps -ef | grep "java"`。
+- `kill -9 进程的pid`:杀死进程(-9 表示强制终止)先用 ps 查找进程,然后用 kill 杀掉。
+- `shutdown`:`shutdown -h now`:指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定 5 分钟后关机,同时送出警告信息给登入用户。
+- `reboot`:`reboot`:重开机。`reboot -w`:做个重开机的模拟(只有纪录并不会真的重开机)。
+
+## Linux 环境变量
+
+在 Linux 系统中,环境变量是用来定义系统运行环境的一些参数,比如每个用户不同的主目录(HOME)。
+
+### 环境变量分类
+
+按照作用域来分,环境变量可以简单的分成:
+
+- 用户级别环境变量 : `~/.bashrc`、`~/.bash_profile`。
+- 系统级别环境变量 : `/etc/bashrc`、`/etc/environment`、`/etc/profile`、`/etc/profile.d`。
+
+上述配置文件执行先后顺序为:`/etc/environment` –> `/etc/profile` –> `/etc/profile.d` –> `~/.bash_profile` –> `/etc/bashrc` –> `~/.bashrc`
+
+如果要修改系统级别环境变量文件,需要管理员具备对该文件的写入权限。
+
+建议用户级别环境变量在 `~/.bash_profile`中配置,系统级别环境变量在 `/etc/profile.d` 中配置。
+
+按照生命周期来分,环境变量可以简单的分成:
+
+- 永久的:需要用户修改相关的配置文件,变量永久生效。
+- 临时的:用户利用 `export` 命令,在当前终端下声明环境变量,关闭 shell 终端失效。
+
+### 读取环境变量
+
+通过 `export` 命令可以输出当前系统定义的所有环境变量。
+
+```bash
+# 列出当前的环境变量值
+export -p
+```
+
+除了 `export` 命令之外, `env` 命令也可以列出所有环境变量。
+
+`echo` 命令可以输出指定环境变量的值。
+
+```bash
+# 输出当前的PATH环境变量的值
+echo $PATH
+# 输出当前的HOME环境变量的值
+echo $HOME
+```
+
+### 环境变量修改
+
+通过 `export`命令可以修改指定的环境变量。不过,这种方式修改环境变量仅仅对当前 shell 终端生效,关闭 shell 终端就会失效。修改完成之后,立即生效。
+
+```bash
+export CLASSPATH=./JAVA_HOME/lib;$JAVA_HOME/jre/lib
+```
+
+通过 `vim` 命令修改环境变量配置文件。这种方式修改环境变量永久有效。
+
+```bash
+vim ~/.bash_profile
+```
+
+如果修改的是系统级别环境变量则对所有用户生效,如果修改的是用户级别环境变量则仅对当前用户生效。
+
+修改完成之后,需要 `source` 命令让其生效或者关闭 shell 终端重新登录。
+
+```bash
+source /etc/profile
+```
+
+
+
diff --git a/docs_en/cs-basics/operating-system/operating-system-basic-questions-01.en.md b/docs_en/cs-basics/operating-system/operating-system-basic-questions-01.en.md
new file mode 100644
index 00000000000..4006ddfae2a
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/operating-system-basic-questions-01.en.md
@@ -0,0 +1,468 @@
+---
+title: 操作系统常见面试题总结(上)
+category: 计算机基础
+tag:
+ - 操作系统
+head:
+ - - meta
+ - name: keywords
+ content: 操作系统面试题,用户态 vs 内核态,进程 vs 线程,死锁必要条件,系统调用过程,进程调度算法,PCB进程控制块,进程间通信IPC,死锁预防避免,操作系统基础高频题,虚拟内存管理
+ - - meta
+ - name: description
+ content: 最新操作系统高频面试题总结(上):用户态/内核态切换、进程线程区别、死锁四条件、系统调用详解、调度算法对比,附图表+⭐️重点标注,一文掌握OS核心考点,快速通关后端技术面试!
+---
+
+
+
+很多读者抱怨计算操作系统的知识点比较繁杂,自己也没有多少耐心去看,但是面试的时候又经常会遇到。所以,我带着我整理好的操作系统的常见问题来啦!这篇文章总结了一些我觉得比较重要的操作系统相关的问题比如 **用户态和内核态、系统调用、进程和线程、死锁、内存管理、虚拟内存、文件系统**等等。
+
+这篇文章只是对一些操作系统比较重要概念的一个概览,深入学习的话,建议大家还是老老实实地去看书。另外, 这篇文章的很多内容参考了《现代操作系统》第三版这本书,非常感谢。
+
+开始本文的内容之前,我们先聊聊为什么要学习操作系统。
+
+- **从对个人能力方面提升来说**:操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
+- **从面试角度来说**:尤其是校招,对于操作系统方面知识的考察是非常非常多的。
+
+**简单来说,学习操作系统能够提高自己思考的深度以及对技术的理解力,并且,操作系统方面的知识也是面试必备。**
+
+## 操作系统基础
+
+
+
+### 什么是操作系统?
+
+通过以下四点可以概括操作系统到底是什么:
+
+1. 操作系统(Operating System,简称 OS)是管理计算机硬件与软件资源的程序,是计算机的基石。
+2. 操作系统本质上是一个运行在计算机上的软件程序 ,主要用于管理计算机硬件和软件资源。 举例:运行在你电脑上的所有应用程序都通过操作系统来调用系统内存以及磁盘等等硬件。
+3. 操作系统存在屏蔽了硬件层的复杂性。 操作系统就像是硬件使用的负责人,统筹着各种相关事项。
+4. 操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。 内核是连接应用程序和硬件的桥梁,决定着系统的性能和稳定性。
+
+很多人容易把操作系统的内核(Kernel)和中央处理器(CPU,Central Processing Unit)弄混。你可以简单从下面两点来区别:
+
+1. 操作系统的内核(Kernel)属于操作系统层面,而 CPU 属于硬件。
+2. CPU 主要提供运算,处理各种指令的能力。内核(Kernel)主要负责系统管理比如内存管理,它屏蔽了对硬件的操作。
+
+下图清晰说明了应用程序、内核、CPU 这三者的关系。
+
+
+
+### 操作系统主要有哪些功能?
+
+从资源管理的角度来看,操作系统有 6 大功能:
+
+1. **进程和线程的管理**:进程的创建、撤销、阻塞、唤醒,进程间的通信等。
+2. **存储管理**:内存的分配和管理、外存(磁盘等)的分配和管理等。
+3. **文件管理**:文件的读、写、创建及删除等。
+4. **设备管理**:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
+5. **网络管理**:操作系统负责管理计算机网络的使用。网络是计算机系统中连接不同计算机的方式,操作系统需要管理计算机网络的配置、连接、通信和安全等,以提供高效可靠的网络服务。
+6. **安全管理**:用户的身份认证、访问控制、文件加密等,以防止非法用户对系统资源的访问和操作。
+
+### 常见的操作系统有哪些?
+
+#### Windows
+
+目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。界面简单易操作,软件生态非常好。
+
+_玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Windows 用于玩游戏,一台 Mac 用于平时日常开发和学习使用。_
+
+
+
+#### Unix
+
+最早的多用户、多任务操作系统 。后面崛起的 Linux 在很多方面都参考了 Unix。
+
+目前这款操作系统已经逐渐逐渐退出操作系统的舞台。
+
+
+
+#### Linux
+
+**Linux 是一套免费使用、开源的类 Unix 操作系统。** Linux 存在着许多不同的发行版本,但它们都使用了 **Linux 内核** 。
+
+> 严格来讲,Linux 这个词本身只表示 Linux 内核,在 GNU/Linux 系统中,Linux 实际就是 Linux 内核,而该系统的其余部分主要是由 GNU 工程编写和提供的程序组成。单独的 Linux 内核并不能成为一个可以正常工作的操作系统。
+>
+> **很多人更倾向使用 “GNU/Linux” 一词来表达人们通常所说的 “Linux”。**
+
+
+
+#### Mac OS
+
+苹果自家的操作系统,编程体验和 Linux 相当,但是界面、软件生态以及用户体验各方面都要比 Linux 操作系统更好。
+
+
+
+### 用户态和内核态
+
+#### 什么是用户态和内核态?
+
+根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
+
+
+
+- **用户态(User Mode)** : 用户态运行的进程可以直接读取用户程序的数据,拥有较低的权限。当应用程序需要执行某些需要特殊权限的操作,例如读写磁盘、网络通信等,就需要向操作系统发起系统调用请求,进入内核态。
+- **内核态(Kernel Mode)** :内核态运行的进程几乎可以访问计算机的任何资源包括系统的内存空间、设备、驱动程序等,不受限制,拥有非常高的权限。当操作系统接收到进程的系统调用请求时,就会从用户态切换到内核态,执行相应的系统调用,并将结果返回给进程,最后再从内核态切换回用户态。
+
+内核态相比用户态拥有更高的特权级别,因此能够执行更底层、更敏感的操作。不过,由于进入内核态需要付出较高的开销(需要进行一系列的上下文切换和权限检查),应该尽量减少进入内核态的次数,以提高系统的性能和稳定性。
+
+#### 为什么要有用户态和内核态?只有一个内核态不行么?
+
+这样设计主要是为了**安全**和**稳定**。
+
+- 在 CPU 的所有指令中,有一些指令是比较危险的比如内存分配、设置时钟、IO 处理等,如果所有的程序都能使用这些指令的话,会对系统的正常运行造成灾难性地影响。因此,我们需要限制这些危险指令只能内核态运行。这些只能由操作系统内核态执行的指令也被叫做 **特权指令** 。
+- 如果计算机系统中只有一个内核态,那么所有程序或进程都必须共享系统资源,例如内存、CPU、硬盘等,这将导致系统资源的竞争和冲突,从而影响系统性能和效率。并且,这样也会让系统的安全性降低,毕竟所有程序或进程都具有相同的特权级别和访问权限。
+
+因此,同时具有用户态和内核态主要是为了保证计算机系统的安全性、稳定性和性能。
+
+#### 用户态和内核态是如何切换的?
+
+
+
+用户态切换到内核态的 3 种方式:
+
+1. **系统调用(Trap)**:这是最主要的方式,是应用程序**主动**发起的。比如,当我们的程序需要读取一个文件或者发送网络数据时,它无法直接操作磁盘或网卡,就必须调用操作系统提供的接口(如 `read()`,`send()`), 这会触发一次从用户态到内核态的切换。
+2. **中断(Interrupt)**:这是**被动**的,由外部硬件设备触发。比如,当硬盘完成了数据读取,会向 CPU 发送一个中断信号,CPU 会暂停当前用户态的程序,切换到内核态去处理这个中断。
+3. **异常(Exception)**:这也是**被动**的,由程序自身错误引起。比如,我们的代码执行了一个除以零的操作,或者访问了一个非法的内存地址(缺页异常),CPU 会捕获这个异常,并切换到内核态去处理它。
+
+在系统的处理上,中断和异常类似,都是通过中断向量表来找到相应的处理程序进行处理。区别在于,中断来自处理器外部,不是由任何一条专门的指令造成,而异常是执行当前指令的结果。
+
+最后,需要强调的是,这种**状态切换是有性能开销的**。因为它涉及到保存用户态的上下文(寄存器等)、切换到内核态执行、再恢复用户态的上下文。因此,在高性能编程中,我们常常需要考虑如何减少这种切换次数,比如通过缓冲 I/O 来批量读写文件,就是一个典型的例子。
+
+### 系统调用
+
+#### 什么是系统调用?
+
+我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的内核态级别的子功能咋办呢?那就需要系统调用了!
+
+也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
+
+
+
+这些系统调用按功能大致可分为如下几类:
+
+- 设备管理:完成设备(输入输出设备和外部存储设备等)的请求或释放,以及设备启动等功能。
+- 文件管理:完成文件的读、写、创建及删除等功能。
+- 进程管理:进程的创建、撤销、阻塞、唤醒,进程间的通信等功能。
+- 内存管理:完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
+
+系统调用和普通库函数调用非常相似,只是系统调用由操作系统内核提供,运行于内核态,而普通的库函数调用由函数库或用户自己提供,运行于用户态。
+
+总结:系统调用是应用程序与操作系统之间进行交互的一种方式,通过系统调用,应用程序可以访问操作系统底层资源例如文件、设备、网络等。
+
+#### 系统调用的过程了解吗?
+
+系统调用的过程可以简单分为以下几个步骤:
+
+1. 用户态的程序发起系统调用,因为系统调用中涉及一些特权指令(只能由操作系统内核态执行的指令),用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
+2. 发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序。内核程序开始执行,也就是开始处理系统调用。
+3. 当系统调用处理完成后,操作系统使用特权指令(如 `iret`、`sysret` 或 `eret`)切换回用户态,恢复用户态的上下文,继续执行用户程序。
+
+
+
+## 进程和线程
+
+### 进程和线程的区别是什么?
+
+进程和线程是操作系统中并发执行的两个核心概念,它们的关系可以理解为 **工厂和工人** 的关系。
+
+**进程(Process)就像一个工厂**。操作系统在分配资源时,是以进程为基本单位的。比如,当我启动一个微信,操作系统就为它建立了一个独立的工厂,分配给它专属的内存空间、文件句柄等资源。这个工厂与其他工厂(比如我打开的浏览器进程)是严格隔离的。
+
+**线程(Thread)则像是工厂里的工人**。一个工厂里可以有很多工人,他们共享这个工厂的资源,但每个工人有自己的工具箱和任务清单,让他们可以独立地执行不同的任务。比如微信这个工厂里,可以有一个工人(线程)负责接收消息,一个工人负责渲染界面。
+
+这是我用 AI 绘制的一张图片,可以说是非常形象了:
+
+
+
+下图是 Java 内存区域,我们从 JVM 的角度来说一下线程和进程之间的关系吧!
+
+
+
+从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
+
+这里从 3 个角度总结下线程和进程的核心区别:
+
+1. **资源所有权:** 进程是资源分配的基本单位,拥有独立的地址空间;而线程是 CPU 调度的基本单位,几乎不拥有系统资源,只保留少量私有数据(PC、栈、寄存器),主要共享其所属进程的资源。
+2. **开销:** 创建或销毁一个工厂(进程)的开销很大,需要分配独立的资源。而雇佣或解雇一个工人(线程)的开销就小得多。同理,进程间的上下文切换开销远大于线程间的切换。
+3. **健壮性:** 工厂之间是隔离的,一个工厂倒闭(进程崩溃)不会影响其他工厂。但一个工厂内的工人之间是共享资源的,一个工人操作失误(比如一个线程访问了非法内存)可能会导致整个工厂停工(整个进程崩溃)。
+
+### 有了进程为什么还需要线程?
+
+核心原因就是**为了在单个应用内实现低开销、高效率的并发**。如果我想让微信同时接收消息和发送文件,如果用两个进程来实现,不仅资源开销巨大,它们之间通信还非常麻烦(需要 IPC)。而使用两个线程,它们不仅切换成本低,还能直接通过共享内存高效通信,从而能更好地利用多核 CPU,提升应用的响应速度和吞吐量。
+
+再那我们上面举的工厂和工人为例:线程=同一屋檐下的轻量级工人,切换成本低、共享内存零拷贝;若换成两个独立进程,就得各建一座工厂(独立地址空间),既费砖又费电(资源与 IPC 开销)。
+
+### 为什么要使用多线程?
+
+先从总体上来说:
+
+- **从计算机底层来说:** 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
+- **从当代互联网发展趋势来说:** 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
+
+再深入到计算机底层来探讨:
+
+- **单核时代**:在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
+- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
+
+### 线程间的同步的方式有哪些?
+
+线程同步是两个或多个共享关键资源的线程的并发执行。应该同步线程以避免关键的资源使用冲突。
+
+下面是几种常见的线程同步的方式:
+
+1. **互斥锁(Mutex)** :采用互斥对象机制,只有拥有互斥对象的线程才有访问公共资源的权限。因为互斥对象只有一个,所以可以保证公共资源不会被多个线程同时访问。比如 Java 中的 `synchronized` 关键词和各种 `Lock` 都是这种机制。
+2. **读写锁(Read-Write Lock)** :允许多个线程同时读取共享资源,但只有一个线程可以对共享资源进行写操作。
+3. **信号量(Semaphore)** :它允许同一时刻多个线程访问同一资源,但是需要控制同一时刻访问此资源的最大线程数量。
+4. **屏障(Barrier)** :屏障是一种同步原语,用于等待多个线程到达某个点再一起继续执行。当一个线程到达屏障时,它会停止执行并等待其他线程到达屏障,直到所有线程都到达屏障后,它们才会一起继续执行。比如 Java 中的 `CyclicBarrier` 是这种机制。
+5. **事件(Event)** :Wait/Notify:通过通知操作的方式来保持多线程同步,还可以方便的实现多线程优先级的比较操作。
+
+### PCB 是什么?包含哪些信息?
+
+**PCB(Process Control Block)** 即进程控制块,是操作系统中用来管理和跟踪进程的数据结构,每个进程都对应着一个独立的 PCB。你可以将 PCB 视为进程的大脑。
+
+当操作系统创建一个新进程时,会为该进程分配一个唯一的进程 ID,并且为该进程创建一个对应的进程控制块。当进程执行时,PCB 中的信息会不断变化,操作系统会根据这些信息来管理和调度进程。
+
+PCB 主要包含下面几部分的内容:
+
+- 进程的描述信息,包括进程的名称、标识符等等;
+- 进程的调度信息,包括进程阻塞原因、进程状态(就绪、运行、阻塞等)、进程优先级(标识进程的重要程度)等等;
+- 进程对资源的需求情况,包括 CPU 时间、内存空间、I/O 设备等等。
+- 进程打开的文件信息,包括文件描述符、文件类型、打开模式等等。
+- 处理机的状态信息(由处理机的各种寄存器中的内容组成的),包括通用寄存器、指令计数器、程序状态字 PSW、用户栈指针。
+- ……
+
+### 进程有哪几种状态?
+
+我们一般把进程大致分为 5 种状态,这一点和线程很像!
+
+- **创建状态(new)**:进程正在被创建,尚未到就绪状态。
+- **就绪状态(ready)**:进程已处于准备运行状态,即进程获得了除了处理器之外的一切所需资源,一旦得到处理器资源(处理器分配的时间片)即可运行。
+- **运行状态(running)**:进程正在处理器上运行(单核 CPU 下任意时刻只有一个进程处于运行状态)。
+- **阻塞状态(waiting)**:又称为等待状态,进程正在等待某一事件而暂停运行如等待某资源为可用或等待 IO 操作完成。即使处理器空闲,该进程也不能运行。
+- **结束状态(terminated)**:进程正在从系统中消失。可能是进程正常结束或其他原因中断退出运行。
+
+
+
+### 进程间的通信方式有哪些?
+
+> 下面这部分总结参考了:[《进程间通信 IPC (InterProcess Communication)》](https://www.jianshu.com/p/c1015f5ffa74) 这篇文章,推荐阅读,总结的非常不错。
+
+1. **管道/匿名管道(Pipes)** :用于具有亲缘关系的父子进程间或者兄弟进程之间的通信。
+2. **有名管道(Named Pipes)** : 匿名管道由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了有名管道。有名管道严格遵循 **先进先出(First In First Out)** 。有名管道以磁盘文件的方式存在,可以实现本机任意两个进程通信。
+3. **信号(Signal)** :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生;
+4. **消息队列(Message Queuing)** :消息队列是消息的链表,具有特定的格式,存放在内存中并由消息队列标识符标识。管道和消息队列的通信数据都是先进先出的原则。与管道(无名管道:只存在于内存中的文件;命名管道:存在于实际的磁盘介质或者文件系统)不同的是消息队列存放在内核中,只有在内核重启(即,操作系统重启)或者显式地删除一个消息队列时,该消息队列才会被真正的删除。消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取.比 FIFO 更有优势。消息队列克服了信号承载信息量少,管道只能承载无格式字 节流以及缓冲区大小受限等缺点。
+5. **信号量(Semaphores)** :信号量是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。这种通信方式主要用于解决与同步相关的问题并避免竞争条件。
+6. **共享内存(Shared memory)** :使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。可以说这是最有用的进程间通信方式。
+7. **套接字(Sockets)** : 此方法主要用于在客户端和服务器之间通过网络进行通信。套接字是支持 TCP/IP 的网络通信的基本操作单元,可以看做是不同主机之间的进程进行双向通信的端点,简单的说就是通信的两方的一种约定,用套接字中的相关函数来完成通信过程。
+
+### 进程的调度算法有哪些?
+
+
+
+进程调度算法的核心目标是决定就绪队列中的哪个进程应该获得 CPU 资源,其设计目标通常是在**吞吐量、周转时间、响应时间**和**公平性**之间做权衡。
+
+我习惯将这些算法分为两大类:**非抢占式**和**抢占式**。
+
+**第一类:非抢占式调度 (Non-Preemptive)**
+
+这种方式下,一旦 CPU 分配给一个进程,它就会一直运行下去,直到任务完成或主动放弃(比如等待 I/O)。
+
+1. **先到先服务调度算法(FCFS,First Come, First Served)** : 这是最简单的,就像排队,谁先来谁先用。优点是公平、实现简单。但缺点很明显,如果一个很长的任务先到了,后面无数个短任务都得等着,这会导致平均等待时间很长,我们称之为“护航效应”。
+2. **短作业优先的调度算法(SJF,Shortest Job First)** : 从就绪队列中选出一个估计运行时间最短的进程为之分配资源。理论上,它的平均等待时间是最短的,吞吐量很高。但缺点是,它需要预测运行时间,这很难做到,而且可能会导致长作业“饿死”,永远得不到执行。
+
+**第二类:抢占式调度 (Preemptive)**
+
+操作系统可以强制剥夺当前进程的 CPU 使用权,分配给其他更重要的进程。现代操作系统基本都采用这种方式。
+
+- **时间片轮转调度算法(RR,Round-Robin)** : 这是最经典、最公平的抢占式算法。它给每个进程分配一个固定的时间片,用完了就把它放到队尾,切换到下一个进程。它非常适合分时系统,保证了每个进程都能得到响应,但时间片的设置很关键:太长了退化成 FCFS,太短了则会导致过于频繁的上下文切换,增加系统开销。
+- **优先级调度算法(Priority)**:每个进程都有一个优先级,进程调度器总是选择优先级最高的进程,具有相同优先级的进程以 FCFS 方式执行。这很灵活,可以根据内存要求,时间要求或任何其他资源要求来确定优先级,但同样可能导致低优先级进程“饿死”。
+
+前面介绍的几种进程调度的算法都有一定的局限性,如:**短进程优先的调度算法,仅照顾了短进程而忽略了长进程** 。那有没有一种结合了上面这些进程调度算法优点的呢?
+
+**多级反馈队列调度算法(MFQ,Multi-level Feedback Queue)** 是现实世界中最常用的一种算法,比如早期的 UNIX。它非常聪明,结合了 RR 和优先级调度。它设置了多个不同优先级的队列,每个队列使用 RR 调度,时间片大小也不同。新进程先进入最高优先级队列;如果在一个时间片内没执行完,就会被降级到下一个队列。这样既照顾了短作业(在高优先级队列中快速完成),也保证了长作业不会饿死(最终会在低优先级队列中得到执行),是一种非常均衡的方案。
+
+### 那究竟是谁来调度这个进程呢?
+
+负责进程调度的核心是操作系统内核中的两个紧密协作的组件:**调度程序(Scheduler)** 和 **分派程序(Dispatcher)**。我们可以把它们理解成一个团队:
+
+- **调度程序 (Scheduler):** 可以看作是决策者。当需要进行调度时,调度程序会被激活,它会根据预设的调度算法(比如我们前面聊到的多级反馈队列),从就绪队列中挑选出下一个应该占用 CPU 的进程。
+- **分派程序 (Dispatcher):** 可以看作是执行者。它负责完成具体的“交接”工作,也就是**上下文切换**。这个过程非常底层,主要包括:
+ - 保存当前进程的上下文(CPU 寄存器状态、程序计数器等)到其进程控制块(PCB)中。
+ - 加载下一个被选中进程的上下文,从其 PCB 中读取状态,恢复到 CPU 寄存器。
+ - 将 CPU 的控制权正式移交给新进程,让它开始运行。
+
+## 死锁
+
+### 什么是死锁?
+
+死锁(Deadlock)描述的是这样一种情况:多个进程/线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于进程/线程被无限期地阻塞,因此程序不可能正常终止。
+
+一个最经典的例子就是**“交叉持锁”**。想象有两个线程和两个锁:
+
+- 线程 1 先拿到了锁 A,然后尝试去获取锁 B。
+- 几乎同时,线程 2 拿到了锁 B,然后尝试去获取锁 A。
+
+这时,线程 1 等着线程 2 释放锁 B,而线程 2 等着线程 1 释放锁 A,双方都持有对方需要的资源,并等待对方释放,就形成了一个“死结”。
+
+ +
+### 产生死锁的四个必要条件是什么?
+
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
+1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
+2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
+3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
+
+**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
+
+下面是百度百科对必要条件的解释:
+
+> 如果没有事物情况 A,则必然没有事物情况 B,也就是说如果有事物情况 B 则一定有事物情况 A,那么 A 就是 B 的必要条件。从逻辑学上看,B 能推导出 A,A 就是 B 的必要条件,等价于 B 是 A 的充分条件。
+
+### 能写一个模拟产生死锁的代码吗?
+
+下面通过一个实际的例子来模拟下图展示的线程死锁:
+
+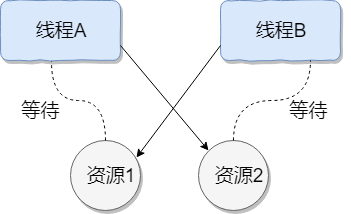
+
+```java
+public class DeadLockDemo {
+ private static Object resource1 = new Object();//资源 1
+ private static Object resource2 = new Object();//资源 2
+
+ public static void main(String[] args) {
+ new Thread(() -> {
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource2");
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ }
+ }
+ }, "线程 1").start();
+
+ new Thread(() -> {
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource1");
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ }
+ }
+ }, "线程 2").start();
+ }
+}
+```
+
+Output
+
+```text
+Thread[线程 1,5,main]get resource1
+Thread[线程 2,5,main]get resource2
+Thread[线程 1,5,main]waiting get resource2
+Thread[线程 2,5,main]waiting get resource1
+```
+
+线程 A 通过 `synchronized (resource1)` 获得 `resource1` 的监视器锁,然后通过`Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 `resource2` 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
+
+### 解决死锁的方法
+
+解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
+
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
+
+#### 死锁的预防
+
+死锁四大必要条件上面都已经列出来了,很显然,只要破坏四个必要条件中的任何一个就能够预防死锁的发生。
+
+破坏第一个条件 **互斥条件**:使得资源是可以同时访问的,这是种简单的方法,磁盘就可以用这种方法管理,但是我们要知道,有很多资源 **往往是不能同时访问的** ,所以这种做法在大多数的场合是行不通的。
+
+破坏第三个条件 **非抢占**:也就是说可以采用 **剥夺式调度算法**,但剥夺式调度方法目前一般仅适用于 **主存资源** 和 **处理器资源** 的分配,并不适用于所有的资源,会导致 **资源利用率下降**。
+
+所以一般比较实用的 **预防死锁的方法**,是通过考虑破坏第二个条件和第四个条件。
+
+**1、静态分配策略**
+
+静态分配策略可以破坏死锁产生的第二个条件(占有并等待)。所谓静态分配策略,就是指一个进程必须在执行前就申请到它所需要的全部资源,并且知道它所要的资源都得到满足之后才开始执行。进程要么占有所有的资源然后开始执行,要么不占有资源,不会出现占有一些资源等待一些资源的情况。
+
+静态分配策略逻辑简单,实现也很容易,但这种策略 **严重地降低了资源利用率**,因为在每个进程所占有的资源中,有些资源是在比较靠后的执行时间里采用的,甚至有些资源是在额外的情况下才使用的,这样就可能造成一个进程占有了一些 **几乎不用的资源而使其他需要该资源的进程产生等待** 的情况。
+
+**2、层次分配策略**
+
+层次分配策略破坏了产生死锁的第四个条件(循环等待)。在层次分配策略下,所有的资源被分成了多个层次,一个进程得到某一次的一个资源后,它只能再申请较高一层的资源;当一个进程要释放某层的一个资源时,必须先释放所占用的较高层的资源,按这种策略,是不可能出现循环等待链的,因为那样的话,就出现了已经申请了较高层的资源,反而去申请了较低层的资源,不符合层次分配策略,证明略。
+
+#### 死锁的避免
+
+上面提到的 **破坏** 死锁产生的四个必要条件之一就可以成功 **预防系统发生死锁** ,但是会导致 **低效的进程运行** 和 **资源使用率** 。而死锁的避免相反,它的角度是允许系统中**同时存在四个必要条件** ,只要掌握并发进程中与每个进程有关的资源动态申请情况,做出 **明智和合理的选择** ,仍然可以避免死锁,因为四大条件仅仅是产生死锁的必要条件。
+
+我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在为申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
+
+> 如果操作系统能够保证所有的进程在有限的时间内得到需要的全部资源,则称系统处于安全状态,否则说系统是不安全的。很显然,系统处于安全状态则不会发生死锁,系统若处于不安全状态则可能发生死锁。
+
+那么如何保证系统保持在安全状态呢?通过算法,其中最具有代表性的 **避免死锁算法** 就是 Dijkstra 的银行家算法,银行家算法用一句话表达就是:当一个进程申请使用资源的时候,**银行家算法** 通过先 **试探** 分配给该进程资源,然后通过 **安全性算法** 判断分配后系统是否处于安全状态,若不安全则试探分配作废,让该进程继续等待,若能够进入到安全的状态,则就 **真的分配资源给该进程**。
+
+银行家算法详情可见:[《一句话+一张图说清楚——银行家算法》](https://blog.csdn.net/qq_33414271/article/details/80245715) 。
+
+操作系统教程书中讲述的银行家算法也比较清晰,可以一看.
+
+死锁的避免(银行家算法)改善了 **资源使用率低的问题** ,但是它要不断地检测每个进程对各类资源的占用和申请情况,以及做 **安全性检查** ,需要花费较多的时间。
+
+#### 死锁的检测
+
+对资源的分配加以限制可以 **预防和避免** 死锁的发生,但是都不利于各进程对系统资源的**充分共享**。解决死锁问题的另一条途径是 **死锁检测和解除** (这里突然联想到了乐观锁和悲观锁,感觉死锁的检测和解除就像是 **乐观锁** ,分配资源时不去提前管会不会发生死锁了,等到真的死锁出现了再来解决嘛,而 **死锁的预防和避免** 更像是悲观锁,总是觉得死锁会出现,所以在分配资源的时候就很谨慎)。
+
+这种方法对资源的分配不加以任何限制,也不采取死锁避免措施,但系统 **定时地运行一个 “死锁检测”** 的程序,判断系统内是否出现死锁,如果检测到系统发生了死锁,再采取措施去解除它。
+
+##### 进程-资源分配图
+
+操作系统中的每一刻时刻的**系统状态**都可以用**进程-资源分配图**来表示,进程-资源分配图是描述进程和资源申请及分配关系的一种有向图,可用于**检测系统是否处于死锁状态**。
+
+用一个方框表示每一个资源类,方框中的黑点表示该资源类中的各个资源,用一个圆圈表示每一个进程,用 **有向边** 来表示**进程申请资源和资源被分配的情况**。
+
+图中 2-21 是**进程-资源分配图**的一个例子,其中共有三个资源类,每个进程的资源占有和申请情况已清楚地表示在图中。在这个例子中,由于存在 **占有和等待资源的环路** ,导致一组进程永远处于等待资源的状态,发生了 **死锁**。
+
+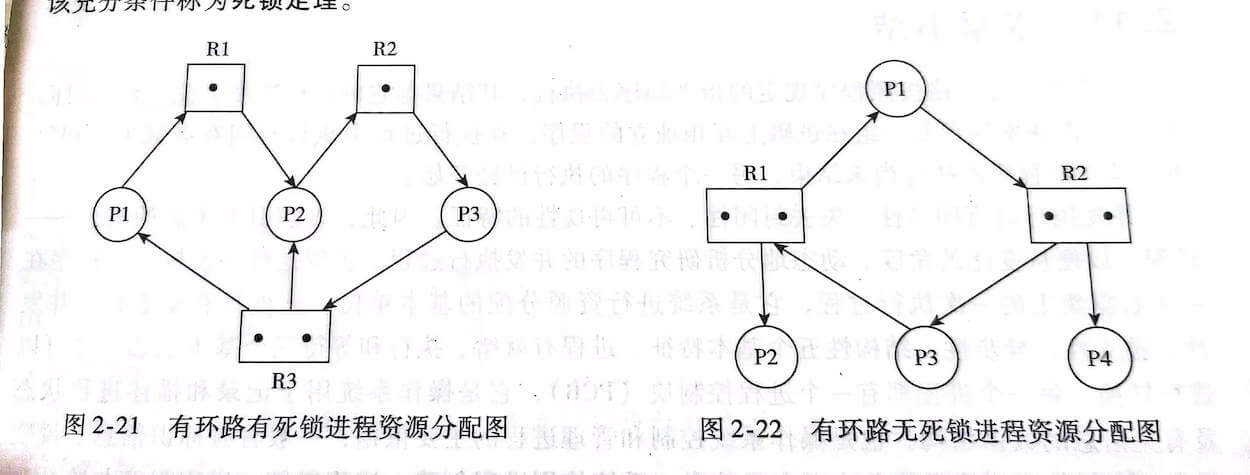
+
+进程-资源分配图中存在环路并不一定是发生了死锁。因为循环等待资源仅仅是死锁发生的必要条件,而不是充分条件。图 2-22 便是一个有环路而无死锁的例子。虽然进程 P1 和进程 P3 分别占用了一个资源 R1 和一个资源 R2,并且因为等待另一个资源 R2 和另一个资源 R1 形成了环路,但进程 P2 和进程 P4 分别占有了一个资源 R1 和一个资源 R2,它们申请的资源得到了满足,在有限的时间里会归还资源,于是进程 P1 或 P3 都能获得另一个所需的资源,环路自动解除,系统也就不存在死锁状态了。
+
+##### 死锁检测步骤
+
+知道了死锁检测的原理,我们可以利用下列步骤编写一个 **死锁检测** 程序,检测系统是否产生了死锁。
+
+1. 如果进程-资源分配图中无环路,则此时系统没有发生死锁
+2. 如果进程-资源分配图中有环路,且每个资源类仅有一个资源,则系统中已经发生了死锁。
+3. 如果进程-资源分配图中有环路,且涉及到的资源类有多个资源,此时系统未必会发生死锁。如果能在进程-资源分配图中找出一个 **既不阻塞又非独立的进程** ,该进程能够在有限的时间内归还占有的资源,也就是把边给消除掉了,重复此过程,直到能在有限的时间内 **消除所有的边** ,则不会发生死锁,否则会发生死锁。(消除边的过程类似于 **拓扑排序**)
+
+#### 死锁的解除
+
+当死锁检测程序检测到存在死锁发生时,应设法让其解除,让系统从死锁状态中恢复过来,常用的解除死锁的方法有以下四种:
+
+1. **立即结束所有进程的执行,重新启动操作系统**:这种方法简单,但以前所在的工作全部作废,损失很大。
+2. **撤销涉及死锁的所有进程,解除死锁后继续运行**:这种方法能彻底打破**死锁的循环等待**条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
+3. **逐个撤销涉及死锁的进程,回收其资源直至死锁解除。**
+4. **抢占资源**:从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
+
+## 参考
+
+- 《计算机操作系统—汤小丹》第四版
+- 《深入理解计算机系统》
+- 《重学操作系统》
+- 操作系统为什么要分用户态和内核态:
+- 从根上理解用户态与内核态:
+- 什么是僵尸进程与孤儿进程:
+
+
+
diff --git a/docs_en/cs-basics/operating-system/operating-system-basic-questions-02.en.md b/docs_en/cs-basics/operating-system/operating-system-basic-questions-02.en.md
new file mode 100644
index 00000000000..bc26a6b4731
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/operating-system-basic-questions-02.en.md
@@ -0,0 +1,418 @@
+---
+title: 操作系统常见面试题总结(下)
+category: 计算机基础
+tag:
+ - 操作系统
+head:
+ - - meta
+ - name: keywords
+ content: 操作系统面试题,虚拟内存详解,分页 vs 分段,页面置换算法,内存碎片,伙伴系统,TLB快表,页缺失,文件系统基础,磁盘调度算法,硬链接 vs 软链接
+ - - meta
+ - name: description
+ content: 最新操作系统高频面试题总结(下):虚拟内存映射、内存碎片/伙伴系统、TLB+页缺失处理、分页分段对比、页面置换算法详解、文件系统&磁盘调度,附图表+⭐️重点标注,一文掌握OS内存/文件考点,快速通关后端面试!
+---
+
+## 内存管理
+
+### 内存管理主要做了什么?
+
+
+
+操作系统的内存管理非常重要,主要负责下面这些事情:
+
+- **内存的分配与回收**:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
+- **地址转换**:将程序中的虚拟地址转换成内存中的物理地址。
+- **内存扩充**:当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
+- **内存映射**:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
+- **内存优化**:通过调整内存分配策略和回收算法来优化内存使用效率。
+- **内存安全**:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
+- ……
+
+### 什么是内存碎片?
+
+内存碎片是由内存的申请和释放产生的,通常分为下面两种:
+
+- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)**:已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
+- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并未分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
+
+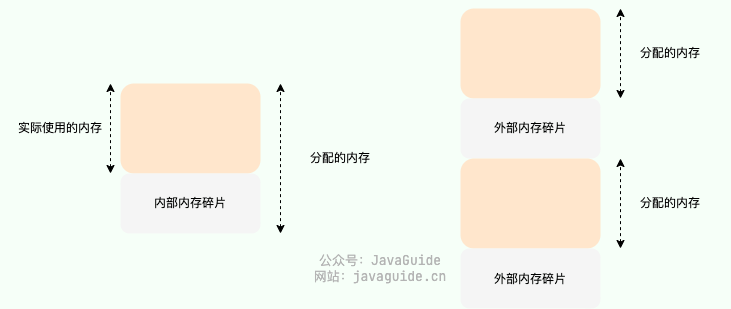
+
+内存碎片会导致内存利用率下降,如何减少内存碎片是内存管理要非常重视的一件事情。
+
+### 常见的内存管理方式有哪些?
+
+内存管理方式可以简单分为下面两种:
+
+- **连续内存管理**:为一个用户程序分配一个连续的内存空间,内存利用率一般不高。
+- **非连续内存管理**:允许一个程序使用的内存分布在离散或者说不相邻的内存中,相对更加灵活一些。
+
+#### 连续内存管理
+
+**块式管理** 是早期计算机操作系统的一种连续内存管理方式,存在严重的内存碎片问题。块式管理会将内存分为几个固定大小的块,每个块中只包含一个进程。如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,我们称之为内部内存碎片。除了内部内存碎片之外,由于两个内存块之间可能还会有外部内存碎片,这些不连续的外部内存碎片由于太小了无法再进行分配。
+
+在 Linux 系统中,连续内存管理采用了 **伙伴系统(Buddy System)算法** 来实现,这是一种经典的连续内存分配算法,可以有效解决外部内存碎片的问题。伙伴系统的主要思想是将内存按 2 的幂次划分(每一块内存大小都是 2 的幂次比如 2^6=64 KB),并将相邻的内存块组合成一对伙伴(注意:**必须是相邻的才是伙伴**)。
+
+当进行内存分配时,伙伴系统会尝试找到大小最合适的内存块。如果找到的内存块过大,就将其一分为二,分成两个大小相等的伙伴块。如果还是大的话,就继续切分,直到到达合适的大小为止。
+
+假设两块相邻的内存块都被释放,系统会将这两个内存块合并,进而形成一个更大的内存块,以便后续的内存分配。这样就可以减少内存碎片的问题,提高内存利用率。
+
+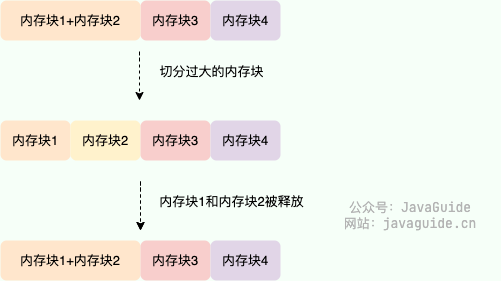
+
+虽然解决了外部内存碎片的问题,但伙伴系统仍然存在内存利用率不高的问题(内部内存碎片)。这主要是因为伙伴系统只能分配大小为 2^n 的内存块,因此当需要分配的内存大小不是 2^n 的整数倍时,会浪费一定的内存空间。举个例子:如果要分配 65 大小的内存快,依然需要分配 2^7=128 大小的内存块。
+
+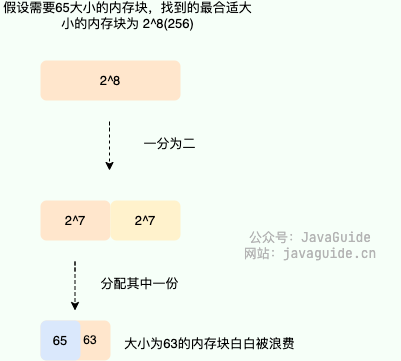
+
+对于内部内存碎片的问题,Linux 采用 **SLAB** 进行解决。由于这部分内容不是本篇文章的重点,这里就不详细介绍了。
+
+#### 非连续内存管理
+
+非连续内存管理存在下面 3 种方式:
+
+- **段式管理**:以段(一段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间也被划分为连续等长的虚拟页,是现代操作系统广泛使用的一种内存管理方式。
+- **段页式管理机制**:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+
+### 虚拟内存
+
+#### 什么是虚拟内存?有什么用?
+
+**虚拟内存(Virtual Memory)** 是计算机系统内存管理非常重要的一个技术,本质上来说它只是逻辑存在的,是一个假想出来的内存空间,主要作用是作为进程访问主存(物理内存)的桥梁并简化内存管理。
+
+
+
+总结来说,虚拟内存主要提供了下面这些能力:
+
+- **隔离进程**:物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
+- **提升物理内存利用率**:有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存。
+- **简化内存管理**:进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
+- **多个进程共享物理内存**:进程在运行过程中,会加载许多操作系统的动态库。这些库对于每个进程而言都是公用的,它们在内存中实际只会加载一份,这部分称为共享内存。
+- **提高内存使用安全性**:控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
+- **提供更大的可使用内存空间**:可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动。
+
+#### 没有虚拟内存有什么问题?
+
+如果没有虚拟内存的话,程序直接访问和操作的都是物理内存,看似少了一层中介,但多了很多问题。
+
+**具体有什么问题呢?** 这里举几个例子说明(参考虚拟内存提供的能力回答这个问题):
+
+1. 用户程序可以访问任意物理内存,可能会不小心操作到系统运行必需的内存,进而造成操作系统崩溃,严重影响系统的安全。
+2. 同时运行多个程序容易崩溃。比如你想同时运行一个微信和一个 QQ 音乐,微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就可能会造成微信这个程序会崩溃。
+3. 程序运行过程中使用的所有数据或指令都要载入物理内存,根据局部性原理,其中很大一部分可能都不会用到,白白占用了宝贵的物理内存资源。
+4. ……
+
+#### 什么是虚拟地址和物理地址?
+
+**物理地址(Physical Address)** 是真正的物理内存中地址,更具体点来说是内存地址寄存器中的地址。程序中访问的内存地址不是物理地址,而是 **虚拟地址(Virtual Address)** 。
+
+也就是说,我们编程开发的时候实际就是在和虚拟地址打交道。比如在 C 语言中,指针里面存储的数值就可以理解成为内存里的一个地址,这个地址也就是我们说的虚拟地址。
+
+操作系统一般通过 CPU 芯片中的一个重要组件 **MMU(Memory Management Unit,内存管理单元)** 将虚拟地址转换为物理地址,这个过程被称为 **地址翻译/地址转换(Address Translation)** 。
+
+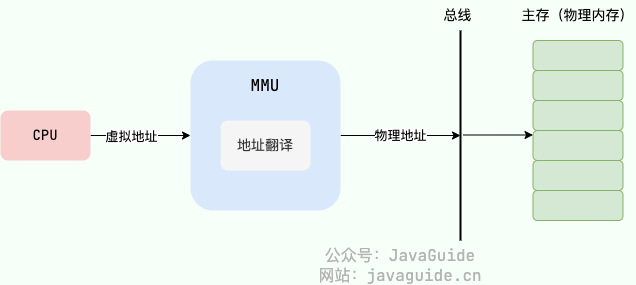
+
+通过 MMU 将虚拟地址转换为物理地址后,再通过总线传到物理内存设备,进而完成相应的物理内存读写请求。
+
+MMU 将虚拟地址翻译为物理地址的主要机制有两种: **分段机制** 和 **分页机制** 。
+
+#### 什么是虚拟地址空间和物理地址空间?
+
+- 虚拟地址空间是虚拟地址的集合,是虚拟内存的范围。每一个进程都有一个一致且私有的虚拟地址空间。
+- 物理地址空间是物理地址的集合,是物理内存的范围。
+
+#### 虚拟地址与物理内存地址是如何映射的?
+
+MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
+
+1. 分段机制
+2. 分页机制
+3. 段页机制
+
+其中,现代操作系统广泛采用分页机制,需要重点关注!
+
+### 分段机制
+
+**分段机制(Segmentation)** 以段(一段 **连续** 的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+
+#### 段表有什么用?地址翻译过程是怎样的?
+
+分段管理通过 **段表(Segment Table)** 映射虚拟地址和物理地址。
+
+分段机制下的虚拟地址由两部分组成:
+
+- **段号**:标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
+- **段内偏移量**:相对于该段起始地址的偏移量。
+
+具体的地址翻译过程如下:
+
+1. MMU 首先解析得到虚拟地址中的段号;
+2. 通过段号去该应用程序的段表中取出对应的段信息(找到对应的段表项);
+3. 从段信息中取出该段的起始地址(物理地址)加上虚拟地址中的段内偏移量得到最终的物理地址。
+
+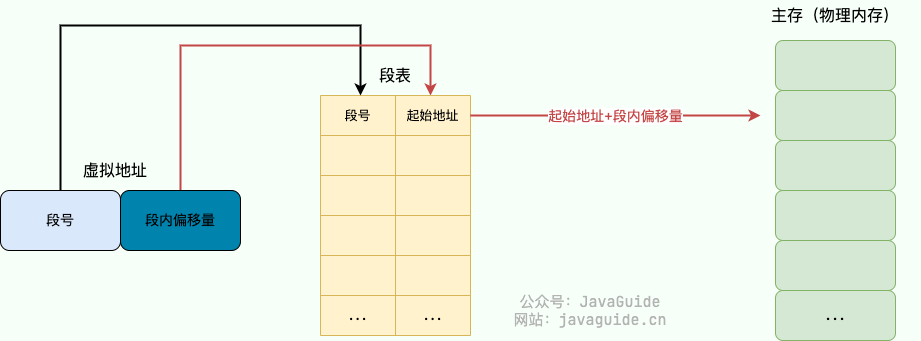
+
+段表中还存有诸如段长(可用于检查虚拟地址是否超出合法范围)、段类型(该段的类型,例如代码段、数据段等)等信息。
+
+**通过段号一定要找到对应的段表项吗?得到最终的物理地址后对应的物理内存一定存在吗?**
+
+不一定。段表项可能并不存在:
+
+- **段表项被删除**:软件错误、软件恶意行为等情况可能会导致段表项被删除。
+- **段表项还未创建**:如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
+
+#### 分段机制为什么会导致内存外部碎片?
+
+分段机制容易出现外部内存碎片,即在段与段之间留下碎片空间(不足以映射给虚拟地址空间中的段)。从而造成物理内存资源利用率的降低。
+
+举个例子:假设可用物理内存为 5G 的系统使用分段机制分配内存。现在有 4 个进程,每个进程的内存占用情况如下:
+
+- 进程 1:0~1G(第 1 段)
+- 进程 2:1~3G(第 2 段)
+- 进程 3:3~4.5G(第 3 段)
+- 进程 4:4.5~5G(第 4 段)
+
+此时,我们关闭了进程 1 和进程 4,则第 1 段和第 4 段的内存会被释放,空闲物理内存还有 1.5G。由于这 1.5G 物理内存并不是连续的,导致没办法将空闲的物理内存分配给一个需要 1.5G 物理内存的进程。
+
+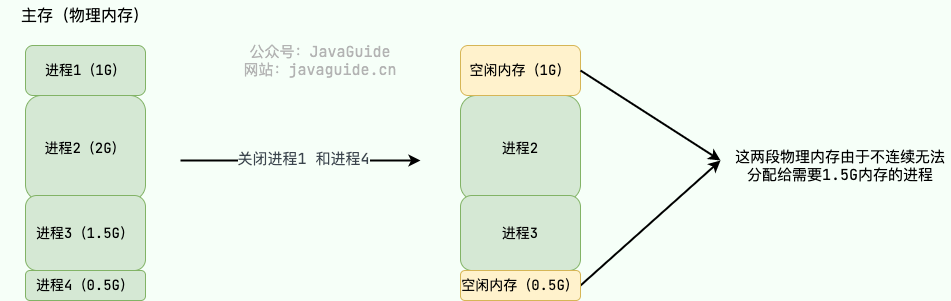
+
+### 分页机制
+
+**分页机制(Paging)** 把主存(物理内存)分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页。现代操作系统广泛采用分页机制。
+
+**注意:这里的页是连续等长的,不同于分段机制下不同长度的段。**
+
+在分页机制下,应用程序虚拟地址空间中的任意虚拟页可以被映射到物理内存中的任意物理页上,因此可以实现物理内存资源的离散分配。分页机制按照固定页大小分配物理内存,使得物理内存资源易于管理,可有效避免分段机制中外部内存碎片的问题。
+
+#### 页表有什么用?地址翻译过程是怎样的?
+
+分页管理通过 **页表(Page Table)** 映射虚拟地址和物理地址。我这里画了一张基于单级页表进行地址翻译的示意图。
+
+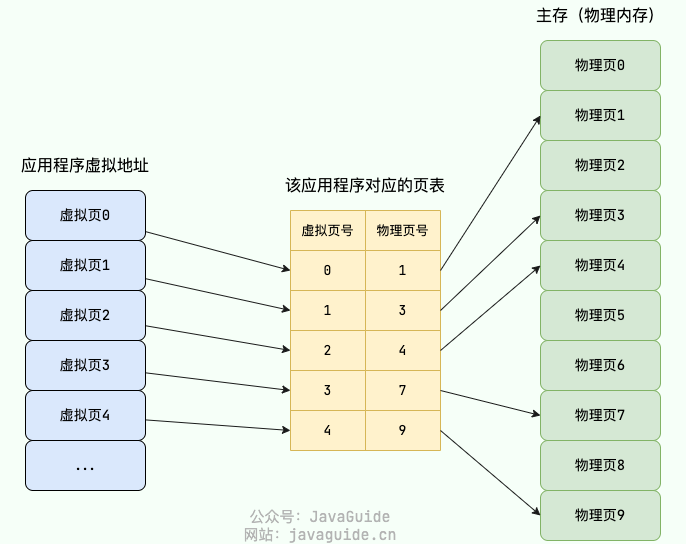
+
+在分页机制下,每个进程都会有一个对应的页表。
+
+分页机制下的虚拟地址由两部分组成:
+
+- **页号**:通过虚拟页号可以从页表中取出对应的物理页号;
+- **页内偏移量**:物理页起始地址+页内偏移量=物理内存地址。
+
+具体的地址翻译过程如下:
+
+1. MMU 首先解析得到虚拟地址中的虚拟页号;
+2. 通过虚拟页号去该应用程序的页表中取出对应的物理页号(找到对应的页表项);
+3. 用该物理页号对应的物理页起始地址(物理地址)加上虚拟地址中的页内偏移量得到最终的物理地址。
+
+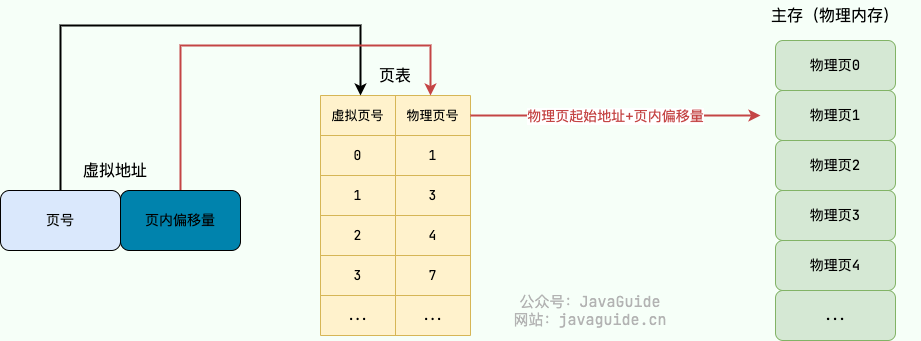
+
+页表中还存有诸如访问标志(标识该页面有没有被访问过)、脏数据标识位等信息。
+
+**通过虚拟页号一定要找到对应的物理页号吗?找到了物理页号得到最终的物理地址后对应的物理页一定存在吗?**
+
+不一定!可能会存在 **页缺失** 。也就是说,物理内存中没有对应的物理页或者物理内存中有对应的物理页但虚拟页还未和物理页建立映射(对应的页表项不存在)。关于页缺失的内容,后面会详细介绍到。
+
+#### 单级页表有什么问题?为什么需要多级页表?
+
+以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`2^20 * 2^2 / 1024 * 1024= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
+
+系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了。
+
+为了解决这个问题,操作系统引入了 **多级页表** ,多级页表对应多个页表,每个页表与前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表。
+
+这里以二级页表为例进行介绍:二级列表分为一级页表和二级页表。一级页表共有 1024 个页表项,一级页表又关联二级页表,二级页表同样共有 1024 个页表项。二级页表中的一级页表项是一对多的关系,二级页表按需加载(只会用到很少一部分二级页表),进而节省空间占用。
+
+假设只需要 2 个二级页表,那两级页表的内存占用情况为: 4KB(一级页表占用) + 4KB \* 2(二级页表占用) = 12 KB。
+
+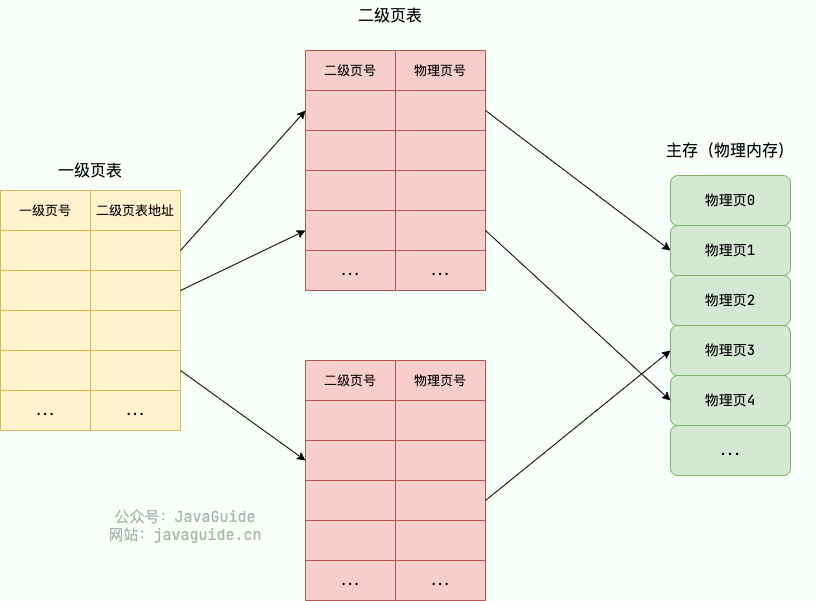
+
+多级页表属于时间换空间的典型场景,利用增加页表查询的次数减少页表占用的空间。
+
+#### TLB 有什么用?使用 TLB 之后的地址翻译流程是怎样的?
+
+为了提高虚拟地址到物理地址的转换速度,操作系统在 **页表方案** 基础之上引入了 **转址旁路缓存(Translation Lookaside Buffer,TLB,也被称为快表)** 。
+
+
+
+在主流的 AArch64 和 x86-64 体系结构下,TLB 属于 (Memory Management Unit,内存管理单元) 内部的单元,本质上就是一块高速缓存(Cache),缓存了虚拟页号到物理页号的映射关系,你可以将其简单看作是存储着键(虚拟页号)值(物理页号)对的哈希表。
+
+使用 TLB 之后的地址翻译流程是这样的:
+
+1. 用虚拟地址中的虚拟页号作为 key 去 TLB 中查询;
+2. 如果能查到对应的物理页的话,就不用再查询页表了,这种情况称为 TLB 命中(TLB hit)。
+3. 如果不能查到对应的物理页的话,还是需要去查询主存中的页表,同时将页表中的该映射表项添加到 TLB 中,这种情况称为 TLB 未命中(TLB miss)。
+4. 当 TLB 填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
+
+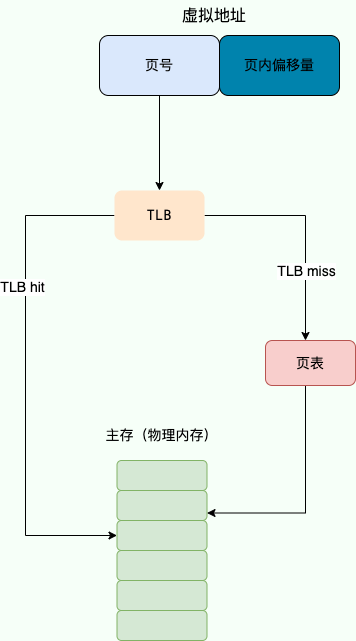
+
+由于页表也在主存中,因此在没有 TLB 之前,每次读写内存数据时 CPU 要访问两次主存。有了 TLB 之后,对于存在于 TLB 中的页表数据只需要访问一次主存即可。
+
+TLB 的设计思想非常简单,但命中率往往非常高,效果很好。这就是因为被频繁访问的页就是其中的很小一部分。
+
+看完了之后你会发现快表和我们平时经常在开发系统中使用的缓存(比如 Redis)很像,的确是这样的,操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。
+
+#### 换页机制有什么用?
+
+换页机制的思想是当物理内存不够用的时候,操作系统选择将一些物理页的内容放到磁盘上去,等要用到的时候再将它们读取到物理内存中。也就是说,换页机制利用磁盘这种较低廉的存储设备扩展的物理内存。
+
+这也就解释了一个日常使用电脑常见的问题:为什么操作系统中所有进程运行所需的物理内存即使比真实的物理内存要大一些,这些进程也是可以正常运行的,只是运行速度会变慢。
+
+这同样是一种时间换空间的策略,你用 CPU 的计算时间,页的调入调出花费的时间,换来了一个虚拟的更大的物理内存空间来支持程序的运行。
+
+#### 什么是页缺失?
+
+根据维基百科:
+
+> 页缺失(Page Fault,又名硬错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等)指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由 MMU 所发出的中断。
+
+常见的页缺失有下面这两种:
+
+- **硬性页缺失(Hard Page Fault)**:物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
+- **软性页缺失(Soft Page Fault)**:物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Handler 会指示 MMU 建立相应的虚拟页和物理页的映射关系。
+
+发生上面这两种缺页错误的时候,应用程序访问的是有效的物理内存,只是出现了物理页缺失或者虚拟页和物理页的映射关系未建立的问题。如果应用程序访问的是无效的物理内存的话,还会出现 **无效缺页错误(Invalid Page Fault)** 。
+
+#### 常见的页面置换算法有哪些?
+
+当发生硬性页缺失时,如果物理内存中没有空闲的物理页面可用的话。操作系统就必须将物理内存中的一个物理页淘汰出去,这样就可以腾出空间来加载新的页面了。
+
+用来选择淘汰哪一个物理页的规则叫做 **页面置换算法** ,我们可以把页面置换算法看成是淘汰物物理页的规则。
+
+页缺失太频繁的发生会非常影响性能,一个好的页面置换算法应该是可以减少页缺失出现的次数。
+
+常见的页面置换算法有下面这 5 种(其他还有很多页面置换算法都是基于这些算法改进得来的):
+
+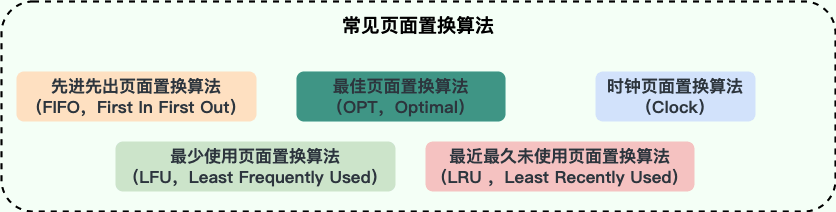
+
+1. **最佳页面置换算法(OPT,Optimal)**:优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
+2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可满足需求。不过,它的性能并不是很好。
+3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)**:LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
+4. **最少使用页面置换算法(LFU,Least Frequently Used)** : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
+5. **时钟页面置换算法(Clock)**:可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
+
+**FIFO 页面置换算法性能为何不好?**
+
+主要原因主要有二:
+
+1. **经常访问或者需要长期存在的页面会被频繁调入调出**:较早调入的页往往是经常被访问或者需要长期存在的页,这些页会被反复调入和调出。
+2. **存在 Belady 现象**:被置换的页面并不是进程不会访问的,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。出现该异常的原因是因为 FIFO 算法只考虑了页面进入内存的顺序,而没有考虑页面访问的频率和紧迫性。
+
+**哪一种页面置换算法实际用的比较多?**
+
+LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT 的页面置换算法。
+
+不过,需要注意的是,实际应用中这些算法会被做一些改进,就比如 InnoDB Buffer Pool( InnoDB 缓冲池,MySQL 数据库中用于管理缓存页面的机制)就改进了传统的 LRU 算法,使用了一种称为"Adaptive LRU"的算法(同时结合了 LRU 和 LFU 算法的思想)。
+
+### 分页机制和分段机制有哪些共同点和区别?
+
+**共同点**:
+
+- 都是非连续内存管理的方式。
+- 都采用了地址映射的方法,将虚拟地址映射到物理地址,以实现对内存的管理和保护。
+
+**区别**:
+
+- 分页机制以页面为单位进行内存管理,而分段机制以段为单位进行内存管理。页的大小是固定的,由操作系统决定,通常为 2 的幂次方。而段的大小不固定,取决于我们当前运行的程序。
+- 页是物理单位,即操作系统将物理内存划分成固定大小的页面,每个页面的大小通常是 2 的幂次方,例如 4KB、8KB 等等。而段则是逻辑单位,是为了满足程序对内存空间的逻辑需求而设计的,通常根据程序中数据和代码的逻辑结构来划分。
+- 分段机制容易出现外部内存碎片,即在段与段之间留下碎片空间(不足以映射给虚拟地址空间中的段)。分页机制解决了外部内存碎片的问题,但仍然可能会出现内部内存碎片。
+- 分页机制采用了页表来完成虚拟地址到物理地址的映射,页表通过一级页表和二级页表来实现多级映射;而分段机制则采用了段表来完成虚拟地址到物理地址的映射,每个段表项中记录了该段的起始地址和长度信息。
+- 分页机制对程序没有任何要求,程序只需要按照虚拟地址进行访问即可;而分段机制需要程序员将程序分为多个段,并且显式地使用段寄存器来访问不同的段。
+
+### 段页机制
+
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
+
+在段页式机制下,地址翻译的过程分为两个步骤:
+
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
+
+### 局部性原理
+
+要想更好地理解虚拟内存技术,必须要知道计算机中著名的 **局部性原理(Locality Principle)**。另外,局部性原理既适用于程序结构,也适用于数据结构,是非常重要的一个概念。
+
+局部性原理是指在程序执行过程中,数据和指令的访问存在一定的空间和时间上的局部性特点。其中,时间局部性是指一个数据项或指令在一段时间内被反复使用的特点,空间局部性是指一个数据项或指令在一段时间内与其相邻的数据项或指令被反复使用的特点。
+
+在分页机制中,页表的作用是将虚拟地址转换为物理地址,从而完成内存访问。在这个过程中,局部性原理的作用体现在两个方面:
+
+- **时间局部性**:由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取。
+- **空间局部性**:由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度。
+
+总之,局部性原理是计算机体系结构设计的重要原则之一,也是许多优化算法的基础。在分页机制中,利用时间局部性和空间局部性,采用缓存和预取技术,可以提高页面的命中率,从而提高内存访问效率
+
+## 文件系统
+
+### 文件系统主要做了什么?
+
+文件系统主要负责管理和组织计算机存储设备上的文件和目录,其功能包括以下几个方面:
+
+1. **存储管理**:将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突。
+2. **文件管理**:文件的创建、删除、移动、重命名、压缩、加密、共享等等。
+3. **目录管理**:目录的创建、删除、移动、重命名等等。
+4. **文件访问控制**:管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性。
+
+### 硬链接和软链接有什么区别?
+
+在 Linux/类 Unix 系统上,文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。常见的文件链接类型有两种:
+
+**1、硬链接(Hard Link)**
+
+- 在 Linux/类 Unix 文件系统中,每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的(可以看作是互为硬链接,源头是同一份文件),删除其中任何一个对另外一个没有影响,可以通过给文件设置硬链接文件来防止重要文件被误删。
+- 只有删除了源文件和所有对应的硬链接文件,该文件才会被真正删除。
+- 硬链接具有一些限制,不能对目录以及不存在的文件创建硬链接,并且,硬链接也不能跨越文件系统。
+- `ln` 命令用于创建硬链接。
+
+**2、软链接(Symbolic Link 或 Symlink)**
+
+- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
+- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
+- 软连接类似于 Windows 系统中的快捷方式。
+- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
+- `ln -s` 命令用于创建软链接。
+
+### 硬链接为什么不能跨文件系统?
+
+我们之前提到过,硬链接是通过 inode 节点号建立连接的,而硬链接和源文件共享相同的 inode 节点号。
+
+然而,每个文件系统都有自己的独立 inode 表,且每个 inode 表只维护该文件系统内的 inode。如果在不同的文件系统之间创建硬链接,可能会导致 inode 节点号冲突的问题,即目标文件的 inode 节点号已经在该文件系统中被使用。
+
+### 提高文件系统性能的方式有哪些?
+
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
+- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
+- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
+- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
+- **对磁盘进行合理的分区**:合理的磁盘分区方案,能够使文件系统在不同的区域存储文件,从而减少文件碎片,提高文件读写性能。
+
+### 常见的磁盘调度算法有哪些?
+
+磁盘调度算法是操作系统中对磁盘访问请求进行排序和调度的算法,其目的是提高磁盘的访问效率。
+
+一次磁盘读写操作的时间由磁盘寻道/寻找时间、延迟时间和传输时间决定。磁盘调度算法可以通过改变到达磁盘请求的处理顺序,减少磁盘寻道时间和延迟时间。
+
+常见的磁盘调度算法有下面这 6 种(其他还有很多磁盘调度算法都是基于这些算法改进得来的):
+
+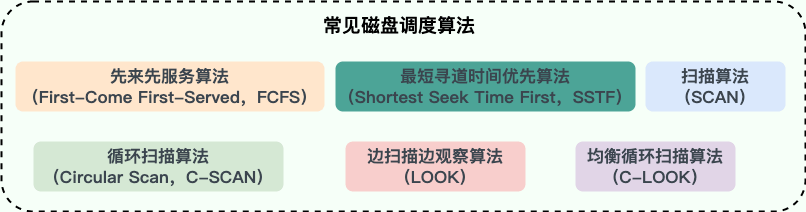
+
+1. **先来先服务算法(First-Come First-Served,FCFS)**:按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务。
+2. **最短寻道时间优先算法(Shortest Seek Time First,SSTF)**:也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题。
+3. **扫描算法(SCAN)**:也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理。
+4. **循环扫描算法(Circular Scan,C-SCAN)**:SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环。
+5. **边扫描边观察算法(LOOK)**:SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK。
+6. **均衡循环扫描算法(C-LOOK)**:C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
+
+## 参考
+
+- 《计算机操作系统—汤小丹》第四版
+- 《深入理解计算机系统》
+- 《重学操作系统》
+- 《现代操作系统原理与实现》
+- 王道考研操作系统知识点整理:
+- 内存管理之伙伴系统与 SLAB:
+- 为什么 Linux 需要虚拟内存:
+- 程序员的自我修养(七):内存缺页错误:
+- 虚拟内存的那点事儿:
+
+
+
diff --git a/docs_en/cs-basics/operating-system/shell-intro.en.md b/docs_en/cs-basics/operating-system/shell-intro.en.md
new file mode 100644
index 00000000000..f915c0f4c77
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/shell-intro.en.md
@@ -0,0 +1,537 @@
+---
+title: Shell 编程基础知识总结
+category: 计算机基础
+tag:
+ - 操作系统
+ - Linux
+head:
+ - - meta
+ - name: description
+ content: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+ - - meta
+ - name: keywords
+ content: Shell,脚本,命令,自动化,运维,Linux,基础语法
+---
+
+Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
+
+这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+
+## 走进 Shell 编程的大门
+
+### 为什么要学 Shell?
+
+学一个东西,我们大部分情况都是往实用性方向着想。从工作角度来讲,学习 Shell 是为了提高我们自己工作效率,提高产出,让我们在更少的时间完成更多的事情。
+
+很多人会说 Shell 编程属于运维方面的知识了,应该是运维人员来做,我们做后端开发的没必要学。我觉得这种说法大错特错,相比于专门做 Linux 运维的人员来说,我们对 Shell 编程掌握程度的要求要比他们低,但是 Shell 编程也是我们必须要掌握的!
+
+目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
+
+两者之间,Shell 几乎是 IT 企业必须使用的运维自动化编程语言,特别是在运维工作中的服务监控、业务快速部署、服务启动停止、数据备份及处理、日志分析等环节里,shell 是不可缺的。Python 更适合处理复杂的业务逻辑,以及开发复杂的运维软件工具,实现通过 web 访问等。Shell 是一个命令解释器,解释执行用户所输入的命令和程序。一输入命令,就立即回应的交互的对话方式。
+
+另外,了解 shell 编程也是大部分互联网公司招聘后端开发人员的要求。下图是我截取的一些知名互联网公司对于 Shell 编程的要求。
+
+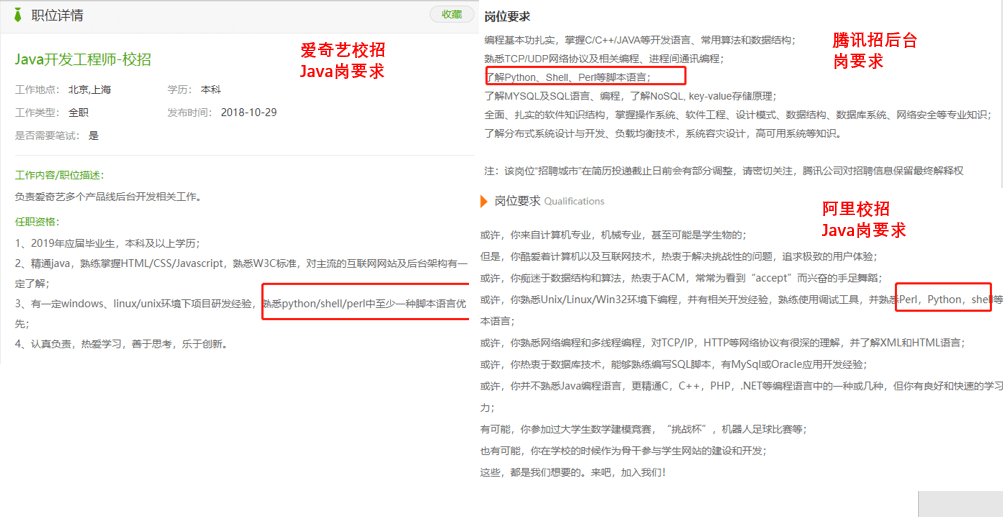
+
+### 什么是 Shell?
+
+简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。
+
+W3Cschool 上的一篇文章是这样介绍 Shell 的,如下图所示。
+
+
+### Shell 编程的 Hello World
+
+学习任何一门编程语言第一件事就是输出 HelloWorld 了!下面我会从新建文件到 shell 代码编写来说下 Shell 编程如何输出 Hello World。
+
+(1)新建一个文件 helloworld.sh :`touch helloworld.sh`,扩展名为 sh(sh 代表 Shell)(扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用 php 好了)
+
+(2) 使脚本具有执行权限:`chmod +x helloworld.sh`
+
+(3) 使用 vim 命令修改 helloworld.sh 文件:`vim helloworld.sh`(vim 文件------>进入文件----->命令模式------>按 i 进入编辑模式----->编辑文件 ------->按 Esc 进入底行模式----->输入:wq/q! (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存。))
+
+helloworld.sh 内容如下:
+
+```shell
+#!/bin/bash
+#第一个shell小程序,echo 是linux中的输出命令。
+echo "helloworld!"
+```
+
+shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在 linux 中,除了 bash shell 以外,还有很多版本的 shell, 例如 zsh、dash 等等...不过 bash shell 还是我们使用最多的。**
+
+(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 helloworld.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
+
+
+
+## Shell 变量
+
+### Shell 编程中的变量介绍
+
+**Shell 编程中一般分为三种变量:**
+
+1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
+2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
+3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
+
+**常用的环境变量:**
+
+> PATH 决定了 shell 将到哪些目录中寻找命令或程序
+> HOME 当前用户主目录
+> HISTSIZE 历史记录数
+> LOGNAME 当前用户的登录名
+> HOSTNAME 指主机的名称
+> SHELL 当前用户 Shell 类型
+> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
+> MAIL 当前用户的邮件存放目录
+> PS1 基本提示符,对于 root 用户是#,对于普通用户是\$
+
+**使用 Linux 已定义的环境变量:**
+
+比如我们要看当前用户目录可以使用:`echo $HOME`命令;如果我们要看当前用户 Shell 类型 可以使用`echo $SHELL`命令。可以看出,使用方法非常简单。
+
+**使用自己定义的变量:**
+
+```shell
+#!/bin/bash
+#自定义变量hello
+hello="hello world"
+echo $hello
+echo "helloworld!"
+```
+
+
+
+**Shell 编程中的变量名的命名的注意事项:**
+
+- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头,但是可以使用下划线(\_)开头。
+- 中间不能有空格,可以使用下划线(\_)。
+- 不能使用标点符号。
+- 不能使用 bash 里的关键字(可用 help 命令查看保留关键字)。
+
+### Shell 字符串入门
+
+字符串是 shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和 Java 中有所不同。
+
+在单引号中所有的特殊符号,如$和反引号都没有特殊含义。在双引号中,除了"$"、"\\"、反引号和感叹号(需开启 `history expansion`),其他的字符没有特殊含义。
+
+**单引号字符串:**
+
+```shell
+#!/bin/bash
+name='SnailClimb'
+hello='Hello, I am $name!'
+echo $hello
+```
+
+输出内容:
+
+```plain
+Hello, I am $name!
+```
+
+**双引号字符串:**
+
+```shell
+#!/bin/bash
+name='SnailClimb'
+hello="Hello, I am $name!"
+echo $hello
+```
+
+输出内容:
+
+```plain
+Hello, I am SnailClimb!
+```
+
+### Shell 字符串常见操作
+
+**拼接字符串:**
+
+```shell
+#!/bin/bash
+name="SnailClimb"
+# 使用双引号拼接
+greeting="hello, "$name" !"
+greeting_1="hello, ${name} !"
+echo $greeting $greeting_1
+# 使用单引号拼接
+greeting_2='hello, '$name' !'
+greeting_3='hello, ${name} !'
+echo $greeting_2 $greeting_3
+```
+
+Output result:
+
+
+
+**Get string length:**
+
+```shell
+#!/bin/bash
+#Get the string length
+name="SnailClimb"
+# The first way
+echo ${#name} #output 10
+# The second way
+expr length "$name";
+```
+
+Output result:
+
+```plain
+10
+10
+```
+
+When using the expr command, spaces must be included around the operator in the expression. If no spaces are included, the expression itself will be output:
+
+```shell
+expr 5+6 // Directly output 5+6
+expr 5 + 6 //output 11
+```
+
+For some operators, we also need to use the symbol `\` to escape, otherwise a syntax error will be prompted.
+
+```shell
+expr 5 * 6 // Output error
+expr 5 \* 6 // Output 30
+```
+
+**Intercept substring:**
+
+Simple string interception:
+
+```shell
+#Truncate 10 characters starting from the first character of the string
+str="SnailClimb is a great man"
+echo ${str:0:10} #Output:SnailClimb
+```
+
+Intercept based on expression:
+
+```shell
+#!bin/bash
+#author:amau
+
+var="https://www.runoob.com/linux/linux-shell-variable.html"
+# % means delete the next match, the shortest result
+# %% means delete the matching from the end, the longest matching result
+# #Indicates deleting matches from the beginning, the shortest result
+# ## indicates deleting the match from the beginning and the longest matching result
+# Note: * is a wildcard character, meaning to match any number of any characters
+s1=${var%%t*} #h
+s2=${var%t*} #https://www.runoob.com/linux/linux-shell-variable.h
+s3=${var%%.*} #https://www
+s4=${var#*/} #/www.runoob.com/linux/linux-shell-variable.html
+s5=${var##*/} #linux-shell-variable.html
+```
+
+### Shell array
+
+bash supports one-dimensional arrays (not multi-dimensional arrays) and does not limit the size of the array. I give you a shell code example about array operations below. Through this example, you can know how to create an array, get the length of the array, get/delete the array element at a specific position, delete the entire array, and traverse the array.
+
+```shell
+#!/bin/bash
+array=(1 2 3 4 5);
+# Get the length of the array
+length=${#array[@]}
+# or
+length2=${#array[*]}
+#Output array length
+echo $length #Output: 5
+echo $length2 #Output: 5
+# Output the third element of the array
+echo ${array[2]} #Output: 3
+unset array[1]# Deleting the element with subscript 1 means deleting the second element
+for i in ${array[@]};do echo $i ;done # Traverse the array, output: 1 3 4 5
+unset array; #Delete all elements in the array
+for i in ${array[@]};do echo $i ;done # Traverse the array, the array elements are empty and there is no output content
+```
+
+## Shell basic operators
+
+> Description: The picture comes from "Rookie Tutorial"
+
+Shell programming supports the following operators
+
+- Arithmetic operators
+- Relational operators
+- Boolean operators
+- String operators
+- File test operator
+
+### Arithmetic operators
+
+
+
+I use the addition operator to make a simple example (note: not single quotes, but backticks):
+
+```shell
+#!/bin/bash
+a=3;b=3;
+val=`expr $a + $b`
+#Output: Total value: 6
+echo "Total value : $val"
+```
+
+### Relational operators
+
+Relational operators only support numbers, not strings, unless the value of the string is a number.
+
+
+
+A simple example demonstrates the use of relational operators. The function of the following shell program is to output A when score=100, otherwise output B.
+
+```shell
+#!/bin/bash
+score=90;
+maxscore=100;
+if [ $score -eq $maxscore ]
+then
+ echo "A"
+else
+ echo "B"
+fi
+```
+
+Output result:
+
+```plain
+B
+```
+
+### Logical operators
+
+
+
+Example:
+
+```shell
+#!/bin/bash
+a=$(( 1 && 0))
+# Output: 0; for logical AND operations, only if both sides of the AND are 1, the result of the AND is 1; otherwise, the result of the AND is 0
+echo $a;
+```
+
+### Boolean operators
+
+
+
+I won’t do a demonstration here, it should be pretty simple.
+
+### String operators
+
+
+
+Simple example:
+
+```shell
+#!/bin/bash
+a="abc";
+b="efg";
+if [ $a = $b ]
+then
+ echo "a equals b"
+else
+ echo "a is not equal to b"
+fi
+```
+
+Output:
+
+```plain
+a is not equal to b
+```
+
+### File related operators
+
+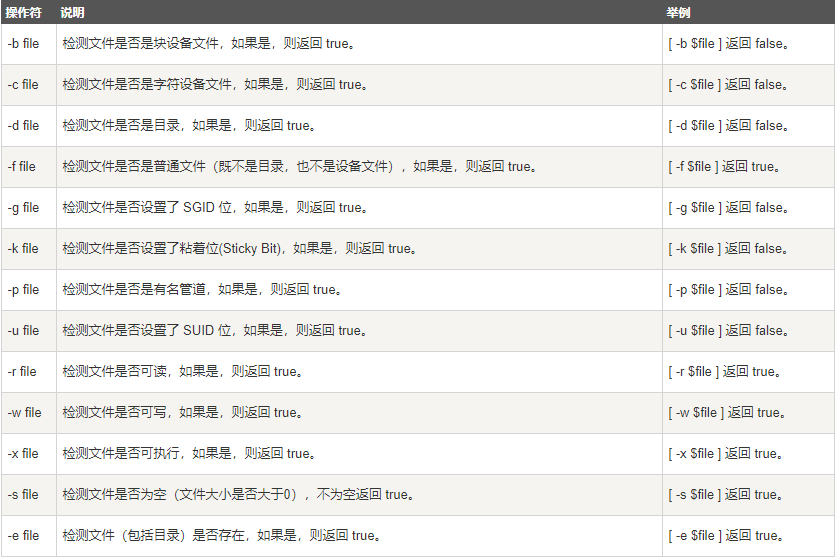
+
+The usage is very simple. For example, we have defined a file path `file="/usr/learnshell/test.sh"`. If we want to determine whether the file is readable, we can do this `if [ -r $file ]`. If we want to determine whether the file is writable, we can do this `-w $file`. Isn’t it very simple?
+
+## Shell process control
+
+### if conditional statement
+
+Simple if else-if else conditional statement example
+
+```shell
+#!/bin/bash
+a=3;
+b=9;
+if [ $a -eq $b ]
+then
+ echo "a equals b"
+elif [ $a -gt $b ]
+then
+ echo "a is greater than b"
+else
+ echo "a is less than b"
+fi
+```
+
+Output result:
+
+```plain
+a is less than b
+```
+
+I believe that through the above examples, you have mastered the if conditional statement in shell programming. However, one thing to mention is that unlike our common if conditional statements in Java and PHP, shell if conditional statements cannot contain empty statements, which are statements that do nothing.
+
+### for loop statement
+
+Learn the most basic use of the for loop statement through the following three simple examples. In fact, the function of the for loop statement is much greater than the examples you see below.
+
+**Output the data in the current list:**
+
+```shell
+for loop in 1 2 3 4 5
+do
+ echo "The value is: $loop"
+done
+```
+
+**Generate 10 random numbers:**
+
+```shell
+#!/bin/bash
+for i in {0..9};
+do
+ echo $RANDOM;
+done
+```
+
+**Output 1 to 5:**
+
+Normally, you need to add \$ when calling shell variables, but it is not required in (()) of for. Let’s look at an example:
+
+```shell
+#!/bin/bash
+length=5
+for((i=1;i<=length;i++));do
+ echo $i;
+done;
+```
+
+### while statement
+
+**Basic while loop statement:**
+
+```shell
+#!/bin/bash
+int=1
+while(( $int<=5 ))
+do
+ echo $int
+ let "int++"
+done
+```
+
+**while loop can be used to read keyboard information:**
+
+```shell
+echo 'Press to exit'
+echo -n 'Enter your favorite movie: '
+while read FILM
+do
+ echo "Yes! $FILM is a good movie"
+done
+```
+
+Output content:
+
+```plain
+Press to exit
+Enter your favorite movie: Transformers
+Yes! Transformers is a good movie
+```**Infinite Loop:**
+
+```shell
+while true
+do
+ command
+done
+```
+
+## Shell function
+
+### Function with no parameters and no return value
+
+```shell
+#!/bin/bash
+hello(){
+ echo "This is my first shell function!"
+}
+echo "-----Function starts execution-----"
+hello
+echo "-----Function execution completed-----"
+```
+
+Output result:
+
+```plain
+-----Function starts execution-----
+This is my first shell function!
+-----Function execution completed-----
+```
+
+### Functions with return values
+
+**Add two numbers after inputting them and return the result: **
+
+```shell
+#!/bin/bash
+funWithReturn(){
+ echo "Enter the first number: "
+ read aNum
+ echo "Enter the second number: "
+ read anotherNum
+ echo "The two numbers are $aNum and $anotherNum!"
+ return $(($aNum+$anotherNum))
+}
+funWithReturn
+echo "The sum of the two numbers entered is $?"
+```
+
+Output result:
+
+```plain
+Enter the first number:
+1
+Enter the second number:
+2
+The two numbers are 1 and 2!
+The sum of the two numbers entered is 3
+```
+
+### Function with parameters
+
+```shell
+#!/bin/bash
+funWithParam(){
+ echo "The first parameter is $1 !"
+ echo "The second parameter is $2 !"
+ echo "The tenth parameter is $10!"
+ echo "The tenth parameter is ${10} !"
+ echo "The eleventh parameter is ${11} !"
+ echo "The total number of parameters is $#!"
+ echo "Output all parameters as a string $* !"
+}
+funWithParam 1 2 3 4 5 6 7 8 9 34 73
+```
+
+Output result:
+
+```plain
+The first parameter is 1 !
+The second parameter is 2!
+The tenth parameter is 10!
+The tenth parameter is 34!
+The eleventh parameter is 73!
+There are 11 parameters in total!
+Output all parameters as a string 1 2 3 4 5 6 7 8 9 34 73 !
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/basis.en.md b/docs_en/database/basis.en.md
new file mode 100644
index 00000000000..c47e63af29f
--- /dev/null
+++ b/docs_en/database/basis.en.md
@@ -0,0 +1,238 @@
+---
+title: 数据库基础知识总结
+category: 数据库
+tag:
+ - 数据库基础
+---
+
+
+
+数据库知识基础,这部分内容一定要理解记忆。虽然这部分内容只是理论知识,但是非常重要,这是后面学习 MySQL 数据库的基础。PS: 这部分内容由于涉及太多概念性内容,所以参考了维基百科和百度百科相应的介绍。
+
+## 什么是数据库, 数据库管理系统, 数据库系统, 数据库管理员?
+
+这四个概念描述了从数据本身到管理整个体系的不同层次,我们常用一个图书馆的例子来把它们串联起来理解。
+
+- **数据库 (Database - DB):** 它就像是图书馆里,书架上存放的所有书籍和资料。从技术上讲,数据库就是按照一定数据模型组织、描述和储存起来的、可以被各种用户共享的结构化数据的集合。它就是我们最终要存取的核心——信息本身。
+- **数据库管理系统 (Database Management System - DBMS):** 它就像是整个图书馆的管理系统,包括图书的分类编目规则、借阅归还流程、安全检查系统等等。从技术上讲,DBMS 是一种大型软件,比如我们常用的 MySQL、Oracle、PostgreSQL 软件。它的核心职责是科学地组织和存储数据、高效地获取和维护数据;为我们屏蔽了底层文件操作的复杂性,提供了一套标准接口(如 SQL)来操纵数据,并负责并发控制、事务管理、权限控制等复杂问题。
+- **数据库系统 (Database System - DBS):** 它就是整个正常运转的图书馆。这是一个更大的概念,不仅包括书(DB)和管理系统(DBMS),还包括了硬件、应用和使用的人。
+- **数据库管理员 (Database Administrator - DBA ):** 他就是图书馆的馆长,负责整个数据库系统正常运行。他的职责非常广泛,包括数据库的设计、安装、监控、性能调优、备份与恢复、安全管理等等,确保整个系统的稳定、高效和安全。
+
+DB 和 DBMS 我们通常会搞混,这里再简单提一下:**通常我们说“用 MySQL 数据库”,其实是用 MySQL(DBMS)来管理一个或多个数据库(DB)。**
+
+## DBMS 有哪些主要的功能
+
+DBMS 通常提供四大核心功能:
+
+1. **数据定义:** 这是 DBMS 的基础。它提供了一套数据定义语言(Data Definition Language - DDL),让我们能够创建、修改和删除数据库中的各种对象。这不仅仅是定义表的结构(比如字段名、数据类型),还包括定义视图、索引、触发器、存储过程等。
+2. **数据操作:** 这是我们作为开发者日常使用最多的功能。它提供了一套数据操作语言(Data Manipulation Language - DML),核心就是我们熟悉的增、删、改、查(CRUD)操作。它让我们能够方便地对数据库中的数据进行操作和检索。
+3. **数据控制:** 这是保证数据正确、安全、可靠的关键。通常包含并发控制、事务管理、完整性约束、权限控制、安全性限制等功能。
+4. **数据库维护:** 这部分功能是为了保障数据库系统的长期稳定运行。它包括了数据的导入导出、数据库的备份与恢复、性能监控与分析、以及系统日志管理等。
+
+## 你知道哪些类型的 DBMS?
+
+### 关系型数据库
+
+除了我们最常用的关系型数据库(RDBMS),比如 MySQL(开源首选)、PostgreSQL(功能最全)、Oracle(企业级),它们基于严格的表结构和 SQL,非常适合结构化数据和需要事务保证的场景,例如银行交易、订单系统。
+
+近年来,为了应对互联网应用带来的海量数据、高并发和多样化数据结构的需求,涌现出了一大批 NoSQL 和 NewSQL 数据库。
+
+### NoSQL 数据库
+
+它们的共同特点是为了极致的性能和水平扩展能力,在某些方面(通常是事务)做了妥协。
+
+**1. 键值数据库,代表是 Redis。**
+
+- **特点:** 数据模型极其简单,就是一个巨大的 Map,通过 Key 来存取 Value。内存操作,性能极高。
+- **适用场景:** 非常适合做缓存、会话存储、计数器等对读写性能要求极高的场景。
+
+**2. 文档数据库,代表是 MongoDB。**
+
+- **特点:** 它存储的是半结构化的文档(比如 JSON/BSON),结构灵活,不需要预先定义表结构。
+- **适用场景:** 特别适合那些数据结构多变、快速迭代的业务,比如用户画像、内容管理系统、日志存储等。
+
+**3. 列式数据库,代表是 HBase, Cassandra。**
+
+- **特点:** 数据是按列族而不是按行来存储的。这使得它在对大量行进行少量列的读取时,性能极高。
+- **适用场景:** 专为海量数据存储和分析设计,非常适合做大数据分析、监控数据存储、推荐系统等需要高吞吐量写入和范围扫描的场景。
+
+**4. 图形数据库,代表是 Neo4j。**
+
+- **特点:** 数据模型是节点(Nodes)和边(Edges),专门用来存储和查询实体之间的复杂关系。
+- **适用场景:** 在社交网络(好友关系)、推荐引擎(用户-商品关系)、知识图谱、欺诈检测(资金流动关系)等场景下,表现远超关系型数据库。
+
+### NewSQL 数据库
+
+由于 NoSQL 不支持事务,很多对于数据安全要去非常高的系统(比如财务系统、订单系统、交易系统)就不太适合使用了。不过,这类系统往往有存储大量数据的需求。
+
+这些系统往往只能通过购买性能更强大的计算机,或者通过数据库中间件来提高存储能力。不过,前者的金钱成本太高,后者的开发成本太高。
+
+于是,**NewSQL** 就来了!
+
+简单来说,NewSQL 就是:**分布式存储+SQL+事务** 。NewSQL 不仅具有 NoSQL 对海量数据的存储管理能力,还保持了传统数据库支持 ACID 和 SQL 等特性。因此,NewSQL 也可以称为 **分布式关系型数据库**。
+
+NewSQL 数据库设计的一些目标:
+
+1. 横向扩展(Scale Out) : 通过增加机器的方式来提高系统的负载能力。与之类似的是 Scale Up(纵向扩展),升级硬件设备的方式来提高系统的负载能力。
+2. 强一致性(Strict Consistency):在任意时刻,所有节点中的数据是一样的。
+3. 高可用(High Availability):系统几乎可以一直提供服务。
+4. 支持标准 SQL(Structured Query Language) :PostgreSQL、MySQL、Oracle 等关系型数据库都支持 SQL 。
+5. 事务(ACID) : 原子性(Atomicity)、一致性(Consistency)、 隔离性(Isolation); 持久性(Durability)。
+6. 兼容主流关系型数据库 : 兼容 MySQL、Oracle、PostgreSQL 等常用关系型数据库。
+7. 云原生 (Cloud Native):可在公有云、私有云、混合云中实现部署工具化、自动化。
+8. HTAP(Hybrid Transactional/Analytical Processing) :支持 OLTP 和 OLAP 混合处理。
+
+NewSQL 数据库代表:Google 的 F1/Spanner、阿里的 [OceanBase](https://open.oceanbase.com/)、PingCAP 的 [TiDB](https://pingcap.com/zh/product-community/) 。
+
+## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
+
+- **元组**:元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
+- **码**:码就是能唯一标识实体的属性,对应表中的列。
+- **候选码**:若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
+- **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
+- **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
+- **主属性**:候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
+- **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
+
+## 什么是 ER 图?
+
+我们做一个项目的时候一定要试着画 ER 图来捋清数据库设计,这个也是面试官问你项目的时候经常会被问到的。
+
+**ER 图** 全称是 Entity Relationship Diagram(实体联系图),提供了表示实体类型、属性和联系的方法。
+
+ER 图由下面 3 个要素组成:
+
+- **实体**:通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
+- **属性**:即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
+- **联系**:即实体与实体之间的关系,在 ER 图中用菱形表示,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
+
+下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
+
+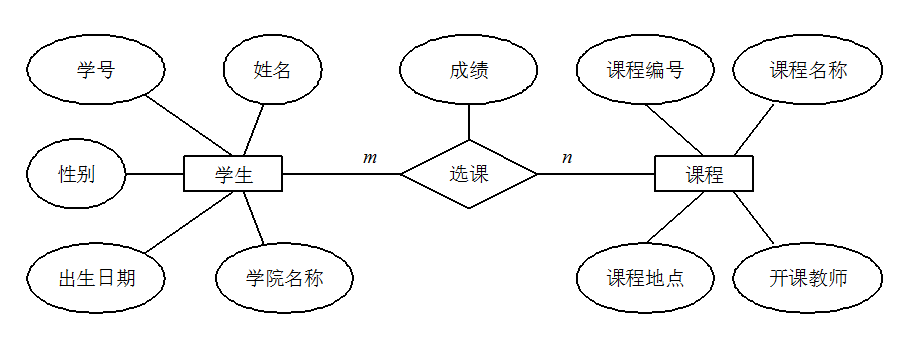
+
+## 数据库范式了解吗?
+
+数据库范式有 3 种:
+
+- 1NF(第一范式):属性不可再分。
+- 2NF(第二范式):1NF 的基础之上,消除了非主属性对于码的部分函数依赖。
+- 3NF(第三范式):3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。
+
+### 1NF(第一范式)
+
+属性(对应于表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再分为多个其他的字段了。**1NF 是所有关系型数据库的最基本要求** ,也就是说关系型数据库中创建的表一定满足第一范式。
+
+### 2NF(第二范式)
+
+2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
+
+
+
+一些重要的概念:
+
+- **函数依赖(functional dependency)**:若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
+- **部分函数依赖(partial functional dependency)**:如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖于(学号,身份证号);
+- **完全函数依赖(Full functional dependency)**:在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
+- **传递函数依赖**:在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。
+
+### 3NF(第三范式)
+
+3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。符合 3NF 要求的数据库设计,**基本**上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。
+
+## 主键和外键有什么区别?
+
+从定义和属性上看,它们的区别是:
+
+- **主键 (Primary Key):** 它的核心作用是唯一标识表中的每一行数据。因此,主键列的值必须是唯一的 (Unique) 且不能为空 (Not Null)。一张表只能有一个主键。主键保证了实体完整性。
+- **外键 (Foreign Key):** 它的核心作用是建立并强制两张表之间的关联关系。一张表中的外键列,其值必须对应另一张表中某行的主键值(或者是一个 NULL 值)。因此,外键的值可以重复,也可以为空。一张表可以有多个外键,分别关联到不同的表。外键保证了引用完整性。
+
+用一个简单的电商例子来说明:假设我们有两张表:`users` (用户表) 和 `orders` (订单表)。
+
+- 在 `users` 表中,`user_id` 列是**主键**。每个用户的 `user_id` 都是独一无二的,我们用它来区分张三和李四。
+- 在 `orders` 表中,`order_id` 是它自己的**主键**。同时,它会有一个 `user_id` 列,这个列就是一个**外键**,它引用了 `users` 表的 `user_id` 主键。
+
+这个外键约束就保证了:
+
+1. 你不能创建一个不属于任何已知用户的订单( `user_id` 在 `users` 表中不存在)。
+2. 你不能删除一个已经下了订单的用户(除非设置了级联删除等特殊规则)。
+
+## 为什么不推荐使用外键与级联?
+
+对于外键和级联,阿里巴巴开发手册这样说到:
+
+> 【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
+>
+> 说明: 以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度
+
+为什么不要用外键呢?大部分人可能会这样回答:
+
+1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如哪天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗数据库资源。如果在应用层面去维护的话,可以减小数据库压力;
+3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
+4. ……
+
+我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
+
+1. 保证了数据库数据的一致性和完整性;
+2. 级联操作方便,减轻了程序代码量;
+3. ……
+
+所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
+
+## 什么是存储过程?
+
+我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候是非常实用的,比如很多时候我们完成一个操作可能需要写一大串 SQL 语句,这时候我们就可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
+
+存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
+
+阿里巴巴 Java 开发手册里要求禁止使用存储过程。
+
+
+
+## drop、delete 与 truncate 区别?
+
+### 用法不同
+
+- `drop`(丢弃数据): `drop table 表名` ,直接将表都删除掉,在删除表的时候使用。
+- `truncate` (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
+- `delete`(删除数据) : `delete from 表名 where 列名=值`,删除某一行的数据,如果不加 `where` 子句和`truncate table 表名`作用类似。
+
+`truncate`, `delete` without `where` clause, and `drop` will delete the data in the table, but **`truncate` and `delete` only delete the data without deleting the structure (definition) of the table. When the `drop` statement is executed, the structure of the table will also be deleted, that is, the corresponding table no longer exists after executing `drop`. **
+
+### Belong to different database languages
+
+`truncate` and `drop` belong to DDL (data definition language) statements, and the operation takes effect immediately. The original data is not placed in the rollback segment, cannot be rolled back, and the operation does not trigger the trigger. The `delete` statement is a DML (database operation language) statement. This operation will be placed in the rollback segment and will only take effect after the transaction is submitted.
+
+**Differences between DML statements and DDL statements:**
+
+- DML is the abbreviation of Database Manipulation Language (Data Manipulation Language). It refers to the operation of table records in the database, mainly including the insertion, update, deletion and query of table records. It is the most frequently used operation by developers in daily life.
+- DDL (Data Definition Language) is the abbreviation of data definition language. Simply put, it is an operating language for creating, deleting, and modifying objects within the database. The biggest difference between it and the DML language is that DML only operates on the internal data of the table, and does not involve the definition of the table, modification of the structure, nor other objects. DDL statements are more commonly used by database administrators (DBAs) and are rarely used by general developers.
+
+In addition, since `select` will not destroy the table, some places also distinguish `select` separately and call it database query language DQL (Data Query Language).
+
+### Different execution speeds
+
+Generally speaking: `drop` > `truncate` > `delete` (I have not actually tested this).
+
+- When the `delete` command is executed, the `binlog` log of the database will be generated. Logging takes time, but it also has the advantage of facilitating data rollback and recovery.
+- The `truncate` command does not generate database logs when executed, so it is faster than `delete`. In addition, the auto-increment value of the table and the index will be restored to the initial size, etc.
+- The `drop` command will release all the space occupied by the table.
+
+Tips: You should focus more on usage scenarios rather than execution efficiency.
+
+## What are the usual steps of database design?
+
+1. **Requirements Analysis**: Analyze user needs, including data, functional and performance requirements.
+2. **Conceptual Structure Design**: Mainly use E-R model for design, including drawing E-R diagram.
+3. **Logical structure design**: Realize the conversion from E-R model to relational model by converting E-R diagram into table.
+4. **Physical structure design**: Mainly to select the appropriate storage structure and access path for the designed database.
+5. **Database Implementation**: including programming, testing and trial operation
+6. **Database Operation and Maintenance**: System operation and daily maintenance of the database.
+
+## Reference
+
+-
+-
+-
+
+
\ No newline at end of file
diff --git a/docs_en/database/character-set.en.md b/docs_en/database/character-set.en.md
new file mode 100644
index 00000000000..439f2ae0dd4
--- /dev/null
+++ b/docs_en/database/character-set.en.md
@@ -0,0 +1,338 @@
+---
+title: 字符集详解
+category: 数据库
+tag:
+ - 数据库基础
+head:
+ - - meta
+ - name: keywords
+ content: 字符集,编码,UTF-8,UTF-16,GBK,utf8mb4,emoji,存储与传输
+ - - meta
+ - name: description
+ content: 从编码与字符集原理入手,解释 utf8 与 utf8mb4 差异与 emoji 存储问题,指导数据库与应用的正确配置。
+---
+
+MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4`**。
+
+如果使用 **`utf8`** 的话,存储 emoji 符号和一些比较复杂的汉字、繁体字就会出错。
+
+为什么会这样呢?这篇文章可以从源头给你解答。
+
+## 字符集是什么?
+
+字符是各种文字和符号的统称,包括各个国家文字、标点符号、表情、数字等等。 **字符集** 就是一系列字符的集合。字符集的种类较多,每个字符集可以表示的字符范围通常不同,就比如说有些字符集是无法表示汉字的。
+
+**计算机只能存储二进制的数据,那英文、汉字、表情等字符应该如何存储呢?**
+
+我们要将这些字符和二进制的数据一一对应起来,比如说字符“a”对应“01100001”,反之,“01100001”对应 “a”。我们将字符对应二进制数据的过程称为"**字符编码**",反之,二进制数据解析成字符的过程称为“**字符解码**”。
+
+## 字符编码是什么?
+
+字符编码是一种将字符集中的字符与计算机中的二进制数据相互转换的方法,可以看作是一种映射规则。也就是说,字符编码的目的是为了让计算机能够存储和传输各种文字信息。
+
+每种字符集都有自己的字符编码规则,常用的字符集编码规则有 ASCII 编码、 GB2312 编码、GBK 编码、GB18030 编码、Big5 编码、UTF-8 编码、UTF-16 编码等。
+
+## 有哪些常见的字符集?
+
+常见的字符集有:ASCII、GB2312、GB18030、GBK、Unicode……。
+
+不同的字符集的主要区别在于:
+
+- 可以表示的字符范围
+- 编码方式
+
+### ASCII
+
+**ASCII** (**A**merican **S**tandard **C**ode for **I**nformation **I**nterchange,美国信息交换标准代码) 是一套主要用于现代美国英语的字符集(这也是 ASCII 字符集的局限性所在)。
+
+**为什么 ASCII 字符集没有考虑到中文等其他字符呢?** 因为计算机是美国人发明的,当时,计算机的发展还处于比较雏形的时代,还未在其他国家大规模使用。因此,美国发布 ASCII 字符集的时候没有考虑兼容其他国家的语言。
+
+ASCII 字符集至今为止共定义了 128 个字符,其中有 33 个控制字符(比如回车、删除)无法显示。
+
+一个 ASCII 码长度是一个字节也就是 8 个 bit,比如“a”对应的 ASCII 码是“01100001”。不过,最高位是 0 仅仅作为校验位,其余 7 位使用 0 和 1 进行组合,所以,ASCII 字符集可以定义 128(2^7)个字符。
+
+由于,ASCII 码可以表示的字符实在是太少了。后来,人们对其进行了扩展得到了 **ASCII 扩展字符集** 。ASCII 扩展字符集使用 8 位(bits)表示一个字符,所以,ASCII 扩展字符集可以定义 256(2^8)个字符。
+
+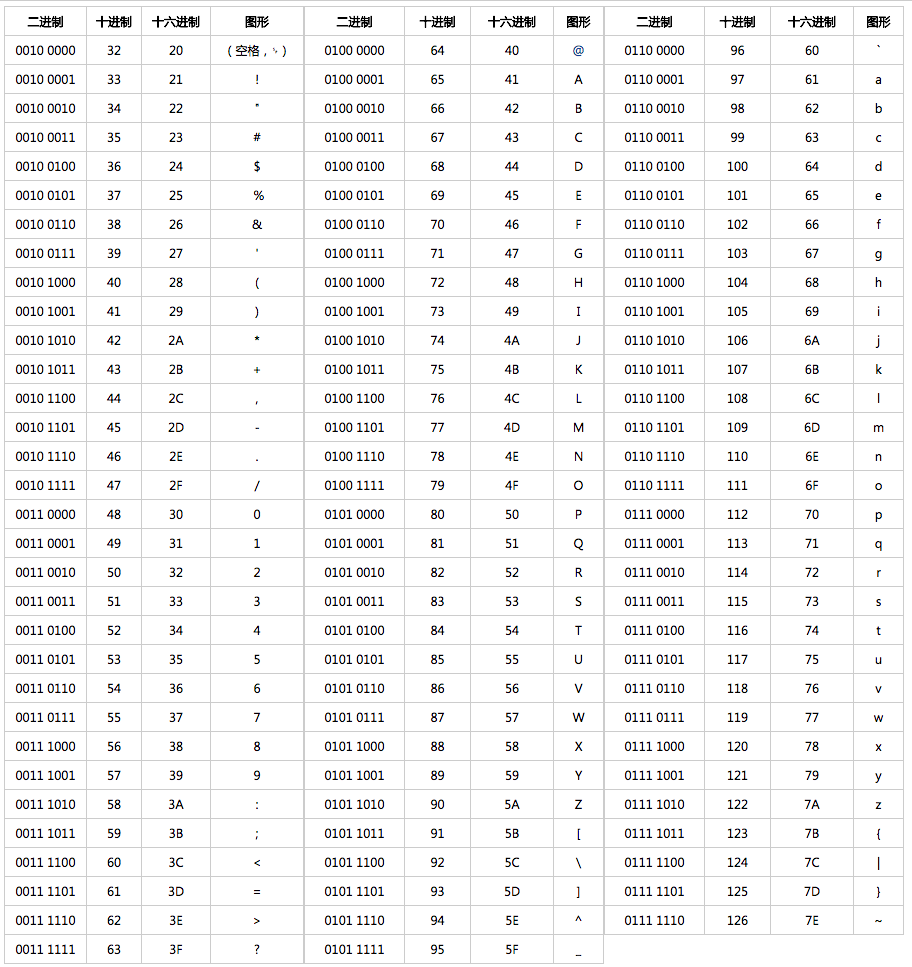
+
+### GB2312
+
+我们上面说了,ASCII 字符集是一种现代美国英语适用的字符集。因此,很多国家都捣鼓了一个适合自己国家语言的字符集。
+
+GB2312 字符集是一种对汉字比较友好的字符集,共收录 6700 多个汉字,基本涵盖了绝大部分常用汉字。不过,GB2312 字符集不支持绝大部分的生僻字和繁体字。
+
+对于英语字符,GB2312 编码和 ASCII 码是相同的,1 字节编码即可。对于非英字符,需要 2 字节编码。
+
+### GBK
+
+GBK 字符集可以看作是 GB2312 字符集的扩展,兼容 GB2312 字符集,共收录了 20000 多个汉字。
+
+GBK 中 K 是汉语拼音 Kuo Zhan(扩展)中的“Kuo”的首字母。
+
+### GB18030
+
+GB18030 完全兼容 GB2312 和 GBK 字符集,纳入中国国内少数民族的文字,且收录了日韩汉字,是目前为止最全面的汉字字符集,共收录汉字 70000 多个。
+
+### BIG5
+
+BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
+
+### Unicode & UTF-8
+
+为了更加适合本国语言,诞生了很多种字符集。
+
+我们上面也说了不同的字符集可以表示的字符范围以及编码规则存在差异。这就导致了一个非常严重的问题:**使用错误的编码方式查看一个包含字符的文件就会产生乱码现象。**
+
+就比如说你使用 UTF-8 编码方式打开 GB2312 编码格式的文件就会出现乱码。示例:“牛”这个汉字 GB2312 编码后的十六进制数值为 “C5A3”,而 “C5A3” 用 UTF-8 解码之后得到的却是 “ţ”。
+
+你可以通过这个网站在线进行编码和解码:
+
+
+
+这样我们就搞懂了乱码的本质:**编码和解码时用了不同或者不兼容的字符集** 。
+
+
+
+为了解决这个问题,人们就想:“如果我们能够有一种字符集将世界上所有的字符都纳入其中就好了!”。
+
+然后,**Unicode** 带着这个使命诞生了。
+
+Unicode 字符集中包含了世界上几乎所有已知的字符。不过,Unicode 字符集并没有规定如何存储这些字符(也就是如何使用二进制数据表示这些字符)。
+
+然后,就有了 **UTF-8**(**8**-bit **U**nicode **T**ransformation **F**ormat)。类似的还有 UTF-16、 UTF-32。
+
+UTF-8 使用 1 到 4 个字节为每个字符编码, UTF-16 使用 2 或 4 个字节为每个字符编码,UTF-32 固定位 4 个字节为每个字符编码。
+
+UTF-8 可以根据不同的符号自动选择编码的长短,像英文字符只需要 1 个字节就够了,这一点 ASCII 字符集一样 。因此,对于英语字符,UTF-8 编码和 ASCII 码是相同的。
+
+UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这类字符消耗的空间是 UTF-8 的 4 倍之多。
+
+**UTF-8** 是目前使用最广的一种字符编码。
+
+
+
+## MySQL 字符集
+
+MySQL 支持很多种字符集的方式,比如 GB2312、GBK、BIG5、多种 Unicode 字符集(UTF-8 编码、UTF-16 编码、UCS-2 编码、UTF-32 编码等等)。
+
+### 查看支持的字符集
+
+你可以通过 `SHOW CHARSET` 命令来查看,支持 like 和 where 子句。
+
+
+
+### 默认字符集
+
+在 MySQL5.7 中,默认字符集是 `latin1` ;在 MySQL8.0 中,默认字符集是 `utf8mb4`
+
+### 字符集的层次级别
+
+MySQL 中的字符集有以下的层次级别:
+
+- `server`(MySQL 实例级别)
+- `database`(库级别)
+- `table`(表级别)
+- `column`(字段级别)
+
+它们的优先级可以简单的认为是从上往下依次增大,也即 `column` 的优先级会大于 `table` 等其余层次的。如指定 MySQL 实例级别字符集是`utf8mb4`,指定某个表字符集是`latin1`,那么这个表的所有字段如果不指定的话,编码就是`latin1`。
+
+#### server
+
+不同版本的 MySQL 其 `server` 级别的字符集默认值不同,在 MySQL5.7 中,其默认值是 `latin1` ;在 MySQL8.0 中,其默认值是 `utf8mb4` 。
+
+当然也可以通过在启动 `mysqld` 时指定 `--character-set-server` 来设置 `server` 级别的字符集。
+
+```bash
+mysqld
+mysqld --character-set-server=utf8mb4
+mysqld --character-set-server=utf8mb4 \
+ --collation-server=utf8mb4_0900_ai_ci
+```
+
+Or if you are starting MySQL from source, you can specify options in the `cmake` command:
+
+```sh
+cmake .-DDEFAULT_CHARSET=latin1
+or
+cmake . -DDEFAULT_CHARSET=latin1 \
+ -DDEFAULT_COLLATION=latin1_german1_ci
+```
+
+In addition, you can also change the value of `character_set_server` at runtime to modify the `server` level character set.
+
+The `server` level character set is a global setting of the MySQL server. It will not only serve as the default character set when creating or modifying the database (if no other character set is specified), but also affects the connection character set between the client and the server. For details, see [MySQL Connector/J 8.0 - 6.7 Using Character Sets and Unicode](https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-charsets.html).
+
+#### database
+
+The `database` level character set is specified when we create and modify the database:
+
+```sql
+CREATE DATABASE db_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [[DEFAULT] COLLATE collation_name]
+
+ALTER DATABASE db_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [[DEFAULT] COLLATE collation_name]
+```
+
+As mentioned earlier, if no character set is specified when executing the above statement, MySQL will use the `server` level character set.
+
+You can check the character set of a database in the following way:
+
+```sql
+USE db_name;
+SELECT @@character_set_database, @@collation_database;
+```
+
+```sql
+SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
+FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name';
+```
+
+#### table
+
+The `table` level character set is specified when creating and modifying the table:
+
+```sql
+CREATE TABLE tbl_name (column_list)
+ [[DEFAULT] CHARACTER SET charset_name]
+ [COLLATE collation_name]]
+
+ALTER TABLE tbl_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [COLLATE collation_name]
+```
+
+If no character set is specified when creating and modifying tables, the `database` level character set will be used.
+
+#### column
+
+The `column` level character set is also specified when creating and modifying the table, but it is defined in the column. Here is an example:
+
+```sql
+CREATE TABLE t1
+(
+ col1 VARCHAR(5)
+ CHARACTER SET latin1
+ COLLATE latin1_german1_ci
+);
+```
+
+If a column-level character set is not specified, the table-level character set will be used.
+
+### Connection character set
+
+As mentioned earlier, the hierarchical levels of character sets are related to storage. The connection character set involves communication with the MySQL server.
+
+The connection character set is closely related to the following variables:
+
+- `character_set_client`: Describes the character set used by the SQL statement sent by the client to the server.
+- `character_set_connection`: Describes what character set the server uses for translation when it receives a SQL statement.
+- `character_set_results`: Describes what character set is used in the results returned by the server to the client.
+
+Their values can be queried through the following SQL statement:
+
+```sql
+SELECT * FROM performance_schema.session_variables
+WHERE VARIABLE_NAME IN (
+'character_set_client', 'character_set_connection',
+'character_set_results', 'collation_connection'
+) ORDER BY VARIABLE_NAME;
+```
+
+```sql
+SHOW SESSION VARIABLES LIKE 'character\_set\_%';
+```
+
+If you want to modify the values of the variables mentioned earlier, you have the following methods:
+
+1. Modify the configuration file
+
+```properties
+[mysql]
+# Only for MySQL client program
+default-character-set=utf8mb4
+```
+
+2. Use SQL statements
+
+```sql
+set names utf8mb4
+# Or modify them one by one
+# SET character_set_client = utf8mb4;
+# SET character_set_results = utf8mb4;
+# SET collation_connection = utf8mb4;
+```
+
+### Impact of JDBC on connection character sets
+
+I don’t know if you have ever encountered a situation where emoji expressions are stored normally, but when you use software like Navicat to query, you find that the emoji expressions turn into question marks. This problem is most likely caused by the JDBC driver.
+
+According to the previous content, we know that the connection character set will also affect the data we store, and the JDBC driver will affect the connection character set.
+
+`mysql-connector-java` (JDBC driver) mainly affects the connection character set through these properties:
+
+- `characterEncoding`
+- `characterSetResults`
+
+Taking `DataGrip 2023.1.2` as an example, in its advanced dialog box for configuring data sources, you can see that the default value of `characterSetResults` is `utf8`. When using `mysql-connector-java 8.0.25`, the connection character set will finally be set to `utf8mb3`. In this case, the emoji expression will be displayed as a question mark, and the current version of the driver does not support setting `characterSetResults` to `utf8mb4`, but it is allowed to change to `mysql-connector-java driver 8.0.29`.
+
+For details, please take a look at StackOverflow's answer [DataGrip MySQL stores emojis correctly but displays them as?](https://stackoverflow.com/questions/54815419/datagrip-mysql-stores-emojis-correctly-but-displays-them-as).
+
+### UTF-8 usage
+
+Normally, we recommend using UTF-8 as the default character encoding.
+
+However, there is a small pit here.
+
+There are two sets of UTF-8 encoding implementations in the MySQL character encoding set:
+
+- **`utf8`**: `utf8` encoding only supports `1-3` bytes. In `utf8` encoding, Chinese characters occupy 3 bytes, and other numbers, English, and symbols occupy one byte. However, emoji symbols occupy 4 bytes, and some more complex text and traditional Chinese characters also occupy 4 bytes.
+- **`utf8mb4`**: Complete implementation of UTF-8, genuine! Supports up to 4 bytes for character representation, so it can be used to store emoji symbols.
+
+**Why are there two sets of UTF-8 encoding implementations? **The reasons are as follows:
+
+
+
+Therefore, if you need to store `emoji` type data or some more complex text or traditional Chinese characters into the MySQL database, the database encoding must be specified as `utf8mb4` instead of `utf8`, otherwise an error will be reported when storing.
+
+Demonstrate it! (Environment: MySQL 5.7+)
+
+The table creation statement is as follows. We specify the database CHARSET as `utf8`.
+
+```sql
+CREATE TABLE `user` (
+ `id` varchar(66) CHARACTER SET utf8mb3 NOT NULL,
+ `name` varchar(33) CHARACTER SET utf8mb3 NOT NULL,
+ `phone` varchar(33) CHARACTER SET utf8mb3 DEFAULT NULL,
+ `password` varchar(100) CHARACTER SET utf8mb3 DEFAULT NULL
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+```
+
+When we execute the following insert statement to insert data into the database, an error is reported!
+
+```sql
+INSERT INTO `user` (`id`, `name`, `phone`, `password`)
+VALUES
+ ('A00003', 'guide brother😘😘😘', '181631312312', '123456');```
+
+The error message is as follows:
+
+```plain
+Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
+```
+
+## Reference
+
+-Charset & Encoding:
+- Understand the character set and character encoding in ten minutes:
+- Unicode-Wikipedia:
+- GB2312-Wikipedia:
+- UTF-8-Wikipedia:
+- GB18030-Wikipedia:
+- MySQL8 documentation:
+- MySQL5.7 documentation:
+- MySQL Connector/J documentation:
+
+
\ No newline at end of file
diff --git a/docs_en/database/elasticsearch/elasticsearch-questions-01.en.md b/docs_en/database/elasticsearch/elasticsearch-questions-01.en.md
new file mode 100644
index 00000000000..a801052566e
--- /dev/null
+++ b/docs_en/database/elasticsearch/elasticsearch-questions-01.en.md
@@ -0,0 +1,22 @@
+---
+title: Summary of common Elasticsearch interview questions (paid)
+category: database
+tag:
+ - NoSQL
+ - Elasticsearch
+head:
+ - - meta
+ - name: keywords
+ content: Elasticsearch interviews, indexing, sharding, inversion, query, aggregation, tuning
+ - - meta
+ - name: description
+ content: Contains Elasticsearch high-frequency interview questions and practical points, focusing on indexing/sharding/inversion and aggregation queries to form a system review list.
+---
+
+**Elasticsearch** The related interview questions are exclusive to my [Knowledge Planet](../../about-the-author/zhishixingqiu-two-years.md) (click the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide North"](../../zhuanlan/java-mian-shi-zhi-bei.md).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/database/mongodb/mongodb-questions-01.en.md b/docs_en/database/mongodb/mongodb-questions-01.en.md
new file mode 100644
index 00000000000..dfed4bd9e29
--- /dev/null
+++ b/docs_en/database/mongodb/mongodb-questions-01.en.md
@@ -0,0 +1,350 @@
+---
+title: MongoDB常见面试题总结(上)
+category: 数据库
+tag:
+ - NoSQL
+ - MongoDB
+head:
+ - - meta
+ - name: keywords
+ content: MongoDB 面试,文档存储,无模式,副本集,分片,索引,一致性
+ - - meta
+ - name: description
+ content: 汇总 MongoDB 基础与架构高频题,涵盖文档模型、索引、副本集与分片,强调高可用与一致性实践。
+---
+
+> 少部分内容参考了 MongoDB 官方文档的描述,在此说明一下。
+
+## MongoDB 基础
+
+### MongoDB 是什么?
+
+MongoDB 是一个基于 **分布式文件存储** 的开源 NoSQL 数据库系统,由 **C++** 编写的。MongoDB 提供了 **面向文档** 的存储方式,操作起来比较简单和容易,支持“**无模式**”的数据建模,可以存储比较复杂的数据类型,是一款非常流行的 **文档类型数据库** 。
+
+在高负载的情况下,MongoDB 天然支持水平扩展和高可用,可以很方便地添加更多的节点/实例,以保证服务性能和可用性。在许多场景下,MongoDB 可以用于代替传统的关系型数据库或键/值存储方式,皆在为 Web 应用提供可扩展的高可用高性能数据存储解决方案。
+
+### MongoDB 的存储结构是什么?
+
+MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三个单元组成:
+
+- **文档(Document)**:MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
+- **集合(Collection)**:一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
+- **数据库(Database)**:一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
+
+也就是说,MongoDB 将数据记录存储为文档 (更具体来说是[BSON 文档](https://www.mongodb.com/docs/manual/core/document/#std-label-bson-document-format)),这些文档在集合中聚集在一起,数据库中存储一个或多个文档集合。
+
+**SQL 与 MongoDB 常见术语对比**:
+
+| SQL | MongoDB |
+| ------------------------ | ------------------------------- |
+| 表(Table) | 集合(Collection) |
+| 行(Row) | 文档(Document) |
+| 列(Col) | 字段(Field) |
+| 主键(Primary Key) | 对象 ID(Objectid) |
+| 索引(Index) | 索引(Index) |
+| 嵌套表(Embedded Table) | 嵌入式文档(Embedded Document) |
+| 数组(Array) | 数组(Array) |
+
+#### 文档
+
+MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。字段的值可能包括其他文档、数组和文档数组。
+
+
+
+文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
+
+- 键不能含有 `\0`(空字符)。这个字符用来表示键的结尾。
+- `.` 和 `$` 有特别的意义,只有在特定环境下才能使用。
+- 以下划线`_`开头的键是保留的(不是严格要求的)。
+
+**BSON [bee·sahn]** 是 Binary [JSON](http://json.org/)的简称,是 JSON 文档的二进制表示,支持将文档和数组嵌入到其他文档和数组中,还包含允许表示不属于 JSON 规范的数据类型的扩展。有关 BSON 规范的内容,可以参考 [bsonspec.org](http://bsonspec.org/),另见[BSON 类型](https://www.mongodb.com/docs/manual/reference/bson-types/)。
+
+根据维基百科对 BJSON 的介绍,BJSON 的遍历速度优于 JSON,这也是 MongoDB 选择 BSON 的主要原因,但 BJSON 需要更多的存储空间。
+
+> 与 JSON 相比,BSON 着眼于提高存储和扫描效率。BSON 文档中的大型元素以长度字段为前缀以便于扫描。在某些情况下,由于长度前缀和显式数组索引的存在,BSON 使用的空间会多于 JSON。
+
+
+
+#### 集合
+
+MongoDB 集合存在于数据库中,**没有固定的结构**,也就是 **无模式** 的,这意味着可以往集合插入不同格式和类型的数据。不过,通常情况下,插入集合中的数据都会有一定的关联性。
+
+
+
+集合不需要事先创建,当第一个文档插入或者第一个索引创建时,如果该集合不存在,则会创建一个新的集合。
+
+集合名可以是满足下列条件的任意 UTF-8 字符串:
+
+- 集合名不能是空字符串`""`。
+- 集合名不能含有 `\0` (空字符),这个字符表示集合名的结尾。
+- 集合名不能以"system."开头,这是为系统集合保留的前缀。例如 `system.users` 这个集合保存着数据库的用户信息,`system.namespaces` 集合保存着所有数据库集合的信息。
+- 集合名必须以下划线或者字母符号开始,并且不能包含 `$`。
+
+#### 数据库
+
+数据库用于存储所有集合,而集合又用于存储所有文档。一个 MongoDB 中可以创建多个数据库,每一个数据库都有自己的集合和权限。
+
+MongoDB 预留了几个特殊的数据库。
+
+- **admin** : admin 数据库主要是保存 root 用户和角色。例如,system.users 表存储用户,system.roles 表存储角色。一般不建议用户直接操作这个数据库。将一个用户添加到这个数据库,且使它拥有 admin 库上的名为 dbAdminAnyDatabase 的角色权限,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如关闭服务器。
+- **local** : local 数据库是不会被复制到其他分片的,因此可以用来存储本地单台服务器的任意 collection。一般不建议用户直接使用 local 库存储任何数据,也不建议进行 CRUD 操作,因为数据无法被正常备份与恢复。
+- **config** : 当 MongoDB 使用分片设置时,config 数据库可用来保存分片的相关信息。
+- **test** : 默认创建的测试库,连接 [mongod](https://mongoing.com/docs/reference/program/mongod.html) 服务时,如果不指定连接的具体数据库,默认就会连接到 test 数据库。
+
+数据库名可以是满足以下条件的任意 UTF-8 字符串:
+
+- 不能是空字符串`""`。
+- 不得含有`' '`(空格)、`.`、`$`、`/`、`\`和 `\0` (空字符)。
+- 应全部小写。
+- 最多 64 字节。
+
+数据库名最终会变成文件系统里的文件,这也就是有如此多限制的原因。
+
+### MongoDB 有什么特点?
+
+- **数据记录被存储为文档**:MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
+- **模式自由**:集合的概念类似 MySQL 里的表,但它不需要定义任何模式,能够用更少的数据对象表现复杂的领域模型对象。
+- **支持多种查询方式**:MongoDB 查询 API 支持读写操作 (CRUD)以及数据聚合、文本搜索和地理空间查询。
+- **支持 ACID 事务**:NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。与关系型数据库一样,MongoDB 事务同样具有 ACID 特性。MongoDB 单文档原生支持原子性,也具备事务的特性。MongoDB 4.0 加入了对多文档事务的支持,但只支持复制集部署模式下的事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了分布式事务,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
+- **高效的二进制存储**:存储在集合中的文档,是以键值对的形式存在的。键用于唯一标识一个文档,一般是 ObjectId 类型,值是以 BSON 形式存在的。BSON = Binary JSON, 是在 JSON 基础上加了一些类型及元数据描述的格式。
+- **自带数据压缩功能**:存储同样的数据所需的资源更少。
+- **支持 mapreduce**:通过分治的方式完成复杂的聚合任务。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
+- **支持多种类型的索引**:MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
+- **支持 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+- **支持分片集群**:MongoDB 支持集群自动切分数据,让集群存储更多的数据,具备更强的性能。在数据插入和更新时,能够自动路由和存储。
+- **支持存储大文件**:MongoDB 的单文档存储空间要求不超过 16MB。对于超过 16MB 的大文件,MongoDB 提供了 GridFS 来进行存储,通过 GridFS,可以将大型数据进行分块处理,然后将这些切分后的小文档保存在数据库中。
+
+### MongoDB 适合什么应用场景?
+
+**MongoDB 的优势在于其数据模型和存储引擎的灵活性、架构的可扩展性以及对强大的索引支持。**
+
+选用 MongoDB 应该充分考虑 MongoDB 的优势,结合实际项目的需求来决定:
+
+- 随着项目的发展,使用类 JSON 格式(BSON)保存数据是否满足项目需求?MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
+- 是否需要大数据量的存储?是否需要快速水平扩展?MongoDB 支持分片集群,可以很方便地添加更多的节点(实例),让集群存储更多的数据,具备更强的性能。
+- 是否需要更多类型索引来满足更多应用场景?MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
+- ……
+
+## MongoDB 存储引擎
+
+### MongoDB 支持哪些存储引擎?
+
+存储引擎(Storage Engine)是数据库的核心组件,负责管理数据在内存和磁盘中的存储方式。
+
+与 MySQL 一样,MongoDB 采用的也是 **插件式的存储引擎架构** ,支持不同类型的存储引擎,不同的存储引擎解决不同场景的问题。在创建数据库或集合时,可以指定存储引擎。
+
+> 插件式的存储引擎架构可以实现 Server 层和存储引擎层的解耦,可以支持多种存储引擎,如 MySQL 既可以支持 B-Tree 结构的 InnoDB 存储引擎,还可以支持 LSM 结构的 RocksDB 存储引擎。
+
+在存储引擎刚出来的时候,默认是使用 MMAPV1 存储引擎,MongoDB4.x 版本不再支持 MMAPv1 存储引擎。
+
+现在主要有下面这两种存储引擎:
+
+- **WiredTiger 存储引擎**:自 MongoDB 3.2 以后,默认的存储引擎为 [WiredTiger 存储引擎](https://www.mongodb.com/docs/manual/core/wiredtiger/) 。非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩(后文会介绍到)等功能。
+- **In-Memory 存储引擎**:[In-Memory 存储引擎](https://www.mongodb.com/docs/manual/core/inmemory/)在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
+
+此外,MongoDB 3.0 提供了 **可插拔的存储引擎 API** ,允许第三方为 MongoDB 开发存储引擎,这点和 MySQL 也比较类似。
+
+### WiredTiger 基于 LSM Tree 还是 B+ Tree?
+
+目前绝大部分流行的数据库存储引擎都是基于 B/B+ Tree 或者 LSM(Log Structured Merge) Tree 来实现的。对于 NoSQL 数据库来说,绝大部分(比如 HBase、Cassandra、RocksDB)都是基于 LSM 树,MongoDB 不太一样。
+
+上面也说了,自 MongoDB 3.2 以后,默认的存储引擎为 WiredTiger 存储引擎。在 WiredTiger 引擎官网上,我们发现 WiredTiger 使用的是 B+ 树作为其存储结构:
+
+```plain
+WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
+```
+
+此外,WiredTiger 还支持 [LSM(Log Structured Merge)](https://source.wiredtiger.com/3.1.0/lsm.html) 树作为存储结构,MongoDB 在使用 WiredTiger 作为存储引擎时,默认使用的是 B+ 树。
+
+如果想要了解 MongoDB 使用 B+ 树的原因,可以看看这篇文章:[【驳斥八股文系列】别瞎分析了,MongoDB 使用的是 B+ 树,不是你们以为的 B 树](https://zhuanlan.zhihu.com/p/519658576)。
+
+使用 B+ 树时,WiredTiger 以 **page** 为基本单位往磁盘读写数据。B+ 树的每个节点为一个 page,共有三种类型的 page:
+
+- **root page(根节点)**:B+ 树的根节点。
+- **internal page(内部节点)**:不实际存储数据的中间索引节点。
+- **leaf page(叶子节点)**:真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
+
+其整体结构如下图所示:
+
+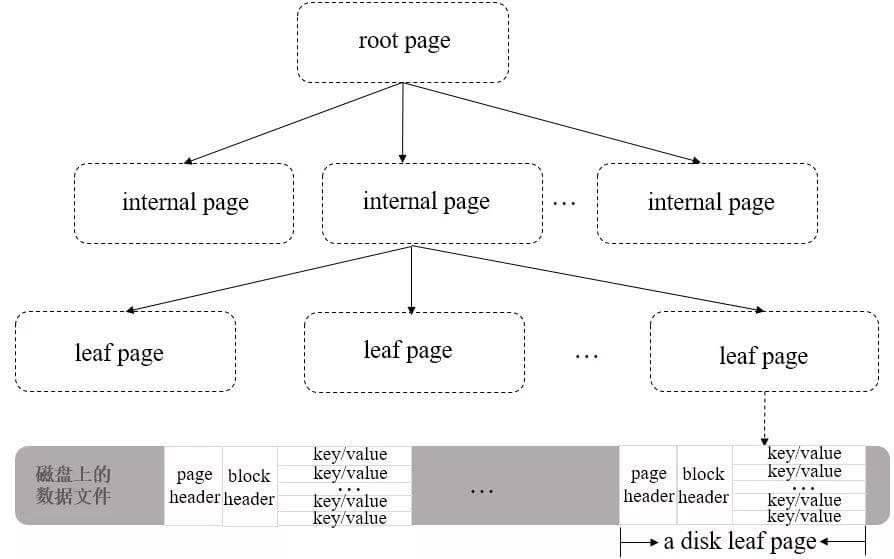
+
+如果想要深入研究学习 WiredTiger 存储引擎,推荐阅读 MongoDB 中文社区的 [WiredTiger 存储引擎系列](https://mongoing.com/archives/category/wiredtiger%e5%ad%98%e5%82%a8%e5%bc%95%e6%93%8e%e7%b3%bb%e5%88%97)。
+
+## MongoDB 聚合
+
+### MongoDB 聚合有什么用?
+
+实际项目中,我们经常需要将多个文档甚至是多个集合汇总到一起计算分析(比如求和、取最大值)并返回计算后的结果,这个过程被称为 **聚合操作** 。
+
+根据官方文档介绍,我们可以使用聚合操作来:
+
+- 将来自多个文档的值组合在一起。
+- 对集合中的数据进行的一系列运算。
+- 分析数据随时间的变化。
+
+### MongoDB 提供了哪几种执行聚合的方法?
+
+MongoDB 提供了两种执行聚合的方法:
+
+- **聚合管道(Aggregation Pipeline)**:执行聚合操作的首选方法。
+- **单一目的聚合方法(Single purpose aggregation methods)**:也就是单一作用的聚合函数比如 `count()`、`distinct()`、`estimatedDocumentCount()`。
+
+绝大部分文章中还提到了 **map-reduce** 这种聚合方法。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
+
+MongoDB 聚合管道由多个阶段组成,每个阶段在文档通过管道时转换文档。每个阶段接收前一个阶段的输出,进一步处理数据,并将其作为输入数据发送到下一个阶段。
+
+每个管道的工作流程是:
+
+1. 接受一系列原始数据文档
+2. 对这些文档进行一系列运算
+3. 结果文档输出给下一个阶段
+
+
+
+**常用阶段操作符**:
+
+| 操作符 | 简述 |
+| --------- | ---------------------------------------------------------------------------------------------------- |
+| \$match | 匹配操作符,用于对文档集合进行筛选 |
+| \$project | 投射操作符,用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段 |
+| \$sort | 排序操作符,用于根据一个或多个字段对文档进行排序 |
+| \$limit | 限制操作符,用于限制返回文档的数量 |
+| \$skip | 跳过操作符,用于跳过指定数量的文档 |
+| \$count | 统计操作符,用于统计文档的数量 |
+| \$group | 分组操作符,用于对文档集合进行分组 |
+| \$unwind | 拆分操作符,用于将数组中的每一个值拆分为单独的文档 |
+| \$lookup | 连接操作符,用于连接同一个数据库中另一个集合,并获取指定的文档,类似于 populate |
+
+更多操作符介绍详见官方文档:
+
+阶段操作符用于 `db.collection.aggregate` 方法里面,数组参数中的第一层。
+
+```sql
+db.collection.aggregate( [ { 阶段操作符:表述 }, { 阶段操作符:表述 }, ... ] )
+```
+
+下面是 MongoDB 官方文档中的一个例子:
+
+```sql
+db.orders.aggregate([
+ # 第一阶段:$match阶段按status字段过滤文档,并将status等于"A"的文档传递到下一阶段。
+ { $match: { status: "A" } },
+ # 第二阶段:$group阶段按cust_id字段将文档分组,以计算每个cust_id唯一值的金额总和。
+ { $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
+])
+```
+
+## MongoDB 事务
+
+> MongoDB 事务想要搞懂原理还是比较花费时间的,我自己也没有搞太明白。因此,我这里只是简单介绍一下 MongoDB 事务,想要了解原理的小伙伴,可以自行搜索查阅相关资料。
+>
+> 这里推荐几篇文章,供大家参考:
+>
+> - [技术干货| MongoDB 事务原理](https://mongoing.com/archives/82187)
+> - [MongoDB 一致性模型设计与实现](https://developer.aliyun.com/article/782494)
+> - [MongoDB 官方文档对事务的介绍](https://www.mongodb.com/docs/upcoming/core/transactions/)
+
+我们在介绍 NoSQL 数据的时候也说过,NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。
+
+与关系型数据库一样,MongoDB 事务同样具有 ACID 特性:
+
+- **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+- **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
+- **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持读未提交( read-uncommitted )、读已提交( read-committed )和快照( snapshot )隔离,MongoDB 启动时默认选快照隔离。在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
+- **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+关于事务的详细介绍这篇文章就不多说了,感兴趣的可以看看我写的[MySQL 常见面试题总结](../mysql/mysql-questions-01.md)这篇文章,里面有详细介绍到。
+
+MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 MongoDB 事务的时候,通常指的是 **多文档** 。MongoDB 4.0 加入了对多文档 ACID 事务的支持,但只支持复制集部署模式下的 ACID 事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了 **分布式事务** ,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
+
+根据官方文档介绍:
+
+> 从 MongoDB 4.2 开始,分布式事务和多文档事务在 MongoDB 中是一个意思。分布式事务是指分片集群和副本集上的多文档事务。从 MongoDB 4.2 开始,多文档事务(无论是在分片集群还是副本集上)也称为分布式事务。
+
+在大多数情况下,多文档事务比单文档写入会产生更大的性能成本。对于大部分场景来说, [非规范化数据模型(嵌入式文档和数组)](https://www.mongodb.com/docs/upcoming/core/data-model-design/#std-label-data-modeling-embedding) 依然是最佳选择。也就是说,适当地对数据进行建模可以最大限度地减少对多文档事务的需求。
+
+**注意**:
+
+- 从 MongoDB 4.2 开始,多文档事务支持副本集和分片集群,其中:主节点使用 WiredTiger 存储引擎,同时从节点使用 WiredTiger 存储引擎或 In-Memory 存储引擎。在 MongoDB 4.0 中,只有使用 WiredTiger 存储引擎的副本集支持事务。
+- 在 MongoDB 4.2 及更早版本中,你无法在事务中创建集合。从 MongoDB 4.4 开始,您可以在事务中创建集合和索引。有关详细信息,请参阅 [在事务中创建集合和索引](https://www.mongodb.com/docs/upcoming/core/transactions/#std-label-transactions-create-collections-indexes)。
+
+## MongoDB 数据压缩
+
+借助 WiredTiger 存储引擎( MongoDB 3.2 后的默认存储引擎),MongoDB 支持对所有集合和索引进行压缩。压缩以额外的 CPU 为代价最大限度地减少存储使用。
+
+By default, WiredTiger uses the [Snappy](https://github.com/google/snappy) compression algorithm (open sourced by Google, designed to achieve very high speed and reasonable compression, with a compression ratio of 3 to 5 times) using block compression for all collections and prefix compression for all indexes.
+
+In addition to Snappy, there are the following compression algorithms for collections:
+
+- [zlib](https://github.com/madler/zlib): Highly compressed algorithm, compression ratio 5 to 7 times
+- [Zstandard](https://github.com/facebook/zstd) (zstd for short): A fast lossless compression algorithm open sourced by Facebook. It provides higher compression rate and lower CPU usage for zlib-level real-time compression scenarios and better compression ratio. It is available in MongoDB 4.2.
+
+WiredTiger logs are also compressed, using the Snappy compression algorithm by default. If a log record is less than or equal to 128 bytes, WiredTiger does not compress the record.
+
+## Differences between Amazon Document and MongoDB
+
+Amazon DocumentDB (compatible with MongoDB) is a fast, reliable, fully managed database service. Amazon DocumentDB makes it easy to set up, operate, and scale MongoDB-compatible databases in the cloud.
+
+### `$vectorSearch` operator
+
+Amazon DocumentDB does not support `$vectorSearch` as a standalone operator. Instead, we support `vectorSearch` internally in the `$search` operator. For more information, see Vector Search Amazon DocumentDB(https://docs.aws.amazon.com/zh_cn/documentdb/latest/developerguide/vector-search.html).
+
+### `OpCountersCommand`
+
+The behavior of Amazon DocumentDB's `OpCountersCommand` deviates from MongoDB's `opcounters.command` as follows:
+
+- MongoDB's `opcounters.command` counts all commands except inserts, updates, and deletes, while Amazon DocumentDB's `OpCountersCommand` also excludes `find` commands.
+- Amazon DocumentDB counts internal commands (such as `getCloudWatchMetricsV2`) against `OpCountersCommand`.
+
+### Manage databases and collections
+
+Amazon DocumentDB does not support managed or local databases, nor the MongoDB `system.*` or `startup_log` collections.
+
+### `cursormaxTimeMS`
+
+In Amazon DocumentDB, `cursor.maxTimeMS` resets the counter for each request. `getMore` So if `maxTimeMS` of 3000MS is specified and the query takes 2800MS and each subsequent `getMore` request takes 300MS, the cursor will not time out. The cursor will timeout `maxTimeMS` only if a single operation (either a query or a single `getMore` request) takes longer than the specified value. In addition, the scanner that checks cursor execution time runs at a five (5) minute interval size.
+
+### explain()
+
+Amazon DocumentDB emulates the MongoDB 4.0 API on a purpose-built database engine that leverages a distributed, fault-tolerant, self-healing storage system. Therefore, query plans and the output of explain() may differ between Amazon DocumentDB and MongoDB. Customers wishing to control their query plans can use the `$hint` operator to force a preferred index.
+
+### Field name restrictions
+
+Amazon DocumentDB does not support dot "." for example, `db.foo.insert({‘x.1':1})` in document field names.
+
+Amazon DocumentDB also does not support the $ prefix in field names.
+
+For example, try the following commands in Amazon DocumentDB or MongoDB:
+
+```shell
+rs0:PRIMARY< db.foo.insert({"a":{"$a":1}})
+```
+
+MongoDB will return the following:
+
+```shell
+WriteResult({ "nInserted" : 1 })
+```
+
+Amazon DocumentDB will return an error:
+
+```shell
+WriteResult({
+ "nInserted" : 0,
+ "writeError" : {
+ "code": 2,
+ "errmsg" : "Document can't have $ prefix field names: $a"
+ }
+})
+```
+
+## Reference
+
+- MongoDB official documents (main reference materials, subject to official documents):
+- "The Definitive Guide to MongoDB"
+- Technical information | MongoDB transaction principles - MongoDB Chinese community:
+- Transactions - MongoDB official documentation:
+- WiredTiger Storage Engine - MongoDB official documentation:
+- One of WiredTiger storage engines: basic data structure analysis:
+
+
\ No newline at end of file
diff --git a/docs_en/database/mongodb/mongodb-questions-02.en.md b/docs_en/database/mongodb/mongodb-questions-02.en.md
new file mode 100644
index 00000000000..cecb3ae48df
--- /dev/null
+++ b/docs_en/database/mongodb/mongodb-questions-02.en.md
@@ -0,0 +1,282 @@
+---
+title: MongoDB常见面试题总结(下)
+category: 数据库
+tag:
+ - NoSQL
+ - MongoDB
+head:
+ - - meta
+ - name: keywords
+ content: MongoDB 索引,复合索引,多键索引,文本索引,地理索引,查询优化
+ - - meta
+ - name: description
+ content: 讲解 MongoDB 常见索引类型与适用场景,结合查询优化与写入开销权衡,提升检索性能与稳定性。
+---
+
+## MongoDB 索引
+
+### MongoDB 索引有什么用?
+
+和关系型数据库类似,MongoDB 中也有索引。索引的目的主要是用来提高查询效率,如果没有索引的话,MongoDB 必须执行 **集合扫描** ,即扫描集合中的每个文档,以选择与查询语句匹配的文档。如果查询存在合适的索引,MongoDB 可以使用该索引来限制它必须检查的文档数量。并且,MongoDB 可以使用索引中的排序返回排序后的结果。
+
+虽然索引可以显著缩短查询时间,但是使用索引、维护索引是有代价的。在执行写入操作时,除了要更新文档之外,还必须更新索引,这必然会影响写入的性能。因此,当有大量写操作而读操作少时,或者不考虑读操作的性能时,都不推荐建立索引。
+
+### MongoDB 支持哪些类型的索引?
+
+**MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。**
+
+- **单字段索引:** 建立在单个字段上的索引,索引创建的排序顺序无所谓,MongoDB 可以头/尾开始遍历。
+- **复合索引:** 建立在多个字段上的索引,也可以称之为组合索引、联合索引。
+- **多键索引**:MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引。MongoDB 会为数组的每个值创建索引。就是说你可以按照数组里面的值做条件来查询,这个时候依然会走索引。
+- **哈希索引**:按数据的哈希值索引,用在哈希分片集群上。
+- **文本索引:** 支持对字符串内容的文本搜索查询。文本索引可以包含任何值为字符串或字符串元素数组的字段。一个集合只能有一个文本搜索索引,但该索引可以覆盖多个字段。MongoDB 虽然支持全文索引,但是性能低下,暂时不建议使用。
+- **地理位置索引:** 基于经纬度的索引,适合 2D 和 3D 的位置查询。
+- **唯一索引**:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
+- **TTL 索引**:TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
+- ……
+
+### 复合索引中字段的顺序有影响吗?
+
+复合索引中字段的顺序非常重要,例如下图中的复合索引由`{userid:1, score:-1}`组成,则该复合索引首先按照`userid`升序排序;然后再每个`userid`的值内,再按照`score`降序排序。
+
+
+
+在复合索引中,按照何种方式排序,决定了该索引在查询中是否能被应用到。
+
+走复合索引的排序:
+
+```sql
+db.s2.find().sort({"userid": 1, "score": -1})
+db.s2.find().sort({"userid": -1, "score": 1})
+```
+
+不走复合索引的排序:
+
+```sql
+db.s2.find().sort({"userid": 1, "score": 1})
+db.s2.find().sort({"userid": -1, "score": -1})
+db.s2.find().sort({"score": 1, "userid": -1})
+db.s2.find().sort({"score": 1, "userid": 1})
+db.s2.find().sort({"score": -1, "userid": -1})
+db.s2.find().sort({"score": -1, "userid": 1})
+```
+
+我们可以通过 explain 进行分析:
+
+```sql
+db.s2.find().sort({"score": -1, "userid": 1}).explain()
+```
+
+### 复合索引遵循左前缀原则吗?
+
+**MongoDB 的复合索引遵循左前缀原则**:拥有多个键的索引,可以同时得到所有这些键的前缀组成的索引,但不包括除左前缀之外的其他子集。比如说,有一个类似 `{a: 1, b: 1, c: 1, ..., z: 1}` 这样的索引,那么实际上也等于有了 `{a: 1}`、`{a: 1, b: 1}`、`{a: 1, b: 1, c: 1}` 等一系列索引,但是不会有 `{b: 1}` 这样的非左前缀的索引。
+
+### 什么是 TTL 索引?
+
+TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间 `expireAfterSeconds` ,当一个文档达到预设的过期时间之后就会被删除。TTL 索引除了有 `expireAfterSeconds` 属性外,和普通索引一样。
+
+数据过期对于某些类型的信息很有用,比如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保存有限的时间。
+
+**TTL 索引运行原理**:
+
+- MongoDB 会开启一个后台线程读取该 TTL 索引的值来判断文档是否过期,但不会保证已过期的数据会立马被删除,因后台线程每 60 秒触发一次删除任务,且如果删除的数据量较大,会存在上一次的删除未完成,而下一次的任务已经开启的情况,导致过期的数据也会出现超过了数据保留时间 60 秒以上的现象。
+- 对于副本集而言,TTL 索引的后台进程只会在 Primary 节点开启,在从节点会始终处于空闲状态,从节点的数据删除是由主库删除后产生的 oplog 来做同步。
+
+**TTL 索引限制**:
+
+- TTL 索引是单字段索引。复合索引不支持 TTL
+- `_id`字段不支持 TTL 索引。
+- 无法在上限集合(Capped Collection)上创建 TTL 索引,因为 MongoDB 无法从上限集合中删除文档。
+- 如果某个字段已经存在非 TTL 索引,那么在该字段上无法再创建 TTL 索引。
+
+### 什么是覆盖索引查询?
+
+根据官方文档介绍,覆盖查询是以下的查询:
+
+- 所有的查询字段是索引的一部分。
+- 结果中返回的所有字段都在同一索引中。
+- 查询中没有字段等于`null`。
+
+由于所有出现在查询中的字段是索引的一部分, MongoDB 无需在整个数据文档中检索匹配查询条件和返回使用相同索引的查询结果。因为索引存在于内存中,从索引中获取数据比通过扫描文档读取数据要快得多。
+
+举个例子:我们有如下 `users` 集合:
+
+```json
+{
+ "_id": ObjectId("53402597d852426020000002"),
+ "contact": "987654321",
+ "dob": "01-01-1991",
+ "gender": "M",
+ "name": "Tom Benzamin",
+ "user_name": "tombenzamin"
+}
+```
+
+我们在 `users` 集合中创建联合索引,字段为 `gender` 和 `user_name` :
+
+```sql
+db.users.ensureIndex({gender:1,user_name:1})
+```
+
+现在,该索引会覆盖以下查询:
+
+```sql
+db.users.find({gender:"M"},{user_name:1,_id:0})
+```
+
+为了让指定的索引覆盖查询,必须显式地指定 `_id: 0` 来从结果中排除 `_id` 字段,因为索引不包括 `_id` 字段。
+
+## MongoDB 高可用
+
+### 复制集群
+
+#### 什么是复制集群?
+
+MongoDB 的复制集群又称为副本集群,是一组维护相同数据集合的 mongod 进程。
+
+客户端连接到整个 Mongodb 复制集群,主节点机负责整个复制集群的写,从节点可以进行读操作,但默认还是主节点负责整个复制集群的读。主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+
+通常来说,一个复制集群包含 1 个主节点(Primary),多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)。
+
+- **主节点**:整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
+- **从节点**:从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
+- **仲裁节点**:这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
+
+下图是一个典型的三成员副本集群:
+
+
+
+主节点与备节点之间是通过 **oplog(操作日志)** 来同步数据的。oplog 是 local 库下的一个特殊的 **上限集合(Capped Collection)** ,用来保存写操作所产生的增量日志,类似于 MySQL 中 的 Binlog。
+
+> 上限集合类似于定长的循环队列,数据顺序追加到集合的尾部,当集合空间达到上限时,它会覆盖集合中最旧的文档。上限集合的数据将会被顺序写入到磁盘的固定空间内,所以,I/O 速度非常快,如果不建立索引,性能更好。
+
+
+
+当主节点上的一个写操作完成后,会向 oplog 集合写入一条对应的日志,而从节点则通过这个 oplog 不断拉取到新的日志,在本地进行回放以达到数据同步的目的。
+
+副本集最多有一个主节点。 如果当前主节点不可用,一个选举会抉择出新的主节点。MongoDB 的节点选举规则能够保证在 Primary 挂掉之后选取的新节点一定是集群中数据最全的一个。
+
+#### 为什么要用复制集群?
+
+- **实现 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+- **实现读写分离**:我们可以设置从节点上可以读取数据,主节点负责写入数据,这样的话就实现了读写分离,减轻了主节点读写压力过大的问题。MongoDB 4.0 之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非业务对响应时间不是非常关注以及读取历史数据接受一定时间延迟。
+
+### 分片集群
+
+#### 什么是分片集群?
+
+分片集群是 MongoDB 的分布式版本,相较副本集,分片集群数据被均衡的分布在不同分片中, 不仅大幅提升了整个集群的数据容量上限,也将读写的压力分散到不同分片,以解决副本集性能瓶颈的难题。
+
+MongoDB 的分片集群由如下三个部分组成(下图来源于[官方文档对分片集群的介绍](https://www.mongodb.com/docs/manual/sharding/)):
+
+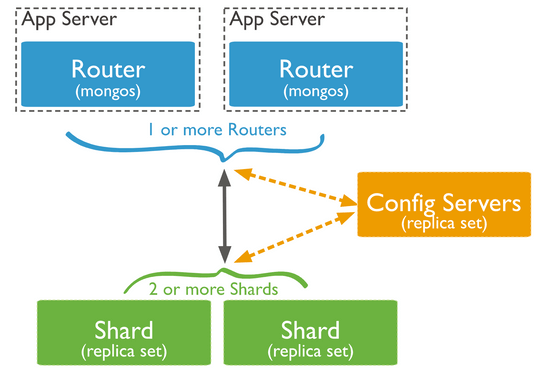
+
+- **Config Servers**:配置服务器,本质上是一个 MongoDB 的副本集,负责存储集群的各种元数据和配置,如分片地址、Chunks 等
+- **Mongos**:路由服务,不存具体数据,从 Config 获取集群配置讲请求转发到特定的分片,并且整合分片结果返回给客户端。
+- **Shard**:每个分片是整体数据的一部分子集,从 MongoDB3.6 版本开始,每个 Shard 必须部署为副本集(replica set)架构
+
+#### 为什么要用分片集群?
+
+随着系统数据量以及吞吐量的增长,常见的解决办法有两种:垂直扩展和水平扩展。
+
+垂直扩展通过增加单个服务器的能力来实现,比如磁盘空间、内存容量、CPU 数量等;水平扩展则通过将数据存储到多个服务器上来实现,根据需要添加额外的服务器以增加容量。
+
+类似于 Redis Cluster,MongoDB 也可以通过分片实现 **水平扩展** 。水平扩展这种方式更灵活,可以满足更大数据量的存储需求,支持更高吞吐量。并且,水平扩展所需的整体成本更低,仅仅需要相对较低配置的单机服务器即可,代价是增加了部署的基础设施和维护的复杂性。
+
+也就是说当你遇到如下问题时,可以使用分片集群解决:
+
+- 存储容量受单机限制,即磁盘资源遭遇瓶颈。
+- 读写能力受单机限制,可能是 CPU、内存或者网卡等资源遭遇瓶颈,导致读写能力无法扩展。
+
+#### 什么是分片键?
+
+**分片键(Shard Key)** 是数据分区的前提, 从而实现数据分发到不同服务器上,减轻服务器的负担。也就是说,分片键决定了集合内的文档如何在集群的多个分片间的分布状况。
+
+分片键就是文档里面的一个字段,但是这个字段不是普通的字段,有一定的要求:
+
+- 它必须在所有文档中都出现。
+- 它必须是集合的一个索引,可以是单索引或复合索引的前缀索引,不能是多索引、文本索引或地理空间位置索引。
+- MongoDB 4.2 之前的版本,文档的分片键字段值不可变。MongoDB 4.2 版本开始,除非分片键字段是不可变的 `_id` 字段,否则您可以更新文档的分片键值。MongoDB 5.0 版本开始,实现了实时重新分片(live resharding),可以实现分片键的完全重新选择。
+- 它的大小不能超过 512 字节。
+
+#### 如何选择分片键?
+
+选择合适的片键对 sharding 效率影响很大,主要基于如下四个因素(摘自[分片集群使用注意事项 - - 腾讯云文档](https://cloud.tencent.com/document/product/240/44611)):
+
+- **取值基数** 取值基数建议尽可能大,如果用小基数的片键,因为备选值有限,那么块的总数量就有限,随着数据增多,块的大小会越来越大,导致水平扩展时移动块会非常困难。 例如:选择年龄做一个基数,范围最多只有 100 个,随着数据量增多,同一个值分布过多时,导致 chunck 的增长超出 chuncksize 的范围,引起 jumbo chunk,从而无法迁移,导致数据分布不均匀,性能瓶颈。
+- **取值分布** 取值分布建议尽量均匀,分布不均匀的片键会造成某些块的数据量非常大,同样有上面数据分布不均匀,性能瓶颈的问题。
+- **查询带分片** 查询时建议带上分片,使用分片键进行条件查询时,mongos 可以直接定位到具体分片,否则 mongos 需要将查询分发到所有分片,再等待响应返回。
+- **避免单调递增或递减** 单调递增的 sharding key,数据文件挪动小,但写入会集中,导致最后一篇的数据量持续增大,不断发生迁移,递减同理。
+
+综上,在选择片键时要考虑以上 4 个条件,尽可能满足更多的条件,才能降低 MoveChunks 对性能的影响,从而获得最优的性能体验。
+
+#### 分片策略有哪些?
+
+MongoDB 支持两种分片算法来满足不同的查询需求(摘自[MongoDB 分片集群介绍 - 阿里云文档](https://help.aliyun.com/document_detail/64561.html?spm=a2c4g.11186623.0.0.3121565eQhUGGB#h2--shard-key-3)):
+
+**1、基于范围的分片**:
+
+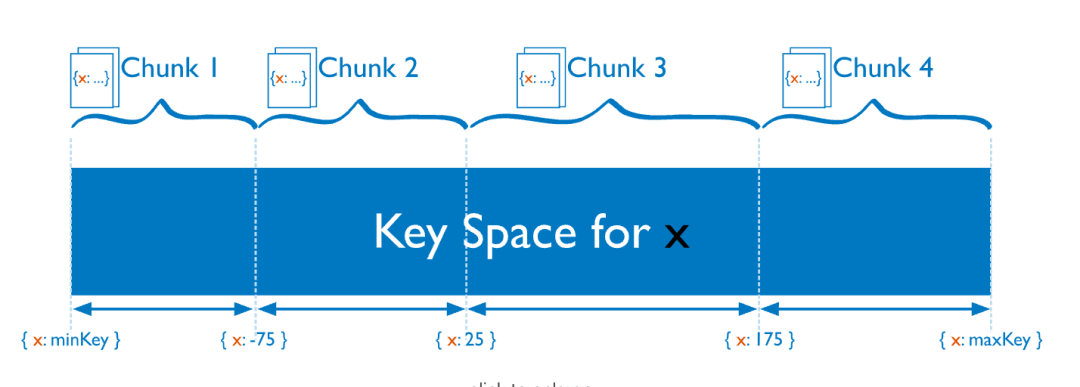
+
+MongoDB 按照分片键(Shard Key)的值的范围将数据拆分为不同的块(Chunk),每个块包含了一段范围内的数据。当分片键的基数大、频率低且值非单调变更时,范围分片更高效。
+
+- 优点:Mongos 可以快速定位请求需要的数据,并将请求转发到相应的 Shard 节点中。
+- 缺点:可能导致数据在 Shard 节点上分布不均衡,容易造成读写热点,且不具备写分散性。
+- 适用场景:分片键的值不是单调递增或单调递减、分片键的值基数大且重复的频率低、需要范围查询等业务场景。
+
+**2、基于 Hash 值的分片**
+
+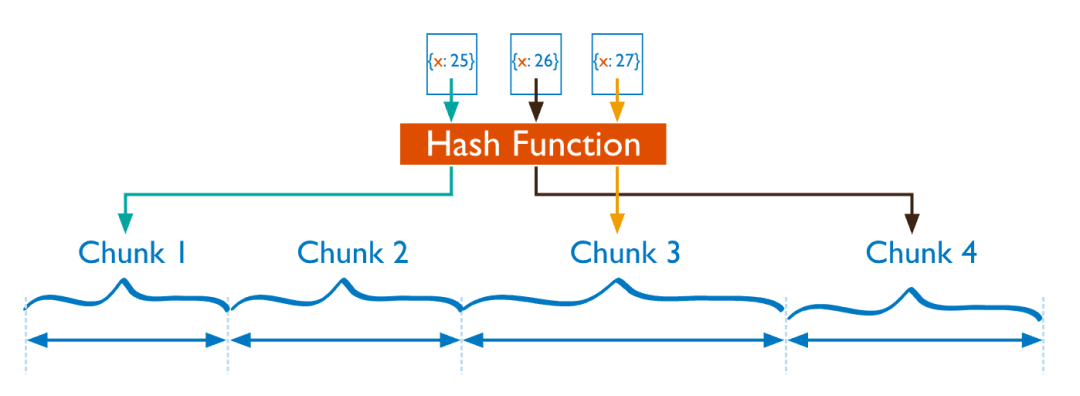
+
+MongoDB 计算单个字段的哈希值作为索引值,并以哈希值的范围将数据拆分为不同的块(Chunk)。
+
+- 优点:可以将数据更加均衡地分布在各 Shard 节点中,具备写分散性。
+- 缺点:不适合进行范围查询,进行范围查询时,需要将读请求分发到所有的 Shard 节点。
+- 适用场景:分片键的值存在单调递增或递减、片键的值基数大且重复的频率低、需要写入的数据随机分发、数据读取随机性较大等业务场景。
+
+除了上述两种分片策略,您还可以配置 **复合片键** ,例如由一个低基数的键和一个单调递增的键组成。
+
+#### 分片数据如何存储?
+
+**Chunk(块)** 是 MongoDB 分片集群的一个核心概念,其本质上就是由一组 Document 组成的逻辑数据单元。每个 Chunk 包含一定范围片键的数据,互不相交且并集为全部数据,即离散数学中**划分**的概念。
+
+分片集群不会记录每条数据在哪个分片上,而是记录 Chunk 在哪个分片上一级这个 Chunk 包含哪些数据。
+
+By default, the maximum size of a Chunk is 64MB (adjustable, the value range is 1~1024 MB. If there are no special requirements, it is recommended to keep the default value). When inserting, updating, or deleting data, if Mongos senses the size of the target Chunk or the amount of data in it exceeds the upper limit, **Chunk split** will be triggered.
+
+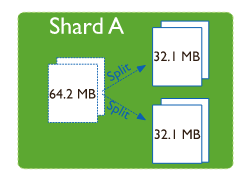
+
+The growth of data will cause more and more chunks to be split. At this time, the number of Chunks on each shard may be unbalanced. The **Balancer** component in Mongos will perform automatic balancing and try to balance the number of Chunks on each Shard. This process is **Rebalance**. By default, Rebalance for databases and collections is turned on.
+
+As shown in the figure below, as data is inserted, the chunks are split, so that the two shards AB have three chunks and the C shard has only one. At this time, one allocated by B will be migrated to the C shard to achieve cluster data balance.
+
+
+
+> Balancer is a background process of MongoDB that runs on the Primary node of Config Server (since MongoDB version 3.4). It monitors the number of Chunks on each shard and migrates them when the number of Chunks on a certain shard reaches a threshold.
+
+Chunks will only be split, not merged, even if the value of chunkSize becomes larger.
+
+The Rebalance operation consumes system resources. We can reduce its impact on the normal use of MongoDB by executing it during low business peak periods, pre-sharding, or setting the Rebalance time window.
+
+#### What is the principle of Chunk migration?
+
+For a detailed introduction to the principles of chunk migration, it is recommended to read the article [Understanding MongoDB chunk migration in one article] (https://mongoing.com/archives/77479) from the MongoDB Chinese community.
+
+## Recommended learning materials
+
+- [MongoDB Chinese Manual|Official Document Chinese Version](https://docs.mongoing.com/) (recommended): Based on version 4.2, it is constantly synchronized with the latest official version.
+- [MongoDB Beginner Tutorial - 7 Days to Learn MongoDB](https://mongoing.com/archives/docs/mongodb%e5%88%9d%e5%ad%a6%e8%80%85%e6%95%99%e7%a8%8b/mon godb%e5%a6%82%e4%bd%95%e5%88%9b%e5%bb%ba%e6%95%b0%e6%8d%ae%e5%ba%93%e5%92%8c%e9%9b%86%e5%90%88): Quick start.
+- [SpringBoot integrates MongoDB in practice - 2022](https://www.cnblogs.com/dxflqm/p/16643981.html): A very good introductory article to MongoDB, which mainly focuses on the use of MongoDB's Java client to introduce basic addition, deletion, modification and query operations.
+
+## Reference
+
+- MongoDB official documents (main reference materials, subject to official documents):
+- "The Definitive Guide to MongoDB"
+- Indexes - MongoDB official documentation:
+- MongoDB - Index Knowledge - Programmer Xiang Zai - 2022:
+- MongoDB - Index:
+- Sharding - MongoDB official documentation:
+- Introduction to MongoDB sharded cluster - Alibaba Cloud Document:
+- Precautions for using sharded clusters - - Tencent Cloud Document:
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/a-thousand-lines-of-mysql-study-notes.en.md b/docs_en/database/mysql/a-thousand-lines-of-mysql-study-notes.en.md
new file mode 100644
index 00000000000..44b18758932
--- /dev/null
+++ b/docs_en/database/mysql/a-thousand-lines-of-mysql-study-notes.en.md
@@ -0,0 +1,962 @@
+---
+title: One Thousand Lines of MySQL Study Notes
+category: database
+tag:
+ -MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL notes, tuning, indexing, transactions, tools, experience summary, practice
+ - - meta
+ - name: description
+ content: Organizes thousands of lines of notes on MySQL learning and practice, condensing tuning ideas, indexing and transaction key points, and tool usage for quick reference and review.
+---
+
+> Original address: , JavaGuide has simplified the layout of this article and added a new table of contents.
+
+A very good summary, I strongly recommend saving it and reading it when needed.
+
+### Basic operations
+
+```sql
+/* Windows service */
+-- Start MySQL
+ net start mysql
+-- Create a Windows service
+ sc create mysql binPath= mysqld_bin_path (note: there is a space between the equal sign and the value)
+/* Connect and disconnect from server */
+-- Connect to MySQL
+ mysql -h address -P port -u username -p password
+-- Show which threads are running
+ SHOW PROCESSLIST
+-- Display system variable information
+ SHOW VARIABLES
+```
+
+### Database operations
+
+```sql
+/* Database operations */
+-- View the current database
+ SELECT DATABASE();
+-- Display the current time, user name, and database version
+ SELECT now(), user(), version();
+--Create library
+ CREATE DATABASE[IF NOT EXISTS] database name database options
+ Database options:
+ CHARACTER SET charset_name
+ COLLATE collation_name
+-- View existing libraries
+ SHOW DATABASES[ LIKE 'PATTERN']
+-- View current library information
+ SHOW CREATE DATABASE database name
+-- Modify library option information
+ ALTER DATABASE library name option information
+-- Delete library
+ DROP DATABASE[IF EXISTS] database name
+ Delete the directory related to the database and its directory contents at the same time
+```
+
+### Table operations
+
+```sql
+/* Table operations */
+--Create table
+ CREATE [TEMPORARY] TABLE[ IF NOT EXISTS] [Library name.] Table name (structure definition of the table) [Table options]
+ Each field must have a data type
+ There cannot be a comma after the last field
+ TEMPORARY temporary table, the table automatically disappears when the session ends
+ For field definition:
+ Field name Data type [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
+-- table options
+ --Character set
+ CHARSET = charset_name
+ If the table is not set, the database character set is used
+ -- storage engine
+ ENGINE = engine_name
+ Tables use different data structures when managing data. Different structures will lead to different processing methods and provided feature operations.
+ Common engines: InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
+ Different engines use different ways to save the structure and data of tables
+ MyISAM table file meaning: .frm table definition, .MYD table data, .MYI table index
+ InnoDB table file meaning: .frm table definition, table space data and log files
+ SHOW ENGINES -- displays storage engine status information
+ SHOW ENGINE engine name {LOGS|STATUS} -- displays the log or status information of the storage engine
+ --increment starting number
+ AUTO_INCREMENT = number of rows
+ --Data file directory
+ DATA DIRECTORY = 'Directory'
+ -- Index file directory
+ INDEX DIRECTORY = 'Directory'
+ -- table comments
+ COMMENT = 'string'
+ --Partition options
+ PARTITION BY ... (see manual for details)
+-- View all tables
+ SHOW TABLES[ LIKE 'pattern']
+ SHOW TABLES FROM library name
+-- View table structure
+ SHOW CREATE TABLE table name (more detailed information)
+ DESC table name / DESCRIBE table name / EXPLAIN table name / SHOW COLUMNS FROM table name [LIKE 'PATTERN']
+ SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
+--Modify table
+ --Modify options for the table itself
+ ALTER TABLE table name table options
+ eg: ALTER TABLE table name ENGINE=MYISAM;
+ -- Rename the table
+ RENAME TABLE original table name TO new table name
+ RENAME TABLE original table name TO database name.table name (the table can be moved to another database)
+ -- RENAME can exchange two table names
+ -- Modify the field structure of the table (13.1.2. ALTER TABLE syntax)
+ ALTER TABLE table name operation name
+ -- operation name
+ ADD[COLUMN] field definition -- add field
+ AFTER field name -- means adding after the field name
+ FIRST -- means adding in the first
+ ADD PRIMARY KEY (field name) -- Create a primary key
+ ADD UNIQUE [index name] (field name)--Create a unique index
+ ADD INDEX [index name] (field name) -- Create a normal index
+ DROP[COLUMN] field name -- delete field
+ MODIFY[COLUMN] Field name Field attribute -- Supports modification of field attributes, field name cannot be modified (all original attributes must also be written)
+ CHANGE[COLUMN] Original field name New field name Field attributes -- Supports modification of field names
+ DROP PRIMARY KEY -- Delete the primary key (you need to delete its AUTO_INCREMENT attribute before deleting the primary key)
+ DROP INDEX index name -- delete index
+ DROP FOREIGN KEY foreign key -- delete foreign key
+-- Delete table
+ DROP TABLE[IF EXISTS] table name ...
+--Clear table data
+ TRUNCATE [TABLE] table name
+--Copy table structure
+ CREATE TABLE table name LIKE table name to copy
+--Copy table structure and data
+ CREATE TABLE table name [AS] SELECT * FROM table name to be copied
+-- Check the table for errors
+ CHECK TABLE tbl_name [, tbl_name] ... [option] ...
+-- Optimize table
+ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+-- Repair table
+ REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
+-- analysis table
+ ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+```
+
+### Data operations
+
+```sql
+/* Data operations */ ------------------
+-- increase
+ INSERT [INTO] table name [(field list)] VALUES (value list)[, (value list), ...]
+ -- The field list can be omitted if the list of values to be inserted contains all fields and is in consistent order.
+ -- Multiple data records can be inserted at the same time!
+ REPLACE is similar to INSERT, the only difference is that for matching rows, the data of the existing row (compared with the primary key/unique key) is replaced, and if there is no existing row, a new row is inserted.
+ INSERT [INTO] table name SET field name=value[, field name=value, ...]
+-- Check
+ SELECT field list FROM table name [other clauses]
+ -- Multiple fields that can come from multiple tables
+ --Other clauses may not be used
+ -- The field list can be replaced by * to indicate all fields
+-- Delete
+ DELETE FROM table name [delete condition clause]
+ Without a conditional clause, all will be deleted
+-- change
+ UPDATE table name SET field name=new value[, field name=new value] [update condition]```
+
+### 字符集编码
+
+```sql
+/* 字符集编码 */ ------------------
+-- MySQL、数据库、表、字段均可设置编码
+-- 数据编码与客户端编码不需一致
+SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项
+ character_set_client 客户端向服务器发送数据时使用的编码
+ character_set_results 服务器端将结果返回给客户端所使用的编码
+ character_set_connection 连接层编码
+SET 变量名 = 变量值
+ SET character_set_client = gbk;
+ SET character_set_results = gbk;
+ SET character_set_connection = gbk;
+SET NAMES GBK; -- 相当于完成以上三个设置
+-- 校对集
+ 校对集用以排序
+ SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集
+ SHOW COLLATION [LIKE 'pattern'] 查看所有校对集
+ CHARSET 字符集编码 设置字符集编码
+ COLLATE 校对集编码 设置校对集编码
+```
+
+### 数据类型(列类型)
+
+```sql
+/* 数据类型(列类型) */ ------------------
+1. 数值类型
+-- a. 整型 ----------
+ 类型 字节 范围(有符号位)
+ tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255
+ smallint 2字节 -32768 ~ 32767
+ mediumint 3字节 -8388608 ~ 8388607
+ int 4字节
+ bigint 8字节
+ int(M) M表示总位数
+ - 默认存在符号位,unsigned 属性修改
+ - 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改
+ 例:int(5) 插入一个数'123',补填后为'00123'
+ - 在满足要求的情况下,越小越好。
+ - 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。
+-- b. 浮点型 ----------
+ 类型 字节 范围
+ float(单精度) 4字节
+ double(双精度) 8字节
+ 浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。
+ 不同于整型,前后均会补填0.
+ 定义浮点型时,需指定总位数和小数位数。
+ float(M, D) double(M, D)
+ M表示总位数,D表示小数位数。
+ M和D的大小会决定浮点数的范围。不同于整型的固定范围。
+ M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。
+ 支持科学计数法表示。
+ 浮点数表示近似值。
+-- c. 定点数 ----------
+ decimal -- 可变长度
+ decimal(M, D) M也表示总位数,D表示小数位数。
+ 保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。
+ 将浮点数转换为字符串来保存,每9位数字保存为4个字节。
+2. 字符串类型
+-- a. char, varchar ----------
+ char 定长字符串,速度快,但浪费空间
+ varchar 变长字符串,速度慢,但节省空间
+ M表示能存储的最大长度,此长度是字符数,非字节数。
+ 不同的编码,所占用的空间不同。
+ char,最多255个字符,与编码无关。
+ varchar,最多65535字符,与编码有关。
+ 一条有效记录最大不能超过65535个字节。
+ utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符
+ varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存。
+ varchar 的最大有效长度由最大行大小和使用的字符集确定。
+ 最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是65535-1-2=65532字节。
+ 例:若一个表定义为 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3
+-- b. blob, text ----------
+ blob 二进制字符串(字节字符串)
+ tinyblob, blob, mediumblob, longblob
+ text 非二进制字符串(字符字符串)
+ tinytext, text, mediumtext, longtext
+ text 在定义时,不需要定义长度,也不会计算总长度。
+ text 类型在定义时,不可给default值
+-- c. binary, varbinary ----------
+ 类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。
+ char, varchar, text 对应 binary, varbinary, blob.
+3. 日期时间类型
+ 一般用整型保存时间戳,因为PHP可以很方便的将时间戳进行格式化。
+ datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59
+ date 3字节 日期 1000-01-01 到 9999-12-31
+ timestamp 4字节 时间戳 19700101000000 到 2038-01-19 03:14:07
+ time 3字节 时间 -838:59:59 到 838:59:59
+ year 1字节 年份 1901 - 2155
+datetime YYYY-MM-DD hh:mm:ss
+timestamp YY-MM-DD hh:mm:ss
+ YYYYMMDDhhmmss
+ YYMMDDhhmmss
+ YYYYMMDDhhmmss
+ YYMMDDhhmmss
+date YYYY-MM-DD
+ YY-MM-DD
+ YYYYMMDD
+ YYMMDD
+ YYYYMMDD
+ YYMMDD
+time hh:mm:ss
+ hhmmss
+ hhmmss
+year YYYY
+ YY
+ YYYY
+ YY
+4. 枚举和集合
+-- 枚举(enum) ----------
+enum(val1, val2, val3...)
+ 在已知的值中进行单选。最大数量为65535.
+ 枚举值在保存时,以2个字节的整型(smallint)保存。每个枚举值,按保存的位置顺序,从1开始逐一递增。
+ 表现为字符串类型,存储却是整型。
+ NULL值的索引是NULL。
+ 空字符串错误值的索引值是0。
+-- 集合(set) ----------
+set(val1, val2, val3...)
+ create table tab ( gender set('男', '女', '无') );
+ insert into tab values ('男, 女');
+ 最多可以有64个不同的成员。以bigint存储,共8个字节。采取位运算的形式。
+ 当创建表时,SET成员值的尾部空格将自动被删除。
+```
+
+### 列属性(列约束)
+
+```sql
+/* 列属性(列约束) */ ------------------
+1. PRIMARY 主键
+ - 能唯一标识记录的字段,可以作为主键。
+ - 一个表只能有一个主键。
+ - 主键具有唯一性。
+ - 声明字段时,用 primary key 标识。
+ 也可以在字段列表之后声明
+ 例:create table tab ( id int, stu varchar(10), primary key (id));
+ - 主键字段的值不能为null。
+ - 主键可以由多个字段共同组成。此时需要在字段列表后声明的方法。
+ 例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age));
+2. UNIQUE 唯一索引(唯一约束)
+ 使得某字段的值也不能重复。
+3. NULL 约束
+ null不是数据类型,是列的一个属性。
+ 表示当前列是否可以为null,表示什么都没有。
+ null, 允许为空。默认。
+ not null, 不允许为空。
+ insert into tab values (null, 'val');
+ -- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null
+4. DEFAULT 默认值属性
+ 当前字段的默认值。
+ insert into tab values (default, 'val'); -- 此时表示强制使用默认值。
+ create table tab ( add_time timestamp default current_timestamp );
+ -- 表示将当前时间的时间戳设为默认值。
+ current_date, current_time
+5. AUTO_INCREMENT 自动增长约束
+ 自动增长必须为索引(主键或unique)
+ 只能存在一个字段为自动增长。
+ 默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x;
+6. COMMENT 注释
+ 例:create table tab ( id int ) comment '注释内容';
+7. FOREIGN KEY 外键约束
+ 用于限制主表与从表数据完整性。
+ alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id);
+ -- 将表t1的t1_id外键关联到表t2的id字段。
+ -- 每个外键都有一个名字,可以通过 constraint 指定
+ 存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
+ 作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。
+ MySQL中,可以对InnoDB引擎使用外键约束:
+ 语法:
+ foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作]
+ 此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。
+ 可以不指定主表记录更改或更新时的动作,那么此时主表的操作被拒绝。
+ 如果指定了 on update 或 on delete:在删除或更新时,有如下几个操作可以选择:
+ 1. cascade,级联操作。主表数据被更新(主键值更新),从表也被更新(外键值更新)。主表记录被删除,从表相关记录也被删除。
+ 2. set null,设置为null。主表数据被更新(主键值更新),从表的外键被设置为null。主表记录被删除,从表相关记录外键被设置成null。但注意,要求该外键列,没有not null属性约束。
+ 3. restrict,拒绝父表删除和更新。
+ 注意,外键只被InnoDB存储引擎所支持。其他引擎是不支持的。
+
+```
+
+### 建表规范
+
+```sql
+/* 建表规范 */ ------------------
+ -- Normal Format, NF
+ - 每个表保存一个实体信息
+ - 每个具有一个ID字段作为主键
+ - ID主键 + 原子表
+ -- 1NF, 第一范式
+ 字段不能再分,就满足第一范式。
+ -- 2NF, 第二范式
+ 满足第一范式的前提下,不能出现部分依赖。
+ 消除复合主键就可以避免部分依赖。增加单列关键字。
+ -- 3NF, 第三范式
+ 满足第二范式的前提下,不能出现传递依赖。
+ 某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
+ 将一个实体信息的数据放在一个表内实现。
+```
+
+### SELECT
+
+```sql
+/* SELECT */ ------------------
+SELECT [ALL|DISTINCT] select_expr FROM -> WHERE -> GROUP BY [合计函数] -> HAVING -> ORDER BY -> LIMIT
+a. select_expr
+ -- 可以用 * 表示所有字段。
+ select * from tb;
+ -- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
+ select stu, 29+25, now() from tb;
+ -- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
+ - 使用 as 关键字,也可省略 as.
+ select stu+10 as add10 from tb;
+b. FROM 子句
+ 用于标识查询来源。
+ -- 可以为表起别名。使用as关键字。
+ SELECT * FROM tb1 AS tt, tb2 AS bb;
+ -- from子句后,可以同时出现多个表。
+ -- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
+ SELECT * FROM tb1, tb2;
+ -- 向优化符提示如何选择索引
+ USE INDEX、IGNORE INDEX、FORCE INDEX
+ SELECT * FROM table1 USE INDEX (key1,key2) WHERE key1=1 AND key2=2 AND key3=3;
+ SELECT * FROM table1 IGNORE INDEX (key3) WHERE key1=1 AND key2=2 AND key3=3;
+c. WHERE 子句
+ -- 从from获得的数据源中进行筛选。
+ -- 整型1表示真,0表示假。
+ -- 表达式由运算符和运算数组成。
+ -- 运算数:变量(字段)、值、函数返回值
+ -- 运算符:
+ =, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
+ in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
+ is/is not 加上true/false/unknown,检验某个值的真假
+ <=>与<>功能相同,<=>可用于null比较
+d. GROUP BY 子句, 分组子句
+ GROUP BY 字段/别名 [排序方式]
+ 分组后会进行排序。升序:ASC,降序:DESC
+ 以下[合计函数]需配合 GROUP BY 使用:
+ count 返回不同的非NULL值数目 count(*)、count(字段)
+ sum 求和
+ max 求最大值
+ min 求最小值
+ avg 求平均值
+ group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
+e. HAVING 子句,条件子句
+ 与 where 功能、用法相同,执行时机不同。
+ where 在开始时执行检测数据,对原数据进行过滤。
+ having 对筛选出的结果再次进行过滤。
+ having 字段必须是查询出来的,where 字段必须是数据表存在的。
+ where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
+ where 不可以使用合计函数。一般需用合计函数才会用 having
+ SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
+f. ORDER BY 子句,排序子句
+ order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
+ 升序:ASC,降序:DESC
+ 支持多个字段的排序。
+g. LIMIT 子句,限制结果数量子句
+ 仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
+ limit 起始位置, 获取条数
+ 省略第一个参数,表示从索引0开始。limit 获取条数
+h. DISTINCT, ALL 选项
+ distinct 去除重复记录
+ 默认为 all, 全部记录
+```
+
+### UNION
+
+```sql
+/* UNION */ ------------------
+ 将多个select查询的结果组合成一个结果集合。
+ SELECT ... UNION [ALL|DISTINCT] SELECT ...
+ 默认 DISTINCT 方式,即所有返回的行都是唯一的
+ 建议,对每个SELECT查询加上小括号包裹。
+ ORDER BY 排序时,需加上 LIMIT 进行结合。
+ 需要各select查询的字段数量一样。
+ 每个select查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select语句为准。
+```
+
+### 子查询
+
+```sql
+/* 子查询 */ ------------------
+ - 子查询需用括号包裹。
+-- from型
+ from后要求是一个表,必须给子查询结果取个别名。
+ - 简化每个查询内的条件。
+ - from型需将结果生成一个临时表格,可用以原表的锁定的释放。
+ - 子查询返回一个表,表型子查询。
+ select * from (select * from tb where id>0) as subfrom where id>1;
+-- where型
+ - 子查询返回一个值,标量子查询。
+ - 不需要给子查询取别名。
+ - where子查询内的表,不能直接用以更新。
+ select * from tb where money = (select max(money) from tb);
+ -- 列子查询
+ 如果子查询结果返回的是一列。
+ 使用 in 或 not in 完成查询
+ exists 和 not exists 条件
+ 如果子查询返回数据,则返回1或0。常用于判断条件。
+ select column1 from t1 where exists (select * from t2);
+ -- 行子查询
+ 查询条件是一个行。
+ select * from t1 where (id, gender) in (select id, gender from t2);
+ 行构造符:(col1, col2, ...) 或 ROW(col1, col2, ...)
+ 行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。
+ -- 特殊运算符
+ != all() 相当于 not in
+ = some() 相当于 in。any 是 some 的别名
+ != some() 不等同于 not in,不等于其中某一个。
+ all, some 可以配合其他运算符一起使用。
+```
+
+### 连接查询(join)
+
+```sql
+/* 连接查询(join) */ ------------------
+ 将多个表的字段进行连接,可以指定连接条件。
+-- 内连接(inner join)
+ - 默认就是内连接,可省略inner。
+ - 只有数据存在时才能发送连接。即连接结果不能出现空行。
+ on 表示连接条件。其条件表达式与where类似。也可以省略条件(表示条件永远为真)
+ 也可用where表示连接条件。
+ 还有 using, 但需字段名相同。 using(字段名)
+ -- 交叉连接 cross join
+ 即,没有条件的内连接。
+ select * from tb1 cross join tb2;
+-- 外连接(outer join)
+ - 如果数据不存在,也会出现在连接结果中。
+ -- 左外连接 left join
+ 如果数据不存在,左表记录会出现,而右表为null填充
+ -- 右外连接 right join
+ 如果数据不存在,右表记录会出现,而左表为null填充
+-- 自然连接(natural join)
+ 自动判断连接条件完成连接。
+ 相当于省略了using,会自动查找相同字段名。
+ natural join
+ natural left join
+ natural right join
+select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id;
+```
+
+### TRUNCATE
+
+```sql
+/* TRUNCATE */ ------------------
+TRUNCATE [TABLE] tbl_name
+清空数据
+删除重建表
+区别:
+1,truncate 是删除表再创建,delete 是逐条删除
+2,truncate 重置auto_increment的值。而delete不会
+3,truncate 不知道删除了几条,而delete知道。
+4,当被用于带分区的表时,truncate 会保留分区
+```
+
+### 备份与还原
+
+```sql
+/* 备份与还原 */ ------------------
+备份,将数据的结构与表内数据保存起来。
+利用 mysqldump 指令完成。
+-- 导出
+mysqldump [options] db_name [tables]
+mysqldump [options] ---database DB1 [DB2 DB3...]
+mysqldump [options] --all--database
+1. 导出一张表
+ mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)
+2. 导出多张表
+ mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)
+3. 导出所有表
+ mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)
+4. 导出一个库
+ mysqldump -u用户名 -p密码 --lock-all-tables --database 库名 > 文件名(D:/a.sql)
+可以-w携带WHERE条件
+-- 导入
+1. 在登录mysql的情况下:
+ source 备份文件
+2. 在不登录的情况下
+ mysql -u用户名 -p密码 库名 < 备份文件
+```
+
+### 视图
+
+```sql
+什么是视图:
+ 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
+ 视图具有表结构文件,但不存在数据文件。
+ 对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。
+ 视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。
+-- 创建视图
+CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
+ - 视图名必须唯一,同时不能与表重名。
+ - 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。
+ - 可以指定视图执行的算法,通过ALGORITHM指定。
+ - column_list如果存在,则数目必须等于SELECT语句检索的列数
+-- 查看结构
+ SHOW CREATE VIEW view_name
+-- 删除视图
+ - 删除视图后,数据依然存在。
+ - 可同时删除多个视图。
+ DROP VIEW [IF EXISTS] view_name ...
+-- 修改视图结构
+ - 一般不修改视图,因为不是所有的更新视图都会映射到表上。
+ ALTER VIEW view_name [(column_list)] AS select_statement
+-- 视图作用
+ 1. 简化业务逻辑
+ 2. 对客户端隐藏真实的表结构
+-- 视图算法(ALGORITHM)
+ MERGE 合并
+ 将视图的查询语句,与外部查询需要先合并再执行!
+ TEMPTABLE 临时表
+ 将视图执行完毕后,形成临时表,再做外层查询!
+ UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。
+```
+
+### 事务(transaction)
+
+```sql
+事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
+ - 支持连续SQL的集体成功或集体撤销。
+ - 事务是数据库在数据完整性方面的一个功能。
+ - 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。
+ - InnoDB被称为事务安全型引擎。
+-- 事务开启
+ START TRANSACTION; 或者 BEGIN;
+ 开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句。
+-- 事务提交
+ COMMIT;
+-- 事务回滚
+ ROLLBACK;
+ 如果部分操作发生问题,映射到事务开启前。
+-- 事务的特性
+ 1. 原子性(Atomicity)
+ 事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
+ 2. 一致性(Consistency)
+ 事务前后数据的完整性必须保持一致。
+ - 事务开始和结束时,外部数据一致
+ - 在整个事务过程中,操作是连续的
+ 3. 隔离性(Isolation)
+ 多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间的数据要相互隔离。
+ 4. 持久性(Durability)
+ 一个事务一旦被提交,它对数据库中的数据改变就是永久性的。
+-- 事务的实现
+ 1. 要求是事务支持的表类型
+ 2. 执行一组相关的操作前开启事务
+ 3. 整组操作完成后,都成功,则提交;如果存在失败,选择回滚,则会回到事务开始的备份点。
+-- 事务的原理
+ 利用InnoDB的自动提交(autocommit)特性完成。
+ 普通的MySQL执行语句后,当前的数据提交操作均可被其他客户端可见。
+ 而事务是暂时关闭“自动提交”机制,需要commit提交持久化数据操作。
+-- 注意
+ 1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。
+ 2. 事务不能被嵌套
+-- 保存点
+ SAVEPOINT 保存点名称 -- 设置一个事务保存点
+ ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
+ RELEASE SAVEPOINT 保存点名称 -- 删除保存点
+-- InnoDB自动提交特性设置
+ SET autocommit = 0|1; 0表示关闭自动提交,1表示开启自动提交。
+ - 如果关闭了,那普通操作的结果对其他客户端也不可见,需要commit提交后才能持久化数据操作。
+ - 也可以关闭自动提交来开启事务。但与START TRANSACTION不同的是,
+ SET autocommit是永久改变服务器的设置,直到下次再次修改该设置。(针对当前连接)
+ 而START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务)
+
+```
+
+### 锁表
+
+```sql
+/* 锁表 */
+表锁定只用于防止其它客户端进行不正当地读取和写入
+MyISAM 支持表锁,InnoDB 支持行锁
+-- 锁定
+ LOCK TABLES tbl_name [AS alias]
+-- 解锁
+ UNLOCK TABLES
+```
+
+### 触发器
+
+```sql
+/* 触发器 */ ------------------
+ 触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
+ 监听:记录的增加、修改、删除。
+-- 创建触发器
+CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
+ 参数:
+ trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
+ trigger_event指明了激活触发程序的语句的类型
+ INSERT:将新行插入表时激活触发程序
+ UPDATE:更改某一行时激活触发程序
+ DELETE:从表中删除某一行时激活触发程序
+ tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
+ trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
+-- 删除
+DROP TRIGGER [schema_name.]trigger_name
+可以使用old和new代替旧的和新的数据
+ 更新操作,更新前是old,更新后是new.
+ 删除操作,只有old.
+ 增加操作,只有new.
+-- 注意
+ 1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
+-- 字符连接函数
+concat(str1,str2,...])
+concat_ws(separator,str1,str2,...)
+-- 分支语句
+if 条件 then
+ 执行语句
+elseif 条件 then
+ 执行语句
+else
+ 执行语句
+end if;
+-- 修改最外层语句结束符
+delimiter 自定义结束符号
+ SQL语句
+自定义结束符号
+delimiter ; -- 修改回原来的分号
+-- 语句块包裹
+begin
+ 语句块
+end
+-- 特殊的执行
+1. 只要添加记录,就会触发程序。
+2. Insert into on duplicate key update 语法会触发:
+ 如果没有重复记录,会触发 before insert, after insert;
+ 如果有重复记录并更新,会触发 before insert, before update, after update;
+ 如果有重复记录但是没有发生更新,则触发 before insert, before update
+3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
+```
+
+### SQL Programming
+
+```sql
+/* SQL programming */ ------------------
+--//Local variables ----------
+-- variable declaration
+ declare var_name[,...] type [default value]
+ This statement is used to declare local variables. To provide a default value for a variable, include a default clause. The value can be specified as an expression and does not need to be a constant. If there is no default clause, the initial value is null.
+-- assignment
+ Use set and select into statements to assign values to variables.
+ - Note: Global variables (user-defined variables) can be used within functions
+--//Global variables ----------
+-- Definition, assignment
+The set statement can define and assign values to variables.
+set @var = value;
+You can also use the select into statement to initialize and assign values to variables. This requires that the select statement can only return one row, but it can be multiple fields, which means that multiple variables are assigned values at the same time. The number of variables needs to be consistent with the number of columns in the query.
+You can also think of the assignment statement as an expression, which is executed through select. At this time, in order to avoid = being treated as a relational operator, use := instead. (The set statement can use = and :=).
+select @var:=20;
+select @v1:=id, @v2=name from t1 limit 1;
+select * from tbl_name where @var:=30;
+Select into can assign the data obtained from the query in the table to a variable.
+ -| select max(height) into @max_height from tb;
+-- Custom variable name
+In order to avoid conflicts between user-defined variables and system identifiers (usually field names) in select statements, user-defined variables use @ as the starting symbol before the variable name.
+@var=10;
+ - Once a variable is defined, it is valid throughout the session (login to logout)
+--//Control structure ----------
+--if statement
+if search_condition then
+ statement_list
+[elseif search_condition then
+ statement_list]
+...
+[else
+ statement_list]
+end if;
+--case statement
+CASE value WHEN [compare-value] THEN result
+[WHEN [compare-value] THEN result ...]
+[ELSE result]
+END
+-- while loop
+[begin_label:] while search_condition do
+ statement_list
+end while [end_label];
+- If you need to terminate the while loop early within the loop, you need to use labels; labels need to appear in pairs.
+ --Exit the loop
+ Exit the entire loop leave
+ Exit the current loop iterate
+ Determine which loop to exit through the exit label
+--//Built-in function ----------
+-- Numerical functions
+abs(x) -- absolute value abs(-10.9) = 10
+format(x, d) -- format the thousandth value format(1234567.456, 2) = 1,234,567.46
+ceil(x) -- round up ceil(10.1) = 11
+floor(x) -- round down floor (10.1) = 10
+round(x) -- round to integer
+mod(m, n) -- m%n m mod n Find remainder 10%3=1
+pi() -- get pi
+pow(m, n) -- m^n
+sqrt(x) -- arithmetic square root
+rand() -- random number
+truncate(x, d) -- truncate to d decimal places
+-- Time and date function
+now(), current_timestamp(); -- current date and time
+current_date(); -- current date
+current_time(); -- current time
+date('yyyy-mm-dd hh:ii:ss'); -- Get the date part
+time('yyyy-mm-dd hh:ii:ss'); -- Get the time part
+date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- formatting time
+unix_timestamp(); -- Get unix timestamp
+from_unixtime(); -- Get time from timestamp
+-- String functions
+length(string) – string length, bytes
+char_length(string) – the number of characters in string
+substring(str, position [,length]) -- Starting from the position of str, take length characters
+replace(str,search_str,replace_str) -- replace search_str with replace_str in str
+instr(string,substring) -- returns the position where substring first appears in string
+concat(string [,...]) -- Concatenate strings
+charset(str) -- Returns the string character set
+lcase(string) -- Convert to lowercase
+left(string, length) -- Take length characters from the left in string2
+load_file(file_name) -- read content from file
+locate(substring, string [,start_position]) -- same as instr, but can specify the starting position
+lpad(string, length, pad) -- Repeat adding pad to the beginning of string until the length of the string is length
+ltrim(string) -- remove leading spaces
+repeat(string, count) -- repeat count times
+rpad(string, length, pad) --Add pad after str until the length is length
+rtrim(string) -- remove trailing spaces
+strcmp(string1,string2) -- compare the size of two strings character by character
+-- Process function
+case when [condition] then result [when [condition] then result ...] [else result] end multi-branch
+if(expr1,expr2,expr3) double branch.
+-- Aggregation function
+count()
+sum();
+max();
+min();
+avg();
+group_concat()
+--Other commonly used functions
+md5();
+default();
+--//Storage function, custom function ----------
+-- New
+ CREATE FUNCTION function_name (parameter list) RETURNS return value type
+ function body
+ - The function name should be a legal identifier and should not conflict with existing keywords.
+ - A function should belong to a certain database. You can use the form of db_name.function_name to execute the database to which the current function belongs, otherwise it is the current database.
+ - The parameter part consists of "parameter name" and "parameter type". Multiple parameters are separated by commas.
+ - The function body consists of multiple available mysql statements, process control, variable declaration and other statements.
+ - Multiple statements should be enclosed using begin...end statement blocks.
+ - There must be a return return value statement.
+-- Delete
+ DROP FUNCTION [IF EXISTS] function_name;
+-- View
+ SHOW FUNCTION STATUS LIKE 'partten'
+ SHOW CREATE FUNCTION function_name;
+-- Modify
+ ALTER FUNCTION function_name function option
+--// Stored procedure, custom function ----------
+-- Definition
+Stored stored procedure is a piece of code (procedure) consisting of SQL stored in the database.
+A stored procedure is usually used to complete a piece of business logic, such as registration, shift payment, order warehousing, etc.
+A function usually focuses on a certain function and is regarded as a service for other programs. It needs to call the function in other statements. However, a stored procedure cannot be called by other people and is executed by itself through call.
+-- create
+CREATE PROCEDURE sp_name (parameter list)
+ process body
+Parameter list: Different from the parameter list of a function, the parameter type needs to be specified
+IN, indicating input type
+OUT, indicating output type
+INOUT, indicating mixed type
+Note that there is no return value.
+```
+
+### Stored procedure
+
+```sql
+/* Stored procedure */ ------------------
+A stored procedure is a collection of executable code. It prefers business logic to functions.
+Call: CALL procedure name
+-- Note
+- No return value.
+- Can only be called alone and cannot be mixed with other statements
+-- Parameters
+IN|OUT|INOUT parameter name data type
+IN input: During the calling process, data is input into the parameters inside the procedure body.
+OUT output: During the calling process, the result of processing the process body is returned to the client.
+INOUT input and output: both input and output
+-- Grammar
+CREATE PROCEDURE procedure name (parameter list)
+BEGIN
+ process body
+END```
+
+### User and permission management
+
+```sql
+/* User and permission management */ ------------------
+-- root password reset
+1. Stop the MySQL service
+2. [Linux] /usr/local/mysql/bin/safe_mysqld --skip-grant-tables &
+ [Windows] mysqld --skip-grant-tables
+3. use mysql;
+4. UPDATE `user` SET PASSWORD=PASSWORD("password") WHERE `user` = "root";
+5. FLUSH PRIVILEGES;
+User information table: mysql.user
+-- Refresh permissions
+FLUSH PRIVILEGES;
+-- Add user
+CREATE USER username IDENTIFIED BY [PASSWORD] password (string)
+ - Must have the global CREATE USER permission of the mysql database, or have the INSERT permission.
+ - Users can only be created, but permissions cannot be granted.
+ - User name, pay attention to the quotation marks: such as 'user_name'@'192.168.1.1'
+ - Passwords also need quotation marks, and pure numeric passwords also need quotation marks.
+ - To specify a password in plain text, ignore the PASSWORD keyword. To specify a password as the hashed value returned by the PASSWORD() function, include the keyword PASSWORD
+-- Rename user
+RENAME USER old_user TO new_user
+-- Set password
+SET PASSWORD = PASSWORD('password') -- Set a password for the current user
+SET PASSWORD FOR username = PASSWORD('password') -- Set a password for the specified user
+-- Delete user
+DROP USER username
+-- Assign permissions/Add users
+GRANT permission list ON table name TO user name [IDENTIFIED BY [PASSWORD] 'password']
+ - all privileges means all permissions
+ - *.* represents all tables in all libraries
+ - Library name.Table name indicates a table under a certain library
+ GRANT ALL PRIVILEGES ON `pms`.* TO 'pms'@'%' IDENTIFIED BY 'pms0817';
+-- View permissions
+SHOW GRANTS FOR username
+ -- View current user permissions
+ SHOW GRANTS; or SHOW GRANTS FOR CURRENT_USER; or SHOW GRANTS FOR CURRENT_USER();
+-- revoke permission
+REVOKE permission list ON table name FROM user name
+REVOKE ALL PRIVILEGES, GRANT OPTION FROM username -- revoke all privileges
+--Permission level
+-- To use GRANT or REVOKE, you must have the GRANT OPTION permission, and you must be using the permission you are granting or revoking.
+Global level: Global permissions apply to all databases in a given server, mysql.user
+ GRANT ALL ON *.* and REVOKE ALL ON *.* only grant and revoke global permissions.
+Database level: Database permissions apply to all targets in a given database, mysql.db, mysql.host
+ GRANT ALL ON db_name.* and REVOKE ALL ON db_name.* only grant and revoke database permissions.
+Table level: Table permissions apply to all columns in a given table, mysql.talbes_priv
+ GRANT ALL ON db_name.tbl_name and REVOKE ALL ON db_name.tbl_name only grant and revoke table permissions.
+Column level: Column permissions apply to a single column in a given table, mysql.columns_priv
+ When using REVOKE, you must specify the same columns as the authorized columns.
+-- Permission list
+ALL [PRIVILEGES] -- Set all simple permissions except GRANT OPTION
+ALTER -- enable ALTER TABLE
+ALTER ROUTINE -- alter or cancel a stored subroutine
+CREATE -- enables the use of CREATE TABLE
+CREATE ROUTINE -- Create a stored subroutine
+CREATE TEMPORARY TABLES -- enables the use of CREATE TEMPORARY TABLE
+CREATE USER -- Allows CREATE USER, DROP USER, RENAME USER and REVOKE ALL PRIVILEGES.
+CREATE VIEW -- enables the use of CREATE VIEW
+DELETE -- allows DELETE to be used
+DROP -- enables the use of DROP TABLE
+EXECUTE -- allows the user to run a stored subroutine
+FILE -- allows SELECT...INTO OUTFILE and LOAD DATA INFILE
+INDEX -- allows CREATE INDEX and DROP INDEX
+INSERT -- Allow the use of INSERT
+LOCK TABLES -- Allows LOCK TABLES on tables for which you have SELECT permissions
+PROCESS -- Allows use of SHOW FULL PROCESSLIST
+REFERENCES -- not implemented
+RELOAD -- Allow the use of FLUSH
+REPLICATION CLIENT -- allows the user to ask for the address of a slave or master server
+REPLICATION SLAVE -- for replication slave servers (read binary log events from the master server)
+SELECT -- Allow the use of SELECT
+SHOW DATABASES -- show all databases
+SHOW VIEW -- enables the use of SHOW CREATE VIEW
+SHUTDOWN -- Allow mysqladmin shutdown
+SUPER -- Allows the use of CHANGE MASTER, KILL, PURGE MASTER LOGS and SET GLOBAL statements, the mysqladmin debug command; allows you to connect (once) even if max_connections have been reached.
+UPDATE -- Allow UPDATE
+USAGE -- synonym for "no permissions"
+GRANT OPTION -- Allow permission to be granted
+```
+
+### Table maintenance
+
+```sql
+/* Table maintenance */
+--Analyze and store keyword distribution of tables
+ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE table name ...
+-- Check one or more tables for errors
+CHECK TABLE tbl_name [, tbl_name] ... [option] ...
+option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
+-- Defragment data files
+OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+```
+
+### Miscellaneous
+
+```sql
+/* Miscellaneous */ ------------------
+1. You can use backticks (`) to wrap identifiers (library names, table names, field names, indexes, aliases) to avoid duplication of keywords! Chinese can also be used as an identifier!
+2. Each library directory contains an option file db.opt that saves the current database.
+3. Notes:
+ Single line comment #Comment content
+ Multi-line comments /* Comment content */
+ Single line comment -- comment content (standard SQL comment style, requiring a space after double dashes (space, TAB, newline, etc.))
+4. Pattern wildcard:
+ _ any single character
+ % any number of characters, even zero characters
+ Single quotes need to be escaped \'
+5. The statement terminator in the CMD command line can be ";", "\G", "\g", which only affects the display results. Elsewhere, end with a semicolon. delimiter can modify the statement terminator of the current conversation.
+6. SQL is not case sensitive
+7. Clear existing statements: \c
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/how-sql-executed-in-mysql.en.md b/docs_en/database/mysql/how-sql-executed-in-mysql.en.md
new file mode 100644
index 00000000000..d43f6e16a78
--- /dev/null
+++ b/docs_en/database/mysql/how-sql-executed-in-mysql.en.md
@@ -0,0 +1,144 @@
+---
+title: SQL语句在MySQL中的执行过程
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 执行流程,解析器,优化器,执行器,缓冲池,日志,架构
+ - - meta
+ - name: description
+ content: 拆解 SQL 在 MySQL 的执行路径,从解析优化到执行与缓存,结合存储引擎交互,构建完整的运行时视角。
+---
+
+> 本文来自[木木匠](https://github.com/kinglaw1204)投稿。
+
+本篇文章会分析下一个 SQL 语句在 MySQL 中的执行流程,包括 SQL 的查询在 MySQL 内部会怎么流转,SQL 语句的更新是怎么完成的。
+
+在分析之前我会先带着你看看 MySQL 的基础架构,知道了 MySQL 由那些组件组成以及这些组件的作用是什么,可以帮助我们理解和解决这些问题。
+
+## 一 MySQL 基础架构分析
+
+### 1.1 MySQL 基本架构概览
+
+下图是 MySQL 的一个简要架构图,从下图你可以很清晰的看到用户的 SQL 语句在 MySQL 内部是如何执行的。
+
+先简单介绍一下下图涉及的一些组件的基本作用帮助大家理解这幅图,在 1.2 节中会详细介绍到这些组件的作用。
+
+- **连接器:** 身份认证和权限相关(登录 MySQL 的时候)。
+- **查询缓存:** 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
+- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
+- **优化器:** 按照 MySQL 认为最优的方案去执行。
+- **执行器:** 执行语句,然后从存储引擎返回数据。 -
+
+
+
+简单来说 MySQL 主要分为 Server 层和存储引擎层:
+
+- **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binlog 日志模块。
+- **存储引擎**:主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5 版本开始就被当做默认存储引擎了。**
+
+### 1.2 Server 层基本组件介绍
+
+#### 1) 连接器
+
+连接器主要和身份认证和权限相关的功能相关,就好比一个级别很高的门卫一样。
+
+主要负责用户登录数据库,进行用户的身份认证,包括校验账户密码,权限等操作,如果用户账户密码已通过,连接器会到权限表中查询该用户的所有权限,之后在这个连接里的权限逻辑判断都是会依赖此时读取到的权限数据,也就是说,后续只要这个连接不断开,即使管理员修改了该用户的权限,该用户也是不受影响的。
+
+#### 2) 查询缓存(MySQL 8.0 版本后移除)
+
+查询缓存主要用来缓存我们所执行的 SELECT 语句以及该语句的结果集。
+
+连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 SQL 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询语句,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
+
+MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。
+
+所以,一般在大多数情况下我们都是不推荐去使用查询缓存的。
+
+MySQL 8.0 版本后删除了缓存的功能,官方也是认为该功能在实际的应用场景比较少,所以干脆直接删掉了。
+
+#### 3) 分析器
+
+MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用来分析 SQL 语句是来干嘛的,分析器也会分为几步:
+
+**第一步,词法分析**,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
+
+**第二步,语法分析**,主要就是判断你输入的 SQL 是否正确,是否符合 MySQL 的语法。
+
+完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
+
+#### 4) 优化器
+
+优化器的作用就是它认为的最优的执行方案去执行(有时候可能也不是最优,这篇文章涉及对这部分知识的深入讲解),比如多个索引的时候该如何选择索引,多表查询的时候如何选择关联顺序等。
+
+可以说,经过了优化器之后可以说这个语句具体该如何执行就已经定下来。
+
+#### 5) 执行器
+
+当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
+
+## 二 语句分析
+
+### 2.1 查询语句
+
+说了以上这么多,那么究竟一条 SQL 语句是如何执行的呢?其实我们的 SQL 可以分为两种,一种是查询,一种是更新(增加,修改,删除)。我们先分析下查询语句,语句如下:
+
+```sql
+select * from tb_student A where A.age='18' and A.name=' 张三 ';
+```
+
+结合上面的说明,我们分析下这个语句的执行流程:
+
+- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
+- 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
+- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
+
+- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
+
+### 2.2 更新语句
+
+以上就是一条查询 SQL 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?SQL 语句如下:
+
+```plain
+update tb_student A set A.age='19' where A.name=' 张三 ';
+```
+
+我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
+
+- 先查询到张三这一条数据,不会走查询缓存,因为更新语句会导致与该表相关的查询缓存失效。
+- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
+- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
+- 更新完成。
+
+**这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
+
+这是因为最开始 MySQL 并没有 InnoDB 引擎(InnoDB 引擎是其他公司以插件形式插入 MySQL 的),MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
+
+It's not that it's impossible to use only one log module, but the InnoDB engine supports transactions through redo log. Then, some students will ask, can I use two log modules, but not so complicated? Why does redo log introduce prepare pre-commit state? Here we use proof by contradiction to explain why we do this?
+
+- **Write the redo log first and submit it directly, then write the binlog**. Suppose that after writing the redo log, the machine hangs up and the binlog log is not written. Then after the machine is restarted, the machine will restore the data through the redo log, but the binlog does not record the data at this time. When the machine is backed up later, this piece of data will be lost, and the master-slave synchronization will also lose this piece of data.
+- **Write the binlog first, and then write the redo log**. Suppose that after writing the binlog, the machine restarts abnormally. Since there is no redo log, the machine cannot restore this record, but there is a record in the binlog. The same reason as above will cause data inconsistency.
+
+If the redo log two-stage submission method is used, it will be different. After writing the binlog, and then submitting the redo log will prevent the above problems and ensure the consistency of the data. So the question is, is there an extreme situation? Assume that the redo log is in the pre-commit state and the binlog has been written. What will happen if an abnormal restart occurs at this time?
+This depends on the processing mechanism of MySQL. The processing process of MySQL is as follows:
+
+- Determine whether the redo log is complete. If it is complete, submit it immediately.
+- If the redo log is only pre-committed but not in commit status, it will be judged at this time whether the binlog is complete. If it is complete, the redo log will be submitted. If it is incomplete, the transaction will be rolled back.
+
+This solves the problem of data consistency.
+
+## Three Summary
+
+- MySQL is mainly divided into the Server layer and the Engine layer. The Server layer mainly includes connectors, query caches, analyzers, optimizers, executors, and a log module (binlog). This log module can be shared by all execution engines. Redolog is only available in InnoDB.
+- The engine layer is plug-in type and currently mainly includes MyISAM, InnoDB, Memory, etc.
+- The execution flow of the query statement is as follows: Permission verification (if the cache is hit)--->Query cache--->Analyzer--->Optimizer--->Permission verification--->Executor--->Engine
+- The update statement execution process is as follows: Analyzer---->Permission Verification---->Executor--->Engine---redo log (prepare status)--->binlog--->redo log (commit status)
+
+## Four References
+
+- "MySQL Practical Lectures 45"
+- MySQL 5.6 Reference Manual:
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/index-invalidation-caused-by-implicit-conversion.en.md b/docs_en/database/mysql/index-invalidation-caused-by-implicit-conversion.en.md
new file mode 100644
index 00000000000..a78c6866c48
--- /dev/null
+++ b/docs_en/database/mysql/index-invalidation-caused-by-implicit-conversion.en.md
@@ -0,0 +1,169 @@
+---
+title: MySQL隐式转换造成索引失效
+category: 数据库
+tag:
+ - MySQL
+ - 性能优化
+head:
+ - - meta
+ - name: keywords
+ content: 隐式转换,索引失效,类型不匹配,函数计算,优化器,性能退化
+ - - meta
+ - name: description
+ content: 解析隐式转换导致的索引失效与性能退化,给出类型规范、语句改写与参数配置建议,避免查询退化。
+---
+
+> 本次测试使用的 MySQL 版本是 `5.7.26`,随着 MySQL 版本的更新某些特性可能会发生改变,本文不代表所述观点和结论于 MySQL 所有版本均准确无误,版本差异请自行甄别。
+>
+> 原文:
+
+## 前言
+
+数据库优化是一个任重而道远的任务,想要做优化必须深入理解数据库的各种特性。在开发过程中我们经常会遇到一些原因很简单但造成的后果却很严重的疑难杂症,这类问题往往还不容易定位,排查费时费力最后发现是一个很小的疏忽造成的,又或者是因为不了解某个技术特性产生的。
+
+于数据库层面,最常见的恐怕就是索引失效了,且一开始因为数据量小还不易被发现。但随着业务的拓展数据量的提升,性能问题慢慢的就体现出来了,处理不及时还很容易造成雪球效应,最终导致数据库卡死甚至瘫痪。造成索引失效的原因可能有很多种,相关技术博客已经有太多了,今天我要记录的是**隐式转换造成的索引失效**。
+
+## 数据准备
+
+首先使用存储过程生成 1000 万条测试数据,
+测试表一共建立了 7 个字段(包括主键),`num1`和`num2`保存的是和`ID`一样的顺序数字,其中`num2`是字符串类型。
+`type1`和`type2`保存的都是主键对 5 的取模,目的是模拟实际应用中常用类似 type 类型的数据,但是`type2`是没有建立索引的。
+`str1`和`str2`都是保存了一个 20 位长度的随机字符串,`str1`不能为`NULL`,`str2`允许为`NULL`,相应的生成测试数据的时候我也会在`str2`字段生产少量`NULL`值(每 100 条数据产生一个`NULL`值)。
+
+```sql
+-- 创建测试数据表
+DROP TABLE IF EXISTS test1;
+CREATE TABLE `test1` (
+ `id` int(11) NOT NULL,
+ `num1` int(11) NOT NULL DEFAULT '0',
+ `num2` varchar(11) NOT NULL DEFAULT '',
+ `type1` int(4) NOT NULL DEFAULT '0',
+ `type2` int(4) NOT NULL DEFAULT '0',
+ `str1` varchar(100) NOT NULL DEFAULT '',
+ `str2` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `num1` (`num1`),
+ KEY `num2` (`num2`),
+ KEY `type1` (`type1`),
+ KEY `str1` (`str1`),
+ KEY `str2` (`str2`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+-- 创建存储过程
+DROP PROCEDURE IF EXISTS pre_test1;
+DELIMITER //
+CREATE PROCEDURE `pre_test1`()
+BEGIN
+ DECLARE i INT DEFAULT 0;
+ SET autocommit = 0;
+ WHILE i < 10000000 DO
+ SET i = i + 1;
+ SET @str1 = SUBSTRING(MD5(RAND()),1,20);
+ -- 每100条数据str2产生一个null值
+ IF i % 100 = 0 THEN
+ SET @str2 = NULL;
+ ELSE
+ SET @str2 = @str1;
+ END IF;
+ INSERT INTO test1 (`id`, `num1`, `num2`,
+ `type1`, `type2`, `str1`, `str2`)
+ VALUES (CONCAT('', i), CONCAT('', i),
+ CONCAT('', i), i%5, i%5, @str1, @str2);
+ -- 事务优化,每一万条数据提交一次事务
+ IF i % 10000 = 0 THEN
+ COMMIT;
+ END IF;
+ END WHILE;
+END;
+// DELIMITER ;
+-- 执行存储过程
+CALL pre_test1();
+```
+
+数据量比较大,还涉及使用`MD5`生成随机字符串,所以速度有点慢,稍安勿躁,耐心等待即可。
+
+1000 万条数据,我用了 33 分钟才跑完(实际时间跟你电脑硬件配置有关)。这里贴几条生成的数据,大致长这样。
+
+
+
+## SQL 测试
+
+先来看这组 SQL,一共四条,我们的测试数据表`num1`是`int`类型,`num2`是`varchar`类型,但是存储的数据都是跟主键`id`一样的顺序数字,两个字段都建立有索引。
+
+```sql
+1: SELECT * FROM `test1` WHERE num1 = 10000;
+2: SELECT * FROM `test1` WHERE num1 = '10000';
+3: SELECT * FROM `test1` WHERE num2 = 10000;
+4: SELECT * FROM `test1` WHERE num2 = '10000';
+```
+
+这四条 SQL 都是有针对性写的,12 查询的字段是 int 类型,34 查询的字段是`varchar`类型。12 或 34 查询的字段虽然都相同,但是一个条件是数字,一个条件是用引号引起来的字符串。这样做有什么区别呢?先不看下边的测试结果你能猜出这四条 SQL 的效率顺序吗?
+
+经测试这四条 SQL 最后的执行结果却相差很大,其中 124 三条 SQL 基本都是瞬间出结果,大概在 0.001~0.005 秒,在千万级的数据量下这样的结果可以判定这三条 SQL 性能基本没差别了。但是第三条 SQL,多次测试耗时基本在 4.5~4.8 秒之间。
+
+为什么 34 两条 SQL 效率相差那么大,但是同样做对比的 12 两条 SQL 却没什么差别呢?查看一下执行计划,下边分别 1234 条 SQL 的执行计划数据:
+
+
+
+可以看到,124 三条 SQL 都能使用到索引,连接类型都为`ref`,扫描行数都为 1,所以效率非常高。再看看第三条 SQL,没有用上索引,所以为全表扫描,`rows`直接到达 1000 万了,所以性能差别才那么大。
+
+仔细观察你会发现,34 两条 SQL 查询的字段`num2`是`varchar`类型的,查询条件等号右边加引号的第 4 条 SQL 是用到索引的,那么是查询的数据类型和字段数据类型不一致造成的吗?如果是这样那 12 两条 SQL 查询的字段`num1`是`int`类型,但是第 2 条 SQL 查询条件右边加了引号为什么还能用上索引呢。
+
+查阅 MySQL 相关文档发现是隐式转换造成的,看一下官方的描述:
+
+> 官方文档:[12.2 Type Conversion in Expression Evaluation](https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html?spm=5176.100239.blogcont47339.5.1FTben)
+>
+> 当操作符与不同类型的操作数一起使用时,会发生类型转换以使操作数兼容。某些转换是隐式发生的。例如,MySQL 会根据需要自动将字符串转换为数字,反之亦然。以下规则描述了比较操作的转换方式:
+>
+> 1. 两个参数至少有一个是`NULL`时,比较的结果也是`NULL`,特殊的情况是使用`<=>`对两个`NULL`做比较时会返回`1`,这两种情况都不需要做类型转换
+> 2. 两个参数都是字符串,会按照字符串来比较,不做类型转换
+> 3. 两个参数都是整数,按照整数来比较,不做类型转换
+> 4. When comparing hexadecimal values with non-numeric values, they will be treated as binary strings.
+> 5. If one parameter is `TIMESTAMP` or `DATETIME`, and the other parameter is a constant, the constant will be converted to `timestamp`
+> 6. One parameter is of type `decimal`. If the other parameter is `decimal` or an integer, the integer will be converted to `decimal` for comparison. If the other parameter is a floating point number, `decimal` will be converted to a floating point number for comparison.
+> 7. **In all other cases, both parameters will be converted to floating point numbers before comparison**
+
+According to the description of the official document, implicit conversion has occurred in our 23rd SQL. The query condition of the 2nd SQL is `num1 = '10000'`. The left side is an `int` type and the right is a string. The 3rd SQL is the opposite. According to the official conversion rule 7, both the left and right sides will be converted to floating point numbers before comparison.
+
+Let’s look at the second SQL first: ``SELECT * FROM `test1` WHERE num1 = '10000';`` **The left side is int type**`10000`, which is still `10000` when converted to a floating point number, and the string type on the right side is `'10000``, which is also `10000` when converted into a floating point number. The conversion results on both sides are unique and certain, so the use of indexes is not affected.
+
+Item 3 SQL: ``SELECT * FROM `test1` WHERE num2 = 10000;`` **The left side is string type**`'10000'', and the conversion result to floating point number 10000 is unique, and the conversion result of `int` type `10000` on the right side is also unique. However, because the left side is the search condition, although it is unique to convert `'10000'` to `10000`, other strings can also be converted to `10000`, such as `'10000a'`, `'010000'', `'10000'', etc. can be converted to floating point number `10000`. In this case, the index cannot be used.
+
+Regarding this **implicit conversion**, we can verify it through query testing. First insert a few pieces of data, including `num2='10000a'`, `'010000'' and `'10000'`:
+
+```sql
+INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000001', '10000', '10000a', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
+INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000002', '10000', '010000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
+INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000003', '10000', ' 10000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
+```
+
+Then use the third SQL statement ``SELECT * FROM `test1` WHERE num2 = 10000;`` to query:
+
+
+
+As you can see from the results, the three pieces of data inserted later also match. So what are the rules for implicit conversion of this string? Why can `num2='10000a'`, `'010000'' and `'10000'' be matched? After consulting relevant information, we found the following rules:
+
+1. Strings **not starting with a number** will be converted to `0`. For example, `'abc'`, `'a123bc'`, `'abc123''` will be converted to `0`;
+2. **Strings starting with a number** will be intercepted during conversion, from the first character to the first non-numeric content. For example, `'123abc'` will be converted to `123`, `'012abc'` will be converted to `012` which is `12`, `'5.3a66b78c'` will be converted to `5.3`, and the others are the same.
+
+Now test and verify the above rules as follows:
+
+
+
+This also confirms the previous query results.
+
+Write a SQL query str1 field again: ``SELECT * FROM `test1` WHERE str1 = 1234;``
+
+
+
+## Analysis and summary
+
+Through the above test, we discovered some features of MySQL operators:
+
+1. When the data types on the left and right sides of the operator are inconsistent, **implicit conversion** will occur.
+2. When the left side of the where query operator is a numeric type, implicit conversion occurs, which has little impact on efficiency, but it is still not recommended.
+3. When the left side of the where query operator is a character type, implicit conversion occurs, which will cause the index to fail and cause the full table scan to be extremely inefficient.
+4. When a string is converted to a numeric type, the string starting with a non-number will be converted to `0`, and the string starting with a number will intercept the value from the first character to the first non-number content as the conversion result.
+
+Therefore, we must develop good habits when writing SQL. Whatever type of field is being queried, the condition on the right side of the equal sign should be written as the corresponding type. Especially when the query field is a string, the condition on the right side of the equal sign must be enclosed in quotation marks to indicate that it is a string. Otherwise, the index will fail and trigger a full table scan.
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/innodb-implementation-of-mvcc.en.md b/docs_en/database/mysql/innodb-implementation-of-mvcc.en.md
new file mode 100644
index 00000000000..805629c180e
--- /dev/null
+++ b/docs_en/database/mysql/innodb-implementation-of-mvcc.en.md
@@ -0,0 +1,266 @@
+---
+title: InnoDB存储引擎对MVCC的实现
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: InnoDB,MVCC,快照读,当前读,一致性视图,隐藏列,事务版本,间隙锁
+ - - meta
+ - name: description
+ content: 深入解析 InnoDB 的 MVCC 实现细节与读写隔离,覆盖一致性视图、快照/当前读与隐藏列、间隙锁的配合。
+---
+
+## 多版本并发控制 (Multi-Version Concurrency Control)
+
+MVCC 是一种并发控制机制,用于在多个并发事务同时读写数据库时保持数据的一致性和隔离性。它是通过在每个数据行上维护多个版本的数据来实现的。当一个事务要对数据库中的数据进行修改时,MVCC 会为该事务创建一个数据快照,而不是直接修改实际的数据行。
+
+1、读操作(SELECT):
+
+当一个事务执行读操作时,它会使用快照读取。快照读取是基于事务开始时数据库中的状态创建的,因此事务不会读取其他事务尚未提交的修改。具体工作情况如下:
+
+- 对于读取操作,事务会查找符合条件的数据行,并选择符合其事务开始时间的数据版本进行读取。
+- 如果某个数据行有多个版本,事务会选择不晚于其开始时间的最新版本,确保事务只读取在它开始之前已经存在的数据。
+- 事务读取的是快照数据,因此其他并发事务对数据行的修改不会影响当前事务的读取操作。
+
+2、写操作(INSERT、UPDATE、DELETE):
+
+当一个事务执行写操作时,它会生成一个新的数据版本,并将修改后的数据写入数据库。具体工作情况如下:
+
+- 对于写操作,事务会为要修改的数据行创建一个新的版本,并将修改后的数据写入新版本。
+- 新版本的数据会带有当前事务的版本号,以便其他事务能够正确读取相应版本的数据。
+- 原始版本的数据仍然存在,供其他事务使用快照读取,这保证了其他事务不受当前事务的写操作影响。
+
+3、事务提交和回滚:
+
+- 当一个事务提交时,它所做的修改将成为数据库的最新版本,并且对其他事务可见。
+- 当一个事务回滚时,它所做的修改将被撤销,对其他事务不可见。
+
+4、版本的回收:
+
+为了防止数据库中的版本无限增长,MVCC 会定期进行版本的回收。回收机制会删除已经不再需要的旧版本数据,从而释放空间。
+
+MVCC 通过创建数据的多个版本和使用快照读取来实现并发控制。读操作使用旧版本数据的快照,写操作创建新版本,并确保原始版本仍然可用。这样,不同的事务可以在一定程度上并发执行,而不会相互干扰,从而提高了数据库的并发性能和数据一致性。
+
+## 一致性非锁定读和锁定读
+
+### 一致性非锁定读
+
+对于 [**一致性非锁定读(Consistent Nonlocking Reads)**](https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html)的实现,通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号 + 1 或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则表示该记录可见
+
+在 `InnoDB` 存储引擎中,[多版本控制 (multi versioning)](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html) 就是对非锁定读的实现。如果读取的行正在执行 `DELETE` 或 `UPDATE` 操作,这时读取操作不会去等待行上锁的释放。相反地,`InnoDB` 存储引擎会去读取行的一个快照数据,对于这种读取历史数据的方式,我们叫它快照读 (snapshot read)
+
+在 `Repeatable Read` 和 `Read Committed` 两个隔离级别下,如果是执行普通的 `select` 语句(不包括 `select ... lock in share mode` ,`select ... for update`)则会使用 `一致性非锁定读(MVCC)`。并且在 `Repeatable Read` 下 `MVCC` 实现了可重复读和防止部分幻读
+
+### 锁定读
+
+如果执行的是下列语句,就是 [**锁定读(Locking Reads)**](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking-reads.html)
+
+- `select ... lock in share mode`
+- `select ... for update`
+- `insert`、`update`、`delete` 操作
+
+在锁定读下,读取的是数据的最新版本,这种读也被称为 `当前读(current read)`。锁定读会对读取到的记录加锁:
+
+- `select ... lock in share mode`:对记录加 `S` 锁,其它事务也可以加`S`锁,如果加 `x` 锁则会被阻塞
+
+- `select ... for update`、`insert`、`update`、`delete`:对记录加 `X` 锁,且其它事务不能加任何锁
+
+在一致性非锁定读下,即使读取的记录已被其它事务加上 `X` 锁,这时记录也是可以被读取的,即读取的快照数据。上面说了,在 `Repeatable Read` 下 `MVCC` 防止了部分幻读,这边的 “部分” 是指在 `一致性非锁定读` 情况下,只能读取到第一次查询之前所插入的数据(根据 Read View 判断数据可见性,Read View 在第一次查询时生成)。但是!如果是 `当前读` ,每次读取的都是最新数据,这时如果两次查询中间有其它事务插入数据,就会产生幻读。所以, **`InnoDB` 在实现`Repeatable Read` 时,如果执行的是当前读,则会对读取的记录使用 `Next-key Lock` ,来防止其它事务在间隙间插入数据**
+
+## InnoDB 对 MVCC 的实现
+
+`MVCC` 的实现依赖于:**隐藏字段、Read View、undo log**。在内部实现中,`InnoDB` 通过数据行的 `DB_TRX_ID` 和 `Read View` 来判断数据的可见性,如不可见,则通过数据行的 `DB_ROLL_PTR` 找到 `undo log` 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 `Read View` 之前已经提交的修改和该事务本身做的修改
+
+### 隐藏字段
+
+在内部,`InnoDB` 存储引擎为每行数据添加了三个 [隐藏字段](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html):
+
+- `DB_TRX_ID(6字节)`:表示最后一次插入或更新该行的事务 id。此外,`delete` 操作在内部被视为更新,只不过会在记录头 `Record header` 中的 `deleted_flag` 字段将其标记为已删除
+- `DB_ROLL_PTR(7字节)` 回滚指针,指向该行的 `undo log` 。如果该行未被更新,则为空
+- `DB_ROW_ID(6字节)`:如果没有设置主键且该表没有唯一非空索引时,`InnoDB` 会使用该 id 来生成聚簇索引
+
+### ReadView
+
+```c
+class ReadView {
+ /* ... */
+private:
+ trx_id_t m_low_limit_id; /* 大于等于这个 ID 的事务均不可见 */
+
+ trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */
+
+ trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */
+
+ trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */
+
+ ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */
+
+ m_closed; /* 标记 Read View 是否 close */
+}
+```
+
+[`Read View`](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L298) 主要是用来做可见性判断,里面保存了 “当前对本事务不可见的其他活跃事务”
+
+主要有以下字段:
+
+- `m_low_limit_id`:目前出现过的最大的事务 ID+1,即下一个将被分配的事务 ID。大于等于这个 ID 的数据版本均不可见
+- `m_up_limit_id`:活跃事务列表 `m_ids` 中最小的事务 ID,如果 `m_ids` 为空,则 `m_up_limit_id` 为 `m_low_limit_id`。小于这个 ID 的数据版本均可见
+- `m_ids`:`Read View` 创建时其他未提交的活跃事务 ID 列表。创建 `Read View`时,将当前未提交事务 ID 记录下来,后续即使它们修改了记录行的值,对于当前事务也是不可见的。`m_ids` 不包括当前事务自己和已提交的事务(正在内存中)
+- `m_creator_trx_id`:创建该 `Read View` 的事务 ID
+
+**事务可见性示意图**([图源](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/#MVCC-1)):
+
+
+
+### undo-log
+
+`undo log` 主要有两个作用:
+
+- 当事务回滚时用于将数据恢复到修改前的样子
+- 另一个作用是 `MVCC` ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 `undo log` 读取之前的版本数据,以此实现非锁定读
+
+**在 `InnoDB` 存储引擎中 `undo log` 分为两种:`insert undo log` 和 `update undo log`:**
+
+1. **`insert undo log`**:指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作
+
+**`insert` 时的数据初始状态:**
+
+
+
+2. **`update undo log`**:`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除
+
+**数据第一次被修改时:**
+
+
+
+**数据第二次被修改时:**
+
+
+
+不同事务或者相同事务的对同一记录行的修改,会使该记录行的 `undo log` 成为一条链表,链首就是最新的记录,链尾就是最早的旧记录。
+
+### 数据可见性算法
+
+在 `InnoDB` 存储引擎中,创建一个新事务后,执行每个 `select` 语句前,都会创建一个快照(Read View),**快照中保存了当前数据库系统中正处于活跃(没有 commit)的事务的 ID 号**。其实简单的说保存的是系统中当前不应该被本事务看到的其他事务 ID 列表(即 m_ids)。当用户在这个事务中要读取某个记录行的时候,`InnoDB` 会将该记录行的 `DB_TRX_ID` 与 `Read View` 中的一些变量及当前事务 ID 进行比较,判断是否满足可见性条件
+
+[具体的比较算法](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L161)如下([图源](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/#MVCC-1)):
+
+
+
+1. 如果记录 DB_TRX_ID < m_up_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之前就提交了,所以该记录行的值对当前事务是可见的
+
+2. 如果 DB_TRX_ID >= m_low_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之后才修改该行,所以该记录行的值对当前事务不可见。跳到步骤 5
+
+3. m_ids 为空,则表明在当前事务创建快照之前,修改该行的事务就已经提交了,所以该记录行的值对当前事务是可见的
+
+4. 如果 m_up_limit_id <= DB_TRX_ID < m_low_limit_id,表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照的时候可能处于“活动状态”或者“已提交状态”;所以就要对活跃事务列表 m_ids 进行查找(源码中是用的二分查找,因为是有序的)
+
+ - 如果在活跃事务列表 m_ids 中能找到 DB_TRX_ID,表明:① 在当前事务创建快照前,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了,但没有提交;或者 ② 在当前事务创建快照后,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了。这些情况下,这个记录行的值对当前事务都是不可见的。跳到步骤 5
+
+ - 在活跃事务列表中找不到,则表明“id 为 trx_id 的事务”在修改“该记录行的值”后,在“当前事务”创建快照前就已经提交了,所以记录行对当前事务可见
+
+5. 在该记录行的 DB_ROLL_PTR 指针所指向的 `undo log` 取出快照记录,用快照记录的 DB_TRX_ID 跳到步骤 1 重新开始判断,直到找到满足的快照版本或返回空
+
+## RC 和 RR 隔离级别下 MVCC 的差异
+
+在事务隔离级别 `RC` 和 `RR` (InnoDB 存储引擎的默认事务隔离级别)下,`InnoDB` 存储引擎使用 `MVCC`(非锁定一致性读),但它们生成 `Read View` 的时机却不同
+
+- 在 RC 隔离级别下的 **`每次select`** 查询前都生成一个`Read View` (m_ids 列表)
+- 在 RR 隔离级别下只在事务开始后 **`第一次select`** 数据前生成一个`Read View`(m_ids 列表)
+
+## MVCC 解决不可重复读问题
+
+虽然 RC 和 RR 都通过 `MVCC` 来读取快照数据,但由于 **生成 Read View 时机不同**,从而在 RR 级别下实现可重复读
+
+举个例子:
+
+
+
+### 在 RC 下 ReadView 生成情况
+
+**1. 假设时间线来到 T4 ,那么此时数据行 id = 1 的版本链为:**
+
+
+
+由于 RC 级别下每次查询都会生成`Read View` ,并且事务 101、102 并未提交,此时 `103` 事务生成的 `Read View` 中活跃的事务 **`m_ids` 为:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
+
+- 此时最新记录的 `DB_TRX_ID` 为 101,m_up_limit_id <= 101 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是 101,不可见
+- 继续找上一条 `DB_TRX_ID`为 1,满足 1 < m_up_limit_id,可见,所以事务 103 查询到数据为 `name = 菜花`
+
+**2. 时间线来到 T6 ,数据的版本链为:**
+
+
+
+因为在 RC 级别下,重新生成 `Read View`,这时事务 101 已经提交,102 并未提交,所以此时 `Read View` 中活跃的事务 **`m_ids`:[102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:102,`m_creator_trx_id`为:103
+
+- 此时最新记录的 `DB_TRX_ID` 为 102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 为 101,满足 101 < m_up_limit_id,记录可见,所以在 `T6` 时间点查询到数据为 `name = 李四`,与时间 T4 查询到的结果不一致,不可重复读!
+
+**3. 时间线来到 T9 ,数据的版本链为:**
+
+
+
+Regenerate `Read View`. At this time, transactions 101 and 102 have been submitted, so **m_ids** is empty, then m_up_limit_id = m_low_limit_id = 104, and the latest version transaction ID is 102, which satisfies 102 < m_low_limit_id. It can be seen that the query result is `name = Zhao Liu`
+
+> **Summary:** **Under the RC isolation level, the transaction will generate and set up a new Read View at the beginning of each query, resulting in non-repeatable reads**
+
+### ReadView generation under RR
+
+At repeatable read level, a Read View (m_ids list) is generated only the first time data is read after the transaction starts.
+
+**1. The version chain in the case of T4 is: **
+
+
+
+A `Read View` is generated when the `select` statement is currently executed. At this time, **`m_ids`: [101,102]**, `m_low_limit_id` is: 104, `m_up_limit_id` is: 101, `m_creator_trx_id` is: 103
+
+This is the same as at RC level:
+
+- The `DB_TRX_ID` of the latest record is 101, m_up_limit_id <= 101 < m_low_limit_id, so you need to search in the `m_ids` list and find that `DB_TRX_ID` exists in the list, then this record is not visible
+- Find the previous version record in the `undo log` based on `DB_ROLL_PTR`. The `DB_TRX_ID` of the previous record is still 101 and is invisible.
+- Continue to find the previous `DB_TRX_ID` as 1, which satisfies 1 < m_up_limit_id and is visible, so transaction 103 queries the data as `name = cauliflower`
+
+**2. In the case of time point T6: **
+
+
+
+`Read View` will only be generated once at the RR level, so **`m_ids`: [101,102]** is still used at this time, `m_low_limit_id` is: 104, `m_up_limit_id` is: 101, `m_creator_trx_id` is: 103
+
+- The `DB_TRX_ID` of the latest record is 102, m_up_limit_id <= 102 < m_low_limit_id, so you need to search in the `m_ids` list and find that `DB_TRX_ID` exists in the list, then this record is not visible
+
+- Find the previous version record in the `undo log` based on `DB_ROLL_PTR`. The `DB_TRX_ID` of the previous record is 101 and is invisible.
+
+- Continue to find the previous version record in the `undo log` based on `DB_ROLL_PTR`. The `DB_TRX_ID` of the previous record is still 101 and is invisible.
+
+- Continue to find the previous `DB_TRX_ID` as 1, which satisfies 1 < m_up_limit_id and is visible, so transaction 103 queries the data as `name = cauliflower`
+
+**3. In the case of time point T9: **
+
+
+
+The situation at this time is exactly the same as T6. Since `Read View` has been generated, **`m_ids`: [101,102]** is still used at this time, so the query result is still `name = cauliflower`
+
+## MVCC➕Next-key-Lock prevents phantom reads
+
+The `InnoDB` storage engine uses `MVCC` and `Next-key Lock` to solve the phantom read problem at the RR level:
+
+**1. Execute ordinary `select`, and the data will be read in the way of `MVCC` snapshot reading**
+
+In the case of snapshot read, the RR isolation level will only generate `Read View` for the first query after the transaction is started, and will be used until the transaction is committed. Therefore, after generating `Read View`, the updated and inserted record versions made by other transactions are not visible to the current transaction, achieving repeatable reading and preventing "phantom reading" under snapshot reading.
+
+**2. Execute select...for update/lock in share mode, insert, update, delete and other current reads**
+
+Under the current read, all the latest data is read. If other transactions insert new records and they happen to be within the query range of the current transaction, phantom reads will occur! `InnoDB` uses [Next-key Lock](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-next-key-locks) to prevent this. When executing the current read, the read records will be locked and their gaps will be locked to prevent other transactions from inserting data within the query range. As long as I don't let you insert, phantom reading won't happen
+
+## Reference
+
+- **"MySQL Technology Insider InnoDB Storage Engine 2nd Edition"**
+- [Relationship between transaction isolation level and locks in Innodb](https://tech.meituan.com/2014/08/20/innodb-lock.html)
+- [MySQL transactions and how MVCC implements isolation levels](https://blog.csdn.net/qq_35190492/article/details/109044141)
+- [InnoDB Transaction Analysis-MVCC](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/)
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-auto-increment-primary-key-continuous.en.md b/docs_en/database/mysql/mysql-auto-increment-primary-key-continuous.en.md
new file mode 100644
index 00000000000..cb8095ca1c6
--- /dev/null
+++ b/docs_en/database/mysql/mysql-auto-increment-primary-key-continuous.en.md
@@ -0,0 +1,228 @@
+---
+title: MySQL自增主键一定是连续的吗
+category: 数据库
+tag:
+ - MySQL
+ - 大厂面试
+head:
+ - - meta
+ - name: keywords
+ content: 自增主键,不连续,事务回滚,并发插入,计数器,聚簇索引
+ - - meta
+ - name: description
+ content: 解析自增主键不连续的根因与触发场景,结合事务回滚与并发插入,说明 InnoDB 计数器与聚簇索引的行为。
+---
+
+> 作者:飞天小牛肉
+>
+> 原文:
+
+众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。
+
+但实际上,MySQL 的自增主键并不能保证一定是连续递增的。
+
+下面举个例子来看下,如下所示创建一张表:
+
+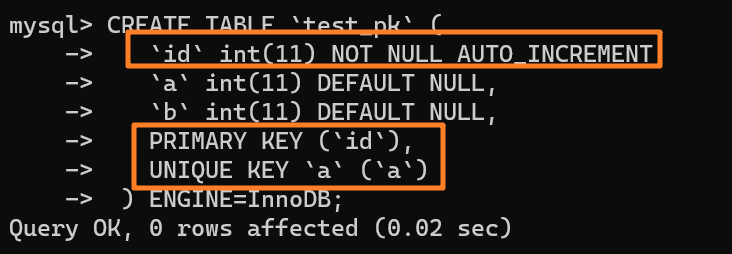
+
+## 自增值保存在哪里?
+
+使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义:
+
+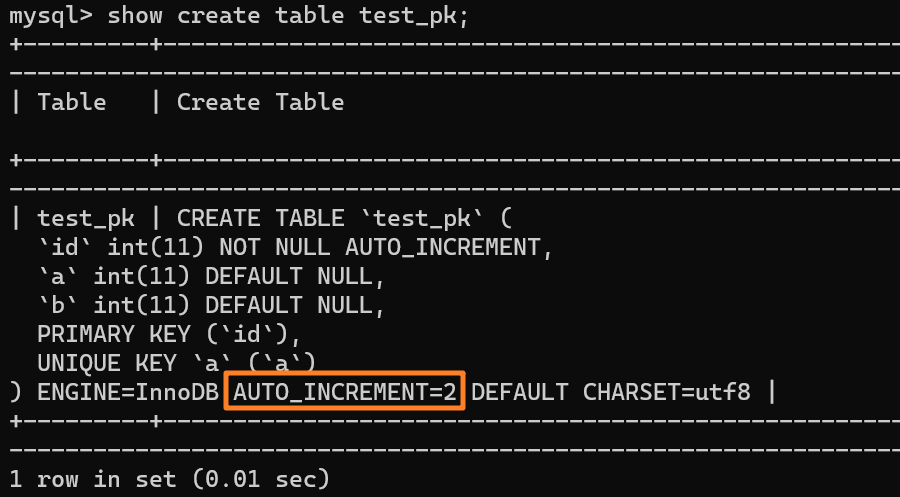
+
+上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件:
+
+
+
+从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。
+
+但需要注意的是,自增值并不会保存在这个表结构也就是 `.frm` 文件中,不同的引擎对于自增值的保存策略不同:
+
+1)MyISAM 引擎的自增值保存在数据文件中
+
+2)InnoDB 引擎的自增值,其实是保存在了内存里,并没有持久化。第一次打开表的时候,都会去找自增值的最大值 `max(id)`,然后将 `max(id)+1` 作为这个表当前的自增值。
+
+举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。
+
+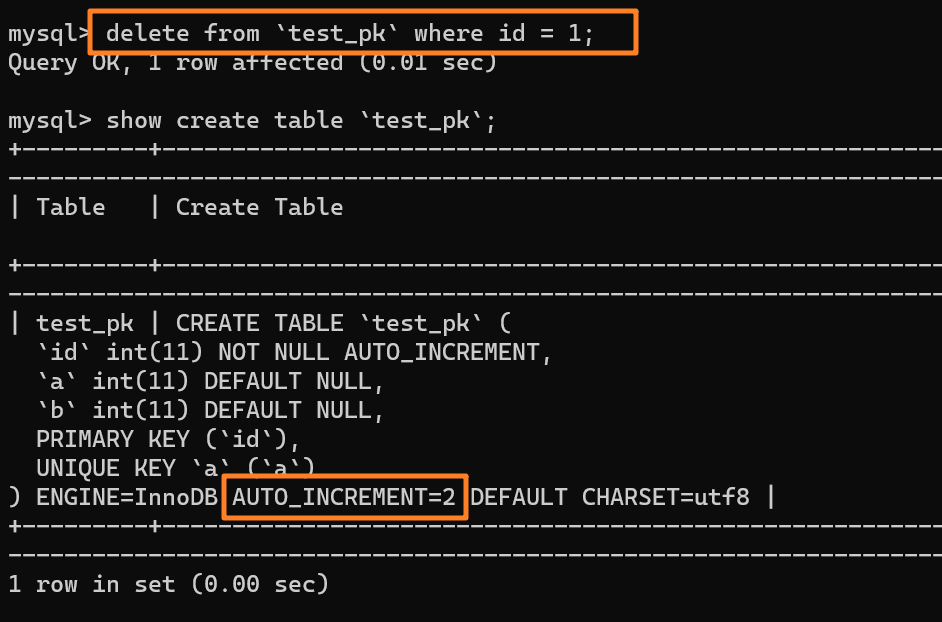
+
+但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。 也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
+
+
+
+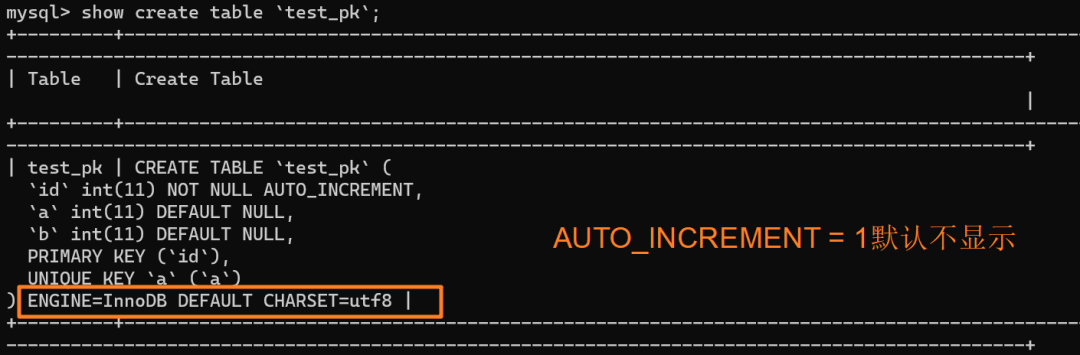
+
+以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值”
+
+也就是说对于上面这个例子来说,重启实例后这个表的 AUTO_INCREMENT 仍然是 2。
+
+理解了 MySQL 自增值到底保存在哪里以后,我们再来看看自增值的修改机制,并以此引出第一种自增值不连续的场景。
+
+## 自增值不连续的场景
+
+### 自增值不连续场景 1
+
+在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
+
+- 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段;
+- 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。
+
+根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设某次要插入的值是 `insert_num`,当前的自增值是 `autoIncrement_num`:
+
+- 如果 `insert_num < autoIncrement_num`,那么这个表的自增值不变
+- 如果 `insert_num >= autoIncrement_num`,就需要把当前自增值修改为新的自增值
+
+也就是说,如果插入的 id 是 100,当前的自增值是 90,`insert_num >= autoIncrement_num`,那么自增值就会被修改为新的自增值即 101
+
+一定是这样吗?
+
+非也~
+
+了解过分布式 id 的小伙伴一定知道,为了避免两个库生成的主键发生冲突,我们可以让一个库的自增 id 都是奇数,另一个库的自增 id 都是偶数
+
+这个奇数偶数其实是通过 `auto_increment_offset` 和 `auto_increment_increment` 这两个参数来决定的,这俩分别用来表示自增的初始值和步长,默认值都是 1。
+
+所以,上面的例子中生成新的自增值的步骤实际是这样的:从 `auto_increment_offset` 开始,以 `auto_increment_increment` 为步长,持续叠加,直到找到第一个大于 100 的值,作为新的自增值。
+
+所以,这种情况下,自增值可能会是 102,103 等等之类的,就会导致不连续的主键 id。
+
+更遗憾的是,即使在自增初始值和步长这两个参数都设置为 1 的时候,自增主键 id 也不一定能保证主键是连续的
+
+### 自增值不连续场景 2
+
+举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧
+
+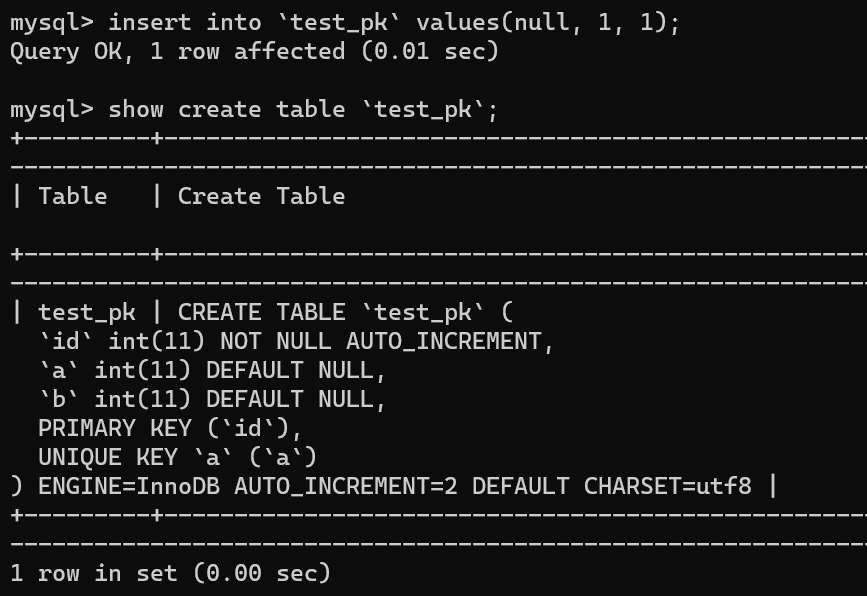
+
+这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`:
+
+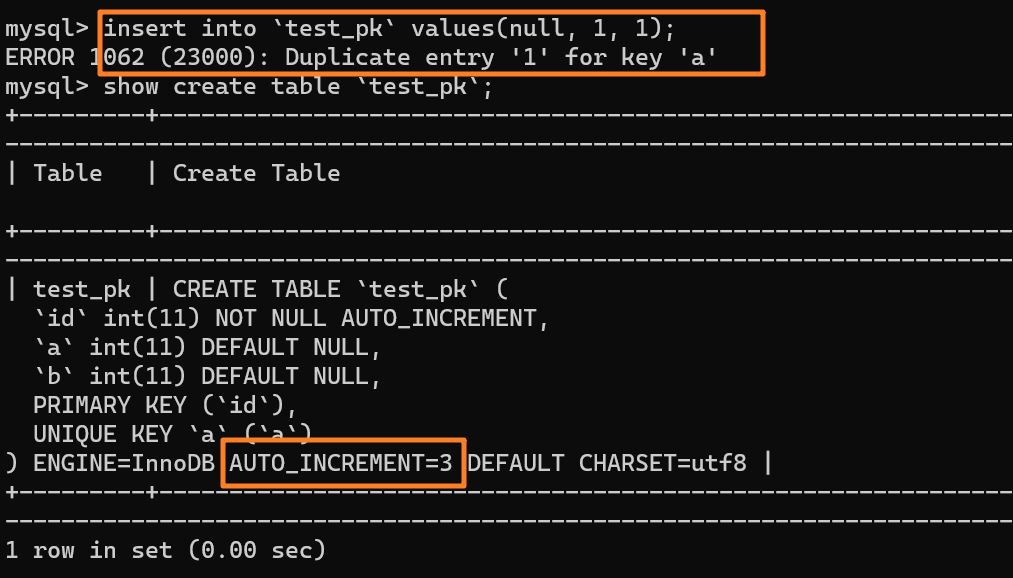
+
+但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3!
+
+这是为啥?
+
+我们来分析下这个 insert 语句的执行流程:
+
+1. 执行器调用 InnoDB 引擎接口准备插入一行记录 (null,1,1);
+2. InnoDB 发现用户没有指定自增 id 的值,则获取表 `test_pk` 当前的自增值 2;
+3. 将传入的记录改成 (2,1,1);
+4. 将表的自增值改成 3;
+5. 继续执行插入数据操作,由于已经存在 a=1 的记录,所以报 Duplicate key error,语句返回
+
+可以看到,自增值修改的这个操作,是在真正执行插入数据的操作之前。
+
+这个语句真正执行的时候,因为碰到唯一键 a 冲突,所以 id = 2 这一行并没有插入成功,但也没有将自增值再改回去。所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。也就是说,出现了自增主键不连续的情况。
+
+至此,我们已经罗列了两种自增主键不连续的情况:
+
+1. 自增初始值和自增步长设置不为 1
+2. 唯一键冲突
+
+除此之外,事务回滚也会导致这种情况
+
+### 自增值不连续场景 3
+
+我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3:
+
+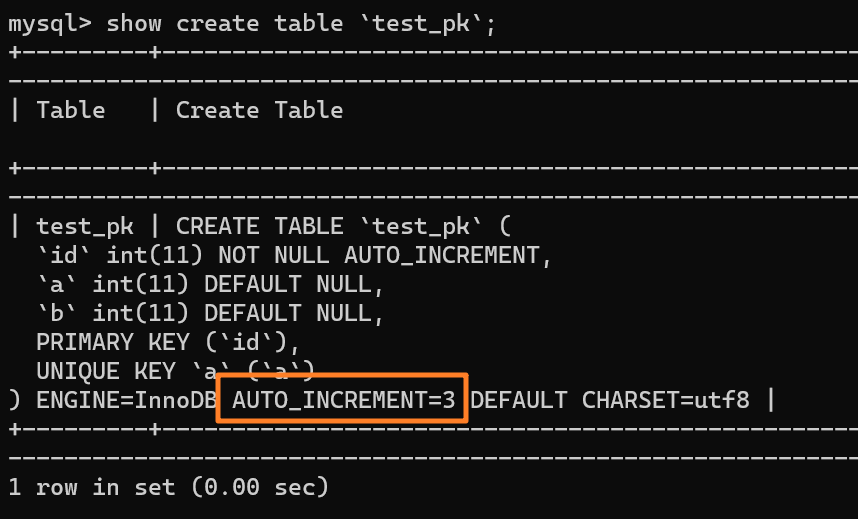
+
+我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4:
+
+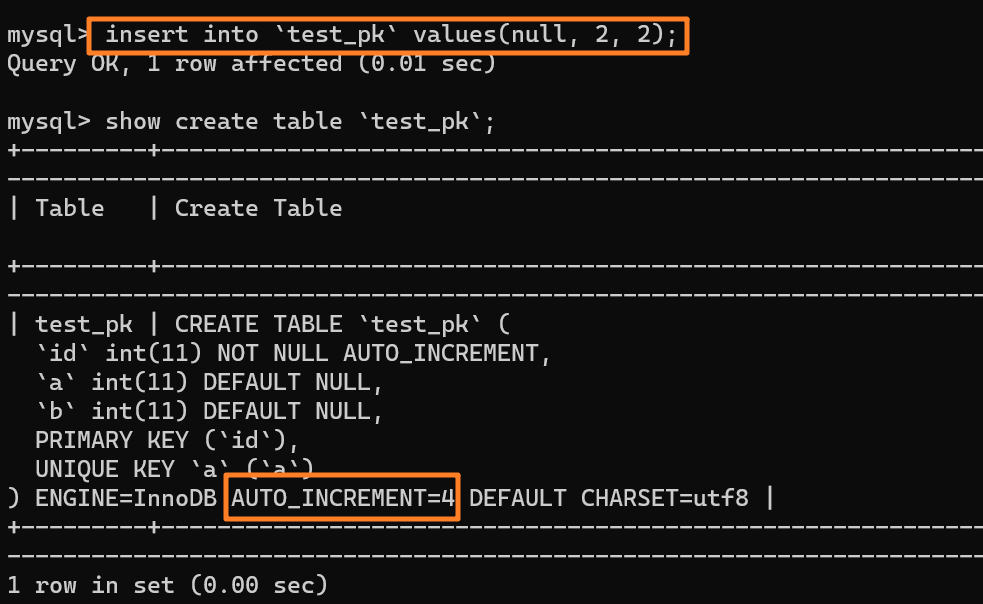
+
+再去执行这样一段 SQL:
+
+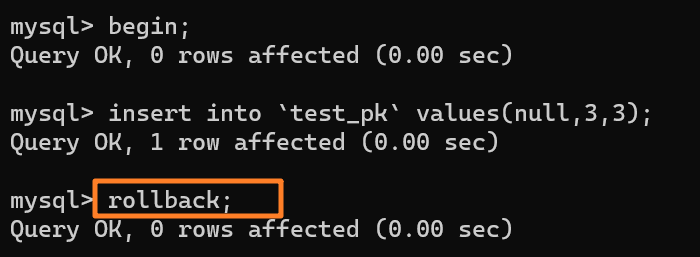
+
+Although we inserted a (null, 3, 3) record, it was rolled back using rollback, so there is no such record in the database:
+
+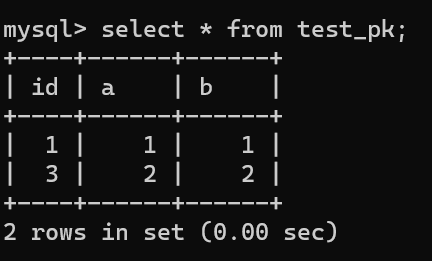
+
+In the case of this transaction rollback, the auto-increment value does not also roll back! As shown in the figure below, the self-increment value still stubbornly increases from 4 to 5:
+
+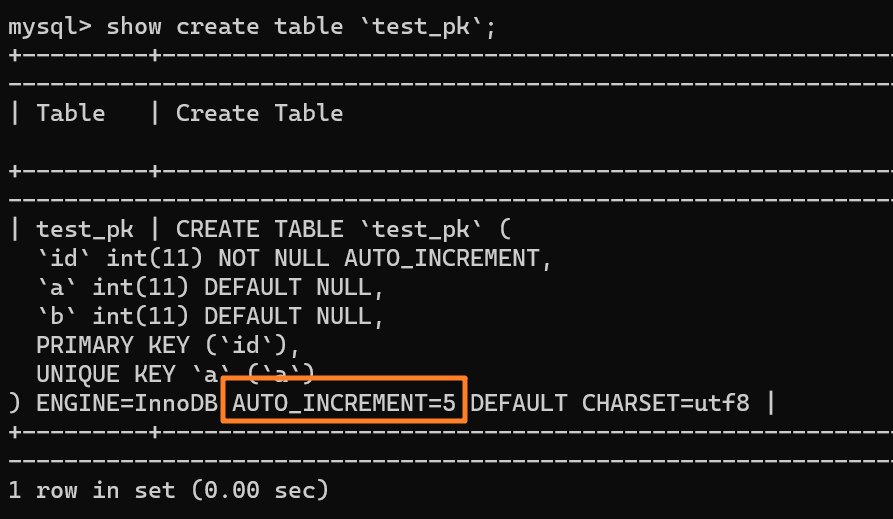
+
+So when we insert a piece of data (null, 3, 3) at this time, the primary key id will be automatically assigned to `5`:
+
+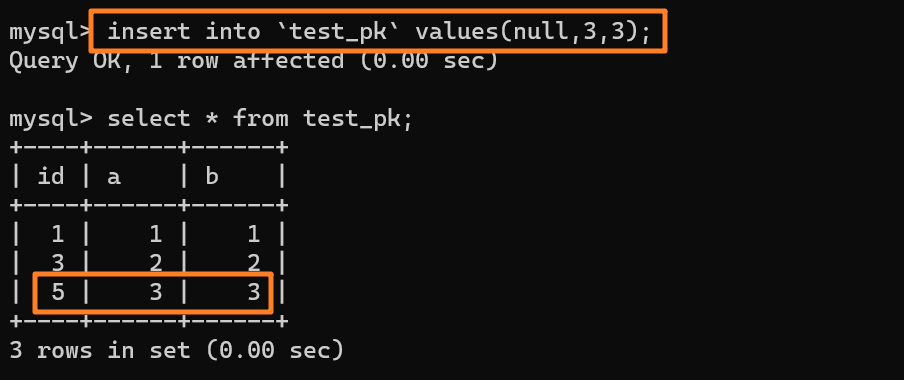
+
+So, why doesn't MySQL change the table's auto-increment value back when a unique key conflict or rollback occurs? If we go back, won't the self-increasing IDs become discontinuous?
+
+In fact, the main reason for doing this is to improve performance.
+
+We directly use proof by contradiction to verify: Assume that MySQL will change the self-increment value back when the transaction is rolled back, what will happen?
+
+Now there are two transactions A and B that are executed in parallel. When applying for auto-increment value, in order to prevent the two transactions from applying for the same auto-increment ID, they must lock and then apply sequentially, right?
+
+1. Assume that transaction A applies for id = 1, and transaction B applies for id = 2. Then the auto-increment value of table t is 3 at this time, and execution continues thereafter.
+2. Transaction B is submitted correctly, but transaction A has a unique key conflict, that is, the insertion of the row record with id = 1 fails. If transaction A is allowed to roll back the auto-incremented id, that is, change the current auto-increment value of the table back to 1, then there will be a situation like this: there is already a row with id = 2 in the table, and the current auto-increment id value is 1.
+3. Next, other transactions that continue to be executed will apply for id=2. At this time, an insert statement error "primary key conflict" will appear.
+
+
+
+In order to resolve this primary key conflict, there are two methods:
+
+1. Before each application for an id, first determine whether the id already exists in the table. If it exists, skip the id.
+2. Expand the lock scope of the self-increasing ID. You must wait until a transaction is completed and submitted before the next transaction can apply for the self-increasing ID.
+
+Obviously, the costs of the above two methods are relatively high and will cause performance problems. The reason is the "allowing auto-increment id fallback" we assumed.
+
+Therefore, InnoDB abandoned this design and will not fall back to incrementing the ID if the statement fails to execute. It is precisely because of this that it is only guaranteed that the auto-incrementing id is increasing, but it is not guaranteed to be continuous.
+
+In summary, three scenarios of discontinuous self-increasing value have been analyzed, and there is also a fourth scenario: batch insertion of data.
+
+### Self-increasing value discontinuous scenario 4
+
+For statements that insert data in batches, MySQL has a strategy to apply for auto-increment IDs in batches:
+
+1. During statement execution, if you apply for an auto-increment ID for the first time, 1 will be allocated;
+2. After 1 is used up, this statement will apply for an auto-increment ID for the second time, and 2 will be allocated;
+3. After 2 are used up, the same statement remains. If you apply for an auto-increment ID for the third time, 4 will be allocated;
+4. By analogy, if you use the same statement to apply for auto-increment IDs, the number of auto-increment IDs applied each time is twice that of the previous time.
+
+Note that the batch insertion of data mentioned here does not include multiple value values in the ordinary insert statement! ! ! , because this type of statement can accurately calculate how many IDs are needed when applying for auto-incrementing IDs, and then apply for them all at once. After the application is completed, the lock can be released.
+
+For statements such as `insert ... select`, replace ... select and load data, MySQL does not know how many IDs need to be applied for, so it adopts this batch application strategy. After all, it is too slow to apply one by one.
+
+For example, assume that our current table has the following data:
+
+
+
+We create a table `test_pk2` with the same structure definition as the current table `test_pk`:
+
+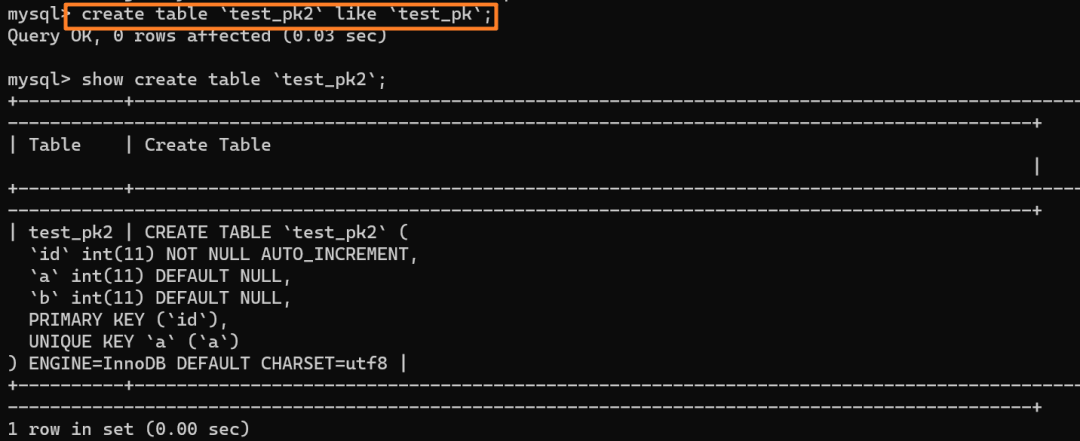
+
+Then use `insert...select` to batch insert data into the `teset_pk2` table:
+
+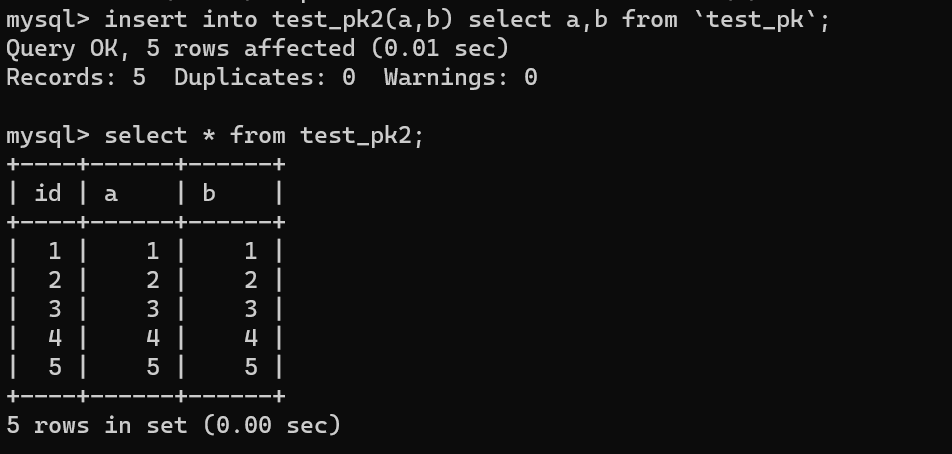
+
+As you can see, the data was successfully imported.
+
+Let’s take a look at the auto-increment value of `test_pk2`:
+
+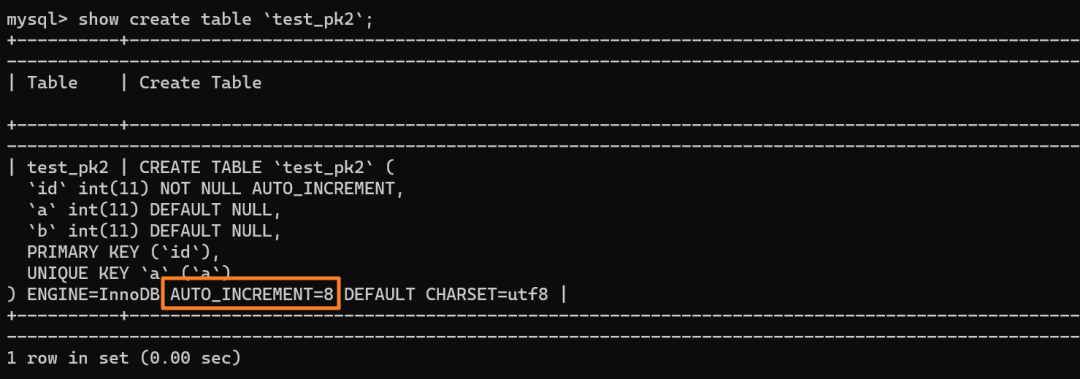
+
+As analyzed above, it is 8 instead of 6
+
+Specifically, insert...select actually inserts 5 rows of data (1 1) (2 2) (3 3) (4 4) (5 5) into the table. However, these five lines of data are self-increasing IDs applied for three times. Combined with the batch application strategy, the number of self-increasing IDs applied for each time is twice that of the previous time, so:
+
+- I applied for an id for the first time: id=1
+- Two ids were assigned for the second time: id=2 and id=3
+- For the third time, 4 ids were assigned: id=4, id = 5, id = 6, id=7
+
+Since this statement actually uses only 5 ids, id=6 and id=7 are wasted. After that, execute `insert into test_pk2 values(null,6,6)`, and the actually inserted data is (8,6,6):
+
+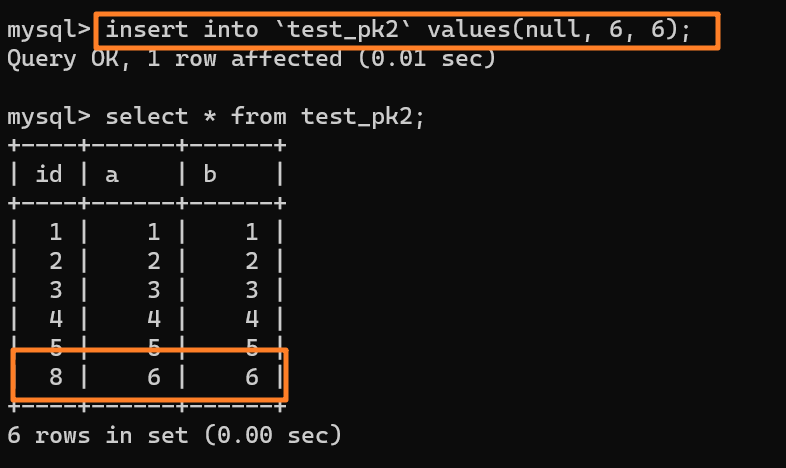
+
+## Summary
+
+This article summarizes four scenarios of discontinuous self-increasing value:
+
+1. The auto-increment initial value and auto-increment step size are not set to 1.
+2. Unique key conflict
+3. Transaction rollback
+4. Batch insertion (such as `insert...select` statement)
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-high-performance-optimization-specification-recommendations.en.md b/docs_en/database/mysql/mysql-high-performance-optimization-specification-recommendations.en.md
new file mode 100644
index 00000000000..29ab4112114
--- /dev/null
+++ b/docs_en/database/mysql/mysql-high-performance-optimization-specification-recommendations.en.md
@@ -0,0 +1,396 @@
+---
+title: MySQL高性能优化规范建议总结
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 优化,索引设计,SQL 规范,表结构,慢查询,参数调优,实践清单
+ - - meta
+ - name: description
+ content: 提炼 MySQL 高性能优化规范,涵盖索引与 SQL、表结构与慢查询、参数与实用清单,提升线上稳定与效率。
+---
+
+> 作者: 听风 原文地址: 。
+>
+> JavaGuide 已获得作者授权,并对原文内容进行了完善补充。
+
+## 数据库命名规范
+
+- 所有数据库对象名称必须使用小写字母并用下划线分割。
+- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)。
+- 数据库对象的命名要能做到见名识义,并且最好不要超过 32 个字符。
+- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀。
+- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。
+
+## 数据库基本设计规范
+
+### 所有表必须使用 InnoDB 存储引擎
+
+没有特殊要求(即 InnoDB 无法满足的功能如:列存储、存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 MyISAM,5.6 以后默认的为 InnoDB)。
+
+InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
+
+### 数据库和表的字符集统一使用 UTF8
+
+兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
+
+推荐阅读一下我写的这篇文章:[MySQL 字符集详解](../character-set.md) 。
+
+### 所有表和字段都需要添加注释
+
+使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护。
+
+### 尽量控制单表数据量的大小,建议控制在 500 万以内
+
+500 万并不是 MySQL 数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
+
+可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
+
+### 谨慎使用 MySQL 分区表
+
+分区表在物理上表现为多个文件,在逻辑上表现为一个表。
+
+谨慎选择分区键,跨分区查询效率可能更低。
+
+建议采用物理分表的方式管理大数据。
+
+### 经常一起使用的列放到一个表中
+
+避免更多的关联操作。
+
+### 禁止在表中建立预留字段
+
+- 预留字段的命名很难做到见名识义。
+- 预留字段无法确认存储的数据类型,所以无法选择合适的类型。
+- 对预留字段类型的修改,会对表进行锁定。
+
+### 禁止在数据库中存储文件(比如图片)这类大的二进制数据
+
+在数据库中存储文件会严重影响数据库性能,消耗过多存储空间。
+
+文件(比如图片)这类大的二进制数据通常存储于文件服务器,数据库只存储文件地址信息。
+
+### 不要被数据库范式所束缚
+
+一般来说,设计关系数据库时需要满足第三范式,但为了满足第三范式,我们可能会拆分出多张表。而在进行查询时需要对多张表进行关联查询,有时为了提高查询效率,会降低范式的要求,在表中保存一定的冗余信息,也叫做反范式。但要注意反范式一定要适度。
+
+### 禁止在线上做数据库压力测试
+
+### 禁止从开发环境、测试环境直接连接生产环境数据库
+
+安全隐患极大,要对生产环境抱有敬畏之心!
+
+## 数据库字段设计规范
+
+### 优先选择符合存储需要的最小的数据类型
+
+存储字节越小,占用空间也就越小,性能也越好。
+
+**a.某些字符串可以转换成数字类型存储,比如可以将 IP 地址转换成整型数据。**
+
+数字是连续的,性能更好,占用空间也更小。
+
+MySQL 提供了两个方法来处理 ip 地址:
+
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位);
+- `INET_NTOA()`:把整型的 ip 转为地址。
+
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型;显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+
+**b.对于非负型的数据 (如自增 ID、整型 IP、年龄) 来说,要优先使用无符号整型来存储。**
+
+无符号相对于有符号可以多出一倍的存储空间:
+
+```sql
+SIGNED INT -2147483648~2147483647
+UNSIGNED INT 0~4294967295
+```
+
+**c.小数值类型(比如年龄、状态表示如 0/1)优先使用 TINYINT 类型。**
+
+### 避免使用 TEXT、BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
+
+**a. 建议把 BLOB 或是 TEXT 列分离到单独的扩展表中。**
+
+MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,MySQL 还是要进行二次查询,会使 sql 性能变得很差,但是不是说一定不能使用这样的数据类型。
+
+如果一定要使用,建议把 BLOB 或是 TEXT 列分离到单独的扩展表中,查询时一定不要使用 `select *`而只需要取出必要的列,不需要 TEXT 列的数据时不要对该列进行查询。
+
+**2、TEXT 或 BLOB 类型只能使用前缀索引**
+
+因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的。
+
+### 避免使用 ENUM 类型
+
+- 修改 ENUM 值需要使用 ALTER 语句。
+- ENUM 类型的 ORDER BY 操作效率低,需要额外操作。
+- ENUM 数据类型存在一些限制,比如建议不要使用数值作为 ENUM 的枚举值。
+
+相关阅读:[是否推荐使用 MySQL 的 enum 类型? - 架构文摘 - 知乎](https://www.zhihu.com/question/404422255/answer/1661698499) 。
+
+### 尽可能把所有列定义为 NOT NULL
+
+除非有特别的原因使用 NULL 值,否则应该总是让字段保持 NOT NULL。
+
+- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间。
+- 进行比较和计算时要对 NULL 值做特别的处理。
+
+相关阅读:[技术分享 | MySQL 默认值选型(是空,还是 NULL)](https://opensource.actionsky.com/20190710-mysql/) 。
+
+### 一定不要用字符串存储日期
+
+对于日期类型来说,一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和数值型时间戳。
+
+这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家在实际开发中选择正确的存放时间的数据类型:
+
+| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
+| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
+| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
+| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
+| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+
+MySQL 时间类型选择的详细介绍请看这篇:[MySQL 时间类型数据存储建议](https://javaguide.cn/database/mysql/some-thoughts-on-database-storage-time.html)。
+
+### 同财务相关的金额类数据必须使用 decimal 类型
+
+- **非精准浮点**:float、double
+- **精准浮点**:decimal
+
+decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据。
+
+不过, 由于 decimal 需要额外的空间和计算开销,应该尽量只在需要对数据进行精确计算时才使用 decimal 。
+
+### 单表不要包含过多字段
+
+如果一个表包含过多字段的话,可以考虑将其分解成多个表,必要时增加中间表进行关联。
+
+## 索引设计规范
+
+### 限制每张表上的索引数量,建议单张表索引不超过 5 个
+
+索引并不是越多越好!索引可以提高效率,同样可以降低效率。
+
+索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
+
+因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划。如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+
+### 禁止使用全文索引
+
+全文索引不适用于 OLTP 场景。
+
+### 禁止给表中的每一列都建立单独的索引
+
+5.6 版本之前,一个 sql 只能使用到一个表中的一个索引;5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
+
+### 每个 InnoDB 表必须有个主键
+
+InnoDB 是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
+
+InnoDB 是按照主键索引的顺序来组织表的。
+
+- 不要使用更新频繁的列作为主键,不使用多列主键(相当于联合索引)。
+- 不要使用 UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)。
+- 主键建议使用自增 ID 值。
+
+### 常见索引列建议
+
+- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列。
+- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段。
+- 不要将符合 1 和 2 中的字段的列都建立一个索引,通常将 1、2 中的字段建立联合索引效果更好。
+- 多表 join 的关联列。
+
+### 如何选择索引列的顺序
+
+建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
+
+- **区分度最高的列放在联合索引的最左侧**:这是最重要的原则。区分度越高,通过索引筛选出的数据就越少,I/O 操作也就越少。计算区分度的方法是 `count(distinct column) / count(*)`。
+- **最频繁使用的列放在联合索引的左侧**:这符合最左前缀匹配原则。将最常用的查询条件列放在最左侧,可以最大程度地利用索引。
+- **字段长度**:字段长度对联合索引非叶子节点的影响很小,因为它存储了所有联合索引字段的值。字段长度主要影响主键和包含在其他索引中的字段的存储空间,以及这些索引的叶子节点的大小。因此,在选择联合索引列的顺序时,字段长度的优先级最低。对于主键和包含在其他索引中的字段,选择较短的字段长度可以节省存储空间和提高 I/O 性能。
+
+### 避免建立冗余索引和重复索引(增加了查询优化器生成执行计划的时间)
+
+- 重复索引示例:primary key(id)、index(id)、unique index(id)。
+- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)。
+
+### 对于频繁的查询,优先考虑使用覆盖索引
+
+> 覆盖索引:就是包含了所有查询字段 (where、select、order by、group by 包含的字段) 的索引
+
+**覆盖索引的好处**:
+
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作**:InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率**:由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+
+---
+
+### 索引 SET 规范
+
+**尽量避免使用外键约束**
+
+- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引。
+- 外键可用于保证数据的参照完整性,但建议在业务端实现。
+- 外键会影响父表和子表的写操作从而降低性能。
+
+## 数据库 SQL 开发规范
+
+### 尽量不在数据库做运算,复杂运算需移到业务应用里完成
+
+尽量不在数据库做运算,复杂运算需移到业务应用里完成。这样可以避免数据库的负担过重,影响数据库的性能和稳定性。数据库的主要作用是存储和管理数据,而不是处理数据。
+
+### 优化对性能影响较大的 SQL 语句
+
+要找到最需要优化的 SQL 语句。要么是使用最频繁的语句,要么是优化后提高最明显的语句,可以通过查询 MySQL 的慢查询日志来发现需要进行优化的 SQL 语句。
+
+### 充分利用表上已经存在的索引
+
+避免使用双%号的查询条件。如:`a like '%123%'`(如果无前置%,只有后置%,是可以用到列上的索引的)。
+
+一个 SQL 只能利用到复合索引中的一列进行范围查询。如:有 a,b,c 列的联合索引,在查询条件中有 a 列的范围查询,则在 b,c 列上的索引将不会被用到。
+
+在定义联合索引时,如果 a 列要用到范围查找的话,就要把 a 列放到联合索引的右侧,使用 left join 或 not exists 来优化 not in 操作,因为 not in 也通常会使用索引失效。
+
+### 禁止使用 SELECT \* 必须使用 SELECT <字段列表> 查询
+
+- `SELECT *` 会消耗更多的 CPU。
+- `SELECT *` 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。
+- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快、效率极高、业界极为推荐的查询优化方式)。
+- `SELECT <字段列表>` 可减少表结构变更带来的影响。
+
+### 禁止使用不含字段列表的 INSERT 语句
+
+**不推荐**:
+
+```sql
+insert into t values ('a','b','c');
+```
+
+**推荐**:
+
+```sql
+insert into t(c1,c2,c3) values ('a','b','c');
+```
+
+### 建议使用预编译语句进行数据库操作
+
+- 预编译语句可以重复使用这些计划,减少 SQL 编译所需要的时间,还可以解决动态 SQL 所带来的 SQL 注入的问题。
+- 只传参数,比传递 SQL 语句更高效。
+- 相同语句可以一次解析,多次使用,提高处理效率。
+
+### 避免数据类型的隐式转换
+
+隐式转换会导致索引失效,如:
+
+```sql
+select name,phone from customer where id = '111';
+```
+
+详细解读可以看:[MySQL 中的隐式转换造成的索引失效](./index-invalidation-caused-by-implicit-conversion.md) 这篇文章。
+
+### 避免使用子查询,可以把子查询优化为 join 操作
+
+通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
+
+**子查询性能差的原因**:子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
+
+### 避免使用 JOIN 关联太多的表
+
+对于 MySQL 来说,是存在关联缓存的,缓存的大小可以由 join_buffer_size 参数进行设置。
+
+在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
+
+如果程序中大量地使用了多表关联的操作,同时 join_buffer_size 设置得也不合理,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
+
+同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 个表,建议不超过 5 个。
+
+### 减少同数据库的交互次数
+
+The database is more suitable for processing batch operations. Merging multiple identical operations together can improve processing efficiency.
+
+### When performing or judgment corresponding to the same column, use in instead of or
+
+Do not exceed 500 values for in. The in operation can make more efficient use of indexes, or indexes can rarely be used in most cases.
+
+### Disable the use of order by rand() for random sorting
+
+order by rand() will load all qualified data in the table into memory, then sort all data in memory according to randomly generated values, and may generate a random value for each row. If the data set that meets the conditions is very large, it will consume a lot of CPU, IO and memory resources.
+
+It is recommended to get a random value in the program and then get the data from the database.
+
+### Disable function transformations and calculations on columns in the WHERE clause
+
+Performing function transformations or calculations on columns results in the index not being able to be used.
+
+**Not recommended**:
+
+```sql
+where date(create_time)='20190101'
+```
+
+**Recommended**:
+
+```sql
+where create_time >= '20190101' and create_time < '20190102'
+```
+
+### Use UNION ALL instead of UNION when it is obvious that there will be no duplicate values
+
+- UNION will put all the data of the two result sets into the temporary table and then perform the deduplication operation.
+- UNION ALL will no longer deduplicate the result set.
+
+### Split a complex large SQL into multiple small SQLs
+
+- Large SQL is logically complex and requires a large amount of CPU for calculation.
+- In MySQL, one SQL can only use one CPU for calculation.
+- After SQL is split, it can be executed in parallel to improve processing efficiency.
+
+### The program connects to different databases using different accounts, and cross-database queries are prohibited.
+
+- Leave room for database migration and sharding of databases and tables.
+- Reduce business coupling.
+- Avoid security risks caused by excessive permissions.
+
+## Database operation code of conduct
+
+### Batch write (UPDATE, DELETE, INSERT) operations of more than 1 million rows must be performed in batches multiple times.
+
+**Large batch operations may cause severe master-slave delays**
+
+In a master-slave environment, large batch operations may cause serious master-slave delays. Large-batch write operations generally take a long time to execute, and only after the execution on the master database is completed, they will be executed on other slave databases, so it will cause a long delay between the master database and the slave database.
+
+**When the binlog log is in row format, a large number of logs will be generated**
+
+Large batch write operations will generate a large number of logs, especially for row format binary data. Since the modification of each row of data is recorded in the row format, the more data we modify at one time, the more logs will be generated, and the longer the log transmission and recovery will take, which is also a reason for the master-slave delay.
+
+**Avoid large transaction operations**
+
+Modifying data in large batches must be done in a transaction, which will cause a large amount of data in the table to be locked, resulting in a large amount of blocking. Blocking will have a great impact on the performance of MySQL.
+
+In particular, long-term blocking will occupy all available connections to the database, which will prevent other applications in the production environment from connecting to the database. Therefore, it is important to pay attention to batching large write operations.
+
+### For large tables, use pt-online-schema-change to modify the table structure.
+
+- Avoid master-slave delays caused by large table modifications.
+- Avoid table locking when modifying table fields.
+
+You must be careful when modifying the data structure of a large table, as it will cause serious table lock operations, which is intolerable especially in a production environment.
+
+pt-online-schema-change will first create a new table with the same structure as the original table, modify the table structure on the new table, then copy the data in the original table to the new table, and add some triggers to the original table. Copy the newly added data in the original table to the new table. After all the row data is copied, name the new table the original table and delete the original table. Break the original DDL operation into multiple small batches.
+
+### It is forbidden to grant super permissions to the account used by the program.
+
+- When the maximum number of connections is reached, 1 user connection with super privileges is also run.
+- Super permissions can only be reserved for the account used by the DBA to handle problems.
+
+### For the program to connect to the database account, follow the principle of least privileges
+
+- The database account used by the program can only be used under one DB, and cross-databases are not allowed.
+- In principle, the account used by the program is not allowed to have drop permissions.
+
+## Recommended reading
+
+- [MySQL design conventions that technical students must learn are painful lessons - Alibaba Developers](https://mp.weixin.qq.com/s/XC8e5iuQtfsrEOERffEZ-Q)
+- [Let’s talk about 15 tips for creating database tables](https://mp.weixin.qq.com/s/NM-aHaW6TXrnO6la6Jfl5A)
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-index.en.md b/docs_en/database/mysql/mysql-index.en.md
new file mode 100644
index 00000000000..f3f9553522b
--- /dev/null
+++ b/docs_en/database/mysql/mysql-index.en.md
@@ -0,0 +1,564 @@
+---
+title: MySQL索引详解
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 索引,B+树,覆盖索引,联合索引,选择性,回表,索引下推
+ - - meta
+ - name: description
+ content: 深入解析 MySQL 索引结构与选型,覆盖 B+ 树、联合与覆盖索引、选择性与回表等关键优化点与实践。
+---
+
+> 感谢[WT-AHA](https://github.com/WT-AHA)对本文的完善,相关 PR: 。
+
+但凡经历过几场面试的小伙伴,应该都清楚,数据库索引这个知识点在面试中出现的频率高到离谱。
+
+除了对于准备面试来说非常重要之外,善用索引对 SQL 的性能提升非常明显,是一个性价比较高的 SQL 优化手段。
+
+## 索引介绍
+
+**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
+
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
+
+## 索引的优缺点
+
+**索引的优点:**
+
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
+
+**索引的缺点:**
+
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
+
+**那么,用了索引就一定能提高查询性能吗?**
+
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
+
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
+
+## 索引底层数据结构选型
+
+### Hash 表
+
+哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
+
+**为何能够通过 key 快速取出 value 呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
+
+```java
+hash = hashfunc(key)
+index = hash % array_size
+```
+
+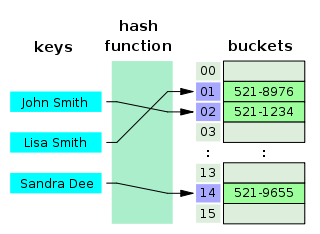
+
+但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了提高链表过长时的搜索效率,引入了红黑树。
+
+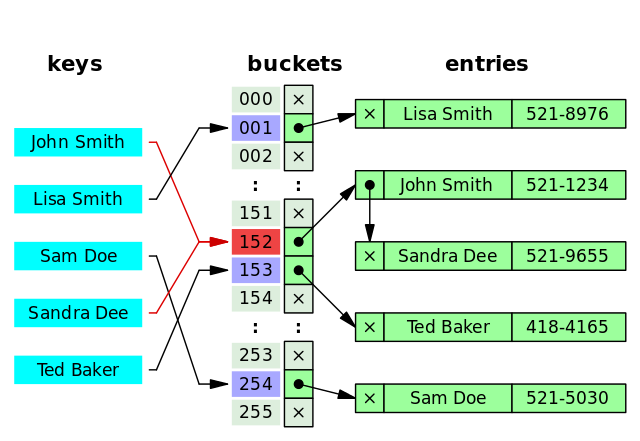
+
+为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
+
+MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,InnoDB 存储引擎中存在一种特殊的“自适应哈希索引”(Adaptive Hash Index),自适应哈希索引并不是传统意义上的纯哈希索引,而是结合了 B+Tree 和哈希索引的特点,以便更好地适应实际应用中的数据访问模式和性能需求。自适应哈希索引的每个哈希桶实际上是一个小型的 B+Tree 结构。这个 B+Tree 结构可以存储多个键值对,而不仅仅是一个键。这有助于减少哈希冲突链的长度,提高了索引的效率。关于 Adaptive Hash Index 的详细介绍,可以查看 [MySQL 各种“Buffer”之 Adaptive Hash Index](https://mp.weixin.qq.com/s/ra4v1XR5pzSWc-qtGO-dBg) 这篇文章。
+
+既然哈希表这么快,**为什么 MySQL 没有使用其作为索引的数据结构呢?** 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
+
+试想一种情况:
+
+```java
+SELECT * FROM tb1 WHERE id < 500;
+```
+
+在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
+
+### 二叉查找树(BST)
+
+二叉查找树(Binary Search Tree)是一种基于二叉树的数据结构,它具有以下特点:
+
+1. 左子树所有节点的值均小于根节点的值。
+2. 右子树所有节点的值均大于根节点的值。
+3. 左右子树也分别为二叉查找树。
+
+当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
+
+
+
+也就是说,**二叉查找树的性能非常依赖于它的平衡程度,这就导致其不适合作为 MySQL 底层索引的数据结构。**
+
+为了解决这个问题,并提高查询效率,人们发明了多种在二叉查找树基础上的改进型数据结构,如平衡二叉树、B-Tree、B+Tree 等。
+
+### AVL 树
+
+AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的名称来自于发明者 G.M. Adelson-Velsky 和 E.M. Landis 的名字缩写。AVL 树的特点是保证任何节点的左右子树高度之差不超过 1,因此也被称为高度平衡二叉树,它的查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。
+
+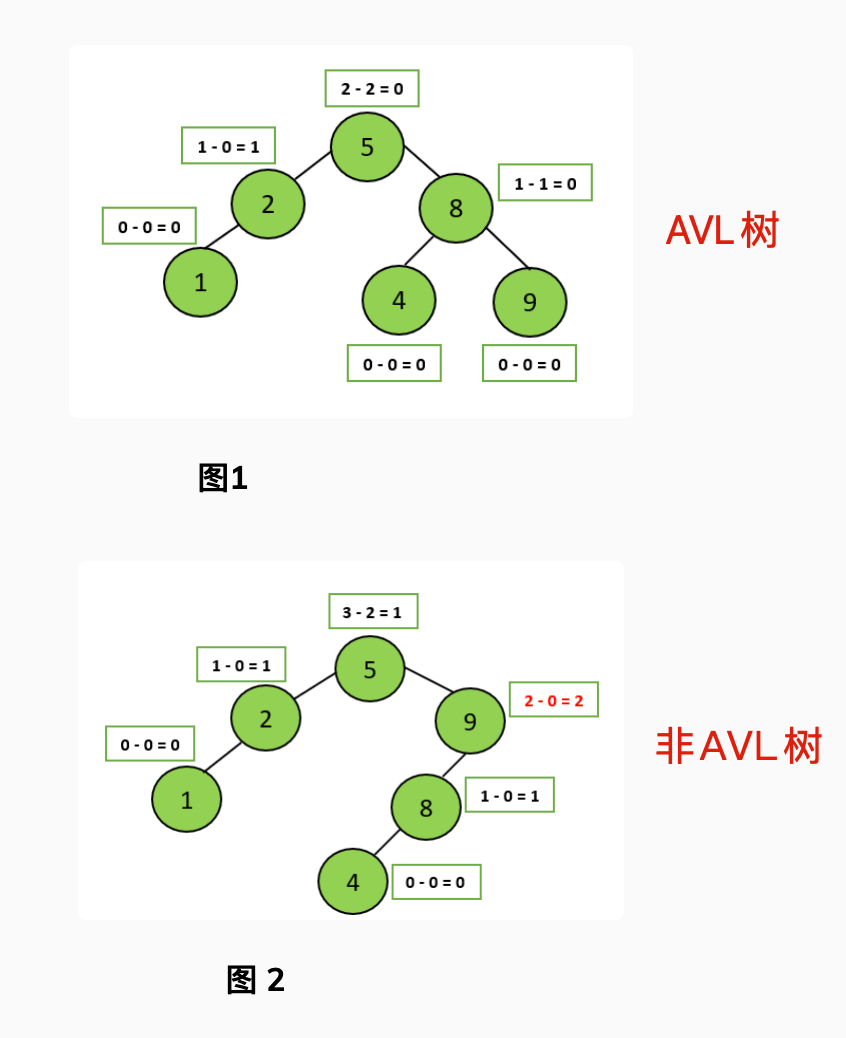
+
+AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
+
+由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。**磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
+
+实际应用中,AVL 树使用的并不多。
+
+### 红黑树
+
+红黑树是一种自平衡二叉查找树,通过在插入和删除节点时进行颜色变换和旋转操作,使得树始终保持平衡状态,它具有以下特点:
+
+1. 每个节点非红即黑;
+2. 根节点总是黑色的;
+3. 每个叶子节点都是黑色的空节点(NIL 节点);
+4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
+5. 从任意节点到它的叶子节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
+
+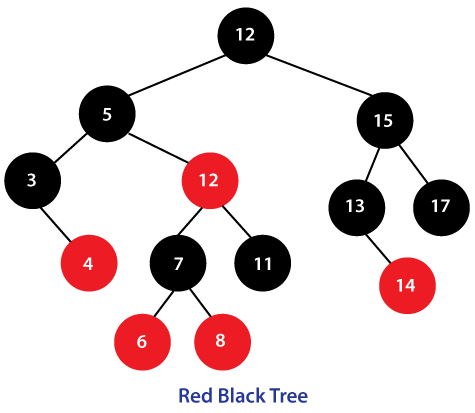
+
+和 AVL 树不同的是,红黑树并不追求严格的平衡,而是大致的平衡。正因如此,红黑树的查询效率稍有下降,因为红黑树的平衡性相对较弱,可能会导致树的高度较高,这可能会导致一些数据需要进行多次磁盘 IO 操作才能查询到,这也是 MySQL 没有选择红黑树的主要原因。也正因如此,红黑树的插入和删除操作效率大大提高了,因为红黑树在插入和删除节点时只需进行 O(1) 次数的旋转和变色操作,即可保持基本平衡状态,而不需要像 AVL 树一样进行 O(logn) 次数的旋转操作。
+
+**红黑树的应用还是比较广泛的,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。对于数据在内存中的这种情况来说,红黑树的表现是非常优异的。**
+
+### B 树& B+ 树
+
+B 树也称 B- 树,全称为 **多路平衡查找树**,B+ 树是 B 树的一种变体。B 树和 B+ 树中的 B 是 `Balanced`(平衡)的意思。
+
+目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
+
+**B 树& B+ 树两者有何异同呢?**
+
+- B 树的所有节点既存放键(key)也存放数据(data),而 B+ 树只有叶子节点存放 key 和 data,其他内节点只存放 key。
+- B 树的叶子节点都是独立的;B+ 树的叶子节点有一条引用链指向与它相邻的叶子节点。
+- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+ 树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+ 树的范围查询,只需要对链表进行遍历即可。
+
+综上,B+ 树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
+
+在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
+
+> MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“**非聚簇索引(非聚集索引)**”。
+>
+> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引**,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
+
+## 索引类型总结
+
+按照数据结构维度划分:
+
+- BTree 索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree,但二者实现方式不一样(前面已经介绍了)。
+- 哈希索引:类似键值对的形式,一次即可定位。
+- RTree 索引:一般不会使用,仅支持 geometry 数据类型,优势在于范围查找,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+
+按照底层存储方式角度划分:
+
+- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
+- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+
+按照应用维度划分:
+
+- 主键索引:加速查询 + 列值唯一(不可以有 NULL)+ 表中只有一个。
+- 普通索引:仅加速查询。
+- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
+- 覆盖索引:一个索引包含(或者说覆盖)所有需要查询的字段的值。
+- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 前缀索引:对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
+
+MySQL 8.x 中实现的索引新特性:
+
+- 隐藏索引:也称为不可见索引,不会被优化器使用,但是仍然需要维护,通常会软删除和灰度发布的场景中使用。主键不能设置为隐藏(包括显式设置或隐式设置)。
+- 降序索引:之前的版本就支持通过 desc 来指定索引为降序,但实际上创建的仍然是常规的升序索引。直到 MySQL 8.x 版本才开始真正支持降序索引。另外,在 MySQL 8.x 版本中,不再对 GROUP BY 语句进行隐式排序。
+- 函数索引:从 MySQL 8.0.13 版本开始支持在索引中使用函数或者表达式的值,也就是在索引中可以包含函数或者表达式。
+
+## 主键索引(Primary Key)
+
+数据表的主键列使用的就是主键索引。
+
+一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
+
+在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在 null 值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
+
+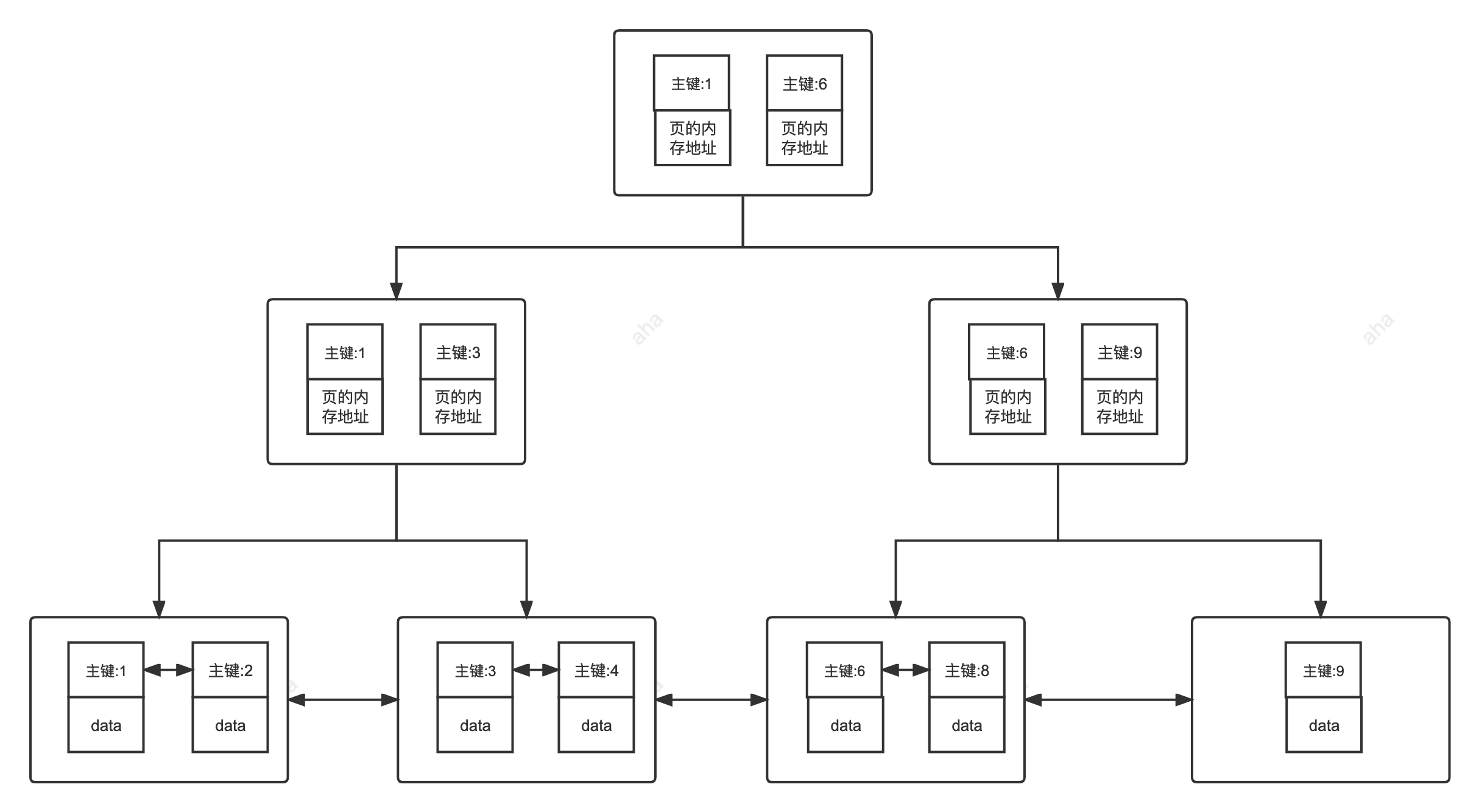
+
+## 二级索引
+
+二级索引(Secondary Index)的叶子节点存储的数据是主键的值,也就是说,通过二级索引可以定位主键的位置,二级索引又称为辅助索引/非主键索引。
+
+唯一索引、普通索引、前缀索引等索引都属于二级索引。
+
+PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
+
+1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据。一张表允许创建多个普通索引,并允许数据重复和 NULL。
+3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
+4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MyISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
+
+二级索引:
+
+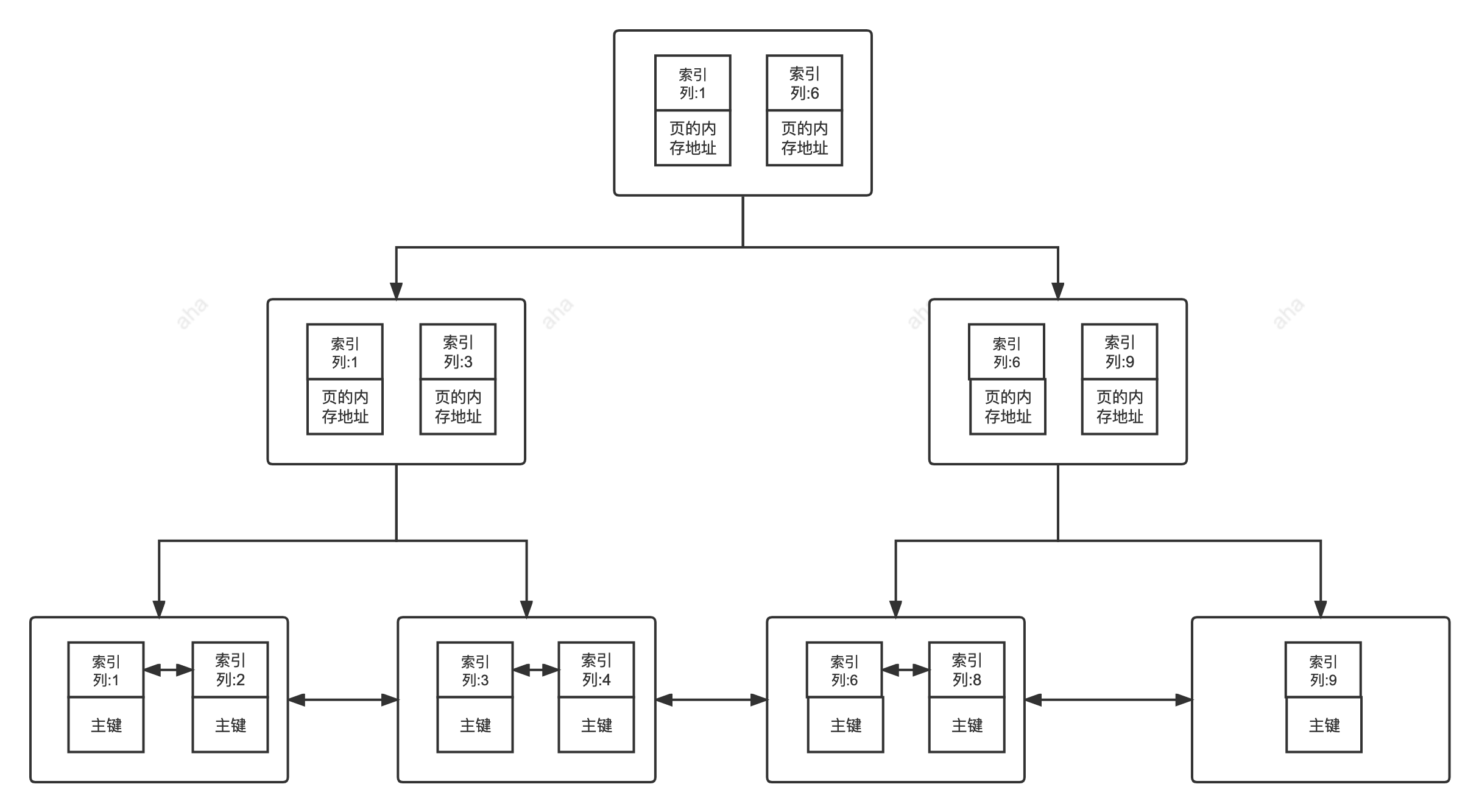
+
+## 聚簇索引与非聚簇索引
+
+### 聚簇索引(聚集索引)
+
+#### 聚簇索引介绍
+
+聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。
+
+在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+ 树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+
+#### 聚簇索引的优缺点
+
+**优点**:
+
+- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+ 树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
+- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
+
+**缺点**:
+
+- **依赖于有序的数据**:因为 B+ 树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
+
+### 非聚簇索引(非聚集索引)
+
+#### 非聚簇索引介绍
+
+非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+
+非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
+
+#### 非聚簇索引的优缺点
+
+**优点**:
+
+更新代价比聚簇索引要小。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
+
+**缺点**:
+
+- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据。
+- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+
+这是 MySQL 的表的文件截图:
+
+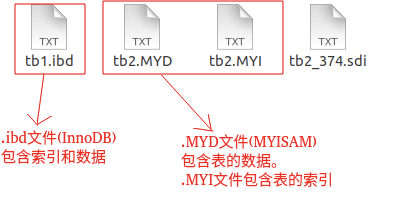
+
+聚簇索引和非聚簇索引:
+
+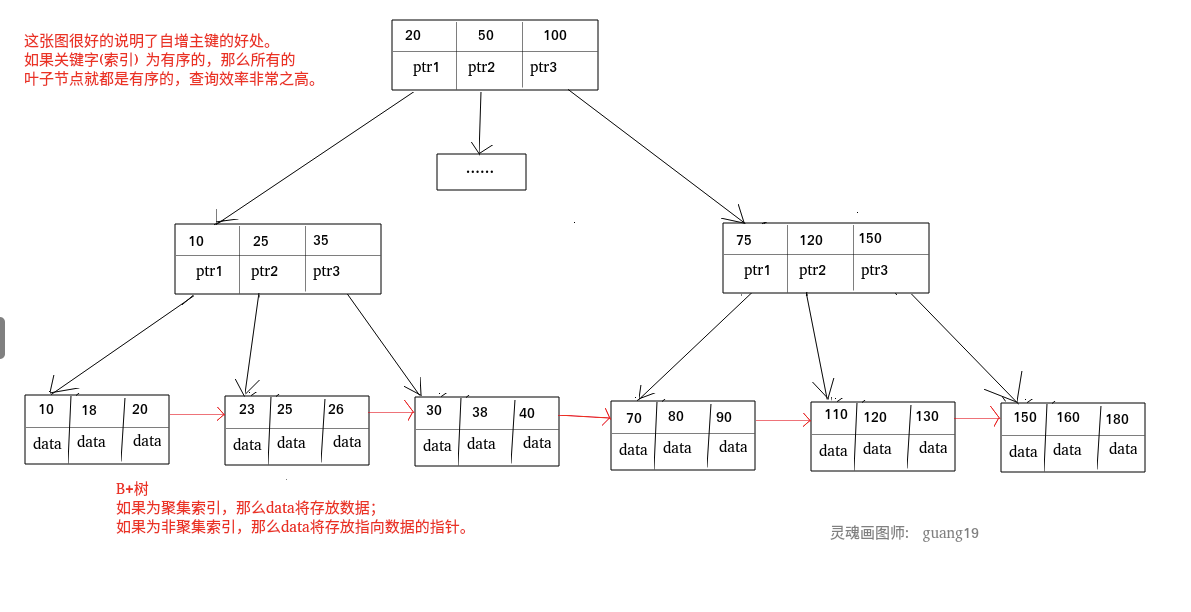
+
+#### 非聚簇索引一定回表查询吗(覆盖索引)?
+
+**非聚簇索引不一定回表查询。**
+
+试想一种情况,用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。
+
+```sql
+ SELECT name FROM table WHERE name='guang19';
+```
+
+那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
+
+即使是 MyISAM 也是这样,虽然 MyISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
+
+```sql
+SELECT id FROM table WHERE id=1;
+```
+
+主键索引本身的 key 就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
+
+## 覆盖索引和联合索引
+
+### 覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
+
+在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。**
+
+> 如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
+> 那么直接根据这个索引就可以查到数据,也无需回表。
+
+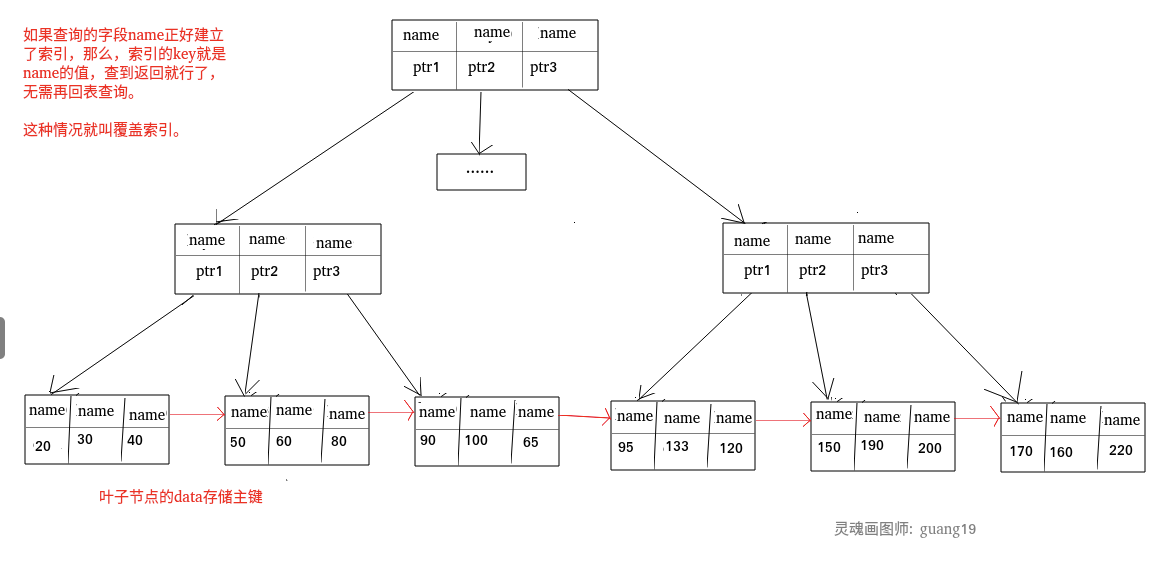
+
+我们这里简单演示一下覆盖索引的效果。
+
+1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便,`cus_order` 这张表只有 `id`、`score`、`name` 这 3 个字段。
+
+```sql
+CREATE TABLE `cus_order` (
+ `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
+ `score` int(11) NOT NULL,
+ `name` varchar(11) NOT NULL DEFAULT '',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=100000 DEFAULT CHARSET=utf8mb4;
+```
+
+2、定义一个简单的存储过程(PROCEDURE)来插入 100w 测试数据。
+
+```sql
+DELIMITER ;;
+CREATE DEFINER=`root`@`%` PROCEDURE `BatchinsertDataToCusOder`(IN start_num INT,IN max_num INT)
+BEGIN
+ DECLARE i INT default start_num;
+ WHILE i < max_num DO
+ insert into `cus_order`(`id`, `score`, `name`)
+ values (i,RAND() * 1000000,CONCAT('user', i));
+ SET i = i + 1;
+ END WHILE;
+ END;;
+DELIMITER ;
+```
+
+存储过程定义完成之后,我们执行存储过程即可!
+
+```sql
+CALL BatchinsertDataToCusOder(1, 1000000); # 插入100w+的随机数据
+```
+
+等待一会,100w 的测试数据就插入完成了!
+
+3、创建覆盖索引并使用 `EXPLAIN` 命令分析。
+
+为了能够对这 100w 数据按照 `score` 进行排序,我们需要执行下面的 SQL 语句。
+
+```sql
+#降序排序
+SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+```
+
+使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort`,我们发现是没有用到覆盖索引的。
+
+
+
+不过这也是理所应当,毕竟我们现在还没有创建索引呢!
+
+我们这里以 `score` 和 `name` 两个字段建立联合索引:
+
+```sql
+ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
+```
+
+创建完成之后,再用 `EXPLAIN` 命令分析再次分析这条 SQL 语句。
+
+
+
+通过 `Extra` 这一列的 `Using index`,说明这条 SQL 语句成功使用了覆盖索引。
+
+关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
+
+### 联合索引
+
+使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
+
+以 `score` 和 `name` 两个字段建立联合索引:
+
+```sql
+ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
+```
+
+### 最左前缀匹配原则
+
+最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据,这样可以提高查询效率。
+
+最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配(相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ))。
+
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+
+我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
+
+我们这里简单演示一下最左前缀匹配的效果。
+
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
+
+```sql
+CREATE TABLE `student` (
+ `id` int NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `class` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `name_class_idx` (`name`,`class`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+2、下面我们分别测试三条不同的 SQL 语句。
+
+
+
+```sql
+# 可以命中索引
+SELECT * FROM student WHERE name = 'Anne Henry';
+EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk';
+# 无法命中索引
+SELECT * FROM student WHERE class = 'lIrm08RYVk';
+```
+
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
+
+先不要往下看答案,给自己 3 分钟时间想一想。
+
+1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
+
+MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
+
+## 索引下推
+
+**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE` 字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
+
+假设我们有一个名为 `user` 的表,其中包含 `id`、`username`、`zipcode` 和 `birthdate` 4 个字段,创建了联合索引 `(zipcode, birthdate)`。
+
+```sql
+CREATE TABLE `user` (
+ `id` int NOT NULL AUTO_INCREMENT,
+ `username` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
+ `zipcode` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
+ `birthdate` date NOT NULL,
+ PRIMARY KEY (`id`),
+ KEY `idx_username_birthdate` (`zipcode`,`birthdate`) ) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4;
+
+# 查询 zipcode 为 431200 且生日在 3 月的用户
+# birthdate 字段使用函数索引失效
+SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
+```
+
+- 没有索引下推之前,即使 `zipcode` 字段利用索引可以帮助我们快速定位到 `zipcode = '431200'` 的用户,但我们仍然需要对每一个找到的用户进行回表操作,获取完整的用户数据,再去判断 `MONTH(birthdate) = 3`。
+- 有了索引下推之后,存储引擎会在使用 `zipcode` 字段索引查找 `zipcode = '431200'` 的用户时,同时判断 `MONTH(birthdate) = 3`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。
+
+
+
+
+
+再来讲讲索引下推的具体原理,先看下面这张 MySQL 简要架构图。
+
+
+
+MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处理查询解析、分析、优化、缓存以及与客户端的交互等操作,而存储引擎层负责数据的存储和读取,MySQL 支持 InnoDB、MyISAM、Memory 等多种存储引擎。
+
+索引下推的 **下推** 其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
+
+我们这里结合索引下推原理再对上面提到的例子进行解释。
+
+没有索引下推之前:
+
+- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户的主键 ID,然后二次回表查询,获取完整的用户数据;
+- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据 `MONTH(birthdate) = 3` 这一条件再进一步做筛选。
+
+有了索引下推之后:
+
+- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户,然后直接判断 `MONTH(birthdate) = 3`,筛选出符合条件的主键 ID;
+- 二次回表查询,根据符合条件的主键 ID 去获取完整的用户数据;
+- 存储引擎层把符合条件的用户数据全部交给 Server 层。
+
+可以看出,**除了可以减少回表次数之外,索引下推还可以减少存储引擎层和 Server 层的数据传输量。**
+
+最后,总结一下索引下推应用范围:
+
+1. 适用于 InnoDB 引擎和 MyISAM 引擎的查询。
+2. 适用于执行计划是 range、ref、eq_ref、ref_or_null 的范围查询。
+3. 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推不会减少 I/O。
+4. 子查询不能使用索引下推,因为子查询通常会创建临时表来处理结果,而这些临时表是没有索引的。
+5. 存储过程不能使用索引下推,因为存储引擎无法调用存储函数。
+
+## 正确使用索引的一些建议
+
+### 选择合适的字段创建索引
+
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0、1、true、false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 被频繁更新的字段应该慎重建立索引
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+### 限制每张表上的索引数量
+
+索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率,同样可以降低效率。
+
+索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
+
+因为 MySQL 优化器在选择如何优化查询时,会根据统计信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+
+### 尽可能的考虑建立联合索引而不是单列索引
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+ 树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+### 注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city)和(name)这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的。在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+### 字符串类型的字段使用前缀索引代替普通索引
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+### 避免索引失效
+
+索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
+
+- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
+- 创建了组合索引,但查询条件未遵守最左匹配原则;
+- 在索引列上进行计算、函数、类型转换等操作;
+- 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
+- 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
+- IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
+- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
+- ……
+
+推荐阅读这篇文章:[美团暑期实习一面:MySQl 索引失效的场景有哪些?](https://mp.weixin.qq.com/s/mwME3qukHBFul57WQLkOYg)。
+
+### 删除长期未使用的索引
+
+删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗。
+
+MySQL 5.7 可以通过查询 `sys` 库的 `schema_unused_indexes` 视图来查询哪些索引从未被使用。
+
+### 知道如何分析 SQL 语句是否走索引查询
+
+我们可以使用 `EXPLAIN` 命令来分析 SQL 的 **执行计划** ,这样就知道语句是否命中索引了。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
+
+`EXPLAIN` 并不会真的去执行相关的语句,而是通过 **查询优化器** 对语句进行分析,找出最优的查询方案,并显示对应的信息。
+
+`EXPLAIN` 的输出格式如下:
+
+```sql
+mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+1 row in set, 1 warning (0.00 sec)
+```
+
+各个字段的含义如下:
+
+| **列名** | **含义** |
+| ------------- | -------------------------------------------- |
+| id | SELECT 查询的序列标识符 |
+| select_type | SELECT 关键字对应的查询类型 |
+| table | 用到的表名 |
+| partitions | 匹配的分区,对于未分区的表,值为 NULL |
+| type | 表的访问方法 |
+| possible_keys | 可能用到的索引 |
+| key | 实际用到的索引 |
+| key_len | 所选索引的长度 |
+| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
+| rows | 预计要读取的行数 |
+| filtered | 按表条件过滤后,留存的记录数的百分比 |
+| Extra | 附加信息 |
+
+篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
+
+
+
diff --git a/docs_en/database/mysql/mysql-logs.en.md b/docs_en/database/mysql/mysql-logs.en.md
new file mode 100644
index 00000000000..a87b372773d
--- /dev/null
+++ b/docs_en/database/mysql/mysql-logs.en.md
@@ -0,0 +1,353 @@
+---
+title: MySQL三大日志(binlog、redo log和undo log)详解
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 日志,binlog,redo log,undo log,两阶段提交,崩溃恢复,复制
+ - - meta
+ - name: description
+ content: 系统解析 MySQL 的 binlog/redo/undo 三大日志与两阶段提交,理解崩溃恢复与主从复制的实现原理与取舍。
+---
+
+> 本文来自公号程序猿阿星投稿,JavaGuide 对其做了补充完善。
+
+## 前言
+
+MySQL 日志 主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。其中,比较重要的还要属二进制日志 binlog(归档日志)和事务日志 redo log(重做日志)和 undo log(回滚日志)。
+
+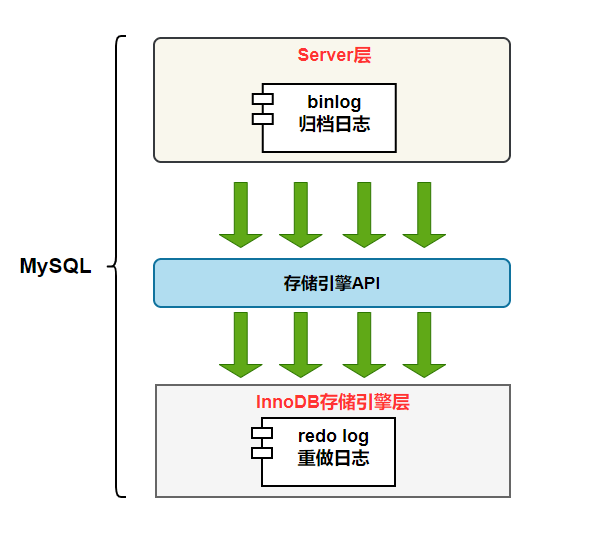
+
+今天就来聊聊 redo log(重做日志)、binlog(归档日志)、两阶段提交、undo log(回滚日志)。
+
+## redo log
+
+redo log(重做日志)是 InnoDB 存储引擎独有的,它让 MySQL 拥有了崩溃恢复能力。
+
+比如 MySQL 实例挂了或宕机了,重启时,InnoDB 存储引擎会使用 redo log 恢复数据,保证数据的持久性与完整性。
+
+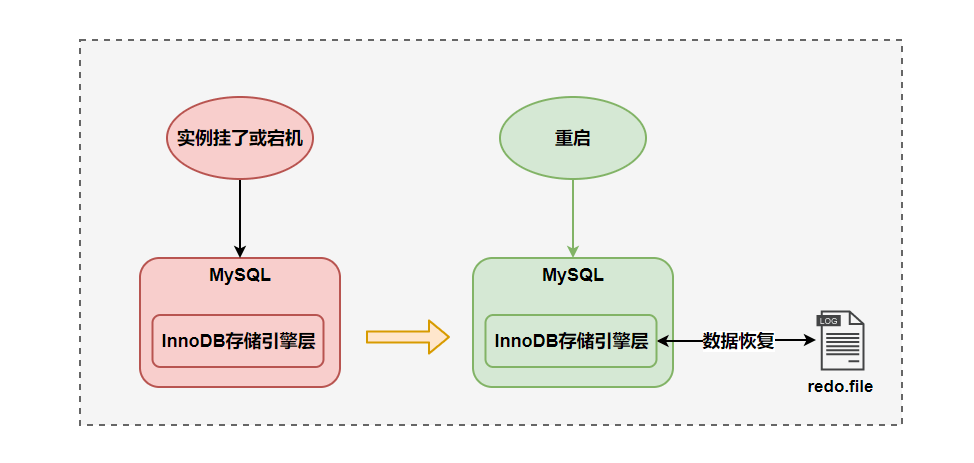
+
+MySQL 中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到 `Buffer Pool` 中。
+
+后续的查询都是先从 `Buffer Pool` 中找,没有命中再去硬盘加载,减少硬盘 IO 开销,提升性能。
+
+更新表数据的时候,也是如此,发现 `Buffer Pool` 里存在要更新的数据,就直接在 `Buffer Pool` 里更新。
+
+然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(`redo log buffer`)里,接着刷盘到 redo log 文件里。
+
+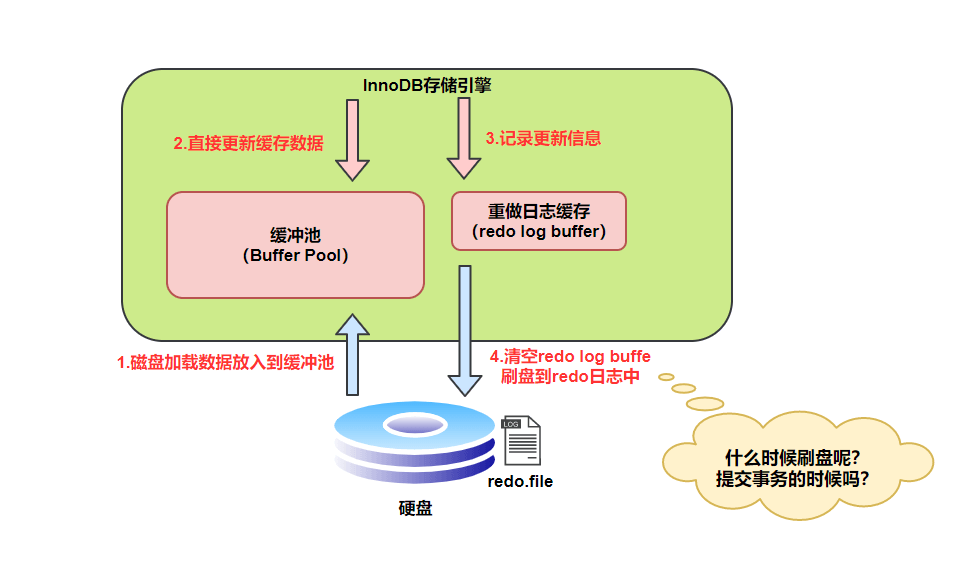
+
+> 图片笔误提示:第 4 步 “清空 redo log buffe 刷盘到 redo 日志中”这句话中的 buffe 应该是 buffer。
+
+理想情况,事务一提交就会进行刷盘操作,但实际上,刷盘的时机是根据策略来进行的。
+
+> 小贴士:每条 redo 记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成
+
+### 刷盘时机
+
+在 InnoDB 存储引擎中,**redo log buffer**(重做日志缓冲区)是一块用于暂存 redo log 的内存区域。为了确保事务的持久性和数据的一致性,InnoDB 会在特定时机将这块缓冲区中的日志数据刷新到磁盘上的 redo log 文件中。这些时机可以归纳为以下六种:
+
+1. **事务提交时(最核心)**:当事务提交时,log buffer 里的 redo log 会被刷新到磁盘(可以通过`innodb_flush_log_at_trx_commit`参数控制,后文会提到)。
+2. **redo log buffer 空间不足时**:这是 InnoDB 的一种主动容量管理策略,旨在避免因缓冲区写满而导致用户线程阻塞。
+ - 当 redo log buffer 的已用空间超过其总容量的**一半 (50%)** 时,后台线程会**主动**将这部分日志刷新到磁盘,为后续的日志写入腾出空间,这是一种“未雨绸缪”的优化。
+ - 如果因为大事务或 I/O 繁忙导致 buffer 被**完全写满**,那么所有试图写入新日志的用户线程都会被**阻塞**,并强制进行一次同步刷盘,直到有可用空间为止。这种情况会影响数据库性能,应尽量避免。
+3. **触发检查点 (Checkpoint) 时**:Checkpoint 是 InnoDB 为了缩短崩溃恢复时间而设计的核心机制。当 Checkpoint 被触发时,InnoDB 需要将在此检查点之前的所有脏页刷写到磁盘。根据 **Write-Ahead Logging (WAL)** 原则,数据页写入磁盘前,其对应的 redo log 必须先落盘。因此,执行 Checkpoint 操作必然会确保相关的 redo log 也已经被刷新到了磁盘。
+4. **后台线程周期性刷新**:InnoDB 有一个后台的 master thread,它会大约每秒执行一次例行任务,其中就包括将 redo log buffer 中的日志刷新到磁盘。这个机制是 `innodb_flush_log_at_trx_commit` 设置为 0 或 2 时的主要持久化保障。
+5. **正常关闭服务器**:在 MySQL 服务器正常关闭的过程中,为了确保所有已提交事务的数据都被完整保存,InnoDB 会执行一次最终的刷盘操作,将 redo log buffer 中剩余的全部日志都清空并写入磁盘文件。
+6. **binlog 切换时**:当开启 binlog 后,在 MySQL 采用 `innodb_flush_log_at_trx_commit=1` 和 `sync_binlog=1` 的 双一配置下,为了保证 redo log 和 binlog 之间状态的一致性(用于崩溃恢复或主从复制),在 binlog 文件写满或者手动执行 flush logs 进行切换时,会触发 redo log 的刷盘动作。
+
+总之,InnoDB 在多种情况下会刷新重做日志,以保证数据的持久性和一致性。
+
+我们要注意设置正确的刷盘策略`innodb_flush_log_at_trx_commit` 。根据 MySQL 配置的刷盘策略的不同,MySQL 宕机之后可能会存在轻微的数据丢失问题。
+
+`innodb_flush_log_at_trx_commit` 的值有 3 种,也就是共有 3 种刷盘策略:
+
+- **0**:设置为 0 的时候,表示每次事务提交时不进行刷盘操作。这种方式性能最高,但是也最不安全,因为如果 MySQL 挂了或宕机了,可能会丢失最近 1 秒内的事务。
+- **1**:设置为 1 的时候,表示每次事务提交时都将进行刷盘操作。这种方式性能最低,但是也最安全,因为只要事务提交成功,redo log 记录就一定在磁盘里,不会有任何数据丢失。
+- **2**:设置为 2 的时候,表示每次事务提交时都只把 log buffer 里的 redo log 内容写入 page cache(文件系统缓存)。page cache 是专门用来缓存文件的,这里被缓存的文件就是 redo log 文件。这种方式的性能和安全性都介于前两者中间。
+
+刷盘策略`innodb_flush_log_at_trx_commit` 的默认值为 1,设置为 1 的时候才不会丢失任何数据。为了保证事务的持久性,我们必须将其设置为 1。
+
+另外,InnoDB 存储引擎有一个后台线程,每隔`1` 秒,就会把 `redo log buffer` 中的内容写到文件系统缓存(`page cache`),然后调用 `fsync` 刷盘。
+
+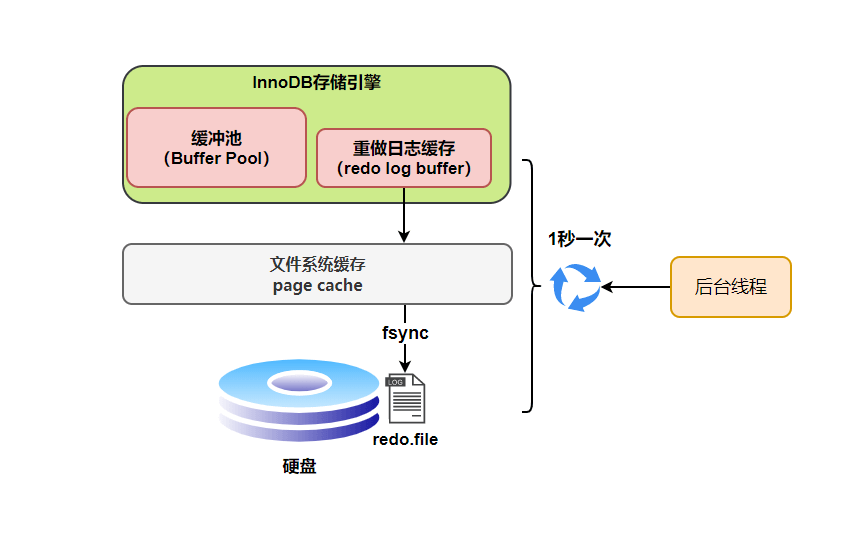
+
+也就是说,一个没有提交事务的 redo log 记录,也可能会刷盘。
+
+**为什么呢?**
+
+因为在事务执行过程 redo log 记录是会写入`redo log buffer` 中,这些 redo log 记录会被后台线程刷盘。
+
+
+
+除了后台线程每秒`1`次的轮询操作,还有一种情况,当 `redo log buffer` 占用的空间即将达到 `innodb_log_buffer_size` 一半的时候,后台线程会主动刷盘。
+
+下面是不同刷盘策略的流程图。
+
+#### innodb_flush_log_at_trx_commit=0
+
+
+
+为`0`时,如果 MySQL 挂了或宕机可能会有`1`秒数据的丢失。
+
+#### innodb_flush_log_at_trx_commit=1
+
+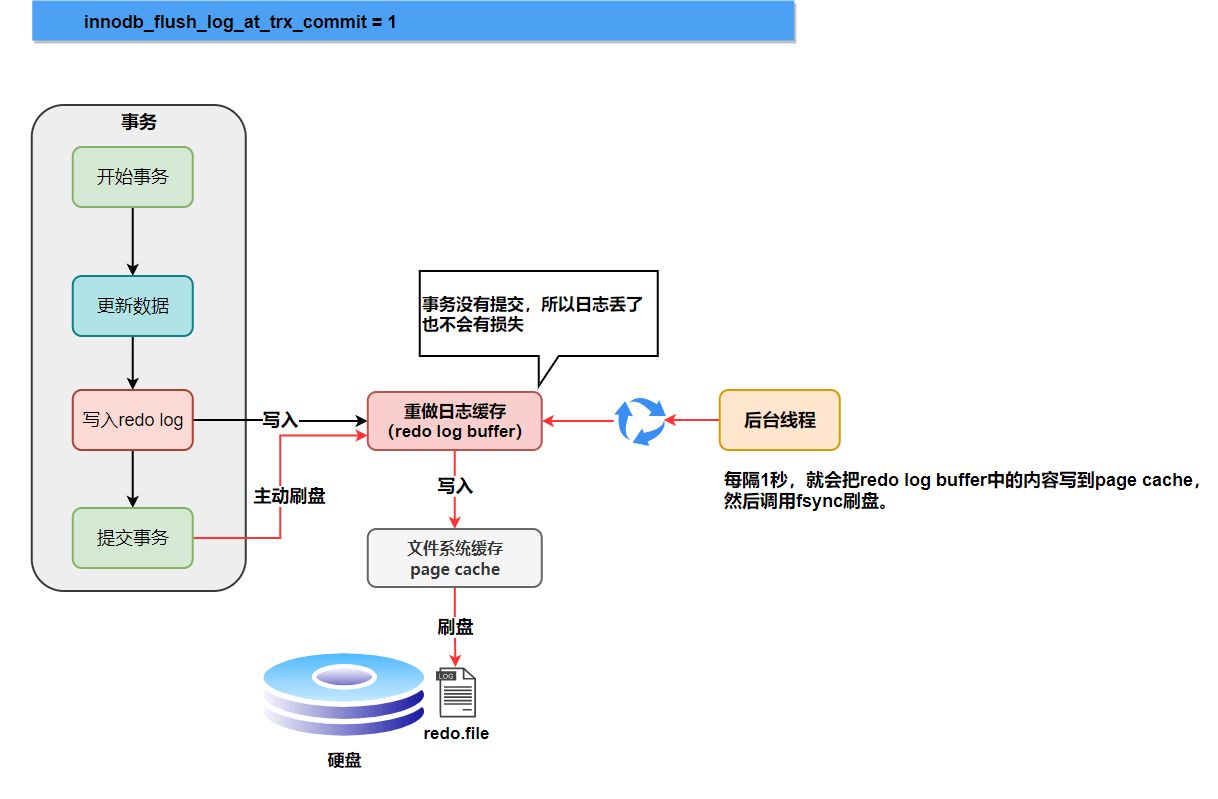
+
+为`1`时, 只要事务提交成功,redo log 记录就一定在硬盘里,不会有任何数据丢失。
+
+如果事务执行期间 MySQL 挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损失。
+
+#### innodb_flush_log_at_trx_commit=2
+
+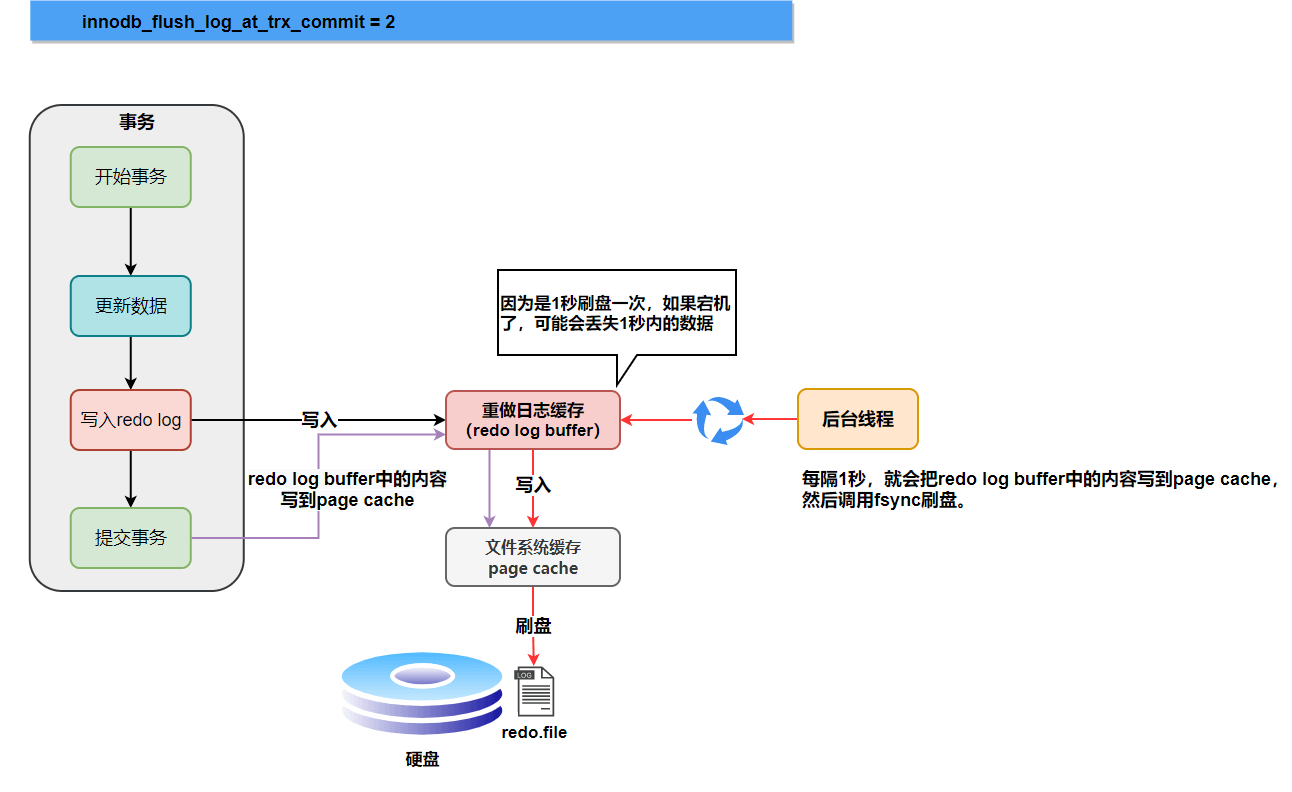
+
+When it is `2`, as long as the transaction is submitted successfully, the contents in `redo log buffer` are only written to the file system cache (`page cache`).
+
+If MySQL is just down, there will be no data loss, but the downtime may result in `1` second of data loss.
+
+### Log file group
+
+There is more than one redo log file stored on the hard disk, but it appears in the form of a **log file group**. The size of each `redo` log file is the same.
+
+For example, it can be configured as a set of `4` files, the size of each file is `1GB`, and the entire redo log log file group can record the contents of `4G`.
+
+It adopts the form of a circular array, writing from the beginning, writing to the end and then returning to the beginning to write in a loop, as shown in the figure below.
+
+
+
+There are two important attributes in this **log file group**, namely `write pos, checkpoint`
+
+- **write pos** is the position of the current record, moving backward while writing
+- **checkpoint** is the current position to be erased, and it is also moved to the future.
+
+Every time the redo log is flushed and recorded in the **log file group**, the `write pos` position will be moved back and updated.
+
+Each time MySQL loads the **log file group** to recover data, the loaded redo log records will be cleared, and the `checkpoint` will be moved back and updated.
+
+The empty part between `write pos` and `checkpoint` can be used to write new redo log records.
+
+
+
+If `write pos` catches up with `checkpoint`, it means that the **log file group** is full. At this time, new redo log records cannot be written. MySQL has to stop, clear some records, and advance `checkpoint`.
+
+
+
+Note that starting from MySQL 8.0.30, the log file group has changed slightly:
+
+> The innodb_redo_log_capacity variable supersedes the innodb_log_files_in_group and innodb_log_file_size variables, which are deprecated. When the innodb_redo_log_capacity setting is defined, the innodb_log_files_in_group and innodb_log_file_size settings are ignored; otherwise, these settings are used to compute the innodb_redo_log_capacity setting (innodb_log_files_in_group \* innodb_log_file_size = innodb_redo_log_capacity). If none of those variables are set, redo log capacity is set to the innodb_redo_log_capacity default value, which is 104857600 bytes (100MB). The maximum redo log capacity is 128GB.
+
+> Redo log files reside in the #innodb_redo directory in the data directory unless a different directory was specified by the innodb_log_group_home_dir variable. If innodb_log_group_home_dir was defined, the redo log files reside in the #innodb_redo directory in that directory. to be used. InnoDB tries to maintain 32 redo log files in total, with each file equal in size to 1/32 \* innodb_redo_log_capacity; however, file sizes may differ for a time after modifying the innodb_redo_log_capacity setting.
+
+This means that before MySQL 8.0.30, you can configure the number and file size of the log file group through `innodb_log_files_in_group` and `innodb_log_file_size`, but in MySQL 8.0.30 and later versions, these two variables have been abandoned, and even if they are specified, they are used to calculate the value of `innodb_redo_log_capacity`. The number of files in the log file group is fixed at 32, and the file size is `innodb_redo_log_capacity / 32`.
+
+Regarding this change, we can verify it.
+
+First create a configuration file and configure the values of `innodb_log_files_in_group` and `innodb_log_file_size`:
+
+```properties
+[mysqld]
+innodb_log_file_size = 10485760
+innodb_log_files_in_group = 64
+```
+
+Docker starts a MySQL 8.0.32 container:
+
+```bash
+docker run -d -p 3312:3309 -e MYSQL_ROOT_PASSWORD=your-password -v /path/to/your/conf:/etc/mysql/conf.d --name
+MySQL830 mysql:8.0.32
+```
+
+Now let's take a look at the startup log:
+
+```plain
+2023-08-03T02:05:11.720357Z 0 [Warning] [MY-013907] [InnoDB] Deprecated configuration parameters innodb_log_file_size and/or innodb_log_files_in_group have been used to compute innodb_redo_log_capacity=671088640. Please use innodb_redo_log_capacity instead.
+```
+
+It is also shown here that the two variables `innodb_log_files_in_group` and `innodb_log_file_size` are used to calculate `innodb_redo_log_capacity` and have been deprecated.
+
+Let’s take a look at the number of files in the log file group:
+
+
+
+You can see that there are exactly 32, and the size of each log file is `671088640 / 32 = 20971520`
+
+Therefore, when using MySQL 8.0.30 and later versions, it is recommended to use the `innodb_redo_log_capacity` variable to configure the log file group
+
+### redo log summary
+
+I believe everyone knows the function of redo log, its flushing time and storage mode.
+
+Now let's think about a question: **As long as the modified data page is flushed directly to the disk every time, what's the point of the redo log? **
+
+Aren't they all brushes? What's the difference?
+
+```java
+1 Byte=8bit
+1 KB = 1024 Byte
+1 MB = 1024 KB
+1 GB = 1024 MB
+1 TB = 1024 GB
+```
+
+In fact, the data page size is `16KB`, and flushing is time-consuming. It may only modify a few `Byte` data in the data page. Is it necessary to flush the complete data page?
+
+Moreover, data page flushing is written randomly, because the corresponding location of a data page may be at a random location in the hard disk file, so the performance is very poor.
+
+If you are writing redo log, one row of records may occupy dozens of `Byte` and only include the table space number, data page number, and disk file offset.
+Amount, update value, plus sequential writing, so the disk flushing speed is very fast.
+
+Therefore, the performance of recording modifications in the form of redo log will far exceed that of refreshing the data page, which also makes the database's concurrency capability stronger.
+
+> In fact, the data pages of the memory will also be flushed at certain times. We call this page merging. We will explain this in detail when we talk about `Buffer Pool`
+
+## binlog
+
+redo log is a physical log that records "what modifications were made on a certain data page" and belongs to the InnoDB storage engine.
+
+Binlog is a logical log, and the record content is the original logic of the statement, similar to "add 1 to the c field of the row with ID=2", and belongs to the `MySQL Server` layer.不管用什么存储引擎,只要发生了表数据更新,都会产生 binlog 日志。
+
+那 binlog 到底是用来干嘛的?
+
+可以说 MySQL 数据库的**数据备份、主备、主主、主从**都离不开 binlog,需要依靠 binlog 来同步数据,保证数据一致性。
+
+
+
+binlog 会记录所有涉及更新数据的逻辑操作,并且是顺序写。
+
+### 记录格式
+
+binlog 日志有三种格式,可以通过`binlog_format`参数指定。
+
+- **statement**
+- **row**
+- **mixed**
+
+指定`statement`,记录的内容是`SQL`语句原文,比如执行一条`update T set update_time=now() where id=1`,记录的内容如下。
+
+
+
+同步数据时,会执行记录的`SQL`语句,但是有个问题,`update_time=now()`这里会获取当前系统时间,直接执行会导致与原库的数据不一致。
+
+为了解决这种问题,我们需要指定为`row`,记录的内容不再是简单的`SQL`语句了,还包含操作的具体数据,记录内容如下。
+
+
+
+`row`格式记录的内容看不到详细信息,要通过`mysqlbinlog`工具解析出来。
+
+`update_time=now()`变成了具体的时间`update_time=1627112756247`,条件后面的@1、@2、@3 都是该行数据第 1 个~3 个字段的原始值(**假设这张表只有 3 个字段**)。
+
+这样就能保证同步数据的一致性,通常情况下都是指定为`row`,这样可以为数据库的恢复与同步带来更好的可靠性。
+
+但是这种格式,需要更大的容量来记录,比较占用空间,恢复与同步时会更消耗 IO 资源,影响执行速度。
+
+所以就有了一种折中的方案,指定为`mixed`,记录的内容是前两者的混合。
+
+MySQL 会判断这条`SQL`语句是否可能引起数据不一致,如果是,就用`row`格式,否则就用`statement`格式。
+
+### 写入机制
+
+binlog 的写入时机也非常简单,事务执行过程中,先把日志写到`binlog cache`,事务提交的时候,再把`binlog cache`写到 binlog 文件中。
+
+因为一个事务的 binlog 不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为`binlog cache`。
+
+我们可以通过`binlog_cache_size`参数控制单个线程 binlog cache 大小,如果存储内容超过了这个参数,就要暂存到磁盘(`Swap`)。
+
+binlog 日志刷盘流程如下
+
+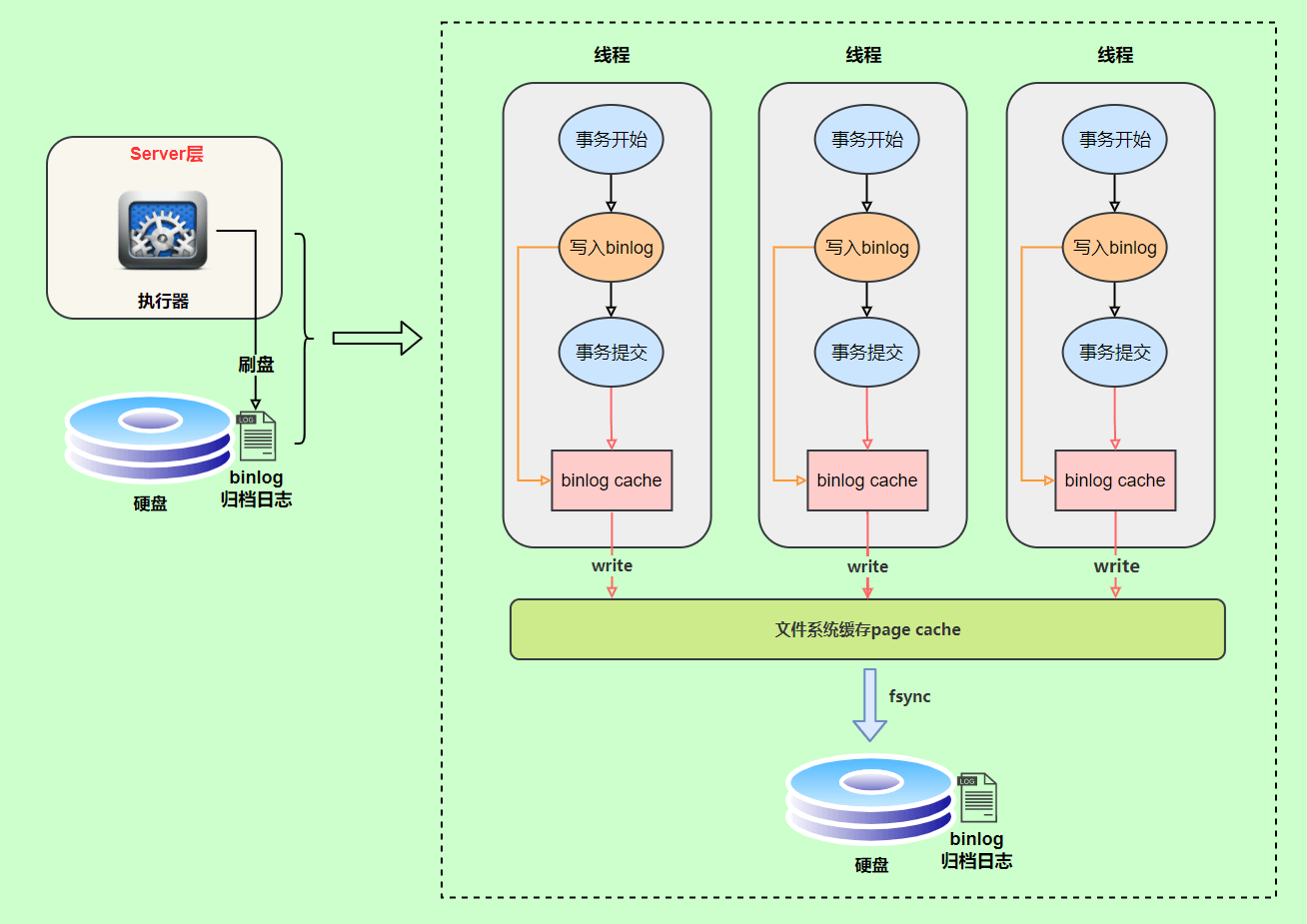
+
+- **上图的 write,是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快**
+- **上图的 fsync,才是将数据持久化到磁盘的操作**
+
+`write`和`fsync`的时机,可以由参数`sync_binlog`控制,默认是`1`。
+
+为`0`的时候,表示每次提交事务都只`write`,由系统自行判断什么时候执行`fsync`。
+
+
+
+虽然性能得到提升,但是机器宕机,`page cache`里面的 binlog 会丢失。
+
+为了安全起见,可以设置为`1`,表示每次提交事务都会执行`fsync`,就如同 **redo log 日志刷盘流程** 一样。
+
+最后还有一种折中方式,可以设置为`N(N>1)`,表示每次提交事务都`write`,但累积`N`个事务后才`fsync`。
+
+
+
+在出现 IO 瓶颈的场景里,将`sync_binlog`设置成一个比较大的值,可以提升性能。
+
+同样的,如果机器宕机,会丢失最近`N`个事务的 binlog 日志。
+
+## 两阶段提交
+
+redo log(重做日志)让 InnoDB 存储引擎拥有了崩溃恢复能力。
+
+binlog(归档日志)保证了 MySQL 集群架构的数据一致性。
+
+虽然它们都属于持久化的保证,但是侧重点不同。
+
+在执行更新语句过程,会记录 redo log 与 binlog 两块日志,以基本的事务为单位,redo log 在事务执行过程中可以不断写入,而 binlog 只有在提交事务时才写入,所以 redo log 与 binlog 的写入时机不一样。
+
+
+
+回到正题,redo log 与 binlog 两份日志之间的逻辑不一致,会出现什么问题?
+
+我们以`update`语句为例,假设`id=2`的记录,字段`c`值是`0`,把字段`c`值更新成`1`,`SQL`语句为`update T set c=1 where id=2`。
+
+假设执行过程中写完 redo log 日志后,binlog 日志写期间发生了异常,会出现什么情况呢?
+
+
+
+由于 binlog 没写完就异常,这时候 binlog 里面没有对应的修改记录。因此,之后用 binlog 日志恢复数据时,就会少这一次更新,恢复出来的这一行`c`值是`0`,而原库因为 redo log 日志恢复,这一行`c`值是`1`,最终数据不一致。
+
+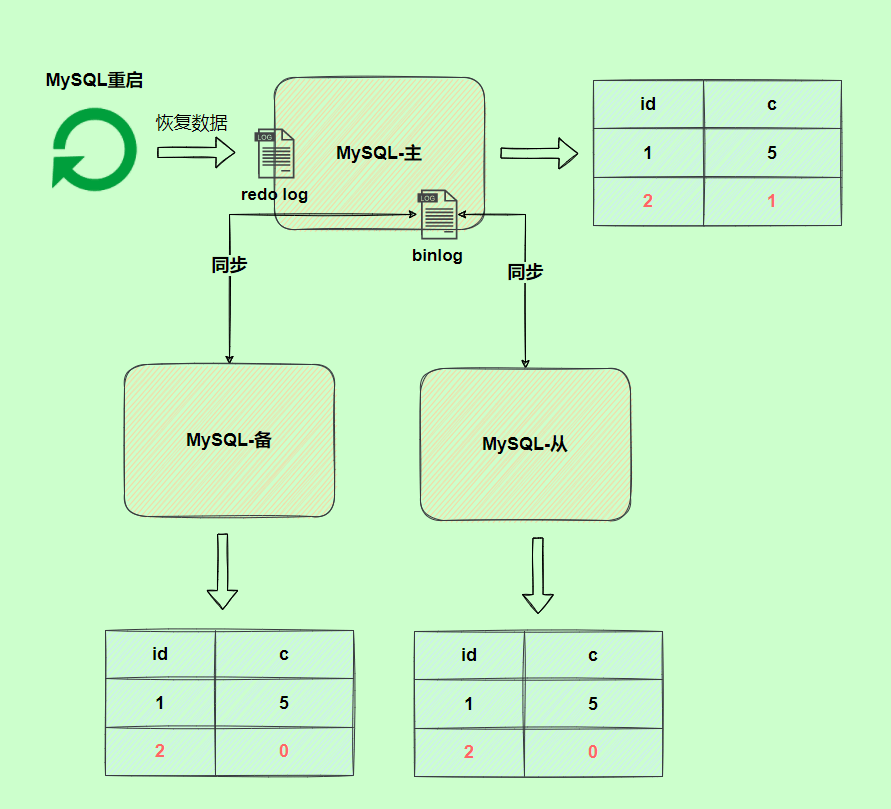
+
+为了解决两份日志之间的逻辑一致问题,InnoDB 存储引擎使用**两阶段提交**方案。
+
+原理很简单,将 redo log 的写入拆成了两个步骤`prepare`和`commit`,这就是**两阶段提交**。
+
+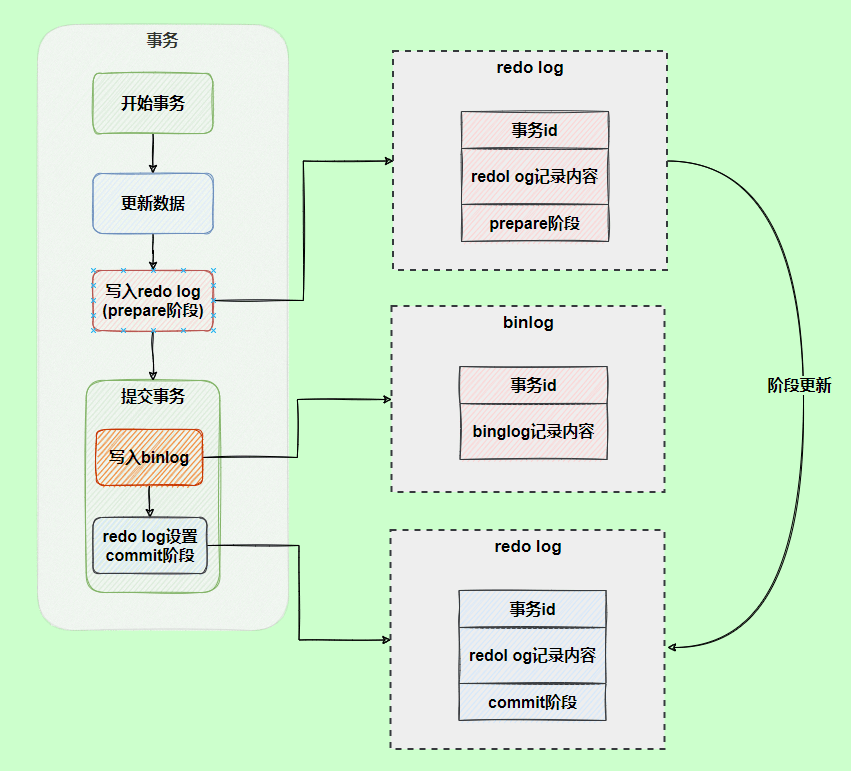
+
+使用**两阶段提交**后,写入 binlog 时发生异常也不会有影响,因为 MySQL 根据 redo log 日志恢复数据时,发现 redo log 还处于`prepare`阶段,并且没有对应 binlog 日志,就会回滚该事务。
+
+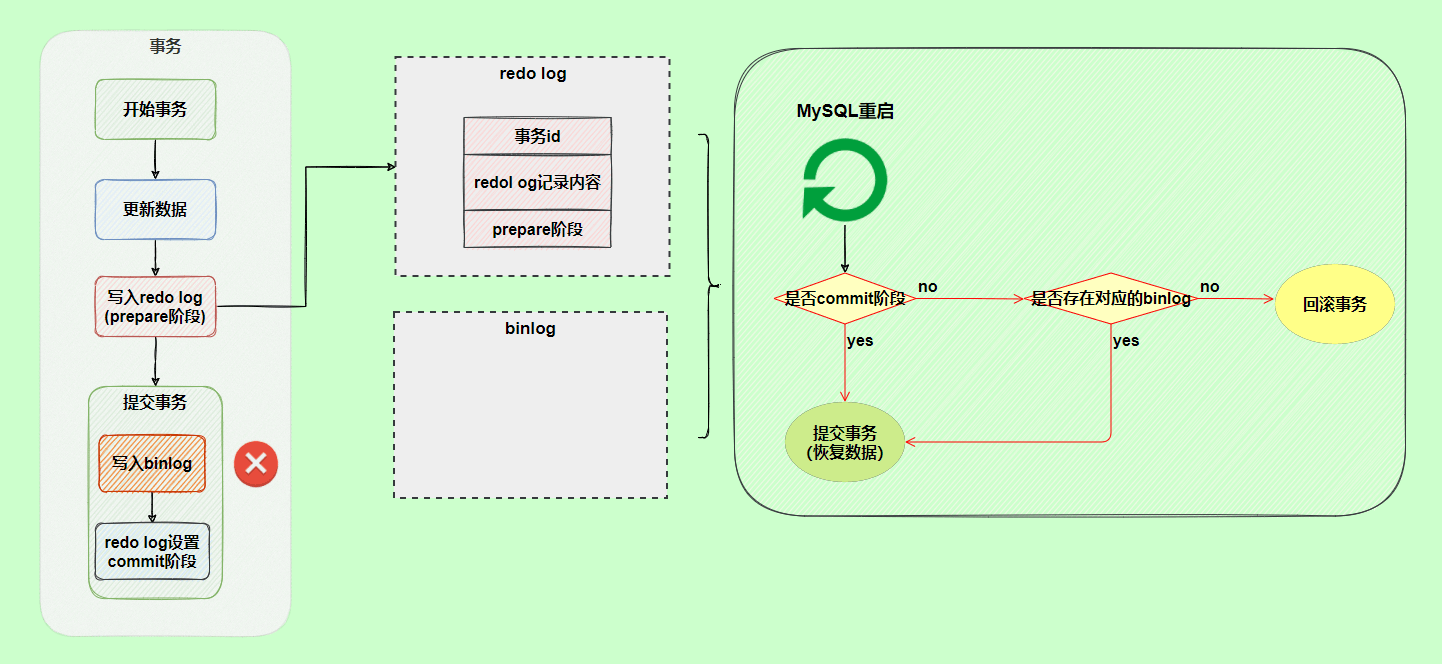
+
+再看一个场景,redo log 设置`commit`阶段发生异常,那会不会回滚事务呢?
+
+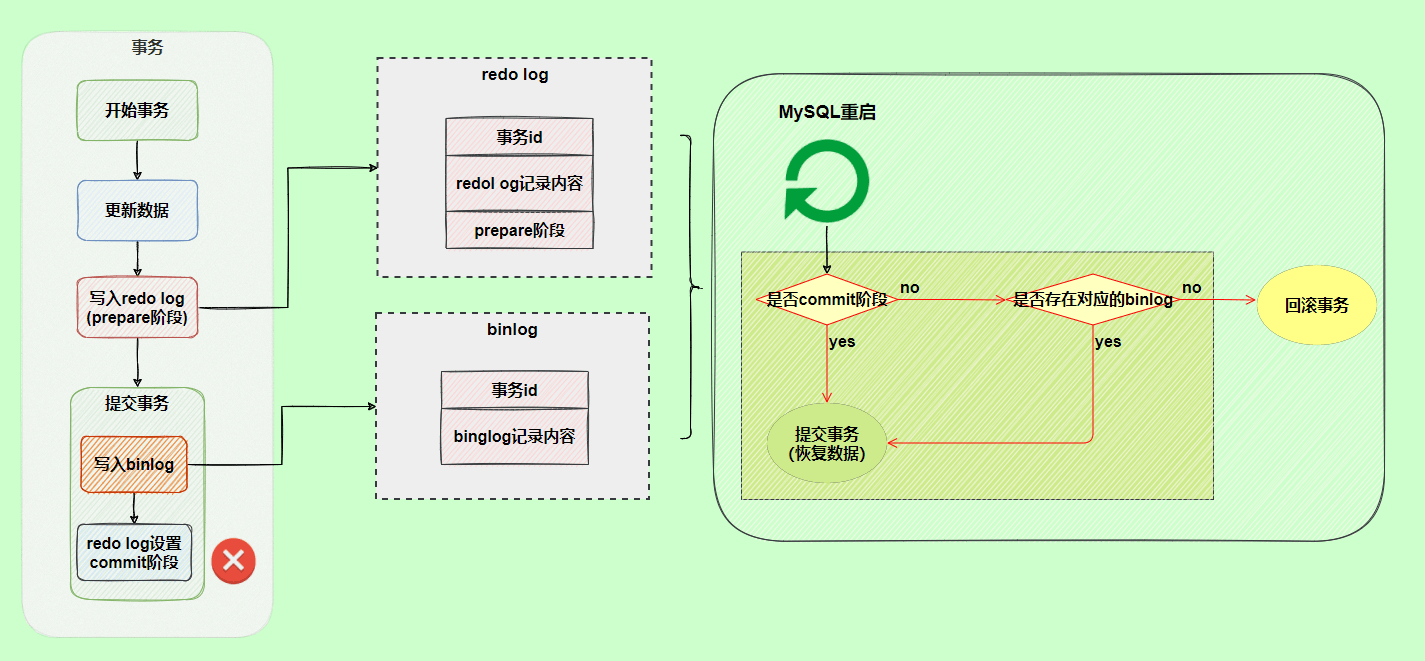
+
+并不会回滚事务,它会执行上图框住的逻辑,虽然 redo log 是处于`prepare`阶段,但是能通过事务`id`找到对应的 binlog 日志,所以 MySQL 认为是完整的,就会提交事务恢复数据。
+
+## undo log
+
+> 这部分内容为 JavaGuide 的补充:
+
+每一个事务对数据的修改都会被记录到 undo log ,当执行事务过程中出现错误或者需要执行回滚操作的话,MySQL 可以利用 undo log 将数据恢复到事务开始之前的状态。
+
+undo log 属于逻辑日志,记录的是 SQL 语句,比如说事务执行一条 DELETE 语句,那 undo log 就会记录一条相对应的 INSERT 语句。同时,undo log 的信息也会被记录到 redo log 中,因为 undo log 也要实现持久性保护。并且,undo-log 本身是会被删除清理的,例如 INSERT 操作,在事务提交之后就可以清除掉了;UPDATE/DELETE 操作在事务提交不会立即删除,会加入 history list,由后台线程 purge 进行清理。
+
+undo log 是采用 segment(段)的方式来记录的,每个 undo 操作在记录的时候占用一个 **undo log segment**(undo 日志段),undo log segment 包含在 **rollback segment**(回滚段)中。事务开始时,需要为其分配一个 rollback segment。每个 rollback segment 有 1024 个 undo log segment,这有助于管理多个并发事务的回滚需求。
+
+Normally, the **rollback segment header** (usually the first page of the rollback segment) is responsible for managing the rollback segment. The rollback segment header is part of the rollback segment, usually on the first page of the rollback segment. **history list** is part of the rollback segment header. Its main function is to record the undo log of all transactions that have been submitted but have not yet been purged. This list enables the purge thread to find and clean up undo log records that are no longer needed.
+
+In addition, the implementation of `MVCC` depends on: **Hidden fields, Read View, and undo log**. In the internal implementation, InnoDB determines the visibility of the data through the `DB_TRX_ID` and `Read View` of the data row. If it is not visible, it uses the `DB_ROLL_PTR` of the data row to find the historical version in the undo log. The data version read by each transaction may be different. In the same transaction, the user can only see the modifications committed before the transaction created `Read View` and the modifications made by the transaction itself.
+
+## Summary
+
+> This part is a supplement to JavaGuide:
+
+The MySQL InnoDB engine uses **redo log (redo log)** to ensure the **durability** of transactions, and uses **undo log (rollback log)** to ensure the **atomicity** of transactions.
+
+The **data backup, primary and secondary, primary-master, and master-slave** of the MySQL database are all inseparable from binlog. Binlog is required to synchronize data and ensure data consistency.
+
+## Reference
+
+- "MySQL Practical Lectures 45"
+- "Take you to become a MySQL practical optimization master from scratch"
+- "How MySQL works: Understanding MySQL from the fundamentals"
+- "MySQL Technology Innodb Storage Engine"
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-query-cache.en.md b/docs_en/database/mysql/mysql-query-cache.en.md
new file mode 100644
index 00000000000..9590b7f4f26
--- /dev/null
+++ b/docs_en/database/mysql/mysql-query-cache.en.md
@@ -0,0 +1,209 @@
+---
+title: MySQL查询缓存详解
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL查询缓存,MySQL缓存机制中的内存管理
+ - - meta
+ - name: description
+ content: 为了提高完全相同的查询语句的响应速度,MySQL Server 会对查询语句进行 Hash 计算得到一个 Hash 值。MySQL Server 不会对 SQL 做任何处理,SQL 必须完全一致 Hash 值才会一样。得到 Hash 值之后,通过该 Hash 值到查询缓存中匹配该查询的结果。MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查询同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。
+---
+
+缓存是一个有效且实用的系统性能优化的手段,不论是操作系统还是各种软件和网站或多或少都用到了缓存。
+
+然而,有经验的 DBA 都建议生产环境中把 MySQL 自带的 Query Cache(查询缓存)给关掉。而且,从 MySQL 5.7.20 开始,就已经默认弃用查询缓存了。在 MySQL 8.0 及之后,更是直接删除了查询缓存的功能。
+
+这又是为什么呢?查询缓存真就这么鸡肋么?
+
+带着如下几个问题,我们正式进入本文。
+
+- MySQL 查询缓存是什么?适用范围?
+- MySQL 缓存规则是什么?
+- MySQL 缓存的优缺点是什么?
+- MySQL 缓存对性能有什么影响?
+
+## MySQL 查询缓存介绍
+
+MySQL 体系架构如下图所示:
+
+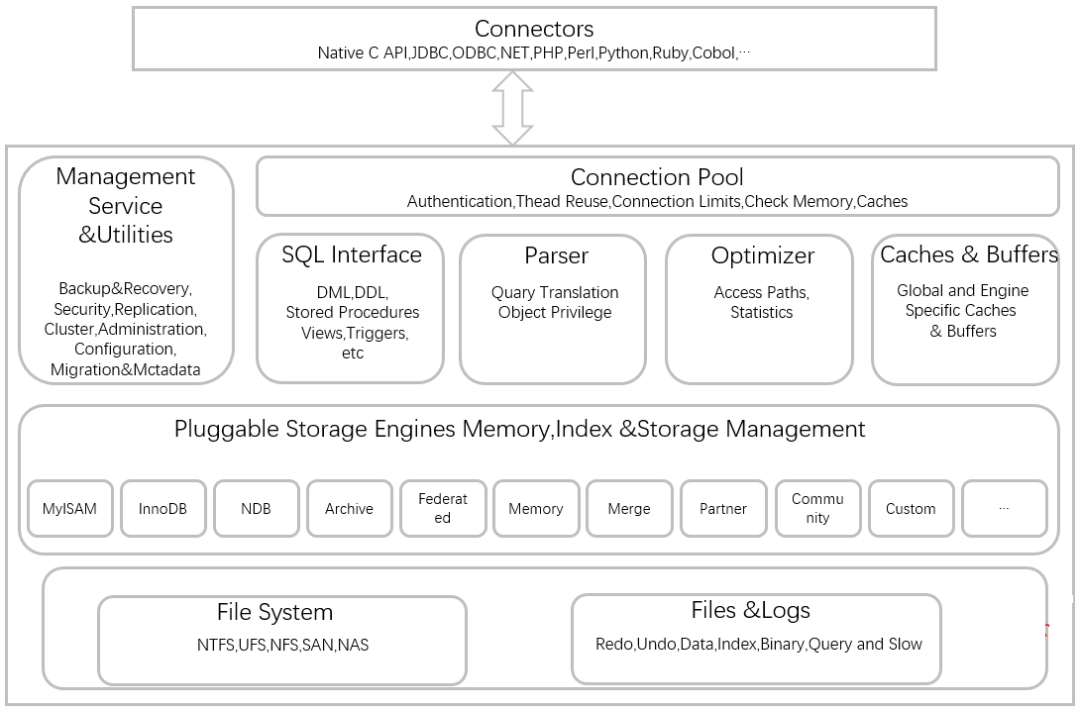
+
+为了提高完全相同的查询语句的响应速度,MySQL Server 会对查询语句进行 Hash 计算得到一个 Hash 值。MySQL Server 不会对 SQL 做任何处理,SQL 必须完全一致 Hash 值才会一样。得到 Hash 值之后,通过该 Hash 值到查询缓存中匹配该查询的结果。
+
+- 如果匹配(命中),则将查询的结果集直接返回给客户端,不必再解析、执行查询。
+- 如果没有匹配(未命中),则将 Hash 值和结果集保存在查询缓存中,以便以后使用。
+
+也就是说,**一个查询语句(select)到了 MySQL Server 之后,会先到查询缓存看看,如果曾经执行过的话,就直接返回结果集给客户端。**
+
+
+
+## MySQL 查询缓存管理和配置
+
+通过 `show variables like '%query_cache%'`命令可以查看查询缓存相关的信息。
+
+8.0 版本之前的话,打印的信息可能是下面这样的:
+
+```bash
+mysql> show variables like '%query_cache%';
++------------------------------+---------+
+| Variable_name | Value |
++------------------------------+---------+
+| have_query_cache | YES |
+| query_cache_limit | 1048576 |
+| query_cache_min_res_unit | 4096 |
+| query_cache_size | 599040 |
+| query_cache_type | ON |
+| query_cache_wlock_invalidate | OFF |
++------------------------------+---------+
+6 rows in set (0.02 sec)
+```
+
+8.0 以及之后版本之后,打印的信息是下面这样的:
+
+```bash
+mysql> show variables like '%query_cache%';
++------------------+-------+
+| Variable_name | Value |
++------------------+-------+
+| have_query_cache | NO |
++------------------+-------+
+1 row in set (0.01 sec)
+```
+
+我们这里对 8.0 版本之前`show variables like '%query_cache%';`命令打印出来的信息进行解释。
+
+- **`have_query_cache`:** 该 MySQL Server 是否支持查询缓存,如果是 YES 表示支持,否则则是不支持。
+- **`query_cache_limit`:** MySQL 查询缓存的最大查询结果,查询结果大于该值时不会被缓存。
+- **`query_cache_min_res_unit`:** 查询缓存分配的最小块的大小(字节)。当查询进行的时候,MySQL 把查询结果保存在查询缓存中,但如果要保存的结果比较大,超过 `query_cache_min_res_unit` 的值 ,这时候 MySQL 将一边检索结果,一边进行保存结果,也就是说,有可能在一次查询中,MySQL 要进行多次内存分配的操作。适当的调节 `query_cache_min_res_unit` 可以优化内存。
+- **`query_cache_size`:** 为缓存查询结果分配的内存的数量,单位是字节,且数值必须是 1024 的整数倍。默认值是 0,即禁用查询缓存。
+- **`query_cache_type`:** 设置查询缓存类型,默认为 ON。设置 GLOBAL 值可以设置后面的所有客户端连接的类型。客户端可以设置 SESSION 值以影响他们自己对查询缓存的使用。
+- **`query_cache_wlock_invalidate`**:如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。
+
+`query_cache_type` 可能的值(修改 `query_cache_type` 需要重启 MySQL Server):
+
+- 0 或 OFF:关闭查询功能。
+- 1 或 ON:开启查询缓存功能,但不缓存 `Select SQL_NO_CACHE` 开头的查询。
+- 2 或 DEMAND:开启查询缓存功能,但仅缓存 `Select SQL_CACHE` 开头的查询。
+
+**建议**:
+
+- `query_cache_size`不建议设置的过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。
+- 建议通过调整 `query_cache_size` 的值来开启、关闭查询缓存,因为修改`query_cache_type` 参数需要重启 MySQL Server 生效。
+
+ 8.0 版本之前,`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
+
+```properties
+query_cache_type=1
+query_cache_size=600000
+```
+
+或者,MySQL 执行以下命令也可以开启查询缓存
+
+```properties
+set global query_cache_type=1;
+set global query_cache_size=600000;
+```
+
+手动清理缓存可以使用下面三个 SQL:
+
+- `flush query cache;`:清理查询缓存内存碎片。
+- `reset query cache;`:从查询缓存中移除所有查询。
+- `flush tables;` 关闭所有打开的表,同时该操作会清空查询缓存中的内容。
+
+## MySQL 缓存机制
+
+### 缓存规则
+
+- 查询缓存会将查询语句和结果集保存到内存(一般是 key-value 的形式,key 是查询语句,value 是查询的结果集),下次再查直接从内存中取。
+- 缓存的结果是通过 sessions 共享的,所以一个 client 查询的缓存结果,另一个 client 也可以使用。
+- SQL 必须完全一致才会导致查询缓存命中(大小写、空格、使用的数据库、协议版本、字符集等必须一致)。检查查询缓存时,MySQL Server 不会对 SQL 做任何处理,它精确的使用客户端传来的查询。
+- 不缓存查询中的子查询结果集,仅缓存查询最终结果集。
+- 不确定的函数将永远不会被缓存, 比如 `now()`、`curdate()`、`last_insert_id()`、`rand()` 等。
+- 不缓存产生告警(Warnings)的查询。
+- 太大的结果集不会被缓存 (< query_cache_limit)。
+- 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
+- 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
+- MySQL 缓存在分库分表环境下是不起作用的。
+- 不缓存使用 `SQL_NO_CACHE` 的查询。
+- ……
+
+查询缓存 `SELECT` 选项示例:
+
+```sql
+SELECT SQL_CACHE id, name FROM customer;# 会缓存
+SELECT SQL_NO_CACHE id, name FROM customer;# 不会缓存
+```
+
+### 缓存机制中的内存管理
+
+查询缓存是完全存储在内存中的,所以在配置和使用它之前,我们需要先了解它是如何使用内存的。
+
+MySQL 查询缓存使用内存池技术,自己管理内存释放和分配,而不是通过操作系统。内存池使用的基本单位是变长的 block, 用来存储类型、大小、数据等信息。一个结果集的缓存通过链表把这些 block 串起来。block 最短长度为 `query_cache_min_res_unit`。
+
+当服务器启动的时候,会初始化缓存需要的内存,是一个完整的空闲块。当查询结果需要缓存的时候,先从空闲块中申请一个数据块为参数 `query_cache_min_res_unit` 配置的空间,即使缓存数据很小,申请数据块也是这个,因为查询开始返回结果的时候就分配空间,此时无法预知结果多大。
+
+分配内存块需要先锁住空间块,所以操作很慢,MySQL 会尽量避免这个操作,选择尽可能小的内存块,如果不够,继续申请,如果存储完时有空余则释放多余的。
+
+但是如果并发的操作,余下的需要回收的空间很小,小于 `query_cache_min_res_unit`,不能再次被使用,就会产生碎片。
+
+## MySQL 查询缓存的优缺点
+
+**优点:**
+
+- 查询缓存的查询,发生在 MySQL 接收到客户端的查询请求、查询权限验证之后和查询 SQL 解析之前。也就是说,当 MySQL 接收到客户端的查询 SQL 之后,仅仅只需要对其进行相应的权限验证之后,就会通过查询缓存来查找结果,甚至都不需要经过 Optimizer 模块进行执行计划的分析优化,更不需要发生任何存储引擎的交互。
+- 由于查询缓存是基于内存的,直接从内存中返回相应的查询结果,因此减少了大量的磁盘 I/O 和 CPU 计算,导致效率非常高。
+
+**缺点:**
+
+- MySQL 会对每条接收到的 SELECT 类型的查询进行 Hash 计算,然后查找这个查询的缓存结果是否存在。虽然 Hash 计算和查找的效率已经足够高了,一条查询语句所带来的开销可以忽略,但一旦涉及到高并发,有成千上万条查询语句时,hash 计算和查找所带来的开销就必须重视了。
+- 查询缓存的失效问题。如果表的变更比较频繁,则会造成查询缓存的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
+- 查询语句不同,但查询结果相同的查询都会被缓存,这样便会造成内存资源的过度消耗。查询语句的字符大小写、空格或者注释的不同,查询缓存都会认为是不同的查询(因为他们的 Hash 值会不同)。
+- 相关系统变量设置不合理会造成大量的内存碎片,这样便会导致查询缓存频繁清理内存。
+
+## MySQL 查询缓存对性能的影响
+
+在 MySQL Server 中打开查询缓存对数据库的读和写都会带来额外的消耗:
+
+- 读查询开始之前必须检查是否命中缓存。
+- 如果读查询可以缓存,那么执行完查询操作后,会查询结果和查询语句写入缓存。
+- 当向某个表写入数据的时候,必须将这个表所有的缓存设置为失效,如果缓存空间很大,则消耗也会很大,可能使系统僵死一段时间,因为这个操作是靠全局锁操作来保护的。
+- 对 InnoDB 表,当修改一个表时,设置了缓存失效,但是多版本特性会暂时将这修改对其他事务屏蔽,在这个事务提交之前,所有查询都无法使用缓存,直到这个事务被提交,所以长时间的事务,会大大降低查询缓存的命中。
+
+## 总结
+
+MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查询同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。
+
+查询缓存是一个适用较少情况的缓存机制。如果你的应用对数据库的更新很少,那么查询缓存将会作用显著。比较典型的如博客系统,一般博客更新相对较慢,数据表相对稳定不变,这时候查询缓存的作用会比较明显。
+
+简单总结一下查询缓存的适用场景:
+
+- 表数据修改不频繁、数据较静态。
+- 查询(Select)重复度高。
+- 查询结果集小于 1 MB。
+
+对于一个更新频繁的系统来说,查询缓存缓存的作用是很微小的,在某些情况下开启查询缓存会带来性能的下降。
+
+简单总结一下查询缓存不适用的场景:
+
+- 表中的数据、表结构或者索引变动频繁
+- 重复的查询很少
+- 查询的结果集很大
+
+《高性能 MySQL》这样写到:
+
+> 根据我们的经验,在高并发压力环境中查询缓存会导致系统性能的下降,甚至僵死。如果你一 定要使用查询缓存,那么不要设置太大内存,而且只有在明确收益的时候才使用(数据库内容修改次数较少)。
+
+**确实是这样的!实际项目中,更建议使用本地缓存(比如 Caffeine)或者分布式缓存(比如 Redis) ,性能更好,更通用一些。**
+
+## 参考
+
+- 《高性能 MySQL》
+- MySQL 缓存机制:
+- RDS MySQL 查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:
+- 8.10.3 The MySQL Query Cache - MySQL 官方文档:
+
+
+
diff --git a/docs_en/database/mysql/mysql-query-execution-plan.en.md b/docs_en/database/mysql/mysql-query-execution-plan.en.md
new file mode 100644
index 00000000000..3c35c989514
--- /dev/null
+++ b/docs_en/database/mysql/mysql-query-execution-plan.en.md
@@ -0,0 +1,145 @@
+---
+title: MySQL execution plan analysis
+category: database
+tag:
+ -MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL basics, MySQL execution plan, EXPLAIN, query optimizer
+ - - meta
+ - name: description
+ content: Execution plan refers to the specific execution method of a SQL statement after being optimized by the MySQL query optimizer. The first step in optimizing SQL should be to understand the execution plan of SQL.
+---
+
+> This article comes from the official MySQL technology, and JavaGuide has supplemented and improved it. Original address:
+
+The first step in optimizing SQL should be to understand the execution plan of SQL. In this article, let’s learn about MySQL `EXPLAIN` execution plan.
+
+## What is an execution plan?
+
+**Execution plan** refers to the specific execution method of a SQL statement after being optimized by **MySQL Query Optimizer**.
+
+Execution plans are usually used in SQL performance analysis, optimization and other scenarios. Through the results of `EXPLAIN`, you can learn information such as the query sequence of the data table, the operation type of the data query operation, which indexes can be hit, which indexes will actually be hit, how many rows of records in each data table are queried, etc.
+
+## How to get the execution plan?
+
+MySQL provides us with the `EXPLAIN` command to obtain information about the execution plan.
+
+It should be noted that the `EXPLAIN` statement does not actually execute the relevant statements. Instead, it analyzes the statements through the query optimizer to find the optimal query plan and displays the corresponding information.
+
+The `EXPLAIN` execution plan supports `SELECT`, `DELETE`, `INSERT`, `REPLACE` and `UPDATE` statements. We usually use it to analyze `SELECT` query statements. It is very simple to use. The syntax is as follows:
+
+```sql
+EXPLAIN + SELECT query statement;
+```
+
+Let’s briefly look at the execution plan of the next query statement:
+
+```sql
+mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>1);
++----+-------------+----------+------------+-------+------------------+----------+----------+------+--------+----------+-------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+----------+------------+-------+------------------+----------+----------+------+--------+----------+-------------+
+| 1 | PRIMARY | dept_emp | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | Using where |
+| 2 | SUBQUERY | dept_emp | NULL | index | PRIMARY,dept_no | PRIMARY | 16 | NULL | 331143 | 100.00 | Using index |
++----+-------------+----------+------------+-------+------------------+----------+----------+------+--------+----------+-------------+
+```
+
+As you can see, there are 12 columns in the execution plan results. The meaning of each column is summarized in the following table:
+
+| **Column Name** | **Meaning** |
+|------------- | ----------------------------------------------- |
+| id | The sequence identifier of the SELECT query |
+| select_type | The query type corresponding to the SELECT keyword |
+| table | table name used |
+| partitions | Matching partitions, or NULL for unpartitioned tables |
+| type | table access method |
+| possible_keys | Possible indexes |
+| key | the actual index used |
+| key_len | The length of the selected index |
+| ref | When using an index equivalent query, the column or constant to compare with the index |
+| rows | The expected number of rows to read |
+| filtered | Percentage of retained records after filtering by table conditions |
+| Extra | Additional Information |
+
+## How to analyze EXPLAIN results?
+
+In order to analyze the execution results of the `EXPLAIN` statement, we need to understand the important fields in the execution plan.
+
+###id
+
+`SELECT` identifier, used to identify the execution order of each `SELECT` statement.
+
+If the ids are the same, execute them in order from top to bottom. The id is different. The larger the id value, the higher the execution priority. If the row refers to the union result of other rows, the value can be NULL.
+
+### select_type
+
+The type of query is mainly used to distinguish between ordinary queries, joint queries, subqueries and other complex queries. Common values are:
+
+- **SIMPLE**: Simple query, does not contain UNION or subquery.
+- **PRIMARY**: If the query contains subqueries or other parts, the outer SELECT will be marked as PRIMARY.
+- **SUBQUERY**: The first SELECT in a subquery.
+- **UNION**: In the UNION statement, SELECT that appears after UNION.
+- **DERIVED**: Subqueries appearing in FROM will be marked as DERIVED.
+- **UNION RESULT**: The result of UNION query.
+
+### table
+
+Each row has a corresponding table name for the table name used in the query. In addition to the normal table, the table name may also be the following values:
+
+- **``**: This line refers to the UNION result of the lines with id M and N;
+- **``**: This line refers to the derived table result generated by the table with id N. Derived tables may be generated from subqueries in the FROM statement.
+- **``**: This line refers to the materialized subquery results generated by the table with id N.
+
+### type (important)
+
+The type of query execution, describes how the query is executed. The order of all values from best to worst is:
+
+system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
+
+The specific meanings of several common types are as follows:
+
+- **system**: If the engine used by the table is accurate for table row count statistics (such as MyISAM), and there is only one row of records in the table, the access method is system, which is a special case of const.
+- **const**: There is at most one row of matching records in the table, which can be found in one query. It is often used to use all fields of the primary key or unique index as query conditions.
+- **eq_ref**: When querying connected tables, the rows of the previous table have only one corresponding row in the current table. It is the best join method besides system and const. It is often used to use all fields of the primary key or unique index as the join condition.
+- **ref**: Use ordinary indexes as query conditions, and the query results may find multiple rows that meet the conditions.
+- **index_merge**: When the query condition uses multiple indexes, it means that Index Merge optimization is turned on. At this time, the key column in the execution plan lists the indexes used.
+- **range**: Perform a range query on the index column. The key column in the execution plan indicates which index is used.- **index**: The query traverses the entire index tree, similar to ALL, except that it scans the index, which is generally in memory and is faster.
+- **ALL**: Full table scan.
+
+### possible_keys
+
+The possible_keys column represents the indexes that MySQL may use when executing the query. If this column is NULL, it means that there is no index that may be used; in this case, you need to check the columns used in the WHERE statement to see if query performance can be improved by adding an index to one or more of these columns.
+
+### key (important)
+
+The key column represents the index actually used by MySQL. If NULL, the index is not used.
+
+### key_len
+
+The key_len column represents the maximum length of the index actually used by MySQL; when a joint index is used, it may be the sum of the lengths of multiple columns. The shorter it is, the better if it meets your needs. If the key column displays NULL , the key_len column also displays NULL .
+
+### rows
+
+The rows column indicates a rough estimate of the number of rows that need to be found or read based on table statistics and selection. The smaller the value, the better.
+
+### Extra (Important)
+
+This column contains additional information about MySQL parsing the query. Through this information, you can more accurately understand how MySQL executes the query. Common values are as follows:
+
+- **Using filesort**: External index sorting is used during sorting, and in-table index is not used for sorting.
+- **Using temporary**: MySQL needs to create a temporary table to store the results of the query, which is common in ORDER BY and GROUP BY.
+- **Using index**: Indicates that the query uses a covering index, without returning the table, and the query efficiency is very high.
+- **Using index condition**: Indicates that the query optimizer chooses to use the index condition push-down feature.
+- **Using where**: Indicates that the query uses the WHERE clause for conditional filtering. This usually occurs when the index is not used.
+- **Using join buffer (Block Nested Loop)**: The method of joining table query, which means that when the driven table does not use an index, MySQL will first read out the driving table and put it into the join buffer, and then traverse the driven table and driving table for query.
+
+As a reminder, when the Extra column contains Using filesort or Using temporary, MySQL performance may have problems and needs to be avoided as much as possible.
+
+## Reference
+
+-
+-
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-questions-01.en.md b/docs_en/database/mysql/mysql-questions-01.en.md
new file mode 100644
index 00000000000..f79a25704b8
--- /dev/null
+++ b/docs_en/database/mysql/mysql-questions-01.en.md
@@ -0,0 +1,1095 @@
+---
+title: MySQL常见面试题总结
+category: 数据库
+tag:
+ - MySQL
+ - 大厂面试
+head:
+ - - meta
+ - name: keywords
+ content: MySQL面试题,MySQL基础架构,InnoDB存储引擎,MySQL索引,B+树索引,事务隔离级别,redo log,undo log,binlog,MVCC,行级锁,慢查询优化
+ - - meta
+ - name: description
+ content: MySQL高频面试题精讲:基础架构、InnoDB引擎、索引原理、B+树、事务ACID、MVCC、redo/undo/binlog日志、行锁/表锁、慢查询优化,一文速通大厂必考点!
+---
+
+
+
+## MySQL 基础
+
+### 什么是关系型数据库?
+
+顾名思义,关系型数据库(RDB,Relational Database)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
+
+关系型数据库中,我们的数据都被存放在了各种表中(比如用户表),表中的每一行就存放着一条数据(比如一个用户的信息)。
+
+
+
+大部分关系型数据库都使用 SQL 来操作数据库中的数据。并且,大部分关系型数据库都支持事务的四大特性(ACID)。
+
+**有哪些常见的关系型数据库呢?**
+
+MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ……。
+
+### 什么是 SQL?
+
+SQL 是一种结构化查询语言(Structured Query Language),专门用来与数据库打交道,目的是提供一种从数据库中读写数据的简单有效的方法。
+
+几乎所有的主流关系数据库都支持 SQL ,适用性非常强。并且,一些非关系型数据库也兼容 SQL 或者使用的是类似于 SQL 的查询语言。
+
+SQL 可以帮助我们:
+
+- 新建数据库、数据表、字段;
+- 在数据库中增加,删除,修改,查询数据;
+- 新建视图、函数、存储过程;
+- 对数据库中的数据进行简单的数据分析;
+- 搭配 Hive,Spark SQL 做大数据;
+- 搭配 SQLFlow 做机器学习;
+- ……
+
+### 什么是 MySQL?
+
+
+
+**MySQL 是一种关系型数据库,主要用于持久化存储我们的系统中的一些数据比如用户信息。**
+
+由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是**3306**。
+
+### ⭐️MySQL 有什么优点?
+
+这个问题本质上是在问 MySQL 如此流行的原因。
+
+MySQL 成功可以归功于在**生态、功能和运维**这三个层面上的综合优势。
+
+**第一,从生态和成本角度看,它的护城河非常深。**
+
+- **开源免费:** 这是它得以广泛普及的基石。任何公司和个人都可以免费使用,极大地降低了技术门槛和初期成本。
+- **社区庞大,生态完善:** 经过几十年的发展,MySQL 拥有极其活跃的社区和丰富的生态系统。这意味着无论你遇到什么问题,几乎都能在网上找到解决方案;同时,市面上所有的主流编程语言、框架、ORM 工具、监控系统都对 MySQL 有完美的支持。它的文档也非常丰富,学习资源唾手可得。
+
+**第二,从核心技术功能上看,它非常强大且均衡。**
+
+- **强大的事务支持:** 这是它作为关系型数据库的立身之本。值得一提的是,InnoDB 默认的可重复读(REPEATABLE-READ)隔离级别,通过 MVCC 和 Next-Key Lock 机制,很大程度上避免了幻读问题,这在很多其他数据库中都需要更高的隔离级别才能做到,兼顾了性能和一致性。详细介绍可以阅读笔者写的这篇文章:[MySQL 事务隔离级别详解](https://javaguide.cn/database/mysql/transaction-isolation-level.html)。
+- **优秀的性能和可扩展性:** MySQL 本身经过了海量互联网业务的严酷考验,单机性能非常出色。更重要的是,它围绕着水平扩展,形成了一套非常成熟的架构方案,比如主从复制、读写分离、以及通过中间件实现的分库分表。这让它能够支撑从初创公司到大型互联网平台的各种规模的业务。
+
+**第三,从运维和使用角度看,它非常‘亲民’。**
+
+- **开箱即用,上手简单:** 相比于 Oracle 等大型商业数据库,MySQL 的安装、配置和日常使用都非常简单直观,学习曲线平缓,对于开发者和初级 DBA 非常友好。
+- **维护成本低:** 由于其简单性和庞大的社区,找到相关的运维人才和解决方案都相对容易,整体的维护成本也更低。
+
+值得一提的是最近几年,PostgreSQL 的势头很猛,甚至压过了 MySQL。网上出现了很多抨击诋毁 MySQL 的文章,笔者认为任何无脑抨击其中一方或者吹捧另外一方的行为都是不可取的。
+
+笔者也写过一篇文章分享对这两个关系型数据库代表的看法,感兴趣的可以看看:[MySQL 被干成老二了?](https://mp.weixin.qq.com/s/APWD-PzTcTqGUuibAw7GGw)。
+
+## MySQL 字段类型
+
+MySQL 字段类型可以简单分为三大类:
+
+- **数值类型**:整型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT)、浮点型(FLOAT 和 DOUBLE)、定点型(DECIMAL)
+- **字符串类型**:CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB 等,最常用的是 CHAR 和 VARCHAR。
+- **日期时间类型**:YEAR、TIME、DATE、DATETIME 和 TIMESTAMP 等。
+
+下面这张图不是我画的,忘记是从哪里保存下来的了,总结的还蛮不错的。
+
+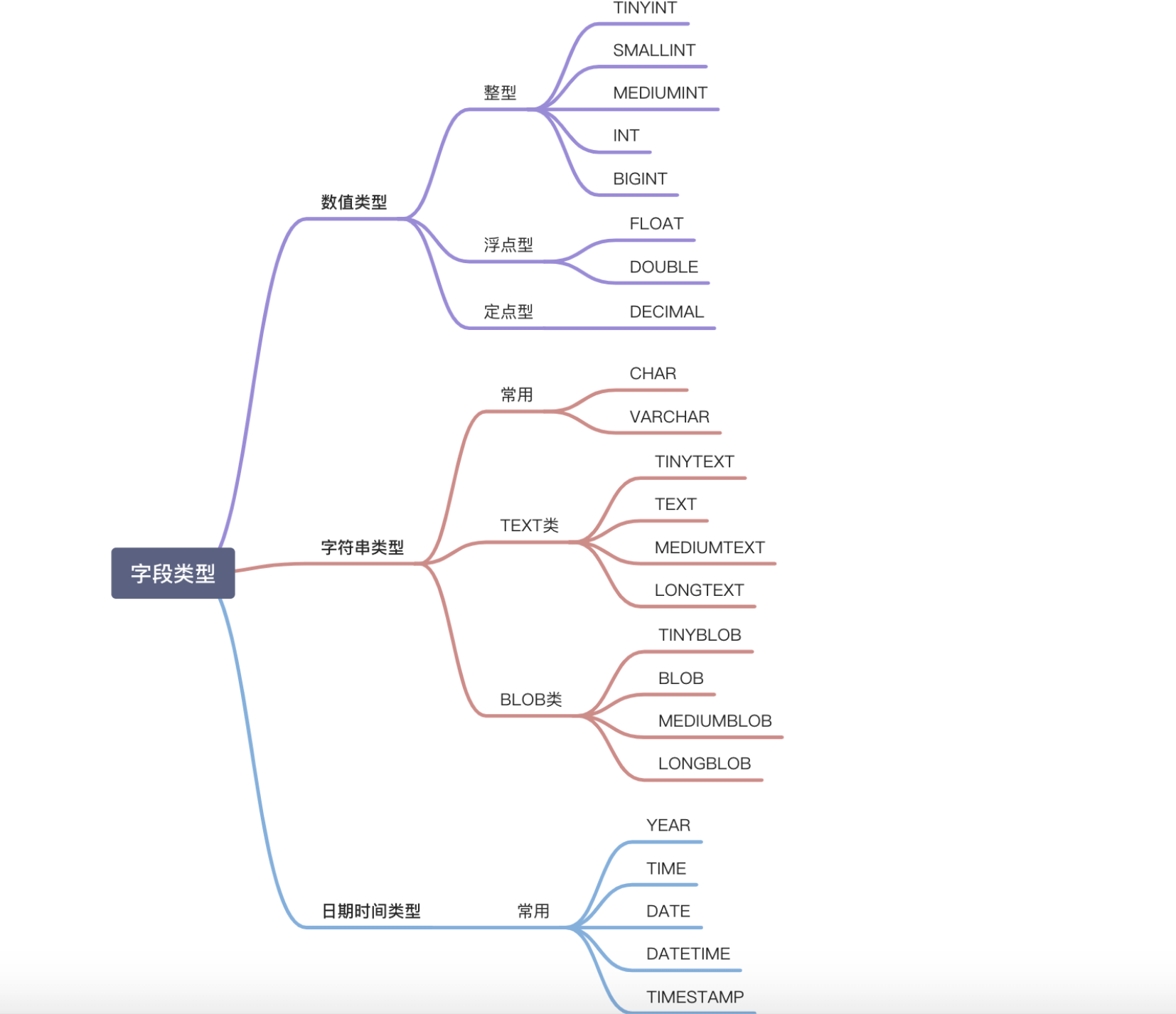
+
+MySQL 字段类型比较多,我这里会挑选一些日常开发使用很频繁且面试常问的字段类型,以面试问题的形式来详细介绍。如无特殊说明,针对的都是 InnoDB 存储引擎。
+
+另外,推荐阅读一下《高性能 MySQL(第三版)》的第四章,有详细介绍 MySQL 字段类型优化。
+
+### ⭐️整数类型的 UNSIGNED 属性有什么用?
+
+MySQL 中的整数类型可以使用可选的 UNSIGNED 属性来表示不允许负值的无符号整数。使用 UNSIGNED 属性可以将正整数的上限提高一倍,因为它不需要存储负数值。
+
+例如, TINYINT UNSIGNED 类型的取值范围是 0 ~ 255,而普通的 TINYINT 类型的值范围是 -128 ~ 127。INT UNSIGNED 类型的取值范围是 0 ~ 4,294,967,295,而普通的 INT 类型的值范围是 -2,147,483,648 ~ 2,147,483,647。
+
+对于从 0 开始递增的 ID 列,使用 UNSIGNED 属性可以非常适合,因为不允许负值并且可以拥有更大的上限范围,提供了更多的 ID 值可用。
+
+### CHAR 和 VARCHAR 的区别是什么?
+
+CHAR 和 VARCHAR 是最常用到的字符串类型,两者的主要区别在于:**CHAR 是定长字符串,VARCHAR 是变长字符串。**
+
+CHAR 在存储时会在右边填充空格以达到指定的长度,检索时会去掉空格;VARCHAR 在存储时需要使用 1 或 2 个额外字节记录字符串的长度,检索时不需要处理。
+
+CHAR 更适合存储长度较短或者长度都差不多的字符串,例如 Bcrypt 算法、MD5 算法加密后的密码、身份证号码。VARCHAR 类型适合存储长度不确定或者差异较大的字符串,例如用户昵称、文章标题等。
+
+CHAR(M) 和 VARCHAR(M) 的 M 都代表能够保存的字符数的最大值,无论是字母、数字还是中文,每个都只占用一个字符。
+
+### VARCHAR(100)和 VARCHAR(10)的区别是什么?
+
+VARCHAR(100)和 VARCHAR(10)都是变长类型,表示能存储最多 100 个字符和 10 个字符。因此,VARCHAR (100) 可以满足更大范围的字符存储需求,有更好的业务拓展性。而 VARCHAR(10)存储超过 10 个字符时,就需要修改表结构才可以。
+
+虽说 VARCHAR(100)和 VARCHAR(10)能存储的字符范围不同,但二者存储相同的字符串,所占用磁盘的存储空间其实是一样的,这也是很多人容易误解的一点。
+
+不过,VARCHAR(100) 会消耗更多的内存。这是因为 VARCHAR 类型在内存中操作时,通常会分配固定大小的内存块来保存值,即使用字符类型中定义的长度。例如在进行排序的时候,VARCHAR(100)是按照 100 这个长度来进行的,也就会消耗更多内存。
+
+### DECIMAL 和 FLOAT/DOUBLE 的区别是什么?
+
+DECIMAL 和 FLOAT 的区别是:**DECIMAL 是定点数,FLOAT/DOUBLE 是浮点数。DECIMAL 可以存储精确的小数值,FLOAT/DOUBLE 只能存储近似的小数值。**
+
+DECIMAL 用于存储具有精度要求的小数,例如与货币相关的数据,可以避免浮点数带来的精度损失。
+
+在 Java 中,MySQL 的 DECIMAL 类型对应的是 Java 类 `java.math.BigDecimal`。
+
+### 为什么不推荐使用 TEXT 和 BLOB?
+
+TEXT 类型类似于 CHAR(0-255 字节)和 VARCHAR(0-65,535 字节),但可以存储更长的字符串,即长文本数据,例如博客内容。
+
+| 类型 | 可存储大小 | 用途 |
+| ---------- | -------------------- | -------------- |
+| TINYTEXT | 0-255 字节 | 一般文本字符串 |
+| TEXT | 0-65,535 字节 | 长文本字符串 |
+| MEDIUMTEXT | 0-16,772,150 字节 | 较大文本数据 |
+| LONGTEXT | 0-4,294,967,295 字节 | 极大文本数据 |
+
+BLOB 类型主要用于存储二进制大对象,例如图片、音视频等文件。
+
+| 类型 | 可存储大小 | 用途 |
+| ---------- | ---------- | ------------------------ |
+| TINYBLOB | 0-255 字节 | 短文本二进制字符串 |
+| BLOB | 0-65KB | 二进制字符串 |
+| MEDIUMBLOB | 0-16MB | 二进制形式的长文本数据 |
+| LONGBLOB | 0-4GB | 二进制形式的极大文本数据 |
+
+在日常开发中,很少使用 TEXT 类型,但偶尔会用到,而 BLOB 类型则基本不常用。如果预期长度范围可以通过 VARCHAR 来满足,建议避免使用 TEXT。
+
+数据库规范通常不推荐使用 BLOB 和 TEXT 类型,这两种类型具有一些缺点和限制,例如:
+
+- 不能有默认值。
+- 在使用临时表时无法使用内存临时表,只能在磁盘上创建临时表(《高性能 MySQL》书中有提到)。
+- 检索效率较低。
+- 不能直接创建索引,需要指定前缀长度。
+- 可能会消耗大量的网络和 IO 带宽。
+- 可能导致表上的 DML 操作变慢。
+- ……
+
+### ⭐️DATETIME 和 TIMESTAMP 的区别是什么?如何选择?
+
+DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
+
+TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
+
+- DATETIME:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- Timestamp:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
+
+`TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+
+如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+
+关于两者的详细对比以及日期存储类型选择建议,请参考我写的这篇文章: [MySQL 时间类型数据存储建议](./some-thoughts-on-database-storage-time.md)。
+
+### NULL 和 '' 的区别是什么?
+
+`NULL` 和 `''` (空字符串) 是两个完全不同的值,它们分别表示不同的含义,并在数据库中有着不同的行为。`NULL` 代表缺失或未知的数据,而 `''` 表示一个已知存在的空字符串。它们的主要区别如下:
+
+1. **含义**:
+ - `NULL` 代表一个不确定的值,它不等于任何值,包括它自身。因此,`SELECT NULL = NULL` 的结果是 `NULL`,而不是 `true` 或 `false`。 `NULL` 意味着缺失或未知的信息。虽然 `NULL` 不等于任何值,但在某些操作中,数据库系统会将 `NULL` 值视为相同的类别进行处理,例如:`DISTINCT`,`GROUP BY`,`ORDER BY`。需要注意的是,这些操作将 `NULL` 值视为相同的类别进行处理,并不意味着 `NULL` 值之间是相等的。 它们只是在特定操作中被特殊处理,以保证结果的正确性和一致性。 这种处理方式是为了方便数据操作,而不是改变了 `NULL` 的语义。
+ - `''` 表示一个空字符串,它是一个已知的值。
+2. **存储空间**:
+ - `NULL` 的存储空间占用取决于数据库的实现,通常需要一些空间来标记该值为空。
+ - `''` 的存储空间占用通常较小,因为它只存储一个空字符串的标志,不需要存储实际的字符。
+3. **比较运算**:
+ - 任何值与 `NULL` 进行比较(例如 `=`, `!=`, `>`, `<` 等)的结果都是 `NULL`,表示结果不确定。要判断一个值是否为 `NULL`,必须使用 `IS NULL` 或 `IS NOT NULL`。
+ - `''` 可以像其他字符串一样进行比较运算。例如,`'' = ''` 的结果是 `true`。
+4. **聚合函数**:
+ - 大多数聚合函数(例如 `SUM`, `AVG`, `MIN`, `MAX`)会忽略 `NULL` 值。
+ - `COUNT(*)` 会统计所有行数,包括包含 `NULL` 值的行。`COUNT(列名)` 会统计指定列中非 `NULL` 值的行数。
+ - 空字符串 `''` 会被聚合函数计算在内。例如,`SUM` 会将其视为 0,`MIN` 和 `MAX` 会将其视为一个空字符串。
+
+看了上面的介绍之后,相信你对另外一个高频面试题:“为什么 MySQL 不建议使用 `NULL` 作为列默认值?”也有了答案。
+
+### ⭐️Boolean 类型如何表示?
+
+MySQL 中没有专门的布尔类型,而是用 `TINYINT(1)` 类型来表示布尔值。`TINYINT(1)` 类型可以存储 0 或 1,分别对应 false 或 true。
+
+### ⭐️手机号存储用 INT 还是 VARCHAR?
+
+存储手机号,**强烈推荐使用 VARCHAR 类型**,而不是 INT 或 BIGINT。主要原因如下:
+
+1. **格式兼容性与完整性:**
+ - 手机号可能包含前导零(如某些地区的固话区号)、国家代码前缀('+'),甚至可能带有分隔符('-' 或空格)。INT 或 BIGINT 这种数字类型会自动丢失这些重要的格式信息(比如前导零会被去掉,'+' 和 '-' 无法存储)。
+ - VARCHAR 可以原样存储各种格式的号码,无论是国内的 11 位手机号,还是带有国家代码的国际号码,都能完美兼容。
+2. **非算术性:**手机号虽然看起来是数字,但我们从不对它进行数学运算(比如求和、平均值)。它本质上是一个标识符,更像是一个字符串。用 VARCHAR 更符合其数据性质。
+3. **查询灵活性:**
+ - 业务中常常需要根据号段(前缀)进行查询,例如查找所有 "138" 开头的用户。使用 VARCHAR 类型配合 `LIKE '138%'` 这样的 SQL 查询既直观又高效。
+ - 如果使用数字类型,进行类似的前缀匹配通常需要复杂的函数转换(如 CAST 或 SUBSTRING),或者使用范围查询(如 `WHERE phone >= 13800000000 AND phone < 13900000000`),这不仅写法繁琐,而且可能无法有效利用索引,导致性能下降。
+4. **加密存储的要求(非常关键):**
+ - 出于数据安全和隐私合规的要求,手机号这类敏感个人信息通常必须加密存储在数据库中。
+- The encrypted data (ciphertext) is a long string of characters (usually composed of letters, numbers, symbols, or Base64/Hex encoded), and the INT or BIGINT types cannot store this ciphertext at all. Only types such as VARCHAR, TEXT, or BLOB will do.
+
+**About VARCHAR length selection:**
+
+- **If stored without encryption (strongly not recommended!):** Considering international numbers and possible format characters, VARCHAR(20) to VARCHAR(32) is usually a relatively safe range, enough to cover the vast majority of mobile phone number formats around the world. VARCHAR(15) may not be sufficient for some numbers with country codes and formatting characters.
+- **If storing encrypted (recommended standard practice):** The length must be accurately calculated and set based on the maximum length of the ciphertext produced by the chosen encryption algorithm, and possible encoding methods (e.g. Base64 will increase the length by about 1/3). Often longer VARCHAR lengths are required, such as VARCHAR(128), VARCHAR(256) or even longer.
+
+Finally, here is a table to summarize:
+
+| Comparing dimensions | VARCHAR type (recommended) | INT/BIGINT type (not recommended) | Description/Remarks |
+|---------------- | ---------------------------------- | ---------------------------------- | ------------------------------------------------------------------------------- |
+| **Format Compatibility** | ✔ Can store leading zeros, "+", "-", spaces, etc. | ✘ Leading zeros are automatically lost and symbols cannot be stored | VARCHAR can store various mobile phone number formats as they are, INT/BIGINT only supports simple numbers, and leading zeros will disappear |
+| **Integrity** | ✔ No format information is lost | ✘ Format information is lost | For example, "013800012345" stored in INT will become 13800012345, and "+" cannot be stored |
+| **Non-arithmetic** | ✔ Suitable for storing "identifiers" | ✘ Only suitable for numerical operations | Mobile phone numbers are essentially string identifiers and do not perform mathematical operations. VARCHAR is more suitable for practical purposes |
+| **Query flexibility** | ✔ Supports `LIKE '138%'`, etc. | ✘ Querying prefixes is inconvenient or has poor performance | Use VARCHAR to efficiently query by number segment/prefix, but the numeric type needs to be converted to a string or other complex processing |
+| **Encrypted storage support** | ✔ Can store encrypted ciphertext (letters, symbols, etc.) | ✘ Unable to store ciphertext | After encrypting the mobile phone number, the ciphertext is a string/binary, only VARCHAR, TEXT, BLOB, etc. are compatible |
+| **Length setting recommendations** | 15~20 (unencrypted), encryption depends on the situation | Meaningless | When not encrypted, VARCHAR(15~20) is universal, the encrypted length depends on the algorithm and encoding method |
+
+## MySQL Infrastructure
+
+> It is recommended to read this article [Execution Process of SQL Statements in MySQL](./how-sql-executed-in-mysql.md) to understand the MySQL infrastructure. In addition, "the execution flow of a SQL statement in MySQL" is also a frequently asked question in interviews.
+
+The following figure is a brief architecture diagram of MySQL. From the figure below, you can clearly see how a SQL statement on the client is executed inside MySQL.
+
+
+
+As can be seen from the above figure, MySQL mainly consists of the following parts:
+
+- **Connector:** Identity authentication and permission related (when logging in to MySQL).
+- **Query cache:** When executing a query statement, the cache will be queried first (removed after MySQL 8.0 version, because this function is not very practical).
+- **Analyzer:** If the cache is not hit, the SQL statement will go through the analyzer. To put it bluntly, the analyzer needs to first see what your SQL statement is doing, and then check whether the syntax of your SQL statement is correct.
+- **Optimizer:** Execute according to the solution considered optimal by MySQL.
+- **Executor:** Execute the statement and return data from the storage engine. Before executing the statement, it will be judged whether there is permission. If there is no permission, an error will be reported.
+- **Plug-in storage engine**: Mainly responsible for data storage and reading. It adopts a plug-in architecture and supports various storage engines such as InnoDB, MyISAM, and Memory. InnoDB is the default storage engine of MySQL. In most scenarios, using InnoDB is the best choice.
+
+## MySQL storage engine
+
+The core of MySQL lies in the storage engine. If you want to learn MySQL in depth, you must study the MySQL storage engine in depth.
+
+### What storage engines does MySQL support? Which one is used by default?
+
+MySQL supports multiple storage engines. You can view all storage engines supported by MySQL through the `SHOW ENGINES` command.
+
+
+
+From the picture above, we can see that MySQL's current default storage engine is InnoDB. Moreover, among all storage engines, only InnoDB is a transactional storage engine, which means that only InnoDB supports transactions.
+
+The MySQL version I use here is 8.x, and there may be differences between different MySQL versions.
+
+Prior to MySQL 5.5.5, MyISAM was the default storage engine for MySQL. After version 5.5.5, InnoDB is the default storage engine for MySQL.
+
+You can check your MySQL version with the `SELECT VERSION()` command.
+
+```bash
+mysql> SELECT VERSION();
++-----------+
+| VERSION() |
++-----------+
+| 8.0.27 |
++-----------+
+1 row in set (0.00 sec)
+```
+
+You can also directly view MySQL's current default storage engine through the `SHOW VARIABLES LIKE '%storage_engine%'` command.
+
+```bash
+mysql> SHOW VARIABLES LIKE '%storage_engine%';
++----------------------------------+----------+
+| Variable_name | Value |
++----------------------------------+----------+
+| default_storage_engine | InnoDB |
+| default_tmp_storage_engine | InnoDB |
+| disabled_storage_engines | |
+| internal_tmp_mem_storage_engine | TempTable |
++----------------------------------+----------+
+4 rows in set (0.00 sec)
+```
+
+If you want to have an in-depth understanding of each storage engine and the differences between them, it is recommended that you read the following introduction in the official MySQL document (the interview will not ask such detailed questions, just understand it):
+
+- Detailed introduction to InnoDB storage engine: .
+- Detailed introduction to other storage engines: .
+
+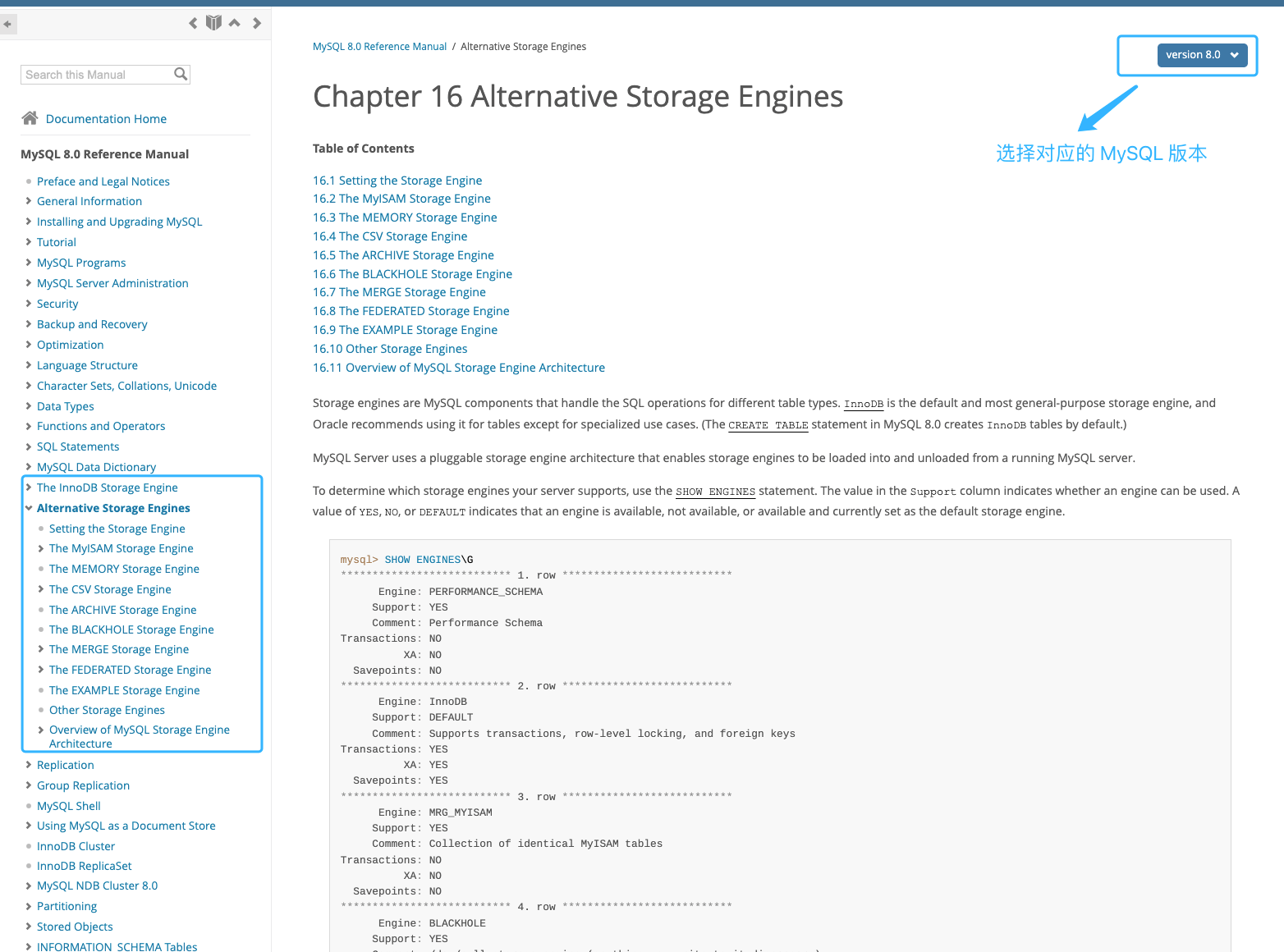
+
+### Do you understand the MySQL storage engine architecture?
+
+The MySQL storage engine adopts a **plug-in architecture** and supports multiple storage engines. We can even set up different storage engines for different database tables to meet the needs of different scenarios. **The storage engine is based on tables, not databases. **
+
+The following diagram shows the MySQL architecture with pluggable storage engines:
+
+你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
+
+MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地址: 。
+
+### ⭐️MyISAM 和 InnoDB 有什么区别?
+
+MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
+
+虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
+
+MySQL 5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。
+
+言归正传!咱们下面还是来简单对比一下两者:
+
+**1、是否支持行级锁**
+
+MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
+
+也就说,MyISAM 一锁就是锁住了整张表,这在并发写的情况下是多么滴憨憨啊!这也是为什么 InnoDB 在并发写的时候,性能更牛皮了!
+
+**2、是否支持事务**
+
+MyISAM 不提供事务支持。
+
+InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别,具有提交(commit)和回滚(rollback)事务的能力。并且,InnoDB 默认使用的 REPEATABLE-READ(可重读)隔离级别是可以解决幻读问题发生的(基于 MVCC 和 Next-Key Lock)。
+
+关于 MySQL 事务的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
+
+**3、是否支持外键**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+外键对于维护数据一致性非常有帮助,但是对性能有一定的损耗。因此,通常情况下,我们是不建议在实际生产项目中使用外键的,在业务代码中进行约束即可!
+
+阿里的《Java 开发手册》也是明确规定禁止使用外键的。
+
+
+
+不过,在代码中进行约束的话,对程序员的能力要求更高,具体是否要采用外键还是要根据你的项目实际情况而定。
+
+总结:一般我们也是不建议在数据库层面使用外键的,应用层面可以解决。不过,这样会对数据的一致性造成威胁。具体要不要使用外键还是要根据你的项目来决定。
+
+**4、是否支持数据库异常崩溃后的安全恢复**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 `redo log` 。
+
+**5、是否支持 MVCC**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+讲真,这个对比有点废话,毕竟 MyISAM 连行级锁都不支持。MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提高性能。
+
+**6、索引实现不一样。**
+
+虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
+
+InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。
+
+详细区别,推荐你看看我写的这篇文章:[MySQL 索引详解](./mysql-index.md)。
+
+**7、性能有差别。**
+
+InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是只读模式下,随着 CPU 核数的增加,InnoDB 的读写能力呈线性增长。MyISAM 因为读写不能并发,它的处理能力跟核数没关系。
+
+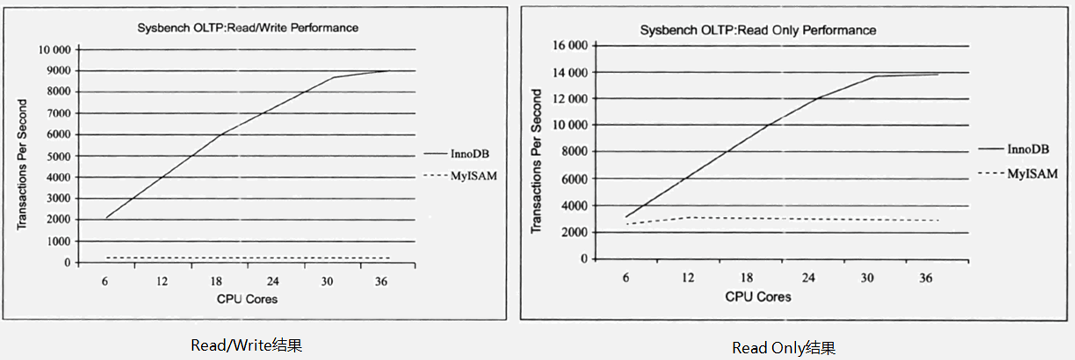
+
+**8、数据缓存策略和机制实现不同。**
+
+InnoDB 使用缓冲池(Buffer Pool)缓存数据页和索引页,MyISAM 使用键缓存(Key Cache)仅缓存索引页而不缓存数据页。
+
+**总结**:
+
+- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
+- MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别。
+- MyISAM 不支持外键,而 InnoDB 支持。
+- MyISAM 不支持 MVCC,而 InnoDB 支持。
+- 虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
+- MyISAM 不支持数据库异常崩溃后的安全恢复,而 InnoDB 支持。
+- InnoDB 的性能比 MyISAM 更强大。
+
+最后,再分享一张图片给你,这张图片详细对比了常见的几种 MySQL 存储引擎。
+
+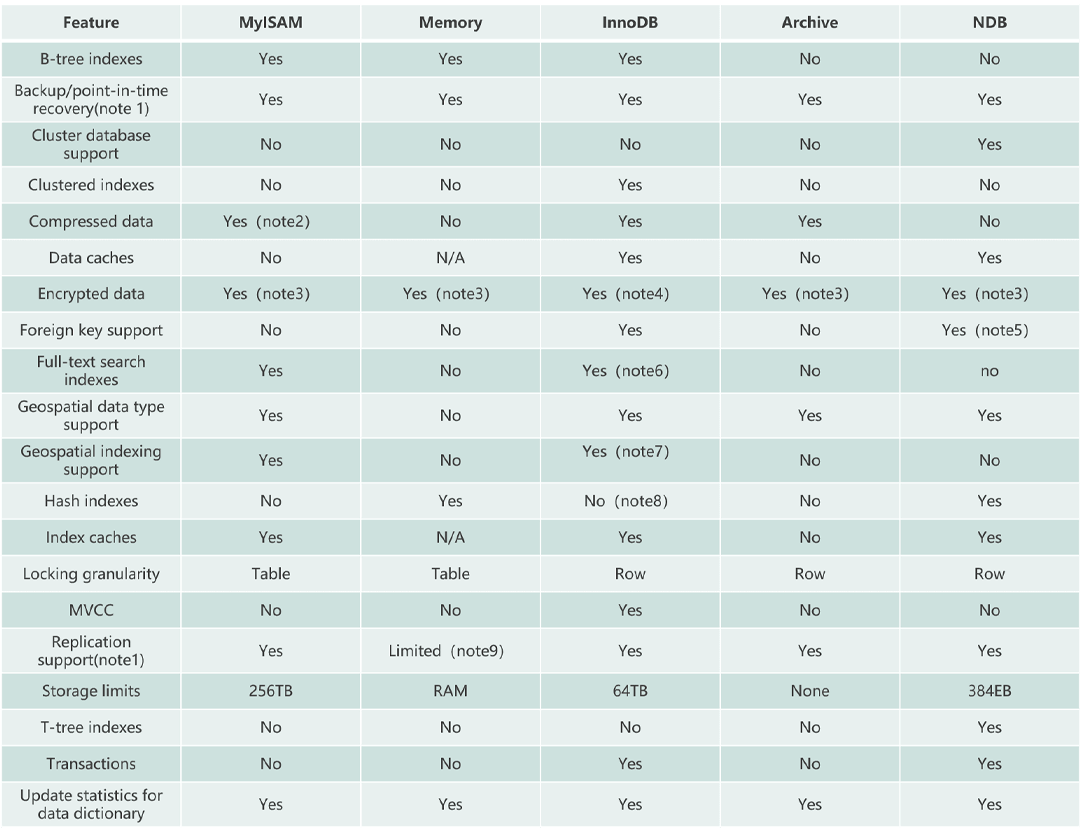
+
+### MyISAM 和 InnoDB 如何选择?
+
+大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊)。
+
+《MySQL 高性能》上面有一句话这样写到:
+
+> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
+
+因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由使用 MyISAM 了,老老实实用默认的 InnoDB 就可以了!
+
+## ⭐️MySQL 索引
+
+MySQL 索引相关的问题比较多,也非常重要,更详细的介绍可以阅读笔者写的这篇文章:[MySQL 索引详解](./mysql-index.md) 。
+
+### 索引是什么?
+
+**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
+
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
+
+**索引的优点:**
+
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
+
+**索引的缺点:**
+
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
+
+**那么,用了索引就一定能提高查询性能吗?**
+
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
+
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
+
+### 索引为什么快?
+
+索引之所以快,核心原因是它**大大减少了磁盘 I/O 的次数**。
+
+它的本质是一种**排好序的数据结构**,就像书的目录,让我们不用一页一页地翻(全表扫描)。
+
+在 MySQL 中,这个数据结构是**B+树**。B+树结构主要从两方面做了优化:
+
+1. B+树的特点是“矮胖”,一个千万数据的表,索引树的高度可能只有 3-4 层。这意味着,最多只需要**3-4 次磁盘 I/O**,就能精确定位到我想要的数据,而全表扫描可能需要成千上万次,所以速度极快。
+2. B+树的叶子节点是**用链表连起来的**。找到开头后,就能顺着链表**顺序读**下去,这对磁盘非常友好,还能触发预读。
+
+### MySQL 索引底层数据结构是什么?
+
+在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,详细介绍可以参考笔者写的这篇文章:[MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html)。
+
+### 为什么 InnoDB 没有使用哈希作为索引的数据结构?
+
+> 我发现很多求职者甚至是面试官对这个问题都有误解,他们相当然的认为 MySQL 底层并没有使用哈希或者 B 树作为索引的数据结构。
+>
+> 实际上,不论是提问还是回答这个问题都要区分好存储引擎。像 MEMORY 引擎就同时支持哈希和 B 树。
+
+哈希索引的底层是哈希表。它的优点是,在进行**精确的等值查询**时,理论上时间复杂度是 **O(1)** ,速度极快。比如 `WHERE id = 123`。
+
+但是,它有几个对于通用数据库来说是致命的缺点:
+
+1. **不支持范围查询:** 这是最主要的原因。哈希函数的一个特点是它会把相邻的输入值(比如 `id=100` 和 `id=101`)映射到哈希表中完全不相邻的位置。这种顺序的破坏,使得我们无法处理像 `WHERE age > 30` 或 `BETWEEN 100 AND 200`这样的范围查询。要完成这种查询,哈希索引只能退化为全表扫描。
+2. **不支持排序:** 同理,因为哈希值是无序的,所以我们无法利用哈希索引来优化 `ORDER BY` 子句。
+3. **不支持部分索引键查询:** 对于联合索引,比如`(col1, col2)`,哈希索引必须使用所有索引列进行查询,它无法单独利用 `col1` 来加速查询。
+4. **哈希冲突问题:** 当不同的键产生相同的哈希值时,需要额外的链表或开放寻址来解决,这会降低性能。
+
+鉴于数据库查询中范围查询和排序是极其常见的操作,一个不支持这些功能的索引结构,显然不能作为默认的、通用的索引类型。
+
+### 为什么 InnoDB 没有使用 B 树作为索引的数据结构?
+
+B 树和 B+树都是优秀的多路平衡搜索树,非常适合磁盘存储,因为它们都很“矮胖”,能最大化地利用每一次磁盘 I/O。
+
+但 B+树是 B 树的一个增强版,它针对数据库场景做了几个关键优化:
+
+1. **I/O 效率更高:** 在 B+树中,只有叶子节点才存储数据(或数据指针),而非叶子节点只存储索引键。因为非叶子节点不存数据,所以它们可以容纳更多的索引键。这意味着 B+树的“扇出”更大,在同样的数据量下,B+树通常会比 B 树更矮,也就意味着查找数据所需的磁盘 I/O 次数更少。
+2. **查询性能更稳定:** 在 B+树中,任何一次查询都必须从根节点走到叶子节点才能找到数据,所以查询路径的长度是固定的。而在 B 树中,如果运气好,可能在非叶子节点就找到了数据,但运气不好也得走到叶子,这导致查询性能不稳定。
+3. **对范围查询极其友好:** 这是 B+树最核心的优势。它的所有叶子节点之间通过一个双向链表连接。当我们执行一个范围查询(比如 `WHERE id > 100`)时,只需要通过树形结构找到 `id=100` 的叶子节点,然后就可以沿着链表向后顺序扫描,而无需再回溯到上层节点。这使得范围查询的效率大大提高。
+
+### 什么是覆盖索引?
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
+
+在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。**
+
+### 请解释一下 MySQL 的联合索引及其最左前缀原则
+
+使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
+
+以 `score` 和 `name` 两个字段建立联合索引:
+
+```sql
+ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
+```
+
+最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据,这样可以提高查询效率。
+
+最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配(相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ))。
+
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+
+我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
+
+我们这里简单演示一下最左前缀匹配的效果。
+
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
+
+```sql
+CREATE TABLE `student` (
+ `id` int NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `class` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `name_class_idx` (`name`,`class`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+2、下面我们分别测试三条不同的 SQL 语句。
+
+
+
+```sql
+# 可以命中索引
+SELECT * FROM student WHERE name = 'Anne Henry';
+EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk';
+# 无法命中索引
+SELECT * FROM student WHERE class = 'lIrm08RYVk';
+```
+
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
+
+先不要往下看答案,给自己 3 分钟时间想一想。
+
+1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
+
+MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
+
+### SELECT \* 会导致索引失效吗?
+
+`SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖。
+
+### 哪些字段适合创建索引?
+
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 索引失效的原因有哪些?
+
+1. 创建了组合索引,但查询条件未遵守最左匹配原则;
+2. 在索引列上进行计算、函数、类型转换等操作;
+3. 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
+4. 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
+5. IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
+6. 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html "隐式转换");
+
+## MySQL 查询缓存
+
+MySQL 查询缓存是查询结果缓存。执行查询语句的时候,会先查询缓存,如果缓存中有对应的查询结果,就会直接返回。
+
+`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
+
+```properties
+query_cache_type=1
+query_cache_size=600000
+```
+
+MySQL 执行以下命令也可以开启查询缓存
+
+```properties
+set global query_cache_type=1;
+set global query_cache_size=600000;
+```
+
+查询缓存会在同样的查询条件和数据情况下,直接返回缓存中的结果。但需要注意的是,查询缓存的匹配条件非常严格,任何细微的差异都会导致缓存无法命中。这里的查询条件包括查询语句本身、当前使用的数据库、以及其他可能影响结果的因素,如客户端协议版本号等。
+
+**查询缓存不命中的情况:**
+
+1. 任何两个查询在任何字符上的不同都会导致缓存不命中。
+2. 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
+3. 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
+
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,还可以通过 `sql_cache` 和 `sql_no_cache` 来控制某个查询语句是否需要缓存:
+
+```sql
+SELECT sql_no_cache COUNT(*) FROM usr;
+```
+
+MySQL 5.6 开始,查询缓存已默认禁用。MySQL 8.0 开始,已经不再支持查询缓存了(具体可以参考这篇文章:[MySQL 8.0: Retiring Support for the Query Cache](https://dev.mysql.com/blog-archive/mysql-8-0-retiring-support-for-the-query-cache/))。
+
+
+
+## ⭐️MySQL 日志
+
+上诉问题的答案可以在[《Java 面试指北》(付费,点击链接领取优惠卷)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 中找到。
+
+
+
+文章地址: (密码获取:)。
+
+## ⭐️MySQL 事务
+
+### 什么是事务?
+
+我们设想一个场景,这个场景中我们需要插入多条相关联的数据到数据库,不幸的是,这个过程可能会遇到下面这些问题:
+
+- 数据库中途突然因为某些原因挂掉了。
+- 客户端突然因为网络原因连接不上数据库了。
+- 并发访问数据库时,多个线程同时写入数据库,覆盖了彼此的更改。
+- ……
+
+上面的任何一个问题都可能会导致数据的不一致性。为了保证数据的一致性,系统必须能够处理这些问题。事务就是我们抽象出来简化这些问题的首选机制。事务的概念起源于数据库,目前,已经成为一个比较广泛的概念。
+
+**何为事务?** 一言蔽之,**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
+
+事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作,这两个操作必须都成功或者都失败。
+
+1. 将小明的余额减少 1000 元
+2. 将小红的余额增加 1000 元。
+
+事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。这样就不会出现小明余额减少而小红的余额却并没有增加的情况。
+
+
+
+### 什么是数据库事务?
+
+大多数情况下,我们在谈论事务的时候,如果没有特指**分布式事务**,往往指的就是**数据库事务**。
+
+数据库事务在我们日常开发中接触的最多了。如果你的项目属于单体架构的话,你接触到的往往就是数据库事务了。
+
+**那数据库事务有什么作用呢?**
+
+简单来说,数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:**要么全部执行成功,要么全部不执行** 。
+
+```sql
+# 开启一个事务
+START TRANSACTION;
+# 多条 SQL 语句
+SQL1,SQL2...
+## 提交事务
+COMMIT;
+```
+
+
+
+另外,关系型数据库(例如:`MySQL`、`SQL Server`、`Oracle` 等)事务都有 **ACID** 特性:
+
+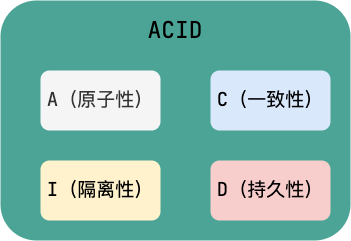
+
+1. **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
+3. **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+🌈 这里要额外补充一点:**只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。也就是说 A、I、D 是手段,C 是目的!** 想必大家也和我一样,被 ACID 这个概念被误导了很久! 我也是看周志明老师的公开课[《周志明的软件架构课》](https://time.geekbang.org/opencourse/intro/100064201)才搞清楚的(多看好书!!!)。
+
+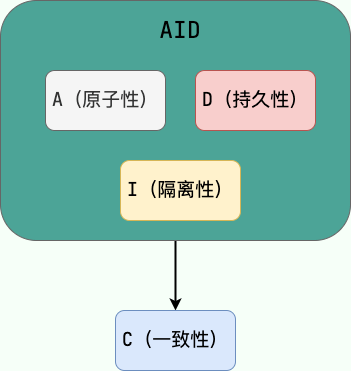
+
+另外,DDIA 也就是 [《Designing Data-Intensive Application(数据密集型应用系统设计)》](https://book.douban.com/subject/30329536/) 的作者在他的这本书中如是说:
+
+> Atomicity, isolation, and durability are properties of the database, whereas consis‐
+> tency (in the ACID sense) is a property of the application. The application may rely
+> on the database’s atomicity and isolation properties in order to achieve consistency,
+> but it’s not up to the database alone.
+>
+> 翻译过来的意思是:原子性,隔离性和持久性是数据库的属性,而一致性(在 ACID 意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母 C 不属于 ACID 。
+
+《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 GitHub 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
+
+
+
+### 并发事务带来了哪些问题?
+
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+
+#### 脏读(Dirty read)
+
+一个事务读取数据并且对数据进行了修改,这个修改对其他事务来说是可见的,即使当前事务没有提交。这时另外一个事务读取了这个还未提交的数据,但第一个事务突然回滚,导致数据并没有被提交到数据库,那第二个事务读取到的就是脏数据,这也就是脏读的由来。
+
+例如:事务 1 读取某表中的数据 A=20,事务 1 修改 A=A-1,事务 2 读取到 A = 19,事务 1 回滚导致对 A 的修改并未提交到数据库, A 的值还是 20。
+
+
+
+#### 丢失修改(Lost to modify)
+
+在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。
+
+例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 先修改 A=A-1,事务 2 后来也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
+
+
+
+#### 不可重复读(Unrepeatable read)
+
+指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
+
+例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 再次读取 A =19,此时读取的结果和第一次读取的结果不同。
+
+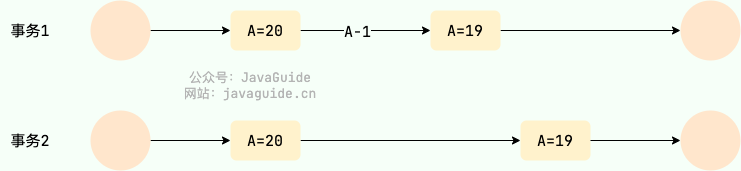
+
+#### 幻读(Phantom read)
+
+幻读与不可重复读类似。它发生在一个事务读取了几行数据,接着另一个并发事务插入了一些数据时。在随后的查询中,第一个事务就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
+
+例如:事务 2 读取某个范围的数据,事务 1 在这个范围插入了新的数据,事务 2 再次读取这个范围的数据发现相比于第一次读取的结果多了新的数据。
+
+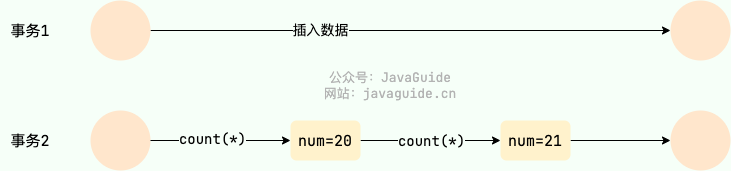
+
+### 不可重复读和幻读有什么区别?
+
+- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
+- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
+
+幻读其实可以看作是不可重复读的一种特殊情况,单独把幻读区分出来的原因主要是解决幻读和不可重复读的方案不一样。
+
+举个例子:执行 `delete` 和 `update` 操作的时候,可以直接对记录加锁,保证事务安全。而执行 `insert` 操作的时候,由于记录锁(Record Lock)只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁(Gap Lock)。也就是说执行 `insert` 操作的时候需要依赖 Next-Key Lock(Record Lock+Gap Lock) 进行加锁来保证不出现幻读。
+
+### 并发事务的控制方式有哪些?
+
+MySQL 中并发事务的控制方式无非就两种:**锁** 和 **MVCC**。锁可以看作是悲观控制的模式,多版本并发控制(MVCC,Multiversion concurrency control)可以看作是乐观控制的模式。
+
+**锁** 控制方式下会通过锁来显式控制共享资源而不是通过调度手段,MySQL 中主要是通过 **读写锁** 来实现并发控制。
+
+- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
+- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
+
+读写锁可以做到读读并行,但是无法做到写读、写写并行。另外,根据根据锁粒度的不同,又被分为 **表级锁(table-level locking)** 和 **行级锁(row-level locking)** 。InnoDB 不光支持表级锁,还支持行级锁,默认为行级锁。行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类。
+
+**MVCC** 是多版本并发控制方法,即对一份数据会存储多个版本,通过事务的可见性来保证事务能看到自己应该看到的版本。通常会有一个全局的版本分配器来为每一行数据设置版本号,版本号是唯一的。
+
+MVCC 在 MySQL 中实现所依赖的手段主要是: **隐藏字段、read view、undo log**。
+
+- undo log : undo log 用于记录某行数据的多个版本的数据。
+- read view 和 隐藏字段 : 用来判断当前版本数据的可见性。
+
+关于 InnoDB 对 MVCC 的具体实现可以看这篇文章:[InnoDB 存储引擎对 MVCC 的实现](./innodb-implementation-of-mvcc.md) 。
+
+### SQL 标准定义了哪些事务隔离级别?
+
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
+
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
+- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
+
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
+
+### MySQL 的默认隔离级别是什么?
+
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```sql
+mysql> SELECT @@tx_isolation;
++-----------------+
+| @@tx_isolation |
++-----------------+
+| REPEATABLE-READ |
++-----------------+
+```
+
+关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
+
+### MySQL 的隔离级别是基于锁实现的吗?
+
+MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
+
+SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+
+## MySQL 锁
+
+锁是一种常见的并发事务的控制方式。
+
+### 表级锁和行级锁了解吗?有什么区别?
+
+MyISAM 仅仅支持表级锁(table-level locking),一锁就锁整张表,这在并发写的情况下性非常差。InnoDB 不光支持表级锁(table-level locking),还支持行级锁(row-level locking),默认为行级锁。
+
+行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。
+
+**表级锁和行级锁对比**:
+
+- **表级锁:** MySQL 中锁定粒度最大的一种锁(全局锁除外),是针对非索引字段加的锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。不过,触发锁冲突的概率最高,高并发下效率极低。表级锁和存储引擎无关,MyISAM 和 InnoDB 引擎都支持表级锁。
+- **行级锁:** MySQL 中锁定粒度最小的一种锁,是 **针对索引字段加的锁** ,只针对当前操作的行记录进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。行级锁和存储引擎有关,是在存储引擎层面实现的。
+
+### 行级锁的使用有什么注意事项?
+
+InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字段加的锁。当我们执行 `UPDATE`、`DELETE` 语句时,如果 `WHERE`条件中字段没有命中唯一索引或者索引失效的话,就会导致扫描全表对表中的所有行记录进行加锁。这个在我们日常工作开发中经常会遇到,一定要多多注意!!!
+
+不过,很多时候即使用了索引也有可能会走全表扫描,这是因为 MySQL 优化器的原因。
+
+### InnoDB 有哪几类行锁?
+
+InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL InnoDB 支持三种行锁定方式:
+
+- **记录锁(Record Lock)**:属于单个行记录上的锁。
+- **间隙锁(Gap Lock)**:锁定一个范围,不包括记录本身。
+- **临键锁(Next-Key Lock)**:Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
+
+**在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围。**
+
+### 共享锁和排他锁呢?
+
+不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类:
+
+- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
+- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
+
+排他锁与任何的锁都不兼容,共享锁仅和共享锁兼容。
+
+| | S 锁 | X 锁 |
+| :--- | :----- | :--- |
+| S 锁 | 不冲突 | 冲突 |
+| X 锁 | 冲突 | 冲突 |
+
+由于 MVCC 的存在,对于一般的 `SELECT` 语句,InnoDB 不会加任何锁。不过, 你可以通过以下语句显式加共享锁或排他锁。
+
+```sql
+# 共享锁 可以在 MySQL 5.7 和 MySQL 8.0 中使用
+SELECT ... LOCK IN SHARE MODE;
+# 共享锁 可以在 MySQL 8.0 中使用
+SELECT ... FOR SHARE;
+# 排他锁
+SELECT ... FOR UPDATE;
+```
+
+### 意向锁有什么作用?
+
+如果需要用到表锁的话,如何判断表中的记录没有行锁呢,一行一行遍历肯定是不行,性能太差。我们需要用到一个叫做意向锁的东东来快速判断是否可以对某个表使用表锁。
+
+意向锁是表级锁,共有两种:
+
+- **意向共享锁(Intention Shared Lock,IS 锁)**:事务有意向对表中的某些记录加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
+- **意向排他锁(Intention Exclusive Lock,IX 锁)**:事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
+
+**意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InnoDB 会先获取该数据行所在在数据表的对应意向锁。**
+
+意向锁之间是互相兼容的。
+
+| | IS 锁 | IX 锁 |
+| ----- | ----- | ----- |
+| IS 锁 | 兼容 | 兼容 |
+| IX 锁 | 兼容 | 兼容 |
+
+意向锁和共享锁和排它锁互斥(这里指的是表级别的共享锁和排他锁,意向锁不会与行级的共享锁和排他锁互斥)。
+
+| | IS 锁 | IX 锁 |
+| ---- | ----- | ----- |
+| S 锁 | 兼容 | 互斥 |
+| X 锁 | 互斥 | 互斥 |
+
+《MySQL 技术内幕 InnoDB 存储引擎》这本书对应的描述应该是笔误了。
+
+
+
+### 当前读和快照读有什么区别?
+
+**快照读**(一致性非锁定读)就是单纯的 `SELECT` 语句,但不包括下面这两类 `SELECT` 语句:
+
+```sql
+SELECT ... FOR UPDATE
+# 共享锁 可以在 MySQL 5.7 和 MySQL 8.0 中使用
+SELECT ... LOCK IN SHARE MODE;
+# 共享锁 可以在 MySQL 8.0 中使用
+SELECT ... FOR SHARE;
+```
+
+快照即记录的历史版本,每行记录可能存在多个历史版本(多版本技术)。
+
+快照读的情况下,如果读取的记录正在执行 UPDATE/DELETE 操作,读取操作不会因此去等待记录上 X 锁的释放,而是会去读取行的一个快照。
+
+只有在事务隔离级别 RC(读取已提交) 和 RR(可重读)下,InnoDB 才会使用一致性非锁定读:
+
+- 在 RC 级别下,对于快照数据,一致性非锁定读总是读取被锁定行的最新一份快照数据。
+- 在 RR 级别下,对于快照数据,一致性非锁定读总是读取本事务开始时的行数据版本。
+
+快照读比较适合对于数据一致性要求不是特别高且追求极致性能的业务场景。
+
+**当前读** (一致性锁定读)就是给行记录加 X 锁或 S 锁。
+
+当前读的一些常见 SQL 语句类型如下:
+
+```sql
+# 对读的记录加一个X锁
+SELECT...FOR UPDATE
+# 对读的记录加一个S锁
+SELECT...LOCK IN SHARE MODE
+# 对读的记录加一个S锁
+SELECT...FOR SHARE
+# 对修改的记录加一个X锁
+INSERT...
+UPDATE...
+DELETE...
+```
+
+### 自增锁有了解吗?
+
+> 不太重要的一个知识点,简单了解即可。
+
+关系型数据库设计表的时候,通常会有一列作为自增主键。InnoDB 中的自增主键会涉及一种比较特殊的表级锁— **自增锁(AUTO-INC Locks)** 。
+
+```sql
+CREATE TABLE `sequence_id` (
+ `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
+ `stub` CHAR(10) NOT NULL DEFAULT '',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `stub` (`stub`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+更准确点来说,不仅仅是自增主键,`AUTO_INCREMENT`的列都会涉及到自增锁,毕竟非主键也可以设置自增长。
+
+如果一个事务正在插入数据到有自增列的表时,会先获取自增锁,拿不到就可能会被阻塞住。这里的阻塞行为只是自增锁行为的其中一种,可以理解为自增锁就是一个接口,其具体的实现有多种。具体的配置项为 `innodb_autoinc_lock_mode` (MySQL 5.1.22 引入),可以选择的值如下:
+
+| innodb_autoinc_lock_mode | 介绍 |
+| :----------------------- | :----------------------------- |
+| 0 | 传统模式 |
+| 1 | 连续模式(MySQL 8.0 之前默认) |
+| 2 | 交错模式(MySQL 8.0 之后默认) |
+
+交错模式下,所有的“INSERT-LIKE”语句(所有的插入语句,包括:`INSERT`、`REPLACE`、`INSERT…SELECT`、`REPLACE…SELECT`、`LOAD DATA`等)都不使用表级锁,使用的是轻量级互斥锁实现,多条插入语句可以并发执行,速度更快,扩展性也更好。
+
+不过,如果你的 MySQL 数据库有主从同步需求并且 Binlog 存储格式为 Statement 的话,不要将 InnoDB 自增锁模式设置为交叉模式,不然会有数据不一致性问题。这是因为并发情况下插入语句的执行顺序就无法得到保障。
+
+> 如果 MySQL 采用的格式为 Statement ,那么 MySQL 的主从同步实际上同步的就是一条一条的 SQL 语句。
+
+最后,再推荐一篇文章:[为什么 MySQL 的自增主键不单调也不连续](https://draveness.me/whys-the-design-mysql-auto-increment/) 。
+
+## ⭐️MySQL 性能优化
+
+关于 MySQL 性能优化的建议总结,请看这篇文章:[MySQL 高性能优化规范建议总结](./mysql-high-performance-optimization-specification-recommendations.md) 。
+
+### 能用 MySQL 直接存储文件(比如图片)吗?
+
+可以是可以,直接存储文件对应的二进制数据即可。不过,还是建议不要在数据库中存储文件,会严重影响数据库性能,消耗过多存储空间。
+
+可以选择使用云服务厂商提供的开箱即用的文件存储服务,成熟稳定,价格也比较低。
+
+
+
+也可以选择自建文件存储服务,实现起来也不难,基于 FastDFS、MinIO(推荐) 等开源项目就可以实现分布式文件服务。
+
+**数据库只存储文件地址信息,文件由文件存储服务负责存储。**
+
+### MySQL 如何存储 IP 地址?
+
+可以将 IP 地址转换成整形数据存储,性能更好,占用空间也更小。
+
+MySQL 提供了两个方法来处理 ip 地址
+
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
+- `INET_NTOA()` :把整型的 ip 转为地址
+
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+
+### 有哪些常见的 SQL 优化手段?
+
+[《Java 面试指北》(付费)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 有一篇文章详细介绍了常见的 SQL 优化手段,非常全面,清晰易懂!
+
+
+
+文章地址:https://www.yuque.com/snailclimb/mf2z3k/abc2sv (密码获取:)。
+
+### 如何分析 SQL 的性能?
+
+我们可以使用 `EXPLAIN` 命令来分析 SQL 的 **执行计划** 。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
+
+`EXPLAIN` 并不会真的去执行相关的语句,而是通过 **查询优化器** 对语句进行分析,找出最优的查询方案,并显示对应的信息。
+
+`EXPLAIN` 适用于 `SELECT`, `DELETE`, `INSERT`, `REPLACE`, 和 `UPDATE`语句,我们一般分析 `SELECT` 查询较多。
+
+我们这里简单来演示一下 `EXPLAIN` 的使用。
+
+`EXPLAIN` 的输出格式如下:
+
+```sql
+mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+1 row in set, 1 warning (0.00 sec)
+```
+
+各个字段的含义如下:
+
+| **列名** | **含义** |
+| ------------- | -------------------------------------------- |
+| id | SELECT 查询的序列标识符 |
+| select_type | SELECT 关键字对应的查询类型 |
+| table | 用到的表名 |
+| partitions | 匹配的分区,对于未分区的表,值为 NULL |
+| type | 表的访问方法 |
+| possible_keys | 可能用到的索引 |
+| key | 实际用到的索引 |
+| key_len | 所选索引的长度 |
+| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
+| rows | 预计要读取的行数 |
+| filtered | 按表条件过滤后,留存的记录数的百分比 |
+| Extra | 附加信息 |
+
+篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](./mysql-query-execution-plan.md)这篇文章。
+
+### 读写分离和分库分表了解吗?
+
+读写分离和分库分表相关的问题比较多,于是,我单独写了一篇文章来介绍:[读写分离和分库分表详解](../../high-performance/read-and-write-separation-and-library-subtable.md)。
+
+### 深度分页如何优化?
+
+[深度分页介绍及优化建议](../../high-performance/deep-pagination-optimization.md)
+
+### 数据冷热分离如何做?
+
+[数据冷热分离详解](../../high-performance/data-cold-hot-separation.md)
+
+### MySQL 性能怎么优化?
+
+MySQL 性能优化是一个系统性工程,涉及多个方面,在面试中不可能面面俱到。因此,建议按照“点-线-面”的思路展开,从核心问题入手,再逐步扩展,展示出你对问题的思考深度和解决能力。
+
+**1. 抓住核心:慢 SQL 定位与分析**
+
+性能优化的第一步永远是找到瓶颈。面试时,建议先从 **慢 SQL 定位和分析** 入手,这不仅能展示你解决问题的思路,还能体现你对数据库性能监控的熟练掌握:
+
+- **监控工具:** 介绍常用的慢 SQL 监控工具,如 **MySQL 慢查询日志**、**Performance Schema** 等,说明你对这些工具的熟悉程度以及如何通过它们定位问题。
+- **EXPLAIN 命令:** 详细说明 `EXPLAIN` 命令的使用,分析查询计划、索引使用情况,可以结合实际案例展示如何解读分析结果,比如执行顺序、索引使用情况、全表扫描等。
+
+**2. 由点及面:索引、表结构和 SQL 优化**
+
+定位到慢 SQL 后,接下来就要针对具体问题进行优化。 这里可以重点介绍索引、表结构和 SQL 编写规范等方面的优化技巧:
+
+- **索引优化:** 这是 MySQL 性能优化的重点,可以介绍索引的创建原则、覆盖索引、最左前缀匹配原则等。如果能结合你项目的实际应用来说明如何选择合适的索引,会更加分一些。
+- **表结构优化:** 优化表结构设计,包括选择合适的字段类型、避免冗余字段、合理使用范式和反范式设计等等。
+- **SQL 优化:** 避免使用 `SELECT *`、尽量使用具体字段、使用连接查询代替子查询、合理使用分页查询、批量操作等,都是 SQL 编写过程中需要注意的细节。
+
+**3. 进阶方案:架构优化**
+
+当面试官对基础优化知识比较满意时,可能会深入探讨一些架构层面的优化方案。以下是一些常见的架构优化策略:
+
+- **读写分离:** 将读操作和写操作分离到不同的数据库实例,提升数据库的并发处理能力。
+- **分库分表:** 将数据分散到多个数据库实例或数据表中,降低单表数据量,提升查询效率。但要权衡其带来的复杂性和维护成本,谨慎使用。
+- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在低成本、低性能的介质中,热数据存储在高性能存储介质中。
+- **缓存机制:** 使用 Redis 等缓存中间件,将热点数据缓存到内存中,减轻数据库压力。这个非常常用,提升效果非常明显,性价比极高!
+
+**4. 其他优化手段**
+
+除了慢 SQL 定位、索引优化和架构优化,还可以提及一些其他优化手段,展示你对 MySQL 性能调优的全面理解:
+
+- **连接池配置:** 配置合理的数据库连接池(如 **连接池大小**、**超时时间** 等),能够有效提升数据库连接的效率,避免频繁的连接开销。
+- **硬件配置:** 提升硬件性能也是优化的重要手段之一。使用高性能服务器、增加内存、使用 **SSD** 硬盘等硬件升级,都可以有效提升数据库的整体性能。
+
+**5.总结**
+
+在面试中,建议按优先级依次介绍慢 SQL 定位、[索引优化](./mysql-index.md)、表结构设计和 [SQL 优化](../../high-performance/sql-optimization.md)等内容。架构层面的优化,如[读写分离和分库分表](../../high-performance/read-and-write-separation-and-library-subtable.md)、[数据冷热分离](../../high-performance/data-cold-hot-separation.md) 应作为最后的手段,除非在特定场景下有明显的性能瓶颈,否则不应轻易使用,因其引入的复杂性会带来额外的维护成本。
+
+## MySQL 学习资料推荐
+
+[**书籍推荐**](../../books/database.md#mysql) 。
+
+**文章推荐** :
+
+- [一树一溪的 MySQL 系列教程](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=Mzg3NTc3NjM4Nw==&action=getalbum&album_id=2372043523518300162&scene=173&from_msgid=2247484308&from_itemidx=1&count=3&nolastread=1#wechat_redirect)
+- [Yes 的 MySQL 系列教程](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzkxNTE3NjQ3MA==&action=getalbum&album_id=1903249596194095112&scene=173&from_msgid=2247490365&from_itemidx=1&count=3&nolastread=1#wechat_redirect)
+- [写完这篇 我的 SQL 优化能力直接进入新层次 - 变成派大星 - 2022](https://juejin.cn/post/7161964571853815822)
+- [两万字详解!InnoDB 锁专题! - 捡田螺的小男孩 - 2022](https://juejin.cn/post/7094049650428084232)
+- [MySQL 的自增主键一定是连续的吗? - 飞天小牛肉 - 2022](https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ)
+- [深入理解 MySQL 索引底层原理 - 腾讯技术工程 - 2020](https://zhuanlan.zhihu.com/p/113917726)
+
+## 参考
+
+- 《高性能 MySQL》第 7 章 MySQL 高级特性
+- 《MySQL 技术内幕 InnoDB 存储引擎》第 6 章 锁
+- Relational Database:
+- 一篇文章看懂 mysql 中 varchar 能存多少汉字、数字,以及 varchar(100)和 varchar(10)的区别:
+- Technology sharing | Isolation level: Correct understanding of phantom reading:
+- MySQL Server Logs - MySQL 5.7 Reference Manual:
+- Redo Log - MySQL 5.7 Reference Manual:
+- Locking Reads - MySQL 5.7 Reference Manual:
+- In-depth understanding of database row locks and table locks
+- Detailed explanation of the role of intention locks in MySQL InnoDB:
+- In-depth analysis of MySQL self-increasing lock:
+- How should non-repeatable reads and phantom reads be distinguished in the database? :
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/some-thoughts-on-database-storage-time.en.md b/docs_en/database/mysql/some-thoughts-on-database-storage-time.en.md
new file mode 100644
index 00000000000..b748f03a788
--- /dev/null
+++ b/docs_en/database/mysql/some-thoughts-on-database-storage-time.en.md
@@ -0,0 +1,201 @@
+---
+title: MySQL日期类型选择建议
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 日期类型选择, MySQL 时间存储最佳实践, MySQL 时间存储效率, MySQL DATETIME 和 TIMESTAMP 区别, MySQL 时间戳存储, MySQL 数据库时间存储类型, MySQL 开发日期推荐, MySQL 字符串存储日期的缺点, MySQL 时区设置方法, MySQL 日期范围对比, 高性能 MySQL 日期存储, MySQL UNIX_TIMESTAMP 用法, 数值型时间戳优缺点, MySQL 时间存储性能优化, MySQL TIMESTAMP 时区转换, MySQL 时间格式转换, MySQL 时间存储空间对比, MySQL 时间类型选择建议, MySQL 日期类型性能分析, 数据库时间存储优化
+---
+
+在日常的软件开发工作中,存储时间是一项基础且常见的需求。无论是记录数据的操作时间、金融交易的发生时间,还是行程的出发时间、用户的下单时间等等,时间信息与我们的业务逻辑和系统功能紧密相关。因此,正确选择和使用 MySQL 的日期时间类型至关重要,其恰当与否甚至可能对业务的准确性和系统的稳定性产生显著影响。
+
+本文旨在帮助开发者重新审视并深入理解 MySQL 中不同的时间存储方式,以便做出更合适项目业务场景的选择。
+
+## 不要用字符串存储日期
+
+和许多数据库初学者一样,笔者在早期学习阶段也曾尝试使用字符串(如 VARCHAR)类型来存储日期和时间,甚至一度认为这是一种简单直观的方法。毕竟,'YYYY-MM-DD HH:MM:SS' 这样的格式看起来清晰易懂。
+
+但是,这是不正确的做法,主要会有下面两个问题:
+
+1. **空间效率**:与 MySQL 内建的日期时间类型相比,字符串通常需要占用更多的存储空间来表示相同的时间信息。
+2. **查询与计算效率低下**:
+ - **比较操作复杂且低效**:基于字符串的日期比较需要按照字典序逐字符进行,这不仅不直观(例如,'2024-05-01' 会小于 '2024-1-10'),而且效率远低于使用原生日期时间类型进行的数值或时间点比较。
+ - **计算功能受限**:无法直接利用数据库提供的丰富日期时间函数进行运算(例如,计算两个日期之间的间隔、对日期进行加减操作等),需要先转换格式,增加了复杂性。
+ - **索引性能不佳**:基于字符串的索引在处理范围查询(如查找特定时间段内的数据)时,其效率和灵活性通常不如原生日期时间类型的索引。
+
+## DATETIME 和 TIMESTAMP 选择
+
+`DATETIME` 和 `TIMESTAMP` 是 MySQL 中两种非常常用的、用于存储包含日期和时间信息的数据类型。它们都可以存储精确到秒(MySQL 5.6.4+ 支持更高精度的小数秒)的时间值。那么,在实际应用中,我们应该如何在这两者之间做出选择呢?
+
+下面我们从几个关键维度对它们进行对比:
+
+### 时区信息
+
+`DATETIME` 类型存储的是**字面量的日期和时间值**,它本身**不包含任何时区信息**。当你插入一个 `DATETIME` 值时,MySQL 存储的就是你提供的那个确切的时间,不会进行任何时区转换。
+
+**这样就会有什么问题呢?** 如果你的应用需要支持多个时区,或者服务器、客户端的时区可能发生变化,那么使用 `DATETIME` 时,应用程序需要自行处理时区的转换和解释。如果处理不当(例如,假设所有存储的时间都属于同一个时区,但实际环境变化了),可能会导致时间显示或计算上的混乱。
+
+**`TIMESTAMP` 和时区有关**。存储时,MySQL 会将当前会话时区下的时间值转换成 UTC(协调世界时)进行内部存储。当查询 `TIMESTAMP` 字段时,MySQL 又会将存储的 UTC 时间转换回当前会话所设置的时区来显示。
+
+这意味着,对于同一条记录的 `TIMESTAMP` 字段,在不同的会话时区设置下查询,可能会看到不同的本地时间表示,但它们都对应着同一个绝对时间点(UTC 时间)。这对于需要全球化、多时区支持的应用来说非常有用。
+
+下面实际演示一下!
+
+建表 SQL 语句:
+
+```sql
+CREATE TABLE `time_zone_test` (
+ `id` bigint(20) NOT NULL AUTO_INCREMENT,
+ `date_time` datetime DEFAULT NULL,
+ `time_stamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+```
+
+插入一条数据(假设当前会话时区为系统默认,例如 UTC+0)::
+
+```sql
+INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
+```
+
+查询数据(在同一时区会话下):
+
+```sql
+SELECT date_time, time_stamp FROM time_zone_test;
+```
+
+结果:
+
+```plain
++---------------------+---------------------+
+| date_time | time_stamp |
++---------------------+---------------------+
+| 2020-01-11 09:53:32 | 2020-01-11 09:53:32 |
++---------------------+---------------------+
+```
+
+现在,修改当前会话的时区为东八区 (UTC+8):
+
+```sql
+SET time_zone = '+8:00';
+```
+
+再次查询数据:
+
+```bash
+# TIMESTAMP 的值自动转换为 UTC+8 时间
++---------------------+---------------------+
+| date_time | time_stamp |
++---------------------+---------------------+
+| 2020-01-11 09:53:32 | 2020-01-11 17:53:32 |
++---------------------+---------------------+
+```
+
+**扩展:MySQL 时区设置常用 SQL 命令**
+
+```sql
+# 查看当前会话时区
+SELECT @@session.time_zone;
+# 设置当前会话时区
+SET time_zone = 'Europe/Helsinki';
+SET time_zone = "+00:00";
+# 数据库全局时区设置
+SELECT @@global.time_zone;
+# 设置全局时区
+SET GLOBAL time_zone = '+8:00';
+SET GLOBAL time_zone = 'Europe/Helsinki';
+```
+
+### 占用空间
+
+下图是 MySQL 日期类型所占的存储空间(官方文档传送门:):
+
+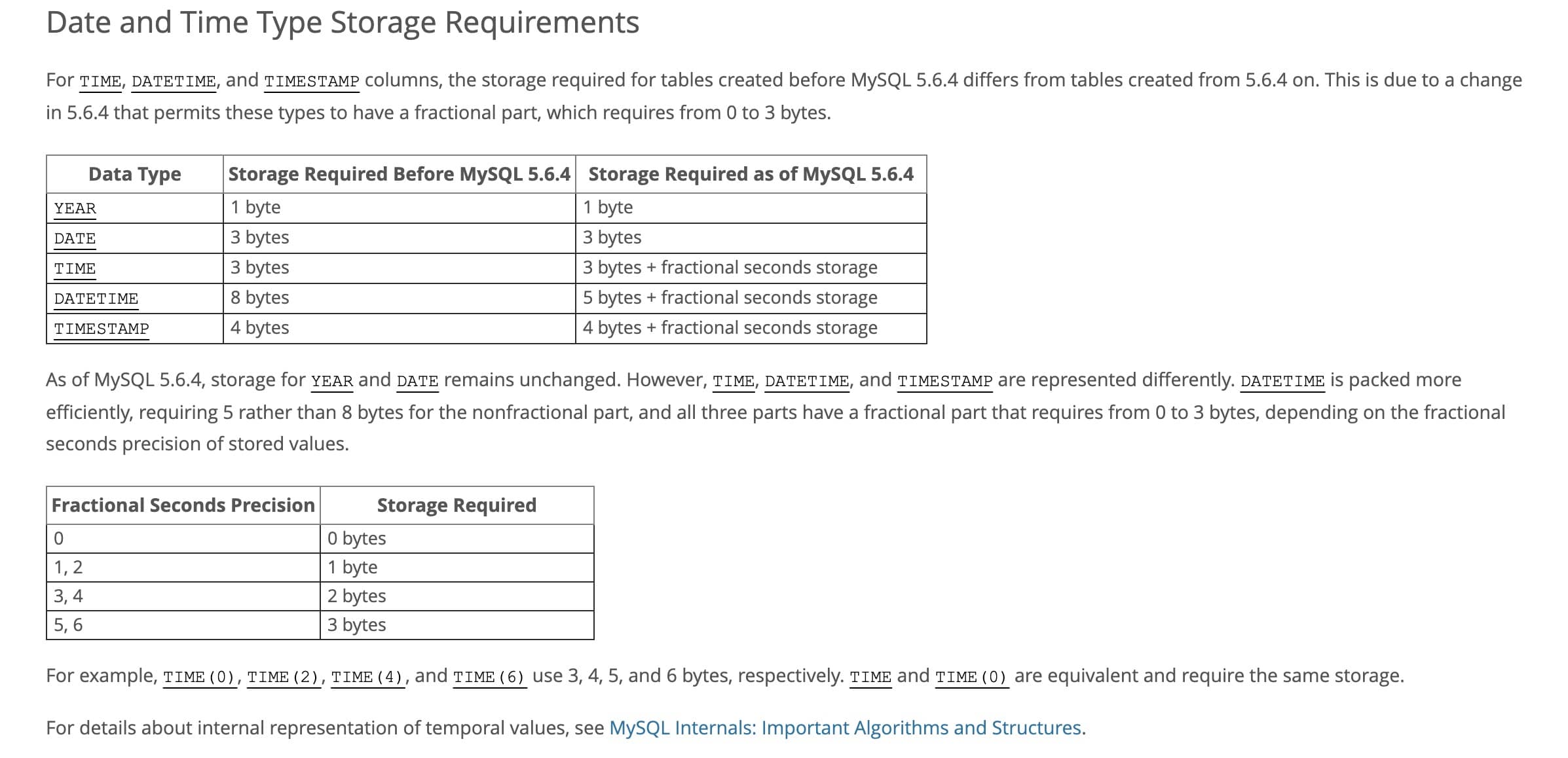
+
+在 MySQL 5.6.4 之前,DateTime 和 TIMESTAMP 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 5~8 字节,TIMESTAMP 的范围是 4~7 字节。
+
+### 表示范围
+
+`TIMESTAMP` 表示的时间范围更小,只能到 2038 年:
+
+- `DATETIME`:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- `TIMESTAMP`:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
+
+### 性能
+
+由于 `TIMESTAMP` 在存储和检索时需要进行 UTC 与当前会话时区的转换,这个过程可能涉及到额外的计算开销,尤其是在需要调用操作系统底层接口获取或处理时区信息时。虽然现代数据库和操作系统对此进行了优化,但在某些极端高并发或对延迟极其敏感的场景下,`DATETIME` 因其不涉及时区转换,处理逻辑相对更简单直接,可能会表现出微弱的性能优势。
+
+In order to obtain predictable behavior and possibly reduce the conversion overhead of `TIMESTAMP`, it is recommended to manage time zones uniformly at the application level, or to explicitly set the `time_zone` parameter at the database connection/session level, rather than relying on the server's default or operating system time zone.
+
+## Are numeric timestamps a better choice?
+
+In addition to the above two types, integer types (`INT` or `BIGINT`) are also commonly used in practice to store the so-called "Unix timestamp" (that is, the total number of seconds, or milliseconds, from January 1, 1970 00:00:00 UTC to the target time).
+
+This storage method has some advantages of the `TIMESTAMP` type, and using it to perform date sorting and comparison operations will be more efficient, and it is also very convenient across systems. After all, it is just a stored value. The disadvantage is also obvious, that is, the readability of the data is too poor, and you cannot intuitively see the specific time.
+
+The timestamp is defined as follows:
+
+> The definition of timestamp is to count from a base time. This base time is "1970-1-1 00:00:00 +0:00". Starting from this time, it is expressed as an integer and measured in seconds. As time goes by, this time integer continues to increase. In this way, I only need one value to perfectly represent time, and this value is an absolute value, that is, no matter where you are in any corner of the earth, the timestamp representing time is the same, and the generated value is the same, and there is no concept of time zone. Therefore, no additional conversion is required during the time transmission in the system. It is converted to local time in string format only when displayed to the user.
+
+Actual operations in the database:
+
+```sql
+-- Convert datetime string to Unix timestamp (seconds)
+mysql> SELECT UNIX_TIMESTAMP('2020-01-11 09:53:32');
++---------------------------------------------+
+| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
++---------------------------------------------+
+| 1578707612 |
++---------------------------------------------+
+1 row in set (0.00 sec)
+
+-- Convert Unix timestamp (seconds) to datetime format
+mysql> SELECT FROM_UNIXTIME(1578707612);
++--------------------------+
+| FROM_UNIXTIME(1578707612) |
++--------------------------+
+| 2020-01-11 09:53:32 |
++--------------------------+
+1 row in set (0.01 sec)
+```
+
+## There is no DATETIME in PostgreSQL
+
+Since some readers mentioned the time type of PostgreSQL (PG), I will expand and add it here. The PG official document describes the time type at: .
+
+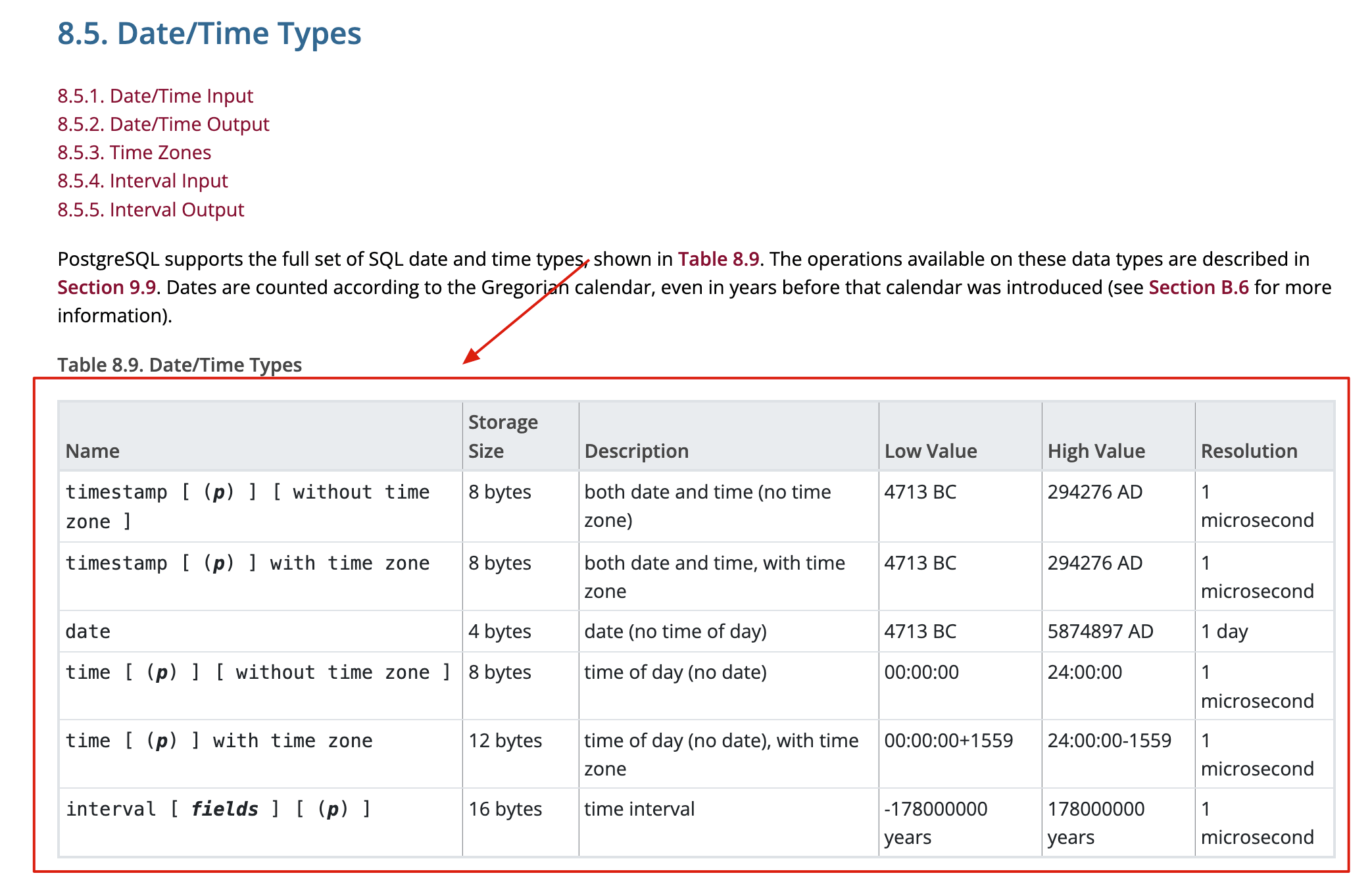
+
+As you can see, PG does not have a type named `DATETIME`:
+
+- PG's `TIMESTAMP WITHOUT TIME ZONE` is functionally closest to MySQL's `DATETIME`. It stores the date and time, but does not contain any time zone information and stores literal values.
+- PG's `TIMESTAMP WITH TIME ZONE` (or `TIMESTAMPTZ`) is equivalent to MySQL's `TIMESTAMP`. It converts the input value to UTC when stored and converted based on the current session's time zone when retrieved for display.
+
+For most application scenarios that require recording precise time points, `TIMESTAMPTZ` is the most recommended and robust choice in PostgreSQL because it can best handle time zone complexities.
+
+## Summary
+
+How to store time in MySQL? `DATETIME`? `TIMESTAMP`? Or a numerical timestamp?
+
+There is no silver bullet. Many programmers think that numeric timestamps are really good, efficient and compatible. However, many people think that it is not intuitive enough.
+
+The author of the magic book "High-Performance MySQL" recommends TIMESTAMP because numerical representation of time is not intuitive enough. The following is the original text:
+
+
+
+### 产生死锁的四个必要条件是什么?
+
+死锁的发生并不是偶然的,它需要同时满足**四个必要条件**:
+
+1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
+2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
+3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
+4. **循环等待**:有一组等待进程 {P0, P1,..., Pn}, P0 等待的资源被 P1 占有,P1 等待的资源被 P2 占有,……,Pn-1 等待的资源被 Pn 占有,Pn 等待的资源被 P0 占有。
+
+**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
+
+下面是百度百科对必要条件的解释:
+
+> 如果没有事物情况 A,则必然没有事物情况 B,也就是说如果有事物情况 B 则一定有事物情况 A,那么 A 就是 B 的必要条件。从逻辑学上看,B 能推导出 A,A 就是 B 的必要条件,等价于 B 是 A 的充分条件。
+
+### 能写一个模拟产生死锁的代码吗?
+
+下面通过一个实际的例子来模拟下图展示的线程死锁:
+
+
+
+```java
+public class DeadLockDemo {
+ private static Object resource1 = new Object();//资源 1
+ private static Object resource2 = new Object();//资源 2
+
+ public static void main(String[] args) {
+ new Thread(() -> {
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource2");
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ }
+ }
+ }, "线程 1").start();
+
+ new Thread(() -> {
+ synchronized (resource2) {
+ System.out.println(Thread.currentThread() + "get resource2");
+ try {
+ Thread.sleep(1000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println(Thread.currentThread() + "waiting get resource1");
+ synchronized (resource1) {
+ System.out.println(Thread.currentThread() + "get resource1");
+ }
+ }
+ }, "线程 2").start();
+ }
+}
+```
+
+Output
+
+```text
+Thread[线程 1,5,main]get resource1
+Thread[线程 2,5,main]get resource2
+Thread[线程 1,5,main]waiting get resource2
+Thread[线程 2,5,main]waiting get resource1
+```
+
+线程 A 通过 `synchronized (resource1)` 获得 `resource1` 的监视器锁,然后通过`Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 `resource2` 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
+
+### 解决死锁的方法
+
+解决死锁的方法可以从多个角度去分析,一般的情况下,有**预防,避免,检测和解除四种**。
+
+- **死锁预防:** 这是我们程序员最常用的方法。通过编码规范来破坏条件。最经典的就是**破坏循环等待**,比如规定所有线程都必须**按相同的顺序**来获取锁(比如先 A 后 B),这样就不会形成环路。
+- **死锁避免:** 这是一种更动态的方法,比如操作系统的**银行家算法**。它会在分配资源前进行预测,如果这次分配可能导致未来发生死锁,就拒绝分配。但这种方法开销很大,在通用系统中用得比较少。
+- **死锁检测与解除:** 这是一种“事后补救”的策略,就像乐观锁。系统允许死锁发生,但会有一个后台线程(或机制)定期检测是否存在死锁环路(比如通过分析线程等待图)。一旦发现,就会采取措施解除,比如**强制剥夺某个线程的资源或直接终止它**。数据库系统中的死锁处理就常常采用这种方式。
+
+#### 死锁的预防
+
+死锁四大必要条件上面都已经列出来了,很显然,只要破坏四个必要条件中的任何一个就能够预防死锁的发生。
+
+破坏第一个条件 **互斥条件**:使得资源是可以同时访问的,这是种简单的方法,磁盘就可以用这种方法管理,但是我们要知道,有很多资源 **往往是不能同时访问的** ,所以这种做法在大多数的场合是行不通的。
+
+破坏第三个条件 **非抢占**:也就是说可以采用 **剥夺式调度算法**,但剥夺式调度方法目前一般仅适用于 **主存资源** 和 **处理器资源** 的分配,并不适用于所有的资源,会导致 **资源利用率下降**。
+
+所以一般比较实用的 **预防死锁的方法**,是通过考虑破坏第二个条件和第四个条件。
+
+**1、静态分配策略**
+
+静态分配策略可以破坏死锁产生的第二个条件(占有并等待)。所谓静态分配策略,就是指一个进程必须在执行前就申请到它所需要的全部资源,并且知道它所要的资源都得到满足之后才开始执行。进程要么占有所有的资源然后开始执行,要么不占有资源,不会出现占有一些资源等待一些资源的情况。
+
+静态分配策略逻辑简单,实现也很容易,但这种策略 **严重地降低了资源利用率**,因为在每个进程所占有的资源中,有些资源是在比较靠后的执行时间里采用的,甚至有些资源是在额外的情况下才使用的,这样就可能造成一个进程占有了一些 **几乎不用的资源而使其他需要该资源的进程产生等待** 的情况。
+
+**2、层次分配策略**
+
+层次分配策略破坏了产生死锁的第四个条件(循环等待)。在层次分配策略下,所有的资源被分成了多个层次,一个进程得到某一次的一个资源后,它只能再申请较高一层的资源;当一个进程要释放某层的一个资源时,必须先释放所占用的较高层的资源,按这种策略,是不可能出现循环等待链的,因为那样的话,就出现了已经申请了较高层的资源,反而去申请了较低层的资源,不符合层次分配策略,证明略。
+
+#### 死锁的避免
+
+上面提到的 **破坏** 死锁产生的四个必要条件之一就可以成功 **预防系统发生死锁** ,但是会导致 **低效的进程运行** 和 **资源使用率** 。而死锁的避免相反,它的角度是允许系统中**同时存在四个必要条件** ,只要掌握并发进程中与每个进程有关的资源动态申请情况,做出 **明智和合理的选择** ,仍然可以避免死锁,因为四大条件仅仅是产生死锁的必要条件。
+
+我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在为申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
+
+> 如果操作系统能够保证所有的进程在有限的时间内得到需要的全部资源,则称系统处于安全状态,否则说系统是不安全的。很显然,系统处于安全状态则不会发生死锁,系统若处于不安全状态则可能发生死锁。
+
+那么如何保证系统保持在安全状态呢?通过算法,其中最具有代表性的 **避免死锁算法** 就是 Dijkstra 的银行家算法,银行家算法用一句话表达就是:当一个进程申请使用资源的时候,**银行家算法** 通过先 **试探** 分配给该进程资源,然后通过 **安全性算法** 判断分配后系统是否处于安全状态,若不安全则试探分配作废,让该进程继续等待,若能够进入到安全的状态,则就 **真的分配资源给该进程**。
+
+银行家算法详情可见:[《一句话+一张图说清楚——银行家算法》](https://blog.csdn.net/qq_33414271/article/details/80245715) 。
+
+操作系统教程书中讲述的银行家算法也比较清晰,可以一看.
+
+死锁的避免(银行家算法)改善了 **资源使用率低的问题** ,但是它要不断地检测每个进程对各类资源的占用和申请情况,以及做 **安全性检查** ,需要花费较多的时间。
+
+#### 死锁的检测
+
+对资源的分配加以限制可以 **预防和避免** 死锁的发生,但是都不利于各进程对系统资源的**充分共享**。解决死锁问题的另一条途径是 **死锁检测和解除** (这里突然联想到了乐观锁和悲观锁,感觉死锁的检测和解除就像是 **乐观锁** ,分配资源时不去提前管会不会发生死锁了,等到真的死锁出现了再来解决嘛,而 **死锁的预防和避免** 更像是悲观锁,总是觉得死锁会出现,所以在分配资源的时候就很谨慎)。
+
+这种方法对资源的分配不加以任何限制,也不采取死锁避免措施,但系统 **定时地运行一个 “死锁检测”** 的程序,判断系统内是否出现死锁,如果检测到系统发生了死锁,再采取措施去解除它。
+
+##### 进程-资源分配图
+
+操作系统中的每一刻时刻的**系统状态**都可以用**进程-资源分配图**来表示,进程-资源分配图是描述进程和资源申请及分配关系的一种有向图,可用于**检测系统是否处于死锁状态**。
+
+用一个方框表示每一个资源类,方框中的黑点表示该资源类中的各个资源,用一个圆圈表示每一个进程,用 **有向边** 来表示**进程申请资源和资源被分配的情况**。
+
+图中 2-21 是**进程-资源分配图**的一个例子,其中共有三个资源类,每个进程的资源占有和申请情况已清楚地表示在图中。在这个例子中,由于存在 **占有和等待资源的环路** ,导致一组进程永远处于等待资源的状态,发生了 **死锁**。
+
+
+
+进程-资源分配图中存在环路并不一定是发生了死锁。因为循环等待资源仅仅是死锁发生的必要条件,而不是充分条件。图 2-22 便是一个有环路而无死锁的例子。虽然进程 P1 和进程 P3 分别占用了一个资源 R1 和一个资源 R2,并且因为等待另一个资源 R2 和另一个资源 R1 形成了环路,但进程 P2 和进程 P4 分别占有了一个资源 R1 和一个资源 R2,它们申请的资源得到了满足,在有限的时间里会归还资源,于是进程 P1 或 P3 都能获得另一个所需的资源,环路自动解除,系统也就不存在死锁状态了。
+
+##### 死锁检测步骤
+
+知道了死锁检测的原理,我们可以利用下列步骤编写一个 **死锁检测** 程序,检测系统是否产生了死锁。
+
+1. 如果进程-资源分配图中无环路,则此时系统没有发生死锁
+2. 如果进程-资源分配图中有环路,且每个资源类仅有一个资源,则系统中已经发生了死锁。
+3. 如果进程-资源分配图中有环路,且涉及到的资源类有多个资源,此时系统未必会发生死锁。如果能在进程-资源分配图中找出一个 **既不阻塞又非独立的进程** ,该进程能够在有限的时间内归还占有的资源,也就是把边给消除掉了,重复此过程,直到能在有限的时间内 **消除所有的边** ,则不会发生死锁,否则会发生死锁。(消除边的过程类似于 **拓扑排序**)
+
+#### 死锁的解除
+
+当死锁检测程序检测到存在死锁发生时,应设法让其解除,让系统从死锁状态中恢复过来,常用的解除死锁的方法有以下四种:
+
+1. **立即结束所有进程的执行,重新启动操作系统**:这种方法简单,但以前所在的工作全部作废,损失很大。
+2. **撤销涉及死锁的所有进程,解除死锁后继续运行**:这种方法能彻底打破**死锁的循环等待**条件,但将付出很大代价,例如有些进程可能已经计算了很长时间,由于被撤销而使产生的部分结果也被消除了,再重新执行时还要再次进行计算。
+3. **逐个撤销涉及死锁的进程,回收其资源直至死锁解除。**
+4. **抢占资源**:从涉及死锁的一个或几个进程中抢占资源,把夺得的资源再分配给涉及死锁的进程直至死锁解除。
+
+## 参考
+
+- 《计算机操作系统—汤小丹》第四版
+- 《深入理解计算机系统》
+- 《重学操作系统》
+- 操作系统为什么要分用户态和内核态:
+- 从根上理解用户态与内核态:
+- 什么是僵尸进程与孤儿进程:
+
+
+
diff --git a/docs_en/cs-basics/operating-system/operating-system-basic-questions-02.en.md b/docs_en/cs-basics/operating-system/operating-system-basic-questions-02.en.md
new file mode 100644
index 00000000000..bc26a6b4731
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/operating-system-basic-questions-02.en.md
@@ -0,0 +1,418 @@
+---
+title: 操作系统常见面试题总结(下)
+category: 计算机基础
+tag:
+ - 操作系统
+head:
+ - - meta
+ - name: keywords
+ content: 操作系统面试题,虚拟内存详解,分页 vs 分段,页面置换算法,内存碎片,伙伴系统,TLB快表,页缺失,文件系统基础,磁盘调度算法,硬链接 vs 软链接
+ - - meta
+ - name: description
+ content: 最新操作系统高频面试题总结(下):虚拟内存映射、内存碎片/伙伴系统、TLB+页缺失处理、分页分段对比、页面置换算法详解、文件系统&磁盘调度,附图表+⭐️重点标注,一文掌握OS内存/文件考点,快速通关后端面试!
+---
+
+## 内存管理
+
+### 内存管理主要做了什么?
+
+
+
+操作系统的内存管理非常重要,主要负责下面这些事情:
+
+- **内存的分配与回收**:对进程所需的内存进行分配和释放,malloc 函数:申请内存,free 函数:释放内存。
+- **地址转换**:将程序中的虚拟地址转换成内存中的物理地址。
+- **内存扩充**:当系统没有足够的内存时,利用虚拟内存技术或自动覆盖技术,从逻辑上扩充内存。
+- **内存映射**:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
+- **内存优化**:通过调整内存分配策略和回收算法来优化内存使用效率。
+- **内存安全**:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
+- ……
+
+### 什么是内存碎片?
+
+内存碎片是由内存的申请和释放产生的,通常分为下面两种:
+
+- **内部内存碎片(Internal Memory Fragmentation,简称为内存碎片)**:已经分配给进程使用但未被使用的内存。导致内部内存碎片的主要原因是,当采用固定比例比如 2 的幂次方进行内存分配时,进程所分配的内存可能会比其实际所需要的大。举个例子,一个进程只需要 65 字节的内存,但为其分配了 128(2^7) 大小的内存,那 63 字节的内存就成为了内部内存碎片。
+- **外部内存碎片(External Memory Fragmentation,简称为外部碎片)**:由于未分配的连续内存区域太小,以至于不能满足任意进程所需要的内存分配请求,这些小片段且不连续的内存空间被称为外部碎片。也就是说,外部内存碎片指的是那些并未分配给进程但又不能使用的内存。我们后面介绍的分段机制就会导致外部内存碎片。
+
+
+
+内存碎片会导致内存利用率下降,如何减少内存碎片是内存管理要非常重视的一件事情。
+
+### 常见的内存管理方式有哪些?
+
+内存管理方式可以简单分为下面两种:
+
+- **连续内存管理**:为一个用户程序分配一个连续的内存空间,内存利用率一般不高。
+- **非连续内存管理**:允许一个程序使用的内存分布在离散或者说不相邻的内存中,相对更加灵活一些。
+
+#### 连续内存管理
+
+**块式管理** 是早期计算机操作系统的一种连续内存管理方式,存在严重的内存碎片问题。块式管理会将内存分为几个固定大小的块,每个块中只包含一个进程。如果程序运行需要内存的话,操作系统就分配给它一块,如果程序运行只需要很小的空间的话,分配的这块内存很大一部分几乎被浪费了。这些在每个块中未被利用的空间,我们称之为内部内存碎片。除了内部内存碎片之外,由于两个内存块之间可能还会有外部内存碎片,这些不连续的外部内存碎片由于太小了无法再进行分配。
+
+在 Linux 系统中,连续内存管理采用了 **伙伴系统(Buddy System)算法** 来实现,这是一种经典的连续内存分配算法,可以有效解决外部内存碎片的问题。伙伴系统的主要思想是将内存按 2 的幂次划分(每一块内存大小都是 2 的幂次比如 2^6=64 KB),并将相邻的内存块组合成一对伙伴(注意:**必须是相邻的才是伙伴**)。
+
+当进行内存分配时,伙伴系统会尝试找到大小最合适的内存块。如果找到的内存块过大,就将其一分为二,分成两个大小相等的伙伴块。如果还是大的话,就继续切分,直到到达合适的大小为止。
+
+假设两块相邻的内存块都被释放,系统会将这两个内存块合并,进而形成一个更大的内存块,以便后续的内存分配。这样就可以减少内存碎片的问题,提高内存利用率。
+
+
+
+虽然解决了外部内存碎片的问题,但伙伴系统仍然存在内存利用率不高的问题(内部内存碎片)。这主要是因为伙伴系统只能分配大小为 2^n 的内存块,因此当需要分配的内存大小不是 2^n 的整数倍时,会浪费一定的内存空间。举个例子:如果要分配 65 大小的内存快,依然需要分配 2^7=128 大小的内存块。
+
+
+
+对于内部内存碎片的问题,Linux 采用 **SLAB** 进行解决。由于这部分内容不是本篇文章的重点,这里就不详细介绍了。
+
+#### 非连续内存管理
+
+非连续内存管理存在下面 3 种方式:
+
+- **段式管理**:以段(一段连续的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+- **页式管理**:把物理内存分为连续等长的物理页,应用程序的虚拟地址空间也被划分为连续等长的虚拟页,是现代操作系统广泛使用的一种内存管理方式。
+- **段页式管理机制**:结合了段式管理和页式管理的一种内存管理机制,把物理内存先分成若干段,每个段又继续分成若干大小相等的页。
+
+### 虚拟内存
+
+#### 什么是虚拟内存?有什么用?
+
+**虚拟内存(Virtual Memory)** 是计算机系统内存管理非常重要的一个技术,本质上来说它只是逻辑存在的,是一个假想出来的内存空间,主要作用是作为进程访问主存(物理内存)的桥梁并简化内存管理。
+
+
+
+总结来说,虚拟内存主要提供了下面这些能力:
+
+- **隔离进程**:物理内存通过虚拟地址空间访问,虚拟地址空间与进程一一对应。每个进程都认为自己拥有了整个物理内存,进程之间彼此隔离,一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
+- **提升物理内存利用率**:有了虚拟地址空间后,操作系统只需要将进程当前正在使用的部分数据或指令加载入物理内存。
+- **简化内存管理**:进程都有一个一致且私有的虚拟地址空间,程序员不用和真正的物理内存打交道,而是借助虚拟地址空间访问物理内存,从而简化了内存管理。
+- **多个进程共享物理内存**:进程在运行过程中,会加载许多操作系统的动态库。这些库对于每个进程而言都是公用的,它们在内存中实际只会加载一份,这部分称为共享内存。
+- **提高内存使用安全性**:控制进程对物理内存的访问,隔离不同进程的访问权限,提高系统的安全性。
+- **提供更大的可使用内存空间**:可以让程序拥有超过系统物理内存大小的可用内存空间。这是因为当物理内存不够用时,可以利用磁盘充当,将物理内存页(通常大小为 4 KB)保存到磁盘文件(会影响读写速度),数据或代码页会根据需要在物理内存与磁盘之间移动。
+
+#### 没有虚拟内存有什么问题?
+
+如果没有虚拟内存的话,程序直接访问和操作的都是物理内存,看似少了一层中介,但多了很多问题。
+
+**具体有什么问题呢?** 这里举几个例子说明(参考虚拟内存提供的能力回答这个问题):
+
+1. 用户程序可以访问任意物理内存,可能会不小心操作到系统运行必需的内存,进而造成操作系统崩溃,严重影响系统的安全。
+2. 同时运行多个程序容易崩溃。比如你想同时运行一个微信和一个 QQ 音乐,微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就可能会造成微信这个程序会崩溃。
+3. 程序运行过程中使用的所有数据或指令都要载入物理内存,根据局部性原理,其中很大一部分可能都不会用到,白白占用了宝贵的物理内存资源。
+4. ……
+
+#### 什么是虚拟地址和物理地址?
+
+**物理地址(Physical Address)** 是真正的物理内存中地址,更具体点来说是内存地址寄存器中的地址。程序中访问的内存地址不是物理地址,而是 **虚拟地址(Virtual Address)** 。
+
+也就是说,我们编程开发的时候实际就是在和虚拟地址打交道。比如在 C 语言中,指针里面存储的数值就可以理解成为内存里的一个地址,这个地址也就是我们说的虚拟地址。
+
+操作系统一般通过 CPU 芯片中的一个重要组件 **MMU(Memory Management Unit,内存管理单元)** 将虚拟地址转换为物理地址,这个过程被称为 **地址翻译/地址转换(Address Translation)** 。
+
+
+
+通过 MMU 将虚拟地址转换为物理地址后,再通过总线传到物理内存设备,进而完成相应的物理内存读写请求。
+
+MMU 将虚拟地址翻译为物理地址的主要机制有两种: **分段机制** 和 **分页机制** 。
+
+#### 什么是虚拟地址空间和物理地址空间?
+
+- 虚拟地址空间是虚拟地址的集合,是虚拟内存的范围。每一个进程都有一个一致且私有的虚拟地址空间。
+- 物理地址空间是物理地址的集合,是物理内存的范围。
+
+#### 虚拟地址与物理内存地址是如何映射的?
+
+MMU 将虚拟地址翻译为物理地址的主要机制有 3 种:
+
+1. 分段机制
+2. 分页机制
+3. 段页机制
+
+其中,现代操作系统广泛采用分页机制,需要重点关注!
+
+### 分段机制
+
+**分段机制(Segmentation)** 以段(一段 **连续** 的物理内存)的形式管理/分配物理内存。应用程序的虚拟地址空间被分为大小不等的段,段是有实际意义的,每个段定义了一组逻辑信息,例如有主程序段 MAIN、子程序段 X、数据段 D 及栈段 S 等。
+
+#### 段表有什么用?地址翻译过程是怎样的?
+
+分段管理通过 **段表(Segment Table)** 映射虚拟地址和物理地址。
+
+分段机制下的虚拟地址由两部分组成:
+
+- **段号**:标识着该虚拟地址属于整个虚拟地址空间中的哪一个段。
+- **段内偏移量**:相对于该段起始地址的偏移量。
+
+具体的地址翻译过程如下:
+
+1. MMU 首先解析得到虚拟地址中的段号;
+2. 通过段号去该应用程序的段表中取出对应的段信息(找到对应的段表项);
+3. 从段信息中取出该段的起始地址(物理地址)加上虚拟地址中的段内偏移量得到最终的物理地址。
+
+
+
+段表中还存有诸如段长(可用于检查虚拟地址是否超出合法范围)、段类型(该段的类型,例如代码段、数据段等)等信息。
+
+**通过段号一定要找到对应的段表项吗?得到最终的物理地址后对应的物理内存一定存在吗?**
+
+不一定。段表项可能并不存在:
+
+- **段表项被删除**:软件错误、软件恶意行为等情况可能会导致段表项被删除。
+- **段表项还未创建**:如果系统内存不足或者无法分配到连续的物理内存块就会导致段表项无法被创建。
+
+#### 分段机制为什么会导致内存外部碎片?
+
+分段机制容易出现外部内存碎片,即在段与段之间留下碎片空间(不足以映射给虚拟地址空间中的段)。从而造成物理内存资源利用率的降低。
+
+举个例子:假设可用物理内存为 5G 的系统使用分段机制分配内存。现在有 4 个进程,每个进程的内存占用情况如下:
+
+- 进程 1:0~1G(第 1 段)
+- 进程 2:1~3G(第 2 段)
+- 进程 3:3~4.5G(第 3 段)
+- 进程 4:4.5~5G(第 4 段)
+
+此时,我们关闭了进程 1 和进程 4,则第 1 段和第 4 段的内存会被释放,空闲物理内存还有 1.5G。由于这 1.5G 物理内存并不是连续的,导致没办法将空闲的物理内存分配给一个需要 1.5G 物理内存的进程。
+
+
+
+### 分页机制
+
+**分页机制(Paging)** 把主存(物理内存)分为连续等长的物理页,应用程序的虚拟地址空间划也被分为连续等长的虚拟页。现代操作系统广泛采用分页机制。
+
+**注意:这里的页是连续等长的,不同于分段机制下不同长度的段。**
+
+在分页机制下,应用程序虚拟地址空间中的任意虚拟页可以被映射到物理内存中的任意物理页上,因此可以实现物理内存资源的离散分配。分页机制按照固定页大小分配物理内存,使得物理内存资源易于管理,可有效避免分段机制中外部内存碎片的问题。
+
+#### 页表有什么用?地址翻译过程是怎样的?
+
+分页管理通过 **页表(Page Table)** 映射虚拟地址和物理地址。我这里画了一张基于单级页表进行地址翻译的示意图。
+
+
+
+在分页机制下,每个进程都会有一个对应的页表。
+
+分页机制下的虚拟地址由两部分组成:
+
+- **页号**:通过虚拟页号可以从页表中取出对应的物理页号;
+- **页内偏移量**:物理页起始地址+页内偏移量=物理内存地址。
+
+具体的地址翻译过程如下:
+
+1. MMU 首先解析得到虚拟地址中的虚拟页号;
+2. 通过虚拟页号去该应用程序的页表中取出对应的物理页号(找到对应的页表项);
+3. 用该物理页号对应的物理页起始地址(物理地址)加上虚拟地址中的页内偏移量得到最终的物理地址。
+
+
+
+页表中还存有诸如访问标志(标识该页面有没有被访问过)、脏数据标识位等信息。
+
+**通过虚拟页号一定要找到对应的物理页号吗?找到了物理页号得到最终的物理地址后对应的物理页一定存在吗?**
+
+不一定!可能会存在 **页缺失** 。也就是说,物理内存中没有对应的物理页或者物理内存中有对应的物理页但虚拟页还未和物理页建立映射(对应的页表项不存在)。关于页缺失的内容,后面会详细介绍到。
+
+#### 单级页表有什么问题?为什么需要多级页表?
+
+以 32 位的环境为例,虚拟地址空间范围共有 2^32(4G)。假设 一个页的大小是 2^12(4KB),那页表项共有 4G / 4K = 2^20 个。每个页表项为一个地址,占用 4 字节,`2^20 * 2^2 / 1024 * 1024= 4MB`。也就是说一个程序啥都不干,页表大小就得占用 4M。
+
+系统运行的应用程序多起来的话,页表的开销还是非常大的。而且,绝大部分应用程序可能只能用到页表中的几项,其他的白白浪费了。
+
+为了解决这个问题,操作系统引入了 **多级页表** ,多级页表对应多个页表,每个页表与前一个页表相关联。32 位系统一般为二级页表,64 位系统一般为四级页表。
+
+这里以二级页表为例进行介绍:二级列表分为一级页表和二级页表。一级页表共有 1024 个页表项,一级页表又关联二级页表,二级页表同样共有 1024 个页表项。二级页表中的一级页表项是一对多的关系,二级页表按需加载(只会用到很少一部分二级页表),进而节省空间占用。
+
+假设只需要 2 个二级页表,那两级页表的内存占用情况为: 4KB(一级页表占用) + 4KB \* 2(二级页表占用) = 12 KB。
+
+
+
+多级页表属于时间换空间的典型场景,利用增加页表查询的次数减少页表占用的空间。
+
+#### TLB 有什么用?使用 TLB 之后的地址翻译流程是怎样的?
+
+为了提高虚拟地址到物理地址的转换速度,操作系统在 **页表方案** 基础之上引入了 **转址旁路缓存(Translation Lookaside Buffer,TLB,也被称为快表)** 。
+
+
+
+在主流的 AArch64 和 x86-64 体系结构下,TLB 属于 (Memory Management Unit,内存管理单元) 内部的单元,本质上就是一块高速缓存(Cache),缓存了虚拟页号到物理页号的映射关系,你可以将其简单看作是存储着键(虚拟页号)值(物理页号)对的哈希表。
+
+使用 TLB 之后的地址翻译流程是这样的:
+
+1. 用虚拟地址中的虚拟页号作为 key 去 TLB 中查询;
+2. 如果能查到对应的物理页的话,就不用再查询页表了,这种情况称为 TLB 命中(TLB hit)。
+3. 如果不能查到对应的物理页的话,还是需要去查询主存中的页表,同时将页表中的该映射表项添加到 TLB 中,这种情况称为 TLB 未命中(TLB miss)。
+4. 当 TLB 填满后,又要登记新页时,就按照一定的淘汰策略淘汰掉快表中的一个页。
+
+
+
+由于页表也在主存中,因此在没有 TLB 之前,每次读写内存数据时 CPU 要访问两次主存。有了 TLB 之后,对于存在于 TLB 中的页表数据只需要访问一次主存即可。
+
+TLB 的设计思想非常简单,但命中率往往非常高,效果很好。这就是因为被频繁访问的页就是其中的很小一部分。
+
+看完了之后你会发现快表和我们平时经常在开发系统中使用的缓存(比如 Redis)很像,的确是这样的,操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。
+
+#### 换页机制有什么用?
+
+换页机制的思想是当物理内存不够用的时候,操作系统选择将一些物理页的内容放到磁盘上去,等要用到的时候再将它们读取到物理内存中。也就是说,换页机制利用磁盘这种较低廉的存储设备扩展的物理内存。
+
+这也就解释了一个日常使用电脑常见的问题:为什么操作系统中所有进程运行所需的物理内存即使比真实的物理内存要大一些,这些进程也是可以正常运行的,只是运行速度会变慢。
+
+这同样是一种时间换空间的策略,你用 CPU 的计算时间,页的调入调出花费的时间,换来了一个虚拟的更大的物理内存空间来支持程序的运行。
+
+#### 什么是页缺失?
+
+根据维基百科:
+
+> 页缺失(Page Fault,又名硬错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等)指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由 MMU 所发出的中断。
+
+常见的页缺失有下面这两种:
+
+- **硬性页缺失(Hard Page Fault)**:物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
+- **软性页缺失(Soft Page Fault)**:物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Handler 会指示 MMU 建立相应的虚拟页和物理页的映射关系。
+
+发生上面这两种缺页错误的时候,应用程序访问的是有效的物理内存,只是出现了物理页缺失或者虚拟页和物理页的映射关系未建立的问题。如果应用程序访问的是无效的物理内存的话,还会出现 **无效缺页错误(Invalid Page Fault)** 。
+
+#### 常见的页面置换算法有哪些?
+
+当发生硬性页缺失时,如果物理内存中没有空闲的物理页面可用的话。操作系统就必须将物理内存中的一个物理页淘汰出去,这样就可以腾出空间来加载新的页面了。
+
+用来选择淘汰哪一个物理页的规则叫做 **页面置换算法** ,我们可以把页面置换算法看成是淘汰物物理页的规则。
+
+页缺失太频繁的发生会非常影响性能,一个好的页面置换算法应该是可以减少页缺失出现的次数。
+
+常见的页面置换算法有下面这 5 种(其他还有很多页面置换算法都是基于这些算法改进得来的):
+
+
+
+1. **最佳页面置换算法(OPT,Optimal)**:优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
+2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可满足需求。不过,它的性能并不是很好。
+3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)**:LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
+4. **最少使用页面置换算法(LFU,Least Frequently Used)** : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
+5. **时钟页面置换算法(Clock)**:可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
+
+**FIFO 页面置换算法性能为何不好?**
+
+主要原因主要有二:
+
+1. **经常访问或者需要长期存在的页面会被频繁调入调出**:较早调入的页往往是经常被访问或者需要长期存在的页,这些页会被反复调入和调出。
+2. **存在 Belady 现象**:被置换的页面并不是进程不会访问的,有时就会出现分配的页面数增多但缺页率反而提高的异常现象。出现该异常的原因是因为 FIFO 算法只考虑了页面进入内存的顺序,而没有考虑页面访问的频率和紧迫性。
+
+**哪一种页面置换算法实际用的比较多?**
+
+LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT 的页面置换算法。
+
+不过,需要注意的是,实际应用中这些算法会被做一些改进,就比如 InnoDB Buffer Pool( InnoDB 缓冲池,MySQL 数据库中用于管理缓存页面的机制)就改进了传统的 LRU 算法,使用了一种称为"Adaptive LRU"的算法(同时结合了 LRU 和 LFU 算法的思想)。
+
+### 分页机制和分段机制有哪些共同点和区别?
+
+**共同点**:
+
+- 都是非连续内存管理的方式。
+- 都采用了地址映射的方法,将虚拟地址映射到物理地址,以实现对内存的管理和保护。
+
+**区别**:
+
+- 分页机制以页面为单位进行内存管理,而分段机制以段为单位进行内存管理。页的大小是固定的,由操作系统决定,通常为 2 的幂次方。而段的大小不固定,取决于我们当前运行的程序。
+- 页是物理单位,即操作系统将物理内存划分成固定大小的页面,每个页面的大小通常是 2 的幂次方,例如 4KB、8KB 等等。而段则是逻辑单位,是为了满足程序对内存空间的逻辑需求而设计的,通常根据程序中数据和代码的逻辑结构来划分。
+- 分段机制容易出现外部内存碎片,即在段与段之间留下碎片空间(不足以映射给虚拟地址空间中的段)。分页机制解决了外部内存碎片的问题,但仍然可能会出现内部内存碎片。
+- 分页机制采用了页表来完成虚拟地址到物理地址的映射,页表通过一级页表和二级页表来实现多级映射;而分段机制则采用了段表来完成虚拟地址到物理地址的映射,每个段表项中记录了该段的起始地址和长度信息。
+- 分页机制对程序没有任何要求,程序只需要按照虚拟地址进行访问即可;而分段机制需要程序员将程序分为多个段,并且显式地使用段寄存器来访问不同的段。
+
+### 段页机制
+
+结合了段式管理和页式管理的一种内存管理机制。程序视角中,内存被划分为多个逻辑段,每个逻辑段进一步被划分为固定大小的页。
+
+在段页式机制下,地址翻译的过程分为两个步骤:
+
+1. **段式地址映射(虚拟地址 → 线性地址):**
+ - 虚拟地址 = 段选择符(段号)+ 段内偏移。
+ - 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
+2. **页式地址映射(线性地址 → 物理地址):**
+ - 线性地址 = 页号 + 页内偏移。
+ - 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
+
+### 局部性原理
+
+要想更好地理解虚拟内存技术,必须要知道计算机中著名的 **局部性原理(Locality Principle)**。另外,局部性原理既适用于程序结构,也适用于数据结构,是非常重要的一个概念。
+
+局部性原理是指在程序执行过程中,数据和指令的访问存在一定的空间和时间上的局部性特点。其中,时间局部性是指一个数据项或指令在一段时间内被反复使用的特点,空间局部性是指一个数据项或指令在一段时间内与其相邻的数据项或指令被反复使用的特点。
+
+在分页机制中,页表的作用是将虚拟地址转换为物理地址,从而完成内存访问。在这个过程中,局部性原理的作用体现在两个方面:
+
+- **时间局部性**:由于程序中存在一定的循环或者重复操作,因此会反复访问同一个页或一些特定的页,这就体现了时间局部性的特点。为了利用时间局部性,分页机制中通常采用缓存机制来提高页面的命中率,即将最近访问过的一些页放入缓存中,如果下一次访问的页已经在缓存中,就不需要再次访问内存,而是直接从缓存中读取。
+- **空间局部性**:由于程序中数据和指令的访问通常是具有一定的空间连续性的,因此当访问某个页时,往往会顺带访问其相邻的一些页。为了利用空间局部性,分页机制中通常采用预取技术来预先将相邻的一些页读入内存缓存中,以便在未来访问时能够直接使用,从而提高访问速度。
+
+总之,局部性原理是计算机体系结构设计的重要原则之一,也是许多优化算法的基础。在分页机制中,利用时间局部性和空间局部性,采用缓存和预取技术,可以提高页面的命中率,从而提高内存访问效率
+
+## 文件系统
+
+### 文件系统主要做了什么?
+
+文件系统主要负责管理和组织计算机存储设备上的文件和目录,其功能包括以下几个方面:
+
+1. **存储管理**:将文件数据存储到物理存储介质中,并且管理空间分配,以确保每个文件都有足够的空间存储,并避免文件之间发生冲突。
+2. **文件管理**:文件的创建、删除、移动、重命名、压缩、加密、共享等等。
+3. **目录管理**:目录的创建、删除、移动、重命名等等。
+4. **文件访问控制**:管理不同用户或进程对文件的访问权限,以确保用户只能访问其被授权访问的文件,以保证文件的安全性和保密性。
+
+### 硬链接和软链接有什么区别?
+
+在 Linux/类 Unix 系统上,文件链接(File Link)是一种特殊的文件类型,可以在文件系统中指向另一个文件。常见的文件链接类型有两种:
+
+**1、硬链接(Hard Link)**
+
+- 在 Linux/类 Unix 文件系统中,每个文件和目录都有一个唯一的索引节点(inode)号,用来标识该文件或目录。硬链接通过 inode 节点号建立连接,硬链接和源文件的 inode 节点号相同,两者对文件系统来说是完全平等的(可以看作是互为硬链接,源头是同一份文件),删除其中任何一个对另外一个没有影响,可以通过给文件设置硬链接文件来防止重要文件被误删。
+- 只有删除了源文件和所有对应的硬链接文件,该文件才会被真正删除。
+- 硬链接具有一些限制,不能对目录以及不存在的文件创建硬链接,并且,硬链接也不能跨越文件系统。
+- `ln` 命令用于创建硬链接。
+
+**2、软链接(Symbolic Link 或 Symlink)**
+
+- 软链接和源文件的 inode 节点号不同,而是指向一个文件路径。
+- 源文件删除后,软链接依然存在,但是指向的是一个无效的文件路径。
+- 软连接类似于 Windows 系统中的快捷方式。
+- 不同于硬链接,可以对目录或者不存在的文件创建软链接,并且,软链接可以跨越文件系统。
+- `ln -s` 命令用于创建软链接。
+
+### 硬链接为什么不能跨文件系统?
+
+我们之前提到过,硬链接是通过 inode 节点号建立连接的,而硬链接和源文件共享相同的 inode 节点号。
+
+然而,每个文件系统都有自己的独立 inode 表,且每个 inode 表只维护该文件系统内的 inode。如果在不同的文件系统之间创建硬链接,可能会导致 inode 节点号冲突的问题,即目标文件的 inode 节点号已经在该文件系统中被使用。
+
+### 提高文件系统性能的方式有哪些?
+
+- **优化硬件**:使用高速硬件设备(如 SSD、NVMe)替代传统的机械硬盘,使用 RAID(Redundant Array of Independent Disks)等技术提高磁盘性能。
+- **选择合适的文件系统选型**:不同的文件系统具有不同的特性,对于不同的应用场景选择合适的文件系统可以提高系统性能。
+- **运用缓存**:访问磁盘的效率比较低,可以运用缓存来减少磁盘的访问次数。不过,需要注意缓存命中率,缓存命中率过低的话,效果太差。
+- **避免磁盘过度使用**:注意磁盘的使用率,避免将磁盘用满,尽量留一些剩余空间,以免对文件系统的性能产生负面影响。
+- **对磁盘进行合理的分区**:合理的磁盘分区方案,能够使文件系统在不同的区域存储文件,从而减少文件碎片,提高文件读写性能。
+
+### 常见的磁盘调度算法有哪些?
+
+磁盘调度算法是操作系统中对磁盘访问请求进行排序和调度的算法,其目的是提高磁盘的访问效率。
+
+一次磁盘读写操作的时间由磁盘寻道/寻找时间、延迟时间和传输时间决定。磁盘调度算法可以通过改变到达磁盘请求的处理顺序,减少磁盘寻道时间和延迟时间。
+
+常见的磁盘调度算法有下面这 6 种(其他还有很多磁盘调度算法都是基于这些算法改进得来的):
+
+
+
+1. **先来先服务算法(First-Come First-Served,FCFS)**:按照请求到达磁盘调度器的顺序进行处理,先到达的请求的先被服务。FCFS 算法实现起来比较简单,不存在算法开销。不过,由于没有考虑磁头移动的路径和方向,平均寻道时间较长。同时,该算法容易出现饥饿问题,即一些后到的磁盘请求可能需要等待很长时间才能得到服务。
+2. **最短寻道时间优先算法(Shortest Seek Time First,SSTF)**:也被称为最佳服务优先(Shortest Service Time First,SSTF)算法,优先选择距离当前磁头位置最近的请求进行服务。SSTF 算法能够最小化磁头的寻道时间,但容易出现饥饿问题,即磁头附近的请求不断被服务,远离磁头的请求长时间得不到响应。实际应用中,需要优化一下该算法的实现,避免出现饥饿问题。
+3. **扫描算法(SCAN)**:也被称为电梯(Elevator)算法,基本思想和电梯非常类似。磁头沿着一个方向扫描磁盘,如果经过的磁道有请求就处理,直到到达磁盘的边界,然后改变移动方向,依此往复。SCAN 算法能够保证所有的请求得到服务,解决了饥饿问题。但是,如果磁头从一个方向刚扫描完,请求才到的话。这个请求就需要等到磁头从相反方向过来之后才能得到处理。
+4. **循环扫描算法(Circular Scan,C-SCAN)**:SCAN 算法的变体,只在磁盘的一侧进行扫描,并且只按照一个方向扫描,直到到达磁盘边界,然后回到磁盘起点,重新开始循环。
+5. **边扫描边观察算法(LOOK)**:SCAN 算法中磁头到了磁盘的边界才改变移动方向,这样可能会做很多无用功,因为磁头移动方向上可能已经没有请求需要处理了。LOOK 算法对 SCAN 算法进行了改进,如果磁头移动方向上已经没有别的请求,就可以立即改变磁头移动方向,依此往复。也就是边扫描边观察指定方向上还有无请求,因此叫 LOOK。
+6. **均衡循环扫描算法(C-LOOK)**:C-SCAN 只有到达磁盘边界时才能改变磁头移动方向,并且磁头返回时也需要返回到磁盘起点,这样可能会做很多无用功。C-LOOK 算法对 C-SCAN 算法进行了改进,如果磁头移动的方向上已经没有磁道访问请求了,就可以立即让磁头返回,并且磁头只需要返回到有磁道访问请求的位置即可。
+
+## 参考
+
+- 《计算机操作系统—汤小丹》第四版
+- 《深入理解计算机系统》
+- 《重学操作系统》
+- 《现代操作系统原理与实现》
+- 王道考研操作系统知识点整理:
+- 内存管理之伙伴系统与 SLAB:
+- 为什么 Linux 需要虚拟内存:
+- 程序员的自我修养(七):内存缺页错误:
+- 虚拟内存的那点事儿:
+
+
+
diff --git a/docs_en/cs-basics/operating-system/shell-intro.en.md b/docs_en/cs-basics/operating-system/shell-intro.en.md
new file mode 100644
index 00000000000..f915c0f4c77
--- /dev/null
+++ b/docs_en/cs-basics/operating-system/shell-intro.en.md
@@ -0,0 +1,537 @@
+---
+title: Shell 编程基础知识总结
+category: 计算机基础
+tag:
+ - 操作系统
+ - Linux
+head:
+ - - meta
+ - name: description
+ content: Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+ - - meta
+ - name: keywords
+ content: Shell,脚本,命令,自动化,运维,Linux,基础语法
+---
+
+Shell 编程在我们的日常开发工作中非常实用,目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
+
+这篇文章我会简单总结一下 Shell 编程基础知识,带你入门 Shell 编程!
+
+## 走进 Shell 编程的大门
+
+### 为什么要学 Shell?
+
+学一个东西,我们大部分情况都是往实用性方向着想。从工作角度来讲,学习 Shell 是为了提高我们自己工作效率,提高产出,让我们在更少的时间完成更多的事情。
+
+很多人会说 Shell 编程属于运维方面的知识了,应该是运维人员来做,我们做后端开发的没必要学。我觉得这种说法大错特错,相比于专门做 Linux 运维的人员来说,我们对 Shell 编程掌握程度的要求要比他们低,但是 Shell 编程也是我们必须要掌握的!
+
+目前 Linux 系统下最流行的运维自动化语言就是 Shell 和 Python 了。
+
+两者之间,Shell 几乎是 IT 企业必须使用的运维自动化编程语言,特别是在运维工作中的服务监控、业务快速部署、服务启动停止、数据备份及处理、日志分析等环节里,shell 是不可缺的。Python 更适合处理复杂的业务逻辑,以及开发复杂的运维软件工具,实现通过 web 访问等。Shell 是一个命令解释器,解释执行用户所输入的命令和程序。一输入命令,就立即回应的交互的对话方式。
+
+另外,了解 shell 编程也是大部分互联网公司招聘后端开发人员的要求。下图是我截取的一些知名互联网公司对于 Shell 编程的要求。
+
+
+
+### 什么是 Shell?
+
+简单来说“Shell 编程就是对一堆 Linux 命令的逻辑化处理”。
+
+W3Cschool 上的一篇文章是这样介绍 Shell 的,如下图所示。
+
+
+### Shell 编程的 Hello World
+
+学习任何一门编程语言第一件事就是输出 HelloWorld 了!下面我会从新建文件到 shell 代码编写来说下 Shell 编程如何输出 Hello World。
+
+(1)新建一个文件 helloworld.sh :`touch helloworld.sh`,扩展名为 sh(sh 代表 Shell)(扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用 php 好了)
+
+(2) 使脚本具有执行权限:`chmod +x helloworld.sh`
+
+(3) 使用 vim 命令修改 helloworld.sh 文件:`vim helloworld.sh`(vim 文件------>进入文件----->命令模式------>按 i 进入编辑模式----->编辑文件 ------->按 Esc 进入底行模式----->输入:wq/q! (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存。))
+
+helloworld.sh 内容如下:
+
+```shell
+#!/bin/bash
+#第一个shell小程序,echo 是linux中的输出命令。
+echo "helloworld!"
+```
+
+shell 中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在 linux 中,除了 bash shell 以外,还有很多版本的 shell, 例如 zsh、dash 等等...不过 bash shell 还是我们使用最多的。**
+
+(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 helloworld.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
+
+
+
+## Shell 变量
+
+### Shell 编程中的变量介绍
+
+**Shell 编程中一般分为三种变量:**
+
+1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
+2. **Linux 已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而 set 命令既可以查看环境变量也可以查看自定义变量。
+3. **Shell 变量**:Shell 变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
+
+**常用的环境变量:**
+
+> PATH 决定了 shell 将到哪些目录中寻找命令或程序
+> HOME 当前用户主目录
+> HISTSIZE 历史记录数
+> LOGNAME 当前用户的登录名
+> HOSTNAME 指主机的名称
+> SHELL 当前用户 Shell 类型
+> LANGUAGE 语言相关的环境变量,多语言可以修改此环境变量
+> MAIL 当前用户的邮件存放目录
+> PS1 基本提示符,对于 root 用户是#,对于普通用户是\$
+
+**使用 Linux 已定义的环境变量:**
+
+比如我们要看当前用户目录可以使用:`echo $HOME`命令;如果我们要看当前用户 Shell 类型 可以使用`echo $SHELL`命令。可以看出,使用方法非常简单。
+
+**使用自己定义的变量:**
+
+```shell
+#!/bin/bash
+#自定义变量hello
+hello="hello world"
+echo $hello
+echo "helloworld!"
+```
+
+
+
+**Shell 编程中的变量名的命名的注意事项:**
+
+- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头,但是可以使用下划线(\_)开头。
+- 中间不能有空格,可以使用下划线(\_)。
+- 不能使用标点符号。
+- 不能使用 bash 里的关键字(可用 help 命令查看保留关键字)。
+
+### Shell 字符串入门
+
+字符串是 shell 编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和 Java 中有所不同。
+
+在单引号中所有的特殊符号,如$和反引号都没有特殊含义。在双引号中,除了"$"、"\\"、反引号和感叹号(需开启 `history expansion`),其他的字符没有特殊含义。
+
+**单引号字符串:**
+
+```shell
+#!/bin/bash
+name='SnailClimb'
+hello='Hello, I am $name!'
+echo $hello
+```
+
+输出内容:
+
+```plain
+Hello, I am $name!
+```
+
+**双引号字符串:**
+
+```shell
+#!/bin/bash
+name='SnailClimb'
+hello="Hello, I am $name!"
+echo $hello
+```
+
+输出内容:
+
+```plain
+Hello, I am SnailClimb!
+```
+
+### Shell 字符串常见操作
+
+**拼接字符串:**
+
+```shell
+#!/bin/bash
+name="SnailClimb"
+# 使用双引号拼接
+greeting="hello, "$name" !"
+greeting_1="hello, ${name} !"
+echo $greeting $greeting_1
+# 使用单引号拼接
+greeting_2='hello, '$name' !'
+greeting_3='hello, ${name} !'
+echo $greeting_2 $greeting_3
+```
+
+Output result:
+
+
+
+**Get string length:**
+
+```shell
+#!/bin/bash
+#Get the string length
+name="SnailClimb"
+# The first way
+echo ${#name} #output 10
+# The second way
+expr length "$name";
+```
+
+Output result:
+
+```plain
+10
+10
+```
+
+When using the expr command, spaces must be included around the operator in the expression. If no spaces are included, the expression itself will be output:
+
+```shell
+expr 5+6 // Directly output 5+6
+expr 5 + 6 //output 11
+```
+
+For some operators, we also need to use the symbol `\` to escape, otherwise a syntax error will be prompted.
+
+```shell
+expr 5 * 6 // Output error
+expr 5 \* 6 // Output 30
+```
+
+**Intercept substring:**
+
+Simple string interception:
+
+```shell
+#Truncate 10 characters starting from the first character of the string
+str="SnailClimb is a great man"
+echo ${str:0:10} #Output:SnailClimb
+```
+
+Intercept based on expression:
+
+```shell
+#!bin/bash
+#author:amau
+
+var="https://www.runoob.com/linux/linux-shell-variable.html"
+# % means delete the next match, the shortest result
+# %% means delete the matching from the end, the longest matching result
+# #Indicates deleting matches from the beginning, the shortest result
+# ## indicates deleting the match from the beginning and the longest matching result
+# Note: * is a wildcard character, meaning to match any number of any characters
+s1=${var%%t*} #h
+s2=${var%t*} #https://www.runoob.com/linux/linux-shell-variable.h
+s3=${var%%.*} #https://www
+s4=${var#*/} #/www.runoob.com/linux/linux-shell-variable.html
+s5=${var##*/} #linux-shell-variable.html
+```
+
+### Shell array
+
+bash supports one-dimensional arrays (not multi-dimensional arrays) and does not limit the size of the array. I give you a shell code example about array operations below. Through this example, you can know how to create an array, get the length of the array, get/delete the array element at a specific position, delete the entire array, and traverse the array.
+
+```shell
+#!/bin/bash
+array=(1 2 3 4 5);
+# Get the length of the array
+length=${#array[@]}
+# or
+length2=${#array[*]}
+#Output array length
+echo $length #Output: 5
+echo $length2 #Output: 5
+# Output the third element of the array
+echo ${array[2]} #Output: 3
+unset array[1]# Deleting the element with subscript 1 means deleting the second element
+for i in ${array[@]};do echo $i ;done # Traverse the array, output: 1 3 4 5
+unset array; #Delete all elements in the array
+for i in ${array[@]};do echo $i ;done # Traverse the array, the array elements are empty and there is no output content
+```
+
+## Shell basic operators
+
+> Description: The picture comes from "Rookie Tutorial"
+
+Shell programming supports the following operators
+
+- Arithmetic operators
+- Relational operators
+- Boolean operators
+- String operators
+- File test operator
+
+### Arithmetic operators
+
+
+
+I use the addition operator to make a simple example (note: not single quotes, but backticks):
+
+```shell
+#!/bin/bash
+a=3;b=3;
+val=`expr $a + $b`
+#Output: Total value: 6
+echo "Total value : $val"
+```
+
+### Relational operators
+
+Relational operators only support numbers, not strings, unless the value of the string is a number.
+
+
+
+A simple example demonstrates the use of relational operators. The function of the following shell program is to output A when score=100, otherwise output B.
+
+```shell
+#!/bin/bash
+score=90;
+maxscore=100;
+if [ $score -eq $maxscore ]
+then
+ echo "A"
+else
+ echo "B"
+fi
+```
+
+Output result:
+
+```plain
+B
+```
+
+### Logical operators
+
+
+
+Example:
+
+```shell
+#!/bin/bash
+a=$(( 1 && 0))
+# Output: 0; for logical AND operations, only if both sides of the AND are 1, the result of the AND is 1; otherwise, the result of the AND is 0
+echo $a;
+```
+
+### Boolean operators
+
+
+
+I won’t do a demonstration here, it should be pretty simple.
+
+### String operators
+
+
+
+Simple example:
+
+```shell
+#!/bin/bash
+a="abc";
+b="efg";
+if [ $a = $b ]
+then
+ echo "a equals b"
+else
+ echo "a is not equal to b"
+fi
+```
+
+Output:
+
+```plain
+a is not equal to b
+```
+
+### File related operators
+
+
+
+The usage is very simple. For example, we have defined a file path `file="/usr/learnshell/test.sh"`. If we want to determine whether the file is readable, we can do this `if [ -r $file ]`. If we want to determine whether the file is writable, we can do this `-w $file`. Isn’t it very simple?
+
+## Shell process control
+
+### if conditional statement
+
+Simple if else-if else conditional statement example
+
+```shell
+#!/bin/bash
+a=3;
+b=9;
+if [ $a -eq $b ]
+then
+ echo "a equals b"
+elif [ $a -gt $b ]
+then
+ echo "a is greater than b"
+else
+ echo "a is less than b"
+fi
+```
+
+Output result:
+
+```plain
+a is less than b
+```
+
+I believe that through the above examples, you have mastered the if conditional statement in shell programming. However, one thing to mention is that unlike our common if conditional statements in Java and PHP, shell if conditional statements cannot contain empty statements, which are statements that do nothing.
+
+### for loop statement
+
+Learn the most basic use of the for loop statement through the following three simple examples. In fact, the function of the for loop statement is much greater than the examples you see below.
+
+**Output the data in the current list:**
+
+```shell
+for loop in 1 2 3 4 5
+do
+ echo "The value is: $loop"
+done
+```
+
+**Generate 10 random numbers:**
+
+```shell
+#!/bin/bash
+for i in {0..9};
+do
+ echo $RANDOM;
+done
+```
+
+**Output 1 to 5:**
+
+Normally, you need to add \$ when calling shell variables, but it is not required in (()) of for. Let’s look at an example:
+
+```shell
+#!/bin/bash
+length=5
+for((i=1;i<=length;i++));do
+ echo $i;
+done;
+```
+
+### while statement
+
+**Basic while loop statement:**
+
+```shell
+#!/bin/bash
+int=1
+while(( $int<=5 ))
+do
+ echo $int
+ let "int++"
+done
+```
+
+**while loop can be used to read keyboard information:**
+
+```shell
+echo 'Press to exit'
+echo -n 'Enter your favorite movie: '
+while read FILM
+do
+ echo "Yes! $FILM is a good movie"
+done
+```
+
+Output content:
+
+```plain
+Press to exit
+Enter your favorite movie: Transformers
+Yes! Transformers is a good movie
+```**Infinite Loop:**
+
+```shell
+while true
+do
+ command
+done
+```
+
+## Shell function
+
+### Function with no parameters and no return value
+
+```shell
+#!/bin/bash
+hello(){
+ echo "This is my first shell function!"
+}
+echo "-----Function starts execution-----"
+hello
+echo "-----Function execution completed-----"
+```
+
+Output result:
+
+```plain
+-----Function starts execution-----
+This is my first shell function!
+-----Function execution completed-----
+```
+
+### Functions with return values
+
+**Add two numbers after inputting them and return the result: **
+
+```shell
+#!/bin/bash
+funWithReturn(){
+ echo "Enter the first number: "
+ read aNum
+ echo "Enter the second number: "
+ read anotherNum
+ echo "The two numbers are $aNum and $anotherNum!"
+ return $(($aNum+$anotherNum))
+}
+funWithReturn
+echo "The sum of the two numbers entered is $?"
+```
+
+Output result:
+
+```plain
+Enter the first number:
+1
+Enter the second number:
+2
+The two numbers are 1 and 2!
+The sum of the two numbers entered is 3
+```
+
+### Function with parameters
+
+```shell
+#!/bin/bash
+funWithParam(){
+ echo "The first parameter is $1 !"
+ echo "The second parameter is $2 !"
+ echo "The tenth parameter is $10!"
+ echo "The tenth parameter is ${10} !"
+ echo "The eleventh parameter is ${11} !"
+ echo "The total number of parameters is $#!"
+ echo "Output all parameters as a string $* !"
+}
+funWithParam 1 2 3 4 5 6 7 8 9 34 73
+```
+
+Output result:
+
+```plain
+The first parameter is 1 !
+The second parameter is 2!
+The tenth parameter is 10!
+The tenth parameter is 34!
+The eleventh parameter is 73!
+There are 11 parameters in total!
+Output all parameters as a string 1 2 3 4 5 6 7 8 9 34 73 !
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/basis.en.md b/docs_en/database/basis.en.md
new file mode 100644
index 00000000000..c47e63af29f
--- /dev/null
+++ b/docs_en/database/basis.en.md
@@ -0,0 +1,238 @@
+---
+title: 数据库基础知识总结
+category: 数据库
+tag:
+ - 数据库基础
+---
+
+
+
+数据库知识基础,这部分内容一定要理解记忆。虽然这部分内容只是理论知识,但是非常重要,这是后面学习 MySQL 数据库的基础。PS: 这部分内容由于涉及太多概念性内容,所以参考了维基百科和百度百科相应的介绍。
+
+## 什么是数据库, 数据库管理系统, 数据库系统, 数据库管理员?
+
+这四个概念描述了从数据本身到管理整个体系的不同层次,我们常用一个图书馆的例子来把它们串联起来理解。
+
+- **数据库 (Database - DB):** 它就像是图书馆里,书架上存放的所有书籍和资料。从技术上讲,数据库就是按照一定数据模型组织、描述和储存起来的、可以被各种用户共享的结构化数据的集合。它就是我们最终要存取的核心——信息本身。
+- **数据库管理系统 (Database Management System - DBMS):** 它就像是整个图书馆的管理系统,包括图书的分类编目规则、借阅归还流程、安全检查系统等等。从技术上讲,DBMS 是一种大型软件,比如我们常用的 MySQL、Oracle、PostgreSQL 软件。它的核心职责是科学地组织和存储数据、高效地获取和维护数据;为我们屏蔽了底层文件操作的复杂性,提供了一套标准接口(如 SQL)来操纵数据,并负责并发控制、事务管理、权限控制等复杂问题。
+- **数据库系统 (Database System - DBS):** 它就是整个正常运转的图书馆。这是一个更大的概念,不仅包括书(DB)和管理系统(DBMS),还包括了硬件、应用和使用的人。
+- **数据库管理员 (Database Administrator - DBA ):** 他就是图书馆的馆长,负责整个数据库系统正常运行。他的职责非常广泛,包括数据库的设计、安装、监控、性能调优、备份与恢复、安全管理等等,确保整个系统的稳定、高效和安全。
+
+DB 和 DBMS 我们通常会搞混,这里再简单提一下:**通常我们说“用 MySQL 数据库”,其实是用 MySQL(DBMS)来管理一个或多个数据库(DB)。**
+
+## DBMS 有哪些主要的功能
+
+DBMS 通常提供四大核心功能:
+
+1. **数据定义:** 这是 DBMS 的基础。它提供了一套数据定义语言(Data Definition Language - DDL),让我们能够创建、修改和删除数据库中的各种对象。这不仅仅是定义表的结构(比如字段名、数据类型),还包括定义视图、索引、触发器、存储过程等。
+2. **数据操作:** 这是我们作为开发者日常使用最多的功能。它提供了一套数据操作语言(Data Manipulation Language - DML),核心就是我们熟悉的增、删、改、查(CRUD)操作。它让我们能够方便地对数据库中的数据进行操作和检索。
+3. **数据控制:** 这是保证数据正确、安全、可靠的关键。通常包含并发控制、事务管理、完整性约束、权限控制、安全性限制等功能。
+4. **数据库维护:** 这部分功能是为了保障数据库系统的长期稳定运行。它包括了数据的导入导出、数据库的备份与恢复、性能监控与分析、以及系统日志管理等。
+
+## 你知道哪些类型的 DBMS?
+
+### 关系型数据库
+
+除了我们最常用的关系型数据库(RDBMS),比如 MySQL(开源首选)、PostgreSQL(功能最全)、Oracle(企业级),它们基于严格的表结构和 SQL,非常适合结构化数据和需要事务保证的场景,例如银行交易、订单系统。
+
+近年来,为了应对互联网应用带来的海量数据、高并发和多样化数据结构的需求,涌现出了一大批 NoSQL 和 NewSQL 数据库。
+
+### NoSQL 数据库
+
+它们的共同特点是为了极致的性能和水平扩展能力,在某些方面(通常是事务)做了妥协。
+
+**1. 键值数据库,代表是 Redis。**
+
+- **特点:** 数据模型极其简单,就是一个巨大的 Map,通过 Key 来存取 Value。内存操作,性能极高。
+- **适用场景:** 非常适合做缓存、会话存储、计数器等对读写性能要求极高的场景。
+
+**2. 文档数据库,代表是 MongoDB。**
+
+- **特点:** 它存储的是半结构化的文档(比如 JSON/BSON),结构灵活,不需要预先定义表结构。
+- **适用场景:** 特别适合那些数据结构多变、快速迭代的业务,比如用户画像、内容管理系统、日志存储等。
+
+**3. 列式数据库,代表是 HBase, Cassandra。**
+
+- **特点:** 数据是按列族而不是按行来存储的。这使得它在对大量行进行少量列的读取时,性能极高。
+- **适用场景:** 专为海量数据存储和分析设计,非常适合做大数据分析、监控数据存储、推荐系统等需要高吞吐量写入和范围扫描的场景。
+
+**4. 图形数据库,代表是 Neo4j。**
+
+- **特点:** 数据模型是节点(Nodes)和边(Edges),专门用来存储和查询实体之间的复杂关系。
+- **适用场景:** 在社交网络(好友关系)、推荐引擎(用户-商品关系)、知识图谱、欺诈检测(资金流动关系)等场景下,表现远超关系型数据库。
+
+### NewSQL 数据库
+
+由于 NoSQL 不支持事务,很多对于数据安全要去非常高的系统(比如财务系统、订单系统、交易系统)就不太适合使用了。不过,这类系统往往有存储大量数据的需求。
+
+这些系统往往只能通过购买性能更强大的计算机,或者通过数据库中间件来提高存储能力。不过,前者的金钱成本太高,后者的开发成本太高。
+
+于是,**NewSQL** 就来了!
+
+简单来说,NewSQL 就是:**分布式存储+SQL+事务** 。NewSQL 不仅具有 NoSQL 对海量数据的存储管理能力,还保持了传统数据库支持 ACID 和 SQL 等特性。因此,NewSQL 也可以称为 **分布式关系型数据库**。
+
+NewSQL 数据库设计的一些目标:
+
+1. 横向扩展(Scale Out) : 通过增加机器的方式来提高系统的负载能力。与之类似的是 Scale Up(纵向扩展),升级硬件设备的方式来提高系统的负载能力。
+2. 强一致性(Strict Consistency):在任意时刻,所有节点中的数据是一样的。
+3. 高可用(High Availability):系统几乎可以一直提供服务。
+4. 支持标准 SQL(Structured Query Language) :PostgreSQL、MySQL、Oracle 等关系型数据库都支持 SQL 。
+5. 事务(ACID) : 原子性(Atomicity)、一致性(Consistency)、 隔离性(Isolation); 持久性(Durability)。
+6. 兼容主流关系型数据库 : 兼容 MySQL、Oracle、PostgreSQL 等常用关系型数据库。
+7. 云原生 (Cloud Native):可在公有云、私有云、混合云中实现部署工具化、自动化。
+8. HTAP(Hybrid Transactional/Analytical Processing) :支持 OLTP 和 OLAP 混合处理。
+
+NewSQL 数据库代表:Google 的 F1/Spanner、阿里的 [OceanBase](https://open.oceanbase.com/)、PingCAP 的 [TiDB](https://pingcap.com/zh/product-community/) 。
+
+## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
+
+- **元组**:元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
+- **码**:码就是能唯一标识实体的属性,对应表中的列。
+- **候选码**:若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
+- **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
+- **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
+- **主属性**:候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
+- **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
+
+## 什么是 ER 图?
+
+我们做一个项目的时候一定要试着画 ER 图来捋清数据库设计,这个也是面试官问你项目的时候经常会被问到的。
+
+**ER 图** 全称是 Entity Relationship Diagram(实体联系图),提供了表示实体类型、属性和联系的方法。
+
+ER 图由下面 3 个要素组成:
+
+- **实体**:通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
+- **属性**:即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
+- **联系**:即实体与实体之间的关系,在 ER 图中用菱形表示,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
+
+下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
+
+
+
+## 数据库范式了解吗?
+
+数据库范式有 3 种:
+
+- 1NF(第一范式):属性不可再分。
+- 2NF(第二范式):1NF 的基础之上,消除了非主属性对于码的部分函数依赖。
+- 3NF(第三范式):3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。
+
+### 1NF(第一范式)
+
+属性(对应于表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再分为多个其他的字段了。**1NF 是所有关系型数据库的最基本要求** ,也就是说关系型数据库中创建的表一定满足第一范式。
+
+### 2NF(第二范式)
+
+2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
+
+
+
+一些重要的概念:
+
+- **函数依赖(functional dependency)**:若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
+- **部分函数依赖(partial functional dependency)**:如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖于(学号,身份证号);
+- **完全函数依赖(Full functional dependency)**:在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
+- **传递函数依赖**:在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。
+
+### 3NF(第三范式)
+
+3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。符合 3NF 要求的数据库设计,**基本**上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。
+
+## 主键和外键有什么区别?
+
+从定义和属性上看,它们的区别是:
+
+- **主键 (Primary Key):** 它的核心作用是唯一标识表中的每一行数据。因此,主键列的值必须是唯一的 (Unique) 且不能为空 (Not Null)。一张表只能有一个主键。主键保证了实体完整性。
+- **外键 (Foreign Key):** 它的核心作用是建立并强制两张表之间的关联关系。一张表中的外键列,其值必须对应另一张表中某行的主键值(或者是一个 NULL 值)。因此,外键的值可以重复,也可以为空。一张表可以有多个外键,分别关联到不同的表。外键保证了引用完整性。
+
+用一个简单的电商例子来说明:假设我们有两张表:`users` (用户表) 和 `orders` (订单表)。
+
+- 在 `users` 表中,`user_id` 列是**主键**。每个用户的 `user_id` 都是独一无二的,我们用它来区分张三和李四。
+- 在 `orders` 表中,`order_id` 是它自己的**主键**。同时,它会有一个 `user_id` 列,这个列就是一个**外键**,它引用了 `users` 表的 `user_id` 主键。
+
+这个外键约束就保证了:
+
+1. 你不能创建一个不属于任何已知用户的订单( `user_id` 在 `users` 表中不存在)。
+2. 你不能删除一个已经下了订单的用户(除非设置了级联删除等特殊规则)。
+
+## 为什么不推荐使用外键与级联?
+
+对于外键和级联,阿里巴巴开发手册这样说到:
+
+> 【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
+>
+> 说明: 以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度
+
+为什么不要用外键呢?大部分人可能会这样回答:
+
+1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如哪天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗数据库资源。如果在应用层面去维护的话,可以减小数据库压力;
+3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
+4. ……
+
+我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
+
+1. 保证了数据库数据的一致性和完整性;
+2. 级联操作方便,减轻了程序代码量;
+3. ……
+
+所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
+
+## 什么是存储过程?
+
+我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候是非常实用的,比如很多时候我们完成一个操作可能需要写一大串 SQL 语句,这时候我们就可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
+
+存储过程在互联网公司应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
+
+阿里巴巴 Java 开发手册里要求禁止使用存储过程。
+
+
+
+## drop、delete 与 truncate 区别?
+
+### 用法不同
+
+- `drop`(丢弃数据): `drop table 表名` ,直接将表都删除掉,在删除表的时候使用。
+- `truncate` (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
+- `delete`(删除数据) : `delete from 表名 where 列名=值`,删除某一行的数据,如果不加 `where` 子句和`truncate table 表名`作用类似。
+
+`truncate`, `delete` without `where` clause, and `drop` will delete the data in the table, but **`truncate` and `delete` only delete the data without deleting the structure (definition) of the table. When the `drop` statement is executed, the structure of the table will also be deleted, that is, the corresponding table no longer exists after executing `drop`. **
+
+### Belong to different database languages
+
+`truncate` and `drop` belong to DDL (data definition language) statements, and the operation takes effect immediately. The original data is not placed in the rollback segment, cannot be rolled back, and the operation does not trigger the trigger. The `delete` statement is a DML (database operation language) statement. This operation will be placed in the rollback segment and will only take effect after the transaction is submitted.
+
+**Differences between DML statements and DDL statements:**
+
+- DML is the abbreviation of Database Manipulation Language (Data Manipulation Language). It refers to the operation of table records in the database, mainly including the insertion, update, deletion and query of table records. It is the most frequently used operation by developers in daily life.
+- DDL (Data Definition Language) is the abbreviation of data definition language. Simply put, it is an operating language for creating, deleting, and modifying objects within the database. The biggest difference between it and the DML language is that DML only operates on the internal data of the table, and does not involve the definition of the table, modification of the structure, nor other objects. DDL statements are more commonly used by database administrators (DBAs) and are rarely used by general developers.
+
+In addition, since `select` will not destroy the table, some places also distinguish `select` separately and call it database query language DQL (Data Query Language).
+
+### Different execution speeds
+
+Generally speaking: `drop` > `truncate` > `delete` (I have not actually tested this).
+
+- When the `delete` command is executed, the `binlog` log of the database will be generated. Logging takes time, but it also has the advantage of facilitating data rollback and recovery.
+- The `truncate` command does not generate database logs when executed, so it is faster than `delete`. In addition, the auto-increment value of the table and the index will be restored to the initial size, etc.
+- The `drop` command will release all the space occupied by the table.
+
+Tips: You should focus more on usage scenarios rather than execution efficiency.
+
+## What are the usual steps of database design?
+
+1. **Requirements Analysis**: Analyze user needs, including data, functional and performance requirements.
+2. **Conceptual Structure Design**: Mainly use E-R model for design, including drawing E-R diagram.
+3. **Logical structure design**: Realize the conversion from E-R model to relational model by converting E-R diagram into table.
+4. **Physical structure design**: Mainly to select the appropriate storage structure and access path for the designed database.
+5. **Database Implementation**: including programming, testing and trial operation
+6. **Database Operation and Maintenance**: System operation and daily maintenance of the database.
+
+## Reference
+
+-
+-
+-
+
+
\ No newline at end of file
diff --git a/docs_en/database/character-set.en.md b/docs_en/database/character-set.en.md
new file mode 100644
index 00000000000..439f2ae0dd4
--- /dev/null
+++ b/docs_en/database/character-set.en.md
@@ -0,0 +1,338 @@
+---
+title: 字符集详解
+category: 数据库
+tag:
+ - 数据库基础
+head:
+ - - meta
+ - name: keywords
+ content: 字符集,编码,UTF-8,UTF-16,GBK,utf8mb4,emoji,存储与传输
+ - - meta
+ - name: description
+ content: 从编码与字符集原理入手,解释 utf8 与 utf8mb4 差异与 emoji 存储问题,指导数据库与应用的正确配置。
+---
+
+MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4`**。
+
+如果使用 **`utf8`** 的话,存储 emoji 符号和一些比较复杂的汉字、繁体字就会出错。
+
+为什么会这样呢?这篇文章可以从源头给你解答。
+
+## 字符集是什么?
+
+字符是各种文字和符号的统称,包括各个国家文字、标点符号、表情、数字等等。 **字符集** 就是一系列字符的集合。字符集的种类较多,每个字符集可以表示的字符范围通常不同,就比如说有些字符集是无法表示汉字的。
+
+**计算机只能存储二进制的数据,那英文、汉字、表情等字符应该如何存储呢?**
+
+我们要将这些字符和二进制的数据一一对应起来,比如说字符“a”对应“01100001”,反之,“01100001”对应 “a”。我们将字符对应二进制数据的过程称为"**字符编码**",反之,二进制数据解析成字符的过程称为“**字符解码**”。
+
+## 字符编码是什么?
+
+字符编码是一种将字符集中的字符与计算机中的二进制数据相互转换的方法,可以看作是一种映射规则。也就是说,字符编码的目的是为了让计算机能够存储和传输各种文字信息。
+
+每种字符集都有自己的字符编码规则,常用的字符集编码规则有 ASCII 编码、 GB2312 编码、GBK 编码、GB18030 编码、Big5 编码、UTF-8 编码、UTF-16 编码等。
+
+## 有哪些常见的字符集?
+
+常见的字符集有:ASCII、GB2312、GB18030、GBK、Unicode……。
+
+不同的字符集的主要区别在于:
+
+- 可以表示的字符范围
+- 编码方式
+
+### ASCII
+
+**ASCII** (**A**merican **S**tandard **C**ode for **I**nformation **I**nterchange,美国信息交换标准代码) 是一套主要用于现代美国英语的字符集(这也是 ASCII 字符集的局限性所在)。
+
+**为什么 ASCII 字符集没有考虑到中文等其他字符呢?** 因为计算机是美国人发明的,当时,计算机的发展还处于比较雏形的时代,还未在其他国家大规模使用。因此,美国发布 ASCII 字符集的时候没有考虑兼容其他国家的语言。
+
+ASCII 字符集至今为止共定义了 128 个字符,其中有 33 个控制字符(比如回车、删除)无法显示。
+
+一个 ASCII 码长度是一个字节也就是 8 个 bit,比如“a”对应的 ASCII 码是“01100001”。不过,最高位是 0 仅仅作为校验位,其余 7 位使用 0 和 1 进行组合,所以,ASCII 字符集可以定义 128(2^7)个字符。
+
+由于,ASCII 码可以表示的字符实在是太少了。后来,人们对其进行了扩展得到了 **ASCII 扩展字符集** 。ASCII 扩展字符集使用 8 位(bits)表示一个字符,所以,ASCII 扩展字符集可以定义 256(2^8)个字符。
+
+
+
+### GB2312
+
+我们上面说了,ASCII 字符集是一种现代美国英语适用的字符集。因此,很多国家都捣鼓了一个适合自己国家语言的字符集。
+
+GB2312 字符集是一种对汉字比较友好的字符集,共收录 6700 多个汉字,基本涵盖了绝大部分常用汉字。不过,GB2312 字符集不支持绝大部分的生僻字和繁体字。
+
+对于英语字符,GB2312 编码和 ASCII 码是相同的,1 字节编码即可。对于非英字符,需要 2 字节编码。
+
+### GBK
+
+GBK 字符集可以看作是 GB2312 字符集的扩展,兼容 GB2312 字符集,共收录了 20000 多个汉字。
+
+GBK 中 K 是汉语拼音 Kuo Zhan(扩展)中的“Kuo”的首字母。
+
+### GB18030
+
+GB18030 完全兼容 GB2312 和 GBK 字符集,纳入中国国内少数民族的文字,且收录了日韩汉字,是目前为止最全面的汉字字符集,共收录汉字 70000 多个。
+
+### BIG5
+
+BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
+
+### Unicode & UTF-8
+
+为了更加适合本国语言,诞生了很多种字符集。
+
+我们上面也说了不同的字符集可以表示的字符范围以及编码规则存在差异。这就导致了一个非常严重的问题:**使用错误的编码方式查看一个包含字符的文件就会产生乱码现象。**
+
+就比如说你使用 UTF-8 编码方式打开 GB2312 编码格式的文件就会出现乱码。示例:“牛”这个汉字 GB2312 编码后的十六进制数值为 “C5A3”,而 “C5A3” 用 UTF-8 解码之后得到的却是 “ţ”。
+
+你可以通过这个网站在线进行编码和解码:
+
+
+
+这样我们就搞懂了乱码的本质:**编码和解码时用了不同或者不兼容的字符集** 。
+
+
+
+为了解决这个问题,人们就想:“如果我们能够有一种字符集将世界上所有的字符都纳入其中就好了!”。
+
+然后,**Unicode** 带着这个使命诞生了。
+
+Unicode 字符集中包含了世界上几乎所有已知的字符。不过,Unicode 字符集并没有规定如何存储这些字符(也就是如何使用二进制数据表示这些字符)。
+
+然后,就有了 **UTF-8**(**8**-bit **U**nicode **T**ransformation **F**ormat)。类似的还有 UTF-16、 UTF-32。
+
+UTF-8 使用 1 到 4 个字节为每个字符编码, UTF-16 使用 2 或 4 个字节为每个字符编码,UTF-32 固定位 4 个字节为每个字符编码。
+
+UTF-8 可以根据不同的符号自动选择编码的长短,像英文字符只需要 1 个字节就够了,这一点 ASCII 字符集一样 。因此,对于英语字符,UTF-8 编码和 ASCII 码是相同的。
+
+UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这类字符消耗的空间是 UTF-8 的 4 倍之多。
+
+**UTF-8** 是目前使用最广的一种字符编码。
+
+
+
+## MySQL 字符集
+
+MySQL 支持很多种字符集的方式,比如 GB2312、GBK、BIG5、多种 Unicode 字符集(UTF-8 编码、UTF-16 编码、UCS-2 编码、UTF-32 编码等等)。
+
+### 查看支持的字符集
+
+你可以通过 `SHOW CHARSET` 命令来查看,支持 like 和 where 子句。
+
+
+
+### 默认字符集
+
+在 MySQL5.7 中,默认字符集是 `latin1` ;在 MySQL8.0 中,默认字符集是 `utf8mb4`
+
+### 字符集的层次级别
+
+MySQL 中的字符集有以下的层次级别:
+
+- `server`(MySQL 实例级别)
+- `database`(库级别)
+- `table`(表级别)
+- `column`(字段级别)
+
+它们的优先级可以简单的认为是从上往下依次增大,也即 `column` 的优先级会大于 `table` 等其余层次的。如指定 MySQL 实例级别字符集是`utf8mb4`,指定某个表字符集是`latin1`,那么这个表的所有字段如果不指定的话,编码就是`latin1`。
+
+#### server
+
+不同版本的 MySQL 其 `server` 级别的字符集默认值不同,在 MySQL5.7 中,其默认值是 `latin1` ;在 MySQL8.0 中,其默认值是 `utf8mb4` 。
+
+当然也可以通过在启动 `mysqld` 时指定 `--character-set-server` 来设置 `server` 级别的字符集。
+
+```bash
+mysqld
+mysqld --character-set-server=utf8mb4
+mysqld --character-set-server=utf8mb4 \
+ --collation-server=utf8mb4_0900_ai_ci
+```
+
+Or if you are starting MySQL from source, you can specify options in the `cmake` command:
+
+```sh
+cmake .-DDEFAULT_CHARSET=latin1
+or
+cmake . -DDEFAULT_CHARSET=latin1 \
+ -DDEFAULT_COLLATION=latin1_german1_ci
+```
+
+In addition, you can also change the value of `character_set_server` at runtime to modify the `server` level character set.
+
+The `server` level character set is a global setting of the MySQL server. It will not only serve as the default character set when creating or modifying the database (if no other character set is specified), but also affects the connection character set between the client and the server. For details, see [MySQL Connector/J 8.0 - 6.7 Using Character Sets and Unicode](https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-charsets.html).
+
+#### database
+
+The `database` level character set is specified when we create and modify the database:
+
+```sql
+CREATE DATABASE db_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [[DEFAULT] COLLATE collation_name]
+
+ALTER DATABASE db_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [[DEFAULT] COLLATE collation_name]
+```
+
+As mentioned earlier, if no character set is specified when executing the above statement, MySQL will use the `server` level character set.
+
+You can check the character set of a database in the following way:
+
+```sql
+USE db_name;
+SELECT @@character_set_database, @@collation_database;
+```
+
+```sql
+SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
+FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name';
+```
+
+#### table
+
+The `table` level character set is specified when creating and modifying the table:
+
+```sql
+CREATE TABLE tbl_name (column_list)
+ [[DEFAULT] CHARACTER SET charset_name]
+ [COLLATE collation_name]]
+
+ALTER TABLE tbl_name
+ [[DEFAULT] CHARACTER SET charset_name]
+ [COLLATE collation_name]
+```
+
+If no character set is specified when creating and modifying tables, the `database` level character set will be used.
+
+#### column
+
+The `column` level character set is also specified when creating and modifying the table, but it is defined in the column. Here is an example:
+
+```sql
+CREATE TABLE t1
+(
+ col1 VARCHAR(5)
+ CHARACTER SET latin1
+ COLLATE latin1_german1_ci
+);
+```
+
+If a column-level character set is not specified, the table-level character set will be used.
+
+### Connection character set
+
+As mentioned earlier, the hierarchical levels of character sets are related to storage. The connection character set involves communication with the MySQL server.
+
+The connection character set is closely related to the following variables:
+
+- `character_set_client`: Describes the character set used by the SQL statement sent by the client to the server.
+- `character_set_connection`: Describes what character set the server uses for translation when it receives a SQL statement.
+- `character_set_results`: Describes what character set is used in the results returned by the server to the client.
+
+Their values can be queried through the following SQL statement:
+
+```sql
+SELECT * FROM performance_schema.session_variables
+WHERE VARIABLE_NAME IN (
+'character_set_client', 'character_set_connection',
+'character_set_results', 'collation_connection'
+) ORDER BY VARIABLE_NAME;
+```
+
+```sql
+SHOW SESSION VARIABLES LIKE 'character\_set\_%';
+```
+
+If you want to modify the values of the variables mentioned earlier, you have the following methods:
+
+1. Modify the configuration file
+
+```properties
+[mysql]
+# Only for MySQL client program
+default-character-set=utf8mb4
+```
+
+2. Use SQL statements
+
+```sql
+set names utf8mb4
+# Or modify them one by one
+# SET character_set_client = utf8mb4;
+# SET character_set_results = utf8mb4;
+# SET collation_connection = utf8mb4;
+```
+
+### Impact of JDBC on connection character sets
+
+I don’t know if you have ever encountered a situation where emoji expressions are stored normally, but when you use software like Navicat to query, you find that the emoji expressions turn into question marks. This problem is most likely caused by the JDBC driver.
+
+According to the previous content, we know that the connection character set will also affect the data we store, and the JDBC driver will affect the connection character set.
+
+`mysql-connector-java` (JDBC driver) mainly affects the connection character set through these properties:
+
+- `characterEncoding`
+- `characterSetResults`
+
+Taking `DataGrip 2023.1.2` as an example, in its advanced dialog box for configuring data sources, you can see that the default value of `characterSetResults` is `utf8`. When using `mysql-connector-java 8.0.25`, the connection character set will finally be set to `utf8mb3`. In this case, the emoji expression will be displayed as a question mark, and the current version of the driver does not support setting `characterSetResults` to `utf8mb4`, but it is allowed to change to `mysql-connector-java driver 8.0.29`.
+
+For details, please take a look at StackOverflow's answer [DataGrip MySQL stores emojis correctly but displays them as?](https://stackoverflow.com/questions/54815419/datagrip-mysql-stores-emojis-correctly-but-displays-them-as).
+
+### UTF-8 usage
+
+Normally, we recommend using UTF-8 as the default character encoding.
+
+However, there is a small pit here.
+
+There are two sets of UTF-8 encoding implementations in the MySQL character encoding set:
+
+- **`utf8`**: `utf8` encoding only supports `1-3` bytes. In `utf8` encoding, Chinese characters occupy 3 bytes, and other numbers, English, and symbols occupy one byte. However, emoji symbols occupy 4 bytes, and some more complex text and traditional Chinese characters also occupy 4 bytes.
+- **`utf8mb4`**: Complete implementation of UTF-8, genuine! Supports up to 4 bytes for character representation, so it can be used to store emoji symbols.
+
+**Why are there two sets of UTF-8 encoding implementations? **The reasons are as follows:
+
+
+
+Therefore, if you need to store `emoji` type data or some more complex text or traditional Chinese characters into the MySQL database, the database encoding must be specified as `utf8mb4` instead of `utf8`, otherwise an error will be reported when storing.
+
+Demonstrate it! (Environment: MySQL 5.7+)
+
+The table creation statement is as follows. We specify the database CHARSET as `utf8`.
+
+```sql
+CREATE TABLE `user` (
+ `id` varchar(66) CHARACTER SET utf8mb3 NOT NULL,
+ `name` varchar(33) CHARACTER SET utf8mb3 NOT NULL,
+ `phone` varchar(33) CHARACTER SET utf8mb3 DEFAULT NULL,
+ `password` varchar(100) CHARACTER SET utf8mb3 DEFAULT NULL
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+```
+
+When we execute the following insert statement to insert data into the database, an error is reported!
+
+```sql
+INSERT INTO `user` (`id`, `name`, `phone`, `password`)
+VALUES
+ ('A00003', 'guide brother😘😘😘', '181631312312', '123456');```
+
+The error message is as follows:
+
+```plain
+Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
+```
+
+## Reference
+
+-Charset & Encoding:
+- Understand the character set and character encoding in ten minutes:
+- Unicode-Wikipedia:
+- GB2312-Wikipedia:
+- UTF-8-Wikipedia:
+- GB18030-Wikipedia:
+- MySQL8 documentation:
+- MySQL5.7 documentation:
+- MySQL Connector/J documentation:
+
+
\ No newline at end of file
diff --git a/docs_en/database/elasticsearch/elasticsearch-questions-01.en.md b/docs_en/database/elasticsearch/elasticsearch-questions-01.en.md
new file mode 100644
index 00000000000..a801052566e
--- /dev/null
+++ b/docs_en/database/elasticsearch/elasticsearch-questions-01.en.md
@@ -0,0 +1,22 @@
+---
+title: Summary of common Elasticsearch interview questions (paid)
+category: database
+tag:
+ - NoSQL
+ - Elasticsearch
+head:
+ - - meta
+ - name: keywords
+ content: Elasticsearch interviews, indexing, sharding, inversion, query, aggregation, tuning
+ - - meta
+ - name: description
+ content: Contains Elasticsearch high-frequency interview questions and practical points, focusing on indexing/sharding/inversion and aggregation queries to form a system review list.
+---
+
+**Elasticsearch** The related interview questions are exclusive to my [Knowledge Planet](../../about-the-author/zhishixingqiu-two-years.md) (click the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide North"](../../zhuanlan/java-mian-shi-zhi-bei.md).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/database/mongodb/mongodb-questions-01.en.md b/docs_en/database/mongodb/mongodb-questions-01.en.md
new file mode 100644
index 00000000000..dfed4bd9e29
--- /dev/null
+++ b/docs_en/database/mongodb/mongodb-questions-01.en.md
@@ -0,0 +1,350 @@
+---
+title: MongoDB常见面试题总结(上)
+category: 数据库
+tag:
+ - NoSQL
+ - MongoDB
+head:
+ - - meta
+ - name: keywords
+ content: MongoDB 面试,文档存储,无模式,副本集,分片,索引,一致性
+ - - meta
+ - name: description
+ content: 汇总 MongoDB 基础与架构高频题,涵盖文档模型、索引、副本集与分片,强调高可用与一致性实践。
+---
+
+> 少部分内容参考了 MongoDB 官方文档的描述,在此说明一下。
+
+## MongoDB 基础
+
+### MongoDB 是什么?
+
+MongoDB 是一个基于 **分布式文件存储** 的开源 NoSQL 数据库系统,由 **C++** 编写的。MongoDB 提供了 **面向文档** 的存储方式,操作起来比较简单和容易,支持“**无模式**”的数据建模,可以存储比较复杂的数据类型,是一款非常流行的 **文档类型数据库** 。
+
+在高负载的情况下,MongoDB 天然支持水平扩展和高可用,可以很方便地添加更多的节点/实例,以保证服务性能和可用性。在许多场景下,MongoDB 可以用于代替传统的关系型数据库或键/值存储方式,皆在为 Web 应用提供可扩展的高可用高性能数据存储解决方案。
+
+### MongoDB 的存储结构是什么?
+
+MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三个单元组成:
+
+- **文档(Document)**:MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
+- **集合(Collection)**:一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
+- **数据库(Database)**:一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
+
+也就是说,MongoDB 将数据记录存储为文档 (更具体来说是[BSON 文档](https://www.mongodb.com/docs/manual/core/document/#std-label-bson-document-format)),这些文档在集合中聚集在一起,数据库中存储一个或多个文档集合。
+
+**SQL 与 MongoDB 常见术语对比**:
+
+| SQL | MongoDB |
+| ------------------------ | ------------------------------- |
+| 表(Table) | 集合(Collection) |
+| 行(Row) | 文档(Document) |
+| 列(Col) | 字段(Field) |
+| 主键(Primary Key) | 对象 ID(Objectid) |
+| 索引(Index) | 索引(Index) |
+| 嵌套表(Embedded Table) | 嵌入式文档(Embedded Document) |
+| 数组(Array) | 数组(Array) |
+
+#### 文档
+
+MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。字段的值可能包括其他文档、数组和文档数组。
+
+
+
+文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
+
+- 键不能含有 `\0`(空字符)。这个字符用来表示键的结尾。
+- `.` 和 `$` 有特别的意义,只有在特定环境下才能使用。
+- 以下划线`_`开头的键是保留的(不是严格要求的)。
+
+**BSON [bee·sahn]** 是 Binary [JSON](http://json.org/)的简称,是 JSON 文档的二进制表示,支持将文档和数组嵌入到其他文档和数组中,还包含允许表示不属于 JSON 规范的数据类型的扩展。有关 BSON 规范的内容,可以参考 [bsonspec.org](http://bsonspec.org/),另见[BSON 类型](https://www.mongodb.com/docs/manual/reference/bson-types/)。
+
+根据维基百科对 BJSON 的介绍,BJSON 的遍历速度优于 JSON,这也是 MongoDB 选择 BSON 的主要原因,但 BJSON 需要更多的存储空间。
+
+> 与 JSON 相比,BSON 着眼于提高存储和扫描效率。BSON 文档中的大型元素以长度字段为前缀以便于扫描。在某些情况下,由于长度前缀和显式数组索引的存在,BSON 使用的空间会多于 JSON。
+
+
+
+#### 集合
+
+MongoDB 集合存在于数据库中,**没有固定的结构**,也就是 **无模式** 的,这意味着可以往集合插入不同格式和类型的数据。不过,通常情况下,插入集合中的数据都会有一定的关联性。
+
+
+
+集合不需要事先创建,当第一个文档插入或者第一个索引创建时,如果该集合不存在,则会创建一个新的集合。
+
+集合名可以是满足下列条件的任意 UTF-8 字符串:
+
+- 集合名不能是空字符串`""`。
+- 集合名不能含有 `\0` (空字符),这个字符表示集合名的结尾。
+- 集合名不能以"system."开头,这是为系统集合保留的前缀。例如 `system.users` 这个集合保存着数据库的用户信息,`system.namespaces` 集合保存着所有数据库集合的信息。
+- 集合名必须以下划线或者字母符号开始,并且不能包含 `$`。
+
+#### 数据库
+
+数据库用于存储所有集合,而集合又用于存储所有文档。一个 MongoDB 中可以创建多个数据库,每一个数据库都有自己的集合和权限。
+
+MongoDB 预留了几个特殊的数据库。
+
+- **admin** : admin 数据库主要是保存 root 用户和角色。例如,system.users 表存储用户,system.roles 表存储角色。一般不建议用户直接操作这个数据库。将一个用户添加到这个数据库,且使它拥有 admin 库上的名为 dbAdminAnyDatabase 的角色权限,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如关闭服务器。
+- **local** : local 数据库是不会被复制到其他分片的,因此可以用来存储本地单台服务器的任意 collection。一般不建议用户直接使用 local 库存储任何数据,也不建议进行 CRUD 操作,因为数据无法被正常备份与恢复。
+- **config** : 当 MongoDB 使用分片设置时,config 数据库可用来保存分片的相关信息。
+- **test** : 默认创建的测试库,连接 [mongod](https://mongoing.com/docs/reference/program/mongod.html) 服务时,如果不指定连接的具体数据库,默认就会连接到 test 数据库。
+
+数据库名可以是满足以下条件的任意 UTF-8 字符串:
+
+- 不能是空字符串`""`。
+- 不得含有`' '`(空格)、`.`、`$`、`/`、`\`和 `\0` (空字符)。
+- 应全部小写。
+- 最多 64 字节。
+
+数据库名最终会变成文件系统里的文件,这也就是有如此多限制的原因。
+
+### MongoDB 有什么特点?
+
+- **数据记录被存储为文档**:MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
+- **模式自由**:集合的概念类似 MySQL 里的表,但它不需要定义任何模式,能够用更少的数据对象表现复杂的领域模型对象。
+- **支持多种查询方式**:MongoDB 查询 API 支持读写操作 (CRUD)以及数据聚合、文本搜索和地理空间查询。
+- **支持 ACID 事务**:NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。与关系型数据库一样,MongoDB 事务同样具有 ACID 特性。MongoDB 单文档原生支持原子性,也具备事务的特性。MongoDB 4.0 加入了对多文档事务的支持,但只支持复制集部署模式下的事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了分布式事务,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
+- **高效的二进制存储**:存储在集合中的文档,是以键值对的形式存在的。键用于唯一标识一个文档,一般是 ObjectId 类型,值是以 BSON 形式存在的。BSON = Binary JSON, 是在 JSON 基础上加了一些类型及元数据描述的格式。
+- **自带数据压缩功能**:存储同样的数据所需的资源更少。
+- **支持 mapreduce**:通过分治的方式完成复杂的聚合任务。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
+- **支持多种类型的索引**:MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
+- **支持 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+- **支持分片集群**:MongoDB 支持集群自动切分数据,让集群存储更多的数据,具备更强的性能。在数据插入和更新时,能够自动路由和存储。
+- **支持存储大文件**:MongoDB 的单文档存储空间要求不超过 16MB。对于超过 16MB 的大文件,MongoDB 提供了 GridFS 来进行存储,通过 GridFS,可以将大型数据进行分块处理,然后将这些切分后的小文档保存在数据库中。
+
+### MongoDB 适合什么应用场景?
+
+**MongoDB 的优势在于其数据模型和存储引擎的灵活性、架构的可扩展性以及对强大的索引支持。**
+
+选用 MongoDB 应该充分考虑 MongoDB 的优势,结合实际项目的需求来决定:
+
+- 随着项目的发展,使用类 JSON 格式(BSON)保存数据是否满足项目需求?MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
+- 是否需要大数据量的存储?是否需要快速水平扩展?MongoDB 支持分片集群,可以很方便地添加更多的节点(实例),让集群存储更多的数据,具备更强的性能。
+- 是否需要更多类型索引来满足更多应用场景?MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
+- ……
+
+## MongoDB 存储引擎
+
+### MongoDB 支持哪些存储引擎?
+
+存储引擎(Storage Engine)是数据库的核心组件,负责管理数据在内存和磁盘中的存储方式。
+
+与 MySQL 一样,MongoDB 采用的也是 **插件式的存储引擎架构** ,支持不同类型的存储引擎,不同的存储引擎解决不同场景的问题。在创建数据库或集合时,可以指定存储引擎。
+
+> 插件式的存储引擎架构可以实现 Server 层和存储引擎层的解耦,可以支持多种存储引擎,如 MySQL 既可以支持 B-Tree 结构的 InnoDB 存储引擎,还可以支持 LSM 结构的 RocksDB 存储引擎。
+
+在存储引擎刚出来的时候,默认是使用 MMAPV1 存储引擎,MongoDB4.x 版本不再支持 MMAPv1 存储引擎。
+
+现在主要有下面这两种存储引擎:
+
+- **WiredTiger 存储引擎**:自 MongoDB 3.2 以后,默认的存储引擎为 [WiredTiger 存储引擎](https://www.mongodb.com/docs/manual/core/wiredtiger/) 。非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩(后文会介绍到)等功能。
+- **In-Memory 存储引擎**:[In-Memory 存储引擎](https://www.mongodb.com/docs/manual/core/inmemory/)在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
+
+此外,MongoDB 3.0 提供了 **可插拔的存储引擎 API** ,允许第三方为 MongoDB 开发存储引擎,这点和 MySQL 也比较类似。
+
+### WiredTiger 基于 LSM Tree 还是 B+ Tree?
+
+目前绝大部分流行的数据库存储引擎都是基于 B/B+ Tree 或者 LSM(Log Structured Merge) Tree 来实现的。对于 NoSQL 数据库来说,绝大部分(比如 HBase、Cassandra、RocksDB)都是基于 LSM 树,MongoDB 不太一样。
+
+上面也说了,自 MongoDB 3.2 以后,默认的存储引擎为 WiredTiger 存储引擎。在 WiredTiger 引擎官网上,我们发现 WiredTiger 使用的是 B+ 树作为其存储结构:
+
+```plain
+WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
+```
+
+此外,WiredTiger 还支持 [LSM(Log Structured Merge)](https://source.wiredtiger.com/3.1.0/lsm.html) 树作为存储结构,MongoDB 在使用 WiredTiger 作为存储引擎时,默认使用的是 B+ 树。
+
+如果想要了解 MongoDB 使用 B+ 树的原因,可以看看这篇文章:[【驳斥八股文系列】别瞎分析了,MongoDB 使用的是 B+ 树,不是你们以为的 B 树](https://zhuanlan.zhihu.com/p/519658576)。
+
+使用 B+ 树时,WiredTiger 以 **page** 为基本单位往磁盘读写数据。B+ 树的每个节点为一个 page,共有三种类型的 page:
+
+- **root page(根节点)**:B+ 树的根节点。
+- **internal page(内部节点)**:不实际存储数据的中间索引节点。
+- **leaf page(叶子节点)**:真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
+
+其整体结构如下图所示:
+
+
+
+如果想要深入研究学习 WiredTiger 存储引擎,推荐阅读 MongoDB 中文社区的 [WiredTiger 存储引擎系列](https://mongoing.com/archives/category/wiredtiger%e5%ad%98%e5%82%a8%e5%bc%95%e6%93%8e%e7%b3%bb%e5%88%97)。
+
+## MongoDB 聚合
+
+### MongoDB 聚合有什么用?
+
+实际项目中,我们经常需要将多个文档甚至是多个集合汇总到一起计算分析(比如求和、取最大值)并返回计算后的结果,这个过程被称为 **聚合操作** 。
+
+根据官方文档介绍,我们可以使用聚合操作来:
+
+- 将来自多个文档的值组合在一起。
+- 对集合中的数据进行的一系列运算。
+- 分析数据随时间的变化。
+
+### MongoDB 提供了哪几种执行聚合的方法?
+
+MongoDB 提供了两种执行聚合的方法:
+
+- **聚合管道(Aggregation Pipeline)**:执行聚合操作的首选方法。
+- **单一目的聚合方法(Single purpose aggregation methods)**:也就是单一作用的聚合函数比如 `count()`、`distinct()`、`estimatedDocumentCount()`。
+
+绝大部分文章中还提到了 **map-reduce** 这种聚合方法。不过,从 MongoDB 5.0 开始,map-reduce 已经不被官方推荐使用了,替代方案是 [聚合管道](https://www.mongodb.com/docs/manual/core/aggregation-pipeline/)。聚合管道提供比 map-reduce 更好的性能和可用性。
+
+MongoDB 聚合管道由多个阶段组成,每个阶段在文档通过管道时转换文档。每个阶段接收前一个阶段的输出,进一步处理数据,并将其作为输入数据发送到下一个阶段。
+
+每个管道的工作流程是:
+
+1. 接受一系列原始数据文档
+2. 对这些文档进行一系列运算
+3. 结果文档输出给下一个阶段
+
+
+
+**常用阶段操作符**:
+
+| 操作符 | 简述 |
+| --------- | ---------------------------------------------------------------------------------------------------- |
+| \$match | 匹配操作符,用于对文档集合进行筛选 |
+| \$project | 投射操作符,用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段 |
+| \$sort | 排序操作符,用于根据一个或多个字段对文档进行排序 |
+| \$limit | 限制操作符,用于限制返回文档的数量 |
+| \$skip | 跳过操作符,用于跳过指定数量的文档 |
+| \$count | 统计操作符,用于统计文档的数量 |
+| \$group | 分组操作符,用于对文档集合进行分组 |
+| \$unwind | 拆分操作符,用于将数组中的每一个值拆分为单独的文档 |
+| \$lookup | 连接操作符,用于连接同一个数据库中另一个集合,并获取指定的文档,类似于 populate |
+
+更多操作符介绍详见官方文档:
+
+阶段操作符用于 `db.collection.aggregate` 方法里面,数组参数中的第一层。
+
+```sql
+db.collection.aggregate( [ { 阶段操作符:表述 }, { 阶段操作符:表述 }, ... ] )
+```
+
+下面是 MongoDB 官方文档中的一个例子:
+
+```sql
+db.orders.aggregate([
+ # 第一阶段:$match阶段按status字段过滤文档,并将status等于"A"的文档传递到下一阶段。
+ { $match: { status: "A" } },
+ # 第二阶段:$group阶段按cust_id字段将文档分组,以计算每个cust_id唯一值的金额总和。
+ { $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
+])
+```
+
+## MongoDB 事务
+
+> MongoDB 事务想要搞懂原理还是比较花费时间的,我自己也没有搞太明白。因此,我这里只是简单介绍一下 MongoDB 事务,想要了解原理的小伙伴,可以自行搜索查阅相关资料。
+>
+> 这里推荐几篇文章,供大家参考:
+>
+> - [技术干货| MongoDB 事务原理](https://mongoing.com/archives/82187)
+> - [MongoDB 一致性模型设计与实现](https://developer.aliyun.com/article/782494)
+> - [MongoDB 官方文档对事务的介绍](https://www.mongodb.com/docs/upcoming/core/transactions/)
+
+我们在介绍 NoSQL 数据的时候也说过,NoSQL 数据库通常不支持事务,为了可扩展和高性能进行了权衡。不过,也有例外,MongoDB 就支持事务。
+
+与关系型数据库一样,MongoDB 事务同样具有 ACID 特性:
+
+- **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+- **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
+- **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持读未提交( read-uncommitted )、读已提交( read-committed )和快照( snapshot )隔离,MongoDB 启动时默认选快照隔离。在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
+- **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+关于事务的详细介绍这篇文章就不多说了,感兴趣的可以看看我写的[MySQL 常见面试题总结](../mysql/mysql-questions-01.md)这篇文章,里面有详细介绍到。
+
+MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 MongoDB 事务的时候,通常指的是 **多文档** 。MongoDB 4.0 加入了对多文档 ACID 事务的支持,但只支持复制集部署模式下的 ACID 事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了 **分布式事务** ,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
+
+根据官方文档介绍:
+
+> 从 MongoDB 4.2 开始,分布式事务和多文档事务在 MongoDB 中是一个意思。分布式事务是指分片集群和副本集上的多文档事务。从 MongoDB 4.2 开始,多文档事务(无论是在分片集群还是副本集上)也称为分布式事务。
+
+在大多数情况下,多文档事务比单文档写入会产生更大的性能成本。对于大部分场景来说, [非规范化数据模型(嵌入式文档和数组)](https://www.mongodb.com/docs/upcoming/core/data-model-design/#std-label-data-modeling-embedding) 依然是最佳选择。也就是说,适当地对数据进行建模可以最大限度地减少对多文档事务的需求。
+
+**注意**:
+
+- 从 MongoDB 4.2 开始,多文档事务支持副本集和分片集群,其中:主节点使用 WiredTiger 存储引擎,同时从节点使用 WiredTiger 存储引擎或 In-Memory 存储引擎。在 MongoDB 4.0 中,只有使用 WiredTiger 存储引擎的副本集支持事务。
+- 在 MongoDB 4.2 及更早版本中,你无法在事务中创建集合。从 MongoDB 4.4 开始,您可以在事务中创建集合和索引。有关详细信息,请参阅 [在事务中创建集合和索引](https://www.mongodb.com/docs/upcoming/core/transactions/#std-label-transactions-create-collections-indexes)。
+
+## MongoDB 数据压缩
+
+借助 WiredTiger 存储引擎( MongoDB 3.2 后的默认存储引擎),MongoDB 支持对所有集合和索引进行压缩。压缩以额外的 CPU 为代价最大限度地减少存储使用。
+
+By default, WiredTiger uses the [Snappy](https://github.com/google/snappy) compression algorithm (open sourced by Google, designed to achieve very high speed and reasonable compression, with a compression ratio of 3 to 5 times) using block compression for all collections and prefix compression for all indexes.
+
+In addition to Snappy, there are the following compression algorithms for collections:
+
+- [zlib](https://github.com/madler/zlib): Highly compressed algorithm, compression ratio 5 to 7 times
+- [Zstandard](https://github.com/facebook/zstd) (zstd for short): A fast lossless compression algorithm open sourced by Facebook. It provides higher compression rate and lower CPU usage for zlib-level real-time compression scenarios and better compression ratio. It is available in MongoDB 4.2.
+
+WiredTiger logs are also compressed, using the Snappy compression algorithm by default. If a log record is less than or equal to 128 bytes, WiredTiger does not compress the record.
+
+## Differences between Amazon Document and MongoDB
+
+Amazon DocumentDB (compatible with MongoDB) is a fast, reliable, fully managed database service. Amazon DocumentDB makes it easy to set up, operate, and scale MongoDB-compatible databases in the cloud.
+
+### `$vectorSearch` operator
+
+Amazon DocumentDB does not support `$vectorSearch` as a standalone operator. Instead, we support `vectorSearch` internally in the `$search` operator. For more information, see Vector Search Amazon DocumentDB(https://docs.aws.amazon.com/zh_cn/documentdb/latest/developerguide/vector-search.html).
+
+### `OpCountersCommand`
+
+The behavior of Amazon DocumentDB's `OpCountersCommand` deviates from MongoDB's `opcounters.command` as follows:
+
+- MongoDB's `opcounters.command` counts all commands except inserts, updates, and deletes, while Amazon DocumentDB's `OpCountersCommand` also excludes `find` commands.
+- Amazon DocumentDB counts internal commands (such as `getCloudWatchMetricsV2`) against `OpCountersCommand`.
+
+### Manage databases and collections
+
+Amazon DocumentDB does not support managed or local databases, nor the MongoDB `system.*` or `startup_log` collections.
+
+### `cursormaxTimeMS`
+
+In Amazon DocumentDB, `cursor.maxTimeMS` resets the counter for each request. `getMore` So if `maxTimeMS` of 3000MS is specified and the query takes 2800MS and each subsequent `getMore` request takes 300MS, the cursor will not time out. The cursor will timeout `maxTimeMS` only if a single operation (either a query or a single `getMore` request) takes longer than the specified value. In addition, the scanner that checks cursor execution time runs at a five (5) minute interval size.
+
+### explain()
+
+Amazon DocumentDB emulates the MongoDB 4.0 API on a purpose-built database engine that leverages a distributed, fault-tolerant, self-healing storage system. Therefore, query plans and the output of explain() may differ between Amazon DocumentDB and MongoDB. Customers wishing to control their query plans can use the `$hint` operator to force a preferred index.
+
+### Field name restrictions
+
+Amazon DocumentDB does not support dot "." for example, `db.foo.insert({‘x.1':1})` in document field names.
+
+Amazon DocumentDB also does not support the $ prefix in field names.
+
+For example, try the following commands in Amazon DocumentDB or MongoDB:
+
+```shell
+rs0:PRIMARY< db.foo.insert({"a":{"$a":1}})
+```
+
+MongoDB will return the following:
+
+```shell
+WriteResult({ "nInserted" : 1 })
+```
+
+Amazon DocumentDB will return an error:
+
+```shell
+WriteResult({
+ "nInserted" : 0,
+ "writeError" : {
+ "code": 2,
+ "errmsg" : "Document can't have $ prefix field names: $a"
+ }
+})
+```
+
+## Reference
+
+- MongoDB official documents (main reference materials, subject to official documents):
+- "The Definitive Guide to MongoDB"
+- Technical information | MongoDB transaction principles - MongoDB Chinese community:
+- Transactions - MongoDB official documentation:
+- WiredTiger Storage Engine - MongoDB official documentation:
+- One of WiredTiger storage engines: basic data structure analysis:
+
+
\ No newline at end of file
diff --git a/docs_en/database/mongodb/mongodb-questions-02.en.md b/docs_en/database/mongodb/mongodb-questions-02.en.md
new file mode 100644
index 00000000000..cecb3ae48df
--- /dev/null
+++ b/docs_en/database/mongodb/mongodb-questions-02.en.md
@@ -0,0 +1,282 @@
+---
+title: MongoDB常见面试题总结(下)
+category: 数据库
+tag:
+ - NoSQL
+ - MongoDB
+head:
+ - - meta
+ - name: keywords
+ content: MongoDB 索引,复合索引,多键索引,文本索引,地理索引,查询优化
+ - - meta
+ - name: description
+ content: 讲解 MongoDB 常见索引类型与适用场景,结合查询优化与写入开销权衡,提升检索性能与稳定性。
+---
+
+## MongoDB 索引
+
+### MongoDB 索引有什么用?
+
+和关系型数据库类似,MongoDB 中也有索引。索引的目的主要是用来提高查询效率,如果没有索引的话,MongoDB 必须执行 **集合扫描** ,即扫描集合中的每个文档,以选择与查询语句匹配的文档。如果查询存在合适的索引,MongoDB 可以使用该索引来限制它必须检查的文档数量。并且,MongoDB 可以使用索引中的排序返回排序后的结果。
+
+虽然索引可以显著缩短查询时间,但是使用索引、维护索引是有代价的。在执行写入操作时,除了要更新文档之外,还必须更新索引,这必然会影响写入的性能。因此,当有大量写操作而读操作少时,或者不考虑读操作的性能时,都不推荐建立索引。
+
+### MongoDB 支持哪些类型的索引?
+
+**MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。**
+
+- **单字段索引:** 建立在单个字段上的索引,索引创建的排序顺序无所谓,MongoDB 可以头/尾开始遍历。
+- **复合索引:** 建立在多个字段上的索引,也可以称之为组合索引、联合索引。
+- **多键索引**:MongoDB 的一个字段可能是数组,在对这种字段创建索引时,就是多键索引。MongoDB 会为数组的每个值创建索引。就是说你可以按照数组里面的值做条件来查询,这个时候依然会走索引。
+- **哈希索引**:按数据的哈希值索引,用在哈希分片集群上。
+- **文本索引:** 支持对字符串内容的文本搜索查询。文本索引可以包含任何值为字符串或字符串元素数组的字段。一个集合只能有一个文本搜索索引,但该索引可以覆盖多个字段。MongoDB 虽然支持全文索引,但是性能低下,暂时不建议使用。
+- **地理位置索引:** 基于经纬度的索引,适合 2D 和 3D 的位置查询。
+- **唯一索引**:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
+- **TTL 索引**:TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
+- ……
+
+### 复合索引中字段的顺序有影响吗?
+
+复合索引中字段的顺序非常重要,例如下图中的复合索引由`{userid:1, score:-1}`组成,则该复合索引首先按照`userid`升序排序;然后再每个`userid`的值内,再按照`score`降序排序。
+
+
+
+在复合索引中,按照何种方式排序,决定了该索引在查询中是否能被应用到。
+
+走复合索引的排序:
+
+```sql
+db.s2.find().sort({"userid": 1, "score": -1})
+db.s2.find().sort({"userid": -1, "score": 1})
+```
+
+不走复合索引的排序:
+
+```sql
+db.s2.find().sort({"userid": 1, "score": 1})
+db.s2.find().sort({"userid": -1, "score": -1})
+db.s2.find().sort({"score": 1, "userid": -1})
+db.s2.find().sort({"score": 1, "userid": 1})
+db.s2.find().sort({"score": -1, "userid": -1})
+db.s2.find().sort({"score": -1, "userid": 1})
+```
+
+我们可以通过 explain 进行分析:
+
+```sql
+db.s2.find().sort({"score": -1, "userid": 1}).explain()
+```
+
+### 复合索引遵循左前缀原则吗?
+
+**MongoDB 的复合索引遵循左前缀原则**:拥有多个键的索引,可以同时得到所有这些键的前缀组成的索引,但不包括除左前缀之外的其他子集。比如说,有一个类似 `{a: 1, b: 1, c: 1, ..., z: 1}` 这样的索引,那么实际上也等于有了 `{a: 1}`、`{a: 1, b: 1}`、`{a: 1, b: 1, c: 1}` 等一系列索引,但是不会有 `{b: 1}` 这样的非左前缀的索引。
+
+### 什么是 TTL 索引?
+
+TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间 `expireAfterSeconds` ,当一个文档达到预设的过期时间之后就会被删除。TTL 索引除了有 `expireAfterSeconds` 属性外,和普通索引一样。
+
+数据过期对于某些类型的信息很有用,比如机器生成的事件数据、日志和会话信息,这些信息只需要在数据库中保存有限的时间。
+
+**TTL 索引运行原理**:
+
+- MongoDB 会开启一个后台线程读取该 TTL 索引的值来判断文档是否过期,但不会保证已过期的数据会立马被删除,因后台线程每 60 秒触发一次删除任务,且如果删除的数据量较大,会存在上一次的删除未完成,而下一次的任务已经开启的情况,导致过期的数据也会出现超过了数据保留时间 60 秒以上的现象。
+- 对于副本集而言,TTL 索引的后台进程只会在 Primary 节点开启,在从节点会始终处于空闲状态,从节点的数据删除是由主库删除后产生的 oplog 来做同步。
+
+**TTL 索引限制**:
+
+- TTL 索引是单字段索引。复合索引不支持 TTL
+- `_id`字段不支持 TTL 索引。
+- 无法在上限集合(Capped Collection)上创建 TTL 索引,因为 MongoDB 无法从上限集合中删除文档。
+- 如果某个字段已经存在非 TTL 索引,那么在该字段上无法再创建 TTL 索引。
+
+### 什么是覆盖索引查询?
+
+根据官方文档介绍,覆盖查询是以下的查询:
+
+- 所有的查询字段是索引的一部分。
+- 结果中返回的所有字段都在同一索引中。
+- 查询中没有字段等于`null`。
+
+由于所有出现在查询中的字段是索引的一部分, MongoDB 无需在整个数据文档中检索匹配查询条件和返回使用相同索引的查询结果。因为索引存在于内存中,从索引中获取数据比通过扫描文档读取数据要快得多。
+
+举个例子:我们有如下 `users` 集合:
+
+```json
+{
+ "_id": ObjectId("53402597d852426020000002"),
+ "contact": "987654321",
+ "dob": "01-01-1991",
+ "gender": "M",
+ "name": "Tom Benzamin",
+ "user_name": "tombenzamin"
+}
+```
+
+我们在 `users` 集合中创建联合索引,字段为 `gender` 和 `user_name` :
+
+```sql
+db.users.ensureIndex({gender:1,user_name:1})
+```
+
+现在,该索引会覆盖以下查询:
+
+```sql
+db.users.find({gender:"M"},{user_name:1,_id:0})
+```
+
+为了让指定的索引覆盖查询,必须显式地指定 `_id: 0` 来从结果中排除 `_id` 字段,因为索引不包括 `_id` 字段。
+
+## MongoDB 高可用
+
+### 复制集群
+
+#### 什么是复制集群?
+
+MongoDB 的复制集群又称为副本集群,是一组维护相同数据集合的 mongod 进程。
+
+客户端连接到整个 Mongodb 复制集群,主节点机负责整个复制集群的写,从节点可以进行读操作,但默认还是主节点负责整个复制集群的读。主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+
+通常来说,一个复制集群包含 1 个主节点(Primary),多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)。
+
+- **主节点**:整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
+- **从节点**:从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
+- **仲裁节点**:这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
+
+下图是一个典型的三成员副本集群:
+
+
+
+主节点与备节点之间是通过 **oplog(操作日志)** 来同步数据的。oplog 是 local 库下的一个特殊的 **上限集合(Capped Collection)** ,用来保存写操作所产生的增量日志,类似于 MySQL 中 的 Binlog。
+
+> 上限集合类似于定长的循环队列,数据顺序追加到集合的尾部,当集合空间达到上限时,它会覆盖集合中最旧的文档。上限集合的数据将会被顺序写入到磁盘的固定空间内,所以,I/O 速度非常快,如果不建立索引,性能更好。
+
+
+
+当主节点上的一个写操作完成后,会向 oplog 集合写入一条对应的日志,而从节点则通过这个 oplog 不断拉取到新的日志,在本地进行回放以达到数据同步的目的。
+
+副本集最多有一个主节点。 如果当前主节点不可用,一个选举会抉择出新的主节点。MongoDB 的节点选举规则能够保证在 Primary 挂掉之后选取的新节点一定是集群中数据最全的一个。
+
+#### 为什么要用复制集群?
+
+- **实现 failover**:提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
+- **实现读写分离**:我们可以设置从节点上可以读取数据,主节点负责写入数据,这样的话就实现了读写分离,减轻了主节点读写压力过大的问题。MongoDB 4.0 之前版本如果主库压力不大,不建议读写分离,因为写会阻塞读,除非业务对响应时间不是非常关注以及读取历史数据接受一定时间延迟。
+
+### 分片集群
+
+#### 什么是分片集群?
+
+分片集群是 MongoDB 的分布式版本,相较副本集,分片集群数据被均衡的分布在不同分片中, 不仅大幅提升了整个集群的数据容量上限,也将读写的压力分散到不同分片,以解决副本集性能瓶颈的难题。
+
+MongoDB 的分片集群由如下三个部分组成(下图来源于[官方文档对分片集群的介绍](https://www.mongodb.com/docs/manual/sharding/)):
+
+
+
+- **Config Servers**:配置服务器,本质上是一个 MongoDB 的副本集,负责存储集群的各种元数据和配置,如分片地址、Chunks 等
+- **Mongos**:路由服务,不存具体数据,从 Config 获取集群配置讲请求转发到特定的分片,并且整合分片结果返回给客户端。
+- **Shard**:每个分片是整体数据的一部分子集,从 MongoDB3.6 版本开始,每个 Shard 必须部署为副本集(replica set)架构
+
+#### 为什么要用分片集群?
+
+随着系统数据量以及吞吐量的增长,常见的解决办法有两种:垂直扩展和水平扩展。
+
+垂直扩展通过增加单个服务器的能力来实现,比如磁盘空间、内存容量、CPU 数量等;水平扩展则通过将数据存储到多个服务器上来实现,根据需要添加额外的服务器以增加容量。
+
+类似于 Redis Cluster,MongoDB 也可以通过分片实现 **水平扩展** 。水平扩展这种方式更灵活,可以满足更大数据量的存储需求,支持更高吞吐量。并且,水平扩展所需的整体成本更低,仅仅需要相对较低配置的单机服务器即可,代价是增加了部署的基础设施和维护的复杂性。
+
+也就是说当你遇到如下问题时,可以使用分片集群解决:
+
+- 存储容量受单机限制,即磁盘资源遭遇瓶颈。
+- 读写能力受单机限制,可能是 CPU、内存或者网卡等资源遭遇瓶颈,导致读写能力无法扩展。
+
+#### 什么是分片键?
+
+**分片键(Shard Key)** 是数据分区的前提, 从而实现数据分发到不同服务器上,减轻服务器的负担。也就是说,分片键决定了集合内的文档如何在集群的多个分片间的分布状况。
+
+分片键就是文档里面的一个字段,但是这个字段不是普通的字段,有一定的要求:
+
+- 它必须在所有文档中都出现。
+- 它必须是集合的一个索引,可以是单索引或复合索引的前缀索引,不能是多索引、文本索引或地理空间位置索引。
+- MongoDB 4.2 之前的版本,文档的分片键字段值不可变。MongoDB 4.2 版本开始,除非分片键字段是不可变的 `_id` 字段,否则您可以更新文档的分片键值。MongoDB 5.0 版本开始,实现了实时重新分片(live resharding),可以实现分片键的完全重新选择。
+- 它的大小不能超过 512 字节。
+
+#### 如何选择分片键?
+
+选择合适的片键对 sharding 效率影响很大,主要基于如下四个因素(摘自[分片集群使用注意事项 - - 腾讯云文档](https://cloud.tencent.com/document/product/240/44611)):
+
+- **取值基数** 取值基数建议尽可能大,如果用小基数的片键,因为备选值有限,那么块的总数量就有限,随着数据增多,块的大小会越来越大,导致水平扩展时移动块会非常困难。 例如:选择年龄做一个基数,范围最多只有 100 个,随着数据量增多,同一个值分布过多时,导致 chunck 的增长超出 chuncksize 的范围,引起 jumbo chunk,从而无法迁移,导致数据分布不均匀,性能瓶颈。
+- **取值分布** 取值分布建议尽量均匀,分布不均匀的片键会造成某些块的数据量非常大,同样有上面数据分布不均匀,性能瓶颈的问题。
+- **查询带分片** 查询时建议带上分片,使用分片键进行条件查询时,mongos 可以直接定位到具体分片,否则 mongos 需要将查询分发到所有分片,再等待响应返回。
+- **避免单调递增或递减** 单调递增的 sharding key,数据文件挪动小,但写入会集中,导致最后一篇的数据量持续增大,不断发生迁移,递减同理。
+
+综上,在选择片键时要考虑以上 4 个条件,尽可能满足更多的条件,才能降低 MoveChunks 对性能的影响,从而获得最优的性能体验。
+
+#### 分片策略有哪些?
+
+MongoDB 支持两种分片算法来满足不同的查询需求(摘自[MongoDB 分片集群介绍 - 阿里云文档](https://help.aliyun.com/document_detail/64561.html?spm=a2c4g.11186623.0.0.3121565eQhUGGB#h2--shard-key-3)):
+
+**1、基于范围的分片**:
+
+
+
+MongoDB 按照分片键(Shard Key)的值的范围将数据拆分为不同的块(Chunk),每个块包含了一段范围内的数据。当分片键的基数大、频率低且值非单调变更时,范围分片更高效。
+
+- 优点:Mongos 可以快速定位请求需要的数据,并将请求转发到相应的 Shard 节点中。
+- 缺点:可能导致数据在 Shard 节点上分布不均衡,容易造成读写热点,且不具备写分散性。
+- 适用场景:分片键的值不是单调递增或单调递减、分片键的值基数大且重复的频率低、需要范围查询等业务场景。
+
+**2、基于 Hash 值的分片**
+
+
+
+MongoDB 计算单个字段的哈希值作为索引值,并以哈希值的范围将数据拆分为不同的块(Chunk)。
+
+- 优点:可以将数据更加均衡地分布在各 Shard 节点中,具备写分散性。
+- 缺点:不适合进行范围查询,进行范围查询时,需要将读请求分发到所有的 Shard 节点。
+- 适用场景:分片键的值存在单调递增或递减、片键的值基数大且重复的频率低、需要写入的数据随机分发、数据读取随机性较大等业务场景。
+
+除了上述两种分片策略,您还可以配置 **复合片键** ,例如由一个低基数的键和一个单调递增的键组成。
+
+#### 分片数据如何存储?
+
+**Chunk(块)** 是 MongoDB 分片集群的一个核心概念,其本质上就是由一组 Document 组成的逻辑数据单元。每个 Chunk 包含一定范围片键的数据,互不相交且并集为全部数据,即离散数学中**划分**的概念。
+
+分片集群不会记录每条数据在哪个分片上,而是记录 Chunk 在哪个分片上一级这个 Chunk 包含哪些数据。
+
+By default, the maximum size of a Chunk is 64MB (adjustable, the value range is 1~1024 MB. If there are no special requirements, it is recommended to keep the default value). When inserting, updating, or deleting data, if Mongos senses the size of the target Chunk or the amount of data in it exceeds the upper limit, **Chunk split** will be triggered.
+
+
+
+The growth of data will cause more and more chunks to be split. At this time, the number of Chunks on each shard may be unbalanced. The **Balancer** component in Mongos will perform automatic balancing and try to balance the number of Chunks on each Shard. This process is **Rebalance**. By default, Rebalance for databases and collections is turned on.
+
+As shown in the figure below, as data is inserted, the chunks are split, so that the two shards AB have three chunks and the C shard has only one. At this time, one allocated by B will be migrated to the C shard to achieve cluster data balance.
+
+
+
+> Balancer is a background process of MongoDB that runs on the Primary node of Config Server (since MongoDB version 3.4). It monitors the number of Chunks on each shard and migrates them when the number of Chunks on a certain shard reaches a threshold.
+
+Chunks will only be split, not merged, even if the value of chunkSize becomes larger.
+
+The Rebalance operation consumes system resources. We can reduce its impact on the normal use of MongoDB by executing it during low business peak periods, pre-sharding, or setting the Rebalance time window.
+
+#### What is the principle of Chunk migration?
+
+For a detailed introduction to the principles of chunk migration, it is recommended to read the article [Understanding MongoDB chunk migration in one article] (https://mongoing.com/archives/77479) from the MongoDB Chinese community.
+
+## Recommended learning materials
+
+- [MongoDB Chinese Manual|Official Document Chinese Version](https://docs.mongoing.com/) (recommended): Based on version 4.2, it is constantly synchronized with the latest official version.
+- [MongoDB Beginner Tutorial - 7 Days to Learn MongoDB](https://mongoing.com/archives/docs/mongodb%e5%88%9d%e5%ad%a6%e8%80%85%e6%95%99%e7%a8%8b/mon godb%e5%a6%82%e4%bd%95%e5%88%9b%e5%bb%ba%e6%95%b0%e6%8d%ae%e5%ba%93%e5%92%8c%e9%9b%86%e5%90%88): Quick start.
+- [SpringBoot integrates MongoDB in practice - 2022](https://www.cnblogs.com/dxflqm/p/16643981.html): A very good introductory article to MongoDB, which mainly focuses on the use of MongoDB's Java client to introduce basic addition, deletion, modification and query operations.
+
+## Reference
+
+- MongoDB official documents (main reference materials, subject to official documents):
+- "The Definitive Guide to MongoDB"
+- Indexes - MongoDB official documentation:
+- MongoDB - Index Knowledge - Programmer Xiang Zai - 2022:
+- MongoDB - Index:
+- Sharding - MongoDB official documentation:
+- Introduction to MongoDB sharded cluster - Alibaba Cloud Document:
+- Precautions for using sharded clusters - - Tencent Cloud Document:
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/a-thousand-lines-of-mysql-study-notes.en.md b/docs_en/database/mysql/a-thousand-lines-of-mysql-study-notes.en.md
new file mode 100644
index 00000000000..44b18758932
--- /dev/null
+++ b/docs_en/database/mysql/a-thousand-lines-of-mysql-study-notes.en.md
@@ -0,0 +1,962 @@
+---
+title: One Thousand Lines of MySQL Study Notes
+category: database
+tag:
+ -MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL notes, tuning, indexing, transactions, tools, experience summary, practice
+ - - meta
+ - name: description
+ content: Organizes thousands of lines of notes on MySQL learning and practice, condensing tuning ideas, indexing and transaction key points, and tool usage for quick reference and review.
+---
+
+> Original address: , JavaGuide has simplified the layout of this article and added a new table of contents.
+
+A very good summary, I strongly recommend saving it and reading it when needed.
+
+### Basic operations
+
+```sql
+/* Windows service */
+-- Start MySQL
+ net start mysql
+-- Create a Windows service
+ sc create mysql binPath= mysqld_bin_path (note: there is a space between the equal sign and the value)
+/* Connect and disconnect from server */
+-- Connect to MySQL
+ mysql -h address -P port -u username -p password
+-- Show which threads are running
+ SHOW PROCESSLIST
+-- Display system variable information
+ SHOW VARIABLES
+```
+
+### Database operations
+
+```sql
+/* Database operations */
+-- View the current database
+ SELECT DATABASE();
+-- Display the current time, user name, and database version
+ SELECT now(), user(), version();
+--Create library
+ CREATE DATABASE[IF NOT EXISTS] database name database options
+ Database options:
+ CHARACTER SET charset_name
+ COLLATE collation_name
+-- View existing libraries
+ SHOW DATABASES[ LIKE 'PATTERN']
+-- View current library information
+ SHOW CREATE DATABASE database name
+-- Modify library option information
+ ALTER DATABASE library name option information
+-- Delete library
+ DROP DATABASE[IF EXISTS] database name
+ Delete the directory related to the database and its directory contents at the same time
+```
+
+### Table operations
+
+```sql
+/* Table operations */
+--Create table
+ CREATE [TEMPORARY] TABLE[ IF NOT EXISTS] [Library name.] Table name (structure definition of the table) [Table options]
+ Each field must have a data type
+ There cannot be a comma after the last field
+ TEMPORARY temporary table, the table automatically disappears when the session ends
+ For field definition:
+ Field name Data type [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
+-- table options
+ --Character set
+ CHARSET = charset_name
+ If the table is not set, the database character set is used
+ -- storage engine
+ ENGINE = engine_name
+ Tables use different data structures when managing data. Different structures will lead to different processing methods and provided feature operations.
+ Common engines: InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
+ Different engines use different ways to save the structure and data of tables
+ MyISAM table file meaning: .frm table definition, .MYD table data, .MYI table index
+ InnoDB table file meaning: .frm table definition, table space data and log files
+ SHOW ENGINES -- displays storage engine status information
+ SHOW ENGINE engine name {LOGS|STATUS} -- displays the log or status information of the storage engine
+ --increment starting number
+ AUTO_INCREMENT = number of rows
+ --Data file directory
+ DATA DIRECTORY = 'Directory'
+ -- Index file directory
+ INDEX DIRECTORY = 'Directory'
+ -- table comments
+ COMMENT = 'string'
+ --Partition options
+ PARTITION BY ... (see manual for details)
+-- View all tables
+ SHOW TABLES[ LIKE 'pattern']
+ SHOW TABLES FROM library name
+-- View table structure
+ SHOW CREATE TABLE table name (more detailed information)
+ DESC table name / DESCRIBE table name / EXPLAIN table name / SHOW COLUMNS FROM table name [LIKE 'PATTERN']
+ SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
+--Modify table
+ --Modify options for the table itself
+ ALTER TABLE table name table options
+ eg: ALTER TABLE table name ENGINE=MYISAM;
+ -- Rename the table
+ RENAME TABLE original table name TO new table name
+ RENAME TABLE original table name TO database name.table name (the table can be moved to another database)
+ -- RENAME can exchange two table names
+ -- Modify the field structure of the table (13.1.2. ALTER TABLE syntax)
+ ALTER TABLE table name operation name
+ -- operation name
+ ADD[COLUMN] field definition -- add field
+ AFTER field name -- means adding after the field name
+ FIRST -- means adding in the first
+ ADD PRIMARY KEY (field name) -- Create a primary key
+ ADD UNIQUE [index name] (field name)--Create a unique index
+ ADD INDEX [index name] (field name) -- Create a normal index
+ DROP[COLUMN] field name -- delete field
+ MODIFY[COLUMN] Field name Field attribute -- Supports modification of field attributes, field name cannot be modified (all original attributes must also be written)
+ CHANGE[COLUMN] Original field name New field name Field attributes -- Supports modification of field names
+ DROP PRIMARY KEY -- Delete the primary key (you need to delete its AUTO_INCREMENT attribute before deleting the primary key)
+ DROP INDEX index name -- delete index
+ DROP FOREIGN KEY foreign key -- delete foreign key
+-- Delete table
+ DROP TABLE[IF EXISTS] table name ...
+--Clear table data
+ TRUNCATE [TABLE] table name
+--Copy table structure
+ CREATE TABLE table name LIKE table name to copy
+--Copy table structure and data
+ CREATE TABLE table name [AS] SELECT * FROM table name to be copied
+-- Check the table for errors
+ CHECK TABLE tbl_name [, tbl_name] ... [option] ...
+-- Optimize table
+ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+-- Repair table
+ REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
+-- analysis table
+ ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+```
+
+### Data operations
+
+```sql
+/* Data operations */ ------------------
+-- increase
+ INSERT [INTO] table name [(field list)] VALUES (value list)[, (value list), ...]
+ -- The field list can be omitted if the list of values to be inserted contains all fields and is in consistent order.
+ -- Multiple data records can be inserted at the same time!
+ REPLACE is similar to INSERT, the only difference is that for matching rows, the data of the existing row (compared with the primary key/unique key) is replaced, and if there is no existing row, a new row is inserted.
+ INSERT [INTO] table name SET field name=value[, field name=value, ...]
+-- Check
+ SELECT field list FROM table name [other clauses]
+ -- Multiple fields that can come from multiple tables
+ --Other clauses may not be used
+ -- The field list can be replaced by * to indicate all fields
+-- Delete
+ DELETE FROM table name [delete condition clause]
+ Without a conditional clause, all will be deleted
+-- change
+ UPDATE table name SET field name=new value[, field name=new value] [update condition]```
+
+### 字符集编码
+
+```sql
+/* 字符集编码 */ ------------------
+-- MySQL、数据库、表、字段均可设置编码
+-- 数据编码与客户端编码不需一致
+SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项
+ character_set_client 客户端向服务器发送数据时使用的编码
+ character_set_results 服务器端将结果返回给客户端所使用的编码
+ character_set_connection 连接层编码
+SET 变量名 = 变量值
+ SET character_set_client = gbk;
+ SET character_set_results = gbk;
+ SET character_set_connection = gbk;
+SET NAMES GBK; -- 相当于完成以上三个设置
+-- 校对集
+ 校对集用以排序
+ SHOW CHARACTER SET [LIKE 'pattern']/SHOW CHARSET [LIKE 'pattern'] 查看所有字符集
+ SHOW COLLATION [LIKE 'pattern'] 查看所有校对集
+ CHARSET 字符集编码 设置字符集编码
+ COLLATE 校对集编码 设置校对集编码
+```
+
+### 数据类型(列类型)
+
+```sql
+/* 数据类型(列类型) */ ------------------
+1. 数值类型
+-- a. 整型 ----------
+ 类型 字节 范围(有符号位)
+ tinyint 1字节 -128 ~ 127 无符号位:0 ~ 255
+ smallint 2字节 -32768 ~ 32767
+ mediumint 3字节 -8388608 ~ 8388607
+ int 4字节
+ bigint 8字节
+ int(M) M表示总位数
+ - 默认存在符号位,unsigned 属性修改
+ - 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改
+ 例:int(5) 插入一个数'123',补填后为'00123'
+ - 在满足要求的情况下,越小越好。
+ - 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。
+-- b. 浮点型 ----------
+ 类型 字节 范围
+ float(单精度) 4字节
+ double(双精度) 8字节
+ 浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。
+ 不同于整型,前后均会补填0.
+ 定义浮点型时,需指定总位数和小数位数。
+ float(M, D) double(M, D)
+ M表示总位数,D表示小数位数。
+ M和D的大小会决定浮点数的范围。不同于整型的固定范围。
+ M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。
+ 支持科学计数法表示。
+ 浮点数表示近似值。
+-- c. 定点数 ----------
+ decimal -- 可变长度
+ decimal(M, D) M也表示总位数,D表示小数位数。
+ 保存一个精确的数值,不会发生数据的改变,不同于浮点数的四舍五入。
+ 将浮点数转换为字符串来保存,每9位数字保存为4个字节。
+2. 字符串类型
+-- a. char, varchar ----------
+ char 定长字符串,速度快,但浪费空间
+ varchar 变长字符串,速度慢,但节省空间
+ M表示能存储的最大长度,此长度是字符数,非字节数。
+ 不同的编码,所占用的空间不同。
+ char,最多255个字符,与编码无关。
+ varchar,最多65535字符,与编码有关。
+ 一条有效记录最大不能超过65535个字节。
+ utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符
+ varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存。
+ varchar 的最大有效长度由最大行大小和使用的字符集确定。
+ 最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是65535-1-2=65532字节。
+ 例:若一个表定义为 CREATE TABLE tb(c1 int, c2 char(30), c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3
+-- b. blob, text ----------
+ blob 二进制字符串(字节字符串)
+ tinyblob, blob, mediumblob, longblob
+ text 非二进制字符串(字符字符串)
+ tinytext, text, mediumtext, longtext
+ text 在定义时,不需要定义长度,也不会计算总长度。
+ text 类型在定义时,不可给default值
+-- c. binary, varbinary ----------
+ 类似于char和varchar,用于保存二进制字符串,也就是保存字节字符串而非字符字符串。
+ char, varchar, text 对应 binary, varbinary, blob.
+3. 日期时间类型
+ 一般用整型保存时间戳,因为PHP可以很方便的将时间戳进行格式化。
+ datetime 8字节 日期及时间 1000-01-01 00:00:00 到 9999-12-31 23:59:59
+ date 3字节 日期 1000-01-01 到 9999-12-31
+ timestamp 4字节 时间戳 19700101000000 到 2038-01-19 03:14:07
+ time 3字节 时间 -838:59:59 到 838:59:59
+ year 1字节 年份 1901 - 2155
+datetime YYYY-MM-DD hh:mm:ss
+timestamp YY-MM-DD hh:mm:ss
+ YYYYMMDDhhmmss
+ YYMMDDhhmmss
+ YYYYMMDDhhmmss
+ YYMMDDhhmmss
+date YYYY-MM-DD
+ YY-MM-DD
+ YYYYMMDD
+ YYMMDD
+ YYYYMMDD
+ YYMMDD
+time hh:mm:ss
+ hhmmss
+ hhmmss
+year YYYY
+ YY
+ YYYY
+ YY
+4. 枚举和集合
+-- 枚举(enum) ----------
+enum(val1, val2, val3...)
+ 在已知的值中进行单选。最大数量为65535.
+ 枚举值在保存时,以2个字节的整型(smallint)保存。每个枚举值,按保存的位置顺序,从1开始逐一递增。
+ 表现为字符串类型,存储却是整型。
+ NULL值的索引是NULL。
+ 空字符串错误值的索引值是0。
+-- 集合(set) ----------
+set(val1, val2, val3...)
+ create table tab ( gender set('男', '女', '无') );
+ insert into tab values ('男, 女');
+ 最多可以有64个不同的成员。以bigint存储,共8个字节。采取位运算的形式。
+ 当创建表时,SET成员值的尾部空格将自动被删除。
+```
+
+### 列属性(列约束)
+
+```sql
+/* 列属性(列约束) */ ------------------
+1. PRIMARY 主键
+ - 能唯一标识记录的字段,可以作为主键。
+ - 一个表只能有一个主键。
+ - 主键具有唯一性。
+ - 声明字段时,用 primary key 标识。
+ 也可以在字段列表之后声明
+ 例:create table tab ( id int, stu varchar(10), primary key (id));
+ - 主键字段的值不能为null。
+ - 主键可以由多个字段共同组成。此时需要在字段列表后声明的方法。
+ 例:create table tab ( id int, stu varchar(10), age int, primary key (stu, age));
+2. UNIQUE 唯一索引(唯一约束)
+ 使得某字段的值也不能重复。
+3. NULL 约束
+ null不是数据类型,是列的一个属性。
+ 表示当前列是否可以为null,表示什么都没有。
+ null, 允许为空。默认。
+ not null, 不允许为空。
+ insert into tab values (null, 'val');
+ -- 此时表示将第一个字段的值设为null, 取决于该字段是否允许为null
+4. DEFAULT 默认值属性
+ 当前字段的默认值。
+ insert into tab values (default, 'val'); -- 此时表示强制使用默认值。
+ create table tab ( add_time timestamp default current_timestamp );
+ -- 表示将当前时间的时间戳设为默认值。
+ current_date, current_time
+5. AUTO_INCREMENT 自动增长约束
+ 自动增长必须为索引(主键或unique)
+ 只能存在一个字段为自动增长。
+ 默认为1开始自动增长。可以通过表属性 auto_increment = x进行设置,或 alter table tbl auto_increment = x;
+6. COMMENT 注释
+ 例:create table tab ( id int ) comment '注释内容';
+7. FOREIGN KEY 外键约束
+ 用于限制主表与从表数据完整性。
+ alter table t1 add constraint `t1_t2_fk` foreign key (t1_id) references t2(id);
+ -- 将表t1的t1_id外键关联到表t2的id字段。
+ -- 每个外键都有一个名字,可以通过 constraint 指定
+ 存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
+ 作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。
+ MySQL中,可以对InnoDB引擎使用外键约束:
+ 语法:
+ foreign key (外键字段) references 主表名 (关联字段) [主表记录删除时的动作] [主表记录更新时的动作]
+ 此时需要检测一个从表的外键需要约束为主表的已存在的值。外键在没有关联的情况下,可以设置为null.前提是该外键列,没有not null。
+ 可以不指定主表记录更改或更新时的动作,那么此时主表的操作被拒绝。
+ 如果指定了 on update 或 on delete:在删除或更新时,有如下几个操作可以选择:
+ 1. cascade,级联操作。主表数据被更新(主键值更新),从表也被更新(外键值更新)。主表记录被删除,从表相关记录也被删除。
+ 2. set null,设置为null。主表数据被更新(主键值更新),从表的外键被设置为null。主表记录被删除,从表相关记录外键被设置成null。但注意,要求该外键列,没有not null属性约束。
+ 3. restrict,拒绝父表删除和更新。
+ 注意,外键只被InnoDB存储引擎所支持。其他引擎是不支持的。
+
+```
+
+### 建表规范
+
+```sql
+/* 建表规范 */ ------------------
+ -- Normal Format, NF
+ - 每个表保存一个实体信息
+ - 每个具有一个ID字段作为主键
+ - ID主键 + 原子表
+ -- 1NF, 第一范式
+ 字段不能再分,就满足第一范式。
+ -- 2NF, 第二范式
+ 满足第一范式的前提下,不能出现部分依赖。
+ 消除复合主键就可以避免部分依赖。增加单列关键字。
+ -- 3NF, 第三范式
+ 满足第二范式的前提下,不能出现传递依赖。
+ 某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
+ 将一个实体信息的数据放在一个表内实现。
+```
+
+### SELECT
+
+```sql
+/* SELECT */ ------------------
+SELECT [ALL|DISTINCT] select_expr FROM -> WHERE -> GROUP BY [合计函数] -> HAVING -> ORDER BY -> LIMIT
+a. select_expr
+ -- 可以用 * 表示所有字段。
+ select * from tb;
+ -- 可以使用表达式(计算公式、函数调用、字段也是个表达式)
+ select stu, 29+25, now() from tb;
+ -- 可以为每个列使用别名。适用于简化列标识,避免多个列标识符重复。
+ - 使用 as 关键字,也可省略 as.
+ select stu+10 as add10 from tb;
+b. FROM 子句
+ 用于标识查询来源。
+ -- 可以为表起别名。使用as关键字。
+ SELECT * FROM tb1 AS tt, tb2 AS bb;
+ -- from子句后,可以同时出现多个表。
+ -- 多个表会横向叠加到一起,而数据会形成一个笛卡尔积。
+ SELECT * FROM tb1, tb2;
+ -- 向优化符提示如何选择索引
+ USE INDEX、IGNORE INDEX、FORCE INDEX
+ SELECT * FROM table1 USE INDEX (key1,key2) WHERE key1=1 AND key2=2 AND key3=3;
+ SELECT * FROM table1 IGNORE INDEX (key3) WHERE key1=1 AND key2=2 AND key3=3;
+c. WHERE 子句
+ -- 从from获得的数据源中进行筛选。
+ -- 整型1表示真,0表示假。
+ -- 表达式由运算符和运算数组成。
+ -- 运算数:变量(字段)、值、函数返回值
+ -- 运算符:
+ =, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
+ in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
+ is/is not 加上true/false/unknown,检验某个值的真假
+ <=>与<>功能相同,<=>可用于null比较
+d. GROUP BY 子句, 分组子句
+ GROUP BY 字段/别名 [排序方式]
+ 分组后会进行排序。升序:ASC,降序:DESC
+ 以下[合计函数]需配合 GROUP BY 使用:
+ count 返回不同的非NULL值数目 count(*)、count(字段)
+ sum 求和
+ max 求最大值
+ min 求最小值
+ avg 求平均值
+ group_concat 返回带有来自一个组的连接的非NULL值的字符串结果。组内字符串连接。
+e. HAVING 子句,条件子句
+ 与 where 功能、用法相同,执行时机不同。
+ where 在开始时执行检测数据,对原数据进行过滤。
+ having 对筛选出的结果再次进行过滤。
+ having 字段必须是查询出来的,where 字段必须是数据表存在的。
+ where 不可以使用字段的别名,having 可以。因为执行WHERE代码时,可能尚未确定列值。
+ where 不可以使用合计函数。一般需用合计函数才会用 having
+ SQL标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列。
+f. ORDER BY 子句,排序子句
+ order by 排序字段/别名 排序方式 [,排序字段/别名 排序方式]...
+ 升序:ASC,降序:DESC
+ 支持多个字段的排序。
+g. LIMIT 子句,限制结果数量子句
+ 仅对处理好的结果进行数量限制。将处理好的结果的看作是一个集合,按照记录出现的顺序,索引从0开始。
+ limit 起始位置, 获取条数
+ 省略第一个参数,表示从索引0开始。limit 获取条数
+h. DISTINCT, ALL 选项
+ distinct 去除重复记录
+ 默认为 all, 全部记录
+```
+
+### UNION
+
+```sql
+/* UNION */ ------------------
+ 将多个select查询的结果组合成一个结果集合。
+ SELECT ... UNION [ALL|DISTINCT] SELECT ...
+ 默认 DISTINCT 方式,即所有返回的行都是唯一的
+ 建议,对每个SELECT查询加上小括号包裹。
+ ORDER BY 排序时,需加上 LIMIT 进行结合。
+ 需要各select查询的字段数量一样。
+ 每个select查询的字段列表(数量、类型)应一致,因为结果中的字段名以第一条select语句为准。
+```
+
+### 子查询
+
+```sql
+/* 子查询 */ ------------------
+ - 子查询需用括号包裹。
+-- from型
+ from后要求是一个表,必须给子查询结果取个别名。
+ - 简化每个查询内的条件。
+ - from型需将结果生成一个临时表格,可用以原表的锁定的释放。
+ - 子查询返回一个表,表型子查询。
+ select * from (select * from tb where id>0) as subfrom where id>1;
+-- where型
+ - 子查询返回一个值,标量子查询。
+ - 不需要给子查询取别名。
+ - where子查询内的表,不能直接用以更新。
+ select * from tb where money = (select max(money) from tb);
+ -- 列子查询
+ 如果子查询结果返回的是一列。
+ 使用 in 或 not in 完成查询
+ exists 和 not exists 条件
+ 如果子查询返回数据,则返回1或0。常用于判断条件。
+ select column1 from t1 where exists (select * from t2);
+ -- 行子查询
+ 查询条件是一个行。
+ select * from t1 where (id, gender) in (select id, gender from t2);
+ 行构造符:(col1, col2, ...) 或 ROW(col1, col2, ...)
+ 行构造符通常用于与对能返回两个或两个以上列的子查询进行比较。
+ -- 特殊运算符
+ != all() 相当于 not in
+ = some() 相当于 in。any 是 some 的别名
+ != some() 不等同于 not in,不等于其中某一个。
+ all, some 可以配合其他运算符一起使用。
+```
+
+### 连接查询(join)
+
+```sql
+/* 连接查询(join) */ ------------------
+ 将多个表的字段进行连接,可以指定连接条件。
+-- 内连接(inner join)
+ - 默认就是内连接,可省略inner。
+ - 只有数据存在时才能发送连接。即连接结果不能出现空行。
+ on 表示连接条件。其条件表达式与where类似。也可以省略条件(表示条件永远为真)
+ 也可用where表示连接条件。
+ 还有 using, 但需字段名相同。 using(字段名)
+ -- 交叉连接 cross join
+ 即,没有条件的内连接。
+ select * from tb1 cross join tb2;
+-- 外连接(outer join)
+ - 如果数据不存在,也会出现在连接结果中。
+ -- 左外连接 left join
+ 如果数据不存在,左表记录会出现,而右表为null填充
+ -- 右外连接 right join
+ 如果数据不存在,右表记录会出现,而左表为null填充
+-- 自然连接(natural join)
+ 自动判断连接条件完成连接。
+ 相当于省略了using,会自动查找相同字段名。
+ natural join
+ natural left join
+ natural right join
+select info.id, info.name, info.stu_num, extra_info.hobby, extra_info.sex from info, extra_info where info.stu_num = extra_info.stu_id;
+```
+
+### TRUNCATE
+
+```sql
+/* TRUNCATE */ ------------------
+TRUNCATE [TABLE] tbl_name
+清空数据
+删除重建表
+区别:
+1,truncate 是删除表再创建,delete 是逐条删除
+2,truncate 重置auto_increment的值。而delete不会
+3,truncate 不知道删除了几条,而delete知道。
+4,当被用于带分区的表时,truncate 会保留分区
+```
+
+### 备份与还原
+
+```sql
+/* 备份与还原 */ ------------------
+备份,将数据的结构与表内数据保存起来。
+利用 mysqldump 指令完成。
+-- 导出
+mysqldump [options] db_name [tables]
+mysqldump [options] ---database DB1 [DB2 DB3...]
+mysqldump [options] --all--database
+1. 导出一张表
+ mysqldump -u用户名 -p密码 库名 表名 > 文件名(D:/a.sql)
+2. 导出多张表
+ mysqldump -u用户名 -p密码 库名 表1 表2 表3 > 文件名(D:/a.sql)
+3. 导出所有表
+ mysqldump -u用户名 -p密码 库名 > 文件名(D:/a.sql)
+4. 导出一个库
+ mysqldump -u用户名 -p密码 --lock-all-tables --database 库名 > 文件名(D:/a.sql)
+可以-w携带WHERE条件
+-- 导入
+1. 在登录mysql的情况下:
+ source 备份文件
+2. 在不登录的情况下
+ mysql -u用户名 -p密码 库名 < 备份文件
+```
+
+### 视图
+
+```sql
+什么是视图:
+ 视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
+ 视图具有表结构文件,但不存在数据文件。
+ 对其中所引用的基础表来说,视图的作用类似于筛选。定义视图的筛选可以来自当前或其它数据库的一个或多个表,或者其它视图。通过视图进行查询没有任何限制,通过它们进行数据修改时的限制也很少。
+ 视图是存储在数据库中的查询的sql语句,它主要出于两种原因:安全原因,视图可以隐藏一些数据,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,另一原因是可使复杂的查询易于理解和使用。
+-- 创建视图
+CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name [(column_list)] AS select_statement
+ - 视图名必须唯一,同时不能与表重名。
+ - 视图可以使用select语句查询到的列名,也可以自己指定相应的列名。
+ - 可以指定视图执行的算法,通过ALGORITHM指定。
+ - column_list如果存在,则数目必须等于SELECT语句检索的列数
+-- 查看结构
+ SHOW CREATE VIEW view_name
+-- 删除视图
+ - 删除视图后,数据依然存在。
+ - 可同时删除多个视图。
+ DROP VIEW [IF EXISTS] view_name ...
+-- 修改视图结构
+ - 一般不修改视图,因为不是所有的更新视图都会映射到表上。
+ ALTER VIEW view_name [(column_list)] AS select_statement
+-- 视图作用
+ 1. 简化业务逻辑
+ 2. 对客户端隐藏真实的表结构
+-- 视图算法(ALGORITHM)
+ MERGE 合并
+ 将视图的查询语句,与外部查询需要先合并再执行!
+ TEMPTABLE 临时表
+ 将视图执行完毕后,形成临时表,再做外层查询!
+ UNDEFINED 未定义(默认),指的是MySQL自主去选择相应的算法。
+```
+
+### 事务(transaction)
+
+```sql
+事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
+ - 支持连续SQL的集体成功或集体撤销。
+ - 事务是数据库在数据完整性方面的一个功能。
+ - 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。
+ - InnoDB被称为事务安全型引擎。
+-- 事务开启
+ START TRANSACTION; 或者 BEGIN;
+ 开启事务后,所有被执行的SQL语句均被认作当前事务内的SQL语句。
+-- 事务提交
+ COMMIT;
+-- 事务回滚
+ ROLLBACK;
+ 如果部分操作发生问题,映射到事务开启前。
+-- 事务的特性
+ 1. 原子性(Atomicity)
+ 事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
+ 2. 一致性(Consistency)
+ 事务前后数据的完整性必须保持一致。
+ - 事务开始和结束时,外部数据一致
+ - 在整个事务过程中,操作是连续的
+ 3. 隔离性(Isolation)
+ 多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间的数据要相互隔离。
+ 4. 持久性(Durability)
+ 一个事务一旦被提交,它对数据库中的数据改变就是永久性的。
+-- 事务的实现
+ 1. 要求是事务支持的表类型
+ 2. 执行一组相关的操作前开启事务
+ 3. 整组操作完成后,都成功,则提交;如果存在失败,选择回滚,则会回到事务开始的备份点。
+-- 事务的原理
+ 利用InnoDB的自动提交(autocommit)特性完成。
+ 普通的MySQL执行语句后,当前的数据提交操作均可被其他客户端可见。
+ 而事务是暂时关闭“自动提交”机制,需要commit提交持久化数据操作。
+-- 注意
+ 1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。
+ 2. 事务不能被嵌套
+-- 保存点
+ SAVEPOINT 保存点名称 -- 设置一个事务保存点
+ ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
+ RELEASE SAVEPOINT 保存点名称 -- 删除保存点
+-- InnoDB自动提交特性设置
+ SET autocommit = 0|1; 0表示关闭自动提交,1表示开启自动提交。
+ - 如果关闭了,那普通操作的结果对其他客户端也不可见,需要commit提交后才能持久化数据操作。
+ - 也可以关闭自动提交来开启事务。但与START TRANSACTION不同的是,
+ SET autocommit是永久改变服务器的设置,直到下次再次修改该设置。(针对当前连接)
+ 而START TRANSACTION记录开启前的状态,而一旦事务提交或回滚后就需要再次开启事务。(针对当前事务)
+
+```
+
+### 锁表
+
+```sql
+/* 锁表 */
+表锁定只用于防止其它客户端进行不正当地读取和写入
+MyISAM 支持表锁,InnoDB 支持行锁
+-- 锁定
+ LOCK TABLES tbl_name [AS alias]
+-- 解锁
+ UNLOCK TABLES
+```
+
+### 触发器
+
+```sql
+/* 触发器 */ ------------------
+ 触发程序是与表有关的命名数据库对象,当该表出现特定事件时,将激活该对象
+ 监听:记录的增加、修改、删除。
+-- 创建触发器
+CREATE TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW trigger_stmt
+ 参数:
+ trigger_time是触发程序的动作时间。它可以是 before 或 after,以指明触发程序是在激活它的语句之前或之后触发。
+ trigger_event指明了激活触发程序的语句的类型
+ INSERT:将新行插入表时激活触发程序
+ UPDATE:更改某一行时激活触发程序
+ DELETE:从表中删除某一行时激活触发程序
+ tbl_name:监听的表,必须是永久性的表,不能将触发程序与TEMPORARY表或视图关联起来。
+ trigger_stmt:当触发程序激活时执行的语句。执行多个语句,可使用BEGIN...END复合语句结构
+-- 删除
+DROP TRIGGER [schema_name.]trigger_name
+可以使用old和new代替旧的和新的数据
+ 更新操作,更新前是old,更新后是new.
+ 删除操作,只有old.
+ 增加操作,只有new.
+-- 注意
+ 1. 对于具有相同触发程序动作时间和事件的给定表,不能有两个触发程序。
+-- 字符连接函数
+concat(str1,str2,...])
+concat_ws(separator,str1,str2,...)
+-- 分支语句
+if 条件 then
+ 执行语句
+elseif 条件 then
+ 执行语句
+else
+ 执行语句
+end if;
+-- 修改最外层语句结束符
+delimiter 自定义结束符号
+ SQL语句
+自定义结束符号
+delimiter ; -- 修改回原来的分号
+-- 语句块包裹
+begin
+ 语句块
+end
+-- 特殊的执行
+1. 只要添加记录,就会触发程序。
+2. Insert into on duplicate key update 语法会触发:
+ 如果没有重复记录,会触发 before insert, after insert;
+ 如果有重复记录并更新,会触发 before insert, before update, after update;
+ 如果有重复记录但是没有发生更新,则触发 before insert, before update
+3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
+```
+
+### SQL Programming
+
+```sql
+/* SQL programming */ ------------------
+--//Local variables ----------
+-- variable declaration
+ declare var_name[,...] type [default value]
+ This statement is used to declare local variables. To provide a default value for a variable, include a default clause. The value can be specified as an expression and does not need to be a constant. If there is no default clause, the initial value is null.
+-- assignment
+ Use set and select into statements to assign values to variables.
+ - Note: Global variables (user-defined variables) can be used within functions
+--//Global variables ----------
+-- Definition, assignment
+The set statement can define and assign values to variables.
+set @var = value;
+You can also use the select into statement to initialize and assign values to variables. This requires that the select statement can only return one row, but it can be multiple fields, which means that multiple variables are assigned values at the same time. The number of variables needs to be consistent with the number of columns in the query.
+You can also think of the assignment statement as an expression, which is executed through select. At this time, in order to avoid = being treated as a relational operator, use := instead. (The set statement can use = and :=).
+select @var:=20;
+select @v1:=id, @v2=name from t1 limit 1;
+select * from tbl_name where @var:=30;
+Select into can assign the data obtained from the query in the table to a variable.
+ -| select max(height) into @max_height from tb;
+-- Custom variable name
+In order to avoid conflicts between user-defined variables and system identifiers (usually field names) in select statements, user-defined variables use @ as the starting symbol before the variable name.
+@var=10;
+ - Once a variable is defined, it is valid throughout the session (login to logout)
+--//Control structure ----------
+--if statement
+if search_condition then
+ statement_list
+[elseif search_condition then
+ statement_list]
+...
+[else
+ statement_list]
+end if;
+--case statement
+CASE value WHEN [compare-value] THEN result
+[WHEN [compare-value] THEN result ...]
+[ELSE result]
+END
+-- while loop
+[begin_label:] while search_condition do
+ statement_list
+end while [end_label];
+- If you need to terminate the while loop early within the loop, you need to use labels; labels need to appear in pairs.
+ --Exit the loop
+ Exit the entire loop leave
+ Exit the current loop iterate
+ Determine which loop to exit through the exit label
+--//Built-in function ----------
+-- Numerical functions
+abs(x) -- absolute value abs(-10.9) = 10
+format(x, d) -- format the thousandth value format(1234567.456, 2) = 1,234,567.46
+ceil(x) -- round up ceil(10.1) = 11
+floor(x) -- round down floor (10.1) = 10
+round(x) -- round to integer
+mod(m, n) -- m%n m mod n Find remainder 10%3=1
+pi() -- get pi
+pow(m, n) -- m^n
+sqrt(x) -- arithmetic square root
+rand() -- random number
+truncate(x, d) -- truncate to d decimal places
+-- Time and date function
+now(), current_timestamp(); -- current date and time
+current_date(); -- current date
+current_time(); -- current time
+date('yyyy-mm-dd hh:ii:ss'); -- Get the date part
+time('yyyy-mm-dd hh:ii:ss'); -- Get the time part
+date_format('yyyy-mm-dd hh:ii:ss', '%d %y %a %d %m %b %j'); -- formatting time
+unix_timestamp(); -- Get unix timestamp
+from_unixtime(); -- Get time from timestamp
+-- String functions
+length(string) – string length, bytes
+char_length(string) – the number of characters in string
+substring(str, position [,length]) -- Starting from the position of str, take length characters
+replace(str,search_str,replace_str) -- replace search_str with replace_str in str
+instr(string,substring) -- returns the position where substring first appears in string
+concat(string [,...]) -- Concatenate strings
+charset(str) -- Returns the string character set
+lcase(string) -- Convert to lowercase
+left(string, length) -- Take length characters from the left in string2
+load_file(file_name) -- read content from file
+locate(substring, string [,start_position]) -- same as instr, but can specify the starting position
+lpad(string, length, pad) -- Repeat adding pad to the beginning of string until the length of the string is length
+ltrim(string) -- remove leading spaces
+repeat(string, count) -- repeat count times
+rpad(string, length, pad) --Add pad after str until the length is length
+rtrim(string) -- remove trailing spaces
+strcmp(string1,string2) -- compare the size of two strings character by character
+-- Process function
+case when [condition] then result [when [condition] then result ...] [else result] end multi-branch
+if(expr1,expr2,expr3) double branch.
+-- Aggregation function
+count()
+sum();
+max();
+min();
+avg();
+group_concat()
+--Other commonly used functions
+md5();
+default();
+--//Storage function, custom function ----------
+-- New
+ CREATE FUNCTION function_name (parameter list) RETURNS return value type
+ function body
+ - The function name should be a legal identifier and should not conflict with existing keywords.
+ - A function should belong to a certain database. You can use the form of db_name.function_name to execute the database to which the current function belongs, otherwise it is the current database.
+ - The parameter part consists of "parameter name" and "parameter type". Multiple parameters are separated by commas.
+ - The function body consists of multiple available mysql statements, process control, variable declaration and other statements.
+ - Multiple statements should be enclosed using begin...end statement blocks.
+ - There must be a return return value statement.
+-- Delete
+ DROP FUNCTION [IF EXISTS] function_name;
+-- View
+ SHOW FUNCTION STATUS LIKE 'partten'
+ SHOW CREATE FUNCTION function_name;
+-- Modify
+ ALTER FUNCTION function_name function option
+--// Stored procedure, custom function ----------
+-- Definition
+Stored stored procedure is a piece of code (procedure) consisting of SQL stored in the database.
+A stored procedure is usually used to complete a piece of business logic, such as registration, shift payment, order warehousing, etc.
+A function usually focuses on a certain function and is regarded as a service for other programs. It needs to call the function in other statements. However, a stored procedure cannot be called by other people and is executed by itself through call.
+-- create
+CREATE PROCEDURE sp_name (parameter list)
+ process body
+Parameter list: Different from the parameter list of a function, the parameter type needs to be specified
+IN, indicating input type
+OUT, indicating output type
+INOUT, indicating mixed type
+Note that there is no return value.
+```
+
+### Stored procedure
+
+```sql
+/* Stored procedure */ ------------------
+A stored procedure is a collection of executable code. It prefers business logic to functions.
+Call: CALL procedure name
+-- Note
+- No return value.
+- Can only be called alone and cannot be mixed with other statements
+-- Parameters
+IN|OUT|INOUT parameter name data type
+IN input: During the calling process, data is input into the parameters inside the procedure body.
+OUT output: During the calling process, the result of processing the process body is returned to the client.
+INOUT input and output: both input and output
+-- Grammar
+CREATE PROCEDURE procedure name (parameter list)
+BEGIN
+ process body
+END```
+
+### User and permission management
+
+```sql
+/* User and permission management */ ------------------
+-- root password reset
+1. Stop the MySQL service
+2. [Linux] /usr/local/mysql/bin/safe_mysqld --skip-grant-tables &
+ [Windows] mysqld --skip-grant-tables
+3. use mysql;
+4. UPDATE `user` SET PASSWORD=PASSWORD("password") WHERE `user` = "root";
+5. FLUSH PRIVILEGES;
+User information table: mysql.user
+-- Refresh permissions
+FLUSH PRIVILEGES;
+-- Add user
+CREATE USER username IDENTIFIED BY [PASSWORD] password (string)
+ - Must have the global CREATE USER permission of the mysql database, or have the INSERT permission.
+ - Users can only be created, but permissions cannot be granted.
+ - User name, pay attention to the quotation marks: such as 'user_name'@'192.168.1.1'
+ - Passwords also need quotation marks, and pure numeric passwords also need quotation marks.
+ - To specify a password in plain text, ignore the PASSWORD keyword. To specify a password as the hashed value returned by the PASSWORD() function, include the keyword PASSWORD
+-- Rename user
+RENAME USER old_user TO new_user
+-- Set password
+SET PASSWORD = PASSWORD('password') -- Set a password for the current user
+SET PASSWORD FOR username = PASSWORD('password') -- Set a password for the specified user
+-- Delete user
+DROP USER username
+-- Assign permissions/Add users
+GRANT permission list ON table name TO user name [IDENTIFIED BY [PASSWORD] 'password']
+ - all privileges means all permissions
+ - *.* represents all tables in all libraries
+ - Library name.Table name indicates a table under a certain library
+ GRANT ALL PRIVILEGES ON `pms`.* TO 'pms'@'%' IDENTIFIED BY 'pms0817';
+-- View permissions
+SHOW GRANTS FOR username
+ -- View current user permissions
+ SHOW GRANTS; or SHOW GRANTS FOR CURRENT_USER; or SHOW GRANTS FOR CURRENT_USER();
+-- revoke permission
+REVOKE permission list ON table name FROM user name
+REVOKE ALL PRIVILEGES, GRANT OPTION FROM username -- revoke all privileges
+--Permission level
+-- To use GRANT or REVOKE, you must have the GRANT OPTION permission, and you must be using the permission you are granting or revoking.
+Global level: Global permissions apply to all databases in a given server, mysql.user
+ GRANT ALL ON *.* and REVOKE ALL ON *.* only grant and revoke global permissions.
+Database level: Database permissions apply to all targets in a given database, mysql.db, mysql.host
+ GRANT ALL ON db_name.* and REVOKE ALL ON db_name.* only grant and revoke database permissions.
+Table level: Table permissions apply to all columns in a given table, mysql.talbes_priv
+ GRANT ALL ON db_name.tbl_name and REVOKE ALL ON db_name.tbl_name only grant and revoke table permissions.
+Column level: Column permissions apply to a single column in a given table, mysql.columns_priv
+ When using REVOKE, you must specify the same columns as the authorized columns.
+-- Permission list
+ALL [PRIVILEGES] -- Set all simple permissions except GRANT OPTION
+ALTER -- enable ALTER TABLE
+ALTER ROUTINE -- alter or cancel a stored subroutine
+CREATE -- enables the use of CREATE TABLE
+CREATE ROUTINE -- Create a stored subroutine
+CREATE TEMPORARY TABLES -- enables the use of CREATE TEMPORARY TABLE
+CREATE USER -- Allows CREATE USER, DROP USER, RENAME USER and REVOKE ALL PRIVILEGES.
+CREATE VIEW -- enables the use of CREATE VIEW
+DELETE -- allows DELETE to be used
+DROP -- enables the use of DROP TABLE
+EXECUTE -- allows the user to run a stored subroutine
+FILE -- allows SELECT...INTO OUTFILE and LOAD DATA INFILE
+INDEX -- allows CREATE INDEX and DROP INDEX
+INSERT -- Allow the use of INSERT
+LOCK TABLES -- Allows LOCK TABLES on tables for which you have SELECT permissions
+PROCESS -- Allows use of SHOW FULL PROCESSLIST
+REFERENCES -- not implemented
+RELOAD -- Allow the use of FLUSH
+REPLICATION CLIENT -- allows the user to ask for the address of a slave or master server
+REPLICATION SLAVE -- for replication slave servers (read binary log events from the master server)
+SELECT -- Allow the use of SELECT
+SHOW DATABASES -- show all databases
+SHOW VIEW -- enables the use of SHOW CREATE VIEW
+SHUTDOWN -- Allow mysqladmin shutdown
+SUPER -- Allows the use of CHANGE MASTER, KILL, PURGE MASTER LOGS and SET GLOBAL statements, the mysqladmin debug command; allows you to connect (once) even if max_connections have been reached.
+UPDATE -- Allow UPDATE
+USAGE -- synonym for "no permissions"
+GRANT OPTION -- Allow permission to be granted
+```
+
+### Table maintenance
+
+```sql
+/* Table maintenance */
+--Analyze and store keyword distribution of tables
+ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE table name ...
+-- Check one or more tables for errors
+CHECK TABLE tbl_name [, tbl_name] ... [option] ...
+option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
+-- Defragment data files
+OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
+```
+
+### Miscellaneous
+
+```sql
+/* Miscellaneous */ ------------------
+1. You can use backticks (`) to wrap identifiers (library names, table names, field names, indexes, aliases) to avoid duplication of keywords! Chinese can also be used as an identifier!
+2. Each library directory contains an option file db.opt that saves the current database.
+3. Notes:
+ Single line comment #Comment content
+ Multi-line comments /* Comment content */
+ Single line comment -- comment content (standard SQL comment style, requiring a space after double dashes (space, TAB, newline, etc.))
+4. Pattern wildcard:
+ _ any single character
+ % any number of characters, even zero characters
+ Single quotes need to be escaped \'
+5. The statement terminator in the CMD command line can be ";", "\G", "\g", which only affects the display results. Elsewhere, end with a semicolon. delimiter can modify the statement terminator of the current conversation.
+6. SQL is not case sensitive
+7. Clear existing statements: \c
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/how-sql-executed-in-mysql.en.md b/docs_en/database/mysql/how-sql-executed-in-mysql.en.md
new file mode 100644
index 00000000000..d43f6e16a78
--- /dev/null
+++ b/docs_en/database/mysql/how-sql-executed-in-mysql.en.md
@@ -0,0 +1,144 @@
+---
+title: SQL语句在MySQL中的执行过程
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 执行流程,解析器,优化器,执行器,缓冲池,日志,架构
+ - - meta
+ - name: description
+ content: 拆解 SQL 在 MySQL 的执行路径,从解析优化到执行与缓存,结合存储引擎交互,构建完整的运行时视角。
+---
+
+> 本文来自[木木匠](https://github.com/kinglaw1204)投稿。
+
+本篇文章会分析下一个 SQL 语句在 MySQL 中的执行流程,包括 SQL 的查询在 MySQL 内部会怎么流转,SQL 语句的更新是怎么完成的。
+
+在分析之前我会先带着你看看 MySQL 的基础架构,知道了 MySQL 由那些组件组成以及这些组件的作用是什么,可以帮助我们理解和解决这些问题。
+
+## 一 MySQL 基础架构分析
+
+### 1.1 MySQL 基本架构概览
+
+下图是 MySQL 的一个简要架构图,从下图你可以很清晰的看到用户的 SQL 语句在 MySQL 内部是如何执行的。
+
+先简单介绍一下下图涉及的一些组件的基本作用帮助大家理解这幅图,在 1.2 节中会详细介绍到这些组件的作用。
+
+- **连接器:** 身份认证和权限相关(登录 MySQL 的时候)。
+- **查询缓存:** 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
+- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
+- **优化器:** 按照 MySQL 认为最优的方案去执行。
+- **执行器:** 执行语句,然后从存储引擎返回数据。 -
+
+
+
+简单来说 MySQL 主要分为 Server 层和存储引擎层:
+
+- **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binlog 日志模块。
+- **存储引擎**:主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5 版本开始就被当做默认存储引擎了。**
+
+### 1.2 Server 层基本组件介绍
+
+#### 1) 连接器
+
+连接器主要和身份认证和权限相关的功能相关,就好比一个级别很高的门卫一样。
+
+主要负责用户登录数据库,进行用户的身份认证,包括校验账户密码,权限等操作,如果用户账户密码已通过,连接器会到权限表中查询该用户的所有权限,之后在这个连接里的权限逻辑判断都是会依赖此时读取到的权限数据,也就是说,后续只要这个连接不断开,即使管理员修改了该用户的权限,该用户也是不受影响的。
+
+#### 2) 查询缓存(MySQL 8.0 版本后移除)
+
+查询缓存主要用来缓存我们所执行的 SELECT 语句以及该语句的结果集。
+
+连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 SQL 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询语句,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
+
+MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。
+
+所以,一般在大多数情况下我们都是不推荐去使用查询缓存的。
+
+MySQL 8.0 版本后删除了缓存的功能,官方也是认为该功能在实际的应用场景比较少,所以干脆直接删掉了。
+
+#### 3) 分析器
+
+MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用来分析 SQL 语句是来干嘛的,分析器也会分为几步:
+
+**第一步,词法分析**,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
+
+**第二步,语法分析**,主要就是判断你输入的 SQL 是否正确,是否符合 MySQL 的语法。
+
+完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
+
+#### 4) 优化器
+
+优化器的作用就是它认为的最优的执行方案去执行(有时候可能也不是最优,这篇文章涉及对这部分知识的深入讲解),比如多个索引的时候该如何选择索引,多表查询的时候如何选择关联顺序等。
+
+可以说,经过了优化器之后可以说这个语句具体该如何执行就已经定下来。
+
+#### 5) 执行器
+
+当选择了执行方案后,MySQL 就准备开始执行了,首先执行前会校验该用户有没有权限,如果没有权限,就会返回错误信息,如果有权限,就会去调用引擎的接口,返回接口执行的结果。
+
+## 二 语句分析
+
+### 2.1 查询语句
+
+说了以上这么多,那么究竟一条 SQL 语句是如何执行的呢?其实我们的 SQL 可以分为两种,一种是查询,一种是更新(增加,修改,删除)。我们先分析下查询语句,语句如下:
+
+```sql
+select * from tb_student A where A.age='18' and A.name=' 张三 ';
+```
+
+结合上面的说明,我们分析下这个语句的执行流程:
+
+- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
+- 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
+- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
+
+- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
+
+### 2.2 更新语句
+
+以上就是一条查询 SQL 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?SQL 语句如下:
+
+```plain
+update tb_student A set A.age='19' where A.name=' 张三 ';
+```
+
+我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
+
+- 先查询到张三这一条数据,不会走查询缓存,因为更新语句会导致与该表相关的查询缓存失效。
+- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
+- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
+- 更新完成。
+
+**这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
+
+这是因为最开始 MySQL 并没有 InnoDB 引擎(InnoDB 引擎是其他公司以插件形式插入 MySQL 的),MySQL 自带的引擎是 MyISAM,但是我们知道 redo log 是 InnoDB 引擎特有的,其他存储引擎都没有,这就导致会没有 crash-safe 的能力(crash-safe 的能力即使数据库发生异常重启,之前提交的记录都不会丢失),binlog 日志只能用来归档。
+
+It's not that it's impossible to use only one log module, but the InnoDB engine supports transactions through redo log. Then, some students will ask, can I use two log modules, but not so complicated? Why does redo log introduce prepare pre-commit state? Here we use proof by contradiction to explain why we do this?
+
+- **Write the redo log first and submit it directly, then write the binlog**. Suppose that after writing the redo log, the machine hangs up and the binlog log is not written. Then after the machine is restarted, the machine will restore the data through the redo log, but the binlog does not record the data at this time. When the machine is backed up later, this piece of data will be lost, and the master-slave synchronization will also lose this piece of data.
+- **Write the binlog first, and then write the redo log**. Suppose that after writing the binlog, the machine restarts abnormally. Since there is no redo log, the machine cannot restore this record, but there is a record in the binlog. The same reason as above will cause data inconsistency.
+
+If the redo log two-stage submission method is used, it will be different. After writing the binlog, and then submitting the redo log will prevent the above problems and ensure the consistency of the data. So the question is, is there an extreme situation? Assume that the redo log is in the pre-commit state and the binlog has been written. What will happen if an abnormal restart occurs at this time?
+This depends on the processing mechanism of MySQL. The processing process of MySQL is as follows:
+
+- Determine whether the redo log is complete. If it is complete, submit it immediately.
+- If the redo log is only pre-committed but not in commit status, it will be judged at this time whether the binlog is complete. If it is complete, the redo log will be submitted. If it is incomplete, the transaction will be rolled back.
+
+This solves the problem of data consistency.
+
+## Three Summary
+
+- MySQL is mainly divided into the Server layer and the Engine layer. The Server layer mainly includes connectors, query caches, analyzers, optimizers, executors, and a log module (binlog). This log module can be shared by all execution engines. Redolog is only available in InnoDB.
+- The engine layer is plug-in type and currently mainly includes MyISAM, InnoDB, Memory, etc.
+- The execution flow of the query statement is as follows: Permission verification (if the cache is hit)--->Query cache--->Analyzer--->Optimizer--->Permission verification--->Executor--->Engine
+- The update statement execution process is as follows: Analyzer---->Permission Verification---->Executor--->Engine---redo log (prepare status)--->binlog--->redo log (commit status)
+
+## Four References
+
+- "MySQL Practical Lectures 45"
+- MySQL 5.6 Reference Manual:
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/index-invalidation-caused-by-implicit-conversion.en.md b/docs_en/database/mysql/index-invalidation-caused-by-implicit-conversion.en.md
new file mode 100644
index 00000000000..a78c6866c48
--- /dev/null
+++ b/docs_en/database/mysql/index-invalidation-caused-by-implicit-conversion.en.md
@@ -0,0 +1,169 @@
+---
+title: MySQL隐式转换造成索引失效
+category: 数据库
+tag:
+ - MySQL
+ - 性能优化
+head:
+ - - meta
+ - name: keywords
+ content: 隐式转换,索引失效,类型不匹配,函数计算,优化器,性能退化
+ - - meta
+ - name: description
+ content: 解析隐式转换导致的索引失效与性能退化,给出类型规范、语句改写与参数配置建议,避免查询退化。
+---
+
+> 本次测试使用的 MySQL 版本是 `5.7.26`,随着 MySQL 版本的更新某些特性可能会发生改变,本文不代表所述观点和结论于 MySQL 所有版本均准确无误,版本差异请自行甄别。
+>
+> 原文:
+
+## 前言
+
+数据库优化是一个任重而道远的任务,想要做优化必须深入理解数据库的各种特性。在开发过程中我们经常会遇到一些原因很简单但造成的后果却很严重的疑难杂症,这类问题往往还不容易定位,排查费时费力最后发现是一个很小的疏忽造成的,又或者是因为不了解某个技术特性产生的。
+
+于数据库层面,最常见的恐怕就是索引失效了,且一开始因为数据量小还不易被发现。但随着业务的拓展数据量的提升,性能问题慢慢的就体现出来了,处理不及时还很容易造成雪球效应,最终导致数据库卡死甚至瘫痪。造成索引失效的原因可能有很多种,相关技术博客已经有太多了,今天我要记录的是**隐式转换造成的索引失效**。
+
+## 数据准备
+
+首先使用存储过程生成 1000 万条测试数据,
+测试表一共建立了 7 个字段(包括主键),`num1`和`num2`保存的是和`ID`一样的顺序数字,其中`num2`是字符串类型。
+`type1`和`type2`保存的都是主键对 5 的取模,目的是模拟实际应用中常用类似 type 类型的数据,但是`type2`是没有建立索引的。
+`str1`和`str2`都是保存了一个 20 位长度的随机字符串,`str1`不能为`NULL`,`str2`允许为`NULL`,相应的生成测试数据的时候我也会在`str2`字段生产少量`NULL`值(每 100 条数据产生一个`NULL`值)。
+
+```sql
+-- 创建测试数据表
+DROP TABLE IF EXISTS test1;
+CREATE TABLE `test1` (
+ `id` int(11) NOT NULL,
+ `num1` int(11) NOT NULL DEFAULT '0',
+ `num2` varchar(11) NOT NULL DEFAULT '',
+ `type1` int(4) NOT NULL DEFAULT '0',
+ `type2` int(4) NOT NULL DEFAULT '0',
+ `str1` varchar(100) NOT NULL DEFAULT '',
+ `str2` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `num1` (`num1`),
+ KEY `num2` (`num2`),
+ KEY `type1` (`type1`),
+ KEY `str1` (`str1`),
+ KEY `str2` (`str2`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+-- 创建存储过程
+DROP PROCEDURE IF EXISTS pre_test1;
+DELIMITER //
+CREATE PROCEDURE `pre_test1`()
+BEGIN
+ DECLARE i INT DEFAULT 0;
+ SET autocommit = 0;
+ WHILE i < 10000000 DO
+ SET i = i + 1;
+ SET @str1 = SUBSTRING(MD5(RAND()),1,20);
+ -- 每100条数据str2产生一个null值
+ IF i % 100 = 0 THEN
+ SET @str2 = NULL;
+ ELSE
+ SET @str2 = @str1;
+ END IF;
+ INSERT INTO test1 (`id`, `num1`, `num2`,
+ `type1`, `type2`, `str1`, `str2`)
+ VALUES (CONCAT('', i), CONCAT('', i),
+ CONCAT('', i), i%5, i%5, @str1, @str2);
+ -- 事务优化,每一万条数据提交一次事务
+ IF i % 10000 = 0 THEN
+ COMMIT;
+ END IF;
+ END WHILE;
+END;
+// DELIMITER ;
+-- 执行存储过程
+CALL pre_test1();
+```
+
+数据量比较大,还涉及使用`MD5`生成随机字符串,所以速度有点慢,稍安勿躁,耐心等待即可。
+
+1000 万条数据,我用了 33 分钟才跑完(实际时间跟你电脑硬件配置有关)。这里贴几条生成的数据,大致长这样。
+
+
+
+## SQL 测试
+
+先来看这组 SQL,一共四条,我们的测试数据表`num1`是`int`类型,`num2`是`varchar`类型,但是存储的数据都是跟主键`id`一样的顺序数字,两个字段都建立有索引。
+
+```sql
+1: SELECT * FROM `test1` WHERE num1 = 10000;
+2: SELECT * FROM `test1` WHERE num1 = '10000';
+3: SELECT * FROM `test1` WHERE num2 = 10000;
+4: SELECT * FROM `test1` WHERE num2 = '10000';
+```
+
+这四条 SQL 都是有针对性写的,12 查询的字段是 int 类型,34 查询的字段是`varchar`类型。12 或 34 查询的字段虽然都相同,但是一个条件是数字,一个条件是用引号引起来的字符串。这样做有什么区别呢?先不看下边的测试结果你能猜出这四条 SQL 的效率顺序吗?
+
+经测试这四条 SQL 最后的执行结果却相差很大,其中 124 三条 SQL 基本都是瞬间出结果,大概在 0.001~0.005 秒,在千万级的数据量下这样的结果可以判定这三条 SQL 性能基本没差别了。但是第三条 SQL,多次测试耗时基本在 4.5~4.8 秒之间。
+
+为什么 34 两条 SQL 效率相差那么大,但是同样做对比的 12 两条 SQL 却没什么差别呢?查看一下执行计划,下边分别 1234 条 SQL 的执行计划数据:
+
+
+
+可以看到,124 三条 SQL 都能使用到索引,连接类型都为`ref`,扫描行数都为 1,所以效率非常高。再看看第三条 SQL,没有用上索引,所以为全表扫描,`rows`直接到达 1000 万了,所以性能差别才那么大。
+
+仔细观察你会发现,34 两条 SQL 查询的字段`num2`是`varchar`类型的,查询条件等号右边加引号的第 4 条 SQL 是用到索引的,那么是查询的数据类型和字段数据类型不一致造成的吗?如果是这样那 12 两条 SQL 查询的字段`num1`是`int`类型,但是第 2 条 SQL 查询条件右边加了引号为什么还能用上索引呢。
+
+查阅 MySQL 相关文档发现是隐式转换造成的,看一下官方的描述:
+
+> 官方文档:[12.2 Type Conversion in Expression Evaluation](https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html?spm=5176.100239.blogcont47339.5.1FTben)
+>
+> 当操作符与不同类型的操作数一起使用时,会发生类型转换以使操作数兼容。某些转换是隐式发生的。例如,MySQL 会根据需要自动将字符串转换为数字,反之亦然。以下规则描述了比较操作的转换方式:
+>
+> 1. 两个参数至少有一个是`NULL`时,比较的结果也是`NULL`,特殊的情况是使用`<=>`对两个`NULL`做比较时会返回`1`,这两种情况都不需要做类型转换
+> 2. 两个参数都是字符串,会按照字符串来比较,不做类型转换
+> 3. 两个参数都是整数,按照整数来比较,不做类型转换
+> 4. When comparing hexadecimal values with non-numeric values, they will be treated as binary strings.
+> 5. If one parameter is `TIMESTAMP` or `DATETIME`, and the other parameter is a constant, the constant will be converted to `timestamp`
+> 6. One parameter is of type `decimal`. If the other parameter is `decimal` or an integer, the integer will be converted to `decimal` for comparison. If the other parameter is a floating point number, `decimal` will be converted to a floating point number for comparison.
+> 7. **In all other cases, both parameters will be converted to floating point numbers before comparison**
+
+According to the description of the official document, implicit conversion has occurred in our 23rd SQL. The query condition of the 2nd SQL is `num1 = '10000'`. The left side is an `int` type and the right is a string. The 3rd SQL is the opposite. According to the official conversion rule 7, both the left and right sides will be converted to floating point numbers before comparison.
+
+Let’s look at the second SQL first: ``SELECT * FROM `test1` WHERE num1 = '10000';`` **The left side is int type**`10000`, which is still `10000` when converted to a floating point number, and the string type on the right side is `'10000``, which is also `10000` when converted into a floating point number. The conversion results on both sides are unique and certain, so the use of indexes is not affected.
+
+Item 3 SQL: ``SELECT * FROM `test1` WHERE num2 = 10000;`` **The left side is string type**`'10000'', and the conversion result to floating point number 10000 is unique, and the conversion result of `int` type `10000` on the right side is also unique. However, because the left side is the search condition, although it is unique to convert `'10000'` to `10000`, other strings can also be converted to `10000`, such as `'10000a'`, `'010000'', `'10000'', etc. can be converted to floating point number `10000`. In this case, the index cannot be used.
+
+Regarding this **implicit conversion**, we can verify it through query testing. First insert a few pieces of data, including `num2='10000a'`, `'010000'' and `'10000'`:
+
+```sql
+INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000001', '10000', '10000a', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
+INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000002', '10000', '010000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
+INSERT INTO `test1` (`id`, `num1`, `num2`, `type1`, `type2`, `str1`, `str2`) VALUES ('10000003', '10000', ' 10000', '0', '0', '2df3d9465ty2e4hd523', '2df3d9465ty2e4hd523');
+```
+
+Then use the third SQL statement ``SELECT * FROM `test1` WHERE num2 = 10000;`` to query:
+
+
+
+As you can see from the results, the three pieces of data inserted later also match. So what are the rules for implicit conversion of this string? Why can `num2='10000a'`, `'010000'' and `'10000'' be matched? After consulting relevant information, we found the following rules:
+
+1. Strings **not starting with a number** will be converted to `0`. For example, `'abc'`, `'a123bc'`, `'abc123''` will be converted to `0`;
+2. **Strings starting with a number** will be intercepted during conversion, from the first character to the first non-numeric content. For example, `'123abc'` will be converted to `123`, `'012abc'` will be converted to `012` which is `12`, `'5.3a66b78c'` will be converted to `5.3`, and the others are the same.
+
+Now test and verify the above rules as follows:
+
+
+
+This also confirms the previous query results.
+
+Write a SQL query str1 field again: ``SELECT * FROM `test1` WHERE str1 = 1234;``
+
+
+
+## Analysis and summary
+
+Through the above test, we discovered some features of MySQL operators:
+
+1. When the data types on the left and right sides of the operator are inconsistent, **implicit conversion** will occur.
+2. When the left side of the where query operator is a numeric type, implicit conversion occurs, which has little impact on efficiency, but it is still not recommended.
+3. When the left side of the where query operator is a character type, implicit conversion occurs, which will cause the index to fail and cause the full table scan to be extremely inefficient.
+4. When a string is converted to a numeric type, the string starting with a non-number will be converted to `0`, and the string starting with a number will intercept the value from the first character to the first non-number content as the conversion result.
+
+Therefore, we must develop good habits when writing SQL. Whatever type of field is being queried, the condition on the right side of the equal sign should be written as the corresponding type. Especially when the query field is a string, the condition on the right side of the equal sign must be enclosed in quotation marks to indicate that it is a string. Otherwise, the index will fail and trigger a full table scan.
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/innodb-implementation-of-mvcc.en.md b/docs_en/database/mysql/innodb-implementation-of-mvcc.en.md
new file mode 100644
index 00000000000..805629c180e
--- /dev/null
+++ b/docs_en/database/mysql/innodb-implementation-of-mvcc.en.md
@@ -0,0 +1,266 @@
+---
+title: InnoDB存储引擎对MVCC的实现
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: InnoDB,MVCC,快照读,当前读,一致性视图,隐藏列,事务版本,间隙锁
+ - - meta
+ - name: description
+ content: 深入解析 InnoDB 的 MVCC 实现细节与读写隔离,覆盖一致性视图、快照/当前读与隐藏列、间隙锁的配合。
+---
+
+## 多版本并发控制 (Multi-Version Concurrency Control)
+
+MVCC 是一种并发控制机制,用于在多个并发事务同时读写数据库时保持数据的一致性和隔离性。它是通过在每个数据行上维护多个版本的数据来实现的。当一个事务要对数据库中的数据进行修改时,MVCC 会为该事务创建一个数据快照,而不是直接修改实际的数据行。
+
+1、读操作(SELECT):
+
+当一个事务执行读操作时,它会使用快照读取。快照读取是基于事务开始时数据库中的状态创建的,因此事务不会读取其他事务尚未提交的修改。具体工作情况如下:
+
+- 对于读取操作,事务会查找符合条件的数据行,并选择符合其事务开始时间的数据版本进行读取。
+- 如果某个数据行有多个版本,事务会选择不晚于其开始时间的最新版本,确保事务只读取在它开始之前已经存在的数据。
+- 事务读取的是快照数据,因此其他并发事务对数据行的修改不会影响当前事务的读取操作。
+
+2、写操作(INSERT、UPDATE、DELETE):
+
+当一个事务执行写操作时,它会生成一个新的数据版本,并将修改后的数据写入数据库。具体工作情况如下:
+
+- 对于写操作,事务会为要修改的数据行创建一个新的版本,并将修改后的数据写入新版本。
+- 新版本的数据会带有当前事务的版本号,以便其他事务能够正确读取相应版本的数据。
+- 原始版本的数据仍然存在,供其他事务使用快照读取,这保证了其他事务不受当前事务的写操作影响。
+
+3、事务提交和回滚:
+
+- 当一个事务提交时,它所做的修改将成为数据库的最新版本,并且对其他事务可见。
+- 当一个事务回滚时,它所做的修改将被撤销,对其他事务不可见。
+
+4、版本的回收:
+
+为了防止数据库中的版本无限增长,MVCC 会定期进行版本的回收。回收机制会删除已经不再需要的旧版本数据,从而释放空间。
+
+MVCC 通过创建数据的多个版本和使用快照读取来实现并发控制。读操作使用旧版本数据的快照,写操作创建新版本,并确保原始版本仍然可用。这样,不同的事务可以在一定程度上并发执行,而不会相互干扰,从而提高了数据库的并发性能和数据一致性。
+
+## 一致性非锁定读和锁定读
+
+### 一致性非锁定读
+
+对于 [**一致性非锁定读(Consistent Nonlocking Reads)**](https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html)的实现,通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号 + 1 或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则表示该记录可见
+
+在 `InnoDB` 存储引擎中,[多版本控制 (multi versioning)](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html) 就是对非锁定读的实现。如果读取的行正在执行 `DELETE` 或 `UPDATE` 操作,这时读取操作不会去等待行上锁的释放。相反地,`InnoDB` 存储引擎会去读取行的一个快照数据,对于这种读取历史数据的方式,我们叫它快照读 (snapshot read)
+
+在 `Repeatable Read` 和 `Read Committed` 两个隔离级别下,如果是执行普通的 `select` 语句(不包括 `select ... lock in share mode` ,`select ... for update`)则会使用 `一致性非锁定读(MVCC)`。并且在 `Repeatable Read` 下 `MVCC` 实现了可重复读和防止部分幻读
+
+### 锁定读
+
+如果执行的是下列语句,就是 [**锁定读(Locking Reads)**](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking-reads.html)
+
+- `select ... lock in share mode`
+- `select ... for update`
+- `insert`、`update`、`delete` 操作
+
+在锁定读下,读取的是数据的最新版本,这种读也被称为 `当前读(current read)`。锁定读会对读取到的记录加锁:
+
+- `select ... lock in share mode`:对记录加 `S` 锁,其它事务也可以加`S`锁,如果加 `x` 锁则会被阻塞
+
+- `select ... for update`、`insert`、`update`、`delete`:对记录加 `X` 锁,且其它事务不能加任何锁
+
+在一致性非锁定读下,即使读取的记录已被其它事务加上 `X` 锁,这时记录也是可以被读取的,即读取的快照数据。上面说了,在 `Repeatable Read` 下 `MVCC` 防止了部分幻读,这边的 “部分” 是指在 `一致性非锁定读` 情况下,只能读取到第一次查询之前所插入的数据(根据 Read View 判断数据可见性,Read View 在第一次查询时生成)。但是!如果是 `当前读` ,每次读取的都是最新数据,这时如果两次查询中间有其它事务插入数据,就会产生幻读。所以, **`InnoDB` 在实现`Repeatable Read` 时,如果执行的是当前读,则会对读取的记录使用 `Next-key Lock` ,来防止其它事务在间隙间插入数据**
+
+## InnoDB 对 MVCC 的实现
+
+`MVCC` 的实现依赖于:**隐藏字段、Read View、undo log**。在内部实现中,`InnoDB` 通过数据行的 `DB_TRX_ID` 和 `Read View` 来判断数据的可见性,如不可见,则通过数据行的 `DB_ROLL_PTR` 找到 `undo log` 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 `Read View` 之前已经提交的修改和该事务本身做的修改
+
+### 隐藏字段
+
+在内部,`InnoDB` 存储引擎为每行数据添加了三个 [隐藏字段](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html):
+
+- `DB_TRX_ID(6字节)`:表示最后一次插入或更新该行的事务 id。此外,`delete` 操作在内部被视为更新,只不过会在记录头 `Record header` 中的 `deleted_flag` 字段将其标记为已删除
+- `DB_ROLL_PTR(7字节)` 回滚指针,指向该行的 `undo log` 。如果该行未被更新,则为空
+- `DB_ROW_ID(6字节)`:如果没有设置主键且该表没有唯一非空索引时,`InnoDB` 会使用该 id 来生成聚簇索引
+
+### ReadView
+
+```c
+class ReadView {
+ /* ... */
+private:
+ trx_id_t m_low_limit_id; /* 大于等于这个 ID 的事务均不可见 */
+
+ trx_id_t m_up_limit_id; /* 小于这个 ID 的事务均可见 */
+
+ trx_id_t m_creator_trx_id; /* 创建该 Read View 的事务ID */
+
+ trx_id_t m_low_limit_no; /* 事务 Number, 小于该 Number 的 Undo Logs 均可以被 Purge */
+
+ ids_t m_ids; /* 创建 Read View 时的活跃事务列表 */
+
+ m_closed; /* 标记 Read View 是否 close */
+}
+```
+
+[`Read View`](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L298) 主要是用来做可见性判断,里面保存了 “当前对本事务不可见的其他活跃事务”
+
+主要有以下字段:
+
+- `m_low_limit_id`:目前出现过的最大的事务 ID+1,即下一个将被分配的事务 ID。大于等于这个 ID 的数据版本均不可见
+- `m_up_limit_id`:活跃事务列表 `m_ids` 中最小的事务 ID,如果 `m_ids` 为空,则 `m_up_limit_id` 为 `m_low_limit_id`。小于这个 ID 的数据版本均可见
+- `m_ids`:`Read View` 创建时其他未提交的活跃事务 ID 列表。创建 `Read View`时,将当前未提交事务 ID 记录下来,后续即使它们修改了记录行的值,对于当前事务也是不可见的。`m_ids` 不包括当前事务自己和已提交的事务(正在内存中)
+- `m_creator_trx_id`:创建该 `Read View` 的事务 ID
+
+**事务可见性示意图**([图源](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/#MVCC-1)):
+
+
+
+### undo-log
+
+`undo log` 主要有两个作用:
+
+- 当事务回滚时用于将数据恢复到修改前的样子
+- 另一个作用是 `MVCC` ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 `undo log` 读取之前的版本数据,以此实现非锁定读
+
+**在 `InnoDB` 存储引擎中 `undo log` 分为两种:`insert undo log` 和 `update undo log`:**
+
+1. **`insert undo log`**:指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作
+
+**`insert` 时的数据初始状态:**
+
+
+
+2. **`update undo log`**:`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除
+
+**数据第一次被修改时:**
+
+
+
+**数据第二次被修改时:**
+
+
+
+不同事务或者相同事务的对同一记录行的修改,会使该记录行的 `undo log` 成为一条链表,链首就是最新的记录,链尾就是最早的旧记录。
+
+### 数据可见性算法
+
+在 `InnoDB` 存储引擎中,创建一个新事务后,执行每个 `select` 语句前,都会创建一个快照(Read View),**快照中保存了当前数据库系统中正处于活跃(没有 commit)的事务的 ID 号**。其实简单的说保存的是系统中当前不应该被本事务看到的其他事务 ID 列表(即 m_ids)。当用户在这个事务中要读取某个记录行的时候,`InnoDB` 会将该记录行的 `DB_TRX_ID` 与 `Read View` 中的一些变量及当前事务 ID 进行比较,判断是否满足可见性条件
+
+[具体的比较算法](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L161)如下([图源](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/#MVCC-1)):
+
+
+
+1. 如果记录 DB_TRX_ID < m_up_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之前就提交了,所以该记录行的值对当前事务是可见的
+
+2. 如果 DB_TRX_ID >= m_low_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之后才修改该行,所以该记录行的值对当前事务不可见。跳到步骤 5
+
+3. m_ids 为空,则表明在当前事务创建快照之前,修改该行的事务就已经提交了,所以该记录行的值对当前事务是可见的
+
+4. 如果 m_up_limit_id <= DB_TRX_ID < m_low_limit_id,表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照的时候可能处于“活动状态”或者“已提交状态”;所以就要对活跃事务列表 m_ids 进行查找(源码中是用的二分查找,因为是有序的)
+
+ - 如果在活跃事务列表 m_ids 中能找到 DB_TRX_ID,表明:① 在当前事务创建快照前,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了,但没有提交;或者 ② 在当前事务创建快照后,该记录行的值被事务 ID 为 DB_TRX_ID 的事务修改了。这些情况下,这个记录行的值对当前事务都是不可见的。跳到步骤 5
+
+ - 在活跃事务列表中找不到,则表明“id 为 trx_id 的事务”在修改“该记录行的值”后,在“当前事务”创建快照前就已经提交了,所以记录行对当前事务可见
+
+5. 在该记录行的 DB_ROLL_PTR 指针所指向的 `undo log` 取出快照记录,用快照记录的 DB_TRX_ID 跳到步骤 1 重新开始判断,直到找到满足的快照版本或返回空
+
+## RC 和 RR 隔离级别下 MVCC 的差异
+
+在事务隔离级别 `RC` 和 `RR` (InnoDB 存储引擎的默认事务隔离级别)下,`InnoDB` 存储引擎使用 `MVCC`(非锁定一致性读),但它们生成 `Read View` 的时机却不同
+
+- 在 RC 隔离级别下的 **`每次select`** 查询前都生成一个`Read View` (m_ids 列表)
+- 在 RR 隔离级别下只在事务开始后 **`第一次select`** 数据前生成一个`Read View`(m_ids 列表)
+
+## MVCC 解决不可重复读问题
+
+虽然 RC 和 RR 都通过 `MVCC` 来读取快照数据,但由于 **生成 Read View 时机不同**,从而在 RR 级别下实现可重复读
+
+举个例子:
+
+
+
+### 在 RC 下 ReadView 生成情况
+
+**1. 假设时间线来到 T4 ,那么此时数据行 id = 1 的版本链为:**
+
+
+
+由于 RC 级别下每次查询都会生成`Read View` ,并且事务 101、102 并未提交,此时 `103` 事务生成的 `Read View` 中活跃的事务 **`m_ids` 为:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103
+
+- 此时最新记录的 `DB_TRX_ID` 为 101,m_up_limit_id <= 101 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是 101,不可见
+- 继续找上一条 `DB_TRX_ID`为 1,满足 1 < m_up_limit_id,可见,所以事务 103 查询到数据为 `name = 菜花`
+
+**2. 时间线来到 T6 ,数据的版本链为:**
+
+
+
+因为在 RC 级别下,重新生成 `Read View`,这时事务 101 已经提交,102 并未提交,所以此时 `Read View` 中活跃的事务 **`m_ids`:[102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:102,`m_creator_trx_id`为:103
+
+- 此时最新记录的 `DB_TRX_ID` 为 102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见
+
+- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 为 101,满足 101 < m_up_limit_id,记录可见,所以在 `T6` 时间点查询到数据为 `name = 李四`,与时间 T4 查询到的结果不一致,不可重复读!
+
+**3. 时间线来到 T9 ,数据的版本链为:**
+
+
+
+Regenerate `Read View`. At this time, transactions 101 and 102 have been submitted, so **m_ids** is empty, then m_up_limit_id = m_low_limit_id = 104, and the latest version transaction ID is 102, which satisfies 102 < m_low_limit_id. It can be seen that the query result is `name = Zhao Liu`
+
+> **Summary:** **Under the RC isolation level, the transaction will generate and set up a new Read View at the beginning of each query, resulting in non-repeatable reads**
+
+### ReadView generation under RR
+
+At repeatable read level, a Read View (m_ids list) is generated only the first time data is read after the transaction starts.
+
+**1. The version chain in the case of T4 is: **
+
+
+
+A `Read View` is generated when the `select` statement is currently executed. At this time, **`m_ids`: [101,102]**, `m_low_limit_id` is: 104, `m_up_limit_id` is: 101, `m_creator_trx_id` is: 103
+
+This is the same as at RC level:
+
+- The `DB_TRX_ID` of the latest record is 101, m_up_limit_id <= 101 < m_low_limit_id, so you need to search in the `m_ids` list and find that `DB_TRX_ID` exists in the list, then this record is not visible
+- Find the previous version record in the `undo log` based on `DB_ROLL_PTR`. The `DB_TRX_ID` of the previous record is still 101 and is invisible.
+- Continue to find the previous `DB_TRX_ID` as 1, which satisfies 1 < m_up_limit_id and is visible, so transaction 103 queries the data as `name = cauliflower`
+
+**2. In the case of time point T6: **
+
+
+
+`Read View` will only be generated once at the RR level, so **`m_ids`: [101,102]** is still used at this time, `m_low_limit_id` is: 104, `m_up_limit_id` is: 101, `m_creator_trx_id` is: 103
+
+- The `DB_TRX_ID` of the latest record is 102, m_up_limit_id <= 102 < m_low_limit_id, so you need to search in the `m_ids` list and find that `DB_TRX_ID` exists in the list, then this record is not visible
+
+- Find the previous version record in the `undo log` based on `DB_ROLL_PTR`. The `DB_TRX_ID` of the previous record is 101 and is invisible.
+
+- Continue to find the previous version record in the `undo log` based on `DB_ROLL_PTR`. The `DB_TRX_ID` of the previous record is still 101 and is invisible.
+
+- Continue to find the previous `DB_TRX_ID` as 1, which satisfies 1 < m_up_limit_id and is visible, so transaction 103 queries the data as `name = cauliflower`
+
+**3. In the case of time point T9: **
+
+
+
+The situation at this time is exactly the same as T6. Since `Read View` has been generated, **`m_ids`: [101,102]** is still used at this time, so the query result is still `name = cauliflower`
+
+## MVCC➕Next-key-Lock prevents phantom reads
+
+The `InnoDB` storage engine uses `MVCC` and `Next-key Lock` to solve the phantom read problem at the RR level:
+
+**1. Execute ordinary `select`, and the data will be read in the way of `MVCC` snapshot reading**
+
+In the case of snapshot read, the RR isolation level will only generate `Read View` for the first query after the transaction is started, and will be used until the transaction is committed. Therefore, after generating `Read View`, the updated and inserted record versions made by other transactions are not visible to the current transaction, achieving repeatable reading and preventing "phantom reading" under snapshot reading.
+
+**2. Execute select...for update/lock in share mode, insert, update, delete and other current reads**
+
+Under the current read, all the latest data is read. If other transactions insert new records and they happen to be within the query range of the current transaction, phantom reads will occur! `InnoDB` uses [Next-key Lock](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-next-key-locks) to prevent this. When executing the current read, the read records will be locked and their gaps will be locked to prevent other transactions from inserting data within the query range. As long as I don't let you insert, phantom reading won't happen
+
+## Reference
+
+- **"MySQL Technology Insider InnoDB Storage Engine 2nd Edition"**
+- [Relationship between transaction isolation level and locks in Innodb](https://tech.meituan.com/2014/08/20/innodb-lock.html)
+- [MySQL transactions and how MVCC implements isolation levels](https://blog.csdn.net/qq_35190492/article/details/109044141)
+- [InnoDB Transaction Analysis-MVCC](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/)
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-auto-increment-primary-key-continuous.en.md b/docs_en/database/mysql/mysql-auto-increment-primary-key-continuous.en.md
new file mode 100644
index 00000000000..cb8095ca1c6
--- /dev/null
+++ b/docs_en/database/mysql/mysql-auto-increment-primary-key-continuous.en.md
@@ -0,0 +1,228 @@
+---
+title: MySQL自增主键一定是连续的吗
+category: 数据库
+tag:
+ - MySQL
+ - 大厂面试
+head:
+ - - meta
+ - name: keywords
+ content: 自增主键,不连续,事务回滚,并发插入,计数器,聚簇索引
+ - - meta
+ - name: description
+ content: 解析自增主键不连续的根因与触发场景,结合事务回滚与并发插入,说明 InnoDB 计数器与聚簇索引的行为。
+---
+
+> 作者:飞天小牛肉
+>
+> 原文:
+
+众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。
+
+但实际上,MySQL 的自增主键并不能保证一定是连续递增的。
+
+下面举个例子来看下,如下所示创建一张表:
+
+
+
+## 自增值保存在哪里?
+
+使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义:
+
+
+
+上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件:
+
+
+
+从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。
+
+但需要注意的是,自增值并不会保存在这个表结构也就是 `.frm` 文件中,不同的引擎对于自增值的保存策略不同:
+
+1)MyISAM 引擎的自增值保存在数据文件中
+
+2)InnoDB 引擎的自增值,其实是保存在了内存里,并没有持久化。第一次打开表的时候,都会去找自增值的最大值 `max(id)`,然后将 `max(id)+1` 作为这个表当前的自增值。
+
+举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。
+
+
+
+但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。 也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
+
+
+
+
+
+以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值”
+
+也就是说对于上面这个例子来说,重启实例后这个表的 AUTO_INCREMENT 仍然是 2。
+
+理解了 MySQL 自增值到底保存在哪里以后,我们再来看看自增值的修改机制,并以此引出第一种自增值不连续的场景。
+
+## 自增值不连续的场景
+
+### 自增值不连续场景 1
+
+在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
+
+- 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段;
+- 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。
+
+根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设某次要插入的值是 `insert_num`,当前的自增值是 `autoIncrement_num`:
+
+- 如果 `insert_num < autoIncrement_num`,那么这个表的自增值不变
+- 如果 `insert_num >= autoIncrement_num`,就需要把当前自增值修改为新的自增值
+
+也就是说,如果插入的 id 是 100,当前的自增值是 90,`insert_num >= autoIncrement_num`,那么自增值就会被修改为新的自增值即 101
+
+一定是这样吗?
+
+非也~
+
+了解过分布式 id 的小伙伴一定知道,为了避免两个库生成的主键发生冲突,我们可以让一个库的自增 id 都是奇数,另一个库的自增 id 都是偶数
+
+这个奇数偶数其实是通过 `auto_increment_offset` 和 `auto_increment_increment` 这两个参数来决定的,这俩分别用来表示自增的初始值和步长,默认值都是 1。
+
+所以,上面的例子中生成新的自增值的步骤实际是这样的:从 `auto_increment_offset` 开始,以 `auto_increment_increment` 为步长,持续叠加,直到找到第一个大于 100 的值,作为新的自增值。
+
+所以,这种情况下,自增值可能会是 102,103 等等之类的,就会导致不连续的主键 id。
+
+更遗憾的是,即使在自增初始值和步长这两个参数都设置为 1 的时候,自增主键 id 也不一定能保证主键是连续的
+
+### 自增值不连续场景 2
+
+举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧
+
+
+
+这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`:
+
+
+
+但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3!
+
+这是为啥?
+
+我们来分析下这个 insert 语句的执行流程:
+
+1. 执行器调用 InnoDB 引擎接口准备插入一行记录 (null,1,1);
+2. InnoDB 发现用户没有指定自增 id 的值,则获取表 `test_pk` 当前的自增值 2;
+3. 将传入的记录改成 (2,1,1);
+4. 将表的自增值改成 3;
+5. 继续执行插入数据操作,由于已经存在 a=1 的记录,所以报 Duplicate key error,语句返回
+
+可以看到,自增值修改的这个操作,是在真正执行插入数据的操作之前。
+
+这个语句真正执行的时候,因为碰到唯一键 a 冲突,所以 id = 2 这一行并没有插入成功,但也没有将自增值再改回去。所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。也就是说,出现了自增主键不连续的情况。
+
+至此,我们已经罗列了两种自增主键不连续的情况:
+
+1. 自增初始值和自增步长设置不为 1
+2. 唯一键冲突
+
+除此之外,事务回滚也会导致这种情况
+
+### 自增值不连续场景 3
+
+我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3:
+
+
+
+我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4:
+
+
+
+再去执行这样一段 SQL:
+
+
+
+Although we inserted a (null, 3, 3) record, it was rolled back using rollback, so there is no such record in the database:
+
+
+
+In the case of this transaction rollback, the auto-increment value does not also roll back! As shown in the figure below, the self-increment value still stubbornly increases from 4 to 5:
+
+
+
+So when we insert a piece of data (null, 3, 3) at this time, the primary key id will be automatically assigned to `5`:
+
+
+
+So, why doesn't MySQL change the table's auto-increment value back when a unique key conflict or rollback occurs? If we go back, won't the self-increasing IDs become discontinuous?
+
+In fact, the main reason for doing this is to improve performance.
+
+We directly use proof by contradiction to verify: Assume that MySQL will change the self-increment value back when the transaction is rolled back, what will happen?
+
+Now there are two transactions A and B that are executed in parallel. When applying for auto-increment value, in order to prevent the two transactions from applying for the same auto-increment ID, they must lock and then apply sequentially, right?
+
+1. Assume that transaction A applies for id = 1, and transaction B applies for id = 2. Then the auto-increment value of table t is 3 at this time, and execution continues thereafter.
+2. Transaction B is submitted correctly, but transaction A has a unique key conflict, that is, the insertion of the row record with id = 1 fails. If transaction A is allowed to roll back the auto-incremented id, that is, change the current auto-increment value of the table back to 1, then there will be a situation like this: there is already a row with id = 2 in the table, and the current auto-increment id value is 1.
+3. Next, other transactions that continue to be executed will apply for id=2. At this time, an insert statement error "primary key conflict" will appear.
+
+
+
+In order to resolve this primary key conflict, there are two methods:
+
+1. Before each application for an id, first determine whether the id already exists in the table. If it exists, skip the id.
+2. Expand the lock scope of the self-increasing ID. You must wait until a transaction is completed and submitted before the next transaction can apply for the self-increasing ID.
+
+Obviously, the costs of the above two methods are relatively high and will cause performance problems. The reason is the "allowing auto-increment id fallback" we assumed.
+
+Therefore, InnoDB abandoned this design and will not fall back to incrementing the ID if the statement fails to execute. It is precisely because of this that it is only guaranteed that the auto-incrementing id is increasing, but it is not guaranteed to be continuous.
+
+In summary, three scenarios of discontinuous self-increasing value have been analyzed, and there is also a fourth scenario: batch insertion of data.
+
+### Self-increasing value discontinuous scenario 4
+
+For statements that insert data in batches, MySQL has a strategy to apply for auto-increment IDs in batches:
+
+1. During statement execution, if you apply for an auto-increment ID for the first time, 1 will be allocated;
+2. After 1 is used up, this statement will apply for an auto-increment ID for the second time, and 2 will be allocated;
+3. After 2 are used up, the same statement remains. If you apply for an auto-increment ID for the third time, 4 will be allocated;
+4. By analogy, if you use the same statement to apply for auto-increment IDs, the number of auto-increment IDs applied each time is twice that of the previous time.
+
+Note that the batch insertion of data mentioned here does not include multiple value values in the ordinary insert statement! ! ! , because this type of statement can accurately calculate how many IDs are needed when applying for auto-incrementing IDs, and then apply for them all at once. After the application is completed, the lock can be released.
+
+For statements such as `insert ... select`, replace ... select and load data, MySQL does not know how many IDs need to be applied for, so it adopts this batch application strategy. After all, it is too slow to apply one by one.
+
+For example, assume that our current table has the following data:
+
+
+
+We create a table `test_pk2` with the same structure definition as the current table `test_pk`:
+
+
+
+Then use `insert...select` to batch insert data into the `teset_pk2` table:
+
+
+
+As you can see, the data was successfully imported.
+
+Let’s take a look at the auto-increment value of `test_pk2`:
+
+
+
+As analyzed above, it is 8 instead of 6
+
+Specifically, insert...select actually inserts 5 rows of data (1 1) (2 2) (3 3) (4 4) (5 5) into the table. However, these five lines of data are self-increasing IDs applied for three times. Combined with the batch application strategy, the number of self-increasing IDs applied for each time is twice that of the previous time, so:
+
+- I applied for an id for the first time: id=1
+- Two ids were assigned for the second time: id=2 and id=3
+- For the third time, 4 ids were assigned: id=4, id = 5, id = 6, id=7
+
+Since this statement actually uses only 5 ids, id=6 and id=7 are wasted. After that, execute `insert into test_pk2 values(null,6,6)`, and the actually inserted data is (8,6,6):
+
+
+
+## Summary
+
+This article summarizes four scenarios of discontinuous self-increasing value:
+
+1. The auto-increment initial value and auto-increment step size are not set to 1.
+2. Unique key conflict
+3. Transaction rollback
+4. Batch insertion (such as `insert...select` statement)
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-high-performance-optimization-specification-recommendations.en.md b/docs_en/database/mysql/mysql-high-performance-optimization-specification-recommendations.en.md
new file mode 100644
index 00000000000..29ab4112114
--- /dev/null
+++ b/docs_en/database/mysql/mysql-high-performance-optimization-specification-recommendations.en.md
@@ -0,0 +1,396 @@
+---
+title: MySQL高性能优化规范建议总结
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 优化,索引设计,SQL 规范,表结构,慢查询,参数调优,实践清单
+ - - meta
+ - name: description
+ content: 提炼 MySQL 高性能优化规范,涵盖索引与 SQL、表结构与慢查询、参数与实用清单,提升线上稳定与效率。
+---
+
+> 作者: 听风 原文地址: 。
+>
+> JavaGuide 已获得作者授权,并对原文内容进行了完善补充。
+
+## 数据库命名规范
+
+- 所有数据库对象名称必须使用小写字母并用下划线分割。
+- 所有数据库对象名称禁止使用 MySQL 保留关键字(如果表名中包含关键字查询时,需要将其用单引号括起来)。
+- 数据库对象的命名要能做到见名识义,并且最好不要超过 32 个字符。
+- 临时库表必须以 `tmp_` 为前缀并以日期为后缀,备份表必须以 `bak_` 为前缀并以日期 (时间戳) 为后缀。
+- 所有存储相同数据的列名和列类型必须一致(一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。
+
+## 数据库基本设计规范
+
+### 所有表必须使用 InnoDB 存储引擎
+
+没有特殊要求(即 InnoDB 无法满足的功能如:列存储、存储空间数据等)的情况下,所有表必须使用 InnoDB 存储引擎(MySQL5.5 之前默认使用 MyISAM,5.6 以后默认的为 InnoDB)。
+
+InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能更好。
+
+### 数据库和表的字符集统一使用 UTF8
+
+兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
+
+推荐阅读一下我写的这篇文章:[MySQL 字符集详解](../character-set.md) 。
+
+### 所有表和字段都需要添加注释
+
+使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护。
+
+### 尽量控制单表数据量的大小,建议控制在 500 万以内
+
+500 万并不是 MySQL 数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
+
+可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
+
+### 谨慎使用 MySQL 分区表
+
+分区表在物理上表现为多个文件,在逻辑上表现为一个表。
+
+谨慎选择分区键,跨分区查询效率可能更低。
+
+建议采用物理分表的方式管理大数据。
+
+### 经常一起使用的列放到一个表中
+
+避免更多的关联操作。
+
+### 禁止在表中建立预留字段
+
+- 预留字段的命名很难做到见名识义。
+- 预留字段无法确认存储的数据类型,所以无法选择合适的类型。
+- 对预留字段类型的修改,会对表进行锁定。
+
+### 禁止在数据库中存储文件(比如图片)这类大的二进制数据
+
+在数据库中存储文件会严重影响数据库性能,消耗过多存储空间。
+
+文件(比如图片)这类大的二进制数据通常存储于文件服务器,数据库只存储文件地址信息。
+
+### 不要被数据库范式所束缚
+
+一般来说,设计关系数据库时需要满足第三范式,但为了满足第三范式,我们可能会拆分出多张表。而在进行查询时需要对多张表进行关联查询,有时为了提高查询效率,会降低范式的要求,在表中保存一定的冗余信息,也叫做反范式。但要注意反范式一定要适度。
+
+### 禁止在线上做数据库压力测试
+
+### 禁止从开发环境、测试环境直接连接生产环境数据库
+
+安全隐患极大,要对生产环境抱有敬畏之心!
+
+## 数据库字段设计规范
+
+### 优先选择符合存储需要的最小的数据类型
+
+存储字节越小,占用空间也就越小,性能也越好。
+
+**a.某些字符串可以转换成数字类型存储,比如可以将 IP 地址转换成整型数据。**
+
+数字是连续的,性能更好,占用空间也更小。
+
+MySQL 提供了两个方法来处理 ip 地址:
+
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位);
+- `INET_NTOA()`:把整型的 ip 转为地址。
+
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型;显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+
+**b.对于非负型的数据 (如自增 ID、整型 IP、年龄) 来说,要优先使用无符号整型来存储。**
+
+无符号相对于有符号可以多出一倍的存储空间:
+
+```sql
+SIGNED INT -2147483648~2147483647
+UNSIGNED INT 0~4294967295
+```
+
+**c.小数值类型(比如年龄、状态表示如 0/1)优先使用 TINYINT 类型。**
+
+### 避免使用 TEXT、BLOB 数据类型,最常见的 TEXT 类型可以存储 64k 的数据
+
+**a. 建议把 BLOB 或是 TEXT 列分离到单独的扩展表中。**
+
+MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,MySQL 还是要进行二次查询,会使 sql 性能变得很差,但是不是说一定不能使用这样的数据类型。
+
+如果一定要使用,建议把 BLOB 或是 TEXT 列分离到单独的扩展表中,查询时一定不要使用 `select *`而只需要取出必要的列,不需要 TEXT 列的数据时不要对该列进行查询。
+
+**2、TEXT 或 BLOB 类型只能使用前缀索引**
+
+因为 MySQL 对索引字段长度是有限制的,所以 TEXT 类型只能使用前缀索引,并且 TEXT 列上是不能有默认值的。
+
+### 避免使用 ENUM 类型
+
+- 修改 ENUM 值需要使用 ALTER 语句。
+- ENUM 类型的 ORDER BY 操作效率低,需要额外操作。
+- ENUM 数据类型存在一些限制,比如建议不要使用数值作为 ENUM 的枚举值。
+
+相关阅读:[是否推荐使用 MySQL 的 enum 类型? - 架构文摘 - 知乎](https://www.zhihu.com/question/404422255/answer/1661698499) 。
+
+### 尽可能把所有列定义为 NOT NULL
+
+除非有特别的原因使用 NULL 值,否则应该总是让字段保持 NOT NULL。
+
+- 索引 NULL 列需要额外的空间来保存,所以要占用更多的空间。
+- 进行比较和计算时要对 NULL 值做特别的处理。
+
+相关阅读:[技术分享 | MySQL 默认值选型(是空,还是 NULL)](https://opensource.actionsky.com/20190710-mysql/) 。
+
+### 一定不要用字符串存储日期
+
+对于日期类型来说,一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和数值型时间戳。
+
+这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家在实际开发中选择正确的存放时间的数据类型:
+
+| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
+| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
+| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
+| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
+| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
+
+MySQL 时间类型选择的详细介绍请看这篇:[MySQL 时间类型数据存储建议](https://javaguide.cn/database/mysql/some-thoughts-on-database-storage-time.html)。
+
+### 同财务相关的金额类数据必须使用 decimal 类型
+
+- **非精准浮点**:float、double
+- **精准浮点**:decimal
+
+decimal 类型为精准浮点数,在计算时不会丢失精度。占用空间由定义的宽度决定,每 4 个字节可以存储 9 位数字,并且小数点要占用一个字节。并且,decimal 可用于存储比 bigint 更大的整型数据。
+
+不过, 由于 decimal 需要额外的空间和计算开销,应该尽量只在需要对数据进行精确计算时才使用 decimal 。
+
+### 单表不要包含过多字段
+
+如果一个表包含过多字段的话,可以考虑将其分解成多个表,必要时增加中间表进行关联。
+
+## 索引设计规范
+
+### 限制每张表上的索引数量,建议单张表索引不超过 5 个
+
+索引并不是越多越好!索引可以提高效率,同样可以降低效率。
+
+索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
+
+因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划。如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+
+### 禁止使用全文索引
+
+全文索引不适用于 OLTP 场景。
+
+### 禁止给表中的每一列都建立单独的索引
+
+5.6 版本之前,一个 sql 只能使用到一个表中的一个索引;5.6 以后,虽然有了合并索引的优化方式,但是还是远远没有使用一个联合索引的查询方式好。
+
+### 每个 InnoDB 表必须有个主键
+
+InnoDB 是一种索引组织表:数据的存储的逻辑顺序和索引的顺序是相同的。每个表都可以有多个索引,但是表的存储顺序只能有一种。
+
+InnoDB 是按照主键索引的顺序来组织表的。
+
+- 不要使用更新频繁的列作为主键,不使用多列主键(相当于联合索引)。
+- 不要使用 UUID、MD5、HASH、字符串列作为主键(无法保证数据的顺序增长)。
+- 主键建议使用自增 ID 值。
+
+### 常见索引列建议
+
+- 出现在 SELECT、UPDATE、DELETE 语句的 WHERE 从句中的列。
+- 包含在 ORDER BY、GROUP BY、DISTINCT 中的字段。
+- 不要将符合 1 和 2 中的字段的列都建立一个索引,通常将 1、2 中的字段建立联合索引效果更好。
+- 多表 join 的关联列。
+
+### 如何选择索引列的顺序
+
+建立索引的目的是:希望通过索引进行数据查找,减少随机 IO,增加查询性能,索引能过滤出越少的数据,则从磁盘中读入的数据也就越少。
+
+- **区分度最高的列放在联合索引的最左侧**:这是最重要的原则。区分度越高,通过索引筛选出的数据就越少,I/O 操作也就越少。计算区分度的方法是 `count(distinct column) / count(*)`。
+- **最频繁使用的列放在联合索引的左侧**:这符合最左前缀匹配原则。将最常用的查询条件列放在最左侧,可以最大程度地利用索引。
+- **字段长度**:字段长度对联合索引非叶子节点的影响很小,因为它存储了所有联合索引字段的值。字段长度主要影响主键和包含在其他索引中的字段的存储空间,以及这些索引的叶子节点的大小。因此,在选择联合索引列的顺序时,字段长度的优先级最低。对于主键和包含在其他索引中的字段,选择较短的字段长度可以节省存储空间和提高 I/O 性能。
+
+### 避免建立冗余索引和重复索引(增加了查询优化器生成执行计划的时间)
+
+- 重复索引示例:primary key(id)、index(id)、unique index(id)。
+- 冗余索引示例:index(a,b,c)、index(a,b)、index(a)。
+
+### 对于频繁的查询,优先考虑使用覆盖索引
+
+> 覆盖索引:就是包含了所有查询字段 (where、select、order by、group by 包含的字段) 的索引
+
+**覆盖索引的好处**:
+
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作**:InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率**:由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+
+---
+
+### 索引 SET 规范
+
+**尽量避免使用外键约束**
+
+- 不建议使用外键约束(foreign key),但一定要在表与表之间的关联键上建立索引。
+- 外键可用于保证数据的参照完整性,但建议在业务端实现。
+- 外键会影响父表和子表的写操作从而降低性能。
+
+## 数据库 SQL 开发规范
+
+### 尽量不在数据库做运算,复杂运算需移到业务应用里完成
+
+尽量不在数据库做运算,复杂运算需移到业务应用里完成。这样可以避免数据库的负担过重,影响数据库的性能和稳定性。数据库的主要作用是存储和管理数据,而不是处理数据。
+
+### 优化对性能影响较大的 SQL 语句
+
+要找到最需要优化的 SQL 语句。要么是使用最频繁的语句,要么是优化后提高最明显的语句,可以通过查询 MySQL 的慢查询日志来发现需要进行优化的 SQL 语句。
+
+### 充分利用表上已经存在的索引
+
+避免使用双%号的查询条件。如:`a like '%123%'`(如果无前置%,只有后置%,是可以用到列上的索引的)。
+
+一个 SQL 只能利用到复合索引中的一列进行范围查询。如:有 a,b,c 列的联合索引,在查询条件中有 a 列的范围查询,则在 b,c 列上的索引将不会被用到。
+
+在定义联合索引时,如果 a 列要用到范围查找的话,就要把 a 列放到联合索引的右侧,使用 left join 或 not exists 来优化 not in 操作,因为 not in 也通常会使用索引失效。
+
+### 禁止使用 SELECT \* 必须使用 SELECT <字段列表> 查询
+
+- `SELECT *` 会消耗更多的 CPU。
+- `SELECT *` 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。
+- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快、效率极高、业界极为推荐的查询优化方式)。
+- `SELECT <字段列表>` 可减少表结构变更带来的影响。
+
+### 禁止使用不含字段列表的 INSERT 语句
+
+**不推荐**:
+
+```sql
+insert into t values ('a','b','c');
+```
+
+**推荐**:
+
+```sql
+insert into t(c1,c2,c3) values ('a','b','c');
+```
+
+### 建议使用预编译语句进行数据库操作
+
+- 预编译语句可以重复使用这些计划,减少 SQL 编译所需要的时间,还可以解决动态 SQL 所带来的 SQL 注入的问题。
+- 只传参数,比传递 SQL 语句更高效。
+- 相同语句可以一次解析,多次使用,提高处理效率。
+
+### 避免数据类型的隐式转换
+
+隐式转换会导致索引失效,如:
+
+```sql
+select name,phone from customer where id = '111';
+```
+
+详细解读可以看:[MySQL 中的隐式转换造成的索引失效](./index-invalidation-caused-by-implicit-conversion.md) 这篇文章。
+
+### 避免使用子查询,可以把子查询优化为 join 操作
+
+通常子查询在 in 子句中,且子查询中为简单 SQL(不包含 union、group by、order by、limit 从句) 时,才可以把子查询转化为关联查询进行优化。
+
+**子查询性能差的原因**:子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
+
+### 避免使用 JOIN 关联太多的表
+
+对于 MySQL 来说,是存在关联缓存的,缓存的大小可以由 join_buffer_size 参数进行设置。
+
+在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
+
+如果程序中大量地使用了多表关联的操作,同时 join_buffer_size 设置得也不合理,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
+
+同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 个表,建议不超过 5 个。
+
+### 减少同数据库的交互次数
+
+The database is more suitable for processing batch operations. Merging multiple identical operations together can improve processing efficiency.
+
+### When performing or judgment corresponding to the same column, use in instead of or
+
+Do not exceed 500 values for in. The in operation can make more efficient use of indexes, or indexes can rarely be used in most cases.
+
+### Disable the use of order by rand() for random sorting
+
+order by rand() will load all qualified data in the table into memory, then sort all data in memory according to randomly generated values, and may generate a random value for each row. If the data set that meets the conditions is very large, it will consume a lot of CPU, IO and memory resources.
+
+It is recommended to get a random value in the program and then get the data from the database.
+
+### Disable function transformations and calculations on columns in the WHERE clause
+
+Performing function transformations or calculations on columns results in the index not being able to be used.
+
+**Not recommended**:
+
+```sql
+where date(create_time)='20190101'
+```
+
+**Recommended**:
+
+```sql
+where create_time >= '20190101' and create_time < '20190102'
+```
+
+### Use UNION ALL instead of UNION when it is obvious that there will be no duplicate values
+
+- UNION will put all the data of the two result sets into the temporary table and then perform the deduplication operation.
+- UNION ALL will no longer deduplicate the result set.
+
+### Split a complex large SQL into multiple small SQLs
+
+- Large SQL is logically complex and requires a large amount of CPU for calculation.
+- In MySQL, one SQL can only use one CPU for calculation.
+- After SQL is split, it can be executed in parallel to improve processing efficiency.
+
+### The program connects to different databases using different accounts, and cross-database queries are prohibited.
+
+- Leave room for database migration and sharding of databases and tables.
+- Reduce business coupling.
+- Avoid security risks caused by excessive permissions.
+
+## Database operation code of conduct
+
+### Batch write (UPDATE, DELETE, INSERT) operations of more than 1 million rows must be performed in batches multiple times.
+
+**Large batch operations may cause severe master-slave delays**
+
+In a master-slave environment, large batch operations may cause serious master-slave delays. Large-batch write operations generally take a long time to execute, and only after the execution on the master database is completed, they will be executed on other slave databases, so it will cause a long delay between the master database and the slave database.
+
+**When the binlog log is in row format, a large number of logs will be generated**
+
+Large batch write operations will generate a large number of logs, especially for row format binary data. Since the modification of each row of data is recorded in the row format, the more data we modify at one time, the more logs will be generated, and the longer the log transmission and recovery will take, which is also a reason for the master-slave delay.
+
+**Avoid large transaction operations**
+
+Modifying data in large batches must be done in a transaction, which will cause a large amount of data in the table to be locked, resulting in a large amount of blocking. Blocking will have a great impact on the performance of MySQL.
+
+In particular, long-term blocking will occupy all available connections to the database, which will prevent other applications in the production environment from connecting to the database. Therefore, it is important to pay attention to batching large write operations.
+
+### For large tables, use pt-online-schema-change to modify the table structure.
+
+- Avoid master-slave delays caused by large table modifications.
+- Avoid table locking when modifying table fields.
+
+You must be careful when modifying the data structure of a large table, as it will cause serious table lock operations, which is intolerable especially in a production environment.
+
+pt-online-schema-change will first create a new table with the same structure as the original table, modify the table structure on the new table, then copy the data in the original table to the new table, and add some triggers to the original table. Copy the newly added data in the original table to the new table. After all the row data is copied, name the new table the original table and delete the original table. Break the original DDL operation into multiple small batches.
+
+### It is forbidden to grant super permissions to the account used by the program.
+
+- When the maximum number of connections is reached, 1 user connection with super privileges is also run.
+- Super permissions can only be reserved for the account used by the DBA to handle problems.
+
+### For the program to connect to the database account, follow the principle of least privileges
+
+- The database account used by the program can only be used under one DB, and cross-databases are not allowed.
+- In principle, the account used by the program is not allowed to have drop permissions.
+
+## Recommended reading
+
+- [MySQL design conventions that technical students must learn are painful lessons - Alibaba Developers](https://mp.weixin.qq.com/s/XC8e5iuQtfsrEOERffEZ-Q)
+- [Let’s talk about 15 tips for creating database tables](https://mp.weixin.qq.com/s/NM-aHaW6TXrnO6la6Jfl5A)
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-index.en.md b/docs_en/database/mysql/mysql-index.en.md
new file mode 100644
index 00000000000..f3f9553522b
--- /dev/null
+++ b/docs_en/database/mysql/mysql-index.en.md
@@ -0,0 +1,564 @@
+---
+title: MySQL索引详解
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 索引,B+树,覆盖索引,联合索引,选择性,回表,索引下推
+ - - meta
+ - name: description
+ content: 深入解析 MySQL 索引结构与选型,覆盖 B+ 树、联合与覆盖索引、选择性与回表等关键优化点与实践。
+---
+
+> 感谢[WT-AHA](https://github.com/WT-AHA)对本文的完善,相关 PR: 。
+
+但凡经历过几场面试的小伙伴,应该都清楚,数据库索引这个知识点在面试中出现的频率高到离谱。
+
+除了对于准备面试来说非常重要之外,善用索引对 SQL 的性能提升非常明显,是一个性价比较高的 SQL 优化手段。
+
+## 索引介绍
+
+**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
+
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
+
+## 索引的优缺点
+
+**索引的优点:**
+
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
+
+**索引的缺点:**
+
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
+
+**那么,用了索引就一定能提高查询性能吗?**
+
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
+
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
+
+## 索引底层数据结构选型
+
+### Hash 表
+
+哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
+
+**为何能够通过 key 快速取出 value 呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
+
+```java
+hash = hashfunc(key)
+index = hash % array_size
+```
+
+
+
+但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了提高链表过长时的搜索效率,引入了红黑树。
+
+
+
+为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
+
+MySQL 的 InnoDB 存储引擎不直接支持常规的哈希索引,但是,InnoDB 存储引擎中存在一种特殊的“自适应哈希索引”(Adaptive Hash Index),自适应哈希索引并不是传统意义上的纯哈希索引,而是结合了 B+Tree 和哈希索引的特点,以便更好地适应实际应用中的数据访问模式和性能需求。自适应哈希索引的每个哈希桶实际上是一个小型的 B+Tree 结构。这个 B+Tree 结构可以存储多个键值对,而不仅仅是一个键。这有助于减少哈希冲突链的长度,提高了索引的效率。关于 Adaptive Hash Index 的详细介绍,可以查看 [MySQL 各种“Buffer”之 Adaptive Hash Index](https://mp.weixin.qq.com/s/ra4v1XR5pzSWc-qtGO-dBg) 这篇文章。
+
+既然哈希表这么快,**为什么 MySQL 没有使用其作为索引的数据结构呢?** 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
+
+试想一种情况:
+
+```java
+SELECT * FROM tb1 WHERE id < 500;
+```
+
+在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
+
+### 二叉查找树(BST)
+
+二叉查找树(Binary Search Tree)是一种基于二叉树的数据结构,它具有以下特点:
+
+1. 左子树所有节点的值均小于根节点的值。
+2. 右子树所有节点的值均大于根节点的值。
+3. 左右子树也分别为二叉查找树。
+
+当二叉查找树是平衡的时候,也就是树的每个节点的左右子树深度相差不超过 1 的时候,查询的时间复杂度为 O(log2(N)),具有比较高的效率。然而,当二叉查找树不平衡时,例如在最坏情况下(有序插入节点),树会退化成线性链表(也被称为斜树),导致查询效率急剧下降,时间复杂退化为 O(N)。
+
+
+
+也就是说,**二叉查找树的性能非常依赖于它的平衡程度,这就导致其不适合作为 MySQL 底层索引的数据结构。**
+
+为了解决这个问题,并提高查询效率,人们发明了多种在二叉查找树基础上的改进型数据结构,如平衡二叉树、B-Tree、B+Tree 等。
+
+### AVL 树
+
+AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的名称来自于发明者 G.M. Adelson-Velsky 和 E.M. Landis 的名字缩写。AVL 树的特点是保证任何节点的左右子树高度之差不超过 1,因此也被称为高度平衡二叉树,它的查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。
+
+
+
+AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
+
+由于 AVL 树需要频繁地进行旋转操作来保持平衡,因此会有较大的计算开销进而降低了数据库写操作的性能。并且, 在使用 AVL 树时,每个树节点仅存储一个数据,而每次进行磁盘 IO 时只能读取一个节点的数据,如果需要查询的数据分布在多个节点上,那么就需要进行多次磁盘 IO。**磁盘 IO 是一项耗时的操作,在设计数据库索引时,我们需要优先考虑如何最大限度地减少磁盘 IO 操作的次数。**
+
+实际应用中,AVL 树使用的并不多。
+
+### 红黑树
+
+红黑树是一种自平衡二叉查找树,通过在插入和删除节点时进行颜色变换和旋转操作,使得树始终保持平衡状态,它具有以下特点:
+
+1. 每个节点非红即黑;
+2. 根节点总是黑色的;
+3. 每个叶子节点都是黑色的空节点(NIL 节点);
+4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
+5. 从任意节点到它的叶子节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
+
+
+
+和 AVL 树不同的是,红黑树并不追求严格的平衡,而是大致的平衡。正因如此,红黑树的查询效率稍有下降,因为红黑树的平衡性相对较弱,可能会导致树的高度较高,这可能会导致一些数据需要进行多次磁盘 IO 操作才能查询到,这也是 MySQL 没有选择红黑树的主要原因。也正因如此,红黑树的插入和删除操作效率大大提高了,因为红黑树在插入和删除节点时只需进行 O(1) 次数的旋转和变色操作,即可保持基本平衡状态,而不需要像 AVL 树一样进行 O(logn) 次数的旋转操作。
+
+**红黑树的应用还是比较广泛的,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。对于数据在内存中的这种情况来说,红黑树的表现是非常优异的。**
+
+### B 树& B+ 树
+
+B 树也称 B- 树,全称为 **多路平衡查找树**,B+ 树是 B 树的一种变体。B 树和 B+ 树中的 B 是 `Balanced`(平衡)的意思。
+
+目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
+
+**B 树& B+ 树两者有何异同呢?**
+
+- B 树的所有节点既存放键(key)也存放数据(data),而 B+ 树只有叶子节点存放 key 和 data,其他内节点只存放 key。
+- B 树的叶子节点都是独立的;B+ 树的叶子节点有一条引用链指向与它相邻的叶子节点。
+- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+ 树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+ 树的范围查询,只需要对链表进行遍历即可。
+
+综上,B+ 树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
+
+在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
+
+> MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“**非聚簇索引(非聚集索引)**”。
+>
+> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引**,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
+
+## 索引类型总结
+
+按照数据结构维度划分:
+
+- BTree 索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree,但二者实现方式不一样(前面已经介绍了)。
+- 哈希索引:类似键值对的形式,一次即可定位。
+- RTree 索引:一般不会使用,仅支持 geometry 数据类型,优势在于范围查找,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+
+按照底层存储方式角度划分:
+
+- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
+- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+
+按照应用维度划分:
+
+- 主键索引:加速查询 + 列值唯一(不可以有 NULL)+ 表中只有一个。
+- 普通索引:仅加速查询。
+- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
+- 覆盖索引:一个索引包含(或者说覆盖)所有需要查询的字段的值。
+- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
+- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR`、`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
+- 前缀索引:对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
+
+MySQL 8.x 中实现的索引新特性:
+
+- 隐藏索引:也称为不可见索引,不会被优化器使用,但是仍然需要维护,通常会软删除和灰度发布的场景中使用。主键不能设置为隐藏(包括显式设置或隐式设置)。
+- 降序索引:之前的版本就支持通过 desc 来指定索引为降序,但实际上创建的仍然是常规的升序索引。直到 MySQL 8.x 版本才开始真正支持降序索引。另外,在 MySQL 8.x 版本中,不再对 GROUP BY 语句进行隐式排序。
+- 函数索引:从 MySQL 8.0.13 版本开始支持在索引中使用函数或者表达式的值,也就是在索引中可以包含函数或者表达式。
+
+## 主键索引(Primary Key)
+
+数据表的主键列使用的就是主键索引。
+
+一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
+
+在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在 null 值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
+
+
+
+## 二级索引
+
+二级索引(Secondary Index)的叶子节点存储的数据是主键的值,也就是说,通过二级索引可以定位主键的位置,二级索引又称为辅助索引/非主键索引。
+
+唯一索引、普通索引、前缀索引等索引都属于二级索引。
+
+PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
+
+1. **唯一索引(Unique Key)**:唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)**:普通索引的唯一作用就是为了快速查询数据。一张表允许创建多个普通索引,并允许数据重复和 NULL。
+3. **前缀索引(Prefix)**:前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
+4. **全文索引(Full Text)**:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MyISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
+
+二级索引:
+
+
+
+## 聚簇索引与非聚簇索引
+
+### 聚簇索引(聚集索引)
+
+#### 聚簇索引介绍
+
+聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。
+
+在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+ 树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+
+#### 聚簇索引的优缺点
+
+**优点**:
+
+- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+ 树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
+- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
+
+**缺点**:
+
+- **依赖于有序的数据**:因为 B+ 树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
+
+### 非聚簇索引(非聚集索引)
+
+#### 非聚簇索引介绍
+
+非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
+
+非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
+
+#### 非聚簇索引的优缺点
+
+**优点**:
+
+更新代价比聚簇索引要小。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的。
+
+**缺点**:
+
+- **依赖于有序的数据**:跟聚簇索引一样,非聚簇索引也依赖于有序的数据。
+- **可能会二次查询(回表)**:这应该是非聚簇索引最大的缺点了。当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+
+这是 MySQL 的表的文件截图:
+
+
+
+聚簇索引和非聚簇索引:
+
+
+
+#### 非聚簇索引一定回表查询吗(覆盖索引)?
+
+**非聚簇索引不一定回表查询。**
+
+试想一种情况,用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。
+
+```sql
+ SELECT name FROM table WHERE name='guang19';
+```
+
+那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
+
+即使是 MyISAM 也是这样,虽然 MyISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
+
+```sql
+SELECT id FROM table WHERE id=1;
+```
+
+主键索引本身的 key 就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
+
+## 覆盖索引和联合索引
+
+### 覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
+
+在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。**
+
+> 如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
+> 那么直接根据这个索引就可以查到数据,也无需回表。
+
+
+
+我们这里简单演示一下覆盖索引的效果。
+
+1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便,`cus_order` 这张表只有 `id`、`score`、`name` 这 3 个字段。
+
+```sql
+CREATE TABLE `cus_order` (
+ `id` int(11) unsigned NOT NULL AUTO_INCREMENT,
+ `score` int(11) NOT NULL,
+ `name` varchar(11) NOT NULL DEFAULT '',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB AUTO_INCREMENT=100000 DEFAULT CHARSET=utf8mb4;
+```
+
+2、定义一个简单的存储过程(PROCEDURE)来插入 100w 测试数据。
+
+```sql
+DELIMITER ;;
+CREATE DEFINER=`root`@`%` PROCEDURE `BatchinsertDataToCusOder`(IN start_num INT,IN max_num INT)
+BEGIN
+ DECLARE i INT default start_num;
+ WHILE i < max_num DO
+ insert into `cus_order`(`id`, `score`, `name`)
+ values (i,RAND() * 1000000,CONCAT('user', i));
+ SET i = i + 1;
+ END WHILE;
+ END;;
+DELIMITER ;
+```
+
+存储过程定义完成之后,我们执行存储过程即可!
+
+```sql
+CALL BatchinsertDataToCusOder(1, 1000000); # 插入100w+的随机数据
+```
+
+等待一会,100w 的测试数据就插入完成了!
+
+3、创建覆盖索引并使用 `EXPLAIN` 命令分析。
+
+为了能够对这 100w 数据按照 `score` 进行排序,我们需要执行下面的 SQL 语句。
+
+```sql
+#降序排序
+SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
+```
+
+使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort`,我们发现是没有用到覆盖索引的。
+
+
+
+不过这也是理所应当,毕竟我们现在还没有创建索引呢!
+
+我们这里以 `score` 和 `name` 两个字段建立联合索引:
+
+```sql
+ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
+```
+
+创建完成之后,再用 `EXPLAIN` 命令分析再次分析这条 SQL 语句。
+
+
+
+通过 `Extra` 这一列的 `Using index`,说明这条 SQL 语句成功使用了覆盖索引。
+
+关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
+
+### 联合索引
+
+使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
+
+以 `score` 和 `name` 两个字段建立联合索引:
+
+```sql
+ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
+```
+
+### 最左前缀匹配原则
+
+最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据,这样可以提高查询效率。
+
+最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配(相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ))。
+
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+
+我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
+
+我们这里简单演示一下最左前缀匹配的效果。
+
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
+
+```sql
+CREATE TABLE `student` (
+ `id` int NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `class` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `name_class_idx` (`name`,`class`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+2、下面我们分别测试三条不同的 SQL 语句。
+
+
+
+```sql
+# 可以命中索引
+SELECT * FROM student WHERE name = 'Anne Henry';
+EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk';
+# 无法命中索引
+SELECT * FROM student WHERE class = 'lIrm08RYVk';
+```
+
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
+
+先不要往下看答案,给自己 3 分钟时间想一想。
+
+1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
+
+MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
+
+## 索引下推
+
+**索引下推(Index Condition Pushdown,简称 ICP)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,它允许存储引擎在索引遍历过程中,执行部分 `WHERE` 字句的判断条件,直接过滤掉不满足条件的记录,从而减少回表次数,提高查询效率。
+
+假设我们有一个名为 `user` 的表,其中包含 `id`、`username`、`zipcode` 和 `birthdate` 4 个字段,创建了联合索引 `(zipcode, birthdate)`。
+
+```sql
+CREATE TABLE `user` (
+ `id` int NOT NULL AUTO_INCREMENT,
+ `username` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
+ `zipcode` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
+ `birthdate` date NOT NULL,
+ PRIMARY KEY (`id`),
+ KEY `idx_username_birthdate` (`zipcode`,`birthdate`) ) ENGINE=InnoDB AUTO_INCREMENT=1001 DEFAULT CHARSET=utf8mb4;
+
+# 查询 zipcode 为 431200 且生日在 3 月的用户
+# birthdate 字段使用函数索引失效
+SELECT * FROM user WHERE zipcode = '431200' AND MONTH(birthdate) = 3;
+```
+
+- 没有索引下推之前,即使 `zipcode` 字段利用索引可以帮助我们快速定位到 `zipcode = '431200'` 的用户,但我们仍然需要对每一个找到的用户进行回表操作,获取完整的用户数据,再去判断 `MONTH(birthdate) = 3`。
+- 有了索引下推之后,存储引擎会在使用 `zipcode` 字段索引查找 `zipcode = '431200'` 的用户时,同时判断 `MONTH(birthdate) = 3`。这样,只有同时满足条件的记录才会被返回,减少了回表次数。
+
+
+
+
+
+再来讲讲索引下推的具体原理,先看下面这张 MySQL 简要架构图。
+
+
+
+MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处理查询解析、分析、优化、缓存以及与客户端的交互等操作,而存储引擎层负责数据的存储和读取,MySQL 支持 InnoDB、MyISAM、Memory 等多种存储引擎。
+
+索引下推的 **下推** 其实就是指将部分上层(Server 层)负责的事情,交给了下层(存储引擎层)去处理。
+
+我们这里结合索引下推原理再对上面提到的例子进行解释。
+
+没有索引下推之前:
+
+- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户的主键 ID,然后二次回表查询,获取完整的用户数据;
+- 存储引擎层把所有 `zipcode = '431200'` 的用户数据全部交给 Server 层,Server 层根据 `MONTH(birthdate) = 3` 这一条件再进一步做筛选。
+
+有了索引下推之后:
+
+- 存储引擎层先根据 `zipcode` 索引字段找到所有 `zipcode = '431200'` 的用户,然后直接判断 `MONTH(birthdate) = 3`,筛选出符合条件的主键 ID;
+- 二次回表查询,根据符合条件的主键 ID 去获取完整的用户数据;
+- 存储引擎层把符合条件的用户数据全部交给 Server 层。
+
+可以看出,**除了可以减少回表次数之外,索引下推还可以减少存储引擎层和 Server 层的数据传输量。**
+
+最后,总结一下索引下推应用范围:
+
+1. 适用于 InnoDB 引擎和 MyISAM 引擎的查询。
+2. 适用于执行计划是 range、ref、eq_ref、ref_or_null 的范围查询。
+3. 对于 InnoDB 表,仅用于非聚簇索引。索引下推的目标是减少全行读取次数,从而减少 I/O 操作。对于 InnoDB 聚集索引,完整的记录已经读入 InnoDB 缓冲区。在这种情况下使用索引下推不会减少 I/O。
+4. 子查询不能使用索引下推,因为子查询通常会创建临时表来处理结果,而这些临时表是没有索引的。
+5. 存储过程不能使用索引下推,因为存储引擎无法调用存储函数。
+
+## 正确使用索引的一些建议
+
+### 选择合适的字段创建索引
+
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0、1、true、false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 被频繁更新的字段应该慎重建立索引
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+### 限制每张表上的索引数量
+
+索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率,同样可以降低效率。
+
+索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
+
+因为 MySQL 优化器在选择如何优化查询时,会根据统计信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
+
+### 尽可能的考虑建立联合索引而不是单列索引
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+ 树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+### 注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city)和(name)这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的。在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+### 字符串类型的字段使用前缀索引代替普通索引
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+### 避免索引失效
+
+索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
+
+- ~~使用 `SELECT *` 进行查询;~~ `SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖;
+- 创建了组合索引,但查询条件未遵守最左匹配原则;
+- 在索引列上进行计算、函数、类型转换等操作;
+- 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
+- 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
+- IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
+- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
+- ……
+
+推荐阅读这篇文章:[美团暑期实习一面:MySQl 索引失效的场景有哪些?](https://mp.weixin.qq.com/s/mwME3qukHBFul57WQLkOYg)。
+
+### 删除长期未使用的索引
+
+删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗。
+
+MySQL 5.7 可以通过查询 `sys` 库的 `schema_unused_indexes` 视图来查询哪些索引从未被使用。
+
+### 知道如何分析 SQL 语句是否走索引查询
+
+我们可以使用 `EXPLAIN` 命令来分析 SQL 的 **执行计划** ,这样就知道语句是否命中索引了。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
+
+`EXPLAIN` 并不会真的去执行相关的语句,而是通过 **查询优化器** 对语句进行分析,找出最优的查询方案,并显示对应的信息。
+
+`EXPLAIN` 的输出格式如下:
+
+```sql
+mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+1 row in set, 1 warning (0.00 sec)
+```
+
+各个字段的含义如下:
+
+| **列名** | **含义** |
+| ------------- | -------------------------------------------- |
+| id | SELECT 查询的序列标识符 |
+| select_type | SELECT 关键字对应的查询类型 |
+| table | 用到的表名 |
+| partitions | 匹配的分区,对于未分区的表,值为 NULL |
+| type | 表的访问方法 |
+| possible_keys | 可能用到的索引 |
+| key | 实际用到的索引 |
+| key_len | 所选索引的长度 |
+| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
+| rows | 预计要读取的行数 |
+| filtered | 按表条件过滤后,留存的记录数的百分比 |
+| Extra | 附加信息 |
+
+篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[MySQL 执行计划分析](./mysql-query-execution-plan.md)这篇文章。
+
+
+
diff --git a/docs_en/database/mysql/mysql-logs.en.md b/docs_en/database/mysql/mysql-logs.en.md
new file mode 100644
index 00000000000..a87b372773d
--- /dev/null
+++ b/docs_en/database/mysql/mysql-logs.en.md
@@ -0,0 +1,353 @@
+---
+title: MySQL三大日志(binlog、redo log和undo log)详解
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 日志,binlog,redo log,undo log,两阶段提交,崩溃恢复,复制
+ - - meta
+ - name: description
+ content: 系统解析 MySQL 的 binlog/redo/undo 三大日志与两阶段提交,理解崩溃恢复与主从复制的实现原理与取舍。
+---
+
+> 本文来自公号程序猿阿星投稿,JavaGuide 对其做了补充完善。
+
+## 前言
+
+MySQL 日志 主要包括错误日志、查询日志、慢查询日志、事务日志、二进制日志几大类。其中,比较重要的还要属二进制日志 binlog(归档日志)和事务日志 redo log(重做日志)和 undo log(回滚日志)。
+
+
+
+今天就来聊聊 redo log(重做日志)、binlog(归档日志)、两阶段提交、undo log(回滚日志)。
+
+## redo log
+
+redo log(重做日志)是 InnoDB 存储引擎独有的,它让 MySQL 拥有了崩溃恢复能力。
+
+比如 MySQL 实例挂了或宕机了,重启时,InnoDB 存储引擎会使用 redo log 恢复数据,保证数据的持久性与完整性。
+
+
+
+MySQL 中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到 `Buffer Pool` 中。
+
+后续的查询都是先从 `Buffer Pool` 中找,没有命中再去硬盘加载,减少硬盘 IO 开销,提升性能。
+
+更新表数据的时候,也是如此,发现 `Buffer Pool` 里存在要更新的数据,就直接在 `Buffer Pool` 里更新。
+
+然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(`redo log buffer`)里,接着刷盘到 redo log 文件里。
+
+
+
+> 图片笔误提示:第 4 步 “清空 redo log buffe 刷盘到 redo 日志中”这句话中的 buffe 应该是 buffer。
+
+理想情况,事务一提交就会进行刷盘操作,但实际上,刷盘的时机是根据策略来进行的。
+
+> 小贴士:每条 redo 记录由“表空间号+数据页号+偏移量+修改数据长度+具体修改的数据”组成
+
+### 刷盘时机
+
+在 InnoDB 存储引擎中,**redo log buffer**(重做日志缓冲区)是一块用于暂存 redo log 的内存区域。为了确保事务的持久性和数据的一致性,InnoDB 会在特定时机将这块缓冲区中的日志数据刷新到磁盘上的 redo log 文件中。这些时机可以归纳为以下六种:
+
+1. **事务提交时(最核心)**:当事务提交时,log buffer 里的 redo log 会被刷新到磁盘(可以通过`innodb_flush_log_at_trx_commit`参数控制,后文会提到)。
+2. **redo log buffer 空间不足时**:这是 InnoDB 的一种主动容量管理策略,旨在避免因缓冲区写满而导致用户线程阻塞。
+ - 当 redo log buffer 的已用空间超过其总容量的**一半 (50%)** 时,后台线程会**主动**将这部分日志刷新到磁盘,为后续的日志写入腾出空间,这是一种“未雨绸缪”的优化。
+ - 如果因为大事务或 I/O 繁忙导致 buffer 被**完全写满**,那么所有试图写入新日志的用户线程都会被**阻塞**,并强制进行一次同步刷盘,直到有可用空间为止。这种情况会影响数据库性能,应尽量避免。
+3. **触发检查点 (Checkpoint) 时**:Checkpoint 是 InnoDB 为了缩短崩溃恢复时间而设计的核心机制。当 Checkpoint 被触发时,InnoDB 需要将在此检查点之前的所有脏页刷写到磁盘。根据 **Write-Ahead Logging (WAL)** 原则,数据页写入磁盘前,其对应的 redo log 必须先落盘。因此,执行 Checkpoint 操作必然会确保相关的 redo log 也已经被刷新到了磁盘。
+4. **后台线程周期性刷新**:InnoDB 有一个后台的 master thread,它会大约每秒执行一次例行任务,其中就包括将 redo log buffer 中的日志刷新到磁盘。这个机制是 `innodb_flush_log_at_trx_commit` 设置为 0 或 2 时的主要持久化保障。
+5. **正常关闭服务器**:在 MySQL 服务器正常关闭的过程中,为了确保所有已提交事务的数据都被完整保存,InnoDB 会执行一次最终的刷盘操作,将 redo log buffer 中剩余的全部日志都清空并写入磁盘文件。
+6. **binlog 切换时**:当开启 binlog 后,在 MySQL 采用 `innodb_flush_log_at_trx_commit=1` 和 `sync_binlog=1` 的 双一配置下,为了保证 redo log 和 binlog 之间状态的一致性(用于崩溃恢复或主从复制),在 binlog 文件写满或者手动执行 flush logs 进行切换时,会触发 redo log 的刷盘动作。
+
+总之,InnoDB 在多种情况下会刷新重做日志,以保证数据的持久性和一致性。
+
+我们要注意设置正确的刷盘策略`innodb_flush_log_at_trx_commit` 。根据 MySQL 配置的刷盘策略的不同,MySQL 宕机之后可能会存在轻微的数据丢失问题。
+
+`innodb_flush_log_at_trx_commit` 的值有 3 种,也就是共有 3 种刷盘策略:
+
+- **0**:设置为 0 的时候,表示每次事务提交时不进行刷盘操作。这种方式性能最高,但是也最不安全,因为如果 MySQL 挂了或宕机了,可能会丢失最近 1 秒内的事务。
+- **1**:设置为 1 的时候,表示每次事务提交时都将进行刷盘操作。这种方式性能最低,但是也最安全,因为只要事务提交成功,redo log 记录就一定在磁盘里,不会有任何数据丢失。
+- **2**:设置为 2 的时候,表示每次事务提交时都只把 log buffer 里的 redo log 内容写入 page cache(文件系统缓存)。page cache 是专门用来缓存文件的,这里被缓存的文件就是 redo log 文件。这种方式的性能和安全性都介于前两者中间。
+
+刷盘策略`innodb_flush_log_at_trx_commit` 的默认值为 1,设置为 1 的时候才不会丢失任何数据。为了保证事务的持久性,我们必须将其设置为 1。
+
+另外,InnoDB 存储引擎有一个后台线程,每隔`1` 秒,就会把 `redo log buffer` 中的内容写到文件系统缓存(`page cache`),然后调用 `fsync` 刷盘。
+
+
+
+也就是说,一个没有提交事务的 redo log 记录,也可能会刷盘。
+
+**为什么呢?**
+
+因为在事务执行过程 redo log 记录是会写入`redo log buffer` 中,这些 redo log 记录会被后台线程刷盘。
+
+
+
+除了后台线程每秒`1`次的轮询操作,还有一种情况,当 `redo log buffer` 占用的空间即将达到 `innodb_log_buffer_size` 一半的时候,后台线程会主动刷盘。
+
+下面是不同刷盘策略的流程图。
+
+#### innodb_flush_log_at_trx_commit=0
+
+
+
+为`0`时,如果 MySQL 挂了或宕机可能会有`1`秒数据的丢失。
+
+#### innodb_flush_log_at_trx_commit=1
+
+
+
+为`1`时, 只要事务提交成功,redo log 记录就一定在硬盘里,不会有任何数据丢失。
+
+如果事务执行期间 MySQL 挂了或宕机,这部分日志丢了,但是事务并没有提交,所以日志丢了也不会有损失。
+
+#### innodb_flush_log_at_trx_commit=2
+
+
+
+When it is `2`, as long as the transaction is submitted successfully, the contents in `redo log buffer` are only written to the file system cache (`page cache`).
+
+If MySQL is just down, there will be no data loss, but the downtime may result in `1` second of data loss.
+
+### Log file group
+
+There is more than one redo log file stored on the hard disk, but it appears in the form of a **log file group**. The size of each `redo` log file is the same.
+
+For example, it can be configured as a set of `4` files, the size of each file is `1GB`, and the entire redo log log file group can record the contents of `4G`.
+
+It adopts the form of a circular array, writing from the beginning, writing to the end and then returning to the beginning to write in a loop, as shown in the figure below.
+
+
+
+There are two important attributes in this **log file group**, namely `write pos, checkpoint`
+
+- **write pos** is the position of the current record, moving backward while writing
+- **checkpoint** is the current position to be erased, and it is also moved to the future.
+
+Every time the redo log is flushed and recorded in the **log file group**, the `write pos` position will be moved back and updated.
+
+Each time MySQL loads the **log file group** to recover data, the loaded redo log records will be cleared, and the `checkpoint` will be moved back and updated.
+
+The empty part between `write pos` and `checkpoint` can be used to write new redo log records.
+
+
+
+If `write pos` catches up with `checkpoint`, it means that the **log file group** is full. At this time, new redo log records cannot be written. MySQL has to stop, clear some records, and advance `checkpoint`.
+
+
+
+Note that starting from MySQL 8.0.30, the log file group has changed slightly:
+
+> The innodb_redo_log_capacity variable supersedes the innodb_log_files_in_group and innodb_log_file_size variables, which are deprecated. When the innodb_redo_log_capacity setting is defined, the innodb_log_files_in_group and innodb_log_file_size settings are ignored; otherwise, these settings are used to compute the innodb_redo_log_capacity setting (innodb_log_files_in_group \* innodb_log_file_size = innodb_redo_log_capacity). If none of those variables are set, redo log capacity is set to the innodb_redo_log_capacity default value, which is 104857600 bytes (100MB). The maximum redo log capacity is 128GB.
+
+> Redo log files reside in the #innodb_redo directory in the data directory unless a different directory was specified by the innodb_log_group_home_dir variable. If innodb_log_group_home_dir was defined, the redo log files reside in the #innodb_redo directory in that directory. to be used. InnoDB tries to maintain 32 redo log files in total, with each file equal in size to 1/32 \* innodb_redo_log_capacity; however, file sizes may differ for a time after modifying the innodb_redo_log_capacity setting.
+
+This means that before MySQL 8.0.30, you can configure the number and file size of the log file group through `innodb_log_files_in_group` and `innodb_log_file_size`, but in MySQL 8.0.30 and later versions, these two variables have been abandoned, and even if they are specified, they are used to calculate the value of `innodb_redo_log_capacity`. The number of files in the log file group is fixed at 32, and the file size is `innodb_redo_log_capacity / 32`.
+
+Regarding this change, we can verify it.
+
+First create a configuration file and configure the values of `innodb_log_files_in_group` and `innodb_log_file_size`:
+
+```properties
+[mysqld]
+innodb_log_file_size = 10485760
+innodb_log_files_in_group = 64
+```
+
+Docker starts a MySQL 8.0.32 container:
+
+```bash
+docker run -d -p 3312:3309 -e MYSQL_ROOT_PASSWORD=your-password -v /path/to/your/conf:/etc/mysql/conf.d --name
+MySQL830 mysql:8.0.32
+```
+
+Now let's take a look at the startup log:
+
+```plain
+2023-08-03T02:05:11.720357Z 0 [Warning] [MY-013907] [InnoDB] Deprecated configuration parameters innodb_log_file_size and/or innodb_log_files_in_group have been used to compute innodb_redo_log_capacity=671088640. Please use innodb_redo_log_capacity instead.
+```
+
+It is also shown here that the two variables `innodb_log_files_in_group` and `innodb_log_file_size` are used to calculate `innodb_redo_log_capacity` and have been deprecated.
+
+Let’s take a look at the number of files in the log file group:
+
+
+
+You can see that there are exactly 32, and the size of each log file is `671088640 / 32 = 20971520`
+
+Therefore, when using MySQL 8.0.30 and later versions, it is recommended to use the `innodb_redo_log_capacity` variable to configure the log file group
+
+### redo log summary
+
+I believe everyone knows the function of redo log, its flushing time and storage mode.
+
+Now let's think about a question: **As long as the modified data page is flushed directly to the disk every time, what's the point of the redo log? **
+
+Aren't they all brushes? What's the difference?
+
+```java
+1 Byte=8bit
+1 KB = 1024 Byte
+1 MB = 1024 KB
+1 GB = 1024 MB
+1 TB = 1024 GB
+```
+
+In fact, the data page size is `16KB`, and flushing is time-consuming. It may only modify a few `Byte` data in the data page. Is it necessary to flush the complete data page?
+
+Moreover, data page flushing is written randomly, because the corresponding location of a data page may be at a random location in the hard disk file, so the performance is very poor.
+
+If you are writing redo log, one row of records may occupy dozens of `Byte` and only include the table space number, data page number, and disk file offset.
+Amount, update value, plus sequential writing, so the disk flushing speed is very fast.
+
+Therefore, the performance of recording modifications in the form of redo log will far exceed that of refreshing the data page, which also makes the database's concurrency capability stronger.
+
+> In fact, the data pages of the memory will also be flushed at certain times. We call this page merging. We will explain this in detail when we talk about `Buffer Pool`
+
+## binlog
+
+redo log is a physical log that records "what modifications were made on a certain data page" and belongs to the InnoDB storage engine.
+
+Binlog is a logical log, and the record content is the original logic of the statement, similar to "add 1 to the c field of the row with ID=2", and belongs to the `MySQL Server` layer.不管用什么存储引擎,只要发生了表数据更新,都会产生 binlog 日志。
+
+那 binlog 到底是用来干嘛的?
+
+可以说 MySQL 数据库的**数据备份、主备、主主、主从**都离不开 binlog,需要依靠 binlog 来同步数据,保证数据一致性。
+
+
+
+binlog 会记录所有涉及更新数据的逻辑操作,并且是顺序写。
+
+### 记录格式
+
+binlog 日志有三种格式,可以通过`binlog_format`参数指定。
+
+- **statement**
+- **row**
+- **mixed**
+
+指定`statement`,记录的内容是`SQL`语句原文,比如执行一条`update T set update_time=now() where id=1`,记录的内容如下。
+
+
+
+同步数据时,会执行记录的`SQL`语句,但是有个问题,`update_time=now()`这里会获取当前系统时间,直接执行会导致与原库的数据不一致。
+
+为了解决这种问题,我们需要指定为`row`,记录的内容不再是简单的`SQL`语句了,还包含操作的具体数据,记录内容如下。
+
+
+
+`row`格式记录的内容看不到详细信息,要通过`mysqlbinlog`工具解析出来。
+
+`update_time=now()`变成了具体的时间`update_time=1627112756247`,条件后面的@1、@2、@3 都是该行数据第 1 个~3 个字段的原始值(**假设这张表只有 3 个字段**)。
+
+这样就能保证同步数据的一致性,通常情况下都是指定为`row`,这样可以为数据库的恢复与同步带来更好的可靠性。
+
+但是这种格式,需要更大的容量来记录,比较占用空间,恢复与同步时会更消耗 IO 资源,影响执行速度。
+
+所以就有了一种折中的方案,指定为`mixed`,记录的内容是前两者的混合。
+
+MySQL 会判断这条`SQL`语句是否可能引起数据不一致,如果是,就用`row`格式,否则就用`statement`格式。
+
+### 写入机制
+
+binlog 的写入时机也非常简单,事务执行过程中,先把日志写到`binlog cache`,事务提交的时候,再把`binlog cache`写到 binlog 文件中。
+
+因为一个事务的 binlog 不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为`binlog cache`。
+
+我们可以通过`binlog_cache_size`参数控制单个线程 binlog cache 大小,如果存储内容超过了这个参数,就要暂存到磁盘(`Swap`)。
+
+binlog 日志刷盘流程如下
+
+
+
+- **上图的 write,是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快**
+- **上图的 fsync,才是将数据持久化到磁盘的操作**
+
+`write`和`fsync`的时机,可以由参数`sync_binlog`控制,默认是`1`。
+
+为`0`的时候,表示每次提交事务都只`write`,由系统自行判断什么时候执行`fsync`。
+
+
+
+虽然性能得到提升,但是机器宕机,`page cache`里面的 binlog 会丢失。
+
+为了安全起见,可以设置为`1`,表示每次提交事务都会执行`fsync`,就如同 **redo log 日志刷盘流程** 一样。
+
+最后还有一种折中方式,可以设置为`N(N>1)`,表示每次提交事务都`write`,但累积`N`个事务后才`fsync`。
+
+
+
+在出现 IO 瓶颈的场景里,将`sync_binlog`设置成一个比较大的值,可以提升性能。
+
+同样的,如果机器宕机,会丢失最近`N`个事务的 binlog 日志。
+
+## 两阶段提交
+
+redo log(重做日志)让 InnoDB 存储引擎拥有了崩溃恢复能力。
+
+binlog(归档日志)保证了 MySQL 集群架构的数据一致性。
+
+虽然它们都属于持久化的保证,但是侧重点不同。
+
+在执行更新语句过程,会记录 redo log 与 binlog 两块日志,以基本的事务为单位,redo log 在事务执行过程中可以不断写入,而 binlog 只有在提交事务时才写入,所以 redo log 与 binlog 的写入时机不一样。
+
+
+
+回到正题,redo log 与 binlog 两份日志之间的逻辑不一致,会出现什么问题?
+
+我们以`update`语句为例,假设`id=2`的记录,字段`c`值是`0`,把字段`c`值更新成`1`,`SQL`语句为`update T set c=1 where id=2`。
+
+假设执行过程中写完 redo log 日志后,binlog 日志写期间发生了异常,会出现什么情况呢?
+
+
+
+由于 binlog 没写完就异常,这时候 binlog 里面没有对应的修改记录。因此,之后用 binlog 日志恢复数据时,就会少这一次更新,恢复出来的这一行`c`值是`0`,而原库因为 redo log 日志恢复,这一行`c`值是`1`,最终数据不一致。
+
+
+
+为了解决两份日志之间的逻辑一致问题,InnoDB 存储引擎使用**两阶段提交**方案。
+
+原理很简单,将 redo log 的写入拆成了两个步骤`prepare`和`commit`,这就是**两阶段提交**。
+
+
+
+使用**两阶段提交**后,写入 binlog 时发生异常也不会有影响,因为 MySQL 根据 redo log 日志恢复数据时,发现 redo log 还处于`prepare`阶段,并且没有对应 binlog 日志,就会回滚该事务。
+
+
+
+再看一个场景,redo log 设置`commit`阶段发生异常,那会不会回滚事务呢?
+
+
+
+并不会回滚事务,它会执行上图框住的逻辑,虽然 redo log 是处于`prepare`阶段,但是能通过事务`id`找到对应的 binlog 日志,所以 MySQL 认为是完整的,就会提交事务恢复数据。
+
+## undo log
+
+> 这部分内容为 JavaGuide 的补充:
+
+每一个事务对数据的修改都会被记录到 undo log ,当执行事务过程中出现错误或者需要执行回滚操作的话,MySQL 可以利用 undo log 将数据恢复到事务开始之前的状态。
+
+undo log 属于逻辑日志,记录的是 SQL 语句,比如说事务执行一条 DELETE 语句,那 undo log 就会记录一条相对应的 INSERT 语句。同时,undo log 的信息也会被记录到 redo log 中,因为 undo log 也要实现持久性保护。并且,undo-log 本身是会被删除清理的,例如 INSERT 操作,在事务提交之后就可以清除掉了;UPDATE/DELETE 操作在事务提交不会立即删除,会加入 history list,由后台线程 purge 进行清理。
+
+undo log 是采用 segment(段)的方式来记录的,每个 undo 操作在记录的时候占用一个 **undo log segment**(undo 日志段),undo log segment 包含在 **rollback segment**(回滚段)中。事务开始时,需要为其分配一个 rollback segment。每个 rollback segment 有 1024 个 undo log segment,这有助于管理多个并发事务的回滚需求。
+
+Normally, the **rollback segment header** (usually the first page of the rollback segment) is responsible for managing the rollback segment. The rollback segment header is part of the rollback segment, usually on the first page of the rollback segment. **history list** is part of the rollback segment header. Its main function is to record the undo log of all transactions that have been submitted but have not yet been purged. This list enables the purge thread to find and clean up undo log records that are no longer needed.
+
+In addition, the implementation of `MVCC` depends on: **Hidden fields, Read View, and undo log**. In the internal implementation, InnoDB determines the visibility of the data through the `DB_TRX_ID` and `Read View` of the data row. If it is not visible, it uses the `DB_ROLL_PTR` of the data row to find the historical version in the undo log. The data version read by each transaction may be different. In the same transaction, the user can only see the modifications committed before the transaction created `Read View` and the modifications made by the transaction itself.
+
+## Summary
+
+> This part is a supplement to JavaGuide:
+
+The MySQL InnoDB engine uses **redo log (redo log)** to ensure the **durability** of transactions, and uses **undo log (rollback log)** to ensure the **atomicity** of transactions.
+
+The **data backup, primary and secondary, primary-master, and master-slave** of the MySQL database are all inseparable from binlog. Binlog is required to synchronize data and ensure data consistency.
+
+## Reference
+
+- "MySQL Practical Lectures 45"
+- "Take you to become a MySQL practical optimization master from scratch"
+- "How MySQL works: Understanding MySQL from the fundamentals"
+- "MySQL Technology Innodb Storage Engine"
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-query-cache.en.md b/docs_en/database/mysql/mysql-query-cache.en.md
new file mode 100644
index 00000000000..9590b7f4f26
--- /dev/null
+++ b/docs_en/database/mysql/mysql-query-cache.en.md
@@ -0,0 +1,209 @@
+---
+title: MySQL查询缓存详解
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL查询缓存,MySQL缓存机制中的内存管理
+ - - meta
+ - name: description
+ content: 为了提高完全相同的查询语句的响应速度,MySQL Server 会对查询语句进行 Hash 计算得到一个 Hash 值。MySQL Server 不会对 SQL 做任何处理,SQL 必须完全一致 Hash 值才会一样。得到 Hash 值之后,通过该 Hash 值到查询缓存中匹配该查询的结果。MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查询同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。
+---
+
+缓存是一个有效且实用的系统性能优化的手段,不论是操作系统还是各种软件和网站或多或少都用到了缓存。
+
+然而,有经验的 DBA 都建议生产环境中把 MySQL 自带的 Query Cache(查询缓存)给关掉。而且,从 MySQL 5.7.20 开始,就已经默认弃用查询缓存了。在 MySQL 8.0 及之后,更是直接删除了查询缓存的功能。
+
+这又是为什么呢?查询缓存真就这么鸡肋么?
+
+带着如下几个问题,我们正式进入本文。
+
+- MySQL 查询缓存是什么?适用范围?
+- MySQL 缓存规则是什么?
+- MySQL 缓存的优缺点是什么?
+- MySQL 缓存对性能有什么影响?
+
+## MySQL 查询缓存介绍
+
+MySQL 体系架构如下图所示:
+
+
+
+为了提高完全相同的查询语句的响应速度,MySQL Server 会对查询语句进行 Hash 计算得到一个 Hash 值。MySQL Server 不会对 SQL 做任何处理,SQL 必须完全一致 Hash 值才会一样。得到 Hash 值之后,通过该 Hash 值到查询缓存中匹配该查询的结果。
+
+- 如果匹配(命中),则将查询的结果集直接返回给客户端,不必再解析、执行查询。
+- 如果没有匹配(未命中),则将 Hash 值和结果集保存在查询缓存中,以便以后使用。
+
+也就是说,**一个查询语句(select)到了 MySQL Server 之后,会先到查询缓存看看,如果曾经执行过的话,就直接返回结果集给客户端。**
+
+
+
+## MySQL 查询缓存管理和配置
+
+通过 `show variables like '%query_cache%'`命令可以查看查询缓存相关的信息。
+
+8.0 版本之前的话,打印的信息可能是下面这样的:
+
+```bash
+mysql> show variables like '%query_cache%';
++------------------------------+---------+
+| Variable_name | Value |
++------------------------------+---------+
+| have_query_cache | YES |
+| query_cache_limit | 1048576 |
+| query_cache_min_res_unit | 4096 |
+| query_cache_size | 599040 |
+| query_cache_type | ON |
+| query_cache_wlock_invalidate | OFF |
++------------------------------+---------+
+6 rows in set (0.02 sec)
+```
+
+8.0 以及之后版本之后,打印的信息是下面这样的:
+
+```bash
+mysql> show variables like '%query_cache%';
++------------------+-------+
+| Variable_name | Value |
++------------------+-------+
+| have_query_cache | NO |
++------------------+-------+
+1 row in set (0.01 sec)
+```
+
+我们这里对 8.0 版本之前`show variables like '%query_cache%';`命令打印出来的信息进行解释。
+
+- **`have_query_cache`:** 该 MySQL Server 是否支持查询缓存,如果是 YES 表示支持,否则则是不支持。
+- **`query_cache_limit`:** MySQL 查询缓存的最大查询结果,查询结果大于该值时不会被缓存。
+- **`query_cache_min_res_unit`:** 查询缓存分配的最小块的大小(字节)。当查询进行的时候,MySQL 把查询结果保存在查询缓存中,但如果要保存的结果比较大,超过 `query_cache_min_res_unit` 的值 ,这时候 MySQL 将一边检索结果,一边进行保存结果,也就是说,有可能在一次查询中,MySQL 要进行多次内存分配的操作。适当的调节 `query_cache_min_res_unit` 可以优化内存。
+- **`query_cache_size`:** 为缓存查询结果分配的内存的数量,单位是字节,且数值必须是 1024 的整数倍。默认值是 0,即禁用查询缓存。
+- **`query_cache_type`:** 设置查询缓存类型,默认为 ON。设置 GLOBAL 值可以设置后面的所有客户端连接的类型。客户端可以设置 SESSION 值以影响他们自己对查询缓存的使用。
+- **`query_cache_wlock_invalidate`**:如果某个表被锁住,是否返回缓存中的数据,默认关闭,也是建议的。
+
+`query_cache_type` 可能的值(修改 `query_cache_type` 需要重启 MySQL Server):
+
+- 0 或 OFF:关闭查询功能。
+- 1 或 ON:开启查询缓存功能,但不缓存 `Select SQL_NO_CACHE` 开头的查询。
+- 2 或 DEMAND:开启查询缓存功能,但仅缓存 `Select SQL_CACHE` 开头的查询。
+
+**建议**:
+
+- `query_cache_size`不建议设置的过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。
+- 建议通过调整 `query_cache_size` 的值来开启、关闭查询缓存,因为修改`query_cache_type` 参数需要重启 MySQL Server 生效。
+
+ 8.0 版本之前,`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
+
+```properties
+query_cache_type=1
+query_cache_size=600000
+```
+
+或者,MySQL 执行以下命令也可以开启查询缓存
+
+```properties
+set global query_cache_type=1;
+set global query_cache_size=600000;
+```
+
+手动清理缓存可以使用下面三个 SQL:
+
+- `flush query cache;`:清理查询缓存内存碎片。
+- `reset query cache;`:从查询缓存中移除所有查询。
+- `flush tables;` 关闭所有打开的表,同时该操作会清空查询缓存中的内容。
+
+## MySQL 缓存机制
+
+### 缓存规则
+
+- 查询缓存会将查询语句和结果集保存到内存(一般是 key-value 的形式,key 是查询语句,value 是查询的结果集),下次再查直接从内存中取。
+- 缓存的结果是通过 sessions 共享的,所以一个 client 查询的缓存结果,另一个 client 也可以使用。
+- SQL 必须完全一致才会导致查询缓存命中(大小写、空格、使用的数据库、协议版本、字符集等必须一致)。检查查询缓存时,MySQL Server 不会对 SQL 做任何处理,它精确的使用客户端传来的查询。
+- 不缓存查询中的子查询结果集,仅缓存查询最终结果集。
+- 不确定的函数将永远不会被缓存, 比如 `now()`、`curdate()`、`last_insert_id()`、`rand()` 等。
+- 不缓存产生告警(Warnings)的查询。
+- 太大的结果集不会被缓存 (< query_cache_limit)。
+- 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
+- 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
+- MySQL 缓存在分库分表环境下是不起作用的。
+- 不缓存使用 `SQL_NO_CACHE` 的查询。
+- ……
+
+查询缓存 `SELECT` 选项示例:
+
+```sql
+SELECT SQL_CACHE id, name FROM customer;# 会缓存
+SELECT SQL_NO_CACHE id, name FROM customer;# 不会缓存
+```
+
+### 缓存机制中的内存管理
+
+查询缓存是完全存储在内存中的,所以在配置和使用它之前,我们需要先了解它是如何使用内存的。
+
+MySQL 查询缓存使用内存池技术,自己管理内存释放和分配,而不是通过操作系统。内存池使用的基本单位是变长的 block, 用来存储类型、大小、数据等信息。一个结果集的缓存通过链表把这些 block 串起来。block 最短长度为 `query_cache_min_res_unit`。
+
+当服务器启动的时候,会初始化缓存需要的内存,是一个完整的空闲块。当查询结果需要缓存的时候,先从空闲块中申请一个数据块为参数 `query_cache_min_res_unit` 配置的空间,即使缓存数据很小,申请数据块也是这个,因为查询开始返回结果的时候就分配空间,此时无法预知结果多大。
+
+分配内存块需要先锁住空间块,所以操作很慢,MySQL 会尽量避免这个操作,选择尽可能小的内存块,如果不够,继续申请,如果存储完时有空余则释放多余的。
+
+但是如果并发的操作,余下的需要回收的空间很小,小于 `query_cache_min_res_unit`,不能再次被使用,就会产生碎片。
+
+## MySQL 查询缓存的优缺点
+
+**优点:**
+
+- 查询缓存的查询,发生在 MySQL 接收到客户端的查询请求、查询权限验证之后和查询 SQL 解析之前。也就是说,当 MySQL 接收到客户端的查询 SQL 之后,仅仅只需要对其进行相应的权限验证之后,就会通过查询缓存来查找结果,甚至都不需要经过 Optimizer 模块进行执行计划的分析优化,更不需要发生任何存储引擎的交互。
+- 由于查询缓存是基于内存的,直接从内存中返回相应的查询结果,因此减少了大量的磁盘 I/O 和 CPU 计算,导致效率非常高。
+
+**缺点:**
+
+- MySQL 会对每条接收到的 SELECT 类型的查询进行 Hash 计算,然后查找这个查询的缓存结果是否存在。虽然 Hash 计算和查找的效率已经足够高了,一条查询语句所带来的开销可以忽略,但一旦涉及到高并发,有成千上万条查询语句时,hash 计算和查找所带来的开销就必须重视了。
+- 查询缓存的失效问题。如果表的变更比较频繁,则会造成查询缓存的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
+- 查询语句不同,但查询结果相同的查询都会被缓存,这样便会造成内存资源的过度消耗。查询语句的字符大小写、空格或者注释的不同,查询缓存都会认为是不同的查询(因为他们的 Hash 值会不同)。
+- 相关系统变量设置不合理会造成大量的内存碎片,这样便会导致查询缓存频繁清理内存。
+
+## MySQL 查询缓存对性能的影响
+
+在 MySQL Server 中打开查询缓存对数据库的读和写都会带来额外的消耗:
+
+- 读查询开始之前必须检查是否命中缓存。
+- 如果读查询可以缓存,那么执行完查询操作后,会查询结果和查询语句写入缓存。
+- 当向某个表写入数据的时候,必须将这个表所有的缓存设置为失效,如果缓存空间很大,则消耗也会很大,可能使系统僵死一段时间,因为这个操作是靠全局锁操作来保护的。
+- 对 InnoDB 表,当修改一个表时,设置了缓存失效,但是多版本特性会暂时将这修改对其他事务屏蔽,在这个事务提交之前,所有查询都无法使用缓存,直到这个事务被提交,所以长时间的事务,会大大降低查询缓存的命中。
+
+## 总结
+
+MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查询同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。
+
+查询缓存是一个适用较少情况的缓存机制。如果你的应用对数据库的更新很少,那么查询缓存将会作用显著。比较典型的如博客系统,一般博客更新相对较慢,数据表相对稳定不变,这时候查询缓存的作用会比较明显。
+
+简单总结一下查询缓存的适用场景:
+
+- 表数据修改不频繁、数据较静态。
+- 查询(Select)重复度高。
+- 查询结果集小于 1 MB。
+
+对于一个更新频繁的系统来说,查询缓存缓存的作用是很微小的,在某些情况下开启查询缓存会带来性能的下降。
+
+简单总结一下查询缓存不适用的场景:
+
+- 表中的数据、表结构或者索引变动频繁
+- 重复的查询很少
+- 查询的结果集很大
+
+《高性能 MySQL》这样写到:
+
+> 根据我们的经验,在高并发压力环境中查询缓存会导致系统性能的下降,甚至僵死。如果你一 定要使用查询缓存,那么不要设置太大内存,而且只有在明确收益的时候才使用(数据库内容修改次数较少)。
+
+**确实是这样的!实际项目中,更建议使用本地缓存(比如 Caffeine)或者分布式缓存(比如 Redis) ,性能更好,更通用一些。**
+
+## 参考
+
+- 《高性能 MySQL》
+- MySQL 缓存机制:
+- RDS MySQL 查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:
+- 8.10.3 The MySQL Query Cache - MySQL 官方文档:
+
+
+
diff --git a/docs_en/database/mysql/mysql-query-execution-plan.en.md b/docs_en/database/mysql/mysql-query-execution-plan.en.md
new file mode 100644
index 00000000000..3c35c989514
--- /dev/null
+++ b/docs_en/database/mysql/mysql-query-execution-plan.en.md
@@ -0,0 +1,145 @@
+---
+title: MySQL execution plan analysis
+category: database
+tag:
+ -MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL basics, MySQL execution plan, EXPLAIN, query optimizer
+ - - meta
+ - name: description
+ content: Execution plan refers to the specific execution method of a SQL statement after being optimized by the MySQL query optimizer. The first step in optimizing SQL should be to understand the execution plan of SQL.
+---
+
+> This article comes from the official MySQL technology, and JavaGuide has supplemented and improved it. Original address:
+
+The first step in optimizing SQL should be to understand the execution plan of SQL. In this article, let’s learn about MySQL `EXPLAIN` execution plan.
+
+## What is an execution plan?
+
+**Execution plan** refers to the specific execution method of a SQL statement after being optimized by **MySQL Query Optimizer**.
+
+Execution plans are usually used in SQL performance analysis, optimization and other scenarios. Through the results of `EXPLAIN`, you can learn information such as the query sequence of the data table, the operation type of the data query operation, which indexes can be hit, which indexes will actually be hit, how many rows of records in each data table are queried, etc.
+
+## How to get the execution plan?
+
+MySQL provides us with the `EXPLAIN` command to obtain information about the execution plan.
+
+It should be noted that the `EXPLAIN` statement does not actually execute the relevant statements. Instead, it analyzes the statements through the query optimizer to find the optimal query plan and displays the corresponding information.
+
+The `EXPLAIN` execution plan supports `SELECT`, `DELETE`, `INSERT`, `REPLACE` and `UPDATE` statements. We usually use it to analyze `SELECT` query statements. It is very simple to use. The syntax is as follows:
+
+```sql
+EXPLAIN + SELECT query statement;
+```
+
+Let’s briefly look at the execution plan of the next query statement:
+
+```sql
+mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_emp GROUP BY emp_no HAVING COUNT(emp_no)>1);
++----+-------------+----------+------------+-------+------------------+----------+----------+------+--------+----------+-------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+----------+------------+-------+------------------+----------+----------+------+--------+----------+-------------+
+| 1 | PRIMARY | dept_emp | NULL | ALL | NULL | NULL | NULL | NULL | 331143 | 100.00 | Using where |
+| 2 | SUBQUERY | dept_emp | NULL | index | PRIMARY,dept_no | PRIMARY | 16 | NULL | 331143 | 100.00 | Using index |
++----+-------------+----------+------------+-------+------------------+----------+----------+------+--------+----------+-------------+
+```
+
+As you can see, there are 12 columns in the execution plan results. The meaning of each column is summarized in the following table:
+
+| **Column Name** | **Meaning** |
+|------------- | ----------------------------------------------- |
+| id | The sequence identifier of the SELECT query |
+| select_type | The query type corresponding to the SELECT keyword |
+| table | table name used |
+| partitions | Matching partitions, or NULL for unpartitioned tables |
+| type | table access method |
+| possible_keys | Possible indexes |
+| key | the actual index used |
+| key_len | The length of the selected index |
+| ref | When using an index equivalent query, the column or constant to compare with the index |
+| rows | The expected number of rows to read |
+| filtered | Percentage of retained records after filtering by table conditions |
+| Extra | Additional Information |
+
+## How to analyze EXPLAIN results?
+
+In order to analyze the execution results of the `EXPLAIN` statement, we need to understand the important fields in the execution plan.
+
+###id
+
+`SELECT` identifier, used to identify the execution order of each `SELECT` statement.
+
+If the ids are the same, execute them in order from top to bottom. The id is different. The larger the id value, the higher the execution priority. If the row refers to the union result of other rows, the value can be NULL.
+
+### select_type
+
+The type of query is mainly used to distinguish between ordinary queries, joint queries, subqueries and other complex queries. Common values are:
+
+- **SIMPLE**: Simple query, does not contain UNION or subquery.
+- **PRIMARY**: If the query contains subqueries or other parts, the outer SELECT will be marked as PRIMARY.
+- **SUBQUERY**: The first SELECT in a subquery.
+- **UNION**: In the UNION statement, SELECT that appears after UNION.
+- **DERIVED**: Subqueries appearing in FROM will be marked as DERIVED.
+- **UNION RESULT**: The result of UNION query.
+
+### table
+
+Each row has a corresponding table name for the table name used in the query. In addition to the normal table, the table name may also be the following values:
+
+- **``**: This line refers to the UNION result of the lines with id M and N;
+- **``**: This line refers to the derived table result generated by the table with id N. Derived tables may be generated from subqueries in the FROM statement.
+- **``**: This line refers to the materialized subquery results generated by the table with id N.
+
+### type (important)
+
+The type of query execution, describes how the query is executed. The order of all values from best to worst is:
+
+system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
+
+The specific meanings of several common types are as follows:
+
+- **system**: If the engine used by the table is accurate for table row count statistics (such as MyISAM), and there is only one row of records in the table, the access method is system, which is a special case of const.
+- **const**: There is at most one row of matching records in the table, which can be found in one query. It is often used to use all fields of the primary key or unique index as query conditions.
+- **eq_ref**: When querying connected tables, the rows of the previous table have only one corresponding row in the current table. It is the best join method besides system and const. It is often used to use all fields of the primary key or unique index as the join condition.
+- **ref**: Use ordinary indexes as query conditions, and the query results may find multiple rows that meet the conditions.
+- **index_merge**: When the query condition uses multiple indexes, it means that Index Merge optimization is turned on. At this time, the key column in the execution plan lists the indexes used.
+- **range**: Perform a range query on the index column. The key column in the execution plan indicates which index is used.- **index**: The query traverses the entire index tree, similar to ALL, except that it scans the index, which is generally in memory and is faster.
+- **ALL**: Full table scan.
+
+### possible_keys
+
+The possible_keys column represents the indexes that MySQL may use when executing the query. If this column is NULL, it means that there is no index that may be used; in this case, you need to check the columns used in the WHERE statement to see if query performance can be improved by adding an index to one or more of these columns.
+
+### key (important)
+
+The key column represents the index actually used by MySQL. If NULL, the index is not used.
+
+### key_len
+
+The key_len column represents the maximum length of the index actually used by MySQL; when a joint index is used, it may be the sum of the lengths of multiple columns. The shorter it is, the better if it meets your needs. If the key column displays NULL , the key_len column also displays NULL .
+
+### rows
+
+The rows column indicates a rough estimate of the number of rows that need to be found or read based on table statistics and selection. The smaller the value, the better.
+
+### Extra (Important)
+
+This column contains additional information about MySQL parsing the query. Through this information, you can more accurately understand how MySQL executes the query. Common values are as follows:
+
+- **Using filesort**: External index sorting is used during sorting, and in-table index is not used for sorting.
+- **Using temporary**: MySQL needs to create a temporary table to store the results of the query, which is common in ORDER BY and GROUP BY.
+- **Using index**: Indicates that the query uses a covering index, without returning the table, and the query efficiency is very high.
+- **Using index condition**: Indicates that the query optimizer chooses to use the index condition push-down feature.
+- **Using where**: Indicates that the query uses the WHERE clause for conditional filtering. This usually occurs when the index is not used.
+- **Using join buffer (Block Nested Loop)**: The method of joining table query, which means that when the driven table does not use an index, MySQL will first read out the driving table and put it into the join buffer, and then traverse the driven table and driving table for query.
+
+As a reminder, when the Extra column contains Using filesort or Using temporary, MySQL performance may have problems and needs to be avoided as much as possible.
+
+## Reference
+
+-
+-
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/mysql-questions-01.en.md b/docs_en/database/mysql/mysql-questions-01.en.md
new file mode 100644
index 00000000000..f79a25704b8
--- /dev/null
+++ b/docs_en/database/mysql/mysql-questions-01.en.md
@@ -0,0 +1,1095 @@
+---
+title: MySQL常见面试题总结
+category: 数据库
+tag:
+ - MySQL
+ - 大厂面试
+head:
+ - - meta
+ - name: keywords
+ content: MySQL面试题,MySQL基础架构,InnoDB存储引擎,MySQL索引,B+树索引,事务隔离级别,redo log,undo log,binlog,MVCC,行级锁,慢查询优化
+ - - meta
+ - name: description
+ content: MySQL高频面试题精讲:基础架构、InnoDB引擎、索引原理、B+树、事务ACID、MVCC、redo/undo/binlog日志、行锁/表锁、慢查询优化,一文速通大厂必考点!
+---
+
+
+
+## MySQL 基础
+
+### 什么是关系型数据库?
+
+顾名思义,关系型数据库(RDB,Relational Database)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
+
+关系型数据库中,我们的数据都被存放在了各种表中(比如用户表),表中的每一行就存放着一条数据(比如一个用户的信息)。
+
+
+
+大部分关系型数据库都使用 SQL 来操作数据库中的数据。并且,大部分关系型数据库都支持事务的四大特性(ACID)。
+
+**有哪些常见的关系型数据库呢?**
+
+MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ……。
+
+### 什么是 SQL?
+
+SQL 是一种结构化查询语言(Structured Query Language),专门用来与数据库打交道,目的是提供一种从数据库中读写数据的简单有效的方法。
+
+几乎所有的主流关系数据库都支持 SQL ,适用性非常强。并且,一些非关系型数据库也兼容 SQL 或者使用的是类似于 SQL 的查询语言。
+
+SQL 可以帮助我们:
+
+- 新建数据库、数据表、字段;
+- 在数据库中增加,删除,修改,查询数据;
+- 新建视图、函数、存储过程;
+- 对数据库中的数据进行简单的数据分析;
+- 搭配 Hive,Spark SQL 做大数据;
+- 搭配 SQLFlow 做机器学习;
+- ……
+
+### 什么是 MySQL?
+
+
+
+**MySQL 是一种关系型数据库,主要用于持久化存储我们的系统中的一些数据比如用户信息。**
+
+由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是**3306**。
+
+### ⭐️MySQL 有什么优点?
+
+这个问题本质上是在问 MySQL 如此流行的原因。
+
+MySQL 成功可以归功于在**生态、功能和运维**这三个层面上的综合优势。
+
+**第一,从生态和成本角度看,它的护城河非常深。**
+
+- **开源免费:** 这是它得以广泛普及的基石。任何公司和个人都可以免费使用,极大地降低了技术门槛和初期成本。
+- **社区庞大,生态完善:** 经过几十年的发展,MySQL 拥有极其活跃的社区和丰富的生态系统。这意味着无论你遇到什么问题,几乎都能在网上找到解决方案;同时,市面上所有的主流编程语言、框架、ORM 工具、监控系统都对 MySQL 有完美的支持。它的文档也非常丰富,学习资源唾手可得。
+
+**第二,从核心技术功能上看,它非常强大且均衡。**
+
+- **强大的事务支持:** 这是它作为关系型数据库的立身之本。值得一提的是,InnoDB 默认的可重复读(REPEATABLE-READ)隔离级别,通过 MVCC 和 Next-Key Lock 机制,很大程度上避免了幻读问题,这在很多其他数据库中都需要更高的隔离级别才能做到,兼顾了性能和一致性。详细介绍可以阅读笔者写的这篇文章:[MySQL 事务隔离级别详解](https://javaguide.cn/database/mysql/transaction-isolation-level.html)。
+- **优秀的性能和可扩展性:** MySQL 本身经过了海量互联网业务的严酷考验,单机性能非常出色。更重要的是,它围绕着水平扩展,形成了一套非常成熟的架构方案,比如主从复制、读写分离、以及通过中间件实现的分库分表。这让它能够支撑从初创公司到大型互联网平台的各种规模的业务。
+
+**第三,从运维和使用角度看,它非常‘亲民’。**
+
+- **开箱即用,上手简单:** 相比于 Oracle 等大型商业数据库,MySQL 的安装、配置和日常使用都非常简单直观,学习曲线平缓,对于开发者和初级 DBA 非常友好。
+- **维护成本低:** 由于其简单性和庞大的社区,找到相关的运维人才和解决方案都相对容易,整体的维护成本也更低。
+
+值得一提的是最近几年,PostgreSQL 的势头很猛,甚至压过了 MySQL。网上出现了很多抨击诋毁 MySQL 的文章,笔者认为任何无脑抨击其中一方或者吹捧另外一方的行为都是不可取的。
+
+笔者也写过一篇文章分享对这两个关系型数据库代表的看法,感兴趣的可以看看:[MySQL 被干成老二了?](https://mp.weixin.qq.com/s/APWD-PzTcTqGUuibAw7GGw)。
+
+## MySQL 字段类型
+
+MySQL 字段类型可以简单分为三大类:
+
+- **数值类型**:整型(TINYINT、SMALLINT、MEDIUMINT、INT 和 BIGINT)、浮点型(FLOAT 和 DOUBLE)、定点型(DECIMAL)
+- **字符串类型**:CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB 等,最常用的是 CHAR 和 VARCHAR。
+- **日期时间类型**:YEAR、TIME、DATE、DATETIME 和 TIMESTAMP 等。
+
+下面这张图不是我画的,忘记是从哪里保存下来的了,总结的还蛮不错的。
+
+
+
+MySQL 字段类型比较多,我这里会挑选一些日常开发使用很频繁且面试常问的字段类型,以面试问题的形式来详细介绍。如无特殊说明,针对的都是 InnoDB 存储引擎。
+
+另外,推荐阅读一下《高性能 MySQL(第三版)》的第四章,有详细介绍 MySQL 字段类型优化。
+
+### ⭐️整数类型的 UNSIGNED 属性有什么用?
+
+MySQL 中的整数类型可以使用可选的 UNSIGNED 属性来表示不允许负值的无符号整数。使用 UNSIGNED 属性可以将正整数的上限提高一倍,因为它不需要存储负数值。
+
+例如, TINYINT UNSIGNED 类型的取值范围是 0 ~ 255,而普通的 TINYINT 类型的值范围是 -128 ~ 127。INT UNSIGNED 类型的取值范围是 0 ~ 4,294,967,295,而普通的 INT 类型的值范围是 -2,147,483,648 ~ 2,147,483,647。
+
+对于从 0 开始递增的 ID 列,使用 UNSIGNED 属性可以非常适合,因为不允许负值并且可以拥有更大的上限范围,提供了更多的 ID 值可用。
+
+### CHAR 和 VARCHAR 的区别是什么?
+
+CHAR 和 VARCHAR 是最常用到的字符串类型,两者的主要区别在于:**CHAR 是定长字符串,VARCHAR 是变长字符串。**
+
+CHAR 在存储时会在右边填充空格以达到指定的长度,检索时会去掉空格;VARCHAR 在存储时需要使用 1 或 2 个额外字节记录字符串的长度,检索时不需要处理。
+
+CHAR 更适合存储长度较短或者长度都差不多的字符串,例如 Bcrypt 算法、MD5 算法加密后的密码、身份证号码。VARCHAR 类型适合存储长度不确定或者差异较大的字符串,例如用户昵称、文章标题等。
+
+CHAR(M) 和 VARCHAR(M) 的 M 都代表能够保存的字符数的最大值,无论是字母、数字还是中文,每个都只占用一个字符。
+
+### VARCHAR(100)和 VARCHAR(10)的区别是什么?
+
+VARCHAR(100)和 VARCHAR(10)都是变长类型,表示能存储最多 100 个字符和 10 个字符。因此,VARCHAR (100) 可以满足更大范围的字符存储需求,有更好的业务拓展性。而 VARCHAR(10)存储超过 10 个字符时,就需要修改表结构才可以。
+
+虽说 VARCHAR(100)和 VARCHAR(10)能存储的字符范围不同,但二者存储相同的字符串,所占用磁盘的存储空间其实是一样的,这也是很多人容易误解的一点。
+
+不过,VARCHAR(100) 会消耗更多的内存。这是因为 VARCHAR 类型在内存中操作时,通常会分配固定大小的内存块来保存值,即使用字符类型中定义的长度。例如在进行排序的时候,VARCHAR(100)是按照 100 这个长度来进行的,也就会消耗更多内存。
+
+### DECIMAL 和 FLOAT/DOUBLE 的区别是什么?
+
+DECIMAL 和 FLOAT 的区别是:**DECIMAL 是定点数,FLOAT/DOUBLE 是浮点数。DECIMAL 可以存储精确的小数值,FLOAT/DOUBLE 只能存储近似的小数值。**
+
+DECIMAL 用于存储具有精度要求的小数,例如与货币相关的数据,可以避免浮点数带来的精度损失。
+
+在 Java 中,MySQL 的 DECIMAL 类型对应的是 Java 类 `java.math.BigDecimal`。
+
+### 为什么不推荐使用 TEXT 和 BLOB?
+
+TEXT 类型类似于 CHAR(0-255 字节)和 VARCHAR(0-65,535 字节),但可以存储更长的字符串,即长文本数据,例如博客内容。
+
+| 类型 | 可存储大小 | 用途 |
+| ---------- | -------------------- | -------------- |
+| TINYTEXT | 0-255 字节 | 一般文本字符串 |
+| TEXT | 0-65,535 字节 | 长文本字符串 |
+| MEDIUMTEXT | 0-16,772,150 字节 | 较大文本数据 |
+| LONGTEXT | 0-4,294,967,295 字节 | 极大文本数据 |
+
+BLOB 类型主要用于存储二进制大对象,例如图片、音视频等文件。
+
+| 类型 | 可存储大小 | 用途 |
+| ---------- | ---------- | ------------------------ |
+| TINYBLOB | 0-255 字节 | 短文本二进制字符串 |
+| BLOB | 0-65KB | 二进制字符串 |
+| MEDIUMBLOB | 0-16MB | 二进制形式的长文本数据 |
+| LONGBLOB | 0-4GB | 二进制形式的极大文本数据 |
+
+在日常开发中,很少使用 TEXT 类型,但偶尔会用到,而 BLOB 类型则基本不常用。如果预期长度范围可以通过 VARCHAR 来满足,建议避免使用 TEXT。
+
+数据库规范通常不推荐使用 BLOB 和 TEXT 类型,这两种类型具有一些缺点和限制,例如:
+
+- 不能有默认值。
+- 在使用临时表时无法使用内存临时表,只能在磁盘上创建临时表(《高性能 MySQL》书中有提到)。
+- 检索效率较低。
+- 不能直接创建索引,需要指定前缀长度。
+- 可能会消耗大量的网络和 IO 带宽。
+- 可能导致表上的 DML 操作变慢。
+- ……
+
+### ⭐️DATETIME 和 TIMESTAMP 的区别是什么?如何选择?
+
+DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
+
+TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
+
+- DATETIME:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- Timestamp:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
+
+`TIMESTAMP` 的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,`TIMESTAMP` 是自然的选择(注意其时间范围限制,也就是 2038 年问题)。
+
+如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,`DATETIME` 是更稳妥的选择。
+
+关于两者的详细对比以及日期存储类型选择建议,请参考我写的这篇文章: [MySQL 时间类型数据存储建议](./some-thoughts-on-database-storage-time.md)。
+
+### NULL 和 '' 的区别是什么?
+
+`NULL` 和 `''` (空字符串) 是两个完全不同的值,它们分别表示不同的含义,并在数据库中有着不同的行为。`NULL` 代表缺失或未知的数据,而 `''` 表示一个已知存在的空字符串。它们的主要区别如下:
+
+1. **含义**:
+ - `NULL` 代表一个不确定的值,它不等于任何值,包括它自身。因此,`SELECT NULL = NULL` 的结果是 `NULL`,而不是 `true` 或 `false`。 `NULL` 意味着缺失或未知的信息。虽然 `NULL` 不等于任何值,但在某些操作中,数据库系统会将 `NULL` 值视为相同的类别进行处理,例如:`DISTINCT`,`GROUP BY`,`ORDER BY`。需要注意的是,这些操作将 `NULL` 值视为相同的类别进行处理,并不意味着 `NULL` 值之间是相等的。 它们只是在特定操作中被特殊处理,以保证结果的正确性和一致性。 这种处理方式是为了方便数据操作,而不是改变了 `NULL` 的语义。
+ - `''` 表示一个空字符串,它是一个已知的值。
+2. **存储空间**:
+ - `NULL` 的存储空间占用取决于数据库的实现,通常需要一些空间来标记该值为空。
+ - `''` 的存储空间占用通常较小,因为它只存储一个空字符串的标志,不需要存储实际的字符。
+3. **比较运算**:
+ - 任何值与 `NULL` 进行比较(例如 `=`, `!=`, `>`, `<` 等)的结果都是 `NULL`,表示结果不确定。要判断一个值是否为 `NULL`,必须使用 `IS NULL` 或 `IS NOT NULL`。
+ - `''` 可以像其他字符串一样进行比较运算。例如,`'' = ''` 的结果是 `true`。
+4. **聚合函数**:
+ - 大多数聚合函数(例如 `SUM`, `AVG`, `MIN`, `MAX`)会忽略 `NULL` 值。
+ - `COUNT(*)` 会统计所有行数,包括包含 `NULL` 值的行。`COUNT(列名)` 会统计指定列中非 `NULL` 值的行数。
+ - 空字符串 `''` 会被聚合函数计算在内。例如,`SUM` 会将其视为 0,`MIN` 和 `MAX` 会将其视为一个空字符串。
+
+看了上面的介绍之后,相信你对另外一个高频面试题:“为什么 MySQL 不建议使用 `NULL` 作为列默认值?”也有了答案。
+
+### ⭐️Boolean 类型如何表示?
+
+MySQL 中没有专门的布尔类型,而是用 `TINYINT(1)` 类型来表示布尔值。`TINYINT(1)` 类型可以存储 0 或 1,分别对应 false 或 true。
+
+### ⭐️手机号存储用 INT 还是 VARCHAR?
+
+存储手机号,**强烈推荐使用 VARCHAR 类型**,而不是 INT 或 BIGINT。主要原因如下:
+
+1. **格式兼容性与完整性:**
+ - 手机号可能包含前导零(如某些地区的固话区号)、国家代码前缀('+'),甚至可能带有分隔符('-' 或空格)。INT 或 BIGINT 这种数字类型会自动丢失这些重要的格式信息(比如前导零会被去掉,'+' 和 '-' 无法存储)。
+ - VARCHAR 可以原样存储各种格式的号码,无论是国内的 11 位手机号,还是带有国家代码的国际号码,都能完美兼容。
+2. **非算术性:**手机号虽然看起来是数字,但我们从不对它进行数学运算(比如求和、平均值)。它本质上是一个标识符,更像是一个字符串。用 VARCHAR 更符合其数据性质。
+3. **查询灵活性:**
+ - 业务中常常需要根据号段(前缀)进行查询,例如查找所有 "138" 开头的用户。使用 VARCHAR 类型配合 `LIKE '138%'` 这样的 SQL 查询既直观又高效。
+ - 如果使用数字类型,进行类似的前缀匹配通常需要复杂的函数转换(如 CAST 或 SUBSTRING),或者使用范围查询(如 `WHERE phone >= 13800000000 AND phone < 13900000000`),这不仅写法繁琐,而且可能无法有效利用索引,导致性能下降。
+4. **加密存储的要求(非常关键):**
+ - 出于数据安全和隐私合规的要求,手机号这类敏感个人信息通常必须加密存储在数据库中。
+- The encrypted data (ciphertext) is a long string of characters (usually composed of letters, numbers, symbols, or Base64/Hex encoded), and the INT or BIGINT types cannot store this ciphertext at all. Only types such as VARCHAR, TEXT, or BLOB will do.
+
+**About VARCHAR length selection:**
+
+- **If stored without encryption (strongly not recommended!):** Considering international numbers and possible format characters, VARCHAR(20) to VARCHAR(32) is usually a relatively safe range, enough to cover the vast majority of mobile phone number formats around the world. VARCHAR(15) may not be sufficient for some numbers with country codes and formatting characters.
+- **If storing encrypted (recommended standard practice):** The length must be accurately calculated and set based on the maximum length of the ciphertext produced by the chosen encryption algorithm, and possible encoding methods (e.g. Base64 will increase the length by about 1/3). Often longer VARCHAR lengths are required, such as VARCHAR(128), VARCHAR(256) or even longer.
+
+Finally, here is a table to summarize:
+
+| Comparing dimensions | VARCHAR type (recommended) | INT/BIGINT type (not recommended) | Description/Remarks |
+|---------------- | ---------------------------------- | ---------------------------------- | ------------------------------------------------------------------------------- |
+| **Format Compatibility** | ✔ Can store leading zeros, "+", "-", spaces, etc. | ✘ Leading zeros are automatically lost and symbols cannot be stored | VARCHAR can store various mobile phone number formats as they are, INT/BIGINT only supports simple numbers, and leading zeros will disappear |
+| **Integrity** | ✔ No format information is lost | ✘ Format information is lost | For example, "013800012345" stored in INT will become 13800012345, and "+" cannot be stored |
+| **Non-arithmetic** | ✔ Suitable for storing "identifiers" | ✘ Only suitable for numerical operations | Mobile phone numbers are essentially string identifiers and do not perform mathematical operations. VARCHAR is more suitable for practical purposes |
+| **Query flexibility** | ✔ Supports `LIKE '138%'`, etc. | ✘ Querying prefixes is inconvenient or has poor performance | Use VARCHAR to efficiently query by number segment/prefix, but the numeric type needs to be converted to a string or other complex processing |
+| **Encrypted storage support** | ✔ Can store encrypted ciphertext (letters, symbols, etc.) | ✘ Unable to store ciphertext | After encrypting the mobile phone number, the ciphertext is a string/binary, only VARCHAR, TEXT, BLOB, etc. are compatible |
+| **Length setting recommendations** | 15~20 (unencrypted), encryption depends on the situation | Meaningless | When not encrypted, VARCHAR(15~20) is universal, the encrypted length depends on the algorithm and encoding method |
+
+## MySQL Infrastructure
+
+> It is recommended to read this article [Execution Process of SQL Statements in MySQL](./how-sql-executed-in-mysql.md) to understand the MySQL infrastructure. In addition, "the execution flow of a SQL statement in MySQL" is also a frequently asked question in interviews.
+
+The following figure is a brief architecture diagram of MySQL. From the figure below, you can clearly see how a SQL statement on the client is executed inside MySQL.
+
+
+
+As can be seen from the above figure, MySQL mainly consists of the following parts:
+
+- **Connector:** Identity authentication and permission related (when logging in to MySQL).
+- **Query cache:** When executing a query statement, the cache will be queried first (removed after MySQL 8.0 version, because this function is not very practical).
+- **Analyzer:** If the cache is not hit, the SQL statement will go through the analyzer. To put it bluntly, the analyzer needs to first see what your SQL statement is doing, and then check whether the syntax of your SQL statement is correct.
+- **Optimizer:** Execute according to the solution considered optimal by MySQL.
+- **Executor:** Execute the statement and return data from the storage engine. Before executing the statement, it will be judged whether there is permission. If there is no permission, an error will be reported.
+- **Plug-in storage engine**: Mainly responsible for data storage and reading. It adopts a plug-in architecture and supports various storage engines such as InnoDB, MyISAM, and Memory. InnoDB is the default storage engine of MySQL. In most scenarios, using InnoDB is the best choice.
+
+## MySQL storage engine
+
+The core of MySQL lies in the storage engine. If you want to learn MySQL in depth, you must study the MySQL storage engine in depth.
+
+### What storage engines does MySQL support? Which one is used by default?
+
+MySQL supports multiple storage engines. You can view all storage engines supported by MySQL through the `SHOW ENGINES` command.
+
+
+
+From the picture above, we can see that MySQL's current default storage engine is InnoDB. Moreover, among all storage engines, only InnoDB is a transactional storage engine, which means that only InnoDB supports transactions.
+
+The MySQL version I use here is 8.x, and there may be differences between different MySQL versions.
+
+Prior to MySQL 5.5.5, MyISAM was the default storage engine for MySQL. After version 5.5.5, InnoDB is the default storage engine for MySQL.
+
+You can check your MySQL version with the `SELECT VERSION()` command.
+
+```bash
+mysql> SELECT VERSION();
++-----------+
+| VERSION() |
++-----------+
+| 8.0.27 |
++-----------+
+1 row in set (0.00 sec)
+```
+
+You can also directly view MySQL's current default storage engine through the `SHOW VARIABLES LIKE '%storage_engine%'` command.
+
+```bash
+mysql> SHOW VARIABLES LIKE '%storage_engine%';
++----------------------------------+----------+
+| Variable_name | Value |
++----------------------------------+----------+
+| default_storage_engine | InnoDB |
+| default_tmp_storage_engine | InnoDB |
+| disabled_storage_engines | |
+| internal_tmp_mem_storage_engine | TempTable |
++----------------------------------+----------+
+4 rows in set (0.00 sec)
+```
+
+If you want to have an in-depth understanding of each storage engine and the differences between them, it is recommended that you read the following introduction in the official MySQL document (the interview will not ask such detailed questions, just understand it):
+
+- Detailed introduction to InnoDB storage engine: .
+- Detailed introduction to other storage engines: .
+
+
+
+### Do you understand the MySQL storage engine architecture?
+
+The MySQL storage engine adopts a **plug-in architecture** and supports multiple storage engines. We can even set up different storage engines for different database tables to meet the needs of different scenarios. **The storage engine is based on tables, not databases. **
+
+The following diagram shows the MySQL architecture with pluggable storage engines:
+
+你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
+
+MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地址: 。
+
+### ⭐️MyISAM 和 InnoDB 有什么区别?
+
+MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
+
+虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
+
+MySQL 5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。
+
+言归正传!咱们下面还是来简单对比一下两者:
+
+**1、是否支持行级锁**
+
+MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
+
+也就说,MyISAM 一锁就是锁住了整张表,这在并发写的情况下是多么滴憨憨啊!这也是为什么 InnoDB 在并发写的时候,性能更牛皮了!
+
+**2、是否支持事务**
+
+MyISAM 不提供事务支持。
+
+InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别,具有提交(commit)和回滚(rollback)事务的能力。并且,InnoDB 默认使用的 REPEATABLE-READ(可重读)隔离级别是可以解决幻读问题发生的(基于 MVCC 和 Next-Key Lock)。
+
+关于 MySQL 事务的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
+
+**3、是否支持外键**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+外键对于维护数据一致性非常有帮助,但是对性能有一定的损耗。因此,通常情况下,我们是不建议在实际生产项目中使用外键的,在业务代码中进行约束即可!
+
+阿里的《Java 开发手册》也是明确规定禁止使用外键的。
+
+
+
+不过,在代码中进行约束的话,对程序员的能力要求更高,具体是否要采用外键还是要根据你的项目实际情况而定。
+
+总结:一般我们也是不建议在数据库层面使用外键的,应用层面可以解决。不过,这样会对数据的一致性造成威胁。具体要不要使用外键还是要根据你的项目来决定。
+
+**4、是否支持数据库异常崩溃后的安全恢复**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 `redo log` 。
+
+**5、是否支持 MVCC**
+
+MyISAM 不支持,而 InnoDB 支持。
+
+讲真,这个对比有点废话,毕竟 MyISAM 连行级锁都不支持。MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提高性能。
+
+**6、索引实现不一样。**
+
+虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
+
+InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。
+
+详细区别,推荐你看看我写的这篇文章:[MySQL 索引详解](./mysql-index.md)。
+
+**7、性能有差别。**
+
+InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是只读模式下,随着 CPU 核数的增加,InnoDB 的读写能力呈线性增长。MyISAM 因为读写不能并发,它的处理能力跟核数没关系。
+
+
+
+**8、数据缓存策略和机制实现不同。**
+
+InnoDB 使用缓冲池(Buffer Pool)缓存数据页和索引页,MyISAM 使用键缓存(Key Cache)仅缓存索引页而不缓存数据页。
+
+**总结**:
+
+- InnoDB 支持行级别的锁粒度,MyISAM 不支持,只支持表级别的锁粒度。
+- MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了 SQL 标准定义了四个隔离级别。
+- MyISAM 不支持外键,而 InnoDB 支持。
+- MyISAM 不支持 MVCC,而 InnoDB 支持。
+- 虽然 MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。
+- MyISAM 不支持数据库异常崩溃后的安全恢复,而 InnoDB 支持。
+- InnoDB 的性能比 MyISAM 更强大。
+
+最后,再分享一张图片给你,这张图片详细对比了常见的几种 MySQL 存储引擎。
+
+
+
+### MyISAM 和 InnoDB 如何选择?
+
+大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊)。
+
+《MySQL 高性能》上面有一句话这样写到:
+
+> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
+
+因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由使用 MyISAM 了,老老实实用默认的 InnoDB 就可以了!
+
+## ⭐️MySQL 索引
+
+MySQL 索引相关的问题比较多,也非常重要,更详细的介绍可以阅读笔者写的这篇文章:[MySQL 索引详解](./mysql-index.md) 。
+
+### 索引是什么?
+
+**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
+
+索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
+
+**索引的优点:**
+
+1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
+2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户 ID、邮箱等。主键本身就是一种唯一索引。
+3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
+
+**索引的缺点:**
+
+1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML 操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
+2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
+3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
+
+**那么,用了索引就一定能提高查询性能吗?**
+
+**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
+
+- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
+- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过 20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机 I/O)的成本可能高于一次顺序的全表扫描。
+- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
+
+### 索引为什么快?
+
+索引之所以快,核心原因是它**大大减少了磁盘 I/O 的次数**。
+
+它的本质是一种**排好序的数据结构**,就像书的目录,让我们不用一页一页地翻(全表扫描)。
+
+在 MySQL 中,这个数据结构是**B+树**。B+树结构主要从两方面做了优化:
+
+1. B+树的特点是“矮胖”,一个千万数据的表,索引树的高度可能只有 3-4 层。这意味着,最多只需要**3-4 次磁盘 I/O**,就能精确定位到我想要的数据,而全表扫描可能需要成千上万次,所以速度极快。
+2. B+树的叶子节点是**用链表连起来的**。找到开头后,就能顺着链表**顺序读**下去,这对磁盘非常友好,还能触发预读。
+
+### MySQL 索引底层数据结构是什么?
+
+在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,详细介绍可以参考笔者写的这篇文章:[MySQL 索引详解](https://javaguide.cn/database/mysql/mysql-index.html)。
+
+### 为什么 InnoDB 没有使用哈希作为索引的数据结构?
+
+> 我发现很多求职者甚至是面试官对这个问题都有误解,他们相当然的认为 MySQL 底层并没有使用哈希或者 B 树作为索引的数据结构。
+>
+> 实际上,不论是提问还是回答这个问题都要区分好存储引擎。像 MEMORY 引擎就同时支持哈希和 B 树。
+
+哈希索引的底层是哈希表。它的优点是,在进行**精确的等值查询**时,理论上时间复杂度是 **O(1)** ,速度极快。比如 `WHERE id = 123`。
+
+但是,它有几个对于通用数据库来说是致命的缺点:
+
+1. **不支持范围查询:** 这是最主要的原因。哈希函数的一个特点是它会把相邻的输入值(比如 `id=100` 和 `id=101`)映射到哈希表中完全不相邻的位置。这种顺序的破坏,使得我们无法处理像 `WHERE age > 30` 或 `BETWEEN 100 AND 200`这样的范围查询。要完成这种查询,哈希索引只能退化为全表扫描。
+2. **不支持排序:** 同理,因为哈希值是无序的,所以我们无法利用哈希索引来优化 `ORDER BY` 子句。
+3. **不支持部分索引键查询:** 对于联合索引,比如`(col1, col2)`,哈希索引必须使用所有索引列进行查询,它无法单独利用 `col1` 来加速查询。
+4. **哈希冲突问题:** 当不同的键产生相同的哈希值时,需要额外的链表或开放寻址来解决,这会降低性能。
+
+鉴于数据库查询中范围查询和排序是极其常见的操作,一个不支持这些功能的索引结构,显然不能作为默认的、通用的索引类型。
+
+### 为什么 InnoDB 没有使用 B 树作为索引的数据结构?
+
+B 树和 B+树都是优秀的多路平衡搜索树,非常适合磁盘存储,因为它们都很“矮胖”,能最大化地利用每一次磁盘 I/O。
+
+但 B+树是 B 树的一个增强版,它针对数据库场景做了几个关键优化:
+
+1. **I/O 效率更高:** 在 B+树中,只有叶子节点才存储数据(或数据指针),而非叶子节点只存储索引键。因为非叶子节点不存数据,所以它们可以容纳更多的索引键。这意味着 B+树的“扇出”更大,在同样的数据量下,B+树通常会比 B 树更矮,也就意味着查找数据所需的磁盘 I/O 次数更少。
+2. **查询性能更稳定:** 在 B+树中,任何一次查询都必须从根节点走到叶子节点才能找到数据,所以查询路径的长度是固定的。而在 B 树中,如果运气好,可能在非叶子节点就找到了数据,但运气不好也得走到叶子,这导致查询性能不稳定。
+3. **对范围查询极其友好:** 这是 B+树最核心的优势。它的所有叶子节点之间通过一个双向链表连接。当我们执行一个范围查询(比如 `WHERE id > 100`)时,只需要通过树形结构找到 `id=100` 的叶子节点,然后就可以沿着链表向后顺序扫描,而无需再回溯到上层节点。这使得范围查询的效率大大提高。
+
+### 什么是覆盖索引?
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)**。
+
+在 InnoDB 存储引擎中,非主键索引的叶子节点包含的是主键的值。这意味着,当使用非主键索引进行查询时,数据库会先找到对应的主键值,然后再通过主键索引来定位和检索完整的行数据。这个过程被称为“回表”。
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。**
+
+### 请解释一下 MySQL 的联合索引及其最左前缀原则
+
+使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
+
+以 `score` 和 `name` 两个字段建立联合索引:
+
+```sql
+ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
+```
+
+最左前缀匹配原则指的是在使用联合索引时,MySQL 会根据索引中的字段顺序,从左到右依次匹配查询条件中的字段。如果查询条件与索引中的最左侧字段相匹配,那么 MySQL 就会使用索引来过滤数据,这样可以提高查询效率。
+
+最左匹配原则会一直向右匹配,直到遇到范围查询(如 >、<)为止。对于 >=、<=、BETWEEN 以及前缀匹配 LIKE 的范围查询,不会停止匹配(相关阅读:[联合索引的最左匹配原则全网都在说的一个错误结论](https://mp.weixin.qq.com/s/8qemhRg5MgXs1So5YCv0fQ))。
+
+假设有一个联合索引 `(column1, column2, column3)`,其从左到右的所有前缀为 `(column1)`、`(column1, column2)`、`(column1, column2, column3)`(创建 1 个联合索引相当于创建了 3 个索引),包含这些列的所有查询都会走索引而不会全表扫描。
+
+我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
+
+我们这里简单演示一下最左前缀匹配的效果。
+
+1、创建一个名为 `student` 的表,这张表只有 `id`、`name`、`class` 这 3 个字段。
+
+```sql
+CREATE TABLE `student` (
+ `id` int NOT NULL,
+ `name` varchar(100) DEFAULT NULL,
+ `class` varchar(100) DEFAULT NULL,
+ PRIMARY KEY (`id`),
+ KEY `name_class_idx` (`name`,`class`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+2、下面我们分别测试三条不同的 SQL 语句。
+
+
+
+```sql
+# 可以命中索引
+SELECT * FROM student WHERE name = 'Anne Henry';
+EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk';
+# 无法命中索引
+SELECT * FROM student WHERE class = 'lIrm08RYVk';
+```
+
+再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
+
+先不要往下看答案,给自己 3 分钟时间想一想。
+
+1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
+2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
+3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
+4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
+
+MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
+
+### SELECT \* 会导致索引失效吗?
+
+`SELECT *` 不会直接导致索引失效(如果不走索引大概率是因为 where 查询范围过大导致的),但它可能会带来一些其他的性能问题比如造成网络传输和数据处理的浪费、无法使用索引覆盖。
+
+### 哪些字段适合创建索引?
+
+- **不为 NULL 的字段**:索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
+- **被频繁查询的字段**:我们创建索引的字段应该是查询操作非常频繁的字段。
+- **被作为条件查询的字段**:被作为 WHERE 条件查询的字段,应该被考虑建立索引。
+- **频繁需要排序的字段**:索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
+- **被经常频繁用于连接的字段**:经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 索引失效的原因有哪些?
+
+1. 创建了组合索引,但查询条件未遵守最左匹配原则;
+2. 在索引列上进行计算、函数、类型转换等操作;
+3. 以 % 开头的 LIKE 查询比如 `LIKE '%abc';`;
+4. 查询条件中使用 OR,且 OR 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
+5. IN 的取值范围较大时会导致索引失效,走全表扫描(NOT IN 和 IN 的失效场景相同);
+6. 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html "隐式转换");
+
+## MySQL 查询缓存
+
+MySQL 查询缓存是查询结果缓存。执行查询语句的时候,会先查询缓存,如果缓存中有对应的查询结果,就会直接返回。
+
+`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
+
+```properties
+query_cache_type=1
+query_cache_size=600000
+```
+
+MySQL 执行以下命令也可以开启查询缓存
+
+```properties
+set global query_cache_type=1;
+set global query_cache_size=600000;
+```
+
+查询缓存会在同样的查询条件和数据情况下,直接返回缓存中的结果。但需要注意的是,查询缓存的匹配条件非常严格,任何细微的差异都会导致缓存无法命中。这里的查询条件包括查询语句本身、当前使用的数据库、以及其他可能影响结果的因素,如客户端协议版本号等。
+
+**查询缓存不命中的情况:**
+
+1. 任何两个查询在任何字符上的不同都会导致缓存不命中。
+2. 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
+3. 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
+
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,还可以通过 `sql_cache` 和 `sql_no_cache` 来控制某个查询语句是否需要缓存:
+
+```sql
+SELECT sql_no_cache COUNT(*) FROM usr;
+```
+
+MySQL 5.6 开始,查询缓存已默认禁用。MySQL 8.0 开始,已经不再支持查询缓存了(具体可以参考这篇文章:[MySQL 8.0: Retiring Support for the Query Cache](https://dev.mysql.com/blog-archive/mysql-8-0-retiring-support-for-the-query-cache/))。
+
+
+
+## ⭐️MySQL 日志
+
+上诉问题的答案可以在[《Java 面试指北》(付费,点击链接领取优惠卷)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 中找到。
+
+
+
+文章地址: (密码获取:)。
+
+## ⭐️MySQL 事务
+
+### 什么是事务?
+
+我们设想一个场景,这个场景中我们需要插入多条相关联的数据到数据库,不幸的是,这个过程可能会遇到下面这些问题:
+
+- 数据库中途突然因为某些原因挂掉了。
+- 客户端突然因为网络原因连接不上数据库了。
+- 并发访问数据库时,多个线程同时写入数据库,覆盖了彼此的更改。
+- ……
+
+上面的任何一个问题都可能会导致数据的不一致性。为了保证数据的一致性,系统必须能够处理这些问题。事务就是我们抽象出来简化这些问题的首选机制。事务的概念起源于数据库,目前,已经成为一个比较广泛的概念。
+
+**何为事务?** 一言蔽之,**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
+
+事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作,这两个操作必须都成功或者都失败。
+
+1. 将小明的余额减少 1000 元
+2. 将小红的余额增加 1000 元。
+
+事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。这样就不会出现小明余额减少而小红的余额却并没有增加的情况。
+
+
+
+### 什么是数据库事务?
+
+大多数情况下,我们在谈论事务的时候,如果没有特指**分布式事务**,往往指的就是**数据库事务**。
+
+数据库事务在我们日常开发中接触的最多了。如果你的项目属于单体架构的话,你接触到的往往就是数据库事务了。
+
+**那数据库事务有什么作用呢?**
+
+简单来说,数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:**要么全部执行成功,要么全部不执行** 。
+
+```sql
+# 开启一个事务
+START TRANSACTION;
+# 多条 SQL 语句
+SQL1,SQL2...
+## 提交事务
+COMMIT;
+```
+
+
+
+另外,关系型数据库(例如:`MySQL`、`SQL Server`、`Oracle` 等)事务都有 **ACID** 特性:
+
+
+
+1. **原子性**(`Atomicity`):事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
+2. **一致性**(`Consistency`):执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
+3. **隔离性**(`Isolation`):并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
+4. **持久性**(`Durability`):一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
+
+🌈 这里要额外补充一点:**只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。也就是说 A、I、D 是手段,C 是目的!** 想必大家也和我一样,被 ACID 这个概念被误导了很久! 我也是看周志明老师的公开课[《周志明的软件架构课》](https://time.geekbang.org/opencourse/intro/100064201)才搞清楚的(多看好书!!!)。
+
+
+
+另外,DDIA 也就是 [《Designing Data-Intensive Application(数据密集型应用系统设计)》](https://book.douban.com/subject/30329536/) 的作者在他的这本书中如是说:
+
+> Atomicity, isolation, and durability are properties of the database, whereas consis‐
+> tency (in the ACID sense) is a property of the application. The application may rely
+> on the database’s atomicity and isolation properties in order to achieve consistency,
+> but it’s not up to the database alone.
+>
+> 翻译过来的意思是:原子性,隔离性和持久性是数据库的属性,而一致性(在 ACID 意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母 C 不属于 ACID 。
+
+《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 GitHub 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
+
+
+
+### 并发事务带来了哪些问题?
+
+在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
+
+#### 脏读(Dirty read)
+
+一个事务读取数据并且对数据进行了修改,这个修改对其他事务来说是可见的,即使当前事务没有提交。这时另外一个事务读取了这个还未提交的数据,但第一个事务突然回滚,导致数据并没有被提交到数据库,那第二个事务读取到的就是脏数据,这也就是脏读的由来。
+
+例如:事务 1 读取某表中的数据 A=20,事务 1 修改 A=A-1,事务 2 读取到 A = 19,事务 1 回滚导致对 A 的修改并未提交到数据库, A 的值还是 20。
+
+
+
+#### 丢失修改(Lost to modify)
+
+在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。
+
+例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 先修改 A=A-1,事务 2 后来也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
+
+
+
+#### 不可重复读(Unrepeatable read)
+
+指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
+
+例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 再次读取 A =19,此时读取的结果和第一次读取的结果不同。
+
+
+
+#### 幻读(Phantom read)
+
+幻读与不可重复读类似。它发生在一个事务读取了几行数据,接着另一个并发事务插入了一些数据时。在随后的查询中,第一个事务就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
+
+例如:事务 2 读取某个范围的数据,事务 1 在这个范围插入了新的数据,事务 2 再次读取这个范围的数据发现相比于第一次读取的结果多了新的数据。
+
+
+
+### 不可重复读和幻读有什么区别?
+
+- 不可重复读的重点是内容修改或者记录减少比如多次读取一条记录发现其中某些记录的值被修改;
+- 幻读的重点在于记录新增比如多次执行同一条查询语句(DQL)时,发现查到的记录增加了。
+
+幻读其实可以看作是不可重复读的一种特殊情况,单独把幻读区分出来的原因主要是解决幻读和不可重复读的方案不一样。
+
+举个例子:执行 `delete` 和 `update` 操作的时候,可以直接对记录加锁,保证事务安全。而执行 `insert` 操作的时候,由于记录锁(Record Lock)只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁(Gap Lock)。也就是说执行 `insert` 操作的时候需要依赖 Next-Key Lock(Record Lock+Gap Lock) 进行加锁来保证不出现幻读。
+
+### 并发事务的控制方式有哪些?
+
+MySQL 中并发事务的控制方式无非就两种:**锁** 和 **MVCC**。锁可以看作是悲观控制的模式,多版本并发控制(MVCC,Multiversion concurrency control)可以看作是乐观控制的模式。
+
+**锁** 控制方式下会通过锁来显式控制共享资源而不是通过调度手段,MySQL 中主要是通过 **读写锁** 来实现并发控制。
+
+- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
+- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条记录加任何类型的锁(锁不兼容)。
+
+读写锁可以做到读读并行,但是无法做到写读、写写并行。另外,根据根据锁粒度的不同,又被分为 **表级锁(table-level locking)** 和 **行级锁(row-level locking)** 。InnoDB 不光支持表级锁,还支持行级锁,默认为行级锁。行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类。
+
+**MVCC** 是多版本并发控制方法,即对一份数据会存储多个版本,通过事务的可见性来保证事务能看到自己应该看到的版本。通常会有一个全局的版本分配器来为每一行数据设置版本号,版本号是唯一的。
+
+MVCC 在 MySQL 中实现所依赖的手段主要是: **隐藏字段、read view、undo log**。
+
+- undo log : undo log 用于记录某行数据的多个版本的数据。
+- read view 和 隐藏字段 : 用来判断当前版本数据的可见性。
+
+关于 InnoDB 对 MVCC 的具体实现可以看这篇文章:[InnoDB 存储引擎对 MVCC 的实现](./innodb-implementation-of-mvcc.md) 。
+
+### SQL 标准定义了哪些事务隔离级别?
+
+SQL 标准定义了四种事务隔离级别,用来平衡事务的隔离性(Isolation)和并发性能。级别越高,数据一致性越好,但并发性能可能越低。这四个级别是:
+
+- **READ-UNCOMMITTED(读取未提交)** :最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。这种级别在实际应用中很少使用,因为它对数据一致性的保证太弱。
+- **READ-COMMITTED(读取已提交)** :允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。这是大多数数据库(如 Oracle, SQL Server)的默认隔离级别。
+- **REPEATABLE-READ(可重复读)** :对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。MySQL InnoDB 存储引擎的默认隔离级别正是 REPEATABLE READ。并且,InnoDB 在此级别下通过 MVCC(多版本并发控制) 和 Next-Key Locks(间隙锁+行锁) 机制,在很大程度上解决了幻读问题。
+- **SERIALIZABLE(可串行化)** :最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
+
+| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
+| ---------------- | ----------------- | -------------------------------- | ---------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (标准) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
+
+### MySQL 的默认隔离级别是什么?
+
+MySQL InnoDB 存储引擎的默认隔离级别是 **REPEATABLE READ**。可以通过以下命令查看:
+
+- MySQL 8.0 之前:`SELECT @@tx_isolation;`
+- MySQL 8.0 及之后:`SELECT @@transaction_isolation;`
+
+```sql
+mysql> SELECT @@tx_isolation;
++-----------------+
+| @@tx_isolation |
++-----------------+
+| REPEATABLE-READ |
++-----------------+
+```
+
+关于 MySQL 事务隔离级别的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](./transaction-isolation-level.md)。
+
+### MySQL 的隔离级别是基于锁实现的吗?
+
+MySQL 的隔离级别基于锁和 MVCC 机制共同实现的。
+
+SERIALIZABLE 隔离级别是通过锁来实现的,READ-COMMITTED 和 REPEATABLE-READ 隔离级别是基于 MVCC 实现的。不过, SERIALIZABLE 之外的其他隔离级别可能也需要用到锁机制,就比如 REPEATABLE-READ 在当前读情况下需要使用加锁读来保证不会出现幻读。
+
+## MySQL 锁
+
+锁是一种常见的并发事务的控制方式。
+
+### 表级锁和行级锁了解吗?有什么区别?
+
+MyISAM 仅仅支持表级锁(table-level locking),一锁就锁整张表,这在并发写的情况下性非常差。InnoDB 不光支持表级锁(table-level locking),还支持行级锁(row-level locking),默认为行级锁。
+
+行级锁的粒度更小,仅对相关的记录上锁即可(对一行或者多行记录加锁),所以对于并发写入操作来说, InnoDB 的性能更高。
+
+**表级锁和行级锁对比**:
+
+- **表级锁:** MySQL 中锁定粒度最大的一种锁(全局锁除外),是针对非索引字段加的锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。不过,触发锁冲突的概率最高,高并发下效率极低。表级锁和存储引擎无关,MyISAM 和 InnoDB 引擎都支持表级锁。
+- **行级锁:** MySQL 中锁定粒度最小的一种锁,是 **针对索引字段加的锁** ,只针对当前操作的行记录进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。行级锁和存储引擎有关,是在存储引擎层面实现的。
+
+### 行级锁的使用有什么注意事项?
+
+InnoDB 的行锁是针对索引字段加的锁,表级锁是针对非索引字段加的锁。当我们执行 `UPDATE`、`DELETE` 语句时,如果 `WHERE`条件中字段没有命中唯一索引或者索引失效的话,就会导致扫描全表对表中的所有行记录进行加锁。这个在我们日常工作开发中经常会遇到,一定要多多注意!!!
+
+不过,很多时候即使用了索引也有可能会走全表扫描,这是因为 MySQL 优化器的原因。
+
+### InnoDB 有哪几类行锁?
+
+InnoDB 行锁是通过对索引数据页上的记录加锁实现的,MySQL InnoDB 支持三种行锁定方式:
+
+- **记录锁(Record Lock)**:属于单个行记录上的锁。
+- **间隙锁(Gap Lock)**:锁定一个范围,不包括记录本身。
+- **临键锁(Next-Key Lock)**:Record Lock+Gap Lock,锁定一个范围,包含记录本身,主要目的是为了解决幻读问题(MySQL 事务部分提到过)。记录锁只能锁住已经存在的记录,为了避免插入新记录,需要依赖间隙锁。
+
+**在 InnoDB 默认的隔离级别 REPEATABLE-READ 下,行锁默认使用的是 Next-Key Lock。但是,如果操作的索引是唯一索引或主键,InnoDB 会对 Next-Key Lock 进行优化,将其降级为 Record Lock,即仅锁住索引本身,而不是范围。**
+
+### 共享锁和排他锁呢?
+
+不论是表级锁还是行级锁,都存在共享锁(Share Lock,S 锁)和排他锁(Exclusive Lock,X 锁)这两类:
+
+- **共享锁(S 锁)**:又称读锁,事务在读取记录的时候获取共享锁,允许多个事务同时获取(锁兼容)。
+- **排他锁(X 锁)**:又称写锁/独占锁,事务在修改记录的时候获取排他锁,不允许多个事务同时获取。如果一个记录已经被加了排他锁,那其他事务不能再对这条事务加任何类型的锁(锁不兼容)。
+
+排他锁与任何的锁都不兼容,共享锁仅和共享锁兼容。
+
+| | S 锁 | X 锁 |
+| :--- | :----- | :--- |
+| S 锁 | 不冲突 | 冲突 |
+| X 锁 | 冲突 | 冲突 |
+
+由于 MVCC 的存在,对于一般的 `SELECT` 语句,InnoDB 不会加任何锁。不过, 你可以通过以下语句显式加共享锁或排他锁。
+
+```sql
+# 共享锁 可以在 MySQL 5.7 和 MySQL 8.0 中使用
+SELECT ... LOCK IN SHARE MODE;
+# 共享锁 可以在 MySQL 8.0 中使用
+SELECT ... FOR SHARE;
+# 排他锁
+SELECT ... FOR UPDATE;
+```
+
+### 意向锁有什么作用?
+
+如果需要用到表锁的话,如何判断表中的记录没有行锁呢,一行一行遍历肯定是不行,性能太差。我们需要用到一个叫做意向锁的东东来快速判断是否可以对某个表使用表锁。
+
+意向锁是表级锁,共有两种:
+
+- **意向共享锁(Intention Shared Lock,IS 锁)**:事务有意向对表中的某些记录加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
+- **意向排他锁(Intention Exclusive Lock,IX 锁)**:事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
+
+**意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InnoDB 会先获取该数据行所在在数据表的对应意向锁。**
+
+意向锁之间是互相兼容的。
+
+| | IS 锁 | IX 锁 |
+| ----- | ----- | ----- |
+| IS 锁 | 兼容 | 兼容 |
+| IX 锁 | 兼容 | 兼容 |
+
+意向锁和共享锁和排它锁互斥(这里指的是表级别的共享锁和排他锁,意向锁不会与行级的共享锁和排他锁互斥)。
+
+| | IS 锁 | IX 锁 |
+| ---- | ----- | ----- |
+| S 锁 | 兼容 | 互斥 |
+| X 锁 | 互斥 | 互斥 |
+
+《MySQL 技术内幕 InnoDB 存储引擎》这本书对应的描述应该是笔误了。
+
+
+
+### 当前读和快照读有什么区别?
+
+**快照读**(一致性非锁定读)就是单纯的 `SELECT` 语句,但不包括下面这两类 `SELECT` 语句:
+
+```sql
+SELECT ... FOR UPDATE
+# 共享锁 可以在 MySQL 5.7 和 MySQL 8.0 中使用
+SELECT ... LOCK IN SHARE MODE;
+# 共享锁 可以在 MySQL 8.0 中使用
+SELECT ... FOR SHARE;
+```
+
+快照即记录的历史版本,每行记录可能存在多个历史版本(多版本技术)。
+
+快照读的情况下,如果读取的记录正在执行 UPDATE/DELETE 操作,读取操作不会因此去等待记录上 X 锁的释放,而是会去读取行的一个快照。
+
+只有在事务隔离级别 RC(读取已提交) 和 RR(可重读)下,InnoDB 才会使用一致性非锁定读:
+
+- 在 RC 级别下,对于快照数据,一致性非锁定读总是读取被锁定行的最新一份快照数据。
+- 在 RR 级别下,对于快照数据,一致性非锁定读总是读取本事务开始时的行数据版本。
+
+快照读比较适合对于数据一致性要求不是特别高且追求极致性能的业务场景。
+
+**当前读** (一致性锁定读)就是给行记录加 X 锁或 S 锁。
+
+当前读的一些常见 SQL 语句类型如下:
+
+```sql
+# 对读的记录加一个X锁
+SELECT...FOR UPDATE
+# 对读的记录加一个S锁
+SELECT...LOCK IN SHARE MODE
+# 对读的记录加一个S锁
+SELECT...FOR SHARE
+# 对修改的记录加一个X锁
+INSERT...
+UPDATE...
+DELETE...
+```
+
+### 自增锁有了解吗?
+
+> 不太重要的一个知识点,简单了解即可。
+
+关系型数据库设计表的时候,通常会有一列作为自增主键。InnoDB 中的自增主键会涉及一种比较特殊的表级锁— **自增锁(AUTO-INC Locks)** 。
+
+```sql
+CREATE TABLE `sequence_id` (
+ `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT,
+ `stub` CHAR(10) NOT NULL DEFAULT '',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `stub` (`stub`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+更准确点来说,不仅仅是自增主键,`AUTO_INCREMENT`的列都会涉及到自增锁,毕竟非主键也可以设置自增长。
+
+如果一个事务正在插入数据到有自增列的表时,会先获取自增锁,拿不到就可能会被阻塞住。这里的阻塞行为只是自增锁行为的其中一种,可以理解为自增锁就是一个接口,其具体的实现有多种。具体的配置项为 `innodb_autoinc_lock_mode` (MySQL 5.1.22 引入),可以选择的值如下:
+
+| innodb_autoinc_lock_mode | 介绍 |
+| :----------------------- | :----------------------------- |
+| 0 | 传统模式 |
+| 1 | 连续模式(MySQL 8.0 之前默认) |
+| 2 | 交错模式(MySQL 8.0 之后默认) |
+
+交错模式下,所有的“INSERT-LIKE”语句(所有的插入语句,包括:`INSERT`、`REPLACE`、`INSERT…SELECT`、`REPLACE…SELECT`、`LOAD DATA`等)都不使用表级锁,使用的是轻量级互斥锁实现,多条插入语句可以并发执行,速度更快,扩展性也更好。
+
+不过,如果你的 MySQL 数据库有主从同步需求并且 Binlog 存储格式为 Statement 的话,不要将 InnoDB 自增锁模式设置为交叉模式,不然会有数据不一致性问题。这是因为并发情况下插入语句的执行顺序就无法得到保障。
+
+> 如果 MySQL 采用的格式为 Statement ,那么 MySQL 的主从同步实际上同步的就是一条一条的 SQL 语句。
+
+最后,再推荐一篇文章:[为什么 MySQL 的自增主键不单调也不连续](https://draveness.me/whys-the-design-mysql-auto-increment/) 。
+
+## ⭐️MySQL 性能优化
+
+关于 MySQL 性能优化的建议总结,请看这篇文章:[MySQL 高性能优化规范建议总结](./mysql-high-performance-optimization-specification-recommendations.md) 。
+
+### 能用 MySQL 直接存储文件(比如图片)吗?
+
+可以是可以,直接存储文件对应的二进制数据即可。不过,还是建议不要在数据库中存储文件,会严重影响数据库性能,消耗过多存储空间。
+
+可以选择使用云服务厂商提供的开箱即用的文件存储服务,成熟稳定,价格也比较低。
+
+
+
+也可以选择自建文件存储服务,实现起来也不难,基于 FastDFS、MinIO(推荐) 等开源项目就可以实现分布式文件服务。
+
+**数据库只存储文件地址信息,文件由文件存储服务负责存储。**
+
+### MySQL 如何存储 IP 地址?
+
+可以将 IP 地址转换成整形数据存储,性能更好,占用空间也更小。
+
+MySQL 提供了两个方法来处理 ip 地址
+
+- `INET_ATON()`:把 ip 转为无符号整型 (4-8 位)
+- `INET_NTOA()` :把整型的 ip 转为地址
+
+插入数据前,先用 `INET_ATON()` 把 ip 地址转为整型,显示数据时,使用 `INET_NTOA()` 把整型的 ip 地址转为地址显示即可。
+
+### 有哪些常见的 SQL 优化手段?
+
+[《Java 面试指北》(付费)](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的 **「技术面试题篇」** 有一篇文章详细介绍了常见的 SQL 优化手段,非常全面,清晰易懂!
+
+
+
+文章地址:https://www.yuque.com/snailclimb/mf2z3k/abc2sv (密码获取:)。
+
+### 如何分析 SQL 的性能?
+
+我们可以使用 `EXPLAIN` 命令来分析 SQL 的 **执行计划** 。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
+
+`EXPLAIN` 并不会真的去执行相关的语句,而是通过 **查询优化器** 对语句进行分析,找出最优的查询方案,并显示对应的信息。
+
+`EXPLAIN` 适用于 `SELECT`, `DELETE`, `INSERT`, `REPLACE`, 和 `UPDATE`语句,我们一般分析 `SELECT` 查询较多。
+
+我们这里简单来演示一下 `EXPLAIN` 的使用。
+
+`EXPLAIN` 的输出格式如下:
+
+```sql
+mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
++----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
+1 row in set, 1 warning (0.00 sec)
+```
+
+各个字段的含义如下:
+
+| **列名** | **含义** |
+| ------------- | -------------------------------------------- |
+| id | SELECT 查询的序列标识符 |
+| select_type | SELECT 关键字对应的查询类型 |
+| table | 用到的表名 |
+| partitions | 匹配的分区,对于未分区的表,值为 NULL |
+| type | 表的访问方法 |
+| possible_keys | 可能用到的索引 |
+| key | 实际用到的索引 |
+| key_len | 所选索引的长度 |
+| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
+| rows | 预计要读取的行数 |
+| filtered | 按表条件过滤后,留存的记录数的百分比 |
+| Extra | 附加信息 |
+
+篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](./mysql-query-execution-plan.md)这篇文章。
+
+### 读写分离和分库分表了解吗?
+
+读写分离和分库分表相关的问题比较多,于是,我单独写了一篇文章来介绍:[读写分离和分库分表详解](../../high-performance/read-and-write-separation-and-library-subtable.md)。
+
+### 深度分页如何优化?
+
+[深度分页介绍及优化建议](../../high-performance/deep-pagination-optimization.md)
+
+### 数据冷热分离如何做?
+
+[数据冷热分离详解](../../high-performance/data-cold-hot-separation.md)
+
+### MySQL 性能怎么优化?
+
+MySQL 性能优化是一个系统性工程,涉及多个方面,在面试中不可能面面俱到。因此,建议按照“点-线-面”的思路展开,从核心问题入手,再逐步扩展,展示出你对问题的思考深度和解决能力。
+
+**1. 抓住核心:慢 SQL 定位与分析**
+
+性能优化的第一步永远是找到瓶颈。面试时,建议先从 **慢 SQL 定位和分析** 入手,这不仅能展示你解决问题的思路,还能体现你对数据库性能监控的熟练掌握:
+
+- **监控工具:** 介绍常用的慢 SQL 监控工具,如 **MySQL 慢查询日志**、**Performance Schema** 等,说明你对这些工具的熟悉程度以及如何通过它们定位问题。
+- **EXPLAIN 命令:** 详细说明 `EXPLAIN` 命令的使用,分析查询计划、索引使用情况,可以结合实际案例展示如何解读分析结果,比如执行顺序、索引使用情况、全表扫描等。
+
+**2. 由点及面:索引、表结构和 SQL 优化**
+
+定位到慢 SQL 后,接下来就要针对具体问题进行优化。 这里可以重点介绍索引、表结构和 SQL 编写规范等方面的优化技巧:
+
+- **索引优化:** 这是 MySQL 性能优化的重点,可以介绍索引的创建原则、覆盖索引、最左前缀匹配原则等。如果能结合你项目的实际应用来说明如何选择合适的索引,会更加分一些。
+- **表结构优化:** 优化表结构设计,包括选择合适的字段类型、避免冗余字段、合理使用范式和反范式设计等等。
+- **SQL 优化:** 避免使用 `SELECT *`、尽量使用具体字段、使用连接查询代替子查询、合理使用分页查询、批量操作等,都是 SQL 编写过程中需要注意的细节。
+
+**3. 进阶方案:架构优化**
+
+当面试官对基础优化知识比较满意时,可能会深入探讨一些架构层面的优化方案。以下是一些常见的架构优化策略:
+
+- **读写分离:** 将读操作和写操作分离到不同的数据库实例,提升数据库的并发处理能力。
+- **分库分表:** 将数据分散到多个数据库实例或数据表中,降低单表数据量,提升查询效率。但要权衡其带来的复杂性和维护成本,谨慎使用。
+- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在低成本、低性能的介质中,热数据存储在高性能存储介质中。
+- **缓存机制:** 使用 Redis 等缓存中间件,将热点数据缓存到内存中,减轻数据库压力。这个非常常用,提升效果非常明显,性价比极高!
+
+**4. 其他优化手段**
+
+除了慢 SQL 定位、索引优化和架构优化,还可以提及一些其他优化手段,展示你对 MySQL 性能调优的全面理解:
+
+- **连接池配置:** 配置合理的数据库连接池(如 **连接池大小**、**超时时间** 等),能够有效提升数据库连接的效率,避免频繁的连接开销。
+- **硬件配置:** 提升硬件性能也是优化的重要手段之一。使用高性能服务器、增加内存、使用 **SSD** 硬盘等硬件升级,都可以有效提升数据库的整体性能。
+
+**5.总结**
+
+在面试中,建议按优先级依次介绍慢 SQL 定位、[索引优化](./mysql-index.md)、表结构设计和 [SQL 优化](../../high-performance/sql-optimization.md)等内容。架构层面的优化,如[读写分离和分库分表](../../high-performance/read-and-write-separation-and-library-subtable.md)、[数据冷热分离](../../high-performance/data-cold-hot-separation.md) 应作为最后的手段,除非在特定场景下有明显的性能瓶颈,否则不应轻易使用,因其引入的复杂性会带来额外的维护成本。
+
+## MySQL 学习资料推荐
+
+[**书籍推荐**](../../books/database.md#mysql) 。
+
+**文章推荐** :
+
+- [一树一溪的 MySQL 系列教程](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=Mzg3NTc3NjM4Nw==&action=getalbum&album_id=2372043523518300162&scene=173&from_msgid=2247484308&from_itemidx=1&count=3&nolastread=1#wechat_redirect)
+- [Yes 的 MySQL 系列教程](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzkxNTE3NjQ3MA==&action=getalbum&album_id=1903249596194095112&scene=173&from_msgid=2247490365&from_itemidx=1&count=3&nolastread=1#wechat_redirect)
+- [写完这篇 我的 SQL 优化能力直接进入新层次 - 变成派大星 - 2022](https://juejin.cn/post/7161964571853815822)
+- [两万字详解!InnoDB 锁专题! - 捡田螺的小男孩 - 2022](https://juejin.cn/post/7094049650428084232)
+- [MySQL 的自增主键一定是连续的吗? - 飞天小牛肉 - 2022](https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ)
+- [深入理解 MySQL 索引底层原理 - 腾讯技术工程 - 2020](https://zhuanlan.zhihu.com/p/113917726)
+
+## 参考
+
+- 《高性能 MySQL》第 7 章 MySQL 高级特性
+- 《MySQL 技术内幕 InnoDB 存储引擎》第 6 章 锁
+- Relational Database:
+- 一篇文章看懂 mysql 中 varchar 能存多少汉字、数字,以及 varchar(100)和 varchar(10)的区别:
+- Technology sharing | Isolation level: Correct understanding of phantom reading:
+- MySQL Server Logs - MySQL 5.7 Reference Manual:
+- Redo Log - MySQL 5.7 Reference Manual:
+- Locking Reads - MySQL 5.7 Reference Manual:
+- In-depth understanding of database row locks and table locks
+- Detailed explanation of the role of intention locks in MySQL InnoDB:
+- In-depth analysis of MySQL self-increasing lock:
+- How should non-repeatable reads and phantom reads be distinguished in the database? :
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/some-thoughts-on-database-storage-time.en.md b/docs_en/database/mysql/some-thoughts-on-database-storage-time.en.md
new file mode 100644
index 00000000000..b748f03a788
--- /dev/null
+++ b/docs_en/database/mysql/some-thoughts-on-database-storage-time.en.md
@@ -0,0 +1,201 @@
+---
+title: MySQL日期类型选择建议
+category: 数据库
+tag:
+ - MySQL
+head:
+ - - meta
+ - name: keywords
+ content: MySQL 日期类型选择, MySQL 时间存储最佳实践, MySQL 时间存储效率, MySQL DATETIME 和 TIMESTAMP 区别, MySQL 时间戳存储, MySQL 数据库时间存储类型, MySQL 开发日期推荐, MySQL 字符串存储日期的缺点, MySQL 时区设置方法, MySQL 日期范围对比, 高性能 MySQL 日期存储, MySQL UNIX_TIMESTAMP 用法, 数值型时间戳优缺点, MySQL 时间存储性能优化, MySQL TIMESTAMP 时区转换, MySQL 时间格式转换, MySQL 时间存储空间对比, MySQL 时间类型选择建议, MySQL 日期类型性能分析, 数据库时间存储优化
+---
+
+在日常的软件开发工作中,存储时间是一项基础且常见的需求。无论是记录数据的操作时间、金融交易的发生时间,还是行程的出发时间、用户的下单时间等等,时间信息与我们的业务逻辑和系统功能紧密相关。因此,正确选择和使用 MySQL 的日期时间类型至关重要,其恰当与否甚至可能对业务的准确性和系统的稳定性产生显著影响。
+
+本文旨在帮助开发者重新审视并深入理解 MySQL 中不同的时间存储方式,以便做出更合适项目业务场景的选择。
+
+## 不要用字符串存储日期
+
+和许多数据库初学者一样,笔者在早期学习阶段也曾尝试使用字符串(如 VARCHAR)类型来存储日期和时间,甚至一度认为这是一种简单直观的方法。毕竟,'YYYY-MM-DD HH:MM:SS' 这样的格式看起来清晰易懂。
+
+但是,这是不正确的做法,主要会有下面两个问题:
+
+1. **空间效率**:与 MySQL 内建的日期时间类型相比,字符串通常需要占用更多的存储空间来表示相同的时间信息。
+2. **查询与计算效率低下**:
+ - **比较操作复杂且低效**:基于字符串的日期比较需要按照字典序逐字符进行,这不仅不直观(例如,'2024-05-01' 会小于 '2024-1-10'),而且效率远低于使用原生日期时间类型进行的数值或时间点比较。
+ - **计算功能受限**:无法直接利用数据库提供的丰富日期时间函数进行运算(例如,计算两个日期之间的间隔、对日期进行加减操作等),需要先转换格式,增加了复杂性。
+ - **索引性能不佳**:基于字符串的索引在处理范围查询(如查找特定时间段内的数据)时,其效率和灵活性通常不如原生日期时间类型的索引。
+
+## DATETIME 和 TIMESTAMP 选择
+
+`DATETIME` 和 `TIMESTAMP` 是 MySQL 中两种非常常用的、用于存储包含日期和时间信息的数据类型。它们都可以存储精确到秒(MySQL 5.6.4+ 支持更高精度的小数秒)的时间值。那么,在实际应用中,我们应该如何在这两者之间做出选择呢?
+
+下面我们从几个关键维度对它们进行对比:
+
+### 时区信息
+
+`DATETIME` 类型存储的是**字面量的日期和时间值**,它本身**不包含任何时区信息**。当你插入一个 `DATETIME` 值时,MySQL 存储的就是你提供的那个确切的时间,不会进行任何时区转换。
+
+**这样就会有什么问题呢?** 如果你的应用需要支持多个时区,或者服务器、客户端的时区可能发生变化,那么使用 `DATETIME` 时,应用程序需要自行处理时区的转换和解释。如果处理不当(例如,假设所有存储的时间都属于同一个时区,但实际环境变化了),可能会导致时间显示或计算上的混乱。
+
+**`TIMESTAMP` 和时区有关**。存储时,MySQL 会将当前会话时区下的时间值转换成 UTC(协调世界时)进行内部存储。当查询 `TIMESTAMP` 字段时,MySQL 又会将存储的 UTC 时间转换回当前会话所设置的时区来显示。
+
+这意味着,对于同一条记录的 `TIMESTAMP` 字段,在不同的会话时区设置下查询,可能会看到不同的本地时间表示,但它们都对应着同一个绝对时间点(UTC 时间)。这对于需要全球化、多时区支持的应用来说非常有用。
+
+下面实际演示一下!
+
+建表 SQL 语句:
+
+```sql
+CREATE TABLE `time_zone_test` (
+ `id` bigint(20) NOT NULL AUTO_INCREMENT,
+ `date_time` datetime DEFAULT NULL,
+ `time_stamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8;
+```
+
+插入一条数据(假设当前会话时区为系统默认,例如 UTC+0)::
+
+```sql
+INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
+```
+
+查询数据(在同一时区会话下):
+
+```sql
+SELECT date_time, time_stamp FROM time_zone_test;
+```
+
+结果:
+
+```plain
++---------------------+---------------------+
+| date_time | time_stamp |
++---------------------+---------------------+
+| 2020-01-11 09:53:32 | 2020-01-11 09:53:32 |
++---------------------+---------------------+
+```
+
+现在,修改当前会话的时区为东八区 (UTC+8):
+
+```sql
+SET time_zone = '+8:00';
+```
+
+再次查询数据:
+
+```bash
+# TIMESTAMP 的值自动转换为 UTC+8 时间
++---------------------+---------------------+
+| date_time | time_stamp |
++---------------------+---------------------+
+| 2020-01-11 09:53:32 | 2020-01-11 17:53:32 |
++---------------------+---------------------+
+```
+
+**扩展:MySQL 时区设置常用 SQL 命令**
+
+```sql
+# 查看当前会话时区
+SELECT @@session.time_zone;
+# 设置当前会话时区
+SET time_zone = 'Europe/Helsinki';
+SET time_zone = "+00:00";
+# 数据库全局时区设置
+SELECT @@global.time_zone;
+# 设置全局时区
+SET GLOBAL time_zone = '+8:00';
+SET GLOBAL time_zone = 'Europe/Helsinki';
+```
+
+### 占用空间
+
+下图是 MySQL 日期类型所占的存储空间(官方文档传送门:):
+
+
+
+在 MySQL 5.6.4 之前,DateTime 和 TIMESTAMP 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 5~8 字节,TIMESTAMP 的范围是 4~7 字节。
+
+### 表示范围
+
+`TIMESTAMP` 表示的时间范围更小,只能到 2038 年:
+
+- `DATETIME`:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'
+- `TIMESTAMP`:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
+
+### 性能
+
+由于 `TIMESTAMP` 在存储和检索时需要进行 UTC 与当前会话时区的转换,这个过程可能涉及到额外的计算开销,尤其是在需要调用操作系统底层接口获取或处理时区信息时。虽然现代数据库和操作系统对此进行了优化,但在某些极端高并发或对延迟极其敏感的场景下,`DATETIME` 因其不涉及时区转换,处理逻辑相对更简单直接,可能会表现出微弱的性能优势。
+
+In order to obtain predictable behavior and possibly reduce the conversion overhead of `TIMESTAMP`, it is recommended to manage time zones uniformly at the application level, or to explicitly set the `time_zone` parameter at the database connection/session level, rather than relying on the server's default or operating system time zone.
+
+## Are numeric timestamps a better choice?
+
+In addition to the above two types, integer types (`INT` or `BIGINT`) are also commonly used in practice to store the so-called "Unix timestamp" (that is, the total number of seconds, or milliseconds, from January 1, 1970 00:00:00 UTC to the target time).
+
+This storage method has some advantages of the `TIMESTAMP` type, and using it to perform date sorting and comparison operations will be more efficient, and it is also very convenient across systems. After all, it is just a stored value. The disadvantage is also obvious, that is, the readability of the data is too poor, and you cannot intuitively see the specific time.
+
+The timestamp is defined as follows:
+
+> The definition of timestamp is to count from a base time. This base time is "1970-1-1 00:00:00 +0:00". Starting from this time, it is expressed as an integer and measured in seconds. As time goes by, this time integer continues to increase. In this way, I only need one value to perfectly represent time, and this value is an absolute value, that is, no matter where you are in any corner of the earth, the timestamp representing time is the same, and the generated value is the same, and there is no concept of time zone. Therefore, no additional conversion is required during the time transmission in the system. It is converted to local time in string format only when displayed to the user.
+
+Actual operations in the database:
+
+```sql
+-- Convert datetime string to Unix timestamp (seconds)
+mysql> SELECT UNIX_TIMESTAMP('2020-01-11 09:53:32');
++---------------------------------------------+
+| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
++---------------------------------------------+
+| 1578707612 |
++---------------------------------------------+
+1 row in set (0.00 sec)
+
+-- Convert Unix timestamp (seconds) to datetime format
+mysql> SELECT FROM_UNIXTIME(1578707612);
++--------------------------+
+| FROM_UNIXTIME(1578707612) |
++--------------------------+
+| 2020-01-11 09:53:32 |
++--------------------------+
+1 row in set (0.01 sec)
+```
+
+## There is no DATETIME in PostgreSQL
+
+Since some readers mentioned the time type of PostgreSQL (PG), I will expand and add it here. The PG official document describes the time type at: .
+
+
+
+As you can see, PG does not have a type named `DATETIME`:
+
+- PG's `TIMESTAMP WITHOUT TIME ZONE` is functionally closest to MySQL's `DATETIME`. It stores the date and time, but does not contain any time zone information and stores literal values.
+- PG's `TIMESTAMP WITH TIME ZONE` (or `TIMESTAMPTZ`) is equivalent to MySQL's `TIMESTAMP`. It converts the input value to UTC when stored and converted based on the current session's time zone when retrieved for display.
+
+For most application scenarios that require recording precise time points, `TIMESTAMPTZ` is the most recommended and robust choice in PostgreSQL because it can best handle time zone complexities.
+
+## Summary
+
+How to store time in MySQL? `DATETIME`? `TIMESTAMP`? Or a numerical timestamp?
+
+There is no silver bullet. Many programmers think that numeric timestamps are really good, efficient and compatible. However, many people think that it is not intuitive enough.
+
+The author of the magic book "High-Performance MySQL" recommends TIMESTAMP because numerical representation of time is not intuitive enough. The following is the original text:
+
+ +
+Each method has its own advantages, and the best way to choose is based on the actual scenario. Let's make a simple comparison of these three methods to help you choose the correct data type for storing time in actual development:
+
+| Type | Storage space | Date format | Date range | Whether to include time zone information |
+| -------------------------- | -------- | ----------------------------- | --------------------------------------------------------------- | ------------- |
+| DATETIME | 5~8 bytes | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | No |
+| TIMESTAMP | 4~7 bytes | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | Yes |
+| Numeric timestamp | 4 bytes | Full number such as 1578707612 | Time after 1970-01-01 00:00:01 | No |
+
+**Summary of selection suggestions:**
+
+- The core strength of `TIMESTAMP` is its built-in time zone handling capabilities. The database takes care of UTC storage and automatic conversion based on the session time zone, simplifying the development of applications that need to handle multiple time zones. If your application needs to handle multiple time zones, or you want the database to automatically manage time zone conversions, `TIMESTAMP` is a natural choice (note its time range limit, aka the 2038 problem).
+- If the application scenario does not involve time zone conversion, or you want the application to have full control over the time zone logic, and need to represent time after 2038, `DATETIME` is a safer choice.
+- Numeric timestamps are a powerful option if comparison performance is of paramount concern, or if time data needs to be passed frequently across systems and the sacrifice of readability (or always conversion at the application layer) is acceptable.
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/transaction-isolation-level.en.md b/docs_en/database/mysql/transaction-isolation-level.en.md
new file mode 100644
index 00000000000..e0dce97f95d
--- /dev/null
+++ b/docs_en/database/mysql/transaction-isolation-level.en.md
@@ -0,0 +1,123 @@
+---
+title: Detailed explanation of MySQL transaction isolation level
+category: database
+tag:
+ -MySQL
+head:
+ - - meta
+ - name: keywords
+ content: transaction, isolation level, read uncommitted, read committed, repeatable read, serializable, MVCC, lock
+ - - meta
+ - name: description
+ Content: Sort out the four major transaction isolation levels and concurrency phenomena, combine InnoDB's MVCC and lock mechanism, and clarify the response strategy for phantom reads/non-repeatable reads.
+---
+
+> This article was jointly written by [SnailClimb](https://github.com/Snailclimb) and [guang19](https://github.com/guang19).
+
+For an introduction to the basic overview of transactions, please read the introduction of this article: [MySQL common knowledge points & summary of interview questions] (./mysql-questions-01.md#MySQL-Transactions)
+
+## Transaction isolation level summary
+
+The SQL standard defines four transaction isolation levels to balance transaction isolation and concurrency performance. The higher the level, the better the data consistency, but the concurrency performance may be lower. The four levels are:
+
+- **READ-UNCOMMITTED (read uncommitted)**: The lowest isolation level, allowing reading of uncommitted data changes, which may lead to dirty reads, phantom reads, or non-repeatable reads. This level is rarely used in practical applications because its guarantee of data consistency is too weak.
+- **READ-COMMITTED (read committed)**: Allows reading of data that has been committed by concurrent transactions, which can prevent dirty reads, but phantom reads or non-repeatable reads may still occur. This is the default isolation level for most databases (such as Oracle, SQL Server).
+- **REPEATABLE-READ (repeatable read)**: The results of multiple reads of the same field are consistent, unless the data is modified by the own transaction itself. Dirty reads and non-repeatable reads can be prevented, but phantom reads may still occur. The default isolation level of the MySQL InnoDB storage engine is REPEATABLE READ. Moreover, InnoDB solves the phantom read problem to a large extent through the MVCC (Multi-version Concurrency Control) and Next-Key Locks (gap lock + row lock) mechanisms at this level.
+- **SERIALIZABLE**: The highest isolation level, fully compliant with ACID isolation level. All transactions are executed one after another in order, so that there is no possibility of interference between transactions. In other words, this level can prevent dirty reads, non-repeatable reads and phantom reads.
+
+| Isolation level | Dirty Read | Non-Repeatable Read | Phantom Read |
+|---------------- | ------------------ | ---------------------------------- | ----------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (Standard) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
+
+**Default level query:**
+
+The default isolation level for the MySQL InnoDB storage engine is **REPEATABLE READ**. You can view it with the following command:
+
+- Before MySQL 8.0: `SELECT @@tx_isolation;`
+- MySQL 8.0 and later: `SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++------------------------+
+| @@transaction_isolation |
++------------------------+
+| REPEATABLE-READ |
++------------------------+
+```
+
+**InnoDB's REPEATABLE READ handles phantom reads:**
+
+In the standard SQL isolation level definition, REPEATABLE READ cannot prevent phantom reads. However, the implementation of InnoDB largely avoids phantom reads through the following mechanisms:
+
+- **Snapshot Read**: Ordinary SELECT statement, implemented through the **MVCC** mechanism. A data snapshot is created when a transaction starts, and subsequent snapshot reads read this version of the data, thereby avoiding seeing newly inserted rows (phantom reads) or modified rows (non-repeatable reads) by other transactions.
+- **Current Read**: Operations like `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE`. InnoDB uses **Next-Key Lock** to lock the scanned index records and the range (gap) between them to prevent other transactions from inserting new records in this range, thereby avoiding phantom reads. Next-Key Lock is a combination of Record Lock and Gap Lock.
+
+It is worth noting that although it is generally believed that the higher the isolation level, the worse the concurrency, but the InnoDB storage engine optimizes the REPEATABLE READ level through the MVCC mechanism. For many common read-only or read-more-write-less scenarios, there may not be a significant performance difference compared to READ COMMITTED. However, in write-intensive scenarios with high concurrency conflicts, RR's gap lock mechanism may cause more lock waits than RC.
+
+In addition, in some specific scenarios, such as distributed transactions that require strict consistency (XA Transactions), InnoDB may require or recommend the use of SERIALIZABLE isolation level to ensure the consistency of global data.
+
+Chapter 7.7 of "MySQL Technology Insider: InnoDB Storage Engine (2nd Edition)" reads:
+
+> The InnoDB storage engine provides support for XA transactions and supports the implementation of distributed transactions through XA transactions. Distributed transactions refer to allowing multiple independent transactional resources to participate in a global transaction. Transactional resources are typically relational database systems, but can be other types of resources. Global transactions require all participating transactions to either commit or roll back, which improves the original ACID requirements for transactions. In addition, when using distributed transactions, the transaction isolation level of the InnoDB storage engine must be set to SERIALIZABLE.
+
+## Actual situation demonstration
+
+Below I will use two command lines MySQL to simulate the problem of dirty reading of the same data by multiple threads (multiple transactions).
+
+In the default configuration of the MySQL command line, transactions are automatically committed, that is, the COMMIT operation will be performed immediately after executing the SQL statement. If you want to explicitly start a transaction, you need to use the command: `START TRANSACTION`.
+
+We can set the isolation level with the following command.
+
+```sql
+SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
+```
+
+Let’s take a look at some of the concurrency control statements we use in the following actual operations:
+
+- `START TRANSACTION` |`BEGIN`: Explicitly start a transaction.
+- `COMMIT`: Commits the transaction, making all modifications to the database permanent.
+- `ROLLBACK`: Rollback ends the user's transaction and undoes all uncommitted modifications in progress.
+
+### Dirty read (read uncommitted)
+
+![]()
+
+### Avoid dirty reads (read committed)
+
+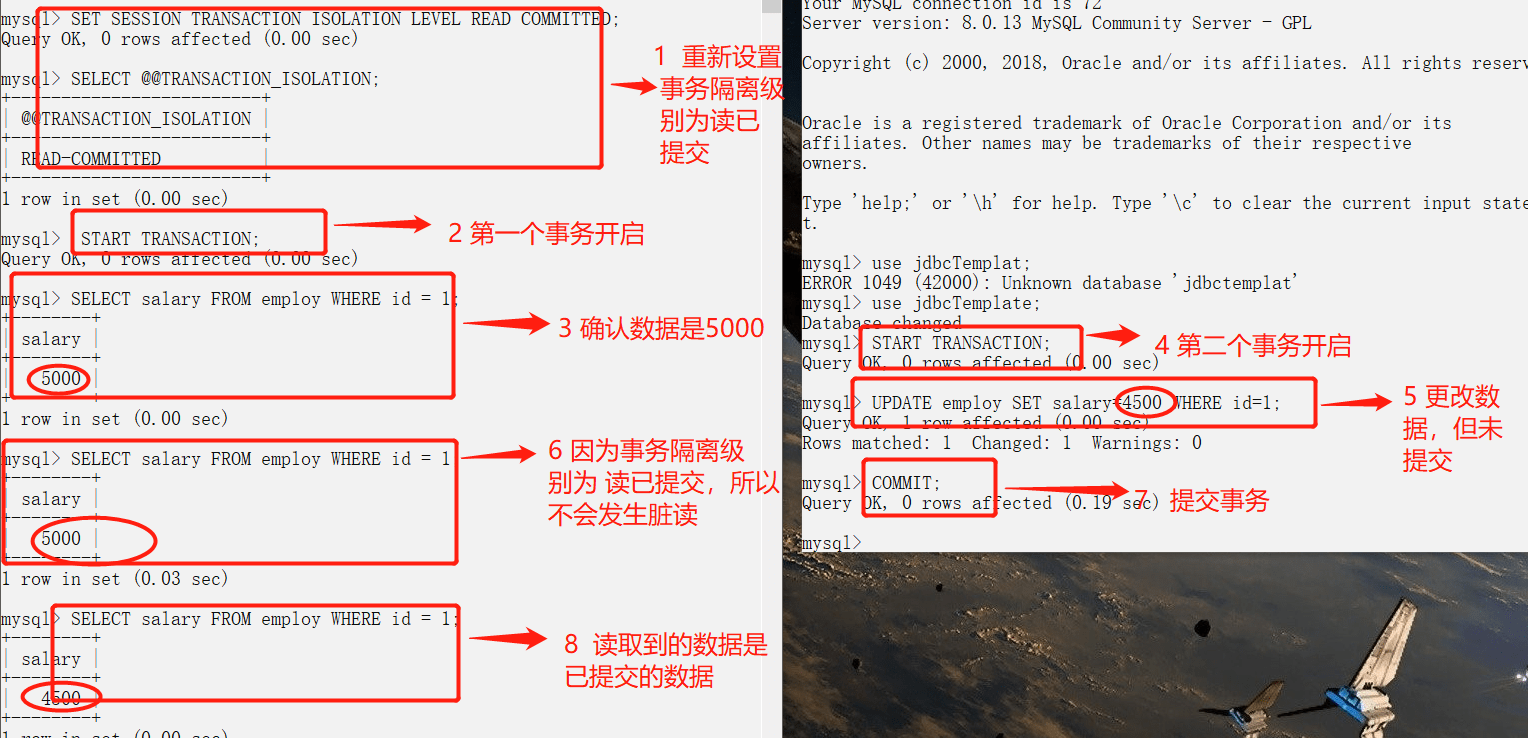
+
+### Non-repeatable read
+
+It is still the same as the read committed picture above. Although it avoids reading uncommitted, the non-repeatable read problem occurs before a transaction is completed.
+
+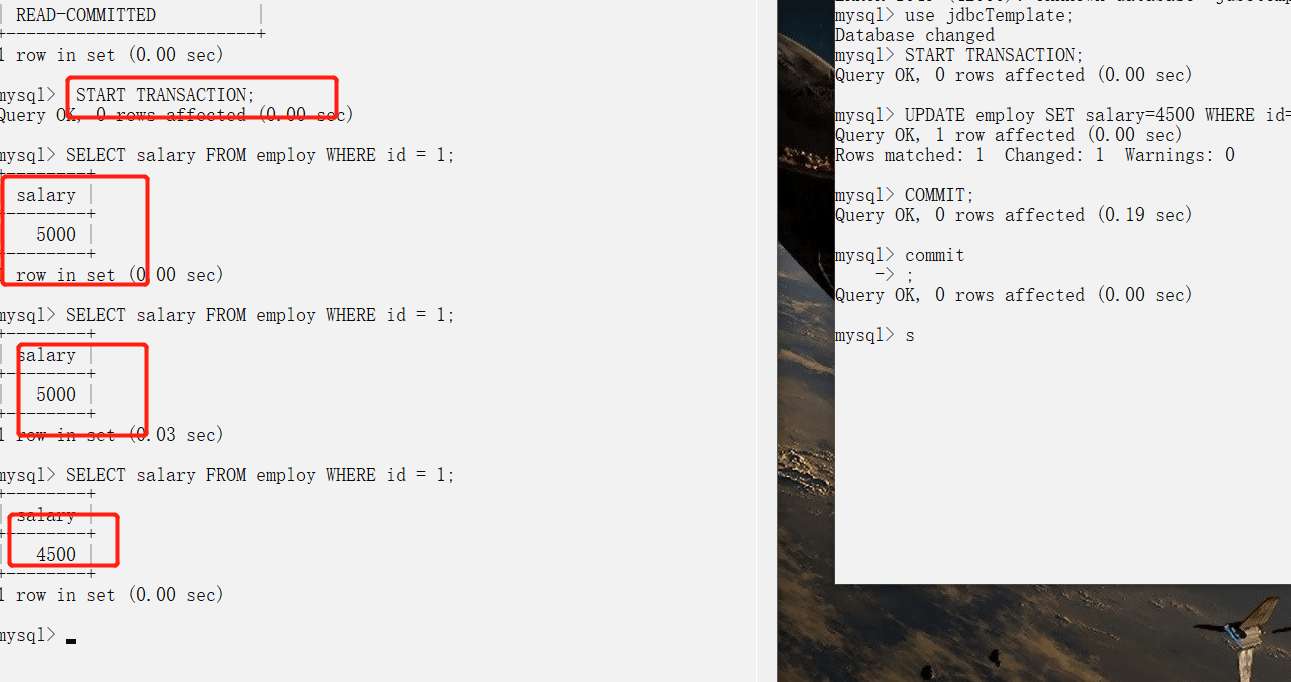
+
+### Repeatable read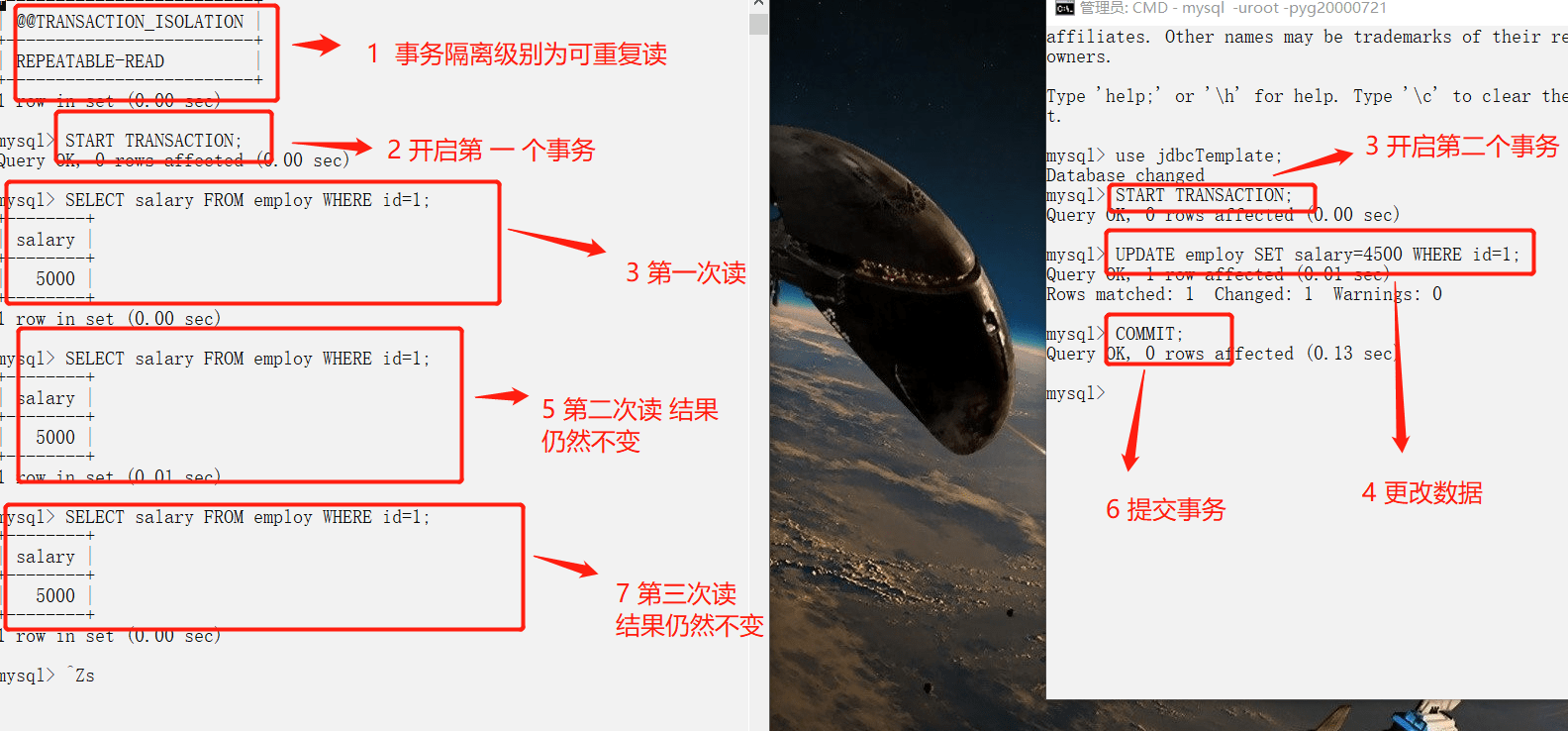
+
+### Phantom reading
+
+#### Demonstrate the occurrence of phantom reading
+
+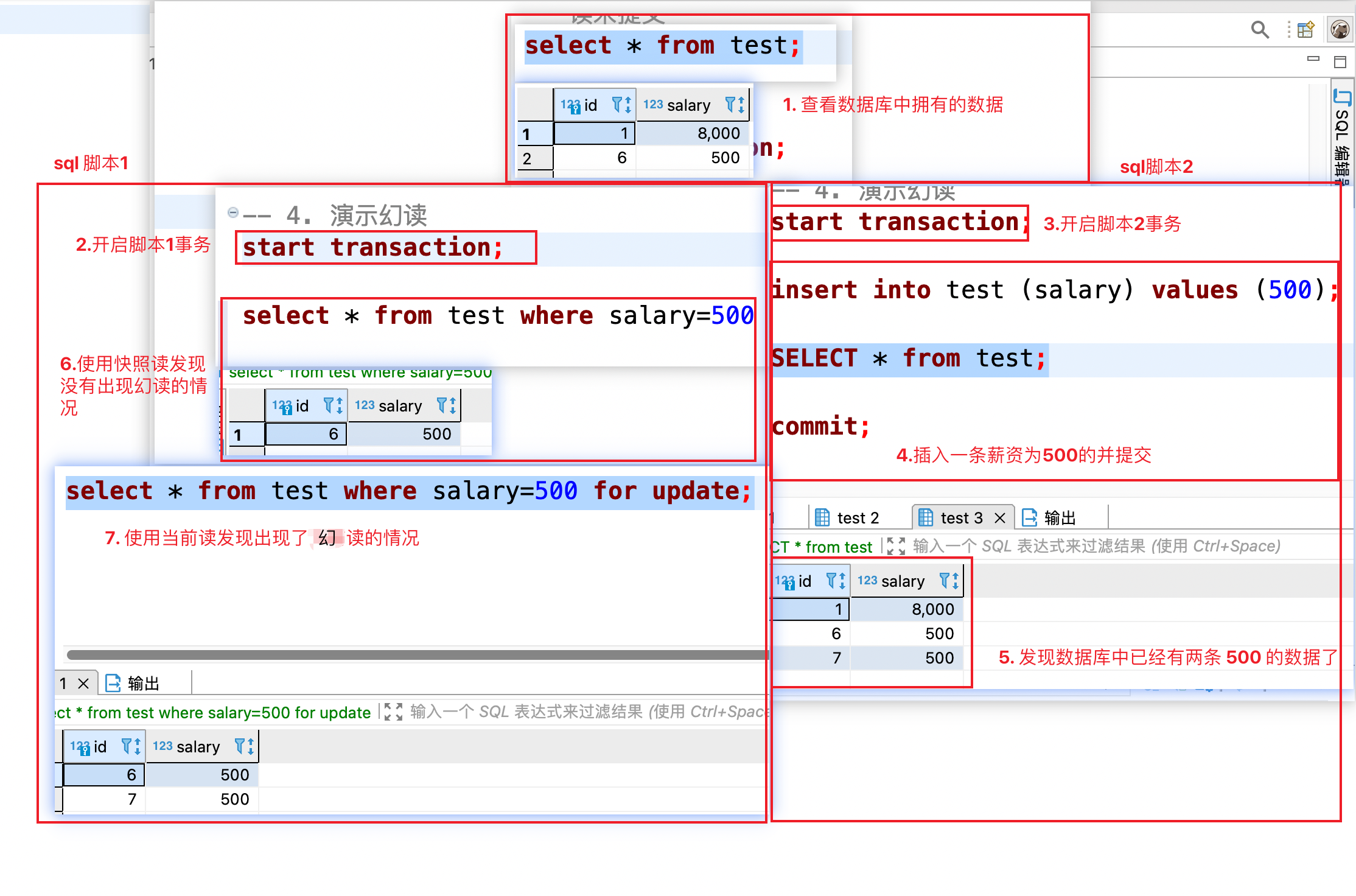
+
+When SQL Script 1 queries for the first time, there is only one record with a salary of 500. SQL Script 2 inserts a record with a salary of 500. After submission, SQL Script 1 uses the current read query again in the same transaction and finds that there are two records with a salary of 500. This is a phantom read.
+
+#### How to solve phantom reading
+
+There are many ways to solve phantom reads, but their core idea is that when one transaction is operating data in a certain table, another transaction is not allowed to add or delete data in this table. The main ways to solve phantom reading are as follows:
+
+1. Adjust the transaction isolation level to `SERIALIZABLE`.
+2. At the repeatable read transaction level, add a table lock to the table in the transaction operation.
+3. Under the transaction level of repeatable read, add `Next-key Lock (Record Lock+Gap Lock)` to the table of transaction operation.
+
+### Reference
+
+- "MySQL Technology Insider: InnoDB Storage Engine"
+-
+- [Mysql Lock: Seven Questions of the Soul](https://tech.youzan.com/seven-questions-about-the-lock-of-MySQL/)
+- [Relationship between transaction isolation level and locks in Innodb](https://tech.meituan.com/2014/08/20/innodb-lock.html)
+
+
\ No newline at end of file
diff --git a/docs_en/database/nosql.en.md b/docs_en/database/nosql.en.md
new file mode 100644
index 00000000000..5428c5d9152
--- /dev/null
+++ b/docs_en/database/nosql.en.md
@@ -0,0 +1,68 @@
+---
+title: Summary of NoSQL basic knowledge
+category: database
+tag:
+ - NoSQL
+ - MongoDB
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: NoSQL, key-value, document, column family, graph database, distributed, scalability, data model
+ - - meta
+ - name: description
+ content: Summarizes the classification and characteristics of NoSQL, compares relational databases, combines distributed and scalable scenarios, and guides model and selection.
+---
+
+## What is NoSQL?
+
+NoSQL (abbreviation for Not Only SQL) generally refers to non-relational databases, mainly targeting key-value, document and graph type data storage. Moreover, NoSQL databases inherently support features such as distribution, data redundancy and data sharding, aiming to provide scalable, highly available and high-performance data storage solutions.
+
+A common misconception is that NoSQL databases, or non-relational databases, do not store relational data well. NoSQL databases can store relational data—they store it differently than relational databases do.
+
+NoSQL database representatives: HBase, Cassandra, MongoDB, Redis.
+
+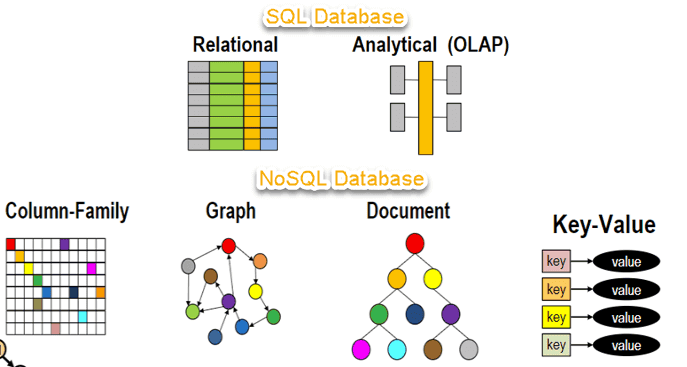
+
+## What is the difference between SQL and NoSQL?
+
+| | SQL database | NoSQL database |
+| :---------- | -------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------- |
+| Data storage model | Structured storage, tables with fixed rows and columns | Unstructured storage. Document: JSON document, Key-value: key-value pairs, Wide-column: Table with rows and dynamic columns, Graph: Nodes and Edges |
+| Development History | Developed in the 1970s with a focus on reducing data duplication | Developed in the late 2000s with a focus on improving scalability and reducing storage costs for large-scale data |
+| Examples | Oracle, MySQL, Microsoft SQL Server, PostgreSQL | Documents: MongoDB, CouchDB, Keys: Redis, DynamoDB, Wide columns: Cassandra, HBase, Charts: Neo4j, Amazon Neptune, Giraph |
+| ACID properties | Provide atomicity, consistency, isolation, and durability (ACID) properties | Generally do not support ACID transactions, trade-offs are made for scalability and high performance, and a few support such as MongoDB. However, MongoDB's support for ACID transactions is still different from MySQL. |
+| Performance | Performance often depends on the disk subsystem. For optimal performance, queries, indexes, and table structures often need to be optimized. | Performance is typically determined by the size of the underlying hardware cluster, network latency, and the calling application. |
+| Expansion | Vertical (use more powerful servers for expansion), read-write separation, database and table sharding | Horizontal (horizontal expansion by adding servers, usually based on sharding mechanism) |
+| Purpose | Data storage for common enterprise-level projects | Wide range of uses, such as graph databases that support analysis and traversal of relationships between connected data, and key-value databases that can handle large amounts of data expansion and extremely high state changes |
+| Query syntax | Structured Query Language (SQL) | Data access syntax may vary from database to database |
+
+## What are the advantages of NoSQL databases?
+
+NoSQL databases are ideal for many modern applications, such as mobile, web, and gaming applications, which require flexible, scalable, high-performance, and powerful databases to provide a superior user experience.
+
+- **Flexibility:** NoSQL databases often offer flexible architectures to enable faster, more iterative development. Flexible data models make NoSQL databases ideal for semi-structured and unstructured data.
+- **Scalability:** NoSQL databases are typically designed to scale horizontally through the use of distributed hardware clusters, rather than vertically by adding expensive and powerful servers.
+- **High Performance:** NoSQL databases are optimized for specific data models and access patterns, which allows for higher performance than trying to accomplish similar functions with relational databases.
+- **Powerful Features:** NoSQL databases provide powerful APIs and data types specifically built for their respective data models.
+
+## What types of NoSQL databases are there?
+
+NoSQL databases can be mainly divided into the following four types:
+
+- **Key-value**: A key-value database is a simpler database where each item contains a key and a value. This is an extremely flexible NoSQL database type because the application has complete control over what is stored in the value field without any restrictions. Redis and DynanoDB are two very popular key-value databases.
+- **Document**: Data in the document database is stored in documents similar to JSON (JavaScript Object Notation) objects, which is very clear and intuitive. Each document contains pairs of fields and values. These values can typically be of various types, including strings, numbers, Boolean values, arrays, or objects, and their structure is usually consistent with the objects developers use in their code. MongoDB is a very popular document database.
+- **Graph**: Graph databases are designed to easily build and run applications that work with highly connected data sets. Typical use cases for graph databases include social networks, recommendation engines, fraud detection, and knowledge graphs. Neo4j and Giraph are two very popular graph databases.
+- **Wide Column**: Wide column storage database is very suitable for storing large amounts of data. Cassandra and HBase are two very popular wide column storage databases.
+
+The picture below comes from [Microsoft's official documentation | Relational data and NoSQL data](https://learn.microsoft.com/en-us/dotnet/architecture/cloud-native/relational-vs-nosql-data).
+
+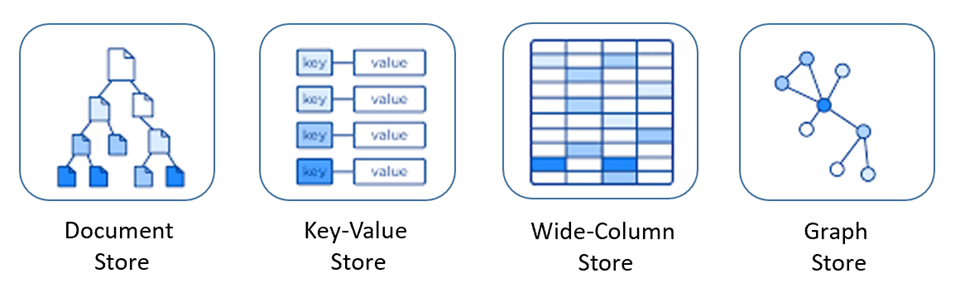
+
+## Reference
+
+- What is NoSQL? - MongoDB official documentation:
+- What is NoSQL? - AWS:
+- NoSQL vs. SQL Databases - MongoDB official documentation:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/3-commonly-used-cache-read-and-write-strategies.en.md b/docs_en/database/redis/3-commonly-used-cache-read-and-write-strategies.en.md
new file mode 100644
index 00000000000..83e894ff4f1
--- /dev/null
+++ b/docs_en/database/redis/3-commonly-used-cache-read-and-write-strategies.en.md
@@ -0,0 +1,126 @@
+---
+title: 3种常用的缓存读写策略详解
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存读写策略,Cache Aside,Read Through,Write Through,一致性,失效
+ - - meta
+ - name: description
+ content: 总结三种常见缓存读写策略及适用场景,分析一致性与失效处理,指导业务选型与问题规避。
+---
+
+看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
+
+在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单写了一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
+
+但是,搞懂 3 种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
+
+**下面介绍到的三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式。**
+
+### Cache Aside Pattern(旁路缓存模式)
+
+**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
+
+Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 db 的结果为准。
+
+下面我们来看一下这个策略模式下的缓存读写步骤。
+
+**写**:
+
+- 先更新 db
+- 然后直接删除 cache 。
+
+简单画了一张图帮助大家理解写的步骤。
+
+
+
+**读** :
+
+- 从 cache 中读取数据,读取到就直接返回
+- cache 中读取不到的话,就从 db 中读取数据返回
+- 再把数据放到 cache 中。
+
+简单画了一张图帮助大家理解读的步骤。
+
+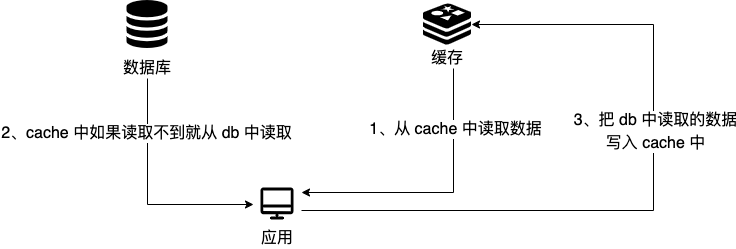
+
+你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
+
+比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 db 么?**”
+
+**答案:** 那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致**的问题。
+
+举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
+
+这个过程可以简单描述为:
+
+> 请求 1 先把 cache 中的 A 数据删除 -> 请求 2 从 db 中读取数据->请求 1 再把 db 中的 A 数据更新
+
+当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?**”
+
+**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
+
+举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。
+
+这个过程可以简单描述为:
+
+> 请求 1 从 db 读数据 A-> 请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 ) -> 请求 1 将数据 A 写入 cache
+
+现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
+
+**缺陷 1:首次请求数据一定不在 cache 的问题**
+
+解决办法:可以将热点数据可以提前放入 cache 中。
+
+**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
+
+解决办法:
+
+- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+
+### Read/Write Through Pattern(读写穿透)
+
+Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。
+
+这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能。
+
+**写(Write Through):**
+
+- 先查 cache,cache 中不存在,直接更新 db。
+- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(**同步更新 cache 和 db**)。
+
+简单画了一张图帮助大家理解写的步骤。
+
+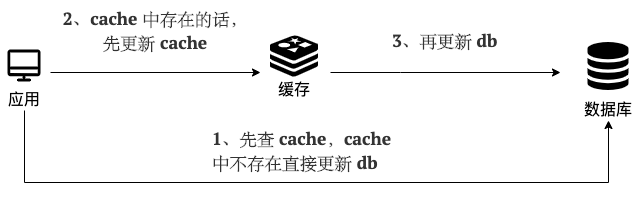
+
+**读(Read Through):**
+
+- 从 cache 中读取数据,读取到就直接返回 。
+- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
+
+简单画了一张图帮助大家理解读的步骤。
+
+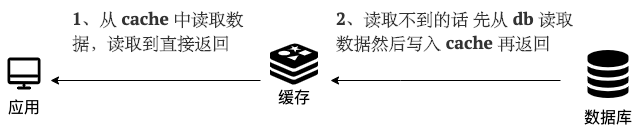
+
+Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
+
+和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
+
+### Write Behind Pattern(异步缓存写入)
+
+Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 db 的读写。
+
+但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新缓存,不直接更新 db,而是改为异步批量的方式来更新 db。**
+
+很明显,这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。
+
+这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
+
+Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
+
+
+
diff --git a/docs_en/database/redis/cache-basics.en.md b/docs_en/database/redis/cache-basics.en.md
new file mode 100644
index 00000000000..7e77ced0782
--- /dev/null
+++ b/docs_en/database/redis/cache-basics.en.md
@@ -0,0 +1,21 @@
+---
+title: Summary of common interview questions on caching basics (paid)
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: cache interview, consistency, elimination strategy, penetration, avalanche, hotspot, architecture
+ - - meta
+ - name: description
+ content: Collects high-frequency questions on caching foundation and architecture, covering consistency and elimination strategies, penetration/avalanche and other issues and management solutions, and builds a system review list.
+---
+
+**Caching Basics** The relevant interview questions are exclusive to my [Knowledge Planet](../../about-the-author/zhishixingqiu-two-years.md) (click the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide"](../../zhuanlan/java-mian-shi-zhi-bei.md).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-cluster.en.md b/docs_en/database/redis/redis-cluster.en.md
new file mode 100644
index 00000000000..327f4e03831
--- /dev/null
+++ b/docs_en/database/redis/redis-cluster.en.md
@@ -0,0 +1,14 @@
+---
+title: Detailed explanation of Redis cluster (paid)
+category: database
+tag:
+ - Redis
+---
+
+**Redis Cluster** The relevant interview questions are my [Knowledge Planet](../../about-the-author/zhishixingqiu-two-years.md) (click the link to view the detailed introduction and how to join) exclusive content, which has been compiled into ["Java Interview Guide North"](../../zhuanlan/java-mian-shi-zhi-bei.md).
+
+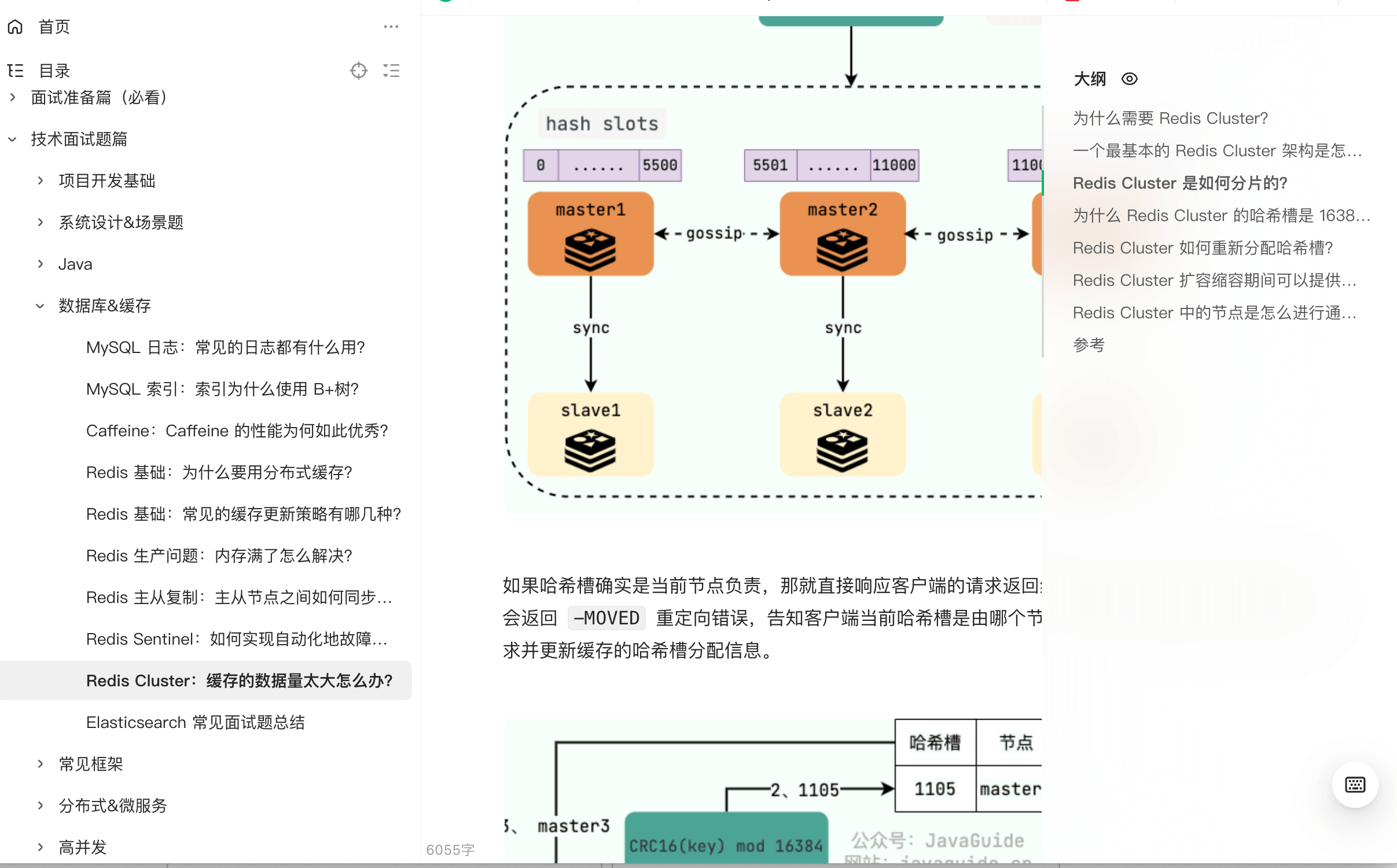
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-common-blocking-problems-summary.en.md b/docs_en/database/redis/redis-common-blocking-problems-summary.en.md
new file mode 100644
index 00000000000..4cf4c445b74
--- /dev/null
+++ b/docs_en/database/redis/redis-common-blocking-problems-summary.en.md
@@ -0,0 +1,178 @@
+---
+title: Redis常见阻塞原因总结
+category: 数据库
+tag:
+ - Redis
+---
+
+> 本文整理完善自: ,作者:阿 Q 说代码
+
+这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
+
+## O(n) 命令
+
+Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
+
+- `KEYS *`:会返回所有符合规则的 key。
+- `HGETALL`:会返回一个 Hash 中所有的键值对。
+- `LRANGE`:会返回 List 中指定范围内的元素。
+- `SMEMBERS`:返回 Set 中的所有元素。
+- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
+- ……
+
+由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长,从而导致客户端阻塞。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
+
+除了这些 O(n)时间复杂度的命令可能会导致阻塞之外, 还有一些时间复杂度可能在 O(N) 以上的命令,例如:
+
+- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- ……
+
+## SAVE 创建 RDB 快照
+
+Redis 提供了两个命令来生成 RDB 快照文件:
+
+- `save` : 同步保存操作,会阻塞 Redis 主线程;
+- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
+
+默认情况下,Redis 默认配置会使用 `bgsave` 命令。如果手动使用 `save` 命令生成 RDB 快照文件的话,就会阻塞主线程。
+
+## AOF
+
+### AOF 日志记录阻塞
+
+Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复)不同。
+
+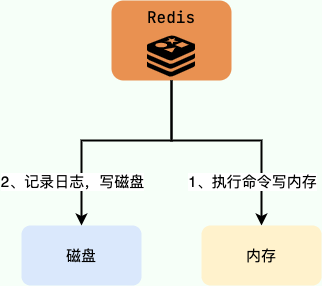
+
+**为什么是在执行完命令之后记录日志呢?**
+
+- 避免额外的检查开销,AOF 记录日志不会对命令进行语法检查;
+- 在命令执行完之后再记录,不会阻塞当前的命令执行。
+
+这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
+
+- 如果刚执行完命令 Redis 就宕机会导致对应的修改丢失;
+- **可能会阻塞后续其他命令的执行(AOF 记录日志是在 Redis 主线程中进行的)**。
+
+### AOF 刷盘阻塞
+
+开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再根据 `appendfsync` 配置来决定何时将其同步到硬盘中的 AOF 文件。
+
+在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
+
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+
+当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
+
+关于 AOF 工作流程的详细介绍可以查看:[Redis 持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
+
+### AOF 重写阻塞
+
+1. fork 出一条子线程来将文件重写,在执行 `BGREWRITEAOF` 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子线程创建新 AOF 文件期间,记录服务器执行的所有写命令。
+2. 当子线程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。
+3. 最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
+
+阻塞就是出现在第 2 步的过程中,将缓冲区中新数据写到新文件的过程中会产生**阻塞**。
+
+相关阅读:[Redis AOF 重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
+
+## 大 Key
+
+如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- string 类型的 value 超过 1MB
+- 复合类型(列表、哈希、集合、有序集合等)的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+
+大 key 造成的阻塞问题如下:
+
+- 客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
+- 引发网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
+- 阻塞工作线程:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
+
+### 查找大 key
+
+当我们在使用 Redis 自带的 `--bigkeys` 参数查找大 key 时,最好选择在从节点上执行该命令,因为主节点上执行时,会**阻塞**主节点。
+
+- 我们还可以使用 SCAN 命令来查找大 key;
+
+- 通过分析 RDB 文件来找出 big key,这种方案的前提是 Redis 采用的是 RDB 持久化。网上有现成的工具:
+
+- - redis-rdb-tools:Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
+ - rdb_bigkeys:Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
+
+### 删除大 key
+
+删除操作的本质是要释放键值对占用的内存空间。
+
+释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,**操作系统需要把释放掉的内存块插入一个空闲内存块的链表**,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会**阻塞**当前释放内存的应用程序。
+
+所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞,如果主线程发生了阻塞,其他所有请求可能都会超时,超时越来越多,会造成 Redis 连接耗尽,产生各种异常。
+
+删除大 key 时建议采用分批次删除和异步删除的方式进行。
+
+## 清空数据库
+
+清空数据库和上面 bigkey 删除也是同样道理,`flushdb`、`flushall` 也涉及到删除和释放所有的键值对,也是 Redis 的阻塞点。
+
+## 集群扩容
+
+Redis 集群可以进行节点的动态扩容缩容,这一过程目前还处于半自动状态,需要人工介入。
+
+在扩缩容的时候,需要进行数据迁移。而 Redis 为了保证迁移的一致性,迁移所有操作都是同步操作。
+
+When performing migration, Redis at both ends will enter a blocking state of varying lengths. For small keys, this time can be ignored. However, if the memory usage of the key is too large, in severe cases, it will trigger a failover within the cluster, causing unnecessary switching.
+
+## Swap (memory swap)
+
+**What is Swap? ** Swap literally means exchange. Swap in Linux is often called memory swap or swap partition. Similar to virtual memory in Windows, when memory is insufficient, part of the hard disk space is virtualized into memory to solve the problem of insufficient memory capacity. Therefore, the role of the Swap partition is to sacrifice the hard disk and increase the memory to solve the problem of insufficient or full VPS memory.
+
+Swap is very fatal for Redis. An important prerequisite for Redis to ensure high performance is that all data is in memory. If the operating system swaps part of the memory used by Redis out of the hard disk, the performance of Redis will drop sharply after the swap because the read and write speeds of the memory and the hard disk are several orders of magnitude different.
+
+The check method to identify Swap in Redis is as follows:
+
+1. Query the Redis process number
+
+```bash
+redis-cli -p 6383 info server | grep process_id
+process_id: 4476
+```
+
+2. Query memory swap information based on process number
+
+```bash
+cat /proc/4476/smaps | grep Swap
+Swap: 0kB
+Swap: 0kB
+Swap: 4kB
+Swap: 0kB
+Swap: 0kB
+.....
+```
+
+If the swap volume is all 0KB or some are 4KB, it is normal.
+
+Methods to prevent memory swapping:
+
+- Ensure that the machine has sufficient available memory
+- Ensure that all Redis instances are set to the maximum available memory (maxmemory) to prevent uncontrollable growth of Redis memory in extreme situations
+- Reduce the system's swap priority, such as `echo 10 > /proc/sys/vm/swappiness`
+
+## CPU competition
+
+Redis is a typical CPU-intensive application and is not recommended to be deployed together with other multi-core CPU-intensive services. When other processes consume the CPU excessively, it will seriously affect the throughput of Redis.
+
+You can get the current Redis usage through `redis-cli --stat`. Use the `top` command to obtain information such as the CPU utilization of the process. Use the `info commandstats` statistical information to analyze the command's unreasonable overhead time and check whether it is due to high algorithm complexity or excessive memory optimization.
+
+## Network problem
+
+Network problems such as connection rejection, network delay, and network card soft interruption may also cause Redis to block.
+
+## Reference
+
+- Analysis and summary of 6 major scenarios of Redis blocking:
+- Redis development and operation notes - Redis nightmare - blocking:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-data-structures-01.en.md b/docs_en/database/redis/redis-data-structures-01.en.md
new file mode 100644
index 00000000000..735de4294cb
--- /dev/null
+++ b/docs_en/database/redis/redis-data-structures-01.en.md
@@ -0,0 +1,499 @@
+---
+title: Detailed explanation of the 5 basic data types of Redis
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis common data types
+ - - meta
+ - name: description
+ content: Summary of Redis basic data types: String (string), List (list), Set (set), Hash (hash), Zset (ordered set)
+---
+
+Redis has 5 basic data types: String (string), List (list), Set (collection), Hash (hash), and Zset (ordered set).
+
+These five data types are directly provided to users and are the storage form of data. Their underlying implementation mainly relies on these eight data structures: simple dynamic string (SDS), LinkedList (double linked list), Dict (hash table/dictionary), SkipList (skip list), Intset (integer collection), ZipList (compressed list), QuickList (quick list).
+
+The underlying data structure corresponding to Redis's five basic data types is implemented as shown in the following table:
+
+| String | List | Hash | Set | Zset |
+| :----- | :--------------------------- | :------------ | :----------- | :---------------- |
+| SDS | LinkedList/ZipList/QuickList | Dict, ZipList | Dict, Intset | ZipList, SkipList |
+
+Before Redis 3.2, the underlying implementation of List was LinkedList or ZipList. After Redis 3.2, QuickList, a combination of LinkedList and ZipList, was introduced, and the underlying implementation of List became QuickList. Starting from Redis 7.0, ZipList is replaced by ListPack.
+
+You can find a very detailed introduction to Redis data types/structures on the Redis official website:
+
+- [Redis Data Structures](https://redis.com/redis-enterprise/data-structures/)
+- [Redis Data types tutorial](https://redis.io/docs/manual/data-types/data-types-tutorial/)
+
+In the future, with the release of new versions of Redis, new data structures may appear. By consulting the corresponding introduction on the Redis official website, you can always get the most reliable information.
+
+
+
+## String
+
+### Introduction
+
+String is the simplest and most commonly used data type in Redis.
+
+String is a binary-safe data type that can be used to store any type of data such as strings, integers, floating point numbers, images (base64 encoding or decoding of images or the path of images), and serialized objects.
+
+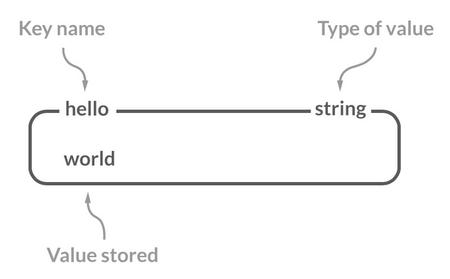
+
+Although Redis is written in C language, Redis does not use C's string representation. Instead, it builds its own **Simple Dynamic String** (**SDS**). Compared with C's native strings, Redis's SDS can save not only text data but also binary data, and the complexity of obtaining the string length is O(1) (C string is O(N)). In addition, Redis's SDS API is safe and will not cause buffer overflow.
+
+### Common commands
+
+| Commands | Introduction |
+| ---------------------------------- | ---------------------------------- |
+| SET key value | Set the value of the specified key |
+| SETNX key value | Set the value of key only if the key does not exist |
+| GET key | Get the value of the specified key |
+| MSET key1 value1 key2 value2 …… | Set the value of one or more specified keys |
+| MGET key1 key2 ... | Get the value of one or more specified keys |
+| STRLEN key | Returns the length of the string value stored in key |
+| INCR key | Increment the numeric value stored in key by one |
+| DECR key | Decrement the numeric value stored in key by one |
+| EXISTS key | Determine whether the specified key exists |
+| DEL key (general) | Delete the specified key |
+| EXPIRE key seconds (general) | Set the expiration time for the specified key |
+
+For more Redis String commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Basic Operation**:
+
+```bash
+> SET key value
+OK
+> GET key
+"value"
+> EXISTS key
+(integer) 1
+> STRLEN key
+(integer) 5
+> DEL key
+(integer) 1
+> GET key
+(nil)
+```
+
+**Batch Settings**:
+
+```bash
+> MSET key1 value1 key2 value2
+OK
+> MGET key1 key2 # Get the values corresponding to multiple keys in batches
+1) "value1"
+2) "value2"
+```
+
+**Counter (can be used when the content of the string is an integer):**
+
+```bash
+>SET number 1
+OK
+> INCR number # Increase the number value stored in key by one
+(integer) 2
+> GET number
+"2"
+> DECR number # Decrement the numeric value stored in key by one
+(integer) 1
+> GET number
+"1"
+```
+
+**Set expiration time (default is never expires)**:
+
+```bash
+> EXPIRE key 60
+(integer) 1
+> SETEX key 60 value # Set value and set expiration time
+OK
+> TTL key
+(integer) 56
+```
+
+### Application scenarios
+
+**Scenarios where regular data needs to be stored**
+
+- Example: Cache Session, Token, image address, serialized object (more memory-saving than Hash storage).
+- Related commands: `SET`, `GET`.
+
+**Scenarios that require counting**
+
+- Examples: the number of user requests per unit time (simple current limiting can be used), the number of page visits per unit time.
+- Related commands: `SET`, `GET`, `INCR`, `DECR`.
+
+**Distributed Lock**
+
+The simplest distributed lock can be implemented using the `SETNX key value` command (there are some flaws, and it is generally not recommended to implement distributed locks this way).
+
+## List
+
+### Introduction
+
+List in Redis is actually the implementation of the linked list data structure. I introduced the linked list data structure in detail in this article [Linear Data Structure: Array, Linked List, Stack, Queue](https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html), so I won’t go into details here.
+
+Many high-level programming languages have built-in implementations of linked lists, such as `LinkedList` in Java, but the C language does not implement linked lists, so Redis implements its own linked list data structure. The implementation of Redis's List is a **doubly linked list**, which can support reverse search and traversal, making it more convenient to operate, but it brings some additional memory overhead.
+
+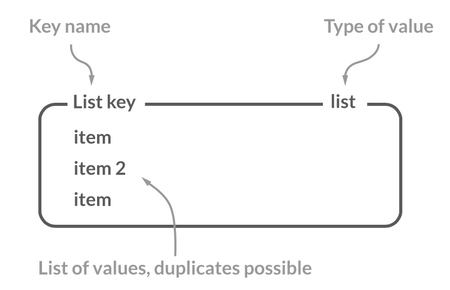
+
+### Common commands
+
+| Commands | Introduction ||-------------------------------- |------------------------------------------------ |
+| RPUSH key value1 value2 ... | Add one or more elements to the tail (right) of the specified list |
+| LPUSH key value1 value2 ... | Add one or more elements to the head (left) of the specified list |
+| LSET key index value | Set the value at the specified list index position to value |
+| LPOP key | Remove and get the first element (leftmost) of the specified list |
+| RPOP key | Remove and get the last element (rightmost) of the specified list |
+| LLEN key | Get the number of list elements |
+| LRANGE key start end | Get the elements between start and end of the list |
+
+For more Redis List commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Queue implementation via `RPUSH/LPOP` or `LPUSH/RPOP`:
+
+```bash
+>RPUSH myList value1
+(integer) 1
+>RPUSH myList value2 value3
+(integer) 3
+> LPOP myList
+"value1"
+> LRANGE myList 0 1
+1) "value2"
+2) "value3"
+> LRANGE myList 0 -1
+1) "value2"
+2) "value3"
+```
+
+**Implementing the stack via `RPUSH/RPOP` or `LPUSH/LPOP`**:
+
+```bash
+>RPUSH myList2 value1 value2 value3
+(integer) 3
+> RPOP myList2 # Take out the rightmost element of the list
+"value3"
+```
+
+I specially drew a picture to help everyone understand the `RPUSH`, `LPOP`, `LPUSH`, `RPOP` commands:
+
+
+
+**View the list elements corresponding to the subscript range through `LRANGE`:
+
+```bash
+>RPUSH myList value1 value2 value3
+(integer) 3
+> LRANGE myList 0 1
+1) "value1"
+2) "value2"
+> LRANGE myList 0 -1
+1) "value1"
+2) "value2"
+3) "value3"
+```
+
+Through the `LRANGE` command, you can implement paging query based on List, and the performance is very high!
+
+**View the length of the linked list through `LLEN`:
+
+```bash
+> LLEN myList
+(integer) 3
+```
+
+### Application scenarios
+
+**Information flow display**
+
+- Examples: latest articles, latest developments.
+- Related commands: `LPUSH`, `LRANGE`.
+
+**Message Queue**
+
+`List` can be used as a message queue, but its function is too simple and has many flaws, so it is not recommended.
+
+Relatively speaking, `Stream`, a newly added data structure in Redis 5.0, is more suitable for message queues, but its function is still very crude. Compared with professional message queues, there are still many shortcomings, such as message loss and accumulation problems that are difficult to solve.
+
+## Hash
+
+### Introduction
+
+Hash in Redis is a String type field-value (key-value pair) mapping table, which is particularly suitable for storing objects. During subsequent operations, you can directly modify the values of certain fields in this object.
+
+Hash is similar to `HashMap` before JDK1.8, and the internal implementation is similar (array + linked list). However, Redis's Hash has been optimized more.
+
+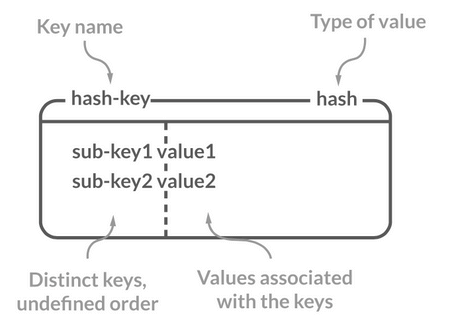
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |---------------------------------------------------------------- |
+| HSET key field value | Set the value of the specified field in the specified hash table |
+| HSETNX key field value | Set the value of the specified field only if the specified field does not exist |
+| HMSET key field1 value1 field2 value2 ... | Set one or more field-value (field-value) pairs into the specified hash table at the same time |
+| HGET key field | Get the value of the specified field in the specified hash table |
+| HMGET key field1 field2 ... | Get the value of one or more specified fields in the specified hash table |
+| HGETALL key | Get all key-value pairs in the specified hash table |
+| HEXISTS key field | Check whether the specified field exists in the specified hash table |
+| HDEL key field1 field2 ... | Delete one or more hash table fields |
+| HLEN key | Get the number of fields in the specified hash table |
+| HINCRBY key field increment | Perform operations on the specified field in the specified hash (positive numbers are added, negative numbers are subtracted) |
+
+For more Redis Hash commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Mock object data storage**:
+
+```bash
+> HMSET userInfoKey name "guide" description "dev" age 24
+OK
+> HEXISTS userInfoKey name # Check whether the field specified in the value corresponding to key exists.
+(integer) 1
+> HGET userInfoKey name # Get the value of the specified field stored in the hash table.
+"guide"
+> HGET userInfoKey age
+"24"
+> HGETALL userInfoKey # Get all fields and values of the specified key in the hash table
+1) "name"
+2) "guide"
+3) "description"
+4) "dev"
+5) "age"
+6) "24"
+> HSET userInfoKey name "GuideGeGe"
+> HGET userInfoKey name
+"GuideGeGe"
+> HINCRBY userInfoKey age 2
+(integer) 26
+```
+
+### Application scenarios
+
+**Object data storage scenario**
+
+- Examples: user information, product information, article information, shopping cart information.
+- Related commands: `HSET` (set the value of a single field), `HMSET` (set the value of multiple fields), `HGET` (get the value of a single field), `HMGET` (get the value of multiple fields).
+
+## Set
+
+### Introduction
+
+The Set type in Redis is an unordered collection. The elements in the collection are not in order but are unique, somewhat similar to `HashSet` in Java. Set is a good choice when you need to store a list of data and do not want duplicate data, and Set provides an important interface for determining whether an element is in a Set collection, which List cannot provide.
+
+You can easily implement intersection, union, and difference operations based on Set. For example, you can store all the followers of a user in one set and all their fans in one set. In this case, Set can very conveniently implement functions such as common following, common fans, and common preferences. This process is also the process of finding intersection.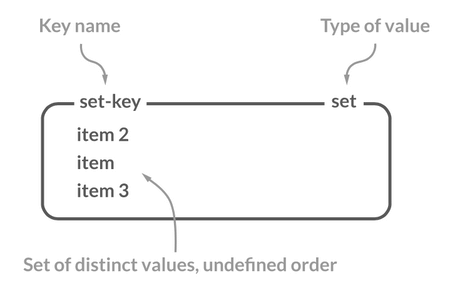
+
+### Common commands
+
+| Commands | Introduction |
+|---------------------------------------- | ------------------------------------------ |
+| SADD key member1 member2 ... | Add one or more elements to the specified collection |
+| SMEMBERS key | Get all elements in the specified collection |
+| SCARD key | Get the number of elements of the specified collection |
+| SISMEMBER key member | Determine whether the specified element is in the specified set |
+| SINTER key1 key2 ... | Get the intersection of all given sets |
+| SINTERSTORE destination key1 key2 ... | Stores the intersection of all the given sets in destination |
+| SUNION key1 key2 ... | Get the union of all given sets |
+| SUNIONSTORE destination key1 key2 ... | Stores the union of all the given sets in destination |
+| SDIFF key1 key2 ... | Get the difference set of all given sets |
+| SDIFFSTORE destination key1 key2 ... | Stores the difference of all given sets in destination |
+| SPOP key count | Randomly remove and obtain one or more elements in the specified collection |
+| SRANDMEMBER key count | Randomly obtain the specified number of elements in the specified collection |
+
+For more Redis Set commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Basic Operation**:
+
+```bash
+> SADD mySet value1 value2
+(integer) 2
+> SADD mySet value1 # Duplicate elements are not allowed, so the addition fails
+(integer) 0
+> SMEMBERS mySet
+1) "value1"
+2) "value2"
+> SCARD mySet
+(integer) 2
+> SISMEMBER mySet value1
+(integer) 1
+>SADD mySet2 value2 value3
+(integer) 2
+```
+
+- `mySet` : `value1`, `value2`.
+- `mySet2`: `value2`, `value3`.
+
+**Find intersection**:
+
+```bash
+> SINTERSTORE mySet3 mySet mySet2
+(integer) 1
+> SMEMBERS mySet3
+1) "value2"
+```
+
+**Find union**:
+
+```bash
+> SUNION mySet mySet2
+1) "value3"
+2) "value2"
+3) "value1"
+```
+
+**Find the difference set**:
+
+```bash
+> SDIFF mySet mySet2 # The difference set is a set composed of all elements that belong to mySet but do not belong to A
+1) "value1"
+```
+
+### Application scenarios
+
+**Scenarios where the data that needs to be stored cannot be repeated**
+
+- Examples: Website UV statistics (`HyperLogLog` is more suitable for scenarios with a huge amount of data), article likes, dynamic likes and other scenarios.
+- Related commands: `SCARD` (get the number of sets).
+
+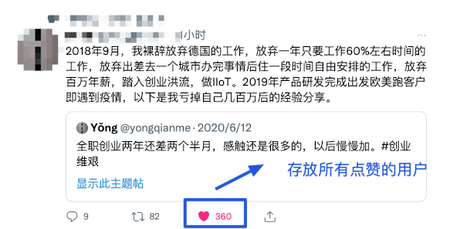
+
+**Scenarios where the intersection, union and difference of multiple data sources need to be obtained**
+
+- Examples: common friends (intersection), common fans (intersection), common following (intersection), friend recommendation (difference set), music recommendation (difference set), subscription account recommendation (difference set + intersection) and other scenarios.
+- Related commands: `SINTER` (intersection), `SINTERSTORE` (intersection), `SUNION` (union), `SUNIONSTORE` (union), `SDIFF` (difference), `SDIFFSTORE` (difference).
+
+
+
+**Scenarios where elements in the data source need to be randomly obtained**
+
+- Examples: Lottery system, random roll call and other scenarios.
+- Related commands: `SPOP` (randomly obtain elements from the set and remove them, suitable for scenarios that do not allow repeated winnings), `SRANDMEMBER` (randomly obtain elements from the set, suitable for scenarios that allow repeated winnings).
+
+## Sorted Set (ordered set)
+
+### Introduction
+
+Sorted Set is similar to Set, but compared with Set, Sorted Set adds a weight parameter `score`, so that the elements in the set can be ordered by `score`, and the list of elements can also be obtained through the range of `score`. It's a bit like a combination of `HashMap` and `TreeSet` in Java.
+
+
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |---------------------------------------------------------------------------------------------------------------- |
+| ZADD key score1 member1 score2 member2 ... | Add one or more elements to the specified sorted set |
+| ZCARD KEY | Get the number of elements of the specified ordered set |
+| ZSCORE key member | Get the score value of the specified element in the specified ordered set |
+| ZINTERSTORE destination numkeys key1 key2 ... | Store the intersection of all given ordered sets in destination, perform a SUM aggregation operation on the score values corresponding to the same elements, numkeys is the number of sets |
+| ZUNIONSTORE destination numkeys key1 key2 ... | Find the union, others are similar to ZINTERSTORE |
+| ZDIFFSTORE destination numkeys key1 key2 ... | Find the difference set, others are similar to ZINTERSTORE || ZRANGE key start end | Get the elements between start and end of the specified ordered set (score from low to high) |
+| ZREVRANGE key start end | Get the elements between start and end of the specified ordered set (score from high to bottom) |
+| ZREVRANK key member | Get the ranking of the specified element in the specified ordered set (score sorted from large to small) |
+
+For more Redis Sorted Set commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Basic Operation**:
+
+```bash
+>ZADD myZset 2.0 value1 1.0 value2
+(integer) 2
+> ZCARD myZset
+2
+> ZSCORE myZset value1
+2.0
+> ZRANGE myZset 0 1
+1) "value2"
+2) "value1"
+> ZREVRANGE myZset 0 1
+1) "value1"
+2) "value2"
+> ZADD myZset2 4.0 value2 3.0 value3
+(integer) 2
+
+```
+
+- `myZset` : `value1`(2.0), `value2`(1.0).
+- `myZset2`: `value2` (4.0), `value3` (3.0).
+
+**Get the ranking of the specified element**:
+
+```bash
+> ZREVRANK myZset value1
+0
+> ZREVRANK myZset value2
+1
+```
+
+**Find intersection**:
+
+```bash
+> ZINTERSTORE myZset3 2 myZset myZset2
+1
+> ZRANGE myZset3 0 1 WITHSCORES
+value2
+5
+```
+
+**Find union**:
+
+```bash
+> ZUNIONSTORE myZset4 2 myZset myZset2
+3
+> ZRANGE myZset4 0 2 WITHSCORES
+value1
+2
+value3
+3
+value2
+5
+```
+
+**Find the difference set**:
+
+```bash
+> ZDIFF 2 myZset myZset2 WITHSCORES
+value1
+2
+```
+
+### Application scenarios
+
+**Scenarios where elements in the data source need to be randomly obtained and sorted according to a certain weight**
+
+- Examples: various rankings, such as the ranking of gifts in the live broadcast room, the WeChat step ranking in the circle of friends, the rank ranking in Honor of Kings, the topic popularity ranking, etc.
+- Related commands: `ZRANGE` (sort from small to large), `ZREVRANGE` (sort from large to small), `ZREVRANK` (specify element ranking).
+
+
+
+There is an article in the "Technical Interview Questions" of ["Java Interview Guide"](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) that details how to use Sorted Set to design and create a ranking list.
+
+
+
+**Scenarios where the data that needs to be stored has priority or importance** such as priority task queue.
+
+- Example: Priority task queue.
+- Related commands: `ZRANGE` (sort from small to large), `ZREVRANGE` (sort from large to small), `ZREVRANK` (specify element ranking).
+
+## Summary
+
+| Data type | Description |
+| -------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| String | A binary safe data type that can be used to store any type of data such as strings, integers, floating point numbers, images (base64 encoding or decoding of images or the path of images), and serialized objects. |
+| List | The implementation of Redis's List is a doubly linked list, which can support reverse search and traversal, making it more convenient to operate, but it brings some additional memory overhead. |
+| Hash | A mapping table of String type field-value (key-value pairs), which is particularly suitable for storing objects. During subsequent operations, you can directly modify the values of certain fields in this object. |
+| Set | An unordered set. The elements in the set are not in order but are unique, somewhat similar to `HashSet` in Java. |
+| Zset | Compared with Set, Sorted Set adds a weight parameter `score`, so that the elements in the set can be ordered by `score`, and the list of elements can also be obtained through the range of `score`. It's a bit like a combination of `HashMap` and `TreeSet` in Java. |
+
+## Reference
+
+- Redis Data Structures: .
+- Redis Commands: .
+- Redis Data types tutorial: .
+- Whether Redis uses Hash or String to store object information:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-data-structures-02.en.md b/docs_en/database/redis/redis-data-structures-02.en.md
new file mode 100644
index 00000000000..a55a96334ab
--- /dev/null
+++ b/docs_en/database/redis/redis-data-structures-02.en.md
@@ -0,0 +1,223 @@
+---
+title: Detailed explanation of three special data types of Redis
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis common data types
+ - - meta
+ - name: description
+ content: Summary of Redis special data types: HyperLogLogs (cardinality statistics), Bitmap (bit storage), Geospatial (geographic location).
+---
+
+In addition to the 5 basic data types, Redis also supports 3 special data types: Bitmap, HyperLogLog, and GEO.
+
+## Bitmap (bitmap)
+
+### Introduction
+
+According to the official website:
+
+> Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type which is treated like a bit vector. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 2^32 different bits.
+>
+> Bitmap is not an actual data type in Redis, but a set of bit-oriented operations defined on the String type, treating it as a bit vector. Since strings are binary-safe blocks and have a maximum length of 512 MB, they are suitable for setting up to 2^32 different bits.
+
+Bitmap stores continuous binary numbers (0 and 1). Through Bitmap, only one bit is needed to represent the value or status corresponding to a certain element, and the key is the corresponding element itself. We know that 8 bits can form a byte, so Bitmap itself will greatly save storage space.
+
+You can think of a Bitmap as an array that stores binary numbers (0s and 1s). The index of each element in the array is called offset.
+
+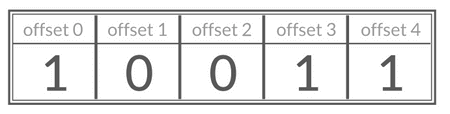
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |---------------------------------------------------------------- |
+| SETBIT key offset value | Set the value at the specified offset position |
+| GETBIT key offset | Get the value at the specified offset position |
+| BITCOUNT key start end | Get the number of elements with a value of 1 between start and end |
+| BITOP operation destkey key1 key2 ... | Operate on one or more Bitmaps. Available operators are AND, OR, XOR and NOT |
+
+**Bitmap basic operation demonstration**:
+
+```bash
+# SETBIT will return the value of the previous bit (default is 0) here will generate 7 bits
+> SETBIT mykey 7 1
+(integer) 0
+> SETBIT mykey 7 0
+(integer) 1
+> GETBIT mykey 7
+(integer) 0
+> SETBIT mykey 6 1
+(integer) 0
+> SETBIT mykey 8 1
+(integer) 0
+# Count the number of bits set to 1 through bitcount.
+> BITCOUNT mykey
+(integer) 2
+```
+
+### Application scenarios
+
+**Scenarios where status information needs to be saved (represented by 0/1)**
+
+- Examples: user check-in status, active user status, user behavior statistics (such as whether a video has been liked).
+- Related commands: `SETBIT`, `GETBIT`, `BITCOUNT`, `BITOP`.
+
+## HyperLogLog (cardinality statistics)
+
+### Introduction
+
+HyperLogLog is a well-known cardinality counting probability algorithm, which is optimized and improved based on LogLog Counting (LLC). It is not unique to Redis. Redis only implements this algorithm and provides some out-of-the-box APIs.
+
+The HyperLogLog provided by Redis takes up very little space, requiring only 12k of space to store close to `2^64` different elements. This is really amazing. Is this the charm of mathematics? Moreover, Redis has optimized the storage structure of HyperLogLog and uses two counting methods:
+
+- **Sparse Matrix**: When the count is small, it takes up very little space.
+- **Dense Matrix**: When the count reaches a certain threshold, it occupies 12k space.
+
+There are corresponding detailed instructions in the official Redis documentation:
+
+
+
+In order to save memory, the cardinality counting probability algorithm does not directly store metadata, but estimates the cardinality value (the number of elements in the set) through a certain probability and statistical method. Therefore, the counting result of HyperLogLog is not an exact value, and there is a certain error (standard error is `0.81%`).
+
+
+
+The use of HyperLogLog is very simple, but the principle is very complex. For the principle of HyperLogLog and its implementation in Redis, you can read this article: [Explanation of the principle of HyperLogLog algorithm and how Redis applies it](https://juejin.cn/post/6844903785744056333).
+
+I recommend another tool that can help understand the principles of HyperLogLog: [Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure](http://content.research.neustar.biz/blog/hll.html).
+
+In addition to HyperLogLog, Redis also provides other probabilistic data structures, corresponding official document address: .
+
+### Common commands
+
+There are very few commands related to HyperLogLog, and the most commonly used are only 3.
+
+| Commands | Introduction |
+|------------------------------------------------ |-------------------------------------------------------------------------------- |
+| PFADD key element1 element2 ... | Add one or more elements to HyperLogLog |
+| PFCOUNT key1 key2 | Get the unique count of one or more HyperLogLogs. |
+| PFMERGE destkey sourcekey1 sourcekey2 ... | Merge multiple HyperLogLogs into destkey. destkey will combine multiple sources to calculate the corresponding unique count. |
+
+**HyperLogLog basic operation demonstration**:
+
+```bash
+> PFADD hll foo bar zap
+(integer) 1
+> PFADD hll zap zap zap
+(integer) 0
+> PFADD hll foo bar
+(integer) 0
+> PFCOUNT hll
+(integer) 3
+> PFADD some-other-hll 1 2 3
+(integer) 1
+> PFCOUNT hll some-other-hll
+(integer) 6
+> PFMERGE desthll hll some-other-hll
+"OK"
+>PFCOUNTdesthll
+(integer) 6```
+
+### Application scenarios
+
+**Huge number of counting scenarios (millions, tens of millions or more)**
+
+- Example: Daily/weekly/monthly access IP statistics of popular websites, UV statistics of popular posts.
+- Related commands: `PFADD`, `PFCOUNT`.
+
+## Geospatial (geographic location)
+
+### Introduction
+
+Geospatial index (GEO for short) is mainly used to store geographical location information and is implemented based on Sorted Set.
+
+Through GEO, we can easily implement functions such as calculating the distance between two locations and obtaining elements near a specified location.
+
+
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |------------------------------------------------------------------------------------------------------------- |
+| GEOADD key longitude1 latitude1 member1 ... | Add the latitude and longitude information corresponding to one or more elements to GEO |
+| GEOPOS key member1 member2 ... | Returns the latitude and longitude information of the given element |
+| GEODIST key member1 member2 M/KM/FT/MI | Returns the distance between two given elements |
+| GEORADIUS key longitude latitude radius distance | Get other elements within the distance range near the specified position, supporting ASC (from near to far), DESC (from far to near), Count (number) and other parameters |
+| GEORADIUSBYMEMBER key member radius distance | Similar to the GEORADIUS command, except that the reference center point is an element in GEO |
+
+**Basic Operation**:
+
+```bash
+> GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3
+3
+> GEOPOS personLocation user1
+116.3299986720085144
+39.89000061669732844
+> GEODIST personLocation user1 user2 km
+1.4018
+```
+
+View `personLocation` through the Redis visualization tool. As expected, the bottom layer is a Sorted Set.
+
+The longitude and latitude data of the geographical location information stored in GEO is converted into an integer through the GeoHash algorithm, and this integer is used as the score (weight parameter) of the Sorted Set.
+
+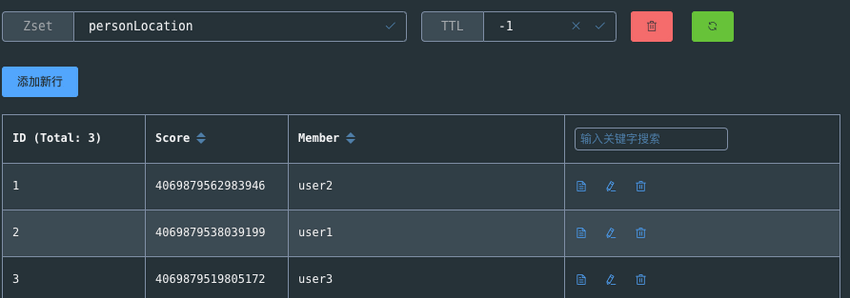
+
+**Get other elements within the specified position range**:
+
+```bash
+> GEORADIUS personLocation 116.33 39.87 3 km
+user3
+user1
+> GEORADIUS personLocation 116.33 39.87 2 km
+> GEORADIUS personLocation 116.33 39.87 5 km
+user3
+user1
+user2
+> GEORADIUSBYMEMBER personLocation user1 5 km
+user3
+user1
+user2
+> GEORADIUSBYMEMBER personLocation user1 2 km
+user1
+user2
+```
+
+For an analysis of the underlying principles of the `GEORADIUS` command, you can read this article by Ali: [How does Redis implement the "people nearby" function? ](https://juejin.cn/post/6844903966061363207).
+
+**Remove element**:
+
+The bottom layer of GEO is Sorted Set, and you can use Sorted Set related commands on GEO.
+
+```bash
+> ZREM personLocation user1
+1
+> ZRANGE personLocation 0 -1
+user3
+user2
+> ZSCORE personLocation user2
+4069879562983946
+```
+
+### Application scenarios
+
+**Scenarios that require management of geospatial data**
+
+- Example: People nearby.
+- Related commands: `GEOADD`, `GEORADIUS`, `GEORADIUSBYMEMBER`.
+
+## Summary
+
+| Data type | Description |
+|---------------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Bitmap | You can think of a Bitmap as an array that stores binary numbers (0 and 1). The subscript of each element in the array is called offset. Through Bitmap, only one bit is needed to represent the value or status corresponding to an element, and the key is the corresponding element itself. We know that 8 bits can form a byte, so Bitmap itself will greatly save storage space. |
+| HyperLogLog | The HyperLogLog provided by Redis takes up very little space, requiring only 12k of space to store close to `2^64` different elements. However, the count result of HyperLogLog is not an exact value and has a certain error (standard error is `0.81%`). |
+| Geospatial index | Geospatial index (GEO) is mainly used to store geographical location information and is implemented based on Sorted Set. |
+
+## Reference
+
+- Redis Data Structures: .
+- "Redis Deep Adventure: Core Principles and Application Practices" 1.6 Four ounces make a huge difference - HyperLogLog
+- Bloom filter, bitmap, HyperLogLog:
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-delayed-task.en.md b/docs_en/database/redis/redis-delayed-task.en.md
new file mode 100644
index 00000000000..a9a392add2a
--- /dev/null
+++ b/docs_en/database/redis/redis-delayed-task.en.md
@@ -0,0 +1,89 @@
+---
+title: How to implement delayed tasks based on Redis
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis, delayed tasks, expiration events, Redisson, DelayedQueue, reliability, consistency
+ - - meta
+ - name: description
+ content: Compare the two solutions of Redis expiration event and Redisson delay queue, analyze the trade-off between reliability and consistency, and give project selection suggestions.
+---
+
+The function of implementing delayed tasks based on Redis is nothing more than the following two options:
+
+1. Redis expiration event monitoring
+2. Redisson’s built-in delay queue
+
+During the interview, you can first say that you have considered these two solutions, but in the end you found that there are many problems with the Redis expiration event monitoring solution, so you finally chose the DelayedQueue solution built into Redisson.
+
+At this time, the interviewer may ask you some relevant questions, which we will mention later, so just prepare in advance.
+
+In addition, in addition to the questions introduced below, it is recommended that you review all the common questions related to Redis. It is not ruled out that the interviewer will ask you some other questions about Redis.
+
+### How does Redis expiration event monitoring implement the delayed task function?
+
+Redis 2.0 introduces publish and subscribe (pub/sub) functionality. In pub/sub, a concept called channel is introduced, which is somewhat similar to topic in message queue.
+
+Pub/sub involves two roles: publisher (publisher) and subscriber (subscriber, also called consumer):
+
+- The publisher delivers messages to the specified channel through `PUBLISH`.
+- Subscribers subscribe to the channels they care about through `SUBSCRIBE`. Moreover, subscribers can subscribe to one or multiple channels.
+
+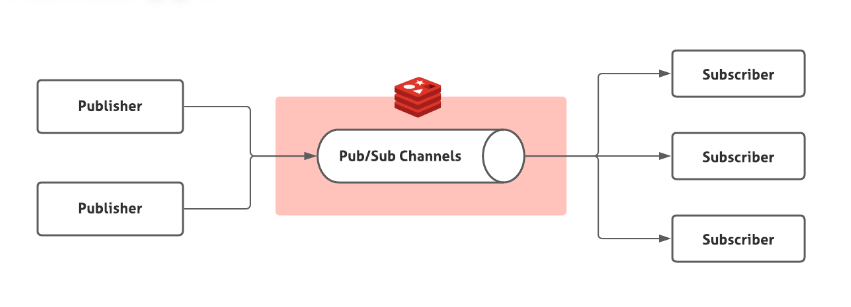
+
+In the pub/sub mode, the producer needs to specify which channel to send the message to, and the consumer subscribes to the corresponding channel to obtain the message.
+
+There are many default channels in Redis, and these channels are sent to them by Redis itself, not by the code we write ourselves. Among them, `__keyevent@0__:expired` is a default channel, responsible for monitoring key expiration events. That is to say, when a key expires, Redis will publish a key expiration event to the channel `__keyevent@__:expired`.
+
+We only need to listen to this channel to get the information about the expired key, thereby realizing the delayed task function.
+
+This function is officially called **keyspace notifications** by Redis, and its function is to monitor changes in Redis keys and values in real time.
+
+### What are the shortcomings of Redis expiration event monitoring to implement the delayed task function?
+
+**1. Poor timeliness**
+
+An introduction in the official document explains the reason for poor timeliness, address: .
+
+
+
+The core of this paragraph is: the expiration event message is published when the Redis server deletes the key, instead of being published directly after a key expires.
+
+We know that there are two commonly used deletion strategies for expired data:
+
+1. **Lazy deletion**: The data will only be checked for expiration when the key is taken out. This is the most CPU-friendly, but may cause too many expired keys to be deleted.
+2. **Periodic deletion**: Extract a batch of keys at regular intervals to delete expired keys. Moreover, the Redis underlying layer will reduce the impact of deletion operations on CPU time by limiting the duration and frequency of deletion operations.
+
+Periodic deletion is more memory friendly, lazy deletion is more CPU friendly. Both have their own merits, so Redis uses **regular deletion + lazy/lazy deletion**.
+
+Therefore, there will be situations where I set the expiration time of the key, but the key has not been deleted by the specified time, and no expiration event is released.
+
+**2. Lost message**
+
+Messages in Redis's pub/sub mode do not support persistence, unlike message queues. In the pub/sub mode of Redis, the publisher sends the message to the specified channel, and the subscriber listens to the corresponding channel to receive the message. When there are no subscribers, the message will be discarded directly and will not be stored in Redis.
+
+**3. Repeated consumption of messages under multiple service instances**
+
+Redis's pub/sub mode currently only has a broadcast mode, which means that when a producer publishes a message to a specific channel, all consumers subscribed to the relevant channel can receive the message.
+
+At this time, we need to pay attention to the problem of multiple service instances repeatedly processing messages, which will increase the amount of code development and maintenance difficulty.
+
+### What is the principle of Redisson delay queue? What are the advantages?
+
+Redisson is an open source Java language Redis client that provides many out-of-the-box features, such as the implementation of multiple distributed locks and delay queues.
+
+We can use Redisson's built-in delay queue RDelayedQueue to implement the delayed task function.
+
+Redisson's delay queue RDelayedQueue is implemented based on Redis' SortedSet. SortedSet is an ordered set in which each element can be set with a score, representing the weight of the element. Redisson takes advantage of this feature to insert tasks that need to be delayed into a SortedSet and set corresponding expiration times as scores for them.
+
+Redisson periodically scans the SortedSet for expired elements using the `zrangebyscore` command, then removes these expired elements from the SortedSet and adds them to the ready message list. The ready message list is a blocking queue, and when a message comes in, it will be monitored by the consumer. This avoids the consumer polling the entire SortedSet and improves execution efficiency.
+
+Compared with Redis expiration event monitoring to implement delayed task function, this method has the following advantages:
+
+1. **Reduces the possibility of message loss**: Messages in DelayedQueue will be persisted. Even if Redis is down, only a few messages may be lost according to the persistence mechanism, which will have little impact. Of course, you can also use database scanning as a compensation mechanism.
+2. **There is no problem of repeated consumption of messages**: Each client obtains tasks from the same target queue, and there is no problem of repeated consumption.
+
+Compared with Redisson's built-in delay queue, the message queue can achieve higher throughput and stronger reliability by ensuring the reliability of message consumption and controlling the number of message producers and consumers. In actual projects, the delayed message solution of the message queue is preferred.
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-memory-fragmentation.en.md b/docs_en/database/redis/redis-memory-fragmentation.en.md
new file mode 100644
index 00000000000..3953a477ed4
--- /dev/null
+++ b/docs_en/database/redis/redis-memory-fragmentation.en.md
@@ -0,0 +1,131 @@
+---
+title: Detailed explanation of Redis memory fragmentation
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis, memory fragmentation, allocator, memory management, memory usage, optimization
+ - - meta
+ - name: description
+ content: Analyze the causes and effects of Redis memory fragmentation, combine allocator and memory management strategies, provide observation and optimization directions, and reduce resource waste.
+---
+
+## What is memory fragmentation?
+
+You can think of memory fragmentation simply as free memory that is not available.
+
+For example: the operating system allocates 32 bytes of continuous memory space for you, but you actually only need to use 24 bytes of memory space to store data. If the extra 8 bytes of memory space cannot be allocated to store other data later, it can be called memory fragmentation.
+
+
+
+Although Redis memory fragmentation will not affect Redis performance, it will increase memory consumption.
+
+## Why is there Redis memory fragmentation?
+
+There are two common reasons for Redis memory fragmentation:
+
+**1. When Redis stores data, the memory space applied to the operating system may be larger than the actual storage space required for the data. **
+
+The following is the original words of Redis official:
+
+> To store user keys, Redis allocates at most as much memory as the `maxmemory` setting enables (however there are small extra allocations possible).
+
+When Redis uses the `zmalloc` method (the memory allocation method implemented by Redis itself) for memory allocation, in addition to allocating memory of the size `size`, it will also allocate more memory of the size `PREFIX_SIZE`.
+
+The source code of the `zmalloc` method is as follows (source code address:
+
+```java
+void *zmalloc(size_t size) {
+ //Allocate memory of specified size
+ void *ptr = malloc(size+PREFIX_SIZE);
+ if (!ptr) zmalloc_oom_handler(size);
+#ifdef HAVE_MALLOC_SIZE
+ update_zmalloc_stat_alloc(zmalloc_size(ptr));
+ return ptr;
+#else
+ *((size_t*)ptr) = size;
+ update_zmalloc_stat_alloc(size+PREFIX_SIZE);
+ return (char*)ptr+PREFIX_SIZE;
+#endif
+}
+```
+
+In addition, Redis can use a variety of memory allocators to allocate memory (libc, jemalloc, tcmalloc). The default is [jemalloc](https://github.com/jemalloc/jemalloc), and jemalloc allocates memory according to a series of fixed sizes (8 bytes, 16 bytes, 32 bytes...). The memory units divided by jemalloc are as shown in the figure below:
+
+
+
+When the memory requested by the program is closest to a certain fixed value, jemalloc will allocate a corresponding size of space to it. For example, if the program needs to apply for 17 bytes of memory, jemalloc will directly allocate 32 bytes of memory to it, which will result in a waste of 15 bytes of memory. However, jemalloc is specially optimized for memory fragmentation problems and generally does not cause excessive fragmentation.
+
+**2. Frequent modification of data in Redis will also cause memory fragmentation. **
+
+When some data in Redis is deleted, Redis usually does not easily release memory to the operating system.
+
+This also has the corresponding original words in the official Redis documentation:
+
+
+
+Document address: .
+
+## How to view Redis memory fragmentation information?
+
+Use the `info memory` command to view Redis memory-related information. The specific meaning of each parameter in the figure below is detailed in the Redis official document: .
+
+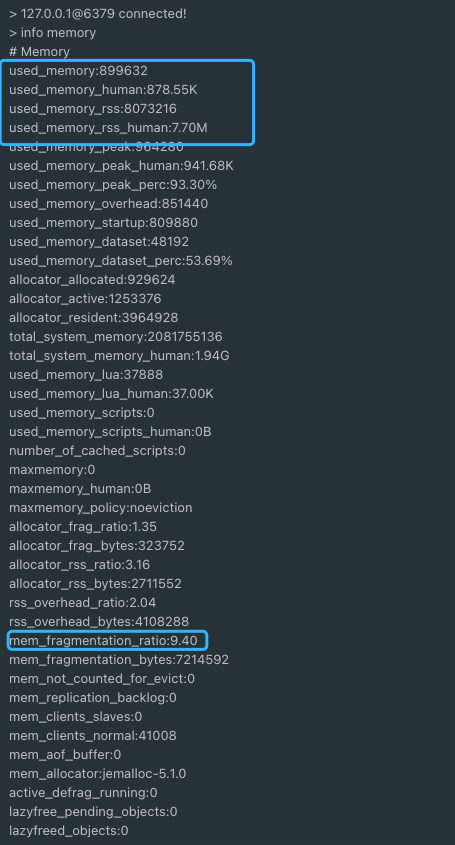
+
+The calculation formula of Redis memory fragmentation rate: `mem_fragmentation_ratio` (memory fragmentation rate) = `used_memory_rss` (the size of physical memory space actually allocated to Redis by the operating system)/ `used_memory` (the size of memory space actually applied for by the Redis memory allocator to store data)
+
+In other words, the larger the value of `mem_fragmentation_ratio` (memory fragmentation rate), the more serious the memory fragmentation rate.
+
+Be sure not to mistake `used_memory_rss` minus `used_memory` value as the size of the memory fragment! ! ! This includes not only memory fragmentation, but also other process overhead, as well as overhead for shared libraries, stacks, etc.
+
+Many friends may ask: "What is the memory fragmentation rate that needs to be cleaned up?".
+
+Normally, we think that memory fragmentation needs to be cleaned up when `mem_fragmentation_ratio > 1.5`. `mem_fragmentation_ratio > 1.5` means that if you use Redis to store data with an actual size of 2G, you will need to use more than 3G of memory.
+
+If you want to quickly check the memory fragmentation rate, you can also use the following command:
+
+```bash
+> redis-cli -p 6379 info | grep mem_fragmentation_ratio
+```
+
+In addition, the memory fragmentation rate may be less than 1. I have never encountered this situation in daily use. Interested friends can read this article [Fault Analysis | What should I do if the memory fragmentation rate of Redis is too low? - Weixin Open Source Community](https://mp.weixin.qq.com/s/drlDvp7bfq5jt2M5pTqJCw).
+
+## How to clean up Redis memory fragments?
+
+Redis4.0-RC3 version comes with memory defragmentation, which can avoid the problem of excessive memory fragmentation rate.
+
+Just set the `activedefrag` configuration item to `yes` directly through the `config set` command.
+
+```bash
+config set activedefrag yes
+```
+
+The specific time to clean up needs to be controlled by the following two parameters:
+
+```bash
+#Start cleaning up when the space occupied by memory fragmentation reaches 500mb
+config set active-defrag-ignore-bytes 500mb
+# Start cleaning when the memory fragmentation rate is greater than 1.5
+config set active-defrag-threshold-lower 50
+```
+
+The Redis automatic memory fragmentation cleaning mechanism may have an impact on Redis performance. We can reduce the impact on Redis performance through the following two parameters:
+
+```bash
+# The proportion of CPU time occupied by memory fragmentation cleaning should not be less than 20%
+config set active-defrag-cycle-min 20
+# The proportion of CPU time occupied by memory fragmentation cleaning is no more than 50%
+config set active-defrag-cycle-max 50
+```
+
+In addition, restarting the node can defragment the memory. If you are using a Redis cluster with a high-availability architecture, you can convert the master node with an excessive fragmentation rate into a slave node for safe restart.
+
+## Reference
+
+- Redis official documentation:
+- Redis core technology and practice - Geek Time - Why is the memory usage still very high after deleting data? :
+- Redis source code analysis - memory allocation: < Source code analysis - memory management>
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-persistence.en.md b/docs_en/database/redis/redis-persistence.en.md
new file mode 100644
index 00000000000..1557daf0b8f
--- /dev/null
+++ b/docs_en/database/redis/redis-persistence.en.md
@@ -0,0 +1,217 @@
+---
+title: Redis持久化机制详解
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis持久化机制详解
+ - - meta
+ - name: description
+ content: Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:快照(snapshotting,RDB)、只追加文件(append-only file, AOF)、RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
+---
+
+使用缓存的时候,我们经常需要对内存中的数据进行持久化也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
+
+Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
+
+- 快照(snapshotting,RDB)
+- 只追加文件(append-only file, AOF)
+- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
+
+官方文档地址: 。
+
+
+
+## RDB 持久化
+
+### 什么是 RDB 持久化?
+
+Redis 可以通过创建快照来获得存储在内存里面的数据在 **某个时间点** 上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
+
+快照持久化是 Redis 默认采用的持久化方式,在 `redis.conf` 配置文件中默认有此下配置:
+
+```clojure
+save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。
+
+save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
+
+save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
+```
+
+### RDB 创建快照时会阻塞主线程吗?
+
+Redis 提供了两个命令来生成 RDB 快照文件:
+
+- `save` : 同步保存操作,会阻塞 Redis 主线程;
+- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
+
+> 这里说 Redis 主线程而不是主进程的主要是因为 Redis 启动之后主要是通过单线程的方式完成主要的工作。如果你想将其描述为 Redis 主进程,也没毛病。
+
+## AOF 持久化
+
+### 什么是 AOF 持久化?
+
+与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化(Redis 6.0 之后已经默认是开启了),可以通过 `appendonly` 参数开启:
+
+```bash
+appendonly yes
+```
+
+开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再写入到 AOF 文件中(此时还在系统内核缓存区未同步到磁盘),最后再根据持久化方式( `fsync`策略)的配置来决定何时将系统内核缓存区的数据同步到硬盘中的。
+
+只有同步到磁盘中才算持久化保存了,否则依然存在数据丢失的风险,比如说:系统内核缓存区的数据还未同步,磁盘机器就宕机了,那这部分数据就算丢失了。
+
+AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 `dir` 参数设置的,默认的文件名是 `appendonly.aof`。
+
+### AOF 工作基本流程是怎样的?
+
+AOF 持久化功能的实现可以简单分为 5 步:
+
+1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
+2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
+3. **文件同步(fsync)**:这一步才是持久化的核心!根据你在 `redis.conf` 文件里 `appendfsync` 配置的策略,Redis 会在不同的时机,调用 `fsync` 函数(系统调用)。`fsync` 针对单个文件操作,对其进行强制硬盘同步(文件在内核缓冲区里的数据写到硬盘),`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
+4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
+5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
+
+> Linux 系统直接提供了一些函数用于对文件和设备进行访问和控制,这些函数被称为 **系统调用(syscall)**。
+
+这里对上面提到的一些 Linux 系统调用再做一遍解释:
+
+- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
+- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
+
+AOF 工作流程图如下:
+
+
+
+### AOF 持久化方式有哪些?
+
+在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
+
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,会立刻调用 `fsync` 函数同步 AOF 文件(刷盘)。主线程会阻塞,直到 `fsync` 将数据完全刷到磁盘后才会返回。这种方式数据最安全,理论上不会有任何数据丢失。但因为每个写操作都会同步阻塞主线程,所以性能极差。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)。这种方式主线程的性能基本不受影响。在性能和数据安全之间做出了绝佳的平衡。不过,在 Redis 异常宕机时,最多可能丢失最近 1 秒内的数据。
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。 这种方式性能最好,因为避免了 `fsync` 的阻塞。但数据安全性最差,宕机时丢失的数据量不可控,取决于操作系统上一次同步的时间点。
+
+可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
+
+为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能受到的影响较小。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
+
+从 Redis 7.0.0 开始,Redis 使用了 **Multi Part AOF** 机制。顾名思义,Multi Part AOF 就是将原来的单个 AOF 文件拆分成多个 AOF 文件。在 Multi Part AOF 中,AOF 文件被分为三种类型,分别为:
+
+- BASE:表示基础 AOF 文件,它一般由子进程通过重写产生,该文件最多只有一个。
+- INCR:表示增量 AOF 文件,它一般会在 AOFRW 开始执行时被创建,该文件可能存在多个。
+- HISTORY:表示历史 AOF 文件,它由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。
+
+Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的[Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
+
+**相关 issue**:[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
+
+### AOF 为什么是在执行完命令之后记录日志?
+
+关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复),而 Redis AOF 持久化机制是在执行完命令之后再记录日志。
+
+
+
+**为什么是在执行完命令之后记录日志呢?**
+
+- 避免额外的检查开销,AOF 记录日志不会对命令进行语法检查;
+- 在命令执行完之后再记录,不会阻塞当前的命令执行。
+
+这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
+
+- 如果刚执行完命令 Redis 就宕机会导致对应的修改丢失;
+- 可能会阻塞后续其他命令的执行(AOF 记录日志是在 Redis 主线程中进行的)。
+
+### AOF 重写了解吗?
+
+当 AOF 变得太大时,Redis 能够在后台自动重写 AOF 产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
+
+
+
+> AOF 重写(rewrite) 是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
+
+由于 AOF 重写会进行大量的写入操作,为了避免对 Redis 正常处理命令请求造成影响,Redis 将 AOF 重写程序放到子进程里执行。
+
+AOF 文件重写期间,Redis 还会维护一个 **AOF 重写缓冲区**,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
+
+开启 AOF 重写功能,可以调用 `BGREWRITEAOF` 命令手动执行,也可以设置下面两个配置项,让程序自动决定触发时机:
+
+- `auto-aof-rewrite-min-size`:如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
+- `auto-aof-rewrite-percentage`:执行 AOF 重写时,当前 AOF 大小(aof_current_size)和上一次重写时 AOF 大小(aof_base_size)的比值。如果当前 AOF 文件大小增加了这个百分比值,将触发 AOF 重写。将此值设置为 0 将禁用自动 AOF 重写。默认值为 100。
+
+Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
+
+Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内容摘自阿里开发者的[从 Redis7.0 发布看 Redis 的过去与未来](https://mp.weixin.qq.com/s/RnoPPL7jiFSKkx3G4p57Pg) 这篇文章。
+
+> AOF 重写期间的增量数据如何处理一直是个问题,在过去写期间的增量数据需要在内存中保留,写结束后再把这部分增量数据写入新的 AOF 文件中以保证数据完整性。可以看出来 AOF 写会额外消耗内存和磁盘 IO,这也是 Redis AOF 写的痛点,虽然之前也进行过多次改进但是资源消耗的本质问题一直没有解决。
+>
+> 阿里云的 Redis 企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
+
+**相关 issue**:[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)。
+
+### AOF 校验机制了解吗?
+
+纯 AOF 模式下,Redis 不会对整个 AOF 文件使用校验和(如 CRC64),而是通过逐条解析文件中的命令来验证文件的有效性。如果解析过程中发现语法错误(如命令不完整、格式错误),Redis 会终止加载并报错,从而避免错误数据载入内存。
+
+在 **混合持久化模式**(Redis 4.0 引入)下,AOF 文件由两部分组成:
+
+- **RDB 快照部分**:文件以固定的 `REDIS` 字符开头,存储某一时刻的内存数据快照,并在快照数据末尾附带一个 CRC64 校验和(位于 RDB 数据块尾部、AOF 增量部分之前)。
+- **AOF 增量部分**:紧随 RDB 快照部分之后,记录 RDB 快照生成后的增量写命令。这部分增量命令以 Redis 协议格式逐条记录,无整体或全局校验和。
+
+RDB 文件结构的核心部分如下:
+
+| **字段** | **解释** |
+| ----------------- | ---------------------------------------------- |
+| `"REDIS"` | 固定以该字符串开始 |
+| `RDB_VERSION` | RDB 文件的版本号 |
+| `DB_NUM` | Redis 数据库编号,指明数据需要存放到哪个数据库 |
+| `KEY_VALUE_PAIRS` | Redis 中具体键值对的存储 |
+| `EOF` | RDB 文件结束标志 |
+| `CHECK_SUM` | 8 字节确保 RDB 完整性的校验和 |
+
+Redis 启动并加载 AOF 文件时,首先会校验文件开头 RDB 快照部分的数据完整性,即计算该部分数据的 CRC64 校验和,并与紧随 RDB 数据之后、AOF 增量部分之前存储的 CRC64 校验和值进行比较。如果 CRC64 校验和不匹配,Redis 将拒绝启动并报告错误。
+
+RDB 部分校验通过后,Redis 随后逐条解析 AOF 部分的增量命令。如果解析过程中出现错误(如不完整的命令或格式错误),Redis 会停止继续加载后续命令,并报告错误,但此时 Redis 已经成功加载了 RDB 快照部分的数据。
+
+## Redis 4.0 对于持久化机制做了什么优化?
+
+由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+
+如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
+
+官方文档地址:
+
+
+
+## 如何选择 RDB 和 AOF?
+
+关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
+
+**RDB 比 AOF 优秀的地方**:
+
+- The content stored in the RDB file is compressed binary data, which saves the data set at a certain point in time. The file is small and suitable for data backup and disaster recovery. AOF files store each write command, similar to MySQL's binlog log, and are usually much larger than RDB files. When the AOF becomes too large, Redis can automatically rewrite the AOF in the background. The new AOF file saves the same database state as the original AOF file, but is smaller in size. However, before Redis 7.0, AOF might use a lot of memory if there were write commands during rewrite, and all write commands arriving during rewrite would be written to disk twice.
+- Use RDB files to restore data and directly parse and restore the data. There is no need to execute commands one by one, and the speed is very fast. AOF needs to execute each write command in sequence, which is very slow. In other words, RDB is faster when restoring large data sets compared to AOF.
+
+**AOF is better than RDB**:
+
+- The data security of RDB is not as good as AOF, and there is no way to persist data in real time or within seconds. The process of generating RDB files is relatively arduous. Although the BGSAVE sub-process writing the RDB files will not block the main thread, it will have an impact on the CPU resources and memory resources of the machine. In severe cases, it may even directly shut down the Redis service. AOF supports second-level data loss (depending on the fsync policy, if it is everysec, up to 1 second of data is lost). It only requires appending commands to the AOF file, and the operation is lightweight.
+- RDB files are saved in a specific binary format, and there are multiple versions of RDB in the evolution of Redis versions, so there is a problem that the old version of the Redis service is not compatible with the new version of the RDB format.
+- AOF contains a log of all operations in a format that is easy to understand and parse. You can easily export AOF files for analysis, and you can also directly manipulate AOF files to solve some problems. For example, if you execute the `FLUSHALL` command and accidentally refresh all the contents, as long as the AOF file has not been overwritten, you can restore the previous state by deleting the latest command and restarting.
+
+**In summary**:
+
+- If there is no impact if some data saved by Redis is lost, you can choose to use RDB.
+- Using AOF alone is not recommended as creating an RDB snapshot from time to time allows for database backups, faster restarts, and troubleshooting AOF engine errors.
+- If the saved data requires relatively high security, it is recommended to enable RDB and AOF persistence at the same time or enable RDB and AOF mixed persistence.
+
+## Reference
+
+- "Redis Design and Implementation"
+- Redis persistence - Redis official documentation:
+- The difference between AOF and RDB persistence:
+- Detailed explanation of Redis AOF persistence - Programmer Li Xiaobing:
+- Redis RDB and AOF persistence · Analyze:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-questions-01.en.md b/docs_en/database/redis/redis-questions-01.en.md
new file mode 100644
index 00000000000..421aa9d10bf
--- /dev/null
+++ b/docs_en/database/redis/redis-questions-01.en.md
@@ -0,0 +1,905 @@
+---
+title: Redis常见面试题总结(上)
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis面试题,Redis基础,Redis数据结构,Redis线程模型,Redis持久化,Redis内存管理,Redis性能优化,Redis分布式锁,Redis消息队列,Redis延时队列,Redis缓存策略,Redis单线程,Redis多线程,Redis过期策略,Redis淘汰策略
+ - - meta
+ - name: description
+ content: 最新Redis面试题总结(上):深入讲解Redis基础、五大常用数据结构、单线程模型原理、持久化机制、内存淘汰与过期策略、分布式锁与消息队列实现。适合准备后端面试的开发者!
+---
+
+
+
+## Redis 基础
+
+### 什么是 Redis?
+
+[Redis](https://redis.io/) (**RE**mote **DI**ctionary **S**erver)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
+
+为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
+
+
+
+Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,官方推荐生产环境使用 Linux 部署 Redis。
+
+个人学习的话,你可以自己本机安装 Redis 或者通过 Redis 官网提供的[在线 Redis 环境](https://try.redis.io/)(少部分命令无法使用)来实际体验 Redis。
+
+
+
+全世界有非常多的网站使用到了 Redis,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis),感兴趣的话可以看看。
+
+### ⭐️Redis 为什么这么快?
+
+Redis 内部做了非常多的性能优化,比较重要的有下面 4 点:
+
+1. **纯内存操作 (Memory-Based Storage)** :这是最主要的原因。Redis 数据读写操作都发生在内存中,访问速度是纳秒级别,而传统数据库频繁读写磁盘的速度是毫秒级别,两者相差数个数量级。
+2. **高效的 I/O 模型 (I/O Multiplexing & Single-Threaded Event Loop)** :Redis 使用单线程事件循环配合 I/O 多路复用技术,让单个线程可以同时处理多个网络连接上的 I/O 事件(如读写),避免了多线程模型中的上下文切换和锁竞争问题。虽然是单线程,但结合内存操作的高效性和 I/O 多路复用,使得 Redis 能轻松处理大量并发请求(Redis 线程模型会在后文中详细介绍到)。
+3. **优化的内部数据结构 (Optimized Data Structures)** :Redis 提供多种数据类型(如 String, List, Hash, Set, Sorted Set 等),其内部实现采用高度优化的编码方式(如 ziplist, quicklist, skiplist, hashtable 等)。Redis 会根据数据大小和类型动态选择最合适的内部编码,以在性能和空间效率之间取得最佳平衡。
+4. **简洁高效的通信协议 (Simple Protocol - RESP)** :Redis 使用的是自己设计的 RESP (REdis Serialization Protocol) 协议。这个协议实现简单、解析性能好,并且是二进制安全的。客户端和服务端之间通信的序列化/反序列化开销很小,有助于提升整体的交互速度。
+
+> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770)。
+
+
+
+那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高,并且 Redis 提供的数据持久化仍然有数据丢失的风险。
+
+### 除了 Redis,你还知道其他分布式缓存方案吗?
+
+如果面试中被问到这个问题的话,面试官主要想看看:
+
+1. 你在选择 Redis 作为分布式缓存方案时,是否是经过严谨的调研和思考,还是只是因为 Redis 是当前的“热门”技术。
+2. 你在分布式缓存方向的技术广度。
+
+如果你了解其他方案,并且能解释为什么最终选择了 Redis(更进一步!),这会对你面试表现加分不少!
+
+下面简单聊聊常见的分布式缓存技术选型。
+
+分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
+
+Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
+
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis)。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ),可以简单参考一下。
+
+不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
+
+目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
+
+- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
+- [KeyDB](https://github.com/Snapchat/KeyDB):Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+
+不过,个人还是建议分布式缓存首选 Redis,毕竟经过了这么多年的考验,生态非常优秀,资料也很全面!
+
+PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详细介绍和对比,感兴趣的话,可以自行研究一下。
+
+### 说一下 Redis 和 Memcached 的区别和共同点
+
+现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
+
+**共同点**:
+
+1. 都是基于内存的数据库,一般都用来当做缓存使用。
+2. 都有过期策略。
+3. 两者的性能都非常高。
+
+**区别**:
+
+1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
+2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
+3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
+4. **线程模型**:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
+5. **特性支持**:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
+6. **过期数据删除**:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
+
+相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
+
+### ⭐️为什么要用 Redis?
+
+**1、访问速度更快**
+
+传统数据库数据保存在磁盘,而 Redis 基于内存,内存的访问速度比磁盘快很多。引入 Redis 之后,我们可以把一些高频访问的数据放到 Redis 中,这样下次就可以直接从内存中读取,速度可以提升几十倍甚至上百倍。
+
+**2、高并发**
+
+一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
+
+> QPS(Query Per Second):服务器每秒可以执行的查询次数;
+
+由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
+
+**3、功能全面**
+
+Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
+
+### ⭐️为什么用 Redis 而不用本地缓存呢?
+
+| 特性 | 本地缓存 | Redis |
+| ------------ | ------------------------------------ | -------------------------------- |
+| 数据一致性 | 多服务器部署时存在数据不一致问题 | 数据一致 |
+| 内存限制 | 受限于单台服务器内存 | 独立部署,内存空间更大 |
+| 数据丢失风险 | 服务器宕机数据丢失 | 可持久化,数据不易丢失 |
+| 管理维护 | 分散,管理不便 | 集中管理,提供丰富的管理工具 |
+| 功能丰富性 | 功能有限,通常只提供简单的键值对存储 | 功能丰富,支持多种数据结构和功能 |
+
+### 常见的缓存读写策略有哪些?
+
+关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html)。
+
+### 什么是 Redis Module?有什么用?
+
+Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特殊的需求。这些 Module 以动态链接库(so 文件)的形式被加载到 Redis 中,这是一种非常灵活的动态扩展功能的实现方式,值得借鉴学习!
+
+我们每个人都可以基于 Redis 去定制化开发自己的 Module,比如实现搜索引擎功能、自定义分布式锁和分布式限流。
+
+目前,被 Redis 官方推荐的 Module 有:
+
+- [RediSearch](https://github.com/RediSearch/RediSearch):用于实现搜索引擎的模块。
+- [RedisJSON](https://github.com/RedisJSON/RedisJSON):用于处理 JSON 数据的模块。
+- [RedisGraph](https://github.com/RedisGraph/RedisGraph):用于实现图形数据库的模块。
+- [RedisTimeSeries](https://github.com/RedisTimeSeries/RedisTimeSeries):用于处理时间序列数据的模块。
+- [RedisBloom](https://github.com/RedisBloom/RedisBloom):用于实现布隆过滤器的模块。
+- [RedisAI](https://github.com/RedisAI/RedisAI):用于执行深度学习/机器学习模型并管理其数据的模块。
+- [RedisCell](https://github.com/brandur/redis-cell):用于实现分布式限流的模块。
+- ……
+
+关于 Redis 模块的详细介绍,可以查看官方文档:。
+
+## ⭐️Redis 应用
+
+### Redis 除了做缓存,还能做什么?
+
+- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html)。
+- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。
+- **消息队列**:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
+- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
+- **分布式 Session**:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
+- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV。
+- ……
+
+### 如何基于 Redis 实现分布式锁?
+
+关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)。
+
+### Redis 可以做消息队列么?
+
+> 实际项目中使用 Redis 来做消息队列的非常少,毕竟有更成熟的消息队列中间件可以用。
+
+先说结论:**可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。**
+
+**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
+
+通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 即可实现简易版消息队列:
+
+```bash
+# 生产者生产消息
+> RPUSH myList msg1 msg2
+(integer) 2
+> RPUSH myList msg3
+(integer) 3
+# 消费者消费消息
+> LPOP myList
+"msg1"
+```
+
+不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+
+因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
+
+```bash
+# 超时时间为 10s
+# 如果有数据立刻返回,否则最多等待10秒
+> BRPOP myList 10
+null
+```
+
+**List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。**
+
+**Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。**
+
+
+
+pub/sub 中引入了一个概念叫 **channel(频道)**,发布订阅机制的实现就是基于这个 channel 来做的。
+
+pub/sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
+
+- 发布者通过 `PUBLISH` 投递消息给指定 channel。
+- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
+
+我们这里启动 3 个 Redis 客户端来简单演示一下:
+
+
+
+pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
+
+为此,Redis 5.0 新增加的一个数据结构 `Stream` 来做消息队列。`Stream` 支持:
+
+- 发布 / 订阅模式;
+- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念);
+- 消息持久化( RDB 和 AOF);
+- ACK 机制(通过确认机制来告知已经成功处理了消息);
+- 阻塞式获取消息。
+
+`Stream` 的结构如下:
+
+
+
+这是一个有序的消息链表,每个消息都有一个唯一的 ID 和对应的内容。ID 是一个时间戳和序列号的组合,用来保证消息的唯一性和递增性。内容是一个或多个键值对(类似 Hash 基本数据类型),用来存储消息的数据。
+
+这里再对图中涉及到的一些概念,进行简单解释:
+
+- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费。
+- `last_delivered_id`:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。
+- `pending_ids`:记录已经被客户端消费但没有 ack 的消息的 ID。
+
+下面是`Stream` 用作消息队列时常用的命令:
+
+- `XADD`:向流中添加新的消息。
+- `XREAD`:从流中读取消息。
+- `XREADGROUP`:从消费组中读取消息。
+- `XRANGE`:根据消息 ID 范围读取流中的消息。
+- `XREVRANGE`:与 `XRANGE` 类似,但以相反顺序返回结果。
+- `XDEL`:从流中删除消息。
+- `XTRIM`:修剪流的长度,可以指定修建策略(`MAXLEN`/`MINID`)。
+- `XLEN`:获取流的长度。
+- `XGROUP CREATE`:创建消费者组。
+- `XGROUP DESTROY`:删除消费者组。
+- `XGROUP DELCONSUMER`:从消费者组中删除一个消费者。
+- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID。
+- `XACK`:确认消费组中的消息已被处理。
+- `XPENDING`:查询消费组中挂起(未确认)的消息。
+- `XCLAIM`:将挂起的消息从一个消费者转移到另一个消费者。
+- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
+
+`Stream` 使用起来相对要麻烦一些,这里就不演示了。
+
+总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中依然会有一些小问题不太好解决,比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
+
+综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方,比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列,比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
+
+相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
+
+### Redis 可以做搜索引擎么?
+
+Redis 是可以实现全文搜索引擎功能的,需要借助 **RediSearch**,这是一个基于 Redis 的搜索引擎模块。
+
+RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
+
+相比较于 Elasticsearch 来说,RediSearch 主要在下面两点上表现更优异一些:
+
+1. 性能更优秀:依赖 Redis 自身的高性能,基于内存操作(Elasticsearch 基于磁盘)。
+2. 较低内存占用实现快速索引:RediSearch 内部使用压缩的倒排索引,所以可以用较低的内存占用来实现索引的快速构建。
+
+对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。
+
+对于比较复杂或者数据规模较大的搜索场景,还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
+
+1. 数据量限制:Elasticsearch 可以支持 PB 级别的数据量,可以轻松扩展到多个节点,利用分片机制提高可用性和性能。RedisSearch 是基于 Redis 实现的,其能存储的数据量受限于 Redis 的内存容量,不太适合存储大规模的数据(内存昂贵,扩展能力较差)。
+2. 分布式能力较差:Elasticsearch 是为分布式环境设计的,可以轻松扩展到多个节点。虽然 RedisSearch 支持分布式部署,但在实际应用中可能会面临一些挑战,如数据分片、节点间通信、数据一致性等问题。
+3. 聚合功能较弱:Elasticsearch 提供了丰富的聚合功能,而 RediSearch 的聚合功能相对较弱,只支持简单的聚合操作。
+4. 生态较差:Elasticsearch 可以轻松和常见的一些系统/软件集成比如 Hadoop、Spark、Kibana,而 RedisSearch 则不具备该优势。
+
+Elasticsearch 适用于全文搜索、复杂查询、实时数据分析和聚合的场景,而 RediSearch 适用于快速数据存储、缓存和简单查询的场景。
+
+### 如何基于 Redis 实现延时任务?
+
+> 类似的问题:
+>
+> - 订单在 10 分钟后未支付就失效,如何用 Redis 实现?
+> - 红包 24 小时未被查收自动退还,如何用 Redis 实现?
+
+基于 Redis 实现延时任务的功能无非就下面两种方案:
+
+1. Redis 过期事件监听。
+2. Redisson 内置的延时队列。
+
+Redis 过期事件监听存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
+
+Redisson 内置的延时队列具备下面这些优势:
+
+1. **减少了丢消息的可能**:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
+2. **消息不存在重复消费问题**:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
+
+关于 Redis 实现延时任务的详细介绍,可以看我写的这篇文章:[如何基于 Redis 实现延时任务?](./redis-delayed-task.md)。
+
+## ⭐️Redis 数据类型
+
+关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/):
+
+- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
+- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
+
+### Redis 常用的数据类型有哪些?
+
+Redis 中比较常见的数据类型有下面这些:
+
+- **5 种基础数据类型**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
+- **3 种特殊数据类型**:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
+
+除了上面提到的之外,还有一些其他的比如 [Bloom filter(布隆过滤器)](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html)、Bitfield(位域)。
+
+### String 的应用场景有哪些?
+
+String 是 Redis 中最简单同时也是最常用的一个数据类型。它是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
+
+String 的常见应用场景如下:
+
+- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
+- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
+- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
+- ……
+
+关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
+
+### String 还是 Hash 存储对象数据更好呢?
+
+简单对比一下二者:
+
+- **对象存储方式**:String 存储的是序列化后的对象数据,存放的是整个对象,操作简单直接。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
+- **内存消耗**:Hash 通常比 String 更节省内存,特别是在字段较多且字段长度较短时。Redis 对小型 Hash 进行优化(如使用 ziplist 存储),进一步降低内存占用。
+- **复杂对象存储**:String 在处理多层嵌套或复杂结构的对象时更方便,因为无需处理每个字段的独立存储和操作。
+- **性能**:String 的操作通常具有 O(1) 的时间复杂度,因为它存储的是整个对象,操作简单直接,整体读写的性能较好。Hash 由于需要处理多个字段的增删改查操作,在字段较多且经常变动的情况下,可能会带来额外的性能开销。
+
+总结:
+
+- 在绝大多数情况下,**String** 更适合存储对象数据,尤其是当对象结构简单且整体读写是主要操作时。
+- 如果你需要频繁操作对象的部分字段或节省内存,**Hash** 可能是更好的选择。
+
+### String 的底层实现是什么?
+
+Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串)来作为底层实现。
+
+SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
+
+Redis7.0 的 SDS 的部分源码如下():
+
+```c
+/* Note: sdshdr5 is never used, we just access the flags byte directly.
+ * However is here to document the layout of type 5 SDS strings. */
+struct __attribute__ ((__packed__)) sdshdr5 {
+ unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr8 {
+ uint8_t len; /* used */
+ uint8_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr16 {
+ uint16_t len; /* used */
+ uint16_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr32 {
+ uint32_t len; /* used */
+ uint32_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr64 {
+ uint64_t len; /* used */
+ uint64_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+```
+
+通过源码可以看出,SDS 共有五种实现方式:SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
+
+| 类型 | 字节 | 位 |
+| -------- | ---- | --- |
+| sdshdr5 | < 1 | <8 |
+| sdshdr8 | 1 | 8 |
+| sdshdr16 | 2 | 16 |
+| sdshdr32 | 4 | 32 |
+| sdshdr64 | 8 | 64 |
+
+对于后四种实现都包含了下面这 4 个属性:
+
+- `len`:字符串的长度也就是已经使用的字节数。
+- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小。
+- `buf[]`:实际存储字符串的数组。
+- `flags`:低三位保存类型标志。
+
+SDS 相比于 C 语言中的字符串有如下提升:
+
+1. **可以避免缓冲区溢出**:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
+2. **获取字符串长度的复杂度较低**:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
+3. **减少内存分配次数**:为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
+4. **二进制安全**:C 语言中的字符串以空字符 `\0` 作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
+
+🤐 多提一嘴,很多文章里 SDS 的定义是下面这样的:
+
+```c
+struct sdshdr {
+ unsigned int len;
+ unsigned int free;
+ char buf[];
+};
+```
+
+这个也没错,Redis 3.2 之前就是这样定义的。后来,由于这种方式的定义存在问题,`len` 和 `free` 的定义用了 4 个字节,造成了浪费。Redis 3.2 之后,Redis 改进了 SDS 的定义,将其划分为了现在的 5 种类型。
+
+### 购物车信息用 String 还是 Hash 存储更好呢?
+
+由于购物车中的商品频繁修改和变动,购物车信息建议使用 Hash 存储:
+
+- 用户 id 为 key
+- 商品 id 为 field,商品数量为 value
+
+
+
+那用户购物车信息的维护具体应该怎么操作呢?
+
+- 用户添加商品就是往 Hash 里面增加新的 field 与 value;
+- 查询购物车信息就是遍历对应的 Hash;
+- 更改商品数量直接修改对应的 value 值(直接 set 或者做运算皆可);
+- 删除商品就是删除 Hash 中对应的 field;
+- 清空购物车直接删除对应的 key 即可。
+
+这里只是以业务比较简单的购物车场景举例,实际电商场景下,field 只保存一个商品 id 是没办法满足需求的。
+
+### 使用 Redis 实现一个排行榜怎么做?
+
+Redis 中有一个叫做 `Sorted Set`(有序集合)的数据类型经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
+
+相关的一些 Redis 命令:`ZRANGE`(从小到大排序)、`ZREVRANGE`(从大到小排序)、`ZREVRANK`(指定元素排名)。
+
+
+
+[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜,感兴趣的小伙伴可以看看。
+
+
+
+### Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+ 树?
+
+这道面试题很多大厂比较喜欢问,难度还是有点大的。
+
+- 平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)**。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
+- 红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
+- B+ 树 vs 跳表:B+ 树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+ 树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+ 树那样插入时发现失衡时还需要对节点分裂与合并。
+
+另外,我还单独写了一篇文章从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握:[Redis 为什么用跳表实现有序集合](https://javaguide.cn/database/redis/redis-skiplist.html)。
+
+### Set 的应用场景是什么?
+
+Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。
+
+`Set` 的常见应用场景如下:
+
+- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog` 更适合一些)、文章点赞、动态点赞等等。
+- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集)等等。
+- 需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。
+
+### 使用 Set 实现抽奖系统怎么做?
+
+如果想要使用 `Set` 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
+
+- `SADD key member1 member2 ...`:向指定集合添加一个或多个元素。
+- `SPOP key count`:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
+- `SRANDMEMBER key count`:随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
+
+### 使用 Bitmap 统计活跃用户怎么做?
+
+Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
+
+你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
+
+
+
+如果想要使用 Bitmap 统计活跃用户的话,可以使用日期(精确到天)作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1。
+
+初始化数据:
+
+```bash
+> SETBIT 20210308 1 1
+(integer) 0
+> SETBIT 20210308 2 1
+(integer) 0
+> SETBIT 20210309 1 1
+(integer) 0
+```
+
+统计 20210308~20210309 总活跃用户数:
+
+```bash
+> BITOP and desk1 20210308 20210309
+(integer) 1
+> BITCOUNT desk1
+(integer) 1
+```
+
+统计 20210308~20210309 在线活跃用户数:
+
+```bash
+> BITOP or desk2 20210308 20210309
+(integer) 1
+> BITCOUNT desk2
+(integer) 2
+```
+
+### HyperLogLog 适合什么场景?
+
+HyperLogLog (HLL) 是一种非常巧妙的概率性数据结构,它专门解决一类非常棘手的大数据问题:在海量数据中,用极小的内存,估算一个集合中不重复元素的数量,也就是我们常说的基数(Cardinality)
+
+HLL 做的最核心的权衡,就是用一点点精确度的损失,来换取巨大的内存空间节省。它给出的不是一个 100%精确的数字,而是一个带有很小标准误差(Redis 中默认是 0.81%)的近似值。
+
+**基于这个核心权衡,HyperLogLog 最适合以下特征的场景:**
+
+1. **数据量巨大,内存敏感:** 这是 HLL 的主战场。比如,要统计一个亿级日活 App 的每日独立访客数。如果用传统的 Set 来存储用户 ID,一个 ID 占几十个字节,上亿个 ID 可能需要几个 GB 甚至几十 GB 的内存,这在很多场景下是不可接受的。而 HLL,在 Redis 中只需要固定的 12KB 内存,就能处理天文数字级别的基数,这是一个颠覆性的优势。
+2. **对结果的精确度要求不是 100%:** 这是使用 HLL 的前提。比如,产品经理想知道一个热门帖子的 UV(独立访客数)是大约 1000 万还是 1010 万,这个细微的差别通常不影响商业决策。但如果场景是统计一个交易系统的准确交易笔数,那 HLL 就完全不适用,因为金融场景要求 100%的精确。
+
+**所以,HyperLogLog 具体的应用场景就非常清晰了:**
+
+- **网站/App 的 UV(Unique Visitor)统计:** 比如统计首页每天有多少个不同的 IP 或用户 ID 访问过。
+- **搜索引擎关键词统计:** 统计每天有多少个不同的用户搜索了某个关键词。
+- **社交网络互动统计:** 比如统计一条微博被多少个不同的用户转发过。
+
+在这些场景下,我们关心的是数量级和趋势,而不是个位数的差异。
+
+最后,Redis 的实现还非常智能,它内部会根据基数的大小,在**稀疏矩阵**(占用空间更小)和**稠密矩阵**(固定的 12KB)之间自动切换,进一步优化了内存使用。总而言之,当您需要对海量数据进行去重计数,并且可以接受微小误差时,HyperLogLog 就是不二之选。
+
+### 使用 HyperLogLog 统计页面 UV 怎么做?
+
+使用 HyperLogLog 统计页面 UV 主要需要用到下面这两个命令:
+
+- `PFADD key element1 element2 ...`:添加一个或多个元素到 HyperLogLog 中。
+- `PFCOUNT key1 key2`:获取一个或者多个 HyperLogLog 的唯一计数。
+
+1、将访问指定页面的每个用户 ID 添加到 `HyperLogLog` 中。
+
+```bash
+PFADD PAGE_1:UV USER1 USER2 ...... USERn
+```
+
+2、统计指定页面的 UV。
+
+```bash
+PFCOUNT PAGE_1:UV
+```
+
+### 如果我想判断一个元素是否不在海量元素集合中,用什么数据类型?
+
+这是布隆过滤器的经典应用场景。布隆过滤器可以告诉你一个元素一定不存在或者可能存在,它也有极高的空间效率和一定的误判率,但绝不会漏报。也就是说,布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
+
+Bloom Filter 的简单原理图如下:
+
+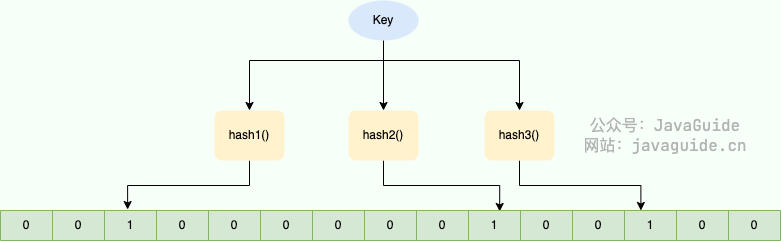
+
+当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
+
+如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+
+## ⭐️Redis 持久化机制(重要)
+
+Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化)相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题:[Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html)。
+
+## ⭐️Redis 线程模型(重要)
+
+对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作,Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
+
+### Redis 单线程模型了解吗?
+
+**Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型**(Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
+
+《Redis 设计与实现》有一段话是这样介绍文件事件处理器的,我觉得写得挺不错。
+
+> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。
+>
+> - 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
+> - 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
+>
+> **虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字**,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
+
+**既然是单线程,那怎么监听大量的客户端连接呢?**
+
+Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
+
+这样的好处非常明显:**I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗**(和 NIO 中的 `Selector` 组件很像)。
+
+文件事件处理器(file event handler)主要是包含 4 个部分:
+
+- 多个 socket(客户端连接)
+- IO 多路复用程序(支持多个客户端连接的关键)
+- 文件事件分派器(将 socket 关联到相应的事件处理器)
+- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
+
+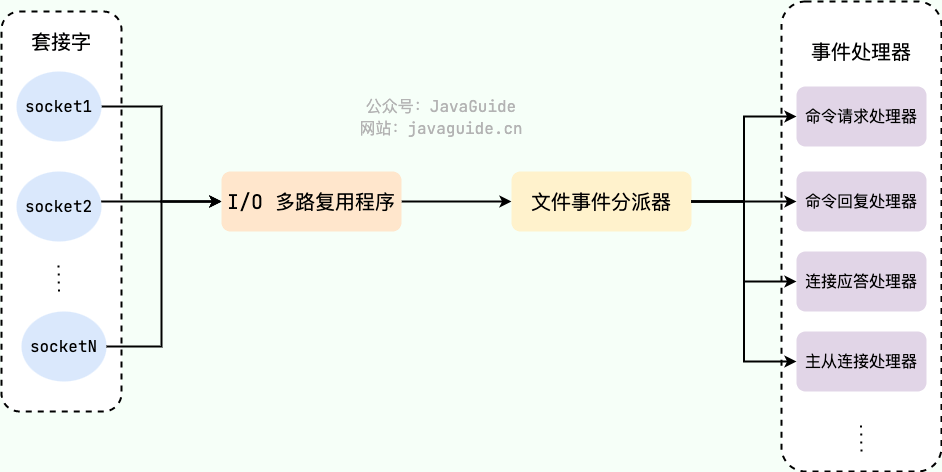
+
+### Redis6.0 之前为什么不使用多线程?
+
+虽然说 Redis 是单线程模型,但实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+
+不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”,从而减少对主线程的影响。
+
+为此,Redis 4.0 之后新增了几个异步命令:
+
+- `UNLINK`:可以看作是 `DEL` 命令的异步版本。
+- `FLUSHALL ASYNC`:用于清空所有数据库的所有键,不限于当前 `SELECT` 的数据库。
+- `FLUSHDB ASYNC`:用于清空当前 `SELECT` 数据库中的所有键。
+
+
+
+总的来说,直到 Redis 6.0 之前,Redis 的主要操作仍然是单线程处理的。
+
+**那 Redis6.0 之前为什么不使用多线程?** 我觉得主要原因有 3 点:
+
+- 单线程编程容易并且更容易维护;
+- Redis 的性能瓶颈不在 CPU,主要在内存和网络;
+- 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
+
+相关阅读:[为什么 Redis 选择单线程模型?](https://draveness.me/whys-the-design-redis-single-thread/)。
+
+### Redis6.0 之后为何引入了多线程?
+
+**Redis6.0 引入多线程主要是为了提高网络 IO 读写性能**,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
+
+虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了,执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
+
+Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要设置 IO 线程数 > 1,需要修改 redis 配置文件 `redis.conf`:
+
+```bash
+io-threads 4 #设置1的话只会开启主线程,官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
+```
+
+另外:
+
+- io-threads 的个数一旦设置,不能通过 config 动态设置。
+- 当设置 ssl 后,io-threads 将不工作。
+
+开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 `redis.conf`:
+
+```bash
+io-threads-do-reads yes
+```
+
+但是官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启。
+
+相关阅读:
+
+- [Redis 6.0 新特性-多线程连环 13 问!](https://mp.weixin.qq.com/s/FZu3acwK6zrCBZQ_3HoUgw)
+- [Redis 多线程网络模型全面揭秘](https://segmentfault.com/a/1190000039223696)(推荐)
+
+### Redis 后台线程了解吗?
+
+我们虽然经常说 Redis 是单线程模型(主要逻辑是单线程完成的),但实际还有一些后台线程用于执行一些比较耗时的操作:
+
+- 通过 `bio_close_file` 后台线程来释放 AOF / RDB 等过程中产生的临时文件资源。
+- 通过 `bio_aof_fsync` 后台线程调用 `fsync` 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘(AOF 文件)。
+- 通过 `bio_lazy_free` 后台线程释放大对象(已删除)占用的内存空间.
+
+在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:):
+
+```java
+#ifndef __BIO_H
+#define __BIO_H
+
+/* Exported API */
+void bioInit(void);
+void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3);
+unsigned long long bioPendingJobsOfType(int type);
+unsigned long long bioWaitStepOfType(int type);
+time_t bioOlderJobOfType(int type);
+void bioKillThreads(void);
+
+/* Background job opcodes */
+#define BIO_CLOSE_FILE 0 /* Deferred close(2) syscall. */
+#define BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */
+#define BIO_LAZY_FREE 2 /* Deferred objects freeing. */
+#define BIO_NUM_OPS 3
+
+#endif
+```
+
+关于 Redis 后台线程的详细介绍可以查看 [Redis 6.0 后台线程有哪些?](https://juejin.cn/post/7102780434739626014) 这篇就文章。
+
+## ⭐️Redis 内存管理
+
+### Redis 给缓存数据设置过期时间有什么用?
+
+一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
+
+内存是有限且珍贵的,如果不对缓存数据设置过期时间,那内存占用就会一直增长,最终可能会导致 OOM 问题。通过设置合理的过期时间,Redis 会自动删除暂时不需要的数据,为新的缓存数据腾出空间。
+
+Redis 自带了给缓存数据设置过期时间的功能,比如:
+
+```bash
+127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
+(integer) 1
+127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
+OK
+127.0.0.1:6379> ttl key # 查看数据还有多久过期
+(integer) 56
+```
+
+注意 ⚠️:Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外,`persist` 命令可以移除一个键的过期时间。
+
+**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
+
+很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效。
+
+如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
+
+### Redis 是如何判断数据是否过期的呢?
+
+Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
+
+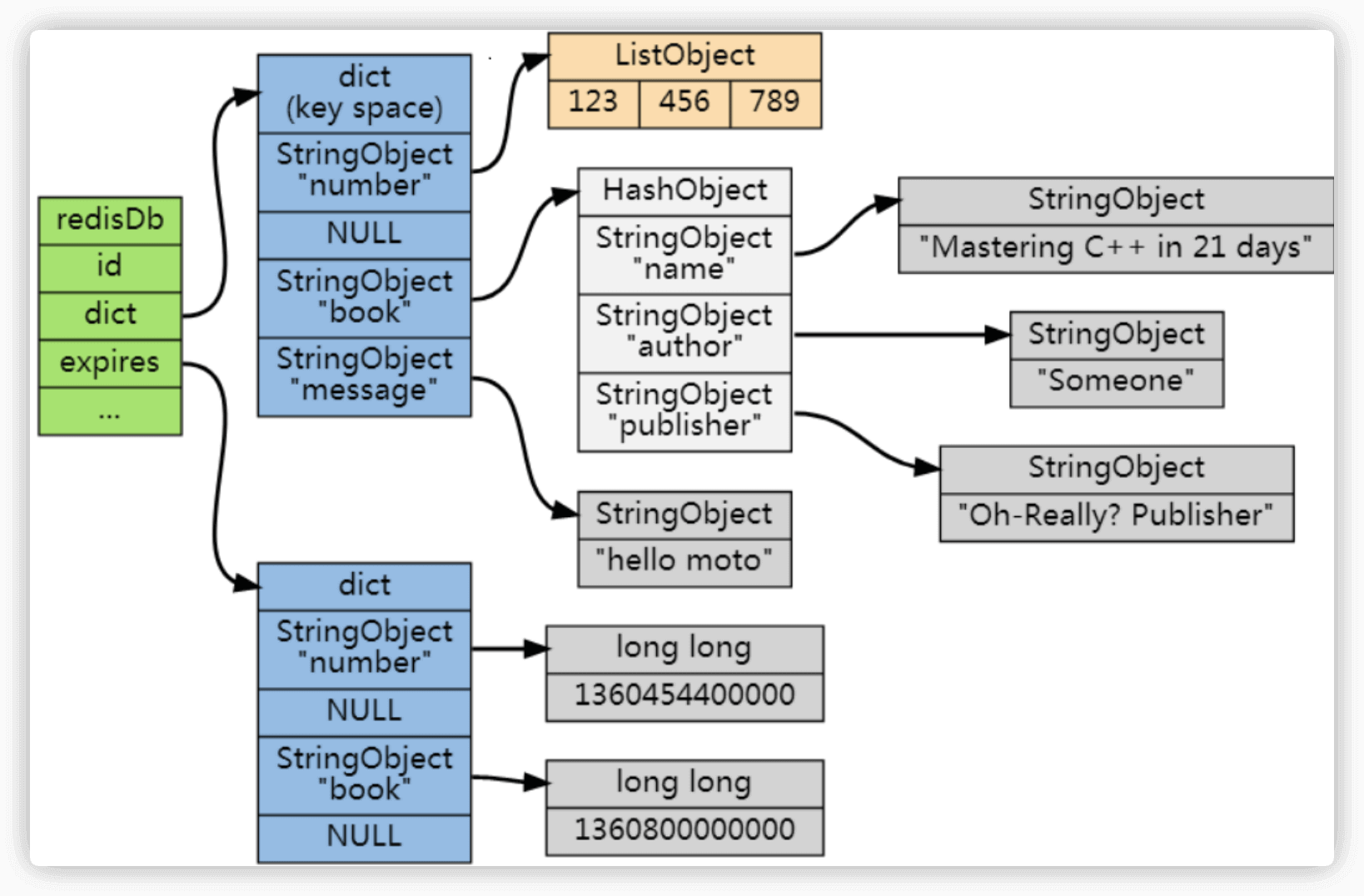
+
+过期字典是存储在 redisDb 这个结构里的:
+
+```c
+typedef struct redisDb {
+ ...
+
+ dict *dict; //数据库键空间,保存着数据库中所有键值对
+ dict *expires // 过期字典,保存着键的过期时间
+ ...
+} redisDb;
+```
+
+在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
+
+### Redis 过期 key 删除策略了解么?
+
+如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
+
+常用的过期数据的删除策略就下面这几种:
+
+1. **惰性删除**:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除**:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
+3. **延迟队列**:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
+4. **定时删除**:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
+
+**Redis 采用的是那种删除策略呢?**
+
+Redis 采用的是 **定期删除+惰性/懒汉式删除** 结合的策略,这也是大部分缓存框架的选择。定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,结合起来使用既能兼顾 CPU 友好,又能兼顾内存友好。
+
+下面是我们详细介绍一下 Redis 中的定期删除具体是如何做的。
+
+Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。这也就解释了为什么有的 key 过期了,并没有被删除。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+
+另外,定期删除还会受到执行时间和过期 key 的比例的影响:
+
+- 执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间。
+- 如果这一批过期的 key 比例超过一个比例,就会重复执行此删除流程,以更积极地清理过期 key。相应地,如果过期的 key 比例低于这个比例,就会中断这一次定期删除循环,避免做过多的工作而获得很少的内存回收。
+
+Redis 7.2 版本的执行时间阈值是 **25ms**,过期 key 比例设定值是 **10%**。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
+#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
+#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
+ we do extra efforts. */
+```
+
+**每次随机抽查数量是多少?**
+
+`expire.c` 中定义了每次随机抽查的数量,Redis 7.2 版本为 20,也就是说每次会随机选择 20 个设置了过期时间的 key 判断是否过期。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
+```
+
+**如何控制定期删除的执行频率?**
+
+在 Redis 中,定期删除的频率是由 **hz** 参数控制的。hz 默认为 10,代表每秒执行 10 次,也就是每秒钟进行 10 次尝试来查找并删除过期的 key。
+
+hz 的取值范围为 1~500。增大 hz 参数的值会提升定期删除的频率。如果你想要更频繁地执行定期删除任务,可以适当增加 hz 的值,但这会增加 CPU 的使用率。根据 Redis 官方建议,hz 的值不建议超过 100,对于大部分用户使用默认的 10 就足够了。
+
+下面是 hz 参数的官方注释,我翻译了其中的重要信息(Redis 7.2 版本)。
+
+
+
+There is also a similar parameter **dynamic-hz**. After this parameter is turned on, Redis will dynamically calculate a value based on hz. Redis provides and enables by default the ability to use adaptive hz values,
+
+Both parameters are in the Redis configuration file `redis.conf`:
+
+```properties
+# Default is 10
+hz 10
+# Enabled by default
+dynamic-hz yes
+```
+
+One more thing to mention, in addition to the periodic task of regularly deleting expired keys, there are also other periodic tasks such as closing timed-out client connections and updating statistics. The execution frequency of these periodic tasks is also determined by the hz parameter.
+
+**Why doesn’t regular deletion delete all expired keys? **
+
+This will have too big an impact on performance. If we have a very large number of keys, traversing the checks one by one is very time-consuming and will seriously affect performance. Redis designed this strategy to balance memory and performance.
+
+**Why not delete the key immediately after it expires? Wouldn't this waste a lot of memory space? **
+
+Because it is not easy to do, or the cost of this deletion method is too high. If we use the delay queue as the deletion strategy, there are the following problems:
+
+1. The overhead of the queue itself may be large: when there are many keys, a delay queue may not be able to accommodate them.
+2. Maintaining the delay queue is too troublesome: modifying the expiration time of a key requires adjusting its position in the delay queue, and concurrency control also needs to be introduced.
+
+### What should I do if a large number of keys expire together?
+
+When a large number of keys in Redis expire at the same point in time, the following problems may occur:
+
+- **Increased request latency**: Redis needs to consume CPU resources when processing expired keys. If the number of expired keys is large, it will cause the CPU usage of the Redis instance to increase, which will affect the processing speed of other requests, causing increased latency.
+- **Memory usage is too high**: Although expired keys have expired, they will still occupy memory space before Redis actually deletes them. If expired keys are not cleaned up in time, it may cause excessive memory usage or even cause a memory overflow.
+
+To avoid these problems, you can take the following options:
+
+1. **Try to avoid centralized expiration of keys**: Try to be as random as possible when setting the expiration time of keys.
+2. **Enable lazy free mechanism**: Modify the `redis.conf` configuration file and set the `lazyfree-lazy-expire` parameter to `yes` to enable the lazy free mechanism. After the lazy free mechanism is enabled, Redis will asynchronously delete expired keys in the background without blocking the main thread, thereby reducing the impact on Redis performance.
+
+### Do you understand the Redis memory elimination strategy?
+
+> Related questions: There are 20 million data in MySQL, but only 20 million data are stored in Redis. How to ensure that the data in Redis are hot data?
+
+Redis's memory elimination policy will only be triggered when the running memory reaches the configured maximum memory threshold, which is defined through the `maxmemory` parameter of `redis.conf`. Under 64-bit operating systems, `maxmemory` defaults to 0, which means there is no limit on the memory size. Under 32-bit operating systems, the default maximum memory value is 3GB.
+
+You can use the command `config get maxmemory` to view the value of `maxmemory`.
+
+```bash
+> config get maxmemory
+maxmemory
+0
+```
+
+Redis provides 6 memory elimination strategies:
+
+1. **volatile-lru (least recently used)**: Select the least recently used data from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+2. **volatile-ttl**: Select the data to be expired from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+3. **volatile-random**: Randomly select data for elimination from the data set (`server.db[i].expires`) with expiration time set.
+4. **allkeys-lru (least recently used)**: Remove the least recently used data from the data set (`server.db[i].dict`).
+5. **allkeys-random**: Randomly select data for elimination from the data set (`server.db[i].dict`).
+6. **no-eviction** (default memory eviction policy): It is forbidden to evict data. When the memory is not enough to accommodate newly written data, an error will be reported for the new write operation.
+
+After version 4.0, the following two types are added:
+
+7. **volatile-lfu (least frequently used)**: Select the least frequently used data from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+8. **allkeys-lfu (least frequently used)**: Remove the least frequently used data from the data set (`server.db[i].dict`).
+
+`allkeys-xxx` means to eliminate data from all key values, while `volatile-xxx` means to eliminate data from key values with an expiration time set.
+
+The enumeration array of memory elimination strategies is defined in `config.c`:
+
+```c
+configEnum maxmemory_policy_enum[] = {
+ {"volatile-lru", MAXMEMORY_VOLATILE_LRU},
+ {"volatile-lfu", MAXMEMORY_VOLATILE_LFU},
+ {"volatile-random",MAXMEMORY_VOLATILE_RANDOM},
+ {"volatile-ttl",MAXMEMORY_VOLATILE_TTL},
+ {"allkeys-lru",MAXMEMORY_ALLKEYS_LRU},
+ {"allkeys-lfu",MAXMEMORY_ALLKEYS_LFU},
+ {"allkeys-random",MAXMEMORY_ALLKEYS_RANDOM},
+ {"noeviction",MAXMEMORY_NO_EVICTION},
+ {NULL, 0}
+};
+```
+
+You can use the `config get maxmemory-policy` command to view the current Redis memory elimination policy.
+
+```bash
+> config get maxmemory-policy
+maxmemory-policy
+noeviction
+```
+
+You can modify the memory elimination policy through the `config set maxmemory-policy memory elimination policy` command, which will take effect immediately. However, it will become invalid after restarting Redis in this way. Modifying the `maxmemory-policy` parameter in `redis.conf` will not be invalidated by restarting. However, it needs to be restarted before the modification can take effect.
+
+```properties
+maxmemory-policy noeviction
+```
+
+For detailed instructions on the elimination strategy, please refer to the official Redis documentation: .
+
+## Reference
+
+- "Redis Development and Operation and Maintenance"
+- "Redis Design and Implementation"
+- "Redis Core Principles and Practical Combat"
+- Redis command manual:
+- RedisSearch Ultimate User Guide, you deserve it! :
+- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-questions-02.en.md b/docs_en/database/redis/redis-questions-02.en.md
new file mode 100644
index 00000000000..2a520856220
--- /dev/null
+++ b/docs_en/database/redis/redis-questions-02.en.md
@@ -0,0 +1,820 @@
+---
+title: Summary of common Redis interview questions (Part 2)
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis interview questions, Redis transactions, Redis performance optimization, Redis cache penetration, Redis cache breakdown, Redis cache avalanche, Redis bigkey, Redis hotkey, Redis slow query, Redis memory fragmentation, Redis cluster, Redis Sentinel, Redis Cluster, Redis pipeline, Redis Lua script
+ - - meta
+ - name: description
+ content: Summary of the latest Redis interview questions (Part 2): In-depth analysis of Redis transaction principles, performance optimization (pipeline/Lua/bigkey/hotkey), cache penetration/breakdown/avalanche solutions, slow queries and memory fragmentation, and detailed explanations of Redis Sentinel and Cluster clusters. Help you easily cope with back-end technical interviews!
+---
+
+
+
+## Redis transactions
+
+### What is a Redis transaction?
+
+You can understand transactions in Redis as: **Redis transactions provide a function to package multiple command requests. Then, execute all the packaged commands in sequence without being interrupted midway. **
+
+Redis transactions are rarely used in actual development, and their functions are relatively useless. Do not confuse them with the transactions of relational databases that we usually understand.
+
+In addition to not meeting atomicity and durability, each command in the transaction will interact with the Redis server through the network, which is a waste of resources. Obviously it is enough to execute multiple commands in batches at one time, but this kind of operation is really incomprehensible.
+
+Therefore, Redis transactions are not recommended for daily development.
+
+### How to use Redis transactions?
+
+Redis can implement transaction functions through commands such as **`MULTI`, `EXEC`, `DISCARD` and `WATCH`**.
+
+```bash
+> MULTI
+OK
+> SET PROJECT "JavaGuide"
+QUEUED
+>GET PROJECT
+QUEUED
+> EXEC
+1) OK
+2) "JavaGuide"
+```
+
+You can enter multiple commands after the [`MULTI`](https://redis.io/commands/multi) command. Redis will not execute these commands immediately, but will put them in the queue. When the [`EXEC`](https://redis.io/commands/exec) command is called, all commands will be executed.
+
+The process goes like this:
+
+1. Start transaction (`MULTI`);
+2. Command enqueue (batch operation of Redis commands, executed in first-in, first-out (FIFO) order);
+3. Execute transaction (`EXEC`).
+
+You can also cancel a transaction through the [`DISCARD`](https://redis.io/commands/discard) command, which will clear all commands saved in the transaction queue.
+
+```bash
+> MULTI
+OK
+> SET PROJECT "JavaGuide"
+QUEUED
+>GET PROJECT
+QUEUED
+> DISCARD
+OK
+```
+
+You can monitor the specified Key through the [`WATCH`](https://redis.io/commands/watch) command. When calling the `EXEC` command to execute a transaction, if a Key monitored by the `WATCH` command is modified by **other clients/Session**, the entire transaction will not be executed.
+
+```bash
+# client 1
+> SET PROJECT "RustGuide"
+OK
+> WATCH PROJECT
+OK
+> MULTI
+OK
+> SET PROJECT "JavaGuide"
+QUEUED
+
+# client 2
+# Modify the value of PROJECT before client 1 executes the EXEC command to commit the transaction
+> SET PROJECT "GoGuide"
+
+# client 1
+# The modification failed because the value of PROJECT was modified by client 2
+> EXEC
+(nil)
+>GET PROJECT
+"GoGuide"
+```
+
+However, if **WATCH** and **Transaction** are in the same Session, and the modification of the Key monitored by **WATCH** occurs within the transaction, the transaction can be executed successfully (related issue: [Different effects when the WATCH command encounters the MULTI command](https://github.com/Snailclimb/JavaGuide/issues/1714)).
+
+Modify the Key monitored by WATCH within the transaction:
+
+```bash
+> SET PROJECT "JavaGuide"
+OK
+> WATCH PROJECT
+OK
+> MULTI
+OK
+> SET PROJECT "JavaGuide1"
+QUEUED
+> SET PROJECT "JavaGuide2"
+QUEUED
+> SET PROJECT "JavaGuide3"
+QUEUED
+> EXEC
+1) OK
+2) OK
+3) OK
+127.0.0.1:6379> GET PROJECT
+"JavaGuide3"
+```
+
+Modify the Key monitored by WATCH outside the transaction:
+
+```bash
+> SET PROJECT "JavaGuide"
+OK
+> WATCH PROJECT
+OK
+> SET PROJECT "JavaGuide2"
+OK
+> MULTI
+OK
+> GET USER
+QUEUED
+> EXEC
+(nil)
+```
+
+The relevant introduction to the Redis official website [https://redis.io/topics/transactions](https://redis.io/topics/transactions) is as follows:
+
+
+
+### Do Redis transactions support atomicity?
+
+Redis transactions are different from the relational database transactions we usually understand. We know that transactions have four major characteristics: **1. Atomicity**, **2. Isolation**, **3. Durability**, **4. Consistency**.
+
+1. **Atomicity**: A transaction is the smallest execution unit and does not allow division. The atomicity of transactions ensures that actions either complete completely or have no effect at all;
+2. **Isolation**: When accessing the database concurrently, a user's transaction will not be interfered by other transactions, and the database is independent between concurrent transactions;
+3. **Durability**: after a transaction is committed. Its changes to the data in the database are durable and should not have any impact even if the database fails;
+4. **Consistency**: The data remains consistent before and after executing a transaction, and the results of multiple transactions reading the same data are the same.
+
+In the case of a Redis transaction running error, except for the command with an error during execution, other commands can be executed normally. Moreover, Redis transactions do not support rollback operations. Therefore, Redis transactions do not actually satisfy atomicity.
+
+The Redis official website also explains why it does not support rollback. To put it simply, Redis developers feel that there is no need to support rollback, which is simpler, more convenient and has better performance. Redis developers feel that even command execution errors should be discovered during the development process rather than during the production process.
+
+
+
+**Related issues**:
+
+- [issue#452: Regarding the issue that Redis transactions do not satisfy atomicity](https://github.com/Snailclimb/JavaGuide/issues/452).
+- [Issue#491: About Redis without transaction rollback? ](https://github.com/Snailclimb/JavaGuide/issues/491).
+
+### Do Redis transactions support persistence?
+
+One important thing that makes Redis different from Memcached is that Redis supports persistence and supports 3 persistence methods:
+
+- Snapshotting (RDB);
+- Append-only file (AOF);
+- Hybrid persistence of RDB and AOF (new in Redis 4.0).
+
+Compared with RDB persistence, AOF persistence has better real-time performance. There are three different AOF persistence methods (`fsync` strategy) in the Redis configuration file. They are:
+
+```bash
+appendfsync always #Every time a data modification occurs, the fsync function will be called to synchronize the AOF file. After fsync is completed, the thread returns, which will seriously reduce the speed of Redis.
+appendfsync everysec #Call the fsync function to synchronize the AOF file once every second
+appendfsync no #Let the operating system decide when to synchronize, usually every 30 seconds
+```
+
+Data loss will occur when the `fsync` policy of AOF persistence is no and everysec. Always can basically meet the persistence requirements, but the performance is too poor and will not be used in the actual development process.
+
+Therefore, the durability of Redis transactions cannot be guaranteed.### 如何解决 Redis 事务的缺陷?
+
+Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常类似。我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
+
+一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
+
+不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此,**严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。**
+
+如果想要让 Lua 脚本中的命令全部执行,必须保证语句语法和命令都是对的。
+
+另外,Redis 7.0 新增了 [Redis functions](https://redis.io/docs/latest/develop/programmability/functions-intro/) 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本。
+
+## ⭐️Redis 性能优化(重要)
+
+除了下面介绍的内容之外,再推荐两篇不错的文章:
+
+- [你的 Redis 真的变慢了吗?性能优化如何做 - 阿里开发者](https://mp.weixin.qq.com/s/nNEuYw0NlYGhuKKKKoWfcQ)。
+- [Redis 常见阻塞原因总结 - JavaGuide](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
+
+### 使用批量操作减少网络传输
+
+一个 Redis 命令的执行可以简化为以下 4 步:
+
+1. 发送命令;
+2. 命令排队;
+3. 命令执行;
+4. 返回结果。
+
+其中,第 1 步和第 4 步耗费时间之和称为 **Round Trip Time(RTT,往返时间)**,也就是数据在网络上传输的时间。
+
+使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
+
+另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在 `read()` 和 `write()` 系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:。
+
+#### 原生批量操作命令
+
+Redis 中有一些原生支持批量操作的命令,比如:
+
+- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
+- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
+- `SADD`(向指定集合添加一个或多个元素)
+- ……
+
+不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
+
+整个步骤的简化版如下(通常由 Redis 客户端实现,无需我们自己再手动实现):
+
+1. 找到 key 对应的所有 hash slot;
+2. 分别向对应的 Redis 节点发起 `MGET` 请求获取数据;
+3. 等待所有请求执行结束,重新组装结果数据,保持跟入参 key 的顺序一致,然后返回结果。
+
+如果想要解决这个多次网络传输的问题,比较常用的办法是自己维护 key 与 slot 的关系。不过这样不太灵活,虽然带来了性能提升,但同样让系统复杂性提升。
+
+> Redis Cluster 并没有使用一致性哈希,采用的是 **哈希槽分区**,每一个键值对都属于一个 **hash slot(哈希槽)**。当客户端发送命令请求的时候,需要先根据 key 通过上面的计算公式找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标 Redis 节点。
+>
+> 我在 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 这篇文章中详细介绍了 Redis Cluster 这部分的内容,感兴趣地可以看看。
+
+#### pipeline
+
+对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
+
+与 `MGET`、`MSET` 等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
+
+原生批量操作命令和 pipeline 的是有区别的,使用的时候需要注意:
+
+- 原生批量操作命令是原子操作,pipeline 是非原子操作。
+- pipeline 可以打包不同的命令,原生批量操作命令不可以。
+- 原生批量操作命令是 Redis 服务端支持实现的,而 pipeline 需要服务端和客户端的共同实现。
+
+顺带补充一下 pipeline 和 Redis 事务的对比:
+
+- 事务是原子操作,pipeline 是非原子操作。两个不同的事务不会同时运行,而 pipeline 可以同时以交错方式执行。
+- Redis 事务中每个命令都需要发送到服务端,而 Pipeline 只需要发送一次,请求次数更少。
+
+> 事务可以看作是一个原子操作,但其实并不满足原子性。当我们提到 Redis 中的原子操作时,主要指的是这个操作(比如事务、Lua 脚本)不会被其他操作(比如其他事务、Lua 脚本)打扰,并不能完全保证这个操作中的所有写命令要么都执行要么都不执行。这主要也是因为 Redis 是不支持回滚操作。
+
+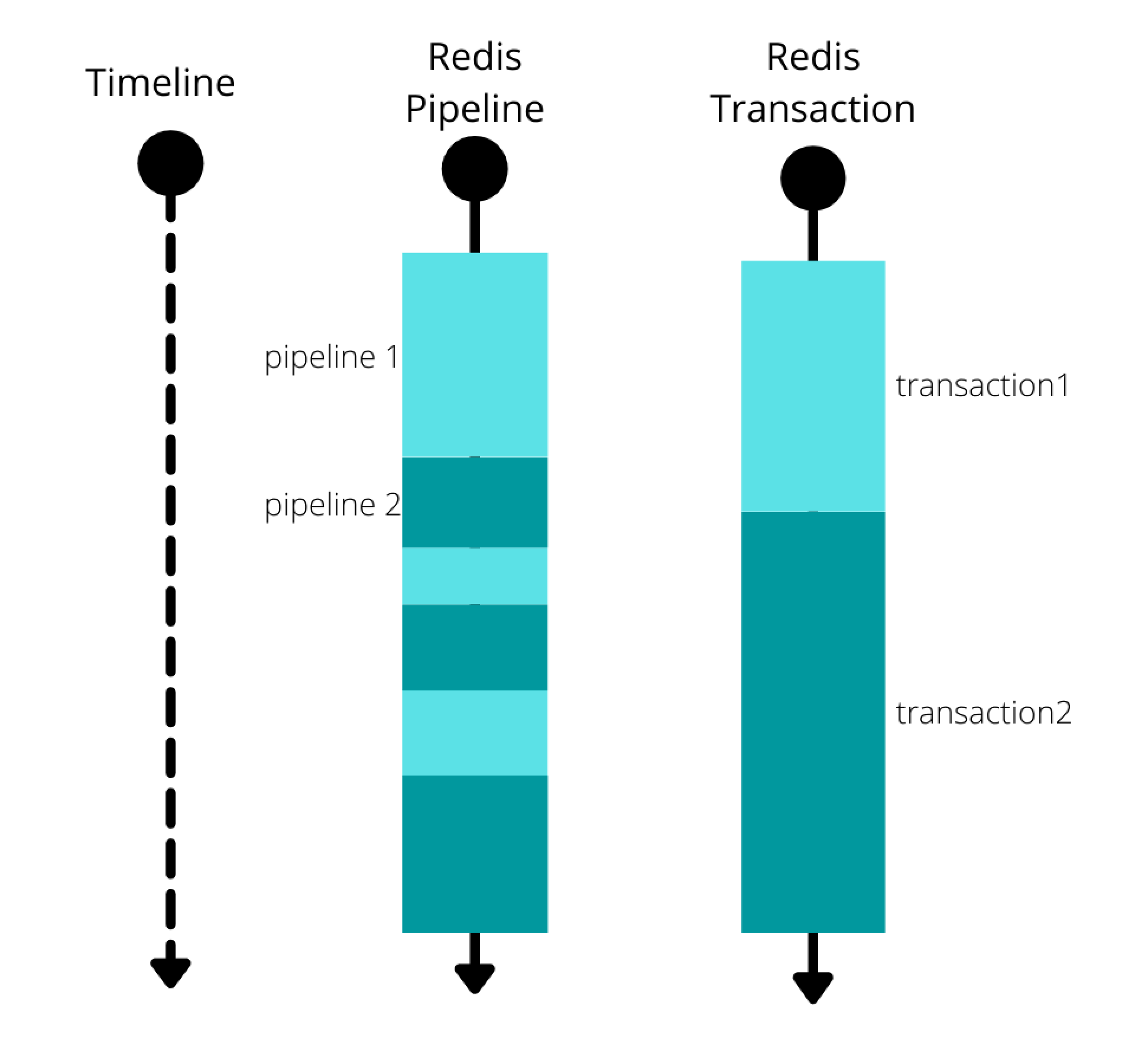
+
+另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 **Lua 脚本**。
+
+#### Lua 脚本
+
+Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 **原子操作**。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
+
+并且,Lua 脚本中支持一些简单的逻辑处理比如使用命令读取值并在 Lua 脚本中进行处理,这同样是 pipeline 所不具备的。
+
+不过, Lua 脚本依然存在下面这些缺陷:
+
+- 如果 Lua 脚本运行时出错并中途结束,之后的操作不会进行,但是之前已经发生的写操作不会撤销,所以即使使用了 Lua 脚本,也不能实现类似数据库回滚的原子性。
+- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。
+
+### 大量 key 集中过期问题
+
+我在前面提到过:对于过期 key,Redis 采用的是 **定期删除+惰性/懒汉式删除** 策略。
+
+定期删除执行过程中,如果突然遇到大量过期 key 的话,客户端请求必须等待定期清理过期 key 任务线程执行完成,因为这个这个定期任务线程是在 Redis 主线程中执行的。这就导致客户端请求没办法被及时处理,响应速度会比较慢。
+
+**如何解决呢?** 下面是两种常见的方法:
+
+1. 给 key 设置随机过期时间。
+2. 开启 lazy-free(惰性删除/延迟释放)。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
+
+个人建议不管是否开启 lazy-free,我们都尽量给 key 设置随机过期时间。
+
+### Redis bigkey(大 Key)
+
+#### 什么是 bigkey?
+
+简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- String 类型的 value 超过 1MB
+- The value of a composite type (List, Hash, Set, Sorted Set, etc.) contains more than 5000 elements (however, for a value of a composite type, the more elements it contains, the more memory it takes up).
+
+
+
+#### How did bigkey come about? What's the harm?
+
+Bigkey is usually generated for the following reasons:
+
+- Improper program design, such as directly using the String type to store binary data corresponding to larger files.
+- Inadequate consideration of the data scale of the business. For example, when using collection types, the rapid growth of data volume was not considered.
+- Failure to clean up junk data in time, such as a large number of redundant useless key-value pairs in the hash.
+
+In addition to consuming more memory space and bandwidth, bigkey will also have a relatively large impact on performance.
+
+In this article [Summary of Common Redis Blocking Causes](./redis-common-blocking-problems-summary.md) we mentioned that large keys can also cause blocking problems. Specifically, it is mainly reflected in the following three aspects:
+
+1. Client timeout blocking: Since Redis executes commands in a single thread, and it takes a long time to operate large keys, Redis will be blocked. From the perspective of the client, there will be no response for a long time.
+2. Network blocking: Each time a large key is obtained, the network traffic is large. If the size of a key is 1 MB and the number of visits per second is 1,000, then 1,000 MB of traffic will be generated per second, which is catastrophic for servers with ordinary Gigabit network cards.
+3. Working thread blocking: If you use del to delete a large key, the working thread will be blocked, making it impossible to process subsequent commands.
+
+The blocking problem caused by large keys will further affect master-slave synchronization and cluster expansion.
+
+In summary, there are many potential problems caused by big keys, and we should try to avoid the existence of big keys in Redis.
+
+#### How to discover bigkey?
+
+**1. Use the `--bigkeys` parameter that comes with Redis to search. **
+
+```bash
+# redis-cli -p 6379 --bigkeys
+
+# Scanning the entire keyspace to find biggest keys as well as
+# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
+# per 100 SCAN commands (not usually needed).
+
+[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes
+[00.00%] Biggest list found so far '"my-list"' with 17 items
+
+-------- summary -------
+
+Sampled 5 keys in the keyspace!
+Total key length in bytes is 264 (avg len 52.80)
+
+Biggest list found '"my-list"' has 17 items
+Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' has 4437 bytes
+
+1 lists with 17 items (20.00% of keys, avg size 17.00)
+0 hashes with 0 fields (00.00% of keys, avg size 0.00)
+4 strings with 4831 bytes (80.00% of keys, avg size 1207.75)
+0 streams with 0 entries (00.00% of keys, avg size 0.00)
+0 sets with 0 members (00.00% of keys, avg size 0.00)
+0 zsets with 0 members (00.00% of keys, avg size 0.00
+```
+
+From the running results of this command, we can see that this command will scan (Scan) all keys in Redis, which will have a slight impact on the performance of Redis. Moreover, this method can only find the top 1 bigkey of each data structure (the String data type that takes up the largest memory, and the composite data type that contains the most elements). However, having many elements in a key does not mean that it takes up more memory. We need to make further judgments based on specific business conditions.
+
+When executing this command online, in order to reduce the impact on Redis, you need to specify the `-i` parameter to control the frequency of scanning. `redis-cli -p 6379 --bigkeys -i 3` means that the rest interval after each scan during the scanning process is 3 seconds.
+
+**2. Use the SCAN command that comes with Redis**
+
+The `SCAN` command can return matching keys according to a certain pattern and number. After obtaining the key, you can use `STRLEN`, `HLEN`, `LLEN` and other commands to return its length or number of members.
+
+| Data structure | Command | Complexity | Result (corresponding to key) |
+| ---------- | ------ | ------ | ------------------ |
+| String | STRLEN | O(1) | The length of the string value |
+| Hash | HLEN | O(1) | Number of fields in the hash table |
+| List | LLEN | O(1) | Number of elements in the list |
+| Set | SCARD | O(1) | Number of set elements |
+| Sorted Set | ZCARD | O(1) | Number of elements in a sorted set |
+
+For collection types, you can also use the `MEMORY USAGE` command (Redis 4.0+). This command will return the memory space occupied by key-value pairs.
+
+**3. Use open source tools to analyze RDB files. **
+
+Find big keys by analyzing RDB files. The premise of this solution is that your Redis uses RDB persistence.
+
+There are ready-made codes/tools available online that can be used directly:
+
+- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools): A tool written in Python language to analyze Redis RDB snapshot files.
+- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys): A tool written in Go language to analyze Redis's RDB snapshot file, with better performance.
+
+**4. Use the Redis analysis service of the public cloud. **
+
+If you are using the public cloud Redis service, you can see if it provides key analysis function (usually it does).
+
+Here we take Alibaba Cloud Redis as an example. It supports bigkey real-time analysis and discovery. The document address is: .
+
+
+
+#### How to deal with bigkey?
+
+Common processing and optimization methods for bigkey are as follows (these methods can be used in conjunction):
+
+- **Split bigkey**: Split a bigkey into multiple small keys. For example, a Hash containing tens of thousands of fields is split into multiple Hash according to a certain strategy (such as secondary hashing).
+- **Manual Cleanup**: Redis 4.0+ can use the `UNLINK` command to asynchronously delete one or more specified keys. For Redis 4.0 and below, you can consider using the `SCAN` command in combination with the `DEL` command to delete in batches.
+- **Adopt appropriate data structures**: For example, do not use String to save file binary data, use HyperLogLog to count page UV, and Bitmap to save status information (0/1).
+- **Turn on lazy-free (lazy deletion/delayed release)**: The lazy-free feature was introduced in Redis 4.0. It means that Redis uses an asynchronous method to delay the release of the memory used by the key, and hands the operation to a separate sub-thread to avoid blocking the main thread.
+
+### Redis hotkey (hot key)
+
+#### What is a hotkey?
+
+If a key is accessed more often and significantly more than other keys, then this key can be regarded as a hotkey. For example, if a Redis instance processes 5,000 requests per second, and a certain key has 2,000 visits per second, then this key can be regarded as a hotkey.
+
+The main reason for the emergence of hotkey is the sudden increase in the number of visits to a certain hot data, such as major hot search events and products participating in flash sales.#### What are the dangers of hotkey?
+
+Processing hotkeys consumes a lot of CPU and bandwidth and may affect the normal processing of other requests by the Redis instance. In addition, if the sudden request to access the hotkey exceeds the processing capacity of Redis, Redis will directly crash. In this case, a large number of requests will fall on the later database, possibly causing the database to crash.
+
+Therefore, hotkey is likely to become the bottleneck of system performance and needs to be optimized separately to ensure high availability and stability of the system.
+
+#### How to find hotkey?
+
+**1. Use the `--hotkeys` parameter that comes with Redis to search. **
+
+The `hotkeys` parameter has been added to Redis version 4.0.3, which can return the number of times all keys have been accessed.
+
+The prerequisite for using this solution is that the `maxmemory-policy` parameter of Redis Server is set to the LFU algorithm, otherwise the error shown below will occur.
+
+```bash
+# redis-cli -p 6379 --hotkeys
+
+# Scanning the entire keyspace to find hot keys as well as
+# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
+# per 100 SCAN commands (not usually needed).
+
+Error: ERR An LFU maxmemory policy is not selected, access frequency not tracked. Please note that when switching between policies at runtime LRU and LFU data will take some time to adjust.
+```
+
+There are two LFU algorithms in Redis:
+
+1. **volatile-lfu (least frequently used)**: Select the least frequently used data from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+2. **allkeys-lfu (least frequently used)**: When the memory is not enough to accommodate newly written data, in the key space, remove the least frequently used key.
+
+The following is an example from the configuration file `redis.conf`:
+
+```properties
+# Use volatile-lfu strategy
+maxmemory-policy volatile-lfu
+
+# Or use allkeys-lfu strategy
+maxmemory-policy allkeys-lfu
+```
+
+It should be noted that the `hotkeys` parameter command will also increase the CPU and memory consumption (global scan) of the Redis instance, so it needs to be used with caution.
+
+**2. Use the `MONITOR` command. **
+
+The `MONITOR` command is a way provided by Redis to view all operations of Redis in real time. It can be used to temporarily monitor the operation of a Redis instance, including read, write, delete and other operations.
+
+Since this command has a large impact on Redis performance, it is prohibited to open `MONITOR` for a long time (it is recommended to use this command with caution in a production environment).
+
+```bash
+#redis-cli
+127.0.0.1:6379>MONITOR
+OK
+1683638260.637378 [0 172.17.0.1:61516] "ping"
+1683638267.144236 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638268.941863 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638269.551671 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638270.646256 [0 172.17.0.1:61516] "ping"
+1683638270.849551 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638271.926945 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638274.276599 [0 172.17.0.1:61518] "smembers" "mySet2"
+1683638276.327234 [0 172.17.0.1:61518] "smembers" "mySet"
+```
+
+In the event of an emergency, we can choose to briefly execute the `MONITOR` command at an appropriate time and redirect the output to a file. After closing the `MONITOR` command, we can find out the hotkey during this period by classifying and analyzing the requests in the file.
+
+**3. Use open source projects. **
+
+JD Retail's [hotkey](https://gitee.com/jd-platform-opensource/hotkey) project not only supports hotkey discovery, but also supports hotkey processing.
+
+
+
+**4. Estimate in advance based on business conditions. **
+
+Some hotkeys can be estimated based on business conditions, such as product data participating in flash sale activities, etc. However, we cannot predict the emergence of all hotkeys, such as breaking hot news events.
+
+**5. Record analysis in business code. **
+
+Add corresponding logic to the business code to record and analyze key access conditions. However, this method will increase the complexity of the business code and is generally not used.
+
+**6. Use the Redis analysis service of the public cloud. **
+
+If you are using the public cloud Redis service, you can see if it provides key analysis function (usually it does).
+
+Here we take Alibaba Cloud Redis as an example. It supports hotkey real-time analysis and discovery. The document address is: .
+
+
+
+#### How to solve hotkey?
+
+Common processing and optimization methods for hotkey are as follows (these methods can be used in conjunction):
+
+- **Read and write separation**: The master node handles write requests, and the slave node handles read requests.
+- **Use Redis Cluster**: Store hotspot data distributedly on multiple Redis nodes.
+- **Level 2 Cache**: Hotkey is processed using Level 2 cache, and a copy of the hotkey is stored in the JVM local memory (Caffeine can be used).
+
+In addition to these methods, if you use the public cloud Redis service, you can also pay attention to the out-of-the-box solutions it provides.
+
+Here we take Alibaba Cloud Redis as an example. It supports optimizing hot key issues through the proxy query cache function (Proxy Query Cache).
+
+
+
+### Slow query command
+
+#### Why are there slow query commands?
+
+We know that the execution of a Redis command can be simplified to the following 4 steps:
+
+1. Send a command;
+2. Command queuing;
+3. Command execution;
+4. Return the result.
+
+Redis slow query counts the time it takes to execute this step of the command. Slow query commands are those commands that take a long time to execute.
+
+Why does Redis have slow query commands?
+
+Most commands in Redis have O(1) time complexity, but there are also a few commands with O(n) time complexity, such as:
+
+- `KEYS *`: will return all keys that match the rules.
+- `HGETALL`: will return all key-value pairs in a Hash.
+- `LRANGE`: Returns elements within the specified range in List.
+- `SMEMBERS`: Returns all elements in Set.
+- `SINTER`/`SUNION`/`SDIFF`: Calculate the intersection/union/difference of multiple Sets.
+-…
+
+Since the time complexity of these commands is O(n), sometimes the entire table will be scanned. As n increases, the execution time will become longer. However, these commands do not necessarily cannot be used, but the value of N needs to be specified. In addition, if you have traversal requirements, you can use `HSCAN`, `SSCAN`, `ZSCAN` instead.
+
+In addition to these O(n) time complexity commands that may cause slow queries, there are also some commands that may have a time complexity above O(N), such as:
+
+- `ZRANGE`/`ZREVRANGE`: Returns all elements within the specified ranking range in the specified Sorted Set. The time complexity is O(log(n)+m), where n is the number of all elements and m is the number of elements returned. When m and n are quite large, the time complexity of O(n) is smaller.- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- ……
+
+#### 如何找到慢查询命令?
+
+Redis 提供了一个内置的**慢查询日志 (Slow Log)** 功能,专门用来记录执行时间超过指定阈值的命令。这对于排查性能瓶颈、找出导致 Redis 阻塞的“慢”操作非常有帮助,原理和 MySQL 的慢查询日志类似。
+
+在 `redis.conf` 文件中,我们可以使用 `slowlog-log-slower-than` 参数设置耗时命令的阈值,并使用 `slowlog-max-len` 参数设置耗时命令的最大记录条数。
+
+当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than` 阈值的命令时,就会将该命令记录在慢查询日志(slow log)中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
+
+⚠️ 注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
+
+`slowlog-log-slower-than` 和 `slowlog-max-len` 的默认配置如下(可以自行修改):
+
+```properties
+# The following time is expressed in microseconds, so 1000000 is equivalent
+# to one second. Note that a negative number disables the slow log, while
+# a value of zero forces the logging of every command.
+slowlog-log-slower-than 10000
+
+# There is no limit to this length. Just be aware that it will consume memory.
+# You can reclaim memory used by the slow log with SLOWLOG RESET.
+slowlog-max-len 128
+```
+
+除了修改配置文件之外,你也可以直接通过 `CONFIG` 命令直接设置:
+
+```bash
+# 命令执行耗时超过 10000 微妙(即10毫秒)就会被记录
+CONFIG SET slowlog-log-slower-than 10000
+# 只保留最近 128 条耗时命令
+CONFIG SET slowlog-max-len 128
+```
+
+获取慢查询日志的内容很简单,直接使用 `SLOWLOG GET` 命令即可。
+
+```bash
+127.0.0.1:6379> SLOWLOG GET #慢日志查询
+ 1) 1) (integer) 5
+ 2) (integer) 1684326682
+ 3) (integer) 12000
+ 4) 1) "KEYS"
+ 2) "*"
+ 5) "172.17.0.1:61152"
+ 6) ""
+ // ...
+```
+
+慢查询日志中的每个条目都由以下六个值组成:
+
+1. **唯一 ID**: 日志条目的唯一标识符。
+2. **时间戳 (Timestamp)**: 命令执行完成时的 Unix 时间戳。
+3. **耗时 (Duration)**: 命令执行所花费的时间,单位是**微秒**。
+4. **命令及参数 (Command)**: 执行的具体命令及其参数数组。
+5. **客户端信息 (Client IP:Port)**: 执行命令的客户端地址和端口。
+6. **客户端名称 (Client Name)**: 如果客户端设置了名称 (CLIENT SETNAME)。
+
+`SLOWLOG GET` 命令默认返回最近 10 条的的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
+
+下面是其他比较常用的慢查询相关的命令:
+
+```bash
+# 返回慢查询命令的数量
+127.0.0.1:6379> SLOWLOG LEN
+(integer) 128
+# 清空慢查询命令
+127.0.0.1:6379> SLOWLOG RESET
+OK
+```
+
+### Redis 内存碎片
+
+**相关问题**:
+
+1. 什么是内存碎片?为什么会有 Redis 内存碎片?
+2. 如何清理 Redis 内存碎片?
+
+**参考答案**:[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
+
+## ⭐️Redis 生产问题(重要)
+
+### 缓存穿透
+
+#### 什么是缓存穿透?
+
+缓存穿透说简单点就是大量请求的 key 是不合理的,**根本不存在于缓存中,也不存在于数据库中**。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+
+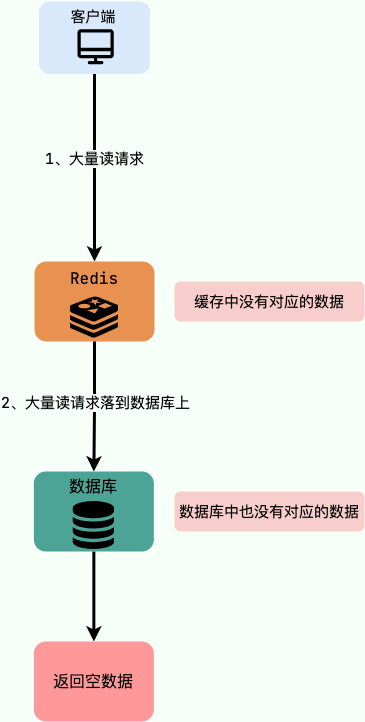
+
+举个例子:某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。也就是说这些请求最终都落到了数据库上,对数据库造成了巨大的压力。
+
+#### 有哪些解决办法?
+
+最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
+
+**1)缓存无效 key**
+
+如果缓存和数据库都查不到某个 key 的数据,就写一个到 Redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点,比如 1 分钟。
+
+另外,这里多说一嘴,一般情况下我们是这样设计 key 的:`表名:列名:主键名:主键值`。
+
+如果用 Java 代码展示的话,差不多是下面这样的:
+
+```java
+public Object getObjectInclNullById(Integer id) {
+ // 从缓存中获取数据
+ Object cacheValue = cache.get(id);
+ // 缓存为空
+ if (cacheValue == null) {
+ // 从数据库中获取
+ Object storageValue = storage.get(key);
+ // 缓存空对象
+ cache.set(key, storageValue);
+ // 如果存储数据为空,需要设置一个过期时间(300秒)
+ if (storageValue == null) {
+ // 必须设置过期时间,否则有被攻击的风险
+ cache.expire(key, 60 * 5);
+ }
+ return storageValue;
+ }
+ return cacheValue;
+}
+```
+
+**2)布隆过滤器**
+
+布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
+
+
+
+Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
+
+
+
+具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
+
+加入布隆过滤器之后的缓存处理流程图如下:
+
+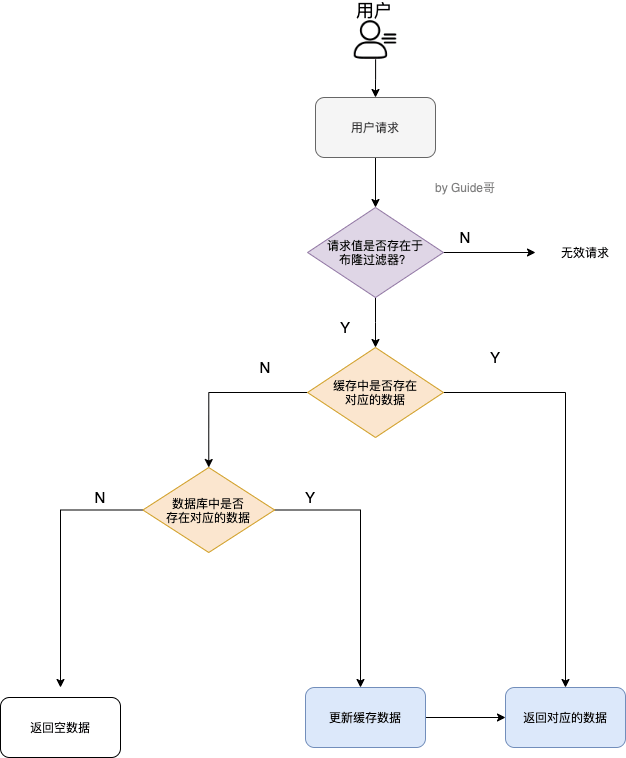
+
+更多关于布隆过滤器的详细介绍可以看看我的这篇原创:[不了解布隆过滤器?一文给你整的明明白白!](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html),强烈推荐。
+
+**3)接口限流**
+
+根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单。
+
+后面提到的缓存击穿和雪崩都可以配合接口限流来解决,毕竟这些问题的关键都是有很多请求落到了数据库上造成数据库压力过大。
+
+限流的具体方案可以参考这篇文章:[服务限流详解](https://javaguide.cn/high-availability/limit-request.html)。
+
+### 缓存击穿
+
+#### 什么是缓存击穿?
+
+缓存击穿中,请求的 key 对应的是 **热点数据**,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)**。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+
+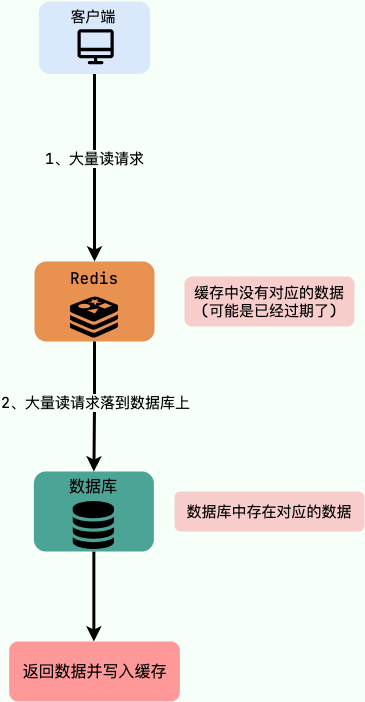
+
+举个例子:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
+
+#### 有哪些解决办法?
+
+1. **永不过期**(不推荐):设置热点数据永不过期或者过期时间比较长。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **加锁**(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
+
+#### 缓存穿透和缓存击穿有什么区别?
+
+缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
+
+缓存击穿中,请求的 key 对应的是 **热点数据** ,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)** 。
+
+### 缓存雪崩
+
+#### 什么是缓存雪崩?
+
+我发现缓存雪崩这名字起的有点意思,哈哈。
+
+实际上,缓存雪崩描述的就是这样一个简单的场景:**缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。** 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
+
+另外,缓存服务宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。
+
+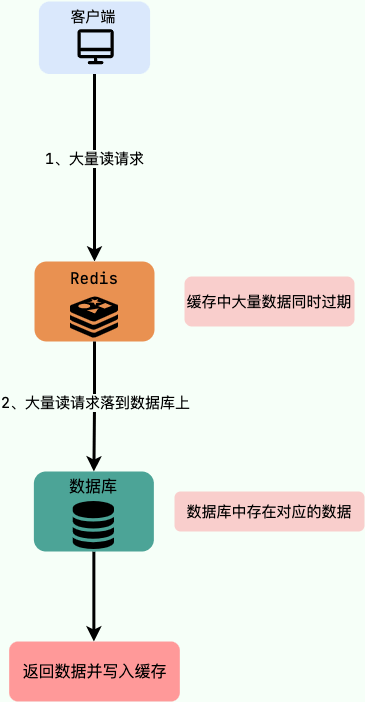
+
+举个例子:缓存中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
+
+#### 有哪些解决办法?
+
+**针对 Redis 服务不可用的情况**:
+
+1. **Redis 集群**:采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。Redis Cluster 和 Redis Sentinel 是两种最常用的 Redis 集群实现方案,详细介绍可以参考:[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
+2. **多级缓存**:设置多级缓存,例如本地缓存+Redis 缓存的二级缓存组合,当 Redis 缓存出现问题时,还可以从本地缓存中获取到部分数据。
+
+**针对大量缓存同时失效的情况**:
+
+1. **设置随机失效时间**(可选):为缓存设置随机的失效时间,例如在固定过期时间的基础上加上一个随机值,这样可以避免大量缓存同时到期,从而减少缓存雪崩的风险。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间,比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **持久缓存策略**(看情况):虽然一般不推荐设置缓存永不过期,但对于某些关键性和变化不频繁的数据,可以考虑这种策略。
+
+#### 缓存预热如何实现?
+
+常见的缓存预热方式有两种:
+
+1. 使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
+2. 使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存。
+
+#### 缓存雪崩和缓存击穿有什么区别?
+
+缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在于缓存中(通常是因为缓存中的那份数据已经过期)。
+
+### 如何保证缓存和数据库数据的一致性?
+
+缓存和数据库一致性是个挺常见的技术挑战。引入缓存主要是为了提升性能、减轻数据库压力,但确实会带来数据不一致的风险。绝对的一致性往往意味着更高的系统复杂度和性能开销,所以实践中我们通常会根据业务场景选择合适的策略,在性能和一致性之间找到一个平衡点。
+
+下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。这是非常常用的一种缓存读写策略,它的读写逻辑是这样的:
+
+- **读操作**:
+ 1. 先尝试从缓存读取数据。
+ 2. 如果缓存命中,直接返回数据。
+ 3. 如果缓存未命中,从数据库查询数据,将查到的数据放入缓存并返回数据。
+- **写操作**:
+ 1. 先更新数据库。
+ 2. 再直接删除缓存中对应的数据。
+
+图解如下:
+
+
+
+
+
+如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说有两个解决方案:
+
+1. **缓存失效时间(TTL - Time To Live)变短**(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
+2. **增加缓存更新重试机制**(常用):如果缓存服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。不过,这里更适合引入消息队列实现异步重试,将删除缓存重试的消息投递到消息队列,然后由专门的消费者来重试,直到成功。虽然说多引入了一个消息队列,但其整体带来的收益还是要更高一些。
+
+相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
+
+### 哪些情况可能会导致 Redis 阻塞?
+
+常见的导致 Redis 阻塞原因有:
+
+- `O(n)` 复杂度命令执行(如 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS` 等),随着数据量增大导致执行时间过长。
+- 执行 `SAVE` 命令生成 RDB 快照时同步阻塞主线程,而 `BGSAVE` 通过 `fork` 子进程避免阻塞。
+- AOF 记录日志在主线程中进行,可能因命令执行后写日志而阻塞后续命令。
+- AOF 刷盘(fsync)时后台线程同步到磁盘,磁盘压力大导致 `fsync` 阻塞,进而阻塞主线程 `write` 操作,尤其在 `appendfsync always` 或 `everysec` 配置下明显。
+- AOF 重写过程中将重写缓冲区内容追加到新 AOF 文件时产生阻塞。
+- Operating large keys (string > 1MB or composite type elements > 5000) causes client timeouts, network blocking, and worker thread blocking.
+- Using `flushdb` or `flushall` to clear the database involves deleting a large number of key-value pairs and releasing memory, causing the main thread to block.
+- Data migration is a synchronous operation when the cluster is expanded or reduced. Migration of large keys causes nodes at both ends to be blocked for a long time, which may trigger failover.
+- Insufficient memory triggers Swap, and the operating system swaps out the Redis memory to the hard disk, causing a sharp decline in read and write performance.
+- Other processes excessively occupy the CPU, causing Redis throughput to decrease.
+- Network problems such as connection rejection, high latency, network card soft interrupt, etc. cause Redis to block.
+
+For a detailed introduction, you can read this article: [Summary of common blocking causes in Redis](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html).
+
+## Redis cluster
+
+**Redis Sentinel**:
+
+1. What is Sentinel? What's the use?
+2. How does Sentinel detect whether a node is offline? What is the difference between subjective offline and objective offline?
+3. How does Sentinel implement failover?
+4. Why is it recommended to deploy multiple sentinel nodes (sentinel cluster)?
+5. How does Sentinel choose a new master (election mechanism)?
+6. How to select Leader from Sentinel cluster?
+7. Can Sentinel prevent split-brain?
+
+**Redis Cluster**:
+
+1. Why do you need Redis Cluster? What problem was solved? What are the advantages?
+2. How is Redis Cluster sharded?
+3. Why are the hash slots of Redis Cluster 16384?
+4. How to determine which hash slot a given key should be distributed to?
+5. Does Redis Cluster support redistribution of hash slots?
+6. Can Redis Cluster provide services during expansion and contraction?
+7. How do nodes in Redis Cluster communicate?
+
+**Reference answer**: [Detailed explanation of Redis cluster (paid)](https://javaguide.cn/database/redis/redis-cluster.html).
+
+## Redis usage specifications
+
+In the actual use of Redis, we try to adhere to some common specifications, such as:
+
+1. Use a connection pool: avoid frequently creating and closing client connections.
+2. Try not to use O(n) commands. When using O(n) commands, pay attention to the number of n: O(n) commands such as `KEYS *`, `HGETALL`, `LRANGE`, `SMEMBERS`, `SINTER`/`SUNION`/`SDIFF` are not unusable, but the value of n needs to be clear. In addition, if you have traversal requirements, you can use `HSCAN`, `SSCAN`, `ZSCAN` instead.
+3. Use batch operations to reduce network transmission: native batch operation commands (such as `MGET`, `MSET`, etc.), pipeline, Lua scripts.
+4. Try not to use Redis transactions: The functions implemented by Redis transactions are relatively useless, and you can use Lua scripts instead.
+5. It is forbidden to turn on the monitor for a long time: it will have a great impact on performance.
+6. Control the life cycle of the key: Avoid storing too much data that is not frequently accessed in Redis.
+7.…
+
+## Reference
+
+- "Redis Development and Operation and Maintenance"
+- "Redis Design and Implementation"
+- Redis Transactions:
+- What is Redis Pipeline:
+- A detailed explanation of the discovery and processing of BigKey and HotKey in Redis:
+- Exploration of ideas and methods for solving Bigkey problems:
+- Comprehensive troubleshooting guide for Redis latency issues:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-skiplist.en.md b/docs_en/database/redis/redis-skiplist.en.md
new file mode 100644
index 00000000000..2ba31c10200
--- /dev/null
+++ b/docs_en/database/redis/redis-skiplist.en.md
@@ -0,0 +1,727 @@
+---
+title: Redis为什么用跳表实现有序集合
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis,跳表,有序集合,ZSet,时间复杂度,平衡树对比,实现原理
+ - - meta
+ - name: description
+ content: 深入讲解 Redis 有序集合为何选择跳表实现,结合时间复杂度与平衡树对比,理解工程权衡与源码细节。
+---
+
+## 前言
+
+近几年针对 Redis 面试时会涉及常见数据结构的底层设计,其中就有这么一道比较有意思的面试题:“Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
+
+本文就以这道大厂常问的面试题为切入点,带大家详细了解一下跳表这个数据结构。
+
+本文整体脉络如下图所示,笔者会从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握。
+
+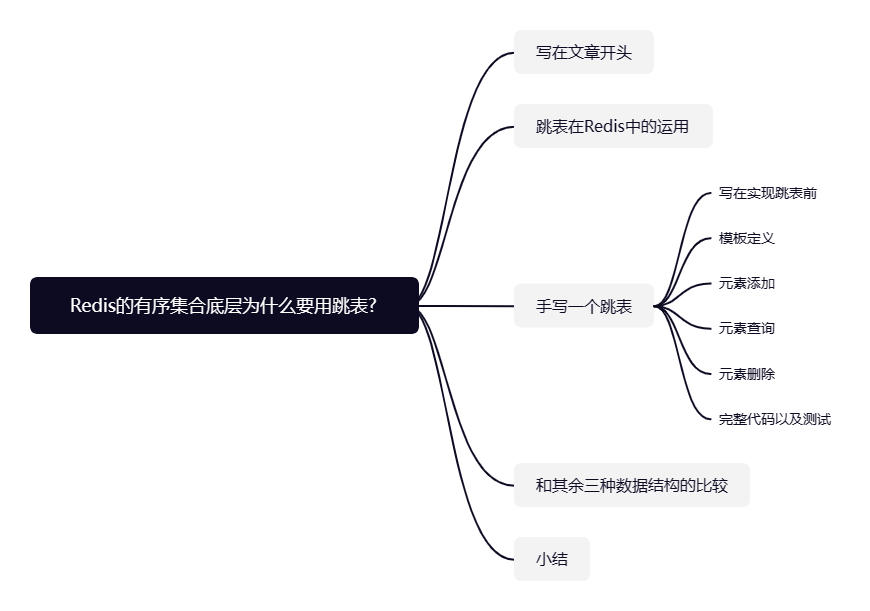
+
+## 跳表在 Redis 中的运用
+
+这里我们需要先了解一下 Redis 用到跳表的数据结构有序集合的使用,Redis 有个比较常用的数据结构叫**有序集合(sorted set,简称 zset)**,正如其名它是一个可以保证有序且元素唯一的集合,所以它经常用于排行榜等需要进行统计排列的场景。
+
+这里我们通过命令行的形式演示一下排行榜的实现,可以看到笔者分别输入 3 名用户:**xiaoming**、**xiaohong**、**xiaowang**,它们的**score**分别是 60、80、60,最终按照成绩升级降序排列。
+
+```bash
+
+127.0.0.1:6379> zadd rankList 60 xiaoming
+(integer) 1
+127.0.0.1:6379> zadd rankList 80 xiaohong
+(integer) 1
+127.0.0.1:6379> zadd rankList 60 xiaowang
+(integer) 1
+
+# 返回有序集中指定区间内的成员,通过索引,分数从高到低
+127.0.0.1:6379> ZREVRANGE rankList 0 100 WITHSCORES
+1) "xiaohong"
+2) "80"
+3) "xiaowang"
+4) "60"
+5) "xiaoming"
+6) "60"
+```
+
+此时我们通过 `object` 指令查看 zset 的数据结构,可以看到当前有序集合存储的还是**ziplist(压缩列表)**。
+
+```bash
+127.0.0.1:6379> object encoding rankList
+"ziplist"
+```
+
+因为设计者考虑到 Redis 数据存放于内存,为了节约宝贵的内存空间,在有序集合元素小于 64 字节且个数小于 128 的时候,会使用 ziplist,而这个阈值的默认值的设置就来自下面这两个配置项。
+
+```bash
+zset-max-ziplist-value 64
+zset-max-ziplist-entries 128
+```
+
+一旦有序集合中的某个元素超出这两个其中的一个阈值它就会转为 **skiplist**(实际是 dict+skiplist,还会借用字典来提高获取指定元素的效率)。
+
+我们不妨在添加一个大于 64 字节的元素,可以看到有序集合的底层存储转为 skiplist。
+
+```bash
+127.0.0.1:6379> zadd rankList 90 yigemingzihuichaoguo64zijiedeyonghumingchengyongyuceshitiaobiaodeshijiyunyong
+(integer) 1
+
+# 超过阈值,转为跳表
+127.0.0.1:6379> object encoding rankList
+"skiplist"
+```
+
+也就是说,ZSet 有两种不同的实现,分别是 ziplist 和 skiplist,具体使用哪种结构进行存储的规则如下:
+
+- 当有序集合对象同时满足以下两个条件时,使用 ziplist:
+ 1. ZSet 保存的键值对数量少于 128 个;
+ 2. 每个元素的长度小于 64 字节。
+- 如果不满足上述两个条件,那么使用 skiplist 。
+
+## 手写一个跳表
+
+为了更好的回答上述问题以及更好的理解和掌握跳表,这里可以通过手写一个简单的跳表的形式来帮助读者理解跳表这个数据结构。
+
+我们都知道有序链表在添加、查询、删除的平均时间复杂都都是 **O(n)** 即线性增长,所以一旦节点数量达到一定体量后其性能表现就会非常差劲。而跳表我们完全可以理解为在原始链表基础上,建立多级索引,通过多级索引检索定位将增删改查的时间复杂度变为 **O(log n)** 。
+
+可能这里说的有些抽象,我们举个例子,以下图跳表为例,其原始链表存储按序存储 1-10,有 2 级索引,每级索引的索引个数都是基于下层元素个数的一半。
+
+
+
+假如我们需要查询元素 6,其工作流程如下:
+
+1. 从 2 级索引开始,先来到节点 4。
+2. 查看 4 的后继节点,是 8 的 2 级索引,这个值大于 6,说明 2 级索引后续的索引都是大于 6 的,没有再往后搜寻的必要,我们索引向下查找。
+3. 来到 4 的 1 级索引,比对其后继节点为 6,查找结束。
+
+相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为**O(log n)**。
+
+
+
+对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到**小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
+
+1. 从 2 级索引开始定位到了元素 4 的索引。
+2. 查看索引 4 的后继索引为 8,索引向下推进。
+3. 来到 1 级索引,发现索引 4 后继索引为 6,小于插入元素 7,指针推进到索引 6 位置。
+4. 继续比较 6 的后继节点为索引 8,大于元素 7,索引继续向下。
+5. 最终我们来到 6 的原始节点,发现其后继节点为 7,指针没有继续向下的空间,自此我们可知元素 6 就是小于插入元素 7 的最大值,于是便将元素 7 插入。
+
+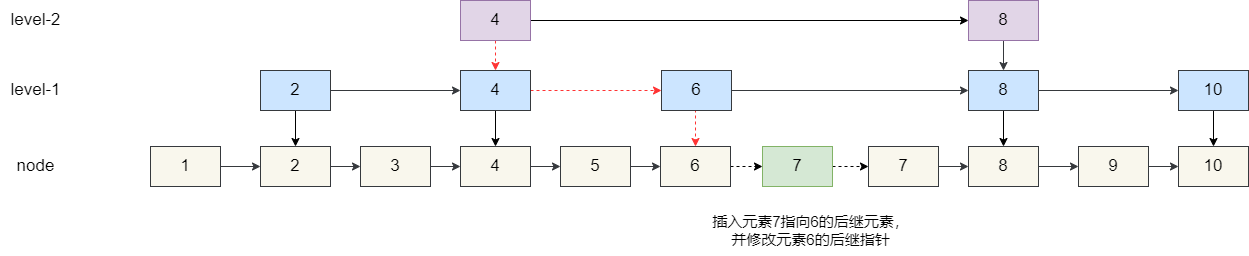
+
+这里我们又面临一个问题,我们是否需要为元素 7 建立索引,索引多高合适?
+
+我们上文提到,理想情况是每一层索引是下一层元素个数的二分之一,假设我们的总共有 16 个元素,对应各级索引元素个数应该是:
+
+```bash
+1. 一级索引:16/2=8
+2. 二级索引:8/2 =4
+3. 三级索引:4/2=2
+```
+
+由此我们用数学归纳法可知:
+
+```bash
+1. 一级索引:16/2=16/2^1=8
+2. 二级索引:8/2 => 16/2^2 =4
+3. 三级索引:4/2=>16/2^3=2
+```
+
+假设元素个数为 n,那么对应 k 层索引的元素个数 r 计算公式为:
+
+```bash
+r=n/2^k
+```
+
+同理我们再来推断以下索引的最大高度,一般来说最高级索引的元素个数为 2,我们设元素总个数为 n,索引高度为 h,代入上述公式可得:
+
+```bash
+2= n/2^h
+=> 2*2^h=n
+=> 2^(h+1)=n
+=> h+1=log2^n
+=> h=log2^n -1
+```
+
+而 Redis 又是内存数据库,我们假设元素最大个数是**65536**,我们把**65536**代入上述公式可知最大高度为 16。所以我们建议添加一个元素后为其建立的索引高度不超过 16。
+
+因为我们要求尽可能保证每一个上级索引都是下级索引的一半,在实现高度生成算法时,我们可以这样设计:
+
+1. 跳表的高度计算从原始链表开始,即默认情况下插入的元素的高度为 1,代表没有索引,只有元素节点。
+2. 设计一个为插入元素生成节点索引高度 level 的方法。
+3. 进行一次随机运算,随机数值范围为 0-1 之间。
+4. 如果随机数大于 0.5 则为当前元素添加一级索引,自此我们保证生成一级索引的概率为 **50%** ,这也就保证了 1 级索引理想情况下只有一半的元素会生成索引。
+5. 同理后续每次随机算法得到的值大于 0.5 时,我们的索引高度就加 1,这样就可以保证节点生成的 2 级索引概率为 **25%** ,3 级索引为 **12.5%** ……
+
+我们回过头,上述插入 7 之后,我们通过随机算法得到 2,即要为其建立 1 级索引:
+
+
+
+Finally, let’s talk about deletion. Suppose we want to delete element 10 here. We must locate the maximum value of the current jump table **each layer** element that is less than 10. The index execution steps are:
+
+1. The successor node of level 2 index 4 is 8, and the pointer advances.
+2. Index 8 has no successor node, there is no element to be deleted in this layer, and the pointer points directly downward.
+3. The successor node of level 1 index 8 is 10, which means that when deleting level 1 index 8, it needs to disconnect its pointer from level 1 index 10 and delete 10.
+4. After the level 1 index is positioned, the pointer moves downward, the subsequent node is 9, and the pointer advances.
+5. The successor node of 9 is 10. Similarly, it needs to point to null and delete 10.
+
+
+
+### Template definition
+
+After having the overall idea, we can start to implement a skip list. First, define the node **Node** in the skip list. From the above demonstration, we can see that each **Node** contains the following elements:
+
+1. The stored **value** value.
+2. The address of the successor node.
+3. Multi-level index.
+
+In order to more conveniently and uniformly manage the **Node** successor node addresses and the element addresses pointed to by the multi-level index, the author set up a **forwards** array in **Node** to record the successor nodes of the original linked list node and the successor node points of the multi-level index.
+
+Take the following figure as an example. The length of our **forwards** array is 5, in which **index 0** records the successor node address of the original linked list node, while the rest from bottom to top represent the successor node points from the 1st level index to the 4th level index.
+
+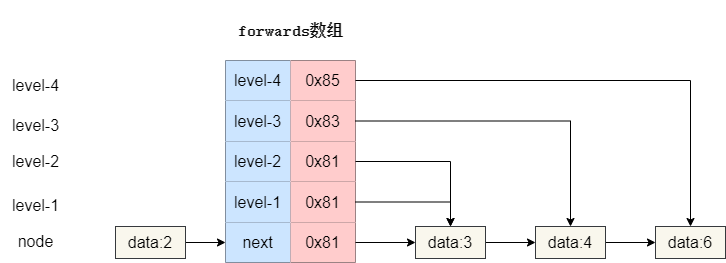
+
+So we have such a code definition. It can be seen that the author sets the length of the array to a fixed 16** (the maximum height calculated above is recommended to be 16)**. The default **data** is -1, and the maximum height of the node **maxLevel** is initialized to 1. Note that the value of **maxLevel** represents the total height of the original linked list plus the index.
+
+```java
+/**
+ * The maximum height of the skip table index is 16
+ */
+private static final int MAX_LEVEL = 16;
+
+class Node {
+ private int data = -1;
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+}
+```
+
+### Element addition
+
+After defining the node, we first add the following elements. When adding elements, the first step is to set **data**. We can directly set the incoming **value** to **data**.
+
+Then there is the setting of the height **maxLevel**. We have also given the idea above. The default height is 1, that is, there is only one original linked list node. Through the random algorithm, the index height is increased by 1 every time it is greater than 0.5. From this, we derive the height calculation algorithm `randomLevel()`:
+
+```java
+/**
+ * Theoretically, the number of elements in the primary index should account for 50% of the original data, the number of elements in the secondary index should account for 25%, and the third-level index should account for 12.5%, all the way to the top.
+ * Because the promotion probability of each level here is 50%. For each newly inserted node, randomLevel needs to be called to generate a reasonable number of levels.
+ * The randomLevel method will randomly generate a number between 1~MAX_LEVEL, and:
+ * 50% probability of returning 1
+ * 25% probability of returning 2
+ * 12.5% probability of returning 3...
+ * @return
+ */
+private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+}
+```
+
+Then set the successor node address of the **Node** and **Node** index currently to be inserted. This step is a little more complicated. We assume that the height of the current node is 4, that is, 1 node plus 3 indexes, so we create an array **maxOfMinArr** with a length of 4, and traverse the maximum value of the index nodes at all levels that is smaller than the current **value**.
+
+Assume that the **value** we want to insert is 5. Our array search result shows that the predecessor node of the current node and the predecessor nodes of the first-level index and the second-level index are all 4, and the third-level index is empty.
+
+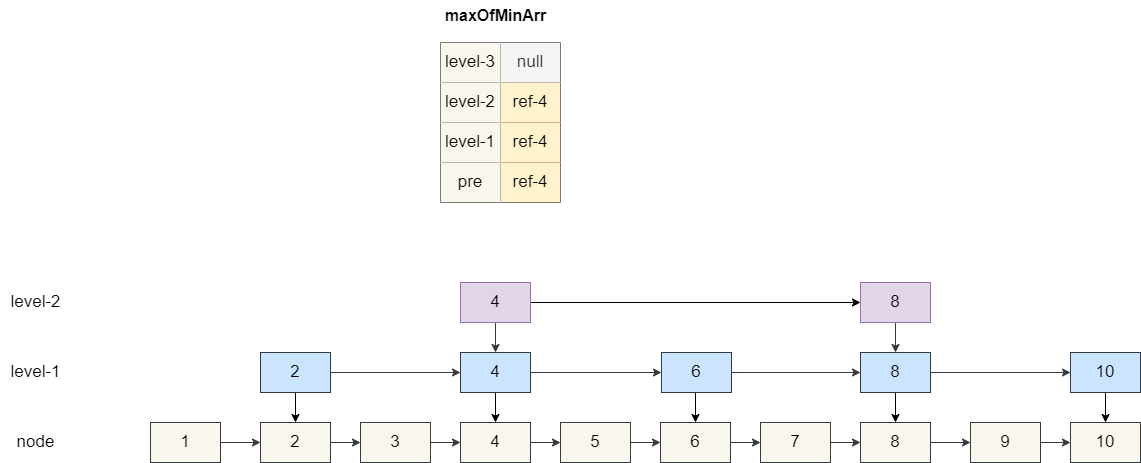
+
+Then we locate the successor nodes at all levels based on this array **maxOfMinArr**, so that the inserted element 5 points to these successor nodes, and **maxOfMinArr** points to 5. The result is as follows:
+
+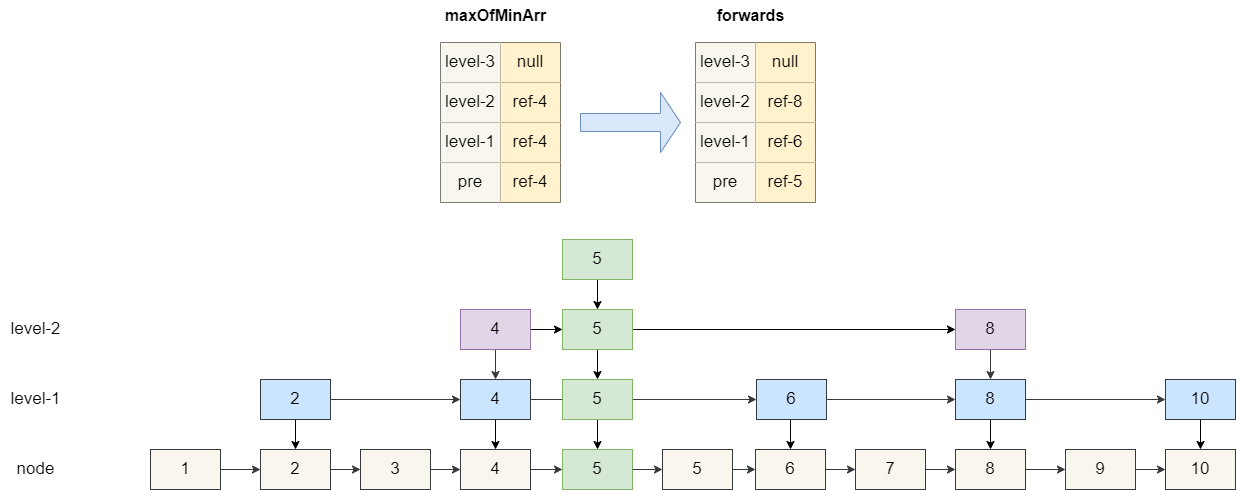
+
+The conversion into code is in the following form. Isn't it very simple? Let's continue:
+
+```java
+/**
+ * The default height is 1, that is, there is only one node of its own.
+ */
+private int levelCount = 1;
+
+/**
+ * The node at the bottom of the jump list, that is, the head node
+ */
+private Node h = new Node();
+
+public void add(int value) {
+ int level = randomLevel(); // Random height of new node
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ //An array used to record the predecessor nodes of each layer
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // Key correction: Start searching from the current highest level of the jump list
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ //Only record the predecessor nodes of the layer that needs to be updated
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ //Insert new node
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ //Update the total height of the jump table
+ if (levelCount < level) {
+ levelCount = level;
+ }
+}
+```
+
+### Element query
+
+The query logic is relatively simple. Start from the highest-level index of the jump table and locate the maximum value that is less than the value to be queried. Take the following figure as an example. We hope to find node 8:
+
+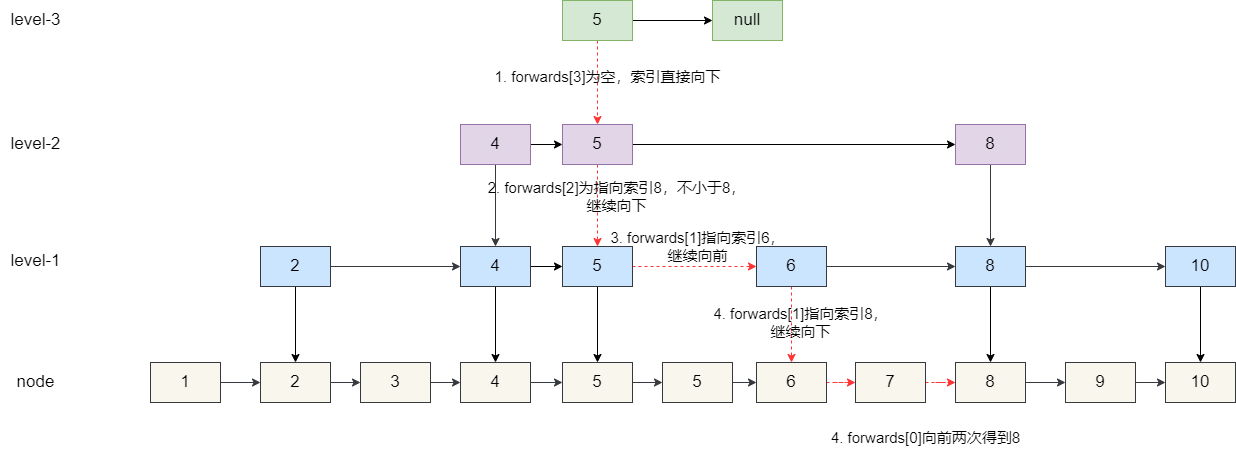
+
+- **Start from the highest level (level 3 index)**: The search pointer `p` starts from the head node. On a level 3 index, `p`'s successor `forwards[2]` (assuming level 3 up, indexing starts at 0) points to node `5`. Since `5 < 8`, pointer `p` moves right to node `5`. The successor `forwards[2]` of node `5` at the level 3 index is `null` (or points to a node greater than `8`, not shown in the figure). The search to the right of the current level ends, pointer `p` remains at node `5`, and moves down to the level 2 index**.
+- **Indexed at Level 2**: Current pointer `p` is node `5`. The successor `forwards[1]` of `p` points to node `8`. Since `8` is not less than `8` (i.e. `8 < 8` is `false`), the current level search to the right ends (`p` will not move to node `8`). Pointer `p` remains at node `5` and moves down to index level 1**.- **在 1 级索引** :当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[0]` 指向最底层的节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到最底层的节点 `5`。此时,当前指针 `p` 为最底层的节点 `5`。其后继 `forwards[0]` 指向最底层的节点 `6`。由于 `6 < 8`,指针 `p` 向右移动到最底层的节点 `6`。当前指针 `p` 为最底层的节点 `6`。其后继 `forwards[0]` 指向最底层的节点 `7`。由于 `7 < 8`,指针 `p` 向右移动到最底层的节点 `7`。当前指针 `p` 为最底层的节点 `7`。其后继 `forwards[0]` 指向最底层的节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束。此时,已经遍历完所有层级,`for` 循环结束。
+- **最终定位与检查** :经过所有层级的查找,指针 `p` 最终停留在最底层(0 级索引)的节点 `7`。这个节点是整个跳表中值小于目标值 `8` 的那个最大的节点。检查节点 `7` 的**后继节点**(即 `p.forwards[0]`):`p.forwards[0]` 指向节点 `8`。判断 `p.forwards[0].data`(即节点 `8` 的值)是否等于目标值 `8`。条件满足(`8 == 8`),**查找成功,找到节点 `8`**。
+
+所以我们的代码实现也很上述步骤差不多,从最高级索引开始向前查找,如果不为空且小于要查找的值,则继续向前搜寻,遇到不小于的节点则继续向下,如此往复,直到得到当前跳表中小于查找值的最大节点,查看其前驱是否等于要查找的值:
+
+```java
+public Node get(int value) {
+ Node p = h; // 从头节点开始
+
+ // 从最高层级索引开始,逐层向下
+ for (int i = levelCount - 1; i >= 0; i--) {
+ // 在当前层级向右查找,直到 p.forwards[i] 为 null
+ // 或者 p.forwards[i].data 大于等于目标值 value
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i]; // 向右移动
+ }
+ // 此时 p.forwards[i] 为 null,或者 p.forwards[i].data >= value
+ // 或者 p 是当前层级中小于 value 的最大节点(如果存在这样的节点)
+ }
+
+ // 经过所有层级的查找,p 现在是原始链表(0级索引)中
+ // 小于目标值 value 的最大节点(或者头节点,如果所有元素都大于等于 value)
+
+ // 检查 p 在原始链表中的下一个节点是否是目标值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0]; // 找到了,返回该节点
+ }
+
+ return null; // 未找到
+}
+```
+
+### 元素删除
+
+最后是删除逻辑,需要查找各层级小于要删除节点的最大值,假设我们要删除 10:
+
+1. 3 级索引得到小于 10 的最大值为 5,继续向下。
+2. 2 级索引从索引 5 开始查找,发现小于 10 的最大值为 8,继续向下。
+3. 同理 1 级索引得到 8,继续向下。
+4. 原始节点找到 9。
+5. 从最高级索引开始,查看每个小于 10 的节点后继节点是否为 10,如果等于 10,则让这个节点指向 10 的后继节点,将节点 10 及其索引交由 GC 回收。
+
+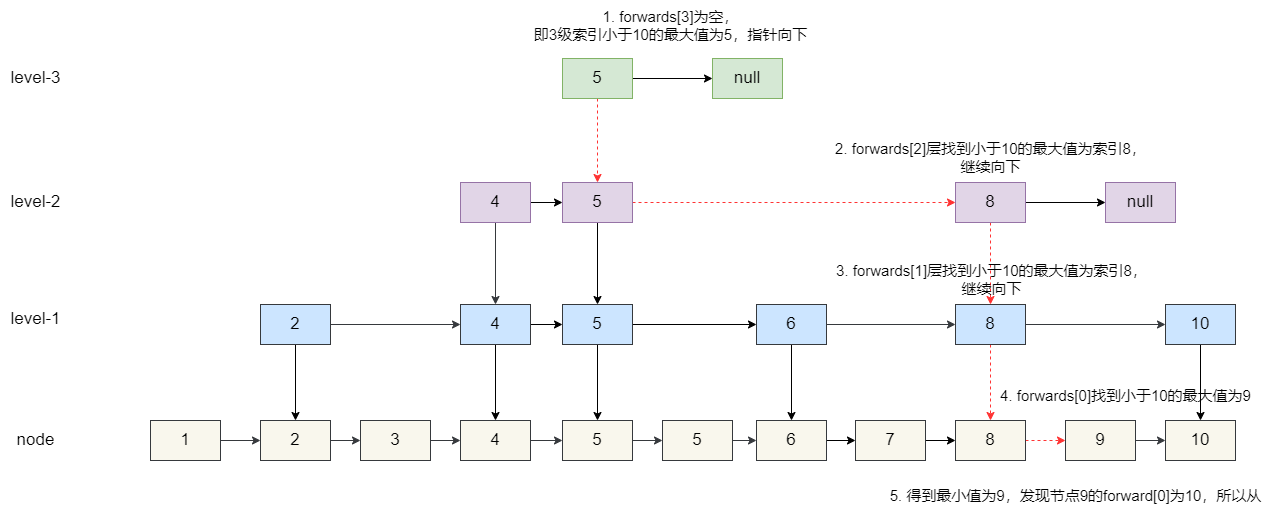
+
+```java
+/**
+ * 删除
+ *
+ * @param value
+ */
+public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+}
+```
+
+### 完整代码以及测试
+
+完整代码如下,读者可自行参阅:
+
+```java
+public class SkipList {
+
+ /**
+ * 跳表索引最大高度为16
+ */
+ private static final int MAX_LEVEL = 16;
+
+ /**
+ * 每个节点添加一层索引高度的概率为二分之一
+ */
+ private static final float PROB = 0.5f;
+
+ /**
+ * 默认情况下的高度为1,即只有自己一个节点
+ */
+ private int levelCount = 1;
+
+ /**
+ * 跳表最底层的节点,即头节点
+ */
+ private Node h = new Node();
+
+ public SkipList() {
+ }
+
+ public class Node {
+
+ private int data = -1;
+ /**
+ *
+ */
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+ @Override
+ public String toString() {
+ return "Node{"
+ + "data=" + data
+ + ", maxLevel=" + maxLevel
+ + '}';
+ }
+ }
+
+ public void add(int value) {
+ int level = randomLevel(); // 新节点的随机高度
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ // 用于记录每层前驱节点的数组
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // 关键修正:从跳表的当前最高层开始查找
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ // 只记录需要更新的层的前驱节点
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ // 插入新节点
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ // 更新跳表的总高度
+ if (levelCount < level) {
+ levelCount = level;
+ }
+ }
+
+ /**
+ * 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
+ * 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。 该 randomLevel
+ * 方法会随机生成 1~MAX_LEVEL 之间的数,且 : 50%的概率返回 1 25%的概率返回 2 12.5%的概率返回 3 ...
+ *
+ * @return
+ */
+ private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+ }
+
+ public Node get(int value) {
+ Node p = h;
+ //找到小于value的最大值
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ }
+ //如果p的前驱节点等于value则直接返回
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0];
+ }
+
+ return null;
+ }
+
+ /**
+ * 删除
+ *
+ * @param value
+ */
+ public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+ }
+
+ public void printAll() {
+ Node p = h;
+ //基于最底层的非索引层进行遍历,只要后继节点不为空,则速速出当前节点,并移动到后继节点
+ while (p.forwards[0] != null) {
+ System.out.println(p.forwards[0]);
+ p = p.forwards[0];
+ }
+
+ }
+}
+
+```
+
+Test code:
+
+```java
+public static void main(String[] args) {
+ SkipList skipList = new SkipList();
+ for (int i = 0; i < 24; i++) {
+ skipList.add(i);
+ }
+
+ System.out.println("************Output added results**********");
+ skipList.printAll();
+
+ SkipList.Node node = skipList.get(22);
+ System.out.println("************query results:" + node+" ************");
+
+ skipList.delete(22);
+ System.out.println("************Delete result**********");
+ skipList.printAll();
+
+
+ }
+```
+
+**Features of Redis skip table**:
+
+1. Using **doubly linked list**, different from the above example, there is a rollback pointer. It is mainly used to simplify operations. For example, when deleting an element, you also need to find the predecessor node of the element. It is very convenient to use the rollback pointer.
+2. The `score` value can be repeated. If the `score` value is the same, it will be sorted according to the ele (the value stored in the node, which is sds) dictionary.
+3. The default maximum number of levels allowed by the Redis jump table is 32, which is defined by `ZSKIPLIST_MAXLEVEL` in the source code.
+
+## Comparison with other three data structures
+
+Finally, let’s answer the interview question at the beginning of the article: “Why does the bottom layer of Redis’s ordered set use a jump table instead of a balanced tree, a red-black tree, or a B+ tree?”
+
+### Balanced tree vs skip list
+
+Let’s first talk about its comparison with the balanced tree. The balanced tree is also called the AVL tree. It is a strictly balanced binary tree. The balance condition must be met (the height difference between the left and right subtrees of all nodes does not exceed 1, that is, the balance factor is in the range `[-1,1]`). The time complexity of insertion, deletion and query of the balanced tree is the same as that of the skip table **O(log n)**.
+
+For range queries, it can also achieve the same effect as skipping tables through in-order traversal. However, every insertion or deletion operation needs to ensure the absolute balance of the left and right nodes of the entire tree. As long as it is unbalanced, it must be maintained through rotation operations. This process is relatively time-consuming.
+
+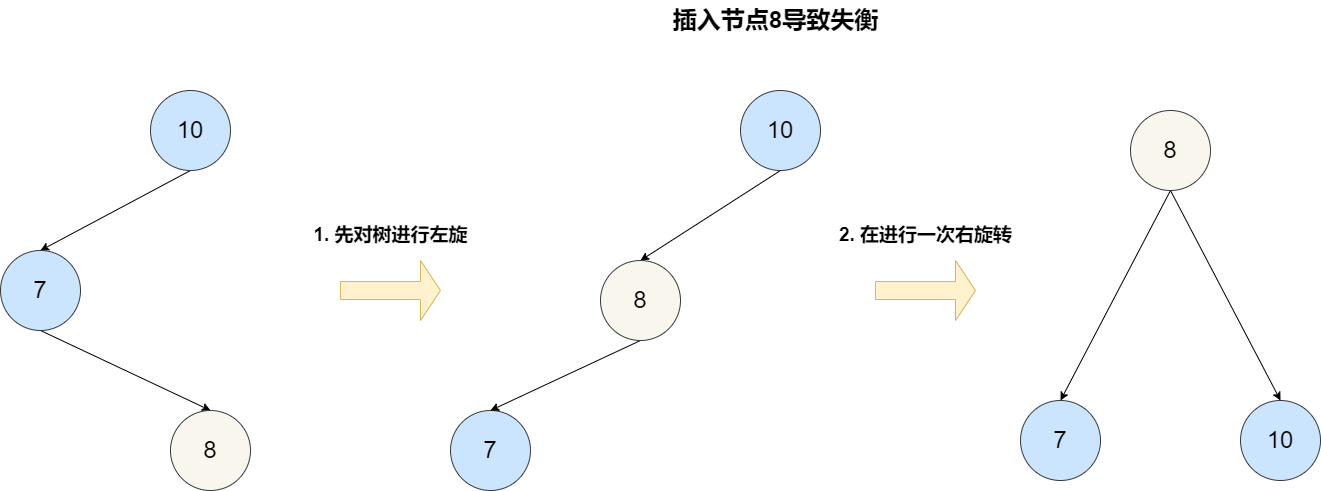
+
+The original intention of the birth of skip lists is to overcome some shortcomings of balanced trees. The inventor of skip lists mentioned in detail in the paper ["Skip lists: a probabilistic alternative to balanced trees"](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf):
+
+
+
+> Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
+>
+> A skip list is a data structure that can be used to replace a balanced tree. Skip lists use probabilistic balancing rather than strictly enforced balancing, so the insertion and deletion algorithms in skip lists are much simpler and faster than the equivalent algorithms for balanced trees.
+
+The author has also posted the core code of the AVL tree insertion operation here. It can be seen that each addition operation requires a recursive positioning to locate the insertion position, and then it is necessary to trace back to the root node to check whether the nodes at each layer along the way are unbalanced, and then adjust the nodes by rotating them.
+
+```java
+//Add new elements (key, value) to the binary search tree
+public void add(K key, V value) {
+ root = add(root, key, value);
+}
+
+// Insert elements (key, value) into the binary search tree rooted at node, recursive algorithm
+// Return the root of the binary search tree after inserting the new node
+private Node add(Node node, K key, V value) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, value);
+ }
+
+ if (key.compareTo(node.key) < 0)
+ node.left = add(node.left, key, value);
+ else if (key.compareTo(node.key) > 0)
+ node.right = add(node.right, key, value);
+ else // key.compareTo(node.key) == 0
+ node.value = value;
+
+ node.height = 1 + Math.max(getHeight(node.left), getHeight(node.right));
+
+ int balanceFactor = getBalanceFactor(node);
+
+ // LL type requires right-hand rotation
+ if (balanceFactor > 1 && getBalanceFactor(node.left) >= 0) {
+ return rightRotate(node);
+ }
+
+ //RR type imbalance requires left rotation
+ if (balanceFactor < -1 && getBalanceFactor(node.right) <= 0) {
+ return leftRotate(node);
+ }
+
+ //LR needs to be rotated left first into LL shape, and then rotated right
+ if (balanceFactor > 1 && getBalanceFactor(node.left) < 0) {
+ node.left = leftRotate(node.left);
+ return rightRotate(node);
+ }
+
+ //RL
+ if (balanceFactor < -1 && getBalanceFactor(node.right) > 0) {
+ node.right = rightRotate(node.right);
+ return leftRotate(node);
+ }
+ return node;
+}
+```
+
+### Red-black tree vs jump list
+
+Red Black Tree is also a self-balancing binary search tree. Its query performance is slightly inferior to AVL tree, but insertion and deletion are more efficient. The time complexity of insertion, deletion and query of red-black tree is the same as that of skip table **O(log n)**.
+
+A red-black tree is a **black balanced tree**, that is, from any node to another leaf node, the black nodes it passes through are the same. When inserting it, it needs to be rotated and dyed (red-to-black conversion) to ensure black balance. However, the overhead of maintaining balance is smaller than that of an AVL tree. For a detailed introduction to red-black trees, you can view this article: [Red-Black Tree](https://javaguide.cn/cs-basics/data-structure/red-black-tree.html).
+
+Compared with red-black trees, the implementation of skip tables is also simpler. Moreover, when searching for data according to intervals, the efficiency of red-black trees is not as high as that of jump tables.
+
+
+
+The core code added corresponding to the red-black tree is as follows, readers can refer to and understand by themselves:
+
+```java
+private Node < K, V > add(Node < K, V > node, K key, V val) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, val);
+
+ }
+
+ if (key.compareTo(node.key) < 0) {
+ node.left = add(node.left, key, val);
+ } else if (key.compareTo(node.key) > 0) {
+ node.right = add(node.right, key, val);
+ } else {
+ node.val = val;
+ }
+
+ //The left node is not red, the right node is red, left rotation
+ if (isRed(node.right) && !isRed(node.left)) {
+ node = leftRotate(node);
+ }
+
+ //Left chain right-hand rotation
+ if (isRed(node.left) && isRed(node.left.left)) {
+ node = rightRotate(node);
+ }
+
+ //color flip
+ if (isRed(node.left) && isRed(node.right)) {
+ flipColors(node);
+ }
+
+ return node;
+}```
+
+### B+ tree vs skip list
+
+Readers who use MySQL must know the data structure of B+ tree. B+ tree is a commonly used data structure with the following characteristics:
+
+1. **Multi-fork tree structure**: It is a multi-fork tree. Each node can contain multiple child nodes, which reduces the height of the tree and has high query efficiency.
+2. **High storage efficiency**: Non-leaf nodes store multiple keys, and leaf nodes store values, so that each node can store more keys, and the query efficiency is higher when performing range queries based on the index. -
+3. **Balance**: It is absolutely balanced, that is, the height of each branch of the tree is not much different, ensuring that the query and insertion time complexity is **O(log n)**.
+4. **Sequential access**: Leaf nodes are connected through linked list pointers, and range queries perform well.
+5. **Uniform distribution of data**: B+ tree insertion may cause data to be redistributed, making the data more evenly distributed throughout the tree and ensuring range query and deletion efficiency.
+
+
+
+Therefore, B+ tree is more suitable as one of the commonly used index structures in databases and file systems. Its core idea is to obtain query data by locating as many indexes as possible with as little IO as possible. For in-memory databases such as Redis, it is not interested in these, because Redis, as an in-memory database, cannot store a large amount of data, so the index does not need to be maintained through B+ trees. It only needs to be randomly maintained according to probability, saving memory. Moreover, using skip tables to implement zset is simpler than the former. When inserting, you only need to insert the data into the appropriate position in the linked list through the index and then randomly maintain an index of a certain height. There is no need to split and merge nodes when an imbalance is found during insertion like the B+ tree.
+
+### Reasons given by the author of Redis
+
+Of course, we can also use the reasons given by the author of Redis himself:
+
+> There are a few reasons:
+> 1. They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
+> 2. A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
+> 3. They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It requires little changes to the code.
+
+Translated it means:
+
+> There are several reasons:
+>
+> 1. They don’t take up much memory. It's mostly up to you. Changing the parameters of a node's probability of having a given number of levels makes them more memory efficient than B-trees.
+>
+> 2. Sorted sets are often the target of many ZRANGE or ZREVRANGE operations, that is, traversing the jump list in a linked list. With this operation, the cache locality of skip lists is at least as good as other types of balanced trees.
+>
+> 3. They are easier to implement, debug, etc. For example, due to the simplicity of skip tables, I received a patch (already in the Redis master branch) to achieve O(log(N)) ZRANK with enhanced skip tables. It requires only minimal modifications to the code.
+
+## Summary
+
+This article introduces the working principle and implementation of skip tables through a large amount of space to help readers become more familiar with the advantages and disadvantages of the skip table data structure. Finally, it compares the characteristics of each data structure operation to help readers better understand this interview question. It is recommended that when readers understand skip tables, they should cooperate with writing simulations as much as possible to understand the detailed process of adding, deleting, modifying and checking skip tables.
+
+## Reference
+
+- Why does redis use skiplist instead of red-black? :
+- Skip List--Skip List (one of the most detailed skip list articles on the entire Internet):
+- Detailed explanation of Redis objects and underlying data structures:
+- Redis ordered set (sorted set):
+- Comparison of red-black trees and skip tables:
+- Why does redis's zset use jump tables instead of b+ trees? :
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-01.en.md b/docs_en/database/sql/sql-questions-01.en.md
new file mode 100644
index 00000000000..36be8817d1c
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-01.en.md
@@ -0,0 +1,1822 @@
+---
+title: Summary of common SQL interview questions (1)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, query, grouping, sorting, connection, subquery, aggregation
+ - - meta
+ - name: description
+ content: Contains basic SQL high-frequency questions and solutions, covering typical scenarios such as query/grouping/sorting/joining, etc., emphasizing the balance between readability and performance.
+---
+
+> The question comes from: [Niuke Question Ba - SQL must be known and mastered](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=298)
+
+## Retrieve data
+
+`SELECT` is used to query data from the database.
+
+### Retrieve all IDs from the Customers table
+
+The existing table `Customers` is as follows:
+
+| cust_id |
+| ------- |
+| A |
+| B |
+| C |
+
+Write SQL statement to retrieve all `cust_id` from `Customers` table.
+
+Answer:
+
+```sql
+SELECT cust_id
+FROM Customers
+```
+
+### Retrieve and list a list of ordered products
+
+The table `OrderItems` contains a non-empty column `prod_id`, which represents the item id and contains all ordered items (some have been ordered multiple times).
+
+| prod_id |
+| ------- |
+|a1|
+|a2|
+| a3 |
+| a4 |
+| a5 |
+| a6 |
+| a7 |
+
+Write a SQL statement to retrieve and list the deduplicated list of all ordered items (`prod_id`).
+
+Answer:
+
+```sql
+SELECT DISTINCT prod_id
+FROM OrderItems
+```
+
+Knowledge point: `DISTINCT` is used to return the unique distinct value in a column.
+
+### Retrieve all columns
+
+Now there is a `Customers` table (the table contains columns `cust_id` represents the customer id and `cust_name` represents the customer name)
+
+| cust_id | cust_name |
+| ------- | --------- |
+| a1 | andy |
+| a2 | ben |
+| a3 | tony |
+| a4 | tom |
+| a5 | an |
+| a6 | lee |
+| a7 | hex |
+
+You need to write SQL statements to retrieve all columns.
+
+Answer:
+
+```sql
+SELECT cust_id, cust_name
+FROM Customers
+```
+
+## Sort retrieval data
+
+`ORDER BY` is used to sort the result set by one column or multiple columns. By default, records are sorted in ascending order. If you need to sort records in descending order, you can use the `DESC` keyword.
+
+### Retrieve customer names and sort them
+
+There is a table `Customers`, `cust_id` represents the customer id, `cust_name` represents the customer name.
+
+| cust_id | cust_name |
+| ------- | --------- |
+| a1 | andy |
+| a2 | ben |
+| a3 | tony |
+| a4 | tom |
+| a5 | an |
+| a6 | lee |
+| a7 | hex |
+
+Retrieve all customer names (`cust_name`) from `Customers` and display the results in order from Z to A.
+
+Answer:
+
+```sql
+SELECT cust_name
+FROM Customers
+ORDER BY cust_name DESC
+```
+
+### Sort by customer ID and date
+
+There is `Orders` table:
+
+| cust_id | order_num | order_date |
+| ------- | --------- | ------------------- |
+| andy | aaaa | 2021-01-01 00:00:00 |
+| andy | bbbb | 2021-01-01 12:00:00 |
+| bob | cccc | 2021-01-10 12:00:00 |
+| dick | dddd | 2021-01-11 00:00:00 |
+
+Write a SQL statement to retrieve the customer ID (`cust_id`) and order number (`order_num`) from the `Orders` table, and sort the results first by customer ID, and then in reverse order by order date.
+
+Answer:
+
+```sql
+# Sort by column name
+# Note: order_date descending order, not order_num
+SELECT cust_id, order_num
+FROM Orders
+ORDER BY cust_id,order_date DESC
+```
+
+Knowledge point: `order by` When sorting multiple columns, the columns that are sorted first are placed in front, and the columns that are sorted later are placed in the back. Also, different columns can have different sorting rules.
+
+### Sort by quantity and price
+
+Suppose there is an `OrderItems` table:
+
+| quantity | item_price |
+| -------- | ---------- |
+| 1 | 100 |
+| 10 | 1003 |
+| 2 | 500 |
+
+Write a SQL statement to display the quantity (`quantity`) and price (`item_price`) in the `OrderItems` table, and sort them by quantity from high to low and price from high to low.
+
+Answer:
+
+```sql
+SELECT quantity, item_price
+FROM OrderItems
+ORDER BY quantity DESC,item_price DESC
+```
+
+### Check SQL statement
+
+There is a `Vendors` table:
+
+| vend_name |
+| --------- |
+| Haidilao |
+| Xiaolongkan |
+| Dalongyi |
+
+Is there something wrong with the following SQL statement? Try to correct it so that it runs correctly and returns the results in reverse order according to `vend_name`.
+
+```sql
+SELECT vend_name,
+FROM Vendors
+ORDER vend_name DESC
+```
+
+After correction:
+
+```sql
+SELECT vend_name
+FROM Vendors
+ORDER BY vend_name DESC
+```
+
+Knowledge points:
+
+- Commas are used to separate columns.
+- ORDER BY contains BY, which needs to be written completely and in the correct position.
+
+## Filter data
+
+`WHERE` can filter the returned data.
+
+The following operators can be used in the `WHERE` clause:
+
+| Operator | Description |
+| :------ | :--------------------------------------------------------------- |
+| = | equals |
+| <> | is not equal to. **Note:** In some versions of SQL, this operator can be written as != |
+| > | greater than |
+| < | less than |
+| >= | Greater than or equal to |
+| <= | Less than or equal to |
+| BETWEEN | Within a range |
+| LIKE | Search for a pattern |
+| IN | Specifies multiple possible values for a column |
+
+### Return fixed price products
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------------- | ---------- || a0018 | sockets | 9.49 |
+| a0019 | iphone13 | 600 |
+| b0018 | gucci t-shirts | 1000 |
+
+[Problem] Retrieving the product ID (`prod_id`) and product name (`prod_name`) from the `Products` table only returns products with a price of $9.49.
+
+Answer:
+
+```sql
+SELECT prod_id, prod_name
+FROM Products
+WHERE prod_price = 9.49
+```
+
+### Return higher priced products
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------------- | ---------- |
+| a0018 | sockets | 9.49 |
+| a0019 | iphone13 | 600 |
+| b0019 | gucci t-shirts | 1000 |
+
+[Problem] Write a SQL statement to retrieve the product ID (`prod_id`) and product name (`prod_name`) from the `Products` table, returning only products with a price of $9 or more.
+
+Answer:
+
+```sql
+SELECT prod_id, prod_name
+FROM Products
+WHERE prod_price >= 9
+```
+
+### Return products and sort them by price
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------- | ---------- |
+| a0011 | egg | 3 |
+| a0019 | sockets | 4 |
+| b0019 | coffee | 15 |
+
+[Question] Write a SQL statement to return the name (`prod_name`) and price (`prod_price`) of all products in the `Products` table with a price between $3 and $6, and then sort the results by price.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_price
+FROM Products
+WHERE prod_price BETWEEN 3 AND 6
+ORDER BY prod_price
+
+# or
+SELECT prod_name, prod_price
+FROM Products
+WHERE prod_price >= 3 AND prod_price <= 6
+ORDER BY prod_price
+```
+
+### Return to more products
+
+The `OrderItems` table contains: order number `order_num`, `quantity` product quantity
+
+| order_num | quantity |
+| --------- | -------- |
+| a1 | 105 |
+| a2 | 1100 |
+| a2 | 200 |
+| a4 | 1121 |
+| a5 | 10 |
+| a2 | 19 |
+| a7 | 5 |
+
+[Problem] Retrieve all distinct and unique order numbers (`order_num`) from the `OrderItems` table, where each order must contain 100 or more products.
+
+Answer:
+
+```sql
+SELECT order_num
+FROM OrderItems
+GROUP BY order_num
+HAVING SUM(quantity) >= 100
+```
+
+## Advanced data filtering
+
+The `AND` and `OR` operators are used to filter records based on more than one condition and can be used in combination. `AND` requires both conditions to be true, and `OR` only needs one of the 2 conditions to be true.
+
+### Retrieve supplier name
+
+The `Vendors` table has fields vendor name (`vend_name`), vendor country (`vend_country`), vendor state (`vend_state`)
+
+| vend_name | vend_country | vend_state |
+| --------- | ------------ | ---------- |
+| apple | USA | CA |
+| vivo | CNA | shenzhen |
+| huawei | CNA | xian |
+
+[Problem] Write a SQL statement to retrieve the vendor name (`vend_name`) from the `Vendors` table and return only suppliers in California (this needs to be filtered by country [USA] and state [CA], maybe there is a CA in other countries)
+
+Answer:
+
+```sql
+SELECT vend_name
+FROM Vendors
+WHERE vend_country = 'USA' AND vend_state = 'CA'
+```
+
+### Retrieve and list a list of ordered products
+
+The `OrderItems` table contains all ordered products (some have been ordered multiple times).
+
+| prod_id | order_num | quantity |
+| ------- | --------- | -------- |
+| BR01 | a1 | 105 |
+| BR02 | a2 | 1100 |
+| BR02 | a2 | 200 |
+| BR03 | a4 | 1121 |
+| BR017 | a5 | 10 |
+| BR02 | a2 | 19 |
+| BR017 | a7 | 5 |
+
+[Question] Write a SQL statement to find all orders for `BR01`, `BR02` or `BR03` with a quantity of at least 100 units. You need to return the order number (`order_num`), product ID (`prod_id`) and quantity (`quantity`) of the `OrderItems` table and filter by product ID and quantity.
+
+Answer:
+
+```sql
+SELECT order_num, prod_id, quantity
+FROM OrderItems
+WHERE prod_id IN ('BR01', 'BR02', 'BR03') AND quantity >= 100
+```
+
+### Returns the name and price of all products priced between $3 and $6
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------- | ---------- |
+| a0011 | egg | 3 |
+| a0019 | sockets | 4 |
+| b0019 | coffee | 15 |
+
+[Question] Write a SQL statement to return the name (`prod_name`) and price (`prod_price`) of all products with a price between $3 and $6, use the AND operator, and then sort the results in ascending order by price.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_price
+FROM Products
+WHERE prod_price >= 3 and prod_price <= 6
+ORDER BY prod_price
+```
+
+### Check SQL statement
+
+The suppliers table `Vendors` has fields supplier name `vend_name`, supplier country `vend_country`, supplier province `vend_state`
+
+| vend_name | vend_country | vend_state |
+| --------- | ------------ | ---------- |
+| apple | USA | CA |
+| vivo | CNA | shenzhen |
+| huawei | CNA | xian |
+
+[Problem] Modify the following sql correctly so that it can be returned correctly.
+
+```sql
+SELECT vend_name
+FROM Vendors
+ORDER BY vend_name
+WHERE vend_country = 'USA' AND vend_state = 'CA';
+```
+
+After modification:
+
+```sql
+SELECT vend_name
+FROM Vendors
+WHERE vend_country = 'USA' AND vend_state = 'CA'
+ORDER BY vend_name
+```
+
+The `ORDER BY` statement must be placed after `WHERE`.
+
+## Use wildcards to filterSQL wildcards must be used with the `LIKE` operator
+
+In SQL, the following wildcard characters can be used:
+
+| wildcard | description |
+| :---------------------------------- | :---------------------------------- |
+| `%` | represents zero or more characters |
+| `_` | Replaces only one character |
+| `[charlist]` | Any single character in a character list |
+| `[^charlist]` or `[!charlist]` | Any single character not in the character list |
+
+### Retrieve product name and description (1)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| ---------- | --------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego toy |
+
+[Problem] Write a SQL statement to retrieve the product name (`prod_name`) and description (`prod_desc`) from the `Products` table and return only the product names that contain the word `toy` in the description.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc LIKE '%toy%'
+```
+
+### Retrieve product name and description (2)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| ---------- | --------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego toy |
+
+[Problem] Write a SQL statement to retrieve the product name (`prod_name`) and description (`prod_desc`) from the `Products` table, return only the products where the word `toy` does not appear in the description, and finally sort the results by "product name".
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc NOT LIKE '%toy%'
+ORDER BY prod_name
+```
+
+### Retrieve product name and description (3)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| --------- | ---------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego carrots toy |
+
+[Problem] Write a SQL statement to retrieve the product name (`prod_name`) and description (`prod_desc`) from the `Products` table, and only return products where `toy` and `carrots` appear in the description. There are several ways to do this, but for this challenge, use `AND` and two `LIKE` comparisons.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc LIKE '%toy%' AND prod_desc LIKE "%carrots%"
+```
+
+### Retrieve product name and description (4)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| --------- | ---------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego toy carrots |
+
+[Problem] Write a SQL statement to retrieve the product name (prod_name) and description (prod_desc) from the Products table, and only return products in which toys and carrots appear in **sequence** in the description. Tip: Just use `LIKE` with three `%` symbols.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc LIKE '%toy%carrots%'
+```
+
+## Create a calculated field
+
+### Alias
+
+A common use of aliases is to rename table column fields in retrieved results (to meet specific reporting requirements or customer needs). There is a table `Vendors` representing supplier information, `vend_id` supplier id, `vend_name` supplier name, `vend_address` supplier address, `vend_city` supplier city.
+
+| vend_id | vend_name | vend_address | vend_city |
+| ------- | ------------- | ------------ | ---------- |
+| a001 | tencent cloud | address1 | shenzhen |
+| a002 | huawei cloud | address2 | dongguan |
+| a003 | aliyun cloud | address3 | hangzhou |
+| a003 | netease cloud | address4 | guangzhou |
+
+[Problem] Write a SQL statement to retrieve `vend_id`, `vend_name`, `vend_address` and `vend_city` from the `Vendors` table, rename `vend_name` to `vname`, rename `vend_city` to `vcity`, rename `vend_address` to `vaddress`, and sort the results in ascending order by vendor name.
+
+Answer:
+
+```sql
+SELECT vend_id, vend_name AS vname, vend_address AS vaddress, vend_city AS vcity
+FROM Vendors
+ORDER BY vname
+# as can be omitted
+SELECT vend_id, vend_name vname, vend_address vaddress, vend_city vcity
+FROM Vendors
+ORDER BY vname
+```
+
+### Discount
+
+Our example store is running a sale with 10% off all products. The `Products` table contains `prod_id` product id, `prod_price` product price.
+
+[Question] Write SQL statements to return `prod_id`, `prod_price` and `sale_price` from the `Products` table. `sale_price` is a calculated field containing the promotional price. Tip: You can multiply by 0.9 to get 90% of the original price (i.e. 10% discount).
+
+Answer:
+
+```sql
+SELECT prod_id, prod_price, prod_price * 0.9 AS sale_price
+FROM Products
+```
+
+Note: `sale_price` is the name of the calculation result, not the original column name.
+
+## Use functions to process data
+
+### Customer login name
+
+Our store is online and customer accounts are being created. All users require a login name, and the default login name is a combination of their name and city.
+
+The `Customers` table is given as follows:
+
+| cust_id | cust_name | cust_contact | cust_city |
+| ------- | --------- | ------------ | --------- |
+| a1 | Andy Li | Andy Li | Oak Park |
+| a2 | Ben Liu | Ben Liu | Oak Park |
+| a3 | Tony Dai | Tony Dai | Oak Park |
+| a4 | Tom Chen | Tom Chen | Oak Park || a5 | An Li | An Li | Oak Park |
+| a6 | Lee Chen | Lee Chen | Oak Park |
+| a7 | Hex Liu | Hex Liu | Oak Park |
+
+[Question] Write a SQL statement to return the customer ID (`cust_id`), customer name (`cust_name`) and login name (`user_login`), where the login name is all uppercase letters and consists of the first two characters of the customer's contact person (`cust_contact`) and the first three characters of the city (`cust_city`). Tip: Requires the use of functions, concatenation and aliases.
+
+Answer:
+
+```sql
+SELECT cust_id, cust_name, UPPER(CONCAT(SUBSTRING(cust_contact, 1, 2), SUBSTRING(cust_city, 1, 3))) AS user_login
+FROM Customers
+```
+
+Knowledge points:
+
+- Interception function `SUBSTRING()`: intercepts a string, `substring(str,n,m)` (n represents the starting interception position, m represents the number of characters to be intercepted) means that the returned string str intercepts m characters starting from the nth character;
+- Concatenation function `CONCAT()`: concatenates two or more strings into one string, select concat(A,B): concatenates strings A and B.
+
+- Uppercase function `UPPER()`: Converts the specified string to uppercase.
+
+### Return the order number and order date of all orders in January 2020
+
+`Orders` order table is as follows:
+
+| order_num | order_date |
+| --------- | ------------------- |
+| a0001 | 2020-01-01 00:00:00 |
+| a0002 | 2020-01-02 00:00:00 |
+| a0003 | 2020-01-01 12:00:00 |
+| a0004 | 2020-02-01 00:00:00 |
+| a0005 | 2020-03-01 00:00:00 |
+
+[Question] Write a SQL statement to return the order number (`order_num`) and order date (`order_date`) of all orders in January 2020, and sort them in ascending order by order date
+
+Answer:
+
+```sql
+SELECT order_num, order_date
+FROM Orders
+WHERE month(order_date) = '01' AND YEAR(order_date) = '2020'
+ORDER BY order_date
+```
+
+You can also use wildcards to do this:
+
+```sql
+SELECT order_num, order_date
+FROM Orders
+WHERE order_date LIKE '2020-01%'
+ORDER BY order_date
+```
+
+Knowledge points:
+
+- Date format: `YYYY-MM-DD`
+- Time format: `HH:MM:SS`
+
+Commonly used functions related to date and time processing:
+
+| function | description |
+| --------------- | ------------------------------- |
+| `ADDDATE()` | Add a date (day, week, etc.) |
+| `ADDTIME()` | Add a time (hour, minute, etc.) |
+| `CURDATE()` | Returns the current date |
+| `CURTIME()` | Return the current time |
+| `DATE()` | Returns the date part of a datetime |
+| `DATEDIFF` | Calculate the difference between two dates |
+| `DATE_FORMAT()` | Returns a formatted date or time string |
+| `DAY()` | Returns the day part of a date |
+| `DAYOFWEEK()` | For a date, return the corresponding day of the week |
+| `HOUR()` | Returns the hour part of a time |
+| `MINUTE()` | Returns the minute part of a time |
+| `MONTH()` | Returns the month part of a date |
+| `NOW()` | Returns the current date and time |
+| `SECOND()` | Returns the seconds part of a time |
+| `TIME()` | Returns the time part of a datetime |
+| `YEAR()` | Returns the year part of a date |
+
+## Summary data
+
+Functions related to summary data:
+
+| function | description |
+| --------- | ---------------- |
+| `AVG()` | Returns the average value of a column |
+| `COUNT()` | Returns the number of rows in a column |
+| `MAX()` | Returns the maximum value of a column |
+| `MIN()` | Returns the minimum value of a column |
+| `SUM()` | Returns the sum of values in a column |
+
+### Determine the total number of products sold
+
+The `OrderItems` table represents the products sold, and `quantity` represents the number of items sold.
+
+| quantity |
+|--------|
+| 10 |
+| 100 |
+| 1000 |
+| 10001 |
+| 2 |
+| 15 |
+
+[Question] Write a SQL statement to determine the total number of products sold.
+
+Answer:
+
+```sql
+SELECT Sum(quantity) AS items_ordered
+FROM OrderItems
+```
+
+### Determine the total number of product items BR01 sold
+
+The `OrderItems` table represents the products sold, `quantity` represents the quantity of items sold, and the product item is `prod_id`.
+
+| quantity | prod_id |
+| -------- | ------- |
+| 10 | AR01 |
+| 100 | AR10 |
+| 1000 | BR01 |
+| 10001 | BR010 |
+
+[Problem] Modify the created statement to determine the total number of product items (`prod_id`) sold as "BR01".
+
+Answer:
+
+```sql
+SELECT Sum(quantity) AS items_ordered
+FROM OrderItems
+WHERE prod_id = 'BR01'
+```
+
+### Determine the price of the most expensive product in the Products table that is $10 or less
+
+The `Products` table is as follows, `prod_price` represents the price of the product.
+
+| prod_price |
+| ---------- |
+| 9.49 |
+| 600 |
+| 1000 |
+
+[Question] Write a SQL statement to determine the price (`prod_price`) of the most expensive product in the `Products` table whose price does not exceed $10. Name the calculated field `max_price`.
+
+Answer:
+
+```sql
+SELECT Max(prod_price) AS max_price
+FROM Products
+WHERE prod_price <= 10
+```
+
+## Grouped data
+
+`GROUP BY`:
+
+- The `GROUP BY` clause groups records into summary rows.
+- `GROUP BY` returns one record for each group.
+- `GROUP BY` usually also involves aggregating `COUNT`, `MAX`, `SUM`, `AVG`, etc.
+- `GROUP BY` can group by one or more columns.
+- `GROUP BY` After sorting by grouping fields, `ORDER BY` can sort by summary fields.
+
+`HAVING`:
+
+- `HAVING` is used to filter aggregated `GROUP BY` results.
+- `HAVING` must be used with `GROUP BY`.
+- `WHERE` and `HAVING` can be in the same query.
+
+`HAVING` vs `WHERE`:
+
+- `WHERE`: Filter the specified rows, and aggregate functions (grouping functions) cannot be added later.
+- `HAVING`: Filter grouping, must be used together with `GROUP BY`, cannot be used alone.
+
+### Return the number of rows for each order number
+
+The `OrderItems` table contains every product for every order
+
+| order_num |
+| --------- |
+| a002 |
+| a002 |
+| a002 |
+| a004 |
+| a007 |
+
+[Question] Write a SQL statement to return the number of rows (`order_lines`) for each order number (`order_num`), and sort the results in ascending order by `order_lines`.
+
+Answer:
+
+```sql
+SELECT order_num, Count(order_num) AS order_lines
+FROM OrderItems
+GROUP BY order_num
+ORDER BY order_lines```
+
+Knowledge points:
+
+1. Both `count(*)` and `count(column name)` are acceptable. The difference is that `count(column name)` counts the number of non-NULL rows;
+2. `order by` is executed last, so column aliases can be used;
+3. Don’t forget to add `group by` when performing group aggregation, otherwise there will only be one row of results.
+
+### Lowest cost product per supplier
+
+There is a `Products` table with fields `prod_price` representing the product price and `vend_id` representing the supplier id.
+
+| vend_id | prod_price |
+| ------- | ---------- |
+| a0011 | 100 |
+| a0019 | 0.1 |
+| b0019 | 1000 |
+| b0019 | 6980 |
+| b0019 | 20 |
+
+[Question] Write a SQL statement that returns a field named `cheapest_item` that contains the lowest cost product from each supplier (using `prod_price` from the `Products` table), and then sorts the results in ascending order from lowest cost to highest cost.
+
+Answer:
+
+```sql
+SELECT vend_id, Min(prod_price) AS cheapest_item
+FROM Products
+GROUP BY vend_id
+ORDER BY cheapest_item
+```
+
+### Return the order numbers of all orders whose total order quantity is not less than 100
+
+`OrderItems` represents the order item table, including: order number `order_num` and order quantity `quantity`.
+
+| order_num | quantity |
+| --------- | -------- |
+| a1 | 105 |
+| a2 | 1100 |
+| a2 | 200 |
+| a4 | 1121 |
+| a5 | 10 |
+| a2 | 19 |
+| a7 | 5 |
+
+[Question] Please write a SQL statement to return all order numbers whose total order quantity is not less than 100. The final results are sorted in ascending order by order number.
+
+Answer:
+
+```sql
+# Direct aggregation
+SELECT order_num
+FROM OrderItems
+GROUP BY order_num
+HAVING Sum(quantity) >= 100
+ORDER BY order_num
+
+# Subquery
+SELECT a.order_num
+FROM (SELECT order_num, Sum(quantity) AS sum_num
+ FROM OrderItems
+ GROUP BY order_num
+ HAVING sum_num >= 100) a
+ORDER BY a.order_num
+```
+
+Knowledge points:
+
+- `where`: Filter the specified rows. Aggregation functions (grouping functions) cannot be added later.
+- `having`: filter grouping, used together with `group by`, cannot be used alone.
+
+### Calculate the sum
+
+The `OrderItems` table represents order information, including fields: order number `order_num` and `item_price` the selling price of the product, `quantity` the quantity of the product.
+
+| order_num | item_price | quantity |
+| --------- | ---------- | -------- |
+| a1 | 10 | 105 |
+| a2 | 1 | 1100 |
+| a2 | 1 | 200 |
+| a4 | 2 | 1121 |
+| a5 | 5 | 10 |
+| a2 | 1 | 19 |
+| a7 | 7 | 5 |
+
+[Question] Write a SQL statement to aggregate based on order numbers and return all order numbers with a total order price of not less than 1,000. The final results are sorted in ascending order by order number.
+
+Tip: total price = item_price times quantity
+
+Answer:
+
+```sql
+SELECT order_num, Sum(item_price * quantity) AS total_price
+FROM OrderItems
+GROUP BY order_num
+HAVING total_price >= 1000
+ORDER BY order_num
+```
+
+### Check SQL statement
+
+`OrderItems` table contains `order_num` order numbers
+
+| order_num |
+| --------- |
+| a002 |
+| a002 |
+| a002 |
+| a004 |
+| a007 |
+
+[Question] Modify the following code correctly and execute it
+
+```sql
+SELECT order_num, COUNT(*) AS items
+FROM OrderItems
+GROUP BY items
+HAVING COUNT(*) >= 3
+ORDER BY items, order_num;
+```
+
+After modification:
+
+```sql
+SELECT order_num, COUNT(*) AS items
+FROM OrderItems
+GROUP BY order_num
+HAVING items >= 3
+ORDER BY items, order_num;
+```
+
+## Use subquery
+
+A subquery is a SQL query nested within a larger query, also called an inner query or inner select, and the statement containing the subquery is also called an outer query or outer select. Simply put, a subquery refers to using the result of a `SELECT` query (subquery) as the data source or judgment condition of another SQL statement (main query).
+
+Subqueries can be embedded in `SELECT`, `INSERT`, `UPDATE` and `DELETE` statements, and can also be used with operators such as `=`, `<`, `>`, `IN`, `BETWEEN`, `EXISTS` and other operators.
+
+Subqueries are often used after the `WHERE` clause and the `FROM` clause:
+
+- When used in the `WHERE` clause, depending on different operators, the subquery can return a single row and a single column, multiple rows and a single column, or a single row and multiple columns of data. A subquery is to return a value that can be used as a WHERE clause query condition.
+- When used in the `FROM` clause, multi-row and multi-column data is generally returned, which is equivalent to returning a temporary table, so as to comply with the rule that `FROM` is followed by a table. This approach can implement joint queries on multiple tables.
+
+> Note: MySQL database only supports subqueries from version 4.1, and earlier versions do not support it.
+
+The basic syntax of a subquery for a `WHERE` clause is as follows:
+
+```sql
+SELECT column_name [, column_name ]
+FROM table1 [, table2 ]
+WHERE column_name operator
+(SELECT column_name [, column_name ]
+FROM table1 [, table2 ]
+[WHERE])
+```
+
+- Subqueries need to be placed within brackets `( )`.
+- `operator` represents the operator used for the `WHERE` clause, which can be a comparison operator (such as `=`, `<`, `>`, `<>`, etc.) or a logical operator (such as `IN`, `NOT IN`, `EXISTS`, `NOT EXISTS`, etc.), which is determined according to the requirements.
+
+The basic syntax of a subquery for a `FROM` clause is as follows:
+
+```sql
+SELECT column_name [, column_name ]
+FROM (SELECT column_name [, column_name ]
+ FROM table1 [, table2 ]
+ [WHERE]) AS temp_table_name [, ...]
+[JOIN type JOIN table_name ON condition]
+WHERE condition;
+```
+
+- The result returned by the subquery for `FROM` is equivalent to a temporary table, so you need to use the AS keyword to give the temporary table a name.
+- Subqueries need to be placed within brackets `( )`.
+- You can specify multiple temporary table names and join these tables using the `JOIN` statement.
+
+### Returns a list of customers who purchased products priced at $10 or more
+
+`OrderItems` represents the order item table, containing fields order number: `order_num`, order price: `item_price`; `Orders` table represents the order information table, containing customer `id: cust_id` and order number: `order_num`
+
+`OrderItems` table:
+
+| order_num | item_price |
+| --------- | ---------- |
+| a1 | 10 |
+| a2 | 1 |
+| a2 | 1 |
+| a4 | 2 |
+| a5 | 5 || a2 | 1 |
+| a7 | 7 |
+
+`Orders` table:
+
+| order_num | cust_id |
+| --------- | ------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a2 | cust1 |
+| a4 | cust2 |
+| a5 | cust5 |
+| a2 | cust1 |
+| a7 | cust7 |
+
+[Problem] Use a subquery to return a list of customers who purchased products with a price of $10 or more. The results do not need to be sorted.
+
+Answer:
+
+```sql
+SELECT cust_id
+FROM Orders
+WHERE order_num IN (SELECT DISTINCT order_num
+ FROM OrderItems
+ where item_price >= 10)
+```
+
+### Determine which orders purchased the product with prod_id BR01 (1)
+
+The table `OrderItems` represents the order product information table, `prod_id` is the product id; the `Orders` table represents the order table, `cust_id` represents the customer id and the order date `order_date`
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+【Question】
+
+Write a SQL statement that uses a subquery to determine which orders (in `OrderItems`) purchased the product with `prod_id` as "BR01", then return the customer ID (`cust_id`) and order date (`order_date`) for each product from the `Orders` table, sorting the results in ascending order by order date.
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT cust_id,order_date
+FROM Orders
+WHERE order_num IN
+ (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01' )
+ORDER BY order_date;
+
+# Writing method 2: Join table
+SELECT b.cust_id, b.order_date
+FROM OrderItems a,Orders b
+WHERE a.order_num = b.order_num AND a.prod_id = 'BR01'
+ORDER BY order_date
+```
+
+### Return the emails of all customers who purchased the product with prod_id BR01 (1)
+
+You want to know the date of ordering BR01 product. The table `OrderItems` represents the order product information table, `prod_id` is the product id; the `Orders` table represents the order table, which has `cust_id` which represents the customer id and the order date `order_date`; the `Customers` table contains `cust_email` customer email and `cust_id` customer id
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+The `Customers` table represents customer information, `cust_id` is the customer id, `cust_email` is the customer email
+
+| cust_id | cust_email |
+| ------- | ------------------ |
+| cust10 | |
+| cust1 | |
+| cust2 | |
+
+[Problem] Return the emails of all customers who purchased the product with `prod_id` as `BR01` (`cust_email` in the `Customers` table) without sorting the results.
+
+Tip: This involves `SELECT` statements, the innermost one returning `order_num` from the `OrderItems` table, and the middle one returning `cust_id` from the `Customers` table.
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT cust_email
+FROM Customers
+WHERE cust_id IN (SELECT cust_id
+ FROM Orders
+ WHERE order_num IN (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01'))
+
+# Writing method 2: Join table (inner join)
+SELECT c.cust_email
+FROM OrderItems a,Orders b,Customers c
+WHERE a.order_num = b.order_num AND b.cust_id = c.cust_id AND a.prod_id = 'BR01'
+
+#Writing 3: Join table (left join)
+SELECT c.cust_email
+FROM ORDERS A LEFT JOIN
+ OrderItems b ON a.order_num = b.order_num LEFT JOIN
+ Customers c ON a.cust_id = c.cust_id
+WHERE b.prod_id = 'BR01'
+```
+
+### Return the total amount of different orders for each customer
+
+We need a list of customer IDs with the total amount they have ordered.
+
+The `OrderItems` table represents order information. The `OrderItems` table has order number: `order_num`, product selling price: `item_price`, and product quantity: `quantity`.
+
+| order_num | item_price | quantity |
+| --------- | ---------- | -------- |
+| a0001 | 10 | 105 |
+| a0002 | 1 | 1100 |
+| a0002 | 1 | 200 |
+| a0013 | 2 | 1121 |
+| a0003 | 5 | 10 |
+| a0003 | 1 | 19 |
+| a0003 | 7 | 5 |
+
+`Orders` table order number: `order_num`, customer id: `cust_id`
+
+| order_num | cust_id |
+| --------- | ------- |
+| a0001 | cust10 |
+| a0002 | cust1 |
+| a0003 | cust1 |
+| a0013 | cust2 |
+
+【Question】
+
+Write a SQL statement that returns the customer ID (`cust_id` in the `Orders` table) and use a subquery to return `total_ordered` to return the total number of orders for each customer, sorting the results by amount from largest to smallest.
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT o.cust_id, SUM(tb.total_ordered) AS `total_ordered`
+FROM (SELECT order_num, SUM(item_price * quantity) AS total_ordered
+ FROM OrderItems
+ GROUP BY order_num) AS tb,
+ Orders o
+WHERE tb.order_num = o.order_num
+GROUP BY o.cust_id
+ORDER BY total_ordered DESC;
+
+# Writing method 2: Join table
+SELECT b.cust_id, Sum(a.quantity * a.item_price) AS total_ordered
+FROM OrderItems a,Orders b
+WHERE a.order_num = b.order_num
+GROUP BY cust_id
+ORDER BY total_ordered DESC```
+
+For a detailed introduction to the writing method, please refer to: [issue#2402: Errors in writing method 1 and how to modify it](https://github.com/Snailclimb/JavaGuide/issues/2402).
+
+### Retrieve all product names and corresponding sales totals from the Products table
+
+Retrieve all product names: `prod_name`, product ids: `prod_id` in the `Products` table
+
+| prod_id | prod_name |
+| ------- | --------- |
+| a0001 | egg |
+| a0002 | sockets |
+| a0013 | coffee |
+| a0003 | cola |
+
+`OrderItems` represents the order item table, order product: `prod_id`, sold quantity: `quantity`
+
+| prod_id | quantity |
+| ------- | -------- |
+| a0001 | 105 |
+| a0002 | 1100 |
+| a0002 | 200 |
+| a0013 | 1121 |
+| a0003 | 10 |
+| a0003 | 19 |
+| a0003 | 5 |
+
+【Question】
+
+Write a SQL statement to retrieve all product names (`prod_name`) from the `Products` table, and a calculated column named `quant_sold` that contains the total number of products sold (retrieved using a subquery and `SUM(quantity)` on the `OrderItems` table).
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT p.prod_name, tb.quant_sold
+FROM (SELECT prod_id, Sum(quantity) AS quant_sold
+ FROM OrderItems
+ GROUP BY prod_id) AS tb,
+ Products p
+WHERE tb.prod_id = p.prod_id
+
+# Writing method 2: Join table
+SELECT p.prod_name, Sum(o.quantity) AS quant_sold
+FROM Products p,
+ OrderItems o
+WHERE p.prod_id = o.prod_id
+GROUP BY p.prod_name (p.prod_id cannot be used here, an error will be reported)
+```
+
+## Join table
+
+JOIN means "connection". As the name suggests, the SQL JOIN clause is used to join two or more tables for query.
+
+When connecting tables, you need to select a field in each table and compare the values of these fields. Two records with the same value will be merged into one. **The essence of joining tables is to merge records from different tables to form a new table. Of course, this new table is only temporary, it only exists for the duration of this query**.
+
+The basic syntax for joining two tables using `JOIN` is as follows:
+
+```sql
+SELECT table1.column1, table2.column2...
+FROM table1
+JOIN table2
+ON table1.common_column1 = table2.common_column2;
+```
+
+`table1.common_column1 = table2.common_column2` is a join condition. Only records that meet this condition will be merged into one row. You can join tables using several operators, such as =, >, <, <>, <=, >=, !=, `between`, `like`, or `not`, but the most common is to use =.
+
+When there are fields with the same name in two tables, in order to help the database engine distinguish the fields of which table, the table name needs to be added when writing the field names with the same name. Of course, if the written field name is unique in the two tables, you can not use the above format and just write the field name.
+
+In addition, if the related field names of the two tables are the same, you can also use the `USING` clause instead of `ON`, for example:
+
+```sql
+# join....on
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+ON c.cust_id = o.cust_id
+ORDER BY c.cust_name
+
+# If the associated field names of the two tables are the same, you can also use the USING clause: JOIN....USING()
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+USING(cust_id)
+ORDER BY c.cust_name
+```
+
+**The difference between `ON` and `WHERE`**:
+
+- When joining tables, SQL will generate a new temporary table based on the join conditions. `ON` is the connection condition, which determines the generation of temporary tables.
+- `WHERE` is to filter the data in the temporary table after the temporary table is generated to generate the final result set. At this time, there is no JOIN-ON.
+
+So in summary: **SQL first generates a temporary table based on ON, and then filters the temporary table based on WHERE**.
+
+SQL allows some modifying keywords to be added to the left of `JOIN` to form different types of connections, as shown in the following table:
+
+| Connection type | Description |
+|------------------------------------------------ |------------------------------------------------------------------------------------------------ |
+| INNER JOIN inner join | (default connection method) Rows will be returned only when there are records that meet the conditions in both tables. |
+| LEFT JOIN / LEFT OUTER JOIN Left (outer) join | Returns all rows in the left table, even if there are no rows in the right table that meet the condition. |
+| RIGHT JOIN / RIGHT OUTER JOIN Right (outer) join | Returns all rows in the right table, even if there are no rows in the left table that meet the condition. |
+| FULL JOIN / FULL OUTER JOIN Full (outer) join | As long as one of the tables has records that meet the conditions, rows will be returned. |
+| SELF JOIN | Joins a table to itself as if the table were two tables. To differentiate between two tables, at least one table needs to be renamed in the SQL statement. |
+| CROSS JOIN | Cross join returns the Cartesian product of record sets from two or more joined tables. |
+
+The figure below shows 7 usages related to LEFT JOIN, RIGHT JOIN, INNER JOIN, and OUTER JOIN.
+
+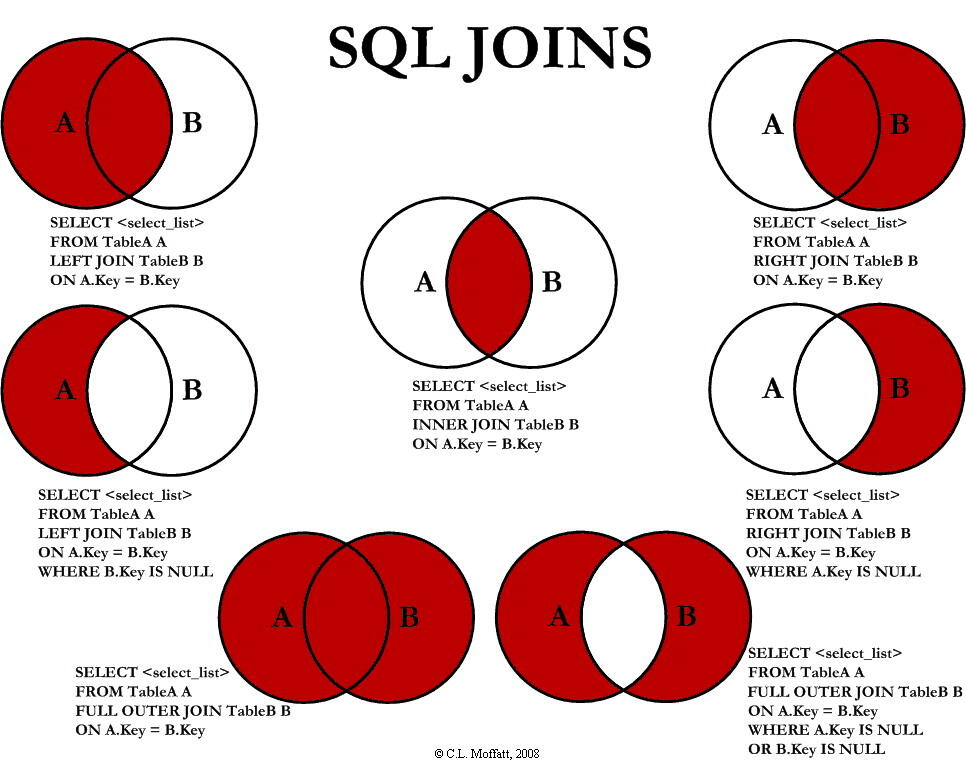
+
+If you just write `JOIN` without adding any modifiers, the default is `INNER JOIN`
+
+For `INNER JOIN`, there is also an implicit way of writing, called "**Implicit inner join**", that is, there is no `INNER JOIN` keyword, and the `WHERE` statement is used to implement the inner join function.
+
+```sql
+#Implicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c,Orders o
+WHERE c.cust_id = o.cust_id
+ORDER BY c.cust_name
+
+#Explicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+USING(cust_id)
+ORDER BY c.cust_name;
+```
+
+### Return customer name and related order number
+
+The `Customers` table has fields customer name `cust_name` and customer id `cust_id`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |`Orders` order information table, containing fields `order_num` order number, `cust_id` customer id
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+[Question] Write a SQL statement to return the customer name (`cust_name`) in the `Customers` table and the related order number (`order_num`) in the `Orders` table, and sort the results by customer name and order number in ascending order. You can try two different writing methods, one using simple equal join syntax, and the other using INNER JOIN.
+
+Answer:
+
+```sql
+#Implicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c,Orders o
+WHERE c.cust_id = o.cust_id
+ORDER BY c.cust_name,o.order_num
+
+#Explicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+USING(cust_id)
+ORDER BY c.cust_name,o.order_num;
+```
+
+### Return the customer name and related order number and the total price of each order
+
+The `Customers` table has fields, customer name: `cust_name`, customer id: `cust_id`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+
+`Orders` order information table, contains fields, order number: `order_num`, customer id: `cust_id`
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+The `OrderItems` table has fields, product order number: `order_num`, product quantity: `quantity`, product price: `item_price`
+
+| order_num | quantity | item_price |
+| --------- | -------- | ---------- |
+| a1 | 1000 | 10 |
+| a2 | 200 | 10 |
+| a3 | 10 | 15 |
+| a4 | 25 | 50 |
+| a5 | 15 | 25 |
+| a7 | 7 | 7 |
+
+[Problem] In addition to returning the customer name and order number, return the customer name (`cust_name`) in the `Customers` table and the related order number (`order_num`) in the `Orders` table, add a third column `OrderTotal`, which contains the total price of each order, and sort the results by customer name and then by order number in ascending order.
+
+```sql
+# Simple equal connection syntax
+SELECT c.cust_name, o.order_num, SUM(quantity * item_price) AS OrderTotal
+FROM Customers c,Orders o,OrderItems oi
+WHERE c.cust_id = o.cust_id AND o.order_num = oi.order_num
+GROUP BY c.cust_name, o.order_num
+ORDER BY c.cust_name, o.order_num
+```
+
+Note, some friends may write like this:
+
+```sql
+SELECT c.cust_name, o.order_num, SUM(quantity * item_price) AS OrderTotal
+FROM Customers c,Orders o,OrderItems oi
+WHERE c.cust_id = o.cust_id AND o.order_num = oi.order_num
+GROUP BY c.cust_name
+ORDER BY c.cust_name,o.order_num
+```
+
+This is wrong! Clustering only `cust_name` does meet the meaning of the question, but it does not comply with the syntax of `GROUP BY`.
+
+In the select statement, if there is no `GROUP BY` statement, then `cust_name` and `order_num` will return several values, while `sum(quantity * item_price)` will only return one value. Through `group by` `cust_name` can make `cust_name` and `sum(quantity * item_price)` correspond one to one, or **clustering**, so the same must be done. `order_num` performs clustering.
+
+> **In a word, the fields in select are either all clustered or none**
+
+### Determine which orders purchased the product with prod_id BR01 (2)
+
+The table `OrderItems` represents the order product information table, `prod_id` is the product id; the `Orders` table represents the order table, `cust_id` represents the customer id and the order date `order_date`
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+【Question】
+
+Write a SQL statement that uses a subquery to determine which orders (in `OrderItems`) purchased the product with `prod_id` as "BR01", then return the customer ID (`cust_id`) and order date (`order_date`) for each product from the `Orders` table, sorting the results in ascending order by order date.
+
+Tip: This time use joins and simple equijoin syntax.
+
+```sql
+# Writing method 1: subquery
+SELECT cust_id, order_date
+FROM Orders
+WHERE order_num IN (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01')
+ORDER BY order_date
+
+#Writing method 2: join table inner join
+SELECT cust_id, order_date
+FROM ORDERS o INNER JOIN
+ (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01') tb ON o.order_num = tb.order_num
+ORDER BY order_date
+
+# Writing method 3: Simplified version of writing method 2
+SELECT cust_id, order_date
+FROM Orders
+INNER JOIN OrderItems USING(order_num)
+WHERE OrderItems.prod_id = 'BR01'
+ORDER BY order_date
+```
+
+### Return the emails of all customers who purchased the product with prod_id BR01 (2)There is a table `OrderItems` representing the order product information table, `prod_id` is the product id; the `Orders` table represents the order table having `cust_id` representing the customer id and the order date `order_date`; the `Customers` table contains `cust_email` customer email and cust_id customer id
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+The `Customers` table represents customer information, `cust_id` is the customer id, `cust_email` is the customer email
+
+| cust_id | cust_email |
+| ------- | ------------------ |
+| cust10 | |
+| cust1 | |
+| cust2 | |
+
+[Problem] Return the emails of all customers who purchased the product with `prod_id` as BR01 (`cust_email` in the `Customers` table) without sorting the results.
+
+Tip: When it comes to the `SELECT` statement, the innermost one returns `order_num` from the `OrderItems` table, and the middle one returns `cust_id` from the `Customers` table, but the INNER JOIN syntax must be used.
+
+```sql
+SELECT cust_email
+FROM Customers
+INNER JOIN Orders using(cust_id)
+INNER JOIN OrderItems using(order_num)
+WHERE OrderItems.prod_id = 'BR01'
+```
+
+### Another way to determine the best customers (2)
+
+The `OrderItems` table represents order information. Another way to determine the best customers is to look at how much they spend. The `OrderItems` table has the order number `order_num` and `item_price` the price at which the item was sold, and `quantity` the quantity of the item.
+
+| order_num | item_price | quantity |
+| --------- | ---------- | -------- |
+| a1 | 10 | 105 |
+| a2 | 1 | 1100 |
+| a2 | 1 | 200 |
+| a4 | 2 | 1121 |
+| a5 | 5 | 10 |
+| a2 | 1 | 19 |
+| a7 | 7 | 5 |
+
+The `Orders` table contains the fields `order_num` order number, `cust_id` customer id
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+The customer table `Customers` has fields `cust_id` customer id, `cust_name` customer name
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+
+[Question] Write a SQL statement to return the customer name and total amount (`order_num` in the `OrderItems` table) whose order total price is not less than 1000.
+
+Tip: Need to calculate the sum (`item_price` times `quantity`). To sort the results by total amount, use the `INNER JOIN` syntax.
+
+```sql
+SELECT cust_name, SUM(item_price * quantity) AS total_price
+FROM Customers
+INNER JOIN Orders USING(cust_id)
+INNER JOIN OrderItems USING(order_num)
+GROUP BY cust_name
+HAVING total_price >= 1000
+ORDER BY total_price
+```
+
+## Create advanced connection
+
+### Retrieve each customer's name and all order numbers (1)
+
+The `Customers` table represents customer information containing customer id `cust_id` and customer name `cust_name`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+
+The `Orders` table represents order information including order number `order_num` and customer id `cust_id`
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+[Problem] Use INNER JOIN to write SQL statements to retrieve the name of each customer (`cust_name` in the `Customers` table) and all order numbers (`order_num` in the `Orders` table), and finally return them in ascending order according to the customer name `cust_name`.
+
+```sql
+SELECT cust_name, order_num
+FROM Customers
+INNER JOIN Orders
+USING(cust_id)
+ORDER BY cust_name
+```
+
+### Retrieve each customer's name and all order numbers (2)
+
+The `Orders` table represents order information including order number `order_num` and customer id `cust_id`
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+The `Customers` table represents customer information containing customer id `cust_id` and customer name `cust_name`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+| cust40 | ace |
+
+[Problem] Retrieve each customer's name (`cust_name` in the `Customers` table) and all order numbers (`order_num` in the Orders table), and list all customers, even if they have not placed an order. Finally, it is returned in ascending order according to the customer name `cust_name`.
+
+```sql
+SELECT cust_name, order_num
+FROM Customers
+LEFT JOIN Orders
+USING(cust_id)
+ORDER BY cust_name```
+
+### Return the product name and the order number associated with it
+
+The `Products` table contains the fields `prod_id` product id, `prod_name` product name for the product information table.
+
+| prod_id | prod_name |
+| ------- | --------- |
+| a0001 | egg |
+| a0002 | sockets |
+| a0013 | coffee |
+| a0003 | cola |
+| a0023 | soda |
+
+The `OrderItems` table contains the fields `order_num`, order number and product id `prod_id` for the order information table.
+
+| prod_id | order_num |
+| ------- | --------- |
+| a0001 | a105 |
+| a0002 | a1100 |
+| a0002 | a200 |
+| a0013 | a1121 |
+| a0003 | a10 |
+| a0003 | a19 |
+| a0003 | a5 |
+
+[Problem] Use outer joins (left join, right join, full join) to join the `Products` table and the `OrderItems` table, return a list of product names (`prod_name`) and related order numbers (`order_num`), and sort them in ascending order by product name.
+
+```sql
+SELECT prod_name, order_num
+FROM Products
+LEFT JOIN OrderItems
+USING(prod_id)
+ORDER BY prod_name
+```
+
+### Return the product name and the total number of orders for each product
+
+The `Products` table contains the fields `prod_id` product id, `prod_name` product name for the product information table.
+
+| prod_id | prod_name |
+| ------- | --------- |
+| a0001 | egg |
+| a0002 | sockets |
+| a0013 | coffee |
+| a0003 | cola |
+| a0023 | soda |
+
+The `OrderItems` table contains the fields `order_num`, order number and product id `prod_id` for the order information table.
+
+| prod_id | order_num |
+| ------- | --------- |
+| a0001 | a105 |
+| a0002 | a1100 |
+| a0002 | a200 |
+| a0013 | a1121 |
+| a0003 | a10 |
+| a0003 | a19 |
+| a0003 | a5 |
+
+【Question】
+
+Use OUTER JOIN to join the `Products` table and the `OrderItems` table, return the product name (`prod_name`) and the total number of orders for each product (not the order number), and sort by product name in ascending order.
+
+```sql
+SELECT prod_name, COUNT(order_num) AS orders
+FROM Products
+LEFT JOIN OrderItems
+USING(prod_id)
+GROUP BY prod_name
+ORDER BY prod_name
+```
+
+### List suppliers and their available product quantities
+
+There is a `Vendors` table containing `vend_id` (vendor id)
+
+| vend_id |
+| ------- |
+| a0002 |
+| a0013 |
+| a0003 |
+| a0010 |
+
+There is a `Products` table containing `vend_id` (vendor id) and prod_id (supplied product id)
+
+| vend_id | prod_id |
+| ------- | -------------------- |
+| a0001 | egg |
+| a0002 | prod_id_iphone |
+| a00113 | prod_id_tea |
+| a0003 | prod_id_vivo phone |
+| a0010 | prod_id_huawei phone |
+
+[Question] List vendors (`vend_id` in `Vendors` table) and their available product quantities, including vendors with no products. You need to use OUTER JOIN and COUNT() aggregate function to calculate the quantity of each product in the `Products` table, and finally sort them in ascending order based on vend_id.
+
+NOTE: The `vend_id` column appears in multiple tables, so it needs to be fully qualified each time it is referenced.
+
+```sql
+SELECT v.vend_id, COUNT(prod_id) AS prod_id
+FROM Vendors v
+LEFT JOIN Products p
+USING(vend_id)
+GROUP BY v.vend_id
+ORDER BY v.vend_id
+```
+
+## Combined query
+
+The `UNION` operator combines the results of two or more queries and produces a result set containing the extracted rows from the participating queries in `UNION`.
+
+`UNION` basic rules:
+
+- The number and order of columns must be the same for all queries.
+- The data types of the columns involved in the tables in each query must be the same or compatible.
+- Usually the column names returned are taken from the first query.
+
+By default, the `UNION` operator selects distinct values. If duplicate values are allowed, use `UNION ALL`.
+
+```sql
+SELECT column_name(s) FROM table1
+UNION ALL
+SELECT column_name(s) FROM table2;
+```
+
+The column names in the `UNION` result set are always equal to the column names in the first `SELECT` statement in the `UNION`.
+
+`JOIN` vs `UNION`:
+
+- The columns of the joined tables in `JOIN` may be different, but in `UNION` the number and order of columns must be the same for all queries.
+- `UNION` puts the rows after the query together (vertically), but `JOIN` puts the columns after the query together (horizontally), i.e. it forms a Cartesian product.
+
+### Combine two SELECT statements (1)
+
+The table `OrderItems` contains order product information. The field `prod_id` represents the product id and `quantity` represents the product quantity.
+
+| prod_id | quantity |
+| ------- | -------- |
+| a0001 | 105 |
+| a0002 | 100 |
+| a0002 | 200 |
+| a0013 | 1121 |
+| a0003 | 10 |
+| a0003 | 19 |
+| a0003 | 5 |
+|BNBG|10002|
+
+[Question] Combine two `SELECT` statements to retrieve product id (`prod_id`) and `quantity` from the `OrderItems` table. One `SELECT` statement filters rows with a quantity of 100, another `SELECT` statement filters products whose id starts with BNBG, and finally sorts the results by product id in ascending order.
+
+```sql
+SELECT prod_id, quantity
+FROM OrderItems
+WHERE quantity = 100
+UNION
+SELECT prod_id, quantity
+FROM OrderItems
+WHERE prod_id LIKE 'BNBG%'
+```
+
+### Combine two SELECT statements (2)
+
+The table `OrderItems` contains order product information, the field `prod_id` represents the product id, and `quantity` represents the product quantity.
+
+| prod_id | quantity |
+| ------- | -------- |
+| a0001 | 105 |
+| a0002 | 100 |
+| a0002 | 200 |
+| a0013 | 1121 |
+| a0003 | 10 |
+| a0003 | 19 |
+| a0003 | 5 |
+|BNBG|10002|
+
+[Question] Combine two `SELECT` statements to retrieve product id (`prod_id`) and `quantity` from the `OrderItems` table. One `SELECT` statement filters rows with a quantity of 100, another `SELECT` statement filters products whose id starts with BNBG, and finally sorts the results by product id in ascending order. NOTE: **Only use a single SELECT statement this time. **
+
+Answer:
+
+If only one select statement is required, use `or` instead of `union`.
+
+```sql
+SELECT prod_id, quantity
+FROM OrderItems
+WHERE quantity = 100 OR prod_id LIKE 'BNBG%'```
+
+### Combine the product names in the Products table and the customer names in the Customers table
+
+The `Products` table contains the field `prod_name` representing the product name
+
+| prod_name |
+| --------- |
+| flower |
+| rice |
+| ring |
+| umbrella |
+
+The Customers table represents customer information, and cust_name represents the customer name.
+
+| cust_name |
+| --------- |
+| andy |
+| ben |
+| tony |
+| tom |
+| an |
+|lee|
+| hex |
+
+[Problem] Write a SQL statement to combine the product name (`prod_name`) in the `Products` table and the customer name (`cust_name`) in the `Customers` table and return it, and then sort the results in ascending order by product name.
+
+```sql
+# The column names in the UNION result set are always equal to the column names in the first SELECT statement in the UNION.
+SELECT prod_name
+FROM Products
+UNION
+SELECT cust_name
+FROM Customers
+ORDER BY prod_name
+```
+
+### Check SQL statement
+
+The table `Customers` contains fields `cust_name` customer name, `cust_contact` customer contact information, `cust_state` customer state, `cust_email` customer `email`
+
+| cust_name | cust_contact | cust_state | cust_email |
+| --------- | ------------ | ---------- | ------------------ |
+| cust10 | 8695192 | MI | |
+| cust1 | 8695193 | MI | |
+| cust2 | 8695194 | IL | |
+
+[Problem] Correct the following incorrect SQL
+
+```sql
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'MI'
+ORDER BY cust_name;
+UNION
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'IL'ORDER BY cust_name;
+```
+
+After correction:
+
+```sql
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'MI'
+UNION
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'IL'
+ORDER BY cust_name;
+```
+
+When using `union` to combine queries, only one `order by` statement can be used, and it must be located after the last `select` statement
+
+Or just use `or` to do it:
+
+```sql
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'MI' or cust_state = 'IL'
+ORDER BY cust_name;
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-02.en.md b/docs_en/database/sql/sql-questions-02.en.md
new file mode 100644
index 00000000000..c1c2986ea02
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-02.en.md
@@ -0,0 +1,451 @@
+---
+title: Summary of common SQL interview questions (2)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, additions, deletions, batch insertions, imports, replacement insertions, constraints
+ - - meta
+ - name: description
+ content: Focus on the analysis of questions on basic operations such as addition, deletion, and modification, and summarize techniques and precautions such as batch insertion/import and replacement insertion.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+## Add, delete, and modify operations
+
+Summary of how SQL inserts records:
+
+- **Normal insert (all fields)**: `INSERT INTO table_name VALUES (value1, value2, ...)`
+- **Normal insert (qualified fields)**: `INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...)`
+- **Multiple inserts at once**: `INSERT INTO table_name (column1, column2, ...) VALUES (value1_1, value1_2, ...), (value2_1, value2_2, ...), ...`
+- **Import from another table**: `INSERT INTO table_name SELECT * FROM table_name2 [WHERE key=value]`
+- **Insert with update**: `REPLACE INTO table_name VALUES (value1, value2, ...)` (note that this principle is to delete the original record and reinsert it after detecting a duplicate primary key or unique index key)
+
+### Insert record (1)
+
+**Description**: Niuke backend will record each user’s test paper answers to the `exam_record` table. The details of the answer records of two users are as follows:
+
+- User 1001 started answering test paper 9001 at 10:11:12 pm on September 1, 2021, and submitted it after 50 minutes, and received 90 points;
+- User 1002 started answering paper 9002 at 7:01:02 AM on September 4, 2021, and exited the platform 10 minutes later.
+
+In the test paper answer record table `exam_record`, the table has been built and its structure is as follows. Please use one statement to insert these two records into the table.
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Answer**:
+
+```sql
+// There is an auto-incrementing primary key, no manual assignment is required
+INSERT INTO exam_record (uid, exam_id, start_time, submit_time, score) VALUES
+(1001, 9001, '2021-09-01 22:11:12', '2021-09-01 23:01:12', 90),
+(1002, 9002, '2021-09-04 07:01:02', NULL, NULL);
+```
+
+### Insert record (2)
+
+**Description**: There is an examination paper answer record table `exam_record`, with the structure as follows, which contains user answer paper records over the years. Due to the increasing amount of data, maintenance is becoming more and more difficult, so the data table content needs to be streamlined and historical data backed up.
+
+Table `exam_record`:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+We have created a new table `exam_record_before_2021` to back up test answer records before 2021. The structure is consistent with the `exam_record` table. Please import the completed test answer records before 2021 into this table.
+
+**Answer**:
+
+```sql
+INSERT INTO exam_record_before_2021 (uid, exam_id, start_time, submit_time, score)
+SELECT uid,exam_id,start_time,submit_time,score
+FROM exam_record
+WHERE YEAR(submit_time) < 2021;
+```
+
+### Insert record (3)
+
+**Description**: There is now a set of difficult SQL test papers with ID 9003, which lasts for one and a half hours. Please insert 2021-01-01 00:00:00 as the release time into the test question information table `examination_info`. Regardless of whether the ID test paper exists, the insertion must be successful. Please try to insert it.
+
+Test question information table `examination_info`:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ------------ | ----------- | ---- | --- | -------------- | ------- | ------------ |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| exam_id | int(11) | NO | UNI | | (NULL) | Exam paper ID |
+| tag | varchar(32) | YES | | | (NULL) | category tag |
+| difficulty | varchar(8) | YES | | | (NULL) | difficulty |
+| duration | int(11) | NO | | | (NULL) | Duration (number of minutes) |
+| release_time | datetime | YES | | | (NULL) | release time |
+
+**Answer**:
+
+```sql
+REPLACE INTO examination_info VALUES
+ (NULL, 9003, "SQL", "hard", 90, "2021-01-01 00:00:00");
+```
+
+### Update record (1)**Description**: There is now a test paper information table `examination_info`. The table structure is as shown below:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ------------ | -------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| exam_id | int(11) | NO | UNI | | (NULL) | Exam paper ID |
+| tag | char(32) | YES | | | (NULL) | Category tag |
+| difficulty | char(8) | YES | | | (NULL) | difficulty |
+| duration | int(11) | NO | | | (NULL) | duration |
+| release_time | datetime | YES | | | (NULL) | release time |
+
+Please modify all the `tag` fields whose `tag` is `PYTHON` in the **examination_info** table to `Python`.
+
+**Idea**: There are two ways to solve this problem. The easiest one to think of is to directly use `update + where` to specify conditional updates. The second one is to search and replace based on the fields to be modified.
+
+**Answer 1**:
+
+```sql
+UPDATE examination_info SET tag = 'Python' WHERE tag='PYTHON'
+```
+
+**Answer 2**:
+
+```sql
+UPDATE examination_info
+SET tag = REPLACE(tag,'PYTHON','Python')
+
+# REPLACE (target field, "find content", "replace content")
+```
+
+### Update record (2)
+
+**Description**: There is an examination paper answer record table exam_record, which contains user answer paper records for many years. The structure is as follows: Answer record table `exam_record`: **`submit_time`** is the completion time (note this sentence)
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Question requirements**: Please change all the == unfinished == records in the `exam_record` table that were started before September 1, 2021 == to passive completion, that is: change the completion time to '2099-01-01 00:00:00', and change the score to 0.
+
+**Idea**: Pay attention to the keyword in the question stem (already highlighted) `" xxx time "` before the condition, then you will immediately think of time comparison here. You can directly `xxx_time < "2021-09-01 00:00:00",` or you can use the `date()` function for comparison; the second condition is `"Unfinished"`, that is, the completion time is NULL, which is the submission time in the question ----- `submit_time is NULL`.
+
+**Answer**:
+
+```sql
+UPDATE exam_record SET submit_time = '2099-01-01 00:00:00', score = 0 WHERE DATE(start_time) < "2021-09-01" AND submit_time IS null
+```
+
+### Delete records (1)
+
+**Description**: There is an exam paper answer record table `exam_record`, which contains user answer paper records for many years. The structure is as follows:
+
+Answer record table `exam_record:` **`start_time`** is the start time of the test paper `submit_time` is the hand-in time, that is, the end time.
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Requirement**: Please delete the records in the `exam_record` table whose answer time is less than 5 minutes and whose score is failing (passing mark is 60 points);
+
+**Idea**: Although this question is an exercise in deletion, if you look carefully, it is indeed an examination of the usage of time functions. Compared with the minutes mentioned here, the commonly used functions are **`TIMEDIFF`** and **`TIMESTAMPDIFF`**. The usage of the two is slightly different, and the latter is more flexible. This all depends on personal habits.
+
+1. `TIMEDIFF`: the difference between two times
+
+```sql
+TIMEDIFF(time1, time2)
+```
+
+Both parameters are required and are both a time or datetime expression. If the specified parameter is illegal or NULL, the function will return NULL.
+
+For this question, it can be used in the minute function, because TIMEDIFF calculates the difference in time. If you put a MINUTE function outside, the calculated number is the number of minutes.
+
+2. `TIMESTAMPDIFF`: used to calculate the time difference between two dates
+
+```sql
+TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2)
+# Parameter description
+#unit: The time difference unit returned by date comparison. Commonly used optional values are as follows:
+SECOND: seconds
+MINUTE: minutes
+HOUR: hours
+DAY: day
+WEEK: week
+MONTH: month
+QUARTER: quarter
+YEAR: year
+# TIMESTAMPDIFF function returns the result of datetime_expr2 - datetime_expr1 (in human words: the latter - the previous one, that is, 2-1), where datetime_expr1 and datetime_expr2 can be DATE or DATETIME type values (in human words: it can be "2023-01-01", or it can be "2023-01-01- 00:00:00")
+```
+
+This question requires a comparison of minutes, so TIMESTAMPDIFF(MINUTE, start time, end time) < 5
+
+**Answer**:
+
+```sql
+DELETE FROM exam_record WHERE MINUTE (TIMEDIFF(submit_time , start_time)) < 5 AND score < 60
+```
+
+```sql
+DELETE FROM exam_record WHERE TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5 AND score < 60
+```### Delete records (2)
+
+**Description**: There is an exam paper answer record table `exam_record`, which contains user answer paper records over the years. The structure is as follows:
+
+Answer record table `exam_record`: `start_time` is the start time of the test paper, `submit_time` is the hand-in time, that is, the end time. If it is not completed, it will be empty.
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Requirement**: Please delete the 3 records with the earliest starting time among the records in the `exam_record` table that have unfinished answers == or == the answer time is less than 5 minutes.
+
+**Idea**: This question is relatively simple, but you should pay attention to the information given in the question stem, the end time, if it is not completed, it will be empty, this is actually a condition
+
+There is another condition that is less than 5 minutes, which is similar to the previous question, but here it is ** or **, that is, only one of the two conditions is met; in addition, the usage of sorting and limit is slightly examined.
+
+**Answer**:
+
+```sql
+DELETE FROM exam_record WHERE submit_time IS null OR TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5
+ORDER BY start_time
+LIMIT 3
+# The default is asc, desc is descending order
+```
+
+### Delete records (3)
+
+**Description**: There is an exam paper answer record table exam_record, which contains user answer paper records for many years. The structure is as follows:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Requirement**: Please delete all records in the `exam_record` table, == and reset the auto-incrementing primary key==
+
+**Idea**: This question examines the difference between three delete statements. Pay attention to the highlighted part, which requires resetting the primary key;
+
+- `DROP`: clear the table, delete the table structure, irreversible
+- `TRUNCATE`: Format the table without deleting the table structure, irreversible
+- `DELETE`: delete data, reversible
+
+The reason why `TRUNCATE` is chosen here is: TRUNCATE can only act on tables; `TRUNCATE` will clear all rows in the table, but the table structure, its constraints, indexes, etc. remain unchanged; `TRUNCATE` will reset the auto-increment value of the table; using `TRUNCATE` will restore the space occupied by the table and indexes to their initial size.
+
+This question can also be done using `DELETE`, but after deletion, you still need to manually `ALTER` the table structure to set the initial value of the primary key;
+
+In the same way, you can also use `DROP` to directly delete the entire table, including the table structure, and then create a new table.
+
+**Answer**:
+
+```sql
+TRUNCATE exam_record;
+```
+
+## Table and index operations
+
+### Create a new table
+
+**Description**: There is currently a user information table, which contains user information that has been registered on the platform over the years. As the Niuke platform continues to grow, the number of users has grown rapidly. In order to efficiently provide services to highly active users, it is now necessary to split some users into a new table.
+
+Original user information table:
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ------------------ | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | Auto-increment ID |
+| uid | int(11) | NO | UNI | (NULL) | | user ID |
+| nick_name | varchar(64) | YES | | (NULL) | | Nickname |
+| achievement | int(11) | YES | | 0 | | achievement value |
+| level | int(11) | YES | | (NULL) | | User level |
+| job | varchar(32) | YES | | (NULL) | | Career direction |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | registration time |
+
+As a data analyst, please create a high-quality user information table user_info_vip** with the same structure as the user information table.
+
+The output you should return is shown in the table below. Please write a table creation statement to record all restrictions and instructions in the table into the table.
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ------------------ | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | Auto-increment ID |
+| uid | int(11) | NO | UNI | (NULL) | | user ID |
+| nick_name | varchar(64) | YES | | (NULL) | | Nickname |
+| achievement | int(11) | YES | | 0 | | achievement value |
+| level | int(11) | YES | | (NULL) | | User level || job | varchar(32) | YES | | (NULL) | | Career direction |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | registration time |
+
+**Idea**: If this question gives the name of the old table, you can directly `create table new table as select * from old table;` However, this question does not give the name of the old table, so you need to create it yourself. Just pay attention to the creation of default values and keys, which is relatively simple. (Note: If it is executed on Niuke.com, please note that the comment must be consistent with the comment in the question, including upper and lower case, otherwise it will not pass, and the characters must also be set)
+
+Answer:
+
+```sql
+CREATE TABLE IF NOT EXISTS user_info_vip(
+ id INT(11) PRIMARY KEY AUTO_INCREMENT COMMENT'Auto-increment ID',
+ uid INT(11) UNIQUE NOT NULL COMMENT 'User ID',
+ nick_name VARCHAR(64) COMMENT'nickname',
+ achievement INT(11) DEFAULT 0 COMMENT 'Achievement value',
+ `level` INT(11) COMMENT 'User level',
+ job VARCHAR(32) COMMENT 'Career direction',
+ register_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT 'Registration time'
+)CHARACTER SET UTF8
+```
+
+### Modify table
+
+**Description**: There is a user information table `user_info`, which contains user information registered on the platform over the years.
+
+**User information table `user_info`:**
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ------------------ | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | Auto-increment ID |
+| uid | int(11) | NO | UNI | (NULL) | | user ID |
+| nick_name | varchar(64) | YES | | (NULL) | | Nickname |
+| achievement | int(11) | YES | | 0 | | achievement value |
+| level | int(11) | YES | | (NULL) | | User level |
+| job | varchar(32) | YES | | (NULL) | | Career direction |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | registration time |
+
+**Requirements:** Please add a field `school` that can store up to 15 Chinese characters in the user information table after the field `level`; change the `job` column name in the table to `profession`, and change the `varchar` field length to 10; set the default value of `achievement` to 0.
+
+**Idea**: Before doing this question first, you need to understand the basic usage of the ALTER statement:
+
+- Add a column: `ALTER TABLE table name ADD COLUMN column name type [first | after field name];` (first: add before a column, after vice versa)
+- Modify the column type or constraint: `ALTER TABLE table name MODIFY COLUMN column name new type [new constraint];`
+- Modify column name: `ALTER TABLE table name change COLUMN old column name new column name type;`
+- Delete column: `ALTER TABLE table name drop COLUMN column name;`
+- Modify table name: `ALTER TABLE table name rename [to] new table name;`
+- Put a column into the first column: `ALTER TABLE table name MODIFY COLUMN column name type first;`
+
+The `COLUMN` keyword can actually be omitted, but it is listed here based on the specification.
+
+When modifying, if there are multiple modification items, you can write them together, but pay attention to the format.
+
+**Answer**:
+
+```sql
+ALTER TABLE user_info
+ ADD school VARCHAR(15) AFTER level,
+ CHANGE job profession VARCHAR(10),
+ MODIFY achievement INT(11) DEFAULT 0;
+```
+
+### Delete table
+
+**Description**: There is an exam paper answer record table `exam_record`, which contains user answer paper records for many years. Generally, a backup table `exam_record_{YEAR} will be created for the `exam_record` table every year, {YEAR}` is the corresponding year.
+
+Now with more and more data and storage shortage, please delete all the backup tables from a long time ago (2011 to 2014) (if they exist).
+
+**Idea**: This question is very simple, just delete it. If you find it troublesome, you can separate the tables to be deleted with commas and write them on one line; there will definitely be friends here asking: What if you want to delete many tables? Don't worry, if you want to delete many tables, you can write a script to delete them.
+
+**Answer**:
+
+```sql
+DROP TABLE IF EXISTS exam_record_2011;
+DROP TABLE IF EXISTS exam_record_2012;
+DROP TABLE IF EXISTS exam_record_2013;
+DROP TABLE IF EXISTS exam_record_2014;
+```
+
+### Create index
+
+**Description**: There is an examination paper information table `examination_info`, which contains information about various types of examination papers. In order to query the table more conveniently and quickly, you need to create the following index in the `examination_info` table,
+
+The rules are as follows: create a normal index `idx_duration` on the `duration` column, create a unique index `uniq_idx_exam_id` on the `exam_id` column, and create a full-text index `full_idx_tag` on the `tag` column.
+
+According to the meaning of the question, the following results will be returned:
+
+| examination_info | 0 | PRIMARY | 1 | id | A | 0 | | | | BTREE |
+| ---------------- | --- | ---------------- | --- | -------- | --- | --- | --- | --- | --- | -------- |
+| examination_info | 0 | uniq_idx_exam_id | 1 | exam_id | A | 0 | | | YES | BTREE |
+| examination_info | 1 | idx_duration | 1 | duration | A | 0 | | | | BTREE |
+| examination_info | 1 | full_idx_tag | 1 | tag | | 0 | | | YES | FULLTEXT |
+
+Note: The background will compare the output results through the `SHOW INDEX FROM examination_info` statement
+
+**Idea**: To answer this question, you first need to understand the common index types:
+
+- B-Tree index: B-Tree (or balanced tree) index is the most common and default index type. It is suitable for various query conditions and can quickly locate data that meets the conditions. B-Tree index is suitable for ordinary search operations and supports equality query, range query and sorting.
+- Unique index: A unique index is similar to a normal B-Tree index, except that it requires the value of the indexed column to be unique. This means that MySQL verifies the uniqueness of index columns when inserting or updating data.
+- Primary key index: The primary key index is a special unique index that is used to uniquely identify each row of data in the table. Each table can only have one primary key index, which can help improve data access speed and data integrity.- Full-text indexing: Full-text indexing is used for full-text search in text data. It supports keyword searches in text fields, not just simple equality or range lookups. Full-text indexing is suitable for application scenarios that require full-text search.
+
+```sql
+-- Example:
+-- Add B-Tree index:
+ CREATE INDEX idx_name (index name) ON table name (field name); -- idx_name is the index name, all of the following
+--Create a unique index:
+ CREATE UNIQUE INDEX idx_name ON table name (field name);
+-- Create a primary key index:
+ ALTER TABLE table name ADD PRIMARY KEY (field name);
+--Create a full-text index
+ ALTER TABLE table name ADD FULLTEXT INDEX idx_name (field name);
+
+-- Through the above example, you can see that both create and alter can add indexes
+```
+
+With the above basic knowledge, the answer to this question will become apparent.
+
+**Answer**:
+
+```sql
+ALTER TABLE examination_info
+ ADD INDEX idx_duration(duration),
+ ADD UNIQUE INDEX uniq_idx_exam_id(exam_id),
+ ADD FULLTEXT INDEX full_idx_tag(tag);
+```
+
+### Delete index
+
+**Description**: Please delete the unique index uniq_idx_exam_id and the full-text index full_idx_tag on the `examination_info` table.
+
+**Idea**: This question examines the basic syntax of deleting an index:
+
+```sql
+-- Use DROP INDEX to delete the index
+DROP INDEX idx_name ON table name;
+
+-- Use ALTER TABLE to delete the index
+ALTER TABLE employees DROP INDEX idx_email;
+```
+
+What needs to be noted here is that in MySQL, deleting multiple indexes at one time is not supported. Each time you delete an index, you can only specify one index name to delete.
+
+And the **DROP** command needs to be used with caution! ! !
+
+**Answer**:
+
+```sql
+DROP INDEX uniq_idx_exam_id ON examination_info;
+DROP INDEX full_idx_tag ON examination_info;
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-03.en.md b/docs_en/database/sql/sql-questions-03.en.md
new file mode 100644
index 00000000000..2199691ade3
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-03.en.md
@@ -0,0 +1,1292 @@
+---
+title: Summary of common SQL interview questions (3)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, aggregate functions, truncated average, window, problem analysis, performance
+ - - meta
+ - name: description
+ Content: Focusing on aggregation functions and complex statistical question types, the solution methods and implementation key points such as truncated average are explained, taking into account performance and correctness.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+You can decide whether to skip more difficult or difficult questions based on your actual situation and interview needs.
+
+## Aggregation function
+
+### Truncated average of scores for difficult papers in the SQL category (harder)
+
+**Description**: Niuke's operations students want to check everyone's scores on the difficult papers in the SQL category.
+
+Please help her calculate the truncated average (the average after removing one maximum value and one minimum value) of the scores of all users who completed the difficult SQL category exams from the `exam_record` data table.
+
+Example data: `examination_info` (`exam_id` test paper ID, tag test paper category, `difficulty` test paper difficulty, `duration` exam duration, `release_time` release time)
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Example data: `exam_record` (uid user ID, exam_id test paper ID, start_time start answering time, submit_time paper submission time, score score)
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
+| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
+| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
+
+The results according to your query are as follows:
+
+| tag | difficulty | clip_avg_score |
+| --- | ---------- | --------------- |
+| SQL | hard | 81.7 |
+
+From the `examination_info` table, we can see that test paper 9001 is a highly difficult SQL test paper. The scores for this test paper are [80,81,84,90,50]. After removing the highest and lowest scores, it is [80,81,84]. The average score is 81.6666667, which is 81.7 after rounding to one decimal place.
+
+**Enter description:**
+
+There are at least 3 valid scores in the input data
+
+**Idea 1:** To find the high-difficulty SQL test papers, you definitely need to connect to the examination_info table, and then find the high-difficulty courses. From examination_info, we know that the exam_id of the high-difficulty SQL is 9001, so later use exam_id = 9001 as the condition to query;
+
+First find exam number 9001 `select * from exam_record where exam_id = 9001`
+
+Then, find the maximum score `select max(score) maximum score from exam_record where exam_id = 9001`
+
+Next, find the minimum score `select min(score) minimum score from exam_record where exam_id = 9001`
+
+In the score result set obtained from the query, to remove the highest score and the lowest score, the most intuitive thing that can be thought of is NOT IN or NOT EXISTS. Here we use NOT IN to do it.
+
+First write out the main body `select tag, difficulty, round(avg(score), 1) clip_avg_score from examination_info info INNER JOIN exam_record record`
+
+**Tips**: MYSQL's `ROUND()` function, `ROUND(X)` returns the nearest integer to parameter
+
+Then put the above "fragmented" statements together. Note that in NOT IN, the two subqueries are related using UNION ALL, and union is used to concentrate the results of max and min in one row, thus forming the effect of one column and multiple rows.
+
+**Answer 1:**
+
+```sql
+SELECT tag, difficulty, ROUND(AVG(score), 1) clip_avg_score
+ FROM examination_info info INNER JOIN exam_record record
+ WHERE info.exam_id = record.exam_id
+ AND record.exam_id = 9001
+ AND record.score NOT IN(
+ SELECT MAX(score)
+ FROM exam_record
+ WHERE exam_id = 9001
+ UNION ALL
+ SELECT MIN(score)
+ FROM exam_record
+ WHERE exam_id = 9001
+ )
+```
+
+This is the most intuitive and easiest solution to think of, but it still needs to be improved. This is considered opportunistic. In fact, strictly according to the requirements of the question, it should be written like this:
+
+```sql
+SELECT tag,
+ difficulty,
+ ROUND(AVG(score), 1) clip_avg_score
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND record.exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' )
+ AND record.score NOT IN
+ (SELECT MAX(score)
+ FROM exam_record
+ WHERE exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' )
+ UNION ALL SELECT MIN(score)
+ FROM exam_record
+ WHERE exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' ) )```
+
+However, you will find that there are many repeated statements, so you can use `WITH` to extract the common parts
+
+**Introduction to `WITH` clause**:
+
+The `WITH` clause, also known as a Common Table Expression (CTE), is the way to define a temporary table in a SQL query. It allows us to create a temporarily named result set in a query and reference that result set in the same query.
+
+Basic usage:
+
+```sql
+WITH cte_name (column1, column2, ..., columnN) AS (
+ -- Query body
+ SELECT...
+ FROM ...
+ WHERE...
+)
+-- Main query
+SELECT...
+FROM cte_name
+WHERE...
+```
+
+The `WITH` clause consists of the following parts:
+
+- `cte_name`: Give the temporary table a name that can be referenced in the main query.
+- `(column1, column2, ..., columnN)`: Optional, specify the column name of the temporary table.
+- `AS`: required, indicates starting to define a temporary table.
+- `CTE query body`: the actual query statement, used to define the data in the temporary table.
+
+One of the primary uses of the `WITH` clause is to enhance the readability and maintainability of queries, especially when multiple nested subqueries are involved or the same query logic needs to be reused. By putting this logic in a named temporary table, we can organize our queries more clearly and eliminate duplicate code.
+
+In addition, the `WITH` clause can also implement recursive queries in complex queries. Recursive queries allow us to perform multiple iterations of the same table in a single query, building the result set incrementally. This is useful in scenarios such as working with hierarchical data, organizational structures, and tree structures.
+
+**Minor detail**: MySQL versions 5.7 and earlier do not support the direct use of aliases in the `WITH` clause.
+
+Here is the improved answer:
+
+```sql
+WITH t1 AS
+ (SELECT record.*,
+ info.tag,
+ info.difficulty
+ FROM exam_record record
+ INNER JOIN examination_info info ON record.exam_id = info.exam_id
+ WHERE info.tag = "SQL"
+ AND info.difficulty = "hard" )
+SELECT tag,
+ difficulty,
+ ROUND(AVG(score), 1)
+FROM t1
+WHERE score NOT IN
+ (SELECT max(score)
+ FROM t1
+ UNION SELECT min(score)
+ FROM t1)
+```
+
+**Idea 2:**
+
+- Filter SQL difficult test papers: `where tag="SQL" and difficulty="hard"`
+- Calculate the truncated average: `(sum-maximum value-minimum value) / (total number-2)`:
+ - `(sum(score) - max(score) - min(score)) / (count(score) - 2)`
+ - One disadvantage is that if there are multiple maximum values and minimum values, this method is difficult to filter out, but the question says ----->**`The average value after removing one maximum value and one minimum value`**, so this formula can be used here.
+
+**Answer 2:**
+
+```sql
+SELECT info.tag,
+ info.difficulty,
+ ROUND((SUM(record.score)- MIN(record.score)- MAX(record.score)) / (COUNT(record.score)- 2), 1) AS clip_avg_score
+FROM examination_info info,
+ exam_record record
+WHERE info.exam_id = record.exam_id
+ AND info.tag = "SQL"
+ AND info.difficulty = "hard";
+```
+
+### Count the number of answers
+
+There is an exam paper answer record table `exam_record`. Please count the total number of answers `total_pv`, the number of completed exam papers `complete_pv`, and the number of completed exam papers `complete_exam_cnt`.
+
+Example data `exam_record` table (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
+| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
+| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
+
+Example output:
+
+| total_pv | complete_pv | complete_exam_cnt |
+| -------- | ----------- | ------------------ |
+| 10 | 7 | 2 |
+
+Explanation: As of now, there are 10 test paper answer records, and the number of completed answers is 7 (those who exited midway are in an unfinished status, and their handover time and number of copies are NULL). There are two completed test papers, 9001 and 9002.
+
+**Idea**: As soon as you see the number of statistics for this question, you will definitely think of using the `COUNT` function to solve it immediately. The problem is to count different records. How to write it? This problem can be solved using subqueries (this problem can also be written using case when, the solution is similar, but the logic is different); first, before doing this problem, let us first understand the basic usage of `COUNT`;
+
+The basic syntax of the `COUNT()` function is as follows:
+
+```sql
+COUNT(expression)
+```
+
+Among them, `expression` can be a column name, expression, constant or wildcard character. Here are some common usage examples:
+
+1. Count the number of all rows in the table:
+
+```sql
+SELECT COUNT(*) FROM table_name;
+```
+
+2. Count the number of non-null (not NULL) values for a specific column:
+
+```sql
+SELECT COUNT(column_name) FROM table_name;
+```
+
+3. Calculate the number of rows that meet the conditions:
+
+```sql
+SELECT COUNT(*) FROM table_name WHERE condition;
+```
+
+4. Combined with `GROUP BY`, calculate the number of rows in each group after grouping:
+
+```sql
+SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
+```
+
+5. Count the number of unique combinations of different column combinations:
+
+```sql
+SELECT COUNT(DISTINCT column_name1, column_name2) FROM table_name;
+```
+
+When using the `COUNT()` function without specifying any arguments or using `COUNT(*)`, all rows will be counted. If you use a column name, only the number of non-null values in that column will be counted.
+
+Additionally, the result of the `COUNT()` function is an integer value. Even if the result is zero, NULL will not be returned, which is something to keep in mind.
+
+**Answer**:
+
+```sql
+SELECT
+ count(*) total_pv,
+ ( SELECT count(*) FROM exam_record WHERE submit_time IS NOT NULL ) complete_pv,
+ ( SELECT COUNT( DISTINCT exam_id, score IS NOT NULL OR NULL ) FROM exam_record ) complete_exam_cnt
+FROM
+ exam_record```
+
+Here we focus on the sentence `COUNT(DISTINCT exam_id, score IS NOT NULL OR NULL)`, which determines whether score is null. If so, it is true, if not, return null; note that if `or null` is not added here, it will only return false if it is not null, that is, return 0;
+
+`COUNT` itself cannot calculate the number of rows in multiple columns. The addition of `distinct` makes multiple columns into a whole, and the number of rows that appear can be calculated; `count distinct` only returns non-null rows during calculation. You should also pay attention to this;
+
+In addition, through this question get arrived ------->count plus conditional common sentence pattern `count (column judgment or null)`
+
+### The lowest score with a score not less than the average score
+
+**Description**: Please find the lowest score of the user whose SQL test paper score is not less than the average score of this type of test paper from the test paper answer record table.
+
+Example data exam_record table (uid user ID, exam_id test paper ID, start_time start answering time, submit_time paper submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 6 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+
+`examination_info` table (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` exam duration, `release_time` release time)
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Example output data:
+
+| min_score_over_avg |
+| ------------------ |
+| 87 |
+
+**Explanation**: Test papers 9001 and 9002 are in the SQL category. The scores for answering these two papers are [80,89,87,90], the average score is 86.5, and the minimum score that is not less than the average score is 87
+
+**Idea**: This type of question is really complicated at first glance because we don’t know where to start. However, after we read and review the question carefully, we must learn to grasp the key information in the question stem. Take this question as an example: `Please find the lowest score of a user whose SQL test paper score is not less than the average score of this type of test paper from the test paper answer record table. `What effective information can you extract from it at a glance as a solution to the problem?
+
+Article 1: Find ==SQL== test paper score
+
+Article 2: This type of test paper == average score ==
+
+Article 3: == user’s minimum score for this type of test paper ==
+
+Then the "bridge" in the middle is == not less than ==
+
+After splitting the conditions, complete them step by step
+
+```sql
+-- Find the score with the tag 'SQL' [80, 89,87,90]
+-- Then calculate the average score of this group
+select ROUND(AVG(score), 1) from examination_info info INNER JOIN exam_record record
+ where info.exam_id = record.exam_id
+ and tag= 'SQL'
+```
+
+Then find the lowest score for this type of test paper, and then compare the result set `[80, 89,87,90]` with the average score to get the final answer.
+
+**Answer**:
+
+```sql
+SELECT MIN(score) AS min_score_over_avg
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND tag= 'SQL'
+ AND score >=
+ (SELECT ROUND(AVG(score), 1)
+ FROM examination_info info
+ INNER JOIN exam_record record
+ WHERE info.exam_id = record.exam_id
+ AND tag= 'SQL' )
+```
+
+In fact, the requirements given by this type of question seem very "convoluted", but in fact, you need to sort it out carefully, split the big conditions into small conditions, and after splitting them one by one, finally put all the conditions together. Anyway, as long as you remember: **Focus on the trunk and manage the branches**, the problem will be easily solved.
+
+## Group query
+
+### Average active days and number of monthly active users
+
+**Description**: The user’s answer records in the Niuke test paper answer area are stored in the table `exam_record`, with the following content:
+
+`exam_record` table (`uid` user ID, `exam_id` test paper ID, `start_time` starting time of answering, `submit_time` handing in time, `score` score)
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
+| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 || 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
+
+Please calculate the average number of monthly active days `avg_active_days` and the number of monthly active users `mau` in the test paper answer area in each month of 2021. The sample output of the above data is as follows:
+
+| month | avg_active_days | mau |
+| ------ | --------------- | --- |
+| 202107 | 1.50 | 2 |
+| 202109 | 1.25 | 4 |
+
+**Explanation**: In July 2021, 2 people were active, and they were active for 3 days in total (1001 was active for 1 day, and 1002 was active for 2 days), and the average number of active days was 1.5; in September 2021, 4 people were active, and they were active for 5 days in total, and the average number of active days was 1.25. The result is rounded to 2 decimal places.
+
+Note: Being active here means having the behavior of == handing in papers ==.
+
+**Idea**: After reading the question, pay attention to the highlighted part first; generally when finding the number of days and monthly active people, you will immediately think of the relevant date function; we will also split this question, refine the problem and then solve it; first, to find the number of active people, you must use `COUNT()`, then there is a pit here. I wonder if you have noticed it? User 1002 took two different test papers in September, so pay attention to removing duplicates here, otherwise the number of active people will be wrong during statistics; the second is to know the format of the date, as shown in the table above, the question is required to be displayed in the date format of `202107`, and `DATE_FORMAT` must be used for formatting.
+
+Basic usage:
+
+`DATE_FORMAT(date_value, format)`
+
+- The `date_value` parameter is the date or time value to be formatted.
+- The `format` parameter is the specified date or time format (this is the same as the date format in Java).
+
+**Answer**:
+
+```sql
+SELECT DATE_FORMAT(submit_time, '%Y%m') MONTH,
+ round(count(DISTINCT UID, DATE_FORMAT(submit_time, '%Y%m%d')) / count(DISTINCT UID), 2) avg_active_days,
+ COUNT(DISTINCT UID) mau
+FROM exam_record
+WHERE YEAR (submit_time) = 2021
+GROUP BY MONTH
+```
+
+One more thing to say here, use `COUNT(DISTINCT uid, DATE_FORMAT(submit_time, '%Y%m%d'))` to count the number of combined values in the `uid` column and `submit_time` column formatted according to year, month and date.
+
+### Total monthly number of questions and average number of questions per day
+
+**Description**: There is a question practice record table `practice_record`. The sample content is as follows:
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
+
+Please count the total number of monthly questions `month_q_cnt` and the average number of daily questions `avg_day_q_cnt` (sorted by month in ascending order) for users in each month of 2021, as well as the overall situation of the year. The sample data output is as follows:
+
+| submit_month | month_q_cnt | avg_day_q_cnt |
+| ------------- | ---------- | ------------- |
+| 202108 | 2 | 0.065 |
+| 202109 | 3 | 0.100 |
+| 2021 Summary | 5 | 0.161 |
+
+**Explanation**: There are 2 records of question brushing in August 2021, and the average number of questions brushed per day is 2/31=0.065 (retaining 3 decimal places); there are 3 records of brushing questions in September 2021, and the average number of questions brushed per day is 3/30=0.100; there are 5 records of brushing questions in 2021 (the annual summary average has no practical significance, here we calculate based on 31 days 5/31=0.161)
+
+> Niuke has adopted the latest Mysql version. If you get an error when running: ONLY_FULL_GROUP_BY, it means: for GROUP BY aggregation operation, if the column in SELECT does not appear in GROUP BY, then this SQL is illegal because the column is not in the GROUP BY clause, which means that the column found must appear after group by otherwise an error will be reported, or this field appears in the aggregate function.
+
+**Idea:**
+
+When you see the instance data, you will immediately think of the related functions. For example, `submit_month` will use `DATE_FORMAT` to format the date. Then find out the number of questions per month.
+
+Number of questions per month
+
+```sql
+SELECT MONTH ( submit_time ), COUNT ( question_id )
+FROM
+ practice_record
+GROUP BY
+ MONTH (submit_time)
+```
+
+Then in the third column, the `DAY(LAST_DAY(date_value))` function is used to find the number of days in the month of a given date.
+
+The sample code is as follows:
+
+```sql
+SELECT DAY(LAST_DAY('2023-07-08')) AS days_in_month;
+-- Output: 31
+
+SELECT DAY(LAST_DAY('2023-02-01')) AS days_in_month;
+-- Output: 28 (February in a leap year)
+
+SELECT DAY(LAST_DAY(NOW())) AS days_in_current_month;
+-- Output: 31 (number of days in current month)
+```
+
+Use the `LAST_DAY()` function to get the last day of the month for a given date, then use the `DAY()` function to extract the number of days for that date. This will get the number of days in the specified month.
+
+It should be noted that the `LAST_DAY()` function returns a date value, while the `DAY()` function is used to extract the day part of the date value.
+
+After the above analysis, you can write the answer immediately. The complexity of this question lies in processing the date, and the logic is not difficult.
+
+**Answer**:
+
+```sql
+SELECT DATE_FORMAT(submit_time, '%Y%m') submit_month,
+ count(question_id) month_q_cnt,
+ ROUND(COUNT(question_id) / DAY (LAST_DAY(submit_time)), 3) avg_day_q_cnt
+FROM practice_record
+WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
+GROUP BY submit_month
+UNION ALL
+SELECT '2021 Summary' AS submit_month,
+ count(question_id) month_q_cnt,
+ ROUND(COUNT(question_id) / 31, 3) avg_day_q_cnt
+FROM practice_record
+WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
+ORDER BY submit_month
+```
+
+In the example data output, because the last row needs to get summary data, `UNION ALL` is added to the result set here; don't forget to sort at the end!
+
+### Valid users with more than 1 unfinished test papers (more difficult)
+
+**Description**: Existing test paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` starting answering time, `submit_time` handing in time, `score` score), sample data is as follows:| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
+| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
+
+还有一张试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间),示例数据如下:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
+
+请统计 2021 年每个未完成试卷作答数大于 1 的有效用户的数据(有效用户指完成试卷作答数至少为 1 且未完成数小于 5),输出用户 ID、未完成试卷作答数、完成试卷作答数、作答过的试卷 tag 集合,按未完成试卷数量由多到少排序。示例数据的输出结果如下:
+
+| uid | incomplete_cnt | complete_cnt | detail |
+| ---- | -------------- | ------------ | --------------------------------------------------------------------------- |
+| 1002 | 2 | 4 | 2021-09-01:算法;2021-07-02:SQL;2021-09-02:SQL;2021-09-05:SQL;2021-07-05:SQL |
+
+**解释**:2021 年的作答记录中,除了 1004,其他用户均满足有效用户定义,但只有 1002 未完成试卷数大于 1,因此只输出 1002,detail 中是 1002 作答过的试卷{日期:tag}集合,日期和 tag 间用 **:** 连接,多元素间用 **;** 连接。
+
+**思路:**
+
+仔细读题后,分析出:首先要联表,因为后面要输出`tag`;
+
+筛选出 2021 年的数据
+
+```sql
+SELECT *
+FROM exam_record er
+LEFT JOIN examination_info ei ON er.exam_id = ei.exam_id
+WHERE YEAR (er.start_time)= 2021
+```
+
+根据 uid 进行分组,然后对每个用户进行条件进行判断,题目中要求`完成试卷数至少为1,未完成试卷数要大于1,小于5`
+
+那么等会儿写 sql 的时候条件应该是:`未完成 > 1 and 已完成 >=1 and 未完成 < 5`
+
+因为最后要用到字符串的拼接,而且还要组合拼接,这个可以用`GROUP_CONCAT`函数,下面简单介绍一下该函数的用法:
+
+基本格式:
+
+```sql
+GROUP_CONCAT([DISTINCT] expr [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [, ...]] [SEPARATOR sep])
+```
+
+- `expr`:要连接的列或表达式。
+- `DISTINCT`:可选参数,用于去重。当指定了 `DISTINCT`,相同的值只会出现一次。
+- `ORDER BY`:可选参数,用于排序连接后的值。可以选择升序 (`ASC`) 或降序 (`DESC`) 排序。
+- `SEPARATOR sep`:可选参数,用于设置连接后的值的分隔符。(本题要用这个参数设置 ; 号 )
+
+`GROUP_CONCAT()` 函数常用于 `GROUP BY` 子句中,将一组行的值连接为一个字符串,并在结果集中以聚合的形式返回。
+
+**答案**:
+
+```sql
+SELECT a.uid,
+ SUM(CASE
+ WHEN a.submit_time IS NULL THEN 1
+ END) AS incomplete_cnt,
+ SUM(CASE
+ WHEN a.submit_time IS NOT NULL THEN 1
+ END) AS complete_cnt,
+ GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag)
+ ORDER BY start_time SEPARATOR ";") AS detail
+FROM exam_record a
+LEFT JOIN examination_info b ON a.exam_id = b.exam_id
+WHERE YEAR (a.start_time)= 2021
+GROUP BY a.uid
+HAVING incomplete_cnt > 1
+AND complete_cnt >= 1
+AND incomplete_cnt < 5
+ORDER BY incomplete_cnt DESC
+```
+
+- `SUM(CASE WHEN a.submit_time IS NULL THEN 1 END)` 统计了每个用户未完成的记录数量。
+- `SUM(CASE WHEN a.submit_time IS NOT NULL THEN 1 END)` 统计了每个用户已完成的记录数量。
+- `GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag) ORDER BY a.start_time SEPARATOR ';')` 将每个用户的考试日期和标签以逗号分隔的形式连接成一个字符串,并按考试开始时间进行排序。
+
+## 嵌套子查询### The category that users who have completed an average of no less than 3 test papers per month like to answer (more difficult)
+
+**Description**: Existing test paper answer record table `exam_record` (`uid`: user ID, `exam_id`: test paper ID, `start_time`: start answering time, `submit_time`: submission time, NULL if not submitted, `score`: score), sample data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | (NULL) | (NULL) |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 5 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 6 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 7 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 8 | 1003 | 9001 | 2021-09-08 13:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
+| 10 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 13 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+Test paper information table `examination_info` (`exam_id`: test paper ID, `tag`: test paper category, `difficulty`: test paper difficulty, `duration`: test duration, `release_time`: release time), sample data is as follows:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Please count from the table the categories and number of answers that users who have an "average number of exam papers completed in the month" are not less than 3, and output them in descending order. The sample output is as follows:
+
+| tag | tag_cnt |
+| ---- | ------- |
+|C++|4|
+| SQL | 2 |
+| Algorithm | 1 |
+
+**Explanation**: The number of test papers completed by users 1002 and 1005 in September 2021 is 3, and the number of other users is less than 3; then the tag distribution results of the test papers answered by users 1002 and 1005, sorted in descending order by the number of answers, are C++, SQL, and algorithm.
+
+**Idea**: This question investigates the joint subquery, and the focus is on `monthly average answer >=3`, but I personally think it is not clearly stated here. It should be easier to understand if it is just checked in September; here is not >=3 every month or all the number of answers/months. Don't get it wrong.
+
+First check which users answer questions more than three times per month
+
+```sql
+SELECT UID
+FROM exam_record record
+GROUP BY UID,
+ MONTH (start_time)
+HAVING count(submit_time) >= 3
+```
+
+After this step, we can go deeper. As long as we can understand the previous step (I mean not to be bothered by the monthly average in the question), then set up a subquery to check which users are included, and then find out the required columns in the question. Remember to sort! !
+
+```sql
+SELECT tag,
+ count(start_time) AS tag_cnt
+FROM exam_record record
+INNER JOIN examination_info info ON record.exam_id = info.exam_id
+WHERE UID IN
+ (SELECT UID
+ FROM exam_record record
+ GROUP BY UID,
+ MONTH (start_time)
+ HAVING count(submit_time) >= 3)
+GROUP BY tag
+ORDER BY tag_cnt DESC
+```
+
+### Number of responders and average score on the day the test paper is released
+
+**Description**: Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time), sample data is as follows:
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2100 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 1500 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1100 | 4 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+**Interpretation**: User 1001’s nickname is Niuke No. 1, achievement value is 3100, user level is level 7, career direction is algorithm, registration time 2020-01-01 10:00:00
+
+Test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time) Sample data is as follows:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 || 3 | 9003 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score) The sample data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-09-01 09:41:01 | 70 |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
+| 6 | 1002 | 9002 | 2021-08-02 12:01:01 | 2021-08-02 12:31:01 | 70 |
+| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 8 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 70 |
+| 12 | 1003 | 9001 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
+| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+Please calculate the number of users with level 5 or above answering `uv` and the average score `avg_score` of each SQL category test paper after it is released, in descending order of the number of people, and for the same number of people, in ascending order of average score. The sample data output is as follows:
+
+| exam_id | uv | avg_score |
+| ------- | --- | --------- |
+| 9001 | 3 | 81.3 |
+
+Explanation: There is only one SQL category test paper, and the test paper ID is 9001. On the day of release (2021-09-01), 1001, 1002, 1003, and 1005 answered, but 1003 is a level 5 user, and the other 3 are level 5 or above. The scores of the three of them are [70, 80, 85, 90], and the average score is 81.3 (reserved 1 decimal places).
+
+**Idea**: This question seems very complicated, but first gradually split the "outer" conditions, and then put them together, and the answer will come out. Anyway, remember to work from the outside to the inside for multi-table queries.
+
+First connect the three tables and give some conditions. For example, if the user in the question requires `Level > 5`, then you can find out first
+
+```sql
+SELECT DISTINCT u_info.uid
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND u_info.LEVEL > 5
+```
+
+Then pay attention to the requirement in the question: `After each sql category test paper is released, users should answer the questions on the same day`. Pay attention to the == on the same day==, then we will immediately think of the need to compare time.
+
+Compare the test paper release date and test start date: `DATE(e_info.release_time) = DATE(record.start_time)`; don’t worry about `submit_time` being null, it will be filtered out in where later.
+
+**Answer**:
+
+```sql
+SELECT record.exam_id AS exam_id,
+ COUNT(DISTINCT u_info.uid) AS uv,
+ ROUND(SUM(record.score) / COUNT(u_info.uid), 1) AS avg_score
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND DATE (e_info.release_time) = DATE (record.start_time)
+ AND submit_time IS NOT NULL
+ AND tag = 'SQL'
+ AND u_info.LEVEL > 5
+GROUP BY record.exam_id
+ORDER BY uv DESC,
+ avg_score ASC
+```
+
+Pay attention to the final grouping order! Arrange them first according to the number of people, and if they are consistent, then arrange them according to the average score.
+
+### User level distribution of people who scored more than 80 on the test paper
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2100 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 1500 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1100 | 4 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- || 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答信息表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 79 |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
+| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 8 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 81 |
+| 12 | 1003 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
+| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+统计作答 SQL 类别的试卷得分大于过 80 的人的用户等级分布,按数量降序排序(保证数量都不同)。 The sample data result output is as follows:
+
+| level | level_cnt |
+| ----- | --------- |
+| 6 | 2 |
+| 5 | 1 |
+
+Explanation: 9001 is a SQL-type test paper. There are 3 people who answered this test paper with a score greater than 80 points: 1002, 1003, and 1005, two at level 6 and one at level 5.
+
+**Idea:** This question is the same as the previous question, but the query conditions have changed. If you understand the previous question, you can solve this question in minutes.
+
+**Answer**:
+
+```sql
+SELECT u_info.LEVEL AS LEVEL,
+ count(u_info.uid) AS level_cnt
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND record.score > 80
+ AND submit_time IS NOT NULL
+ AND tag = 'SQL'
+GROUP BY LEVEL
+ORDER BY level_cnt DESC
+```
+
+## Combined query
+
+### The number of people and times that each question and each test paper was answered
+
+**Description**:
+
+现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 3 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 4 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+
+Question practice table practice_record (uid user ID, question_id question ID, submit_time submission time, score score):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1003 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 6 | 1003 | 8001 | 2021-08-02 19:48:01 | 90 |
+| 7 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
+
+请统计每个题目和每份试卷被作答的人数和次数,分别按照"试卷"和"题目"的 uv & pv 降序显示,示例数据结果输出如下:
+
+| tid | uv | pv |
+| ---- | --- | --- |
+| 9001 | 3 | 3 |
+| 9002 | 1 | 3 |
+| 8001 | 3 | 5 |
+| 8002 | 2 | 2 |
+
+**解释**:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002**Idea**: The difficulty and error-prone point of this question lies in the simultaneous use of `UNION` and `ORDER BY`
+
+There are the following situations: using `union` and multiple `order by` without brackets, an error will be reported!
+
+`order by` has no effect in clauses joined by `union`;
+
+For example, without parentheses:
+
+```sql
+SELECT exam_id AS tid,
+ COUNT(DISTINCT UID) AS uv,
+ COUNT(UID) AS pv
+FROM exam_record
+GROUP BY exam_id
+ORDER BY uv DESC,
+ pvDESC
+UNION
+SELECT question_id AS tid,
+ COUNT(DISTINCT UID) AS uv,
+ COUNT(UID) AS pv
+FROM practice_record
+GROUP BY question_id
+ORDER BY uv DESC,
+ pvDESC
+```
+
+Report a syntax error directly. If there are no brackets, there can only be one `order by`
+
+There is also a situation where `order by` does not work, but it works in clauses of clauses. The solution here is to put another layer of query outside.
+
+**Answer**:
+
+```sql
+SELECT *
+FROM
+ (SELECT exam_id AS tid,
+ COUNT(DISTINCT exam_record.uid) uv,
+ COUNT(*)pv
+ FROM exam_record
+ GROUP BY exam_id
+ ORDER BY uv DESC, pv DESC) t1
+UNION
+SELECT *
+FROM
+ (SELECT question_id AS tid,
+ COUNT(DISTINCT practice_record.uid) uv,
+ COUNT(*)pv
+ FROM practice_record
+ GROUP BY question_id
+ ORDER BY uv DESC, pv DESC) t2;
+```
+
+### People who satisfy two activities respectively
+
+**Description**: In order to promote more users to learn and improve on the Niuke platform, we will often provide benefits to some users who are both active and perform well. Suppose we had two operations in the past, and issued welfare coupons to those who scored 85 points on each test paper (activity1), and to those who completed the difficult test paper in half the time at least once with a score greater than 80 (activity2).
+
+Now, you need to screen out the people who satisfy these two activities at once and hand them over to the operations students. Please write a SQL implementation: Output the IDs and activity numbers of all people who can score 85 points on every test paper in 2021, and those who have completed a difficult test paper in half the time at least once with a score greater than 80. Sort the output by user ID.
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | **86** |
+| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 89 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+
+Sample data output:
+
+| uid | activity |
+| ---- | --------- |
+| 1001 | activity2 |
+| 1003 | activity1 |
+| 1004 | activity1 |
+| 1004 | activity2 |
+
+**Explanation**: User 1001's minimum score of 81 does not meet activity 1, but he completed the 60-minute test paper in 29 minutes and 59 seconds with a score of 81, which meets activity 2; 1003's minimum score of 86 meets activity 1, and the completion time is greater than half of the test paper length, which does not meet activity 2; User 1004 completed the test paper in exactly half the time (30 minutes) and scored 85, which meets activity 1 and activity 2.
+
+**Idea**: This question involves time subtraction, and you need to use the `TIMESTAMPDIFF()` function to calculate the minute difference between two timestamps.
+
+Let’s take a look at the basic usage
+
+Example:
+
+```sql
+TIMESTAMPDIFF(MINUTE, start_time, end_time)
+```
+
+The first parameter of the `TIMESTAMPDIFF()` function is the time unit. Here we choose `MINUTE` to return the minute difference. The second parameter is the earlier timestamp and the third parameter is the later timestamp. The function returns the difference in minutes between them
+
+After understanding the usage of this function, let's go back and look at the requirements of `activity1`. Just ask for the score to be greater than 85. So let's write this out first, and the subsequent ideas will be much clearer.
+
+```sql
+SELECT DISTINCT UID
+FROM exam_record
+WHERE score >= 85
+ AND YEAR (start_time) = '2021'
+```
+
+According to condition 2, then write `people who completed the difficult test paper in half the time and scored more than 80'
+
+```sql
+SELECT UID
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND (TIMESTAMPDIFF(MINUTE, start_time, submit_time)) < (info.duration / 2)
+ AND difficulty = 'hard'
+ AND score >= 80
+```
+
+Then just `UNION` the two. (Special attention should be paid to the bracket problem and the position of `order by` here. The specific usage has been mentioned in the previous article)
+
+**Answer**:
+
+```sql
+SELECT DISTINCT UID UID,
+ 'activity1' activity
+FROM exam_record
+WHERE UID not in
+ (SELECT UID
+ FROM exam_record
+ WHERE score<85
+ AND YEAR(submit_time) = 2021 )
+UNION
+SELECT DISTINCT UID UID,
+ 'activity2' activity
+FROM exam_record e_r
+LEFT JOIN examination_info e_i ON e_r.exam_id = e_i.exam_id
+WHERE YEAR(submit_time) = 2021
+ AND difficulty = 'hard'
+ AND TIMESTAMPDIFF(SECOND, start_time, submit_time) <= duration *30
+ AND score>80
+ORDER BY UID
+```
+
+## Connection query
+
+### The number of test papers completed and the number of question exercises (difficulty) for users who meet the conditions
+
+**Description**:Existing user information table user_info (uid user ID, nick_name nickname, achievement achievement value, level level, job career direction, register_time registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2300 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 2500 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 2000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table examination_info (exam_id examination paper ID, tag examination paper category, difficulty examination paper difficulty, duration examination duration, release_time release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table exam_record (uid user ID, exam_id examination paper ID, start_time start answering time, submit_time submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
+| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 6 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 7 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
+| 8 | 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 80 |
+
+Question practice record table practice_record (uid user ID, question_id question ID, submit_time submission time, score score):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 6 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 7 | 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
+| 8 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 9 | 1004 | 8002 | 2021-08-02 19:58:01 | 94 |
+| 10 | 1004 | 8003 | 2021-08-02 19:38:01 | 70 |
+| 11 | 1004 | 8003 | 2021-08-02 19:48:01 | 90 |
+| 12 | 1004 | 8003 | 2021-08-01 19:38:01 | 80 |
+
+Please find famous experts whose average scores on the difficult SQL test papers are greater than 80 and who are level 7, count their total number of completed test papers and total number of practice questions in 2021, and only retain users who have completed test paper records in 2021. The results are in ascending order by the number of completed test papers and in descending order by the number of practice questions.
+
+Sample data output is as follows:
+
+| uid | exam_cnt | question_cnt |
+| ---- | -------- | ------------ |
+| 1001 | 1 | 2 |
+| 1003 | 2 | 0 |
+
+Explanation: Users 1001, 1003, 1004, and 1006 meet the requirements of the high-difficulty SQL test paper with an average score greater than 80, but only 1001 and 1003 are level 7 famous bosses; 1001 completed 1 test paper 1001 and practiced the questions 2 times; 1003 completed 2 test papers 9001, 9002, question not practiced (so count is 0)
+
+**Idea:**
+
+First conduct preliminary screening of conditions, for example, first find users who have taken difficult SQL test papers
+
+```sql
+SELECT
+ record.uid
+FROM
+ exam_record record
+ INNER JOIN examination_info e_info ON record.exam_id = e_info.exam_id
+ JOIN user_info u_info ON record.uid = u_info.uid
+WHERE
+ e_info.tag = 'SQL'
+ AND e_info.difficulty = 'hard'
+```
+
+Then according to the requirements of the question, just add the conditions;
+
+But here’s something to note:
+
+First: You cannot put the `YEAR(submit_time)= 2021` condition at the end, but in the `ON` condition, because there is a situation where the left join returns all the rows of the left table and the right table is null. The purpose of placing it in the `ON` clause of the `JOIN` condition is to ensure that when connecting two tables, only records that meet the year condition will be connected. This prevents records from other years from being included in the results. That is, 1001 has taken the 2021 test paper but has not practiced it. If the condition is placed at the end, this situation will be eliminated.
+
+Second, it must be `COUNT(distinct er.exam_id) exam_cnt, COUNT(distinct pr.id) question_cnt, `should be added distinct, because there are many duplicate values generated by left joins.
+
+**Answer**:
+
+```sql
+SELECT er.uid AS UID,
+ count(DISTINCT er.exam_id) AS exam_cnt,
+ count(DISTINCT pr.id) AS question_cnt
+FROM exam_recorder
+LEFT JOIN practice_record pr ON er.uid = pr.uid
+AND YEAR (er.submit_time)= 2021
+AND YEAR (pr.submit_time)= 2021
+WHERE er.uid IN
+ (SELECT er.uid
+ FROM exam_recorder
+ LEFT JOIN examination_info ei ON er.exam_id = ei.exam_id
+ LEFT JOIN user_info ui ON er.uid = ui.uid
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard'
+ AND LEVEL = 7
+ GROUP BY er.uid
+ HAVING avg(score) > 80)
+GROUP BY er.uid
+ORDER BY exam_cnt,
+ question_cnt DESC```
+
+Careful friends may find out why user 1003 can still find two exam records despite clearly limiting the conditions to `tag = 'SQL' AND difficulty = 'hard'`, one of which has an exam `tag` of `C++`; This is due to the characteristics of `LEFT JOIN`, even if there are no rows matching the right table, all records in the left table will still be retained.
+
+### Activity status of each level 6/7 user (difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2300 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 2500 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 2600 | 7 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| uid | exam_id | start_time | submit_time | score |
+| ---- | ------- | ------------------- | ------------------- | ------ |
+| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
+| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 1005 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:59 | 84 |
+| 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 81 |
+| 1002 | 9001 | 2020-09-01 13:01:01 | 2020-09-01 13:41:01 | 81 |
+| 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+
+Question practice record table `practice_record` (`uid` user ID, `question_id` question ID, `submit_time` submission time, `score` score):
+
+| uid | question_id | submit_time | score |
+| ---- | ----------- | ------------------- | ----- |
+| 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
+| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 1006 | 8002 | 2021-08-04 19:58:01 | 94 |
+| 1006 | 8003 | 2021-08-03 19:38:01 | 70 |
+| 1006 | 8003 | 2021-08-02 19:48:01 | 90 |
+| 1006 | 8003 | 2020-08-01 19:38:01 | 80 |
+
+Please count the total number of active months, number of active days in 2021, number of active days in answering test papers in 2021, and number of active days in answering questions for each level 6/7 user, and sort them in descending order according to the total number of active months and number of active days in 2021. The output from the sample data is as follows:
+
+| uid | act_month_total | act_days_2021 | act_days_2021_exam |
+| ---- | --------------- | ------------- | ------------------ |
+| 1006 | 3 | 4 | 1 |
+| 1001 | 2 | 2 | 1 |
+| 1005 | 1 | 1 | 1 |
+| 1002 | 1 | 0 | 0 |
+| 1003 | 0 | 0 | 0 |
+
+**Explanation**: There are 5 level 6/7 users, of which 1006 was active for a total of 3 months in 202109, 202108, and 202008. The active dates in 2021 are 20210907, 20210804, 20210803, and 20210802 for a total of 4 days. In 2021, it is in the test paper answer area. 20210907 has been active for 1 day and has been active in the question practice area for 3 days.
+
+**Idea:**
+
+The key to this question lies in the use of `CASE WHEN THEN`, otherwise you have to write a lot of `left join` because it will produce a lot of result sets.
+
+The `CASE WHEN THEN` statement is a conditional expression used in SQL to perform different operations or return different results based on conditions.
+
+The syntax structure is as follows:
+
+```sql
+CASE
+ WHEN condition1 THEN result1
+ WHEN condition2 THEN result2
+ ...
+ ELSE result
+END
+```
+
+In this structure, you can add multiple WHEN clauses as needed, each WHEN clause is followed by a condition and a result. The condition can be any logical expression. If the condition is met, the corresponding result will be returned.
+
+The final ELSE clause is optional and is used to specify the default return result when all previous conditions are not met. If no `ELSE` clause is provided, `NULL` is returned by default.For example:
+
+```sql
+SELECT score,
+ CASE
+ WHEN score >= 90 THEN 'Excellent'
+ WHEN score >= 80 THEN 'Good'
+ WHEN score >= 60 THEN 'pass'
+ ELSE 'failed'
+ END AS grade
+FROM student_scores;
+```
+
+In the above example, the CASE WHEN THEN statement is used to return the corresponding grade based on different ranges of student scores. If the score is greater than or equal to 90, "Excellent" is returned; if the score is greater than or equal to 80, "Good" is returned; if the score is greater than or equal to 60, "Pass" is returned; otherwise, "Fail" is returned.
+
+After understanding the above usage, look back at the question and ask to list different active days.
+
+```sql
+count(distinct act_month) as act_month_total,
+count(distinct case when year(act_time)='2021'then act_day end) as act_days_2021,
+count(distinct case when year(act_time)='2021' and tag='exam' then act_day end) as act_days_2021_exam,
+count(distinct case when year(act_time)='2021' and tag='question'then act_day end) as act_days_2021_question
+```
+
+The tag here is given first to facilitate the differentiation of queries and to separate exams and answers.
+
+Find the users in the test paper answer area
+
+```sql
+SELECT
+ uid,
+ exam_id AS ans_id,
+ start_time AS act_time,
+ date_format( start_time, '%Y%m' ) AS act_month,
+ date_format( start_time, '%Y%m%d' ) AS act_day,
+ 'exam' AS tag
+ FROM
+ exam_record
+```
+
+Then there are the users in the question and answer area.
+
+```sql
+SELECT
+ uid,
+ question_id AS ans_id,
+ submit_time AS act_time,
+ date_format( submit_time, '%Y%m' ) AS act_month,
+ date_format( submit_time, '%Y%m%d' ) AS act_day,
+ 'question' AS tag
+ FROM
+ practice_record
+```
+
+Finally, `UNION` the two results. Finally, don’t forget to sort the results (this question is somewhat similar to the idea of divide and conquer)
+
+**Answer**:
+
+```sql
+SELECT user_info.uid,
+ count(DISTINCT act_month) AS act_month_total,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021' THEN act_day
+ END) AS act_days_2021,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021'
+ AND tag = 'exam' THEN act_day
+ END) AS act_days_2021_exam,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021'
+ AND tag = 'question' THEN act_day
+ END) AS act_days_2021_question
+FROM
+ (SELECT UID,
+ exam_id AS ans_id,
+ start_time AS act_time,
+ date_format(start_time, '%Y%m') AS act_month,
+ date_format(start_time, '%Y%m%d') AS act_day,
+ 'exam' AS tag
+ FROM exam_record
+ UNION ALL SELECT UID,
+ question_id AS ans_id,
+ submit_time AS act_time,
+ date_format(submit_time, '%Y%m') AS act_month,
+ date_format(submit_time, '%Y%m%d') AS act_day,
+ 'question' AS tag
+ FROM practice_record) total
+RIGHT JOIN user_info ON total.uid = user_info.uid
+WHERE user_info.LEVEL IN (6,
+ 7)
+GROUP BY user_info.uid
+ORDER BY act_month_total DESC,
+ act_days_2021 DESC
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-04.en.md b/docs_en/database/sql/sql-questions-04.en.md
new file mode 100644
index 00000000000..9c380b6e605
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-04.en.md
@@ -0,0 +1,830 @@
+---
+title: Summary of common SQL interview questions (4)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, window function, ROW_NUMBER, ranking, grouping, MySQL 8
+ - - meta
+ - name: description
+ content: Summarizes the usage of window functions introduced in MySQL 8, including high-frequency questions and implementation techniques for sorting and grouping statistical scenarios.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+You can decide whether to skip more difficult or difficult questions based on your actual situation and interview needs.
+
+##Specialized window functions
+
+MySQL version 8.0 introduced support for window functions. The following are common window functions and their usage in MySQL:
+
+1. `ROW_NUMBER()`: Assign a unique integer value to each row in the query result set.
+
+```sql
+SELECT col1, col2, ROW_NUMBER() OVER (ORDER BY col1) AS row_num
+FROM table;
+```
+
+2. `RANK()`: Calculate the ranking of each row in the sorted results.
+
+```sql
+SELECT col1, col2, RANK() OVER (ORDER BY col1 DESC) AS ranking
+FROM table;
+```
+
+3. `DENSE_RANK()`: Calculate the ranking of each row in the sorted results, keeping the same ranking.
+
+```sql
+SELECT col1, col2, DENSE_RANK() OVER (ORDER BY col1 DESC) AS ranking
+FROM table;
+```
+
+4. `NTILE(n)`: Divide the results into n substantially uniform buckets and assign an identification number to each bucket.
+
+```sql
+SELECT col1, col2, NTILE(4) OVER (ORDER BY col1) AS bucket
+FROM table;
+```
+
+5. `SUM()`, `AVG()`, `COUNT()`, `MIN()`, `MAX()`: These aggregate functions can also be used in conjunction with window functions to calculate the summary, average, count, minimum and maximum values of specified columns within the window.
+
+```sql
+SELECT col1, col2, SUM(col1) OVER () AS sum_col
+FROM table;
+```
+
+6. `LEAD()` and `LAG()`: The LEAD function is used to get the value of the row at an offset after the current row, while the LAG function is used to get the value of the row at an offset before the current row.
+
+```sql
+SELECT col1, col2, LEAD(col1, 1) OVER (ORDER BY col1) AS next_col1,
+ LAG(col1, 1) OVER (ORDER BY col1) AS prev_col1
+FROM table;
+```
+
+7. `FIRST_VALUE()` and `LAST_VALUE()`: The FIRST_VALUE function is used to get the first value of the specified column in the window, and the LAST_VALUE function is used to get the last value of the specified column in the window.
+
+```sql
+SELECT col1, col2, FIRST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS first_val,
+ LAST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS last_val
+FROM table;
+```
+
+Window functions usually need to be used together with the OVER clause to define the size, sorting rules and grouping method of the window.
+
+### The top three scores in each type of test paper
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
+| 2 | 1002 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 4 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
+| 5 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 6 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 7 | 1005 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 8 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
+| 9 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 10 | 1003 | 9002 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+
+Find the top 3 scores for each type of test paper. If the two have the same maximum score, choose the one with the larger minimum score. If they are still the same, choose the one with the larger uid. The output from the sample data is as follows:
+
+| tid | uid | ranking |
+| ---- | ---- | ------- |
+| SQL | 1003 | 1 |
+| SQL | 1004 | 2 |
+| SQL | 1002 | 3 |
+| Algorithm | 1005 | 1 |
+| Algorithm | 1006 | 2 |
+| Algorithm | 1003 | 3 |
+
+**Explanation**: The test paper tags with answer score records include SQL and algorithm. SQL test paper users 1001, 1002, 1003, and 1004 have answer scores. The highest scores are 81, 81, 89, and 85 respectively, and the lowest scores are 78, 81, 86, and 40. Therefore, the top three are ranked according to the highest score first and then the lowest score, which are 1003, 1004, and 1002.
+
+**Answer**:
+
+```sql
+SELECT tag,
+ UID,
+ ranking
+FROM
+ (SELECT b.tag AS tag,
+ a.uid AS UID,
+ ROW_NUMBER() OVER (PARTITION BY b.tag
+ ORDER BY b.tag,
+ max(a.score) DESC,
+ min(a.score) DESC,
+ a.uid DESC) AS ranking
+ FROM exam_record a
+ LEFT JOIN examination_info b ON a.exam_id = b.exam_id
+ GROUP BY b.tag,
+ a.uid) t
+WHERE ranking <= 3```
+
+### The second fastest/slowest test paper whose time difference is greater than half the test paper length (more difficult)
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:51:01 | 78 |
+| 2 | 1001 | 9002 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 4 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:59:01 | 86 |
+| 5 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 6 | 1004 | 9002 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 7 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 8 | 1006 | 9001 | 2021-09-07 10:02:01 | 2021-09-07 10:21:01 | 84 |
+| 9 | 1003 | 9001 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 10 | 1003 | 9002 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 11 | 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 12 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+
+Find the test paper information where the difference between the second fastest and the second slowest time is greater than half of the test paper length, and sort by test paper ID in descending order. The output from the sample data is as follows:
+
+| exam_id | duration | release_time |
+| ------- | -------- | ------------------- |
+| 9001 | 60 | 2021-09-01 06:00:00 |
+
+**Explanation**: Test paper 9001 takes 50 minutes, 58 minutes, 30 minutes and 1 second, 19 minutes, and 10 minutes. The difference between the second fastest and the second slowest time is 50 minutes - 19 minutes = 31 minutes. The test paper duration is 60 minutes. Therefore, the condition of being greater than half of the test paper length is met, and the test paper ID, duration, and release time are output.
+
+**Idea:**
+
+The first step is to find the sequential ranking and reverse ranking of the completion time of each test paper, which is Table a;
+
+In the second step, establish an inner connection with the passed test paper information table b, group it according to the test paper id, use `having` to filter the ranking into the second data, convert seconds into minutes and compare, and finally sort according to the test paper id in reverse order.
+
+**Answer**:
+
+```sql
+SELECT a.exam_id,
+ b.duration,
+ b.release_time
+FROM
+ (SELECT exam_id,
+ row_number() OVER (PARTITION BY exam_id
+ ORDER BY timestampdiff(SECOND, start_time, submit_time) DESC) rn1,
+ row_number() OVER (PARTITION BY exam_id
+ ORDER BY timestampdiff(SECOND, start_time, submit_time) ASC) rn2,
+ timestampdiff(SECOND, start_time, submit_time) timex
+ FROM exam_record
+ WHERE score IS NOT NULL ) a
+INNER JOIN examination_info b ON a.exam_id = b.exam_id
+GROUP BY a.exam_id
+HAVING (max(IF (rn1 = 2, a.timex, 0))- max(IF (rn2 = 2, a.timex, 0)))/ 60 > b.duration / 2
+ORDER BY a.exam_id DESC
+```
+
+### The maximum time window for answering the test paper twice in a row (more difficult)
+
+**Description**
+
+Existing exam paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` starting answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:02 | 84 |
+| 2 | 1006 | 9001 | 2021-09-01 12:11:01 | 2021-09-01 12:31:01 | 89 |
+| 3 | 1006 | 9002 | 2021-09-06 10:01:01 | 2021-09-06 10:21:01 | 81 |
+| 4 | 1005 | 9002 | 2021-09-05 10:01:01 | 2021-09-05 10:21:01 | 81 |
+| 5 | 1005 | 9001 | 2021-09-05 10:31:01 | 2021-09-05 10:51:01 | 81 |
+
+Please calculate among those who have answered the test paper on at least two days in 2021, calculate the maximum time window `days_window` for answering the test paper twice in a row in that year, then according to the historical rules of the year, how many sets of test papers he will take on average in `days_window` days, sort in reverse order by the maximum time window and the average number of sets of answer papers. The output from the sample data is as follows:
+
+| uid | days_window | avg_exam_cnt |
+| ---- | ----------- | ------------ |
+| 1006 | 6 | 2.57 |**Explanation**: User 1006 answered 3 test papers in 20210901, 20210906, and 20210907 respectively. The maximum time window for two consecutive responses is 6 days (1st to 6th). He took a total of 3 test papers in the 7 days from 1st to 7th. On average, 3/7=0.428571 papers per day, so on average he will do 3 test papers in 6 days. 0.428571\*6=2.57 test papers (keep two decimal places); User 1005 took two test papers in 20210905, but only had one day's answer records, so filter them out.
+
+**Idea:**
+
+The above explanation reminds you to remove duplicates from the answer records. Don’t be fooled and don’t delete duplicates! If you remove duplicates, the test case will fail. Note that the restriction is in 2021;
+
+And please note that the time difference is +1 day; also note that == unsubmitted papers are also counted ==! ! ! ! (Anyway, I feel that the description of this question is unclear and the answer is not very good)
+
+**Answer**:
+
+```sql
+SELECT UID,
+ max(datediff(next_time, start_time)) + 1 AS days_window,
+ round(count(start_time)/(datediff(max(start_time), min(start_time))+ 1) * (max(datediff(next_time, start_time))+ 1), 2) AS avg_exam_cnt
+FROM
+ (SELECT UID,
+ start_time,
+ lead(start_time, 1) OVER (PARTITION BY UID
+ ORDER BY start_time) AS next_time
+ FROM exam_record
+ WHERE YEAR (start_time) = '2021' ) a
+GROUP BY UID
+HAVING count(DISTINCT date(start_time)) > 1
+ORDER BY days_window DESC,
+ avg_exam_cnt DESC
+```
+
+### The completion status of users who have not completed 0 in the past three months
+
+**Description**:
+
+Existing test paper answer record table `exam_record` (`uid`: user ID, `exam_id`: test paper ID, `start_time`: start answering time, `submit_time`: handing in time, if it is empty, it means not completed, `score`: score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1006 | 9003 | 2021-09-06 10:01:01 | 2021-09-06 10:21:02 | 84 |
+| 2 | 1006 | 9001 | 2021-08-02 12:11:01 | 2021-08-02 12:31:01 | 89 |
+| 3 | 1006 | 9002 | 2021-06-06 10:01:01 | 2021-06-06 10:21:01 | 81 |
+| 4 | 1006 | 9002 | 2021-05-06 10:01:01 | 2021-05-06 10:21:01 | 81 |
+| 5 | 1006 | 9001 | 2021-05-01 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9001 | 2021-09-05 10:31:01 | 2021-09-05 10:51:01 | 81 |
+| 7 | 1001 | 9003 | 2021-08-01 09:01:01 | 2021-08-01 09:51:11 | 78 |
+| 8 | 1001 | 9002 | 2021-07-01 09:01:01 | 2021-07-01 09:31:00 | 81 |
+| 9 | 1001 | 9002 | 2021-07-01 12:01:01 | 2021-07-01 12:31:01 | 81 |
+| 10 | 1001 | 9002 | 2021-07-01 12:01:01 | (NULL) | (NULL) |
+
+Find the number of test paper completions for users who have no test paper in the unfinished status in the last three months for each person who has test paper answer records, and rank them in descending order by the number of test paper completions and user ID. The output from the sample data is as follows:
+
+| uid | exam_complete_cnt |
+| ---- | ------------------ |
+| 1006 | 3 |
+
+**Explanation**: User 1006 has answered test papers in the last three months of 202109, 202108, and 202106, and the number of answered test papers is 3, all of which have been completed; User 1001 has answered test papers in the last three months of 202109, 202108, and 202107, and the number of answered test papers is 5, and the number of completed test papers is 4. Because there are unfinished test papers, they are filtered out.
+
+**Idea:**
+
+1. `Find the number of completed test papers for users who have no test paper answer records in the past three months and have no test paper answer records.` First of all, look at this sentence. You must first group them according to people.
+2. In the past three months, you can use continuous repeated ranking, sort in reverse order, ranking <=3
+3. Count the number of answers
+4. Assemble remaining conditions
+5. Sort
+
+**Answer**:
+
+```sql
+SELECT UID,
+ count(score) exam_complete_cnt
+FROM
+ (SELECT *, DENSE_RANK() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) dr
+ FROM exam_record) t1
+WHERE dr <= 3
+GROUP BY UID
+HAVING count(dr)= count(score)
+ORDER BY exam_complete_cnt DESC,
+ UID DESC
+```
+
+### Response status of the 50% users with high incompleteness rate in the past three months (difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3200 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2500 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 2200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | Algorithm | hard | 80 | 2020-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 15 | 1002 | 9001 | 2020-01-01 18:01:01 | 2020-01-01 18:59:02 | 90 |
+| 13 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | | |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | | |
+| 5 | 1001 | 9001 | 2020-03-01 12:01:01 | | |
+| 6 | 1002 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | | |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 14 | 1001 | 9002 | 2020-01-01 12:11:01 | | |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1002 | 9002 | 2020-02-02 12:01:01 | | |
+| 11 | 1002 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1002 | 9002 | 2020-03-02 12:11:01 | | |
+| 17 | 1001 | 9002 | 2020-05-05 18:01:01 | | |
+| 16 | 1002 | 9003 | 2020-05-06 12:01:01 | | |
+
+请统计 SQL 试卷上未完成率较高的 50%用户中,6 级和 7 级用户在有试卷作答记录的近三个月中,每个月的答卷数目和完成数目。按用户 ID、月份升序排序。
+
+由示例数据结果输出如下:
+
+| uid | start_month | total_cnt | complete_cnt |
+| ---- | ----------- | --------- | ------------ |
+| 1002 | 202002 | 3 | 1 |
+| 1002 | 202003 | 2 | 1 |
+| 1002 | 202005 | 2 | 1 |
+
+解释:各个用户对 SQL 试卷的未完成数、作答总数、未完成率如下:
+
+| uid | incomplete_cnt | total_cnt | incomplete_rate |
+| ---- | -------------- | --------- | --------------- |
+| 1001 | 3 | 7 | 0.4286 |
+| 1002 | 4 | 8 | 0.5000 |
+| 1003 | 1 | 1 | 1.0000 |
+
+1001、1002、1003 分别排在 1.0、0.5、0.0 的位置,因此较高的 50%用户(排位<=0.5)为 1002、1003;
+
+1003 不是 6 级或 7 级;
+
+有试卷作答记录的近三个月为 202005、202003、202002;
+
+这三个月里 1002 的作答题数分别为 3、2、2,完成数目分别为 1、1、1。
+
+**思路:**
+
+注意点:这题注意求的是所有的答题次数和完成次数,而 sql 类别的试卷是限制未完成率排名,6, 7 级用户限制的是做题记录。
+
+先求出未完成率的排名
+
+```sql
+SELECT UID,
+ count(submit_time IS NULL
+ OR NULL)/ count(start_time) AS num,
+ PERCENT_RANK() OVER (
+ ORDER BY count(submit_time IS NULL
+ OR NULL)/ count(start_time)) AS ranking
+FROM exam_record
+LEFT JOIN examination_info USING (exam_id)
+WHERE tag = 'SQL'
+GROUP BY UID
+```
+
+再求出最近三个月的练习记录
+
+```sql
+SELECT UID,
+ date_format(start_time, '%Y%m') AS month_d,
+ submit_time,
+ exam_id,
+ dense_rank() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) AS ranking
+FROM exam_record
+LEFT JOIN user_info USING (UID)
+WHERE LEVEL IN (6,7)
+```
+
+**答案**:
+
+```sql
+SELECT t1.uid,
+ t1.month_d,
+ count(*) AS total_cnt,
+ count(t1.submit_time) AS complete_cnt
+FROM-- 先求出未完成率的排名
+
+ (SELECT UID,
+ count(submit_time IS NULL OR NULL)/ count(start_time) AS num,
+ PERCENT_RANK() OVER (
+ ORDER BY count(submit_time IS NULL OR NULL)/ count(start_time)) AS ranking
+ FROM exam_record
+ LEFT JOIN examination_info USING (exam_id)
+ WHERE tag = 'SQL'
+ GROUP BY UID) t
+INNER JOIN
+ (-- 再求出近三个月的练习记录
+ SELECT UID,
+ date_format(start_time, '%Y%m') AS month_d,
+ submit_time,
+ exam_id,
+ dense_rank() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) AS ranking
+ FROM exam_record
+ LEFT JOIN user_info USING (UID)
+ WHERE LEVEL IN (6,7) ) t1 USING (UID)
+WHERE t1.ranking <= 3 AND t.ranking >= 0.5 -- 使用限制找到符合条件的记录
+
+GROUP BY t1.uid,
+ t1.month_d
+ORDER BY t1.uid,
+ t1.month_d```
+
+### 试卷完成数同比 2020 年的增长率及排名变化(困难)
+
+**描述**:
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2021-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-08-02 10:01:01 | 2020-08-02 10:31:01 | 89 |
+| 2 | 1002 | 9001 | 2020-04-01 18:01:01 | 2020-04-01 18:59:02 | 90 |
+| 3 | 1001 | 9001 | 2020-04-01 09:01:01 | 2020-04-01 09:21:59 | 80 |
+| 5 | 1002 | 9001 | 2021-03-02 19:01:01 | 2021-03-02 19:32:00 | 20 |
+| 8 | 1003 | 9001 | 2021-05-02 12:01:01 | 2021-05-02 12:31:01 | 98 |
+| 13 | 1003 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 9 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1002 | 9002 | 2021-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 11 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 16 | 1002 | 9002 | 2020-02-02 12:01:01 | | |
+| 17 | 1002 | 9002 | 2020-03-02 12:11:01 | | |
+| 18 | 1001 | 9002 | 2021-05-05 18:01:01 | | |
+| 4 | 1002 | 9003 | 2021-01-20 10:01:01 | 2021-01-20 10:10:01 | 81 |
+| 6 | 1001 | 9003 | 2021-04-02 19:01:01 | 2021-04-02 19:40:01 | 89 |
+| 15 | 1002 | 9003 | 2021-01-01 18:01:01 | 2021-01-01 18:59:02 | 90 |
+| 7 | 1004 | 9004 | 2020-05-02 12:01:01 | 2020-05-02 12:20:01 | 99 |
+| 12 | 1001 | 9004 | 2021-09-02 12:11:01 | | |
+| 14 | 1002 | 9004 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+
+请计算 2021 年上半年各类试卷的做完次数相比 2020 年上半年同期的增长率(百分比格式,保留 1 位小数),以及做完次数排名变化,按增长率和 21 年排名降序输出。
+
+由示例数据结果输出如下:
+
+| tag | exam_cnt_20 | exam_cnt_21 | growth_rate | exam_cnt_rank_20 | exam_cnt_rank_21 | rank_delta |
+| --- | ----------- | ----------- | ----------- | ---------------- | ---------------- | ---------- |
+| SQL | 3 | 2 | -33.3% | 1 | 2 | 1 |
+
+解释:2020 年上半年有 3 个 tag 有作答完成的记录,分别是 C++、SQL、PYTHON,它们被做完的次数分别是 3、3、2,做完次数排名为 1、1(并列)、3;
+
+2021 年上半年有 2 个 tag 有作答完成的记录,分别是算法、SQL,它们被做完的次数分别是 3、2,做完次数排名为 1、2;具体如下:
+
+| tag | start_year | exam_cnt | exam_cnt_rank |
+| ------ | ---------- | -------- | ------------- |
+| C++ | 2020 | 3 | 1 |
+| SQL | 2020 | 3 | 1 |
+| PYTHON | 2020 | 2 | 3 |
+| 算法 | 2021 | 3 | 1 |
+| SQL | 2021 | 2 | 2 |
+
+因此能输出同比结果的 tag 只有 SQL,从 2020 到 2021 年,做完次数 3=>2,减少 33.3%(保留 1 位小数);排名 1=>2,后退 1 名。
+
+**思路:**
+
+本题难点在于长整型的数据类型要求不能有负号产生,用 cast 函数转换数据类型为 signed。
+
+以及用到的`增长率计算公式:(exam_cnt_21-exam_cnt_20)/exam_cnt_20`
+
+做完次数排名变化(2021 年和 2020 年比排名升了或者降了多少)
+
+计算公式:`exam_cnt_rank_21 - exam_cnt_rank_20`
+
+在 MySQL 中,`CAST()` 函数用于将一个表达式的数据类型转换为另一个数据类型。它的基本语法如下:
+
+```sql
+CAST(expression AS data_type)
+
+-- 将一个字符串转换成整数
+SELECT CAST('123' AS INT);
+```
+
+示例就不一一举例了,这个函数很简单
+
+**答案**:
+
+```sql
+SELECT
+ tag,
+ exam_cnt_20,
+ exam_cnt_21,
+ concat(
+ round(
+ 100 * (exam_cnt_21 - exam_cnt_20) / exam_cnt_20,
+ 1
+ ),
+ '%'
+ ) AS growth_rate,
+ exam_cnt_rank_20,
+ exam_cnt_rank_21,
+ cast(exam_cnt_rank_21 AS signed) - cast(exam_cnt_rank_20 AS signed) AS rank_delta
+FROM
+ (
+ #2020年、2021年上半年各类试卷的做完次数和做完次数排名
+ SELECT
+ tag,
+ count(
+ IF (
+ date_format(start_time, '%Y%m%d') BETWEEN '20200101'
+ AND '20200630',
+ start_time,
+ NULL
+ )
+ ) AS exam_cnt_20,
+ count(
+ IF (
+ substring(start_time, 1, 10) BETWEEN '2021-01-01'
+ AND '2021-06-30',
+ start_time,
+ NULL
+ )
+ ) AS exam_cnt_21,
+ rank() over (
+ ORDER BY
+ count(
+ IF (
+ date_format(start_time, '%Y%m%d') BETWEEN '20200101'
+ AND '20200630',
+ start_time,
+ NULL
+ )
+ ) DESC
+ ) AS exam_cnt_rank_20,
+ rank() over (
+ ORDER BY
+ count(
+ IF (
+ substring(start_time, 1, 10) BETWEEN '2021-01-01'
+ AND '2021-06-30',
+ start_time,
+ NULL
+ )
+ ) DESC
+ ) AS exam_cnt_rank_21
+ FROM
+ examination_info
+ JOIN exam_record USING (exam_id)
+ WHERE
+ submit_time IS NOT NULL
+ GROUP BY
+ tag
+ ) main
+WHERE
+ exam_cnt_21 * exam_cnt_20 <> 0
+ORDER BY
+ growth_rate DESC,
+ exam_cnt_rank_21 DESC
+```
+
+## Aggregation window function
+
+### Perform min-max normalization on test paper scores
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | Algorithm | hard | 80 | 2020-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 6 | 1003 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 68 |
+| 9 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 12 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
+| 3 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
+| 2 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
+| 7 | 1001 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
+| 10 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
+| 5 | 1002 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 90 |
+| 11 | 1002 | 9004 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1001 | 9005 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
+
+In physics and statistical data calculation, there is a concept called min-max standardization, also known as dispersion standardization, which is a linear transformation of the original data so that the result value is mapped to [0 - 1].
+
+The conversion function is:
+
+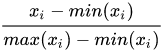
+
+Please perform min-max normalization on each test paper's answer record and scale it to the [0,100] interval, and output the user ID, test paper ID, and average score after normalization; finally, output the test paper ID in ascending order and the normalized score in descending order. (Note: The score interval defaults to [0,100]. If there is only one score in the answer record of a certain test paper, there is no need to use a formula. The score will still be the original score after normalization and scaling).
+
+The output from the sample data is as follows:
+
+| uid | exam_id | avg_new_score |
+| ---- | ------- | ------------- |
+| 1001 | 9001 | 98 |
+| 1003 | 9001 | 0 |
+| 1002 | 9002 | 88 |
+| 1003 | 9002 | 75 |
+| 1001 | 9002 | 70 |
+| 1004 | 9002 | 0 |
+
+Explanation: The difficult papers are 9001, 9002, and 9003;
+
+There are 3 records of answering 9001, and the scores are 68, 89, and 90 respectively. After normalization according to the given formula, the scores are: 0, 95, 100, and the latter two scores are answered by user 1001. Therefore, user 1001’s new score for test paper 9001 is (95+100)/2≈98 (only the integer part is retained). User 1003’s score for the test paper 9001 has a new score of 0. The final results are output in ascending order of test paper ID and descending order of normalized scores.
+
+**Idea:**
+
+Note:
+
+1. For difficult test papers, use the max/min (col) over() window function to find the maximum and minimum values in each group according to the scores of each type of test paper, and then calculate the normalized formula. The scaling interval is [0,100], that is, min_max\*100
+2. If a certain type of test paper has only one score, there is no need to use the normalization formula, because there is only one score max_score=min_score,score, and the result may become 0 after the formula.
+3. The final results are grouped by uid and exam_id to find the normalized mean. Those with a score of NULL should be filtered out.
+
+The last thing is to look carefully at the above formula (to be honest, this question seems very convoluted)
+
+**Answer**:
+
+```sql
+SELECT
+ uid,
+ exam_id,
+ round(sum(min_max) / count(score), 0) AS avg_new_score
+FROM
+ (
+ SELECT
+ *,
+ IF (
+ max_score = min_score,
+ score,
+ (score - min_score) / (max_score - min_score) * 100
+ ) AS min_max
+ FROM
+ (
+ SELECT
+ uid,
+ a.exam_id,
+ score,
+ max(score) over (PARTITION BY a.exam_id) AS max_score,
+ min(score) over (PARTITION BY a.exam_id) AS min_score
+ FROM
+ exam_record a
+ LEFT JOIN examination_info b USING (exam_id)
+ WHERE
+ difficulty = 'hard'
+ ) t
+ WHERE
+ score IS NOT NULL
+ ) t1
+GROUP BY
+ uid,
+ exam_id
+ORDER BY
+ exam_id ASC,
+ avg_new_score DESC;
+```
+
+### The number of answers per test paper per month and the total number of answers as of the current month
+
+**Description:**
+
+Existing test paper answer record table exam_record (uid user ID, exam_id test paper ID, start_time start answering time, submit_time handover time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ || 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1003 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1004 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1003 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 68 |
+| 11 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1001 | 9002 | 2020-03-02 12:11:01 | (NULL) | (NULL) |
+
+Please output the number of responses per month for each test paper and the total number of responses as of the current month.
+The output from the sample data is as follows:
+
+| exam_id | start_month | month_cnt | cum_exam_cnt |
+| ------- | ----------- | --------- | ----------- |
+| 9001 | 202001 | 2 | 2 |
+| 9001 | 202002 | 1 | 3 |
+| 9001 | 202003 | 3 | 6 |
+| 9001 | 202005 | 1 | 7 |
+| 9002 | 202001 | 1 | 1 |
+| 9002 | 202002 | 3 | 4 |
+| 9002 | 202003 | 1 | 5 |
+
+Explanation: Test paper 9001 has been answered in 4 months, 202001, 202002, 202003, and 202005. The number of answers per month is 2, 1, 3, and 1 respectively. The total number of answers as of the current month is 2, 3, 6, and 7.
+
+**Idea:**
+
+This question has two key points: counting the total number of answers as of the current month, outputting the number of monthly responses for each test paper, and outputting the total number of responses as of the current month.
+
+This is the key `**sum(count(*)) over(partition by exam_id order by date_format(start_time,'%Y%m'))**`
+
+**Answer**:
+
+```sql
+SELECT exam_id,
+ date_format(start_time, '%Y%m') AS start_month,
+ count(*) AS month_cnt,
+ sum(count(*)) OVER (PARTITION BY exam_id
+ ORDER BY date_format(start_time, '%Y%m')) AS cum_exam_cnt
+FROM exam_record
+GROUP BY exam_id,
+ start_month
+```
+
+### Question answering status every month and as of the current month (more difficult)
+
+**Description**: Existing test paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1003 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1004 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1003 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 68 |
+| 11 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1001 | 9002 | 2020-03-02 12:11:01 | (NULL) | (NULL) |
+
+Please output the number of monthly active users, the number of new users, the maximum number of new users in a single month as of the current month, and the cumulative number of users as of the current month in the monthly test paper response records since the user's answer record was created. The results are output in ascending order of month.
+
+The output from the sample data is as follows:
+
+| start_month | mau | month_add_uv | max_month_add_uv | cum_sum_uv |
+| ----------- | --- | ------------ | ---------------- | ---------- |
+| 202001 | 2 | 2 | 2 | 2 |
+| 202002 | 4 | 2 | 2 | 4 |
+| 202003 | 3 | 0 | 2 | 4 |
+| 202005 | 1 | 0 | 2 | 4 |
+
+| month | 1001 | 1002 | 1003 | 1004 |
+| ------ | ---- | ---- | ---- | ---- |
+| 202001 | 1 | 1 | | |
+| 202002 | 1 | 1 | 1 | 1 |
+| 202003 | 1 | | 1 | 1 |
+| 202005 | | 1 | | |As can be seen from the above matrix, there were 2 active users in January 2020 (mau=2), and the number of new users that month was 2;
+
+There were 4 active users in February 2020, the number of new users in that month was 2, the maximum number of new users in a single month was 2, and the current cumulative number of users was 4.
+
+**Idea:**
+
+Difficulties:
+
+1. How to find new users every month
+
+2. Answers as of the current month
+
+Rough process:
+
+(1) Count each person’s first login month `min()`
+
+(2) Statistics of monthly active and new users: first get each person’s first login month, and then sum up the first login month grouping to get the number of new users in that month.
+
+(3) Count the maximum number of new users in a single month as of the current month, the cumulative number of users as of the current month, and finally output them in ascending order by month
+
+**Answer**:
+
+```sql
+--The maximum number of new users in a single month as of the current month and the cumulative number of users as of the current month, output in ascending order by month
+SELECT
+ start_month,
+ mau,
+ month_add_uv,
+ max( month_add_uv ) over ( ORDER BY start_month ),
+ sum( month_add_uv ) over ( ORDER BY start_month )
+FROM
+ (
+ -- Statistics of monthly active users and number of new users
+ SELECT
+ date_format( a.start_time, '%Y%m' ) AS start_month,
+ count( DISTINCT a.uid ) AS mau,
+ count( DISTINCT b.uid ) AS month_add_uv
+ FROM
+ exam_record a
+ LEFT JOIN (
+ -- Count each person's first login month
+ SELECT uid, min( date_format( start_time, '%Y%m' )) AS first_month FROM exam_record GROUP BY uid ) b ON date_format( a.start_time, '%Y%m' ) = b.first_month
+ GROUP BY
+ start_month
+ ) main
+ORDER BY
+ start_month
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-05.en.md b/docs_en/database/sql/sql-questions-05.en.md
new file mode 100644
index 00000000000..849447aeb08
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-05.en.md
@@ -0,0 +1,1037 @@
+---
+title: Summary of common SQL interview questions (5)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, null value processing, statistics, incomplete rate, CASE, aggregation
+ - - meta
+ - name: description
+ Content: Analyzes null value processing and statistics topics, combines CASE and aggregate functions to provide a robust implementation, and avoid common pitfalls.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+You can decide whether to skip more difficult or difficult questions based on your actual situation and interview needs.
+
+## Null value handling
+
+### Count the number of unfinished papers and their unfinished rate
+
+**Description**:
+
+The existing examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` starting answering time, `submit_time` handing in time, `score` score), the data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+
+Please count the number of incomplete_cnt and incomplete_rate of the test papers with incomplete status. The output from the sample data is as follows:
+
+| exam_id | incomplete_cnt | complete_rate |
+| ------- | -------------- | ------------- |
+| 9001 | 1 | 0.333 |
+
+Explanation: Test Paper 9001 has records of being answered three times, of which two were completed and one was incomplete. Therefore, the number of incompletes is 1 and the incomplete rate is 0.333 (retaining 3 decimal places)
+
+**Ideas**:
+
+For this question, you only need to note that one has conditional restrictions and the other does not have conditional restrictions; either query the conditions separately and then merge them; or perform conditional judgment directly in select.
+
+**Answer**:
+
+Writing method 1:
+
+```sql
+SELECT
+ exam_id,
+ (COUNT(*) - COUNT(submit_time)) AS incomplete_cnt,
+ ROUND((COUNT(*) - COUNT(submit_time)) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ (COUNT(*) - COUNT(submit_time)) > 0;
+```
+
+Use `COUNT(*)` to count the total number of records in the group, `COUNT(submit_time)` only counts the number of records whose `submit_time` field is not NULL (that is, the number of completed records). Subtracting the two is the unfinished number.
+
+Writing method 2:
+
+```sql
+SELECT
+ exam_id,
+ COUNT(CASE WHEN submit_time IS NULL THEN 1 END) AS incomplete_cnt,
+ ROUND(COUNT(CASE WHEN submit_time IS NULL THEN 1 END) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ COUNT(CASE WHEN submit_time IS NULL THEN 1 END) > 0;
+```
+
+Use a `CASE` expression to return a non-`NULL` value (such as 1) when the condition is met, otherwise return `NULL`. Then use the `COUNT` function to count the number of non-`NULL` values.
+
+Writing method 3:
+
+```sql
+SELECT
+ exam_id,
+ SUM(submit_time IS NULL) AS incomplete_cnt,
+ ROUND(SUM(submit_time IS NULL) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ incomplete_cnt > 0;
+```
+
+Use the `SUM` function to sum an expression. The expression `(submit_time IS NULL)` evaluates to 1 (TRUE) when `submit_time` is `NULL` and 0 (FALSE) otherwise. Adding these 1s and 0s together gives you the number of outstanding items.
+
+### Average time and average score of high-difficulty test papers for level 0 users
+
+**Description**:
+
+The existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time), the data is as follows:
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 10 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2100 | 6 | Algorithm | 2020-01-01 10:00:00 |
+
+Test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time), the data is as follows:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-01-01 10:00:00 |
+| 3 | 9004 | algorithm | medium | 80 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` submission time, `score` score), the data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 || 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+
+Please output the average test time and average score of all high-difficulty test papers for each level 0 user, the maximum test time and 0-point processing for unfinished default test papers. The output from the sample data is as follows:
+
+| uid | avg_score | avg_time_took |
+| ---- | --------- | ------------- |
+| 1001 | 33 | 36.7 |
+
+Explanation: There are 1001 level 0 users, 9001 high-difficulty test papers, and there are 3 records of 1001 answering 9001, which took 20 minutes, incomplete (the test paper lasted 60 minutes), and 30 minutes (less than 31 minutes). The scores were 80 points, incomplete (processed with 0 points), and 20 points respectively. Therefore his average time is 110/3=36.7 (rounded to one decimal place) and his average score is 33 points (rounded)
+
+**Idea**: It is most convenient to use `IF` for this question because it involves the judgment of NULL values. Of course, `case when` can also be used, which is very similar. The difficulty of this question lies in the processing of null values. I believe that other query conditions and so on will not be difficult for everyone.
+
+**Answer**:
+
+```sql
+SELECT UID,
+ round(avg(new_socre)) AS avg_score,
+ round(avg(time_diff), 1) AS avg_time_took
+FROM
+ (SELECT er.uid,
+ IF (er.submit_time IS NOT NULL, TIMESTAMPDIFF(MINUTE, start_time, submit_time), ef.duration) AS time_diff,
+ IF (er.submit_time IS NOT NULL,er.score,0) AS new_socre
+ FROM exam_recorder
+ LEFT JOIN user_info uf ON er.uid = uf.uid
+ LEFT JOIN examination_info ef ON er.exam_id = ef.exam_id
+ WHERE uf.LEVEL = 0 AND ef.difficulty = 'hard' ) t
+GROUP BY UID
+ORDER BY UID
+```
+
+## Advanced conditional statements
+
+### Filter users with limited nickname achievement value and active date (harder)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 1000 | 2 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Attack No. 3 | 2200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 2500 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 3000 | 7 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
+| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
+| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
+| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
+
+Question practice record table `practice_record` (`uid` user ID, `question_id` question ID, `submit_time` submission time, `score` score):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 || 5 | 1003 | 8002 | 2021-09-01 19:38:01 | 80 |
+
+Please find the user information whose nickname starts with "Niuke" and ends with "号", whose achievement value is between 1200 and 2500, and who was last active (answering questions or answering papers) in September 2021.
+
+The output from the sample data is as follows:
+
+| uid | nick_name | achievement |
+| ---- | --------- | ----------- |
+| 1002 | Niuke No. 2 | 1200 |
+
+**Explanation**: There are 1002 and 1004 whose nicknames start with "Niuke" and end with "号" and have achievement values between 1200 and 2500;
+
+1002 The last active test paper area was September 2021, and the last active question area was September 2021; 1004 The last active test paper area was August 2021, and the question area was not active.
+
+Therefore, only 1002 finally meets the condition.
+
+**Ideas**:
+
+First list the main query statements according to the conditions
+
+Nickname starts with "Niuke" and ends with "number": `nick_name LIKE "牛客%号"`
+
+Achievement value is between 1200~2500: `achievement BETWEEN 1200 AND 2500`
+
+The third condition is limited to September, so just write it directly: `( date_format( record.submit_time, '%Y%m' )= 202109 OR date_format( pr.submit_time, '%Y%m' )= 202109 )`
+
+**Answer**:
+
+```sql
+SELECT DISTINCT u_info.uid,
+ u_info.nick_name,
+ u_info.achievement
+FROM user_info u_info
+LEFT JOIN exam_record record ON record.uid = u_info.uid
+LEFT JOIN practice_record pr ON u_info.uid = pr.uid
+WHERE u_info.nick_name LIKE "nickname%"
+ AND u_info.achievement BETWEEN 1200
+ AND 2500
+ AND (date_format(record.submit_time, '%Y%m')= 202109
+ OR date_format(pr.submit_time, '%Y%m')= 202109)
+GROUP BY u_info.uid
+```
+
+### Filter the answer records of nickname rules and test paper rules (more difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 1900 | 2 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 2200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 2500 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | --- | ---------- | -------- | ------------------- |
+| 1 | 9001 | C++ | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | c# | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
+| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
+| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
+| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 || 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-09-01 11:31:01 | 84 |
+
+Find the completed test paper IDs and average scores for test paper categories starting with the letter c (such as C, C++, c#, etc.) for users whose nicknames consist of "Niuke" + pure numbers + "号" or pure numbers, and sort them in ascending order by user ID and average score. The output from the sample data is as follows:
+
+| uid | exam_id | avg_score |
+| ---- | ------- | --------- |
+| 1002 | 9001 | 81 |
+| 1002 | 9002 | 85 |
+| 1005 | 9001 | 84 |
+| 1006 | 9001 | 84 |
+
+Explanation: The users whose nicknames meet the conditions are 1002, 1004, 1005, and 1006;
+
+The test papers starting with c include 9001 and 9002;
+
+Among the answer records that meet the above conditions, the scores for 1002 and 9001 are 81 and 80, with an average score of 81 (80.5 is rounded up to 81);
+
+1002 completed 9002 with scores of 90, 82, and 83, with an average score of 85;
+
+**Ideas**:
+
+It’s still the same as before. Since the conditions are given, write out each condition first.
+
+Find users whose nicknames consist of "Niuke" + pure numbers + "号" or pure numbers: I initially wrote this: `nick_name LIKE 'Nuke% number' OR nick_name REGEXP '^[0-9]+$'`. If there is a "Nike H number" in the table, it will also pass.
+
+So you have to use regular rules here: `nick_name LIKE '^nickel[0-9]+号'`
+
+For test paper categories starting with the letter c: `e_info.tag LIKE 'c%'` or `tag regexp '^c|^C'` The first one can also match the uppercase C
+
+**Answer**:
+
+```sql
+SELECT UID,
+ exam_id,
+ ROUND(AVG(score), 0) avg_score
+FROM exam_record
+WHERE UID IN
+ (SELECT UID
+ FROM user_info
+ WHERE nick_name RLIKE "^nickname[0-9]+number $"
+ OR nick_name RLIKE "^[0-9]+$")
+ AND exam_id IN
+ (SELECT exam_id
+ FROM examination_info
+ WHERE tag RLIKE "^[cC]")
+ AND score IS NOT NULL
+GROUP BY UID,exam_id
+ORDER BY UID,avg_score;
+```
+
+### Output different situations based on whether the specified record exists (difficulty)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Attack No. 3 | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
+| 8 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 9 | 1002 | 9003 | 2020-02-02 12:11:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
+| 11 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 12 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+
+Please filter the data in the table. When the number of uncompleted test papers for any level 0 user is greater than 2, output the number of uncompleted test papers and the uncompleted rate (retaining 3 decimal places) for each level 0 user. If there is no such user, output these two indicators for all users with answer records. Results are sorted in ascending order by incomplete rate.
+
+The output from the sample data is as follows:
+
+| uid | incomplete_cnt | incomplete_rate |
+| ---- | -------------- | --------------- |
+| 1004 | 0 | 0.000 |
+| 1003 | 1 | 0.500 |
+| 1001 | 4 | 0.667 |
+
+**Explanation**: There are 1001, 1003, and 1004 level 0 users; the number of test papers they answered and the number of unfinished papers are: 6:4, 2:1, and 0:0 respectively;
+
+There is a level 0 user 1001 whose number of unfinished test papers is greater than 2, so the unfinished number and uncompleted rate of these three users are output (1004 has not answered the test paper, and the unfinished rate is filled with 0 by default, and it is 0.000 after retaining 3 decimal places);
+
+Results are sorted in ascending order by incomplete rate.
+
+Attachment: If 1001 does not satisfy "the number of unfinished test papers is greater than 2", you need to output the two indicators of 1001, 1002, and 1003, because there are only the answer records of these three users in the test paper answer record table.
+
+**Ideas**:
+
+First write out the SQL that may satisfy the condition **"The number of unfinished test papers for level 0 users is greater than 2"**
+
+```sql
+SELECT ui.uid UID
+FROM user_info ui
+LEFT JOIN exam_record er ON ui.uid = er.uid
+WHERE ui.uid IN
+ (SELECT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 )
+GROUP BY ui.uid
+HAVING sum(IF(er.submit_time IS NULL, 1, 0)) > 2```
+
+Then write the SQL query statements for the two situations:
+
+Situation 1. Query the uncompleted rate of test papers for level 0 users with conditional requirements
+
+```sql
+SELECT
+ tmp1.uid uid,
+ sum(
+ IF
+ ( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 )) incomplete_cnt,
+ round(
+ sum(
+ IF
+ (er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0))/ count(tmp1.uid),
+ 3
+ ) incomplete_rate
+FROM
+ (
+ SELECT DISTINCT
+ ui.uid
+ FROM
+ user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE
+ er.submit_time IS NULL
+ AND ui.LEVEL = 0
+ ) tmp1
+ LEFT JOIN exam_record er ON tmp1.uid = er.uid
+GROUP BY
+ tmp1.uid
+ORDER BY
+ incomplete_rate
+```
+
+Situation 2. Query the uncompletion rate of all yong users who have answer records when there are no conditional requirements.
+
+```sql
+SELECT
+ ui.uid uid,
+ sum( CASE WHEN er.submit_time IS NULL AND er.start_time IS NOT NULL THEN 1 ELSE 0 END ) incomplete_cnt,
+ round(
+ sum(
+ IF
+ ( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 ))/ count( ui.uid ),
+ 3
+ ) incomplete_rate
+FROM
+ user_info ui
+ JOIN exam_record er ON ui.uid = er.uid
+GROUP BY
+ ui.uid
+ORDER BY
+ incomplete_rate
+```
+
+Putting them together is the answer
+
+```sql
+WITH host_user AS
+ (SELECT ui.uid UID
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE ui.uid IN
+ (SELECT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 )
+ GROUP BY ui.uid
+ HAVING sum(IF (er.submit_time IS NULL, 1, 0))> 2),
+ tt1AS
+ (SELECT tmp1.uid UID,
+ sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0)) incomplete_cnt,
+ round(sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0))/ count(tmp1.uid), 3) incomplete_rate
+ FROM
+ (SELECT DISTINCT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 ) tmp1
+ LEFT JOIN exam_record er ON tmp1.uid = er.uid
+ GROUP BY tmp1.uid
+ ORDER BY incomplete_rate),
+ tt2AS
+ (SELECT ui.uid UID,
+ sum(CASE
+ WHEN er.submit_time IS NULL
+ AND er.start_time IS NOT NULL THEN 1
+ ELSE 0
+ END) incomplete_cnt,
+ round(sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0))/ count(ui.uid), 3) incomplete_rate
+ FROM user_info ui
+ JOIN exam_record er ON ui.uid = er.uid
+ GROUP BY ui.uid
+ ORDER BY incomplete_rate)
+ (SELECT tt1.*
+ FROM tt1
+ LEFT JOIN
+ (SELECT UID
+ FROM host_user) t1 ON 1 = 1
+ WHERE t1.uid IS NOT NULL )
+UNION ALL
+ (SELECT tt2.*
+ FROM tt2
+ LEFT JOIN
+ (SELECT UID
+ FROM host_user) t2 ON 1 = 1
+ WHERE t2.uid IS NULL)
+```
+
+V2 version (based on the improvements made above, the answer is shortened and the logic is stronger):
+
+```sql
+SELECT
+ ui.uid,
+ SUM(
+ IF
+ ( start_time IS NOT NULL AND score IS NULL, 1, 0 )) AS incomplete_cnt, #3. The number of incomplete test papers
+ ROUND( AVG( IF ( start_time IS NOT NULL AND score IS NULL, 1, 0 )), 3 ) AS incomplete_rate #4. Incomplete rate
+
+FROM
+ user_info ui
+ LEFT JOIN exam_record USING ( uid )
+WHERE
+CASE
+
+ WHEN (#1. When any level 0 user has more than 2 uncompleted test papers
+ SELECT
+ MAX(lv0_incom_cnt)
+ FROM
+ (
+ SELECT
+ SUM(
+ IF
+ ( score IS NULL, 1, 0 )) AS lv0_incom_cnt
+ FROM
+ user_info
+ JOIN exam_record USING ( uid )
+ WHERE
+ LEVEL = 0
+ GROUP BY
+ uid
+ ) table1
+ )> 2 THEN
+ uid IN ( #1.1 Find each level 0 user
+ SELECT uid FROM user_info WHERE LEVEL = 0 ) ELSE uid IN ( #2. If there is no such user, find the user with the answer record
+ SELECT DISTINCT uid FROM exam_record )
+ END
+ GROUP BY
+ ui.uid
+ ORDER BY
+ incomplete_rate #5.The results are sorted in ascending order by incomplete rate
+```
+
+### The proportion of different score performance of each user level (more difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 || 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper answer record table exam_record (uid user ID, exam_id examination paper ID, start_time start answering time, submit_time submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 75 |
+| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:11:01 | 60 |
+| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | 2021-09-02 12:41:01 | 90 |
+| 6 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 7 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 8 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
+| 9 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
+| 10 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 11 | 1002 | 9003 | 2020-02-02 12:11:01 | 2020-02-02 12:41:01 | 76 |
+
+In order to obtain the qualitative performance of the user's answer to the test paper, we divided the test paper scores into four score levels of excellent, medium and poor according to the cut-off point [90, 75, 60] (the cut-off point is divided into the left interval). Please count the proportion of each score level in the completed test papers of people with different user levels (the results are retained to 3 decimal places). Users who have not completed the test paper do not need to output. The results are sorted in descending order of user level and proportion.
+
+The output from the sample data is as follows:
+
+| level | score_grade | ratio |
+| ----- | ----------- | ----- |
+| 3 | Good | 0.667 |
+| 3 | Excellent | 0.333 |
+| 0 | Good | 0.500 |
+| 0 | Medium | 0.167 |
+| 0 | Excellent | 0.167 |
+| 0 | Difference | 0.167 |
+
+Explanation: The number of users who have completed the test paper are 1001 and 1002; the user levels and score levels corresponding to the completed test papers are as follows:
+
+| uid | exam_id | score | level | score_grade |
+| ---- | ------- | ----- | ----- | ----------- |
+| 1001 | 9001 | 80 | 0 | Good |
+| 1001 | 9002 | 75 | 0 | Good |
+| 1001 | 9002 | 60 | 0 | Medium |
+| 1001 | 9003 | 90 | 0 | Excellent |
+| 1001 | 9001 | 20 | 0 | Poor |
+| 1001 | 9002 | 89 | 0 | Good |
+| 1002 | 9001 | 99 | 3 | Excellent |
+| 1002 | 9003 | 82 | 3 | Good |
+| 1002 | 9003 | 76 | 3 | Good |
+
+Therefore, the proportion of each score level for level 0 users (only 1001) is: excellent 1/6, good 1/6, average 1/6, and poor 3/6; the proportion of each score level for level 3 users (only 1002) is: excellent 1/3, good 2/3. The result is rounded to 3 decimal places.
+
+**Ideas**:
+
+First write out the condition **"Divide the test paper scores into four score levels according to the cut-off points [90, 75, 60]: excellent, medium and poor"**, you can use `case when` here
+
+```sql
+CASE
+ WHEN a.score >= 90 THEN
+ 'Excellent'
+ WHEN a.score < 90 AND a.score >= 75 THEN
+ 'good'
+ WHEN a.score < 75 AND a.score >= 60 THEN
+ 'medium' ELSE 'poor'
+END
+```
+
+The key point of this question is this, the rest is conditional splicing
+
+**Answer**:
+
+```sql
+SELECT a.LEVEL,
+ a.score_grade,
+ ROUND(a.cur_count / b.total_num, 3) AS ratio
+FROM
+ (SELECT b.LEVEL AS LEVEL,
+ (CASE
+ WHEN a.score >= 90 THEN 'Excellent'
+ WHEN a.score < 90
+ AND a.score >= 75 THEN 'good'
+ WHEN a.score < 75
+ AND a.score >= 60 THEN 'medium'
+ ELSE 'poor'
+ END) AS score_grade,
+ count(1) AS cur_count
+ FROM exam_record a
+ LEFT JOIN user_info b ON a.uid = b.uid
+ WHERE a.submit_time IS NOT NULL
+ GROUP BY b.LEVEL,
+ score_grade) a
+LEFT JOIN
+ (SELECT b.LEVEL AS LEVEL,
+ count(b.LEVEL) AS total_num
+ FROM exam_record a
+ LEFT JOIN user_info b ON a.uid = b.uid
+ WHERE a.submit_time IS NOT NULL
+ GROUP BY b.LEVEL) b ON a.LEVEL = b.LEVEL
+ORDER BY a.LEVEL DESC,
+ ratioDESC
+```
+
+## Limited query
+
+### The three people with the earliest registration time
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time || --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-02-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-02 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 5 | 1005 | Niuke No. 555 | 4000 | 7 | C++ | 2020-01-11 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-11-01 10:00:00 |
+
+Please find the 3 people with the earliest registration time. The output from the sample data is as follows:
+
+| uid | nick_name | register_time |
+| ---- | ------------ | ------------------- |
+| 1001 | Niuke 1 | 2020-01-01 10:00:00 |
+| 1003 | Niuke No. 3 ♂ | 2020-01-02 10:00:00 |
+| 1004 | Niuke No. 4 | 2020-01-02 11:00:00 |
+
+Explanation: Select the top three after sorting by registration time, and output their user ID, nickname, and registration time.
+
+**Answer**:
+
+```sql
+SELECT uid, nick_name, register_time
+ FROM user_info
+ ORDER BY register_time
+ LIMIT 3
+```
+
+### Completed the third page of the test paper list on the day of registration (more difficult)
+
+**Description**: Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 4000 | 7 | Algorithm | 2020-01-11 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 7 | 1007 | Niuke No. 7 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 8 | 1008 | Niuke No. 8 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 9 | 1009 | Niuke No. 9 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 10 | 1010 | Niuke No. 10 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 11 | 1011 | 666666 | 3000 | 6 | C++ | 2020-01-02 10:00:00 |
+
+Examination paper information table examination_info (exam_id examination paper ID, tag examination paper category, difficulty examination paper difficulty, duration examination duration, release_time release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | algorithm | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | Algorithm | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
+| 3 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
+| 5 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
+| 6 | 1005 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
+| 7 | 1006 | 9001 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 20 |
+| 8 | 1007 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
+| 9 | 1008 | 9003 | 2020-01-02 12:01:01 | 2020-01-02 12:20:01 | 99 |
+| 10 | 1008 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 98 |
+| 11 | 1009 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 82 |
+| 12 | 1010 | 9002 | 2020-01-02 12:11:01 | 2020-01-02 12:41:01 | 76 |
+| 13 | 1011 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+
+Those who are looking for a job as an algorithm engineer and have completed the algorithm test paper on the day of registration will be ranked according to the highest scores in all exams they have taken. The ranking list is very long. We will display it in pages, with 3 items per page. Now you need to take out the information of the people on page 3 (the page number starts from 1).
+
+The output from the sample data is as follows:
+
+| uid | level | register_time | max_score |
+| ---- | ----- | ------------------- | --------- |
+| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
+| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
+| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
+
+Explanation: Except for 1011, all other users are looking for algorithm engineers; there are 9001 and 9002 algorithm test papers, and all 11 users completed the algorithm test papers on the day of registration; calculating the maximum time points of all their exams, only 1002 and 1008 completed two exams, and the others only completed one exam. The highest score for 1002 in the two exams was 81, and the highest score for 1008 was 99.
+
+Ranking by highest score is as follows:
+
+| uid | level | register_time | max_score |
+| ---- | ----- | ------------------- | --------- |
+| 1008 | 0 | 2020-01-02 11:00:00 | 99 |
+| 1005 | 7 | 2020-01-01 10:00:00 | 90 |
+| 1007 | 0 | 2020-01-02 11:00:00 | 89 |
+| 1002 | 3 | 2020-01-01 10:00:00 | 83 |
+| 1009 | 0 | 2020-01-02 11:00:00 | 82 |
+| 1001 | 0 | 2020-01-01 10:00:00 | 80 |
+| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
+| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
+| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
+| 1006 | 0 | 2020-01-02 11:00:00 | 20 |
+
+There are 3 items per page, and the third page is the 7th to 9th items. Just return row records of 1010, 1003, and 1004.
+
+**Ideas**:
+
+1. Three items per page, that is, the information of the person on the third page needs to be retrieved, so `limit` must be used.
+
+2. Statistics of people who are looking for jobs as algorithm engineers and who have completed the algorithm test paper on the day of registration and the scores for each record. First find the users who meet the conditions, and then use left join to connect to find the information and the scores for each record.
+
+**Answer**:
+
+```sql
+SELECT t1.uid,
+ LEVEL,
+ register_time,
+ max(score) AS max_score
+FROM exam_record t
+JOIN examination_info USING (exam_id)
+JOIN user_info t1 ON t.uid = t1.uid
+AND date(t.submit_time) = date(t1.register_time)
+WHERE job = 'algorithm'
+ AND tag = 'algorithm'
+GROUP BY t1.uid,
+ LEVEL,
+ register_time
+ORDER BY max_score DESC
+LIMIT 6,3
+```
+
+## Text conversion function
+
+### Repair serialized records
+
+**Description**: Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` exam duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | -------------- | ---------- | -------- | ------------------- |
+| 1 | 9001 | algorithm | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | Algorithm | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 4 | 9004 | Algorithm,medium,80 | | 0 | 2021-01-01 10:00:00 |
+
+A student who recorded the questions accidentally entered the test category tag, difficulty, and duration of some records into the tag field at the same time. Please help find these incorrect records, split them, and output them in the correct column type.
+
+The output from the sample data is as follows:
+
+| exam_id | tag | difficulty | duration |
+| ------- | ---- | ---------- | -------- |
+| 9004 | algorithm | medium | 80 |
+
+**Ideas**:
+
+Let’s first learn the functions used in this question
+
+The `SUBSTRING_INDEX` function is used to extract the portion of a string with a specified delimiter. It accepts three parameters: the original string, the delimiter, and the number of parts specified to be returned.
+
+The following is the syntax of the `SUBSTRING_INDEX` function:
+
+```sql
+SUBSTRING_INDEX(str, delimiter, count)
+```
+
+- `str`: the original string to be split.
+- `delimiter`: string or character used as delimiter.
+- `count`: Specifies the number of parts to return.
+ - If `count` is greater than 0, return the first `count` parts starting from the left (bounded by the delimiter).
+ - If `count` is less than 0, return the first `count` parts (bounded by the delimiter) starting from the right, counting from the right to the left.
+
+Here are some examples demonstrating the use of the `SUBSTRING_INDEX` function:
+
+1. Extract the first part of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 1);
+ -- Output result: 'apple'
+ ```
+
+2. Extract the last part of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -1);
+ -- Output result: 'cherry'
+ ```
+
+3. Extract the first two parts of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 2);
+ -- Output result: 'apple,banana'
+ ```
+
+4. Extract the last two parts of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -2);
+ -- Output result: 'banana,cherry'
+ ```
+
+**Answer**:
+
+```sql
+SELECT
+ exam_id,
+ substring_index( tag, ',', 1 ) tag,
+ substring_index( substring_index( tag, ',', 2 ), ',',- 1 ) difficulty,
+ substring_index( tag, ',',- 1 ) duration
+FROM
+ examination_info
+WHERE
+ difficulty = ''
+```
+
+### Interception processing of nicknames that are too long
+
+**Description**: Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------------------- | ----------- | ----- | ---- | ------------------- || 1 | 1001 | Niuke 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 11:00:00 |
+| 5 | 1005 | Niuke No. 5678901234 | 4000 | 7 | Algorithm | 2020-01-11 10:00:00 |
+| 6 | 1006 | Niuke No. 67890123456789 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+
+Some users' nicknames are particularly long, which may cause style confusion in some display scenarios. Therefore, particularly long nicknames need to be converted before outputting. Please output user information with more than 10 characters. For users with more than 13 characters, output the first 10 characters and then add three periods: "...".
+
+The output from the sample data is as follows:
+
+| uid | nick_name |
+| ---- | ------------------ |
+| 1005 | Niuke No. 5678901234 |
+| 1006 | Niuke 67890123... |
+
+Explanation: There are 1005 and 1006 users with more than 10 characters, and the lengths are 13 and 17 respectively; therefore, the output of the nickname of 1006 needs to be truncated.
+
+**Ideas**:
+
+This question involves character calculation. To calculate the number of characters in a string (that is, the length of the string), you can use the `LENGTH` function or the `CHAR_LENGTH` function. The difference between these two functions is the way multibyte characters are treated.
+
+1. `LENGTH` function: It returns the number of bytes of the given string. For strings containing multibyte characters, each character is counted as a byte.
+
+Example:
+
+```sql
+SELECT LENGTH('Hello'); -- Output result: 6, because each Chinese character in 'Hello' occupies 3 bytes each
+```
+
+1. `CHAR_LENGTH` function: It returns the number of characters of the given string. For strings containing multibyte characters, each character is counted as one character.
+
+Example:
+
+```sql
+SELECT CHAR_LENGTH('Hello'); -- Output result: 2, because there are two characters in 'Hello', that is, two Chinese characters
+```
+
+**Answer**:
+
+```sql
+SELECT
+ uid,
+CASE
+
+ WHEN CHAR_LENGTH( nick_name ) > 13 THEN
+ CONCAT( SUBSTR( nick_name, 1, 10 ), '...' ) ELSE nick_name
+ END AS nick_name
+FROM
+ user_info
+WHERE
+ CHAR_LENGTH( nick_name ) > 10
+GROUP BY
+ uid;
+```
+
+### Filter statistics when case is confused (difficult)
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | algorithm | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 4 | 9004 | sql | medium | 70 | 2021-01-01 10:00:00 |
+| 5 | 9005 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 6 | 9006 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 7 | 9007 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 8 | 9008 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 9 | 9009 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 10 | 9010 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+
+Examination paper answer information table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 80 |
+| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
+| 3 | 1002 | 9002 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1005 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1006 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 20 |
+| 8 | 1007 | 9003 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
+| 9 | 1008 | 9004 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1008 | 9001 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 98 |
+| 11 | 1009 | 9002 | 2020-02-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
+| 12 | 1010 | 9001 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
+| 13 | 1010 | 9001 | 2020-02-02 12:01:01 | 2020-01-02 10:31:01 | 89 |
+
+The category tags of the test paper may have mixed case. Please first filter out the category tags with less than 3 answers in the test paper, and count the corresponding number of answers in the original test paper after converting them to uppercase.
+
+If the tag has not changed after conversion, the result will not be output.
+
+The output from the sample data is as follows:
+
+| tag | answer_cnt |
+| --- | ---------- |
+|C++|6|
+
+Explanation: The papers that have been answered include 9001, 9002, 9003, and 9004. Their tags and the number of times they have been answered are as follows:
+
+| exam_id | tag | answer_cnt |
+| ------- | ---- | ---------- || 9001 | Algorithm | 4 |
+| 9002 | C++ | 6 |
+| 9003 | c++ | 2 |
+| 9004 | sql | 2 |
+
+Tags with less than 3 answers include c++ and sql. However, after being converted to uppercase, only C++ has an original answer count. Therefore, the output number of c++ after being converted to uppercase is 6.
+
+**Ideas**:
+
+First of all, this question is a bit confusing. According to the sample data, 9004 is found only once, but here it is shown that there are two times.
+
+Let’s take a look at the case conversion function first:
+
+1. The `UPPER(s)` or `UCASE(s)` function can convert all alphabetic characters in the string s into uppercase letters;
+
+2. The `LOWER(s)` or `LCASE(s)` function can convert all alphabetic characters in the string s into lowercase letters.
+
+The difficulty is that when joining the same table, you need to query different values.
+
+**Answer**:
+
+```sql
+WITH a AS
+ (SELECT tag,
+ COUNT(start_time) AS answer_cnt
+ FROM exam_recorder
+ JOIN examination_info ei ON er.exam_id = ei.exam_id
+ GROUP BY tag)
+SELECT a.tag,
+ b.answer_cnt
+FROM a
+INNER JOIN a AS b ON UPPER(a.tag)= b.tag #a lower case b upper case
+AND a.tag != b.tag
+WHERE a.answer_cnt < 3;
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-syntax-summary.en.md b/docs_en/database/sql/sql-syntax-summary.en.md
new file mode 100644
index 00000000000..87185b87558
--- /dev/null
+++ b/docs_en/database/sql/sql-syntax-summary.en.md
@@ -0,0 +1,1208 @@
+---
+title: Summary of basic knowledge of SQL syntax
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL syntax, DDL, DML, DQL, constraints, transactions, indexes, paradigms
+ - - meta
+ - name: description
+ content: Systematically organizes basic SQL syntax and terminology, covering DDL/DML/DQL, constraints and transaction indexes, forming a knowledge path from entry to practice.
+---
+
+> This article is compiled and improved from the following two materials:
+>
+> - [SQL Syntax Quick Manual](https://juejin.cn/post/6844903790571700231)
+> - [MySQL Super Complete Tutorial](https://www.begtut.com/mysql/mysql-tutorial.html)
+
+## Basic concepts
+
+### Database terminology
+
+- `database` - A container (usually a file or set of files) that holds organized data.
+- `table` - a structured list of data of a specific type.
+- `schema` - information about the layout and properties of databases and tables. The schema defines how data is stored in the table, including what kind of data is stored, how the data is decomposed, how each part of the information is named, and other information. Both databases and tables have schemas.
+- `column` – a field in a table. All tables are composed of one or more columns.
+- `row(row)` - a record in the table.
+- `primary key` - a column (or set of columns) whose value uniquely identifies each row in a table.
+
+### SQL syntax
+
+SQL (Structured Query Language), standard SQL is managed by the ANSI Standards Committee, so it is called ANSI SQL. Each DBMS has its own implementation, such as PL/SQL, Transact-SQL, etc.
+
+#### SQL syntax structure
+
+
+
+SQL syntax structures include:
+
+- **`clause`** - is the component of statements and queries. (In some cases, these are optional.)
+- **`expression`** - can produce any scalar value, or a database table consisting of columns and rows
+- **`Predicate`** - Specify conditions for SQL three-valued logic (3VL) (true/false/unknown) or Boolean truth values that need to be evaluated, and limit the effects of statements and queries, or change program flow.
+- **`Query`** - Retrieve data based on specific criteria. This is an important part of SQL.
+- **`Statement`** - Can permanently affect the schema and data, and can also control database transactions, program flow, connections, sessions, or diagnostics.
+
+#### SQL syntax points
+
+- **SQL statements are not case-sensitive**, but whether database table names, column names and values are distinguished depends on the specific DBMS and configuration. For example: `SELECT` is the same as `select`, `Select`.
+- **Multiple SQL statements must be separated by semicolons (`;`)**.
+- **All spaces are ignored** when processing SQL statements.
+
+SQL statements can be written in one line or divided into multiple lines.
+
+```sql
+-- One line of SQL statement
+
+UPDATE user SET username='robot', password='robot' WHERE username = 'root';
+
+--Multi-line SQL statement
+UPDATE user
+SET username='robot', password='robot'
+WHERE username = 'root';
+```
+
+SQL supports three types of comments:
+
+```sql
+## Note 1
+-- Note 2
+/* Note 3 */
+```
+
+### SQL Classification
+
+#### Data Definition Language (DDL)
+
+Data Definition Language (DDL) is a language in the SQL language that is responsible for the definition of data structures and database objects.
+
+The main function of DDL is to define database objects.
+
+The core instructions of DDL are `CREATE`, `ALTER`, and `DROP`.
+
+#### Data Manipulation Language (DML)
+
+Data Manipulation Language (DML) is a programming statement used for database operations to access objects and data in the database.
+
+The main function of DML is to **access data**, so its syntax is mainly based on **reading and writing database**.
+
+The core instructions of DML are `INSERT`, `UPDATE`, `DELETE`, and `SELECT`. These four instructions are collectively called CRUD (Create, Read, Update, Delete), which means add, delete, modify, and query.
+
+#### Transaction Control Language (TCL)
+
+Transaction Control Language (TCL) is used to manage transactions in the database. These are used to manage changes made by DML statements. It also allows statements to be grouped into logical transactions.
+
+The core instructions of TCL are `COMMIT` and `ROLLBACK`.
+
+#### Data Control Language (DCL)
+
+Data Control Language (DCL) is an instruction that can control data access rights. It can control the control rights of specific user accounts to database objects such as data tables, view tables, stored procedures, and user-defined functions.
+
+The core instructions of DCL are `GRANT` and `REVOKE`.
+
+DCL mainly focuses on controlling user access rights, so its instruction method is not complicated. The permissions that can be controlled by DCL are: `CONNECT`, `SELECT`, `INSERT`, `UPDATE`, `DELETE`, `EXECUTE`, `USAGE`, `REFERENCES`.
+
+Different DBMSs and different security entities support different permission controls.
+
+**Let’s first introduce the usage of DML statements. The main function of DML is to read and write databases to implement additions, deletions, modifications and queries. **
+
+## Add, delete, modify and check
+
+Add, delete, modify, and query, also known as CRUD, is a basic operation in basic database operations.
+
+### Insert data
+
+The `INSERT INTO` statement is used to insert new records into the table.
+
+**INSERT COMPLETE ROW**
+
+```sql
+# insert a row
+INSERT INTO user
+VALUES (10, 'root', 'root', 'xxxx@163.com');
+# Insert multiple rows
+INSERT INTO user
+VALUES (10, 'root', 'root', 'xxxx@163.com'), (12, 'user1', 'user1', 'xxxx@163.com'), (18, 'user2', 'user2', 'xxxx@163.com');
+```
+
+**Insert part of row**
+
+```sql
+INSERT INTO user(username, password, email)
+VALUES ('admin', 'admin', 'xxxx@163.com');
+```
+
+**Insert the queried data**
+
+```sql
+INSERT INTO user(username)
+SELECT name
+FROM account;
+```
+
+### Update data
+
+The `UPDATE` statement is used to update records in a table.
+
+```sql
+UPDATE user
+SET username='robot', password='robot'
+WHERE username = 'root';
+```
+
+### Delete data
+
+- The `DELETE` statement is used to delete records from a table.
+- `TRUNCATE TABLE` can clear the table, that is, delete all rows. Explanation: The `TRUNCATE` statement does not belong to DML syntax but DDL syntax.
+
+**Delete specified data in the table**
+
+```sql
+DELETE FROM user
+WHERE username = 'robot';
+```
+
+**Clear the data in the table**
+
+```sql
+TRUNCATE TABLE user;
+```
+
+### Query data
+
+The `SELECT` statement is used to query data from the database.
+
+`DISTINCT` is used to return uniquely different values. It operates on all columns, which means that all columns must have the same value to be considered the same.
+
+`LIMIT` limits the number of rows returned. It can have two parameters. The first parameter is the starting row, starting from 0; the second parameter is the total number of rows returned.
+
+- `ASC`: ascending order (default)
+- `DESC`: descending order
+
+**Query single column**
+
+```sql
+SELECT prod_name
+FROM products;
+```
+
+**Query multiple columns**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products;
+```
+
+**Query all columns**
+
+```sql
+SELECT *
+FROM products;
+```
+
+**Query for different values**
+
+```sql
+SELECT DISTINCT
+vend_id FROM products;
+```
+
+**Limit query results**
+
+```sql
+-- Return the first 5 rows
+SELECT * FROM mytable LIMIT 5;
+SELECT * FROM mytable LIMIT 0, 5;
+-- Return to lines 3 ~ 5
+SELECT * FROM mytable LIMIT 2, 3;
+```
+
+## Sort`order by` is used to sort the result set by one column or multiple columns. By default, records are sorted in ascending order. If you need to sort records in descending order, you can use the `desc` keyword.
+
+`order by` When sorting multiple columns, the column that is sorted first is placed in front, and the column that is sorted later is placed in the back. Also, different columns can have different sorting rules.
+
+```sql
+SELECT * FROM products
+ORDER BY prod_price DESC, prod_name ASC;
+```
+
+## Grouping
+
+**`group by`**:
+
+- The `group by` clause groups records into summary rows.
+- `group by` returns one record for each group.
+- `group by` usually also involves aggregating `count`, `max`, `sum`, `avg`, etc.
+- `group by` can group by one or more columns.
+- `group by` After sorting by group field, `order by` can sort by summary field.
+
+**Group**
+
+```sql
+SELECT cust_name, COUNT(cust_address) AS addr_num
+FROM Customers GROUP BY cust_name;
+```
+
+**Sort after grouping**
+
+```sql
+SELECT cust_name, COUNT(cust_address) AS addr_num
+FROM Customers GROUP BY cust_name
+ORDER BY cust_name DESC;
+```
+
+**`having`**:
+
+- `having` is used to filter the aggregated `group by` results.
+- `having` is usually used together with `group by`.
+- `where` and `having` can be in the same query.
+
+**Filter data using WHERE and HAVING**
+
+```sql
+SELECT cust_name, COUNT(*) AS NumberOfOrders
+FROM Customers
+WHERE cust_email IS NOT NULL
+GROUP BY cust_name
+HAVING COUNT(*) > 1;
+```
+
+**`having` vs `where`**:
+
+- `where`: Filter the specified rows. Aggregation functions (grouping functions) cannot be added later. `where` before `group by`.
+- `having`: Filter grouping, usually used in conjunction with `group by` and cannot be used alone. `having` comes after `group by`.
+
+## Subquery
+
+A subquery is a SQL query nested within a larger query, also called an inner query or inner select, and the statement containing the subquery is also called an outer query or outer select. Simply put, a subquery refers to using the result of a `select` query (subquery) as the data source or judgment condition of another SQL statement (main query).
+
+Subqueries can be embedded in `SELECT`, `INSERT`, `UPDATE` and `DELETE` statements, and can also be used with operators such as `=`, `<`, `>`, `IN`, `BETWEEN`, `EXISTS` and other operators.
+
+Subqueries are often used after the `WHERE` clause and the `FROM` clause:
+
+- When used in the `WHERE` clause, depending on different operators, the subquery can return a single row and a single column, multiple rows and a single column, or a single row and multiple columns of data. The subquery is to return a value that can be used as the query condition of the `WHERE` clause.
+- When used in the `FROM` clause, multi-row and multi-column data is generally returned, which is equivalent to returning a temporary table, so as to comply with the rule that `FROM` is followed by a table. This approach can implement joint queries on multiple tables.
+
+> Note: MYSQL database only supports subqueries from version 4.1, and earlier versions do not support it.
+
+The basic syntax of a subquery for a `WHERE` clause is as follows:
+
+```sql
+select column_name [, column_name ]
+from table1 [, table2 ]
+where column_name operator
+ (select column_name [, column_name ]
+ from table1 [, table2 ]
+ [where])
+```
+
+- Subqueries need to be placed within brackets `( )`.
+- `operator` represents the operator used in the where clause.
+
+The basic syntax of a subquery for a `FROM` clause is as follows:
+
+```sql
+select column_name [, column_name ]
+from (select column_name [, column_name ]
+ from table1 [, table2 ]
+ [where]) as temp_table_name
+where condition
+```
+
+The result returned by the subquery for `FROM` is equivalent to a temporary table, so you need to use the AS keyword to give the temporary table a name.
+
+**Subquery of subqueries**
+
+```sql
+SELECT cust_name, cust_contact
+FROM customers
+WHERE cust_id IN (SELECT cust_id
+ FROM orders
+ WHERE order_num IN (SELECT order_num
+ FROM orderitems
+ WHERE prod_id = 'RGAN01'));
+```
+
+The inner query is executed first before its parent query so that the results of the inner query can be passed to the outer query. You can refer to the following figure for the execution process:
+
+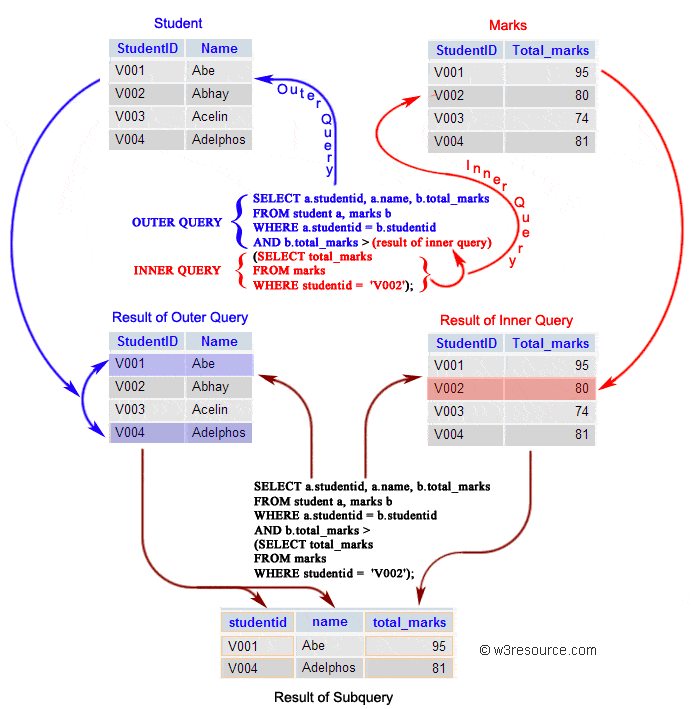
+
+### WHERE
+
+- The `WHERE` clause is used to filter records, that is, to narrow the scope of accessed data.
+- `WHERE` followed by a condition that returns `true` or `false`.
+- `WHERE` can be used with `SELECT`, `UPDATE` and `DELETE`.
+- Operators that can be used in the `WHERE` clause.
+
+| Operator | Description |
+| ------- | ------------------------------------------------------- |
+| = | equals |
+| <> | is not equal to. Note: In some versions of SQL, this operator can be written as != |
+| > | greater than |
+| < | less than |
+| >= | Greater than or equal to |
+| <= | Less than or equal to |
+| BETWEEN | Within a range |
+| LIKE | Search for a pattern |
+| IN | Specifies multiple possible values for a column |
+
+**The `WHERE` clause in the `SELECT` statement**
+
+```ini
+SELECT * FROM Customers
+WHERE cust_name = 'Kids Place';
+```
+
+**The `WHERE` clause in the `UPDATE` statement**
+
+```ini
+UPDATECustomers
+SET cust_name = 'Jack Jones'
+WHERE cust_name = 'Kids Place';
+```
+
+**The `WHERE` clause in the `DELETE` statement**
+
+```ini
+DELETE FROM Customers
+WHERE cust_name = 'Kids Place';
+```
+
+### IN AND BETWEEN
+
+- The `IN` operator is used in the `WHERE` clause to select any one of several specified values.
+- The `BETWEEN` operator is used in the `WHERE` clause to select values within a certain range.
+
+**IN Example**
+
+```sql
+SELECT *
+FROM products
+WHERE vend_id IN ('DLL01', 'BRS01');
+```
+
+**BETWEEN EXAMPLE**
+
+```sql
+SELECT *
+FROM products
+WHERE prod_price BETWEEN 3 AND 5;
+```
+
+### AND, OR, NOT- `AND`, `OR`, `NOT` are logical processing instructions for filtering conditions.
+- `AND` has higher priority than `OR`. To clarify the processing order, you can use `()`.
+- The `AND` operator indicates that both left and right conditions must be met.
+- The `OR` operator means that any one of the left and right conditions must be met.
+- The `NOT` operator is used to negate a condition.
+
+**AND Example**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE vend_id = 'DLL01' AND prod_price <= 4;
+```
+
+**OR Example**
+
+```ini
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE vend_id = 'DLL01' OR vend_id = 'BRS01';
+```
+
+**NOT Example**
+
+```sql
+SELECT *
+FROM products
+WHERE prod_price NOT BETWEEN 3 AND 5;
+```
+
+### LIKE
+
+- The `LIKE` operator is used in the `WHERE` clause to determine whether a string matches a pattern.
+- Use `LIKE` only if the field is a text value.
+- `LIKE` supports two wildcard matching options: `%` and `_`.
+- Don't abuse wildcards, matching at the beginning will be very slow.
+- `%` means any character appearing any number of times.
+- `_` means any character appears once.
+
+**% Example**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE prod_name LIKE '%bean bag%';
+```
+
+**\_ Example**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE prod_name LIKE '__ inch teddy bear';
+```
+
+## Connect
+
+JOIN means "connection". As the name suggests, the SQL JOIN clause is used to join two or more tables for query.
+
+When connecting tables, you need to select a field in each table and compare the values of these fields. Two records with the same value will be merged into one. **The essence of joining tables is to merge records from different tables to form a new table. Of course, this new table is only temporary, it only exists for the duration of this query**.
+
+The basic syntax for joining two tables using `JOIN` is as follows:
+
+```sql
+select table1.column1, table2.column2...
+from table1
+join table2
+on table1.common_column1 = table2.common_column2;
+```
+
+`table1.common_column1 = table2.common_column2` is a join condition. Only records that meet this condition will be merged into one row. You can join tables using several operators, such as =, >, <, <>, <=, >=, !=, `between`, `like`, or `not`, but the most common is to use =.
+
+When there are fields with the same name in two tables, in order to help the database engine distinguish the fields of which table, the table name needs to be added when writing the field names with the same name. Of course, if the written field name is unique in the two tables, you can not use the above format and just write the field name.
+
+In addition, if the related field names of the two tables are the same, you can also use the `USING` clause instead of `ON`, for example:
+
+```sql
+# join....on
+select c.cust_name, o.order_num
+from Customers c
+inner join Orders o
+on c.cust_id = o.cust_id
+order by c.cust_name;
+
+# If the associated field names of the two tables are the same, you can also use the USING clause: join....using()
+select c.cust_name, o.order_num
+from Customers c
+inner join Orders o
+using(cust_id)
+order by c.cust_name;
+```
+
+**The difference between `ON` and `WHERE`**:
+
+- When joining tables, SQL will generate a new temporary table based on the join conditions. `ON` is the connection condition, which determines the generation of temporary tables.
+- `WHERE` is to filter the data in the temporary table after the temporary table is generated to generate the final result set. At this time, there is no JOIN-ON.
+
+So in summary: **SQL first generates a temporary table based on ON, and then filters the temporary table based on WHERE**.
+
+SQL allows some modifying keywords to be added to the left of `JOIN` to form different types of connections, as shown in the following table:
+
+| Connection type | Description |
+|------------------------------------------------ |------------------------------------------------------------------------------------------------ |
+| INNER JOIN inner join | (default connection method) Rows will be returned only when there are records that meet the conditions in both tables. |
+| LEFT JOIN / LEFT OUTER JOIN Left (outer) join | Returns all rows in the left table, even if there are no rows in the right table that meet the condition. |
+| RIGHT JOIN / RIGHT OUTER JOIN Right (outer) join | Returns all rows in the right table, even if there are no rows in the left table that meet the condition. |
+| FULL JOIN / FULL OUTER JOIN Full (outer) join | As long as one of the tables has records that meet the conditions, rows will be returned. |
+| SELF JOIN | Joins a table to itself as if the table were two tables. To differentiate between two tables, at least one table needs to be renamed in the SQL statement. |
+| CROSS JOIN | Cross join returns the Cartesian product of record sets from two or more joined tables. |
+
+The figure below shows 7 usages related to LEFT JOIN, RIGHT JOIN, INNER JOIN, and OUTER JOIN.
+
+
+
+If you just write `JOIN` without adding any modifiers, the default is `INNER JOIN`
+
+For `INNER JOIN`, there is also an implicit way of writing, called "**Implicit inner join**", that is, there is no `INNER JOIN` keyword, and the `WHERE` statement is used to implement the inner join function.
+
+```sql
+#Implicit inner join
+select c.cust_name, o.order_num
+from Customers c, Orders o
+where c.cust_id = o.cust_id
+order by c.cust_name;
+
+#Explicit inner join
+select c.cust_name, o.order_num
+from Customers c inner join Orders o
+using(cust_id)
+order by c.cust_name;
+```
+
+## Combination
+
+The `UNION` operator combines the results of two or more queries and produces a result set containing the extracted rows from the participating queries in `UNION`.
+
+`UNION` basic rules:
+
+- The number and order of columns must be the same for all queries.
+- The data types of the columns involved in the tables in each query must be the same or compatible.
+- Usually the column names returned are taken from the first query.
+
+By default, the `UNION` operator selects distinct values. If duplicate values are allowed, use `UNION ALL`.
+
+```sql
+SELECT column_name(s) FROM table1
+UNION ALL
+SELECT column_name(s) FROM table2;
+```
+
+The column names in the `UNION` result set are always equal to the column names in the first `SELECT` statement in the `UNION`.
+
+`JOIN` vs `UNION`:
+
+- The columns of the joined tables in `JOIN` may be different, but in `UNION` the number and order of columns must be the same for all queries.
+- `UNION` puts the rows after the query together (vertically), but `JOIN` puts the columns after the query together (horizontally), i.e. it forms a Cartesian product.
+
+## Function
+
+Functions tend to differ from database to database and are therefore not portable. This section mainly uses MySQL functions as an example.### Text processing
+
+| Function | Description |
+| -------------------------- | -------------------------- |
+| `LEFT()`, `RIGHT()` | The character on the left or right |
+| `LOWER()`, `UPPER()` | Convert to lowercase or uppercase |
+| `LTRIM()`, `RTRIM()` | Remove spaces on the left or right side |
+| `LENGTH()` | Length in bytes |
+| `SOUNDEX()` | Convert to speech value |
+
+Among them, **`SOUNDEX()`** can convert a string into an alphanumeric pattern that describes its phonetic representation.
+
+```sql
+SELECT *
+FROM mytable
+WHERE SOUNDEX(col1) = SOUNDEX('apple')
+```
+
+### Date and time processing
+
+- Date format: `YYYY-MM-DD`
+- Time format: `HH:MM:SS`
+
+| function | description |
+| --------------- | ------------------------------- |
+| `AddDate()` | Add a date (day, week, etc.) |
+| `AddTime()` | Add a time (hour, minute, etc.) |
+| `CurDate()` | Returns the current date |
+| `CurTime()` | Returns the current time |
+| `Date()` | Returns the date part of a datetime |
+| `DateDiff()` | Calculate the difference between two dates |
+| `Date_Add()` | Highly flexible date operation function |
+| `Date_Format()` | Returns a formatted date or time string |
+| `Day()` | Returns the day part of a date |
+| `DayOfWeek()` | For a date, return the corresponding day of the week |
+| `Hour()` | Returns the hour part of a time |
+| `Minute()` | Returns the minute part of a time |
+| `Month()` | Returns the month part of a date |
+| `Now()` | Returns the current date and time |
+| `Second()` | Returns the second part of a time |
+| `Time()` | Returns the time part of a datetime |
+| `Year()` | Returns the year part of a date |
+
+### Numerical processing
+
+| Function | Description |
+| ------ | ------ |
+| SIN() | sine |
+| COS() | cosine |
+| TAN() | tangent |
+| ABS() | Absolute value |
+| SQRT() | Square root |
+| MOD() | Remainder |
+| EXP() | index |
+| PI() | Pi |
+| RAND() | Random number |
+
+### Summary
+
+| function | description |
+| --------- | ---------------- |
+| `AVG()` | Returns the average value of a column |
+| `COUNT()` | Returns the number of rows in a column |
+| `MAX()` | Returns the maximum value of a column |
+| `MIN()` | Returns the minimum value of a column |
+| `SUM()` | Returns the sum of values in a column |
+
+`AVG()` ignores NULL rows.
+
+Use `DISTINCT` to have summary function values summarize different values.
+
+```sql
+SELECT AVG(DISTINCT col1) AS avg_col
+FROM mytable
+```
+
+**Next, let’s introduce the usage of DDL statements. The main function of DDL is to define database objects (such as databases, data tables, views, indexes, etc.)**
+
+## Data definition
+
+### Database (DATABASE)
+
+#### Create database
+
+```sql
+CREATE DATABASE test;
+```
+
+#### Delete database
+
+```sql
+DROP DATABASE test;
+```
+
+#### Select database
+
+```sql
+USE test;
+```
+
+### Data table (TABLE)
+
+#### Create data table
+
+**Normal creation**
+
+```sql
+CREATE TABLE user (
+ id int(10) unsigned NOT NULL COMMENT 'Id',
+ username varchar(64) NOT NULL DEFAULT 'default' COMMENT 'username',
+ password varchar(64) NOT NULL DEFAULT 'default' COMMENT 'password',
+ email varchar(64) NOT NULL DEFAULT 'default' COMMENT 'email'
+) COMMENT='user table';
+```
+
+**Create a new table based on an existing table**
+
+```sql
+CREATE TABLE vip_user AS
+SELECT * FROM user;
+```
+
+#### Delete data table
+
+```sql
+DROP TABLE user;
+```
+
+#### Modify data table
+
+**Add Column**
+
+```sql
+ALTER TABLE user
+ADD age int(3);
+```
+
+**Delete Column**
+
+```sql
+ALTER TABLE user
+DROP COLUMN age;
+```
+
+**Modify column**
+
+```sql
+ALTER TABLE `user`
+MODIFY COLUMN age tinyint;
+```
+
+**Add primary key**
+
+```sql
+ALTER TABLE user
+ADD PRIMARY KEY (id);
+```
+
+**Delete primary key**
+
+```sql
+ALTER TABLE user
+DROP PRIMARY KEY;
+```
+
+### View (VIEW)
+
+Definition:
+
+- A view is a table that visualizes the result set of a SQL statement.
+- A view is a virtual table and does not contain data, so it cannot be indexed. Operations on views are the same as operations on ordinary tables.
+
+Function:
+
+- Simplify complex SQL operations, such as complex joins;
+- Only use part of the data from the actual table;
+- Ensure data security by only giving users permission to access views;
+- Change data format and presentation.
+
+
+
+#### Create view
+
+```sql
+CREATE VIEW top_10_user_view AS
+SELECT id, username
+FROM user
+WHERE id < 10;
+```
+
+#### Delete view
+
+```sql
+DROP VIEW top_10_user_view;
+```
+
+### Index (INDEX)
+
+**Index is a data structure used for quick query and retrieval of data. Its essence can be regarded as a sorted data structure. **
+
+The function of the index is equivalent to the table of contents of the book. For example: when we look up a dictionary, if there is no table of contents, then we can only go page by page to find the word we need to look up, which is very slow. If there is a table of contents, we only need to search the position of the word in the table of contents first, and then directly turn to that page.
+
+**Advantages**:
+
+- Using indexes can greatly speed up data retrieval (greatly reduce the amount of data retrieved), which is also the main reason for creating indexes.
+- By creating a unique index, you can ensure the uniqueness of each row of data in the database table.
+
+**Disadvantages**:
+
+- Creating and maintaining indexes takes a lot of time. When adding, deleting, or modifying data in a table, if the data has an index, the index also needs to be dynamically modified, which will reduce SQL execution efficiency.
+- Indexes require physical file storage and will also consume a certain amount of space.
+
+However, **Does using indexes definitely improve query performance?**
+
+In most cases, index queries are faster than full table scans. But if the amount of data in the database is not large, using indexes may not necessarily bring about a big improvement.
+
+For a detailed introduction to indexes, please read my article [MySQL Index Detailed Explanation](https://javaguide.cn/database/mysql/mysql-index.html).
+
+#### Create index
+
+```sql
+CREATE INDEX user_index
+ON user(id);
+```
+
+#### Add index
+
+```sql
+ALTER table user ADD INDEX user_index(id)
+```
+
+#### Create a unique index
+
+```sql
+CREATE UNIQUE INDEX user_index
+ON user(id);
+```
+
+#### Delete index
+
+```sql
+ALTER TABLE user
+DROP INDEX user_index;```
+
+### Constraints
+
+SQL constraints are used to specify rules for data in a table.
+
+If there is a data behavior that violates the constraint, the behavior will be terminated by the constraint.
+
+Constraints can be specified when the table is created (via the CREATE TABLE statement), or after the table is created (via the ALTER TABLE statement).
+
+Constraint type:
+
+- `NOT NULL` - Indicates that a column cannot store NULL values.
+- `UNIQUE` - Guarantees that each row of a column must have a unique value.
+- `PRIMARY KEY` - Combination of NOT NULL and UNIQUE. Ensuring that a column (or a combination of two or more columns) is uniquely identified can help make it easier and faster to find a specific record in a table.
+- `FOREIGN KEY` - Ensures referential integrity that data in one table matches values in another table.
+- `CHECK` - Ensures that the values in the column meet the specified conditions.
+- `DEFAULT` - Specifies the default value when no value is assigned to the column.
+
+Use constraints when creating tables:
+
+```sql
+CREATE TABLE Users (
+ Id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment Id',
+ Username VARCHAR(64) NOT NULL UNIQUE DEFAULT 'default' COMMENT 'username',
+ Password VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT 'password',
+ Email VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT 'Email address',
+ Enabled TINYINT(4) DEFAULT NULL COMMENT 'Is it valid',
+ PRIMARY KEY (Id)
+) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='User table';
+```
+
+**Next, let’s introduce the usage of TCL statements. The main function of TCL is to manage transactions in the database. **
+
+## Transaction processing
+
+The `SELECT` statement cannot be rolled back, and it is meaningless to roll back the `SELECT` statement; the `CREATE` and `DROP` statements cannot be rolled back.
+
+**MySQL defaults to implicit commit**. Each time a statement is executed, the statement is regarded as a transaction and then submitted. When the `START TRANSACTION` statement appears, implicit commit will be turned off; when the `COMMIT` or `ROLLBACK` statement is executed, the transaction will be automatically closed and implicit commit will be restored.
+
+Autocommit can be canceled by `set autocommit=0` and will not be committed until `set autocommit=1`; the `autocommit` flag is for each connection and not for the server.
+
+Instructions:
+
+- `START TRANSACTION` - directive is used to mark the starting point of a transaction.
+- `SAVEPOINT` - directive is used to create a save point.
+- `ROLLBACK TO` - The instruction is used to roll back to the specified retention point; if no retention point is set, it will roll back to the `START TRANSACTION` statement.
+- `COMMIT` - Commit the transaction.
+
+```sql
+-- Start transaction
+START TRANSACTION;
+
+-- Insert operation A
+INSERT INTO `user`
+VALUES (1, 'root1', 'root1', 'xxxx@163.com');
+
+-- Create a retention point updateA
+SAVEPOINT updateA;
+
+-- Insert operation B
+INSERT INTO `user`
+VALUES (2, 'root2', 'root2', 'xxxx@163.com');
+
+-- Roll back to retention point updateA
+ROLLBACK TO updateA;
+
+-- Submit the transaction, only operation A takes effect
+COMMIT;
+```
+
+**Next, let’s introduce the usage of DCL statements. The main function of DCL is to control user access rights. **
+
+## Permission control
+
+To grant permissions to a user account, use the `GRANT` command. To revoke a user's permissions, use the `REVOKE` command. Here, MySQL is used as an example to introduce the practical application of permission control.
+
+`GRANT` grant permission syntax:
+
+```sql
+GRANT privilege,[privilege],.. ON privilege_level
+TO user [IDENTIFIED BY password]
+[REQUIRE tsl_option]
+[WITH [GRANT_OPTION | resource_option]];
+```
+
+Just explain it briefly:
+
+1. Specify one or more permissions after the `GRANT` keyword. If the user is granted multiple permissions, each permission is separated by a comma.
+2. `ON privilege_level` determines the level of permission application. MySQL supports global (`*.*`), database (`database.*`), table (`database.table`) and column levels. If you use column permission levels, you must specify one or a comma-separated list of columns after each permission.
+3. `user` is the user to whom permissions are to be granted. If the user already exists, the `GRANT` statement will modify its permissions. Otherwise, the `GRANT` statement will create a new user. The optional clause `IDENTIFIED BY` allows you to set a new password for the user.
+4. `REQUIRE tsl_option` specifies whether users must connect to the database server through secure connections such as SSL, X059, etc.
+5. The optional `WITH GRANT OPTION` clause allows you to grant or remove permissions that you have from other users. In addition, you can use the `WITH` clause to allocate the resources of the MySQL database server, for example, to set the number of connections or statements that a user can use per hour. This is useful in shared environments such as MySQL shared hosting.
+
+`REVOKE` revoke permission syntax:
+
+```sql
+REVOKE privilege_type [(column_list)]
+ [, priv_type [(column_list)]]...
+ON [object_type] privilege_level
+FROM user [, user]...
+```
+
+Just explain it briefly:
+
+1. Specify the list of permissions to be revoked from the user after the `REVOKE` keyword. You need to separate permissions with commas.
+2. Specify the privilege level at which privileges are revoked in the `ON` clause.
+3. Specify the user account whose permissions are to be revoked in the `FROM` clause.
+
+`GRANT` and `REVOKE` control access at several levels:
+
+- The entire server, using `GRANT ALL` and `REVOKE ALL`;
+- The entire database, use `ON database.*`;
+- For a specific table, use `ON database.table`;
+- specific columns;
+- Specific stored procedures.
+
+Newly created accounts do not have any permissions. Accounts are defined in the form `username@host`, and `username@%` uses the default hostname. MySQL account information is stored in the mysql database.
+
+```sql
+USE mysql;
+SELECT user FROM user;
+```
+
+The following table illustrates all allowed permissions available for the `GRANT` and `REVOKE` statements:
+
+| **Privilege** | **Description** | **Level** | | | | | |
+| ----------------------- | ----------------------------------------------------------------------------------------------- | -------- | ------ | -------- | -------- | --- | --- |
+| **Global** | Database | **Table** | **Column** | **Program** | **Agent** | | |
+| ALL [PRIVILEGES] | Grants all privileges to the specified access level except GRANT OPTION | | | | | | |
+| ALTER | Allows users to use the ALTER TABLE statement || ALTER ROUTINE | Allows the user to change or delete a stored routine |
+| CREATE | Allows users to create databases and tables | X |
+| CREATE ROUTINE | Allows the user to create a stored routine |
+| CREATE TABLESPACE | Allows users to create, alter, or delete tablespaces and log file groups | X | | | | | |
+| CREATE TEMPORARY TABLES | Allows users to create temporary tables using CREATE TEMPORARY TABLE | X |
+| CREATE USER | Allows users to use the CREATE USER, DROP USER, RENAME USER and REVOKE ALL PRIVILEGES statements. | X | | | | | |
+| CREATE VIEW | Allows users to create or modify views. |
+| DELETE | Allow users to use DELETE |
+| DROP | Allows users to drop databases, tables and views |
+| EVENT | Enables event usage by the event scheduler. |
+| EXECUTE | Allows the user to execute a stored routine |
+| FILE | Allows users to read any file in the database directory. | X | | | | | |
+| GRANT OPTION | Allows a user to have the ability to grant or revoke permissions from other accounts. |
+| INDEX | Allows users to create or delete indexes. |
+| INSERT | Allows users to use the INSERT statement |
+| LOCK TABLES | Allows users to use LOCK TABLES on tables with SELECT permission |
+| PROCESS | Allows users to view all processes using the SHOW PROCESSLIST statement. | X | | | | | |
+| PROXY | Enable user agent. | | | | | | |
+| REFERENCES | Allows users to create foreign keys |
+| RELOAD | Allows users to use FLUSH operations | X | | | | | |
+| REPLICATION CLIENT | Allows users to query to see the location of a master or slave server | X | | | | | |
+| REPLICATION SLAVE | Allows users to read binary log events from the master server using a replication slave. | X | | | | | || SELECT | Allows users to use the SELECT statement |
+| SHOW DATABASES | Allows the user to show all databases |
+| SHOW VIEW | Allows users to use the SHOW CREATE VIEW statement |
+| SHUTDOWN | Allows users to use the mysqladmin shutdown command |
+| SUPER | Allows users to use other administrative operations such as CHANGE MASTER TO, KILL, PURGE BINARY LOGS, SET GLOBAL and mysqladmin commands |
+| TRIGGER | Allows the user to use the TRIGGER operation. |
+| UPDATE | Allows users to use the UPDATE statement |
+| USAGE | Equivalent to "no privileges" | | | | | | |
+
+### Create account
+
+```sql
+CREATE USER myuser IDENTIFIED BY 'mypassword';
+```
+
+### Modify account name
+
+```sql
+UPDATE user SET user='newuser' WHERE user='myuser';
+FLUSH PRIVILEGES;
+```
+
+### Delete account
+
+```sql
+DROP USER myuser;
+```
+
+### View permissions
+
+```sql
+SHOW GRANTS FOR myuser;
+```
+
+### Grant permissions
+
+```sql
+GRANT SELECT, INSERT ON *.* TO myuser;
+```
+
+### Delete permissions
+
+```sql
+REVOKE SELECT, INSERT ON *.* FROM myuser;
+```
+
+### Change password
+
+```sql
+SET PASSWORD FOR myuser = 'mypass';
+```
+
+## Stored procedure
+
+Stored procedures can be thought of as batch processing of a series of SQL operations. Stored procedures can be called by triggers, other stored procedures, and applications such as Java, Python, PHP, etc.
+
+
+
+Benefits of using stored procedures:
+
+- Code encapsulation ensures a certain level of security;
+- Code reuse;
+- High performance since it is pre-compiled.
+
+Create stored procedure:
+
+- Creating a stored procedure in the command line requires custom delimiters, because the command line ends with `;`, and the stored procedure also contains a semicolon, so this part of the semicolon will be mistakenly regarded as the terminator, causing a syntax error.
+- Contains three parameters: `in`, `out` and `inout`.
+- To assign a value to a variable, you need to use the `select into` statement.
+- Only one variable can be assigned a value at a time, and collection operations are not supported.
+
+It should be noted that: **Alibaba's "Java Development Manual" forcibly prohibits the use of stored procedures. Because stored procedures are difficult to debug and extend, they are not portable. **
+
+
+
+As for whether to use it in the project, it still depends on the actual needs of the project, and just weigh the pros and cons!
+
+### Create stored procedure
+
+```sql
+DROP PROCEDURE IF EXISTS `proc_adder`;
+DELIMITER ;;
+CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
+BEGIN
+ DECLARE c int;
+ if a is null then set a = 0;
+ end if;
+
+ if b is null then set b = 0;
+ end if;
+
+ set sum = a + b;
+END
+;;
+DELIMITER;
+```
+
+### Use stored procedures
+
+```less
+set @b=5;
+call proc_adder(2,@b,@s);
+select @s as sum;
+```
+
+## Cursor
+
+A cursor is a database query stored on the DBMS server. It is not a `SELECT` statement, but the result set retrieved by the statement.
+
+Cursors can be used in stored procedures to traverse a result set.
+
+Cursors are primarily used in interactive applications where the user needs to scroll through data on the screen and browse or make changes to the data.
+
+A few clear steps for using cursors:
+
+- Before using a cursor, you must declare (define) it. This procedure does not actually retrieve data, it simply defines the `SELECT` statement and cursor options to be used.
+
+- Once declared, the cursor must be opened for use. This process uses the SELECT statement defined earlier to actually retrieve the data.
+
+- For cursors filled with data, fetch (retrieve) rows as needed.
+
+- When ending use of a cursor, the cursor must be closed and, if possible, released (depending on the tool).
+
+ DBMS).
+
+```sql
+DELIMITER $
+CREATE PROCEDURE getTotal()
+BEGIN
+ DECLARE total INT;
+ --Create a variable to receive cursor data
+ DECLARE sid INT;
+ DECLARE sname VARCHAR(10);
+ --Create a total variable
+ DECLARE sage INT;
+ --Create an end flag variable
+ DECLARE done INT DEFAULT false;
+ --Create cursor
+ DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30;
+ --Specify the return value at the end of the cursor loop
+ DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
+ SET total = 0;
+ OPEN cur;
+ FETCH cur INTO sid, sname, sage;
+ WHILE(NOT done)
+ DO
+ SET total = total + 1;
+ FETCH cur INTO sid, sname, sage;
+ END WHILE;
+
+ CLOSE cur;
+ SELECT total;
+END $
+DELIMITER;
+
+-- Call stored procedure
+call getTotal();
+```
+
+## Trigger
+
+A trigger is a database object related to table operations. When a specified event occurs on the table where the trigger is located, the object will be called, that is, the operation event of the table triggers the execution of the trigger on the table.We can use triggers for audit tracking and record changes to another table.
+
+Advantages of using triggers:
+
+- SQL triggers provide another way to check data integrity.
+- SQL triggers can capture errors in business logic in the database layer.
+- SQL triggers provide another way to run scheduled tasks. By using SQL triggers, you don't have to wait for a scheduled task to run because the trigger is automatically called before or after changes are made to the data in the table.
+- SQL triggers are useful for auditing changes to data in tables.
+
+Disadvantages of using triggers:
+
+- SQL triggers can only provide extended validation and cannot replace all validation. Some simple validation must be done in the application layer. For example, you can validate user input on the client side using JavaScript, or on the server side using a server-side scripting language (such as JSP, PHP, ASP.NET, Perl).
+- SQL triggers are not visible when called and executed from the client application, so it is difficult to figure out what is going on in the database layer.
+- SQL triggers may add overhead to the database server.
+
+MySQL does not allow the use of CALL statements in triggers, that is, stored procedures cannot be called.
+
+> Note: In MySQL, the semicolon `;` is the identifier of the end of a statement. Encountering a semicolon indicates that the statement has ended and MySQL can start execution. Therefore, the interpreter starts execution after encountering the semicolon in the trigger execution action, and then reports an error because no END matching BEGIN is found.
+>
+> The `DELIMITER` command will be used at this time (DELIMITER is the delimiter, which means the separator). It is a command and does not require an end-of-statement identifier. The syntax is: `DELIMITER new_delimiter`. `new_delimiter` can be set to 1 or more length symbols, the default is semicolon `;`, we can modify it to other symbols, such as `$` - `DELIMITER $`. The statement after this ends with a semicolon, and the interpreter will not react. Only when `$` is encountered, the statement is considered to have ended. Note that after using it, we should remember to modify it back.
+
+Prior to MySQL version 5.7.2, up to six triggers could be defined per table.
+
+- `BEFORE INSERT` - Activate before inserting data into the table.
+- `AFTER INSERT` - activated after inserting data into the table.
+- `BEFORE UPDATE` - Activate before updating data in the table.
+- `AFTER UPDATE` - activated after updating data in the table.
+- `BEFORE DELETE` - Activate before deleting data from the table.
+- `AFTER DELETE` - activated after deleting data from the table.
+
+However, starting with MySQL version 5.7.2+, multiple triggers can be defined for the same trigger event and action time.
+
+**`NEW` and `OLD`**:
+
+- The `NEW` and `OLD` keywords are defined in MySQL, which are used to indicate the row of data in the table where the trigger is located that triggered the trigger.
+- In `INSERT` type triggers, `NEW` is used to indicate new data that will be (`BEFORE`) or has been (`AFTER`) inserted;
+- In `UPDATE` type triggers, `OLD` is used to represent the original data that will be or has been modified, and `NEW` is used to represent the new data that will be or has been modified;
+- In `DELETE` type triggers, `OLD` is used to represent the original data that will be or has been deleted;
+- Usage: `NEW.columnName` (columnName is a column name of the corresponding data table)
+
+### Create trigger
+
+> Tip: In order to understand the gist of triggers, it is necessary to first understand the instructions for creating triggers.
+
+The `CREATE TRIGGER` command is used to create a trigger.
+
+Syntax:
+
+```sql
+CREATE TRIGGER trigger_name
+trigger_time
+trigger_event
+ON table_name
+FOR EACH ROW
+BEGIN
+ trigger_statements
+END;
+```
+
+Description:
+
+- `trigger_name`: trigger name
+- `trigger_time`: The trigger firing time. The value is `BEFORE` or `AFTER`.
+- `trigger_event`: The listening event of the trigger. The value is `INSERT`, `UPDATE` or `DELETE`.
+- `table_name`: The listening target of the trigger. Specify the table on which to create the trigger.
+- `FOR EACH ROW`: Row-level monitoring, Mysql fixed writing method, different from other DBMS.
+- `trigger_statements`: Trigger execution actions. Is a list of one or more SQL statements. Each statement in the list must be terminated with a semicolon `;`.
+
+When the triggering condition of the trigger is met, the trigger execution action between `BEGIN` and `END` will be executed.
+
+Example:
+
+```sql
+DELIMITER $
+CREATE TRIGGER `trigger_insert_user`
+AFTER INSERT ON `user`
+FOR EACH ROW
+BEGIN
+ INSERT INTO `user_history`(user_id, operate_type, operate_time)
+ VALUES (NEW.id, 'add a user', now());
+END $
+DELIMITER;
+```
+
+### View triggers
+
+```sql
+SHOW TRIGGERS;
+```
+
+### Delete trigger
+
+```sql
+DROP TRIGGER IF EXISTS trigger_insert_user;
+```
+
+## Article recommendation
+
+- [A must-have for back-end programmers: SQL high-performance optimization guide! 35+ optimization suggestions GET now!](https://mp.weixin.qq.com/s/I-ZT3zGTNBZ6egS7T09jyQ)
+- [Must-have for back-end programmers: 30 tips for writing high-quality SQL suggestions](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486461&idx=1&sn=60a22279196d084cc398936fe3b37772&c hksm=cea24436f9d5cd20a4fa0e907590f3e700d7378b3f608d7b33bb52cfb96f503b7ccb65a1deed&token=1987003517&lang=zh_CN#rd)
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/api-gateway.en.md b/docs_en/distributed-system/api-gateway.en.md
new file mode 100644
index 00000000000..413afc10d82
--- /dev/null
+++ b/docs_en/distributed-system/api-gateway.en.md
@@ -0,0 +1,209 @@
+---
+title: API网关基础知识总结
+category: 分布式
+---
+
+## 什么是网关?
+
+微服务背景下,一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
+
+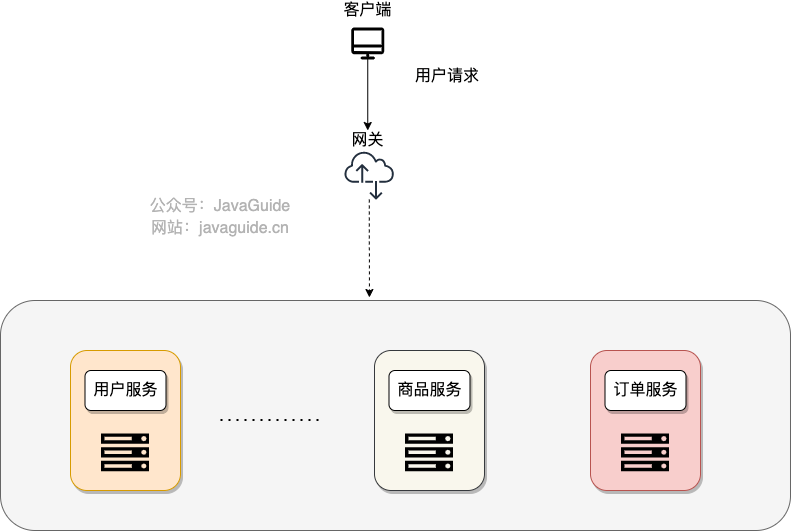
+
+一般情况下,网关可以为我们提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。
+
+上面介绍了这么多功能,实际上,网关主要做了两件事情:**请求转发** + **请求过滤**。
+
+由于引入网关之后,会多一步网络转发,因此性能会有一点影响(几乎可以忽略不计,尤其是内网访问的情况下)。 另外,我们需要保障网关服务的高可用,避免单点风险。
+
+如下图所示,网关服务外层通过 Nginx(其他负载均衡设备/软件也行) 进⾏负载转发以达到⾼可⽤。Nginx 在部署的时候,尽量也要考虑高可用,避免单点风险。
+
+
+
+## 网关能提供哪些功能?
+
+绝大部分网关可以提供下面这些功能(有一些功能需要借助其他框架或者中间件):
+
+- **请求转发**:将请求转发到目标微服务。
+- **负载均衡**:根据各个微服务实例的负载情况或者具体的负载均衡策略配置对请求实现动态的负载均衡。
+- **安全认证**:对用户请求进行身份验证并仅允许可信客户端访问 API,并且还能够使用类似 RBAC 等方式来授权。
+- **参数校验**:支持参数映射与校验逻辑。
+- **日志记录**:记录所有请求的行为日志供后续使用。
+- **监控告警**:从业务指标、机器指标、JVM 指标等方面进行监控并提供配套的告警机制。
+- **流量控制**:对请求的流量进行控制,也就是限制某一时刻内的请求数。
+- **熔断降级**:实时监控请求的统计信息,达到配置的失败阈值后,自动熔断,返回默认值。
+- **响应缓存**:当用户请求获取的是一些静态的或更新不频繁的数据时,一段时间内多次请求获取到的数据很可能是一样的。对于这种情况可以将响应缓存起来。这样用户请求可以直接在网关层得到响应数据,无需再去访问业务服务,减轻业务服务的负担。
+- **响应聚合**:某些情况下用户请求要获取的响应内容可能会来自于多个业务服务。网关作为业务服务的调用方,可以把多个服务的响应整合起来,再一并返回给用户。
+- **灰度发布**:将请求动态分流到不同的服务版本(最基本的一种灰度发布)。
+- **异常处理**:对于业务服务返回的异常响应,可以在网关层在返回给用户之前做转换处理。这样可以把一些业务侧返回的异常细节隐藏,转换成用户友好的错误提示返回。
+- **API 文档:** 如果计划将 API 暴露给组织以外的开发人员,那么必须考虑使用 API 文档,例如 Swagger 或 OpenAPI。
+- **协议转换**:通过协议转换整合后台基于 REST、AMQP、Dubbo 等不同风格和实现技术的微服务,面向 Web Mobile、开放平台等特定客户端提供统一服务。
+- **证书管理**:将 SSL 证书部署到 API 网关,由一个统一的入口管理接口,降低了证书更换时的复杂度。
+
+下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
+
+
+
+## 有哪些常见的网关系统?
+
+### Netflix Zuul
+
+Zuul 是 Netflix 开发的一款提供动态路由、监控、弹性、安全的网关服务,基于 Java 技术栈开发,可以和 Eureka、Ribbon、Hystrix 等组件配合使用。
+
+Zuul 核心架构如下:
+
+
+
+Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网关必备的各种功能。
+
+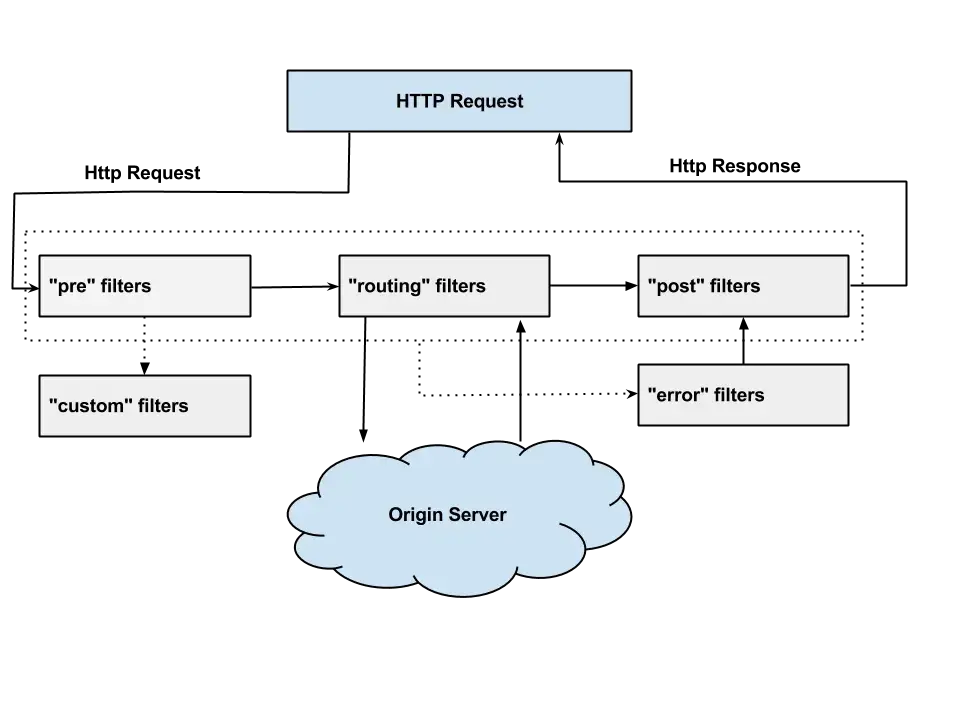
+
+我们可以自定义过滤器来处理请求,并且,Zuul 生态本身就有很多现成的过滤器供我们使用。就比如限流可以直接用国外朋友写的 [spring-cloud-zuul-ratelimit](https://github.com/marcosbarbero/spring-cloud-zuul-ratelimit) (这里只是举例说明,一般是配合 hystrix 来做限流):
+
+```xml
+
+ org.springframework.cloud
+ spring-cloud-starter-netflix-zuul
+
+
+ com.marcosbarbero.cloud
+ spring-cloud-zuul-ratelimit
+ 2.2.0.RELEASE
+
+```
+
+[Zuul 1.x](https://netflixtechblog.com/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee) 基于同步 IO,性能较差。[Zuul 2.x](https://netflixtechblog.com/open-sourcing-zuul-2-82ea476cb2b3) 基于 Netty 实现了异步 IO,性能得到了大幅改进。
+
+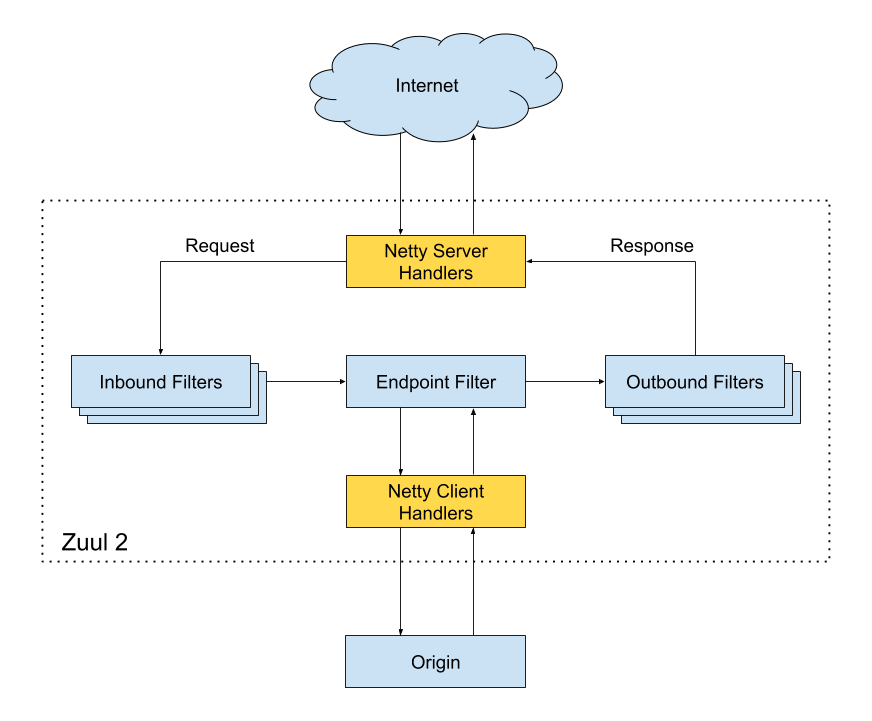
+
+- GitHub 地址:
+- 官方 Wiki:
+
+### Spring Cloud Gateway
+
+SpringCloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**。准确点来说,应该是 Zuul 1.x。SpringCloud Gateway 起步要比 Zuul 2.x 更早。
+
+为了提升网关的性能,SpringCloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现同步非阻塞的 I/O。
+
+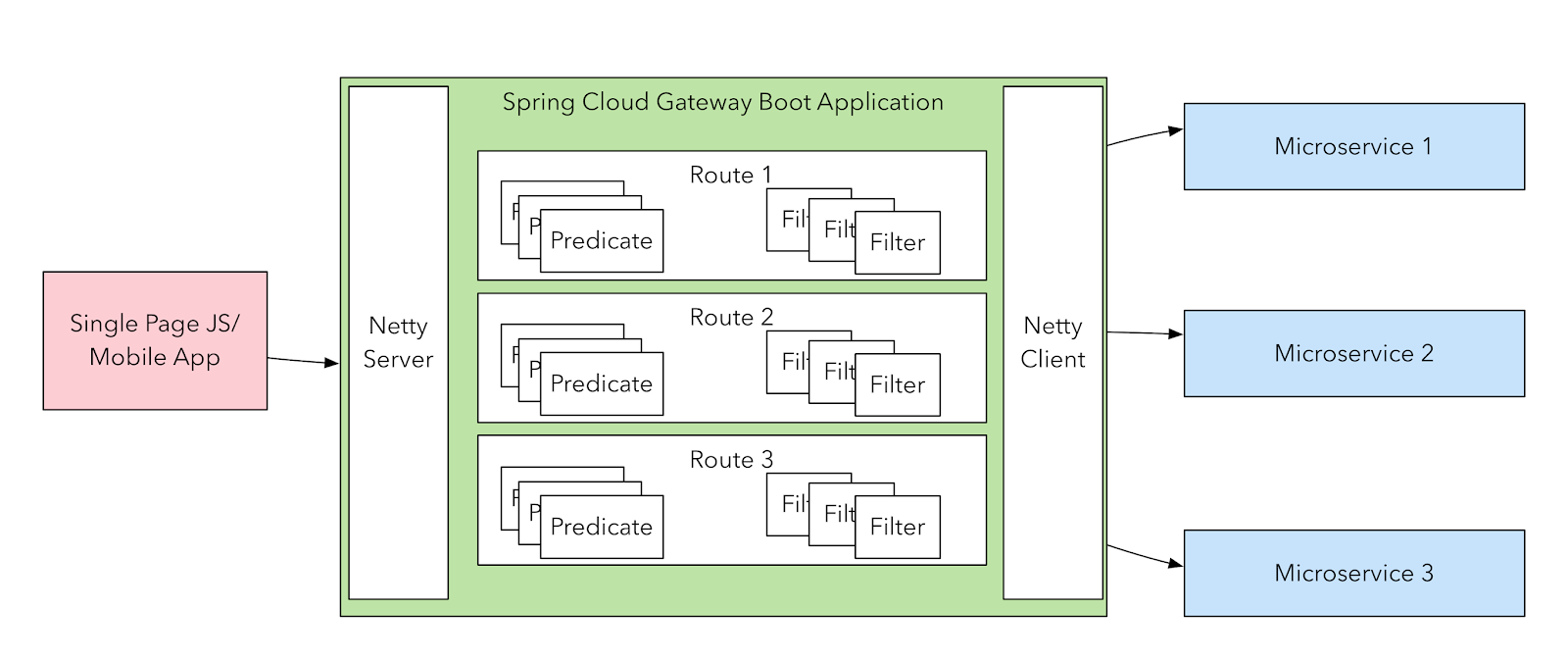
+
+Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,限流。
+
+Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
+
+- Github 地址:
+- 官网:
+
+### OpenResty
+
+根据官方介绍:
+
+> OpenResty is a high-performance web platform based on Nginx and Lua. It integrates a large number of sophisticated Lua libraries, third-party modules and most dependencies. Used to easily build dynamic web applications, web services and dynamic gateways that can handle ultra-high concurrency and high scalability.
+
+
+
+OpenResty is based on Nginx, mainly because of its excellent high concurrency capabilities. However, because Nginx is developed in C language, the threshold for secondary development is relatively high. If you want to implement some custom logic or functions on Nginx, you need to write a C language module and recompile Nginx.
+
+In order to solve this problem, OpenResty perfectly integrates Lua/LuaJIT into Nginx by implementing Nginx modules such as `ngx_lua` and `stream_lua`, which allows us to embed Lua scripts inside Nginx, so that the functions of the gateway can be extended through simple Lua language, such as implementing custom routing rules, filters, caching strategies, etc.
+
+> Lua is a very fast dynamic scripting language that runs as fast as C. LuaJIT is a just-in-time compiler for Lua that can significantly improve the execution efficiency of Lua code. LuaJIT precompiles and caches some commonly used Lua functions and tool libraries, so that the cached bytecode can be used directly the next time it is called, thus greatly speeding up execution.
+
+It is recommended to read this article for getting started with OpenResty and practical gateway security: [Getting started with OpenResty and practical gateway security that every backend should know] (https://mp.weixin.qq.com/s/3HglZs06W95vF3tSa3KrXw).
+
+- Github address:
+- Official website address:
+
+### Kong
+
+Kong is a high-performance, cloud-native, scalable, and ecologically rich gateway system based on [OpenResty](https://github.com/openresty/) (Nginx + Lua). It mainly consists of 3 components:
+
+- Kong Server: Nginx-based server used to receive API requests.
+- Apache Cassandra/PostgreSQL: used to store operational data.
+- Kong Dashboard: Officially recommended UI management tool. Of course, you can also use the RESTful method to manage the Admin api.
+
+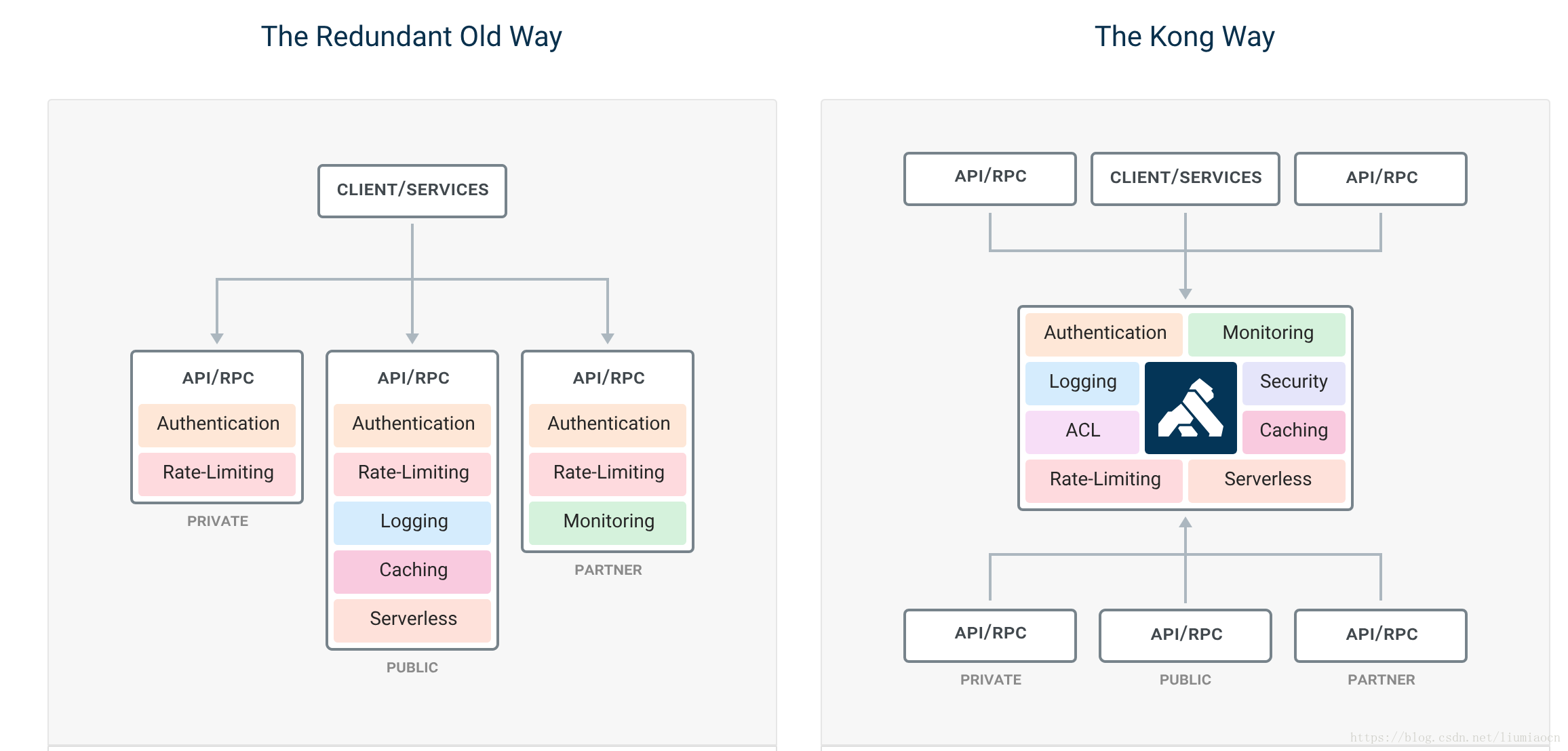
+
+Since Apache Cassandra/PostgreSQL is used to store data by default, Kong's entire architecture is bloated and will cause high availability problems.
+
+Kong provides a plug-in mechanism to extend its functionality. Plug-ins are executed during the life cycle of the API request response cycle. For example, enable the Zipkin plug-in on the service:
+
+```shell
+$ curl -X POST http://kong:8001/services/{service}/plugins \
+ --data "name=zipkin" \
+ --data "config.http_endpoint=http://your.zipkin.collector:9411/api/v2/spans" \
+ --data "config.sample_ratio=0.001"
+```
+
+Kong itself is a Lua application, and it is an encapsulated application based on Openresty. The final analysis is to use Lua to embed Nginx to give Nginx programmable capabilities, so that unlimited imagination can be done at the Nginx level in the form of plug-ins. For example, current limiting, security access policy, routing, load balancing, etc. To write a Kong plug-in, you need to follow the Kong plug-in writing specifications, write your own customized Lua script, then load it into Kong, and finally quote it.
+
+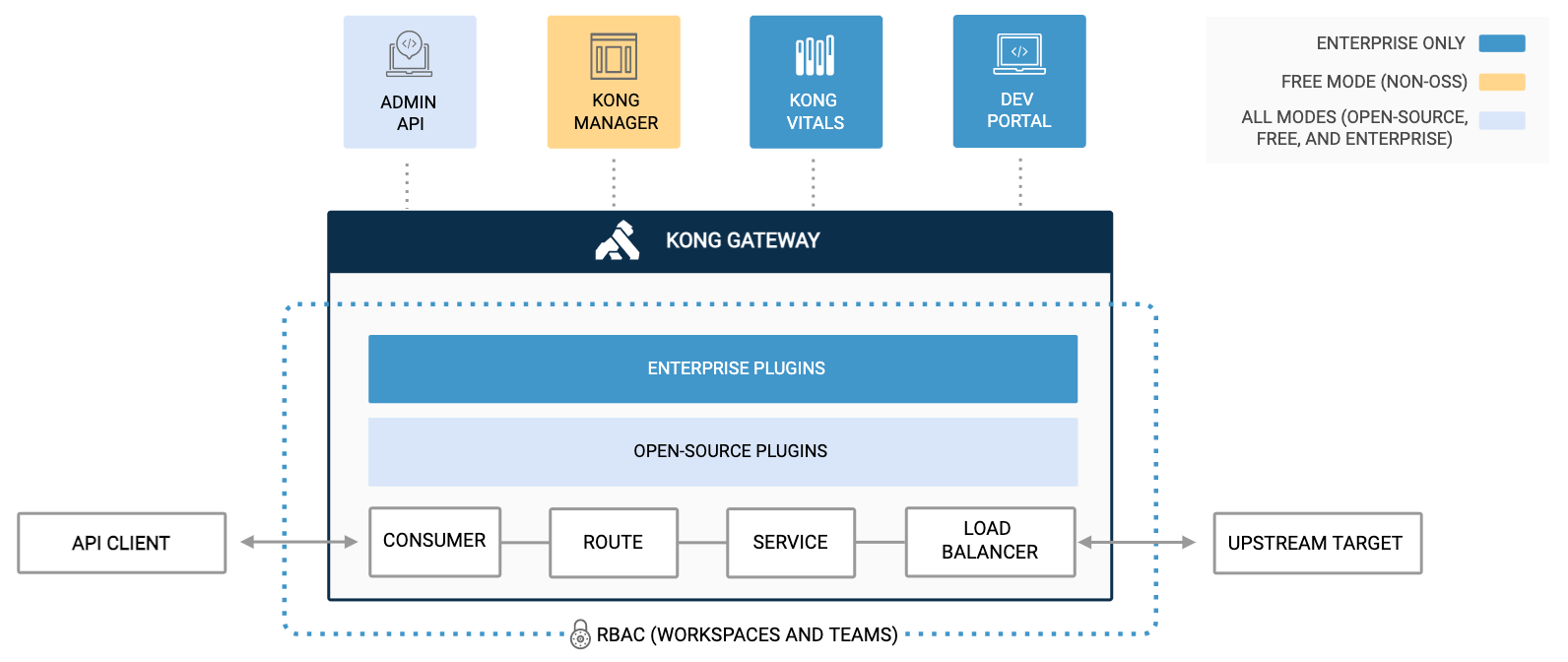
+
+In addition to Lua, Kong can also develop plug-ins based on Go, JavaScript, Python and other languages, thanks to the corresponding PDK (plug-in development kit).
+
+For a detailed introduction to the Kong plug-in, it is recommended to read the official document: , which is written in more detail.
+
+- Github address:
+- Official website address:
+
+### APISIX
+
+APISIX is a high-performance, cloud-native, scalable gateway system based on OpenResty and etcd.
+
+> etcd is an open source, highly available distributed key-value storage system developed using the Go language, and uses the Raft protocol for distributed consensus.
+
+Compared with traditional API gateways, APISIX has dynamic routing and plug-in hot loading, which is particularly suitable for API management under microservice systems. Moreover, APISIX is very convenient to connect with DevOps ecological tools such as SkyWalking (distributed link tracking system), Zipkin (distributed link tracking system), and Prometheus (monitoring system).
+
+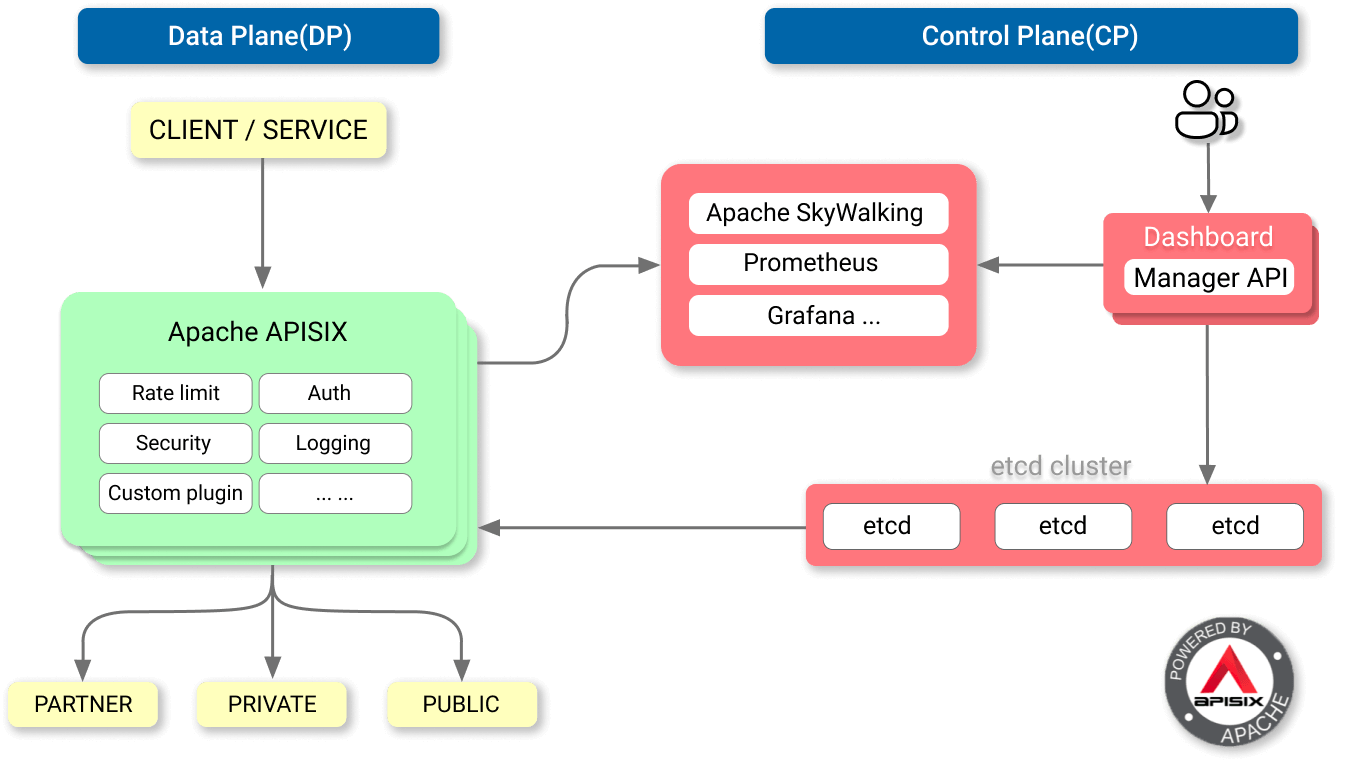
+
+As an alternative project to Nginx and Kong, APISIX is currently Apache's top open source project and the fastest graduating domestic open source project. There are currently many well-known domestic companies (such as Kingsoft, Youzan, iQiyi, Tencent, and Shell) using APISIX to handle core business traffic.
+
+According to the official website: "APISIX is already in production and available, and its functions, performance, and architecture are all superior to Kong."
+
+APISIX also supports customized plug-in development. In addition to using the Lua language to develop plug-ins, developers can also develop in the following two ways to avoid the learning cost of the Lua language:
+
+- Support more mainstream programming languages (such as Java, Python, Go, etc.) through Plugin Runner. In this way, back-end engineers can communicate through local RPC and develop APISIX plug-ins using familiar programming languages. The advantage of this is that it reduces development costs and improves development efficiency, but there will be some loss in performance.
+- Use Wasm (WebAssembly) to develop plug-ins. Wasm is embedded into APISIX, and users can use Wasm to compile into Wasm bytecode and run it in APISIX.
+
+> Wasm is a binary instruction format for stack-based virtual machines, a low-level assembly language designed to be very close to compiled machine code, and very close to native performance. Wasm was originally built for the browser, but as the technology matures, it's seeing more and more use cases on the server side.
+
+
+
+- Github address:
+- Official website address:
+
+Related reading:
+
+- [Why is Apache APISIX the best API gateway? ](https://mp.weixin.qq.com/s/j8ggPGEHFu3x5ekJZyeZnA)
+- [With NGINX and Kong, why do we need Apache APISIX](https://www.apiseven.com/zh/blog/why-we-need-Apache-APISIX)
+- [APISIX Technology Blog](https://www.apiseven.com/zh/blog)
+- [APISIX User Cases](https://www.apiseven.com/zh/usercases) (recommended)
+
+### Shenyu
+
+Shenyu is a scalable, high-performance, responsive gateway based on WebFlux, a top Apache open source project.
+
+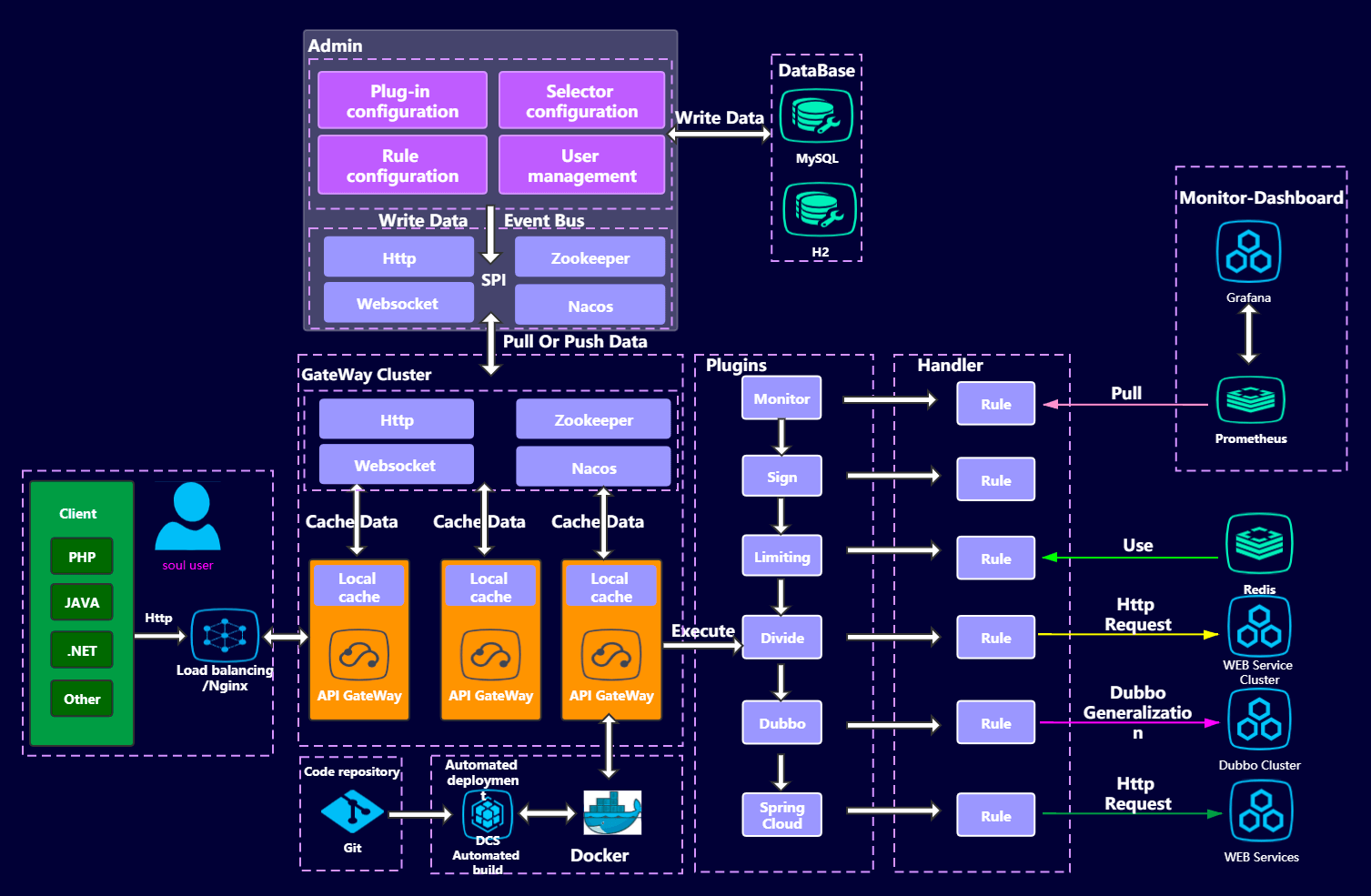
+
+Shenyu extends its functionality through plug-ins, which are the soul of ShenYu and are also expandable and hot-swappable. Different plug-ins implement different functions. Shenyu comes with plug-ins such as current limiting, circuit breaker, forwarding, rewriting, redirection, and route monitoring.- Github address:
+- Official website address:
+
+## How to choose?
+
+Among the several common gateway systems introduced above, the three most commonly used ones are Spring Cloud Gateway, Kong, and APISIX.
+
+For companies whose business uses Java as the main development language, Spring Cloud Gateway is usually a good choice. Its advantages include: simple and easy to use, mature and stable, compatible with the Spring Cloud ecosystem, mature Spring community, etc. However, Spring Cloud Gateway also has some limitations and shortcomings, and generally needs to be used in conjunction with other gateways such as OpenResty. Moreover, its performance is still worse than Kong and APISIX. If you have high performance requirements, Spring Cloud Gateway is not a good choice.
+
+Kong and APISIX have richer functions, more powerful performance, and their technical architecture is more cloud-native. Kong is the originator of open source API gateways, with a rich ecosystem and a large user base. APISIX is a latecomer and is better. According to the APISIX official website: "APISIX is already in production and available, and its functions, performance, and architecture are all superior to Kong." Let’s briefly compare the two:
+
+- APISIX is based on etcd as the configuration center, so there is no single point of problem and is cloud-native friendly; while Kong is based on Apache Cassandra/PostgreSQL, which has a single point of risk and requires additional infrastructure to ensure high availability.
+- APISIX supports hot updates and implements millisecond-level hot update response; while Kong does not support hot updates.
+- APISIX performs better than Kong.
+- APISIX supports more plug-ins and has richer functions.
+
+## Reference
+
+- Kong plug-in development tutorial [easy to understand]:
+- API gateway Kong in action:
+- Spring Cloud Gateway principle introduction and application:
+- Why do microservices use API gateways? :
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-configuration-center.en.md b/docs_en/distributed-system/distributed-configuration-center.en.md
new file mode 100644
index 00000000000..8909fc790cc
--- /dev/null
+++ b/docs_en/distributed-system/distributed-configuration-center.en.md
@@ -0,0 +1,12 @@
+---
+title: Summary of Frequently Asked Questions in Distributed Configuration Center (Paid)
+category: distributed
+---
+
+**Distributed Configuration Center** The relevant interview questions are my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click the link to view the detailed introduction and how to join) exclusive content, which has been compiled into the "Java Interview Guide".
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-id-design.en.md b/docs_en/distributed-system/distributed-id-design.en.md
new file mode 100644
index 00000000000..4a28ef3793c
--- /dev/null
+++ b/docs_en/distributed-system/distributed-id-design.en.md
@@ -0,0 +1,173 @@
+---
+title: 分布式ID设计指南
+category: 分布式
+---
+
+::: tip
+
+看到百度 Geek 说的一篇结合具体场景聊分布式 ID 设计的文章,感觉挺不错的。于是,我将这篇文章的部分内容整理到了这里。原文传送门:[分布式 ID 生成服务的技术原理和项目实战](https://mp.weixin.qq.com/s/bFDLb6U6EgI-DvCdLTq_QA) 。
+
+:::
+
+网上绝大多数的分布式 ID 生成服务,一般着重于技术原理剖析,很少见到根据具体的业务场景去选型 ID 生成服务的文章。
+
+本文结合一些使用场景,进一步探讨业务场景中对 ID 有哪些具体的要求。
+
+## 场景一:订单系统
+
+我们在商场买东西一码付二维码,下单生成的订单号,使用到的优惠券码,联合商品兑换券码,这些是在网上购物经常使用到的单号,那么为什么有些单号那么长,有些只有几位数?有些单号一看就知道年月日的信息,有些却看不出任何意义?下面展开分析下订单系统中不同场景的 id 服务的具体实现。
+
+### 1、一码付
+
+我们常见的一码付,指的是一个二维码可以使用支付宝或者微信进行扫码支付。
+
+二维码的本质是一个字符串。聚合码的本质就是一个链接地址。用户使用支付宝微信直接扫一个码付钱,不用担心拿支付宝扫了微信的收款码或者用微信扫了支付宝的收款码,这极大减少了用户扫码支付的时间。
+
+实现原理是当客户用 APP 扫码后,网站后台就会判断客户的扫码环境。(微信、支付宝、QQ 钱包、京东支付、云闪付等)。
+
+判断扫码环境的原理就是根据打开链接浏览器的 HTTP header。任何浏览器打开 http 链接时,请求的 header 都会有 User-Agent(UA、用户代理)信息。
+
+UA 是一个特殊字符串头,服务器依次可以识别出客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等很多信息。
+
+各渠道对应支付产品的名称不一样,一定要仔细看各支付产品的 API 介绍。
+
+1. 微信支付:JSAPI 支付支付
+2. 支付宝:手机网站支付
+3. QQ 钱包:公众号支付
+
+其本质均为在 APP 内置浏览器中实现 HTML5 支付。
+
+
+
+文库的研发同学在这个思路上,做了优化迭代。动态生成一码付的二维码预先绑定用户所选的商品信息和价格,根据用户所选的商品动态更新。这样不仅支持一码多平台调起支付,而且不用用户选择商品输入金额,即可完成订单支付的功能,很丝滑。用户在真正扫码后,服务端才通过前端获取用户 UID,结合二维码绑定的商品信息,真正的生成订单,发送支付信息到第三方(qq、微信、支付宝),第三方生成支付订单推给用户设备,从而调起支付。
+
+区别于固定的一码付,在文库的应用中,使用到了动态二维码,二维码本质是一个短网址,ID 服务提供短网址的唯一标志参数。唯一的短网址映射的 ID 绑定了商品的订单信息,技术和业务的深度结合,缩短了支付流程,提升用户的支付体验。
+
+### 2、订单号
+
+订单号在实际的业务过程中作为一个订单的唯一标识码存在,一般实现以下业务场景:
+
+1. 用户订单遇到问题,需要找客服进行协助;
+2. 对订单进行操作,如线下收款,订单核销;
+3. 下单,改单,成单,退单,售后等系统内部的订单流程处理和跟进。
+
+很多时候搜索订单相关信息的时候都是以订单 ID 作为唯一标识符,这是由于订单号的生成规则的唯一性决定的。从技术角度看,除了 ID 服务必要的特性之外,在订单号的设计上需要体现几个特性:
+
+**(1)信息安全**
+
+编号不能透露公司的运营情况,比如日销、公司流水号等信息,以及商业信息和用户手机号,身份证等隐私信息。并且不能有明显的整体规律(可以有局部规律),任意修改一个字符就能查询到另一个订单信息,这也是不允许的。
+
+类比于我们高考时候的考生编号的生成规则,一定不能是连号的,否则只需要根据顺序往下查询就能搜索到别的考生的成绩,这是绝对不可允许。
+
+**(2)部分可读**
+
+位数要便于操作,因此要求订单号的位数适中,且局部有规律。这样可以方便在订单异常,或者退货时客服查询。
+
+过长的订单号或易读性差的订单号会导致客服输入困难且易错率较高,影响用户体验的售后体验。因此在实际的业务场景中,订单号的设计通常都会适当携带一些允许公开的对使用场景有帮助的信息,如时间,星期,类型等等,这个主要根据所涉及的编号对应的使用场景来。
+
+而且像时间、星期这些自增长的属于作为订单号的设计的一部分元素,有助于解决业务累积而导致的订单号重复的问题。
+
+**(3)查询效率**
+
+常见的电商平台订单号大多是纯数字组成,兼具可读性的同时,int 类型相对 varchar 类型的查询效率更高,对在线业务更加友好。
+
+### 3、优惠券和兑换券
+
+优惠券、兑换券是运营推广最常用的促销工具之一,合理使用它们,可以让买家得到实惠,商家提升商品销量。常见场景有:
+
+1. 在文库购买【文库 VIP+QQ 音乐年卡】联合商品,支付成功后会得到 QQ 音乐年卡的兑换码,可以去 QQ 音乐 App 兑换音乐会员年卡;
+2. 疫情期间,部分地方政府发放的消费券;
+3. 瓶装饮料经常会出现输入优惠编码兑换奖品。
+
+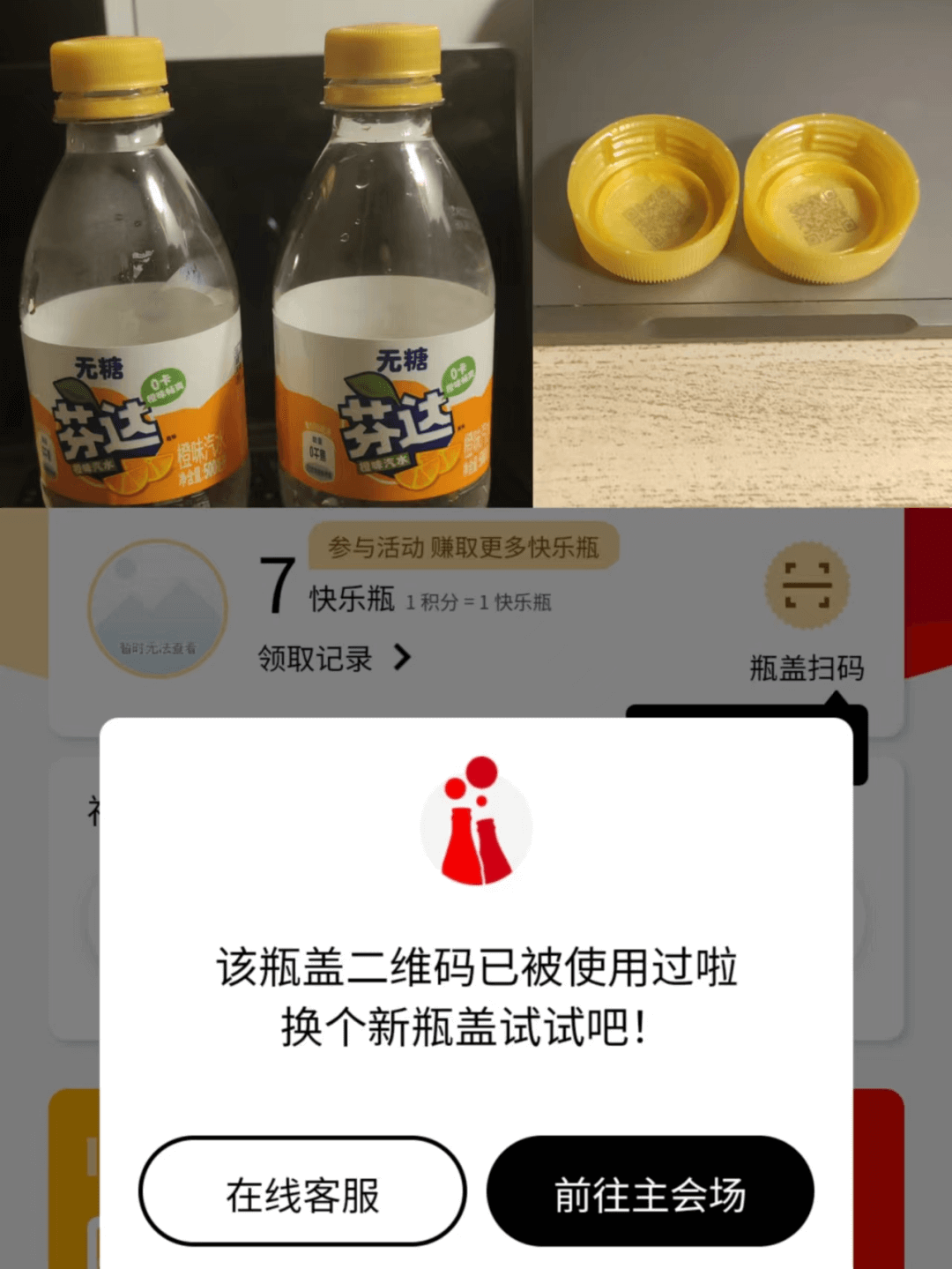
+
+从技术角度看,有些场景适合 ID 即时生成,比如电商平台购物领取的优惠券,只需要在用户领取时分配优惠券信息即可。有些线上线下结合的场景,比如疫情优惠券,瓶盖开奖,京东卡,超市卡这种,则需要预先生成,预先生成的券码具备以下特性:
+
+1.预先生成,在活动正式开始前提供出来进行活动预热;
+
+2.优惠券体量大,以万为单位,通常在 10 万级别以上;
+
+3.不可破解、仿制券码;
+
+4.支持用后核销;
+
+5.优惠券、兑换券属于广撒网的策略,所以利用率低,也就不适合使用数据库进行存储 **(占空间,有效的数据又少)**。
+
+设计思路上,需要设计一种有效的兑换码生成策略,支持预先生成,支持校验,内容简洁,生成的兑换码都具有唯一性,那么这种策略就是一种特殊的编解码策略,按照约定的编解码规则支撑上述需求。
+
+既然是一种编解码规则,那么需要约定编码空间(也就是用户看到的组成兑换码的字符),编码空间由字符 a-z,A-Z,数字 0-9 组成,为了增强兑换码的可识别度,剔除大写字母 O 以及 I,可用字符如下所示,共 60 个字符:
+
+abcdefghijklmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXZY0123456789
+
+之前说过,兑换码要求尽可能简洁,那么设计时就需要考虑兑换码的字符数,假设上限为 12 位,而字符空间有 60 位,那么可以表示的空间范围为 60^12=130606940160000000000000(也就是可以 12 位的兑换码可以生成天量,应该够运营同学挥霍了),转换成 2 进制:
+
+1001000100000000101110011001101101110011000000000000000000000(61 位)
+
+**兑换码组成成分分析**
+
+兑换码可以预先生成,并且不需要额外的存储空间保存这些信息,每一个优惠方案都有独立的一组兑换码(指运营同学组织的每一场运营活动都有不同的兑换码,不能混合使用, 例如双 11 兑换码不能使用在双 12 活动上),每个兑换码有自己的编号,防止重复,为了保证兑换码的有效性,对兑换码的数据需要进行校验,当前兑换码的数据组成如下所示:
+
+优惠方案 ID + 兑换码序列号 i + 校验码
+
+**编码方案**
+
+1. 兑换码序列号 i,代表当前兑换码是当前活动中第 i 个兑换码,兑换码序列号的空间范围决定了优惠活动可以发行的兑换码数目,当前采用 30 位 bit 位表示,可表示范围:1073741824(10 亿个券码)。
+2. 优惠方案 ID, 代表当前优惠方案的 ID 号,优惠方案的空间范围决定了可以组织的优惠活动次数,当前采用 15 位表示,可以表示范围:32768(考虑到运营活动的频率,以及 ID 的初始值 10000,15 位足够,365 天每天有运营活动,可以使用 54 年)。
+3. 校验码,校验兑换码是否有效,主要为了快捷的校验兑换码信息的是否正确,其次可以起到填充数据的目的,增强数据的散列性,使用 13 位表示校验位,其中分为两部分,前 6 位和后 7 位。
+
+深耕业务还会有区分通用券和单独券的情况,分别具备以下特点,技术实现需要因地制宜地思考。
+
+1. 通用券:多个玩家都可以输入兑换,然后有总量限制,期限限制。
+2. 单独券:运营同学可以在后台设置兑换码的奖励物品、期限、个数,然后由后台生成兑换码的列表,兑换之后核销。
+
+## 场景二:Tracing
+
+### 1、日志跟踪
+
+在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求经过的哪个服务出了故障或者处理过慢都会对前端造成影响。
+
+To process multiple services called by a Web request, in order to more conveniently query which link of the service has a problem, a common solution now is to introduce distributed link tracking into the entire system.
+
+
+
+There are two important concepts in distributed link tracing: trace and span. Trace is the view of the entire link in the distributed system requested, and span represents the internal view of different services in the entire link. The span combined together is the view of the entire trace.
+
+In the entire request call chain, the request will always carry the traceid and be passed to the downstream service. Each service will also generate its own spanid internally to generate its own internal call view, and pass it to the downstream service together with the traceid.
+
+### 2. TraceId generation rules
+
+In this scenario, the generated ID must not only be unique, but also must be generated with high efficiency and high throughput. The traceid needs to have the ability to be generated independently by the server instance of the access layer. If the ID in each trace needs to be generated by requesting a public ID service, it will be a pure waste of network bandwidth resources. And it will block the transmission of user requests to downstream, increase the response time, and increase unnecessary risks. Therefore, if a server instance is required, it is best to calculate tracid and spanid by itself to avoid relying on external services.
+
+Generation rules: server IP + ID generation time + auto-increment sequence + current process number, for example:
+
+0ad1348f1403169275002100356696
+
+The first 8 digits 0ad1348f are the IP of the machine that generated the TraceId. This is a hexadecimal number. Each two digits represents a segment of the IP. We convert this number into decimal for each digit to get the common IP address representation 10.209.52.143. You can also use this rule to find the first server that the request passes through.
+
+The following 13 bits 1403169275002 are the time when the TraceId was generated. The next four digits 1003 are a self-increasing sequence, rising from 1000 to 9000. After reaching 9000, it returns to 1000 and starts to rise again. The last 5 digits 56696 are the current process ID. In order to prevent TraceId conflicts in single-machine multiple processes, the current process ID is added at the end of TraceId.
+
+### 3. SpanId generation rules
+
+span means layer. For example, the first instance is considered the first layer, and the request is proxied or offloaded to the next instance for processing, which is the second layer, and so on. By layer, SpanId represents the position of this call in the entire call link tree.
+
+Assume that a server instance A receives a user request, which represents the root node of the entire call. Then the spanid value of the non-service call log record generated by layer A when processing this request is all 0. Layer A needs to call three server instances B, C, and D in sequence through RPC. Then in the log of A, the SpanId is 0.1, 0.2, and 0.3 respectively. In B, C, and D, the SpanId is also respectively. 0.1, 0.2 and 0.3; if system C calls two server instances of E and F when processing the request, then the corresponding spanids in system C are 0.2.1 and 0.2.2, and the corresponding logs of systems E and F are also 0.2.1 and 0.2.2.
+
+According to the above description, we can know that if all the SpanIds in a call are collected, a complete link tree can be formed.
+
+The essence of **spanid generation: it is achieved by controlling the automatic increment of the size and version numbers while transmitting transparently across layers. **
+
+## Scenario 3: Short URL
+
+The main functions of short URL include URL shortening and restoration. Compared with long URLs, short URLs can be spread more easily on emails, social networks, Weibo, and mobile phones. For example, a URL that was originally very long can be generated into a corresponding short URL through a URL shortening service to avoid line breaks or exceeding character limits.
+
+
+
+Commonly used ID generation services such as: MySQL ID auto-increment, Redis key auto-increment, number segment mode, the generated IDs are all a string of numbers. The URL shortening service converts the customer's long URL into a short URL.
+
+In fact, the newly generated numeric ID is spliced after the dwz.cn domain name, and the numeric ID is used directly. The length of the URL is also a bit long. The service can compress the length by converting the numeric ID to a higher base. This algorithm is increasingly used in the technical implementation of short URLs, and it can further compress the URL length. The hexadecimal compression algorithm has a wide range of application scenarios in life, for example:
+
+- Customer's long URL:
+- ID mapped short URL: (for demonstration use, may not open correctly)
+- Shortened URL after conversion: (for demonstration use, it may not open correctly)
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-id.en.md b/docs_en/distributed-system/distributed-id.en.md
new file mode 100644
index 00000000000..25a6cefd964
--- /dev/null
+++ b/docs_en/distributed-system/distributed-id.en.md
@@ -0,0 +1,395 @@
+---
+title: 分布式ID介绍&实现方案总结
+category: 分布式
+---
+
+## 分布式 ID 介绍
+
+### 什么是 ID?
+
+日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
+
+我们现实生活中也有各种 ID,比如身份证 ID 对应且仅对应一个人、地址 ID 对应且仅对应一个地址。
+
+简单来说,**ID 就是数据的唯一标识**。
+
+### 什么是分布式 ID?
+
+分布式 ID 是分布式系统下的 ID。分布式 ID 不存在与现实生活中,属于计算机系统中的一个概念。
+
+我简单举一个分库分表的例子。
+
+我司的一个项目,使用的是单机 MySQL 。但是,没想到的是,项目上线一个月之后,随着使用人数越来越多,整个系统的数据量将越来越大。单机 MySQL 已经没办法支撑了,需要进行分库分表(推荐 Sharding-JDBC)。
+
+在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。**我们如何为不同的数据节点生成全局唯一主键呢?**
+
+这个时候就需要生成**分布式 ID**了。
+
+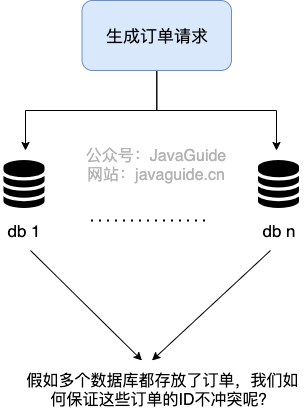
+
+### 分布式 ID 需要满足哪些要求?
+
+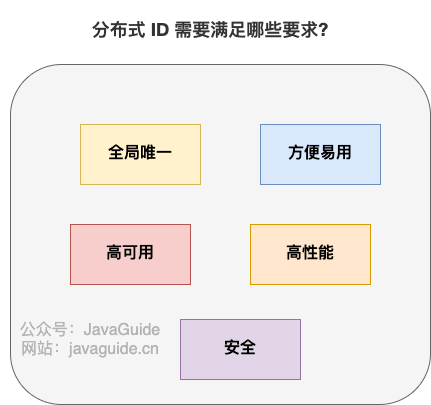
+
+分布式 ID 作为分布式系统中必不可少的一环,很多地方都要用到分布式 ID。
+
+一个最基本的分布式 ID 需要满足下面这些要求:
+
+- **全局唯一**:ID 的全局唯一性肯定是首先要满足的!
+- **高性能**:分布式 ID 的生成速度要快,对本地资源消耗要小。
+- **高可用**:生成分布式 ID 的服务要保证可用性无限接近于 100%。
+- **方便易用**:拿来即用,使用方便,快速接入!
+
+除了这些之外,一个比较好的分布式 ID 还应保证:
+
+- **安全**:ID 中不包含敏感信息。
+- **有序递增**:如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
+- **有具体的业务含义**:生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
+- **独立部署**:也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
+
+## 分布式 ID 常见解决方案
+
+### 数据库
+
+#### 数据库主键自增
+
+这种方式就比较简单直白了,就是通过关系型数据库的自增主键产生来唯一的 ID。
+
+
+
+以 MySQL 举例,我们通过下面的方式即可。
+
+**1.创建一个数据库表。**
+
+```sql
+CREATE TABLE `sequence_id` (
+ `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
+ `stub` char(10) NOT NULL DEFAULT '',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `stub` (`stub`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+`stub` 字段无意义,只是为了占位,便于我们插入或者修改数据。并且,给 `stub` 字段创建了唯一索引,保证其唯一性。
+
+**2.通过 `replace into` 来插入数据。**
+
+```java
+BEGIN;
+REPLACE INTO sequence_id (stub) VALUES ('stub');
+SELECT LAST_INSERT_ID();
+COMMIT;
+```
+
+插入数据这里,我们没有使用 `insert into` 而是使用 `replace into` 来插入数据,具体步骤是这样的:
+
+- 第一步:尝试把数据插入到表中。
+
+- 第二步:如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
+
+这种方式的优缺点也比较明显:
+
+- **优点**:实现起来比较简单、ID 有序递增、存储消耗空间小
+- **缺点**:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
+
+#### 数据库号段模式
+
+数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,ID 需求比较大的时候,肯定是不行的。
+
+如果我们可以批量获取,然后存在在内存里面,需要用到的时候,直接从内存里面拿就舒服了!这也就是我们说的 **基于数据库的号段模式来生成分布式 ID。**
+
+数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的[Tinyid](https://github.com/didi/tinyid/wiki/tinyid原理介绍) 就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化。
+
+以 MySQL 举例,我们通过下面的方式即可。
+
+**1. 创建一个数据库表。**
+
+```sql
+CREATE TABLE `sequence_id_generator` (
+ `id` int(10) NOT NULL,
+ `current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
+ `step` int(10) NOT NULL COMMENT '号段的长度',
+ `version` int(20) NOT NULL COMMENT '版本号',
+ `biz_type` int(20) NOT NULL COMMENT '业务类型',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+`current_max_id` 字段和`step`字段主要用于获取批量 ID,获取的批量 id 为:`current_max_id ~ current_max_id+step`。
+
+
+
+`version` 字段主要用于解决并发问题(乐观锁),`biz_type` 主要用于表示业务类型。
+
+**2. 先插入一行数据。**
+
+```sql
+INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
+VALUES
+ (1, 0, 100, 0, 101);
+```
+
+**3. 通过 SELECT 获取指定业务下的批量唯一 ID**
+
+```sql
+SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
+```
+
+结果:
+
+```plain
+id current_max_id step version biz_type
+1 0 100 0 101
+```
+
+**4. 不够用的话,更新之后重新 SELECT 即可。**
+
+```sql
+UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
+SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
+```
+
+结果:
+
+```plain
+id current_max_id step version biz_type
+1 100 100 1 101
+```
+
+相比于数据库主键自增的方式,**数据库的号段模式对于数据库的访问次数更少,数据库压力更小。**
+
+另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
+
+**数据库号段模式的优缺点:**
+
+- **优点**:ID 有序递增、存储消耗空间小
+- **缺点**:存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
+
+#### NoSQL
+
+
+
+一般情况下,NoSQL 方案使用 Redis 多一些。我们通过 Redis 的 `incr` 命令即可实现对 id 原子顺序递增。
+
+```bash
+127.0.0.1:6379> set sequence_id_biz_type 1
+OK
+127.0.0.1:6379> incr sequence_id_biz_type
+(integer) 2
+127.0.0.1:6379> get sequence_id_biz_type
+"2"
+```
+
+为了提高可用性和并发,我们可以使用 Redis Cluster。Redis Cluster 是 Redis 官方提供的 Redis 集群解决方案(3.0+版本)。
+
+除了 Redis Cluster 之外,你也可以使用开源的 Redis 集群方案[Codis](https://github.com/CodisLabs/codis) (大规模集群比如上百个节点的时候比较推荐)。
+
+除了高可用和并发之外,我们知道 Redis 基于内存,我们需要持久化数据,避免重启机器或者机器故障后数据丢失。Redis 支持两种不同的持久化方式:**快照(snapshotting,RDB)**、**只追加文件(append-only file, AOF)**。 并且,Redis 4.0 开始支持 **RDB 和 AOF 的混合持久化**(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+
+关于 Redis 持久化,我这里就不过多介绍。不了解这部分内容的小伙伴,可以看看 [Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html)这篇文章。
+
+**Redis 方案的优缺点:**
+
+- **优点**:性能不错并且生成的 ID 是有序递增的
+- **缺点**:和数据库主键自增方案的缺点类似
+
+除了 Redis 之外,MongoDB ObjectId 经常也会被拿来当做分布式 ID 的解决方案。
+
+
+
+MongoDB ObjectId 一共需要 12 个字节存储:
+
+- 0~3:时间戳
+- 3~6:代表机器 ID
+- 7~8:机器进程 ID
+- 9~11:自增值
+
+**MongoDB 方案的优缺点:**
+
+- **优点**:性能不错并且生成的 ID 是有序递增的
+- **缺点**:需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)
+
+### 算法
+
+#### UUID
+
+UUID 是 Universally Unique Identifier(通用唯一标识符) 的缩写。UUID 包含 32 个 16 进制数字(8-4-4-4-12)。
+
+JDK 就提供了现成的生成 UUID 的方法,一行代码就行了。
+
+```java
+//输出示例:cb4a9ede-fa5e-4585-b9bb-d60bce986eaa
+UUID.randomUUID()
+```
+
+[RFC 4122](https://tools.ietf.org/html/rfc4122) 中关于 UUID 的示例是这样的:
+
+
+
+我们这里重点关注一下这个 Version(版本),不同的版本对应的 UUID 的生成规则是不同的。
+
+8 种不同的 Version(版本)值分别对应的含义(参考[维基百科对于 UUID 的介绍](https://zh.wikipedia.org/wiki/通用唯一识别码)):
+
+- **版本 1 (基于时间和节点 ID)** : 基于时间戳(通常是当前时间)和节点 ID(通常为设备的 MAC 地址)生成。当包含 MAC 地址时,可以保证全球唯一性,但也因此存在隐私泄露的风险。
+- **版本 2 (基于标识符、时间和节点 ID)** : 与版本 1 类似,也基于时间和节点 ID,但额外包含了本地标识符(例如用户 ID 或组 ID)。
+- **版本 3 (基于命名空间和名称的 MD5 哈希)**:使用 MD5 哈希算法,将命名空间标识符(一个 UUID)和名称字符串组合计算得到。相同的命名空间和名称总是生成相同的 UUID(**确定性生成**)。
+- **版本 4 (基于随机数)**:几乎完全基于随机数生成,通常使用伪随机数生成器(PRNG)或加密安全随机数生成器(CSPRNG)来生成。 虽然理论上存在碰撞的可能性,但理论上碰撞概率极低(2^122 的可能性),可以认为在实际应用中是唯一的。
+- **版本 5 (基于命名空间和名称的 SHA-1 哈希)**:类似于版本 3,但使用 SHA-1 哈希算法。
+- **版本 6 (基于时间戳、计数器和节点 ID)**:改进了版本 1,将时间戳放在最高有效位(Most Significant Bit,MSB),使得 UUID 可以直接按时间排序。
+- **版本 7 (基于时间戳和随机数据)**:基于 Unix 时间戳和随机数据生成。 由于时间戳位于最高有效位,因此支持按时间排序。并且,不依赖 MAC 地址或节点 ID,避免了隐私问题。
+- **版本 8 (自定义)**:允许用户根据自己的需求定义 UUID 的生成方式。其结构和内容由用户决定,提供更大的灵活性。
+
+下面是 Version 1 版本下生成的 UUID 的示例:
+
+
+
+JDK 中通过 `UUID` 的 `randomUUID()` 方法生成的 UUID 的版本默认为 4。
+
+```java
+UUID uuid = UUID.randomUUID();
+int version = uuid.version();// 4
+```
+
+另外,Variant(变体)也有 4 种不同的值,这种值分别对应不同的含义。这里就不介绍了,貌似平时也不怎么需要关注。
+
+需要用到的时候,去看看维基百科对于 UUID 的 Variant(变体) 相关的介绍即可。
+
+从上面的介绍中可以看出,UUID 可以保证唯一性,因为其生成规则包括 MAC 地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,计算机基于这些规则生成的 UUID 是肯定不会重复的。
+
+虽然,UUID 可以做到全局唯一性,但是,我们一般很少会使用它。
+
+比如使用 UUID 作为 MySQL 数据库主键的时候就非常不合适:
+
+- 数据库主键要尽量越短越好,而 UUID 的消耗的存储空间比较大(32 个字符串,128 位)。
+- UUID 是无顺序的,InnoDB 引擎下,数据库主键的无序性会严重影响数据库性能。
+
+最后,我们再简单分析一下 **UUID 的优缺点** (面试的时候可能会被问到的哦!) :
+
+- **优点**:生成速度通常比较快、简单易用
+- **缺点**:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
+
+#### Snowflake(雪花算法)
+
+Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
+
+
+
+- **sign(1bit)**:符号位(标识正负),始终为 0,代表生成的 ID 为正数。
+- **timestamp (41 bits)**:一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
+- **datacenter id + worker id (10 bits)**:一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
+- **sequence (12 bits)**:一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
+
+在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在 Snowflake 算法生成的 ID 中加入业务类型信息。
+
+我们再来看看 Snowflake 算法的优缺点:
+
+- **优点**:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
+- **缺点**:需要解决重复 ID 问题(ID 生成依赖时间,在获取时间的时候,可能会出现时间回拨的问题,也就是服务器上的时间突然倒退到之前的时间,进而导致会产生重复 ID)、依赖机器 ID 对分布式环境不友好(当需要自动启停或增减机器时,固定的机器 ID 可能不够灵活)。
+
+如果你想要使用 Snowflake 算法的话,一般不需要你自己再造轮子。有很多基于 Snowflake 算法的开源实现比如美团 的 Leaf、百度的 UidGenerator(后面会提到),并且这些开源实现对原有的 Snowflake 算法进行了优化,性能更优秀,还解决了 Snowflake 算法的时间回拨问题和依赖机器 ID 的问题。
+
+并且,Seata 还提出了“改良版雪花算法”,针对原版雪花算法进行了一定的优化改良,解决了时间回拨问题,大幅提高的 QPS。具体介绍和改进原理,可以参考下面这两篇文章:
+
+- [Seata 基于改良版雪花算法的分布式 UUID 生成器分析](https://seata.io/zh-cn/blog/seata-analysis-UUID-generator.html)
+- [在开源项目中看到一个改良版的雪花算法,现在它是你的了。](https://www.cnblogs.com/thisiswhy/p/17611163.html)
+
+### 开源框架
+
+#### UidGenerator(百度)
+
+[UidGenerator](https://github.com/baidu/uid-generator) 是百度开源的一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
+
+不过,UidGenerator 对 Snowflake(雪花算法)进行了改进,生成的唯一 ID 组成如下:
+
+
+
+- **sign(1bit)**:符号位(标识正负),始终为 0,代表生成的 ID 为正数。
+- **delta seconds (28 bits)**:当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约 8.7 年
+- **worker id (22 bits)**:机器 id,最多可支持约 420w 次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
+- **sequence (13 bits)**:每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
+
+可以看出,和原始 Snowflake(雪花算法)生成的唯一 ID 的组成不太一样。并且,上面这些参数我们都可以自定义。
+
+UidGenerator 官方文档中的介绍如下:
+
+
+
+自 18 年后,UidGenerator 就基本没有再维护了,我这里也不过多介绍。想要进一步了解的朋友,可以看看 [UidGenerator 的官方介绍](https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md)。
+
+#### Leaf(美团)
+
+[Leaf](https://github.com/Meituan-Dianping/Leaf) 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话:“There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
+
+Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId) 。
+
+Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的方法多种多样以及不可靠的问题。
+
+Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))。
+
+
+
+根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
+
+#### Tinyid(滴滴)
+
+[Tinyid](https://github.com/didi/tinyid) 是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
+
+数据库号段模式的原理我们在上面已经介绍过了。**Tinyid 有哪些亮点呢?**
+
+为了搞清楚这个问题,我们先来看看基于数据库号段模式的简单架构方案。(图片来自于 Tinyid 的官方 wiki:[《Tinyid 原理介绍》](https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D))
+
+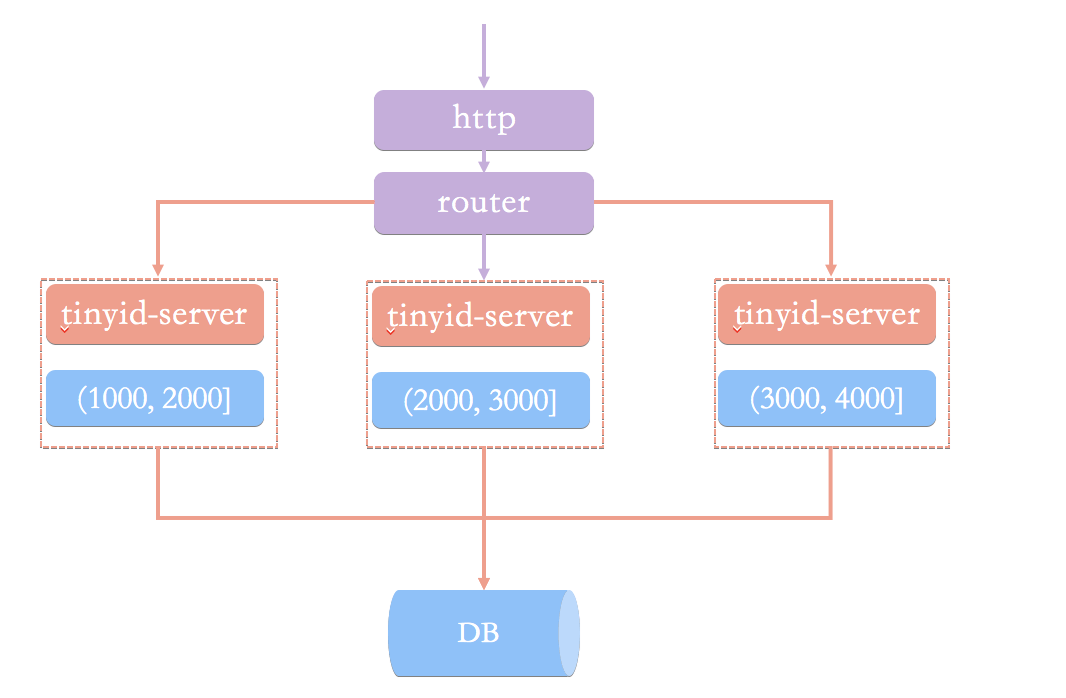
+
+在这种架构模式下,我们通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server。
+
+这种方案有什么问题呢?在我看来(Tinyid 官方 wiki 也有介绍到),主要由下面这 2 个问题:
+
+- 获取新号段的情况下,程序获取唯一 ID 的速度比较慢。
+- 需要保证 DB 高可用,这个是比较麻烦且耗费资源的。
+
+除此之外,HTTP 调用也存在网络开销。
+
+Tinyid 的原理比较简单,其架构如下图所示:
+
+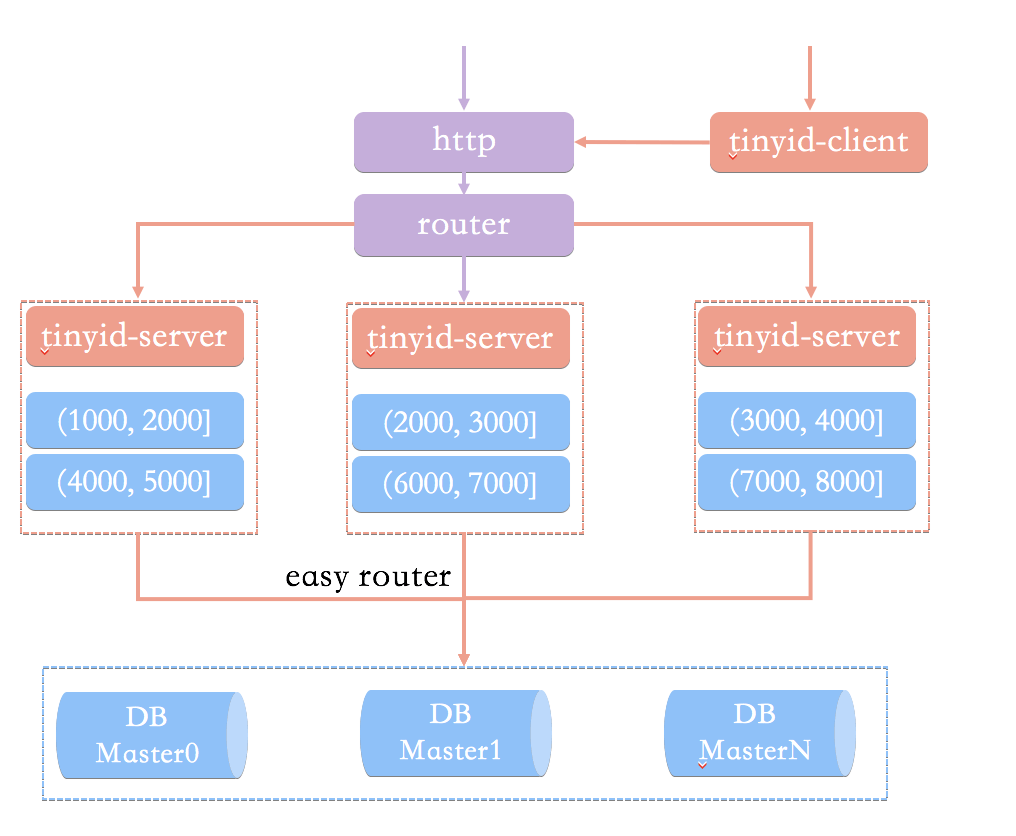
+
+相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
+
+- **双号段缓存**:为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
+- **增加多 db 支持**:支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
+- **增加 tinyid-client**:纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
+
+Tinyid 的优缺点这里就不分析了,结合数据库号段模式的优缺点和 Tinyid 的原理就能知道。
+
+#### IdGenerator(个人)
+
+和 UidGenerator、Leaf 一样,[IdGenerator](https://github.com/yitter/IdGenerator) 也是一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
+
+IdGenerator 有如下特点:
+
+- 生成的唯一 ID 更短;
+- Compatible with all snowflake algorithms (number segment mode or classic mode, big factory or small factory);
+- Natively supports C#/Java/Go/C/Rust/Python/Node.js/PHP (C extension)/SQL/ and other languages, and provides multi-threaded safe dynamic library calling (FFI);
+- Solve the time callback problem and support manual insertion of new IDs (when the business needs to generate new IDs in historical time, the reserved bits of this algorithm can generate 5000 per second);
+- Does not rely on external storage systems;
+- In the default configuration, IDs are available for 71000 years without duplication.
+
+The unique ID generated by the IdGenerator consists of:
+
+
+
+- **timestamp (number of digits is not fixed)**: The time difference is the total time difference (in milliseconds) from the system time when the ID is generated minus BaseTime (base time, also called base time, origin time, epoch time, the default value is 2020). Initial is 5bits and increases with running time. If you feel that the default value is too old, you can reset it, but be aware that it is best not to change this value in the future.
+- **worker id (default 6 bits)**: machine id, machine code, the most important parameter, is the unique ID that distinguishes different machines or different applications. The maximum value is limited by `WorkerIdBitLength` (default 6). If a server deploys multiple independent services, you need to specify a different WorkerId for each service.
+- **sequence (default 6 bits)**: The number of sequences, which is the number of sequences per millisecond, is limited by the `SeqBitLength` (default 6) in the parameter. Increasing `SeqBitLength` will result in better performance, but the generated IDs will also be longer.
+
+Java language usage example: .
+
+## Summary
+
+Through this article, I have basically summarized the most common distributed ID generation solutions.
+
+In addition to the methods introduced above, middleware like ZooKeeper can also help us generate unique IDs. **There is no silver bullet. You must choose the solution that best suits you based on the actual project. **
+
+However, this article mainly introduces the theoretical knowledge of distributed ID. In an actual interview, the interviewer may examine your design of distributed ID based on specific business scenarios. You can refer to this article: [Distributed ID Design Guide](./distributed-id-design) (it is also very helpful for the design of distributed ID in actual work).
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-lock-implementations.en.md b/docs_en/distributed-system/distributed-lock-implementations.en.md
new file mode 100644
index 00000000000..bea69b2329a
--- /dev/null
+++ b/docs_en/distributed-system/distributed-lock-implementations.en.md
@@ -0,0 +1,372 @@
+---
+title: Summary of common implementation solutions for distributed locks
+category: distributed
+---
+
+
+
+Under normal circumstances, we generally choose to implement distributed locks based on Redis or ZooKeeper. Redis is used more often. I will first introduce the implementation of distributed locks using Redis as an example.
+
+## Implement distributed lock based on Redis
+
+### How to implement the simplest distributed lock based on Redis?
+
+Whether it is a local lock or a distributed lock, the core lies in "mutual exclusion".
+
+In Redis, the `SETNX` command can help us achieve mutual exclusion. `SETNX` is **SET** if **N**ot e**X**ists (corresponding to the `setIfAbsent` method in Java). If the key does not exist, the value of the key will be set. If key already exists, `SETNX` does nothing.
+
+```bash
+> SETNX lockKey uniqueValue
+(integer) 1
+> SETNX lockKey uniqueValue
+(integer) 0
+```
+
+To release the lock, delete the corresponding key directly through the `DEL` command.
+
+```bash
+> DEL lockKey
+(integer) 1
+```
+
+In order to prevent accidentally deleting other locks, we recommend using Lua script to judge by the value (unique value) corresponding to the key.
+
+The Lua script was chosen to ensure the atomicity of the unlocking operation. Because Redis can execute Lua scripts in an atomic manner, thus ensuring the atomicity of the lock release operation.
+
+```lua
+// When releasing the lock, first compare the value values corresponding to the lock to see if they are equal to avoid accidentally releasing the lock.
+if redis.call("get",KEYS[1]) == ARGV[1] then
+ return redis.call("del",KEYS[1])
+else
+ return 0
+end
+```
+
+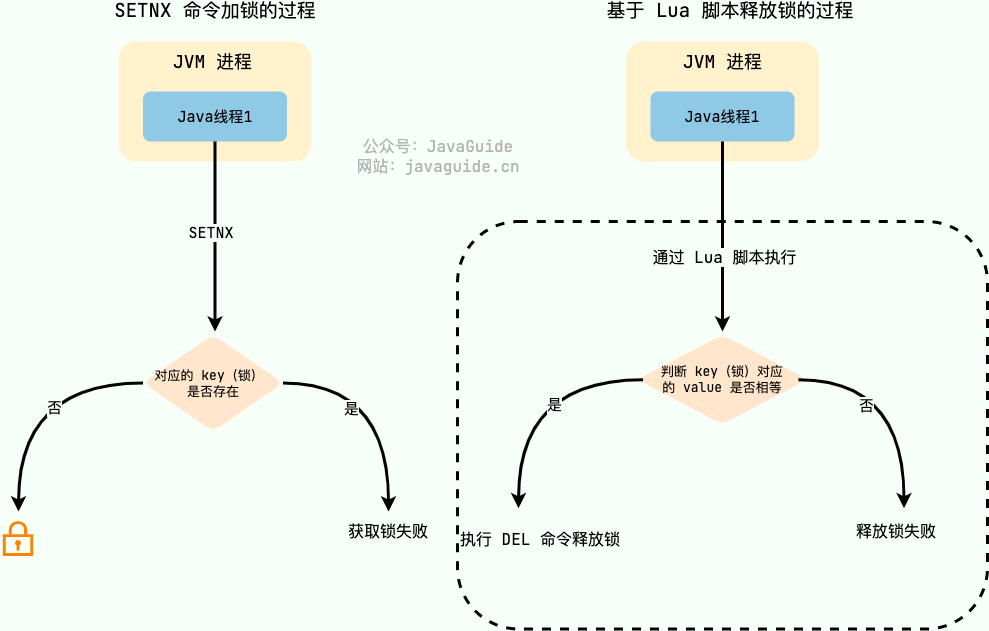
+
+This is the simplest Redis distributed lock implementation. The implementation method is relatively simple and the performance is very efficient. However, there are some problems with implementing distributed locking in this way. For example, if the application encounters some problems, such as the logic of releasing the lock suddenly hangs up, the lock may not be released, and the shared resources can no longer be accessed by other threads/processes.
+
+### Why do we need to set an expiration time for the lock?
+
+In order to prevent the lock from being released, one solution we can think of is: **Set an expiration time** for this key (that is, the lock).
+
+```bash
+127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
+OK
+```
+
+- **lockKey**: the lock name;
+- **uniqueValue**: a random string that uniquely identifies the lock;
+- **NX**: SET can only succeed when the key value corresponding to lockKey does not exist;
+- **EX**: Expiration time setting (in seconds) EX 3 indicates that this lock has an automatic expiration time of 3 seconds. Corresponding to EX is PX (in milliseconds), both of which are expiration time settings.
+
+**Be sure to ensure that setting the value and expiration time of the specified key is an atomic operation! ! ! ** Otherwise, there may still be a problem that the lock cannot be released.
+
+This can indeed solve the problem, but this solution also has loopholes: **If the time to operate the shared resource is greater than the expiration time, there will be a problem of early expiration of the lock, which will lead to the direct failure of the distributed lock. If the lock timeout is set too long, performance will be affected. **
+
+You may be thinking: **If the operation of operating shared resources has not been completed, it would be great if the lock expiration time could be renewed by itself! **
+
+### How to achieve graceful renewal of locks?
+
+For Java development partners, there is already a ready-made solution: **[Redisson](https://github.com/redisson/redisson)**. Solutions in other languages can be found in the official Redis documentation at: .
+
+
+
+Redisson is an open source Java language Redis client that provides many out-of-the-box features, including not only the implementation of multiple distributed locks. Moreover, Redisson also supports multiple deployment architectures such as Redis stand-alone, Redis Sentinel, and Redis Cluster.
+
+The distributed lock in Redisson comes with an automatic renewal mechanism. It is very simple to use and the principle is relatively simple. It provides a **Watch Dog** specially used to monitor and renew the lock. If the thread operating the shared resource has not completed execution, the Watch Dog will continuously extend the expiration time of the lock, thereby ensuring that the lock will not be released due to timeout.
+
+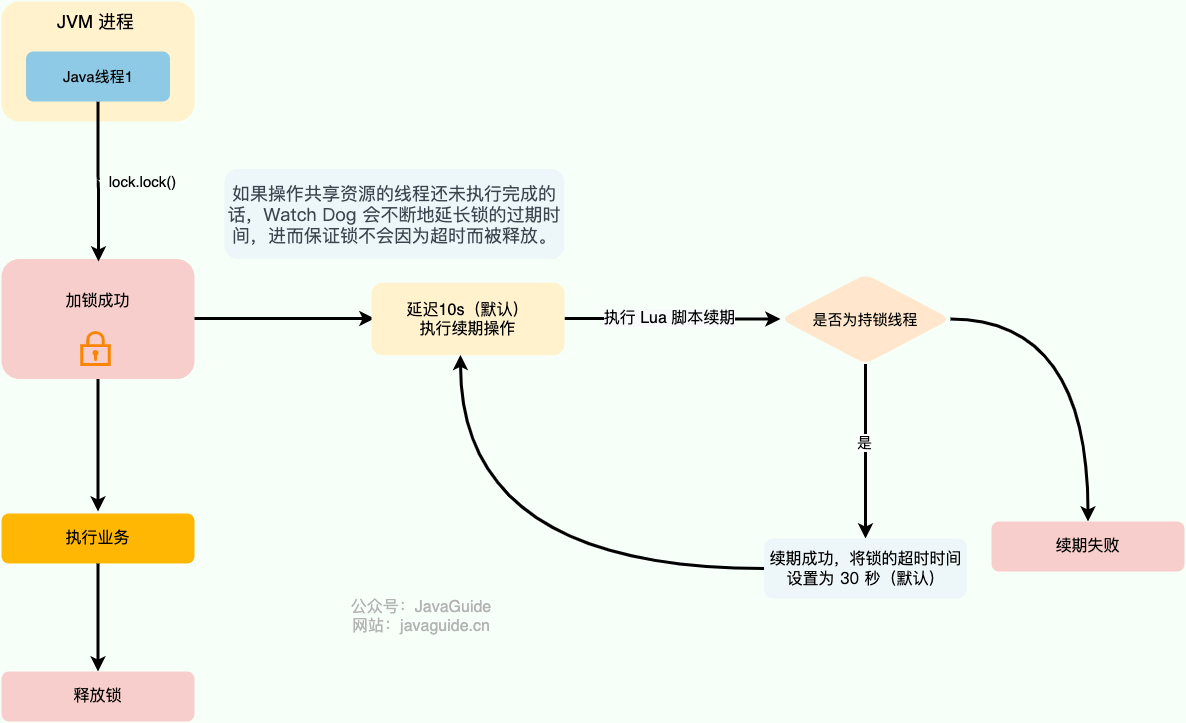
+
+The name of the watchdog comes from the `getLockWatchdogTimeout()` method. This method returns the expiration time for the watchdog to renew the lock. The default is 30 seconds ([redisson-3.17.6](https://github.com/redisson/redisson/releases/tag/redisson-3.17.6)).
+
+```java
+//Default 30 seconds, supports modification
+private long lockWatchdogTimeout = 30 * 1000;
+
+public Config setLockWatchdogTimeout(long lockWatchdogTimeout) {
+ this.lockWatchdogTimeout = lockWatchdogTimeout;
+ return this;
+}
+public long getLockWatchdogTimeout() {
+ return lockWatchdogTimeout;
+}
+```
+
+The `renewExpiration()` method contains the main logic of the watchdog:
+
+```java
+private void renewExpiration() {
+ //......
+ Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
+ @Override
+ public void run(Timeout timeout) throws Exception {
+ //......
+ //Asynchronous renewal, based on Lua script
+ CompletionStage future = renewExpirationAsync(threadId);
+ future.whenComplete((res, e) -> {
+ if (e != null) {
+ //Cannot renew
+ log.error("Can't update lock " + getRawName() + " expiration", e);
+ EXPIRATION_RENEWAL_MAP.remove(getEntryName());
+ return;
+ }
+
+ if (res) {
+ // Recursive call to implement renewal
+ renewExpiration();
+ } else {
+ // Cancel renewal
+ cancelExpirationRenewal(null);
+ }
+ });
+ }
+ // Delay internalLockLeaseTime/3 (default 10s, which is 30/3) before calling
+ }, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
+
+ ee.setTimeout(task);
+ }
+```默认情况下,每过 10 秒,看门狗就会执行续期操作,将锁的超时时间设置为 30 秒。看门狗续期前也会先判断是否需要执行续期操作,需要才会执行续期,否则取消续期操作。
+
+Watch Dog 通过调用 `renewExpirationAsync()` 方法实现锁的异步续期:
+
+```java
+protected CompletionStage renewExpirationAsync(long threadId) {
+ return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
+ // 判断是否为持锁线程,如果是就执行续期操作,就锁的过期时间设置为 30s(默认)
+ "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
+ "redis.call('pexpire', KEYS[1], ARGV[1]); " +
+ "return 1; " +
+ "end; " +
+ "return 0;",
+ Collections.singletonList(getRawName()),
+ internalLockLeaseTime, getLockName(threadId));
+}
+```
+
+可以看出, `renewExpirationAsync` 方法其实是调用 Lua 脚本实现的续期,这样做主要是为了保证续期操作的原子性。
+
+我这里以 Redisson 的分布式可重入锁 `RLock` 为例来说明如何使用 Redisson 实现分布式锁:
+
+```java
+// 1.获取指定的分布式锁对象
+RLock lock = redisson.getLock("lock");
+// 2.拿锁且不设置锁超时时间,具备 Watch Dog 自动续期机制
+lock.lock();
+// 3.执行业务
+...
+// 4.释放锁
+lock.unlock();
+```
+
+只有未指定锁超时时间,才会使用到 Watch Dog 自动续期机制。
+
+```java
+// 手动给锁设置过期时间,不具备 Watch Dog 自动续期机制
+lock.lock(10, TimeUnit.SECONDS);
+```
+
+如果使用 Redis 来实现分布式锁的话,还是比较推荐直接基于 Redisson 来做的。
+
+### 如何实现可重入锁?
+
+所谓可重入锁指的是在一个线程中可以多次获取同一把锁,比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法即可重入 ,而无需重新获得锁。像 Java 中的 `synchronized` 和 `ReentrantLock` 都属于可重入锁。
+
+**不可重入的分布式锁基本可以满足绝大部分业务场景了,一些特殊的场景可能会需要使用可重入的分布式锁。**
+
+可重入分布式锁的实现核心思路是线程在获取锁的时候判断是否为自己的锁,如果是的话,就不用再重新获取了。为此,我们可以为每个锁关联一个可重入计数器和一个占有它的线程。当可重入计数器大于 0 时,则锁被占有,需要判断占有该锁的线程和请求获取锁的线程是否为同一个。
+
+实际项目中,我们不需要自己手动实现,推荐使用我们上面提到的 **Redisson** ,其内置了多种类型的锁比如可重入锁(Reentrant Lock)、自旋锁(Spin Lock)、公平锁(Fair Lock)、多重锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)。
+
+
+
+### Redis 如何解决集群情况下分布式锁的可靠性?
+
+为了避免单点故障,生产环境下的 Redis 服务通常是集群化部署的。
+
+Redis 集群下,上面介绍到的分布式锁的实现会存在一些问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
+
+
+
+针对这个问题,Redis 之父 antirez 设计了 [Redlock 算法](https://redis.io/topics/distlock) 来解决。
+
+
+
+Redlock 算法的思想是让客户端向 Redis 集群中的多个独立的 Redis 实例依次请求申请加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
+
+即使部分 Redis 节点出现问题,只要保证 Redis 集群中有半数以上的 Redis 节点可用,分布式锁服务就是正常的。
+
+Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的,这样才可以避免 Redis 集群主从切换导致的锁丢失问题。
+
+Redlock 实现比较复杂,性能比较差,发生时钟变迁的情况下还存在安全性隐患。《数据密集型应用系统设计》一书的作者 Martin Kleppmann 曾经专门发文([How to do distributed locking - Martin Kleppmann - 2016](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html))怼过 Redlock,他认为这是一个很差的分布式锁实现。感兴趣的朋友可以看看[Redis 锁从面试连环炮聊到神仙打架](https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505097&idx=1&sn=5c03cb769c4458350f4d4a321ad51f5a&source=41#wechat_redirect)这篇文章,有详细介绍到 antirez 和 Martin Kleppmann 关于 Redlock 的激烈辩论。
+
+实际项目中不建议使用 Redlock 算法,成本和收益不成正比,可以考虑基于 Redis 主从复制+哨兵模式实现分布式锁。
+
+## 基于 ZooKeeper 实现分布式锁
+
+ZooKeeper 相比于 Redis 实现分布式锁,除了提供相对更高的可靠性之外,在功能层面还有一个非常有用的特性:**Watch 机制**。这个机制可以用来实现公平的分布式锁。不过,使用 ZooKeeper 实现的分布式锁在性能方面相对较差,因此如果对性能要求比较高的话,ZooKeeper 可能就不太适合了。
+
+### 如何基于 ZooKeeper 实现分布式锁?
+
+ZooKeeper 分布式锁是基于 **临时顺序节点** 和 **Watcher(事件监听器)** 实现的。
+
+获取锁:
+
+1. 首先我们要有一个持久节点`/locks`,客户端获取锁就是在`locks`下创建临时顺序节点。
+2. 假设客户端 1 创建了`/locks/lock1`节点,创建成功之后,会判断 `lock1`是否是 `/locks` 下最小的子节点。
+3. 如果 `lock1`是最小的子节点,则获取锁成功。否则,获取锁失败。
+4. 如果获取锁失败,则说明有其他的客户端已经成功获取锁。客户端 1 并不会不停地循环去尝试加锁,而是在前一个节点比如`/locks/lock0`上注册一个事件监听器。这个监听器的作用是当前一个节点释放锁之后通知客户端 1(避免无效自旋),这样客户端 1 就加锁成功了。
+
+释放锁:
+
+1. 成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
+2. 成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
+3. 我们前面说的事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
+
+
+
+In actual projects, it is recommended to use Curator to implement ZooKeeper distributed locks. Curator is a set of ZooKeeper Java client frameworks open sourced by Netflix. Compared with ZooKeeper's own client zookeeper, Curator's encapsulation is more complete, and various APIs can be used more conveniently.
+
+`Curator` mainly implements the following four locks:
+
+- `InterProcessMutex`: distributed reentrant exclusive lock
+- `InterProcessSemaphoreMutex`: distributed non-reentrant exclusive lock
+- `InterProcessReadWriteLock`: distributed read-write lock
+- `InterProcessMultiLock`: A container that manages multiple locks as a single entity. When acquiring a lock, all locks are acquired. Releasing the lock will also release all lock resources (ignore locks that fail to be released).
+
+```java
+CuratorFramework client = ZKUtils.getClient();
+client.start();
+// Distributed reentrant exclusive lock
+InterProcessLock lock1 = new InterProcessMutex(client, lockPath1);
+// Distributed non-reentrant exclusive lock
+InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2);
+// Treat multiple locks as a whole
+InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));
+
+if (!lock.acquire(10, TimeUnit.SECONDS)) {
+ throw new IllegalStateException("Cannot acquire multiple locks");
+}
+System.out.println("Multiple locks acquired");
+System.out.println("Is there the first lock: " + lock1.isAcquiredInThisProcess());
+System.out.println("Is there a second lock: " + lock2.isAcquiredInThisProcess());
+try {
+ // Resource operations
+ resource.use();
+} finally {
+ System.out.println("Release multiple locks");
+ lock.release();
+}
+System.out.println("Is there the first lock: " + lock1.isAcquiredInThisProcess());
+System.out.println("Is there a second lock: " + lock2.isAcquiredInThisProcess());
+client.close();
+```
+
+### Why use temporary sequential nodes?
+
+Each data node is called **znode** in ZooKeeper, which is the smallest unit of data in ZooKeeper.
+
+We usually divide znodes into 4 major categories:
+
+- **persistent (PERSISTENT) node**: Once created, it will always exist even if the ZooKeeper cluster goes down, until it is deleted.
+- **Temporary (EPHEMERAL) node**: The life cycle of the temporary node is bound to the **client session (session)**. **The node disappears when the session disappears**. Moreover, **temporary nodes can only be used as leaf nodes** and cannot create child nodes.
+- **Persistent Sequence (PERSISTENT_SEQUENTIAL) node**: In addition to the characteristics of the persistent (PERSISTENT) node, the names of child nodes are also sequential. For example `/node1/app0000000001`, `/node1/app0000000002`.
+- **Temporary Sequential (EPHEMERAL_SEQUENTIAL) Node**: In addition to having the characteristics of temporary (EPHEMERAL) nodes, the names of child nodes are also sequential.
+
+It can be seen that compared with persistent nodes, the most important thing about temporary nodes is that they handle session failure differently. When the temporary node session disappears, the corresponding node disappears. In this case, it doesn't matter if an exception occurs on the client and the lock is not released in time. The session invalid node will be automatically deleted and deadlock will not occur.
+
+When using Redis to implement distributed locks, we use the expiration time to avoid deadlock problems caused by the lock being unable to be released, while ZooKeeper can directly use the characteristics of temporary nodes.
+
+Assuming that sequential nodes are not used, all clients that try to acquire a lock will add listeners to the child nodes holding the lock. When the lock is released, it will inevitably cause all clients trying to obtain the lock to compete for the lock, which is not friendly to performance. After using sequential nodes, you only need to listen to the previous node, which is more performance-friendly.
+
+### Why do we need to set up monitoring on the previous node?
+
+> Watcher (event listener) is a very important feature in ZooKeeper. ZooKeeper allows users to register some Watchers on designated nodes, and when certain events are triggered, the ZooKeeper server will notify interested clients of the event. This mechanism is an important feature of ZooKeeper in implementing distributed coordination services.
+
+During the same time period, many clients may acquire the lock at the same time, but only one can acquire it successfully. If the lock acquisition fails, it means that another client has successfully acquired the lock. The client that fails to acquire the lock will not keep looping to try to acquire the lock, but will register an event listener on the previous node.
+
+The function of this event listener is: **After the client corresponding to the current node releases the lock (that is, after the previous node is deleted, the listening event is the deletion event), notify the client that failed to acquire the lock (wake up the waiting thread, `wait/notifyAll` in Java), let it try to acquire the lock, and then successfully acquire the lock. **
+
+### How to implement reentrant lock?
+
+Here we use Curator's `InterProcessMutex` to introduce the implementation of reentrant locks (source code address: [InterProcessMutex.java](https://github.com/apache/curator/blob/master/curator-recipes/src/main/java/org/apache/curator/framework/recipes/locks/InterProcessMutex.java)).
+
+When we call the `InterProcessMutex#acquire` method to acquire the lock, the `InterProcessMutex#internalLock` method will be called.
+
+```java
+// Acquire the reentrant mutex until the acquisition is successful
+@Override
+public void acquire() throws Exception {
+ if (!internalLock(-1, null)) {
+ throw new IOException("Lost connection while trying to acquire lock: " + basePath);
+ }
+}
+```
+
+The `internalLock` method will first obtain the thread currently requesting the lock, and then obtain the `lockData` corresponding to the current thread from `threadData` (`ConcurrentMap` type). `lockData` contains lock information and the number of locks, which is the key to implementing reentrant locks.
+
+When the lock is acquired for the first time, `lockData` is `null`. After successfully acquiring the lock, the current thread and the corresponding `lockData` will be placed in `threadData`
+
+```java
+private boolean internalLock(long time, TimeUnit unit) throws Exception {
+ // Get the thread currently requesting the lock
+ Thread currentThread = Thread.currentThread();
+ // Get the corresponding lockData
+ LockData lockData = threadData.get(currentThread);
+ // When acquiring the lock for the first time, lockData is null
+ if (lockData != null) {
+ //After the current thread acquires the lock once
+ // Because the current thread's lock exists, lockCount is incremented and then returned to achieve lock reentrancy.
+ lockData.lockCount.incrementAndGet();
+ return true;
+ }
+ //Try to acquire the lock
+ String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
+ if (lockPath != null) {
+ LockData newLockData = new LockData(currentThread, lockPath);
+ // After successfully acquiring the lock, put the current thread and the corresponding lockData into threadData.
+ threadData.put(currentThread, newLockData);
+ return true;
+ }
+
+ return false;
+}
+```
+
+`LockData` is a static inner class in `InterProcessMutex`.
+
+```java
+private final ConcurrentMap threadData = Maps.newConcurrentMap();
+
+private static class LockData
+{
+ //The thread currently holding the lock
+ final Thread owningThread;
+ // Lock the corresponding child node
+ final String lockPath;
+ //Number of locks
+ final AtomicInteger lockCount = new AtomicInteger(1);
+
+ private LockData(Thread owningThread, String lockPath)
+ {
+ this.owningThread = owningThread;
+ this.lockPath = lockPath;
+ }
+}```
+
+If the lock has been acquired once and you acquire the lock again later, it will be blocked directly at `if (lockData != null)`, and then `lockData.lockCount.incrementAndGet();` will be executed to increase the number of locks by 1.
+
+The implementation logic of the entire reentrant lock is very simple. You can directly determine whether the current thread has acquired the lock on the client side. If so, just add 1 to the number of locks.
+
+## Summary
+
+In this article, I introduced two common ways to implement distributed locks: **Redis** and **ZooKeeper**. As for the specific choice of Redis or ZooKeeper to implement distributed locks, it still depends on the specific needs of the business.
+
+- If the performance requirements are relatively high, it is recommended to use Redis to implement distributed locks. It is recommended to choose the ready-made distributed lock provided by **Redisson** instead of implementing it yourself. It is not recommended to use the Redlock algorithm in actual projects because the costs and benefits are not proportional. You can consider implementing distributed locks based on Redis master-slave replication + sentinel mode.
+- If the reliability requirements are relatively high, it is recommended to use ZooKeeper to implement distributed locks, and it is recommended to implement it based on the **Curator** framework. However, many projects now do not use ZooKeeper. It is not advisable to introduce ZooKeeper simply because of distributed locks. It is not recommended. It increases the complexity of the system for a small function.
+
+It should be noted that no matter which method you choose to implement distributed locks, including Redis, ZooKeeper or Etcd (not introduced in this article, but often used to implement distributed locks), there is no guarantee of 100% security, especially when encountering abnormal situations such as process garbage collection (GC) and network delays.
+
+In order to further improve the reliability of the system, it is recommended to introduce a safety net mechanism. For example, concurrency conflicts can be avoided through the **version number (Fencing Token) mechanism**.
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-lock.en.md b/docs_en/distributed-system/distributed-lock.en.md
new file mode 100644
index 00000000000..7caa7daf74e
--- /dev/null
+++ b/docs_en/distributed-system/distributed-lock.en.md
@@ -0,0 +1,85 @@
+---
+title: 分布式锁介绍
+category: 分布式
+---
+
+
+
+网上有很多分布式锁相关的文章,写了一个相对简洁易懂的版本,针对面试和工作应该够用了。
+
+这篇文章我们先介绍一下分布式锁的基本概念。
+
+## 为什么需要分布式锁?
+
+在多线程环境中,如果多个线程同时访问共享资源(例如商品库存、外卖订单),会发生数据竞争,可能会导致出现脏数据或者系统问题,威胁到程序的正常运行。
+
+举个例子,假设现在有 100 个用户参与某个限时秒杀活动,每位用户限购 1 件商品,且商品的数量只有 3 个。如果不对共享资源进行互斥访问,就可能出现以下情况:
+
+- 线程 1、2、3 等多个线程同时进入抢购方法,每一个线程对应一个用户。
+- 线程 1 查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
+- 线程 2 也执行查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
+- 线程 1 继续执行,将库存数量减少 1 个,然后返回成功。
+- 线程 2 继续执行,将库存数量减少 1 个,然后返回成功。
+- 此时就发生了超卖问题,导致商品被多卖了一份。
+
+
+
+为了保证共享资源被安全地访问,我们需要使用互斥操作对共享资源进行保护,即同一时刻只允许一个线程访问共享资源,其他线程需要等待当前线程释放后才能访问。这样可以避免数据竞争和脏数据问题,保证程序的正确性和稳定性。
+
+**如何才能实现共享资源的互斥访问呢?** 锁是一个比较通用的解决方案,更准确点来说是悲观锁。
+
+悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**。
+
+对于单机多线程来说,在 Java 中,我们通常使用 `ReentrantLock` 类、`synchronized` 关键字这类 JDK 自带的 **本地锁** 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
+
+下面是我对本地锁画的一张示意图。
+
+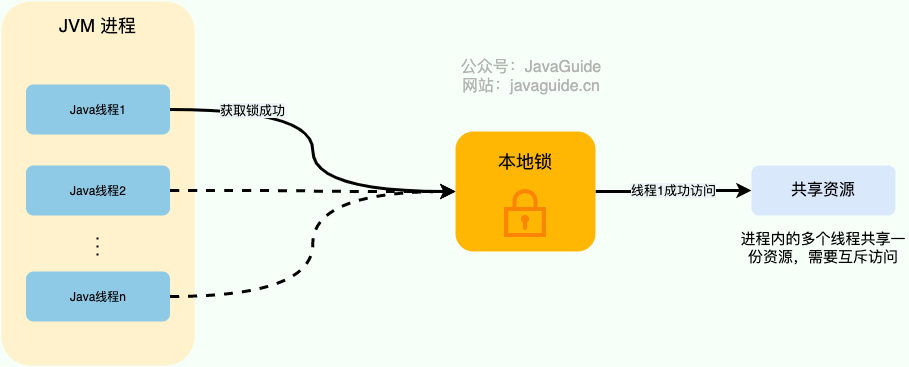
+
+从图中可以看出,这些线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到本地锁访问共享资源。
+
+分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。于是,**分布式锁** 就诞生了。
+
+举个例子:系统的订单服务一共部署了 3 份,都对外提供服务。用户下订单之前需要检查库存,为了防止超卖,这里需要加锁以实现对检查库存操作的同步访问。由于订单服务位于不同的 JVM 进程中,本地锁在这种情况下就没办法正常工作了。我们需要用到分布式锁,这样的话,即使多个线程不在同一个 JVM 进程中也能获取到同一把锁,进而实现共享资源的互斥访问。
+
+下面是我对分布式锁画的一张示意图。
+
+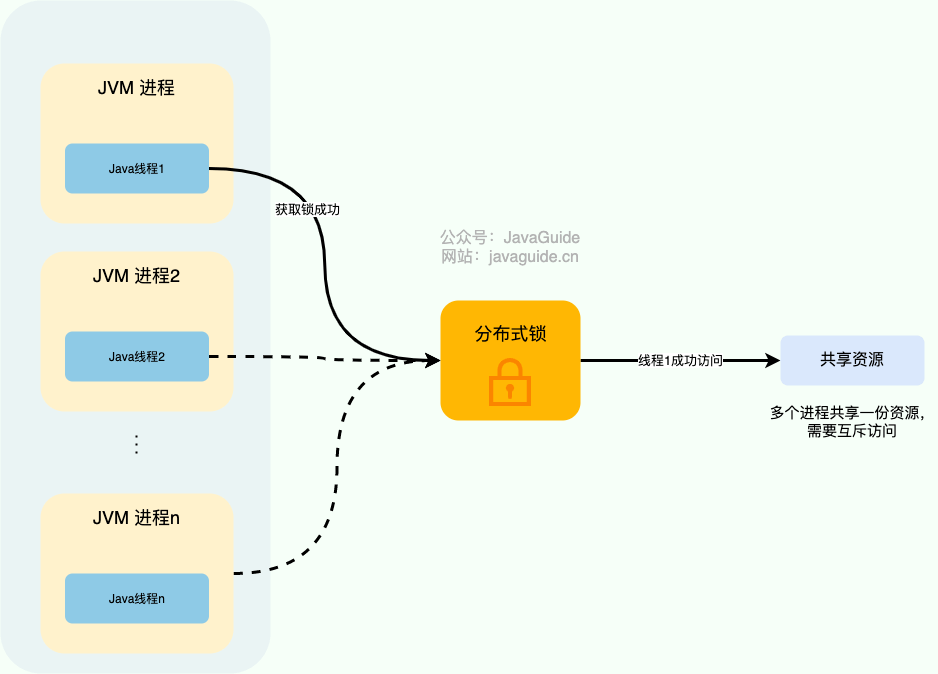
+
+从图中可以看出,这些独立的进程中的线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到分布式锁访问共享资源。
+
+## 分布式锁应该具备哪些条件?
+
+一个最基本的分布式锁需要满足:
+
+- **互斥**:任意一个时刻,锁只能被一个线程持有。
+- **高可用**:锁服务是高可用的,当一个锁服务出现问题,能够自动切换到另外一个锁服务。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。这一般是通过超时机制实现的。
+- **可重入**:一个节点获取了锁之后,还可以再次获取锁。
+
+除了上面这三个基本条件之外,一个好的分布式锁还需要满足下面这些条件:
+
+- **高性能**:获取和释放锁的操作应该快速完成,并且不应该对整个系统的性能造成过大影响。
+- **非阻塞**:如果获取不到锁,不能无限期等待,避免对系统正常运行造成影响。
+
+## 分布式锁的常见实现方式有哪些?
+
+常见分布式锁实现方案如下:
+
+- 基于关系型数据库比如 MySQL 实现分布式锁。
+- 基于分布式协调服务 ZooKeeper 实现分布式锁。
+- 基于分布式键值存储系统比如 Redis 、Etcd 实现分布式锁。
+
+关系型数据库的方式一般是通过唯一索引或者排他锁实现。不过,一般不会使用这种方式,问题太多比如性能太差、不具备锁失效机制。
+
+基于 ZooKeeper 或者 Redis 实现分布式锁这两种实现方式要用的更多一些,我专门写了一篇文章来详细介绍这两种方案:[分布式锁常见实现方案总结](./distributed-lock-implementations.md)。
+
+## 总结
+
+这篇文章我们主要介绍了:
+
+- 分布式锁的用途:分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。
+- 分布式锁的应该具备的条件:互斥、高可用、可重入、高性能、非阻塞。
+- 分布式锁的常见实现方式:关系型数据库比如 MySQL、分布式协调服务 ZooKeeper、分布式键值存储系统比如 Redis 、Etcd 。
+
+
+
diff --git a/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.en.md b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.en.md
new file mode 100644
index 00000000000..33a12bb2026
--- /dev/null
+++ b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.en.md
@@ -0,0 +1,296 @@
+---
+title: ZooKeeper in action
+category: distributed
+tag:
+ - ZooKeeper
+---
+
+This article briefly demonstrates the use of common ZooKeeper commands and the basic use of ZooKeeper Java client Curator. The contents introduced are all the most basic operations, which can meet the basic needs of daily work.
+
+If there is anything that needs to be improved or perfected in the article, please point it out in the comment area and make progress together!
+
+## ZooKeeper installation
+
+### Install zookeeper using Docker
+
+**a. Download ZooKeeper using Docker**
+
+```shell
+docker pull zookeeper:3.5.8
+```
+
+**b.Run ZooKeeper**
+
+```shell
+docker run -d --name zookeeper -p 2181:2181 zookeeper:3.5.8
+```
+
+### Connect to ZooKeeper service
+
+**a. Enter the ZooKeeper container**
+
+First use `docker ps` to view the ContainerID of ZooKeeper, and then use the `docker exec -it ContainerID /bin/bash` command to enter the container.
+
+**b. First enter the bin directory, and then connect to the ZooKeeper service through the `./zkCli.sh -server 127.0.0.1:2181` command**
+
+```bash
+root@eaf70fc620cb:/apache-zookeeper-3.5.8-bin# cd bin
+```
+
+If you see the following information printed out successfully on the console, it means you have successfully connected to the ZooKeeper service.
+
+
+
+## ZooKeeper common command demonstration
+
+### View commonly used commands (help command)
+
+Use the `help` command to view common ZooKeeper commands
+
+### Create node (create command)
+
+The node1 node was created in the root directory through the `create` command, and the string associated with it is "node1"
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 34] create /node1 "node1"
+```
+
+The node1 node was created in the root directory through the `create` command, and the content associated with it is the number 123
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 1] create /node1/node1.1 123
+Created /node1/node1.1
+```
+
+### Update node data content (set command)
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 11] set /node1 "set node1"
+```
+
+### Get node data (get command)
+
+The `get` command can obtain the data content of the specified node and the status of the node. It can be seen that we have changed the node data content to "set node1" through the `set` command.
+
+```shell
+[zk: zookeeper(CONNECTED) 12] get -s /node1
+set node1
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x4b
+mtime = Sun Jan 20 10:41:10 CST 2019
+pZxid = 0x4a
+cversion=1
+dataVersion = 1
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 9
+numChildren = 1
+
+```
+
+### View subnodes in a directory (ls command)
+
+Use the `ls` command to view the nodes in the root directory
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 37] ls /
+[dubbo, ZooKeeper, node1]
+```
+
+Use the `ls` command to view the nodes in the node1 directory
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 5] ls /node1
+[node1.1]
+```
+
+The ls command in ZooKeeper is similar to the ls command in Linux. This command will list all child node information under the absolute path path (listing level 1, not recursively)
+
+### View node status (stat command)
+
+Check node status through `stat` command
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 10] stat /node1
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x47
+mtime = Sun Jan 20 10:22:59 CST 2019
+pZxid = 0x4a
+cversion=1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 11
+numChildren = 1
+```
+
+Some of the information displayed above, such as cversion, aclVersion, numChildren, etc., I have already introduced in the above article "[ZooKeeper Related Concept Summary (Getting Started)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html)".
+
+### View node information and status (ls2 command)
+
+The `ls2` command is more like a combination of the `ls` command and the `stat` command. The information returned by the `ls2` command includes 2 parts:
+
+1. Child node list
+2. The stat information of the current node.
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 7] ls2 /node1
+[node1.1]
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x47
+mtime = Sun Jan 20 10:22:59 CST 2019
+pZxid = 0x4a
+cversion=1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 11
+numChildren = 1
+
+```
+
+### Delete node (delete command)
+
+This command is very simple, but one thing to note is that if you want to delete a node, the node must have no child nodes.
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 3] delete /node1/node1.1
+```
+
+Later I will introduce the use of Java client API and the use of open source ZooKeeper client ZkClient and Curator.
+
+## ZooKeeper Java client Curator is easy to use
+
+Curator is a set of ZooKeeper Java client frameworks open sourced by Netflix. Compared with the client zookeeper that comes with Zookeeper, Curator's encapsulation is more complete, and various APIs can be used more conveniently.
+
+
+
+Let’s briefly demonstrate the use of Curator!
+
+Curator4.0+ version has better support for ZooKeeper 3.5.x. Before starting, please add the following dependencies to your project.
+
+```xml
+
+ org.apache.curator
+ curator-framework
+ 4.2.0
+
+
+ org.apache.curator
+ curator-recipes
+ 4.2.0
+
+```
+
+### Connect to ZooKeeper client
+
+Create a `CuratorFramework` object through `CuratorFrameworkFactory`, and then call the `start()` method of the `CuratorFramework` object!
+
+```java
+private static final int BASE_SLEEP_TIME = 1000;
+private static final int MAX_RETRIES = 3;
+
+// Retry strategy. Retry 3 times, and will increase the sleep time between retries.
+RetryPolicy retryPolicy = new ExponentialBackoffRetry(BASE_SLEEP_TIME, MAX_RETRIES);
+CuratorFramework zkClient = CuratorFrameworkFactory.builder()
+ // the server to connect to (can be a server list)
+ .connectString("127.0.0.1:2181")
+ .retryPolicy(retryPolicy)
+ .build();
+zkClient.start();```
+
+Description of some basic parameters:
+
+- `baseSleepTimeMs`: initial time to wait between retries
+- `maxRetries`: Maximum number of retries
+- `connectString`: list of servers to connect to
+- `retryPolicy`: retry policy
+
+### Add, delete, modify and query data nodes
+
+#### Create node
+
+We introduced in [ZooKeeper Common Concepts Interpretation](./zookeeper-intro.md) that we usually divide znode into 4 major categories:
+
+- **persistent (PERSISTENT) node**: Once created, it will always exist even if the ZooKeeper cluster goes down, until it is deleted.
+- **Temporary (EPHEMERAL) node**: The life cycle of the temporary node is bound to the **client session (session)**. **The node disappears when the session disappears**. Moreover, temporary nodes **can only be used as leaf nodes** and cannot create child nodes.
+- **Persistent Sequence (PERSISTENT_SEQUENTIAL) node**: In addition to the characteristics of the persistent (PERSISTENT) node, the names of child nodes are also sequential. For example `/node1/app0000000001`, `/node1/app0000000002`.
+- **Temporary Sequential (EPHEMERAL_SEQUENTIAL) Node**: In addition to having the characteristics of temporary (EPHEMERAL) nodes, the names of child nodes are also sequential.
+
+When you use ZooKeeper, you will find that there are actually 7 znode types in the `CreateMode` class, but the 4 types introduced above are the most used.
+
+**a.Create persistence node**
+
+You can create persistent nodes in the following two ways.
+
+```java
+//Note: The following code will report an error. The specific reasons are explained below.
+zkClient.create().forPath("/node1/00001");
+zkClient.create().withMode(CreateMode.PERSISTENT).forPath("/node1/00002");
+```
+
+However, you will get an error when you run the above code. This is because the parent node `node1` has not been created yet.
+
+You can create the parent node `node1` first, and then execute the above code without error.
+
+```java
+zkClient.create().forPath("/node1");
+```
+
+The more recommended way is to use the following line of code, **`creatingParentsIfNeeded()` can ensure that the parent node is automatically created when the parent node does not exist, which is very useful. **
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/node1/00001");
+```
+
+**b. Create temporary nodes**
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001");
+```
+
+**c. Create nodes and specify data content**
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001","java".getBytes());
+zkClient.getData().forPath("/node1/00001");//Get the data content of the node, and get the byte array
+```
+
+**d. Check whether the node is created successfully**
+
+```java
+zkClient.checkExists().forPath("/node1/00001");//If it is not null, it means the node was created successfully
+```
+
+#### Delete node
+
+**a.Delete a child node**
+
+```java
+zkClient.delete().forPath("/node1/00001");
+```
+
+**b. Delete a node and all its child nodes**
+
+```java
+zkClient.delete().deletingChildrenIfNeeded().forPath("/node1");
+```
+
+#### Get/update node data content
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001","java".getBytes());
+zkClient.getData().forPath("/node1/00001");//Get the data content of the node
+zkClient.setData().forPath("/node1/00001","c++".getBytes());//Update node data content
+```
+
+#### Get the paths of all child nodes of a node
+
+```java
+List childrenPaths = zkClient.getChildren().forPath("/node1");
+```
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.en.md b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.en.md
new file mode 100644
index 00000000000..49c08efc404
--- /dev/null
+++ b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.en.md
@@ -0,0 +1,314 @@
+---
+title: ZooKeeper相关概念总结(入门)
+category: 分布式
+tag:
+ - ZooKeeper
+---
+
+相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 到底有啥用不?如果别人/面试官让你给他讲讲对于 ZooKeeper 的认识,你能回答到什么地步呢?
+
+拿我自己来说吧!我本人在大学曾经使用 Dubbo 来做分布式项目的时候,使用了 ZooKeeper 作为注册中心。为了保证分布式系统能够同步访问某个资源,我还使用 ZooKeeper 做过分布式锁。另外,我在学习 Kafka 的时候,知道 Kafka 很多功能的实现依赖了 ZooKeeper。
+
+前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西?想了半天,脑海中只是简单的能浮现出几句话:
+
+1. ZooKeeper 可以被用作注册中心、分布式锁;
+2. ZooKeeper 是 Hadoop 生态系统的一员;
+3. 构建 ZooKeeper 集群的时候,使用的服务器最好是奇数台。
+
+由此可见,我对于 ZooKeeper 的理解仅仅是停留在了表面。
+
+所以,通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。如果没有学过 ZooKeeper ,那么本文将会是你进入 ZooKeeper 大门的垫脚砖。如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。
+
+另外,本文不光会涉及到 ZooKeeper 的一些概念,后面的文章会介绍到 ZooKeeper 常见命令的使用以及使用 Apache Curator 作为 ZooKeeper 的客户端。
+
+_如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!_
+
+## ZooKeeper 介绍
+
+### ZooKeeper 由来
+
+正式介绍 ZooKeeper 之前,我们先来看看 ZooKeeper 的由来,还挺有意思的。
+
+下面这段内容摘自《从 Paxos 到 ZooKeeper》第四章第一节,推荐大家阅读一下:
+
+> ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
+>
+> 关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的 Pig 项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家 RaghuRamakrishnan 开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而 ZooKeeper 正好要用来进行分布式环境的协调一一于是,ZooKeeper 的名字也就由此诞生了。
+
+### ZooKeeper 概览
+
+ZooKeeper 是一个开源的**分布式协调服务**,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
+
+> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性,即原语的执行必须是连续的,在执行过程中不允许被中断。
+
+ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。这些功能的实现主要依赖于 ZooKeeper 提供的 **数据存储+事件监听** 功能(后文会详细介绍到) 。
+
+ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景)。
+
+另外,很多顶级的开源项目都用到了 ZooKeeper,比如:
+
+- **Kafka** : ZooKeeper 主要为 Kafka 提供 Broker 和 Topic 的注册以及多个 Partition 的负载均衡等功能。不过,在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构。
+- **Hbase** : ZooKeeper 为 Hbase 提供确保整个集群只有一个 Master 以及保存和提供 regionserver 状态信息(是否在线)等功能。
+- **Hadoop** : ZooKeeper 为 Namenode 提供高可用支持。
+
+### ZooKeeper 特点
+
+- **顺序一致性:** 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
+- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
+- **单一系统映像:** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
+- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
+- **实时性:** 一旦数据发生变更,其他节点会实时感知到。每个客户端的系统视图都是最新的。
+- **集群部署**:3~5 台(最好奇数台)机器就可以组成一个集群,每台机器都在内存保存了 ZooKeeper 的全部数据,机器之间互相通信同步数据,客户端连接任何一台机器都可以。
+- **高可用:**如果某台机器宕机,会保证数据不丢失。集群中挂掉不超过一半的机器,都能保证集群可用。比如 3 台机器可以挂 1 台,5 台机器可以挂 2 台。
+
+### ZooKeeper 应用场景
+
+ZooKeeper 概览中,我们介绍到使用其通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
+
+下面选 3 个典型的应用场景来专门说说:
+
+1. **命名服务**:可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
+2. **数据发布/订阅**:通过 **Watcher 机制** 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
+3. **分布式锁**:通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。分布式锁的实现也需要用到 **Watcher 机制** ,我在 [分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 这篇文章中有详细介绍到如何基于 ZooKeeper 实现分布式锁。
+
+实际上,这些功能的实现基本都得益于 ZooKeeper 可以保存数据的功能,但是 ZooKeeper 不适合保存大量数据,这一点需要注意。
+
+## ZooKeeper 重要概念
+
+_破音:拿出小本本,下面的内容非常重要哦!_
+
+### Data model(数据模型)
+
+ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二进制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
+
+强调一句:**ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的每个节点的数据大小上限是 1M 。**
+
+从下图可以更直观地看出:ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
+
+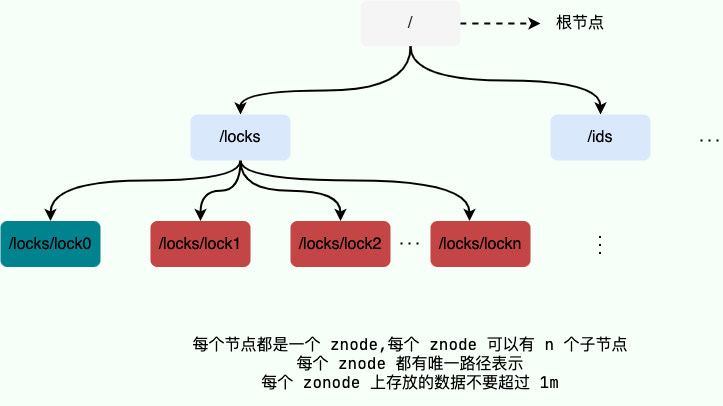
+
+### znode(数据节点)
+
+介绍了 ZooKeeper 树形数据模型之后,我们知道每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。你要存放的数据就放在上面,是你使用 ZooKeeper 过程中经常需要接触到的一个概念。
+
+我们通常是将 znode 分为 4 大类:
+
+- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
+- **Temporary (EPHEMERAL) node**: The life cycle of the temporary node is bound to the **client session (session)**. **When the session disappears, the node disappears**. Moreover, **temporary nodes can only be used as leaf nodes** and cannot create child nodes.
+- **Persistent Sequence (PERSISTENT_SEQUENTIAL) node**: In addition to the characteristics of the persistent (PERSISTENT) node, the names of child nodes are also sequential. For example `/node1/app0000000001`, `/node1/app0000000002`.
+- **Temporary Sequential (EPHEMERAL_SEQUENTIAL) Node**: In addition to having the characteristics of temporary (EPHEMERAL) nodes, the names of child nodes also have sequential properties.
+
+Each znode consists of 2 parts:
+
+- **stat**: status information
+- **data**: The specific content of the data stored in the node
+
+As shown below, I use the get command to obtain the contents of the dubbo node in the root directory. (The get command will be introduced below).
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 6] get /dubbo
+#The data content associated with this data node is empty
+null
+#The following is some status information of the data node, which is actually the formatted output of the Stat object.
+cZxid = 0x2
+ctime = Tue Nov 27 11:05:34 CST 2018
+mZxid = 0x2
+mtime = Tue Nov 27 11:05:34 CST 2018
+pZxid = 0x3
+cversion=1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 0
+numChildren = 1
+```
+
+The Stat class contains fields for all status information of a data node, including transaction ID (cZxid), node creation time (ctime), number of child nodes (numChildren), etc.
+
+Let’s take a look at what each znode status information actually represents! (The following content comes from "From Paxos to ZooKeeper Distributed Consistency Principles and Practices", because the Guide is indeed not particularly clear, so you need to learn the reference materials!):
+
+| znode status information | explanation |
+| -------------- | ------------------------------------------------------------------------------------------------------------------ |
+| cZxid | create ZXID, which is the transaction id when the data node was created |
+| ctime | create time, that is, the creation time of the node |
+| mZxid | modified ZXID, which is the transaction id when the node was last updated |
+| mtime | modified time, which is the last update time of the node |
+| pZxid | The transaction id when the node's child node list was last modified. Only changes in the child node list will update pZxid, and changes in the child node content will not be updated |
+| cversion | The version number of the child node, the value increases by 1 every time the child node of the current node changes |
+| dataVersion | Data node content version number. It is 0 when the node is created. Every time the node content is updated (regardless of whether the content changes or not), the value of the version number increases by 1 |
+| aclVersion | The ACL version number of the node, indicating the number of changes to the ACL information of the node |
+| ephemeralOwner | sessionId of the session that created this temporary node; if the current node is a persistent node, ephemeralOwner=0 |
+| dataLength | Data node content length |
+| numChildren | The number of child nodes of the current node |
+
+### Version
+
+As we mentioned before, corresponding to each znode, ZooKeeper will maintain a data structure called **Stat** for it. Stat records three related versions of this znode:
+
+- **dataVersion**: The version number of the current znode node
+- **cversion**: The version of the current znode child node
+- **aclVersion**: The version of the ACL of the current znode.
+
+### ACL (Authority Control)
+
+ZooKeeper uses the ACL (AccessControlLists) policy for permission control, which is similar to the permission control of UNIX file systems.
+
+For znode operation permissions, ZooKeeper provides the following 5 types:
+
+- **CREATE** : Can create child nodes
+- **READ**: Can obtain node data and list its child nodes
+- **WRITE** : Can set/update node data
+- **DELETE** : can delete child nodes
+- **ADMIN**: Permission to set node ACL
+
+What needs special attention is that both **CREATE** and **DELETE** are permission controls for **child nodes**.
+
+For identity authentication, the following methods are provided:
+
+- **world**: Default mode, all users can access unconditionally.
+- **auth**: does not use any id, represents any authenticated user.
+- **digest** :username:password authentication method: _username:password_.
+- **ip**: Restrict the specified IP.
+
+### Watcher (event listener)
+
+Watcher (event listener) is a very important feature in ZooKeeper. ZooKeeper allows users to register some Watchers on designated nodes, and when certain events are triggered, the ZooKeeper server will notify interested clients of the event. This mechanism is an important feature of ZooKeeper in implementing distributed coordination services.
+
+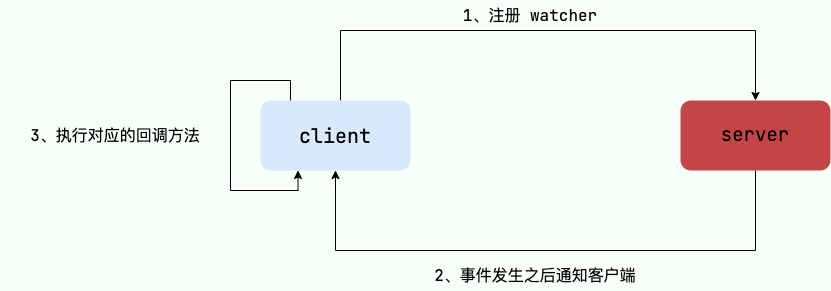
+
+_Poyin: A very useful feature. I took out a small notebook and memorized it. The Watcher (event listener) mechanism is basically inseparable from ZooKeeper when used later. _
+
+### Session
+
+Session can be regarded as a long TCP connection between the ZooKeeper server and the client. Through this connection, the client can maintain a valid session with the server through heartbeat detection, and can also send requests to the ZooKeeper server and receive responses. It can also receive Watcher event notifications from the server through this connection.
+
+Session has a property called: `sessionTimeout`, `sessionTimeout` represents the session timeout. When the client connection is disconnected due to various reasons such as excessive server pressure, network failure, or the client actively disconnects, as long as any server in the cluster can be reconnected within the time specified by `sessionTimeout`, the previously created session will still be valid.
+
+In addition, before creating a session for a client, the server first assigns a `sessionID` to each client. Since `sessionID` is an important identifier of a ZooKeeper session, many session-related operating mechanisms are based on this `sessionID`. Therefore, no matter which server assigns `sessionID` to the client, it must be globally unique.
+
+## ZooKeeper cluster
+
+In order to ensure high availability, it is best to deploy ZooKeeper in a cluster form, so that as long as most of the machines in the cluster are available (can tolerate certain machine failures), ZooKeeper itself will still be available. Usually 3 servers can form a ZooKeeper cluster. The architecture diagram officially provided by ZooKeeper is a ZooKeeper cluster that provides services to the outside world as a whole.
+
+上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
+
+**最典型集群模式:Master/Slave 模式(主备模式)**。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
+
+### ZooKeeper 集群角色
+
+但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示
+
+
+
+ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定一台称为 “**Leader**” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,**Follower** 和 **Observer** 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
+
+| 角色 | 说明 |
+| -------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
+| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
+| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
+
+### ZooKeeper 集群 Leader 选举过程
+
+当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
+
+这个过程大致是这样的:
+
+1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
+2. **Discovery(发现阶段)**:在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
+3. **Synchronization(同步阶段)**:同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
+4. **Broadcast(广播阶段)**:到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
+
+ZooKeeper 集群中的服务器状态有下面几种:
+
+- **LOOKING**:寻找 Leader。
+- **LEADING**:Leader 状态,对应的节点为 Leader。
+- **FOLLOWING**:Follower 状态,对应的节点为 Follower。
+- **OBSERVING**:Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
+
+### ZooKeeper 集群为啥最好奇数台?
+
+ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
+
+比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。
+假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
+
+综上,何必增加那一个不必要的 ZooKeeper 呢?
+
+### ZooKeeper 选举的过半机制防止脑裂
+
+**何为集群脑裂?**
+
+对于一个集群,通常多台机器会部署在不同机房,来提高这个集群的可用性。保证可用性的同时,会发生一种机房间网络线路故障,导致机房间网络不通,而集群被割裂成几个小集群。这时候子集群各自选主导致“脑裂”的情况。
+
+举例说明:比如现在有一个由 6 台服务器所组成的一个集群,部署在了 2 个机房,每个机房 3 台。正常情况下只有 1 个 leader,但是当两个机房中间网络断开的时候,每个机房的 3 台服务器都会认为另一个机房的 3 台服务器下线,而选出自己的 leader 并对外提供服务。若没有过半机制,当网络恢复的时候会发现有 2 个 leader。仿佛是 1 个大脑(leader)分散成了 2 个大脑,这就发生了脑裂现象。脑裂期间 2 个大脑都可能对外提供了服务,这将会带来数据一致性等问题。
+
+**过半机制是如何防止脑裂现象产生的?**
+
+ZooKeeper 的过半机制导致不可能产生 2 个 leader,因为少于等于一半是不可能产生 leader 的,这就使得不论机房的机器如何分配都不可能发生脑裂。
+
+## ZAB 协议和 Paxos 算法
+
+Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos 算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在 ZooKeeper 的官方文档中也指出,ZAB 协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为 Zookeeper 设计的崩溃可恢复的原子消息广播算法。
+
+### ZAB 协议介绍
+
+ZAB(ZooKeeper Atomic Broadcast,原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
+
+### ZAB 协议两种基本的模式:崩溃恢复和消息广播
+
+ZAB 协议包括两种基本的模式,分别是
+
+- **崩溃恢复**:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
+- **Message Broadcast**:** When more than half of the Follower servers in the cluster have completed the status synchronization with the Leader server, then the entire service framework can enter the message broadcast mode. ** When a server that also complies with the ZAB protocol joins the cluster after being started, if there is already a Leader server in the cluster responsible for message broadcast, then the newly added server will consciously enter the data recovery mode: find the server where the Leader is located, synchronize data with it, and then participate in the message broadcast process together.
+
+### ZAB Protocol & Paxos Algorithm Article Recommendations
+
+There are too many things that need to be talked about and understood about **ZAB protocol & Paxos algorithm**. For details, you can read the following articles:
+
+- [Detailed explanation of Paxos algorithm](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
+- [ZooKeeper and Zab Protocol · Analyze](https://wingsxdu.com/posts/database/zookeeper/)
+- [Detailed explanation of Raft algorithm](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
+
+## ZooKeeper VS ETCD
+
+[ETCD](https://etcd.io/) is a strongly consistent distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or machine cluster. ETCD internally uses [Raft algorithm](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html) as the consistency algorithm, which is implemented based on Go language.
+
+Similar to ZooKeeper, ETCD can also be used in data publishing/subscription, load balancing, naming services, distributed coordination/notification, distributed locks and other scenarios. So how to choose between the two?
+
+This article by Dewu Technology [A brief analysis of how to implement high-availability architecture based on ZooKeeper] (https://mp.weixin.qq.com/s/pBI3rjv5NdS1124Z7HQ-JA) provides the following comparison table (I have further optimized it), which can be used as a reference:
+
+| | ZooKeeper | ETCD |
+|---------------- |-------------------------------------------------------------------------------- | ------------------------------------------------------------------ |
+| **Language** | Java | Go |
+| **Protocol** | TCP | Grpc |
+| **Interface Call** | You must use your own client to call | Can be transmitted through HTTP, you can call it through commands such as CURL |
+| **Consensus Algorithm** | Zab Protocol | Raft Algorithm |
+| **Watcher mechanism** | Limited, one-time trigger | One Watch can monitor all events |
+| **Data model** | Directory-based hierarchical model | Refers to zk's data model, which is a flat kv model |
+| **Storage** | kv storage, using ConcurrentHashMap, memory storage, generally not recommended to store large amounts of data | kv storage, using the bbolt storage engine, can handle several GB of data. |
+| **MVCC** | Not supported | Supported, version control through two B+ Trees |
+| **Global Session** | Defects | Implementation is more flexible and avoids security issues |
+| **Permission Verification** | ACL | RBAC |
+| **Transaction Capability** | Provides simple transaction capabilities | Only provides version number checking capabilities |
+| **Deployment and Maintenance** | Complex | Simple |
+
+ZooKeeper has certain limitations in storage performance, global Session, Watcher mechanism, etc. More and more open source projects are replacing ZooKeeper with Raft implementation or other distributed coordination services, such as: [Kafka Needs No Keeper - Removing ZooKeeper Dependency (confluent.io)](https://www.confluent.io/blog/removing-zookeeper-dependency-in-kafka/), [Moving Toward a ZooKeeper-Less Apache Pulsar (streamnative.io)](https://streamnative.io/blog/moving-toward-zookeeper-less-apache-pulsar).
+
+ETCD is relatively better, providing more stable high-load reading and writing capabilities, and improving and optimizing many problems exposed by ZooKeeper. Moreover, ETCD can basically cover all application scenarios of ZooKeeper and replace it.
+
+## Summary
+
+1. ZooKeeper itself is a distributed program (as long as more than half of the nodes survive, ZooKeeper can serve normally).
+2. In order to ensure high availability, it is best to deploy ZooKeeper in a cluster form. In this way, as long as most of the machines in the cluster are available (can tolerate certain machine failures), ZooKeeper itself will still be available.
+3. ZooKeeper stores data in memory, which ensures high throughput and low latency (however, the memory limits the amount of data that can be stored, and this limitation is also a further reason to keep the amount of data stored in znodes small).
+4. ZooKeeper is high performance. This is especially true in applications where there are more reads than writes, since the writes cause all inter-server states to be synchronized. (More "reads" than "writes" are a typical scenario for coordinating services.)
+5. ZooKeeper has the concept of temporary nodes. Transient nodes exist as long as the client session that created the transient node remains active. When the session ends, the transient node is deleted. A persistent node means that once the znode is created, the znode will always be saved on ZooKeeper unless the znode is actively removed.
+6. The bottom layer of ZooKeeper actually only provides two functions: ① manage (storage, read) data submitted by user programs; ② provide data node monitoring services for user programs.
+
+## Reference
+
+- "Principles and Practices of Distributed Consistency from Paxos to ZooKeeper"
+- Talk about the limitations of ZooKeeper:
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.en.md b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.en.md
new file mode 100644
index 00000000000..70708cac863
--- /dev/null
+++ b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.en.md
@@ -0,0 +1,387 @@
+---
+title: ZooKeeper相关概念总结(进阶)
+category: 分布式
+tag:
+ - ZooKeeper
+---
+
+> [FrancisQ](https://juejin.im/user/5c33853851882525ea106810) 投稿。
+
+## 什么是 ZooKeeper
+
+`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理等。
+
+简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
+
+其实解释到分布式这个概念的时候,我发现有些同学并不是能把 **分布式和集群** 这两个概念很好的理解透。前段时间有同学和我探讨起分布式的东西,他说分布式不就是加机器吗?一台机器不够用再加一台抗压呗。当然加机器这种说法也无可厚非,你一个分布式系统必定涉及到多个机器,但是你别忘了,计算机学科中还有一个相似的概念—— `Cluster` ,集群不也是加机器吗?但是 集群 和 分布式 其实就是两个完全不同的概念。
+
+比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 **一样** 提供秒杀服务,这个时候就是 **`Cluster` 集群** 。
+
+
+
+但是,我现在换一种方式,我将一个秒杀服务 **拆分成多个子服务** ,比如创建订单服务,增加积分服务,扣优惠券服务等等,**然后我将这些子服务都部署在不同的服务器上** ,这个时候就是 **`Distributed` 分布式** 。
+
+
+
+而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。
+
+
+
+比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。`ZooKeeper` 主要就是解决这些问题的。
+
+## 一致性问题
+
+设计一个分布式系统必定会遇到一个问题—— **因为分区容忍性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡** 。这就是著名的 `CAP` 定理。
+
+理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
+
+
+
+而上述前者就是 `Eureka` 的处理方式,它保证了 AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了 CP(数据一致性)。
+
+## 一致性协议和算法
+
+而为了解决数据一致性问题,在科学家和程序员的不断探索中,就出现了很多的一致性协议和算法。比如 2PC(两阶段提交),3PC(三阶段提交),Paxos 算法等等。
+
+这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
+
+
+
+这个时候就引申出一个概念—— **拜占庭将军问题** 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
+
+而为什么要去解决数据一致性的问题?你想想,如果一个秒杀系统将服务拆分成了下订单和加积分服务,这两个服务部署在不同的机器上了,万一在消息的传播过程中积分系统宕机了,总不能你这边下了订单却没加积分吧?你总得保证两边的数据需要一致吧?
+
+### 2PC(两阶段提交)
+
+两阶段提交是一种保证分布式系统数据一致性的协议,现在很多数据库都是采用的两阶段提交协议来完成 **分布式事务** 的处理。
+
+在介绍 2PC 之前,我们先来想想分布式事务到底有什么问题呢?
+
+还拿秒杀系统的下订单和加积分两个系统来举例吧(我想你们可能都吐了 🤮🤮🤮),我们此时下完订单会发个消息给积分系统告诉它下面该增加积分了。如果我们仅仅是发送一个消息也不收回复,那么我们的订单系统怎么能知道积分系统的收到消息的情况呢?如果我们增加一个收回复的过程,那么当积分系统收到消息后返回给订单系统一个 `Response` ,但在中间出现了网络波动,那个回复消息没有发送成功,订单系统是不是以为积分系统消息接收失败了?它是不是会回滚事务?但此时积分系统是成功收到消息的,它就会去处理消息然后给用户增加积分,这个时候就会出现积分加了但是订单没下成功。
+
+所以我们所需要解决的是在分布式系统中,整个调用链中,我们所有服务的数据处理要么都成功要么都失败,即所有服务的 **原子性问题** 。
+
+在两阶段提交中,主要涉及到两个角色,分别是协调者和参与者。
+
+第一阶段:当要执行一个分布式事务的时候,事务发起者首先向协调者发起事务请求,然后协调者会给所有参与者发送 `prepare` 请求(其中包括事务内容)告诉参与者你们需要执行事务了,如果能执行我发的事务内容那么就先执行但不提交,执行后请给我回复。然后参与者收到 `prepare` 消息后,他们会开始执行事务(但不提交),并将 `Undo` 和 `Redo` 信息记入事务日志中,之后参与者就向协调者反馈是否准备好了。
+
+第二阶段:第二阶段主要是协调者根据参与者反馈的情况来决定接下来是否可以进行事务的提交操作,即提交事务或者回滚事务。
+
+比如这个时候 **所有的参与者** 都返回了准备好了的消息,这个时候就进行事务的提交,协调者此时会给所有的参与者发送 **`Commit` 请求** ,当参与者收到 `Commit` 请求的时候会执行前面执行的事务的 **提交操作** ,提交完毕之后将给协调者发送提交成功的响应。
+
+而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 **回滚事务的 `rollback` 请求**,参与者收到之后将会 **回滚它在第一阶段所做的事务处理** ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
+
+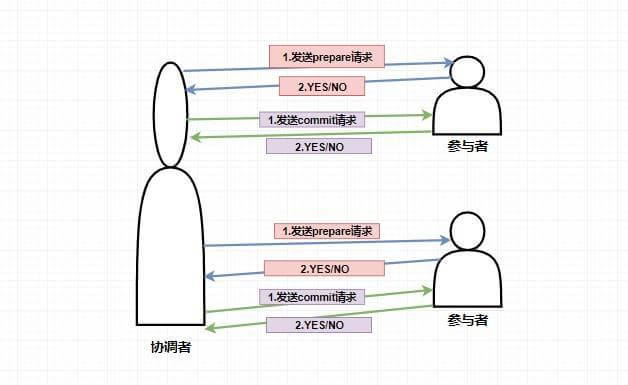
+
+个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
+
+
+
+- **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
+- **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
+- **数据不一致问题**,比如当第二阶段,协调者只发送了一部分的 `commit` 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
+
+### 3PC(三阶段提交)
+
+因为 2PC 存在的一系列问题,比如单点,容错机制缺陷等等,从而产生了 **3PC(三阶段提交)** 。那么这三阶段又分别是什么呢?
+
+> 千万不要吧 PC 理解成个人电脑了,其实他们是 phase-commit 的缩写,即阶段提交。
+
+1. **CanCommit 阶段**:协调者向所有参与者发送 `CanCommit` 请求,参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。
+2. **PreCommit 阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
+3. **DoCommit 阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
+
+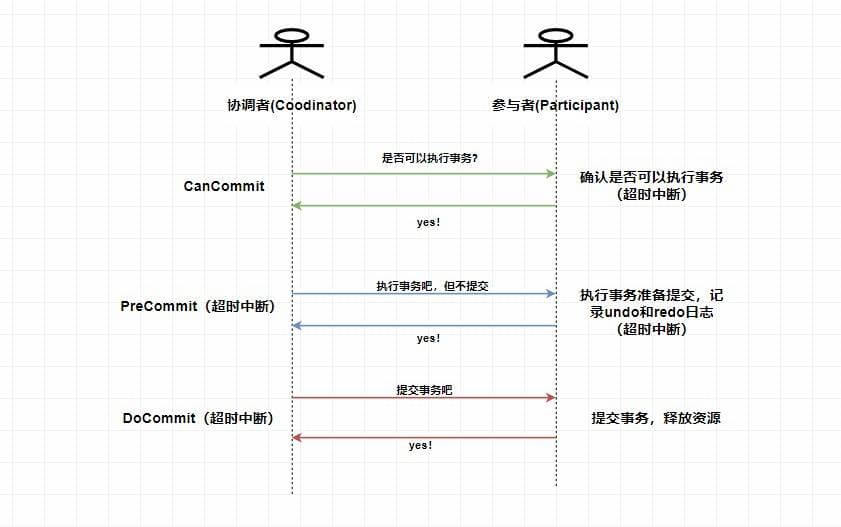
+
+> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内未收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
+
+总之,`3PC` 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 `DoCommit` 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
+
+所以,要解决一致性问题还需要靠 `Paxos` 算法 ⭐️ ⭐️ ⭐️ 。
+
+### `Paxos` 算法
+
+`Paxos` 算法是基于**消息传递且具有高度容错特性的一致性算法**,是目前公认的解决分布式一致性问题最有效的算法之一,**其解决的问题就是在分布式系统中如何就某个值(决议)达成一致** 。
+
+在 `Paxos` 中主要有三个角色,分别为 `Proposer提案者`、`Acceptor表决者`、`Learner学习者`。`Paxos` 算法和 `2PC` 一样,也有两个阶段,分别为 `Prepare` 和 `accept` 阶段。
+
+#### prepare 阶段
+
+- `Proposer提案者`:负责提出 `proposal`,每个提案者在提出提案时都会首先获取到一个 **具有全局唯一性的、递增的提案编号 N**,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在**第一阶段是只将提案编号发送给所有的表决者**。
+- `Acceptor表决者`:每个表决者在 `accept` 某提案后,会将该提案编号 N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个**编号最大的提案**,其编号假设为 `maxN`。每个表决者仅会 `accept` 编号大于自己本地 `maxN` 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 `Proposer` 。
+
+> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
+
+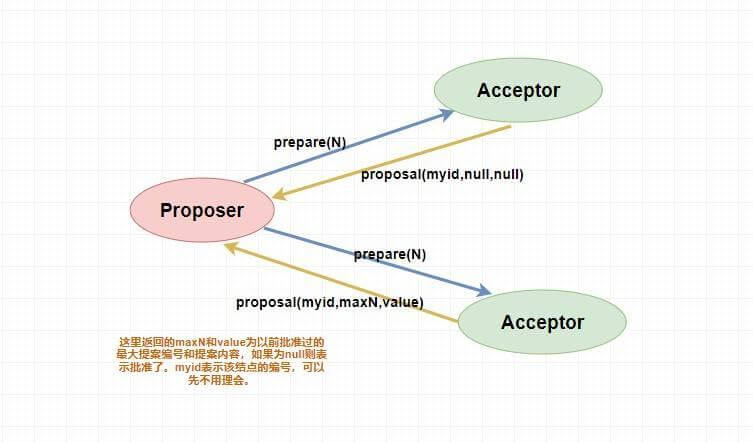
+
+#### accept 阶段
+
+当一个提案被 `Proposer` 提出后,如果 `Proposer` 收到了超过半数的 `Acceptor` 的批准(`Proposer` 本身同意),那么此时 `Proposer` 会给所有的 `Acceptor` 发送真正的提案(你可以理解为第一阶段为试探),这个时候 `Proposer` 就会发送提案的内容和提案编号。
+
+表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 `accept` 该提案(此时执行提案内容但不提交),随后将情况返回给 `Proposer` 。如果不满足则不回应或者返回 NO 。
+
+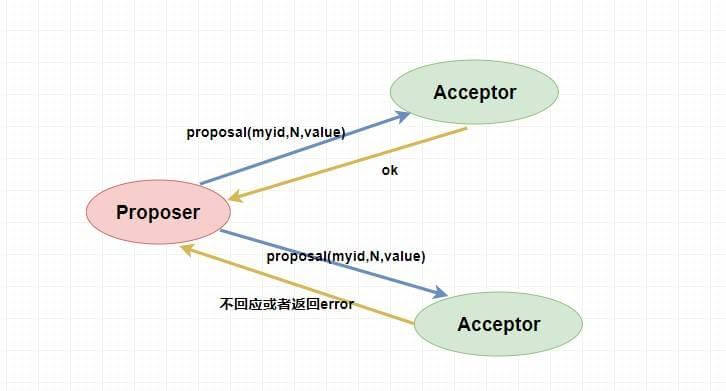
+
+当 `Proposer` 收到超过半数的 `accept` ,那么它这个时候会向所有的 `acceptor` 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 `acceptor` 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**,而对于前面已经批准过该提案的 `acceptor` 来说 **仅仅需要发送该提案的编号** ,让 `acceptor` 执行提交就行了。
+
+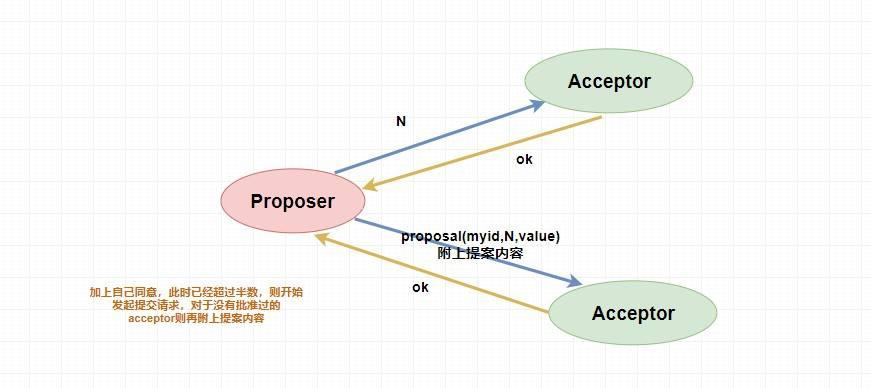
+
+而如果 `Proposer` 如果没有收到超过半数的 `accept` 那么它将会将 **递增** 该 `Proposal` 的编号,然后 **重新进入 `Prepare` 阶段** 。
+
+> 对于 `Learner` 来说如何去学习 `Acceptor` 批准的提案内容,这有很多方式,读者可以自己去了解一下,这里不做过多解释。
+
+#### paxos 算法的死循环问题
+
+其实就有点类似于两个人吵架,小明说我是对的,小红说我才是对的,两个人据理力争的谁也不让谁 🤬🤬。
+
+比如说,此时提案者 P1 提出一个方案 M1,完成了 `Prepare` 阶段的工作,这个时候 `acceptor` 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 `Prepare` 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 `acceptor` 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 `Prepare` 阶段,然后 `acceptor` ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 `Prepare` 阶段。。。
+
+就这样无休无止的永远提案下去,这就是 `paxos` 算法的死循环问题。
+
+
+
+那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
+
+## 引出 ZAB
+
+### Zookeeper 架构
+
+作为一个优秀高效且可靠的分布式协调框架,`ZooKeeper` 在解决分布式数据一致性问题时并没有直接使用 `Paxos` ,而是专门定制了一致性协议叫做 `ZAB(ZooKeeper Atomic Broadcast)` 原子广播协议,该协议能够很好地支持 **崩溃恢复** 。
+
+
+
+### ZAB 中的三个角色
+
+和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
+
+- `Leader`:集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
+- `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
+- `Observer`:就是没有选举权和被选举权的 `Follower` 。
+
+在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
+
+### 消息广播模式
+
+说白了就是 `ZAB` 协议是如何处理写请求的,上面我们不是说只有 `Leader` 能处理写请求嘛?那么我们的 `Follower` 和 `Observer` 是不是也需要 **同步更新数据** 呢?总不能数据只在 `Leader` 中更新了,其他角色都没有得到更新吧?
+
+不就是 **在整个集群中保持数据的一致性** 嘛?如果是你,你会怎么做呢?
+
+废话,第一步肯定需要 `Leader` 将写请求 **广播** 出去呀,让 `Leader` 问问 `Followers` 是否同意更新,如果超过半数以上的同意那么就进行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一样)。当然这么说有点虚,画张图理解一下。
+
+
+
+嗯。。。看起来很简单,貌似懂了 🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求 A,此时 `Leader` 将请求 A 广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1 因为网络原因没有收到,而 `Leader` 又广播了一个请求 B,因为网络原因,F1 竟然先收到了请求 B 然后才收到了请求 A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
+
+所以在 `Leader` 这端,它为每个其他的 `zkServer` 准备了一个 **队列** ,采用先进先出的方式发送消息。由于协议是 **通过 `TCP`** 来进行网络通信的,保证了消息的发送顺序性,接受顺序性也得到了保证。
+
+除此之外,在 `ZAB` 中还定义了一个 **全局单调递增的事务 ID `ZXID`** ,它是一个 64 位 long 型,其中高 32 位表示 `epoch` 年代,低 32 位表示事务 id。`epoch` 是会根据 `Leader` 的变化而变化的,当一个 `Leader` 挂了,新的 `Leader` 上位的时候,年代(`epoch`)就变了。而低 32 位可以简单理解为递增的事务 id。
+
+定义这个的原因也是为了顺序性,每个 `proposal` 在 `Leader` 中生成后需要 **通过其 `ZXID` 来进行排序** ,才能得到处理。
+
+### 崩溃恢复模式
+
+说到崩溃恢复我们首先要提到 `ZAB` 中的 `Leader` 选举算法,当系统出现崩溃影响最大应该是 `Leader` 的崩溃,因为我们只有一个 `Leader` ,所以当 `Leader` 出现问题的时候我们势必需要重新选举 `Leader` 。
+
+`Leader` 选举可以分为两个不同的阶段,第一个是我们提到的 `Leader` 宕机需要重新选举,第二则是当 `Zookeeper` 启动时需要进行系统的 `Leader` 初始化选举。下面我先来介绍一下 `ZAB` 是如何进行初始化选举的。
+
+假设我们集群中有 3 台机器,那也就意味着我们需要两台以上同意(超过半数)。比如这个时候我们启动了 `server1` ,它会首先 **投票给自己** ,投票内容为服务器的 `myid` 和 `ZXID` ,因为初始化所以 `ZXID` 都为 0,此时 `server1` 发出的投票为 (1,0)。但此时 `server1` 的投票仅为 1,所以不能作为 `Leader` ,此时还在选举阶段所以整个集群处于 **`Looking` 状态**。
+
+接着 `server2` 启动了,它首先也会将投票选给自己(2,0),并将投票信息广播出去(`server1`也会,只是它那时没有其他的服务器了),`server1` 在收到 `server2` 的投票信息后会将投票信息与自己的作比较。**首先它会比较 `ZXID` ,`ZXID` 大的优先为 `Leader`,如果相同则比较 `myid`,`myid` 大的优先作为 `Leader`**。所以此时`server1` 发现 `server2` 更适合做 `Leader`,它就会将自己的投票信息更改为(2,0)然后再广播出去,之后`server2` 收到之后发现和自己的一样无需做更改,并且自己的 **投票已经超过半数** ,则 **确定 `server2` 为 `Leader`**,`server1` 也会将自己服务器设置为 `Following` 变为 `Follower`。整个服务器就从 `Looking` 变为了正常状态。
+
+当 `server3` 启动发现集群没有处于 `Looking` 状态时,它会直接以 `Follower` 的身份加入集群。
+
+还是前面三个 `server` 的例子,如果在整个集群运行的过程中 `server2` 挂了,那么整个集群会如何重新选举 `Leader` 呢?其实和初始化选举差不多。
+
+首先毫无疑问的是剩下的两个 `Follower` 会将自己的状态 **从 `Following` 变为 `Looking` 状态** ,然后每个 `server` 会向初始化投票一样首先给自己投票(这不过这里的 `zxid` 可能不是 0 了,这里为了方便随便取个数字)。
+
+假设 `server1` 给自己投票为(1,99),然后广播给其他 `server`,`server3` 首先也会给自己投票(3,95),然后也广播给其他 `server`。`server1` 和 `server3` 此时会收到彼此的投票信息,和一开始选举一样,他们也会比较自己的投票和收到的投票(`zxid` 大的优先,如果相同那么就 `myid` 大的优先)。这个时候 `server1` 收到了 `server3` 的投票发现没自己的合适故不变,`server3` 收到 `server1` 的投票结果后发现比自己的合适于是更改投票为(1,99)然后广播出去,最后 `server1` 收到了发现自己的投票已经超过半数就把自己设为 `Leader`,`server3` 也随之变为 `Follower`。
+
+> 请注意 `ZooKeeper` 为什么要设置奇数个结点?比如这里我们是三个,挂了一个我们还能正常工作,挂了两个我们就不能正常工作了(已经没有超过半数的节点数了,所以无法进行投票等操作了)。而假设我们现在有四个,挂了一个也能工作,**但是挂了两个也不能正常工作了**,这是和三个一样的,而三个比四个还少一个,带来的效益是一样的,所以 `Zookeeper` 推荐奇数个 `server` 。
+
+那么说完了 `ZAB` 中的 `Leader` 选举方式之后我们再来了解一下 **崩溃恢复** 是什么玩意?
+
+其实主要就是 **当集群中有机器挂了,我们整个集群如何保证数据一致性?**
+
+如果只是 `Follower` 挂了,而且挂的没超过半数的时候,因为我们一开始讲了在 `Leader` 中会维护队列,所以不用担心后面的数据没接收到导致数据不一致性。
+
+如果 `Leader` 挂了那就麻烦了,我们肯定需要先暂停服务变为 `Looking` 状态然后进行 `Leader` 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 **确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交** 和 **跳过那些已经被丢弃的提案** 。
+
+确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交是什么意思呢?
+
+假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
+
+
+
+那怎么解决呢?
+
+聪明的同学肯定会质疑,**这个时候 `server1` 已经不可能成为 `Leader` 了,因为 `server1` 和 `server3` 进行投票选举的时候会比较 `ZXID` ,而此时 `server3` 的 `ZXID` 肯定比 `server1` 的大了**。(不理解可以看前面的选举算法)
+
+那么跳过那些已经被丢弃的提案又是什么意思呢?
+
+假设 `Leader (server2)` 此时同意了提案 N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案 N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案 N1 了,这样就会出现数据不一致性问题了,所以 **该提案 N1 最终需要被抛弃掉** 。
+
+
+
+## Zookeeper 的几个理论知识
+
+了解了 `ZAB` 协议还不够,它仅仅是 `Zookeeper` 内部实现的一种方式,而我们如何通过 `Zookeeper` 去做一些典型的应用场景呢?比如说集群管理,分布式锁,`Master` 选举等等。
+
+这就涉及到如何使用 `Zookeeper` 了,但在使用之前我们还需要掌握几个概念。比如 `Zookeeper` 的 **数据模型**、**会话机制**、**ACL**、**Watcher 机制** 等等。
+
+### 数据模型
+
+`zookeeper` 数据存储结构与标准的 `Unix` 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 `zookeeper` 中没有文件系统中目录与文件的概念,而是 **使用了 `znode` 作为数据节点** 。`znode` 是 `zookeeper` 中的最小数据单元,每个 `znode` 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
+
+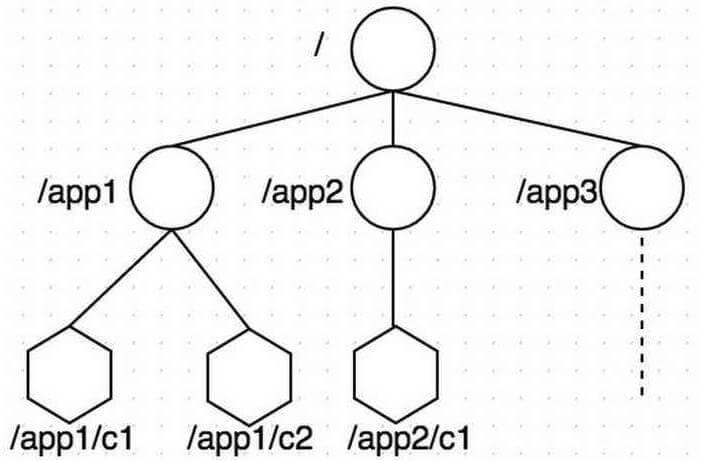
+
+每个 `znode` 都有自己所属的 **节点类型** 和 **节点状态**。
+
+其中节点类型可以分为 **持久节点**、**持久顺序节点**、**临时节点** 和 **临时顺序节点**。
+
+- 持久节点:一旦创建就一直存在,直到将其删除。
+- 持久顺序节点:一个父节点可以为其子节点 **维护一个创建的先后顺序** ,这个顺序体现在 **节点名称** 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
+- 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
+- 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
+
+节点状态中包含了很多节点的属性比如 `czxid`、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
+
+- `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务 ID。
+- `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务 ID。
+- `ctime`:`Created Time`,该节点被创建的时间。
+- `mtime`:`Modified Time`,该节点最后一次被修改的时间。
+- `version`:节点的版本号。
+- `cversion`:**子节点** 的版本号。
+- `aversion`:节点的 `ACL` 版本号。
+- `ephemeralOwner`:创建该节点的会话的 `sessionID` ,如果该节点为持久节点,该值为 0。
+- `dataLength`:节点数据内容的长度。
+- `numChildre`:该节点的子节点个数,如果为临时节点为 0。
+- `pzxid`:该节点子节点列表最后一次被修改时的事务 ID,注意是子节点的 **列表** ,不是内容。
+
+### 会话
+
+我想这个对于后端开发的朋友肯定不陌生,不就是 `session` 吗?只不过 `zk` 客户端和服务端是通过 **`TCP` 长连接** 维持的会话机制,其实对于会话来说你可以理解为 **保持连接状态** 。
+
+在 `zookeeper` 中,会话还有对应的事件,比如 `CONNECTION_LOSS 连接丢失事件`、`SESSION_MOVED 会话转移事件`、`SESSION_EXPIRED 会话超时失效事件` 。
+
+### ACL
+
+`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了 5 种权限,它们分别为:
+
+- `CREATE`:创建子节点的权限。
+- `READ`:获取节点数据和子节点列表的权限。
+- `WRITE`:更新节点数据的权限。
+- `DELETE`:删除子节点的权限。
+- `ADMIN`:设置节点 ACL 的权限。
+
+### Watcher 机制
+
+`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
+
+
+
+## Zookeeper 的几个典型应用场景
+
+前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
+
+
+
+### 选主
+
+还记得上面我们的所说的临时节点吗?因为 `Zookeeper` 的强一致性,能够很好地在保证 **在高并发的情况下保证节点创建的全局唯一性** (即无法重复创建同样的节点)。
+
+利用这个特性,我们可以 **让多个客户端创建一个指定的节点** ,创建成功的就是 `master`。
+
+但是,如果这个 `master` 挂了怎么办???
+
+你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?`master` 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 `watcher` 吗?我们是不是可以 **让其他不是 `master` 的节点监听节点的状态** ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 `master` 挂了,这个时候我们 **触发回调函数进行重新选举** ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 `master` 是否挂了等等。
+
+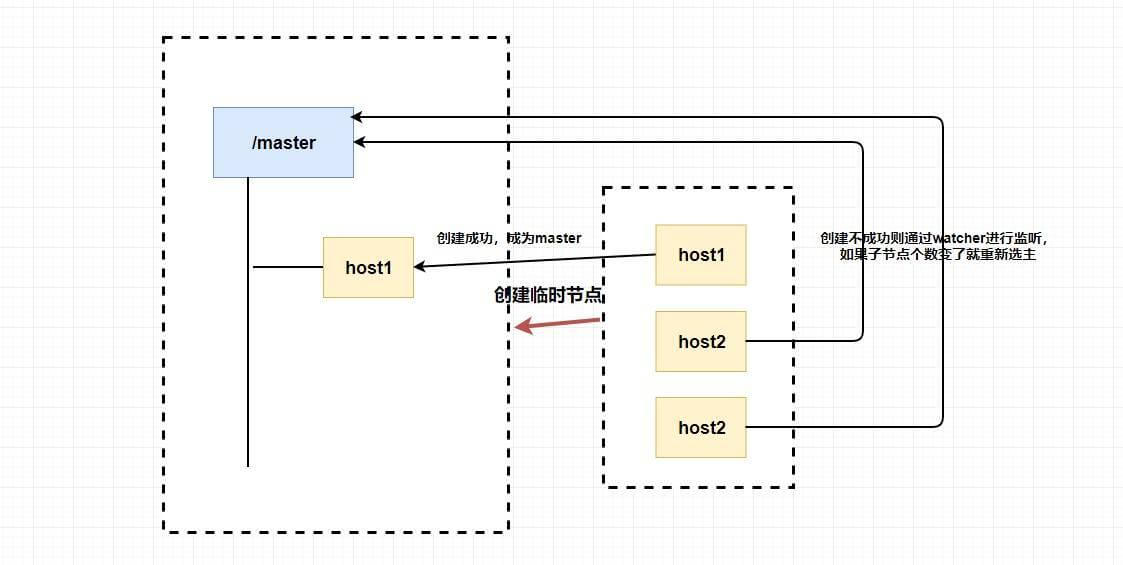
+
+总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
+
+### 数据发布/订阅
+
+还记得 Zookeeper 的 `Watcher` 机制吗? Zookeeper 通过这种推拉相结合的方式实现客户端与服务端的交互:客户端向服务端注册节点,一旦相应节点的数据变更,服务端就会向“监听”该节点的客户端发送 `Watcher` 事件通知,客户端接收到通知后需要 **主动** 到服务端获取最新的数据。基于这种方式,Zookeeper 实现了 **数据发布/订阅** 功能。
+
+一个典型的应用场景为 **全局配置信息的集中管理**。 客户端在启动时会主动到 Zookeeper 服务端获取配置信息,同时 **在指定节点注册一个** `Watcher` **监听**。当配置信息发生变更,服务端通知所有订阅的客户端重新获取配置信息,实现配置信息的实时更新。
+
+上面所提到的全局配置信息通常包括机器列表信息、运行时的开关配置、数据库配置信息等。需要注意的是,这类全局配置信息通常具备以下特性:
+
+- 数据量较小
+- 数据内容在运行时动态变化
+- 集群中机器共享一致配置
+
+### 负载均衡
+
+可以通过 Zookeeper 的 **临时节点** 实现负载均衡。回顾一下临时节点的特性:当创建节点的客户端与服务端之间断开连接,即客户端会话(session)消失时,对应节点也会自动消失。因此,我们可以使用临时节点来维护 Server 的地址列表,从而保证请求不会被分配到已停机的服务上。
+
+具体地,我们需要在集群的每一个 Server 中都使用 Zookeeper 客户端连接 Zookeeper 服务端,同时用 Server **自身的地址信息**在服务端指定目录下创建临时节点。当客户端请求调用集群服务时,首先通过 Zookeeper 获取该目录下的节点列表 (即所有可用的 Server),随后根据不同的负载均衡策略将请求转发到某一具体的 Server。
+
+### 分布式锁
+
+分布式锁的实现方式有很多种,比如 `Redis`、数据库、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
+
+上面我们已经提到过了 **zk 在高并发的情况下保证节点创建的全局唯一性**,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。
+
+如何实现呢?这玩意其实跟选主基本一样,我们也可以利用临时节点的创建来实现。
+
+首先肯定是如何获取锁,因为创建节点的唯一性,我们可以让多个客户端同时创建一个临时节点,**创建成功的就说明获取到了锁** 。然后没有获取到锁的客户端也像上面选主的非主节点创建一个 `watcher` 进行节点状态的监听,如果这个互斥锁被释放了(可能获取锁的客户端宕机了,或者那个客户端主动释放了锁)可以调用回调函数重新获得锁。
+
+> `zk` 中不需要向 `redis` 那样考虑锁得不到释放的问题了,因为当客户端挂了,节点也挂了,锁也释放了。是不是很简单?
+
+那能不能使用 `zookeeper` 同时实现 **共享锁和独占锁** 呢?答案是可以的,不过稍微有点复杂而已。
+
+还记得 **有序的节点** 吗?
+
+这个时候我规定所有创建节点必须有序,当你是读请求(要获取共享锁)的话,如果 **没有比自己更小的节点,或比自己小的节点都是读请求** ,则可以获取到读锁,然后就可以开始读了。**若比自己小的节点中有写请求** ,则当前客户端无法获取到读锁,只能等待前面的写请求完成。
+
+如果你是写请求(获取独占锁),若 **没有比自己更小的节点** ,则表示当前客户端可以直接获取到写锁,对数据进行修改。若发现 **有比自己更小的节点,无论是读操作还是写操作,当前客户端都无法获取到写锁** ,等待所有前面的操作完成。
+
+这就很好地同时实现了共享锁和独占锁,当然还有优化的地方,比如当一个锁得到释放它会通知所有等待的客户端从而造成 **羊群效应** 。此时你可以通过让等待的节点只监听他们前面的节点。
+
+具体怎么做呢?其实也很简单,你可以让 **读请求监听比自己小的最后一个写请求节点,写请求只监听比自己小的最后一个节点** ,感兴趣的小伙伴可以自己去研究一下。
+
+### 命名服务
+
+如何给一个对象设置 ID,大家可能都会想到 `UUID`,但是 `UUID` 最大的问题就在于它太长了。。。(太长不一定是好事,嘿嘿嘿)。那么在条件允许的情况下,我们能不能使用 `zookeeper` 来实现呢?
+
+我们之前提到过 `zookeeper` 是通过 **树形结构** 来存储数据节点的,那也就是说,对于每个节点的 **全路径**,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的 ID 设置可以更加便于理解。
+
+### 集群管理和注册中心
+
+看到这里是不是觉得 `zookeeper` 实在是太强大了,它怎么能这么能干!
+
+别急,它能干的事情还很多呢。可能我们会有这样的需求,我们需要了解整个集群中有多少机器在工作,我们想对集群中的每台机器的运行时状态进行数据采集,对集群中机器进行上下线操作等等。
+
+而 `zookeeper` 天然支持的 `watcher` 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 `watcher` 进行状态监控和回调。
+
+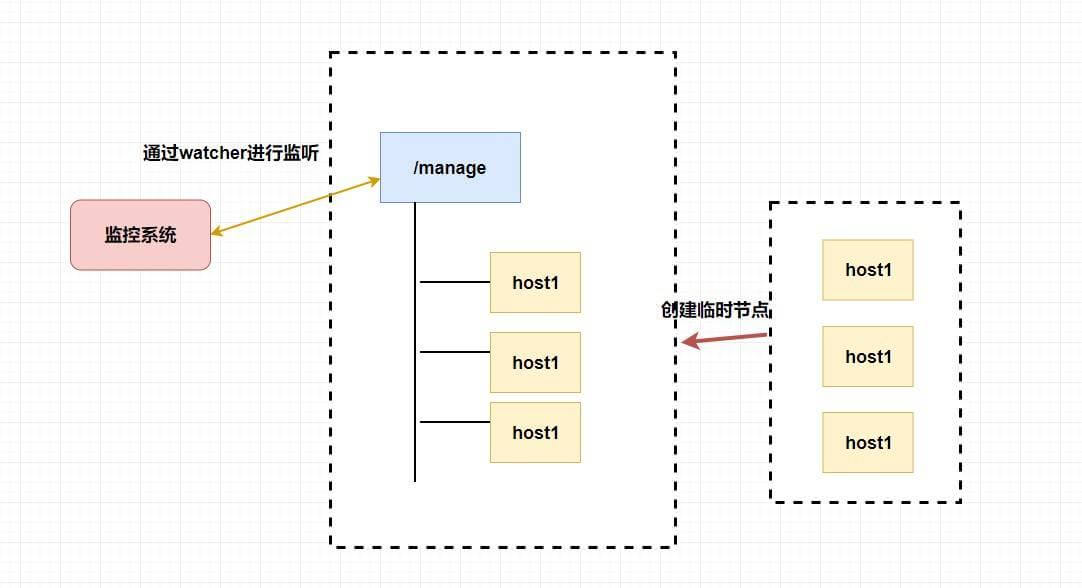
+
+至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP 端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
+
+当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
+
+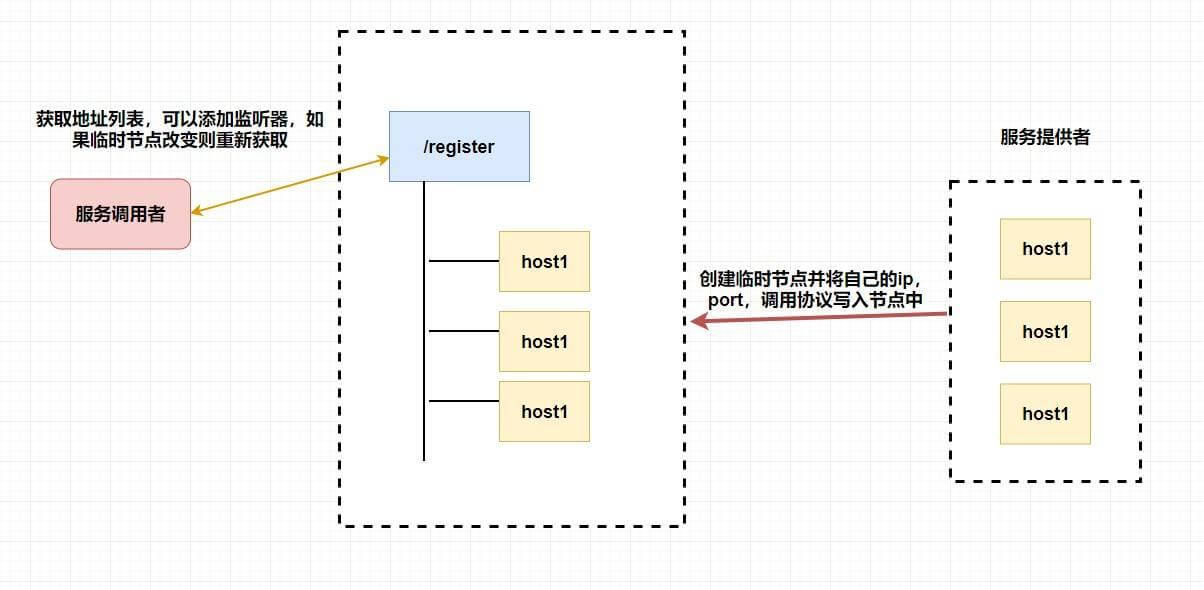
+
+## 总结
+
+看到这里的同学实在是太有耐心了 👍👍👍 不知道大家是否还记得我讲了什么 😒。
+
+
+
+这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
+
+- 分布式与集群的区别
+
+- `2PC`、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
+
+- `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
+
+- `zookeeper` 中的一些基本概念,比如 `ACL`,数据节点,会话,`watcher`机制等等。
+
+- `zookeeper` 的典型应用场景,比如选主,注册中心等等。
+
+ 如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出 🤝🤝🤝。
+
+
+
diff --git a/docs_en/distributed-system/distributed-transaction.en.md b/docs_en/distributed-system/distributed-transaction.en.md
new file mode 100644
index 00000000000..64569e131f3
--- /dev/null
+++ b/docs_en/distributed-system/distributed-transaction.en.md
@@ -0,0 +1,12 @@
+---
+title: Summary of common solutions for distributed transactions (paid)
+category: distributed
+---
+
+**Distributed Transactions** The related interview questions are exclusive to my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click the link to view the detailed introduction and how to join), which has been compiled into the "Java Interview Guide".
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/cap-and-base-theorem.en.md b/docs_en/distributed-system/protocol/cap-and-base-theorem.en.md
new file mode 100644
index 00000000000..e50a63e7ad9
--- /dev/null
+++ b/docs_en/distributed-system/protocol/cap-and-base-theorem.en.md
@@ -0,0 +1,161 @@
+---
+title: CAP & BASE理论详解
+category: 分布式
+tag:
+ - 分布式理论
+---
+
+经历过技术面试的小伙伴想必对 CAP & BASE 这个两个理论已经再熟悉不过了!
+
+我当年参加面试的时候,不夸张地说,只要问到分布式相关的内容,面试官几乎是必定会问这两个分布式相关的理论。一是因为这两个分布式基础理论是学习分布式知识的必备前置基础,二是因为很多面试官自己比较熟悉这两个理论(方便提问)。
+
+我们非常有必要将这两个理论搞懂,并且能够用自己的理解给别人讲出来。
+
+## CAP 理论
+
+[CAP 理论/定理](https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86)起源于 2000 年,由加州大学伯克利分校的 Eric Brewer 教授在分布式计算原理研讨会(PODC)上提出,因此 CAP 定理又被称作 **布鲁尔定理(Brewer’s theorem)**
+
+2 年后,麻省理工学院的 Seth Gilbert 和 Nancy Lynch 发表了布鲁尔猜想的证明,CAP 理论正式成为分布式领域的定理。
+
+### 简介
+
+**CAP** 也就是 **Consistency(一致性)**、**Availability(可用性)**、**Partition Tolerance(分区容错性)** 这三个单词首字母组合。
+
+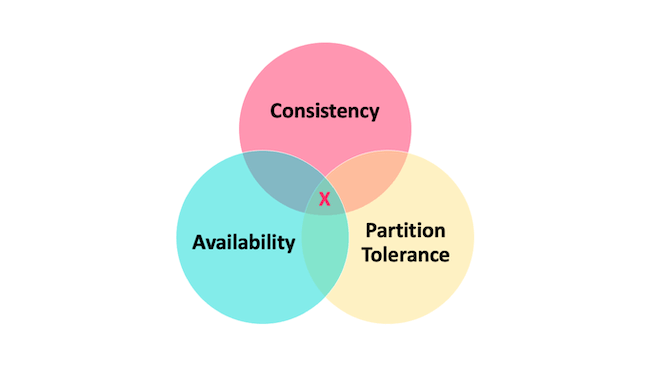
+
+CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细定义 **Consistency**、**Availability**、**Partition Tolerance** 三个单词的明确定义。
+
+因此,对于 CAP 的民间解读有很多,一般比较被大家推荐的是下面 👇 这种版本的解读。
+
+在理论计算机科学中,CAP 定理(CAP theorem)指出对于一个分布式系统来说,当设计读写操作时,只能同时满足以下三点中的两个:
+
+- **一致性(Consistency)** : 所有节点访问同一份最新的数据副本
+- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
+- **分区容错性(Partition Tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
+
+**什么是网络分区?**
+
+分布式系统中,多个节点之间的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫 **网络分区**。
+
+
+
+### 不是所谓的“3 选 2”
+
+大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
+
+> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。也就是说当网络分区之后 P 是前提,决定了 P 之后才有 C 和 A 的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。**
+>
+> 简而言之就是:CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。
+
+因此,**分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。** 比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。
+
+**为啥不可能选择 CA 架构呢?** 举个例子:若系统出现“分区”,系统中的某个节点在进行写操作。为了保证 C, 必须要禁止其他节点的读写操作,这就和 A 发生冲突了。如果为了保证 A,其他节点的读写操作正常的话,那就和 C 发生冲突了。
+
+**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。**
+
+另外,需要补充说明的一点是:**如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。**
+
+### CAP 实际应用案例
+
+我这里以注册中心来探讨一下 CAP 的实际应用。考虑到很多小伙伴不知道注册中心是干嘛的,这里简单以 Dubbo 为例说一说。
+
+下图是 Dubbo 的架构图。**注册中心 Registry 在其中扮演了什么角色呢?提供了什么服务呢?**
+
+注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
+
+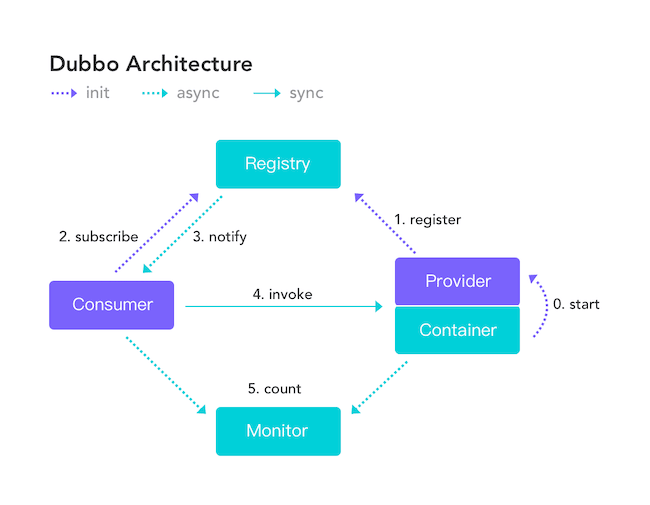
+
+常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。
+
+1. **ZooKeeper 保证的是 CP。** 任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。
+2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
+3. **Nacos 不仅支持 CP 也支持 AP。**
+
+**🐛 修正(参见:[issue#1906](https://github.com/Snailclimb/JavaGuide/issues/1906))**:
+
+ZooKeeper 通过可线性化(Linearizable)写入、全局 FIFO 顺序访问等机制来保障数据一致性。多节点部署的情况下, ZooKeeper 集群处于 Quorum 模式。Quorum 模式下的 ZooKeeper 集群, 是一组 ZooKeeper 服务器节点组成的集合,其中大多数节点必须同意任何变更才能被视为有效。
+
+由于 Quorum 模式下的读请求不会触发各个 ZooKeeper 节点之间的数据同步,因此在某些情况下还是可能会存在读取到旧数据的情况,导致不同的客户端视图上看到的结果不同,这可能是由于网络延迟、丢包、重传等原因造成的。ZooKeeper 为了解决这个问题,提供了 Watcher 机制和版本号机制来帮助客户端检测数据的变化和版本号的变更,以保证数据的一致性。
+
+### 总结
+
+在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等
+
+在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区”
+
+如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。
+
+总结:**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+
+### 推荐阅读
+
+1. [CAP 定理简化](https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4) (英文,有趣的案例)
+2. [神一样的 CAP 理论被应用在何方](https://juejin.im/post/6844903936718012430) (中文,列举了很多实际的例子)
+3. [请停止呼叫数据库 CP 或 AP](https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html) (英文,带给你不一样的思考)
+
+## BASE 理论
+
+[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年, 由 eBay 的架构师 Dan Pritchett 在 ACM 上发表。
+
+### 简介
+
+**BASE** 是 **Basically Available(基本可用)**、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+
+### BASE 理论的核心思想
+
+即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
+
+> That is to say, data consistency is sacrificed to meet the high availability of the system. When part of the data in the system is unavailable or inconsistent, the entire system still needs to be kept "mainly available".
+
+**BASE theory is essentially an extension and supplement to CAP, more specifically, a supplement to the AP scheme in CAP. **
+
+**Why do you say this? **
+
+We have also said this in the CAP theory section:
+
+> If the system is not "partitioned" and the network connection communication between nodes is normal, there will be no P. At this time, we can guarantee C and A at the same time. Therefore, if the system is "partitioned", we need to consider whether to choose CP or AP. If the system is not "partitioned", we need to think about how to ensure CA. **
+
+Therefore, the AP scheme only gives up consistency when the system is partitioned, rather than giving up consistency forever. After recovery from a partition failure, the system should reach eventual consistency. This is actually where BASE theory extends.
+
+### Three elements of BASE theory
+
+
+
+#### Basically available
+
+Basic availability means that the distributed system is allowed to lose part of its availability when unpredictable failures occur. However, this is by no means equivalent to the system being unavailable.
+
+**What does it mean to allow partial loss of availability? **
+
+- **Loss in response time**: Under normal circumstances, it takes 0.5s to process a user request and return a result, but due to a system failure, the time to process a user request becomes 3 s.
+- **Loss of system functions**: Under normal circumstances, users can use all functions of the system, but due to a sudden increase in system visits, some non-core functions of the system cannot be used.
+
+#### Soft state
+
+Soft state refers to allowing the data in the system to exist in an intermediate state (**data inconsistency in CAP theory**), and believing that the existence of this intermediate state will not affect the overall availability of the system, that is, allowing the system to have a delay in the process of data synchronization between data copies of different nodes.
+
+####Eventual consistency
+
+Eventual consistency emphasizes that all data copies in the system can eventually reach a consistent state after a period of synchronization. Therefore, the essence of eventual consistency is that the system needs to ensure that the final data can be consistent, but it does not need to ensure the strong consistency of the system data in real time.
+
+> 3 levels of distributed consistency:
+>
+> 1. **Strong consistency**: Whatever the system writes is what is read out.
+> 2. **Weak consistency**: It is not necessarily possible to read the latest written value, nor is it guaranteed that the data read after a certain amount of time will be the latest, but it will try to ensure that the data is consistent at a certain moment.
+> 3. **Eventual Consistency**: An upgraded version of weak consistency. The system will ensure that data is consistent within a certain period of time.
+>
+> **The industry recommends the ultimate consistency level, but in some scenarios that have very strict data consistency requirements, such as bank transfers, strong consistency must be ensured. **
+
+So what is the specific way to achieve eventual consistency? ["Distributed Protocols and Algorithms in Practice"] (http://gk.link/a/10rZM) is introduced like this:
+
+> - **Repair while reading**: When reading data, detect data inconsistencies and repair them. For example, Cassandra's Read Repair implementation. Specifically, when querying data from the Cassandra system, if it detects that the replica data on different nodes is inconsistent, the system will automatically repair the data.
+> - **Repair on write**: When writing data and detecting data inconsistencies, repair them. For example, Cassandra’s Hinted Handoff implementation. Specifically, when writing data remotely between nodes in the Cassandra cluster, if the writing fails, the data will be cached and then retransmitted regularly to repair data inconsistencies.
+> - **Asynchronous Repair**: This is the most commonly used method, which detects the consistency of the copy data through regular reconciliation and repairs it.
+
+**Repair on write** is recommended. This method has lower performance consumption.
+
+### Summary
+
+**ACID is the theory of database transaction integrity, CAP is the distributed system design theory, and BASE is an extension of the AP scheme in the CAP theory. **
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/consistent-hashing.en.md b/docs_en/distributed-system/protocol/consistent-hashing.en.md
new file mode 100644
index 00000000000..7a320ae2ff8
--- /dev/null
+++ b/docs_en/distributed-system/protocol/consistent-hashing.en.md
@@ -0,0 +1,131 @@
+---
+title: 一致性哈希算法详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 哈希算法
+---
+
+开始之前,先说两个常见的场景:
+
+1. **负载均衡**:由于访问人数太多,我们的网站部署了多台服务器个共同提供相同的服务,但每台服务器上存储的数据不同。为了保证请求的正确响应,相同参数(key)的请求(比如同个 IP 的请求、同一个用户的请求)需要发到同一台服务器处理。
+2. **分布式缓存**:由于缓存数据量太大,我们部署了多台缓存服务器共同提供缓存服务。缓存数据需要尽可能均匀地分布式在这些缓存服务器上,通过 key 可以找到对应的缓存服务器。
+
+这两种场景的本质,都是需要建立一个**从 key 到服务器/节点的稳定映射关系**。
+
+为了实现这个目标,你首先会想到什么方案呢?
+
+## 普通哈希算法
+
+相信大家很快就能想到 **“哈希+取模”** 这个经典组合。通过哈希函数计算出 key 的哈希值,再对服务器数量取模,从而将 key 映射到固定的服务器上。
+
+公式也很简单:
+
+```java
+node_number = hash(key) % N
+```
+
+- `hash(key)`: 使用哈希函数(建议使用性能较好的非加密哈希函数,例如 SipHash、MurMurHash3、CRC32、DJB)对唯一键进行哈希。
+- `% N`: 对哈希值取模,将哈希值映射到一个介于 0 到 N-1 之间的值,N 为节点数/服务器数。
+
+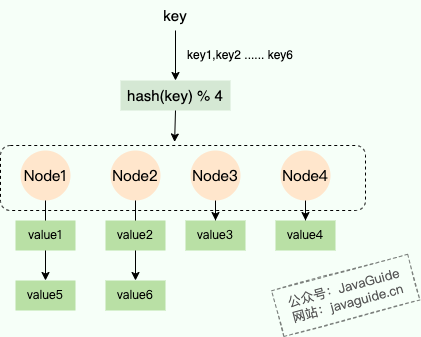
+
+然而,传统的哈希取模算法有一个比较大的缺陷就是:**无法很好的解决机器/节点动态减少(比如某台机器宕机)或者增加的场景(比如又增加了一台机器)。**
+
+想象一下,服务器的初始数量为 4 台 (N = 4),如果其中一台服务器宕机,N 就变成了 3。此时,对于同一个 key,`hash(key) % 3` 的结果很可能与 `hash(key) % 4` 完全不同。
+
+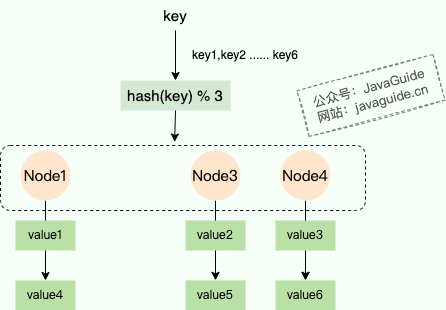
+
+这意味着几乎所有的数据映射关系都会错乱。在分布式缓存场景下,这会导致**大规模的缓存失效和缓存穿透**,瞬间将压力全部打到后端的数据库上,引发系统雪崩。
+
+据估算,当节点数量从 N 变为 N-1 时,平均有 (N-1)/N 比例的数据需要迁移,这个比例 **趋近于 100%** 。这种“牵一发而动全身”的效应,在生产环境中是完全不可接受的。
+
+为了更好地解决这个问题,一致性哈希算法诞生了。
+
+## 一致性哈希算法
+
+一致性哈希算法在 1997 年由麻省理工学院提出(这篇论文的 PDF 在线阅读地址:),是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了传统哈希算法在分布式[哈希表](https://baike.baidu.com/item/哈希表/5981869)(Distributed Hash Table,DHT)中存在的动态伸缩等问题 。
+
+一致性哈希算法的底层原理也很简单,关键在于**哈希环**的引入。
+
+### 哈希环
+
+一致性哈希算法将哈希空间组织成一个环形结构,将数据和节点都映射到这个环上,然后根据顺时针的规则确定数据或请求应该分配到哪个节点上。通常情况下,哈希环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 **[0, 2^32-1]** 。
+
+传统哈希算法是对服务器数量取模,一致性哈希算法是对哈希环的范围取模,固定值,通常为 2^32:
+
+```java
+node_number = hash(key) % 2^32
+```
+
+服务器/节点如何映射到哈希环上呢?也是哈希取模。例如,一般我们会根据服务器的 IP 或者主机名进行哈希,然后再取模。
+
+```java
+hash(服务器ip)% 2^32
+```
+
+如下图所示:
+
+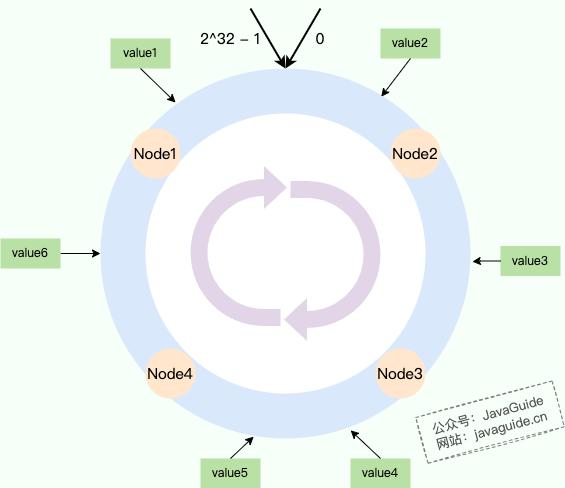
+
+我们将数据和节点都映射到哈希环上,环上的每个节点都负责一个区间。对于上图来说,每个节点负责的数据情况如下:
+
+- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。
+- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1, value2)。
+- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value3)。
+- **Node4:** 负责 Node3 到 Node4 之间的区域(包含 value4, value5)。
+
+### 节点移除/增加
+
+新增节点和移除节点的情况下,哈希环的引入可以避免影响范围太大,减少需要迁移的数据。
+
+还是用上面分享的哈希环示意图为例,假设 Node2 节点被移除的话,那 Node3 就要负责 Node2 的数据,直接迁移 Node2 的数据到 Node3 即可,其他节点不受影响。
+
+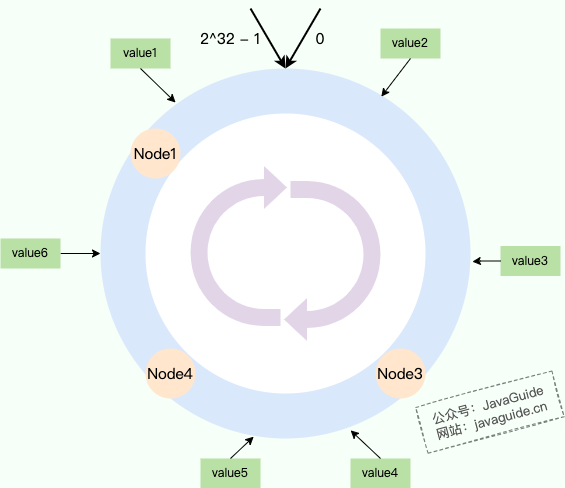
+
+同样地,如果我们在 Node1 和 Node2 之间新增一个节点 Node5,那么原本应该由 Node2 负责的一部分数据(即哈希值落在 Node1 和 Node5 之间的数据,如图中的 value1)现在会由 Node5 负责。我们只需要将这部分数据从 Node2 迁移到 Node5 即可,同样只影响了相邻的节点,影响范围非常小。
+
+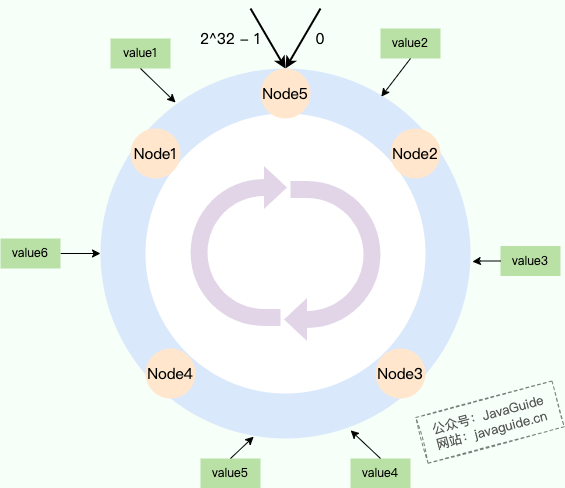
+
+### 数据倾斜问题
+
+理想情况下,节点在环上是均匀分布的。然而,现实可能并不是这样的,尤其是节点数量比较少的时候。节点可能被映射到附近的区域,这样的话,就会导致绝大部分数据都由其中一个节点负责。
+
+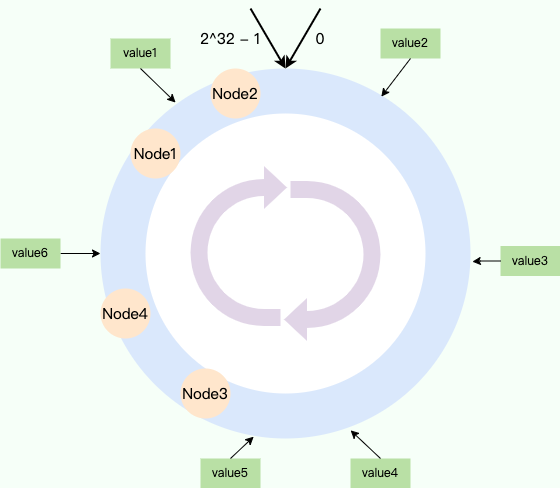
+
+对于上图来说,每个节点负责的数据情况如下:
+
+- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。
+- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1)。
+- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value2,value3, value4, value5)。
+- **Node4:** 负责 Node3 到 Node4 之间的区域。
+
+除了数据倾斜问题,还有一个隐患。当新增或者删除节点的时候,数据分配不均衡。例如,Node3 被移除的话,Node3 负责的所有数据都要交给 Node4,随后所有的请求都要达到 Node4 上。假设 Node4 的服务器处理能力比较差的话,那可能直接就被干崩了。理想情况下,应该有更多节点来分担压力。
+
+如何解决这些问题呢?答案是引入**虚拟节点**。
+
+### 虚拟节点
+
+虚拟节点就是对真实的物理节点在哈希环上虚拟出几个它的分身节点。数据落到分身节点上实际上就是落到真实的物理节点上,通过将虚拟节点均匀分散在哈希环的各个部分。
+
+如下图所示,Node1、Node2、Node3、Node4 这 4 个节点都对应 3 个虚拟节点(下图只是为了演示,实际情况节点分布不会这么有规律)。
+
+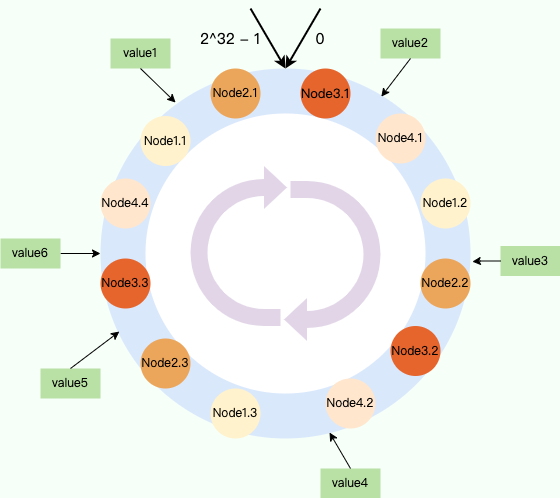
+
+对于上图来说,每个节点最终负责的数据情况如下:
+
+- **Node1**:value4
+- **Node2**:value1,value3
+- **Node3**:value5
+- **Node4**:value2,value6
+
+**The benefits of introducing virtual nodes are huge:**
+
+1. **Data balancing:** The more virtual nodes there are, the denser the "server points" on the ring are, the more even the data distribution will naturally be, fundamentally solving the problem of data skew. Typically, the number of virtual nodes corresponding to each real node is between 100 and 200. For example, Nginx chooses to allocate 160 virtual nodes for each weight. The weight here is to distinguish servers. For example, a server with stronger processing power has a higher weight, which leads to more corresponding virtual nodes and a greater probability of being hit.
+2. **Enhanced fault tolerance:** This is the most subtle thing about virtual nodes. When a physical node goes down, it is equivalent to multiple virtual nodes on the ring going offline at the same time. The data and traffic originally responsible for these virtual nodes will be naturally and evenly distributed to multiple other physical nodes on the ring to take over, without concentrating the pressure on a certain neighbor node. This greatly improves the stability and fault tolerance of the system.
+
+## Reference
+
+- In-depth analysis of Nginx Load balancing algorithm:
+- Reading source code architecture series: consistent hashing:
+- Summary of the principles of consistent Hash algorithm:
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/gossip-protocl.en.md b/docs_en/distributed-system/protocol/gossip-protocl.en.md
new file mode 100644
index 00000000000..803b31d8c0b
--- /dev/null
+++ b/docs_en/distributed-system/protocol/gossip-protocl.en.md
@@ -0,0 +1,145 @@
+---
+title: Gossip 协议详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 共识算法
+---
+
+## 背景
+
+在分布式系统中,不同的节点进行数据/信息共享是一个基本的需求。
+
+一种比较简单粗暴的方法就是 **集中式发散消息**,简单来说就是一个主节点同时共享最新信息给其他所有节点,比较适合中心化系统。这种方法的缺陷也很明显,节点多的时候不光同步消息的效率低,还太依赖与中心节点,存在单点风险问题。
+
+于是,**分散式发散消息** 的 **Gossip 协议** 就诞生了。
+
+## Gossip 协议介绍
+
+Gossip 直译过来就是闲话、流言蜚语的意思。流言蜚语有什么特点呢?容易被传播且传播速度还快,你传我我传他,然后大家都知道了。
+
+
+
+**Gossip 协议** 也叫 Epidemic 协议(流行病协议)或者 Epidemic propagation 算法(疫情传播算法),别名很多。不过,这些名字的特点都具有 **随机传播特性** (联想一下病毒传播、癌细胞扩散等生活中常见的情景),这也正是 Gossip 协议最主要的特点。
+
+Gossip 协议最早是在 ACM 上的一篇 1987 年发表的论文 [《Epidemic Algorithms for Replicated Database Maintenance》](https://dl.acm.org/doi/10.1145/41840.41841)中被提出的。根据论文标题,我们大概就能知道 Gossip 协议当时提出的主要应用是在分布式数据库系统中各个副本节点同步数据。
+
+正如 Gossip 协议其名一样,这是一种随机且带有传染性的方式将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。
+
+在 Gossip 协议下,没有所谓的中心节点,每个节点周期性地随机找一个节点互相同步彼此的信息,理论上来说,各个节点的状态最终会保持一致。
+
+下面我们来对 Gossip 协议的定义做一个总结:**Gossip 协议是一种允许在分布式系统中共享状态的去中心化通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。**
+
+## Gossip 协议应用
+
+NoSQL 数据库 Redis 和 Apache Cassandra、服务网格解决方案 Consul 等知名项目都用到了 Gossip 协议,学习 Gossip 协议有助于我们搞清很多技术的底层原理。
+
+我们这里以 Redis Cluster 为例说明 Gossip 协议的实际应用。
+
+我们经常使用的分布式缓存 Redis 的官方集群解决方案(3.0 版本引入) Redis Cluster 就是基于 Gossip 协议来实现集群中各个节点数据的最终一致性。
+
+
+
+Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节点需要互相通信。既然要相互通信就要遵循一致的通信协议,Redis Cluster 中的各个节点基于 **Gossip 协议** 来进行通信共享信息,每个 Redis 节点都维护了一份集群的状态信息。
+
+Redis Cluster 的节点之间会相互发送多种 Gossip 消息:
+
+- **MEET**:在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
+- **PING/PONG**:Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
+- **FAIL**:Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
+- ……
+
+下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信 ,实线表示主从复制。
+
+
+
+有了 Redis Cluster 之后,不需要专门部署 Sentinel 集群服务了。Redis Cluster 相当于是内置了 Sentinel 机制,Redis Cluster 内部的各个 Redis 节点通过 Gossip 协议共享集群内信息。
+
+关于 Redis Cluster 的详细介绍,可以查看这篇文章 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 。
+
+## Gossip 协议消息传播模式
+
+Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)** 和 **传谣(Rumor-Mongering)**。
+
+### 反熵(Anti-entropy)
+
+根据维基百科:
+
+> 熵的概念最早起源于[物理学](https://zh.wikipedia.org/wiki/物理学),用于度量一个热力学系统的混乱程度。熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。
+
+在这里,你可以把反熵中的熵理解为节点之间数据的混乱程度/差异性,反熵就是指消除不同节点中数据的差异,提升节点间数据的相似度,从而降低熵值。
+
+具体是如何反熵的呢?集群中的节点,每隔段时间就随机选择某个其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性。
+
+在实现反熵的时候,主要有推、拉和推拉三种方式:
+
+- 推方式,就是将自己的所有副本数据,推给对方,修复对方副本中的熵。
+- 拉方式,就是拉取对方的所有副本数据,修复自己副本中的熵。
+- 推拉就是同时修复自己副本和对方副本中的熵。
+
+伪代码如下:
+
+
+
+在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是可以设计成一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
+
+
+
+1. 节点 A 推送数据给节点 B,节点 B 获取到节点 A 中的最新数据。
+2. 节点 B 推送数据给 C,节点 C 获取到节点 A,B 中的最新数据。
+3. 节点 C 推送数据给 A,节点 A 获取到节点 B,C 中的最新数据。
+4. 节点 A 再推送数据给 B 形成闭环,这样节点 B 就获取到节点 C 中的最新数据。
+
+虽然反熵很简单实用,但是,节点过多或者节点动态变化的话,反熵就不太适用了。这个时候,我们想要实现最终一致性就要靠 **谣言传播(Rumor mongering)** 。
+
+### 谣言传播(Rumor mongering)
+
+谣言传播指的是分布式系统中的一个节点一旦有了新数据之后,就会变为活跃节点,活跃节点会周期性地联系其他节点向其发送新数据,直到所有的节点都存储了该新数据。
+
+如下图所示(下图来自于[INTRODUCTION TO GOSSIP](https://managementfromscratch.wordpress.com/2016/04/01/introduction-to-gossip/) 这篇文章):
+
+
+
+伪代码如下:
+
+
+
+谣言传播比较适合节点数量比较多的情况,不过,这种模式下要尽量避免传播的信息包不能太大,避免网络消耗太大。
+
+### 总结
+
+- 反熵(Anti-Entropy)会传播节点的所有数据,而谣言传播(Rumor-Mongering)只会传播节点新增的数据。
+- 我们一般会给反熵设计一个闭环。
+- 谣言传播(Rumor-Mongering)比较适合节点数量比较多或者节点动态变化的场景。
+
+## Gossip 协议优势和缺陷
+
+**优势:**
+
+1、相比于其他分布式协议/算法来说,Gossip 协议理解起来非常简单。
+
+2、能够容忍网络上节点的随意地增加或者减少,宕机或者重启,因为 Gossip 协议下这些节点都是平等的,去中心化的。新增加或者重启的节点在理想情况下最终是一定会和其他节点的状态达到一致。
+
+3. The speed is relatively fast. When the number of nodes is relatively large, the diffusion speed is faster than a master node disseminating information to other nodes (multicast).
+
+**Defects**:
+
+1. Messages need to be propagated to the entire network through multiple rounds of propagation. Therefore, the status of each node will inevitably be inconsistent. After all, the Gossip protocol emphasizes eventual consistency, and no one knows how long it will take to reach a consistent state of each node.
+
+2. Due to the Byzantine Generals Problem, malicious nodes are not allowed to exist.
+
+3. There may be message redundancy issues. Due to the random nature of message propagation, the same node may receive the same message repeatedly.
+
+## Summary
+
+- Gossip protocol is a communication protocol that allows sharing state in a distributed system, through this communication protocol we can disseminate information to all members of the network or cluster.
+- The Gossip protocol is used by projects such as Redis, Apache Cassandra, and Consul.
+- Rumor-Mongering is more suitable for scenarios where the number of nodes is large or nodes change dynamically.
+
+## Reference
+
+- A 10,000-word detailed explanation of the Redis Cluster Gossip protocol:
+- "Distributed Protocols and Algorithms in Practice"
+- "Redis Design and Implementation"
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/paxos-algorithm.en.md b/docs_en/distributed-system/protocol/paxos-algorithm.en.md
new file mode 100644
index 00000000000..d0ca0b8f051
--- /dev/null
+++ b/docs_en/distributed-system/protocol/paxos-algorithm.en.md
@@ -0,0 +1,84 @@
+---
+title: Paxos 算法详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 共识算法
+---
+
+## 背景
+
+Paxos 算法是 Leslie Lamport([莱斯利·兰伯特](https://zh.wikipedia.org/wiki/莱斯利·兰伯特))在 **1990** 年提出了一种分布式系统 **共识** 算法。这也是第一个被证明完备的共识算法(前提是不存在拜占庭将军问题,也就是没有恶意节点)。
+
+为了介绍 Paxos 算法,兰伯特专门写了一篇幽默风趣的论文。在这篇论文中,他虚拟了一个叫做 Paxos 的希腊城邦来更形象化地介绍 Paxos 算法。
+
+不过,审稿人并不认可这篇论文的幽默。于是,他们就给兰伯特说:“如果你想要成功发表这篇论文的话,必须删除所有 Paxos 相关的故事背景”。兰伯特一听就不开心了:“我凭什么修改啊,你们这些审稿人就是缺乏幽默细胞,发不了就不发了呗!”。
+
+于是乎,提出 Paxos 算法的那篇论文在当时并没有被成功发表。
+
+直到 1998 年,系统研究中心 (Systems Research Center,SRC)的两个技术研究员需要找一些合适的分布式算法来服务他们正在构建的分布式系统,Paxos 算法刚好可以解决他们的部分需求。因此,兰伯特就把论文发给了他们。在看了论文之后,这俩大佬觉得论文还是挺不错的。于是,兰伯特在 **1998** 年重新发表论文 [《The Part-Time Parliament》](http://lamport.azurewebsites.net/pubs/lamport-paxos.pdf)。
+
+论文发表之后,各路学者直呼看不懂,言语中还略显调侃之意。这谁忍得了,在 **2001** 年的时候,兰伯特专门又写了一篇 [《Paxos Made Simple》](http://lamport.azurewebsites.net/pubs/paxos-simple.pdf) 的论文来简化对 Paxos 的介绍,主要讲述两阶段共识协议部分,顺便还不忘嘲讽一下这群学者。
+
+《Paxos Made Simple》这篇论文就 14 页,相比于 《The Part-Time Parliament》的 33 页精简了不少。最关键的是这篇论文的摘要就一句话:
+
+
+
+> The Paxos algorithm, when presented in plain English, is very simple.
+
+翻译过来的意思大概就是:当我用无修饰的英文来描述时,Paxos 算法真心简单!
+
+有没有感觉到来自兰伯特大佬满满地嘲讽的味道?
+
+## 介绍
+
+Paxos 算法是第一个被证明完备的分布式系统共识算法。共识算法的作用是让分布式系统中的多个节点之间对某个提案(Proposal)达成一致的看法。提案的含义在分布式系统中十分宽泛,像哪一个节点是 Leader 节点、多个事件发生的顺序等等都可以是一个提案。
+
+兰伯特当时提出的 Paxos 算法主要包含 2 个部分:
+
+- **Basic Paxos 算法**:描述的是多节点之间如何就某个值(提案 Value)达成共识。
+- **Multi-Paxos 思想**:描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。Multi-Paxos 说白了就是执行多次 Basic Paxos ,核心还是 Basic Paxos 。
+
+由于 Paxos 算法在国际上被公认的非常难以理解和实现,因此不断有人尝试简化这一算法。到了 2013 年才诞生了一个比 Paxos 算法更易理解和实现的共识算法—[Raft 算法](https://javaguide.cn/distributed-system/theorem&algorithm&protocol/raft-algorithm.html) 。更具体点来说,Raft 是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现。
+
+针对没有恶意节点的情况,除了 Raft 算法之外,当前最常用的一些共识算法比如 **ZAB 协议**、 **Fast Paxos** 算法都是基于 Paxos 算法改进的。
+
+针对存在恶意节点的情况,一般使用的是 **工作量证明(POW,Proof-of-Work)**、 **权益证明(PoS,Proof-of-Stake )** 等共识算法。这类共识算法最典型的应用就是区块链,就比如说前段时间以太坊官方宣布其共识机制正在从工作量证明(PoW)转变为权益证明(PoS)。
+
+区块链系统使用的共识算法需要解决的核心问题是 **拜占庭将军问题** ,这和我们日常接触到的 ZooKeeper、Etcd、Consul 等分布式中间件不太一样。
+
+下面我们来对 Paxos 算法的定义做一个总结:
+
+- Paxos 算法是兰伯特在 **1990** 年提出了一种分布式系统共识算法。
+- 兰伯特当时提出的 Paxos 算法主要包含 2 个部分: Basic Paxos 算法和 Multi-Paxos 思想。
+- Raft 算法、ZAB 协议、 Fast Paxos 算法都是基于 Paxos 算法改进而来。
+
+## Basic Paxos 算法
+
+Basic Paxos 中存在 3 个重要的角色:
+
+1. **提议者(Proposer)**:也可以叫做协调者(coordinator),提议者负责接受客户端的请求并发起提案。提案信息通常包括提案编号 (Proposal ID) 和提议的值 (Value)。
+2. **接受者(Acceptor)**:也可以叫做投票员(voter),负责对提议者的提案进行投票,同时需要记住自己的投票历史;
+3. **学习者(Learner)**:如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
+
+
+
+为了减少实现该算法所需的节点数,一个节点可以身兼多个角色。并且,一个提案被选定需要被半数以上的 Acceptor 接受。这样的话,Basic Paxos 算法还具备容错性,在少于一半的节点出现故障时,集群仍能正常工作。
+
+## Multi Paxos 思想
+
+Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Multi Paxos 思想。
+
+⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
+
+由于兰伯特提到的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者),所以在理解和实现上比较困难。
+
+不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。像 Raft 算法就是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。
+
+## 参考
+
+-
+- 分布式系统中的一致性与共识算法:
+
+
+
diff --git a/docs_en/distributed-system/protocol/raft-algorithm.en.md b/docs_en/distributed-system/protocol/raft-algorithm.en.md
new file mode 100644
index 00000000000..914de02ad9d
--- /dev/null
+++ b/docs_en/distributed-system/protocol/raft-algorithm.en.md
@@ -0,0 +1,171 @@
+---
+title: Raft 算法详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 共识算法
+---
+
+> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [Xieqijun](https://github.com/jun0315) 共同完成。
+
+## 1 背景
+
+当今的数据中心和应用程序在高度动态的环境中运行,为了应对高度动态的环境,它们通过额外的服务器进行横向扩展,并且根据需求进行扩展和收缩。同时,服务器和网络故障也很常见。
+
+因此,系统必须在正常操作期间处理服务器的上下线。它们必须对变故做出反应并在几秒钟内自动适应;对客户来说的话,明显的中断通常是不可接受的。
+
+幸运的是,分布式共识可以帮助应对这些挑战。
+
+### 1.1 拜占庭将军
+
+在介绍共识算法之前,先介绍一个简化版拜占庭将军的例子来帮助理解共识算法。
+
+> 假设多位拜占庭将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成是否要进攻的一致性决定?
+
+解决方案大致可以理解成:先在所有的将军中选出一个大将军,用来做出所有的决定。
+
+举例如下:假如现在一共有 3 个将军 A,B 和 C,每个将军都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军 B 和 C,如果将军 B 和 C 还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军 A,信使回到将军 A 时,将军 A 知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军 A 决定,然后再去派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军 B 和 C 的回复(信使可能会被暗杀),那就再重派一个信使,直到收到回复。
+
+### 1.2 共识算法
+
+共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
+
+共识算法允许一组节点像一个整体一样一起工作,即使其中的一些节点出现故障也能够继续工作下去,其正确性主要是源于复制状态机的性质:一组`Server`的状态机计算相同状态的副本,即使有一部分的`Server`宕机了它们仍然能够继续运行。
+
+
+
+`图-1 复制状态机架构`
+
+一般通过使用复制日志来实现复制状态机。每个`Server`存储着一份包括命令序列的日志文件,状态机会按顺序执行这些命令。因为每个日志包含相同的命令,并且顺序也相同,所以每个状态机处理相同的命令序列。由于状态机是确定性的,所以处理相同的状态,得到相同的输出。
+
+因此共识算法的工作就是保持复制日志的一致性。服务器上的共识模块从客户端接收命令并将它们添加到日志中。它与其他服务器上的共识模块通信,以确保即使某些服务器发生故障。每个日志最终包含相同顺序的请求。一旦命令被正确地复制,它们就被称为已提交。每个服务器的状态机按照日志顺序处理已提交的命令,并将输出返回给客户端,因此,这些服务器形成了一个单一的、高度可靠的状态机。
+
+适用于实际系统的共识算法通常具有以下特性:
+
+- 安全。确保在非拜占庭条件(也就是上文中提到的简易版拜占庭)下的安全性,包括网络延迟、分区、包丢失、复制和重新排序。
+- 高可用。只要大多数服务器都是可操作的,并且可以相互通信,也可以与客户端进行通信,那么这些服务器就可以看作完全功能可用的。因此,一个典型的由五台服务器组成的集群可以容忍任何两台服务器端故障。假设服务器因停止而发生故障;它们稍后可能会从稳定存储上的状态中恢复并重新加入集群。
+- 一致性不依赖时序。错误的时钟和极端的消息延迟,在最坏的情况下也只会造成可用性问题,而不会产生一致性问题。
+
+- 在集群中大多数服务器响应,命令就可以完成,不会被少数运行缓慢的服务器来影响整体系统性能。
+
+## 2 基础
+
+### 2.1 节点类型
+
+一个 Raft 集群包括若干服务器,以典型的 5 服务器集群举例。在任意的时间,每个服务器一定会处于以下三个状态中的一个:
+
+- `Leader`:负责发起心跳,响应客户端,创建日志,同步日志。
+- `Candidate`:Leader 选举过程中的临时角色,由 Follower 转化而来,发起投票参与竞选。
+- `Follower`:接受 Leader 的心跳和日志同步数据,投票给 Candidate。
+
+在正常的情况下,只有一个服务器是 Leader,剩下的服务器是 Follower。Follower 是被动的,它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。
+
+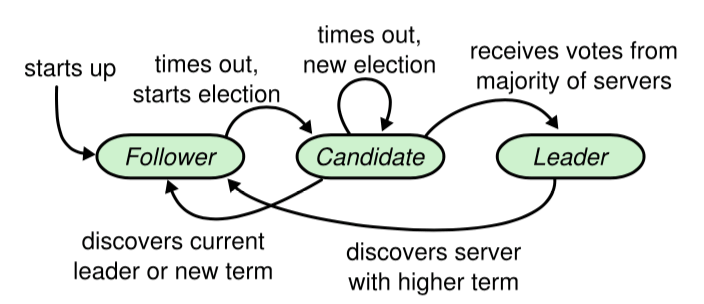
+
+`图-2:服务器的状态`
+
+### 2.2 任期
+
+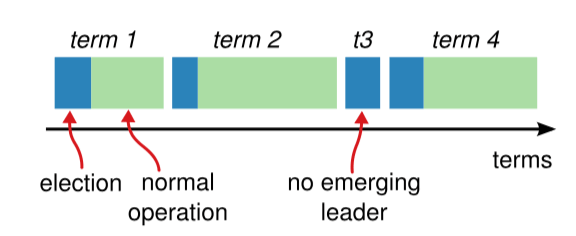
+
+`图-3:任期`
+
+如图 3 所示,raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader,将会开启另一个任期,并立刻开始下一次选举。raft 算法保证在给定的一个任期最少要有一个 Leader。
+
+每个节点都会存储当前的 term 号,当服务器之间进行通信时会交换当前的 term 号;如果有服务器发现自己的 term 号比其他人小,那么他会更新到较大的 term 值。如果一个 Candidate 或者 Leader 发现自己的 term 过期了,他会立即退回成 Follower。如果一台服务器收到的请求的 term 号是过期的,那么它会拒绝此次请求。
+
+### 2.3 日志
+
+- `entry`:每一个事件成为 entry,只有 Leader 可以创建 entry。entry 的内容为``其中 cmd 是可以应用到状态机的操作。
+- `log`:由 entry 构成的数组,每一个 entry 都有一个表明自己在 log 中的 index。只有 Leader 才可以改变其他节点的 log。entry 总是先被 Leader 添加到自己的 log 数组中,然后再发起共识请求,获得同意后才会被 Leader 提交给状态机。Follower 只能从 Leader 获取新日志和当前的 commitIndex,然后把对应的 entry 应用到自己的状态机中。
+
+## 3 领导人选举
+
+raft 使用心跳机制来触发 Leader 的选举。
+
+如果一台服务器能够收到来自 Leader 或者 Candidate 的有效信息,那么它会一直保持为 Follower 状态,并且刷新自己的 electionElapsed,重新计时。
+
+Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader 地位。如果一个 Follower 在一个周期内没有收到心跳信息,就叫做选举超时,然后它就会认为此时没有可用的 Leader,并且开始进行一次选举以选出一个新的 Leader。
+
+为了开始新的选举,Follower 会自增自己的 term 号并且转换状态为 Candidate。然后他会向所有节点发起 RequestVoteRPC 请求, Candidate 的状态会持续到以下情况发生:
+
+- 赢得选举
+- 其他节点赢得选举
+- 一轮选举结束,无人胜出
+
+赢得选举的条件是:一个 Candidate 在一个任期内收到了来自集群内的多数选票`(N/2+1)`,就可以成为 Leader。
+
+在 Candidate 等待选票的时候,它可能收到其他节点声明自己是 Leader 的心跳,此时有两种情况:
+
+- 该 Leader 的 term 号大于等于自己的 term 号,说明对方已经成为 Leader,则自己回退为 Follower。
+- 该 Leader 的 term 号小于自己的 term 号,那么会拒绝该请求并让该节点更新 term。
+
+由于可能同一时刻出现多个 Candidate,导致没有 Candidate 获得大多数选票,如果没有其他手段来重新分配选票的话,那么可能会无限重复下去。
+
+raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的选举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
+
+## 4 日志复制
+
+一旦选出了 Leader,它就开始接受客户端的请求。每一个客户端的请求都包含一条需要被复制状态机(`Replicated State Machine`)执行的命令。
+
+Leader 收到客户端请求后,会生成一个 entry,包含``,再将这个 entry 添加到自己的日志末尾后,向所有的节点广播该 entry,要求其他服务器复制这条 entry。
+
+If the Follower accepts the entry, it will add the entry to the end of its own log and return it to the Leader for approval.
+
+If the Leader receives a majority of successful responses, the Leader will apply the entry to its own state machine, and then call the entry committed and return the execution result to the client.
+
+raft guarantees the following two properties:
+
+- In two logs, if there are two entries with the same index and term, then they must have the same cmd
+- In two logs, if there are two entries with the same index and term, then the entries in front of them must also be the same.
+
+The first property is guaranteed by "only the Leader can generate entries", and the second property requires a consistency check to ensure it.
+
+Under normal circumstances, the logs of the Leader and Follower are consistent. However, the crash of the Leader will cause the logs to be different, so the consistency check will fail. Leader handles log inconsistencies by forcing Followers to copy their own logs. This means that the conflict log on the Follower will be overwritten by the leader's log.
+
+In order to make the Follower's log consistent with its own log, the Leader needs to find the place where the Follower's log is consistent with its own log, then delete the Follower's log after that position, and then send the following log to the Follower.
+
+`Leader` maintains a `nextIndex` for each `Follower`, which represents the index of the next log entry that `Leader` will send to the follower. When a `Leader` takes power, it initializes `nextIndex` to its latest log entry index + 1. If the log of a `Follower` is inconsistent with that of the `Leader`, the `AppendEntries` consistency check will return failure at the next `AppendEntries RPC`. After a failure, `Leader` will decrement `nextIndex` and retry `AppendEntries RPC`. Eventually `nextIndex` will reach a place where `Leader` and `Follower` logs are consistent. At this point, `AppendEntries` will return successfully, the conflicting log entries in `Follower` will be removed, and the missing `Leader` log entries will be added. Once `AppendEntries` returns successfully, the logs of `Follower` and `Leader` are consistent, and this state will remain until the end of the term.
+
+## 5 Security
+
+### 5.1 Election restrictions
+
+The Leader needs to ensure that it stores all submitted log entries. This allows log entries to flow in only one direction: from Leader to Follower, and Leader will never overwrite existing log entries.
+
+When each Candidate sends RequestVoteRPC, it will bring the last entry information. When all nodes receive the voting information, they will compare the entry. If they find their own updates, they will refuse to vote for the candidate.
+
+The way to judge the old and new logs: if the terms of the two logs are different, the larger term is updated; if the terms are the same, the longer index is updated.
+
+### 5.2 Node crash
+
+If the Leader crashes and the nodes in the cluster do not receive the Leader's heartbeat information within the electionTimeout time, a new round of leader election will be triggered. During the leader election period, the entire cluster will be unavailable to the outside world.
+
+If Follower and Candidate crash, the handling will be much simpler. Subsequent RequestVoteRPC and AppendEntriesRPC sent to it will fail. Since all raft requests are idempotent, they will be retried infinitely if they fail. If the crash is recovered, you can receive new requests and choose to append or reject the entry.
+
+### 5.3 Timing and Availability
+
+One of the requirements of raft is that security does not depend on time: the system cannot fail just because some events occur faster or slower than expected. In order to ensure the above requirements, it is best to meet the following time conditions:
+
+`broadcastTime << electionTimeout << MTBF`
+
+- `broadcastTime`: the average response time for concurrently sending messages to other nodes;
+- `electionTimeout`: election timeout;
+- `MTBF(mean time between failures)`: the average health time of a single machine;
+
+`broadcastTime` should be an order of magnitude smaller than `electionTimeout`, in order to enable `Leader` to continuously send heartbeat information (heartbeat) to prevent `Follower` from starting an election;
+
+`electionTimeout` is also several orders of magnitude smaller than `MTBF` in order to make the system run stably. When the `Leader` crashes, it will be unavailable for approximately the entire `electionTimeout`; we hope that this will only be a small fraction of the total time.
+
+Since `broadcastTime` and `MTBF` are properties determined by the system, the time of `electionTimeout` needs to be determined.
+
+Generally speaking, broadcastTime is generally `0.5~20ms`, electionTimeout can be set to `10~500ms`, and MTBF is generally one or two months.
+
+## 6 Reference
+
+-
+-
+-
+-
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/rpc/dubbo.en.md b/docs_en/distributed-system/rpc/dubbo.en.md
new file mode 100644
index 00000000000..cc14665ee07
--- /dev/null
+++ b/docs_en/distributed-system/rpc/dubbo.en.md
@@ -0,0 +1,459 @@
+---
+title: Dubbo常见问题总结
+category: 分布式
+tag:
+ - rpc
+---
+
+::: tip
+
+- Dubbo3 已经发布,这篇文章是基于 Dubbo2 写的。Dubbo3 基于 Dubbo2 演进而来,在保持原有核心功能特性的同时, Dubbo3 在易用性、超大规模微服务实践、云原生基础设施适配、安全设计等几大方向上进行了全面升级。
+- 本文中的很多链接已经失效,主要原因是因为 Dubbo 官方文档进行了修改导致 URL 失效。
+
+:::
+
+这篇文章是我根据官方文档以及自己平时的使用情况,对 Dubbo 所做的一个总结。欢迎补充!
+
+## Dubbo 基础
+
+### 什么是 Dubbo?
+
+
+
+[Apache Dubbo](https://github.com/apache/dubbo) |ˈdʌbəʊ| 是一款高性能、轻量级的开源 WEB 和 RPC 框架。
+
+根据 [Dubbo 官方文档](https://dubbo.apache.org/zh/)的介绍,Dubbo 提供了六大核心能力
+
+1. 面向接口代理的高性能 RPC 调用。
+2. 智能容错和负载均衡。
+3. 服务自动注册和发现。
+4. 高度可扩展能力。
+5. 运行期流量调度。
+6. 可视化的服务治理与运维。
+
+
+
+简单来说就是:**Dubbo 不光可以帮助我们调用远程服务,还提供了一些其他开箱即用的功能比如智能负载均衡。**
+
+Dubbo 目前已经有接近 34.4 k 的 Star 。
+
+在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第 7 名。相比几年前来说,热度和排名有所下降。
+
+
+
+Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
+
+### 为什么要用 Dubbo?
+
+随着互联网的发展,网站的规模越来越大,用户数量越来越多。单一应用架构、垂直应用架构无法满足我们的需求,这个时候分布式服务架构就诞生了。
+
+分布式服务架构下,系统被拆分成不同的服务比如短信服务、安全服务,每个服务独立提供系统的某个核心服务。
+
+我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian 这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
+
+不过,Dubbo 的出现让上述问题得到了解决。**Dubbo 帮助我们解决了什么问题呢?**
+
+1. **负载均衡**:同一个服务部署在不同的机器时该调用哪一台机器上的服务。
+2. **服务调用链路生成**:随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
+3. **服务访问压力以及时长统计、资源调度和治理**:基于访问压力实时管理集群容量,提高集群利用率。
+4. ……
+
+
+
+另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
+
+**我们刚刚提到了分布式这个概念,下面再给大家介绍一下什么是分布式?为什么要分布式?**
+
+## 分布式基础
+
+### 什么是分布式?
+
+分布式或者说 SOA 分布式重要的就是面向服务,说简单的分布式就是我们把整个系统拆分成不同的服务然后将这些服务放在不同的服务器上减轻单体服务的压力提高并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
+
+
+
+### 为什么要分布式?
+
+从开发角度来讲单体应用的代码都集中在一起,而分布式系统的代码根据业务被拆分。所以,每个团队可以负责一个服务的开发,这样提升了开发效率。另外,代码根据业务拆分之后更加便于维护和扩展。
+
+另外,我觉得将系统拆分成分布式之后不光便于系统扩展和维护,更能提高整个系统的性能。你想一想嘛?把整个系统拆分成不同的服务/系统,然后每个服务/系统 单独部署在一台服务器上,是不是很大程度上提高了系统性能呢?
+
+## Dubbo 架构
+
+### Dubbo 架构中的核心角色有哪些?
+
+[官方文档中的框架设计章节](https://dubbo.apache.org/zh/docs/v2.7/dev/design/) 已经介绍的非常详细了,我这里把一些比较重要的点再提一下。
+
+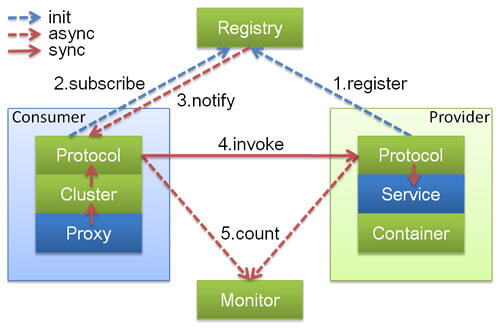
+
+上述节点简单介绍以及他们之间的关系:
+
+- **Container:** 服务运行容器,负责加载、运行服务提供者。必须。
+- **Provider:** 暴露服务的服务提供方,会向注册中心注册自己提供的服务。必须。
+- **Consumer:** 调用远程服务的服务消费方,会向注册中心订阅自己所需的服务。必须。
+- **Registry:** 服务注册与发现的注册中心。注册中心会返回服务提供者地址列表给消费者。非必须。
+- **Monitor:** 统计服务的调用次数和调用时间的监控中心。服务消费者和提供者会定时发送统计数据到监控中心。 非必须。
+
+### Dubbo 中的 Invoker 概念了解么?
+
+`Invoker` 是 Dubbo 领域模型中非常重要的一个概念,你如果阅读过 Dubbo 源码的话,你会无数次看到这玩意。就比如下面我要说的负载均衡这块的源码中就有大量 `Invoker` 的身影。
+
+简单来说,`Invoker` 就是 Dubbo 对远程调用的抽象。
+
+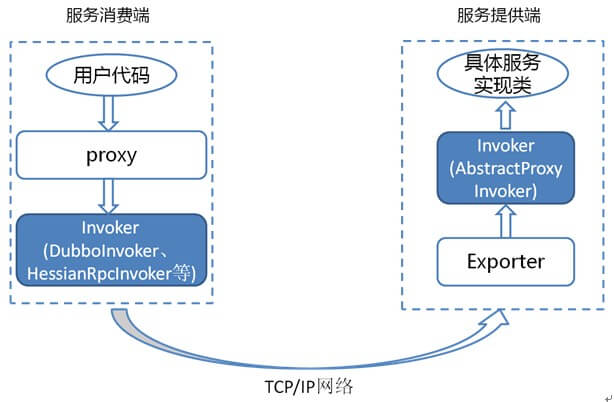
+
+按照 Dubbo 官方的话来说,`Invoker` 分为
+
+- 服务提供 `Invoker`
+- 服务消费 `Invoker`
+
+假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的 `Invoker` 实现, `Invoker` 实现了真正的远程服务调用。
+
+### Dubbo 的工作原理了解么?
+
+下图是 Dubbo 的整体设计,从下至上分为十层,各层均为单向依赖。
+
+> 左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
+
+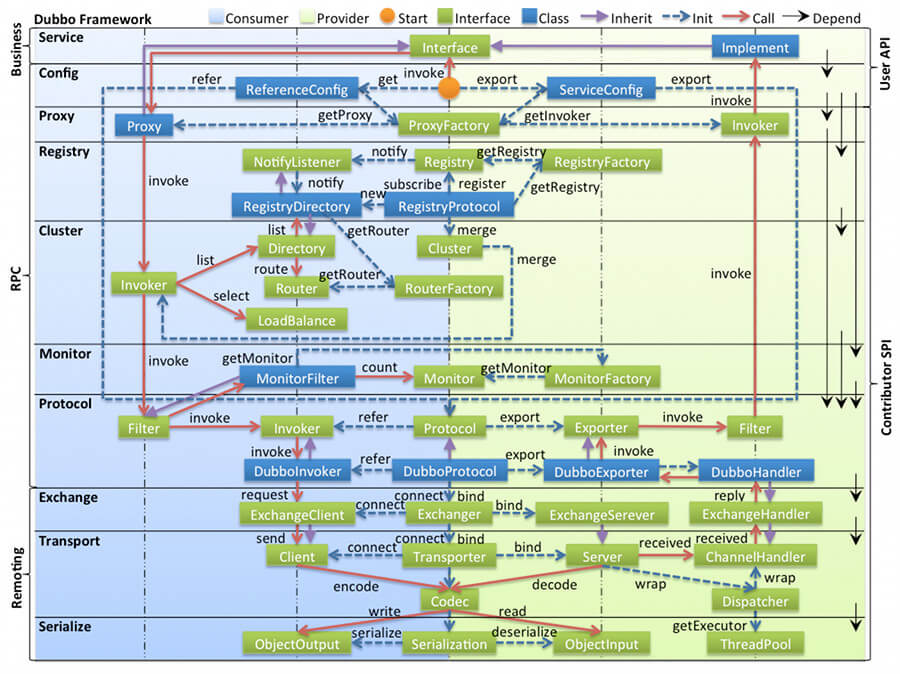
+
+- **config 配置层**:Dubbo 相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以 `ServiceConfig`, `ReferenceConfig` 为中心
+- **proxy 服务代理层**:调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以 `ServiceProxy` 为中心。
+- **registry 注册中心层**:封装服务地址的注册与发现。
+- **cluster 路由层**:封装多个提供者的路由及负载均衡,并桥接注册中心,以 `Invoker` 为中心。
+- **monitor 监控层**:RPC 调用次数和调用时间监控,以 `Statistics` 为中心。
+- **protocol 远程调用层**:封装 RPC 调用,以 `Invocation`, `Result` 为中心。
+- **exchange 信息交换层**:封装请求响应模式,同步转异步,以 `Request`, `Response` 为中心。
+- **transport 网络传输层**:抽象 mina 和 netty 为统一接口,以 `Message` 为中心。
+- **serialize 数据序列化层**:对需要在网络传输的数据进行序列化。
+
+### Dubbo 的 SPI 机制了解么? 如何扩展 Dubbo 中的默认实现?
+
+SPI(Service Provider Interface) 机制被大量用在开源项目中,它可以帮助我们动态寻找服务/功能(比如负载均衡策略)的实现。
+
+SPI 的具体原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
+
+Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java 原生的 SPI 机制进行了增强,以便更好满足自己的需求。
+
+**那我们如何扩展 Dubbo 中的默认实现呢?**
+
+比如说我们想要实现自己的负载均衡策略,我们创建对应的实现类 `XxxLoadBalance` 实现 `LoadBalance` 接口或者 `AbstractLoadBalance` 类。
+
+```java
+package com.xxx;
+
+import org.apache.dubbo.rpc.cluster.LoadBalance;
+import org.apache.dubbo.rpc.Invoker;
+import org.apache.dubbo.rpc.Invocation;
+import org.apache.dubbo.rpc.RpcException;
+
+public class XxxLoadBalance implements LoadBalance {
+ public Invoker select(List> invokers, Invocation invocation) throws RpcException {
+ // ...
+ }
+}
+```
+
+我们将这个实现类的路径写入到`resources` 目录下的 `META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance`文件中即可。
+
+```java
+src
+ |-main
+ |-java
+ |-com
+ |-xxx
+ |-XxxLoadBalance.java (实现LoadBalance接口)
+ |-resources
+ |-META-INF
+ |-dubbo
+ |-org.apache.dubbo.rpc.cluster.LoadBalance (纯文本文件,内容为:xxx=com.xxx.XxxLoadBalance)
+```
+
+`org.apache.dubbo.rpc.cluster.LoadBalance`
+
+```plain
+xxx=com.xxx.XxxLoadBalance
+```
+
+其他还有很多可供扩展的选择,你可以在[官方文档](https://cn.dubbo.apache.org/zh-cn/overview/home/)中找到。
+
+### Dubbo 的微内核架构了解吗?
+
+Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来说就是微内核架构。微内核只负责组装插件。
+
+**何为微内核架构呢?** 《软件架构模式》 这本书是这样介绍的:
+
+> 微内核架构模式(有时被称为插件架构模式)是实现基于产品应用程序的一种自然模式。基于产品的应用程序是已经打包好并且拥有不同版本,可作为第三方插件下载的。然后,很多公司也在开发、发布自己内部商业应用像有版本号、说明及可加载插件式的应用软件(这也是这种模式的特征)。微内核系统可让用户添加额外的应用如插件,到核心应用,继而提供了可扩展性和功能分离的用法。
+
+微内核架构包含两类组件:**核心系统(core system)** 和 **插件模块(plug-in modules)**。
+
+
+
+核心系统提供系统所需核心能力,插件模块可以扩展系统的功能。因此, 基于微内核架构的系统,非常易于扩展功能。
+
+我们常见的一些 IDE,都可以看作是基于微内核架构设计的。绝大多数 IDE 比如 IDEA、VSCode 都提供了插件来丰富自己的功能。
+
+正是因为 Dubbo 基于微内核架构,才使得我们可以随心所欲替换 Dubbo 的功能点。比如你觉得 Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
+
+通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件:**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
+
+### 关于 Dubbo 架构的一些自测小问题
+
+#### 注册中心的作用了解么?
+
+注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互。
+
+#### 服务提供者宕机后,注册中心会做什么?
+
+注册中心会立即推送事件通知消费者。
+
+#### 监控中心的作用呢?
+
+监控中心负责统计各服务调用次数,调用时间等。
+
+#### 注册中心和监控中心都宕机的话,服务都会挂掉吗?
+
+不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
+
+## Dubbo 的负载均衡策略
+
+### 什么是负载均衡?
+
+先来看一下稍微官方点的解释。下面这段话摘自维基百科对负载均衡的定义:
+
+> 负载均衡改善了跨多个计算资源(例如计算机,计算机集群,网络链接,中央处理单元或磁盘驱动)的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间,并避免任何单个资源的过载。使用具有负载平衡而不是单个组件的多个组件可以通过冗余提高可靠性和可用性。负载平衡通常涉及专用软件或硬件。
+
+**上面讲的大家可能不太好理解,再用通俗的话给大家说一下。**
+
+我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡的这四个字就能明显感受到它的意义。
+
+### Dubbo 提供的负载均衡策略有哪些?
+
+在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 `random` 随机调用。我们还可以自行扩展负载均衡策略(参考 Dubbo SPI 机制)。
+
+在 Dubbo 中,所有负载均衡实现类均继承自 `AbstractLoadBalance`,该类实现了 `LoadBalance` 接口,并封装了一些公共的逻辑。
+
+```java
+public abstract class AbstractLoadBalance implements LoadBalance {
+
+ static int calculateWarmupWeight(int uptime, int warmup, int weight) {
+ }
+
+ @Override
+ public Invoker select(List> invokers, URL url, Invocation invocation) {
+ }
+
+ protected abstract Invoker doSelect(List> invokers, URL url, Invocation invocation);
+
+
+ int getWeight(Invoker invoker, Invocation invocation) {
+
+ }
+}
+```
+
+`AbstractLoadBalance` 的实现类有下面这些:
+
+
+
+The official document introduces this part of load balancing in great detail. It is recommended that friends take a look at the address: [https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance).
+
+#### RandomLoadBalance
+
+Random selection based on weights (an implementation of the weighted random algorithm). This is a load balancing strategy adopted by Dubbo by default.
+
+The specific implementation principle of `RandomLoadBalance` is very simple. Suppose there are two servers S1 and S2 that provide the same service. The weight of S1 is 7 and the weight of S2 is 3.
+
+When we distribute these weight values in the coordinate interval, we will get: S1->[0, 7), S2->[7, 10). We generate a random number between [0, 10), and when the random number falls into the corresponding interval, we select the corresponding server to handle the request.
+
+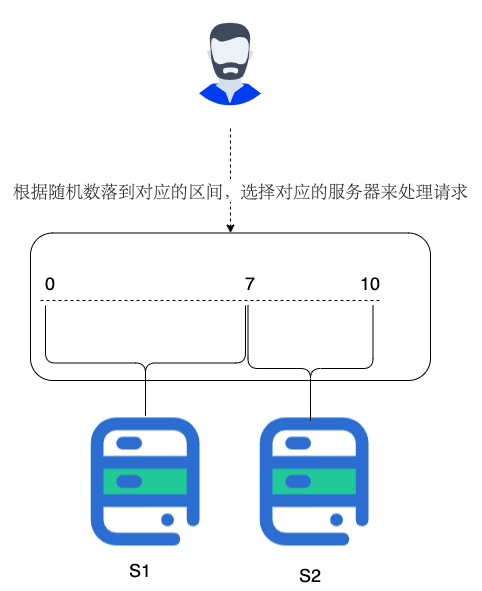
+
+The source code of `RandomLoadBalance` is very simple, just take a few minutes to look at it.
+
+> The following source code comes from the latest version 2.7.9 on the Dubbo master branch.
+
+```java
+public class RandomLoadBalance extends AbstractLoadBalance {
+
+ public static final String NAME = "random";
+
+ @Override
+ protected Invoker doSelect(List> invokers, URL url, Invocation invocation) {
+
+ int length = invokers.size();
+ boolean sameWeight = true;
+ int[] weights = new int[length];
+ int totalWeight = 0;
+ //The main function of the following for loop is to calculate the sum of the weights of all providers of the service totalWeight(),
+ // In addition, it will also check whether the weight of each service provider is the same
+ for (int i = 0; i < length; i++) {
+ int weight = getWeight(invokers.get(i), invocation);
+ totalWeight += weight;
+ weights[i] = totalWeight;
+ if (sameWeight && totalWeight != weight * (i + 1)) {
+ sameWeight = false;
+ }
+ }
+ if (totalWeight > 0 && !sameWeight) {
+ // Randomly generate a number in the range [0, totalWeight)
+ int offset = ThreadLocalRandom.current().nextInt(totalWeight);
+ // Determine which service provider range it will fall into
+ for (int i = 0; i < length; i++) {
+ if (offset < weights[i]) {
+ return invokers.get(i);
+ }
+ }
+
+ return invokers.get(ThreadLocalRandom.current().nextInt(length));
+ }
+
+}
+
+```
+
+#### LeastActiveLoadBalance
+
+`LeastActiveLoadBalance` literally translates to **least active number load balancing**.
+
+This name is a bit unintuitive. If you don’t read the official definition of active number carefully, you won’t know what this thing is for.
+
+Let me put it this way! In the initial state, the activity number of all service providers is 0 (specific methods of each service provider correspond to an activity number, which I will mention in the source code later). After each request is received, the activity number of the corresponding service provider is +1. When the request is processed, the activity number is -1.
+
+Therefore, **Dubbo believes that whoever has fewer active numbers will have faster processing speed and better performance. In this case, I will give priority to the request to the service provider with fewer active numbers. **
+
+**What if there are multiple service providers with equal active numbers? **
+
+Very simple, just go through `RandomLoadBalance` again.
+
+```java
+public class LeastActiveLoadBalance extends AbstractLoadBalance {
+
+ public static final String NAME = "leastactive";
+
+ @Override
+ protected Invoker doSelect(List> invokers, URL url, Invocation invocation) {
+ int length = invokers.size();
+ leastActive = -1;
+ leastCount = 0;
+ int[] leastIndexes = new int[length];
+ int[] weights = new int[length];
+ int totalWeight = 0;
+ int firstWeight = 0;
+ boolean sameWeight = true;
+ //The main function of this for loop is to traverse the invokers list and find the Invoker with the smallest active number
+ // If there are multiple Invokers with the same minimum active number, the subscripts of these Invokers in the invokers collection will also be recorded, their weights will be accumulated, and their weight values will be compared to see if they are equal.
+ for (int i = 0; i < length; i++) {
+ Invoker invoker = invokers.get(i);
+ // Get the active number corresponding to invoker
+ int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
+ int afterWarmup = getWeight(invoker, invocation);
+ weights[i] = afterWarmup;
+ if (leastActive == -1 || active < leastActive) {
+ leastActive = active;
+ leastCount = 1;
+ leastIndexes[0] = i;
+ totalWeight = afterWarmup;
+ firstWeight = afterWarmup;
+ sameWeight = true;
+ } else if (active == leastActive) {
+ leastIndexes[leastCount++] = i;
+ totalWeight += afterWarmup;
+ if (sameWeight && afterWarmup != firstWeight) {
+ sameWeight = false;
+ }
+ }
+ }
+ // If there is only one Invoker with the minimum active number, just return the Invoker directly.
+ if (leastCount == 1) {
+ return invokers.get(leastIndexes[0]);
+ }
+ // If there are multiple Invokers with the same minimum active number, but different weights between them
+ //The processing method here is consistent with RandomLoadBalance
+ if (!sameWeight && totalWeight > 0) {
+ int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
+ for (int i = 0; i < leastCount; i++) {
+ int leastIndex = leastIndexes[i];
+ offsetWeight -= weights[leastIndex];
+ if (offsetWeight < 0) {
+ return invokers.get(leastIndex);
+ }
+ }
+ }
+ return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
+ }
+}```
+
+The activity number is saved through a `ConcurrentMap` in `RpcStatus`. According to the URL and the name of the method called by the service provider, we can get the corresponding activity number. That is to say, the activity number of each method in the service provider is independent of each other.
+
+```java
+public class RpcStatus {
+
+ private static final ConcurrentMap> METHOD_STATISTICS =
+ new ConcurrentHashMap>();
+
+ public static RpcStatus getStatus(URL url, String methodName) {
+ String uri = url.toIdentityString();
+ ConcurrentMap map = METHOD_STATISTICS.computeIfAbsent(uri, k -> new ConcurrentHashMap<>());
+ return map.computeIfAbsent(methodName, k -> new RpcStatus());
+ }
+ public int getActive() {
+ return active.get();
+ }
+
+}
+```
+
+#### ConsistentHashLoadBalance
+
+`ConsistentHashLoadBalance` Friends should be familiar with it. This load balancing strategy is often used in sub-databases, tables, and various clusters.
+
+`ConsistentHashLoadBalance` is the **consistent Hash load balancing strategy**. There is no concept of weight in `ConsistentHashLoadBalance`. Which service provider handles the request is determined by the parameters of your request. That is to say, requests with the same parameters are always sent to the same service provider.
+
+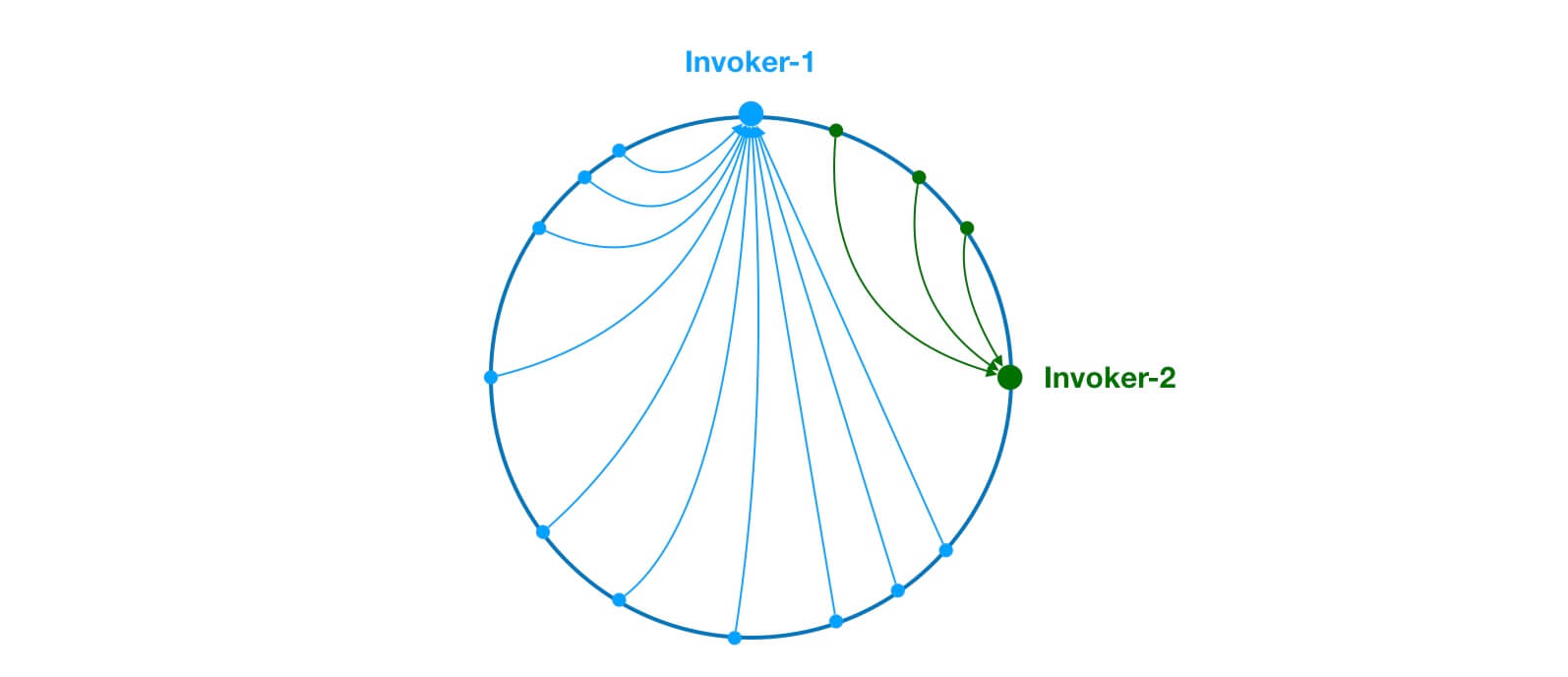
+
+In addition, Dubbo also introduces the concept of virtual nodes in order to avoid data skew problems (nodes are not dispersed enough and a large number of requests fall on the same node). Virtual nodes can make nodes more dispersed and effectively balance the request volume of each node.
+
+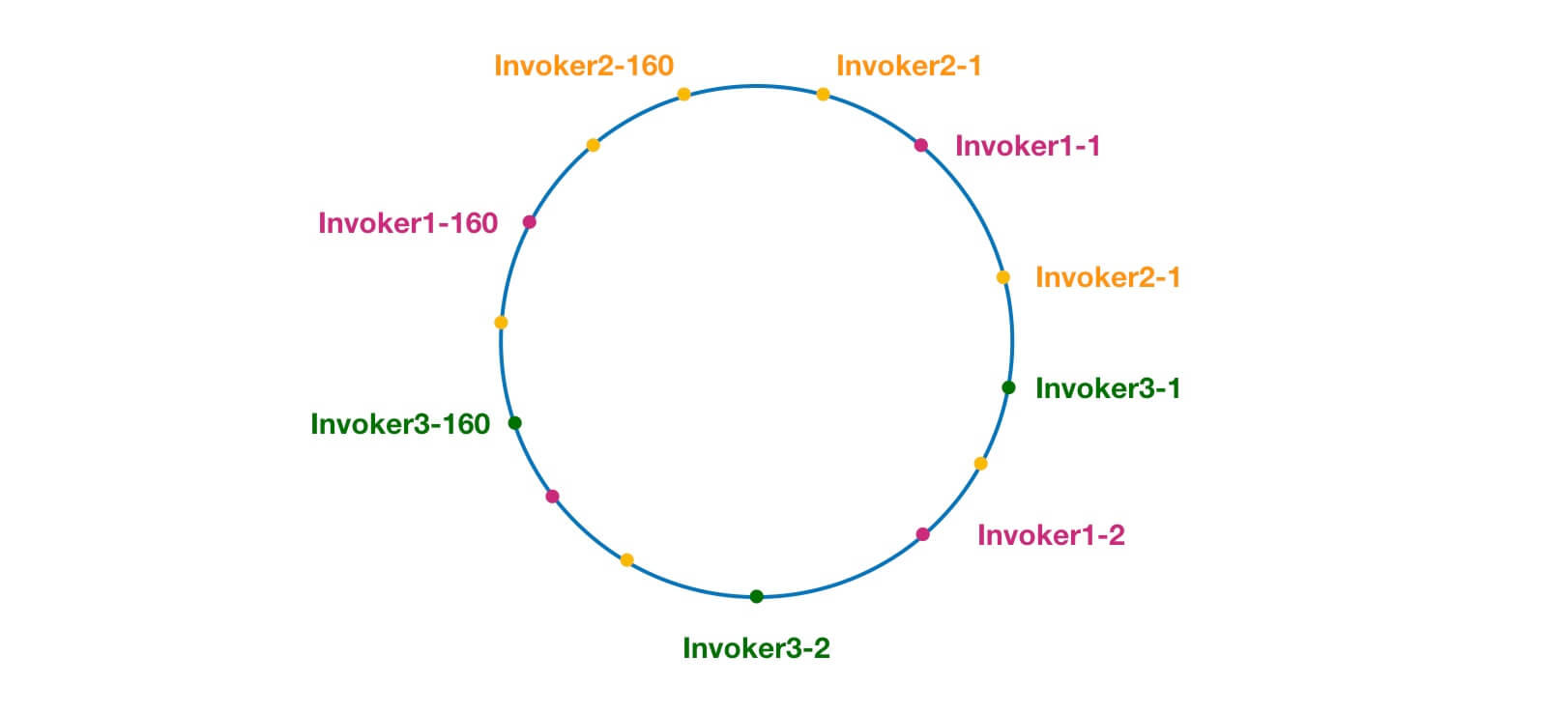
+
+The official has detailed source code analysis: [https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance). There is also a related [PR#5440](https://github.com/apache/dubbo/pull/5440) to fix some bugs in ConsistentHashLoadBalance in the old version. Interested friends can spend more time researching it. I won’t analyze any more here, I’ll leave this homework to you!
+
+#### RoundRobinLoadBalance
+
+Weighted round-robin load balancing.
+
+Polling is to assign requests to each service provider in turn. Weighted polling is based on polling, allowing more requests to fall on service providers with greater weight. For example, if there are two servers S1 and S2 that provide the same service, the weight of S1 is 7 and the weight of S2 is 3.
+
+If we have 10 requests, 7 will be processed by S1 and 3 by S2.
+
+However, if it is `RandomLoadBalance`, it is likely that 9 out of 10 requests will be processed by S1 (a probabilistic problem).
+
+The code implementation of `RoundRobinLoadBalance` in Dubbo has been modified and rebuilt several times. Dubbo-2.6.5 version of `RoundRobinLoadBalance` is a smooth weighted polling algorithm.
+
+## Dubbo serialization protocol
+
+### What serialization methods does Dubbo support?
+
+
+
+Dubbo supports multiple serialization methods: JDK's own serialization, hessian2, JSON, Kryo, FST, Protostuff, ProtoBuf, etc.
+
+The default serialization method used by Dubbo is hessian2.
+
+### Tell us what you know about these serialization protocols?
+
+Generally we do not directly use the serialization method that comes with the JDK. There are two main reasons:
+
+1. **Cross-language calling is not supported**: If you are calling services developed in other languages, it is not supported.
+2. **Poor performance**: Compared with other serialization frameworks, the performance is lower. The main reason is that the byte array after serialization is larger in size, resulting in increased transmission costs.
+
+We generally do not consider using JSON serialization due to performance issues.
+
+Protostuff, ProtoBuf, and hessian2 are all cross-language serialization methods. You can consider using them if you have cross-language requirements.
+
+The two serialization methods Kryo and FST were introduced by Dubbo later and have very good performance. However, both are specific to the Java language. An article on the Dubbo official website mentioned that it is recommended to use Kryo as the serialization method for production environments.
+
+There is also a performance comparison chart of these [serialization protocols] (https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization) in Dubbo’s official documentation for reference.
+
+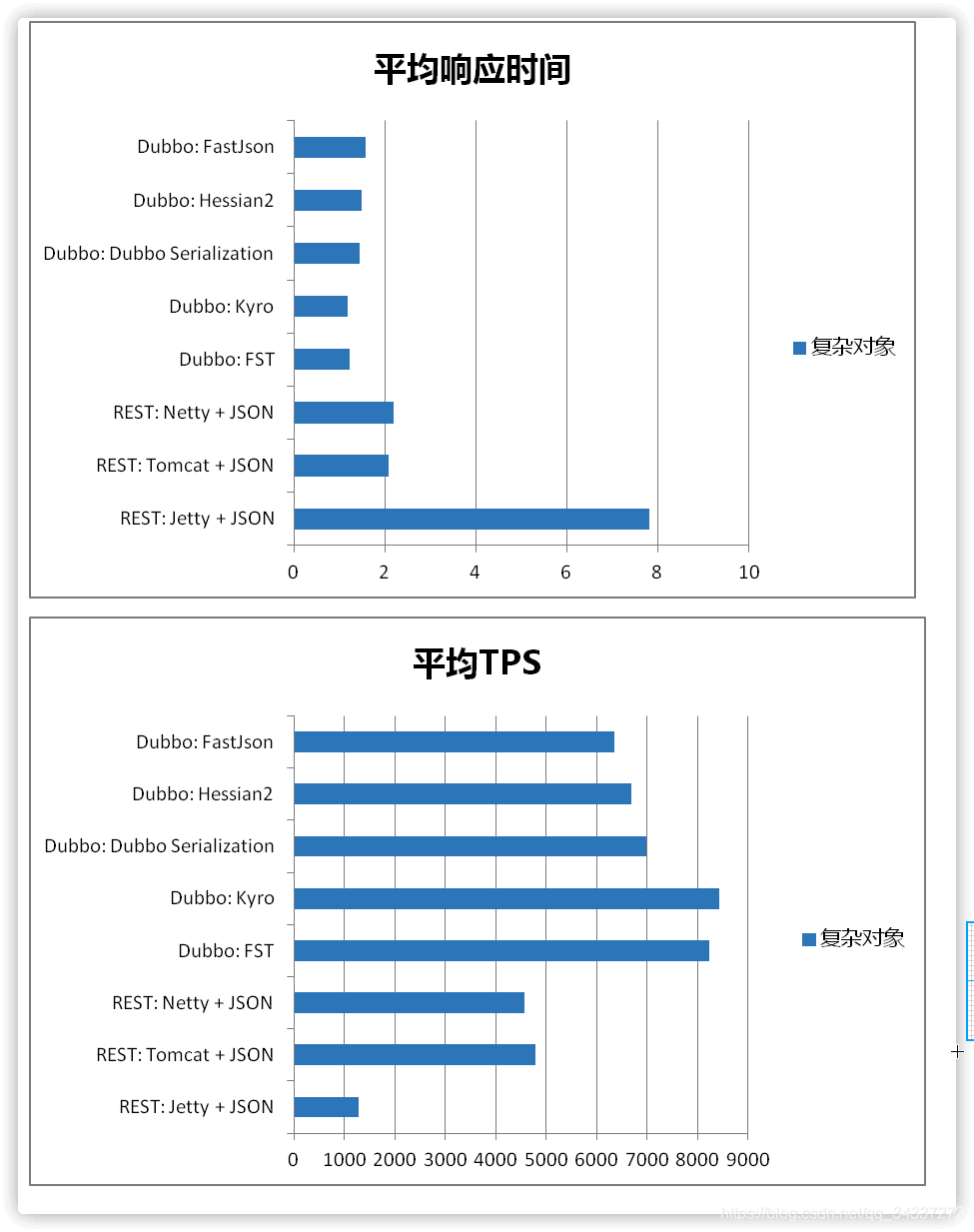
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/rpc/http&rpc.en.md b/docs_en/distributed-system/rpc/http&rpc.en.md
new file mode 100644
index 00000000000..a8e5e4491de
--- /dev/null
+++ b/docs_en/distributed-system/rpc/http&rpc.en.md
@@ -0,0 +1,197 @@
+---
+title: 有了 HTTP 协议,为什么还要有 RPC ?
+category: 分布式
+tag:
+ - rpc
+---
+
+> 本文来自[小白 debug](https://juejin.cn/user/4001878057422087)投稿,原文: 。
+
+我想起了我刚工作的时候,第一次接触 RPC 协议,当时就很懵,我 HTTP 协议用的好好的,为什么还要用 RPC 协议?
+
+于是就到网上去搜。
+
+不少解释显得非常官方,我相信大家在各种平台上也都看到过,解释了又好像没解释,都在**用一个我们不认识的概念去解释另外一个我们不认识的概念**,懂的人不需要看,不懂的人看了还是不懂。
+
+这种看了,又好像没看的感觉,云里雾里的很难受,**我懂**。
+
+为了避免大家有强烈的**审丑疲劳**,今天我们来尝试重新换个方式讲一讲。
+
+## 从 TCP 聊起
+
+作为一个程序员,假设我们需要在 A 电脑的进程发一段数据到 B 电脑的进程,我们一般会在代码里使用 socket 进行编程。
+
+这时候,我们可选项一般也就**TCP 和 UDP 二选一。TCP 可靠,UDP 不可靠。** 除非是马总这种神级程序员(早期 QQ 大量使用 UDP),否则,只要稍微对可靠性有些要求,普通人一般无脑选 TCP 就对了。
+
+类似下面这样。
+
+```ini
+fd = socket(AF_INET,SOCK_STREAM,0);
+```
+
+其中`SOCK_STREAM`,是指使用**字节流**传输数据,说白了就是**TCP 协议**。
+
+在定义了 socket 之后,我们就可以愉快的对这个 socket 进行操作,比如用`bind()`绑定 IP 端口,用`connect()`发起建连。
+
+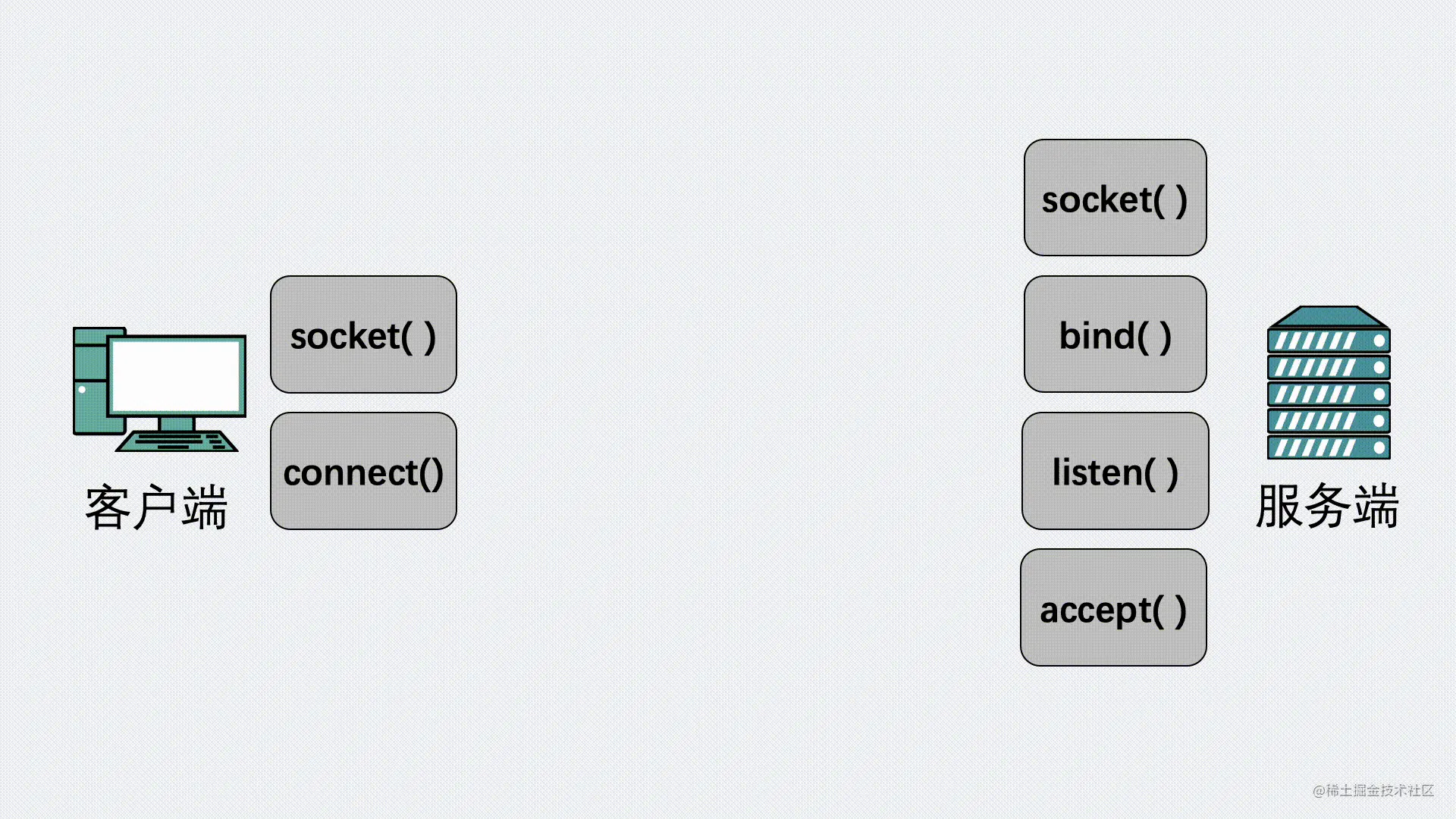
+
+在连接建立之后,我们就可以使用`send()`发送数据,`recv()`接收数据。
+
+光这样一个纯裸的 TCP 连接,就可以做到收发数据了,那是不是就够了?
+
+不行,这么用会有问题。
+
+## 使用纯裸 TCP 会有什么问题
+
+八股文常背,TCP 是有三个特点,**面向连接**、**可靠**、基于**字节流**。
+
+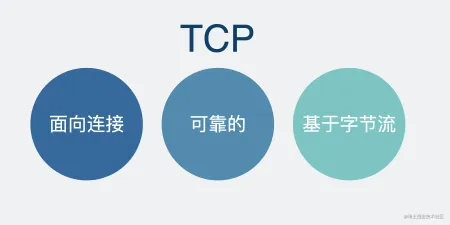
+
+这三个特点真的概括的 **非常精辟** ,这个八股文我们没白背。
+
+每个特点展开都能聊一篇文章,而今天我们需要关注的是 **基于字节流** 这一点。
+
+字节流可以理解为一个双向的通道里流淌的二进制数据,也就是 **01 串** 。纯裸 TCP 收发的这些 01 串之间是 **没有任何边界** 的,你根本不知道到哪个地方才算一条完整消息。
+
+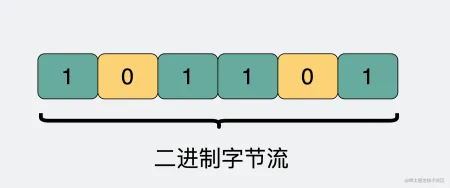
+
+正因为这个没有任何边界的特点,所以当我们选择使用 TCP 发送 **"夏洛"和"特烦恼"** 的时候,接收端收到的就是 **"夏洛特烦恼"** ,这时候接收端没发区分你是想要表达 **"夏洛"+"特烦恼"** 还是 **"夏洛特"+"烦恼"** 。
+
+
+
+这就是所谓的 **粘包问题**,之前也写过一篇专门的[文章](https://mp.weixin.qq.com/s/0-YBxU1cSbDdzcZEZjmQYA)聊过这个问题。
+
+说这个的目的是为了告诉大家,纯裸 TCP 是不能直接拿来用的,你需要在这个基础上加入一些 **自定义的规则** ,用于区分 **消息边界** 。
+
+于是我们会把每条要发送的数据都包装一下,比如加入 **消息头** ,消息头里写清楚一个完整的包长度是多少,根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的 **消息体** 。
+
+
+
+而这里头提到的 **消息头** ,还可以放各种东西,比如消息体是否被压缩过和消息体格式之类的,只要上下游都约定好了,互相都认就可以了,这就是所谓的 **协议。**
+
+每个使用 TCP 的项目都可能会定义一套类似这样的协议解析标准,他们可能 **有区别,但原理都类似**。
+
+**于是基于 TCP,就衍生了非常多的协议,比如 HTTP 和 RPC。**
+
+## HTTP 和 RPC
+
+### RPC 其实是一种调用方式
+
+我们回过头来看网络的分层图。
+
+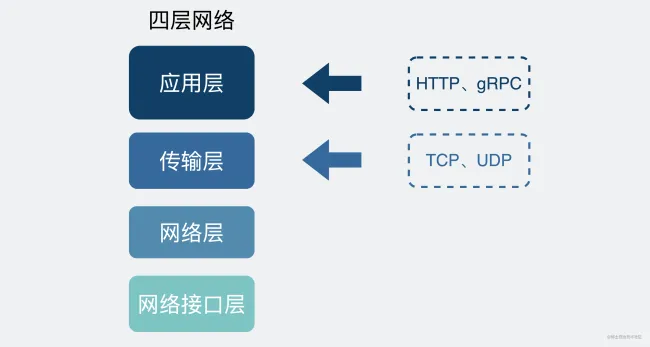
+
+**TCP 是传输层的协议** ,而基于 TCP 造出来的 HTTP 和各类 RPC 协议,它们都只是定义了不同消息格式的 **应用层协议** 而已。
+
+**HTTP**(**H**yper **T**ext **T**ransfer **P**rotocol)协议又叫做 **超文本传输协议** 。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。
+
+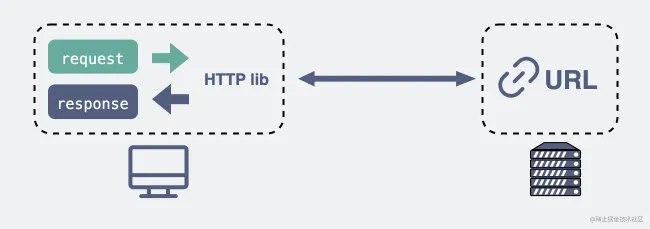
+
+而 **RPC**(**R**emote **P**rocedure **C**all)又叫做 **远程过程调用**,它本身并不是一个具体的协议,而是一种 **调用方式** 。
+
+举个例子,我们平时调用一个 **本地方法** 就像下面这样。
+
+```ini
+ res = localFunc(req)
+```
+
+如果现在这不是个本地方法,而是个**远端服务器**暴露出来的一个方法`remoteFunc`,如果我们还能像调用本地方法那样去调用它,这样就可以**屏蔽掉一些网络细节**,用起来更方便,岂不美哉?
+
+```ini
+res = remoteFunc(req)
+```
+
+
+
+基于这个思路,大佬们造出了非常多款式的 RPC 协议,比如比较有名的`gRPC`,`thrift`。
+
+值得注意的是,虽然大部分 RPC 协议底层使用 TCP,但实际上 **它们不一定非得使用 TCP,改用 UDP 或者 HTTP,其实也可以做到类似的功能。**
+
+到这里,我们回到文章标题的问题。
+
+### 那既然有 RPC 了,为什么还要有 HTTP 呢?
+
+其实,TCP 是 **70 年** 代出来的协议,而 HTTP 是 **90 年代** 才开始流行的。而直接使用裸 TCP 会有问题,可想而知,这中间这么多年有多少自定义的协议,而这里面就有 **80 年代** 出来的`RPC`。
+
+所以我们该问的不是 **既然有 HTTP 协议为什么要有 RPC** ,而是 **为什么有 RPC 还要有 HTTP 协议?**
+
+现在电脑上装的各种联网软件,比如 xx 管家,xx 卫士,它们都作为客户端(Client) 需要跟服务端(Server) 建立连接收发消息,此时都会用到应用层协议,在这种 Client/Server (C/S) 架构下,它们可以使用自家造的 RPC 协议,因为它只管连自己公司的服务器就 ok 了。
+
+但有个软件不同,浏览器(Browser) ,不管是 Chrome 还是 IE,它们不仅要能访问自家公司的**服务器(Server)** ,还需要访问其他公司的网站服务器,因此它们需要有个统一的标准,不然大家没法交流。于是,HTTP 就是那个时代用于统一 **Browser/Server (B/S)** 的协议。
+
+也就是说在多年以前,**HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。** 很多软件同时支持多端,比如某度云盘,既要支持**网页版**,还要支持**手机端和 PC 端**,如果通信协议都用 HTTP 的话,那服务器只用同一套就够了。而 RPC 就开始退居幕后,一般用于公司内部集群里,各个微服务之间的通讯。
+
+那这么说的话,**都用 HTTP 得了,还用什么 RPC?**
+
+仿佛又回到了文章开头的样子,那这就要从它们之间的区别开始说起。
+
+### HTTP 和 RPC 有什么区别
+
+我们来看看 RPC 和 HTTP 区别比较明显的几个点。
+
+#### 服务发现
+
+首先要向某个服务器发起请求,你得先建立连接,而建立连接的前提是,你得知道 **IP 地址和端口** 。这个找到服务对应的 IP 端口的过程,其实就是 **服务发现**。
+
+在 **HTTP** 中,你知道服务的域名,就可以通过 **DNS 服务** 去解析得到它背后的 IP 地址,默认 **80 端口**。
+
+而 **RPC** 的话,就有些区别,一般会有专门的中间服务去保存服务名和 IP 信息,比如 **Consul、Etcd、Nacos、ZooKeeper,甚至是 Redis**。想要访问某个服务,就去这些中间服务去获得 IP 和端口信息。由于 DNS 也是服务发现的一种,所以也有基于 DNS 去做服务发现的组件,比如 **CoreDNS**。
+
+可以看出服务发现这一块,两者是有些区别,但不太能分高低。
+
+#### 底层连接形式
+
+以主流的 **HTTP1.1** 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接(**keep alive**),之后的请求和响应都会复用这条连接。
+
+而 **RPC** 协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 协议一般还会再建个 **连接池**,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。
+
+
+
+由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 Go 就是这么干的。
+
+可以看出这一块两者也没太大区别,所以也不是关键。
+
+#### 传输的内容
+
+基于 TCP 传输的消息,说到底,无非都是 **消息头 Header 和消息体 Body。**
+
+**Header** 是用于标记一些特殊信息,其中最重要的是 **消息体长度**。
+
+**Body** 则是放我们真正需要传输的内容,而这些内容只能是二进制 01 串,毕竟计算机只认识这玩意。所以 TCP 传字符串和数字都问题不大,因为字符串可以转成编码再变成 01 串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制 01 串,这样的方案现在也有很多现成的,比如 **JSON,Protocol Buffers (Protobuf)** 。
+
+这个将结构体转为二进制数组的过程就叫 **序列化** ,反过来将二进制数组复原成结构体的过程叫 **反序列化**。
+
+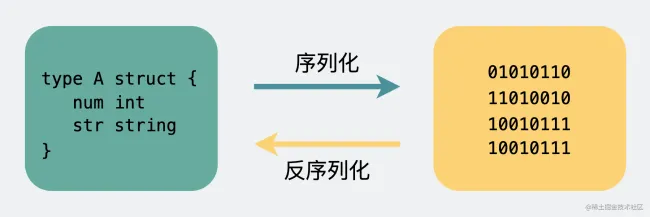
+
+对于主流的 HTTP1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计 初是用于做网页文本展示的,所以它传的内容以字符串为主。Header 和 Body 都是如此。在 Body 这块,它使用 **JSON** 来 **序列化** 结构体数据。
+
+我们可以随便截个图直观看下。
+
+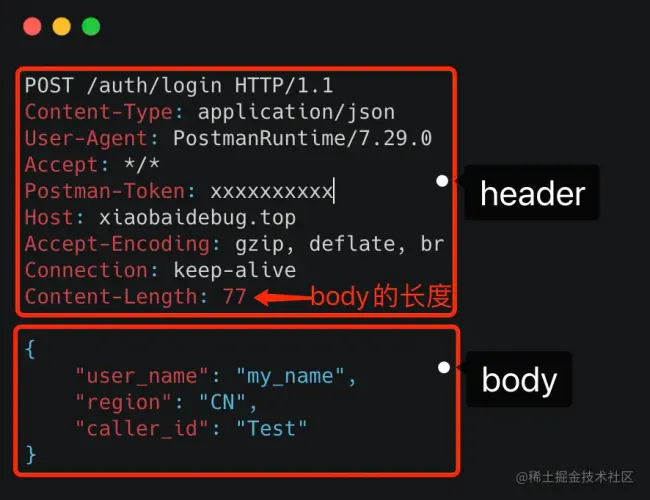
+
+可以看到这里面的内容非常多的冗余,显得非常啰嗦。最明显的,像 Header 里的那些信息,其实如果我们约定好头部的第几位是 `Content-Type`,就不需要每次都真的把 `Content-Type` 这个字段都传过来,类似的情况其实在 Body 的 JSON 结构里也特别明显。
+
+而 RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。**因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。**
+
+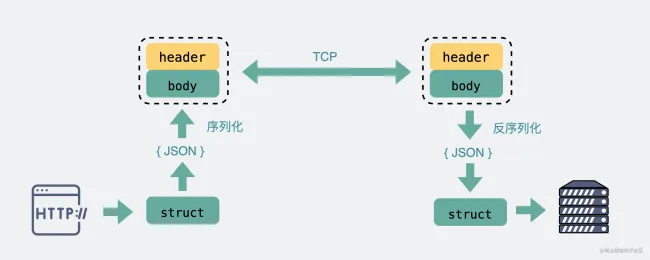
+
+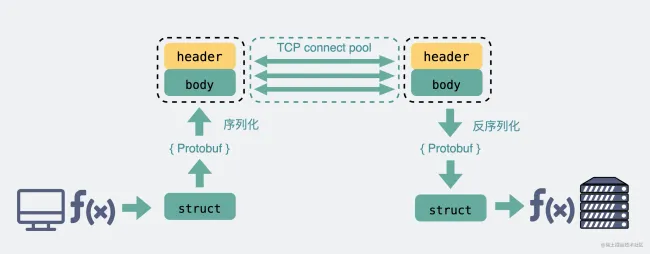
+
+当然上面说的 HTTP,其实 **特指的是现在主流使用的 HTTP1.1**,`HTTP2`在前者的基础上做了很多改进,所以 **性能可能比很多 RPC 协议还要好**,甚至连`gRPC`底层都直接用的`HTTP2`。
+
+那么问题又来了。
+
+### 为什么既然有了 HTTP2,还要有 RPC 协议?
+
+这个是由于 HTTP2 是 2015 年出来的。那时候很多公司内部的 RPC 协议都已经跑了好些年了,基于历史原因,一般也没必要去换了。
+
+## 总结
+
+- 纯裸 TCP 是能收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义 **消息边界** 。于是就有了各种协议,HTTP 和各类 RPC 协议就是在 TCP 之上定义的应用层协议。
+- **RPC 本质上不算是协议,而是一种调用方式**,而像 gRPC 和 Thrift 这样的具体实现,才是协议,它们是实现了 RPC 调用的协议。目的是希望程序员能像调用本地方法那样去调用远端的服务方法。同时 RPC 有很多种实现方式,**不一定非得基于 TCP 协议**。
+- 从发展历史来说,**HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。** 很多软件同时支持多端,所以对外一般用 HTTP 协议,而内部集群的微服务之间则采用 RPC 协议进行通讯。
+- RPC 其实比 HTTP 出现的要早,且比目前主流的 HTTP1.1 性能要更好,所以大部分公司内部都还在使用 RPC。
+- **HTTP2.0** 在 **HTTP1.1** 的基础上做了优化,性能可能比很多 RPC 协议都要好,但由于是这几年才出来的,所以也不太可能取代掉 RPC。
+
+
+
diff --git a/docs_en/distributed-system/rpc/rpc-intro.en.md b/docs_en/distributed-system/rpc/rpc-intro.en.md
new file mode 100644
index 00000000000..10b28b2f1ac
--- /dev/null
+++ b/docs_en/distributed-system/rpc/rpc-intro.en.md
@@ -0,0 +1,140 @@
+---
+title: RPC基础知识总结
+category: 分布式
+tag:
+ - rpc
+---
+
+这篇文章会简单介绍一下 RPC 相关的基础概念。
+
+## RPC 是什么?
+
+**RPC(Remote Procedure Call)** 即远程过程调用,通过名字我们就能看出 RPC 关注的是远程调用而非本地调用。
+
+**为什么要 RPC ?** 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
+
+**RPC 能帮助我们做什么呢?** 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
+
+举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
+
+一言蔽之:**RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。**
+
+## RPC 的原理是什么?
+
+为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
+
+1. **客户端(服务消费端)**:调用远程方法的一端。
+1. **客户端 Stub(桩)**:这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
+1. **网络传输**:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
+1. **服务端 Stub(桩)**:这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
+1. **服务端(服务提供端)**:提供远程方法的一端。
+
+具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
+
+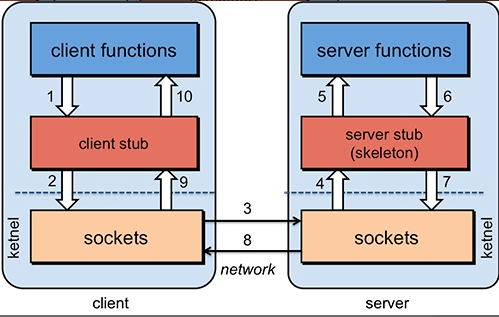
+
+1. 服务消费端(client)以本地调用的方式调用远程服务;
+1. 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):`RpcRequest`;
+1. 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
+1. 服务端 Stub(桩)收到消息将消息反序列化为 Java 对象: `RpcRequest`;
+1. 服务端 Stub(桩)根据`RpcRequest`中的类、方法、方法参数等信息调用本地的方法;
+1. 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:`RpcResponse`(序列化)发送至消费方;
+1. 客户端 Stub(client stub)接收到消息并将消息反序列化为 Java 对象:`RpcResponse` ,这样也就得到了最终结果。over!
+
+相信小伙伴们看完上面的讲解之后,已经了解了 RPC 的原理。
+
+虽然篇幅不多,但是基本把 RPC 框架的核心原理讲清楚了!另外,对于上面的技术细节,我会在后面的章节介绍到。
+
+**最后,对于 RPC 的原理,希望小伙伴不单单要理解,还要能够自己画出来并且能够给别人讲出来。因为,在面试中这个问题在面试官问到 RPC 相关内容的时候基本都会碰到。**
+
+## 有哪些常见的 RPC 框架?
+
+我们这里说的 RPC 框架指的是可以让客户端直接调用服务端方法,就像调用本地方法一样简单的框架,比如我下面介绍的 Dubbo、Motan、gRPC 这些。 如果需要和 HTTP 协议打交道,解析和封装 HTTP 请求和响应。这类框架并不能算是“RPC 框架”,比如 Feign。
+
+### Dubbo
+
+
+
+Apache Dubbo 是一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案,
+涵盖 Java、Golang 等多种语言 SDK 实现。
+
+Dubbo 提供了从服务定义、服务发现、服务通信到流量管控等几乎所有的服务治理能力,支持 Triple 协议(基于 HTTP/2 之上定义的下一代 RPC 通信协议)、应用级服务发现、Dubbo Mesh (Dubbo3 赋予了很多云原生友好的新特性)等特性。
+
+
+
+Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
+
+Dubbo 算的是比较优秀的国产开源项目了,它的源码也是非常值得学习和阅读的!
+
+- GitHub:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
+- 官网:
+
+### Motan
+
+Motan 是新浪微博开源的一款 RPC 框架,据说在新浪微博正支撑着千亿次调用。不过笔者倒是很少看到有公司使用,而且网上的资料也比较少。
+
+很多人喜欢拿 Motan 和 Dubbo 作比较,毕竟都是国内大公司开源的。笔者在查阅了很多资料,以及简单查看了其源码之后发现:**Motan 更像是一个精简版的 Dubbo,可能是借鉴了 Dubbo 的思想,Motan 的设计更加精简,功能更加纯粹。**
+
+不过,我不推荐你在实际项目中使用 Motan。如果你要是公司实际使用的话,还是推荐 Dubbo ,其社区活跃度以及生态都要好很多。
+
+- 从 Motan 看 RPC 框架设计:[http://kriszhang.com/motan-rpc-impl/](http://kriszhang.com/motan-rpc-impl/ "http://kriszhang.com/motan-rpc-impl/")
+- Motan 中文文档:[https://github.com/weibocom/motan/wiki/zh_overview](https://github.com/weibocom/motan/wiki/zh_overview "https://github.com/weibocom/motan/wiki/zh_overview")
+
+### gRPC
+
+
+
+gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2 协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
+
+**何谓 ProtoBuf?** [ProtoBuf( Protocol Buffer)](https://github.com/protocolbuffers/protobuf) 是一种更加灵活、高效的数据格式,可用于通讯协议、数据存储等领域,基本支持所有主流编程语言且与平台无关。不过,通过 ProtoBuf 定义接口和数据类型还挺繁琐的,这是一个小问题。
+
+
+
+不得不说,gRPC 的通信层的设计还是非常优秀的,[Dubbo-go 3.0](https://dubbogo.github.io/) 的通信层改进主要借鉴了 gRPC。
+
+不过,gRPC 的设计导致其几乎没有服务治理能力。如果你想要解决这个问题的话,就需要依赖其他组件比如腾讯的 PolarisMesh(北极星)了。
+
+- GitHub:[https://github.com/grpc/grpc](https://github.com/grpc/grpc "https://github.com/grpc/grpc")
+- 官网:[https://grpc.io/](https://grpc.io/ "https://grpc.io/")
+
+### Thrift
+Apache Thrift is Facebook's open source cross-language RPC communication framework. It has been donated to the Apache Foundation for management. Due to its cross-language features and excellent performance, it is used by many Internet companies. Competent companies will even develop a distributed service framework based on Thrift to add functions such as service registration and service discovery.
+
+`Thrift` supports a variety of **programming languages**, including `C++`, `Java`, `Python`, `PHP`, `Ruby`, etc. (compared to gRPC, it supports more languages).
+
+- Official website: [https://thrift.apache.org/](https://thrift.apache.org/ "https://thrift.apache.org/")
+- Brief introduction to Thrift: [https://www.jianshu.com/p/8f25d057a5a9](https://www.jianshu.com/p/8f25d057a5a9 "https://www.jianshu.com/p/8f25d057a5a9")
+
+### Summary
+
+Although gRPC and Thrift support cross-language RPC calls, they only provide the most basic RPC framework functions and lack the support of a series of supporting service components and service governance functions.
+
+Dubbo is the best in terms of functionality, ecosystem, and community activity. Moreover, Dubbo has many successful cases in China such as Dangdang, Didi, etc. It is a mature and stable RPC framework that can withstand the test of production. The most important thing is that you can also find a lot of Dubbo reference materials, and the learning cost is relatively low.
+
+The diagram below shows Dubbo’s ecosystem.
+
+
+
+Dubbo is also a component in Spring Cloud Alibaba.
+
+
+
+However, Dubbo and Motan are mainly used by the Java language. Although Dubbo and Motan are currently compatible with some languages, they are not recommended. If you need to call across multiple languages, consider using gRPC.
+
+In summary, if it is a Java back-end technology stack and you are struggling with which RPC framework to choose, I recommend you to consider Dubbo.
+
+## How to design and implement an RPC framework?
+
+**"Handwritten RPC Framework"** is an internal booklet of my [Knowledge Planet] (https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html). I wrote 12 articles to explain how to implement a simple RPC framework from scratch based on Netty+Kyro+Zookeeper.
+
+Although Sparrow is small, it has all the necessary features. The project code has detailed comments and clear structure. It also integrates the Check Style standard code structure, making it very suitable for reading and learning.
+
+**Content Overview**:
+
+
+
+## Now that we have the HTTP protocol, why do we need RPC?
+
+For a detailed answer to this question, please see this article: [With HTTP protocol, why do we need RPC? ](http&rpc.md) .
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/spring-cloud-gateway-questions.en.md b/docs_en/distributed-system/spring-cloud-gateway-questions.en.md
new file mode 100644
index 00000000000..f55eaf16c2e
--- /dev/null
+++ b/docs_en/distributed-system/spring-cloud-gateway-questions.en.md
@@ -0,0 +1,157 @@
+---
+title: Spring Cloud Gateway常见问题总结
+category: 分布式
+---
+
+> 本文重构完善自[6000 字 | 16 图 | 深入理解 Spring Cloud Gateway 的原理 - 悟空聊架构](https://mp.weixin.qq.com/s/XjFYsP1IUqNzWqXZdJn-Aw)这篇文章。
+
+## 什么是 Spring Cloud Gateway?
+
+Spring Cloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**。准确点来说,应该是 Zuul 1.x。Spring Cloud Gateway 起步要比 Zuul 2.x 更早。
+
+为了提升网关的性能,Spring Cloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现同步非阻塞的 I/O。
+
+
+
+Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,限流。
+
+Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
+
+- GitHub 地址:
+- 官网:
+
+## Spring Cloud Gateway 的工作流程?
+
+Spring Cloud Gateway 的工作流程如下图所示:
+
+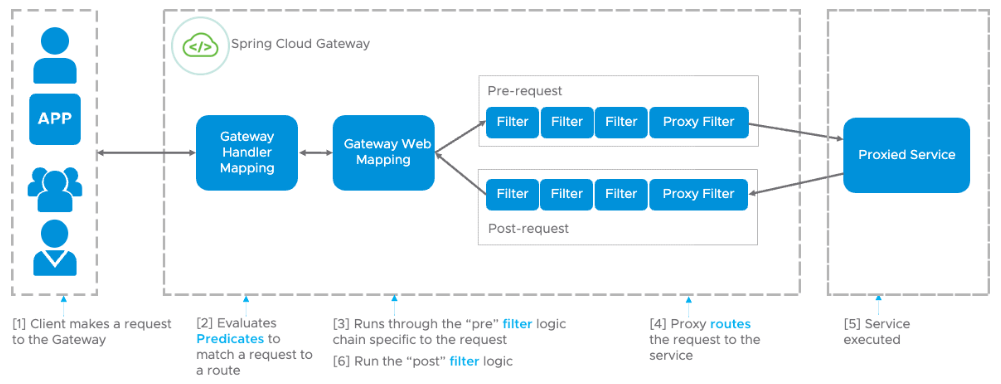
+
+这是 Spring 官方博客中的一张图,原文地址:。
+
+具体的流程分析:
+
+1. **路由判断**:客户端的请求到达网关后,先经过 Gateway Handler Mapping 处理,这里面会做断言(Predicate)判断,看下符合哪个路由规则,这个路由映射后端的某个服务。
+2. **请求过滤**:然后请求到达 Gateway Web Handler,这里面有很多过滤器,组成过滤器链(Filter Chain),这些过滤器可以对请求进行拦截和修改,比如添加请求头、参数校验等等,有点像净化污水。然后将请求转发到实际的后端服务。这些过滤器逻辑上可以称作 Pre-Filters,Pre 可以理解为“在...之前”。
+3. **服务处理**:后端服务会对请求进行处理。
+4. **响应过滤**:后端处理完结果后,返回给 Gateway 的过滤器再次做处理,逻辑上可以称作 Post-Filters,Post 可以理解为“在...之后”。
+5. **响应返回**:响应经过过滤处理后,返回给客户端。
+
+总结:客户端的请求先通过匹配规则找到合适的路由,就能映射到具体的服务。然后请求经过过滤器处理后转发给具体的服务,服务处理后,再次经过过滤器处理,最后返回给客户端。
+
+## Spring Cloud Gateway 的断言是什么?
+
+断言(Predicate)这个词听起来极其深奥,它是一种编程术语,我们生活中根本就不会用它。说白了它就是对一个表达式进行 if 判断,结果为真或假,如果为真则做这件事,否则做那件事。
+
+在 Gateway 中,如果客户端发送的请求满足了断言的条件,则映射到指定的路由器,就能转发到指定的服务上进行处理。
+
+断言配置的示例如下,配置了两个路由规则,有一个 predicates 断言配置,当请求 url 中包含 `api/thirdparty`,就匹配到了第一个路由 `route_thirdparty`。
+
+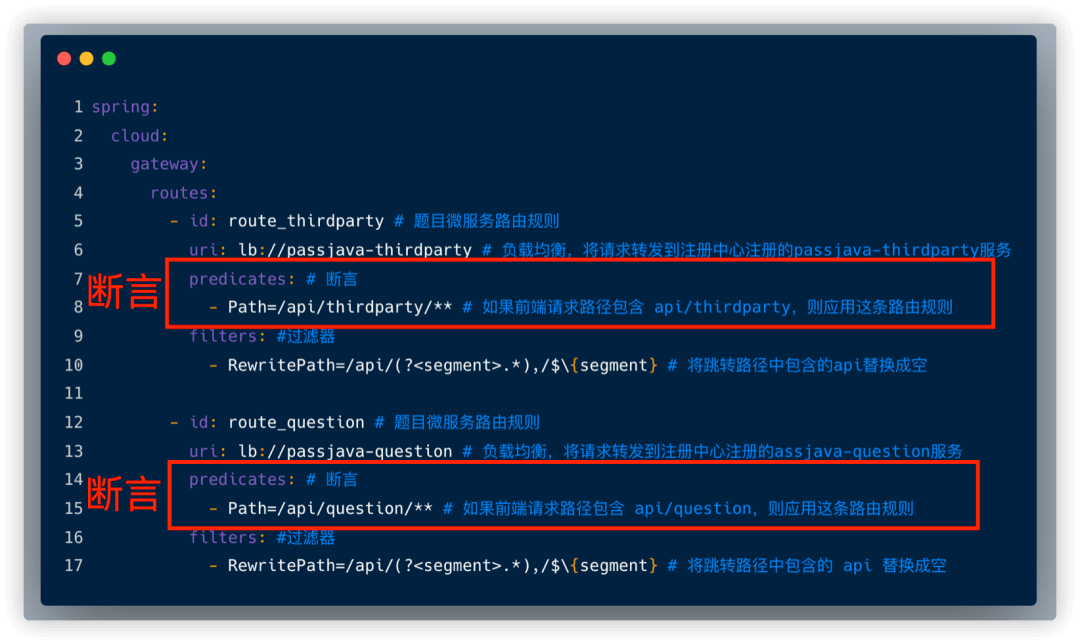
+
+常见的路由断言规则如下图所示:
+
+
+
+## Spring Cloud Gateway 的路由和断言是什么关系?
+
+Route 路由和 Predicate 断言的对应关系如下::
+
+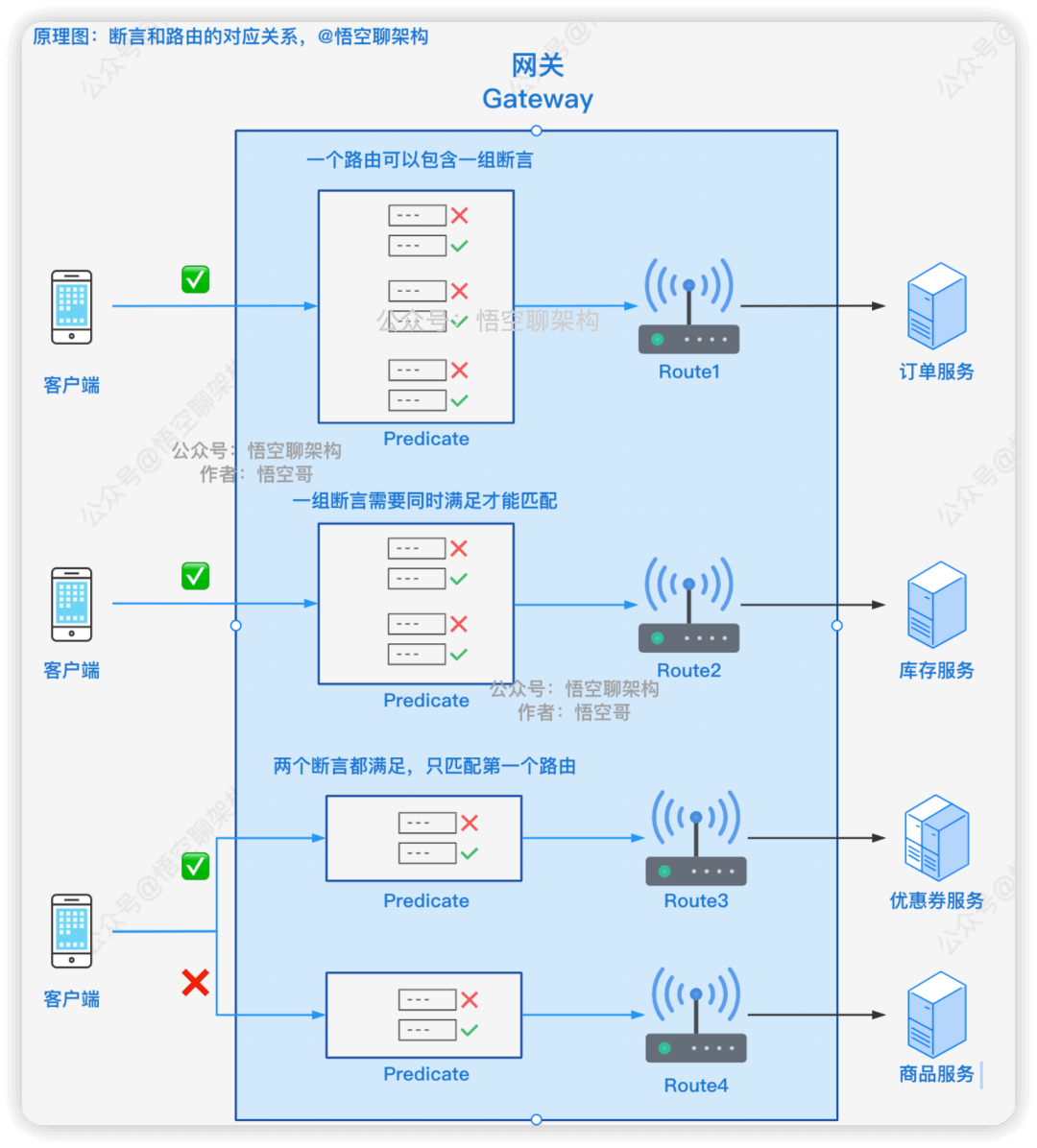
+
+- **一对多**:一个路由规则可以包含多个断言。如上图中路由 Route1 配置了三个断言 Predicate。
+- **同时满足**:如果一个路由规则中有多个断言,则需要同时满足才能匹配。如上图中路由 Route2 配置了两个断言,客户端发送的请求必须同时满足这两个断言,才能匹配路由 Route2。
+- **第一个匹配成功**:如果一个请求可以匹配多个路由,则映射第一个匹配成功的路由。如上图所示,客户端发送的请求满足 Route3 和 Route4 的断言,但是 Route3 的配置在配置文件中靠前,所以只会匹配 Route3。
+
+## Spring Cloud Gateway 如何实现动态路由?
+
+在使用 Spring Cloud Gateway 的时候,官方文档提供的方案总是基于配置文件或代码配置的方式。
+
+Spring Cloud Gateway 作为微服务的入口,需要尽量避免重启,而现在配置更改需要重启服务不能满足实际生产过程中的动态刷新、实时变更的业务需求,所以我们需要在 Spring Cloud Gateway 运行时动态配置网关。
+
+实现动态路由的方式有很多种,其中一种推荐的方式是基于 Nacos 注册中心来做。 Spring Cloud Gateway 可以从注册中心获取服务的元数据(例如服务名称、路径等),然后根据这些信息自动生成路由规则。这样,当你添加、移除或更新服务实例时,网关会自动感知并相应地调整路由规则,无需手动维护路由配置。
+
+其实这些复杂的步骤并不需要我们手动实现,通过 Nacos Server 和 Spring Cloud Alibaba Nacos Config 即可实现配置的动态变更,官方文档地址: 。
+
+## Spring Cloud Gateway 的过滤器有哪些?
+
+过滤器 Filter 按照请求和响应可以分为两种:
+
+- **Pre 类型**:在请求被转发到微服务之前,对请求进行拦截和修改,例如参数校验、权限校验、流量监控、日志输出以及协议转换等操作。
+- **Post 类型**:微服务处理完请求后,返回响应给网关,网关可以再次进行处理,例如修改响应内容或响应头、日志输出、流量监控等。
+
+另外一种分类是按照过滤器 Filter 作用的范围进行划分:
+
+- **GatewayFilter**:局部过滤器,应用在单个路由或一组路由上的过滤器。标红色表示比较常用的过滤器。
+- **GlobalFilter**:全局过滤器,应用在所有路由上的过滤器。
+
+### 局部过滤器
+
+常见的局部过滤器如下图所示:
+
+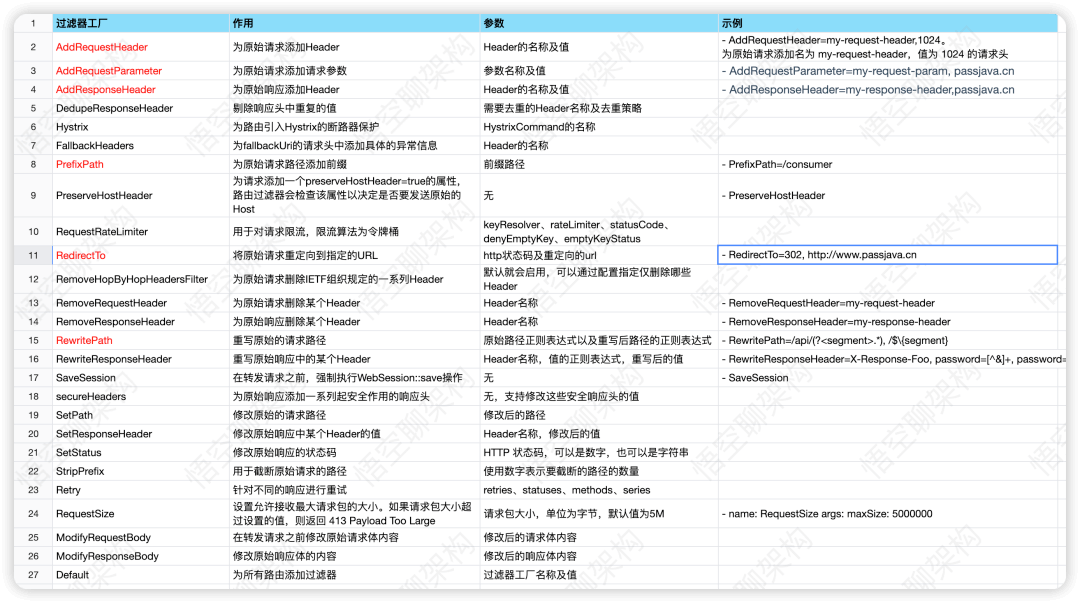
+
+具体怎么用呢?这里有个示例,如果 URL 匹配成功,则去掉 URL 中的 “api”。
+
+```yaml
+filters: #过滤器
+ - RewritePath=/api/(?.*),/$\{segment} # 将跳转路径中包含的 “api” 替换成空
+```
+
+Of course, we can also customize filters, which we will not expand on in this article.
+
+### Global filter
+
+Common global filters are shown below:
+
+
+
+The most common use of global filters is for load balancing. The configuration is as follows:
+
+```yaml
+spring:
+ cloud:
+ gateway:
+ routes:
+ - id: route_member # Third-party microservice routing rules
+ uri: lb://passjava-member # Load balancing, forward the request to the passjava-member service registered in the registration center
+ predicates: # assertion
+ - Path=/api/member/** # If the front-end request path contains api/member, this routing rule will be applied
+ filters: #Filter
+ - RewritePath=/api/(?.*),/$\{segment} # Replace the api contained in the jump path with empty
+```
+
+There is a keyword `lb` here, which uses the global filter `LoadBalancerClientFilter`. When this route is matched, the request will be forwarded to the passjava-member service, and load balancing forwarding is supported, that is, passjava-member is first parsed into the host and port of the actual microservice, and then forwarded to the actual microservice.
+
+## Does Spring Cloud Gateway support current limiting?
+
+Spring Cloud Gateway comes with a current limiting filter, and the corresponding interface is `RateLimiter`. The `RateLimiter` interface has only one implementation class `RedisRateLimiter` (current limiting based on Redis + Lua). The current limiting function provided is relatively simple and difficult to use.
+
+Starting from Sentinel version 1.6.0, Sentinel has introduced the Spring Cloud Gateway adaptation module, which can provide current limiting in two resource dimensions: route dimension and custom API dimension. In other words, Spring Cloud Gateway can be combined with Sentinel to achieve more powerful gateway traffic control.
+
+## How does Spring Cloud Gateway customize global exception handling?
+
+In the SpringBoot project, to catch global exceptions, we only need to configure `@RestControllerAdvice` and `@ExceptionHandler` in the project. However, this method is not applicable under Spring Cloud Gateway.
+
+Spring Cloud Gateway provides a variety of global processing methods. The more commonly used one is to implement `ErrorWebExceptionHandler` and rewrite the `handle` method in it.
+
+```java
+@Order(-1)
+@Component
+@RequiredArgsConstructor
+public class GlobalErrorWebExceptionHandler implements ErrorWebExceptionHandler {
+ private final ObjectMapper objectMapper;
+
+ @Override
+ public Mono handle(ServerWebExchange exchange, Throwable ex) {
+ // ...
+ }
+}
+```
+
+## Reference
+
+- Spring Cloud Gateway official documentation:
+- Creating a custom Spring Cloud Gateway Filter:
+- Global exception handling:
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/fallback-and-circuit-breaker.en.md b/docs_en/high-availability/fallback-and-circuit-breaker.en.md
new file mode 100644
index 00000000000..3c8c5a6c967
--- /dev/null
+++ b/docs_en/high-availability/fallback-and-circuit-breaker.en.md
@@ -0,0 +1,13 @@
+---
+title: Detailed explanation of downgrade and circuit breaker (paid)
+category: high availability
+icon: circuit
+---
+
+**Downgrade & Circuit Breaker** The relevant interview questions are exclusive to my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click on the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide North"](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/high-availability-system-design.en.md b/docs_en/high-availability/high-availability-system-design.en.md
new file mode 100644
index 00000000000..b2ceaef044e
--- /dev/null
+++ b/docs_en/high-availability/high-availability-system-design.en.md
@@ -0,0 +1,72 @@
+---
+title: 高可用系统设计指南
+category: 高可用
+icon: design
+---
+
+## 什么是高可用?可用性的判断标准是啥?
+
+高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
+
+一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。
+
+除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
+
+## 哪些情况会导致系统不可用?
+
+1. 黑客攻击;
+2. 硬件故障,比如服务器坏掉。
+3. 并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用。
+4. 代码中的坏味道导致内存泄漏或者其他问题导致程序挂掉。
+5. 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用。
+6. 自然灾害或者人为破坏。
+7. ……
+
+## 有哪些提高系统可用性的方法?
+
+### 注重代码质量,测试严格把关
+
+我觉得这个是最最最重要的,代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。大家都喜欢谈限流、降级、熔断,但是我觉得从代码质量这个源头把关是首先要做好的一件很重要的事情。如何提高代码质量?比较实际可用的就是 CodeReview,不要在乎每天多花的那 1 个小时左右的时间,作用可大着呢!
+
+另外,安利几个对提高代码质量有实际效果的神器:
+
+- [Sonarqube](https://www.sonarqube.org/);
+- Alibaba 开源的 Java 诊断工具 [Arthas](https://arthas.aliyun.com/doc/);
+- [阿里巴巴 Java 代码规范](https://github.com/alibaba/p3c)(Alibaba Java Code Guidelines);
+- IDEA 自带的代码分析等工具。
+
+### 使用集群,减少单点故障
+
+先拿常用的 Redis 举个例子!我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。
+
+### 限流
+
+流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。——来自 [alibaba-Sentinel](https://github.com/alibaba/Sentinel "Sentinel") 的 wiki。
+
+### 超时和重试机制设置
+
+一旦用户请求超过某个时间的得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为没有进行超时设置或者超时设置的方式不对导致的。我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。
+
+### 熔断机制
+
+超时和重试机制设置之外,熔断机制也是很重要的。 熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。 比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。
+
+### 异步调用
+
+异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。但是,使用异步之后我们可能需要 **适当修改业务流程进行配合**,比如**用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**。除了可以在程序中实现异步之外,我们常常还使用消息队列,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。
+
+### 使用缓存
+
+如果我们的系统属于并发量比较高的话,如果我们单纯使用数据库的话,当大量请求直接落到数据库可能数据库就会直接挂掉。使用缓存缓存热点数据,因为缓存存储在内存中,所以速度相当地快!
+
+### 其他
+
+- **核心应用和服务优先使用更好的硬件**
+- **监控系统资源使用情况增加报警设置。**
+- **注意备份,必要时候回滚。**
+- **灰度发布:** 将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可
+- **定期检查/更换硬件:** 如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。
+- ……
+
+
+
diff --git a/docs_en/high-availability/idempotency.en.md b/docs_en/high-availability/idempotency.en.md
new file mode 100644
index 00000000000..a2c7c7ab4b8
--- /dev/null
+++ b/docs_en/high-availability/idempotency.en.md
@@ -0,0 +1,13 @@
+---
+title: Summary of interface idempotent solutions (paid)
+category: high availability
+icon: security-fill
+---
+
+**Interface Idempotent** The related interview questions are exclusive to my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide North"](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/limit-request.en.md b/docs_en/high-availability/limit-request.en.md
new file mode 100644
index 00000000000..bf28639b8b0
--- /dev/null
+++ b/docs_en/high-availability/limit-request.en.md
@@ -0,0 +1,296 @@
+---
+title: 服务限流详解
+category: 高可用
+icon: limit_rate
+---
+
+针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。毕竟,软件系统的处理能力是有限的。如果说超过了其处理能力的范围,软件系统可能直接就挂掉了。
+
+限流可能会导致用户的请求无法被正确处理或者无法立即被处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
+
+现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
+
+## 常见限流算法有哪些?
+
+简单介绍 4 种非常好理解并且容易实现的限流算法!
+
+> 图片来源于 InfoQ 的一篇文章[《分布式服务限流实战,已经为你排好坑了》](https://www.infoq.cn/article/Qg2tX8fyw5Vt-f3HH673)。
+
+### 固定窗口计数器算法
+
+固定窗口其实就是时间窗口,其原理是将时间划分为固定大小的窗口,在每个窗口内限制请求的数量或速率,即固定窗口计数器算法规定了系统单位时间处理的请求数量。
+
+假如我们规定系统中某个接口 1 分钟只能被访问 33 次的话,使用固定窗口计数器算法的实现思路如下:
+
+- 将时间划分固定大小窗口,这里是 1 分钟一个窗口。
+- 给定一个变量 `counter` 来记录当前接口处理的请求数量,初始值为 0(代表接口当前 1 分钟内还未处理请求)。
+- 1 分钟之内每处理一个请求之后就将 `counter+1` ,当 `counter=33` 之后(也就是说在这 1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。
+- 等到 1 分钟结束后,将 `counter` 重置 0,重新开始计数。
+
+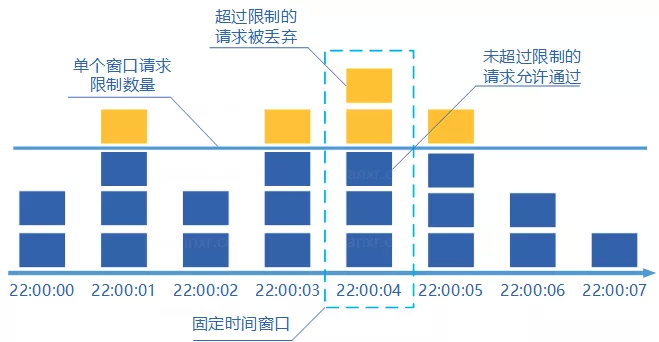
+
+优点:实现简单,易于理解。
+
+缺点:
+
+- 限流不够平滑。例如,我们限制某个接口每分钟只能访问 30 次,假设前 30 秒就有 30 个请求到达的话,那后续 30 秒将无法处理请求,这是不可取的,用户体验极差!
+- 无法保证限流速率,因而无法应对突然激增的流量。例如,我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
+
+### 滑动窗口计数器算法
+
+**滑动窗口计数器算法** 算的上是固定窗口计数器算法的升级版,限流的颗粒度更小。
+
+滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:**它把时间以一定比例分片** 。
+
+例如我们的接口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理不大于 `60(请求数)/60(窗口数)` 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
+
+很显然, **当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。**
+
+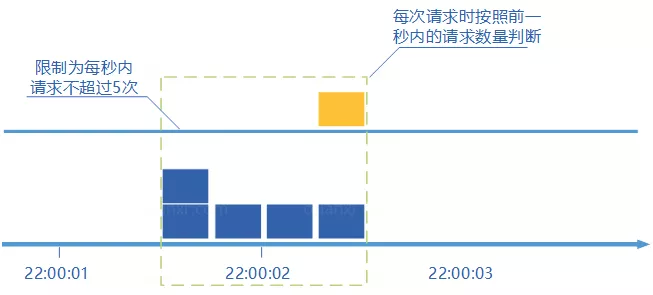
+
+优点:
+
+- 相比于固定窗口算法,滑动窗口计数器算法可以应对突然激增的流量。
+- 相比于固定窗口算法,滑动窗口计数器算法的颗粒度更小,可以提供更精确的限流控制。
+
+缺点:
+
+- 与固定窗口计数器算法类似,滑动窗口计数器算法依然存在限流不够平滑的问题。
+- 相比较于固定窗口计数器算法,滑动窗口计数器算法实现和理解起来更复杂一些。
+
+### 漏桶算法
+
+我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
+
+如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)。
+
+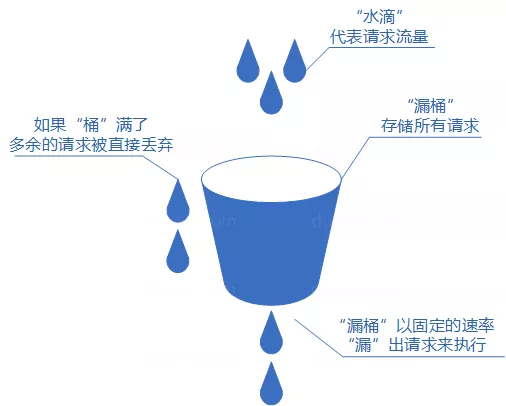
+
+优点:
+
+- 实现简单,易于理解。
+- 可以控制限流速率,避免网络拥塞和系统过载。
+
+缺点:
+
+- 无法应对突然激增的流量,因为只能以固定的速率处理请求,对系统资源利用不够友好。
+- 桶流入水(发请求)的速率如果一直大于桶流出水(处理请求)的速率的话,那么桶会一直是满的,一部分新的请求会被丢弃,导致服务质量下降。
+
+实际业务场景中,基本不会使用漏桶算法。
+
+### 令牌桶算法
+
+令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
+
+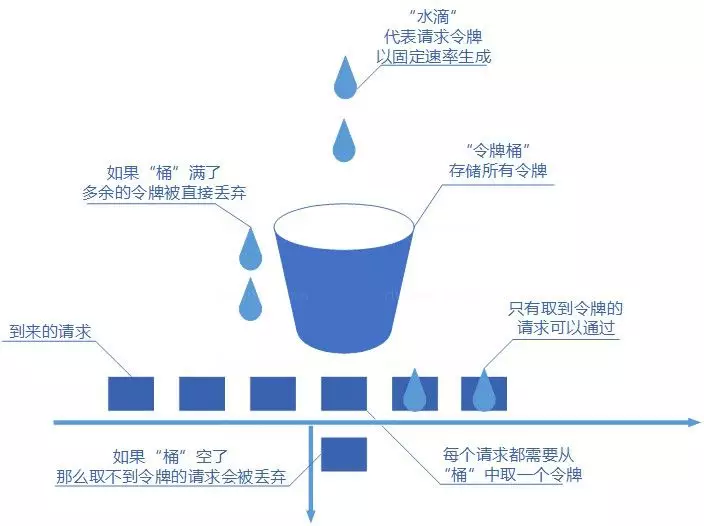
+
+优点:
+
+- 可以限制平均速率和应对突然激增的流量。
+- 可以动态调整生成令牌的速率。
+
+缺点:
+
+- 如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
+- 相比于其他限流算法,实现和理解起来更复杂一些。
+
+## 针对什么来进行限流?
+
+实际项目中,还需要确定限流对象,也就是针对什么来进行限流。常见的限流对象如下:
+
+- IP :针对 IP 进行限流,适用面较广,简单粗暴。
+- 业务 ID:挑选唯一的业务 ID 以实现更针对性地限流。例如,基于用户 ID 进行限流。
+- 个性化:根据用户的属性或行为,进行不同的限流策略。例如, VIP 用户不限流,而普通用户限流。根据系统的运行指标(如 QPS、并发调用数、系统负载等),动态调整限流策略。例如,当系统负载较高的时候,控制每秒通过的请求减少。
+
+针对 IP 进行限流是目前比较常用的一个方案。不过,实际应用中需要注意用户真实 IP 地址的正确获取。常用的真实 IP 获取方法有 X-Forwarded-For 和 TCP Options 字段承载真实源 IP 信息。虽然 X-Forwarded-For 字段可能会被伪造,但因为其实现简单方便,很多项目还是直接用的这种方法。
+
+除了我上面介绍到的限流对象之外,还有一些其他较为复杂的限流对象策略,比如阿里的 Sentinel 还支持 [基于调用关系的限流](https://github.com/alibaba/Sentinel/wiki/流量控制#基于调用关系的流量控制)(包括基于调用方限流、基于调用链入口限流、关联流量限流等)以及更细维度的 [热点参数限流](https://github.com/alibaba/Sentinel/wiki/热点参数限流)(实时的统计热点参数并针对热点参数的资源调用进行流量控制)。
+
+另外,一个项目可以根据具体的业务需求选择多种不同的限流对象搭配使用。
+
+## 单机限流怎么做?
+
+单机限流针对的是单体架构应用。
+
+单机限流可以直接使用 Google Guava 自带的限流工具类 `RateLimiter` 。 `RateLimiter` 基于令牌桶算法,可以应对突发流量。
+
+> Guava 地址:
+
+除了最基本的令牌桶算法(平滑突发限流)实现之外,Guava 的`RateLimiter`还提供了 **平滑预热限流** 的算法实现。
+
+平滑突发限流就是按照指定的速率放令牌到桶里,而平滑预热限流会有一段预热时间,预热时间之内,速率会逐渐提升到配置的速率。
+
+我们下面通过两个简单的小例子来详细了解吧!
+
+我们直接在项目中引入 Guava 相关的依赖即可使用。
+
+```xml
+
+ com.google.guava
+ guava
+ 31.0.1-jre
+
+```
+
+下面是一个简单的 Guava 平滑突发限流的 Demo。
+
+```java
+import com.google.common.util.concurrent.RateLimiter;
+
+/**
+ * 微信搜 JavaGuide 回复"面试突击"即可免费领取个人原创的 Java 面试手册
+ *
+ * @author Guide哥
+ * @date 2021/10/08 19:12
+ **/
+public class RateLimiterDemo {
+
+ public static void main(String[] args) {
+ // 1s 放 5 个令牌到桶里也就是 0.2s 放 1个令牌到桶里
+ RateLimiter rateLimiter = RateLimiter.create(5);
+ for (int i = 0; i < 10; i++) {
+ double sleepingTime = rateLimiter.acquire(1);
+ System.out.printf("get 1 tokens: %ss%n", sleepingTime);
+ }
+ }
+}
+
+```
+
+Output:
+
+```bash
+get 1 tokens: 0.0s
+get 1 tokens: 0.188413s
+get 1 tokens: 0.197811s
+get 1 tokens: 0.198316s
+get 1 tokens: 0.19864s
+get 1 tokens: 0.199363s
+get 1 tokens: 0.193997s
+get 1 tokens: 0.199623s
+get 1 tokens: 0.199357s
+get 1 tokens: 0.195676s
+```
+
+Below is a simple demo of Guava smooth preheating and current limiting.
+
+```java
+import com.google.common.util.concurrent.RateLimiter;
+import java.util.concurrent.TimeUnit;
+
+/**
+ * Search JavaGuide on WeChat and reply to "Interview Assault" to get your own original Java interview manual for free
+ *
+ * @author Guide brother
+ * @date 2021/10/08 19:12
+ **/
+public class RateLimiterDemo {
+
+ public static void main(String[] args) {
+ // 1s puts 5 tokens into the bucket, that is, 0.2s puts 1 token into the bucket
+ // The warm-up time is 3s, which means that the card issuance rate will gradually increase to 0.2s in the first 3s. Put 1 token into the bucket.
+ RateLimiter rateLimiter = RateLimiter.create(5, 3, TimeUnit.SECONDS);
+ for (int i = 0; i < 20; i++) {
+ double sleepingTime = rateLimiter.acquire(1);
+ System.out.printf("get 1 tokens: %sds%n", sleepingTime);
+ }
+ }
+}
+```
+
+Output:
+
+```bash
+get 1 tokens: 0.0s
+get 1 tokens: 0.561919s
+get 1 tokens: 0.516931s
+get 1 tokens: 0.463798s
+get 1 tokens: 0.41286s
+get 1 tokens: 0.356172s
+get 1 tokens: 0.300489s
+get 1 tokens: 0.252545s
+get 1 tokens: 0.203996s
+get 1 tokens: 0.198359s
+```
+
+In addition, **Bucket4j** is a very good current limiting library based on the token/leaky bucket algorithm.
+
+> Bucket4j address:
+
+Compared with Guava's current limiting tool class, the current limiting function provided by Bucket4j is more comprehensive. Not only does it support stand-alone current limiting and distributed current limiting, it can also integrate monitoring and be used with Prometheus and Grafana.
+
+However, after all, Guava is just a comprehensive tool library, and the out-of-the-box current limiting function it provides is quite practical in many stand-alone scenarios.
+
+The early version of stand-alone current limiting that comes with Spring Cloud Gateway was implemented based on Bucket4j. Later, it was replaced by **Resilience4j**.
+
+Resilience4j is a lightweight fault-tolerant component inspired by Hystrix. Since [Netflix announced that it will no longer actively develop Hystrix](https://github.com/NETFLIX/Hystrix/commit/a7df971cbaddd8c5e976b3cc5f14013fe6ad00e6), both Spring officials and Netflix recommend using Resilience4j for current limiting and fusing.
+
+> Resilience4j address:
+
+Under normal circumstances, in order to ensure the high availability of the system, the current limiting and circuit breaker of the project must be done together.
+
+Resilience4j not only provides current limiting, but also provides out-of-the-box functions such as fusing, load protection, and automatic retry to ensure system high availability. Moreover, the ecosystem of Resilience4j is also better. Many gateways use Resilience4j for current limiting and circuit breaker.
+
+Therefore, Resilience4j may be a better choice in most scenarios. For some relatively simple current limiting scenarios, Guava or Bucket4j are also good choices.
+
+## How to implement distributed current limiting?
+
+Distributed current limiting is targeted at distributed/microservice application architecture applications. Under this architecture, single-machine current limiting is not applicable because there will be multiple services, and multiple copies of a service may be deployed.
+
+Common solutions for distributed current limiting:
+
+- **Current limiting with middleware**: You can use Sentinel or Redis to implement the corresponding current limiting logic yourself.
+- **Gateway layer current limiting**: A relatively common solution, which arranges the current limiting directly at the gateway layer. However, gateway layer current limiting usually requires the help of middleware/framework. For example, Spring Cloud Gateway's distributed current limiting implementation `RedisRateLimiter` is based on Redis+Lua. Another example is that Spring Cloud Gateway can also integrate Sentinel for current limiting.
+
+If you want to manually implement current limiting logic based on Redis, it is recommended to do it with Lua script.
+
+**Why is the Redis+Lua approach recommended? ** There are two main reasons:
+
+- **Reduced network overhead**: We can use Lua scripts to execute multiple Redis commands in batches. These Redis commands will be submitted to the Redis server for execution at one time, which greatly reduces network overhead.
+- **Atomicity**: A Lua script can be executed as a command. During the execution of a Lua script, no other scripts or Redis commands will be executed at the same time, ensuring that the operation will not be inserted or interrupted by other instructions.
+
+I won’t include the specific current limiting script code here. There are many excellent ready-made current limiting scripts on the Internet for your reference. For example, the RateLimiter current limiting plug-in of the Apache gateway project ShenYu implements the token bucket algorithm/concurrent token bucket algorithm, leaky bucket algorithm, and sliding window algorithm based on Redis + Lua.
+
+> ShenYu address:
+
+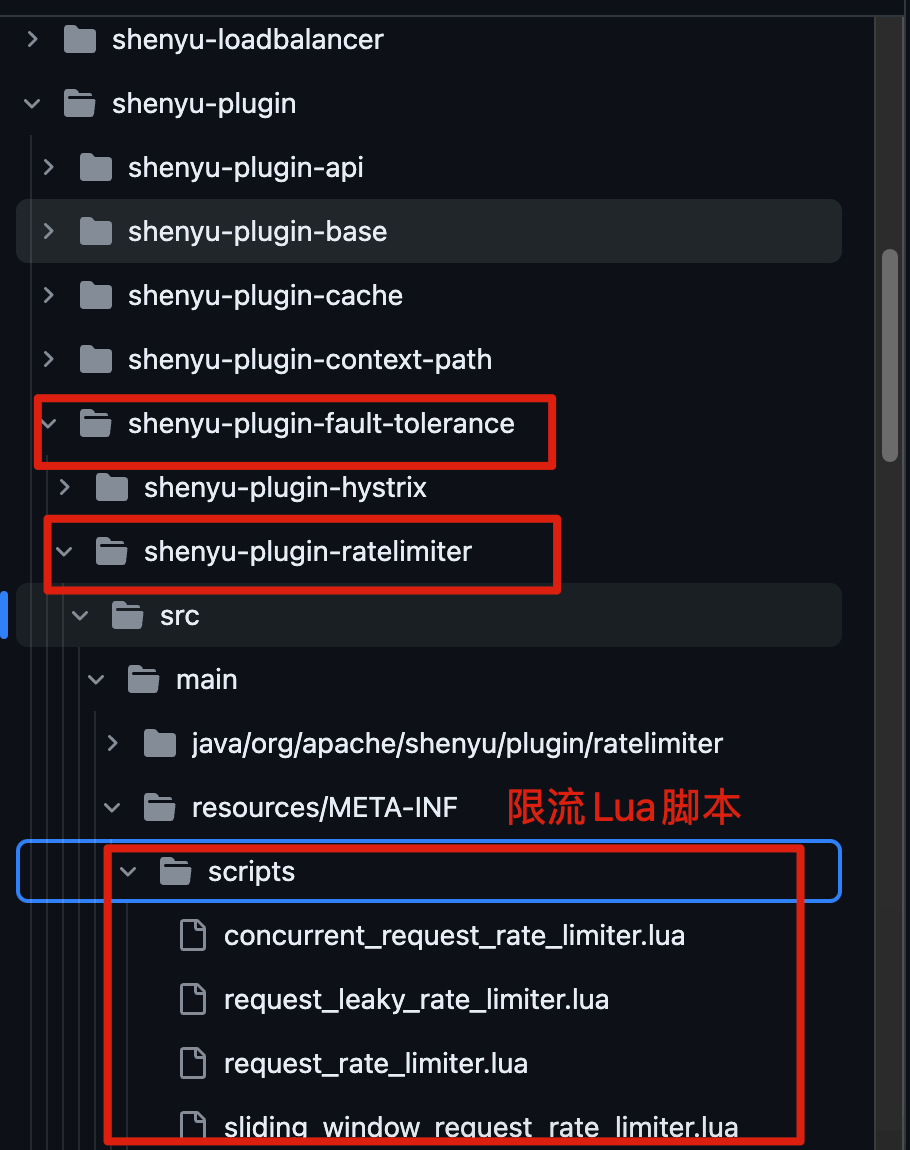
+
+In addition, if you don’t want to write Lua scripts yourself, you can also directly use `RRateLimiter` in Redisson to implement distributed current limiting. Its underlying implementation is based on Lua code + token bucket algorithm.
+
+Redisson is an open source Java language Redis client that provides many out-of-the-box features, such as data structure implementations commonly used in Java, distributed locks, delay queues, etc. Moreover, Redisson also supports multiple deployment architectures such as Redis stand-alone, Redis Sentinel, and Redis Cluster.
+
+`RRateLimiter` is very simple to use. We first need to obtain a `RRateLimiter` object, which can be obtained directly through the Redisson client. Then, just set the current limiting rules.
+
+```java
+//Create a Redisson client instance
+RedissonClient redissonClient = Redisson.create();
+// Get a current limiter object named "javaguide.limiter"
+RRateLimiter rateLimiter = redissonClient.getRateLimiter("javaguide.limiter");
+// Try setting the limiter at a rate of 100 times per hour
+// There are two types of RateType, OVERALL is global current limiting, ER_CLIENT is single Client current limiting (it can be considered as single-machine current limiting)
+rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.HOURS);
+```
+
+Next we call the `acquire()` method or the `tryAcquire()` method to obtain the permission.
+
+```java
+// Get a license and wait if the rate of the current limiter is exceeded
+// acquire() is a synchronous method, the corresponding asynchronous method: acquireAsync()
+rateLimiter.acquire(1);
+//Try to obtain a license within 5 seconds, return true if successful, false otherwise
+// tryAcquire() is a synchronous method, the corresponding asynchronous method: tryAcquireAsync()
+boolean res = rateLimiter.tryAcquire(1, 5, TimeUnit.SECONDS);
+```
+
+## Summary
+
+This article mainly introduces common current limiting algorithms, the selection of current limiting objects, and how to implement single-machine current limiting and distributed current limiting respectively.
+
+## refer to- Resilience4j, a lightweight circuit breaker framework for service governance:
+- Super detailed analysis of Guava RateLimiter current limiting principle:
+- Practical use of Spring Cloud Gateway current limiting 👍:
+- Detailed explanation of the implementation principle of Redisson distributed current limiting:
+- A detailed explanation of Java current limiting interface implementation - Alibaba Cloud Developer:
+- Exploration and practice of distributed current limiting solutions - Tencent Cloud Developer:
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/performance-test.en.md b/docs_en/high-availability/performance-test.en.md
new file mode 100644
index 00000000000..99202f236da
--- /dev/null
+++ b/docs_en/high-availability/performance-test.en.md
@@ -0,0 +1,179 @@
+---
+title: 性能测试入门
+category: 高可用
+icon: et-performance
+---
+
+性能测试一般情况下都是由测试这个职位去做的,那还需要我们开发学这个干嘛呢?了解性能测试的指标、分类以及工具等知识有助于我们更好地去写出性能更好的程序,另外作为开发这个角色,如果你会性能测试的话,相信也会为你的履历加分不少。
+
+这篇文章是我会结合自己的实际经历以及在测试这里取的经所得,除此之外,我还借鉴了一些优秀书籍,希望对你有帮助。
+
+## 不同角色看网站性能
+
+### 用户
+
+当用户打开一个网站的时候,最关注的是什么?当然是网站响应速度的快慢。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。
+
+所以,用户在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。
+
+### 开发人员
+
+用户与开发人员都关注速度,这个速度实际上就是我们的系统**处理用户请求的速度**。
+
+开发人员一般情况下很难直观的去评判自己网站的性能,我们往往会根据网站当前的架构以及基础设施情况给一个大概的值,比如:
+
+1. 项目架构是分布式的吗?
+2. 用到了缓存和消息队列没有?
+3. 高并发的业务有没有特殊处理?
+4. 数据库设计是否合理?
+5. 系统用到的算法是否还需要优化?
+6. 系统是否存在内存泄露的问题?
+7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
+8. ……
+
+### 测试人员
+
+测试人员一般会根据性能测试工具来测试,然后一般会做出一个表格。这个表格可能会涵盖下面这些重要的内容:
+
+1. 响应时间;
+2. 请求成功率;
+3. 吞吐量;
+4. ……
+
+### 运维人员
+
+运维人员会倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。
+
+## 性能测试需要注意的点
+
+几乎没有文章在讲性能测试的时候提到这个问题,大家都会讲如何去性能测试,有哪些性能测试指标这些东西。
+
+### 了解系统的业务场景
+
+**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件, 还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧!
+
+### 历史数据非常有用
+
+当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些服务承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
+
+另外,这些地方也就像这个系统的一个短板一样,优化好了这些地方会为我们的系统带来质的提升。
+
+## 常见性能指标
+
+### 响应时间
+
+**响应时间 RT(Response-time)就是用户发出请求到用户收到系统处理结果所需要的时间。**
+
+RT 是一个非常重要且直观的指标,RT 数值大小直接反应了系统处理用户请求速度的快慢。
+
+### 并发数
+
+**并发数可以简单理解为系统能够同时供多少人访问使用也就是说系统同时能处理的请求数量。**
+
+并发数反应了系统的负载能力。
+
+### QPS 和 TPS
+
+- **QPS(Query Per Second)** :服务器每秒可以执行的查询次数;
+- **TPS(Transaction Per Second)** :服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
+
+书中是这样描述 QPS 和 TPS 的区别的。
+
+> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
+
+### 吞吐量
+
+**吞吐量指的是系统单位时间内系统处理的请求数量。**
+
+一个系统的吞吐量与请求对系统的资源消耗等紧密关联。请求对系统资源消耗越多,系统吞吐能力越低,反之则越高。
+
+TPS、QPS 都是吞吐量的常用量化指标。
+
+- **QPS(TPS)** = 并发数/平均响应时间(RT)
+- **并发数** = QPS \* 平均响应时间(RT)
+
+## 系统活跃度指标
+
+### PV(Page View)
+
+访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录 1 次,多次打开或刷新同一页面则浏览量累计。UV 从网页打开的数量/刷新的次数的角度来统计的。
+
+### UV(Unique Visitor)
+
+独立访客,统计 1 天内访问某站点的用户数。1 天内相同访客多次访问网站,只计算为 1 个独立访客。UV 是从用户个体的角度来统计的。
+
+### DAU(Daily Active User)
+
+日活跃用户数量。
+
+### MAU(monthly active users)
+
+月活跃用户人数。
+
+举例:某网站 DAU 为 1200w, 用户日均使用时长 1 小时,RT 为 0.5s,求并发量和 QPS。
+
+平均并发量 = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数(86400)=1200w/24 = 50w
+
+真实并发量(考虑到某些时间段使用人数比较少) = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数-访问量比较小的时间段假设为 8 小时(57600)=1200w/16 = 75w
+
+峰值并发量 = 平均并发量 \* 6 = 300w
+
+QPS = 真实并发量/RT = 75W/0.5=150w/s
+
+## 性能测试分类
+
+### 性能测试
+
+性能测试方法是通过测试工具模拟用户请求系统,目的主要是为了测试系统的性能是否满足要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。
+
+性能测试是你在对系统性能已经有了解的前提之后进行的,并且有明确的性能指标。
+
+### 负载测试
+
+对被测试的系统继续加大请求压力,直到服务器的某个资源已经达到饱和了,比如系统的缓存已经不够用了或者系统的响应时间已经不满足要求了。
+
+负载测试说白点就是测试系统的上限。
+
+### 压力测试
+
+不去管系统资源的使用情况,对系统继续加大请求压力,直到服务器崩溃无法再继续提供服务。
+
+### 稳定性测试
+
+模拟真实场景,给系统一定压力,看看业务是否能稳定运行。
+
+## 常用性能测试工具
+
+### 后端常用
+
+既然系统设计涉及到系统性能方面的问题,那在面试的时候,面试官就很可能会问:**你是如何进行性能测试的?**
+
+推荐 4 个比较常用的性能测试工具:
+
+1. **Jmeter** :Apache JMeter 是 JAVA 开发的性能测试工具。
+2. **LoadRunner**:一款商业的性能测试工具。
+3. **Galtling** :一款基于 Scala 开发的高性能服务器性能测试工具。
+4. **ab** :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
+
+没记错的话,除了 **LoadRunner** 其他几款性能测试工具都是开源免费的。
+
+### 前端常用
+
+1. **Fiddler**:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
+2. **HttpWatch**: 可用于录制 HTTP 请求信息的工具。
+
+## 常见的性能优化策略
+
+性能优化之前我们需要对请求经历的各个环节进行分析,排查出可能出现性能瓶颈的地方,定位问题。
+
+下面是一些性能优化时,我经常拿来自问的一些问题:
+
+1. 系统是否需要缓存?
+2. 系统架构本身是不是就有问题?
+3. 系统是否存在死锁的地方?
+4. 系统是否存在内存泄漏?(Java 的自动回收内存虽然很方便,但是,有时候代码写的不好真的会造成内存泄漏)
+5. 数据库索引使用是否合理?
+6. ……
+
+
+
diff --git a/docs_en/high-availability/redundancy.en.md b/docs_en/high-availability/redundancy.en.md
new file mode 100644
index 00000000000..07323dfb1b9
--- /dev/null
+++ b/docs_en/high-availability/redundancy.en.md
@@ -0,0 +1,47 @@
+---
+title: Detailed explanation of redundant design
+category: high availability
+icon: cluster
+---
+
+Redundant design is the most common means to ensure high availability of systems and data.
+
+For services, the idea of redundancy is to deploy multiple copies of the same service. If the service being used suddenly hangs up, the system can quickly switch to the backup service, greatly reducing the system's unavailability time and improving system availability.
+
+For data, the idea of redundancy is to back up multiple copies of the same data, which can easily improve data security.
+
+In fact, there are many applications of redundant ideas in daily life.
+
+For myself, my method of saving important files is the application of redundant thinking. The important files I use daily are synchronized on GitHub and my personal cloud disk. This ensures that even if my computer hard drive is damaged, I can retrieve my important files through GitHub or my personal cloud disk.
+
+High Availability Cluster (HA Cluster for short), same-city disaster recovery, remote disaster recovery, same-city multi-active and remote multi-active are the most typical applications of redundancy ideas in high-availability system design.
+
+- **High Availability Cluster**: Deploy two or more copies of the same service. If the service being used suddenly hangs up, you can switch to another service to ensure high availability of the service.
+- **Same-city disaster recovery**: An entire cluster can be deployed in the same computer room, while in same-city disaster recovery the same services are deployed in different computer rooms in the same city. Also, the backup service does not handle requests. This can avoid unexpected situations such as power outages and fires in the computer room.
+- **Remote disaster recovery**: Similar to same-city disaster recovery, the difference is that the same service is deployed in different computer rooms in different locations (usually far away, or even in different cities or countries)
+- **Multi-active in the same city**: Similar to the same city disaster recovery, but the backup service can handle requests, which can make full use of system resources and improve system concurrency.
+- **Multi-Activity in Remote Locations**: Deploy services in different computer rooms in different locations, and they can provide services to the outside world at the same time.
+
+High-availability clusters are purely for service redundancy and do not emphasize geography. Intra-city disaster recovery, remote disaster recovery, same-city multi-activity and remote multi-activity realize geographical redundancy.
+
+The main difference between the same city and another place is the distance between computer rooms. The distance is usually far away, even in different cities or countries.
+
+Compared with the traditional disaster recovery design, the most obvious change between multi-activity in the same city and multi-activity in different places is "multi-activity", that is, all sites provide services to the outside world at the same time. Living more in different places is to cope with emergencies such as fires, earthquakes and other natural or man-made disasters.
+
+Redundancy alone is not enough, it must be coupled with **failover**! The so-called failover simply means the rapid and automatic switching of unavailable services to available services. The entire process does not require human intervention.
+
+For example: In the Sentinel mode Redis cluster, if Sentinel detects that the master node fails, it will help us implement failover and automatically upgrade a slave to the master to ensure the availability of the entire Redis system. The entire process is completely automatic and requires no manual intervention. I have introduced the knowledge points and interview questions related to Redis cluster in detail in the database section of "Technical Interview Questions" in ["Java Interview Guide"](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7). Interested friends can take a look.
+
+Another example: Nginx can be combined with Keepalived to achieve high availability. If the Nginx master server goes down, Keepalived can automatically perform failover and the backup Nginx master server is upgraded to the main service. Moreover, this switch is transparent to the outside world, because the virtual IP used will not change. I introduced the Nginx related knowledge points and interview questions in detail in the "Server" section of the "Technical Interview Questions" of ["Java Interview Guide"](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7). Interested friends can take a look.
+
+It is very difficult to implement a remote multi-active architecture, and there are many factors that need to be considered. I am not talented and have never practiced the remote multi-active architecture in actual projects. My understanding of it is still based on book knowledge.
+
+If you want to learn more about living in a different place, I recommend a few articles that I think are pretty good:
+
+- [To understand how to live in a different place, just read this article - Water Drops and Silver Bullets - 2021](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q)
+- [Four steps to build remote multi-activity](https://mp.weixin.qq.com/s/hMD-IS__4JE5_nQhYPYSTg)
+- ["Learning Architecture from Scratch" — 28 | Guarantee of high business availability: multi-active remote architecture](http://gk.link/a/10pKZ)
+
+However, most of these articles also introduce conceptual knowledge. At present, there is still a lack of information on the Internet that truly introduces how to implement the multi-active architecture in different locations.
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/timeout-and-retry.en.md b/docs_en/high-availability/timeout-and-retry.en.md
new file mode 100644
index 00000000000..4f5d7262ab2
--- /dev/null
+++ b/docs_en/high-availability/timeout-and-retry.en.md
@@ -0,0 +1,87 @@
+---
+title: 超时&重试详解
+category: 高可用
+icon: retry
+---
+
+由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
+
+为了最大限度的减小系统或者服务出现故障之后带来的影响,我们需要用到的 **超时(Timeout)** 和 **重试(Retry)** 机制。
+
+想要把超时和重试机制讲清楚其实很简单,因为它俩本身就不是什么高深的概念。
+
+虽然超时和重试机制的思想很简单,但是它俩是真的非常实用。你平时接触到的绝大部分涉及到远程调用的系统或者服务都会应用超时和重试机制。尤其是对于微服务系统来说,正确设置超时和重试非常重要。单体服务通常只涉及数据库、缓存、第三方 API、中间件等的网络调用,而微服务系统内部各个服务之间还存在着网络调用。
+
+## 超时机制
+
+### 什么是超时机制?
+
+超时机制说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 `504 Gateway Timeout`)。
+
+我们平时接触到的超时可以简单分为下面 2 种:
+
+- **连接超时(ConnectTimeout)**:客户端与服务端建立连接的最长等待时间。
+- **读取超时(ReadTimeout)**:客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
+
+一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。
+
+如果没有设置超时的话,就可能会导致服务端连接数爆炸和大量请求堆积的问题。
+
+这些堆积的连接和请求会消耗系统资源,影响新收到的请求的处理。严重的情况下,甚至会拖垮整个系统或者服务。
+
+我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。
+
+### 超时时间应该如何设置?
+
+超时到底设置多长时间是一个难题!超时值设置太高或者太低都有风险。如果设置太高的话,会降低超时机制的有效性,比如你设置超时为 10s 的话,那设置超时就没啥意义了,系统依然可能会出现大量慢请求堆积的问题。如果设置太低的话,就可能会导致在系统或者服务在某些处理请求速度变慢的情况下(比如请求突然增多),大量请求重试(超时通常会结合重试)继续加重系统或者服务的压力,进而导致整个系统或者服务被拖垮的问题。
+
+通常情况下,我们建议读取超时设置为 **1500ms** ,这是一个比较普适的值。如果你的系统或者服务对于延迟比较敏感的话,那读取超时值可以适当在 **1500ms** 的基础上进行缩短。反之,读取超时值也可以在 **1500ms** 的基础上进行加长,不过,尽量还是不要超过 **1500ms** 。连接超时可以适当设置长一些,建议在 **1000ms ~ 5000ms** 之内。
+
+没有银弹!超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
+
+更上一层,参考[美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
+
+## 重试机制
+
+### 什么是重试机制?
+
+重试机制一般配合超时机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障。
+
+瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。
+
+重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。
+
+### 常见的重试策略有哪些?
+
+常见的重试策略有两种:
+
+1. **固定间隔时间重试**:每次重试之间都使用相同的时间间隔,比如每隔 1.5 秒进行一次重试。这种重试策略的优点是实现起来比较简单,不需要考虑重试次数和时间的关系,也不需要维护额外的状态信息。但是这种重试策略的缺点是可能会导致重试过于频繁或过于稀疏,从而影响系统的性能和效率。如果重试间隔太短,可能会对目标系统造成过大的压力,导致雪崩效应;如果重试间隔太长,可能会导致用户等待时间过长,影响用户体验。
+2. **梯度间隔重试**:根据重试次数的增加去延长下次重试时间,比如第一次重试间隔为 1 秒,第二次为 2 秒,第三次为 4 秒,以此类推。这种重试策略的优点是能够有效提高重试成功的几率(随着重试次数增加,但是重试依然不成功,说明目标系统恢复时间比较长,因此可以根据重试次数延长下次重试时间),也能通过柔性化的重试避免对下游系统造成更大压力。但是这种重试策略的缺点是实现起来比较复杂,需要考虑重试次数和时间的关系,以及设置合理的上限和下限值。另外,这种重试策略也可能会导致用户等待时间过长,影响用户体验。
+
+这两种适合的场景各不相同。固定间隔时间重试适用于目标系统恢复时间比较稳定和可预测的场景,比如网络波动或服务重启。梯度间隔重试适用于目标系统恢复时间比较长或不可预测的场景,比如网络故障和服务故障。
+
+### 重试的次数如何设置?
+
+重试的次数不宜过多,否则依然会对系统负载造成比较大的压力。
+
+重试的次数通常建议设为 3 次。大部分情况下,我们还是更建议使用梯度间隔重试策略,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。
+
+### 什么是重试幂等?
+
+超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
+
+什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
+
+举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
+
+### Java 中如何实现重试?
+
+如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现,例如 Spring Retry、Resilience4j、Guava Retrying。
+
+## 参考
+
+- 微服务之间调用超时的设置治理:
+- 超时、重试和抖动回退:
+
+
+
diff --git a/docs_en/high-performance/cdn.en.md b/docs_en/high-performance/cdn.en.md
new file mode 100644
index 00000000000..b238a5c4fe6
--- /dev/null
+++ b/docs_en/high-performance/cdn.en.md
@@ -0,0 +1,135 @@
+---
+title: CDN工作原理详解
+category: 高性能
+head:
+ - - meta
+ - name: keywords
+ content: CDN,内容分发网络
+ - - meta
+ - name: description
+ content: CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。
+---
+
+## 什么是 CDN ?
+
+**CDN** 全称是 Content Delivery Network/Content Distribution Network,翻译过的意思是 **内容分发网络** 。
+
+我们可以将内容分发网络拆开来看:
+
+- 内容:指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
+- 分发网络:指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
+
+所以,简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。**
+
+类似于京东建立的庞大的仓储运输体系,京东物流在全国拥有非常多的仓库,仓储网络几乎覆盖全国所有区县。这样的话,用户下单的第一时间,商品就从距离用户最近的仓库,直接发往对应的配送站,再由京东小哥送到你家。
+
+
+
+你可以将 CDN 看作是服务上一层的特殊缓存服务,分布在全国各地,主要用来处理静态资源的请求。
+
+
+
+我们经常拿全站加速和内容分发网络做对比,不要把两者搞混了!全站加速(不同云服务商叫法不同,腾讯云叫 ECDN、阿里云叫 DCDN)既可以加速静态资源又可以加速动态资源,内容分发网络(CDN)主要针对的是 **静态资源** 。
+
+
+
+绝大部分公司都会在项目开发中使用 CDN 服务,但很少会有自建 CDN 服务的公司。基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云、青云)或者 CDN 厂商(比如网宿、蓝汛)提供的开箱即用的 CDN 服务。
+
+很多朋友可能要问了:**既然是就近访问,为什么不直接将服务部署在多个不同的地方呢?**
+
+- 成本太高,需要部署多份相同的服务。
+- 静态资源通常占用空间比较大且经常会被访问到,如果直接使用服务器或者缓存来处理静态资源请求的话,对系统资源消耗非常大,可能会影响到系统其他服务的正常运行。
+
+同一个服务在在多个不同的地方部署多份(比如同城灾备、异地灾备、同城多活、异地多活)是为了实现系统的高可用而不是就近访问。
+
+## CDN 工作原理是什么?
+
+搞懂下面 3 个问题也就搞懂了 CDN 的工作原理:
+
+1. 静态资源是如何被缓存到 CDN 节点中的?
+2. 如何找到最合适的 CDN 节点?
+3. 如何防止静态资源被盗用?
+
+### 静态资源是如何被缓存到 CDN 节点中的?
+
+你可以通过 **预热** 的方式将源站的资源同步到 CDN 的节点中。这样的话,用户首次请求资源可以直接从 CDN 节点中取,无需回源。这样可以降低源站压力,提升用户体验。
+
+如果不预热的话,你访问的资源可能不在 CDN 节点中,这个时候 CDN 节点将请求源站获取资源,这个过程是大家经常说的 **回源**。
+
+> - 回源:当 CDN 节点上没有用户请求的资源或该资源的缓存已经过期时,CDN 节点需要从原始服务器获取最新的资源内容,这个过程就是回源。当用户请求发生回源的话,会导致该请求的响应速度比未使用 CDN 还慢,因为相比于未使用 CDN 还多了一层 CDN 的调用流程。
+> - 预热:预热是指在 CDN 上提前将内容缓存到 CDN 节点上。这样当用户在请求这些资源时,能够快速地从最近的 CDN 节点获取到而不需要回源,进而减少了对源站的访问压力,提高了访问速度。
+
+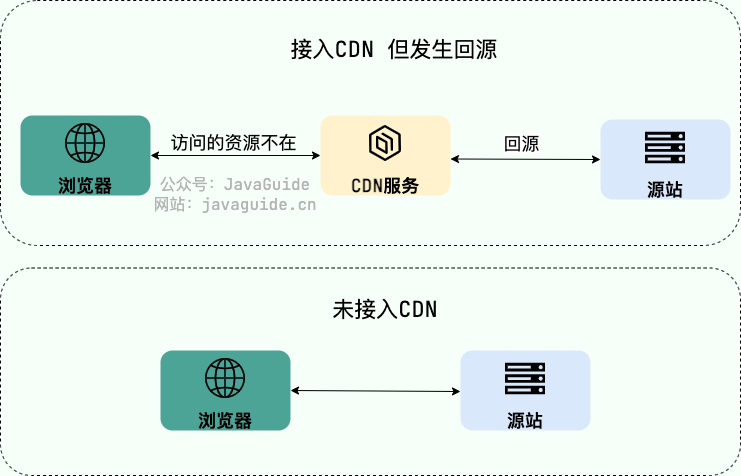
+
+如果资源有更新的话,你也可以对其 **刷新** ,删除 CDN 节点上缓存的旧资源,并强制 CDN 节点回源站获取最新资源。
+
+几乎所有云厂商提供的 CDN 服务都具备缓存的刷新和预热功能(下图是阿里云 CDN 服务提供的相应功能):
+
+
+
+**命中率** 和 **回源率** 是衡量 CDN 服务质量两个重要指标。命中率越高越好,回源率越低越好。
+
+### 如何找到最合适的 CDN 节点?
+
+GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个 CDN 节点之间相互协作,最常用的是基于 DNS 的 GSLB。
+
+CDN 会通过 GSLB 找到最合适的 CDN 节点,更具体点来说是下面这样的:
+
+1. 浏览器向 DNS 服务器发送域名请求;
+2. DNS 服务器向根据 CNAME( Canonical Name ) 别名记录向 GSLB 发送请求;
+3. GSLB 返回性能最好(通常距离请求地址最近)的 CDN 节点(边缘服务器,真正缓存内容的地方)的地址给浏览器;
+4. 浏览器直接访问指定的 CDN 节点。
+
+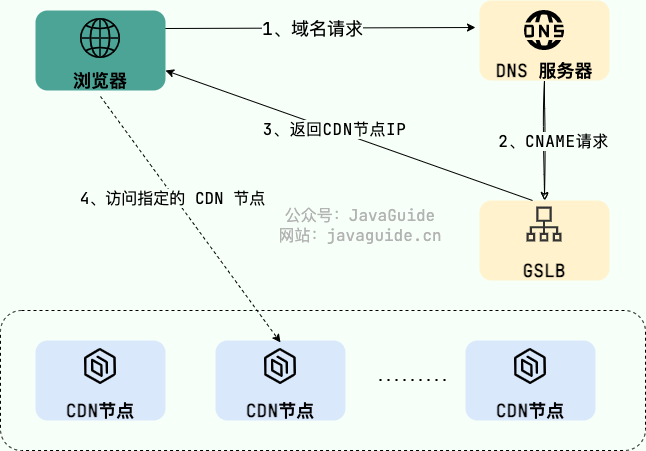
+
+为了方便理解,上图其实做了一点简化。GSLB 内部可以看作是 CDN 专用 DNS 服务器和负载均衡系统组合。CDN 专用 DNS 服务器会返回负载均衡系统 IP 地址给浏览器,浏览器使用 IP 地址请求负载均衡系统进而找到对应的 CDN 节点。
+
+**GSLB 是如何选择出最合适的 CDN 节点呢?** GSLB 会根据请求的 IP 地址、CDN 节点状态(比如负载情况、性能、响应时间、带宽)等指标来综合判断具体返回哪一个 CDN 节点的地址。
+
+### 如何防止资源被盗刷?
+
+如果我们的资源被其他用户或者网站非法盗刷的话,将会是一笔不小的开支。
+
+解决这个问题最常用最简单的办法设置 **Referer 防盗链**,具体来说就是根据 HTTP 请求的头信息里面的 Referer 字段对请求进行限制。我们可以通过 Referer 字段获取到当前请求页面的来源页面的网站地址,这样我们就能确定请求是否来自合法的网站。
+
+CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。
+
+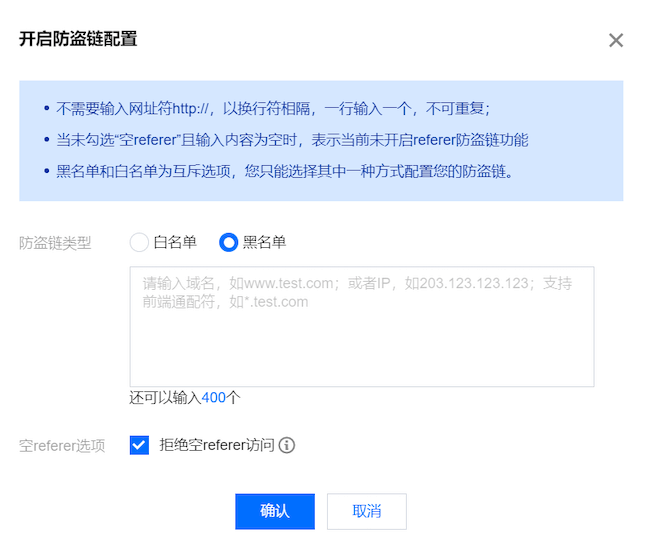
+
+不过,如果站点的防盗链配置允许 Referer 为空的话,通过隐藏 Referer,可以直接绕开防盗链。
+
+通常情况下,我们会配合其他机制来确保静态资源被盗用,一种常用的机制是 **时间戳防盗链** 。相比之下,**时间戳防盗链** 的安全性更强一些。时间戳防盗链加密的 URL 具有时效性,过期之后就无法再被允许访问。
+
+时间戳防盗链的 URL 通常会有两个参数一个是签名字符串,一个是过期时间。签名字符串一般是通过对用户设定的加密字符串、请求路径、过期时间通过 MD5 哈希算法取哈希的方式获得。
+
+时间戳防盗链 URL 示例:
+
+```plain
+http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
+```
+
+- `wsSecret`:签名字符串。
+- `wsTime`: 过期时间。
+
+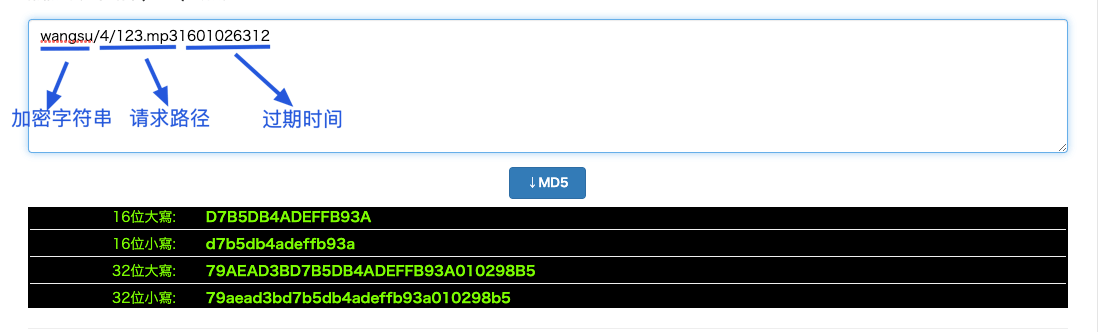
+
+时间戳防盗链的实现也比较简单,并且可靠性较高,推荐使用。并且,绝大部分 CDN 服务提供商都提供了开箱即用的时间戳防盗链机制。
+
+
+
+In addition to Referer anti-hotlinking and timestamp anti-hotlinking, you can also configure IP black and white list, IP access frequency limit configuration and other mechanisms to prevent theft.
+
+## Summary
+
+- CDN is to distribute static resources to multiple different places to achieve nearby access, thereby speeding up the access speed of static resources and reducing the burden on servers and bandwidth.
+- Based on cost, stability and ease of use, it is recommended to directly choose the out-of-the-box CDN service provided by professional cloud vendors (such as Alibaba Cloud, Tencent Cloud, Huawei Cloud, Qingyun) or CDN vendors (such as Wangsu, Lanxun).
+- GSLB (Global Server Load Balance, global load balancing) is the brain of CDN and is responsible for the cooperation between multiple CDN nodes. The most commonly used one is DNS-based GSLB. CDN will find the most suitable CDN node through GSLB.
+- In order to prevent static resources from being stolen, we can use **Referer anti-hotlinking** + **Timestamp anti-hotlinking**.
+
+## Reference
+
+- Timestamp hotlinking prevention - Qiniu Cloud CDN:
+- What is a CDN? One article explains it clearly:
+- "HTTP Protocol in Perspective" - 37 | CDN: Accelerate our network services:
+
+
\ No newline at end of file
diff --git a/docs_en/high-performance/data-cold-hot-separation.en.md b/docs_en/high-performance/data-cold-hot-separation.en.md
new file mode 100644
index 00000000000..54637b7ddbe
--- /dev/null
+++ b/docs_en/high-performance/data-cold-hot-separation.en.md
@@ -0,0 +1,68 @@
+---
+title: Detailed explanation of hot and cold data separation
+category: high performance
+head:
+ - - meta
+ - name: keywords
+ content: Separation of hot and cold data, cold data migration, cold data storage
+ - - meta
+ - name: description
+ content: Separation of hot and cold data refers to dividing data into cold data and hot data based on the access frequency and business importance of the data. Cold data is generally stored in low-cost, low-performance media, and hot data is stored in high-performance storage media.
+---
+
+## What is the separation of hot and cold data?
+
+Separation of hot and cold data refers to dividing data into cold data and hot data based on the access frequency and business importance of the data. Cold data is generally stored in low-cost, low-performance media, and hot data is stored in high-performance storage media.
+
+### Cold data and hot data
+
+Hot data refers to data that is frequently accessed and modified and needs to be accessed quickly. Cold data refers to data that is not accessed frequently and has low value to the current project, but needs to be preserved for a long time.
+
+How to distinguish between hot and cold data? There are two common ways to differentiate:
+
+1. **Time dimension distinction**: According to the creation time, update time, expiration time, etc. of the data, the data within a certain time period is regarded as hot data, and the data beyond this time period is regarded as cold data. For example, the order system can treat order data 1 year ago as cold data and order data within 1 year as hot data. This method is suitable for scenarios where there is a strong correlation between data access frequency and time.
+2. **Access frequency differentiation**: Data with high frequency access is regarded as hot data, and data with low frequency access is regarded as cold data. For example, the content system can treat articles with very low page views as cold data and articles with high page views as hot data. This method needs to record the access frequency of the data, which is relatively expensive and is suitable for scenarios where there is a strong correlation between the access frequency and the data itself.
+
+Data from a few years ago is not necessarily cold data. For example, some high-quality articles are still visited by many people a few years after they were published, but most newly published articles by ordinary users are rarely visited by anyone.
+
+These two methods of distinguishing hot and cold data have their own advantages and disadvantages. In actual projects, they can be used in combination.
+
+### The idea of separation of hot and cold
+
+The idea of hot and cold separation is very simple, which is to classify the data and store it separately. The idea of hot and cold separation can be applied to many fields and scenarios, not just data storage, for example:
+
+- In the email system, you can put recent, more important emails in your inbox, and older, less important emails in the archive.
+- In daily life, you can place commonly used items in a conspicuous place, and put infrequently used items in the storage room or attic.
+- In the library, the most popular and frequently borrowed books can be placed in a conspicuous area alone, and the less frequently borrowed books can be placed in an inconspicuous location.
+-…
+
+### Advantages and Disadvantages of Separating Hot and Cold Data
+
+- Advantages: The query performance of hot data is optimized (most users' operating experience will be better), cost saving (the corresponding database type and hardware configuration can be selected according to the different storage requirements of hot and cold data, such as placing hot data on SSD and cold data on HDD)
+- Disadvantages: Increased system complexity and risks (hot and cold data need to be separated, increased risk of data errors), low statistical efficiency (cold storage data may be needed for statistics).
+
+## How to migrate cold data?
+
+Cold data migration solution:
+
+1. Business layer code implementation: When there is a write operation on data, the logic of hot and cold separation is triggered to determine whether the data is cold data or hot data. Cold data is put into the cold storage, and hot data is put into the hot storage. This solution will affect performance and the judgment logic of hot and cold data is not easy to determine. It also requires modification of the business layer code, so it is generally not used.
+2. Task scheduling: You can use xxl-job or other distributed task scheduling platforms to regularly scan the database to find data that meets the cold data conditions, then copy them to the cold storage in batches and delete them from the hot storage. This method requires very little code modification and is very suitable for scenarios where hot and cold data are distinguished based on time.
+3. Monitor the change log binlog of the database: extract the data that meets the cold data conditions from the binlog, then copy it to the cold storage, and delete it from the hot storage. This method does not require modifying the code, but it is not suitable for scenarios where hot and cold data are distinguished based on the time dimension.
+
+If your company has a DBA, you can also ask the DBA to manually migrate the cold data and complete the migration of the cold data to the cold storage in one go. Then, use the solution introduced above to implement subsequent cold data migration.
+
+## How to store cold data?
+
+The storage requirements of cold data are mainly large capacity, low cost, high reliability, and access speed can be appropriately sacrificed.
+
+Cold data storage solution:
+
+- Small and medium-sized factories: Just use MySQL/PostgreSQL directly (do not change the database selection and keep it consistent with the database currently used by the project), such as adding a table to store cold data of a certain business or using a separate cold storage to store cold data (involving cross-database queries, increasing system complexity and maintenance difficulty)
+- Major manufacturers: Hbase (commonly used), RocksDB, Doris, Cassandra
+
+If the company's cost budget is sufficient, it can also directly use a distributed relational database such as TiDB to get it done in one step. TiDB 6.0 officially supports the separation of hot and cold data storage, which can reduce the cost of SSD usage. Using the data placement function of TiDB 6.0, you can realize hot and cold storage of massive data in the same cluster, store new hot data in SSD, and store historical cold data in HDD.
+
+## Case sharing
+
+- [How to quickly optimize an order form with tens of millions of data - Programmer Jidian - 2023](https://www.cnblogs.com/fulongyuanjushi/p/17910420.html)
+- [Mass data hot and cold separation scheme and practice - ByteDance technical team - 2022](https://mp.weixin.qq.com/s/ZKRkZP6rLHuTE1wvnqmAPQ)
\ No newline at end of file
diff --git a/docs_en/high-performance/deep-pagination-optimization.en.md b/docs_en/high-performance/deep-pagination-optimization.en.md
new file mode 100644
index 00000000000..3e79bab2571
--- /dev/null
+++ b/docs_en/high-performance/deep-pagination-optimization.en.md
@@ -0,0 +1,143 @@
+---
+title: 深度分页介绍及优化建议
+category: 高性能
+head:
+ - - meta
+ - name: keywords
+ content: 深度分页
+ - - meta
+ - name: description
+ content: 查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低。深度分页可以采用范围查询、子查询、INNER JOIN 延迟关联、覆盖索引等方法进行优化。
+---
+
+## 深度分页介绍
+
+查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如:
+
+```sql
+# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
+SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
+```
+
+## 深度分页问题的原因
+
+当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。这是因为扫描索引和跳过大量记录可能比直接全表扫描更耗费资源。
+
+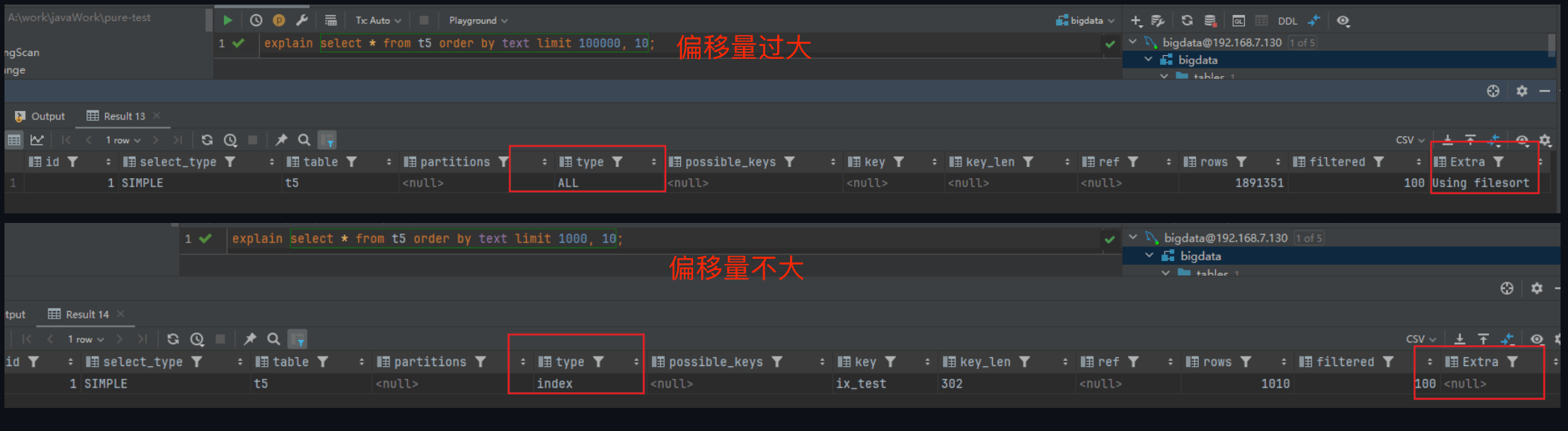
+
+不同机器上这个查询偏移量过大的临界点可能不同,取决于多个因素,包括硬件配置(如 CPU 性能、磁盘速度)、表的大小、索引的类型和统计信息等。
+
+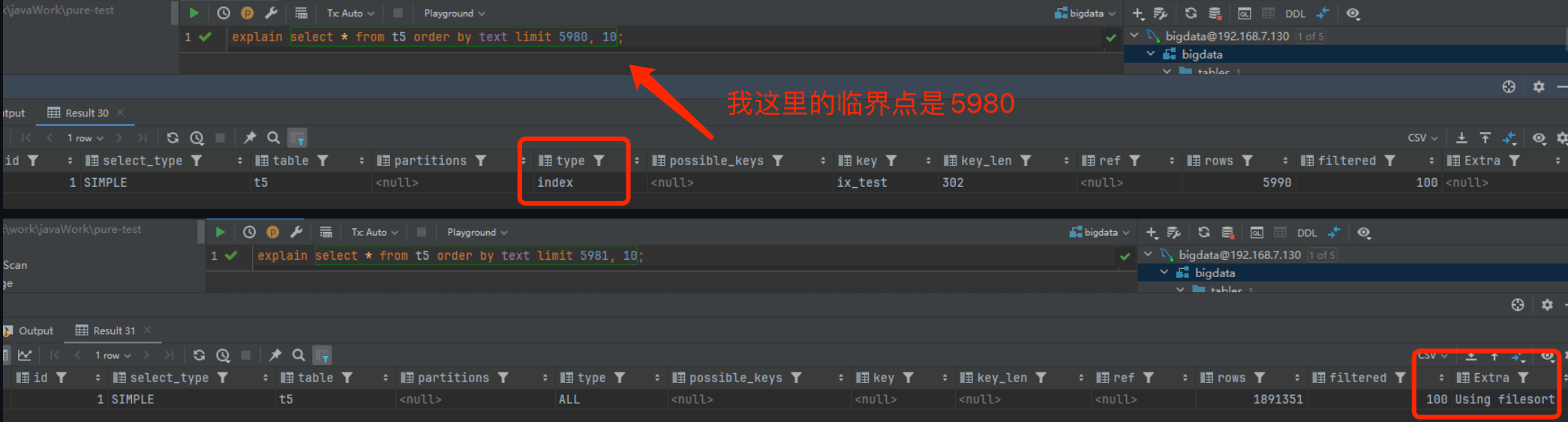
+
+MySQL 的查询优化器采用基于成本的策略来选择最优的查询执行计划。它会根据 CPU 和 I/O 的成本来决定是否使用索引扫描或全表扫描。如果优化器认为全表扫描的成本更低,它就会放弃使用索引。不过,即使偏移量很大,如果查询中使用了覆盖索引(covering index),MySQL 仍然可能会使用索引,避免回表操作。
+
+## 深度分页优化建议
+
+这里以 MySQL 数据库为例介绍一下如何优化深度分页。
+
+### 范围查询
+
+当可以保证 ID 的连续性时,根据 ID 范围进行分页是比较好的解决方案:
+
+```sql
+# 查询指定 ID 范围的数据
+SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
+# 也可以通过记录上次查询结果的最后一条记录的ID进行下一页的查询:
+SELECT * FROM t_order WHERE id > 100000 LIMIT 10
+```
+
+这种基于 ID 范围的深度分页优化方式存在很大限制:
+
+1. **ID 连续性要求高**: 实际项目中,数据库自增 ID 往往因为各种原因(例如删除数据、事务回滚等)导致 ID 不连续,难以保证连续性。
+2. **排序问题**: 如果查询需要按照其他字段(例如创建时间、更新时间等)排序,而不是按照 ID 排序,那么这种方法就不再适用。
+3. **并发场景**: 在高并发场景下,单纯依赖记录上次查询的最后一条记录的 ID 进行分页,容易出现数据重复或遗漏的问题。
+
+### 子查询
+
+我们先查询出 limit 第一个参数对应的主键值,再根据这个主键值再去过滤并 limit,这样效率会更快一些。
+
+阿里巴巴《Java 开发手册》中也有对应的描述:
+
+> 利用延迟关联或者子查询优化超多分页场景。
+>
+> 
+
+```sql
+-- 先通过子查询在主键索引上进行偏移,快速找到起始ID
+SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order LIMIT 1000000, 1) LIMIT 10;
+```
+
+**工作原理**:
+
+1. 子查询 `(SELECT id FROM t_order where id > 1000000 limit 1)` 会利用主键索引快速定位到第 1000001 条记录,并返回其 ID 值。
+2. 主查询 `SELECT * FROM t_order WHERE id >= ... LIMIT 10` 将子查询返回的起始 ID 作为过滤条件,使用 `id >=` 获取从该 ID 开始的后续 10 条记录。
+
+不过,子查询的结果会产生一张新表,会影响性能,应该尽量避免大量使用子查询。并且,这种方法只适用于 ID 是正序的。在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的 ID,此时的 ID 是离散且不连续的。
+
+当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。
+
+### 延迟关联
+
+延迟关联与子查询的优化思路类似,都是通过将 `LIMIT` 操作转移到主键索引树上,减少回表次数。相比直接使用子查询,延迟关联通过 `INNER JOIN` 将子查询结果集成到主查询中,避免了子查询可能产生的临时表。在执行 `INNER JOIN` 时,MySQL 优化器能够利用索引进行高效的连接操作(如索引扫描或其他优化策略),因此在深度分页场景下,性能通常优于直接使用子查询。
+
+```sql
+-- 使用 INNER JOIN 进行延迟关联
+SELECT t1.*
+FROM t_order t1
+INNER JOIN (
+ -- 这里的子查询可以利用覆盖索引,性能极高
+ SELECT id FROM t_order LIMIT 1000000, 10
+) t2 ON t1.id = t2.id;
+```
+
+**工作原理**:
+
+1. 子查询 `(SELECT id FROM t_order where id > 1000000 LIMIT 10)` 利用主键索引快速定位目标分页的 10 条记录的 ID。
+2. 通过 `INNER JOIN` 将子查询结果与主表 `t_order` 关联,获取完整的记录数据。
+
+除了使用 INNER JOIN 之外,还可以使用逗号连接子查询。
+
+```sql
+-- 使用逗号进行延迟关联
+SELECT t1.* FROM t_order t1,
+(SELECT id FROM t_order where id > 1000000 LIMIT 10) t2
+WHERE t1.id = t2.id;
+```
+
+**注意**: 虽然逗号连接子查询也能实现类似的效果,但为了代码可读性和可维护性,建议使用更规范的 `INNER JOIN` 语法。
+
+### 覆盖索引
+
+索引中已经包含了所有需要获取的字段的查询方式称为覆盖索引。
+
+**覆盖索引的好处:**
+
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+
+```sql
+# 如果只需要查询 id, code, type 这三列,可建立 code 和 type 的覆盖索引
+SELECT id, code, type FROM t_order
+ORDER BY code
+LIMIT 1000000, 10;
+```
+
+**⚠️注意**:
+
+- 当查询的结果集占表的总行数的很大一部分时,MySQL 查询优化器可能选择放弃使用索引,自动转换为全表扫描。
+- 虽然可以使用 `FORCE INDEX` 强制查询优化器走索引,但这种方式可能会导致查询优化器无法选择更优的执行计划,效果并不总是理想。
+
+## 总结
+
+本文总结了几种常见的深度分页优化方案:
+
+1. **范围查询**: 基于 ID 连续性进行分页,通过记录上一页最后一条记录的 ID 来获取下一页数据。适合 ID 连续且按 ID 查询的场景,但在 ID 不连续或需要按其他字段排序时存在局限。
+2. **子查询**: 先通过子查询获取分页的起始主键值,再根据主键进行筛选分页。利用主键索引提高效率,但子查询会生成临时表,复杂场景下性能不佳。
+3. **延迟关联 (INNER JOIN)**: 使用 `INNER JOIN` 将分页操作转移到主键索引上,减少回表次数。相比子查询,延迟关联的性能更优,适合大数据量的分页查询。
+4. **覆盖索引**: 通过索引直接获取所需字段,避免回表操作,减少 IO 开销,适合查询特定字段的场景。但当结果集较大时,MySQL 可能会选择全表扫描。
+
+## 参考
+
+- Let’s talk about how to solve the MySQL deep paging problem - The little boy picking up snails:
+- Database deep paging introduction and optimization plan - JD retail technology:
+
+Each method has its own advantages, and the best way to choose is based on the actual scenario. Let's make a simple comparison of these three methods to help you choose the correct data type for storing time in actual development:
+
+| Type | Storage space | Date format | Date range | Whether to include time zone information |
+| -------------------------- | -------- | ----------------------------- | --------------------------------------------------------------- | ------------- |
+| DATETIME | 5~8 bytes | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | No |
+| TIMESTAMP | 4~7 bytes | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | Yes |
+| Numeric timestamp | 4 bytes | Full number such as 1578707612 | Time after 1970-01-01 00:00:01 | No |
+
+**Summary of selection suggestions:**
+
+- The core strength of `TIMESTAMP` is its built-in time zone handling capabilities. The database takes care of UTC storage and automatic conversion based on the session time zone, simplifying the development of applications that need to handle multiple time zones. If your application needs to handle multiple time zones, or you want the database to automatically manage time zone conversions, `TIMESTAMP` is a natural choice (note its time range limit, aka the 2038 problem).
+- If the application scenario does not involve time zone conversion, or you want the application to have full control over the time zone logic, and need to represent time after 2038, `DATETIME` is a safer choice.
+- Numeric timestamps are a powerful option if comparison performance is of paramount concern, or if time data needs to be passed frequently across systems and the sacrifice of readability (or always conversion at the application layer) is acceptable.
+
+
\ No newline at end of file
diff --git a/docs_en/database/mysql/transaction-isolation-level.en.md b/docs_en/database/mysql/transaction-isolation-level.en.md
new file mode 100644
index 00000000000..e0dce97f95d
--- /dev/null
+++ b/docs_en/database/mysql/transaction-isolation-level.en.md
@@ -0,0 +1,123 @@
+---
+title: Detailed explanation of MySQL transaction isolation level
+category: database
+tag:
+ -MySQL
+head:
+ - - meta
+ - name: keywords
+ content: transaction, isolation level, read uncommitted, read committed, repeatable read, serializable, MVCC, lock
+ - - meta
+ - name: description
+ Content: Sort out the four major transaction isolation levels and concurrency phenomena, combine InnoDB's MVCC and lock mechanism, and clarify the response strategy for phantom reads/non-repeatable reads.
+---
+
+> This article was jointly written by [SnailClimb](https://github.com/Snailclimb) and [guang19](https://github.com/guang19).
+
+For an introduction to the basic overview of transactions, please read the introduction of this article: [MySQL common knowledge points & summary of interview questions] (./mysql-questions-01.md#MySQL-Transactions)
+
+## Transaction isolation level summary
+
+The SQL standard defines four transaction isolation levels to balance transaction isolation and concurrency performance. The higher the level, the better the data consistency, but the concurrency performance may be lower. The four levels are:
+
+- **READ-UNCOMMITTED (read uncommitted)**: The lowest isolation level, allowing reading of uncommitted data changes, which may lead to dirty reads, phantom reads, or non-repeatable reads. This level is rarely used in practical applications because its guarantee of data consistency is too weak.
+- **READ-COMMITTED (read committed)**: Allows reading of data that has been committed by concurrent transactions, which can prevent dirty reads, but phantom reads or non-repeatable reads may still occur. This is the default isolation level for most databases (such as Oracle, SQL Server).
+- **REPEATABLE-READ (repeatable read)**: The results of multiple reads of the same field are consistent, unless the data is modified by the own transaction itself. Dirty reads and non-repeatable reads can be prevented, but phantom reads may still occur. The default isolation level of the MySQL InnoDB storage engine is REPEATABLE READ. Moreover, InnoDB solves the phantom read problem to a large extent through the MVCC (Multi-version Concurrency Control) and Next-Key Locks (gap lock + row lock) mechanisms at this level.
+- **SERIALIZABLE**: The highest isolation level, fully compliant with ACID isolation level. All transactions are executed one after another in order, so that there is no possibility of interference between transactions. In other words, this level can prevent dirty reads, non-repeatable reads and phantom reads.
+
+| Isolation level | Dirty Read | Non-Repeatable Read | Phantom Read |
+|---------------- | ------------------ | ---------------------------------- | ----------------------- |
+| READ UNCOMMITTED | √ | √ | √ |
+| READ COMMITTED | × | √ | √ |
+| REPEATABLE READ | × | × | √ (Standard) / ≈× (InnoDB) |
+| SERIALIZABLE | × | × | × |
+
+**Default level query:**
+
+The default isolation level for the MySQL InnoDB storage engine is **REPEATABLE READ**. You can view it with the following command:
+
+- Before MySQL 8.0: `SELECT @@tx_isolation;`
+- MySQL 8.0 and later: `SELECT @@transaction_isolation;`
+
+```bash
+mysql> SELECT @@transaction_isolation;
++------------------------+
+| @@transaction_isolation |
++------------------------+
+| REPEATABLE-READ |
++------------------------+
+```
+
+**InnoDB's REPEATABLE READ handles phantom reads:**
+
+In the standard SQL isolation level definition, REPEATABLE READ cannot prevent phantom reads. However, the implementation of InnoDB largely avoids phantom reads through the following mechanisms:
+
+- **Snapshot Read**: Ordinary SELECT statement, implemented through the **MVCC** mechanism. A data snapshot is created when a transaction starts, and subsequent snapshot reads read this version of the data, thereby avoiding seeing newly inserted rows (phantom reads) or modified rows (non-repeatable reads) by other transactions.
+- **Current Read**: Operations like `SELECT ... FOR UPDATE`, `SELECT ... LOCK IN SHARE MODE`, `INSERT`, `UPDATE`, `DELETE`. InnoDB uses **Next-Key Lock** to lock the scanned index records and the range (gap) between them to prevent other transactions from inserting new records in this range, thereby avoiding phantom reads. Next-Key Lock is a combination of Record Lock and Gap Lock.
+
+It is worth noting that although it is generally believed that the higher the isolation level, the worse the concurrency, but the InnoDB storage engine optimizes the REPEATABLE READ level through the MVCC mechanism. For many common read-only or read-more-write-less scenarios, there may not be a significant performance difference compared to READ COMMITTED. However, in write-intensive scenarios with high concurrency conflicts, RR's gap lock mechanism may cause more lock waits than RC.
+
+In addition, in some specific scenarios, such as distributed transactions that require strict consistency (XA Transactions), InnoDB may require or recommend the use of SERIALIZABLE isolation level to ensure the consistency of global data.
+
+Chapter 7.7 of "MySQL Technology Insider: InnoDB Storage Engine (2nd Edition)" reads:
+
+> The InnoDB storage engine provides support for XA transactions and supports the implementation of distributed transactions through XA transactions. Distributed transactions refer to allowing multiple independent transactional resources to participate in a global transaction. Transactional resources are typically relational database systems, but can be other types of resources. Global transactions require all participating transactions to either commit or roll back, which improves the original ACID requirements for transactions. In addition, when using distributed transactions, the transaction isolation level of the InnoDB storage engine must be set to SERIALIZABLE.
+
+## Actual situation demonstration
+
+Below I will use two command lines MySQL to simulate the problem of dirty reading of the same data by multiple threads (multiple transactions).
+
+In the default configuration of the MySQL command line, transactions are automatically committed, that is, the COMMIT operation will be performed immediately after executing the SQL statement. If you want to explicitly start a transaction, you need to use the command: `START TRANSACTION`.
+
+We can set the isolation level with the following command.
+
+```sql
+SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
+```
+
+Let’s take a look at some of the concurrency control statements we use in the following actual operations:
+
+- `START TRANSACTION` |`BEGIN`: Explicitly start a transaction.
+- `COMMIT`: Commits the transaction, making all modifications to the database permanent.
+- `ROLLBACK`: Rollback ends the user's transaction and undoes all uncommitted modifications in progress.
+
+### Dirty read (read uncommitted)
+
+![]()
+
+### Avoid dirty reads (read committed)
+
+
+
+### Non-repeatable read
+
+It is still the same as the read committed picture above. Although it avoids reading uncommitted, the non-repeatable read problem occurs before a transaction is completed.
+
+
+
+### Repeatable read
+
+### Phantom reading
+
+#### Demonstrate the occurrence of phantom reading
+
+
+
+When SQL Script 1 queries for the first time, there is only one record with a salary of 500. SQL Script 2 inserts a record with a salary of 500. After submission, SQL Script 1 uses the current read query again in the same transaction and finds that there are two records with a salary of 500. This is a phantom read.
+
+#### How to solve phantom reading
+
+There are many ways to solve phantom reads, but their core idea is that when one transaction is operating data in a certain table, another transaction is not allowed to add or delete data in this table. The main ways to solve phantom reading are as follows:
+
+1. Adjust the transaction isolation level to `SERIALIZABLE`.
+2. At the repeatable read transaction level, add a table lock to the table in the transaction operation.
+3. Under the transaction level of repeatable read, add `Next-key Lock (Record Lock+Gap Lock)` to the table of transaction operation.
+
+### Reference
+
+- "MySQL Technology Insider: InnoDB Storage Engine"
+-
+- [Mysql Lock: Seven Questions of the Soul](https://tech.youzan.com/seven-questions-about-the-lock-of-MySQL/)
+- [Relationship between transaction isolation level and locks in Innodb](https://tech.meituan.com/2014/08/20/innodb-lock.html)
+
+
\ No newline at end of file
diff --git a/docs_en/database/nosql.en.md b/docs_en/database/nosql.en.md
new file mode 100644
index 00000000000..5428c5d9152
--- /dev/null
+++ b/docs_en/database/nosql.en.md
@@ -0,0 +1,68 @@
+---
+title: Summary of NoSQL basic knowledge
+category: database
+tag:
+ - NoSQL
+ - MongoDB
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: NoSQL, key-value, document, column family, graph database, distributed, scalability, data model
+ - - meta
+ - name: description
+ content: Summarizes the classification and characteristics of NoSQL, compares relational databases, combines distributed and scalable scenarios, and guides model and selection.
+---
+
+## What is NoSQL?
+
+NoSQL (abbreviation for Not Only SQL) generally refers to non-relational databases, mainly targeting key-value, document and graph type data storage. Moreover, NoSQL databases inherently support features such as distribution, data redundancy and data sharding, aiming to provide scalable, highly available and high-performance data storage solutions.
+
+A common misconception is that NoSQL databases, or non-relational databases, do not store relational data well. NoSQL databases can store relational data—they store it differently than relational databases do.
+
+NoSQL database representatives: HBase, Cassandra, MongoDB, Redis.
+
+
+
+## What is the difference between SQL and NoSQL?
+
+| | SQL database | NoSQL database |
+| :---------- | -------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------- |
+| Data storage model | Structured storage, tables with fixed rows and columns | Unstructured storage. Document: JSON document, Key-value: key-value pairs, Wide-column: Table with rows and dynamic columns, Graph: Nodes and Edges |
+| Development History | Developed in the 1970s with a focus on reducing data duplication | Developed in the late 2000s with a focus on improving scalability and reducing storage costs for large-scale data |
+| Examples | Oracle, MySQL, Microsoft SQL Server, PostgreSQL | Documents: MongoDB, CouchDB, Keys: Redis, DynamoDB, Wide columns: Cassandra, HBase, Charts: Neo4j, Amazon Neptune, Giraph |
+| ACID properties | Provide atomicity, consistency, isolation, and durability (ACID) properties | Generally do not support ACID transactions, trade-offs are made for scalability and high performance, and a few support such as MongoDB. However, MongoDB's support for ACID transactions is still different from MySQL. |
+| Performance | Performance often depends on the disk subsystem. For optimal performance, queries, indexes, and table structures often need to be optimized. | Performance is typically determined by the size of the underlying hardware cluster, network latency, and the calling application. |
+| Expansion | Vertical (use more powerful servers for expansion), read-write separation, database and table sharding | Horizontal (horizontal expansion by adding servers, usually based on sharding mechanism) |
+| Purpose | Data storage for common enterprise-level projects | Wide range of uses, such as graph databases that support analysis and traversal of relationships between connected data, and key-value databases that can handle large amounts of data expansion and extremely high state changes |
+| Query syntax | Structured Query Language (SQL) | Data access syntax may vary from database to database |
+
+## What are the advantages of NoSQL databases?
+
+NoSQL databases are ideal for many modern applications, such as mobile, web, and gaming applications, which require flexible, scalable, high-performance, and powerful databases to provide a superior user experience.
+
+- **Flexibility:** NoSQL databases often offer flexible architectures to enable faster, more iterative development. Flexible data models make NoSQL databases ideal for semi-structured and unstructured data.
+- **Scalability:** NoSQL databases are typically designed to scale horizontally through the use of distributed hardware clusters, rather than vertically by adding expensive and powerful servers.
+- **High Performance:** NoSQL databases are optimized for specific data models and access patterns, which allows for higher performance than trying to accomplish similar functions with relational databases.
+- **Powerful Features:** NoSQL databases provide powerful APIs and data types specifically built for their respective data models.
+
+## What types of NoSQL databases are there?
+
+NoSQL databases can be mainly divided into the following four types:
+
+- **Key-value**: A key-value database is a simpler database where each item contains a key and a value. This is an extremely flexible NoSQL database type because the application has complete control over what is stored in the value field without any restrictions. Redis and DynanoDB are two very popular key-value databases.
+- **Document**: Data in the document database is stored in documents similar to JSON (JavaScript Object Notation) objects, which is very clear and intuitive. Each document contains pairs of fields and values. These values can typically be of various types, including strings, numbers, Boolean values, arrays, or objects, and their structure is usually consistent with the objects developers use in their code. MongoDB is a very popular document database.
+- **Graph**: Graph databases are designed to easily build and run applications that work with highly connected data sets. Typical use cases for graph databases include social networks, recommendation engines, fraud detection, and knowledge graphs. Neo4j and Giraph are two very popular graph databases.
+- **Wide Column**: Wide column storage database is very suitable for storing large amounts of data. Cassandra and HBase are two very popular wide column storage databases.
+
+The picture below comes from [Microsoft's official documentation | Relational data and NoSQL data](https://learn.microsoft.com/en-us/dotnet/architecture/cloud-native/relational-vs-nosql-data).
+
+
+
+## Reference
+
+- What is NoSQL? - MongoDB official documentation:
+- What is NoSQL? - AWS:
+- NoSQL vs. SQL Databases - MongoDB official documentation:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/3-commonly-used-cache-read-and-write-strategies.en.md b/docs_en/database/redis/3-commonly-used-cache-read-and-write-strategies.en.md
new file mode 100644
index 00000000000..83e894ff4f1
--- /dev/null
+++ b/docs_en/database/redis/3-commonly-used-cache-read-and-write-strategies.en.md
@@ -0,0 +1,126 @@
+---
+title: 3种常用的缓存读写策略详解
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: 缓存读写策略,Cache Aside,Read Through,Write Through,一致性,失效
+ - - meta
+ - name: description
+ content: 总结三种常见缓存读写策略及适用场景,分析一致性与失效处理,指导业务选型与问题规避。
+---
+
+看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
+
+在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单写了一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
+
+但是,搞懂 3 种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
+
+**下面介绍到的三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式。**
+
+### Cache Aside Pattern(旁路缓存模式)
+
+**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
+
+Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 db 的结果为准。
+
+下面我们来看一下这个策略模式下的缓存读写步骤。
+
+**写**:
+
+- 先更新 db
+- 然后直接删除 cache 。
+
+简单画了一张图帮助大家理解写的步骤。
+
+
+
+**读** :
+
+- 从 cache 中读取数据,读取到就直接返回
+- cache 中读取不到的话,就从 db 中读取数据返回
+- 再把数据放到 cache 中。
+
+简单画了一张图帮助大家理解读的步骤。
+
+
+
+你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
+
+比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 db 么?**”
+
+**答案:** 那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致**的问题。
+
+举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
+
+这个过程可以简单描述为:
+
+> 请求 1 先把 cache 中的 A 数据删除 -> 请求 2 从 db 中读取数据->请求 1 再把 db 中的 A 数据更新
+
+当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?**”
+
+**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
+
+举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。
+
+这个过程可以简单描述为:
+
+> 请求 1 从 db 读数据 A-> 请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 ) -> 请求 1 将数据 A 写入 cache
+
+现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
+
+**缺陷 1:首次请求数据一定不在 cache 的问题**
+
+解决办法:可以将热点数据可以提前放入 cache 中。
+
+**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
+
+解决办法:
+
+- 数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁/分布式锁来保证更新 cache 的时候不存在线程安全问题。
+- 可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
+
+### Read/Write Through Pattern(读写穿透)
+
+Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责。
+
+这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能。
+
+**写(Write Through):**
+
+- 先查 cache,cache 中不存在,直接更新 db。
+- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(**同步更新 cache 和 db**)。
+
+简单画了一张图帮助大家理解写的步骤。
+
+
+
+**读(Read Through):**
+
+- 从 cache 中读取数据,读取到就直接返回 。
+- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
+
+简单画了一张图帮助大家理解读的步骤。
+
+
+
+Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
+
+和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
+
+### Write Behind Pattern(异步缓存写入)
+
+Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 db 的读写。
+
+但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新缓存,不直接更新 db,而是改为异步批量的方式来更新 db。**
+
+很明显,这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。
+
+这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
+
+Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
+
+
+
diff --git a/docs_en/database/redis/cache-basics.en.md b/docs_en/database/redis/cache-basics.en.md
new file mode 100644
index 00000000000..7e77ced0782
--- /dev/null
+++ b/docs_en/database/redis/cache-basics.en.md
@@ -0,0 +1,21 @@
+---
+title: Summary of common interview questions on caching basics (paid)
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: cache interview, consistency, elimination strategy, penetration, avalanche, hotspot, architecture
+ - - meta
+ - name: description
+ content: Collects high-frequency questions on caching foundation and architecture, covering consistency and elimination strategies, penetration/avalanche and other issues and management solutions, and builds a system review list.
+---
+
+**Caching Basics** The relevant interview questions are exclusive to my [Knowledge Planet](../../about-the-author/zhishixingqiu-two-years.md) (click the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide"](../../zhuanlan/java-mian-shi-zhi-bei.md).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-cluster.en.md b/docs_en/database/redis/redis-cluster.en.md
new file mode 100644
index 00000000000..327f4e03831
--- /dev/null
+++ b/docs_en/database/redis/redis-cluster.en.md
@@ -0,0 +1,14 @@
+---
+title: Detailed explanation of Redis cluster (paid)
+category: database
+tag:
+ - Redis
+---
+
+**Redis Cluster** The relevant interview questions are my [Knowledge Planet](../../about-the-author/zhishixingqiu-two-years.md) (click the link to view the detailed introduction and how to join) exclusive content, which has been compiled into ["Java Interview Guide North"](../../zhuanlan/java-mian-shi-zhi-bei.md).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-common-blocking-problems-summary.en.md b/docs_en/database/redis/redis-common-blocking-problems-summary.en.md
new file mode 100644
index 00000000000..4cf4c445b74
--- /dev/null
+++ b/docs_en/database/redis/redis-common-blocking-problems-summary.en.md
@@ -0,0 +1,178 @@
+---
+title: Redis常见阻塞原因总结
+category: 数据库
+tag:
+ - Redis
+---
+
+> 本文整理完善自: ,作者:阿 Q 说代码
+
+这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
+
+## O(n) 命令
+
+Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
+
+- `KEYS *`:会返回所有符合规则的 key。
+- `HGETALL`:会返回一个 Hash 中所有的键值对。
+- `LRANGE`:会返回 List 中指定范围内的元素。
+- `SMEMBERS`:返回 Set 中的所有元素。
+- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
+- ……
+
+由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长,从而导致客户端阻塞。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
+
+除了这些 O(n)时间复杂度的命令可能会导致阻塞之外, 还有一些时间复杂度可能在 O(N) 以上的命令,例如:
+
+- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- ……
+
+## SAVE 创建 RDB 快照
+
+Redis 提供了两个命令来生成 RDB 快照文件:
+
+- `save` : 同步保存操作,会阻塞 Redis 主线程;
+- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
+
+默认情况下,Redis 默认配置会使用 `bgsave` 命令。如果手动使用 `save` 命令生成 RDB 快照文件的话,就会阻塞主线程。
+
+## AOF
+
+### AOF 日志记录阻塞
+
+Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复)不同。
+
+
+
+**为什么是在执行完命令之后记录日志呢?**
+
+- 避免额外的检查开销,AOF 记录日志不会对命令进行语法检查;
+- 在命令执行完之后再记录,不会阻塞当前的命令执行。
+
+这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
+
+- 如果刚执行完命令 Redis 就宕机会导致对应的修改丢失;
+- **可能会阻塞后续其他命令的执行(AOF 记录日志是在 Redis 主线程中进行的)**。
+
+### AOF 刷盘阻塞
+
+开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再根据 `appendfsync` 配置来决定何时将其同步到硬盘中的 AOF 文件。
+
+在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
+
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
+
+当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
+
+关于 AOF 工作流程的详细介绍可以查看:[Redis 持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
+
+### AOF 重写阻塞
+
+1. fork 出一条子线程来将文件重写,在执行 `BGREWRITEAOF` 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子线程创建新 AOF 文件期间,记录服务器执行的所有写命令。
+2. 当子线程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。
+3. 最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
+
+阻塞就是出现在第 2 步的过程中,将缓冲区中新数据写到新文件的过程中会产生**阻塞**。
+
+相关阅读:[Redis AOF 重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
+
+## 大 Key
+
+如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- string 类型的 value 超过 1MB
+- 复合类型(列表、哈希、集合、有序集合等)的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
+
+大 key 造成的阻塞问题如下:
+
+- 客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
+- 引发网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
+- 阻塞工作线程:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
+
+### 查找大 key
+
+当我们在使用 Redis 自带的 `--bigkeys` 参数查找大 key 时,最好选择在从节点上执行该命令,因为主节点上执行时,会**阻塞**主节点。
+
+- 我们还可以使用 SCAN 命令来查找大 key;
+
+- 通过分析 RDB 文件来找出 big key,这种方案的前提是 Redis 采用的是 RDB 持久化。网上有现成的工具:
+
+- - redis-rdb-tools:Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
+ - rdb_bigkeys:Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
+
+### 删除大 key
+
+删除操作的本质是要释放键值对占用的内存空间。
+
+释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,**操作系统需要把释放掉的内存块插入一个空闲内存块的链表**,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会**阻塞**当前释放内存的应用程序。
+
+所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞,如果主线程发生了阻塞,其他所有请求可能都会超时,超时越来越多,会造成 Redis 连接耗尽,产生各种异常。
+
+删除大 key 时建议采用分批次删除和异步删除的方式进行。
+
+## 清空数据库
+
+清空数据库和上面 bigkey 删除也是同样道理,`flushdb`、`flushall` 也涉及到删除和释放所有的键值对,也是 Redis 的阻塞点。
+
+## 集群扩容
+
+Redis 集群可以进行节点的动态扩容缩容,这一过程目前还处于半自动状态,需要人工介入。
+
+在扩缩容的时候,需要进行数据迁移。而 Redis 为了保证迁移的一致性,迁移所有操作都是同步操作。
+
+When performing migration, Redis at both ends will enter a blocking state of varying lengths. For small keys, this time can be ignored. However, if the memory usage of the key is too large, in severe cases, it will trigger a failover within the cluster, causing unnecessary switching.
+
+## Swap (memory swap)
+
+**What is Swap? ** Swap literally means exchange. Swap in Linux is often called memory swap or swap partition. Similar to virtual memory in Windows, when memory is insufficient, part of the hard disk space is virtualized into memory to solve the problem of insufficient memory capacity. Therefore, the role of the Swap partition is to sacrifice the hard disk and increase the memory to solve the problem of insufficient or full VPS memory.
+
+Swap is very fatal for Redis. An important prerequisite for Redis to ensure high performance is that all data is in memory. If the operating system swaps part of the memory used by Redis out of the hard disk, the performance of Redis will drop sharply after the swap because the read and write speeds of the memory and the hard disk are several orders of magnitude different.
+
+The check method to identify Swap in Redis is as follows:
+
+1. Query the Redis process number
+
+```bash
+redis-cli -p 6383 info server | grep process_id
+process_id: 4476
+```
+
+2. Query memory swap information based on process number
+
+```bash
+cat /proc/4476/smaps | grep Swap
+Swap: 0kB
+Swap: 0kB
+Swap: 4kB
+Swap: 0kB
+Swap: 0kB
+.....
+```
+
+If the swap volume is all 0KB or some are 4KB, it is normal.
+
+Methods to prevent memory swapping:
+
+- Ensure that the machine has sufficient available memory
+- Ensure that all Redis instances are set to the maximum available memory (maxmemory) to prevent uncontrollable growth of Redis memory in extreme situations
+- Reduce the system's swap priority, such as `echo 10 > /proc/sys/vm/swappiness`
+
+## CPU competition
+
+Redis is a typical CPU-intensive application and is not recommended to be deployed together with other multi-core CPU-intensive services. When other processes consume the CPU excessively, it will seriously affect the throughput of Redis.
+
+You can get the current Redis usage through `redis-cli --stat`. Use the `top` command to obtain information such as the CPU utilization of the process. Use the `info commandstats` statistical information to analyze the command's unreasonable overhead time and check whether it is due to high algorithm complexity or excessive memory optimization.
+
+## Network problem
+
+Network problems such as connection rejection, network delay, and network card soft interruption may also cause Redis to block.
+
+## Reference
+
+- Analysis and summary of 6 major scenarios of Redis blocking:
+- Redis development and operation notes - Redis nightmare - blocking:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-data-structures-01.en.md b/docs_en/database/redis/redis-data-structures-01.en.md
new file mode 100644
index 00000000000..735de4294cb
--- /dev/null
+++ b/docs_en/database/redis/redis-data-structures-01.en.md
@@ -0,0 +1,499 @@
+---
+title: Detailed explanation of the 5 basic data types of Redis
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis common data types
+ - - meta
+ - name: description
+ content: Summary of Redis basic data types: String (string), List (list), Set (set), Hash (hash), Zset (ordered set)
+---
+
+Redis has 5 basic data types: String (string), List (list), Set (collection), Hash (hash), and Zset (ordered set).
+
+These five data types are directly provided to users and are the storage form of data. Their underlying implementation mainly relies on these eight data structures: simple dynamic string (SDS), LinkedList (double linked list), Dict (hash table/dictionary), SkipList (skip list), Intset (integer collection), ZipList (compressed list), QuickList (quick list).
+
+The underlying data structure corresponding to Redis's five basic data types is implemented as shown in the following table:
+
+| String | List | Hash | Set | Zset |
+| :----- | :--------------------------- | :------------ | :----------- | :---------------- |
+| SDS | LinkedList/ZipList/QuickList | Dict, ZipList | Dict, Intset | ZipList, SkipList |
+
+Before Redis 3.2, the underlying implementation of List was LinkedList or ZipList. After Redis 3.2, QuickList, a combination of LinkedList and ZipList, was introduced, and the underlying implementation of List became QuickList. Starting from Redis 7.0, ZipList is replaced by ListPack.
+
+You can find a very detailed introduction to Redis data types/structures on the Redis official website:
+
+- [Redis Data Structures](https://redis.com/redis-enterprise/data-structures/)
+- [Redis Data types tutorial](https://redis.io/docs/manual/data-types/data-types-tutorial/)
+
+In the future, with the release of new versions of Redis, new data structures may appear. By consulting the corresponding introduction on the Redis official website, you can always get the most reliable information.
+
+
+
+## String
+
+### Introduction
+
+String is the simplest and most commonly used data type in Redis.
+
+String is a binary-safe data type that can be used to store any type of data such as strings, integers, floating point numbers, images (base64 encoding or decoding of images or the path of images), and serialized objects.
+
+
+
+Although Redis is written in C language, Redis does not use C's string representation. Instead, it builds its own **Simple Dynamic String** (**SDS**). Compared with C's native strings, Redis's SDS can save not only text data but also binary data, and the complexity of obtaining the string length is O(1) (C string is O(N)). In addition, Redis's SDS API is safe and will not cause buffer overflow.
+
+### Common commands
+
+| Commands | Introduction |
+| ---------------------------------- | ---------------------------------- |
+| SET key value | Set the value of the specified key |
+| SETNX key value | Set the value of key only if the key does not exist |
+| GET key | Get the value of the specified key |
+| MSET key1 value1 key2 value2 …… | Set the value of one or more specified keys |
+| MGET key1 key2 ... | Get the value of one or more specified keys |
+| STRLEN key | Returns the length of the string value stored in key |
+| INCR key | Increment the numeric value stored in key by one |
+| DECR key | Decrement the numeric value stored in key by one |
+| EXISTS key | Determine whether the specified key exists |
+| DEL key (general) | Delete the specified key |
+| EXPIRE key seconds (general) | Set the expiration time for the specified key |
+
+For more Redis String commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Basic Operation**:
+
+```bash
+> SET key value
+OK
+> GET key
+"value"
+> EXISTS key
+(integer) 1
+> STRLEN key
+(integer) 5
+> DEL key
+(integer) 1
+> GET key
+(nil)
+```
+
+**Batch Settings**:
+
+```bash
+> MSET key1 value1 key2 value2
+OK
+> MGET key1 key2 # Get the values corresponding to multiple keys in batches
+1) "value1"
+2) "value2"
+```
+
+**Counter (can be used when the content of the string is an integer):**
+
+```bash
+>SET number 1
+OK
+> INCR number # Increase the number value stored in key by one
+(integer) 2
+> GET number
+"2"
+> DECR number # Decrement the numeric value stored in key by one
+(integer) 1
+> GET number
+"1"
+```
+
+**Set expiration time (default is never expires)**:
+
+```bash
+> EXPIRE key 60
+(integer) 1
+> SETEX key 60 value # Set value and set expiration time
+OK
+> TTL key
+(integer) 56
+```
+
+### Application scenarios
+
+**Scenarios where regular data needs to be stored**
+
+- Example: Cache Session, Token, image address, serialized object (more memory-saving than Hash storage).
+- Related commands: `SET`, `GET`.
+
+**Scenarios that require counting**
+
+- Examples: the number of user requests per unit time (simple current limiting can be used), the number of page visits per unit time.
+- Related commands: `SET`, `GET`, `INCR`, `DECR`.
+
+**Distributed Lock**
+
+The simplest distributed lock can be implemented using the `SETNX key value` command (there are some flaws, and it is generally not recommended to implement distributed locks this way).
+
+## List
+
+### Introduction
+
+List in Redis is actually the implementation of the linked list data structure. I introduced the linked list data structure in detail in this article [Linear Data Structure: Array, Linked List, Stack, Queue](https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html), so I won’t go into details here.
+
+Many high-level programming languages have built-in implementations of linked lists, such as `LinkedList` in Java, but the C language does not implement linked lists, so Redis implements its own linked list data structure. The implementation of Redis's List is a **doubly linked list**, which can support reverse search and traversal, making it more convenient to operate, but it brings some additional memory overhead.
+
+
+
+### Common commands
+
+| Commands | Introduction ||-------------------------------- |------------------------------------------------ |
+| RPUSH key value1 value2 ... | Add one or more elements to the tail (right) of the specified list |
+| LPUSH key value1 value2 ... | Add one or more elements to the head (left) of the specified list |
+| LSET key index value | Set the value at the specified list index position to value |
+| LPOP key | Remove and get the first element (leftmost) of the specified list |
+| RPOP key | Remove and get the last element (rightmost) of the specified list |
+| LLEN key | Get the number of list elements |
+| LRANGE key start end | Get the elements between start and end of the list |
+
+For more Redis List commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Queue implementation via `RPUSH/LPOP` or `LPUSH/RPOP`:
+
+```bash
+>RPUSH myList value1
+(integer) 1
+>RPUSH myList value2 value3
+(integer) 3
+> LPOP myList
+"value1"
+> LRANGE myList 0 1
+1) "value2"
+2) "value3"
+> LRANGE myList 0 -1
+1) "value2"
+2) "value3"
+```
+
+**Implementing the stack via `RPUSH/RPOP` or `LPUSH/LPOP`**:
+
+```bash
+>RPUSH myList2 value1 value2 value3
+(integer) 3
+> RPOP myList2 # Take out the rightmost element of the list
+"value3"
+```
+
+I specially drew a picture to help everyone understand the `RPUSH`, `LPOP`, `LPUSH`, `RPOP` commands:
+
+
+
+**View the list elements corresponding to the subscript range through `LRANGE`:
+
+```bash
+>RPUSH myList value1 value2 value3
+(integer) 3
+> LRANGE myList 0 1
+1) "value1"
+2) "value2"
+> LRANGE myList 0 -1
+1) "value1"
+2) "value2"
+3) "value3"
+```
+
+Through the `LRANGE` command, you can implement paging query based on List, and the performance is very high!
+
+**View the length of the linked list through `LLEN`:
+
+```bash
+> LLEN myList
+(integer) 3
+```
+
+### Application scenarios
+
+**Information flow display**
+
+- Examples: latest articles, latest developments.
+- Related commands: `LPUSH`, `LRANGE`.
+
+**Message Queue**
+
+`List` can be used as a message queue, but its function is too simple and has many flaws, so it is not recommended.
+
+Relatively speaking, `Stream`, a newly added data structure in Redis 5.0, is more suitable for message queues, but its function is still very crude. Compared with professional message queues, there are still many shortcomings, such as message loss and accumulation problems that are difficult to solve.
+
+## Hash
+
+### Introduction
+
+Hash in Redis is a String type field-value (key-value pair) mapping table, which is particularly suitable for storing objects. During subsequent operations, you can directly modify the values of certain fields in this object.
+
+Hash is similar to `HashMap` before JDK1.8, and the internal implementation is similar (array + linked list). However, Redis's Hash has been optimized more.
+
+
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |---------------------------------------------------------------- |
+| HSET key field value | Set the value of the specified field in the specified hash table |
+| HSETNX key field value | Set the value of the specified field only if the specified field does not exist |
+| HMSET key field1 value1 field2 value2 ... | Set one or more field-value (field-value) pairs into the specified hash table at the same time |
+| HGET key field | Get the value of the specified field in the specified hash table |
+| HMGET key field1 field2 ... | Get the value of one or more specified fields in the specified hash table |
+| HGETALL key | Get all key-value pairs in the specified hash table |
+| HEXISTS key field | Check whether the specified field exists in the specified hash table |
+| HDEL key field1 field2 ... | Delete one or more hash table fields |
+| HLEN key | Get the number of fields in the specified hash table |
+| HINCRBY key field increment | Perform operations on the specified field in the specified hash (positive numbers are added, negative numbers are subtracted) |
+
+For more Redis Hash commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Mock object data storage**:
+
+```bash
+> HMSET userInfoKey name "guide" description "dev" age 24
+OK
+> HEXISTS userInfoKey name # Check whether the field specified in the value corresponding to key exists.
+(integer) 1
+> HGET userInfoKey name # Get the value of the specified field stored in the hash table.
+"guide"
+> HGET userInfoKey age
+"24"
+> HGETALL userInfoKey # Get all fields and values of the specified key in the hash table
+1) "name"
+2) "guide"
+3) "description"
+4) "dev"
+5) "age"
+6) "24"
+> HSET userInfoKey name "GuideGeGe"
+> HGET userInfoKey name
+"GuideGeGe"
+> HINCRBY userInfoKey age 2
+(integer) 26
+```
+
+### Application scenarios
+
+**Object data storage scenario**
+
+- Examples: user information, product information, article information, shopping cart information.
+- Related commands: `HSET` (set the value of a single field), `HMSET` (set the value of multiple fields), `HGET` (get the value of a single field), `HMGET` (get the value of multiple fields).
+
+## Set
+
+### Introduction
+
+The Set type in Redis is an unordered collection. The elements in the collection are not in order but are unique, somewhat similar to `HashSet` in Java. Set is a good choice when you need to store a list of data and do not want duplicate data, and Set provides an important interface for determining whether an element is in a Set collection, which List cannot provide.
+
+You can easily implement intersection, union, and difference operations based on Set. For example, you can store all the followers of a user in one set and all their fans in one set. In this case, Set can very conveniently implement functions such as common following, common fans, and common preferences. This process is also the process of finding intersection.
+
+### Common commands
+
+| Commands | Introduction |
+|---------------------------------------- | ------------------------------------------ |
+| SADD key member1 member2 ... | Add one or more elements to the specified collection |
+| SMEMBERS key | Get all elements in the specified collection |
+| SCARD key | Get the number of elements of the specified collection |
+| SISMEMBER key member | Determine whether the specified element is in the specified set |
+| SINTER key1 key2 ... | Get the intersection of all given sets |
+| SINTERSTORE destination key1 key2 ... | Stores the intersection of all the given sets in destination |
+| SUNION key1 key2 ... | Get the union of all given sets |
+| SUNIONSTORE destination key1 key2 ... | Stores the union of all the given sets in destination |
+| SDIFF key1 key2 ... | Get the difference set of all given sets |
+| SDIFFSTORE destination key1 key2 ... | Stores the difference of all given sets in destination |
+| SPOP key count | Randomly remove and obtain one or more elements in the specified collection |
+| SRANDMEMBER key count | Randomly obtain the specified number of elements in the specified collection |
+
+For more Redis Set commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Basic Operation**:
+
+```bash
+> SADD mySet value1 value2
+(integer) 2
+> SADD mySet value1 # Duplicate elements are not allowed, so the addition fails
+(integer) 0
+> SMEMBERS mySet
+1) "value1"
+2) "value2"
+> SCARD mySet
+(integer) 2
+> SISMEMBER mySet value1
+(integer) 1
+>SADD mySet2 value2 value3
+(integer) 2
+```
+
+- `mySet` : `value1`, `value2`.
+- `mySet2`: `value2`, `value3`.
+
+**Find intersection**:
+
+```bash
+> SINTERSTORE mySet3 mySet mySet2
+(integer) 1
+> SMEMBERS mySet3
+1) "value2"
+```
+
+**Find union**:
+
+```bash
+> SUNION mySet mySet2
+1) "value3"
+2) "value2"
+3) "value1"
+```
+
+**Find the difference set**:
+
+```bash
+> SDIFF mySet mySet2 # The difference set is a set composed of all elements that belong to mySet but do not belong to A
+1) "value1"
+```
+
+### Application scenarios
+
+**Scenarios where the data that needs to be stored cannot be repeated**
+
+- Examples: Website UV statistics (`HyperLogLog` is more suitable for scenarios with a huge amount of data), article likes, dynamic likes and other scenarios.
+- Related commands: `SCARD` (get the number of sets).
+
+
+
+**Scenarios where the intersection, union and difference of multiple data sources need to be obtained**
+
+- Examples: common friends (intersection), common fans (intersection), common following (intersection), friend recommendation (difference set), music recommendation (difference set), subscription account recommendation (difference set + intersection) and other scenarios.
+- Related commands: `SINTER` (intersection), `SINTERSTORE` (intersection), `SUNION` (union), `SUNIONSTORE` (union), `SDIFF` (difference), `SDIFFSTORE` (difference).
+
+
+
+**Scenarios where elements in the data source need to be randomly obtained**
+
+- Examples: Lottery system, random roll call and other scenarios.
+- Related commands: `SPOP` (randomly obtain elements from the set and remove them, suitable for scenarios that do not allow repeated winnings), `SRANDMEMBER` (randomly obtain elements from the set, suitable for scenarios that allow repeated winnings).
+
+## Sorted Set (ordered set)
+
+### Introduction
+
+Sorted Set is similar to Set, but compared with Set, Sorted Set adds a weight parameter `score`, so that the elements in the set can be ordered by `score`, and the list of elements can also be obtained through the range of `score`. It's a bit like a combination of `HashMap` and `TreeSet` in Java.
+
+
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |---------------------------------------------------------------------------------------------------------------- |
+| ZADD key score1 member1 score2 member2 ... | Add one or more elements to the specified sorted set |
+| ZCARD KEY | Get the number of elements of the specified ordered set |
+| ZSCORE key member | Get the score value of the specified element in the specified ordered set |
+| ZINTERSTORE destination numkeys key1 key2 ... | Store the intersection of all given ordered sets in destination, perform a SUM aggregation operation on the score values corresponding to the same elements, numkeys is the number of sets |
+| ZUNIONSTORE destination numkeys key1 key2 ... | Find the union, others are similar to ZINTERSTORE |
+| ZDIFFSTORE destination numkeys key1 key2 ... | Find the difference set, others are similar to ZINTERSTORE || ZRANGE key start end | Get the elements between start and end of the specified ordered set (score from low to high) |
+| ZREVRANGE key start end | Get the elements between start and end of the specified ordered set (score from high to bottom) |
+| ZREVRANK key member | Get the ranking of the specified element in the specified ordered set (score sorted from large to small) |
+
+For more Redis Sorted Set commands and detailed usage guides, please view the corresponding introduction on the Redis official website: .
+
+**Basic Operation**:
+
+```bash
+>ZADD myZset 2.0 value1 1.0 value2
+(integer) 2
+> ZCARD myZset
+2
+> ZSCORE myZset value1
+2.0
+> ZRANGE myZset 0 1
+1) "value2"
+2) "value1"
+> ZREVRANGE myZset 0 1
+1) "value1"
+2) "value2"
+> ZADD myZset2 4.0 value2 3.0 value3
+(integer) 2
+
+```
+
+- `myZset` : `value1`(2.0), `value2`(1.0).
+- `myZset2`: `value2` (4.0), `value3` (3.0).
+
+**Get the ranking of the specified element**:
+
+```bash
+> ZREVRANK myZset value1
+0
+> ZREVRANK myZset value2
+1
+```
+
+**Find intersection**:
+
+```bash
+> ZINTERSTORE myZset3 2 myZset myZset2
+1
+> ZRANGE myZset3 0 1 WITHSCORES
+value2
+5
+```
+
+**Find union**:
+
+```bash
+> ZUNIONSTORE myZset4 2 myZset myZset2
+3
+> ZRANGE myZset4 0 2 WITHSCORES
+value1
+2
+value3
+3
+value2
+5
+```
+
+**Find the difference set**:
+
+```bash
+> ZDIFF 2 myZset myZset2 WITHSCORES
+value1
+2
+```
+
+### Application scenarios
+
+**Scenarios where elements in the data source need to be randomly obtained and sorted according to a certain weight**
+
+- Examples: various rankings, such as the ranking of gifts in the live broadcast room, the WeChat step ranking in the circle of friends, the rank ranking in Honor of Kings, the topic popularity ranking, etc.
+- Related commands: `ZRANGE` (sort from small to large), `ZREVRANGE` (sort from large to small), `ZREVRANK` (specify element ranking).
+
+
+
+There is an article in the "Technical Interview Questions" of ["Java Interview Guide"](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) that details how to use Sorted Set to design and create a ranking list.
+
+
+
+**Scenarios where the data that needs to be stored has priority or importance** such as priority task queue.
+
+- Example: Priority task queue.
+- Related commands: `ZRANGE` (sort from small to large), `ZREVRANGE` (sort from large to small), `ZREVRANK` (specify element ranking).
+
+## Summary
+
+| Data type | Description |
+| -------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| String | A binary safe data type that can be used to store any type of data such as strings, integers, floating point numbers, images (base64 encoding or decoding of images or the path of images), and serialized objects. |
+| List | The implementation of Redis's List is a doubly linked list, which can support reverse search and traversal, making it more convenient to operate, but it brings some additional memory overhead. |
+| Hash | A mapping table of String type field-value (key-value pairs), which is particularly suitable for storing objects. During subsequent operations, you can directly modify the values of certain fields in this object. |
+| Set | An unordered set. The elements in the set are not in order but are unique, somewhat similar to `HashSet` in Java. |
+| Zset | Compared with Set, Sorted Set adds a weight parameter `score`, so that the elements in the set can be ordered by `score`, and the list of elements can also be obtained through the range of `score`. It's a bit like a combination of `HashMap` and `TreeSet` in Java. |
+
+## Reference
+
+- Redis Data Structures: .
+- Redis Commands: .
+- Redis Data types tutorial: .
+- Whether Redis uses Hash or String to store object information:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-data-structures-02.en.md b/docs_en/database/redis/redis-data-structures-02.en.md
new file mode 100644
index 00000000000..a55a96334ab
--- /dev/null
+++ b/docs_en/database/redis/redis-data-structures-02.en.md
@@ -0,0 +1,223 @@
+---
+title: Detailed explanation of three special data types of Redis
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis common data types
+ - - meta
+ - name: description
+ content: Summary of Redis special data types: HyperLogLogs (cardinality statistics), Bitmap (bit storage), Geospatial (geographic location).
+---
+
+In addition to the 5 basic data types, Redis also supports 3 special data types: Bitmap, HyperLogLog, and GEO.
+
+## Bitmap (bitmap)
+
+### Introduction
+
+According to the official website:
+
+> Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type which is treated like a bit vector. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 2^32 different bits.
+>
+> Bitmap is not an actual data type in Redis, but a set of bit-oriented operations defined on the String type, treating it as a bit vector. Since strings are binary-safe blocks and have a maximum length of 512 MB, they are suitable for setting up to 2^32 different bits.
+
+Bitmap stores continuous binary numbers (0 and 1). Through Bitmap, only one bit is needed to represent the value or status corresponding to a certain element, and the key is the corresponding element itself. We know that 8 bits can form a byte, so Bitmap itself will greatly save storage space.
+
+You can think of a Bitmap as an array that stores binary numbers (0s and 1s). The index of each element in the array is called offset.
+
+
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |---------------------------------------------------------------- |
+| SETBIT key offset value | Set the value at the specified offset position |
+| GETBIT key offset | Get the value at the specified offset position |
+| BITCOUNT key start end | Get the number of elements with a value of 1 between start and end |
+| BITOP operation destkey key1 key2 ... | Operate on one or more Bitmaps. Available operators are AND, OR, XOR and NOT |
+
+**Bitmap basic operation demonstration**:
+
+```bash
+# SETBIT will return the value of the previous bit (default is 0) here will generate 7 bits
+> SETBIT mykey 7 1
+(integer) 0
+> SETBIT mykey 7 0
+(integer) 1
+> GETBIT mykey 7
+(integer) 0
+> SETBIT mykey 6 1
+(integer) 0
+> SETBIT mykey 8 1
+(integer) 0
+# Count the number of bits set to 1 through bitcount.
+> BITCOUNT mykey
+(integer) 2
+```
+
+### Application scenarios
+
+**Scenarios where status information needs to be saved (represented by 0/1)**
+
+- Examples: user check-in status, active user status, user behavior statistics (such as whether a video has been liked).
+- Related commands: `SETBIT`, `GETBIT`, `BITCOUNT`, `BITOP`.
+
+## HyperLogLog (cardinality statistics)
+
+### Introduction
+
+HyperLogLog is a well-known cardinality counting probability algorithm, which is optimized and improved based on LogLog Counting (LLC). It is not unique to Redis. Redis only implements this algorithm and provides some out-of-the-box APIs.
+
+The HyperLogLog provided by Redis takes up very little space, requiring only 12k of space to store close to `2^64` different elements. This is really amazing. Is this the charm of mathematics? Moreover, Redis has optimized the storage structure of HyperLogLog and uses two counting methods:
+
+- **Sparse Matrix**: When the count is small, it takes up very little space.
+- **Dense Matrix**: When the count reaches a certain threshold, it occupies 12k space.
+
+There are corresponding detailed instructions in the official Redis documentation:
+
+
+
+In order to save memory, the cardinality counting probability algorithm does not directly store metadata, but estimates the cardinality value (the number of elements in the set) through a certain probability and statistical method. Therefore, the counting result of HyperLogLog is not an exact value, and there is a certain error (standard error is `0.81%`).
+
+
+
+The use of HyperLogLog is very simple, but the principle is very complex. For the principle of HyperLogLog and its implementation in Redis, you can read this article: [Explanation of the principle of HyperLogLog algorithm and how Redis applies it](https://juejin.cn/post/6844903785744056333).
+
+I recommend another tool that can help understand the principles of HyperLogLog: [Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure](http://content.research.neustar.biz/blog/hll.html).
+
+In addition to HyperLogLog, Redis also provides other probabilistic data structures, corresponding official document address: .
+
+### Common commands
+
+There are very few commands related to HyperLogLog, and the most commonly used are only 3.
+
+| Commands | Introduction |
+|------------------------------------------------ |-------------------------------------------------------------------------------- |
+| PFADD key element1 element2 ... | Add one or more elements to HyperLogLog |
+| PFCOUNT key1 key2 | Get the unique count of one or more HyperLogLogs. |
+| PFMERGE destkey sourcekey1 sourcekey2 ... | Merge multiple HyperLogLogs into destkey. destkey will combine multiple sources to calculate the corresponding unique count. |
+
+**HyperLogLog basic operation demonstration**:
+
+```bash
+> PFADD hll foo bar zap
+(integer) 1
+> PFADD hll zap zap zap
+(integer) 0
+> PFADD hll foo bar
+(integer) 0
+> PFCOUNT hll
+(integer) 3
+> PFADD some-other-hll 1 2 3
+(integer) 1
+> PFCOUNT hll some-other-hll
+(integer) 6
+> PFMERGE desthll hll some-other-hll
+"OK"
+>PFCOUNTdesthll
+(integer) 6```
+
+### Application scenarios
+
+**Huge number of counting scenarios (millions, tens of millions or more)**
+
+- Example: Daily/weekly/monthly access IP statistics of popular websites, UV statistics of popular posts.
+- Related commands: `PFADD`, `PFCOUNT`.
+
+## Geospatial (geographic location)
+
+### Introduction
+
+Geospatial index (GEO for short) is mainly used to store geographical location information and is implemented based on Sorted Set.
+
+Through GEO, we can easily implement functions such as calculating the distance between two locations and obtaining elements near a specified location.
+
+
+
+### Common commands
+
+| Commands | Introduction |
+|------------------------------------------------ |------------------------------------------------------------------------------------------------------------- |
+| GEOADD key longitude1 latitude1 member1 ... | Add the latitude and longitude information corresponding to one or more elements to GEO |
+| GEOPOS key member1 member2 ... | Returns the latitude and longitude information of the given element |
+| GEODIST key member1 member2 M/KM/FT/MI | Returns the distance between two given elements |
+| GEORADIUS key longitude latitude radius distance | Get other elements within the distance range near the specified position, supporting ASC (from near to far), DESC (from far to near), Count (number) and other parameters |
+| GEORADIUSBYMEMBER key member radius distance | Similar to the GEORADIUS command, except that the reference center point is an element in GEO |
+
+**Basic Operation**:
+
+```bash
+> GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3
+3
+> GEOPOS personLocation user1
+116.3299986720085144
+39.89000061669732844
+> GEODIST personLocation user1 user2 km
+1.4018
+```
+
+View `personLocation` through the Redis visualization tool. As expected, the bottom layer is a Sorted Set.
+
+The longitude and latitude data of the geographical location information stored in GEO is converted into an integer through the GeoHash algorithm, and this integer is used as the score (weight parameter) of the Sorted Set.
+
+
+
+**Get other elements within the specified position range**:
+
+```bash
+> GEORADIUS personLocation 116.33 39.87 3 km
+user3
+user1
+> GEORADIUS personLocation 116.33 39.87 2 km
+> GEORADIUS personLocation 116.33 39.87 5 km
+user3
+user1
+user2
+> GEORADIUSBYMEMBER personLocation user1 5 km
+user3
+user1
+user2
+> GEORADIUSBYMEMBER personLocation user1 2 km
+user1
+user2
+```
+
+For an analysis of the underlying principles of the `GEORADIUS` command, you can read this article by Ali: [How does Redis implement the "people nearby" function? ](https://juejin.cn/post/6844903966061363207).
+
+**Remove element**:
+
+The bottom layer of GEO is Sorted Set, and you can use Sorted Set related commands on GEO.
+
+```bash
+> ZREM personLocation user1
+1
+> ZRANGE personLocation 0 -1
+user3
+user2
+> ZSCORE personLocation user2
+4069879562983946
+```
+
+### Application scenarios
+
+**Scenarios that require management of geospatial data**
+
+- Example: People nearby.
+- Related commands: `GEOADD`, `GEORADIUS`, `GEORADIUSBYMEMBER`.
+
+## Summary
+
+| Data type | Description |
+|---------------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Bitmap | You can think of a Bitmap as an array that stores binary numbers (0 and 1). The subscript of each element in the array is called offset. Through Bitmap, only one bit is needed to represent the value or status corresponding to an element, and the key is the corresponding element itself. We know that 8 bits can form a byte, so Bitmap itself will greatly save storage space. |
+| HyperLogLog | The HyperLogLog provided by Redis takes up very little space, requiring only 12k of space to store close to `2^64` different elements. However, the count result of HyperLogLog is not an exact value and has a certain error (standard error is `0.81%`). |
+| Geospatial index | Geospatial index (GEO) is mainly used to store geographical location information and is implemented based on Sorted Set. |
+
+## Reference
+
+- Redis Data Structures: .
+- "Redis Deep Adventure: Core Principles and Application Practices" 1.6 Four ounces make a huge difference - HyperLogLog
+- Bloom filter, bitmap, HyperLogLog:
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-delayed-task.en.md b/docs_en/database/redis/redis-delayed-task.en.md
new file mode 100644
index 00000000000..a9a392add2a
--- /dev/null
+++ b/docs_en/database/redis/redis-delayed-task.en.md
@@ -0,0 +1,89 @@
+---
+title: How to implement delayed tasks based on Redis
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis, delayed tasks, expiration events, Redisson, DelayedQueue, reliability, consistency
+ - - meta
+ - name: description
+ content: Compare the two solutions of Redis expiration event and Redisson delay queue, analyze the trade-off between reliability and consistency, and give project selection suggestions.
+---
+
+The function of implementing delayed tasks based on Redis is nothing more than the following two options:
+
+1. Redis expiration event monitoring
+2. Redisson’s built-in delay queue
+
+During the interview, you can first say that you have considered these two solutions, but in the end you found that there are many problems with the Redis expiration event monitoring solution, so you finally chose the DelayedQueue solution built into Redisson.
+
+At this time, the interviewer may ask you some relevant questions, which we will mention later, so just prepare in advance.
+
+In addition, in addition to the questions introduced below, it is recommended that you review all the common questions related to Redis. It is not ruled out that the interviewer will ask you some other questions about Redis.
+
+### How does Redis expiration event monitoring implement the delayed task function?
+
+Redis 2.0 introduces publish and subscribe (pub/sub) functionality. In pub/sub, a concept called channel is introduced, which is somewhat similar to topic in message queue.
+
+Pub/sub involves two roles: publisher (publisher) and subscriber (subscriber, also called consumer):
+
+- The publisher delivers messages to the specified channel through `PUBLISH`.
+- Subscribers subscribe to the channels they care about through `SUBSCRIBE`. Moreover, subscribers can subscribe to one or multiple channels.
+
+
+
+In the pub/sub mode, the producer needs to specify which channel to send the message to, and the consumer subscribes to the corresponding channel to obtain the message.
+
+There are many default channels in Redis, and these channels are sent to them by Redis itself, not by the code we write ourselves. Among them, `__keyevent@0__:expired` is a default channel, responsible for monitoring key expiration events. That is to say, when a key expires, Redis will publish a key expiration event to the channel `__keyevent@__:expired`.
+
+We only need to listen to this channel to get the information about the expired key, thereby realizing the delayed task function.
+
+This function is officially called **keyspace notifications** by Redis, and its function is to monitor changes in Redis keys and values in real time.
+
+### What are the shortcomings of Redis expiration event monitoring to implement the delayed task function?
+
+**1. Poor timeliness**
+
+An introduction in the official document explains the reason for poor timeliness, address: .
+
+
+
+The core of this paragraph is: the expiration event message is published when the Redis server deletes the key, instead of being published directly after a key expires.
+
+We know that there are two commonly used deletion strategies for expired data:
+
+1. **Lazy deletion**: The data will only be checked for expiration when the key is taken out. This is the most CPU-friendly, but may cause too many expired keys to be deleted.
+2. **Periodic deletion**: Extract a batch of keys at regular intervals to delete expired keys. Moreover, the Redis underlying layer will reduce the impact of deletion operations on CPU time by limiting the duration and frequency of deletion operations.
+
+Periodic deletion is more memory friendly, lazy deletion is more CPU friendly. Both have their own merits, so Redis uses **regular deletion + lazy/lazy deletion**.
+
+Therefore, there will be situations where I set the expiration time of the key, but the key has not been deleted by the specified time, and no expiration event is released.
+
+**2. Lost message**
+
+Messages in Redis's pub/sub mode do not support persistence, unlike message queues. In the pub/sub mode of Redis, the publisher sends the message to the specified channel, and the subscriber listens to the corresponding channel to receive the message. When there are no subscribers, the message will be discarded directly and will not be stored in Redis.
+
+**3. Repeated consumption of messages under multiple service instances**
+
+Redis's pub/sub mode currently only has a broadcast mode, which means that when a producer publishes a message to a specific channel, all consumers subscribed to the relevant channel can receive the message.
+
+At this time, we need to pay attention to the problem of multiple service instances repeatedly processing messages, which will increase the amount of code development and maintenance difficulty.
+
+### What is the principle of Redisson delay queue? What are the advantages?
+
+Redisson is an open source Java language Redis client that provides many out-of-the-box features, such as the implementation of multiple distributed locks and delay queues.
+
+We can use Redisson's built-in delay queue RDelayedQueue to implement the delayed task function.
+
+Redisson's delay queue RDelayedQueue is implemented based on Redis' SortedSet. SortedSet is an ordered set in which each element can be set with a score, representing the weight of the element. Redisson takes advantage of this feature to insert tasks that need to be delayed into a SortedSet and set corresponding expiration times as scores for them.
+
+Redisson periodically scans the SortedSet for expired elements using the `zrangebyscore` command, then removes these expired elements from the SortedSet and adds them to the ready message list. The ready message list is a blocking queue, and when a message comes in, it will be monitored by the consumer. This avoids the consumer polling the entire SortedSet and improves execution efficiency.
+
+Compared with Redis expiration event monitoring to implement delayed task function, this method has the following advantages:
+
+1. **Reduces the possibility of message loss**: Messages in DelayedQueue will be persisted. Even if Redis is down, only a few messages may be lost according to the persistence mechanism, which will have little impact. Of course, you can also use database scanning as a compensation mechanism.
+2. **There is no problem of repeated consumption of messages**: Each client obtains tasks from the same target queue, and there is no problem of repeated consumption.
+
+Compared with Redisson's built-in delay queue, the message queue can achieve higher throughput and stronger reliability by ensuring the reliability of message consumption and controlling the number of message producers and consumers. In actual projects, the delayed message solution of the message queue is preferred.
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-memory-fragmentation.en.md b/docs_en/database/redis/redis-memory-fragmentation.en.md
new file mode 100644
index 00000000000..3953a477ed4
--- /dev/null
+++ b/docs_en/database/redis/redis-memory-fragmentation.en.md
@@ -0,0 +1,131 @@
+---
+title: Detailed explanation of Redis memory fragmentation
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis, memory fragmentation, allocator, memory management, memory usage, optimization
+ - - meta
+ - name: description
+ content: Analyze the causes and effects of Redis memory fragmentation, combine allocator and memory management strategies, provide observation and optimization directions, and reduce resource waste.
+---
+
+## What is memory fragmentation?
+
+You can think of memory fragmentation simply as free memory that is not available.
+
+For example: the operating system allocates 32 bytes of continuous memory space for you, but you actually only need to use 24 bytes of memory space to store data. If the extra 8 bytes of memory space cannot be allocated to store other data later, it can be called memory fragmentation.
+
+
+
+Although Redis memory fragmentation will not affect Redis performance, it will increase memory consumption.
+
+## Why is there Redis memory fragmentation?
+
+There are two common reasons for Redis memory fragmentation:
+
+**1. When Redis stores data, the memory space applied to the operating system may be larger than the actual storage space required for the data. **
+
+The following is the original words of Redis official:
+
+> To store user keys, Redis allocates at most as much memory as the `maxmemory` setting enables (however there are small extra allocations possible).
+
+When Redis uses the `zmalloc` method (the memory allocation method implemented by Redis itself) for memory allocation, in addition to allocating memory of the size `size`, it will also allocate more memory of the size `PREFIX_SIZE`.
+
+The source code of the `zmalloc` method is as follows (source code address:
+
+```java
+void *zmalloc(size_t size) {
+ //Allocate memory of specified size
+ void *ptr = malloc(size+PREFIX_SIZE);
+ if (!ptr) zmalloc_oom_handler(size);
+#ifdef HAVE_MALLOC_SIZE
+ update_zmalloc_stat_alloc(zmalloc_size(ptr));
+ return ptr;
+#else
+ *((size_t*)ptr) = size;
+ update_zmalloc_stat_alloc(size+PREFIX_SIZE);
+ return (char*)ptr+PREFIX_SIZE;
+#endif
+}
+```
+
+In addition, Redis can use a variety of memory allocators to allocate memory (libc, jemalloc, tcmalloc). The default is [jemalloc](https://github.com/jemalloc/jemalloc), and jemalloc allocates memory according to a series of fixed sizes (8 bytes, 16 bytes, 32 bytes...). The memory units divided by jemalloc are as shown in the figure below:
+
+
+
+When the memory requested by the program is closest to a certain fixed value, jemalloc will allocate a corresponding size of space to it. For example, if the program needs to apply for 17 bytes of memory, jemalloc will directly allocate 32 bytes of memory to it, which will result in a waste of 15 bytes of memory. However, jemalloc is specially optimized for memory fragmentation problems and generally does not cause excessive fragmentation.
+
+**2. Frequent modification of data in Redis will also cause memory fragmentation. **
+
+When some data in Redis is deleted, Redis usually does not easily release memory to the operating system.
+
+This also has the corresponding original words in the official Redis documentation:
+
+
+
+Document address: .
+
+## How to view Redis memory fragmentation information?
+
+Use the `info memory` command to view Redis memory-related information. The specific meaning of each parameter in the figure below is detailed in the Redis official document: .
+
+
+
+The calculation formula of Redis memory fragmentation rate: `mem_fragmentation_ratio` (memory fragmentation rate) = `used_memory_rss` (the size of physical memory space actually allocated to Redis by the operating system)/ `used_memory` (the size of memory space actually applied for by the Redis memory allocator to store data)
+
+In other words, the larger the value of `mem_fragmentation_ratio` (memory fragmentation rate), the more serious the memory fragmentation rate.
+
+Be sure not to mistake `used_memory_rss` minus `used_memory` value as the size of the memory fragment! ! ! This includes not only memory fragmentation, but also other process overhead, as well as overhead for shared libraries, stacks, etc.
+
+Many friends may ask: "What is the memory fragmentation rate that needs to be cleaned up?".
+
+Normally, we think that memory fragmentation needs to be cleaned up when `mem_fragmentation_ratio > 1.5`. `mem_fragmentation_ratio > 1.5` means that if you use Redis to store data with an actual size of 2G, you will need to use more than 3G of memory.
+
+If you want to quickly check the memory fragmentation rate, you can also use the following command:
+
+```bash
+> redis-cli -p 6379 info | grep mem_fragmentation_ratio
+```
+
+In addition, the memory fragmentation rate may be less than 1. I have never encountered this situation in daily use. Interested friends can read this article [Fault Analysis | What should I do if the memory fragmentation rate of Redis is too low? - Weixin Open Source Community](https://mp.weixin.qq.com/s/drlDvp7bfq5jt2M5pTqJCw).
+
+## How to clean up Redis memory fragments?
+
+Redis4.0-RC3 version comes with memory defragmentation, which can avoid the problem of excessive memory fragmentation rate.
+
+Just set the `activedefrag` configuration item to `yes` directly through the `config set` command.
+
+```bash
+config set activedefrag yes
+```
+
+The specific time to clean up needs to be controlled by the following two parameters:
+
+```bash
+#Start cleaning up when the space occupied by memory fragmentation reaches 500mb
+config set active-defrag-ignore-bytes 500mb
+# Start cleaning when the memory fragmentation rate is greater than 1.5
+config set active-defrag-threshold-lower 50
+```
+
+The Redis automatic memory fragmentation cleaning mechanism may have an impact on Redis performance. We can reduce the impact on Redis performance through the following two parameters:
+
+```bash
+# The proportion of CPU time occupied by memory fragmentation cleaning should not be less than 20%
+config set active-defrag-cycle-min 20
+# The proportion of CPU time occupied by memory fragmentation cleaning is no more than 50%
+config set active-defrag-cycle-max 50
+```
+
+In addition, restarting the node can defragment the memory. If you are using a Redis cluster with a high-availability architecture, you can convert the master node with an excessive fragmentation rate into a slave node for safe restart.
+
+## Reference
+
+- Redis official documentation:
+- Redis core technology and practice - Geek Time - Why is the memory usage still very high after deleting data? :
+- Redis source code analysis - memory allocation: < Source code analysis - memory management>
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-persistence.en.md b/docs_en/database/redis/redis-persistence.en.md
new file mode 100644
index 00000000000..1557daf0b8f
--- /dev/null
+++ b/docs_en/database/redis/redis-persistence.en.md
@@ -0,0 +1,217 @@
+---
+title: Redis持久化机制详解
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis持久化机制详解
+ - - meta
+ - name: description
+ content: Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:快照(snapshotting,RDB)、只追加文件(append-only file, AOF)、RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
+---
+
+使用缓存的时候,我们经常需要对内存中的数据进行持久化也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
+
+Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
+
+- 快照(snapshotting,RDB)
+- 只追加文件(append-only file, AOF)
+- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
+
+官方文档地址: 。
+
+
+
+## RDB 持久化
+
+### 什么是 RDB 持久化?
+
+Redis 可以通过创建快照来获得存储在内存里面的数据在 **某个时间点** 上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
+
+快照持久化是 Redis 默认采用的持久化方式,在 `redis.conf` 配置文件中默认有此下配置:
+
+```clojure
+save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。
+
+save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
+
+save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
+```
+
+### RDB 创建快照时会阻塞主线程吗?
+
+Redis 提供了两个命令来生成 RDB 快照文件:
+
+- `save` : 同步保存操作,会阻塞 Redis 主线程;
+- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
+
+> 这里说 Redis 主线程而不是主进程的主要是因为 Redis 启动之后主要是通过单线程的方式完成主要的工作。如果你想将其描述为 Redis 主进程,也没毛病。
+
+## AOF 持久化
+
+### 什么是 AOF 持久化?
+
+与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化(Redis 6.0 之后已经默认是开启了),可以通过 `appendonly` 参数开启:
+
+```bash
+appendonly yes
+```
+
+开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再写入到 AOF 文件中(此时还在系统内核缓存区未同步到磁盘),最后再根据持久化方式( `fsync`策略)的配置来决定何时将系统内核缓存区的数据同步到硬盘中的。
+
+只有同步到磁盘中才算持久化保存了,否则依然存在数据丢失的风险,比如说:系统内核缓存区的数据还未同步,磁盘机器就宕机了,那这部分数据就算丢失了。
+
+AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 `dir` 参数设置的,默认的文件名是 `appendonly.aof`。
+
+### AOF 工作基本流程是怎样的?
+
+AOF 持久化功能的实现可以简单分为 5 步:
+
+1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
+2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
+3. **文件同步(fsync)**:这一步才是持久化的核心!根据你在 `redis.conf` 文件里 `appendfsync` 配置的策略,Redis 会在不同的时机,调用 `fsync` 函数(系统调用)。`fsync` 针对单个文件操作,对其进行强制硬盘同步(文件在内核缓冲区里的数据写到硬盘),`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
+4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
+5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
+
+> Linux 系统直接提供了一些函数用于对文件和设备进行访问和控制,这些函数被称为 **系统调用(syscall)**。
+
+这里对上面提到的一些 Linux 系统调用再做一遍解释:
+
+- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
+- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
+
+AOF 工作流程图如下:
+
+
+
+### AOF 持久化方式有哪些?
+
+在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
+
+1. `appendfsync always`:主线程调用 `write` 执行写操作后,会立刻调用 `fsync` 函数同步 AOF 文件(刷盘)。主线程会阻塞,直到 `fsync` 将数据完全刷到磁盘后才会返回。这种方式数据最安全,理论上不会有任何数据丢失。但因为每个写操作都会同步阻塞主线程,所以性能极差。
+2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)。这种方式主线程的性能基本不受影响。在性能和数据安全之间做出了绝佳的平衡。不过,在 Redis 异常宕机时,最多可能丢失最近 1 秒内的数据。
+3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。 这种方式性能最好,因为避免了 `fsync` 的阻塞。但数据安全性最差,宕机时丢失的数据量不可控,取决于操作系统上一次同步的时间点。
+
+可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
+
+为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能受到的影响较小。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
+
+从 Redis 7.0.0 开始,Redis 使用了 **Multi Part AOF** 机制。顾名思义,Multi Part AOF 就是将原来的单个 AOF 文件拆分成多个 AOF 文件。在 Multi Part AOF 中,AOF 文件被分为三种类型,分别为:
+
+- BASE:表示基础 AOF 文件,它一般由子进程通过重写产生,该文件最多只有一个。
+- INCR:表示增量 AOF 文件,它一般会在 AOFRW 开始执行时被创建,该文件可能存在多个。
+- HISTORY:表示历史 AOF 文件,它由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。
+
+Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的[Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
+
+**相关 issue**:[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
+
+### AOF 为什么是在执行完命令之后记录日志?
+
+关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复),而 Redis AOF 持久化机制是在执行完命令之后再记录日志。
+
+
+
+**为什么是在执行完命令之后记录日志呢?**
+
+- 避免额外的检查开销,AOF 记录日志不会对命令进行语法检查;
+- 在命令执行完之后再记录,不会阻塞当前的命令执行。
+
+这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
+
+- 如果刚执行完命令 Redis 就宕机会导致对应的修改丢失;
+- 可能会阻塞后续其他命令的执行(AOF 记录日志是在 Redis 主线程中进行的)。
+
+### AOF 重写了解吗?
+
+当 AOF 变得太大时,Redis 能够在后台自动重写 AOF 产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
+
+
+
+> AOF 重写(rewrite) 是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
+
+由于 AOF 重写会进行大量的写入操作,为了避免对 Redis 正常处理命令请求造成影响,Redis 将 AOF 重写程序放到子进程里执行。
+
+AOF 文件重写期间,Redis 还会维护一个 **AOF 重写缓冲区**,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
+
+开启 AOF 重写功能,可以调用 `BGREWRITEAOF` 命令手动执行,也可以设置下面两个配置项,让程序自动决定触发时机:
+
+- `auto-aof-rewrite-min-size`:如果 AOF 文件大小小于该值,则不会触发 AOF 重写。默认值为 64 MB;
+- `auto-aof-rewrite-percentage`:执行 AOF 重写时,当前 AOF 大小(aof_current_size)和上一次重写时 AOF 大小(aof_base_size)的比值。如果当前 AOF 文件大小增加了这个百分比值,将触发 AOF 重写。将此值设置为 0 将禁用自动 AOF 重写。默认值为 100。
+
+Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
+
+Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内容摘自阿里开发者的[从 Redis7.0 发布看 Redis 的过去与未来](https://mp.weixin.qq.com/s/RnoPPL7jiFSKkx3G4p57Pg) 这篇文章。
+
+> AOF 重写期间的增量数据如何处理一直是个问题,在过去写期间的增量数据需要在内存中保留,写结束后再把这部分增量数据写入新的 AOF 文件中以保证数据完整性。可以看出来 AOF 写会额外消耗内存和磁盘 IO,这也是 Redis AOF 写的痛点,虽然之前也进行过多次改进但是资源消耗的本质问题一直没有解决。
+>
+> 阿里云的 Redis 企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
+
+**相关 issue**:[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)。
+
+### AOF 校验机制了解吗?
+
+纯 AOF 模式下,Redis 不会对整个 AOF 文件使用校验和(如 CRC64),而是通过逐条解析文件中的命令来验证文件的有效性。如果解析过程中发现语法错误(如命令不完整、格式错误),Redis 会终止加载并报错,从而避免错误数据载入内存。
+
+在 **混合持久化模式**(Redis 4.0 引入)下,AOF 文件由两部分组成:
+
+- **RDB 快照部分**:文件以固定的 `REDIS` 字符开头,存储某一时刻的内存数据快照,并在快照数据末尾附带一个 CRC64 校验和(位于 RDB 数据块尾部、AOF 增量部分之前)。
+- **AOF 增量部分**:紧随 RDB 快照部分之后,记录 RDB 快照生成后的增量写命令。这部分增量命令以 Redis 协议格式逐条记录,无整体或全局校验和。
+
+RDB 文件结构的核心部分如下:
+
+| **字段** | **解释** |
+| ----------------- | ---------------------------------------------- |
+| `"REDIS"` | 固定以该字符串开始 |
+| `RDB_VERSION` | RDB 文件的版本号 |
+| `DB_NUM` | Redis 数据库编号,指明数据需要存放到哪个数据库 |
+| `KEY_VALUE_PAIRS` | Redis 中具体键值对的存储 |
+| `EOF` | RDB 文件结束标志 |
+| `CHECK_SUM` | 8 字节确保 RDB 完整性的校验和 |
+
+Redis 启动并加载 AOF 文件时,首先会校验文件开头 RDB 快照部分的数据完整性,即计算该部分数据的 CRC64 校验和,并与紧随 RDB 数据之后、AOF 增量部分之前存储的 CRC64 校验和值进行比较。如果 CRC64 校验和不匹配,Redis 将拒绝启动并报告错误。
+
+RDB 部分校验通过后,Redis 随后逐条解析 AOF 部分的增量命令。如果解析过程中出现错误(如不完整的命令或格式错误),Redis 会停止继续加载后续命令,并报告错误,但此时 Redis 已经成功加载了 RDB 快照部分的数据。
+
+## Redis 4.0 对于持久化机制做了什么优化?
+
+由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+
+如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
+
+官方文档地址:
+
+
+
+## 如何选择 RDB 和 AOF?
+
+关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
+
+**RDB 比 AOF 优秀的地方**:
+
+- The content stored in the RDB file is compressed binary data, which saves the data set at a certain point in time. The file is small and suitable for data backup and disaster recovery. AOF files store each write command, similar to MySQL's binlog log, and are usually much larger than RDB files. When the AOF becomes too large, Redis can automatically rewrite the AOF in the background. The new AOF file saves the same database state as the original AOF file, but is smaller in size. However, before Redis 7.0, AOF might use a lot of memory if there were write commands during rewrite, and all write commands arriving during rewrite would be written to disk twice.
+- Use RDB files to restore data and directly parse and restore the data. There is no need to execute commands one by one, and the speed is very fast. AOF needs to execute each write command in sequence, which is very slow. In other words, RDB is faster when restoring large data sets compared to AOF.
+
+**AOF is better than RDB**:
+
+- The data security of RDB is not as good as AOF, and there is no way to persist data in real time or within seconds. The process of generating RDB files is relatively arduous. Although the BGSAVE sub-process writing the RDB files will not block the main thread, it will have an impact on the CPU resources and memory resources of the machine. In severe cases, it may even directly shut down the Redis service. AOF supports second-level data loss (depending on the fsync policy, if it is everysec, up to 1 second of data is lost). It only requires appending commands to the AOF file, and the operation is lightweight.
+- RDB files are saved in a specific binary format, and there are multiple versions of RDB in the evolution of Redis versions, so there is a problem that the old version of the Redis service is not compatible with the new version of the RDB format.
+- AOF contains a log of all operations in a format that is easy to understand and parse. You can easily export AOF files for analysis, and you can also directly manipulate AOF files to solve some problems. For example, if you execute the `FLUSHALL` command and accidentally refresh all the contents, as long as the AOF file has not been overwritten, you can restore the previous state by deleting the latest command and restarting.
+
+**In summary**:
+
+- If there is no impact if some data saved by Redis is lost, you can choose to use RDB.
+- Using AOF alone is not recommended as creating an RDB snapshot from time to time allows for database backups, faster restarts, and troubleshooting AOF engine errors.
+- If the saved data requires relatively high security, it is recommended to enable RDB and AOF persistence at the same time or enable RDB and AOF mixed persistence.
+
+## Reference
+
+- "Redis Design and Implementation"
+- Redis persistence - Redis official documentation:
+- The difference between AOF and RDB persistence:
+- Detailed explanation of Redis AOF persistence - Programmer Li Xiaobing:
+- Redis RDB and AOF persistence · Analyze:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-questions-01.en.md b/docs_en/database/redis/redis-questions-01.en.md
new file mode 100644
index 00000000000..421aa9d10bf
--- /dev/null
+++ b/docs_en/database/redis/redis-questions-01.en.md
@@ -0,0 +1,905 @@
+---
+title: Redis常见面试题总结(上)
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis面试题,Redis基础,Redis数据结构,Redis线程模型,Redis持久化,Redis内存管理,Redis性能优化,Redis分布式锁,Redis消息队列,Redis延时队列,Redis缓存策略,Redis单线程,Redis多线程,Redis过期策略,Redis淘汰策略
+ - - meta
+ - name: description
+ content: 最新Redis面试题总结(上):深入讲解Redis基础、五大常用数据结构、单线程模型原理、持久化机制、内存淘汰与过期策略、分布式锁与消息队列实现。适合准备后端面试的开发者!
+---
+
+
+
+## Redis 基础
+
+### 什么是 Redis?
+
+[Redis](https://redis.io/) (**RE**mote **DI**ctionary **S**erver)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
+
+为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布订阅模型、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
+
+
+
+Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,官方推荐生产环境使用 Linux 部署 Redis。
+
+个人学习的话,你可以自己本机安装 Redis 或者通过 Redis 官网提供的[在线 Redis 环境](https://try.redis.io/)(少部分命令无法使用)来实际体验 Redis。
+
+
+
+全世界有非常多的网站使用到了 Redis,[techstacks.io](https://techstacks.io/) 专门维护了一个[使用 Redis 的热门站点列表](https://techstacks.io/tech/redis),感兴趣的话可以看看。
+
+### ⭐️Redis 为什么这么快?
+
+Redis 内部做了非常多的性能优化,比较重要的有下面 4 点:
+
+1. **纯内存操作 (Memory-Based Storage)** :这是最主要的原因。Redis 数据读写操作都发生在内存中,访问速度是纳秒级别,而传统数据库频繁读写磁盘的速度是毫秒级别,两者相差数个数量级。
+2. **高效的 I/O 模型 (I/O Multiplexing & Single-Threaded Event Loop)** :Redis 使用单线程事件循环配合 I/O 多路复用技术,让单个线程可以同时处理多个网络连接上的 I/O 事件(如读写),避免了多线程模型中的上下文切换和锁竞争问题。虽然是单线程,但结合内存操作的高效性和 I/O 多路复用,使得 Redis 能轻松处理大量并发请求(Redis 线程模型会在后文中详细介绍到)。
+3. **优化的内部数据结构 (Optimized Data Structures)** :Redis 提供多种数据类型(如 String, List, Hash, Set, Sorted Set 等),其内部实现采用高度优化的编码方式(如 ziplist, quicklist, skiplist, hashtable 等)。Redis 会根据数据大小和类型动态选择最合适的内部编码,以在性能和空间效率之间取得最佳平衡。
+4. **简洁高效的通信协议 (Simple Protocol - RESP)** :Redis 使用的是自己设计的 RESP (REdis Serialization Protocol) 协议。这个协议实现简单、解析性能好,并且是二进制安全的。客户端和服务端之间通信的序列化/反序列化开销很小,有助于提升整体的交互速度。
+
+> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770)。
+
+
+
+那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高,并且 Redis 提供的数据持久化仍然有数据丢失的风险。
+
+### 除了 Redis,你还知道其他分布式缓存方案吗?
+
+如果面试中被问到这个问题的话,面试官主要想看看:
+
+1. 你在选择 Redis 作为分布式缓存方案时,是否是经过严谨的调研和思考,还是只是因为 Redis 是当前的“热门”技术。
+2. 你在分布式缓存方向的技术广度。
+
+如果你了解其他方案,并且能解释为什么最终选择了 Redis(更进一步!),这会对你面试表现加分不少!
+
+下面简单聊聊常见的分布式缓存技术选型。
+
+分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
+
+Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
+
+有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis)。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ),可以简单参考一下。
+
+不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
+
+目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
+
+- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
+- [KeyDB](https://github.com/Snapchat/KeyDB):Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
+
+不过,个人还是建议分布式缓存首选 Redis,毕竟经过了这么多年的考验,生态非常优秀,资料也很全面!
+
+PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详细介绍和对比,感兴趣的话,可以自行研究一下。
+
+### 说一下 Redis 和 Memcached 的区别和共同点
+
+现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
+
+**共同点**:
+
+1. 都是基于内存的数据库,一般都用来当做缓存使用。
+2. 都有过期策略。
+3. 两者的性能都非常高。
+
+**区别**:
+
+1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
+2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
+3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
+4. **线程模型**:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
+5. **特性支持**:Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
+6. **过期数据删除**:Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。
+
+相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
+
+### ⭐️为什么要用 Redis?
+
+**1、访问速度更快**
+
+传统数据库数据保存在磁盘,而 Redis 基于内存,内存的访问速度比磁盘快很多。引入 Redis 之后,我们可以把一些高频访问的数据放到 Redis 中,这样下次就可以直接从内存中读取,速度可以提升几十倍甚至上百倍。
+
+**2、高并发**
+
+一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
+
+> QPS(Query Per Second):服务器每秒可以执行的查询次数;
+
+由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
+
+**3、功能全面**
+
+Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
+
+### ⭐️为什么用 Redis 而不用本地缓存呢?
+
+| 特性 | 本地缓存 | Redis |
+| ------------ | ------------------------------------ | -------------------------------- |
+| 数据一致性 | 多服务器部署时存在数据不一致问题 | 数据一致 |
+| 内存限制 | 受限于单台服务器内存 | 独立部署,内存空间更大 |
+| 数据丢失风险 | 服务器宕机数据丢失 | 可持久化,数据不易丢失 |
+| 管理维护 | 分散,管理不便 | 集中管理,提供丰富的管理工具 |
+| 功能丰富性 | 功能有限,通常只提供简单的键值对存储 | 功能丰富,支持多种数据结构和功能 |
+
+### 常见的缓存读写策略有哪些?
+
+关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html)。
+
+### 什么是 Redis Module?有什么用?
+
+Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特殊的需求。这些 Module 以动态链接库(so 文件)的形式被加载到 Redis 中,这是一种非常灵活的动态扩展功能的实现方式,值得借鉴学习!
+
+我们每个人都可以基于 Redis 去定制化开发自己的 Module,比如实现搜索引擎功能、自定义分布式锁和分布式限流。
+
+目前,被 Redis 官方推荐的 Module 有:
+
+- [RediSearch](https://github.com/RediSearch/RediSearch):用于实现搜索引擎的模块。
+- [RedisJSON](https://github.com/RedisJSON/RedisJSON):用于处理 JSON 数据的模块。
+- [RedisGraph](https://github.com/RedisGraph/RedisGraph):用于实现图形数据库的模块。
+- [RedisTimeSeries](https://github.com/RedisTimeSeries/RedisTimeSeries):用于处理时间序列数据的模块。
+- [RedisBloom](https://github.com/RedisBloom/RedisBloom):用于实现布隆过滤器的模块。
+- [RedisAI](https://github.com/RedisAI/RedisAI):用于执行深度学习/机器学习模型并管理其数据的模块。
+- [RedisCell](https://github.com/brandur/redis-cell):用于实现分布式限流的模块。
+- ……
+
+关于 Redis 模块的详细介绍,可以查看官方文档:。
+
+## ⭐️Redis 应用
+
+### Redis 除了做缓存,还能做什么?
+
+- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html)。
+- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码+令牌桶算法。
+- **消息队列**:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
+- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
+- **分布式 Session**:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
+- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜、通过 HyperLogLog 统计网站 UV 和 PV。
+- ……
+
+### 如何基于 Redis 实现分布式锁?
+
+关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)。
+
+### Redis 可以做消息队列么?
+
+> 实际项目中使用 Redis 来做消息队列的非常少,毕竟有更成熟的消息队列中间件可以用。
+
+先说结论:**可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。**
+
+**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
+
+通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 即可实现简易版消息队列:
+
+```bash
+# 生产者生产消息
+> RPUSH myList msg1 msg2
+(integer) 2
+> RPUSH myList msg3
+(integer) 3
+# 消费者消费消息
+> LPOP myList
+"msg1"
+```
+
+不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
+
+因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
+
+```bash
+# 超时时间为 10s
+# 如果有数据立刻返回,否则最多等待10秒
+> BRPOP myList 10
+null
+```
+
+**List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。**
+
+**Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。**
+
+
+
+pub/sub 中引入了一个概念叫 **channel(频道)**,发布订阅机制的实现就是基于这个 channel 来做的。
+
+pub/sub 涉及发布者(Publisher)和订阅者(Subscriber,也叫消费者)两个角色:
+
+- 发布者通过 `PUBLISH` 投递消息给指定 channel。
+- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
+
+我们这里启动 3 个 Redis 客户端来简单演示一下:
+
+
+
+pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
+
+为此,Redis 5.0 新增加的一个数据结构 `Stream` 来做消息队列。`Stream` 支持:
+
+- 发布 / 订阅模式;
+- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念);
+- 消息持久化( RDB 和 AOF);
+- ACK 机制(通过确认机制来告知已经成功处理了消息);
+- 阻塞式获取消息。
+
+`Stream` 的结构如下:
+
+
+
+这是一个有序的消息链表,每个消息都有一个唯一的 ID 和对应的内容。ID 是一个时间戳和序列号的组合,用来保证消息的唯一性和递增性。内容是一个或多个键值对(类似 Hash 基本数据类型),用来存储消息的数据。
+
+这里再对图中涉及到的一些概念,进行简单解释:
+
+- `Consumer Group`:消费者组用于组织和管理多个消费者。消费者组本身不处理消息,而是再将消息分发给消费者,由消费者进行真正的消费。
+- `last_delivered_id`:标识消费者组当前消费位置的游标,消费者组中任意一个消费者读取了消息都会使 last_delivered_id 往前移动。
+- `pending_ids`:记录已经被客户端消费但没有 ack 的消息的 ID。
+
+下面是`Stream` 用作消息队列时常用的命令:
+
+- `XADD`:向流中添加新的消息。
+- `XREAD`:从流中读取消息。
+- `XREADGROUP`:从消费组中读取消息。
+- `XRANGE`:根据消息 ID 范围读取流中的消息。
+- `XREVRANGE`:与 `XRANGE` 类似,但以相反顺序返回结果。
+- `XDEL`:从流中删除消息。
+- `XTRIM`:修剪流的长度,可以指定修建策略(`MAXLEN`/`MINID`)。
+- `XLEN`:获取流的长度。
+- `XGROUP CREATE`:创建消费者组。
+- `XGROUP DESTROY`:删除消费者组。
+- `XGROUP DELCONSUMER`:从消费者组中删除一个消费者。
+- `XGROUP SETID`:为消费者组设置新的最后递送消息 ID。
+- `XACK`:确认消费组中的消息已被处理。
+- `XPENDING`:查询消费组中挂起(未确认)的消息。
+- `XCLAIM`:将挂起的消息从一个消费者转移到另一个消费者。
+- `XINFO`:获取流(`XINFO STREAM`)、消费组(`XINFO GROUPS`)或消费者(`XINFO CONSUMERS`)的详细信息。
+
+`Stream` 使用起来相对要麻烦一些,这里就不演示了。
+
+总的来说,`Stream` 已经可以满足一个消息队列的基本要求了。不过,`Stream` 在实际使用中依然会有一些小问题不太好解决,比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
+
+综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方,比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列,比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议你优先考虑 `Stream`,这是目前相对最优的 Redis 消息队列实现。
+
+相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
+
+### Redis 可以做搜索引擎么?
+
+Redis 是可以实现全文搜索引擎功能的,需要借助 **RediSearch**,这是一个基于 Redis 的搜索引擎模块。
+
+RediSearch 支持中文分词、聚合统计、停用词、同义词、拼写检查、标签查询、向量相似度查询、多关键词搜索、分页搜索等功能,算是一个功能比较完善的全文搜索引擎了。
+
+相比较于 Elasticsearch 来说,RediSearch 主要在下面两点上表现更优异一些:
+
+1. 性能更优秀:依赖 Redis 自身的高性能,基于内存操作(Elasticsearch 基于磁盘)。
+2. 较低内存占用实现快速索引:RediSearch 内部使用压缩的倒排索引,所以可以用较低的内存占用来实现索引的快速构建。
+
+对于小型项目的简单搜索场景来说,使用 RediSearch 来作为搜索引擎还是没有问题的(搭配 RedisJSON 使用)。
+
+对于比较复杂或者数据规模较大的搜索场景,还是不太建议使用 RediSearch 来作为搜索引擎,主要是因为下面这些限制和问题:
+
+1. 数据量限制:Elasticsearch 可以支持 PB 级别的数据量,可以轻松扩展到多个节点,利用分片机制提高可用性和性能。RedisSearch 是基于 Redis 实现的,其能存储的数据量受限于 Redis 的内存容量,不太适合存储大规模的数据(内存昂贵,扩展能力较差)。
+2. 分布式能力较差:Elasticsearch 是为分布式环境设计的,可以轻松扩展到多个节点。虽然 RedisSearch 支持分布式部署,但在实际应用中可能会面临一些挑战,如数据分片、节点间通信、数据一致性等问题。
+3. 聚合功能较弱:Elasticsearch 提供了丰富的聚合功能,而 RediSearch 的聚合功能相对较弱,只支持简单的聚合操作。
+4. 生态较差:Elasticsearch 可以轻松和常见的一些系统/软件集成比如 Hadoop、Spark、Kibana,而 RedisSearch 则不具备该优势。
+
+Elasticsearch 适用于全文搜索、复杂查询、实时数据分析和聚合的场景,而 RediSearch 适用于快速数据存储、缓存和简单查询的场景。
+
+### 如何基于 Redis 实现延时任务?
+
+> 类似的问题:
+>
+> - 订单在 10 分钟后未支付就失效,如何用 Redis 实现?
+> - 红包 24 小时未被查收自动退还,如何用 Redis 实现?
+
+基于 Redis 实现延时任务的功能无非就下面两种方案:
+
+1. Redis 过期事件监听。
+2. Redisson 内置的延时队列。
+
+Redis 过期事件监听存在时效性较差、丢消息、多服务实例下消息重复消费等问题,不被推荐使用。
+
+Redisson 内置的延时队列具备下面这些优势:
+
+1. **减少了丢消息的可能**:DelayedQueue 中的消息会被持久化,即使 Redis 宕机了,根据持久化机制,也只可能丢失一点消息,影响不大。当然了,你也可以使用扫描数据库的方法作为补偿机制。
+2. **消息不存在重复消费问题**:每个客户端都是从同一个目标队列中获取任务的,不存在重复消费的问题。
+
+关于 Redis 实现延时任务的详细介绍,可以看我写的这篇文章:[如何基于 Redis 实现延时任务?](./redis-delayed-task.md)。
+
+## ⭐️Redis 数据类型
+
+关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/):
+
+- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
+- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
+
+### Redis 常用的数据类型有哪些?
+
+Redis 中比较常见的数据类型有下面这些:
+
+- **5 种基础数据类型**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
+- **3 种特殊数据类型**:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
+
+除了上面提到的之外,还有一些其他的比如 [Bloom filter(布隆过滤器)](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html)、Bitfield(位域)。
+
+### String 的应用场景有哪些?
+
+String 是 Redis 中最简单同时也是最常用的一个数据类型。它是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
+
+String 的常见应用场景如下:
+
+- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
+- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
+- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
+- ……
+
+关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
+
+### String 还是 Hash 存储对象数据更好呢?
+
+简单对比一下二者:
+
+- **对象存储方式**:String 存储的是序列化后的对象数据,存放的是整个对象,操作简单直接。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
+- **内存消耗**:Hash 通常比 String 更节省内存,特别是在字段较多且字段长度较短时。Redis 对小型 Hash 进行优化(如使用 ziplist 存储),进一步降低内存占用。
+- **复杂对象存储**:String 在处理多层嵌套或复杂结构的对象时更方便,因为无需处理每个字段的独立存储和操作。
+- **性能**:String 的操作通常具有 O(1) 的时间复杂度,因为它存储的是整个对象,操作简单直接,整体读写的性能较好。Hash 由于需要处理多个字段的增删改查操作,在字段较多且经常变动的情况下,可能会带来额外的性能开销。
+
+总结:
+
+- 在绝大多数情况下,**String** 更适合存储对象数据,尤其是当对象结构简单且整体读写是主要操作时。
+- 如果你需要频繁操作对象的部分字段或节省内存,**Hash** 可能是更好的选择。
+
+### String 的底层实现是什么?
+
+Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 `\0` 结尾的字符数组),而是自己编写了 [SDS](https://github.com/antirez/sds)(Simple Dynamic String,简单动态字符串)来作为底层实现。
+
+SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
+
+Redis7.0 的 SDS 的部分源码如下():
+
+```c
+/* Note: sdshdr5 is never used, we just access the flags byte directly.
+ * However is here to document the layout of type 5 SDS strings. */
+struct __attribute__ ((__packed__)) sdshdr5 {
+ unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr8 {
+ uint8_t len; /* used */
+ uint8_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr16 {
+ uint16_t len; /* used */
+ uint16_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr32 {
+ uint32_t len; /* used */
+ uint32_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+struct __attribute__ ((__packed__)) sdshdr64 {
+ uint64_t len; /* used */
+ uint64_t alloc; /* excluding the header and null terminator */
+ unsigned char flags; /* 3 lsb of type, 5 unused bits */
+ char buf[];
+};
+```
+
+通过源码可以看出,SDS 共有五种实现方式:SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
+
+| 类型 | 字节 | 位 |
+| -------- | ---- | --- |
+| sdshdr5 | < 1 | <8 |
+| sdshdr8 | 1 | 8 |
+| sdshdr16 | 2 | 16 |
+| sdshdr32 | 4 | 32 |
+| sdshdr64 | 8 | 64 |
+
+对于后四种实现都包含了下面这 4 个属性:
+
+- `len`:字符串的长度也就是已经使用的字节数。
+- `alloc`:总共可用的字符空间大小,alloc-len 就是 SDS 剩余的空间大小。
+- `buf[]`:实际存储字符串的数组。
+- `flags`:低三位保存类型标志。
+
+SDS 相比于 C 语言中的字符串有如下提升:
+
+1. **可以避免缓冲区溢出**:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
+2. **获取字符串长度的复杂度较低**:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
+3. **减少内存分配次数**:为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
+4. **二进制安全**:C 语言中的字符串以空字符 `\0` 作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题。
+
+🤐 多提一嘴,很多文章里 SDS 的定义是下面这样的:
+
+```c
+struct sdshdr {
+ unsigned int len;
+ unsigned int free;
+ char buf[];
+};
+```
+
+这个也没错,Redis 3.2 之前就是这样定义的。后来,由于这种方式的定义存在问题,`len` 和 `free` 的定义用了 4 个字节,造成了浪费。Redis 3.2 之后,Redis 改进了 SDS 的定义,将其划分为了现在的 5 种类型。
+
+### 购物车信息用 String 还是 Hash 存储更好呢?
+
+由于购物车中的商品频繁修改和变动,购物车信息建议使用 Hash 存储:
+
+- 用户 id 为 key
+- 商品 id 为 field,商品数量为 value
+
+
+
+那用户购物车信息的维护具体应该怎么操作呢?
+
+- 用户添加商品就是往 Hash 里面增加新的 field 与 value;
+- 查询购物车信息就是遍历对应的 Hash;
+- 更改商品数量直接修改对应的 value 值(直接 set 或者做运算皆可);
+- 删除商品就是删除 Hash 中对应的 field;
+- 清空购物车直接删除对应的 key 即可。
+
+这里只是以业务比较简单的购物车场景举例,实际电商场景下,field 只保存一个商品 id 是没办法满足需求的。
+
+### 使用 Redis 实现一个排行榜怎么做?
+
+Redis 中有一个叫做 `Sorted Set`(有序集合)的数据类型经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
+
+相关的一些 Redis 命令:`ZRANGE`(从小到大排序)、`ZREVRANGE`(从大到小排序)、`ZREVRANK`(指定元素排名)。
+
+
+
+[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜,感兴趣的小伙伴可以看看。
+
+
+
+### Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+ 树?
+
+这道面试题很多大厂比较喜欢问,难度还是有点大的。
+
+- 平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)**。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
+- 红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
+- B+ 树 vs 跳表:B+ 树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+ 树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+ 树那样插入时发现失衡时还需要对节点分裂与合并。
+
+另外,我还单独写了一篇文章从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握:[Redis 为什么用跳表实现有序集合](https://javaguide.cn/database/redis/redis-skiplist.html)。
+
+### Set 的应用场景是什么?
+
+Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。
+
+`Set` 的常见应用场景如下:
+
+- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog` 更适合一些)、文章点赞、动态点赞等等。
+- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集)等等。
+- 需要随机获取数据源中的元素的场景:抽奖系统、随机点名等等。
+
+### 使用 Set 实现抽奖系统怎么做?
+
+如果想要使用 `Set` 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
+
+- `SADD key member1 member2 ...`:向指定集合添加一个或多个元素。
+- `SPOP key count`:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
+- `SRANDMEMBER key count`:随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
+
+### 使用 Bitmap 统计活跃用户怎么做?
+
+Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
+
+你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
+
+
+
+如果想要使用 Bitmap 统计活跃用户的话,可以使用日期(精确到天)作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1。
+
+初始化数据:
+
+```bash
+> SETBIT 20210308 1 1
+(integer) 0
+> SETBIT 20210308 2 1
+(integer) 0
+> SETBIT 20210309 1 1
+(integer) 0
+```
+
+统计 20210308~20210309 总活跃用户数:
+
+```bash
+> BITOP and desk1 20210308 20210309
+(integer) 1
+> BITCOUNT desk1
+(integer) 1
+```
+
+统计 20210308~20210309 在线活跃用户数:
+
+```bash
+> BITOP or desk2 20210308 20210309
+(integer) 1
+> BITCOUNT desk2
+(integer) 2
+```
+
+### HyperLogLog 适合什么场景?
+
+HyperLogLog (HLL) 是一种非常巧妙的概率性数据结构,它专门解决一类非常棘手的大数据问题:在海量数据中,用极小的内存,估算一个集合中不重复元素的数量,也就是我们常说的基数(Cardinality)
+
+HLL 做的最核心的权衡,就是用一点点精确度的损失,来换取巨大的内存空间节省。它给出的不是一个 100%精确的数字,而是一个带有很小标准误差(Redis 中默认是 0.81%)的近似值。
+
+**基于这个核心权衡,HyperLogLog 最适合以下特征的场景:**
+
+1. **数据量巨大,内存敏感:** 这是 HLL 的主战场。比如,要统计一个亿级日活 App 的每日独立访客数。如果用传统的 Set 来存储用户 ID,一个 ID 占几十个字节,上亿个 ID 可能需要几个 GB 甚至几十 GB 的内存,这在很多场景下是不可接受的。而 HLL,在 Redis 中只需要固定的 12KB 内存,就能处理天文数字级别的基数,这是一个颠覆性的优势。
+2. **对结果的精确度要求不是 100%:** 这是使用 HLL 的前提。比如,产品经理想知道一个热门帖子的 UV(独立访客数)是大约 1000 万还是 1010 万,这个细微的差别通常不影响商业决策。但如果场景是统计一个交易系统的准确交易笔数,那 HLL 就完全不适用,因为金融场景要求 100%的精确。
+
+**所以,HyperLogLog 具体的应用场景就非常清晰了:**
+
+- **网站/App 的 UV(Unique Visitor)统计:** 比如统计首页每天有多少个不同的 IP 或用户 ID 访问过。
+- **搜索引擎关键词统计:** 统计每天有多少个不同的用户搜索了某个关键词。
+- **社交网络互动统计:** 比如统计一条微博被多少个不同的用户转发过。
+
+在这些场景下,我们关心的是数量级和趋势,而不是个位数的差异。
+
+最后,Redis 的实现还非常智能,它内部会根据基数的大小,在**稀疏矩阵**(占用空间更小)和**稠密矩阵**(固定的 12KB)之间自动切换,进一步优化了内存使用。总而言之,当您需要对海量数据进行去重计数,并且可以接受微小误差时,HyperLogLog 就是不二之选。
+
+### 使用 HyperLogLog 统计页面 UV 怎么做?
+
+使用 HyperLogLog 统计页面 UV 主要需要用到下面这两个命令:
+
+- `PFADD key element1 element2 ...`:添加一个或多个元素到 HyperLogLog 中。
+- `PFCOUNT key1 key2`:获取一个或者多个 HyperLogLog 的唯一计数。
+
+1、将访问指定页面的每个用户 ID 添加到 `HyperLogLog` 中。
+
+```bash
+PFADD PAGE_1:UV USER1 USER2 ...... USERn
+```
+
+2、统计指定页面的 UV。
+
+```bash
+PFCOUNT PAGE_1:UV
+```
+
+### 如果我想判断一个元素是否不在海量元素集合中,用什么数据类型?
+
+这是布隆过滤器的经典应用场景。布隆过滤器可以告诉你一个元素一定不存在或者可能存在,它也有极高的空间效率和一定的误判率,但绝不会漏报。也就是说,布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
+
+Bloom Filter 的简单原理图如下:
+
+
+
+当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
+
+如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
+
+## ⭐️Redis 持久化机制(重要)
+
+Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化)相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题:[Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html)。
+
+## ⭐️Redis 线程模型(重要)
+
+对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作,Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
+
+### Redis 单线程模型了解吗?
+
+**Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型**(Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
+
+《Redis 设计与实现》有一段话是这样介绍文件事件处理器的,我觉得写得挺不错。
+
+> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。
+>
+> - 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
+> - 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
+>
+> **虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字**,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
+
+**既然是单线程,那怎么监听大量的客户端连接呢?**
+
+Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
+
+这样的好处非常明显:**I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗**(和 NIO 中的 `Selector` 组件很像)。
+
+文件事件处理器(file event handler)主要是包含 4 个部分:
+
+- 多个 socket(客户端连接)
+- IO 多路复用程序(支持多个客户端连接的关键)
+- 文件事件分派器(将 socket 关联到相应的事件处理器)
+- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
+
+
+
+### Redis6.0 之前为什么不使用多线程?
+
+虽然说 Redis 是单线程模型,但实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
+
+不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”,从而减少对主线程的影响。
+
+为此,Redis 4.0 之后新增了几个异步命令:
+
+- `UNLINK`:可以看作是 `DEL` 命令的异步版本。
+- `FLUSHALL ASYNC`:用于清空所有数据库的所有键,不限于当前 `SELECT` 的数据库。
+- `FLUSHDB ASYNC`:用于清空当前 `SELECT` 数据库中的所有键。
+
+
+
+总的来说,直到 Redis 6.0 之前,Redis 的主要操作仍然是单线程处理的。
+
+**那 Redis6.0 之前为什么不使用多线程?** 我觉得主要原因有 3 点:
+
+- 单线程编程容易并且更容易维护;
+- Redis 的性能瓶颈不在 CPU,主要在内存和网络;
+- 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
+
+相关阅读:[为什么 Redis 选择单线程模型?](https://draveness.me/whys-the-design-redis-single-thread/)。
+
+### Redis6.0 之后为何引入了多线程?
+
+**Redis6.0 引入多线程主要是为了提高网络 IO 读写性能**,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
+
+虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了,执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
+
+Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要设置 IO 线程数 > 1,需要修改 redis 配置文件 `redis.conf`:
+
+```bash
+io-threads 4 #设置1的话只会开启主线程,官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
+```
+
+另外:
+
+- io-threads 的个数一旦设置,不能通过 config 动态设置。
+- 当设置 ssl 后,io-threads 将不工作。
+
+开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 `redis.conf`:
+
+```bash
+io-threads-do-reads yes
+```
+
+但是官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启。
+
+相关阅读:
+
+- [Redis 6.0 新特性-多线程连环 13 问!](https://mp.weixin.qq.com/s/FZu3acwK6zrCBZQ_3HoUgw)
+- [Redis 多线程网络模型全面揭秘](https://segmentfault.com/a/1190000039223696)(推荐)
+
+### Redis 后台线程了解吗?
+
+我们虽然经常说 Redis 是单线程模型(主要逻辑是单线程完成的),但实际还有一些后台线程用于执行一些比较耗时的操作:
+
+- 通过 `bio_close_file` 后台线程来释放 AOF / RDB 等过程中产生的临时文件资源。
+- 通过 `bio_aof_fsync` 后台线程调用 `fsync` 函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘(AOF 文件)。
+- 通过 `bio_lazy_free` 后台线程释放大对象(已删除)占用的内存空间.
+
+在`bio.h` 文件中有定义(Redis 6.0 版本,源码地址:):
+
+```java
+#ifndef __BIO_H
+#define __BIO_H
+
+/* Exported API */
+void bioInit(void);
+void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3);
+unsigned long long bioPendingJobsOfType(int type);
+unsigned long long bioWaitStepOfType(int type);
+time_t bioOlderJobOfType(int type);
+void bioKillThreads(void);
+
+/* Background job opcodes */
+#define BIO_CLOSE_FILE 0 /* Deferred close(2) syscall. */
+#define BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */
+#define BIO_LAZY_FREE 2 /* Deferred objects freeing. */
+#define BIO_NUM_OPS 3
+
+#endif
+```
+
+关于 Redis 后台线程的详细介绍可以查看 [Redis 6.0 后台线程有哪些?](https://juejin.cn/post/7102780434739626014) 这篇就文章。
+
+## ⭐️Redis 内存管理
+
+### Redis 给缓存数据设置过期时间有什么用?
+
+一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
+
+内存是有限且珍贵的,如果不对缓存数据设置过期时间,那内存占用就会一直增长,最终可能会导致 OOM 问题。通过设置合理的过期时间,Redis 会自动删除暂时不需要的数据,为新的缓存数据腾出空间。
+
+Redis 自带了给缓存数据设置过期时间的功能,比如:
+
+```bash
+127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
+(integer) 1
+127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
+OK
+127.0.0.1:6379> ttl key # 查看数据还有多久过期
+(integer) 56
+```
+
+注意 ⚠️:Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外,`persist` 命令可以移除一个键的过期时间。
+
+**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
+
+很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效。
+
+如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
+
+### Redis 是如何判断数据是否过期的呢?
+
+Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
+
+
+
+过期字典是存储在 redisDb 这个结构里的:
+
+```c
+typedef struct redisDb {
+ ...
+
+ dict *dict; //数据库键空间,保存着数据库中所有键值对
+ dict *expires // 过期字典,保存着键的过期时间
+ ...
+} redisDb;
+```
+
+在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
+
+### Redis 过期 key 删除策略了解么?
+
+如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
+
+常用的过期数据的删除策略就下面这几种:
+
+1. **惰性删除**:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
+2. **定期删除**:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
+3. **延迟队列**:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
+4. **定时删除**:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
+
+**Redis 采用的是那种删除策略呢?**
+
+Redis 采用的是 **定期删除+惰性/懒汉式删除** 结合的策略,这也是大部分缓存框架的选择。定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,结合起来使用既能兼顾 CPU 友好,又能兼顾内存友好。
+
+下面是我们详细介绍一下 Redis 中的定期删除具体是如何做的。
+
+Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。这也就解释了为什么有的 key 过期了,并没有被删除。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
+
+另外,定期删除还会受到执行时间和过期 key 的比例的影响:
+
+- 执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间。
+- 如果这一批过期的 key 比例超过一个比例,就会重复执行此删除流程,以更积极地清理过期 key。相应地,如果过期的 key 比例低于这个比例,就会中断这一次定期删除循环,避免做过多的工作而获得很少的内存回收。
+
+Redis 7.2 版本的执行时间阈值是 **25ms**,过期 key 比例设定值是 **10%**。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
+#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
+#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
+ we do extra efforts. */
+```
+
+**每次随机抽查数量是多少?**
+
+`expire.c` 中定义了每次随机抽查的数量,Redis 7.2 版本为 20,也就是说每次会随机选择 20 个设置了过期时间的 key 判断是否过期。
+
+```c
+#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
+```
+
+**如何控制定期删除的执行频率?**
+
+在 Redis 中,定期删除的频率是由 **hz** 参数控制的。hz 默认为 10,代表每秒执行 10 次,也就是每秒钟进行 10 次尝试来查找并删除过期的 key。
+
+hz 的取值范围为 1~500。增大 hz 参数的值会提升定期删除的频率。如果你想要更频繁地执行定期删除任务,可以适当增加 hz 的值,但这会增加 CPU 的使用率。根据 Redis 官方建议,hz 的值不建议超过 100,对于大部分用户使用默认的 10 就足够了。
+
+下面是 hz 参数的官方注释,我翻译了其中的重要信息(Redis 7.2 版本)。
+
+
+
+There is also a similar parameter **dynamic-hz**. After this parameter is turned on, Redis will dynamically calculate a value based on hz. Redis provides and enables by default the ability to use adaptive hz values,
+
+Both parameters are in the Redis configuration file `redis.conf`:
+
+```properties
+# Default is 10
+hz 10
+# Enabled by default
+dynamic-hz yes
+```
+
+One more thing to mention, in addition to the periodic task of regularly deleting expired keys, there are also other periodic tasks such as closing timed-out client connections and updating statistics. The execution frequency of these periodic tasks is also determined by the hz parameter.
+
+**Why doesn’t regular deletion delete all expired keys? **
+
+This will have too big an impact on performance. If we have a very large number of keys, traversing the checks one by one is very time-consuming and will seriously affect performance. Redis designed this strategy to balance memory and performance.
+
+**Why not delete the key immediately after it expires? Wouldn't this waste a lot of memory space? **
+
+Because it is not easy to do, or the cost of this deletion method is too high. If we use the delay queue as the deletion strategy, there are the following problems:
+
+1. The overhead of the queue itself may be large: when there are many keys, a delay queue may not be able to accommodate them.
+2. Maintaining the delay queue is too troublesome: modifying the expiration time of a key requires adjusting its position in the delay queue, and concurrency control also needs to be introduced.
+
+### What should I do if a large number of keys expire together?
+
+When a large number of keys in Redis expire at the same point in time, the following problems may occur:
+
+- **Increased request latency**: Redis needs to consume CPU resources when processing expired keys. If the number of expired keys is large, it will cause the CPU usage of the Redis instance to increase, which will affect the processing speed of other requests, causing increased latency.
+- **Memory usage is too high**: Although expired keys have expired, they will still occupy memory space before Redis actually deletes them. If expired keys are not cleaned up in time, it may cause excessive memory usage or even cause a memory overflow.
+
+To avoid these problems, you can take the following options:
+
+1. **Try to avoid centralized expiration of keys**: Try to be as random as possible when setting the expiration time of keys.
+2. **Enable lazy free mechanism**: Modify the `redis.conf` configuration file and set the `lazyfree-lazy-expire` parameter to `yes` to enable the lazy free mechanism. After the lazy free mechanism is enabled, Redis will asynchronously delete expired keys in the background without blocking the main thread, thereby reducing the impact on Redis performance.
+
+### Do you understand the Redis memory elimination strategy?
+
+> Related questions: There are 20 million data in MySQL, but only 20 million data are stored in Redis. How to ensure that the data in Redis are hot data?
+
+Redis's memory elimination policy will only be triggered when the running memory reaches the configured maximum memory threshold, which is defined through the `maxmemory` parameter of `redis.conf`. Under 64-bit operating systems, `maxmemory` defaults to 0, which means there is no limit on the memory size. Under 32-bit operating systems, the default maximum memory value is 3GB.
+
+You can use the command `config get maxmemory` to view the value of `maxmemory`.
+
+```bash
+> config get maxmemory
+maxmemory
+0
+```
+
+Redis provides 6 memory elimination strategies:
+
+1. **volatile-lru (least recently used)**: Select the least recently used data from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+2. **volatile-ttl**: Select the data to be expired from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+3. **volatile-random**: Randomly select data for elimination from the data set (`server.db[i].expires`) with expiration time set.
+4. **allkeys-lru (least recently used)**: Remove the least recently used data from the data set (`server.db[i].dict`).
+5. **allkeys-random**: Randomly select data for elimination from the data set (`server.db[i].dict`).
+6. **no-eviction** (default memory eviction policy): It is forbidden to evict data. When the memory is not enough to accommodate newly written data, an error will be reported for the new write operation.
+
+After version 4.0, the following two types are added:
+
+7. **volatile-lfu (least frequently used)**: Select the least frequently used data from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+8. **allkeys-lfu (least frequently used)**: Remove the least frequently used data from the data set (`server.db[i].dict`).
+
+`allkeys-xxx` means to eliminate data from all key values, while `volatile-xxx` means to eliminate data from key values with an expiration time set.
+
+The enumeration array of memory elimination strategies is defined in `config.c`:
+
+```c
+configEnum maxmemory_policy_enum[] = {
+ {"volatile-lru", MAXMEMORY_VOLATILE_LRU},
+ {"volatile-lfu", MAXMEMORY_VOLATILE_LFU},
+ {"volatile-random",MAXMEMORY_VOLATILE_RANDOM},
+ {"volatile-ttl",MAXMEMORY_VOLATILE_TTL},
+ {"allkeys-lru",MAXMEMORY_ALLKEYS_LRU},
+ {"allkeys-lfu",MAXMEMORY_ALLKEYS_LFU},
+ {"allkeys-random",MAXMEMORY_ALLKEYS_RANDOM},
+ {"noeviction",MAXMEMORY_NO_EVICTION},
+ {NULL, 0}
+};
+```
+
+You can use the `config get maxmemory-policy` command to view the current Redis memory elimination policy.
+
+```bash
+> config get maxmemory-policy
+maxmemory-policy
+noeviction
+```
+
+You can modify the memory elimination policy through the `config set maxmemory-policy memory elimination policy` command, which will take effect immediately. However, it will become invalid after restarting Redis in this way. Modifying the `maxmemory-policy` parameter in `redis.conf` will not be invalidated by restarting. However, it needs to be restarted before the modification can take effect.
+
+```properties
+maxmemory-policy noeviction
+```
+
+For detailed instructions on the elimination strategy, please refer to the official Redis documentation: .
+
+## Reference
+
+- "Redis Development and Operation and Maintenance"
+- "Redis Design and Implementation"
+- "Redis Core Principles and Practical Combat"
+- Redis command manual:
+- RedisSearch Ultimate User Guide, you deserve it! :
+- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-questions-02.en.md b/docs_en/database/redis/redis-questions-02.en.md
new file mode 100644
index 00000000000..2a520856220
--- /dev/null
+++ b/docs_en/database/redis/redis-questions-02.en.md
@@ -0,0 +1,820 @@
+---
+title: Summary of common Redis interview questions (Part 2)
+category: database
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis interview questions, Redis transactions, Redis performance optimization, Redis cache penetration, Redis cache breakdown, Redis cache avalanche, Redis bigkey, Redis hotkey, Redis slow query, Redis memory fragmentation, Redis cluster, Redis Sentinel, Redis Cluster, Redis pipeline, Redis Lua script
+ - - meta
+ - name: description
+ content: Summary of the latest Redis interview questions (Part 2): In-depth analysis of Redis transaction principles, performance optimization (pipeline/Lua/bigkey/hotkey), cache penetration/breakdown/avalanche solutions, slow queries and memory fragmentation, and detailed explanations of Redis Sentinel and Cluster clusters. Help you easily cope with back-end technical interviews!
+---
+
+
+
+## Redis transactions
+
+### What is a Redis transaction?
+
+You can understand transactions in Redis as: **Redis transactions provide a function to package multiple command requests. Then, execute all the packaged commands in sequence without being interrupted midway. **
+
+Redis transactions are rarely used in actual development, and their functions are relatively useless. Do not confuse them with the transactions of relational databases that we usually understand.
+
+In addition to not meeting atomicity and durability, each command in the transaction will interact with the Redis server through the network, which is a waste of resources. Obviously it is enough to execute multiple commands in batches at one time, but this kind of operation is really incomprehensible.
+
+Therefore, Redis transactions are not recommended for daily development.
+
+### How to use Redis transactions?
+
+Redis can implement transaction functions through commands such as **`MULTI`, `EXEC`, `DISCARD` and `WATCH`**.
+
+```bash
+> MULTI
+OK
+> SET PROJECT "JavaGuide"
+QUEUED
+>GET PROJECT
+QUEUED
+> EXEC
+1) OK
+2) "JavaGuide"
+```
+
+You can enter multiple commands after the [`MULTI`](https://redis.io/commands/multi) command. Redis will not execute these commands immediately, but will put them in the queue. When the [`EXEC`](https://redis.io/commands/exec) command is called, all commands will be executed.
+
+The process goes like this:
+
+1. Start transaction (`MULTI`);
+2. Command enqueue (batch operation of Redis commands, executed in first-in, first-out (FIFO) order);
+3. Execute transaction (`EXEC`).
+
+You can also cancel a transaction through the [`DISCARD`](https://redis.io/commands/discard) command, which will clear all commands saved in the transaction queue.
+
+```bash
+> MULTI
+OK
+> SET PROJECT "JavaGuide"
+QUEUED
+>GET PROJECT
+QUEUED
+> DISCARD
+OK
+```
+
+You can monitor the specified Key through the [`WATCH`](https://redis.io/commands/watch) command. When calling the `EXEC` command to execute a transaction, if a Key monitored by the `WATCH` command is modified by **other clients/Session**, the entire transaction will not be executed.
+
+```bash
+# client 1
+> SET PROJECT "RustGuide"
+OK
+> WATCH PROJECT
+OK
+> MULTI
+OK
+> SET PROJECT "JavaGuide"
+QUEUED
+
+# client 2
+# Modify the value of PROJECT before client 1 executes the EXEC command to commit the transaction
+> SET PROJECT "GoGuide"
+
+# client 1
+# The modification failed because the value of PROJECT was modified by client 2
+> EXEC
+(nil)
+>GET PROJECT
+"GoGuide"
+```
+
+However, if **WATCH** and **Transaction** are in the same Session, and the modification of the Key monitored by **WATCH** occurs within the transaction, the transaction can be executed successfully (related issue: [Different effects when the WATCH command encounters the MULTI command](https://github.com/Snailclimb/JavaGuide/issues/1714)).
+
+Modify the Key monitored by WATCH within the transaction:
+
+```bash
+> SET PROJECT "JavaGuide"
+OK
+> WATCH PROJECT
+OK
+> MULTI
+OK
+> SET PROJECT "JavaGuide1"
+QUEUED
+> SET PROJECT "JavaGuide2"
+QUEUED
+> SET PROJECT "JavaGuide3"
+QUEUED
+> EXEC
+1) OK
+2) OK
+3) OK
+127.0.0.1:6379> GET PROJECT
+"JavaGuide3"
+```
+
+Modify the Key monitored by WATCH outside the transaction:
+
+```bash
+> SET PROJECT "JavaGuide"
+OK
+> WATCH PROJECT
+OK
+> SET PROJECT "JavaGuide2"
+OK
+> MULTI
+OK
+> GET USER
+QUEUED
+> EXEC
+(nil)
+```
+
+The relevant introduction to the Redis official website [https://redis.io/topics/transactions](https://redis.io/topics/transactions) is as follows:
+
+
+
+### Do Redis transactions support atomicity?
+
+Redis transactions are different from the relational database transactions we usually understand. We know that transactions have four major characteristics: **1. Atomicity**, **2. Isolation**, **3. Durability**, **4. Consistency**.
+
+1. **Atomicity**: A transaction is the smallest execution unit and does not allow division. The atomicity of transactions ensures that actions either complete completely or have no effect at all;
+2. **Isolation**: When accessing the database concurrently, a user's transaction will not be interfered by other transactions, and the database is independent between concurrent transactions;
+3. **Durability**: after a transaction is committed. Its changes to the data in the database are durable and should not have any impact even if the database fails;
+4. **Consistency**: The data remains consistent before and after executing a transaction, and the results of multiple transactions reading the same data are the same.
+
+In the case of a Redis transaction running error, except for the command with an error during execution, other commands can be executed normally. Moreover, Redis transactions do not support rollback operations. Therefore, Redis transactions do not actually satisfy atomicity.
+
+The Redis official website also explains why it does not support rollback. To put it simply, Redis developers feel that there is no need to support rollback, which is simpler, more convenient and has better performance. Redis developers feel that even command execution errors should be discovered during the development process rather than during the production process.
+
+
+
+**Related issues**:
+
+- [issue#452: Regarding the issue that Redis transactions do not satisfy atomicity](https://github.com/Snailclimb/JavaGuide/issues/452).
+- [Issue#491: About Redis without transaction rollback? ](https://github.com/Snailclimb/JavaGuide/issues/491).
+
+### Do Redis transactions support persistence?
+
+One important thing that makes Redis different from Memcached is that Redis supports persistence and supports 3 persistence methods:
+
+- Snapshotting (RDB);
+- Append-only file (AOF);
+- Hybrid persistence of RDB and AOF (new in Redis 4.0).
+
+Compared with RDB persistence, AOF persistence has better real-time performance. There are three different AOF persistence methods (`fsync` strategy) in the Redis configuration file. They are:
+
+```bash
+appendfsync always #Every time a data modification occurs, the fsync function will be called to synchronize the AOF file. After fsync is completed, the thread returns, which will seriously reduce the speed of Redis.
+appendfsync everysec #Call the fsync function to synchronize the AOF file once every second
+appendfsync no #Let the operating system decide when to synchronize, usually every 30 seconds
+```
+
+Data loss will occur when the `fsync` policy of AOF persistence is no and everysec. Always can basically meet the persistence requirements, but the performance is too poor and will not be used in the actual development process.
+
+Therefore, the durability of Redis transactions cannot be guaranteed.### 如何解决 Redis 事务的缺陷?
+
+Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常类似。我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
+
+一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
+
+不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此,**严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。**
+
+如果想要让 Lua 脚本中的命令全部执行,必须保证语句语法和命令都是对的。
+
+另外,Redis 7.0 新增了 [Redis functions](https://redis.io/docs/latest/develop/programmability/functions-intro/) 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本。
+
+## ⭐️Redis 性能优化(重要)
+
+除了下面介绍的内容之外,再推荐两篇不错的文章:
+
+- [你的 Redis 真的变慢了吗?性能优化如何做 - 阿里开发者](https://mp.weixin.qq.com/s/nNEuYw0NlYGhuKKKKoWfcQ)。
+- [Redis 常见阻塞原因总结 - JavaGuide](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html)。
+
+### 使用批量操作减少网络传输
+
+一个 Redis 命令的执行可以简化为以下 4 步:
+
+1. 发送命令;
+2. 命令排队;
+3. 命令执行;
+4. 返回结果。
+
+其中,第 1 步和第 4 步耗费时间之和称为 **Round Trip Time(RTT,往返时间)**,也就是数据在网络上传输的时间。
+
+使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
+
+另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在 `read()` 和 `write()` 系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:。
+
+#### 原生批量操作命令
+
+Redis 中有一些原生支持批量操作的命令,比如:
+
+- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
+- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
+- `SADD`(向指定集合添加一个或多个元素)
+- ……
+
+不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
+
+整个步骤的简化版如下(通常由 Redis 客户端实现,无需我们自己再手动实现):
+
+1. 找到 key 对应的所有 hash slot;
+2. 分别向对应的 Redis 节点发起 `MGET` 请求获取数据;
+3. 等待所有请求执行结束,重新组装结果数据,保持跟入参 key 的顺序一致,然后返回结果。
+
+如果想要解决这个多次网络传输的问题,比较常用的办法是自己维护 key 与 slot 的关系。不过这样不太灵活,虽然带来了性能提升,但同样让系统复杂性提升。
+
+> Redis Cluster 并没有使用一致性哈希,采用的是 **哈希槽分区**,每一个键值对都属于一个 **hash slot(哈希槽)**。当客户端发送命令请求的时候,需要先根据 key 通过上面的计算公式找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标 Redis 节点。
+>
+> 我在 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 这篇文章中详细介绍了 Redis Cluster 这部分的内容,感兴趣地可以看看。
+
+#### pipeline
+
+对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
+
+与 `MGET`、`MSET` 等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
+
+原生批量操作命令和 pipeline 的是有区别的,使用的时候需要注意:
+
+- 原生批量操作命令是原子操作,pipeline 是非原子操作。
+- pipeline 可以打包不同的命令,原生批量操作命令不可以。
+- 原生批量操作命令是 Redis 服务端支持实现的,而 pipeline 需要服务端和客户端的共同实现。
+
+顺带补充一下 pipeline 和 Redis 事务的对比:
+
+- 事务是原子操作,pipeline 是非原子操作。两个不同的事务不会同时运行,而 pipeline 可以同时以交错方式执行。
+- Redis 事务中每个命令都需要发送到服务端,而 Pipeline 只需要发送一次,请求次数更少。
+
+> 事务可以看作是一个原子操作,但其实并不满足原子性。当我们提到 Redis 中的原子操作时,主要指的是这个操作(比如事务、Lua 脚本)不会被其他操作(比如其他事务、Lua 脚本)打扰,并不能完全保证这个操作中的所有写命令要么都执行要么都不执行。这主要也是因为 Redis 是不支持回滚操作。
+
+
+
+另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 **Lua 脚本**。
+
+#### Lua 脚本
+
+Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 **原子操作**。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
+
+并且,Lua 脚本中支持一些简单的逻辑处理比如使用命令读取值并在 Lua 脚本中进行处理,这同样是 pipeline 所不具备的。
+
+不过, Lua 脚本依然存在下面这些缺陷:
+
+- 如果 Lua 脚本运行时出错并中途结束,之后的操作不会进行,但是之前已经发生的写操作不会撤销,所以即使使用了 Lua 脚本,也不能实现类似数据库回滚的原子性。
+- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 **hash slot(哈希槽)** 上。
+
+### 大量 key 集中过期问题
+
+我在前面提到过:对于过期 key,Redis 采用的是 **定期删除+惰性/懒汉式删除** 策略。
+
+定期删除执行过程中,如果突然遇到大量过期 key 的话,客户端请求必须等待定期清理过期 key 任务线程执行完成,因为这个这个定期任务线程是在 Redis 主线程中执行的。这就导致客户端请求没办法被及时处理,响应速度会比较慢。
+
+**如何解决呢?** 下面是两种常见的方法:
+
+1. 给 key 设置随机过期时间。
+2. 开启 lazy-free(惰性删除/延迟释放)。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
+
+个人建议不管是否开启 lazy-free,我们都尽量给 key 设置随机过期时间。
+
+### Redis bigkey(大 Key)
+
+#### 什么是 bigkey?
+
+简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
+
+- String 类型的 value 超过 1MB
+- The value of a composite type (List, Hash, Set, Sorted Set, etc.) contains more than 5000 elements (however, for a value of a composite type, the more elements it contains, the more memory it takes up).
+
+
+
+#### How did bigkey come about? What's the harm?
+
+Bigkey is usually generated for the following reasons:
+
+- Improper program design, such as directly using the String type to store binary data corresponding to larger files.
+- Inadequate consideration of the data scale of the business. For example, when using collection types, the rapid growth of data volume was not considered.
+- Failure to clean up junk data in time, such as a large number of redundant useless key-value pairs in the hash.
+
+In addition to consuming more memory space and bandwidth, bigkey will also have a relatively large impact on performance.
+
+In this article [Summary of Common Redis Blocking Causes](./redis-common-blocking-problems-summary.md) we mentioned that large keys can also cause blocking problems. Specifically, it is mainly reflected in the following three aspects:
+
+1. Client timeout blocking: Since Redis executes commands in a single thread, and it takes a long time to operate large keys, Redis will be blocked. From the perspective of the client, there will be no response for a long time.
+2. Network blocking: Each time a large key is obtained, the network traffic is large. If the size of a key is 1 MB and the number of visits per second is 1,000, then 1,000 MB of traffic will be generated per second, which is catastrophic for servers with ordinary Gigabit network cards.
+3. Working thread blocking: If you use del to delete a large key, the working thread will be blocked, making it impossible to process subsequent commands.
+
+The blocking problem caused by large keys will further affect master-slave synchronization and cluster expansion.
+
+In summary, there are many potential problems caused by big keys, and we should try to avoid the existence of big keys in Redis.
+
+#### How to discover bigkey?
+
+**1. Use the `--bigkeys` parameter that comes with Redis to search. **
+
+```bash
+# redis-cli -p 6379 --bigkeys
+
+# Scanning the entire keyspace to find biggest keys as well as
+# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
+# per 100 SCAN commands (not usually needed).
+
+[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes
+[00.00%] Biggest list found so far '"my-list"' with 17 items
+
+-------- summary -------
+
+Sampled 5 keys in the keyspace!
+Total key length in bytes is 264 (avg len 52.80)
+
+Biggest list found '"my-list"' has 17 items
+Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' has 4437 bytes
+
+1 lists with 17 items (20.00% of keys, avg size 17.00)
+0 hashes with 0 fields (00.00% of keys, avg size 0.00)
+4 strings with 4831 bytes (80.00% of keys, avg size 1207.75)
+0 streams with 0 entries (00.00% of keys, avg size 0.00)
+0 sets with 0 members (00.00% of keys, avg size 0.00)
+0 zsets with 0 members (00.00% of keys, avg size 0.00
+```
+
+From the running results of this command, we can see that this command will scan (Scan) all keys in Redis, which will have a slight impact on the performance of Redis. Moreover, this method can only find the top 1 bigkey of each data structure (the String data type that takes up the largest memory, and the composite data type that contains the most elements). However, having many elements in a key does not mean that it takes up more memory. We need to make further judgments based on specific business conditions.
+
+When executing this command online, in order to reduce the impact on Redis, you need to specify the `-i` parameter to control the frequency of scanning. `redis-cli -p 6379 --bigkeys -i 3` means that the rest interval after each scan during the scanning process is 3 seconds.
+
+**2. Use the SCAN command that comes with Redis**
+
+The `SCAN` command can return matching keys according to a certain pattern and number. After obtaining the key, you can use `STRLEN`, `HLEN`, `LLEN` and other commands to return its length or number of members.
+
+| Data structure | Command | Complexity | Result (corresponding to key) |
+| ---------- | ------ | ------ | ------------------ |
+| String | STRLEN | O(1) | The length of the string value |
+| Hash | HLEN | O(1) | Number of fields in the hash table |
+| List | LLEN | O(1) | Number of elements in the list |
+| Set | SCARD | O(1) | Number of set elements |
+| Sorted Set | ZCARD | O(1) | Number of elements in a sorted set |
+
+For collection types, you can also use the `MEMORY USAGE` command (Redis 4.0+). This command will return the memory space occupied by key-value pairs.
+
+**3. Use open source tools to analyze RDB files. **
+
+Find big keys by analyzing RDB files. The premise of this solution is that your Redis uses RDB persistence.
+
+There are ready-made codes/tools available online that can be used directly:
+
+- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools): A tool written in Python language to analyze Redis RDB snapshot files.
+- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys): A tool written in Go language to analyze Redis's RDB snapshot file, with better performance.
+
+**4. Use the Redis analysis service of the public cloud. **
+
+If you are using the public cloud Redis service, you can see if it provides key analysis function (usually it does).
+
+Here we take Alibaba Cloud Redis as an example. It supports bigkey real-time analysis and discovery. The document address is: .
+
+
+
+#### How to deal with bigkey?
+
+Common processing and optimization methods for bigkey are as follows (these methods can be used in conjunction):
+
+- **Split bigkey**: Split a bigkey into multiple small keys. For example, a Hash containing tens of thousands of fields is split into multiple Hash according to a certain strategy (such as secondary hashing).
+- **Manual Cleanup**: Redis 4.0+ can use the `UNLINK` command to asynchronously delete one or more specified keys. For Redis 4.0 and below, you can consider using the `SCAN` command in combination with the `DEL` command to delete in batches.
+- **Adopt appropriate data structures**: For example, do not use String to save file binary data, use HyperLogLog to count page UV, and Bitmap to save status information (0/1).
+- **Turn on lazy-free (lazy deletion/delayed release)**: The lazy-free feature was introduced in Redis 4.0. It means that Redis uses an asynchronous method to delay the release of the memory used by the key, and hands the operation to a separate sub-thread to avoid blocking the main thread.
+
+### Redis hotkey (hot key)
+
+#### What is a hotkey?
+
+If a key is accessed more often and significantly more than other keys, then this key can be regarded as a hotkey. For example, if a Redis instance processes 5,000 requests per second, and a certain key has 2,000 visits per second, then this key can be regarded as a hotkey.
+
+The main reason for the emergence of hotkey is the sudden increase in the number of visits to a certain hot data, such as major hot search events and products participating in flash sales.#### What are the dangers of hotkey?
+
+Processing hotkeys consumes a lot of CPU and bandwidth and may affect the normal processing of other requests by the Redis instance. In addition, if the sudden request to access the hotkey exceeds the processing capacity of Redis, Redis will directly crash. In this case, a large number of requests will fall on the later database, possibly causing the database to crash.
+
+Therefore, hotkey is likely to become the bottleneck of system performance and needs to be optimized separately to ensure high availability and stability of the system.
+
+#### How to find hotkey?
+
+**1. Use the `--hotkeys` parameter that comes with Redis to search. **
+
+The `hotkeys` parameter has been added to Redis version 4.0.3, which can return the number of times all keys have been accessed.
+
+The prerequisite for using this solution is that the `maxmemory-policy` parameter of Redis Server is set to the LFU algorithm, otherwise the error shown below will occur.
+
+```bash
+# redis-cli -p 6379 --hotkeys
+
+# Scanning the entire keyspace to find hot keys as well as
+# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
+# per 100 SCAN commands (not usually needed).
+
+Error: ERR An LFU maxmemory policy is not selected, access frequency not tracked. Please note that when switching between policies at runtime LRU and LFU data will take some time to adjust.
+```
+
+There are two LFU algorithms in Redis:
+
+1. **volatile-lfu (least frequently used)**: Select the least frequently used data from the data set (`server.db[i].expires`) with an expiration time set for elimination.
+2. **allkeys-lfu (least frequently used)**: When the memory is not enough to accommodate newly written data, in the key space, remove the least frequently used key.
+
+The following is an example from the configuration file `redis.conf`:
+
+```properties
+# Use volatile-lfu strategy
+maxmemory-policy volatile-lfu
+
+# Or use allkeys-lfu strategy
+maxmemory-policy allkeys-lfu
+```
+
+It should be noted that the `hotkeys` parameter command will also increase the CPU and memory consumption (global scan) of the Redis instance, so it needs to be used with caution.
+
+**2. Use the `MONITOR` command. **
+
+The `MONITOR` command is a way provided by Redis to view all operations of Redis in real time. It can be used to temporarily monitor the operation of a Redis instance, including read, write, delete and other operations.
+
+Since this command has a large impact on Redis performance, it is prohibited to open `MONITOR` for a long time (it is recommended to use this command with caution in a production environment).
+
+```bash
+#redis-cli
+127.0.0.1:6379>MONITOR
+OK
+1683638260.637378 [0 172.17.0.1:61516] "ping"
+1683638267.144236 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638268.941863 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638269.551671 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638270.646256 [0 172.17.0.1:61516] "ping"
+1683638270.849551 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638271.926945 [0 172.17.0.1:61518] "smembers" "mySet"
+1683638274.276599 [0 172.17.0.1:61518] "smembers" "mySet2"
+1683638276.327234 [0 172.17.0.1:61518] "smembers" "mySet"
+```
+
+In the event of an emergency, we can choose to briefly execute the `MONITOR` command at an appropriate time and redirect the output to a file. After closing the `MONITOR` command, we can find out the hotkey during this period by classifying and analyzing the requests in the file.
+
+**3. Use open source projects. **
+
+JD Retail's [hotkey](https://gitee.com/jd-platform-opensource/hotkey) project not only supports hotkey discovery, but also supports hotkey processing.
+
+
+
+**4. Estimate in advance based on business conditions. **
+
+Some hotkeys can be estimated based on business conditions, such as product data participating in flash sale activities, etc. However, we cannot predict the emergence of all hotkeys, such as breaking hot news events.
+
+**5. Record analysis in business code. **
+
+Add corresponding logic to the business code to record and analyze key access conditions. However, this method will increase the complexity of the business code and is generally not used.
+
+**6. Use the Redis analysis service of the public cloud. **
+
+If you are using the public cloud Redis service, you can see if it provides key analysis function (usually it does).
+
+Here we take Alibaba Cloud Redis as an example. It supports hotkey real-time analysis and discovery. The document address is: .
+
+
+
+#### How to solve hotkey?
+
+Common processing and optimization methods for hotkey are as follows (these methods can be used in conjunction):
+
+- **Read and write separation**: The master node handles write requests, and the slave node handles read requests.
+- **Use Redis Cluster**: Store hotspot data distributedly on multiple Redis nodes.
+- **Level 2 Cache**: Hotkey is processed using Level 2 cache, and a copy of the hotkey is stored in the JVM local memory (Caffeine can be used).
+
+In addition to these methods, if you use the public cloud Redis service, you can also pay attention to the out-of-the-box solutions it provides.
+
+Here we take Alibaba Cloud Redis as an example. It supports optimizing hot key issues through the proxy query cache function (Proxy Query Cache).
+
+
+
+### Slow query command
+
+#### Why are there slow query commands?
+
+We know that the execution of a Redis command can be simplified to the following 4 steps:
+
+1. Send a command;
+2. Command queuing;
+3. Command execution;
+4. Return the result.
+
+Redis slow query counts the time it takes to execute this step of the command. Slow query commands are those commands that take a long time to execute.
+
+Why does Redis have slow query commands?
+
+Most commands in Redis have O(1) time complexity, but there are also a few commands with O(n) time complexity, such as:
+
+- `KEYS *`: will return all keys that match the rules.
+- `HGETALL`: will return all key-value pairs in a Hash.
+- `LRANGE`: Returns elements within the specified range in List.
+- `SMEMBERS`: Returns all elements in Set.
+- `SINTER`/`SUNION`/`SDIFF`: Calculate the intersection/union/difference of multiple Sets.
+-…
+
+Since the time complexity of these commands is O(n), sometimes the entire table will be scanned. As n increases, the execution time will become longer. However, these commands do not necessarily cannot be used, but the value of N needs to be specified. In addition, if you have traversal requirements, you can use `HSCAN`, `SSCAN`, `ZSCAN` instead.
+
+In addition to these O(n) time complexity commands that may cause slow queries, there are also some commands that may have a time complexity above O(N), such as:
+
+- `ZRANGE`/`ZREVRANGE`: Returns all elements within the specified ranking range in the specified Sorted Set. The time complexity is O(log(n)+m), where n is the number of all elements and m is the number of elements returned. When m and n are quite large, the time complexity of O(n) is smaller.- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
+- ……
+
+#### 如何找到慢查询命令?
+
+Redis 提供了一个内置的**慢查询日志 (Slow Log)** 功能,专门用来记录执行时间超过指定阈值的命令。这对于排查性能瓶颈、找出导致 Redis 阻塞的“慢”操作非常有帮助,原理和 MySQL 的慢查询日志类似。
+
+在 `redis.conf` 文件中,我们可以使用 `slowlog-log-slower-than` 参数设置耗时命令的阈值,并使用 `slowlog-max-len` 参数设置耗时命令的最大记录条数。
+
+当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than` 阈值的命令时,就会将该命令记录在慢查询日志(slow log)中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
+
+⚠️ 注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
+
+`slowlog-log-slower-than` 和 `slowlog-max-len` 的默认配置如下(可以自行修改):
+
+```properties
+# The following time is expressed in microseconds, so 1000000 is equivalent
+# to one second. Note that a negative number disables the slow log, while
+# a value of zero forces the logging of every command.
+slowlog-log-slower-than 10000
+
+# There is no limit to this length. Just be aware that it will consume memory.
+# You can reclaim memory used by the slow log with SLOWLOG RESET.
+slowlog-max-len 128
+```
+
+除了修改配置文件之外,你也可以直接通过 `CONFIG` 命令直接设置:
+
+```bash
+# 命令执行耗时超过 10000 微妙(即10毫秒)就会被记录
+CONFIG SET slowlog-log-slower-than 10000
+# 只保留最近 128 条耗时命令
+CONFIG SET slowlog-max-len 128
+```
+
+获取慢查询日志的内容很简单,直接使用 `SLOWLOG GET` 命令即可。
+
+```bash
+127.0.0.1:6379> SLOWLOG GET #慢日志查询
+ 1) 1) (integer) 5
+ 2) (integer) 1684326682
+ 3) (integer) 12000
+ 4) 1) "KEYS"
+ 2) "*"
+ 5) "172.17.0.1:61152"
+ 6) ""
+ // ...
+```
+
+慢查询日志中的每个条目都由以下六个值组成:
+
+1. **唯一 ID**: 日志条目的唯一标识符。
+2. **时间戳 (Timestamp)**: 命令执行完成时的 Unix 时间戳。
+3. **耗时 (Duration)**: 命令执行所花费的时间,单位是**微秒**。
+4. **命令及参数 (Command)**: 执行的具体命令及其参数数组。
+5. **客户端信息 (Client IP:Port)**: 执行命令的客户端地址和端口。
+6. **客户端名称 (Client Name)**: 如果客户端设置了名称 (CLIENT SETNAME)。
+
+`SLOWLOG GET` 命令默认返回最近 10 条的的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
+
+下面是其他比较常用的慢查询相关的命令:
+
+```bash
+# 返回慢查询命令的数量
+127.0.0.1:6379> SLOWLOG LEN
+(integer) 128
+# 清空慢查询命令
+127.0.0.1:6379> SLOWLOG RESET
+OK
+```
+
+### Redis 内存碎片
+
+**相关问题**:
+
+1. 什么是内存碎片?为什么会有 Redis 内存碎片?
+2. 如何清理 Redis 内存碎片?
+
+**参考答案**:[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
+
+## ⭐️Redis 生产问题(重要)
+
+### 缓存穿透
+
+#### 什么是缓存穿透?
+
+缓存穿透说简单点就是大量请求的 key 是不合理的,**根本不存在于缓存中,也不存在于数据库中**。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+
+
+
+举个例子:某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。也就是说这些请求最终都落到了数据库上,对数据库造成了巨大的压力。
+
+#### 有哪些解决办法?
+
+最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
+
+**1)缓存无效 key**
+
+如果缓存和数据库都查不到某个 key 的数据,就写一个到 Redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点,比如 1 分钟。
+
+另外,这里多说一嘴,一般情况下我们是这样设计 key 的:`表名:列名:主键名:主键值`。
+
+如果用 Java 代码展示的话,差不多是下面这样的:
+
+```java
+public Object getObjectInclNullById(Integer id) {
+ // 从缓存中获取数据
+ Object cacheValue = cache.get(id);
+ // 缓存为空
+ if (cacheValue == null) {
+ // 从数据库中获取
+ Object storageValue = storage.get(key);
+ // 缓存空对象
+ cache.set(key, storageValue);
+ // 如果存储数据为空,需要设置一个过期时间(300秒)
+ if (storageValue == null) {
+ // 必须设置过期时间,否则有被攻击的风险
+ cache.expire(key, 60 * 5);
+ }
+ return storageValue;
+ }
+ return cacheValue;
+}
+```
+
+**2)布隆过滤器**
+
+布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
+
+
+
+Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 KB ≈ 122KB 的空间。
+
+
+
+具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
+
+加入布隆过滤器之后的缓存处理流程图如下:
+
+
+
+更多关于布隆过滤器的详细介绍可以看看我的这篇原创:[不了解布隆过滤器?一文给你整的明明白白!](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html),强烈推荐。
+
+**3)接口限流**
+
+根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单。
+
+后面提到的缓存击穿和雪崩都可以配合接口限流来解决,毕竟这些问题的关键都是有很多请求落到了数据库上造成数据库压力过大。
+
+限流的具体方案可以参考这篇文章:[服务限流详解](https://javaguide.cn/high-availability/limit-request.html)。
+
+### 缓存击穿
+
+#### 什么是缓存击穿?
+
+缓存击穿中,请求的 key 对应的是 **热点数据**,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)**。这就可能会导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。
+
+
+
+举个例子:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
+
+#### 有哪些解决办法?
+
+1. **永不过期**(不推荐):设置热点数据永不过期或者过期时间比较长。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **加锁**(看情况):在缓存失效后,通过设置互斥锁确保只有一个请求去查询数据库并更新缓存。
+
+#### 缓存穿透和缓存击穿有什么区别?
+
+缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
+
+缓存击穿中,请求的 key 对应的是 **热点数据** ,该数据 **存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期)** 。
+
+### 缓存雪崩
+
+#### 什么是缓存雪崩?
+
+我发现缓存雪崩这名字起的有点意思,哈哈。
+
+实际上,缓存雪崩描述的就是这样一个简单的场景:**缓存在同一时间大面积的失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。** 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
+
+另外,缓存服务宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。
+
+
+
+举个例子:缓存中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
+
+#### 有哪些解决办法?
+
+**针对 Redis 服务不可用的情况**:
+
+1. **Redis 集群**:采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。Redis Cluster 和 Redis Sentinel 是两种最常用的 Redis 集群实现方案,详细介绍可以参考:[Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html)。
+2. **多级缓存**:设置多级缓存,例如本地缓存+Redis 缓存的二级缓存组合,当 Redis 缓存出现问题时,还可以从本地缓存中获取到部分数据。
+
+**针对大量缓存同时失效的情况**:
+
+1. **设置随机失效时间**(可选):为缓存设置随机的失效时间,例如在固定过期时间的基础上加上一个随机值,这样可以避免大量缓存同时到期,从而减少缓存雪崩的风险。
+2. **提前预热**(推荐):针对热点数据提前预热,将其存入缓存中并设置合理的过期时间,比如秒杀场景下的数据在秒杀结束之前不过期。
+3. **持久缓存策略**(看情况):虽然一般不推荐设置缓存永不过期,但对于某些关键性和变化不频繁的数据,可以考虑这种策略。
+
+#### 缓存预热如何实现?
+
+常见的缓存预热方式有两种:
+
+1. 使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
+2. 使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存。
+
+#### 缓存雪崩和缓存击穿有什么区别?
+
+缓存雪崩和缓存击穿比较像,但缓存雪崩导致的原因是缓存中的大量或者所有数据失效,缓存击穿导致的原因主要是某个热点数据不存在于缓存中(通常是因为缓存中的那份数据已经过期)。
+
+### 如何保证缓存和数据库数据的一致性?
+
+缓存和数据库一致性是个挺常见的技术挑战。引入缓存主要是为了提升性能、减轻数据库压力,但确实会带来数据不一致的风险。绝对的一致性往往意味着更高的系统复杂度和性能开销,所以实践中我们通常会根据业务场景选择合适的策略,在性能和一致性之间找到一个平衡点。
+
+下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。这是非常常用的一种缓存读写策略,它的读写逻辑是这样的:
+
+- **读操作**:
+ 1. 先尝试从缓存读取数据。
+ 2. 如果缓存命中,直接返回数据。
+ 3. 如果缓存未命中,从数据库查询数据,将查到的数据放入缓存并返回数据。
+- **写操作**:
+ 1. 先更新数据库。
+ 2. 再直接删除缓存中对应的数据。
+
+图解如下:
+
+
+
+
+
+如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说有两个解决方案:
+
+1. **缓存失效时间(TTL - Time To Live)变短**(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
+2. **增加缓存更新重试机制**(常用):如果缓存服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。不过,这里更适合引入消息队列实现异步重试,将删除缓存重试的消息投递到消息队列,然后由专门的消费者来重试,直到成功。虽然说多引入了一个消息队列,但其整体带来的收益还是要更高一些。
+
+相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
+
+### 哪些情况可能会导致 Redis 阻塞?
+
+常见的导致 Redis 阻塞原因有:
+
+- `O(n)` 复杂度命令执行(如 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS` 等),随着数据量增大导致执行时间过长。
+- 执行 `SAVE` 命令生成 RDB 快照时同步阻塞主线程,而 `BGSAVE` 通过 `fork` 子进程避免阻塞。
+- AOF 记录日志在主线程中进行,可能因命令执行后写日志而阻塞后续命令。
+- AOF 刷盘(fsync)时后台线程同步到磁盘,磁盘压力大导致 `fsync` 阻塞,进而阻塞主线程 `write` 操作,尤其在 `appendfsync always` 或 `everysec` 配置下明显。
+- AOF 重写过程中将重写缓冲区内容追加到新 AOF 文件时产生阻塞。
+- Operating large keys (string > 1MB or composite type elements > 5000) causes client timeouts, network blocking, and worker thread blocking.
+- Using `flushdb` or `flushall` to clear the database involves deleting a large number of key-value pairs and releasing memory, causing the main thread to block.
+- Data migration is a synchronous operation when the cluster is expanded or reduced. Migration of large keys causes nodes at both ends to be blocked for a long time, which may trigger failover.
+- Insufficient memory triggers Swap, and the operating system swaps out the Redis memory to the hard disk, causing a sharp decline in read and write performance.
+- Other processes excessively occupy the CPU, causing Redis throughput to decrease.
+- Network problems such as connection rejection, high latency, network card soft interrupt, etc. cause Redis to block.
+
+For a detailed introduction, you can read this article: [Summary of common blocking causes in Redis](https://javaguide.cn/database/redis/redis-common-blocking-problems-summary.html).
+
+## Redis cluster
+
+**Redis Sentinel**:
+
+1. What is Sentinel? What's the use?
+2. How does Sentinel detect whether a node is offline? What is the difference between subjective offline and objective offline?
+3. How does Sentinel implement failover?
+4. Why is it recommended to deploy multiple sentinel nodes (sentinel cluster)?
+5. How does Sentinel choose a new master (election mechanism)?
+6. How to select Leader from Sentinel cluster?
+7. Can Sentinel prevent split-brain?
+
+**Redis Cluster**:
+
+1. Why do you need Redis Cluster? What problem was solved? What are the advantages?
+2. How is Redis Cluster sharded?
+3. Why are the hash slots of Redis Cluster 16384?
+4. How to determine which hash slot a given key should be distributed to?
+5. Does Redis Cluster support redistribution of hash slots?
+6. Can Redis Cluster provide services during expansion and contraction?
+7. How do nodes in Redis Cluster communicate?
+
+**Reference answer**: [Detailed explanation of Redis cluster (paid)](https://javaguide.cn/database/redis/redis-cluster.html).
+
+## Redis usage specifications
+
+In the actual use of Redis, we try to adhere to some common specifications, such as:
+
+1. Use a connection pool: avoid frequently creating and closing client connections.
+2. Try not to use O(n) commands. When using O(n) commands, pay attention to the number of n: O(n) commands such as `KEYS *`, `HGETALL`, `LRANGE`, `SMEMBERS`, `SINTER`/`SUNION`/`SDIFF` are not unusable, but the value of n needs to be clear. In addition, if you have traversal requirements, you can use `HSCAN`, `SSCAN`, `ZSCAN` instead.
+3. Use batch operations to reduce network transmission: native batch operation commands (such as `MGET`, `MSET`, etc.), pipeline, Lua scripts.
+4. Try not to use Redis transactions: The functions implemented by Redis transactions are relatively useless, and you can use Lua scripts instead.
+5. It is forbidden to turn on the monitor for a long time: it will have a great impact on performance.
+6. Control the life cycle of the key: Avoid storing too much data that is not frequently accessed in Redis.
+7.…
+
+## Reference
+
+- "Redis Development and Operation and Maintenance"
+- "Redis Design and Implementation"
+- Redis Transactions:
+- What is Redis Pipeline:
+- A detailed explanation of the discovery and processing of BigKey and HotKey in Redis:
+- Exploration of ideas and methods for solving Bigkey problems:
+- Comprehensive troubleshooting guide for Redis latency issues:
+
+
\ No newline at end of file
diff --git a/docs_en/database/redis/redis-skiplist.en.md b/docs_en/database/redis/redis-skiplist.en.md
new file mode 100644
index 00000000000..2ba31c10200
--- /dev/null
+++ b/docs_en/database/redis/redis-skiplist.en.md
@@ -0,0 +1,727 @@
+---
+title: Redis为什么用跳表实现有序集合
+category: 数据库
+tag:
+ - Redis
+head:
+ - - meta
+ - name: keywords
+ content: Redis,跳表,有序集合,ZSet,时间复杂度,平衡树对比,实现原理
+ - - meta
+ - name: description
+ content: 深入讲解 Redis 有序集合为何选择跳表实现,结合时间复杂度与平衡树对比,理解工程权衡与源码细节。
+---
+
+## 前言
+
+近几年针对 Redis 面试时会涉及常见数据结构的底层设计,其中就有这么一道比较有意思的面试题:“Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
+
+本文就以这道大厂常问的面试题为切入点,带大家详细了解一下跳表这个数据结构。
+
+本文整体脉络如下图所示,笔者会从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握。
+
+
+
+## 跳表在 Redis 中的运用
+
+这里我们需要先了解一下 Redis 用到跳表的数据结构有序集合的使用,Redis 有个比较常用的数据结构叫**有序集合(sorted set,简称 zset)**,正如其名它是一个可以保证有序且元素唯一的集合,所以它经常用于排行榜等需要进行统计排列的场景。
+
+这里我们通过命令行的形式演示一下排行榜的实现,可以看到笔者分别输入 3 名用户:**xiaoming**、**xiaohong**、**xiaowang**,它们的**score**分别是 60、80、60,最终按照成绩升级降序排列。
+
+```bash
+
+127.0.0.1:6379> zadd rankList 60 xiaoming
+(integer) 1
+127.0.0.1:6379> zadd rankList 80 xiaohong
+(integer) 1
+127.0.0.1:6379> zadd rankList 60 xiaowang
+(integer) 1
+
+# 返回有序集中指定区间内的成员,通过索引,分数从高到低
+127.0.0.1:6379> ZREVRANGE rankList 0 100 WITHSCORES
+1) "xiaohong"
+2) "80"
+3) "xiaowang"
+4) "60"
+5) "xiaoming"
+6) "60"
+```
+
+此时我们通过 `object` 指令查看 zset 的数据结构,可以看到当前有序集合存储的还是**ziplist(压缩列表)**。
+
+```bash
+127.0.0.1:6379> object encoding rankList
+"ziplist"
+```
+
+因为设计者考虑到 Redis 数据存放于内存,为了节约宝贵的内存空间,在有序集合元素小于 64 字节且个数小于 128 的时候,会使用 ziplist,而这个阈值的默认值的设置就来自下面这两个配置项。
+
+```bash
+zset-max-ziplist-value 64
+zset-max-ziplist-entries 128
+```
+
+一旦有序集合中的某个元素超出这两个其中的一个阈值它就会转为 **skiplist**(实际是 dict+skiplist,还会借用字典来提高获取指定元素的效率)。
+
+我们不妨在添加一个大于 64 字节的元素,可以看到有序集合的底层存储转为 skiplist。
+
+```bash
+127.0.0.1:6379> zadd rankList 90 yigemingzihuichaoguo64zijiedeyonghumingchengyongyuceshitiaobiaodeshijiyunyong
+(integer) 1
+
+# 超过阈值,转为跳表
+127.0.0.1:6379> object encoding rankList
+"skiplist"
+```
+
+也就是说,ZSet 有两种不同的实现,分别是 ziplist 和 skiplist,具体使用哪种结构进行存储的规则如下:
+
+- 当有序集合对象同时满足以下两个条件时,使用 ziplist:
+ 1. ZSet 保存的键值对数量少于 128 个;
+ 2. 每个元素的长度小于 64 字节。
+- 如果不满足上述两个条件,那么使用 skiplist 。
+
+## 手写一个跳表
+
+为了更好的回答上述问题以及更好的理解和掌握跳表,这里可以通过手写一个简单的跳表的形式来帮助读者理解跳表这个数据结构。
+
+我们都知道有序链表在添加、查询、删除的平均时间复杂都都是 **O(n)** 即线性增长,所以一旦节点数量达到一定体量后其性能表现就会非常差劲。而跳表我们完全可以理解为在原始链表基础上,建立多级索引,通过多级索引检索定位将增删改查的时间复杂度变为 **O(log n)** 。
+
+可能这里说的有些抽象,我们举个例子,以下图跳表为例,其原始链表存储按序存储 1-10,有 2 级索引,每级索引的索引个数都是基于下层元素个数的一半。
+
+
+
+假如我们需要查询元素 6,其工作流程如下:
+
+1. 从 2 级索引开始,先来到节点 4。
+2. 查看 4 的后继节点,是 8 的 2 级索引,这个值大于 6,说明 2 级索引后续的索引都是大于 6 的,没有再往后搜寻的必要,我们索引向下查找。
+3. 来到 4 的 1 级索引,比对其后继节点为 6,查找结束。
+
+相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为**O(log n)**。
+
+
+
+对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到**小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
+
+1. 从 2 级索引开始定位到了元素 4 的索引。
+2. 查看索引 4 的后继索引为 8,索引向下推进。
+3. 来到 1 级索引,发现索引 4 后继索引为 6,小于插入元素 7,指针推进到索引 6 位置。
+4. 继续比较 6 的后继节点为索引 8,大于元素 7,索引继续向下。
+5. 最终我们来到 6 的原始节点,发现其后继节点为 7,指针没有继续向下的空间,自此我们可知元素 6 就是小于插入元素 7 的最大值,于是便将元素 7 插入。
+
+
+
+这里我们又面临一个问题,我们是否需要为元素 7 建立索引,索引多高合适?
+
+我们上文提到,理想情况是每一层索引是下一层元素个数的二分之一,假设我们的总共有 16 个元素,对应各级索引元素个数应该是:
+
+```bash
+1. 一级索引:16/2=8
+2. 二级索引:8/2 =4
+3. 三级索引:4/2=2
+```
+
+由此我们用数学归纳法可知:
+
+```bash
+1. 一级索引:16/2=16/2^1=8
+2. 二级索引:8/2 => 16/2^2 =4
+3. 三级索引:4/2=>16/2^3=2
+```
+
+假设元素个数为 n,那么对应 k 层索引的元素个数 r 计算公式为:
+
+```bash
+r=n/2^k
+```
+
+同理我们再来推断以下索引的最大高度,一般来说最高级索引的元素个数为 2,我们设元素总个数为 n,索引高度为 h,代入上述公式可得:
+
+```bash
+2= n/2^h
+=> 2*2^h=n
+=> 2^(h+1)=n
+=> h+1=log2^n
+=> h=log2^n -1
+```
+
+而 Redis 又是内存数据库,我们假设元素最大个数是**65536**,我们把**65536**代入上述公式可知最大高度为 16。所以我们建议添加一个元素后为其建立的索引高度不超过 16。
+
+因为我们要求尽可能保证每一个上级索引都是下级索引的一半,在实现高度生成算法时,我们可以这样设计:
+
+1. 跳表的高度计算从原始链表开始,即默认情况下插入的元素的高度为 1,代表没有索引,只有元素节点。
+2. 设计一个为插入元素生成节点索引高度 level 的方法。
+3. 进行一次随机运算,随机数值范围为 0-1 之间。
+4. 如果随机数大于 0.5 则为当前元素添加一级索引,自此我们保证生成一级索引的概率为 **50%** ,这也就保证了 1 级索引理想情况下只有一半的元素会生成索引。
+5. 同理后续每次随机算法得到的值大于 0.5 时,我们的索引高度就加 1,这样就可以保证节点生成的 2 级索引概率为 **25%** ,3 级索引为 **12.5%** ……
+
+我们回过头,上述插入 7 之后,我们通过随机算法得到 2,即要为其建立 1 级索引:
+
+
+
+Finally, let’s talk about deletion. Suppose we want to delete element 10 here. We must locate the maximum value of the current jump table **each layer** element that is less than 10. The index execution steps are:
+
+1. The successor node of level 2 index 4 is 8, and the pointer advances.
+2. Index 8 has no successor node, there is no element to be deleted in this layer, and the pointer points directly downward.
+3. The successor node of level 1 index 8 is 10, which means that when deleting level 1 index 8, it needs to disconnect its pointer from level 1 index 10 and delete 10.
+4. After the level 1 index is positioned, the pointer moves downward, the subsequent node is 9, and the pointer advances.
+5. The successor node of 9 is 10. Similarly, it needs to point to null and delete 10.
+
+
+
+### Template definition
+
+After having the overall idea, we can start to implement a skip list. First, define the node **Node** in the skip list. From the above demonstration, we can see that each **Node** contains the following elements:
+
+1. The stored **value** value.
+2. The address of the successor node.
+3. Multi-level index.
+
+In order to more conveniently and uniformly manage the **Node** successor node addresses and the element addresses pointed to by the multi-level index, the author set up a **forwards** array in **Node** to record the successor nodes of the original linked list node and the successor node points of the multi-level index.
+
+Take the following figure as an example. The length of our **forwards** array is 5, in which **index 0** records the successor node address of the original linked list node, while the rest from bottom to top represent the successor node points from the 1st level index to the 4th level index.
+
+
+
+So we have such a code definition. It can be seen that the author sets the length of the array to a fixed 16** (the maximum height calculated above is recommended to be 16)**. The default **data** is -1, and the maximum height of the node **maxLevel** is initialized to 1. Note that the value of **maxLevel** represents the total height of the original linked list plus the index.
+
+```java
+/**
+ * The maximum height of the skip table index is 16
+ */
+private static final int MAX_LEVEL = 16;
+
+class Node {
+ private int data = -1;
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+}
+```
+
+### Element addition
+
+After defining the node, we first add the following elements. When adding elements, the first step is to set **data**. We can directly set the incoming **value** to **data**.
+
+Then there is the setting of the height **maxLevel**. We have also given the idea above. The default height is 1, that is, there is only one original linked list node. Through the random algorithm, the index height is increased by 1 every time it is greater than 0.5. From this, we derive the height calculation algorithm `randomLevel()`:
+
+```java
+/**
+ * Theoretically, the number of elements in the primary index should account for 50% of the original data, the number of elements in the secondary index should account for 25%, and the third-level index should account for 12.5%, all the way to the top.
+ * Because the promotion probability of each level here is 50%. For each newly inserted node, randomLevel needs to be called to generate a reasonable number of levels.
+ * The randomLevel method will randomly generate a number between 1~MAX_LEVEL, and:
+ * 50% probability of returning 1
+ * 25% probability of returning 2
+ * 12.5% probability of returning 3...
+ * @return
+ */
+private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+}
+```
+
+Then set the successor node address of the **Node** and **Node** index currently to be inserted. This step is a little more complicated. We assume that the height of the current node is 4, that is, 1 node plus 3 indexes, so we create an array **maxOfMinArr** with a length of 4, and traverse the maximum value of the index nodes at all levels that is smaller than the current **value**.
+
+Assume that the **value** we want to insert is 5. Our array search result shows that the predecessor node of the current node and the predecessor nodes of the first-level index and the second-level index are all 4, and the third-level index is empty.
+
+
+
+Then we locate the successor nodes at all levels based on this array **maxOfMinArr**, so that the inserted element 5 points to these successor nodes, and **maxOfMinArr** points to 5. The result is as follows:
+
+
+
+The conversion into code is in the following form. Isn't it very simple? Let's continue:
+
+```java
+/**
+ * The default height is 1, that is, there is only one node of its own.
+ */
+private int levelCount = 1;
+
+/**
+ * The node at the bottom of the jump list, that is, the head node
+ */
+private Node h = new Node();
+
+public void add(int value) {
+ int level = randomLevel(); // Random height of new node
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ //An array used to record the predecessor nodes of each layer
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // Key correction: Start searching from the current highest level of the jump list
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ //Only record the predecessor nodes of the layer that needs to be updated
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ //Insert new node
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ //Update the total height of the jump table
+ if (levelCount < level) {
+ levelCount = level;
+ }
+}
+```
+
+### Element query
+
+The query logic is relatively simple. Start from the highest-level index of the jump table and locate the maximum value that is less than the value to be queried. Take the following figure as an example. We hope to find node 8:
+
+
+
+- **Start from the highest level (level 3 index)**: The search pointer `p` starts from the head node. On a level 3 index, `p`'s successor `forwards[2]` (assuming level 3 up, indexing starts at 0) points to node `5`. Since `5 < 8`, pointer `p` moves right to node `5`. The successor `forwards[2]` of node `5` at the level 3 index is `null` (or points to a node greater than `8`, not shown in the figure). The search to the right of the current level ends, pointer `p` remains at node `5`, and moves down to the level 2 index**.
+- **Indexed at Level 2**: Current pointer `p` is node `5`. The successor `forwards[1]` of `p` points to node `8`. Since `8` is not less than `8` (i.e. `8 < 8` is `false`), the current level search to the right ends (`p` will not move to node `8`). Pointer `p` remains at node `5` and moves down to index level 1**.- **在 1 级索引** :当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[0]` 指向最底层的节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到最底层的节点 `5`。此时,当前指针 `p` 为最底层的节点 `5`。其后继 `forwards[0]` 指向最底层的节点 `6`。由于 `6 < 8`,指针 `p` 向右移动到最底层的节点 `6`。当前指针 `p` 为最底层的节点 `6`。其后继 `forwards[0]` 指向最底层的节点 `7`。由于 `7 < 8`,指针 `p` 向右移动到最底层的节点 `7`。当前指针 `p` 为最底层的节点 `7`。其后继 `forwards[0]` 指向最底层的节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束。此时,已经遍历完所有层级,`for` 循环结束。
+- **最终定位与检查** :经过所有层级的查找,指针 `p` 最终停留在最底层(0 级索引)的节点 `7`。这个节点是整个跳表中值小于目标值 `8` 的那个最大的节点。检查节点 `7` 的**后继节点**(即 `p.forwards[0]`):`p.forwards[0]` 指向节点 `8`。判断 `p.forwards[0].data`(即节点 `8` 的值)是否等于目标值 `8`。条件满足(`8 == 8`),**查找成功,找到节点 `8`**。
+
+所以我们的代码实现也很上述步骤差不多,从最高级索引开始向前查找,如果不为空且小于要查找的值,则继续向前搜寻,遇到不小于的节点则继续向下,如此往复,直到得到当前跳表中小于查找值的最大节点,查看其前驱是否等于要查找的值:
+
+```java
+public Node get(int value) {
+ Node p = h; // 从头节点开始
+
+ // 从最高层级索引开始,逐层向下
+ for (int i = levelCount - 1; i >= 0; i--) {
+ // 在当前层级向右查找,直到 p.forwards[i] 为 null
+ // 或者 p.forwards[i].data 大于等于目标值 value
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i]; // 向右移动
+ }
+ // 此时 p.forwards[i] 为 null,或者 p.forwards[i].data >= value
+ // 或者 p 是当前层级中小于 value 的最大节点(如果存在这样的节点)
+ }
+
+ // 经过所有层级的查找,p 现在是原始链表(0级索引)中
+ // 小于目标值 value 的最大节点(或者头节点,如果所有元素都大于等于 value)
+
+ // 检查 p 在原始链表中的下一个节点是否是目标值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0]; // 找到了,返回该节点
+ }
+
+ return null; // 未找到
+}
+```
+
+### 元素删除
+
+最后是删除逻辑,需要查找各层级小于要删除节点的最大值,假设我们要删除 10:
+
+1. 3 级索引得到小于 10 的最大值为 5,继续向下。
+2. 2 级索引从索引 5 开始查找,发现小于 10 的最大值为 8,继续向下。
+3. 同理 1 级索引得到 8,继续向下。
+4. 原始节点找到 9。
+5. 从最高级索引开始,查看每个小于 10 的节点后继节点是否为 10,如果等于 10,则让这个节点指向 10 的后继节点,将节点 10 及其索引交由 GC 回收。
+
+
+
+```java
+/**
+ * 删除
+ *
+ * @param value
+ */
+public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+}
+```
+
+### 完整代码以及测试
+
+完整代码如下,读者可自行参阅:
+
+```java
+public class SkipList {
+
+ /**
+ * 跳表索引最大高度为16
+ */
+ private static final int MAX_LEVEL = 16;
+
+ /**
+ * 每个节点添加一层索引高度的概率为二分之一
+ */
+ private static final float PROB = 0.5f;
+
+ /**
+ * 默认情况下的高度为1,即只有自己一个节点
+ */
+ private int levelCount = 1;
+
+ /**
+ * 跳表最底层的节点,即头节点
+ */
+ private Node h = new Node();
+
+ public SkipList() {
+ }
+
+ public class Node {
+
+ private int data = -1;
+ /**
+ *
+ */
+ private Node[] forwards = new Node[MAX_LEVEL];
+ private int maxLevel = 0;
+
+ @Override
+ public String toString() {
+ return "Node{"
+ + "data=" + data
+ + ", maxLevel=" + maxLevel
+ + '}';
+ }
+ }
+
+ public void add(int value) {
+ int level = randomLevel(); // 新节点的随机高度
+
+ Node newNode = new Node();
+ newNode.data = value;
+ newNode.maxLevel = level;
+
+ // 用于记录每层前驱节点的数组
+ Node[] update = new Node[level];
+ for (int i = 0; i < level; i++) {
+ update[i] = h;
+ }
+
+ Node p = h;
+ // 关键修正:从跳表的当前最高层开始查找
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ // 只记录需要更新的层的前驱节点
+ if (i < level) {
+ update[i] = p;
+ }
+ }
+
+ // 插入新节点
+ for (int i = 0; i < level; i++) {
+ newNode.forwards[i] = update[i].forwards[i];
+ update[i].forwards[i] = newNode;
+ }
+
+ // 更新跳表的总高度
+ if (levelCount < level) {
+ levelCount = level;
+ }
+ }
+
+ /**
+ * 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
+ * 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。 该 randomLevel
+ * 方法会随机生成 1~MAX_LEVEL 之间的数,且 : 50%的概率返回 1 25%的概率返回 2 12.5%的概率返回 3 ...
+ *
+ * @return
+ */
+ private int randomLevel() {
+ int level = 1;
+ while (Math.random() > PROB && level < MAX_LEVEL) {
+ ++level;
+ }
+ return level;
+ }
+
+ public Node get(int value) {
+ Node p = h;
+ //找到小于value的最大值
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ }
+ //如果p的前驱节点等于value则直接返回
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ return p.forwards[0];
+ }
+
+ return null;
+ }
+
+ /**
+ * 删除
+ *
+ * @param value
+ */
+ public void delete(int value) {
+ Node p = h;
+ //找到各级节点小于value的最大值
+ Node[] updateArr = new Node[levelCount];
+ for (int i = levelCount - 1; i >= 0; i--) {
+ while (p.forwards[i] != null && p.forwards[i].data < value) {
+ p = p.forwards[i];
+ }
+ updateArr[i] = p;
+ }
+ //查看原始层节点前驱是否等于value,若等于则说明存在要删除的值
+ if (p.forwards[0] != null && p.forwards[0].data == value) {
+ //从最高级索引开始查看其前驱是否等于value,若等于则将当前节点指向value节点的后继节点
+ for (int i = levelCount - 1; i >= 0; i--) {
+ if (updateArr[i].forwards[i] != null && updateArr[i].forwards[i].data == value) {
+ updateArr[i].forwards[i] = updateArr[i].forwards[i].forwards[i];
+ }
+ }
+ }
+
+ //从最高级开始查看是否有一级索引为空,若为空则层级减1
+ while (levelCount > 1 && h.forwards[levelCount - 1] == null) {
+ levelCount--;
+ }
+
+ }
+
+ public void printAll() {
+ Node p = h;
+ //基于最底层的非索引层进行遍历,只要后继节点不为空,则速速出当前节点,并移动到后继节点
+ while (p.forwards[0] != null) {
+ System.out.println(p.forwards[0]);
+ p = p.forwards[0];
+ }
+
+ }
+}
+
+```
+
+Test code:
+
+```java
+public static void main(String[] args) {
+ SkipList skipList = new SkipList();
+ for (int i = 0; i < 24; i++) {
+ skipList.add(i);
+ }
+
+ System.out.println("************Output added results**********");
+ skipList.printAll();
+
+ SkipList.Node node = skipList.get(22);
+ System.out.println("************query results:" + node+" ************");
+
+ skipList.delete(22);
+ System.out.println("************Delete result**********");
+ skipList.printAll();
+
+
+ }
+```
+
+**Features of Redis skip table**:
+
+1. Using **doubly linked list**, different from the above example, there is a rollback pointer. It is mainly used to simplify operations. For example, when deleting an element, you also need to find the predecessor node of the element. It is very convenient to use the rollback pointer.
+2. The `score` value can be repeated. If the `score` value is the same, it will be sorted according to the ele (the value stored in the node, which is sds) dictionary.
+3. The default maximum number of levels allowed by the Redis jump table is 32, which is defined by `ZSKIPLIST_MAXLEVEL` in the source code.
+
+## Comparison with other three data structures
+
+Finally, let’s answer the interview question at the beginning of the article: “Why does the bottom layer of Redis’s ordered set use a jump table instead of a balanced tree, a red-black tree, or a B+ tree?”
+
+### Balanced tree vs skip list
+
+Let’s first talk about its comparison with the balanced tree. The balanced tree is also called the AVL tree. It is a strictly balanced binary tree. The balance condition must be met (the height difference between the left and right subtrees of all nodes does not exceed 1, that is, the balance factor is in the range `[-1,1]`). The time complexity of insertion, deletion and query of the balanced tree is the same as that of the skip table **O(log n)**.
+
+For range queries, it can also achieve the same effect as skipping tables through in-order traversal. However, every insertion or deletion operation needs to ensure the absolute balance of the left and right nodes of the entire tree. As long as it is unbalanced, it must be maintained through rotation operations. This process is relatively time-consuming.
+
+
+
+The original intention of the birth of skip lists is to overcome some shortcomings of balanced trees. The inventor of skip lists mentioned in detail in the paper ["Skip lists: a probabilistic alternative to balanced trees"](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf):
+
+
+
+> Skip lists are a data structure that can be used in place of balanced trees. Skip lists use probabilistic balancing rather than strictly enforced balancing and as a result the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
+>
+> A skip list is a data structure that can be used to replace a balanced tree. Skip lists use probabilistic balancing rather than strictly enforced balancing, so the insertion and deletion algorithms in skip lists are much simpler and faster than the equivalent algorithms for balanced trees.
+
+The author has also posted the core code of the AVL tree insertion operation here. It can be seen that each addition operation requires a recursive positioning to locate the insertion position, and then it is necessary to trace back to the root node to check whether the nodes at each layer along the way are unbalanced, and then adjust the nodes by rotating them.
+
+```java
+//Add new elements (key, value) to the binary search tree
+public void add(K key, V value) {
+ root = add(root, key, value);
+}
+
+// Insert elements (key, value) into the binary search tree rooted at node, recursive algorithm
+// Return the root of the binary search tree after inserting the new node
+private Node add(Node node, K key, V value) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, value);
+ }
+
+ if (key.compareTo(node.key) < 0)
+ node.left = add(node.left, key, value);
+ else if (key.compareTo(node.key) > 0)
+ node.right = add(node.right, key, value);
+ else // key.compareTo(node.key) == 0
+ node.value = value;
+
+ node.height = 1 + Math.max(getHeight(node.left), getHeight(node.right));
+
+ int balanceFactor = getBalanceFactor(node);
+
+ // LL type requires right-hand rotation
+ if (balanceFactor > 1 && getBalanceFactor(node.left) >= 0) {
+ return rightRotate(node);
+ }
+
+ //RR type imbalance requires left rotation
+ if (balanceFactor < -1 && getBalanceFactor(node.right) <= 0) {
+ return leftRotate(node);
+ }
+
+ //LR needs to be rotated left first into LL shape, and then rotated right
+ if (balanceFactor > 1 && getBalanceFactor(node.left) < 0) {
+ node.left = leftRotate(node.left);
+ return rightRotate(node);
+ }
+
+ //RL
+ if (balanceFactor < -1 && getBalanceFactor(node.right) > 0) {
+ node.right = rightRotate(node.right);
+ return leftRotate(node);
+ }
+ return node;
+}
+```
+
+### Red-black tree vs jump list
+
+Red Black Tree is also a self-balancing binary search tree. Its query performance is slightly inferior to AVL tree, but insertion and deletion are more efficient. The time complexity of insertion, deletion and query of red-black tree is the same as that of skip table **O(log n)**.
+
+A red-black tree is a **black balanced tree**, that is, from any node to another leaf node, the black nodes it passes through are the same. When inserting it, it needs to be rotated and dyed (red-to-black conversion) to ensure black balance. However, the overhead of maintaining balance is smaller than that of an AVL tree. For a detailed introduction to red-black trees, you can view this article: [Red-Black Tree](https://javaguide.cn/cs-basics/data-structure/red-black-tree.html).
+
+Compared with red-black trees, the implementation of skip tables is also simpler. Moreover, when searching for data according to intervals, the efficiency of red-black trees is not as high as that of jump tables.
+
+
+
+The core code added corresponding to the red-black tree is as follows, readers can refer to and understand by themselves:
+
+```java
+private Node < K, V > add(Node < K, V > node, K key, V val) {
+
+ if (node == null) {
+ size++;
+ return new Node(key, val);
+
+ }
+
+ if (key.compareTo(node.key) < 0) {
+ node.left = add(node.left, key, val);
+ } else if (key.compareTo(node.key) > 0) {
+ node.right = add(node.right, key, val);
+ } else {
+ node.val = val;
+ }
+
+ //The left node is not red, the right node is red, left rotation
+ if (isRed(node.right) && !isRed(node.left)) {
+ node = leftRotate(node);
+ }
+
+ //Left chain right-hand rotation
+ if (isRed(node.left) && isRed(node.left.left)) {
+ node = rightRotate(node);
+ }
+
+ //color flip
+ if (isRed(node.left) && isRed(node.right)) {
+ flipColors(node);
+ }
+
+ return node;
+}```
+
+### B+ tree vs skip list
+
+Readers who use MySQL must know the data structure of B+ tree. B+ tree is a commonly used data structure with the following characteristics:
+
+1. **Multi-fork tree structure**: It is a multi-fork tree. Each node can contain multiple child nodes, which reduces the height of the tree and has high query efficiency.
+2. **High storage efficiency**: Non-leaf nodes store multiple keys, and leaf nodes store values, so that each node can store more keys, and the query efficiency is higher when performing range queries based on the index. -
+3. **Balance**: It is absolutely balanced, that is, the height of each branch of the tree is not much different, ensuring that the query and insertion time complexity is **O(log n)**.
+4. **Sequential access**: Leaf nodes are connected through linked list pointers, and range queries perform well.
+5. **Uniform distribution of data**: B+ tree insertion may cause data to be redistributed, making the data more evenly distributed throughout the tree and ensuring range query and deletion efficiency.
+
+
+
+Therefore, B+ tree is more suitable as one of the commonly used index structures in databases and file systems. Its core idea is to obtain query data by locating as many indexes as possible with as little IO as possible. For in-memory databases such as Redis, it is not interested in these, because Redis, as an in-memory database, cannot store a large amount of data, so the index does not need to be maintained through B+ trees. It only needs to be randomly maintained according to probability, saving memory. Moreover, using skip tables to implement zset is simpler than the former. When inserting, you only need to insert the data into the appropriate position in the linked list through the index and then randomly maintain an index of a certain height. There is no need to split and merge nodes when an imbalance is found during insertion like the B+ tree.
+
+### Reasons given by the author of Redis
+
+Of course, we can also use the reasons given by the author of Redis himself:
+
+> There are a few reasons:
+> 1. They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
+> 2. A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
+> 3. They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It requires little changes to the code.
+
+Translated it means:
+
+> There are several reasons:
+>
+> 1. They don’t take up much memory. It's mostly up to you. Changing the parameters of a node's probability of having a given number of levels makes them more memory efficient than B-trees.
+>
+> 2. Sorted sets are often the target of many ZRANGE or ZREVRANGE operations, that is, traversing the jump list in a linked list. With this operation, the cache locality of skip lists is at least as good as other types of balanced trees.
+>
+> 3. They are easier to implement, debug, etc. For example, due to the simplicity of skip tables, I received a patch (already in the Redis master branch) to achieve O(log(N)) ZRANK with enhanced skip tables. It requires only minimal modifications to the code.
+
+## Summary
+
+This article introduces the working principle and implementation of skip tables through a large amount of space to help readers become more familiar with the advantages and disadvantages of the skip table data structure. Finally, it compares the characteristics of each data structure operation to help readers better understand this interview question. It is recommended that when readers understand skip tables, they should cooperate with writing simulations as much as possible to understand the detailed process of adding, deleting, modifying and checking skip tables.
+
+## Reference
+
+- Why does redis use skiplist instead of red-black? :
+- Skip List--Skip List (one of the most detailed skip list articles on the entire Internet):
+- Detailed explanation of Redis objects and underlying data structures:
+- Redis ordered set (sorted set):
+- Comparison of red-black trees and skip tables:
+- Why does redis's zset use jump tables instead of b+ trees? :
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-01.en.md b/docs_en/database/sql/sql-questions-01.en.md
new file mode 100644
index 00000000000..36be8817d1c
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-01.en.md
@@ -0,0 +1,1822 @@
+---
+title: Summary of common SQL interview questions (1)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, query, grouping, sorting, connection, subquery, aggregation
+ - - meta
+ - name: description
+ content: Contains basic SQL high-frequency questions and solutions, covering typical scenarios such as query/grouping/sorting/joining, etc., emphasizing the balance between readability and performance.
+---
+
+> The question comes from: [Niuke Question Ba - SQL must be known and mastered](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=298)
+
+## Retrieve data
+
+`SELECT` is used to query data from the database.
+
+### Retrieve all IDs from the Customers table
+
+The existing table `Customers` is as follows:
+
+| cust_id |
+| ------- |
+| A |
+| B |
+| C |
+
+Write SQL statement to retrieve all `cust_id` from `Customers` table.
+
+Answer:
+
+```sql
+SELECT cust_id
+FROM Customers
+```
+
+### Retrieve and list a list of ordered products
+
+The table `OrderItems` contains a non-empty column `prod_id`, which represents the item id and contains all ordered items (some have been ordered multiple times).
+
+| prod_id |
+| ------- |
+|a1|
+|a2|
+| a3 |
+| a4 |
+| a5 |
+| a6 |
+| a7 |
+
+Write a SQL statement to retrieve and list the deduplicated list of all ordered items (`prod_id`).
+
+Answer:
+
+```sql
+SELECT DISTINCT prod_id
+FROM OrderItems
+```
+
+Knowledge point: `DISTINCT` is used to return the unique distinct value in a column.
+
+### Retrieve all columns
+
+Now there is a `Customers` table (the table contains columns `cust_id` represents the customer id and `cust_name` represents the customer name)
+
+| cust_id | cust_name |
+| ------- | --------- |
+| a1 | andy |
+| a2 | ben |
+| a3 | tony |
+| a4 | tom |
+| a5 | an |
+| a6 | lee |
+| a7 | hex |
+
+You need to write SQL statements to retrieve all columns.
+
+Answer:
+
+```sql
+SELECT cust_id, cust_name
+FROM Customers
+```
+
+## Sort retrieval data
+
+`ORDER BY` is used to sort the result set by one column or multiple columns. By default, records are sorted in ascending order. If you need to sort records in descending order, you can use the `DESC` keyword.
+
+### Retrieve customer names and sort them
+
+There is a table `Customers`, `cust_id` represents the customer id, `cust_name` represents the customer name.
+
+| cust_id | cust_name |
+| ------- | --------- |
+| a1 | andy |
+| a2 | ben |
+| a3 | tony |
+| a4 | tom |
+| a5 | an |
+| a6 | lee |
+| a7 | hex |
+
+Retrieve all customer names (`cust_name`) from `Customers` and display the results in order from Z to A.
+
+Answer:
+
+```sql
+SELECT cust_name
+FROM Customers
+ORDER BY cust_name DESC
+```
+
+### Sort by customer ID and date
+
+There is `Orders` table:
+
+| cust_id | order_num | order_date |
+| ------- | --------- | ------------------- |
+| andy | aaaa | 2021-01-01 00:00:00 |
+| andy | bbbb | 2021-01-01 12:00:00 |
+| bob | cccc | 2021-01-10 12:00:00 |
+| dick | dddd | 2021-01-11 00:00:00 |
+
+Write a SQL statement to retrieve the customer ID (`cust_id`) and order number (`order_num`) from the `Orders` table, and sort the results first by customer ID, and then in reverse order by order date.
+
+Answer:
+
+```sql
+# Sort by column name
+# Note: order_date descending order, not order_num
+SELECT cust_id, order_num
+FROM Orders
+ORDER BY cust_id,order_date DESC
+```
+
+Knowledge point: `order by` When sorting multiple columns, the columns that are sorted first are placed in front, and the columns that are sorted later are placed in the back. Also, different columns can have different sorting rules.
+
+### Sort by quantity and price
+
+Suppose there is an `OrderItems` table:
+
+| quantity | item_price |
+| -------- | ---------- |
+| 1 | 100 |
+| 10 | 1003 |
+| 2 | 500 |
+
+Write a SQL statement to display the quantity (`quantity`) and price (`item_price`) in the `OrderItems` table, and sort them by quantity from high to low and price from high to low.
+
+Answer:
+
+```sql
+SELECT quantity, item_price
+FROM OrderItems
+ORDER BY quantity DESC,item_price DESC
+```
+
+### Check SQL statement
+
+There is a `Vendors` table:
+
+| vend_name |
+| --------- |
+| Haidilao |
+| Xiaolongkan |
+| Dalongyi |
+
+Is there something wrong with the following SQL statement? Try to correct it so that it runs correctly and returns the results in reverse order according to `vend_name`.
+
+```sql
+SELECT vend_name,
+FROM Vendors
+ORDER vend_name DESC
+```
+
+After correction:
+
+```sql
+SELECT vend_name
+FROM Vendors
+ORDER BY vend_name DESC
+```
+
+Knowledge points:
+
+- Commas are used to separate columns.
+- ORDER BY contains BY, which needs to be written completely and in the correct position.
+
+## Filter data
+
+`WHERE` can filter the returned data.
+
+The following operators can be used in the `WHERE` clause:
+
+| Operator | Description |
+| :------ | :--------------------------------------------------------------- |
+| = | equals |
+| <> | is not equal to. **Note:** In some versions of SQL, this operator can be written as != |
+| > | greater than |
+| < | less than |
+| >= | Greater than or equal to |
+| <= | Less than or equal to |
+| BETWEEN | Within a range |
+| LIKE | Search for a pattern |
+| IN | Specifies multiple possible values for a column |
+
+### Return fixed price products
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------------- | ---------- || a0018 | sockets | 9.49 |
+| a0019 | iphone13 | 600 |
+| b0018 | gucci t-shirts | 1000 |
+
+[Problem] Retrieving the product ID (`prod_id`) and product name (`prod_name`) from the `Products` table only returns products with a price of $9.49.
+
+Answer:
+
+```sql
+SELECT prod_id, prod_name
+FROM Products
+WHERE prod_price = 9.49
+```
+
+### Return higher priced products
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------------- | ---------- |
+| a0018 | sockets | 9.49 |
+| a0019 | iphone13 | 600 |
+| b0019 | gucci t-shirts | 1000 |
+
+[Problem] Write a SQL statement to retrieve the product ID (`prod_id`) and product name (`prod_name`) from the `Products` table, returning only products with a price of $9 or more.
+
+Answer:
+
+```sql
+SELECT prod_id, prod_name
+FROM Products
+WHERE prod_price >= 9
+```
+
+### Return products and sort them by price
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------- | ---------- |
+| a0011 | egg | 3 |
+| a0019 | sockets | 4 |
+| b0019 | coffee | 15 |
+
+[Question] Write a SQL statement to return the name (`prod_name`) and price (`prod_price`) of all products in the `Products` table with a price between $3 and $6, and then sort the results by price.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_price
+FROM Products
+WHERE prod_price BETWEEN 3 AND 6
+ORDER BY prod_price
+
+# or
+SELECT prod_name, prod_price
+FROM Products
+WHERE prod_price >= 3 AND prod_price <= 6
+ORDER BY prod_price
+```
+
+### Return to more products
+
+The `OrderItems` table contains: order number `order_num`, `quantity` product quantity
+
+| order_num | quantity |
+| --------- | -------- |
+| a1 | 105 |
+| a2 | 1100 |
+| a2 | 200 |
+| a4 | 1121 |
+| a5 | 10 |
+| a2 | 19 |
+| a7 | 5 |
+
+[Problem] Retrieve all distinct and unique order numbers (`order_num`) from the `OrderItems` table, where each order must contain 100 or more products.
+
+Answer:
+
+```sql
+SELECT order_num
+FROM OrderItems
+GROUP BY order_num
+HAVING SUM(quantity) >= 100
+```
+
+## Advanced data filtering
+
+The `AND` and `OR` operators are used to filter records based on more than one condition and can be used in combination. `AND` requires both conditions to be true, and `OR` only needs one of the 2 conditions to be true.
+
+### Retrieve supplier name
+
+The `Vendors` table has fields vendor name (`vend_name`), vendor country (`vend_country`), vendor state (`vend_state`)
+
+| vend_name | vend_country | vend_state |
+| --------- | ------------ | ---------- |
+| apple | USA | CA |
+| vivo | CNA | shenzhen |
+| huawei | CNA | xian |
+
+[Problem] Write a SQL statement to retrieve the vendor name (`vend_name`) from the `Vendors` table and return only suppliers in California (this needs to be filtered by country [USA] and state [CA], maybe there is a CA in other countries)
+
+Answer:
+
+```sql
+SELECT vend_name
+FROM Vendors
+WHERE vend_country = 'USA' AND vend_state = 'CA'
+```
+
+### Retrieve and list a list of ordered products
+
+The `OrderItems` table contains all ordered products (some have been ordered multiple times).
+
+| prod_id | order_num | quantity |
+| ------- | --------- | -------- |
+| BR01 | a1 | 105 |
+| BR02 | a2 | 1100 |
+| BR02 | a2 | 200 |
+| BR03 | a4 | 1121 |
+| BR017 | a5 | 10 |
+| BR02 | a2 | 19 |
+| BR017 | a7 | 5 |
+
+[Question] Write a SQL statement to find all orders for `BR01`, `BR02` or `BR03` with a quantity of at least 100 units. You need to return the order number (`order_num`), product ID (`prod_id`) and quantity (`quantity`) of the `OrderItems` table and filter by product ID and quantity.
+
+Answer:
+
+```sql
+SELECT order_num, prod_id, quantity
+FROM OrderItems
+WHERE prod_id IN ('BR01', 'BR02', 'BR03') AND quantity >= 100
+```
+
+### Returns the name and price of all products priced between $3 and $6
+
+There is table `Products`:
+
+| prod_id | prod_name | prod_price |
+| ------- | --------- | ---------- |
+| a0011 | egg | 3 |
+| a0019 | sockets | 4 |
+| b0019 | coffee | 15 |
+
+[Question] Write a SQL statement to return the name (`prod_name`) and price (`prod_price`) of all products with a price between $3 and $6, use the AND operator, and then sort the results in ascending order by price.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_price
+FROM Products
+WHERE prod_price >= 3 and prod_price <= 6
+ORDER BY prod_price
+```
+
+### Check SQL statement
+
+The suppliers table `Vendors` has fields supplier name `vend_name`, supplier country `vend_country`, supplier province `vend_state`
+
+| vend_name | vend_country | vend_state |
+| --------- | ------------ | ---------- |
+| apple | USA | CA |
+| vivo | CNA | shenzhen |
+| huawei | CNA | xian |
+
+[Problem] Modify the following sql correctly so that it can be returned correctly.
+
+```sql
+SELECT vend_name
+FROM Vendors
+ORDER BY vend_name
+WHERE vend_country = 'USA' AND vend_state = 'CA';
+```
+
+After modification:
+
+```sql
+SELECT vend_name
+FROM Vendors
+WHERE vend_country = 'USA' AND vend_state = 'CA'
+ORDER BY vend_name
+```
+
+The `ORDER BY` statement must be placed after `WHERE`.
+
+## Use wildcards to filterSQL wildcards must be used with the `LIKE` operator
+
+In SQL, the following wildcard characters can be used:
+
+| wildcard | description |
+| :---------------------------------- | :---------------------------------- |
+| `%` | represents zero or more characters |
+| `_` | Replaces only one character |
+| `[charlist]` | Any single character in a character list |
+| `[^charlist]` or `[!charlist]` | Any single character not in the character list |
+
+### Retrieve product name and description (1)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| ---------- | --------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego toy |
+
+[Problem] Write a SQL statement to retrieve the product name (`prod_name`) and description (`prod_desc`) from the `Products` table and return only the product names that contain the word `toy` in the description.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc LIKE '%toy%'
+```
+
+### Retrieve product name and description (2)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| ---------- | --------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego toy |
+
+[Problem] Write a SQL statement to retrieve the product name (`prod_name`) and description (`prod_desc`) from the `Products` table, return only the products where the word `toy` does not appear in the description, and finally sort the results by "product name".
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc NOT LIKE '%toy%'
+ORDER BY prod_name
+```
+
+### Retrieve product name and description (3)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| --------- | ---------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego carrots toy |
+
+[Problem] Write a SQL statement to retrieve the product name (`prod_name`) and description (`prod_desc`) from the `Products` table, and only return products where `toy` and `carrots` appear in the description. There are several ways to do this, but for this challenge, use `AND` and two `LIKE` comparisons.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc LIKE '%toy%' AND prod_desc LIKE "%carrots%"
+```
+
+### Retrieve product name and description (4)
+
+The `Products` table is as follows:
+
+| prod_name | prod_desc |
+| --------- | ---------------- |
+| a0011 | usb |
+| a0019 | iphone13 |
+| b0019 | gucci t-shirts |
+| c0019 | gucci toy |
+| d0019 | lego toy carrots |
+
+[Problem] Write a SQL statement to retrieve the product name (prod_name) and description (prod_desc) from the Products table, and only return products in which toys and carrots appear in **sequence** in the description. Tip: Just use `LIKE` with three `%` symbols.
+
+Answer:
+
+```sql
+SELECT prod_name, prod_desc
+FROM Products
+WHERE prod_desc LIKE '%toy%carrots%'
+```
+
+## Create a calculated field
+
+### Alias
+
+A common use of aliases is to rename table column fields in retrieved results (to meet specific reporting requirements or customer needs). There is a table `Vendors` representing supplier information, `vend_id` supplier id, `vend_name` supplier name, `vend_address` supplier address, `vend_city` supplier city.
+
+| vend_id | vend_name | vend_address | vend_city |
+| ------- | ------------- | ------------ | ---------- |
+| a001 | tencent cloud | address1 | shenzhen |
+| a002 | huawei cloud | address2 | dongguan |
+| a003 | aliyun cloud | address3 | hangzhou |
+| a003 | netease cloud | address4 | guangzhou |
+
+[Problem] Write a SQL statement to retrieve `vend_id`, `vend_name`, `vend_address` and `vend_city` from the `Vendors` table, rename `vend_name` to `vname`, rename `vend_city` to `vcity`, rename `vend_address` to `vaddress`, and sort the results in ascending order by vendor name.
+
+Answer:
+
+```sql
+SELECT vend_id, vend_name AS vname, vend_address AS vaddress, vend_city AS vcity
+FROM Vendors
+ORDER BY vname
+# as can be omitted
+SELECT vend_id, vend_name vname, vend_address vaddress, vend_city vcity
+FROM Vendors
+ORDER BY vname
+```
+
+### Discount
+
+Our example store is running a sale with 10% off all products. The `Products` table contains `prod_id` product id, `prod_price` product price.
+
+[Question] Write SQL statements to return `prod_id`, `prod_price` and `sale_price` from the `Products` table. `sale_price` is a calculated field containing the promotional price. Tip: You can multiply by 0.9 to get 90% of the original price (i.e. 10% discount).
+
+Answer:
+
+```sql
+SELECT prod_id, prod_price, prod_price * 0.9 AS sale_price
+FROM Products
+```
+
+Note: `sale_price` is the name of the calculation result, not the original column name.
+
+## Use functions to process data
+
+### Customer login name
+
+Our store is online and customer accounts are being created. All users require a login name, and the default login name is a combination of their name and city.
+
+The `Customers` table is given as follows:
+
+| cust_id | cust_name | cust_contact | cust_city |
+| ------- | --------- | ------------ | --------- |
+| a1 | Andy Li | Andy Li | Oak Park |
+| a2 | Ben Liu | Ben Liu | Oak Park |
+| a3 | Tony Dai | Tony Dai | Oak Park |
+| a4 | Tom Chen | Tom Chen | Oak Park || a5 | An Li | An Li | Oak Park |
+| a6 | Lee Chen | Lee Chen | Oak Park |
+| a7 | Hex Liu | Hex Liu | Oak Park |
+
+[Question] Write a SQL statement to return the customer ID (`cust_id`), customer name (`cust_name`) and login name (`user_login`), where the login name is all uppercase letters and consists of the first two characters of the customer's contact person (`cust_contact`) and the first three characters of the city (`cust_city`). Tip: Requires the use of functions, concatenation and aliases.
+
+Answer:
+
+```sql
+SELECT cust_id, cust_name, UPPER(CONCAT(SUBSTRING(cust_contact, 1, 2), SUBSTRING(cust_city, 1, 3))) AS user_login
+FROM Customers
+```
+
+Knowledge points:
+
+- Interception function `SUBSTRING()`: intercepts a string, `substring(str,n,m)` (n represents the starting interception position, m represents the number of characters to be intercepted) means that the returned string str intercepts m characters starting from the nth character;
+- Concatenation function `CONCAT()`: concatenates two or more strings into one string, select concat(A,B): concatenates strings A and B.
+
+- Uppercase function `UPPER()`: Converts the specified string to uppercase.
+
+### Return the order number and order date of all orders in January 2020
+
+`Orders` order table is as follows:
+
+| order_num | order_date |
+| --------- | ------------------- |
+| a0001 | 2020-01-01 00:00:00 |
+| a0002 | 2020-01-02 00:00:00 |
+| a0003 | 2020-01-01 12:00:00 |
+| a0004 | 2020-02-01 00:00:00 |
+| a0005 | 2020-03-01 00:00:00 |
+
+[Question] Write a SQL statement to return the order number (`order_num`) and order date (`order_date`) of all orders in January 2020, and sort them in ascending order by order date
+
+Answer:
+
+```sql
+SELECT order_num, order_date
+FROM Orders
+WHERE month(order_date) = '01' AND YEAR(order_date) = '2020'
+ORDER BY order_date
+```
+
+You can also use wildcards to do this:
+
+```sql
+SELECT order_num, order_date
+FROM Orders
+WHERE order_date LIKE '2020-01%'
+ORDER BY order_date
+```
+
+Knowledge points:
+
+- Date format: `YYYY-MM-DD`
+- Time format: `HH:MM:SS`
+
+Commonly used functions related to date and time processing:
+
+| function | description |
+| --------------- | ------------------------------- |
+| `ADDDATE()` | Add a date (day, week, etc.) |
+| `ADDTIME()` | Add a time (hour, minute, etc.) |
+| `CURDATE()` | Returns the current date |
+| `CURTIME()` | Return the current time |
+| `DATE()` | Returns the date part of a datetime |
+| `DATEDIFF` | Calculate the difference between two dates |
+| `DATE_FORMAT()` | Returns a formatted date or time string |
+| `DAY()` | Returns the day part of a date |
+| `DAYOFWEEK()` | For a date, return the corresponding day of the week |
+| `HOUR()` | Returns the hour part of a time |
+| `MINUTE()` | Returns the minute part of a time |
+| `MONTH()` | Returns the month part of a date |
+| `NOW()` | Returns the current date and time |
+| `SECOND()` | Returns the seconds part of a time |
+| `TIME()` | Returns the time part of a datetime |
+| `YEAR()` | Returns the year part of a date |
+
+## Summary data
+
+Functions related to summary data:
+
+| function | description |
+| --------- | ---------------- |
+| `AVG()` | Returns the average value of a column |
+| `COUNT()` | Returns the number of rows in a column |
+| `MAX()` | Returns the maximum value of a column |
+| `MIN()` | Returns the minimum value of a column |
+| `SUM()` | Returns the sum of values in a column |
+
+### Determine the total number of products sold
+
+The `OrderItems` table represents the products sold, and `quantity` represents the number of items sold.
+
+| quantity |
+|--------|
+| 10 |
+| 100 |
+| 1000 |
+| 10001 |
+| 2 |
+| 15 |
+
+[Question] Write a SQL statement to determine the total number of products sold.
+
+Answer:
+
+```sql
+SELECT Sum(quantity) AS items_ordered
+FROM OrderItems
+```
+
+### Determine the total number of product items BR01 sold
+
+The `OrderItems` table represents the products sold, `quantity` represents the quantity of items sold, and the product item is `prod_id`.
+
+| quantity | prod_id |
+| -------- | ------- |
+| 10 | AR01 |
+| 100 | AR10 |
+| 1000 | BR01 |
+| 10001 | BR010 |
+
+[Problem] Modify the created statement to determine the total number of product items (`prod_id`) sold as "BR01".
+
+Answer:
+
+```sql
+SELECT Sum(quantity) AS items_ordered
+FROM OrderItems
+WHERE prod_id = 'BR01'
+```
+
+### Determine the price of the most expensive product in the Products table that is $10 or less
+
+The `Products` table is as follows, `prod_price` represents the price of the product.
+
+| prod_price |
+| ---------- |
+| 9.49 |
+| 600 |
+| 1000 |
+
+[Question] Write a SQL statement to determine the price (`prod_price`) of the most expensive product in the `Products` table whose price does not exceed $10. Name the calculated field `max_price`.
+
+Answer:
+
+```sql
+SELECT Max(prod_price) AS max_price
+FROM Products
+WHERE prod_price <= 10
+```
+
+## Grouped data
+
+`GROUP BY`:
+
+- The `GROUP BY` clause groups records into summary rows.
+- `GROUP BY` returns one record for each group.
+- `GROUP BY` usually also involves aggregating `COUNT`, `MAX`, `SUM`, `AVG`, etc.
+- `GROUP BY` can group by one or more columns.
+- `GROUP BY` After sorting by grouping fields, `ORDER BY` can sort by summary fields.
+
+`HAVING`:
+
+- `HAVING` is used to filter aggregated `GROUP BY` results.
+- `HAVING` must be used with `GROUP BY`.
+- `WHERE` and `HAVING` can be in the same query.
+
+`HAVING` vs `WHERE`:
+
+- `WHERE`: Filter the specified rows, and aggregate functions (grouping functions) cannot be added later.
+- `HAVING`: Filter grouping, must be used together with `GROUP BY`, cannot be used alone.
+
+### Return the number of rows for each order number
+
+The `OrderItems` table contains every product for every order
+
+| order_num |
+| --------- |
+| a002 |
+| a002 |
+| a002 |
+| a004 |
+| a007 |
+
+[Question] Write a SQL statement to return the number of rows (`order_lines`) for each order number (`order_num`), and sort the results in ascending order by `order_lines`.
+
+Answer:
+
+```sql
+SELECT order_num, Count(order_num) AS order_lines
+FROM OrderItems
+GROUP BY order_num
+ORDER BY order_lines```
+
+Knowledge points:
+
+1. Both `count(*)` and `count(column name)` are acceptable. The difference is that `count(column name)` counts the number of non-NULL rows;
+2. `order by` is executed last, so column aliases can be used;
+3. Don’t forget to add `group by` when performing group aggregation, otherwise there will only be one row of results.
+
+### Lowest cost product per supplier
+
+There is a `Products` table with fields `prod_price` representing the product price and `vend_id` representing the supplier id.
+
+| vend_id | prod_price |
+| ------- | ---------- |
+| a0011 | 100 |
+| a0019 | 0.1 |
+| b0019 | 1000 |
+| b0019 | 6980 |
+| b0019 | 20 |
+
+[Question] Write a SQL statement that returns a field named `cheapest_item` that contains the lowest cost product from each supplier (using `prod_price` from the `Products` table), and then sorts the results in ascending order from lowest cost to highest cost.
+
+Answer:
+
+```sql
+SELECT vend_id, Min(prod_price) AS cheapest_item
+FROM Products
+GROUP BY vend_id
+ORDER BY cheapest_item
+```
+
+### Return the order numbers of all orders whose total order quantity is not less than 100
+
+`OrderItems` represents the order item table, including: order number `order_num` and order quantity `quantity`.
+
+| order_num | quantity |
+| --------- | -------- |
+| a1 | 105 |
+| a2 | 1100 |
+| a2 | 200 |
+| a4 | 1121 |
+| a5 | 10 |
+| a2 | 19 |
+| a7 | 5 |
+
+[Question] Please write a SQL statement to return all order numbers whose total order quantity is not less than 100. The final results are sorted in ascending order by order number.
+
+Answer:
+
+```sql
+# Direct aggregation
+SELECT order_num
+FROM OrderItems
+GROUP BY order_num
+HAVING Sum(quantity) >= 100
+ORDER BY order_num
+
+# Subquery
+SELECT a.order_num
+FROM (SELECT order_num, Sum(quantity) AS sum_num
+ FROM OrderItems
+ GROUP BY order_num
+ HAVING sum_num >= 100) a
+ORDER BY a.order_num
+```
+
+Knowledge points:
+
+- `where`: Filter the specified rows. Aggregation functions (grouping functions) cannot be added later.
+- `having`: filter grouping, used together with `group by`, cannot be used alone.
+
+### Calculate the sum
+
+The `OrderItems` table represents order information, including fields: order number `order_num` and `item_price` the selling price of the product, `quantity` the quantity of the product.
+
+| order_num | item_price | quantity |
+| --------- | ---------- | -------- |
+| a1 | 10 | 105 |
+| a2 | 1 | 1100 |
+| a2 | 1 | 200 |
+| a4 | 2 | 1121 |
+| a5 | 5 | 10 |
+| a2 | 1 | 19 |
+| a7 | 7 | 5 |
+
+[Question] Write a SQL statement to aggregate based on order numbers and return all order numbers with a total order price of not less than 1,000. The final results are sorted in ascending order by order number.
+
+Tip: total price = item_price times quantity
+
+Answer:
+
+```sql
+SELECT order_num, Sum(item_price * quantity) AS total_price
+FROM OrderItems
+GROUP BY order_num
+HAVING total_price >= 1000
+ORDER BY order_num
+```
+
+### Check SQL statement
+
+`OrderItems` table contains `order_num` order numbers
+
+| order_num |
+| --------- |
+| a002 |
+| a002 |
+| a002 |
+| a004 |
+| a007 |
+
+[Question] Modify the following code correctly and execute it
+
+```sql
+SELECT order_num, COUNT(*) AS items
+FROM OrderItems
+GROUP BY items
+HAVING COUNT(*) >= 3
+ORDER BY items, order_num;
+```
+
+After modification:
+
+```sql
+SELECT order_num, COUNT(*) AS items
+FROM OrderItems
+GROUP BY order_num
+HAVING items >= 3
+ORDER BY items, order_num;
+```
+
+## Use subquery
+
+A subquery is a SQL query nested within a larger query, also called an inner query or inner select, and the statement containing the subquery is also called an outer query or outer select. Simply put, a subquery refers to using the result of a `SELECT` query (subquery) as the data source or judgment condition of another SQL statement (main query).
+
+Subqueries can be embedded in `SELECT`, `INSERT`, `UPDATE` and `DELETE` statements, and can also be used with operators such as `=`, `<`, `>`, `IN`, `BETWEEN`, `EXISTS` and other operators.
+
+Subqueries are often used after the `WHERE` clause and the `FROM` clause:
+
+- When used in the `WHERE` clause, depending on different operators, the subquery can return a single row and a single column, multiple rows and a single column, or a single row and multiple columns of data. A subquery is to return a value that can be used as a WHERE clause query condition.
+- When used in the `FROM` clause, multi-row and multi-column data is generally returned, which is equivalent to returning a temporary table, so as to comply with the rule that `FROM` is followed by a table. This approach can implement joint queries on multiple tables.
+
+> Note: MySQL database only supports subqueries from version 4.1, and earlier versions do not support it.
+
+The basic syntax of a subquery for a `WHERE` clause is as follows:
+
+```sql
+SELECT column_name [, column_name ]
+FROM table1 [, table2 ]
+WHERE column_name operator
+(SELECT column_name [, column_name ]
+FROM table1 [, table2 ]
+[WHERE])
+```
+
+- Subqueries need to be placed within brackets `( )`.
+- `operator` represents the operator used for the `WHERE` clause, which can be a comparison operator (such as `=`, `<`, `>`, `<>`, etc.) or a logical operator (such as `IN`, `NOT IN`, `EXISTS`, `NOT EXISTS`, etc.), which is determined according to the requirements.
+
+The basic syntax of a subquery for a `FROM` clause is as follows:
+
+```sql
+SELECT column_name [, column_name ]
+FROM (SELECT column_name [, column_name ]
+ FROM table1 [, table2 ]
+ [WHERE]) AS temp_table_name [, ...]
+[JOIN type JOIN table_name ON condition]
+WHERE condition;
+```
+
+- The result returned by the subquery for `FROM` is equivalent to a temporary table, so you need to use the AS keyword to give the temporary table a name.
+- Subqueries need to be placed within brackets `( )`.
+- You can specify multiple temporary table names and join these tables using the `JOIN` statement.
+
+### Returns a list of customers who purchased products priced at $10 or more
+
+`OrderItems` represents the order item table, containing fields order number: `order_num`, order price: `item_price`; `Orders` table represents the order information table, containing customer `id: cust_id` and order number: `order_num`
+
+`OrderItems` table:
+
+| order_num | item_price |
+| --------- | ---------- |
+| a1 | 10 |
+| a2 | 1 |
+| a2 | 1 |
+| a4 | 2 |
+| a5 | 5 || a2 | 1 |
+| a7 | 7 |
+
+`Orders` table:
+
+| order_num | cust_id |
+| --------- | ------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a2 | cust1 |
+| a4 | cust2 |
+| a5 | cust5 |
+| a2 | cust1 |
+| a7 | cust7 |
+
+[Problem] Use a subquery to return a list of customers who purchased products with a price of $10 or more. The results do not need to be sorted.
+
+Answer:
+
+```sql
+SELECT cust_id
+FROM Orders
+WHERE order_num IN (SELECT DISTINCT order_num
+ FROM OrderItems
+ where item_price >= 10)
+```
+
+### Determine which orders purchased the product with prod_id BR01 (1)
+
+The table `OrderItems` represents the order product information table, `prod_id` is the product id; the `Orders` table represents the order table, `cust_id` represents the customer id and the order date `order_date`
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+【Question】
+
+Write a SQL statement that uses a subquery to determine which orders (in `OrderItems`) purchased the product with `prod_id` as "BR01", then return the customer ID (`cust_id`) and order date (`order_date`) for each product from the `Orders` table, sorting the results in ascending order by order date.
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT cust_id,order_date
+FROM Orders
+WHERE order_num IN
+ (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01' )
+ORDER BY order_date;
+
+# Writing method 2: Join table
+SELECT b.cust_id, b.order_date
+FROM OrderItems a,Orders b
+WHERE a.order_num = b.order_num AND a.prod_id = 'BR01'
+ORDER BY order_date
+```
+
+### Return the emails of all customers who purchased the product with prod_id BR01 (1)
+
+You want to know the date of ordering BR01 product. The table `OrderItems` represents the order product information table, `prod_id` is the product id; the `Orders` table represents the order table, which has `cust_id` which represents the customer id and the order date `order_date`; the `Customers` table contains `cust_email` customer email and `cust_id` customer id
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+The `Customers` table represents customer information, `cust_id` is the customer id, `cust_email` is the customer email
+
+| cust_id | cust_email |
+| ------- | ------------------ |
+| cust10 | |
+| cust1 | |
+| cust2 | |
+
+[Problem] Return the emails of all customers who purchased the product with `prod_id` as `BR01` (`cust_email` in the `Customers` table) without sorting the results.
+
+Tip: This involves `SELECT` statements, the innermost one returning `order_num` from the `OrderItems` table, and the middle one returning `cust_id` from the `Customers` table.
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT cust_email
+FROM Customers
+WHERE cust_id IN (SELECT cust_id
+ FROM Orders
+ WHERE order_num IN (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01'))
+
+# Writing method 2: Join table (inner join)
+SELECT c.cust_email
+FROM OrderItems a,Orders b,Customers c
+WHERE a.order_num = b.order_num AND b.cust_id = c.cust_id AND a.prod_id = 'BR01'
+
+#Writing 3: Join table (left join)
+SELECT c.cust_email
+FROM ORDERS A LEFT JOIN
+ OrderItems b ON a.order_num = b.order_num LEFT JOIN
+ Customers c ON a.cust_id = c.cust_id
+WHERE b.prod_id = 'BR01'
+```
+
+### Return the total amount of different orders for each customer
+
+We need a list of customer IDs with the total amount they have ordered.
+
+The `OrderItems` table represents order information. The `OrderItems` table has order number: `order_num`, product selling price: `item_price`, and product quantity: `quantity`.
+
+| order_num | item_price | quantity |
+| --------- | ---------- | -------- |
+| a0001 | 10 | 105 |
+| a0002 | 1 | 1100 |
+| a0002 | 1 | 200 |
+| a0013 | 2 | 1121 |
+| a0003 | 5 | 10 |
+| a0003 | 1 | 19 |
+| a0003 | 7 | 5 |
+
+`Orders` table order number: `order_num`, customer id: `cust_id`
+
+| order_num | cust_id |
+| --------- | ------- |
+| a0001 | cust10 |
+| a0002 | cust1 |
+| a0003 | cust1 |
+| a0013 | cust2 |
+
+【Question】
+
+Write a SQL statement that returns the customer ID (`cust_id` in the `Orders` table) and use a subquery to return `total_ordered` to return the total number of orders for each customer, sorting the results by amount from largest to smallest.
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT o.cust_id, SUM(tb.total_ordered) AS `total_ordered`
+FROM (SELECT order_num, SUM(item_price * quantity) AS total_ordered
+ FROM OrderItems
+ GROUP BY order_num) AS tb,
+ Orders o
+WHERE tb.order_num = o.order_num
+GROUP BY o.cust_id
+ORDER BY total_ordered DESC;
+
+# Writing method 2: Join table
+SELECT b.cust_id, Sum(a.quantity * a.item_price) AS total_ordered
+FROM OrderItems a,Orders b
+WHERE a.order_num = b.order_num
+GROUP BY cust_id
+ORDER BY total_ordered DESC```
+
+For a detailed introduction to the writing method, please refer to: [issue#2402: Errors in writing method 1 and how to modify it](https://github.com/Snailclimb/JavaGuide/issues/2402).
+
+### Retrieve all product names and corresponding sales totals from the Products table
+
+Retrieve all product names: `prod_name`, product ids: `prod_id` in the `Products` table
+
+| prod_id | prod_name |
+| ------- | --------- |
+| a0001 | egg |
+| a0002 | sockets |
+| a0013 | coffee |
+| a0003 | cola |
+
+`OrderItems` represents the order item table, order product: `prod_id`, sold quantity: `quantity`
+
+| prod_id | quantity |
+| ------- | -------- |
+| a0001 | 105 |
+| a0002 | 1100 |
+| a0002 | 200 |
+| a0013 | 1121 |
+| a0003 | 10 |
+| a0003 | 19 |
+| a0003 | 5 |
+
+【Question】
+
+Write a SQL statement to retrieve all product names (`prod_name`) from the `Products` table, and a calculated column named `quant_sold` that contains the total number of products sold (retrieved using a subquery and `SUM(quantity)` on the `OrderItems` table).
+
+Answer:
+
+```sql
+# Writing method 1: subquery
+SELECT p.prod_name, tb.quant_sold
+FROM (SELECT prod_id, Sum(quantity) AS quant_sold
+ FROM OrderItems
+ GROUP BY prod_id) AS tb,
+ Products p
+WHERE tb.prod_id = p.prod_id
+
+# Writing method 2: Join table
+SELECT p.prod_name, Sum(o.quantity) AS quant_sold
+FROM Products p,
+ OrderItems o
+WHERE p.prod_id = o.prod_id
+GROUP BY p.prod_name (p.prod_id cannot be used here, an error will be reported)
+```
+
+## Join table
+
+JOIN means "connection". As the name suggests, the SQL JOIN clause is used to join two or more tables for query.
+
+When connecting tables, you need to select a field in each table and compare the values of these fields. Two records with the same value will be merged into one. **The essence of joining tables is to merge records from different tables to form a new table. Of course, this new table is only temporary, it only exists for the duration of this query**.
+
+The basic syntax for joining two tables using `JOIN` is as follows:
+
+```sql
+SELECT table1.column1, table2.column2...
+FROM table1
+JOIN table2
+ON table1.common_column1 = table2.common_column2;
+```
+
+`table1.common_column1 = table2.common_column2` is a join condition. Only records that meet this condition will be merged into one row. You can join tables using several operators, such as =, >, <, <>, <=, >=, !=, `between`, `like`, or `not`, but the most common is to use =.
+
+When there are fields with the same name in two tables, in order to help the database engine distinguish the fields of which table, the table name needs to be added when writing the field names with the same name. Of course, if the written field name is unique in the two tables, you can not use the above format and just write the field name.
+
+In addition, if the related field names of the two tables are the same, you can also use the `USING` clause instead of `ON`, for example:
+
+```sql
+# join....on
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+ON c.cust_id = o.cust_id
+ORDER BY c.cust_name
+
+# If the associated field names of the two tables are the same, you can also use the USING clause: JOIN....USING()
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+USING(cust_id)
+ORDER BY c.cust_name
+```
+
+**The difference between `ON` and `WHERE`**:
+
+- When joining tables, SQL will generate a new temporary table based on the join conditions. `ON` is the connection condition, which determines the generation of temporary tables.
+- `WHERE` is to filter the data in the temporary table after the temporary table is generated to generate the final result set. At this time, there is no JOIN-ON.
+
+So in summary: **SQL first generates a temporary table based on ON, and then filters the temporary table based on WHERE**.
+
+SQL allows some modifying keywords to be added to the left of `JOIN` to form different types of connections, as shown in the following table:
+
+| Connection type | Description |
+|------------------------------------------------ |------------------------------------------------------------------------------------------------ |
+| INNER JOIN inner join | (default connection method) Rows will be returned only when there are records that meet the conditions in both tables. |
+| LEFT JOIN / LEFT OUTER JOIN Left (outer) join | Returns all rows in the left table, even if there are no rows in the right table that meet the condition. |
+| RIGHT JOIN / RIGHT OUTER JOIN Right (outer) join | Returns all rows in the right table, even if there are no rows in the left table that meet the condition. |
+| FULL JOIN / FULL OUTER JOIN Full (outer) join | As long as one of the tables has records that meet the conditions, rows will be returned. |
+| SELF JOIN | Joins a table to itself as if the table were two tables. To differentiate between two tables, at least one table needs to be renamed in the SQL statement. |
+| CROSS JOIN | Cross join returns the Cartesian product of record sets from two or more joined tables. |
+
+The figure below shows 7 usages related to LEFT JOIN, RIGHT JOIN, INNER JOIN, and OUTER JOIN.
+
+
+
+If you just write `JOIN` without adding any modifiers, the default is `INNER JOIN`
+
+For `INNER JOIN`, there is also an implicit way of writing, called "**Implicit inner join**", that is, there is no `INNER JOIN` keyword, and the `WHERE` statement is used to implement the inner join function.
+
+```sql
+#Implicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c,Orders o
+WHERE c.cust_id = o.cust_id
+ORDER BY c.cust_name
+
+#Explicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+USING(cust_id)
+ORDER BY c.cust_name;
+```
+
+### Return customer name and related order number
+
+The `Customers` table has fields customer name `cust_name` and customer id `cust_id`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |`Orders` order information table, containing fields `order_num` order number, `cust_id` customer id
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+[Question] Write a SQL statement to return the customer name (`cust_name`) in the `Customers` table and the related order number (`order_num`) in the `Orders` table, and sort the results by customer name and order number in ascending order. You can try two different writing methods, one using simple equal join syntax, and the other using INNER JOIN.
+
+Answer:
+
+```sql
+#Implicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c,Orders o
+WHERE c.cust_id = o.cust_id
+ORDER BY c.cust_name,o.order_num
+
+#Explicit inner join
+SELECT c.cust_name, o.order_num
+FROM Customers c
+INNER JOIN Orders o
+USING(cust_id)
+ORDER BY c.cust_name,o.order_num;
+```
+
+### Return the customer name and related order number and the total price of each order
+
+The `Customers` table has fields, customer name: `cust_name`, customer id: `cust_id`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+
+`Orders` order information table, contains fields, order number: `order_num`, customer id: `cust_id`
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+The `OrderItems` table has fields, product order number: `order_num`, product quantity: `quantity`, product price: `item_price`
+
+| order_num | quantity | item_price |
+| --------- | -------- | ---------- |
+| a1 | 1000 | 10 |
+| a2 | 200 | 10 |
+| a3 | 10 | 15 |
+| a4 | 25 | 50 |
+| a5 | 15 | 25 |
+| a7 | 7 | 7 |
+
+[Problem] In addition to returning the customer name and order number, return the customer name (`cust_name`) in the `Customers` table and the related order number (`order_num`) in the `Orders` table, add a third column `OrderTotal`, which contains the total price of each order, and sort the results by customer name and then by order number in ascending order.
+
+```sql
+# Simple equal connection syntax
+SELECT c.cust_name, o.order_num, SUM(quantity * item_price) AS OrderTotal
+FROM Customers c,Orders o,OrderItems oi
+WHERE c.cust_id = o.cust_id AND o.order_num = oi.order_num
+GROUP BY c.cust_name, o.order_num
+ORDER BY c.cust_name, o.order_num
+```
+
+Note, some friends may write like this:
+
+```sql
+SELECT c.cust_name, o.order_num, SUM(quantity * item_price) AS OrderTotal
+FROM Customers c,Orders o,OrderItems oi
+WHERE c.cust_id = o.cust_id AND o.order_num = oi.order_num
+GROUP BY c.cust_name
+ORDER BY c.cust_name,o.order_num
+```
+
+This is wrong! Clustering only `cust_name` does meet the meaning of the question, but it does not comply with the syntax of `GROUP BY`.
+
+In the select statement, if there is no `GROUP BY` statement, then `cust_name` and `order_num` will return several values, while `sum(quantity * item_price)` will only return one value. Through `group by` `cust_name` can make `cust_name` and `sum(quantity * item_price)` correspond one to one, or **clustering**, so the same must be done. `order_num` performs clustering.
+
+> **In a word, the fields in select are either all clustered or none**
+
+### Determine which orders purchased the product with prod_id BR01 (2)
+
+The table `OrderItems` represents the order product information table, `prod_id` is the product id; the `Orders` table represents the order table, `cust_id` represents the customer id and the order date `order_date`
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+【Question】
+
+Write a SQL statement that uses a subquery to determine which orders (in `OrderItems`) purchased the product with `prod_id` as "BR01", then return the customer ID (`cust_id`) and order date (`order_date`) for each product from the `Orders` table, sorting the results in ascending order by order date.
+
+Tip: This time use joins and simple equijoin syntax.
+
+```sql
+# Writing method 1: subquery
+SELECT cust_id, order_date
+FROM Orders
+WHERE order_num IN (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01')
+ORDER BY order_date
+
+#Writing method 2: join table inner join
+SELECT cust_id, order_date
+FROM ORDERS o INNER JOIN
+ (SELECT order_num
+ FROM OrderItems
+ WHERE prod_id = 'BR01') tb ON o.order_num = tb.order_num
+ORDER BY order_date
+
+# Writing method 3: Simplified version of writing method 2
+SELECT cust_id, order_date
+FROM Orders
+INNER JOIN OrderItems USING(order_num)
+WHERE OrderItems.prod_id = 'BR01'
+ORDER BY order_date
+```
+
+### Return the emails of all customers who purchased the product with prod_id BR01 (2)There is a table `OrderItems` representing the order product information table, `prod_id` is the product id; the `Orders` table represents the order table having `cust_id` representing the customer id and the order date `order_date`; the `Customers` table contains `cust_email` customer email and cust_id customer id
+
+`OrderItems` table:
+
+| prod_id | order_num |
+| ------- | --------- |
+| BR01 | a0001 |
+| BR01 | a0002 |
+| BR02 | a0003 |
+| BR02 | a0013 |
+
+`Orders` table:
+
+| order_num | cust_id | order_date |
+| --------- | ------- | ------------------- |
+| a0001 | cust10 | 2022-01-01 00:00:00 |
+| a0002 | cust1 | 2022-01-01 00:01:00 |
+| a0003 | cust1 | 2022-01-02 00:00:00 |
+| a0013 | cust2 | 2022-01-01 00:20:00 |
+
+The `Customers` table represents customer information, `cust_id` is the customer id, `cust_email` is the customer email
+
+| cust_id | cust_email |
+| ------- | ------------------ |
+| cust10 | |
+| cust1 | |
+| cust2 | |
+
+[Problem] Return the emails of all customers who purchased the product with `prod_id` as BR01 (`cust_email` in the `Customers` table) without sorting the results.
+
+Tip: When it comes to the `SELECT` statement, the innermost one returns `order_num` from the `OrderItems` table, and the middle one returns `cust_id` from the `Customers` table, but the INNER JOIN syntax must be used.
+
+```sql
+SELECT cust_email
+FROM Customers
+INNER JOIN Orders using(cust_id)
+INNER JOIN OrderItems using(order_num)
+WHERE OrderItems.prod_id = 'BR01'
+```
+
+### Another way to determine the best customers (2)
+
+The `OrderItems` table represents order information. Another way to determine the best customers is to look at how much they spend. The `OrderItems` table has the order number `order_num` and `item_price` the price at which the item was sold, and `quantity` the quantity of the item.
+
+| order_num | item_price | quantity |
+| --------- | ---------- | -------- |
+| a1 | 10 | 105 |
+| a2 | 1 | 1100 |
+| a2 | 1 | 200 |
+| a4 | 2 | 1121 |
+| a5 | 5 | 10 |
+| a2 | 1 | 19 |
+| a7 | 7 | 5 |
+
+The `Orders` table contains the fields `order_num` order number, `cust_id` customer id
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+The customer table `Customers` has fields `cust_id` customer id, `cust_name` customer name
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+
+[Question] Write a SQL statement to return the customer name and total amount (`order_num` in the `OrderItems` table) whose order total price is not less than 1000.
+
+Tip: Need to calculate the sum (`item_price` times `quantity`). To sort the results by total amount, use the `INNER JOIN` syntax.
+
+```sql
+SELECT cust_name, SUM(item_price * quantity) AS total_price
+FROM Customers
+INNER JOIN Orders USING(cust_id)
+INNER JOIN OrderItems USING(order_num)
+GROUP BY cust_name
+HAVING total_price >= 1000
+ORDER BY total_price
+```
+
+## Create advanced connection
+
+### Retrieve each customer's name and all order numbers (1)
+
+The `Customers` table represents customer information containing customer id `cust_id` and customer name `cust_name`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+
+The `Orders` table represents order information including order number `order_num` and customer id `cust_id`
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+[Problem] Use INNER JOIN to write SQL statements to retrieve the name of each customer (`cust_name` in the `Customers` table) and all order numbers (`order_num` in the `Orders` table), and finally return them in ascending order according to the customer name `cust_name`.
+
+```sql
+SELECT cust_name, order_num
+FROM Customers
+INNER JOIN Orders
+USING(cust_id)
+ORDER BY cust_name
+```
+
+### Retrieve each customer's name and all order numbers (2)
+
+The `Orders` table represents order information including order number `order_num` and customer id `cust_id`
+
+| order_num | cust_id |
+| --------- | -------- |
+| a1 | cust10 |
+| a2 | cust1 |
+| a3 | cust2 |
+| a4 | cust22 |
+| a5 | cust221 |
+| a7 | cust2217 |
+
+The `Customers` table represents customer information containing customer id `cust_id` and customer name `cust_name`
+
+| cust_id | cust_name |
+|--------|---------|
+| cust10 | andy |
+| cust1 | ben |
+| cust2 | tony |
+| cust22 | tom |
+| cust221 | an |
+| cust2217 | hex |
+| cust40 | ace |
+
+[Problem] Retrieve each customer's name (`cust_name` in the `Customers` table) and all order numbers (`order_num` in the Orders table), and list all customers, even if they have not placed an order. Finally, it is returned in ascending order according to the customer name `cust_name`.
+
+```sql
+SELECT cust_name, order_num
+FROM Customers
+LEFT JOIN Orders
+USING(cust_id)
+ORDER BY cust_name```
+
+### Return the product name and the order number associated with it
+
+The `Products` table contains the fields `prod_id` product id, `prod_name` product name for the product information table.
+
+| prod_id | prod_name |
+| ------- | --------- |
+| a0001 | egg |
+| a0002 | sockets |
+| a0013 | coffee |
+| a0003 | cola |
+| a0023 | soda |
+
+The `OrderItems` table contains the fields `order_num`, order number and product id `prod_id` for the order information table.
+
+| prod_id | order_num |
+| ------- | --------- |
+| a0001 | a105 |
+| a0002 | a1100 |
+| a0002 | a200 |
+| a0013 | a1121 |
+| a0003 | a10 |
+| a0003 | a19 |
+| a0003 | a5 |
+
+[Problem] Use outer joins (left join, right join, full join) to join the `Products` table and the `OrderItems` table, return a list of product names (`prod_name`) and related order numbers (`order_num`), and sort them in ascending order by product name.
+
+```sql
+SELECT prod_name, order_num
+FROM Products
+LEFT JOIN OrderItems
+USING(prod_id)
+ORDER BY prod_name
+```
+
+### Return the product name and the total number of orders for each product
+
+The `Products` table contains the fields `prod_id` product id, `prod_name` product name for the product information table.
+
+| prod_id | prod_name |
+| ------- | --------- |
+| a0001 | egg |
+| a0002 | sockets |
+| a0013 | coffee |
+| a0003 | cola |
+| a0023 | soda |
+
+The `OrderItems` table contains the fields `order_num`, order number and product id `prod_id` for the order information table.
+
+| prod_id | order_num |
+| ------- | --------- |
+| a0001 | a105 |
+| a0002 | a1100 |
+| a0002 | a200 |
+| a0013 | a1121 |
+| a0003 | a10 |
+| a0003 | a19 |
+| a0003 | a5 |
+
+【Question】
+
+Use OUTER JOIN to join the `Products` table and the `OrderItems` table, return the product name (`prod_name`) and the total number of orders for each product (not the order number), and sort by product name in ascending order.
+
+```sql
+SELECT prod_name, COUNT(order_num) AS orders
+FROM Products
+LEFT JOIN OrderItems
+USING(prod_id)
+GROUP BY prod_name
+ORDER BY prod_name
+```
+
+### List suppliers and their available product quantities
+
+There is a `Vendors` table containing `vend_id` (vendor id)
+
+| vend_id |
+| ------- |
+| a0002 |
+| a0013 |
+| a0003 |
+| a0010 |
+
+There is a `Products` table containing `vend_id` (vendor id) and prod_id (supplied product id)
+
+| vend_id | prod_id |
+| ------- | -------------------- |
+| a0001 | egg |
+| a0002 | prod_id_iphone |
+| a00113 | prod_id_tea |
+| a0003 | prod_id_vivo phone |
+| a0010 | prod_id_huawei phone |
+
+[Question] List vendors (`vend_id` in `Vendors` table) and their available product quantities, including vendors with no products. You need to use OUTER JOIN and COUNT() aggregate function to calculate the quantity of each product in the `Products` table, and finally sort them in ascending order based on vend_id.
+
+NOTE: The `vend_id` column appears in multiple tables, so it needs to be fully qualified each time it is referenced.
+
+```sql
+SELECT v.vend_id, COUNT(prod_id) AS prod_id
+FROM Vendors v
+LEFT JOIN Products p
+USING(vend_id)
+GROUP BY v.vend_id
+ORDER BY v.vend_id
+```
+
+## Combined query
+
+The `UNION` operator combines the results of two or more queries and produces a result set containing the extracted rows from the participating queries in `UNION`.
+
+`UNION` basic rules:
+
+- The number and order of columns must be the same for all queries.
+- The data types of the columns involved in the tables in each query must be the same or compatible.
+- Usually the column names returned are taken from the first query.
+
+By default, the `UNION` operator selects distinct values. If duplicate values are allowed, use `UNION ALL`.
+
+```sql
+SELECT column_name(s) FROM table1
+UNION ALL
+SELECT column_name(s) FROM table2;
+```
+
+The column names in the `UNION` result set are always equal to the column names in the first `SELECT` statement in the `UNION`.
+
+`JOIN` vs `UNION`:
+
+- The columns of the joined tables in `JOIN` may be different, but in `UNION` the number and order of columns must be the same for all queries.
+- `UNION` puts the rows after the query together (vertically), but `JOIN` puts the columns after the query together (horizontally), i.e. it forms a Cartesian product.
+
+### Combine two SELECT statements (1)
+
+The table `OrderItems` contains order product information. The field `prod_id` represents the product id and `quantity` represents the product quantity.
+
+| prod_id | quantity |
+| ------- | -------- |
+| a0001 | 105 |
+| a0002 | 100 |
+| a0002 | 200 |
+| a0013 | 1121 |
+| a0003 | 10 |
+| a0003 | 19 |
+| a0003 | 5 |
+|BNBG|10002|
+
+[Question] Combine two `SELECT` statements to retrieve product id (`prod_id`) and `quantity` from the `OrderItems` table. One `SELECT` statement filters rows with a quantity of 100, another `SELECT` statement filters products whose id starts with BNBG, and finally sorts the results by product id in ascending order.
+
+```sql
+SELECT prod_id, quantity
+FROM OrderItems
+WHERE quantity = 100
+UNION
+SELECT prod_id, quantity
+FROM OrderItems
+WHERE prod_id LIKE 'BNBG%'
+```
+
+### Combine two SELECT statements (2)
+
+The table `OrderItems` contains order product information, the field `prod_id` represents the product id, and `quantity` represents the product quantity.
+
+| prod_id | quantity |
+| ------- | -------- |
+| a0001 | 105 |
+| a0002 | 100 |
+| a0002 | 200 |
+| a0013 | 1121 |
+| a0003 | 10 |
+| a0003 | 19 |
+| a0003 | 5 |
+|BNBG|10002|
+
+[Question] Combine two `SELECT` statements to retrieve product id (`prod_id`) and `quantity` from the `OrderItems` table. One `SELECT` statement filters rows with a quantity of 100, another `SELECT` statement filters products whose id starts with BNBG, and finally sorts the results by product id in ascending order. NOTE: **Only use a single SELECT statement this time. **
+
+Answer:
+
+If only one select statement is required, use `or` instead of `union`.
+
+```sql
+SELECT prod_id, quantity
+FROM OrderItems
+WHERE quantity = 100 OR prod_id LIKE 'BNBG%'```
+
+### Combine the product names in the Products table and the customer names in the Customers table
+
+The `Products` table contains the field `prod_name` representing the product name
+
+| prod_name |
+| --------- |
+| flower |
+| rice |
+| ring |
+| umbrella |
+
+The Customers table represents customer information, and cust_name represents the customer name.
+
+| cust_name |
+| --------- |
+| andy |
+| ben |
+| tony |
+| tom |
+| an |
+|lee|
+| hex |
+
+[Problem] Write a SQL statement to combine the product name (`prod_name`) in the `Products` table and the customer name (`cust_name`) in the `Customers` table and return it, and then sort the results in ascending order by product name.
+
+```sql
+# The column names in the UNION result set are always equal to the column names in the first SELECT statement in the UNION.
+SELECT prod_name
+FROM Products
+UNION
+SELECT cust_name
+FROM Customers
+ORDER BY prod_name
+```
+
+### Check SQL statement
+
+The table `Customers` contains fields `cust_name` customer name, `cust_contact` customer contact information, `cust_state` customer state, `cust_email` customer `email`
+
+| cust_name | cust_contact | cust_state | cust_email |
+| --------- | ------------ | ---------- | ------------------ |
+| cust10 | 8695192 | MI | |
+| cust1 | 8695193 | MI | |
+| cust2 | 8695194 | IL | |
+
+[Problem] Correct the following incorrect SQL
+
+```sql
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'MI'
+ORDER BY cust_name;
+UNION
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'IL'ORDER BY cust_name;
+```
+
+After correction:
+
+```sql
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'MI'
+UNION
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'IL'
+ORDER BY cust_name;
+```
+
+When using `union` to combine queries, only one `order by` statement can be used, and it must be located after the last `select` statement
+
+Or just use `or` to do it:
+
+```sql
+SELECT cust_name, cust_contact, cust_email
+FROM Customers
+WHERE cust_state = 'MI' or cust_state = 'IL'
+ORDER BY cust_name;
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-02.en.md b/docs_en/database/sql/sql-questions-02.en.md
new file mode 100644
index 00000000000..c1c2986ea02
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-02.en.md
@@ -0,0 +1,451 @@
+---
+title: Summary of common SQL interview questions (2)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, additions, deletions, batch insertions, imports, replacement insertions, constraints
+ - - meta
+ - name: description
+ content: Focus on the analysis of questions on basic operations such as addition, deletion, and modification, and summarize techniques and precautions such as batch insertion/import and replacement insertion.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+## Add, delete, and modify operations
+
+Summary of how SQL inserts records:
+
+- **Normal insert (all fields)**: `INSERT INTO table_name VALUES (value1, value2, ...)`
+- **Normal insert (qualified fields)**: `INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...)`
+- **Multiple inserts at once**: `INSERT INTO table_name (column1, column2, ...) VALUES (value1_1, value1_2, ...), (value2_1, value2_2, ...), ...`
+- **Import from another table**: `INSERT INTO table_name SELECT * FROM table_name2 [WHERE key=value]`
+- **Insert with update**: `REPLACE INTO table_name VALUES (value1, value2, ...)` (note that this principle is to delete the original record and reinsert it after detecting a duplicate primary key or unique index key)
+
+### Insert record (1)
+
+**Description**: Niuke backend will record each user’s test paper answers to the `exam_record` table. The details of the answer records of two users are as follows:
+
+- User 1001 started answering test paper 9001 at 10:11:12 pm on September 1, 2021, and submitted it after 50 minutes, and received 90 points;
+- User 1002 started answering paper 9002 at 7:01:02 AM on September 4, 2021, and exited the platform 10 minutes later.
+
+In the test paper answer record table `exam_record`, the table has been built and its structure is as follows. Please use one statement to insert these two records into the table.
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Answer**:
+
+```sql
+// There is an auto-incrementing primary key, no manual assignment is required
+INSERT INTO exam_record (uid, exam_id, start_time, submit_time, score) VALUES
+(1001, 9001, '2021-09-01 22:11:12', '2021-09-01 23:01:12', 90),
+(1002, 9002, '2021-09-04 07:01:02', NULL, NULL);
+```
+
+### Insert record (2)
+
+**Description**: There is an examination paper answer record table `exam_record`, with the structure as follows, which contains user answer paper records over the years. Due to the increasing amount of data, maintenance is becoming more and more difficult, so the data table content needs to be streamlined and historical data backed up.
+
+Table `exam_record`:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+We have created a new table `exam_record_before_2021` to back up test answer records before 2021. The structure is consistent with the `exam_record` table. Please import the completed test answer records before 2021 into this table.
+
+**Answer**:
+
+```sql
+INSERT INTO exam_record_before_2021 (uid, exam_id, start_time, submit_time, score)
+SELECT uid,exam_id,start_time,submit_time,score
+FROM exam_record
+WHERE YEAR(submit_time) < 2021;
+```
+
+### Insert record (3)
+
+**Description**: There is now a set of difficult SQL test papers with ID 9003, which lasts for one and a half hours. Please insert 2021-01-01 00:00:00 as the release time into the test question information table `examination_info`. Regardless of whether the ID test paper exists, the insertion must be successful. Please try to insert it.
+
+Test question information table `examination_info`:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ------------ | ----------- | ---- | --- | -------------- | ------- | ------------ |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| exam_id | int(11) | NO | UNI | | (NULL) | Exam paper ID |
+| tag | varchar(32) | YES | | | (NULL) | category tag |
+| difficulty | varchar(8) | YES | | | (NULL) | difficulty |
+| duration | int(11) | NO | | | (NULL) | Duration (number of minutes) |
+| release_time | datetime | YES | | | (NULL) | release time |
+
+**Answer**:
+
+```sql
+REPLACE INTO examination_info VALUES
+ (NULL, 9003, "SQL", "hard", 90, "2021-01-01 00:00:00");
+```
+
+### Update record (1)**Description**: There is now a test paper information table `examination_info`. The table structure is as shown below:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ------------ | -------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| exam_id | int(11) | NO | UNI | | (NULL) | Exam paper ID |
+| tag | char(32) | YES | | | (NULL) | Category tag |
+| difficulty | char(8) | YES | | | (NULL) | difficulty |
+| duration | int(11) | NO | | | (NULL) | duration |
+| release_time | datetime | YES | | | (NULL) | release time |
+
+Please modify all the `tag` fields whose `tag` is `PYTHON` in the **examination_info** table to `Python`.
+
+**Idea**: There are two ways to solve this problem. The easiest one to think of is to directly use `update + where` to specify conditional updates. The second one is to search and replace based on the fields to be modified.
+
+**Answer 1**:
+
+```sql
+UPDATE examination_info SET tag = 'Python' WHERE tag='PYTHON'
+```
+
+**Answer 2**:
+
+```sql
+UPDATE examination_info
+SET tag = REPLACE(tag,'PYTHON','Python')
+
+# REPLACE (target field, "find content", "replace content")
+```
+
+### Update record (2)
+
+**Description**: There is an examination paper answer record table exam_record, which contains user answer paper records for many years. The structure is as follows: Answer record table `exam_record`: **`submit_time`** is the completion time (note this sentence)
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Question requirements**: Please change all the == unfinished == records in the `exam_record` table that were started before September 1, 2021 == to passive completion, that is: change the completion time to '2099-01-01 00:00:00', and change the score to 0.
+
+**Idea**: Pay attention to the keyword in the question stem (already highlighted) `" xxx time "` before the condition, then you will immediately think of time comparison here. You can directly `xxx_time < "2021-09-01 00:00:00",` or you can use the `date()` function for comparison; the second condition is `"Unfinished"`, that is, the completion time is NULL, which is the submission time in the question ----- `submit_time is NULL`.
+
+**Answer**:
+
+```sql
+UPDATE exam_record SET submit_time = '2099-01-01 00:00:00', score = 0 WHERE DATE(start_time) < "2021-09-01" AND submit_time IS null
+```
+
+### Delete records (1)
+
+**Description**: There is an exam paper answer record table `exam_record`, which contains user answer paper records for many years. The structure is as follows:
+
+Answer record table `exam_record:` **`start_time`** is the start time of the test paper `submit_time` is the hand-in time, that is, the end time.
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Requirement**: Please delete the records in the `exam_record` table whose answer time is less than 5 minutes and whose score is failing (passing mark is 60 points);
+
+**Idea**: Although this question is an exercise in deletion, if you look carefully, it is indeed an examination of the usage of time functions. Compared with the minutes mentioned here, the commonly used functions are **`TIMEDIFF`** and **`TIMESTAMPDIFF`**. The usage of the two is slightly different, and the latter is more flexible. This all depends on personal habits.
+
+1. `TIMEDIFF`: the difference between two times
+
+```sql
+TIMEDIFF(time1, time2)
+```
+
+Both parameters are required and are both a time or datetime expression. If the specified parameter is illegal or NULL, the function will return NULL.
+
+For this question, it can be used in the minute function, because TIMEDIFF calculates the difference in time. If you put a MINUTE function outside, the calculated number is the number of minutes.
+
+2. `TIMESTAMPDIFF`: used to calculate the time difference between two dates
+
+```sql
+TIMESTAMPDIFF(unit,datetime_expr1,datetime_expr2)
+# Parameter description
+#unit: The time difference unit returned by date comparison. Commonly used optional values are as follows:
+SECOND: seconds
+MINUTE: minutes
+HOUR: hours
+DAY: day
+WEEK: week
+MONTH: month
+QUARTER: quarter
+YEAR: year
+# TIMESTAMPDIFF function returns the result of datetime_expr2 - datetime_expr1 (in human words: the latter - the previous one, that is, 2-1), where datetime_expr1 and datetime_expr2 can be DATE or DATETIME type values (in human words: it can be "2023-01-01", or it can be "2023-01-01- 00:00:00")
+```
+
+This question requires a comparison of minutes, so TIMESTAMPDIFF(MINUTE, start time, end time) < 5
+
+**Answer**:
+
+```sql
+DELETE FROM exam_record WHERE MINUTE (TIMEDIFF(submit_time , start_time)) < 5 AND score < 60
+```
+
+```sql
+DELETE FROM exam_record WHERE TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5 AND score < 60
+```### Delete records (2)
+
+**Description**: There is an exam paper answer record table `exam_record`, which contains user answer paper records over the years. The structure is as follows:
+
+Answer record table `exam_record`: `start_time` is the start time of the test paper, `submit_time` is the hand-in time, that is, the end time. If it is not completed, it will be empty.
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Requirement**: Please delete the 3 records with the earliest starting time among the records in the `exam_record` table that have unfinished answers == or == the answer time is less than 5 minutes.
+
+**Idea**: This question is relatively simple, but you should pay attention to the information given in the question stem, the end time, if it is not completed, it will be empty, this is actually a condition
+
+There is another condition that is less than 5 minutes, which is similar to the previous question, but here it is ** or **, that is, only one of the two conditions is met; in addition, the usage of sorting and limit is slightly examined.
+
+**Answer**:
+
+```sql
+DELETE FROM exam_record WHERE submit_time IS null OR TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5
+ORDER BY start_time
+LIMIT 3
+# The default is asc, desc is descending order
+```
+
+### Delete records (3)
+
+**Description**: There is an exam paper answer record table exam_record, which contains user answer paper records for many years. The structure is as follows:
+
+| Filed | Type | Null | Key | Extra | Default | Comment |
+| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
+| id | int(11) | NO | PRI | auto_increment | (NULL) | Auto-increment ID |
+| uid | int(11) | NO | | | (NULL) | user ID |
+| exam_id | int(11) | NO | | | (NULL) | Exam ID |
+| start_time | datetime | NO | | | (NULL) | start time |
+| submit_time | datetime | YES | | | (NULL) | Submit time |
+| score | tinyint(4) | YES | | | (NULL) | score |
+
+**Requirement**: Please delete all records in the `exam_record` table, == and reset the auto-incrementing primary key==
+
+**Idea**: This question examines the difference between three delete statements. Pay attention to the highlighted part, which requires resetting the primary key;
+
+- `DROP`: clear the table, delete the table structure, irreversible
+- `TRUNCATE`: Format the table without deleting the table structure, irreversible
+- `DELETE`: delete data, reversible
+
+The reason why `TRUNCATE` is chosen here is: TRUNCATE can only act on tables; `TRUNCATE` will clear all rows in the table, but the table structure, its constraints, indexes, etc. remain unchanged; `TRUNCATE` will reset the auto-increment value of the table; using `TRUNCATE` will restore the space occupied by the table and indexes to their initial size.
+
+This question can also be done using `DELETE`, but after deletion, you still need to manually `ALTER` the table structure to set the initial value of the primary key;
+
+In the same way, you can also use `DROP` to directly delete the entire table, including the table structure, and then create a new table.
+
+**Answer**:
+
+```sql
+TRUNCATE exam_record;
+```
+
+## Table and index operations
+
+### Create a new table
+
+**Description**: There is currently a user information table, which contains user information that has been registered on the platform over the years. As the Niuke platform continues to grow, the number of users has grown rapidly. In order to efficiently provide services to highly active users, it is now necessary to split some users into a new table.
+
+Original user information table:
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ------------------ | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | Auto-increment ID |
+| uid | int(11) | NO | UNI | (NULL) | | user ID |
+| nick_name | varchar(64) | YES | | (NULL) | | Nickname |
+| achievement | int(11) | YES | | 0 | | achievement value |
+| level | int(11) | YES | | (NULL) | | User level |
+| job | varchar(32) | YES | | (NULL) | | Career direction |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | registration time |
+
+As a data analyst, please create a high-quality user information table user_info_vip** with the same structure as the user information table.
+
+The output you should return is shown in the table below. Please write a table creation statement to record all restrictions and instructions in the table into the table.
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ------------------ | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | Auto-increment ID |
+| uid | int(11) | NO | UNI | (NULL) | | user ID |
+| nick_name | varchar(64) | YES | | (NULL) | | Nickname |
+| achievement | int(11) | YES | | 0 | | achievement value |
+| level | int(11) | YES | | (NULL) | | User level || job | varchar(32) | YES | | (NULL) | | Career direction |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | registration time |
+
+**Idea**: If this question gives the name of the old table, you can directly `create table new table as select * from old table;` However, this question does not give the name of the old table, so you need to create it yourself. Just pay attention to the creation of default values and keys, which is relatively simple. (Note: If it is executed on Niuke.com, please note that the comment must be consistent with the comment in the question, including upper and lower case, otherwise it will not pass, and the characters must also be set)
+
+Answer:
+
+```sql
+CREATE TABLE IF NOT EXISTS user_info_vip(
+ id INT(11) PRIMARY KEY AUTO_INCREMENT COMMENT'Auto-increment ID',
+ uid INT(11) UNIQUE NOT NULL COMMENT 'User ID',
+ nick_name VARCHAR(64) COMMENT'nickname',
+ achievement INT(11) DEFAULT 0 COMMENT 'Achievement value',
+ `level` INT(11) COMMENT 'User level',
+ job VARCHAR(32) COMMENT 'Career direction',
+ register_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT 'Registration time'
+)CHARACTER SET UTF8
+```
+
+### Modify table
+
+**Description**: There is a user information table `user_info`, which contains user information registered on the platform over the years.
+
+**User information table `user_info`:**
+
+| Filed | Type | Null | Key | Default | Extra | Comment |
+| ------------- | ----------- | ---- | --- | ------------------ | -------------- | -------- |
+| id | int(11) | NO | PRI | (NULL) | auto_increment | Auto-increment ID |
+| uid | int(11) | NO | UNI | (NULL) | | user ID |
+| nick_name | varchar(64) | YES | | (NULL) | | Nickname |
+| achievement | int(11) | YES | | 0 | | achievement value |
+| level | int(11) | YES | | (NULL) | | User level |
+| job | varchar(32) | YES | | (NULL) | | Career direction |
+| register_time | datetime | YES | | CURRENT_TIMESTAMP | | registration time |
+
+**Requirements:** Please add a field `school` that can store up to 15 Chinese characters in the user information table after the field `level`; change the `job` column name in the table to `profession`, and change the `varchar` field length to 10; set the default value of `achievement` to 0.
+
+**Idea**: Before doing this question first, you need to understand the basic usage of the ALTER statement:
+
+- Add a column: `ALTER TABLE table name ADD COLUMN column name type [first | after field name];` (first: add before a column, after vice versa)
+- Modify the column type or constraint: `ALTER TABLE table name MODIFY COLUMN column name new type [new constraint];`
+- Modify column name: `ALTER TABLE table name change COLUMN old column name new column name type;`
+- Delete column: `ALTER TABLE table name drop COLUMN column name;`
+- Modify table name: `ALTER TABLE table name rename [to] new table name;`
+- Put a column into the first column: `ALTER TABLE table name MODIFY COLUMN column name type first;`
+
+The `COLUMN` keyword can actually be omitted, but it is listed here based on the specification.
+
+When modifying, if there are multiple modification items, you can write them together, but pay attention to the format.
+
+**Answer**:
+
+```sql
+ALTER TABLE user_info
+ ADD school VARCHAR(15) AFTER level,
+ CHANGE job profession VARCHAR(10),
+ MODIFY achievement INT(11) DEFAULT 0;
+```
+
+### Delete table
+
+**Description**: There is an exam paper answer record table `exam_record`, which contains user answer paper records for many years. Generally, a backup table `exam_record_{YEAR} will be created for the `exam_record` table every year, {YEAR}` is the corresponding year.
+
+Now with more and more data and storage shortage, please delete all the backup tables from a long time ago (2011 to 2014) (if they exist).
+
+**Idea**: This question is very simple, just delete it. If you find it troublesome, you can separate the tables to be deleted with commas and write them on one line; there will definitely be friends here asking: What if you want to delete many tables? Don't worry, if you want to delete many tables, you can write a script to delete them.
+
+**Answer**:
+
+```sql
+DROP TABLE IF EXISTS exam_record_2011;
+DROP TABLE IF EXISTS exam_record_2012;
+DROP TABLE IF EXISTS exam_record_2013;
+DROP TABLE IF EXISTS exam_record_2014;
+```
+
+### Create index
+
+**Description**: There is an examination paper information table `examination_info`, which contains information about various types of examination papers. In order to query the table more conveniently and quickly, you need to create the following index in the `examination_info` table,
+
+The rules are as follows: create a normal index `idx_duration` on the `duration` column, create a unique index `uniq_idx_exam_id` on the `exam_id` column, and create a full-text index `full_idx_tag` on the `tag` column.
+
+According to the meaning of the question, the following results will be returned:
+
+| examination_info | 0 | PRIMARY | 1 | id | A | 0 | | | | BTREE |
+| ---------------- | --- | ---------------- | --- | -------- | --- | --- | --- | --- | --- | -------- |
+| examination_info | 0 | uniq_idx_exam_id | 1 | exam_id | A | 0 | | | YES | BTREE |
+| examination_info | 1 | idx_duration | 1 | duration | A | 0 | | | | BTREE |
+| examination_info | 1 | full_idx_tag | 1 | tag | | 0 | | | YES | FULLTEXT |
+
+Note: The background will compare the output results through the `SHOW INDEX FROM examination_info` statement
+
+**Idea**: To answer this question, you first need to understand the common index types:
+
+- B-Tree index: B-Tree (or balanced tree) index is the most common and default index type. It is suitable for various query conditions and can quickly locate data that meets the conditions. B-Tree index is suitable for ordinary search operations and supports equality query, range query and sorting.
+- Unique index: A unique index is similar to a normal B-Tree index, except that it requires the value of the indexed column to be unique. This means that MySQL verifies the uniqueness of index columns when inserting or updating data.
+- Primary key index: The primary key index is a special unique index that is used to uniquely identify each row of data in the table. Each table can only have one primary key index, which can help improve data access speed and data integrity.- Full-text indexing: Full-text indexing is used for full-text search in text data. It supports keyword searches in text fields, not just simple equality or range lookups. Full-text indexing is suitable for application scenarios that require full-text search.
+
+```sql
+-- Example:
+-- Add B-Tree index:
+ CREATE INDEX idx_name (index name) ON table name (field name); -- idx_name is the index name, all of the following
+--Create a unique index:
+ CREATE UNIQUE INDEX idx_name ON table name (field name);
+-- Create a primary key index:
+ ALTER TABLE table name ADD PRIMARY KEY (field name);
+--Create a full-text index
+ ALTER TABLE table name ADD FULLTEXT INDEX idx_name (field name);
+
+-- Through the above example, you can see that both create and alter can add indexes
+```
+
+With the above basic knowledge, the answer to this question will become apparent.
+
+**Answer**:
+
+```sql
+ALTER TABLE examination_info
+ ADD INDEX idx_duration(duration),
+ ADD UNIQUE INDEX uniq_idx_exam_id(exam_id),
+ ADD FULLTEXT INDEX full_idx_tag(tag);
+```
+
+### Delete index
+
+**Description**: Please delete the unique index uniq_idx_exam_id and the full-text index full_idx_tag on the `examination_info` table.
+
+**Idea**: This question examines the basic syntax of deleting an index:
+
+```sql
+-- Use DROP INDEX to delete the index
+DROP INDEX idx_name ON table name;
+
+-- Use ALTER TABLE to delete the index
+ALTER TABLE employees DROP INDEX idx_email;
+```
+
+What needs to be noted here is that in MySQL, deleting multiple indexes at one time is not supported. Each time you delete an index, you can only specify one index name to delete.
+
+And the **DROP** command needs to be used with caution! ! !
+
+**Answer**:
+
+```sql
+DROP INDEX uniq_idx_exam_id ON examination_info;
+DROP INDEX full_idx_tag ON examination_info;
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-03.en.md b/docs_en/database/sql/sql-questions-03.en.md
new file mode 100644
index 00000000000..2199691ade3
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-03.en.md
@@ -0,0 +1,1292 @@
+---
+title: Summary of common SQL interview questions (3)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, aggregate functions, truncated average, window, problem analysis, performance
+ - - meta
+ - name: description
+ Content: Focusing on aggregation functions and complex statistical question types, the solution methods and implementation key points such as truncated average are explained, taking into account performance and correctness.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+You can decide whether to skip more difficult or difficult questions based on your actual situation and interview needs.
+
+## Aggregation function
+
+### Truncated average of scores for difficult papers in the SQL category (harder)
+
+**Description**: Niuke's operations students want to check everyone's scores on the difficult papers in the SQL category.
+
+Please help her calculate the truncated average (the average after removing one maximum value and one minimum value) of the scores of all users who completed the difficult SQL category exams from the `exam_record` data table.
+
+Example data: `examination_info` (`exam_id` test paper ID, tag test paper category, `difficulty` test paper difficulty, `duration` exam duration, `release_time` release time)
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Example data: `exam_record` (uid user ID, exam_id test paper ID, start_time start answering time, submit_time paper submission time, score score)
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
+| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
+| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
+
+The results according to your query are as follows:
+
+| tag | difficulty | clip_avg_score |
+| --- | ---------- | --------------- |
+| SQL | hard | 81.7 |
+
+From the `examination_info` table, we can see that test paper 9001 is a highly difficult SQL test paper. The scores for this test paper are [80,81,84,90,50]. After removing the highest and lowest scores, it is [80,81,84]. The average score is 81.6666667, which is 81.7 after rounding to one decimal place.
+
+**Enter description:**
+
+There are at least 3 valid scores in the input data
+
+**Idea 1:** To find the high-difficulty SQL test papers, you definitely need to connect to the examination_info table, and then find the high-difficulty courses. From examination_info, we know that the exam_id of the high-difficulty SQL is 9001, so later use exam_id = 9001 as the condition to query;
+
+First find exam number 9001 `select * from exam_record where exam_id = 9001`
+
+Then, find the maximum score `select max(score) maximum score from exam_record where exam_id = 9001`
+
+Next, find the minimum score `select min(score) minimum score from exam_record where exam_id = 9001`
+
+In the score result set obtained from the query, to remove the highest score and the lowest score, the most intuitive thing that can be thought of is NOT IN or NOT EXISTS. Here we use NOT IN to do it.
+
+First write out the main body `select tag, difficulty, round(avg(score), 1) clip_avg_score from examination_info info INNER JOIN exam_record record`
+
+**Tips**: MYSQL's `ROUND()` function, `ROUND(X)` returns the nearest integer to parameter
+
+Then put the above "fragmented" statements together. Note that in NOT IN, the two subqueries are related using UNION ALL, and union is used to concentrate the results of max and min in one row, thus forming the effect of one column and multiple rows.
+
+**Answer 1:**
+
+```sql
+SELECT tag, difficulty, ROUND(AVG(score), 1) clip_avg_score
+ FROM examination_info info INNER JOIN exam_record record
+ WHERE info.exam_id = record.exam_id
+ AND record.exam_id = 9001
+ AND record.score NOT IN(
+ SELECT MAX(score)
+ FROM exam_record
+ WHERE exam_id = 9001
+ UNION ALL
+ SELECT MIN(score)
+ FROM exam_record
+ WHERE exam_id = 9001
+ )
+```
+
+This is the most intuitive and easiest solution to think of, but it still needs to be improved. This is considered opportunistic. In fact, strictly according to the requirements of the question, it should be written like this:
+
+```sql
+SELECT tag,
+ difficulty,
+ ROUND(AVG(score), 1) clip_avg_score
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND record.exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' )
+ AND record.score NOT IN
+ (SELECT MAX(score)
+ FROM exam_record
+ WHERE exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' )
+ UNION ALL SELECT MIN(score)
+ FROM exam_record
+ WHERE exam_id =
+ (SELECT examination_info.exam_id
+ FROM examination_info
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard' ) )```
+
+However, you will find that there are many repeated statements, so you can use `WITH` to extract the common parts
+
+**Introduction to `WITH` clause**:
+
+The `WITH` clause, also known as a Common Table Expression (CTE), is the way to define a temporary table in a SQL query. It allows us to create a temporarily named result set in a query and reference that result set in the same query.
+
+Basic usage:
+
+```sql
+WITH cte_name (column1, column2, ..., columnN) AS (
+ -- Query body
+ SELECT...
+ FROM ...
+ WHERE...
+)
+-- Main query
+SELECT...
+FROM cte_name
+WHERE...
+```
+
+The `WITH` clause consists of the following parts:
+
+- `cte_name`: Give the temporary table a name that can be referenced in the main query.
+- `(column1, column2, ..., columnN)`: Optional, specify the column name of the temporary table.
+- `AS`: required, indicates starting to define a temporary table.
+- `CTE query body`: the actual query statement, used to define the data in the temporary table.
+
+One of the primary uses of the `WITH` clause is to enhance the readability and maintainability of queries, especially when multiple nested subqueries are involved or the same query logic needs to be reused. By putting this logic in a named temporary table, we can organize our queries more clearly and eliminate duplicate code.
+
+In addition, the `WITH` clause can also implement recursive queries in complex queries. Recursive queries allow us to perform multiple iterations of the same table in a single query, building the result set incrementally. This is useful in scenarios such as working with hierarchical data, organizational structures, and tree structures.
+
+**Minor detail**: MySQL versions 5.7 and earlier do not support the direct use of aliases in the `WITH` clause.
+
+Here is the improved answer:
+
+```sql
+WITH t1 AS
+ (SELECT record.*,
+ info.tag,
+ info.difficulty
+ FROM exam_record record
+ INNER JOIN examination_info info ON record.exam_id = info.exam_id
+ WHERE info.tag = "SQL"
+ AND info.difficulty = "hard" )
+SELECT tag,
+ difficulty,
+ ROUND(AVG(score), 1)
+FROM t1
+WHERE score NOT IN
+ (SELECT max(score)
+ FROM t1
+ UNION SELECT min(score)
+ FROM t1)
+```
+
+**Idea 2:**
+
+- Filter SQL difficult test papers: `where tag="SQL" and difficulty="hard"`
+- Calculate the truncated average: `(sum-maximum value-minimum value) / (total number-2)`:
+ - `(sum(score) - max(score) - min(score)) / (count(score) - 2)`
+ - One disadvantage is that if there are multiple maximum values and minimum values, this method is difficult to filter out, but the question says ----->**`The average value after removing one maximum value and one minimum value`**, so this formula can be used here.
+
+**Answer 2:**
+
+```sql
+SELECT info.tag,
+ info.difficulty,
+ ROUND((SUM(record.score)- MIN(record.score)- MAX(record.score)) / (COUNT(record.score)- 2), 1) AS clip_avg_score
+FROM examination_info info,
+ exam_record record
+WHERE info.exam_id = record.exam_id
+ AND info.tag = "SQL"
+ AND info.difficulty = "hard";
+```
+
+### Count the number of answers
+
+There is an exam paper answer record table `exam_record`. Please count the total number of answers `total_pv`, the number of completed exam papers `complete_pv`, and the number of completed exam papers `complete_exam_cnt`.
+
+Example data `exam_record` table (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
+| 4 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 5 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 8 | 1002 | 9001 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 9 | 1003 | 9001 | 2021-09-07 12:01:01 | 2021-09-07 10:31:01 | 50 |
+| 10 | 1004 | 9001 | 2021-09-06 10:01:01 | (NULL) | (NULL) |
+
+Example output:
+
+| total_pv | complete_pv | complete_exam_cnt |
+| -------- | ----------- | ------------------ |
+| 10 | 7 | 2 |
+
+Explanation: As of now, there are 10 test paper answer records, and the number of completed answers is 7 (those who exited midway are in an unfinished status, and their handover time and number of copies are NULL). There are two completed test papers, 9001 and 9002.
+
+**Idea**: As soon as you see the number of statistics for this question, you will definitely think of using the `COUNT` function to solve it immediately. The problem is to count different records. How to write it? This problem can be solved using subqueries (this problem can also be written using case when, the solution is similar, but the logic is different); first, before doing this problem, let us first understand the basic usage of `COUNT`;
+
+The basic syntax of the `COUNT()` function is as follows:
+
+```sql
+COUNT(expression)
+```
+
+Among them, `expression` can be a column name, expression, constant or wildcard character. Here are some common usage examples:
+
+1. Count the number of all rows in the table:
+
+```sql
+SELECT COUNT(*) FROM table_name;
+```
+
+2. Count the number of non-null (not NULL) values for a specific column:
+
+```sql
+SELECT COUNT(column_name) FROM table_name;
+```
+
+3. Calculate the number of rows that meet the conditions:
+
+```sql
+SELECT COUNT(*) FROM table_name WHERE condition;
+```
+
+4. Combined with `GROUP BY`, calculate the number of rows in each group after grouping:
+
+```sql
+SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
+```
+
+5. Count the number of unique combinations of different column combinations:
+
+```sql
+SELECT COUNT(DISTINCT column_name1, column_name2) FROM table_name;
+```
+
+When using the `COUNT()` function without specifying any arguments or using `COUNT(*)`, all rows will be counted. If you use a column name, only the number of non-null values in that column will be counted.
+
+Additionally, the result of the `COUNT()` function is an integer value. Even if the result is zero, NULL will not be returned, which is something to keep in mind.
+
+**Answer**:
+
+```sql
+SELECT
+ count(*) total_pv,
+ ( SELECT count(*) FROM exam_record WHERE submit_time IS NOT NULL ) complete_pv,
+ ( SELECT COUNT( DISTINCT exam_id, score IS NOT NULL OR NULL ) FROM exam_record ) complete_exam_cnt
+FROM
+ exam_record```
+
+Here we focus on the sentence `COUNT(DISTINCT exam_id, score IS NOT NULL OR NULL)`, which determines whether score is null. If so, it is true, if not, return null; note that if `or null` is not added here, it will only return false if it is not null, that is, return 0;
+
+`COUNT` itself cannot calculate the number of rows in multiple columns. The addition of `distinct` makes multiple columns into a whole, and the number of rows that appear can be calculated; `count distinct` only returns non-null rows during calculation. You should also pay attention to this;
+
+In addition, through this question get arrived ------->count plus conditional common sentence pattern `count (column judgment or null)`
+
+### The lowest score with a score not less than the average score
+
+**Description**: Please find the lowest score of the user whose SQL test paper score is not less than the average score of this type of test paper from the test paper answer record table.
+
+Example data exam_record table (uid user ID, exam_id test paper ID, start_time start answering time, submit_time paper submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 6 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+
+`examination_info` table (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` exam duration, `release_time` release time)
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Example output data:
+
+| min_score_over_avg |
+| ------------------ |
+| 87 |
+
+**Explanation**: Test papers 9001 and 9002 are in the SQL category. The scores for answering these two papers are [80,89,87,90], the average score is 86.5, and the minimum score that is not less than the average score is 87
+
+**Idea**: This type of question is really complicated at first glance because we don’t know where to start. However, after we read and review the question carefully, we must learn to grasp the key information in the question stem. Take this question as an example: `Please find the lowest score of a user whose SQL test paper score is not less than the average score of this type of test paper from the test paper answer record table. `What effective information can you extract from it at a glance as a solution to the problem?
+
+Article 1: Find ==SQL== test paper score
+
+Article 2: This type of test paper == average score ==
+
+Article 3: == user’s minimum score for this type of test paper ==
+
+Then the "bridge" in the middle is == not less than ==
+
+After splitting the conditions, complete them step by step
+
+```sql
+-- Find the score with the tag 'SQL' [80, 89,87,90]
+-- Then calculate the average score of this group
+select ROUND(AVG(score), 1) from examination_info info INNER JOIN exam_record record
+ where info.exam_id = record.exam_id
+ and tag= 'SQL'
+```
+
+Then find the lowest score for this type of test paper, and then compare the result set `[80, 89,87,90]` with the average score to get the final answer.
+
+**Answer**:
+
+```sql
+SELECT MIN(score) AS min_score_over_avg
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND tag= 'SQL'
+ AND score >=
+ (SELECT ROUND(AVG(score), 1)
+ FROM examination_info info
+ INNER JOIN exam_record record
+ WHERE info.exam_id = record.exam_id
+ AND tag= 'SQL' )
+```
+
+In fact, the requirements given by this type of question seem very "convoluted", but in fact, you need to sort it out carefully, split the big conditions into small conditions, and after splitting them one by one, finally put all the conditions together. Anyway, as long as you remember: **Focus on the trunk and manage the branches**, the problem will be easily solved.
+
+## Group query
+
+### Average active days and number of monthly active users
+
+**Description**: The user’s answer records in the Niuke test paper answer area are stored in the table `exam_record`, with the following content:
+
+`exam_record` table (`uid` user ID, `exam_id` test paper ID, `start_time` starting time of answering, `submit_time` handing in time, `score` score)
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
+| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 || 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
+
+Please calculate the average number of monthly active days `avg_active_days` and the number of monthly active users `mau` in the test paper answer area in each month of 2021. The sample output of the above data is as follows:
+
+| month | avg_active_days | mau |
+| ------ | --------------- | --- |
+| 202107 | 1.50 | 2 |
+| 202109 | 1.25 | 4 |
+
+**Explanation**: In July 2021, 2 people were active, and they were active for 3 days in total (1001 was active for 1 day, and 1002 was active for 2 days), and the average number of active days was 1.5; in September 2021, 4 people were active, and they were active for 5 days in total, and the average number of active days was 1.25. The result is rounded to 2 decimal places.
+
+Note: Being active here means having the behavior of == handing in papers ==.
+
+**Idea**: After reading the question, pay attention to the highlighted part first; generally when finding the number of days and monthly active people, you will immediately think of the relevant date function; we will also split this question, refine the problem and then solve it; first, to find the number of active people, you must use `COUNT()`, then there is a pit here. I wonder if you have noticed it? User 1002 took two different test papers in September, so pay attention to removing duplicates here, otherwise the number of active people will be wrong during statistics; the second is to know the format of the date, as shown in the table above, the question is required to be displayed in the date format of `202107`, and `DATE_FORMAT` must be used for formatting.
+
+Basic usage:
+
+`DATE_FORMAT(date_value, format)`
+
+- The `date_value` parameter is the date or time value to be formatted.
+- The `format` parameter is the specified date or time format (this is the same as the date format in Java).
+
+**Answer**:
+
+```sql
+SELECT DATE_FORMAT(submit_time, '%Y%m') MONTH,
+ round(count(DISTINCT UID, DATE_FORMAT(submit_time, '%Y%m%d')) / count(DISTINCT UID), 2) avg_active_days,
+ COUNT(DISTINCT UID) mau
+FROM exam_record
+WHERE YEAR (submit_time) = 2021
+GROUP BY MONTH
+```
+
+One more thing to say here, use `COUNT(DISTINCT uid, DATE_FORMAT(submit_time, '%Y%m%d'))` to count the number of combined values in the `uid` column and `submit_time` column formatted according to year, month and date.
+
+### Total monthly number of questions and average number of questions per day
+
+**Description**: There is a question practice record table `practice_record`. The sample content is as follows:
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
+
+Please count the total number of monthly questions `month_q_cnt` and the average number of daily questions `avg_day_q_cnt` (sorted by month in ascending order) for users in each month of 2021, as well as the overall situation of the year. The sample data output is as follows:
+
+| submit_month | month_q_cnt | avg_day_q_cnt |
+| ------------- | ---------- | ------------- |
+| 202108 | 2 | 0.065 |
+| 202109 | 3 | 0.100 |
+| 2021 Summary | 5 | 0.161 |
+
+**Explanation**: There are 2 records of question brushing in August 2021, and the average number of questions brushed per day is 2/31=0.065 (retaining 3 decimal places); there are 3 records of brushing questions in September 2021, and the average number of questions brushed per day is 3/30=0.100; there are 5 records of brushing questions in 2021 (the annual summary average has no practical significance, here we calculate based on 31 days 5/31=0.161)
+
+> Niuke has adopted the latest Mysql version. If you get an error when running: ONLY_FULL_GROUP_BY, it means: for GROUP BY aggregation operation, if the column in SELECT does not appear in GROUP BY, then this SQL is illegal because the column is not in the GROUP BY clause, which means that the column found must appear after group by otherwise an error will be reported, or this field appears in the aggregate function.
+
+**Idea:**
+
+When you see the instance data, you will immediately think of the related functions. For example, `submit_month` will use `DATE_FORMAT` to format the date. Then find out the number of questions per month.
+
+Number of questions per month
+
+```sql
+SELECT MONTH ( submit_time ), COUNT ( question_id )
+FROM
+ practice_record
+GROUP BY
+ MONTH (submit_time)
+```
+
+Then in the third column, the `DAY(LAST_DAY(date_value))` function is used to find the number of days in the month of a given date.
+
+The sample code is as follows:
+
+```sql
+SELECT DAY(LAST_DAY('2023-07-08')) AS days_in_month;
+-- Output: 31
+
+SELECT DAY(LAST_DAY('2023-02-01')) AS days_in_month;
+-- Output: 28 (February in a leap year)
+
+SELECT DAY(LAST_DAY(NOW())) AS days_in_current_month;
+-- Output: 31 (number of days in current month)
+```
+
+Use the `LAST_DAY()` function to get the last day of the month for a given date, then use the `DAY()` function to extract the number of days for that date. This will get the number of days in the specified month.
+
+It should be noted that the `LAST_DAY()` function returns a date value, while the `DAY()` function is used to extract the day part of the date value.
+
+After the above analysis, you can write the answer immediately. The complexity of this question lies in processing the date, and the logic is not difficult.
+
+**Answer**:
+
+```sql
+SELECT DATE_FORMAT(submit_time, '%Y%m') submit_month,
+ count(question_id) month_q_cnt,
+ ROUND(COUNT(question_id) / DAY (LAST_DAY(submit_time)), 3) avg_day_q_cnt
+FROM practice_record
+WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
+GROUP BY submit_month
+UNION ALL
+SELECT '2021 Summary' AS submit_month,
+ count(question_id) month_q_cnt,
+ ROUND(COUNT(question_id) / 31, 3) avg_day_q_cnt
+FROM practice_record
+WHERE DATE_FORMAT(submit_time, '%Y') = '2021'
+ORDER BY submit_month
+```
+
+In the example data output, because the last row needs to get summary data, `UNION ALL` is added to the result set here; don't forget to sort at the end!
+
+### Valid users with more than 1 unfinished test papers (more difficult)
+
+**Description**: Existing test paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` starting answering time, `submit_time` handing in time, `score` score), sample data is as follows:| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
+| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 4 | 1002 | 9003 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1002 | 9001 | 2021-07-02 19:01:01 | 2021-07-02 19:30:01 | 82 |
+| 6 | 1002 | 9002 | 2021-07-05 18:01:01 | 2021-07-05 18:59:02 | 90 |
+| 7 | 1003 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 9 | 1004 | 9003 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1006 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+| 13 | 1007 | 9002 | 2020-09-02 12:11:01 | 2020-09-02 12:31:01 | 89 |
+
+还有一张试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间),示例数据如下:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
+
+请统计 2021 年每个未完成试卷作答数大于 1 的有效用户的数据(有效用户指完成试卷作答数至少为 1 且未完成数小于 5),输出用户 ID、未完成试卷作答数、完成试卷作答数、作答过的试卷 tag 集合,按未完成试卷数量由多到少排序。示例数据的输出结果如下:
+
+| uid | incomplete_cnt | complete_cnt | detail |
+| ---- | -------------- | ------------ | --------------------------------------------------------------------------- |
+| 1002 | 2 | 4 | 2021-09-01:算法;2021-07-02:SQL;2021-09-02:SQL;2021-09-05:SQL;2021-07-05:SQL |
+
+**解释**:2021 年的作答记录中,除了 1004,其他用户均满足有效用户定义,但只有 1002 未完成试卷数大于 1,因此只输出 1002,detail 中是 1002 作答过的试卷{日期:tag}集合,日期和 tag 间用 **:** 连接,多元素间用 **;** 连接。
+
+**思路:**
+
+仔细读题后,分析出:首先要联表,因为后面要输出`tag`;
+
+筛选出 2021 年的数据
+
+```sql
+SELECT *
+FROM exam_record er
+LEFT JOIN examination_info ei ON er.exam_id = ei.exam_id
+WHERE YEAR (er.start_time)= 2021
+```
+
+根据 uid 进行分组,然后对每个用户进行条件进行判断,题目中要求`完成试卷数至少为1,未完成试卷数要大于1,小于5`
+
+那么等会儿写 sql 的时候条件应该是:`未完成 > 1 and 已完成 >=1 and 未完成 < 5`
+
+因为最后要用到字符串的拼接,而且还要组合拼接,这个可以用`GROUP_CONCAT`函数,下面简单介绍一下该函数的用法:
+
+基本格式:
+
+```sql
+GROUP_CONCAT([DISTINCT] expr [ORDER BY {unsigned_integer | col_name | expr} [ASC | DESC] [, ...]] [SEPARATOR sep])
+```
+
+- `expr`:要连接的列或表达式。
+- `DISTINCT`:可选参数,用于去重。当指定了 `DISTINCT`,相同的值只会出现一次。
+- `ORDER BY`:可选参数,用于排序连接后的值。可以选择升序 (`ASC`) 或降序 (`DESC`) 排序。
+- `SEPARATOR sep`:可选参数,用于设置连接后的值的分隔符。(本题要用这个参数设置 ; 号 )
+
+`GROUP_CONCAT()` 函数常用于 `GROUP BY` 子句中,将一组行的值连接为一个字符串,并在结果集中以聚合的形式返回。
+
+**答案**:
+
+```sql
+SELECT a.uid,
+ SUM(CASE
+ WHEN a.submit_time IS NULL THEN 1
+ END) AS incomplete_cnt,
+ SUM(CASE
+ WHEN a.submit_time IS NOT NULL THEN 1
+ END) AS complete_cnt,
+ GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag)
+ ORDER BY start_time SEPARATOR ";") AS detail
+FROM exam_record a
+LEFT JOIN examination_info b ON a.exam_id = b.exam_id
+WHERE YEAR (a.start_time)= 2021
+GROUP BY a.uid
+HAVING incomplete_cnt > 1
+AND complete_cnt >= 1
+AND incomplete_cnt < 5
+ORDER BY incomplete_cnt DESC
+```
+
+- `SUM(CASE WHEN a.submit_time IS NULL THEN 1 END)` 统计了每个用户未完成的记录数量。
+- `SUM(CASE WHEN a.submit_time IS NOT NULL THEN 1 END)` 统计了每个用户已完成的记录数量。
+- `GROUP_CONCAT(DISTINCT CONCAT(DATE_FORMAT(a.start_time, '%Y-%m-%d'), ':', b.tag) ORDER BY a.start_time SEPARATOR ';')` 将每个用户的考试日期和标签以逗号分隔的形式连接成一个字符串,并按考试开始时间进行排序。
+
+## 嵌套子查询### The category that users who have completed an average of no less than 3 test papers per month like to answer (more difficult)
+
+**Description**: Existing test paper answer record table `exam_record` (`uid`: user ID, `exam_id`: test paper ID, `start_time`: start answering time, `submit_time`: submission time, NULL if not submitted, `score`: score), sample data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | (NULL) | (NULL) |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
+| 5 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 6 | 1003 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 7 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 8 | 1003 | 9001 | 2021-09-08 13:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
+| 10 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 11 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 12 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 13 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+Test paper information table `examination_info` (`exam_id`: test paper ID, `tag`: test paper category, `difficulty`: test paper difficulty, `duration`: test duration, `release_time`: release time), sample data is as follows:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Please count from the table the categories and number of answers that users who have an "average number of exam papers completed in the month" are not less than 3, and output them in descending order. The sample output is as follows:
+
+| tag | tag_cnt |
+| ---- | ------- |
+|C++|4|
+| SQL | 2 |
+| Algorithm | 1 |
+
+**Explanation**: The number of test papers completed by users 1002 and 1005 in September 2021 is 3, and the number of other users is less than 3; then the tag distribution results of the test papers answered by users 1002 and 1005, sorted in descending order by the number of answers, are C++, SQL, and algorithm.
+
+**Idea**: This question investigates the joint subquery, and the focus is on `monthly average answer >=3`, but I personally think it is not clearly stated here. It should be easier to understand if it is just checked in September; here is not >=3 every month or all the number of answers/months. Don't get it wrong.
+
+First check which users answer questions more than three times per month
+
+```sql
+SELECT UID
+FROM exam_record record
+GROUP BY UID,
+ MONTH (start_time)
+HAVING count(submit_time) >= 3
+```
+
+After this step, we can go deeper. As long as we can understand the previous step (I mean not to be bothered by the monthly average in the question), then set up a subquery to check which users are included, and then find out the required columns in the question. Remember to sort! !
+
+```sql
+SELECT tag,
+ count(start_time) AS tag_cnt
+FROM exam_record record
+INNER JOIN examination_info info ON record.exam_id = info.exam_id
+WHERE UID IN
+ (SELECT UID
+ FROM exam_record record
+ GROUP BY UID,
+ MONTH (start_time)
+ HAVING count(submit_time) >= 3)
+GROUP BY tag
+ORDER BY tag_cnt DESC
+```
+
+### Number of responders and average score on the day the test paper is released
+
+**Description**: Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time), sample data is as follows:
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2100 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 1500 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1100 | 4 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+**Interpretation**: User 1001’s nickname is Niuke No. 1, achievement value is 3100, user level is level 7, career direction is algorithm, registration time 2020-01-01 10:00:00
+
+Test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time) Sample data is as follows:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 || 3 | 9003 | algorithm | medium | 80 | 2020-08-02 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score) The sample data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-09-01 09:41:01 | 70 |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
+| 6 | 1002 | 9002 | 2021-08-02 12:01:01 | 2021-08-02 12:31:01 | 70 |
+| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 8 | 1002 | 9002 | 2021-07-06 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 70 |
+| 12 | 1003 | 9001 | 2021-09-08 14:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
+| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+Please calculate the number of users with level 5 or above answering `uv` and the average score `avg_score` of each SQL category test paper after it is released, in descending order of the number of people, and for the same number of people, in ascending order of average score. The sample data output is as follows:
+
+| exam_id | uv | avg_score |
+| ------- | --- | --------- |
+| 9001 | 3 | 81.3 |
+
+Explanation: There is only one SQL category test paper, and the test paper ID is 9001. On the day of release (2021-09-01), 1001, 1002, 1003, and 1005 answered, but 1003 is a level 5 user, and the other 3 are level 5 or above. The scores of the three of them are [70, 80, 85, 90], and the average score is 81.3 (reserved 1 decimal places).
+
+**Idea**: This question seems very complicated, but first gradually split the "outer" conditions, and then put them together, and the answer will come out. Anyway, remember to work from the outside to the inside for multi-table queries.
+
+First connect the three tables and give some conditions. For example, if the user in the question requires `Level > 5`, then you can find out first
+
+```sql
+SELECT DISTINCT u_info.uid
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND u_info.LEVEL > 5
+```
+
+Then pay attention to the requirement in the question: `After each sql category test paper is released, users should answer the questions on the same day`. Pay attention to the == on the same day==, then we will immediately think of the need to compare time.
+
+Compare the test paper release date and test start date: `DATE(e_info.release_time) = DATE(record.start_time)`; don’t worry about `submit_time` being null, it will be filtered out in where later.
+
+**Answer**:
+
+```sql
+SELECT record.exam_id AS exam_id,
+ COUNT(DISTINCT u_info.uid) AS uv,
+ ROUND(SUM(record.score) / COUNT(u_info.uid), 1) AS avg_score
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND DATE (e_info.release_time) = DATE (record.start_time)
+ AND submit_time IS NOT NULL
+ AND tag = 'SQL'
+ AND u_info.LEVEL > 5
+GROUP BY record.exam_id
+ORDER BY uv DESC,
+ avg_score ASC
+```
+
+Pay attention to the final grouping order! Arrange them first according to the number of people, and if they are consistent, then arrange them according to the average score.
+
+### User level distribution of people who scored more than 80 on the test paper
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2100 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 1500 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1100 | 4 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- || 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+试卷作答信息表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 79 |
+| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 4 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 5 | 1002 | 9003 | 2021-08-01 12:01:01 | 2021-08-01 12:21:01 | 60 |
+| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 7 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 8 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9002 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 86 |
+| 10 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 11 | 1003 | 9003 | 2021-09-01 13:01:01 | 2021-09-01 13:41:01 | 81 |
+| 12 | 1003 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9002 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 90 |
+| 15 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 88 |
+| 16 | 1005 | 9002 | 2021-09-02 12:11:01 | 2021-09-02 12:31:01 | 89 |
+
+统计作答 SQL 类别的试卷得分大于过 80 的人的用户等级分布,按数量降序排序(保证数量都不同)。 The sample data result output is as follows:
+
+| level | level_cnt |
+| ----- | --------- |
+| 6 | 2 |
+| 5 | 1 |
+
+Explanation: 9001 is a SQL-type test paper. There are 3 people who answered this test paper with a score greater than 80 points: 1002, 1003, and 1005, two at level 6 and one at level 5.
+
+**Idea:** This question is the same as the previous question, but the query conditions have changed. If you understand the previous question, you can solve this question in minutes.
+
+**Answer**:
+
+```sql
+SELECT u_info.LEVEL AS LEVEL,
+ count(u_info.uid) AS level_cnt
+FROM examination_info e_info
+INNER JOIN exam_record record
+INNER JOIN user_info u_info
+WHERE e_info.exam_id = record.exam_id
+ AND u_info.uid = record.uid
+ AND record.score > 80
+ AND submit_time IS NOT NULL
+ AND tag = 'SQL'
+GROUP BY LEVEL
+ORDER BY level_cnt DESC
+```
+
+## Combined query
+
+### The number of people and times that each question and each test paper was answered
+
+**Description**:
+
+现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 3 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
+| 4 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 85 |
+| 6 | 1002 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+
+Question practice table practice_record (uid user ID, question_id question ID, submit_time submission time, score score):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1003 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 6 | 1003 | 8001 | 2021-08-02 19:48:01 | 90 |
+| 7 | 1003 | 8002 | 2021-08-01 19:38:01 | 80 |
+
+请统计每个题目和每份试卷被作答的人数和次数,分别按照"试卷"和"题目"的 uv & pv 降序显示,示例数据结果输出如下:
+
+| tid | uv | pv |
+| ---- | --- | --- |
+| 9001 | 3 | 3 |
+| 9002 | 1 | 3 |
+| 8001 | 3 | 5 |
+| 8002 | 2 | 2 |
+
+**解释**:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002**Idea**: The difficulty and error-prone point of this question lies in the simultaneous use of `UNION` and `ORDER BY`
+
+There are the following situations: using `union` and multiple `order by` without brackets, an error will be reported!
+
+`order by` has no effect in clauses joined by `union`;
+
+For example, without parentheses:
+
+```sql
+SELECT exam_id AS tid,
+ COUNT(DISTINCT UID) AS uv,
+ COUNT(UID) AS pv
+FROM exam_record
+GROUP BY exam_id
+ORDER BY uv DESC,
+ pvDESC
+UNION
+SELECT question_id AS tid,
+ COUNT(DISTINCT UID) AS uv,
+ COUNT(UID) AS pv
+FROM practice_record
+GROUP BY question_id
+ORDER BY uv DESC,
+ pvDESC
+```
+
+Report a syntax error directly. If there are no brackets, there can only be one `order by`
+
+There is also a situation where `order by` does not work, but it works in clauses of clauses. The solution here is to put another layer of query outside.
+
+**Answer**:
+
+```sql
+SELECT *
+FROM
+ (SELECT exam_id AS tid,
+ COUNT(DISTINCT exam_record.uid) uv,
+ COUNT(*)pv
+ FROM exam_record
+ GROUP BY exam_id
+ ORDER BY uv DESC, pv DESC) t1
+UNION
+SELECT *
+FROM
+ (SELECT question_id AS tid,
+ COUNT(DISTINCT practice_record.uid) uv,
+ COUNT(*)pv
+ FROM practice_record
+ GROUP BY question_id
+ ORDER BY uv DESC, pv DESC) t2;
+```
+
+### People who satisfy two activities respectively
+
+**Description**: In order to promote more users to learn and improve on the Niuke platform, we will often provide benefits to some users who are both active and perform well. Suppose we had two operations in the past, and issued welfare coupons to those who scored 85 points on each test paper (activity1), and to those who completed the difficult test paper in half the time at least once with a score greater than 80 (activity2).
+
+Now, you need to screen out the people who satisfy these two activities at once and hand them over to the operations students. Please write a SQL implementation: Output the IDs and activity numbers of all people who can score 85 points on every test paper in 2021, and those who have completed a difficult test paper in half the time at least once with a score greater than 80. Sort the output by user ID.
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
+| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | **86** |
+| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 89 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+
+Sample data output:
+
+| uid | activity |
+| ---- | --------- |
+| 1001 | activity2 |
+| 1003 | activity1 |
+| 1004 | activity1 |
+| 1004 | activity2 |
+
+**Explanation**: User 1001's minimum score of 81 does not meet activity 1, but he completed the 60-minute test paper in 29 minutes and 59 seconds with a score of 81, which meets activity 2; 1003's minimum score of 86 meets activity 1, and the completion time is greater than half of the test paper length, which does not meet activity 2; User 1004 completed the test paper in exactly half the time (30 minutes) and scored 85, which meets activity 1 and activity 2.
+
+**Idea**: This question involves time subtraction, and you need to use the `TIMESTAMPDIFF()` function to calculate the minute difference between two timestamps.
+
+Let’s take a look at the basic usage
+
+Example:
+
+```sql
+TIMESTAMPDIFF(MINUTE, start_time, end_time)
+```
+
+The first parameter of the `TIMESTAMPDIFF()` function is the time unit. Here we choose `MINUTE` to return the minute difference. The second parameter is the earlier timestamp and the third parameter is the later timestamp. The function returns the difference in minutes between them
+
+After understanding the usage of this function, let's go back and look at the requirements of `activity1`. Just ask for the score to be greater than 85. So let's write this out first, and the subsequent ideas will be much clearer.
+
+```sql
+SELECT DISTINCT UID
+FROM exam_record
+WHERE score >= 85
+ AND YEAR (start_time) = '2021'
+```
+
+According to condition 2, then write `people who completed the difficult test paper in half the time and scored more than 80'
+
+```sql
+SELECT UID
+FROM examination_info info
+INNER JOIN exam_record record
+WHERE info.exam_id = record.exam_id
+ AND (TIMESTAMPDIFF(MINUTE, start_time, submit_time)) < (info.duration / 2)
+ AND difficulty = 'hard'
+ AND score >= 80
+```
+
+Then just `UNION` the two. (Special attention should be paid to the bracket problem and the position of `order by` here. The specific usage has been mentioned in the previous article)
+
+**Answer**:
+
+```sql
+SELECT DISTINCT UID UID,
+ 'activity1' activity
+FROM exam_record
+WHERE UID not in
+ (SELECT UID
+ FROM exam_record
+ WHERE score<85
+ AND YEAR(submit_time) = 2021 )
+UNION
+SELECT DISTINCT UID UID,
+ 'activity2' activity
+FROM exam_record e_r
+LEFT JOIN examination_info e_i ON e_r.exam_id = e_i.exam_id
+WHERE YEAR(submit_time) = 2021
+ AND difficulty = 'hard'
+ AND TIMESTAMPDIFF(SECOND, start_time, submit_time) <= duration *30
+ AND score>80
+ORDER BY UID
+```
+
+## Connection query
+
+### The number of test papers completed and the number of question exercises (difficulty) for users who meet the conditions
+
+**Description**:Existing user information table user_info (uid user ID, nick_name nickname, achievement achievement value, level level, job career direction, register_time registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2300 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 2500 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 2000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table examination_info (exam_id examination paper ID, tag examination paper category, difficulty examination paper difficulty, duration examination duration, release_time release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table exam_record (uid user ID, exam_id examination paper ID, start_time start answering time, submit_time submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
+| 4 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 5 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 6 | 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 7 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
+| 8 | 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 80 |
+
+Question practice record table practice_record (uid user ID, question_id question ID, submit_time submission time, score score):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 |
+| 5 | 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 6 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 7 | 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
+| 8 | 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 9 | 1004 | 8002 | 2021-08-02 19:58:01 | 94 |
+| 10 | 1004 | 8003 | 2021-08-02 19:38:01 | 70 |
+| 11 | 1004 | 8003 | 2021-08-02 19:48:01 | 90 |
+| 12 | 1004 | 8003 | 2021-08-01 19:38:01 | 80 |
+
+Please find famous experts whose average scores on the difficult SQL test papers are greater than 80 and who are level 7, count their total number of completed test papers and total number of practice questions in 2021, and only retain users who have completed test paper records in 2021. The results are in ascending order by the number of completed test papers and in descending order by the number of practice questions.
+
+Sample data output is as follows:
+
+| uid | exam_cnt | question_cnt |
+| ---- | -------- | ------------ |
+| 1001 | 1 | 2 |
+| 1003 | 2 | 0 |
+
+Explanation: Users 1001, 1003, 1004, and 1006 meet the requirements of the high-difficulty SQL test paper with an average score greater than 80, but only 1001 and 1003 are level 7 famous bosses; 1001 completed 1 test paper 1001 and practiced the questions 2 times; 1003 completed 2 test papers 9001, 9002, question not practiced (so count is 0)
+
+**Idea:**
+
+First conduct preliminary screening of conditions, for example, first find users who have taken difficult SQL test papers
+
+```sql
+SELECT
+ record.uid
+FROM
+ exam_record record
+ INNER JOIN examination_info e_info ON record.exam_id = e_info.exam_id
+ JOIN user_info u_info ON record.uid = u_info.uid
+WHERE
+ e_info.tag = 'SQL'
+ AND e_info.difficulty = 'hard'
+```
+
+Then according to the requirements of the question, just add the conditions;
+
+But here’s something to note:
+
+First: You cannot put the `YEAR(submit_time)= 2021` condition at the end, but in the `ON` condition, because there is a situation where the left join returns all the rows of the left table and the right table is null. The purpose of placing it in the `ON` clause of the `JOIN` condition is to ensure that when connecting two tables, only records that meet the year condition will be connected. This prevents records from other years from being included in the results. That is, 1001 has taken the 2021 test paper but has not practiced it. If the condition is placed at the end, this situation will be eliminated.
+
+Second, it must be `COUNT(distinct er.exam_id) exam_cnt, COUNT(distinct pr.id) question_cnt, `should be added distinct, because there are many duplicate values generated by left joins.
+
+**Answer**:
+
+```sql
+SELECT er.uid AS UID,
+ count(DISTINCT er.exam_id) AS exam_cnt,
+ count(DISTINCT pr.id) AS question_cnt
+FROM exam_recorder
+LEFT JOIN practice_record pr ON er.uid = pr.uid
+AND YEAR (er.submit_time)= 2021
+AND YEAR (pr.submit_time)= 2021
+WHERE er.uid IN
+ (SELECT er.uid
+ FROM exam_recorder
+ LEFT JOIN examination_info ei ON er.exam_id = ei.exam_id
+ LEFT JOIN user_info ui ON er.uid = ui.uid
+ WHERE tag = 'SQL'
+ AND difficulty = 'hard'
+ AND LEVEL = 7
+ GROUP BY er.uid
+ HAVING avg(score) > 80)
+GROUP BY er.uid
+ORDER BY exam_cnt,
+ question_cnt DESC```
+
+Careful friends may find out why user 1003 can still find two exam records despite clearly limiting the conditions to `tag = 'SQL' AND difficulty = 'hard'`, one of which has an exam `tag` of `C++`; This is due to the characteristics of `LEFT JOIN`, even if there are no rows matching the right table, all records in the left table will still be retained.
+
+### Activity status of each level 6/7 user (difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3100 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2300 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 | 2500 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 1200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 1600 | 6 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 2600 | 7 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| uid | exam_id | start_time | submit_time | score |
+| ---- | ------- | ------------------- | ------------------- | ------ |
+| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
+| 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 1005 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 1005 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:59 | 84 |
+| 1006 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 81 |
+| 1002 | 9001 | 2020-09-01 13:01:01 | 2020-09-01 13:41:01 | 81 |
+| 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+
+Question practice record table `practice_record` (`uid` user ID, `question_id` question ID, `submit_time` submission time, `score` score):
+
+| uid | question_id | submit_time | score |
+| ---- | ----------- | ------------------- | ----- |
+| 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 1004 | 8001 | 2021-08-02 19:38:01 | 70 |
+| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 1001 | 8002 | 2021-08-02 19:38:01 | 70 |
+| 1004 | 8002 | 2021-08-02 19:48:01 | 90 |
+| 1006 | 8002 | 2021-08-04 19:58:01 | 94 |
+| 1006 | 8003 | 2021-08-03 19:38:01 | 70 |
+| 1006 | 8003 | 2021-08-02 19:48:01 | 90 |
+| 1006 | 8003 | 2020-08-01 19:38:01 | 80 |
+
+Please count the total number of active months, number of active days in 2021, number of active days in answering test papers in 2021, and number of active days in answering questions for each level 6/7 user, and sort them in descending order according to the total number of active months and number of active days in 2021. The output from the sample data is as follows:
+
+| uid | act_month_total | act_days_2021 | act_days_2021_exam |
+| ---- | --------------- | ------------- | ------------------ |
+| 1006 | 3 | 4 | 1 |
+| 1001 | 2 | 2 | 1 |
+| 1005 | 1 | 1 | 1 |
+| 1002 | 1 | 0 | 0 |
+| 1003 | 0 | 0 | 0 |
+
+**Explanation**: There are 5 level 6/7 users, of which 1006 was active for a total of 3 months in 202109, 202108, and 202008. The active dates in 2021 are 20210907, 20210804, 20210803, and 20210802 for a total of 4 days. In 2021, it is in the test paper answer area. 20210907 has been active for 1 day and has been active in the question practice area for 3 days.
+
+**Idea:**
+
+The key to this question lies in the use of `CASE WHEN THEN`, otherwise you have to write a lot of `left join` because it will produce a lot of result sets.
+
+The `CASE WHEN THEN` statement is a conditional expression used in SQL to perform different operations or return different results based on conditions.
+
+The syntax structure is as follows:
+
+```sql
+CASE
+ WHEN condition1 THEN result1
+ WHEN condition2 THEN result2
+ ...
+ ELSE result
+END
+```
+
+In this structure, you can add multiple WHEN clauses as needed, each WHEN clause is followed by a condition and a result. The condition can be any logical expression. If the condition is met, the corresponding result will be returned.
+
+The final ELSE clause is optional and is used to specify the default return result when all previous conditions are not met. If no `ELSE` clause is provided, `NULL` is returned by default.For example:
+
+```sql
+SELECT score,
+ CASE
+ WHEN score >= 90 THEN 'Excellent'
+ WHEN score >= 80 THEN 'Good'
+ WHEN score >= 60 THEN 'pass'
+ ELSE 'failed'
+ END AS grade
+FROM student_scores;
+```
+
+In the above example, the CASE WHEN THEN statement is used to return the corresponding grade based on different ranges of student scores. If the score is greater than or equal to 90, "Excellent" is returned; if the score is greater than or equal to 80, "Good" is returned; if the score is greater than or equal to 60, "Pass" is returned; otherwise, "Fail" is returned.
+
+After understanding the above usage, look back at the question and ask to list different active days.
+
+```sql
+count(distinct act_month) as act_month_total,
+count(distinct case when year(act_time)='2021'then act_day end) as act_days_2021,
+count(distinct case when year(act_time)='2021' and tag='exam' then act_day end) as act_days_2021_exam,
+count(distinct case when year(act_time)='2021' and tag='question'then act_day end) as act_days_2021_question
+```
+
+The tag here is given first to facilitate the differentiation of queries and to separate exams and answers.
+
+Find the users in the test paper answer area
+
+```sql
+SELECT
+ uid,
+ exam_id AS ans_id,
+ start_time AS act_time,
+ date_format( start_time, '%Y%m' ) AS act_month,
+ date_format( start_time, '%Y%m%d' ) AS act_day,
+ 'exam' AS tag
+ FROM
+ exam_record
+```
+
+Then there are the users in the question and answer area.
+
+```sql
+SELECT
+ uid,
+ question_id AS ans_id,
+ submit_time AS act_time,
+ date_format( submit_time, '%Y%m' ) AS act_month,
+ date_format( submit_time, '%Y%m%d' ) AS act_day,
+ 'question' AS tag
+ FROM
+ practice_record
+```
+
+Finally, `UNION` the two results. Finally, don’t forget to sort the results (this question is somewhat similar to the idea of divide and conquer)
+
+**Answer**:
+
+```sql
+SELECT user_info.uid,
+ count(DISTINCT act_month) AS act_month_total,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021' THEN act_day
+ END) AS act_days_2021,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021'
+ AND tag = 'exam' THEN act_day
+ END) AS act_days_2021_exam,
+ count(DISTINCT CASE
+ WHEN YEAR (act_time)= '2021'
+ AND tag = 'question' THEN act_day
+ END) AS act_days_2021_question
+FROM
+ (SELECT UID,
+ exam_id AS ans_id,
+ start_time AS act_time,
+ date_format(start_time, '%Y%m') AS act_month,
+ date_format(start_time, '%Y%m%d') AS act_day,
+ 'exam' AS tag
+ FROM exam_record
+ UNION ALL SELECT UID,
+ question_id AS ans_id,
+ submit_time AS act_time,
+ date_format(submit_time, '%Y%m') AS act_month,
+ date_format(submit_time, '%Y%m%d') AS act_day,
+ 'question' AS tag
+ FROM practice_record) total
+RIGHT JOIN user_info ON total.uid = user_info.uid
+WHERE user_info.LEVEL IN (6,
+ 7)
+GROUP BY user_info.uid
+ORDER BY act_month_total DESC,
+ act_days_2021 DESC
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-04.en.md b/docs_en/database/sql/sql-questions-04.en.md
new file mode 100644
index 00000000000..9c380b6e605
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-04.en.md
@@ -0,0 +1,830 @@
+---
+title: Summary of common SQL interview questions (4)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, window function, ROW_NUMBER, ranking, grouping, MySQL 8
+ - - meta
+ - name: description
+ content: Summarizes the usage of window functions introduced in MySQL 8, including high-frequency questions and implementation techniques for sorting and grouping statistical scenarios.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+You can decide whether to skip more difficult or difficult questions based on your actual situation and interview needs.
+
+##Specialized window functions
+
+MySQL version 8.0 introduced support for window functions. The following are common window functions and their usage in MySQL:
+
+1. `ROW_NUMBER()`: Assign a unique integer value to each row in the query result set.
+
+```sql
+SELECT col1, col2, ROW_NUMBER() OVER (ORDER BY col1) AS row_num
+FROM table;
+```
+
+2. `RANK()`: Calculate the ranking of each row in the sorted results.
+
+```sql
+SELECT col1, col2, RANK() OVER (ORDER BY col1 DESC) AS ranking
+FROM table;
+```
+
+3. `DENSE_RANK()`: Calculate the ranking of each row in the sorted results, keeping the same ranking.
+
+```sql
+SELECT col1, col2, DENSE_RANK() OVER (ORDER BY col1 DESC) AS ranking
+FROM table;
+```
+
+4. `NTILE(n)`: Divide the results into n substantially uniform buckets and assign an identification number to each bucket.
+
+```sql
+SELECT col1, col2, NTILE(4) OVER (ORDER BY col1) AS bucket
+FROM table;
+```
+
+5. `SUM()`, `AVG()`, `COUNT()`, `MIN()`, `MAX()`: These aggregate functions can also be used in conjunction with window functions to calculate the summary, average, count, minimum and maximum values of specified columns within the window.
+
+```sql
+SELECT col1, col2, SUM(col1) OVER () AS sum_col
+FROM table;
+```
+
+6. `LEAD()` and `LAG()`: The LEAD function is used to get the value of the row at an offset after the current row, while the LAG function is used to get the value of the row at an offset before the current row.
+
+```sql
+SELECT col1, col2, LEAD(col1, 1) OVER (ORDER BY col1) AS next_col1,
+ LAG(col1, 1) OVER (ORDER BY col1) AS prev_col1
+FROM table;
+```
+
+7. `FIRST_VALUE()` and `LAST_VALUE()`: The FIRST_VALUE function is used to get the first value of the specified column in the window, and the LAST_VALUE function is used to get the last value of the specified column in the window.
+
+```sql
+SELECT col1, col2, FIRST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS first_val,
+ LAST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2) AS last_val
+FROM table;
+```
+
+Window functions usually need to be used together with the OVER clause to define the size, sorting rules and grouping method of the window.
+
+### The top three scores in each type of test paper
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
+| 2 | 1002 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 4 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
+| 5 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 6 | 1004 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 7 | 1005 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 8 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:01 | 84 |
+| 9 | 1003 | 9003 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 10 | 1003 | 9002 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+
+Find the top 3 scores for each type of test paper. If the two have the same maximum score, choose the one with the larger minimum score. If they are still the same, choose the one with the larger uid. The output from the sample data is as follows:
+
+| tid | uid | ranking |
+| ---- | ---- | ------- |
+| SQL | 1003 | 1 |
+| SQL | 1004 | 2 |
+| SQL | 1002 | 3 |
+| Algorithm | 1005 | 1 |
+| Algorithm | 1006 | 2 |
+| Algorithm | 1003 | 3 |
+
+**Explanation**: The test paper tags with answer score records include SQL and algorithm. SQL test paper users 1001, 1002, 1003, and 1004 have answer scores. The highest scores are 81, 81, 89, and 85 respectively, and the lowest scores are 78, 81, 86, and 40. Therefore, the top three are ranked according to the highest score first and then the lowest score, which are 1003, 1004, and 1002.
+
+**Answer**:
+
+```sql
+SELECT tag,
+ UID,
+ ranking
+FROM
+ (SELECT b.tag AS tag,
+ a.uid AS UID,
+ ROW_NUMBER() OVER (PARTITION BY b.tag
+ ORDER BY b.tag,
+ max(a.score) DESC,
+ min(a.score) DESC,
+ a.uid DESC) AS ranking
+ FROM exam_record a
+ LEFT JOIN examination_info b ON a.exam_id = b.exam_id
+ GROUP BY b.tag,
+ a.uid) t
+WHERE ranking <= 3```
+
+### The second fastest/slowest test paper whose time difference is greater than half the test paper length (more difficult)
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
+| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
+| 3 | 9003 | algorithm | medium | 80 | 2021-09-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:51:01 | 78 |
+| 2 | 1001 | 9002 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
+| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
+| 4 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:59:01 | 86 |
+| 5 | 1003 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:51 | 89 |
+| 6 | 1004 | 9002 | 2021-09-01 19:01:01 | 2021-09-01 19:30:01 | 85 |
+| 7 | 1005 | 9001 | 2021-09-01 12:01:01 | 2021-09-01 12:31:02 | 85 |
+| 8 | 1006 | 9001 | 2021-09-07 10:02:01 | 2021-09-07 10:21:01 | 84 |
+| 9 | 1003 | 9001 | 2021-09-08 12:01:01 | 2021-09-08 12:11:01 | 40 |
+| 10 | 1003 | 9002 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 11 | 1005 | 9001 | 2021-09-01 14:01:01 | (NULL) | (NULL) |
+| 12 | 1003 | 9003 | 2021-09-08 15:01:01 | (NULL) | (NULL) |
+
+Find the test paper information where the difference between the second fastest and the second slowest time is greater than half of the test paper length, and sort by test paper ID in descending order. The output from the sample data is as follows:
+
+| exam_id | duration | release_time |
+| ------- | -------- | ------------------- |
+| 9001 | 60 | 2021-09-01 06:00:00 |
+
+**Explanation**: Test paper 9001 takes 50 minutes, 58 minutes, 30 minutes and 1 second, 19 minutes, and 10 minutes. The difference between the second fastest and the second slowest time is 50 minutes - 19 minutes = 31 minutes. The test paper duration is 60 minutes. Therefore, the condition of being greater than half of the test paper length is met, and the test paper ID, duration, and release time are output.
+
+**Idea:**
+
+The first step is to find the sequential ranking and reverse ranking of the completion time of each test paper, which is Table a;
+
+In the second step, establish an inner connection with the passed test paper information table b, group it according to the test paper id, use `having` to filter the ranking into the second data, convert seconds into minutes and compare, and finally sort according to the test paper id in reverse order.
+
+**Answer**:
+
+```sql
+SELECT a.exam_id,
+ b.duration,
+ b.release_time
+FROM
+ (SELECT exam_id,
+ row_number() OVER (PARTITION BY exam_id
+ ORDER BY timestampdiff(SECOND, start_time, submit_time) DESC) rn1,
+ row_number() OVER (PARTITION BY exam_id
+ ORDER BY timestampdiff(SECOND, start_time, submit_time) ASC) rn2,
+ timestampdiff(SECOND, start_time, submit_time) timex
+ FROM exam_record
+ WHERE score IS NOT NULL ) a
+INNER JOIN examination_info b ON a.exam_id = b.exam_id
+GROUP BY a.exam_id
+HAVING (max(IF (rn1 = 2, a.timex, 0))- max(IF (rn2 = 2, a.timex, 0)))/ 60 > b.duration / 2
+ORDER BY a.exam_id DESC
+```
+
+### The maximum time window for answering the test paper twice in a row (more difficult)
+
+**Description**
+
+Existing exam paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` starting answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:02 | 84 |
+| 2 | 1006 | 9001 | 2021-09-01 12:11:01 | 2021-09-01 12:31:01 | 89 |
+| 3 | 1006 | 9002 | 2021-09-06 10:01:01 | 2021-09-06 10:21:01 | 81 |
+| 4 | 1005 | 9002 | 2021-09-05 10:01:01 | 2021-09-05 10:21:01 | 81 |
+| 5 | 1005 | 9001 | 2021-09-05 10:31:01 | 2021-09-05 10:51:01 | 81 |
+
+Please calculate among those who have answered the test paper on at least two days in 2021, calculate the maximum time window `days_window` for answering the test paper twice in a row in that year, then according to the historical rules of the year, how many sets of test papers he will take on average in `days_window` days, sort in reverse order by the maximum time window and the average number of sets of answer papers. The output from the sample data is as follows:
+
+| uid | days_window | avg_exam_cnt |
+| ---- | ----------- | ------------ |
+| 1006 | 6 | 2.57 |**Explanation**: User 1006 answered 3 test papers in 20210901, 20210906, and 20210907 respectively. The maximum time window for two consecutive responses is 6 days (1st to 6th). He took a total of 3 test papers in the 7 days from 1st to 7th. On average, 3/7=0.428571 papers per day, so on average he will do 3 test papers in 6 days. 0.428571\*6=2.57 test papers (keep two decimal places); User 1005 took two test papers in 20210905, but only had one day's answer records, so filter them out.
+
+**Idea:**
+
+The above explanation reminds you to remove duplicates from the answer records. Don’t be fooled and don’t delete duplicates! If you remove duplicates, the test case will fail. Note that the restriction is in 2021;
+
+And please note that the time difference is +1 day; also note that == unsubmitted papers are also counted ==! ! ! ! (Anyway, I feel that the description of this question is unclear and the answer is not very good)
+
+**Answer**:
+
+```sql
+SELECT UID,
+ max(datediff(next_time, start_time)) + 1 AS days_window,
+ round(count(start_time)/(datediff(max(start_time), min(start_time))+ 1) * (max(datediff(next_time, start_time))+ 1), 2) AS avg_exam_cnt
+FROM
+ (SELECT UID,
+ start_time,
+ lead(start_time, 1) OVER (PARTITION BY UID
+ ORDER BY start_time) AS next_time
+ FROM exam_record
+ WHERE YEAR (start_time) = '2021' ) a
+GROUP BY UID
+HAVING count(DISTINCT date(start_time)) > 1
+ORDER BY days_window DESC,
+ avg_exam_cnt DESC
+```
+
+### The completion status of users who have not completed 0 in the past three months
+
+**Description**:
+
+Existing test paper answer record table `exam_record` (`uid`: user ID, `exam_id`: test paper ID, `start_time`: start answering time, `submit_time`: handing in time, if it is empty, it means not completed, `score`: score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1006 | 9003 | 2021-09-06 10:01:01 | 2021-09-06 10:21:02 | 84 |
+| 2 | 1006 | 9001 | 2021-08-02 12:11:01 | 2021-08-02 12:31:01 | 89 |
+| 3 | 1006 | 9002 | 2021-06-06 10:01:01 | 2021-06-06 10:21:01 | 81 |
+| 4 | 1006 | 9002 | 2021-05-06 10:01:01 | 2021-05-06 10:21:01 | 81 |
+| 5 | 1006 | 9001 | 2021-05-01 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9001 | 2021-09-05 10:31:01 | 2021-09-05 10:51:01 | 81 |
+| 7 | 1001 | 9003 | 2021-08-01 09:01:01 | 2021-08-01 09:51:11 | 78 |
+| 8 | 1001 | 9002 | 2021-07-01 09:01:01 | 2021-07-01 09:31:00 | 81 |
+| 9 | 1001 | 9002 | 2021-07-01 12:01:01 | 2021-07-01 12:31:01 | 81 |
+| 10 | 1001 | 9002 | 2021-07-01 12:01:01 | (NULL) | (NULL) |
+
+Find the number of test paper completions for users who have no test paper in the unfinished status in the last three months for each person who has test paper answer records, and rank them in descending order by the number of test paper completions and user ID. The output from the sample data is as follows:
+
+| uid | exam_complete_cnt |
+| ---- | ------------------ |
+| 1006 | 3 |
+
+**Explanation**: User 1006 has answered test papers in the last three months of 202109, 202108, and 202106, and the number of answered test papers is 3, all of which have been completed; User 1001 has answered test papers in the last three months of 202109, 202108, and 202107, and the number of answered test papers is 5, and the number of completed test papers is 4. Because there are unfinished test papers, they are filtered out.
+
+**Idea:**
+
+1. `Find the number of completed test papers for users who have no test paper answer records in the past three months and have no test paper answer records.` First of all, look at this sentence. You must first group them according to people.
+2. In the past three months, you can use continuous repeated ranking, sort in reverse order, ranking <=3
+3. Count the number of answers
+4. Assemble remaining conditions
+5. Sort
+
+**Answer**:
+
+```sql
+SELECT UID,
+ count(score) exam_complete_cnt
+FROM
+ (SELECT *, DENSE_RANK() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) dr
+ FROM exam_record) t1
+WHERE dr <= 3
+GROUP BY UID
+HAVING count(dr)= count(score)
+ORDER BY exam_complete_cnt DESC,
+ UID DESC
+```
+
+### Response status of the 50% users with high incompleteness rate in the past three months (difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 3200 | 7 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2500 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 2200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | Algorithm | hard | 80 | 2020-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 15 | 1002 | 9001 | 2020-01-01 18:01:01 | 2020-01-01 18:59:02 | 90 |
+| 13 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | | |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | | |
+| 5 | 1001 | 9001 | 2020-03-01 12:01:01 | | |
+| 6 | 1002 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | | |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 14 | 1001 | 9002 | 2020-01-01 12:11:01 | | |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1002 | 9002 | 2020-02-02 12:01:01 | | |
+| 11 | 1002 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1002 | 9002 | 2020-03-02 12:11:01 | | |
+| 17 | 1001 | 9002 | 2020-05-05 18:01:01 | | |
+| 16 | 1002 | 9003 | 2020-05-06 12:01:01 | | |
+
+请统计 SQL 试卷上未完成率较高的 50%用户中,6 级和 7 级用户在有试卷作答记录的近三个月中,每个月的答卷数目和完成数目。按用户 ID、月份升序排序。
+
+由示例数据结果输出如下:
+
+| uid | start_month | total_cnt | complete_cnt |
+| ---- | ----------- | --------- | ------------ |
+| 1002 | 202002 | 3 | 1 |
+| 1002 | 202003 | 2 | 1 |
+| 1002 | 202005 | 2 | 1 |
+
+解释:各个用户对 SQL 试卷的未完成数、作答总数、未完成率如下:
+
+| uid | incomplete_cnt | total_cnt | incomplete_rate |
+| ---- | -------------- | --------- | --------------- |
+| 1001 | 3 | 7 | 0.4286 |
+| 1002 | 4 | 8 | 0.5000 |
+| 1003 | 1 | 1 | 1.0000 |
+
+1001、1002、1003 分别排在 1.0、0.5、0.0 的位置,因此较高的 50%用户(排位<=0.5)为 1002、1003;
+
+1003 不是 6 级或 7 级;
+
+有试卷作答记录的近三个月为 202005、202003、202002;
+
+这三个月里 1002 的作答题数分别为 3、2、2,完成数目分别为 1、1、1。
+
+**思路:**
+
+注意点:这题注意求的是所有的答题次数和完成次数,而 sql 类别的试卷是限制未完成率排名,6, 7 级用户限制的是做题记录。
+
+先求出未完成率的排名
+
+```sql
+SELECT UID,
+ count(submit_time IS NULL
+ OR NULL)/ count(start_time) AS num,
+ PERCENT_RANK() OVER (
+ ORDER BY count(submit_time IS NULL
+ OR NULL)/ count(start_time)) AS ranking
+FROM exam_record
+LEFT JOIN examination_info USING (exam_id)
+WHERE tag = 'SQL'
+GROUP BY UID
+```
+
+再求出最近三个月的练习记录
+
+```sql
+SELECT UID,
+ date_format(start_time, '%Y%m') AS month_d,
+ submit_time,
+ exam_id,
+ dense_rank() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) AS ranking
+FROM exam_record
+LEFT JOIN user_info USING (UID)
+WHERE LEVEL IN (6,7)
+```
+
+**答案**:
+
+```sql
+SELECT t1.uid,
+ t1.month_d,
+ count(*) AS total_cnt,
+ count(t1.submit_time) AS complete_cnt
+FROM-- 先求出未完成率的排名
+
+ (SELECT UID,
+ count(submit_time IS NULL OR NULL)/ count(start_time) AS num,
+ PERCENT_RANK() OVER (
+ ORDER BY count(submit_time IS NULL OR NULL)/ count(start_time)) AS ranking
+ FROM exam_record
+ LEFT JOIN examination_info USING (exam_id)
+ WHERE tag = 'SQL'
+ GROUP BY UID) t
+INNER JOIN
+ (-- 再求出近三个月的练习记录
+ SELECT UID,
+ date_format(start_time, '%Y%m') AS month_d,
+ submit_time,
+ exam_id,
+ dense_rank() OVER (PARTITION BY UID
+ ORDER BY date_format(start_time, '%Y%m') DESC) AS ranking
+ FROM exam_record
+ LEFT JOIN user_info USING (UID)
+ WHERE LEVEL IN (6,7) ) t1 USING (UID)
+WHERE t1.ranking <= 3 AND t.ranking >= 0.5 -- 使用限制找到符合条件的记录
+
+GROUP BY t1.uid,
+ t1.month_d
+ORDER BY t1.uid,
+ t1.month_d```
+
+### 试卷完成数同比 2020 年的增长率及排名变化(困难)
+
+**描述**:
+
+现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2021-01-01 10:00:00 |
+
+试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-08-02 10:01:01 | 2020-08-02 10:31:01 | 89 |
+| 2 | 1002 | 9001 | 2020-04-01 18:01:01 | 2020-04-01 18:59:02 | 90 |
+| 3 | 1001 | 9001 | 2020-04-01 09:01:01 | 2020-04-01 09:21:59 | 80 |
+| 5 | 1002 | 9001 | 2021-03-02 19:01:01 | 2021-03-02 19:32:00 | 20 |
+| 8 | 1003 | 9001 | 2021-05-02 12:01:01 | 2021-05-02 12:31:01 | 98 |
+| 13 | 1003 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 9 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1002 | 9002 | 2021-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 11 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 16 | 1002 | 9002 | 2020-02-02 12:01:01 | | |
+| 17 | 1002 | 9002 | 2020-03-02 12:11:01 | | |
+| 18 | 1001 | 9002 | 2021-05-05 18:01:01 | | |
+| 4 | 1002 | 9003 | 2021-01-20 10:01:01 | 2021-01-20 10:10:01 | 81 |
+| 6 | 1001 | 9003 | 2021-04-02 19:01:01 | 2021-04-02 19:40:01 | 89 |
+| 15 | 1002 | 9003 | 2021-01-01 18:01:01 | 2021-01-01 18:59:02 | 90 |
+| 7 | 1004 | 9004 | 2020-05-02 12:01:01 | 2020-05-02 12:20:01 | 99 |
+| 12 | 1001 | 9004 | 2021-09-02 12:11:01 | | |
+| 14 | 1002 | 9004 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+
+请计算 2021 年上半年各类试卷的做完次数相比 2020 年上半年同期的增长率(百分比格式,保留 1 位小数),以及做完次数排名变化,按增长率和 21 年排名降序输出。
+
+由示例数据结果输出如下:
+
+| tag | exam_cnt_20 | exam_cnt_21 | growth_rate | exam_cnt_rank_20 | exam_cnt_rank_21 | rank_delta |
+| --- | ----------- | ----------- | ----------- | ---------------- | ---------------- | ---------- |
+| SQL | 3 | 2 | -33.3% | 1 | 2 | 1 |
+
+解释:2020 年上半年有 3 个 tag 有作答完成的记录,分别是 C++、SQL、PYTHON,它们被做完的次数分别是 3、3、2,做完次数排名为 1、1(并列)、3;
+
+2021 年上半年有 2 个 tag 有作答完成的记录,分别是算法、SQL,它们被做完的次数分别是 3、2,做完次数排名为 1、2;具体如下:
+
+| tag | start_year | exam_cnt | exam_cnt_rank |
+| ------ | ---------- | -------- | ------------- |
+| C++ | 2020 | 3 | 1 |
+| SQL | 2020 | 3 | 1 |
+| PYTHON | 2020 | 2 | 3 |
+| 算法 | 2021 | 3 | 1 |
+| SQL | 2021 | 2 | 2 |
+
+因此能输出同比结果的 tag 只有 SQL,从 2020 到 2021 年,做完次数 3=>2,减少 33.3%(保留 1 位小数);排名 1=>2,后退 1 名。
+
+**思路:**
+
+本题难点在于长整型的数据类型要求不能有负号产生,用 cast 函数转换数据类型为 signed。
+
+以及用到的`增长率计算公式:(exam_cnt_21-exam_cnt_20)/exam_cnt_20`
+
+做完次数排名变化(2021 年和 2020 年比排名升了或者降了多少)
+
+计算公式:`exam_cnt_rank_21 - exam_cnt_rank_20`
+
+在 MySQL 中,`CAST()` 函数用于将一个表达式的数据类型转换为另一个数据类型。它的基本语法如下:
+
+```sql
+CAST(expression AS data_type)
+
+-- 将一个字符串转换成整数
+SELECT CAST('123' AS INT);
+```
+
+示例就不一一举例了,这个函数很简单
+
+**答案**:
+
+```sql
+SELECT
+ tag,
+ exam_cnt_20,
+ exam_cnt_21,
+ concat(
+ round(
+ 100 * (exam_cnt_21 - exam_cnt_20) / exam_cnt_20,
+ 1
+ ),
+ '%'
+ ) AS growth_rate,
+ exam_cnt_rank_20,
+ exam_cnt_rank_21,
+ cast(exam_cnt_rank_21 AS signed) - cast(exam_cnt_rank_20 AS signed) AS rank_delta
+FROM
+ (
+ #2020年、2021年上半年各类试卷的做完次数和做完次数排名
+ SELECT
+ tag,
+ count(
+ IF (
+ date_format(start_time, '%Y%m%d') BETWEEN '20200101'
+ AND '20200630',
+ start_time,
+ NULL
+ )
+ ) AS exam_cnt_20,
+ count(
+ IF (
+ substring(start_time, 1, 10) BETWEEN '2021-01-01'
+ AND '2021-06-30',
+ start_time,
+ NULL
+ )
+ ) AS exam_cnt_21,
+ rank() over (
+ ORDER BY
+ count(
+ IF (
+ date_format(start_time, '%Y%m%d') BETWEEN '20200101'
+ AND '20200630',
+ start_time,
+ NULL
+ )
+ ) DESC
+ ) AS exam_cnt_rank_20,
+ rank() over (
+ ORDER BY
+ count(
+ IF (
+ substring(start_time, 1, 10) BETWEEN '2021-01-01'
+ AND '2021-06-30',
+ start_time,
+ NULL
+ )
+ ) DESC
+ ) AS exam_cnt_rank_21
+ FROM
+ examination_info
+ JOIN exam_record USING (exam_id)
+ WHERE
+ submit_time IS NOT NULL
+ GROUP BY
+ tag
+ ) main
+WHERE
+ exam_cnt_21 * exam_cnt_20 <> 0
+ORDER BY
+ growth_rate DESC,
+ exam_cnt_rank_21 DESC
+```
+
+## Aggregation window function
+
+### Perform min-max normalization on test paper scores
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ------ | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | Algorithm | hard | 80 | 2020-01-01 10:00:00 |
+| 4 | 9004 | PYTHON | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 6 | 1003 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 68 |
+| 9 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 12 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
+| 3 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
+| 2 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
+| 7 | 1001 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
+| 10 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
+| 5 | 1002 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 90 |
+| 11 | 1002 | 9004 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 8 | 1001 | 9005 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
+
+In physics and statistical data calculation, there is a concept called min-max standardization, also known as dispersion standardization, which is a linear transformation of the original data so that the result value is mapped to [0 - 1].
+
+The conversion function is:
+
+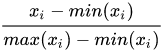
+
+Please perform min-max normalization on each test paper's answer record and scale it to the [0,100] interval, and output the user ID, test paper ID, and average score after normalization; finally, output the test paper ID in ascending order and the normalized score in descending order. (Note: The score interval defaults to [0,100]. If there is only one score in the answer record of a certain test paper, there is no need to use a formula. The score will still be the original score after normalization and scaling).
+
+The output from the sample data is as follows:
+
+| uid | exam_id | avg_new_score |
+| ---- | ------- | ------------- |
+| 1001 | 9001 | 98 |
+| 1003 | 9001 | 0 |
+| 1002 | 9002 | 88 |
+| 1003 | 9002 | 75 |
+| 1001 | 9002 | 70 |
+| 1004 | 9002 | 0 |
+
+Explanation: The difficult papers are 9001, 9002, and 9003;
+
+There are 3 records of answering 9001, and the scores are 68, 89, and 90 respectively. After normalization according to the given formula, the scores are: 0, 95, 100, and the latter two scores are answered by user 1001. Therefore, user 1001’s new score for test paper 9001 is (95+100)/2≈98 (only the integer part is retained). User 1003’s score for the test paper 9001 has a new score of 0. The final results are output in ascending order of test paper ID and descending order of normalized scores.
+
+**Idea:**
+
+Note:
+
+1. For difficult test papers, use the max/min (col) over() window function to find the maximum and minimum values in each group according to the scores of each type of test paper, and then calculate the normalized formula. The scaling interval is [0,100], that is, min_max\*100
+2. If a certain type of test paper has only one score, there is no need to use the normalization formula, because there is only one score max_score=min_score,score, and the result may become 0 after the formula.
+3. The final results are grouped by uid and exam_id to find the normalized mean. Those with a score of NULL should be filtered out.
+
+The last thing is to look carefully at the above formula (to be honest, this question seems very convoluted)
+
+**Answer**:
+
+```sql
+SELECT
+ uid,
+ exam_id,
+ round(sum(min_max) / count(score), 0) AS avg_new_score
+FROM
+ (
+ SELECT
+ *,
+ IF (
+ max_score = min_score,
+ score,
+ (score - min_score) / (max_score - min_score) * 100
+ ) AS min_max
+ FROM
+ (
+ SELECT
+ uid,
+ a.exam_id,
+ score,
+ max(score) over (PARTITION BY a.exam_id) AS max_score,
+ min(score) over (PARTITION BY a.exam_id) AS min_score
+ FROM
+ exam_record a
+ LEFT JOIN examination_info b USING (exam_id)
+ WHERE
+ difficulty = 'hard'
+ ) t
+ WHERE
+ score IS NOT NULL
+ ) t1
+GROUP BY
+ uid,
+ exam_id
+ORDER BY
+ exam_id ASC,
+ avg_new_score DESC;
+```
+
+### The number of answers per test paper per month and the total number of answers as of the current month
+
+**Description:**
+
+Existing test paper answer record table exam_record (uid user ID, exam_id test paper ID, start_time start answering time, submit_time handover time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ || 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1003 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1004 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1003 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 68 |
+| 11 | 1001 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1001 | 9002 | 2020-03-02 12:11:01 | (NULL) | (NULL) |
+
+Please output the number of responses per month for each test paper and the total number of responses as of the current month.
+The output from the sample data is as follows:
+
+| exam_id | start_month | month_cnt | cum_exam_cnt |
+| ------- | ----------- | --------- | ----------- |
+| 9001 | 202001 | 2 | 2 |
+| 9001 | 202002 | 1 | 3 |
+| 9001 | 202003 | 3 | 6 |
+| 9001 | 202005 | 1 | 7 |
+| 9002 | 202001 | 1 | 1 |
+| 9002 | 202002 | 3 | 4 |
+| 9002 | 202003 | 1 | 5 |
+
+Explanation: Test paper 9001 has been answered in 4 months, 202001, 202002, 202003, and 202005. The number of answers per month is 2, 1, 3, and 1 respectively. The total number of answers as of the current month is 2, 3, 6, and 7.
+
+**Idea:**
+
+This question has two key points: counting the total number of answers as of the current month, outputting the number of monthly responses for each test paper, and outputting the total number of responses as of the current month.
+
+This is the key `**sum(count(*)) over(partition by exam_id order by date_format(start_time,'%Y%m'))**`
+
+**Answer**:
+
+```sql
+SELECT exam_id,
+ date_format(start_time, '%Y%m') AS start_month,
+ count(*) AS month_cnt,
+ sum(count(*)) OVER (PARTITION BY exam_id
+ ORDER BY date_format(start_time, '%Y%m')) AS cum_exam_cnt
+FROM exam_record
+GROUP BY exam_id,
+ start_month
+```
+
+### Question answering status every month and as of the current month (more difficult)
+
+**Description**: Existing test paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
+| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
+| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9001 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1003 | 9001 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1002 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 90 |
+| 8 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:59:01 | 69 |
+| 9 | 1004 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1003 | 9002 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 68 |
+| 11 | 1001 | 9002 | 2020-01-02 19:01:01 | 2020-02-02 12:43:01 | 81 |
+| 12 | 1001 | 9002 | 2020-03-02 12:11:01 | (NULL) | (NULL) |
+
+Please output the number of monthly active users, the number of new users, the maximum number of new users in a single month as of the current month, and the cumulative number of users as of the current month in the monthly test paper response records since the user's answer record was created. The results are output in ascending order of month.
+
+The output from the sample data is as follows:
+
+| start_month | mau | month_add_uv | max_month_add_uv | cum_sum_uv |
+| ----------- | --- | ------------ | ---------------- | ---------- |
+| 202001 | 2 | 2 | 2 | 2 |
+| 202002 | 4 | 2 | 2 | 4 |
+| 202003 | 3 | 0 | 2 | 4 |
+| 202005 | 1 | 0 | 2 | 4 |
+
+| month | 1001 | 1002 | 1003 | 1004 |
+| ------ | ---- | ---- | ---- | ---- |
+| 202001 | 1 | 1 | | |
+| 202002 | 1 | 1 | 1 | 1 |
+| 202003 | 1 | | 1 | 1 |
+| 202005 | | 1 | | |As can be seen from the above matrix, there were 2 active users in January 2020 (mau=2), and the number of new users that month was 2;
+
+There were 4 active users in February 2020, the number of new users in that month was 2, the maximum number of new users in a single month was 2, and the current cumulative number of users was 4.
+
+**Idea:**
+
+Difficulties:
+
+1. How to find new users every month
+
+2. Answers as of the current month
+
+Rough process:
+
+(1) Count each person’s first login month `min()`
+
+(2) Statistics of monthly active and new users: first get each person’s first login month, and then sum up the first login month grouping to get the number of new users in that month.
+
+(3) Count the maximum number of new users in a single month as of the current month, the cumulative number of users as of the current month, and finally output them in ascending order by month
+
+**Answer**:
+
+```sql
+--The maximum number of new users in a single month as of the current month and the cumulative number of users as of the current month, output in ascending order by month
+SELECT
+ start_month,
+ mau,
+ month_add_uv,
+ max( month_add_uv ) over ( ORDER BY start_month ),
+ sum( month_add_uv ) over ( ORDER BY start_month )
+FROM
+ (
+ -- Statistics of monthly active users and number of new users
+ SELECT
+ date_format( a.start_time, '%Y%m' ) AS start_month,
+ count( DISTINCT a.uid ) AS mau,
+ count( DISTINCT b.uid ) AS month_add_uv
+ FROM
+ exam_record a
+ LEFT JOIN (
+ -- Count each person's first login month
+ SELECT uid, min( date_format( start_time, '%Y%m' )) AS first_month FROM exam_record GROUP BY uid ) b ON date_format( a.start_time, '%Y%m' ) = b.first_month
+ GROUP BY
+ start_month
+ ) main
+ORDER BY
+ start_month
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-questions-05.en.md b/docs_en/database/sql/sql-questions-05.en.md
new file mode 100644
index 00000000000..849447aeb08
--- /dev/null
+++ b/docs_en/database/sql/sql-questions-05.en.md
@@ -0,0 +1,1037 @@
+---
+title: Summary of common SQL interview questions (5)
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL interview questions, null value processing, statistics, incomplete rate, CASE, aggregation
+ - - meta
+ - name: description
+ Content: Analyzes null value processing and statistics topics, combines CASE and aggregate functions to provide a robust implementation, and avoid common pitfalls.
+---
+
+> The question comes from: [Niuke Question Ba - SQL Advanced Challenge](https://www.nowcoder.com/exam/oj?page=1&tab=SQL%E7%AF%87&topicId=240)
+
+You can decide whether to skip more difficult or difficult questions based on your actual situation and interview needs.
+
+## Null value handling
+
+### Count the number of unfinished papers and their unfinished rate
+
+**Description**:
+
+The existing examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` starting answering time, `submit_time` handing in time, `score` score), the data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
+| 3 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+
+Please count the number of incomplete_cnt and incomplete_rate of the test papers with incomplete status. The output from the sample data is as follows:
+
+| exam_id | incomplete_cnt | complete_rate |
+| ------- | -------------- | ------------- |
+| 9001 | 1 | 0.333 |
+
+Explanation: Test Paper 9001 has records of being answered three times, of which two were completed and one was incomplete. Therefore, the number of incompletes is 1 and the incomplete rate is 0.333 (retaining 3 decimal places)
+
+**Ideas**:
+
+For this question, you only need to note that one has conditional restrictions and the other does not have conditional restrictions; either query the conditions separately and then merge them; or perform conditional judgment directly in select.
+
+**Answer**:
+
+Writing method 1:
+
+```sql
+SELECT
+ exam_id,
+ (COUNT(*) - COUNT(submit_time)) AS incomplete_cnt,
+ ROUND((COUNT(*) - COUNT(submit_time)) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ (COUNT(*) - COUNT(submit_time)) > 0;
+```
+
+Use `COUNT(*)` to count the total number of records in the group, `COUNT(submit_time)` only counts the number of records whose `submit_time` field is not NULL (that is, the number of completed records). Subtracting the two is the unfinished number.
+
+Writing method 2:
+
+```sql
+SELECT
+ exam_id,
+ COUNT(CASE WHEN submit_time IS NULL THEN 1 END) AS incomplete_cnt,
+ ROUND(COUNT(CASE WHEN submit_time IS NULL THEN 1 END) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ COUNT(CASE WHEN submit_time IS NULL THEN 1 END) > 0;
+```
+
+Use a `CASE` expression to return a non-`NULL` value (such as 1) when the condition is met, otherwise return `NULL`. Then use the `COUNT` function to count the number of non-`NULL` values.
+
+Writing method 3:
+
+```sql
+SELECT
+ exam_id,
+ SUM(submit_time IS NULL) AS incomplete_cnt,
+ ROUND(SUM(submit_time IS NULL) / COUNT(*), 3) AS incomplete_rate
+FROM
+ exam_record
+GROUP BY
+ exam_id
+HAVING
+ incomplete_cnt > 0;
+```
+
+Use the `SUM` function to sum an expression. The expression `(submit_time IS NULL)` evaluates to 1 (TRUE) when `submit_time` is `NULL` and 0 (FALSE) otherwise. Adding these 1s and 0s together gives you the number of outstanding items.
+
+### Average time and average score of high-difficulty test papers for level 0 users
+
+**Description**:
+
+The existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time), the data is as follows:
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 10 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 2100 | 6 | Algorithm | 2020-01-01 10:00:00 |
+
+Test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time), the data is as follows:
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | SQL | easy | 60 | 2020-01-01 10:00:00 |
+| 3 | 9004 | algorithm | medium | 80 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` submission time, `score` score), the data is as follows:
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 || 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+
+Please output the average test time and average score of all high-difficulty test papers for each level 0 user, the maximum test time and 0-point processing for unfinished default test papers. The output from the sample data is as follows:
+
+| uid | avg_score | avg_time_took |
+| ---- | --------- | ------------- |
+| 1001 | 33 | 36.7 |
+
+Explanation: There are 1001 level 0 users, 9001 high-difficulty test papers, and there are 3 records of 1001 answering 9001, which took 20 minutes, incomplete (the test paper lasted 60 minutes), and 30 minutes (less than 31 minutes). The scores were 80 points, incomplete (processed with 0 points), and 20 points respectively. Therefore his average time is 110/3=36.7 (rounded to one decimal place) and his average score is 33 points (rounded)
+
+**Idea**: It is most convenient to use `IF` for this question because it involves the judgment of NULL values. Of course, `case when` can also be used, which is very similar. The difficulty of this question lies in the processing of null values. I believe that other query conditions and so on will not be difficult for everyone.
+
+**Answer**:
+
+```sql
+SELECT UID,
+ round(avg(new_socre)) AS avg_score,
+ round(avg(time_diff), 1) AS avg_time_took
+FROM
+ (SELECT er.uid,
+ IF (er.submit_time IS NOT NULL, TIMESTAMPDIFF(MINUTE, start_time, submit_time), ef.duration) AS time_diff,
+ IF (er.submit_time IS NOT NULL,er.score,0) AS new_socre
+ FROM exam_recorder
+ LEFT JOIN user_info uf ON er.uid = uf.uid
+ LEFT JOIN examination_info ef ON er.exam_id = ef.exam_id
+ WHERE uf.LEVEL = 0 AND ef.difficulty = 'hard' ) t
+GROUP BY UID
+ORDER BY UID
+```
+
+## Advanced conditional statements
+
+### Filter users with limited nickname achievement value and active date (harder)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 1000 | 2 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Attack No. 3 | 2200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 2500 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 5 | 3000 | 7 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
+| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
+| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
+| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
+| 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 |
+
+Question practice record table `practice_record` (`uid` user ID, `question_id` question ID, `submit_time` submission time, `score` score):
+
+| id | uid | question_id | submit_time | score |
+| --- | ---- | ----------- | ------------------- | ----- |
+| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
+| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
+| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
+| 4 | 1002 | 8002 | 2021-09-02 19:38:01 | 70 || 5 | 1003 | 8002 | 2021-09-01 19:38:01 | 80 |
+
+Please find the user information whose nickname starts with "Niuke" and ends with "号", whose achievement value is between 1200 and 2500, and who was last active (answering questions or answering papers) in September 2021.
+
+The output from the sample data is as follows:
+
+| uid | nick_name | achievement |
+| ---- | --------- | ----------- |
+| 1002 | Niuke No. 2 | 1200 |
+
+**Explanation**: There are 1002 and 1004 whose nicknames start with "Niuke" and end with "号" and have achievement values between 1200 and 2500;
+
+1002 The last active test paper area was September 2021, and the last active question area was September 2021; 1004 The last active test paper area was August 2021, and the question area was not active.
+
+Therefore, only 1002 finally meets the condition.
+
+**Ideas**:
+
+First list the main query statements according to the conditions
+
+Nickname starts with "Niuke" and ends with "number": `nick_name LIKE "牛客%号"`
+
+Achievement value is between 1200~2500: `achievement BETWEEN 1200 AND 2500`
+
+The third condition is limited to September, so just write it directly: `( date_format( record.submit_time, '%Y%m' )= 202109 OR date_format( pr.submit_time, '%Y%m' )= 202109 )`
+
+**Answer**:
+
+```sql
+SELECT DISTINCT u_info.uid,
+ u_info.nick_name,
+ u_info.achievement
+FROM user_info u_info
+LEFT JOIN exam_record record ON record.uid = u_info.uid
+LEFT JOIN practice_record pr ON u_info.uid = pr.uid
+WHERE u_info.nick_name LIKE "nickname%"
+ AND u_info.achievement BETWEEN 1200
+ AND 2500
+ AND (date_format(record.submit_time, '%Y%m')= 202109
+ OR date_format(pr.submit_time, '%Y%m')= 202109)
+GROUP BY u_info.uid
+```
+
+### Filter the answer records of nickname rules and test paper rules (more difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 1900 | 2 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 2200 | 5 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 2500 | 6 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper information table `examination_info` (`exam_id` examination paper ID, `tag` examination paper category, `difficulty` examination paper difficulty, `duration` examination duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | --- | ---------- | -------- | ------------------- |
+| 1 | 9001 | C++ | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | c# | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 5 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 6 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 11 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 81 |
+| 16 | 1002 | 9001 | 2021-09-06 12:01:01 | 2021-09-06 12:21:01 | 80 |
+| 17 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 18 | 1002 | 9001 | 2021-09-07 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9002 | 2021-05-05 18:01:01 | 2021-05-05 18:59:02 | 90 |
+| 12 | 1002 | 9002 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 13 | 1002 | 9002 | 2020-02-02 12:11:01 | 2020-02-02 12:31:01 | 83 |
+| 9 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+| 8 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 10 | 1004 | 9002 | 2021-08-06 12:01:01 | (NULL) | (NULL) |
+| 14 | 1005 | 9001 | 2021-02-01 11:01:01 | 2021-02-01 11:31:01 | 84 || 15 | 1006 | 9001 | 2021-02-01 11:01:01 | 2021-09-01 11:31:01 | 84 |
+
+Find the completed test paper IDs and average scores for test paper categories starting with the letter c (such as C, C++, c#, etc.) for users whose nicknames consist of "Niuke" + pure numbers + "号" or pure numbers, and sort them in ascending order by user ID and average score. The output from the sample data is as follows:
+
+| uid | exam_id | avg_score |
+| ---- | ------- | --------- |
+| 1002 | 9001 | 81 |
+| 1002 | 9002 | 85 |
+| 1005 | 9001 | 84 |
+| 1006 | 9001 | 84 |
+
+Explanation: The users whose nicknames meet the conditions are 1002, 1004, 1005, and 1006;
+
+The test papers starting with c include 9001 and 9002;
+
+Among the answer records that meet the above conditions, the scores for 1002 and 9001 are 81 and 80, with an average score of 81 (80.5 is rounded up to 81);
+
+1002 completed 9002 with scores of 90, 82, and 83, with an average score of 85;
+
+**Ideas**:
+
+It’s still the same as before. Since the conditions are given, write out each condition first.
+
+Find users whose nicknames consist of "Niuke" + pure numbers + "号" or pure numbers: I initially wrote this: `nick_name LIKE 'Nuke% number' OR nick_name REGEXP '^[0-9]+$'`. If there is a "Nike H number" in the table, it will also pass.
+
+So you have to use regular rules here: `nick_name LIKE '^nickel[0-9]+号'`
+
+For test paper categories starting with the letter c: `e_info.tag LIKE 'c%'` or `tag regexp '^c|^C'` The first one can also match the uppercase C
+
+**Answer**:
+
+```sql
+SELECT UID,
+ exam_id,
+ ROUND(AVG(score), 0) avg_score
+FROM exam_record
+WHERE UID IN
+ (SELECT UID
+ FROM user_info
+ WHERE nick_name RLIKE "^nickname[0-9]+number $"
+ OR nick_name RLIKE "^[0-9]+$")
+ AND exam_id IN
+ (SELECT exam_id
+ FROM examination_info
+ WHERE tag RLIKE "^[cC]")
+ AND score IS NOT NULL
+GROUP BY UID,exam_id
+ORDER BY UID,avg_score;
+```
+
+### Output different situations based on whether the specified record exists (difficulty)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Attack No. 3 | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
+| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | (NULL) | (NULL) |
+| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
+| 6 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
+| 7 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
+| 8 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 9 | 1002 | 9003 | 2020-02-02 12:11:01 | (NULL) | (NULL) |
+| 10 | 1002 | 9002 | 2021-05-05 18:01:01 | (NULL) | (NULL) |
+| 11 | 1002 | 9001 | 2021-09-06 12:01:01 | (NULL) | (NULL) |
+| 12 | 1003 | 9003 | 2021-02-06 12:01:01 | (NULL) | (NULL) |
+| 13 | 1003 | 9001 | 2021-09-07 10:01:01 | 2021-09-07 10:31:01 | 89 |
+
+Please filter the data in the table. When the number of uncompleted test papers for any level 0 user is greater than 2, output the number of uncompleted test papers and the uncompleted rate (retaining 3 decimal places) for each level 0 user. If there is no such user, output these two indicators for all users with answer records. Results are sorted in ascending order by incomplete rate.
+
+The output from the sample data is as follows:
+
+| uid | incomplete_cnt | incomplete_rate |
+| ---- | -------------- | --------------- |
+| 1004 | 0 | 0.000 |
+| 1003 | 1 | 0.500 |
+| 1001 | 4 | 0.667 |
+
+**Explanation**: There are 1001, 1003, and 1004 level 0 users; the number of test papers they answered and the number of unfinished papers are: 6:4, 2:1, and 0:0 respectively;
+
+There is a level 0 user 1001 whose number of unfinished test papers is greater than 2, so the unfinished number and uncompleted rate of these three users are output (1004 has not answered the test paper, and the unfinished rate is filled with 0 by default, and it is 0.000 after retaining 3 decimal places);
+
+Results are sorted in ascending order by incomplete rate.
+
+Attachment: If 1001 does not satisfy "the number of unfinished test papers is greater than 2", you need to output the two indicators of 1001, 1002, and 1003, because there are only the answer records of these three users in the test paper answer record table.
+
+**Ideas**:
+
+First write out the SQL that may satisfy the condition **"The number of unfinished test papers for level 0 users is greater than 2"**
+
+```sql
+SELECT ui.uid UID
+FROM user_info ui
+LEFT JOIN exam_record er ON ui.uid = er.uid
+WHERE ui.uid IN
+ (SELECT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 )
+GROUP BY ui.uid
+HAVING sum(IF(er.submit_time IS NULL, 1, 0)) > 2```
+
+Then write the SQL query statements for the two situations:
+
+Situation 1. Query the uncompleted rate of test papers for level 0 users with conditional requirements
+
+```sql
+SELECT
+ tmp1.uid uid,
+ sum(
+ IF
+ ( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 )) incomplete_cnt,
+ round(
+ sum(
+ IF
+ (er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0))/ count(tmp1.uid),
+ 3
+ ) incomplete_rate
+FROM
+ (
+ SELECT DISTINCT
+ ui.uid
+ FROM
+ user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE
+ er.submit_time IS NULL
+ AND ui.LEVEL = 0
+ ) tmp1
+ LEFT JOIN exam_record er ON tmp1.uid = er.uid
+GROUP BY
+ tmp1.uid
+ORDER BY
+ incomplete_rate
+```
+
+Situation 2. Query the uncompletion rate of all yong users who have answer records when there are no conditional requirements.
+
+```sql
+SELECT
+ ui.uid uid,
+ sum( CASE WHEN er.submit_time IS NULL AND er.start_time IS NOT NULL THEN 1 ELSE 0 END ) incomplete_cnt,
+ round(
+ sum(
+ IF
+ ( er.submit_time IS NULL AND er.start_time IS NOT NULL, 1, 0 ))/ count( ui.uid ),
+ 3
+ ) incomplete_rate
+FROM
+ user_info ui
+ JOIN exam_record er ON ui.uid = er.uid
+GROUP BY
+ ui.uid
+ORDER BY
+ incomplete_rate
+```
+
+Putting them together is the answer
+
+```sql
+WITH host_user AS
+ (SELECT ui.uid UID
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE ui.uid IN
+ (SELECT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 )
+ GROUP BY ui.uid
+ HAVING sum(IF (er.submit_time IS NULL, 1, 0))> 2),
+ tt1AS
+ (SELECT tmp1.uid UID,
+ sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0)) incomplete_cnt,
+ round(sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0))/ count(tmp1.uid), 3) incomplete_rate
+ FROM
+ (SELECT DISTINCT ui.uid
+ FROM user_info ui
+ LEFT JOIN exam_record er ON ui.uid = er.uid
+ WHERE er.submit_time IS NULL
+ AND ui.LEVEL = 0 ) tmp1
+ LEFT JOIN exam_record er ON tmp1.uid = er.uid
+ GROUP BY tmp1.uid
+ ORDER BY incomplete_rate),
+ tt2AS
+ (SELECT ui.uid UID,
+ sum(CASE
+ WHEN er.submit_time IS NULL
+ AND er.start_time IS NOT NULL THEN 1
+ ELSE 0
+ END) incomplete_cnt,
+ round(sum(IF (er.submit_time IS NULL
+ AND er.start_time IS NOT NULL, 1, 0))/ count(ui.uid), 3) incomplete_rate
+ FROM user_info ui
+ JOIN exam_record er ON ui.uid = er.uid
+ GROUP BY ui.uid
+ ORDER BY incomplete_rate)
+ (SELECT tt1.*
+ FROM tt1
+ LEFT JOIN
+ (SELECT UID
+ FROM host_user) t1 ON 1 = 1
+ WHERE t1.uid IS NOT NULL )
+UNION ALL
+ (SELECT tt2.*
+ FROM tt2
+ LEFT JOIN
+ (SELECT UID
+ FROM host_user) t2 ON 1 = 1
+ WHERE t2.uid IS NULL)
+```
+
+V2 version (based on the improvements made above, the answer is shortened and the logic is stronger):
+
+```sql
+SELECT
+ ui.uid,
+ SUM(
+ IF
+ ( start_time IS NOT NULL AND score IS NULL, 1, 0 )) AS incomplete_cnt, #3. The number of incomplete test papers
+ ROUND( AVG( IF ( start_time IS NOT NULL AND score IS NULL, 1, 0 )), 3 ) AS incomplete_rate #4. Incomplete rate
+
+FROM
+ user_info ui
+ LEFT JOIN exam_record USING ( uid )
+WHERE
+CASE
+
+ WHEN (#1. When any level 0 user has more than 2 uncompleted test papers
+ SELECT
+ MAX(lv0_incom_cnt)
+ FROM
+ (
+ SELECT
+ SUM(
+ IF
+ ( score IS NULL, 1, 0 )) AS lv0_incom_cnt
+ FROM
+ user_info
+ JOIN exam_record USING ( uid )
+ WHERE
+ LEVEL = 0
+ GROUP BY
+ uid
+ ) table1
+ )> 2 THEN
+ uid IN ( #1.1 Find each level 0 user
+ SELECT uid FROM user_info WHERE LEVEL = 0 ) ELSE uid IN ( #2. If there is no such user, find the user with the answer record
+ SELECT DISTINCT uid FROM exam_record )
+ END
+ GROUP BY
+ ui.uid
+ ORDER BY
+ incomplete_rate #5.The results are sorted in ascending order by incomplete rate
+```
+
+### The proportion of different score performance of each user level (more difficult)
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 || 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 2000 | 7 | C++ | 2020-01-01 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-01-01 10:00:00 |
+
+Examination paper answer record table exam_record (uid user ID, exam_id examination paper ID, start_time start answering time, submit_time submission time, score score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
+| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 75 |
+| 4 | 1001 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:11:01 | 60 |
+| 5 | 1001 | 9003 | 2021-09-02 12:01:01 | 2021-09-02 12:41:01 | 90 |
+| 6 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
+| 7 | 1001 | 9002 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
+| 8 | 1001 | 9004 | 2021-09-03 12:01:01 | (NULL) | (NULL) |
+| 9 | 1002 | 9001 | 2020-01-01 12:01:01 | 2020-01-01 12:31:01 | 99 |
+| 10 | 1002 | 9003 | 2020-02-01 12:01:01 | 2020-02-01 12:31:01 | 82 |
+| 11 | 1002 | 9003 | 2020-02-02 12:11:01 | 2020-02-02 12:41:01 | 76 |
+
+In order to obtain the qualitative performance of the user's answer to the test paper, we divided the test paper scores into four score levels of excellent, medium and poor according to the cut-off point [90, 75, 60] (the cut-off point is divided into the left interval). Please count the proportion of each score level in the completed test papers of people with different user levels (the results are retained to 3 decimal places). Users who have not completed the test paper do not need to output. The results are sorted in descending order of user level and proportion.
+
+The output from the sample data is as follows:
+
+| level | score_grade | ratio |
+| ----- | ----------- | ----- |
+| 3 | Good | 0.667 |
+| 3 | Excellent | 0.333 |
+| 0 | Good | 0.500 |
+| 0 | Medium | 0.167 |
+| 0 | Excellent | 0.167 |
+| 0 | Difference | 0.167 |
+
+Explanation: The number of users who have completed the test paper are 1001 and 1002; the user levels and score levels corresponding to the completed test papers are as follows:
+
+| uid | exam_id | score | level | score_grade |
+| ---- | ------- | ----- | ----- | ----------- |
+| 1001 | 9001 | 80 | 0 | Good |
+| 1001 | 9002 | 75 | 0 | Good |
+| 1001 | 9002 | 60 | 0 | Medium |
+| 1001 | 9003 | 90 | 0 | Excellent |
+| 1001 | 9001 | 20 | 0 | Poor |
+| 1001 | 9002 | 89 | 0 | Good |
+| 1002 | 9001 | 99 | 3 | Excellent |
+| 1002 | 9003 | 82 | 3 | Good |
+| 1002 | 9003 | 76 | 3 | Good |
+
+Therefore, the proportion of each score level for level 0 users (only 1001) is: excellent 1/6, good 1/6, average 1/6, and poor 3/6; the proportion of each score level for level 3 users (only 1002) is: excellent 1/3, good 2/3. The result is rounded to 3 decimal places.
+
+**Ideas**:
+
+First write out the condition **"Divide the test paper scores into four score levels according to the cut-off points [90, 75, 60]: excellent, medium and poor"**, you can use `case when` here
+
+```sql
+CASE
+ WHEN a.score >= 90 THEN
+ 'Excellent'
+ WHEN a.score < 90 AND a.score >= 75 THEN
+ 'good'
+ WHEN a.score < 75 AND a.score >= 60 THEN
+ 'medium' ELSE 'poor'
+END
+```
+
+The key point of this question is this, the rest is conditional splicing
+
+**Answer**:
+
+```sql
+SELECT a.LEVEL,
+ a.score_grade,
+ ROUND(a.cur_count / b.total_num, 3) AS ratio
+FROM
+ (SELECT b.LEVEL AS LEVEL,
+ (CASE
+ WHEN a.score >= 90 THEN 'Excellent'
+ WHEN a.score < 90
+ AND a.score >= 75 THEN 'good'
+ WHEN a.score < 75
+ AND a.score >= 60 THEN 'medium'
+ ELSE 'poor'
+ END) AS score_grade,
+ count(1) AS cur_count
+ FROM exam_record a
+ LEFT JOIN user_info b ON a.uid = b.uid
+ WHERE a.submit_time IS NOT NULL
+ GROUP BY b.LEVEL,
+ score_grade) a
+LEFT JOIN
+ (SELECT b.LEVEL AS LEVEL,
+ count(b.LEVEL) AS total_num
+ FROM exam_record a
+ LEFT JOIN user_info b ON a.uid = b.uid
+ WHERE a.submit_time IS NOT NULL
+ GROUP BY b.LEVEL) b ON a.LEVEL = b.LEVEL
+ORDER BY a.LEVEL DESC,
+ ratioDESC
+```
+
+## Limited query
+
+### The three people with the earliest registration time
+
+**Description**:
+
+Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time || --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke No. 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-02-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-02 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 5 | 1005 | Niuke No. 555 | 4000 | 7 | C++ | 2020-01-11 10:00:00 |
+| 6 | 1006 | 666666 | 3000 | 6 | C++ | 2020-11-01 10:00:00 |
+
+Please find the 3 people with the earliest registration time. The output from the sample data is as follows:
+
+| uid | nick_name | register_time |
+| ---- | ------------ | ------------------- |
+| 1001 | Niuke 1 | 2020-01-01 10:00:00 |
+| 1003 | Niuke No. 3 ♂ | 2020-01-02 10:00:00 |
+| 1004 | Niuke No. 4 | 2020-01-02 11:00:00 |
+
+Explanation: Select the top three after sorting by registration time, and output their user ID, nickname, and registration time.
+
+**Answer**:
+
+```sql
+SELECT uid, nick_name, register_time
+ FROM user_info
+ ORDER BY register_time
+ LIMIT 3
+```
+
+### Completed the third page of the test paper list on the day of registration (more difficult)
+
+**Description**: Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
+| 1 | 1001 | Niuke 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 5 | 1005 | Niuke No. 555 | 4000 | 7 | Algorithm | 2020-01-11 10:00:00 |
+| 6 | 1006 | Niuke No. 6 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 7 | 1007 | Niuke No. 7 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 8 | 1008 | Niuke No. 8 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 9 | 1009 | Niuke No. 9 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 10 | 1010 | Niuke No. 10 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+| 11 | 1011 | 666666 | 3000 | 6 | C++ | 2020-01-02 10:00:00 |
+
+Examination paper information table examination_info (exam_id examination paper ID, tag examination paper category, difficulty examination paper difficulty, duration examination duration, release_time release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | algorithm | hard | 60 | 2020-01-01 10:00:00 |
+| 2 | 9002 | Algorithm | hard | 80 | 2020-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
+
+Examination paper answer record table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ----- |
+| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
+| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
+| 3 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-01-01 19:01:01 | 2020-01-01 19:30:01 | 75 |
+| 5 | 1004 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:11:01 | 60 |
+| 6 | 1005 | 9002 | 2020-01-01 12:01:01 | 2020-01-01 12:41:01 | 90 |
+| 7 | 1006 | 9001 | 2020-01-02 19:01:01 | 2020-01-02 19:32:00 | 20 |
+| 8 | 1007 | 9002 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
+| 9 | 1008 | 9003 | 2020-01-02 12:01:01 | 2020-01-02 12:20:01 | 99 |
+| 10 | 1008 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 98 |
+| 11 | 1009 | 9002 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 82 |
+| 12 | 1010 | 9002 | 2020-01-02 12:11:01 | 2020-01-02 12:41:01 | 76 |
+| 13 | 1011 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
+
+Those who are looking for a job as an algorithm engineer and have completed the algorithm test paper on the day of registration will be ranked according to the highest scores in all exams they have taken. The ranking list is very long. We will display it in pages, with 3 items per page. Now you need to take out the information of the people on page 3 (the page number starts from 1).
+
+The output from the sample data is as follows:
+
+| uid | level | register_time | max_score |
+| ---- | ----- | ------------------- | --------- |
+| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
+| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
+| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
+
+Explanation: Except for 1011, all other users are looking for algorithm engineers; there are 9001 and 9002 algorithm test papers, and all 11 users completed the algorithm test papers on the day of registration; calculating the maximum time points of all their exams, only 1002 and 1008 completed two exams, and the others only completed one exam. The highest score for 1002 in the two exams was 81, and the highest score for 1008 was 99.
+
+Ranking by highest score is as follows:
+
+| uid | level | register_time | max_score |
+| ---- | ----- | ------------------- | --------- |
+| 1008 | 0 | 2020-01-02 11:00:00 | 99 |
+| 1005 | 7 | 2020-01-01 10:00:00 | 90 |
+| 1007 | 0 | 2020-01-02 11:00:00 | 89 |
+| 1002 | 3 | 2020-01-01 10:00:00 | 83 |
+| 1009 | 0 | 2020-01-02 11:00:00 | 82 |
+| 1001 | 0 | 2020-01-01 10:00:00 | 80 |
+| 1010 | 0 | 2020-01-02 11:00:00 | 76 |
+| 1003 | 0 | 2020-01-01 10:00:00 | 75 |
+| 1004 | 0 | 2020-01-01 11:00:00 | 60 |
+| 1006 | 0 | 2020-01-02 11:00:00 | 20 |
+
+There are 3 items per page, and the third page is the 7th to 9th items. Just return row records of 1010, 1003, and 1004.
+
+**Ideas**:
+
+1. Three items per page, that is, the information of the person on the third page needs to be retrieved, so `limit` must be used.
+
+2. Statistics of people who are looking for jobs as algorithm engineers and who have completed the algorithm test paper on the day of registration and the scores for each record. First find the users who meet the conditions, and then use left join to connect to find the information and the scores for each record.
+
+**Answer**:
+
+```sql
+SELECT t1.uid,
+ LEVEL,
+ register_time,
+ max(score) AS max_score
+FROM exam_record t
+JOIN examination_info USING (exam_id)
+JOIN user_info t1 ON t.uid = t1.uid
+AND date(t.submit_time) = date(t1.register_time)
+WHERE job = 'algorithm'
+ AND tag = 'algorithm'
+GROUP BY t1.uid,
+ LEVEL,
+ register_time
+ORDER BY max_score DESC
+LIMIT 6,3
+```
+
+## Text conversion function
+
+### Repair serialized records
+
+**Description**: Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` exam duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | -------------- | ---------- | -------- | ------------------- |
+| 1 | 9001 | algorithm | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | Algorithm | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 4 | 9004 | Algorithm,medium,80 | | 0 | 2021-01-01 10:00:00 |
+
+A student who recorded the questions accidentally entered the test category tag, difficulty, and duration of some records into the tag field at the same time. Please help find these incorrect records, split them, and output them in the correct column type.
+
+The output from the sample data is as follows:
+
+| exam_id | tag | difficulty | duration |
+| ------- | ---- | ---------- | -------- |
+| 9004 | algorithm | medium | 80 |
+
+**Ideas**:
+
+Let’s first learn the functions used in this question
+
+The `SUBSTRING_INDEX` function is used to extract the portion of a string with a specified delimiter. It accepts three parameters: the original string, the delimiter, and the number of parts specified to be returned.
+
+The following is the syntax of the `SUBSTRING_INDEX` function:
+
+```sql
+SUBSTRING_INDEX(str, delimiter, count)
+```
+
+- `str`: the original string to be split.
+- `delimiter`: string or character used as delimiter.
+- `count`: Specifies the number of parts to return.
+ - If `count` is greater than 0, return the first `count` parts starting from the left (bounded by the delimiter).
+ - If `count` is less than 0, return the first `count` parts (bounded by the delimiter) starting from the right, counting from the right to the left.
+
+Here are some examples demonstrating the use of the `SUBSTRING_INDEX` function:
+
+1. Extract the first part of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 1);
+ -- Output result: 'apple'
+ ```
+
+2. Extract the last part of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -1);
+ -- Output result: 'cherry'
+ ```
+
+3. Extract the first two parts of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', 2);
+ -- Output result: 'apple,banana'
+ ```
+
+4. Extract the last two parts of the string:
+
+ ```sql
+ SELECT SUBSTRING_INDEX('apple,banana,cherry', ',', -2);
+ -- Output result: 'banana,cherry'
+ ```
+
+**Answer**:
+
+```sql
+SELECT
+ exam_id,
+ substring_index( tag, ',', 1 ) tag,
+ substring_index( substring_index( tag, ',', 2 ), ',',- 1 ) difficulty,
+ substring_index( tag, ',',- 1 ) duration
+FROM
+ examination_info
+WHERE
+ difficulty = ''
+```
+
+### Interception processing of nicknames that are too long
+
+**Description**: Existing user information table `user_info` (`uid` user ID, `nick_name` nickname, `achievement` achievement value, `level` level, `job` career direction, `register_time` registration time):
+
+| id | uid | nick_name | achievement | level | job | register_time |
+| --- | ---- | ----------------------- | ----------- | ----- | ---- | ------------------- || 1 | 1001 | Niuke 1 | 19 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 2 | 1002 | Niuke No. 2 | 1200 | 3 | Algorithm | 2020-01-01 10:00:00 |
+| 3 | 1003 | Niuke No. 3 ♂ | 22 | 0 | Algorithm | 2020-01-01 10:00:00 |
+| 4 | 1004 | Niuke No. 4 | 25 | 0 | Algorithm | 2020-01-01 11:00:00 |
+| 5 | 1005 | Niuke No. 5678901234 | 4000 | 7 | Algorithm | 2020-01-11 10:00:00 |
+| 6 | 1006 | Niuke No. 67890123456789 | 25 | 0 | Algorithm | 2020-01-02 11:00:00 |
+
+Some users' nicknames are particularly long, which may cause style confusion in some display scenarios. Therefore, particularly long nicknames need to be converted before outputting. Please output user information with more than 10 characters. For users with more than 13 characters, output the first 10 characters and then add three periods: "...".
+
+The output from the sample data is as follows:
+
+| uid | nick_name |
+| ---- | ------------------ |
+| 1005 | Niuke No. 5678901234 |
+| 1006 | Niuke 67890123... |
+
+Explanation: There are 1005 and 1006 users with more than 10 characters, and the lengths are 13 and 17 respectively; therefore, the output of the nickname of 1006 needs to be truncated.
+
+**Ideas**:
+
+This question involves character calculation. To calculate the number of characters in a string (that is, the length of the string), you can use the `LENGTH` function or the `CHAR_LENGTH` function. The difference between these two functions is the way multibyte characters are treated.
+
+1. `LENGTH` function: It returns the number of bytes of the given string. For strings containing multibyte characters, each character is counted as a byte.
+
+Example:
+
+```sql
+SELECT LENGTH('Hello'); -- Output result: 6, because each Chinese character in 'Hello' occupies 3 bytes each
+```
+
+1. `CHAR_LENGTH` function: It returns the number of characters of the given string. For strings containing multibyte characters, each character is counted as one character.
+
+Example:
+
+```sql
+SELECT CHAR_LENGTH('Hello'); -- Output result: 2, because there are two characters in 'Hello', that is, two Chinese characters
+```
+
+**Answer**:
+
+```sql
+SELECT
+ uid,
+CASE
+
+ WHEN CHAR_LENGTH( nick_name ) > 13 THEN
+ CONCAT( SUBSTR( nick_name, 1, 10 ), '...' ) ELSE nick_name
+ END AS nick_name
+FROM
+ user_info
+WHERE
+ CHAR_LENGTH( nick_name ) > 10
+GROUP BY
+ uid;
+```
+
+### Filter statistics when case is confused (difficult)
+
+**Description**:
+
+Existing test paper information table `examination_info` (`exam_id` test paper ID, `tag` test paper category, `difficulty` test paper difficulty, `duration` test duration, `release_time` release time):
+
+| id | exam_id | tag | difficulty | duration | release_time |
+| --- | ------- | ---- | ---------- | -------- | ------------------- |
+| 1 | 9001 | algorithm | hard | 60 | 2021-01-01 10:00:00 |
+| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 3 | 9003 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 4 | 9004 | sql | medium | 70 | 2021-01-01 10:00:00 |
+| 5 | 9005 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 6 | 9006 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 7 | 9007 | C++ | hard | 80 | 2021-01-01 10:00:00 |
+| 8 | 9008 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 9 | 9009 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+| 10 | 9010 | SQL | medium | 70 | 2021-01-01 10:00:00 |
+
+Examination paper answer information table `exam_record` (`uid` user ID, `exam_id` test paper ID, `start_time` start answering time, `submit_time` handing in time, `score` score):
+
+| id | uid | exam_id | start_time | submit_time | score |
+| --- | ---- | ------- | ------------------- | ------------------- | ------ |
+| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 80 |
+| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
+| 3 | 1002 | 9002 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
+| 4 | 1003 | 9002 | 2020-03-01 19:01:01 | 2020-03-01 19:30:01 | 75 |
+| 5 | 1004 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:11:01 | 60 |
+| 6 | 1005 | 9002 | 2020-03-01 12:01:01 | 2020-03-01 12:41:01 | 90 |
+| 7 | 1006 | 9001 | 2020-05-02 19:01:01 | 2020-05-02 19:32:00 | 20 |
+| 8 | 1007 | 9003 | 2020-01-02 19:01:01 | 2020-01-02 19:40:01 | 89 |
+| 9 | 1008 | 9004 | 2020-02-02 12:01:01 | 2020-02-02 12:20:01 | 99 |
+| 10 | 1008 | 9001 | 2020-02-02 12:01:01 | 2020-02-02 12:31:01 | 98 |
+| 11 | 1009 | 9002 | 2020-02-02 12:01:01 | 2020-01-02 12:43:01 | 81 |
+| 12 | 1010 | 9001 | 2020-01-02 12:11:01 | (NULL) | (NULL) |
+| 13 | 1010 | 9001 | 2020-02-02 12:01:01 | 2020-01-02 10:31:01 | 89 |
+
+The category tags of the test paper may have mixed case. Please first filter out the category tags with less than 3 answers in the test paper, and count the corresponding number of answers in the original test paper after converting them to uppercase.
+
+If the tag has not changed after conversion, the result will not be output.
+
+The output from the sample data is as follows:
+
+| tag | answer_cnt |
+| --- | ---------- |
+|C++|6|
+
+Explanation: The papers that have been answered include 9001, 9002, 9003, and 9004. Their tags and the number of times they have been answered are as follows:
+
+| exam_id | tag | answer_cnt |
+| ------- | ---- | ---------- || 9001 | Algorithm | 4 |
+| 9002 | C++ | 6 |
+| 9003 | c++ | 2 |
+| 9004 | sql | 2 |
+
+Tags with less than 3 answers include c++ and sql. However, after being converted to uppercase, only C++ has an original answer count. Therefore, the output number of c++ after being converted to uppercase is 6.
+
+**Ideas**:
+
+First of all, this question is a bit confusing. According to the sample data, 9004 is found only once, but here it is shown that there are two times.
+
+Let’s take a look at the case conversion function first:
+
+1. The `UPPER(s)` or `UCASE(s)` function can convert all alphabetic characters in the string s into uppercase letters;
+
+2. The `LOWER(s)` or `LCASE(s)` function can convert all alphabetic characters in the string s into lowercase letters.
+
+The difficulty is that when joining the same table, you need to query different values.
+
+**Answer**:
+
+```sql
+WITH a AS
+ (SELECT tag,
+ COUNT(start_time) AS answer_cnt
+ FROM exam_recorder
+ JOIN examination_info ei ON er.exam_id = ei.exam_id
+ GROUP BY tag)
+SELECT a.tag,
+ b.answer_cnt
+FROM a
+INNER JOIN a AS b ON UPPER(a.tag)= b.tag #a lower case b upper case
+AND a.tag != b.tag
+WHERE a.answer_cnt < 3;
+```
+
+
\ No newline at end of file
diff --git a/docs_en/database/sql/sql-syntax-summary.en.md b/docs_en/database/sql/sql-syntax-summary.en.md
new file mode 100644
index 00000000000..87185b87558
--- /dev/null
+++ b/docs_en/database/sql/sql-syntax-summary.en.md
@@ -0,0 +1,1208 @@
+---
+title: Summary of basic knowledge of SQL syntax
+category: database
+tag:
+ - Database basics
+ - SQL
+head:
+ - - meta
+ - name: keywords
+ content: SQL syntax, DDL, DML, DQL, constraints, transactions, indexes, paradigms
+ - - meta
+ - name: description
+ content: Systematically organizes basic SQL syntax and terminology, covering DDL/DML/DQL, constraints and transaction indexes, forming a knowledge path from entry to practice.
+---
+
+> This article is compiled and improved from the following two materials:
+>
+> - [SQL Syntax Quick Manual](https://juejin.cn/post/6844903790571700231)
+> - [MySQL Super Complete Tutorial](https://www.begtut.com/mysql/mysql-tutorial.html)
+
+## Basic concepts
+
+### Database terminology
+
+- `database` - A container (usually a file or set of files) that holds organized data.
+- `table` - a structured list of data of a specific type.
+- `schema` - information about the layout and properties of databases and tables. The schema defines how data is stored in the table, including what kind of data is stored, how the data is decomposed, how each part of the information is named, and other information. Both databases and tables have schemas.
+- `column` – a field in a table. All tables are composed of one or more columns.
+- `row(row)` - a record in the table.
+- `primary key` - a column (or set of columns) whose value uniquely identifies each row in a table.
+
+### SQL syntax
+
+SQL (Structured Query Language), standard SQL is managed by the ANSI Standards Committee, so it is called ANSI SQL. Each DBMS has its own implementation, such as PL/SQL, Transact-SQL, etc.
+
+#### SQL syntax structure
+
+
+
+SQL syntax structures include:
+
+- **`clause`** - is the component of statements and queries. (In some cases, these are optional.)
+- **`expression`** - can produce any scalar value, or a database table consisting of columns and rows
+- **`Predicate`** - Specify conditions for SQL three-valued logic (3VL) (true/false/unknown) or Boolean truth values that need to be evaluated, and limit the effects of statements and queries, or change program flow.
+- **`Query`** - Retrieve data based on specific criteria. This is an important part of SQL.
+- **`Statement`** - Can permanently affect the schema and data, and can also control database transactions, program flow, connections, sessions, or diagnostics.
+
+#### SQL syntax points
+
+- **SQL statements are not case-sensitive**, but whether database table names, column names and values are distinguished depends on the specific DBMS and configuration. For example: `SELECT` is the same as `select`, `Select`.
+- **Multiple SQL statements must be separated by semicolons (`;`)**.
+- **All spaces are ignored** when processing SQL statements.
+
+SQL statements can be written in one line or divided into multiple lines.
+
+```sql
+-- One line of SQL statement
+
+UPDATE user SET username='robot', password='robot' WHERE username = 'root';
+
+--Multi-line SQL statement
+UPDATE user
+SET username='robot', password='robot'
+WHERE username = 'root';
+```
+
+SQL supports three types of comments:
+
+```sql
+## Note 1
+-- Note 2
+/* Note 3 */
+```
+
+### SQL Classification
+
+#### Data Definition Language (DDL)
+
+Data Definition Language (DDL) is a language in the SQL language that is responsible for the definition of data structures and database objects.
+
+The main function of DDL is to define database objects.
+
+The core instructions of DDL are `CREATE`, `ALTER`, and `DROP`.
+
+#### Data Manipulation Language (DML)
+
+Data Manipulation Language (DML) is a programming statement used for database operations to access objects and data in the database.
+
+The main function of DML is to **access data**, so its syntax is mainly based on **reading and writing database**.
+
+The core instructions of DML are `INSERT`, `UPDATE`, `DELETE`, and `SELECT`. These four instructions are collectively called CRUD (Create, Read, Update, Delete), which means add, delete, modify, and query.
+
+#### Transaction Control Language (TCL)
+
+Transaction Control Language (TCL) is used to manage transactions in the database. These are used to manage changes made by DML statements. It also allows statements to be grouped into logical transactions.
+
+The core instructions of TCL are `COMMIT` and `ROLLBACK`.
+
+#### Data Control Language (DCL)
+
+Data Control Language (DCL) is an instruction that can control data access rights. It can control the control rights of specific user accounts to database objects such as data tables, view tables, stored procedures, and user-defined functions.
+
+The core instructions of DCL are `GRANT` and `REVOKE`.
+
+DCL mainly focuses on controlling user access rights, so its instruction method is not complicated. The permissions that can be controlled by DCL are: `CONNECT`, `SELECT`, `INSERT`, `UPDATE`, `DELETE`, `EXECUTE`, `USAGE`, `REFERENCES`.
+
+Different DBMSs and different security entities support different permission controls.
+
+**Let’s first introduce the usage of DML statements. The main function of DML is to read and write databases to implement additions, deletions, modifications and queries. **
+
+## Add, delete, modify and check
+
+Add, delete, modify, and query, also known as CRUD, is a basic operation in basic database operations.
+
+### Insert data
+
+The `INSERT INTO` statement is used to insert new records into the table.
+
+**INSERT COMPLETE ROW**
+
+```sql
+# insert a row
+INSERT INTO user
+VALUES (10, 'root', 'root', 'xxxx@163.com');
+# Insert multiple rows
+INSERT INTO user
+VALUES (10, 'root', 'root', 'xxxx@163.com'), (12, 'user1', 'user1', 'xxxx@163.com'), (18, 'user2', 'user2', 'xxxx@163.com');
+```
+
+**Insert part of row**
+
+```sql
+INSERT INTO user(username, password, email)
+VALUES ('admin', 'admin', 'xxxx@163.com');
+```
+
+**Insert the queried data**
+
+```sql
+INSERT INTO user(username)
+SELECT name
+FROM account;
+```
+
+### Update data
+
+The `UPDATE` statement is used to update records in a table.
+
+```sql
+UPDATE user
+SET username='robot', password='robot'
+WHERE username = 'root';
+```
+
+### Delete data
+
+- The `DELETE` statement is used to delete records from a table.
+- `TRUNCATE TABLE` can clear the table, that is, delete all rows. Explanation: The `TRUNCATE` statement does not belong to DML syntax but DDL syntax.
+
+**Delete specified data in the table**
+
+```sql
+DELETE FROM user
+WHERE username = 'robot';
+```
+
+**Clear the data in the table**
+
+```sql
+TRUNCATE TABLE user;
+```
+
+### Query data
+
+The `SELECT` statement is used to query data from the database.
+
+`DISTINCT` is used to return uniquely different values. It operates on all columns, which means that all columns must have the same value to be considered the same.
+
+`LIMIT` limits the number of rows returned. It can have two parameters. The first parameter is the starting row, starting from 0; the second parameter is the total number of rows returned.
+
+- `ASC`: ascending order (default)
+- `DESC`: descending order
+
+**Query single column**
+
+```sql
+SELECT prod_name
+FROM products;
+```
+
+**Query multiple columns**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products;
+```
+
+**Query all columns**
+
+```sql
+SELECT *
+FROM products;
+```
+
+**Query for different values**
+
+```sql
+SELECT DISTINCT
+vend_id FROM products;
+```
+
+**Limit query results**
+
+```sql
+-- Return the first 5 rows
+SELECT * FROM mytable LIMIT 5;
+SELECT * FROM mytable LIMIT 0, 5;
+-- Return to lines 3 ~ 5
+SELECT * FROM mytable LIMIT 2, 3;
+```
+
+## Sort`order by` is used to sort the result set by one column or multiple columns. By default, records are sorted in ascending order. If you need to sort records in descending order, you can use the `desc` keyword.
+
+`order by` When sorting multiple columns, the column that is sorted first is placed in front, and the column that is sorted later is placed in the back. Also, different columns can have different sorting rules.
+
+```sql
+SELECT * FROM products
+ORDER BY prod_price DESC, prod_name ASC;
+```
+
+## Grouping
+
+**`group by`**:
+
+- The `group by` clause groups records into summary rows.
+- `group by` returns one record for each group.
+- `group by` usually also involves aggregating `count`, `max`, `sum`, `avg`, etc.
+- `group by` can group by one or more columns.
+- `group by` After sorting by group field, `order by` can sort by summary field.
+
+**Group**
+
+```sql
+SELECT cust_name, COUNT(cust_address) AS addr_num
+FROM Customers GROUP BY cust_name;
+```
+
+**Sort after grouping**
+
+```sql
+SELECT cust_name, COUNT(cust_address) AS addr_num
+FROM Customers GROUP BY cust_name
+ORDER BY cust_name DESC;
+```
+
+**`having`**:
+
+- `having` is used to filter the aggregated `group by` results.
+- `having` is usually used together with `group by`.
+- `where` and `having` can be in the same query.
+
+**Filter data using WHERE and HAVING**
+
+```sql
+SELECT cust_name, COUNT(*) AS NumberOfOrders
+FROM Customers
+WHERE cust_email IS NOT NULL
+GROUP BY cust_name
+HAVING COUNT(*) > 1;
+```
+
+**`having` vs `where`**:
+
+- `where`: Filter the specified rows. Aggregation functions (grouping functions) cannot be added later. `where` before `group by`.
+- `having`: Filter grouping, usually used in conjunction with `group by` and cannot be used alone. `having` comes after `group by`.
+
+## Subquery
+
+A subquery is a SQL query nested within a larger query, also called an inner query or inner select, and the statement containing the subquery is also called an outer query or outer select. Simply put, a subquery refers to using the result of a `select` query (subquery) as the data source or judgment condition of another SQL statement (main query).
+
+Subqueries can be embedded in `SELECT`, `INSERT`, `UPDATE` and `DELETE` statements, and can also be used with operators such as `=`, `<`, `>`, `IN`, `BETWEEN`, `EXISTS` and other operators.
+
+Subqueries are often used after the `WHERE` clause and the `FROM` clause:
+
+- When used in the `WHERE` clause, depending on different operators, the subquery can return a single row and a single column, multiple rows and a single column, or a single row and multiple columns of data. The subquery is to return a value that can be used as the query condition of the `WHERE` clause.
+- When used in the `FROM` clause, multi-row and multi-column data is generally returned, which is equivalent to returning a temporary table, so as to comply with the rule that `FROM` is followed by a table. This approach can implement joint queries on multiple tables.
+
+> Note: MYSQL database only supports subqueries from version 4.1, and earlier versions do not support it.
+
+The basic syntax of a subquery for a `WHERE` clause is as follows:
+
+```sql
+select column_name [, column_name ]
+from table1 [, table2 ]
+where column_name operator
+ (select column_name [, column_name ]
+ from table1 [, table2 ]
+ [where])
+```
+
+- Subqueries need to be placed within brackets `( )`.
+- `operator` represents the operator used in the where clause.
+
+The basic syntax of a subquery for a `FROM` clause is as follows:
+
+```sql
+select column_name [, column_name ]
+from (select column_name [, column_name ]
+ from table1 [, table2 ]
+ [where]) as temp_table_name
+where condition
+```
+
+The result returned by the subquery for `FROM` is equivalent to a temporary table, so you need to use the AS keyword to give the temporary table a name.
+
+**Subquery of subqueries**
+
+```sql
+SELECT cust_name, cust_contact
+FROM customers
+WHERE cust_id IN (SELECT cust_id
+ FROM orders
+ WHERE order_num IN (SELECT order_num
+ FROM orderitems
+ WHERE prod_id = 'RGAN01'));
+```
+
+The inner query is executed first before its parent query so that the results of the inner query can be passed to the outer query. You can refer to the following figure for the execution process:
+
+
+
+### WHERE
+
+- The `WHERE` clause is used to filter records, that is, to narrow the scope of accessed data.
+- `WHERE` followed by a condition that returns `true` or `false`.
+- `WHERE` can be used with `SELECT`, `UPDATE` and `DELETE`.
+- Operators that can be used in the `WHERE` clause.
+
+| Operator | Description |
+| ------- | ------------------------------------------------------- |
+| = | equals |
+| <> | is not equal to. Note: In some versions of SQL, this operator can be written as != |
+| > | greater than |
+| < | less than |
+| >= | Greater than or equal to |
+| <= | Less than or equal to |
+| BETWEEN | Within a range |
+| LIKE | Search for a pattern |
+| IN | Specifies multiple possible values for a column |
+
+**The `WHERE` clause in the `SELECT` statement**
+
+```ini
+SELECT * FROM Customers
+WHERE cust_name = 'Kids Place';
+```
+
+**The `WHERE` clause in the `UPDATE` statement**
+
+```ini
+UPDATECustomers
+SET cust_name = 'Jack Jones'
+WHERE cust_name = 'Kids Place';
+```
+
+**The `WHERE` clause in the `DELETE` statement**
+
+```ini
+DELETE FROM Customers
+WHERE cust_name = 'Kids Place';
+```
+
+### IN AND BETWEEN
+
+- The `IN` operator is used in the `WHERE` clause to select any one of several specified values.
+- The `BETWEEN` operator is used in the `WHERE` clause to select values within a certain range.
+
+**IN Example**
+
+```sql
+SELECT *
+FROM products
+WHERE vend_id IN ('DLL01', 'BRS01');
+```
+
+**BETWEEN EXAMPLE**
+
+```sql
+SELECT *
+FROM products
+WHERE prod_price BETWEEN 3 AND 5;
+```
+
+### AND, OR, NOT- `AND`, `OR`, `NOT` are logical processing instructions for filtering conditions.
+- `AND` has higher priority than `OR`. To clarify the processing order, you can use `()`.
+- The `AND` operator indicates that both left and right conditions must be met.
+- The `OR` operator means that any one of the left and right conditions must be met.
+- The `NOT` operator is used to negate a condition.
+
+**AND Example**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE vend_id = 'DLL01' AND prod_price <= 4;
+```
+
+**OR Example**
+
+```ini
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE vend_id = 'DLL01' OR vend_id = 'BRS01';
+```
+
+**NOT Example**
+
+```sql
+SELECT *
+FROM products
+WHERE prod_price NOT BETWEEN 3 AND 5;
+```
+
+### LIKE
+
+- The `LIKE` operator is used in the `WHERE` clause to determine whether a string matches a pattern.
+- Use `LIKE` only if the field is a text value.
+- `LIKE` supports two wildcard matching options: `%` and `_`.
+- Don't abuse wildcards, matching at the beginning will be very slow.
+- `%` means any character appearing any number of times.
+- `_` means any character appears once.
+
+**% Example**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE prod_name LIKE '%bean bag%';
+```
+
+**\_ Example**
+
+```sql
+SELECT prod_id, prod_name, prod_price
+FROM products
+WHERE prod_name LIKE '__ inch teddy bear';
+```
+
+## Connect
+
+JOIN means "connection". As the name suggests, the SQL JOIN clause is used to join two or more tables for query.
+
+When connecting tables, you need to select a field in each table and compare the values of these fields. Two records with the same value will be merged into one. **The essence of joining tables is to merge records from different tables to form a new table. Of course, this new table is only temporary, it only exists for the duration of this query**.
+
+The basic syntax for joining two tables using `JOIN` is as follows:
+
+```sql
+select table1.column1, table2.column2...
+from table1
+join table2
+on table1.common_column1 = table2.common_column2;
+```
+
+`table1.common_column1 = table2.common_column2` is a join condition. Only records that meet this condition will be merged into one row. You can join tables using several operators, such as =, >, <, <>, <=, >=, !=, `between`, `like`, or `not`, but the most common is to use =.
+
+When there are fields with the same name in two tables, in order to help the database engine distinguish the fields of which table, the table name needs to be added when writing the field names with the same name. Of course, if the written field name is unique in the two tables, you can not use the above format and just write the field name.
+
+In addition, if the related field names of the two tables are the same, you can also use the `USING` clause instead of `ON`, for example:
+
+```sql
+# join....on
+select c.cust_name, o.order_num
+from Customers c
+inner join Orders o
+on c.cust_id = o.cust_id
+order by c.cust_name;
+
+# If the associated field names of the two tables are the same, you can also use the USING clause: join....using()
+select c.cust_name, o.order_num
+from Customers c
+inner join Orders o
+using(cust_id)
+order by c.cust_name;
+```
+
+**The difference between `ON` and `WHERE`**:
+
+- When joining tables, SQL will generate a new temporary table based on the join conditions. `ON` is the connection condition, which determines the generation of temporary tables.
+- `WHERE` is to filter the data in the temporary table after the temporary table is generated to generate the final result set. At this time, there is no JOIN-ON.
+
+So in summary: **SQL first generates a temporary table based on ON, and then filters the temporary table based on WHERE**.
+
+SQL allows some modifying keywords to be added to the left of `JOIN` to form different types of connections, as shown in the following table:
+
+| Connection type | Description |
+|------------------------------------------------ |------------------------------------------------------------------------------------------------ |
+| INNER JOIN inner join | (default connection method) Rows will be returned only when there are records that meet the conditions in both tables. |
+| LEFT JOIN / LEFT OUTER JOIN Left (outer) join | Returns all rows in the left table, even if there are no rows in the right table that meet the condition. |
+| RIGHT JOIN / RIGHT OUTER JOIN Right (outer) join | Returns all rows in the right table, even if there are no rows in the left table that meet the condition. |
+| FULL JOIN / FULL OUTER JOIN Full (outer) join | As long as one of the tables has records that meet the conditions, rows will be returned. |
+| SELF JOIN | Joins a table to itself as if the table were two tables. To differentiate between two tables, at least one table needs to be renamed in the SQL statement. |
+| CROSS JOIN | Cross join returns the Cartesian product of record sets from two or more joined tables. |
+
+The figure below shows 7 usages related to LEFT JOIN, RIGHT JOIN, INNER JOIN, and OUTER JOIN.
+
+
+
+If you just write `JOIN` without adding any modifiers, the default is `INNER JOIN`
+
+For `INNER JOIN`, there is also an implicit way of writing, called "**Implicit inner join**", that is, there is no `INNER JOIN` keyword, and the `WHERE` statement is used to implement the inner join function.
+
+```sql
+#Implicit inner join
+select c.cust_name, o.order_num
+from Customers c, Orders o
+where c.cust_id = o.cust_id
+order by c.cust_name;
+
+#Explicit inner join
+select c.cust_name, o.order_num
+from Customers c inner join Orders o
+using(cust_id)
+order by c.cust_name;
+```
+
+## Combination
+
+The `UNION` operator combines the results of two or more queries and produces a result set containing the extracted rows from the participating queries in `UNION`.
+
+`UNION` basic rules:
+
+- The number and order of columns must be the same for all queries.
+- The data types of the columns involved in the tables in each query must be the same or compatible.
+- Usually the column names returned are taken from the first query.
+
+By default, the `UNION` operator selects distinct values. If duplicate values are allowed, use `UNION ALL`.
+
+```sql
+SELECT column_name(s) FROM table1
+UNION ALL
+SELECT column_name(s) FROM table2;
+```
+
+The column names in the `UNION` result set are always equal to the column names in the first `SELECT` statement in the `UNION`.
+
+`JOIN` vs `UNION`:
+
+- The columns of the joined tables in `JOIN` may be different, but in `UNION` the number and order of columns must be the same for all queries.
+- `UNION` puts the rows after the query together (vertically), but `JOIN` puts the columns after the query together (horizontally), i.e. it forms a Cartesian product.
+
+## Function
+
+Functions tend to differ from database to database and are therefore not portable. This section mainly uses MySQL functions as an example.### Text processing
+
+| Function | Description |
+| -------------------------- | -------------------------- |
+| `LEFT()`, `RIGHT()` | The character on the left or right |
+| `LOWER()`, `UPPER()` | Convert to lowercase or uppercase |
+| `LTRIM()`, `RTRIM()` | Remove spaces on the left or right side |
+| `LENGTH()` | Length in bytes |
+| `SOUNDEX()` | Convert to speech value |
+
+Among them, **`SOUNDEX()`** can convert a string into an alphanumeric pattern that describes its phonetic representation.
+
+```sql
+SELECT *
+FROM mytable
+WHERE SOUNDEX(col1) = SOUNDEX('apple')
+```
+
+### Date and time processing
+
+- Date format: `YYYY-MM-DD`
+- Time format: `HH:MM:SS`
+
+| function | description |
+| --------------- | ------------------------------- |
+| `AddDate()` | Add a date (day, week, etc.) |
+| `AddTime()` | Add a time (hour, minute, etc.) |
+| `CurDate()` | Returns the current date |
+| `CurTime()` | Returns the current time |
+| `Date()` | Returns the date part of a datetime |
+| `DateDiff()` | Calculate the difference between two dates |
+| `Date_Add()` | Highly flexible date operation function |
+| `Date_Format()` | Returns a formatted date or time string |
+| `Day()` | Returns the day part of a date |
+| `DayOfWeek()` | For a date, return the corresponding day of the week |
+| `Hour()` | Returns the hour part of a time |
+| `Minute()` | Returns the minute part of a time |
+| `Month()` | Returns the month part of a date |
+| `Now()` | Returns the current date and time |
+| `Second()` | Returns the second part of a time |
+| `Time()` | Returns the time part of a datetime |
+| `Year()` | Returns the year part of a date |
+
+### Numerical processing
+
+| Function | Description |
+| ------ | ------ |
+| SIN() | sine |
+| COS() | cosine |
+| TAN() | tangent |
+| ABS() | Absolute value |
+| SQRT() | Square root |
+| MOD() | Remainder |
+| EXP() | index |
+| PI() | Pi |
+| RAND() | Random number |
+
+### Summary
+
+| function | description |
+| --------- | ---------------- |
+| `AVG()` | Returns the average value of a column |
+| `COUNT()` | Returns the number of rows in a column |
+| `MAX()` | Returns the maximum value of a column |
+| `MIN()` | Returns the minimum value of a column |
+| `SUM()` | Returns the sum of values in a column |
+
+`AVG()` ignores NULL rows.
+
+Use `DISTINCT` to have summary function values summarize different values.
+
+```sql
+SELECT AVG(DISTINCT col1) AS avg_col
+FROM mytable
+```
+
+**Next, let’s introduce the usage of DDL statements. The main function of DDL is to define database objects (such as databases, data tables, views, indexes, etc.)**
+
+## Data definition
+
+### Database (DATABASE)
+
+#### Create database
+
+```sql
+CREATE DATABASE test;
+```
+
+#### Delete database
+
+```sql
+DROP DATABASE test;
+```
+
+#### Select database
+
+```sql
+USE test;
+```
+
+### Data table (TABLE)
+
+#### Create data table
+
+**Normal creation**
+
+```sql
+CREATE TABLE user (
+ id int(10) unsigned NOT NULL COMMENT 'Id',
+ username varchar(64) NOT NULL DEFAULT 'default' COMMENT 'username',
+ password varchar(64) NOT NULL DEFAULT 'default' COMMENT 'password',
+ email varchar(64) NOT NULL DEFAULT 'default' COMMENT 'email'
+) COMMENT='user table';
+```
+
+**Create a new table based on an existing table**
+
+```sql
+CREATE TABLE vip_user AS
+SELECT * FROM user;
+```
+
+#### Delete data table
+
+```sql
+DROP TABLE user;
+```
+
+#### Modify data table
+
+**Add Column**
+
+```sql
+ALTER TABLE user
+ADD age int(3);
+```
+
+**Delete Column**
+
+```sql
+ALTER TABLE user
+DROP COLUMN age;
+```
+
+**Modify column**
+
+```sql
+ALTER TABLE `user`
+MODIFY COLUMN age tinyint;
+```
+
+**Add primary key**
+
+```sql
+ALTER TABLE user
+ADD PRIMARY KEY (id);
+```
+
+**Delete primary key**
+
+```sql
+ALTER TABLE user
+DROP PRIMARY KEY;
+```
+
+### View (VIEW)
+
+Definition:
+
+- A view is a table that visualizes the result set of a SQL statement.
+- A view is a virtual table and does not contain data, so it cannot be indexed. Operations on views are the same as operations on ordinary tables.
+
+Function:
+
+- Simplify complex SQL operations, such as complex joins;
+- Only use part of the data from the actual table;
+- Ensure data security by only giving users permission to access views;
+- Change data format and presentation.
+
+
+
+#### Create view
+
+```sql
+CREATE VIEW top_10_user_view AS
+SELECT id, username
+FROM user
+WHERE id < 10;
+```
+
+#### Delete view
+
+```sql
+DROP VIEW top_10_user_view;
+```
+
+### Index (INDEX)
+
+**Index is a data structure used for quick query and retrieval of data. Its essence can be regarded as a sorted data structure. **
+
+The function of the index is equivalent to the table of contents of the book. For example: when we look up a dictionary, if there is no table of contents, then we can only go page by page to find the word we need to look up, which is very slow. If there is a table of contents, we only need to search the position of the word in the table of contents first, and then directly turn to that page.
+
+**Advantages**:
+
+- Using indexes can greatly speed up data retrieval (greatly reduce the amount of data retrieved), which is also the main reason for creating indexes.
+- By creating a unique index, you can ensure the uniqueness of each row of data in the database table.
+
+**Disadvantages**:
+
+- Creating and maintaining indexes takes a lot of time. When adding, deleting, or modifying data in a table, if the data has an index, the index also needs to be dynamically modified, which will reduce SQL execution efficiency.
+- Indexes require physical file storage and will also consume a certain amount of space.
+
+However, **Does using indexes definitely improve query performance?**
+
+In most cases, index queries are faster than full table scans. But if the amount of data in the database is not large, using indexes may not necessarily bring about a big improvement.
+
+For a detailed introduction to indexes, please read my article [MySQL Index Detailed Explanation](https://javaguide.cn/database/mysql/mysql-index.html).
+
+#### Create index
+
+```sql
+CREATE INDEX user_index
+ON user(id);
+```
+
+#### Add index
+
+```sql
+ALTER table user ADD INDEX user_index(id)
+```
+
+#### Create a unique index
+
+```sql
+CREATE UNIQUE INDEX user_index
+ON user(id);
+```
+
+#### Delete index
+
+```sql
+ALTER TABLE user
+DROP INDEX user_index;```
+
+### Constraints
+
+SQL constraints are used to specify rules for data in a table.
+
+If there is a data behavior that violates the constraint, the behavior will be terminated by the constraint.
+
+Constraints can be specified when the table is created (via the CREATE TABLE statement), or after the table is created (via the ALTER TABLE statement).
+
+Constraint type:
+
+- `NOT NULL` - Indicates that a column cannot store NULL values.
+- `UNIQUE` - Guarantees that each row of a column must have a unique value.
+- `PRIMARY KEY` - Combination of NOT NULL and UNIQUE. Ensuring that a column (or a combination of two or more columns) is uniquely identified can help make it easier and faster to find a specific record in a table.
+- `FOREIGN KEY` - Ensures referential integrity that data in one table matches values in another table.
+- `CHECK` - Ensures that the values in the column meet the specified conditions.
+- `DEFAULT` - Specifies the default value when no value is assigned to the column.
+
+Use constraints when creating tables:
+
+```sql
+CREATE TABLE Users (
+ Id INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment Id',
+ Username VARCHAR(64) NOT NULL UNIQUE DEFAULT 'default' COMMENT 'username',
+ Password VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT 'password',
+ Email VARCHAR(64) NOT NULL DEFAULT 'default' COMMENT 'Email address',
+ Enabled TINYINT(4) DEFAULT NULL COMMENT 'Is it valid',
+ PRIMARY KEY (Id)
+) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='User table';
+```
+
+**Next, let’s introduce the usage of TCL statements. The main function of TCL is to manage transactions in the database. **
+
+## Transaction processing
+
+The `SELECT` statement cannot be rolled back, and it is meaningless to roll back the `SELECT` statement; the `CREATE` and `DROP` statements cannot be rolled back.
+
+**MySQL defaults to implicit commit**. Each time a statement is executed, the statement is regarded as a transaction and then submitted. When the `START TRANSACTION` statement appears, implicit commit will be turned off; when the `COMMIT` or `ROLLBACK` statement is executed, the transaction will be automatically closed and implicit commit will be restored.
+
+Autocommit can be canceled by `set autocommit=0` and will not be committed until `set autocommit=1`; the `autocommit` flag is for each connection and not for the server.
+
+Instructions:
+
+- `START TRANSACTION` - directive is used to mark the starting point of a transaction.
+- `SAVEPOINT` - directive is used to create a save point.
+- `ROLLBACK TO` - The instruction is used to roll back to the specified retention point; if no retention point is set, it will roll back to the `START TRANSACTION` statement.
+- `COMMIT` - Commit the transaction.
+
+```sql
+-- Start transaction
+START TRANSACTION;
+
+-- Insert operation A
+INSERT INTO `user`
+VALUES (1, 'root1', 'root1', 'xxxx@163.com');
+
+-- Create a retention point updateA
+SAVEPOINT updateA;
+
+-- Insert operation B
+INSERT INTO `user`
+VALUES (2, 'root2', 'root2', 'xxxx@163.com');
+
+-- Roll back to retention point updateA
+ROLLBACK TO updateA;
+
+-- Submit the transaction, only operation A takes effect
+COMMIT;
+```
+
+**Next, let’s introduce the usage of DCL statements. The main function of DCL is to control user access rights. **
+
+## Permission control
+
+To grant permissions to a user account, use the `GRANT` command. To revoke a user's permissions, use the `REVOKE` command. Here, MySQL is used as an example to introduce the practical application of permission control.
+
+`GRANT` grant permission syntax:
+
+```sql
+GRANT privilege,[privilege],.. ON privilege_level
+TO user [IDENTIFIED BY password]
+[REQUIRE tsl_option]
+[WITH [GRANT_OPTION | resource_option]];
+```
+
+Just explain it briefly:
+
+1. Specify one or more permissions after the `GRANT` keyword. If the user is granted multiple permissions, each permission is separated by a comma.
+2. `ON privilege_level` determines the level of permission application. MySQL supports global (`*.*`), database (`database.*`), table (`database.table`) and column levels. If you use column permission levels, you must specify one or a comma-separated list of columns after each permission.
+3. `user` is the user to whom permissions are to be granted. If the user already exists, the `GRANT` statement will modify its permissions. Otherwise, the `GRANT` statement will create a new user. The optional clause `IDENTIFIED BY` allows you to set a new password for the user.
+4. `REQUIRE tsl_option` specifies whether users must connect to the database server through secure connections such as SSL, X059, etc.
+5. The optional `WITH GRANT OPTION` clause allows you to grant or remove permissions that you have from other users. In addition, you can use the `WITH` clause to allocate the resources of the MySQL database server, for example, to set the number of connections or statements that a user can use per hour. This is useful in shared environments such as MySQL shared hosting.
+
+`REVOKE` revoke permission syntax:
+
+```sql
+REVOKE privilege_type [(column_list)]
+ [, priv_type [(column_list)]]...
+ON [object_type] privilege_level
+FROM user [, user]...
+```
+
+Just explain it briefly:
+
+1. Specify the list of permissions to be revoked from the user after the `REVOKE` keyword. You need to separate permissions with commas.
+2. Specify the privilege level at which privileges are revoked in the `ON` clause.
+3. Specify the user account whose permissions are to be revoked in the `FROM` clause.
+
+`GRANT` and `REVOKE` control access at several levels:
+
+- The entire server, using `GRANT ALL` and `REVOKE ALL`;
+- The entire database, use `ON database.*`;
+- For a specific table, use `ON database.table`;
+- specific columns;
+- Specific stored procedures.
+
+Newly created accounts do not have any permissions. Accounts are defined in the form `username@host`, and `username@%` uses the default hostname. MySQL account information is stored in the mysql database.
+
+```sql
+USE mysql;
+SELECT user FROM user;
+```
+
+The following table illustrates all allowed permissions available for the `GRANT` and `REVOKE` statements:
+
+| **Privilege** | **Description** | **Level** | | | | | |
+| ----------------------- | ----------------------------------------------------------------------------------------------- | -------- | ------ | -------- | -------- | --- | --- |
+| **Global** | Database | **Table** | **Column** | **Program** | **Agent** | | |
+| ALL [PRIVILEGES] | Grants all privileges to the specified access level except GRANT OPTION | | | | | | |
+| ALTER | Allows users to use the ALTER TABLE statement || ALTER ROUTINE | Allows the user to change or delete a stored routine |
+| CREATE | Allows users to create databases and tables | X |
+| CREATE ROUTINE | Allows the user to create a stored routine |
+| CREATE TABLESPACE | Allows users to create, alter, or delete tablespaces and log file groups | X | | | | | |
+| CREATE TEMPORARY TABLES | Allows users to create temporary tables using CREATE TEMPORARY TABLE | X |
+| CREATE USER | Allows users to use the CREATE USER, DROP USER, RENAME USER and REVOKE ALL PRIVILEGES statements. | X | | | | | |
+| CREATE VIEW | Allows users to create or modify views. |
+| DELETE | Allow users to use DELETE |
+| DROP | Allows users to drop databases, tables and views |
+| EVENT | Enables event usage by the event scheduler. |
+| EXECUTE | Allows the user to execute a stored routine |
+| FILE | Allows users to read any file in the database directory. | X | | | | | |
+| GRANT OPTION | Allows a user to have the ability to grant or revoke permissions from other accounts. |
+| INDEX | Allows users to create or delete indexes. |
+| INSERT | Allows users to use the INSERT statement |
+| LOCK TABLES | Allows users to use LOCK TABLES on tables with SELECT permission |
+| PROCESS | Allows users to view all processes using the SHOW PROCESSLIST statement. | X | | | | | |
+| PROXY | Enable user agent. | | | | | | |
+| REFERENCES | Allows users to create foreign keys |
+| RELOAD | Allows users to use FLUSH operations | X | | | | | |
+| REPLICATION CLIENT | Allows users to query to see the location of a master or slave server | X | | | | | |
+| REPLICATION SLAVE | Allows users to read binary log events from the master server using a replication slave. | X | | | | | || SELECT | Allows users to use the SELECT statement |
+| SHOW DATABASES | Allows the user to show all databases |
+| SHOW VIEW | Allows users to use the SHOW CREATE VIEW statement |
+| SHUTDOWN | Allows users to use the mysqladmin shutdown command |
+| SUPER | Allows users to use other administrative operations such as CHANGE MASTER TO, KILL, PURGE BINARY LOGS, SET GLOBAL and mysqladmin commands |
+| TRIGGER | Allows the user to use the TRIGGER operation. |
+| UPDATE | Allows users to use the UPDATE statement |
+| USAGE | Equivalent to "no privileges" | | | | | | |
+
+### Create account
+
+```sql
+CREATE USER myuser IDENTIFIED BY 'mypassword';
+```
+
+### Modify account name
+
+```sql
+UPDATE user SET user='newuser' WHERE user='myuser';
+FLUSH PRIVILEGES;
+```
+
+### Delete account
+
+```sql
+DROP USER myuser;
+```
+
+### View permissions
+
+```sql
+SHOW GRANTS FOR myuser;
+```
+
+### Grant permissions
+
+```sql
+GRANT SELECT, INSERT ON *.* TO myuser;
+```
+
+### Delete permissions
+
+```sql
+REVOKE SELECT, INSERT ON *.* FROM myuser;
+```
+
+### Change password
+
+```sql
+SET PASSWORD FOR myuser = 'mypass';
+```
+
+## Stored procedure
+
+Stored procedures can be thought of as batch processing of a series of SQL operations. Stored procedures can be called by triggers, other stored procedures, and applications such as Java, Python, PHP, etc.
+
+
+
+Benefits of using stored procedures:
+
+- Code encapsulation ensures a certain level of security;
+- Code reuse;
+- High performance since it is pre-compiled.
+
+Create stored procedure:
+
+- Creating a stored procedure in the command line requires custom delimiters, because the command line ends with `;`, and the stored procedure also contains a semicolon, so this part of the semicolon will be mistakenly regarded as the terminator, causing a syntax error.
+- Contains three parameters: `in`, `out` and `inout`.
+- To assign a value to a variable, you need to use the `select into` statement.
+- Only one variable can be assigned a value at a time, and collection operations are not supported.
+
+It should be noted that: **Alibaba's "Java Development Manual" forcibly prohibits the use of stored procedures. Because stored procedures are difficult to debug and extend, they are not portable. **
+
+
+
+As for whether to use it in the project, it still depends on the actual needs of the project, and just weigh the pros and cons!
+
+### Create stored procedure
+
+```sql
+DROP PROCEDURE IF EXISTS `proc_adder`;
+DELIMITER ;;
+CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
+BEGIN
+ DECLARE c int;
+ if a is null then set a = 0;
+ end if;
+
+ if b is null then set b = 0;
+ end if;
+
+ set sum = a + b;
+END
+;;
+DELIMITER;
+```
+
+### Use stored procedures
+
+```less
+set @b=5;
+call proc_adder(2,@b,@s);
+select @s as sum;
+```
+
+## Cursor
+
+A cursor is a database query stored on the DBMS server. It is not a `SELECT` statement, but the result set retrieved by the statement.
+
+Cursors can be used in stored procedures to traverse a result set.
+
+Cursors are primarily used in interactive applications where the user needs to scroll through data on the screen and browse or make changes to the data.
+
+A few clear steps for using cursors:
+
+- Before using a cursor, you must declare (define) it. This procedure does not actually retrieve data, it simply defines the `SELECT` statement and cursor options to be used.
+
+- Once declared, the cursor must be opened for use. This process uses the SELECT statement defined earlier to actually retrieve the data.
+
+- For cursors filled with data, fetch (retrieve) rows as needed.
+
+- When ending use of a cursor, the cursor must be closed and, if possible, released (depending on the tool).
+
+ DBMS).
+
+```sql
+DELIMITER $
+CREATE PROCEDURE getTotal()
+BEGIN
+ DECLARE total INT;
+ --Create a variable to receive cursor data
+ DECLARE sid INT;
+ DECLARE sname VARCHAR(10);
+ --Create a total variable
+ DECLARE sage INT;
+ --Create an end flag variable
+ DECLARE done INT DEFAULT false;
+ --Create cursor
+ DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30;
+ --Specify the return value at the end of the cursor loop
+ DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true;
+ SET total = 0;
+ OPEN cur;
+ FETCH cur INTO sid, sname, sage;
+ WHILE(NOT done)
+ DO
+ SET total = total + 1;
+ FETCH cur INTO sid, sname, sage;
+ END WHILE;
+
+ CLOSE cur;
+ SELECT total;
+END $
+DELIMITER;
+
+-- Call stored procedure
+call getTotal();
+```
+
+## Trigger
+
+A trigger is a database object related to table operations. When a specified event occurs on the table where the trigger is located, the object will be called, that is, the operation event of the table triggers the execution of the trigger on the table.We can use triggers for audit tracking and record changes to another table.
+
+Advantages of using triggers:
+
+- SQL triggers provide another way to check data integrity.
+- SQL triggers can capture errors in business logic in the database layer.
+- SQL triggers provide another way to run scheduled tasks. By using SQL triggers, you don't have to wait for a scheduled task to run because the trigger is automatically called before or after changes are made to the data in the table.
+- SQL triggers are useful for auditing changes to data in tables.
+
+Disadvantages of using triggers:
+
+- SQL triggers can only provide extended validation and cannot replace all validation. Some simple validation must be done in the application layer. For example, you can validate user input on the client side using JavaScript, or on the server side using a server-side scripting language (such as JSP, PHP, ASP.NET, Perl).
+- SQL triggers are not visible when called and executed from the client application, so it is difficult to figure out what is going on in the database layer.
+- SQL triggers may add overhead to the database server.
+
+MySQL does not allow the use of CALL statements in triggers, that is, stored procedures cannot be called.
+
+> Note: In MySQL, the semicolon `;` is the identifier of the end of a statement. Encountering a semicolon indicates that the statement has ended and MySQL can start execution. Therefore, the interpreter starts execution after encountering the semicolon in the trigger execution action, and then reports an error because no END matching BEGIN is found.
+>
+> The `DELIMITER` command will be used at this time (DELIMITER is the delimiter, which means the separator). It is a command and does not require an end-of-statement identifier. The syntax is: `DELIMITER new_delimiter`. `new_delimiter` can be set to 1 or more length symbols, the default is semicolon `;`, we can modify it to other symbols, such as `$` - `DELIMITER $`. The statement after this ends with a semicolon, and the interpreter will not react. Only when `$` is encountered, the statement is considered to have ended. Note that after using it, we should remember to modify it back.
+
+Prior to MySQL version 5.7.2, up to six triggers could be defined per table.
+
+- `BEFORE INSERT` - Activate before inserting data into the table.
+- `AFTER INSERT` - activated after inserting data into the table.
+- `BEFORE UPDATE` - Activate before updating data in the table.
+- `AFTER UPDATE` - activated after updating data in the table.
+- `BEFORE DELETE` - Activate before deleting data from the table.
+- `AFTER DELETE` - activated after deleting data from the table.
+
+However, starting with MySQL version 5.7.2+, multiple triggers can be defined for the same trigger event and action time.
+
+**`NEW` and `OLD`**:
+
+- The `NEW` and `OLD` keywords are defined in MySQL, which are used to indicate the row of data in the table where the trigger is located that triggered the trigger.
+- In `INSERT` type triggers, `NEW` is used to indicate new data that will be (`BEFORE`) or has been (`AFTER`) inserted;
+- In `UPDATE` type triggers, `OLD` is used to represent the original data that will be or has been modified, and `NEW` is used to represent the new data that will be or has been modified;
+- In `DELETE` type triggers, `OLD` is used to represent the original data that will be or has been deleted;
+- Usage: `NEW.columnName` (columnName is a column name of the corresponding data table)
+
+### Create trigger
+
+> Tip: In order to understand the gist of triggers, it is necessary to first understand the instructions for creating triggers.
+
+The `CREATE TRIGGER` command is used to create a trigger.
+
+Syntax:
+
+```sql
+CREATE TRIGGER trigger_name
+trigger_time
+trigger_event
+ON table_name
+FOR EACH ROW
+BEGIN
+ trigger_statements
+END;
+```
+
+Description:
+
+- `trigger_name`: trigger name
+- `trigger_time`: The trigger firing time. The value is `BEFORE` or `AFTER`.
+- `trigger_event`: The listening event of the trigger. The value is `INSERT`, `UPDATE` or `DELETE`.
+- `table_name`: The listening target of the trigger. Specify the table on which to create the trigger.
+- `FOR EACH ROW`: Row-level monitoring, Mysql fixed writing method, different from other DBMS.
+- `trigger_statements`: Trigger execution actions. Is a list of one or more SQL statements. Each statement in the list must be terminated with a semicolon `;`.
+
+When the triggering condition of the trigger is met, the trigger execution action between `BEGIN` and `END` will be executed.
+
+Example:
+
+```sql
+DELIMITER $
+CREATE TRIGGER `trigger_insert_user`
+AFTER INSERT ON `user`
+FOR EACH ROW
+BEGIN
+ INSERT INTO `user_history`(user_id, operate_type, operate_time)
+ VALUES (NEW.id, 'add a user', now());
+END $
+DELIMITER;
+```
+
+### View triggers
+
+```sql
+SHOW TRIGGERS;
+```
+
+### Delete trigger
+
+```sql
+DROP TRIGGER IF EXISTS trigger_insert_user;
+```
+
+## Article recommendation
+
+- [A must-have for back-end programmers: SQL high-performance optimization guide! 35+ optimization suggestions GET now!](https://mp.weixin.qq.com/s/I-ZT3zGTNBZ6egS7T09jyQ)
+- [Must-have for back-end programmers: 30 tips for writing high-quality SQL suggestions](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486461&idx=1&sn=60a22279196d084cc398936fe3b37772&c hksm=cea24436f9d5cd20a4fa0e907590f3e700d7378b3f608d7b33bb52cfb96f503b7ccb65a1deed&token=1987003517&lang=zh_CN#rd)
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/api-gateway.en.md b/docs_en/distributed-system/api-gateway.en.md
new file mode 100644
index 00000000000..413afc10d82
--- /dev/null
+++ b/docs_en/distributed-system/api-gateway.en.md
@@ -0,0 +1,209 @@
+---
+title: API网关基础知识总结
+category: 分布式
+---
+
+## 什么是网关?
+
+微服务背景下,一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
+
+
+
+一般情况下,网关可以为我们提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、降级熔断、日志、监控、参数校验、协议转换等功能。
+
+上面介绍了这么多功能,实际上,网关主要做了两件事情:**请求转发** + **请求过滤**。
+
+由于引入网关之后,会多一步网络转发,因此性能会有一点影响(几乎可以忽略不计,尤其是内网访问的情况下)。 另外,我们需要保障网关服务的高可用,避免单点风险。
+
+如下图所示,网关服务外层通过 Nginx(其他负载均衡设备/软件也行) 进⾏负载转发以达到⾼可⽤。Nginx 在部署的时候,尽量也要考虑高可用,避免单点风险。
+
+
+
+## 网关能提供哪些功能?
+
+绝大部分网关可以提供下面这些功能(有一些功能需要借助其他框架或者中间件):
+
+- **请求转发**:将请求转发到目标微服务。
+- **负载均衡**:根据各个微服务实例的负载情况或者具体的负载均衡策略配置对请求实现动态的负载均衡。
+- **安全认证**:对用户请求进行身份验证并仅允许可信客户端访问 API,并且还能够使用类似 RBAC 等方式来授权。
+- **参数校验**:支持参数映射与校验逻辑。
+- **日志记录**:记录所有请求的行为日志供后续使用。
+- **监控告警**:从业务指标、机器指标、JVM 指标等方面进行监控并提供配套的告警机制。
+- **流量控制**:对请求的流量进行控制,也就是限制某一时刻内的请求数。
+- **熔断降级**:实时监控请求的统计信息,达到配置的失败阈值后,自动熔断,返回默认值。
+- **响应缓存**:当用户请求获取的是一些静态的或更新不频繁的数据时,一段时间内多次请求获取到的数据很可能是一样的。对于这种情况可以将响应缓存起来。这样用户请求可以直接在网关层得到响应数据,无需再去访问业务服务,减轻业务服务的负担。
+- **响应聚合**:某些情况下用户请求要获取的响应内容可能会来自于多个业务服务。网关作为业务服务的调用方,可以把多个服务的响应整合起来,再一并返回给用户。
+- **灰度发布**:将请求动态分流到不同的服务版本(最基本的一种灰度发布)。
+- **异常处理**:对于业务服务返回的异常响应,可以在网关层在返回给用户之前做转换处理。这样可以把一些业务侧返回的异常细节隐藏,转换成用户友好的错误提示返回。
+- **API 文档:** 如果计划将 API 暴露给组织以外的开发人员,那么必须考虑使用 API 文档,例如 Swagger 或 OpenAPI。
+- **协议转换**:通过协议转换整合后台基于 REST、AMQP、Dubbo 等不同风格和实现技术的微服务,面向 Web Mobile、开放平台等特定客户端提供统一服务。
+- **证书管理**:将 SSL 证书部署到 API 网关,由一个统一的入口管理接口,降低了证书更换时的复杂度。
+
+下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
+
+
+
+## 有哪些常见的网关系统?
+
+### Netflix Zuul
+
+Zuul 是 Netflix 开发的一款提供动态路由、监控、弹性、安全的网关服务,基于 Java 技术栈开发,可以和 Eureka、Ribbon、Hystrix 等组件配合使用。
+
+Zuul 核心架构如下:
+
+
+
+Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网关必备的各种功能。
+
+
+
+我们可以自定义过滤器来处理请求,并且,Zuul 生态本身就有很多现成的过滤器供我们使用。就比如限流可以直接用国外朋友写的 [spring-cloud-zuul-ratelimit](https://github.com/marcosbarbero/spring-cloud-zuul-ratelimit) (这里只是举例说明,一般是配合 hystrix 来做限流):
+
+```xml
+
+ org.springframework.cloud
+ spring-cloud-starter-netflix-zuul
+
+
+ com.marcosbarbero.cloud
+ spring-cloud-zuul-ratelimit
+ 2.2.0.RELEASE
+
+```
+
+[Zuul 1.x](https://netflixtechblog.com/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee) 基于同步 IO,性能较差。[Zuul 2.x](https://netflixtechblog.com/open-sourcing-zuul-2-82ea476cb2b3) 基于 Netty 实现了异步 IO,性能得到了大幅改进。
+
+
+
+- GitHub 地址:
+- 官方 Wiki:
+
+### Spring Cloud Gateway
+
+SpringCloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**。准确点来说,应该是 Zuul 1.x。SpringCloud Gateway 起步要比 Zuul 2.x 更早。
+
+为了提升网关的性能,SpringCloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现同步非阻塞的 I/O。
+
+
+
+Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,限流。
+
+Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
+
+- Github 地址:
+- 官网:
+
+### OpenResty
+
+根据官方介绍:
+
+> OpenResty is a high-performance web platform based on Nginx and Lua. It integrates a large number of sophisticated Lua libraries, third-party modules and most dependencies. Used to easily build dynamic web applications, web services and dynamic gateways that can handle ultra-high concurrency and high scalability.
+
+
+
+OpenResty is based on Nginx, mainly because of its excellent high concurrency capabilities. However, because Nginx is developed in C language, the threshold for secondary development is relatively high. If you want to implement some custom logic or functions on Nginx, you need to write a C language module and recompile Nginx.
+
+In order to solve this problem, OpenResty perfectly integrates Lua/LuaJIT into Nginx by implementing Nginx modules such as `ngx_lua` and `stream_lua`, which allows us to embed Lua scripts inside Nginx, so that the functions of the gateway can be extended through simple Lua language, such as implementing custom routing rules, filters, caching strategies, etc.
+
+> Lua is a very fast dynamic scripting language that runs as fast as C. LuaJIT is a just-in-time compiler for Lua that can significantly improve the execution efficiency of Lua code. LuaJIT precompiles and caches some commonly used Lua functions and tool libraries, so that the cached bytecode can be used directly the next time it is called, thus greatly speeding up execution.
+
+It is recommended to read this article for getting started with OpenResty and practical gateway security: [Getting started with OpenResty and practical gateway security that every backend should know] (https://mp.weixin.qq.com/s/3HglZs06W95vF3tSa3KrXw).
+
+- Github address:
+- Official website address:
+
+### Kong
+
+Kong is a high-performance, cloud-native, scalable, and ecologically rich gateway system based on [OpenResty](https://github.com/openresty/) (Nginx + Lua). It mainly consists of 3 components:
+
+- Kong Server: Nginx-based server used to receive API requests.
+- Apache Cassandra/PostgreSQL: used to store operational data.
+- Kong Dashboard: Officially recommended UI management tool. Of course, you can also use the RESTful method to manage the Admin api.
+
+
+
+Since Apache Cassandra/PostgreSQL is used to store data by default, Kong's entire architecture is bloated and will cause high availability problems.
+
+Kong provides a plug-in mechanism to extend its functionality. Plug-ins are executed during the life cycle of the API request response cycle. For example, enable the Zipkin plug-in on the service:
+
+```shell
+$ curl -X POST http://kong:8001/services/{service}/plugins \
+ --data "name=zipkin" \
+ --data "config.http_endpoint=http://your.zipkin.collector:9411/api/v2/spans" \
+ --data "config.sample_ratio=0.001"
+```
+
+Kong itself is a Lua application, and it is an encapsulated application based on Openresty. The final analysis is to use Lua to embed Nginx to give Nginx programmable capabilities, so that unlimited imagination can be done at the Nginx level in the form of plug-ins. For example, current limiting, security access policy, routing, load balancing, etc. To write a Kong plug-in, you need to follow the Kong plug-in writing specifications, write your own customized Lua script, then load it into Kong, and finally quote it.
+
+
+
+In addition to Lua, Kong can also develop plug-ins based on Go, JavaScript, Python and other languages, thanks to the corresponding PDK (plug-in development kit).
+
+For a detailed introduction to the Kong plug-in, it is recommended to read the official document: , which is written in more detail.
+
+- Github address:
+- Official website address:
+
+### APISIX
+
+APISIX is a high-performance, cloud-native, scalable gateway system based on OpenResty and etcd.
+
+> etcd is an open source, highly available distributed key-value storage system developed using the Go language, and uses the Raft protocol for distributed consensus.
+
+Compared with traditional API gateways, APISIX has dynamic routing and plug-in hot loading, which is particularly suitable for API management under microservice systems. Moreover, APISIX is very convenient to connect with DevOps ecological tools such as SkyWalking (distributed link tracking system), Zipkin (distributed link tracking system), and Prometheus (monitoring system).
+
+
+
+As an alternative project to Nginx and Kong, APISIX is currently Apache's top open source project and the fastest graduating domestic open source project. There are currently many well-known domestic companies (such as Kingsoft, Youzan, iQiyi, Tencent, and Shell) using APISIX to handle core business traffic.
+
+According to the official website: "APISIX is already in production and available, and its functions, performance, and architecture are all superior to Kong."
+
+APISIX also supports customized plug-in development. In addition to using the Lua language to develop plug-ins, developers can also develop in the following two ways to avoid the learning cost of the Lua language:
+
+- Support more mainstream programming languages (such as Java, Python, Go, etc.) through Plugin Runner. In this way, back-end engineers can communicate through local RPC and develop APISIX plug-ins using familiar programming languages. The advantage of this is that it reduces development costs and improves development efficiency, but there will be some loss in performance.
+- Use Wasm (WebAssembly) to develop plug-ins. Wasm is embedded into APISIX, and users can use Wasm to compile into Wasm bytecode and run it in APISIX.
+
+> Wasm is a binary instruction format for stack-based virtual machines, a low-level assembly language designed to be very close to compiled machine code, and very close to native performance. Wasm was originally built for the browser, but as the technology matures, it's seeing more and more use cases on the server side.
+
+
+
+- Github address:
+- Official website address:
+
+Related reading:
+
+- [Why is Apache APISIX the best API gateway? ](https://mp.weixin.qq.com/s/j8ggPGEHFu3x5ekJZyeZnA)
+- [With NGINX and Kong, why do we need Apache APISIX](https://www.apiseven.com/zh/blog/why-we-need-Apache-APISIX)
+- [APISIX Technology Blog](https://www.apiseven.com/zh/blog)
+- [APISIX User Cases](https://www.apiseven.com/zh/usercases) (recommended)
+
+### Shenyu
+
+Shenyu is a scalable, high-performance, responsive gateway based on WebFlux, a top Apache open source project.
+
+
+
+Shenyu extends its functionality through plug-ins, which are the soul of ShenYu and are also expandable and hot-swappable. Different plug-ins implement different functions. Shenyu comes with plug-ins such as current limiting, circuit breaker, forwarding, rewriting, redirection, and route monitoring.- Github address:
+- Official website address:
+
+## How to choose?
+
+Among the several common gateway systems introduced above, the three most commonly used ones are Spring Cloud Gateway, Kong, and APISIX.
+
+For companies whose business uses Java as the main development language, Spring Cloud Gateway is usually a good choice. Its advantages include: simple and easy to use, mature and stable, compatible with the Spring Cloud ecosystem, mature Spring community, etc. However, Spring Cloud Gateway also has some limitations and shortcomings, and generally needs to be used in conjunction with other gateways such as OpenResty. Moreover, its performance is still worse than Kong and APISIX. If you have high performance requirements, Spring Cloud Gateway is not a good choice.
+
+Kong and APISIX have richer functions, more powerful performance, and their technical architecture is more cloud-native. Kong is the originator of open source API gateways, with a rich ecosystem and a large user base. APISIX is a latecomer and is better. According to the APISIX official website: "APISIX is already in production and available, and its functions, performance, and architecture are all superior to Kong." Let’s briefly compare the two:
+
+- APISIX is based on etcd as the configuration center, so there is no single point of problem and is cloud-native friendly; while Kong is based on Apache Cassandra/PostgreSQL, which has a single point of risk and requires additional infrastructure to ensure high availability.
+- APISIX supports hot updates and implements millisecond-level hot update response; while Kong does not support hot updates.
+- APISIX performs better than Kong.
+- APISIX supports more plug-ins and has richer functions.
+
+## Reference
+
+- Kong plug-in development tutorial [easy to understand]:
+- API gateway Kong in action:
+- Spring Cloud Gateway principle introduction and application:
+- Why do microservices use API gateways? :
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-configuration-center.en.md b/docs_en/distributed-system/distributed-configuration-center.en.md
new file mode 100644
index 00000000000..8909fc790cc
--- /dev/null
+++ b/docs_en/distributed-system/distributed-configuration-center.en.md
@@ -0,0 +1,12 @@
+---
+title: Summary of Frequently Asked Questions in Distributed Configuration Center (Paid)
+category: distributed
+---
+
+**Distributed Configuration Center** The relevant interview questions are my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click the link to view the detailed introduction and how to join) exclusive content, which has been compiled into the "Java Interview Guide".
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-id-design.en.md b/docs_en/distributed-system/distributed-id-design.en.md
new file mode 100644
index 00000000000..4a28ef3793c
--- /dev/null
+++ b/docs_en/distributed-system/distributed-id-design.en.md
@@ -0,0 +1,173 @@
+---
+title: 分布式ID设计指南
+category: 分布式
+---
+
+::: tip
+
+看到百度 Geek 说的一篇结合具体场景聊分布式 ID 设计的文章,感觉挺不错的。于是,我将这篇文章的部分内容整理到了这里。原文传送门:[分布式 ID 生成服务的技术原理和项目实战](https://mp.weixin.qq.com/s/bFDLb6U6EgI-DvCdLTq_QA) 。
+
+:::
+
+网上绝大多数的分布式 ID 生成服务,一般着重于技术原理剖析,很少见到根据具体的业务场景去选型 ID 生成服务的文章。
+
+本文结合一些使用场景,进一步探讨业务场景中对 ID 有哪些具体的要求。
+
+## 场景一:订单系统
+
+我们在商场买东西一码付二维码,下单生成的订单号,使用到的优惠券码,联合商品兑换券码,这些是在网上购物经常使用到的单号,那么为什么有些单号那么长,有些只有几位数?有些单号一看就知道年月日的信息,有些却看不出任何意义?下面展开分析下订单系统中不同场景的 id 服务的具体实现。
+
+### 1、一码付
+
+我们常见的一码付,指的是一个二维码可以使用支付宝或者微信进行扫码支付。
+
+二维码的本质是一个字符串。聚合码的本质就是一个链接地址。用户使用支付宝微信直接扫一个码付钱,不用担心拿支付宝扫了微信的收款码或者用微信扫了支付宝的收款码,这极大减少了用户扫码支付的时间。
+
+实现原理是当客户用 APP 扫码后,网站后台就会判断客户的扫码环境。(微信、支付宝、QQ 钱包、京东支付、云闪付等)。
+
+判断扫码环境的原理就是根据打开链接浏览器的 HTTP header。任何浏览器打开 http 链接时,请求的 header 都会有 User-Agent(UA、用户代理)信息。
+
+UA 是一个特殊字符串头,服务器依次可以识别出客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等很多信息。
+
+各渠道对应支付产品的名称不一样,一定要仔细看各支付产品的 API 介绍。
+
+1. 微信支付:JSAPI 支付支付
+2. 支付宝:手机网站支付
+3. QQ 钱包:公众号支付
+
+其本质均为在 APP 内置浏览器中实现 HTML5 支付。
+
+
+
+文库的研发同学在这个思路上,做了优化迭代。动态生成一码付的二维码预先绑定用户所选的商品信息和价格,根据用户所选的商品动态更新。这样不仅支持一码多平台调起支付,而且不用用户选择商品输入金额,即可完成订单支付的功能,很丝滑。用户在真正扫码后,服务端才通过前端获取用户 UID,结合二维码绑定的商品信息,真正的生成订单,发送支付信息到第三方(qq、微信、支付宝),第三方生成支付订单推给用户设备,从而调起支付。
+
+区别于固定的一码付,在文库的应用中,使用到了动态二维码,二维码本质是一个短网址,ID 服务提供短网址的唯一标志参数。唯一的短网址映射的 ID 绑定了商品的订单信息,技术和业务的深度结合,缩短了支付流程,提升用户的支付体验。
+
+### 2、订单号
+
+订单号在实际的业务过程中作为一个订单的唯一标识码存在,一般实现以下业务场景:
+
+1. 用户订单遇到问题,需要找客服进行协助;
+2. 对订单进行操作,如线下收款,订单核销;
+3. 下单,改单,成单,退单,售后等系统内部的订单流程处理和跟进。
+
+很多时候搜索订单相关信息的时候都是以订单 ID 作为唯一标识符,这是由于订单号的生成规则的唯一性决定的。从技术角度看,除了 ID 服务必要的特性之外,在订单号的设计上需要体现几个特性:
+
+**(1)信息安全**
+
+编号不能透露公司的运营情况,比如日销、公司流水号等信息,以及商业信息和用户手机号,身份证等隐私信息。并且不能有明显的整体规律(可以有局部规律),任意修改一个字符就能查询到另一个订单信息,这也是不允许的。
+
+类比于我们高考时候的考生编号的生成规则,一定不能是连号的,否则只需要根据顺序往下查询就能搜索到别的考生的成绩,这是绝对不可允许。
+
+**(2)部分可读**
+
+位数要便于操作,因此要求订单号的位数适中,且局部有规律。这样可以方便在订单异常,或者退货时客服查询。
+
+过长的订单号或易读性差的订单号会导致客服输入困难且易错率较高,影响用户体验的售后体验。因此在实际的业务场景中,订单号的设计通常都会适当携带一些允许公开的对使用场景有帮助的信息,如时间,星期,类型等等,这个主要根据所涉及的编号对应的使用场景来。
+
+而且像时间、星期这些自增长的属于作为订单号的设计的一部分元素,有助于解决业务累积而导致的订单号重复的问题。
+
+**(3)查询效率**
+
+常见的电商平台订单号大多是纯数字组成,兼具可读性的同时,int 类型相对 varchar 类型的查询效率更高,对在线业务更加友好。
+
+### 3、优惠券和兑换券
+
+优惠券、兑换券是运营推广最常用的促销工具之一,合理使用它们,可以让买家得到实惠,商家提升商品销量。常见场景有:
+
+1. 在文库购买【文库 VIP+QQ 音乐年卡】联合商品,支付成功后会得到 QQ 音乐年卡的兑换码,可以去 QQ 音乐 App 兑换音乐会员年卡;
+2. 疫情期间,部分地方政府发放的消费券;
+3. 瓶装饮料经常会出现输入优惠编码兑换奖品。
+
+
+
+从技术角度看,有些场景适合 ID 即时生成,比如电商平台购物领取的优惠券,只需要在用户领取时分配优惠券信息即可。有些线上线下结合的场景,比如疫情优惠券,瓶盖开奖,京东卡,超市卡这种,则需要预先生成,预先生成的券码具备以下特性:
+
+1.预先生成,在活动正式开始前提供出来进行活动预热;
+
+2.优惠券体量大,以万为单位,通常在 10 万级别以上;
+
+3.不可破解、仿制券码;
+
+4.支持用后核销;
+
+5.优惠券、兑换券属于广撒网的策略,所以利用率低,也就不适合使用数据库进行存储 **(占空间,有效的数据又少)**。
+
+设计思路上,需要设计一种有效的兑换码生成策略,支持预先生成,支持校验,内容简洁,生成的兑换码都具有唯一性,那么这种策略就是一种特殊的编解码策略,按照约定的编解码规则支撑上述需求。
+
+既然是一种编解码规则,那么需要约定编码空间(也就是用户看到的组成兑换码的字符),编码空间由字符 a-z,A-Z,数字 0-9 组成,为了增强兑换码的可识别度,剔除大写字母 O 以及 I,可用字符如下所示,共 60 个字符:
+
+abcdefghijklmnopqrstuvwxyzABCDEFGHJKLMNPQRSTUVWXZY0123456789
+
+之前说过,兑换码要求尽可能简洁,那么设计时就需要考虑兑换码的字符数,假设上限为 12 位,而字符空间有 60 位,那么可以表示的空间范围为 60^12=130606940160000000000000(也就是可以 12 位的兑换码可以生成天量,应该够运营同学挥霍了),转换成 2 进制:
+
+1001000100000000101110011001101101110011000000000000000000000(61 位)
+
+**兑换码组成成分分析**
+
+兑换码可以预先生成,并且不需要额外的存储空间保存这些信息,每一个优惠方案都有独立的一组兑换码(指运营同学组织的每一场运营活动都有不同的兑换码,不能混合使用, 例如双 11 兑换码不能使用在双 12 活动上),每个兑换码有自己的编号,防止重复,为了保证兑换码的有效性,对兑换码的数据需要进行校验,当前兑换码的数据组成如下所示:
+
+优惠方案 ID + 兑换码序列号 i + 校验码
+
+**编码方案**
+
+1. 兑换码序列号 i,代表当前兑换码是当前活动中第 i 个兑换码,兑换码序列号的空间范围决定了优惠活动可以发行的兑换码数目,当前采用 30 位 bit 位表示,可表示范围:1073741824(10 亿个券码)。
+2. 优惠方案 ID, 代表当前优惠方案的 ID 号,优惠方案的空间范围决定了可以组织的优惠活动次数,当前采用 15 位表示,可以表示范围:32768(考虑到运营活动的频率,以及 ID 的初始值 10000,15 位足够,365 天每天有运营活动,可以使用 54 年)。
+3. 校验码,校验兑换码是否有效,主要为了快捷的校验兑换码信息的是否正确,其次可以起到填充数据的目的,增强数据的散列性,使用 13 位表示校验位,其中分为两部分,前 6 位和后 7 位。
+
+深耕业务还会有区分通用券和单独券的情况,分别具备以下特点,技术实现需要因地制宜地思考。
+
+1. 通用券:多个玩家都可以输入兑换,然后有总量限制,期限限制。
+2. 单独券:运营同学可以在后台设置兑换码的奖励物品、期限、个数,然后由后台生成兑换码的列表,兑换之后核销。
+
+## 场景二:Tracing
+
+### 1、日志跟踪
+
+在分布式服务架构下,一个 Web 请求从网关流入,有可能会调用多个服务对请求进行处理,拿到最终结果。这个过程中每个服务之间的通信又是单独的网络请求,无论请求经过的哪个服务出了故障或者处理过慢都会对前端造成影响。
+
+To process multiple services called by a Web request, in order to more conveniently query which link of the service has a problem, a common solution now is to introduce distributed link tracking into the entire system.
+
+
+
+There are two important concepts in distributed link tracing: trace and span. Trace is the view of the entire link in the distributed system requested, and span represents the internal view of different services in the entire link. The span combined together is the view of the entire trace.
+
+In the entire request call chain, the request will always carry the traceid and be passed to the downstream service. Each service will also generate its own spanid internally to generate its own internal call view, and pass it to the downstream service together with the traceid.
+
+### 2. TraceId generation rules
+
+In this scenario, the generated ID must not only be unique, but also must be generated with high efficiency and high throughput. The traceid needs to have the ability to be generated independently by the server instance of the access layer. If the ID in each trace needs to be generated by requesting a public ID service, it will be a pure waste of network bandwidth resources. And it will block the transmission of user requests to downstream, increase the response time, and increase unnecessary risks. Therefore, if a server instance is required, it is best to calculate tracid and spanid by itself to avoid relying on external services.
+
+Generation rules: server IP + ID generation time + auto-increment sequence + current process number, for example:
+
+0ad1348f1403169275002100356696
+
+The first 8 digits 0ad1348f are the IP of the machine that generated the TraceId. This is a hexadecimal number. Each two digits represents a segment of the IP. We convert this number into decimal for each digit to get the common IP address representation 10.209.52.143. You can also use this rule to find the first server that the request passes through.
+
+The following 13 bits 1403169275002 are the time when the TraceId was generated. The next four digits 1003 are a self-increasing sequence, rising from 1000 to 9000. After reaching 9000, it returns to 1000 and starts to rise again. The last 5 digits 56696 are the current process ID. In order to prevent TraceId conflicts in single-machine multiple processes, the current process ID is added at the end of TraceId.
+
+### 3. SpanId generation rules
+
+span means layer. For example, the first instance is considered the first layer, and the request is proxied or offloaded to the next instance for processing, which is the second layer, and so on. By layer, SpanId represents the position of this call in the entire call link tree.
+
+Assume that a server instance A receives a user request, which represents the root node of the entire call. Then the spanid value of the non-service call log record generated by layer A when processing this request is all 0. Layer A needs to call three server instances B, C, and D in sequence through RPC. Then in the log of A, the SpanId is 0.1, 0.2, and 0.3 respectively. In B, C, and D, the SpanId is also respectively. 0.1, 0.2 and 0.3; if system C calls two server instances of E and F when processing the request, then the corresponding spanids in system C are 0.2.1 and 0.2.2, and the corresponding logs of systems E and F are also 0.2.1 and 0.2.2.
+
+According to the above description, we can know that if all the SpanIds in a call are collected, a complete link tree can be formed.
+
+The essence of **spanid generation: it is achieved by controlling the automatic increment of the size and version numbers while transmitting transparently across layers. **
+
+## Scenario 3: Short URL
+
+The main functions of short URL include URL shortening and restoration. Compared with long URLs, short URLs can be spread more easily on emails, social networks, Weibo, and mobile phones. For example, a URL that was originally very long can be generated into a corresponding short URL through a URL shortening service to avoid line breaks or exceeding character limits.
+
+
+
+Commonly used ID generation services such as: MySQL ID auto-increment, Redis key auto-increment, number segment mode, the generated IDs are all a string of numbers. The URL shortening service converts the customer's long URL into a short URL.
+
+In fact, the newly generated numeric ID is spliced after the dwz.cn domain name, and the numeric ID is used directly. The length of the URL is also a bit long. The service can compress the length by converting the numeric ID to a higher base. This algorithm is increasingly used in the technical implementation of short URLs, and it can further compress the URL length. The hexadecimal compression algorithm has a wide range of application scenarios in life, for example:
+
+- Customer's long URL:
+- ID mapped short URL: (for demonstration use, may not open correctly)
+- Shortened URL after conversion: (for demonstration use, it may not open correctly)
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-id.en.md b/docs_en/distributed-system/distributed-id.en.md
new file mode 100644
index 00000000000..25a6cefd964
--- /dev/null
+++ b/docs_en/distributed-system/distributed-id.en.md
@@ -0,0 +1,395 @@
+---
+title: 分布式ID介绍&实现方案总结
+category: 分布式
+---
+
+## 分布式 ID 介绍
+
+### 什么是 ID?
+
+日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
+
+我们现实生活中也有各种 ID,比如身份证 ID 对应且仅对应一个人、地址 ID 对应且仅对应一个地址。
+
+简单来说,**ID 就是数据的唯一标识**。
+
+### 什么是分布式 ID?
+
+分布式 ID 是分布式系统下的 ID。分布式 ID 不存在与现实生活中,属于计算机系统中的一个概念。
+
+我简单举一个分库分表的例子。
+
+我司的一个项目,使用的是单机 MySQL 。但是,没想到的是,项目上线一个月之后,随着使用人数越来越多,整个系统的数据量将越来越大。单机 MySQL 已经没办法支撑了,需要进行分库分表(推荐 Sharding-JDBC)。
+
+在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。**我们如何为不同的数据节点生成全局唯一主键呢?**
+
+这个时候就需要生成**分布式 ID**了。
+
+
+
+### 分布式 ID 需要满足哪些要求?
+
+
+
+分布式 ID 作为分布式系统中必不可少的一环,很多地方都要用到分布式 ID。
+
+一个最基本的分布式 ID 需要满足下面这些要求:
+
+- **全局唯一**:ID 的全局唯一性肯定是首先要满足的!
+- **高性能**:分布式 ID 的生成速度要快,对本地资源消耗要小。
+- **高可用**:生成分布式 ID 的服务要保证可用性无限接近于 100%。
+- **方便易用**:拿来即用,使用方便,快速接入!
+
+除了这些之外,一个比较好的分布式 ID 还应保证:
+
+- **安全**:ID 中不包含敏感信息。
+- **有序递增**:如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
+- **有具体的业务含义**:生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
+- **独立部署**:也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
+
+## 分布式 ID 常见解决方案
+
+### 数据库
+
+#### 数据库主键自增
+
+这种方式就比较简单直白了,就是通过关系型数据库的自增主键产生来唯一的 ID。
+
+
+
+以 MySQL 举例,我们通过下面的方式即可。
+
+**1.创建一个数据库表。**
+
+```sql
+CREATE TABLE `sequence_id` (
+ `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
+ `stub` char(10) NOT NULL DEFAULT '',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `stub` (`stub`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+`stub` 字段无意义,只是为了占位,便于我们插入或者修改数据。并且,给 `stub` 字段创建了唯一索引,保证其唯一性。
+
+**2.通过 `replace into` 来插入数据。**
+
+```java
+BEGIN;
+REPLACE INTO sequence_id (stub) VALUES ('stub');
+SELECT LAST_INSERT_ID();
+COMMIT;
+```
+
+插入数据这里,我们没有使用 `insert into` 而是使用 `replace into` 来插入数据,具体步骤是这样的:
+
+- 第一步:尝试把数据插入到表中。
+
+- 第二步:如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
+
+这种方式的优缺点也比较明显:
+
+- **优点**:实现起来比较简单、ID 有序递增、存储消耗空间小
+- **缺点**:支持的并发量不大、存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )、每次获取 ID 都要访问一次数据库(增加了对数据库的压力,获取速度也慢)
+
+#### 数据库号段模式
+
+数据库主键自增这种模式,每次获取 ID 都要访问一次数据库,ID 需求比较大的时候,肯定是不行的。
+
+如果我们可以批量获取,然后存在在内存里面,需要用到的时候,直接从内存里面拿就舒服了!这也就是我们说的 **基于数据库的号段模式来生成分布式 ID。**
+
+数据库的号段模式也是目前比较主流的一种分布式 ID 生成方式。像滴滴开源的[Tinyid](https://github.com/didi/tinyid/wiki/tinyid原理介绍) 就是基于这种方式来做的。不过,TinyId 使用了双号段缓存、增加多 db 支持等方式来进一步优化。
+
+以 MySQL 举例,我们通过下面的方式即可。
+
+**1. 创建一个数据库表。**
+
+```sql
+CREATE TABLE `sequence_id_generator` (
+ `id` int(10) NOT NULL,
+ `current_max_id` bigint(20) NOT NULL COMMENT '当前最大id',
+ `step` int(10) NOT NULL COMMENT '号段的长度',
+ `version` int(20) NOT NULL COMMENT '版本号',
+ `biz_type` int(20) NOT NULL COMMENT '业务类型',
+ PRIMARY KEY (`id`)
+) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
+```
+
+`current_max_id` 字段和`step`字段主要用于获取批量 ID,获取的批量 id 为:`current_max_id ~ current_max_id+step`。
+
+
+
+`version` 字段主要用于解决并发问题(乐观锁),`biz_type` 主要用于表示业务类型。
+
+**2. 先插入一行数据。**
+
+```sql
+INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
+VALUES
+ (1, 0, 100, 0, 101);
+```
+
+**3. 通过 SELECT 获取指定业务下的批量唯一 ID**
+
+```sql
+SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
+```
+
+结果:
+
+```plain
+id current_max_id step version biz_type
+1 0 100 0 101
+```
+
+**4. 不够用的话,更新之后重新 SELECT 即可。**
+
+```sql
+UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
+SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
+```
+
+结果:
+
+```plain
+id current_max_id step version biz_type
+1 100 100 1 101
+```
+
+相比于数据库主键自增的方式,**数据库的号段模式对于数据库的访问次数更少,数据库压力更小。**
+
+另外,为了避免单点问题,你可以从使用主从模式来提高可用性。
+
+**数据库号段模式的优缺点:**
+
+- **优点**:ID 有序递增、存储消耗空间小
+- **缺点**:存在数据库单点问题(可以使用数据库集群解决,不过增加了复杂度)、ID 没有具体业务含义、安全问题(比如根据订单 ID 的递增规律就能推算出每天的订单量,商业机密啊! )
+
+#### NoSQL
+
+
+
+一般情况下,NoSQL 方案使用 Redis 多一些。我们通过 Redis 的 `incr` 命令即可实现对 id 原子顺序递增。
+
+```bash
+127.0.0.1:6379> set sequence_id_biz_type 1
+OK
+127.0.0.1:6379> incr sequence_id_biz_type
+(integer) 2
+127.0.0.1:6379> get sequence_id_biz_type
+"2"
+```
+
+为了提高可用性和并发,我们可以使用 Redis Cluster。Redis Cluster 是 Redis 官方提供的 Redis 集群解决方案(3.0+版本)。
+
+除了 Redis Cluster 之外,你也可以使用开源的 Redis 集群方案[Codis](https://github.com/CodisLabs/codis) (大规模集群比如上百个节点的时候比较推荐)。
+
+除了高可用和并发之外,我们知道 Redis 基于内存,我们需要持久化数据,避免重启机器或者机器故障后数据丢失。Redis 支持两种不同的持久化方式:**快照(snapshotting,RDB)**、**只追加文件(append-only file, AOF)**。 并且,Redis 4.0 开始支持 **RDB 和 AOF 的混合持久化**(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
+
+关于 Redis 持久化,我这里就不过多介绍。不了解这部分内容的小伙伴,可以看看 [Redis 持久化机制详解](https://javaguide.cn/database/redis/redis-persistence.html)这篇文章。
+
+**Redis 方案的优缺点:**
+
+- **优点**:性能不错并且生成的 ID 是有序递增的
+- **缺点**:和数据库主键自增方案的缺点类似
+
+除了 Redis 之外,MongoDB ObjectId 经常也会被拿来当做分布式 ID 的解决方案。
+
+
+
+MongoDB ObjectId 一共需要 12 个字节存储:
+
+- 0~3:时间戳
+- 3~6:代表机器 ID
+- 7~8:机器进程 ID
+- 9~11:自增值
+
+**MongoDB 方案的优缺点:**
+
+- **优点**:性能不错并且生成的 ID 是有序递增的
+- **缺点**:需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)、有安全性问题(ID 生成有规律性)
+
+### 算法
+
+#### UUID
+
+UUID 是 Universally Unique Identifier(通用唯一标识符) 的缩写。UUID 包含 32 个 16 进制数字(8-4-4-4-12)。
+
+JDK 就提供了现成的生成 UUID 的方法,一行代码就行了。
+
+```java
+//输出示例:cb4a9ede-fa5e-4585-b9bb-d60bce986eaa
+UUID.randomUUID()
+```
+
+[RFC 4122](https://tools.ietf.org/html/rfc4122) 中关于 UUID 的示例是这样的:
+
+
+
+我们这里重点关注一下这个 Version(版本),不同的版本对应的 UUID 的生成规则是不同的。
+
+8 种不同的 Version(版本)值分别对应的含义(参考[维基百科对于 UUID 的介绍](https://zh.wikipedia.org/wiki/通用唯一识别码)):
+
+- **版本 1 (基于时间和节点 ID)** : 基于时间戳(通常是当前时间)和节点 ID(通常为设备的 MAC 地址)生成。当包含 MAC 地址时,可以保证全球唯一性,但也因此存在隐私泄露的风险。
+- **版本 2 (基于标识符、时间和节点 ID)** : 与版本 1 类似,也基于时间和节点 ID,但额外包含了本地标识符(例如用户 ID 或组 ID)。
+- **版本 3 (基于命名空间和名称的 MD5 哈希)**:使用 MD5 哈希算法,将命名空间标识符(一个 UUID)和名称字符串组合计算得到。相同的命名空间和名称总是生成相同的 UUID(**确定性生成**)。
+- **版本 4 (基于随机数)**:几乎完全基于随机数生成,通常使用伪随机数生成器(PRNG)或加密安全随机数生成器(CSPRNG)来生成。 虽然理论上存在碰撞的可能性,但理论上碰撞概率极低(2^122 的可能性),可以认为在实际应用中是唯一的。
+- **版本 5 (基于命名空间和名称的 SHA-1 哈希)**:类似于版本 3,但使用 SHA-1 哈希算法。
+- **版本 6 (基于时间戳、计数器和节点 ID)**:改进了版本 1,将时间戳放在最高有效位(Most Significant Bit,MSB),使得 UUID 可以直接按时间排序。
+- **版本 7 (基于时间戳和随机数据)**:基于 Unix 时间戳和随机数据生成。 由于时间戳位于最高有效位,因此支持按时间排序。并且,不依赖 MAC 地址或节点 ID,避免了隐私问题。
+- **版本 8 (自定义)**:允许用户根据自己的需求定义 UUID 的生成方式。其结构和内容由用户决定,提供更大的灵活性。
+
+下面是 Version 1 版本下生成的 UUID 的示例:
+
+
+
+JDK 中通过 `UUID` 的 `randomUUID()` 方法生成的 UUID 的版本默认为 4。
+
+```java
+UUID uuid = UUID.randomUUID();
+int version = uuid.version();// 4
+```
+
+另外,Variant(变体)也有 4 种不同的值,这种值分别对应不同的含义。这里就不介绍了,貌似平时也不怎么需要关注。
+
+需要用到的时候,去看看维基百科对于 UUID 的 Variant(变体) 相关的介绍即可。
+
+从上面的介绍中可以看出,UUID 可以保证唯一性,因为其生成规则包括 MAC 地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素,计算机基于这些规则生成的 UUID 是肯定不会重复的。
+
+虽然,UUID 可以做到全局唯一性,但是,我们一般很少会使用它。
+
+比如使用 UUID 作为 MySQL 数据库主键的时候就非常不合适:
+
+- 数据库主键要尽量越短越好,而 UUID 的消耗的存储空间比较大(32 个字符串,128 位)。
+- UUID 是无顺序的,InnoDB 引擎下,数据库主键的无序性会严重影响数据库性能。
+
+最后,我们再简单分析一下 **UUID 的优缺点** (面试的时候可能会被问到的哦!) :
+
+- **优点**:生成速度通常比较快、简单易用
+- **缺点**:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
+
+#### Snowflake(雪花算法)
+
+Snowflake 是 Twitter 开源的分布式 ID 生成算法。Snowflake 由 64 bit 的二进制数字组成,这 64bit 的二进制被分成了几部分,每一部分存储的数据都有特定的含义:
+
+
+
+- **sign(1bit)**:符号位(标识正负),始终为 0,代表生成的 ID 为正数。
+- **timestamp (41 bits)**:一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
+- **datacenter id + worker id (10 bits)**:一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
+- **sequence (12 bits)**:一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
+
+在实际项目中,我们一般也会对 Snowflake 算法进行改造,最常见的就是在 Snowflake 算法生成的 ID 中加入业务类型信息。
+
+我们再来看看 Snowflake 算法的优缺点:
+
+- **优点**:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
+- **缺点**:需要解决重复 ID 问题(ID 生成依赖时间,在获取时间的时候,可能会出现时间回拨的问题,也就是服务器上的时间突然倒退到之前的时间,进而导致会产生重复 ID)、依赖机器 ID 对分布式环境不友好(当需要自动启停或增减机器时,固定的机器 ID 可能不够灵活)。
+
+如果你想要使用 Snowflake 算法的话,一般不需要你自己再造轮子。有很多基于 Snowflake 算法的开源实现比如美团 的 Leaf、百度的 UidGenerator(后面会提到),并且这些开源实现对原有的 Snowflake 算法进行了优化,性能更优秀,还解决了 Snowflake 算法的时间回拨问题和依赖机器 ID 的问题。
+
+并且,Seata 还提出了“改良版雪花算法”,针对原版雪花算法进行了一定的优化改良,解决了时间回拨问题,大幅提高的 QPS。具体介绍和改进原理,可以参考下面这两篇文章:
+
+- [Seata 基于改良版雪花算法的分布式 UUID 生成器分析](https://seata.io/zh-cn/blog/seata-analysis-UUID-generator.html)
+- [在开源项目中看到一个改良版的雪花算法,现在它是你的了。](https://www.cnblogs.com/thisiswhy/p/17611163.html)
+
+### 开源框架
+
+#### UidGenerator(百度)
+
+[UidGenerator](https://github.com/baidu/uid-generator) 是百度开源的一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
+
+不过,UidGenerator 对 Snowflake(雪花算法)进行了改进,生成的唯一 ID 组成如下:
+
+
+
+- **sign(1bit)**:符号位(标识正负),始终为 0,代表生成的 ID 为正数。
+- **delta seconds (28 bits)**:当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约 8.7 年
+- **worker id (22 bits)**:机器 id,最多可支持约 420w 次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。
+- **sequence (13 bits)**:每秒下的并发序列,13 bits 可支持每秒 8192 个并发。
+
+可以看出,和原始 Snowflake(雪花算法)生成的唯一 ID 的组成不太一样。并且,上面这些参数我们都可以自定义。
+
+UidGenerator 官方文档中的介绍如下:
+
+
+
+自 18 年后,UidGenerator 就基本没有再维护了,我这里也不过多介绍。想要进一步了解的朋友,可以看看 [UidGenerator 的官方介绍](https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md)。
+
+#### Leaf(美团)
+
+[Leaf](https://github.com/Meituan-Dianping/Leaf) 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话:“There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
+
+Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper(使用 Zookeeper 作为注册中心,通过在特定路径下读取和创建子节点来管理 workId) 。
+
+Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的方法多种多样以及不可靠的问题。
+
+Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))。
+
+
+
+根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
+
+#### Tinyid(滴滴)
+
+[Tinyid](https://github.com/didi/tinyid) 是滴滴开源的一款基于数据库号段模式的唯一 ID 生成器。
+
+数据库号段模式的原理我们在上面已经介绍过了。**Tinyid 有哪些亮点呢?**
+
+为了搞清楚这个问题,我们先来看看基于数据库号段模式的简单架构方案。(图片来自于 Tinyid 的官方 wiki:[《Tinyid 原理介绍》](https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D))
+
+
+
+在这种架构模式下,我们通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server。
+
+这种方案有什么问题呢?在我看来(Tinyid 官方 wiki 也有介绍到),主要由下面这 2 个问题:
+
+- 获取新号段的情况下,程序获取唯一 ID 的速度比较慢。
+- 需要保证 DB 高可用,这个是比较麻烦且耗费资源的。
+
+除此之外,HTTP 调用也存在网络开销。
+
+Tinyid 的原理比较简单,其架构如下图所示:
+
+
+
+相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
+
+- **双号段缓存**:为了避免在获取新号段的情况下,程序获取唯一 ID 的速度比较慢。 Tinyid 中的号段在用到一定程度的时候,就会去异步加载下一个号段,保证内存中始终有可用号段。
+- **增加多 db 支持**:支持多个 DB,并且,每个 DB 都能生成唯一 ID,提高了可用性。
+- **增加 tinyid-client**:纯本地操作,无 HTTP 请求消耗,性能和可用性都有很大提升。
+
+Tinyid 的优缺点这里就不分析了,结合数据库号段模式的优缺点和 Tinyid 的原理就能知道。
+
+#### IdGenerator(个人)
+
+和 UidGenerator、Leaf 一样,[IdGenerator](https://github.com/yitter/IdGenerator) 也是一款基于 Snowflake(雪花算法)的唯一 ID 生成器。
+
+IdGenerator 有如下特点:
+
+- 生成的唯一 ID 更短;
+- Compatible with all snowflake algorithms (number segment mode or classic mode, big factory or small factory);
+- Natively supports C#/Java/Go/C/Rust/Python/Node.js/PHP (C extension)/SQL/ and other languages, and provides multi-threaded safe dynamic library calling (FFI);
+- Solve the time callback problem and support manual insertion of new IDs (when the business needs to generate new IDs in historical time, the reserved bits of this algorithm can generate 5000 per second);
+- Does not rely on external storage systems;
+- In the default configuration, IDs are available for 71000 years without duplication.
+
+The unique ID generated by the IdGenerator consists of:
+
+
+
+- **timestamp (number of digits is not fixed)**: The time difference is the total time difference (in milliseconds) from the system time when the ID is generated minus BaseTime (base time, also called base time, origin time, epoch time, the default value is 2020). Initial is 5bits and increases with running time. If you feel that the default value is too old, you can reset it, but be aware that it is best not to change this value in the future.
+- **worker id (default 6 bits)**: machine id, machine code, the most important parameter, is the unique ID that distinguishes different machines or different applications. The maximum value is limited by `WorkerIdBitLength` (default 6). If a server deploys multiple independent services, you need to specify a different WorkerId for each service.
+- **sequence (default 6 bits)**: The number of sequences, which is the number of sequences per millisecond, is limited by the `SeqBitLength` (default 6) in the parameter. Increasing `SeqBitLength` will result in better performance, but the generated IDs will also be longer.
+
+Java language usage example: .
+
+## Summary
+
+Through this article, I have basically summarized the most common distributed ID generation solutions.
+
+In addition to the methods introduced above, middleware like ZooKeeper can also help us generate unique IDs. **There is no silver bullet. You must choose the solution that best suits you based on the actual project. **
+
+However, this article mainly introduces the theoretical knowledge of distributed ID. In an actual interview, the interviewer may examine your design of distributed ID based on specific business scenarios. You can refer to this article: [Distributed ID Design Guide](./distributed-id-design) (it is also very helpful for the design of distributed ID in actual work).
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-lock-implementations.en.md b/docs_en/distributed-system/distributed-lock-implementations.en.md
new file mode 100644
index 00000000000..bea69b2329a
--- /dev/null
+++ b/docs_en/distributed-system/distributed-lock-implementations.en.md
@@ -0,0 +1,372 @@
+---
+title: Summary of common implementation solutions for distributed locks
+category: distributed
+---
+
+
+
+Under normal circumstances, we generally choose to implement distributed locks based on Redis or ZooKeeper. Redis is used more often. I will first introduce the implementation of distributed locks using Redis as an example.
+
+## Implement distributed lock based on Redis
+
+### How to implement the simplest distributed lock based on Redis?
+
+Whether it is a local lock or a distributed lock, the core lies in "mutual exclusion".
+
+In Redis, the `SETNX` command can help us achieve mutual exclusion. `SETNX` is **SET** if **N**ot e**X**ists (corresponding to the `setIfAbsent` method in Java). If the key does not exist, the value of the key will be set. If key already exists, `SETNX` does nothing.
+
+```bash
+> SETNX lockKey uniqueValue
+(integer) 1
+> SETNX lockKey uniqueValue
+(integer) 0
+```
+
+To release the lock, delete the corresponding key directly through the `DEL` command.
+
+```bash
+> DEL lockKey
+(integer) 1
+```
+
+In order to prevent accidentally deleting other locks, we recommend using Lua script to judge by the value (unique value) corresponding to the key.
+
+The Lua script was chosen to ensure the atomicity of the unlocking operation. Because Redis can execute Lua scripts in an atomic manner, thus ensuring the atomicity of the lock release operation.
+
+```lua
+// When releasing the lock, first compare the value values corresponding to the lock to see if they are equal to avoid accidentally releasing the lock.
+if redis.call("get",KEYS[1]) == ARGV[1] then
+ return redis.call("del",KEYS[1])
+else
+ return 0
+end
+```
+
+
+
+This is the simplest Redis distributed lock implementation. The implementation method is relatively simple and the performance is very efficient. However, there are some problems with implementing distributed locking in this way. For example, if the application encounters some problems, such as the logic of releasing the lock suddenly hangs up, the lock may not be released, and the shared resources can no longer be accessed by other threads/processes.
+
+### Why do we need to set an expiration time for the lock?
+
+In order to prevent the lock from being released, one solution we can think of is: **Set an expiration time** for this key (that is, the lock).
+
+```bash
+127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
+OK
+```
+
+- **lockKey**: the lock name;
+- **uniqueValue**: a random string that uniquely identifies the lock;
+- **NX**: SET can only succeed when the key value corresponding to lockKey does not exist;
+- **EX**: Expiration time setting (in seconds) EX 3 indicates that this lock has an automatic expiration time of 3 seconds. Corresponding to EX is PX (in milliseconds), both of which are expiration time settings.
+
+**Be sure to ensure that setting the value and expiration time of the specified key is an atomic operation! ! ! ** Otherwise, there may still be a problem that the lock cannot be released.
+
+This can indeed solve the problem, but this solution also has loopholes: **If the time to operate the shared resource is greater than the expiration time, there will be a problem of early expiration of the lock, which will lead to the direct failure of the distributed lock. If the lock timeout is set too long, performance will be affected. **
+
+You may be thinking: **If the operation of operating shared resources has not been completed, it would be great if the lock expiration time could be renewed by itself! **
+
+### How to achieve graceful renewal of locks?
+
+For Java development partners, there is already a ready-made solution: **[Redisson](https://github.com/redisson/redisson)**. Solutions in other languages can be found in the official Redis documentation at: .
+
+
+
+Redisson is an open source Java language Redis client that provides many out-of-the-box features, including not only the implementation of multiple distributed locks. Moreover, Redisson also supports multiple deployment architectures such as Redis stand-alone, Redis Sentinel, and Redis Cluster.
+
+The distributed lock in Redisson comes with an automatic renewal mechanism. It is very simple to use and the principle is relatively simple. It provides a **Watch Dog** specially used to monitor and renew the lock. If the thread operating the shared resource has not completed execution, the Watch Dog will continuously extend the expiration time of the lock, thereby ensuring that the lock will not be released due to timeout.
+
+
+
+The name of the watchdog comes from the `getLockWatchdogTimeout()` method. This method returns the expiration time for the watchdog to renew the lock. The default is 30 seconds ([redisson-3.17.6](https://github.com/redisson/redisson/releases/tag/redisson-3.17.6)).
+
+```java
+//Default 30 seconds, supports modification
+private long lockWatchdogTimeout = 30 * 1000;
+
+public Config setLockWatchdogTimeout(long lockWatchdogTimeout) {
+ this.lockWatchdogTimeout = lockWatchdogTimeout;
+ return this;
+}
+public long getLockWatchdogTimeout() {
+ return lockWatchdogTimeout;
+}
+```
+
+The `renewExpiration()` method contains the main logic of the watchdog:
+
+```java
+private void renewExpiration() {
+ //......
+ Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
+ @Override
+ public void run(Timeout timeout) throws Exception {
+ //......
+ //Asynchronous renewal, based on Lua script
+ CompletionStage future = renewExpirationAsync(threadId);
+ future.whenComplete((res, e) -> {
+ if (e != null) {
+ //Cannot renew
+ log.error("Can't update lock " + getRawName() + " expiration", e);
+ EXPIRATION_RENEWAL_MAP.remove(getEntryName());
+ return;
+ }
+
+ if (res) {
+ // Recursive call to implement renewal
+ renewExpiration();
+ } else {
+ // Cancel renewal
+ cancelExpirationRenewal(null);
+ }
+ });
+ }
+ // Delay internalLockLeaseTime/3 (default 10s, which is 30/3) before calling
+ }, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
+
+ ee.setTimeout(task);
+ }
+```默认情况下,每过 10 秒,看门狗就会执行续期操作,将锁的超时时间设置为 30 秒。看门狗续期前也会先判断是否需要执行续期操作,需要才会执行续期,否则取消续期操作。
+
+Watch Dog 通过调用 `renewExpirationAsync()` 方法实现锁的异步续期:
+
+```java
+protected CompletionStage renewExpirationAsync(long threadId) {
+ return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
+ // 判断是否为持锁线程,如果是就执行续期操作,就锁的过期时间设置为 30s(默认)
+ "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
+ "redis.call('pexpire', KEYS[1], ARGV[1]); " +
+ "return 1; " +
+ "end; " +
+ "return 0;",
+ Collections.singletonList(getRawName()),
+ internalLockLeaseTime, getLockName(threadId));
+}
+```
+
+可以看出, `renewExpirationAsync` 方法其实是调用 Lua 脚本实现的续期,这样做主要是为了保证续期操作的原子性。
+
+我这里以 Redisson 的分布式可重入锁 `RLock` 为例来说明如何使用 Redisson 实现分布式锁:
+
+```java
+// 1.获取指定的分布式锁对象
+RLock lock = redisson.getLock("lock");
+// 2.拿锁且不设置锁超时时间,具备 Watch Dog 自动续期机制
+lock.lock();
+// 3.执行业务
+...
+// 4.释放锁
+lock.unlock();
+```
+
+只有未指定锁超时时间,才会使用到 Watch Dog 自动续期机制。
+
+```java
+// 手动给锁设置过期时间,不具备 Watch Dog 自动续期机制
+lock.lock(10, TimeUnit.SECONDS);
+```
+
+如果使用 Redis 来实现分布式锁的话,还是比较推荐直接基于 Redisson 来做的。
+
+### 如何实现可重入锁?
+
+所谓可重入锁指的是在一个线程中可以多次获取同一把锁,比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法即可重入 ,而无需重新获得锁。像 Java 中的 `synchronized` 和 `ReentrantLock` 都属于可重入锁。
+
+**不可重入的分布式锁基本可以满足绝大部分业务场景了,一些特殊的场景可能会需要使用可重入的分布式锁。**
+
+可重入分布式锁的实现核心思路是线程在获取锁的时候判断是否为自己的锁,如果是的话,就不用再重新获取了。为此,我们可以为每个锁关联一个可重入计数器和一个占有它的线程。当可重入计数器大于 0 时,则锁被占有,需要判断占有该锁的线程和请求获取锁的线程是否为同一个。
+
+实际项目中,我们不需要自己手动实现,推荐使用我们上面提到的 **Redisson** ,其内置了多种类型的锁比如可重入锁(Reentrant Lock)、自旋锁(Spin Lock)、公平锁(Fair Lock)、多重锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)。
+
+
+
+### Redis 如何解决集群情况下分布式锁的可靠性?
+
+为了避免单点故障,生产环境下的 Redis 服务通常是集群化部署的。
+
+Redis 集群下,上面介绍到的分布式锁的实现会存在一些问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
+
+
+
+针对这个问题,Redis 之父 antirez 设计了 [Redlock 算法](https://redis.io/topics/distlock) 来解决。
+
+
+
+Redlock 算法的思想是让客户端向 Redis 集群中的多个独立的 Redis 实例依次请求申请加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
+
+即使部分 Redis 节点出现问题,只要保证 Redis 集群中有半数以上的 Redis 节点可用,分布式锁服务就是正常的。
+
+Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的,这样才可以避免 Redis 集群主从切换导致的锁丢失问题。
+
+Redlock 实现比较复杂,性能比较差,发生时钟变迁的情况下还存在安全性隐患。《数据密集型应用系统设计》一书的作者 Martin Kleppmann 曾经专门发文([How to do distributed locking - Martin Kleppmann - 2016](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html))怼过 Redlock,他认为这是一个很差的分布式锁实现。感兴趣的朋友可以看看[Redis 锁从面试连环炮聊到神仙打架](https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505097&idx=1&sn=5c03cb769c4458350f4d4a321ad51f5a&source=41#wechat_redirect)这篇文章,有详细介绍到 antirez 和 Martin Kleppmann 关于 Redlock 的激烈辩论。
+
+实际项目中不建议使用 Redlock 算法,成本和收益不成正比,可以考虑基于 Redis 主从复制+哨兵模式实现分布式锁。
+
+## 基于 ZooKeeper 实现分布式锁
+
+ZooKeeper 相比于 Redis 实现分布式锁,除了提供相对更高的可靠性之外,在功能层面还有一个非常有用的特性:**Watch 机制**。这个机制可以用来实现公平的分布式锁。不过,使用 ZooKeeper 实现的分布式锁在性能方面相对较差,因此如果对性能要求比较高的话,ZooKeeper 可能就不太适合了。
+
+### 如何基于 ZooKeeper 实现分布式锁?
+
+ZooKeeper 分布式锁是基于 **临时顺序节点** 和 **Watcher(事件监听器)** 实现的。
+
+获取锁:
+
+1. 首先我们要有一个持久节点`/locks`,客户端获取锁就是在`locks`下创建临时顺序节点。
+2. 假设客户端 1 创建了`/locks/lock1`节点,创建成功之后,会判断 `lock1`是否是 `/locks` 下最小的子节点。
+3. 如果 `lock1`是最小的子节点,则获取锁成功。否则,获取锁失败。
+4. 如果获取锁失败,则说明有其他的客户端已经成功获取锁。客户端 1 并不会不停地循环去尝试加锁,而是在前一个节点比如`/locks/lock0`上注册一个事件监听器。这个监听器的作用是当前一个节点释放锁之后通知客户端 1(避免无效自旋),这样客户端 1 就加锁成功了。
+
+释放锁:
+
+1. 成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
+2. 成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
+3. 我们前面说的事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
+
+
+
+In actual projects, it is recommended to use Curator to implement ZooKeeper distributed locks. Curator is a set of ZooKeeper Java client frameworks open sourced by Netflix. Compared with ZooKeeper's own client zookeeper, Curator's encapsulation is more complete, and various APIs can be used more conveniently.
+
+`Curator` mainly implements the following four locks:
+
+- `InterProcessMutex`: distributed reentrant exclusive lock
+- `InterProcessSemaphoreMutex`: distributed non-reentrant exclusive lock
+- `InterProcessReadWriteLock`: distributed read-write lock
+- `InterProcessMultiLock`: A container that manages multiple locks as a single entity. When acquiring a lock, all locks are acquired. Releasing the lock will also release all lock resources (ignore locks that fail to be released).
+
+```java
+CuratorFramework client = ZKUtils.getClient();
+client.start();
+// Distributed reentrant exclusive lock
+InterProcessLock lock1 = new InterProcessMutex(client, lockPath1);
+// Distributed non-reentrant exclusive lock
+InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2);
+// Treat multiple locks as a whole
+InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));
+
+if (!lock.acquire(10, TimeUnit.SECONDS)) {
+ throw new IllegalStateException("Cannot acquire multiple locks");
+}
+System.out.println("Multiple locks acquired");
+System.out.println("Is there the first lock: " + lock1.isAcquiredInThisProcess());
+System.out.println("Is there a second lock: " + lock2.isAcquiredInThisProcess());
+try {
+ // Resource operations
+ resource.use();
+} finally {
+ System.out.println("Release multiple locks");
+ lock.release();
+}
+System.out.println("Is there the first lock: " + lock1.isAcquiredInThisProcess());
+System.out.println("Is there a second lock: " + lock2.isAcquiredInThisProcess());
+client.close();
+```
+
+### Why use temporary sequential nodes?
+
+Each data node is called **znode** in ZooKeeper, which is the smallest unit of data in ZooKeeper.
+
+We usually divide znodes into 4 major categories:
+
+- **persistent (PERSISTENT) node**: Once created, it will always exist even if the ZooKeeper cluster goes down, until it is deleted.
+- **Temporary (EPHEMERAL) node**: The life cycle of the temporary node is bound to the **client session (session)**. **The node disappears when the session disappears**. Moreover, **temporary nodes can only be used as leaf nodes** and cannot create child nodes.
+- **Persistent Sequence (PERSISTENT_SEQUENTIAL) node**: In addition to the characteristics of the persistent (PERSISTENT) node, the names of child nodes are also sequential. For example `/node1/app0000000001`, `/node1/app0000000002`.
+- **Temporary Sequential (EPHEMERAL_SEQUENTIAL) Node**: In addition to having the characteristics of temporary (EPHEMERAL) nodes, the names of child nodes are also sequential.
+
+It can be seen that compared with persistent nodes, the most important thing about temporary nodes is that they handle session failure differently. When the temporary node session disappears, the corresponding node disappears. In this case, it doesn't matter if an exception occurs on the client and the lock is not released in time. The session invalid node will be automatically deleted and deadlock will not occur.
+
+When using Redis to implement distributed locks, we use the expiration time to avoid deadlock problems caused by the lock being unable to be released, while ZooKeeper can directly use the characteristics of temporary nodes.
+
+Assuming that sequential nodes are not used, all clients that try to acquire a lock will add listeners to the child nodes holding the lock. When the lock is released, it will inevitably cause all clients trying to obtain the lock to compete for the lock, which is not friendly to performance. After using sequential nodes, you only need to listen to the previous node, which is more performance-friendly.
+
+### Why do we need to set up monitoring on the previous node?
+
+> Watcher (event listener) is a very important feature in ZooKeeper. ZooKeeper allows users to register some Watchers on designated nodes, and when certain events are triggered, the ZooKeeper server will notify interested clients of the event. This mechanism is an important feature of ZooKeeper in implementing distributed coordination services.
+
+During the same time period, many clients may acquire the lock at the same time, but only one can acquire it successfully. If the lock acquisition fails, it means that another client has successfully acquired the lock. The client that fails to acquire the lock will not keep looping to try to acquire the lock, but will register an event listener on the previous node.
+
+The function of this event listener is: **After the client corresponding to the current node releases the lock (that is, after the previous node is deleted, the listening event is the deletion event), notify the client that failed to acquire the lock (wake up the waiting thread, `wait/notifyAll` in Java), let it try to acquire the lock, and then successfully acquire the lock. **
+
+### How to implement reentrant lock?
+
+Here we use Curator's `InterProcessMutex` to introduce the implementation of reentrant locks (source code address: [InterProcessMutex.java](https://github.com/apache/curator/blob/master/curator-recipes/src/main/java/org/apache/curator/framework/recipes/locks/InterProcessMutex.java)).
+
+When we call the `InterProcessMutex#acquire` method to acquire the lock, the `InterProcessMutex#internalLock` method will be called.
+
+```java
+// Acquire the reentrant mutex until the acquisition is successful
+@Override
+public void acquire() throws Exception {
+ if (!internalLock(-1, null)) {
+ throw new IOException("Lost connection while trying to acquire lock: " + basePath);
+ }
+}
+```
+
+The `internalLock` method will first obtain the thread currently requesting the lock, and then obtain the `lockData` corresponding to the current thread from `threadData` (`ConcurrentMap` type). `lockData` contains lock information and the number of locks, which is the key to implementing reentrant locks.
+
+When the lock is acquired for the first time, `lockData` is `null`. After successfully acquiring the lock, the current thread and the corresponding `lockData` will be placed in `threadData`
+
+```java
+private boolean internalLock(long time, TimeUnit unit) throws Exception {
+ // Get the thread currently requesting the lock
+ Thread currentThread = Thread.currentThread();
+ // Get the corresponding lockData
+ LockData lockData = threadData.get(currentThread);
+ // When acquiring the lock for the first time, lockData is null
+ if (lockData != null) {
+ //After the current thread acquires the lock once
+ // Because the current thread's lock exists, lockCount is incremented and then returned to achieve lock reentrancy.
+ lockData.lockCount.incrementAndGet();
+ return true;
+ }
+ //Try to acquire the lock
+ String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
+ if (lockPath != null) {
+ LockData newLockData = new LockData(currentThread, lockPath);
+ // After successfully acquiring the lock, put the current thread and the corresponding lockData into threadData.
+ threadData.put(currentThread, newLockData);
+ return true;
+ }
+
+ return false;
+}
+```
+
+`LockData` is a static inner class in `InterProcessMutex`.
+
+```java
+private final ConcurrentMap threadData = Maps.newConcurrentMap();
+
+private static class LockData
+{
+ //The thread currently holding the lock
+ final Thread owningThread;
+ // Lock the corresponding child node
+ final String lockPath;
+ //Number of locks
+ final AtomicInteger lockCount = new AtomicInteger(1);
+
+ private LockData(Thread owningThread, String lockPath)
+ {
+ this.owningThread = owningThread;
+ this.lockPath = lockPath;
+ }
+}```
+
+If the lock has been acquired once and you acquire the lock again later, it will be blocked directly at `if (lockData != null)`, and then `lockData.lockCount.incrementAndGet();` will be executed to increase the number of locks by 1.
+
+The implementation logic of the entire reentrant lock is very simple. You can directly determine whether the current thread has acquired the lock on the client side. If so, just add 1 to the number of locks.
+
+## Summary
+
+In this article, I introduced two common ways to implement distributed locks: **Redis** and **ZooKeeper**. As for the specific choice of Redis or ZooKeeper to implement distributed locks, it still depends on the specific needs of the business.
+
+- If the performance requirements are relatively high, it is recommended to use Redis to implement distributed locks. It is recommended to choose the ready-made distributed lock provided by **Redisson** instead of implementing it yourself. It is not recommended to use the Redlock algorithm in actual projects because the costs and benefits are not proportional. You can consider implementing distributed locks based on Redis master-slave replication + sentinel mode.
+- If the reliability requirements are relatively high, it is recommended to use ZooKeeper to implement distributed locks, and it is recommended to implement it based on the **Curator** framework. However, many projects now do not use ZooKeeper. It is not advisable to introduce ZooKeeper simply because of distributed locks. It is not recommended. It increases the complexity of the system for a small function.
+
+It should be noted that no matter which method you choose to implement distributed locks, including Redis, ZooKeeper or Etcd (not introduced in this article, but often used to implement distributed locks), there is no guarantee of 100% security, especially when encountering abnormal situations such as process garbage collection (GC) and network delays.
+
+In order to further improve the reliability of the system, it is recommended to introduce a safety net mechanism. For example, concurrency conflicts can be avoided through the **version number (Fencing Token) mechanism**.
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-lock.en.md b/docs_en/distributed-system/distributed-lock.en.md
new file mode 100644
index 00000000000..7caa7daf74e
--- /dev/null
+++ b/docs_en/distributed-system/distributed-lock.en.md
@@ -0,0 +1,85 @@
+---
+title: 分布式锁介绍
+category: 分布式
+---
+
+
+
+网上有很多分布式锁相关的文章,写了一个相对简洁易懂的版本,针对面试和工作应该够用了。
+
+这篇文章我们先介绍一下分布式锁的基本概念。
+
+## 为什么需要分布式锁?
+
+在多线程环境中,如果多个线程同时访问共享资源(例如商品库存、外卖订单),会发生数据竞争,可能会导致出现脏数据或者系统问题,威胁到程序的正常运行。
+
+举个例子,假设现在有 100 个用户参与某个限时秒杀活动,每位用户限购 1 件商品,且商品的数量只有 3 个。如果不对共享资源进行互斥访问,就可能出现以下情况:
+
+- 线程 1、2、3 等多个线程同时进入抢购方法,每一个线程对应一个用户。
+- 线程 1 查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
+- 线程 2 也执行查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
+- 线程 1 继续执行,将库存数量减少 1 个,然后返回成功。
+- 线程 2 继续执行,将库存数量减少 1 个,然后返回成功。
+- 此时就发生了超卖问题,导致商品被多卖了一份。
+
+
+
+为了保证共享资源被安全地访问,我们需要使用互斥操作对共享资源进行保护,即同一时刻只允许一个线程访问共享资源,其他线程需要等待当前线程释放后才能访问。这样可以避免数据竞争和脏数据问题,保证程序的正确性和稳定性。
+
+**如何才能实现共享资源的互斥访问呢?** 锁是一个比较通用的解决方案,更准确点来说是悲观锁。
+
+悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**。
+
+对于单机多线程来说,在 Java 中,我们通常使用 `ReentrantLock` 类、`synchronized` 关键字这类 JDK 自带的 **本地锁** 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
+
+下面是我对本地锁画的一张示意图。
+
+
+
+从图中可以看出,这些线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到本地锁访问共享资源。
+
+分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。于是,**分布式锁** 就诞生了。
+
+举个例子:系统的订单服务一共部署了 3 份,都对外提供服务。用户下订单之前需要检查库存,为了防止超卖,这里需要加锁以实现对检查库存操作的同步访问。由于订单服务位于不同的 JVM 进程中,本地锁在这种情况下就没办法正常工作了。我们需要用到分布式锁,这样的话,即使多个线程不在同一个 JVM 进程中也能获取到同一把锁,进而实现共享资源的互斥访问。
+
+下面是我对分布式锁画的一张示意图。
+
+
+
+从图中可以看出,这些独立的进程中的线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到分布式锁访问共享资源。
+
+## 分布式锁应该具备哪些条件?
+
+一个最基本的分布式锁需要满足:
+
+- **互斥**:任意一个时刻,锁只能被一个线程持有。
+- **高可用**:锁服务是高可用的,当一个锁服务出现问题,能够自动切换到另外一个锁服务。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。这一般是通过超时机制实现的。
+- **可重入**:一个节点获取了锁之后,还可以再次获取锁。
+
+除了上面这三个基本条件之外,一个好的分布式锁还需要满足下面这些条件:
+
+- **高性能**:获取和释放锁的操作应该快速完成,并且不应该对整个系统的性能造成过大影响。
+- **非阻塞**:如果获取不到锁,不能无限期等待,避免对系统正常运行造成影响。
+
+## 分布式锁的常见实现方式有哪些?
+
+常见分布式锁实现方案如下:
+
+- 基于关系型数据库比如 MySQL 实现分布式锁。
+- 基于分布式协调服务 ZooKeeper 实现分布式锁。
+- 基于分布式键值存储系统比如 Redis 、Etcd 实现分布式锁。
+
+关系型数据库的方式一般是通过唯一索引或者排他锁实现。不过,一般不会使用这种方式,问题太多比如性能太差、不具备锁失效机制。
+
+基于 ZooKeeper 或者 Redis 实现分布式锁这两种实现方式要用的更多一些,我专门写了一篇文章来详细介绍这两种方案:[分布式锁常见实现方案总结](./distributed-lock-implementations.md)。
+
+## 总结
+
+这篇文章我们主要介绍了:
+
+- 分布式锁的用途:分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。
+- 分布式锁的应该具备的条件:互斥、高可用、可重入、高性能、非阻塞。
+- 分布式锁的常见实现方式:关系型数据库比如 MySQL、分布式协调服务 ZooKeeper、分布式键值存储系统比如 Redis 、Etcd 。
+
+
+
diff --git a/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.en.md b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.en.md
new file mode 100644
index 00000000000..33a12bb2026
--- /dev/null
+++ b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-in-action.en.md
@@ -0,0 +1,296 @@
+---
+title: ZooKeeper in action
+category: distributed
+tag:
+ - ZooKeeper
+---
+
+This article briefly demonstrates the use of common ZooKeeper commands and the basic use of ZooKeeper Java client Curator. The contents introduced are all the most basic operations, which can meet the basic needs of daily work.
+
+If there is anything that needs to be improved or perfected in the article, please point it out in the comment area and make progress together!
+
+## ZooKeeper installation
+
+### Install zookeeper using Docker
+
+**a. Download ZooKeeper using Docker**
+
+```shell
+docker pull zookeeper:3.5.8
+```
+
+**b.Run ZooKeeper**
+
+```shell
+docker run -d --name zookeeper -p 2181:2181 zookeeper:3.5.8
+```
+
+### Connect to ZooKeeper service
+
+**a. Enter the ZooKeeper container**
+
+First use `docker ps` to view the ContainerID of ZooKeeper, and then use the `docker exec -it ContainerID /bin/bash` command to enter the container.
+
+**b. First enter the bin directory, and then connect to the ZooKeeper service through the `./zkCli.sh -server 127.0.0.1:2181` command**
+
+```bash
+root@eaf70fc620cb:/apache-zookeeper-3.5.8-bin# cd bin
+```
+
+If you see the following information printed out successfully on the console, it means you have successfully connected to the ZooKeeper service.
+
+
+
+## ZooKeeper common command demonstration
+
+### View commonly used commands (help command)
+
+Use the `help` command to view common ZooKeeper commands
+
+### Create node (create command)
+
+The node1 node was created in the root directory through the `create` command, and the string associated with it is "node1"
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 34] create /node1 "node1"
+```
+
+The node1 node was created in the root directory through the `create` command, and the content associated with it is the number 123
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 1] create /node1/node1.1 123
+Created /node1/node1.1
+```
+
+### Update node data content (set command)
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 11] set /node1 "set node1"
+```
+
+### Get node data (get command)
+
+The `get` command can obtain the data content of the specified node and the status of the node. It can be seen that we have changed the node data content to "set node1" through the `set` command.
+
+```shell
+[zk: zookeeper(CONNECTED) 12] get -s /node1
+set node1
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x4b
+mtime = Sun Jan 20 10:41:10 CST 2019
+pZxid = 0x4a
+cversion=1
+dataVersion = 1
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 9
+numChildren = 1
+
+```
+
+### View subnodes in a directory (ls command)
+
+Use the `ls` command to view the nodes in the root directory
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 37] ls /
+[dubbo, ZooKeeper, node1]
+```
+
+Use the `ls` command to view the nodes in the node1 directory
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 5] ls /node1
+[node1.1]
+```
+
+The ls command in ZooKeeper is similar to the ls command in Linux. This command will list all child node information under the absolute path path (listing level 1, not recursively)
+
+### View node status (stat command)
+
+Check node status through `stat` command
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 10] stat /node1
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x47
+mtime = Sun Jan 20 10:22:59 CST 2019
+pZxid = 0x4a
+cversion=1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 11
+numChildren = 1
+```
+
+Some of the information displayed above, such as cversion, aclVersion, numChildren, etc., I have already introduced in the above article "[ZooKeeper Related Concept Summary (Getting Started)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html)".
+
+### View node information and status (ls2 command)
+
+The `ls2` command is more like a combination of the `ls` command and the `stat` command. The information returned by the `ls2` command includes 2 parts:
+
+1. Child node list
+2. The stat information of the current node.
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 7] ls2 /node1
+[node1.1]
+cZxid = 0x47
+ctime = Sun Jan 20 10:22:59 CST 2019
+mZxid = 0x47
+mtime = Sun Jan 20 10:22:59 CST 2019
+pZxid = 0x4a
+cversion=1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 11
+numChildren = 1
+
+```
+
+### Delete node (delete command)
+
+This command is very simple, but one thing to note is that if you want to delete a node, the node must have no child nodes.
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 3] delete /node1/node1.1
+```
+
+Later I will introduce the use of Java client API and the use of open source ZooKeeper client ZkClient and Curator.
+
+## ZooKeeper Java client Curator is easy to use
+
+Curator is a set of ZooKeeper Java client frameworks open sourced by Netflix. Compared with the client zookeeper that comes with Zookeeper, Curator's encapsulation is more complete, and various APIs can be used more conveniently.
+
+
+
+Let’s briefly demonstrate the use of Curator!
+
+Curator4.0+ version has better support for ZooKeeper 3.5.x. Before starting, please add the following dependencies to your project.
+
+```xml
+
+ org.apache.curator
+ curator-framework
+ 4.2.0
+
+
+ org.apache.curator
+ curator-recipes
+ 4.2.0
+
+```
+
+### Connect to ZooKeeper client
+
+Create a `CuratorFramework` object through `CuratorFrameworkFactory`, and then call the `start()` method of the `CuratorFramework` object!
+
+```java
+private static final int BASE_SLEEP_TIME = 1000;
+private static final int MAX_RETRIES = 3;
+
+// Retry strategy. Retry 3 times, and will increase the sleep time between retries.
+RetryPolicy retryPolicy = new ExponentialBackoffRetry(BASE_SLEEP_TIME, MAX_RETRIES);
+CuratorFramework zkClient = CuratorFrameworkFactory.builder()
+ // the server to connect to (can be a server list)
+ .connectString("127.0.0.1:2181")
+ .retryPolicy(retryPolicy)
+ .build();
+zkClient.start();```
+
+Description of some basic parameters:
+
+- `baseSleepTimeMs`: initial time to wait between retries
+- `maxRetries`: Maximum number of retries
+- `connectString`: list of servers to connect to
+- `retryPolicy`: retry policy
+
+### Add, delete, modify and query data nodes
+
+#### Create node
+
+We introduced in [ZooKeeper Common Concepts Interpretation](./zookeeper-intro.md) that we usually divide znode into 4 major categories:
+
+- **persistent (PERSISTENT) node**: Once created, it will always exist even if the ZooKeeper cluster goes down, until it is deleted.
+- **Temporary (EPHEMERAL) node**: The life cycle of the temporary node is bound to the **client session (session)**. **The node disappears when the session disappears**. Moreover, temporary nodes **can only be used as leaf nodes** and cannot create child nodes.
+- **Persistent Sequence (PERSISTENT_SEQUENTIAL) node**: In addition to the characteristics of the persistent (PERSISTENT) node, the names of child nodes are also sequential. For example `/node1/app0000000001`, `/node1/app0000000002`.
+- **Temporary Sequential (EPHEMERAL_SEQUENTIAL) Node**: In addition to having the characteristics of temporary (EPHEMERAL) nodes, the names of child nodes are also sequential.
+
+When you use ZooKeeper, you will find that there are actually 7 znode types in the `CreateMode` class, but the 4 types introduced above are the most used.
+
+**a.Create persistence node**
+
+You can create persistent nodes in the following two ways.
+
+```java
+//Note: The following code will report an error. The specific reasons are explained below.
+zkClient.create().forPath("/node1/00001");
+zkClient.create().withMode(CreateMode.PERSISTENT).forPath("/node1/00002");
+```
+
+However, you will get an error when you run the above code. This is because the parent node `node1` has not been created yet.
+
+You can create the parent node `node1` first, and then execute the above code without error.
+
+```java
+zkClient.create().forPath("/node1");
+```
+
+The more recommended way is to use the following line of code, **`creatingParentsIfNeeded()` can ensure that the parent node is automatically created when the parent node does not exist, which is very useful. **
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/node1/00001");
+```
+
+**b. Create temporary nodes**
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001");
+```
+
+**c. Create nodes and specify data content**
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001","java".getBytes());
+zkClient.getData().forPath("/node1/00001");//Get the data content of the node, and get the byte array
+```
+
+**d. Check whether the node is created successfully**
+
+```java
+zkClient.checkExists().forPath("/node1/00001");//If it is not null, it means the node was created successfully
+```
+
+#### Delete node
+
+**a.Delete a child node**
+
+```java
+zkClient.delete().forPath("/node1/00001");
+```
+
+**b. Delete a node and all its child nodes**
+
+```java
+zkClient.delete().deletingChildrenIfNeeded().forPath("/node1");
+```
+
+#### Get/update node data content
+
+```java
+zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001","java".getBytes());
+zkClient.getData().forPath("/node1/00001");//Get the data content of the node
+zkClient.setData().forPath("/node1/00001","c++".getBytes());//Update node data content
+```
+
+#### Get the paths of all child nodes of a node
+
+```java
+List childrenPaths = zkClient.getChildren().forPath("/node1");
+```
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.en.md b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.en.md
new file mode 100644
index 00000000000..49c08efc404
--- /dev/null
+++ b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.en.md
@@ -0,0 +1,314 @@
+---
+title: ZooKeeper相关概念总结(入门)
+category: 分布式
+tag:
+ - ZooKeeper
+---
+
+相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 到底有啥用不?如果别人/面试官让你给他讲讲对于 ZooKeeper 的认识,你能回答到什么地步呢?
+
+拿我自己来说吧!我本人在大学曾经使用 Dubbo 来做分布式项目的时候,使用了 ZooKeeper 作为注册中心。为了保证分布式系统能够同步访问某个资源,我还使用 ZooKeeper 做过分布式锁。另外,我在学习 Kafka 的时候,知道 Kafka 很多功能的实现依赖了 ZooKeeper。
+
+前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西?想了半天,脑海中只是简单的能浮现出几句话:
+
+1. ZooKeeper 可以被用作注册中心、分布式锁;
+2. ZooKeeper 是 Hadoop 生态系统的一员;
+3. 构建 ZooKeeper 集群的时候,使用的服务器最好是奇数台。
+
+由此可见,我对于 ZooKeeper 的理解仅仅是停留在了表面。
+
+所以,通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。如果没有学过 ZooKeeper ,那么本文将会是你进入 ZooKeeper 大门的垫脚砖。如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。
+
+另外,本文不光会涉及到 ZooKeeper 的一些概念,后面的文章会介绍到 ZooKeeper 常见命令的使用以及使用 Apache Curator 作为 ZooKeeper 的客户端。
+
+_如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!_
+
+## ZooKeeper 介绍
+
+### ZooKeeper 由来
+
+正式介绍 ZooKeeper 之前,我们先来看看 ZooKeeper 的由来,还挺有意思的。
+
+下面这段内容摘自《从 Paxos 到 ZooKeeper》第四章第一节,推荐大家阅读一下:
+
+> ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。
+>
+> 关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的 Pig 项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家 RaghuRamakrishnan 开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而 ZooKeeper 正好要用来进行分布式环境的协调一一于是,ZooKeeper 的名字也就由此诞生了。
+
+### ZooKeeper 概览
+
+ZooKeeper 是一个开源的**分布式协调服务**,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
+
+> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性,即原语的执行必须是连续的,在执行过程中不允许被中断。
+
+ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。这些功能的实现主要依赖于 ZooKeeper 提供的 **数据存储+事件监听** 功能(后文会详细介绍到) 。
+
+ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景)。
+
+另外,很多顶级的开源项目都用到了 ZooKeeper,比如:
+
+- **Kafka** : ZooKeeper 主要为 Kafka 提供 Broker 和 Topic 的注册以及多个 Partition 的负载均衡等功能。不过,在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式,不再依赖 Zookeeper,大大简化了 Kafka 的架构。
+- **Hbase** : ZooKeeper 为 Hbase 提供确保整个集群只有一个 Master 以及保存和提供 regionserver 状态信息(是否在线)等功能。
+- **Hadoop** : ZooKeeper 为 Namenode 提供高可用支持。
+
+### ZooKeeper 特点
+
+- **顺序一致性:** 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
+- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
+- **单一系统映像:** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
+- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
+- **实时性:** 一旦数据发生变更,其他节点会实时感知到。每个客户端的系统视图都是最新的。
+- **集群部署**:3~5 台(最好奇数台)机器就可以组成一个集群,每台机器都在内存保存了 ZooKeeper 的全部数据,机器之间互相通信同步数据,客户端连接任何一台机器都可以。
+- **高可用:**如果某台机器宕机,会保证数据不丢失。集群中挂掉不超过一半的机器,都能保证集群可用。比如 3 台机器可以挂 1 台,5 台机器可以挂 2 台。
+
+### ZooKeeper 应用场景
+
+ZooKeeper 概览中,我们介绍到使用其通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
+
+下面选 3 个典型的应用场景来专门说说:
+
+1. **命名服务**:可以通过 ZooKeeper 的顺序节点生成全局唯一 ID。
+2. **数据发布/订阅**:通过 **Watcher 机制** 可以很方便地实现数据发布/订阅。当你将数据发布到 ZooKeeper 被监听的节点上,其他机器可通过监听 ZooKeeper 上节点的变化来实现配置的动态更新。
+3. **分布式锁**:通过创建唯一节点获得分布式锁,当获得锁的一方执行完相关代码或者是挂掉之后就释放锁。分布式锁的实现也需要用到 **Watcher 机制** ,我在 [分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 这篇文章中有详细介绍到如何基于 ZooKeeper 实现分布式锁。
+
+实际上,这些功能的实现基本都得益于 ZooKeeper 可以保存数据的功能,但是 ZooKeeper 不适合保存大量数据,这一点需要注意。
+
+## ZooKeeper 重要概念
+
+_破音:拿出小本本,下面的内容非常重要哦!_
+
+### Data model(数据模型)
+
+ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二进制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
+
+强调一句:**ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的每个节点的数据大小上限是 1M 。**
+
+从下图可以更直观地看出:ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
+
+
+
+### znode(数据节点)
+
+介绍了 ZooKeeper 树形数据模型之后,我们知道每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。你要存放的数据就放在上面,是你使用 ZooKeeper 过程中经常需要接触到的一个概念。
+
+我们通常是将 znode 分为 4 大类:
+
+- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
+- **Temporary (EPHEMERAL) node**: The life cycle of the temporary node is bound to the **client session (session)**. **When the session disappears, the node disappears**. Moreover, **temporary nodes can only be used as leaf nodes** and cannot create child nodes.
+- **Persistent Sequence (PERSISTENT_SEQUENTIAL) node**: In addition to the characteristics of the persistent (PERSISTENT) node, the names of child nodes are also sequential. For example `/node1/app0000000001`, `/node1/app0000000002`.
+- **Temporary Sequential (EPHEMERAL_SEQUENTIAL) Node**: In addition to having the characteristics of temporary (EPHEMERAL) nodes, the names of child nodes also have sequential properties.
+
+Each znode consists of 2 parts:
+
+- **stat**: status information
+- **data**: The specific content of the data stored in the node
+
+As shown below, I use the get command to obtain the contents of the dubbo node in the root directory. (The get command will be introduced below).
+
+```shell
+[zk: 127.0.0.1:2181(CONNECTED) 6] get /dubbo
+#The data content associated with this data node is empty
+null
+#The following is some status information of the data node, which is actually the formatted output of the Stat object.
+cZxid = 0x2
+ctime = Tue Nov 27 11:05:34 CST 2018
+mZxid = 0x2
+mtime = Tue Nov 27 11:05:34 CST 2018
+pZxid = 0x3
+cversion=1
+dataVersion = 0
+aclVersion = 0
+ephemeralOwner = 0x0
+dataLength = 0
+numChildren = 1
+```
+
+The Stat class contains fields for all status information of a data node, including transaction ID (cZxid), node creation time (ctime), number of child nodes (numChildren), etc.
+
+Let’s take a look at what each znode status information actually represents! (The following content comes from "From Paxos to ZooKeeper Distributed Consistency Principles and Practices", because the Guide is indeed not particularly clear, so you need to learn the reference materials!):
+
+| znode status information | explanation |
+| -------------- | ------------------------------------------------------------------------------------------------------------------ |
+| cZxid | create ZXID, which is the transaction id when the data node was created |
+| ctime | create time, that is, the creation time of the node |
+| mZxid | modified ZXID, which is the transaction id when the node was last updated |
+| mtime | modified time, which is the last update time of the node |
+| pZxid | The transaction id when the node's child node list was last modified. Only changes in the child node list will update pZxid, and changes in the child node content will not be updated |
+| cversion | The version number of the child node, the value increases by 1 every time the child node of the current node changes |
+| dataVersion | Data node content version number. It is 0 when the node is created. Every time the node content is updated (regardless of whether the content changes or not), the value of the version number increases by 1 |
+| aclVersion | The ACL version number of the node, indicating the number of changes to the ACL information of the node |
+| ephemeralOwner | sessionId of the session that created this temporary node; if the current node is a persistent node, ephemeralOwner=0 |
+| dataLength | Data node content length |
+| numChildren | The number of child nodes of the current node |
+
+### Version
+
+As we mentioned before, corresponding to each znode, ZooKeeper will maintain a data structure called **Stat** for it. Stat records three related versions of this znode:
+
+- **dataVersion**: The version number of the current znode node
+- **cversion**: The version of the current znode child node
+- **aclVersion**: The version of the ACL of the current znode.
+
+### ACL (Authority Control)
+
+ZooKeeper uses the ACL (AccessControlLists) policy for permission control, which is similar to the permission control of UNIX file systems.
+
+For znode operation permissions, ZooKeeper provides the following 5 types:
+
+- **CREATE** : Can create child nodes
+- **READ**: Can obtain node data and list its child nodes
+- **WRITE** : Can set/update node data
+- **DELETE** : can delete child nodes
+- **ADMIN**: Permission to set node ACL
+
+What needs special attention is that both **CREATE** and **DELETE** are permission controls for **child nodes**.
+
+For identity authentication, the following methods are provided:
+
+- **world**: Default mode, all users can access unconditionally.
+- **auth**: does not use any id, represents any authenticated user.
+- **digest** :username:password authentication method: _username:password_.
+- **ip**: Restrict the specified IP.
+
+### Watcher (event listener)
+
+Watcher (event listener) is a very important feature in ZooKeeper. ZooKeeper allows users to register some Watchers on designated nodes, and when certain events are triggered, the ZooKeeper server will notify interested clients of the event. This mechanism is an important feature of ZooKeeper in implementing distributed coordination services.
+
+
+
+_Poyin: A very useful feature. I took out a small notebook and memorized it. The Watcher (event listener) mechanism is basically inseparable from ZooKeeper when used later. _
+
+### Session
+
+Session can be regarded as a long TCP connection between the ZooKeeper server and the client. Through this connection, the client can maintain a valid session with the server through heartbeat detection, and can also send requests to the ZooKeeper server and receive responses. It can also receive Watcher event notifications from the server through this connection.
+
+Session has a property called: `sessionTimeout`, `sessionTimeout` represents the session timeout. When the client connection is disconnected due to various reasons such as excessive server pressure, network failure, or the client actively disconnects, as long as any server in the cluster can be reconnected within the time specified by `sessionTimeout`, the previously created session will still be valid.
+
+In addition, before creating a session for a client, the server first assigns a `sessionID` to each client. Since `sessionID` is an important identifier of a ZooKeeper session, many session-related operating mechanisms are based on this `sessionID`. Therefore, no matter which server assigns `sessionID` to the client, it must be globally unique.
+
+## ZooKeeper cluster
+
+In order to ensure high availability, it is best to deploy ZooKeeper in a cluster form, so that as long as most of the machines in the cluster are available (can tolerate certain machine failures), ZooKeeper itself will still be available. Usually 3 servers can form a ZooKeeper cluster. The architecture diagram officially provided by ZooKeeper is a ZooKeeper cluster that provides services to the outside world as a whole.
+
+上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
+
+**最典型集群模式:Master/Slave 模式(主备模式)**。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
+
+### ZooKeeper 集群角色
+
+但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示
+
+
+
+ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定一台称为 “**Leader**” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,**Follower** 和 **Observer** 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
+
+| 角色 | 说明 |
+| -------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
+| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
+| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
+
+### ZooKeeper 集群 Leader 选举过程
+
+当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
+
+这个过程大致是这样的:
+
+1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
+2. **Discovery(发现阶段)**:在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
+3. **Synchronization(同步阶段)**:同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
+4. **Broadcast(广播阶段)**:到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
+
+ZooKeeper 集群中的服务器状态有下面几种:
+
+- **LOOKING**:寻找 Leader。
+- **LEADING**:Leader 状态,对应的节点为 Leader。
+- **FOLLOWING**:Follower 状态,对应的节点为 Follower。
+- **OBSERVING**:Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
+
+### ZooKeeper 集群为啥最好奇数台?
+
+ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
+
+比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。
+假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
+
+综上,何必增加那一个不必要的 ZooKeeper 呢?
+
+### ZooKeeper 选举的过半机制防止脑裂
+
+**何为集群脑裂?**
+
+对于一个集群,通常多台机器会部署在不同机房,来提高这个集群的可用性。保证可用性的同时,会发生一种机房间网络线路故障,导致机房间网络不通,而集群被割裂成几个小集群。这时候子集群各自选主导致“脑裂”的情况。
+
+举例说明:比如现在有一个由 6 台服务器所组成的一个集群,部署在了 2 个机房,每个机房 3 台。正常情况下只有 1 个 leader,但是当两个机房中间网络断开的时候,每个机房的 3 台服务器都会认为另一个机房的 3 台服务器下线,而选出自己的 leader 并对外提供服务。若没有过半机制,当网络恢复的时候会发现有 2 个 leader。仿佛是 1 个大脑(leader)分散成了 2 个大脑,这就发生了脑裂现象。脑裂期间 2 个大脑都可能对外提供了服务,这将会带来数据一致性等问题。
+
+**过半机制是如何防止脑裂现象产生的?**
+
+ZooKeeper 的过半机制导致不可能产生 2 个 leader,因为少于等于一半是不可能产生 leader 的,这就使得不论机房的机器如何分配都不可能发生脑裂。
+
+## ZAB 协议和 Paxos 算法
+
+Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos 算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在 ZooKeeper 的官方文档中也指出,ZAB 协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为 Zookeeper 设计的崩溃可恢复的原子消息广播算法。
+
+### ZAB 协议介绍
+
+ZAB(ZooKeeper Atomic Broadcast,原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
+
+### ZAB 协议两种基本的模式:崩溃恢复和消息广播
+
+ZAB 协议包括两种基本的模式,分别是
+
+- **崩溃恢复**:当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入恢复模式并选举产生新的 Leader 服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该 Leader 服务器完成了状态同步之后,ZAB 协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和 Leader 服务器的数据状态保持一致**。
+- **Message Broadcast**:** When more than half of the Follower servers in the cluster have completed the status synchronization with the Leader server, then the entire service framework can enter the message broadcast mode. ** When a server that also complies with the ZAB protocol joins the cluster after being started, if there is already a Leader server in the cluster responsible for message broadcast, then the newly added server will consciously enter the data recovery mode: find the server where the Leader is located, synchronize data with it, and then participate in the message broadcast process together.
+
+### ZAB Protocol & Paxos Algorithm Article Recommendations
+
+There are too many things that need to be talked about and understood about **ZAB protocol & Paxos algorithm**. For details, you can read the following articles:
+
+- [Detailed explanation of Paxos algorithm](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
+- [ZooKeeper and Zab Protocol · Analyze](https://wingsxdu.com/posts/database/zookeeper/)
+- [Detailed explanation of Raft algorithm](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
+
+## ZooKeeper VS ETCD
+
+[ETCD](https://etcd.io/) is a strongly consistent distributed key-value store that provides a reliable way to store data that needs to be accessed by a distributed system or machine cluster. ETCD internally uses [Raft algorithm](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html) as the consistency algorithm, which is implemented based on Go language.
+
+Similar to ZooKeeper, ETCD can also be used in data publishing/subscription, load balancing, naming services, distributed coordination/notification, distributed locks and other scenarios. So how to choose between the two?
+
+This article by Dewu Technology [A brief analysis of how to implement high-availability architecture based on ZooKeeper] (https://mp.weixin.qq.com/s/pBI3rjv5NdS1124Z7HQ-JA) provides the following comparison table (I have further optimized it), which can be used as a reference:
+
+| | ZooKeeper | ETCD |
+|---------------- |-------------------------------------------------------------------------------- | ------------------------------------------------------------------ |
+| **Language** | Java | Go |
+| **Protocol** | TCP | Grpc |
+| **Interface Call** | You must use your own client to call | Can be transmitted through HTTP, you can call it through commands such as CURL |
+| **Consensus Algorithm** | Zab Protocol | Raft Algorithm |
+| **Watcher mechanism** | Limited, one-time trigger | One Watch can monitor all events |
+| **Data model** | Directory-based hierarchical model | Refers to zk's data model, which is a flat kv model |
+| **Storage** | kv storage, using ConcurrentHashMap, memory storage, generally not recommended to store large amounts of data | kv storage, using the bbolt storage engine, can handle several GB of data. |
+| **MVCC** | Not supported | Supported, version control through two B+ Trees |
+| **Global Session** | Defects | Implementation is more flexible and avoids security issues |
+| **Permission Verification** | ACL | RBAC |
+| **Transaction Capability** | Provides simple transaction capabilities | Only provides version number checking capabilities |
+| **Deployment and Maintenance** | Complex | Simple |
+
+ZooKeeper has certain limitations in storage performance, global Session, Watcher mechanism, etc. More and more open source projects are replacing ZooKeeper with Raft implementation or other distributed coordination services, such as: [Kafka Needs No Keeper - Removing ZooKeeper Dependency (confluent.io)](https://www.confluent.io/blog/removing-zookeeper-dependency-in-kafka/), [Moving Toward a ZooKeeper-Less Apache Pulsar (streamnative.io)](https://streamnative.io/blog/moving-toward-zookeeper-less-apache-pulsar).
+
+ETCD is relatively better, providing more stable high-load reading and writing capabilities, and improving and optimizing many problems exposed by ZooKeeper. Moreover, ETCD can basically cover all application scenarios of ZooKeeper and replace it.
+
+## Summary
+
+1. ZooKeeper itself is a distributed program (as long as more than half of the nodes survive, ZooKeeper can serve normally).
+2. In order to ensure high availability, it is best to deploy ZooKeeper in a cluster form. In this way, as long as most of the machines in the cluster are available (can tolerate certain machine failures), ZooKeeper itself will still be available.
+3. ZooKeeper stores data in memory, which ensures high throughput and low latency (however, the memory limits the amount of data that can be stored, and this limitation is also a further reason to keep the amount of data stored in znodes small).
+4. ZooKeeper is high performance. This is especially true in applications where there are more reads than writes, since the writes cause all inter-server states to be synchronized. (More "reads" than "writes" are a typical scenario for coordinating services.)
+5. ZooKeeper has the concept of temporary nodes. Transient nodes exist as long as the client session that created the transient node remains active. When the session ends, the transient node is deleted. A persistent node means that once the znode is created, the znode will always be saved on ZooKeeper unless the znode is actively removed.
+6. The bottom layer of ZooKeeper actually only provides two functions: ① manage (storage, read) data submitted by user programs; ② provide data node monitoring services for user programs.
+
+## Reference
+
+- "Principles and Practices of Distributed Consistency from Paxos to ZooKeeper"
+- Talk about the limitations of ZooKeeper:
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.en.md b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.en.md
new file mode 100644
index 00000000000..70708cac863
--- /dev/null
+++ b/docs_en/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.en.md
@@ -0,0 +1,387 @@
+---
+title: ZooKeeper相关概念总结(进阶)
+category: 分布式
+tag:
+ - ZooKeeper
+---
+
+> [FrancisQ](https://juejin.im/user/5c33853851882525ea106810) 投稿。
+
+## 什么是 ZooKeeper
+
+`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理等。
+
+简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
+
+其实解释到分布式这个概念的时候,我发现有些同学并不是能把 **分布式和集群** 这两个概念很好的理解透。前段时间有同学和我探讨起分布式的东西,他说分布式不就是加机器吗?一台机器不够用再加一台抗压呗。当然加机器这种说法也无可厚非,你一个分布式系统必定涉及到多个机器,但是你别忘了,计算机学科中还有一个相似的概念—— `Cluster` ,集群不也是加机器吗?但是 集群 和 分布式 其实就是两个完全不同的概念。
+
+比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 **一样** 提供秒杀服务,这个时候就是 **`Cluster` 集群** 。
+
+
+
+但是,我现在换一种方式,我将一个秒杀服务 **拆分成多个子服务** ,比如创建订单服务,增加积分服务,扣优惠券服务等等,**然后我将这些子服务都部署在不同的服务器上** ,这个时候就是 **`Distributed` 分布式** 。
+
+
+
+而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。
+
+
+
+比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。`ZooKeeper` 主要就是解决这些问题的。
+
+## 一致性问题
+
+设计一个分布式系统必定会遇到一个问题—— **因为分区容忍性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡** 。这就是著名的 `CAP` 定理。
+
+理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
+
+
+
+而上述前者就是 `Eureka` 的处理方式,它保证了 AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了 CP(数据一致性)。
+
+## 一致性协议和算法
+
+而为了解决数据一致性问题,在科学家和程序员的不断探索中,就出现了很多的一致性协议和算法。比如 2PC(两阶段提交),3PC(三阶段提交),Paxos 算法等等。
+
+这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
+
+
+
+这个时候就引申出一个概念—— **拜占庭将军问题** 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
+
+而为什么要去解决数据一致性的问题?你想想,如果一个秒杀系统将服务拆分成了下订单和加积分服务,这两个服务部署在不同的机器上了,万一在消息的传播过程中积分系统宕机了,总不能你这边下了订单却没加积分吧?你总得保证两边的数据需要一致吧?
+
+### 2PC(两阶段提交)
+
+两阶段提交是一种保证分布式系统数据一致性的协议,现在很多数据库都是采用的两阶段提交协议来完成 **分布式事务** 的处理。
+
+在介绍 2PC 之前,我们先来想想分布式事务到底有什么问题呢?
+
+还拿秒杀系统的下订单和加积分两个系统来举例吧(我想你们可能都吐了 🤮🤮🤮),我们此时下完订单会发个消息给积分系统告诉它下面该增加积分了。如果我们仅仅是发送一个消息也不收回复,那么我们的订单系统怎么能知道积分系统的收到消息的情况呢?如果我们增加一个收回复的过程,那么当积分系统收到消息后返回给订单系统一个 `Response` ,但在中间出现了网络波动,那个回复消息没有发送成功,订单系统是不是以为积分系统消息接收失败了?它是不是会回滚事务?但此时积分系统是成功收到消息的,它就会去处理消息然后给用户增加积分,这个时候就会出现积分加了但是订单没下成功。
+
+所以我们所需要解决的是在分布式系统中,整个调用链中,我们所有服务的数据处理要么都成功要么都失败,即所有服务的 **原子性问题** 。
+
+在两阶段提交中,主要涉及到两个角色,分别是协调者和参与者。
+
+第一阶段:当要执行一个分布式事务的时候,事务发起者首先向协调者发起事务请求,然后协调者会给所有参与者发送 `prepare` 请求(其中包括事务内容)告诉参与者你们需要执行事务了,如果能执行我发的事务内容那么就先执行但不提交,执行后请给我回复。然后参与者收到 `prepare` 消息后,他们会开始执行事务(但不提交),并将 `Undo` 和 `Redo` 信息记入事务日志中,之后参与者就向协调者反馈是否准备好了。
+
+第二阶段:第二阶段主要是协调者根据参与者反馈的情况来决定接下来是否可以进行事务的提交操作,即提交事务或者回滚事务。
+
+比如这个时候 **所有的参与者** 都返回了准备好了的消息,这个时候就进行事务的提交,协调者此时会给所有的参与者发送 **`Commit` 请求** ,当参与者收到 `Commit` 请求的时候会执行前面执行的事务的 **提交操作** ,提交完毕之后将给协调者发送提交成功的响应。
+
+而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 **回滚事务的 `rollback` 请求**,参与者收到之后将会 **回滚它在第一阶段所做的事务处理** ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
+
+
+
+个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
+
+
+
+- **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
+- **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
+- **数据不一致问题**,比如当第二阶段,协调者只发送了一部分的 `commit` 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
+
+### 3PC(三阶段提交)
+
+因为 2PC 存在的一系列问题,比如单点,容错机制缺陷等等,从而产生了 **3PC(三阶段提交)** 。那么这三阶段又分别是什么呢?
+
+> 千万不要吧 PC 理解成个人电脑了,其实他们是 phase-commit 的缩写,即阶段提交。
+
+1. **CanCommit 阶段**:协调者向所有参与者发送 `CanCommit` 请求,参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。
+2. **PreCommit 阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
+3. **DoCommit 阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
+
+
+
+> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内未收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
+
+总之,`3PC` 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 `DoCommit` 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
+
+所以,要解决一致性问题还需要靠 `Paxos` 算法 ⭐️ ⭐️ ⭐️ 。
+
+### `Paxos` 算法
+
+`Paxos` 算法是基于**消息传递且具有高度容错特性的一致性算法**,是目前公认的解决分布式一致性问题最有效的算法之一,**其解决的问题就是在分布式系统中如何就某个值(决议)达成一致** 。
+
+在 `Paxos` 中主要有三个角色,分别为 `Proposer提案者`、`Acceptor表决者`、`Learner学习者`。`Paxos` 算法和 `2PC` 一样,也有两个阶段,分别为 `Prepare` 和 `accept` 阶段。
+
+#### prepare 阶段
+
+- `Proposer提案者`:负责提出 `proposal`,每个提案者在提出提案时都会首先获取到一个 **具有全局唯一性的、递增的提案编号 N**,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在**第一阶段是只将提案编号发送给所有的表决者**。
+- `Acceptor表决者`:每个表决者在 `accept` 某提案后,会将该提案编号 N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个**编号最大的提案**,其编号假设为 `maxN`。每个表决者仅会 `accept` 编号大于自己本地 `maxN` 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 `Proposer` 。
+
+> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
+
+
+
+#### accept 阶段
+
+当一个提案被 `Proposer` 提出后,如果 `Proposer` 收到了超过半数的 `Acceptor` 的批准(`Proposer` 本身同意),那么此时 `Proposer` 会给所有的 `Acceptor` 发送真正的提案(你可以理解为第一阶段为试探),这个时候 `Proposer` 就会发送提案的内容和提案编号。
+
+表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 `accept` 该提案(此时执行提案内容但不提交),随后将情况返回给 `Proposer` 。如果不满足则不回应或者返回 NO 。
+
+
+
+当 `Proposer` 收到超过半数的 `accept` ,那么它这个时候会向所有的 `acceptor` 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 `acceptor` 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**,而对于前面已经批准过该提案的 `acceptor` 来说 **仅仅需要发送该提案的编号** ,让 `acceptor` 执行提交就行了。
+
+
+
+而如果 `Proposer` 如果没有收到超过半数的 `accept` 那么它将会将 **递增** 该 `Proposal` 的编号,然后 **重新进入 `Prepare` 阶段** 。
+
+> 对于 `Learner` 来说如何去学习 `Acceptor` 批准的提案内容,这有很多方式,读者可以自己去了解一下,这里不做过多解释。
+
+#### paxos 算法的死循环问题
+
+其实就有点类似于两个人吵架,小明说我是对的,小红说我才是对的,两个人据理力争的谁也不让谁 🤬🤬。
+
+比如说,此时提案者 P1 提出一个方案 M1,完成了 `Prepare` 阶段的工作,这个时候 `acceptor` 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 `Prepare` 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 `acceptor` 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 `Prepare` 阶段,然后 `acceptor` ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 `Prepare` 阶段。。。
+
+就这样无休无止的永远提案下去,这就是 `paxos` 算法的死循环问题。
+
+
+
+那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
+
+## 引出 ZAB
+
+### Zookeeper 架构
+
+作为一个优秀高效且可靠的分布式协调框架,`ZooKeeper` 在解决分布式数据一致性问题时并没有直接使用 `Paxos` ,而是专门定制了一致性协议叫做 `ZAB(ZooKeeper Atomic Broadcast)` 原子广播协议,该协议能够很好地支持 **崩溃恢复** 。
+
+
+
+### ZAB 中的三个角色
+
+和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
+
+- `Leader`:集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
+- `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
+- `Observer`:就是没有选举权和被选举权的 `Follower` 。
+
+在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
+
+### 消息广播模式
+
+说白了就是 `ZAB` 协议是如何处理写请求的,上面我们不是说只有 `Leader` 能处理写请求嘛?那么我们的 `Follower` 和 `Observer` 是不是也需要 **同步更新数据** 呢?总不能数据只在 `Leader` 中更新了,其他角色都没有得到更新吧?
+
+不就是 **在整个集群中保持数据的一致性** 嘛?如果是你,你会怎么做呢?
+
+废话,第一步肯定需要 `Leader` 将写请求 **广播** 出去呀,让 `Leader` 问问 `Followers` 是否同意更新,如果超过半数以上的同意那么就进行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一样)。当然这么说有点虚,画张图理解一下。
+
+
+
+嗯。。。看起来很简单,貌似懂了 🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求 A,此时 `Leader` 将请求 A 广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1 因为网络原因没有收到,而 `Leader` 又广播了一个请求 B,因为网络原因,F1 竟然先收到了请求 B 然后才收到了请求 A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
+
+所以在 `Leader` 这端,它为每个其他的 `zkServer` 准备了一个 **队列** ,采用先进先出的方式发送消息。由于协议是 **通过 `TCP`** 来进行网络通信的,保证了消息的发送顺序性,接受顺序性也得到了保证。
+
+除此之外,在 `ZAB` 中还定义了一个 **全局单调递增的事务 ID `ZXID`** ,它是一个 64 位 long 型,其中高 32 位表示 `epoch` 年代,低 32 位表示事务 id。`epoch` 是会根据 `Leader` 的变化而变化的,当一个 `Leader` 挂了,新的 `Leader` 上位的时候,年代(`epoch`)就变了。而低 32 位可以简单理解为递增的事务 id。
+
+定义这个的原因也是为了顺序性,每个 `proposal` 在 `Leader` 中生成后需要 **通过其 `ZXID` 来进行排序** ,才能得到处理。
+
+### 崩溃恢复模式
+
+说到崩溃恢复我们首先要提到 `ZAB` 中的 `Leader` 选举算法,当系统出现崩溃影响最大应该是 `Leader` 的崩溃,因为我们只有一个 `Leader` ,所以当 `Leader` 出现问题的时候我们势必需要重新选举 `Leader` 。
+
+`Leader` 选举可以分为两个不同的阶段,第一个是我们提到的 `Leader` 宕机需要重新选举,第二则是当 `Zookeeper` 启动时需要进行系统的 `Leader` 初始化选举。下面我先来介绍一下 `ZAB` 是如何进行初始化选举的。
+
+假设我们集群中有 3 台机器,那也就意味着我们需要两台以上同意(超过半数)。比如这个时候我们启动了 `server1` ,它会首先 **投票给自己** ,投票内容为服务器的 `myid` 和 `ZXID` ,因为初始化所以 `ZXID` 都为 0,此时 `server1` 发出的投票为 (1,0)。但此时 `server1` 的投票仅为 1,所以不能作为 `Leader` ,此时还在选举阶段所以整个集群处于 **`Looking` 状态**。
+
+接着 `server2` 启动了,它首先也会将投票选给自己(2,0),并将投票信息广播出去(`server1`也会,只是它那时没有其他的服务器了),`server1` 在收到 `server2` 的投票信息后会将投票信息与自己的作比较。**首先它会比较 `ZXID` ,`ZXID` 大的优先为 `Leader`,如果相同则比较 `myid`,`myid` 大的优先作为 `Leader`**。所以此时`server1` 发现 `server2` 更适合做 `Leader`,它就会将自己的投票信息更改为(2,0)然后再广播出去,之后`server2` 收到之后发现和自己的一样无需做更改,并且自己的 **投票已经超过半数** ,则 **确定 `server2` 为 `Leader`**,`server1` 也会将自己服务器设置为 `Following` 变为 `Follower`。整个服务器就从 `Looking` 变为了正常状态。
+
+当 `server3` 启动发现集群没有处于 `Looking` 状态时,它会直接以 `Follower` 的身份加入集群。
+
+还是前面三个 `server` 的例子,如果在整个集群运行的过程中 `server2` 挂了,那么整个集群会如何重新选举 `Leader` 呢?其实和初始化选举差不多。
+
+首先毫无疑问的是剩下的两个 `Follower` 会将自己的状态 **从 `Following` 变为 `Looking` 状态** ,然后每个 `server` 会向初始化投票一样首先给自己投票(这不过这里的 `zxid` 可能不是 0 了,这里为了方便随便取个数字)。
+
+假设 `server1` 给自己投票为(1,99),然后广播给其他 `server`,`server3` 首先也会给自己投票(3,95),然后也广播给其他 `server`。`server1` 和 `server3` 此时会收到彼此的投票信息,和一开始选举一样,他们也会比较自己的投票和收到的投票(`zxid` 大的优先,如果相同那么就 `myid` 大的优先)。这个时候 `server1` 收到了 `server3` 的投票发现没自己的合适故不变,`server3` 收到 `server1` 的投票结果后发现比自己的合适于是更改投票为(1,99)然后广播出去,最后 `server1` 收到了发现自己的投票已经超过半数就把自己设为 `Leader`,`server3` 也随之变为 `Follower`。
+
+> 请注意 `ZooKeeper` 为什么要设置奇数个结点?比如这里我们是三个,挂了一个我们还能正常工作,挂了两个我们就不能正常工作了(已经没有超过半数的节点数了,所以无法进行投票等操作了)。而假设我们现在有四个,挂了一个也能工作,**但是挂了两个也不能正常工作了**,这是和三个一样的,而三个比四个还少一个,带来的效益是一样的,所以 `Zookeeper` 推荐奇数个 `server` 。
+
+那么说完了 `ZAB` 中的 `Leader` 选举方式之后我们再来了解一下 **崩溃恢复** 是什么玩意?
+
+其实主要就是 **当集群中有机器挂了,我们整个集群如何保证数据一致性?**
+
+如果只是 `Follower` 挂了,而且挂的没超过半数的时候,因为我们一开始讲了在 `Leader` 中会维护队列,所以不用担心后面的数据没接收到导致数据不一致性。
+
+如果 `Leader` 挂了那就麻烦了,我们肯定需要先暂停服务变为 `Looking` 状态然后进行 `Leader` 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 **确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交** 和 **跳过那些已经被丢弃的提案** 。
+
+确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交是什么意思呢?
+
+假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
+
+
+
+那怎么解决呢?
+
+聪明的同学肯定会质疑,**这个时候 `server1` 已经不可能成为 `Leader` 了,因为 `server1` 和 `server3` 进行投票选举的时候会比较 `ZXID` ,而此时 `server3` 的 `ZXID` 肯定比 `server1` 的大了**。(不理解可以看前面的选举算法)
+
+那么跳过那些已经被丢弃的提案又是什么意思呢?
+
+假设 `Leader (server2)` 此时同意了提案 N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案 N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案 N1 了,这样就会出现数据不一致性问题了,所以 **该提案 N1 最终需要被抛弃掉** 。
+
+
+
+## Zookeeper 的几个理论知识
+
+了解了 `ZAB` 协议还不够,它仅仅是 `Zookeeper` 内部实现的一种方式,而我们如何通过 `Zookeeper` 去做一些典型的应用场景呢?比如说集群管理,分布式锁,`Master` 选举等等。
+
+这就涉及到如何使用 `Zookeeper` 了,但在使用之前我们还需要掌握几个概念。比如 `Zookeeper` 的 **数据模型**、**会话机制**、**ACL**、**Watcher 机制** 等等。
+
+### 数据模型
+
+`zookeeper` 数据存储结构与标准的 `Unix` 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 `zookeeper` 中没有文件系统中目录与文件的概念,而是 **使用了 `znode` 作为数据节点** 。`znode` 是 `zookeeper` 中的最小数据单元,每个 `znode` 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
+
+
+
+每个 `znode` 都有自己所属的 **节点类型** 和 **节点状态**。
+
+其中节点类型可以分为 **持久节点**、**持久顺序节点**、**临时节点** 和 **临时顺序节点**。
+
+- 持久节点:一旦创建就一直存在,直到将其删除。
+- 持久顺序节点:一个父节点可以为其子节点 **维护一个创建的先后顺序** ,这个顺序体现在 **节点名称** 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
+- 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
+- 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
+
+节点状态中包含了很多节点的属性比如 `czxid`、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
+
+- `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务 ID。
+- `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务 ID。
+- `ctime`:`Created Time`,该节点被创建的时间。
+- `mtime`:`Modified Time`,该节点最后一次被修改的时间。
+- `version`:节点的版本号。
+- `cversion`:**子节点** 的版本号。
+- `aversion`:节点的 `ACL` 版本号。
+- `ephemeralOwner`:创建该节点的会话的 `sessionID` ,如果该节点为持久节点,该值为 0。
+- `dataLength`:节点数据内容的长度。
+- `numChildre`:该节点的子节点个数,如果为临时节点为 0。
+- `pzxid`:该节点子节点列表最后一次被修改时的事务 ID,注意是子节点的 **列表** ,不是内容。
+
+### 会话
+
+我想这个对于后端开发的朋友肯定不陌生,不就是 `session` 吗?只不过 `zk` 客户端和服务端是通过 **`TCP` 长连接** 维持的会话机制,其实对于会话来说你可以理解为 **保持连接状态** 。
+
+在 `zookeeper` 中,会话还有对应的事件,比如 `CONNECTION_LOSS 连接丢失事件`、`SESSION_MOVED 会话转移事件`、`SESSION_EXPIRED 会话超时失效事件` 。
+
+### ACL
+
+`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了 5 种权限,它们分别为:
+
+- `CREATE`:创建子节点的权限。
+- `READ`:获取节点数据和子节点列表的权限。
+- `WRITE`:更新节点数据的权限。
+- `DELETE`:删除子节点的权限。
+- `ADMIN`:设置节点 ACL 的权限。
+
+### Watcher 机制
+
+`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
+
+
+
+## Zookeeper 的几个典型应用场景
+
+前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
+
+
+
+### 选主
+
+还记得上面我们的所说的临时节点吗?因为 `Zookeeper` 的强一致性,能够很好地在保证 **在高并发的情况下保证节点创建的全局唯一性** (即无法重复创建同样的节点)。
+
+利用这个特性,我们可以 **让多个客户端创建一个指定的节点** ,创建成功的就是 `master`。
+
+但是,如果这个 `master` 挂了怎么办???
+
+你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?`master` 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 `watcher` 吗?我们是不是可以 **让其他不是 `master` 的节点监听节点的状态** ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 `master` 挂了,这个时候我们 **触发回调函数进行重新选举** ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 `master` 是否挂了等等。
+
+
+
+总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
+
+### 数据发布/订阅
+
+还记得 Zookeeper 的 `Watcher` 机制吗? Zookeeper 通过这种推拉相结合的方式实现客户端与服务端的交互:客户端向服务端注册节点,一旦相应节点的数据变更,服务端就会向“监听”该节点的客户端发送 `Watcher` 事件通知,客户端接收到通知后需要 **主动** 到服务端获取最新的数据。基于这种方式,Zookeeper 实现了 **数据发布/订阅** 功能。
+
+一个典型的应用场景为 **全局配置信息的集中管理**。 客户端在启动时会主动到 Zookeeper 服务端获取配置信息,同时 **在指定节点注册一个** `Watcher` **监听**。当配置信息发生变更,服务端通知所有订阅的客户端重新获取配置信息,实现配置信息的实时更新。
+
+上面所提到的全局配置信息通常包括机器列表信息、运行时的开关配置、数据库配置信息等。需要注意的是,这类全局配置信息通常具备以下特性:
+
+- 数据量较小
+- 数据内容在运行时动态变化
+- 集群中机器共享一致配置
+
+### 负载均衡
+
+可以通过 Zookeeper 的 **临时节点** 实现负载均衡。回顾一下临时节点的特性:当创建节点的客户端与服务端之间断开连接,即客户端会话(session)消失时,对应节点也会自动消失。因此,我们可以使用临时节点来维护 Server 的地址列表,从而保证请求不会被分配到已停机的服务上。
+
+具体地,我们需要在集群的每一个 Server 中都使用 Zookeeper 客户端连接 Zookeeper 服务端,同时用 Server **自身的地址信息**在服务端指定目录下创建临时节点。当客户端请求调用集群服务时,首先通过 Zookeeper 获取该目录下的节点列表 (即所有可用的 Server),随后根据不同的负载均衡策略将请求转发到某一具体的 Server。
+
+### 分布式锁
+
+分布式锁的实现方式有很多种,比如 `Redis`、数据库、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
+
+上面我们已经提到过了 **zk 在高并发的情况下保证节点创建的全局唯一性**,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。
+
+如何实现呢?这玩意其实跟选主基本一样,我们也可以利用临时节点的创建来实现。
+
+首先肯定是如何获取锁,因为创建节点的唯一性,我们可以让多个客户端同时创建一个临时节点,**创建成功的就说明获取到了锁** 。然后没有获取到锁的客户端也像上面选主的非主节点创建一个 `watcher` 进行节点状态的监听,如果这个互斥锁被释放了(可能获取锁的客户端宕机了,或者那个客户端主动释放了锁)可以调用回调函数重新获得锁。
+
+> `zk` 中不需要向 `redis` 那样考虑锁得不到释放的问题了,因为当客户端挂了,节点也挂了,锁也释放了。是不是很简单?
+
+那能不能使用 `zookeeper` 同时实现 **共享锁和独占锁** 呢?答案是可以的,不过稍微有点复杂而已。
+
+还记得 **有序的节点** 吗?
+
+这个时候我规定所有创建节点必须有序,当你是读请求(要获取共享锁)的话,如果 **没有比自己更小的节点,或比自己小的节点都是读请求** ,则可以获取到读锁,然后就可以开始读了。**若比自己小的节点中有写请求** ,则当前客户端无法获取到读锁,只能等待前面的写请求完成。
+
+如果你是写请求(获取独占锁),若 **没有比自己更小的节点** ,则表示当前客户端可以直接获取到写锁,对数据进行修改。若发现 **有比自己更小的节点,无论是读操作还是写操作,当前客户端都无法获取到写锁** ,等待所有前面的操作完成。
+
+这就很好地同时实现了共享锁和独占锁,当然还有优化的地方,比如当一个锁得到释放它会通知所有等待的客户端从而造成 **羊群效应** 。此时你可以通过让等待的节点只监听他们前面的节点。
+
+具体怎么做呢?其实也很简单,你可以让 **读请求监听比自己小的最后一个写请求节点,写请求只监听比自己小的最后一个节点** ,感兴趣的小伙伴可以自己去研究一下。
+
+### 命名服务
+
+如何给一个对象设置 ID,大家可能都会想到 `UUID`,但是 `UUID` 最大的问题就在于它太长了。。。(太长不一定是好事,嘿嘿嘿)。那么在条件允许的情况下,我们能不能使用 `zookeeper` 来实现呢?
+
+我们之前提到过 `zookeeper` 是通过 **树形结构** 来存储数据节点的,那也就是说,对于每个节点的 **全路径**,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的 ID 设置可以更加便于理解。
+
+### 集群管理和注册中心
+
+看到这里是不是觉得 `zookeeper` 实在是太强大了,它怎么能这么能干!
+
+别急,它能干的事情还很多呢。可能我们会有这样的需求,我们需要了解整个集群中有多少机器在工作,我们想对集群中的每台机器的运行时状态进行数据采集,对集群中机器进行上下线操作等等。
+
+而 `zookeeper` 天然支持的 `watcher` 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 `watcher` 进行状态监控和回调。
+
+
+
+至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP 端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
+
+当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
+
+
+
+## 总结
+
+看到这里的同学实在是太有耐心了 👍👍👍 不知道大家是否还记得我讲了什么 😒。
+
+
+
+这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
+
+- 分布式与集群的区别
+
+- `2PC`、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
+
+- `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
+
+- `zookeeper` 中的一些基本概念,比如 `ACL`,数据节点,会话,`watcher`机制等等。
+
+- `zookeeper` 的典型应用场景,比如选主,注册中心等等。
+
+ 如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出 🤝🤝🤝。
+
+
+
diff --git a/docs_en/distributed-system/distributed-transaction.en.md b/docs_en/distributed-system/distributed-transaction.en.md
new file mode 100644
index 00000000000..64569e131f3
--- /dev/null
+++ b/docs_en/distributed-system/distributed-transaction.en.md
@@ -0,0 +1,12 @@
+---
+title: Summary of common solutions for distributed transactions (paid)
+category: distributed
+---
+
+**Distributed Transactions** The related interview questions are exclusive to my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click the link to view the detailed introduction and how to join), which has been compiled into the "Java Interview Guide".
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/cap-and-base-theorem.en.md b/docs_en/distributed-system/protocol/cap-and-base-theorem.en.md
new file mode 100644
index 00000000000..e50a63e7ad9
--- /dev/null
+++ b/docs_en/distributed-system/protocol/cap-and-base-theorem.en.md
@@ -0,0 +1,161 @@
+---
+title: CAP & BASE理论详解
+category: 分布式
+tag:
+ - 分布式理论
+---
+
+经历过技术面试的小伙伴想必对 CAP & BASE 这个两个理论已经再熟悉不过了!
+
+我当年参加面试的时候,不夸张地说,只要问到分布式相关的内容,面试官几乎是必定会问这两个分布式相关的理论。一是因为这两个分布式基础理论是学习分布式知识的必备前置基础,二是因为很多面试官自己比较熟悉这两个理论(方便提问)。
+
+我们非常有必要将这两个理论搞懂,并且能够用自己的理解给别人讲出来。
+
+## CAP 理论
+
+[CAP 理论/定理](https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86)起源于 2000 年,由加州大学伯克利分校的 Eric Brewer 教授在分布式计算原理研讨会(PODC)上提出,因此 CAP 定理又被称作 **布鲁尔定理(Brewer’s theorem)**
+
+2 年后,麻省理工学院的 Seth Gilbert 和 Nancy Lynch 发表了布鲁尔猜想的证明,CAP 理论正式成为分布式领域的定理。
+
+### 简介
+
+**CAP** 也就是 **Consistency(一致性)**、**Availability(可用性)**、**Partition Tolerance(分区容错性)** 这三个单词首字母组合。
+
+
+
+CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细定义 **Consistency**、**Availability**、**Partition Tolerance** 三个单词的明确定义。
+
+因此,对于 CAP 的民间解读有很多,一般比较被大家推荐的是下面 👇 这种版本的解读。
+
+在理论计算机科学中,CAP 定理(CAP theorem)指出对于一个分布式系统来说,当设计读写操作时,只能同时满足以下三点中的两个:
+
+- **一致性(Consistency)** : 所有节点访问同一份最新的数据副本
+- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
+- **分区容错性(Partition Tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
+
+**什么是网络分区?**
+
+分布式系统中,多个节点之间的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫 **网络分区**。
+
+
+
+### 不是所谓的“3 选 2”
+
+大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
+
+> **当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能 2 选 1。也就是说当网络分区之后 P 是前提,决定了 P 之后才有 C 和 A 的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。**
+>
+> 简而言之就是:CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。
+
+因此,**分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。** 比如 ZooKeeper、HBase 就是 CP 架构,Cassandra、Eureka 就是 AP 架构,Nacos 不仅支持 CP 架构也支持 AP 架构。
+
+**为啥不可能选择 CA 架构呢?** 举个例子:若系统出现“分区”,系统中的某个节点在进行写操作。为了保证 C, 必须要禁止其他节点的读写操作,这就和 A 发生冲突了。如果为了保证 A,其他节点的读写操作正常的话,那就和 C 发生冲突了。
+
+**选择 CP 还是 AP 的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。**
+
+另外,需要补充说明的一点是:**如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。**
+
+### CAP 实际应用案例
+
+我这里以注册中心来探讨一下 CAP 的实际应用。考虑到很多小伙伴不知道注册中心是干嘛的,这里简单以 Dubbo 为例说一说。
+
+下图是 Dubbo 的架构图。**注册中心 Registry 在其中扮演了什么角色呢?提供了什么服务呢?**
+
+注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。
+
+
+
+常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。
+
+1. **ZooKeeper 保证的是 CP。** 任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。
+2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
+3. **Nacos 不仅支持 CP 也支持 AP。**
+
+**🐛 修正(参见:[issue#1906](https://github.com/Snailclimb/JavaGuide/issues/1906))**:
+
+ZooKeeper 通过可线性化(Linearizable)写入、全局 FIFO 顺序访问等机制来保障数据一致性。多节点部署的情况下, ZooKeeper 集群处于 Quorum 模式。Quorum 模式下的 ZooKeeper 集群, 是一组 ZooKeeper 服务器节点组成的集合,其中大多数节点必须同意任何变更才能被视为有效。
+
+由于 Quorum 模式下的读请求不会触发各个 ZooKeeper 节点之间的数据同步,因此在某些情况下还是可能会存在读取到旧数据的情况,导致不同的客户端视图上看到的结果不同,这可能是由于网络延迟、丢包、重传等原因造成的。ZooKeeper 为了解决这个问题,提供了 Watcher 机制和版本号机制来帮助客户端检测数据的变化和版本号的变更,以保证数据的一致性。
+
+### 总结
+
+在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等
+
+在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区”
+
+如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。
+
+总结:**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
+
+### 推荐阅读
+
+1. [CAP 定理简化](https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4) (英文,有趣的案例)
+2. [神一样的 CAP 理论被应用在何方](https://juejin.im/post/6844903936718012430) (中文,列举了很多实际的例子)
+3. [请停止呼叫数据库 CP 或 AP](https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html) (英文,带给你不一样的思考)
+
+## BASE 理论
+
+[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年, 由 eBay 的架构师 Dan Pritchett 在 ACM 上发表。
+
+### 简介
+
+**BASE** 是 **Basically Available(基本可用)**、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+
+### BASE 理论的核心思想
+
+即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
+
+> That is to say, data consistency is sacrificed to meet the high availability of the system. When part of the data in the system is unavailable or inconsistent, the entire system still needs to be kept "mainly available".
+
+**BASE theory is essentially an extension and supplement to CAP, more specifically, a supplement to the AP scheme in CAP. **
+
+**Why do you say this? **
+
+We have also said this in the CAP theory section:
+
+> If the system is not "partitioned" and the network connection communication between nodes is normal, there will be no P. At this time, we can guarantee C and A at the same time. Therefore, if the system is "partitioned", we need to consider whether to choose CP or AP. If the system is not "partitioned", we need to think about how to ensure CA. **
+
+Therefore, the AP scheme only gives up consistency when the system is partitioned, rather than giving up consistency forever. After recovery from a partition failure, the system should reach eventual consistency. This is actually where BASE theory extends.
+
+### Three elements of BASE theory
+
+
+
+#### Basically available
+
+Basic availability means that the distributed system is allowed to lose part of its availability when unpredictable failures occur. However, this is by no means equivalent to the system being unavailable.
+
+**What does it mean to allow partial loss of availability? **
+
+- **Loss in response time**: Under normal circumstances, it takes 0.5s to process a user request and return a result, but due to a system failure, the time to process a user request becomes 3 s.
+- **Loss of system functions**: Under normal circumstances, users can use all functions of the system, but due to a sudden increase in system visits, some non-core functions of the system cannot be used.
+
+#### Soft state
+
+Soft state refers to allowing the data in the system to exist in an intermediate state (**data inconsistency in CAP theory**), and believing that the existence of this intermediate state will not affect the overall availability of the system, that is, allowing the system to have a delay in the process of data synchronization between data copies of different nodes.
+
+####Eventual consistency
+
+Eventual consistency emphasizes that all data copies in the system can eventually reach a consistent state after a period of synchronization. Therefore, the essence of eventual consistency is that the system needs to ensure that the final data can be consistent, but it does not need to ensure the strong consistency of the system data in real time.
+
+> 3 levels of distributed consistency:
+>
+> 1. **Strong consistency**: Whatever the system writes is what is read out.
+> 2. **Weak consistency**: It is not necessarily possible to read the latest written value, nor is it guaranteed that the data read after a certain amount of time will be the latest, but it will try to ensure that the data is consistent at a certain moment.
+> 3. **Eventual Consistency**: An upgraded version of weak consistency. The system will ensure that data is consistent within a certain period of time.
+>
+> **The industry recommends the ultimate consistency level, but in some scenarios that have very strict data consistency requirements, such as bank transfers, strong consistency must be ensured. **
+
+So what is the specific way to achieve eventual consistency? ["Distributed Protocols and Algorithms in Practice"] (http://gk.link/a/10rZM) is introduced like this:
+
+> - **Repair while reading**: When reading data, detect data inconsistencies and repair them. For example, Cassandra's Read Repair implementation. Specifically, when querying data from the Cassandra system, if it detects that the replica data on different nodes is inconsistent, the system will automatically repair the data.
+> - **Repair on write**: When writing data and detecting data inconsistencies, repair them. For example, Cassandra’s Hinted Handoff implementation. Specifically, when writing data remotely between nodes in the Cassandra cluster, if the writing fails, the data will be cached and then retransmitted regularly to repair data inconsistencies.
+> - **Asynchronous Repair**: This is the most commonly used method, which detects the consistency of the copy data through regular reconciliation and repairs it.
+
+**Repair on write** is recommended. This method has lower performance consumption.
+
+### Summary
+
+**ACID is the theory of database transaction integrity, CAP is the distributed system design theory, and BASE is an extension of the AP scheme in the CAP theory. **
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/consistent-hashing.en.md b/docs_en/distributed-system/protocol/consistent-hashing.en.md
new file mode 100644
index 00000000000..7a320ae2ff8
--- /dev/null
+++ b/docs_en/distributed-system/protocol/consistent-hashing.en.md
@@ -0,0 +1,131 @@
+---
+title: 一致性哈希算法详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 哈希算法
+---
+
+开始之前,先说两个常见的场景:
+
+1. **负载均衡**:由于访问人数太多,我们的网站部署了多台服务器个共同提供相同的服务,但每台服务器上存储的数据不同。为了保证请求的正确响应,相同参数(key)的请求(比如同个 IP 的请求、同一个用户的请求)需要发到同一台服务器处理。
+2. **分布式缓存**:由于缓存数据量太大,我们部署了多台缓存服务器共同提供缓存服务。缓存数据需要尽可能均匀地分布式在这些缓存服务器上,通过 key 可以找到对应的缓存服务器。
+
+这两种场景的本质,都是需要建立一个**从 key 到服务器/节点的稳定映射关系**。
+
+为了实现这个目标,你首先会想到什么方案呢?
+
+## 普通哈希算法
+
+相信大家很快就能想到 **“哈希+取模”** 这个经典组合。通过哈希函数计算出 key 的哈希值,再对服务器数量取模,从而将 key 映射到固定的服务器上。
+
+公式也很简单:
+
+```java
+node_number = hash(key) % N
+```
+
+- `hash(key)`: 使用哈希函数(建议使用性能较好的非加密哈希函数,例如 SipHash、MurMurHash3、CRC32、DJB)对唯一键进行哈希。
+- `% N`: 对哈希值取模,将哈希值映射到一个介于 0 到 N-1 之间的值,N 为节点数/服务器数。
+
+
+
+然而,传统的哈希取模算法有一个比较大的缺陷就是:**无法很好的解决机器/节点动态减少(比如某台机器宕机)或者增加的场景(比如又增加了一台机器)。**
+
+想象一下,服务器的初始数量为 4 台 (N = 4),如果其中一台服务器宕机,N 就变成了 3。此时,对于同一个 key,`hash(key) % 3` 的结果很可能与 `hash(key) % 4` 完全不同。
+
+
+
+这意味着几乎所有的数据映射关系都会错乱。在分布式缓存场景下,这会导致**大规模的缓存失效和缓存穿透**,瞬间将压力全部打到后端的数据库上,引发系统雪崩。
+
+据估算,当节点数量从 N 变为 N-1 时,平均有 (N-1)/N 比例的数据需要迁移,这个比例 **趋近于 100%** 。这种“牵一发而动全身”的效应,在生产环境中是完全不可接受的。
+
+为了更好地解决这个问题,一致性哈希算法诞生了。
+
+## 一致性哈希算法
+
+一致性哈希算法在 1997 年由麻省理工学院提出(这篇论文的 PDF 在线阅读地址:),是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了传统哈希算法在分布式[哈希表](https://baike.baidu.com/item/哈希表/5981869)(Distributed Hash Table,DHT)中存在的动态伸缩等问题 。
+
+一致性哈希算法的底层原理也很简单,关键在于**哈希环**的引入。
+
+### 哈希环
+
+一致性哈希算法将哈希空间组织成一个环形结构,将数据和节点都映射到这个环上,然后根据顺时针的规则确定数据或请求应该分配到哪个节点上。通常情况下,哈希环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 **[0, 2^32-1]** 。
+
+传统哈希算法是对服务器数量取模,一致性哈希算法是对哈希环的范围取模,固定值,通常为 2^32:
+
+```java
+node_number = hash(key) % 2^32
+```
+
+服务器/节点如何映射到哈希环上呢?也是哈希取模。例如,一般我们会根据服务器的 IP 或者主机名进行哈希,然后再取模。
+
+```java
+hash(服务器ip)% 2^32
+```
+
+如下图所示:
+
+
+
+我们将数据和节点都映射到哈希环上,环上的每个节点都负责一个区间。对于上图来说,每个节点负责的数据情况如下:
+
+- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。
+- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1, value2)。
+- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value3)。
+- **Node4:** 负责 Node3 到 Node4 之间的区域(包含 value4, value5)。
+
+### 节点移除/增加
+
+新增节点和移除节点的情况下,哈希环的引入可以避免影响范围太大,减少需要迁移的数据。
+
+还是用上面分享的哈希环示意图为例,假设 Node2 节点被移除的话,那 Node3 就要负责 Node2 的数据,直接迁移 Node2 的数据到 Node3 即可,其他节点不受影响。
+
+
+
+同样地,如果我们在 Node1 和 Node2 之间新增一个节点 Node5,那么原本应该由 Node2 负责的一部分数据(即哈希值落在 Node1 和 Node5 之间的数据,如图中的 value1)现在会由 Node5 负责。我们只需要将这部分数据从 Node2 迁移到 Node5 即可,同样只影响了相邻的节点,影响范围非常小。
+
+
+
+### 数据倾斜问题
+
+理想情况下,节点在环上是均匀分布的。然而,现实可能并不是这样的,尤其是节点数量比较少的时候。节点可能被映射到附近的区域,这样的话,就会导致绝大部分数据都由其中一个节点负责。
+
+
+
+对于上图来说,每个节点负责的数据情况如下:
+
+- **Node1:** 负责 Node4 到 Node1 之间的区域(包含 value6)。
+- **Node2:** 负责 Node1 到 Node2 之间的区域(包含 value1)。
+- **Node3:** 负责 Node2 到 Node3 之间的区域(包含 value2,value3, value4, value5)。
+- **Node4:** 负责 Node3 到 Node4 之间的区域。
+
+除了数据倾斜问题,还有一个隐患。当新增或者删除节点的时候,数据分配不均衡。例如,Node3 被移除的话,Node3 负责的所有数据都要交给 Node4,随后所有的请求都要达到 Node4 上。假设 Node4 的服务器处理能力比较差的话,那可能直接就被干崩了。理想情况下,应该有更多节点来分担压力。
+
+如何解决这些问题呢?答案是引入**虚拟节点**。
+
+### 虚拟节点
+
+虚拟节点就是对真实的物理节点在哈希环上虚拟出几个它的分身节点。数据落到分身节点上实际上就是落到真实的物理节点上,通过将虚拟节点均匀分散在哈希环的各个部分。
+
+如下图所示,Node1、Node2、Node3、Node4 这 4 个节点都对应 3 个虚拟节点(下图只是为了演示,实际情况节点分布不会这么有规律)。
+
+
+
+对于上图来说,每个节点最终负责的数据情况如下:
+
+- **Node1**:value4
+- **Node2**:value1,value3
+- **Node3**:value5
+- **Node4**:value2,value6
+
+**The benefits of introducing virtual nodes are huge:**
+
+1. **Data balancing:** The more virtual nodes there are, the denser the "server points" on the ring are, the more even the data distribution will naturally be, fundamentally solving the problem of data skew. Typically, the number of virtual nodes corresponding to each real node is between 100 and 200. For example, Nginx chooses to allocate 160 virtual nodes for each weight. The weight here is to distinguish servers. For example, a server with stronger processing power has a higher weight, which leads to more corresponding virtual nodes and a greater probability of being hit.
+2. **Enhanced fault tolerance:** This is the most subtle thing about virtual nodes. When a physical node goes down, it is equivalent to multiple virtual nodes on the ring going offline at the same time. The data and traffic originally responsible for these virtual nodes will be naturally and evenly distributed to multiple other physical nodes on the ring to take over, without concentrating the pressure on a certain neighbor node. This greatly improves the stability and fault tolerance of the system.
+
+## Reference
+
+- In-depth analysis of Nginx Load balancing algorithm:
+- Reading source code architecture series: consistent hashing:
+- Summary of the principles of consistent Hash algorithm:
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/gossip-protocl.en.md b/docs_en/distributed-system/protocol/gossip-protocl.en.md
new file mode 100644
index 00000000000..803b31d8c0b
--- /dev/null
+++ b/docs_en/distributed-system/protocol/gossip-protocl.en.md
@@ -0,0 +1,145 @@
+---
+title: Gossip 协议详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 共识算法
+---
+
+## 背景
+
+在分布式系统中,不同的节点进行数据/信息共享是一个基本的需求。
+
+一种比较简单粗暴的方法就是 **集中式发散消息**,简单来说就是一个主节点同时共享最新信息给其他所有节点,比较适合中心化系统。这种方法的缺陷也很明显,节点多的时候不光同步消息的效率低,还太依赖与中心节点,存在单点风险问题。
+
+于是,**分散式发散消息** 的 **Gossip 协议** 就诞生了。
+
+## Gossip 协议介绍
+
+Gossip 直译过来就是闲话、流言蜚语的意思。流言蜚语有什么特点呢?容易被传播且传播速度还快,你传我我传他,然后大家都知道了。
+
+
+
+**Gossip 协议** 也叫 Epidemic 协议(流行病协议)或者 Epidemic propagation 算法(疫情传播算法),别名很多。不过,这些名字的特点都具有 **随机传播特性** (联想一下病毒传播、癌细胞扩散等生活中常见的情景),这也正是 Gossip 协议最主要的特点。
+
+Gossip 协议最早是在 ACM 上的一篇 1987 年发表的论文 [《Epidemic Algorithms for Replicated Database Maintenance》](https://dl.acm.org/doi/10.1145/41840.41841)中被提出的。根据论文标题,我们大概就能知道 Gossip 协议当时提出的主要应用是在分布式数据库系统中各个副本节点同步数据。
+
+正如 Gossip 协议其名一样,这是一种随机且带有传染性的方式将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。
+
+在 Gossip 协议下,没有所谓的中心节点,每个节点周期性地随机找一个节点互相同步彼此的信息,理论上来说,各个节点的状态最终会保持一致。
+
+下面我们来对 Gossip 协议的定义做一个总结:**Gossip 协议是一种允许在分布式系统中共享状态的去中心化通信协议,通过这种通信协议,我们可以将信息传播给网络或集群中的所有成员。**
+
+## Gossip 协议应用
+
+NoSQL 数据库 Redis 和 Apache Cassandra、服务网格解决方案 Consul 等知名项目都用到了 Gossip 协议,学习 Gossip 协议有助于我们搞清很多技术的底层原理。
+
+我们这里以 Redis Cluster 为例说明 Gossip 协议的实际应用。
+
+我们经常使用的分布式缓存 Redis 的官方集群解决方案(3.0 版本引入) Redis Cluster 就是基于 Gossip 协议来实现集群中各个节点数据的最终一致性。
+
+
+
+Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节点需要互相通信。既然要相互通信就要遵循一致的通信协议,Redis Cluster 中的各个节点基于 **Gossip 协议** 来进行通信共享信息,每个 Redis 节点都维护了一份集群的状态信息。
+
+Redis Cluster 的节点之间会相互发送多种 Gossip 消息:
+
+- **MEET**:在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
+- **PING/PONG**:Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
+- **FAIL**:Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
+- ……
+
+下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信 ,实线表示主从复制。
+
+
+
+有了 Redis Cluster 之后,不需要专门部署 Sentinel 集群服务了。Redis Cluster 相当于是内置了 Sentinel 机制,Redis Cluster 内部的各个 Redis 节点通过 Gossip 协议共享集群内信息。
+
+关于 Redis Cluster 的详细介绍,可以查看这篇文章 [Redis 集群详解(付费)](https://javaguide.cn/database/redis/redis-cluster.html) 。
+
+## Gossip 协议消息传播模式
+
+Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)** 和 **传谣(Rumor-Mongering)**。
+
+### 反熵(Anti-entropy)
+
+根据维基百科:
+
+> 熵的概念最早起源于[物理学](https://zh.wikipedia.org/wiki/物理学),用于度量一个热力学系统的混乱程度。熵最好理解为不确定性的量度而不是确定性的量度,因为越随机的信源的熵越大。
+
+在这里,你可以把反熵中的熵理解为节点之间数据的混乱程度/差异性,反熵就是指消除不同节点中数据的差异,提升节点间数据的相似度,从而降低熵值。
+
+具体是如何反熵的呢?集群中的节点,每隔段时间就随机选择某个其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性。
+
+在实现反熵的时候,主要有推、拉和推拉三种方式:
+
+- 推方式,就是将自己的所有副本数据,推给对方,修复对方副本中的熵。
+- 拉方式,就是拉取对方的所有副本数据,修复自己副本中的熵。
+- 推拉就是同时修复自己副本和对方副本中的熵。
+
+伪代码如下:
+
+
+
+在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是可以设计成一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
+
+
+
+1. 节点 A 推送数据给节点 B,节点 B 获取到节点 A 中的最新数据。
+2. 节点 B 推送数据给 C,节点 C 获取到节点 A,B 中的最新数据。
+3. 节点 C 推送数据给 A,节点 A 获取到节点 B,C 中的最新数据。
+4. 节点 A 再推送数据给 B 形成闭环,这样节点 B 就获取到节点 C 中的最新数据。
+
+虽然反熵很简单实用,但是,节点过多或者节点动态变化的话,反熵就不太适用了。这个时候,我们想要实现最终一致性就要靠 **谣言传播(Rumor mongering)** 。
+
+### 谣言传播(Rumor mongering)
+
+谣言传播指的是分布式系统中的一个节点一旦有了新数据之后,就会变为活跃节点,活跃节点会周期性地联系其他节点向其发送新数据,直到所有的节点都存储了该新数据。
+
+如下图所示(下图来自于[INTRODUCTION TO GOSSIP](https://managementfromscratch.wordpress.com/2016/04/01/introduction-to-gossip/) 这篇文章):
+
+
+
+伪代码如下:
+
+
+
+谣言传播比较适合节点数量比较多的情况,不过,这种模式下要尽量避免传播的信息包不能太大,避免网络消耗太大。
+
+### 总结
+
+- 反熵(Anti-Entropy)会传播节点的所有数据,而谣言传播(Rumor-Mongering)只会传播节点新增的数据。
+- 我们一般会给反熵设计一个闭环。
+- 谣言传播(Rumor-Mongering)比较适合节点数量比较多或者节点动态变化的场景。
+
+## Gossip 协议优势和缺陷
+
+**优势:**
+
+1、相比于其他分布式协议/算法来说,Gossip 协议理解起来非常简单。
+
+2、能够容忍网络上节点的随意地增加或者减少,宕机或者重启,因为 Gossip 协议下这些节点都是平等的,去中心化的。新增加或者重启的节点在理想情况下最终是一定会和其他节点的状态达到一致。
+
+3. The speed is relatively fast. When the number of nodes is relatively large, the diffusion speed is faster than a master node disseminating information to other nodes (multicast).
+
+**Defects**:
+
+1. Messages need to be propagated to the entire network through multiple rounds of propagation. Therefore, the status of each node will inevitably be inconsistent. After all, the Gossip protocol emphasizes eventual consistency, and no one knows how long it will take to reach a consistent state of each node.
+
+2. Due to the Byzantine Generals Problem, malicious nodes are not allowed to exist.
+
+3. There may be message redundancy issues. Due to the random nature of message propagation, the same node may receive the same message repeatedly.
+
+## Summary
+
+- Gossip protocol is a communication protocol that allows sharing state in a distributed system, through this communication protocol we can disseminate information to all members of the network or cluster.
+- The Gossip protocol is used by projects such as Redis, Apache Cassandra, and Consul.
+- Rumor-Mongering is more suitable for scenarios where the number of nodes is large or nodes change dynamically.
+
+## Reference
+
+- A 10,000-word detailed explanation of the Redis Cluster Gossip protocol:
+- "Distributed Protocols and Algorithms in Practice"
+- "Redis Design and Implementation"
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/protocol/paxos-algorithm.en.md b/docs_en/distributed-system/protocol/paxos-algorithm.en.md
new file mode 100644
index 00000000000..d0ca0b8f051
--- /dev/null
+++ b/docs_en/distributed-system/protocol/paxos-algorithm.en.md
@@ -0,0 +1,84 @@
+---
+title: Paxos 算法详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 共识算法
+---
+
+## 背景
+
+Paxos 算法是 Leslie Lamport([莱斯利·兰伯特](https://zh.wikipedia.org/wiki/莱斯利·兰伯特))在 **1990** 年提出了一种分布式系统 **共识** 算法。这也是第一个被证明完备的共识算法(前提是不存在拜占庭将军问题,也就是没有恶意节点)。
+
+为了介绍 Paxos 算法,兰伯特专门写了一篇幽默风趣的论文。在这篇论文中,他虚拟了一个叫做 Paxos 的希腊城邦来更形象化地介绍 Paxos 算法。
+
+不过,审稿人并不认可这篇论文的幽默。于是,他们就给兰伯特说:“如果你想要成功发表这篇论文的话,必须删除所有 Paxos 相关的故事背景”。兰伯特一听就不开心了:“我凭什么修改啊,你们这些审稿人就是缺乏幽默细胞,发不了就不发了呗!”。
+
+于是乎,提出 Paxos 算法的那篇论文在当时并没有被成功发表。
+
+直到 1998 年,系统研究中心 (Systems Research Center,SRC)的两个技术研究员需要找一些合适的分布式算法来服务他们正在构建的分布式系统,Paxos 算法刚好可以解决他们的部分需求。因此,兰伯特就把论文发给了他们。在看了论文之后,这俩大佬觉得论文还是挺不错的。于是,兰伯特在 **1998** 年重新发表论文 [《The Part-Time Parliament》](http://lamport.azurewebsites.net/pubs/lamport-paxos.pdf)。
+
+论文发表之后,各路学者直呼看不懂,言语中还略显调侃之意。这谁忍得了,在 **2001** 年的时候,兰伯特专门又写了一篇 [《Paxos Made Simple》](http://lamport.azurewebsites.net/pubs/paxos-simple.pdf) 的论文来简化对 Paxos 的介绍,主要讲述两阶段共识协议部分,顺便还不忘嘲讽一下这群学者。
+
+《Paxos Made Simple》这篇论文就 14 页,相比于 《The Part-Time Parliament》的 33 页精简了不少。最关键的是这篇论文的摘要就一句话:
+
+
+
+> The Paxos algorithm, when presented in plain English, is very simple.
+
+翻译过来的意思大概就是:当我用无修饰的英文来描述时,Paxos 算法真心简单!
+
+有没有感觉到来自兰伯特大佬满满地嘲讽的味道?
+
+## 介绍
+
+Paxos 算法是第一个被证明完备的分布式系统共识算法。共识算法的作用是让分布式系统中的多个节点之间对某个提案(Proposal)达成一致的看法。提案的含义在分布式系统中十分宽泛,像哪一个节点是 Leader 节点、多个事件发生的顺序等等都可以是一个提案。
+
+兰伯特当时提出的 Paxos 算法主要包含 2 个部分:
+
+- **Basic Paxos 算法**:描述的是多节点之间如何就某个值(提案 Value)达成共识。
+- **Multi-Paxos 思想**:描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。Multi-Paxos 说白了就是执行多次 Basic Paxos ,核心还是 Basic Paxos 。
+
+由于 Paxos 算法在国际上被公认的非常难以理解和实现,因此不断有人尝试简化这一算法。到了 2013 年才诞生了一个比 Paxos 算法更易理解和实现的共识算法—[Raft 算法](https://javaguide.cn/distributed-system/theorem&algorithm&protocol/raft-algorithm.html) 。更具体点来说,Raft 是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现。
+
+针对没有恶意节点的情况,除了 Raft 算法之外,当前最常用的一些共识算法比如 **ZAB 协议**、 **Fast Paxos** 算法都是基于 Paxos 算法改进的。
+
+针对存在恶意节点的情况,一般使用的是 **工作量证明(POW,Proof-of-Work)**、 **权益证明(PoS,Proof-of-Stake )** 等共识算法。这类共识算法最典型的应用就是区块链,就比如说前段时间以太坊官方宣布其共识机制正在从工作量证明(PoW)转变为权益证明(PoS)。
+
+区块链系统使用的共识算法需要解决的核心问题是 **拜占庭将军问题** ,这和我们日常接触到的 ZooKeeper、Etcd、Consul 等分布式中间件不太一样。
+
+下面我们来对 Paxos 算法的定义做一个总结:
+
+- Paxos 算法是兰伯特在 **1990** 年提出了一种分布式系统共识算法。
+- 兰伯特当时提出的 Paxos 算法主要包含 2 个部分: Basic Paxos 算法和 Multi-Paxos 思想。
+- Raft 算法、ZAB 协议、 Fast Paxos 算法都是基于 Paxos 算法改进而来。
+
+## Basic Paxos 算法
+
+Basic Paxos 中存在 3 个重要的角色:
+
+1. **提议者(Proposer)**:也可以叫做协调者(coordinator),提议者负责接受客户端的请求并发起提案。提案信息通常包括提案编号 (Proposal ID) 和提议的值 (Value)。
+2. **接受者(Acceptor)**:也可以叫做投票员(voter),负责对提议者的提案进行投票,同时需要记住自己的投票历史;
+3. **学习者(Learner)**:如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
+
+
+
+为了减少实现该算法所需的节点数,一个节点可以身兼多个角色。并且,一个提案被选定需要被半数以上的 Acceptor 接受。这样的话,Basic Paxos 算法还具备容错性,在少于一半的节点出现故障时,集群仍能正常工作。
+
+## Multi Paxos 思想
+
+Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Multi Paxos 思想。
+
+⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
+
+由于兰伯特提到的 Multi-Paxos 思想缺少代码实现的必要细节(比如怎么选举领导者),所以在理解和实现上比较困难。
+
+不过,也不需要担心,我们并不需要自己实现基于 Multi-Paxos 思想的共识算法,业界已经有了比较出名的实现。像 Raft 算法就是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现,实际项目中可以优先考虑 Raft 算法。
+
+## 参考
+
+-
+- 分布式系统中的一致性与共识算法:
+
+
+
diff --git a/docs_en/distributed-system/protocol/raft-algorithm.en.md b/docs_en/distributed-system/protocol/raft-algorithm.en.md
new file mode 100644
index 00000000000..914de02ad9d
--- /dev/null
+++ b/docs_en/distributed-system/protocol/raft-algorithm.en.md
@@ -0,0 +1,171 @@
+---
+title: Raft 算法详解
+category: 分布式
+tag:
+ - 分布式协议&算法
+ - 共识算法
+---
+
+> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [Xieqijun](https://github.com/jun0315) 共同完成。
+
+## 1 背景
+
+当今的数据中心和应用程序在高度动态的环境中运行,为了应对高度动态的环境,它们通过额外的服务器进行横向扩展,并且根据需求进行扩展和收缩。同时,服务器和网络故障也很常见。
+
+因此,系统必须在正常操作期间处理服务器的上下线。它们必须对变故做出反应并在几秒钟内自动适应;对客户来说的话,明显的中断通常是不可接受的。
+
+幸运的是,分布式共识可以帮助应对这些挑战。
+
+### 1.1 拜占庭将军
+
+在介绍共识算法之前,先介绍一个简化版拜占庭将军的例子来帮助理解共识算法。
+
+> 假设多位拜占庭将军中没有叛军,信使的信息可靠但有可能被暗杀的情况下,将军们如何达成是否要进攻的一致性决定?
+
+解决方案大致可以理解成:先在所有的将军中选出一个大将军,用来做出所有的决定。
+
+举例如下:假如现在一共有 3 个将军 A,B 和 C,每个将军都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军 B 和 C,如果将军 B 和 C 还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军 A,信使回到将军 A 时,将军 A 知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军 A 决定,然后再去派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军 B 和 C 的回复(信使可能会被暗杀),那就再重派一个信使,直到收到回复。
+
+### 1.2 共识算法
+
+共识是可容错系统中的一个基本问题:即使面对故障,服务器也可以在共享状态上达成一致。
+
+共识算法允许一组节点像一个整体一样一起工作,即使其中的一些节点出现故障也能够继续工作下去,其正确性主要是源于复制状态机的性质:一组`Server`的状态机计算相同状态的副本,即使有一部分的`Server`宕机了它们仍然能够继续运行。
+
+
+
+`图-1 复制状态机架构`
+
+一般通过使用复制日志来实现复制状态机。每个`Server`存储着一份包括命令序列的日志文件,状态机会按顺序执行这些命令。因为每个日志包含相同的命令,并且顺序也相同,所以每个状态机处理相同的命令序列。由于状态机是确定性的,所以处理相同的状态,得到相同的输出。
+
+因此共识算法的工作就是保持复制日志的一致性。服务器上的共识模块从客户端接收命令并将它们添加到日志中。它与其他服务器上的共识模块通信,以确保即使某些服务器发生故障。每个日志最终包含相同顺序的请求。一旦命令被正确地复制,它们就被称为已提交。每个服务器的状态机按照日志顺序处理已提交的命令,并将输出返回给客户端,因此,这些服务器形成了一个单一的、高度可靠的状态机。
+
+适用于实际系统的共识算法通常具有以下特性:
+
+- 安全。确保在非拜占庭条件(也就是上文中提到的简易版拜占庭)下的安全性,包括网络延迟、分区、包丢失、复制和重新排序。
+- 高可用。只要大多数服务器都是可操作的,并且可以相互通信,也可以与客户端进行通信,那么这些服务器就可以看作完全功能可用的。因此,一个典型的由五台服务器组成的集群可以容忍任何两台服务器端故障。假设服务器因停止而发生故障;它们稍后可能会从稳定存储上的状态中恢复并重新加入集群。
+- 一致性不依赖时序。错误的时钟和极端的消息延迟,在最坏的情况下也只会造成可用性问题,而不会产生一致性问题。
+
+- 在集群中大多数服务器响应,命令就可以完成,不会被少数运行缓慢的服务器来影响整体系统性能。
+
+## 2 基础
+
+### 2.1 节点类型
+
+一个 Raft 集群包括若干服务器,以典型的 5 服务器集群举例。在任意的时间,每个服务器一定会处于以下三个状态中的一个:
+
+- `Leader`:负责发起心跳,响应客户端,创建日志,同步日志。
+- `Candidate`:Leader 选举过程中的临时角色,由 Follower 转化而来,发起投票参与竞选。
+- `Follower`:接受 Leader 的心跳和日志同步数据,投票给 Candidate。
+
+在正常的情况下,只有一个服务器是 Leader,剩下的服务器是 Follower。Follower 是被动的,它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。
+
+
+
+`图-2:服务器的状态`
+
+### 2.2 任期
+
+
+
+`图-3:任期`
+
+如图 3 所示,raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader,将会开启另一个任期,并立刻开始下一次选举。raft 算法保证在给定的一个任期最少要有一个 Leader。
+
+每个节点都会存储当前的 term 号,当服务器之间进行通信时会交换当前的 term 号;如果有服务器发现自己的 term 号比其他人小,那么他会更新到较大的 term 值。如果一个 Candidate 或者 Leader 发现自己的 term 过期了,他会立即退回成 Follower。如果一台服务器收到的请求的 term 号是过期的,那么它会拒绝此次请求。
+
+### 2.3 日志
+
+- `entry`:每一个事件成为 entry,只有 Leader 可以创建 entry。entry 的内容为``其中 cmd 是可以应用到状态机的操作。
+- `log`:由 entry 构成的数组,每一个 entry 都有一个表明自己在 log 中的 index。只有 Leader 才可以改变其他节点的 log。entry 总是先被 Leader 添加到自己的 log 数组中,然后再发起共识请求,获得同意后才会被 Leader 提交给状态机。Follower 只能从 Leader 获取新日志和当前的 commitIndex,然后把对应的 entry 应用到自己的状态机中。
+
+## 3 领导人选举
+
+raft 使用心跳机制来触发 Leader 的选举。
+
+如果一台服务器能够收到来自 Leader 或者 Candidate 的有效信息,那么它会一直保持为 Follower 状态,并且刷新自己的 electionElapsed,重新计时。
+
+Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader 地位。如果一个 Follower 在一个周期内没有收到心跳信息,就叫做选举超时,然后它就会认为此时没有可用的 Leader,并且开始进行一次选举以选出一个新的 Leader。
+
+为了开始新的选举,Follower 会自增自己的 term 号并且转换状态为 Candidate。然后他会向所有节点发起 RequestVoteRPC 请求, Candidate 的状态会持续到以下情况发生:
+
+- 赢得选举
+- 其他节点赢得选举
+- 一轮选举结束,无人胜出
+
+赢得选举的条件是:一个 Candidate 在一个任期内收到了来自集群内的多数选票`(N/2+1)`,就可以成为 Leader。
+
+在 Candidate 等待选票的时候,它可能收到其他节点声明自己是 Leader 的心跳,此时有两种情况:
+
+- 该 Leader 的 term 号大于等于自己的 term 号,说明对方已经成为 Leader,则自己回退为 Follower。
+- 该 Leader 的 term 号小于自己的 term 号,那么会拒绝该请求并让该节点更新 term。
+
+由于可能同一时刻出现多个 Candidate,导致没有 Candidate 获得大多数选票,如果没有其他手段来重新分配选票的话,那么可能会无限重复下去。
+
+raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的选举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
+
+## 4 日志复制
+
+一旦选出了 Leader,它就开始接受客户端的请求。每一个客户端的请求都包含一条需要被复制状态机(`Replicated State Machine`)执行的命令。
+
+Leader 收到客户端请求后,会生成一个 entry,包含``,再将这个 entry 添加到自己的日志末尾后,向所有的节点广播该 entry,要求其他服务器复制这条 entry。
+
+If the Follower accepts the entry, it will add the entry to the end of its own log and return it to the Leader for approval.
+
+If the Leader receives a majority of successful responses, the Leader will apply the entry to its own state machine, and then call the entry committed and return the execution result to the client.
+
+raft guarantees the following two properties:
+
+- In two logs, if there are two entries with the same index and term, then they must have the same cmd
+- In two logs, if there are two entries with the same index and term, then the entries in front of them must also be the same.
+
+The first property is guaranteed by "only the Leader can generate entries", and the second property requires a consistency check to ensure it.
+
+Under normal circumstances, the logs of the Leader and Follower are consistent. However, the crash of the Leader will cause the logs to be different, so the consistency check will fail. Leader handles log inconsistencies by forcing Followers to copy their own logs. This means that the conflict log on the Follower will be overwritten by the leader's log.
+
+In order to make the Follower's log consistent with its own log, the Leader needs to find the place where the Follower's log is consistent with its own log, then delete the Follower's log after that position, and then send the following log to the Follower.
+
+`Leader` maintains a `nextIndex` for each `Follower`, which represents the index of the next log entry that `Leader` will send to the follower. When a `Leader` takes power, it initializes `nextIndex` to its latest log entry index + 1. If the log of a `Follower` is inconsistent with that of the `Leader`, the `AppendEntries` consistency check will return failure at the next `AppendEntries RPC`. After a failure, `Leader` will decrement `nextIndex` and retry `AppendEntries RPC`. Eventually `nextIndex` will reach a place where `Leader` and `Follower` logs are consistent. At this point, `AppendEntries` will return successfully, the conflicting log entries in `Follower` will be removed, and the missing `Leader` log entries will be added. Once `AppendEntries` returns successfully, the logs of `Follower` and `Leader` are consistent, and this state will remain until the end of the term.
+
+## 5 Security
+
+### 5.1 Election restrictions
+
+The Leader needs to ensure that it stores all submitted log entries. This allows log entries to flow in only one direction: from Leader to Follower, and Leader will never overwrite existing log entries.
+
+When each Candidate sends RequestVoteRPC, it will bring the last entry information. When all nodes receive the voting information, they will compare the entry. If they find their own updates, they will refuse to vote for the candidate.
+
+The way to judge the old and new logs: if the terms of the two logs are different, the larger term is updated; if the terms are the same, the longer index is updated.
+
+### 5.2 Node crash
+
+If the Leader crashes and the nodes in the cluster do not receive the Leader's heartbeat information within the electionTimeout time, a new round of leader election will be triggered. During the leader election period, the entire cluster will be unavailable to the outside world.
+
+If Follower and Candidate crash, the handling will be much simpler. Subsequent RequestVoteRPC and AppendEntriesRPC sent to it will fail. Since all raft requests are idempotent, they will be retried infinitely if they fail. If the crash is recovered, you can receive new requests and choose to append or reject the entry.
+
+### 5.3 Timing and Availability
+
+One of the requirements of raft is that security does not depend on time: the system cannot fail just because some events occur faster or slower than expected. In order to ensure the above requirements, it is best to meet the following time conditions:
+
+`broadcastTime << electionTimeout << MTBF`
+
+- `broadcastTime`: the average response time for concurrently sending messages to other nodes;
+- `electionTimeout`: election timeout;
+- `MTBF(mean time between failures)`: the average health time of a single machine;
+
+`broadcastTime` should be an order of magnitude smaller than `electionTimeout`, in order to enable `Leader` to continuously send heartbeat information (heartbeat) to prevent `Follower` from starting an election;
+
+`electionTimeout` is also several orders of magnitude smaller than `MTBF` in order to make the system run stably. When the `Leader` crashes, it will be unavailable for approximately the entire `electionTimeout`; we hope that this will only be a small fraction of the total time.
+
+Since `broadcastTime` and `MTBF` are properties determined by the system, the time of `electionTimeout` needs to be determined.
+
+Generally speaking, broadcastTime is generally `0.5~20ms`, electionTimeout can be set to `10~500ms`, and MTBF is generally one or two months.
+
+## 6 Reference
+
+-
+-
+-
+-
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/rpc/dubbo.en.md b/docs_en/distributed-system/rpc/dubbo.en.md
new file mode 100644
index 00000000000..cc14665ee07
--- /dev/null
+++ b/docs_en/distributed-system/rpc/dubbo.en.md
@@ -0,0 +1,459 @@
+---
+title: Dubbo常见问题总结
+category: 分布式
+tag:
+ - rpc
+---
+
+::: tip
+
+- Dubbo3 已经发布,这篇文章是基于 Dubbo2 写的。Dubbo3 基于 Dubbo2 演进而来,在保持原有核心功能特性的同时, Dubbo3 在易用性、超大规模微服务实践、云原生基础设施适配、安全设计等几大方向上进行了全面升级。
+- 本文中的很多链接已经失效,主要原因是因为 Dubbo 官方文档进行了修改导致 URL 失效。
+
+:::
+
+这篇文章是我根据官方文档以及自己平时的使用情况,对 Dubbo 所做的一个总结。欢迎补充!
+
+## Dubbo 基础
+
+### 什么是 Dubbo?
+
+
+
+[Apache Dubbo](https://github.com/apache/dubbo) |ˈdʌbəʊ| 是一款高性能、轻量级的开源 WEB 和 RPC 框架。
+
+根据 [Dubbo 官方文档](https://dubbo.apache.org/zh/)的介绍,Dubbo 提供了六大核心能力
+
+1. 面向接口代理的高性能 RPC 调用。
+2. 智能容错和负载均衡。
+3. 服务自动注册和发现。
+4. 高度可扩展能力。
+5. 运行期流量调度。
+6. 可视化的服务治理与运维。
+
+
+
+简单来说就是:**Dubbo 不光可以帮助我们调用远程服务,还提供了一些其他开箱即用的功能比如智能负载均衡。**
+
+Dubbo 目前已经有接近 34.4 k 的 Star 。
+
+在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第 7 名。相比几年前来说,热度和排名有所下降。
+
+
+
+Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
+
+### 为什么要用 Dubbo?
+
+随着互联网的发展,网站的规模越来越大,用户数量越来越多。单一应用架构、垂直应用架构无法满足我们的需求,这个时候分布式服务架构就诞生了。
+
+分布式服务架构下,系统被拆分成不同的服务比如短信服务、安全服务,每个服务独立提供系统的某个核心服务。
+
+我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian 这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
+
+不过,Dubbo 的出现让上述问题得到了解决。**Dubbo 帮助我们解决了什么问题呢?**
+
+1. **负载均衡**:同一个服务部署在不同的机器时该调用哪一台机器上的服务。
+2. **服务调用链路生成**:随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
+3. **服务访问压力以及时长统计、资源调度和治理**:基于访问压力实时管理集群容量,提高集群利用率。
+4. ……
+
+
+
+另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
+
+**我们刚刚提到了分布式这个概念,下面再给大家介绍一下什么是分布式?为什么要分布式?**
+
+## 分布式基础
+
+### 什么是分布式?
+
+分布式或者说 SOA 分布式重要的就是面向服务,说简单的分布式就是我们把整个系统拆分成不同的服务然后将这些服务放在不同的服务器上减轻单体服务的压力提高并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
+
+
+
+### 为什么要分布式?
+
+从开发角度来讲单体应用的代码都集中在一起,而分布式系统的代码根据业务被拆分。所以,每个团队可以负责一个服务的开发,这样提升了开发效率。另外,代码根据业务拆分之后更加便于维护和扩展。
+
+另外,我觉得将系统拆分成分布式之后不光便于系统扩展和维护,更能提高整个系统的性能。你想一想嘛?把整个系统拆分成不同的服务/系统,然后每个服务/系统 单独部署在一台服务器上,是不是很大程度上提高了系统性能呢?
+
+## Dubbo 架构
+
+### Dubbo 架构中的核心角色有哪些?
+
+[官方文档中的框架设计章节](https://dubbo.apache.org/zh/docs/v2.7/dev/design/) 已经介绍的非常详细了,我这里把一些比较重要的点再提一下。
+
+
+
+上述节点简单介绍以及他们之间的关系:
+
+- **Container:** 服务运行容器,负责加载、运行服务提供者。必须。
+- **Provider:** 暴露服务的服务提供方,会向注册中心注册自己提供的服务。必须。
+- **Consumer:** 调用远程服务的服务消费方,会向注册中心订阅自己所需的服务。必须。
+- **Registry:** 服务注册与发现的注册中心。注册中心会返回服务提供者地址列表给消费者。非必须。
+- **Monitor:** 统计服务的调用次数和调用时间的监控中心。服务消费者和提供者会定时发送统计数据到监控中心。 非必须。
+
+### Dubbo 中的 Invoker 概念了解么?
+
+`Invoker` 是 Dubbo 领域模型中非常重要的一个概念,你如果阅读过 Dubbo 源码的话,你会无数次看到这玩意。就比如下面我要说的负载均衡这块的源码中就有大量 `Invoker` 的身影。
+
+简单来说,`Invoker` 就是 Dubbo 对远程调用的抽象。
+
+
+
+按照 Dubbo 官方的话来说,`Invoker` 分为
+
+- 服务提供 `Invoker`
+- 服务消费 `Invoker`
+
+假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的 `Invoker` 实现, `Invoker` 实现了真正的远程服务调用。
+
+### Dubbo 的工作原理了解么?
+
+下图是 Dubbo 的整体设计,从下至上分为十层,各层均为单向依赖。
+
+> 左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
+
+
+
+- **config 配置层**:Dubbo 相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以 `ServiceConfig`, `ReferenceConfig` 为中心
+- **proxy 服务代理层**:调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以 `ServiceProxy` 为中心。
+- **registry 注册中心层**:封装服务地址的注册与发现。
+- **cluster 路由层**:封装多个提供者的路由及负载均衡,并桥接注册中心,以 `Invoker` 为中心。
+- **monitor 监控层**:RPC 调用次数和调用时间监控,以 `Statistics` 为中心。
+- **protocol 远程调用层**:封装 RPC 调用,以 `Invocation`, `Result` 为中心。
+- **exchange 信息交换层**:封装请求响应模式,同步转异步,以 `Request`, `Response` 为中心。
+- **transport 网络传输层**:抽象 mina 和 netty 为统一接口,以 `Message` 为中心。
+- **serialize 数据序列化层**:对需要在网络传输的数据进行序列化。
+
+### Dubbo 的 SPI 机制了解么? 如何扩展 Dubbo 中的默认实现?
+
+SPI(Service Provider Interface) 机制被大量用在开源项目中,它可以帮助我们动态寻找服务/功能(比如负载均衡策略)的实现。
+
+SPI 的具体原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
+
+Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java 原生的 SPI 机制进行了增强,以便更好满足自己的需求。
+
+**那我们如何扩展 Dubbo 中的默认实现呢?**
+
+比如说我们想要实现自己的负载均衡策略,我们创建对应的实现类 `XxxLoadBalance` 实现 `LoadBalance` 接口或者 `AbstractLoadBalance` 类。
+
+```java
+package com.xxx;
+
+import org.apache.dubbo.rpc.cluster.LoadBalance;
+import org.apache.dubbo.rpc.Invoker;
+import org.apache.dubbo.rpc.Invocation;
+import org.apache.dubbo.rpc.RpcException;
+
+public class XxxLoadBalance implements LoadBalance {
+ public Invoker select(List> invokers, Invocation invocation) throws RpcException {
+ // ...
+ }
+}
+```
+
+我们将这个实现类的路径写入到`resources` 目录下的 `META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance`文件中即可。
+
+```java
+src
+ |-main
+ |-java
+ |-com
+ |-xxx
+ |-XxxLoadBalance.java (实现LoadBalance接口)
+ |-resources
+ |-META-INF
+ |-dubbo
+ |-org.apache.dubbo.rpc.cluster.LoadBalance (纯文本文件,内容为:xxx=com.xxx.XxxLoadBalance)
+```
+
+`org.apache.dubbo.rpc.cluster.LoadBalance`
+
+```plain
+xxx=com.xxx.XxxLoadBalance
+```
+
+其他还有很多可供扩展的选择,你可以在[官方文档](https://cn.dubbo.apache.org/zh-cn/overview/home/)中找到。
+
+### Dubbo 的微内核架构了解吗?
+
+Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来说就是微内核架构。微内核只负责组装插件。
+
+**何为微内核架构呢?** 《软件架构模式》 这本书是这样介绍的:
+
+> 微内核架构模式(有时被称为插件架构模式)是实现基于产品应用程序的一种自然模式。基于产品的应用程序是已经打包好并且拥有不同版本,可作为第三方插件下载的。然后,很多公司也在开发、发布自己内部商业应用像有版本号、说明及可加载插件式的应用软件(这也是这种模式的特征)。微内核系统可让用户添加额外的应用如插件,到核心应用,继而提供了可扩展性和功能分离的用法。
+
+微内核架构包含两类组件:**核心系统(core system)** 和 **插件模块(plug-in modules)**。
+
+
+
+核心系统提供系统所需核心能力,插件模块可以扩展系统的功能。因此, 基于微内核架构的系统,非常易于扩展功能。
+
+我们常见的一些 IDE,都可以看作是基于微内核架构设计的。绝大多数 IDE 比如 IDEA、VSCode 都提供了插件来丰富自己的功能。
+
+正是因为 Dubbo 基于微内核架构,才使得我们可以随心所欲替换 Dubbo 的功能点。比如你觉得 Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
+
+通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件:**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
+
+### 关于 Dubbo 架构的一些自测小问题
+
+#### 注册中心的作用了解么?
+
+注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互。
+
+#### 服务提供者宕机后,注册中心会做什么?
+
+注册中心会立即推送事件通知消费者。
+
+#### 监控中心的作用呢?
+
+监控中心负责统计各服务调用次数,调用时间等。
+
+#### 注册中心和监控中心都宕机的话,服务都会挂掉吗?
+
+不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
+
+## Dubbo 的负载均衡策略
+
+### 什么是负载均衡?
+
+先来看一下稍微官方点的解释。下面这段话摘自维基百科对负载均衡的定义:
+
+> 负载均衡改善了跨多个计算资源(例如计算机,计算机集群,网络链接,中央处理单元或磁盘驱动)的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间,并避免任何单个资源的过载。使用具有负载平衡而不是单个组件的多个组件可以通过冗余提高可靠性和可用性。负载平衡通常涉及专用软件或硬件。
+
+**上面讲的大家可能不太好理解,再用通俗的话给大家说一下。**
+
+我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡的这四个字就能明显感受到它的意义。
+
+### Dubbo 提供的负载均衡策略有哪些?
+
+在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 `random` 随机调用。我们还可以自行扩展负载均衡策略(参考 Dubbo SPI 机制)。
+
+在 Dubbo 中,所有负载均衡实现类均继承自 `AbstractLoadBalance`,该类实现了 `LoadBalance` 接口,并封装了一些公共的逻辑。
+
+```java
+public abstract class AbstractLoadBalance implements LoadBalance {
+
+ static int calculateWarmupWeight(int uptime, int warmup, int weight) {
+ }
+
+ @Override
+ public Invoker select(List> invokers, URL url, Invocation invocation) {
+ }
+
+ protected abstract Invoker doSelect(List> invokers, URL url, Invocation invocation);
+
+
+ int getWeight(Invoker invoker, Invocation invocation) {
+
+ }
+}
+```
+
+`AbstractLoadBalance` 的实现类有下面这些:
+
+
+
+The official document introduces this part of load balancing in great detail. It is recommended that friends take a look at the address: [https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance).
+
+#### RandomLoadBalance
+
+Random selection based on weights (an implementation of the weighted random algorithm). This is a load balancing strategy adopted by Dubbo by default.
+
+The specific implementation principle of `RandomLoadBalance` is very simple. Suppose there are two servers S1 and S2 that provide the same service. The weight of S1 is 7 and the weight of S2 is 3.
+
+When we distribute these weight values in the coordinate interval, we will get: S1->[0, 7), S2->[7, 10). We generate a random number between [0, 10), and when the random number falls into the corresponding interval, we select the corresponding server to handle the request.
+
+
+
+The source code of `RandomLoadBalance` is very simple, just take a few minutes to look at it.
+
+> The following source code comes from the latest version 2.7.9 on the Dubbo master branch.
+
+```java
+public class RandomLoadBalance extends AbstractLoadBalance {
+
+ public static final String NAME = "random";
+
+ @Override
+ protected Invoker doSelect(List> invokers, URL url, Invocation invocation) {
+
+ int length = invokers.size();
+ boolean sameWeight = true;
+ int[] weights = new int[length];
+ int totalWeight = 0;
+ //The main function of the following for loop is to calculate the sum of the weights of all providers of the service totalWeight(),
+ // In addition, it will also check whether the weight of each service provider is the same
+ for (int i = 0; i < length; i++) {
+ int weight = getWeight(invokers.get(i), invocation);
+ totalWeight += weight;
+ weights[i] = totalWeight;
+ if (sameWeight && totalWeight != weight * (i + 1)) {
+ sameWeight = false;
+ }
+ }
+ if (totalWeight > 0 && !sameWeight) {
+ // Randomly generate a number in the range [0, totalWeight)
+ int offset = ThreadLocalRandom.current().nextInt(totalWeight);
+ // Determine which service provider range it will fall into
+ for (int i = 0; i < length; i++) {
+ if (offset < weights[i]) {
+ return invokers.get(i);
+ }
+ }
+
+ return invokers.get(ThreadLocalRandom.current().nextInt(length));
+ }
+
+}
+
+```
+
+#### LeastActiveLoadBalance
+
+`LeastActiveLoadBalance` literally translates to **least active number load balancing**.
+
+This name is a bit unintuitive. If you don’t read the official definition of active number carefully, you won’t know what this thing is for.
+
+Let me put it this way! In the initial state, the activity number of all service providers is 0 (specific methods of each service provider correspond to an activity number, which I will mention in the source code later). After each request is received, the activity number of the corresponding service provider is +1. When the request is processed, the activity number is -1.
+
+Therefore, **Dubbo believes that whoever has fewer active numbers will have faster processing speed and better performance. In this case, I will give priority to the request to the service provider with fewer active numbers. **
+
+**What if there are multiple service providers with equal active numbers? **
+
+Very simple, just go through `RandomLoadBalance` again.
+
+```java
+public class LeastActiveLoadBalance extends AbstractLoadBalance {
+
+ public static final String NAME = "leastactive";
+
+ @Override
+ protected Invoker doSelect(List> invokers, URL url, Invocation invocation) {
+ int length = invokers.size();
+ leastActive = -1;
+ leastCount = 0;
+ int[] leastIndexes = new int[length];
+ int[] weights = new int[length];
+ int totalWeight = 0;
+ int firstWeight = 0;
+ boolean sameWeight = true;
+ //The main function of this for loop is to traverse the invokers list and find the Invoker with the smallest active number
+ // If there are multiple Invokers with the same minimum active number, the subscripts of these Invokers in the invokers collection will also be recorded, their weights will be accumulated, and their weight values will be compared to see if they are equal.
+ for (int i = 0; i < length; i++) {
+ Invoker invoker = invokers.get(i);
+ // Get the active number corresponding to invoker
+ int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive();
+ int afterWarmup = getWeight(invoker, invocation);
+ weights[i] = afterWarmup;
+ if (leastActive == -1 || active < leastActive) {
+ leastActive = active;
+ leastCount = 1;
+ leastIndexes[0] = i;
+ totalWeight = afterWarmup;
+ firstWeight = afterWarmup;
+ sameWeight = true;
+ } else if (active == leastActive) {
+ leastIndexes[leastCount++] = i;
+ totalWeight += afterWarmup;
+ if (sameWeight && afterWarmup != firstWeight) {
+ sameWeight = false;
+ }
+ }
+ }
+ // If there is only one Invoker with the minimum active number, just return the Invoker directly.
+ if (leastCount == 1) {
+ return invokers.get(leastIndexes[0]);
+ }
+ // If there are multiple Invokers with the same minimum active number, but different weights between them
+ //The processing method here is consistent with RandomLoadBalance
+ if (!sameWeight && totalWeight > 0) {
+ int offsetWeight = ThreadLocalRandom.current().nextInt(totalWeight);
+ for (int i = 0; i < leastCount; i++) {
+ int leastIndex = leastIndexes[i];
+ offsetWeight -= weights[leastIndex];
+ if (offsetWeight < 0) {
+ return invokers.get(leastIndex);
+ }
+ }
+ }
+ return invokers.get(leastIndexes[ThreadLocalRandom.current().nextInt(leastCount)]);
+ }
+}```
+
+The activity number is saved through a `ConcurrentMap` in `RpcStatus`. According to the URL and the name of the method called by the service provider, we can get the corresponding activity number. That is to say, the activity number of each method in the service provider is independent of each other.
+
+```java
+public class RpcStatus {
+
+ private static final ConcurrentMap> METHOD_STATISTICS =
+ new ConcurrentHashMap>();
+
+ public static RpcStatus getStatus(URL url, String methodName) {
+ String uri = url.toIdentityString();
+ ConcurrentMap map = METHOD_STATISTICS.computeIfAbsent(uri, k -> new ConcurrentHashMap<>());
+ return map.computeIfAbsent(methodName, k -> new RpcStatus());
+ }
+ public int getActive() {
+ return active.get();
+ }
+
+}
+```
+
+#### ConsistentHashLoadBalance
+
+`ConsistentHashLoadBalance` Friends should be familiar with it. This load balancing strategy is often used in sub-databases, tables, and various clusters.
+
+`ConsistentHashLoadBalance` is the **consistent Hash load balancing strategy**. There is no concept of weight in `ConsistentHashLoadBalance`. Which service provider handles the request is determined by the parameters of your request. That is to say, requests with the same parameters are always sent to the same service provider.
+
+
+
+In addition, Dubbo also introduces the concept of virtual nodes in order to avoid data skew problems (nodes are not dispersed enough and a large number of requests fall on the same node). Virtual nodes can make nodes more dispersed and effectively balance the request volume of each node.
+
+
+
+The official has detailed source code analysis: [https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance). There is also a related [PR#5440](https://github.com/apache/dubbo/pull/5440) to fix some bugs in ConsistentHashLoadBalance in the old version. Interested friends can spend more time researching it. I won’t analyze any more here, I’ll leave this homework to you!
+
+#### RoundRobinLoadBalance
+
+Weighted round-robin load balancing.
+
+Polling is to assign requests to each service provider in turn. Weighted polling is based on polling, allowing more requests to fall on service providers with greater weight. For example, if there are two servers S1 and S2 that provide the same service, the weight of S1 is 7 and the weight of S2 is 3.
+
+If we have 10 requests, 7 will be processed by S1 and 3 by S2.
+
+However, if it is `RandomLoadBalance`, it is likely that 9 out of 10 requests will be processed by S1 (a probabilistic problem).
+
+The code implementation of `RoundRobinLoadBalance` in Dubbo has been modified and rebuilt several times. Dubbo-2.6.5 version of `RoundRobinLoadBalance` is a smooth weighted polling algorithm.
+
+## Dubbo serialization protocol
+
+### What serialization methods does Dubbo support?
+
+
+
+Dubbo supports multiple serialization methods: JDK's own serialization, hessian2, JSON, Kryo, FST, Protostuff, ProtoBuf, etc.
+
+The default serialization method used by Dubbo is hessian2.
+
+### Tell us what you know about these serialization protocols?
+
+Generally we do not directly use the serialization method that comes with the JDK. There are two main reasons:
+
+1. **Cross-language calling is not supported**: If you are calling services developed in other languages, it is not supported.
+2. **Poor performance**: Compared with other serialization frameworks, the performance is lower. The main reason is that the byte array after serialization is larger in size, resulting in increased transmission costs.
+
+We generally do not consider using JSON serialization due to performance issues.
+
+Protostuff, ProtoBuf, and hessian2 are all cross-language serialization methods. You can consider using them if you have cross-language requirements.
+
+The two serialization methods Kryo and FST were introduced by Dubbo later and have very good performance. However, both are specific to the Java language. An article on the Dubbo official website mentioned that it is recommended to use Kryo as the serialization method for production environments.
+
+There is also a performance comparison chart of these [serialization protocols] (https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization) in Dubbo’s official documentation for reference.
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/rpc/http&rpc.en.md b/docs_en/distributed-system/rpc/http&rpc.en.md
new file mode 100644
index 00000000000..a8e5e4491de
--- /dev/null
+++ b/docs_en/distributed-system/rpc/http&rpc.en.md
@@ -0,0 +1,197 @@
+---
+title: 有了 HTTP 协议,为什么还要有 RPC ?
+category: 分布式
+tag:
+ - rpc
+---
+
+> 本文来自[小白 debug](https://juejin.cn/user/4001878057422087)投稿,原文: 。
+
+我想起了我刚工作的时候,第一次接触 RPC 协议,当时就很懵,我 HTTP 协议用的好好的,为什么还要用 RPC 协议?
+
+于是就到网上去搜。
+
+不少解释显得非常官方,我相信大家在各种平台上也都看到过,解释了又好像没解释,都在**用一个我们不认识的概念去解释另外一个我们不认识的概念**,懂的人不需要看,不懂的人看了还是不懂。
+
+这种看了,又好像没看的感觉,云里雾里的很难受,**我懂**。
+
+为了避免大家有强烈的**审丑疲劳**,今天我们来尝试重新换个方式讲一讲。
+
+## 从 TCP 聊起
+
+作为一个程序员,假设我们需要在 A 电脑的进程发一段数据到 B 电脑的进程,我们一般会在代码里使用 socket 进行编程。
+
+这时候,我们可选项一般也就**TCP 和 UDP 二选一。TCP 可靠,UDP 不可靠。** 除非是马总这种神级程序员(早期 QQ 大量使用 UDP),否则,只要稍微对可靠性有些要求,普通人一般无脑选 TCP 就对了。
+
+类似下面这样。
+
+```ini
+fd = socket(AF_INET,SOCK_STREAM,0);
+```
+
+其中`SOCK_STREAM`,是指使用**字节流**传输数据,说白了就是**TCP 协议**。
+
+在定义了 socket 之后,我们就可以愉快的对这个 socket 进行操作,比如用`bind()`绑定 IP 端口,用`connect()`发起建连。
+
+
+
+在连接建立之后,我们就可以使用`send()`发送数据,`recv()`接收数据。
+
+光这样一个纯裸的 TCP 连接,就可以做到收发数据了,那是不是就够了?
+
+不行,这么用会有问题。
+
+## 使用纯裸 TCP 会有什么问题
+
+八股文常背,TCP 是有三个特点,**面向连接**、**可靠**、基于**字节流**。
+
+
+
+这三个特点真的概括的 **非常精辟** ,这个八股文我们没白背。
+
+每个特点展开都能聊一篇文章,而今天我们需要关注的是 **基于字节流** 这一点。
+
+字节流可以理解为一个双向的通道里流淌的二进制数据,也就是 **01 串** 。纯裸 TCP 收发的这些 01 串之间是 **没有任何边界** 的,你根本不知道到哪个地方才算一条完整消息。
+
+
+
+正因为这个没有任何边界的特点,所以当我们选择使用 TCP 发送 **"夏洛"和"特烦恼"** 的时候,接收端收到的就是 **"夏洛特烦恼"** ,这时候接收端没发区分你是想要表达 **"夏洛"+"特烦恼"** 还是 **"夏洛特"+"烦恼"** 。
+
+
+
+这就是所谓的 **粘包问题**,之前也写过一篇专门的[文章](https://mp.weixin.qq.com/s/0-YBxU1cSbDdzcZEZjmQYA)聊过这个问题。
+
+说这个的目的是为了告诉大家,纯裸 TCP 是不能直接拿来用的,你需要在这个基础上加入一些 **自定义的规则** ,用于区分 **消息边界** 。
+
+于是我们会把每条要发送的数据都包装一下,比如加入 **消息头** ,消息头里写清楚一个完整的包长度是多少,根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的 **消息体** 。
+
+
+
+而这里头提到的 **消息头** ,还可以放各种东西,比如消息体是否被压缩过和消息体格式之类的,只要上下游都约定好了,互相都认就可以了,这就是所谓的 **协议。**
+
+每个使用 TCP 的项目都可能会定义一套类似这样的协议解析标准,他们可能 **有区别,但原理都类似**。
+
+**于是基于 TCP,就衍生了非常多的协议,比如 HTTP 和 RPC。**
+
+## HTTP 和 RPC
+
+### RPC 其实是一种调用方式
+
+我们回过头来看网络的分层图。
+
+
+
+**TCP 是传输层的协议** ,而基于 TCP 造出来的 HTTP 和各类 RPC 协议,它们都只是定义了不同消息格式的 **应用层协议** 而已。
+
+**HTTP**(**H**yper **T**ext **T**ransfer **P**rotocol)协议又叫做 **超文本传输协议** 。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。
+
+
+
+而 **RPC**(**R**emote **P**rocedure **C**all)又叫做 **远程过程调用**,它本身并不是一个具体的协议,而是一种 **调用方式** 。
+
+举个例子,我们平时调用一个 **本地方法** 就像下面这样。
+
+```ini
+ res = localFunc(req)
+```
+
+如果现在这不是个本地方法,而是个**远端服务器**暴露出来的一个方法`remoteFunc`,如果我们还能像调用本地方法那样去调用它,这样就可以**屏蔽掉一些网络细节**,用起来更方便,岂不美哉?
+
+```ini
+res = remoteFunc(req)
+```
+
+
+
+基于这个思路,大佬们造出了非常多款式的 RPC 协议,比如比较有名的`gRPC`,`thrift`。
+
+值得注意的是,虽然大部分 RPC 协议底层使用 TCP,但实际上 **它们不一定非得使用 TCP,改用 UDP 或者 HTTP,其实也可以做到类似的功能。**
+
+到这里,我们回到文章标题的问题。
+
+### 那既然有 RPC 了,为什么还要有 HTTP 呢?
+
+其实,TCP 是 **70 年** 代出来的协议,而 HTTP 是 **90 年代** 才开始流行的。而直接使用裸 TCP 会有问题,可想而知,这中间这么多年有多少自定义的协议,而这里面就有 **80 年代** 出来的`RPC`。
+
+所以我们该问的不是 **既然有 HTTP 协议为什么要有 RPC** ,而是 **为什么有 RPC 还要有 HTTP 协议?**
+
+现在电脑上装的各种联网软件,比如 xx 管家,xx 卫士,它们都作为客户端(Client) 需要跟服务端(Server) 建立连接收发消息,此时都会用到应用层协议,在这种 Client/Server (C/S) 架构下,它们可以使用自家造的 RPC 协议,因为它只管连自己公司的服务器就 ok 了。
+
+但有个软件不同,浏览器(Browser) ,不管是 Chrome 还是 IE,它们不仅要能访问自家公司的**服务器(Server)** ,还需要访问其他公司的网站服务器,因此它们需要有个统一的标准,不然大家没法交流。于是,HTTP 就是那个时代用于统一 **Browser/Server (B/S)** 的协议。
+
+也就是说在多年以前,**HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。** 很多软件同时支持多端,比如某度云盘,既要支持**网页版**,还要支持**手机端和 PC 端**,如果通信协议都用 HTTP 的话,那服务器只用同一套就够了。而 RPC 就开始退居幕后,一般用于公司内部集群里,各个微服务之间的通讯。
+
+那这么说的话,**都用 HTTP 得了,还用什么 RPC?**
+
+仿佛又回到了文章开头的样子,那这就要从它们之间的区别开始说起。
+
+### HTTP 和 RPC 有什么区别
+
+我们来看看 RPC 和 HTTP 区别比较明显的几个点。
+
+#### 服务发现
+
+首先要向某个服务器发起请求,你得先建立连接,而建立连接的前提是,你得知道 **IP 地址和端口** 。这个找到服务对应的 IP 端口的过程,其实就是 **服务发现**。
+
+在 **HTTP** 中,你知道服务的域名,就可以通过 **DNS 服务** 去解析得到它背后的 IP 地址,默认 **80 端口**。
+
+而 **RPC** 的话,就有些区别,一般会有专门的中间服务去保存服务名和 IP 信息,比如 **Consul、Etcd、Nacos、ZooKeeper,甚至是 Redis**。想要访问某个服务,就去这些中间服务去获得 IP 和端口信息。由于 DNS 也是服务发现的一种,所以也有基于 DNS 去做服务发现的组件,比如 **CoreDNS**。
+
+可以看出服务发现这一块,两者是有些区别,但不太能分高低。
+
+#### 底层连接形式
+
+以主流的 **HTTP1.1** 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接(**keep alive**),之后的请求和响应都会复用这条连接。
+
+而 **RPC** 协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 协议一般还会再建个 **连接池**,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。
+
+
+
+由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池,比如 Go 就是这么干的。
+
+可以看出这一块两者也没太大区别,所以也不是关键。
+
+#### 传输的内容
+
+基于 TCP 传输的消息,说到底,无非都是 **消息头 Header 和消息体 Body。**
+
+**Header** 是用于标记一些特殊信息,其中最重要的是 **消息体长度**。
+
+**Body** 则是放我们真正需要传输的内容,而这些内容只能是二进制 01 串,毕竟计算机只认识这玩意。所以 TCP 传字符串和数字都问题不大,因为字符串可以转成编码再变成 01 串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制 01 串,这样的方案现在也有很多现成的,比如 **JSON,Protocol Buffers (Protobuf)** 。
+
+这个将结构体转为二进制数组的过程就叫 **序列化** ,反过来将二进制数组复原成结构体的过程叫 **反序列化**。
+
+
+
+对于主流的 HTTP1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计 初是用于做网页文本展示的,所以它传的内容以字符串为主。Header 和 Body 都是如此。在 Body 这块,它使用 **JSON** 来 **序列化** 结构体数据。
+
+我们可以随便截个图直观看下。
+
+
+
+可以看到这里面的内容非常多的冗余,显得非常啰嗦。最明显的,像 Header 里的那些信息,其实如果我们约定好头部的第几位是 `Content-Type`,就不需要每次都真的把 `Content-Type` 这个字段都传过来,类似的情况其实在 Body 的 JSON 结构里也特别明显。
+
+而 RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。**因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。**
+
+
+
+
+
+当然上面说的 HTTP,其实 **特指的是现在主流使用的 HTTP1.1**,`HTTP2`在前者的基础上做了很多改进,所以 **性能可能比很多 RPC 协议还要好**,甚至连`gRPC`底层都直接用的`HTTP2`。
+
+那么问题又来了。
+
+### 为什么既然有了 HTTP2,还要有 RPC 协议?
+
+这个是由于 HTTP2 是 2015 年出来的。那时候很多公司内部的 RPC 协议都已经跑了好些年了,基于历史原因,一般也没必要去换了。
+
+## 总结
+
+- 纯裸 TCP 是能收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义 **消息边界** 。于是就有了各种协议,HTTP 和各类 RPC 协议就是在 TCP 之上定义的应用层协议。
+- **RPC 本质上不算是协议,而是一种调用方式**,而像 gRPC 和 Thrift 这样的具体实现,才是协议,它们是实现了 RPC 调用的协议。目的是希望程序员能像调用本地方法那样去调用远端的服务方法。同时 RPC 有很多种实现方式,**不一定非得基于 TCP 协议**。
+- 从发展历史来说,**HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。** 很多软件同时支持多端,所以对外一般用 HTTP 协议,而内部集群的微服务之间则采用 RPC 协议进行通讯。
+- RPC 其实比 HTTP 出现的要早,且比目前主流的 HTTP1.1 性能要更好,所以大部分公司内部都还在使用 RPC。
+- **HTTP2.0** 在 **HTTP1.1** 的基础上做了优化,性能可能比很多 RPC 协议都要好,但由于是这几年才出来的,所以也不太可能取代掉 RPC。
+
+
+
diff --git a/docs_en/distributed-system/rpc/rpc-intro.en.md b/docs_en/distributed-system/rpc/rpc-intro.en.md
new file mode 100644
index 00000000000..10b28b2f1ac
--- /dev/null
+++ b/docs_en/distributed-system/rpc/rpc-intro.en.md
@@ -0,0 +1,140 @@
+---
+title: RPC基础知识总结
+category: 分布式
+tag:
+ - rpc
+---
+
+这篇文章会简单介绍一下 RPC 相关的基础概念。
+
+## RPC 是什么?
+
+**RPC(Remote Procedure Call)** 即远程过程调用,通过名字我们就能看出 RPC 关注的是远程调用而非本地调用。
+
+**为什么要 RPC ?** 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
+
+**RPC 能帮助我们做什么呢?** 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
+
+举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
+
+一言蔽之:**RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。**
+
+## RPC 的原理是什么?
+
+为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
+
+1. **客户端(服务消费端)**:调用远程方法的一端。
+1. **客户端 Stub(桩)**:这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
+1. **网络传输**:网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
+1. **服务端 Stub(桩)**:这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
+1. **服务端(服务提供端)**:提供远程方法的一端。
+
+具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
+
+
+
+1. 服务消费端(client)以本地调用的方式调用远程服务;
+1. 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):`RpcRequest`;
+1. 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
+1. 服务端 Stub(桩)收到消息将消息反序列化为 Java 对象: `RpcRequest`;
+1. 服务端 Stub(桩)根据`RpcRequest`中的类、方法、方法参数等信息调用本地的方法;
+1. 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:`RpcResponse`(序列化)发送至消费方;
+1. 客户端 Stub(client stub)接收到消息并将消息反序列化为 Java 对象:`RpcResponse` ,这样也就得到了最终结果。over!
+
+相信小伙伴们看完上面的讲解之后,已经了解了 RPC 的原理。
+
+虽然篇幅不多,但是基本把 RPC 框架的核心原理讲清楚了!另外,对于上面的技术细节,我会在后面的章节介绍到。
+
+**最后,对于 RPC 的原理,希望小伙伴不单单要理解,还要能够自己画出来并且能够给别人讲出来。因为,在面试中这个问题在面试官问到 RPC 相关内容的时候基本都会碰到。**
+
+## 有哪些常见的 RPC 框架?
+
+我们这里说的 RPC 框架指的是可以让客户端直接调用服务端方法,就像调用本地方法一样简单的框架,比如我下面介绍的 Dubbo、Motan、gRPC 这些。 如果需要和 HTTP 协议打交道,解析和封装 HTTP 请求和响应。这类框架并不能算是“RPC 框架”,比如 Feign。
+
+### Dubbo
+
+
+
+Apache Dubbo 是一款微服务框架,为大规模微服务实践提供高性能 RPC 通信、流量治理、可观测性等解决方案,
+涵盖 Java、Golang 等多种语言 SDK 实现。
+
+Dubbo 提供了从服务定义、服务发现、服务通信到流量管控等几乎所有的服务治理能力,支持 Triple 协议(基于 HTTP/2 之上定义的下一代 RPC 通信协议)、应用级服务发现、Dubbo Mesh (Dubbo3 赋予了很多云原生友好的新特性)等特性。
+
+
+
+Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
+
+Dubbo 算的是比较优秀的国产开源项目了,它的源码也是非常值得学习和阅读的!
+
+- GitHub:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo "https://github.com/apache/incubator-dubbo")
+- 官网:
+
+### Motan
+
+Motan 是新浪微博开源的一款 RPC 框架,据说在新浪微博正支撑着千亿次调用。不过笔者倒是很少看到有公司使用,而且网上的资料也比较少。
+
+很多人喜欢拿 Motan 和 Dubbo 作比较,毕竟都是国内大公司开源的。笔者在查阅了很多资料,以及简单查看了其源码之后发现:**Motan 更像是一个精简版的 Dubbo,可能是借鉴了 Dubbo 的思想,Motan 的设计更加精简,功能更加纯粹。**
+
+不过,我不推荐你在实际项目中使用 Motan。如果你要是公司实际使用的话,还是推荐 Dubbo ,其社区活跃度以及生态都要好很多。
+
+- 从 Motan 看 RPC 框架设计:[http://kriszhang.com/motan-rpc-impl/](http://kriszhang.com/motan-rpc-impl/ "http://kriszhang.com/motan-rpc-impl/")
+- Motan 中文文档:[https://github.com/weibocom/motan/wiki/zh_overview](https://github.com/weibocom/motan/wiki/zh_overview "https://github.com/weibocom/motan/wiki/zh_overview")
+
+### gRPC
+
+
+
+gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2 协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
+
+**何谓 ProtoBuf?** [ProtoBuf( Protocol Buffer)](https://github.com/protocolbuffers/protobuf) 是一种更加灵活、高效的数据格式,可用于通讯协议、数据存储等领域,基本支持所有主流编程语言且与平台无关。不过,通过 ProtoBuf 定义接口和数据类型还挺繁琐的,这是一个小问题。
+
+
+
+不得不说,gRPC 的通信层的设计还是非常优秀的,[Dubbo-go 3.0](https://dubbogo.github.io/) 的通信层改进主要借鉴了 gRPC。
+
+不过,gRPC 的设计导致其几乎没有服务治理能力。如果你想要解决这个问题的话,就需要依赖其他组件比如腾讯的 PolarisMesh(北极星)了。
+
+- GitHub:[https://github.com/grpc/grpc](https://github.com/grpc/grpc "https://github.com/grpc/grpc")
+- 官网:[https://grpc.io/](https://grpc.io/ "https://grpc.io/")
+
+### Thrift
+Apache Thrift is Facebook's open source cross-language RPC communication framework. It has been donated to the Apache Foundation for management. Due to its cross-language features and excellent performance, it is used by many Internet companies. Competent companies will even develop a distributed service framework based on Thrift to add functions such as service registration and service discovery.
+
+`Thrift` supports a variety of **programming languages**, including `C++`, `Java`, `Python`, `PHP`, `Ruby`, etc. (compared to gRPC, it supports more languages).
+
+- Official website: [https://thrift.apache.org/](https://thrift.apache.org/ "https://thrift.apache.org/")
+- Brief introduction to Thrift: [https://www.jianshu.com/p/8f25d057a5a9](https://www.jianshu.com/p/8f25d057a5a9 "https://www.jianshu.com/p/8f25d057a5a9")
+
+### Summary
+
+Although gRPC and Thrift support cross-language RPC calls, they only provide the most basic RPC framework functions and lack the support of a series of supporting service components and service governance functions.
+
+Dubbo is the best in terms of functionality, ecosystem, and community activity. Moreover, Dubbo has many successful cases in China such as Dangdang, Didi, etc. It is a mature and stable RPC framework that can withstand the test of production. The most important thing is that you can also find a lot of Dubbo reference materials, and the learning cost is relatively low.
+
+The diagram below shows Dubbo’s ecosystem.
+
+
+
+Dubbo is also a component in Spring Cloud Alibaba.
+
+
+
+However, Dubbo and Motan are mainly used by the Java language. Although Dubbo and Motan are currently compatible with some languages, they are not recommended. If you need to call across multiple languages, consider using gRPC.
+
+In summary, if it is a Java back-end technology stack and you are struggling with which RPC framework to choose, I recommend you to consider Dubbo.
+
+## How to design and implement an RPC framework?
+
+**"Handwritten RPC Framework"** is an internal booklet of my [Knowledge Planet] (https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html). I wrote 12 articles to explain how to implement a simple RPC framework from scratch based on Netty+Kyro+Zookeeper.
+
+Although Sparrow is small, it has all the necessary features. The project code has detailed comments and clear structure. It also integrates the Check Style standard code structure, making it very suitable for reading and learning.
+
+**Content Overview**:
+
+
+
+## Now that we have the HTTP protocol, why do we need RPC?
+
+For a detailed answer to this question, please see this article: [With HTTP protocol, why do we need RPC? ](http&rpc.md) .
+
+
\ No newline at end of file
diff --git a/docs_en/distributed-system/spring-cloud-gateway-questions.en.md b/docs_en/distributed-system/spring-cloud-gateway-questions.en.md
new file mode 100644
index 00000000000..f55eaf16c2e
--- /dev/null
+++ b/docs_en/distributed-system/spring-cloud-gateway-questions.en.md
@@ -0,0 +1,157 @@
+---
+title: Spring Cloud Gateway常见问题总结
+category: 分布式
+---
+
+> 本文重构完善自[6000 字 | 16 图 | 深入理解 Spring Cloud Gateway 的原理 - 悟空聊架构](https://mp.weixin.qq.com/s/XjFYsP1IUqNzWqXZdJn-Aw)这篇文章。
+
+## 什么是 Spring Cloud Gateway?
+
+Spring Cloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**。准确点来说,应该是 Zuul 1.x。Spring Cloud Gateway 起步要比 Zuul 2.x 更早。
+
+为了提升网关的性能,Spring Cloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现同步非阻塞的 I/O。
+
+
+
+Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,限流。
+
+Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
+
+- GitHub 地址:
+- 官网:
+
+## Spring Cloud Gateway 的工作流程?
+
+Spring Cloud Gateway 的工作流程如下图所示:
+
+
+
+这是 Spring 官方博客中的一张图,原文地址:。
+
+具体的流程分析:
+
+1. **路由判断**:客户端的请求到达网关后,先经过 Gateway Handler Mapping 处理,这里面会做断言(Predicate)判断,看下符合哪个路由规则,这个路由映射后端的某个服务。
+2. **请求过滤**:然后请求到达 Gateway Web Handler,这里面有很多过滤器,组成过滤器链(Filter Chain),这些过滤器可以对请求进行拦截和修改,比如添加请求头、参数校验等等,有点像净化污水。然后将请求转发到实际的后端服务。这些过滤器逻辑上可以称作 Pre-Filters,Pre 可以理解为“在...之前”。
+3. **服务处理**:后端服务会对请求进行处理。
+4. **响应过滤**:后端处理完结果后,返回给 Gateway 的过滤器再次做处理,逻辑上可以称作 Post-Filters,Post 可以理解为“在...之后”。
+5. **响应返回**:响应经过过滤处理后,返回给客户端。
+
+总结:客户端的请求先通过匹配规则找到合适的路由,就能映射到具体的服务。然后请求经过过滤器处理后转发给具体的服务,服务处理后,再次经过过滤器处理,最后返回给客户端。
+
+## Spring Cloud Gateway 的断言是什么?
+
+断言(Predicate)这个词听起来极其深奥,它是一种编程术语,我们生活中根本就不会用它。说白了它就是对一个表达式进行 if 判断,结果为真或假,如果为真则做这件事,否则做那件事。
+
+在 Gateway 中,如果客户端发送的请求满足了断言的条件,则映射到指定的路由器,就能转发到指定的服务上进行处理。
+
+断言配置的示例如下,配置了两个路由规则,有一个 predicates 断言配置,当请求 url 中包含 `api/thirdparty`,就匹配到了第一个路由 `route_thirdparty`。
+
+
+
+常见的路由断言规则如下图所示:
+
+
+
+## Spring Cloud Gateway 的路由和断言是什么关系?
+
+Route 路由和 Predicate 断言的对应关系如下::
+
+
+
+- **一对多**:一个路由规则可以包含多个断言。如上图中路由 Route1 配置了三个断言 Predicate。
+- **同时满足**:如果一个路由规则中有多个断言,则需要同时满足才能匹配。如上图中路由 Route2 配置了两个断言,客户端发送的请求必须同时满足这两个断言,才能匹配路由 Route2。
+- **第一个匹配成功**:如果一个请求可以匹配多个路由,则映射第一个匹配成功的路由。如上图所示,客户端发送的请求满足 Route3 和 Route4 的断言,但是 Route3 的配置在配置文件中靠前,所以只会匹配 Route3。
+
+## Spring Cloud Gateway 如何实现动态路由?
+
+在使用 Spring Cloud Gateway 的时候,官方文档提供的方案总是基于配置文件或代码配置的方式。
+
+Spring Cloud Gateway 作为微服务的入口,需要尽量避免重启,而现在配置更改需要重启服务不能满足实际生产过程中的动态刷新、实时变更的业务需求,所以我们需要在 Spring Cloud Gateway 运行时动态配置网关。
+
+实现动态路由的方式有很多种,其中一种推荐的方式是基于 Nacos 注册中心来做。 Spring Cloud Gateway 可以从注册中心获取服务的元数据(例如服务名称、路径等),然后根据这些信息自动生成路由规则。这样,当你添加、移除或更新服务实例时,网关会自动感知并相应地调整路由规则,无需手动维护路由配置。
+
+其实这些复杂的步骤并不需要我们手动实现,通过 Nacos Server 和 Spring Cloud Alibaba Nacos Config 即可实现配置的动态变更,官方文档地址: 。
+
+## Spring Cloud Gateway 的过滤器有哪些?
+
+过滤器 Filter 按照请求和响应可以分为两种:
+
+- **Pre 类型**:在请求被转发到微服务之前,对请求进行拦截和修改,例如参数校验、权限校验、流量监控、日志输出以及协议转换等操作。
+- **Post 类型**:微服务处理完请求后,返回响应给网关,网关可以再次进行处理,例如修改响应内容或响应头、日志输出、流量监控等。
+
+另外一种分类是按照过滤器 Filter 作用的范围进行划分:
+
+- **GatewayFilter**:局部过滤器,应用在单个路由或一组路由上的过滤器。标红色表示比较常用的过滤器。
+- **GlobalFilter**:全局过滤器,应用在所有路由上的过滤器。
+
+### 局部过滤器
+
+常见的局部过滤器如下图所示:
+
+
+
+具体怎么用呢?这里有个示例,如果 URL 匹配成功,则去掉 URL 中的 “api”。
+
+```yaml
+filters: #过滤器
+ - RewritePath=/api/(?.*),/$\{segment} # 将跳转路径中包含的 “api” 替换成空
+```
+
+Of course, we can also customize filters, which we will not expand on in this article.
+
+### Global filter
+
+Common global filters are shown below:
+
+
+
+The most common use of global filters is for load balancing. The configuration is as follows:
+
+```yaml
+spring:
+ cloud:
+ gateway:
+ routes:
+ - id: route_member # Third-party microservice routing rules
+ uri: lb://passjava-member # Load balancing, forward the request to the passjava-member service registered in the registration center
+ predicates: # assertion
+ - Path=/api/member/** # If the front-end request path contains api/member, this routing rule will be applied
+ filters: #Filter
+ - RewritePath=/api/(?.*),/$\{segment} # Replace the api contained in the jump path with empty
+```
+
+There is a keyword `lb` here, which uses the global filter `LoadBalancerClientFilter`. When this route is matched, the request will be forwarded to the passjava-member service, and load balancing forwarding is supported, that is, passjava-member is first parsed into the host and port of the actual microservice, and then forwarded to the actual microservice.
+
+## Does Spring Cloud Gateway support current limiting?
+
+Spring Cloud Gateway comes with a current limiting filter, and the corresponding interface is `RateLimiter`. The `RateLimiter` interface has only one implementation class `RedisRateLimiter` (current limiting based on Redis + Lua). The current limiting function provided is relatively simple and difficult to use.
+
+Starting from Sentinel version 1.6.0, Sentinel has introduced the Spring Cloud Gateway adaptation module, which can provide current limiting in two resource dimensions: route dimension and custom API dimension. In other words, Spring Cloud Gateway can be combined with Sentinel to achieve more powerful gateway traffic control.
+
+## How does Spring Cloud Gateway customize global exception handling?
+
+In the SpringBoot project, to catch global exceptions, we only need to configure `@RestControllerAdvice` and `@ExceptionHandler` in the project. However, this method is not applicable under Spring Cloud Gateway.
+
+Spring Cloud Gateway provides a variety of global processing methods. The more commonly used one is to implement `ErrorWebExceptionHandler` and rewrite the `handle` method in it.
+
+```java
+@Order(-1)
+@Component
+@RequiredArgsConstructor
+public class GlobalErrorWebExceptionHandler implements ErrorWebExceptionHandler {
+ private final ObjectMapper objectMapper;
+
+ @Override
+ public Mono handle(ServerWebExchange exchange, Throwable ex) {
+ // ...
+ }
+}
+```
+
+## Reference
+
+- Spring Cloud Gateway official documentation:
+- Creating a custom Spring Cloud Gateway Filter:
+- Global exception handling:
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/fallback-and-circuit-breaker.en.md b/docs_en/high-availability/fallback-and-circuit-breaker.en.md
new file mode 100644
index 00000000000..3c8c5a6c967
--- /dev/null
+++ b/docs_en/high-availability/fallback-and-circuit-breaker.en.md
@@ -0,0 +1,13 @@
+---
+title: Detailed explanation of downgrade and circuit breaker (paid)
+category: high availability
+icon: circuit
+---
+
+**Downgrade & Circuit Breaker** The relevant interview questions are exclusive to my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click on the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide North"](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/high-availability-system-design.en.md b/docs_en/high-availability/high-availability-system-design.en.md
new file mode 100644
index 00000000000..b2ceaef044e
--- /dev/null
+++ b/docs_en/high-availability/high-availability-system-design.en.md
@@ -0,0 +1,72 @@
+---
+title: 高可用系统设计指南
+category: 高可用
+icon: design
+---
+
+## 什么是高可用?可用性的判断标准是啥?
+
+高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
+
+一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。
+
+除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
+
+## 哪些情况会导致系统不可用?
+
+1. 黑客攻击;
+2. 硬件故障,比如服务器坏掉。
+3. 并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用。
+4. 代码中的坏味道导致内存泄漏或者其他问题导致程序挂掉。
+5. 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用。
+6. 自然灾害或者人为破坏。
+7. ……
+
+## 有哪些提高系统可用性的方法?
+
+### 注重代码质量,测试严格把关
+
+我觉得这个是最最最重要的,代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。大家都喜欢谈限流、降级、熔断,但是我觉得从代码质量这个源头把关是首先要做好的一件很重要的事情。如何提高代码质量?比较实际可用的就是 CodeReview,不要在乎每天多花的那 1 个小时左右的时间,作用可大着呢!
+
+另外,安利几个对提高代码质量有实际效果的神器:
+
+- [Sonarqube](https://www.sonarqube.org/);
+- Alibaba 开源的 Java 诊断工具 [Arthas](https://arthas.aliyun.com/doc/);
+- [阿里巴巴 Java 代码规范](https://github.com/alibaba/p3c)(Alibaba Java Code Guidelines);
+- IDEA 自带的代码分析等工具。
+
+### 使用集群,减少单点故障
+
+先拿常用的 Redis 举个例子!我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。
+
+### 限流
+
+流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。——来自 [alibaba-Sentinel](https://github.com/alibaba/Sentinel "Sentinel") 的 wiki。
+
+### 超时和重试机制设置
+
+一旦用户请求超过某个时间的得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为没有进行超时设置或者超时设置的方式不对导致的。我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。
+
+### 熔断机制
+
+超时和重试机制设置之外,熔断机制也是很重要的。 熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。 比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。
+
+### 异步调用
+
+异步调用的话我们不需要关心最后的结果,这样我们就可以用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是蛮多的。但是,使用异步之后我们可能需要 **适当修改业务流程进行配合**,比如**用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**。除了可以在程序中实现异步之外,我们常常还使用消息队列,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。
+
+### 使用缓存
+
+如果我们的系统属于并发量比较高的话,如果我们单纯使用数据库的话,当大量请求直接落到数据库可能数据库就会直接挂掉。使用缓存缓存热点数据,因为缓存存储在内存中,所以速度相当地快!
+
+### 其他
+
+- **核心应用和服务优先使用更好的硬件**
+- **监控系统资源使用情况增加报警设置。**
+- **注意备份,必要时候回滚。**
+- **灰度发布:** 将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可
+- **定期检查/更换硬件:** 如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。
+- ……
+
+
+
diff --git a/docs_en/high-availability/idempotency.en.md b/docs_en/high-availability/idempotency.en.md
new file mode 100644
index 00000000000..a2c7c7ab4b8
--- /dev/null
+++ b/docs_en/high-availability/idempotency.en.md
@@ -0,0 +1,13 @@
+---
+title: Summary of interface idempotent solutions (paid)
+category: high availability
+icon: security-fill
+---
+
+**Interface Idempotent** The related interview questions are exclusive to my [Knowledge Planet](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html) (click the link to view the detailed introduction and how to join), which has been compiled into ["Java Interview Guide North"](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html).
+
+
+
+
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/limit-request.en.md b/docs_en/high-availability/limit-request.en.md
new file mode 100644
index 00000000000..bf28639b8b0
--- /dev/null
+++ b/docs_en/high-availability/limit-request.en.md
@@ -0,0 +1,296 @@
+---
+title: 服务限流详解
+category: 高可用
+icon: limit_rate
+---
+
+针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。毕竟,软件系统的处理能力是有限的。如果说超过了其处理能力的范围,软件系统可能直接就挂掉了。
+
+限流可能会导致用户的请求无法被正确处理或者无法立即被处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
+
+现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
+
+## 常见限流算法有哪些?
+
+简单介绍 4 种非常好理解并且容易实现的限流算法!
+
+> 图片来源于 InfoQ 的一篇文章[《分布式服务限流实战,已经为你排好坑了》](https://www.infoq.cn/article/Qg2tX8fyw5Vt-f3HH673)。
+
+### 固定窗口计数器算法
+
+固定窗口其实就是时间窗口,其原理是将时间划分为固定大小的窗口,在每个窗口内限制请求的数量或速率,即固定窗口计数器算法规定了系统单位时间处理的请求数量。
+
+假如我们规定系统中某个接口 1 分钟只能被访问 33 次的话,使用固定窗口计数器算法的实现思路如下:
+
+- 将时间划分固定大小窗口,这里是 1 分钟一个窗口。
+- 给定一个变量 `counter` 来记录当前接口处理的请求数量,初始值为 0(代表接口当前 1 分钟内还未处理请求)。
+- 1 分钟之内每处理一个请求之后就将 `counter+1` ,当 `counter=33` 之后(也就是说在这 1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。
+- 等到 1 分钟结束后,将 `counter` 重置 0,重新开始计数。
+
+
+
+优点:实现简单,易于理解。
+
+缺点:
+
+- 限流不够平滑。例如,我们限制某个接口每分钟只能访问 30 次,假设前 30 秒就有 30 个请求到达的话,那后续 30 秒将无法处理请求,这是不可取的,用户体验极差!
+- 无法保证限流速率,因而无法应对突然激增的流量。例如,我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
+
+### 滑动窗口计数器算法
+
+**滑动窗口计数器算法** 算的上是固定窗口计数器算法的升级版,限流的颗粒度更小。
+
+滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:**它把时间以一定比例分片** 。
+
+例如我们的接口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理不大于 `60(请求数)/60(窗口数)` 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
+
+很显然, **当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。**
+
+
+
+优点:
+
+- 相比于固定窗口算法,滑动窗口计数器算法可以应对突然激增的流量。
+- 相比于固定窗口算法,滑动窗口计数器算法的颗粒度更小,可以提供更精确的限流控制。
+
+缺点:
+
+- 与固定窗口计数器算法类似,滑动窗口计数器算法依然存在限流不够平滑的问题。
+- 相比较于固定窗口计数器算法,滑动窗口计数器算法实现和理解起来更复杂一些。
+
+### 漏桶算法
+
+我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
+
+如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)。
+
+
+
+优点:
+
+- 实现简单,易于理解。
+- 可以控制限流速率,避免网络拥塞和系统过载。
+
+缺点:
+
+- 无法应对突然激增的流量,因为只能以固定的速率处理请求,对系统资源利用不够友好。
+- 桶流入水(发请求)的速率如果一直大于桶流出水(处理请求)的速率的话,那么桶会一直是满的,一部分新的请求会被丢弃,导致服务质量下降。
+
+实际业务场景中,基本不会使用漏桶算法。
+
+### 令牌桶算法
+
+令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
+
+
+
+优点:
+
+- 可以限制平均速率和应对突然激增的流量。
+- 可以动态调整生成令牌的速率。
+
+缺点:
+
+- 如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
+- 相比于其他限流算法,实现和理解起来更复杂一些。
+
+## 针对什么来进行限流?
+
+实际项目中,还需要确定限流对象,也就是针对什么来进行限流。常见的限流对象如下:
+
+- IP :针对 IP 进行限流,适用面较广,简单粗暴。
+- 业务 ID:挑选唯一的业务 ID 以实现更针对性地限流。例如,基于用户 ID 进行限流。
+- 个性化:根据用户的属性或行为,进行不同的限流策略。例如, VIP 用户不限流,而普通用户限流。根据系统的运行指标(如 QPS、并发调用数、系统负载等),动态调整限流策略。例如,当系统负载较高的时候,控制每秒通过的请求减少。
+
+针对 IP 进行限流是目前比较常用的一个方案。不过,实际应用中需要注意用户真实 IP 地址的正确获取。常用的真实 IP 获取方法有 X-Forwarded-For 和 TCP Options 字段承载真实源 IP 信息。虽然 X-Forwarded-For 字段可能会被伪造,但因为其实现简单方便,很多项目还是直接用的这种方法。
+
+除了我上面介绍到的限流对象之外,还有一些其他较为复杂的限流对象策略,比如阿里的 Sentinel 还支持 [基于调用关系的限流](https://github.com/alibaba/Sentinel/wiki/流量控制#基于调用关系的流量控制)(包括基于调用方限流、基于调用链入口限流、关联流量限流等)以及更细维度的 [热点参数限流](https://github.com/alibaba/Sentinel/wiki/热点参数限流)(实时的统计热点参数并针对热点参数的资源调用进行流量控制)。
+
+另外,一个项目可以根据具体的业务需求选择多种不同的限流对象搭配使用。
+
+## 单机限流怎么做?
+
+单机限流针对的是单体架构应用。
+
+单机限流可以直接使用 Google Guava 自带的限流工具类 `RateLimiter` 。 `RateLimiter` 基于令牌桶算法,可以应对突发流量。
+
+> Guava 地址:
+
+除了最基本的令牌桶算法(平滑突发限流)实现之外,Guava 的`RateLimiter`还提供了 **平滑预热限流** 的算法实现。
+
+平滑突发限流就是按照指定的速率放令牌到桶里,而平滑预热限流会有一段预热时间,预热时间之内,速率会逐渐提升到配置的速率。
+
+我们下面通过两个简单的小例子来详细了解吧!
+
+我们直接在项目中引入 Guava 相关的依赖即可使用。
+
+```xml
+
+ com.google.guava
+ guava
+ 31.0.1-jre
+
+```
+
+下面是一个简单的 Guava 平滑突发限流的 Demo。
+
+```java
+import com.google.common.util.concurrent.RateLimiter;
+
+/**
+ * 微信搜 JavaGuide 回复"面试突击"即可免费领取个人原创的 Java 面试手册
+ *
+ * @author Guide哥
+ * @date 2021/10/08 19:12
+ **/
+public class RateLimiterDemo {
+
+ public static void main(String[] args) {
+ // 1s 放 5 个令牌到桶里也就是 0.2s 放 1个令牌到桶里
+ RateLimiter rateLimiter = RateLimiter.create(5);
+ for (int i = 0; i < 10; i++) {
+ double sleepingTime = rateLimiter.acquire(1);
+ System.out.printf("get 1 tokens: %ss%n", sleepingTime);
+ }
+ }
+}
+
+```
+
+Output:
+
+```bash
+get 1 tokens: 0.0s
+get 1 tokens: 0.188413s
+get 1 tokens: 0.197811s
+get 1 tokens: 0.198316s
+get 1 tokens: 0.19864s
+get 1 tokens: 0.199363s
+get 1 tokens: 0.193997s
+get 1 tokens: 0.199623s
+get 1 tokens: 0.199357s
+get 1 tokens: 0.195676s
+```
+
+Below is a simple demo of Guava smooth preheating and current limiting.
+
+```java
+import com.google.common.util.concurrent.RateLimiter;
+import java.util.concurrent.TimeUnit;
+
+/**
+ * Search JavaGuide on WeChat and reply to "Interview Assault" to get your own original Java interview manual for free
+ *
+ * @author Guide brother
+ * @date 2021/10/08 19:12
+ **/
+public class RateLimiterDemo {
+
+ public static void main(String[] args) {
+ // 1s puts 5 tokens into the bucket, that is, 0.2s puts 1 token into the bucket
+ // The warm-up time is 3s, which means that the card issuance rate will gradually increase to 0.2s in the first 3s. Put 1 token into the bucket.
+ RateLimiter rateLimiter = RateLimiter.create(5, 3, TimeUnit.SECONDS);
+ for (int i = 0; i < 20; i++) {
+ double sleepingTime = rateLimiter.acquire(1);
+ System.out.printf("get 1 tokens: %sds%n", sleepingTime);
+ }
+ }
+}
+```
+
+Output:
+
+```bash
+get 1 tokens: 0.0s
+get 1 tokens: 0.561919s
+get 1 tokens: 0.516931s
+get 1 tokens: 0.463798s
+get 1 tokens: 0.41286s
+get 1 tokens: 0.356172s
+get 1 tokens: 0.300489s
+get 1 tokens: 0.252545s
+get 1 tokens: 0.203996s
+get 1 tokens: 0.198359s
+```
+
+In addition, **Bucket4j** is a very good current limiting library based on the token/leaky bucket algorithm.
+
+> Bucket4j address:
+
+Compared with Guava's current limiting tool class, the current limiting function provided by Bucket4j is more comprehensive. Not only does it support stand-alone current limiting and distributed current limiting, it can also integrate monitoring and be used with Prometheus and Grafana.
+
+However, after all, Guava is just a comprehensive tool library, and the out-of-the-box current limiting function it provides is quite practical in many stand-alone scenarios.
+
+The early version of stand-alone current limiting that comes with Spring Cloud Gateway was implemented based on Bucket4j. Later, it was replaced by **Resilience4j**.
+
+Resilience4j is a lightweight fault-tolerant component inspired by Hystrix. Since [Netflix announced that it will no longer actively develop Hystrix](https://github.com/NETFLIX/Hystrix/commit/a7df971cbaddd8c5e976b3cc5f14013fe6ad00e6), both Spring officials and Netflix recommend using Resilience4j for current limiting and fusing.
+
+> Resilience4j address:
+
+Under normal circumstances, in order to ensure the high availability of the system, the current limiting and circuit breaker of the project must be done together.
+
+Resilience4j not only provides current limiting, but also provides out-of-the-box functions such as fusing, load protection, and automatic retry to ensure system high availability. Moreover, the ecosystem of Resilience4j is also better. Many gateways use Resilience4j for current limiting and circuit breaker.
+
+Therefore, Resilience4j may be a better choice in most scenarios. For some relatively simple current limiting scenarios, Guava or Bucket4j are also good choices.
+
+## How to implement distributed current limiting?
+
+Distributed current limiting is targeted at distributed/microservice application architecture applications. Under this architecture, single-machine current limiting is not applicable because there will be multiple services, and multiple copies of a service may be deployed.
+
+Common solutions for distributed current limiting:
+
+- **Current limiting with middleware**: You can use Sentinel or Redis to implement the corresponding current limiting logic yourself.
+- **Gateway layer current limiting**: A relatively common solution, which arranges the current limiting directly at the gateway layer. However, gateway layer current limiting usually requires the help of middleware/framework. For example, Spring Cloud Gateway's distributed current limiting implementation `RedisRateLimiter` is based on Redis+Lua. Another example is that Spring Cloud Gateway can also integrate Sentinel for current limiting.
+
+If you want to manually implement current limiting logic based on Redis, it is recommended to do it with Lua script.
+
+**Why is the Redis+Lua approach recommended? ** There are two main reasons:
+
+- **Reduced network overhead**: We can use Lua scripts to execute multiple Redis commands in batches. These Redis commands will be submitted to the Redis server for execution at one time, which greatly reduces network overhead.
+- **Atomicity**: A Lua script can be executed as a command. During the execution of a Lua script, no other scripts or Redis commands will be executed at the same time, ensuring that the operation will not be inserted or interrupted by other instructions.
+
+I won’t include the specific current limiting script code here. There are many excellent ready-made current limiting scripts on the Internet for your reference. For example, the RateLimiter current limiting plug-in of the Apache gateway project ShenYu implements the token bucket algorithm/concurrent token bucket algorithm, leaky bucket algorithm, and sliding window algorithm based on Redis + Lua.
+
+> ShenYu address:
+
+
+
+In addition, if you don’t want to write Lua scripts yourself, you can also directly use `RRateLimiter` in Redisson to implement distributed current limiting. Its underlying implementation is based on Lua code + token bucket algorithm.
+
+Redisson is an open source Java language Redis client that provides many out-of-the-box features, such as data structure implementations commonly used in Java, distributed locks, delay queues, etc. Moreover, Redisson also supports multiple deployment architectures such as Redis stand-alone, Redis Sentinel, and Redis Cluster.
+
+`RRateLimiter` is very simple to use. We first need to obtain a `RRateLimiter` object, which can be obtained directly through the Redisson client. Then, just set the current limiting rules.
+
+```java
+//Create a Redisson client instance
+RedissonClient redissonClient = Redisson.create();
+// Get a current limiter object named "javaguide.limiter"
+RRateLimiter rateLimiter = redissonClient.getRateLimiter("javaguide.limiter");
+// Try setting the limiter at a rate of 100 times per hour
+// There are two types of RateType, OVERALL is global current limiting, ER_CLIENT is single Client current limiting (it can be considered as single-machine current limiting)
+rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.HOURS);
+```
+
+Next we call the `acquire()` method or the `tryAcquire()` method to obtain the permission.
+
+```java
+// Get a license and wait if the rate of the current limiter is exceeded
+// acquire() is a synchronous method, the corresponding asynchronous method: acquireAsync()
+rateLimiter.acquire(1);
+//Try to obtain a license within 5 seconds, return true if successful, false otherwise
+// tryAcquire() is a synchronous method, the corresponding asynchronous method: tryAcquireAsync()
+boolean res = rateLimiter.tryAcquire(1, 5, TimeUnit.SECONDS);
+```
+
+## Summary
+
+This article mainly introduces common current limiting algorithms, the selection of current limiting objects, and how to implement single-machine current limiting and distributed current limiting respectively.
+
+## refer to- Resilience4j, a lightweight circuit breaker framework for service governance:
+- Super detailed analysis of Guava RateLimiter current limiting principle:
+- Practical use of Spring Cloud Gateway current limiting 👍:
+- Detailed explanation of the implementation principle of Redisson distributed current limiting:
+- A detailed explanation of Java current limiting interface implementation - Alibaba Cloud Developer:
+- Exploration and practice of distributed current limiting solutions - Tencent Cloud Developer:
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/performance-test.en.md b/docs_en/high-availability/performance-test.en.md
new file mode 100644
index 00000000000..99202f236da
--- /dev/null
+++ b/docs_en/high-availability/performance-test.en.md
@@ -0,0 +1,179 @@
+---
+title: 性能测试入门
+category: 高可用
+icon: et-performance
+---
+
+性能测试一般情况下都是由测试这个职位去做的,那还需要我们开发学这个干嘛呢?了解性能测试的指标、分类以及工具等知识有助于我们更好地去写出性能更好的程序,另外作为开发这个角色,如果你会性能测试的话,相信也会为你的履历加分不少。
+
+这篇文章是我会结合自己的实际经历以及在测试这里取的经所得,除此之外,我还借鉴了一些优秀书籍,希望对你有帮助。
+
+## 不同角色看网站性能
+
+### 用户
+
+当用户打开一个网站的时候,最关注的是什么?当然是网站响应速度的快慢。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。
+
+所以,用户在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。
+
+### 开发人员
+
+用户与开发人员都关注速度,这个速度实际上就是我们的系统**处理用户请求的速度**。
+
+开发人员一般情况下很难直观的去评判自己网站的性能,我们往往会根据网站当前的架构以及基础设施情况给一个大概的值,比如:
+
+1. 项目架构是分布式的吗?
+2. 用到了缓存和消息队列没有?
+3. 高并发的业务有没有特殊处理?
+4. 数据库设计是否合理?
+5. 系统用到的算法是否还需要优化?
+6. 系统是否存在内存泄露的问题?
+7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
+8. ……
+
+### 测试人员
+
+测试人员一般会根据性能测试工具来测试,然后一般会做出一个表格。这个表格可能会涵盖下面这些重要的内容:
+
+1. 响应时间;
+2. 请求成功率;
+3. 吞吐量;
+4. ……
+
+### 运维人员
+
+运维人员会倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。
+
+## 性能测试需要注意的点
+
+几乎没有文章在讲性能测试的时候提到这个问题,大家都会讲如何去性能测试,有哪些性能测试指标这些东西。
+
+### 了解系统的业务场景
+
+**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件, 还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧!
+
+### 历史数据非常有用
+
+当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些服务承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
+
+另外,这些地方也就像这个系统的一个短板一样,优化好了这些地方会为我们的系统带来质的提升。
+
+## 常见性能指标
+
+### 响应时间
+
+**响应时间 RT(Response-time)就是用户发出请求到用户收到系统处理结果所需要的时间。**
+
+RT 是一个非常重要且直观的指标,RT 数值大小直接反应了系统处理用户请求速度的快慢。
+
+### 并发数
+
+**并发数可以简单理解为系统能够同时供多少人访问使用也就是说系统同时能处理的请求数量。**
+
+并发数反应了系统的负载能力。
+
+### QPS 和 TPS
+
+- **QPS(Query Per Second)** :服务器每秒可以执行的查询次数;
+- **TPS(Transaction Per Second)** :服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
+
+书中是这样描述 QPS 和 TPS 的区别的。
+
+> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
+
+### 吞吐量
+
+**吞吐量指的是系统单位时间内系统处理的请求数量。**
+
+一个系统的吞吐量与请求对系统的资源消耗等紧密关联。请求对系统资源消耗越多,系统吞吐能力越低,反之则越高。
+
+TPS、QPS 都是吞吐量的常用量化指标。
+
+- **QPS(TPS)** = 并发数/平均响应时间(RT)
+- **并发数** = QPS \* 平均响应时间(RT)
+
+## 系统活跃度指标
+
+### PV(Page View)
+
+访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录 1 次,多次打开或刷新同一页面则浏览量累计。UV 从网页打开的数量/刷新的次数的角度来统计的。
+
+### UV(Unique Visitor)
+
+独立访客,统计 1 天内访问某站点的用户数。1 天内相同访客多次访问网站,只计算为 1 个独立访客。UV 是从用户个体的角度来统计的。
+
+### DAU(Daily Active User)
+
+日活跃用户数量。
+
+### MAU(monthly active users)
+
+月活跃用户人数。
+
+举例:某网站 DAU 为 1200w, 用户日均使用时长 1 小时,RT 为 0.5s,求并发量和 QPS。
+
+平均并发量 = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数(86400)=1200w/24 = 50w
+
+真实并发量(考虑到某些时间段使用人数比较少) = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数-访问量比较小的时间段假设为 8 小时(57600)=1200w/16 = 75w
+
+峰值并发量 = 平均并发量 \* 6 = 300w
+
+QPS = 真实并发量/RT = 75W/0.5=150w/s
+
+## 性能测试分类
+
+### 性能测试
+
+性能测试方法是通过测试工具模拟用户请求系统,目的主要是为了测试系统的性能是否满足要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。
+
+性能测试是你在对系统性能已经有了解的前提之后进行的,并且有明确的性能指标。
+
+### 负载测试
+
+对被测试的系统继续加大请求压力,直到服务器的某个资源已经达到饱和了,比如系统的缓存已经不够用了或者系统的响应时间已经不满足要求了。
+
+负载测试说白点就是测试系统的上限。
+
+### 压力测试
+
+不去管系统资源的使用情况,对系统继续加大请求压力,直到服务器崩溃无法再继续提供服务。
+
+### 稳定性测试
+
+模拟真实场景,给系统一定压力,看看业务是否能稳定运行。
+
+## 常用性能测试工具
+
+### 后端常用
+
+既然系统设计涉及到系统性能方面的问题,那在面试的时候,面试官就很可能会问:**你是如何进行性能测试的?**
+
+推荐 4 个比较常用的性能测试工具:
+
+1. **Jmeter** :Apache JMeter 是 JAVA 开发的性能测试工具。
+2. **LoadRunner**:一款商业的性能测试工具。
+3. **Galtling** :一款基于 Scala 开发的高性能服务器性能测试工具。
+4. **ab** :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
+
+没记错的话,除了 **LoadRunner** 其他几款性能测试工具都是开源免费的。
+
+### 前端常用
+
+1. **Fiddler**:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
+2. **HttpWatch**: 可用于录制 HTTP 请求信息的工具。
+
+## 常见的性能优化策略
+
+性能优化之前我们需要对请求经历的各个环节进行分析,排查出可能出现性能瓶颈的地方,定位问题。
+
+下面是一些性能优化时,我经常拿来自问的一些问题:
+
+1. 系统是否需要缓存?
+2. 系统架构本身是不是就有问题?
+3. 系统是否存在死锁的地方?
+4. 系统是否存在内存泄漏?(Java 的自动回收内存虽然很方便,但是,有时候代码写的不好真的会造成内存泄漏)
+5. 数据库索引使用是否合理?
+6. ……
+
+
+
diff --git a/docs_en/high-availability/redundancy.en.md b/docs_en/high-availability/redundancy.en.md
new file mode 100644
index 00000000000..07323dfb1b9
--- /dev/null
+++ b/docs_en/high-availability/redundancy.en.md
@@ -0,0 +1,47 @@
+---
+title: Detailed explanation of redundant design
+category: high availability
+icon: cluster
+---
+
+Redundant design is the most common means to ensure high availability of systems and data.
+
+For services, the idea of redundancy is to deploy multiple copies of the same service. If the service being used suddenly hangs up, the system can quickly switch to the backup service, greatly reducing the system's unavailability time and improving system availability.
+
+For data, the idea of redundancy is to back up multiple copies of the same data, which can easily improve data security.
+
+In fact, there are many applications of redundant ideas in daily life.
+
+For myself, my method of saving important files is the application of redundant thinking. The important files I use daily are synchronized on GitHub and my personal cloud disk. This ensures that even if my computer hard drive is damaged, I can retrieve my important files through GitHub or my personal cloud disk.
+
+High Availability Cluster (HA Cluster for short), same-city disaster recovery, remote disaster recovery, same-city multi-active and remote multi-active are the most typical applications of redundancy ideas in high-availability system design.
+
+- **High Availability Cluster**: Deploy two or more copies of the same service. If the service being used suddenly hangs up, you can switch to another service to ensure high availability of the service.
+- **Same-city disaster recovery**: An entire cluster can be deployed in the same computer room, while in same-city disaster recovery the same services are deployed in different computer rooms in the same city. Also, the backup service does not handle requests. This can avoid unexpected situations such as power outages and fires in the computer room.
+- **Remote disaster recovery**: Similar to same-city disaster recovery, the difference is that the same service is deployed in different computer rooms in different locations (usually far away, or even in different cities or countries)
+- **Multi-active in the same city**: Similar to the same city disaster recovery, but the backup service can handle requests, which can make full use of system resources and improve system concurrency.
+- **Multi-Activity in Remote Locations**: Deploy services in different computer rooms in different locations, and they can provide services to the outside world at the same time.
+
+High-availability clusters are purely for service redundancy and do not emphasize geography. Intra-city disaster recovery, remote disaster recovery, same-city multi-activity and remote multi-activity realize geographical redundancy.
+
+The main difference between the same city and another place is the distance between computer rooms. The distance is usually far away, even in different cities or countries.
+
+Compared with the traditional disaster recovery design, the most obvious change between multi-activity in the same city and multi-activity in different places is "multi-activity", that is, all sites provide services to the outside world at the same time. Living more in different places is to cope with emergencies such as fires, earthquakes and other natural or man-made disasters.
+
+Redundancy alone is not enough, it must be coupled with **failover**! The so-called failover simply means the rapid and automatic switching of unavailable services to available services. The entire process does not require human intervention.
+
+For example: In the Sentinel mode Redis cluster, if Sentinel detects that the master node fails, it will help us implement failover and automatically upgrade a slave to the master to ensure the availability of the entire Redis system. The entire process is completely automatic and requires no manual intervention. I have introduced the knowledge points and interview questions related to Redis cluster in detail in the database section of "Technical Interview Questions" in ["Java Interview Guide"](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7). Interested friends can take a look.
+
+Another example: Nginx can be combined with Keepalived to achieve high availability. If the Nginx master server goes down, Keepalived can automatically perform failover and the backup Nginx master server is upgraded to the main service. Moreover, this switch is transparent to the outside world, because the virtual IP used will not change. I introduced the Nginx related knowledge points and interview questions in detail in the "Server" section of the "Technical Interview Questions" of ["Java Interview Guide"](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7). Interested friends can take a look.
+
+It is very difficult to implement a remote multi-active architecture, and there are many factors that need to be considered. I am not talented and have never practiced the remote multi-active architecture in actual projects. My understanding of it is still based on book knowledge.
+
+If you want to learn more about living in a different place, I recommend a few articles that I think are pretty good:
+
+- [To understand how to live in a different place, just read this article - Water Drops and Silver Bullets - 2021](https://mp.weixin.qq.com/s/T6mMDdtTfBuIiEowCpqu6Q)
+- [Four steps to build remote multi-activity](https://mp.weixin.qq.com/s/hMD-IS__4JE5_nQhYPYSTg)
+- ["Learning Architecture from Scratch" — 28 | Guarantee of high business availability: multi-active remote architecture](http://gk.link/a/10pKZ)
+
+However, most of these articles also introduce conceptual knowledge. At present, there is still a lack of information on the Internet that truly introduces how to implement the multi-active architecture in different locations.
+
+
\ No newline at end of file
diff --git a/docs_en/high-availability/timeout-and-retry.en.md b/docs_en/high-availability/timeout-and-retry.en.md
new file mode 100644
index 00000000000..4f5d7262ab2
--- /dev/null
+++ b/docs_en/high-availability/timeout-and-retry.en.md
@@ -0,0 +1,87 @@
+---
+title: 超时&重试详解
+category: 高可用
+icon: retry
+---
+
+由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
+
+为了最大限度的减小系统或者服务出现故障之后带来的影响,我们需要用到的 **超时(Timeout)** 和 **重试(Retry)** 机制。
+
+想要把超时和重试机制讲清楚其实很简单,因为它俩本身就不是什么高深的概念。
+
+虽然超时和重试机制的思想很简单,但是它俩是真的非常实用。你平时接触到的绝大部分涉及到远程调用的系统或者服务都会应用超时和重试机制。尤其是对于微服务系统来说,正确设置超时和重试非常重要。单体服务通常只涉及数据库、缓存、第三方 API、中间件等的网络调用,而微服务系统内部各个服务之间还存在着网络调用。
+
+## 超时机制
+
+### 什么是超时机制?
+
+超时机制说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 `504 Gateway Timeout`)。
+
+我们平时接触到的超时可以简单分为下面 2 种:
+
+- **连接超时(ConnectTimeout)**:客户端与服务端建立连接的最长等待时间。
+- **读取超时(ReadTimeout)**:客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
+
+一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。
+
+如果没有设置超时的话,就可能会导致服务端连接数爆炸和大量请求堆积的问题。
+
+这些堆积的连接和请求会消耗系统资源,影响新收到的请求的处理。严重的情况下,甚至会拖垮整个系统或者服务。
+
+我之前在实际项目就遇到过类似的问题,整个网站无法正常处理请求,服务器负载直接快被拉满。后面发现原因是项目超时设置错误加上客户端请求处理异常,导致服务端连接数直接接近 40w+,这么多堆积的连接直接把系统干趴了。
+
+### 超时时间应该如何设置?
+
+超时到底设置多长时间是一个难题!超时值设置太高或者太低都有风险。如果设置太高的话,会降低超时机制的有效性,比如你设置超时为 10s 的话,那设置超时就没啥意义了,系统依然可能会出现大量慢请求堆积的问题。如果设置太低的话,就可能会导致在系统或者服务在某些处理请求速度变慢的情况下(比如请求突然增多),大量请求重试(超时通常会结合重试)继续加重系统或者服务的压力,进而导致整个系统或者服务被拖垮的问题。
+
+通常情况下,我们建议读取超时设置为 **1500ms** ,这是一个比较普适的值。如果你的系统或者服务对于延迟比较敏感的话,那读取超时值可以适当在 **1500ms** 的基础上进行缩短。反之,读取超时值也可以在 **1500ms** 的基础上进行加长,不过,尽量还是不要超过 **1500ms** 。连接超时可以适当设置长一些,建议在 **1000ms ~ 5000ms** 之内。
+
+没有银弹!超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
+
+更上一层,参考[美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
+
+## 重试机制
+
+### 什么是重试机制?
+
+重试机制一般配合超时机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障。
+
+瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。
+
+重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。
+
+### 常见的重试策略有哪些?
+
+常见的重试策略有两种:
+
+1. **固定间隔时间重试**:每次重试之间都使用相同的时间间隔,比如每隔 1.5 秒进行一次重试。这种重试策略的优点是实现起来比较简单,不需要考虑重试次数和时间的关系,也不需要维护额外的状态信息。但是这种重试策略的缺点是可能会导致重试过于频繁或过于稀疏,从而影响系统的性能和效率。如果重试间隔太短,可能会对目标系统造成过大的压力,导致雪崩效应;如果重试间隔太长,可能会导致用户等待时间过长,影响用户体验。
+2. **梯度间隔重试**:根据重试次数的增加去延长下次重试时间,比如第一次重试间隔为 1 秒,第二次为 2 秒,第三次为 4 秒,以此类推。这种重试策略的优点是能够有效提高重试成功的几率(随着重试次数增加,但是重试依然不成功,说明目标系统恢复时间比较长,因此可以根据重试次数延长下次重试时间),也能通过柔性化的重试避免对下游系统造成更大压力。但是这种重试策略的缺点是实现起来比较复杂,需要考虑重试次数和时间的关系,以及设置合理的上限和下限值。另外,这种重试策略也可能会导致用户等待时间过长,影响用户体验。
+
+这两种适合的场景各不相同。固定间隔时间重试适用于目标系统恢复时间比较稳定和可预测的场景,比如网络波动或服务重启。梯度间隔重试适用于目标系统恢复时间比较长或不可预测的场景,比如网络故障和服务故障。
+
+### 重试的次数如何设置?
+
+重试的次数不宜过多,否则依然会对系统负载造成比较大的压力。
+
+重试的次数通常建议设为 3 次。大部分情况下,我们还是更建议使用梯度间隔重试策略,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。
+
+### 什么是重试幂等?
+
+超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
+
+什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
+
+举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
+
+### Java 中如何实现重试?
+
+如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现,例如 Spring Retry、Resilience4j、Guava Retrying。
+
+## 参考
+
+- 微服务之间调用超时的设置治理:
+- 超时、重试和抖动回退:
+
+
+
diff --git a/docs_en/high-performance/cdn.en.md b/docs_en/high-performance/cdn.en.md
new file mode 100644
index 00000000000..b238a5c4fe6
--- /dev/null
+++ b/docs_en/high-performance/cdn.en.md
@@ -0,0 +1,135 @@
+---
+title: CDN工作原理详解
+category: 高性能
+head:
+ - - meta
+ - name: keywords
+ content: CDN,内容分发网络
+ - - meta
+ - name: description
+ content: CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。
+---
+
+## 什么是 CDN ?
+
+**CDN** 全称是 Content Delivery Network/Content Distribution Network,翻译过的意思是 **内容分发网络** 。
+
+我们可以将内容分发网络拆开来看:
+
+- 内容:指的是静态资源比如图片、视频、文档、JS、CSS、HTML。
+- 分发网络:指的是将这些静态资源分发到位于多个不同的地理位置机房中的服务器上,这样,就可以实现静态资源的就近访问比如北京的用户直接访问北京机房的数据。
+
+所以,简单来说,**CDN 就是将静态资源分发到多个不同的地方以实现就近访问,进而加快静态资源的访问速度,减轻服务器以及带宽的负担。**
+
+类似于京东建立的庞大的仓储运输体系,京东物流在全国拥有非常多的仓库,仓储网络几乎覆盖全国所有区县。这样的话,用户下单的第一时间,商品就从距离用户最近的仓库,直接发往对应的配送站,再由京东小哥送到你家。
+
+
+
+你可以将 CDN 看作是服务上一层的特殊缓存服务,分布在全国各地,主要用来处理静态资源的请求。
+
+
+
+我们经常拿全站加速和内容分发网络做对比,不要把两者搞混了!全站加速(不同云服务商叫法不同,腾讯云叫 ECDN、阿里云叫 DCDN)既可以加速静态资源又可以加速动态资源,内容分发网络(CDN)主要针对的是 **静态资源** 。
+
+
+
+绝大部分公司都会在项目开发中使用 CDN 服务,但很少会有自建 CDN 服务的公司。基于成本、稳定性和易用性考虑,建议直接选择专业的云厂商(比如阿里云、腾讯云、华为云、青云)或者 CDN 厂商(比如网宿、蓝汛)提供的开箱即用的 CDN 服务。
+
+很多朋友可能要问了:**既然是就近访问,为什么不直接将服务部署在多个不同的地方呢?**
+
+- 成本太高,需要部署多份相同的服务。
+- 静态资源通常占用空间比较大且经常会被访问到,如果直接使用服务器或者缓存来处理静态资源请求的话,对系统资源消耗非常大,可能会影响到系统其他服务的正常运行。
+
+同一个服务在在多个不同的地方部署多份(比如同城灾备、异地灾备、同城多活、异地多活)是为了实现系统的高可用而不是就近访问。
+
+## CDN 工作原理是什么?
+
+搞懂下面 3 个问题也就搞懂了 CDN 的工作原理:
+
+1. 静态资源是如何被缓存到 CDN 节点中的?
+2. 如何找到最合适的 CDN 节点?
+3. 如何防止静态资源被盗用?
+
+### 静态资源是如何被缓存到 CDN 节点中的?
+
+你可以通过 **预热** 的方式将源站的资源同步到 CDN 的节点中。这样的话,用户首次请求资源可以直接从 CDN 节点中取,无需回源。这样可以降低源站压力,提升用户体验。
+
+如果不预热的话,你访问的资源可能不在 CDN 节点中,这个时候 CDN 节点将请求源站获取资源,这个过程是大家经常说的 **回源**。
+
+> - 回源:当 CDN 节点上没有用户请求的资源或该资源的缓存已经过期时,CDN 节点需要从原始服务器获取最新的资源内容,这个过程就是回源。当用户请求发生回源的话,会导致该请求的响应速度比未使用 CDN 还慢,因为相比于未使用 CDN 还多了一层 CDN 的调用流程。
+> - 预热:预热是指在 CDN 上提前将内容缓存到 CDN 节点上。这样当用户在请求这些资源时,能够快速地从最近的 CDN 节点获取到而不需要回源,进而减少了对源站的访问压力,提高了访问速度。
+
+
+
+如果资源有更新的话,你也可以对其 **刷新** ,删除 CDN 节点上缓存的旧资源,并强制 CDN 节点回源站获取最新资源。
+
+几乎所有云厂商提供的 CDN 服务都具备缓存的刷新和预热功能(下图是阿里云 CDN 服务提供的相应功能):
+
+
+
+**命中率** 和 **回源率** 是衡量 CDN 服务质量两个重要指标。命中率越高越好,回源率越低越好。
+
+### 如何找到最合适的 CDN 节点?
+
+GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个 CDN 节点之间相互协作,最常用的是基于 DNS 的 GSLB。
+
+CDN 会通过 GSLB 找到最合适的 CDN 节点,更具体点来说是下面这样的:
+
+1. 浏览器向 DNS 服务器发送域名请求;
+2. DNS 服务器向根据 CNAME( Canonical Name ) 别名记录向 GSLB 发送请求;
+3. GSLB 返回性能最好(通常距离请求地址最近)的 CDN 节点(边缘服务器,真正缓存内容的地方)的地址给浏览器;
+4. 浏览器直接访问指定的 CDN 节点。
+
+
+
+为了方便理解,上图其实做了一点简化。GSLB 内部可以看作是 CDN 专用 DNS 服务器和负载均衡系统组合。CDN 专用 DNS 服务器会返回负载均衡系统 IP 地址给浏览器,浏览器使用 IP 地址请求负载均衡系统进而找到对应的 CDN 节点。
+
+**GSLB 是如何选择出最合适的 CDN 节点呢?** GSLB 会根据请求的 IP 地址、CDN 节点状态(比如负载情况、性能、响应时间、带宽)等指标来综合判断具体返回哪一个 CDN 节点的地址。
+
+### 如何防止资源被盗刷?
+
+如果我们的资源被其他用户或者网站非法盗刷的话,将会是一笔不小的开支。
+
+解决这个问题最常用最简单的办法设置 **Referer 防盗链**,具体来说就是根据 HTTP 请求的头信息里面的 Referer 字段对请求进行限制。我们可以通过 Referer 字段获取到当前请求页面的来源页面的网站地址,这样我们就能确定请求是否来自合法的网站。
+
+CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。
+
+
+
+不过,如果站点的防盗链配置允许 Referer 为空的话,通过隐藏 Referer,可以直接绕开防盗链。
+
+通常情况下,我们会配合其他机制来确保静态资源被盗用,一种常用的机制是 **时间戳防盗链** 。相比之下,**时间戳防盗链** 的安全性更强一些。时间戳防盗链加密的 URL 具有时效性,过期之后就无法再被允许访问。
+
+时间戳防盗链的 URL 通常会有两个参数一个是签名字符串,一个是过期时间。签名字符串一般是通过对用户设定的加密字符串、请求路径、过期时间通过 MD5 哈希算法取哈希的方式获得。
+
+时间戳防盗链 URL 示例:
+
+```plain
+http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
+```
+
+- `wsSecret`:签名字符串。
+- `wsTime`: 过期时间。
+
+
+
+时间戳防盗链的实现也比较简单,并且可靠性较高,推荐使用。并且,绝大部分 CDN 服务提供商都提供了开箱即用的时间戳防盗链机制。
+
+
+
+In addition to Referer anti-hotlinking and timestamp anti-hotlinking, you can also configure IP black and white list, IP access frequency limit configuration and other mechanisms to prevent theft.
+
+## Summary
+
+- CDN is to distribute static resources to multiple different places to achieve nearby access, thereby speeding up the access speed of static resources and reducing the burden on servers and bandwidth.
+- Based on cost, stability and ease of use, it is recommended to directly choose the out-of-the-box CDN service provided by professional cloud vendors (such as Alibaba Cloud, Tencent Cloud, Huawei Cloud, Qingyun) or CDN vendors (such as Wangsu, Lanxun).
+- GSLB (Global Server Load Balance, global load balancing) is the brain of CDN and is responsible for the cooperation between multiple CDN nodes. The most commonly used one is DNS-based GSLB. CDN will find the most suitable CDN node through GSLB.
+- In order to prevent static resources from being stolen, we can use **Referer anti-hotlinking** + **Timestamp anti-hotlinking**.
+
+## Reference
+
+- Timestamp hotlinking prevention - Qiniu Cloud CDN:
+- What is a CDN? One article explains it clearly:
+- "HTTP Protocol in Perspective" - 37 | CDN: Accelerate our network services:
+
+
\ No newline at end of file
diff --git a/docs_en/high-performance/data-cold-hot-separation.en.md b/docs_en/high-performance/data-cold-hot-separation.en.md
new file mode 100644
index 00000000000..54637b7ddbe
--- /dev/null
+++ b/docs_en/high-performance/data-cold-hot-separation.en.md
@@ -0,0 +1,68 @@
+---
+title: Detailed explanation of hot and cold data separation
+category: high performance
+head:
+ - - meta
+ - name: keywords
+ content: Separation of hot and cold data, cold data migration, cold data storage
+ - - meta
+ - name: description
+ content: Separation of hot and cold data refers to dividing data into cold data and hot data based on the access frequency and business importance of the data. Cold data is generally stored in low-cost, low-performance media, and hot data is stored in high-performance storage media.
+---
+
+## What is the separation of hot and cold data?
+
+Separation of hot and cold data refers to dividing data into cold data and hot data based on the access frequency and business importance of the data. Cold data is generally stored in low-cost, low-performance media, and hot data is stored in high-performance storage media.
+
+### Cold data and hot data
+
+Hot data refers to data that is frequently accessed and modified and needs to be accessed quickly. Cold data refers to data that is not accessed frequently and has low value to the current project, but needs to be preserved for a long time.
+
+How to distinguish between hot and cold data? There are two common ways to differentiate:
+
+1. **Time dimension distinction**: According to the creation time, update time, expiration time, etc. of the data, the data within a certain time period is regarded as hot data, and the data beyond this time period is regarded as cold data. For example, the order system can treat order data 1 year ago as cold data and order data within 1 year as hot data. This method is suitable for scenarios where there is a strong correlation between data access frequency and time.
+2. **Access frequency differentiation**: Data with high frequency access is regarded as hot data, and data with low frequency access is regarded as cold data. For example, the content system can treat articles with very low page views as cold data and articles with high page views as hot data. This method needs to record the access frequency of the data, which is relatively expensive and is suitable for scenarios where there is a strong correlation between the access frequency and the data itself.
+
+Data from a few years ago is not necessarily cold data. For example, some high-quality articles are still visited by many people a few years after they were published, but most newly published articles by ordinary users are rarely visited by anyone.
+
+These two methods of distinguishing hot and cold data have their own advantages and disadvantages. In actual projects, they can be used in combination.
+
+### The idea of separation of hot and cold
+
+The idea of hot and cold separation is very simple, which is to classify the data and store it separately. The idea of hot and cold separation can be applied to many fields and scenarios, not just data storage, for example:
+
+- In the email system, you can put recent, more important emails in your inbox, and older, less important emails in the archive.
+- In daily life, you can place commonly used items in a conspicuous place, and put infrequently used items in the storage room or attic.
+- In the library, the most popular and frequently borrowed books can be placed in a conspicuous area alone, and the less frequently borrowed books can be placed in an inconspicuous location.
+-…
+
+### Advantages and Disadvantages of Separating Hot and Cold Data
+
+- Advantages: The query performance of hot data is optimized (most users' operating experience will be better), cost saving (the corresponding database type and hardware configuration can be selected according to the different storage requirements of hot and cold data, such as placing hot data on SSD and cold data on HDD)
+- Disadvantages: Increased system complexity and risks (hot and cold data need to be separated, increased risk of data errors), low statistical efficiency (cold storage data may be needed for statistics).
+
+## How to migrate cold data?
+
+Cold data migration solution:
+
+1. Business layer code implementation: When there is a write operation on data, the logic of hot and cold separation is triggered to determine whether the data is cold data or hot data. Cold data is put into the cold storage, and hot data is put into the hot storage. This solution will affect performance and the judgment logic of hot and cold data is not easy to determine. It also requires modification of the business layer code, so it is generally not used.
+2. Task scheduling: You can use xxl-job or other distributed task scheduling platforms to regularly scan the database to find data that meets the cold data conditions, then copy them to the cold storage in batches and delete them from the hot storage. This method requires very little code modification and is very suitable for scenarios where hot and cold data are distinguished based on time.
+3. Monitor the change log binlog of the database: extract the data that meets the cold data conditions from the binlog, then copy it to the cold storage, and delete it from the hot storage. This method does not require modifying the code, but it is not suitable for scenarios where hot and cold data are distinguished based on the time dimension.
+
+If your company has a DBA, you can also ask the DBA to manually migrate the cold data and complete the migration of the cold data to the cold storage in one go. Then, use the solution introduced above to implement subsequent cold data migration.
+
+## How to store cold data?
+
+The storage requirements of cold data are mainly large capacity, low cost, high reliability, and access speed can be appropriately sacrificed.
+
+Cold data storage solution:
+
+- Small and medium-sized factories: Just use MySQL/PostgreSQL directly (do not change the database selection and keep it consistent with the database currently used by the project), such as adding a table to store cold data of a certain business or using a separate cold storage to store cold data (involving cross-database queries, increasing system complexity and maintenance difficulty)
+- Major manufacturers: Hbase (commonly used), RocksDB, Doris, Cassandra
+
+If the company's cost budget is sufficient, it can also directly use a distributed relational database such as TiDB to get it done in one step. TiDB 6.0 officially supports the separation of hot and cold data storage, which can reduce the cost of SSD usage. Using the data placement function of TiDB 6.0, you can realize hot and cold storage of massive data in the same cluster, store new hot data in SSD, and store historical cold data in HDD.
+
+## Case sharing
+
+- [How to quickly optimize an order form with tens of millions of data - Programmer Jidian - 2023](https://www.cnblogs.com/fulongyuanjushi/p/17910420.html)
+- [Mass data hot and cold separation scheme and practice - ByteDance technical team - 2022](https://mp.weixin.qq.com/s/ZKRkZP6rLHuTE1wvnqmAPQ)
\ No newline at end of file
diff --git a/docs_en/high-performance/deep-pagination-optimization.en.md b/docs_en/high-performance/deep-pagination-optimization.en.md
new file mode 100644
index 00000000000..3e79bab2571
--- /dev/null
+++ b/docs_en/high-performance/deep-pagination-optimization.en.md
@@ -0,0 +1,143 @@
+---
+title: 深度分页介绍及优化建议
+category: 高性能
+head:
+ - - meta
+ - name: keywords
+ content: 深度分页
+ - - meta
+ - name: description
+ content: 查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低。深度分页可以采用范围查询、子查询、INNER JOIN 延迟关联、覆盖索引等方法进行优化。
+---
+
+## 深度分页介绍
+
+查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如:
+
+```sql
+# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
+SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
+```
+
+## 深度分页问题的原因
+
+当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。这是因为扫描索引和跳过大量记录可能比直接全表扫描更耗费资源。
+
+
+
+不同机器上这个查询偏移量过大的临界点可能不同,取决于多个因素,包括硬件配置(如 CPU 性能、磁盘速度)、表的大小、索引的类型和统计信息等。
+
+
+
+MySQL 的查询优化器采用基于成本的策略来选择最优的查询执行计划。它会根据 CPU 和 I/O 的成本来决定是否使用索引扫描或全表扫描。如果优化器认为全表扫描的成本更低,它就会放弃使用索引。不过,即使偏移量很大,如果查询中使用了覆盖索引(covering index),MySQL 仍然可能会使用索引,避免回表操作。
+
+## 深度分页优化建议
+
+这里以 MySQL 数据库为例介绍一下如何优化深度分页。
+
+### 范围查询
+
+当可以保证 ID 的连续性时,根据 ID 范围进行分页是比较好的解决方案:
+
+```sql
+# 查询指定 ID 范围的数据
+SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
+# 也可以通过记录上次查询结果的最后一条记录的ID进行下一页的查询:
+SELECT * FROM t_order WHERE id > 100000 LIMIT 10
+```
+
+这种基于 ID 范围的深度分页优化方式存在很大限制:
+
+1. **ID 连续性要求高**: 实际项目中,数据库自增 ID 往往因为各种原因(例如删除数据、事务回滚等)导致 ID 不连续,难以保证连续性。
+2. **排序问题**: 如果查询需要按照其他字段(例如创建时间、更新时间等)排序,而不是按照 ID 排序,那么这种方法就不再适用。
+3. **并发场景**: 在高并发场景下,单纯依赖记录上次查询的最后一条记录的 ID 进行分页,容易出现数据重复或遗漏的问题。
+
+### 子查询
+
+我们先查询出 limit 第一个参数对应的主键值,再根据这个主键值再去过滤并 limit,这样效率会更快一些。
+
+阿里巴巴《Java 开发手册》中也有对应的描述:
+
+> 利用延迟关联或者子查询优化超多分页场景。
+>
+> 
+
+```sql
+-- 先通过子查询在主键索引上进行偏移,快速找到起始ID
+SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order LIMIT 1000000, 1) LIMIT 10;
+```
+
+**工作原理**:
+
+1. 子查询 `(SELECT id FROM t_order where id > 1000000 limit 1)` 会利用主键索引快速定位到第 1000001 条记录,并返回其 ID 值。
+2. 主查询 `SELECT * FROM t_order WHERE id >= ... LIMIT 10` 将子查询返回的起始 ID 作为过滤条件,使用 `id >=` 获取从该 ID 开始的后续 10 条记录。
+
+不过,子查询的结果会产生一张新表,会影响性能,应该尽量避免大量使用子查询。并且,这种方法只适用于 ID 是正序的。在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的 ID,此时的 ID 是离散且不连续的。
+
+当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。
+
+### 延迟关联
+
+延迟关联与子查询的优化思路类似,都是通过将 `LIMIT` 操作转移到主键索引树上,减少回表次数。相比直接使用子查询,延迟关联通过 `INNER JOIN` 将子查询结果集成到主查询中,避免了子查询可能产生的临时表。在执行 `INNER JOIN` 时,MySQL 优化器能够利用索引进行高效的连接操作(如索引扫描或其他优化策略),因此在深度分页场景下,性能通常优于直接使用子查询。
+
+```sql
+-- 使用 INNER JOIN 进行延迟关联
+SELECT t1.*
+FROM t_order t1
+INNER JOIN (
+ -- 这里的子查询可以利用覆盖索引,性能极高
+ SELECT id FROM t_order LIMIT 1000000, 10
+) t2 ON t1.id = t2.id;
+```
+
+**工作原理**:
+
+1. 子查询 `(SELECT id FROM t_order where id > 1000000 LIMIT 10)` 利用主键索引快速定位目标分页的 10 条记录的 ID。
+2. 通过 `INNER JOIN` 将子查询结果与主表 `t_order` 关联,获取完整的记录数据。
+
+除了使用 INNER JOIN 之外,还可以使用逗号连接子查询。
+
+```sql
+-- 使用逗号进行延迟关联
+SELECT t1.* FROM t_order t1,
+(SELECT id FROM t_order where id > 1000000 LIMIT 10) t2
+WHERE t1.id = t2.id;
+```
+
+**注意**: 虽然逗号连接子查询也能实现类似的效果,但为了代码可读性和可维护性,建议使用更规范的 `INNER JOIN` 语法。
+
+### 覆盖索引
+
+索引中已经包含了所有需要获取的字段的查询方式称为覆盖索引。
+
+**覆盖索引的好处:**
+
+- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
+- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
+
+```sql
+# 如果只需要查询 id, code, type 这三列,可建立 code 和 type 的覆盖索引
+SELECT id, code, type FROM t_order
+ORDER BY code
+LIMIT 1000000, 10;
+```
+
+**⚠️注意**:
+
+- 当查询的结果集占表的总行数的很大一部分时,MySQL 查询优化器可能选择放弃使用索引,自动转换为全表扫描。
+- 虽然可以使用 `FORCE INDEX` 强制查询优化器走索引,但这种方式可能会导致查询优化器无法选择更优的执行计划,效果并不总是理想。
+
+## 总结
+
+本文总结了几种常见的深度分页优化方案:
+
+1. **范围查询**: 基于 ID 连续性进行分页,通过记录上一页最后一条记录的 ID 来获取下一页数据。适合 ID 连续且按 ID 查询的场景,但在 ID 不连续或需要按其他字段排序时存在局限。
+2. **子查询**: 先通过子查询获取分页的起始主键值,再根据主键进行筛选分页。利用主键索引提高效率,但子查询会生成临时表,复杂场景下性能不佳。
+3. **延迟关联 (INNER JOIN)**: 使用 `INNER JOIN` 将分页操作转移到主键索引上,减少回表次数。相比子查询,延迟关联的性能更优,适合大数据量的分页查询。
+4. **覆盖索引**: 通过索引直接获取所需字段,避免回表操作,减少 IO 开销,适合查询特定字段的场景。但当结果集较大时,MySQL 可能会选择全表扫描。
+
+## 参考
+
+- Let’s talk about how to solve the MySQL deep paging problem - The little boy picking up snails:
+- Database deep paging introduction and optimization plan - JD retail technology:  +
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
+
diff --git a/docs_en/about-the-author/dog-that-copies-other-people-essay.en.md b/docs_en/about-the-author/dog-that-copies-other-people-essay.en.md
new file mode 100644
index 00000000000..048f6b3de28
--- /dev/null
+++ b/docs_en/about-the-author/dog-that-copies-other-people-essay.en.md
@@ -0,0 +1,56 @@
+---
+Title: Plagiarism dog, your feet will be cold when you sleep in winter! ! !
+category: Get to know the author
+tag:
+ - Miscellaneous talk
+---
+
+Plagiarism dogs are really annoying. . .
+
+I heard from a friend that my article was stolen again on Zhihu, and was used intact by others to divert traffic.
+
+
+
+And! ! ! This is not the most annoying thing.
+
+The original source that this person also noted at the end of the article is not mine. . .
+
+
+
+In other words, there is another plagiarism dog in CSDN who stole this article of mine and claimed the originality. Zhihu plagiarism dog has moved the article of this CSDN plagiarism dog intact.
+
+It’s so outrageous that his mother opened the door for outrageous things. It’s so outrageous.
+
+
+
+I opened the original source link marked by Zhihu Plagiarism Dog. Oh my god, it’s exactly the same content, and it also shows the originality.
+
+
+
+I took a look at the CSDN plagiarism dog's article. He has moved my highly praised answer all over the place. . . Really diligent. . .
+
+I don’t want to say more about CSDN. It’s just a large article dump, filled with all kinds of non-standard reprints and all kinds of garbage resources for paid downloads. This technology website, which is said to have the largest traffic in the country, is disgusting. It’s so popular that it’s ugly. If you can’t use it, don’t use it!
+
+For example, when I usually search on Google, I directly block the CSDN site. Just download a Chrome extension called Personal Blocklist and add blog.csdn.net to the blacklist.
+
+
+
+My articles have basically been stolen. The key is that I don’t get much traffic when I post them myself. On the contrary, the people who steal my articles have more traffic than me, the original author.
+
+What kind of world is this? Is it the distortion of human nature or the loss of morality?
+
+However, it doesn’t matter. It doesn’t matter if CSDN, a junk website, doesn’t post articles.
+
+Take a look at what kind of garbage the articles on the CSDN hot list are. They are either various advertisements or some patchwork articles with no quality.
+
+
+
+Of course, there are also a very small number of high-quality articles, such as articles by bloggers such as Tao Ge, Er Ge, Binghe, and Micro Technology.
+
+There are also many video platforms (such as Douyin and Bilibili) where many bloggers directly use other people’s original works to make videos to attract traffic or fans.
+
+The stolen article mentioned today was once used by a training institution to make a video to attract traffic.
+
+
+
+As individuals, we have no choice but to report everyone we encounter. . .
\ No newline at end of file
diff --git a/docs_en/about-the-author/feelings-after-one-month-of-induction-training.en.md b/docs_en/about-the-author/feelings-after-one-month-of-induction-training.en.md
new file mode 100644
index 00000000000..6a4858e307f
--- /dev/null
+++ b/docs_en/about-the-author/feelings-after-one-month-of-induction-training.en.md
@@ -0,0 +1,24 @@
+---
+title: Reflections After One Month of Induction Training
+category: About the Author
+tag:
+ - Personal Experience
+---
+
+It's hard to believe it's been over a month since I started. Before this, I had never interned or worked at a company, so many things were quite new to me. The transition from school to the workplace brings a change in roles, and the differences vary from person to person. For me, in school, I could selectively absorb what the teacher taught based on my interests, and I could even skip classes I didn't want to attend. It's different at a company. You have to learn the skills the company requires, unless you want to quit. In school, most people code to pass exams or find a good job; very few are driven by genuine interest. In the workplace, we code more because of job requirements, which is generally more challenging and stressful than in school. In school, our main responsibility is to ourselves, constantly learning to arm ourselves with knowledge. But at a company, we are responsible not only to ourselves but also to the company. After all, the company is paying you, not for you to be "on the beach."
+
+When I first joined the company, I switched to a Mac computer as required. Since I had always used Windows, I was very uncomfortable with it. I was clumsy at first and felt my programming efficiency drop by at least 30%. I was quite frustrated and often complained to myself about why we couldn't just use Windows or Linux. But strangely, after about a week, I slowly started to get used to programming on a Mac and even grew to like it. I don't want to compare the programming experience of Mac and Windows here; I think it varies from person to person. For the same price, a Mac's hardware specs are indeed a few steps behind Windows. However, the programming and user experience on a Mac are excellent. Of course, you can also choose to use Linux for daily development, which I believe would be great. Also, you can't play some mainstream online games on a Mac, which is a good choice for friends who can't resist the temptation to play games.
+
+I have to say that ThoughtWorks' training program is very good. Graduates are usually scheduled for training after joining. Unlike previous years, this year's training included a local China class (TWU-C). As a member of the first local class, I can honestly say it was great. The 8-week training, in addition to basic technologies needed for work like ES6 and SpringBoot, also included training on essential skills for new employees, such as how to hold efficient meetings, how to give proper feedback, how to refactor code, how to practice TDD, and so on. There were also regular activities during the training, such as Weekend Trips, City Tours, Cake Time, etc. The last three weeks included a simulated real-world project, which was very similar to the actual projects we work on, and I found it to be a great experience. This project has now completed one iteration, and I feel that the biggest takeaway was not the technology used, but how to collaborate as a team, how to use Git for team development, what a complete iteration looks like, what problems might be encountered during a project, and the entire workflow of a project.
+
+ThoughtWorks strongly encourages sharing and helping others grow, and I have felt this deeply during my time at the company. During the training, each of us had a Trainer who was responsible for our daily classes and projects. One Trainer was responsible for about 5-6 people. The Trainers regularly gave us feedback on our recent performance. I don't think this was just a formality; the Trainers were very responsible and often chatted with us after work. Colleagues are also very enthusiastic. If you have a problem and ask someone, they will usually tell you everything they know without reservation. If it's a problem that most people don't understand, they might even organize a technical session to share knowledge. Last Friday, I gave a technical sharing session in our group about Feign remote calls because the team was not very familiar with this topic, but it was likely to be used in future project development. I had just researched this topic, so I shared it with other colleagues in the group to help the project proceed more smoothly.
+
+In addition, ThoughtWorks is a company that strongly advocates a feedback culture. Feedback is about telling people our opinion of their performance and how they can do better. At first, I didn't pay much attention to it, but gradually I realized that giving proper feedback can be very helpful to others. This is because when people are doing things, it's hard for them to notice small problems that are obvious to others. For example, there's an interesting phenomenon: if you don't have a tester role in your project, and you've completed your module and tested it many times yourself, you might think there are no problems. However, when it's actually used, problems you never noticed before are very likely to appear. The explanation for this is that everyone has blind spots in their vision, which are closely related to our focus. We often can't find many problems in our own work even after testing it many times, but if we ask someone else to test it for us, they are very likely to find many obvious issues.
+
+
+
+After starting work, I have less time to update my public account, columns, and maintain my GitHub. In fact, many times after work, I have my own time to do my own things, but I always make excuses like being too tired from work or having fragmented time. Today, I looked at GitHub and suddenly realized that I hadn't handled a PR that someone submitted to me 14 days ago. This is indeed something I haven't done well; I haven't managed my time properly. I actually have a lot of things I want to write, and I will gradually put them on the agenda. After starting work, I've realized how important it is to spend the few hours after work. If you feel you haven't finished your work during the day, you can continue working on it after you get off work. If you can handle your daytime work with ease, you can do things you are interested in and learn technologies you are interested in after you get home. Do everything based on your own foundation, and don't aim too high.
+
+After starting work, I am also surrounded by many talented people. I think every professional should learn from others. Among the colleagues who trained with us this time, some are very skilled technically, while others may not be as strong technically but have excellent organizational and teamwork skills. There is a particularly brilliant colleague who, while we were still learning the various syntaxes of SpringBoot, wrote a simplified version of SpringBoot in his spare time, covering some common Spring annotations like `@RestController`, `@Autowired`, `@PathVariable`, `@RequestParam`, and so on (I have already contacted this colleague and asked him to open-source it, and I will share it on my public account as soon as possible, so look forward to it!). I think this colleague has a real interest in programming. He seems to have started programming in junior high school and is very interested in various underlying knowledge. He has written and implemented many low-level things himself. His dream is to create a project with over 20k stars on GitHub. I believe that with his abilities, he will definitely achieve this goal. I wish him all the best and hope he can achieve this goal soon.
+
+These are my personal feelings after more than a month of work. Many parts are just touched upon briefly. I will take the time to share more useful knowledge I have learned at the company or in my spare time with you all. I hope everyone who reads it can gain something.
diff --git a/docs_en/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.en.md b/docs_en/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.en.md
new file mode 100644
index 00000000000..dd10aebde90
--- /dev/null
+++ b/docs_en/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.en.md
@@ -0,0 +1,54 @@
+---
+title: Reflections on the Six Months Since Graduation and Starting Work
+category: About the Author
+tag:
+ - Personal Experience
+---
+
+If you've read my previous introductions, you'll know I'm one of the millions of fresh graduates from 2019. This article is mainly about my feelings after working for over half a year. It contains many of my own subjective thoughts, so if you disagree with anything, feel free to say so in the comments. I respect others' opinions.
+
+Let me briefly describe my situation. I'm currently working at a foreign company, and my daily job, like most people's, is development. It's been over half a year since I graduated, and I've passed the company's 6-month probation period. I've worked on two business-oriented projects, one of which is ongoing. You might find it hard to imagine that the backends of these two projects don't involve distributed systems or microservices, nor have I had practical experience with "high-end" technologies like Redis or Kafka.
+
+The first project was an internal one—an employee growth system. Beyond the name, the system was essentially for performance appraisals, like evaluating your performance in a project team. The tech stack was Spring Boot, JPA, Spring Security, K8S, Docker, and React. The second project, which I'm currently working on, integrates a game (Cocos), a web admin panel (Spring Boot + Vue), and a mini-program (Taro).
+
+Yes, most of my time at work is related to CRUD, and I also write front-end pages every day. A friend of mine was baffled when he heard that most of my work involves writing business logic. He thought that just writing business code doesn't lead to growth. What? You're a fresh graduate who can't even write business code properly, and you're telling me this! So, **I'm puzzled as to why so many people who can't even write good business code have an aversion to CRUD. At least in my time working, I feel my code quality has improved, my ability to locate problems has greatly enhanced, I have a deeper understanding of the business, and I can now independently handle some front-end development.**
+
+Personally, I don't think writing good business code is that easy. Before complaining about doing CRUD work all day, take a look at whether your own CRUD code is well-written. In other words, while writing CRUD, have you figured out the common annotations or classes you use? It's like someone who only knows the simplest annotations like `@Service`, `@Autowired`, and `@RestController` claiming to have mastered Spring Boot.
+
+I don't know when it started, but everyone seems to think that having practical experience with Redis or MQ is impressive. This might be related to the current interview environment. You need to differentiate yourself from others, and if you want to get into a big tech company, it seems you must be proficient in these technologies. Well, not "seems"—let's be confident and say that for most job seekers, these technologies are considered a prerequisite.
+
+**To be honest, I fell into this "false proposition" in college.** In my sophomore year, I was exposed to Java because I joined a tech-oriented campus media group. At that time, our goal for learning Java was to develop a campus app. As a sophomore with only a beginner's level of programming skills, it took me some time to master the basics of Java. Then, I started learning Android development.
+
+It wasn't until the first semester of my junior year that I truly decided to pursue a career in Java backend development. After about three months of learning the basics of web development, I started studying distributed systems concepts like Redis and Dubbo. I learned through a combination of books, videos, and blogs. During my self-study, I completed two full projects by following video tutorials: one was a regular business system, and the other was a distributed system. **At that time, I thought I was pretty awesome after finishing them. I felt that simple CRUD work was beneath my skill level. Haha! Looking back now, I was so naive!**
+
+And then, problems arose when I worked on a project with a professor during my junior year summer break. The project was a performance appraisal system with moderate business complexity. The tech stack was SSM + Shiro + JSP. At that time, I encountered all sorts of problems. I couldn't write code that I thought I knew how to write. Even a simple CRUD operation took me several days. So, I was reviewing, learning, and coding at the same time. Although it was tiring, I learned a lot and became more grounded in my approach to technology. I think the phrase "**this project is no longer maintainable**" is the biggest negation of the project I worked on.
+
+Technology is ever-changing; mastering the core principles is what matters. A few years ago, we might have been using Spring with traditional XML for development, but now almost everyone uses Spring Boot to speed up development. Similarly, a few years ago, we might have used ActiveMQ for message queuing, but today, it's hardly used. The more common choices are RocketMQ and Kafka. With technology evolving so quickly, you can't possibly learn every single framework or tool.
+
+**Many beginners want to learn by doing projects right away, especially in a company setting. I think this is not advisable.** If your Java or Spring Boot fundamentals are weak, I suggest you study them beforehand before starting a project through videos or other means. **Another point is, I don't know why everyone says that learning while working on a project is the most effective way. I think this requires a prerequisite: you must have a basic understanding of the technology or a certain level of programming knowledge.**
+
+**Key point!!! If your foundation is not solid, simply following along with a video is useless. You'll find that after watching the video, you still can't write the code yourself.**
+
+I don't know what it's like for programmers at other companies. I feel that technical growth largely depends on what you do in your spare time. Relying solely on work, in most cases, will only make you more proficient at completing tasks. Of course, after writing a lot of code, your understanding of code quality will improve to some extent (provided you are conscious of it).
+
+Outside of work, I use my spare time to learn things I'm interested in. For example, in my first project at the company, we used Spring Security + JWT. Since I wasn't familiar with it, I spent about a week of my own time learning it and created a demo to share. GitHub address:
+
+这句话表面上看似有道理,但实际上却暴露了一个人的**无知和偏执**。
+
+**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
+
+举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
+
+在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
+
+
+
+这本书一共 **1010** 页,我当时可以说是废寝忘食地学,花了很长时间才把整本书完全“啃”下来。
+
+回头来看,我如果能有意识地避免学习这些已经淘汰的技术,真的可以节省大量时间去学习更加主流和实用的内容。
+
+那么,这些被淘汰的技术有用吗?说句实话,**屁用没有,纯粹浪费时间**。
+
+**既然都要花时间学习,为什么不去学那些更主流、更有实际价值的技术呢?**
+
+现在本身就很卷,不管是 Java 方向还是其他技术方向,要学习的技术都很多。
+
+想要理解所谓的“底层思想”,与其浪费时间在 JSP 这种已经不具备实际应用价值的技术上,不如深入学习一下 Servlet,研究 Spring 的 AOP 和 IoC 原理,从源码角度理解 Spring MVC 的工作机制。
+
+这些内容,不仅能帮助你掌握核心的思想,还能在实际开发中真正派上用场,这难道不比花大量时间在 JSP 上更有意义吗?
+
+## 还有公司在用的技术就要学吗?
+
+我把这篇文章的相关言论发表在我的[公众号](https://mp.weixin.qq.com/s/lf2dXHcrUSU1pn28Ercj0w)之后,又收到另外一类在我看来非常傻叉的言论:
+
+- “虽然 JSP 很老了,但还是得学学,会用就行,因为我们很多老项目还在用。”
+- “很多央企和国企的老项目还在用,肯定得学学啊!”
+
+这种观点完全是钻牛角尖!如果按这种逻辑,那你还需要去学 Struts2、SVN、JavaFX 等过时技术,因为它们也还有公司在用。我有一位大学同学毕业后去了武汉的一家国企,写了一年 JavaFX 就受不了跑了。他在之前从来没有接触过 JavaFX,招聘时也没被问过相关问题。
+
+一定不要假设自己要面对的是过时技术栈的项目。你要找工作肯定要用主流技术栈去找,还要尽量找能让自己技术有成长,干着也舒服点。真要是找不到合适的工作,去维护老项目,那都是后话,现学现卖就行了。
+
+**对于初学者来说别人劝了还非要学习淘汰的技术,多少脑子有点不够用,基本可以告别这一行了!**
+
diff --git a/docs_en/about-the-author/dog-that-copies-other-people-essay.en.md b/docs_en/about-the-author/dog-that-copies-other-people-essay.en.md
new file mode 100644
index 00000000000..048f6b3de28
--- /dev/null
+++ b/docs_en/about-the-author/dog-that-copies-other-people-essay.en.md
@@ -0,0 +1,56 @@
+---
+Title: Plagiarism dog, your feet will be cold when you sleep in winter! ! !
+category: Get to know the author
+tag:
+ - Miscellaneous talk
+---
+
+Plagiarism dogs are really annoying. . .
+
+I heard from a friend that my article was stolen again on Zhihu, and was used intact by others to divert traffic.
+
+
+
+And! ! ! This is not the most annoying thing.
+
+The original source that this person also noted at the end of the article is not mine. . .
+
+
+
+In other words, there is another plagiarism dog in CSDN who stole this article of mine and claimed the originality. Zhihu plagiarism dog has moved the article of this CSDN plagiarism dog intact.
+
+It’s so outrageous that his mother opened the door for outrageous things. It’s so outrageous.
+
+
+
+I opened the original source link marked by Zhihu Plagiarism Dog. Oh my god, it’s exactly the same content, and it also shows the originality.
+
+
+
+I took a look at the CSDN plagiarism dog's article. He has moved my highly praised answer all over the place. . . Really diligent. . .
+
+I don’t want to say more about CSDN. It’s just a large article dump, filled with all kinds of non-standard reprints and all kinds of garbage resources for paid downloads. This technology website, which is said to have the largest traffic in the country, is disgusting. It’s so popular that it’s ugly. If you can’t use it, don’t use it!
+
+For example, when I usually search on Google, I directly block the CSDN site. Just download a Chrome extension called Personal Blocklist and add blog.csdn.net to the blacklist.
+
+
+
+My articles have basically been stolen. The key is that I don’t get much traffic when I post them myself. On the contrary, the people who steal my articles have more traffic than me, the original author.
+
+What kind of world is this? Is it the distortion of human nature or the loss of morality?
+
+However, it doesn’t matter. It doesn’t matter if CSDN, a junk website, doesn’t post articles.
+
+Take a look at what kind of garbage the articles on the CSDN hot list are. They are either various advertisements or some patchwork articles with no quality.
+
+
+
+Of course, there are also a very small number of high-quality articles, such as articles by bloggers such as Tao Ge, Er Ge, Binghe, and Micro Technology.
+
+There are also many video platforms (such as Douyin and Bilibili) where many bloggers directly use other people’s original works to make videos to attract traffic or fans.
+
+The stolen article mentioned today was once used by a training institution to make a video to attract traffic.
+
+
+
+As individuals, we have no choice but to report everyone we encounter. . .
\ No newline at end of file
diff --git a/docs_en/about-the-author/feelings-after-one-month-of-induction-training.en.md b/docs_en/about-the-author/feelings-after-one-month-of-induction-training.en.md
new file mode 100644
index 00000000000..6a4858e307f
--- /dev/null
+++ b/docs_en/about-the-author/feelings-after-one-month-of-induction-training.en.md
@@ -0,0 +1,24 @@
+---
+title: Reflections After One Month of Induction Training
+category: About the Author
+tag:
+ - Personal Experience
+---
+
+It's hard to believe it's been over a month since I started. Before this, I had never interned or worked at a company, so many things were quite new to me. The transition from school to the workplace brings a change in roles, and the differences vary from person to person. For me, in school, I could selectively absorb what the teacher taught based on my interests, and I could even skip classes I didn't want to attend. It's different at a company. You have to learn the skills the company requires, unless you want to quit. In school, most people code to pass exams or find a good job; very few are driven by genuine interest. In the workplace, we code more because of job requirements, which is generally more challenging and stressful than in school. In school, our main responsibility is to ourselves, constantly learning to arm ourselves with knowledge. But at a company, we are responsible not only to ourselves but also to the company. After all, the company is paying you, not for you to be "on the beach."
+
+When I first joined the company, I switched to a Mac computer as required. Since I had always used Windows, I was very uncomfortable with it. I was clumsy at first and felt my programming efficiency drop by at least 30%. I was quite frustrated and often complained to myself about why we couldn't just use Windows or Linux. But strangely, after about a week, I slowly started to get used to programming on a Mac and even grew to like it. I don't want to compare the programming experience of Mac and Windows here; I think it varies from person to person. For the same price, a Mac's hardware specs are indeed a few steps behind Windows. However, the programming and user experience on a Mac are excellent. Of course, you can also choose to use Linux for daily development, which I believe would be great. Also, you can't play some mainstream online games on a Mac, which is a good choice for friends who can't resist the temptation to play games.
+
+I have to say that ThoughtWorks' training program is very good. Graduates are usually scheduled for training after joining. Unlike previous years, this year's training included a local China class (TWU-C). As a member of the first local class, I can honestly say it was great. The 8-week training, in addition to basic technologies needed for work like ES6 and SpringBoot, also included training on essential skills for new employees, such as how to hold efficient meetings, how to give proper feedback, how to refactor code, how to practice TDD, and so on. There were also regular activities during the training, such as Weekend Trips, City Tours, Cake Time, etc. The last three weeks included a simulated real-world project, which was very similar to the actual projects we work on, and I found it to be a great experience. This project has now completed one iteration, and I feel that the biggest takeaway was not the technology used, but how to collaborate as a team, how to use Git for team development, what a complete iteration looks like, what problems might be encountered during a project, and the entire workflow of a project.
+
+ThoughtWorks strongly encourages sharing and helping others grow, and I have felt this deeply during my time at the company. During the training, each of us had a Trainer who was responsible for our daily classes and projects. One Trainer was responsible for about 5-6 people. The Trainers regularly gave us feedback on our recent performance. I don't think this was just a formality; the Trainers were very responsible and often chatted with us after work. Colleagues are also very enthusiastic. If you have a problem and ask someone, they will usually tell you everything they know without reservation. If it's a problem that most people don't understand, they might even organize a technical session to share knowledge. Last Friday, I gave a technical sharing session in our group about Feign remote calls because the team was not very familiar with this topic, but it was likely to be used in future project development. I had just researched this topic, so I shared it with other colleagues in the group to help the project proceed more smoothly.
+
+In addition, ThoughtWorks is a company that strongly advocates a feedback culture. Feedback is about telling people our opinion of their performance and how they can do better. At first, I didn't pay much attention to it, but gradually I realized that giving proper feedback can be very helpful to others. This is because when people are doing things, it's hard for them to notice small problems that are obvious to others. For example, there's an interesting phenomenon: if you don't have a tester role in your project, and you've completed your module and tested it many times yourself, you might think there are no problems. However, when it's actually used, problems you never noticed before are very likely to appear. The explanation for this is that everyone has blind spots in their vision, which are closely related to our focus. We often can't find many problems in our own work even after testing it many times, but if we ask someone else to test it for us, they are very likely to find many obvious issues.
+
+
+
+After starting work, I have less time to update my public account, columns, and maintain my GitHub. In fact, many times after work, I have my own time to do my own things, but I always make excuses like being too tired from work or having fragmented time. Today, I looked at GitHub and suddenly realized that I hadn't handled a PR that someone submitted to me 14 days ago. This is indeed something I haven't done well; I haven't managed my time properly. I actually have a lot of things I want to write, and I will gradually put them on the agenda. After starting work, I've realized how important it is to spend the few hours after work. If you feel you haven't finished your work during the day, you can continue working on it after you get off work. If you can handle your daytime work with ease, you can do things you are interested in and learn technologies you are interested in after you get home. Do everything based on your own foundation, and don't aim too high.
+
+After starting work, I am also surrounded by many talented people. I think every professional should learn from others. Among the colleagues who trained with us this time, some are very skilled technically, while others may not be as strong technically but have excellent organizational and teamwork skills. There is a particularly brilliant colleague who, while we were still learning the various syntaxes of SpringBoot, wrote a simplified version of SpringBoot in his spare time, covering some common Spring annotations like `@RestController`, `@Autowired`, `@PathVariable`, `@RequestParam`, and so on (I have already contacted this colleague and asked him to open-source it, and I will share it on my public account as soon as possible, so look forward to it!). I think this colleague has a real interest in programming. He seems to have started programming in junior high school and is very interested in various underlying knowledge. He has written and implemented many low-level things himself. His dream is to create a project with over 20k stars on GitHub. I believe that with his abilities, he will definitely achieve this goal. I wish him all the best and hope he can achieve this goal soon.
+
+These are my personal feelings after more than a month of work. Many parts are just touched upon briefly. I will take the time to share more useful knowledge I have learned at the company or in my spare time with you all. I hope everyone who reads it can gain something.
diff --git a/docs_en/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.en.md b/docs_en/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.en.md
new file mode 100644
index 00000000000..dd10aebde90
--- /dev/null
+++ b/docs_en/about-the-author/feelings-of-half-a-year-from-graduation-to-entry.en.md
@@ -0,0 +1,54 @@
+---
+title: Reflections on the Six Months Since Graduation and Starting Work
+category: About the Author
+tag:
+ - Personal Experience
+---
+
+If you've read my previous introductions, you'll know I'm one of the millions of fresh graduates from 2019. This article is mainly about my feelings after working for over half a year. It contains many of my own subjective thoughts, so if you disagree with anything, feel free to say so in the comments. I respect others' opinions.
+
+Let me briefly describe my situation. I'm currently working at a foreign company, and my daily job, like most people's, is development. It's been over half a year since I graduated, and I've passed the company's 6-month probation period. I've worked on two business-oriented projects, one of which is ongoing. You might find it hard to imagine that the backends of these two projects don't involve distributed systems or microservices, nor have I had practical experience with "high-end" technologies like Redis or Kafka.
+
+The first project was an internal one—an employee growth system. Beyond the name, the system was essentially for performance appraisals, like evaluating your performance in a project team. The tech stack was Spring Boot, JPA, Spring Security, K8S, Docker, and React. The second project, which I'm currently working on, integrates a game (Cocos), a web admin panel (Spring Boot + Vue), and a mini-program (Taro).
+
+Yes, most of my time at work is related to CRUD, and I also write front-end pages every day. A friend of mine was baffled when he heard that most of my work involves writing business logic. He thought that just writing business code doesn't lead to growth. What? You're a fresh graduate who can't even write business code properly, and you're telling me this! So, **I'm puzzled as to why so many people who can't even write good business code have an aversion to CRUD. At least in my time working, I feel my code quality has improved, my ability to locate problems has greatly enhanced, I have a deeper understanding of the business, and I can now independently handle some front-end development.**
+
+Personally, I don't think writing good business code is that easy. Before complaining about doing CRUD work all day, take a look at whether your own CRUD code is well-written. In other words, while writing CRUD, have you figured out the common annotations or classes you use? It's like someone who only knows the simplest annotations like `@Service`, `@Autowired`, and `@RestController` claiming to have mastered Spring Boot.
+
+I don't know when it started, but everyone seems to think that having practical experience with Redis or MQ is impressive. This might be related to the current interview environment. You need to differentiate yourself from others, and if you want to get into a big tech company, it seems you must be proficient in these technologies. Well, not "seems"—let's be confident and say that for most job seekers, these technologies are considered a prerequisite.
+
+**To be honest, I fell into this "false proposition" in college.** In my sophomore year, I was exposed to Java because I joined a tech-oriented campus media group. At that time, our goal for learning Java was to develop a campus app. As a sophomore with only a beginner's level of programming skills, it took me some time to master the basics of Java. Then, I started learning Android development.
+
+It wasn't until the first semester of my junior year that I truly decided to pursue a career in Java backend development. After about three months of learning the basics of web development, I started studying distributed systems concepts like Redis and Dubbo. I learned through a combination of books, videos, and blogs. During my self-study, I completed two full projects by following video tutorials: one was a regular business system, and the other was a distributed system. **At that time, I thought I was pretty awesome after finishing them. I felt that simple CRUD work was beneath my skill level. Haha! Looking back now, I was so naive!**
+
+And then, problems arose when I worked on a project with a professor during my junior year summer break. The project was a performance appraisal system with moderate business complexity. The tech stack was SSM + Shiro + JSP. At that time, I encountered all sorts of problems. I couldn't write code that I thought I knew how to write. Even a simple CRUD operation took me several days. So, I was reviewing, learning, and coding at the same time. Although it was tiring, I learned a lot and became more grounded in my approach to technology. I think the phrase "**this project is no longer maintainable**" is the biggest negation of the project I worked on.
+
+Technology is ever-changing; mastering the core principles is what matters. A few years ago, we might have been using Spring with traditional XML for development, but now almost everyone uses Spring Boot to speed up development. Similarly, a few years ago, we might have used ActiveMQ for message queuing, but today, it's hardly used. The more common choices are RocketMQ and Kafka. With technology evolving so quickly, you can't possibly learn every single framework or tool.
+
+**Many beginners want to learn by doing projects right away, especially in a company setting. I think this is not advisable.** If your Java or Spring Boot fundamentals are weak, I suggest you study them beforehand before starting a project through videos or other means. **Another point is, I don't know why everyone says that learning while working on a project is the most effective way. I think this requires a prerequisite: you must have a basic understanding of the technology or a certain level of programming knowledge.**
+
+**Key point!!! If your foundation is not solid, simply following along with a video is useless. You'll find that after watching the video, you still can't write the code yourself.**
+
+I don't know what it's like for programmers at other companies. I feel that technical growth largely depends on what you do in your spare time. Relying solely on work, in most cases, will only make you more proficient at completing tasks. Of course, after writing a lot of code, your understanding of code quality will improve to some extent (provided you are conscious of it).
+
+Outside of work, I use my spare time to learn things I'm interested in. For example, in my first project at the company, we used Spring Security + JWT. Since I wasn't familiar with it, I spent about a week of my own time learning it and created a demo to share. GitHub address: