'+ escapeHtml(title) + '
' + escapeHtml(summary) +'
Page not found
+LightGBMLSS - An extension of LightGBM to probabilistic forecasting
+ + + +datasets
+
+
+LightGBMLSS - An extension of LightGBM to probabilistic forecasting
+ + + +data_loader
+
+
+load_simulated_gaussian_data()
+
+Returns train/test dataframe of a simulated example.
+ +y int64: response +x int64: x-feature +X1:X10 int64: random noise features
+lightgbmlss/datasets/data_loader.py5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 | |
load_simulated_studentT_data()
+
+Returns train/test dataframe of a simulated example.
+ +y int64: response +x int64: x-feature +X1:X10 int64: random noise features
+lightgbmlss/datasets/data_loader.py24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 | |
distributions
+
+
+LightGBMLSS - An extension of LightGBM to probabilistic forecasting
+ + + +Beta
+
+
+Beta
+
+
+
+ Bases: DistributionClass
Beta distribution class.
+concentration1: torch.Tensor + 1st concentration parameter of the distribution (often referred to as alpha). +concentration0: torch.Tensor + 2nd concentration parameter of the distribution (often referred to as beta).
+https://pytorch.org/docs/stable/distributions.html#beta
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/Beta.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
Cauchy
+
+
+Cauchy
+
+
+
+ Bases: DistributionClass
Cauchy distribution class.
+loc: torch.Tensor + Mode or median of the distribution. +scale: torch.Tensor + Half width at half maximum.
+https://pytorch.org/docs/stable/distributions.html#cauchy
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/Cauchy.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
Expectile
+
+
+Expectile
+
+
+
+ Bases: DistributionClass
Expectile distribution class.
+expectile: List + List of specified expectiles.
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +expectiles: List + List of expectiles in increasing order. +penalize_crossing: bool + Whether to include a penalty term to discourage crossing of expectiles.
+ +lightgbmlss/distributions/Expectile.py11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 | |
Expectile_Torch
+
+
+
+ Bases: Distribution
PyTorch implementation of expectiles.
+expectiles : List[torch.Tensor] + List of expectiles. +penalize_crossing : bool + Whether to include a penalty term to discourage crossing of expectiles.
+ +lightgbmlss/distributions/Expectile.py68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 | |
log_prob(value, tau)
+
+Returns the log of the probability density function evaluated at value.
value : torch.Tensor + Response for which log probability is to be calculated. +tau : List[torch.Tensor] + List of asymmetry parameters.
+torch.Tensor
+ Log probability of value.
lightgbmlss/distributions/Expectile.py88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 | |
expectile_norm(tau=0.5, m=0, sd=1)
+
+Calculates expectiles from Normal distribution for given tau values. +For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html
+Arguments
+tau : np.ndarray + Vector of expectiles from the respective distribution. +m : np.ndarray + Mean of the Normal distribution. +sd : np.ndarray + Standard deviation of the Normal distribution.
+Returns
+np.ndarray
+ +lightgbmlss/distributions/Expectile.py158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 | |
expectile_pnorm(tau=0.5, m=0, sd=1)
+
+Normal Expectile Distribution Function. +For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html
+Arguments
+tau : np.ndarray + Vector of expectiles from the respective distribution. +m : np.ndarray + Mean of the Normal distribution. +sd : np.ndarray + Standard deviation of the Normal distribution.
+Returns
+tau : np.ndarray + Expectiles from the Normal distribution.
+ +lightgbmlss/distributions/Expectile.py127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 | |
Gamma
+
+
+Gamma
+
+
+
+ Bases: DistributionClass
Gamma distribution class.
+concentration: torch.Tensor + shape parameter of the distribution (often referred to as alpha) +rate: torch.Tensor + rate = 1 / scale of the distribution (often referred to as beta)
+https://pytorch.org/docs/stable/distributions.html#gamma
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/Gamma.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
Gaussian
+
+
+Gaussian
+
+
+
+ Bases: DistributionClass
Gaussian distribution class.
+loc: torch.Tensor + Mean of the distribution (often referred to as mu). +scale: torch.Tensor + Standard deviation of the distribution (often referred to as sigma).
+https://pytorch.org/docs/stable/distributions.html#normal
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/Gaussian.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
Gumbel
+
+
+Gumbel
+
+
+
+ Bases: DistributionClass
Gumbel distribution class.
+loc: torch.Tensor + Location parameter of the distribution. +scale: torch.Tensor + Scale parameter of the distribution.
+https://pytorch.org/docs/stable/distributions.html#gumbel
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/Gumbel.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
Laplace
+
+
+Laplace
+
+
+
+ Bases: DistributionClass
Laplace distribution class.
+loc: torch.Tensor + Mean of the distribution. +scale: torch.Tensor + Scale of the distribution.
+https://pytorch.org/docs/stable/distributions.html#laplace
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/Laplace.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
LogNormal
+
+
+LogNormal
+
+
+
+ Bases: DistributionClass
LogNormal distribution class.
+loc: torch.Tensor + Mean of log of distribution. +scale: torch.Tensor + Standard deviation of log of the distribution.
+https://pytorch.org/docs/stable/distributions.html#lognormal
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/LogNormal.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
NegativeBinomial
+
+
+NegativeBinomial
+
+
+
+ Bases: DistributionClass
NegativeBinomial distribution class.
+total_count: torch.Tensor + Non-negative number of negative Bernoulli trials to stop. +probs: torch.Tensor + Event probabilities of success in the half open interval [0, 1). +logits: torch.Tensor + Event log-odds for probabilities of success.
+https://pytorch.org/docs/stable/distributions.html#negativebinomial
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn_total_count: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential), "softplus" (softplus) or "relu" (rectified linear unit). +response_fn_probs: str + Response function for transforming the distributional parameters to the correct support. Options are + "sigmoid" (sigmoid). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood).
+ +lightgbmlss/distributions/NegativeBinomial.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 +69 +70 +71 +72 +73 +74 +75 +76 +77 +78 +79 | |
Poisson
+
+
+Poisson
+
+
+
+ Bases: DistributionClass
Poisson distribution class.
+rate: torch.Tensor + Rate parameter of the distribution (often referred to as lambda).
+https://pytorch.org/docs/stable/distributions.html#poisson
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential), "softplus" (softplus) or "relu" (rectified linear unit). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood).
+ +lightgbmlss/distributions/Poisson.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 | |
SplineFlow
+
+
+SplineFlow
+
+
+
+ Bases: NormalizingFlowClass
Spline Flow class.
+The spline flow is a normalizing flow based on element-wise rational spline bijections of linear and quadratic +order (Durkan et al., 2019; Dolatabadi et al., 2020). Rational splines are functions that are comprised of segments +that are the ratio of two polynomials. Rational splines offer an excellent combination of functional flexibility +whilst maintaining a numerically stable inverse.
+For more details, see: +- Durkan, C., Bekasov, A., Murray, I. and Papamakarios, G. Neural Spline Flows. NeurIPS 2019. +- Dolatabadi, H. M., Erfani, S. and Leckie, C., Invertible Generative Modeling using Linear Rational Splines. AISTATS 2020.
+https://docs.pyro.ai/en/stable/distributions.html#pyro.distributions.transforms.Spline
+target_support: str + The target support. Options are + - "real": [-inf, inf] + - "positive": [0, inf] + - "positive_integer": [0, 1, 2, 3, ...] + - "unit_interval": [0, 1] +count_bins: int + The number of segments comprising the spline. +bound: float + The quantity "K" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the + "K" value, you can control the size of the bounding box and consequently control the range of inputs that + the spline transform operates on. Larger values of "K" will result in a wider valid range for the spline + transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen + based on the range of the data. +order: str + The order of the spline. Options are "linear" or "quadratic". +stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD" or "L2". +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/SplineFlow.py9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 | |
StudentT
+
+
+StudentT
+
+
+
+ Bases: DistributionClass
Student-T Distribution Class
+df: torch.Tensor + Degrees of freedom. +loc: torch.Tensor + Mean of the distribution. +scale: torch.Tensor + Scale of the distribution.
+https://pytorch.org/docs/stable/distributions.html#studentt
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/StudentT.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 +69 +70 +71 +72 | |
Weibull
+
+
+Weibull
+
+
+
+ Bases: DistributionClass
Weibull distribution class.
+scale: torch.Tensor + Scale parameter of distribution (lambda). +concentration: torch.Tensor + Concentration parameter of distribution (k/shape).
+https://pytorch.org/docs/stable/distributions.html#weibull
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/Weibull.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 | |
ZABeta
+
+
+ZABeta
+
+
+
+ Bases: DistributionClass
Zero-Adjusted Beta distribution class.
+The zero-adjusted Beta distribution is similar to the Beta distribution but allows zeros as y values.
+concentration1: torch.Tensor + 1st concentration parameter of the distribution (often referred to as alpha). +concentration0: torch.Tensor + 2nd concentration parameter of the distribution (often referred to as beta). +gate: torch.Tensor + Probability of zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood).
+ +lightgbmlss/distributions/ZABeta.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 +69 | |
ZAGamma
+
+
+ZAGamma
+
+
+
+ Bases: DistributionClass
Zero-Adjusted Gamma distribution class.
+The zero-adjusted Gamma distribution is similar to the Gamma distribution but allows zeros as y values.
+concentration: torch.Tensor + shape parameter of the distribution (often referred to as alpha) +rate: torch.Tensor + rate = 1 / scale of the distribution (often referred to as beta) +gate: torch.Tensor + Probability of zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood).
+ +lightgbmlss/distributions/ZAGamma.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 +69 | |
ZALN
+
+
+ZALN
+
+
+
+ Bases: DistributionClass
Zero-Adjusted LogNormal distribution class.
+The zero-adjusted Log-Normal distribution is similar to the Log-Normal distribution but allows zeros as y values.
+loc: torch.Tensor + Mean of log of distribution. +scale: torch.Tensor + Standard deviation of log of the distribution. +gate: torch.Tensor + Probability of zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential) or "softplus" (softplus). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood).
+ +lightgbmlss/distributions/ZALN.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 +69 | |
ZINB
+
+
+ZINB
+
+
+
+ Bases: DistributionClass
Zero-Inflated Negative Binomial distribution class.
+total_count: torch.Tensor + Non-negative number of negative Bernoulli trials to stop. +probs: torch.Tensor + Event probabilities of success in the half open interval [0, 1). +gate: torch.Tensor + Probability of extra zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn_total_count: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential), "softplus" (softplus) or "relu" (rectified linear unit). +response_fn_probs: str + Response function for transforming the distributional parameters to the correct support. Options are + "sigmoid" (sigmoid). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood).
+ +lightgbmlss/distributions/ZINB.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 +69 +70 +71 +72 +73 +74 +75 +76 +77 +78 +79 | |
ZIPoisson
+
+
+ZIPoisson
+
+
+
+ Bases: DistributionClass
Zero-Inflated Poisson distribution class.
+rate: torch.Tensor + Rate parameter of the distribution (often referred to as lambda). +gate: torch.Tensor + Probability of extra zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121
+stabilization: str + Stabilization method for the Gradient and Hessian. Options are "None", "MAD", "L2". +response_fn: str + Response function for transforming the distributional parameters to the correct support. Options are + "exp" (exponential), "softplus" (softplus) or "relu" (rectified linear unit). +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood).
+ +lightgbmlss/distributions/ZIPoisson.py6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 | |
distribution_utils
+
+
+DistributionClass
+
+
+Generic class that contains general functions for univariate distributions.
+distribution: torch.distributions.Distribution + PyTorch Distribution class. +univariate: bool + Whether the distribution is univariate or multivariate. +discrete: bool + Whether the support of the distribution is discrete or continuous. +n_dist_param: int + Number of distributional parameters. +stabilization: str + Stabilization method. +param_dict: Dict[str, Any] + Dictionary that maps distributional parameters to their response scale. +distribution_arg_names: List + List of distributional parameter names. +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function. +tau: List + List of expectiles. Only used for Expectile distributon. +penalize_crossing: bool + Whether to include a penalty term to discourage crossing of expectiles. Only used for Expectile distribution.
+ +lightgbmlss/distributions/distribution_utils.py16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 +286 +287 +288 +289 +290 +291 +292 +293 +294 +295 +296 +297 +298 +299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 +319 +320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 +336 +337 +338 +339 +340 +341 +342 +343 +344 +345 +346 +347 +348 +349 +350 +351 +352 +353 +354 +355 +356 +357 +358 +359 +360 +361 +362 +363 +364 +365 +366 +367 +368 +369 +370 +371 +372 +373 +374 +375 +376 +377 +378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 +402 +403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 +421 +422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 +433 +434 +435 +436 +437 +438 +439 +440 +441 +442 +443 +444 +445 +446 +447 +448 +449 +450 +451 +452 +453 +454 +455 +456 +457 +458 +459 +460 +461 +462 +463 +464 +465 +466 +467 +468 +469 +470 +471 +472 +473 +474 +475 +476 +477 +478 +479 +480 +481 +482 +483 +484 +485 +486 +487 +488 +489 +490 +491 +492 +493 +494 +495 +496 +497 +498 +499 +500 +501 +502 +503 +504 +505 +506 +507 +508 +509 +510 +511 +512 +513 +514 +515 +516 +517 +518 +519 +520 +521 +522 +523 +524 +525 +526 +527 +528 +529 +530 +531 +532 +533 +534 +535 +536 +537 +538 +539 +540 +541 +542 +543 +544 +545 +546 +547 +548 +549 +550 +551 +552 +553 +554 +555 +556 +557 +558 +559 +560 +561 +562 +563 +564 +565 +566 +567 +568 +569 +570 +571 +572 +573 +574 +575 +576 +577 +578 +579 +580 +581 +582 +583 +584 +585 +586 +587 +588 +589 +590 +591 +592 +593 +594 +595 +596 +597 +598 +599 +600 +601 +602 +603 +604 +605 +606 +607 +608 +609 +610 +611 +612 +613 +614 +615 +616 +617 +618 +619 +620 +621 +622 +623 +624 +625 +626 +627 +628 +629 +630 +631 +632 +633 +634 +635 +636 +637 +638 +639 +640 +641 +642 +643 +644 +645 +646 +647 +648 +649 +650 +651 +652 +653 +654 +655 +656 +657 +658 +659 +660 +661 +662 +663 +664 +665 +666 +667 +668 +669 +670 +671 +672 +673 +674 +675 +676 +677 +678 +679 +680 +681 +682 +683 +684 +685 +686 +687 +688 +689 +690 +691 +692 +693 +694 +695 +696 +697 +698 +699 +700 +701 +702 +703 +704 | |
calculate_start_values(target, max_iter=50)
+
+Function that calculates the starting values for each distributional parameter.
+target: np.ndarray + Data from which starting values are calculated. +max_iter: int + Maximum number of iterations.
+loss: float + Loss value. +start_values: np.ndarray + Starting values for each distributional parameter.
+ +lightgbmlss/distributions/distribution_utils.py177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 | |
compute_gradients_and_hessians(loss, predt, weights)
+
+Calculates gradients and hessians.
+Output gradients and hessians have shape (n_samples*n_outputs, 1).
+loss: torch.Tensor + Loss. +predt: torch.Tensor + List of predicted parameters. +weights: np.ndarray + Weights.
+grad: torch.Tensor + Gradients. +hess: torch.Tensor + Hessians.
+ +lightgbmlss/distributions/distribution_utils.py422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 +433 +434 +435 +436 +437 +438 +439 +440 +441 +442 +443 +444 +445 +446 +447 +448 +449 +450 +451 +452 +453 +454 +455 +456 +457 +458 +459 +460 +461 +462 +463 +464 +465 +466 +467 +468 +469 +470 +471 +472 +473 +474 +475 +476 +477 +478 +479 +480 +481 +482 +483 +484 +485 +486 +487 +488 +489 +490 +491 +492 +493 +494 +495 +496 +497 +498 | |
crps_score(y, yhat_dist)
+
+Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples.
+y: torch.Tensor + Response variable of shape (n_observations,1). +yhat_dist: torch.Tensor + Predicted samples of shape (n_samples, n_observations).
+crps: torch.Tensor + CRPS score.
+Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. +Journal of the American Statistical Association. 102. 359-378.
+https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549
+ +lightgbmlss/distributions/distribution_utils.py543 +544 +545 +546 +547 +548 +549 +550 +551 +552 +553 +554 +555 +556 +557 +558 +559 +560 +561 +562 +563 +564 +565 +566 +567 +568 +569 +570 +571 +572 +573 +574 +575 +576 +577 +578 +579 +580 +581 +582 +583 +584 +585 +586 +587 +588 +589 +590 +591 +592 +593 +594 +595 | |
dist_select(target, candidate_distributions, max_iter=100, n_samples=1000, plot=False, figure_size=(10, 5))
+
+Function that selects the most suitable distribution among the candidate_distributions for the target variable, +based on the NegLogLikelihood (lower is better).
+target: np.ndarray + Response variable. +candidate_distributions: List + List of candidate distributions. +max_iter: int + Maximum number of iterations for the optimization. +n_samples: int + Number of samples to draw from the fitted distribution. +plot: bool + If True, a density plot of the actual and fitted distribution is created. +figure_size: tuple + Figure size of the density plot.
+fit_df: pd.DataFrame + Dataframe with the loss values of the fitted candidate distributions.
+ +lightgbmlss/distributions/distribution_utils.py597 +598 +599 +600 +601 +602 +603 +604 +605 +606 +607 +608 +609 +610 +611 +612 +613 +614 +615 +616 +617 +618 +619 +620 +621 +622 +623 +624 +625 +626 +627 +628 +629 +630 +631 +632 +633 +634 +635 +636 +637 +638 +639 +640 +641 +642 +643 +644 +645 +646 +647 +648 +649 +650 +651 +652 +653 +654 +655 +656 +657 +658 +659 +660 +661 +662 +663 +664 +665 +666 +667 +668 +669 +670 +671 +672 +673 +674 +675 +676 +677 +678 +679 +680 +681 +682 +683 +684 +685 +686 +687 +688 +689 +690 +691 +692 +693 +694 +695 +696 +697 +698 +699 +700 +701 +702 +703 +704 | |
draw_samples(predt_params, n_samples=1000, seed=123)
+
+Function that draws n_samples from a predicted distribution.
+predt_params: pd.DataFrame + pd.DataFrame with predicted distributional parameters. +n_samples: int + Number of sample to draw from predicted response distribution. +seed: int + Manual seed.
+pred_dist: pd.DataFrame + DataFrame with n_samples drawn from predicted response distribution.
+ +lightgbmlss/distributions/distribution_utils.py297 +298 +299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 +319 +320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 | |
get_params_loss(predt, target, start_values, requires_grad=False)
+
+Function that returns the predicted parameters and the loss.
+predt: np.ndarray + Predicted values. +target: torch.Tensor + Target values. +start_values: List + Starting values for each distributional parameter. +requires_grad: bool + Whether to add to the computational graph or not.
+predt: torch.Tensor + Predicted parameters. +loss: torch.Tensor + Loss value.
+ +lightgbmlss/distributions/distribution_utils.py235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 +286 +287 +288 +289 +290 +291 +292 +293 +294 +295 | |
loss_fn_start_values(params, target)
+
+Function that calculates the loss for a given set of distributional parameters. Only used for calculating +the loss for the start values.
+params: torch.Tensor + Distributional parameters. +target: torch.Tensor + Target values.
+loss: torch.Tensor + Loss value.
+ +lightgbmlss/distributions/distribution_utils.py139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 | |
metric_fn(predt, data)
+
+Function that evaluates the predictions using the negative log-likelihood.
+predt: np.ndarray + Predicted values. +data: lgb.Dataset + Data used for training.
+name: str + Name of the evaluation metric. +nll: float + Negative log-likelihood. +is_higher_better: bool + Whether a higher value of the metric is better or not.
+ +lightgbmlss/distributions/distribution_utils.py107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 | |
objective_fn(predt, data)
+
+Function to estimate gradients and hessians of distributional parameters.
+predt: np.ndarray + Predicted values. +data: lgb.DMatrix + Data used for training.
+grad: np.ndarray + Gradient. +hess: np.ndarray + Hessian.
+ +lightgbmlss/distributions/distribution_utils.py69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 | |
predict_dist(booster, data, start_values, pred_type='parameters', n_samples=1000, quantiles=[0.1, 0.5, 0.9], seed=123)
+
+Function that predicts from the trained model.
+booster : lgb.Booster + Trained model. +data : pd.DataFrame + Data to predict from. +start_values : np.ndarray. + Starting values for each distributional parameter. +pred_type : str + Type of prediction: + - "samples" draws n_samples from the predicted distribution. + - "quantiles" calculates the quantiles from the predicted distribution. + - "parameters" returns the predicted distributional parameters. + - "expectiles" returns the predicted expectiles. +n_samples : int + Number of samples to draw from the predicted distribution. +quantiles : List[float] + List of quantiles to calculate from the predicted distribution. +seed : int + Seed for random number generator used to draw samples from the predicted distribution.
+pred : pd.DataFrame + Predictions.
+ +lightgbmlss/distributions/distribution_utils.py337 +338 +339 +340 +341 +342 +343 +344 +345 +346 +347 +348 +349 +350 +351 +352 +353 +354 +355 +356 +357 +358 +359 +360 +361 +362 +363 +364 +365 +366 +367 +368 +369 +370 +371 +372 +373 +374 +375 +376 +377 +378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 +402 +403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 | |
stabilize_derivative(input_der, type='MAD')
+
+Function that stabilizes Gradients and Hessians.
+As LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important +that these are comparable in magnitude for all distributional parameters. Due to imbalances regarding the ranges, +the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. +Another way to improve convergence might be to standardize the response variable. This is especially useful if the +range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and +the standardization of the response are not always advised but need to be carefully considered. +Source: https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173
+input_der : torch.Tensor + Input derivative, either Gradient or Hessian. +type: str + Stabilization method. Can be either "None", "MAD" or "L2".
+stab_der : torch.Tensor + Stabilized Gradient or Hessian.
+ +lightgbmlss/distributions/distribution_utils.py500 +501 +502 +503 +504 +505 +506 +507 +508 +509 +510 +511 +512 +513 +514 +515 +516 +517 +518 +519 +520 +521 +522 +523 +524 +525 +526 +527 +528 +529 +530 +531 +532 +533 +534 +535 +536 +537 +538 +539 +540 +541 | |
flow_utils
+
+
+NormalizingFlowClass
+
+
+Generic class that contains general functions for normalizing flows.
+base_dist: torch.distributions.Distribution + PyTorch Distribution class. Currently only Normal is supported. +flow_transform: Transform + Specify the normalizing flow transform. +count_bins: Optional[int] + The number of segments comprising the spline. Only used if flow_transform is Spline. +bound: Optional[float] + The quantity "K" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the + "K" value, you can control the size of the bounding box and consequently control the range of inputs that + the spline transform operates on. Larger values of "K" will result in a wider valid range for the spline + transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen + based on the range of the data. Only used if flow_transform is Spline. +order: Optional[str] + The order of the spline. Options are "linear" or "quadratic". Only used if flow_transform is Spline. +n_dist_param: int + Number of parameters. +param_dict: Dict[str, Any] + Dictionary that maps parameters to their response scale. +target_transform: Transform + Specify the target transform. +discrete: bool + Whether the target is discrete or not. +univariate: bool + Whether the distribution is univariate or multivariate. +stabilization: str + Stabilization method. Options are "None", "MAD" or "L2". +loss_fn: str + Loss function. Options are "nll" (negative log-likelihood) or "crps" (continuous ranked probability score). + Note that if "crps" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. + Hence, using the CRPS disregards any variation in the curvature of the loss function.
+ +lightgbmlss/distributions/flow_utils.py18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 +286 +287 +288 +289 +290 +291 +292 +293 +294 +295 +296 +297 +298 +299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 +319 +320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 +336 +337 +338 +339 +340 +341 +342 +343 +344 +345 +346 +347 +348 +349 +350 +351 +352 +353 +354 +355 +356 +357 +358 +359 +360 +361 +362 +363 +364 +365 +366 +367 +368 +369 +370 +371 +372 +373 +374 +375 +376 +377 +378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 +402 +403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 +421 +422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 +433 +434 +435 +436 +437 +438 +439 +440 +441 +442 +443 +444 +445 +446 +447 +448 +449 +450 +451 +452 +453 +454 +455 +456 +457 +458 +459 +460 +461 +462 +463 +464 +465 +466 +467 +468 +469 +470 +471 +472 +473 +474 +475 +476 +477 +478 +479 +480 +481 +482 +483 +484 +485 +486 +487 +488 +489 +490 +491 +492 +493 +494 +495 +496 +497 +498 +499 +500 +501 +502 +503 +504 +505 +506 +507 +508 +509 +510 +511 +512 +513 +514 +515 +516 +517 +518 +519 +520 +521 +522 +523 +524 +525 +526 +527 +528 +529 +530 +531 +532 +533 +534 +535 +536 +537 +538 +539 +540 +541 +542 +543 +544 +545 +546 +547 +548 +549 +550 +551 +552 +553 +554 +555 +556 +557 +558 +559 +560 +561 +562 +563 +564 +565 +566 +567 +568 +569 +570 +571 +572 +573 +574 +575 +576 +577 +578 +579 +580 +581 +582 +583 +584 +585 +586 +587 +588 +589 +590 +591 +592 +593 +594 +595 +596 +597 +598 +599 +600 +601 +602 +603 +604 +605 +606 +607 +608 +609 +610 +611 +612 +613 +614 +615 +616 +617 +618 +619 +620 +621 +622 +623 +624 +625 +626 +627 +628 +629 +630 +631 +632 +633 +634 +635 +636 +637 +638 +639 +640 +641 +642 +643 +644 +645 +646 +647 +648 +649 +650 +651 +652 +653 +654 +655 +656 +657 +658 +659 +660 +661 +662 +663 +664 +665 +666 +667 +668 +669 +670 +671 +672 +673 +674 +675 +676 +677 +678 +679 +680 +681 +682 +683 +684 +685 +686 +687 +688 +689 +690 +691 +692 +693 +694 +695 +696 +697 +698 +699 +700 +701 +702 +703 +704 +705 +706 +707 +708 +709 +710 +711 +712 +713 +714 +715 +716 +717 +718 +719 +720 +721 +722 +723 +724 +725 +726 +727 +728 +729 +730 +731 +732 +733 +734 +735 +736 +737 +738 +739 +740 +741 +742 | |
calculate_start_values(target, max_iter=50)
+
+Function that calculates starting values for each parameter.
+target: np.ndarray + Data from which starting values are calculated. +max_iter: int + Maximum number of iterations.
+loss: float + Loss value. +start_values: np.ndarray + Starting values for each parameter.
+ +lightgbmlss/distributions/flow_utils.py151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 | |
compute_gradients_and_hessians(loss, predt, weights)
+
+Calculates gradients and hessians.
+Output gradients and hessians have shape (n_samples*n_outputs, 1).
+loss: torch.Tensor + Loss. +predt: torch.Tensor + List of predicted parameters. +weights: np.ndarray + Weights.
+grad: torch.Tensor + Gradients. +hess: torch.Tensor + Hessians.
+ +lightgbmlss/distributions/flow_utils.py482 +483 +484 +485 +486 +487 +488 +489 +490 +491 +492 +493 +494 +495 +496 +497 +498 +499 +500 +501 +502 +503 +504 +505 +506 +507 +508 +509 +510 +511 +512 +513 +514 +515 +516 +517 +518 +519 +520 +521 +522 +523 +524 +525 +526 +527 +528 +529 +530 +531 +532 +533 +534 | |
create_spline_flow(input_dim=None)
+
+Function that constructs a Normalizing Flow.
+input_dim: int + Input dimension.
+spline_flow: Transform + Normalizing Flow.
+ +lightgbmlss/distributions/flow_utils.py286 +287 +288 +289 +290 +291 +292 +293 +294 +295 +296 +297 +298 +299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 | |
crps_score(y, yhat_dist)
+
+Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples.
+y: torch.Tensor + Response variable of shape (n_observations,1). +yhat_dist: torch.Tensor + Predicted samples of shape (n_samples, n_observations).
+crps: torch.Tensor + CRPS score.
+Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. +Journal of the American Statistical Association. 102. 359-378.
+https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549
+ +lightgbmlss/distributions/flow_utils.py582 +583 +584 +585 +586 +587 +588 +589 +590 +591 +592 +593 +594 +595 +596 +597 +598 +599 +600 +601 +602 +603 +604 +605 +606 +607 +608 +609 +610 +611 +612 +613 +614 +615 +616 +617 +618 +619 +620 +621 +622 +623 +624 +625 +626 +627 +628 +629 +630 +631 +632 +633 +634 | |
draw_samples(predt_params, n_samples=1000, seed=123)
+
+Function that draws n_samples from a predicted distribution.
+predt_params: pd.DataFrame + pd.DataFrame with predicted distributional parameters. +n_samples: int + Number of sample to draw from predicted response distribution. +seed: int + Manual seed.
+pred_dist: pd.DataFrame + DataFrame with n_samples drawn from predicted response distribution.
+ +lightgbmlss/distributions/flow_utils.py361 +362 +363 +364 +365 +366 +367 +368 +369 +370 +371 +372 +373 +374 +375 +376 +377 +378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 | |
flow_select(target, candidate_flows, max_iter=100, n_samples=1000, plot=False, figure_size=(10, 5))
+
+Function that selects the most suitable normalizing flow specification among the candidate_flow for the +target variable, based on the NegLogLikelihood (lower is better).
+target: np.ndarray + Response variable. +candidate_flows: List + List of candidate normalizing flow specifications. +max_iter: int + Maximum number of iterations for the optimization. +n_samples: int + Number of samples drawn from the fitted distribution. +plot: bool + If True, a density plot of the actual and fitted distribution is created. +figure_size: tuple + Figure size of the density plot.
+fit_df: pd.DataFrame + Dataframe with the loss values of the fitted normalizing flow.
+ +lightgbmlss/distributions/flow_utils.py636 +637 +638 +639 +640 +641 +642 +643 +644 +645 +646 +647 +648 +649 +650 +651 +652 +653 +654 +655 +656 +657 +658 +659 +660 +661 +662 +663 +664 +665 +666 +667 +668 +669 +670 +671 +672 +673 +674 +675 +676 +677 +678 +679 +680 +681 +682 +683 +684 +685 +686 +687 +688 +689 +690 +691 +692 +693 +694 +695 +696 +697 +698 +699 +700 +701 +702 +703 +704 +705 +706 +707 +708 +709 +710 +711 +712 +713 +714 +715 +716 +717 +718 +719 +720 +721 +722 +723 +724 +725 +726 +727 +728 +729 +730 +731 +732 +733 +734 +735 +736 +737 +738 +739 +740 +741 +742 | |
get_params_loss(predt, target, start_values, requires_grad=False)
+
+Function that returns the predicted parameters and the loss.
+predt: np.ndarray + Predicted values. +target: torch.Tensor + Target values. +start_values: List + Starting values for each parameter.
+predt: torch.Tensor + Predicted parameters. +loss: torch.Tensor + Loss value.
+ +lightgbmlss/distributions/flow_utils.py230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 | |
metric_fn(predt, data)
+
+Function that evaluates the predictions using the specified loss function.
+predt: np.ndarray + Predicted values. +data: lgb.Dataset + Data used for training.
+name: str + Name of the evaluation metric. +loss: float + Loss value.
+ +lightgbmlss/distributions/flow_utils.py121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 | |
objective_fn(predt, data)
+
+Function to estimate gradients and hessians of normalizing flow parameters.
+predt: np.ndarray + Predicted values. +data: lgb.Dataset + Data used for training.
+grad: np.ndarray + Gradient. +hess: np.ndarray + Hessian.
+ +lightgbmlss/distributions/flow_utils.py83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 | |
predict_dist(booster, data, start_values, pred_type='parameters', n_samples=1000, quantiles=[0.1, 0.5, 0.9], seed=123)
+
+Function that predicts from the trained model.
+booster : lgb.Booster + Trained model. +start_values : np.ndarray + Starting values for each distributional parameter. +data : pd.DataFrame + Data to predict from. +pred_type : str + Type of prediction: + - "samples" draws n_samples from the predicted distribution. + - "quantiles" calculates the quantiles from the predicted distribution. + - "parameters" returns the predicted distributional parameters. + - "expectiles" returns the predicted expectiles. +n_samples : int + Number of samples to draw from the predicted distribution. +quantiles : List[float] + List of quantiles to calculate from the predicted distribution. +seed : int + Seed for random number generator used to draw samples from the predicted distribution.
+pred : pd.DataFrame + Predictions.
+ +lightgbmlss/distributions/flow_utils.py403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 +421 +422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 +433 +434 +435 +436 +437 +438 +439 +440 +441 +442 +443 +444 +445 +446 +447 +448 +449 +450 +451 +452 +453 +454 +455 +456 +457 +458 +459 +460 +461 +462 +463 +464 +465 +466 +467 +468 +469 +470 +471 +472 +473 +474 +475 +476 +477 +478 +479 +480 | |
replace_parameters(params, flow_dist)
+
+Replace parameters with estimated ones.
+params: torch.Tensor + Estimated parameters. +flow_dist: Transform + Normalizing Flow.
+params_list: List + List of estimated parameters. +flow_dist: Transform + Normalizing Flow with estimated parameters.
+ +lightgbmlss/distributions/flow_utils.py320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 +336 +337 +338 +339 +340 +341 +342 +343 +344 +345 +346 +347 +348 +349 +350 +351 +352 +353 +354 +355 +356 +357 +358 +359 | |
stabilize_derivative(input_der, type='MAD')
+
+Function that stabilizes Gradients and Hessians.
+Since parameters are estimated by optimizing Gradients and Hessians, it is important that these are comparable +in magnitude for all parameters. Due to imbalances regarding the ranges, the estimation might become unstable +so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve +convergence might be to standardize the response variable. This is especially useful if the range of the +response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the +standardization of the response are not always advised but need to be carefully considered.
+https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173
+input_der : torch.Tensor + Input derivative, either Gradient or Hessian. +type: str + Stabilization method. Can be either "None", "MAD" or "L2".
+stab_der : torch.Tensor + Stabilized Gradient or Hessian.
+ +lightgbmlss/distributions/flow_utils.py536 +537 +538 +539 +540 +541 +542 +543 +544 +545 +546 +547 +548 +549 +550 +551 +552 +553 +554 +555 +556 +557 +558 +559 +560 +561 +562 +563 +564 +565 +566 +567 +568 +569 +570 +571 +572 +573 +574 +575 +576 +577 +578 +579 +580 | |
zero_inflated
+
+
+ZeroAdjustedBeta
+
+
+
+ Bases: ZeroInflatedDistribution
A Zero-Adjusted Beta distribution.
+concentration1: torch.Tensor + 1st concentration parameter of the distribution (often referred to as alpha). +concentration0: torch.Tensor + 2nd concentration parameter of the distribution (often referred to as beta). +gate: torch.Tensor + Probability of zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py
+ +lightgbmlss/distributions/zero_inflated.py299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 +319 +320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 | |
ZeroAdjustedGamma
+
+
+
+ Bases: ZeroInflatedDistribution
A Zero-Adjusted Gamma distribution.
+concentration: torch.Tensor + shape parameter of the distribution (often referred to as alpha) +rate: torch.Tensor + rate = 1 / scale of the distribution (often referred to as beta) +gate: torch.Tensor + Probability of zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py
+ +lightgbmlss/distributions/zero_inflated.py221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 | |
ZeroAdjustedLogNormal
+
+
+
+ Bases: ZeroInflatedDistribution
A Zero-Adjusted Log-Normal distribution.
+loc: torch.Tensor + Mean of log of distribution. +scale: torch.Tensor + Standard deviation of log of the distribution. +gate: torch.Tensor + Probability of zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py
+ +lightgbmlss/distributions/zero_inflated.py260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 +286 +287 +288 +289 +290 +291 +292 +293 +294 +295 +296 | |
ZeroInflatedDistribution
+
+
+
+ Bases: TorchDistribution
Generic Zero Inflated distribution.
+This can be used directly or can be used as a base class as e.g. for
+:class:ZeroInflatedPoisson and :class:ZeroInflatedNegativeBinomial.
gate : torch.Tensor + Probability of extra zeros given via a Bernoulli distribution. +base_dist : torch.distributions.Distribution + The base distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L18
+ +lightgbmlss/distributions/zero_inflated.py20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 | |
ZeroInflatedNegativeBinomial
+
+
+
+ Bases: ZeroInflatedDistribution
A Zero Inflated Negative Binomial distribution.
+total_count: torch.Tensor + Non-negative number of negative Bernoulli trial. +probs: torch.Tensor + Event probabilities of success in the half open interval [0, 1). +logits: torch.Tensor + Event log-odds of success (log(p/(1-p))). +gate: torch.Tensor + Probability of extra zeros given via a Bernoulli distribution.
+lightgbmlss/distributions/zero_inflated.py174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 | |
ZeroInflatedPoisson
+
+
+
+ Bases: ZeroInflatedDistribution
A Zero-Inflated Poisson distribution.
+rate: torch.Tensor + The rate of the Poisson distribution. +gate: torch.Tensor + Probability of extra zeros given via a Bernoulli distribution.
+https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121
+ +lightgbmlss/distributions/zero_inflated.py142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 | |
model
+
+
+LightGBMLSS
+
+
+LightGBMLSS model class
+dist : Distribution + DistributionClass object. + start_values : np.ndarray + Starting values for each distributional parameter.
+ +lightgbmlss/model.py51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 +286 +287 +288 +289 +290 +291 +292 +293 +294 +295 +296 +297 +298 +299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 +319 +320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 +336 +337 +338 +339 +340 +341 +342 +343 +344 +345 +346 +347 +348 +349 +350 +351 +352 +353 +354 +355 +356 +357 +358 +359 +360 +361 +362 +363 +364 +365 +366 +367 +368 +369 +370 +371 +372 +373 +374 +375 +376 +377 +378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 +402 +403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 +421 +422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 +433 +434 +435 +436 +437 +438 +439 +440 +441 +442 +443 +444 +445 +446 +447 +448 +449 +450 +451 +452 +453 +454 +455 +456 +457 +458 +459 +460 +461 +462 +463 +464 +465 +466 +467 +468 +469 +470 +471 +472 +473 +474 +475 +476 +477 +478 +479 +480 +481 +482 +483 +484 +485 +486 +487 +488 +489 +490 +491 +492 +493 +494 +495 +496 +497 +498 +499 +500 +501 +502 +503 +504 +505 +506 +507 +508 +509 +510 +511 +512 +513 +514 +515 +516 +517 +518 +519 +520 +521 +522 +523 +524 +525 +526 +527 +528 +529 +530 +531 +532 +533 +534 +535 +536 +537 +538 +539 +540 +541 +542 +543 +544 +545 +546 +547 +548 +549 +550 +551 +552 +553 +554 +555 +556 +557 +558 +559 +560 +561 +562 +563 +564 +565 +566 +567 +568 +569 +570 +571 +572 +573 +574 +575 +576 +577 +578 +579 +580 +581 +582 +583 +584 +585 +586 +587 +588 +589 +590 +591 +592 +593 +594 +595 +596 +597 +598 +599 +600 +601 +602 +603 +604 +605 +606 +607 +608 +609 +610 +611 +612 +613 +614 +615 +616 | |
cv(params, train_set, num_boost_round=100, folds=None, nfold=5, stratified=True, shuffle=True, init_model=None, feature_name='auto', categorical_feature='auto', fpreproc=None, seed=123, callbacks=None, eval_train_metric=False, return_cvbooster=False)
+
+Function to cross-validate a LightGBMLSS model with given parameters.
+params : dict
+ Parameters for training. Values passed through params take precedence over those
+ supplied via arguments.
+train_set : Dataset
+ Data to be trained on.
+num_boost_round : int, optional (default=100)
+ Number of boosting iterations.
+folds : generator or iterator of (train_idx, test_idx) tuples, scikit-learn splitter object or None, optional (default=None)
+ If generator or iterator, it should yield the train and test indices for each fold.
+ If object, it should be one of the scikit-learn splitter classes
+ (https://scikit-learn.org/stable/modules/classes.html#splitter-classes)
+ and have split method.
+ This argument has highest priority over other data split arguments.
+nfold : int, optional (default=5)
+ Number of folds in CV.
+stratified : bool, optional (default=True)
+ Whether to perform stratified sampling.
+shuffle : bool, optional (default=True)
+ Whether to shuffle before splitting data.
+init_model : str, pathlib.Path, Booster or None, optional (default=None)
+ Filename of LightGBM model or Booster instance used for continue training.
+feature_name : list of str, or 'auto', optional (default="auto")
+ Feature names.
+ If 'auto' and data is pandas DataFrame, data columns names are used.
+categorical_feature : list of str or int, or 'auto', optional (default="auto")
+ Categorical features.
+ If list of int, interpreted as indices.
+ If list of str, interpreted as feature names (need to specify feature_name as well).
+ If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used.
+ All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647).
+ Large values could be memory consuming. Consider using consecutive integers starting from zero.
+ All negative values in categorical features will be treated as missing values.
+ The output cannot be monotonically constrained with respect to a categorical feature.
+ Floating point numbers in categorical features will be rounded towards 0.
+fpreproc : callable or None, optional (default=None)
+ Preprocessing function that takes (dtrain, dtest, params)
+ and returns transformed versions of those.
+seed : int, optional (default=0)
+ Seed used to generate the folds (passed to numpy.random.seed).
+callbacks : list of callable, or None, optional (default=None)
+ List of callback functions that are applied at each iteration.
+ See Callbacks in Python API for more information.
+eval_train_metric : bool, optional (default=False)
+ Whether to display the train metric in progress.
+ The score of the metric is calculated again after each training step, so there is some impact on performance.
+return_cvbooster : bool, optional (default=False)
+ Whether to return Booster models trained on each fold through CVBooster.
eval_hist : dict
+ Evaluation history.
+ The dictionary has the following format:
+ {'metric1-mean': [values], 'metric1-stdv': [values],
+ 'metric2-mean': [values], 'metric2-stdv': [values],
+ ...}.
+ If return_cvbooster=True, also returns trained boosters wrapped in a CVBooster object via cvbooster key.
lightgbmlss/model.py184 +185 +186 +187 +188 +189 +190 +191 +192 +193 +194 +195 +196 +197 +198 +199 +200 +201 +202 +203 +204 +205 +206 +207 +208 +209 +210 +211 +212 +213 +214 +215 +216 +217 +218 +219 +220 +221 +222 +223 +224 +225 +226 +227 +228 +229 +230 +231 +232 +233 +234 +235 +236 +237 +238 +239 +240 +241 +242 +243 +244 +245 +246 +247 +248 +249 +250 +251 +252 +253 +254 +255 +256 +257 +258 +259 +260 +261 +262 +263 +264 +265 +266 +267 +268 +269 +270 +271 +272 +273 +274 +275 +276 +277 +278 +279 +280 +281 +282 +283 +284 +285 | |
expectile_plot(X, feature='x', expectile='0.05', plot_type='Partial_Dependence')
+
+LightGBMLSS function for plotting expectile SHapley values.
+ +Train/Test Data
+feature: str + Specifies which feature to use for plotting Partial_Dependence plot. +expectile: str + Specifies which expectile to plot. +plot_type: str + Specifies which SHapley-plot to visualize. Currently, "Partial_Dependence" and "Feature_Importance" + are supported.
+ +lightgbmlss/model.py520 +521 +522 +523 +524 +525 +526 +527 +528 +529 +530 +531 +532 +533 +534 +535 +536 +537 +538 +539 +540 +541 +542 +543 +544 +545 +546 +547 +548 | |
hyper_opt(hp_dict, train_set, num_boost_round=500, nfold=10, early_stopping_rounds=20, max_minutes=10, n_trials=None, study_name=None, silence=False, seed=None, hp_seed=None)
+
+Function to tune hyperparameters using optuna.
+hp_dict: dict + Dictionary of hyperparameters to tune. +train_set: lgb.Dataset + Training data. +num_boost_round: int + Number of boosting iterations. +nfold: int + Number of folds in CV. +early_stopping_rounds: int + Activates early stopping. Cross-Validation metric (average of validation + metric computed over CV folds) needs to improve at least once in + every early_stopping_rounds round(s) to continue training. + The last entry in the evaluation history will represent the best iteration. + If there's more than one metric in the eval_metric parameter given in + params, the last metric will be used for early stopping. +max_minutes: int + Time budget in minutes, i.e., stop study after the given number of minutes. +n_trials: int + The number of trials. If this argument is set to None, there is no limitation on the number of trials. +study_name: str + Name of the hyperparameter study. +silence: bool + Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. +seed: int + Seed used to generate the folds (passed to numpy.random.seed). +hp_seed: int + Seed for random number generator used in the Bayesian hyper-parameter search.
+opt_params : dict + Optimal hyper-parameters.
+ +lightgbmlss/model.py287 +288 +289 +290 +291 +292 +293 +294 +295 +296 +297 +298 +299 +300 +301 +302 +303 +304 +305 +306 +307 +308 +309 +310 +311 +312 +313 +314 +315 +316 +317 +318 +319 +320 +321 +322 +323 +324 +325 +326 +327 +328 +329 +330 +331 +332 +333 +334 +335 +336 +337 +338 +339 +340 +341 +342 +343 +344 +345 +346 +347 +348 +349 +350 +351 +352 +353 +354 +355 +356 +357 +358 +359 +360 +361 +362 +363 +364 +365 +366 +367 +368 +369 +370 +371 +372 +373 +374 +375 +376 +377 +378 +379 +380 +381 +382 +383 +384 +385 +386 +387 +388 +389 +390 +391 +392 +393 +394 +395 +396 +397 +398 +399 +400 +401 +402 +403 +404 +405 +406 +407 +408 +409 +410 +411 +412 +413 +414 +415 +416 +417 +418 +419 +420 +421 +422 +423 +424 +425 +426 +427 +428 +429 +430 +431 +432 | |
load_model(model_path)
+
+
+ staticmethod
+
+
+Load the model from a file.
+model_path : str + The path to the saved model.
+The loaded model.
+ +lightgbmlss/model.py601 +602 +603 +604 +605 +606 +607 +608 +609 +610 +611 +612 +613 +614 +615 +616 | |
plot(X, feature='x', parameter='loc', max_display=15, plot_type='Partial_Dependence')
+
+LightGBMLSS SHap plotting function.
+X: pd.DataFrame + Train/Test Data +feature: str + Specifies which feature is to be plotted. +parameter: str + Specifies which distributional parameter is to be plotted. +max_display: int + Specifies the maximum number of features to be displayed. +plot_type: str + Specifies the type of plot: + "Partial_Dependence" plots the partial dependence of the parameter on the feature. + "Feature_Importance" plots the feature importance of the parameter.
+ +lightgbmlss/model.py477 +478 +479 +480 +481 +482 +483 +484 +485 +486 +487 +488 +489 +490 +491 +492 +493 +494 +495 +496 +497 +498 +499 +500 +501 +502 +503 +504 +505 +506 +507 +508 +509 +510 +511 +512 +513 +514 +515 +516 +517 +518 | |
predict(data, pred_type='parameters', n_samples=1000, quantiles=[0.1, 0.5, 0.9], seed=123)
+
+Function that predicts from the trained model.
+data : pd.DataFrame + Data to predict from. +pred_type : str + Type of prediction: + - "samples" draws n_samples from the predicted distribution. + - "quantiles" calculates the quantiles from the predicted distribution. + - "parameters" returns the predicted distributional parameters. + - "expectiles" returns the predicted expectiles. +n_samples : int + Number of samples to draw from the predicted distribution. +quantiles : List[float] + List of quantiles to calculate from the predicted distribution. +seed : int + Seed for random number generator used to draw samples from the predicted distribution.
+predt_df : pd.DataFrame + Predictions.
+ +lightgbmlss/model.py434 +435 +436 +437 +438 +439 +440 +441 +442 +443 +444 +445 +446 +447 +448 +449 +450 +451 +452 +453 +454 +455 +456 +457 +458 +459 +460 +461 +462 +463 +464 +465 +466 +467 +468 +469 +470 +471 +472 +473 +474 +475 | |
save_model(model_path)
+
+Save the model to a file.
+model_path : str + The path to save the model.
+None
+ +lightgbmlss/model.py583 +584 +585 +586 +587 +588 +589 +590 +591 +592 +593 +594 +595 +596 +597 +598 +599 | |
set_init_score(dmatrix)
+
+Set init_score for distributions.
+dmatrix : Dataset + Dataset to set base margin for.
+None
+ +lightgbmlss/model.py89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 | |
set_params(params)
+
+Set parameters for distributional model.
+params : Dict[str, Any] + Parameters for model.
+params : Dict[str, Any] + Updated Parameters for model.
+ +lightgbmlss/model.py66 +67 +68 +69 +70 +71 +72 +73 +74 +75 +76 +77 +78 +79 +80 +81 +82 +83 +84 +85 +86 +87 | |
set_valid_margin(valid_sets, start_values)
+
+Function that sets the base margin for the validation set.
+valid_sets : list + List of tuples containing the train and evaluation set. +valid_names: list + List of tuples containing the name of train and evaluation set. +start_values : np.ndarray + Array containing the start values for the distributional parameters.
+valid_sets : list + List of tuples containing the train and evaluation set.
+ +lightgbmlss/model.py550 +551 +552 +553 +554 +555 +556 +557 +558 +559 +560 +561 +562 +563 +564 +565 +566 +567 +568 +569 +570 +571 +572 +573 +574 +575 +576 +577 +578 +579 +580 +581 | |
train(params, train_set, num_boost_round=100, valid_sets=None, valid_names=None, init_model=None, feature_name='auto', categorical_feature='auto', keep_training_booster=False, callbacks=None)
+
+Function to perform the training of a LightGBMLSS model with given parameters.
+params : dict
+ Parameters for training. Values passed through params take precedence over those
+ supplied via arguments.
+train_set : Dataset
+ Data to be trained on.
+num_boost_round : int, optional (default=100)
+ Number of boosting iterations.
+valid_sets : list of Dataset, or None, optional (default=None)
+ List of data to be evaluated on during training.
+valid_names : list of str, or None, optional (default=None)
+ Names of valid_sets.
+init_model : str, pathlib.Path, Booster or None, optional (default=None)
+ Filename of LightGBM model or Booster instance used for continue training.
+feature_name : list of str, or 'auto', optional (default="auto")
+ Feature names.
+ If 'auto' and data is pandas DataFrame, data columns names are used.
+categorical_feature : list of str or int, or 'auto', optional (default="auto")
+ Categorical features.
+ If list of int, interpreted as indices.
+ If list of str, interpreted as feature names (need to specify feature_name as well).
+ If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used.
+ All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647).
+ Large values could be memory consuming. Consider using consecutive integers starting from zero.
+ All negative values in categorical features will be treated as missing values.
+ The output cannot be monotonically constrained with respect to a categorical feature.
+ Floating point numbers in categorical features will be rounded towards 0.
+keep_training_booster : bool, optional (default=False)
+ Whether the returned Booster will be used to keep training.
+ If False, the returned value will be converted into _InnerPredictor before returning.
+ This means you won't be able to use eval, eval_train or eval_valid methods of the returned Booster.
+ When your model is very large and cause the memory error,
+ you can try to set this param to True to avoid the model conversion performed during the internal call of model_to_string.
+ You can still use _InnerPredictor as init_model for future continue training.
+callbacks : list of callable, or None, optional (default=None)
+ List of callback functions that are applied at each iteration.
+ See Callbacks in Python API for more information.
booster : Booster + The trained Booster model.
+ +lightgbmlss/model.py107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 | |
utils
+
+
+exp_fn(predt)
+
+Exponential function used to ensure predt is strictly positive.
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 | |
exp_fn_df(predt)
+
+Exponential function used for Student-T distribution.
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 | |
identity_fn(predt)
+
+Identity mapping of predt.
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 | |
log_fn(predt)
+
+Inverse of exp_fn function.
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py61 +62 +63 +64 +65 +66 +67 +68 +69 +70 +71 +72 +73 +74 +75 +76 +77 +78 | |
relu_fn(predt)
+
+Function used to ensure predt are scaled to max(0, predt).
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 | |
sigmoid_fn(predt)
+
+Function used to ensure predt are scaled to (0,1).
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 | |
softplus_fn(predt)
+
+Softplus function used to ensure predt is strictly positive.
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py81 +82 +83 +84 +85 +86 +87 +88 +89 +90 +91 +92 +93 +94 +95 +96 +97 +98 +99 | |
softplus_fn_df(predt)
+
+Softplus function used for Student-T distribution.
+predt: torch.tensor + Predicted values.
+predt: torch.tensor + Predicted values.
+ +lightgbmlss/utils.py102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 | |
+''Practitioners expect forecasting to reduce future uncertainty by providing accurate predictions like those in hard sciences. However, this is a great misconception. A major purpose of forecasting is not to reduce uncertainty but reveal its full extent and implications by estimating it as precisely as possible. [...] The challenge for the forecasting field is how to persuade practitioners of the reality that all forecasts are uncertain and that this uncertainty cannot be ignored, as doing so could lead to catastrophic consequences.'' Makridakis (2022b) ++ +It has not been too long, though, that most regression models focused on estimating the conditional mean $\mathbb{E}(Y|\mathbf{X} = \mathbf{x})$ only, implicitly treating higher moments of the conditional distribution $F_{Y}(y|\mathbf{x})$ as fixed nuisance parameters. As such, models that minimize an $\ell_{2}$-type loss for the conditional mean are not able to fully exploit the information contained in the data, since this is equivalent to assuming a Normal distribution with constant variance. In real world situations, however, the data generating process is usually less well behaved, exhibiting characteristics such as heteroskedasticity, varying degrees of skewness and kurtosis or intermittent and sporadic behaviour. In recent years, however, there has been a clear shift in both academic and corporate research toward modelling the entire conditional distribution. This change in attention is most evident in the recent M5 forecasting competition (Makridakis et al., 2022a,b), which differed from previous ones in that it consisted of two parallel competitions: in addition to providing accurate point forecasts, participants were also asked to forecast nine different quantiles to approximate the distribution of future sales. + +# Distributional Gradient Boosting Machines + +This section introduces the general idea of distributional modelling. For a more thorough introduction, we refer the interested reader to Rigby and Stasinopoulos (2005); Klein et al. (2015); Stasinopoulos et al. (2017). + +## GAMLSS + +Probabilistic forecasts are predictions in the form of a probability distribution, rather than a single point estimate only. In this context, the introduction of Generalized Additive Models for Location Scale and Shape (GAMLSS) by Rigby and Stasinopoulos (2005) has stimulated a lot of research and culminated in a new research branch that focuses on modelling the entire conditional distribution in dependence of covariates. + +### Univariate Targets + +In its original formulation, GAMLSS assume a univariate response to follow a distribution $\mathcal{D}$ that depends on up to four parameters, i.e., $y_{i} \stackrel{ind}{\sim} \mathcal{D}(\mu_{i}, \sigma^{2}_{i}, \nu_{i}, \tau_{i}), i=1,\ldots,N$, where $\mu_{i}$ and $\sigma^{2}_{i}$ are often location and scale parameters, respectively, while $\nu_{i}$ and $\tau_{i}$ correspond to shape parameters such as skewness and kurtosis. Hence, the framework allows to model not only the mean (or location) but all parameters as functions of explanatory variables. It is important to note that distributional modelling implies that observations are independent, but not necessarily identical realizations $y \stackrel{ind}{\sim} \mathcal{D}\big(\mathbf{\theta}(\mathbf{x})\big)$, since all distributional parameters $\mathbf{\theta}(\mathbf{x})$ are related to and allowed to change with covariates. In contrast to Generalized Linear (GLM) and Generalized Additive Models (GAM), the assumption of the response distribution belonging to an exponential family is relaxed in GAMLSS and replaced by a more general class of distributions, including highly skewed and/or kurtotic continuous, discrete and mixed discrete, as well as zero-inflated distributions. While the original formulation of GAMLSS in Rigby and Stasinopoulos (2005) suggests that any distribution can be described by location, scale and shape parameters, it is not necessarily true that the observed data distribution can actually be characterized by all of these parameters. Hence, we follow Klein et al. (2015) and use the term distributional modelling and GAMLSS interchangeably. + +From a frequentist point of view, distributional modelling can be formulated as follows + +\begin{equation} +y_{i} \stackrel{ind}{\sim} \mathcal{D} + \begin{pmatrix} + h_{1}\bigl(\theta_{i1}(x_{i})\bigr) = \eta_{i1} \\ + h_{2}\bigl(\theta_{i2}(x_{i})\bigr) = \eta_{i2} \\ + \vdots \\ + h_{K}\bigl(\theta_{iK}(x_{i})\bigr) = \eta_{iK} +\end{pmatrix} +\end{equation} + +for $i = 1, \ldots, N$, where $\mathcal{D}$ denotes a parametric distribution for the response $\textbf{y} = (y_{1}, \ldots, y_{N})^{\prime}$ that depends on $K$ distributional parameters $\theta_{k}$, $k = 1, \ldots, K$, and with $h_{k}(\cdot)$ denoting a known function relating distributional parameters to predictors $\eta_{k}$. In its most generic form, the predictor $\eta_{k}$ is given by + +\begin{equation} +\eta_{k} = f_{k}(\mathbf{x}), \qquad k = 1, \ldots, K +\end{equation} + +Within the original distributional regression framework, the functions $f_{k}(\cdot)$ usually represent a combination of linear and GAM-type predictors, which allows to estimate linear effects or categorical variables, as well as highly non-linear and spatial effects using a Spline-based basis function approach. The predictor specification $\eta_{k}$ is generic enough to use tree-based models as well, which allows us to extend LightGBM to a probabilistic framework. + +## Normalizing Flows + +Although the GAMLSS framework offers considerable flexibility, parametric distributions may prove not flexible enough to provide a reasonable approximation for certain dataset, e.g., for multi-modal distributions. For such cases, it is preferable to relax the assumption of a parametric distribution and approximate the data non-parametrically. While there are several alternatives for learning conditional distributions, we propose to use Normalizing Flows for their ability to fit complex distributions with only a few parameters. + +The principle that underlies Normalizing Flows is to turn a simple base distribution, e.g., $F_{Z}(\mathbf{z}) = N(0,1)$, into a more complex and realistic distribution of the target variable $F_{Y}(\mathbf{y})$ by applying several bijective transformations $h_{j}$, $j = 1, \ldots, J$ to the variable of the base distribution + +\begin{equation} + \mathbf{y} = h_{J} \circ h_{J-1} \circ \cdots \circ h_{1}(\mathbf{z}) +\end{equation} + +Based on the complete transformation function $h=h_{J}\circ\ldots\circ h_{1}$, the density of $\mathbf{y}$ is then given by the change of variables theorem + +\begin{equation} + f_{Y}(\mathbf{y}) = f_{Z}\big(h(\mathbf{y})\big) \cdot \Bigg|\frac{\partial h(\mathbf{y})}{\partial \mathbf{y}}\Bigg| \end{equation} + +where scaling with the Jacobian determinant $|h^{\prime}(\mathbf{y})| = |\partial h(\mathbf{y}) / \partial \mathbf{y}|$ ensures $f_{Y}(\mathbf{y})$ to be a proper density integrating to one. The composition of these transformations is invertible, allowing one to sample from the complex distribution by transforming samples from the base distribution. + +
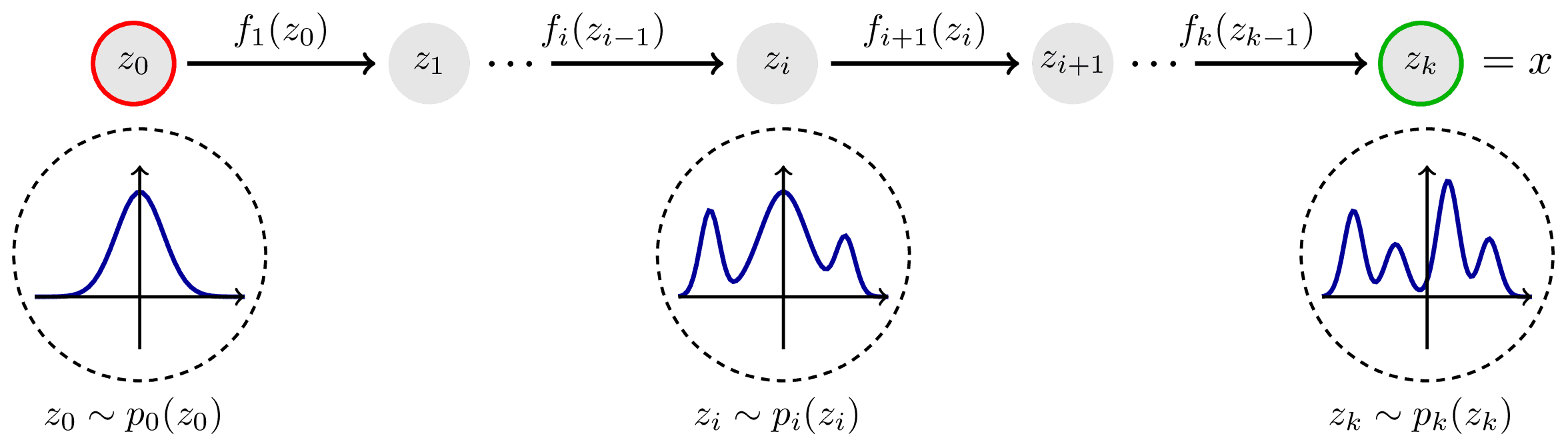 +
+The development of modelling approaches that approximate and describe the data generating processes underlying the observed data in as much detail as possible is a guiding principle in both statistics and machine learning. We therefore strongly agree with the statement of Hothorn et al. (2014) that ''the ultimate goal of any regression analysis is to obtain information about the entire conditional distribution \(F_{Y}(y|\mathbf{x})\) of a response given a set of explanatory variables''.
++''Practitioners expect forecasting to reduce future uncertainty by providing accurate predictions like those in hard sciences. However, this is a great misconception. A major purpose of forecasting is not to reduce uncertainty but reveal its full extent and implications by estimating it as precisely as possible. [...] The challenge for the forecasting field is how to persuade practitioners of the reality that all forecasts are uncertain and that this uncertainty cannot be ignored, as doing so could lead to catastrophic consequences.'' Makridakis (2022b) ++ +
It has not been too long, though, that most regression models focused on estimating the conditional mean \(\mathbb{E}(Y|\mathbf{X} = \mathbf{x})\) only, implicitly treating higher moments of the conditional distribution \(F_{Y}(y|\mathbf{x})\) as fixed nuisance parameters. As such, models that minimize an \(\ell_{2}\)-type loss for the conditional mean are not able to fully exploit the information contained in the data, since this is equivalent to assuming a Normal distribution with constant variance. In real world situations, however, the data generating process is usually less well behaved, exhibiting characteristics such as heteroskedasticity, varying degrees of skewness and kurtosis or intermittent and sporadic behaviour. In recent years, however, there has been a clear shift in both academic and corporate research toward modelling the entire conditional distribution. This change in attention is most evident in the recent M5 forecasting competition (Makridakis et al., 2022a,b), which differed from previous ones in that it consisted of two parallel competitions: in addition to providing accurate point forecasts, participants were also asked to forecast nine different quantiles to approximate the distribution of future sales.
+This section introduces the general idea of distributional modelling. For a more thorough introduction, we refer the interested reader to Rigby and Stasinopoulos (2005); Klein et al. (2015); Stasinopoulos et al. (2017).
+Probabilistic forecasts are predictions in the form of a probability distribution, rather than a single point estimate only. In this context, the introduction of Generalized Additive Models for Location Scale and Shape (GAMLSS) by Rigby and Stasinopoulos (2005) has stimulated a lot of research and culminated in a new research branch that focuses on modelling the entire conditional distribution in dependence of covariates.
+In its original formulation, GAMLSS assume a univariate response to follow a distribution \(\mathcal{D}\) that depends on up to four parameters, i.e., \(y_{i} \stackrel{ind}{\sim} \mathcal{D}(\mu_{i}, \sigma^{2}_{i}, \nu_{i}, \tau_{i}), i=1,\ldots,N\), where \(\mu_{i}\) and \(\sigma^{2}_{i}\) are often location and scale parameters, respectively, while \(\nu_{i}\) and \(\tau_{i}\) correspond to shape parameters such as skewness and kurtosis. Hence, the framework allows to model not only the mean (or location) but all parameters as functions of explanatory variables. It is important to note that distributional modelling implies that observations are independent, but not necessarily identical realizations \(y \stackrel{ind}{\sim} \mathcal{D}\big(\mathbf{\theta}(\mathbf{x})\big)\), since all distributional parameters \(\mathbf{\theta}(\mathbf{x})\) are related to and allowed to change with covariates. In contrast to Generalized Linear (GLM) and Generalized Additive Models (GAM), the assumption of the response distribution belonging to an exponential family is relaxed in GAMLSS and replaced by a more general class of distributions, including highly skewed and/or kurtotic continuous, discrete and mixed discrete, as well as zero-inflated distributions. While the original formulation of GAMLSS in Rigby and Stasinopoulos (2005) suggests that any distribution can be described by location, scale and shape parameters, it is not necessarily true that the observed data distribution can actually be characterized by all of these parameters. Hence, we follow Klein et al. (2015) and use the term distributional modelling and GAMLSS interchangeably.
+From a frequentist point of view, distributional modelling can be formulated as follows
+for \(i = 1, \ldots, N\), where \(\mathcal{D}\) denotes a parametric distribution for the response \(\textbf{y} = (y_{1}, \ldots, y_{N})^{\prime}\) that depends on \(K\) distributional parameters \(\theta_{k}\), \(k = 1, \ldots, K\), and with \(h_{k}(\cdot)\) denoting a known function relating distributional parameters to predictors \(\eta_{k}\). In its most generic form, the predictor \(\eta_{k}\) is given by
+Within the original distributional regression framework, the functions \(f_{k}(\cdot)\) usually represent a combination of linear and GAM-type predictors, which allows to estimate linear effects or categorical variables, as well as highly non-linear and spatial effects using a Spline-based basis function approach. The predictor specification \(\eta_{k}\) is generic enough to use tree-based models as well, which allows us to extend LightGBM to a probabilistic framework.
+Although the GAMLSS framework offers considerable flexibility, parametric distributions may prove not flexible enough to provide a reasonable approximation for certain dataset, e.g., for multi-modal distributions. For such cases, it is preferable to relax the assumption of a parametric distribution and approximate the data non-parametrically. While there are several alternatives for learning conditional distributions, we propose to use Normalizing Flows for their ability to fit complex distributions with only a few parameters.
+The principle that underlies Normalizing Flows is to turn a simple base distribution, e.g., \(F_{Z}(\mathbf{z}) = N(0,1)\), into a more complex and realistic distribution of the target variable \(F_{Y}(\mathbf{y})\) by applying several bijective transformations \(h_{j}\), \(j = 1, \ldots, J\) to the variable of the base distribution
+Based on the complete transformation function \(h=h_{J}\circ\ldots\circ h_{1}\), the density of \(\mathbf{y}\) is then given by the change of variables theorem
+where scaling with the Jacobian determinant \(|h^{\prime}(\mathbf{y})| = |\partial h(\mathbf{y}) / \partial \mathbf{y}|\) ensures \(f_{Y}(\mathbf{y})\) to be a proper density integrating to one. The composition of these transformations is invertible, allowing one to sample from the complex distribution by transforming samples from the base distribution.
+
++
Our Normalizing Flow approach is based on element-wise rational splines of linear or quadratic order as introduced by Durkan (2019) and Dolatabadi (2020) and implemented in Pyro, since they offer a combination of functional flexibility and numerical stability. Despite this specific choice, our framework is generic enough to accommodate the use of other parametrizable Normalizing Flows.
+We draw inspiration from GAMLSS and label our model as LightGBM for Location, Scale and Shape (LightGBMLSS). Despite its nominal reference to GAMLSS, our framework is designed in such a way to accommodate the modeling of a wide range of parametrizable distributions that go beyond location, scale and shape. LightGBMLSS requires the specification of a suitable distribution from which Gradients and Hessians are derived. These represent the partial first and second order derivatives of the log-likelihood with respect to the parameter of interest. GBMLSS are based on multi-parameter optimization, where a separate tree is grown for each parameter. Estimation of Gradients and Hessians, as well as the evaluation of the loss function is done simultaneously for all parameters. Gradients and Hessians are derived using PyTorch's automatic differentiation capabilities. The flexibility offered by automatic differentiation allows users to easily implement novel or customized parametric distributions for which Gradients and Hessians are difficult to derive analytically. It also facilitates the usage of Normalizing Flows, or to add additional constraints to the loss function. To improve the convergence and stability of GBMLSS estimation, unconditional Maximum Likelihood estimates of the parameters are used as offset values. To enable a deeper understanding of the data generating process, GBMLSS also provide attribute importance and partial dependence plots using the Shapley-Value approach.
+LightGBMLSS is built upon PyTorch and Pyro, enabling users to harness a diverse set of distributional families and to leverage automatic differentiation capabilities. This greatly expands the options for probabilistic modeling and uncertainty estimation and allows users to tackle complex regression tasks.
+LightGBMLSS currently supports the following univariate distributions.
+| Distribution | +Usage | +Type | +Support | +Number of Parameters | +
|---|---|---|---|---|
| Beta | +Beta() |
+Continuous (Univariate) |
+\(y \in (0, 1)\) | +2 | +
| Cauchy | +Cauchy() |
+Continuous (Univariate) |
+\(y \in (-\infty,\infty)\) | +2 | +
| Expectile | +Expectile() |
+Continuous (Univariate) |
+\(y \in (-\infty,\infty)\) | +Number of expectiles | +
| Gamma | +Gamma() |
+Continuous (Univariate) |
+\(y \in (0, \infty)\) | +2 | +
| Gaussian | +Gaussian() |
+Continuous (Univariate) |
+\(y \in (-\infty,\infty)\) | +2 | +
| Gumbel | +Gumbel() |
+Continuous (Univariate) |
+\(y \in (-\infty,\infty)\) | +2 | +
| Laplace | +Laplace() |
+Continuous (Univariate) |
+\(y \in (-\infty,\infty)\) | +2 | +
| LogNormal | +LogNormal() |
+Continuous (Univariate) |
+\(y \in (0,\infty)\) | +2 | +
| Negative Binomial | +NegativeBinomial() |
+Discrete Count (Univariate) |
+\(y \in (0, 1, 2, 3, \ldots)\) | +2 | +
| Poisson | +Poisson() |
+Discrete Count (Univariate) |
+\(y \in (0, 1, 2, 3, \ldots)\) | +1 | +
| Spline Flow | +SplineFlow() |
+Continuous \& Discrete Count (Univariate) |
+\(y \in (-\infty,\infty)\) \(y \in [0, \infty)\) \(y \in [0, 1]\) \(y \in (0, 1, 2, 3, \ldots)\) |
+2xcount_bins + (count_bins-1) (order=quadratic) 3xcount_bins + (count_bins-1) (order=linear) |
+
| Student-T | +StudentT() |
+Continuous (Univariate) |
+\(y \in (-\infty,\infty)\) | +3 | +
| Weibull | +Weibull() |
+Continuous (Univariate) |
+\(y \in [0, \infty)\) | +2 | +
| Zero-Adjusted Beta | +ZABeta() |
+Discrete-Continuous (Univariate) |
+\(y \in [0, 1)\) | +3 | +
| Zero-Adjusted Gamma | +ZAGamma() |
+Discrete-Continuous (Univariate) |
+\(y \in [0, \infty)\) | +3 | +
| Zero-Adjusted LogNormal | +ZALN() |
+Discrete-Continuous (Univariate) |
+\(y \in [0, \infty)\) | +3 | +
| Zero-Inflated Negative Binomial | +ZINB() |
+Discrete-Count (Univariate) |
+\(y \in [0, 1, 2, 3, \ldots)\) | +3 | +
| Zero-Inflated Poisson | +ZIPoisson() |
+Discrete-Count (Univariate) |
+\(y \in [0, 1, 2, 3, \ldots)\) | +2 | +
| \n", + " | expectile_0.05 | \n", + "expectile_0.95 | \n", + "
|---|---|---|
| 0 | \n", + "6.695340 | \n", + "13.277894 | \n", + "
| 1 | \n", + "6.615792 | \n", + "13.277894 | \n", + "
| 2 | \n", + "8.519470 | \n", + "11.511595 | \n", + "
| 3 | \n", + "4.557220 | \n", + "14.967069 | \n", + "
| 4 | \n", + "6.615792 | \n", + "13.367647 | \n", + "

![]()
from lightgbmlss.model import *
+from lightgbmlss.distributions.Expectile import *
+from lightgbmlss.datasets.data_loader import load_simulated_gaussian_data
+
+import plotnine
+from plotnine import *
+plotnine.options.figure_size = (20, 10)
+# The data is a simulated Gaussian as follows, where x is the only true feature and all others are noise variables
+ # loc = 10
+ # scale = 1 + 4*((0.3 < x) & (x < 0.5)) + 2*(x > 0.7)
+
+train, test = load_simulated_gaussian_data()
+
+X_train, y_train = train.filter(regex="x"), train["y"].values
+X_test, y_test = test.filter(regex="x"), test["y"].values
+
+dtrain = lgb.Dataset(X_train, label=y_train)
+lgblss = LightGBMLSS(
+ Expectile(stabilization="None", # Options are "None", "MAD", "L2".
+ expectiles = [0.05, 0.95], # List of expectiles to be estimated, in increasing order.
+ penalize_crossing = True # Whether to include a penalty term to discourage crossing of expectiles.
+ )
+)
+Any LightGBM hyperparameter can be tuned, where the structure of the parameter dictionary needs to be as follows:
+- Float/Int sample_type
+ - {"param_name": ["sample_type", low, high, log]}
+ - sample_type: str, Type of sampling, e.g., "float" or "int"
+ - low: int, Lower endpoint of the range of suggested values
+ - high: int, Upper endpoint of the range of suggested values
+ - log: bool, Flag to sample the value from the log domain or not
+ - Example: {"eta": "float", low=1e-5, high=1, log=True]}
+
+- Categorical sample_type
+ - {"param_name": ["sample_type", ["choice1", "choice2", "choice3", "..."]]}
+ - sample_type: str, Type of sampling, either "categorical"
+ - choice1, choice2, choice3, ...: str, Possible choices for the parameter
+ - Example: {"boosting": ["categorical", ["gbdt", "dart"]]}
+
+- For parameters without tunable choice (this is needed if tree_method = "gpu_hist" and gpu_id needs to be specified)
+ - {"param_name": ["none", [value]]},
+ - param_name: str, Name of the parameter
+ - value: int, Value of the parameter
+ - Example: {"gpu_id": ["none", [0]]}param_dict = {
+ "eta": ["float", {"low": 1e-5, "high": 1, "log": True}],
+ "max_depth": ["int", {"low": 1, "high": 10, "log": False}],
+ "num_leaves": ["int", {"low": 255, "high": 255, "log": False}], # set to constant for this example
+ "min_data_in_leaf": ["int", {"low": 20, "high": 20, "log": False}], # set to constant for this example
+ "min_gain_to_split": ["float", {"low": 1e-8, "high": 40, "log": False}],
+ "min_sum_hessian_in_leaf": ["float", {"low": 1e-8, "high": 500, "log": True}],
+ "subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "boosting": ["categorical", ["gbdt"]],
+}
+
+np.random.seed(123)
+opt_param = lgblss.hyper_opt(param_dict,
+ dtrain,
+ num_boost_round=100, # Number of boosting iterations.
+ nfold=5, # Number of cv-folds.
+ early_stopping_rounds=20, # Number of early-stopping rounds
+ max_minutes=10, # Time budget in minutes, i.e., stop study after the given number of minutes.
+ n_trials=30, # The number of trials. If this argument is set to None, there is no limitation on the number of trials.
+ silence=False, # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail.
+ seed=123, # Seed used to generate cv-folds.
+ hp_seed=None # Seed for random number generator used in the Bayesian hyperparameter search.
+ )
+[I 2023-08-11 12:21:09,469] A new study created in memory with name: LightGBMLSS Hyper-Parameter Optimization ++
0%| | 0/30 [00:00<?, ?it/s]+
[I 2023-08-11 12:21:12,718] Trial 0 finished with value: 2455.671630859375 and parameters: {'eta': 4.999979903379203e-05, 'max_depth': 6, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 21.93993866573528, 'min_sum_hessian_in_leaf': 0.0003530133520827798, 'subsample': 0.4971819264686692, 'feature_fraction': 0.3707311537482785, 'boosting': 'gbdt'}. Best is trial 0 with value: 2455.671630859375.
+[I 2023-08-11 12:21:14,662] Trial 1 finished with value: 1905.1077880859375 and parameters: {'eta': 0.031600943671035775, 'max_depth': 3, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 25.283240746368264, 'min_sum_hessian_in_leaf': 49.082392515255734, 'subsample': 0.6788944834474666, 'feature_fraction': 0.9258044091945574, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:18,260] Trial 2 finished with value: 2163.520751953125 and parameters: {'eta': 0.005894981780547752, 'max_depth': 9, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 10.409790461895193, 'min_sum_hessian_in_leaf': 0.0008141832901711874, 'subsample': 0.4070793729617024, 'feature_fraction': 0.6846602442537073, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:20,956] Trial 3 finished with value: 2340.4150390625 and parameters: {'eta': 0.001961322558956042, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 12.389445813281812, 'min_sum_hessian_in_leaf': 0.0001665823267805825, 'subsample': 0.8122180498006835, 'feature_fraction': 0.5881597651097203, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:23,663] Trial 4 finished with value: 2455.928955078125 and parameters: {'eta': 4.876502677739385e-05, 'max_depth': 2, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 4.557086477842732, 'min_sum_hessian_in_leaf': 8.971172534030456e-08, 'subsample': 0.43772569367787945, 'feature_fraction': 0.33757411361894973, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:26,413] Trial 5 finished with value: 2020.169677734375 and parameters: {'eta': 0.015583832782804402, 'max_depth': 6, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 17.990075586462332, 'min_sum_hessian_in_leaf': 9.047858492815616e-06, 'subsample': 0.2661853234410493, 'feature_fraction': 0.43711054797968024, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:29,603] Trial 6 finished with value: 2453.094970703125 and parameters: {'eta': 3.192833281012269e-05, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 4.179852781197093, 'min_sum_hessian_in_leaf': 0.0013367062405656063, 'subsample': 0.760623390889942, 'feature_fraction': 0.9918521803651483, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:33,061] Trial 7 finished with value: 2390.234375 and parameters: {'eta': 0.001099408166117131, 'max_depth': 7, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 5.928259874226358, 'min_sum_hessian_in_leaf': 22.801819887756512, 'subsample': 0.8539904207951285, 'feature_fraction': 0.5227409182953131, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:36,013] Trial 8 finished with value: 1914.283935546875 and parameters: {'eta': 0.2493102080752807, 'max_depth': 1, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 9.13540771750102, 'min_sum_hessian_in_leaf': 0.34110612176978133, 'subsample': 0.5308020126325235, 'feature_fraction': 0.8641969342663409, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:36,677] Trial 9 finished with value: 1937.4613037109375 and parameters: {'eta': 0.9636709157054849, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 32.67317336133683, 'min_sum_hessian_in_leaf': 1.2744267371826801e-08, 'subsample': 0.9935887353691604, 'feature_fraction': 0.943953338852964, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:38,579] Trial 10 finished with value: 1946.8072509765625 and parameters: {'eta': 0.04879973495349672, 'max_depth': 3, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 39.06107022051272, 'min_sum_hessian_in_leaf': 106.46715749293509, 'subsample': 0.6595408126514654, 'feature_fraction': 0.7942683208717877, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:40,307] Trial 11 finished with value: 1942.6409912109375 and parameters: {'eta': 0.3475471835643695, 'max_depth': 1, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 23.567503144962224, 'min_sum_hessian_in_leaf': 0.4888567766798536, 'subsample': 0.598911344176229, 'feature_fraction': 0.8378628459298021, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:43,076] Trial 12 finished with value: 1970.949951171875 and parameters: {'eta': 0.1355810372876077, 'max_depth': 1, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 27.308295812909954, 'min_sum_hessian_in_leaf': 0.45165961145216943, 'subsample': 0.5607270559851195, 'feature_fraction': 0.8192697272856723, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:43,791] Trial 13 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:21:45,120] Trial 14 finished with value: 1917.481201171875 and parameters: {'eta': 0.1918179723427333, 'max_depth': 2, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 0.5575780726770159, 'min_sum_hessian_in_leaf': 0.38144740122258586, 'subsample': 0.5276921773301158, 'feature_fraction': 0.8851651910106035, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:46,648] Trial 15 finished with value: 1908.2398681640625 and parameters: {'eta': 0.06814525677756796, 'max_depth': 3, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 13.416527851881755, 'min_sum_hessian_in_leaf': 1.5533574937270136, 'subsample': 0.6891248913559522, 'feature_fraction': 0.9718069324964819, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:47,454] Trial 16 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:21:48,239] Trial 17 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:21:49,033] Trial 18 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:21:49,857] Trial 19 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:21:51,393] Trial 20 finished with value: 1911.4632568359375 and parameters: {'eta': 0.06986238192969108, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 29.160727721810346, 'min_sum_hessian_in_leaf': 0.016442500462406705, 'subsample': 0.6023777335914249, 'feature_fraction': 0.9155248389222844, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:52,873] Trial 21 finished with value: 1911.5198974609375 and parameters: {'eta': 0.07161895441713878, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 29.27696506397222, 'min_sum_hessian_in_leaf': 0.020946061323593588, 'subsample': 0.6163027333377462, 'feature_fraction': 0.9137504739618006, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:53,660] Trial 22 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:21:55,121] Trial 23 finished with value: 1908.989501953125 and parameters: {'eta': 0.08734639812497531, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 30.42886083118784, 'min_sum_hessian_in_leaf': 0.03828710084297306, 'subsample': 0.7131459665462002, 'feature_fraction': 0.7904449014182882, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:55,893] Trial 24 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:21:57,012] Trial 25 finished with value: 1917.7242431640625 and parameters: {'eta': 0.1615054287282905, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 20.364960331001463, 'min_sum_hessian_in_leaf': 3.329890678595058, 'subsample': 0.7972962597807455, 'feature_fraction': 0.8464533630717106, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:57,915] Trial 26 finished with value: 1909.692626953125 and parameters: {'eta': 0.5158300039154515, 'max_depth': 2, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 25.112985606000265, 'min_sum_hessian_in_leaf': 0.05243689522362543, 'subsample': 0.6973560330154309, 'feature_fraction': 0.7889207482360956, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:21:58,767] Trial 27 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:22:00,393] Trial 28 finished with value: 1921.2425537109375 and parameters: {'eta': 0.09255361005893879, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 14.802111899924473, 'min_sum_hessian_in_leaf': 1.7943497012679166, 'subsample': 0.692797127315583, 'feature_fraction': 0.6813967545026932, 'boosting': 'gbdt'}. Best is trial 1 with value: 1905.1077880859375.
+[I 2023-08-11 12:22:01,231] Trial 29 pruned. Trial was pruned at iteration 20.
+
+Hyper-Parameter Optimization successfully finished.
+ Number of finished trials: 30
+ Best trial:
+ Value: 1905.1077880859375
+ Params:
+ eta: 0.031600943671035775
+ max_depth: 3
+ num_leaves: 255
+ min_data_in_leaf: 20
+ min_gain_to_split: 25.283240746368264
+ min_sum_hessian_in_leaf: 49.082392515255734
+ subsample: 0.6788944834474666
+ feature_fraction: 0.9258044091945574
+ boosting: gbdt
+ opt_rounds: 55
+
+np.random.seed(123)
+
+opt_params = opt_param.copy()
+n_rounds = opt_params["opt_rounds"]
+del opt_params["opt_rounds"]
+
+# Train Model with optimized hyperparameters
+lgblss.train(opt_params,
+ dtrain,
+ num_boost_round=n_rounds
+ )
+# Predicted expectiles
+pred_expectile = lgblss.predict(X_test, pred_type="expectiles")
+pred_expectile.head()
+| + | expectile_0.05 | +expectile_0.95 | +
|---|---|---|
| 0 | +6.695340 | +13.277894 | +
| 1 | +6.615792 | +13.277894 | +
| 2 | +8.519470 | +11.511595 | +
| 3 | +4.557220 | +14.967069 | +
| 4 | +6.615792 | +13.367647 | +
# Partial Dependence Plot of how x acts on selected expectile
+lgblss.expectile_plot(X_test,
+ expectile="expectile_0.95",
+ feature="x_true",
+ plot_type="Partial_Dependence")
+ +
+# Partial Dependence Plot of how x acts on selected expectile
+lgblss.expectile_plot(X_test,
+ expectile="expectile_0.05",
+ feature="x_true",
+ plot_type="Partial_Dependence")
+ +
+# Global Feature Importance of selected expectile
+lgblss.expectile_plot(X_test,
+ expectile="expectile_0.95",
+ plot_type="Feature_Importance")
+ +
+np.random.seed(123)
+
+###
+# Actual Expectiles
+###
+y_loc = np.array([10])
+y_scale = np.array([1 + 4*((0.3 < test["x_true"].values) & (test["x_true"].values < 0.5)) + 2*(test["x_true"].values > 0.7)])
+tau_lower = np.array([lgblss.dist.tau[0]])
+tau_upper = np.array([lgblss.dist.tau[1]])
+
+# Calculates exact expectiles assuming a Normal distribution
+expectile_lb = expectile_norm(tau=tau_lower,
+ m=y_loc,
+ sd=y_scale).reshape(-1,)
+expectile_ub = expectile_norm(tau=tau_upper,
+ m=y_loc,
+ sd=y_scale).reshape(-1,)
+
+test["expect"] = np.where(test["y"].values < expectile_lb, 0, np.where(test["y"].values < expectile_ub, 1, 2))
+test["alpha"] = np.where(test["y"].values <= expectile_lb, 1, np.where(test["y"].values >= expectile_ub, 1, 0))
+df_expectiles = test[test["alpha"] == 1]
+
+# Lower Bound
+yl = list(set(expectile_lb))
+yl.sort()
+yl = [yl[2],yl[0],yl[2],yl[1],yl[1]]
+sfunl = pd.DataFrame({"x_true":[0, 0.3, 0.5, 0.7, 1],
+ "y":yl})
+
+# Upper Bound
+yu = list(set(expectile_ub))
+yu.sort()
+yu = [yu[0],yu[2],yu[0],yu[1],yu[1]]
+sfunu = pd.DataFrame({"x_true":[0, 0.3, 0.5, 0.7, 1],
+ "y":yu})
+
+
+
+###
+# Forecasted Expectiles
+###
+test["lb"] = pred_expectile.iloc[:,0]
+test["ub"] = pred_expectile.iloc[:,1]
+
+
+
+###
+# Plot
+###
+(ggplot(test,
+ aes("x_true",
+ "y")) +
+ geom_point(alpha = 0.2, color = "black", size = 2) +
+ theme_bw(base_size=15) +
+ theme(legend_position="bottom",
+ plot_title = element_text(hjust = 0.5)) +
+ labs(title = "LightGBMLSS Expectile Regression - Simulated Data Example") +
+ geom_line(aes("x_true",
+ "ub"),
+ size = 1.5,
+ color = "blue",
+ alpha = 0.7) +
+ geom_line(aes("x_true",
+ "lb"),
+ size = 1.5,
+ color = "blue",
+ alpha = 0.7) +
+ geom_point(df_expectiles,
+ aes("x_true",
+ "y"),
+ color = "red",
+ alpha = 0.7,
+ size = 2) +
+ geom_step(sfunl,
+ aes("x_true",
+ "y"),
+ size = 1,
+ linetype = "dashed") +
+ geom_step(sfunu,
+ aes("x_true",
+ "y"),
+ size = 1,
+ linetype = "dashed")
+)
+ +
+<Figure Size: (2000 x 1000)>+
| \n", + " | y_sample0 | \n", + "y_sample1 | \n", + "y_sample2 | \n", + "y_sample3 | \n", + "y_sample4 | \n", + "y_sample5 | \n", + "y_sample6 | \n", + "y_sample7 | \n", + "y_sample8 | \n", + "y_sample9 | \n", + "... | \n", + "y_sample990 | \n", + "y_sample991 | \n", + "y_sample992 | \n", + "y_sample993 | \n", + "y_sample994 | \n", + "y_sample995 | \n", + "y_sample996 | \n", + "y_sample997 | \n", + "y_sample998 | \n", + "y_sample999 | \n", + "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", + "1.803845 | \n", + "2.055054 | \n", + "3.721187 | \n", + "2.103017 | \n", + "2.785087 | \n", + "1.427447 | \n", + "2.607677 | \n", + "1.835255 | \n", + "2.056286 | \n", + "1.429045 | \n", + "... | \n", + "1.519037 | \n", + "1.412902 | \n", + "1.625722 | \n", + "1.990941 | \n", + "1.041016 | \n", + "1.458764 | \n", + "2.493577 | \n", + "2.022398 | \n", + "2.520749 | \n", + "1.871148 | \n", + "
| 1 | \n", + "0.955117 | \n", + "0.304340 | \n", + "0.505187 | \n", + "0.712550 | \n", + "1.216954 | \n", + "0.933732 | \n", + "0.380238 | \n", + "1.482657 | \n", + "0.736652 | \n", + "0.427856 | \n", + "... | \n", + "1.171600 | \n", + "1.010972 | \n", + "0.735717 | \n", + "1.319169 | \n", + "1.202447 | \n", + "0.967412 | \n", + "0.966288 | \n", + "1.435245 | \n", + "0.821253 | \n", + "0.793779 | \n", + "
| 2 | \n", + "1.144286 | \n", + "3.009341 | \n", + "1.845451 | \n", + "3.251571 | \n", + "2.020669 | \n", + "1.400807 | \n", + "2.169500 | \n", + "1.314221 | \n", + "1.898889 | \n", + "1.066060 | \n", + "... | \n", + "1.997797 | \n", + "1.747813 | \n", + "2.150669 | \n", + "2.500485 | \n", + "1.338773 | \n", + "1.857834 | \n", + "1.787327 | \n", + "1.801178 | \n", + "2.843899 | \n", + "1.567025 | \n", + "
| 3 | \n", + "1.808418 | \n", + "3.125320 | \n", + "1.761757 | \n", + "1.979179 | \n", + "2.679116 | \n", + "1.515085 | \n", + "1.274946 | \n", + "1.122176 | \n", + "2.836676 | \n", + "2.317276 | \n", + "... | \n", + "1.435263 | \n", + "1.846332 | \n", + "1.362321 | \n", + "1.321298 | \n", + "1.959441 | \n", + "1.562435 | \n", + "1.587221 | \n", + "1.903269 | \n", + "1.783693 | \n", + "1.171151 | \n", + "
| 4 | \n", + "4.249149 | \n", + "3.424617 | \n", + "3.813255 | \n", + "3.438753 | \n", + "2.999937 | \n", + "3.809508 | \n", + "3.346083 | \n", + "2.839856 | \n", + "3.459303 | \n", + "3.179483 | \n", + "... | \n", + "3.772136 | \n", + "3.544357 | \n", + "3.080696 | \n", + "6.813697 | \n", + "4.206345 | \n", + "2.519868 | \n", + "3.878748 | \n", + "5.277604 | \n", + "4.116862 | \n", + "3.673533 | \n", + "
5 rows × 1000 columns
\n", + "" + ], + "text/plain": [ + " y_sample0 y_sample1 y_sample2 y_sample3 y_sample4 y_sample5 \\\n", + "0 1.803845 2.055054 3.721187 2.103017 2.785087 1.427447 \n", + "1 0.955117 0.304340 0.505187 0.712550 1.216954 0.933732 \n", + "2 1.144286 3.009341 1.845451 3.251571 2.020669 1.400807 \n", + "3 1.808418 3.125320 1.761757 1.979179 2.679116 1.515085 \n", + "4 4.249149 3.424617 3.813255 3.438753 2.999937 3.809508 \n", + "\n", + " y_sample6 y_sample7 y_sample8 y_sample9 ... y_sample990 y_sample991 \\\n", + "0 2.607677 1.835255 2.056286 1.429045 ... 1.519037 1.412902 \n", + "1 0.380238 1.482657 0.736652 0.427856 ... 1.171600 1.010972 \n", + "2 2.169500 1.314221 1.898889 1.066060 ... 1.997797 1.747813 \n", + "3 1.274946 1.122176 2.836676 2.317276 ... 1.435263 1.846332 \n", + "4 3.346083 2.839856 3.459303 3.179483 ... 3.772136 3.544357 \n", + "\n", + " y_sample992 y_sample993 y_sample994 y_sample995 y_sample996 \\\n", + "0 1.625722 1.990941 1.041016 1.458764 2.493577 \n", + "1 0.735717 1.319169 1.202447 0.967412 0.966288 \n", + "2 2.150669 2.500485 1.338773 1.857834 1.787327 \n", + "3 1.362321 1.321298 1.959441 1.562435 1.587221 \n", + "4 3.080696 6.813697 4.206345 2.519868 3.878748 \n", + "\n", + " y_sample997 y_sample998 y_sample999 \n", + "0 2.022398 2.520749 1.871148 \n", + "1 1.435245 0.821253 0.793779 \n", + "2 1.801178 2.843899 1.567025 \n", + "3 1.903269 1.783693 1.171151 \n", + "4 5.277604 4.116862 3.673533 \n", + "\n", + "[5 rows x 1000 columns]" + ] + }, + "execution_count": 8, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pred_samples.head()" + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "metadata": { + "ExecuteTime": { + "end_time": "2023-05-18T06:35:13.604570800Z", + "start_time": "2023-05-18T06:35:13.588949200Z" + } + }, + "outputs": [ + { + "data": { + "text/html": [ + "| \n", + " | quant_0.05 | \n", + "quant_0.95 | \n", + "
|---|---|---|
| 0 | \n", + "1.104986 | \n", + "2.876080 | \n", + "
| 1 | \n", + "0.493789 | \n", + "1.469833 | \n", + "
| 2 | \n", + "0.998464 | \n", + "2.626445 | \n", + "
| 3 | \n", + "1.021038 | \n", + "2.662356 | \n", + "
| 4 | \n", + "2.412530 | \n", + "5.914484 | \n", + "
| \n", + " | concentration | \n", + "rate | \n", + "
|---|---|---|
| 0 | \n", + "12.671469 | \n", + "6.625142 | \n", + "
| 1 | \n", + "9.840599 | \n", + "10.347679 | \n", + "
| 2 | \n", + "12.215254 | \n", + "7.179342 | \n", + "
| 3 | \n", + "11.811074 | \n", + "6.747012 | \n", + "
| 4 | \n", + "13.350488 | \n", + "3.346810 | \n", + "
![]()
from lightgbmlss.model import *
+from lightgbmlss.distributions.Gamma import *
+
+from sklearn import datasets
+from sklearn.model_selection import train_test_split
+housing_data = datasets.fetch_california_housing()
+X, y = housing_data["data"], housing_data["target"]
+feature_names = housing_data["feature_names"]
+
+X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
+
+dtrain = lgb.Dataset(X_train, label=y_train)
+# Specifies Gamma distribution with exp response function and option to stabilize Gradient/Hessian. Type ?Gamma for an overview.
+lgblss = LightGBMLSS(
+ Gamma(stabilization="L2", # Options are "None", "MAD", "L2".
+ response_fn="softplus", # Function to transform the concentration and rate parameters, e.g., "exp" or "softplus".
+ loss_fn="nll" # Loss function. Options are "nll" (negative log-likelihood) or "crps"(continuous ranked probability score).
+ )
+)
+Any LightGBM hyperparameter can be tuned, where the structure of the parameter dictionary needs to be as follows:
+- Float/Int sample_type
+ - {"param_name": ["sample_type", low, high, log]}
+ - sample_type: str, Type of sampling, e.g., "float" or "int"
+ - low: int, Lower endpoint of the range of suggested values
+ - high: int, Upper endpoint of the range of suggested values
+ - log: bool, Flag to sample the value from the log domain or not
+ - Example: {"eta": "float", low=1e-5, high=1, log=True]}
+
+- Categorical sample_type
+ - {"param_name": ["sample_type", ["choice1", "choice2", "choice3", "..."]]}
+ - sample_type: str, Type of sampling, either "categorical"
+ - choice1, choice2, choice3, ...: str, Possible choices for the parameter
+ - Example: {"boosting": ["categorical", ["gbdt", "dart"]]}
+
+- For parameters without tunable choice (this is needed if tree_method = "gpu_hist" and gpu_id needs to be specified)
+ - {"param_name": ["none", [value]]},
+ - param_name: str, Name of the parameter
+ - value: int, Value of the parameter
+ - Example: {"gpu_id": ["none", [0]]}param_dict = {
+ "eta": ["float", {"low": 1e-5, "high": 1, "log": True}],
+ "max_depth": ["int", {"low": 1, "high": 10, "log": False}],
+ "subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "boosting": ["categorical", ["gbdt"]],
+}
+
+np.random.seed(123)
+opt_param = lgblss.hyper_opt(param_dict,
+ dtrain,
+ num_boost_round=100, # Number of boosting iterations.
+ nfold=5, # Number of cv-folds.
+ early_stopping_rounds=20, # Number of early-stopping rounds
+ max_minutes=20, # Time budget in minutes, i.e., stop study after the given number of minutes.
+ n_trials=30, # The number of trials. If this argument is set to None, there is no limitation on the number of trials.
+ silence=False, # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail.
+ seed=123, # Seed used to generate cv-folds.
+ hp_seed=None # Seed for random number generator used in the Bayesian hyperparameter search.
+ )
+[I 2023-08-11 12:29:16,191] A new study created in memory with name: LightGBMLSS Hyper-Parameter Optimization ++
0%| | 0/30 [00:00<?, ?it/s]+
[I 2023-08-11 12:29:30,946] Trial 0 finished with value: 3655.994319219647 and parameters: {'eta': 0.0055601230544869195, 'max_depth': 7, 'subsample': 0.9477091024240025, 'feature_fraction': 0.9480677544137415, 'boosting': 'gbdt'}. Best is trial 0 with value: 3655.994319219647.
+[I 2023-08-11 12:29:43,746] Trial 1 finished with value: 4227.673235529888 and parameters: {'eta': 0.0023020600298896826, 'max_depth': 4, 'subsample': 0.8651585394401682, 'feature_fraction': 0.8334419259540924, 'boosting': 'gbdt'}. Best is trial 0 with value: 3655.994319219647.
+[I 2023-08-11 12:29:56,252] Trial 2 finished with value: 4339.068493424474 and parameters: {'eta': 0.0027858552626389625, 'max_depth': 4, 'subsample': 0.7481047090926836, 'feature_fraction': 0.28093366785144963, 'boosting': 'gbdt'}. Best is trial 0 with value: 3655.994319219647.
+[I 2023-08-11 12:30:09,051] Trial 3 finished with value: 4654.563387175151 and parameters: {'eta': 0.000444156259151128, 'max_depth': 3, 'subsample': 0.6107418507428386, 'feature_fraction': 0.3863125393663567, 'boosting': 'gbdt'}. Best is trial 0 with value: 3655.994319219647.
+[I 2023-08-11 12:30:22,971] Trial 4 finished with value: 4561.714498700547 and parameters: {'eta': 0.0006413188632848346, 'max_depth': 7, 'subsample': 0.8415936831413335, 'feature_fraction': 0.5304303058022481, 'boosting': 'gbdt'}. Best is trial 0 with value: 3655.994319219647.
+[I 2023-08-11 12:30:36,725] Trial 5 finished with value: 3940.645249758013 and parameters: {'eta': 0.004514061436631957, 'max_depth': 8, 'subsample': 0.6813546073094912, 'feature_fraction': 0.37103056892915803, 'boosting': 'gbdt'}. Best is trial 0 with value: 3655.994319219647.
+[I 2023-08-11 12:30:49,208] Trial 6 finished with value: 2313.9436995982674 and parameters: {'eta': 0.34104448990548714, 'max_depth': 2, 'subsample': 0.49381730590587314, 'feature_fraction': 0.48051971736040777, 'boosting': 'gbdt'}. Best is trial 6 with value: 2313.9436995982674.
+[I 2023-08-11 12:31:01,412] Trial 7 finished with value: 4716.048776510342 and parameters: {'eta': 4.121739938983374e-05, 'max_depth': 3, 'subsample': 0.8639944116265685, 'feature_fraction': 0.8978770904112527, 'boosting': 'gbdt'}. Best is trial 6 with value: 2313.9436995982674.
+[I 2023-08-11 12:31:15,571] Trial 8 finished with value: 4633.214125114749 and parameters: {'eta': 0.00030771118259821184, 'max_depth': 9, 'subsample': 0.8618195165072102, 'feature_fraction': 0.9999114906902047, 'boosting': 'gbdt'}. Best is trial 6 with value: 2313.9436995982674.
+[I 2023-08-11 12:31:29,560] Trial 9 finished with value: 3478.353837243644 and parameters: {'eta': 0.01610742689419875, 'max_depth': 9, 'subsample': 0.33497542766410426, 'feature_fraction': 0.29392943880535444, 'boosting': 'gbdt'}. Best is trial 6 with value: 2313.9436995982674.
+[I 2023-08-11 12:31:41,953] Trial 10 finished with value: 2325.067843452219 and parameters: {'eta': 0.8686888033261265, 'max_depth': 1, 'subsample': 0.4392043546139532, 'feature_fraction': 0.6492156437954112, 'boosting': 'gbdt'}. Best is trial 6 with value: 2313.9436995982674.
+[I 2023-08-11 12:31:54,009] Trial 11 finished with value: 2380.659260562121 and parameters: {'eta': 0.7699218284463614, 'max_depth': 1, 'subsample': 0.4581350563769593, 'feature_fraction': 0.6781897708396918, 'boosting': 'gbdt'}. Best is trial 6 with value: 2313.9436995982674.
+[I 2023-08-11 12:32:06,259] Trial 12 finished with value: 2300.620681894269 and parameters: {'eta': 0.9611466035281578, 'max_depth': 1, 'subsample': 0.4748729196012275, 'feature_fraction': 0.5804945378046049, 'boosting': 'gbdt'}. Best is trial 12 with value: 2300.620681894269.
+[I 2023-08-11 12:32:18,560] Trial 13 finished with value: 3140.364558904482 and parameters: {'eta': 0.13151506526519777, 'max_depth': 1, 'subsample': 0.20986359097182283, 'feature_fraction': 0.49641299908154024, 'boosting': 'gbdt'}. Best is trial 12 with value: 2300.620681894269.
+[I 2023-08-11 12:32:31,398] Trial 14 finished with value: 2607.970802667295 and parameters: {'eta': 0.13257582555637926, 'max_depth': 3, 'subsample': 0.5234273923433372, 'feature_fraction': 0.560112443439662, 'boosting': 'gbdt'}. Best is trial 12 with value: 2300.620681894269.
+[I 2023-08-11 12:32:44,762] Trial 15 finished with value: 2385.2393013330156 and parameters: {'eta': 0.11688247797482056, 'max_depth': 5, 'subsample': 0.5485181191665621, 'feature_fraction': 0.7236071396551794, 'boosting': 'gbdt'}. Best is trial 12 with value: 2300.620681894269.
+[I 2023-08-11 12:32:56,986] Trial 16 finished with value: 1972.3296999647914 and parameters: {'eta': 0.9322627775031824, 'max_depth': 2, 'subsample': 0.3884067129956542, 'feature_fraction': 0.46443454447840615, 'boosting': 'gbdt'}. Best is trial 16 with value: 1972.3296999647914.
+[I 2023-08-11 12:33:09,216] Trial 17 finished with value: 3338.4070116064154 and parameters: {'eta': 0.050131523125958345, 'max_depth': 2, 'subsample': 0.3614410986311337, 'feature_fraction': 0.20670293691731673, 'boosting': 'gbdt'}. Best is trial 16 with value: 1972.3296999647914.
+[I 2023-08-11 12:33:13,236] Trial 18 finished with value: 3389.8614075906107 and parameters: {'eta': 0.986925756263617, 'max_depth': 5, 'subsample': 0.6167322950411971, 'feature_fraction': 0.5972303136885762, 'boosting': 'gbdt'}. Best is trial 16 with value: 1972.3296999647914.
+[I 2023-08-11 12:33:16,990] Trial 19 pruned. Trial was pruned at iteration 30.
+[I 2023-08-11 12:33:30,329] Trial 20 finished with value: 1808.1962308645848 and parameters: {'eta': 0.3847448879651696, 'max_depth': 6, 'subsample': 0.2765534220110189, 'feature_fraction': 0.4489981481795888, 'boosting': 'gbdt'}. Best is trial 20 with value: 1808.1962308645848.
+[I 2023-08-11 12:33:45,265] Trial 21 finished with value: 1899.1444205576186 and parameters: {'eta': 0.3036015753737849, 'max_depth': 6, 'subsample': 0.23678743004304076, 'feature_fraction': 0.4675647812287519, 'boosting': 'gbdt'}. Best is trial 20 with value: 1808.1962308645848.
+[I 2023-08-11 12:33:58,702] Trial 22 finished with value: 1908.5410750844935 and parameters: {'eta': 0.29460827340472634, 'max_depth': 6, 'subsample': 0.237820065177013, 'feature_fraction': 0.44683152950742716, 'boosting': 'gbdt'}. Best is trial 20 with value: 1808.1962308645848.
+[I 2023-08-11 12:34:12,440] Trial 23 finished with value: 1929.1341625507328 and parameters: {'eta': 0.3229800617391119, 'max_depth': 6, 'subsample': 0.2055577261442562, 'feature_fraction': 0.43369472632611744, 'boosting': 'gbdt'}. Best is trial 20 with value: 1808.1962308645848.
+[I 2023-08-11 12:34:25,588] Trial 24 finished with value: 2699.3212142027087 and parameters: {'eta': 0.07071121976729182, 'max_depth': 6, 'subsample': 0.2792800081576346, 'feature_fraction': 0.4327598617720121, 'boosting': 'gbdt'}. Best is trial 20 with value: 1808.1962308645848.
+[I 2023-08-11 12:34:39,033] Trial 25 finished with value: 1917.4633105999606 and parameters: {'eta': 0.27555064079028785, 'max_depth': 7, 'subsample': 0.28227436090885094, 'feature_fraction': 0.5387936166895363, 'boosting': 'gbdt'}. Best is trial 20 with value: 1808.1962308645848.
+[I 2023-08-11 12:34:41,956] Trial 26 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:34:55,636] Trial 27 finished with value: 2011.3551667558138 and parameters: {'eta': 0.23623752924982647, 'max_depth': 6, 'subsample': 0.21095407561350688, 'feature_fraction': 0.5018294529971035, 'boosting': 'gbdt'}. Best is trial 20 with value: 1808.1962308645848.
+[I 2023-08-11 12:34:59,898] Trial 28 pruned. Trial was pruned at iteration 31.
+[I 2023-08-11 12:35:02,824] Trial 29 pruned. Trial was pruned at iteration 20.
+
+Hyper-Parameter Optimization successfully finished.
+ Number of finished trials: 30
+ Best trial:
+ Value: 1808.1962308645848
+ Params:
+ eta: 0.3847448879651696
+ max_depth: 6
+ subsample: 0.2765534220110189
+ feature_fraction: 0.4489981481795888
+ boosting: gbdt
+ opt_rounds: 100
+
+np.random.seed(123)
+
+opt_params = opt_param.copy()
+n_rounds = opt_params["opt_rounds"]
+del opt_params["opt_rounds"]
+
+# Train Model with optimized hyperparameters
+lgblss.train(opt_params,
+ dtrain,
+ num_boost_round=n_rounds
+ )
+# Set seed for reproducibility
+torch.manual_seed(123)
+
+# Number of samples to draw from predicted distribution
+n_samples = 1000
+quant_sel = [0.05, 0.95] # Quantiles to calculate from predicted distribution
+
+# Sample from predicted distribution
+pred_samples = lgblss.predict(X_test,
+ pred_type="samples",
+ n_samples=n_samples,
+ seed=123)
+
+# Calculate quantiles from predicted distribution
+pred_quantiles = lgblss.predict(X_test,
+ pred_type="quantiles",
+ n_samples=n_samples,
+ quantiles=quant_sel)
+
+# Returns predicted distributional parameters
+pred_params = lgblss.predict(X_test,
+ pred_type="parameters")
+pred_samples.head()
+| + | y_sample0 | +y_sample1 | +y_sample2 | +y_sample3 | +y_sample4 | +y_sample5 | +y_sample6 | +y_sample7 | +y_sample8 | +y_sample9 | +... | +y_sample990 | +y_sample991 | +y_sample992 | +y_sample993 | +y_sample994 | +y_sample995 | +y_sample996 | +y_sample997 | +y_sample998 | +y_sample999 | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | +1.803845 | +2.055054 | +3.721187 | +2.103017 | +2.785087 | +1.427447 | +2.607677 | +1.835255 | +2.056286 | +1.429045 | +... | +1.519037 | +1.412902 | +1.625722 | +1.990941 | +1.041016 | +1.458764 | +2.493577 | +2.022398 | +2.520749 | +1.871148 | +
| 1 | +0.955117 | +0.304340 | +0.505187 | +0.712550 | +1.216954 | +0.933732 | +0.380238 | +1.482657 | +0.736652 | +0.427856 | +... | +1.171600 | +1.010972 | +0.735717 | +1.319169 | +1.202447 | +0.967412 | +0.966288 | +1.435245 | +0.821253 | +0.793779 | +
| 2 | +1.144286 | +3.009341 | +1.845451 | +3.251571 | +2.020669 | +1.400807 | +2.169500 | +1.314221 | +1.898889 | +1.066060 | +... | +1.997797 | +1.747813 | +2.150669 | +2.500485 | +1.338773 | +1.857834 | +1.787327 | +1.801178 | +2.843899 | +1.567025 | +
| 3 | +1.808418 | +3.125320 | +1.761757 | +1.979179 | +2.679116 | +1.515085 | +1.274946 | +1.122176 | +2.836676 | +2.317276 | +... | +1.435263 | +1.846332 | +1.362321 | +1.321298 | +1.959441 | +1.562435 | +1.587221 | +1.903269 | +1.783693 | +1.171151 | +
| 4 | +4.249149 | +3.424617 | +3.813255 | +3.438753 | +2.999937 | +3.809508 | +3.346083 | +2.839856 | +3.459303 | +3.179483 | +... | +3.772136 | +3.544357 | +3.080696 | +6.813697 | +4.206345 | +2.519868 | +3.878748 | +5.277604 | +4.116862 | +3.673533 | +
5 rows × 1000 columns
+pred_quantiles.head()
+| + | quant_0.05 | +quant_0.95 | +
|---|---|---|
| 0 | +1.104986 | +2.876080 | +
| 1 | +0.493789 | +1.469833 | +
| 2 | +0.998464 | +2.626445 | +
| 3 | +1.021038 | +2.662356 | +
| 4 | +2.412530 | +5.914484 | +
pred_params.head()
+| + | concentration | +rate | +
|---|---|---|
| 0 | +12.671469 | +6.625142 | +
| 1 | +9.840599 | +10.347679 | +
| 2 | +12.215254 | +7.179342 | +
| 3 | +11.811074 | +6.747012 | +
| 4 | +13.350488 | +3.346810 | +
# Partial Dependence Plot
+shap_df = pd.DataFrame(X_train, columns=feature_names)
+
+lgblss.plot(shap_df,
+ parameter="concentration",
+ feature=feature_names[0],
+ plot_type="Partial_Dependence")
+ +
+# Feature Importance
+lgblss.plot(shap_df,
+ parameter="concentration",
+ plot_type="Feature_Importance")
+ +
+| \n", + " | y_sample0 | \n", + "y_sample1 | \n", + "y_sample2 | \n", + "y_sample3 | \n", + "y_sample4 | \n", + "y_sample5 | \n", + "y_sample6 | \n", + "y_sample7 | \n", + "y_sample8 | \n", + "y_sample9 | \n", + "... | \n", + "y_sample990 | \n", + "y_sample991 | \n", + "y_sample992 | \n", + "y_sample993 | \n", + "y_sample994 | \n", + "y_sample995 | \n", + "y_sample996 | \n", + "y_sample997 | \n", + "y_sample998 | \n", + "y_sample999 | \n", + "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", + "10.969691 | \n", + "8.598016 | \n", + "11.316233 | \n", + "11.196012 | \n", + "-0.772420 | \n", + "10.135987 | \n", + "14.128653 | \n", + "7.630763 | \n", + "12.698465 | \n", + "8.239548 | \n", + "... | \n", + "10.933374 | \n", + "11.149927 | \n", + "8.531628 | \n", + "9.486668 | \n", + "10.501742 | \n", + "9.149441 | \n", + "11.645898 | \n", + "7.640362 | \n", + "9.958486 | \n", + "6.289453 | \n", + "
| 1 | \n", + "9.461757 | \n", + "9.600316 | \n", + "10.147589 | \n", + "12.562353 | \n", + "16.377707 | \n", + "10.912953 | \n", + "9.325396 | \n", + "9.916863 | \n", + "7.682811 | \n", + "17.506680 | \n", + "... | \n", + "10.509146 | \n", + "7.077166 | \n", + "2.610499 | \n", + "8.764830 | \n", + "16.280003 | \n", + "8.840451 | \n", + "8.440387 | \n", + "16.157856 | \n", + "9.217056 | \n", + "8.147191 | \n", + "
| 2 | \n", + "9.655623 | \n", + "10.095434 | \n", + "10.497488 | \n", + "8.415718 | \n", + "10.877867 | \n", + "8.264465 | \n", + "10.300594 | \n", + "11.423710 | \n", + "10.838738 | \n", + "9.795403 | \n", + "... | \n", + "11.465590 | \n", + "10.625634 | \n", + "8.727895 | \n", + "9.756786 | \n", + "8.575561 | \n", + "9.242844 | \n", + "9.997345 | \n", + "10.150554 | \n", + "10.739549 | \n", + "9.458581 | \n", + "
| 3 | \n", + "7.315505 | \n", + "15.109694 | \n", + "9.312259 | \n", + "-3.643276 | \n", + "12.262859 | \n", + "8.238321 | \n", + "7.009054 | \n", + "6.200121 | \n", + "3.878844 | \n", + "13.135740 | \n", + "... | \n", + "19.848660 | \n", + "15.314698 | \n", + "8.589100 | \n", + "12.168641 | \n", + "8.016486 | \n", + "13.352606 | \n", + "9.907011 | \n", + "8.088248 | \n", + "12.577316 | \n", + "7.965759 | \n", + "
| 4 | \n", + "11.067125 | \n", + "10.200111 | \n", + "9.035689 | \n", + "8.689579 | \n", + "10.475836 | \n", + "8.348648 | \n", + "6.953860 | \n", + "7.018825 | \n", + "11.546731 | \n", + "4.925195 | \n", + "... | \n", + "9.588341 | \n", + "12.277424 | \n", + "9.194149 | \n", + "13.164710 | \n", + "11.918127 | \n", + "7.771739 | \n", + "10.544153 | \n", + "9.177776 | \n", + "7.839355 | \n", + "11.506623 | \n", + "
5 rows × 1000 columns
\n", + "" + ], + "text/plain": [ + " y_sample0 y_sample1 y_sample2 y_sample3 y_sample4 y_sample5 \\\n", + "0 10.969691 8.598016 11.316233 11.196012 -0.772420 10.135987 \n", + "1 9.461757 9.600316 10.147589 12.562353 16.377707 10.912953 \n", + "2 9.655623 10.095434 10.497488 8.415718 10.877867 8.264465 \n", + "3 7.315505 15.109694 9.312259 -3.643276 12.262859 8.238321 \n", + "4 11.067125 10.200111 9.035689 8.689579 10.475836 8.348648 \n", + "\n", + " y_sample6 y_sample7 y_sample8 y_sample9 ... y_sample990 y_sample991 \\\n", + "0 14.128653 7.630763 12.698465 8.239548 ... 10.933374 11.149927 \n", + "1 9.325396 9.916863 7.682811 17.506680 ... 10.509146 7.077166 \n", + "2 10.300594 11.423710 10.838738 9.795403 ... 11.465590 10.625634 \n", + "3 7.009054 6.200121 3.878844 13.135740 ... 19.848660 15.314698 \n", + "4 6.953860 7.018825 11.546731 4.925195 ... 9.588341 12.277424 \n", + "\n", + " y_sample992 y_sample993 y_sample994 y_sample995 y_sample996 \\\n", + "0 8.531628 9.486668 10.501742 9.149441 11.645898 \n", + "1 2.610499 8.764830 16.280003 8.840451 8.440387 \n", + "2 8.727895 9.756786 8.575561 9.242844 9.997345 \n", + "3 8.589100 12.168641 8.016486 13.352606 9.907011 \n", + "4 9.194149 13.164710 11.918127 7.771739 10.544153 \n", + "\n", + " y_sample997 y_sample998 y_sample999 \n", + "0 7.640362 9.958486 6.289453 \n", + "1 16.157856 9.217056 8.147191 \n", + "2 10.150554 10.739549 9.458581 \n", + "3 8.088248 12.577316 7.965759 \n", + "4 9.177776 7.839355 11.506623 \n", + "\n", + "[5 rows x 1000 columns]" + ] + }, + "execution_count": 8, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pred_samples.head()" + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "metadata": { + "ExecuteTime": { + "end_time": "2023-05-18T06:23:27.863941100Z", + "start_time": "2023-05-18T06:23:27.837972100Z" + } + }, + "outputs": [ + { + "data": { + "text/html": [ + "| \n", + " | quant_0.05 | \n", + "quant_0.95 | \n", + "
|---|---|---|
| 0 | \n", + "5.405031 | \n", + "14.896293 | \n", + "
| 1 | \n", + "5.210804 | \n", + "15.007315 | \n", + "
| 2 | \n", + "8.298658 | \n", + "11.832828 | \n", + "
| 3 | \n", + "2.962531 | \n", + "17.087187 | \n", + "
| 4 | \n", + "4.807709 | \n", + "14.909888 | \n", + "
| \n", + " | loc | \n", + "scale | \n", + "
|---|---|---|
| 0 | \n", + "9.984035 | \n", + "2.921586 | \n", + "
| 1 | \n", + "9.979074 | \n", + "2.909918 | \n", + "
| 2 | \n", + "9.979074 | \n", + "1.065636 | \n", + "
| 3 | \n", + "9.979074 | \n", + "4.529788 | \n", + "
| 4 | \n", + "9.979074 | \n", + "3.121158 | \n", + "
![]()
In this example, we model and predict all parameters of a univariate Normal distribution. Recall that distributional regression models and predicts all parameters $\theta_{ik}, k=1, \ldots, K$ parameters of a distribution $\mathcal{D}$ as a function of covariates:
+\begin{equation} +y_{i} \stackrel{ind}{\sim} \mathcal{D} + \begin{pmatrix} + h_{1}\bigl(\theta_{i1}(x_{i})\bigr) = \eta_{i1} \\ + h_{2}\bigl(\theta_{i2}(x_{i})\bigr) = \eta_{i2} \\ + \vdots \\ + h_{K}\bigl(\theta_{iK}(x_{i})\bigr) = \eta_{iK} +\end{pmatrix} +\quad ,i=1, \ldots, N. +\end{equation}
+where $h_{k}(\cdot)$ transforms each distributional parameter to the corresponding parameter scale. For the univariate Normal case, we can specify the above as $y_{i} \stackrel{ind}{\sim} \mathcal{N}\bigl(\mu_{i}(x_{i}), \sigma_{i}(x_{i})\bigr)$. Since $\mu_{i}(\cdot) \in \mathbb{R}$ and since the standard-deviation cannot be negative, $h_{k}(\cdot)$ is applied to $\sigma_{i}(\cdot)$ only. Typical choices are the exponential or the softplus function.
+First, we import the necessary functions.
+from lightgbmlss.model import *
+from lightgbmlss.distributions.Gaussian import *
+from lightgbmlss.datasets.data_loader import load_simulated_gaussian_data
+from scipy.stats import norm
+
+import plotnine
+from plotnine import *
+plotnine.options.figure_size = (12, 8)
+The data is simulated as a Gaussian, where $x_{true}$ is the only true feature and all others are noise variables:
+We first load the simulated dataset, filter for the target and covariates and then create the lgb.Dataset. LightGBMLSS is designed to closely resemble the usage of LightGBM, ensuring ease of adoption and full compatibility.
train, test = load_simulated_gaussian_data()
+
+X_train, y_train = train.filter(regex="x"), train["y"].values
+X_test, y_test = test.filter(regex="x"), test["y"].values
+
+dtrain = lgb.Dataset(X_train, label=y_train)
+Next, we specify a Gaussian distribution. By modifying the specification in the following, the user can specify alternative distributional assumptions. This includes the option to choose from a wide range of parametric univariate distributions, as well as to model the data using Normalizing Flows. The user also has different function arguments for each distribution:
+stabilization: specifies the stabilization method for the Gradient and Hessian. Options are None, MAD and L2.response_fn: specifies $h_{k}(\cdot)$ and transforms the distributional parameter to the correct support. Here, we specify an exponential for $\sigma_{i}(\cdot)$ only.loss_fn: specifies the loss function used for training. Options are nll (negative log-likelihood) or crps (continuous ranked probability score).For additional details, see ?Gaussian.
lgblss = LightGBMLSS(
+ Gaussian(stabilization="None",
+ response_fn="exp",
+ loss_fn="nll"
+ )
+)
+Any LightGBM hyperparameter can be tuned, where the structure of the parameter dictionary needs to be as follows:
+- Float/Int sample_type
+ - {"param_name": ["sample_type", low, high, log]}
+ - sample_type: str, Type of sampling, e.g., "float" or "int"
+ - low: int, Lower endpoint of the range of suggested values
+ - high: int, Upper endpoint of the range of suggested values
+ - log: bool, Flag to sample the value from the log domain or not
+ - Example: {"eta": "float", low=1e-5, high=1, log=True]}
+
+- Categorical sample_type
+ - {"param_name": ["sample_type", ["choice1", "choice2", "choice3", "..."]]}
+ - sample_type: str, Type of sampling, either "categorical"
+ - choice1, choice2, choice3, ...: str, Possible choices for the parameter
+ - Example: {"boosting": ["categorical", ["gbdt", "dart"]]}
+
+- For parameters without tunable choice (this is needed if tree_method = "gpu_hist" and gpu_id needs to be specified)
+ - {"param_name": ["none", [value]]},
+ - param_name: str, Name of the parameter
+ - value: int, Value of the parameter
+ - Example: {"gpu_id": ["none", [0]]}param_dict = {
+ "eta": ["float", {"low": 1e-5, "high": 1, "log": True}],
+ "max_depth": ["int", {"low": 1, "high": 10, "log": False}],
+ "num_leaves": ["int", {"low": 255, "high": 255, "log": False}], # set to constant for this example
+ "min_data_in_leaf": ["int", {"low": 20, "high": 20, "log": False}], # set to constant for this example
+ "min_gain_to_split": ["float", {"low": 1e-8, "high": 40, "log": False}],
+ "min_sum_hessian_in_leaf": ["float", {"low": 1e-8, "high": 500, "log": True}],
+ "subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "boosting": ["categorical", ["gbdt"]],
+}
+
+np.random.seed(123)
+opt_param = lgblss.hyper_opt(param_dict,
+ dtrain,
+ num_boost_round=100, # Number of boosting iterations.
+ nfold=5, # Number of cv-folds.
+ early_stopping_rounds=20, # Number of early-stopping rounds
+ max_minutes=10, # Time budget in minutes, i.e., stop study after the given number of minutes.
+ n_trials=30 , # The number of trials. If this argument is set to None, there is no limitation on the number of trials.
+ silence=True, # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail.
+ seed=123, # Seed used to generate cv-folds.
+ hp_seed=123 # Seed for random number generator used in the Bayesian hyperparameter search.
+ )
+0%| | 0/30 [00:00<?, ?it/s]+
+Hyper-Parameter Optimization successfully finished. + Number of finished trials: 30 + Best trial: + Value: 2916.681710293905 + Params: + eta: 0.04397442966488241 + max_depth: 3 + num_leaves: 255 + min_data_in_leaf: 20 + min_gain_to_split: 9.411991003859868 + min_sum_hessian_in_leaf: 462.25410582290624 + subsample: 0.9517916433037966 + feature_fraction: 0.5063785131055764 + boosting: gbdt + opt_rounds: 97 ++
We use the optimized hyper-parameters and train the model.
+np.random.seed(123)
+
+opt_params = opt_param.copy()
+n_rounds = opt_params["opt_rounds"]
+del opt_params["opt_rounds"]
+
+# Train Model with optimized hyperparameters
+lgblss.train(opt_params,
+ dtrain,
+ num_boost_round=n_rounds
+ )
+Similar to a LightGBM model, we now predict from the trained model. Different options are available:
+samples: draws n_samples from the predicted distribution.quantiles: calculates quantiles from the predicted distribution.parameters: returns predicted distributional parameters.# Set seed for reproducibility
+torch.manual_seed(123)
+
+# Number of samples to draw from predicted distribution
+n_samples = 1000
+quant_sel = [0.05, 0.95] # Quantiles to calculate from predicted distribution
+
+# Sample from predicted distribution
+pred_samples = lgblss.predict(X_test,
+ pred_type="samples",
+ n_samples=n_samples,
+ seed=123)
+
+# Calculate quantiles from predicted distribution
+pred_quantiles = lgblss.predict(X_test,
+ pred_type="quantiles",
+ n_samples=n_samples,
+ quantiles=quant_sel)
+
+# Return predicted distributional parameters
+pred_params = lgblss.predict(X_test,
+ pred_type="parameters")
+pred_samples.head()
+| + | y_sample0 | +y_sample1 | +y_sample2 | +y_sample3 | +y_sample4 | +y_sample5 | +y_sample6 | +y_sample7 | +y_sample8 | +y_sample9 | +... | +y_sample990 | +y_sample991 | +y_sample992 | +y_sample993 | +y_sample994 | +y_sample995 | +y_sample996 | +y_sample997 | +y_sample998 | +y_sample999 | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | +10.969691 | +8.598016 | +11.316233 | +11.196012 | +-0.772420 | +10.135987 | +14.128653 | +7.630763 | +12.698465 | +8.239548 | +... | +10.933374 | +11.149927 | +8.531628 | +9.486668 | +10.501742 | +9.149441 | +11.645898 | +7.640362 | +9.958486 | +6.289453 | +
| 1 | +9.461757 | +9.600316 | +10.147589 | +12.562353 | +16.377707 | +10.912953 | +9.325396 | +9.916863 | +7.682811 | +17.506680 | +... | +10.509146 | +7.077166 | +2.610499 | +8.764830 | +16.280003 | +8.840451 | +8.440387 | +16.157856 | +9.217056 | +8.147191 | +
| 2 | +9.655623 | +10.095434 | +10.497488 | +8.415718 | +10.877867 | +8.264465 | +10.300594 | +11.423710 | +10.838738 | +9.795403 | +... | +11.465590 | +10.625634 | +8.727895 | +9.756786 | +8.575561 | +9.242844 | +9.997345 | +10.150554 | +10.739549 | +9.458581 | +
| 3 | +7.315505 | +15.109694 | +9.312259 | +-3.643276 | +12.262859 | +8.238321 | +7.009054 | +6.200121 | +3.878844 | +13.135740 | +... | +19.848660 | +15.314698 | +8.589100 | +12.168641 | +8.016486 | +13.352606 | +9.907011 | +8.088248 | +12.577316 | +7.965759 | +
| 4 | +11.067125 | +10.200111 | +9.035689 | +8.689579 | +10.475836 | +8.348648 | +6.953860 | +7.018825 | +11.546731 | +4.925195 | +... | +9.588341 | +12.277424 | +9.194149 | +13.164710 | +11.918127 | +7.771739 | +10.544153 | +9.177776 | +7.839355 | +11.506623 | +
5 rows × 1000 columns
+pred_quantiles.head()
+| + | quant_0.05 | +quant_0.95 | +
|---|---|---|
| 0 | +5.405031 | +14.896293 | +
| 1 | +5.210804 | +15.007315 | +
| 2 | +8.298658 | +11.832828 | +
| 3 | +2.962531 | +17.087187 | +
| 4 | +4.807709 | +14.909888 | +
pred_params.head()
+| + | loc | +scale | +
|---|---|---|
| 0 | +9.984035 | +2.921586 | +
| 1 | +9.979074 | +2.909918 | +
| 2 | +9.979074 | +1.065636 | +
| 3 | +9.979074 | +4.529788 | +
| 4 | +9.979074 | +3.121158 | +
To get a deeper understanding of the data generating process, LightGBMLSS also provides attribute importance and partial dependence plots using the Shapley-Value approach.
+# Partial Dependence Plot of how x_true acts on variance
+lgblss.plot(X_test,
+ parameter="scale",
+ feature="x_true",
+ plot_type="Partial_Dependence")
+ +
+# Feature Importance of scale parameter
+lgblss.plot(X_test,
+ parameter="scale",
+ plot_type="Feature_Importance")
+ +
+In the following, we plot the predicted quantiles (blue) and compare them to the actual quantiles (dashed-black).
+np.random.seed(123)
+
+###
+# Actual Quantiles
+###
+q1 = norm.ppf(quant_sel[0], loc = 10, scale = 1 + 4*((0.3 < test["x_true"].values) & (test["x_true"].values < 0.5)) + 2*(test["x_true"].values > 0.7))
+q2 = norm.ppf(quant_sel[1], loc = 10, scale = 1 + 4*((0.3 < test["x_true"].values) & (test["x_true"].values < 0.5)) + 2*(test["x_true"].values > 0.7))
+test["quant"] = np.where(test["y"].values < q1, 0, np.where(test["y"].values < q2, 1, 2))
+test["alpha"] = np.where(test["y"].values <= q1, 1, np.where(test["y"].values >= q2, 1, 0))
+df_quantiles = test[test["alpha"] == 1]
+
+# Lower Bound
+yl = list(set(q1))
+yl.sort()
+yl = [yl[2],yl[0],yl[2],yl[1],yl[1]]
+sfunl = pd.DataFrame({"x_true":[0, 0.3, 0.5, 0.7, 1], "y":yl})
+
+# Upper Bound
+yu = list(set(q2))
+yu.sort()
+yu = [yu[0],yu[2],yu[0],yu[1],yu[1]]
+sfunu = pd.DataFrame({"x_true":[0, 0.3, 0.5, 0.7, 1], "y":yu})
+
+###
+# Predicted Quantiles
+###
+test["lb"] = pred_quantiles.iloc[:,0]
+test["ub"] = pred_quantiles.iloc[:,1]
+
+###
+# Plot
+###
+(ggplot(test,
+ aes("x_true",
+ "y")) +
+ geom_point(alpha = 0.2, color = "black", size = 2) +
+ theme_bw(base_size=15) +
+ theme(legend_position="none",
+ plot_title = element_text(hjust = 0.5),
+ plot_subtitle = element_text(hjust = 0.5)) +
+ labs(title = "LightGBMLSS Regression - Simulated Data Example",
+ subtitle = "Comparison of Actual (black) vs. Predicted Quantiles (blue)",
+ x="x") +
+ geom_line(aes("x_true",
+ "ub"),
+ size = 1,
+ color = "blue",
+ alpha = 0.7) +
+ geom_line(aes("x_true",
+ "lb"),
+ size = 1,
+ color = "blue",
+ alpha = 0.7) +
+ geom_point(df_quantiles,
+ aes("x_true",
+ "y"),
+ color = "red",
+ alpha = 0.7,
+ size = 2) +
+ geom_step(sfunl,
+ aes("x_true",
+ "y"),
+ size = 1,
+ linetype = "dashed") +
+ geom_step(sfunu,
+ aes("x_true",
+ "y"),
+ size = 1,
+ linetype = "dashed")
+)
+ +
+<Figure Size: (1200 x 800)>+
In the following figure, we compare the true parameters of the Gaussian with the ones predicted by LightGBMLSS. The below figure shows that the estimated parameters closely match the true ones (recall that the location parameter $\mu=10$ is simulated as being a constant).
+pred_params["x_true"] = X_test["x_true"].values
+dist_params = list(lgblss.dist.param_dict.keys())
+
+# Data with actual values
+plot_df_actual = pd.melt(test[["x_true"] + dist_params],
+ id_vars="x_true",
+ value_vars=dist_params)
+plot_df_actual["type"] = "TRUE"
+
+# Data with predicted values
+plot_df_predt = pd.melt(pred_params[["x_true"] + dist_params],
+ id_vars="x_true",
+ value_vars=dist_params)
+plot_df_predt["type"] = "PREDICT"
+
+plot_df = pd.concat([plot_df_predt, plot_df_actual])
+
+plot_df["variable"] = plot_df.variable.str.upper()
+plot_df["type"] = pd.Categorical(plot_df["type"], categories = ["PREDICT", "TRUE"])
+
+(ggplot(plot_df,
+ aes(x="x_true",
+ y="value",
+ color="type")) +
+ geom_line(size=1.1) +
+ facet_wrap("variable",
+ scales="free") +
+ labs(title="Parameters of univariate Gaussian predicted with LightGBMLSS",
+ x="",
+ y="") +
+ theme_bw(base_size=15) +
+ theme(legend_position="bottom",
+ plot_title = element_text(hjust = 0.5),
+ legend_title = element_blank())
+)
+ +
+<Figure Size: (1200 x 800)>+
Since we predict the entire conditional distribution, we can overlay the point predictions with predicted densities, from which we can also derive quantiles of interest.
+y_pred = []
+
+n_examples = 9
+
+for i in range(n_examples):
+ y_samples = pd.DataFrame(pred_samples.values[i,:].reshape(-1,1), columns=["PREDICT_DENSITY"])
+ y_samples["PREDICT_POINT"] = y_samples["PREDICT_DENSITY"].mean()
+ y_samples["PREDICT_Q05"] = y_samples["PREDICT_DENSITY"].quantile(q=quant_sel[0])
+ y_samples["PREDICT_Q95"] = y_samples["PREDICT_DENSITY"].quantile(q=quant_sel[1])
+ y_samples["ACTUAL"] = y_test[i]
+ y_samples["obs"]= f"Obervation {i+1}"
+ y_pred.append(y_samples)
+
+pred_df = pd.melt(pd.concat(y_pred, axis=0), id_vars="obs")
+pred_df["obs"] = pd.Categorical(pred_df["obs"], categories=[f"Obervation {i+1}" for i in range(n_examples)])
+df_actual, df_pred_dens, df_pred_point, df_q05, df_q95 = [x for _, x in pred_df.groupby("variable")]
+
+plot_pred = (
+ ggplot(pred_df,
+ aes(color="variable")) +
+ stat_density(df_pred_dens,
+ aes(x="value"),
+ size=1.1) +
+ geom_point(df_pred_point,
+ aes(x="value",
+ y=0),
+ size=1.4) +
+ geom_point(df_actual,
+ aes(x="value",
+ y=0),
+ size=1.4) +
+ geom_vline(df_q05,
+ aes(xintercept="value",
+ fill="variable",
+ color="variable"),
+ linetype="dashed",
+ size=1.1) +
+ geom_vline(df_q95,
+ aes(xintercept="value",
+ fill="variable",
+ color="variable"),
+ linetype="dashed",
+ size=1.1) +
+ facet_wrap("obs",
+ scales="free",
+ ncol=3) +
+ labs(title="Predicted vs. Actual \n",
+ x = "") +
+ theme_bw(base_size=15) +
+ scale_fill_brewer(type="qual", palette="Dark2") +
+ theme(legend_position="bottom",
+ plot_title = element_text(hjust = 0.5),
+ legend_title = element_blank()
+ )
+)
+
+print(plot_pred)
+ +
+++
| \n", + " | nll | \n", + "distribution | \n", + "
|---|---|---|
| rank | \n", + "\n", + " | \n", + " |
| 1 | \n", + "23596.791908 | \n", + "LogNormal | \n", + "
| 2 | \n", + "23632.597656 | \n", + "Gamma | \n", + "
| 3 | \n", + "23899.039920 | \n", + "Gumbel | \n", + "
| 4 | \n", + "24083.658916 | \n", + "Weibull | \n", + "
| 5 | \n", + "25690.867630 | \n", + "StudentT | \n", + "
| 6 | \n", + "25796.219456 | \n", + "Gaussian | \n", + "
| 7 | \n", + "25925.138312 | \n", + "Laplace | \n", + "
| 8 | \n", + "27559.623077 | \n", + "Cauchy | \n", + "
![]()
In this example we will show how to select a distribution for a univariate target variable. We use the California housing dataset and select a distribution for the target variable median_house_value.
from lightgbmlss.distributions import *
+from lightgbmlss.distributions.distribution_utils import DistributionClass
+from sklearn import datasets
+from sklearn.model_selection import train_test_split
+housing_data = datasets.fetch_california_housing()
+X, y = housing_data["data"], housing_data["target"]
+feature_names = housing_data["feature_names"]
+
+X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
+In the following, we specify a list of candidate distributions. The function dist_select returns the negative log-likelihood of each distribution for the target variable. The distribution with the lowest negative log-likelihood is selected. The function also plots the density of the target variable and the fitted density, using the best suitable distribution among the specified ones.
It is important to note that the list of candidate distributions should be chosen to be suitable for the target variable at hand. For example, if the target variable is a count variable, then the list of candidate distributions should include the Poisson and Negative Binomial. Similarly, if the target variable is on the positive real scale, then the list of continuous candidate distributions should be chosen accordingly.
+lgblss_dist_class = DistributionClass()
+candidate_distributions = [Gaussian, StudentT, Gamma, Cauchy, LogNormal, Weibull, Gumbel, Laplace]
+
+dist_nll = lgblss_dist_class.dist_select(target=y_train, candidate_distributions=candidate_distributions, max_iter=50, plot=True, figure_size=(10, 5))
+dist_nll
+Fitting of candidate distributions completed: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 8/8 [00:12<00:00, 1.58s/it] ++
 +
+| + | nll | +distribution | +
|---|---|---|
| rank | ++ | + |
| 1 | +23596.791908 | +LogNormal | +
| 2 | +23632.597656 | +Gamma | +
| 3 | +23899.039920 | +Gumbel | +
| 4 | +24083.658916 | +Weibull | +
| 5 | +25690.867630 | +StudentT | +
| 6 | +25796.219456 | +Gaussian | +
| 7 | +25925.138312 | +Laplace | +
| 8 | +27559.623077 | +Cauchy | +
 \n",
+ "
\n",
+ "| \n", + " | nll | \n", + "NormFlow | \n", + "
|---|---|---|
| rank | \n", + "\n", + " | \n", + " |
| 1 | \n", + "16595.917006 | \n", + "SplineFlow(count_bins: 20, order: linear) | \n", + "
| 2 | \n", + "16608.693807 | \n", + "SplineFlow(count_bins: 12, order: quadratic) | \n", + "
| 3 | \n", + "16622.862265 | \n", + "SplineFlow(count_bins: 16, order: quadratic) | \n", + "
| 4 | \n", + "16640.156074 | \n", + "SplineFlow(count_bins: 6, order: linear) | \n", + "
| 5 | \n", + "16640.611035 | \n", + "SplineFlow(count_bins: 16, order: linear) | \n", + "
| 6 | \n", + "16649.404709 | \n", + "SplineFlow(count_bins: 8, order: linear) | \n", + "
| 7 | \n", + "16651.375456 | \n", + "SplineFlow(count_bins: 8, order: quadratic) | \n", + "
| 8 | \n", + "16653.378393 | \n", + "SplineFlow(count_bins: 6, order: quadratic) | \n", + "
| 9 | \n", + "16674.331780 | \n", + "SplineFlow(count_bins: 12, order: linear) | \n", + "
| 10 | \n", + "16822.629927 | \n", + "SplineFlow(count_bins: 4, order: quadratic) | \n", + "
| 11 | \n", + "16902.398862 | \n", + "SplineFlow(count_bins: 20, order: quadratic) | \n", + "
| 12 | \n", + "17538.588405 | \n", + "SplineFlow(count_bins: 4, order: linear) | \n", + "
| 13 | \n", + "17692.968508 | \n", + "SplineFlow(count_bins: 2, order: linear) | \n", + "
| 14 | \n", + "17737.569055 | \n", + "SplineFlow(count_bins: 2, order: quadratic) | \n", + "
| \n", + " | y_sample0 | \n", + "y_sample1 | \n", + "y_sample2 | \n", + "y_sample3 | \n", + "y_sample4 | \n", + "y_sample5 | \n", + "y_sample6 | \n", + "y_sample7 | \n", + "y_sample8 | \n", + "y_sample9 | \n", + "... | \n", + "y_sample9990 | \n", + "y_sample9991 | \n", + "y_sample9992 | \n", + "y_sample9993 | \n", + "y_sample9994 | \n", + "y_sample9995 | \n", + "y_sample9996 | \n", + "y_sample9997 | \n", + "y_sample9998 | \n", + "y_sample9999 | \n", + "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", + "12.315617 | \n", + "11.148891 | \n", + "4.624041 | \n", + "11.273465 | \n", + "4.864611 | \n", + "13.651609 | \n", + "11.573423 | \n", + "14.295194 | \n", + "9.939115 | \n", + "8.728693 | \n", + "... | \n", + "13.490867 | \n", + "9.317229 | \n", + "8.216475 | \n", + "11.480260 | \n", + "9.670330 | \n", + "14.858524 | \n", + "5.511271 | \n", + "10.839365 | \n", + "11.708204 | \n", + "6.417930 | \n", + "
| 1 | \n", + "16.409412 | \n", + "8.340928 | \n", + "10.923915 | \n", + "13.388198 | \n", + "8.266445 | \n", + "10.249456 | \n", + "12.452267 | \n", + "10.588787 | \n", + "12.331830 | \n", + "9.027943 | \n", + "... | \n", + "10.883108 | \n", + "2.895114 | \n", + "11.342189 | \n", + "13.237988 | \n", + "6.858677 | \n", + "15.392724 | \n", + "9.221172 | \n", + "9.709686 | \n", + "4.011642 | \n", + "10.250503 | \n", + "
| 2 | \n", + "11.589569 | \n", + "9.669224 | \n", + "9.724932 | \n", + "10.960885 | \n", + "13.362031 | \n", + "11.276797 | \n", + "10.801574 | \n", + "9.534609 | \n", + "9.327179 | \n", + "10.494802 | \n", + "... | \n", + "10.138949 | \n", + "11.022624 | \n", + "8.731875 | \n", + "10.401649 | \n", + "9.127348 | \n", + "10.243149 | \n", + "9.944046 | \n", + "8.483890 | \n", + "10.321774 | \n", + "10.243544 | \n", + "
| 3 | \n", + "10.743192 | \n", + "9.116656 | \n", + "12.323032 | \n", + "5.270192 | \n", + "15.528632 | \n", + "15.910578 | \n", + "8.639240 | \n", + "16.705225 | \n", + "7.853291 | \n", + "9.957293 | \n", + "... | \n", + "1.351381 | \n", + "9.039200 | \n", + "16.516144 | \n", + "8.261804 | \n", + "4.777587 | \n", + "9.089480 | \n", + "12.751478 | \n", + "12.829519 | \n", + "12.620325 | \n", + "9.282865 | \n", + "
| 4 | \n", + "12.725435 | \n", + "8.629576 | \n", + "7.140886 | \n", + "5.782235 | \n", + "6.844902 | \n", + "10.355301 | \n", + "7.330880 | \n", + "14.259795 | \n", + "10.242219 | \n", + "15.360129 | \n", + "... | \n", + "9.775837 | \n", + "8.244545 | \n", + "9.040227 | \n", + "11.909575 | \n", + "8.996835 | \n", + "8.084206 | \n", + "13.316805 | \n", + "10.463615 | \n", + "8.097854 | \n", + "9.440963 | \n", + "
5 rows × 10000 columns
\n", + "" + ], + "text/plain": [ + " y_sample0 y_sample1 y_sample2 y_sample3 y_sample4 y_sample5 \\\n", + "0 12.315617 11.148891 4.624041 11.273465 4.864611 13.651609 \n", + "1 16.409412 8.340928 10.923915 13.388198 8.266445 10.249456 \n", + "2 11.589569 9.669224 9.724932 10.960885 13.362031 11.276797 \n", + "3 10.743192 9.116656 12.323032 5.270192 15.528632 15.910578 \n", + "4 12.725435 8.629576 7.140886 5.782235 6.844902 10.355301 \n", + "\n", + " y_sample6 y_sample7 y_sample8 y_sample9 ... y_sample9990 \\\n", + "0 11.573423 14.295194 9.939115 8.728693 ... 13.490867 \n", + "1 12.452267 10.588787 12.331830 9.027943 ... 10.883108 \n", + "2 10.801574 9.534609 9.327179 10.494802 ... 10.138949 \n", + "3 8.639240 16.705225 7.853291 9.957293 ... 1.351381 \n", + "4 7.330880 14.259795 10.242219 15.360129 ... 9.775837 \n", + "\n", + " y_sample9991 y_sample9992 y_sample9993 y_sample9994 y_sample9995 \\\n", + "0 9.317229 8.216475 11.480260 9.670330 14.858524 \n", + "1 2.895114 11.342189 13.237988 6.858677 15.392724 \n", + "2 11.022624 8.731875 10.401649 9.127348 10.243149 \n", + "3 9.039200 16.516144 8.261804 4.777587 9.089480 \n", + "4 8.244545 9.040227 11.909575 8.996835 8.084206 \n", + "\n", + " y_sample9996 y_sample9997 y_sample9998 y_sample9999 \n", + "0 5.511271 10.839365 11.708204 6.417930 \n", + "1 9.221172 9.709686 4.011642 10.250503 \n", + "2 9.944046 8.483890 10.321774 10.243544 \n", + "3 12.751478 12.829519 12.620325 9.282865 \n", + "4 13.316805 10.463615 8.097854 9.440963 \n", + "\n", + "[5 rows x 10000 columns]" + ] + }, + "execution_count": 20, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pred_samples.head()" + ] + }, + { + "cell_type": "code", + "execution_count": 21, + "metadata": { + "ExecuteTime": { + "end_time": "2023-05-18T06:23:27.863941100Z", + "start_time": "2023-05-18T06:23:27.837972100Z" + } + }, + "outputs": [ + { + "data": { + "text/html": [ + "| \n", + " | quant_0.05 | \n", + "quant_0.95 | \n", + "
|---|---|---|
| 0 | \n", + "5.220628 | \n", + "14.963007 | \n", + "
| 1 | \n", + "5.365820 | \n", + "15.105494 | \n", + "
| 2 | \n", + "8.211895 | \n", + "11.933730 | \n", + "
| 3 | \n", + "2.047034 | \n", + "17.560992 | \n", + "
| 4 | \n", + "5.048092 | \n", + "15.145446 | \n", + "
| \n", + " | param_1 | \n", + "param_2 | \n", + "param_3 | \n", + "param_4 | \n", + "param_5 | \n", + "param_6 | \n", + "param_7 | \n", + "param_8 | \n", + "param_9 | \n", + "param_10 | \n", + "... | \n", + "param_22 | \n", + "param_23 | \n", + "param_24 | \n", + "param_25 | \n", + "param_26 | \n", + "param_27 | \n", + "param_28 | \n", + "param_29 | \n", + "param_30 | \n", + "param_31 | \n", + "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", + "-0.418612 | \n", + "-0.302259 | \n", + "-0.532314 | \n", + "-0.775419 | \n", + "0.697199 | \n", + "-0.227767 | \n", + "-3.043896 | \n", + "1.286783 | \n", + "1.113216 | \n", + "0.349978 | \n", + "... | \n", + "1.817143 | \n", + "0.570572 | \n", + "0.945506 | \n", + "0.805746 | \n", + "0.693497 | \n", + "0.639612 | \n", + "1.854735 | \n", + "1.306370 | \n", + "0.909254 | \n", + "0.839281 | \n", + "
| 1 | \n", + "-0.418612 | \n", + "-0.302259 | \n", + "-0.532314 | \n", + "-0.775419 | \n", + "0.697199 | \n", + "-0.227767 | \n", + "-3.043896 | \n", + "1.286783 | \n", + "1.113216 | \n", + "0.349978 | \n", + "... | \n", + "1.777844 | \n", + "0.570572 | \n", + "0.945506 | \n", + "0.805746 | \n", + "0.693497 | \n", + "0.639612 | \n", + "1.854735 | \n", + "1.306370 | \n", + "0.909254 | \n", + "0.839281 | \n", + "
| 2 | \n", + "-0.418612 | \n", + "-0.302259 | \n", + "-0.532314 | \n", + "-0.775419 | \n", + "0.697199 | \n", + "-0.227767 | \n", + "-3.043896 | \n", + "1.286783 | \n", + "1.113216 | \n", + "0.349978 | \n", + "... | \n", + "1.495455 | \n", + "0.570572 | \n", + "0.945506 | \n", + "0.805746 | \n", + "0.693497 | \n", + "0.639612 | \n", + "0.868014 | \n", + "2.313089 | \n", + "0.909254 | \n", + "0.839281 | \n", + "
| 3 | \n", + "-0.418612 | \n", + "-0.302259 | \n", + "-0.532314 | \n", + "-0.775419 | \n", + "0.697199 | \n", + "-0.227767 | \n", + "-3.043896 | \n", + "1.286783 | \n", + "1.113216 | \n", + "0.349978 | \n", + "... | \n", + "1.276525 | \n", + "0.570572 | \n", + "0.945506 | \n", + "0.805746 | \n", + "0.693497 | \n", + "0.639612 | \n", + "2.172172 | \n", + "-1.196684 | \n", + "0.909254 | \n", + "0.839281 | \n", + "
| 4 | \n", + "-0.418612 | \n", + "-0.302259 | \n", + "-0.532314 | \n", + "-0.775419 | \n", + "0.697199 | \n", + "-0.227767 | \n", + "-3.043896 | \n", + "1.286783 | \n", + "1.113216 | \n", + "0.349978 | \n", + "... | \n", + "1.535858 | \n", + "0.570572 | \n", + "0.945506 | \n", + "0.805746 | \n", + "0.693497 | \n", + "0.639612 | \n", + "1.854735 | \n", + "1.127365 | \n", + "0.909254 | \n", + "0.839281 | \n", + "
5 rows × 31 columns
\n", + "![]()
Normalizing flows transform a simple distribution into a complex data distribution through a series of invertible transformations. The key steps involved in the operation of normalizing flows are as follows (from left to right):
+
+By stacking multiple transformations in a sequence, normalizing flows can model complex and multi-modal distributions while providing the ability to compute the likelihood of the data and perform efficient sampling in both directions (from base to complex and vice versa). However, it is important to note that since LightGBMLSS is based on a one vs. all estimation strategy, where a separate tree is grown for each parameter, estimating many parameters for a large dataset can become computationally expensive. For more details, we refer to our related paper Alexander März and Thomas Kneib (2022): Distributional Gradient Boosting Machines.
+from lightgbmlss.model import *
+from lightgbmlss.distributions.SplineFlow import *
+from lightgbmlss.distributions.flow_utils import NormalizingFlowClass
+from lightgbmlss.datasets.data_loader import load_simulated_gaussian_data
+from scipy.stats import norm
+
+import plotnine
+from plotnine import *
+plotnine.options.figure_size = (20, 10)
+# The data is simulated as a Gaussian, where x is the only true feature and all others are noise variables
+ # loc = 10
+ # scale = 1 + 4 * ((0.3 < x) & (x < 0.5)) + 2 * (x > 0.7)
+
+train, test = load_simulated_gaussian_data()
+
+X_train, y_train = train.filter(regex="x"), train["y"].values
+X_test, y_test = test.filter(regex="x"), test["y"].values
+
+dtrain = lgb.Dataset(X_train, label=y_train)
+In the following, we specify a list of candidate normalizing flows. The function flow_select returns the negative log-likelihood of each specification. The normalizing flow with the lowest negative log-likelihood is selected. The function also plots the density of the target variable and the fitted density, using the best suitable normalizing flow among the specified ones. However, note that choosing the best performing flow based solely on training data may lead to overfitting, since normalizing flows have a higher risk of overfitting compared to parametric distributions. When using normalizing flows, it is crucial to carefully select the specifications to strike a balance between model complexity and generalization ability.
+# See ?SplineFlow for an overview.
+bound = np.max([np.abs(y_train.min()), y_train.max()])
+target_support = "real"
+
+candidate_flows = [
+
+ SplineFlow(target_support=target_support, count_bins=2, bound=bound, order="linear"),
+ SplineFlow(target_support=target_support, count_bins=4, bound=bound, order="linear"),
+ SplineFlow(target_support=target_support, count_bins=6, bound=bound, order="linear"),
+ SplineFlow(target_support=target_support, count_bins=8, bound=bound, order="linear"),
+ SplineFlow(target_support=target_support, count_bins=12, bound=bound, order="linear"),
+ SplineFlow(target_support=target_support, count_bins=16, bound=bound, order="linear"),
+ SplineFlow(target_support=target_support, count_bins=20, bound=bound, order="linear"),
+
+ SplineFlow(target_support=target_support, count_bins=2, bound=bound, order="quadratic"),
+ SplineFlow(target_support=target_support, count_bins=4, bound=bound, order="quadratic"),
+ SplineFlow(target_support=target_support, count_bins=6, bound=bound, order="quadratic"),
+ SplineFlow(target_support=target_support, count_bins=8, bound=bound, order="quadratic"),
+ SplineFlow(target_support=target_support, count_bins=12, bound=bound, order="quadratic"),
+ SplineFlow(target_support=target_support, count_bins=16, bound=bound, order="quadratic"),
+ SplineFlow(target_support=target_support, count_bins=20, bound=bound, order="quadratic"),
+
+]
+
+flow_nll = NormalizingFlowClass().flow_select(target=y_train, candidate_flows=candidate_flows, max_iter=50, n_samples=10000, plot=True, figure_size=(12, 5))
+flow_nll
+Fitting of candidate normalizing flows completed: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 14/14 [01:20<00:00, 5.78s/it] ++
 +
+| + | nll | +NormFlow | +
|---|---|---|
| rank | ++ | + |
| 1 | +16595.917006 | +SplineFlow(count_bins: 20, order: linear) | +
| 2 | +16608.693807 | +SplineFlow(count_bins: 12, order: quadratic) | +
| 3 | +16622.862265 | +SplineFlow(count_bins: 16, order: quadratic) | +
| 4 | +16640.156074 | +SplineFlow(count_bins: 6, order: linear) | +
| 5 | +16640.611035 | +SplineFlow(count_bins: 16, order: linear) | +
| 6 | +16649.404709 | +SplineFlow(count_bins: 8, order: linear) | +
| 7 | +16651.375456 | +SplineFlow(count_bins: 8, order: quadratic) | +
| 8 | +16653.378393 | +SplineFlow(count_bins: 6, order: quadratic) | +
| 9 | +16674.331780 | +SplineFlow(count_bins: 12, order: linear) | +
| 10 | +16822.629927 | +SplineFlow(count_bins: 4, order: quadratic) | +
| 11 | +16902.398862 | +SplineFlow(count_bins: 20, order: quadratic) | +
| 12 | +17538.588405 | +SplineFlow(count_bins: 4, order: linear) | +
| 13 | +17692.968508 | +SplineFlow(count_bins: 2, order: linear) | +
| 14 | +17737.569055 | +SplineFlow(count_bins: 2, order: quadratic) | +
Even though SplineFlow(count_bins: 20, order: linear) shows the best fit to the data, we choose a more parameter parsimonious specification (recall that a separate tree is grown for each parameter):
+# Specifies Spline-Flow. See ?SplineFlow for an overview.
+bound = np.max([np.abs(y_train.min()), y_train.max()])
+
+lgblss = LightGBMLSS(
+ SplineFlow(target_support="real", # Specifies the support of the target. Options are "real", "positive", "positive_integer" or "unit_interval"
+ count_bins=8, # The number of segments comprising the spline.
+ bound=bound, # By adjusting the value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on.
+ order="linear", # The order of the spline. Options are "linear" or "quadratic".
+ stabilization="None", # Options are "None", "MAD" or "L2".
+ loss_fn="nll" # Loss function. Options are "nll" (negative log-likelihood) or "crps"(continuous ranked probability score).
+ )
+)
+Any LightGBM hyperparameter can be tuned, where the structure of the parameter dictionary needs to be as follows:
+- Float/Int sample_type
+ - {"param_name": ["sample_type", low, high, log]}
+ - sample_type: str, Type of sampling, e.g., "float" or "int"
+ - low: int, Lower endpoint of the range of suggested values
+ - high: int, Upper endpoint of the range of suggested values
+ - log: bool, Flag to sample the value from the log domain or not
+ - Example: {"eta": "float", low=1e-5, high=1, log=True]}
+
+- Categorical sample_type
+ - {"param_name": ["sample_type", ["choice1", "choice2", "choice3", "..."]]}
+ - sample_type: str, Type of sampling, either "categorical"
+ - choice1, choice2, choice3, ...: str, Possible choices for the parameter
+ - Example: {"boosting": ["categorical", ["gbdt", "dart"]]}
+
+- For parameters without tunable choice (this is needed if tree_method = "gpu_hist" and gpu_id needs to be specified)
+ - {"param_name": ["none", [value]]},
+ - param_name: str, Name of the parameter
+ - value: int, Value of the parameter
+ - Example: {"gpu_id": ["none", [0]]}param_dict = {
+ "eta": ["float", {"low": 1e-5, "high": 1, "log": True}],
+ "max_depth": ["int", {"low": 1, "high": 10, "log": False}],
+ "num_leaves": ["int", {"low": 255, "high": 255, "log": False}], # set to constant for this example
+ "min_data_in_leaf": ["int", {"low": 20, "high": 20, "log": False}], # set to constant for this example
+ "min_gain_to_split": ["float", {"low": 1e-8, "high": 40, "log": False}],
+ "min_sum_hessian_in_leaf": ["float", {"low": 1e-8, "high": 500, "log": True}],
+ "subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "boosting": ["categorical", ["gbdt"]],
+}
+
+np.random.seed(123)
+opt_param = lgblss.hyper_opt(param_dict,
+ dtrain,
+ num_boost_round=100, # Number of boosting iterations.
+ nfold=5, # Number of cv-folds.
+ early_stopping_rounds=20, # Number of early-stopping rounds
+ max_minutes=1000, # Time budget in minutes, i.e., stop study after the given number of minutes.
+ n_trials=50, # The number of trials. If this argument is set to None, there is no limitation on the number of trials.
+ silence=False, # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail.
+ seed=123, # Seed used to generate cv-folds.
+ hp_seed=None # Seed for random number generator used in the Bayesian hyperparameter search.
+ )
+[I 2023-08-11 12:37:41,890] A new study created in memory with name: LightGBMLSS Hyper-Parameter Optimization ++
0%| | 0/50 [00:00<?, ?it/s]+
[I 2023-08-11 12:38:01,301] Trial 0 finished with value: 367804.0625 and parameters: {'eta': 0.010375304627985965, 'max_depth': 7, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 30.21888913980533, 'min_sum_hessian_in_leaf': 5.864939907646467e-06, 'subsample': 0.658481420114019, 'feature_fraction': 0.9114946619928868, 'boosting': 'gbdt'}. Best is trial 0 with value: 367804.0625.
+[I 2023-08-11 12:38:15,005] Trial 1 finished with value: 327890.15625 and parameters: {'eta': 5.3460212858136167e-05, 'max_depth': 6, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 22.51771738796101, 'min_sum_hessian_in_leaf': 3.782715103966255e-06, 'subsample': 0.8565244625430195, 'feature_fraction': 0.8120123399840897, 'boosting': 'gbdt'}. Best is trial 1 with value: 327890.15625.
+[I 2023-08-11 12:38:55,787] Trial 2 finished with value: 3321.39404296875 and parameters: {'eta': 2.778156946755216e-05, 'max_depth': 3, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 30.563335570212864, 'min_sum_hessian_in_leaf': 0.018998048940462937, 'subsample': 0.5982826614247189, 'feature_fraction': 0.9178957649663875, 'boosting': 'gbdt'}. Best is trial 2 with value: 3321.39404296875.
+[I 2023-08-11 12:39:41,746] Trial 3 finished with value: 3264.73486328125 and parameters: {'eta': 0.00016286470418944287, 'max_depth': 8, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 0.010186033781953225, 'min_sum_hessian_in_leaf': 0.0320584443452124, 'subsample': 0.521567388874646, 'feature_fraction': 0.6273169259837587, 'boosting': 'gbdt'}. Best is trial 3 with value: 3264.73486328125.
+[I 2023-08-11 12:39:51,741] Trial 4 finished with value: 376967.6875 and parameters: {'eta': 1.5684870736165636e-05, 'max_depth': 8, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 33.8874711080051, 'min_sum_hessian_in_leaf': 1.8783327364128395e-08, 'subsample': 0.8823849618907202, 'feature_fraction': 0.7045235387891493, 'boosting': 'gbdt'}. Best is trial 3 with value: 3264.73486328125.
+[I 2023-08-11 12:40:02,153] Trial 5 finished with value: 398357.78125 and parameters: {'eta': 0.5548705152962901, 'max_depth': 8, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 13.667421918402665, 'min_sum_hessian_in_leaf': 4.6972881363604445e-07, 'subsample': 0.20226750190291407, 'feature_fraction': 0.6190150789735767, 'boosting': 'gbdt'}. Best is trial 3 with value: 3264.73486328125.
+[I 2023-08-11 12:40:12,081] Trial 6 finished with value: 400577.875 and parameters: {'eta': 0.1234951759976552, 'max_depth': 9, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 33.13372404468565, 'min_sum_hessian_in_leaf': 1.2261575574099422e-07, 'subsample': 0.940693907349371, 'feature_fraction': 0.9449458870167231, 'boosting': 'gbdt'}. Best is trial 3 with value: 3264.73486328125.
+[I 2023-08-11 12:40:52,496] Trial 7 finished with value: 142739.59375 and parameters: {'eta': 0.0003413864481981204, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 22.366955613110136, 'min_sum_hessian_in_leaf': 6.002551849974542e-05, 'subsample': 0.6991813218844587, 'feature_fraction': 0.234857420886585, 'boosting': 'gbdt'}. Best is trial 3 with value: 3264.73486328125.
+[I 2023-08-11 12:41:01,002] Trial 8 finished with value: 365344.75 and parameters: {'eta': 0.00020409810478252383, 'max_depth': 1, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 36.855824335790395, 'min_sum_hessian_in_leaf': 1.2378209039169021e-08, 'subsample': 0.770484341624629, 'feature_fraction': 0.5551457106408251, 'boosting': 'gbdt'}. Best is trial 3 with value: 3264.73486328125.
+[I 2023-08-11 12:41:40,436] Trial 9 finished with value: 3135.341064453125 and parameters: {'eta': 0.015236694462247857, 'max_depth': 2, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 19.349498338142997, 'min_sum_hessian_in_leaf': 56.443023006446865, 'subsample': 0.7640980691353356, 'feature_fraction': 0.41488213555402687, 'boosting': 'gbdt'}. Best is trial 9 with value: 3135.341064453125.
+[I 2023-08-11 12:41:55,509] Trial 10 pruned. Trial was pruned at iteration 36.
+[I 2023-08-11 12:42:12,555] Trial 11 pruned. Trial was pruned at iteration 36.
+[I 2023-08-11 12:42:56,725] Trial 12 finished with value: 3256.26220703125 and parameters: {'eta': 0.0018049878745409515, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 3.374230470458916, 'min_sum_hessian_in_leaf': 0.0530979406814048, 'subsample': 0.4960846397538058, 'feature_fraction': 0.40371528463535267, 'boosting': 'gbdt'}. Best is trial 9 with value: 3135.341064453125.
+[I 2023-08-11 12:43:10,887] Trial 13 pruned. Trial was pruned at iteration 32.
+[I 2023-08-11 12:43:55,548] Trial 14 finished with value: 3212.943359375 and parameters: {'eta': 0.025859495137694966, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 6.685774705475238, 'min_sum_hessian_in_leaf': 222.98371851641804, 'subsample': 0.7995471962331264, 'feature_fraction': 0.47768677368077295, 'boosting': 'gbdt'}. Best is trial 9 with value: 3135.341064453125.
+[I 2023-08-11 12:44:03,829] Trial 15 finished with value: 3329.883544921875 and parameters: {'eta': 0.03539939269416217, 'max_depth': 2, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 9.188990720570771, 'min_sum_hessian_in_leaf': 488.0785240623253, 'subsample': 0.7894909220530997, 'feature_fraction': 0.5151030280739416, 'boosting': 'gbdt'}. Best is trial 9 with value: 3135.341064453125.
+[I 2023-08-11 12:44:43,469] Trial 16 finished with value: 3026.395263671875 and parameters: {'eta': 0.07594812682515821, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 17.792180133102768, 'min_sum_hessian_in_leaf': 22.17210994438013, 'subsample': 0.776822951588817, 'feature_fraction': 0.2890728975559498, 'boosting': 'gbdt'}. Best is trial 16 with value: 3026.395263671875.
+[I 2023-08-11 12:45:09,701] Trial 17 finished with value: 3024.16162109375 and parameters: {'eta': 0.14050335876069467, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 17.26511630421208, 'min_sum_hessian_in_leaf': 8.270011184858163, 'subsample': 0.9896356934682706, 'feature_fraction': 0.24430206777352248, 'boosting': 'gbdt'}. Best is trial 17 with value: 3024.16162109375.
+[I 2023-08-11 12:45:29,462] Trial 18 finished with value: 3172.02294921875 and parameters: {'eta': 0.7236262880129627, 'max_depth': 6, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 26.302808049098353, 'min_sum_hessian_in_leaf': 4.65621731262215, 'subsample': 0.9798594849561478, 'feature_fraction': 0.21013091104429663, 'boosting': 'gbdt'}. Best is trial 17 with value: 3024.16162109375.
+[I 2023-08-11 12:46:09,170] Trial 19 finished with value: 3030.934326171875 and parameters: {'eta': 0.11541934708482965, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 17.39372679689958, 'min_sum_hessian_in_leaf': 0.4875471297011469, 'subsample': 0.8735372230489282, 'feature_fraction': 0.29512485474393757, 'boosting': 'gbdt'}. Best is trial 17 with value: 3024.16162109375.
+[I 2023-08-11 12:46:49,777] Trial 20 finished with value: 3013.43505859375 and parameters: {'eta': 0.10851774600973758, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 12.778099763813188, 'min_sum_hessian_in_leaf': 19.409084894454672, 'subsample': 0.9906733215538556, 'feature_fraction': 0.31427354411349523, 'boosting': 'gbdt'}. Best is trial 20 with value: 3013.43505859375.
+[I 2023-08-11 12:47:31,244] Trial 21 finished with value: 3020.79150390625 and parameters: {'eta': 0.10941312206423358, 'max_depth': 5, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 12.955452035644882, 'min_sum_hessian_in_leaf': 34.43299195414659, 'subsample': 0.993865946118584, 'feature_fraction': 0.29169024300447044, 'boosting': 'gbdt'}. Best is trial 20 with value: 3013.43505859375.
+[I 2023-08-11 12:47:54,911] Trial 22 finished with value: 3017.7353515625 and parameters: {'eta': 0.27099448628298356, 'max_depth': 6, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 12.164474712430403, 'min_sum_hessian_in_leaf': 41.68415304679111, 'subsample': 0.9980808126058845, 'feature_fraction': 0.3153447935530275, 'boosting': 'gbdt'}. Best is trial 20 with value: 3013.43505859375.
+[I 2023-08-11 12:48:20,851] Trial 23 finished with value: 3019.21435546875 and parameters: {'eta': 0.30191668351694284, 'max_depth': 7, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 11.917898671607471, 'min_sum_hessian_in_leaf': 44.28300751774489, 'subsample': 0.9273319278552463, 'feature_fraction': 0.3276698697022868, 'boosting': 'gbdt'}. Best is trial 20 with value: 3013.43505859375.
+[I 2023-08-11 12:48:29,020] Trial 24 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:48:50,180] Trial 25 finished with value: 3018.3837890625 and parameters: {'eta': 0.3692147736260462, 'max_depth': 7, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 10.83827075251106, 'min_sum_hessian_in_leaf': 54.98180387829638, 'subsample': 0.9355321657142412, 'feature_fraction': 0.3542729437699873, 'boosting': 'gbdt'}. Best is trial 20 with value: 3013.43505859375.
+[I 2023-08-11 12:48:58,960] Trial 26 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:49:07,470] Trial 27 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:49:20,520] Trial 28 pruned. Trial was pruned at iteration 32.
+[I 2023-08-11 12:49:36,017] Trial 29 pruned. Trial was pruned at iteration 38.
+[I 2023-08-11 12:49:52,087] Trial 30 pruned. Trial was pruned at iteration 39.
+[I 2023-08-11 12:50:24,408] Trial 31 finished with value: 3019.494873046875 and parameters: {'eta': 0.2725991488316807, 'max_depth': 7, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 11.759315835515839, 'min_sum_hessian_in_leaf': 26.987460432181546, 'subsample': 0.998147928571545, 'feature_fraction': 0.32559028682493446, 'boosting': 'gbdt'}. Best is trial 20 with value: 3013.43505859375.
+[I 2023-08-11 12:50:43,988] Trial 32 finished with value: 3015.494140625 and parameters: {'eta': 0.3829501207030448, 'max_depth': 6, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 10.006822682462404, 'min_sum_hessian_in_leaf': 9.670757510705382, 'subsample': 0.9424904465703395, 'feature_fraction': 0.3111946445504374, 'boosting': 'gbdt'}. Best is trial 20 with value: 3013.43505859375.
+[I 2023-08-11 12:50:52,661] Trial 33 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:51:33,990] Trial 34 finished with value: 3005.75537109375 and parameters: {'eta': 0.06012752850837495, 'max_depth': 6, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 5.803902946638742, 'min_sum_hessian_in_leaf': 2.3261118096334563, 'subsample': 0.9482108811109413, 'feature_fraction': 0.41287326458142043, 'boosting': 'gbdt'}. Best is trial 34 with value: 3005.75537109375.
+[I 2023-08-11 12:52:15,466] Trial 35 finished with value: 3000.99462890625 and parameters: {'eta': 0.06943267180218958, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 4.133726741234719, 'min_sum_hessian_in_leaf': 1.7385973286087377, 'subsample': 0.8908962112260067, 'feature_fraction': 0.42160506776781076, 'boosting': 'gbdt'}. Best is trial 35 with value: 3000.99462890625.
+[I 2023-08-11 12:52:26,240] Trial 36 pruned. Trial was pruned at iteration 24.
+[I 2023-08-11 12:52:36,406] Trial 37 pruned. Trial was pruned at iteration 24.
+[I 2023-08-11 12:52:45,020] Trial 38 pruned. Trial was pruned at iteration 21.
+[I 2023-08-11 12:52:53,486] Trial 39 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:53:02,563] Trial 40 pruned. Trial was pruned at iteration 21.
+[I 2023-08-11 12:53:41,543] Trial 41 finished with value: 3005.391845703125 and parameters: {'eta': 0.15498347493908707, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 7.365763456361323, 'min_sum_hessian_in_leaf': 12.723870730914529, 'subsample': 0.9556994060266463, 'feature_fraction': 0.3792850237470474, 'boosting': 'gbdt'}. Best is trial 35 with value: 3000.99462890625.
+[I 2023-08-11 12:54:21,491] Trial 42 finished with value: 3007.25048828125 and parameters: {'eta': 0.1548185495847896, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 7.156358312749202, 'min_sum_hessian_in_leaf': 9.06469298926148, 'subsample': 0.9562432564521889, 'feature_fraction': 0.3674839079182071, 'boosting': 'gbdt'}. Best is trial 35 with value: 3000.99462890625.
+[I 2023-08-11 12:54:29,988] Trial 43 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:54:38,844] Trial 44 pruned. Trial was pruned at iteration 21.
+[I 2023-08-11 12:54:47,767] Trial 45 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:54:56,168] Trial 46 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:55:23,650] Trial 47 finished with value: 3023.676025390625 and parameters: {'eta': 0.16467209050245155, 'max_depth': 4, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 3.230462326784356, 'min_sum_hessian_in_leaf': 1.1106443915756805, 'subsample': 0.8624551086972744, 'feature_fraction': 0.45067165580000546, 'boosting': 'gbdt'}. Best is trial 35 with value: 3000.99462890625.
+[I 2023-08-11 12:55:32,412] Trial 48 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:56:15,258] Trial 49 finished with value: 3001.418212890625 and parameters: {'eta': 0.08071812906410179, 'max_depth': 3, 'num_leaves': 255, 'min_data_in_leaf': 20, 'min_gain_to_split': 4.294318716703948, 'min_sum_hessian_in_leaf': 2.6750545089295956, 'subsample': 0.9632339172694735, 'feature_fraction': 0.5074780056230868, 'boosting': 'gbdt'}. Best is trial 35 with value: 3000.99462890625.
+
+Hyper-Parameter Optimization successfully finished.
+ Number of finished trials: 50
+ Best trial:
+ Value: 3000.99462890625
+ Params:
+ eta: 0.06943267180218958
+ max_depth: 4
+ num_leaves: 255
+ min_data_in_leaf: 20
+ min_gain_to_split: 4.133726741234719
+ min_sum_hessian_in_leaf: 1.7385973286087377
+ subsample: 0.8908962112260067
+ feature_fraction: 0.42160506776781076
+ boosting: gbdt
+ opt_rounds: 90
+
+np.random.seed(123)
+
+opt_params = opt_param.copy()
+n_rounds = opt_params["opt_rounds"]
+del opt_params["opt_rounds"]
+
+# Train Model with optimized hyperparameters
+lgblss.train(opt_params,
+ dtrain,
+ num_boost_round=n_rounds
+ )
+# Set seed for reproducibility
+torch.manual_seed(123)
+
+# Number of samples to draw from predicted distribution
+n_samples = 10000
+# Quantiles to calculate from predicted distribution
+quant_sel = [0.05, 0.95]
+
+# Sample from predicted distribution
+pred_samples = lgblss.predict(X_test,
+ pred_type="samples",
+ n_samples=n_samples,
+ seed=123)
+
+# Calculate quantiles from predicted distribution
+pred_quantiles = lgblss.predict(X_test,
+ pred_type="quantiles",
+ n_samples=n_samples,
+ quantiles=quant_sel)
+
+# Returns predicted parameters
+pred_params = lgblss.predict(X_test,
+ pred_type="parameters")
+pred_samples.head()
+| + | y_sample0 | +y_sample1 | +y_sample2 | +y_sample3 | +y_sample4 | +y_sample5 | +y_sample6 | +y_sample7 | +y_sample8 | +y_sample9 | +... | +y_sample9990 | +y_sample9991 | +y_sample9992 | +y_sample9993 | +y_sample9994 | +y_sample9995 | +y_sample9996 | +y_sample9997 | +y_sample9998 | +y_sample9999 | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | +12.315617 | +11.148891 | +4.624041 | +11.273465 | +4.864611 | +13.651609 | +11.573423 | +14.295194 | +9.939115 | +8.728693 | +... | +13.490867 | +9.317229 | +8.216475 | +11.480260 | +9.670330 | +14.858524 | +5.511271 | +10.839365 | +11.708204 | +6.417930 | +
| 1 | +16.409412 | +8.340928 | +10.923915 | +13.388198 | +8.266445 | +10.249456 | +12.452267 | +10.588787 | +12.331830 | +9.027943 | +... | +10.883108 | +2.895114 | +11.342189 | +13.237988 | +6.858677 | +15.392724 | +9.221172 | +9.709686 | +4.011642 | +10.250503 | +
| 2 | +11.589569 | +9.669224 | +9.724932 | +10.960885 | +13.362031 | +11.276797 | +10.801574 | +9.534609 | +9.327179 | +10.494802 | +... | +10.138949 | +11.022624 | +8.731875 | +10.401649 | +9.127348 | +10.243149 | +9.944046 | +8.483890 | +10.321774 | +10.243544 | +
| 3 | +10.743192 | +9.116656 | +12.323032 | +5.270192 | +15.528632 | +15.910578 | +8.639240 | +16.705225 | +7.853291 | +9.957293 | +... | +1.351381 | +9.039200 | +16.516144 | +8.261804 | +4.777587 | +9.089480 | +12.751478 | +12.829519 | +12.620325 | +9.282865 | +
| 4 | +12.725435 | +8.629576 | +7.140886 | +5.782235 | +6.844902 | +10.355301 | +7.330880 | +14.259795 | +10.242219 | +15.360129 | +... | +9.775837 | +8.244545 | +9.040227 | +11.909575 | +8.996835 | +8.084206 | +13.316805 | +10.463615 | +8.097854 | +9.440963 | +
5 rows × 10000 columns
+pred_quantiles.head()
+| + | quant_0.05 | +quant_0.95 | +
|---|---|---|
| 0 | +5.220628 | +14.963007 | +
| 1 | +5.365820 | +15.105494 | +
| 2 | +8.211895 | +11.933730 | +
| 3 | +2.047034 | +17.560992 | +
| 4 | +5.048092 | +15.145446 | +
pred_params.head()
+| + | param_1 | +param_2 | +param_3 | +param_4 | +param_5 | +param_6 | +param_7 | +param_8 | +param_9 | +param_10 | +... | +param_22 | +param_23 | +param_24 | +param_25 | +param_26 | +param_27 | +param_28 | +param_29 | +param_30 | +param_31 | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | +-0.418612 | +-0.302259 | +-0.532314 | +-0.775419 | +0.697199 | +-0.227767 | +-3.043896 | +1.286783 | +1.113216 | +0.349978 | +... | +1.817143 | +0.570572 | +0.945506 | +0.805746 | +0.693497 | +0.639612 | +1.854735 | +1.306370 | +0.909254 | +0.839281 | +
| 1 | +-0.418612 | +-0.302259 | +-0.532314 | +-0.775419 | +0.697199 | +-0.227767 | +-3.043896 | +1.286783 | +1.113216 | +0.349978 | +... | +1.777844 | +0.570572 | +0.945506 | +0.805746 | +0.693497 | +0.639612 | +1.854735 | +1.306370 | +0.909254 | +0.839281 | +
| 2 | +-0.418612 | +-0.302259 | +-0.532314 | +-0.775419 | +0.697199 | +-0.227767 | +-3.043896 | +1.286783 | +1.113216 | +0.349978 | +... | +1.495455 | +0.570572 | +0.945506 | +0.805746 | +0.693497 | +0.639612 | +0.868014 | +2.313089 | +0.909254 | +0.839281 | +
| 3 | +-0.418612 | +-0.302259 | +-0.532314 | +-0.775419 | +0.697199 | +-0.227767 | +-3.043896 | +1.286783 | +1.113216 | +0.349978 | +... | +1.276525 | +0.570572 | +0.945506 | +0.805746 | +0.693497 | +0.639612 | +2.172172 | +-1.196684 | +0.909254 | +0.839281 | +
| 4 | +-0.418612 | +-0.302259 | +-0.532314 | +-0.775419 | +0.697199 | +-0.227767 | +-3.043896 | +1.286783 | +1.113216 | +0.349978 | +... | +1.535858 | +0.570572 | +0.945506 | +0.805746 | +0.693497 | +0.639612 | +1.854735 | +1.127365 | +0.909254 | +0.839281 | +
5 rows × 31 columns
+Note that in contrast to parametric distributions, the parameters of the Spline-Flow do not have a direct interpretation.
+# Partial Dependence Plot of how x acts on param_21
+lgblss.plot(X_test,
+ parameter="param_21",
+ feature="x_true",
+ plot_type="Partial_Dependence")
+ +
+# Feature Importance of param_21
+lgblss.plot(X_test,
+ parameter="param_21",
+ plot_type="Feature_Importance")
+ +
+np.random.seed(123)
+
+###
+# Actual Quantiles
+###
+q1 = norm.ppf(quant_sel[0], loc = 10, scale = 1 + 4*((0.3 < test["x_true"].values) & (test["x_true"].values < 0.5)) + 2*(test["x_true"].values > 0.7))
+q2 = norm.ppf(quant_sel[1], loc = 10, scale = 1 + 4*((0.3 < test["x_true"].values) & (test["x_true"].values < 0.5)) + 2*(test["x_true"].values > 0.7))
+test["quant"] = np.where(test["y"].values < q1, 0, np.where(test["y"].values < q2, 1, 2))
+test["alpha"] = np.where(test["y"].values <= q1, 1, np.where(test["y"].values >= q2, 1, 0))
+df_quantiles = test[test["alpha"] == 1]
+
+# Lower Bound
+yl = list(set(q1))
+yl.sort()
+yl = [yl[2],yl[0],yl[2],yl[1],yl[1]]
+sfunl = pd.DataFrame({"x_true":[0, 0.3, 0.5, 0.7, 1], "y":yl})
+
+# Upper Bound
+yu = list(set(q2))
+yu.sort()
+yu = [yu[0],yu[2],yu[0],yu[1],yu[1]]
+sfunu = pd.DataFrame({"x_true":[0, 0.3, 0.5, 0.7, 1], "y":yu})
+
+###
+# Predicted Quantiles
+###
+test["lb"] = pred_quantiles.iloc[:,0]
+test["ub"] = pred_quantiles.iloc[:,1]
+
+###
+# Plot
+###
+(ggplot(test,
+ aes("x_true",
+ "y")) +
+ geom_point(alpha = 0.2, color = "black", size = 2) +
+ theme_bw(base_size=15) +
+ theme(legend_position="none",
+ plot_title = element_text(hjust = 0.5)) +
+ labs(title = "LightGBMLSS Regression - Simulated Data Example",
+ x="x") +
+ geom_line(aes("x_true",
+ "ub"),
+ size = 1,
+ color = "blue",
+ alpha = 0.7) +
+ geom_line(aes("x_true",
+ "lb"),
+ size = 1,
+ color = "blue",
+ alpha = 0.7) +
+ geom_point(df_quantiles,
+ aes("x_true",
+ "y"),
+ color = "red",
+ alpha = 0.7,
+ size = 2) +
+ geom_step(sfunl,
+ aes("x_true",
+ "y"),
+ size = 1,
+ linetype = "dashed") +
+ geom_step(sfunu,
+ aes("x_true",
+ "y"),
+ size = 1,
+ linetype = "dashed")
+)
+ +
+<Figure Size: (2000 x 1000)>+
In the following figure, we compare the true parameters of the Gaussian with the ones predicted by LightGBMLSS. The below figure shows that the estimated parameters closely match the true ones (recall that the location parameter $\mu=10$ is simulated as being a constant).
+dist_params = ["loc", "scale"]
+
+# Calculate parameters from samples
+sample_params = pd.DataFrame.from_dict(
+ {
+ "loc": pred_samples.mean(axis=1),
+ "scale": pred_samples.std(axis=1),
+ "x_true": X_test["x_true"].values
+ }
+)
+
+# Data with predicted values
+plot_df_predt = pd.melt(sample_params[["x_true"] + dist_params],
+ id_vars="x_true",
+ value_vars=dist_params)
+plot_df_predt["type"] = "PREDICT"
+
+# Data with actual values
+plot_df_actual = pd.melt(test[["x_true"] + dist_params],
+ id_vars="x_true",
+ value_vars=dist_params)
+plot_df_actual["type"] = "TRUE"
+
+# Combine data for plotting
+plot_df = pd.concat([plot_df_predt, plot_df_actual])
+plot_df["variable"] = plot_df.variable.str.upper()
+plot_df["type"] = pd.Categorical(plot_df["type"], categories = ["PREDICT", "TRUE"])
+
+# Plot
+(ggplot(plot_df,
+ aes(x="x_true",
+ y="value",
+ color="type")) +
+ geom_line(size=1.1) +
+ facet_wrap("variable",
+ scales="free") +
+ labs(title="Parameters of univariate Gaussian predicted with LightGBMLSS",
+ x="",
+ y="") +
+ theme_bw(base_size=15) +
+ theme(legend_position="bottom",
+ plot_title = element_text(hjust = 0.5),
+ legend_title = element_blank())
+)
+ +
+<Figure Size: (2000 x 1000)>+
pred_df = pd.melt(pred_samples.iloc[:,0:5])
+actual_df = pd.DataFrame.from_dict({"variable": "ACTUAL", "value": y_test.reshape(-1,)})
+plot_df = pd.concat([pred_df, actual_df])
+
+(
+ ggplot(plot_df,
+ aes(x="value",
+ color="variable",
+ fill="variable")) +
+ geom_density(alpha=0.4) +
+ facet_wrap("variable",
+ ncol=2) +
+ theme_bw(base_size=15) +
+ theme(plot_title = element_text(hjust = 0.5)) +
+ theme(legend_position="none")
+)
+ +
+<Figure Size: (2000 x 1000)>+
Since we predict the entire conditional distribution, we can overlay the point predictions with predicted densities, from which we can also derive quantiles of interest.
+y_pred = []
+
+n_examples = 8
+q_sel = [0.05, 0.95]
+y_sel=0
+samples_arr = pred_samples.values.reshape(-1,n_samples)
+
+for i in range(n_examples):
+ y_samples = pd.DataFrame(samples_arr[i,:].reshape(-1,1), columns=["PREDICT_DENSITY"])
+ y_samples["PREDICT_POINT"] = y_samples["PREDICT_DENSITY"].mean()
+ y_samples["PREDICT_Q05"] = y_samples["PREDICT_DENSITY"].quantile(q=q_sel[0])
+ y_samples["PREDICT_Q95"] = y_samples["PREDICT_DENSITY"].quantile(q=q_sel[1])
+ y_samples["ACTUAL"] = y_test[i]
+ y_samples["obs"]= f"Obervation {i+1}"
+ y_pred.append(y_samples)
+
+pred_df = pd.melt(pd.concat(y_pred, axis=0), id_vars="obs")
+pred_df["obs"] = pd.Categorical(pred_df["obs"], categories=[f"Obervation {i+1}" for i in range(n_examples)])
+df_actual, df_pred_dens, df_pred_point, df_q05, df_q95 = [x for _, x in pred_df.groupby("variable")]
+
+plot_pred = (
+ ggplot(pred_df,
+ aes(color="variable")) +
+ stat_density(df_pred_dens,
+ aes(x="value"),
+ size=1.1) +
+ geom_point(df_pred_point,
+ aes(x="value",
+ y=0),
+ size=1.4) +
+ geom_point(df_actual,
+ aes(x="value",
+ y=0),
+ size=1.4) +
+ geom_vline(df_q05,
+ aes(xintercept="value",
+ fill="variable",
+ color="variable"),
+ linetype="dashed",
+ size=1.1) +
+ geom_vline(df_q95,
+ aes(xintercept="value",
+ fill="variable",
+ color="variable"),
+ linetype="dashed",
+ size=1.1) +
+ facet_wrap("obs",
+ scales="free",
+ ncol=4) +
+ labs(title="Predicted vs. Actual \n",
+ x = "") +
+ theme_bw(base_size=15) +
+ theme(plot_title = element_text(hjust = 0.5)) +
+ scale_fill_brewer(type="qual", palette="Dark2") +
+ theme(legend_position="bottom",
+ legend_title = element_blank()
+ )
+)
+
+print(plot_pred)
+ +
+++
| \n", + " | y_sample0 | \n", + "y_sample1 | \n", + "y_sample2 | \n", + "y_sample3 | \n", + "y_sample4 | \n", + "y_sample5 | \n", + "y_sample6 | \n", + "y_sample7 | \n", + "y_sample8 | \n", + "y_sample9 | \n", + "... | \n", + "y_sample990 | \n", + "y_sample991 | \n", + "y_sample992 | \n", + "y_sample993 | \n", + "y_sample994 | \n", + "y_sample995 | \n", + "y_sample996 | \n", + "y_sample997 | \n", + "y_sample998 | \n", + "y_sample999 | \n", + "
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "69.516289 | \n", + "0.000000 | \n", + "0.000000 | \n", + "... | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "
| 1 | \n", + "60.929550 | \n", + "105.531929 | \n", + "64.138367 | \n", + "110.538750 | \n", + "83.007111 | \n", + "65.914368 | \n", + "114.569489 | \n", + "83.754181 | \n", + "76.929359 | \n", + "106.249832 | \n", + "... | \n", + "126.694046 | \n", + "58.902824 | \n", + "106.914062 | \n", + "109.303070 | \n", + "64.697182 | \n", + "71.515106 | \n", + "96.678009 | \n", + "93.943962 | \n", + "62.027760 | \n", + "0.000000 | \n", + "
| 2 | \n", + "37.353783 | \n", + "32.012577 | \n", + "31.435833 | \n", + "38.747078 | \n", + "74.590515 | \n", + "53.662891 | \n", + "22.332142 | \n", + "55.751812 | \n", + "19.008478 | \n", + "32.330696 | \n", + "... | \n", + "0.000000 | \n", + "28.788361 | \n", + "22.363855 | \n", + "16.031998 | \n", + "38.852062 | \n", + "25.945065 | \n", + "30.270662 | \n", + "23.981115 | \n", + "37.747807 | \n", + "25.279463 | \n", + "
| 3 | \n", + "30.415985 | \n", + "51.455875 | \n", + "47.262981 | \n", + "56.843914 | \n", + "75.915627 | \n", + "90.310211 | \n", + "78.174225 | \n", + "73.345291 | \n", + "48.665390 | \n", + "84.060516 | \n", + "... | \n", + "35.612038 | \n", + "56.444321 | \n", + "64.669716 | \n", + "63.445686 | \n", + "94.317162 | \n", + "33.868572 | \n", + "28.650946 | \n", + "30.990072 | \n", + "83.390099 | \n", + "59.522594 | \n", + "
| 4 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "23.404318 | \n", + "0.000000 | \n", + "46.938168 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "... | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "0.000000 | \n", + "
5 rows × 1000 columns
\n", + "" + ], + "text/plain": [ + " y_sample0 y_sample1 y_sample2 y_sample3 y_sample4 y_sample5 \\\n", + "0 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 \n", + "1 60.929550 105.531929 64.138367 110.538750 83.007111 65.914368 \n", + "2 37.353783 32.012577 31.435833 38.747078 74.590515 53.662891 \n", + "3 30.415985 51.455875 47.262981 56.843914 75.915627 90.310211 \n", + "4 0.000000 0.000000 0.000000 23.404318 0.000000 46.938168 \n", + "\n", + " y_sample6 y_sample7 y_sample8 y_sample9 ... y_sample990 \\\n", + "0 0.000000 69.516289 0.000000 0.000000 ... 0.000000 \n", + "1 114.569489 83.754181 76.929359 106.249832 ... 126.694046 \n", + "2 22.332142 55.751812 19.008478 32.330696 ... 0.000000 \n", + "3 78.174225 73.345291 48.665390 84.060516 ... 35.612038 \n", + "4 0.000000 0.000000 0.000000 0.000000 ... 0.000000 \n", + "\n", + " y_sample991 y_sample992 y_sample993 y_sample994 y_sample995 \\\n", + "0 0.000000 0.000000 0.000000 0.000000 0.000000 \n", + "1 58.902824 106.914062 109.303070 64.697182 71.515106 \n", + "2 28.788361 22.363855 16.031998 38.852062 25.945065 \n", + "3 56.444321 64.669716 63.445686 94.317162 33.868572 \n", + "4 0.000000 0.000000 0.000000 0.000000 0.000000 \n", + "\n", + " y_sample996 y_sample997 y_sample998 y_sample999 \n", + "0 0.000000 0.000000 0.000000 0.000000 \n", + "1 96.678009 93.943962 62.027760 0.000000 \n", + "2 30.270662 23.981115 37.747807 25.279463 \n", + "3 28.650946 30.990072 83.390099 59.522594 \n", + "4 0.000000 0.000000 0.000000 0.000000 \n", + "\n", + "[5 rows x 1000 columns]" + ] + }, + "execution_count": 8, + "metadata": {}, + "output_type": "execute_result" + } + ], + "source": [ + "pred_samples.head()" + ] + }, + { + "cell_type": "code", + "execution_count": 9, + "metadata": { + "ExecuteTime": { + "end_time": "2023-05-18T06:23:27.863941100Z", + "start_time": "2023-05-18T06:23:27.837972100Z" + }, + "tags": [] + }, + "outputs": [ + { + "data": { + "text/html": [ + "| \n", + " | quant_0.05 | \n", + "quant_0.95 | \n", + "
|---|---|---|
| 0 | \n", + "0.0 | \n", + "77.157624 | \n", + "
| 1 | \n", + "0.0 | \n", + "133.450491 | \n", + "
| 2 | \n", + "0.0 | \n", + "51.579050 | \n", + "
| 3 | \n", + "0.0 | \n", + "91.223141 | \n", + "
| 4 | \n", + "0.0 | \n", + "24.037125 | \n", + "
| \n", + " | concentration | \n", + "rate | \n", + "gate | \n", + "
|---|---|---|---|
| 0 | \n", + "13.424025 | \n", + "0.149034 | \n", + "0.943975 | \n", + "
| 1 | \n", + "13.424025 | \n", + "0.149034 | \n", + "0.054856 | \n", + "
| 2 | \n", + "9.111379 | \n", + "0.275753 | \n", + "0.054856 | \n", + "
| 3 | \n", + "9.111379 | \n", + "0.158935 | \n", + "0.054856 | \n", + "
| 4 | \n", + "9.111379 | \n", + "0.275753 | \n", + "0.943975 | \n", + "
![]()
from lightgbmlss.model import *
+from lightgbmlss.distributions.ZAGamma import *
+
+from sklearn.model_selection import train_test_split
+import pandas as pd
+import plotnine
+from plotnine import *
+plotnine.options.figure_size = (18, 9)
+# The simulation example closely follows https://towardsdatascience.com/zero-inflated-regression-c7dfc656d8af
+np.random.seed(123)
+n_samples = 1000
+
+data = pd.DataFrame({"age": np.random.randint(1, 100, size=n_samples)})
+data["income"] = np.where((data.age > 17) & (data.age < 70), 1500*data.age + 5000 + 10000*np.random.randn(n_samples), 0) / 1000
+
+y = data["income"].values
+X = data.drop(columns="income")
+X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
+
+dtrain = lgb.Dataset(X_train, label=y_train)
+# Specifies Zero-Adjusted Gamma distribution. See ?ZAGamma for an overview.
+lgblss = LightGBMLSS(
+ ZAGamma(stabilization="None", # Options are "None", "MAD", "L2".
+ response_fn="exp", # Function to transform the concentration and rate parameters, e.g., "exp" or "softplus".
+ loss_fn="nll" # Loss function. Options are "nll" (negative log-likelihood) or "crps"(continuous ranked probability score).)
+ )
+)
+Any LightGBM hyperparameter can be tuned, where the structure of the parameter dictionary needs to be as follows:
+- Float/Int sample_type
+ - {"param_name": ["sample_type", low, high, log]}
+ - sample_type: str, Type of sampling, e.g., "float" or "int"
+ - low: int, Lower endpoint of the range of suggested values
+ - high: int, Upper endpoint of the range of suggested values
+ - log: bool, Flag to sample the value from the log domain or not
+ - Example: {"eta": "float", low=1e-5, high=1, log=True]}
+
+- Categorical sample_type
+ - {"param_name": ["sample_type", ["choice1", "choice2", "choice3", "..."]]}
+ - sample_type: str, Type of sampling, either "categorical"
+ - choice1, choice2, choice3, ...: str, Possible choices for the parameter
+ - Example: {"boosting": ["categorical", ["gbdt", "dart"]]}
+
+- For parameters without tunable choice (this is needed if tree_method = "gpu_hist" and gpu_id needs to be specified)
+ - {"param_name": ["none", [value]]},
+ - param_name: str, Name of the parameter
+ - value: int, Value of the parameter
+ - Example: {"gpu_id": ["none", [0]]}param_dict = {
+ "eta": ["float", {"low": 1e-5, "high": 1, "log": True}],
+ "max_depth": ["int", {"low": 1, "high": 10, "log": False}],
+ "min_gain_to_split": ["float", {"low": 1e-8, "high": 40, "log": False}],
+ "min_sum_hessian_in_leaf": ["float", {"low": 1e-8, "high": 500, "log": True}],
+ "subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
+ "boosting": ["categorical", ["gbdt"]],
+}
+
+np.random.seed(123)
+opt_param = lgblss.hyper_opt(param_dict,
+ dtrain,
+ num_boost_round=100, # Number of boosting iterations.
+ nfold=5, # Number of cv-folds.
+ early_stopping_rounds=20, # Number of early-stopping rounds
+ max_minutes=5, # Time budget in minutes, i.e., stop study after the given number of minutes.
+ n_trials=20, # The number of trials. If this argument is set to None, there is no limitation on the number of trials.
+ silence=False, # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail.
+ seed=123, # Seed used to generate cv-folds.
+ hp_seed=None # Seed for random number generator used in the Bayesian hyperparameter search.
+ )
+[I 2023-08-11 12:13:43,049] A new study created in memory with name: LightGBMLSS Hyper-Parameter Optimization ++
0%| | 0/20 [00:00<?, ?it/s]+
[I 2023-08-11 12:13:46,907] Trial 0 finished with value: 493.3361578406364 and parameters: {'eta': 0.0003914367990686954, 'max_depth': 8, 'min_gain_to_split': 33.26852906521015, 'min_sum_hessian_in_leaf': 0.08584812980967063, 'subsample': 0.8021623973944538, 'feature_fraction': 0.8005070720671894, 'boosting': 'gbdt'}. Best is trial 0 with value: 493.3361578406364.
+[I 2023-08-11 12:13:47,643] Trial 1 finished with value: 471.35372890681646 and parameters: {'eta': 0.40295767323333237, 'max_depth': 10, 'min_gain_to_split': 24.549932527360678, 'min_sum_hessian_in_leaf': 256.4870626827937, 'subsample': 0.8683684494312434, 'feature_fraction': 0.7849944406887219, 'boosting': 'gbdt'}. Best is trial 1 with value: 471.35372890681646.
+[I 2023-08-11 12:13:51,060] Trial 2 finished with value: 503.6348357284388 and parameters: {'eta': 1.222371366077261e-05, 'max_depth': 4, 'min_gain_to_split': 28.061063870566468, 'min_sum_hessian_in_leaf': 0.0007422808244019155, 'subsample': 0.5522281492920988, 'feature_fraction': 0.6521861926605665, 'boosting': 'gbdt'}. Best is trial 1 with value: 471.35372890681646.
+[I 2023-08-11 12:13:54,435] Trial 3 finished with value: 503.3457675319369 and parameters: {'eta': 2.274369193692896e-05, 'max_depth': 5, 'min_gain_to_split': 39.238368142734814, 'min_sum_hessian_in_leaf': 0.0006223989318040594, 'subsample': 0.7412515727598581, 'feature_fraction': 0.9452613103135388, 'boosting': 'gbdt'}. Best is trial 1 with value: 471.35372890681646.
+[I 2023-08-11 12:13:57,807] Trial 4 finished with value: 502.3184990853341 and parameters: {'eta': 5.598186442465094e-05, 'max_depth': 3, 'min_gain_to_split': 21.23896288198938, 'min_sum_hessian_in_leaf': 0.21992447027885145, 'subsample': 0.45542723654621087, 'feature_fraction': 0.8855719650525622, 'boosting': 'gbdt'}. Best is trial 1 with value: 471.35372890681646.
+[I 2023-08-11 12:13:59,599] Trial 5 finished with value: 401.0408565228521 and parameters: {'eta': 0.041701168766377694, 'max_depth': 8, 'min_gain_to_split': 17.301602719722112, 'min_sum_hessian_in_leaf': 32.73881939196468, 'subsample': 0.7377555648382916, 'feature_fraction': 0.9073126421475854, 'boosting': 'gbdt'}. Best is trial 5 with value: 401.0408565228521.
+[I 2023-08-11 12:14:02,830] Trial 6 finished with value: 407.386455067243 and parameters: {'eta': 0.007126608872225107, 'max_depth': 5, 'min_gain_to_split': 24.033222285497697, 'min_sum_hessian_in_leaf': 8.907709262528446, 'subsample': 0.4954284084741154, 'feature_fraction': 0.8681250783490104, 'boosting': 'gbdt'}. Best is trial 5 with value: 401.0408565228521.
+[I 2023-08-11 12:14:06,129] Trial 7 finished with value: 496.7796683249693 and parameters: {'eta': 0.00026493753680363304, 'max_depth': 3, 'min_gain_to_split': 38.809508809426916, 'min_sum_hessian_in_leaf': 6.812433286336614e-05, 'subsample': 0.21286798118279357, 'feature_fraction': 0.6112152779922334, 'boosting': 'gbdt'}. Best is trial 5 with value: 401.0408565228521.
+[I 2023-08-11 12:14:09,346] Trial 8 finished with value: 407.1040293789821 and parameters: {'eta': 0.007732793896149601, 'max_depth': 3, 'min_gain_to_split': 37.84720417299646, 'min_sum_hessian_in_leaf': 6.236162955045407e-08, 'subsample': 0.9353287449899692, 'feature_fraction': 0.3984151482200087, 'boosting': 'gbdt'}. Best is trial 5 with value: 401.0408565228521.
+
+C:\Users\maerzale\.virtualenvs\LightGBMLSS--u9b4l4T\lib\site-packages\numpy\core\_methods.py:236: RuntimeWarning: invalid value encountered in subtract ++
[I 2023-08-11 12:14:10,085] Trial 9 finished with value: 435.35091073184594 and parameters: {'eta': 0.9428989545188251, 'max_depth': 10, 'min_gain_to_split': 4.488114462250434, 'min_sum_hessian_in_leaf': 1.7998195761788722, 'subsample': 0.29209480384149383, 'feature_fraction': 0.9592081048531047, 'boosting': 'gbdt'}. Best is trial 5 with value: 401.0408565228521.
+[I 2023-08-11 12:14:11,097] Trial 10 finished with value: 469.6566333865485 and parameters: {'eta': 0.20312012140237876, 'max_depth': 7, 'min_gain_to_split': 12.765970540892038, 'min_sum_hessian_in_leaf': 167.938324975031, 'subsample': 0.7047234963516413, 'feature_fraction': 0.26898548607003475, 'boosting': 'gbdt'}. Best is trial 5 with value: 401.0408565228521.
+[I 2023-08-11 12:14:14,892] Trial 11 finished with value: 410.651136877749 and parameters: {'eta': 0.016887194634392852, 'max_depth': 1, 'min_gain_to_split': 16.11709690117341, 'min_sum_hessian_in_leaf': 7.572146181609595e-08, 'subsample': 0.9978336630147084, 'feature_fraction': 0.4268355236219649, 'boosting': 'gbdt'}. Best is trial 5 with value: 401.0408565228521.
+[I 2023-08-11 12:14:17,623] Trial 12 finished with value: 377.60158084711895 and parameters: {'eta': 0.03699519752376613, 'max_depth': 7, 'min_gain_to_split': 29.510639132062416, 'min_sum_hessian_in_leaf': 1.251547058329255e-08, 'subsample': 0.9633512537434151, 'feature_fraction': 0.482137842472506, 'boosting': 'gbdt'}. Best is trial 12 with value: 377.60158084711895.
+[I 2023-08-11 12:14:19,401] Trial 13 finished with value: 377.8206629881021 and parameters: {'eta': 0.0764582042253138, 'max_depth': 8, 'min_gain_to_split': 30.97426056045043, 'min_sum_hessian_in_leaf': 6.7959924810432435e-06, 'subsample': 0.8745012211500811, 'feature_fraction': 0.6773493987586585, 'boosting': 'gbdt'}. Best is trial 12 with value: 377.60158084711895.
+[I 2023-08-11 12:14:21,249] Trial 14 finished with value: 377.08800070558675 and parameters: {'eta': 0.0763535359468984, 'max_depth': 7, 'min_gain_to_split': 30.028503666783337, 'min_sum_hessian_in_leaf': 2.4843843388235532e-06, 'subsample': 0.9967113125593, 'feature_fraction': 0.5022537683346732, 'boosting': 'gbdt'}. Best is trial 14 with value: 377.08800070558675.
+[I 2023-08-11 12:14:22,835] Trial 15 finished with value: 376.7629699437488 and parameters: {'eta': 0.09620102011855627, 'max_depth': 7, 'min_gain_to_split': 29.437274575766544, 'min_sum_hessian_in_leaf': 1.1839961164729091e-08, 'subsample': 0.9694329011088387, 'feature_fraction': 0.5286979187071998, 'boosting': 'gbdt'}. Best is trial 15 with value: 376.7629699437488.
+[I 2023-08-11 12:14:24,205] Trial 16 finished with value: 377.7666131850925 and parameters: {'eta': 0.149654603762201, 'max_depth': 6, 'min_gain_to_split': 33.99184916354226, 'min_sum_hessian_in_leaf': 8.319116968525249e-07, 'subsample': 0.990017156839053, 'feature_fraction': 0.5284298109620141, 'boosting': 'gbdt'}. Best is trial 15 with value: 376.7629699437488.
+[I 2023-08-11 12:14:25,170] Trial 17 pruned. Trial was pruned at iteration 20.
+[I 2023-08-11 12:14:26,420] Trial 18 finished with value: 364.798082239509 and parameters: {'eta': 0.8932571745812234, 'max_depth': 6, 'min_gain_to_split': 32.84914712406526, 'min_sum_hessian_in_leaf': 1.2602701826082383e-05, 'subsample': 0.6414980864372755, 'feature_fraction': 0.2984688213287875, 'boosting': 'gbdt'}. Best is trial 18 with value: 364.798082239509.
+[I 2023-08-11 12:14:27,424] Trial 19 finished with value: 374.1395215044128 and parameters: {'eta': 0.7729049694175503, 'max_depth': 6, 'min_gain_to_split': 36.447746033684936, 'min_sum_hessian_in_leaf': 1.8155247988671537e-05, 'subsample': 0.6136889714080027, 'feature_fraction': 0.24597577103025603, 'boosting': 'gbdt'}. Best is trial 18 with value: 364.798082239509.
+
+Hyper-Parameter Optimization successfully finished.
+ Number of finished trials: 20
+ Best trial:
+ Value: 364.798082239509
+ Params:
+ eta: 0.8932571745812234
+ max_depth: 6
+ min_gain_to_split: 32.84914712406526
+ min_sum_hessian_in_leaf: 1.2602701826082383e-05
+ subsample: 0.6414980864372755
+ feature_fraction: 0.2984688213287875
+ boosting: gbdt
+ opt_rounds: 9
+
+np.random.seed(123)
+
+opt_params = opt_param.copy()
+n_rounds = opt_params["opt_rounds"]
+del opt_params["opt_rounds"]
+
+# Train Model with optimized hyperparameters
+lgblss.train(opt_params,
+ dtrain,
+ num_boost_round=n_rounds
+ )
+# Set seed for reproducibility
+torch.manual_seed(123)
+
+# Number of samples to draw from predicted distribution
+n_samples = 1000
+# Quantiles to calculate from predicted distribution
+quant_sel = [0.05, 0.95]
+
+# Sample from predicted distribution
+pred_samples = lgblss.predict(X_test,
+ pred_type="samples",
+ n_samples=n_samples,
+ seed=123)
+
+# Calculate quantiles from predicted distribution
+pred_quantiles = lgblss.predict(X_test,
+ pred_type="quantiles",
+ n_samples=n_samples,
+ quantiles=quant_sel)
+
+# Returns predicted distributional parameters
+pred_params = lgblss.predict(X_test,
+ pred_type="parameters")
+pred_samples.head()
+| + | y_sample0 | +y_sample1 | +y_sample2 | +y_sample3 | +y_sample4 | +y_sample5 | +y_sample6 | +y_sample7 | +y_sample8 | +y_sample9 | +... | +y_sample990 | +y_sample991 | +y_sample992 | +y_sample993 | +y_sample994 | +y_sample995 | +y_sample996 | +y_sample997 | +y_sample998 | +y_sample999 | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +69.516289 | +0.000000 | +0.000000 | +... | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +
| 1 | +60.929550 | +105.531929 | +64.138367 | +110.538750 | +83.007111 | +65.914368 | +114.569489 | +83.754181 | +76.929359 | +106.249832 | +... | +126.694046 | +58.902824 | +106.914062 | +109.303070 | +64.697182 | +71.515106 | +96.678009 | +93.943962 | +62.027760 | +0.000000 | +
| 2 | +37.353783 | +32.012577 | +31.435833 | +38.747078 | +74.590515 | +53.662891 | +22.332142 | +55.751812 | +19.008478 | +32.330696 | +... | +0.000000 | +28.788361 | +22.363855 | +16.031998 | +38.852062 | +25.945065 | +30.270662 | +23.981115 | +37.747807 | +25.279463 | +
| 3 | +30.415985 | +51.455875 | +47.262981 | +56.843914 | +75.915627 | +90.310211 | +78.174225 | +73.345291 | +48.665390 | +84.060516 | +... | +35.612038 | +56.444321 | +64.669716 | +63.445686 | +94.317162 | +33.868572 | +28.650946 | +30.990072 | +83.390099 | +59.522594 | +
| 4 | +0.000000 | +0.000000 | +0.000000 | +23.404318 | +0.000000 | +46.938168 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +... | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +0.000000 | +
5 rows × 1000 columns
+pred_quantiles.head()
+| + | quant_0.05 | +quant_0.95 | +
|---|---|---|
| 0 | +0.0 | +77.157624 | +
| 1 | +0.0 | +133.450491 | +
| 2 | +0.0 | +51.579050 | +
| 3 | +0.0 | +91.223141 | +
| 4 | +0.0 | +24.037125 | +
pred_params.head()
+| + | concentration | +rate | +gate | +
|---|---|---|---|
| 0 | +13.424025 | +0.149034 | +0.943975 | +
| 1 | +13.424025 | +0.149034 | +0.054856 | +
| 2 | +9.111379 | +0.275753 | +0.054856 | +
| 3 | +9.111379 | +0.158935 | +0.054856 | +
| 4 | +9.111379 | +0.275753 | +0.943975 | +
# Partial Dependence Plot of concentration parameter
+lgblss.plot(X_test,
+ parameter="concentration",
+ feature="age",
+ plot_type="Partial_Dependence")
+ +
+# Feature Importance of gate parameter
+lgblss.plot(X_test,
+ parameter="gate",
+ plot_type="Feature_Importance")
+ +
+pred_df = pd.melt(pred_samples.iloc[:,0:5])
+actual_df = pd.DataFrame.from_dict({"variable": "ACTUAL", "value": y_test.reshape(-1,)})
+plot_df = pd.concat([pred_df, actual_df])
+
+(
+ ggplot(plot_df,
+ aes(x="value",
+ color="variable",
+ fill="variable")) +
+ geom_density(alpha=0.4) +
+ facet_wrap("variable",
+ scales="free_y",
+ ncol=2) +
+ theme_bw(base_size=15) +
+ theme(legend_position="none")
+)
+ +
+<Figure Size: (1800 x 900)>+

We introduce a comprehensive framework that models and predicts the full conditional distribution of a univariate target as a function of covariate. Choosing from a wide range of continuous, discrete, and mixed discrete-continuous distributions, modelling and predicting the entire conditional distribution greatly enhances the flexibility of LightGBM, as it allows to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived.
+To install LightGBMLSS, please first run
+pip install git+https://github.com/StatMixedML/LightGBMLSS.git
+Then, to install the shap-dependency, run
+pip install git+https://github.com/dsgibbons/shap.git
+Since LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to variability regarding the ranges, the estimation of Gradients and Hessians might become unstable so that LightGBMLSS might not converge or might converge very slowly. To mitigate these effects, we have implemented a stabilization of Gradients and Hessians.
+For improved convergence, an alternative approach is to standardize the (continuous) response variable, such as dividing it by 100 (e.g., y/100). This approach proves especially valuable when the response range significantly differs from that of Gradients and Hessians. Nevertheless, it is essential to carefully evaluate and apply both the built-in stabilization and response standardization techniques in consideration of the specific dataset at hand.
+Since LightGBMLSS is based on a one vs. all estimation strategy, where a separate tree is grown for each distributional parameter, it requires training [number of iterations] * [number of distributional parameters] trees. Hence, the runtime of LightGBMLSS is generally slightly higher for univariate distributions as compared to LightGBM, which requires training [number of iterations] trees only.
März, A. and Kneib, T.: (2022) Distributional Gradient Boosting Machines.
+März, Alexander (2019): XGBoostLSS - An extension of XGBoost to probabilistic forecasting.
+
+# LightGBMLSS - An extension of LightGBM to probabilistic modelling and prediction
+We introduce a comprehensive framework that models and predicts the full conditional distribution of a univariate target as a function of covariate. Choosing from a wide range of continuous, discrete, and mixed discrete-continuous distributions, modelling and predicting the entire conditional distribution greatly enhances the flexibility of LightGBM, as it allows to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived.
+
+## Features
+- Estimation of all distributional parameters. ' + escapeHtml(summary) +'
' + noResultsText + '
'); + } +} + +function doSearch () { + var query = document.getElementById('mkdocs-search-query').value; + if (query.length > min_search_length) { + if (!window.Worker) { + displayResults(search(query)); + } else { + searchWorker.postMessage({query: query}); + } + } else { + // Clear results for short queries + displayResults([]); + } +} + +function initSearch () { + var search_input = document.getElementById('mkdocs-search-query'); + if (search_input) { + search_input.addEventListener("keyup", doSearch); + } + var term = getSearchTermFromLocation(); + if (term) { + search_input.value = term; + doSearch(); + } +} + +function onWorkerMessage (e) { + if (e.data.allowSearch) { + initSearch(); + } else if (e.data.results) { + var results = e.data.results; + displayResults(results); + } else if (e.data.config) { + min_search_length = e.data.config.min_search_length-1; + } +} + +if (!window.Worker) { + console.log('Web Worker API not supported'); + // load index in main thread + $.getScript(joinUrl(base_url, "search/worker.js")).done(function () { + console.log('Loaded worker'); + init(); + window.postMessage = function (msg) { + onWorkerMessage({data: msg}); + }; + }).fail(function (jqxhr, settings, exception) { + console.error('Could not load worker.js'); + }); +} else { + // Wrap search in a web worker + var searchWorker = new Worker(joinUrl(base_url, "search/worker.js")); + searchWorker.postMessage({init: true}); + searchWorker.onmessage = onWorkerMessage; +} diff --git a/search/search_index.json b/search/search_index.json new file mode 100644 index 0000000..2b71285 --- /dev/null +++ b/search/search_index.json @@ -0,0 +1 @@ +{"config":{"indexing":"full","lang":["en"],"min_search_length":3,"prebuild_index":false,"separator":"[\\s\\-]+"},"docs":[{"location":"","text":"LightGBMLSS - An extension of LightGBM to probabilistic modelling and prediction We introduce a comprehensive framework that models and predicts the full conditional distribution of a univariate target as a function of covariate. Choosing from a wide range of continuous, discrete, and mixed discrete-continuous distributions, modelling and predicting the entire conditional distribution greatly enhances the flexibility of LightGBM, as it allows to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived. Features Estimation of all distributional parameters. Normalizing Flows allow modelling of complex and multi-modal distributions. Zero-Adjusted and Zero-Inflated Distributions for modelling excess of zeros in the data. Automatic derivation of Gradients and Hessian of all distributional parameters using PyTorch . Automated hyper-parameter search, including pruning, is done via Optuna . The output of LightGBMLSS is explained using SHapley Additive exPlanations . LightGBMLSS provides full compatibility with all the features and functionality of LightGBM. LightGBMLSS is available in Python. Installation To install LightGBMLSS, please first run pip install git+https://github.com/StatMixedML/LightGBMLSS.git Then, to install the shap-dependency, run pip install git+https://github.com/dsgibbons/shap.git Some Notes Stabilization Since LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to variability regarding the ranges, the estimation of Gradients and Hessians might become unstable so that LightGBMLSS might not converge or might converge very slowly. To mitigate these effects, we have implemented a stabilization of Gradients and Hessians. For improved convergence, an alternative approach is to standardize the (continuous) response variable, such as dividing it by 100 (e.g., y/100). This approach proves especially valuable when the response range significantly differs from that of Gradients and Hessians. Nevertheless, it is essential to carefully evaluate and apply both the built-in stabilization and response standardization techniques in consideration of the specific dataset at hand. Runtime Since LightGBMLSS is based on a one vs. all estimation strategy , where a separate tree is grown for each distributional parameter, it requires training [number of iterations] * [number of distributional parameters] trees. Hence, the runtime of LightGBMLSS is generally slightly higher for univariate distributions as compared to LightGBM, which requires training [number of iterations] trees only. Reference Paper M\u00e4rz, A. and Kneib, T.: (2022) Distributional Gradient Boosting Machines . M\u00e4rz, Alexander (2019): XGBoostLSS - An extension of XGBoost to probabilistic forecasting .","title":"Home"},{"location":"#lightgbmlss-an-extension-of-lightgbm-to-probabilistic-modelling-and-prediction","text":"We introduce a comprehensive framework that models and predicts the full conditional distribution of a univariate target as a function of covariate. Choosing from a wide range of continuous, discrete, and mixed discrete-continuous distributions, modelling and predicting the entire conditional distribution greatly enhances the flexibility of LightGBM, as it allows to create probabilistic forecasts from which prediction intervals and quantiles of interest can be derived.","title":"LightGBMLSS - An extension of LightGBM to probabilistic modelling and prediction"},{"location":"#features","text":"Estimation of all distributional parameters. Normalizing Flows allow modelling of complex and multi-modal distributions. Zero-Adjusted and Zero-Inflated Distributions for modelling excess of zeros in the data. Automatic derivation of Gradients and Hessian of all distributional parameters using PyTorch . Automated hyper-parameter search, including pruning, is done via Optuna . The output of LightGBMLSS is explained using SHapley Additive exPlanations . LightGBMLSS provides full compatibility with all the features and functionality of LightGBM. LightGBMLSS is available in Python.","title":"Features"},{"location":"#installation","text":"To install LightGBMLSS, please first run pip install git+https://github.com/StatMixedML/LightGBMLSS.git Then, to install the shap-dependency, run pip install git+https://github.com/dsgibbons/shap.git","title":"Installation"},{"location":"#some-notes","text":"","title":"Some Notes"},{"location":"#stabilization","text":"Since LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to variability regarding the ranges, the estimation of Gradients and Hessians might become unstable so that LightGBMLSS might not converge or might converge very slowly. To mitigate these effects, we have implemented a stabilization of Gradients and Hessians. For improved convergence, an alternative approach is to standardize the (continuous) response variable, such as dividing it by 100 (e.g., y/100). This approach proves especially valuable when the response range significantly differs from that of Gradients and Hessians. Nevertheless, it is essential to carefully evaluate and apply both the built-in stabilization and response standardization techniques in consideration of the specific dataset at hand.","title":"Stabilization"},{"location":"#runtime","text":"Since LightGBMLSS is based on a one vs. all estimation strategy , where a separate tree is grown for each distributional parameter, it requires training [number of iterations] * [number of distributional parameters] trees. Hence, the runtime of LightGBMLSS is generally slightly higher for univariate distributions as compared to LightGBM, which requires training [number of iterations] trees only.","title":"Runtime"},{"location":"#reference-paper","text":"M\u00e4rz, A. and Kneib, T.: (2022) Distributional Gradient Boosting Machines . M\u00e4rz, Alexander (2019): XGBoostLSS - An extension of XGBoost to probabilistic forecasting .","title":"Reference Paper"},{"location":"api/","text":"API references LightGBMLSS - An extension of LightGBM to probabilistic forecasting datasets LightGBMLSS - An extension of LightGBM to probabilistic forecasting data_loader load_simulated_gaussian_data () Returns train/test dataframe of a simulated example. Contains the following columns y int64: response x int64: x-feature X1:X10 int64: random noise features Source code in lightgbmlss/datasets/data_loader.py 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def load_simulated_gaussian_data (): \"\"\" Returns train/test dataframe of a simulated example. Contains the following columns: y int64: response x int64: x-feature X1:X10 int64: random noise features \"\"\" train_path = pkg_resources . resource_stream ( __name__ , \"gaussian_train_sim.csv\" ) train_df = pd . read_csv ( train_path ) test_path = pkg_resources . resource_stream ( __name__ , \"gaussian_test_sim.csv\" ) test_df = pd . read_csv ( test_path ) return train_df , test_df load_simulated_studentT_data () Returns train/test dataframe of a simulated example. Contains the following columns y int64: response x int64: x-feature X1:X10 int64: random noise features Source code in lightgbmlss/datasets/data_loader.py 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def load_simulated_studentT_data (): \"\"\" Returns train/test dataframe of a simulated example. Contains the following columns: y int64: response x int64: x-feature X1:X10 int64: random noise features \"\"\" train_path = pkg_resources . resource_stream ( __name__ , \"studentT_train_sim.csv\" ) train_df = pd . read_csv ( train_path ) test_path = pkg_resources . resource_stream ( __name__ , \"studentT_test_sim.csv\" ) test_df = pd . read_csv ( test_path ) return train_df , test_df distributions LightGBMLSS - An extension of LightGBM to probabilistic forecasting Beta Beta Bases: DistributionClass Beta distribution class. Distributional Parameters concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). Source https://pytorch.org/docs/stable/distributions.html#beta Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Beta.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Beta ( DistributionClass ): \"\"\" Beta distribution class. Distributional Parameters ------------------------- concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#beta Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Beta_Torch param_dict = { \"concentration1\" : response_fn , \"concentration0\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) Cauchy Cauchy Bases: DistributionClass Cauchy distribution class. Distributional Parameters loc: torch.Tensor Mode or median of the distribution. scale: torch.Tensor Half width at half maximum. Source https://pytorch.org/docs/stable/distributions.html#cauchy Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Cauchy.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Cauchy ( DistributionClass ): \"\"\" Cauchy distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mode or median of the distribution. scale: torch.Tensor Half width at half maximum. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#cauchy Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Cauchy_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) Expectile Expectile Bases: DistributionClass Expectile distribution class. Distributional Parameters expectile: List List of specified expectiles. Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". expectiles: List List of expectiles in increasing order. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. Source code in lightgbmlss/distributions/Expectile.py 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class Expectile ( DistributionClass ): \"\"\" Expectile distribution class. Distributional Parameters ------------------------- expectile: List List of specified expectiles. Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". expectiles: List List of expectiles in increasing order. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. \"\"\" def __init__ ( self , stabilization : str = \"None\" , expectiles : List = [ 0.1 , 0.5 , 0.9 ], penalize_crossing : bool = False , ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if not isinstance ( expectiles , list ): raise ValueError ( \"Expectiles must be a list.\" ) if not all ([ 0 < expectile < 1 for expectile in expectiles ]): raise ValueError ( \"Expectiles must be between 0 and 1.\" ) if not isinstance ( penalize_crossing , bool ): raise ValueError ( \"penalize_crossing must be a boolean. Please choose from True or False.\" ) # Set the parameters specific to the distribution distribution = Expectile_Torch torch . distributions . Distribution . set_default_validate_args ( False ) expectiles . sort () param_dict = {} for expectile in expectiles : key = f \"expectile_ { expectile } \" param_dict [ key ] = identity_fn # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = \"nll\" , tau = torch . tensor ( expectiles ), penalize_crossing = penalize_crossing ) Expectile_Torch Bases: Distribution PyTorch implementation of expectiles. Arguments expectiles : List[torch.Tensor] List of expectiles. penalize_crossing : bool Whether to include a penalty term to discourage crossing of expectiles. Source code in lightgbmlss/distributions/Expectile.py 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 class Expectile_Torch ( Distribution ): \"\"\" PyTorch implementation of expectiles. Arguments --------- expectiles : List[torch.Tensor] List of expectiles. penalize_crossing : bool Whether to include a penalty term to discourage crossing of expectiles. \"\"\" def __init__ ( self , expectiles : List [ torch . Tensor ], penalize_crossing : bool = False , ): super ( Expectile_Torch ) . __init__ () self . expectiles = expectiles self . penalize_crossing = penalize_crossing self . __class__ . __name__ = \"Expectile\" def log_prob ( self , value : torch . Tensor , tau : List [ torch . Tensor ]) -> torch . Tensor : \"\"\" Returns the log of the probability density function evaluated at `value`. Arguments --------- value : torch.Tensor Response for which log probability is to be calculated. tau : List[torch.Tensor] List of asymmetry parameters. Returns ------- torch.Tensor Log probability of `value`. \"\"\" value = value . reshape ( - 1 , 1 ) loss = torch . tensor ( 0.0 , dtype = torch . float32 ) penalty = torch . tensor ( 0.0 , dtype = torch . float32 ) # Calculate loss predt_expectiles = [] for expectile , tau_value in zip ( self . expectiles , tau ): weight = torch . where ( value - expectile >= 0 , tau_value , 1 - tau_value ) loss += torch . nansum ( weight * ( value - expectile ) ** 2 ) predt_expectiles . append ( expectile . reshape ( - 1 , 1 )) # Penalty term to discourage crossing of expectiles if self . penalize_crossing : predt_expectiles = torch . cat ( predt_expectiles , dim = 1 ) penalty = torch . mean ( ( ~ torch . all ( torch . diff ( predt_expectiles , dim = 1 ) > 0 , dim = 1 )) . float () ) loss = ( loss * ( 1 + penalty )) / len ( self . expectiles ) return - loss log_prob ( value , tau ) Returns the log of the probability density function evaluated at value . Arguments value : torch.Tensor Response for which log probability is to be calculated. tau : List[torch.Tensor] List of asymmetry parameters. Returns torch.Tensor Log probability of value . Source code in lightgbmlss/distributions/Expectile.py 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 def log_prob ( self , value : torch . Tensor , tau : List [ torch . Tensor ]) -> torch . Tensor : \"\"\" Returns the log of the probability density function evaluated at `value`. Arguments --------- value : torch.Tensor Response for which log probability is to be calculated. tau : List[torch.Tensor] List of asymmetry parameters. Returns ------- torch.Tensor Log probability of `value`. \"\"\" value = value . reshape ( - 1 , 1 ) loss = torch . tensor ( 0.0 , dtype = torch . float32 ) penalty = torch . tensor ( 0.0 , dtype = torch . float32 ) # Calculate loss predt_expectiles = [] for expectile , tau_value in zip ( self . expectiles , tau ): weight = torch . where ( value - expectile >= 0 , tau_value , 1 - tau_value ) loss += torch . nansum ( weight * ( value - expectile ) ** 2 ) predt_expectiles . append ( expectile . reshape ( - 1 , 1 )) # Penalty term to discourage crossing of expectiles if self . penalize_crossing : predt_expectiles = torch . cat ( predt_expectiles , dim = 1 ) penalty = torch . mean ( ( ~ torch . all ( torch . diff ( predt_expectiles , dim = 1 ) > 0 , dim = 1 )) . float () ) loss = ( loss * ( 1 + penalty )) / len ( self . expectiles ) return - loss expectile_norm ( tau = 0.5 , m = 0 , sd = 1 ) Calculates expectiles from Normal distribution for given tau values. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns np.ndarray Source code in lightgbmlss/distributions/Expectile.py 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 def expectile_norm ( tau : np . ndarray = 0.5 , m : np . ndarray = 0 , sd : np . ndarray = 1 ): \"\"\" Calculates expectiles from Normal distribution for given tau values. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments _________ tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns _______ np.ndarray \"\"\" tau [ tau > 1 or tau < 0 ] = np . nan zz = 0 * tau lower = np . array ( - 10 , dtype = \"float\" ) lower = np . repeat ( lower [ np . newaxis , ... ], len ( tau ), axis = 0 ) upper = np . array ( 10 , dtype = \"float\" ) upper = np . repeat ( upper [ np . newaxis , ... ], len ( tau ), axis = 0 ) diff = 1 index = 0 while ( diff > 1e-10 ) and ( index < 1000 ): root = expectile_pnorm ( zz ) - tau root [ np . isnan ( root )] = 0 lower [ root < 0 ] = zz [ root < 0 ] upper [ root > 0 ] = zz [ root > 0 ] zz = ( upper + lower ) / 2 diff = np . nanmax ( np . abs ( root )) index = index + 1 zz [ np . isnan ( tau )] = np . nan return zz * sd + m expectile_pnorm ( tau = 0.5 , m = 0 , sd = 1 ) Normal Expectile Distribution Function. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns tau : np.ndarray Expectiles from the Normal distribution. Source code in lightgbmlss/distributions/Expectile.py 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 def expectile_pnorm ( tau : np . ndarray = 0.5 , m : np . ndarray = 0 , sd : np . ndarray = 1 ): \"\"\" Normal Expectile Distribution Function. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments _________ tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns _______ tau : np.ndarray Expectiles from the Normal distribution. \"\"\" z = ( tau - m ) / sd p = norm . cdf ( z , loc = m , scale = sd ) d = norm . pdf ( z , loc = m , scale = sd ) u = - d - z * p tau = u / ( 2 * u + z ) return tau Gamma Gamma Bases: DistributionClass Gamma distribution class. Distributional Parameters concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) Source https://pytorch.org/docs/stable/distributions.html#gamma Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Gamma.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Gamma ( DistributionClass ): \"\"\" Gamma distribution class. Distributional Parameters -------------------------- concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) Source ------------------------- https://pytorch.org/docs/stable/distributions.html#gamma Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Gamma_Torch param_dict = { \"concentration\" : response_fn , \"rate\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) Gaussian Gaussian Bases: DistributionClass Gaussian distribution class. Distributional Parameters loc: torch.Tensor Mean of the distribution (often referred to as mu). scale: torch.Tensor Standard deviation of the distribution (often referred to as sigma). Source https://pytorch.org/docs/stable/distributions.html#normal Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Gaussian.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Gaussian ( DistributionClass ): \"\"\" Gaussian distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mean of the distribution (often referred to as mu). scale: torch.Tensor Standard deviation of the distribution (often referred to as sigma). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#normal Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Gaussian_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) Gumbel Gumbel Bases: DistributionClass Gumbel distribution class. Distributional Parameters loc: torch.Tensor Location parameter of the distribution. scale: torch.Tensor Scale parameter of the distribution. Source https://pytorch.org/docs/stable/distributions.html#gumbel Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Gumbel.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Gumbel ( DistributionClass ): \"\"\" Gumbel distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Location parameter of the distribution. scale: torch.Tensor Scale parameter of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#gumbel Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Gumbel_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) Laplace Laplace Bases: DistributionClass Laplace distribution class. Distributional Parameters loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution. Source https://pytorch.org/docs/stable/distributions.html#laplace Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Laplace.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Laplace ( DistributionClass ): \"\"\" Laplace distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#laplace Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Laplace_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) LogNormal LogNormal Bases: DistributionClass LogNormal distribution class. Distributional Parameters loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. Source https://pytorch.org/docs/stable/distributions.html#lognormal Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/LogNormal.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class LogNormal ( DistributionClass ): \"\"\" LogNormal distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#lognormal Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = LogNormal_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) NegativeBinomial NegativeBinomial Bases: DistributionClass NegativeBinomial distribution class. Distributional Parameters total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds for probabilities of success. Source https://pytorch.org/docs/stable/distributions.html#negativebinomial Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/NegativeBinomial.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 class NegativeBinomial ( DistributionClass ): \"\"\" NegativeBinomial distribution class. Distributional Parameters ------------------------- total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds for probabilities of success. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#negativebinomial Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn_total_count : str = \"relu\" , response_fn_probs : str = \"sigmoid\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions for total_count response_functions_total_count = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn_total_count in response_functions_total_count : response_fn_total_count = response_functions_total_count [ response_fn_total_count ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Specify Response Functions for probs response_functions_probs = { \"sigmoid\" : sigmoid_fn } if response_fn_probs in response_functions_probs : response_fn_probs = response_functions_probs [ response_fn_probs ] else : raise ValueError ( \"Invalid response function for probs. Please select 'sigmoid'.\" ) # Set the parameters specific to the distribution distribution = NegativeBinomial_Torch param_dict = { \"total_count\" : response_fn_total_count , \"probs\" : response_fn_probs } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) Poisson Poisson Bases: DistributionClass Poisson distribution class. Distributional Parameters rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda). Source https://pytorch.org/docs/stable/distributions.html#poisson Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/Poisson.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class Poisson ( DistributionClass ): \"\"\" Poisson distribution class. Distributional Parameters ------------------------- rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#poisson Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"relu\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Set the parameters specific to the distribution distribution = Poisson_Torch param_dict = { \"rate\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) SplineFlow SplineFlow Bases: NormalizingFlowClass Spline Flow class. The spline flow is a normalizing flow based on element-wise rational spline bijections of linear and quadratic order (Durkan et al., 2019; Dolatabadi et al., 2020). Rational splines are functions that are comprised of segments that are the ratio of two polynomials. Rational splines offer an excellent combination of functional flexibility whilst maintaining a numerically stable inverse. For more details, see: - Durkan, C., Bekasov, A., Murray, I. and Papamakarios, G. Neural Spline Flows. NeurIPS 2019. - Dolatabadi, H. M., Erfani, S. and Leckie, C., Invertible Generative Modeling using Linear Rational Splines. AISTATS 2020. Source https://docs.pyro.ai/en/stable/distributions.html#pyro.distributions.transforms.Spline Arguments target_support: str The target support. Options are - \"real\": [-inf, inf] - \"positive\": [0, inf] - \"positive_integer\": [0, 1, 2, 3, ...] - \"unit_interval\": [0, 1] count_bins: int The number of segments comprising the spline. bound: float The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. order: str The order of the spline. Options are \"linear\" or \"quadratic\". stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/SplineFlow.py 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 class SplineFlow ( NormalizingFlowClass ): \"\"\" Spline Flow class. The spline flow is a normalizing flow based on element-wise rational spline bijections of linear and quadratic order (Durkan et al., 2019; Dolatabadi et al., 2020). Rational splines are functions that are comprised of segments that are the ratio of two polynomials. Rational splines offer an excellent combination of functional flexibility whilst maintaining a numerically stable inverse. For more details, see: - Durkan, C., Bekasov, A., Murray, I. and Papamakarios, G. Neural Spline Flows. NeurIPS 2019. - Dolatabadi, H. M., Erfani, S. and Leckie, C., Invertible Generative Modeling using Linear Rational Splines. AISTATS 2020. Source --------- https://docs.pyro.ai/en/stable/distributions.html#pyro.distributions.transforms.Spline Arguments --------- target_support: str The target support. Options are - \"real\": [-inf, inf] - \"positive\": [0, inf] - \"positive_integer\": [0, 1, 2, 3, ...] - \"unit_interval\": [0, 1] count_bins: int The number of segments comprising the spline. bound: float The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. order: str The order of the spline. Options are \"linear\" or \"quadratic\". stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , target_support : str = \"real\" , count_bins : int = 8 , bound : float = 3.0 , order : str = \"linear\" , stabilization : str = \"None\" , loss_fn : str = \"nll\" ): # Specify Target Transform if not isinstance ( target_support , str ): raise ValueError ( \"target_support must be a string.\" ) transforms = { \"real\" : ( identity_transform , False ), \"positive\" : ( SoftplusTransform (), False ), \"positive_integer\" : ( SoftplusTransform (), True ), \"unit_interval\" : ( SigmoidTransform (), False ) } if target_support in transforms : target_transform , discrete = transforms [ target_support ] else : raise ValueError ( \"Invalid target_support. Options are 'real', 'positive', 'positive_integer', or 'unit_interval'.\" ) # Check if count_bins is valid if not isinstance ( count_bins , int ): raise ValueError ( \"count_bins must be an integer.\" ) if count_bins <= 0 : raise ValueError ( \"count_bins must be a positive integer > 0.\" ) # Check if bound is float if not isinstance ( bound , float ): raise ValueError ( \"bound must be a float.\" ) # Number of parameters if not isinstance ( order , str ): raise ValueError ( \"order must be a string.\" ) order_params = { \"quadratic\" : 2 * count_bins + ( count_bins - 1 ), \"linear\" : 3 * count_bins + ( count_bins - 1 ) } if order in order_params : n_params = order_params [ order ] else : raise ValueError ( \"Invalid order specification. Options are 'linear' or 'quadratic'.\" ) # Check if stabilization method is valid. if not isinstance ( stabilization , str ): raise ValueError ( \"stabilization must be a string.\" ) if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Options are 'None', 'MAD' or 'L2'.\" ) # Check if loss function is valid. if not isinstance ( loss_fn , str ): raise ValueError ( \"loss_fn must be a string.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss_fn. Options are 'nll' or 'crps'.\" ) # Specify parameter dictionary param_dict = { f \"param_ { i + 1 } \" : identity_fn for i in range ( n_params )} torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Normalizing Flow Class super () . __init__ ( base_dist = Normal , # Base distribution, currently only Normal is supported. flow_transform = Spline , count_bins = count_bins , bound = bound , order = order , n_dist_param = n_params , param_dict = param_dict , target_transform = target_transform , discrete = discrete , univariate = True , stabilization = stabilization , loss_fn = loss_fn ) StudentT StudentT Bases: DistributionClass Student-T Distribution Class Distributional Parameters df: torch.Tensor Degrees of freedom. loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution. Source https://pytorch.org/docs/stable/distributions.html#studentt Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/StudentT.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 class StudentT ( DistributionClass ): \"\"\" Student-T Distribution Class Distributional Parameters ------------------------- df: torch.Tensor Degrees of freedom. loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#studentt Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : ( exp_fn , exp_fn_df ), \"softplus\" : ( softplus_fn , softplus_fn_df ) } if response_fn in response_functions : response_fn , response_fn_df = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = StudentT_Torch param_dict = { \"df\" : response_fn_df , \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) Weibull Weibull Bases: DistributionClass Weibull distribution class. Distributional Parameters scale: torch.Tensor Scale parameter of distribution (lambda). concentration: torch.Tensor Concentration parameter of distribution (k/shape). Source https://pytorch.org/docs/stable/distributions.html#weibull Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Weibull.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Weibull ( DistributionClass ): \"\"\" Weibull distribution class. Distributional Parameters ------------------------- scale: torch.Tensor Scale parameter of distribution (lambda). concentration: torch.Tensor Concentration parameter of distribution (k/shape). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#weibull Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Weibull_Torch param_dict = { \"scale\" : response_fn , \"concentration\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) ZABeta ZABeta Bases: DistributionClass Zero-Adjusted Beta distribution class. The zero-adjusted Beta distribution is similar to the Beta distribution but allows zeros as y values. Distributional Parameters concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZABeta.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class ZABeta ( DistributionClass ): \"\"\" Zero-Adjusted Beta distribution class. The zero-adjusted Beta distribution is similar to the Beta distribution but allows zeros as y values. Distributional Parameters ------------------------- concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = ZeroAdjustedBeta_Torch param_dict = { \"concentration1\" : response_fn , \"concentration0\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) ZAGamma ZAGamma Bases: DistributionClass Zero-Adjusted Gamma distribution class. The zero-adjusted Gamma distribution is similar to the Gamma distribution but allows zeros as y values. Distributional Parameters concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZAGamma.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class ZAGamma ( DistributionClass ): \"\"\" Zero-Adjusted Gamma distribution class. The zero-adjusted Gamma distribution is similar to the Gamma distribution but allows zeros as y values. Distributional Parameters -------------------------- concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = ZeroAdjustedGamma_Torch param_dict = { \"concentration\" : response_fn , \"rate\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) ZALN ZALN Bases: DistributionClass Zero-Adjusted LogNormal distribution class. The zero-adjusted Log-Normal distribution is similar to the Log-Normal distribution but allows zeros as y values. Distributional Parameters loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZALN.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class ZALN ( DistributionClass ): \"\"\" Zero-Adjusted LogNormal distribution class. The zero-adjusted Log-Normal distribution is similar to the Log-Normal distribution but allows zeros as y values. Distributional Parameters ------------------------- loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = ZeroAdjustedLogNormal_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) ZINB ZINB Bases: DistributionClass Zero-Inflated Negative Binomial distribution class. Distributional Parameters total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZINB.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 class ZINB ( DistributionClass ): \"\"\" Zero-Inflated Negative Binomial distribution class. Distributional Parameters ------------------------- total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn_total_count : str = \"relu\" , response_fn_probs : str = \"sigmoid\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions for total_count response_functions_total_count = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn_total_count in response_functions_total_count : response_fn_total_count = response_functions_total_count [ response_fn_total_count ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Specify Response Functions for probs response_functions_probs = { \"sigmoid\" : sigmoid_fn } if response_fn_probs in response_functions_probs : response_fn_probs = response_functions_probs [ response_fn_probs ] else : raise ValueError ( \"Invalid response function for probs. Please select 'sigmoid'.\" ) # Set the parameters specific to the distribution distribution = ZeroInflatedNegativeBinomial_Torch param_dict = { \"total_count\" : response_fn_total_count , \"probs\" : response_fn_probs , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) ZIPoisson ZIPoisson Bases: DistributionClass Zero-Inflated Poisson distribution class. Distributional Parameters rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121 Parameters stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZIPoisson.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class ZIPoisson ( DistributionClass ): \"\"\" Zero-Inflated Poisson distribution class. Distributional Parameters ------------------------- rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"relu\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Set the parameters specific to the distribution distribution = ZeroInflatedPoisson_Torch param_dict = { \"rate\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn ) distribution_utils DistributionClass Generic class that contains general functions for univariate distributions. Arguments distribution: torch.distributions.Distribution PyTorch Distribution class. univariate: bool Whether the distribution is univariate or multivariate. discrete: bool Whether the support of the distribution is discrete or continuous. n_dist_param: int Number of distributional parameters. stabilization: str Stabilization method. param_dict: Dict[str, Any] Dictionary that maps distributional parameters to their response scale. distribution_arg_names: List List of distributional parameter names. loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. tau: List List of expectiles. Only used for Expectile distributon. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. Only used for Expectile distribution. Source code in lightgbmlss/distributions/distribution_utils.py 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 class DistributionClass : \"\"\" Generic class that contains general functions for univariate distributions. Arguments --------- distribution: torch.distributions.Distribution PyTorch Distribution class. univariate: bool Whether the distribution is univariate or multivariate. discrete: bool Whether the support of the distribution is discrete or continuous. n_dist_param: int Number of distributional parameters. stabilization: str Stabilization method. param_dict: Dict[str, Any] Dictionary that maps distributional parameters to their response scale. distribution_arg_names: List List of distributional parameter names. loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. tau: List List of expectiles. Only used for Expectile distributon. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. Only used for Expectile distribution. \"\"\" def __init__ ( self , distribution : torch . distributions . Distribution = None , univariate : bool = True , discrete : bool = False , n_dist_param : int = None , stabilization : str = \"None\" , param_dict : Dict [ str , Any ] = None , distribution_arg_names : List = None , loss_fn : str = \"nll\" , tau : Optional [ List [ torch . Tensor ]] = None , penalize_crossing : bool = False , ): self . distribution = distribution self . univariate = univariate self . discrete = discrete self . n_dist_param = n_dist_param self . stabilization = stabilization self . param_dict = param_dict self . distribution_arg_names = distribution_arg_names self . loss_fn = loss_fn self . tau = tau self . penalize_crossing = penalize_crossing def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of distributional parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.DMatrix Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values , requires_grad = True ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the negative log-likelihood. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. nll: float Negative log-likelihood. is_higher_better: bool Whether a higher value of the metric is better or not. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values , requires_grad = False ) return self . loss_fn , loss , is_higher_better def loss_fn_start_values ( self , params : torch . Tensor , target : torch . Tensor ) -> torch . Tensor : \"\"\" Function that calculates the loss for a given set of distributional parameters. Only used for calculating the loss for the start values. Parameter --------- params: torch.Tensor Distributional parameters. target: torch.Tensor Target values. Returns ------- loss: torch.Tensor Loss value. \"\"\" # Transform parameters to response scale params = [ response_fn ( params [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Replace NaNs and infinity values with 0.5 nan_inf_idx = torch . isnan ( torch . stack ( params )) | torch . isinf ( torch . stack ( params )) params = torch . where ( nan_inf_idx , torch . tensor ( 0.5 ), torch . stack ( params )) # Specify Distribution and Loss if self . tau is None : dist = self . distribution ( * params ) loss = - torch . nansum ( dist . log_prob ( target )) else : dist = self . distribution ( params , self . penalize_crossing ) loss = - torch . nansum ( dist . log_prob ( target , self . tau )) return loss def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates the starting values for each distributional parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each distributional parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Initialize parameters params = [ torch . tensor ( 0.5 , requires_grad = True ) for _ in range ( self . n_dist_param )] # Specify optimizer optimizer = LBFGS ( params , lr = 0.1 , max_iter = np . min ([ int ( max_iter / 4 ), 20 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 10 ) # Define closure def closure (): optimizer . zero_grad () loss = self . loss_fn_start_values ( params , target ) loss . backward () return loss # Optimize parameters loss_vals = [] for epoch in range ( max_iter ): loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = np . array ([ params [ i ] . detach () for i in range ( self . n_dist_param )]) # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each distributional parameter. requires_grad: bool Whether to add to the computational graph or not. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = [ torch . tensor ( predt [:, i ] . reshape ( - 1 , 1 ), requires_grad = requires_grad ) for i in range ( self . n_dist_param ) ] # Predicted Parameters transformed to response scale predt_transformed = [ response_fn ( predt [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Specify Distribution and Loss if self . tau is None : dist_kwargs = dict ( zip ( self . distribution_arg_names , predt_transformed )) dist_fit = self . distribution ( ** dist_kwargs ) if self . loss_fn == \"nll\" : loss = - torch . nansum ( dist_fit . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = dist_fit . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) else : dist_fit = self . distribution ( predt_transformed , self . penalize_crossing ) loss = - torch . nansum ( dist_fit . log_prob ( target , self . tau )) return predt , loss def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) if self . tau is None : pred_params = torch . tensor ( predt_params . values ) dist_kwargs = { arg_name : param for arg_name , param in zip ( self . distribution_arg_names , pred_params . T )} dist_pred = self . distribution ( ** dist_kwargs ) dist_samples = dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T dist_samples = pd . DataFrame ( dist_samples ) dist_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( dist_samples . shape [ 1 ])] else : dist_samples = None if self . discrete : dist_samples = dist_samples . astype ( int ) return dist_samples def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. data : pd.DataFrame Data to predict from. start_values : np.ndarray. Starting values for each distributional parameter. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. # Hence, it needs to be added manually with the corresponding transform for each distributional parameter. dist_params_predt = np . concatenate ( [ response_fun ( predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( self . param_dict . items ()) ], axis = 1 , ) dist_params_predt = pd . DataFrame ( dist_params_predt ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"expectiles\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # # Approximation of Hessian # step_size = 1e-6 # predt_upper = [ # response_fn(predt[i] + step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_upper = dict(zip(self.distribution_arg_names, predt_upper)) # dist_fit_upper = self.distribution(**dist_kwargs_upper) # dist_samples_upper = dist_fit_upper.rsample((30,)).squeeze(-1) # loss_upper = torch.nansum(self.crps_score(self.target, dist_samples_upper)) # # predt_lower = [ # response_fn(predt[i] - step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_lower = dict(zip(self.distribution_arg_names, predt_lower)) # dist_fit_lower = self.distribution(**dist_kwargs_lower) # dist_samples_lower = dist_fit_lower.rsample((30,)).squeeze(-1) # loss_lower = torch.nansum(self.crps_score(self.target, dist_samples_lower)) # # grad_upper = autograd(loss_upper, inputs=predt_upper) # grad_lower = autograd(loss_lower, inputs=predt_lower) # hess = [(grad_upper[i] - grad_lower[i]) / (2 * step_size) for i in range(len(grad))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. As LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source: https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Parameters ---------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns ------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Parameters ---------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns ------- crps: torch.Tensor CRPS score. References ---------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source ------ https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps def dist_select ( self , target : np . ndarray , candidate_distributions : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable distribution among the candidate_distributions for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_distributions: List List of candidate distributions. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples to draw from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted candidate distributions. \"\"\" dist_list = [] total_iterations = len ( candidate_distributions ) with tqdm ( total = total_iterations , desc = \"Fitting candidate distributions\" ) as pbar : for i in range ( len ( candidate_distributions )): dist_name = candidate_distributions [ i ] . __name__ . split ( \".\" )[ 2 ] pbar . set_description ( f \"Fitting { dist_name } distribution\" ) dist_sel = getattr ( candidate_distributions [ i ], dist_name )() try : loss , params = dist_sel . calculate_start_values ( target = target . reshape ( - 1 , 1 ), max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { self . loss_fn : loss . reshape ( - 1 ,), \"distribution\" : str ( dist_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { dist_name } distribution: { str ( e ) } \" ) fit_df = pd . DataFrame ( { self . loss_fn : np . nan , \"distribution\" : str ( dist_name ), \"params\" : [ np . nan ] * self . n_dist_param } ) dist_list . append ( fit_df ) fit_df = pd . concat ( dist_list ) . sort_values ( by = self . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ self . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate distributions completed\" ) if plot : # Select best distribution best_dist = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for dist in candidate_distributions : if dist . __name__ . split ( \".\" )[ 2 ] == best_dist [ \"distribution\" ] . values [ 0 ]: best_dist_sel = dist break best_dist_sel = getattr ( best_dist_sel , best_dist [ \"distribution\" ] . values [ 0 ])() params = torch . tensor ( best_dist [ \"params\" ][ 0 ]) . reshape ( - 1 , best_dist_sel . n_dist_param ) # Transform parameters to the response scale and draw samples fitted_params = np . concatenate ( [ response_fun ( params [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( best_dist_sel . param_dict . items ()) ], axis = 1 , ) fitted_params = pd . DataFrame ( fitted_params , columns = best_dist_sel . param_dict . keys ()) fitted_params . columns = best_dist_sel . param_dict . keys () dist_samples = best_dist_sel . draw_samples ( fitted_params , n_samples = n_samples , seed = 123 ) . values # Plot actual and fitted distribution plot_df_actual = pd . DataFrame ({ \"y\" : target . reshape ( - 1 ,), \"type\" : \"Actual\" }) plot_df_fitted = pd . DataFrame ({ \"y\" : dist_samples . reshape ( - 1 ,), \"type\" : f \"Best-Fit: { best_dist [ 'distribution' ] . values [ 0 ] } \" }) plot_df = pd . concat ([ plot_df_actual , plot_df_fitted ]) print ( ggplot ( plot_df , aes ( x = \"y\" , color = \"type\" )) + geom_density ( alpha = 0.5 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df calculate_start_values ( target , max_iter = 50 ) Function that calculates the starting values for each distributional parameter. Arguments target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns loss: float Loss value. start_values: np.ndarray Starting values for each distributional parameter. Source code in lightgbmlss/distributions/distribution_utils.py 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates the starting values for each distributional parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each distributional parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Initialize parameters params = [ torch . tensor ( 0.5 , requires_grad = True ) for _ in range ( self . n_dist_param )] # Specify optimizer optimizer = LBFGS ( params , lr = 0.1 , max_iter = np . min ([ int ( max_iter / 4 ), 20 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 10 ) # Define closure def closure (): optimizer . zero_grad () loss = self . loss_fn_start_values ( params , target ) loss . backward () return loss # Optimize parameters loss_vals = [] for epoch in range ( max_iter ): loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = np . array ([ params [ i ] . detach () for i in range ( self . n_dist_param )]) # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values compute_gradients_and_hessians ( loss , predt , weights ) Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. Source code in lightgbmlss/distributions/distribution_utils.py 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # # Approximation of Hessian # step_size = 1e-6 # predt_upper = [ # response_fn(predt[i] + step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_upper = dict(zip(self.distribution_arg_names, predt_upper)) # dist_fit_upper = self.distribution(**dist_kwargs_upper) # dist_samples_upper = dist_fit_upper.rsample((30,)).squeeze(-1) # loss_upper = torch.nansum(self.crps_score(self.target, dist_samples_upper)) # # predt_lower = [ # response_fn(predt[i] - step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_lower = dict(zip(self.distribution_arg_names, predt_lower)) # dist_fit_lower = self.distribution(**dist_kwargs_lower) # dist_samples_lower = dist_fit_lower.rsample((30,)).squeeze(-1) # loss_lower = torch.nansum(self.crps_score(self.target, dist_samples_lower)) # # grad_upper = autograd(loss_upper, inputs=predt_upper) # grad_lower = autograd(loss_lower, inputs=predt_lower) # hess = [(grad_upper[i] - grad_lower[i]) / (2 * step_size) for i in range(len(grad))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess crps_score ( y , yhat_dist ) Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Parameters y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns crps: torch.Tensor CRPS score. References Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 Source code in lightgbmlss/distributions/distribution_utils.py 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Parameters ---------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns ------- crps: torch.Tensor CRPS score. References ---------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source ------ https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps dist_select ( target , candidate_distributions , max_iter = 100 , n_samples = 1000 , plot = False , figure_size = ( 10 , 5 )) Function that selects the most suitable distribution among the candidate_distributions for the target variable, based on the NegLogLikelihood (lower is better). Parameters target: np.ndarray Response variable. candidate_distributions: List List of candidate distributions. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples to draw from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns fit_df: pd.DataFrame Dataframe with the loss values of the fitted candidate distributions. Source code in lightgbmlss/distributions/distribution_utils.py 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 def dist_select ( self , target : np . ndarray , candidate_distributions : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable distribution among the candidate_distributions for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_distributions: List List of candidate distributions. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples to draw from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted candidate distributions. \"\"\" dist_list = [] total_iterations = len ( candidate_distributions ) with tqdm ( total = total_iterations , desc = \"Fitting candidate distributions\" ) as pbar : for i in range ( len ( candidate_distributions )): dist_name = candidate_distributions [ i ] . __name__ . split ( \".\" )[ 2 ] pbar . set_description ( f \"Fitting { dist_name } distribution\" ) dist_sel = getattr ( candidate_distributions [ i ], dist_name )() try : loss , params = dist_sel . calculate_start_values ( target = target . reshape ( - 1 , 1 ), max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { self . loss_fn : loss . reshape ( - 1 ,), \"distribution\" : str ( dist_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { dist_name } distribution: { str ( e ) } \" ) fit_df = pd . DataFrame ( { self . loss_fn : np . nan , \"distribution\" : str ( dist_name ), \"params\" : [ np . nan ] * self . n_dist_param } ) dist_list . append ( fit_df ) fit_df = pd . concat ( dist_list ) . sort_values ( by = self . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ self . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate distributions completed\" ) if plot : # Select best distribution best_dist = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for dist in candidate_distributions : if dist . __name__ . split ( \".\" )[ 2 ] == best_dist [ \"distribution\" ] . values [ 0 ]: best_dist_sel = dist break best_dist_sel = getattr ( best_dist_sel , best_dist [ \"distribution\" ] . values [ 0 ])() params = torch . tensor ( best_dist [ \"params\" ][ 0 ]) . reshape ( - 1 , best_dist_sel . n_dist_param ) # Transform parameters to the response scale and draw samples fitted_params = np . concatenate ( [ response_fun ( params [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( best_dist_sel . param_dict . items ()) ], axis = 1 , ) fitted_params = pd . DataFrame ( fitted_params , columns = best_dist_sel . param_dict . keys ()) fitted_params . columns = best_dist_sel . param_dict . keys () dist_samples = best_dist_sel . draw_samples ( fitted_params , n_samples = n_samples , seed = 123 ) . values # Plot actual and fitted distribution plot_df_actual = pd . DataFrame ({ \"y\" : target . reshape ( - 1 ,), \"type\" : \"Actual\" }) plot_df_fitted = pd . DataFrame ({ \"y\" : dist_samples . reshape ( - 1 ,), \"type\" : f \"Best-Fit: { best_dist [ 'distribution' ] . values [ 0 ] } \" }) plot_df = pd . concat ([ plot_df_actual , plot_df_fitted ]) print ( ggplot ( plot_df , aes ( x = \"y\" , color = \"type\" )) + geom_density ( alpha = 0.5 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df draw_samples ( predt_params , n_samples = 1000 , seed = 123 ) Function that draws n_samples from a predicted distribution. Arguments predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. Source code in lightgbmlss/distributions/distribution_utils.py 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) if self . tau is None : pred_params = torch . tensor ( predt_params . values ) dist_kwargs = { arg_name : param for arg_name , param in zip ( self . distribution_arg_names , pred_params . T )} dist_pred = self . distribution ( ** dist_kwargs ) dist_samples = dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T dist_samples = pd . DataFrame ( dist_samples ) dist_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( dist_samples . shape [ 1 ])] else : dist_samples = None if self . discrete : dist_samples = dist_samples . astype ( int ) return dist_samples get_params_loss ( predt , target , start_values , requires_grad = False ) Function that returns the predicted parameters and the loss. Arguments predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each distributional parameter. requires_grad: bool Whether to add to the computational graph or not. Returns predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. Source code in lightgbmlss/distributions/distribution_utils.py 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each distributional parameter. requires_grad: bool Whether to add to the computational graph or not. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = [ torch . tensor ( predt [:, i ] . reshape ( - 1 , 1 ), requires_grad = requires_grad ) for i in range ( self . n_dist_param ) ] # Predicted Parameters transformed to response scale predt_transformed = [ response_fn ( predt [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Specify Distribution and Loss if self . tau is None : dist_kwargs = dict ( zip ( self . distribution_arg_names , predt_transformed )) dist_fit = self . distribution ( ** dist_kwargs ) if self . loss_fn == \"nll\" : loss = - torch . nansum ( dist_fit . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = dist_fit . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) else : dist_fit = self . distribution ( predt_transformed , self . penalize_crossing ) loss = - torch . nansum ( dist_fit . log_prob ( target , self . tau )) return predt , loss loss_fn_start_values ( params , target ) Function that calculates the loss for a given set of distributional parameters. Only used for calculating the loss for the start values. Parameter params: torch.Tensor Distributional parameters. target: torch.Tensor Target values. Returns loss: torch.Tensor Loss value. Source code in lightgbmlss/distributions/distribution_utils.py 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 def loss_fn_start_values ( self , params : torch . Tensor , target : torch . Tensor ) -> torch . Tensor : \"\"\" Function that calculates the loss for a given set of distributional parameters. Only used for calculating the loss for the start values. Parameter --------- params: torch.Tensor Distributional parameters. target: torch.Tensor Target values. Returns ------- loss: torch.Tensor Loss value. \"\"\" # Transform parameters to response scale params = [ response_fn ( params [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Replace NaNs and infinity values with 0.5 nan_inf_idx = torch . isnan ( torch . stack ( params )) | torch . isinf ( torch . stack ( params )) params = torch . where ( nan_inf_idx , torch . tensor ( 0.5 ), torch . stack ( params )) # Specify Distribution and Loss if self . tau is None : dist = self . distribution ( * params ) loss = - torch . nansum ( dist . log_prob ( target )) else : dist = self . distribution ( params , self . penalize_crossing ) loss = - torch . nansum ( dist . log_prob ( target , self . tau )) return loss metric_fn ( predt , data ) Function that evaluates the predictions using the negative log-likelihood. Arguments predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns name: str Name of the evaluation metric. nll: float Negative log-likelihood. is_higher_better: bool Whether a higher value of the metric is better or not. Source code in lightgbmlss/distributions/distribution_utils.py 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the negative log-likelihood. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. nll: float Negative log-likelihood. is_higher_better: bool Whether a higher value of the metric is better or not. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values , requires_grad = False ) return self . loss_fn , loss , is_higher_better objective_fn ( predt , data ) Function to estimate gradients and hessians of distributional parameters. Arguments predt: np.ndarray Predicted values. data: lgb.DMatrix Data used for training. Returns grad: np.ndarray Gradient. hess: np.ndarray Hessian. Source code in lightgbmlss/distributions/distribution_utils.py 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of distributional parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.DMatrix Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values , requires_grad = True ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess predict_dist ( booster , data , start_values , pred_type = 'parameters' , n_samples = 1000 , quantiles = [ 0.1 , 0.5 , 0.9 ], seed = 123 ) Function that predicts from the trained model. Arguments booster : lgb.Booster Trained model. data : pd.DataFrame Data to predict from. start_values : np.ndarray. Starting values for each distributional parameter. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns pred : pd.DataFrame Predictions. Source code in lightgbmlss/distributions/distribution_utils.py 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. data : pd.DataFrame Data to predict from. start_values : np.ndarray. Starting values for each distributional parameter. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. # Hence, it needs to be added manually with the corresponding transform for each distributional parameter. dist_params_predt = np . concatenate ( [ response_fun ( predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( self . param_dict . items ()) ], axis = 1 , ) dist_params_predt = pd . DataFrame ( dist_params_predt ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"expectiles\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df stabilize_derivative ( input_der , type = 'MAD' ) Function that stabilizes Gradients and Hessians. As LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source: https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Parameters input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns stab_der : torch.Tensor Stabilized Gradient or Hessian. Source code in lightgbmlss/distributions/distribution_utils.py 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. As LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source: https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Parameters ---------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns ------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der flow_utils NormalizingFlowClass Generic class that contains general functions for normalizing flows. Arguments base_dist: torch.distributions.Distribution PyTorch Distribution class. Currently only Normal is supported. flow_transform: Transform Specify the normalizing flow transform. count_bins: Optional[int] The number of segments comprising the spline. Only used if flow_transform is Spline. bound: Optional[float] The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. Only used if flow_transform is Spline. order: Optional[str] The order of the spline. Options are \"linear\" or \"quadratic\". Only used if flow_transform is Spline. n_dist_param: int Number of parameters. param_dict: Dict[str, Any] Dictionary that maps parameters to their response scale. target_transform: Transform Specify the target transform. discrete: bool Whether the target is discrete or not. univariate: bool Whether the distribution is univariate or multivariate. stabilization: str Stabilization method. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/flow_utils.py 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 class NormalizingFlowClass : \"\"\" Generic class that contains general functions for normalizing flows. Arguments --------- base_dist: torch.distributions.Distribution PyTorch Distribution class. Currently only Normal is supported. flow_transform: Transform Specify the normalizing flow transform. count_bins: Optional[int] The number of segments comprising the spline. Only used if flow_transform is Spline. bound: Optional[float] The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. Only used if flow_transform is Spline. order: Optional[str] The order of the spline. Options are \"linear\" or \"quadratic\". Only used if flow_transform is Spline. n_dist_param: int Number of parameters. param_dict: Dict[str, Any] Dictionary that maps parameters to their response scale. target_transform: Transform Specify the target transform. discrete: bool Whether the target is discrete or not. univariate: bool Whether the distribution is univariate or multivariate. stabilization: str Stabilization method. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , base_dist : torch . distributions . Distribution = None , flow_transform : Transform = None , count_bins : Optional [ int ] = 8 , bound : Optional [ float ] = 3.0 , order : Optional [ str ] = \"quadratic\" , n_dist_param : int = None , param_dict : Dict [ str , Any ] = None , target_transform : Transform = None , discrete : bool = False , univariate : bool = True , stabilization : str = \"None\" , loss_fn : str = \"nll\" , ): self . base_dist = base_dist self . flow_transform = flow_transform self . count_bins = count_bins self . bound = bound self . order = order self . n_dist_param = n_dist_param self . param_dict = param_dict self . target_transform = target_transform self . discrete = discrete self . univariate = univariate self . stabilization = stabilization self . loss_fn = loss_fn def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of normalizing flow parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the specified loss function. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. loss: float Loss value. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values ) return self . loss_fn , loss . detach (), is_higher_better def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates starting values for each parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Create Normalizing Flow flow_dist = self . create_spline_flow ( input_dim = 1 ) # Specify optimizer optimizer = LBFGS ( flow_dist . transforms [ 0 ] . parameters (), lr = 0.3 , max_iter = np . min ([ int ( max_iter / 4 ), 50 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 5 ) # Define closure def closure (): optimizer . zero_grad () loss = - torch . nansum ( flow_dist . log_prob ( target )) loss . backward () flow_dist . clear_cache () return loss # Optimize parameters loss_vals = [] tolerance = 1e-5 # Tolerance level for loss change patience = 5 # Patience level for loss change best_loss = float ( \"inf\" ) epochs_without_change = 0 for epoch in range ( max_iter ): optimizer . zero_grad () loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Stopping criterion (no improvement in loss) if loss . item () < best_loss - tolerance : best_loss = loss . item () epochs_without_change = 0 else : epochs_without_change += 1 if epochs_without_change >= patience : break # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = list ( flow_dist . transforms [ 0 ] . parameters ()) start_values = torch . cat ([ param . view ( - 1 ) for param in start_values ]) . detach () . numpy () # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each parameter. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Reshape Target target = target . view ( - 1 ) # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = torch . tensor ( predt , dtype = torch . float32 ) # Specify Normalizing Flow flow_dist = self . create_spline_flow ( target . shape [ 0 ]) # Replace parameters with estimated ones params , flow_dist = self . replace_parameters ( predt , flow_dist ) # Calculate loss if self . loss_fn == \"nll\" : loss = - torch . nansum ( flow_dist . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = flow_dist . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) return params , loss def create_spline_flow ( self , input_dim : int = None , ) -> Transform : \"\"\" Function that constructs a Normalizing Flow. Arguments --------- input_dim: int Input dimension. Returns ------- spline_flow: Transform Normalizing Flow. \"\"\" # Create flow distribution (currently only Normal) loc , scale = torch . zeros ( input_dim ), torch . ones ( input_dim ) flow_dist = self . base_dist ( loc , scale ) # Create Spline Transform torch . manual_seed ( 123 ) spline_transform = self . flow_transform ( input_dim , count_bins = self . count_bins , bound = self . bound , order = self . order ) # Create Normalizing Flow spline_flow = TransformedDistribution ( flow_dist , [ spline_transform , self . target_transform ]) return spline_flow def replace_parameters ( self , params : torch . Tensor , flow_dist : Transform , ) -> Tuple [ List , Transform ]: \"\"\" Replace parameters with estimated ones. Arguments --------- params: torch.Tensor Estimated parameters. flow_dist: Transform Normalizing Flow. Returns ------- params_list: List List of estimated parameters. flow_dist: Transform Normalizing Flow with estimated parameters. \"\"\" # Split parameters into list if self . order == \"quadratic\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 ], dim = 1 ) elif self . order == \"linear\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 , self . count_bins ], dim = 1 ) # Replace parameters for param , new_value in zip ( flow_dist . transforms [ 0 ] . parameters (), params_list ): param . data = new_value # Get parameters (including require_grad=True) params_list = list ( flow_dist . transforms [ 0 ] . parameters ()) return params_list , flow_dist def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) # Specify Normalizing Flow pred_params = torch . tensor ( predt_params . values ) flow_dist_pred = self . create_spline_flow ( pred_params . shape [ 0 ]) # Replace parameters with estimated ones _ , flow_dist_pred = self . replace_parameters ( pred_params , flow_dist_pred ) # Draw samples flow_samples = pd . DataFrame ( flow_dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) flow_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( flow_samples . shape [ 1 ])] if self . discrete : flow_samples = flow_samples . astype ( int ) return flow_samples def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. start_values : np.ndarray Starting values for each distributional parameter. data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" # Predict raw scores predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. Hence, it needs to be # added manually. dist_params_predt = pd . DataFrame ( np . concatenate ( [ predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 ) for i in range ( self . n_dist_param )], axis = 1 ) ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. Since parameters are estimated by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source --------- https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Arguments --------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns --------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Arguments --------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns --------- crps: torch.Tensor CRPS score. References --------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source --------- https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps def flow_select ( self , target : np . ndarray , candidate_flows : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable normalizing flow specification among the candidate_flow for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_flows: List List of candidate normalizing flow specifications. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples drawn from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted normalizing flow. \"\"\" flow_list = [] total_iterations = len ( candidate_flows ) with tqdm ( total = total_iterations , desc = \"Fitting candidate normalizing flows\" ) as pbar : for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec pbar . set_description ( f \"Fitting { flow_name } \" ) flow_sel = flow try : loss , params = flow_sel . calculate_start_values ( target = target , max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { flow_sel . loss_fn : loss . reshape ( - 1 , ), \"NormFlow\" : str ( flow_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { flow_sel } NormFlow: { str ( e ) } \" ) fit_df = pd . DataFrame ( { flow_sel . loss_fn : np . nan , \"NormFlow\" : str ( flow_sel ), \"params\" : [ np . nan ] * flow_sel . n_dist_param } ) flow_list . append ( fit_df ) fit_df = pd . concat ( flow_list ) . sort_values ( by = flow_sel . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ flow_sel . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate normalizing flows completed\" ) if plot : # Select normalizing flow with the lowest loss best_flow = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec if flow_name == best_flow [ \"NormFlow\" ] . values [ 0 ]: best_flow_sel = flow break # Draw samples from distribution flow_params = torch . tensor ( best_flow [ \"params\" ][ 0 ]) . reshape ( 1 , - 1 ) flow_dist_sel = best_flow_sel . create_spline_flow ( input_dim = 1 ) _ , flow_dist_sel = best_flow_sel . replace_parameters ( flow_params , flow_dist_sel ) flow_samples = pd . DataFrame ( flow_dist_sel . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) # Plot actual and fitted distribution flow_samples [ \"type\" ] = f \"Best-Fit: { best_flow [ 'NormFlow' ] . values [ 0 ] } \" df_actual = pd . DataFrame ( target ) df_actual [ \"type\" ] = \"Data\" plot_df = pd . concat ([ df_actual , flow_samples ]) . rename ( columns = { 0 : \"variable\" }) print ( ggplot ( plot_df , aes ( x = \"variable\" , color = \"type\" )) + geom_density ( size = 1.1 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" , x = \"\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df calculate_start_values ( target , max_iter = 50 ) Function that calculates starting values for each parameter. Arguments target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns loss: float Loss value. start_values: np.ndarray Starting values for each parameter. Source code in lightgbmlss/distributions/flow_utils.py 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates starting values for each parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Create Normalizing Flow flow_dist = self . create_spline_flow ( input_dim = 1 ) # Specify optimizer optimizer = LBFGS ( flow_dist . transforms [ 0 ] . parameters (), lr = 0.3 , max_iter = np . min ([ int ( max_iter / 4 ), 50 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 5 ) # Define closure def closure (): optimizer . zero_grad () loss = - torch . nansum ( flow_dist . log_prob ( target )) loss . backward () flow_dist . clear_cache () return loss # Optimize parameters loss_vals = [] tolerance = 1e-5 # Tolerance level for loss change patience = 5 # Patience level for loss change best_loss = float ( \"inf\" ) epochs_without_change = 0 for epoch in range ( max_iter ): optimizer . zero_grad () loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Stopping criterion (no improvement in loss) if loss . item () < best_loss - tolerance : best_loss = loss . item () epochs_without_change = 0 else : epochs_without_change += 1 if epochs_without_change >= patience : break # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = list ( flow_dist . transforms [ 0 ] . parameters ()) start_values = torch . cat ([ param . view ( - 1 ) for param in start_values ]) . detach () . numpy () # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values compute_gradients_and_hessians ( loss , predt , weights ) Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. Source code in lightgbmlss/distributions/flow_utils.py 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess create_spline_flow ( input_dim = None ) Function that constructs a Normalizing Flow. Arguments input_dim: int Input dimension. Returns spline_flow: Transform Normalizing Flow. Source code in lightgbmlss/distributions/flow_utils.py 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 def create_spline_flow ( self , input_dim : int = None , ) -> Transform : \"\"\" Function that constructs a Normalizing Flow. Arguments --------- input_dim: int Input dimension. Returns ------- spline_flow: Transform Normalizing Flow. \"\"\" # Create flow distribution (currently only Normal) loc , scale = torch . zeros ( input_dim ), torch . ones ( input_dim ) flow_dist = self . base_dist ( loc , scale ) # Create Spline Transform torch . manual_seed ( 123 ) spline_transform = self . flow_transform ( input_dim , count_bins = self . count_bins , bound = self . bound , order = self . order ) # Create Normalizing Flow spline_flow = TransformedDistribution ( flow_dist , [ spline_transform , self . target_transform ]) return spline_flow crps_score ( y , yhat_dist ) Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Arguments y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns crps: torch.Tensor CRPS score. References Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 Source code in lightgbmlss/distributions/flow_utils.py 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Arguments --------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns --------- crps: torch.Tensor CRPS score. References --------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source --------- https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps draw_samples ( predt_params , n_samples = 1000 , seed = 123 ) Function that draws n_samples from a predicted distribution. Arguments predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. Source code in lightgbmlss/distributions/flow_utils.py 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) # Specify Normalizing Flow pred_params = torch . tensor ( predt_params . values ) flow_dist_pred = self . create_spline_flow ( pred_params . shape [ 0 ]) # Replace parameters with estimated ones _ , flow_dist_pred = self . replace_parameters ( pred_params , flow_dist_pred ) # Draw samples flow_samples = pd . DataFrame ( flow_dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) flow_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( flow_samples . shape [ 1 ])] if self . discrete : flow_samples = flow_samples . astype ( int ) return flow_samples flow_select ( target , candidate_flows , max_iter = 100 , n_samples = 1000 , plot = False , figure_size = ( 10 , 5 )) Function that selects the most suitable normalizing flow specification among the candidate_flow for the target variable, based on the NegLogLikelihood (lower is better). Parameters target: np.ndarray Response variable. candidate_flows: List List of candidate normalizing flow specifications. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples drawn from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns fit_df: pd.DataFrame Dataframe with the loss values of the fitted normalizing flow. Source code in lightgbmlss/distributions/flow_utils.py 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 def flow_select ( self , target : np . ndarray , candidate_flows : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable normalizing flow specification among the candidate_flow for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_flows: List List of candidate normalizing flow specifications. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples drawn from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted normalizing flow. \"\"\" flow_list = [] total_iterations = len ( candidate_flows ) with tqdm ( total = total_iterations , desc = \"Fitting candidate normalizing flows\" ) as pbar : for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec pbar . set_description ( f \"Fitting { flow_name } \" ) flow_sel = flow try : loss , params = flow_sel . calculate_start_values ( target = target , max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { flow_sel . loss_fn : loss . reshape ( - 1 , ), \"NormFlow\" : str ( flow_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { flow_sel } NormFlow: { str ( e ) } \" ) fit_df = pd . DataFrame ( { flow_sel . loss_fn : np . nan , \"NormFlow\" : str ( flow_sel ), \"params\" : [ np . nan ] * flow_sel . n_dist_param } ) flow_list . append ( fit_df ) fit_df = pd . concat ( flow_list ) . sort_values ( by = flow_sel . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ flow_sel . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate normalizing flows completed\" ) if plot : # Select normalizing flow with the lowest loss best_flow = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec if flow_name == best_flow [ \"NormFlow\" ] . values [ 0 ]: best_flow_sel = flow break # Draw samples from distribution flow_params = torch . tensor ( best_flow [ \"params\" ][ 0 ]) . reshape ( 1 , - 1 ) flow_dist_sel = best_flow_sel . create_spline_flow ( input_dim = 1 ) _ , flow_dist_sel = best_flow_sel . replace_parameters ( flow_params , flow_dist_sel ) flow_samples = pd . DataFrame ( flow_dist_sel . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) # Plot actual and fitted distribution flow_samples [ \"type\" ] = f \"Best-Fit: { best_flow [ 'NormFlow' ] . values [ 0 ] } \" df_actual = pd . DataFrame ( target ) df_actual [ \"type\" ] = \"Data\" plot_df = pd . concat ([ df_actual , flow_samples ]) . rename ( columns = { 0 : \"variable\" }) print ( ggplot ( plot_df , aes ( x = \"variable\" , color = \"type\" )) + geom_density ( size = 1.1 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" , x = \"\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df get_params_loss ( predt , target , start_values , requires_grad = False ) Function that returns the predicted parameters and the loss. Arguments predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each parameter. Returns predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. Source code in lightgbmlss/distributions/flow_utils.py 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each parameter. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Reshape Target target = target . view ( - 1 ) # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = torch . tensor ( predt , dtype = torch . float32 ) # Specify Normalizing Flow flow_dist = self . create_spline_flow ( target . shape [ 0 ]) # Replace parameters with estimated ones params , flow_dist = self . replace_parameters ( predt , flow_dist ) # Calculate loss if self . loss_fn == \"nll\" : loss = - torch . nansum ( flow_dist . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = flow_dist . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) return params , loss metric_fn ( predt , data ) Function that evaluates the predictions using the specified loss function. Arguments predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns name: str Name of the evaluation metric. loss: float Loss value. Source code in lightgbmlss/distributions/flow_utils.py 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the specified loss function. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. loss: float Loss value. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values ) return self . loss_fn , loss . detach (), is_higher_better objective_fn ( predt , data ) Function to estimate gradients and hessians of normalizing flow parameters. Arguments predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns grad: np.ndarray Gradient. hess: np.ndarray Hessian. Source code in lightgbmlss/distributions/flow_utils.py 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of normalizing flow parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess predict_dist ( booster , data , start_values , pred_type = 'parameters' , n_samples = 1000 , quantiles = [ 0.1 , 0.5 , 0.9 ], seed = 123 ) Function that predicts from the trained model. Arguments booster : lgb.Booster Trained model. start_values : np.ndarray Starting values for each distributional parameter. data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns pred : pd.DataFrame Predictions. Source code in lightgbmlss/distributions/flow_utils.py 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. start_values : np.ndarray Starting values for each distributional parameter. data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" # Predict raw scores predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. Hence, it needs to be # added manually. dist_params_predt = pd . DataFrame ( np . concatenate ( [ predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 ) for i in range ( self . n_dist_param )], axis = 1 ) ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df replace_parameters ( params , flow_dist ) Replace parameters with estimated ones. Arguments params: torch.Tensor Estimated parameters. flow_dist: Transform Normalizing Flow. Returns params_list: List List of estimated parameters. flow_dist: Transform Normalizing Flow with estimated parameters. Source code in lightgbmlss/distributions/flow_utils.py 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 def replace_parameters ( self , params : torch . Tensor , flow_dist : Transform , ) -> Tuple [ List , Transform ]: \"\"\" Replace parameters with estimated ones. Arguments --------- params: torch.Tensor Estimated parameters. flow_dist: Transform Normalizing Flow. Returns ------- params_list: List List of estimated parameters. flow_dist: Transform Normalizing Flow with estimated parameters. \"\"\" # Split parameters into list if self . order == \"quadratic\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 ], dim = 1 ) elif self . order == \"linear\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 , self . count_bins ], dim = 1 ) # Replace parameters for param , new_value in zip ( flow_dist . transforms [ 0 ] . parameters (), params_list ): param . data = new_value # Get parameters (including require_grad=True) params_list = list ( flow_dist . transforms [ 0 ] . parameters ()) return params_list , flow_dist stabilize_derivative ( input_der , type = 'MAD' ) Function that stabilizes Gradients and Hessians. Since parameters are estimated by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Arguments input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns stab_der : torch.Tensor Stabilized Gradient or Hessian. Source code in lightgbmlss/distributions/flow_utils.py 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. Since parameters are estimated by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source --------- https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Arguments --------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns --------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der zero_inflated ZeroAdjustedBeta Bases: ZeroInflatedDistribution A Zero-Adjusted Beta distribution. Parameter concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Source code in lightgbmlss/distributions/zero_inflated.py 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 class ZeroAdjustedBeta ( ZeroInflatedDistribution ): \"\"\" A Zero-Adjusted Beta distribution. Parameter --------- concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py \"\"\" arg_constraints = { \"concentration1\" : constraints . positive , \"concentration0\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . unit_interval def __init__ ( self , concentration1 , concentration0 , gate = None , validate_args = None ): base_dist = Beta ( concentration1 = concentration1 , concentration0 = concentration0 , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def concentration1 ( self ): return self . base_dist . concentration1 @property def concentration0 ( self ): return self . base_dist . concentration0 ZeroAdjustedGamma Bases: ZeroInflatedDistribution A Zero-Adjusted Gamma distribution. Parameter concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Source code in lightgbmlss/distributions/zero_inflated.py 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 class ZeroAdjustedGamma ( ZeroInflatedDistribution ): \"\"\" A Zero-Adjusted Gamma distribution. Parameter --------- concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py \"\"\" arg_constraints = { \"concentration\" : constraints . positive , \"rate\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative def __init__ ( self , concentration , rate , gate = None , validate_args = None ): base_dist = Gamma ( concentration = concentration , rate = rate , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def concentration ( self ): return self . base_dist . concentration @property def rate ( self ): return self . base_dist . rate ZeroAdjustedLogNormal Bases: ZeroInflatedDistribution A Zero-Adjusted Log-Normal distribution. Parameter loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Source code in lightgbmlss/distributions/zero_inflated.py 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 class ZeroAdjustedLogNormal ( ZeroInflatedDistribution ): \"\"\" A Zero-Adjusted Log-Normal distribution. Parameter --------- loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py \"\"\" arg_constraints = { \"loc\" : constraints . real , \"scale\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative def __init__ ( self , loc , scale , gate = None , validate_args = None ): base_dist = LogNormal ( loc = loc , scale = scale , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def loc ( self ): return self . base_dist . loc @property def scale ( self ): return self . base_dist . scale ZeroInflatedDistribution Bases: TorchDistribution Generic Zero Inflated distribution. This can be used directly or can be used as a base class as e.g. for :class: ZeroInflatedPoisson and :class: ZeroInflatedNegativeBinomial . Parameters gate : torch.Tensor Probability of extra zeros given via a Bernoulli distribution. base_dist : torch.distributions.Distribution The base distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L18 Source code in lightgbmlss/distributions/zero_inflated.py 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 class ZeroInflatedDistribution ( TorchDistribution ): \"\"\" Generic Zero Inflated distribution. This can be used directly or can be used as a base class as e.g. for :class:`ZeroInflatedPoisson` and :class:`ZeroInflatedNegativeBinomial`. Parameters ---------- gate : torch.Tensor Probability of extra zeros given via a Bernoulli distribution. base_dist : torch.distributions.Distribution The base distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L18 \"\"\" arg_constraints = { \"gate\" : constraints . unit_interval , \"gate_logits\" : constraints . real , } def __init__ ( self , base_dist , * , gate = None , gate_logits = None , validate_args = None ): if ( gate is None ) == ( gate_logits is None ): raise ValueError ( \"Either `gate` or `gate_logits` must be specified, but not both.\" ) if gate is not None : batch_shape = broadcast_shape ( gate . shape , base_dist . batch_shape ) self . gate = gate . expand ( batch_shape ) else : batch_shape = broadcast_shape ( gate_logits . shape , base_dist . batch_shape ) self . gate_logits = gate_logits . expand ( batch_shape ) if base_dist . event_shape : raise ValueError ( \"ZeroInflatedDistribution expected empty \" \"base_dist.event_shape but got {} \" . format ( base_dist . event_shape ) ) self . base_dist = base_dist . expand ( batch_shape ) event_shape = torch . Size () super () . __init__ ( batch_shape , event_shape , validate_args ) @constraints . dependent_property def support ( self ): return self . base_dist . support @lazy_property def gate ( self ): return logits_to_probs ( self . gate_logits ) @lazy_property def gate_logits ( self ): return probs_to_logits ( self . gate ) def log_prob ( self , value ): if self . _validate_args : self . _validate_sample ( value ) zero_idx = ( value == 0 ) support = self . support epsilon = abs ( torch . finfo ( value . dtype ) . eps ) if hasattr ( support , \"lower_bound\" ): if is_identically_zero ( getattr ( support , \"lower_bound\" , None )): value = value . clamp_min ( epsilon ) if hasattr ( support , \"upper_bound\" ): if is_identically_one ( getattr ( support , \"upper_bound\" , None )) & ( value . max () == 1.0 ): value = value . clamp_max ( 1 - epsilon ) if \"gate\" in self . __dict__ : gate , value = broadcast_all ( self . gate , value ) log_prob = ( - gate ) . log1p () + self . base_dist . log_prob ( value ) log_prob = torch . where ( zero_idx , ( gate + log_prob . exp ()) . log (), log_prob ) else : gate_logits , value = broadcast_all ( self . gate_logits , value ) log_prob_minus_log_gate = - gate_logits + self . base_dist . log_prob ( value ) log_gate = - softplus ( - gate_logits ) log_prob = log_prob_minus_log_gate + log_gate zero_log_prob = softplus ( log_prob_minus_log_gate ) + log_gate log_prob = torch . where ( zero_idx , zero_log_prob , log_prob ) return log_prob def sample ( self , sample_shape = torch . Size ()): shape = self . _extended_shape ( sample_shape ) with torch . no_grad (): mask = torch . bernoulli ( self . gate . expand ( shape )) . bool () samples = self . base_dist . expand ( shape ) . sample () samples = torch . where ( mask , samples . new_zeros (()), samples ) return samples @lazy_property def mean ( self ): return ( 1 - self . gate ) * self . base_dist . mean @lazy_property def variance ( self ): return ( 1 - self . gate ) * ( self . base_dist . mean ** 2 + self . base_dist . variance ) - self . mean ** 2 def expand ( self , batch_shape , _instance = None ): new = self . _get_checked_instance ( type ( self ), _instance ) batch_shape = torch . Size ( batch_shape ) gate = self . gate . expand ( batch_shape ) if \"gate\" in self . __dict__ else None gate_logits = ( self . gate_logits . expand ( batch_shape ) if \"gate_logits\" in self . __dict__ else None ) base_dist = self . base_dist . expand ( batch_shape ) ZeroInflatedDistribution . __init__ ( new , base_dist , gate = gate , gate_logits = gate_logits , validate_args = False ) new . _validate_args = self . _validate_args return new ZeroInflatedNegativeBinomial Bases: ZeroInflatedDistribution A Zero Inflated Negative Binomial distribution. Parameter total_count: torch.Tensor Non-negative number of negative Bernoulli trial. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds of success (log(p/(1-p))). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Source code in lightgbmlss/distributions/zero_inflated.py 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 class ZeroInflatedNegativeBinomial ( ZeroInflatedDistribution ): \"\"\" A Zero Inflated Negative Binomial distribution. Parameter --------- total_count: torch.Tensor Non-negative number of negative Bernoulli trial. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds of success (log(p/(1-p))). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------ - https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 \"\"\" arg_constraints = { \"total_count\" : constraints . greater_than_eq ( 0 ), \"probs\" : constraints . half_open_interval ( 0.0 , 1.0 ), \"logits\" : constraints . real , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative_integer def __init__ ( self , total_count , probs = None , gate = None , validate_args = None ): base_dist = NegativeBinomial ( total_count = total_count , probs = probs , logits = None , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def total_count ( self ): return self . base_dist . total_count @property def probs ( self ): return self . base_dist . probs @property def logits ( self ): return self . base_dist . logits ZeroInflatedPoisson Bases: ZeroInflatedDistribution A Zero-Inflated Poisson distribution. Parameter rate: torch.Tensor The rate of the Poisson distribution. gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121 Source code in lightgbmlss/distributions/zero_inflated.py 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 class ZeroInflatedPoisson ( ZeroInflatedDistribution ): \"\"\" A Zero-Inflated Poisson distribution. Parameter --------- rate: torch.Tensor The rate of the Poisson distribution. gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121 \"\"\" arg_constraints = { \"rate\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative_integer def __init__ ( self , rate , gate = None , validate_args = None ): base_dist = Poisson ( rate = rate , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def rate ( self ): return self . base_dist . rate model LightGBMLSS LightGBMLSS model class Parameters dist : Distribution DistributionClass object. start_values : np.ndarray Starting values for each distributional parameter. Source code in lightgbmlss/model.py 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 class LightGBMLSS : \"\"\" LightGBMLSS model class Parameters ---------- dist : Distribution DistributionClass object. start_values : np.ndarray Starting values for each distributional parameter. \"\"\" def __init__ ( self , dist ): self . dist = dist # Distribution object self . start_values = None # Starting values for distributional parameters def set_params ( self , params : Dict [ str , Any ]) -> Dict [ str , Any ]: \"\"\" Set parameters for distributional model. Arguments --------- params : Dict[str, Any] Parameters for model. Returns ------- params : Dict[str, Any] Updated Parameters for model. \"\"\" params_adj = { \"num_class\" : self . dist . n_dist_param , \"metric\" : \"None\" , \"objective\" : \"None\" , \"random_seed\" : 123 , \"verbose\" : - 1 } params . update ( params_adj ) return params def set_init_score ( self , dmatrix : Dataset ) -> None : \"\"\" Set init_score for distributions. Arguments --------- dmatrix : Dataset Dataset to set base margin for. Returns ------- None \"\"\" if self . start_values is None : _ , self . start_values = self . dist . calculate_start_values ( dmatrix . get_label ()) init_score = ( np . ones ( shape = ( dmatrix . get_label () . shape [ 0 ], 1 ))) * self . start_values dmatrix . set_init_score ( init_score . ravel ( order = \"F\" )) def train ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , valid_sets : Optional [ List [ Dataset ]] = None , valid_names : Optional [ List [ str ]] = None , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , keep_training_booster : bool = False , callbacks : Optional [ List [ Callable ]] = None ) -> Booster : \"\"\"Function to perform the training of a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. valid_sets : list of Dataset, or None, optional (default=None) List of data to be evaluated on during training. valid_names : list of str, or None, optional (default=None) Names of ``valid_sets``. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. keep_training_booster : bool, optional (default=False) Whether the returned Booster will be used to keep training. If False, the returned value will be converted into _InnerPredictor before returning. This means you won't be able to use ``eval``, ``eval_train`` or ``eval_valid`` methods of the returned Booster. When your model is very large and cause the memory error, you can try to set this param to ``True`` to avoid the model conversion performed during the internal call of ``model_to_string``. You can still use _InnerPredictor as ``init_model`` for future continue training. callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. Returns ------- booster : Booster The trained Booster model. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) if valid_sets is not None : valid_sets = self . set_valid_margin ( valid_sets , self . start_values ) self . booster = lgb . train ( params , train_set , num_boost_round = num_boost_round , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , valid_sets = valid_sets , valid_names = valid_names , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , keep_training_booster = keep_training_booster , callbacks = callbacks ) def cv ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , folds : Optional [ Union [ Iterable [ Tuple [ np . ndarray , np . ndarray ]], _LGBMBaseCrossValidator ]] = None , nfold : int = 5 , stratified : bool = True , shuffle : bool = True , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , fpreproc : Optional [ _LGBM_PreprocFunction ] = None , seed : int = 123 , callbacks : Optional [ List [ Callable ]] = None , eval_train_metric : bool = False , return_cvbooster : bool = False ) -> Dict [ str , Union [ List [ float ], CVBooster ]]: \"\"\"Function to cross-validate a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. folds : generator or iterator of (train_idx, test_idx) tuples, scikit-learn splitter object or None, optional (default=None) If generator or iterator, it should yield the train and test indices for each fold. If object, it should be one of the scikit-learn splitter classes (https://scikit-learn.org/stable/modules/classes.html#splitter-classes) and have ``split`` method. This argument has highest priority over other data split arguments. nfold : int, optional (default=5) Number of folds in CV. stratified : bool, optional (default=True) Whether to perform stratified sampling. shuffle : bool, optional (default=True) Whether to shuffle before splitting data. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. fpreproc : callable or None, optional (default=None) Preprocessing function that takes (dtrain, dtest, params) and returns transformed versions of those. seed : int, optional (default=0) Seed used to generate the folds (passed to numpy.random.seed). callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. eval_train_metric : bool, optional (default=False) Whether to display the train metric in progress. The score of the metric is calculated again after each training step, so there is some impact on performance. return_cvbooster : bool, optional (default=False) Whether to return Booster models trained on each fold through ``CVBooster``. Returns ------- eval_hist : dict Evaluation history. The dictionary has the following format: {'metric1-mean': [values], 'metric1-stdv': [values], 'metric2-mean': [values], 'metric2-stdv': [values], ...}. If ``return_cvbooster=True``, also returns trained boosters wrapped in a ``CVBooster`` object via ``cvbooster`` key. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) self . bstLSS_cv = lgb . cv ( params , train_set , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , num_boost_round = num_boost_round , folds = folds , nfold = nfold , stratified = False , shuffle = False , metrics = None , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , fpreproc = fpreproc , seed = seed , callbacks = callbacks , eval_train_metric = eval_train_metric , return_cvbooster = return_cvbooster ) return self . bstLSS_cv def hyper_opt ( self , hp_dict : Dict , train_set : lgb . Dataset , num_boost_round = 500 , nfold = 10 , early_stopping_rounds = 20 , max_minutes = 10 , n_trials = None , study_name = None , silence = False , seed = None , hp_seed = None ): \"\"\" Function to tune hyperparameters using optuna. Arguments ---------- hp_dict: dict Dictionary of hyperparameters to tune. train_set: lgb.Dataset Training data. num_boost_round: int Number of boosting iterations. nfold: int Number of folds in CV. early_stopping_rounds: int Activates early stopping. Cross-Validation metric (average of validation metric computed over CV folds) needs to improve at least once in every **early_stopping_rounds** round(s) to continue training. The last entry in the evaluation history will represent the best iteration. If there's more than one metric in the **eval_metric** parameter given in **params**, the last metric will be used for early stopping. max_minutes: int Time budget in minutes, i.e., stop study after the given number of minutes. n_trials: int The number of trials. If this argument is set to None, there is no limitation on the number of trials. study_name: str Name of the hyperparameter study. silence: bool Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed: int Seed used to generate the folds (passed to numpy.random.seed). hp_seed: int Seed for random number generator used in the Bayesian hyper-parameter search. Returns ------- opt_params : dict Optimal hyper-parameters. \"\"\" def objective ( trial ): hyper_params = {} for param_name , param_value in hp_dict . items (): param_type = param_value [ 0 ] if param_type == \"categorical\" or param_type == \"none\" : hyper_params . update ({ param_name : trial . suggest_categorical ( param_name , param_value [ 1 ])}) elif param_type == \"float\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_float ( param_name , low = param_low , high = param_high , log = param_log ) }) elif param_type == \"int\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_int ( param_name , low = param_low , high = param_high , log = param_log ) }) # Add booster if not included in dictionary if \"boosting\" not in hyper_params . keys (): hyper_params . update ({ \"boosting\" : trial . suggest_categorical ( \"boosting\" , [ \"gbdt\" ])}) # Add pruning and early stopping pruning_callback = LightGBMPruningCallback ( trial , self . dist . loss_fn ) early_stopping_callback = lgb . early_stopping ( stopping_rounds = early_stopping_rounds , verbose = False ) lgblss_param_tuning = self . cv ( hyper_params , train_set , num_boost_round = num_boost_round , nfold = nfold , callbacks = [ pruning_callback , early_stopping_callback ], seed = seed , ) # Extract the optimal number of boosting rounds opt_rounds = np . argmin ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) + 1 trial . set_user_attr ( \"opt_round\" , int ( opt_rounds )) # Extract the best score best_score = np . min ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) return best_score if study_name is None : study_name = \"LightGBMLSS Hyper-Parameter Optimization\" if silence : optuna . logging . set_verbosity ( optuna . logging . WARNING ) if hp_seed is not None : sampler = TPESampler ( seed = hp_seed ) else : sampler = TPESampler () pruner = optuna . pruners . MedianPruner ( n_startup_trials = 10 , n_warmup_steps = 20 ) study = optuna . create_study ( sampler = sampler , pruner = pruner , direction = \"minimize\" , study_name = study_name ) study . optimize ( objective , n_trials = n_trials , timeout = 60 * max_minutes , show_progress_bar = True ) print ( \" \\n Hyper-Parameter Optimization successfully finished.\" ) print ( \" Number of finished trials: \" , len ( study . trials )) print ( \" Best trial:\" ) opt_param = study . best_trial # Add optimal stopping round opt_param . params [ \"opt_rounds\" ] = study . trials_dataframe ()[ \"user_attrs_opt_round\" ][ study . trials_dataframe ()[ \"value\" ] . idxmin ()] opt_param . params [ \"opt_rounds\" ] = int ( opt_param . params [ \"opt_rounds\" ]) print ( \" Value: {} \" . format ( opt_param . value )) print ( \" Params: \" ) for key , value in opt_param . params . items (): print ( \" {} : {} \" . format ( key , value )) return opt_param . params def predict ( self , data : pd . DataFrame , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ): \"\"\" Function that predicts from the trained model. Arguments --------- data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- predt_df : pd.DataFrame Predictions. \"\"\" # Predict predt_df = self . dist . predict_dist ( booster = self . booster , data = data , start_values = self . start_values , pred_type = pred_type , n_samples = n_samples , quantiles = quantiles , seed = seed ) return predt_df def plot ( self , X : pd . DataFrame , feature : str = \"x\" , parameter : str = \"loc\" , max_display : int = 15 , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS SHap plotting function. Arguments: --------- X: pd.DataFrame Train/Test Data feature: str Specifies which feature is to be plotted. parameter: str Specifies which distributional parameter is to be plotted. max_display: int Specifies the maximum number of features to be displayed. plot_type: str Specifies the type of plot: \"Partial_Dependence\" plots the partial dependence of the parameter on the feature. \"Feature_Importance\" plots the feature importance of the parameter. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) param_pos = self . dist . distribution_arg_names . index ( parameter ) if plot_type == \"Partial_Dependence\" : if self . dist . n_dist_param == 1 : shap . plots . scatter ( shap_values [:, feature ], color = shap_values [:, feature ]) else : shap . plots . scatter ( shap_values [:, feature ][:, param_pos ], color = shap_values [:, feature ][:, param_pos ]) elif plot_type == \"Feature_Importance\" : if self . dist . n_dist_param == 1 : shap . plots . bar ( shap_values , max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ]) else : shap . plots . bar ( shap_values [:, :, param_pos ], max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ] ) def expectile_plot ( self , X : pd . DataFrame , feature : str = \"x\" , expectile : str = \"0.05\" , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS function for plotting expectile SHapley values. X: pd.DataFrame Train/Test Data feature: str Specifies which feature to use for plotting Partial_Dependence plot. expectile: str Specifies which expectile to plot. plot_type: str Specifies which SHapley-plot to visualize. Currently, \"Partial_Dependence\" and \"Feature_Importance\" are supported. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) expect_pos = list ( self . dist . param_dict . keys ()) . index ( expectile ) if plot_type == \"Partial_Dependence\" : shap . plots . scatter ( shap_values [:, feature ][:, expect_pos ], color = shap_values [:, feature ][:, expect_pos ]) elif plot_type == \"Feature_Importance\" : shap . plots . bar ( shap_values [:, :, expect_pos ], max_display = 15 if X . shape [ 1 ] > 15 else X . shape [ 1 ]) def set_valid_margin ( self , valid_sets : list , start_values : np . ndarray ) -> list : \"\"\" Function that sets the base margin for the validation set. Arguments --------- valid_sets : list List of tuples containing the train and evaluation set. valid_names: list List of tuples containing the name of train and evaluation set. start_values : np.ndarray Array containing the start values for the distributional parameters. Returns ------- valid_sets : list List of tuples containing the train and evaluation set. \"\"\" valid_sets1 = valid_sets [ 0 ] init_score_val1 = ( np . ones ( shape = ( valid_sets1 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets1 . set_init_score ( init_score_val1 . ravel ( order = \"F\" )) valid_sets2 = valid_sets [ 1 ] init_score_val2 = ( np . ones ( shape = ( valid_sets2 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets2 . set_init_score ( init_score_val2 . ravel ( order = \"F\" )) valid_sets = [ valid_sets1 , valid_sets2 ] return valid_sets def save_model ( self , model_path : str ) -> None : \"\"\" Save the model to a file. Parameters ---------- model_path : str The path to save the model. Returns ------- None \"\"\" with open ( model_path , \"wb\" ) as f : pickle . dump ( self , f ) @staticmethod def load_model ( model_path : str ): \"\"\" Load the model from a file. Parameters ---------- model_path : str The path to the saved model. Returns ------- The loaded model. \"\"\" with open ( model_path , \"rb\" ) as f : return pickle . load ( f ) cv ( params , train_set , num_boost_round = 100 , folds = None , nfold = 5 , stratified = True , shuffle = True , init_model = None , feature_name = 'auto' , categorical_feature = 'auto' , fpreproc = None , seed = 123 , callbacks = None , eval_train_metric = False , return_cvbooster = False ) Function to cross-validate a LightGBMLSS model with given parameters. Parameters params : dict Parameters for training. Values passed through params take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. folds : generator or iterator of (train_idx, test_idx) tuples, scikit-learn splitter object or None, optional (default=None) If generator or iterator, it should yield the train and test indices for each fold. If object, it should be one of the scikit-learn splitter classes (https://scikit-learn.org/stable/modules/classes.html#splitter-classes) and have split method. This argument has highest priority over other data split arguments. nfold : int, optional (default=5) Number of folds in CV. stratified : bool, optional (default=True) Whether to perform stratified sampling. shuffle : bool, optional (default=True) Whether to shuffle before splitting data. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify feature_name as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. fpreproc : callable or None, optional (default=None) Preprocessing function that takes (dtrain, dtest, params) and returns transformed versions of those. seed : int, optional (default=0) Seed used to generate the folds (passed to numpy.random.seed). callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. eval_train_metric : bool, optional (default=False) Whether to display the train metric in progress. The score of the metric is calculated again after each training step, so there is some impact on performance. return_cvbooster : bool, optional (default=False) Whether to return Booster models trained on each fold through CVBooster . Returns eval_hist : dict Evaluation history. The dictionary has the following format: {'metric1-mean': [values], 'metric1-stdv': [values], 'metric2-mean': [values], 'metric2-stdv': [values], ...}. If return_cvbooster=True , also returns trained boosters wrapped in a CVBooster object via cvbooster key. Source code in lightgbmlss/model.py 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 def cv ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , folds : Optional [ Union [ Iterable [ Tuple [ np . ndarray , np . ndarray ]], _LGBMBaseCrossValidator ]] = None , nfold : int = 5 , stratified : bool = True , shuffle : bool = True , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , fpreproc : Optional [ _LGBM_PreprocFunction ] = None , seed : int = 123 , callbacks : Optional [ List [ Callable ]] = None , eval_train_metric : bool = False , return_cvbooster : bool = False ) -> Dict [ str , Union [ List [ float ], CVBooster ]]: \"\"\"Function to cross-validate a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. folds : generator or iterator of (train_idx, test_idx) tuples, scikit-learn splitter object or None, optional (default=None) If generator or iterator, it should yield the train and test indices for each fold. If object, it should be one of the scikit-learn splitter classes (https://scikit-learn.org/stable/modules/classes.html#splitter-classes) and have ``split`` method. This argument has highest priority over other data split arguments. nfold : int, optional (default=5) Number of folds in CV. stratified : bool, optional (default=True) Whether to perform stratified sampling. shuffle : bool, optional (default=True) Whether to shuffle before splitting data. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. fpreproc : callable or None, optional (default=None) Preprocessing function that takes (dtrain, dtest, params) and returns transformed versions of those. seed : int, optional (default=0) Seed used to generate the folds (passed to numpy.random.seed). callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. eval_train_metric : bool, optional (default=False) Whether to display the train metric in progress. The score of the metric is calculated again after each training step, so there is some impact on performance. return_cvbooster : bool, optional (default=False) Whether to return Booster models trained on each fold through ``CVBooster``. Returns ------- eval_hist : dict Evaluation history. The dictionary has the following format: {'metric1-mean': [values], 'metric1-stdv': [values], 'metric2-mean': [values], 'metric2-stdv': [values], ...}. If ``return_cvbooster=True``, also returns trained boosters wrapped in a ``CVBooster`` object via ``cvbooster`` key. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) self . bstLSS_cv = lgb . cv ( params , train_set , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , num_boost_round = num_boost_round , folds = folds , nfold = nfold , stratified = False , shuffle = False , metrics = None , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , fpreproc = fpreproc , seed = seed , callbacks = callbacks , eval_train_metric = eval_train_metric , return_cvbooster = return_cvbooster ) return self . bstLSS_cv expectile_plot ( X , feature = 'x' , expectile = '0.05' , plot_type = 'Partial_Dependence' ) LightGBMLSS function for plotting expectile SHapley values. pd.DataFrame Train/Test Data feature: str Specifies which feature to use for plotting Partial_Dependence plot. expectile: str Specifies which expectile to plot. plot_type: str Specifies which SHapley-plot to visualize. Currently, \"Partial_Dependence\" and \"Feature_Importance\" are supported. Source code in lightgbmlss/model.py 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 def expectile_plot ( self , X : pd . DataFrame , feature : str = \"x\" , expectile : str = \"0.05\" , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS function for plotting expectile SHapley values. X: pd.DataFrame Train/Test Data feature: str Specifies which feature to use for plotting Partial_Dependence plot. expectile: str Specifies which expectile to plot. plot_type: str Specifies which SHapley-plot to visualize. Currently, \"Partial_Dependence\" and \"Feature_Importance\" are supported. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) expect_pos = list ( self . dist . param_dict . keys ()) . index ( expectile ) if plot_type == \"Partial_Dependence\" : shap . plots . scatter ( shap_values [:, feature ][:, expect_pos ], color = shap_values [:, feature ][:, expect_pos ]) elif plot_type == \"Feature_Importance\" : shap . plots . bar ( shap_values [:, :, expect_pos ], max_display = 15 if X . shape [ 1 ] > 15 else X . shape [ 1 ]) hyper_opt ( hp_dict , train_set , num_boost_round = 500 , nfold = 10 , early_stopping_rounds = 20 , max_minutes = 10 , n_trials = None , study_name = None , silence = False , seed = None , hp_seed = None ) Function to tune hyperparameters using optuna. Arguments hp_dict: dict Dictionary of hyperparameters to tune. train_set: lgb.Dataset Training data. num_boost_round: int Number of boosting iterations. nfold: int Number of folds in CV. early_stopping_rounds: int Activates early stopping. Cross-Validation metric (average of validation metric computed over CV folds) needs to improve at least once in every early_stopping_rounds round(s) to continue training. The last entry in the evaluation history will represent the best iteration. If there's more than one metric in the eval_metric parameter given in params , the last metric will be used for early stopping. max_minutes: int Time budget in minutes, i.e., stop study after the given number of minutes. n_trials: int The number of trials. If this argument is set to None, there is no limitation on the number of trials. study_name: str Name of the hyperparameter study. silence: bool Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed: int Seed used to generate the folds (passed to numpy.random.seed). hp_seed: int Seed for random number generator used in the Bayesian hyper-parameter search. Returns opt_params : dict Optimal hyper-parameters. Source code in lightgbmlss/model.py 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 def hyper_opt ( self , hp_dict : Dict , train_set : lgb . Dataset , num_boost_round = 500 , nfold = 10 , early_stopping_rounds = 20 , max_minutes = 10 , n_trials = None , study_name = None , silence = False , seed = None , hp_seed = None ): \"\"\" Function to tune hyperparameters using optuna. Arguments ---------- hp_dict: dict Dictionary of hyperparameters to tune. train_set: lgb.Dataset Training data. num_boost_round: int Number of boosting iterations. nfold: int Number of folds in CV. early_stopping_rounds: int Activates early stopping. Cross-Validation metric (average of validation metric computed over CV folds) needs to improve at least once in every **early_stopping_rounds** round(s) to continue training. The last entry in the evaluation history will represent the best iteration. If there's more than one metric in the **eval_metric** parameter given in **params**, the last metric will be used for early stopping. max_minutes: int Time budget in minutes, i.e., stop study after the given number of minutes. n_trials: int The number of trials. If this argument is set to None, there is no limitation on the number of trials. study_name: str Name of the hyperparameter study. silence: bool Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed: int Seed used to generate the folds (passed to numpy.random.seed). hp_seed: int Seed for random number generator used in the Bayesian hyper-parameter search. Returns ------- opt_params : dict Optimal hyper-parameters. \"\"\" def objective ( trial ): hyper_params = {} for param_name , param_value in hp_dict . items (): param_type = param_value [ 0 ] if param_type == \"categorical\" or param_type == \"none\" : hyper_params . update ({ param_name : trial . suggest_categorical ( param_name , param_value [ 1 ])}) elif param_type == \"float\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_float ( param_name , low = param_low , high = param_high , log = param_log ) }) elif param_type == \"int\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_int ( param_name , low = param_low , high = param_high , log = param_log ) }) # Add booster if not included in dictionary if \"boosting\" not in hyper_params . keys (): hyper_params . update ({ \"boosting\" : trial . suggest_categorical ( \"boosting\" , [ \"gbdt\" ])}) # Add pruning and early stopping pruning_callback = LightGBMPruningCallback ( trial , self . dist . loss_fn ) early_stopping_callback = lgb . early_stopping ( stopping_rounds = early_stopping_rounds , verbose = False ) lgblss_param_tuning = self . cv ( hyper_params , train_set , num_boost_round = num_boost_round , nfold = nfold , callbacks = [ pruning_callback , early_stopping_callback ], seed = seed , ) # Extract the optimal number of boosting rounds opt_rounds = np . argmin ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) + 1 trial . set_user_attr ( \"opt_round\" , int ( opt_rounds )) # Extract the best score best_score = np . min ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) return best_score if study_name is None : study_name = \"LightGBMLSS Hyper-Parameter Optimization\" if silence : optuna . logging . set_verbosity ( optuna . logging . WARNING ) if hp_seed is not None : sampler = TPESampler ( seed = hp_seed ) else : sampler = TPESampler () pruner = optuna . pruners . MedianPruner ( n_startup_trials = 10 , n_warmup_steps = 20 ) study = optuna . create_study ( sampler = sampler , pruner = pruner , direction = \"minimize\" , study_name = study_name ) study . optimize ( objective , n_trials = n_trials , timeout = 60 * max_minutes , show_progress_bar = True ) print ( \" \\n Hyper-Parameter Optimization successfully finished.\" ) print ( \" Number of finished trials: \" , len ( study . trials )) print ( \" Best trial:\" ) opt_param = study . best_trial # Add optimal stopping round opt_param . params [ \"opt_rounds\" ] = study . trials_dataframe ()[ \"user_attrs_opt_round\" ][ study . trials_dataframe ()[ \"value\" ] . idxmin ()] opt_param . params [ \"opt_rounds\" ] = int ( opt_param . params [ \"opt_rounds\" ]) print ( \" Value: {} \" . format ( opt_param . value )) print ( \" Params: \" ) for key , value in opt_param . params . items (): print ( \" {} : {} \" . format ( key , value )) return opt_param . params load_model ( model_path ) staticmethod Load the model from a file. Parameters model_path : str The path to the saved model. Returns The loaded model. Source code in lightgbmlss/model.py 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 @staticmethod def load_model ( model_path : str ): \"\"\" Load the model from a file. Parameters ---------- model_path : str The path to the saved model. Returns ------- The loaded model. \"\"\" with open ( model_path , \"rb\" ) as f : return pickle . load ( f ) plot ( X , feature = 'x' , parameter = 'loc' , max_display = 15 , plot_type = 'Partial_Dependence' ) LightGBMLSS SHap plotting function. Arguments: X: pd.DataFrame Train/Test Data feature: str Specifies which feature is to be plotted. parameter: str Specifies which distributional parameter is to be plotted. max_display: int Specifies the maximum number of features to be displayed. plot_type: str Specifies the type of plot: \"Partial_Dependence\" plots the partial dependence of the parameter on the feature. \"Feature_Importance\" plots the feature importance of the parameter. Source code in lightgbmlss/model.py 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 def plot ( self , X : pd . DataFrame , feature : str = \"x\" , parameter : str = \"loc\" , max_display : int = 15 , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS SHap plotting function. Arguments: --------- X: pd.DataFrame Train/Test Data feature: str Specifies which feature is to be plotted. parameter: str Specifies which distributional parameter is to be plotted. max_display: int Specifies the maximum number of features to be displayed. plot_type: str Specifies the type of plot: \"Partial_Dependence\" plots the partial dependence of the parameter on the feature. \"Feature_Importance\" plots the feature importance of the parameter. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) param_pos = self . dist . distribution_arg_names . index ( parameter ) if plot_type == \"Partial_Dependence\" : if self . dist . n_dist_param == 1 : shap . plots . scatter ( shap_values [:, feature ], color = shap_values [:, feature ]) else : shap . plots . scatter ( shap_values [:, feature ][:, param_pos ], color = shap_values [:, feature ][:, param_pos ]) elif plot_type == \"Feature_Importance\" : if self . dist . n_dist_param == 1 : shap . plots . bar ( shap_values , max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ]) else : shap . plots . bar ( shap_values [:, :, param_pos ], max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ] ) predict ( data , pred_type = 'parameters' , n_samples = 1000 , quantiles = [ 0.1 , 0.5 , 0.9 ], seed = 123 ) Function that predicts from the trained model. Arguments data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns predt_df : pd.DataFrame Predictions. Source code in lightgbmlss/model.py 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 def predict ( self , data : pd . DataFrame , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ): \"\"\" Function that predicts from the trained model. Arguments --------- data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- predt_df : pd.DataFrame Predictions. \"\"\" # Predict predt_df = self . dist . predict_dist ( booster = self . booster , data = data , start_values = self . start_values , pred_type = pred_type , n_samples = n_samples , quantiles = quantiles , seed = seed ) return predt_df save_model ( model_path ) Save the model to a file. Parameters model_path : str The path to save the model. Returns None Source code in lightgbmlss/model.py 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 def save_model ( self , model_path : str ) -> None : \"\"\" Save the model to a file. Parameters ---------- model_path : str The path to save the model. Returns ------- None \"\"\" with open ( model_path , \"wb\" ) as f : pickle . dump ( self , f ) set_init_score ( dmatrix ) Set init_score for distributions. Arguments dmatrix : Dataset Dataset to set base margin for. Returns None Source code in lightgbmlss/model.py 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 def set_init_score ( self , dmatrix : Dataset ) -> None : \"\"\" Set init_score for distributions. Arguments --------- dmatrix : Dataset Dataset to set base margin for. Returns ------- None \"\"\" if self . start_values is None : _ , self . start_values = self . dist . calculate_start_values ( dmatrix . get_label ()) init_score = ( np . ones ( shape = ( dmatrix . get_label () . shape [ 0 ], 1 ))) * self . start_values dmatrix . set_init_score ( init_score . ravel ( order = \"F\" )) set_params ( params ) Set parameters for distributional model. Arguments params : Dict[str, Any] Parameters for model. Returns params : Dict[str, Any] Updated Parameters for model. Source code in lightgbmlss/model.py 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 def set_params ( self , params : Dict [ str , Any ]) -> Dict [ str , Any ]: \"\"\" Set parameters for distributional model. Arguments --------- params : Dict[str, Any] Parameters for model. Returns ------- params : Dict[str, Any] Updated Parameters for model. \"\"\" params_adj = { \"num_class\" : self . dist . n_dist_param , \"metric\" : \"None\" , \"objective\" : \"None\" , \"random_seed\" : 123 , \"verbose\" : - 1 } params . update ( params_adj ) return params set_valid_margin ( valid_sets , start_values ) Function that sets the base margin for the validation set. Arguments valid_sets : list List of tuples containing the train and evaluation set. valid_names: list List of tuples containing the name of train and evaluation set. start_values : np.ndarray Array containing the start values for the distributional parameters. Returns valid_sets : list List of tuples containing the train and evaluation set. Source code in lightgbmlss/model.py 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 def set_valid_margin ( self , valid_sets : list , start_values : np . ndarray ) -> list : \"\"\" Function that sets the base margin for the validation set. Arguments --------- valid_sets : list List of tuples containing the train and evaluation set. valid_names: list List of tuples containing the name of train and evaluation set. start_values : np.ndarray Array containing the start values for the distributional parameters. Returns ------- valid_sets : list List of tuples containing the train and evaluation set. \"\"\" valid_sets1 = valid_sets [ 0 ] init_score_val1 = ( np . ones ( shape = ( valid_sets1 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets1 . set_init_score ( init_score_val1 . ravel ( order = \"F\" )) valid_sets2 = valid_sets [ 1 ] init_score_val2 = ( np . ones ( shape = ( valid_sets2 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets2 . set_init_score ( init_score_val2 . ravel ( order = \"F\" )) valid_sets = [ valid_sets1 , valid_sets2 ] return valid_sets train ( params , train_set , num_boost_round = 100 , valid_sets = None , valid_names = None , init_model = None , feature_name = 'auto' , categorical_feature = 'auto' , keep_training_booster = False , callbacks = None ) Function to perform the training of a LightGBMLSS model with given parameters. Parameters params : dict Parameters for training. Values passed through params take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. valid_sets : list of Dataset, or None, optional (default=None) List of data to be evaluated on during training. valid_names : list of str, or None, optional (default=None) Names of valid_sets . init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify feature_name as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. keep_training_booster : bool, optional (default=False) Whether the returned Booster will be used to keep training. If False, the returned value will be converted into _InnerPredictor before returning. This means you won't be able to use eval , eval_train or eval_valid methods of the returned Booster. When your model is very large and cause the memory error, you can try to set this param to True to avoid the model conversion performed during the internal call of model_to_string . You can still use _InnerPredictor as init_model for future continue training. callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. Returns booster : Booster The trained Booster model. Source code in lightgbmlss/model.py 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 def train ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , valid_sets : Optional [ List [ Dataset ]] = None , valid_names : Optional [ List [ str ]] = None , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , keep_training_booster : bool = False , callbacks : Optional [ List [ Callable ]] = None ) -> Booster : \"\"\"Function to perform the training of a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. valid_sets : list of Dataset, or None, optional (default=None) List of data to be evaluated on during training. valid_names : list of str, or None, optional (default=None) Names of ``valid_sets``. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. keep_training_booster : bool, optional (default=False) Whether the returned Booster will be used to keep training. If False, the returned value will be converted into _InnerPredictor before returning. This means you won't be able to use ``eval``, ``eval_train`` or ``eval_valid`` methods of the returned Booster. When your model is very large and cause the memory error, you can try to set this param to ``True`` to avoid the model conversion performed during the internal call of ``model_to_string``. You can still use _InnerPredictor as ``init_model`` for future continue training. callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. Returns ------- booster : Booster The trained Booster model. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) if valid_sets is not None : valid_sets = self . set_valid_margin ( valid_sets , self . start_values ) self . booster = lgb . train ( params , train_set , num_boost_round = num_boost_round , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , valid_sets = valid_sets , valid_names = valid_names , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , keep_training_booster = keep_training_booster , callbacks = callbacks ) utils exp_fn ( predt ) Exponential function used to ensure predt is strictly positive. Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def exp_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Exponential function used to ensure predt is strictly positive. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . exp ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt exp_fn_df ( predt ) Exponential function used for Student-T distribution. Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def exp_fn_df ( predt : torch . tensor ) -> torch . tensor : \"\"\" Exponential function used for Student-T distribution. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . exp ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt + torch . tensor ( 2.0 , dtype = predt . dtype ) identity_fn ( predt ) Identity mapping of predt. Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def identity_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Identity mapping of predt. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" return predt log_fn ( predt ) Inverse of exp_fn function. Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 def log_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Inverse of exp_fn function. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . log ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + float ( 1e-06 ) return predt relu_fn ( predt ) Function used to ensure predt are scaled to max(0, predt). Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 def relu_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Function used to ensure predt are scaled to max(0, predt). Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . relu ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-6 , dtype = predt . dtype ) return predt sigmoid_fn ( predt ) Function used to ensure predt are scaled to (0,1). Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 def sigmoid_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Function used to ensure predt are scaled to (0,1). Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . sigmoid ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) predt = torch . clamp ( predt , 1e-03 , 1 - 1e-03 ) return predt softplus_fn ( predt ) Softplus function used to ensure predt is strictly positive. Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 def softplus_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Softplus function used to ensure predt is strictly positive. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . log1p ( torch . exp ( - torch . abs ( predt ))) + torch . maximum ( predt , torch . tensor ( 0. )) predt [ predt == 0 ] = torch . tensor ( 1e-06 , dtype = predt . dtype ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt softplus_fn_df ( predt ) Softplus function used for Student-T distribution. Arguments predt: torch.tensor Predicted values. Returns predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 def softplus_fn_df ( predt : torch . tensor ) -> torch . tensor : \"\"\" Softplus function used for Student-T distribution. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . log1p ( torch . exp ( - torch . abs ( predt ))) + torch . maximum ( predt , torch . tensor ( 0. )) predt [ predt == 0 ] = torch . tensor ( 1e-06 , dtype = predt . dtype ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt + torch . tensor ( 2.0 , dtype = predt . dtype )","title":"API Docs"},{"location":"api/#api-references","text":"LightGBMLSS - An extension of LightGBM to probabilistic forecasting","title":"API references"},{"location":"api/#lightgbmlss.datasets","text":"LightGBMLSS - An extension of LightGBM to probabilistic forecasting","title":"datasets"},{"location":"api/#lightgbmlss.datasets.data_loader","text":"","title":"data_loader"},{"location":"api/#lightgbmlss.datasets.data_loader.load_simulated_gaussian_data","text":"Returns train/test dataframe of a simulated example. Contains the following columns y int64: response x int64: x-feature X1:X10 int64: random noise features Source code in lightgbmlss/datasets/data_loader.py 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def load_simulated_gaussian_data (): \"\"\" Returns train/test dataframe of a simulated example. Contains the following columns: y int64: response x int64: x-feature X1:X10 int64: random noise features \"\"\" train_path = pkg_resources . resource_stream ( __name__ , \"gaussian_train_sim.csv\" ) train_df = pd . read_csv ( train_path ) test_path = pkg_resources . resource_stream ( __name__ , \"gaussian_test_sim.csv\" ) test_df = pd . read_csv ( test_path ) return train_df , test_df","title":"load_simulated_gaussian_data()"},{"location":"api/#lightgbmlss.datasets.data_loader.load_simulated_studentT_data","text":"Returns train/test dataframe of a simulated example. Contains the following columns y int64: response x int64: x-feature X1:X10 int64: random noise features Source code in lightgbmlss/datasets/data_loader.py 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def load_simulated_studentT_data (): \"\"\" Returns train/test dataframe of a simulated example. Contains the following columns: y int64: response x int64: x-feature X1:X10 int64: random noise features \"\"\" train_path = pkg_resources . resource_stream ( __name__ , \"studentT_train_sim.csv\" ) train_df = pd . read_csv ( train_path ) test_path = pkg_resources . resource_stream ( __name__ , \"studentT_test_sim.csv\" ) test_df = pd . read_csv ( test_path ) return train_df , test_df","title":"load_simulated_studentT_data()"},{"location":"api/#lightgbmlss.distributions","text":"LightGBMLSS - An extension of LightGBM to probabilistic forecasting","title":"distributions"},{"location":"api/#lightgbmlss.distributions.Beta","text":"","title":"Beta"},{"location":"api/#lightgbmlss.distributions.Beta.Beta","text":"Bases: DistributionClass Beta distribution class.","title":"Beta"},{"location":"api/#lightgbmlss.distributions.Beta.Beta--distributional-parameters","text":"concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta).","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Beta.Beta--source","text":"https://pytorch.org/docs/stable/distributions.html#beta","title":"Source"},{"location":"api/#lightgbmlss.distributions.Beta.Beta--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Beta.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Beta ( DistributionClass ): \"\"\" Beta distribution class. Distributional Parameters ------------------------- concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#beta Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Beta_Torch param_dict = { \"concentration1\" : response_fn , \"concentration0\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Cauchy","text":"","title":"Cauchy"},{"location":"api/#lightgbmlss.distributions.Cauchy.Cauchy","text":"Bases: DistributionClass Cauchy distribution class.","title":"Cauchy"},{"location":"api/#lightgbmlss.distributions.Cauchy.Cauchy--distributional-parameters","text":"loc: torch.Tensor Mode or median of the distribution. scale: torch.Tensor Half width at half maximum.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Cauchy.Cauchy--source","text":"https://pytorch.org/docs/stable/distributions.html#cauchy","title":"Source"},{"location":"api/#lightgbmlss.distributions.Cauchy.Cauchy--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Cauchy.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Cauchy ( DistributionClass ): \"\"\" Cauchy distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mode or median of the distribution. scale: torch.Tensor Half width at half maximum. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#cauchy Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Cauchy_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Expectile","text":"","title":"Expectile"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile","text":"Bases: DistributionClass Expectile distribution class.","title":"Expectile"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile--distributional-parameters","text":"expectile: List List of specified expectiles.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". expectiles: List List of expectiles in increasing order. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. Source code in lightgbmlss/distributions/Expectile.py 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class Expectile ( DistributionClass ): \"\"\" Expectile distribution class. Distributional Parameters ------------------------- expectile: List List of specified expectiles. Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". expectiles: List List of expectiles in increasing order. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. \"\"\" def __init__ ( self , stabilization : str = \"None\" , expectiles : List = [ 0.1 , 0.5 , 0.9 ], penalize_crossing : bool = False , ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if not isinstance ( expectiles , list ): raise ValueError ( \"Expectiles must be a list.\" ) if not all ([ 0 < expectile < 1 for expectile in expectiles ]): raise ValueError ( \"Expectiles must be between 0 and 1.\" ) if not isinstance ( penalize_crossing , bool ): raise ValueError ( \"penalize_crossing must be a boolean. Please choose from True or False.\" ) # Set the parameters specific to the distribution distribution = Expectile_Torch torch . distributions . Distribution . set_default_validate_args ( False ) expectiles . sort () param_dict = {} for expectile in expectiles : key = f \"expectile_ { expectile } \" param_dict [ key ] = identity_fn # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = \"nll\" , tau = torch . tensor ( expectiles ), penalize_crossing = penalize_crossing )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile_Torch","text":"Bases: Distribution PyTorch implementation of expectiles.","title":"Expectile_Torch"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile_Torch--arguments","text":"expectiles : List[torch.Tensor] List of expectiles. penalize_crossing : bool Whether to include a penalty term to discourage crossing of expectiles. Source code in lightgbmlss/distributions/Expectile.py 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 class Expectile_Torch ( Distribution ): \"\"\" PyTorch implementation of expectiles. Arguments --------- expectiles : List[torch.Tensor] List of expectiles. penalize_crossing : bool Whether to include a penalty term to discourage crossing of expectiles. \"\"\" def __init__ ( self , expectiles : List [ torch . Tensor ], penalize_crossing : bool = False , ): super ( Expectile_Torch ) . __init__ () self . expectiles = expectiles self . penalize_crossing = penalize_crossing self . __class__ . __name__ = \"Expectile\" def log_prob ( self , value : torch . Tensor , tau : List [ torch . Tensor ]) -> torch . Tensor : \"\"\" Returns the log of the probability density function evaluated at `value`. Arguments --------- value : torch.Tensor Response for which log probability is to be calculated. tau : List[torch.Tensor] List of asymmetry parameters. Returns ------- torch.Tensor Log probability of `value`. \"\"\" value = value . reshape ( - 1 , 1 ) loss = torch . tensor ( 0.0 , dtype = torch . float32 ) penalty = torch . tensor ( 0.0 , dtype = torch . float32 ) # Calculate loss predt_expectiles = [] for expectile , tau_value in zip ( self . expectiles , tau ): weight = torch . where ( value - expectile >= 0 , tau_value , 1 - tau_value ) loss += torch . nansum ( weight * ( value - expectile ) ** 2 ) predt_expectiles . append ( expectile . reshape ( - 1 , 1 )) # Penalty term to discourage crossing of expectiles if self . penalize_crossing : predt_expectiles = torch . cat ( predt_expectiles , dim = 1 ) penalty = torch . mean ( ( ~ torch . all ( torch . diff ( predt_expectiles , dim = 1 ) > 0 , dim = 1 )) . float () ) loss = ( loss * ( 1 + penalty )) / len ( self . expectiles ) return - loss","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile_Torch.log_prob","text":"Returns the log of the probability density function evaluated at value .","title":"log_prob()"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile_Torch.log_prob--arguments","text":"value : torch.Tensor Response for which log probability is to be calculated. tau : List[torch.Tensor] List of asymmetry parameters.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.Expectile.Expectile_Torch.log_prob--returns","text":"torch.Tensor Log probability of value . Source code in lightgbmlss/distributions/Expectile.py 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 def log_prob ( self , value : torch . Tensor , tau : List [ torch . Tensor ]) -> torch . Tensor : \"\"\" Returns the log of the probability density function evaluated at `value`. Arguments --------- value : torch.Tensor Response for which log probability is to be calculated. tau : List[torch.Tensor] List of asymmetry parameters. Returns ------- torch.Tensor Log probability of `value`. \"\"\" value = value . reshape ( - 1 , 1 ) loss = torch . tensor ( 0.0 , dtype = torch . float32 ) penalty = torch . tensor ( 0.0 , dtype = torch . float32 ) # Calculate loss predt_expectiles = [] for expectile , tau_value in zip ( self . expectiles , tau ): weight = torch . where ( value - expectile >= 0 , tau_value , 1 - tau_value ) loss += torch . nansum ( weight * ( value - expectile ) ** 2 ) predt_expectiles . append ( expectile . reshape ( - 1 , 1 )) # Penalty term to discourage crossing of expectiles if self . penalize_crossing : predt_expectiles = torch . cat ( predt_expectiles , dim = 1 ) penalty = torch . mean ( ( ~ torch . all ( torch . diff ( predt_expectiles , dim = 1 ) > 0 , dim = 1 )) . float () ) loss = ( loss * ( 1 + penalty )) / len ( self . expectiles ) return - loss","title":"Returns"},{"location":"api/#lightgbmlss.distributions.Expectile.expectile_norm","text":"Calculates expectiles from Normal distribution for given tau values. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns np.ndarray Source code in lightgbmlss/distributions/Expectile.py 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 def expectile_norm ( tau : np . ndarray = 0.5 , m : np . ndarray = 0 , sd : np . ndarray = 1 ): \"\"\" Calculates expectiles from Normal distribution for given tau values. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments _________ tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns _______ np.ndarray \"\"\" tau [ tau > 1 or tau < 0 ] = np . nan zz = 0 * tau lower = np . array ( - 10 , dtype = \"float\" ) lower = np . repeat ( lower [ np . newaxis , ... ], len ( tau ), axis = 0 ) upper = np . array ( 10 , dtype = \"float\" ) upper = np . repeat ( upper [ np . newaxis , ... ], len ( tau ), axis = 0 ) diff = 1 index = 0 while ( diff > 1e-10 ) and ( index < 1000 ): root = expectile_pnorm ( zz ) - tau root [ np . isnan ( root )] = 0 lower [ root < 0 ] = zz [ root < 0 ] upper [ root > 0 ] = zz [ root > 0 ] zz = ( upper + lower ) / 2 diff = np . nanmax ( np . abs ( root )) index = index + 1 zz [ np . isnan ( tau )] = np . nan return zz * sd + m","title":"expectile_norm()"},{"location":"api/#lightgbmlss.distributions.Expectile.expectile_pnorm","text":"Normal Expectile Distribution Function. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns tau : np.ndarray Expectiles from the Normal distribution. Source code in lightgbmlss/distributions/Expectile.py 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 def expectile_pnorm ( tau : np . ndarray = 0.5 , m : np . ndarray = 0 , sd : np . ndarray = 1 ): \"\"\" Normal Expectile Distribution Function. For more details and distributions see https://rdrr.io/cran/expectreg/man/enorm.html Arguments _________ tau : np.ndarray Vector of expectiles from the respective distribution. m : np.ndarray Mean of the Normal distribution. sd : np.ndarray Standard deviation of the Normal distribution. Returns _______ tau : np.ndarray Expectiles from the Normal distribution. \"\"\" z = ( tau - m ) / sd p = norm . cdf ( z , loc = m , scale = sd ) d = norm . pdf ( z , loc = m , scale = sd ) u = - d - z * p tau = u / ( 2 * u + z ) return tau","title":"expectile_pnorm()"},{"location":"api/#lightgbmlss.distributions.Gamma","text":"","title":"Gamma"},{"location":"api/#lightgbmlss.distributions.Gamma.Gamma","text":"Bases: DistributionClass Gamma distribution class.","title":"Gamma"},{"location":"api/#lightgbmlss.distributions.Gamma.Gamma--distributional-parameters","text":"concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta)","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Gamma.Gamma--source","text":"https://pytorch.org/docs/stable/distributions.html#gamma","title":"Source"},{"location":"api/#lightgbmlss.distributions.Gamma.Gamma--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Gamma.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Gamma ( DistributionClass ): \"\"\" Gamma distribution class. Distributional Parameters -------------------------- concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) Source ------------------------- https://pytorch.org/docs/stable/distributions.html#gamma Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Gamma_Torch param_dict = { \"concentration\" : response_fn , \"rate\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Gaussian","text":"","title":"Gaussian"},{"location":"api/#lightgbmlss.distributions.Gaussian.Gaussian","text":"Bases: DistributionClass Gaussian distribution class.","title":"Gaussian"},{"location":"api/#lightgbmlss.distributions.Gaussian.Gaussian--distributional-parameters","text":"loc: torch.Tensor Mean of the distribution (often referred to as mu). scale: torch.Tensor Standard deviation of the distribution (often referred to as sigma).","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Gaussian.Gaussian--source","text":"https://pytorch.org/docs/stable/distributions.html#normal","title":"Source"},{"location":"api/#lightgbmlss.distributions.Gaussian.Gaussian--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Gaussian.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Gaussian ( DistributionClass ): \"\"\" Gaussian distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mean of the distribution (often referred to as mu). scale: torch.Tensor Standard deviation of the distribution (often referred to as sigma). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#normal Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Gaussian_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Gumbel","text":"","title":"Gumbel"},{"location":"api/#lightgbmlss.distributions.Gumbel.Gumbel","text":"Bases: DistributionClass Gumbel distribution class.","title":"Gumbel"},{"location":"api/#lightgbmlss.distributions.Gumbel.Gumbel--distributional-parameters","text":"loc: torch.Tensor Location parameter of the distribution. scale: torch.Tensor Scale parameter of the distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Gumbel.Gumbel--source","text":"https://pytorch.org/docs/stable/distributions.html#gumbel","title":"Source"},{"location":"api/#lightgbmlss.distributions.Gumbel.Gumbel--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Gumbel.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Gumbel ( DistributionClass ): \"\"\" Gumbel distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Location parameter of the distribution. scale: torch.Tensor Scale parameter of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#gumbel Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Gumbel_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Laplace","text":"","title":"Laplace"},{"location":"api/#lightgbmlss.distributions.Laplace.Laplace","text":"Bases: DistributionClass Laplace distribution class.","title":"Laplace"},{"location":"api/#lightgbmlss.distributions.Laplace.Laplace--distributional-parameters","text":"loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Laplace.Laplace--source","text":"https://pytorch.org/docs/stable/distributions.html#laplace","title":"Source"},{"location":"api/#lightgbmlss.distributions.Laplace.Laplace--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Laplace.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Laplace ( DistributionClass ): \"\"\" Laplace distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#laplace Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Laplace_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.LogNormal","text":"","title":"LogNormal"},{"location":"api/#lightgbmlss.distributions.LogNormal.LogNormal","text":"Bases: DistributionClass LogNormal distribution class.","title":"LogNormal"},{"location":"api/#lightgbmlss.distributions.LogNormal.LogNormal--distributional-parameters","text":"loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.LogNormal.LogNormal--source","text":"https://pytorch.org/docs/stable/distributions.html#lognormal","title":"Source"},{"location":"api/#lightgbmlss.distributions.LogNormal.LogNormal--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/LogNormal.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class LogNormal ( DistributionClass ): \"\"\" LogNormal distribution class. Distributional Parameters ------------------------- loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#lognormal Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = LogNormal_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.NegativeBinomial","text":"","title":"NegativeBinomial"},{"location":"api/#lightgbmlss.distributions.NegativeBinomial.NegativeBinomial","text":"Bases: DistributionClass NegativeBinomial distribution class.","title":"NegativeBinomial"},{"location":"api/#lightgbmlss.distributions.NegativeBinomial.NegativeBinomial--distributional-parameters","text":"total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds for probabilities of success.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.NegativeBinomial.NegativeBinomial--source","text":"https://pytorch.org/docs/stable/distributions.html#negativebinomial","title":"Source"},{"location":"api/#lightgbmlss.distributions.NegativeBinomial.NegativeBinomial--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/NegativeBinomial.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 class NegativeBinomial ( DistributionClass ): \"\"\" NegativeBinomial distribution class. Distributional Parameters ------------------------- total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds for probabilities of success. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#negativebinomial Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn_total_count : str = \"relu\" , response_fn_probs : str = \"sigmoid\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions for total_count response_functions_total_count = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn_total_count in response_functions_total_count : response_fn_total_count = response_functions_total_count [ response_fn_total_count ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Specify Response Functions for probs response_functions_probs = { \"sigmoid\" : sigmoid_fn } if response_fn_probs in response_functions_probs : response_fn_probs = response_functions_probs [ response_fn_probs ] else : raise ValueError ( \"Invalid response function for probs. Please select 'sigmoid'.\" ) # Set the parameters specific to the distribution distribution = NegativeBinomial_Torch param_dict = { \"total_count\" : response_fn_total_count , \"probs\" : response_fn_probs } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Poisson","text":"","title":"Poisson"},{"location":"api/#lightgbmlss.distributions.Poisson.Poisson","text":"Bases: DistributionClass Poisson distribution class.","title":"Poisson"},{"location":"api/#lightgbmlss.distributions.Poisson.Poisson--distributional-parameters","text":"rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda).","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Poisson.Poisson--source","text":"https://pytorch.org/docs/stable/distributions.html#poisson","title":"Source"},{"location":"api/#lightgbmlss.distributions.Poisson.Poisson--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/Poisson.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 class Poisson ( DistributionClass ): \"\"\" Poisson distribution class. Distributional Parameters ------------------------- rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#poisson Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"relu\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Set the parameters specific to the distribution distribution = Poisson_Torch param_dict = { \"rate\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.SplineFlow","text":"","title":"SplineFlow"},{"location":"api/#lightgbmlss.distributions.SplineFlow.SplineFlow","text":"Bases: NormalizingFlowClass Spline Flow class. The spline flow is a normalizing flow based on element-wise rational spline bijections of linear and quadratic order (Durkan et al., 2019; Dolatabadi et al., 2020). Rational splines are functions that are comprised of segments that are the ratio of two polynomials. Rational splines offer an excellent combination of functional flexibility whilst maintaining a numerically stable inverse. For more details, see: - Durkan, C., Bekasov, A., Murray, I. and Papamakarios, G. Neural Spline Flows. NeurIPS 2019. - Dolatabadi, H. M., Erfani, S. and Leckie, C., Invertible Generative Modeling using Linear Rational Splines. AISTATS 2020.","title":"SplineFlow"},{"location":"api/#lightgbmlss.distributions.SplineFlow.SplineFlow--source","text":"https://docs.pyro.ai/en/stable/distributions.html#pyro.distributions.transforms.Spline","title":"Source"},{"location":"api/#lightgbmlss.distributions.SplineFlow.SplineFlow--arguments","text":"target_support: str The target support. Options are - \"real\": [-inf, inf] - \"positive\": [0, inf] - \"positive_integer\": [0, 1, 2, 3, ...] - \"unit_interval\": [0, 1] count_bins: int The number of segments comprising the spline. bound: float The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. order: str The order of the spline. Options are \"linear\" or \"quadratic\". stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/SplineFlow.py 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 class SplineFlow ( NormalizingFlowClass ): \"\"\" Spline Flow class. The spline flow is a normalizing flow based on element-wise rational spline bijections of linear and quadratic order (Durkan et al., 2019; Dolatabadi et al., 2020). Rational splines are functions that are comprised of segments that are the ratio of two polynomials. Rational splines offer an excellent combination of functional flexibility whilst maintaining a numerically stable inverse. For more details, see: - Durkan, C., Bekasov, A., Murray, I. and Papamakarios, G. Neural Spline Flows. NeurIPS 2019. - Dolatabadi, H. M., Erfani, S. and Leckie, C., Invertible Generative Modeling using Linear Rational Splines. AISTATS 2020. Source --------- https://docs.pyro.ai/en/stable/distributions.html#pyro.distributions.transforms.Spline Arguments --------- target_support: str The target support. Options are - \"real\": [-inf, inf] - \"positive\": [0, inf] - \"positive_integer\": [0, 1, 2, 3, ...] - \"unit_interval\": [0, 1] count_bins: int The number of segments comprising the spline. bound: float The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. order: str The order of the spline. Options are \"linear\" or \"quadratic\". stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , target_support : str = \"real\" , count_bins : int = 8 , bound : float = 3.0 , order : str = \"linear\" , stabilization : str = \"None\" , loss_fn : str = \"nll\" ): # Specify Target Transform if not isinstance ( target_support , str ): raise ValueError ( \"target_support must be a string.\" ) transforms = { \"real\" : ( identity_transform , False ), \"positive\" : ( SoftplusTransform (), False ), \"positive_integer\" : ( SoftplusTransform (), True ), \"unit_interval\" : ( SigmoidTransform (), False ) } if target_support in transforms : target_transform , discrete = transforms [ target_support ] else : raise ValueError ( \"Invalid target_support. Options are 'real', 'positive', 'positive_integer', or 'unit_interval'.\" ) # Check if count_bins is valid if not isinstance ( count_bins , int ): raise ValueError ( \"count_bins must be an integer.\" ) if count_bins <= 0 : raise ValueError ( \"count_bins must be a positive integer > 0.\" ) # Check if bound is float if not isinstance ( bound , float ): raise ValueError ( \"bound must be a float.\" ) # Number of parameters if not isinstance ( order , str ): raise ValueError ( \"order must be a string.\" ) order_params = { \"quadratic\" : 2 * count_bins + ( count_bins - 1 ), \"linear\" : 3 * count_bins + ( count_bins - 1 ) } if order in order_params : n_params = order_params [ order ] else : raise ValueError ( \"Invalid order specification. Options are 'linear' or 'quadratic'.\" ) # Check if stabilization method is valid. if not isinstance ( stabilization , str ): raise ValueError ( \"stabilization must be a string.\" ) if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Options are 'None', 'MAD' or 'L2'.\" ) # Check if loss function is valid. if not isinstance ( loss_fn , str ): raise ValueError ( \"loss_fn must be a string.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss_fn. Options are 'nll' or 'crps'.\" ) # Specify parameter dictionary param_dict = { f \"param_ { i + 1 } \" : identity_fn for i in range ( n_params )} torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Normalizing Flow Class super () . __init__ ( base_dist = Normal , # Base distribution, currently only Normal is supported. flow_transform = Spline , count_bins = count_bins , bound = bound , order = order , n_dist_param = n_params , param_dict = param_dict , target_transform = target_transform , discrete = discrete , univariate = True , stabilization = stabilization , loss_fn = loss_fn )","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.StudentT","text":"","title":"StudentT"},{"location":"api/#lightgbmlss.distributions.StudentT.StudentT","text":"Bases: DistributionClass Student-T Distribution Class","title":"StudentT"},{"location":"api/#lightgbmlss.distributions.StudentT.StudentT--distributional-parameters","text":"df: torch.Tensor Degrees of freedom. loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.StudentT.StudentT--source","text":"https://pytorch.org/docs/stable/distributions.html#studentt","title":"Source"},{"location":"api/#lightgbmlss.distributions.StudentT.StudentT--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/StudentT.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 class StudentT ( DistributionClass ): \"\"\" Student-T Distribution Class Distributional Parameters ------------------------- df: torch.Tensor Degrees of freedom. loc: torch.Tensor Mean of the distribution. scale: torch.Tensor Scale of the distribution. Source ------------------------- https://pytorch.org/docs/stable/distributions.html#studentt Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : ( exp_fn , exp_fn_df ), \"softplus\" : ( softplus_fn , softplus_fn_df ) } if response_fn in response_functions : response_fn , response_fn_df = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = StudentT_Torch param_dict = { \"df\" : response_fn_df , \"loc\" : identity_fn , \"scale\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.Weibull","text":"","title":"Weibull"},{"location":"api/#lightgbmlss.distributions.Weibull.Weibull","text":"Bases: DistributionClass Weibull distribution class.","title":"Weibull"},{"location":"api/#lightgbmlss.distributions.Weibull.Weibull--distributional-parameters","text":"scale: torch.Tensor Scale parameter of distribution (lambda). concentration: torch.Tensor Concentration parameter of distribution (k/shape).","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.Weibull.Weibull--source","text":"https://pytorch.org/docs/stable/distributions.html#weibull","title":"Source"},{"location":"api/#lightgbmlss.distributions.Weibull.Weibull--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/Weibull.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Weibull ( DistributionClass ): \"\"\" Weibull distribution class. Distributional Parameters ------------------------- scale: torch.Tensor Scale parameter of distribution (lambda). concentration: torch.Tensor Concentration parameter of distribution (k/shape). Source ------------------------- https://pytorch.org/docs/stable/distributions.html#weibull Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" , \"crps\" ]: raise ValueError ( \"Invalid loss function. Please choose from 'nll' or 'crps'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = Weibull_Torch param_dict = { \"scale\" : response_fn , \"concentration\" : response_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.ZABeta","text":"","title":"ZABeta"},{"location":"api/#lightgbmlss.distributions.ZABeta.ZABeta","text":"Bases: DistributionClass Zero-Adjusted Beta distribution class. The zero-adjusted Beta distribution is similar to the Beta distribution but allows zeros as y values.","title":"ZABeta"},{"location":"api/#lightgbmlss.distributions.ZABeta.ZABeta--distributional-parameters","text":"concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.ZABeta.ZABeta--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py","title":"Source"},{"location":"api/#lightgbmlss.distributions.ZABeta.ZABeta--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZABeta.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class ZABeta ( DistributionClass ): \"\"\" Zero-Adjusted Beta distribution class. The zero-adjusted Beta distribution is similar to the Beta distribution but allows zeros as y values. Distributional Parameters ------------------------- concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = ZeroAdjustedBeta_Torch param_dict = { \"concentration1\" : response_fn , \"concentration0\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.ZAGamma","text":"","title":"ZAGamma"},{"location":"api/#lightgbmlss.distributions.ZAGamma.ZAGamma","text":"Bases: DistributionClass Zero-Adjusted Gamma distribution class. The zero-adjusted Gamma distribution is similar to the Gamma distribution but allows zeros as y values.","title":"ZAGamma"},{"location":"api/#lightgbmlss.distributions.ZAGamma.ZAGamma--distributional-parameters","text":"concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.ZAGamma.ZAGamma--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150","title":"Source"},{"location":"api/#lightgbmlss.distributions.ZAGamma.ZAGamma--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZAGamma.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class ZAGamma ( DistributionClass ): \"\"\" Zero-Adjusted Gamma distribution class. The zero-adjusted Gamma distribution is similar to the Gamma distribution but allows zeros as y values. Distributional Parameters -------------------------- concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = ZeroAdjustedGamma_Torch param_dict = { \"concentration\" : response_fn , \"rate\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.ZALN","text":"","title":"ZALN"},{"location":"api/#lightgbmlss.distributions.ZALN.ZALN","text":"Bases: DistributionClass Zero-Adjusted LogNormal distribution class. The zero-adjusted Log-Normal distribution is similar to the Log-Normal distribution but allows zeros as y values.","title":"ZALN"},{"location":"api/#lightgbmlss.distributions.ZALN.ZALN--distributional-parameters","text":"loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.ZALN.ZALN--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150","title":"Source"},{"location":"api/#lightgbmlss.distributions.ZALN.ZALN--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZALN.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 class ZALN ( DistributionClass ): \"\"\" Zero-Adjusted LogNormal distribution class. The zero-adjusted Log-Normal distribution is similar to the Log-Normal distribution but allows zeros as y values. Distributional Parameters ------------------------- loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential) or \"softplus\" (softplus). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"exp\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function. Please choose from 'exp' or 'softplus'.\" ) # Set the parameters specific to the distribution distribution = ZeroAdjustedLogNormal_Torch param_dict = { \"loc\" : identity_fn , \"scale\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = False , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.ZINB","text":"","title":"ZINB"},{"location":"api/#lightgbmlss.distributions.ZINB.ZINB","text":"Bases: DistributionClass Zero-Inflated Negative Binomial distribution class.","title":"ZINB"},{"location":"api/#lightgbmlss.distributions.ZINB.ZINB--distributional-parameters","text":"total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.ZINB.ZINB--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150","title":"Source"},{"location":"api/#lightgbmlss.distributions.ZINB.ZINB--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZINB.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 class ZINB ( DistributionClass ): \"\"\" Zero-Inflated Negative Binomial distribution class. Distributional Parameters ------------------------- total_count: torch.Tensor Non-negative number of negative Bernoulli trials to stop. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn_total_count: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). response_fn_probs: str Response function for transforming the distributional parameters to the correct support. Options are \"sigmoid\" (sigmoid). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn_total_count : str = \"relu\" , response_fn_probs : str = \"sigmoid\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions for total_count response_functions_total_count = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn_total_count in response_functions_total_count : response_fn_total_count = response_functions_total_count [ response_fn_total_count ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Specify Response Functions for probs response_functions_probs = { \"sigmoid\" : sigmoid_fn } if response_fn_probs in response_functions_probs : response_fn_probs = response_functions_probs [ response_fn_probs ] else : raise ValueError ( \"Invalid response function for probs. Please select 'sigmoid'.\" ) # Set the parameters specific to the distribution distribution = ZeroInflatedNegativeBinomial_Torch param_dict = { \"total_count\" : response_fn_total_count , \"probs\" : response_fn_probs , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.ZIPoisson","text":"","title":"ZIPoisson"},{"location":"api/#lightgbmlss.distributions.ZIPoisson.ZIPoisson","text":"Bases: DistributionClass Zero-Inflated Poisson distribution class.","title":"ZIPoisson"},{"location":"api/#lightgbmlss.distributions.ZIPoisson.ZIPoisson--distributional-parameters","text":"rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution.","title":"Distributional Parameters"},{"location":"api/#lightgbmlss.distributions.ZIPoisson.ZIPoisson--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121","title":"Source"},{"location":"api/#lightgbmlss.distributions.ZIPoisson.ZIPoisson--parameters","text":"stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). Source code in lightgbmlss/distributions/ZIPoisson.py 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 class ZIPoisson ( DistributionClass ): \"\"\" Zero-Inflated Poisson distribution class. Distributional Parameters ------------------------- rate: torch.Tensor Rate parameter of the distribution (often referred to as lambda). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------------------------- https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121 Parameters ------------------------- stabilization: str Stabilization method for the Gradient and Hessian. Options are \"None\", \"MAD\", \"L2\". response_fn: str Response function for transforming the distributional parameters to the correct support. Options are \"exp\" (exponential), \"softplus\" (softplus) or \"relu\" (rectified linear unit). loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood). \"\"\" def __init__ ( self , stabilization : str = \"None\" , response_fn : str = \"relu\" , loss_fn : str = \"nll\" ): # Input Checks if stabilization not in [ \"None\" , \"MAD\" , \"L2\" ]: raise ValueError ( \"Invalid stabilization method. Please choose from 'None', 'MAD' or 'L2'.\" ) if loss_fn not in [ \"nll\" ]: raise ValueError ( \"Invalid loss function. Please select 'nll'.\" ) # Specify Response Functions response_functions = { \"exp\" : exp_fn , \"softplus\" : softplus_fn , \"relu\" : relu_fn } if response_fn in response_functions : response_fn = response_functions [ response_fn ] else : raise ValueError ( \"Invalid response function for total_count. Please choose from 'exp', 'softplus' or 'relu'.\" ) # Set the parameters specific to the distribution distribution = ZeroInflatedPoisson_Torch param_dict = { \"rate\" : response_fn , \"gate\" : sigmoid_fn } torch . distributions . Distribution . set_default_validate_args ( False ) # Specify Distribution Class super () . __init__ ( distribution = distribution , univariate = True , discrete = True , n_dist_param = len ( param_dict ), stabilization = stabilization , param_dict = param_dict , distribution_arg_names = list ( param_dict . keys ()), loss_fn = loss_fn )","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.distribution_utils","text":"","title":"distribution_utils"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass","text":"Generic class that contains general functions for univariate distributions.","title":"DistributionClass"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass--arguments","text":"distribution: torch.distributions.Distribution PyTorch Distribution class. univariate: bool Whether the distribution is univariate or multivariate. discrete: bool Whether the support of the distribution is discrete or continuous. n_dist_param: int Number of distributional parameters. stabilization: str Stabilization method. param_dict: Dict[str, Any] Dictionary that maps distributional parameters to their response scale. distribution_arg_names: List List of distributional parameter names. loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. tau: List List of expectiles. Only used for Expectile distributon. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. Only used for Expectile distribution. Source code in lightgbmlss/distributions/distribution_utils.py 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 class DistributionClass : \"\"\" Generic class that contains general functions for univariate distributions. Arguments --------- distribution: torch.distributions.Distribution PyTorch Distribution class. univariate: bool Whether the distribution is univariate or multivariate. discrete: bool Whether the support of the distribution is discrete or continuous. n_dist_param: int Number of distributional parameters. stabilization: str Stabilization method. param_dict: Dict[str, Any] Dictionary that maps distributional parameters to their response scale. distribution_arg_names: List List of distributional parameter names. loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. tau: List List of expectiles. Only used for Expectile distributon. penalize_crossing: bool Whether to include a penalty term to discourage crossing of expectiles. Only used for Expectile distribution. \"\"\" def __init__ ( self , distribution : torch . distributions . Distribution = None , univariate : bool = True , discrete : bool = False , n_dist_param : int = None , stabilization : str = \"None\" , param_dict : Dict [ str , Any ] = None , distribution_arg_names : List = None , loss_fn : str = \"nll\" , tau : Optional [ List [ torch . Tensor ]] = None , penalize_crossing : bool = False , ): self . distribution = distribution self . univariate = univariate self . discrete = discrete self . n_dist_param = n_dist_param self . stabilization = stabilization self . param_dict = param_dict self . distribution_arg_names = distribution_arg_names self . loss_fn = loss_fn self . tau = tau self . penalize_crossing = penalize_crossing def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of distributional parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.DMatrix Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values , requires_grad = True ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the negative log-likelihood. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. nll: float Negative log-likelihood. is_higher_better: bool Whether a higher value of the metric is better or not. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values , requires_grad = False ) return self . loss_fn , loss , is_higher_better def loss_fn_start_values ( self , params : torch . Tensor , target : torch . Tensor ) -> torch . Tensor : \"\"\" Function that calculates the loss for a given set of distributional parameters. Only used for calculating the loss for the start values. Parameter --------- params: torch.Tensor Distributional parameters. target: torch.Tensor Target values. Returns ------- loss: torch.Tensor Loss value. \"\"\" # Transform parameters to response scale params = [ response_fn ( params [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Replace NaNs and infinity values with 0.5 nan_inf_idx = torch . isnan ( torch . stack ( params )) | torch . isinf ( torch . stack ( params )) params = torch . where ( nan_inf_idx , torch . tensor ( 0.5 ), torch . stack ( params )) # Specify Distribution and Loss if self . tau is None : dist = self . distribution ( * params ) loss = - torch . nansum ( dist . log_prob ( target )) else : dist = self . distribution ( params , self . penalize_crossing ) loss = - torch . nansum ( dist . log_prob ( target , self . tau )) return loss def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates the starting values for each distributional parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each distributional parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Initialize parameters params = [ torch . tensor ( 0.5 , requires_grad = True ) for _ in range ( self . n_dist_param )] # Specify optimizer optimizer = LBFGS ( params , lr = 0.1 , max_iter = np . min ([ int ( max_iter / 4 ), 20 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 10 ) # Define closure def closure (): optimizer . zero_grad () loss = self . loss_fn_start_values ( params , target ) loss . backward () return loss # Optimize parameters loss_vals = [] for epoch in range ( max_iter ): loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = np . array ([ params [ i ] . detach () for i in range ( self . n_dist_param )]) # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each distributional parameter. requires_grad: bool Whether to add to the computational graph or not. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = [ torch . tensor ( predt [:, i ] . reshape ( - 1 , 1 ), requires_grad = requires_grad ) for i in range ( self . n_dist_param ) ] # Predicted Parameters transformed to response scale predt_transformed = [ response_fn ( predt [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Specify Distribution and Loss if self . tau is None : dist_kwargs = dict ( zip ( self . distribution_arg_names , predt_transformed )) dist_fit = self . distribution ( ** dist_kwargs ) if self . loss_fn == \"nll\" : loss = - torch . nansum ( dist_fit . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = dist_fit . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) else : dist_fit = self . distribution ( predt_transformed , self . penalize_crossing ) loss = - torch . nansum ( dist_fit . log_prob ( target , self . tau )) return predt , loss def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) if self . tau is None : pred_params = torch . tensor ( predt_params . values ) dist_kwargs = { arg_name : param for arg_name , param in zip ( self . distribution_arg_names , pred_params . T )} dist_pred = self . distribution ( ** dist_kwargs ) dist_samples = dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T dist_samples = pd . DataFrame ( dist_samples ) dist_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( dist_samples . shape [ 1 ])] else : dist_samples = None if self . discrete : dist_samples = dist_samples . astype ( int ) return dist_samples def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. data : pd.DataFrame Data to predict from. start_values : np.ndarray. Starting values for each distributional parameter. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. # Hence, it needs to be added manually with the corresponding transform for each distributional parameter. dist_params_predt = np . concatenate ( [ response_fun ( predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( self . param_dict . items ()) ], axis = 1 , ) dist_params_predt = pd . DataFrame ( dist_params_predt ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"expectiles\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # # Approximation of Hessian # step_size = 1e-6 # predt_upper = [ # response_fn(predt[i] + step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_upper = dict(zip(self.distribution_arg_names, predt_upper)) # dist_fit_upper = self.distribution(**dist_kwargs_upper) # dist_samples_upper = dist_fit_upper.rsample((30,)).squeeze(-1) # loss_upper = torch.nansum(self.crps_score(self.target, dist_samples_upper)) # # predt_lower = [ # response_fn(predt[i] - step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_lower = dict(zip(self.distribution_arg_names, predt_lower)) # dist_fit_lower = self.distribution(**dist_kwargs_lower) # dist_samples_lower = dist_fit_lower.rsample((30,)).squeeze(-1) # loss_lower = torch.nansum(self.crps_score(self.target, dist_samples_lower)) # # grad_upper = autograd(loss_upper, inputs=predt_upper) # grad_lower = autograd(loss_lower, inputs=predt_lower) # hess = [(grad_upper[i] - grad_lower[i]) / (2 * step_size) for i in range(len(grad))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. As LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source: https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Parameters ---------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns ------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Parameters ---------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns ------- crps: torch.Tensor CRPS score. References ---------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source ------ https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps def dist_select ( self , target : np . ndarray , candidate_distributions : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable distribution among the candidate_distributions for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_distributions: List List of candidate distributions. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples to draw from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted candidate distributions. \"\"\" dist_list = [] total_iterations = len ( candidate_distributions ) with tqdm ( total = total_iterations , desc = \"Fitting candidate distributions\" ) as pbar : for i in range ( len ( candidate_distributions )): dist_name = candidate_distributions [ i ] . __name__ . split ( \".\" )[ 2 ] pbar . set_description ( f \"Fitting { dist_name } distribution\" ) dist_sel = getattr ( candidate_distributions [ i ], dist_name )() try : loss , params = dist_sel . calculate_start_values ( target = target . reshape ( - 1 , 1 ), max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { self . loss_fn : loss . reshape ( - 1 ,), \"distribution\" : str ( dist_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { dist_name } distribution: { str ( e ) } \" ) fit_df = pd . DataFrame ( { self . loss_fn : np . nan , \"distribution\" : str ( dist_name ), \"params\" : [ np . nan ] * self . n_dist_param } ) dist_list . append ( fit_df ) fit_df = pd . concat ( dist_list ) . sort_values ( by = self . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ self . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate distributions completed\" ) if plot : # Select best distribution best_dist = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for dist in candidate_distributions : if dist . __name__ . split ( \".\" )[ 2 ] == best_dist [ \"distribution\" ] . values [ 0 ]: best_dist_sel = dist break best_dist_sel = getattr ( best_dist_sel , best_dist [ \"distribution\" ] . values [ 0 ])() params = torch . tensor ( best_dist [ \"params\" ][ 0 ]) . reshape ( - 1 , best_dist_sel . n_dist_param ) # Transform parameters to the response scale and draw samples fitted_params = np . concatenate ( [ response_fun ( params [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( best_dist_sel . param_dict . items ()) ], axis = 1 , ) fitted_params = pd . DataFrame ( fitted_params , columns = best_dist_sel . param_dict . keys ()) fitted_params . columns = best_dist_sel . param_dict . keys () dist_samples = best_dist_sel . draw_samples ( fitted_params , n_samples = n_samples , seed = 123 ) . values # Plot actual and fitted distribution plot_df_actual = pd . DataFrame ({ \"y\" : target . reshape ( - 1 ,), \"type\" : \"Actual\" }) plot_df_fitted = pd . DataFrame ({ \"y\" : dist_samples . reshape ( - 1 ,), \"type\" : f \"Best-Fit: { best_dist [ 'distribution' ] . values [ 0 ] } \" }) plot_df = pd . concat ([ plot_df_actual , plot_df_fitted ]) print ( ggplot ( plot_df , aes ( x = \"y\" , color = \"type\" )) + geom_density ( alpha = 0.5 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.calculate_start_values","text":"Function that calculates the starting values for each distributional parameter.","title":"calculate_start_values()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.calculate_start_values--arguments","text":"target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.calculate_start_values--returns","text":"loss: float Loss value. start_values: np.ndarray Starting values for each distributional parameter. Source code in lightgbmlss/distributions/distribution_utils.py 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates the starting values for each distributional parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each distributional parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Initialize parameters params = [ torch . tensor ( 0.5 , requires_grad = True ) for _ in range ( self . n_dist_param )] # Specify optimizer optimizer = LBFGS ( params , lr = 0.1 , max_iter = np . min ([ int ( max_iter / 4 ), 20 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 10 ) # Define closure def closure (): optimizer . zero_grad () loss = self . loss_fn_start_values ( params , target ) loss . backward () return loss # Optimize parameters loss_vals = [] for epoch in range ( max_iter ): loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = np . array ([ params [ i ] . detach () for i in range ( self . n_dist_param )]) # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.compute_gradients_and_hessians","text":"Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1).","title":"compute_gradients_and_hessians()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.compute_gradients_and_hessians--arguments","text":"loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights.","title":"Arguments:"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.compute_gradients_and_hessians--returns","text":"grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. Source code in lightgbmlss/distributions/distribution_utils.py 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # # Approximation of Hessian # step_size = 1e-6 # predt_upper = [ # response_fn(predt[i] + step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_upper = dict(zip(self.distribution_arg_names, predt_upper)) # dist_fit_upper = self.distribution(**dist_kwargs_upper) # dist_samples_upper = dist_fit_upper.rsample((30,)).squeeze(-1) # loss_upper = torch.nansum(self.crps_score(self.target, dist_samples_upper)) # # predt_lower = [ # response_fn(predt[i] - step_size).reshape(-1, 1) for i, response_fn in # enumerate(self.param_dict.values()) # ] # dist_kwargs_lower = dict(zip(self.distribution_arg_names, predt_lower)) # dist_fit_lower = self.distribution(**dist_kwargs_lower) # dist_samples_lower = dist_fit_lower.rsample((30,)).squeeze(-1) # loss_lower = torch.nansum(self.crps_score(self.target, dist_samples_lower)) # # grad_upper = autograd(loss_upper, inputs=predt_upper) # grad_lower = autograd(loss_lower, inputs=predt_lower) # hess = [(grad_upper[i] - grad_lower[i]) / (2 * step_size) for i in range(len(grad))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess","title":"Returns:"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.crps_score","text":"Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples.","title":"crps_score()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.crps_score--parameters","text":"y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations).","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.crps_score--returns","text":"crps: torch.Tensor CRPS score.","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.crps_score--references","text":"Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378.","title":"References"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.crps_score--source","text":"https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 Source code in lightgbmlss/distributions/distribution_utils.py 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Parameters ---------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns ------- crps: torch.Tensor CRPS score. References ---------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source ------ https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps","title":"Source"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.dist_select","text":"Function that selects the most suitable distribution among the candidate_distributions for the target variable, based on the NegLogLikelihood (lower is better).","title":"dist_select()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.dist_select--parameters","text":"target: np.ndarray Response variable. candidate_distributions: List List of candidate distributions. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples to draw from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot.","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.dist_select--returns","text":"fit_df: pd.DataFrame Dataframe with the loss values of the fitted candidate distributions. Source code in lightgbmlss/distributions/distribution_utils.py 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 def dist_select ( self , target : np . ndarray , candidate_distributions : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable distribution among the candidate_distributions for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_distributions: List List of candidate distributions. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples to draw from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted candidate distributions. \"\"\" dist_list = [] total_iterations = len ( candidate_distributions ) with tqdm ( total = total_iterations , desc = \"Fitting candidate distributions\" ) as pbar : for i in range ( len ( candidate_distributions )): dist_name = candidate_distributions [ i ] . __name__ . split ( \".\" )[ 2 ] pbar . set_description ( f \"Fitting { dist_name } distribution\" ) dist_sel = getattr ( candidate_distributions [ i ], dist_name )() try : loss , params = dist_sel . calculate_start_values ( target = target . reshape ( - 1 , 1 ), max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { self . loss_fn : loss . reshape ( - 1 ,), \"distribution\" : str ( dist_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { dist_name } distribution: { str ( e ) } \" ) fit_df = pd . DataFrame ( { self . loss_fn : np . nan , \"distribution\" : str ( dist_name ), \"params\" : [ np . nan ] * self . n_dist_param } ) dist_list . append ( fit_df ) fit_df = pd . concat ( dist_list ) . sort_values ( by = self . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ self . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate distributions completed\" ) if plot : # Select best distribution best_dist = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for dist in candidate_distributions : if dist . __name__ . split ( \".\" )[ 2 ] == best_dist [ \"distribution\" ] . values [ 0 ]: best_dist_sel = dist break best_dist_sel = getattr ( best_dist_sel , best_dist [ \"distribution\" ] . values [ 0 ])() params = torch . tensor ( best_dist [ \"params\" ][ 0 ]) . reshape ( - 1 , best_dist_sel . n_dist_param ) # Transform parameters to the response scale and draw samples fitted_params = np . concatenate ( [ response_fun ( params [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( best_dist_sel . param_dict . items ()) ], axis = 1 , ) fitted_params = pd . DataFrame ( fitted_params , columns = best_dist_sel . param_dict . keys ()) fitted_params . columns = best_dist_sel . param_dict . keys () dist_samples = best_dist_sel . draw_samples ( fitted_params , n_samples = n_samples , seed = 123 ) . values # Plot actual and fitted distribution plot_df_actual = pd . DataFrame ({ \"y\" : target . reshape ( - 1 ,), \"type\" : \"Actual\" }) plot_df_fitted = pd . DataFrame ({ \"y\" : dist_samples . reshape ( - 1 ,), \"type\" : f \"Best-Fit: { best_dist [ 'distribution' ] . values [ 0 ] } \" }) plot_df = pd . concat ([ plot_df_actual , plot_df_fitted ]) print ( ggplot ( plot_df , aes ( x = \"y\" , color = \"type\" )) + geom_density ( alpha = 0.5 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.draw_samples","text":"Function that draws n_samples from a predicted distribution.","title":"draw_samples()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.draw_samples--arguments","text":"predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.draw_samples--returns","text":"pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. Source code in lightgbmlss/distributions/distribution_utils.py 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) if self . tau is None : pred_params = torch . tensor ( predt_params . values ) dist_kwargs = { arg_name : param for arg_name , param in zip ( self . distribution_arg_names , pred_params . T )} dist_pred = self . distribution ( ** dist_kwargs ) dist_samples = dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T dist_samples = pd . DataFrame ( dist_samples ) dist_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( dist_samples . shape [ 1 ])] else : dist_samples = None if self . discrete : dist_samples = dist_samples . astype ( int ) return dist_samples","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.get_params_loss","text":"Function that returns the predicted parameters and the loss.","title":"get_params_loss()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.get_params_loss--arguments","text":"predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each distributional parameter. requires_grad: bool Whether to add to the computational graph or not.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.get_params_loss--returns","text":"predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. Source code in lightgbmlss/distributions/distribution_utils.py 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each distributional parameter. requires_grad: bool Whether to add to the computational graph or not. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = [ torch . tensor ( predt [:, i ] . reshape ( - 1 , 1 ), requires_grad = requires_grad ) for i in range ( self . n_dist_param ) ] # Predicted Parameters transformed to response scale predt_transformed = [ response_fn ( predt [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Specify Distribution and Loss if self . tau is None : dist_kwargs = dict ( zip ( self . distribution_arg_names , predt_transformed )) dist_fit = self . distribution ( ** dist_kwargs ) if self . loss_fn == \"nll\" : loss = - torch . nansum ( dist_fit . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = dist_fit . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) else : dist_fit = self . distribution ( predt_transformed , self . penalize_crossing ) loss = - torch . nansum ( dist_fit . log_prob ( target , self . tau )) return predt , loss","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.loss_fn_start_values","text":"Function that calculates the loss for a given set of distributional parameters. Only used for calculating the loss for the start values.","title":"loss_fn_start_values()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.loss_fn_start_values--parameter","text":"params: torch.Tensor Distributional parameters. target: torch.Tensor Target values.","title":"Parameter"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.loss_fn_start_values--returns","text":"loss: torch.Tensor Loss value. Source code in lightgbmlss/distributions/distribution_utils.py 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 def loss_fn_start_values ( self , params : torch . Tensor , target : torch . Tensor ) -> torch . Tensor : \"\"\" Function that calculates the loss for a given set of distributional parameters. Only used for calculating the loss for the start values. Parameter --------- params: torch.Tensor Distributional parameters. target: torch.Tensor Target values. Returns ------- loss: torch.Tensor Loss value. \"\"\" # Transform parameters to response scale params = [ response_fn ( params [ i ] . reshape ( - 1 , 1 )) for i , response_fn in enumerate ( self . param_dict . values ()) ] # Replace NaNs and infinity values with 0.5 nan_inf_idx = torch . isnan ( torch . stack ( params )) | torch . isinf ( torch . stack ( params )) params = torch . where ( nan_inf_idx , torch . tensor ( 0.5 ), torch . stack ( params )) # Specify Distribution and Loss if self . tau is None : dist = self . distribution ( * params ) loss = - torch . nansum ( dist . log_prob ( target )) else : dist = self . distribution ( params , self . penalize_crossing ) loss = - torch . nansum ( dist . log_prob ( target , self . tau )) return loss","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.metric_fn","text":"Function that evaluates the predictions using the negative log-likelihood.","title":"metric_fn()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.metric_fn--arguments","text":"predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.metric_fn--returns","text":"name: str Name of the evaluation metric. nll: float Negative log-likelihood. is_higher_better: bool Whether a higher value of the metric is better or not. Source code in lightgbmlss/distributions/distribution_utils.py 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the negative log-likelihood. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. nll: float Negative log-likelihood. is_higher_better: bool Whether a higher value of the metric is better or not. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values , requires_grad = False ) return self . loss_fn , loss , is_higher_better","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.objective_fn","text":"Function to estimate gradients and hessians of distributional parameters.","title":"objective_fn()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.objective_fn--arguments","text":"predt: np.ndarray Predicted values. data: lgb.DMatrix Data used for training.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.objective_fn--returns","text":"grad: np.ndarray Gradient. hess: np.ndarray Hessian. Source code in lightgbmlss/distributions/distribution_utils.py 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of distributional parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.DMatrix Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values , requires_grad = True ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.predict_dist","text":"Function that predicts from the trained model.","title":"predict_dist()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.predict_dist--arguments","text":"booster : lgb.Booster Trained model. data : pd.DataFrame Data to predict from. start_values : np.ndarray. Starting values for each distributional parameter. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.predict_dist--returns","text":"pred : pd.DataFrame Predictions. Source code in lightgbmlss/distributions/distribution_utils.py 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. data : pd.DataFrame Data to predict from. start_values : np.ndarray. Starting values for each distributional parameter. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. # Hence, it needs to be added manually with the corresponding transform for each distributional parameter. dist_params_predt = np . concatenate ( [ response_fun ( predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 )) . numpy () for i , ( dist_param , response_fun ) in enumerate ( self . param_dict . items ()) ], axis = 1 , ) dist_params_predt = pd . DataFrame ( dist_params_predt ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"expectiles\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df","title":"Returns"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.stabilize_derivative","text":"Function that stabilizes Gradients and Hessians. As LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source: https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173","title":"stabilize_derivative()"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.stabilize_derivative--parameters","text":"input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\".","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.distribution_utils.DistributionClass.stabilize_derivative--returns","text":"stab_der : torch.Tensor Stabilized Gradient or Hessian. Source code in lightgbmlss/distributions/distribution_utils.py 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. As LightGBMLSS updates the parameter estimates by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all distributional parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source: https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Parameters ---------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns ------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils","text":"","title":"flow_utils"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass","text":"Generic class that contains general functions for normalizing flows.","title":"NormalizingFlowClass"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass--arguments","text":"base_dist: torch.distributions.Distribution PyTorch Distribution class. Currently only Normal is supported. flow_transform: Transform Specify the normalizing flow transform. count_bins: Optional[int] The number of segments comprising the spline. Only used if flow_transform is Spline. bound: Optional[float] The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. Only used if flow_transform is Spline. order: Optional[str] The order of the spline. Options are \"linear\" or \"quadratic\". Only used if flow_transform is Spline. n_dist_param: int Number of parameters. param_dict: Dict[str, Any] Dictionary that maps parameters to their response scale. target_transform: Transform Specify the target transform. discrete: bool Whether the target is discrete or not. univariate: bool Whether the distribution is univariate or multivariate. stabilization: str Stabilization method. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. Source code in lightgbmlss/distributions/flow_utils.py 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 class NormalizingFlowClass : \"\"\" Generic class that contains general functions for normalizing flows. Arguments --------- base_dist: torch.distributions.Distribution PyTorch Distribution class. Currently only Normal is supported. flow_transform: Transform Specify the normalizing flow transform. count_bins: Optional[int] The number of segments comprising the spline. Only used if flow_transform is Spline. bound: Optional[float] The quantity \"K\" determining the bounding box, [-K,K] x [-K,K] of the spline. By adjusting the \"K\" value, you can control the size of the bounding box and consequently control the range of inputs that the spline transform operates on. Larger values of \"K\" will result in a wider valid range for the spline transformation, while smaller values will restrict the valid range to a smaller region. Should be chosen based on the range of the data. Only used if flow_transform is Spline. order: Optional[str] The order of the spline. Options are \"linear\" or \"quadratic\". Only used if flow_transform is Spline. n_dist_param: int Number of parameters. param_dict: Dict[str, Any] Dictionary that maps parameters to their response scale. target_transform: Transform Specify the target transform. discrete: bool Whether the target is discrete or not. univariate: bool Whether the distribution is univariate or multivariate. stabilization: str Stabilization method. Options are \"None\", \"MAD\" or \"L2\". loss_fn: str Loss function. Options are \"nll\" (negative log-likelihood) or \"crps\" (continuous ranked probability score). Note that if \"crps\" is used, the Hessian is set to 1, as the current CRPS version is not twice differentiable. Hence, using the CRPS disregards any variation in the curvature of the loss function. \"\"\" def __init__ ( self , base_dist : torch . distributions . Distribution = None , flow_transform : Transform = None , count_bins : Optional [ int ] = 8 , bound : Optional [ float ] = 3.0 , order : Optional [ str ] = \"quadratic\" , n_dist_param : int = None , param_dict : Dict [ str , Any ] = None , target_transform : Transform = None , discrete : bool = False , univariate : bool = True , stabilization : str = \"None\" , loss_fn : str = \"nll\" , ): self . base_dist = base_dist self . flow_transform = flow_transform self . count_bins = count_bins self . bound = bound self . order = order self . n_dist_param = n_dist_param self . param_dict = param_dict self . target_transform = target_transform self . discrete = discrete self . univariate = univariate self . stabilization = stabilization self . loss_fn = loss_fn def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of normalizing flow parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the specified loss function. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. loss: float Loss value. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values ) return self . loss_fn , loss . detach (), is_higher_better def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates starting values for each parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Create Normalizing Flow flow_dist = self . create_spline_flow ( input_dim = 1 ) # Specify optimizer optimizer = LBFGS ( flow_dist . transforms [ 0 ] . parameters (), lr = 0.3 , max_iter = np . min ([ int ( max_iter / 4 ), 50 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 5 ) # Define closure def closure (): optimizer . zero_grad () loss = - torch . nansum ( flow_dist . log_prob ( target )) loss . backward () flow_dist . clear_cache () return loss # Optimize parameters loss_vals = [] tolerance = 1e-5 # Tolerance level for loss change patience = 5 # Patience level for loss change best_loss = float ( \"inf\" ) epochs_without_change = 0 for epoch in range ( max_iter ): optimizer . zero_grad () loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Stopping criterion (no improvement in loss) if loss . item () < best_loss - tolerance : best_loss = loss . item () epochs_without_change = 0 else : epochs_without_change += 1 if epochs_without_change >= patience : break # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = list ( flow_dist . transforms [ 0 ] . parameters ()) start_values = torch . cat ([ param . view ( - 1 ) for param in start_values ]) . detach () . numpy () # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each parameter. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Reshape Target target = target . view ( - 1 ) # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = torch . tensor ( predt , dtype = torch . float32 ) # Specify Normalizing Flow flow_dist = self . create_spline_flow ( target . shape [ 0 ]) # Replace parameters with estimated ones params , flow_dist = self . replace_parameters ( predt , flow_dist ) # Calculate loss if self . loss_fn == \"nll\" : loss = - torch . nansum ( flow_dist . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = flow_dist . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) return params , loss def create_spline_flow ( self , input_dim : int = None , ) -> Transform : \"\"\" Function that constructs a Normalizing Flow. Arguments --------- input_dim: int Input dimension. Returns ------- spline_flow: Transform Normalizing Flow. \"\"\" # Create flow distribution (currently only Normal) loc , scale = torch . zeros ( input_dim ), torch . ones ( input_dim ) flow_dist = self . base_dist ( loc , scale ) # Create Spline Transform torch . manual_seed ( 123 ) spline_transform = self . flow_transform ( input_dim , count_bins = self . count_bins , bound = self . bound , order = self . order ) # Create Normalizing Flow spline_flow = TransformedDistribution ( flow_dist , [ spline_transform , self . target_transform ]) return spline_flow def replace_parameters ( self , params : torch . Tensor , flow_dist : Transform , ) -> Tuple [ List , Transform ]: \"\"\" Replace parameters with estimated ones. Arguments --------- params: torch.Tensor Estimated parameters. flow_dist: Transform Normalizing Flow. Returns ------- params_list: List List of estimated parameters. flow_dist: Transform Normalizing Flow with estimated parameters. \"\"\" # Split parameters into list if self . order == \"quadratic\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 ], dim = 1 ) elif self . order == \"linear\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 , self . count_bins ], dim = 1 ) # Replace parameters for param , new_value in zip ( flow_dist . transforms [ 0 ] . parameters (), params_list ): param . data = new_value # Get parameters (including require_grad=True) params_list = list ( flow_dist . transforms [ 0 ] . parameters ()) return params_list , flow_dist def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) # Specify Normalizing Flow pred_params = torch . tensor ( predt_params . values ) flow_dist_pred = self . create_spline_flow ( pred_params . shape [ 0 ]) # Replace parameters with estimated ones _ , flow_dist_pred = self . replace_parameters ( pred_params , flow_dist_pred ) # Draw samples flow_samples = pd . DataFrame ( flow_dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) flow_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( flow_samples . shape [ 1 ])] if self . discrete : flow_samples = flow_samples . astype ( int ) return flow_samples def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. start_values : np.ndarray Starting values for each distributional parameter. data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" # Predict raw scores predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. Hence, it needs to be # added manually. dist_params_predt = pd . DataFrame ( np . concatenate ( [ predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 ) for i in range ( self . n_dist_param )], axis = 1 ) ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. Since parameters are estimated by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source --------- https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Arguments --------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns --------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Arguments --------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns --------- crps: torch.Tensor CRPS score. References --------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source --------- https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps def flow_select ( self , target : np . ndarray , candidate_flows : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable normalizing flow specification among the candidate_flow for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_flows: List List of candidate normalizing flow specifications. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples drawn from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted normalizing flow. \"\"\" flow_list = [] total_iterations = len ( candidate_flows ) with tqdm ( total = total_iterations , desc = \"Fitting candidate normalizing flows\" ) as pbar : for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec pbar . set_description ( f \"Fitting { flow_name } \" ) flow_sel = flow try : loss , params = flow_sel . calculate_start_values ( target = target , max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { flow_sel . loss_fn : loss . reshape ( - 1 , ), \"NormFlow\" : str ( flow_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { flow_sel } NormFlow: { str ( e ) } \" ) fit_df = pd . DataFrame ( { flow_sel . loss_fn : np . nan , \"NormFlow\" : str ( flow_sel ), \"params\" : [ np . nan ] * flow_sel . n_dist_param } ) flow_list . append ( fit_df ) fit_df = pd . concat ( flow_list ) . sort_values ( by = flow_sel . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ flow_sel . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate normalizing flows completed\" ) if plot : # Select normalizing flow with the lowest loss best_flow = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec if flow_name == best_flow [ \"NormFlow\" ] . values [ 0 ]: best_flow_sel = flow break # Draw samples from distribution flow_params = torch . tensor ( best_flow [ \"params\" ][ 0 ]) . reshape ( 1 , - 1 ) flow_dist_sel = best_flow_sel . create_spline_flow ( input_dim = 1 ) _ , flow_dist_sel = best_flow_sel . replace_parameters ( flow_params , flow_dist_sel ) flow_samples = pd . DataFrame ( flow_dist_sel . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) # Plot actual and fitted distribution flow_samples [ \"type\" ] = f \"Best-Fit: { best_flow [ 'NormFlow' ] . values [ 0 ] } \" df_actual = pd . DataFrame ( target ) df_actual [ \"type\" ] = \"Data\" plot_df = pd . concat ([ df_actual , flow_samples ]) . rename ( columns = { 0 : \"variable\" }) print ( ggplot ( plot_df , aes ( x = \"variable\" , color = \"type\" )) + geom_density ( size = 1.1 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" , x = \"\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.calculate_start_values","text":"Function that calculates starting values for each parameter.","title":"calculate_start_values()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.calculate_start_values--arguments","text":"target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.calculate_start_values--returns","text":"loss: float Loss value. start_values: np.ndarray Starting values for each parameter. Source code in lightgbmlss/distributions/flow_utils.py 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 def calculate_start_values ( self , target : np . ndarray , max_iter : int = 50 ) -> Tuple [ float , np . ndarray ]: \"\"\" Function that calculates starting values for each parameter. Arguments --------- target: np.ndarray Data from which starting values are calculated. max_iter: int Maximum number of iterations. Returns ------- loss: float Loss value. start_values: np.ndarray Starting values for each parameter. \"\"\" # Convert target to torch.tensor target = torch . tensor ( target ) . reshape ( - 1 , 1 ) # Create Normalizing Flow flow_dist = self . create_spline_flow ( input_dim = 1 ) # Specify optimizer optimizer = LBFGS ( flow_dist . transforms [ 0 ] . parameters (), lr = 0.3 , max_iter = np . min ([ int ( max_iter / 4 ), 50 ]), line_search_fn = \"strong_wolfe\" ) # Define learning rate scheduler lr_scheduler = ReduceLROnPlateau ( optimizer , mode = \"min\" , factor = 0.5 , patience = 5 ) # Define closure def closure (): optimizer . zero_grad () loss = - torch . nansum ( flow_dist . log_prob ( target )) loss . backward () flow_dist . clear_cache () return loss # Optimize parameters loss_vals = [] tolerance = 1e-5 # Tolerance level for loss change patience = 5 # Patience level for loss change best_loss = float ( \"inf\" ) epochs_without_change = 0 for epoch in range ( max_iter ): optimizer . zero_grad () loss = optimizer . step ( closure ) lr_scheduler . step ( loss ) loss_vals . append ( loss . item ()) # Stopping criterion (no improvement in loss) if loss . item () < best_loss - tolerance : best_loss = loss . item () epochs_without_change = 0 else : epochs_without_change += 1 if epochs_without_change >= patience : break # Get final loss loss = np . array ( loss_vals [ - 1 ]) # Get start values start_values = list ( flow_dist . transforms [ 0 ] . parameters ()) start_values = torch . cat ([ param . view ( - 1 ) for param in start_values ]) . detach () . numpy () # Replace any remaining NaNs or infinity values with 0.5 start_values = np . nan_to_num ( start_values , nan = 0.5 , posinf = 0.5 , neginf = 0.5 ) return loss , start_values","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.compute_gradients_and_hessians","text":"Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1).","title":"compute_gradients_and_hessians()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.compute_gradients_and_hessians--arguments","text":"loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights.","title":"Arguments:"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.compute_gradients_and_hessians--returns","text":"grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. Source code in lightgbmlss/distributions/flow_utils.py 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 def compute_gradients_and_hessians ( self , loss : torch . tensor , predt : torch . tensor , weights : np . ndarray ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Calculates gradients and hessians. Output gradients and hessians have shape (n_samples*n_outputs, 1). Arguments: --------- loss: torch.Tensor Loss. predt: torch.Tensor List of predicted parameters. weights: np.ndarray Weights. Returns: ------- grad: torch.Tensor Gradients. hess: torch.Tensor Hessians. \"\"\" if self . loss_fn == \"nll\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ autograd ( grad [ i ] . nansum (), inputs = predt [ i ], retain_graph = True )[ 0 ] for i in range ( len ( grad ))] elif self . loss_fn == \"crps\" : # Gradient and Hessian grad = autograd ( loss , inputs = predt , create_graph = True ) hess = [ torch . ones_like ( grad [ i ]) for i in range ( len ( grad ))] # Stabilization of Derivatives if self . stabilization != \"None\" : grad = [ self . stabilize_derivative ( grad [ i ], type = self . stabilization ) for i in range ( len ( grad ))] hess = [ self . stabilize_derivative ( hess [ i ], type = self . stabilization ) for i in range ( len ( hess ))] # Reshape grad = torch . cat ( grad , axis = 1 ) . detach () . numpy () hess = torch . cat ( hess , axis = 1 ) . detach () . numpy () # Weighting grad *= weights hess *= weights # Reshape grad = grad . ravel ( order = \"F\" ) hess = hess . ravel ( order = \"F\" ) return grad , hess","title":"Returns:"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.create_spline_flow","text":"Function that constructs a Normalizing Flow.","title":"create_spline_flow()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.create_spline_flow--arguments","text":"input_dim: int Input dimension.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.create_spline_flow--returns","text":"spline_flow: Transform Normalizing Flow. Source code in lightgbmlss/distributions/flow_utils.py 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 def create_spline_flow ( self , input_dim : int = None , ) -> Transform : \"\"\" Function that constructs a Normalizing Flow. Arguments --------- input_dim: int Input dimension. Returns ------- spline_flow: Transform Normalizing Flow. \"\"\" # Create flow distribution (currently only Normal) loc , scale = torch . zeros ( input_dim ), torch . ones ( input_dim ) flow_dist = self . base_dist ( loc , scale ) # Create Spline Transform torch . manual_seed ( 123 ) spline_transform = self . flow_transform ( input_dim , count_bins = self . count_bins , bound = self . bound , order = self . order ) # Create Normalizing Flow spline_flow = TransformedDistribution ( flow_dist , [ spline_transform , self . target_transform ]) return spline_flow","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.crps_score","text":"Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples.","title":"crps_score()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.crps_score--arguments","text":"y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations).","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.crps_score--returns","text":"crps: torch.Tensor CRPS score.","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.crps_score--references","text":"Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378.","title":"References"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.crps_score--source","text":"https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 Source code in lightgbmlss/distributions/flow_utils.py 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 def crps_score ( self , y : torch . tensor , yhat_dist : torch . tensor ) -> torch . tensor : \"\"\" Function that calculates the Continuous Ranked Probability Score (CRPS) for a given set of predicted samples. Arguments --------- y: torch.Tensor Response variable of shape (n_observations,1). yhat_dist: torch.Tensor Predicted samples of shape (n_samples, n_observations). Returns --------- crps: torch.Tensor CRPS score. References --------- Gneiting, Tilmann & Raftery, Adrian. (2007). Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association. 102. 359-378. Source --------- https://github.com/elephaint/pgbm/blob/main/pgbm/torch/pgbm_dist.py#L549 \"\"\" # Get the number of observations n_samples = yhat_dist . shape [ 0 ] # Sort the forecasts in ascending order yhat_dist_sorted , _ = torch . sort ( yhat_dist , 0 ) # Create temporary tensors y_cdf = torch . zeros_like ( y ) yhat_cdf = torch . zeros_like ( y ) yhat_prev = torch . zeros_like ( y ) crps = torch . zeros_like ( y ) # Loop over the predicted samples generated per observation for yhat in yhat_dist_sorted : yhat = yhat . reshape ( - 1 , 1 ) flag = ( y_cdf == 0 ) * ( y < yhat ) crps += flag * (( y - yhat_prev ) * yhat_cdf ** 2 ) crps += flag * (( yhat - y ) * ( yhat_cdf - 1 ) ** 2 ) crps += ( ~ flag ) * (( yhat - yhat_prev ) * ( yhat_cdf - y_cdf ) ** 2 ) y_cdf += flag yhat_cdf += 1 / n_samples yhat_prev = yhat # In case y_cdf == 0 after the loop flag = ( y_cdf == 0 ) crps += flag * ( y - yhat ) return crps","title":"Source"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.draw_samples","text":"Function that draws n_samples from a predicted distribution.","title":"draw_samples()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.draw_samples--arguments","text":"predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.draw_samples--returns","text":"pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. Source code in lightgbmlss/distributions/flow_utils.py 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 def draw_samples ( self , predt_params : pd . DataFrame , n_samples : int = 1000 , seed : int = 123 ) -> pd . DataFrame : \"\"\" Function that draws n_samples from a predicted distribution. Arguments --------- predt_params: pd.DataFrame pd.DataFrame with predicted distributional parameters. n_samples: int Number of sample to draw from predicted response distribution. seed: int Manual seed. Returns ------- pred_dist: pd.DataFrame DataFrame with n_samples drawn from predicted response distribution. \"\"\" torch . manual_seed ( seed ) # Specify Normalizing Flow pred_params = torch . tensor ( predt_params . values ) flow_dist_pred = self . create_spline_flow ( pred_params . shape [ 0 ]) # Replace parameters with estimated ones _ , flow_dist_pred = self . replace_parameters ( pred_params , flow_dist_pred ) # Draw samples flow_samples = pd . DataFrame ( flow_dist_pred . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) flow_samples . columns = [ str ( \"y_sample\" ) + str ( i ) for i in range ( flow_samples . shape [ 1 ])] if self . discrete : flow_samples = flow_samples . astype ( int ) return flow_samples","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.flow_select","text":"Function that selects the most suitable normalizing flow specification among the candidate_flow for the target variable, based on the NegLogLikelihood (lower is better).","title":"flow_select()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.flow_select--parameters","text":"target: np.ndarray Response variable. candidate_flows: List List of candidate normalizing flow specifications. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples drawn from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot.","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.flow_select--returns","text":"fit_df: pd.DataFrame Dataframe with the loss values of the fitted normalizing flow. Source code in lightgbmlss/distributions/flow_utils.py 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 def flow_select ( self , target : np . ndarray , candidate_flows : List , max_iter : int = 100 , n_samples : int = 1000 , plot : bool = False , figure_size : tuple = ( 10 , 5 ), ) -> pd . DataFrame : \"\"\" Function that selects the most suitable normalizing flow specification among the candidate_flow for the target variable, based on the NegLogLikelihood (lower is better). Parameters ---------- target: np.ndarray Response variable. candidate_flows: List List of candidate normalizing flow specifications. max_iter: int Maximum number of iterations for the optimization. n_samples: int Number of samples drawn from the fitted distribution. plot: bool If True, a density plot of the actual and fitted distribution is created. figure_size: tuple Figure size of the density plot. Returns ------- fit_df: pd.DataFrame Dataframe with the loss values of the fitted normalizing flow. \"\"\" flow_list = [] total_iterations = len ( candidate_flows ) with tqdm ( total = total_iterations , desc = \"Fitting candidate normalizing flows\" ) as pbar : for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec pbar . set_description ( f \"Fitting { flow_name } \" ) flow_sel = flow try : loss , params = flow_sel . calculate_start_values ( target = target , max_iter = max_iter ) fit_df = pd . DataFrame . from_dict ( { flow_sel . loss_fn : loss . reshape ( - 1 , ), \"NormFlow\" : str ( flow_name ), \"params\" : [ params ] } ) except Exception as e : warnings . warn ( f \"Error fitting { flow_sel } NormFlow: { str ( e ) } \" ) fit_df = pd . DataFrame ( { flow_sel . loss_fn : np . nan , \"NormFlow\" : str ( flow_sel ), \"params\" : [ np . nan ] * flow_sel . n_dist_param } ) flow_list . append ( fit_df ) fit_df = pd . concat ( flow_list ) . sort_values ( by = flow_sel . loss_fn , ascending = True ) fit_df [ \"rank\" ] = fit_df [ flow_sel . loss_fn ] . rank () . astype ( int ) fit_df . set_index ( fit_df [ \"rank\" ], inplace = True ) pbar . update ( 1 ) pbar . set_description ( f \"Fitting of candidate normalizing flows completed\" ) if plot : # Select normalizing flow with the lowest loss best_flow = fit_df [ fit_df [ \"rank\" ] == 1 ] . reset_index ( drop = True ) for flow in candidate_flows : flow_name = str ( flow . __class__ ) . split ( \".\" )[ - 1 ] . split ( \"'>\" )[ 0 ] flow_spec = f \"(count_bins: { flow . count_bins } , order: { flow . order } )\" flow_name = flow_name + flow_spec if flow_name == best_flow [ \"NormFlow\" ] . values [ 0 ]: best_flow_sel = flow break # Draw samples from distribution flow_params = torch . tensor ( best_flow [ \"params\" ][ 0 ]) . reshape ( 1 , - 1 ) flow_dist_sel = best_flow_sel . create_spline_flow ( input_dim = 1 ) _ , flow_dist_sel = best_flow_sel . replace_parameters ( flow_params , flow_dist_sel ) flow_samples = pd . DataFrame ( flow_dist_sel . sample (( n_samples ,)) . squeeze () . detach () . numpy () . T ) # Plot actual and fitted distribution flow_samples [ \"type\" ] = f \"Best-Fit: { best_flow [ 'NormFlow' ] . values [ 0 ] } \" df_actual = pd . DataFrame ( target ) df_actual [ \"type\" ] = \"Data\" plot_df = pd . concat ([ df_actual , flow_samples ]) . rename ( columns = { 0 : \"variable\" }) print ( ggplot ( plot_df , aes ( x = \"variable\" , color = \"type\" )) + geom_density ( size = 1.1 ) + theme_bw ( base_size = 15 ) + theme ( figure_size = figure_size , legend_position = \"right\" , legend_title = element_blank (), plot_title = element_text ( hjust = 0.5 )) + labs ( title = f \"Actual vs. Fitted Density\" , x = \"\" ) ) fit_df . drop ( columns = [ \"rank\" , \"params\" ], inplace = True ) return fit_df","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.get_params_loss","text":"Function that returns the predicted parameters and the loss.","title":"get_params_loss()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.get_params_loss--arguments","text":"predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each parameter.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.get_params_loss--returns","text":"predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. Source code in lightgbmlss/distributions/flow_utils.py 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 def get_params_loss ( self , predt : np . ndarray , target : torch . Tensor , start_values : List [ float ], requires_grad : bool = False , ) -> Tuple [ List [ torch . Tensor ], np . ndarray ]: \"\"\" Function that returns the predicted parameters and the loss. Arguments --------- predt: np.ndarray Predicted values. target: torch.Tensor Target values. start_values: List Starting values for each parameter. Returns ------- predt: torch.Tensor Predicted parameters. loss: torch.Tensor Loss value. \"\"\" # Reshape Target target = target . view ( - 1 ) # Predicted Parameters predt = predt . reshape ( - 1 , self . n_dist_param , order = \"F\" ) # Replace NaNs and infinity values with unconditional start values nan_inf_mask = np . isnan ( predt ) | np . isinf ( predt ) predt [ nan_inf_mask ] = np . take ( start_values , np . where ( nan_inf_mask )[ 1 ]) # Convert to torch.tensor predt = torch . tensor ( predt , dtype = torch . float32 ) # Specify Normalizing Flow flow_dist = self . create_spline_flow ( target . shape [ 0 ]) # Replace parameters with estimated ones params , flow_dist = self . replace_parameters ( predt , flow_dist ) # Calculate loss if self . loss_fn == \"nll\" : loss = - torch . nansum ( flow_dist . log_prob ( target )) elif self . loss_fn == \"crps\" : torch . manual_seed ( 123 ) dist_samples = flow_dist . rsample (( 30 ,)) . squeeze ( - 1 ) loss = torch . nansum ( self . crps_score ( target , dist_samples )) else : raise ValueError ( \"Invalid loss function. Please select 'nll' or 'crps'.\" ) return params , loss","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.metric_fn","text":"Function that evaluates the predictions using the specified loss function.","title":"metric_fn()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.metric_fn--arguments","text":"predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.metric_fn--returns","text":"name: str Name of the evaluation metric. loss: float Loss value. Source code in lightgbmlss/distributions/flow_utils.py 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 def metric_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ str , float , bool ]: \"\"\" Function that evaluates the predictions using the specified loss function. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- name: str Name of the evaluation metric. loss: float Loss value. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate loss is_higher_better = False _ , loss = self . get_params_loss ( predt , target , start_values ) return self . loss_fn , loss . detach (), is_higher_better","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.objective_fn","text":"Function to estimate gradients and hessians of normalizing flow parameters.","title":"objective_fn()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.objective_fn--arguments","text":"predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.objective_fn--returns","text":"grad: np.ndarray Gradient. hess: np.ndarray Hessian. Source code in lightgbmlss/distributions/flow_utils.py 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 def objective_fn ( self , predt : np . ndarray , data : lgb . Dataset ) -> Tuple [ np . ndarray , np . ndarray ]: \"\"\" Function to estimate gradients and hessians of normalizing flow parameters. Arguments --------- predt: np.ndarray Predicted values. data: lgb.Dataset Data used for training. Returns ------- grad: np.ndarray Gradient. hess: np.ndarray Hessian. \"\"\" # Target target = torch . tensor ( data . get_label () . reshape ( - 1 , 1 )) # Weights if data . weight is None : # Use 1 as weight if no weights are specified weights = torch . ones_like ( target , dtype = target . dtype ) . numpy () else : weights = data . get_weight () . reshape ( - 1 , 1 ) # Start values (needed to replace NaNs in predt) start_values = data . get_init_score () . reshape ( - 1 , self . n_dist_param )[ 0 , :] . tolist () # Calculate gradients and hessians predt , loss = self . get_params_loss ( predt , target , start_values ) grad , hess = self . compute_gradients_and_hessians ( loss , predt , weights ) return grad , hess","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.predict_dist","text":"Function that predicts from the trained model.","title":"predict_dist()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.predict_dist--arguments","text":"booster : lgb.Booster Trained model. start_values : np.ndarray Starting values for each distributional parameter. data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.predict_dist--returns","text":"pred : pd.DataFrame Predictions. Source code in lightgbmlss/distributions/flow_utils.py 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 def predict_dist ( self , booster : lgb . Booster , data : pd . DataFrame , start_values : np . ndarray , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ) -> pd . DataFrame : \"\"\" Function that predicts from the trained model. Arguments --------- booster : lgb.Booster Trained model. start_values : np.ndarray Starting values for each distributional parameter. data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- pred : pd.DataFrame Predictions. \"\"\" # Predict raw scores predt = torch . tensor ( booster . predict ( data , raw_score = True ), dtype = torch . float32 ) . reshape ( - 1 , self . n_dist_param ) # Set init_score as starting point for each distributional parameter. init_score_pred = torch . tensor ( np . ones ( shape = ( data . shape [ 0 ], 1 )) * start_values , dtype = torch . float32 ) # The predictions don't include the init_score specified in creating the train data. Hence, it needs to be # added manually. dist_params_predt = pd . DataFrame ( np . concatenate ( [ predt [:, i ] . reshape ( - 1 , 1 ) + init_score_pred [:, i ] . reshape ( - 1 , 1 ) for i in range ( self . n_dist_param )], axis = 1 ) ) dist_params_predt . columns = self . param_dict . keys () # Draw samples from predicted response distribution pred_samples_df = self . draw_samples ( predt_params = dist_params_predt , n_samples = n_samples , seed = seed ) if pred_type == \"parameters\" : return dist_params_predt elif pred_type == \"samples\" : return pred_samples_df elif pred_type == \"quantiles\" : # Calculate quantiles from predicted response distribution pred_quant_df = pred_samples_df . quantile ( quantiles , axis = 1 ) . T pred_quant_df . columns = [ str ( \"quant_\" ) + str ( quantiles [ i ]) for i in range ( len ( quantiles ))] if self . discrete : pred_quant_df = pred_quant_df . astype ( int ) return pred_quant_df","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.replace_parameters","text":"Replace parameters with estimated ones.","title":"replace_parameters()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.replace_parameters--arguments","text":"params: torch.Tensor Estimated parameters. flow_dist: Transform Normalizing Flow.","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.replace_parameters--returns","text":"params_list: List List of estimated parameters. flow_dist: Transform Normalizing Flow with estimated parameters. Source code in lightgbmlss/distributions/flow_utils.py 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 def replace_parameters ( self , params : torch . Tensor , flow_dist : Transform , ) -> Tuple [ List , Transform ]: \"\"\" Replace parameters with estimated ones. Arguments --------- params: torch.Tensor Estimated parameters. flow_dist: Transform Normalizing Flow. Returns ------- params_list: List List of estimated parameters. flow_dist: Transform Normalizing Flow with estimated parameters. \"\"\" # Split parameters into list if self . order == \"quadratic\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 ], dim = 1 ) elif self . order == \"linear\" : params_list = torch . split ( params , [ self . count_bins , self . count_bins , self . count_bins - 1 , self . count_bins ], dim = 1 ) # Replace parameters for param , new_value in zip ( flow_dist . transforms [ 0 ] . parameters (), params_list ): param . data = new_value # Get parameters (including require_grad=True) params_list = list ( flow_dist . transforms [ 0 ] . parameters ()) return params_list , flow_dist","title":"Returns"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.stabilize_derivative","text":"Function that stabilizes Gradients and Hessians. Since parameters are estimated by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered.","title":"stabilize_derivative()"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.stabilize_derivative--source","text":"https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173","title":"Source"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.stabilize_derivative--arguments","text":"input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\".","title":"Arguments"},{"location":"api/#lightgbmlss.distributions.flow_utils.NormalizingFlowClass.stabilize_derivative--returns","text":"stab_der : torch.Tensor Stabilized Gradient or Hessian. Source code in lightgbmlss/distributions/flow_utils.py 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 def stabilize_derivative ( self , input_der : torch . Tensor , type : str = \"MAD\" ) -> torch . Tensor : \"\"\" Function that stabilizes Gradients and Hessians. Since parameters are estimated by optimizing Gradients and Hessians, it is important that these are comparable in magnitude for all parameters. Due to imbalances regarding the ranges, the estimation might become unstable so that it does not converge (or converge very slowly) to the optimal solution. Another way to improve convergence might be to standardize the response variable. This is especially useful if the range of the response differs strongly from the range of the Gradients and Hessians. Both, the stabilization and the standardization of the response are not always advised but need to be carefully considered. Source --------- https://github.com/boost-R/gamboostLSS/blob/7792951d2984f289ed7e530befa42a2a4cb04d1d/R/helpers.R#L173 Arguments --------- input_der : torch.Tensor Input derivative, either Gradient or Hessian. type: str Stabilization method. Can be either \"None\", \"MAD\" or \"L2\". Returns --------- stab_der : torch.Tensor Stabilized Gradient or Hessian. \"\"\" if type == \"MAD\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . nanmedian ( torch . abs ( input_der - torch . nanmedian ( input_der ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) stab_der = input_der / div if type == \"L2\" : input_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) div = torch . sqrt ( torch . nanmean ( input_der . pow ( 2 ))) div = torch . where ( div < torch . tensor ( 1e-04 ), torch . tensor ( 1e-04 ), div ) div = torch . where ( div > torch . tensor ( 10000.0 ), torch . tensor ( 10000.0 ), div ) stab_der = input_der / div if type == \"None\" : stab_der = torch . nan_to_num ( input_der , nan = float ( torch . nanmean ( input_der ))) return stab_der","title":"Returns"},{"location":"api/#lightgbmlss.distributions.zero_inflated","text":"","title":"zero_inflated"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedBeta","text":"Bases: ZeroInflatedDistribution A Zero-Adjusted Beta distribution.","title":"ZeroAdjustedBeta"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedBeta--parameter","text":"concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution.","title":"Parameter"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedBeta--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Source code in lightgbmlss/distributions/zero_inflated.py 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 class ZeroAdjustedBeta ( ZeroInflatedDistribution ): \"\"\" A Zero-Adjusted Beta distribution. Parameter --------- concentration1: torch.Tensor 1st concentration parameter of the distribution (often referred to as alpha). concentration0: torch.Tensor 2nd concentration parameter of the distribution (often referred to as beta). gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py \"\"\" arg_constraints = { \"concentration1\" : constraints . positive , \"concentration0\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . unit_interval def __init__ ( self , concentration1 , concentration0 , gate = None , validate_args = None ): base_dist = Beta ( concentration1 = concentration1 , concentration0 = concentration0 , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def concentration1 ( self ): return self . base_dist . concentration1 @property def concentration0 ( self ): return self . base_dist . concentration0","title":"Source"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedGamma","text":"Bases: ZeroInflatedDistribution A Zero-Adjusted Gamma distribution.","title":"ZeroAdjustedGamma"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedGamma--parameter","text":"concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution.","title":"Parameter"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedGamma--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Source code in lightgbmlss/distributions/zero_inflated.py 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 class ZeroAdjustedGamma ( ZeroInflatedDistribution ): \"\"\" A Zero-Adjusted Gamma distribution. Parameter --------- concentration: torch.Tensor shape parameter of the distribution (often referred to as alpha) rate: torch.Tensor rate = 1 / scale of the distribution (often referred to as beta) gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py \"\"\" arg_constraints = { \"concentration\" : constraints . positive , \"rate\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative def __init__ ( self , concentration , rate , gate = None , validate_args = None ): base_dist = Gamma ( concentration = concentration , rate = rate , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def concentration ( self ): return self . base_dist . concentration @property def rate ( self ): return self . base_dist . rate","title":"Source"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedLogNormal","text":"Bases: ZeroInflatedDistribution A Zero-Adjusted Log-Normal distribution.","title":"ZeroAdjustedLogNormal"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedLogNormal--parameter","text":"loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution.","title":"Parameter"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroAdjustedLogNormal--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py Source code in lightgbmlss/distributions/zero_inflated.py 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 class ZeroAdjustedLogNormal ( ZeroInflatedDistribution ): \"\"\" A Zero-Adjusted Log-Normal distribution. Parameter --------- loc: torch.Tensor Mean of log of distribution. scale: torch.Tensor Standard deviation of log of the distribution. gate: torch.Tensor Probability of zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py \"\"\" arg_constraints = { \"loc\" : constraints . real , \"scale\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative def __init__ ( self , loc , scale , gate = None , validate_args = None ): base_dist = LogNormal ( loc = loc , scale = scale , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def loc ( self ): return self . base_dist . loc @property def scale ( self ): return self . base_dist . scale","title":"Source"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedDistribution","text":"Bases: TorchDistribution Generic Zero Inflated distribution. This can be used directly or can be used as a base class as e.g. for :class: ZeroInflatedPoisson and :class: ZeroInflatedNegativeBinomial .","title":"ZeroInflatedDistribution"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedDistribution--parameters","text":"gate : torch.Tensor Probability of extra zeros given via a Bernoulli distribution. base_dist : torch.distributions.Distribution The base distribution.","title":"Parameters"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedDistribution--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L18 Source code in lightgbmlss/distributions/zero_inflated.py 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 class ZeroInflatedDistribution ( TorchDistribution ): \"\"\" Generic Zero Inflated distribution. This can be used directly or can be used as a base class as e.g. for :class:`ZeroInflatedPoisson` and :class:`ZeroInflatedNegativeBinomial`. Parameters ---------- gate : torch.Tensor Probability of extra zeros given via a Bernoulli distribution. base_dist : torch.distributions.Distribution The base distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L18 \"\"\" arg_constraints = { \"gate\" : constraints . unit_interval , \"gate_logits\" : constraints . real , } def __init__ ( self , base_dist , * , gate = None , gate_logits = None , validate_args = None ): if ( gate is None ) == ( gate_logits is None ): raise ValueError ( \"Either `gate` or `gate_logits` must be specified, but not both.\" ) if gate is not None : batch_shape = broadcast_shape ( gate . shape , base_dist . batch_shape ) self . gate = gate . expand ( batch_shape ) else : batch_shape = broadcast_shape ( gate_logits . shape , base_dist . batch_shape ) self . gate_logits = gate_logits . expand ( batch_shape ) if base_dist . event_shape : raise ValueError ( \"ZeroInflatedDistribution expected empty \" \"base_dist.event_shape but got {} \" . format ( base_dist . event_shape ) ) self . base_dist = base_dist . expand ( batch_shape ) event_shape = torch . Size () super () . __init__ ( batch_shape , event_shape , validate_args ) @constraints . dependent_property def support ( self ): return self . base_dist . support @lazy_property def gate ( self ): return logits_to_probs ( self . gate_logits ) @lazy_property def gate_logits ( self ): return probs_to_logits ( self . gate ) def log_prob ( self , value ): if self . _validate_args : self . _validate_sample ( value ) zero_idx = ( value == 0 ) support = self . support epsilon = abs ( torch . finfo ( value . dtype ) . eps ) if hasattr ( support , \"lower_bound\" ): if is_identically_zero ( getattr ( support , \"lower_bound\" , None )): value = value . clamp_min ( epsilon ) if hasattr ( support , \"upper_bound\" ): if is_identically_one ( getattr ( support , \"upper_bound\" , None )) & ( value . max () == 1.0 ): value = value . clamp_max ( 1 - epsilon ) if \"gate\" in self . __dict__ : gate , value = broadcast_all ( self . gate , value ) log_prob = ( - gate ) . log1p () + self . base_dist . log_prob ( value ) log_prob = torch . where ( zero_idx , ( gate + log_prob . exp ()) . log (), log_prob ) else : gate_logits , value = broadcast_all ( self . gate_logits , value ) log_prob_minus_log_gate = - gate_logits + self . base_dist . log_prob ( value ) log_gate = - softplus ( - gate_logits ) log_prob = log_prob_minus_log_gate + log_gate zero_log_prob = softplus ( log_prob_minus_log_gate ) + log_gate log_prob = torch . where ( zero_idx , zero_log_prob , log_prob ) return log_prob def sample ( self , sample_shape = torch . Size ()): shape = self . _extended_shape ( sample_shape ) with torch . no_grad (): mask = torch . bernoulli ( self . gate . expand ( shape )) . bool () samples = self . base_dist . expand ( shape ) . sample () samples = torch . where ( mask , samples . new_zeros (()), samples ) return samples @lazy_property def mean ( self ): return ( 1 - self . gate ) * self . base_dist . mean @lazy_property def variance ( self ): return ( 1 - self . gate ) * ( self . base_dist . mean ** 2 + self . base_dist . variance ) - self . mean ** 2 def expand ( self , batch_shape , _instance = None ): new = self . _get_checked_instance ( type ( self ), _instance ) batch_shape = torch . Size ( batch_shape ) gate = self . gate . expand ( batch_shape ) if \"gate\" in self . __dict__ else None gate_logits = ( self . gate_logits . expand ( batch_shape ) if \"gate_logits\" in self . __dict__ else None ) base_dist = self . base_dist . expand ( batch_shape ) ZeroInflatedDistribution . __init__ ( new , base_dist , gate = gate , gate_logits = gate_logits , validate_args = False ) new . _validate_args = self . _validate_args return new","title":"Source"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedNegativeBinomial","text":"Bases: ZeroInflatedDistribution A Zero Inflated Negative Binomial distribution.","title":"ZeroInflatedNegativeBinomial"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedNegativeBinomial--parameter","text":"total_count: torch.Tensor Non-negative number of negative Bernoulli trial. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds of success (log(p/(1-p))). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution.","title":"Parameter"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedNegativeBinomial--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 Source code in lightgbmlss/distributions/zero_inflated.py 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 class ZeroInflatedNegativeBinomial ( ZeroInflatedDistribution ): \"\"\" A Zero Inflated Negative Binomial distribution. Parameter --------- total_count: torch.Tensor Non-negative number of negative Bernoulli trial. probs: torch.Tensor Event probabilities of success in the half open interval [0, 1). logits: torch.Tensor Event log-odds of success (log(p/(1-p))). gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------ - https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L150 \"\"\" arg_constraints = { \"total_count\" : constraints . greater_than_eq ( 0 ), \"probs\" : constraints . half_open_interval ( 0.0 , 1.0 ), \"logits\" : constraints . real , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative_integer def __init__ ( self , total_count , probs = None , gate = None , validate_args = None ): base_dist = NegativeBinomial ( total_count = total_count , probs = probs , logits = None , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def total_count ( self ): return self . base_dist . total_count @property def probs ( self ): return self . base_dist . probs @property def logits ( self ): return self . base_dist . logits","title":"Source"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedPoisson","text":"Bases: ZeroInflatedDistribution A Zero-Inflated Poisson distribution.","title":"ZeroInflatedPoisson"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedPoisson--parameter","text":"rate: torch.Tensor The rate of the Poisson distribution. gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution.","title":"Parameter"},{"location":"api/#lightgbmlss.distributions.zero_inflated.ZeroInflatedPoisson--source","text":"https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121 Source code in lightgbmlss/distributions/zero_inflated.py 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 class ZeroInflatedPoisson ( ZeroInflatedDistribution ): \"\"\" A Zero-Inflated Poisson distribution. Parameter --------- rate: torch.Tensor The rate of the Poisson distribution. gate: torch.Tensor Probability of extra zeros given via a Bernoulli distribution. Source ------ https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/zero_inflated.py#L121 \"\"\" arg_constraints = { \"rate\" : constraints . positive , \"gate\" : constraints . unit_interval , } support = constraints . nonnegative_integer def __init__ ( self , rate , gate = None , validate_args = None ): base_dist = Poisson ( rate = rate , validate_args = False ) base_dist . _validate_args = validate_args super () . __init__ ( base_dist , gate = gate , validate_args = validate_args ) @property def rate ( self ): return self . base_dist . rate","title":"Source"},{"location":"api/#lightgbmlss.model","text":"","title":"model"},{"location":"api/#lightgbmlss.model.LightGBMLSS","text":"LightGBMLSS model class","title":"LightGBMLSS"},{"location":"api/#lightgbmlss.model.LightGBMLSS--parameters","text":"dist : Distribution DistributionClass object. start_values : np.ndarray Starting values for each distributional parameter. Source code in lightgbmlss/model.py 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 class LightGBMLSS : \"\"\" LightGBMLSS model class Parameters ---------- dist : Distribution DistributionClass object. start_values : np.ndarray Starting values for each distributional parameter. \"\"\" def __init__ ( self , dist ): self . dist = dist # Distribution object self . start_values = None # Starting values for distributional parameters def set_params ( self , params : Dict [ str , Any ]) -> Dict [ str , Any ]: \"\"\" Set parameters for distributional model. Arguments --------- params : Dict[str, Any] Parameters for model. Returns ------- params : Dict[str, Any] Updated Parameters for model. \"\"\" params_adj = { \"num_class\" : self . dist . n_dist_param , \"metric\" : \"None\" , \"objective\" : \"None\" , \"random_seed\" : 123 , \"verbose\" : - 1 } params . update ( params_adj ) return params def set_init_score ( self , dmatrix : Dataset ) -> None : \"\"\" Set init_score for distributions. Arguments --------- dmatrix : Dataset Dataset to set base margin for. Returns ------- None \"\"\" if self . start_values is None : _ , self . start_values = self . dist . calculate_start_values ( dmatrix . get_label ()) init_score = ( np . ones ( shape = ( dmatrix . get_label () . shape [ 0 ], 1 ))) * self . start_values dmatrix . set_init_score ( init_score . ravel ( order = \"F\" )) def train ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , valid_sets : Optional [ List [ Dataset ]] = None , valid_names : Optional [ List [ str ]] = None , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , keep_training_booster : bool = False , callbacks : Optional [ List [ Callable ]] = None ) -> Booster : \"\"\"Function to perform the training of a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. valid_sets : list of Dataset, or None, optional (default=None) List of data to be evaluated on during training. valid_names : list of str, or None, optional (default=None) Names of ``valid_sets``. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. keep_training_booster : bool, optional (default=False) Whether the returned Booster will be used to keep training. If False, the returned value will be converted into _InnerPredictor before returning. This means you won't be able to use ``eval``, ``eval_train`` or ``eval_valid`` methods of the returned Booster. When your model is very large and cause the memory error, you can try to set this param to ``True`` to avoid the model conversion performed during the internal call of ``model_to_string``. You can still use _InnerPredictor as ``init_model`` for future continue training. callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. Returns ------- booster : Booster The trained Booster model. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) if valid_sets is not None : valid_sets = self . set_valid_margin ( valid_sets , self . start_values ) self . booster = lgb . train ( params , train_set , num_boost_round = num_boost_round , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , valid_sets = valid_sets , valid_names = valid_names , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , keep_training_booster = keep_training_booster , callbacks = callbacks ) def cv ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , folds : Optional [ Union [ Iterable [ Tuple [ np . ndarray , np . ndarray ]], _LGBMBaseCrossValidator ]] = None , nfold : int = 5 , stratified : bool = True , shuffle : bool = True , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , fpreproc : Optional [ _LGBM_PreprocFunction ] = None , seed : int = 123 , callbacks : Optional [ List [ Callable ]] = None , eval_train_metric : bool = False , return_cvbooster : bool = False ) -> Dict [ str , Union [ List [ float ], CVBooster ]]: \"\"\"Function to cross-validate a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. folds : generator or iterator of (train_idx, test_idx) tuples, scikit-learn splitter object or None, optional (default=None) If generator or iterator, it should yield the train and test indices for each fold. If object, it should be one of the scikit-learn splitter classes (https://scikit-learn.org/stable/modules/classes.html#splitter-classes) and have ``split`` method. This argument has highest priority over other data split arguments. nfold : int, optional (default=5) Number of folds in CV. stratified : bool, optional (default=True) Whether to perform stratified sampling. shuffle : bool, optional (default=True) Whether to shuffle before splitting data. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. fpreproc : callable or None, optional (default=None) Preprocessing function that takes (dtrain, dtest, params) and returns transformed versions of those. seed : int, optional (default=0) Seed used to generate the folds (passed to numpy.random.seed). callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. eval_train_metric : bool, optional (default=False) Whether to display the train metric in progress. The score of the metric is calculated again after each training step, so there is some impact on performance. return_cvbooster : bool, optional (default=False) Whether to return Booster models trained on each fold through ``CVBooster``. Returns ------- eval_hist : dict Evaluation history. The dictionary has the following format: {'metric1-mean': [values], 'metric1-stdv': [values], 'metric2-mean': [values], 'metric2-stdv': [values], ...}. If ``return_cvbooster=True``, also returns trained boosters wrapped in a ``CVBooster`` object via ``cvbooster`` key. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) self . bstLSS_cv = lgb . cv ( params , train_set , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , num_boost_round = num_boost_round , folds = folds , nfold = nfold , stratified = False , shuffle = False , metrics = None , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , fpreproc = fpreproc , seed = seed , callbacks = callbacks , eval_train_metric = eval_train_metric , return_cvbooster = return_cvbooster ) return self . bstLSS_cv def hyper_opt ( self , hp_dict : Dict , train_set : lgb . Dataset , num_boost_round = 500 , nfold = 10 , early_stopping_rounds = 20 , max_minutes = 10 , n_trials = None , study_name = None , silence = False , seed = None , hp_seed = None ): \"\"\" Function to tune hyperparameters using optuna. Arguments ---------- hp_dict: dict Dictionary of hyperparameters to tune. train_set: lgb.Dataset Training data. num_boost_round: int Number of boosting iterations. nfold: int Number of folds in CV. early_stopping_rounds: int Activates early stopping. Cross-Validation metric (average of validation metric computed over CV folds) needs to improve at least once in every **early_stopping_rounds** round(s) to continue training. The last entry in the evaluation history will represent the best iteration. If there's more than one metric in the **eval_metric** parameter given in **params**, the last metric will be used for early stopping. max_minutes: int Time budget in minutes, i.e., stop study after the given number of minutes. n_trials: int The number of trials. If this argument is set to None, there is no limitation on the number of trials. study_name: str Name of the hyperparameter study. silence: bool Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed: int Seed used to generate the folds (passed to numpy.random.seed). hp_seed: int Seed for random number generator used in the Bayesian hyper-parameter search. Returns ------- opt_params : dict Optimal hyper-parameters. \"\"\" def objective ( trial ): hyper_params = {} for param_name , param_value in hp_dict . items (): param_type = param_value [ 0 ] if param_type == \"categorical\" or param_type == \"none\" : hyper_params . update ({ param_name : trial . suggest_categorical ( param_name , param_value [ 1 ])}) elif param_type == \"float\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_float ( param_name , low = param_low , high = param_high , log = param_log ) }) elif param_type == \"int\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_int ( param_name , low = param_low , high = param_high , log = param_log ) }) # Add booster if not included in dictionary if \"boosting\" not in hyper_params . keys (): hyper_params . update ({ \"boosting\" : trial . suggest_categorical ( \"boosting\" , [ \"gbdt\" ])}) # Add pruning and early stopping pruning_callback = LightGBMPruningCallback ( trial , self . dist . loss_fn ) early_stopping_callback = lgb . early_stopping ( stopping_rounds = early_stopping_rounds , verbose = False ) lgblss_param_tuning = self . cv ( hyper_params , train_set , num_boost_round = num_boost_round , nfold = nfold , callbacks = [ pruning_callback , early_stopping_callback ], seed = seed , ) # Extract the optimal number of boosting rounds opt_rounds = np . argmin ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) + 1 trial . set_user_attr ( \"opt_round\" , int ( opt_rounds )) # Extract the best score best_score = np . min ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) return best_score if study_name is None : study_name = \"LightGBMLSS Hyper-Parameter Optimization\" if silence : optuna . logging . set_verbosity ( optuna . logging . WARNING ) if hp_seed is not None : sampler = TPESampler ( seed = hp_seed ) else : sampler = TPESampler () pruner = optuna . pruners . MedianPruner ( n_startup_trials = 10 , n_warmup_steps = 20 ) study = optuna . create_study ( sampler = sampler , pruner = pruner , direction = \"minimize\" , study_name = study_name ) study . optimize ( objective , n_trials = n_trials , timeout = 60 * max_minutes , show_progress_bar = True ) print ( \" \\n Hyper-Parameter Optimization successfully finished.\" ) print ( \" Number of finished trials: \" , len ( study . trials )) print ( \" Best trial:\" ) opt_param = study . best_trial # Add optimal stopping round opt_param . params [ \"opt_rounds\" ] = study . trials_dataframe ()[ \"user_attrs_opt_round\" ][ study . trials_dataframe ()[ \"value\" ] . idxmin ()] opt_param . params [ \"opt_rounds\" ] = int ( opt_param . params [ \"opt_rounds\" ]) print ( \" Value: {} \" . format ( opt_param . value )) print ( \" Params: \" ) for key , value in opt_param . params . items (): print ( \" {} : {} \" . format ( key , value )) return opt_param . params def predict ( self , data : pd . DataFrame , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ): \"\"\" Function that predicts from the trained model. Arguments --------- data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- predt_df : pd.DataFrame Predictions. \"\"\" # Predict predt_df = self . dist . predict_dist ( booster = self . booster , data = data , start_values = self . start_values , pred_type = pred_type , n_samples = n_samples , quantiles = quantiles , seed = seed ) return predt_df def plot ( self , X : pd . DataFrame , feature : str = \"x\" , parameter : str = \"loc\" , max_display : int = 15 , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS SHap plotting function. Arguments: --------- X: pd.DataFrame Train/Test Data feature: str Specifies which feature is to be plotted. parameter: str Specifies which distributional parameter is to be plotted. max_display: int Specifies the maximum number of features to be displayed. plot_type: str Specifies the type of plot: \"Partial_Dependence\" plots the partial dependence of the parameter on the feature. \"Feature_Importance\" plots the feature importance of the parameter. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) param_pos = self . dist . distribution_arg_names . index ( parameter ) if plot_type == \"Partial_Dependence\" : if self . dist . n_dist_param == 1 : shap . plots . scatter ( shap_values [:, feature ], color = shap_values [:, feature ]) else : shap . plots . scatter ( shap_values [:, feature ][:, param_pos ], color = shap_values [:, feature ][:, param_pos ]) elif plot_type == \"Feature_Importance\" : if self . dist . n_dist_param == 1 : shap . plots . bar ( shap_values , max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ]) else : shap . plots . bar ( shap_values [:, :, param_pos ], max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ] ) def expectile_plot ( self , X : pd . DataFrame , feature : str = \"x\" , expectile : str = \"0.05\" , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS function for plotting expectile SHapley values. X: pd.DataFrame Train/Test Data feature: str Specifies which feature to use for plotting Partial_Dependence plot. expectile: str Specifies which expectile to plot. plot_type: str Specifies which SHapley-plot to visualize. Currently, \"Partial_Dependence\" and \"Feature_Importance\" are supported. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) expect_pos = list ( self . dist . param_dict . keys ()) . index ( expectile ) if plot_type == \"Partial_Dependence\" : shap . plots . scatter ( shap_values [:, feature ][:, expect_pos ], color = shap_values [:, feature ][:, expect_pos ]) elif plot_type == \"Feature_Importance\" : shap . plots . bar ( shap_values [:, :, expect_pos ], max_display = 15 if X . shape [ 1 ] > 15 else X . shape [ 1 ]) def set_valid_margin ( self , valid_sets : list , start_values : np . ndarray ) -> list : \"\"\" Function that sets the base margin for the validation set. Arguments --------- valid_sets : list List of tuples containing the train and evaluation set. valid_names: list List of tuples containing the name of train and evaluation set. start_values : np.ndarray Array containing the start values for the distributional parameters. Returns ------- valid_sets : list List of tuples containing the train and evaluation set. \"\"\" valid_sets1 = valid_sets [ 0 ] init_score_val1 = ( np . ones ( shape = ( valid_sets1 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets1 . set_init_score ( init_score_val1 . ravel ( order = \"F\" )) valid_sets2 = valid_sets [ 1 ] init_score_val2 = ( np . ones ( shape = ( valid_sets2 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets2 . set_init_score ( init_score_val2 . ravel ( order = \"F\" )) valid_sets = [ valid_sets1 , valid_sets2 ] return valid_sets def save_model ( self , model_path : str ) -> None : \"\"\" Save the model to a file. Parameters ---------- model_path : str The path to save the model. Returns ------- None \"\"\" with open ( model_path , \"wb\" ) as f : pickle . dump ( self , f ) @staticmethod def load_model ( model_path : str ): \"\"\" Load the model from a file. Parameters ---------- model_path : str The path to the saved model. Returns ------- The loaded model. \"\"\" with open ( model_path , \"rb\" ) as f : return pickle . load ( f )","title":"Parameters"},{"location":"api/#lightgbmlss.model.LightGBMLSS.cv","text":"Function to cross-validate a LightGBMLSS model with given parameters.","title":"cv()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.cv--parameters","text":"params : dict Parameters for training. Values passed through params take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. folds : generator or iterator of (train_idx, test_idx) tuples, scikit-learn splitter object or None, optional (default=None) If generator or iterator, it should yield the train and test indices for each fold. If object, it should be one of the scikit-learn splitter classes (https://scikit-learn.org/stable/modules/classes.html#splitter-classes) and have split method. This argument has highest priority over other data split arguments. nfold : int, optional (default=5) Number of folds in CV. stratified : bool, optional (default=True) Whether to perform stratified sampling. shuffle : bool, optional (default=True) Whether to shuffle before splitting data. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify feature_name as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. fpreproc : callable or None, optional (default=None) Preprocessing function that takes (dtrain, dtest, params) and returns transformed versions of those. seed : int, optional (default=0) Seed used to generate the folds (passed to numpy.random.seed). callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. eval_train_metric : bool, optional (default=False) Whether to display the train metric in progress. The score of the metric is calculated again after each training step, so there is some impact on performance. return_cvbooster : bool, optional (default=False) Whether to return Booster models trained on each fold through CVBooster .","title":"Parameters"},{"location":"api/#lightgbmlss.model.LightGBMLSS.cv--returns","text":"eval_hist : dict Evaluation history. The dictionary has the following format: {'metric1-mean': [values], 'metric1-stdv': [values], 'metric2-mean': [values], 'metric2-stdv': [values], ...}. If return_cvbooster=True , also returns trained boosters wrapped in a CVBooster object via cvbooster key. Source code in lightgbmlss/model.py 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 def cv ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , folds : Optional [ Union [ Iterable [ Tuple [ np . ndarray , np . ndarray ]], _LGBMBaseCrossValidator ]] = None , nfold : int = 5 , stratified : bool = True , shuffle : bool = True , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , fpreproc : Optional [ _LGBM_PreprocFunction ] = None , seed : int = 123 , callbacks : Optional [ List [ Callable ]] = None , eval_train_metric : bool = False , return_cvbooster : bool = False ) -> Dict [ str , Union [ List [ float ], CVBooster ]]: \"\"\"Function to cross-validate a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. folds : generator or iterator of (train_idx, test_idx) tuples, scikit-learn splitter object or None, optional (default=None) If generator or iterator, it should yield the train and test indices for each fold. If object, it should be one of the scikit-learn splitter classes (https://scikit-learn.org/stable/modules/classes.html#splitter-classes) and have ``split`` method. This argument has highest priority over other data split arguments. nfold : int, optional (default=5) Number of folds in CV. stratified : bool, optional (default=True) Whether to perform stratified sampling. shuffle : bool, optional (default=True) Whether to shuffle before splitting data. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. fpreproc : callable or None, optional (default=None) Preprocessing function that takes (dtrain, dtest, params) and returns transformed versions of those. seed : int, optional (default=0) Seed used to generate the folds (passed to numpy.random.seed). callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. eval_train_metric : bool, optional (default=False) Whether to display the train metric in progress. The score of the metric is calculated again after each training step, so there is some impact on performance. return_cvbooster : bool, optional (default=False) Whether to return Booster models trained on each fold through ``CVBooster``. Returns ------- eval_hist : dict Evaluation history. The dictionary has the following format: {'metric1-mean': [values], 'metric1-stdv': [values], 'metric2-mean': [values], 'metric2-stdv': [values], ...}. If ``return_cvbooster=True``, also returns trained boosters wrapped in a ``CVBooster`` object via ``cvbooster`` key. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) self . bstLSS_cv = lgb . cv ( params , train_set , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , num_boost_round = num_boost_round , folds = folds , nfold = nfold , stratified = False , shuffle = False , metrics = None , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , fpreproc = fpreproc , seed = seed , callbacks = callbacks , eval_train_metric = eval_train_metric , return_cvbooster = return_cvbooster ) return self . bstLSS_cv","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.expectile_plot","text":"LightGBMLSS function for plotting expectile SHapley values. pd.DataFrame Train/Test Data feature: str Specifies which feature to use for plotting Partial_Dependence plot. expectile: str Specifies which expectile to plot. plot_type: str Specifies which SHapley-plot to visualize. Currently, \"Partial_Dependence\" and \"Feature_Importance\" are supported. Source code in lightgbmlss/model.py 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 def expectile_plot ( self , X : pd . DataFrame , feature : str = \"x\" , expectile : str = \"0.05\" , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS function for plotting expectile SHapley values. X: pd.DataFrame Train/Test Data feature: str Specifies which feature to use for plotting Partial_Dependence plot. expectile: str Specifies which expectile to plot. plot_type: str Specifies which SHapley-plot to visualize. Currently, \"Partial_Dependence\" and \"Feature_Importance\" are supported. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) expect_pos = list ( self . dist . param_dict . keys ()) . index ( expectile ) if plot_type == \"Partial_Dependence\" : shap . plots . scatter ( shap_values [:, feature ][:, expect_pos ], color = shap_values [:, feature ][:, expect_pos ]) elif plot_type == \"Feature_Importance\" : shap . plots . bar ( shap_values [:, :, expect_pos ], max_display = 15 if X . shape [ 1 ] > 15 else X . shape [ 1 ])","title":"expectile_plot()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.hyper_opt","text":"Function to tune hyperparameters using optuna.","title":"hyper_opt()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.hyper_opt--arguments","text":"hp_dict: dict Dictionary of hyperparameters to tune. train_set: lgb.Dataset Training data. num_boost_round: int Number of boosting iterations. nfold: int Number of folds in CV. early_stopping_rounds: int Activates early stopping. Cross-Validation metric (average of validation metric computed over CV folds) needs to improve at least once in every early_stopping_rounds round(s) to continue training. The last entry in the evaluation history will represent the best iteration. If there's more than one metric in the eval_metric parameter given in params , the last metric will be used for early stopping. max_minutes: int Time budget in minutes, i.e., stop study after the given number of minutes. n_trials: int The number of trials. If this argument is set to None, there is no limitation on the number of trials. study_name: str Name of the hyperparameter study. silence: bool Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed: int Seed used to generate the folds (passed to numpy.random.seed). hp_seed: int Seed for random number generator used in the Bayesian hyper-parameter search.","title":"Arguments"},{"location":"api/#lightgbmlss.model.LightGBMLSS.hyper_opt--returns","text":"opt_params : dict Optimal hyper-parameters. Source code in lightgbmlss/model.py 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 def hyper_opt ( self , hp_dict : Dict , train_set : lgb . Dataset , num_boost_round = 500 , nfold = 10 , early_stopping_rounds = 20 , max_minutes = 10 , n_trials = None , study_name = None , silence = False , seed = None , hp_seed = None ): \"\"\" Function to tune hyperparameters using optuna. Arguments ---------- hp_dict: dict Dictionary of hyperparameters to tune. train_set: lgb.Dataset Training data. num_boost_round: int Number of boosting iterations. nfold: int Number of folds in CV. early_stopping_rounds: int Activates early stopping. Cross-Validation metric (average of validation metric computed over CV folds) needs to improve at least once in every **early_stopping_rounds** round(s) to continue training. The last entry in the evaluation history will represent the best iteration. If there's more than one metric in the **eval_metric** parameter given in **params**, the last metric will be used for early stopping. max_minutes: int Time budget in minutes, i.e., stop study after the given number of minutes. n_trials: int The number of trials. If this argument is set to None, there is no limitation on the number of trials. study_name: str Name of the hyperparameter study. silence: bool Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed: int Seed used to generate the folds (passed to numpy.random.seed). hp_seed: int Seed for random number generator used in the Bayesian hyper-parameter search. Returns ------- opt_params : dict Optimal hyper-parameters. \"\"\" def objective ( trial ): hyper_params = {} for param_name , param_value in hp_dict . items (): param_type = param_value [ 0 ] if param_type == \"categorical\" or param_type == \"none\" : hyper_params . update ({ param_name : trial . suggest_categorical ( param_name , param_value [ 1 ])}) elif param_type == \"float\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_float ( param_name , low = param_low , high = param_high , log = param_log ) }) elif param_type == \"int\" : param_constraints = param_value [ 1 ] param_low = param_constraints [ \"low\" ] param_high = param_constraints [ \"high\" ] param_log = param_constraints [ \"log\" ] hyper_params . update ( { param_name : trial . suggest_int ( param_name , low = param_low , high = param_high , log = param_log ) }) # Add booster if not included in dictionary if \"boosting\" not in hyper_params . keys (): hyper_params . update ({ \"boosting\" : trial . suggest_categorical ( \"boosting\" , [ \"gbdt\" ])}) # Add pruning and early stopping pruning_callback = LightGBMPruningCallback ( trial , self . dist . loss_fn ) early_stopping_callback = lgb . early_stopping ( stopping_rounds = early_stopping_rounds , verbose = False ) lgblss_param_tuning = self . cv ( hyper_params , train_set , num_boost_round = num_boost_round , nfold = nfold , callbacks = [ pruning_callback , early_stopping_callback ], seed = seed , ) # Extract the optimal number of boosting rounds opt_rounds = np . argmin ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) + 1 trial . set_user_attr ( \"opt_round\" , int ( opt_rounds )) # Extract the best score best_score = np . min ( np . array ( lgblss_param_tuning [ f \" { self . dist . loss_fn } -mean\" ])) return best_score if study_name is None : study_name = \"LightGBMLSS Hyper-Parameter Optimization\" if silence : optuna . logging . set_verbosity ( optuna . logging . WARNING ) if hp_seed is not None : sampler = TPESampler ( seed = hp_seed ) else : sampler = TPESampler () pruner = optuna . pruners . MedianPruner ( n_startup_trials = 10 , n_warmup_steps = 20 ) study = optuna . create_study ( sampler = sampler , pruner = pruner , direction = \"minimize\" , study_name = study_name ) study . optimize ( objective , n_trials = n_trials , timeout = 60 * max_minutes , show_progress_bar = True ) print ( \" \\n Hyper-Parameter Optimization successfully finished.\" ) print ( \" Number of finished trials: \" , len ( study . trials )) print ( \" Best trial:\" ) opt_param = study . best_trial # Add optimal stopping round opt_param . params [ \"opt_rounds\" ] = study . trials_dataframe ()[ \"user_attrs_opt_round\" ][ study . trials_dataframe ()[ \"value\" ] . idxmin ()] opt_param . params [ \"opt_rounds\" ] = int ( opt_param . params [ \"opt_rounds\" ]) print ( \" Value: {} \" . format ( opt_param . value )) print ( \" Params: \" ) for key , value in opt_param . params . items (): print ( \" {} : {} \" . format ( key , value )) return opt_param . params","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.load_model","text":"Load the model from a file.","title":"load_model()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.load_model--parameters","text":"model_path : str The path to the saved model.","title":"Parameters"},{"location":"api/#lightgbmlss.model.LightGBMLSS.load_model--returns","text":"The loaded model. Source code in lightgbmlss/model.py 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 @staticmethod def load_model ( model_path : str ): \"\"\" Load the model from a file. Parameters ---------- model_path : str The path to the saved model. Returns ------- The loaded model. \"\"\" with open ( model_path , \"rb\" ) as f : return pickle . load ( f )","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.plot","text":"LightGBMLSS SHap plotting function.","title":"plot()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.plot--arguments","text":"X: pd.DataFrame Train/Test Data feature: str Specifies which feature is to be plotted. parameter: str Specifies which distributional parameter is to be plotted. max_display: int Specifies the maximum number of features to be displayed. plot_type: str Specifies the type of plot: \"Partial_Dependence\" plots the partial dependence of the parameter on the feature. \"Feature_Importance\" plots the feature importance of the parameter. Source code in lightgbmlss/model.py 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 def plot ( self , X : pd . DataFrame , feature : str = \"x\" , parameter : str = \"loc\" , max_display : int = 15 , plot_type : str = \"Partial_Dependence\" ): \"\"\" LightGBMLSS SHap plotting function. Arguments: --------- X: pd.DataFrame Train/Test Data feature: str Specifies which feature is to be plotted. parameter: str Specifies which distributional parameter is to be plotted. max_display: int Specifies the maximum number of features to be displayed. plot_type: str Specifies the type of plot: \"Partial_Dependence\" plots the partial dependence of the parameter on the feature. \"Feature_Importance\" plots the feature importance of the parameter. \"\"\" shap . initjs () explainer = shap . TreeExplainer ( self . booster ) shap_values = explainer ( X ) param_pos = self . dist . distribution_arg_names . index ( parameter ) if plot_type == \"Partial_Dependence\" : if self . dist . n_dist_param == 1 : shap . plots . scatter ( shap_values [:, feature ], color = shap_values [:, feature ]) else : shap . plots . scatter ( shap_values [:, feature ][:, param_pos ], color = shap_values [:, feature ][:, param_pos ]) elif plot_type == \"Feature_Importance\" : if self . dist . n_dist_param == 1 : shap . plots . bar ( shap_values , max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ]) else : shap . plots . bar ( shap_values [:, :, param_pos ], max_display = max_display if X . shape [ 1 ] > max_display else X . shape [ 1 ] )","title":"Arguments:"},{"location":"api/#lightgbmlss.model.LightGBMLSS.predict","text":"Function that predicts from the trained model.","title":"predict()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.predict--arguments","text":"data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution.","title":"Arguments"},{"location":"api/#lightgbmlss.model.LightGBMLSS.predict--returns","text":"predt_df : pd.DataFrame Predictions. Source code in lightgbmlss/model.py 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 def predict ( self , data : pd . DataFrame , pred_type : str = \"parameters\" , n_samples : int = 1000 , quantiles : list = [ 0.1 , 0.5 , 0.9 ], seed : str = 123 ): \"\"\" Function that predicts from the trained model. Arguments --------- data : pd.DataFrame Data to predict from. pred_type : str Type of prediction: - \"samples\" draws n_samples from the predicted distribution. - \"quantiles\" calculates the quantiles from the predicted distribution. - \"parameters\" returns the predicted distributional parameters. - \"expectiles\" returns the predicted expectiles. n_samples : int Number of samples to draw from the predicted distribution. quantiles : List[float] List of quantiles to calculate from the predicted distribution. seed : int Seed for random number generator used to draw samples from the predicted distribution. Returns ------- predt_df : pd.DataFrame Predictions. \"\"\" # Predict predt_df = self . dist . predict_dist ( booster = self . booster , data = data , start_values = self . start_values , pred_type = pred_type , n_samples = n_samples , quantiles = quantiles , seed = seed ) return predt_df","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.save_model","text":"Save the model to a file.","title":"save_model()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.save_model--parameters","text":"model_path : str The path to save the model.","title":"Parameters"},{"location":"api/#lightgbmlss.model.LightGBMLSS.save_model--returns","text":"None Source code in lightgbmlss/model.py 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 def save_model ( self , model_path : str ) -> None : \"\"\" Save the model to a file. Parameters ---------- model_path : str The path to save the model. Returns ------- None \"\"\" with open ( model_path , \"wb\" ) as f : pickle . dump ( self , f )","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_init_score","text":"Set init_score for distributions.","title":"set_init_score()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_init_score--arguments","text":"dmatrix : Dataset Dataset to set base margin for.","title":"Arguments"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_init_score--returns","text":"None Source code in lightgbmlss/model.py 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 def set_init_score ( self , dmatrix : Dataset ) -> None : \"\"\" Set init_score for distributions. Arguments --------- dmatrix : Dataset Dataset to set base margin for. Returns ------- None \"\"\" if self . start_values is None : _ , self . start_values = self . dist . calculate_start_values ( dmatrix . get_label ()) init_score = ( np . ones ( shape = ( dmatrix . get_label () . shape [ 0 ], 1 ))) * self . start_values dmatrix . set_init_score ( init_score . ravel ( order = \"F\" ))","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_params","text":"Set parameters for distributional model.","title":"set_params()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_params--arguments","text":"params : Dict[str, Any] Parameters for model.","title":"Arguments"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_params--returns","text":"params : Dict[str, Any] Updated Parameters for model. Source code in lightgbmlss/model.py 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 def set_params ( self , params : Dict [ str , Any ]) -> Dict [ str , Any ]: \"\"\" Set parameters for distributional model. Arguments --------- params : Dict[str, Any] Parameters for model. Returns ------- params : Dict[str, Any] Updated Parameters for model. \"\"\" params_adj = { \"num_class\" : self . dist . n_dist_param , \"metric\" : \"None\" , \"objective\" : \"None\" , \"random_seed\" : 123 , \"verbose\" : - 1 } params . update ( params_adj ) return params","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_valid_margin","text":"Function that sets the base margin for the validation set.","title":"set_valid_margin()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_valid_margin--arguments","text":"valid_sets : list List of tuples containing the train and evaluation set. valid_names: list List of tuples containing the name of train and evaluation set. start_values : np.ndarray Array containing the start values for the distributional parameters.","title":"Arguments"},{"location":"api/#lightgbmlss.model.LightGBMLSS.set_valid_margin--returns","text":"valid_sets : list List of tuples containing the train and evaluation set. Source code in lightgbmlss/model.py 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 def set_valid_margin ( self , valid_sets : list , start_values : np . ndarray ) -> list : \"\"\" Function that sets the base margin for the validation set. Arguments --------- valid_sets : list List of tuples containing the train and evaluation set. valid_names: list List of tuples containing the name of train and evaluation set. start_values : np.ndarray Array containing the start values for the distributional parameters. Returns ------- valid_sets : list List of tuples containing the train and evaluation set. \"\"\" valid_sets1 = valid_sets [ 0 ] init_score_val1 = ( np . ones ( shape = ( valid_sets1 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets1 . set_init_score ( init_score_val1 . ravel ( order = \"F\" )) valid_sets2 = valid_sets [ 1 ] init_score_val2 = ( np . ones ( shape = ( valid_sets2 . get_label () . shape [ 0 ], 1 ))) * start_values valid_sets2 . set_init_score ( init_score_val2 . ravel ( order = \"F\" )) valid_sets = [ valid_sets1 , valid_sets2 ] return valid_sets","title":"Returns"},{"location":"api/#lightgbmlss.model.LightGBMLSS.train","text":"Function to perform the training of a LightGBMLSS model with given parameters.","title":"train()"},{"location":"api/#lightgbmlss.model.LightGBMLSS.train--parameters","text":"params : dict Parameters for training. Values passed through params take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. valid_sets : list of Dataset, or None, optional (default=None) List of data to be evaluated on during training. valid_names : list of str, or None, optional (default=None) Names of valid_sets . init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify feature_name as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. keep_training_booster : bool, optional (default=False) Whether the returned Booster will be used to keep training. If False, the returned value will be converted into _InnerPredictor before returning. This means you won't be able to use eval , eval_train or eval_valid methods of the returned Booster. When your model is very large and cause the memory error, you can try to set this param to True to avoid the model conversion performed during the internal call of model_to_string . You can still use _InnerPredictor as init_model for future continue training. callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information.","title":"Parameters"},{"location":"api/#lightgbmlss.model.LightGBMLSS.train--returns","text":"booster : Booster The trained Booster model. Source code in lightgbmlss/model.py 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 def train ( self , params : Dict [ str , Any ], train_set : Dataset , num_boost_round : int = 100 , valid_sets : Optional [ List [ Dataset ]] = None , valid_names : Optional [ List [ str ]] = None , init_model : Optional [ Union [ str , Path , Booster ]] = None , feature_name : _LGBM_FeatureNameConfiguration = 'auto' , categorical_feature : _LGBM_CategoricalFeatureConfiguration = 'auto' , keep_training_booster : bool = False , callbacks : Optional [ List [ Callable ]] = None ) -> Booster : \"\"\"Function to perform the training of a LightGBMLSS model with given parameters. Parameters ---------- params : dict Parameters for training. Values passed through ``params`` take precedence over those supplied via arguments. train_set : Dataset Data to be trained on. num_boost_round : int, optional (default=100) Number of boosting iterations. valid_sets : list of Dataset, or None, optional (default=None) List of data to be evaluated on during training. valid_names : list of str, or None, optional (default=None) Names of ``valid_sets``. init_model : str, pathlib.Path, Booster or None, optional (default=None) Filename of LightGBM model or Booster instance used for continue training. feature_name : list of str, or 'auto', optional (default=\"auto\") Feature names. If 'auto' and data is pandas DataFrame, data columns names are used. categorical_feature : list of str or int, or 'auto', optional (default=\"auto\") Categorical features. If list of int, interpreted as indices. If list of str, interpreted as feature names (need to specify ``feature_name`` as well). If 'auto' and data is pandas DataFrame, pandas unordered categorical columns are used. All values in categorical features will be cast to int32 and thus should be less than int32 max value (2147483647). Large values could be memory consuming. Consider using consecutive integers starting from zero. All negative values in categorical features will be treated as missing values. The output cannot be monotonically constrained with respect to a categorical feature. Floating point numbers in categorical features will be rounded towards 0. keep_training_booster : bool, optional (default=False) Whether the returned Booster will be used to keep training. If False, the returned value will be converted into _InnerPredictor before returning. This means you won't be able to use ``eval``, ``eval_train`` or ``eval_valid`` methods of the returned Booster. When your model is very large and cause the memory error, you can try to set this param to ``True`` to avoid the model conversion performed during the internal call of ``model_to_string``. You can still use _InnerPredictor as ``init_model`` for future continue training. callbacks : list of callable, or None, optional (default=None) List of callback functions that are applied at each iteration. See Callbacks in Python API for more information. Returns ------- booster : Booster The trained Booster model. \"\"\" self . set_params ( params ) self . set_init_score ( train_set ) if valid_sets is not None : valid_sets = self . set_valid_margin ( valid_sets , self . start_values ) self . booster = lgb . train ( params , train_set , num_boost_round = num_boost_round , fobj = self . dist . objective_fn , feval = self . dist . metric_fn , valid_sets = valid_sets , valid_names = valid_names , init_model = init_model , feature_name = feature_name , categorical_feature = categorical_feature , keep_training_booster = keep_training_booster , callbacks = callbacks )","title":"Returns"},{"location":"api/#lightgbmlss.utils","text":"","title":"utils"},{"location":"api/#lightgbmlss.utils.exp_fn","text":"Exponential function used to ensure predt is strictly positive.","title":"exp_fn()"},{"location":"api/#lightgbmlss.utils.exp_fn--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.exp_fn--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def exp_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Exponential function used to ensure predt is strictly positive. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . exp ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt","title":"Returns"},{"location":"api/#lightgbmlss.utils.exp_fn_df","text":"Exponential function used for Student-T distribution.","title":"exp_fn_df()"},{"location":"api/#lightgbmlss.utils.exp_fn_df--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.exp_fn_df--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 def exp_fn_df ( predt : torch . tensor ) -> torch . tensor : \"\"\" Exponential function used for Student-T distribution. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . exp ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt + torch . tensor ( 2.0 , dtype = predt . dtype )","title":"Returns"},{"location":"api/#lightgbmlss.utils.identity_fn","text":"Identity mapping of predt.","title":"identity_fn()"},{"location":"api/#lightgbmlss.utils.identity_fn--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.identity_fn--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def identity_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Identity mapping of predt. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" return predt","title":"Returns"},{"location":"api/#lightgbmlss.utils.log_fn","text":"Inverse of exp_fn function.","title":"log_fn()"},{"location":"api/#lightgbmlss.utils.log_fn--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.log_fn--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 def log_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Inverse of exp_fn function. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . log ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + float ( 1e-06 ) return predt","title":"Returns"},{"location":"api/#lightgbmlss.utils.relu_fn","text":"Function used to ensure predt are scaled to max(0, predt).","title":"relu_fn()"},{"location":"api/#lightgbmlss.utils.relu_fn--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.relu_fn--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 def relu_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Function used to ensure predt are scaled to max(0, predt). Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . relu ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-6 , dtype = predt . dtype ) return predt","title":"Returns"},{"location":"api/#lightgbmlss.utils.sigmoid_fn","text":"Function used to ensure predt are scaled to (0,1).","title":"sigmoid_fn()"},{"location":"api/#lightgbmlss.utils.sigmoid_fn--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.sigmoid_fn--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 def sigmoid_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Function used to ensure predt are scaled to (0,1). Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . sigmoid ( predt ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) predt = torch . clamp ( predt , 1e-03 , 1 - 1e-03 ) return predt","title":"Returns"},{"location":"api/#lightgbmlss.utils.softplus_fn","text":"Softplus function used to ensure predt is strictly positive.","title":"softplus_fn()"},{"location":"api/#lightgbmlss.utils.softplus_fn--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.softplus_fn--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 def softplus_fn ( predt : torch . tensor ) -> torch . tensor : \"\"\" Softplus function used to ensure predt is strictly positive. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . log1p ( torch . exp ( - torch . abs ( predt ))) + torch . maximum ( predt , torch . tensor ( 0. )) predt [ predt == 0 ] = torch . tensor ( 1e-06 , dtype = predt . dtype ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt","title":"Returns"},{"location":"api/#lightgbmlss.utils.softplus_fn_df","text":"Softplus function used for Student-T distribution.","title":"softplus_fn_df()"},{"location":"api/#lightgbmlss.utils.softplus_fn_df--arguments","text":"predt: torch.tensor Predicted values.","title":"Arguments"},{"location":"api/#lightgbmlss.utils.softplus_fn_df--returns","text":"predt: torch.tensor Predicted values. Source code in lightgbmlss/utils.py 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 def softplus_fn_df ( predt : torch . tensor ) -> torch . tensor : \"\"\" Softplus function used for Student-T distribution. Arguments --------- predt: torch.tensor Predicted values. Returns ------- predt: torch.tensor Predicted values. \"\"\" predt = torch . log1p ( torch . exp ( - torch . abs ( predt ))) + torch . maximum ( predt , torch . tensor ( 0. )) predt [ predt == 0 ] = torch . tensor ( 1e-06 , dtype = predt . dtype ) predt = torch . nan_to_num ( predt , nan = float ( torch . nanmean ( predt ))) + torch . tensor ( 1e-06 , dtype = predt . dtype ) return predt + torch . tensor ( 2.0 , dtype = predt . dtype )","title":"Returns"},{"location":"dgbm/","text":"Introduction The development of modelling approaches that approximate and describe the data generating processes underlying the observed data in as much detail as possible is a guiding principle in both statistics and machine learning. We therefore strongly agree with the statement of Hothorn et al. (2014) that ''the ultimate goal of any regression analysis is to obtain information about the entire conditional distribution \\(F_{Y}(y|\\mathbf{x})\\) of a response given a set of explanatory variables'' . ''Practitioners expect forecasting to reduce future uncertainty by providing accurate predictions like those in hard sciences. However, this is a great misconception. A major purpose of forecasting is not to reduce uncertainty but reveal its full extent and implications by estimating it as precisely as possible. [...] The challenge for the forecasting field is how to persuade practitioners of the reality that all forecasts are uncertain and that this uncertainty cannot be ignored, as doing so could lead to catastrophic consequences.'' Makridakis (2022b) It has not been too long, though, that most regression models focused on estimating the conditional mean \\(\\mathbb{E}(Y|\\mathbf{X} = \\mathbf{x})\\) only, implicitly treating higher moments of the conditional distribution \\(F_{Y}(y|\\mathbf{x})\\) as fixed nuisance parameters. As such, models that minimize an \\(\\ell_{2}\\) -type loss for the conditional mean are not able to fully exploit the information contained in the data, since this is equivalent to assuming a Normal distribution with constant variance. In real world situations, however, the data generating process is usually less well behaved, exhibiting characteristics such as heteroskedasticity, varying degrees of skewness and kurtosis or intermittent and sporadic behaviour. In recent years, however, there has been a clear shift in both academic and corporate research toward modelling the entire conditional distribution. This change in attention is most evident in the recent M5 forecasting competition (Makridakis et al., 2022a,b), which differed from previous ones in that it consisted of two parallel competitions: in addition to providing accurate point forecasts, participants were also asked to forecast nine different quantiles to approximate the distribution of future sales. Distributional Gradient Boosting Machines This section introduces the general idea of distributional modelling. For a more thorough introduction, we refer the interested reader to Rigby and Stasinopoulos (2005); Klein et al. (2015); Stasinopoulos et al. (2017). GAMLSS Probabilistic forecasts are predictions in the form of a probability distribution, rather than a single point estimate only. In this context, the introduction of Generalized Additive Models for Location Scale and Shape (GAMLSS) by Rigby and Stasinopoulos (2005) has stimulated a lot of research and culminated in a new research branch that focuses on modelling the entire conditional distribution in dependence of covariates. Univariate Targets In its original formulation, GAMLSS assume a univariate response to follow a distribution \\(\\mathcal{D}\\) that depends on up to four parameters, i.e., \\(y_{i} \\stackrel{ind}{\\sim} \\mathcal{D}(\\mu_{i}, \\sigma^{2}_{i}, \\nu_{i}, \\tau_{i}), i=1,\\ldots,N\\) , where \\(\\mu_{i}\\) and \\(\\sigma^{2}_{i}\\) are often location and scale parameters, respectively, while \\(\\nu_{i}\\) and \\(\\tau_{i}\\) correspond to shape parameters such as skewness and kurtosis. Hence, the framework allows to model not only the mean (or location) but all parameters as functions of explanatory variables. It is important to note that distributional modelling implies that observations are independent, but not necessarily identical realizations \\(y \\stackrel{ind}{\\sim} \\mathcal{D}\\big(\\mathbf{\\theta}(\\mathbf{x})\\big)\\) , since all distributional parameters \\(\\mathbf{\\theta}(\\mathbf{x})\\) are related to and allowed to change with covariates. In contrast to Generalized Linear (GLM) and Generalized Additive Models (GAM), the assumption of the response distribution belonging to an exponential family is relaxed in GAMLSS and replaced by a more general class of distributions, including highly skewed and/or kurtotic continuous, discrete and mixed discrete, as well as zero-inflated distributions. While the original formulation of GAMLSS in Rigby and Stasinopoulos (2005) suggests that any distribution can be described by location, scale and shape parameters, it is not necessarily true that the observed data distribution can actually be characterized by all of these parameters. Hence, we follow Klein et al. (2015) and use the term distributional modelling and GAMLSS interchangeably. From a frequentist point of view, distributional modelling can be formulated as follows \\[\\begin{equation} y_{i} \\stackrel{ind}{\\sim} \\mathcal{D} \\begin{pmatrix} h_{1}\\bigl(\\theta_{i1}(x_{i})\\bigr) = \\eta_{i1} \\\\ h_{2}\\bigl(\\theta_{i2}(x_{i})\\bigr) = \\eta_{i2} \\\\ \\vdots \\\\ h_{K}\\bigl(\\theta_{iK}(x_{i})\\bigr) = \\eta_{iK} \\end{pmatrix} \\end{equation}\\] for \\(i = 1, \\ldots, N\\) , where \\(\\mathcal{D}\\) denotes a parametric distribution for the response \\(\\textbf{y} = (y_{1}, \\ldots, y_{N})^{\\prime}\\) that depends on \\(K\\) distributional parameters \\(\\theta_{k}\\) , \\(k = 1, \\ldots, K\\) , and with \\(h_{k}(\\cdot)\\) denoting a known function relating distributional parameters to predictors \\(\\eta_{k}\\) . In its most generic form, the predictor \\(\\eta_{k}\\) is given by \\[\\begin{equation} \\eta_{k} = f_{k}(\\mathbf{x}), \\qquad k = 1, \\ldots, K \\end{equation}\\] Within the original distributional regression framework, the functions \\(f_{k}(\\cdot)\\) usually represent a combination of linear and GAM-type predictors, which allows to estimate linear effects or categorical variables, as well as highly non-linear and spatial effects using a Spline-based basis function approach. The predictor specification \\(\\eta_{k}\\) is generic enough to use tree-based models as well, which allows us to extend LightGBM to a probabilistic framework. Normalizing Flows Although the GAMLSS framework offers considerable flexibility, parametric distributions may prove not flexible enough to provide a reasonable approximation for certain dataset, e.g., for multi-modal distributions. For such cases, it is preferable to relax the assumption of a parametric distribution and approximate the data non-parametrically. While there are several alternatives for learning conditional distributions, we propose to use Normalizing Flows for their ability to fit complex distributions with only a few parameters. The principle that underlies Normalizing Flows is to turn a simple base distribution, e.g., \\(F_{Z}(\\mathbf{z}) = N(0,1)\\) , into a more complex and realistic distribution of the target variable \\(F_{Y}(\\mathbf{y})\\) by applying several bijective transformations \\(h_{j}\\) , \\(j = 1, \\ldots, J\\) to the variable of the base distribution \\[\\begin{equation} \\mathbf{y} = h_{J} \\circ h_{J-1} \\circ \\cdots \\circ h_{1}(\\mathbf{z}) \\end{equation}\\] Based on the complete transformation function \\(h=h_{J}\\circ\\ldots\\circ h_{1}\\) , the density of \\(\\mathbf{y}\\) is then given by the change of variables theorem \\[\\begin{equation} f_{Y}(\\mathbf{y}) = f_{Z}\\big(h(\\mathbf{y})\\big) \\cdot \\Bigg|\\frac{\\partial h(\\mathbf{y})}{\\partial \\mathbf{y}}\\Bigg| \\end{equation}\\] where scaling with the Jacobian determinant \\(|h^{\\prime}(\\mathbf{y})| = |\\partial h(\\mathbf{y}) / \\partial \\mathbf{y}|\\) ensures \\(f_{Y}(\\mathbf{y})\\) to be a proper density integrating to one. The composition of these transformations is invertible, allowing one to sample from the complex distribution by transforming samples from the base distribution. Image source: https://tikz.net/janosh/normalizing-flow.png Our Normalizing Flow approach is based on element-wise rational splines of linear or quadratic order as introduced by Durkan (2019) and Dolatabadi (2020) and implemented in Pyro, since they offer a combination of functional flexibility and numerical stability. Despite this specific choice, our framework is generic enough to accommodate the use of other parametrizable Normalizing Flows. Gradient Boosting Machines for Location, Scale and Shape We draw inspiration from GAMLSS and label our model as LightGBM for Location, Scale and Shape (LightGBMLSS). Despite its nominal reference to GAMLSS, our framework is designed in such a way to accommodate the modeling of a wide range of parametrizable distributions that go beyond location, scale and shape. LightGBMLSS requires the specification of a suitable distribution from which Gradients and Hessians are derived. These represent the partial first and second order derivatives of the log-likelihood with respect to the parameter of interest. GBMLSS are based on multi-parameter optimization, where a separate tree is grown for each parameter. Estimation of Gradients and Hessians, as well as the evaluation of the loss function is done simultaneously for all parameters. Gradients and Hessians are derived using PyTorch's automatic differentiation capabilities. The flexibility offered by automatic differentiation allows users to easily implement novel or customized parametric distributions for which Gradients and Hessians are difficult to derive analytically. It also facilitates the usage of Normalizing Flows, or to add additional constraints to the loss function. To improve the convergence and stability of GBMLSS estimation, unconditional Maximum Likelihood estimates of the parameters are used as offset values. To enable a deeper understanding of the data generating process, GBMLSS also provide attribute importance and partial dependence plots using the Shapley-Value approach. References Hadi Mohaghegh Dolatabadi, Sarah Erfani, and Christopher Leckie. Invertible Generative Modeling using Linear Rational Splines. In The 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), 4236\u20134246, 2020. Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. Neural Spline Flows. In Proceedings of the 33rd International Conference on Neural Information Processing Systems. 2019. Nadja Klein, Thomas Kneib, and Stefan Lang. Bayesian Generalized Additive Models for Location, Scale, and Shape for Zero-Inflated and Overdispersed Count Data. Journal of the American Statistical Association, 110(509):405\u2013419, 2015. Alexander M\u00e4rz, and Thomas Kneib. Distributional Gradient Boosting Machines, 2022b. Alexander M\u00e4rz. XGBoostLSS - An extension of XGBoost to probabilistic forecasting, 2019. Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The M5 competition: Background, organization, and implementation. International Journal of Forecasting, 38(4):1325\u20131336, 2022a. Spyros Makridakis, Evangelos Spiliotis, Vassilios Assimakopoulos, Zhi Chen, Anil Gaba, Ilia Tsetlin, and Robert L. Winkler. The M5 uncertainty competition: Results, findings and conclusions. International Journal of Forecasting, 38(4):1365\u20131385, 2022b. R. A. Rigby and D. M. Stasinopoulos. Generalized additive models for location, scale and shape. Journal of the Royal Statistical Society: Series C (Applied Statistics), 54(3):507\u2013554, 2005. Mikis D. Stasinopoulos, Robert A. Rigby, Gillian Z. Heller, Vlasios Voudouris, and Fernanda de Bastiani. Flexible Regression and Smoothing: Using GAMLSS in R. Chapman & Hall / CRC The R Series. CRC Press, London, 2017.","title":"Distributional Modelling"},{"location":"dgbm/#introduction","text":"The development of modelling approaches that approximate and describe the data generating processes underlying the observed data in as much detail as possible is a guiding principle in both statistics and machine learning. We therefore strongly agree with the statement of Hothorn et al. (2014) that ''the ultimate goal of any regression analysis is to obtain information about the entire conditional distribution \\(F_{Y}(y|\\mathbf{x})\\) of a response given a set of explanatory variables'' . ''Practitioners expect forecasting to reduce future uncertainty by providing accurate predictions like those in hard sciences. However, this is a great misconception. A major purpose of forecasting is not to reduce uncertainty but reveal its full extent and implications by estimating it as precisely as possible. [...] The challenge for the forecasting field is how to persuade practitioners of the reality that all forecasts are uncertain and that this uncertainty cannot be ignored, as doing so could lead to catastrophic consequences.'' Makridakis (2022b) It has not been too long, though, that most regression models focused on estimating the conditional mean \\(\\mathbb{E}(Y|\\mathbf{X} = \\mathbf{x})\\) only, implicitly treating higher moments of the conditional distribution \\(F_{Y}(y|\\mathbf{x})\\) as fixed nuisance parameters. As such, models that minimize an \\(\\ell_{2}\\) -type loss for the conditional mean are not able to fully exploit the information contained in the data, since this is equivalent to assuming a Normal distribution with constant variance. In real world situations, however, the data generating process is usually less well behaved, exhibiting characteristics such as heteroskedasticity, varying degrees of skewness and kurtosis or intermittent and sporadic behaviour. In recent years, however, there has been a clear shift in both academic and corporate research toward modelling the entire conditional distribution. This change in attention is most evident in the recent M5 forecasting competition (Makridakis et al., 2022a,b), which differed from previous ones in that it consisted of two parallel competitions: in addition to providing accurate point forecasts, participants were also asked to forecast nine different quantiles to approximate the distribution of future sales.","title":"Introduction"},{"location":"dgbm/#distributional-gradient-boosting-machines","text":"This section introduces the general idea of distributional modelling. For a more thorough introduction, we refer the interested reader to Rigby and Stasinopoulos (2005); Klein et al. (2015); Stasinopoulos et al. (2017).","title":"Distributional Gradient Boosting Machines"},{"location":"dgbm/#gamlss","text":"Probabilistic forecasts are predictions in the form of a probability distribution, rather than a single point estimate only. In this context, the introduction of Generalized Additive Models for Location Scale and Shape (GAMLSS) by Rigby and Stasinopoulos (2005) has stimulated a lot of research and culminated in a new research branch that focuses on modelling the entire conditional distribution in dependence of covariates.","title":"GAMLSS"},{"location":"dgbm/#univariate-targets","text":"In its original formulation, GAMLSS assume a univariate response to follow a distribution \\(\\mathcal{D}\\) that depends on up to four parameters, i.e., \\(y_{i} \\stackrel{ind}{\\sim} \\mathcal{D}(\\mu_{i}, \\sigma^{2}_{i}, \\nu_{i}, \\tau_{i}), i=1,\\ldots,N\\) , where \\(\\mu_{i}\\) and \\(\\sigma^{2}_{i}\\) are often location and scale parameters, respectively, while \\(\\nu_{i}\\) and \\(\\tau_{i}\\) correspond to shape parameters such as skewness and kurtosis. Hence, the framework allows to model not only the mean (or location) but all parameters as functions of explanatory variables. It is important to note that distributional modelling implies that observations are independent, but not necessarily identical realizations \\(y \\stackrel{ind}{\\sim} \\mathcal{D}\\big(\\mathbf{\\theta}(\\mathbf{x})\\big)\\) , since all distributional parameters \\(\\mathbf{\\theta}(\\mathbf{x})\\) are related to and allowed to change with covariates. In contrast to Generalized Linear (GLM) and Generalized Additive Models (GAM), the assumption of the response distribution belonging to an exponential family is relaxed in GAMLSS and replaced by a more general class of distributions, including highly skewed and/or kurtotic continuous, discrete and mixed discrete, as well as zero-inflated distributions. While the original formulation of GAMLSS in Rigby and Stasinopoulos (2005) suggests that any distribution can be described by location, scale and shape parameters, it is not necessarily true that the observed data distribution can actually be characterized by all of these parameters. Hence, we follow Klein et al. (2015) and use the term distributional modelling and GAMLSS interchangeably. From a frequentist point of view, distributional modelling can be formulated as follows \\[\\begin{equation} y_{i} \\stackrel{ind}{\\sim} \\mathcal{D} \\begin{pmatrix} h_{1}\\bigl(\\theta_{i1}(x_{i})\\bigr) = \\eta_{i1} \\\\ h_{2}\\bigl(\\theta_{i2}(x_{i})\\bigr) = \\eta_{i2} \\\\ \\vdots \\\\ h_{K}\\bigl(\\theta_{iK}(x_{i})\\bigr) = \\eta_{iK} \\end{pmatrix} \\end{equation}\\] for \\(i = 1, \\ldots, N\\) , where \\(\\mathcal{D}\\) denotes a parametric distribution for the response \\(\\textbf{y} = (y_{1}, \\ldots, y_{N})^{\\prime}\\) that depends on \\(K\\) distributional parameters \\(\\theta_{k}\\) , \\(k = 1, \\ldots, K\\) , and with \\(h_{k}(\\cdot)\\) denoting a known function relating distributional parameters to predictors \\(\\eta_{k}\\) . In its most generic form, the predictor \\(\\eta_{k}\\) is given by \\[\\begin{equation} \\eta_{k} = f_{k}(\\mathbf{x}), \\qquad k = 1, \\ldots, K \\end{equation}\\] Within the original distributional regression framework, the functions \\(f_{k}(\\cdot)\\) usually represent a combination of linear and GAM-type predictors, which allows to estimate linear effects or categorical variables, as well as highly non-linear and spatial effects using a Spline-based basis function approach. The predictor specification \\(\\eta_{k}\\) is generic enough to use tree-based models as well, which allows us to extend LightGBM to a probabilistic framework.","title":"Univariate Targets"},{"location":"dgbm/#normalizing-flows","text":"Although the GAMLSS framework offers considerable flexibility, parametric distributions may prove not flexible enough to provide a reasonable approximation for certain dataset, e.g., for multi-modal distributions. For such cases, it is preferable to relax the assumption of a parametric distribution and approximate the data non-parametrically. While there are several alternatives for learning conditional distributions, we propose to use Normalizing Flows for their ability to fit complex distributions with only a few parameters. The principle that underlies Normalizing Flows is to turn a simple base distribution, e.g., \\(F_{Z}(\\mathbf{z}) = N(0,1)\\) , into a more complex and realistic distribution of the target variable \\(F_{Y}(\\mathbf{y})\\) by applying several bijective transformations \\(h_{j}\\) , \\(j = 1, \\ldots, J\\) to the variable of the base distribution \\[\\begin{equation} \\mathbf{y} = h_{J} \\circ h_{J-1} \\circ \\cdots \\circ h_{1}(\\mathbf{z}) \\end{equation}\\] Based on the complete transformation function \\(h=h_{J}\\circ\\ldots\\circ h_{1}\\) , the density of \\(\\mathbf{y}\\) is then given by the change of variables theorem \\[\\begin{equation} f_{Y}(\\mathbf{y}) = f_{Z}\\big(h(\\mathbf{y})\\big) \\cdot \\Bigg|\\frac{\\partial h(\\mathbf{y})}{\\partial \\mathbf{y}}\\Bigg| \\end{equation}\\] where scaling with the Jacobian determinant \\(|h^{\\prime}(\\mathbf{y})| = |\\partial h(\\mathbf{y}) / \\partial \\mathbf{y}|\\) ensures \\(f_{Y}(\\mathbf{y})\\) to be a proper density integrating to one. The composition of these transformations is invertible, allowing one to sample from the complex distribution by transforming samples from the base distribution.","title":"Normalizing Flows"},{"location":"dgbm/#gradient-boosting-machines-for-location-scale-and-shape","text":"We draw inspiration from GAMLSS and label our model as LightGBM for Location, Scale and Shape (LightGBMLSS). Despite its nominal reference to GAMLSS, our framework is designed in such a way to accommodate the modeling of a wide range of parametrizable distributions that go beyond location, scale and shape. LightGBMLSS requires the specification of a suitable distribution from which Gradients and Hessians are derived. These represent the partial first and second order derivatives of the log-likelihood with respect to the parameter of interest. GBMLSS are based on multi-parameter optimization, where a separate tree is grown for each parameter. Estimation of Gradients and Hessians, as well as the evaluation of the loss function is done simultaneously for all parameters. Gradients and Hessians are derived using PyTorch's automatic differentiation capabilities. The flexibility offered by automatic differentiation allows users to easily implement novel or customized parametric distributions for which Gradients and Hessians are difficult to derive analytically. It also facilitates the usage of Normalizing Flows, or to add additional constraints to the loss function. To improve the convergence and stability of GBMLSS estimation, unconditional Maximum Likelihood estimates of the parameters are used as offset values. To enable a deeper understanding of the data generating process, GBMLSS also provide attribute importance and partial dependence plots using the Shapley-Value approach.","title":"Gradient Boosting Machines for Location, Scale and Shape"},{"location":"dgbm/#references","text":"Hadi Mohaghegh Dolatabadi, Sarah Erfani, and Christopher Leckie. Invertible Generative Modeling using Linear Rational Splines. In The 23rd International Conference on Artificial Intelligence and Statistics (AISTATS), 4236\u20134246, 2020. Conor Durkan, Artur Bekasov, Iain Murray, and George Papamakarios. Neural Spline Flows. In Proceedings of the 33rd International Conference on Neural Information Processing Systems. 2019. Nadja Klein, Thomas Kneib, and Stefan Lang. Bayesian Generalized Additive Models for Location, Scale, and Shape for Zero-Inflated and Overdispersed Count Data. Journal of the American Statistical Association, 110(509):405\u2013419, 2015. Alexander M\u00e4rz, and Thomas Kneib. Distributional Gradient Boosting Machines, 2022b. Alexander M\u00e4rz. XGBoostLSS - An extension of XGBoost to probabilistic forecasting, 2019. Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The M5 competition: Background, organization, and implementation. International Journal of Forecasting, 38(4):1325\u20131336, 2022a. Spyros Makridakis, Evangelos Spiliotis, Vassilios Assimakopoulos, Zhi Chen, Anil Gaba, Ilia Tsetlin, and Robert L. Winkler. The M5 uncertainty competition: Results, findings and conclusions. International Journal of Forecasting, 38(4):1365\u20131385, 2022b. R. A. Rigby and D. M. Stasinopoulos. Generalized additive models for location, scale and shape. Journal of the Royal Statistical Society: Series C (Applied Statistics), 54(3):507\u2013554, 2005. Mikis D. Stasinopoulos, Robert A. Rigby, Gillian Z. Heller, Vlasios Voudouris, and Fernanda de Bastiani. Flexible Regression and Smoothing: Using GAMLSS in R. Chapman & Hall / CRC The R Series. CRC Press, London, 2017.","title":"References"},{"location":"distributions/","text":"Available Distributions LightGBMLSS is built upon PyTorch and Pyro, enabling users to harness a diverse set of distributional families and to leverage automatic differentiation capabilities. This greatly expands the options for probabilistic modeling and uncertainty estimation and allows users to tackle complex regression tasks. LightGBMLSS currently supports the following univariate distributions. Distribution Usage Type Support Number of Parameters Beta Beta() Continuous (Univariate) \\(y \\in (0, 1)\\) 2 Cauchy Cauchy() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 Expectile Expectile() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) Number of expectiles Gamma Gamma() Continuous (Univariate) \\(y \\in (0, \\infty)\\) 2 Gaussian Gaussian() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 Gumbel Gumbel() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 Laplace Laplace() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 LogNormal LogNormal() Continuous (Univariate) \\(y \\in (0,\\infty)\\) 2 Negative Binomial NegativeBinomial() Discrete Count (Univariate) \\(y \\in (0, 1, 2, 3, \\ldots)\\) 2 Poisson Poisson() Discrete Count (Univariate) \\(y \\in (0, 1, 2, 3, \\ldots)\\) 1 Spline Flow SplineFlow() Continuous \\& Discrete Count (Univariate) \\(y \\in (-\\infty,\\infty)\\) \\(y \\in [0, \\infty)\\) \\(y \\in [0, 1]\\) \\(y \\in (0, 1, 2, 3, \\ldots)\\) 2xcount_bins + (count_bins-1) (order=quadratic) 3xcount_bins + (count_bins-1) (order=linear) Student-T StudentT() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 3 Weibull Weibull() Continuous (Univariate) \\(y \\in [0, \\infty)\\) 2 Zero-Adjusted Beta ZABeta() Discrete-Continuous (Univariate) \\(y \\in [0, 1)\\) 3 Zero-Adjusted Gamma ZAGamma() Discrete-Continuous (Univariate) \\(y \\in [0, \\infty)\\) 3 Zero-Adjusted LogNormal ZALN() Discrete-Continuous (Univariate) \\(y \\in [0, \\infty)\\) 3 Zero-Inflated Negative Binomial ZINB() Discrete-Count (Univariate) \\(y \\in [0, 1, 2, 3, \\ldots)\\) 3 Zero-Inflated Poisson ZIPoisson() Discrete-Count (Univariate) \\(y \\in [0, 1, 2, 3, \\ldots)\\) 2","title":"Available Distributions"},{"location":"distributions/#available-distributions","text":"LightGBMLSS is built upon PyTorch and Pyro, enabling users to harness a diverse set of distributional families and to leverage automatic differentiation capabilities. This greatly expands the options for probabilistic modeling and uncertainty estimation and allows users to tackle complex regression tasks. LightGBMLSS currently supports the following univariate distributions. Distribution Usage Type Support Number of Parameters Beta Beta() Continuous (Univariate) \\(y \\in (0, 1)\\) 2 Cauchy Cauchy() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 Expectile Expectile() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) Number of expectiles Gamma Gamma() Continuous (Univariate) \\(y \\in (0, \\infty)\\) 2 Gaussian Gaussian() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 Gumbel Gumbel() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 Laplace Laplace() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 2 LogNormal LogNormal() Continuous (Univariate) \\(y \\in (0,\\infty)\\) 2 Negative Binomial NegativeBinomial() Discrete Count (Univariate) \\(y \\in (0, 1, 2, 3, \\ldots)\\) 2 Poisson Poisson() Discrete Count (Univariate) \\(y \\in (0, 1, 2, 3, \\ldots)\\) 1 Spline Flow SplineFlow() Continuous \\& Discrete Count (Univariate) \\(y \\in (-\\infty,\\infty)\\) \\(y \\in [0, \\infty)\\) \\(y \\in [0, 1]\\) \\(y \\in (0, 1, 2, 3, \\ldots)\\) 2xcount_bins + (count_bins-1) (order=quadratic) 3xcount_bins + (count_bins-1) (order=linear) Student-T StudentT() Continuous (Univariate) \\(y \\in (-\\infty,\\infty)\\) 3 Weibull Weibull() Continuous (Univariate) \\(y \\in [0, \\infty)\\) 2 Zero-Adjusted Beta ZABeta() Discrete-Continuous (Univariate) \\(y \\in [0, 1)\\) 3 Zero-Adjusted Gamma ZAGamma() Discrete-Continuous (Univariate) \\(y \\in [0, \\infty)\\) 3 Zero-Adjusted LogNormal ZALN() Discrete-Continuous (Univariate) \\(y \\in [0, \\infty)\\) 3 Zero-Inflated Negative Binomial ZINB() Discrete-Count (Univariate) \\(y \\in [0, 1, 2, 3, \\ldots)\\) 3 Zero-Inflated Poisson ZIPoisson() Discrete-Count (Univariate) \\(y \\in [0, 1, 2, 3, \\ldots)\\) 2","title":"Available Distributions"},{"location":"examples/Expectile_Regression/","text":"(function (global, factory) { typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() : typeof define === 'function' && define.amd ? define(factory) : (global = global || self, global.ClipboardCopyElement = factory()); }(this, function () { 'use strict'; function createNode(text) { const node = document.createElement('pre'); node.style.width = '1px'; node.style.height = '1px'; node.style.position = 'fixed'; node.style.top = '5px'; node.textContent = text; return node; } function copyNode(node) { if ('clipboard' in navigator) { // eslint-disable-next-line flowtype/no-flow-fix-me-comments // $FlowFixMe Clipboard is not defined in Flow yet. return navigator.clipboard.writeText(node.textContent); } const selection = getSelection(); if (selection == null) { return Promise.reject(new Error()); } selection.removeAllRanges(); const range = document.createRange(); range.selectNodeContents(node); selection.addRange(range); document.execCommand('copy'); selection.removeAllRanges(); return Promise.resolve(); } function copyText(text) { if ('clipboard' in navigator) { // eslint-disable-next-line flowtype/no-flow-fix-me-comments // $FlowFixMe Clipboard is not defined in Flow yet. return navigator.clipboard.writeText(text); } const body = document.body; if (!body) { return Promise.reject(new Error()); } const node = createNode(text); body.appendChild(node); copyNode(node); body.removeChild(node); return Promise.resolve(); } function copy(button) { const id = button.getAttribute('for'); const text = button.getAttribute('value'); function trigger() { button.dispatchEvent(new CustomEvent('clipboard-copy', { bubbles: true })); } if (text) { copyText(text).then(trigger); } else if (id) { const root = 'getRootNode' in Element.prototype ? button.getRootNode() : button.ownerDocument; if (!(root instanceof Document || 'ShadowRoot' in window && root instanceof ShadowRoot)) return; const node = root.getElementById(id); if (node) copyTarget(node).then(trigger); } } function copyTarget(content) { if (content instanceof HTMLInputElement || content instanceof HTMLTextAreaElement) { return copyText(content.value); } else if (content instanceof HTMLAnchorElement && content.hasAttribute('href')) { return copyText(content.href); } else { return copyNode(content); } } function clicked(event) { const button = event.currentTarget; if (button instanceof HTMLElement) { copy(button); } } function keydown(event) { if (event.key === ' ' || event.key === 'Enter') { const button = event.currentTarget; if (button instanceof HTMLElement) { event.preventDefault(); copy(button); } } } function focused(event) { event.currentTarget.addEventListener('keydown', keydown); } function blurred(event) { event.currentTarget.removeEventListener('keydown', keydown); } class ClipboardCopyElement extends HTMLElement { constructor() { super(); this.addEventListener('click', clicked); this.addEventListener('focus', focused); this.addEventListener('blur', blurred); } connectedCallback() { if (!this.hasAttribute('tabindex')) { this.setAttribute('tabindex', '0'); } if (!this.hasAttribute('role')) { this.setAttribute('role', 'button'); } } get value() { return this.getAttribute('value') || ''; } set value(text) { this.setAttribute('value', text); } } if (!window.customElements.get('clipboard-copy')) { window.ClipboardCopyElement = ClipboardCopyElement; window.customElements.define('clipboard-copy', ClipboardCopyElement); } return ClipboardCopyElement; })); document.addEventListener('clipboard-copy', function(event) { const notice = event.target.querySelector('.notice') notice.hidden = false setTimeout(function() { notice.hidden = true }, 1000) }) pre { line-height: 125%; } td.linenos .normal { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } span.linenos { color: inherit; background-color: transparent; padding-left: 5px; padding-right: 5px; } td.linenos .special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } span.linenos.special { color: #000000; background-color: #ffffc0; padding-left: 5px; padding-right: 5px; } .highlight-ipynb .hll { background-color: var(--jp-cell-editor-active-background) } .highlight-ipynb { background: var(--jp-cell-editor-background); color: var(--jp-mirror-editor-variable-color) } .highlight-ipynb .c { color: var(--jp-mirror-editor-comment-color); font-style: italic } /* Comment */ .highlight-ipynb .err { color: var(--jp-mirror-editor-error-color) } /* Error */ .highlight-ipynb .k { color: var(--jp-mirror-editor-keyword-color); font-weight: bold } /* Keyword */ .highlight-ipynb .o { color: var(--jp-mirror-editor-operator-color); font-weight: bold } /* Operator */ .highlight-ipynb .p { color: var(--jp-mirror-editor-punctuation-color) } /* Punctuation */ .highlight-ipynb .ch { color: var(--jp-mirror-editor-comment-color); font-style: italic } /* Comment.Hashbang */ .highlight-ipynb .cm { color: var(--jp-mirror-editor-comment-color); font-style: italic } /* Comment.Multiline */ .highlight-ipynb .cp { color: var(--jp-mirror-editor-comment-color); font-style: italic } /* Comment.Preproc */ .highlight-ipynb .cpf { color: var(--jp-mirror-editor-comment-color); font-style: italic } /* Comment.PreprocFile */ .highlight-ipynb .c1 { color: var(--jp-mirror-editor-comment-color); font-style: italic } /* Comment.Single */ .highlight-ipynb .cs { color: var(--jp-mirror-editor-comment-color); font-style: italic } /* Comment.Special */ .highlight-ipynb .kc { color: var(--jp-mirror-editor-keyword-color); font-weight: bold } /* Keyword.Constant */ .highlight-ipynb .kd { color: var(--jp-mirror-editor-keyword-color); font-weight: bold } /* Keyword.Declaration */ .highlight-ipynb .kn { color: var(--jp-mirror-editor-keyword-color); font-weight: bold } /* Keyword.Namespace */ .highlight-ipynb .kp { color: var(--jp-mirror-editor-keyword-color); font-weight: bold } /* Keyword.Pseudo */ .highlight-ipynb .kr { color: var(--jp-mirror-editor-keyword-color); font-weight: bold } /* Keyword.Reserved */ .highlight-ipynb .kt { color: var(--jp-mirror-editor-keyword-color); font-weight: bold } /* Keyword.Type */ .highlight-ipynb .m { color: var(--jp-mirror-editor-number-color) } /* Literal.Number */ .highlight-ipynb .s { color: var(--jp-mirror-editor-string-color) } /* Literal.String */ .highlight-ipynb .ow { color: var(--jp-mirror-editor-operator-color); font-weight: bold } /* Operator.Word */ .highlight-ipynb .pm { color: var(--jp-mirror-editor-punctuation-color) } /* Punctuation.Marker */ .highlight-ipynb .w { color: var(--jp-mirror-editor-variable-color) } /* Text.Whitespace */ .highlight-ipynb .mb { color: var(--jp-mirror-editor-number-color) } /* Literal.Number.Bin */ .highlight-ipynb .mf { color: var(--jp-mirror-editor-number-color) } /* Literal.Number.Float */ .highlight-ipynb .mh { color: var(--jp-mirror-editor-number-color) } /* Literal.Number.Hex */ .highlight-ipynb .mi { color: var(--jp-mirror-editor-number-color) } /* Literal.Number.Integer */ .highlight-ipynb .mo { color: var(--jp-mirror-editor-number-color) } /* Literal.Number.Oct */ .highlight-ipynb .sa { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Affix */ .highlight-ipynb .sb { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Backtick */ .highlight-ipynb .sc { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Char */ .highlight-ipynb .dl { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Delimiter */ .highlight-ipynb .sd { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Doc */ .highlight-ipynb .s2 { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Double */ .highlight-ipynb .se { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Escape */ .highlight-ipynb .sh { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Heredoc */ .highlight-ipynb .si { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Interpol */ .highlight-ipynb .sx { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Other */ .highlight-ipynb .sr { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Regex */ .highlight-ipynb .s1 { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Single */ .highlight-ipynb .ss { color: var(--jp-mirror-editor-string-color) } /* Literal.String.Symbol */ .highlight-ipynb .il { color: var(--jp-mirror-editor-number-color) } /* Literal.Number.Integer.Long */ /* This file is taken from the built JupyterLab theme.css Found on share/nbconvert/templates/lab/static Some changes have been made and marked with CHANGE */ .jupyter-wrapper { /* Elevation * * We style box-shadows using Material Design's idea of elevation. These particular numbers are taken from here: * * https://github.com/material-components/material-components-web * https://material-components-web.appspot.com/elevation.html */ --jp-shadow-base-lightness: 0; --jp-shadow-umbra-color: rgba( var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), 0.2 ); --jp-shadow-penumbra-color: rgba( var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), 0.14 ); --jp-shadow-ambient-color: rgba( var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), 0.12 ); --jp-elevation-z0: none; --jp-elevation-z1: 0px 2px 1px -1px var(--jp-shadow-umbra-color), 0px 1px 1px 0px var(--jp-shadow-penumbra-color), 0px 1px 3px 0px var(--jp-shadow-ambient-color); --jp-elevation-z2: 0px 3px 1px -2px var(--jp-shadow-umbra-color), 0px 2px 2px 0px var(--jp-shadow-penumbra-color), 0px 1px 5px 0px var(--jp-shadow-ambient-color); --jp-elevation-z4: 0px 2px 4px -1px var(--jp-shadow-umbra-color), 0px 4px 5px 0px var(--jp-shadow-penumbra-color), 0px 1px 10px 0px var(--jp-shadow-ambient-color); --jp-elevation-z6: 0px 3px 5px -1px var(--jp-shadow-umbra-color), 0px 6px 10px 0px var(--jp-shadow-penumbra-color), 0px 1px 18px 0px var(--jp-shadow-ambient-color); --jp-elevation-z8: 0px 5px 5px -3px var(--jp-shadow-umbra-color), 0px 8px 10px 1px var(--jp-shadow-penumbra-color), 0px 3px 14px 2px var(--jp-shadow-ambient-color); --jp-elevation-z12: 0px 7px 8px -4px var(--jp-shadow-umbra-color), 0px 12px 17px 2px var(--jp-shadow-penumbra-color), 0px 5px 22px 4px var(--jp-shadow-ambient-color); --jp-elevation-z16: 0px 8px 10px -5px var(--jp-shadow-umbra-color), 0px 16px 24px 2px var(--jp-shadow-penumbra-color), 0px 6px 30px 5px var(--jp-shadow-ambient-color); --jp-elevation-z20: 0px 10px 13px -6px var(--jp-shadow-umbra-color), 0px 20px 31px 3px var(--jp-shadow-penumbra-color), 0px 8px 38px 7px var(--jp-shadow-ambient-color); --jp-elevation-z24: 0px 11px 15px -7px var(--jp-shadow-umbra-color), 0px 24px 38px 3px var(--jp-shadow-penumbra-color), 0px 9px 46px 8px var(--jp-shadow-ambient-color); /* Borders * * The following variables, specify the visual styling of borders in JupyterLab. */ --jp-border-width: 1px; --jp-border-color0: var(--md-grey-400); --jp-border-color1: var(--md-grey-400); --jp-border-color2: var(--md-grey-300); --jp-border-color3: var(--md-grey-200); --jp-border-radius: 2px; /* UI Fonts * * The UI font CSS variables are used for the typography all of the JupyterLab * user interface elements that are not directly user generated content. * * The font sizing here is done assuming that the body font size of --jp-ui-font-size1 * is applied to a parent element. When children elements, such as headings, are sized * in em all things will be computed relative to that body size. */ --jp-ui-font-scale-factor: 1.2; --jp-ui-font-size0: 0.83333em; --jp-ui-font-size1: 13px; /* Base font size */ --jp-ui-font-size2: 1.2em; --jp-ui-font-size3: 1.44em; --jp-ui-font-family: -apple-system, BlinkMacSystemFont, \"Segoe UI\", Helvetica, Arial, sans-serif, \"Apple Color Emoji\", \"Segoe UI Emoji\", \"Segoe UI Symbol\"; /* * Use these font colors against the corresponding main layout colors. * In a light theme, these go from dark to light. */ /* Defaults use Material Design specification */ --jp-ui-font-color0: rgba(0, 0, 0, 1); --jp-ui-font-color1: rgba(0, 0, 0, 0.87); --jp-ui-font-color2: rgba(0, 0, 0, 0.54); --jp-ui-font-color3: rgba(0, 0, 0, 0.38); /* * Use these against the brand/accent/warn/error colors. * These will typically go from light to darker, in both a dark and light theme. */ --jp-ui-inverse-font-color0: rgba(255, 255, 255, 1); --jp-ui-inverse-font-color1: rgba(255, 255, 255, 1); --jp-ui-inverse-font-color2: rgba(255, 255, 255, 0.7); --jp-ui-inverse-font-color3: rgba(255, 255, 255, 0.5); /* Content Fonts * * Content font variables are used for typography of user generated content. * * The font sizing here is done assuming that the body font size of --jp-content-font-size1 * is applied to a parent element. When children elements, such as headings, are sized * in em all things will be computed relative to that body size. */ --jp-content-line-height: 1.6; --jp-content-font-scale-factor: 1.2; --jp-content-font-size0: 0.83333em; --jp-content-font-size1: 14px; /* Base font size */ --jp-content-font-size2: 1.2em; --jp-content-font-size3: 1.44em; --jp-content-font-size4: 1.728em; --jp-content-font-size5: 2.0736em; /* This gives a magnification of about 125% in presentation mode over normal. */ --jp-content-presentation-font-size1: 17px; --jp-content-heading-line-height: 1; --jp-content-heading-margin-top: 1.2em; --jp-content-heading-margin-bottom: 0.8em; --jp-content-heading-font-weight: 500; /* Defaults use Material Design specification */ --jp-content-font-color0: rgba(0, 0, 0, 1); --jp-content-font-color1: rgba(0, 0, 0, 0.87); --jp-content-font-color2: rgba(0, 0, 0, 0.54); --jp-content-font-color3: rgba(0, 0, 0, 0.38); --jp-content-link-color: var(--md-blue-700); --jp-content-font-family: -apple-system, BlinkMacSystemFont, \"Segoe UI\", Helvetica, Arial, sans-serif, \"Apple Color Emoji\", \"Segoe UI Emoji\", \"Segoe UI Symbol\"; /* * Code Fonts * * Code font variables are used for typography of code and other monospaces content. */ --jp-code-font-size: 13px; --jp-code-line-height: 1.3077; /* 17px for 13px base */ --jp-code-padding: 5px; /* 5px for 13px base, codemirror highlighting needs integer px value */ --jp-code-font-family-default: Menlo, Consolas, \"DejaVu Sans Mono\", monospace; --jp-code-font-family: var(--jp-code-font-family-default); /* This gives a magnification of about 125% in presentation mode over normal. */ --jp-code-presentation-font-size: 16px; /* may need to tweak cursor width if you change font size */ --jp-code-cursor-width0: 1.4px; --jp-code-cursor-width1: 2px; --jp-code-cursor-width2: 4px; /* Layout * * The following are the main layout colors use in JupyterLab. In a light * theme these would go from light to dark. */ --jp-layout-color0: white; --jp-layout-color1: white; --jp-layout-color2: var(--md-grey-200); --jp-layout-color3: var(--md-grey-400); --jp-layout-color4: var(--md-grey-600); /* Inverse Layout * * The following are the inverse layout colors use in JupyterLab. In a light * theme these would go from dark to light. */ --jp-inverse-layout-color0: #111111; --jp-inverse-layout-color1: var(--md-grey-900); --jp-inverse-layout-color2: var(--md-grey-800); --jp-inverse-layout-color3: var(--md-grey-700); --jp-inverse-layout-color4: var(--md-grey-600); /* Brand/accent */ --jp-brand-color0: var(--md-blue-900); --jp-brand-color1: var(--md-blue-700); --jp-brand-color2: var(--md-blue-300); --jp-brand-color3: var(--md-blue-100); --jp-brand-color4: var(--md-blue-50); --jp-accent-color0: var(--md-green-900); --jp-accent-color1: var(--md-green-700); --jp-accent-color2: var(--md-green-300); --jp-accent-color3: var(--md-green-100); /* State colors (warn, error, success, info) */ --jp-warn-color0: var(--md-orange-900); --jp-warn-color1: var(--md-orange-700); --jp-warn-color2: var(--md-orange-300); --jp-warn-color3: var(--md-orange-100); --jp-error-color0: var(--md-red-900); --jp-error-color1: var(--md-red-700); --jp-error-color2: var(--md-red-300); --jp-error-color3: var(--md-red-100); --jp-success-color0: var(--md-green-900); --jp-success-color1: var(--md-green-700); --jp-success-color2: var(--md-green-300); --jp-success-color3: var(--md-green-100); --jp-info-color0: var(--md-cyan-900); --jp-info-color1: var(--md-cyan-700); --jp-info-color2: var(--md-cyan-300); --jp-info-color3: var(--md-cyan-100); /* Cell specific styles */ --jp-cell-padding: 5px; --jp-cell-collapser-width: 8px; --jp-cell-collapser-min-height: 20px; --jp-cell-collapser-not-active-hover-opacity: 0.6; --jp-cell-editor-background: var(--md-grey-100); --jp-cell-editor-border-color: var(--md-grey-300); --jp-cell-editor-box-shadow: inset 0 0 2px var(--md-blue-300); --jp-cell-editor-active-background: var(--jp-layout-color0); --jp-cell-editor-active-border-color: var(--jp-brand-color1); --jp-cell-prompt-width: 64px; --jp-cell-prompt-font-family: var(--jp-code-font-family-default); --jp-cell-prompt-letter-spacing: 0px; --jp-cell-prompt-opacity: 1; --jp-cell-prompt-not-active-opacity: 0.5; --jp-cell-prompt-not-active-font-color: var(--md-grey-700); /* A custom blend of MD grey and blue 600 * See https://meyerweb.com/eric/tools/color-blend/#546E7A:1E88E5:5:hex */ --jp-cell-inprompt-font-color: #307fc1; /* A custom blend of MD grey and orange 600 * https://meyerweb.com/eric/tools/color-blend/#546E7A:F4511E:5:hex */ --jp-cell-outprompt-font-color: #bf5b3d; /* Notebook specific styles */ --jp-notebook-padding: 10px; --jp-notebook-select-background: var(--jp-layout-color1); --jp-notebook-multiselected-color: var(--md-blue-50); /* The scroll padding is calculated to fill enough space at the bottom of the notebook to show one single-line cell (with appropriate padding) at the top when the notebook is scrolled all the way to the bottom. We also subtract one pixel so that no scrollbar appears if we have just one single-line cell in the notebook. This padding is to enable a 'scroll past end' feature in a notebook. */ --jp-notebook-scroll-padding: calc( 100% - var(--jp-code-font-size) * var(--jp-code-line-height) - var(--jp-code-padding) - var(--jp-cell-padding) - 1px ); /* Rendermime styles */ --jp-rendermime-error-background: #fdd; --jp-rendermime-table-row-background: var(--md-grey-100); --jp-rendermime-table-row-hover-background: var(--md-light-blue-50); /* Dialog specific styles */ --jp-dialog-background: rgba(0, 0, 0, 0.25); /* Console specific styles */ --jp-console-padding: 10px; /* Toolbar specific styles */ --jp-toolbar-border-color: var(--jp-border-color1); --jp-toolbar-micro-height: 8px; --jp-toolbar-background: var(--jp-layout-color1); --jp-toolbar-box-shadow: 0px 0px 2px 0px rgba(0, 0, 0, 0.24); --jp-toolbar-header-margin: 4px 4px 0px 4px; --jp-toolbar-active-background: var(--md-grey-300); /* Statusbar specific styles */ --jp-statusbar-height: 24px; /* Input field styles */ --jp-input-box-shadow: inset 0 0 2px var(--md-blue-300); --jp-input-active-background: var(--jp-layout-color1); --jp-input-hover-background: var(--jp-layout-color1); --jp-input-background: var(--md-grey-100); --jp-input-border-color: var(--jp-border-color1); --jp-input-active-border-color: var(--jp-brand-color1); --jp-input-active-box-shadow-color: rgba(19, 124, 189, 0.3); /* General editor styles */ --jp-editor-selected-background: #d9d9d9; --jp-editor-selected-focused-background: #d7d4f0; --jp-editor-cursor-color: var(--jp-ui-font-color0); /* Code mirror specific styles */ --jp-mirror-editor-keyword-color: #008000; --jp-mirror-editor-atom-color: #88f; --jp-mirror-editor-number-color: #080; --jp-mirror-editor-def-color: #00f; --jp-mirror-editor-variable-color: var(--md-grey-900); --jp-mirror-editor-variable-2-color: #05a; --jp-mirror-editor-variable-3-color: #085; --jp-mirror-editor-punctuation-color: #05a; --jp-mirror-editor-property-color: #05a; --jp-mirror-editor-operator-color: #aa22ff; --jp-mirror-editor-comment-color: #408080; --jp-mirror-editor-string-color: #ba2121; --jp-mirror-editor-string-2-color: #708; --jp-mirror-editor-meta-color: #aa22ff; --jp-mirror-editor-qualifier-color: #555; --jp-mirror-editor-builtin-color: #008000; --jp-mirror-editor-bracket-color: #997; --jp-mirror-editor-tag-color: #170; --jp-mirror-editor-attribute-color: #00c; --jp-mirror-editor-header-color: blue; --jp-mirror-editor-quote-color: #090; --jp-mirror-editor-link-color: #00c; --jp-mirror-editor-error-color: #f00; --jp-mirror-editor-hr-color: #999; /* Vega extension styles */ --jp-vega-background: white; /* Sidebar-related styles */ --jp-sidebar-min-width: 250px; /* Search-related styles */ --jp-search-toggle-off-opacity: 0.5; --jp-search-toggle-hover-opacity: 0.8; --jp-search-toggle-on-opacity: 1; --jp-search-selected-match-background-color: rgb(245, 200, 0); --jp-search-selected-match-color: black; --jp-search-unselected-match-background-color: var( --jp-inverse-layout-color0 ); --jp-search-unselected-match-color: var(--jp-ui-inverse-font-color0); /* Icon colors that work well with light or dark backgrounds */ --jp-icon-contrast-color0: var(--md-purple-600); --jp-icon-contrast-color1: var(--md-green-600); --jp-icon-contrast-color2: var(--md-pink-600); --jp-icon-contrast-color3: var(--md-blue-600); } [data-md-color-scheme=\"slate\"] .jupyter-wrapper { /* Elevation * * We style box-shadows using Material Design's idea of elevation. These particular numbers are taken from here: * * https://github.com/material-components/material-components-web * https://material-components-web.appspot.com/elevation.html */ /* The dark theme shadows need a bit of work, but this will probably also require work on the core layout * colors used in the theme as well. */ --jp-shadow-base-lightness: 32; --jp-shadow-umbra-color: rgba( var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), 0.2 ); --jp-shadow-penumbra-color: rgba( var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), 0.14 ); --jp-shadow-ambient-color: rgba( var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), var(--jp-shadow-base-lightness), 0.12 ); --jp-elevation-z0: none; --jp-elevation-z1: 0px 2px 1px -1px var(--jp-shadow-umbra-color), 0px 1px 1px 0px var(--jp-shadow-penumbra-color), 0px 1px 3px 0px var(--jp-shadow-ambient-color); --jp-elevation-z2: 0px 3px 1px -2px var(--jp-shadow-umbra-color), 0px 2px 2px 0px var(--jp-shadow-penumbra-color), 0px 1px 5px 0px var(--jp-shadow-ambient-color); --jp-elevation-z4: 0px 2px 4px -1px var(--jp-shadow-umbra-color), 0px 4px 5px 0px var(--jp-shadow-penumbra-color), 0px 1px 10px 0px var(--jp-shadow-ambient-color); --jp-elevation-z6: 0px 3px 5px -1px var(--jp-shadow-umbra-color), 0px 6px 10px 0px var(--jp-shadow-penumbra-color), 0px 1px 18px 0px var(--jp-shadow-ambient-color); --jp-elevation-z8: 0px 5px 5px -3px var(--jp-shadow-umbra-color), 0px 8px 10px 1px var(--jp-shadow-penumbra-color), 0px 3px 14px 2px var(--jp-shadow-ambient-color); --jp-elevation-z12: 0px 7px 8px -4px var(--jp-shadow-umbra-color), 0px 12px 17px 2px var(--jp-shadow-penumbra-color), 0px 5px 22px 4px var(--jp-shadow-ambient-color); --jp-elevation-z16: 0px 8px 10px -5px var(--jp-shadow-umbra-color), 0px 16px 24px 2px var(--jp-shadow-penumbra-color), 0px 6px 30px 5px var(--jp-shadow-ambient-color); --jp-elevation-z20: 0px 10px 13px -6px var(--jp-shadow-umbra-color), 0px 20px 31px 3px var(--jp-shadow-penumbra-color), 0px 8px 38px 7px var(--jp-shadow-ambient-color); --jp-elevation-z24: 0px 11px 15px -7px var(--jp-shadow-umbra-color), 0px 24px 38px 3px var(--jp-shadow-penumbra-color), 0px 9px 46px 8px var(--jp-shadow-ambient-color); /* Borders * * The following variables, specify the visual styling of borders in JupyterLab. */ --jp-border-width: 1px; --jp-border-color0: var(--md-grey-700); --jp-border-color1: var(--md-grey-700); --jp-border-color2: var(--md-grey-800); --jp-border-color3: var(--md-grey-900); --jp-border-radius: 2px; /* UI Fonts * * The UI font CSS variables are used for the typography all of the JupyterLab * user interface elements that are not directly user generated content. * * The font sizing here is done assuming that the body font size of --jp-ui-font-size1 * is applied to a parent element. When children elements, such as headings, are sized * in em all things will be computed relative to that body size. */ --jp-ui-font-scale-factor: 1.2; --jp-ui-font-size0: 0.83333em; --jp-ui-font-size1: 13px; /* Base font size */ --jp-ui-font-size2: 1.2em; --jp-ui-font-size3: 1.44em; --jp-ui-font-family: -apple-system, BlinkMacSystemFont, \"Segoe UI\", Helvetica, Arial, sans-serif, \"Apple Color Emoji\", \"Segoe UI Emoji\", \"Segoe UI Symbol\"; /* * Use these font colors against the corresponding main layout colors. * In a light theme, these go from dark to light. */ /* Defaults use Material Design specification */ --jp-ui-font-color0: rgba(255, 255, 255, 1); --jp-ui-font-color1: rgba(255, 255, 255, 0.87); --jp-ui-font-color2: rgba(255, 255, 255, 0.54); --jp-ui-font-color3: rgba(255, 255, 255, 0.38); /* * Use these against the brand/accent/warn/error colors. * These will typically go from light to darker, in both a dark and light theme. */ --jp-ui-inverse-font-color0: rgba(0, 0, 0, 1); --jp-ui-inverse-font-color1: rgba(0, 0, 0, 0.8); --jp-ui-inverse-font-color2: rgba(0, 0, 0, 0.5); --jp-ui-inverse-font-color3: rgba(0, 0, 0, 0.3); /* Content Fonts * * Content font variables are used for typography of user generated content. * * The font sizing here is done assuming that the body font size of --jp-content-font-size1 * is applied to a parent element. When children elements, such as headings, are sized * in em all things will be computed relative to that body size. */ --jp-content-line-height: 1.6; --jp-content-font-scale-factor: 1.2; --jp-content-font-size0: 0.83333em; --jp-content-font-size1: 14px; /* Base font size */ --jp-content-font-size2: 1.2em; --jp-content-font-size3: 1.44em; --jp-content-font-size4: 1.728em; --jp-content-font-size5: 2.0736em; /* This gives a magnification of about 125% in presentation mode over normal. */ --jp-content-presentation-font-size1: 17px; --jp-content-heading-line-height: 1; --jp-content-heading-margin-top: 1.2em; --jp-content-heading-margin-bottom: 0.8em; --jp-content-heading-font-weight: 500; /* Defaults use Material Design specification */ --jp-content-font-color0: rgba(255, 255, 255, 1); --jp-content-font-color1: rgba(255, 255, 255, 1); --jp-content-font-color2: rgba(255, 255, 255, 0.7); --jp-content-font-color3: rgba(255, 255, 255, 0.5); --jp-content-link-color: var(--md-blue-300); --jp-content-font-family: -apple-system, BlinkMacSystemFont, \"Segoe UI\", Helvetica, Arial, sans-serif, \"Apple Color Emoji\", \"Segoe UI Emoji\", \"Segoe UI Symbol\"; /* * Code Fonts * * Code font variables are used for typography of code and other monospaces content. */ --jp-code-font-size: 13px; --jp-code-line-height: 1.3077; /* 17px for 13px base */ --jp-code-padding: 5px; /* 5px for 13px base, codemirror highlighting needs integer px value */ --jp-code-font-family-default: Menlo, Consolas, \"DejaVu Sans Mono\", monospace; --jp-code-font-family: var(--jp-code-font-family-default); /* This gives a magnification of about 125% in presentation mode over normal. */ --jp-code-presentation-font-size: 16px; /* may need to tweak cursor width if you change font size */ --jp-code-cursor-width0: 1.4px; --jp-code-cursor-width1: 2px; --jp-code-cursor-width2: 4px; /* Layout * * The following are the main layout colors use in JupyterLab. In a light * theme these would go from light to dark. */ --jp-layout-color0: #111111; --jp-layout-color1: var(--md-grey-900); --jp-layout-color2: var(--md-grey-800); --jp-layout-color3: var(--md-grey-700); --jp-layout-color4: var(--md-grey-600); /* Inverse Layout * * The following are the inverse layout colors use in JupyterLab. In a light * theme these would go from dark to light. */ --jp-inverse-layout-color0: white; --jp-inverse-layout-color1: white; --jp-inverse-layout-color2: var(--md-grey-200); --jp-inverse-layout-color3: var(--md-grey-400); --jp-inverse-layout-color4: var(--md-grey-600); /* Brand/accent */ --jp-brand-color0: var(--md-blue-700); --jp-brand-color1: var(--md-blue-500); --jp-brand-color2: var(--md-blue-300); --jp-brand-color3: var(--md-blue-100); --jp-brand-color4: var(--md-blue-50); --jp-accent-color0: var(--md-green-700); --jp-accent-color1: var(--md-green-500); --jp-accent-color2: var(--md-green-300); --jp-accent-color3: var(--md-green-100); /* State colors (warn, error, success, info) */ --jp-warn-color0: var(--md-orange-700); --jp-warn-color1: var(--md-orange-500); --jp-warn-color2: var(--md-orange-300); --jp-warn-color3: var(--md-orange-100); --jp-error-color0: var(--md-red-700); --jp-error-color1: var(--md-red-500); --jp-error-color2: var(--md-red-300); --jp-error-color3: var(--md-red-100); --jp-success-color0: var(--md-green-700); --jp-success-color1: var(--md-green-500); --jp-success-color2: var(--md-green-300); --jp-success-color3: var(--md-green-100); --jp-info-color0: var(--md-cyan-700); --jp-info-color1: var(--md-cyan-500); --jp-info-color2: var(--md-cyan-300); --jp-info-color3: var(--md-cyan-100); /* Cell specific styles */ --jp-cell-padding: 5px; --jp-cell-collapser-width: 8px; --jp-cell-collapser-min-height: 20px; --jp-cell-collapser-not-active-hover-opacity: 0.6; --jp-cell-editor-background: var(--jp-layout-color1); --jp-cell-editor-border-color: var(--md-grey-700); --jp-cell-editor-box-shadow: inset 0 0 2px var(--md-blue-300); --jp-cell-editor-active-background: var(--jp-layout-color0); --jp-cell-editor-active-border-color: var(--jp-brand-color1); --jp-cell-prompt-width: 64px; --jp-cell-prompt-font-family: var(--jp-code-font-family-default); --jp-cell-prompt-letter-spacing: 0px; --jp-cell-prompt-opacity: 1; --jp-cell-prompt-not-active-opacity: 1; --jp-cell-prompt-not-active-font-color: var(--md-grey-300); /* A custom blend of MD grey and blue 600 * See https://meyerweb.com/eric/tools/color-blend/#546E7A:1E88E5:5:hex */ --jp-cell-inprompt-font-color: #307fc1; /* A custom blend of MD grey and orange 600 * https://meyerweb.com/eric/tools/color-blend/#546E7A:F4511E:5:hex */ --jp-cell-outprompt-font-color: #bf5b3d; /* Notebook specific styles */ --jp-notebook-padding: 10px; --jp-notebook-select-background: var(--jp-layout-color1); --jp-notebook-multiselected-color: rgba(33, 150, 243, 0.24); /* The scroll padding is calculated to fill enough space at the bottom of the notebook to show one single-line cell (with appropriate padding) at the top when the notebook is scrolled all the way to the bottom. We also subtract one pixel so that no scrollbar appears if we have just one single-line cell in the notebook. This padding is to enable a 'scroll past end' feature in a notebook. */ --jp-notebook-scroll-padding: calc( 100% - var(--jp-code-font-size) * var(--jp-code-line-height) - var(--jp-code-padding) - var(--jp-cell-padding) - 1px ); /* Rendermime styles */ --jp-rendermime-error-background: rgba(244, 67, 54, 0.28); --jp-rendermime-table-row-background: var(--md-grey-900); --jp-rendermime-table-row-hover-background: rgba(3, 169, 244, 0.2); /* Dialog specific styles */ --jp-dialog-background: rgba(0, 0, 0, 0.6); /* Console specific styles */ --jp-console-padding: 10px; /* Toolbar specific styles */ --jp-toolbar-border-color: var(--jp-border-color2); --jp-toolbar-micro-height: 8px; --jp-toolbar-background: var(--jp-layout-color1); --jp-toolbar-box-shadow: 0px 0px 2px 0px rgba(0, 0, 0, 0.8); --jp-toolbar-header-margin: 4px 4px 0px 4px; --jp-toolbar-active-background: var(--jp-layout-color0); /* Statusbar specific styles */ --jp-statusbar-height: 24px; /* Input field styles */ --jp-input-box-shadow: inset 0 0 2px var(--md-blue-300); --jp-input-active-background: var(--jp-layout-color0); --jp-input-hover-background: var(--jp-layout-color2); --jp-input-background: var(--md-grey-800); --jp-input-border-color: var(--jp-border-color1); --jp-input-active-border-color: var(--jp-brand-color1); --jp-input-active-box-shadow-color: rgba(19, 124, 189, 0.3); /* General editor styles */ --jp-editor-selected-background: var(--jp-layout-color2); --jp-editor-selected-focused-background: rgba(33, 150, 243, 0.24); --jp-editor-cursor-color: var(--jp-ui-font-color0); /* Code mirror specific styles */ --jp-mirror-editor-keyword-color: var(--md-green-500); --jp-mirror-editor-atom-color: var(--md-blue-300); --jp-mirror-editor-number-color: var(--md-green-400); --jp-mirror-editor-def-color: var(--md-blue-600); --jp-mirror-editor-variable-color: var(--md-grey-300); --jp-mirror-editor-variable-2-color: var(--md-blue-400); --jp-mirror-editor-variable-3-color: var(--md-green-600); --jp-mirror-editor-punctuation-color: var(--md-blue-400); --jp-mirror-editor-property-color: var(--md-blue-400); --jp-mirror-editor-operator-color: #aa22ff; --jp-mirror-editor-comment-color: #408080; --jp-mirror-editor-string-color: #ff7070; --jp-mirror-editor-string-2-color: var(--md-purple-300); --jp-mirror-editor-meta-color: #aa22ff; --jp-mirror-editor-qualifier-color: #555; --jp-mirror-editor-builtin-color: var(--md-green-600); --jp-mirror-editor-bracket-color: #997; --jp-mirror-editor-tag-color: var(--md-green-700); --jp-mirror-editor-attribute-color: var(--md-blue-700); --jp-mirror-editor-header-color: var(--md-blue-500); --jp-mirror-editor-quote-color: var(--md-green-300); --jp-mirror-editor-link-color: var(--md-blue-700); --jp-mirror-editor-error-color: #f00; --jp-mirror-editor-hr-color: #999; /* Vega extension styles */ --jp-vega-background: var(--md-grey-400); /* Sidebar-related styles */ --jp-sidebar-min-width: 250px; /* Search-related styles */ --jp-search-toggle-off-opacity: 0.6; --jp-search-toggle-hover-opacity: 0.8; --jp-search-toggle-on-opacity: 1; --jp-search-selected-match-background-color: rgb(255, 225, 0); --jp-search-selected-match-color: black; --jp-search-unselected-match-background-color: var( --jp-inverse-layout-color0 ); --jp-search-unselected-match-color: var(--jp-ui-inverse-font-color0); /* scrollbar related styles. Supports every browser except Edge. */ /* colors based on JetBrain's Darcula theme */ --jp-scrollbar-background-color: #3f4244; --jp-scrollbar-thumb-color: 88, 96, 97; /* need to specify thumb color as an RGB triplet */ --jp-scrollbar-endpad: 3px; /* the minimum gap between the thumb and the ends of a scrollbar */ /* hacks for setting the thumb shape. These do nothing in Firefox */ --jp-scrollbar-thumb-margin: 3.5px; /* the space in between the sides of the thumb and the track */ --jp-scrollbar-thumb-radius: 9px; /* set to a large-ish value for rounded endcaps on the thumb */ /* Icon colors that work well with light or dark backgrounds */ --jp-icon-contrast-color0: var(--md-purple-600); --jp-icon-contrast-color1: var(--md-green-600); --jp-icon-contrast-color2: var(--md-pink-600); --jp-icon-contrast-color3: var(--md-blue-600); } :root{--md-red-50: #ffebee;--md-red-100: #ffcdd2;--md-red-200: #ef9a9a;--md-red-300: #e57373;--md-red-400: #ef5350;--md-red-500: #f44336;--md-red-600: #e53935;--md-red-700: #d32f2f;--md-red-800: #c62828;--md-red-900: #b71c1c;--md-red-A100: #ff8a80;--md-red-A200: #ff5252;--md-red-A400: #ff1744;--md-red-A700: #d50000;--md-pink-50: #fce4ec;--md-pink-100: #f8bbd0;--md-pink-200: #f48fb1;--md-pink-300: #f06292;--md-pink-400: #ec407a;--md-pink-500: #e91e63;--md-pink-600: #d81b60;--md-pink-700: #c2185b;--md-pink-800: #ad1457;--md-pink-900: #880e4f;--md-pink-A100: #ff80ab;--md-pink-A200: #ff4081;--md-pink-A400: #f50057;--md-pink-A700: #c51162;--md-purple-50: #f3e5f5;--md-purple-100: #e1bee7;--md-purple-200: #ce93d8;--md-purple-300: #ba68c8;--md-purple-400: #ab47bc;--md-purple-500: #9c27b0;--md-purple-600: #8e24aa;--md-purple-700: #7b1fa2;--md-purple-800: #6a1b9a;--md-purple-900: #4a148c;--md-purple-A100: #ea80fc;--md-purple-A200: #e040fb;--md-purple-A400: #d500f9;--md-purple-A700: #aa00ff;--md-deep-purple-50: #ede7f6;--md-deep-purple-100: #d1c4e9;--md-deep-purple-200: #b39ddb;--md-deep-purple-300: #9575cd;--md-deep-purple-400: #7e57c2;--md-deep-purple-500: #673ab7;--md-deep-purple-600: #5e35b1;--md-deep-purple-700: #512da8;--md-deep-purple-800: #4527a0;--md-deep-purple-900: #311b92;--md-deep-purple-A100: #b388ff;--md-deep-purple-A200: #7c4dff;--md-deep-purple-A400: #651fff;--md-deep-purple-A700: #6200ea;--md-indigo-50: #e8eaf6;--md-indigo-100: #c5cae9;--md-indigo-200: #9fa8da;--md-indigo-300: #7986cb;--md-indigo-400: #5c6bc0;--md-indigo-500: #3f51b5;--md-indigo-600: #3949ab;--md-indigo-700: #303f9f;--md-indigo-800: #283593;--md-indigo-900: #1a237e;--md-indigo-A100: #8c9eff;--md-indigo-A200: #536dfe;--md-indigo-A400: #3d5afe;--md-indigo-A700: #304ffe;--md-blue-50: #e3f2fd;--md-blue-100: #bbdefb;--md-blue-200: #90caf9;--md-blue-300: #64b5f6;--md-blue-400: #42a5f5;--md-blue-500: #2196f3;--md-blue-600: #1e88e5;--md-blue-700: #1976d2;--md-blue-800: #1565c0;--md-blue-900: #0d47a1;--md-blue-A100: #82b1ff;--md-blue-A200: #448aff;--md-blue-A400: #2979ff;--md-blue-A700: #2962ff;--md-light-blue-50: #e1f5fe;--md-light-blue-100: #b3e5fc;--md-light-blue-200: #81d4fa;--md-light-blue-300: #4fc3f7;--md-light-blue-400: #29b6f6;--md-light-blue-500: #03a9f4;--md-light-blue-600: #039be5;--md-light-blue-700: #0288d1;--md-light-blue-800: #0277bd;--md-light-blue-900: #01579b;--md-light-blue-A100: #80d8ff;--md-light-blue-A200: #40c4ff;--md-light-blue-A400: #00b0ff;--md-light-blue-A700: #0091ea;--md-cyan-50: #e0f7fa;--md-cyan-100: #b2ebf2;--md-cyan-200: #80deea;--md-cyan-300: #4dd0e1;--md-cyan-400: #26c6da;--md-cyan-500: #00bcd4;--md-cyan-600: #00acc1;--md-cyan-700: #0097a7;--md-cyan-800: #00838f;--md-cyan-900: #006064;--md-cyan-A100: #84ffff;--md-cyan-A200: #18ffff;--md-cyan-A400: #00e5ff;--md-cyan-A700: #00b8d4;--md-teal-50: #e0f2f1;--md-teal-100: #b2dfdb;--md-teal-200: #80cbc4;--md-teal-300: #4db6ac;--md-teal-400: #26a69a;--md-teal-500: #009688;--md-teal-600: #00897b;--md-teal-700: #00796b;--md-teal-800: #00695c;--md-teal-900: #004d40;--md-teal-A100: #a7ffeb;--md-teal-A200: #64ffda;--md-teal-A400: #1de9b6;--md-teal-A700: #00bfa5;--md-green-50: #e8f5e9;--md-green-100: #c8e6c9;--md-green-200: #a5d6a7;--md-green-300: #81c784;--md-green-400: #66bb6a;--md-green-500: #4caf50;--md-green-600: #43a047;--md-green-700: #388e3c;--md-green-800: #2e7d32;--md-green-900: #1b5e20;--md-green-A100: #b9f6ca;--md-green-A200: #69f0ae;--md-green-A400: #00e676;--md-green-A700: #00c853;--md-light-green-50: #f1f8e9;--md-light-green-100: #dcedc8;--md-light-green-200: #c5e1a5;--md-light-green-300: #aed581;--md-light-green-400: #9ccc65;--md-light-green-500: #8bc34a;--md-light-green-600: #7cb342;--md-light-green-700: #689f38;--md-light-green-800: #558b2f;--md-light-green-900: #33691e;--md-light-green-A100: #ccff90;--md-light-green-A200: #b2ff59;--md-light-green-A400: #76ff03;--md-light-green-A700: #64dd17;--md-lime-50: #f9fbe7;--md-lime-100: #f0f4c3;--md-lime-200: #e6ee9c;--md-lime-300: #dce775;--md-lime-400: #d4e157;--md-lime-500: #cddc39;--md-lime-600: #c0ca33;--md-lime-700: #afb42b;--md-lime-800: #9e9d24;--md-lime-900: #827717;--md-lime-A100: #f4ff81;--md-lime-A200: #eeff41;--md-lime-A400: #c6ff00;--md-lime-A700: #aeea00;--md-yellow-50: #fffde7;--md-yellow-100: #fff9c4;--md-yellow-200: #fff59d;--md-yellow-300: #fff176;--md-yellow-400: #ffee58;--md-yellow-500: #ffeb3b;--md-yellow-600: #fdd835;--md-yellow-700: #fbc02d;--md-yellow-800: #f9a825;--md-yellow-900: #f57f17;--md-yellow-A100: #ffff8d;--md-yellow-A200: #ffff00;--md-yellow-A400: #ffea00;--md-yellow-A700: #ffd600;--md-amber-50: #fff8e1;--md-amber-100: #ffecb3;--md-amber-200: #ffe082;--md-amber-300: #ffd54f;--md-amber-400: #ffca28;--md-amber-500: #ffc107;--md-amber-600: #ffb300;--md-amber-700: #ffa000;--md-amber-800: #ff8f00;--md-amber-900: #ff6f00;--md-amber-A100: #ffe57f;--md-amber-A200: #ffd740;--md-amber-A400: #ffc400;--md-amber-A700: #ffab00;--md-orange-50: #fff3e0;--md-orange-100: #ffe0b2;--md-orange-200: #ffcc80;--md-orange-300: #ffb74d;--md-orange-400: #ffa726;--md-orange-500: #ff9800;--md-orange-600: #fb8c00;--md-orange-700: #f57c00;--md-orange-800: #ef6c00;--md-orange-900: #e65100;--md-orange-A100: #ffd180;--md-orange-A200: #ffab40;--md-orange-A400: #ff9100;--md-orange-A700: #ff6d00;--md-deep-orange-50: #fbe9e7;--md-deep-orange-100: #ffccbc;--md-deep-orange-200: #ffab91;--md-deep-orange-300: #ff8a65;--md-deep-orange-400: #ff7043;--md-deep-orange-500: #ff5722;--md-deep-orange-600: #f4511e;--md-deep-orange-700: #e64a19;--md-deep-orange-800: #d84315;--md-deep-orange-900: #bf360c;--md-deep-orange-A100: #ff9e80;--md-deep-orange-A200: #ff6e40;--md-deep-orange-A400: #ff3d00;--md-deep-orange-A700: #dd2c00;--md-brown-50: #efebe9;--md-brown-100: #d7ccc8;--md-brown-200: #bcaaa4;--md-brown-300: #a1887f;--md-brown-400: #8d6e63;--md-brown-500: #795548;--md-brown-600: #6d4c41;--md-brown-700: #5d4037;--md-brown-800: #4e342e;--md-brown-900: #3e2723;--md-grey-50: #fafafa;--md-grey-100: #f5f5f5;--md-grey-200: #eeeeee;--md-grey-300: #e0e0e0;--md-grey-400: #bdbdbd;--md-grey-500: #9e9e9e;--md-grey-600: #757575;--md-grey-700: #616161;--md-grey-800: #424242;--md-grey-900: #212121;--md-blue-grey-50: #eceff1;--md-blue-grey-100: #cfd8dc;--md-blue-grey-200: #b0bec5;--md-blue-grey-300: #90a4ae;--md-blue-grey-400: #78909c;--md-blue-grey-500: #607d8b;--md-blue-grey-600: #546e7a;--md-blue-grey-700: #455a64;--md-blue-grey-800: #37474f;--md-blue-grey-900: #263238}.jupyter-wrapper{/*! Copyright 2015-present Palantir Technologies, Inc. All rights reserved. Licensed under the Apache License, Version 2.0. *//*! Copyright 2017-present Palantir Technologies, Inc. All rights reserved. Licensed under the Apache License, Version 2.0. */}.jupyter-wrapper [data-jp-theme-scrollbars=true]{scrollbar-color:rgb(var(--jp-scrollbar-thumb-color)) var(--jp-scrollbar-background-color)}.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-hscrollbar,.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-vscrollbar{scrollbar-color:rgba(var(--jp-scrollbar-thumb-color), 0.5) rgba(0,0,0,0)}.jupyter-wrapper [data-jp-theme-scrollbars=true] ::-webkit-scrollbar,.jupyter-wrapper [data-jp-theme-scrollbars=true] ::-webkit-scrollbar-corner{background:var(--jp-scrollbar-background-color)}.jupyter-wrapper [data-jp-theme-scrollbars=true] ::-webkit-scrollbar-thumb{background:rgb(var(--jp-scrollbar-thumb-color));border:var(--jp-scrollbar-thumb-margin) solid rgba(0,0,0,0);background-clip:content-box;border-radius:var(--jp-scrollbar-thumb-radius)}.jupyter-wrapper [data-jp-theme-scrollbars=true] ::-webkit-scrollbar-track:horizontal{border-left:var(--jp-scrollbar-endpad) solid var(--jp-scrollbar-background-color);border-right:var(--jp-scrollbar-endpad) solid var(--jp-scrollbar-background-color)}.jupyter-wrapper [data-jp-theme-scrollbars=true] ::-webkit-scrollbar-track:vertical{border-top:var(--jp-scrollbar-endpad) solid var(--jp-scrollbar-background-color);border-bottom:var(--jp-scrollbar-endpad) solid var(--jp-scrollbar-background-color)}.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-hscrollbar::-webkit-scrollbar,.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-vscrollbar::-webkit-scrollbar,.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-hscrollbar::-webkit-scrollbar-corner,.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-vscrollbar::-webkit-scrollbar-corner{background-color:rgba(0,0,0,0)}.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-hscrollbar::-webkit-scrollbar-thumb,.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-vscrollbar::-webkit-scrollbar-thumb{background:rgba(var(--jp-scrollbar-thumb-color), 0.5);border:var(--jp-scrollbar-thumb-margin) solid rgba(0,0,0,0);background-clip:content-box;border-radius:var(--jp-scrollbar-thumb-radius)}.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-hscrollbar::-webkit-scrollbar-track:horizontal{border-left:var(--jp-scrollbar-endpad) solid rgba(0,0,0,0);border-right:var(--jp-scrollbar-endpad) solid rgba(0,0,0,0)}.jupyter-wrapper [data-jp-theme-scrollbars=true] .CodeMirror-vscrollbar::-webkit-scrollbar-track:vertical{border-top:var(--jp-scrollbar-endpad) solid rgba(0,0,0,0);border-bottom:var(--jp-scrollbar-endpad) solid rgba(0,0,0,0)}.jupyter-wrapper .lm-ScrollBar[data-orientation=horizontal]{min-height:16px;max-height:16px;min-width:45px;border-top:1px solid #a0a0a0}.jupyter-wrapper .lm-ScrollBar[data-orientation=vertical]{min-width:16px;max-width:16px;min-height:45px;border-left:1px solid #a0a0a0}.jupyter-wrapper .lm-ScrollBar-button{background-color:#f0f0f0;background-position:center center;min-height:15px;max-height:15px;min-width:15px;max-width:15px}.jupyter-wrapper .lm-ScrollBar-button:hover{background-color:#dadada}.jupyter-wrapper .lm-ScrollBar-button.lm-mod-active{background-color:#cdcdcd}.jupyter-wrapper .lm-ScrollBar-track{background:#f0f0f0}.jupyter-wrapper .lm-ScrollBar-thumb{background:#cdcdcd}.jupyter-wrapper .lm-ScrollBar-thumb:hover{background:#bababa}.jupyter-wrapper .lm-ScrollBar-thumb.lm-mod-active{background:#a0a0a0}.jupyter-wrapper .lm-ScrollBar[data-orientation=horizontal] .lm-ScrollBar-thumb{height:100%;min-width:15px;border-left:1px solid #a0a0a0;border-right:1px solid #a0a0a0}.jupyter-wrapper .lm-ScrollBar[data-orientation=vertical] .lm-ScrollBar-thumb{width:100%;min-height:15px;border-top:1px solid #a0a0a0;border-bottom:1px solid #a0a0a0}.jupyter-wrapper .lm-ScrollBar[data-orientation=horizontal] .lm-ScrollBar-button[data-action=decrement]{background-image:var(--jp-icon-caret-left);background-size:17px}.jupyter-wrapper .lm-ScrollBar[data-orientation=horizontal] .lm-ScrollBar-button[data-action=increment]{background-image:var(--jp-icon-caret-right);background-size:17px}.jupyter-wrapper .lm-ScrollBar[data-orientation=vertical] .lm-ScrollBar-button[data-action=decrement]{background-image:var(--jp-icon-caret-up);background-size:17px}.jupyter-wrapper .lm-ScrollBar[data-orientation=vertical] .lm-ScrollBar-button[data-action=increment]{background-image:var(--jp-icon-caret-down);background-size:17px}.jupyter-wrapper .p-Widget,.jupyter-wrapper .lm-Widget{box-sizing:border-box;position:relative;overflow:hidden;cursor:default}.jupyter-wrapper .p-Widget.p-mod-hidden,.jupyter-wrapper .lm-Widget.lm-mod-hidden{display:none !important}.jupyter-wrapper .p-CommandPalette,.jupyter-wrapper .lm-CommandPalette{display:flex;flex-direction:column;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .p-CommandPalette-search,.jupyter-wrapper .lm-CommandPalette-search{flex:0 0 auto}.jupyter-wrapper .p-CommandPalette-content,.jupyter-wrapper .lm-CommandPalette-content{flex:1 1 auto;margin:0;padding:0;min-height:0;overflow:auto;list-style-type:none}.jupyter-wrapper .p-CommandPalette-header,.jupyter-wrapper .lm-CommandPalette-header{overflow:hidden;white-space:nowrap;text-overflow:ellipsis}.jupyter-wrapper .p-CommandPalette-item,.jupyter-wrapper .lm-CommandPalette-item{display:flex;flex-direction:row}.jupyter-wrapper .p-CommandPalette-itemIcon,.jupyter-wrapper .lm-CommandPalette-itemIcon{flex:0 0 auto}.jupyter-wrapper .p-CommandPalette-itemContent,.jupyter-wrapper .lm-CommandPalette-itemContent{flex:1 1 auto;overflow:hidden}.jupyter-wrapper .p-CommandPalette-itemShortcut,.jupyter-wrapper .lm-CommandPalette-itemShortcut{flex:0 0 auto}.jupyter-wrapper .p-CommandPalette-itemLabel,.jupyter-wrapper .lm-CommandPalette-itemLabel{overflow:hidden;white-space:nowrap;text-overflow:ellipsis}.jupyter-wrapper .p-DockPanel,.jupyter-wrapper .lm-DockPanel{z-index:0}.jupyter-wrapper .p-DockPanel-widget,.jupyter-wrapper .lm-DockPanel-widget{z-index:0}.jupyter-wrapper .p-DockPanel-tabBar,.jupyter-wrapper .lm-DockPanel-tabBar{z-index:1}.jupyter-wrapper .p-DockPanel-handle,.jupyter-wrapper .lm-DockPanel-handle{z-index:2}.jupyter-wrapper .p-DockPanel-handle.p-mod-hidden,.jupyter-wrapper .lm-DockPanel-handle.lm-mod-hidden{display:none !important}.jupyter-wrapper .p-DockPanel-handle:after,.jupyter-wrapper .lm-DockPanel-handle:after{position:absolute;top:0;left:0;width:100%;height:100%;content:\"\"}.jupyter-wrapper .p-DockPanel-handle[data-orientation=horizontal],.jupyter-wrapper .lm-DockPanel-handle[data-orientation=horizontal]{cursor:ew-resize}.jupyter-wrapper .p-DockPanel-handle[data-orientation=vertical],.jupyter-wrapper .lm-DockPanel-handle[data-orientation=vertical]{cursor:ns-resize}.jupyter-wrapper .p-DockPanel-handle[data-orientation=horizontal]:after,.jupyter-wrapper .lm-DockPanel-handle[data-orientation=horizontal]:after{left:50%;min-width:8px;transform:translateX(-50%)}.jupyter-wrapper .p-DockPanel-handle[data-orientation=vertical]:after,.jupyter-wrapper .lm-DockPanel-handle[data-orientation=vertical]:after{top:50%;min-height:8px;transform:translateY(-50%)}.jupyter-wrapper .p-DockPanel-overlay,.jupyter-wrapper .lm-DockPanel-overlay{z-index:3;box-sizing:border-box;pointer-events:none}.jupyter-wrapper .p-DockPanel-overlay.p-mod-hidden,.jupyter-wrapper .lm-DockPanel-overlay.lm-mod-hidden{display:none !important}.jupyter-wrapper .p-Menu,.jupyter-wrapper .lm-Menu{z-index:10000;position:absolute;white-space:nowrap;overflow-x:hidden;overflow-y:auto;outline:none;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .p-Menu-content,.jupyter-wrapper .lm-Menu-content{margin:0;padding:0;display:table;list-style-type:none}.jupyter-wrapper .p-Menu-item,.jupyter-wrapper .lm-Menu-item{display:table-row}.jupyter-wrapper .p-Menu-item.p-mod-hidden,.jupyter-wrapper .p-Menu-item.p-mod-collapsed,.jupyter-wrapper .lm-Menu-item.lm-mod-hidden,.jupyter-wrapper .lm-Menu-item.lm-mod-collapsed{display:none !important}.jupyter-wrapper .p-Menu-itemIcon,.jupyter-wrapper .p-Menu-itemSubmenuIcon,.jupyter-wrapper .lm-Menu-itemIcon,.jupyter-wrapper .lm-Menu-itemSubmenuIcon{display:table-cell;text-align:center}.jupyter-wrapper .p-Menu-itemLabel,.jupyter-wrapper .lm-Menu-itemLabel{display:table-cell;text-align:left}.jupyter-wrapper .p-Menu-itemShortcut,.jupyter-wrapper .lm-Menu-itemShortcut{display:table-cell;text-align:right}.jupyter-wrapper .p-MenuBar,.jupyter-wrapper .lm-MenuBar{outline:none;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .p-MenuBar-content,.jupyter-wrapper .lm-MenuBar-content{margin:0;padding:0;display:flex;flex-direction:row;list-style-type:none}.jupyter-wrapper .p--MenuBar-item,.jupyter-wrapper .lm-MenuBar-item{box-sizing:border-box}.jupyter-wrapper .p-MenuBar-itemIcon,.jupyter-wrapper .p-MenuBar-itemLabel,.jupyter-wrapper .lm-MenuBar-itemIcon,.jupyter-wrapper .lm-MenuBar-itemLabel{display:inline-block}.jupyter-wrapper .p-ScrollBar,.jupyter-wrapper .lm-ScrollBar{display:flex;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .p-ScrollBar[data-orientation=horizontal],.jupyter-wrapper .lm-ScrollBar[data-orientation=horizontal]{flex-direction:row}.jupyter-wrapper .p-ScrollBar[data-orientation=vertical],.jupyter-wrapper .lm-ScrollBar[data-orientation=vertical]{flex-direction:column}.jupyter-wrapper .p-ScrollBar-button,.jupyter-wrapper .lm-ScrollBar-button{box-sizing:border-box;flex:0 0 auto}.jupyter-wrapper .p-ScrollBar-track,.jupyter-wrapper .lm-ScrollBar-track{box-sizing:border-box;position:relative;overflow:hidden;flex:1 1 auto}.jupyter-wrapper .p-ScrollBar-thumb,.jupyter-wrapper .lm-ScrollBar-thumb{box-sizing:border-box;position:absolute}.jupyter-wrapper .p-SplitPanel-child,.jupyter-wrapper .lm-SplitPanel-child{z-index:0}.jupyter-wrapper .p-SplitPanel-handle,.jupyter-wrapper .lm-SplitPanel-handle{z-index:1}.jupyter-wrapper .p-SplitPanel-handle.p-mod-hidden,.jupyter-wrapper .lm-SplitPanel-handle.lm-mod-hidden{display:none !important}.jupyter-wrapper .p-SplitPanel-handle:after,.jupyter-wrapper .lm-SplitPanel-handle:after{position:absolute;top:0;left:0;width:100%;height:100%;content:\"\"}.jupyter-wrapper .p-SplitPanel[data-orientation=horizontal]>.p-SplitPanel-handle,.jupyter-wrapper .lm-SplitPanel[data-orientation=horizontal]>.lm-SplitPanel-handle{cursor:ew-resize}.jupyter-wrapper .p-SplitPanel[data-orientation=vertical]>.p-SplitPanel-handle,.jupyter-wrapper .lm-SplitPanel[data-orientation=vertical]>.lm-SplitPanel-handle{cursor:ns-resize}.jupyter-wrapper .p-SplitPanel[data-orientation=horizontal]>.p-SplitPanel-handle:after,.jupyter-wrapper .lm-SplitPanel[data-orientation=horizontal]>.lm-SplitPanel-handle:after{left:50%;min-width:8px;transform:translateX(-50%)}.jupyter-wrapper .p-SplitPanel[data-orientation=vertical]>.p-SplitPanel-handle:after,.jupyter-wrapper .lm-SplitPanel[data-orientation=vertical]>.lm-SplitPanel-handle:after{top:50%;min-height:8px;transform:translateY(-50%)}.jupyter-wrapper .p-TabBar,.jupyter-wrapper .lm-TabBar{display:flex;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .p-TabBar[data-orientation=horizontal],.jupyter-wrapper .lm-TabBar[data-orientation=horizontal]{flex-direction:row}.jupyter-wrapper .p-TabBar[data-orientation=vertical],.jupyter-wrapper .lm-TabBar[data-orientation=vertical]{flex-direction:column}.jupyter-wrapper .p-TabBar-content,.jupyter-wrapper .lm-TabBar-content{margin:0;padding:0;display:flex;flex:1 1 auto;list-style-type:none}.jupyter-wrapper .p-TabBar[data-orientation=horizontal]>.p-TabBar-content,.jupyter-wrapper .lm-TabBar[data-orientation=horizontal]>.lm-TabBar-content{flex-direction:row}.jupyter-wrapper .p-TabBar[data-orientation=vertical]>.p-TabBar-content,.jupyter-wrapper .lm-TabBar[data-orientation=vertical]>.lm-TabBar-content{flex-direction:column}.jupyter-wrapper .p-TabBar-tab,.jupyter-wrapper .lm-TabBar-tab{display:flex;flex-direction:row;box-sizing:border-box;overflow:hidden}.jupyter-wrapper .p-TabBar-tabIcon,.jupyter-wrapper .p-TabBar-tabCloseIcon,.jupyter-wrapper .lm-TabBar-tabIcon,.jupyter-wrapper .lm-TabBar-tabCloseIcon{flex:0 0 auto}.jupyter-wrapper .p-TabBar-tabLabel,.jupyter-wrapper .lm-TabBar-tabLabel{flex:1 1 auto;overflow:hidden;white-space:nowrap}.jupyter-wrapper .p-TabBar-tab.p-mod-hidden,.jupyter-wrapper .lm-TabBar-tab.lm-mod-hidden{display:none !important}.jupyter-wrapper .p-TabBar.p-mod-dragging .p-TabBar-tab,.jupyter-wrapper .lm-TabBar.lm-mod-dragging .lm-TabBar-tab{position:relative}.jupyter-wrapper .p-TabBar.p-mod-dragging[data-orientation=horizontal] .p-TabBar-tab,.jupyter-wrapper .lm-TabBar.lm-mod-dragging[data-orientation=horizontal] .lm-TabBar-tab{left:0;transition:left 150ms ease}.jupyter-wrapper .p-TabBar.p-mod-dragging[data-orientation=vertical] .p-TabBar-tab,.jupyter-wrapper .lm-TabBar.lm-mod-dragging[data-orientation=vertical] .lm-TabBar-tab{top:0;transition:top 150ms ease}.jupyter-wrapper .p-TabBar.p-mod-dragging .p-TabBar-tab.p-mod-dragging .lm-TabBar.lm-mod-dragging .lm-TabBar-tab.lm-mod-dragging{transition:none}.jupyter-wrapper .p-TabPanel-tabBar,.jupyter-wrapper .lm-TabPanel-tabBar{z-index:1}.jupyter-wrapper .p-TabPanel-stackedPanel,.jupyter-wrapper .lm-TabPanel-stackedPanel{z-index:0}.jupyter-wrapper ::-moz-selection{background:rgba(125,188,255,.6)}.jupyter-wrapper ::selection{background:rgba(125,188,255,.6)}.jupyter-wrapper .bp3-heading{color:#182026;font-weight:600;margin:0 0 10px;padding:0}.jupyter-wrapper .bp3-dark .bp3-heading{color:#f5f8fa}.jupyter-wrapper h1.bp3-heading,.jupyter-wrapper .bp3-running-text h1{line-height:40px;font-size:36px}.jupyter-wrapper h2.bp3-heading,.jupyter-wrapper .bp3-running-text h2{line-height:32px;font-size:28px}.jupyter-wrapper h3.bp3-heading,.jupyter-wrapper .bp3-running-text h3{line-height:25px;font-size:22px}.jupyter-wrapper h4.bp3-heading,.jupyter-wrapper .bp3-running-text h4{line-height:21px;font-size:18px}.jupyter-wrapper h5.bp3-heading,.jupyter-wrapper .bp3-running-text h5{line-height:19px;font-size:16px}.jupyter-wrapper h6.bp3-heading,.jupyter-wrapper .bp3-running-text h6{line-height:16px;font-size:14px}.jupyter-wrapper .bp3-ui-text{text-transform:none;line-height:1.28581;letter-spacing:0;font-size:14px;font-weight:400}.jupyter-wrapper .bp3-monospace-text{text-transform:none;font-family:monospace}.jupyter-wrapper .bp3-text-muted{color:#5c7080}.jupyter-wrapper .bp3-dark .bp3-text-muted{color:#a7b6c2}.jupyter-wrapper .bp3-text-disabled{color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-dark .bp3-text-disabled{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-text-overflow-ellipsis{overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal}.jupyter-wrapper .bp3-running-text{line-height:1.5;font-size:14px}.jupyter-wrapper .bp3-running-text h1{color:#182026;font-weight:600;margin-top:40px;margin-bottom:20px}.jupyter-wrapper .bp3-dark .bp3-running-text h1{color:#f5f8fa}.jupyter-wrapper .bp3-running-text h2{color:#182026;font-weight:600;margin-top:40px;margin-bottom:20px}.jupyter-wrapper .bp3-dark .bp3-running-text h2{color:#f5f8fa}.jupyter-wrapper .bp3-running-text h3{color:#182026;font-weight:600;margin-top:40px;margin-bottom:20px}.jupyter-wrapper .bp3-dark .bp3-running-text h3{color:#f5f8fa}.jupyter-wrapper .bp3-running-text h4{color:#182026;font-weight:600;margin-top:40px;margin-bottom:20px}.jupyter-wrapper .bp3-dark .bp3-running-text h4{color:#f5f8fa}.jupyter-wrapper .bp3-running-text h5{color:#182026;font-weight:600;margin-top:40px;margin-bottom:20px}.jupyter-wrapper .bp3-dark .bp3-running-text h5{color:#f5f8fa}.jupyter-wrapper .bp3-running-text h6{color:#182026;font-weight:600;margin-top:40px;margin-bottom:20px}.jupyter-wrapper .bp3-dark .bp3-running-text h6{color:#f5f8fa}.jupyter-wrapper .bp3-running-text hr{margin:20px 0;border:none;border-bottom:1px solid rgba(16,22,26,.15)}.jupyter-wrapper .bp3-dark .bp3-running-text hr{border-color:rgba(255,255,255,.15)}.jupyter-wrapper .bp3-running-text p{margin:0 0 10px;padding:0}.jupyter-wrapper .bp3-text-large{font-size:16px}.jupyter-wrapper .bp3-text-small{font-size:12px}.jupyter-wrapper a{text-decoration:none;color:#106ba3}.jupyter-wrapper a:hover{cursor:pointer;text-decoration:underline;color:#106ba3}.jupyter-wrapper a .bp3-icon,.jupyter-wrapper a .bp3-icon-standard,.jupyter-wrapper a .bp3-icon-large{color:inherit}.jupyter-wrapper a code,.jupyter-wrapper .bp3-dark a code{color:inherit}.jupyter-wrapper .bp3-dark a,.jupyter-wrapper .bp3-dark a:hover{color:#48aff0}.jupyter-wrapper .bp3-dark a .bp3-icon,.jupyter-wrapper .bp3-dark a .bp3-icon-standard,.jupyter-wrapper .bp3-dark a .bp3-icon-large,.jupyter-wrapper .bp3-dark a:hover .bp3-icon,.jupyter-wrapper .bp3-dark a:hover .bp3-icon-standard,.jupyter-wrapper .bp3-dark a:hover .bp3-icon-large{color:inherit}.jupyter-wrapper .bp3-running-text code,.jupyter-wrapper .bp3-code{text-transform:none;font-family:monospace;border-radius:3px;-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2);background:rgba(255,255,255,.7);padding:2px 5px;color:#5c7080;font-size:smaller}.jupyter-wrapper .bp3-dark .bp3-running-text code,.jupyter-wrapper .bp3-running-text .bp3-dark code,.jupyter-wrapper .bp3-dark .bp3-code{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);background:rgba(16,22,26,.3);color:#a7b6c2}.jupyter-wrapper .bp3-running-text a>code,.jupyter-wrapper a>.bp3-code{color:#137cbd}.jupyter-wrapper .bp3-dark .bp3-running-text a>code,.jupyter-wrapper .bp3-running-text .bp3-dark a>code,.jupyter-wrapper .bp3-dark a>.bp3-code{color:inherit}.jupyter-wrapper .bp3-running-text pre,.jupyter-wrapper .bp3-code-block{text-transform:none;font-family:monospace;display:block;margin:10px 0;border-radius:3px;-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.15);box-shadow:inset 0 0 0 1px rgba(16,22,26,.15);background:rgba(255,255,255,.7);padding:13px 15px 12px;line-height:1.4;color:#182026;font-size:13px;word-break:break-all;word-wrap:break-word}.jupyter-wrapper .bp3-dark .bp3-running-text pre,.jupyter-wrapper .bp3-running-text .bp3-dark pre,.jupyter-wrapper .bp3-dark .bp3-code-block{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);background:rgba(16,22,26,.3);color:#f5f8fa}.jupyter-wrapper .bp3-running-text pre>code,.jupyter-wrapper .bp3-code-block>code{-webkit-box-shadow:none;box-shadow:none;background:none;padding:0;color:inherit;font-size:inherit}.jupyter-wrapper .bp3-running-text kbd,.jupyter-wrapper .bp3-key{display:-webkit-inline-box;display:-ms-inline-flexbox;display:inline-flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:center;-ms-flex-pack:center;justify-content:center;border-radius:3px;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2);background:#fff;min-width:24px;height:24px;padding:3px 6px;vertical-align:middle;line-height:24px;color:#5c7080;font-family:inherit;font-size:12px}.jupyter-wrapper .bp3-running-text kbd .bp3-icon,.jupyter-wrapper .bp3-key .bp3-icon,.jupyter-wrapper .bp3-running-text kbd .bp3-icon-standard,.jupyter-wrapper .bp3-key .bp3-icon-standard,.jupyter-wrapper .bp3-running-text kbd .bp3-icon-large,.jupyter-wrapper .bp3-key .bp3-icon-large{margin-right:5px}.jupyter-wrapper .bp3-dark .bp3-running-text kbd,.jupyter-wrapper .bp3-running-text .bp3-dark kbd,.jupyter-wrapper .bp3-dark .bp3-key{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4);background:#394b59;color:#a7b6c2}.jupyter-wrapper .bp3-running-text blockquote,.jupyter-wrapper .bp3-blockquote{margin:0 0 10px;border-left:solid 4px rgba(167,182,194,.5);padding:0 20px}.jupyter-wrapper .bp3-dark .bp3-running-text blockquote,.jupyter-wrapper .bp3-running-text .bp3-dark blockquote,.jupyter-wrapper .bp3-dark .bp3-blockquote{border-color:rgba(115,134,148,.5)}.jupyter-wrapper .bp3-running-text ul,.jupyter-wrapper .bp3-running-text ol,.jupyter-wrapper .bp3-list{margin:10px 0;padding-left:30px}.jupyter-wrapper .bp3-running-text ul li:not(:last-child),.jupyter-wrapper .bp3-running-text ol li:not(:last-child),.jupyter-wrapper .bp3-list li:not(:last-child){margin-bottom:5px}.jupyter-wrapper .bp3-running-text ul ol,.jupyter-wrapper .bp3-running-text ol ol,.jupyter-wrapper .bp3-list ol,.jupyter-wrapper .bp3-running-text ul ul,.jupyter-wrapper .bp3-running-text ol ul,.jupyter-wrapper .bp3-list ul{margin-top:5px}.jupyter-wrapper .bp3-list-unstyled{margin:0;padding:0;list-style:none}.jupyter-wrapper .bp3-list-unstyled li{padding:0}.jupyter-wrapper .bp3-rtl{text-align:right}.jupyter-wrapper .bp3-dark{color:#f5f8fa}.jupyter-wrapper :focus{outline:rgba(19,124,189,.6) auto 2px;outline-offset:2px;-moz-outline-radius:6px}.jupyter-wrapper .bp3-focus-disabled :focus{outline:none !important}.jupyter-wrapper .bp3-focus-disabled :focus~.bp3-control-indicator{outline:none !important}.jupyter-wrapper .bp3-alert{max-width:400px;padding:20px}.jupyter-wrapper .bp3-alert-body{display:-webkit-box;display:-ms-flexbox;display:flex}.jupyter-wrapper .bp3-alert-body .bp3-icon{margin-top:0;margin-right:20px;font-size:40px}.jupyter-wrapper .bp3-alert-footer{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:horizontal;-webkit-box-direction:reverse;-ms-flex-direction:row-reverse;flex-direction:row-reverse;margin-top:10px}.jupyter-wrapper .bp3-alert-footer .bp3-button{margin-left:10px}.jupyter-wrapper .bp3-breadcrumbs{display:-webkit-box;display:-ms-flexbox;display:flex;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-align:center;-ms-flex-align:center;align-items:center;margin:0;cursor:default;height:30px;padding:0;list-style:none}.jupyter-wrapper .bp3-breadcrumbs>li{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center}.jupyter-wrapper .bp3-breadcrumbs>li::after{display:block;margin:0 5px;background:url(\"data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16'%3e%3cpath fill-rule='evenodd' clip-rule='evenodd' d='M10.71 7.29l-4-4a1.003 1.003 0 0 0-1.42 1.42L8.59 8 5.3 11.29c-.19.18-.3.43-.3.71a1.003 1.003 0 0 0 1.71.71l4-4c.18-.18.29-.43.29-.71 0-.28-.11-.53-.29-.71z' fill='%235C7080'/%3e%3c/svg%3e\");width:16px;height:16px;content:\"\"}.jupyter-wrapper .bp3-breadcrumbs>li:last-of-type::after{display:none}.jupyter-wrapper .bp3-breadcrumb,.jupyter-wrapper .bp3-breadcrumb-current,.jupyter-wrapper .bp3-breadcrumbs-collapsed{display:-webkit-inline-box;display:-ms-inline-flexbox;display:inline-flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center;font-size:16px}.jupyter-wrapper .bp3-breadcrumb,.jupyter-wrapper .bp3-breadcrumbs-collapsed{color:#5c7080}.jupyter-wrapper .bp3-breadcrumb:hover{text-decoration:none}.jupyter-wrapper .bp3-breadcrumb.bp3-disabled{cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-breadcrumb .bp3-icon{margin-right:5px}.jupyter-wrapper .bp3-breadcrumb-current{color:inherit;font-weight:600}.jupyter-wrapper .bp3-breadcrumb-current .bp3-input{vertical-align:baseline;font-size:inherit;font-weight:inherit}.jupyter-wrapper .bp3-breadcrumbs-collapsed{margin-right:2px;border:none;border-radius:3px;background:#ced9e0;cursor:pointer;padding:1px 5px;vertical-align:text-bottom}.jupyter-wrapper .bp3-breadcrumbs-collapsed::before{display:block;background:url(\"data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16'%3e%3cg fill='%235C7080'%3e%3ccircle cx='2' cy='8.03' r='2'/%3e%3ccircle cx='14' cy='8.03' r='2'/%3e%3ccircle cx='8' cy='8.03' r='2'/%3e%3c/g%3e%3c/svg%3e\") center no-repeat;width:16px;height:16px;content:\"\"}.jupyter-wrapper .bp3-breadcrumbs-collapsed:hover{background:#bfccd6;text-decoration:none;color:#182026}.jupyter-wrapper .bp3-dark .bp3-breadcrumb,.jupyter-wrapper .bp3-dark .bp3-breadcrumbs-collapsed{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-breadcrumbs>li::after{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-breadcrumb.bp3-disabled{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-breadcrumb-current{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-breadcrumbs-collapsed{background:rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-breadcrumbs-collapsed:hover{background:rgba(16,22,26,.6);color:#f5f8fa}.jupyter-wrapper .bp3-button{display:-webkit-inline-box;display:-ms-inline-flexbox;display:inline-flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:center;-ms-flex-pack:center;justify-content:center;border:none;border-radius:3px;cursor:pointer;padding:5px 10px;vertical-align:middle;text-align:left;font-size:14px;min-width:30px;min-height:30px}.jupyter-wrapper .bp3-button>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-button>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-button::before,.jupyter-wrapper .bp3-button>*{margin-right:7px}.jupyter-wrapper .bp3-button:empty::before,.jupyter-wrapper .bp3-button>:last-child{margin-right:0}.jupyter-wrapper .bp3-button:empty{padding:0 !important}.jupyter-wrapper .bp3-button:disabled,.jupyter-wrapper .bp3-button.bp3-disabled{cursor:not-allowed}.jupyter-wrapper .bp3-button.bp3-fill{display:-webkit-box;display:-ms-flexbox;display:flex;width:100%}.jupyter-wrapper .bp3-button.bp3-align-right,.jupyter-wrapper .bp3-align-right .bp3-button{text-align:right}.jupyter-wrapper .bp3-button.bp3-align-left,.jupyter-wrapper .bp3-align-left .bp3-button{text-align:left}.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]){-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-color:#f5f8fa;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.8)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.8), rgba(255, 255, 255, 0));color:#182026}.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]):hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-clip:padding-box;background-color:#ebf1f5}.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]):active,.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]).bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);background-color:#d8e1e8;background-image:none}.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]):disabled,.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]).bp3-disabled{outline:none;-webkit-box-shadow:none;box-shadow:none;background-color:rgba(206,217,224,.5);background-image:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]):disabled.bp3-active,.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]):disabled.bp3-active:hover,.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]).bp3-disabled.bp3-active,.jupyter-wrapper .bp3-button:not([class*=bp3-intent-]).bp3-disabled.bp3-active:hover{background:rgba(206,217,224,.7)}.jupyter-wrapper .bp3-button.bp3-intent-primary{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#137cbd;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.1)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.1), rgba(255, 255, 255, 0));color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-primary:hover,.jupyter-wrapper .bp3-button.bp3-intent-primary:active,.jupyter-wrapper .bp3-button.bp3-intent-primary.bp3-active{color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-primary:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#106ba3}.jupyter-wrapper .bp3-button.bp3-intent-primary:active,.jupyter-wrapper .bp3-button.bp3-intent-primary.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background-color:#0e5a8a;background-image:none}.jupyter-wrapper .bp3-button.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-button.bp3-intent-primary.bp3-disabled{border-color:rgba(0,0,0,0);-webkit-box-shadow:none;box-shadow:none;background-color:rgba(19,124,189,.5);background-image:none;color:rgba(255,255,255,.6)}.jupyter-wrapper .bp3-button.bp3-intent-success{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#0f9960;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.1)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.1), rgba(255, 255, 255, 0));color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-success:hover,.jupyter-wrapper .bp3-button.bp3-intent-success:active,.jupyter-wrapper .bp3-button.bp3-intent-success.bp3-active{color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-success:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#0d8050}.jupyter-wrapper .bp3-button.bp3-intent-success:active,.jupyter-wrapper .bp3-button.bp3-intent-success.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background-color:#0a6640;background-image:none}.jupyter-wrapper .bp3-button.bp3-intent-success:disabled,.jupyter-wrapper .bp3-button.bp3-intent-success.bp3-disabled{border-color:rgba(0,0,0,0);-webkit-box-shadow:none;box-shadow:none;background-color:rgba(15,153,96,.5);background-image:none;color:rgba(255,255,255,.6)}.jupyter-wrapper .bp3-button.bp3-intent-warning{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#d9822b;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.1)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.1), rgba(255, 255, 255, 0));color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-warning:hover,.jupyter-wrapper .bp3-button.bp3-intent-warning:active,.jupyter-wrapper .bp3-button.bp3-intent-warning.bp3-active{color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-warning:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#bf7326}.jupyter-wrapper .bp3-button.bp3-intent-warning:active,.jupyter-wrapper .bp3-button.bp3-intent-warning.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background-color:#a66321;background-image:none}.jupyter-wrapper .bp3-button.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-button.bp3-intent-warning.bp3-disabled{border-color:rgba(0,0,0,0);-webkit-box-shadow:none;box-shadow:none;background-color:rgba(217,130,43,.5);background-image:none;color:rgba(255,255,255,.6)}.jupyter-wrapper .bp3-button.bp3-intent-danger{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#db3737;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.1)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.1), rgba(255, 255, 255, 0));color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-danger:hover,.jupyter-wrapper .bp3-button.bp3-intent-danger:active,.jupyter-wrapper .bp3-button.bp3-intent-danger.bp3-active{color:#fff}.jupyter-wrapper .bp3-button.bp3-intent-danger:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#c23030}.jupyter-wrapper .bp3-button.bp3-intent-danger:active,.jupyter-wrapper .bp3-button.bp3-intent-danger.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background-color:#a82a2a;background-image:none}.jupyter-wrapper .bp3-button.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-button.bp3-intent-danger.bp3-disabled{border-color:rgba(0,0,0,0);-webkit-box-shadow:none;box-shadow:none;background-color:rgba(219,55,55,.5);background-image:none;color:rgba(255,255,255,.6)}.jupyter-wrapper .bp3-button[class*=bp3-intent-] .bp3-button-spinner .bp3-spinner-head{stroke:#fff}.jupyter-wrapper .bp3-button.bp3-large,.jupyter-wrapper .bp3-large .bp3-button{min-width:40px;min-height:40px;padding:5px 15px;font-size:16px}.jupyter-wrapper .bp3-button.bp3-large::before,.jupyter-wrapper .bp3-button.bp3-large>*,.jupyter-wrapper .bp3-large .bp3-button::before,.jupyter-wrapper .bp3-large .bp3-button>*{margin-right:10px}.jupyter-wrapper .bp3-button.bp3-large:empty::before,.jupyter-wrapper .bp3-button.bp3-large>:last-child,.jupyter-wrapper .bp3-large .bp3-button:empty::before,.jupyter-wrapper .bp3-large .bp3-button>:last-child{margin-right:0}.jupyter-wrapper .bp3-button.bp3-small,.jupyter-wrapper .bp3-small .bp3-button{min-width:24px;min-height:24px;padding:0 7px}.jupyter-wrapper .bp3-button.bp3-loading{position:relative}.jupyter-wrapper .bp3-button.bp3-loading[class*=bp3-icon-]::before{visibility:hidden}.jupyter-wrapper .bp3-button.bp3-loading .bp3-button-spinner{position:absolute;margin:0}.jupyter-wrapper .bp3-button.bp3-loading>:not(.bp3-button-spinner){visibility:hidden}.jupyter-wrapper .bp3-button[class*=bp3-icon-]::before{line-height:1;font-family:\"Icons16\",sans-serif;font-size:16px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;color:#5c7080}.jupyter-wrapper .bp3-button .bp3-icon,.jupyter-wrapper .bp3-button .bp3-icon-standard,.jupyter-wrapper .bp3-button .bp3-icon-large{color:#5c7080}.jupyter-wrapper .bp3-button .bp3-icon.bp3-align-right,.jupyter-wrapper .bp3-button .bp3-icon-standard.bp3-align-right,.jupyter-wrapper .bp3-button .bp3-icon-large.bp3-align-right{margin-left:7px}.jupyter-wrapper .bp3-button .bp3-icon:first-child:last-child,.jupyter-wrapper .bp3-button .bp3-spinner+.bp3-icon:last-child{margin:0 -7px}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]){-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#394b59;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.05)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.05), rgba(255, 255, 255, 0));color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]):hover,.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]):active,.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]).bp3-active{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]):hover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#30404d}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]):active,.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]).bp3-active{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);background-color:#202b33;background-image:none}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]):disabled,.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]).bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background-color:rgba(57,75,89,.5);background-image:none;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]):disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]).bp3-disabled.bp3-active{background:rgba(57,75,89,.7)}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]) .bp3-button-spinner .bp3-spinner-head{background:rgba(16,22,26,.5);stroke:#8a9ba8}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-])[class*=bp3-icon-]::before{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]) .bp3-icon,.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]) .bp3-icon-standard,.jupyter-wrapper .bp3-dark .bp3-button:not([class*=bp3-intent-]) .bp3-icon-large{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-button[class*=bp3-intent-]{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-button[class*=bp3-intent-]:hover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-button[class*=bp3-intent-]:active,.jupyter-wrapper .bp3-dark .bp3-button[class*=bp3-intent-].bp3-active{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-dark .bp3-button[class*=bp3-intent-]:disabled,.jupyter-wrapper .bp3-dark .bp3-button[class*=bp3-intent-].bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background-image:none;color:rgba(255,255,255,.3)}.jupyter-wrapper .bp3-dark .bp3-button[class*=bp3-intent-] .bp3-button-spinner .bp3-spinner-head{stroke:#8a9ba8}.jupyter-wrapper .bp3-button:disabled::before,.jupyter-wrapper .bp3-button:disabled .bp3-icon,.jupyter-wrapper .bp3-button:disabled .bp3-icon-standard,.jupyter-wrapper .bp3-button:disabled .bp3-icon-large,.jupyter-wrapper .bp3-button.bp3-disabled::before,.jupyter-wrapper .bp3-button.bp3-disabled .bp3-icon,.jupyter-wrapper .bp3-button.bp3-disabled .bp3-icon-standard,.jupyter-wrapper .bp3-button.bp3-disabled .bp3-icon-large,.jupyter-wrapper .bp3-button[class*=bp3-intent-]::before,.jupyter-wrapper .bp3-button[class*=bp3-intent-] .bp3-icon,.jupyter-wrapper .bp3-button[class*=bp3-intent-] .bp3-icon-standard,.jupyter-wrapper .bp3-button[class*=bp3-intent-] .bp3-icon-large{color:inherit !important}.jupyter-wrapper .bp3-button.bp3-minimal{-webkit-box-shadow:none;box-shadow:none;background:none}.jupyter-wrapper .bp3-button.bp3-minimal:hover{-webkit-box-shadow:none;box-shadow:none;background:rgba(167,182,194,.3);text-decoration:none;color:#182026}.jupyter-wrapper .bp3-button.bp3-minimal:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:rgba(115,134,148,.3);color:#182026}.jupyter-wrapper .bp3-button.bp3-minimal:disabled,.jupyter-wrapper .bp3-button.bp3-minimal:disabled:hover,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-disabled,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-disabled:hover{background:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-button.bp3-minimal:disabled.bp3-active,.jupyter-wrapper .bp3-button.bp3-minimal:disabled:hover.bp3-active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-disabled:hover.bp3-active{background:rgba(115,134,148,.3)}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal{-webkit-box-shadow:none;box-shadow:none;background:none;color:inherit}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:hover,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:hover{background:rgba(138,155,168,.15)}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-active{background:rgba(138,155,168,.3);color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:disabled,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:disabled:hover,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-disabled:hover{background:none;cursor:not-allowed;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal:disabled:hover.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-disabled:hover.bp3-active{background:rgba(138,155,168,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary{color:#106ba3}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary:hover,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#106ba3}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary:hover{background:rgba(19,124,189,.15);color:#106ba3}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary.bp3-active{background:rgba(19,124,189,.3);color:#106ba3}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary.bp3-disabled{background:none;color:rgba(16,107,163,.5)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary.bp3-disabled.bp3-active{background:rgba(19,124,189,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-primary .bp3-button-spinner .bp3-spinner-head{stroke:#106ba3}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary:hover{background:rgba(19,124,189,.2);color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary:active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary.bp3-active{background:rgba(19,124,189,.3);color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary.bp3-disabled{background:none;color:rgba(72,175,240,.5)}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-primary.bp3-disabled.bp3-active{background:rgba(19,124,189,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success{color:#0d8050}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success:hover,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#0d8050}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success:hover{background:rgba(15,153,96,.15);color:#0d8050}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success.bp3-active{background:rgba(15,153,96,.3);color:#0d8050}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success:disabled,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success.bp3-disabled{background:none;color:rgba(13,128,80,.5)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success.bp3-disabled.bp3-active{background:rgba(15,153,96,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-success .bp3-button-spinner .bp3-spinner-head{stroke:#0d8050}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success{color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success:hover{background:rgba(15,153,96,.2);color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success:active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success.bp3-active{background:rgba(15,153,96,.3);color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success:disabled,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success.bp3-disabled{background:none;color:rgba(61,204,145,.5)}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-success.bp3-disabled.bp3-active{background:rgba(15,153,96,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning{color:#bf7326}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning:hover,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#bf7326}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning:hover{background:rgba(217,130,43,.15);color:#bf7326}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning.bp3-active{background:rgba(217,130,43,.3);color:#bf7326}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning.bp3-disabled{background:none;color:rgba(191,115,38,.5)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning.bp3-disabled.bp3-active{background:rgba(217,130,43,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-warning .bp3-button-spinner .bp3-spinner-head{stroke:#bf7326}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning{color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning:hover{background:rgba(217,130,43,.2);color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning:active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning.bp3-active{background:rgba(217,130,43,.3);color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning.bp3-disabled{background:none;color:rgba(255,179,102,.5)}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-warning.bp3-disabled.bp3-active{background:rgba(217,130,43,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger{color:#c23030}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger:hover,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#c23030}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger:hover{background:rgba(219,55,55,.15);color:#c23030}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger:active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger.bp3-active{background:rgba(219,55,55,.3);color:#c23030}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger.bp3-disabled{background:none;color:rgba(194,48,48,.5)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger.bp3-disabled.bp3-active{background:rgba(219,55,55,.3)}.jupyter-wrapper .bp3-button.bp3-minimal.bp3-intent-danger .bp3-button-spinner .bp3-spinner-head{stroke:#c23030}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger{color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger:hover{background:rgba(219,55,55,.2);color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger:active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger.bp3-active{background:rgba(219,55,55,.3);color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger.bp3-disabled{background:none;color:rgba(255,115,115,.5)}.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button.bp3-minimal.bp3-intent-danger.bp3-disabled.bp3-active{background:rgba(219,55,55,.3)}.jupyter-wrapper a.bp3-button{text-align:center;text-decoration:none;-webkit-transition:none;transition:none}.jupyter-wrapper a.bp3-button,.jupyter-wrapper a.bp3-button:hover,.jupyter-wrapper a.bp3-button:active{color:#182026}.jupyter-wrapper a.bp3-button.bp3-disabled{color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-button-text{-webkit-box-flex:0;-ms-flex:0 1 auto;flex:0 1 auto}.jupyter-wrapper .bp3-button.bp3-align-left .bp3-button-text,.jupyter-wrapper .bp3-button.bp3-align-right .bp3-button-text,.jupyter-wrapper .bp3-button-group.bp3-align-left .bp3-button-text,.jupyter-wrapper .bp3-button-group.bp3-align-right .bp3-button-text{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto}.jupyter-wrapper .bp3-button-group{display:-webkit-inline-box;display:-ms-inline-flexbox;display:inline-flex}.jupyter-wrapper .bp3-button-group .bp3-button{-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;position:relative;z-index:4}.jupyter-wrapper .bp3-button-group .bp3-button:focus{z-index:5}.jupyter-wrapper .bp3-button-group .bp3-button:hover{z-index:6}.jupyter-wrapper .bp3-button-group .bp3-button:active,.jupyter-wrapper .bp3-button-group .bp3-button.bp3-active{z-index:7}.jupyter-wrapper .bp3-button-group .bp3-button:disabled,.jupyter-wrapper .bp3-button-group .bp3-button.bp3-disabled{z-index:3}.jupyter-wrapper .bp3-button-group .bp3-button[class*=bp3-intent-]{z-index:9}.jupyter-wrapper .bp3-button-group .bp3-button[class*=bp3-intent-]:focus{z-index:10}.jupyter-wrapper .bp3-button-group .bp3-button[class*=bp3-intent-]:hover{z-index:11}.jupyter-wrapper .bp3-button-group .bp3-button[class*=bp3-intent-]:active,.jupyter-wrapper .bp3-button-group .bp3-button[class*=bp3-intent-].bp3-active{z-index:12}.jupyter-wrapper .bp3-button-group .bp3-button[class*=bp3-intent-]:disabled,.jupyter-wrapper .bp3-button-group .bp3-button[class*=bp3-intent-].bp3-disabled{z-index:8}.jupyter-wrapper .bp3-button-group:not(.bp3-minimal)>.bp3-popover-wrapper:not(:first-child) .bp3-button,.jupyter-wrapper .bp3-button-group:not(.bp3-minimal)>.bp3-button:not(:first-child){border-top-left-radius:0;border-bottom-left-radius:0}.jupyter-wrapper .bp3-button-group:not(.bp3-minimal)>.bp3-popover-wrapper:not(:last-child) .bp3-button,.jupyter-wrapper .bp3-button-group:not(.bp3-minimal)>.bp3-button:not(:last-child){margin-right:-1px;border-top-right-radius:0;border-bottom-right-radius:0}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button{-webkit-box-shadow:none;box-shadow:none;background:none}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button:hover{-webkit-box-shadow:none;box-shadow:none;background:rgba(167,182,194,.3);text-decoration:none;color:#182026}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:rgba(115,134,148,.3);color:#182026}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button:disabled,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button:disabled:hover,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled:hover{background:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button:disabled.bp3-active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button:disabled:hover.bp3-active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled:hover.bp3-active{background:rgba(115,134,148,.3)}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button{-webkit-box-shadow:none;box-shadow:none;background:none;color:inherit}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:hover,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:hover{background:rgba(138,155,168,.15)}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-active{background:rgba(138,155,168,.3);color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:disabled,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:disabled:hover,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled:hover{background:none;cursor:not-allowed;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button:disabled:hover.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-disabled:hover.bp3-active{background:rgba(138,155,168,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary{color:#106ba3}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:hover,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#106ba3}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:hover{background:rgba(19,124,189,.15);color:#106ba3}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary.bp3-active{background:rgba(19,124,189,.3);color:#106ba3}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary.bp3-disabled{background:none;color:rgba(16,107,163,.5)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary.bp3-disabled.bp3-active{background:rgba(19,124,189,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary .bp3-button-spinner .bp3-spinner-head{stroke:#106ba3}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:hover{background:rgba(19,124,189,.2);color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary.bp3-active{background:rgba(19,124,189,.3);color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary.bp3-disabled{background:none;color:rgba(72,175,240,.5)}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-primary.bp3-disabled.bp3-active{background:rgba(19,124,189,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success{color:#0d8050}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:hover,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#0d8050}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:hover{background:rgba(15,153,96,.15);color:#0d8050}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success.bp3-active{background:rgba(15,153,96,.3);color:#0d8050}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:disabled,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success.bp3-disabled{background:none;color:rgba(13,128,80,.5)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success.bp3-disabled.bp3-active{background:rgba(15,153,96,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success .bp3-button-spinner .bp3-spinner-head{stroke:#0d8050}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success{color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:hover{background:rgba(15,153,96,.2);color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success.bp3-active{background:rgba(15,153,96,.3);color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:disabled,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success.bp3-disabled{background:none;color:rgba(61,204,145,.5)}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-success.bp3-disabled.bp3-active{background:rgba(15,153,96,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning{color:#bf7326}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:hover,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#bf7326}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:hover{background:rgba(217,130,43,.15);color:#bf7326}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning.bp3-active{background:rgba(217,130,43,.3);color:#bf7326}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning.bp3-disabled{background:none;color:rgba(191,115,38,.5)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning.bp3-disabled.bp3-active{background:rgba(217,130,43,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning .bp3-button-spinner .bp3-spinner-head{stroke:#bf7326}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning{color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:hover{background:rgba(217,130,43,.2);color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning.bp3-active{background:rgba(217,130,43,.3);color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning.bp3-disabled{background:none;color:rgba(255,179,102,.5)}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-warning.bp3-disabled.bp3-active{background:rgba(217,130,43,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger{color:#c23030}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:hover,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#c23030}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:hover{background:rgba(219,55,55,.15);color:#c23030}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger.bp3-active{background:rgba(219,55,55,.3);color:#c23030}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger.bp3-disabled{background:none;color:rgba(194,48,48,.5)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger.bp3-disabled.bp3-active{background:rgba(219,55,55,.3)}.jupyter-wrapper .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger .bp3-button-spinner .bp3-spinner-head{stroke:#c23030}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger{color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:hover{background:rgba(219,55,55,.2);color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger.bp3-active{background:rgba(219,55,55,.3);color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger.bp3-disabled{background:none;color:rgba(255,115,115,.5)}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-minimal .bp3-button.bp3-intent-danger.bp3-disabled.bp3-active{background:rgba(219,55,55,.3)}.jupyter-wrapper .bp3-button-group .bp3-popover-wrapper,.jupyter-wrapper .bp3-button-group .bp3-popover-target{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto}.jupyter-wrapper .bp3-button-group.bp3-fill{display:-webkit-box;display:-ms-flexbox;display:flex;width:100%}.jupyter-wrapper .bp3-button-group .bp3-button.bp3-fill,.jupyter-wrapper .bp3-button-group.bp3-fill .bp3-button:not(.bp3-fixed){-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto}.jupyter-wrapper .bp3-button-group.bp3-vertical{-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;-webkit-box-align:stretch;-ms-flex-align:stretch;align-items:stretch;vertical-align:top}.jupyter-wrapper .bp3-button-group.bp3-vertical.bp3-fill{width:unset;height:100%}.jupyter-wrapper .bp3-button-group.bp3-vertical .bp3-button{margin-right:0 !important;width:100%}.jupyter-wrapper .bp3-button-group.bp3-vertical:not(.bp3-minimal)>.bp3-popover-wrapper:first-child .bp3-button,.jupyter-wrapper .bp3-button-group.bp3-vertical:not(.bp3-minimal)>.bp3-button:first-child{border-radius:3px 3px 0 0}.jupyter-wrapper .bp3-button-group.bp3-vertical:not(.bp3-minimal)>.bp3-popover-wrapper:last-child .bp3-button,.jupyter-wrapper .bp3-button-group.bp3-vertical:not(.bp3-minimal)>.bp3-button:last-child{border-radius:0 0 3px 3px}.jupyter-wrapper .bp3-button-group.bp3-vertical:not(.bp3-minimal)>.bp3-popover-wrapper:not(:last-child) .bp3-button,.jupyter-wrapper .bp3-button-group.bp3-vertical:not(.bp3-minimal)>.bp3-button:not(:last-child){margin-bottom:-1px}.jupyter-wrapper .bp3-button-group.bp3-align-left .bp3-button{text-align:left}.jupyter-wrapper .bp3-dark .bp3-button-group:not(.bp3-minimal)>.bp3-popover-wrapper:not(:last-child) .bp3-button,.jupyter-wrapper .bp3-dark .bp3-button-group:not(.bp3-minimal)>.bp3-button:not(:last-child){margin-right:1px}.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-vertical>.bp3-popover-wrapper:not(:last-child) .bp3-button,.jupyter-wrapper .bp3-dark .bp3-button-group.bp3-vertical>.bp3-button:not(:last-child){margin-bottom:1px}.jupyter-wrapper .bp3-callout{line-height:1.5;font-size:14px;position:relative;border-radius:3px;background-color:rgba(138,155,168,.15);width:100%;padding:10px 12px 9px}.jupyter-wrapper .bp3-callout[class*=bp3-icon-]{padding-left:40px}.jupyter-wrapper .bp3-callout[class*=bp3-icon-]::before{line-height:1;font-family:\"Icons20\",sans-serif;font-size:20px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;position:absolute;top:10px;left:10px;color:#5c7080}.jupyter-wrapper .bp3-callout.bp3-callout-icon{padding-left:40px}.jupyter-wrapper .bp3-callout.bp3-callout-icon>.bp3-icon:first-child{position:absolute;top:10px;left:10px;color:#5c7080}.jupyter-wrapper .bp3-callout .bp3-heading{margin-top:0;margin-bottom:5px;line-height:20px}.jupyter-wrapper .bp3-callout .bp3-heading:last-child{margin-bottom:0}.jupyter-wrapper .bp3-dark .bp3-callout{background-color:rgba(138,155,168,.2)}.jupyter-wrapper .bp3-dark .bp3-callout[class*=bp3-icon-]::before{color:#a7b6c2}.jupyter-wrapper .bp3-callout.bp3-intent-primary{background-color:rgba(19,124,189,.15)}.jupyter-wrapper .bp3-callout.bp3-intent-primary[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-callout.bp3-intent-primary>.bp3-icon:first-child,.jupyter-wrapper .bp3-callout.bp3-intent-primary .bp3-heading{color:#106ba3}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-primary{background-color:rgba(19,124,189,.25)}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-primary[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-primary>.bp3-icon:first-child,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-primary .bp3-heading{color:#48aff0}.jupyter-wrapper .bp3-callout.bp3-intent-success{background-color:rgba(15,153,96,.15)}.jupyter-wrapper .bp3-callout.bp3-intent-success[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-callout.bp3-intent-success>.bp3-icon:first-child,.jupyter-wrapper .bp3-callout.bp3-intent-success .bp3-heading{color:#0d8050}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-success{background-color:rgba(15,153,96,.25)}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-success[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-success>.bp3-icon:first-child,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-success .bp3-heading{color:#3dcc91}.jupyter-wrapper .bp3-callout.bp3-intent-warning{background-color:rgba(217,130,43,.15)}.jupyter-wrapper .bp3-callout.bp3-intent-warning[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-callout.bp3-intent-warning>.bp3-icon:first-child,.jupyter-wrapper .bp3-callout.bp3-intent-warning .bp3-heading{color:#bf7326}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-warning{background-color:rgba(217,130,43,.25)}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-warning[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-warning>.bp3-icon:first-child,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-warning .bp3-heading{color:#ffb366}.jupyter-wrapper .bp3-callout.bp3-intent-danger{background-color:rgba(219,55,55,.15)}.jupyter-wrapper .bp3-callout.bp3-intent-danger[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-callout.bp3-intent-danger>.bp3-icon:first-child,.jupyter-wrapper .bp3-callout.bp3-intent-danger .bp3-heading{color:#c23030}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-danger{background-color:rgba(219,55,55,.25)}.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-danger[class*=bp3-icon-]::before,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-danger>.bp3-icon:first-child,.jupyter-wrapper .bp3-dark .bp3-callout.bp3-intent-danger .bp3-heading{color:#ff7373}.jupyter-wrapper .bp3-running-text .bp3-callout{margin:20px 0}.jupyter-wrapper .bp3-card{border-radius:3px;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.15),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0);box-shadow:0 0 0 1px rgba(16,22,26,.15),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0);background-color:#fff;padding:20px;-webkit-transition:-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9),box-shadow 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9),box-shadow 200ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 200ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-card.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-card{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0);box-shadow:0 0 0 1px rgba(16,22,26,.4),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0);background-color:#30404d}.jupyter-wrapper .bp3-elevation-0{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.15),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0);box-shadow:0 0 0 1px rgba(16,22,26,.15),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0)}.jupyter-wrapper .bp3-elevation-0.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-elevation-0{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0);box-shadow:0 0 0 1px rgba(16,22,26,.4),0 0 0 rgba(16,22,26,0),0 0 0 rgba(16,22,26,0)}.jupyter-wrapper .bp3-elevation-1{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-elevation-1.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-elevation-1{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-elevation-2{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 1px 1px rgba(16,22,26,.2),0 2px 6px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 1px 1px rgba(16,22,26,.2),0 2px 6px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-elevation-2.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-elevation-2{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.4),0 2px 6px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.4),0 2px 6px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-elevation-3{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-elevation-3.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-elevation-3{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-elevation-4{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-elevation-4.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-elevation-4{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-card.bp3-interactive:hover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);cursor:pointer}.jupyter-wrapper .bp3-card.bp3-interactive:hover.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-card.bp3-interactive:hover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-card.bp3-interactive:active{opacity:.9;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2);-webkit-transition-duration:0;transition-duration:0}.jupyter-wrapper .bp3-card.bp3-interactive:active.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-card.bp3-interactive:active{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-collapse{height:0;overflow-y:hidden;-webkit-transition:height 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:height 200ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-collapse .bp3-collapse-body{-webkit-transition:-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-collapse .bp3-collapse-body[aria-hidden=true]{display:none}.jupyter-wrapper .bp3-context-menu .bp3-popover-target{display:block}.jupyter-wrapper .bp3-context-menu-popover-target{position:fixed}.jupyter-wrapper .bp3-divider{margin:5px;border-right:1px solid rgba(16,22,26,.15);border-bottom:1px solid rgba(16,22,26,.15)}.jupyter-wrapper .bp3-dark .bp3-divider{border-color:rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dialog-container{opacity:1;-webkit-transform:scale(1);transform:scale(1);display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:center;-ms-flex-pack:center;justify-content:center;width:100%;min-height:100%;pointer-events:none;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-dialog-container.bp3-overlay-enter>.bp3-dialog,.jupyter-wrapper .bp3-dialog-container.bp3-overlay-appear>.bp3-dialog{opacity:0;-webkit-transform:scale(0.5);transform:scale(0.5)}.jupyter-wrapper .bp3-dialog-container.bp3-overlay-enter-active>.bp3-dialog,.jupyter-wrapper .bp3-dialog-container.bp3-overlay-appear-active>.bp3-dialog{opacity:1;-webkit-transform:scale(1);transform:scale(1);-webkit-transition-property:opacity,-webkit-transform;transition-property:opacity,-webkit-transform;transition-property:opacity,transform;transition-property:opacity,transform,-webkit-transform;-webkit-transition-duration:300ms;transition-duration:300ms;-webkit-transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-dialog-container.bp3-overlay-exit>.bp3-dialog{opacity:1;-webkit-transform:scale(1);transform:scale(1)}.jupyter-wrapper .bp3-dialog-container.bp3-overlay-exit-active>.bp3-dialog{opacity:0;-webkit-transform:scale(0.5);transform:scale(0.5);-webkit-transition-property:opacity,-webkit-transform;transition-property:opacity,-webkit-transform;transition-property:opacity,transform;transition-property:opacity,transform,-webkit-transform;-webkit-transition-duration:300ms;transition-duration:300ms;-webkit-transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-dialog{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;margin:30px 0;border-radius:6px;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2);background:#ebf1f5;width:500px;padding-bottom:20px;pointer-events:all;-webkit-user-select:text;-moz-user-select:text;-ms-user-select:text;user-select:text}.jupyter-wrapper .bp3-dialog:focus{outline:0}.jupyter-wrapper .bp3-dialog.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-dialog{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4);background:#293742;color:#f5f8fa}.jupyter-wrapper .bp3-dialog-header{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;-webkit-box-align:center;-ms-flex-align:center;align-items:center;border-radius:6px 6px 0 0;-webkit-box-shadow:0 1px 0 rgba(16,22,26,.15);box-shadow:0 1px 0 rgba(16,22,26,.15);background:#fff;min-height:40px;padding-right:5px;padding-left:20px}.jupyter-wrapper .bp3-dialog-header .bp3-icon-large,.jupyter-wrapper .bp3-dialog-header .bp3-icon{-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;margin-right:10px;color:#5c7080}.jupyter-wrapper .bp3-dialog-header .bp3-heading{overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal;-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;margin:0;line-height:inherit}.jupyter-wrapper .bp3-dialog-header .bp3-heading:last-child{margin-right:20px}.jupyter-wrapper .bp3-dark .bp3-dialog-header{-webkit-box-shadow:0 1px 0 rgba(16,22,26,.4);box-shadow:0 1px 0 rgba(16,22,26,.4);background:#30404d}.jupyter-wrapper .bp3-dark .bp3-dialog-header .bp3-icon-large,.jupyter-wrapper .bp3-dark .bp3-dialog-header .bp3-icon{color:#a7b6c2}.jupyter-wrapper .bp3-dialog-body{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;margin:20px;line-height:18px}.jupyter-wrapper .bp3-dialog-footer{-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;margin:0 20px}.jupyter-wrapper .bp3-dialog-footer-actions{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-pack:end;-ms-flex-pack:end;justify-content:flex-end}.jupyter-wrapper .bp3-dialog-footer-actions .bp3-button{margin-left:10px}.jupyter-wrapper .bp3-drawer{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;margin:0;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2);background:#fff;padding:0}.jupyter-wrapper .bp3-drawer:focus{outline:0}.jupyter-wrapper .bp3-drawer.bp3-position-top{top:0;right:0;left:0;height:50%}.jupyter-wrapper .bp3-drawer.bp3-position-top.bp3-overlay-enter,.jupyter-wrapper .bp3-drawer.bp3-position-top.bp3-overlay-appear{-webkit-transform:translateY(-100%);transform:translateY(-100%)}.jupyter-wrapper .bp3-drawer.bp3-position-top.bp3-overlay-enter-active,.jupyter-wrapper .bp3-drawer.bp3-position-top.bp3-overlay-appear-active{-webkit-transform:translateY(0);transform:translateY(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-position-top.bp3-overlay-exit{-webkit-transform:translateY(0);transform:translateY(0)}.jupyter-wrapper .bp3-drawer.bp3-position-top.bp3-overlay-exit-active{-webkit-transform:translateY(-100%);transform:translateY(-100%);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-position-bottom{right:0;bottom:0;left:0;height:50%}.jupyter-wrapper .bp3-drawer.bp3-position-bottom.bp3-overlay-enter,.jupyter-wrapper .bp3-drawer.bp3-position-bottom.bp3-overlay-appear{-webkit-transform:translateY(100%);transform:translateY(100%)}.jupyter-wrapper .bp3-drawer.bp3-position-bottom.bp3-overlay-enter-active,.jupyter-wrapper .bp3-drawer.bp3-position-bottom.bp3-overlay-appear-active{-webkit-transform:translateY(0);transform:translateY(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-position-bottom.bp3-overlay-exit{-webkit-transform:translateY(0);transform:translateY(0)}.jupyter-wrapper .bp3-drawer.bp3-position-bottom.bp3-overlay-exit-active{-webkit-transform:translateY(100%);transform:translateY(100%);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-position-left{top:0;bottom:0;left:0;width:50%}.jupyter-wrapper .bp3-drawer.bp3-position-left.bp3-overlay-enter,.jupyter-wrapper .bp3-drawer.bp3-position-left.bp3-overlay-appear{-webkit-transform:translateX(-100%);transform:translateX(-100%)}.jupyter-wrapper .bp3-drawer.bp3-position-left.bp3-overlay-enter-active,.jupyter-wrapper .bp3-drawer.bp3-position-left.bp3-overlay-appear-active{-webkit-transform:translateX(0);transform:translateX(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-position-left.bp3-overlay-exit{-webkit-transform:translateX(0);transform:translateX(0)}.jupyter-wrapper .bp3-drawer.bp3-position-left.bp3-overlay-exit-active{-webkit-transform:translateX(-100%);transform:translateX(-100%);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-position-right{top:0;right:0;bottom:0;width:50%}.jupyter-wrapper .bp3-drawer.bp3-position-right.bp3-overlay-enter,.jupyter-wrapper .bp3-drawer.bp3-position-right.bp3-overlay-appear{-webkit-transform:translateX(100%);transform:translateX(100%)}.jupyter-wrapper .bp3-drawer.bp3-position-right.bp3-overlay-enter-active,.jupyter-wrapper .bp3-drawer.bp3-position-right.bp3-overlay-appear-active{-webkit-transform:translateX(0);transform:translateX(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-position-right.bp3-overlay-exit{-webkit-transform:translateX(0);transform:translateX(0)}.jupyter-wrapper .bp3-drawer.bp3-position-right.bp3-overlay-exit-active{-webkit-transform:translateX(100%);transform:translateX(100%);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right):not(.bp3-vertical){top:0;right:0;bottom:0;width:50%}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right):not(.bp3-vertical).bp3-overlay-enter,.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right):not(.bp3-vertical).bp3-overlay-appear{-webkit-transform:translateX(100%);transform:translateX(100%)}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right):not(.bp3-vertical).bp3-overlay-enter-active,.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right):not(.bp3-vertical).bp3-overlay-appear-active{-webkit-transform:translateX(0);transform:translateX(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right):not(.bp3-vertical).bp3-overlay-exit{-webkit-transform:translateX(0);transform:translateX(0)}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right):not(.bp3-vertical).bp3-overlay-exit-active{-webkit-transform:translateX(100%);transform:translateX(100%);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right).bp3-vertical{right:0;bottom:0;left:0;height:50%}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right).bp3-vertical.bp3-overlay-enter,.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right).bp3-vertical.bp3-overlay-appear{-webkit-transform:translateY(100%);transform:translateY(100%)}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right).bp3-vertical.bp3-overlay-enter-active,.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right).bp3-vertical.bp3-overlay-appear-active{-webkit-transform:translateY(0);transform:translateY(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right).bp3-vertical.bp3-overlay-exit{-webkit-transform:translateY(0);transform:translateY(0)}.jupyter-wrapper .bp3-drawer:not(.bp3-position-top):not(.bp3-position-bottom):not(.bp3-position-left):not(.bp3-position-right).bp3-vertical.bp3-overlay-exit-active{-webkit-transform:translateY(100%);transform:translateY(100%);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-drawer.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-drawer{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4);background:#30404d;color:#f5f8fa}.jupyter-wrapper .bp3-drawer-header{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;-webkit-box-align:center;-ms-flex-align:center;align-items:center;position:relative;border-radius:0;-webkit-box-shadow:0 1px 0 rgba(16,22,26,.15);box-shadow:0 1px 0 rgba(16,22,26,.15);min-height:40px;padding:5px;padding-left:20px}.jupyter-wrapper .bp3-drawer-header .bp3-icon-large,.jupyter-wrapper .bp3-drawer-header .bp3-icon{-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;margin-right:10px;color:#5c7080}.jupyter-wrapper .bp3-drawer-header .bp3-heading{overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal;-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;margin:0;line-height:inherit}.jupyter-wrapper .bp3-drawer-header .bp3-heading:last-child{margin-right:20px}.jupyter-wrapper .bp3-dark .bp3-drawer-header{-webkit-box-shadow:0 1px 0 rgba(16,22,26,.4);box-shadow:0 1px 0 rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-drawer-header .bp3-icon-large,.jupyter-wrapper .bp3-dark .bp3-drawer-header .bp3-icon{color:#a7b6c2}.jupyter-wrapper .bp3-drawer-body{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;overflow:auto;line-height:18px}.jupyter-wrapper .bp3-drawer-footer{-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;position:relative;-webkit-box-shadow:inset 0 1px 0 rgba(16,22,26,.15);box-shadow:inset 0 1px 0 rgba(16,22,26,.15);padding:10px 20px}.jupyter-wrapper .bp3-dark .bp3-drawer-footer{-webkit-box-shadow:inset 0 1px 0 rgba(16,22,26,.4);box-shadow:inset 0 1px 0 rgba(16,22,26,.4)}.jupyter-wrapper .bp3-editable-text{display:inline-block;position:relative;cursor:text;max-width:100%;vertical-align:top;white-space:nowrap}.jupyter-wrapper .bp3-editable-text::before{position:absolute;top:-3px;right:-3px;bottom:-3px;left:-3px;border-radius:3px;content:\"\";-webkit-transition:background-color 100ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:background-color 100ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:background-color 100ms cubic-bezier(0.4, 1, 0.75, 0.9),box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:background-color 100ms cubic-bezier(0.4, 1, 0.75, 0.9),box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-editable-text:hover::before{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.15);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.15)}.jupyter-wrapper .bp3-editable-text.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);background-color:#fff}.jupyter-wrapper .bp3-editable-text.bp3-disabled::before{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-editable-text.bp3-intent-primary .bp3-editable-text-input,.jupyter-wrapper .bp3-editable-text.bp3-intent-primary .bp3-editable-text-content{color:#137cbd}.jupyter-wrapper .bp3-editable-text.bp3-intent-primary:hover::before{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(19,124,189,.4);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(19,124,189,.4)}.jupyter-wrapper .bp3-editable-text.bp3-intent-primary.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-editable-text.bp3-intent-success .bp3-editable-text-input,.jupyter-wrapper .bp3-editable-text.bp3-intent-success .bp3-editable-text-content{color:#0f9960}.jupyter-wrapper .bp3-editable-text.bp3-intent-success:hover::before{-webkit-box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px rgba(15,153,96,.4);box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px rgba(15,153,96,.4)}.jupyter-wrapper .bp3-editable-text.bp3-intent-success.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-editable-text.bp3-intent-warning .bp3-editable-text-input,.jupyter-wrapper .bp3-editable-text.bp3-intent-warning .bp3-editable-text-content{color:#d9822b}.jupyter-wrapper .bp3-editable-text.bp3-intent-warning:hover::before{-webkit-box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px rgba(217,130,43,.4);box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px rgba(217,130,43,.4)}.jupyter-wrapper .bp3-editable-text.bp3-intent-warning.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-editable-text.bp3-intent-danger .bp3-editable-text-input,.jupyter-wrapper .bp3-editable-text.bp3-intent-danger .bp3-editable-text-content{color:#db3737}.jupyter-wrapper .bp3-editable-text.bp3-intent-danger:hover::before{-webkit-box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px rgba(219,55,55,.4);box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px rgba(219,55,55,.4)}.jupyter-wrapper .bp3-editable-text.bp3-intent-danger.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-dark .bp3-editable-text:hover::before{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(255,255,255,.15);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(255,255,255,.15)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);background-color:rgba(16,22,26,.3)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-disabled::before{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-primary .bp3-editable-text-content{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-primary:hover::before{-webkit-box-shadow:0 0 0 0 rgba(72,175,240,0),0 0 0 0 rgba(72,175,240,0),inset 0 0 0 1px rgba(72,175,240,.4);box-shadow:0 0 0 0 rgba(72,175,240,0),0 0 0 0 rgba(72,175,240,0),inset 0 0 0 1px rgba(72,175,240,.4)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-primary.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #48aff0,0 0 0 3px rgba(72,175,240,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #48aff0,0 0 0 3px rgba(72,175,240,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-success .bp3-editable-text-content{color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-success:hover::before{-webkit-box-shadow:0 0 0 0 rgba(61,204,145,0),0 0 0 0 rgba(61,204,145,0),inset 0 0 0 1px rgba(61,204,145,.4);box-shadow:0 0 0 0 rgba(61,204,145,0),0 0 0 0 rgba(61,204,145,0),inset 0 0 0 1px rgba(61,204,145,.4)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-success.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #3dcc91,0 0 0 3px rgba(61,204,145,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #3dcc91,0 0 0 3px rgba(61,204,145,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-warning .bp3-editable-text-content{color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-warning:hover::before{-webkit-box-shadow:0 0 0 0 rgba(255,179,102,0),0 0 0 0 rgba(255,179,102,0),inset 0 0 0 1px rgba(255,179,102,.4);box-shadow:0 0 0 0 rgba(255,179,102,0),0 0 0 0 rgba(255,179,102,0),inset 0 0 0 1px rgba(255,179,102,.4)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-warning.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #ffb366,0 0 0 3px rgba(255,179,102,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #ffb366,0 0 0 3px rgba(255,179,102,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-danger .bp3-editable-text-content{color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-danger:hover::before{-webkit-box-shadow:0 0 0 0 rgba(255,115,115,0),0 0 0 0 rgba(255,115,115,0),inset 0 0 0 1px rgba(255,115,115,.4);box-shadow:0 0 0 0 rgba(255,115,115,0),0 0 0 0 rgba(255,115,115,0),inset 0 0 0 1px rgba(255,115,115,.4)}.jupyter-wrapper .bp3-dark .bp3-editable-text.bp3-intent-danger.bp3-editable-text-editing::before{-webkit-box-shadow:0 0 0 1px #ff7373,0 0 0 3px rgba(255,115,115,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #ff7373,0 0 0 3px rgba(255,115,115,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-editable-text-input,.jupyter-wrapper .bp3-editable-text-content{display:inherit;position:relative;min-width:inherit;max-width:inherit;vertical-align:top;text-transform:inherit;letter-spacing:inherit;color:inherit;font:inherit;resize:none}.jupyter-wrapper .bp3-editable-text-input{border:none;-webkit-box-shadow:none;box-shadow:none;background:none;width:100%;padding:0;white-space:pre-wrap}.jupyter-wrapper .bp3-editable-text-input::-webkit-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-editable-text-input::-moz-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-editable-text-input:-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-editable-text-input::-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-editable-text-input::placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-editable-text-input:focus{outline:none}.jupyter-wrapper .bp3-editable-text-input::-ms-clear{display:none}.jupyter-wrapper .bp3-editable-text-content{overflow:hidden;padding-right:2px;text-overflow:ellipsis;white-space:pre}.jupyter-wrapper .bp3-editable-text-editing>.bp3-editable-text-content{position:absolute;left:0;visibility:hidden}.jupyter-wrapper .bp3-editable-text-placeholder>.bp3-editable-text-content{color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-dark .bp3-editable-text-placeholder>.bp3-editable-text-content{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-editable-text.bp3-multiline{display:block}.jupyter-wrapper .bp3-editable-text.bp3-multiline .bp3-editable-text-content{overflow:auto;white-space:pre-wrap;word-wrap:break-word}.jupyter-wrapper .bp3-control-group{-webkit-transform:translateZ(0);transform:translateZ(0);display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:stretch;-ms-flex-align:stretch;align-items:stretch}.jupyter-wrapper .bp3-control-group>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-control-group>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-control-group .bp3-button,.jupyter-wrapper .bp3-control-group .bp3-html-select,.jupyter-wrapper .bp3-control-group .bp3-input,.jupyter-wrapper .bp3-control-group .bp3-select{position:relative}.jupyter-wrapper .bp3-control-group .bp3-input{z-index:2;border-radius:inherit}.jupyter-wrapper .bp3-control-group .bp3-input:focus{z-index:14;border-radius:3px}.jupyter-wrapper .bp3-control-group .bp3-input[class*=bp3-intent]{z-index:13}.jupyter-wrapper .bp3-control-group .bp3-input[class*=bp3-intent]:focus{z-index:15}.jupyter-wrapper .bp3-control-group .bp3-input[readonly],.jupyter-wrapper .bp3-control-group .bp3-input:disabled,.jupyter-wrapper .bp3-control-group .bp3-input.bp3-disabled{z-index:1}.jupyter-wrapper .bp3-control-group .bp3-input-group[class*=bp3-intent] .bp3-input{z-index:13}.jupyter-wrapper .bp3-control-group .bp3-input-group[class*=bp3-intent] .bp3-input:focus{z-index:15}.jupyter-wrapper .bp3-control-group .bp3-button,.jupyter-wrapper .bp3-control-group .bp3-html-select select,.jupyter-wrapper .bp3-control-group .bp3-select select{-webkit-transform:translateZ(0);transform:translateZ(0);z-index:4;border-radius:inherit}.jupyter-wrapper .bp3-control-group .bp3-button:focus,.jupyter-wrapper .bp3-control-group .bp3-html-select select:focus,.jupyter-wrapper .bp3-control-group .bp3-select select:focus{z-index:5}.jupyter-wrapper .bp3-control-group .bp3-button:hover,.jupyter-wrapper .bp3-control-group .bp3-html-select select:hover,.jupyter-wrapper .bp3-control-group .bp3-select select:hover{z-index:6}.jupyter-wrapper .bp3-control-group .bp3-button:active,.jupyter-wrapper .bp3-control-group .bp3-html-select select:active,.jupyter-wrapper .bp3-control-group .bp3-select select:active{z-index:7}.jupyter-wrapper .bp3-control-group .bp3-button[readonly],.jupyter-wrapper .bp3-control-group .bp3-button:disabled,.jupyter-wrapper .bp3-control-group .bp3-button.bp3-disabled,.jupyter-wrapper .bp3-control-group .bp3-html-select select[readonly],.jupyter-wrapper .bp3-control-group .bp3-html-select select:disabled,.jupyter-wrapper .bp3-control-group .bp3-html-select select.bp3-disabled,.jupyter-wrapper .bp3-control-group .bp3-select select[readonly],.jupyter-wrapper .bp3-control-group .bp3-select select:disabled,.jupyter-wrapper .bp3-control-group .bp3-select select.bp3-disabled{z-index:3}.jupyter-wrapper .bp3-control-group .bp3-button[class*=bp3-intent],.jupyter-wrapper .bp3-control-group .bp3-html-select select[class*=bp3-intent],.jupyter-wrapper .bp3-control-group .bp3-select select[class*=bp3-intent]{z-index:9}.jupyter-wrapper .bp3-control-group .bp3-button[class*=bp3-intent]:focus,.jupyter-wrapper .bp3-control-group .bp3-html-select select[class*=bp3-intent]:focus,.jupyter-wrapper .bp3-control-group .bp3-select select[class*=bp3-intent]:focus{z-index:10}.jupyter-wrapper .bp3-control-group .bp3-button[class*=bp3-intent]:hover,.jupyter-wrapper .bp3-control-group .bp3-html-select select[class*=bp3-intent]:hover,.jupyter-wrapper .bp3-control-group .bp3-select select[class*=bp3-intent]:hover{z-index:11}.jupyter-wrapper .bp3-control-group .bp3-button[class*=bp3-intent]:active,.jupyter-wrapper .bp3-control-group .bp3-html-select select[class*=bp3-intent]:active,.jupyter-wrapper .bp3-control-group .bp3-select select[class*=bp3-intent]:active{z-index:12}.jupyter-wrapper .bp3-control-group .bp3-button[class*=bp3-intent][readonly],.jupyter-wrapper .bp3-control-group .bp3-button[class*=bp3-intent]:disabled,.jupyter-wrapper .bp3-control-group .bp3-button[class*=bp3-intent].bp3-disabled,.jupyter-wrapper .bp3-control-group .bp3-html-select select[class*=bp3-intent][readonly],.jupyter-wrapper .bp3-control-group .bp3-html-select select[class*=bp3-intent]:disabled,.jupyter-wrapper .bp3-control-group .bp3-html-select select[class*=bp3-intent].bp3-disabled,.jupyter-wrapper .bp3-control-group .bp3-select select[class*=bp3-intent][readonly],.jupyter-wrapper .bp3-control-group .bp3-select select[class*=bp3-intent]:disabled,.jupyter-wrapper .bp3-control-group .bp3-select select[class*=bp3-intent].bp3-disabled{z-index:8}.jupyter-wrapper .bp3-control-group .bp3-input-group>.bp3-icon,.jupyter-wrapper .bp3-control-group .bp3-input-group>.bp3-button,.jupyter-wrapper .bp3-control-group .bp3-input-group>.bp3-input-action{z-index:16}.jupyter-wrapper .bp3-control-group .bp3-select::after,.jupyter-wrapper .bp3-control-group .bp3-html-select::after,.jupyter-wrapper .bp3-control-group .bp3-select>.bp3-icon,.jupyter-wrapper .bp3-control-group .bp3-html-select>.bp3-icon{z-index:17}.jupyter-wrapper .bp3-control-group:not(.bp3-vertical)>*{margin-right:-1px}.jupyter-wrapper .bp3-dark .bp3-control-group:not(.bp3-vertical)>*{margin-right:0}.jupyter-wrapper .bp3-dark .bp3-control-group:not(.bp3-vertical)>.bp3-button+.bp3-button{margin-left:1px}.jupyter-wrapper .bp3-control-group .bp3-popover-wrapper,.jupyter-wrapper .bp3-control-group .bp3-popover-target{border-radius:inherit}.jupyter-wrapper .bp3-control-group>:first-child{border-radius:3px 0 0 3px}.jupyter-wrapper .bp3-control-group>:last-child{margin-right:0;border-radius:0 3px 3px 0}.jupyter-wrapper .bp3-control-group>:only-child{margin-right:0;border-radius:3px}.jupyter-wrapper .bp3-control-group .bp3-input-group .bp3-button{border-radius:3px}.jupyter-wrapper .bp3-control-group>.bp3-fill{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto}.jupyter-wrapper .bp3-control-group.bp3-fill>*:not(.bp3-fixed){-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto}.jupyter-wrapper .bp3-control-group.bp3-vertical{-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column}.jupyter-wrapper .bp3-control-group.bp3-vertical>*{margin-top:-1px}.jupyter-wrapper .bp3-control-group.bp3-vertical>:first-child{margin-top:0;border-radius:3px 3px 0 0}.jupyter-wrapper .bp3-control-group.bp3-vertical>:last-child{border-radius:0 0 3px 3px}.jupyter-wrapper .bp3-control{display:block;position:relative;margin-bottom:10px;cursor:pointer;text-transform:none}.jupyter-wrapper .bp3-control input:checked~.bp3-control-indicator{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#137cbd;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.1)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.1), rgba(255, 255, 255, 0));color:#fff}.jupyter-wrapper .bp3-control:hover input:checked~.bp3-control-indicator{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#106ba3}.jupyter-wrapper .bp3-control input:not(:disabled):active:checked~.bp3-control-indicator{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background:#0e5a8a}.jupyter-wrapper .bp3-control input:disabled:checked~.bp3-control-indicator{-webkit-box-shadow:none;box-shadow:none;background:rgba(19,124,189,.5)}.jupyter-wrapper .bp3-dark .bp3-control input:checked~.bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-control:hover input:checked~.bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#106ba3}.jupyter-wrapper .bp3-dark .bp3-control input:not(:disabled):active:checked~.bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background-color:#0e5a8a}.jupyter-wrapper .bp3-dark .bp3-control input:disabled:checked~.bp3-control-indicator{-webkit-box-shadow:none;box-shadow:none;background:rgba(14,90,138,.5)}.jupyter-wrapper .bp3-control:not(.bp3-align-right){padding-left:26px}.jupyter-wrapper .bp3-control:not(.bp3-align-right) .bp3-control-indicator{margin-left:-26px}.jupyter-wrapper .bp3-control.bp3-align-right{padding-right:26px}.jupyter-wrapper .bp3-control.bp3-align-right .bp3-control-indicator{margin-right:-26px}.jupyter-wrapper .bp3-control.bp3-disabled{cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-control.bp3-inline{display:inline-block;margin-right:20px}.jupyter-wrapper .bp3-control input{position:absolute;top:0;left:0;opacity:0;z-index:-1}.jupyter-wrapper .bp3-control .bp3-control-indicator{display:inline-block;position:relative;margin-top:-3px;margin-right:10px;border:none;-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-clip:padding-box;background-color:#f5f8fa;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.8)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.8), rgba(255, 255, 255, 0));cursor:pointer;width:1em;height:1em;vertical-align:middle;font-size:16px;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-control .bp3-control-indicator::before{display:block;width:1em;height:1em;content:\"\"}.jupyter-wrapper .bp3-control:hover .bp3-control-indicator{background-color:#ebf1f5}.jupyter-wrapper .bp3-control input:not(:disabled):active~.bp3-control-indicator{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);background:#d8e1e8}.jupyter-wrapper .bp3-control input:disabled~.bp3-control-indicator{-webkit-box-shadow:none;box-shadow:none;background:rgba(206,217,224,.5);cursor:not-allowed}.jupyter-wrapper .bp3-control input:focus~.bp3-control-indicator{outline:rgba(19,124,189,.6) auto 2px;outline-offset:2px;-moz-outline-radius:6px}.jupyter-wrapper .bp3-control.bp3-align-right .bp3-control-indicator{float:right;margin-top:1px;margin-left:10px}.jupyter-wrapper .bp3-control.bp3-large{font-size:16px}.jupyter-wrapper .bp3-control.bp3-large:not(.bp3-align-right){padding-left:30px}.jupyter-wrapper .bp3-control.bp3-large:not(.bp3-align-right) .bp3-control-indicator{margin-left:-30px}.jupyter-wrapper .bp3-control.bp3-large.bp3-align-right{padding-right:30px}.jupyter-wrapper .bp3-control.bp3-large.bp3-align-right .bp3-control-indicator{margin-right:-30px}.jupyter-wrapper .bp3-control.bp3-large .bp3-control-indicator{font-size:20px}.jupyter-wrapper .bp3-control.bp3-large.bp3-align-right .bp3-control-indicator{margin-top:0}.jupyter-wrapper .bp3-control.bp3-checkbox input:indeterminate~.bp3-control-indicator{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#137cbd;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.1)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.1), rgba(255, 255, 255, 0));color:#fff}.jupyter-wrapper .bp3-control.bp3-checkbox:hover input:indeterminate~.bp3-control-indicator{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 -1px 0 rgba(16,22,26,.2);background-color:#106ba3}.jupyter-wrapper .bp3-control.bp3-checkbox input:not(:disabled):active:indeterminate~.bp3-control-indicator{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background:#0e5a8a}.jupyter-wrapper .bp3-control.bp3-checkbox input:disabled:indeterminate~.bp3-control-indicator{-webkit-box-shadow:none;box-shadow:none;background:rgba(19,124,189,.5)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-checkbox input:indeterminate~.bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-checkbox:hover input:indeterminate~.bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#106ba3}.jupyter-wrapper .bp3-dark .bp3-control.bp3-checkbox input:not(:disabled):active:indeterminate~.bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.4),inset 0 1px 2px rgba(16,22,26,.2);background-color:#0e5a8a}.jupyter-wrapper .bp3-dark .bp3-control.bp3-checkbox input:disabled:indeterminate~.bp3-control-indicator{-webkit-box-shadow:none;box-shadow:none;background:rgba(14,90,138,.5)}.jupyter-wrapper .bp3-control.bp3-checkbox .bp3-control-indicator{border-radius:3px}.jupyter-wrapper .bp3-control.bp3-checkbox input:checked~.bp3-control-indicator::before{background-image:url(\"data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16'%3e%3cpath fill-rule='evenodd' clip-rule='evenodd' d='M12 5c-.28 0-.53.11-.71.29L7 9.59l-2.29-2.3a1.003 1.003 0 0 0-1.42 1.42l3 3c.18.18.43.29.71.29s.53-.11.71-.29l5-5A1.003 1.003 0 0 0 12 5z' fill='white'/%3e%3c/svg%3e\")}.jupyter-wrapper .bp3-control.bp3-checkbox input:indeterminate~.bp3-control-indicator::before{background-image:url(\"data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16'%3e%3cpath fill-rule='evenodd' clip-rule='evenodd' d='M11 7H5c-.55 0-1 .45-1 1s.45 1 1 1h6c.55 0 1-.45 1-1s-.45-1-1-1z' fill='white'/%3e%3c/svg%3e\")}.jupyter-wrapper .bp3-control.bp3-radio .bp3-control-indicator{border-radius:50%}.jupyter-wrapper .bp3-control.bp3-radio input:checked~.bp3-control-indicator::before{background-image:radial-gradient(#ffffff, #ffffff 28%, transparent 32%)}.jupyter-wrapper .bp3-control.bp3-radio input:checked:disabled~.bp3-control-indicator::before{opacity:.5}.jupyter-wrapper .bp3-control.bp3-radio input:focus~.bp3-control-indicator{-moz-outline-radius:16px}.jupyter-wrapper .bp3-control.bp3-switch input~.bp3-control-indicator{background:rgba(167,182,194,.5)}.jupyter-wrapper .bp3-control.bp3-switch:hover input~.bp3-control-indicator{background:rgba(115,134,148,.5)}.jupyter-wrapper .bp3-control.bp3-switch input:not(:disabled):active~.bp3-control-indicator{background:rgba(92,112,128,.5)}.jupyter-wrapper .bp3-control.bp3-switch input:disabled~.bp3-control-indicator{background:rgba(206,217,224,.5)}.jupyter-wrapper .bp3-control.bp3-switch input:disabled~.bp3-control-indicator::before{background:rgba(255,255,255,.8)}.jupyter-wrapper .bp3-control.bp3-switch input:checked~.bp3-control-indicator{background:#137cbd}.jupyter-wrapper .bp3-control.bp3-switch:hover input:checked~.bp3-control-indicator{background:#106ba3}.jupyter-wrapper .bp3-control.bp3-switch input:checked:not(:disabled):active~.bp3-control-indicator{background:#0e5a8a}.jupyter-wrapper .bp3-control.bp3-switch input:checked:disabled~.bp3-control-indicator{background:rgba(19,124,189,.5)}.jupyter-wrapper .bp3-control.bp3-switch input:checked:disabled~.bp3-control-indicator::before{background:rgba(255,255,255,.8)}.jupyter-wrapper .bp3-control.bp3-switch:not(.bp3-align-right){padding-left:38px}.jupyter-wrapper .bp3-control.bp3-switch:not(.bp3-align-right) .bp3-control-indicator{margin-left:-38px}.jupyter-wrapper .bp3-control.bp3-switch.bp3-align-right{padding-right:38px}.jupyter-wrapper .bp3-control.bp3-switch.bp3-align-right .bp3-control-indicator{margin-right:-38px}.jupyter-wrapper .bp3-control.bp3-switch .bp3-control-indicator{border:none;border-radius:1.75em;-webkit-box-shadow:none !important;box-shadow:none !important;width:auto;min-width:1.75em;-webkit-transition:background-color 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:background-color 100ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-control.bp3-switch .bp3-control-indicator::before{position:absolute;left:0;margin:2px;border-radius:50%;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.2);background:#fff;width:calc(1em - 4px);height:calc(1em - 4px);-webkit-transition:left 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:left 100ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-control.bp3-switch input:checked~.bp3-control-indicator::before{left:calc(100% - 1em)}.jupyter-wrapper .bp3-control.bp3-switch.bp3-large:not(.bp3-align-right){padding-left:45px}.jupyter-wrapper .bp3-control.bp3-switch.bp3-large:not(.bp3-align-right) .bp3-control-indicator{margin-left:-45px}.jupyter-wrapper .bp3-control.bp3-switch.bp3-large.bp3-align-right{padding-right:45px}.jupyter-wrapper .bp3-control.bp3-switch.bp3-large.bp3-align-right .bp3-control-indicator{margin-right:-45px}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input~.bp3-control-indicator{background:rgba(16,22,26,.5)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch:hover input~.bp3-control-indicator{background:rgba(16,22,26,.7)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:not(:disabled):active~.bp3-control-indicator{background:rgba(16,22,26,.9)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:disabled~.bp3-control-indicator{background:rgba(57,75,89,.5)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:disabled~.bp3-control-indicator::before{background:rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:checked~.bp3-control-indicator{background:#137cbd}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch:hover input:checked~.bp3-control-indicator{background:#106ba3}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:checked:not(:disabled):active~.bp3-control-indicator{background:#0e5a8a}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:checked:disabled~.bp3-control-indicator{background:rgba(14,90,138,.5)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:checked:disabled~.bp3-control-indicator::before{background:rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch .bp3-control-indicator::before{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background:#394b59}.jupyter-wrapper .bp3-dark .bp3-control.bp3-switch input:checked~.bp3-control-indicator::before{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-control.bp3-switch .bp3-switch-inner-text{text-align:center;font-size:.7em}.jupyter-wrapper .bp3-control.bp3-switch .bp3-control-indicator-child:first-child{visibility:hidden;margin-right:1.2em;margin-left:.5em;line-height:0}.jupyter-wrapper .bp3-control.bp3-switch .bp3-control-indicator-child:last-child{visibility:visible;margin-right:.5em;margin-left:1.2em;line-height:1em}.jupyter-wrapper .bp3-control.bp3-switch input:checked~.bp3-control-indicator .bp3-control-indicator-child:first-child{visibility:visible;line-height:1em}.jupyter-wrapper .bp3-control.bp3-switch input:checked~.bp3-control-indicator .bp3-control-indicator-child:last-child{visibility:hidden;line-height:0}.jupyter-wrapper .bp3-dark .bp3-control{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-control.bp3-disabled{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-control .bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#394b59;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.05)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.05), rgba(255, 255, 255, 0))}.jupyter-wrapper .bp3-dark .bp3-control:hover .bp3-control-indicator{background-color:#30404d}.jupyter-wrapper .bp3-dark .bp3-control input:not(:disabled):active~.bp3-control-indicator{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);background:#202b33}.jupyter-wrapper .bp3-dark .bp3-control input:disabled~.bp3-control-indicator{-webkit-box-shadow:none;box-shadow:none;background:rgba(57,75,89,.5);cursor:not-allowed}.jupyter-wrapper .bp3-dark .bp3-control.bp3-checkbox input:disabled:checked~.bp3-control-indicator,.jupyter-wrapper .bp3-dark .bp3-control.bp3-checkbox input:disabled:indeterminate~.bp3-control-indicator{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-file-input{display:inline-block;position:relative;cursor:pointer;height:30px}.jupyter-wrapper .bp3-file-input input{opacity:0;margin:0;min-width:200px}.jupyter-wrapper .bp3-file-input input:disabled+.bp3-file-upload-input,.jupyter-wrapper .bp3-file-input input.bp3-disabled+.bp3-file-upload-input{-webkit-box-shadow:none;box-shadow:none;background:rgba(206,217,224,.5);cursor:not-allowed;color:rgba(92,112,128,.6);resize:none}.jupyter-wrapper .bp3-file-input input:disabled+.bp3-file-upload-input::after,.jupyter-wrapper .bp3-file-input input.bp3-disabled+.bp3-file-upload-input::after{outline:none;-webkit-box-shadow:none;box-shadow:none;background-color:rgba(206,217,224,.5);background-image:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-file-input input:disabled+.bp3-file-upload-input::after.bp3-active,.jupyter-wrapper .bp3-file-input input:disabled+.bp3-file-upload-input::after.bp3-active:hover,.jupyter-wrapper .bp3-file-input input.bp3-disabled+.bp3-file-upload-input::after.bp3-active,.jupyter-wrapper .bp3-file-input input.bp3-disabled+.bp3-file-upload-input::after.bp3-active:hover{background:rgba(206,217,224,.7)}.jupyter-wrapper .bp3-dark .bp3-file-input input:disabled+.bp3-file-upload-input,.jupyter-wrapper .bp3-dark .bp3-file-input input.bp3-disabled+.bp3-file-upload-input{-webkit-box-shadow:none;box-shadow:none;background:rgba(57,75,89,.5);color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-input input:disabled+.bp3-file-upload-input::after,.jupyter-wrapper .bp3-dark .bp3-file-input input.bp3-disabled+.bp3-file-upload-input::after{-webkit-box-shadow:none;box-shadow:none;background-color:rgba(57,75,89,.5);background-image:none;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-input input:disabled+.bp3-file-upload-input::after.bp3-active,.jupyter-wrapper .bp3-dark .bp3-file-input input.bp3-disabled+.bp3-file-upload-input::after.bp3-active{background:rgba(57,75,89,.7)}.jupyter-wrapper .bp3-file-input.bp3-file-input-has-selection .bp3-file-upload-input{color:#182026}.jupyter-wrapper .bp3-dark .bp3-file-input.bp3-file-input-has-selection .bp3-file-upload-input{color:#f5f8fa}.jupyter-wrapper .bp3-file-input.bp3-fill{width:100%}.jupyter-wrapper .bp3-file-input.bp3-large,.jupyter-wrapper .bp3-large .bp3-file-input{height:40px}.jupyter-wrapper .bp3-file-input .bp3-file-upload-input-custom-text::after{content:attr(bp3-button-text)}.jupyter-wrapper .bp3-file-upload-input{outline:none;border:none;border-radius:3px;-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);background:#fff;height:30px;padding:0 10px;vertical-align:middle;line-height:30px;color:#182026;font-size:14px;font-weight:400;-webkit-transition:-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-appearance:none;-moz-appearance:none;appearance:none;overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal;position:absolute;top:0;right:0;left:0;padding-right:80px;color:rgba(92,112,128,.6);-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-file-upload-input::-webkit-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-file-upload-input::-moz-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-file-upload-input:-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-file-upload-input::-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-file-upload-input::placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-file-upload-input:focus,.jupyter-wrapper .bp3-file-upload-input.bp3-active{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-file-upload-input[type=search],.jupyter-wrapper .bp3-file-upload-input.bp3-round{border-radius:30px;-webkit-box-sizing:border-box;box-sizing:border-box;padding-left:10px}.jupyter-wrapper .bp3-file-upload-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.15);box-shadow:inset 0 0 0 1px rgba(16,22,26,.15)}.jupyter-wrapper .bp3-file-upload-input:disabled,.jupyter-wrapper .bp3-file-upload-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background:rgba(206,217,224,.5);cursor:not-allowed;color:rgba(92,112,128,.6);resize:none}.jupyter-wrapper .bp3-file-upload-input::after{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-color:#f5f8fa;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.8)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.8), rgba(255, 255, 255, 0));color:#182026;min-width:24px;min-height:24px;overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal;position:absolute;top:0;right:0;margin:3px;border-radius:3px;width:70px;text-align:center;line-height:24px;content:\"Browse\"}.jupyter-wrapper .bp3-file-upload-input::after:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-clip:padding-box;background-color:#ebf1f5}.jupyter-wrapper .bp3-file-upload-input::after:active,.jupyter-wrapper .bp3-file-upload-input::after.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);background-color:#d8e1e8;background-image:none}.jupyter-wrapper .bp3-file-upload-input::after:disabled,.jupyter-wrapper .bp3-file-upload-input::after.bp3-disabled{outline:none;-webkit-box-shadow:none;box-shadow:none;background-color:rgba(206,217,224,.5);background-image:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-file-upload-input::after:disabled.bp3-active,.jupyter-wrapper .bp3-file-upload-input::after:disabled.bp3-active:hover,.jupyter-wrapper .bp3-file-upload-input::after.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-file-upload-input::after.bp3-disabled.bp3-active:hover{background:rgba(206,217,224,.7)}.jupyter-wrapper .bp3-file-upload-input:hover::after{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-clip:padding-box;background-color:#ebf1f5}.jupyter-wrapper .bp3-file-upload-input:active::after{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);background-color:#d8e1e8;background-image:none}.jupyter-wrapper .bp3-large .bp3-file-upload-input{height:40px;line-height:40px;font-size:16px;padding-right:95px}.jupyter-wrapper .bp3-large .bp3-file-upload-input[type=search],.jupyter-wrapper .bp3-large .bp3-file-upload-input.bp3-round{padding:0 15px}.jupyter-wrapper .bp3-large .bp3-file-upload-input::after{min-width:30px;min-height:30px;margin:5px;width:85px;line-height:30px}.jupyter-wrapper .bp3-dark .bp3-file-upload-input{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);background:rgba(16,22,26,.3);color:#f5f8fa;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::-webkit-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::-moz-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input:-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input:focus{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input:disabled,.jupyter-wrapper .bp3-dark .bp3-file-upload-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background:rgba(57,75,89,.5);color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#394b59;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.05)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.05), rgba(255, 255, 255, 0));color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after:hover,.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after:active,.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after.bp3-active{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after:hover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#30404d}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after:active,.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after.bp3-active{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);background-color:#202b33;background-image:none}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after:disabled,.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background-color:rgba(57,75,89,.5);background-image:none;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after.bp3-disabled.bp3-active{background:rgba(57,75,89,.7)}.jupyter-wrapper .bp3-dark .bp3-file-upload-input::after .bp3-button-spinner .bp3-spinner-head{background:rgba(16,22,26,.5);stroke:#8a9ba8}.jupyter-wrapper .bp3-dark .bp3-file-upload-input:hover::after{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#30404d}.jupyter-wrapper .bp3-dark .bp3-file-upload-input:active::after{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);background-color:#202b33;background-image:none}.jupyter-wrapper .bp3-file-upload-input::after{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1)}.jupyter-wrapper .bp3-form-group{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;margin:0 0 15px}.jupyter-wrapper .bp3-form-group label.bp3-label{margin-bottom:5px}.jupyter-wrapper .bp3-form-group .bp3-control{margin-top:7px}.jupyter-wrapper .bp3-form-group .bp3-form-helper-text{margin-top:5px;color:#5c7080;font-size:12px}.jupyter-wrapper .bp3-form-group.bp3-intent-primary .bp3-form-helper-text{color:#106ba3}.jupyter-wrapper .bp3-form-group.bp3-intent-success .bp3-form-helper-text{color:#0d8050}.jupyter-wrapper .bp3-form-group.bp3-intent-warning .bp3-form-helper-text{color:#bf7326}.jupyter-wrapper .bp3-form-group.bp3-intent-danger .bp3-form-helper-text{color:#c23030}.jupyter-wrapper .bp3-form-group.bp3-inline{-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:start;-ms-flex-align:start;align-items:flex-start}.jupyter-wrapper .bp3-form-group.bp3-inline.bp3-large label.bp3-label{margin:0 10px 0 0;line-height:40px}.jupyter-wrapper .bp3-form-group.bp3-inline label.bp3-label{margin:0 10px 0 0;line-height:30px}.jupyter-wrapper .bp3-form-group.bp3-disabled .bp3-label,.jupyter-wrapper .bp3-form-group.bp3-disabled .bp3-text-muted,.jupyter-wrapper .bp3-form-group.bp3-disabled .bp3-form-helper-text{color:rgba(92,112,128,.6) !important}.jupyter-wrapper .bp3-dark .bp3-form-group.bp3-intent-primary .bp3-form-helper-text{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-form-group.bp3-intent-success .bp3-form-helper-text{color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-form-group.bp3-intent-warning .bp3-form-helper-text{color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-form-group.bp3-intent-danger .bp3-form-helper-text{color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-form-group .bp3-form-helper-text{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-form-group.bp3-disabled .bp3-label,.jupyter-wrapper .bp3-dark .bp3-form-group.bp3-disabled .bp3-text-muted,.jupyter-wrapper .bp3-dark .bp3-form-group.bp3-disabled .bp3-form-helper-text{color:rgba(167,182,194,.6) !important}.jupyter-wrapper .bp3-input-group{display:block;position:relative}.jupyter-wrapper .bp3-input-group .bp3-input{position:relative;width:100%}.jupyter-wrapper .bp3-input-group .bp3-input:not(:first-child){padding-left:30px}.jupyter-wrapper .bp3-input-group .bp3-input:not(:last-child){padding-right:30px}.jupyter-wrapper .bp3-input-group .bp3-input-action,.jupyter-wrapper .bp3-input-group>.bp3-button,.jupyter-wrapper .bp3-input-group>.bp3-icon{position:absolute;top:0}.jupyter-wrapper .bp3-input-group .bp3-input-action:first-child,.jupyter-wrapper .bp3-input-group>.bp3-button:first-child,.jupyter-wrapper .bp3-input-group>.bp3-icon:first-child{left:0}.jupyter-wrapper .bp3-input-group .bp3-input-action:last-child,.jupyter-wrapper .bp3-input-group>.bp3-button:last-child,.jupyter-wrapper .bp3-input-group>.bp3-icon:last-child{right:0}.jupyter-wrapper .bp3-input-group .bp3-button{min-width:24px;min-height:24px;margin:3px;padding:0 7px}.jupyter-wrapper .bp3-input-group .bp3-button:empty{padding:0}.jupyter-wrapper .bp3-input-group>.bp3-icon{z-index:1;color:#5c7080}.jupyter-wrapper .bp3-input-group>.bp3-icon:empty{line-height:1;font-family:\"Icons16\",sans-serif;font-size:16px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased}.jupyter-wrapper .bp3-input-group>.bp3-icon,.jupyter-wrapper .bp3-input-group .bp3-input-action>.bp3-spinner{margin:7px}.jupyter-wrapper .bp3-input-group .bp3-tag{margin:5px}.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:not(:hover):not(:focus),.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:not(:hover):not(:focus){color:#5c7080}.jupyter-wrapper .bp3-dark .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:not(:hover):not(:focus),.jupyter-wrapper .bp3-dark .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:not(:hover):not(:focus){color:#a7b6c2}.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:not(:hover):not(:focus) .bp3-icon,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:not(:hover):not(:focus) .bp3-icon-standard,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:not(:hover):not(:focus) .bp3-icon-large,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:not(:hover):not(:focus) .bp3-icon,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:not(:hover):not(:focus) .bp3-icon-standard,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:not(:hover):not(:focus) .bp3-icon-large{color:#5c7080}.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:disabled,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:disabled{color:rgba(92,112,128,.6) !important}.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:disabled .bp3-icon,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:disabled .bp3-icon-standard,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-button.bp3-minimal:disabled .bp3-icon-large,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:disabled .bp3-icon,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:disabled .bp3-icon-standard,.jupyter-wrapper .bp3-input-group .bp3-input:not(:focus)+.bp3-input-action .bp3-button.bp3-minimal:disabled .bp3-icon-large{color:rgba(92,112,128,.6) !important}.jupyter-wrapper .bp3-input-group.bp3-disabled{cursor:not-allowed}.jupyter-wrapper .bp3-input-group.bp3-disabled .bp3-icon{color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input-group.bp3-large .bp3-button{min-width:30px;min-height:30px;margin:5px}.jupyter-wrapper .bp3-input-group.bp3-large>.bp3-icon,.jupyter-wrapper .bp3-input-group.bp3-large .bp3-input-action>.bp3-spinner{margin:12px}.jupyter-wrapper .bp3-input-group.bp3-large .bp3-input{height:40px;line-height:40px;font-size:16px}.jupyter-wrapper .bp3-input-group.bp3-large .bp3-input[type=search],.jupyter-wrapper .bp3-input-group.bp3-large .bp3-input.bp3-round{padding:0 15px}.jupyter-wrapper .bp3-input-group.bp3-large .bp3-input:not(:first-child){padding-left:40px}.jupyter-wrapper .bp3-input-group.bp3-large .bp3-input:not(:last-child){padding-right:40px}.jupyter-wrapper .bp3-input-group.bp3-small .bp3-button{min-width:20px;min-height:20px;margin:2px}.jupyter-wrapper .bp3-input-group.bp3-small .bp3-tag{min-width:20px;min-height:20px;margin:2px}.jupyter-wrapper .bp3-input-group.bp3-small>.bp3-icon,.jupyter-wrapper .bp3-input-group.bp3-small .bp3-input-action>.bp3-spinner{margin:4px}.jupyter-wrapper .bp3-input-group.bp3-small .bp3-input{height:24px;padding-right:8px;padding-left:8px;line-height:24px;font-size:12px}.jupyter-wrapper .bp3-input-group.bp3-small .bp3-input[type=search],.jupyter-wrapper .bp3-input-group.bp3-small .bp3-input.bp3-round{padding:0 12px}.jupyter-wrapper .bp3-input-group.bp3-small .bp3-input:not(:first-child){padding-left:24px}.jupyter-wrapper .bp3-input-group.bp3-small .bp3-input:not(:last-child){padding-right:24px}.jupyter-wrapper .bp3-input-group.bp3-fill{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;width:100%}.jupyter-wrapper .bp3-input-group.bp3-round .bp3-button,.jupyter-wrapper .bp3-input-group.bp3-round .bp3-input,.jupyter-wrapper .bp3-input-group.bp3-round .bp3-tag{border-radius:30px}.jupyter-wrapper .bp3-dark .bp3-input-group .bp3-icon{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-input-group.bp3-disabled .bp3-icon{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-input-group.bp3-intent-primary .bp3-input{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px #137cbd,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px #137cbd,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-primary .bp3-input:focus{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-primary .bp3-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px #137cbd;box-shadow:inset 0 0 0 1px #137cbd}.jupyter-wrapper .bp3-input-group.bp3-intent-primary .bp3-input:disabled,.jupyter-wrapper .bp3-input-group.bp3-intent-primary .bp3-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input-group.bp3-intent-primary>.bp3-icon{color:#106ba3}.jupyter-wrapper .bp3-dark .bp3-input-group.bp3-intent-primary>.bp3-icon{color:#48aff0}.jupyter-wrapper .bp3-input-group.bp3-intent-success .bp3-input{-webkit-box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px #0f9960,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px #0f9960,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-success .bp3-input:focus{-webkit-box-shadow:0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-success .bp3-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px #0f9960;box-shadow:inset 0 0 0 1px #0f9960}.jupyter-wrapper .bp3-input-group.bp3-intent-success .bp3-input:disabled,.jupyter-wrapper .bp3-input-group.bp3-intent-success .bp3-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input-group.bp3-intent-success>.bp3-icon{color:#0d8050}.jupyter-wrapper .bp3-dark .bp3-input-group.bp3-intent-success>.bp3-icon{color:#3dcc91}.jupyter-wrapper .bp3-input-group.bp3-intent-warning .bp3-input{-webkit-box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px #d9822b,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px #d9822b,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-warning .bp3-input:focus{-webkit-box-shadow:0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-warning .bp3-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px #d9822b;box-shadow:inset 0 0 0 1px #d9822b}.jupyter-wrapper .bp3-input-group.bp3-intent-warning .bp3-input:disabled,.jupyter-wrapper .bp3-input-group.bp3-intent-warning .bp3-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input-group.bp3-intent-warning>.bp3-icon{color:#bf7326}.jupyter-wrapper .bp3-dark .bp3-input-group.bp3-intent-warning>.bp3-icon{color:#ffb366}.jupyter-wrapper .bp3-input-group.bp3-intent-danger .bp3-input{-webkit-box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px #db3737,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px #db3737,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-danger .bp3-input:focus{-webkit-box-shadow:0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input-group.bp3-intent-danger .bp3-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px #db3737;box-shadow:inset 0 0 0 1px #db3737}.jupyter-wrapper .bp3-input-group.bp3-intent-danger .bp3-input:disabled,.jupyter-wrapper .bp3-input-group.bp3-intent-danger .bp3-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input-group.bp3-intent-danger>.bp3-icon{color:#c23030}.jupyter-wrapper .bp3-dark .bp3-input-group.bp3-intent-danger>.bp3-icon{color:#ff7373}.jupyter-wrapper .bp3-input{outline:none;border:none;border-radius:3px;-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);background:#fff;height:30px;padding:0 10px;vertical-align:middle;line-height:30px;color:#182026;font-size:14px;font-weight:400;-webkit-transition:-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-box-shadow 100ms cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-appearance:none;-moz-appearance:none;appearance:none}.jupyter-wrapper .bp3-input::-webkit-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input::-moz-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input:-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input::-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input::placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input:focus,.jupyter-wrapper .bp3-input.bp3-active{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input[type=search],.jupyter-wrapper .bp3-input.bp3-round{border-radius:30px;-webkit-box-sizing:border-box;box-sizing:border-box;padding-left:10px}.jupyter-wrapper .bp3-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.15);box-shadow:inset 0 0 0 1px rgba(16,22,26,.15)}.jupyter-wrapper .bp3-input:disabled,.jupyter-wrapper .bp3-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background:rgba(206,217,224,.5);cursor:not-allowed;color:rgba(92,112,128,.6);resize:none}.jupyter-wrapper .bp3-input.bp3-large{height:40px;line-height:40px;font-size:16px}.jupyter-wrapper .bp3-input.bp3-large[type=search],.jupyter-wrapper .bp3-input.bp3-large.bp3-round{padding:0 15px}.jupyter-wrapper .bp3-input.bp3-small{height:24px;padding-right:8px;padding-left:8px;line-height:24px;font-size:12px}.jupyter-wrapper .bp3-input.bp3-small[type=search],.jupyter-wrapper .bp3-input.bp3-small.bp3-round{padding:0 12px}.jupyter-wrapper .bp3-input.bp3-fill{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;width:100%}.jupyter-wrapper .bp3-dark .bp3-input{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);background:rgba(16,22,26,.3);color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-input::-webkit-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-input::-moz-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-input:-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-input::-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-input::placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-input:focus{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input:disabled,.jupyter-wrapper .bp3-dark .bp3-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background:rgba(57,75,89,.5);color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-input.bp3-intent-primary{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px #137cbd,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px #137cbd,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-primary:focus{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-primary[readonly]{-webkit-box-shadow:inset 0 0 0 1px #137cbd;box-shadow:inset 0 0 0 1px #137cbd}.jupyter-wrapper .bp3-input.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-input.bp3-intent-primary.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-primary{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px #137cbd,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px #137cbd,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-primary:focus{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-primary[readonly]{-webkit-box-shadow:inset 0 0 0 1px #137cbd;box-shadow:inset 0 0 0 1px #137cbd}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-primary.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input.bp3-intent-success{-webkit-box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px #0f9960,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px #0f9960,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-success:focus{-webkit-box-shadow:0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-success[readonly]{-webkit-box-shadow:inset 0 0 0 1px #0f9960;box-shadow:inset 0 0 0 1px #0f9960}.jupyter-wrapper .bp3-input.bp3-intent-success:disabled,.jupyter-wrapper .bp3-input.bp3-intent-success.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-success{-webkit-box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px #0f9960,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),0 0 0 0 rgba(15,153,96,0),inset 0 0 0 1px #0f9960,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-success:focus{-webkit-box-shadow:0 0 0 1px #0f9960,0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #0f9960,0 0 0 1px #0f9960,0 0 0 3px rgba(15,153,96,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-success[readonly]{-webkit-box-shadow:inset 0 0 0 1px #0f9960;box-shadow:inset 0 0 0 1px #0f9960}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-success:disabled,.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-success.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input.bp3-intent-warning{-webkit-box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px #d9822b,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px #d9822b,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-warning:focus{-webkit-box-shadow:0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-warning[readonly]{-webkit-box-shadow:inset 0 0 0 1px #d9822b;box-shadow:inset 0 0 0 1px #d9822b}.jupyter-wrapper .bp3-input.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-input.bp3-intent-warning.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-warning{-webkit-box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px #d9822b,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),0 0 0 0 rgba(217,130,43,0),inset 0 0 0 1px #d9822b,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-warning:focus{-webkit-box-shadow:0 0 0 1px #d9822b,0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #d9822b,0 0 0 1px #d9822b,0 0 0 3px rgba(217,130,43,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-warning[readonly]{-webkit-box-shadow:inset 0 0 0 1px #d9822b;box-shadow:inset 0 0 0 1px #d9822b}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-warning.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input.bp3-intent-danger{-webkit-box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px #db3737,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px #db3737,inset 0 0 0 1px rgba(16,22,26,.15),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-danger:focus{-webkit-box-shadow:0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-input.bp3-intent-danger[readonly]{-webkit-box-shadow:inset 0 0 0 1px #db3737;box-shadow:inset 0 0 0 1px #db3737}.jupyter-wrapper .bp3-input.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-input.bp3-intent-danger.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-danger{-webkit-box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px #db3737,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),0 0 0 0 rgba(219,55,55,0),inset 0 0 0 1px #db3737,inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-danger:focus{-webkit-box-shadow:0 0 0 1px #db3737,0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #db3737,0 0 0 1px #db3737,0 0 0 3px rgba(219,55,55,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-danger[readonly]{-webkit-box-shadow:inset 0 0 0 1px #db3737;box-shadow:inset 0 0 0 1px #db3737}.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-dark .bp3-input.bp3-intent-danger.bp3-disabled{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-input::-ms-clear{display:none}.jupyter-wrapper textarea.bp3-input{max-width:100%;padding:10px}.jupyter-wrapper textarea.bp3-input,.jupyter-wrapper textarea.bp3-input.bp3-large,.jupyter-wrapper textarea.bp3-input.bp3-small{height:auto;line-height:inherit}.jupyter-wrapper textarea.bp3-input.bp3-small{padding:8px}.jupyter-wrapper .bp3-dark textarea.bp3-input{-webkit-box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),0 0 0 0 rgba(19,124,189,0),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);background:rgba(16,22,26,.3);color:#f5f8fa}.jupyter-wrapper .bp3-dark textarea.bp3-input::-webkit-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark textarea.bp3-input::-moz-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark textarea.bp3-input:-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark textarea.bp3-input::-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark textarea.bp3-input::placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark textarea.bp3-input:focus{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark textarea.bp3-input[readonly]{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.4);box-shadow:inset 0 0 0 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark textarea.bp3-input:disabled,.jupyter-wrapper .bp3-dark textarea.bp3-input.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background:rgba(57,75,89,.5);color:rgba(167,182,194,.6)}.jupyter-wrapper label.bp3-label{display:block;margin-top:0;margin-bottom:15px}.jupyter-wrapper label.bp3-label .bp3-html-select,.jupyter-wrapper label.bp3-label .bp3-input,.jupyter-wrapper label.bp3-label .bp3-select,.jupyter-wrapper label.bp3-label .bp3-slider,.jupyter-wrapper label.bp3-label .bp3-popover-wrapper{display:block;margin-top:5px;text-transform:none}.jupyter-wrapper label.bp3-label .bp3-button-group{margin-top:5px}.jupyter-wrapper label.bp3-label .bp3-select select,.jupyter-wrapper label.bp3-label .bp3-html-select select{width:100%;vertical-align:top;font-weight:400}.jupyter-wrapper label.bp3-label.bp3-disabled,.jupyter-wrapper label.bp3-label.bp3-disabled .bp3-text-muted{color:rgba(92,112,128,.6)}.jupyter-wrapper label.bp3-label.bp3-inline{line-height:30px}.jupyter-wrapper label.bp3-label.bp3-inline .bp3-html-select,.jupyter-wrapper label.bp3-label.bp3-inline .bp3-input,.jupyter-wrapper label.bp3-label.bp3-inline .bp3-input-group,.jupyter-wrapper label.bp3-label.bp3-inline .bp3-select,.jupyter-wrapper label.bp3-label.bp3-inline .bp3-popover-wrapper{display:inline-block;margin:0 0 0 5px;vertical-align:top}.jupyter-wrapper label.bp3-label.bp3-inline .bp3-button-group{margin:0 0 0 5px}.jupyter-wrapper label.bp3-label.bp3-inline .bp3-input-group .bp3-input{margin-left:0}.jupyter-wrapper label.bp3-label.bp3-inline.bp3-large{line-height:40px}.jupyter-wrapper label.bp3-label:not(.bp3-inline) .bp3-popover-target{display:block}.jupyter-wrapper .bp3-dark label.bp3-label{color:#f5f8fa}.jupyter-wrapper .bp3-dark label.bp3-label.bp3-disabled,.jupyter-wrapper .bp3-dark label.bp3-label.bp3-disabled .bp3-text-muted{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-numeric-input .bp3-button-group.bp3-vertical>.bp3-button{-webkit-box-flex:1;-ms-flex:1 1 14px;flex:1 1 14px;width:30px;min-height:0;padding:0}.jupyter-wrapper .bp3-numeric-input .bp3-button-group.bp3-vertical>.bp3-button:first-child{border-radius:0 3px 0 0}.jupyter-wrapper .bp3-numeric-input .bp3-button-group.bp3-vertical>.bp3-button:last-child{border-radius:0 0 3px 0}.jupyter-wrapper .bp3-numeric-input .bp3-button-group.bp3-vertical:first-child>.bp3-button:first-child{border-radius:3px 0 0 0}.jupyter-wrapper .bp3-numeric-input .bp3-button-group.bp3-vertical:first-child>.bp3-button:last-child{border-radius:0 0 0 3px}.jupyter-wrapper .bp3-numeric-input.bp3-large .bp3-button-group.bp3-vertical>.bp3-button{width:40px}.jupyter-wrapper form{display:block}.jupyter-wrapper .bp3-html-select select,.jupyter-wrapper .bp3-select select{display:-webkit-inline-box;display:-ms-inline-flexbox;display:inline-flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:center;-ms-flex-pack:center;justify-content:center;border:none;border-radius:3px;cursor:pointer;padding:5px 10px;vertical-align:middle;text-align:left;font-size:14px;-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-color:#f5f8fa;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.8)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.8), rgba(255, 255, 255, 0));color:#182026;border-radius:3px;width:100%;height:30px;padding:0 25px 0 10px;-moz-appearance:none;-webkit-appearance:none}.jupyter-wrapper .bp3-html-select select>*,.jupyter-wrapper .bp3-select select>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-html-select select>.bp3-fill,.jupyter-wrapper .bp3-select select>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-html-select select::before,.jupyter-wrapper .bp3-select select::before,.jupyter-wrapper .bp3-html-select select>*,.jupyter-wrapper .bp3-select select>*{margin-right:7px}.jupyter-wrapper .bp3-html-select select:empty::before,.jupyter-wrapper .bp3-select select:empty::before,.jupyter-wrapper .bp3-html-select select>:last-child,.jupyter-wrapper .bp3-select select>:last-child{margin-right:0}.jupyter-wrapper .bp3-html-select select:hover,.jupyter-wrapper .bp3-select select:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-clip:padding-box;background-color:#ebf1f5}.jupyter-wrapper .bp3-html-select select:active,.jupyter-wrapper .bp3-select select:active,.jupyter-wrapper .bp3-html-select select.bp3-active,.jupyter-wrapper .bp3-select select.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);background-color:#d8e1e8;background-image:none}.jupyter-wrapper .bp3-html-select select:disabled,.jupyter-wrapper .bp3-select select:disabled,.jupyter-wrapper .bp3-html-select select.bp3-disabled,.jupyter-wrapper .bp3-select select.bp3-disabled{outline:none;-webkit-box-shadow:none;box-shadow:none;background-color:rgba(206,217,224,.5);background-image:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-html-select select:disabled.bp3-active,.jupyter-wrapper .bp3-select select:disabled.bp3-active,.jupyter-wrapper .bp3-html-select select:disabled.bp3-active:hover,.jupyter-wrapper .bp3-select select:disabled.bp3-active:hover,.jupyter-wrapper .bp3-html-select select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-html-select select.bp3-disabled.bp3-active:hover,.jupyter-wrapper .bp3-select select.bp3-disabled.bp3-active:hover{background:rgba(206,217,224,.7)}.jupyter-wrapper .bp3-html-select.bp3-minimal select,.jupyter-wrapper .bp3-select.bp3-minimal select{-webkit-box-shadow:none;box-shadow:none;background:none}.jupyter-wrapper .bp3-html-select.bp3-minimal select:hover,.jupyter-wrapper .bp3-select.bp3-minimal select:hover{-webkit-box-shadow:none;box-shadow:none;background:rgba(167,182,194,.3);text-decoration:none;color:#182026}.jupyter-wrapper .bp3-html-select.bp3-minimal select:active,.jupyter-wrapper .bp3-select.bp3-minimal select:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:rgba(115,134,148,.3);color:#182026}.jupyter-wrapper .bp3-html-select.bp3-minimal select:disabled,.jupyter-wrapper .bp3-select.bp3-minimal select:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal select:disabled:hover,.jupyter-wrapper .bp3-select.bp3-minimal select:disabled:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-disabled:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-disabled:hover{background:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-html-select.bp3-minimal select:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal select:disabled:hover.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select:disabled:hover.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-disabled:hover.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-disabled:hover.bp3-active{background:rgba(115,134,148,.3)}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select{-webkit-box-shadow:none;box-shadow:none;background:none;color:inherit}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:hover,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:hover{background:rgba(138,155,168,.15)}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-active{background:rgba(138,155,168,.3);color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:disabled,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:disabled:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:disabled:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:disabled:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:disabled:hover,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-disabled:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-disabled:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-disabled:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-disabled:hover{background:none;cursor:not-allowed;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select:disabled:hover.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select:disabled:hover.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select:disabled:hover.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select:disabled:hover.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-disabled:hover.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-disabled:hover.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-disabled:hover.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-disabled:hover.bp3-active{background:rgba(138,155,168,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary{color:#106ba3}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#106ba3}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary:hover{background:rgba(19,124,189,.15);color:#106ba3}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary.bp3-active{background:rgba(19,124,189,.3);color:#106ba3}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary.bp3-disabled{background:none;color:rgba(16,107,163,.5)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary.bp3-disabled.bp3-active{background:rgba(19,124,189,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-primary .bp3-button-spinner .bp3-spinner-head,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-primary .bp3-button-spinner .bp3-spinner-head{stroke:#106ba3}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary:hover{background:rgba(19,124,189,.2);color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary:active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary:active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary:active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary:active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary.bp3-active{background:rgba(19,124,189,.3);color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary:disabled,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary.bp3-disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary.bp3-disabled{background:none;color:rgba(72,175,240,.5)}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-primary.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-primary.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-primary.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-primary.bp3-disabled.bp3-active{background:rgba(19,124,189,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success{color:#0d8050}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#0d8050}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success:hover{background:rgba(15,153,96,.15);color:#0d8050}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success.bp3-active{background:rgba(15,153,96,.3);color:#0d8050}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success:disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success.bp3-disabled{background:none;color:rgba(13,128,80,.5)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success.bp3-disabled.bp3-active{background:rgba(15,153,96,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-success .bp3-button-spinner .bp3-spinner-head,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-success .bp3-button-spinner .bp3-spinner-head{stroke:#0d8050}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success{color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success:hover{background:rgba(15,153,96,.2);color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success:active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success:active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success:active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success:active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success.bp3-active{background:rgba(15,153,96,.3);color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success:disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success:disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success:disabled,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success.bp3-disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success.bp3-disabled{background:none;color:rgba(61,204,145,.5)}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-success.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-success.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-success.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-success.bp3-disabled.bp3-active{background:rgba(15,153,96,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning{color:#bf7326}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#bf7326}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning:hover{background:rgba(217,130,43,.15);color:#bf7326}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning.bp3-active{background:rgba(217,130,43,.3);color:#bf7326}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning.bp3-disabled{background:none;color:rgba(191,115,38,.5)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning.bp3-disabled.bp3-active{background:rgba(217,130,43,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-warning .bp3-button-spinner .bp3-spinner-head,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-warning .bp3-button-spinner .bp3-spinner-head{stroke:#bf7326}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning{color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning:hover{background:rgba(217,130,43,.2);color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning:active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning:active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning:active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning:active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning.bp3-active{background:rgba(217,130,43,.3);color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning:disabled,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning.bp3-disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning.bp3-disabled{background:none;color:rgba(255,179,102,.5)}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-warning.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-warning.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-warning.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-warning.bp3-disabled.bp3-active{background:rgba(217,130,43,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger{color:#c23030}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger.bp3-active{-webkit-box-shadow:none;box-shadow:none;background:none;color:#c23030}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger:hover,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger:hover{background:rgba(219,55,55,.15);color:#c23030}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger:active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger:active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger.bp3-active{background:rgba(219,55,55,.3);color:#c23030}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger.bp3-disabled{background:none;color:rgba(194,48,48,.5)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger.bp3-disabled.bp3-active{background:rgba(219,55,55,.3)}.jupyter-wrapper .bp3-html-select.bp3-minimal select.bp3-intent-danger .bp3-button-spinner .bp3-spinner-head,.jupyter-wrapper .bp3-select.bp3-minimal select.bp3-intent-danger .bp3-button-spinner .bp3-spinner-head{stroke:#c23030}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger{color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger:hover,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger:hover,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger:hover,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger:hover{background:rgba(219,55,55,.2);color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger:active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger:active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger:active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger:active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger.bp3-active{background:rgba(219,55,55,.3);color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger:disabled,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger.bp3-disabled,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger.bp3-disabled,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger.bp3-disabled{background:none;color:rgba(255,115,115,.5)}.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select.bp3-minimal select.bp3-intent-danger.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-html-select.bp3-minimal .bp3-dark select.bp3-intent-danger.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select.bp3-minimal select.bp3-intent-danger.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-select.bp3-minimal .bp3-dark select.bp3-intent-danger.bp3-disabled.bp3-active{background:rgba(219,55,55,.3)}.jupyter-wrapper .bp3-html-select.bp3-large select,.jupyter-wrapper .bp3-select.bp3-large select{height:40px;padding-right:35px;font-size:16px}.jupyter-wrapper .bp3-dark .bp3-html-select select,.jupyter-wrapper .bp3-dark .bp3-select select{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#394b59;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.05)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.05), rgba(255, 255, 255, 0));color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-html-select select:hover,.jupyter-wrapper .bp3-dark .bp3-select select:hover,.jupyter-wrapper .bp3-dark .bp3-html-select select:active,.jupyter-wrapper .bp3-dark .bp3-select select:active,.jupyter-wrapper .bp3-dark .bp3-html-select select.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select select.bp3-active{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-html-select select:hover,.jupyter-wrapper .bp3-dark .bp3-select select:hover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#30404d}.jupyter-wrapper .bp3-dark .bp3-html-select select:active,.jupyter-wrapper .bp3-dark .bp3-select select:active,.jupyter-wrapper .bp3-dark .bp3-html-select select.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select select.bp3-active{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);background-color:#202b33;background-image:none}.jupyter-wrapper .bp3-dark .bp3-html-select select:disabled,.jupyter-wrapper .bp3-dark .bp3-select select:disabled,.jupyter-wrapper .bp3-dark .bp3-html-select select.bp3-disabled,.jupyter-wrapper .bp3-dark .bp3-select select.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background-color:rgba(57,75,89,.5);background-image:none;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-html-select select:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select select:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-html-select select.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-select select.bp3-disabled.bp3-active{background:rgba(57,75,89,.7)}.jupyter-wrapper .bp3-dark .bp3-html-select select .bp3-button-spinner .bp3-spinner-head,.jupyter-wrapper .bp3-dark .bp3-select select .bp3-button-spinner .bp3-spinner-head{background:rgba(16,22,26,.5);stroke:#8a9ba8}.jupyter-wrapper .bp3-html-select select:disabled,.jupyter-wrapper .bp3-select select:disabled{-webkit-box-shadow:none;box-shadow:none;background-color:rgba(206,217,224,.5);cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-html-select .bp3-icon,.jupyter-wrapper .bp3-select .bp3-icon,.jupyter-wrapper .bp3-select::after{position:absolute;top:7px;right:7px;color:#5c7080;pointer-events:none}.jupyter-wrapper .bp3-html-select .bp3-disabled.bp3-icon,.jupyter-wrapper .bp3-select .bp3-disabled.bp3-icon,.jupyter-wrapper .bp3-disabled.bp3-select::after{color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-html-select,.jupyter-wrapper .bp3-select{display:inline-block;position:relative;vertical-align:middle;letter-spacing:normal}.jupyter-wrapper .bp3-html-select select::-ms-expand,.jupyter-wrapper .bp3-select select::-ms-expand{display:none}.jupyter-wrapper .bp3-html-select .bp3-icon,.jupyter-wrapper .bp3-select .bp3-icon{color:#5c7080}.jupyter-wrapper .bp3-html-select .bp3-icon:hover,.jupyter-wrapper .bp3-select .bp3-icon:hover{color:#182026}.jupyter-wrapper .bp3-dark .bp3-html-select .bp3-icon,.jupyter-wrapper .bp3-dark .bp3-select .bp3-icon{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-html-select .bp3-icon:hover,.jupyter-wrapper .bp3-dark .bp3-select .bp3-icon:hover{color:#f5f8fa}.jupyter-wrapper .bp3-html-select.bp3-large::after,.jupyter-wrapper .bp3-html-select.bp3-large .bp3-icon,.jupyter-wrapper .bp3-select.bp3-large::after,.jupyter-wrapper .bp3-select.bp3-large .bp3-icon{top:12px;right:12px}.jupyter-wrapper .bp3-html-select.bp3-fill,.jupyter-wrapper .bp3-html-select.bp3-fill select,.jupyter-wrapper .bp3-select.bp3-fill,.jupyter-wrapper .bp3-select.bp3-fill select{width:100%}.jupyter-wrapper .bp3-dark .bp3-html-select option,.jupyter-wrapper .bp3-dark .bp3-select option{background-color:#30404d;color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-html-select::after,.jupyter-wrapper .bp3-dark .bp3-select::after{color:#a7b6c2}.jupyter-wrapper .bp3-select::after{line-height:1;font-family:\"Icons16\",sans-serif;font-size:16px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;content:\"\ue6c6\"}.jupyter-wrapper .bp3-running-text table,.jupyter-wrapper table.bp3-html-table{border-spacing:0;font-size:14px}.jupyter-wrapper .bp3-running-text table th,.jupyter-wrapper table.bp3-html-table th,.jupyter-wrapper .bp3-running-text table td,.jupyter-wrapper table.bp3-html-table td{padding:11px;vertical-align:top;text-align:left}.jupyter-wrapper .bp3-running-text table th,.jupyter-wrapper table.bp3-html-table th{color:#182026;font-weight:600}.jupyter-wrapper .bp3-running-text table td,.jupyter-wrapper table.bp3-html-table td{color:#182026}.jupyter-wrapper .bp3-running-text table tbody tr:first-child th,.jupyter-wrapper table.bp3-html-table tbody tr:first-child th,.jupyter-wrapper .bp3-running-text table tbody tr:first-child td,.jupyter-wrapper table.bp3-html-table tbody tr:first-child td{-webkit-box-shadow:inset 0 1px 0 0 rgba(16,22,26,.15);box-shadow:inset 0 1px 0 0 rgba(16,22,26,.15)}.jupyter-wrapper .bp3-dark .bp3-running-text table th,.jupyter-wrapper .bp3-running-text .bp3-dark table th,.jupyter-wrapper .bp3-dark table.bp3-html-table th{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-running-text table td,.jupyter-wrapper .bp3-running-text .bp3-dark table td,.jupyter-wrapper .bp3-dark table.bp3-html-table td{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-running-text table tbody tr:first-child th,.jupyter-wrapper .bp3-running-text .bp3-dark table tbody tr:first-child th,.jupyter-wrapper .bp3-dark table.bp3-html-table tbody tr:first-child th,.jupyter-wrapper .bp3-dark .bp3-running-text table tbody tr:first-child td,.jupyter-wrapper .bp3-running-text .bp3-dark table tbody tr:first-child td,.jupyter-wrapper .bp3-dark table.bp3-html-table tbody tr:first-child td{-webkit-box-shadow:inset 0 1px 0 0 rgba(255,255,255,.15);box-shadow:inset 0 1px 0 0 rgba(255,255,255,.15)}.jupyter-wrapper table.bp3-html-table.bp3-html-table-condensed th,.jupyter-wrapper table.bp3-html-table.bp3-html-table-condensed td,.jupyter-wrapper table.bp3-html-table.bp3-small th,.jupyter-wrapper table.bp3-html-table.bp3-small td{padding-top:6px;padding-bottom:6px}.jupyter-wrapper table.bp3-html-table.bp3-html-table-striped tbody tr:nth-child(odd) td{background:rgba(191,204,214,.15)}.jupyter-wrapper table.bp3-html-table.bp3-html-table-bordered th:not(:first-child){-webkit-box-shadow:inset 1px 0 0 0 rgba(16,22,26,.15);box-shadow:inset 1px 0 0 0 rgba(16,22,26,.15)}.jupyter-wrapper table.bp3-html-table.bp3-html-table-bordered tbody tr td{-webkit-box-shadow:inset 0 1px 0 0 rgba(16,22,26,.15);box-shadow:inset 0 1px 0 0 rgba(16,22,26,.15)}.jupyter-wrapper table.bp3-html-table.bp3-html-table-bordered tbody tr td:not(:first-child){-webkit-box-shadow:inset 1px 1px 0 0 rgba(16,22,26,.15);box-shadow:inset 1px 1px 0 0 rgba(16,22,26,.15)}.jupyter-wrapper table.bp3-html-table.bp3-html-table-bordered.bp3-html-table-striped tbody tr:not(:first-child) td{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper table.bp3-html-table.bp3-html-table-bordered.bp3-html-table-striped tbody tr:not(:first-child) td:not(:first-child){-webkit-box-shadow:inset 1px 0 0 0 rgba(16,22,26,.15);box-shadow:inset 1px 0 0 0 rgba(16,22,26,.15)}.jupyter-wrapper table.bp3-html-table.bp3-interactive tbody tr:hover td{background-color:rgba(191,204,214,.3);cursor:pointer}.jupyter-wrapper table.bp3-html-table.bp3-interactive tbody tr:active td{background-color:rgba(191,204,214,.4)}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-html-table-striped tbody tr:nth-child(odd) td{background:rgba(92,112,128,.15)}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-html-table-bordered th:not(:first-child){-webkit-box-shadow:inset 1px 0 0 0 rgba(255,255,255,.15);box-shadow:inset 1px 0 0 0 rgba(255,255,255,.15)}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-html-table-bordered tbody tr td{-webkit-box-shadow:inset 0 1px 0 0 rgba(255,255,255,.15);box-shadow:inset 0 1px 0 0 rgba(255,255,255,.15)}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-html-table-bordered tbody tr td:not(:first-child){-webkit-box-shadow:inset 1px 1px 0 0 rgba(255,255,255,.15);box-shadow:inset 1px 1px 0 0 rgba(255,255,255,.15)}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-html-table-bordered.bp3-html-table-striped tbody tr:not(:first-child) td{-webkit-box-shadow:inset 1px 0 0 0 rgba(255,255,255,.15);box-shadow:inset 1px 0 0 0 rgba(255,255,255,.15)}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-html-table-bordered.bp3-html-table-striped tbody tr:not(:first-child) td:first-child{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-interactive tbody tr:hover td{background-color:rgba(92,112,128,.3);cursor:pointer}.jupyter-wrapper .bp3-dark table.bp3-html-table.bp3-interactive tbody tr:active td{background-color:rgba(92,112,128,.4)}.jupyter-wrapper .bp3-key-combo{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:center;-ms-flex-align:center;align-items:center}.jupyter-wrapper .bp3-key-combo>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-key-combo>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-key-combo::before,.jupyter-wrapper .bp3-key-combo>*{margin-right:5px}.jupyter-wrapper .bp3-key-combo:empty::before,.jupyter-wrapper .bp3-key-combo>:last-child{margin-right:0}.jupyter-wrapper .bp3-hotkey-dialog{top:40px;padding-bottom:0}.jupyter-wrapper .bp3-hotkey-dialog .bp3-dialog-body{margin:0;padding:0}.jupyter-wrapper .bp3-hotkey-dialog .bp3-hotkey-label{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1}.jupyter-wrapper .bp3-hotkey-column{margin:auto;max-height:80vh;overflow-y:auto;padding:30px}.jupyter-wrapper .bp3-hotkey-column .bp3-heading{margin-bottom:20px}.jupyter-wrapper .bp3-hotkey-column .bp3-heading:not(:first-child){margin-top:40px}.jupyter-wrapper .bp3-hotkey{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:justify;-ms-flex-pack:justify;justify-content:space-between;margin-right:0;margin-left:0}.jupyter-wrapper .bp3-hotkey:not(:last-child){margin-bottom:10px}.jupyter-wrapper .bp3-icon{display:inline-block;-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;vertical-align:text-bottom}.jupyter-wrapper .bp3-icon:not(:empty)::before{content:\"\" !important;content:unset !important}.jupyter-wrapper .bp3-icon>svg{display:block}.jupyter-wrapper .bp3-icon>svg:not([fill]){fill:currentColor}.jupyter-wrapper .bp3-icon.bp3-intent-primary,.jupyter-wrapper .bp3-icon-standard.bp3-intent-primary,.jupyter-wrapper .bp3-icon-large.bp3-intent-primary{color:#106ba3}.jupyter-wrapper .bp3-dark .bp3-icon.bp3-intent-primary,.jupyter-wrapper .bp3-dark .bp3-icon-standard.bp3-intent-primary,.jupyter-wrapper .bp3-dark .bp3-icon-large.bp3-intent-primary{color:#48aff0}.jupyter-wrapper .bp3-icon.bp3-intent-success,.jupyter-wrapper .bp3-icon-standard.bp3-intent-success,.jupyter-wrapper .bp3-icon-large.bp3-intent-success{color:#0d8050}.jupyter-wrapper .bp3-dark .bp3-icon.bp3-intent-success,.jupyter-wrapper .bp3-dark .bp3-icon-standard.bp3-intent-success,.jupyter-wrapper .bp3-dark .bp3-icon-large.bp3-intent-success{color:#3dcc91}.jupyter-wrapper .bp3-icon.bp3-intent-warning,.jupyter-wrapper .bp3-icon-standard.bp3-intent-warning,.jupyter-wrapper .bp3-icon-large.bp3-intent-warning{color:#bf7326}.jupyter-wrapper .bp3-dark .bp3-icon.bp3-intent-warning,.jupyter-wrapper .bp3-dark .bp3-icon-standard.bp3-intent-warning,.jupyter-wrapper .bp3-dark .bp3-icon-large.bp3-intent-warning{color:#ffb366}.jupyter-wrapper .bp3-icon.bp3-intent-danger,.jupyter-wrapper .bp3-icon-standard.bp3-intent-danger,.jupyter-wrapper .bp3-icon-large.bp3-intent-danger{color:#c23030}.jupyter-wrapper .bp3-dark .bp3-icon.bp3-intent-danger,.jupyter-wrapper .bp3-dark .bp3-icon-standard.bp3-intent-danger,.jupyter-wrapper .bp3-dark .bp3-icon-large.bp3-intent-danger{color:#ff7373}.jupyter-wrapper span.bp3-icon-standard{line-height:1;font-family:\"Icons16\",sans-serif;font-size:16px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;display:inline-block}.jupyter-wrapper span.bp3-icon-large{line-height:1;font-family:\"Icons20\",sans-serif;font-size:20px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;display:inline-block}.jupyter-wrapper span.bp3-icon:empty{line-height:1;font-family:\"Icons20\";font-size:inherit;font-weight:400;font-style:normal}.jupyter-wrapper span.bp3-icon:empty::before{-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased}.jupyter-wrapper .bp3-icon-add::before{content:\"\ue63e\"}.jupyter-wrapper .bp3-icon-add-column-left::before{content:\"\ue6f9\"}.jupyter-wrapper .bp3-icon-add-column-right::before{content:\"\ue6fa\"}.jupyter-wrapper .bp3-icon-add-row-bottom::before{content:\"\ue6f8\"}.jupyter-wrapper .bp3-icon-add-row-top::before{content:\"\ue6f7\"}.jupyter-wrapper .bp3-icon-add-to-artifact::before{content:\"\ue67c\"}.jupyter-wrapper .bp3-icon-add-to-folder::before{content:\"\ue6d2\"}.jupyter-wrapper .bp3-icon-airplane::before{content:\"\ue74b\"}.jupyter-wrapper .bp3-icon-align-center::before{content:\"\ue603\"}.jupyter-wrapper .bp3-icon-align-justify::before{content:\"\ue605\"}.jupyter-wrapper .bp3-icon-align-left::before{content:\"\ue602\"}.jupyter-wrapper .bp3-icon-align-right::before{content:\"\ue604\"}.jupyter-wrapper .bp3-icon-alignment-bottom::before{content:\"\ue727\"}.jupyter-wrapper .bp3-icon-alignment-horizontal-center::before{content:\"\ue726\"}.jupyter-wrapper .bp3-icon-alignment-left::before{content:\"\ue722\"}.jupyter-wrapper .bp3-icon-alignment-right::before{content:\"\ue724\"}.jupyter-wrapper .bp3-icon-alignment-top::before{content:\"\ue725\"}.jupyter-wrapper .bp3-icon-alignment-vertical-center::before{content:\"\ue723\"}.jupyter-wrapper .bp3-icon-annotation::before{content:\"\ue6f0\"}.jupyter-wrapper .bp3-icon-application::before{content:\"\ue735\"}.jupyter-wrapper .bp3-icon-applications::before{content:\"\ue621\"}.jupyter-wrapper .bp3-icon-archive::before{content:\"\ue907\"}.jupyter-wrapper .bp3-icon-arrow-bottom-left::before{content:\"\u2199\"}.jupyter-wrapper .bp3-icon-arrow-bottom-right::before{content:\"\u2198\"}.jupyter-wrapper .bp3-icon-arrow-down::before{content:\"\u2193\"}.jupyter-wrapper .bp3-icon-arrow-left::before{content:\"\u2190\"}.jupyter-wrapper .bp3-icon-arrow-right::before{content:\"\u2192\"}.jupyter-wrapper .bp3-icon-arrow-top-left::before{content:\"\u2196\"}.jupyter-wrapper .bp3-icon-arrow-top-right::before{content:\"\u2197\"}.jupyter-wrapper .bp3-icon-arrow-up::before{content:\"\u2191\"}.jupyter-wrapper .bp3-icon-arrows-horizontal::before{content:\"\u2194\"}.jupyter-wrapper .bp3-icon-arrows-vertical::before{content:\"\u2195\"}.jupyter-wrapper .bp3-icon-asterisk::before{content:\"*\"}.jupyter-wrapper .bp3-icon-automatic-updates::before{content:\"\ue65f\"}.jupyter-wrapper .bp3-icon-badge::before{content:\"\ue6e3\"}.jupyter-wrapper .bp3-icon-ban-circle::before{content:\"\ue69d\"}.jupyter-wrapper .bp3-icon-bank-account::before{content:\"\ue76f\"}.jupyter-wrapper .bp3-icon-barcode::before{content:\"\ue676\"}.jupyter-wrapper .bp3-icon-blank::before{content:\"\ue900\"}.jupyter-wrapper .bp3-icon-blocked-person::before{content:\"\ue768\"}.jupyter-wrapper .bp3-icon-bold::before{content:\"\ue606\"}.jupyter-wrapper .bp3-icon-book::before{content:\"\ue6b8\"}.jupyter-wrapper .bp3-icon-bookmark::before{content:\"\ue61a\"}.jupyter-wrapper .bp3-icon-box::before{content:\"\ue6bf\"}.jupyter-wrapper .bp3-icon-briefcase::before{content:\"\ue674\"}.jupyter-wrapper .bp3-icon-bring-data::before{content:\"\ue90a\"}.jupyter-wrapper .bp3-icon-build::before{content:\"\ue72d\"}.jupyter-wrapper .bp3-icon-calculator::before{content:\"\ue70b\"}.jupyter-wrapper .bp3-icon-calendar::before{content:\"\ue62b\"}.jupyter-wrapper .bp3-icon-camera::before{content:\"\ue69e\"}.jupyter-wrapper .bp3-icon-caret-down::before{content:\"\u2304\"}.jupyter-wrapper .bp3-icon-caret-left::before{content:\"\u2329\"}.jupyter-wrapper .bp3-icon-caret-right::before{content:\"\u232a\"}.jupyter-wrapper .bp3-icon-caret-up::before{content:\"\u2303\"}.jupyter-wrapper .bp3-icon-cell-tower::before{content:\"\ue770\"}.jupyter-wrapper .bp3-icon-changes::before{content:\"\ue623\"}.jupyter-wrapper .bp3-icon-chart::before{content:\"\ue67e\"}.jupyter-wrapper .bp3-icon-chat::before{content:\"\ue689\"}.jupyter-wrapper .bp3-icon-chevron-backward::before{content:\"\ue6df\"}.jupyter-wrapper .bp3-icon-chevron-down::before{content:\"\ue697\"}.jupyter-wrapper .bp3-icon-chevron-forward::before{content:\"\ue6e0\"}.jupyter-wrapper .bp3-icon-chevron-left::before{content:\"\ue694\"}.jupyter-wrapper .bp3-icon-chevron-right::before{content:\"\ue695\"}.jupyter-wrapper .bp3-icon-chevron-up::before{content:\"\ue696\"}.jupyter-wrapper .bp3-icon-circle::before{content:\"\ue66a\"}.jupyter-wrapper .bp3-icon-circle-arrow-down::before{content:\"\ue68e\"}.jupyter-wrapper .bp3-icon-circle-arrow-left::before{content:\"\ue68c\"}.jupyter-wrapper .bp3-icon-circle-arrow-right::before{content:\"\ue68b\"}.jupyter-wrapper .bp3-icon-circle-arrow-up::before{content:\"\ue68d\"}.jupyter-wrapper .bp3-icon-citation::before{content:\"\ue61b\"}.jupyter-wrapper .bp3-icon-clean::before{content:\"\ue7c5\"}.jupyter-wrapper .bp3-icon-clipboard::before{content:\"\ue61d\"}.jupyter-wrapper .bp3-icon-cloud::before{content:\"\u2601\"}.jupyter-wrapper .bp3-icon-cloud-download::before{content:\"\ue690\"}.jupyter-wrapper .bp3-icon-cloud-upload::before{content:\"\ue691\"}.jupyter-wrapper .bp3-icon-code::before{content:\"\ue661\"}.jupyter-wrapper .bp3-icon-code-block::before{content:\"\ue6c5\"}.jupyter-wrapper .bp3-icon-cog::before{content:\"\ue645\"}.jupyter-wrapper .bp3-icon-collapse-all::before{content:\"\ue763\"}.jupyter-wrapper .bp3-icon-column-layout::before{content:\"\ue6da\"}.jupyter-wrapper .bp3-icon-comment::before{content:\"\ue68a\"}.jupyter-wrapper .bp3-icon-comparison::before{content:\"\ue637\"}.jupyter-wrapper .bp3-icon-compass::before{content:\"\ue79c\"}.jupyter-wrapper .bp3-icon-compressed::before{content:\"\ue6c0\"}.jupyter-wrapper .bp3-icon-confirm::before{content:\"\ue639\"}.jupyter-wrapper .bp3-icon-console::before{content:\"\ue79b\"}.jupyter-wrapper .bp3-icon-contrast::before{content:\"\ue6cb\"}.jupyter-wrapper .bp3-icon-control::before{content:\"\ue67f\"}.jupyter-wrapper .bp3-icon-credit-card::before{content:\"\ue649\"}.jupyter-wrapper .bp3-icon-cross::before{content:\"\u2717\"}.jupyter-wrapper .bp3-icon-crown::before{content:\"\ue7b4\"}.jupyter-wrapper .bp3-icon-cube::before{content:\"\ue7c8\"}.jupyter-wrapper .bp3-icon-cube-add::before{content:\"\ue7c9\"}.jupyter-wrapper .bp3-icon-cube-remove::before{content:\"\ue7d0\"}.jupyter-wrapper .bp3-icon-curved-range-chart::before{content:\"\ue71b\"}.jupyter-wrapper .bp3-icon-cut::before{content:\"\ue6ef\"}.jupyter-wrapper .bp3-icon-dashboard::before{content:\"\ue751\"}.jupyter-wrapper .bp3-icon-data-lineage::before{content:\"\ue908\"}.jupyter-wrapper .bp3-icon-database::before{content:\"\ue683\"}.jupyter-wrapper .bp3-icon-delete::before{content:\"\ue644\"}.jupyter-wrapper .bp3-icon-delta::before{content:\"\u0394\"}.jupyter-wrapper .bp3-icon-derive-column::before{content:\"\ue739\"}.jupyter-wrapper .bp3-icon-desktop::before{content:\"\ue6af\"}.jupyter-wrapper .bp3-icon-diagram-tree::before{content:\"\ue7b3\"}.jupyter-wrapper .bp3-icon-direction-left::before{content:\"\ue681\"}.jupyter-wrapper .bp3-icon-direction-right::before{content:\"\ue682\"}.jupyter-wrapper .bp3-icon-disable::before{content:\"\ue600\"}.jupyter-wrapper .bp3-icon-document::before{content:\"\ue630\"}.jupyter-wrapper .bp3-icon-document-open::before{content:\"\ue71e\"}.jupyter-wrapper .bp3-icon-document-share::before{content:\"\ue71f\"}.jupyter-wrapper .bp3-icon-dollar::before{content:\"$\"}.jupyter-wrapper .bp3-icon-dot::before{content:\"\u2022\"}.jupyter-wrapper .bp3-icon-double-caret-horizontal::before{content:\"\ue6c7\"}.jupyter-wrapper .bp3-icon-double-caret-vertical::before{content:\"\ue6c6\"}.jupyter-wrapper .bp3-icon-double-chevron-down::before{content:\"\ue703\"}.jupyter-wrapper .bp3-icon-double-chevron-left::before{content:\"\ue6ff\"}.jupyter-wrapper .bp3-icon-double-chevron-right::before{content:\"\ue701\"}.jupyter-wrapper .bp3-icon-double-chevron-up::before{content:\"\ue702\"}.jupyter-wrapper .bp3-icon-doughnut-chart::before{content:\"\ue6ce\"}.jupyter-wrapper .bp3-icon-download::before{content:\"\ue62f\"}.jupyter-wrapper .bp3-icon-drag-handle-horizontal::before{content:\"\ue716\"}.jupyter-wrapper .bp3-icon-drag-handle-vertical::before{content:\"\ue715\"}.jupyter-wrapper .bp3-icon-draw::before{content:\"\ue66b\"}.jupyter-wrapper .bp3-icon-drive-time::before{content:\"\ue615\"}.jupyter-wrapper .bp3-icon-duplicate::before{content:\"\ue69c\"}.jupyter-wrapper .bp3-icon-edit::before{content:\"\u270e\"}.jupyter-wrapper .bp3-icon-eject::before{content:\"\u23cf\"}.jupyter-wrapper .bp3-icon-endorsed::before{content:\"\ue75f\"}.jupyter-wrapper .bp3-icon-envelope::before{content:\"\u2709\"}.jupyter-wrapper .bp3-icon-equals::before{content:\"\ue7d9\"}.jupyter-wrapper .bp3-icon-eraser::before{content:\"\ue773\"}.jupyter-wrapper .bp3-icon-error::before{content:\"\ue648\"}.jupyter-wrapper .bp3-icon-euro::before{content:\"\u20ac\"}.jupyter-wrapper .bp3-icon-exchange::before{content:\"\ue636\"}.jupyter-wrapper .bp3-icon-exclude-row::before{content:\"\ue6ea\"}.jupyter-wrapper .bp3-icon-expand-all::before{content:\"\ue764\"}.jupyter-wrapper .bp3-icon-export::before{content:\"\ue633\"}.jupyter-wrapper .bp3-icon-eye-off::before{content:\"\ue6cc\"}.jupyter-wrapper .bp3-icon-eye-on::before{content:\"\ue75a\"}.jupyter-wrapper .bp3-icon-eye-open::before{content:\"\ue66f\"}.jupyter-wrapper .bp3-icon-fast-backward::before{content:\"\ue6a8\"}.jupyter-wrapper .bp3-icon-fast-forward::before{content:\"\ue6ac\"}.jupyter-wrapper .bp3-icon-feed::before{content:\"\ue656\"}.jupyter-wrapper .bp3-icon-feed-subscribed::before{content:\"\ue78f\"}.jupyter-wrapper .bp3-icon-film::before{content:\"\ue6a1\"}.jupyter-wrapper .bp3-icon-filter::before{content:\"\ue638\"}.jupyter-wrapper .bp3-icon-filter-keep::before{content:\"\ue78c\"}.jupyter-wrapper .bp3-icon-filter-list::before{content:\"\ue6ee\"}.jupyter-wrapper .bp3-icon-filter-open::before{content:\"\ue7d7\"}.jupyter-wrapper .bp3-icon-filter-remove::before{content:\"\ue78d\"}.jupyter-wrapper .bp3-icon-flag::before{content:\"\u2691\"}.jupyter-wrapper .bp3-icon-flame::before{content:\"\ue7a9\"}.jupyter-wrapper .bp3-icon-flash::before{content:\"\ue6b3\"}.jupyter-wrapper .bp3-icon-floppy-disk::before{content:\"\ue6b7\"}.jupyter-wrapper .bp3-icon-flow-branch::before{content:\"\ue7c1\"}.jupyter-wrapper .bp3-icon-flow-end::before{content:\"\ue7c4\"}.jupyter-wrapper .bp3-icon-flow-linear::before{content:\"\ue7c0\"}.jupyter-wrapper .bp3-icon-flow-review::before{content:\"\ue7c2\"}.jupyter-wrapper .bp3-icon-flow-review-branch::before{content:\"\ue7c3\"}.jupyter-wrapper .bp3-icon-flows::before{content:\"\ue659\"}.jupyter-wrapper .bp3-icon-folder-close::before{content:\"\ue652\"}.jupyter-wrapper .bp3-icon-folder-new::before{content:\"\ue7b0\"}.jupyter-wrapper .bp3-icon-folder-open::before{content:\"\ue651\"}.jupyter-wrapper .bp3-icon-folder-shared::before{content:\"\ue653\"}.jupyter-wrapper .bp3-icon-folder-shared-open::before{content:\"\ue670\"}.jupyter-wrapper .bp3-icon-follower::before{content:\"\ue760\"}.jupyter-wrapper .bp3-icon-following::before{content:\"\ue761\"}.jupyter-wrapper .bp3-icon-font::before{content:\"\ue6b4\"}.jupyter-wrapper .bp3-icon-fork::before{content:\"\ue63a\"}.jupyter-wrapper .bp3-icon-form::before{content:\"\ue795\"}.jupyter-wrapper .bp3-icon-full-circle::before{content:\"\ue685\"}.jupyter-wrapper .bp3-icon-full-stacked-chart::before{content:\"\ue75e\"}.jupyter-wrapper .bp3-icon-fullscreen::before{content:\"\ue699\"}.jupyter-wrapper .bp3-icon-function::before{content:\"\ue6e5\"}.jupyter-wrapper .bp3-icon-gantt-chart::before{content:\"\ue6f4\"}.jupyter-wrapper .bp3-icon-geolocation::before{content:\"\ue640\"}.jupyter-wrapper .bp3-icon-geosearch::before{content:\"\ue613\"}.jupyter-wrapper .bp3-icon-git-branch::before{content:\"\ue72a\"}.jupyter-wrapper .bp3-icon-git-commit::before{content:\"\ue72b\"}.jupyter-wrapper .bp3-icon-git-merge::before{content:\"\ue729\"}.jupyter-wrapper .bp3-icon-git-new-branch::before{content:\"\ue749\"}.jupyter-wrapper .bp3-icon-git-pull::before{content:\"\ue728\"}.jupyter-wrapper .bp3-icon-git-push::before{content:\"\ue72c\"}.jupyter-wrapper .bp3-icon-git-repo::before{content:\"\ue748\"}.jupyter-wrapper .bp3-icon-glass::before{content:\"\ue6b1\"}.jupyter-wrapper .bp3-icon-globe::before{content:\"\ue666\"}.jupyter-wrapper .bp3-icon-globe-network::before{content:\"\ue7b5\"}.jupyter-wrapper .bp3-icon-graph::before{content:\"\ue673\"}.jupyter-wrapper .bp3-icon-graph-remove::before{content:\"\ue609\"}.jupyter-wrapper .bp3-icon-greater-than::before{content:\"\ue7e1\"}.jupyter-wrapper .bp3-icon-greater-than-or-equal-to::before{content:\"\ue7e2\"}.jupyter-wrapper .bp3-icon-grid::before{content:\"\ue6d0\"}.jupyter-wrapper .bp3-icon-grid-view::before{content:\"\ue6e4\"}.jupyter-wrapper .bp3-icon-group-objects::before{content:\"\ue60a\"}.jupyter-wrapper .bp3-icon-grouped-bar-chart::before{content:\"\ue75d\"}.jupyter-wrapper .bp3-icon-hand::before{content:\"\ue6de\"}.jupyter-wrapper .bp3-icon-hand-down::before{content:\"\ue6bb\"}.jupyter-wrapper .bp3-icon-hand-left::before{content:\"\ue6bc\"}.jupyter-wrapper .bp3-icon-hand-right::before{content:\"\ue6b9\"}.jupyter-wrapper .bp3-icon-hand-up::before{content:\"\ue6ba\"}.jupyter-wrapper .bp3-icon-header::before{content:\"\ue6b5\"}.jupyter-wrapper .bp3-icon-header-one::before{content:\"\ue793\"}.jupyter-wrapper .bp3-icon-header-two::before{content:\"\ue794\"}.jupyter-wrapper .bp3-icon-headset::before{content:\"\ue6dc\"}.jupyter-wrapper .bp3-icon-heart::before{content:\"\u2665\"}.jupyter-wrapper .bp3-icon-heart-broken::before{content:\"\ue7a2\"}.jupyter-wrapper .bp3-icon-heat-grid::before{content:\"\ue6f3\"}.jupyter-wrapper .bp3-icon-heatmap::before{content:\"\ue614\"}.jupyter-wrapper .bp3-icon-help::before{content:\"?\"}.jupyter-wrapper .bp3-icon-helper-management::before{content:\"\ue66d\"}.jupyter-wrapper .bp3-icon-highlight::before{content:\"\ue6ed\"}.jupyter-wrapper .bp3-icon-history::before{content:\"\ue64a\"}.jupyter-wrapper .bp3-icon-home::before{content:\"\u2302\"}.jupyter-wrapper .bp3-icon-horizontal-bar-chart::before{content:\"\ue70c\"}.jupyter-wrapper .bp3-icon-horizontal-bar-chart-asc::before{content:\"\ue75c\"}.jupyter-wrapper .bp3-icon-horizontal-bar-chart-desc::before{content:\"\ue71d\"}.jupyter-wrapper .bp3-icon-horizontal-distribution::before{content:\"\ue720\"}.jupyter-wrapper .bp3-icon-id-number::before{content:\"\ue771\"}.jupyter-wrapper .bp3-icon-image-rotate-left::before{content:\"\ue73a\"}.jupyter-wrapper .bp3-icon-image-rotate-right::before{content:\"\ue73b\"}.jupyter-wrapper .bp3-icon-import::before{content:\"\ue632\"}.jupyter-wrapper .bp3-icon-inbox::before{content:\"\ue629\"}.jupyter-wrapper .bp3-icon-inbox-filtered::before{content:\"\ue7d1\"}.jupyter-wrapper .bp3-icon-inbox-geo::before{content:\"\ue7d2\"}.jupyter-wrapper .bp3-icon-inbox-search::before{content:\"\ue7d3\"}.jupyter-wrapper .bp3-icon-inbox-update::before{content:\"\ue7d4\"}.jupyter-wrapper .bp3-icon-info-sign::before{content:\"\u2139\"}.jupyter-wrapper .bp3-icon-inheritance::before{content:\"\ue7d5\"}.jupyter-wrapper .bp3-icon-inner-join::before{content:\"\ue7a3\"}.jupyter-wrapper .bp3-icon-insert::before{content:\"\ue66c\"}.jupyter-wrapper .bp3-icon-intersection::before{content:\"\ue765\"}.jupyter-wrapper .bp3-icon-ip-address::before{content:\"\ue772\"}.jupyter-wrapper .bp3-icon-issue::before{content:\"\ue774\"}.jupyter-wrapper .bp3-icon-issue-closed::before{content:\"\ue776\"}.jupyter-wrapper .bp3-icon-issue-new::before{content:\"\ue775\"}.jupyter-wrapper .bp3-icon-italic::before{content:\"\ue607\"}.jupyter-wrapper .bp3-icon-join-table::before{content:\"\ue738\"}.jupyter-wrapper .bp3-icon-key::before{content:\"\ue78e\"}.jupyter-wrapper .bp3-icon-key-backspace::before{content:\"\ue707\"}.jupyter-wrapper .bp3-icon-key-command::before{content:\"\ue705\"}.jupyter-wrapper .bp3-icon-key-control::before{content:\"\ue704\"}.jupyter-wrapper .bp3-icon-key-delete::before{content:\"\ue708\"}.jupyter-wrapper .bp3-icon-key-enter::before{content:\"\ue70a\"}.jupyter-wrapper .bp3-icon-key-escape::before{content:\"\ue709\"}.jupyter-wrapper .bp3-icon-key-option::before{content:\"\ue742\"}.jupyter-wrapper .bp3-icon-key-shift::before{content:\"\ue706\"}.jupyter-wrapper .bp3-icon-key-tab::before{content:\"\ue757\"}.jupyter-wrapper .bp3-icon-known-vehicle::before{content:\"\ue73c\"}.jupyter-wrapper .bp3-icon-label::before{content:\"\ue665\"}.jupyter-wrapper .bp3-icon-layer::before{content:\"\ue6cf\"}.jupyter-wrapper .bp3-icon-layers::before{content:\"\ue618\"}.jupyter-wrapper .bp3-icon-layout::before{content:\"\ue60c\"}.jupyter-wrapper .bp3-icon-layout-auto::before{content:\"\ue60d\"}.jupyter-wrapper .bp3-icon-layout-balloon::before{content:\"\ue6d3\"}.jupyter-wrapper .bp3-icon-layout-circle::before{content:\"\ue60e\"}.jupyter-wrapper .bp3-icon-layout-grid::before{content:\"\ue610\"}.jupyter-wrapper .bp3-icon-layout-group-by::before{content:\"\ue611\"}.jupyter-wrapper .bp3-icon-layout-hierarchy::before{content:\"\ue60f\"}.jupyter-wrapper .bp3-icon-layout-linear::before{content:\"\ue6c3\"}.jupyter-wrapper .bp3-icon-layout-skew-grid::before{content:\"\ue612\"}.jupyter-wrapper .bp3-icon-layout-sorted-clusters::before{content:\"\ue6d4\"}.jupyter-wrapper .bp3-icon-learning::before{content:\"\ue904\"}.jupyter-wrapper .bp3-icon-left-join::before{content:\"\ue7a4\"}.jupyter-wrapper .bp3-icon-less-than::before{content:\"\ue7e3\"}.jupyter-wrapper .bp3-icon-less-than-or-equal-to::before{content:\"\ue7e4\"}.jupyter-wrapper .bp3-icon-lifesaver::before{content:\"\ue7c7\"}.jupyter-wrapper .bp3-icon-lightbulb::before{content:\"\ue6b0\"}.jupyter-wrapper .bp3-icon-link::before{content:\"\ue62d\"}.jupyter-wrapper .bp3-icon-list::before{content:\"\u2630\"}.jupyter-wrapper .bp3-icon-list-columns::before{content:\"\ue7b9\"}.jupyter-wrapper .bp3-icon-list-detail-view::before{content:\"\ue743\"}.jupyter-wrapper .bp3-icon-locate::before{content:\"\ue619\"}.jupyter-wrapper .bp3-icon-lock::before{content:\"\ue625\"}.jupyter-wrapper .bp3-icon-log-in::before{content:\"\ue69a\"}.jupyter-wrapper .bp3-icon-log-out::before{content:\"\ue64c\"}.jupyter-wrapper .bp3-icon-manual::before{content:\"\ue6f6\"}.jupyter-wrapper .bp3-icon-manually-entered-data::before{content:\"\ue74a\"}.jupyter-wrapper .bp3-icon-map::before{content:\"\ue662\"}.jupyter-wrapper .bp3-icon-map-create::before{content:\"\ue741\"}.jupyter-wrapper .bp3-icon-map-marker::before{content:\"\ue67d\"}.jupyter-wrapper .bp3-icon-maximize::before{content:\"\ue635\"}.jupyter-wrapper .bp3-icon-media::before{content:\"\ue62c\"}.jupyter-wrapper .bp3-icon-menu::before{content:\"\ue762\"}.jupyter-wrapper .bp3-icon-menu-closed::before{content:\"\ue655\"}.jupyter-wrapper .bp3-icon-menu-open::before{content:\"\ue654\"}.jupyter-wrapper .bp3-icon-merge-columns::before{content:\"\ue74f\"}.jupyter-wrapper .bp3-icon-merge-links::before{content:\"\ue60b\"}.jupyter-wrapper .bp3-icon-minimize::before{content:\"\ue634\"}.jupyter-wrapper .bp3-icon-minus::before{content:\"\u2212\"}.jupyter-wrapper .bp3-icon-mobile-phone::before{content:\"\ue717\"}.jupyter-wrapper .bp3-icon-mobile-video::before{content:\"\ue69f\"}.jupyter-wrapper .bp3-icon-moon::before{content:\"\ue754\"}.jupyter-wrapper .bp3-icon-more::before{content:\"\ue62a\"}.jupyter-wrapper .bp3-icon-mountain::before{content:\"\ue7b1\"}.jupyter-wrapper .bp3-icon-move::before{content:\"\ue693\"}.jupyter-wrapper .bp3-icon-mugshot::before{content:\"\ue6db\"}.jupyter-wrapper .bp3-icon-multi-select::before{content:\"\ue680\"}.jupyter-wrapper .bp3-icon-music::before{content:\"\ue6a6\"}.jupyter-wrapper .bp3-icon-new-drawing::before{content:\"\ue905\"}.jupyter-wrapper .bp3-icon-new-grid-item::before{content:\"\ue747\"}.jupyter-wrapper .bp3-icon-new-layer::before{content:\"\ue902\"}.jupyter-wrapper .bp3-icon-new-layers::before{content:\"\ue903\"}.jupyter-wrapper .bp3-icon-new-link::before{content:\"\ue65c\"}.jupyter-wrapper .bp3-icon-new-object::before{content:\"\ue65d\"}.jupyter-wrapper .bp3-icon-new-person::before{content:\"\ue6e9\"}.jupyter-wrapper .bp3-icon-new-prescription::before{content:\"\ue78b\"}.jupyter-wrapper .bp3-icon-new-text-box::before{content:\"\ue65b\"}.jupyter-wrapper .bp3-icon-ninja::before{content:\"\ue675\"}.jupyter-wrapper .bp3-icon-not-equal-to::before{content:\"\ue7e0\"}.jupyter-wrapper .bp3-icon-notifications::before{content:\"\ue624\"}.jupyter-wrapper .bp3-icon-notifications-updated::before{content:\"\ue7b8\"}.jupyter-wrapper .bp3-icon-numbered-list::before{content:\"\ue746\"}.jupyter-wrapper .bp3-icon-numerical::before{content:\"\ue756\"}.jupyter-wrapper .bp3-icon-office::before{content:\"\ue69b\"}.jupyter-wrapper .bp3-icon-offline::before{content:\"\ue67a\"}.jupyter-wrapper .bp3-icon-oil-field::before{content:\"\ue73f\"}.jupyter-wrapper .bp3-icon-one-column::before{content:\"\ue658\"}.jupyter-wrapper .bp3-icon-outdated::before{content:\"\ue7a8\"}.jupyter-wrapper .bp3-icon-page-layout::before{content:\"\ue660\"}.jupyter-wrapper .bp3-icon-panel-stats::before{content:\"\ue777\"}.jupyter-wrapper .bp3-icon-panel-table::before{content:\"\ue778\"}.jupyter-wrapper .bp3-icon-paperclip::before{content:\"\ue664\"}.jupyter-wrapper .bp3-icon-paragraph::before{content:\"\ue76c\"}.jupyter-wrapper .bp3-icon-path::before{content:\"\ue753\"}.jupyter-wrapper .bp3-icon-path-search::before{content:\"\ue65e\"}.jupyter-wrapper .bp3-icon-pause::before{content:\"\ue6a9\"}.jupyter-wrapper .bp3-icon-people::before{content:\"\ue63d\"}.jupyter-wrapper .bp3-icon-percentage::before{content:\"\ue76a\"}.jupyter-wrapper .bp3-icon-person::before{content:\"\ue63c\"}.jupyter-wrapper .bp3-icon-phone::before{content:\"\u260e\"}.jupyter-wrapper .bp3-icon-pie-chart::before{content:\"\ue684\"}.jupyter-wrapper .bp3-icon-pin::before{content:\"\ue646\"}.jupyter-wrapper .bp3-icon-pivot::before{content:\"\ue6f1\"}.jupyter-wrapper .bp3-icon-pivot-table::before{content:\"\ue6eb\"}.jupyter-wrapper .bp3-icon-play::before{content:\"\ue6ab\"}.jupyter-wrapper .bp3-icon-plus::before{content:\"+\"}.jupyter-wrapper .bp3-icon-polygon-filter::before{content:\"\ue6d1\"}.jupyter-wrapper .bp3-icon-power::before{content:\"\ue6d9\"}.jupyter-wrapper .bp3-icon-predictive-analysis::before{content:\"\ue617\"}.jupyter-wrapper .bp3-icon-prescription::before{content:\"\ue78a\"}.jupyter-wrapper .bp3-icon-presentation::before{content:\"\ue687\"}.jupyter-wrapper .bp3-icon-print::before{content:\"\u2399\"}.jupyter-wrapper .bp3-icon-projects::before{content:\"\ue622\"}.jupyter-wrapper .bp3-icon-properties::before{content:\"\ue631\"}.jupyter-wrapper .bp3-icon-property::before{content:\"\ue65a\"}.jupyter-wrapper .bp3-icon-publish-function::before{content:\"\ue752\"}.jupyter-wrapper .bp3-icon-pulse::before{content:\"\ue6e8\"}.jupyter-wrapper .bp3-icon-random::before{content:\"\ue698\"}.jupyter-wrapper .bp3-icon-record::before{content:\"\ue6ae\"}.jupyter-wrapper .bp3-icon-redo::before{content:\"\ue6c4\"}.jupyter-wrapper .bp3-icon-refresh::before{content:\"\ue643\"}.jupyter-wrapper .bp3-icon-regression-chart::before{content:\"\ue758\"}.jupyter-wrapper .bp3-icon-remove::before{content:\"\ue63f\"}.jupyter-wrapper .bp3-icon-remove-column::before{content:\"\ue755\"}.jupyter-wrapper .bp3-icon-remove-column-left::before{content:\"\ue6fd\"}.jupyter-wrapper .bp3-icon-remove-column-right::before{content:\"\ue6fe\"}.jupyter-wrapper .bp3-icon-remove-row-bottom::before{content:\"\ue6fc\"}.jupyter-wrapper .bp3-icon-remove-row-top::before{content:\"\ue6fb\"}.jupyter-wrapper .bp3-icon-repeat::before{content:\"\ue692\"}.jupyter-wrapper .bp3-icon-reset::before{content:\"\ue7d6\"}.jupyter-wrapper .bp3-icon-resolve::before{content:\"\ue672\"}.jupyter-wrapper .bp3-icon-rig::before{content:\"\ue740\"}.jupyter-wrapper .bp3-icon-right-join::before{content:\"\ue7a5\"}.jupyter-wrapper .bp3-icon-ring::before{content:\"\ue6f2\"}.jupyter-wrapper .bp3-icon-rotate-document::before{content:\"\ue6e1\"}.jupyter-wrapper .bp3-icon-rotate-page::before{content:\"\ue6e2\"}.jupyter-wrapper .bp3-icon-satellite::before{content:\"\ue76b\"}.jupyter-wrapper .bp3-icon-saved::before{content:\"\ue6b6\"}.jupyter-wrapper .bp3-icon-scatter-plot::before{content:\"\ue73e\"}.jupyter-wrapper .bp3-icon-search::before{content:\"\ue64b\"}.jupyter-wrapper .bp3-icon-search-around::before{content:\"\ue608\"}.jupyter-wrapper .bp3-icon-search-template::before{content:\"\ue628\"}.jupyter-wrapper .bp3-icon-search-text::before{content:\"\ue663\"}.jupyter-wrapper .bp3-icon-segmented-control::before{content:\"\ue6ec\"}.jupyter-wrapper .bp3-icon-select::before{content:\"\ue616\"}.jupyter-wrapper .bp3-icon-selection::before{content:\"\u29bf\"}.jupyter-wrapper .bp3-icon-send-to::before{content:\"\ue66e\"}.jupyter-wrapper .bp3-icon-send-to-graph::before{content:\"\ue736\"}.jupyter-wrapper .bp3-icon-send-to-map::before{content:\"\ue737\"}.jupyter-wrapper .bp3-icon-series-add::before{content:\"\ue796\"}.jupyter-wrapper .bp3-icon-series-configuration::before{content:\"\ue79a\"}.jupyter-wrapper .bp3-icon-series-derived::before{content:\"\ue799\"}.jupyter-wrapper .bp3-icon-series-filtered::before{content:\"\ue798\"}.jupyter-wrapper .bp3-icon-series-search::before{content:\"\ue797\"}.jupyter-wrapper .bp3-icon-settings::before{content:\"\ue6a2\"}.jupyter-wrapper .bp3-icon-share::before{content:\"\ue62e\"}.jupyter-wrapper .bp3-icon-shield::before{content:\"\ue7b2\"}.jupyter-wrapper .bp3-icon-shop::before{content:\"\ue6c2\"}.jupyter-wrapper .bp3-icon-shopping-cart::before{content:\"\ue6c1\"}.jupyter-wrapper .bp3-icon-signal-search::before{content:\"\ue909\"}.jupyter-wrapper .bp3-icon-sim-card::before{content:\"\ue718\"}.jupyter-wrapper .bp3-icon-slash::before{content:\"\ue769\"}.jupyter-wrapper .bp3-icon-small-cross::before{content:\"\ue6d7\"}.jupyter-wrapper .bp3-icon-small-minus::before{content:\"\ue70e\"}.jupyter-wrapper .bp3-icon-small-plus::before{content:\"\ue70d\"}.jupyter-wrapper .bp3-icon-small-tick::before{content:\"\ue6d8\"}.jupyter-wrapper .bp3-icon-snowflake::before{content:\"\ue7b6\"}.jupyter-wrapper .bp3-icon-social-media::before{content:\"\ue671\"}.jupyter-wrapper .bp3-icon-sort::before{content:\"\ue64f\"}.jupyter-wrapper .bp3-icon-sort-alphabetical::before{content:\"\ue64d\"}.jupyter-wrapper .bp3-icon-sort-alphabetical-desc::before{content:\"\ue6c8\"}.jupyter-wrapper .bp3-icon-sort-asc::before{content:\"\ue6d5\"}.jupyter-wrapper .bp3-icon-sort-desc::before{content:\"\ue6d6\"}.jupyter-wrapper .bp3-icon-sort-numerical::before{content:\"\ue64e\"}.jupyter-wrapper .bp3-icon-sort-numerical-desc::before{content:\"\ue6c9\"}.jupyter-wrapper .bp3-icon-split-columns::before{content:\"\ue750\"}.jupyter-wrapper .bp3-icon-square::before{content:\"\ue686\"}.jupyter-wrapper .bp3-icon-stacked-chart::before{content:\"\ue6e7\"}.jupyter-wrapper .bp3-icon-star::before{content:\"\u2605\"}.jupyter-wrapper .bp3-icon-star-empty::before{content:\"\u2606\"}.jupyter-wrapper .bp3-icon-step-backward::before{content:\"\ue6a7\"}.jupyter-wrapper .bp3-icon-step-chart::before{content:\"\ue70f\"}.jupyter-wrapper .bp3-icon-step-forward::before{content:\"\ue6ad\"}.jupyter-wrapper .bp3-icon-stop::before{content:\"\ue6aa\"}.jupyter-wrapper .bp3-icon-stopwatch::before{content:\"\ue901\"}.jupyter-wrapper .bp3-icon-strikethrough::before{content:\"\ue7a6\"}.jupyter-wrapper .bp3-icon-style::before{content:\"\ue601\"}.jupyter-wrapper .bp3-icon-swap-horizontal::before{content:\"\ue745\"}.jupyter-wrapper .bp3-icon-swap-vertical::before{content:\"\ue744\"}.jupyter-wrapper .bp3-icon-symbol-circle::before{content:\"\ue72e\"}.jupyter-wrapper .bp3-icon-symbol-cross::before{content:\"\ue731\"}.jupyter-wrapper .bp3-icon-symbol-diamond::before{content:\"\ue730\"}.jupyter-wrapper .bp3-icon-symbol-square::before{content:\"\ue72f\"}.jupyter-wrapper .bp3-icon-symbol-triangle-down::before{content:\"\ue733\"}.jupyter-wrapper .bp3-icon-symbol-triangle-up::before{content:\"\ue732\"}.jupyter-wrapper .bp3-icon-tag::before{content:\"\ue61c\"}.jupyter-wrapper .bp3-icon-take-action::before{content:\"\ue6ca\"}.jupyter-wrapper .bp3-icon-taxi::before{content:\"\ue79e\"}.jupyter-wrapper .bp3-icon-text-highlight::before{content:\"\ue6dd\"}.jupyter-wrapper .bp3-icon-th::before{content:\"\ue667\"}.jupyter-wrapper .bp3-icon-th-derived::before{content:\"\ue669\"}.jupyter-wrapper .bp3-icon-th-disconnect::before{content:\"\ue7d8\"}.jupyter-wrapper .bp3-icon-th-filtered::before{content:\"\ue7c6\"}.jupyter-wrapper .bp3-icon-th-list::before{content:\"\ue668\"}.jupyter-wrapper .bp3-icon-thumbs-down::before{content:\"\ue6be\"}.jupyter-wrapper .bp3-icon-thumbs-up::before{content:\"\ue6bd\"}.jupyter-wrapper .bp3-icon-tick::before{content:\"\u2713\"}.jupyter-wrapper .bp3-icon-tick-circle::before{content:\"\ue779\"}.jupyter-wrapper .bp3-icon-time::before{content:\"\u23f2\"}.jupyter-wrapper .bp3-icon-timeline-area-chart::before{content:\"\ue6cd\"}.jupyter-wrapper .bp3-icon-timeline-bar-chart::before{content:\"\ue620\"}.jupyter-wrapper .bp3-icon-timeline-events::before{content:\"\ue61e\"}.jupyter-wrapper .bp3-icon-timeline-line-chart::before{content:\"\ue61f\"}.jupyter-wrapper .bp3-icon-tint::before{content:\"\ue6b2\"}.jupyter-wrapper .bp3-icon-torch::before{content:\"\ue677\"}.jupyter-wrapper .bp3-icon-tractor::before{content:\"\ue90c\"}.jupyter-wrapper .bp3-icon-train::before{content:\"\ue79f\"}.jupyter-wrapper .bp3-icon-translate::before{content:\"\ue759\"}.jupyter-wrapper .bp3-icon-trash::before{content:\"\ue63b\"}.jupyter-wrapper .bp3-icon-tree::before{content:\"\ue7b7\"}.jupyter-wrapper .bp3-icon-trending-down::before{content:\"\ue71a\"}.jupyter-wrapper .bp3-icon-trending-up::before{content:\"\ue719\"}.jupyter-wrapper .bp3-icon-truck::before{content:\"\ue90b\"}.jupyter-wrapper .bp3-icon-two-columns::before{content:\"\ue657\"}.jupyter-wrapper .bp3-icon-unarchive::before{content:\"\ue906\"}.jupyter-wrapper .bp3-icon-underline::before{content:\"\u2381\"}.jupyter-wrapper .bp3-icon-undo::before{content:\"\u238c\"}.jupyter-wrapper .bp3-icon-ungroup-objects::before{content:\"\ue688\"}.jupyter-wrapper .bp3-icon-unknown-vehicle::before{content:\"\ue73d\"}.jupyter-wrapper .bp3-icon-unlock::before{content:\"\ue626\"}.jupyter-wrapper .bp3-icon-unpin::before{content:\"\ue650\"}.jupyter-wrapper .bp3-icon-unresolve::before{content:\"\ue679\"}.jupyter-wrapper .bp3-icon-updated::before{content:\"\ue7a7\"}.jupyter-wrapper .bp3-icon-upload::before{content:\"\ue68f\"}.jupyter-wrapper .bp3-icon-user::before{content:\"\ue627\"}.jupyter-wrapper .bp3-icon-variable::before{content:\"\ue6f5\"}.jupyter-wrapper .bp3-icon-vertical-bar-chart-asc::before{content:\"\ue75b\"}.jupyter-wrapper .bp3-icon-vertical-bar-chart-desc::before{content:\"\ue71c\"}.jupyter-wrapper .bp3-icon-vertical-distribution::before{content:\"\ue721\"}.jupyter-wrapper .bp3-icon-video::before{content:\"\ue6a0\"}.jupyter-wrapper .bp3-icon-volume-down::before{content:\"\ue6a4\"}.jupyter-wrapper .bp3-icon-volume-off::before{content:\"\ue6a3\"}.jupyter-wrapper .bp3-icon-volume-up::before{content:\"\ue6a5\"}.jupyter-wrapper .bp3-icon-walk::before{content:\"\ue79d\"}.jupyter-wrapper .bp3-icon-warning-sign::before{content:\"\ue647\"}.jupyter-wrapper .bp3-icon-waterfall-chart::before{content:\"\ue6e6\"}.jupyter-wrapper .bp3-icon-widget::before{content:\"\ue678\"}.jupyter-wrapper .bp3-icon-widget-button::before{content:\"\ue790\"}.jupyter-wrapper .bp3-icon-widget-footer::before{content:\"\ue792\"}.jupyter-wrapper .bp3-icon-widget-header::before{content:\"\ue791\"}.jupyter-wrapper .bp3-icon-wrench::before{content:\"\ue734\"}.jupyter-wrapper .bp3-icon-zoom-in::before{content:\"\ue641\"}.jupyter-wrapper .bp3-icon-zoom-out::before{content:\"\ue642\"}.jupyter-wrapper .bp3-icon-zoom-to-fit::before{content:\"\ue67b\"}.jupyter-wrapper .bp3-submenu>.bp3-popover-wrapper{display:block}.jupyter-wrapper .bp3-submenu .bp3-popover-target{display:block}.jupyter-wrapper .bp3-submenu.bp3-popover{-webkit-box-shadow:none;box-shadow:none;padding:0 5px}.jupyter-wrapper .bp3-submenu.bp3-popover>.bp3-popover-content{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-dark .bp3-submenu.bp3-popover,.jupyter-wrapper .bp3-submenu.bp3-popover.bp3-dark{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-dark .bp3-submenu.bp3-popover>.bp3-popover-content,.jupyter-wrapper .bp3-submenu.bp3-popover.bp3-dark>.bp3-popover-content{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-menu{margin:0;border-radius:3px;background:#fff;min-width:180px;padding:5px;list-style:none;text-align:left;color:#182026}.jupyter-wrapper .bp3-menu-divider{display:block;margin:5px;border-top:1px solid rgba(16,22,26,.15)}.jupyter-wrapper .bp3-dark .bp3-menu-divider{border-top-color:rgba(255,255,255,.15)}.jupyter-wrapper .bp3-menu-item{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:start;-ms-flex-align:start;align-items:flex-start;border-radius:2px;padding:5px 7px;text-decoration:none;line-height:20px;color:inherit;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-menu-item>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-menu-item>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-menu-item::before,.jupyter-wrapper .bp3-menu-item>*{margin-right:7px}.jupyter-wrapper .bp3-menu-item:empty::before,.jupyter-wrapper .bp3-menu-item>:last-child{margin-right:0}.jupyter-wrapper .bp3-menu-item>.bp3-fill{word-break:break-word}.jupyter-wrapper .bp3-menu-item:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-menu-item{background-color:rgba(167,182,194,.3);cursor:pointer;text-decoration:none}.jupyter-wrapper .bp3-menu-item.bp3-disabled{background-color:inherit;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-dark .bp3-menu-item{color:inherit}.jupyter-wrapper .bp3-dark .bp3-menu-item:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-menu-item{background-color:rgba(138,155,168,.15);color:inherit}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-disabled{background-color:inherit;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-menu-item.bp3-intent-primary{color:#106ba3}.jupyter-wrapper .bp3-menu-item.bp3-intent-primary .bp3-icon{color:inherit}.jupyter-wrapper .bp3-menu-item.bp3-intent-primary::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary .bp3-menu-item-label{color:#106ba3}.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary.bp3-active{background-color:#137cbd}.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:active{background-color:#106ba3}.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:hover::before,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:hover::after,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:active,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary:active .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary.bp3-active,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary.bp3-active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary.bp3-active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-primary.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-menu-item.bp3-intent-success{color:#0d8050}.jupyter-wrapper .bp3-menu-item.bp3-intent-success .bp3-icon{color:inherit}.jupyter-wrapper .bp3-menu-item.bp3-intent-success::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-success::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-success .bp3-menu-item-label{color:#0d8050}.jupyter-wrapper .bp3-menu-item.bp3-intent-success:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-success.bp3-active{background-color:#0f9960}.jupyter-wrapper .bp3-menu-item.bp3-intent-success:active{background-color:#0d8050}.jupyter-wrapper .bp3-menu-item.bp3-intent-success:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-success:hover::before,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-success:hover::after,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-success:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-success:active,.jupyter-wrapper .bp3-menu-item.bp3-intent-success:active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-success:active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-success:active .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-success.bp3-active,.jupyter-wrapper .bp3-menu-item.bp3-intent-success.bp3-active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-success.bp3-active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-success.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-menu-item.bp3-intent-warning{color:#bf7326}.jupyter-wrapper .bp3-menu-item.bp3-intent-warning .bp3-icon{color:inherit}.jupyter-wrapper .bp3-menu-item.bp3-intent-warning::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning .bp3-menu-item-label{color:#bf7326}.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning.bp3-active{background-color:#d9822b}.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:active{background-color:#bf7326}.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:hover::before,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:hover::after,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:active,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning:active .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning.bp3-active,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning.bp3-active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning.bp3-active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-warning.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-menu-item.bp3-intent-danger{color:#c23030}.jupyter-wrapper .bp3-menu-item.bp3-intent-danger .bp3-icon{color:inherit}.jupyter-wrapper .bp3-menu-item.bp3-intent-danger::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger .bp3-menu-item-label{color:#c23030}.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger.bp3-active{background-color:#db3737}.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:active{background-color:#c23030}.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:hover::before,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:hover::after,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:active,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger:active .bp3-menu-item-label,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger.bp3-active,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger.bp3-active::before,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger.bp3-active::after,.jupyter-wrapper .bp3-menu-item.bp3-intent-danger.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-menu-item::before{line-height:1;font-family:\"Icons16\",sans-serif;font-size:16px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;margin-right:7px}.jupyter-wrapper .bp3-menu-item::before,.jupyter-wrapper .bp3-menu-item>.bp3-icon{margin-top:2px;color:#5c7080}.jupyter-wrapper .bp3-menu-item .bp3-menu-item-label{color:#5c7080}.jupyter-wrapper .bp3-menu-item:hover,.jupyter-wrapper .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-menu-item{color:inherit}.jupyter-wrapper .bp3-menu-item.bp3-active,.jupyter-wrapper .bp3-menu-item:active{background-color:rgba(115,134,148,.3)}.jupyter-wrapper .bp3-menu-item.bp3-disabled{outline:none !important;background-color:inherit !important;cursor:not-allowed !important;color:rgba(92,112,128,.6) !important}.jupyter-wrapper .bp3-menu-item.bp3-disabled::before,.jupyter-wrapper .bp3-menu-item.bp3-disabled>.bp3-icon,.jupyter-wrapper .bp3-menu-item.bp3-disabled .bp3-menu-item-label{color:rgba(92,112,128,.6) !important}.jupyter-wrapper .bp3-large .bp3-menu-item{padding:9px 7px;line-height:22px;font-size:16px}.jupyter-wrapper .bp3-large .bp3-menu-item .bp3-icon{margin-top:3px}.jupyter-wrapper .bp3-large .bp3-menu-item::before{line-height:1;font-family:\"Icons20\",sans-serif;font-size:20px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;margin-top:1px;margin-right:10px}.jupyter-wrapper button.bp3-menu-item{border:none;background:none;width:100%;text-align:left}.jupyter-wrapper .bp3-menu-header{display:block;margin:5px;border-top:1px solid rgba(16,22,26,.15);cursor:default;padding-left:2px}.jupyter-wrapper .bp3-dark .bp3-menu-header{border-top-color:rgba(255,255,255,.15)}.jupyter-wrapper .bp3-menu-header:first-of-type{border-top:none}.jupyter-wrapper .bp3-menu-header>h6{color:#182026;font-weight:600;overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal;margin:0;padding:10px 7px 0 1px;line-height:17px}.jupyter-wrapper .bp3-dark .bp3-menu-header>h6{color:#f5f8fa}.jupyter-wrapper .bp3-menu-header:first-of-type>h6{padding-top:0}.jupyter-wrapper .bp3-large .bp3-menu-header>h6{padding-top:15px;padding-bottom:5px;font-size:18px}.jupyter-wrapper .bp3-large .bp3-menu-header:first-of-type>h6{padding-top:0}.jupyter-wrapper .bp3-dark .bp3-menu{background:#30404d;color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary .bp3-icon{color:inherit}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary .bp3-menu-item-label{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary.bp3-active{background-color:#137cbd}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:active{background-color:#106ba3}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:hover::before,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item::before,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:hover::after,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item::after,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-primary.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary:active .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary.bp3-active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary.bp3-active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary.bp3-active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-primary.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success{color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success .bp3-icon{color:inherit}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success .bp3-menu-item-label{color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success.bp3-active{background-color:#0f9960}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:active{background-color:#0d8050}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:hover::before,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item::before,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:hover::after,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item::after,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-success.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success:active .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success.bp3-active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success.bp3-active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success.bp3-active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-success.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning{color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning .bp3-icon{color:inherit}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning .bp3-menu-item-label{color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning.bp3-active{background-color:#d9822b}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:active{background-color:#bf7326}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:hover::before,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item::before,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:hover::after,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item::after,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-warning.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning:active .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning.bp3-active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning.bp3-active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning.bp3-active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-warning.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger{color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger .bp3-icon{color:inherit}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger .bp3-menu-item-label{color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger.bp3-active{background-color:#db3737}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:active{background-color:#c23030}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:hover,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:hover::before,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item::before,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:hover::after,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item::after,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:hover .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-submenu .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-submenu .bp3-dark .bp3-popover-target.bp3-popover-open>.bp3-intent-danger.bp3-menu-item .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger:active .bp3-menu-item-label,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger.bp3-active,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger.bp3-active::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger.bp3-active::after,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-intent-danger.bp3-active .bp3-menu-item-label{color:#fff}.jupyter-wrapper .bp3-dark .bp3-menu-item::before,.jupyter-wrapper .bp3-dark .bp3-menu-item>.bp3-icon{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-menu-item .bp3-menu-item-label{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-active,.jupyter-wrapper .bp3-dark .bp3-menu-item:active{background-color:rgba(138,155,168,.3)}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-disabled{color:rgba(167,182,194,.6) !important}.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-disabled::before,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-disabled>.bp3-icon,.jupyter-wrapper .bp3-dark .bp3-menu-item.bp3-disabled .bp3-menu-item-label{color:rgba(167,182,194,.6) !important}.jupyter-wrapper .bp3-dark .bp3-menu-divider,.jupyter-wrapper .bp3-dark .bp3-menu-header{border-color:rgba(255,255,255,.15)}.jupyter-wrapper .bp3-dark .bp3-menu-header>h6{color:#f5f8fa}.jupyter-wrapper .bp3-label .bp3-menu{margin-top:5px}.jupyter-wrapper .bp3-navbar{position:relative;z-index:10;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.2);background-color:#fff;width:100%;height:50px;padding:0 15px}.jupyter-wrapper .bp3-navbar.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-navbar{background-color:#394b59}.jupyter-wrapper .bp3-navbar.bp3-dark{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-navbar{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 0 0 rgba(16,22,26,0),0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-navbar.bp3-fixed-top{position:fixed;top:0;right:0;left:0}.jupyter-wrapper .bp3-navbar-heading{margin-right:15px;font-size:16px}.jupyter-wrapper .bp3-navbar-group{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center;height:50px}.jupyter-wrapper .bp3-navbar-group.bp3-align-left{float:left}.jupyter-wrapper .bp3-navbar-group.bp3-align-right{float:right}.jupyter-wrapper .bp3-navbar-divider{margin:0 10px;border-left:1px solid rgba(16,22,26,.15);height:20px}.jupyter-wrapper .bp3-dark .bp3-navbar-divider{border-left-color:rgba(255,255,255,.15)}.jupyter-wrapper .bp3-non-ideal-state{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:center;-ms-flex-pack:center;justify-content:center;width:100%;height:100%;text-align:center}.jupyter-wrapper .bp3-non-ideal-state>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-non-ideal-state>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-non-ideal-state::before,.jupyter-wrapper .bp3-non-ideal-state>*{margin-bottom:20px}.jupyter-wrapper .bp3-non-ideal-state:empty::before,.jupyter-wrapper .bp3-non-ideal-state>:last-child{margin-bottom:0}.jupyter-wrapper .bp3-non-ideal-state>*{max-width:400px}.jupyter-wrapper .bp3-non-ideal-state-visual{color:rgba(92,112,128,.6);font-size:60px}.jupyter-wrapper .bp3-dark .bp3-non-ideal-state-visual{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-overflow-list{display:-webkit-box;display:-ms-flexbox;display:flex;-ms-flex-wrap:nowrap;flex-wrap:nowrap;min-width:0}.jupyter-wrapper .bp3-overflow-list-spacer{-ms-flex-negative:1;flex-shrink:1;width:1px}.jupyter-wrapper body.bp3-overlay-open{overflow:hidden}.jupyter-wrapper .bp3-overlay{position:static;top:0;right:0;bottom:0;left:0;z-index:20}.jupyter-wrapper .bp3-overlay:not(.bp3-overlay-open){pointer-events:none}.jupyter-wrapper .bp3-overlay.bp3-overlay-container{position:fixed;overflow:hidden}.jupyter-wrapper .bp3-overlay.bp3-overlay-container.bp3-overlay-inline{position:absolute}.jupyter-wrapper .bp3-overlay.bp3-overlay-scroll-container{position:fixed;overflow:auto}.jupyter-wrapper .bp3-overlay.bp3-overlay-scroll-container.bp3-overlay-inline{position:absolute}.jupyter-wrapper .bp3-overlay.bp3-overlay-inline{display:inline;overflow:visible}.jupyter-wrapper .bp3-overlay-content{position:fixed;z-index:20}.jupyter-wrapper .bp3-overlay-inline .bp3-overlay-content,.jupyter-wrapper .bp3-overlay-scroll-container .bp3-overlay-content{position:absolute}.jupyter-wrapper .bp3-overlay-backdrop{position:fixed;top:0;right:0;bottom:0;left:0;opacity:1;z-index:20;background-color:rgba(16,22,26,.7);overflow:auto;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-overlay-backdrop.bp3-overlay-enter,.jupyter-wrapper .bp3-overlay-backdrop.bp3-overlay-appear{opacity:0}.jupyter-wrapper .bp3-overlay-backdrop.bp3-overlay-enter-active,.jupyter-wrapper .bp3-overlay-backdrop.bp3-overlay-appear-active{opacity:1;-webkit-transition-property:opacity;transition-property:opacity;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-overlay-backdrop.bp3-overlay-exit{opacity:1}.jupyter-wrapper .bp3-overlay-backdrop.bp3-overlay-exit-active{opacity:0;-webkit-transition-property:opacity;transition-property:opacity;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-overlay-backdrop:focus{outline:none}.jupyter-wrapper .bp3-overlay-inline .bp3-overlay-backdrop{position:absolute}.jupyter-wrapper .bp3-panel-stack{position:relative;overflow:hidden}.jupyter-wrapper .bp3-panel-stack-header{display:-webkit-box;display:-ms-flexbox;display:flex;-ms-flex-negative:0;flex-shrink:0;-webkit-box-align:center;-ms-flex-align:center;align-items:center;z-index:1;-webkit-box-shadow:0 1px rgba(16,22,26,.15);box-shadow:0 1px rgba(16,22,26,.15);height:30px}.jupyter-wrapper .bp3-dark .bp3-panel-stack-header{-webkit-box-shadow:0 1px rgba(255,255,255,.15);box-shadow:0 1px rgba(255,255,255,.15)}.jupyter-wrapper .bp3-panel-stack-header>span{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-flex:1;-ms-flex:1;flex:1;-webkit-box-align:stretch;-ms-flex-align:stretch;align-items:stretch}.jupyter-wrapper .bp3-panel-stack-header .bp3-heading{margin:0 5px}.jupyter-wrapper .bp3-button.bp3-panel-stack-header-back{margin-left:5px;padding-left:0;white-space:nowrap}.jupyter-wrapper .bp3-button.bp3-panel-stack-header-back .bp3-icon{margin:0 2px}.jupyter-wrapper .bp3-panel-stack-view{position:absolute;top:0;right:0;bottom:0;left:0;display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;margin-right:-1px;border-right:1px solid rgba(16,22,26,.15);background-color:#fff;overflow-y:auto}.jupyter-wrapper .bp3-dark .bp3-panel-stack-view{background-color:#30404d}.jupyter-wrapper .bp3-panel-stack-push .bp3-panel-stack-enter,.jupyter-wrapper .bp3-panel-stack-push .bp3-panel-stack-appear{-webkit-transform:translateX(100%);transform:translateX(100%);opacity:0}.jupyter-wrapper .bp3-panel-stack-push .bp3-panel-stack-enter-active,.jupyter-wrapper .bp3-panel-stack-push .bp3-panel-stack-appear-active{-webkit-transform:translate(0%);transform:translate(0%);opacity:1;-webkit-transition-property:opacity,-webkit-transform;transition-property:opacity,-webkit-transform;transition-property:transform,opacity;transition-property:transform,opacity,-webkit-transform;-webkit-transition-duration:400ms;transition-duration:400ms;-webkit-transition-timing-function:ease;transition-timing-function:ease;-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-panel-stack-push .bp3-panel-stack-exit{-webkit-transform:translate(0%);transform:translate(0%);opacity:1}.jupyter-wrapper .bp3-panel-stack-push .bp3-panel-stack-exit-active{-webkit-transform:translateX(-50%);transform:translateX(-50%);opacity:0;-webkit-transition-property:opacity,-webkit-transform;transition-property:opacity,-webkit-transform;transition-property:transform,opacity;transition-property:transform,opacity,-webkit-transform;-webkit-transition-duration:400ms;transition-duration:400ms;-webkit-transition-timing-function:ease;transition-timing-function:ease;-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-panel-stack-pop .bp3-panel-stack-enter,.jupyter-wrapper .bp3-panel-stack-pop .bp3-panel-stack-appear{-webkit-transform:translateX(-50%);transform:translateX(-50%);opacity:0}.jupyter-wrapper .bp3-panel-stack-pop .bp3-panel-stack-enter-active,.jupyter-wrapper .bp3-panel-stack-pop .bp3-panel-stack-appear-active{-webkit-transform:translate(0%);transform:translate(0%);opacity:1;-webkit-transition-property:opacity,-webkit-transform;transition-property:opacity,-webkit-transform;transition-property:transform,opacity;transition-property:transform,opacity,-webkit-transform;-webkit-transition-duration:400ms;transition-duration:400ms;-webkit-transition-timing-function:ease;transition-timing-function:ease;-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-panel-stack-pop .bp3-panel-stack-exit{-webkit-transform:translate(0%);transform:translate(0%);opacity:1}.jupyter-wrapper .bp3-panel-stack-pop .bp3-panel-stack-exit-active{-webkit-transform:translateX(100%);transform:translateX(100%);opacity:0;-webkit-transition-property:opacity,-webkit-transform;transition-property:opacity,-webkit-transform;transition-property:transform,opacity;transition-property:transform,opacity,-webkit-transform;-webkit-transition-duration:400ms;transition-duration:400ms;-webkit-transition-timing-function:ease;transition-timing-function:ease;-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-popover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);-webkit-transform:scale(1);transform:scale(1);display:inline-block;z-index:20;border-radius:3px}.jupyter-wrapper .bp3-popover .bp3-popover-arrow{position:absolute;width:30px;height:30px}.jupyter-wrapper .bp3-popover .bp3-popover-arrow::before{margin:5px;width:20px;height:20px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-top>.bp3-popover{margin-top:-17px;margin-bottom:17px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-top>.bp3-popover>.bp3-popover-arrow{bottom:-11px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-top>.bp3-popover>.bp3-popover-arrow svg{-webkit-transform:rotate(-90deg);transform:rotate(-90deg)}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-right>.bp3-popover{margin-left:17px}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-right>.bp3-popover>.bp3-popover-arrow{left:-11px}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-right>.bp3-popover>.bp3-popover-arrow svg{-webkit-transform:rotate(0);transform:rotate(0)}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-bottom>.bp3-popover{margin-top:17px}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-bottom>.bp3-popover>.bp3-popover-arrow{top:-11px}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-bottom>.bp3-popover>.bp3-popover-arrow svg{-webkit-transform:rotate(90deg);transform:rotate(90deg)}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-left>.bp3-popover{margin-right:17px;margin-left:-17px}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-left>.bp3-popover>.bp3-popover-arrow{right:-11px}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-left>.bp3-popover>.bp3-popover-arrow svg{-webkit-transform:rotate(180deg);transform:rotate(180deg)}.jupyter-wrapper .bp3-tether-element-attached-middle>.bp3-popover>.bp3-popover-arrow{top:50%;-webkit-transform:translateY(-50%);transform:translateY(-50%)}.jupyter-wrapper .bp3-tether-element-attached-center>.bp3-popover>.bp3-popover-arrow{right:50%;-webkit-transform:translateX(50%);transform:translateX(50%)}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-top>.bp3-popover>.bp3-popover-arrow{top:-0.3934px}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-right>.bp3-popover>.bp3-popover-arrow{right:-0.3934px}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-left>.bp3-popover>.bp3-popover-arrow{left:-0.3934px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-bottom>.bp3-popover>.bp3-popover-arrow{bottom:-0.3934px}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-element-attached-left>.bp3-popover{-webkit-transform-origin:top left;transform-origin:top left}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-element-attached-center>.bp3-popover{-webkit-transform-origin:top center;transform-origin:top center}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-element-attached-right>.bp3-popover{-webkit-transform-origin:top right;transform-origin:top right}.jupyter-wrapper .bp3-tether-element-attached-middle.bp3-tether-element-attached-left>.bp3-popover{-webkit-transform-origin:center left;transform-origin:center left}.jupyter-wrapper .bp3-tether-element-attached-middle.bp3-tether-element-attached-center>.bp3-popover{-webkit-transform-origin:center center;transform-origin:center center}.jupyter-wrapper .bp3-tether-element-attached-middle.bp3-tether-element-attached-right>.bp3-popover{-webkit-transform-origin:center right;transform-origin:center right}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-element-attached-left>.bp3-popover{-webkit-transform-origin:bottom left;transform-origin:bottom left}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-element-attached-center>.bp3-popover{-webkit-transform-origin:bottom center;transform-origin:bottom center}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-element-attached-right>.bp3-popover{-webkit-transform-origin:bottom right;transform-origin:bottom right}.jupyter-wrapper .bp3-popover .bp3-popover-content{background:#fff;color:inherit}.jupyter-wrapper .bp3-popover .bp3-popover-arrow::before{-webkit-box-shadow:1px 1px 6px rgba(16,22,26,.2);box-shadow:1px 1px 6px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-popover .bp3-popover-arrow-border{fill:#10161a;fill-opacity:.1}.jupyter-wrapper .bp3-popover .bp3-popover-arrow-fill{fill:#fff}.jupyter-wrapper .bp3-popover-enter>.bp3-popover,.jupyter-wrapper .bp3-popover-appear>.bp3-popover{-webkit-transform:scale(0.3);transform:scale(0.3)}.jupyter-wrapper .bp3-popover-enter-active>.bp3-popover,.jupyter-wrapper .bp3-popover-appear-active>.bp3-popover{-webkit-transform:scale(1);transform:scale(1);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:300ms;transition-duration:300ms;-webkit-transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-popover-exit>.bp3-popover{-webkit-transform:scale(1);transform:scale(1)}.jupyter-wrapper .bp3-popover-exit-active>.bp3-popover{-webkit-transform:scale(0.3);transform:scale(0.3);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:300ms;transition-duration:300ms;-webkit-transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-popover .bp3-popover-content{position:relative;border-radius:3px}.jupyter-wrapper .bp3-popover.bp3-popover-content-sizing .bp3-popover-content{max-width:350px;padding:20px}.jupyter-wrapper .bp3-popover-target+.bp3-overlay .bp3-popover.bp3-popover-content-sizing{width:350px}.jupyter-wrapper .bp3-popover.bp3-minimal{margin:0 !important}.jupyter-wrapper .bp3-popover.bp3-minimal .bp3-popover-arrow{display:none}.jupyter-wrapper .bp3-popover.bp3-minimal.bp3-popover{-webkit-transform:scale(1);transform:scale(1)}.jupyter-wrapper .bp3-popover-enter>.bp3-popover.bp3-minimal.bp3-popover,.jupyter-wrapper .bp3-popover-appear>.bp3-popover.bp3-minimal.bp3-popover{-webkit-transform:scale(1);transform:scale(1)}.jupyter-wrapper .bp3-popover-enter-active>.bp3-popover.bp3-minimal.bp3-popover,.jupyter-wrapper .bp3-popover-appear-active>.bp3-popover.bp3-minimal.bp3-popover{-webkit-transform:scale(1);transform:scale(1);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-popover-exit>.bp3-popover.bp3-minimal.bp3-popover{-webkit-transform:scale(1);transform:scale(1)}.jupyter-wrapper .bp3-popover-exit-active>.bp3-popover.bp3-minimal.bp3-popover{-webkit-transform:scale(1);transform:scale(1);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-popover.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-popover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-popover.bp3-dark .bp3-popover-content,.jupyter-wrapper .bp3-dark .bp3-popover .bp3-popover-content{background:#30404d;color:inherit}.jupyter-wrapper .bp3-popover.bp3-dark .bp3-popover-arrow::before,.jupyter-wrapper .bp3-dark .bp3-popover .bp3-popover-arrow::before{-webkit-box-shadow:1px 1px 6px rgba(16,22,26,.4);box-shadow:1px 1px 6px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-popover.bp3-dark .bp3-popover-arrow-border,.jupyter-wrapper .bp3-dark .bp3-popover .bp3-popover-arrow-border{fill:#10161a;fill-opacity:.2}.jupyter-wrapper .bp3-popover.bp3-dark .bp3-popover-arrow-fill,.jupyter-wrapper .bp3-dark .bp3-popover .bp3-popover-arrow-fill{fill:#30404d}.jupyter-wrapper .bp3-popover-arrow::before{display:block;position:absolute;-webkit-transform:rotate(45deg);transform:rotate(45deg);border-radius:2px;content:\"\"}.jupyter-wrapper .bp3-tether-pinned .bp3-popover-arrow{display:none}.jupyter-wrapper .bp3-popover-backdrop{background:rgba(255,255,255,0)}.jupyter-wrapper .bp3-transition-container{opacity:1;display:-webkit-box;display:-ms-flexbox;display:flex;z-index:20}.jupyter-wrapper .bp3-transition-container.bp3-popover-enter,.jupyter-wrapper .bp3-transition-container.bp3-popover-appear{opacity:0}.jupyter-wrapper .bp3-transition-container.bp3-popover-enter-active,.jupyter-wrapper .bp3-transition-container.bp3-popover-appear-active{opacity:1;-webkit-transition-property:opacity;transition-property:opacity;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-transition-container.bp3-popover-exit{opacity:1}.jupyter-wrapper .bp3-transition-container.bp3-popover-exit-active{opacity:0;-webkit-transition-property:opacity;transition-property:opacity;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-transition-container:focus{outline:none}.jupyter-wrapper .bp3-transition-container.bp3-popover-leave .bp3-popover-content{pointer-events:none}.jupyter-wrapper .bp3-transition-container[data-x-out-of-boundaries]{display:none}.jupyter-wrapper span.bp3-popover-target{display:inline-block}.jupyter-wrapper .bp3-popover-wrapper.bp3-fill{width:100%}.jupyter-wrapper .bp3-portal{position:absolute;top:0;right:0;left:0}@-webkit-keyframes linear-progress-bar-stripes{from{background-position:0 0}to{background-position:30px 0}}@keyframes linear-progress-bar-stripes{from{background-position:0 0}to{background-position:30px 0}}.jupyter-wrapper .bp3-progress-bar{display:block;position:relative;border-radius:40px;background:rgba(92,112,128,.2);width:100%;height:8px;overflow:hidden}.jupyter-wrapper .bp3-progress-bar .bp3-progress-meter{position:absolute;border-radius:40px;background:linear-gradient(-45deg, rgba(255, 255, 255, 0.2) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.2) 50%, rgba(255, 255, 255, 0.2) 75%, transparent 75%);background-color:rgba(92,112,128,.8);background-size:30px 30px;width:100%;height:100%;-webkit-transition:width 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:width 200ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-progress-bar:not(.bp3-no-animation):not(.bp3-no-stripes) .bp3-progress-meter{animation:linear-progress-bar-stripes 300ms linear infinite reverse}.jupyter-wrapper .bp3-progress-bar.bp3-no-stripes .bp3-progress-meter{background-image:none}.jupyter-wrapper .bp3-dark .bp3-progress-bar{background:rgba(16,22,26,.5)}.jupyter-wrapper .bp3-dark .bp3-progress-bar .bp3-progress-meter{background-color:#8a9ba8}.jupyter-wrapper .bp3-progress-bar.bp3-intent-primary .bp3-progress-meter{background-color:#137cbd}.jupyter-wrapper .bp3-progress-bar.bp3-intent-success .bp3-progress-meter{background-color:#0f9960}.jupyter-wrapper .bp3-progress-bar.bp3-intent-warning .bp3-progress-meter{background-color:#d9822b}.jupyter-wrapper .bp3-progress-bar.bp3-intent-danger .bp3-progress-meter{background-color:#db3737}@-webkit-keyframes skeleton-glow{from{border-color:rgba(206,217,224,.2);background:rgba(206,217,224,.2)}to{border-color:rgba(92,112,128,.2);background:rgba(92,112,128,.2)}}@keyframes skeleton-glow{from{border-color:rgba(206,217,224,.2);background:rgba(206,217,224,.2)}to{border-color:rgba(92,112,128,.2);background:rgba(92,112,128,.2)}}.jupyter-wrapper .bp3-skeleton{border-color:rgba(206,217,224,.2) !important;border-radius:2px;-webkit-box-shadow:none !important;box-shadow:none !important;background:rgba(206,217,224,.2);background-clip:padding-box !important;cursor:default;color:rgba(0,0,0,0) !important;-webkit-animation:1000ms linear infinite alternate skeleton-glow;animation:1000ms linear infinite alternate skeleton-glow;pointer-events:none;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-skeleton::before,.jupyter-wrapper .bp3-skeleton::after,.jupyter-wrapper .bp3-skeleton *{visibility:hidden !important}.jupyter-wrapper .bp3-slider{width:100%;min-width:150px;height:40px;position:relative;outline:none;cursor:default;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-slider:hover{cursor:pointer}.jupyter-wrapper .bp3-slider:active{cursor:-webkit-grabbing;cursor:grabbing}.jupyter-wrapper .bp3-slider.bp3-disabled{opacity:.5;cursor:not-allowed}.jupyter-wrapper .bp3-slider.bp3-slider-unlabeled{height:16px}.jupyter-wrapper .bp3-slider-track,.jupyter-wrapper .bp3-slider-progress{top:5px;right:0;left:0;height:6px;position:absolute}.jupyter-wrapper .bp3-slider-track{border-radius:3px;overflow:hidden}.jupyter-wrapper .bp3-slider-progress{background:rgba(92,112,128,.2)}.jupyter-wrapper .bp3-dark .bp3-slider-progress{background:rgba(16,22,26,.5)}.jupyter-wrapper .bp3-slider-progress.bp3-intent-primary{background-color:#137cbd}.jupyter-wrapper .bp3-slider-progress.bp3-intent-success{background-color:#0f9960}.jupyter-wrapper .bp3-slider-progress.bp3-intent-warning{background-color:#d9822b}.jupyter-wrapper .bp3-slider-progress.bp3-intent-danger{background-color:#db3737}.jupyter-wrapper .bp3-slider-handle{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-color:#f5f8fa;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.8)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.8), rgba(255, 255, 255, 0));color:#182026;position:absolute;top:0;left:0;border-radius:3px;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.2);cursor:pointer;width:16px;height:16px}.jupyter-wrapper .bp3-slider-handle:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-clip:padding-box;background-color:#ebf1f5}.jupyter-wrapper .bp3-slider-handle:active,.jupyter-wrapper .bp3-slider-handle.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);background-color:#d8e1e8;background-image:none}.jupyter-wrapper .bp3-slider-handle:disabled,.jupyter-wrapper .bp3-slider-handle.bp3-disabled{outline:none;-webkit-box-shadow:none;box-shadow:none;background-color:rgba(206,217,224,.5);background-image:none;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-slider-handle:disabled.bp3-active,.jupyter-wrapper .bp3-slider-handle:disabled.bp3-active:hover,.jupyter-wrapper .bp3-slider-handle.bp3-disabled.bp3-active,.jupyter-wrapper .bp3-slider-handle.bp3-disabled.bp3-active:hover{background:rgba(206,217,224,.7)}.jupyter-wrapper .bp3-slider-handle:focus{z-index:1}.jupyter-wrapper .bp3-slider-handle:hover{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 -1px 0 rgba(16,22,26,.1);background-clip:padding-box;background-color:#ebf1f5;z-index:2;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 1px 1px rgba(16,22,26,.2);cursor:-webkit-grab;cursor:grab}.jupyter-wrapper .bp3-slider-handle.bp3-active{-webkit-box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:inset 0 0 0 1px rgba(16,22,26,.2),inset 0 1px 2px rgba(16,22,26,.2);background-color:#d8e1e8;background-image:none;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),inset 0 1px 1px rgba(16,22,26,.1);box-shadow:0 0 0 1px rgba(16,22,26,.2),inset 0 1px 1px rgba(16,22,26,.1);cursor:-webkit-grabbing;cursor:grabbing}.jupyter-wrapper .bp3-disabled .bp3-slider-handle{-webkit-box-shadow:none;box-shadow:none;background:#bfccd6;pointer-events:none}.jupyter-wrapper .bp3-dark .bp3-slider-handle{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#394b59;background-image:-webkit-gradient(linear, left top, left bottom, from(rgba(255, 255, 255, 0.05)), to(rgba(255, 255, 255, 0)));background-image:linear-gradient(to bottom, rgba(255, 255, 255, 0.05), rgba(255, 255, 255, 0));color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-slider-handle:hover,.jupyter-wrapper .bp3-dark .bp3-slider-handle:active,.jupyter-wrapper .bp3-dark .bp3-slider-handle.bp3-active{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-slider-handle:hover{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.4);background-color:#30404d}.jupyter-wrapper .bp3-dark .bp3-slider-handle:active,.jupyter-wrapper .bp3-dark .bp3-slider-handle.bp3-active{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.6),inset 0 1px 2px rgba(16,22,26,.2);background-color:#202b33;background-image:none}.jupyter-wrapper .bp3-dark .bp3-slider-handle:disabled,.jupyter-wrapper .bp3-dark .bp3-slider-handle.bp3-disabled{-webkit-box-shadow:none;box-shadow:none;background-color:rgba(57,75,89,.5);background-image:none;color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-slider-handle:disabled.bp3-active,.jupyter-wrapper .bp3-dark .bp3-slider-handle.bp3-disabled.bp3-active{background:rgba(57,75,89,.7)}.jupyter-wrapper .bp3-dark .bp3-slider-handle .bp3-button-spinner .bp3-spinner-head{background:rgba(16,22,26,.5);stroke:#8a9ba8}.jupyter-wrapper .bp3-dark .bp3-slider-handle,.jupyter-wrapper .bp3-dark .bp3-slider-handle:hover{background-color:#394b59}.jupyter-wrapper .bp3-dark .bp3-slider-handle.bp3-active{background-color:#293742}.jupyter-wrapper .bp3-dark .bp3-disabled .bp3-slider-handle{border-color:#5c7080;-webkit-box-shadow:none;box-shadow:none;background:#5c7080}.jupyter-wrapper .bp3-slider-handle .bp3-slider-label{margin-left:8px;border-radius:3px;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);background:#394b59;color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-slider-handle .bp3-slider-label{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);background:#e1e8ed;color:#394b59}.jupyter-wrapper .bp3-disabled .bp3-slider-handle .bp3-slider-label{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-slider-handle.bp3-start,.jupyter-wrapper .bp3-slider-handle.bp3-end{width:8px}.jupyter-wrapper .bp3-slider-handle.bp3-start{border-top-right-radius:0;border-bottom-right-radius:0}.jupyter-wrapper .bp3-slider-handle.bp3-end{margin-left:8px;border-top-left-radius:0;border-bottom-left-radius:0}.jupyter-wrapper .bp3-slider-handle.bp3-end .bp3-slider-label{margin-left:0}.jupyter-wrapper .bp3-slider-label{-webkit-transform:translate(-50%, 20px);transform:translate(-50%, 20px);display:inline-block;position:absolute;padding:2px 5px;vertical-align:top;line-height:1;font-size:12px}.jupyter-wrapper .bp3-slider.bp3-vertical{width:40px;min-width:40px;height:150px}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-track,.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-progress{top:0;bottom:0;left:5px;width:6px;height:auto}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-progress{top:auto}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-label{-webkit-transform:translate(20px, 50%);transform:translate(20px, 50%)}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-handle{top:auto}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-handle .bp3-slider-label{margin-top:-8px;margin-left:0}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-handle.bp3-end,.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-handle.bp3-start{margin-left:0;width:16px;height:8px}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-handle.bp3-start{border-top-left-radius:0;border-bottom-right-radius:3px}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-handle.bp3-start .bp3-slider-label{-webkit-transform:translate(20px);transform:translate(20px)}.jupyter-wrapper .bp3-slider.bp3-vertical .bp3-slider-handle.bp3-end{margin-bottom:8px;border-top-left-radius:3px;border-bottom-left-radius:0;border-bottom-right-radius:0}@-webkit-keyframes pt-spinner-animation{from{-webkit-transform:rotate(0deg);transform:rotate(0deg)}to{-webkit-transform:rotate(360deg);transform:rotate(360deg)}}@keyframes pt-spinner-animation{from{-webkit-transform:rotate(0deg);transform:rotate(0deg)}to{-webkit-transform:rotate(360deg);transform:rotate(360deg)}}.jupyter-wrapper .bp3-spinner{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:center;-ms-flex-pack:center;justify-content:center;overflow:visible;vertical-align:middle}.jupyter-wrapper .bp3-spinner svg{display:block}.jupyter-wrapper .bp3-spinner path{fill-opacity:0}.jupyter-wrapper .bp3-spinner .bp3-spinner-head{-webkit-transform-origin:center;transform-origin:center;-webkit-transition:stroke-dashoffset 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:stroke-dashoffset 200ms cubic-bezier(0.4, 1, 0.75, 0.9);stroke:rgba(92,112,128,.8);stroke-linecap:round}.jupyter-wrapper .bp3-spinner .bp3-spinner-track{stroke:rgba(92,112,128,.2)}.jupyter-wrapper .bp3-spinner-animation{-webkit-animation:pt-spinner-animation 500ms linear infinite;animation:pt-spinner-animation 500ms linear infinite}.jupyter-wrapper .bp3-no-spin>.bp3-spinner-animation{-webkit-animation:none;animation:none}.jupyter-wrapper .bp3-dark .bp3-spinner .bp3-spinner-head{stroke:#8a9ba8}.jupyter-wrapper .bp3-dark .bp3-spinner .bp3-spinner-track{stroke:rgba(16,22,26,.5)}.jupyter-wrapper .bp3-spinner.bp3-intent-primary .bp3-spinner-head{stroke:#137cbd}.jupyter-wrapper .bp3-spinner.bp3-intent-success .bp3-spinner-head{stroke:#0f9960}.jupyter-wrapper .bp3-spinner.bp3-intent-warning .bp3-spinner-head{stroke:#d9822b}.jupyter-wrapper .bp3-spinner.bp3-intent-danger .bp3-spinner-head{stroke:#db3737}.jupyter-wrapper .bp3-tabs.bp3-vertical{display:-webkit-box;display:-ms-flexbox;display:flex}.jupyter-wrapper .bp3-tabs.bp3-vertical>.bp3-tab-list{-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;-webkit-box-align:start;-ms-flex-align:start;align-items:flex-start}.jupyter-wrapper .bp3-tabs.bp3-vertical>.bp3-tab-list .bp3-tab{border-radius:3px;width:100%;padding:0 10px}.jupyter-wrapper .bp3-tabs.bp3-vertical>.bp3-tab-list .bp3-tab[aria-selected=true]{-webkit-box-shadow:none;box-shadow:none;background-color:rgba(19,124,189,.2)}.jupyter-wrapper .bp3-tabs.bp3-vertical>.bp3-tab-list .bp3-tab-indicator-wrapper .bp3-tab-indicator{top:0;right:0;bottom:0;left:0;border-radius:3px;background-color:rgba(19,124,189,.2);height:auto}.jupyter-wrapper .bp3-tabs.bp3-vertical>.bp3-tab-panel{margin-top:0;padding-left:20px}.jupyter-wrapper .bp3-tab-list{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;-webkit-box-align:end;-ms-flex-align:end;align-items:flex-end;position:relative;margin:0;border:none;padding:0;list-style:none}.jupyter-wrapper .bp3-tab-list>*:not(:last-child){margin-right:20px}.jupyter-wrapper .bp3-tab{overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal;-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;position:relative;cursor:pointer;max-width:100%;vertical-align:top;line-height:30px;color:#182026;font-size:14px}.jupyter-wrapper .bp3-tab a{display:block;text-decoration:none;color:inherit}.jupyter-wrapper .bp3-tab-indicator-wrapper~.bp3-tab{-webkit-box-shadow:none !important;box-shadow:none !important;background-color:rgba(0,0,0,0) !important}.jupyter-wrapper .bp3-tab[aria-disabled=true]{cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-tab[aria-selected=true]{border-radius:0;-webkit-box-shadow:inset 0 -3px 0 #106ba3;box-shadow:inset 0 -3px 0 #106ba3}.jupyter-wrapper .bp3-tab[aria-selected=true],.jupyter-wrapper .bp3-tab:not([aria-disabled=true]):hover{color:#106ba3}.jupyter-wrapper .bp3-tab:focus{-moz-outline-radius:0}.jupyter-wrapper .bp3-large>.bp3-tab{line-height:40px;font-size:16px}.jupyter-wrapper .bp3-tab-panel{margin-top:20px}.jupyter-wrapper .bp3-tab-panel[aria-hidden=true]{display:none}.jupyter-wrapper .bp3-tab-indicator-wrapper{position:absolute;top:0;left:0;-webkit-transform:translateX(0),translateY(0);transform:translateX(0),translateY(0);-webkit-transition:height,width,-webkit-transform;transition:height,width,-webkit-transform;transition:height,transform,width;transition:height,transform,width,-webkit-transform;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);pointer-events:none}.jupyter-wrapper .bp3-tab-indicator-wrapper .bp3-tab-indicator{position:absolute;right:0;bottom:0;left:0;background-color:#106ba3;height:3px}.jupyter-wrapper .bp3-tab-indicator-wrapper.bp3-no-animation{-webkit-transition:none;transition:none}.jupyter-wrapper .bp3-dark .bp3-tab{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-tab[aria-disabled=true]{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-tab[aria-selected=true]{-webkit-box-shadow:inset 0 -3px 0 #48aff0;box-shadow:inset 0 -3px 0 #48aff0}.jupyter-wrapper .bp3-dark .bp3-tab[aria-selected=true],.jupyter-wrapper .bp3-dark .bp3-tab:not([aria-disabled=true]):hover{color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-tab-indicator{background-color:#48aff0}.jupyter-wrapper .bp3-flex-expander{-webkit-box-flex:1;-ms-flex:1 1;flex:1 1}.jupyter-wrapper .bp3-tag{display:-webkit-inline-box;display:-ms-inline-flexbox;display:inline-flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:center;-ms-flex-align:center;align-items:center;position:relative;border:none;border-radius:3px;-webkit-box-shadow:none;box-shadow:none;background-color:#5c7080;min-width:20px;max-width:100%;min-height:20px;padding:2px 6px;line-height:16px;color:#f5f8fa;font-size:12px}.jupyter-wrapper .bp3-tag.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-interactive:hover{background-color:rgba(92,112,128,.85)}.jupyter-wrapper .bp3-tag.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-interactive:active{background-color:rgba(92,112,128,.7)}.jupyter-wrapper .bp3-tag>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-tag>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-tag::before,.jupyter-wrapper .bp3-tag>*{margin-right:4px}.jupyter-wrapper .bp3-tag:empty::before,.jupyter-wrapper .bp3-tag>:last-child{margin-right:0}.jupyter-wrapper .bp3-tag:focus{outline:rgba(19,124,189,.6) auto 2px;outline-offset:0;-moz-outline-radius:6px}.jupyter-wrapper .bp3-tag.bp3-round{border-radius:30px;padding-right:8px;padding-left:8px}.jupyter-wrapper .bp3-dark .bp3-tag{background-color:#bfccd6;color:#182026}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-interactive:hover{background-color:rgba(191,204,214,.85)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-interactive:active{background-color:rgba(191,204,214,.7)}.jupyter-wrapper .bp3-dark .bp3-tag>.bp3-icon,.jupyter-wrapper .bp3-dark .bp3-tag .bp3-icon-standard,.jupyter-wrapper .bp3-dark .bp3-tag .bp3-icon-large{fill:currentColor}.jupyter-wrapper .bp3-tag>.bp3-icon,.jupyter-wrapper .bp3-tag .bp3-icon-standard,.jupyter-wrapper .bp3-tag .bp3-icon-large{fill:#fff}.jupyter-wrapper .bp3-tag.bp3-large,.jupyter-wrapper .bp3-large .bp3-tag{min-width:30px;min-height:30px;padding:0 10px;line-height:20px;font-size:14px}.jupyter-wrapper .bp3-tag.bp3-large::before,.jupyter-wrapper .bp3-tag.bp3-large>*,.jupyter-wrapper .bp3-large .bp3-tag::before,.jupyter-wrapper .bp3-large .bp3-tag>*{margin-right:7px}.jupyter-wrapper .bp3-tag.bp3-large:empty::before,.jupyter-wrapper .bp3-tag.bp3-large>:last-child,.jupyter-wrapper .bp3-large .bp3-tag:empty::before,.jupyter-wrapper .bp3-large .bp3-tag>:last-child{margin-right:0}.jupyter-wrapper .bp3-tag.bp3-large.bp3-round,.jupyter-wrapper .bp3-large .bp3-tag.bp3-round{padding-right:12px;padding-left:12px}.jupyter-wrapper .bp3-tag.bp3-intent-primary{background:#137cbd;color:#fff}.jupyter-wrapper .bp3-tag.bp3-intent-primary.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-intent-primary.bp3-interactive:hover{background-color:rgba(19,124,189,.85)}.jupyter-wrapper .bp3-tag.bp3-intent-primary.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-intent-primary.bp3-interactive:active{background-color:rgba(19,124,189,.7)}.jupyter-wrapper .bp3-tag.bp3-intent-success{background:#0f9960;color:#fff}.jupyter-wrapper .bp3-tag.bp3-intent-success.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-intent-success.bp3-interactive:hover{background-color:rgba(15,153,96,.85)}.jupyter-wrapper .bp3-tag.bp3-intent-success.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-intent-success.bp3-interactive:active{background-color:rgba(15,153,96,.7)}.jupyter-wrapper .bp3-tag.bp3-intent-warning{background:#d9822b;color:#fff}.jupyter-wrapper .bp3-tag.bp3-intent-warning.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-intent-warning.bp3-interactive:hover{background-color:rgba(217,130,43,.85)}.jupyter-wrapper .bp3-tag.bp3-intent-warning.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-intent-warning.bp3-interactive:active{background-color:rgba(217,130,43,.7)}.jupyter-wrapper .bp3-tag.bp3-intent-danger{background:#db3737;color:#fff}.jupyter-wrapper .bp3-tag.bp3-intent-danger.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-intent-danger.bp3-interactive:hover{background-color:rgba(219,55,55,.85)}.jupyter-wrapper .bp3-tag.bp3-intent-danger.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-intent-danger.bp3-interactive:active{background-color:rgba(219,55,55,.7)}.jupyter-wrapper .bp3-tag.bp3-fill{display:-webkit-box;display:-ms-flexbox;display:flex;width:100%}.jupyter-wrapper .bp3-tag.bp3-minimal>.bp3-icon,.jupyter-wrapper .bp3-tag.bp3-minimal .bp3-icon-standard,.jupyter-wrapper .bp3-tag.bp3-minimal .bp3-icon-large{fill:#5c7080}.jupyter-wrapper .bp3-tag.bp3-minimal:not([class*=bp3-intent-]){background-color:rgba(138,155,168,.2);color:#182026}.jupyter-wrapper .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive:hover{background-color:rgba(92,112,128,.3)}.jupyter-wrapper .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive:active{background-color:rgba(92,112,128,.4)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-]){color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive:hover{background-color:rgba(191,204,214,.3)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive.bp3-active,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-]).bp3-interactive:active{background-color:rgba(191,204,214,.4)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-])>.bp3-icon,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-]) .bp3-icon-standard,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal:not([class*=bp3-intent-]) .bp3-icon-large{fill:#a7b6c2}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary{background-color:rgba(19,124,189,.15);color:#106ba3}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive:hover{background-color:rgba(19,124,189,.25)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive:active{background-color:rgba(19,124,189,.35)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary>.bp3-icon,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary .bp3-icon-standard,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-primary .bp3-icon-large{fill:#137cbd}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-primary{background-color:rgba(19,124,189,.25);color:#48aff0}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive:hover{background-color:rgba(19,124,189,.35)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-primary.bp3-interactive:active{background-color:rgba(19,124,189,.45)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success{background-color:rgba(15,153,96,.15);color:#0d8050}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive:hover{background-color:rgba(15,153,96,.25)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive:active{background-color:rgba(15,153,96,.35)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success>.bp3-icon,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success .bp3-icon-standard,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-success .bp3-icon-large{fill:#0f9960}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-success{background-color:rgba(15,153,96,.25);color:#3dcc91}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive:hover{background-color:rgba(15,153,96,.35)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-success.bp3-interactive:active{background-color:rgba(15,153,96,.45)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning{background-color:rgba(217,130,43,.15);color:#bf7326}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive:hover{background-color:rgba(217,130,43,.25)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive:active{background-color:rgba(217,130,43,.35)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning>.bp3-icon,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning .bp3-icon-standard,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-warning .bp3-icon-large{fill:#d9822b}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-warning{background-color:rgba(217,130,43,.25);color:#ffb366}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive:hover{background-color:rgba(217,130,43,.35)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-warning.bp3-interactive:active{background-color:rgba(217,130,43,.45)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger{background-color:rgba(219,55,55,.15);color:#c23030}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive:hover{background-color:rgba(219,55,55,.25)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive:active{background-color:rgba(219,55,55,.35)}.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger>.bp3-icon,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger .bp3-icon-standard,.jupyter-wrapper .bp3-tag.bp3-minimal.bp3-intent-danger .bp3-icon-large{fill:#db3737}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-danger{background-color:rgba(219,55,55,.25);color:#ff7373}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive{cursor:pointer}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive:hover{background-color:rgba(219,55,55,.35)}.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive.bp3-active,.jupyter-wrapper .bp3-dark .bp3-tag.bp3-minimal.bp3-intent-danger.bp3-interactive:active{background-color:rgba(219,55,55,.45)}.jupyter-wrapper .bp3-tag-remove{display:-webkit-box;display:-ms-flexbox;display:flex;opacity:.5;margin-top:-2px;margin-right:-6px !important;margin-bottom:-2px;border:none;background:none;cursor:pointer;padding:2px;padding-left:0;color:inherit}.jupyter-wrapper .bp3-tag-remove:hover{opacity:.8;background:none;text-decoration:none}.jupyter-wrapper .bp3-tag-remove:active{opacity:1}.jupyter-wrapper .bp3-tag-remove:empty::before{line-height:1;font-family:\"Icons16\",sans-serif;font-size:16px;font-weight:400;font-style:normal;-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;content:\"\ue6d7\"}.jupyter-wrapper .bp3-large .bp3-tag-remove{margin-right:-10px !important;padding:5px;padding-left:0}.jupyter-wrapper .bp3-large .bp3-tag-remove:empty::before{line-height:1;font-family:\"Icons20\",sans-serif;font-size:20px;font-weight:400;font-style:normal}.jupyter-wrapper .bp3-tag-input{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-webkit-box-align:start;-ms-flex-align:start;align-items:flex-start;cursor:text;height:auto;min-height:30px;padding-right:0;padding-left:5px;line-height:inherit}.jupyter-wrapper .bp3-tag-input>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-tag-input>.bp3-tag-input-values{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-icon{margin-top:7px;margin-right:7px;margin-left:2px;color:#5c7080}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-orient:horizontal;-webkit-box-direction:normal;-ms-flex-direction:row;flex-direction:row;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-ms-flex-item-align:stretch;align-self:stretch;margin-top:5px;margin-right:7px;min-width:0}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values>*{-webkit-box-flex:0;-ms-flex-positive:0;flex-grow:0;-ms-flex-negative:0;flex-shrink:0}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values>.bp3-fill{-webkit-box-flex:1;-ms-flex-positive:1;flex-grow:1;-ms-flex-negative:1;flex-shrink:1}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values::before,.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values>*{margin-right:5px}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values:empty::before,.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values>:last-child{margin-right:0}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values:first-child .bp3-input-ghost:first-child{padding-left:5px}.jupyter-wrapper .bp3-tag-input .bp3-tag-input-values>*{margin-bottom:5px}.jupyter-wrapper .bp3-tag-input .bp3-tag{overflow-wrap:break-word}.jupyter-wrapper .bp3-tag-input .bp3-tag.bp3-active{outline:rgba(19,124,189,.6) auto 2px;outline-offset:0;-moz-outline-radius:6px}.jupyter-wrapper .bp3-tag-input .bp3-input-ghost{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;width:80px;line-height:20px}.jupyter-wrapper .bp3-tag-input .bp3-input-ghost:disabled,.jupyter-wrapper .bp3-tag-input .bp3-input-ghost.bp3-disabled{cursor:not-allowed}.jupyter-wrapper .bp3-tag-input .bp3-button,.jupyter-wrapper .bp3-tag-input .bp3-spinner{margin:3px;margin-left:0}.jupyter-wrapper .bp3-tag-input .bp3-button{min-width:24px;min-height:24px;padding:0 7px}.jupyter-wrapper .bp3-tag-input.bp3-large{height:auto;min-height:40px}.jupyter-wrapper .bp3-tag-input.bp3-large::before,.jupyter-wrapper .bp3-tag-input.bp3-large>*{margin-right:10px}.jupyter-wrapper .bp3-tag-input.bp3-large:empty::before,.jupyter-wrapper .bp3-tag-input.bp3-large>:last-child{margin-right:0}.jupyter-wrapper .bp3-tag-input.bp3-large .bp3-tag-input-icon{margin-top:10px;margin-left:5px}.jupyter-wrapper .bp3-tag-input.bp3-large .bp3-input-ghost{line-height:30px}.jupyter-wrapper .bp3-tag-input.bp3-large .bp3-button{min-width:30px;min-height:30px;padding:5px 10px;margin:5px;margin-left:0}.jupyter-wrapper .bp3-tag-input.bp3-large .bp3-spinner{margin:8px;margin-left:0}.jupyter-wrapper .bp3-tag-input.bp3-active{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 1px 1px rgba(16,22,26,.2);background-color:#fff}.jupyter-wrapper .bp3-tag-input.bp3-active.bp3-intent-primary{-webkit-box-shadow:0 0 0 1px #106ba3,0 0 0 3px rgba(16,107,163,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #106ba3,0 0 0 3px rgba(16,107,163,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-tag-input.bp3-active.bp3-intent-success{-webkit-box-shadow:0 0 0 1px #0d8050,0 0 0 3px rgba(13,128,80,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #0d8050,0 0 0 3px rgba(13,128,80,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-tag-input.bp3-active.bp3-intent-warning{-webkit-box-shadow:0 0 0 1px #bf7326,0 0 0 3px rgba(191,115,38,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #bf7326,0 0 0 3px rgba(191,115,38,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-tag-input.bp3-active.bp3-intent-danger{-webkit-box-shadow:0 0 0 1px #c23030,0 0 0 3px rgba(194,48,48,.3),inset 0 1px 1px rgba(16,22,26,.2);box-shadow:0 0 0 1px #c23030,0 0 0 3px rgba(194,48,48,.3),inset 0 1px 1px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-dark .bp3-tag-input .bp3-tag-input-icon,.jupyter-wrapper .bp3-tag-input.bp3-dark .bp3-tag-input-icon{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-tag-input .bp3-input-ghost,.jupyter-wrapper .bp3-tag-input.bp3-dark .bp3-input-ghost{color:#f5f8fa}.jupyter-wrapper .bp3-dark .bp3-tag-input .bp3-input-ghost::-webkit-input-placeholder,.jupyter-wrapper .bp3-tag-input.bp3-dark .bp3-input-ghost::-webkit-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-tag-input .bp3-input-ghost::-moz-placeholder,.jupyter-wrapper .bp3-tag-input.bp3-dark .bp3-input-ghost::-moz-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-tag-input .bp3-input-ghost:-ms-input-placeholder,.jupyter-wrapper .bp3-tag-input.bp3-dark .bp3-input-ghost:-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-tag-input .bp3-input-ghost::-ms-input-placeholder,.jupyter-wrapper .bp3-tag-input.bp3-dark .bp3-input-ghost::-ms-input-placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-tag-input .bp3-input-ghost::placeholder,.jupyter-wrapper .bp3-tag-input.bp3-dark .bp3-input-ghost::placeholder{color:rgba(167,182,194,.6)}.jupyter-wrapper .bp3-dark .bp3-tag-input.bp3-active,.jupyter-wrapper .bp3-tag-input.bp3-dark.bp3-active{-webkit-box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #137cbd,0 0 0 1px #137cbd,0 0 0 3px rgba(19,124,189,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);background-color:rgba(16,22,26,.3)}.jupyter-wrapper .bp3-dark .bp3-tag-input.bp3-active.bp3-intent-primary,.jupyter-wrapper .bp3-tag-input.bp3-dark.bp3-active.bp3-intent-primary{-webkit-box-shadow:0 0 0 1px #106ba3,0 0 0 3px rgba(16,107,163,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #106ba3,0 0 0 3px rgba(16,107,163,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-tag-input.bp3-active.bp3-intent-success,.jupyter-wrapper .bp3-tag-input.bp3-dark.bp3-active.bp3-intent-success{-webkit-box-shadow:0 0 0 1px #0d8050,0 0 0 3px rgba(13,128,80,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #0d8050,0 0 0 3px rgba(13,128,80,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-tag-input.bp3-active.bp3-intent-warning,.jupyter-wrapper .bp3-tag-input.bp3-dark.bp3-active.bp3-intent-warning{-webkit-box-shadow:0 0 0 1px #bf7326,0 0 0 3px rgba(191,115,38,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #bf7326,0 0 0 3px rgba(191,115,38,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-dark .bp3-tag-input.bp3-active.bp3-intent-danger,.jupyter-wrapper .bp3-tag-input.bp3-dark.bp3-active.bp3-intent-danger{-webkit-box-shadow:0 0 0 1px #c23030,0 0 0 3px rgba(194,48,48,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4);box-shadow:0 0 0 1px #c23030,0 0 0 3px rgba(194,48,48,.3),inset 0 0 0 1px rgba(16,22,26,.3),inset 0 1px 1px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-input-ghost{border:none;-webkit-box-shadow:none;box-shadow:none;background:none;padding:0}.jupyter-wrapper .bp3-input-ghost::-webkit-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input-ghost::-moz-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input-ghost:-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input-ghost::-ms-input-placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input-ghost::placeholder{opacity:1;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-input-ghost:focus{outline:none !important}.jupyter-wrapper .bp3-toast{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:start;-ms-flex-align:start;align-items:flex-start;position:relative !important;margin:20px 0 0;border-radius:3px;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);background-color:#fff;min-width:300px;max-width:500px;pointer-events:all}.jupyter-wrapper .bp3-toast.bp3-toast-enter,.jupyter-wrapper .bp3-toast.bp3-toast-appear{-webkit-transform:translateY(-40px);transform:translateY(-40px)}.jupyter-wrapper .bp3-toast.bp3-toast-enter-active,.jupyter-wrapper .bp3-toast.bp3-toast-appear-active{-webkit-transform:translateY(0);transform:translateY(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:300ms;transition-duration:300ms;-webkit-transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-toast.bp3-toast-enter~.bp3-toast,.jupyter-wrapper .bp3-toast.bp3-toast-appear~.bp3-toast{-webkit-transform:translateY(-40px);transform:translateY(-40px)}.jupyter-wrapper .bp3-toast.bp3-toast-enter-active~.bp3-toast,.jupyter-wrapper .bp3-toast.bp3-toast-appear-active~.bp3-toast{-webkit-transform:translateY(0);transform:translateY(0);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:300ms;transition-duration:300ms;-webkit-transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);transition-timing-function:cubic-bezier(0.54, 1.12, 0.38, 1.11);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-toast.bp3-toast-exit{opacity:1;-webkit-filter:blur(0);filter:blur(0)}.jupyter-wrapper .bp3-toast.bp3-toast-exit-active{opacity:0;-webkit-filter:blur(10px);filter:blur(10px);-webkit-transition-property:opacity,-webkit-filter;transition-property:opacity,-webkit-filter;transition-property:opacity,filter;transition-property:opacity,filter,-webkit-filter;-webkit-transition-duration:300ms;transition-duration:300ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-toast.bp3-toast-exit~.bp3-toast{-webkit-transform:translateY(0);transform:translateY(0)}.jupyter-wrapper .bp3-toast.bp3-toast-exit-active~.bp3-toast{-webkit-transform:translateY(-40px);transform:translateY(-40px);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:50ms;transition-delay:50ms}.jupyter-wrapper .bp3-toast .bp3-button-group{-webkit-box-flex:0;-ms-flex:0 0 auto;flex:0 0 auto;padding:5px;padding-left:0}.jupyter-wrapper .bp3-toast>.bp3-icon{margin:12px;margin-right:0;color:#5c7080}.jupyter-wrapper .bp3-toast.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-toast{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);background-color:#394b59}.jupyter-wrapper .bp3-toast.bp3-dark>.bp3-icon,.jupyter-wrapper .bp3-dark .bp3-toast>.bp3-icon{color:#a7b6c2}.jupyter-wrapper .bp3-toast[class*=bp3-intent-] a{color:rgba(255,255,255,.7)}.jupyter-wrapper .bp3-toast[class*=bp3-intent-] a:hover{color:#fff}.jupyter-wrapper .bp3-toast[class*=bp3-intent-]>.bp3-icon{color:#fff}.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button,.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button::before,.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button .bp3-icon,.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button:active{color:rgba(255,255,255,.7) !important}.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button:focus{outline-color:rgba(255,255,255,.5)}.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button:hover{background-color:rgba(255,255,255,.15) !important;color:#fff !important}.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button:active{background-color:rgba(255,255,255,.3) !important;color:#fff !important}.jupyter-wrapper .bp3-toast[class*=bp3-intent-] .bp3-button::after{background:rgba(255,255,255,.3) !important}.jupyter-wrapper .bp3-toast.bp3-intent-primary{background-color:#137cbd;color:#fff}.jupyter-wrapper .bp3-toast.bp3-intent-success{background-color:#0f9960;color:#fff}.jupyter-wrapper .bp3-toast.bp3-intent-warning{background-color:#d9822b;color:#fff}.jupyter-wrapper .bp3-toast.bp3-intent-danger{background-color:#db3737;color:#fff}.jupyter-wrapper .bp3-toast-message{-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;padding:11px;word-break:break-word}.jupyter-wrapper .bp3-toast-container{display:-webkit-box !important;display:-ms-flexbox !important;display:flex !important;-webkit-box-orient:vertical;-webkit-box-direction:normal;-ms-flex-direction:column;flex-direction:column;-webkit-box-align:center;-ms-flex-align:center;align-items:center;position:fixed;right:0;left:0;z-index:40;overflow:hidden;padding:0 20px 20px;pointer-events:none}.jupyter-wrapper .bp3-toast-container.bp3-toast-container-top{top:0;bottom:auto}.jupyter-wrapper .bp3-toast-container.bp3-toast-container-bottom{-webkit-box-orient:vertical;-webkit-box-direction:reverse;-ms-flex-direction:column-reverse;flex-direction:column-reverse;top:auto;bottom:0}.jupyter-wrapper .bp3-toast-container.bp3-toast-container-left{-webkit-box-align:start;-ms-flex-align:start;align-items:flex-start}.jupyter-wrapper .bp3-toast-container.bp3-toast-container-right{-webkit-box-align:end;-ms-flex-align:end;align-items:flex-end}.jupyter-wrapper .bp3-toast-container-bottom .bp3-toast.bp3-toast-enter:not(.bp3-toast-enter-active),.jupyter-wrapper .bp3-toast-container-bottom .bp3-toast.bp3-toast-enter:not(.bp3-toast-enter-active)~.bp3-toast,.jupyter-wrapper .bp3-toast-container-bottom .bp3-toast.bp3-toast-appear:not(.bp3-toast-appear-active),.jupyter-wrapper .bp3-toast-container-bottom .bp3-toast.bp3-toast-appear:not(.bp3-toast-appear-active)~.bp3-toast,.jupyter-wrapper .bp3-toast-container-bottom .bp3-toast.bp3-toast-leave-active~.bp3-toast{-webkit-transform:translateY(60px);transform:translateY(60px)}.jupyter-wrapper .bp3-tooltip{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 2px 4px rgba(16,22,26,.2),0 8px 24px rgba(16,22,26,.2);-webkit-transform:scale(1);transform:scale(1)}.jupyter-wrapper .bp3-tooltip .bp3-popover-arrow{position:absolute;width:22px;height:22px}.jupyter-wrapper .bp3-tooltip .bp3-popover-arrow::before{margin:4px;width:14px;height:14px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-top>.bp3-tooltip{margin-top:-11px;margin-bottom:11px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-top>.bp3-tooltip>.bp3-popover-arrow{bottom:-8px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-top>.bp3-tooltip>.bp3-popover-arrow svg{-webkit-transform:rotate(-90deg);transform:rotate(-90deg)}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-right>.bp3-tooltip{margin-left:11px}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-right>.bp3-tooltip>.bp3-popover-arrow{left:-8px}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-right>.bp3-tooltip>.bp3-popover-arrow svg{-webkit-transform:rotate(0);transform:rotate(0)}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-bottom>.bp3-tooltip{margin-top:11px}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-bottom>.bp3-tooltip>.bp3-popover-arrow{top:-8px}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-bottom>.bp3-tooltip>.bp3-popover-arrow svg{-webkit-transform:rotate(90deg);transform:rotate(90deg)}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-left>.bp3-tooltip{margin-right:11px;margin-left:-11px}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-left>.bp3-tooltip>.bp3-popover-arrow{right:-8px}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-left>.bp3-tooltip>.bp3-popover-arrow svg{-webkit-transform:rotate(180deg);transform:rotate(180deg)}.jupyter-wrapper .bp3-tether-element-attached-middle>.bp3-tooltip>.bp3-popover-arrow{top:50%;-webkit-transform:translateY(-50%);transform:translateY(-50%)}.jupyter-wrapper .bp3-tether-element-attached-center>.bp3-tooltip>.bp3-popover-arrow{right:50%;-webkit-transform:translateX(50%);transform:translateX(50%)}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-target-attached-top>.bp3-tooltip>.bp3-popover-arrow{top:-0.22183px}.jupyter-wrapper .bp3-tether-element-attached-right.bp3-tether-target-attached-right>.bp3-tooltip>.bp3-popover-arrow{right:-0.22183px}.jupyter-wrapper .bp3-tether-element-attached-left.bp3-tether-target-attached-left>.bp3-tooltip>.bp3-popover-arrow{left:-0.22183px}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-target-attached-bottom>.bp3-tooltip>.bp3-popover-arrow{bottom:-0.22183px}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-element-attached-left>.bp3-tooltip{-webkit-transform-origin:top left;transform-origin:top left}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-element-attached-center>.bp3-tooltip{-webkit-transform-origin:top center;transform-origin:top center}.jupyter-wrapper .bp3-tether-element-attached-top.bp3-tether-element-attached-right>.bp3-tooltip{-webkit-transform-origin:top right;transform-origin:top right}.jupyter-wrapper .bp3-tether-element-attached-middle.bp3-tether-element-attached-left>.bp3-tooltip{-webkit-transform-origin:center left;transform-origin:center left}.jupyter-wrapper .bp3-tether-element-attached-middle.bp3-tether-element-attached-center>.bp3-tooltip{-webkit-transform-origin:center center;transform-origin:center center}.jupyter-wrapper .bp3-tether-element-attached-middle.bp3-tether-element-attached-right>.bp3-tooltip{-webkit-transform-origin:center right;transform-origin:center right}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-element-attached-left>.bp3-tooltip{-webkit-transform-origin:bottom left;transform-origin:bottom left}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-element-attached-center>.bp3-tooltip{-webkit-transform-origin:bottom center;transform-origin:bottom center}.jupyter-wrapper .bp3-tether-element-attached-bottom.bp3-tether-element-attached-right>.bp3-tooltip{-webkit-transform-origin:bottom right;transform-origin:bottom right}.jupyter-wrapper .bp3-tooltip .bp3-popover-content{background:#394b59;color:#f5f8fa}.jupyter-wrapper .bp3-tooltip .bp3-popover-arrow::before{-webkit-box-shadow:1px 1px 6px rgba(16,22,26,.2);box-shadow:1px 1px 6px rgba(16,22,26,.2)}.jupyter-wrapper .bp3-tooltip .bp3-popover-arrow-border{fill:#10161a;fill-opacity:.1}.jupyter-wrapper .bp3-tooltip .bp3-popover-arrow-fill{fill:#394b59}.jupyter-wrapper .bp3-popover-enter>.bp3-tooltip,.jupyter-wrapper .bp3-popover-appear>.bp3-tooltip{-webkit-transform:scale(0.8);transform:scale(0.8)}.jupyter-wrapper .bp3-popover-enter-active>.bp3-tooltip,.jupyter-wrapper .bp3-popover-appear-active>.bp3-tooltip{-webkit-transform:scale(1);transform:scale(1);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-popover-exit>.bp3-tooltip{-webkit-transform:scale(1);transform:scale(1)}.jupyter-wrapper .bp3-popover-exit-active>.bp3-tooltip{-webkit-transform:scale(0.8);transform:scale(0.8);-webkit-transition-property:-webkit-transform;transition-property:-webkit-transform;transition-property:transform;transition-property:transform,-webkit-transform;-webkit-transition-duration:100ms;transition-duration:100ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-tooltip .bp3-popover-content{padding:10px 12px}.jupyter-wrapper .bp3-tooltip.bp3-dark,.jupyter-wrapper .bp3-dark .bp3-tooltip{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 2px 4px rgba(16,22,26,.4),0 8px 24px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-tooltip.bp3-dark .bp3-popover-content,.jupyter-wrapper .bp3-dark .bp3-tooltip .bp3-popover-content{background:#e1e8ed;color:#394b59}.jupyter-wrapper .bp3-tooltip.bp3-dark .bp3-popover-arrow::before,.jupyter-wrapper .bp3-dark .bp3-tooltip .bp3-popover-arrow::before{-webkit-box-shadow:1px 1px 6px rgba(16,22,26,.4);box-shadow:1px 1px 6px rgba(16,22,26,.4)}.jupyter-wrapper .bp3-tooltip.bp3-dark .bp3-popover-arrow-border,.jupyter-wrapper .bp3-dark .bp3-tooltip .bp3-popover-arrow-border{fill:#10161a;fill-opacity:.2}.jupyter-wrapper .bp3-tooltip.bp3-dark .bp3-popover-arrow-fill,.jupyter-wrapper .bp3-dark .bp3-tooltip .bp3-popover-arrow-fill{fill:#e1e8ed}.jupyter-wrapper .bp3-tooltip.bp3-intent-primary .bp3-popover-content{background:#137cbd;color:#fff}.jupyter-wrapper .bp3-tooltip.bp3-intent-primary .bp3-popover-arrow-fill{fill:#137cbd}.jupyter-wrapper .bp3-tooltip.bp3-intent-success .bp3-popover-content{background:#0f9960;color:#fff}.jupyter-wrapper .bp3-tooltip.bp3-intent-success .bp3-popover-arrow-fill{fill:#0f9960}.jupyter-wrapper .bp3-tooltip.bp3-intent-warning .bp3-popover-content{background:#d9822b;color:#fff}.jupyter-wrapper .bp3-tooltip.bp3-intent-warning .bp3-popover-arrow-fill{fill:#d9822b}.jupyter-wrapper .bp3-tooltip.bp3-intent-danger .bp3-popover-content{background:#db3737;color:#fff}.jupyter-wrapper .bp3-tooltip.bp3-intent-danger .bp3-popover-arrow-fill{fill:#db3737}.jupyter-wrapper .bp3-tooltip-indicator{border-bottom:dotted 1px;cursor:help}.jupyter-wrapper .bp3-tree .bp3-icon,.jupyter-wrapper .bp3-tree .bp3-icon-standard,.jupyter-wrapper .bp3-tree .bp3-icon-large{color:#5c7080}.jupyter-wrapper .bp3-tree .bp3-icon.bp3-intent-primary,.jupyter-wrapper .bp3-tree .bp3-icon-standard.bp3-intent-primary,.jupyter-wrapper .bp3-tree .bp3-icon-large.bp3-intent-primary{color:#137cbd}.jupyter-wrapper .bp3-tree .bp3-icon.bp3-intent-success,.jupyter-wrapper .bp3-tree .bp3-icon-standard.bp3-intent-success,.jupyter-wrapper .bp3-tree .bp3-icon-large.bp3-intent-success{color:#0f9960}.jupyter-wrapper .bp3-tree .bp3-icon.bp3-intent-warning,.jupyter-wrapper .bp3-tree .bp3-icon-standard.bp3-intent-warning,.jupyter-wrapper .bp3-tree .bp3-icon-large.bp3-intent-warning{color:#d9822b}.jupyter-wrapper .bp3-tree .bp3-icon.bp3-intent-danger,.jupyter-wrapper .bp3-tree .bp3-icon-standard.bp3-intent-danger,.jupyter-wrapper .bp3-tree .bp3-icon-large.bp3-intent-danger{color:#db3737}.jupyter-wrapper .bp3-tree-node-list{margin:0;padding-left:0;list-style:none}.jupyter-wrapper .bp3-tree-root{position:relative;background-color:rgba(0,0,0,0);cursor:default;padding-left:0}.jupyter-wrapper .bp3-tree-node-content-0{padding-left:0px}.jupyter-wrapper .bp3-tree-node-content-1{padding-left:23px}.jupyter-wrapper .bp3-tree-node-content-2{padding-left:46px}.jupyter-wrapper .bp3-tree-node-content-3{padding-left:69px}.jupyter-wrapper .bp3-tree-node-content-4{padding-left:92px}.jupyter-wrapper .bp3-tree-node-content-5{padding-left:115px}.jupyter-wrapper .bp3-tree-node-content-6{padding-left:138px}.jupyter-wrapper .bp3-tree-node-content-7{padding-left:161px}.jupyter-wrapper .bp3-tree-node-content-8{padding-left:184px}.jupyter-wrapper .bp3-tree-node-content-9{padding-left:207px}.jupyter-wrapper .bp3-tree-node-content-10{padding-left:230px}.jupyter-wrapper .bp3-tree-node-content-11{padding-left:253px}.jupyter-wrapper .bp3-tree-node-content-12{padding-left:276px}.jupyter-wrapper .bp3-tree-node-content-13{padding-left:299px}.jupyter-wrapper .bp3-tree-node-content-14{padding-left:322px}.jupyter-wrapper .bp3-tree-node-content-15{padding-left:345px}.jupyter-wrapper .bp3-tree-node-content-16{padding-left:368px}.jupyter-wrapper .bp3-tree-node-content-17{padding-left:391px}.jupyter-wrapper .bp3-tree-node-content-18{padding-left:414px}.jupyter-wrapper .bp3-tree-node-content-19{padding-left:437px}.jupyter-wrapper .bp3-tree-node-content-20{padding-left:460px}.jupyter-wrapper .bp3-tree-node-content{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center;width:100%;height:30px;padding-right:5px}.jupyter-wrapper .bp3-tree-node-content:hover{background-color:rgba(191,204,214,.4)}.jupyter-wrapper .bp3-tree-node-caret,.jupyter-wrapper .bp3-tree-node-caret-none{min-width:30px}.jupyter-wrapper .bp3-tree-node-caret{color:#5c7080;-webkit-transform:rotate(0deg);transform:rotate(0deg);cursor:pointer;padding:7px;-webkit-transition:-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9);transition:transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9),-webkit-transform 200ms cubic-bezier(0.4, 1, 0.75, 0.9)}.jupyter-wrapper .bp3-tree-node-caret:hover{color:#182026}.jupyter-wrapper .bp3-dark .bp3-tree-node-caret{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-tree-node-caret:hover{color:#f5f8fa}.jupyter-wrapper .bp3-tree-node-caret.bp3-tree-node-caret-open{-webkit-transform:rotate(90deg);transform:rotate(90deg)}.jupyter-wrapper .bp3-tree-node-caret.bp3-icon-standard::before{content:\"\ue695\"}.jupyter-wrapper .bp3-tree-node-icon{position:relative;margin-right:7px}.jupyter-wrapper .bp3-tree-node-label{overflow:hidden;text-overflow:ellipsis;white-space:nowrap;word-wrap:normal;-webkit-box-flex:1;-ms-flex:1 1 auto;flex:1 1 auto;position:relative;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-tree-node-label span{display:inline}.jupyter-wrapper .bp3-tree-node-secondary-label{padding:0 5px;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .bp3-tree-node-secondary-label .bp3-popover-wrapper,.jupyter-wrapper .bp3-tree-node-secondary-label .bp3-popover-target{display:-webkit-box;display:-ms-flexbox;display:flex;-webkit-box-align:center;-ms-flex-align:center;align-items:center}.jupyter-wrapper .bp3-tree-node.bp3-disabled .bp3-tree-node-content{background-color:inherit;cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-tree-node.bp3-disabled .bp3-tree-node-caret,.jupyter-wrapper .bp3-tree-node.bp3-disabled .bp3-tree-node-icon{cursor:not-allowed;color:rgba(92,112,128,.6)}.jupyter-wrapper .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content{background-color:#137cbd}.jupyter-wrapper .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content,.jupyter-wrapper .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content .bp3-icon,.jupyter-wrapper .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content .bp3-icon-standard,.jupyter-wrapper .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content .bp3-icon-large{color:#fff}.jupyter-wrapper .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content .bp3-tree-node-caret::before{color:rgba(255,255,255,.7)}.jupyter-wrapper .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content .bp3-tree-node-caret:hover::before{color:#fff}.jupyter-wrapper .bp3-dark .bp3-tree-node-content:hover{background-color:rgba(92,112,128,.3)}.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-standard,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-large{color:#a7b6c2}.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon.bp3-intent-primary,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-standard.bp3-intent-primary,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-large.bp3-intent-primary{color:#137cbd}.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon.bp3-intent-success,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-standard.bp3-intent-success,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-large.bp3-intent-success{color:#0f9960}.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon.bp3-intent-warning,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-standard.bp3-intent-warning,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-large.bp3-intent-warning{color:#d9822b}.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon.bp3-intent-danger,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-standard.bp3-intent-danger,.jupyter-wrapper .bp3-dark .bp3-tree .bp3-icon-large.bp3-intent-danger{color:#db3737}.jupyter-wrapper .bp3-dark .bp3-tree-node.bp3-tree-node-selected>.bp3-tree-node-content{background-color:#137cbd}.jupyter-wrapper .bp3-omnibar{-webkit-filter:blur(0);filter:blur(0);opacity:1;top:20vh;left:calc(50% - 250px);z-index:21;border-radius:3px;-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2);box-shadow:0 0 0 1px rgba(16,22,26,.1),0 4px 8px rgba(16,22,26,.2),0 18px 46px 6px rgba(16,22,26,.2);background-color:#fff;width:500px}.jupyter-wrapper .bp3-omnibar.bp3-overlay-enter,.jupyter-wrapper .bp3-omnibar.bp3-overlay-appear{-webkit-filter:blur(20px);filter:blur(20px);opacity:.2}.jupyter-wrapper .bp3-omnibar.bp3-overlay-enter-active,.jupyter-wrapper .bp3-omnibar.bp3-overlay-appear-active{-webkit-filter:blur(0);filter:blur(0);opacity:1;-webkit-transition-property:opacity,-webkit-filter;transition-property:opacity,-webkit-filter;transition-property:filter,opacity;transition-property:filter,opacity,-webkit-filter;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-omnibar.bp3-overlay-exit{-webkit-filter:blur(0);filter:blur(0);opacity:1}.jupyter-wrapper .bp3-omnibar.bp3-overlay-exit-active{-webkit-filter:blur(20px);filter:blur(20px);opacity:.2;-webkit-transition-property:opacity,-webkit-filter;transition-property:opacity,-webkit-filter;transition-property:filter,opacity;transition-property:filter,opacity,-webkit-filter;-webkit-transition-duration:200ms;transition-duration:200ms;-webkit-transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);transition-timing-function:cubic-bezier(0.4, 1, 0.75, 0.9);-webkit-transition-delay:0;transition-delay:0}.jupyter-wrapper .bp3-omnibar .bp3-input{border-radius:0;background-color:rgba(0,0,0,0)}.jupyter-wrapper .bp3-omnibar .bp3-input,.jupyter-wrapper .bp3-omnibar .bp3-input:focus{-webkit-box-shadow:none;box-shadow:none}.jupyter-wrapper .bp3-omnibar .bp3-menu{border-radius:0;-webkit-box-shadow:inset 0 1px 0 rgba(16,22,26,.15);box-shadow:inset 0 1px 0 rgba(16,22,26,.15);background-color:rgba(0,0,0,0);max-height:calc(60vh - 40px);overflow:auto}.jupyter-wrapper .bp3-omnibar .bp3-menu:empty{display:none}.jupyter-wrapper .bp3-dark .bp3-omnibar,.jupyter-wrapper .bp3-omnibar.bp3-dark{-webkit-box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4);box-shadow:0 0 0 1px rgba(16,22,26,.2),0 4px 8px rgba(16,22,26,.4),0 18px 46px 6px rgba(16,22,26,.4);background-color:#30404d}.jupyter-wrapper .bp3-omnibar-overlay .bp3-overlay-backdrop{background-color:rgba(16,22,26,.2)}.jupyter-wrapper .bp3-select-popover .bp3-popover-content{padding:5px}.jupyter-wrapper .bp3-select-popover .bp3-input-group{margin-bottom:0}.jupyter-wrapper .bp3-select-popover .bp3-menu{max-width:400px;max-height:300px;overflow:auto;padding:0}.jupyter-wrapper .bp3-select-popover .bp3-menu:not(:first-child){padding-top:5px}.jupyter-wrapper .bp3-multi-select{min-width:150px}.jupyter-wrapper .bp3-multi-select-popover .bp3-menu{max-width:400px;max-height:300px;overflow:auto}.jupyter-wrapper .bp3-select-popover .bp3-popover-content{padding:5px}.jupyter-wrapper .bp3-select-popover .bp3-input-group{margin-bottom:0}.jupyter-wrapper .bp3-select-popover .bp3-menu{max-width:400px;max-height:300px;overflow:auto;padding:0}.jupyter-wrapper .bp3-select-popover .bp3-menu:not(:first-child){padding-top:5px}.jupyter-wrapper :root{--jp-icon-add: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTE5IDEzaC02djZoLTJ2LTZINXYtMmg2VjVoMnY2aDZ2MnoiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-bug: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTIwIDhoLTIuODFjLS40NS0uNzgtMS4wNy0xLjQ1LTEuODItMS45NkwxNyA0LjQxIDE1LjU5IDNsLTIuMTcgMi4xN0MxMi45NiA1LjA2IDEyLjQ5IDUgMTIgNWMtLjQ5IDAtLjk2LjA2LTEuNDEuMTdMOC40MSAzIDcgNC40MWwxLjYyIDEuNjNDNy44OCA2LjU1IDcuMjYgNy4yMiA2LjgxIDhINHYyaDIuMDljLS4wNS4zMy0uMDkuNjYtLjA5IDF2MUg0djJoMnYxYzAgLjM0LjA0LjY3LjA5IDFINHYyaDIuODFjMS4wNCAxLjc5IDIuOTcgMyA1LjE5IDNzNC4xNS0xLjIxIDUuMTktM0gyMHYtMmgtMi4wOWMuMDUtLjMzLjA5LS42Ni4wOS0xdi0xaDJ2LTJoLTJ2LTFjMC0uMzQtLjA0LS42Ny0uMDktMUgyMFY4em0tNiA4aC00di0yaDR2MnptMC00aC00di0yaDR2MnoiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-build: url(data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMTYiIHZpZXdCb3g9IjAgMCAyNCAyNCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTE0LjkgMTcuNDVDMTYuMjUgMTcuNDUgMTcuMzUgMTYuMzUgMTcuMzUgMTVDMTcuMzUgMTMuNjUgMTYuMjUgMTIuNTUgMTQuOSAxMi41NUMxMy41NCAxMi41NSAxMi40NSAxMy42NSAxMi40NSAxNUMxMi40NSAxNi4zNSAxMy41NCAxNy40NSAxNC45IDE3LjQ1Wk0yMC4xIDE1LjY4TDIxLjU4IDE2Ljg0QzIxLjcxIDE2Ljk1IDIxLjc1IDE3LjEzIDIxLjY2IDE3LjI5TDIwLjI2IDE5LjcxQzIwLjE3IDE5Ljg2IDIwIDE5LjkyIDE5LjgzIDE5Ljg2TDE4LjA5IDE5LjE2QzE3LjczIDE5LjQ0IDE3LjMzIDE5LjY3IDE2LjkxIDE5Ljg1TDE2LjY0IDIxLjdDMTYuNjIgMjEuODcgMTYuNDcgMjIgMTYuMyAyMkgxMy41QzEzLjMyIDIyIDEzLjE4IDIxLjg3IDEzLjE1IDIxLjdMMTIuODkgMTkuODVDMTIuNDYgMTkuNjcgMTIuMDcgMTkuNDQgMTEuNzEgMTkuMTZMOS45NjAwMiAxOS44NkM5LjgxMDAyIDE5LjkyIDkuNjIwMDIgMTkuODYgOS41NDAwMiAxOS43MUw4LjE0MDAyIDE3LjI5QzguMDUwMDIgMTcuMTMgOC4wOTAwMiAxNi45NSA4LjIyMDAyIDE2Ljg0TDkuNzAwMDIgMTUuNjhMOS42NTAwMSAxNUw5LjcwMDAyIDE0LjMxTDguMjIwMDIgMTMuMTZDOC4wOTAwMiAxMy4wNSA4LjA1MDAyIDEyLjg2IDguMTQwMDIgMTIuNzFMOS41NDAwMiAxMC4yOUM5LjYyMDAyIDEwLjEzIDkuODEwMDIgMTAuMDcgOS45NjAwMiAxMC4xM0wxMS43MSAxMC44NEMxMi4wNyAxMC41NiAxMi40NiAxMC4zMiAxMi44OSAxMC4xNUwxMy4xNSA4LjI4OTk4QzEzLjE4IDguMTI5OTggMTMuMzIgNy45OTk5OCAxMy41IDcuOTk5OThIMTYuM0MxNi40NyA3Ljk5OTk4IDE2LjYyIDguMTI5OTggMTYuNjQgOC4yODk5OEwxNi45MSAxMC4xNUMxNy4zMyAxMC4zMiAxNy43MyAxMC41NiAxOC4wOSAxMC44NEwxOS44MyAxMC4xM0MyMCAxMC4wNyAyMC4xNyAxMC4xMyAyMC4yNiAxMC4yOUwyMS42NiAxMi43MUMyMS43NSAxMi44NiAyMS43MSAxMy4wNSAyMS41OCAxMy4xNkwyMC4xIDE0LjMxTDIwLjE1IDE1TDIwLjEgMTUuNjhaIi8+CiAgICA8cGF0aCBkPSJNNy4zMjk2NiA3LjQ0NDU0QzguMDgzMSA3LjAwOTU0IDguMzM5MzIgNi4wNTMzMiA3LjkwNDMyIDUuMjk5ODhDNy40NjkzMiA0LjU0NjQzIDYuNTA4MSA0LjI4MTU2IDUuNzU0NjYgNC43MTY1NkM1LjM5MTc2IDQuOTI2MDggNS4xMjY5NSA1LjI3MTE4IDUuMDE4NDkgNS42NzU5NEM0LjkxMDA0IDYuMDgwNzEgNC45NjY4MiA2LjUxMTk4IDUuMTc2MzQgNi44NzQ4OEM1LjYxMTM0IDcuNjI4MzIgNi41NzYyMiA3Ljg3OTU0IDcuMzI5NjYgNy40NDQ1NFpNOS42NTcxOCA0Ljc5NTkzTDEwLjg2NzIgNC45NTE3OUMxMC45NjI4IDQuOTc3NDEgMTEuMDQwMiA1LjA3MTMzIDExLjAzODIgNS4xODc5M0wxMS4wMzg4IDYuOTg4OTNDMTEuMDQ1NSA3LjEwMDU0IDEwLjk2MTYgNy4xOTUxOCAxMC44NTUgNy4yMTA1NEw5LjY2MDAxIDcuMzgwODNMOS4yMzkxNSA4LjEzMTg4TDkuNjY5NjEgOS4yNTc0NUM5LjcwNzI5IDkuMzYyNzEgOS42NjkzNCA5LjQ3Njk5IDkuNTc0MDggOS41MzE5OUw4LjAxNTIzIDEwLjQzMkM3LjkxMTMxIDEwLjQ5MiA3Ljc5MzM3IDEwLjQ2NzcgNy43MjEwNSAxMC4zODI0TDYuOTg3NDggOS40MzE4OEw2LjEwOTMxIDkuNDMwODNMNS4zNDcwNCAxMC4zOTA1QzUuMjg5MDkgMTAuNDcwMiA1LjE3MzgzIDEwLjQ5MDUgNS4wNzE4NyAxMC40MzM5TDMuNTEyNDUgOS41MzI5M0MzLjQxMDQ5IDkuNDc2MzMgMy4zNzY0NyA5LjM1NzQxIDMuNDEwNzUgOS4yNTY3OUwzLjg2MzQ3IDguMTQwOTNMMy42MTc0OSA3Ljc3NDg4TDMuNDIzNDcgNy4zNzg4M0wyLjIzMDc1IDcuMjEyOTdDMi4xMjY0NyA3LjE5MjM1IDIuMDQwNDkgNy4xMDM0MiAyLjA0MjQ1IDYuOTg2ODJMMi4wNDE4NyA1LjE4NTgyQzIuMDQzODMgNS4wNjkyMiAyLjExOTA5IDQuOTc5NTggMi4yMTcwNCA0Ljk2OTIyTDMuNDIwNjUgNC43OTM5M0wzLjg2NzQ5IDQuMDI3ODhMMy40MTEwNSAyLjkxNzMxQzMuMzczMzcgMi44MTIwNCAzLjQxMTMxIDIuNjk3NzYgMy41MTUyMyAyLjYzNzc2TDUuMDc0MDggMS43Mzc3NkM1LjE2OTM0IDEuNjgyNzYgNS4yODcyOSAxLjcwNzA0IDUuMzU5NjEgMS43OTIzMUw2LjExOTE1IDIuNzI3ODhMNi45ODAwMSAyLjczODkzTDcuNzI0OTYgMS43ODkyMkM3Ljc5MTU2IDEuNzA0NTggNy45MTU0OCAxLjY3OTIyIDguMDA4NzkgMS43NDA4Mkw5LjU2ODIxIDIuNjQxODJDOS42NzAxNyAyLjY5ODQyIDkuNzEyODUgMi44MTIzNCA5LjY4NzIzIDIuOTA3OTdMOS4yMTcxOCA0LjAzMzgzTDkuNDYzMTYgNC4zOTk4OEw5LjY1NzE4IDQuNzk1OTNaIi8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-caret-down-empty-thin: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIwIDIwIj4KCTxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSIgc2hhcGUtcmVuZGVyaW5nPSJnZW9tZXRyaWNQcmVjaXNpb24iPgoJCTxwb2x5Z29uIGNsYXNzPSJzdDEiIHBvaW50cz0iOS45LDEzLjYgMy42LDcuNCA0LjQsNi42IDkuOSwxMi4yIDE1LjQsNi43IDE2LjEsNy40ICIvPgoJPC9nPgo8L3N2Zz4K);--jp-icon-caret-down-empty: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDE4IDE4Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiIHNoYXBlLXJlbmRlcmluZz0iZ2VvbWV0cmljUHJlY2lzaW9uIj4KICAgIDxwYXRoIGQ9Ik01LjIsNS45TDksOS43bDMuOC0zLjhsMS4yLDEuMmwtNC45LDVsLTQuOS01TDUuMiw1Ljl6Ii8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-caret-down: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDE4IDE4Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiIHNoYXBlLXJlbmRlcmluZz0iZ2VvbWV0cmljUHJlY2lzaW9uIj4KICAgIDxwYXRoIGQ9Ik01LjIsNy41TDksMTEuMmwzLjgtMy44SDUuMnoiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-caret-left: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDE4IDE4Ij4KCTxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSIgc2hhcGUtcmVuZGVyaW5nPSJnZW9tZXRyaWNQcmVjaXNpb24iPgoJCTxwYXRoIGQ9Ik0xMC44LDEyLjhMNy4xLDlsMy44LTMuOGwwLDcuNkgxMC44eiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-caret-right: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDE4IDE4Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiIHNoYXBlLXJlbmRlcmluZz0iZ2VvbWV0cmljUHJlY2lzaW9uIj4KICAgIDxwYXRoIGQ9Ik03LjIsNS4yTDEwLjksOWwtMy44LDMuOFY1LjJINy4yeiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-caret-up-empty-thin: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIwIDIwIj4KCTxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSIgc2hhcGUtcmVuZGVyaW5nPSJnZW9tZXRyaWNQcmVjaXNpb24iPgoJCTxwb2x5Z29uIGNsYXNzPSJzdDEiIHBvaW50cz0iMTUuNCwxMy4zIDkuOSw3LjcgNC40LDEzLjIgMy42LDEyLjUgOS45LDYuMyAxNi4xLDEyLjYgIi8+Cgk8L2c+Cjwvc3ZnPgo=);--jp-icon-caret-up: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDE4IDE4Ij4KCTxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSIgc2hhcGUtcmVuZGVyaW5nPSJnZW9tZXRyaWNQcmVjaXNpb24iPgoJCTxwYXRoIGQ9Ik01LjIsMTAuNUw5LDYuOGwzLjgsMy44SDUuMnoiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-case-sensitive: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIwIDIwIj4KICA8ZyBjbGFzcz0ianAtaWNvbjIiIGZpbGw9IiM0MTQxNDEiPgogICAgPHJlY3QgeD0iMiIgeT0iMiIgd2lkdGg9IjE2IiBoZWlnaHQ9IjE2Ii8+CiAgPC9nPgogIDxnIGNsYXNzPSJqcC1pY29uLWFjY2VudDIiIGZpbGw9IiNGRkYiPgogICAgPHBhdGggZD0iTTcuNiw4aDAuOWwzLjUsOGgtMS4xTDEwLDE0SDZsLTAuOSwySDRMNy42LDh6IE04LDkuMUw2LjQsMTNoMy4yTDgsOS4xeiIvPgogICAgPHBhdGggZD0iTTE2LjYsOS44Yy0wLjIsMC4xLTAuNCwwLjEtMC43LDAuMWMtMC4yLDAtMC40LTAuMS0wLjYtMC4yYy0wLjEtMC4xLTAuMi0wLjQtMC4yLTAuNyBjLTAuMywwLjMtMC42LDAuNS0wLjksMC43Yy0wLjMsMC4xLTAuNywwLjItMS4xLDAuMmMtMC4zLDAtMC41LDAtMC43LTAuMWMtMC4yLTAuMS0wLjQtMC4yLTAuNi0wLjNjLTAuMi0wLjEtMC4zLTAuMy0wLjQtMC41IGMtMC4xLTAuMi0wLjEtMC40LTAuMS0wLjdjMC0wLjMsMC4xLTAuNiwwLjItMC44YzAuMS0wLjIsMC4zLTAuNCwwLjQtMC41QzEyLDcsMTIuMiw2LjksMTIuNSw2LjhjMC4yLTAuMSwwLjUtMC4xLDAuNy0wLjIgYzAuMy0wLjEsMC41LTAuMSwwLjctMC4xYzAuMiwwLDAuNC0wLjEsMC42LTAuMWMwLjIsMCwwLjMtMC4xLDAuNC0wLjJjMC4xLTAuMSwwLjItMC4yLDAuMi0wLjRjMC0xLTEuMS0xLTEuMy0xIGMtMC40LDAtMS40LDAtMS40LDEuMmgtMC45YzAtMC40LDAuMS0wLjcsMC4yLTFjMC4xLTAuMiwwLjMtMC40LDAuNS0wLjZjMC4yLTAuMiwwLjUtMC4zLDAuOC0wLjNDMTMuMyw0LDEzLjYsNCwxMy45LDQgYzAuMywwLDAuNSwwLDAuOCwwLjFjMC4zLDAsMC41LDAuMSwwLjcsMC4yYzAuMiwwLjEsMC40LDAuMywwLjUsMC41QzE2LDUsMTYsNS4yLDE2LDUuNnYyLjljMCwwLjIsMCwwLjQsMCwwLjUgYzAsMC4xLDAuMSwwLjIsMC4zLDAuMmMwLjEsMCwwLjIsMCwwLjMsMFY5Ljh6IE0xNS4yLDYuOWMtMS4yLDAuNi0zLjEsMC4yLTMuMSwxLjRjMCwxLjQsMy4xLDEsMy4xLTAuNVY2Ljl6Ii8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-check: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTkgMTYuMTdMNC44MyAxMmwtMS40MiAxLjQxTDkgMTkgMjEgN2wtMS40MS0xLjQxeiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-circle-empty: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTEyIDJDNi40NyAyIDIgNi40NyAyIDEyczQuNDcgMTAgMTAgMTAgMTAtNC40NyAxMC0xMFMxNy41MyAyIDEyIDJ6bTAgMThjLTQuNDEgMC04LTMuNTktOC04czMuNTktOCA4LTggOCAzLjU5IDggOC0zLjU5IDgtOCA4eiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-circle: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMTggMTgiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPGNpcmNsZSBjeD0iOSIgY3k9IjkiIHI9IjgiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-clear: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8bWFzayBpZD0iZG9udXRIb2xlIj4KICAgIDxyZWN0IHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgZmlsbD0id2hpdGUiIC8+CiAgICA8Y2lyY2xlIGN4PSIxMiIgY3k9IjEyIiByPSI4IiBmaWxsPSJibGFjayIvPgogIDwvbWFzaz4KCiAgPGcgY2xhc3M9ImpwLWljb24zIiBmaWxsPSIjNjE2MTYxIj4KICAgIDxyZWN0IGhlaWdodD0iMTgiIHdpZHRoPSIyIiB4PSIxMSIgeT0iMyIgdHJhbnNmb3JtPSJyb3RhdGUoMzE1LCAxMiwgMTIpIi8+CiAgICA8Y2lyY2xlIGN4PSIxMiIgY3k9IjEyIiByPSIxMCIgbWFzaz0idXJsKCNkb251dEhvbGUpIi8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-close: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbi1ub25lIGpwLWljb24tc2VsZWN0YWJsZS1pbnZlcnNlIGpwLWljb24zLWhvdmVyIiBmaWxsPSJub25lIj4KICAgIDxjaXJjbGUgY3g9IjEyIiBjeT0iMTIiIHI9IjExIi8+CiAgPC9nPgoKICA8ZyBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIGpwLWljb24tYWNjZW50Mi1ob3ZlciIgZmlsbD0iIzYxNjE2MSI+CiAgICA8cGF0aCBkPSJNMTkgNi40MUwxNy41OSA1IDEyIDEwLjU5IDYuNDEgNSA1IDYuNDEgMTAuNTkgMTIgNSAxNy41OSA2LjQxIDE5IDEyIDEzLjQxIDE3LjU5IDE5IDE5IDE3LjU5IDEzLjQxIDEyeiIvPgogIDwvZz4KCiAgPGcgY2xhc3M9ImpwLWljb24tbm9uZSBqcC1pY29uLWJ1c3kiIGZpbGw9Im5vbmUiPgogICAgPGNpcmNsZSBjeD0iMTIiIGN5PSIxMiIgcj0iNyIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-console: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIwMCAyMDAiPgogIDxnIGNsYXNzPSJqcC1pY29uLWJyYW5kMSBqcC1pY29uLXNlbGVjdGFibGUiIGZpbGw9IiMwMjg4RDEiPgogICAgPHBhdGggZD0iTTIwIDE5LjhoMTYwdjE1OS45SDIweiIvPgogIDwvZz4KICA8ZyBjbGFzcz0ianAtaWNvbi1zZWxlY3RhYmxlLWludmVyc2UiIGZpbGw9IiNmZmYiPgogICAgPHBhdGggZD0iTTEwNSAxMjcuM2g0MHYxMi44aC00MHpNNTEuMSA3N0w3NCA5OS45bC0yMy4zIDIzLjMgMTAuNSAxMC41IDIzLjMtMjMuM0w5NSA5OS45IDg0LjUgODkuNCA2MS42IDY2LjV6Ii8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-copy: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMTggMTgiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTExLjksMUgzLjJDMi40LDEsMS43LDEuNywxLjcsMi41djEwLjJoMS41VjIuNWg4LjdWMXogTTE0LjEsMy45aC04Yy0wLjgsMC0xLjUsMC43LTEuNSwxLjV2MTAuMmMwLDAuOCwwLjcsMS41LDEuNSwxLjVoOCBjMC44LDAsMS41LTAuNywxLjUtMS41VjUuNEMxNS41LDQuNiwxNC45LDMuOSwxNC4xLDMuOXogTTE0LjEsMTUuNWgtOFY1LjRoOFYxNS41eiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-cut: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTkuNjQgNy42NGMuMjMtLjUuMzYtMS4wNS4zNi0xLjY0IDAtMi4yMS0xLjc5LTQtNC00UzIgMy43OSAyIDZzMS43OSA0IDQgNGMuNTkgMCAxLjE0LS4xMyAxLjY0LS4zNkwxMCAxMmwtMi4zNiAyLjM2QzcuMTQgMTQuMTMgNi41OSAxNCA2IDE0Yy0yLjIxIDAtNCAxLjc5LTQgNHMxLjc5IDQgNCA0IDQtMS43OSA0LTRjMC0uNTktLjEzLTEuMTQtLjM2LTEuNjRMMTIgMTRsNyA3aDN2LTFMOS42NCA3LjY0ek02IDhjLTEuMSAwLTItLjg5LTItMnMuOS0yIDItMiAyIC44OSAyIDItLjkgMi0yIDJ6bTAgMTJjLTEuMSAwLTItLjg5LTItMnMuOS0yIDItMiAyIC44OSAyIDItLjkgMi0yIDJ6bTYtNy41Yy0uMjggMC0uNS0uMjItLjUtLjVzLjIyLS41LjUtLjUuNS4yMi41LjUtLjIyLjUtLjUuNXpNMTkgM2wtNiA2IDIgMiA3LTdWM3oiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-download: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTE5IDloLTRWM0g5djZINWw3IDcgNy03ek01IDE4djJoMTR2LTJINXoiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-edit: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTMgMTcuMjVWMjFoMy43NUwxNy44MSA5Ljk0bC0zLjc1LTMuNzVMMyAxNy4yNXpNMjAuNzEgNy4wNGMuMzktLjM5LjM5LTEuMDIgMC0xLjQxbC0yLjM0LTIuMzRjLS4zOS0uMzktMS4wMi0uMzktMS40MSAwbC0xLjgzIDEuODMgMy43NSAzLjc1IDEuODMtMS44M3oiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-ellipses: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPGNpcmNsZSBjeD0iNSIgY3k9IjEyIiByPSIyIi8+CiAgICA8Y2lyY2xlIGN4PSIxMiIgY3k9IjEyIiByPSIyIi8+CiAgICA8Y2lyY2xlIGN4PSIxOSIgY3k9IjEyIiByPSIyIi8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-extension: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTIwLjUgMTFIMTlWN2MwLTEuMS0uOS0yLTItMmgtNFYzLjVDMTMgMi4xMiAxMS44OCAxIDEwLjUgMVM4IDIuMTIgOCAzLjVWNUg0Yy0xLjEgMC0xLjk5LjktMS45OSAydjMuOEgzLjVjMS40OSAwIDIuNyAxLjIxIDIuNyAyLjdzLTEuMjEgMi43LTIuNyAyLjdIMlYyMGMwIDEuMS45IDIgMiAyaDMuOHYtMS41YzAtMS40OSAxLjIxLTIuNyAyLjctMi43IDEuNDkgMCAyLjcgMS4yMSAyLjcgMi43VjIySDE3YzEuMSAwIDItLjkgMi0ydi00aDEuNWMxLjM4IDAgMi41LTEuMTIgMi41LTIuNVMyMS44OCAxMSAyMC41IDExeiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-fast-forward: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyNCIgaGVpZ2h0PSIyNCIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICAgIDxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSI+CiAgICAgICAgPHBhdGggZD0iTTQgMThsOC41LTZMNCA2djEyem05LTEydjEybDguNS02TDEzIDZ6Ii8+CiAgICA8L2c+Cjwvc3ZnPgo=);--jp-icon-file-upload: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTkgMTZoNnYtNmg0bC03LTctNyA3aDR6bS00IDJoMTR2Mkg1eiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-file: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8cGF0aCBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNjE2MTYxIiBkPSJNMTkuMyA4LjJsLTUuNS01LjVjLS4zLS4zLS43LS41LTEuMi0uNUgzLjljLS44LjEtMS42LjktMS42IDEuOHYxNC4xYzAgLjkuNyAxLjYgMS42IDEuNmgxNC4yYy45IDAgMS42LS43IDEuNi0xLjZWOS40Yy4xLS41LS4xLS45LS40LTEuMnptLTUuOC0zLjNsMy40IDMuNmgtMy40VjQuOXptMy45IDEyLjdINC43Yy0uMSAwLS4yIDAtLjItLjJWNC43YzAtLjIuMS0uMy4yLS4zaDcuMnY0LjRzMCAuOC4zIDEuMWMuMy4zIDEuMS4zIDEuMS4zaDQuM3Y3LjJzLS4xLjItLjIuMnoiLz4KPC9zdmc+Cg==);--jp-icon-filter-list: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTEwIDE4aDR2LTJoLTR2MnpNMyA2djJoMThWNkgzem0zIDdoMTJ2LTJINnYyeiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-folder: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8cGF0aCBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNjE2MTYxIiBkPSJNMTAgNEg0Yy0xLjEgMC0xLjk5LjktMS45OSAyTDIgMThjMCAxLjEuOSAyIDIgMmgxNmMxLjEgMCAyLS45IDItMlY4YzAtMS4xLS45LTItMi0yaC04bC0yLTJ6Ii8+Cjwvc3ZnPgo=);--jp-icon-html5: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDUxMiA1MTIiPgogIDxwYXRoIGNsYXNzPSJqcC1pY29uMCBqcC1pY29uLXNlbGVjdGFibGUiIGZpbGw9IiMwMDAiIGQ9Ik0xMDguNCAwaDIzdjIyLjhoMjEuMlYwaDIzdjY5aC0yM1Y0NmgtMjF2MjNoLTIzLjJNMjA2IDIzaC0yMC4zVjBoNjMuN3YyM0gyMjl2NDZoLTIzbTUzLjUtNjloMjQuMWwxNC44IDI0LjNMMzEzLjIgMGgyNC4xdjY5aC0yM1YzNC44bC0xNi4xIDI0LjgtMTYuMS0yNC44VjY5aC0yMi42bTg5LjItNjloMjN2NDYuMmgzMi42VjY5aC01NS42Ii8+CiAgPHBhdGggY2xhc3M9ImpwLWljb24tc2VsZWN0YWJsZSIgZmlsbD0iI2U0NGQyNiIgZD0iTTEwNy42IDQ3MWwtMzMtMzcwLjRoMzYyLjhsLTMzIDM3MC4yTDI1NS43IDUxMiIvPgogIDxwYXRoIGNsYXNzPSJqcC1pY29uLXNlbGVjdGFibGUiIGZpbGw9IiNmMTY1MjkiIGQ9Ik0yNTYgNDgwLjVWMTMxaDE0OC4zTDM3NiA0NDciLz4KICA8cGF0aCBjbGFzcz0ianAtaWNvbi1zZWxlY3RhYmxlLWludmVyc2UiIGZpbGw9IiNlYmViZWIiIGQ9Ik0xNDIgMTc2LjNoMTE0djQ1LjRoLTY0LjJsNC4yIDQ2LjVoNjB2NDUuM0gxNTQuNG0yIDIyLjhIMjAybDMuMiAzNi4zIDUwLjggMTMuNnY0Ny40bC05My4yLTI2Ii8+CiAgPHBhdGggY2xhc3M9ImpwLWljb24tc2VsZWN0YWJsZS1pbnZlcnNlIiBmaWxsPSIjZmZmIiBkPSJNMzY5LjYgMTc2LjNIMjU1Ljh2NDUuNGgxMDkuNm0tNC4xIDQ2LjVIMjU1Ljh2NDUuNGg1NmwtNS4zIDU5LTUwLjcgMTMuNnY0Ny4ybDkzLTI1LjgiLz4KPC9zdmc+Cg==);--jp-icon-image: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8cGF0aCBjbGFzcz0ianAtaWNvbi1icmFuZDQganAtaWNvbi1zZWxlY3RhYmxlLWludmVyc2UiIGZpbGw9IiNGRkYiIGQ9Ik0yLjIgMi4yaDE3LjV2MTcuNUgyLjJ6Ii8+CiAgPHBhdGggY2xhc3M9ImpwLWljb24tYnJhbmQwIGpwLWljb24tc2VsZWN0YWJsZSIgZmlsbD0iIzNGNTFCNSIgZD0iTTIuMiAyLjJ2MTcuNWgxNy41bC4xLTE3LjVIMi4yem0xMi4xIDIuMmMxLjIgMCAyLjIgMSAyLjIgMi4ycy0xIDIuMi0yLjIgMi4yLTIuMi0xLTIuMi0yLjIgMS0yLjIgMi4yLTIuMnpNNC40IDE3LjZsMy4zLTguOCAzLjMgNi42IDIuMi0zLjIgNC40IDUuNEg0LjR6Ii8+Cjwvc3ZnPgo=);--jp-icon-inspector: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8cGF0aCBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNjE2MTYxIiBkPSJNMjAgNEg0Yy0xLjEgMC0xLjk5LjktMS45OSAyTDIgMThjMCAxLjEuOSAyIDIgMmgxNmMxLjEgMCAyLS45IDItMlY2YzAtMS4xLS45LTItMi0yem0tNSAxNEg0di00aDExdjR6bTAtNUg0VjloMTF2NHptNSA1aC00VjloNHY5eiIvPgo8L3N2Zz4K);--jp-icon-json: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8ZyBjbGFzcz0ianAtaWNvbi13YXJuMSBqcC1pY29uLXNlbGVjdGFibGUiIGZpbGw9IiNGOUE4MjUiPgogICAgPHBhdGggZD0iTTIwLjIgMTEuOGMtMS42IDAtMS43LjUtMS43IDEgMCAuNC4xLjkuMSAxLjMuMS41LjEuOS4xIDEuMyAwIDEuNy0xLjQgMi4zLTMuNSAyLjNoLS45di0xLjloLjVjMS4xIDAgMS40IDAgMS40LS44IDAtLjMgMC0uNi0uMS0xIDAtLjQtLjEtLjgtLjEtMS4yIDAtMS4zIDAtMS44IDEuMy0yLTEuMy0uMi0xLjMtLjctMS4zLTIgMC0uNC4xLS44LjEtMS4yLjEtLjQuMS0uNy4xLTEgMC0uOC0uNC0uNy0xLjQtLjhoLS41VjQuMWguOWMyLjIgMCAzLjUuNyAzLjUgMi4zIDAgLjQtLjEuOS0uMSAxLjMtLjEuNS0uMS45LS4xIDEuMyAwIC41LjIgMSAxLjcgMXYxLjh6TTEuOCAxMC4xYzEuNiAwIDEuNy0uNSAxLjctMSAwLS40LS4xLS45LS4xLTEuMy0uMS0uNS0uMS0uOS0uMS0xLjMgMC0xLjYgMS40LTIuMyAzLjUtMi4zaC45djEuOWgtLjVjLTEgMC0xLjQgMC0xLjQuOCAwIC4zIDAgLjYuMSAxIDAgLjIuMS42LjEgMSAwIDEuMyAwIDEuOC0xLjMgMkM2IDExLjIgNiAxMS43IDYgMTNjMCAuNC0uMS44LS4xIDEuMi0uMS4zLS4xLjctLjEgMSAwIC44LjMuOCAxLjQuOGguNXYxLjloLS45Yy0yLjEgMC0zLjUtLjYtMy41LTIuMyAwLS40LjEtLjkuMS0xLjMuMS0uNS4xLS45LjEtMS4zIDAtLjUtLjItMS0xLjctMXYtMS45eiIvPgogICAgPGNpcmNsZSBjeD0iMTEiIGN5PSIxMy44IiByPSIyLjEiLz4KICAgIDxjaXJjbGUgY3g9IjExIiBjeT0iOC4yIiByPSIyLjEiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-jupyter-favicon: url(data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMTUyIiBoZWlnaHQ9IjE2NSIgdmlld0JveD0iMCAwIDE1MiAxNjUiIHZlcnNpb249IjEuMSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbi13YXJuMCIgZmlsbD0iI0YzNzcyNiI+CiAgICA8cGF0aCB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLjA3ODk0NywgMTEwLjU4MjkyNykiIGQ9Ik03NS45NDIyODQyLDI5LjU4MDQ1NjEgQzQzLjMwMjM5NDcsMjkuNTgwNDU2MSAxNC43OTY3ODMyLDE3LjY1MzQ2MzQgMCwwIEM1LjUxMDgzMjExLDE1Ljg0MDY4MjkgMTUuNzgxNTM4OSwyOS41NjY3NzMyIDI5LjM5MDQ5NDcsMzkuMjc4NDE3MSBDNDIuOTk5Nyw0OC45ODk4NTM3IDU5LjI3MzcsNTQuMjA2NzgwNSA3NS45NjA1Nzg5LDU0LjIwNjc4MDUgQzkyLjY0NzQ1NzksNTQuMjA2NzgwNSAxMDguOTIxNDU4LDQ4Ljk4OTg1MzcgMTIyLjUzMDY2MywzOS4yNzg0MTcxIEMxMzYuMTM5NDUzLDI5LjU2Njc3MzIgMTQ2LjQxMDI4NCwxNS44NDA2ODI5IDE1MS45MjExNTgsMCBDMTM3LjA4Nzg2OCwxNy42NTM0NjM0IDEwOC41ODI1ODksMjkuNTgwNDU2MSA3NS45NDIyODQyLDI5LjU4MDQ1NjEgTDc1Ljk0MjI4NDIsMjkuNTgwNDU2MSBaIiAvPgogICAgPHBhdGggdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMC4wMzczNjgsIDAuNzA0ODc4KSIgZD0iTTc1Ljk3ODQ1NzksMjQuNjI2NDA3MyBDMTA4LjYxODc2MywyNC42MjY0MDczIDEzNy4xMjQ0NTgsMzYuNTUzNDQxNSAxNTEuOTIxMTU4LDU0LjIwNjc4MDUgQzE0Ni40MTAyODQsMzguMzY2MjIyIDEzNi4xMzk0NTMsMjQuNjQwMTMxNyAxMjIuNTMwNjYzLDE0LjkyODQ4NzggQzEwOC45MjE0NTgsNS4yMTY4NDM5IDkyLjY0NzQ1NzksMCA3NS45NjA1Nzg5LDAgQzU5LjI3MzcsMCA0Mi45OTk3LDUuMjE2ODQzOSAyOS4zOTA0OTQ3LDE0LjkyODQ4NzggQzE1Ljc4MTUzODksMjQuNjQwMTMxNyA1LjUxMDgzMjExLDM4LjM2NjIyMiAwLDU0LjIwNjc4MDUgQzE0LjgzMzA4MTYsMzYuNTg5OTI5MyA0My4zMzg1Njg0LDI0LjYyNjQwNzMgNzUuOTc4NDU3OSwyNC42MjY0MDczIEw3NS45Nzg0NTc5LDI0LjYyNjQwNzMgWiIgLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-jupyter: url(data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMzkiIGhlaWdodD0iNTEiIHZpZXdCb3g9IjAgMCAzOSA1MSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgtMTYzOCAtMjI4MSkiPgogICAgPGcgY2xhc3M9ImpwLWljb24td2FybjAiIGZpbGw9IiNGMzc3MjYiPgogICAgICA8cGF0aCB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjM5Ljc0IDIzMTEuOTgpIiBkPSJNIDE4LjI2NDYgNy4xMzQxMUMgMTAuNDE0NSA3LjEzNDExIDMuNTU4NzIgNC4yNTc2IDAgMEMgMS4zMjUzOSAzLjgyMDQgMy43OTU1NiA3LjEzMDgxIDcuMDY4NiA5LjQ3MzAzQyAxMC4zNDE3IDExLjgxNTIgMTQuMjU1NyAxMy4wNzM0IDE4LjI2OSAxMy4wNzM0QyAyMi4yODIzIDEzLjA3MzQgMjYuMTk2MyAxMS44MTUyIDI5LjQ2OTQgOS40NzMwM0MgMzIuNzQyNCA3LjEzMDgxIDM1LjIxMjYgMy44MjA0IDM2LjUzOCAwQyAzMi45NzA1IDQuMjU3NiAyNi4xMTQ4IDcuMTM0MTEgMTguMjY0NiA3LjEzNDExWiIvPgogICAgICA8cGF0aCB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjM5LjczIDIyODUuNDgpIiBkPSJNIDE4LjI3MzMgNS45MzkzMUMgMjYuMTIzNSA1LjkzOTMxIDMyLjk3OTMgOC44MTU4MyAzNi41MzggMTMuMDczNEMgMzUuMjEyNiA5LjI1MzAzIDMyLjc0MjQgNS45NDI2MiAyOS40Njk0IDMuNjAwNEMgMjYuMTk2MyAxLjI1ODE4IDIyLjI4MjMgMCAxOC4yNjkgMEMgMTQuMjU1NyAwIDEwLjM0MTcgMS4yNTgxOCA3LjA2ODYgMy42MDA0QyAzLjc5NTU2IDUuOTQyNjIgMS4zMjUzOSA5LjI1MzAzIDAgMTMuMDczNEMgMy41Njc0NSA4LjgyNDYzIDEwLjQyMzIgNS45MzkzMSAxOC4yNzMzIDUuOTM5MzFaIi8+CiAgICA8L2c+CiAgICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgICA8cGF0aCB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjY5LjMgMjI4MS4zMSkiIGQ9Ik0gNS44OTM1MyAyLjg0NEMgNS45MTg4OSAzLjQzMTY1IDUuNzcwODUgNC4wMTM2NyA1LjQ2ODE1IDQuNTE2NDVDIDUuMTY1NDUgNS4wMTkyMiA0LjcyMTY4IDUuNDIwMTUgNC4xOTI5OSA1LjY2ODUxQyAzLjY2NDMgNS45MTY4OCAzLjA3NDQ0IDYuMDAxNTEgMi40OTgwNSA1LjkxMTcxQyAxLjkyMTY2IDUuODIxOSAxLjM4NDYzIDUuNTYxNyAwLjk1NDg5OCA1LjE2NDAxQyAwLjUyNTE3IDQuNzY2MzMgMC4yMjIwNTYgNC4yNDkwMyAwLjA4MzkwMzcgMy42Nzc1N0MgLTAuMDU0MjQ4MyAzLjEwNjExIC0wLjAyMTIzIDIuNTA2MTcgMC4xNzg3ODEgMS45NTM2NEMgMC4zNzg3OTMgMS40MDExIDAuNzM2ODA5IDAuOTIwODE3IDEuMjA3NTQgMC41NzM1MzhDIDEuNjc4MjYgMC4yMjYyNTkgMi4yNDA1NSAwLjAyNzU5MTkgMi44MjMyNiAwLjAwMjY3MjI5QyAzLjYwMzg5IC0wLjAzMDcxMTUgNC4zNjU3MyAwLjI0OTc4OSA0Ljk0MTQyIDAuNzgyNTUxQyA1LjUxNzExIDEuMzE1MzEgNS44NTk1NiAyLjA1Njc2IDUuODkzNTMgMi44NDRaIi8+CiAgICAgIDxwYXRoIHRyYW5zZm9ybT0idHJhbnNsYXRlKDE2MzkuOCAyMzIzLjgxKSIgZD0iTSA3LjQyNzg5IDMuNTgzMzhDIDcuNDYwMDggNC4zMjQzIDcuMjczNTUgNS4wNTgxOSA2Ljg5MTkzIDUuNjkyMTNDIDYuNTEwMzEgNi4zMjYwNyA1Ljk1MDc1IDYuODMxNTYgNS4yODQxMSA3LjE0NDZDIDQuNjE3NDcgNy40NTc2MyAzLjg3MzcxIDcuNTY0MTQgMy4xNDcwMiA3LjQ1MDYzQyAyLjQyMDMyIDcuMzM3MTIgMS43NDMzNiA3LjAwODcgMS4yMDE4NCA2LjUwNjk1QyAwLjY2MDMyOCA2LjAwNTIgMC4yNzg2MSA1LjM1MjY4IDAuMTA1MDE3IDQuNjMyMDJDIC0wLjA2ODU3NTcgMy45MTEzNSAtMC4wMjYyMzYxIDMuMTU0OTQgMC4yMjY2NzUgMi40NTg1NkMgMC40Nzk1ODcgMS43NjIxNyAwLjkzMTY5NyAxLjE1NzEzIDEuNTI1NzYgMC43MjAwMzNDIDIuMTE5ODMgMC4yODI5MzUgMi44MjkxNCAwLjAzMzQzOTUgMy41NjM4OSAwLjAwMzEzMzQ0QyA0LjU0NjY3IC0wLjAzNzQwMzMgNS41MDUyOSAwLjMxNjcwNiA2LjIyOTYxIDAuOTg3ODM1QyA2Ljk1MzkzIDEuNjU4OTYgNy4zODQ4NCAyLjU5MjM1IDcuNDI3ODkgMy41ODMzOEwgNy40Mjc4OSAzLjU4MzM4WiIvPgogICAgICA8cGF0aCB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxNjM4LjM2IDIyODYuMDYpIiBkPSJNIDIuMjc0NzEgNC4zOTYyOUMgMS44NDM2MyA0LjQxNTA4IDEuNDE2NzEgNC4zMDQ0NSAxLjA0Nzk5IDQuMDc4NDNDIDAuNjc5MjY4IDMuODUyNCAwLjM4NTMyOCAzLjUyMTE0IDAuMjAzMzcxIDMuMTI2NTZDIDAuMDIxNDEzNiAyLjczMTk4IC0wLjA0MDM3OTggMi4yOTE4MyAwLjAyNTgxMTYgMS44NjE4MUMgMC4wOTIwMDMxIDEuNDMxOCAwLjI4MzIwNCAxLjAzMTI2IDAuNTc1MjEzIDAuNzEwODgzQyAwLjg2NzIyMiAwLjM5MDUxIDEuMjQ2OTEgMC4xNjQ3MDggMS42NjYyMiAwLjA2MjA1OTJDIDIuMDg1NTMgLTAuMDQwNTg5NyAyLjUyNTYxIC0wLjAxNTQ3MTQgMi45MzA3NiAwLjEzNDIzNUMgMy4zMzU5MSAwLjI4Mzk0MSAzLjY4NzkyIDAuNTUxNTA1IDMuOTQyMjIgMC45MDMwNkMgNC4xOTY1MiAxLjI1NDYyIDQuMzQxNjkgMS42NzQzNiA0LjM1OTM1IDIuMTA5MTZDIDQuMzgyOTkgMi42OTEwNyA0LjE3Njc4IDMuMjU4NjkgMy43ODU5NyAzLjY4NzQ2QyAzLjM5NTE2IDQuMTE2MjQgMi44NTE2NiA0LjM3MTE2IDIuMjc0NzEgNC4zOTYyOUwgMi4yNzQ3MSA0LjM5NjI5WiIvPgogICAgPC9nPgogIDwvZz4+Cjwvc3ZnPgo=);--jp-icon-jupyterlab-wordmark: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIyMDAiIHZpZXdCb3g9IjAgMCAxODYwLjggNDc1Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjIiIGZpbGw9IiM0RTRFNEUiIHRyYW5zZm9ybT0idHJhbnNsYXRlKDQ4MC4xMzY0MDEsIDY0LjI3MTQ5MykiPgogICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMC4wMDAwMDAsIDU4Ljg3NTU2NikiPgogICAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgwLjA4NzYwMywgMC4xNDAyOTQpIj4KICAgICAgICA8cGF0aCBkPSJNLTQyNi45LDE2OS44YzAsNDguNy0zLjcsNjQuNy0xMy42LDc2LjRjLTEwLjgsMTAtMjUsMTUuNS0zOS43LDE1LjVsMy43LDI5IGMyMi44LDAuMyw0NC44LTcuOSw2MS45LTIzLjFjMTcuOC0xOC41LDI0LTQ0LjEsMjQtODMuM1YwSC00Mjd2MTcwLjFMLTQyNi45LDE2OS44TC00MjYuOSwxNjkuOHoiLz4KICAgICAgPC9nPgogICAgPC9nPgogICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMTU1LjA0NTI5NiwgNTYuODM3MTA0KSI+CiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEuNTYyNDUzLCAxLjc5OTg0MikiPgogICAgICAgIDxwYXRoIGQ9Ik0tMzEyLDE0OGMwLDIxLDAsMzkuNSwxLjcsNTUuNGgtMzEuOGwtMi4xLTMzLjNoLTAuOGMtNi43LDExLjYtMTYuNCwyMS4zLTI4LDI3LjkgYy0xMS42LDYuNi0yNC44LDEwLTM4LjIsOS44Yy0zMS40LDAtNjktMTcuNy02OS04OVYwaDM2LjR2MTEyLjdjMCwzOC43LDExLjYsNjQuNyw0NC42LDY0LjdjMTAuMy0wLjIsMjAuNC0zLjUsMjguOS05LjQgYzguNS01LjksMTUuMS0xNC4zLDE4LjktMjMuOWMyLjItNi4xLDMuMy0xMi41LDMuMy0xOC45VjAuMmgzNi40VjE0OEgtMzEyTC0zMTIsMTQ4eiIvPgogICAgICA8L2c+CiAgICA8L2c+CiAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzOTAuMDEzMzIyLCA1My40Nzk2MzgpIj4KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMS43MDY0NTgsIDAuMjMxNDI1KSI+CiAgICAgICAgPHBhdGggZD0iTS00NzguNiw3MS40YzAtMjYtMC44LTQ3LTEuNy02Ni43aDMyLjdsMS43LDM0LjhoMC44YzcuMS0xMi41LDE3LjUtMjIuOCwzMC4xLTI5LjcgYzEyLjUtNywyNi43LTEwLjMsNDEtOS44YzQ4LjMsMCw4NC43LDQxLjcsODQuNywxMDMuM2MwLDczLjEtNDMuNywxMDkuMi05MSwxMDkuMmMtMTIuMSwwLjUtMjQuMi0yLjItMzUtNy44IGMtMTAuOC01LjYtMTkuOS0xMy45LTI2LjYtMjQuMmgtMC44VjI5MWgtMzZ2LTIyMEwtNDc4LjYsNzEuNEwtNDc4LjYsNzEuNHogTS00NDIuNiwxMjUuNmMwLjEsNS4xLDAuNiwxMC4xLDEuNywxNS4xIGMzLDEyLjMsOS45LDIzLjMsMTkuOCwzMS4xYzkuOSw3LjgsMjIuMSwxMi4xLDM0LjcsMTIuMWMzOC41LDAsNjAuNy0zMS45LDYwLjctNzguNWMwLTQwLjctMjEuMS03NS42LTU5LjUtNzUuNiBjLTEyLjksMC40LTI1LjMsNS4xLTM1LjMsMTMuNGMtOS45LDguMy0xNi45LDE5LjctMTkuNiwzMi40Yy0xLjUsNC45LTIuMywxMC0yLjUsMTUuMVYxMjUuNkwtNDQyLjYsMTI1LjZMLTQ0Mi42LDEyNS42eiIvPgogICAgICA8L2c+CiAgICA8L2c+CiAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSg2MDYuNzQwNzI2LCA1Ni44MzcxMDQpIj4KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMC43NTEyMjYsIDEuOTg5Mjk5KSI+CiAgICAgICAgPHBhdGggZD0iTS00NDAuOCwwbDQzLjcsMTIwLjFjNC41LDEzLjQsOS41LDI5LjQsMTIuOCw0MS43aDAuOGMzLjctMTIuMiw3LjktMjcuNywxMi44LTQyLjQgbDM5LjctMTE5LjJoMzguNUwtMzQ2LjksMTQ1Yy0yNiw2OS43LTQzLjcsMTA1LjQtNjguNiwxMjcuMmMtMTIuNSwxMS43LTI3LjksMjAtNDQuNiwyMy45bC05LjEtMzEuMSBjMTEuNy0zLjksMjIuNS0xMC4xLDMxLjgtMTguMWMxMy4yLTExLjEsMjMuNy0yNS4yLDMwLjYtNDEuMmMxLjUtMi44LDIuNS01LjcsMi45LTguOGMtMC4zLTMuMy0xLjItNi42LTIuNS05LjdMLTQ4MC4yLDAuMSBoMzkuN0wtNDQwLjgsMEwtNDQwLjgsMHoiLz4KICAgICAgPC9nPgogICAgPC9nPgogICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoODIyLjc0ODEwNCwgMC4wMDAwMDApIj4KICAgICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoMS40NjQwNTAsIDAuMzc4OTE0KSI+CiAgICAgICAgPHBhdGggZD0iTS00MTMuNywwdjU4LjNoNTJ2MjguMmgtNTJWMTk2YzAsMjUsNywzOS41LDI3LjMsMzkuNWM3LjEsMC4xLDE0LjItMC43LDIxLjEtMi41IGwxLjcsMjcuN2MtMTAuMywzLjctMjEuMyw1LjQtMzIuMiw1Yy03LjMsMC40LTE0LjYtMC43LTIxLjMtMy40Yy02LjgtMi43LTEyLjktNi44LTE3LjktMTIuMWMtMTAuMy0xMC45LTE0LjEtMjktMTQuMS01Mi45IFY4Ni41aC0zMVY1OC4zaDMxVjkuNkwtNDEzLjcsMEwtNDEzLjcsMHoiLz4KICAgICAgPC9nPgogICAgPC9nPgogICAgPGcgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOTc0LjQzMzI4NiwgNTMuNDc5NjM4KSI+CiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDAuOTkwMDM0LCAwLjYxMDMzOSkiPgogICAgICAgIDxwYXRoIGQ9Ik0tNDQ1LjgsMTEzYzAuOCw1MCwzMi4yLDcwLjYsNjguNiw3MC42YzE5LDAuNiwzNy45LTMsNTUuMy0xMC41bDYuMiwyNi40IGMtMjAuOSw4LjktNDMuNSwxMy4xLTY2LjIsMTIuNmMtNjEuNSwwLTk4LjMtNDEuMi05OC4zLTEwMi41Qy00ODAuMiw0OC4yLTQ0NC43LDAtMzg2LjUsMGM2NS4yLDAsODIuNyw1OC4zLDgyLjcsOTUuNyBjLTAuMSw1LjgtMC41LDExLjUtMS4yLDE3LjJoLTE0MC42SC00NDUuOEwtNDQ1LjgsMTEzeiBNLTMzOS4yLDg2LjZjMC40LTIzLjUtOS41LTYwLjEtNTAuNC02MC4xIGMtMzYuOCwwLTUyLjgsMzQuNC01NS43LDYwLjFILTMzOS4yTC0zMzkuMiw4Ni42TC0zMzkuMiw4Ni42eiIvPgogICAgICA8L2c+CiAgICA8L2c+CiAgICA8ZyB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxMjAxLjk2MTA1OCwgNTMuNDc5NjM4KSI+CiAgICAgIDxnIHRyYW5zZm9ybT0idHJhbnNsYXRlKDEuMTc5NjQwLCAwLjcwNTA2OCkiPgogICAgICAgIDxwYXRoIGQ9Ik0tNDc4LjYsNjhjMC0yMy45LTAuNC00NC41LTEuNy02My40aDMxLjhsMS4yLDM5LjloMS43YzkuMS0yNy4zLDMxLTQ0LjUsNTUuMy00NC41IGMzLjUtMC4xLDcsMC40LDEwLjMsMS4ydjM0LjhjLTQuMS0wLjktOC4yLTEuMy0xMi40LTEuMmMtMjUuNiwwLTQzLjcsMTkuNy00OC43LDQ3LjRjLTEsNS43LTEuNiwxMS41LTEuNywxNy4ydjEwOC4zaC0zNlY2OCBMLTQ3OC42LDY4eiIvPgogICAgICA8L2c+CiAgICA8L2c+CiAgPC9nPgoKICA8ZyBjbGFzcz0ianAtaWNvbi13YXJuMCIgZmlsbD0iI0YzNzcyNiI+CiAgICA8cGF0aCBkPSJNMTM1Mi4zLDMyNi4yaDM3VjI4aC0zN1YzMjYuMnogTTE2MDQuOCwzMjYuMmMtMi41LTEzLjktMy40LTMxLjEtMy40LTQ4Ljd2LTc2IGMwLTQwLjctMTUuMS04My4xLTc3LjMtODMuMWMtMjUuNiwwLTUwLDcuMS02Ni44LDE4LjFsOC40LDI0LjRjMTQuMy05LjIsMzQtMTUuMSw1My0xNS4xYzQxLjYsMCw0Ni4yLDMwLjIsNDYuMiw0N3Y0LjIgYy03OC42LTAuNC0xMjIuMywyNi41LTEyMi4zLDc1LjZjMCwyOS40LDIxLDU4LjQsNjIuMiw1OC40YzI5LDAsNTAuOS0xNC4zLDYyLjItMzAuMmgxLjNsMi45LDI1LjZIMTYwNC44eiBNMTU2NS43LDI1Ny43IGMwLDMuOC0wLjgsOC0yLjEsMTEuOGMtNS45LDE3LjItMjIuNywzNC00OS4yLDM0Yy0xOC45LDAtMzQuOS0xMS4zLTM0LjktMzUuM2MwLTM5LjUsNDUuOC00Ni42LDg2LjItNDUuOFYyNTcuN3ogTTE2OTguNSwzMjYuMiBsMS43LTMzLjZoMS4zYzE1LjEsMjYuOSwzOC43LDM4LjIsNjguMSwzOC4yYzQ1LjQsMCw5MS4yLTM2LjEsOTEuMi0xMDguOGMwLjQtNjEuNy0zNS4zLTEwMy43LTg1LjctMTAzLjcgYy0zMi44LDAtNTYuMywxNC43LTY5LjMsMzcuNGgtMC44VjI4aC0zNi42djI0NS43YzAsMTguMS0wLjgsMzguNi0xLjcsNTIuNUgxNjk4LjV6IE0xNzA0LjgsMjA4LjJjMC01LjksMS4zLTEwLjksMi4xLTE1LjEgYzcuNi0yOC4xLDMxLjEtNDUuNCw1Ni4zLTQ1LjRjMzkuNSwwLDYwLjUsMzQuOSw2MC41LDc1LjZjMCw0Ni42LTIzLjEsNzguMS02MS44LDc4LjFjLTI2LjksMC00OC4zLTE3LjYtNTUuNS00My4zIGMtMC44LTQuMi0xLjctOC44LTEuNy0xMy40VjIwOC4yeiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-kernel: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICAgIDxwYXRoIGNsYXNzPSJqcC1pY29uMiIgZmlsbD0iIzYxNjE2MSIgZD0iTTE1IDlIOXY2aDZWOXptLTIgNGgtMnYtMmgydjJ6bTgtMlY5aC0yVjdjMC0xLjEtLjktMi0yLTJoLTJWM2gtMnYyaC0yVjNIOXYySDdjLTEuMSAwLTIgLjktMiAydjJIM3YyaDJ2MkgzdjJoMnYyYzAgMS4xLjkgMiAyIDJoMnYyaDJ2LTJoMnYyaDJ2LTJoMmMxLjEgMCAyLS45IDItMnYtMmgydi0yaC0ydi0yaDJ6bS00IDZIN1Y3aDEwdjEweiIvPgo8L3N2Zz4K);--jp-icon-keyboard: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8cGF0aCBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNjE2MTYxIiBkPSJNMjAgNUg0Yy0xLjEgMC0xLjk5LjktMS45OSAyTDIgMTdjMCAxLjEuOSAyIDIgMmgxNmMxLjEgMCAyLS45IDItMlY3YzAtMS4xLS45LTItMi0yem0tOSAzaDJ2MmgtMlY4em0wIDNoMnYyaC0ydi0yek04IDhoMnYySDhWOHptMCAzaDJ2Mkg4di0yem0tMSAySDV2LTJoMnYyem0wLTNINVY4aDJ2MnptOSA3SDh2LTJoOHYyem0wLTRoLTJ2LTJoMnYyem0wLTNoLTJWOGgydjJ6bTMgM2gtMnYtMmgydjJ6bTAtM2gtMlY4aDJ2MnoiLz4KPC9zdmc+Cg==);--jp-icon-launcher: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8cGF0aCBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNjE2MTYxIiBkPSJNMTkgMTlINVY1aDdWM0g1YTIgMiAwIDAwLTIgMnYxNGEyIDIgMCAwMDIgMmgxNGMxLjEgMCAyLS45IDItMnYtN2gtMnY3ek0xNCAzdjJoMy41OWwtOS44MyA5LjgzIDEuNDEgMS40MUwxOSA2LjQxVjEwaDJWM2gtN3oiLz4KPC9zdmc+Cg==);--jp-icon-line-form: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICAgIDxwYXRoIGZpbGw9IndoaXRlIiBkPSJNNS44OCA0LjEyTDEzLjc2IDEybC03Ljg4IDcuODhMOCAyMmwxMC0xMEw4IDJ6Ii8+Cjwvc3ZnPgo=);--jp-icon-link: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTMuOSAxMmMwLTEuNzEgMS4zOS0zLjEgMy4xLTMuMWg0VjdIN2MtMi43NiAwLTUgMi4yNC01IDVzMi4yNCA1IDUgNWg0di0xLjlIN2MtMS43MSAwLTMuMS0xLjM5LTMuMS0zLjF6TTggMTNoOHYtMkg4djJ6bTktNmgtNHYxLjloNGMxLjcxIDAgMy4xIDEuMzkgMy4xIDMuMXMtMS4zOSAzLjEtMy4xIDMuMWgtNFYxN2g0YzIuNzYgMCA1LTIuMjQgNS01cy0yLjI0LTUtNS01eiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-list: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICAgIDxwYXRoIGNsYXNzPSJqcC1pY29uMiBqcC1pY29uLXNlbGVjdGFibGUiIGZpbGw9IiM2MTYxNjEiIGQ9Ik0xOSA1djE0SDVWNWgxNG0xLjEtMkgzLjljLS41IDAtLjkuNC0uOS45djE2LjJjMCAuNC40LjkuOS45aDE2LjJjLjQgMCAuOS0uNS45LS45VjMuOWMwLS41LS41LS45LS45LS45ek0xMSA3aDZ2MmgtNlY3em0wIDRoNnYyaC02di0yem0wIDRoNnYyaC02ek03IDdoMnYySDd6bTAgNGgydjJIN3ptMCA0aDJ2Mkg3eiIvPgo8L3N2Zz4=);--jp-icon-listings-info: url(data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0iMS4wIiBlbmNvZGluZz0iaXNvLTg4NTktMSI/Pg0KPHN2ZyB2ZXJzaW9uPSIxLjEiIGlkPSJDYXBhXzEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyIgeG1sbnM6eGxpbms9Imh0dHA6Ly93d3cudzMub3JnLzE5OTkveGxpbmsiIHg9IjBweCIgeT0iMHB4Ig0KCSB2aWV3Qm94PSIwIDAgNTAuOTc4IDUwLjk3OCIgc3R5bGU9ImVuYWJsZS1iYWNrZ3JvdW5kOm5ldyAwIDAgNTAuOTc4IDUwLjk3ODsiIHhtbDpzcGFjZT0icHJlc2VydmUiPg0KPGc+DQoJPGc+DQoJCTxnPg0KCQkJPHBhdGggc3R5bGU9ImZpbGw6IzAxMDAwMjsiIGQ9Ik00My41Miw3LjQ1OEMzOC43MTEsMi42NDgsMzIuMzA3LDAsMjUuNDg5LDBDMTguNjcsMCwxMi4yNjYsMi42NDgsNy40NTgsNy40NTgNCgkJCQljLTkuOTQzLDkuOTQxLTkuOTQzLDI2LjExOSwwLDM2LjA2MmM0LjgwOSw0LjgwOSwxMS4yMTIsNy40NTYsMTguMDMxLDcuNDU4YzAsMCwwLjAwMSwwLDAuMDAyLDANCgkJCQljNi44MTYsMCwxMy4yMjEtMi42NDgsMTguMDI5LTcuNDU4YzQuODA5LTQuODA5LDcuNDU3LTExLjIxMiw3LjQ1Ny0xOC4wM0M1MC45NzcsMTguNjcsNDguMzI4LDEyLjI2Niw0My41Miw3LjQ1OHoNCgkJCQkgTTQyLjEwNiw0Mi4xMDVjLTQuNDMyLDQuNDMxLTEwLjMzMiw2Ljg3Mi0xNi42MTUsNi44NzJoLTAuMDAyYy02LjI4NS0wLjAwMS0xMi4xODctMi40NDEtMTYuNjE3LTYuODcyDQoJCQkJYy05LjE2Mi05LjE2My05LjE2Mi0yNC4wNzEsMC0zMy4yMzNDMTMuMzAzLDQuNDQsMTkuMjA0LDIsMjUuNDg5LDJjNi4yODQsMCwxMi4xODYsMi40NCwxNi42MTcsNi44NzINCgkJCQljNC40MzEsNC40MzEsNi44NzEsMTAuMzMyLDYuODcxLDE2LjYxN0M0OC45NzcsMzEuNzcyLDQ2LjUzNiwzNy42NzUsNDIuMTA2LDQyLjEwNXoiLz4NCgkJPC9nPg0KCQk8Zz4NCgkJCTxwYXRoIHN0eWxlPSJmaWxsOiMwMTAwMDI7IiBkPSJNMjMuNTc4LDMyLjIxOGMtMC4wMjMtMS43MzQsMC4xNDMtMy4wNTksMC40OTYtMy45NzJjMC4zNTMtMC45MTMsMS4xMS0xLjk5NywyLjI3Mi0zLjI1Mw0KCQkJCWMwLjQ2OC0wLjUzNiwwLjkyMy0xLjA2MiwxLjM2Ny0xLjU3NWMwLjYyNi0wLjc1MywxLjEwNC0xLjQ3OCwxLjQzNi0yLjE3NWMwLjMzMS0wLjcwNywwLjQ5NS0xLjU0MSwwLjQ5NS0yLjUNCgkJCQljMC0xLjA5Ni0wLjI2LTIuMDg4LTAuNzc5LTIuOTc5Yy0wLjU2NS0wLjg3OS0xLjUwMS0xLjMzNi0yLjgwNi0xLjM2OWMtMS44MDIsMC4wNTctMi45ODUsMC42NjctMy41NSwxLjgzMg0KCQkJCWMtMC4zMDEsMC41MzUtMC41MDMsMS4xNDEtMC42MDcsMS44MTRjLTAuMTM5LDAuNzA3LTAuMjA3LDEuNDMyLTAuMjA3LDIuMTc0aC0yLjkzN2MtMC4wOTEtMi4yMDgsMC40MDctNC4xMTQsMS40OTMtNS43MTkNCgkJCQljMS4wNjItMS42NCwyLjg1NS0yLjQ4MSw1LjM3OC0yLjUyN2MyLjE2LDAuMDIzLDMuODc0LDAuNjA4LDUuMTQxLDEuNzU4YzEuMjc4LDEuMTYsMS45MjksMi43NjQsMS45NSw0LjgxMQ0KCQkJCWMwLDEuMTQyLTAuMTM3LDIuMTExLTAuNDEsMi45MTFjLTAuMzA5LDAuODQ1LTAuNzMxLDEuNTkzLTEuMjY4LDIuMjQzYy0wLjQ5MiwwLjY1LTEuMDY4LDEuMzE4LTEuNzMsMi4wMDINCgkJCQljLTAuNjUsMC42OTctMS4zMTMsMS40NzktMS45ODcsMi4zNDZjLTAuMjM5LDAuMzc3LTAuNDI5LDAuNzc3LTAuNTY1LDEuMTk5Yy0wLjE2LDAuOTU5LTAuMjE3LDEuOTUxLTAuMTcxLDIuOTc5DQoJCQkJQzI2LjU4OSwzMi4yMTgsMjMuNTc4LDMyLjIxOCwyMy41NzgsMzIuMjE4eiBNMjMuNTc4LDM4LjIydi0zLjQ4NGgzLjA3NnYzLjQ4NEgyMy41Nzh6Ii8+DQoJCTwvZz4NCgk8L2c+DQo8L2c+DQo8Zz4NCjwvZz4NCjxnPg0KPC9nPg0KPGc+DQo8L2c+DQo8Zz4NCjwvZz4NCjxnPg0KPC9nPg0KPGc+DQo8L2c+DQo8Zz4NCjwvZz4NCjxnPg0KPC9nPg0KPGc+DQo8L2c+DQo8Zz4NCjwvZz4NCjxnPg0KPC9nPg0KPGc+DQo8L2c+DQo8Zz4NCjwvZz4NCjxnPg0KPC9nPg0KPGc+DQo8L2c+DQo8L3N2Zz4NCg==);--jp-icon-markdown: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8cGF0aCBjbGFzcz0ianAtaWNvbi1jb250cmFzdDAganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjN0IxRkEyIiBkPSJNNSAxNC45aDEybC02LjEgNnptOS40LTYuOGMwLTEuMy0uMS0yLjktLjEtNC41LS40IDEuNC0uOSAyLjktMS4zIDQuM2wtMS4zIDQuM2gtMkw4LjUgNy45Yy0uNC0xLjMtLjctMi45LTEtNC4zLS4xIDEuNi0uMSAzLjItLjIgNC42TDcgMTIuNEg0LjhsLjctMTFoMy4zTDEwIDVjLjQgMS4yLjcgMi43IDEgMy45LjMtMS4yLjctMi42IDEtMy45bDEuMi0zLjdoMy4zbC42IDExaC0yLjRsLS4zLTQuMnoiLz4KPC9zdmc+Cg==);--jp-icon-new-folder: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTIwIDZoLThsLTItMkg0Yy0xLjExIDAtMS45OS44OS0xLjk5IDJMMiAxOGMwIDEuMTEuODkgMiAyIDJoMTZjMS4xMSAwIDItLjg5IDItMlY4YzAtMS4xMS0uODktMi0yLTJ6bS0xIDhoLTN2M2gtMnYtM2gtM3YtMmgzVjloMnYzaDN2MnoiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-not-trusted: url(data:image/svg+xml;base64,PHN2ZyBmaWxsPSJub25lIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI1IDI1Ij4KICAgIDxwYXRoIGNsYXNzPSJqcC1pY29uMiIgc3Ryb2tlPSIjMzMzMzMzIiBzdHJva2Utd2lkdGg9IjIiIHRyYW5zZm9ybT0idHJhbnNsYXRlKDMgMykiIGQ9Ik0xLjg2MDk0IDExLjQ0MDlDMC44MjY0NDggOC43NzAyNyAwLjg2Mzc3OSA2LjA1NzY0IDEuMjQ5MDcgNC4xOTkzMkMyLjQ4MjA2IDMuOTMzNDcgNC4wODA2OCAzLjQwMzQ3IDUuNjAxMDIgMi44NDQ5QzcuMjM1NDkgMi4yNDQ0IDguODU2NjYgMS41ODE1IDkuOTg3NiAxLjA5NTM5QzExLjA1OTcgMS41ODM0MSAxMi42MDk0IDIuMjQ0NCAxNC4yMTggMi44NDMzOUMxNS43NTAzIDMuNDEzOTQgMTcuMzk5NSAzLjk1MjU4IDE4Ljc1MzkgNC4yMTM4NUMxOS4xMzY0IDYuMDcxNzcgMTkuMTcwOSA4Ljc3NzIyIDE4LjEzOSAxMS40NDA5QzE3LjAzMDMgMTQuMzAzMiAxNC42NjY4IDE3LjE4NDQgOS45OTk5OSAxOC45MzU0QzUuMzMzMTkgMTcuMTg0NCAyLjk2OTY4IDE0LjMwMzIgMS44NjA5NCAxMS40NDA5WiIvPgogICAgPHBhdGggY2xhc3M9ImpwLWljb24yIiBzdHJva2U9IiMzMzMzMzMiIHN0cm9rZS13aWR0aD0iMiIgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOS4zMTU5MiA5LjMyMDMxKSIgZD0iTTcuMzY4NDIgMEwwIDcuMzY0NzkiLz4KICAgIDxwYXRoIGNsYXNzPSJqcC1pY29uMiIgc3Ryb2tlPSIjMzMzMzMzIiBzdHJva2Utd2lkdGg9IjIiIHRyYW5zZm9ybT0idHJhbnNsYXRlKDkuMzE1OTIgMTYuNjgzNikgc2NhbGUoMSAtMSkiIGQ9Ik03LjM2ODQyIDBMMCA3LjM2NDc5Ii8+Cjwvc3ZnPgo=);--jp-icon-notebook: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8ZyBjbGFzcz0ianAtaWNvbi13YXJuMCBqcC1pY29uLXNlbGVjdGFibGUiIGZpbGw9IiNFRjZDMDAiPgogICAgPHBhdGggZD0iTTE4LjcgMy4zdjE1LjRIMy4zVjMuM2gxNS40bTEuNS0xLjVIMS44djE4LjNoMTguM2wuMS0xOC4zeiIvPgogICAgPHBhdGggZD0iTTE2LjUgMTYuNWwtNS40LTQuMy01LjYgNC4zdi0xMWgxMXoiLz4KICA8L2c+Cjwvc3ZnPgo=);--jp-icon-palette: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTE4IDEzVjIwSDRWNkg5LjAyQzkuMDcgNS4yOSA5LjI0IDQuNjIgOS41IDRINEMyLjkgNCAyIDQuOSAyIDZWMjBDMiAyMS4xIDIuOSAyMiA0IDIySDE4QzE5LjEgMjIgMjAgMjEuMSAyMCAyMFYxNUwxOCAxM1pNMTkuMyA4Ljg5QzE5Ljc0IDguMTkgMjAgNy4zOCAyMCA2LjVDMjAgNC4wMSAxNy45OSAyIDE1LjUgMkMxMy4wMSAyIDExIDQuMDEgMTEgNi41QzExIDguOTkgMTMuMDEgMTEgMTUuNDkgMTFDMTYuMzcgMTEgMTcuMTkgMTAuNzQgMTcuODggMTAuM0wyMSAxMy40MkwyMi40MiAxMkwxOS4zIDguODlaTTE1LjUgOUMxNC4xMiA5IDEzIDcuODggMTMgNi41QzEzIDUuMTIgMTQuMTIgNCAxNS41IDRDMTYuODggNCAxOCA1LjEyIDE4IDYuNUMxOCA3Ljg4IDE2Ljg4IDkgMTUuNSA5WiIvPgogICAgPHBhdGggZmlsbC1ydWxlPSJldmVub2RkIiBjbGlwLXJ1bGU9ImV2ZW5vZGQiIGQ9Ik00IDZIOS4wMTg5NEM5LjAwNjM5IDYuMTY1MDIgOSA2LjMzMTc2IDkgNi41QzkgOC44MTU3NyAxMC4yMTEgMTAuODQ4NyAxMi4wMzQzIDEySDlWMTRIMTZWMTIuOTgxMUMxNi41NzAzIDEyLjkzNzcgMTcuMTIgMTIuODIwNyAxNy42Mzk2IDEyLjYzOTZMMTggMTNWMjBINFY2Wk04IDhINlYxMEg4VjhaTTYgMTJIOFYxNEg2VjEyWk04IDE2SDZWMThIOFYxNlpNOSAxNkgxNlYxOEg5VjE2WiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-paste: url(data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9IjI0IiB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIyNCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICAgIDxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSI+CiAgICAgICAgPHBhdGggZD0iTTE5IDJoLTQuMThDMTQuNC44NCAxMy4zIDAgMTIgMGMtMS4zIDAtMi40Ljg0LTIuODIgMkg1Yy0xLjEgMC0yIC45LTIgMnYxNmMwIDEuMS45IDIgMiAyaDE0YzEuMSAwIDItLjkgMi0yVjRjMC0xLjEtLjktMi0yLTJ6bS03IDBjLjU1IDAgMSAuNDUgMSAxcy0uNDUgMS0xIDEtMS0uNDUtMS0xIC40NS0xIDEtMXptNyAxOEg1VjRoMnYzaDEwVjRoMnYxNnoiLz4KICAgIDwvZz4KPC9zdmc+Cg==);--jp-icon-python: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8ZyBjbGFzcz0ianAtaWNvbi1icmFuZDAganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjMEQ0N0ExIj4KICAgIDxwYXRoIGQ9Ik0xMS4xIDYuOVY1LjhINi45YzAtLjUgMC0xLjMuMi0xLjYuNC0uNy44LTEuMSAxLjctMS40IDEuNy0uMyAyLjUtLjMgMy45LS4xIDEgLjEgMS45LjkgMS45IDEuOXY0LjJjMCAuNS0uOSAxLjYtMiAxLjZIOC44Yy0xLjUgMC0yLjQgMS40LTIuNCAyLjh2Mi4ySDQuN0MzLjUgMTUuMSAzIDE0IDMgMTMuMVY5Yy0uMS0xIC42LTIgMS44LTIgMS41LS4xIDYuMy0uMSA2LjMtLjF6Ii8+CiAgICA8cGF0aCBkPSJNMTAuOSAxNS4xdjEuMWg0LjJjMCAuNSAwIDEuMy0uMiAxLjYtLjQuNy0uOCAxLjEtMS43IDEuNC0xLjcuMy0yLjUuMy0zLjkuMS0xLS4xLTEuOS0uOS0xLjktMS45di00LjJjMC0uNS45LTEuNiAyLTEuNmgzLjhjMS41IDAgMi40LTEuNCAyLjQtMi44VjYuNmgxLjdDMTguNSA2LjkgMTkgOCAxOSA4LjlWMTNjMCAxLS43IDIuMS0xLjkgMi4xaC02LjJ6Ii8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-r-kernel: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8cGF0aCBjbGFzcz0ianAtaWNvbi1jb250cmFzdDMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjMjE5NkYzIiBkPSJNNC40IDIuNWMxLjItLjEgMi45LS4zIDQuOS0uMyAyLjUgMCA0LjEuNCA1LjIgMS4zIDEgLjcgMS41IDEuOSAxLjUgMy41IDAgMi0xLjQgMy41LTIuOSA0LjEgMS4yLjQgMS43IDEuNiAyLjIgMyAuNiAxLjkgMSAzLjkgMS4zIDQuNmgtMy44Yy0uMy0uNC0uOC0xLjctMS4yLTMuN3MtMS4yLTIuNi0yLjYtMi42aC0uOXY2LjRINC40VjIuNXptMy43IDYuOWgxLjRjMS45IDAgMi45LS45IDIuOS0yLjNzLTEtMi4zLTIuOC0yLjNjLS43IDAtMS4zIDAtMS42LjJ2NC41aC4xdi0uMXoiLz4KPC9zdmc+Cg==);--jp-icon-react: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMTUwIDE1MCA1NDEuOSAyOTUuMyI+CiAgPGcgY2xhc3M9ImpwLWljb24tYnJhbmQyIGpwLWljb24tc2VsZWN0YWJsZSIgZmlsbD0iIzYxREFGQiI+CiAgICA8cGF0aCBkPSJNNjY2LjMgMjk2LjVjMC0zMi41LTQwLjctNjMuMy0xMDMuMS04Mi40IDE0LjQtNjMuNiA4LTExNC4yLTIwLjItMTMwLjQtNi41LTMuOC0xNC4xLTUuNi0yMi40LTUuNnYyMi4zYzQuNiAwIDguMy45IDExLjQgMi42IDEzLjYgNy44IDE5LjUgMzcuNSAxNC45IDc1LjctMS4xIDkuNC0yLjkgMTkuMy01LjEgMjkuNC0xOS42LTQuOC00MS04LjUtNjMuNS0xMC45LTEzLjUtMTguNS0yNy41LTM1LjMtNDEuNi01MCAzMi42LTMwLjMgNjMuMi00Ni45IDg0LTQ2LjlWNzhjLTI3LjUgMC02My41IDE5LjYtOTkuOSA1My42LTM2LjQtMzMuOC03Mi40LTUzLjItOTkuOS01My4ydjIyLjNjMjAuNyAwIDUxLjQgMTYuNSA4NCA0Ni42LTE0IDE0LjctMjggMzEuNC00MS4zIDQ5LjktMjIuNiAyLjQtNDQgNi4xLTYzLjYgMTEtMi4zLTEwLTQtMTkuNy01LjItMjktNC43LTM4LjIgMS4xLTY3LjkgMTQuNi03NS44IDMtMS44IDYuOS0yLjYgMTEuNS0yLjZWNzguNWMtOC40IDAtMTYgMS44LTIyLjYgNS42LTI4LjEgMTYuMi0zNC40IDY2LjctMTkuOSAxMzAuMS02Mi4yIDE5LjItMTAyLjcgNDkuOS0xMDIuNyA4Mi4zIDAgMzIuNSA0MC43IDYzLjMgMTAzLjEgODIuNC0xNC40IDYzLjYtOCAxMTQuMiAyMC4yIDEzMC40IDYuNSAzLjggMTQuMSA1LjYgMjIuNSA1LjYgMjcuNSAwIDYzLjUtMTkuNiA5OS45LTUzLjYgMzYuNCAzMy44IDcyLjQgNTMuMiA5OS45IDUzLjIgOC40IDAgMTYtMS44IDIyLjYtNS42IDI4LjEtMTYuMiAzNC40LTY2LjcgMTkuOS0xMzAuMSA2Mi0xOS4xIDEwMi41LTQ5LjkgMTAyLjUtODIuM3ptLTEzMC4yLTY2LjdjLTMuNyAxMi45LTguMyAyNi4yLTEzLjUgMzkuNS00LjEtOC04LjQtMTYtMTMuMS0yNC00LjYtOC05LjUtMTUuOC0xNC40LTIzLjQgMTQuMiAyLjEgMjcuOSA0LjcgNDEgNy45em0tNDUuOCAxMDYuNWMtNy44IDEzLjUtMTUuOCAyNi4zLTI0LjEgMzguMi0xNC45IDEuMy0zMCAyLTQ1LjIgMi0xNS4xIDAtMzAuMi0uNy00NS0xLjktOC4zLTExLjktMTYuNC0yNC42LTI0LjItMzgtNy42LTEzLjEtMTQuNS0yNi40LTIwLjgtMzkuOCA2LjItMTMuNCAxMy4yLTI2LjggMjAuNy0zOS45IDcuOC0xMy41IDE1LjgtMjYuMyAyNC4xLTM4LjIgMTQuOS0xLjMgMzAtMiA0NS4yLTIgMTUuMSAwIDMwLjIuNyA0NSAxLjkgOC4zIDExLjkgMTYuNCAyNC42IDI0LjIgMzggNy42IDEzLjEgMTQuNSAyNi40IDIwLjggMzkuOC02LjMgMTMuNC0xMy4yIDI2LjgtMjAuNyAzOS45em0zMi4zLTEzYzUuNCAxMy40IDEwIDI2LjggMTMuOCAzOS44LTEzLjEgMy4yLTI2LjkgNS45LTQxLjIgOCA0LjktNy43IDkuOC0xNS42IDE0LjQtMjMuNyA0LjYtOCA4LjktMTYuMSAxMy0yNC4xek00MjEuMiA0MzBjLTkuMy05LjYtMTguNi0yMC4zLTI3LjgtMzIgOSAuNCAxOC4yLjcgMjcuNS43IDkuNCAwIDE4LjctLjIgMjcuOC0uNy05IDExLjctMTguMyAyMi40LTI3LjUgMzJ6bS03NC40LTU4LjljLTE0LjItMi4xLTI3LjktNC43LTQxLTcuOSAzLjctMTIuOSA4LjMtMjYuMiAxMy41LTM5LjUgNC4xIDggOC40IDE2IDEzLjEgMjQgNC43IDggOS41IDE1LjggMTQuNCAyMy40ek00MjAuNyAxNjNjOS4zIDkuNiAxOC42IDIwLjMgMjcuOCAzMi05LS40LTE4LjItLjctMjcuNS0uNy05LjQgMC0xOC43LjItMjcuOC43IDktMTEuNyAxOC4zLTIyLjQgMjcuNS0zMnptLTc0IDU4LjljLTQuOSA3LjctOS44IDE1LjYtMTQuNCAyMy43LTQuNiA4LTguOSAxNi0xMyAyNC01LjQtMTMuNC0xMC0yNi44LTEzLjgtMzkuOCAxMy4xLTMuMSAyNi45LTUuOCA0MS4yLTcuOXptLTkwLjUgMTI1LjJjLTM1LjQtMTUuMS01OC4zLTM0LjktNTguMy01MC42IDAtMTUuNyAyMi45LTM1LjYgNTguMy01MC42IDguNi0zLjcgMTgtNyAyNy43LTEwLjEgNS43IDE5LjYgMTMuMiA0MCAyMi41IDYwLjktOS4yIDIwLjgtMTYuNiA0MS4xLTIyLjIgNjAuNi05LjktMy4xLTE5LjMtNi41LTI4LTEwLjJ6TTMxMCA0OTBjLTEzLjYtNy44LTE5LjUtMzcuNS0xNC45LTc1LjcgMS4xLTkuNCAyLjktMTkuMyA1LjEtMjkuNCAxOS42IDQuOCA0MSA4LjUgNjMuNSAxMC45IDEzLjUgMTguNSAyNy41IDM1LjMgNDEuNiA1MC0zMi42IDMwLjMtNjMuMiA0Ni45LTg0IDQ2LjktNC41LS4xLTguMy0xLTExLjMtMi43em0yMzcuMi03Ni4yYzQuNyAzOC4yLTEuMSA2Ny45LTE0LjYgNzUuOC0zIDEuOC02LjkgMi42LTExLjUgMi42LTIwLjcgMC01MS40LTE2LjUtODQtNDYuNiAxNC0xNC43IDI4LTMxLjQgNDEuMy00OS45IDIyLjYtMi40IDQ0LTYuMSA2My42LTExIDIuMyAxMC4xIDQuMSAxOS44IDUuMiAyOS4xem0zOC41LTY2LjdjLTguNiAzLjctMTggNy0yNy43IDEwLjEtNS43LTE5LjYtMTMuMi00MC0yMi41LTYwLjkgOS4yLTIwLjggMTYuNi00MS4xIDIyLjItNjAuNiA5LjkgMy4xIDE5LjMgNi41IDI4LjEgMTAuMiAzNS40IDE1LjEgNTguMyAzNC45IDU4LjMgNTAuNi0uMSAxNS43LTIzIDM1LjYtNTguNCA1MC42ek0zMjAuOCA3OC40eiIvPgogICAgPGNpcmNsZSBjeD0iNDIwLjkiIGN5PSIyOTYuNSIgcj0iNDUuNyIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-refresh: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDE4IDE4Ij4KICAgIDxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSI+CiAgICAgICAgPHBhdGggZD0iTTkgMTMuNWMtMi40OSAwLTQuNS0yLjAxLTQuNS00LjVTNi41MSA0LjUgOSA0LjVjMS4yNCAwIDIuMzYuNTIgMy4xNyAxLjMzTDEwIDhoNVYzbC0xLjc2IDEuNzZDMTIuMTUgMy42OCAxMC42NiAzIDkgMyA1LjY5IDMgMy4wMSA1LjY5IDMuMDEgOVM1LjY5IDE1IDkgMTVjMi45NyAwIDUuNDMtMi4xNiA1LjktNWgtMS41MmMtLjQ2IDItMi4yNCAzLjUtNC4zOCAzLjV6Ii8+CiAgICA8L2c+Cjwvc3ZnPgo=);--jp-icon-regex: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIwIDIwIj4KICA8ZyBjbGFzcz0ianAtaWNvbjIiIGZpbGw9IiM0MTQxNDEiPgogICAgPHJlY3QgeD0iMiIgeT0iMiIgd2lkdGg9IjE2IiBoZWlnaHQ9IjE2Ii8+CiAgPC9nPgoKICA8ZyBjbGFzcz0ianAtaWNvbi1hY2NlbnQyIiBmaWxsPSIjRkZGIj4KICAgIDxjaXJjbGUgY2xhc3M9InN0MiIgY3g9IjUuNSIgY3k9IjE0LjUiIHI9IjEuNSIvPgogICAgPHJlY3QgeD0iMTIiIHk9IjQiIGNsYXNzPSJzdDIiIHdpZHRoPSIxIiBoZWlnaHQ9IjgiLz4KICAgIDxyZWN0IHg9IjguNSIgeT0iNy41IiB0cmFuc2Zvcm09Im1hdHJpeCgwLjg2NiAtMC41IDAuNSAwLjg2NiAtMi4zMjU1IDcuMzIxOSkiIGNsYXNzPSJzdDIiIHdpZHRoPSI4IiBoZWlnaHQ9IjEiLz4KICAgIDxyZWN0IHg9IjEyIiB5PSI0IiB0cmFuc2Zvcm09Im1hdHJpeCgwLjUgLTAuODY2IDAuODY2IDAuNSAtMC42Nzc5IDE0LjgyNTIpIiBjbGFzcz0ic3QyIiB3aWR0aD0iMSIgaGVpZ2h0PSI4Ii8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-run: url(data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9IjI0IiB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIyNCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICAgIDxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSI+CiAgICAgICAgPHBhdGggZD0iTTggNXYxNGwxMS03eiIvPgogICAgPC9nPgo8L3N2Zz4K);--jp-icon-running: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDUxMiA1MTIiPgogIDxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSI+CiAgICA8cGF0aCBkPSJNMjU2IDhDMTE5IDggOCAxMTkgOCAyNTZzMTExIDI0OCAyNDggMjQ4IDI0OC0xMTEgMjQ4LTI0OFMzOTMgOCAyNTYgOHptOTYgMzI4YzAgOC44LTcuMiAxNi0xNiAxNkgxNzZjLTguOCAwLTE2LTcuMi0xNi0xNlYxNzZjMC04LjggNy4yLTE2IDE2LTE2aDE2MGM4LjggMCAxNiA3LjIgMTYgMTZ2MTYweiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-save: url(data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9IjI0IiB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIyNCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICAgIDxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSI+CiAgICAgICAgPHBhdGggZD0iTTE3IDNINWMtMS4xMSAwLTIgLjktMiAydjE0YzAgMS4xLjg5IDIgMiAyaDE0YzEuMSAwIDItLjkgMi0yVjdsLTQtNHptLTUgMTZjLTEuNjYgMC0zLTEuMzQtMy0zczEuMzQtMyAzLTMgMyAxLjM0IDMgMy0xLjM0IDMtMyAzem0zLTEwSDVWNWgxMHY0eiIvPgogICAgPC9nPgo8L3N2Zz4K);--jp-icon-search: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMTggMTgiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTEyLjEsMTAuOWgtMC43bC0wLjItMC4yYzAuOC0wLjksMS4zLTIuMiwxLjMtMy41YzAtMy0yLjQtNS40LTUuNC01LjRTMS44LDQuMiwxLjgsNy4xczIuNCw1LjQsNS40LDUuNCBjMS4zLDAsMi41LTAuNSwzLjUtMS4zbDAuMiwwLjJ2MC43bDQuMSw0LjFsMS4yLTEuMkwxMi4xLDEwLjl6IE03LjEsMTAuOWMtMi4xLDAtMy43LTEuNy0zLjctMy43czEuNy0zLjcsMy43LTMuN3MzLjcsMS43LDMuNywzLjcgUzkuMiwxMC45LDcuMSwxMC45eiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-settings: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8cGF0aCBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNjE2MTYxIiBkPSJNMTkuNDMgMTIuOThjLjA0LS4zMi4wNy0uNjQuMDctLjk4cy0uMDMtLjY2LS4wNy0uOThsMi4xMS0xLjY1Yy4xOS0uMTUuMjQtLjQyLjEyLS42NGwtMi0zLjQ2Yy0uMTItLjIyLS4zOS0uMy0uNjEtLjIybC0yLjQ5IDFjLS41Mi0uNC0xLjA4LS43My0xLjY5LS45OGwtLjM4LTIuNjVBLjQ4OC40ODggMCAwMDE0IDJoLTRjLS4yNSAwLS40Ni4xOC0uNDkuNDJsLS4zOCAyLjY1Yy0uNjEuMjUtMS4xNy41OS0xLjY5Ljk4bC0yLjQ5LTFjLS4yMy0uMDktLjQ5IDAtLjYxLjIybC0yIDMuNDZjLS4xMy4yMi0uMDcuNDkuMTIuNjRsMi4xMSAxLjY1Yy0uMDQuMzItLjA3LjY1LS4wNy45OHMuMDMuNjYuMDcuOThsLTIuMTEgMS42NWMtLjE5LjE1LS4yNC40Mi0uMTIuNjRsMiAzLjQ2Yy4xMi4yMi4zOS4zLjYxLjIybDIuNDktMWMuNTIuNCAxLjA4LjczIDEuNjkuOThsLjM4IDIuNjVjLjAzLjI0LjI0LjQyLjQ5LjQyaDRjLjI1IDAgLjQ2LS4xOC40OS0uNDJsLjM4LTIuNjVjLjYxLS4yNSAxLjE3LS41OSAxLjY5LS45OGwyLjQ5IDFjLjIzLjA5LjQ5IDAgLjYxLS4yMmwyLTMuNDZjLjEyLS4yMi4wNy0uNDktLjEyLS42NGwtMi4xMS0xLjY1ek0xMiAxNS41Yy0xLjkzIDAtMy41LTEuNTctMy41LTMuNXMxLjU3LTMuNSAzLjUtMy41IDMuNSAxLjU3IDMuNSAzLjUtMS41NyAzLjUtMy41IDMuNXoiLz4KPC9zdmc+Cg==);--jp-icon-spreadsheet: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8cGF0aCBjbGFzcz0ianAtaWNvbi1jb250cmFzdDEganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNENBRjUwIiBkPSJNMi4yIDIuMnYxNy42aDE3LjZWMi4ySDIuMnptMTUuNCA3LjdoLTUuNVY0LjRoNS41djUuNXpNOS45IDQuNHY1LjVINC40VjQuNGg1LjV6bS01LjUgNy43aDUuNXY1LjVINC40di01LjV6bTcuNyA1LjV2LTUuNWg1LjV2NS41aC01LjV6Ii8+Cjwvc3ZnPgo=);--jp-icon-stop: url(data:image/svg+xml;base64,PHN2ZyBoZWlnaHQ9IjI0IiB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIyNCIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICAgIDxnIGNsYXNzPSJqcC1pY29uMyIgZmlsbD0iIzYxNjE2MSI+CiAgICAgICAgPHBhdGggZD0iTTAgMGgyNHYyNEgweiIgZmlsbD0ibm9uZSIvPgogICAgICAgIDxwYXRoIGQ9Ik02IDZoMTJ2MTJINnoiLz4KICAgIDwvZz4KPC9zdmc+Cg==);--jp-icon-tab: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTIxIDNIM2MtMS4xIDAtMiAuOS0yIDJ2MTRjMCAxLjEuOSAyIDIgMmgxOGMxLjEgMCAyLS45IDItMlY1YzAtMS4xLS45LTItMi0yem0wIDE2SDNWNWgxMHY0aDh2MTB6Ii8+CiAgPC9nPgo8L3N2Zz4K);--jp-icon-terminal: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0IiA+CiAgICA8cmVjdCBjbGFzcz0ianAtaWNvbjIganAtaWNvbi1zZWxlY3RhYmxlIiB3aWR0aD0iMjAiIGhlaWdodD0iMjAiIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIgMikiIGZpbGw9IiMzMzMzMzMiLz4KICAgIDxwYXRoIGNsYXNzPSJqcC1pY29uLWFjY2VudDIganAtaWNvbi1zZWxlY3RhYmxlLWludmVyc2UiIGQ9Ik01LjA1NjY0IDguNzYxNzJDNS4wNTY2NCA4LjU5NzY2IDUuMDMxMjUgOC40NTMxMiA0Ljk4MDQ3IDguMzI4MTJDNC45MzM1OSA4LjE5OTIyIDQuODU1NDcgOC4wODIwMyA0Ljc0NjA5IDcuOTc2NTZDNC42NDA2MiA3Ljg3MTA5IDQuNSA3Ljc3NTM5IDQuMzI0MjIgNy42ODk0NUM0LjE1MjM0IDcuNTk5NjEgMy45NDMzNiA3LjUxMTcyIDMuNjk3MjcgNy40MjU3OEMzLjMwMjczIDcuMjg1MTYgMi45NDMzNiA3LjEzNjcyIDIuNjE5MTQgNi45ODA0N0MyLjI5NDkyIDYuODI0MjIgMi4wMTc1OCA2LjY0MjU4IDEuNzg3MTEgNi40MzU1NUMxLjU2MDU1IDYuMjI4NTIgMS4zODQ3NyA1Ljk4ODI4IDEuMjU5NzcgNS43MTQ4NEMxLjEzNDc3IDUuNDM3NSAxLjA3MjI3IDUuMTA5MzggMS4wNzIyNyA0LjczMDQ3QzEuMDcyMjcgNC4zOTg0NCAxLjEyODkxIDQuMDk1NyAxLjI0MjE5IDMuODIyMjdDMS4zNTU0NyAzLjU0NDkyIDEuNTE1NjIgMy4zMDQ2OSAxLjcyMjY2IDMuMTAxNTZDMS45Mjk2OSAyLjg5ODQ0IDIuMTc5NjkgMi43MzQzNyAyLjQ3MjY2IDIuNjA5MzhDMi43NjU2MiAyLjQ4NDM4IDMuMDkxOCAyLjQwNDMgMy40NTExNyAyLjM2OTE0VjEuMTA5MzhINC4zODg2N1YyLjM4MDg2QzQuNzQwMjMgMi40Mjc3MyA1LjA1NjY0IDIuNTIzNDQgNS4zMzc4OSAyLjY2Nzk3QzUuNjE5MTQgMi44MTI1IDUuODU3NDIgMy4wMDE5NSA2LjA1MjczIDMuMjM2MzNDNi4yNTE5NSAzLjQ2NjggNi40MDQzIDMuNzQwMjMgNi41MDk3NyA0LjA1NjY0QzYuNjE5MTQgNC4zNjkxNCA2LjY3MzgzIDQuNzIwNyA2LjY3MzgzIDUuMTExMzNINS4wNDQ5MkM1LjA0NDkyIDQuNjM4NjcgNC45Mzc1IDQuMjgxMjUgNC43MjI2NiA0LjAzOTA2QzQuNTA3ODEgMy43OTI5NyA0LjIxNjggMy42Njk5MiAzLjg0OTYxIDMuNjY5OTJDMy42NTAzOSAzLjY2OTkyIDMuNDc2NTYgMy42OTcyNyAzLjMyODEyIDMuNzUxOTVDMy4xODM1OSAzLjgwMjczIDMuMDY0NDUgMy44NzY5NSAyLjk3MDcgMy45NzQ2MUMyLjg3Njk1IDQuMDY4MzYgMi44MDY2NCA0LjE3OTY5IDIuNzU5NzcgNC4zMDg1OUMyLjcxNjggNC40Mzc1IDIuNjk1MzEgNC41NzgxMiAyLjY5NTMxIDQuNzMwNDdDMi42OTUzMSA0Ljg4MjgxIDIuNzE2OCA1LjAxOTUzIDIuNzU5NzcgNS4xNDA2MkMyLjgwNjY0IDUuMjU3ODEgMi44ODI4MSA1LjM2NzE5IDIuOTg4MjggNS40Njg3NUMzLjA5NzY2IDUuNTcwMzEgMy4yNDAyMyA1LjY2Nzk3IDMuNDE2MDIgNS43NjE3MkMzLjU5MTggNS44NTE1NiAzLjgxMDU1IDUuOTQzMzYgNC4wNzIyNyA2LjAzNzExQzQuNDY2OCA2LjE4NTU1IDQuODI0MjIgNi4zMzk4NCA1LjE0NDUzIDYuNUM1LjQ2NDg0IDYuNjU2MjUgNS43MzgyOCA2LjgzOTg0IDUuOTY0ODQgNy4wNTA3OEM2LjE5NTMxIDcuMjU3ODEgNi4zNzEwOSA3LjUgNi40OTIxOSA3Ljc3NzM0QzYuNjE3MTkgOC4wNTA3OCA2LjY3OTY5IDguMzc1IDYuNjc5NjkgOC43NUM2LjY3OTY5IDkuMDkzNzUgNi42MjMwNSA5LjQwNDMgNi41MDk3NyA5LjY4MTY0QzYuMzk2NDggOS45NTUwOCA2LjIzNDM4IDEwLjE5MTQgNi4wMjM0NCAxMC4zOTA2QzUuODEyNSAxMC41ODk4IDUuNTU4NTkgMTAuNzUgNS4yNjE3MiAxMC44NzExQzQuOTY0ODQgMTAuOTg4MyA0LjYzMjgxIDExLjA2NDUgNC4yNjU2MiAxMS4wOTk2VjEyLjI0OEgzLjMzMzk4VjExLjA5OTZDMy4wMDE5NSAxMS4wNjg0IDIuNjc5NjkgMTAuOTk2MSAyLjM2NzE5IDEwLjg4MjhDMi4wNTQ2OSAxMC43NjU2IDEuNzc3MzQgMTAuNTk3NyAxLjUzNTE2IDEwLjM3ODlDMS4yOTY4OCAxMC4xNjAyIDEuMTA1NDcgOS44ODQ3NyAwLjk2MDkzOCA5LjU1MjczQzAuODE2NDA2IDkuMjE2OCAwLjc0NDE0MSA4LjgxNDQ1IDAuNzQ0MTQxIDguMzQ1N0gyLjM3ODkxQzIuMzc4OTEgOC42MjY5NSAyLjQxOTkyIDguODYzMjggMi41MDE5NSA5LjA1NDY5QzIuNTgzOTggOS4yNDIxOSAyLjY4OTQ1IDkuMzkyNTggMi44MTgzNiA5LjUwNTg2QzIuOTUxMTcgOS42MTUyMyAzLjEwMTU2IDkuNjkzMzYgMy4yNjk1MyA5Ljc0MDIzQzMuNDM3NSA5Ljc4NzExIDMuNjA5MzggOS44MTA1NSAzLjc4NTE2IDkuODEwNTVDNC4yMDMxMiA5LjgxMDU1IDQuNTE5NTMgOS43MTI4OSA0LjczNDM4IDkuNTE3NThDNC45NDkyMiA5LjMyMjI3IDUuMDU2NjQgOS4wNzAzMSA1LjA1NjY0IDguNzYxNzJaTTEzLjQxOCAxMi4yNzE1SDguMDc0MjJWMTFIMTMuNDE4VjEyLjI3MTVaIiB0cmFuc2Zvcm09InRyYW5zbGF0ZSgzLjk1MjY0IDYpIiBmaWxsPSJ3aGl0ZSIvPgo8L3N2Zz4K);--jp-icon-text-editor: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI0Ij4KICA8cGF0aCBjbGFzcz0ianAtaWNvbjMganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjNjE2MTYxIiBkPSJNMTUgMTVIM3YyaDEydi0yem0wLThIM3YyaDEyVjd6TTMgMTNoMTh2LTJIM3Yyem0wIDhoMTh2LTJIM3Yyek0zIDN2MmgxOFYzSDN6Ii8+Cjwvc3ZnPgo=);--jp-icon-trusted: url(data:image/svg+xml;base64,PHN2ZyBmaWxsPSJub25lIiB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDI0IDI1Ij4KICAgIDxwYXRoIGNsYXNzPSJqcC1pY29uMiIgc3Ryb2tlPSIjMzMzMzMzIiBzdHJva2Utd2lkdGg9IjIiIHRyYW5zZm9ybT0idHJhbnNsYXRlKDIgMykiIGQ9Ik0xLjg2MDk0IDExLjQ0MDlDMC44MjY0NDggOC43NzAyNyAwLjg2Mzc3OSA2LjA1NzY0IDEuMjQ5MDcgNC4xOTkzMkMyLjQ4MjA2IDMuOTMzNDcgNC4wODA2OCAzLjQwMzQ3IDUuNjAxMDIgMi44NDQ5QzcuMjM1NDkgMi4yNDQ0IDguODU2NjYgMS41ODE1IDkuOTg3NiAxLjA5NTM5QzExLjA1OTcgMS41ODM0MSAxMi42MDk0IDIuMjQ0NCAxNC4yMTggMi44NDMzOUMxNS43NTAzIDMuNDEzOTQgMTcuMzk5NSAzLjk1MjU4IDE4Ljc1MzkgNC4yMTM4NUMxOS4xMzY0IDYuMDcxNzcgMTkuMTcwOSA4Ljc3NzIyIDE4LjEzOSAxMS40NDA5QzE3LjAzMDMgMTQuMzAzMiAxNC42NjY4IDE3LjE4NDQgOS45OTk5OSAxOC45MzU0QzUuMzMzMiAxNy4xODQ0IDIuOTY5NjggMTQuMzAzMiAxLjg2MDk0IDExLjQ0MDlaIi8+CiAgICA8cGF0aCBjbGFzcz0ianAtaWNvbjIiIGZpbGw9IiMzMzMzMzMiIHN0cm9rZT0iIzMzMzMzMyIgdHJhbnNmb3JtPSJ0cmFuc2xhdGUoOCA5Ljg2NzE5KSIgZD0iTTIuODYwMTUgNC44NjUzNUwwLjcyNjU0OSAyLjk5OTU5TDAgMy42MzA0NUwyLjg2MDE1IDYuMTMxNTdMOCAwLjYzMDg3Mkw3LjI3ODU3IDBMMi44NjAxNSA0Ljg2NTM1WiIvPgo8L3N2Zz4K);--jp-icon-undo: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMjQgMjQiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTEyLjUgOGMtMi42NSAwLTUuMDUuOTktNi45IDIuNkwyIDd2OWg5bC0zLjYyLTMuNjJjMS4zOS0xLjE2IDMuMTYtMS44OCA1LjEyLTEuODggMy41NCAwIDYuNTUgMi4zMSA3LjYgNS41bDIuMzctLjc4QzIxLjA4IDExLjAzIDE3LjE1IDggMTIuNSA4eiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-vega: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8ZyBjbGFzcz0ianAtaWNvbjEganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjMjEyMTIxIj4KICAgIDxwYXRoIGQ9Ik0xMC42IDUuNGwyLjItMy4ySDIuMnY3LjNsNC02LjZ6Ii8+CiAgICA8cGF0aCBkPSJNMTUuOCAyLjJsLTQuNCA2LjZMNyA2LjNsLTQuOCA4djUuNWgxNy42VjIuMmgtNHptLTcgMTUuNEg1LjV2LTQuNGgzLjN2NC40em00LjQgMEg5LjhWOS44aDMuNHY3Ljh6bTQuNCAwaC0zLjRWNi41aDMuNHYxMS4xeiIvPgogIDwvZz4KPC9zdmc+Cg==);--jp-icon-yaml: url(data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxNiIgdmlld0JveD0iMCAwIDIyIDIyIj4KICA8ZyBjbGFzcz0ianAtaWNvbi1jb250cmFzdDIganAtaWNvbi1zZWxlY3RhYmxlIiBmaWxsPSIjRDgxQjYwIj4KICAgIDxwYXRoIGQ9Ik03LjIgMTguNnYtNS40TDMgNS42aDMuM2wxLjQgMy4xYy4zLjkuNiAxLjYgMSAyLjUuMy0uOC42LTEuNiAxLTIuNWwxLjQtMy4xaDMuNGwtNC40IDcuNnY1LjVsLTIuOS0uMXoiLz4KICAgIDxjaXJjbGUgY2xhc3M9InN0MCIgY3g9IjE3LjYiIGN5PSIxNi41IiByPSIyLjEiLz4KICAgIDxjaXJjbGUgY2xhc3M9InN0MCIgY3g9IjE3LjYiIGN5PSIxMSIgcj0iMi4xIi8+CiAgPC9nPgo8L3N2Zz4K)}.jupyter-wrapper .jp-AddIcon{background-image:var(--jp-icon-add)}.jupyter-wrapper .jp-BugIcon{background-image:var(--jp-icon-bug)}.jupyter-wrapper .jp-BuildIcon{background-image:var(--jp-icon-build)}.jupyter-wrapper .jp-CaretDownEmptyIcon{background-image:var(--jp-icon-caret-down-empty)}.jupyter-wrapper .jp-CaretDownEmptyThinIcon{background-image:var(--jp-icon-caret-down-empty-thin)}.jupyter-wrapper .jp-CaretDownIcon{background-image:var(--jp-icon-caret-down)}.jupyter-wrapper .jp-CaretLeftIcon{background-image:var(--jp-icon-caret-left)}.jupyter-wrapper .jp-CaretRightIcon{background-image:var(--jp-icon-caret-right)}.jupyter-wrapper .jp-CaretUpEmptyThinIcon{background-image:var(--jp-icon-caret-up-empty-thin)}.jupyter-wrapper .jp-CaretUpIcon{background-image:var(--jp-icon-caret-up)}.jupyter-wrapper .jp-CaseSensitiveIcon{background-image:var(--jp-icon-case-sensitive)}.jupyter-wrapper .jp-CheckIcon{background-image:var(--jp-icon-check)}.jupyter-wrapper .jp-CircleEmptyIcon{background-image:var(--jp-icon-circle-empty)}.jupyter-wrapper .jp-CircleIcon{background-image:var(--jp-icon-circle)}.jupyter-wrapper .jp-ClearIcon{background-image:var(--jp-icon-clear)}.jupyter-wrapper .jp-CloseIcon{background-image:var(--jp-icon-close)}.jupyter-wrapper .jp-ConsoleIcon{background-image:var(--jp-icon-console)}.jupyter-wrapper .jp-CopyIcon{background-image:var(--jp-icon-copy)}.jupyter-wrapper .jp-CutIcon{background-image:var(--jp-icon-cut)}.jupyter-wrapper .jp-DownloadIcon{background-image:var(--jp-icon-download)}.jupyter-wrapper .jp-EditIcon{background-image:var(--jp-icon-edit)}.jupyter-wrapper .jp-EllipsesIcon{background-image:var(--jp-icon-ellipses)}.jupyter-wrapper .jp-ExtensionIcon{background-image:var(--jp-icon-extension)}.jupyter-wrapper .jp-FastForwardIcon{background-image:var(--jp-icon-fast-forward)}.jupyter-wrapper .jp-FileIcon{background-image:var(--jp-icon-file)}.jupyter-wrapper .jp-FileUploadIcon{background-image:var(--jp-icon-file-upload)}.jupyter-wrapper .jp-FilterListIcon{background-image:var(--jp-icon-filter-list)}.jupyter-wrapper .jp-FolderIcon{background-image:var(--jp-icon-folder)}.jupyter-wrapper .jp-Html5Icon{background-image:var(--jp-icon-html5)}.jupyter-wrapper .jp-ImageIcon{background-image:var(--jp-icon-image)}.jupyter-wrapper .jp-InspectorIcon{background-image:var(--jp-icon-inspector)}.jupyter-wrapper .jp-JsonIcon{background-image:var(--jp-icon-json)}.jupyter-wrapper .jp-JupyterFaviconIcon{background-image:var(--jp-icon-jupyter-favicon)}.jupyter-wrapper .jp-JupyterIcon{background-image:var(--jp-icon-jupyter)}.jupyter-wrapper .jp-JupyterlabWordmarkIcon{background-image:var(--jp-icon-jupyterlab-wordmark)}.jupyter-wrapper .jp-KernelIcon{background-image:var(--jp-icon-kernel)}.jupyter-wrapper .jp-KeyboardIcon{background-image:var(--jp-icon-keyboard)}.jupyter-wrapper .jp-LauncherIcon{background-image:var(--jp-icon-launcher)}.jupyter-wrapper .jp-LineFormIcon{background-image:var(--jp-icon-line-form)}.jupyter-wrapper .jp-LinkIcon{background-image:var(--jp-icon-link)}.jupyter-wrapper .jp-ListIcon{background-image:var(--jp-icon-list)}.jupyter-wrapper .jp-ListingsInfoIcon{background-image:var(--jp-icon-listings-info)}.jupyter-wrapper .jp-MarkdownIcon{background-image:var(--jp-icon-markdown)}.jupyter-wrapper .jp-NewFolderIcon{background-image:var(--jp-icon-new-folder)}.jupyter-wrapper .jp-NotTrustedIcon{background-image:var(--jp-icon-not-trusted)}.jupyter-wrapper .jp-NotebookIcon{background-image:var(--jp-icon-notebook)}.jupyter-wrapper .jp-PaletteIcon{background-image:var(--jp-icon-palette)}.jupyter-wrapper .jp-PasteIcon{background-image:var(--jp-icon-paste)}.jupyter-wrapper .jp-PythonIcon{background-image:var(--jp-icon-python)}.jupyter-wrapper .jp-RKernelIcon{background-image:var(--jp-icon-r-kernel)}.jupyter-wrapper .jp-ReactIcon{background-image:var(--jp-icon-react)}.jupyter-wrapper .jp-RefreshIcon{background-image:var(--jp-icon-refresh)}.jupyter-wrapper .jp-RegexIcon{background-image:var(--jp-icon-regex)}.jupyter-wrapper .jp-RunIcon{background-image:var(--jp-icon-run)}.jupyter-wrapper .jp-RunningIcon{background-image:var(--jp-icon-running)}.jupyter-wrapper .jp-SaveIcon{background-image:var(--jp-icon-save)}.jupyter-wrapper .jp-SearchIcon{background-image:var(--jp-icon-search)}.jupyter-wrapper .jp-SettingsIcon{background-image:var(--jp-icon-settings)}.jupyter-wrapper .jp-SpreadsheetIcon{background-image:var(--jp-icon-spreadsheet)}.jupyter-wrapper .jp-StopIcon{background-image:var(--jp-icon-stop)}.jupyter-wrapper .jp-TabIcon{background-image:var(--jp-icon-tab)}.jupyter-wrapper .jp-TerminalIcon{background-image:var(--jp-icon-terminal)}.jupyter-wrapper .jp-TextEditorIcon{background-image:var(--jp-icon-text-editor)}.jupyter-wrapper .jp-TrustedIcon{background-image:var(--jp-icon-trusted)}.jupyter-wrapper .jp-UndoIcon{background-image:var(--jp-icon-undo)}.jupyter-wrapper .jp-VegaIcon{background-image:var(--jp-icon-vega)}.jupyter-wrapper .jp-YamlIcon{background-image:var(--jp-icon-yaml)}.jupyter-wrapper :root{--jp-icon-search-white: url(data:image/svg+xml;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMTggMTgiIHdpZHRoPSIxNiIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIj4KICA8ZyBjbGFzcz0ianAtaWNvbjMiIGZpbGw9IiM2MTYxNjEiPgogICAgPHBhdGggZD0iTTEyLjEsMTAuOWgtMC43bC0wLjItMC4yYzAuOC0wLjksMS4zLTIuMiwxLjMtMy41YzAtMy0yLjQtNS40LTUuNC01LjRTMS44LDQuMiwxLjgsNy4xczIuNCw1LjQsNS40LDUuNCBjMS4zLDAsMi41LTAuNSwzLjUtMS4zbDAuMiwwLjJ2MC43bDQuMSw0LjFsMS4yLTEuMkwxMi4xLDEwLjl6IE03LjEsMTAuOWMtMi4xLDAtMy43LTEuNy0zLjctMy43czEuNy0zLjcsMy43LTMuN3MzLjcsMS43LDMuNywzLjcgUzkuMiwxMC45LDcuMSwxMC45eiIvPgogIDwvZz4KPC9zdmc+Cg==)}.jupyter-wrapper .jp-Icon,.jupyter-wrapper .jp-MaterialIcon{background-position:center;background-repeat:no-repeat;background-size:16px;min-width:16px;min-height:16px}.jupyter-wrapper .jp-Icon-cover{background-position:center;background-repeat:no-repeat;background-size:cover}.jupyter-wrapper .jp-Icon-16{background-size:16px;min-width:16px;min-height:16px}.jupyter-wrapper .jp-Icon-18{background-size:18px;min-width:18px;min-height:18px}.jupyter-wrapper .jp-Icon-20{background-size:20px;min-width:20px;min-height:20px}.jupyter-wrapper .jp-icon0[fill]{fill:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon1[fill]{fill:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon2[fill]{fill:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon3[fill]{fill:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon4[fill]{fill:var(--jp-inverse-layout-color4)}.jupyter-wrapper .jp-icon0[stroke]{stroke:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon1[stroke]{stroke:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon2[stroke]{stroke:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon3[stroke]{stroke:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon4[stroke]{stroke:var(--jp-inverse-layout-color4)}.jupyter-wrapper .jp-icon-accent0[fill]{fill:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-accent1[fill]{fill:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-accent2[fill]{fill:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-accent3[fill]{fill:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-accent4[fill]{fill:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-accent0[stroke]{stroke:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-accent1[stroke]{stroke:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-accent2[stroke]{stroke:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-accent3[stroke]{stroke:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-accent4[stroke]{stroke:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-none[fill]{fill:none}.jupyter-wrapper .jp-icon-none[stroke]{stroke:none}.jupyter-wrapper .jp-icon-brand0[fill]{fill:var(--jp-brand-color0)}.jupyter-wrapper .jp-icon-brand1[fill]{fill:var(--jp-brand-color1)}.jupyter-wrapper .jp-icon-brand2[fill]{fill:var(--jp-brand-color2)}.jupyter-wrapper .jp-icon-brand3[fill]{fill:var(--jp-brand-color3)}.jupyter-wrapper .jp-icon-brand4[fill]{fill:var(--jp-brand-color4)}.jupyter-wrapper .jp-icon-brand0[stroke]{stroke:var(--jp-brand-color0)}.jupyter-wrapper .jp-icon-brand1[stroke]{stroke:var(--jp-brand-color1)}.jupyter-wrapper .jp-icon-brand2[stroke]{stroke:var(--jp-brand-color2)}.jupyter-wrapper .jp-icon-brand3[stroke]{stroke:var(--jp-brand-color3)}.jupyter-wrapper .jp-icon-brand4[stroke]{stroke:var(--jp-brand-color4)}.jupyter-wrapper .jp-icon-warn0[fill]{fill:var(--jp-warn-color0)}.jupyter-wrapper .jp-icon-warn1[fill]{fill:var(--jp-warn-color1)}.jupyter-wrapper .jp-icon-warn2[fill]{fill:var(--jp-warn-color2)}.jupyter-wrapper .jp-icon-warn3[fill]{fill:var(--jp-warn-color3)}.jupyter-wrapper .jp-icon-warn0[stroke]{stroke:var(--jp-warn-color0)}.jupyter-wrapper .jp-icon-warn1[stroke]{stroke:var(--jp-warn-color1)}.jupyter-wrapper .jp-icon-warn2[stroke]{stroke:var(--jp-warn-color2)}.jupyter-wrapper .jp-icon-warn3[stroke]{stroke:var(--jp-warn-color3)}.jupyter-wrapper .jp-icon-contrast0[fill]{fill:var(--jp-icon-contrast-color0)}.jupyter-wrapper .jp-icon-contrast1[fill]{fill:var(--jp-icon-contrast-color1)}.jupyter-wrapper .jp-icon-contrast2[fill]{fill:var(--jp-icon-contrast-color2)}.jupyter-wrapper .jp-icon-contrast3[fill]{fill:var(--jp-icon-contrast-color3)}.jupyter-wrapper .jp-icon-contrast0[stroke]{stroke:var(--jp-icon-contrast-color0)}.jupyter-wrapper .jp-icon-contrast1[stroke]{stroke:var(--jp-icon-contrast-color1)}.jupyter-wrapper .jp-icon-contrast2[stroke]{stroke:var(--jp-icon-contrast-color2)}.jupyter-wrapper .jp-icon-contrast3[stroke]{stroke:var(--jp-icon-contrast-color3)}.jupyter-wrapper #setting-editor .jp-PluginList .jp-mod-selected .jp-icon-selectable[fill]{fill:#fff}.jupyter-wrapper #setting-editor .jp-PluginList .jp-mod-selected .jp-icon-selectable-inverse[fill]{fill:var(--jp-brand-color1)}.jupyter-wrapper .jp-DirListing-item.jp-mod-selected .jp-icon-selectable[fill]{fill:#fff}.jupyter-wrapper .jp-DirListing-item.jp-mod-selected .jp-icon-selectable-inverse[fill]{fill:var(--jp-brand-color1)}.jupyter-wrapper #tab-manager .lm-TabBar-tab.jp-mod-active .jp-icon-selectable[fill]{fill:#fff}.jupyter-wrapper #tab-manager .lm-TabBar-tab.jp-mod-active .jp-icon-selectable-inverse[fill]{fill:var(--jp-brand-color1)}.jupyter-wrapper #tab-manager .lm-TabBar-tab.jp-mod-active .jp-icon-hover :hover .jp-icon-selectable[fill]{fill:var(--jp-brand-color1)}.jupyter-wrapper #tab-manager .lm-TabBar-tab.jp-mod-active .jp-icon-hover :hover .jp-icon-selectable-inverse[fill]{fill:#fff}.jupyter-wrapper #tab-manager .lm-TabBar-tab.jp-mod-dirty>.lm-TabBar-tabCloseIcon>:not(:hover)>.jp-icon3[fill]{fill:none}.jupyter-wrapper #tab-manager .lm-TabBar-tab.jp-mod-dirty>.lm-TabBar-tabCloseIcon>:not(:hover)>.jp-icon-busy[fill]{fill:var(--jp-inverse-layout-color3)}.jupyter-wrapper #tab-manager .lm-TabBar-tab.jp-mod-dirty.jp-mod-active>.lm-TabBar-tabCloseIcon>:not(:hover)>.jp-icon-busy[fill]{fill:#fff}.jupyter-wrapper .lm-DockPanel-tabBar .lm-TabBar-tab.lm-mod-closable.jp-mod-dirty>.lm-TabBar-tabCloseIcon>:not(:hover)>.jp-icon3[fill]{fill:none}.jupyter-wrapper .lm-DockPanel-tabBar .lm-TabBar-tab.lm-mod-closable.jp-mod-dirty>.lm-TabBar-tabCloseIcon>:not(:hover)>.jp-icon-busy[fill]{fill:var(--jp-inverse-layout-color3)}.jupyter-wrapper #jp-main-statusbar .jp-mod-selected .jp-icon-selectable[fill]{fill:#fff}.jupyter-wrapper #jp-main-statusbar .jp-mod-selected .jp-icon-selectable-inverse[fill]{fill:var(--jp-brand-color1)}.jupyter-wrapper :root{--jp-warn-color0: var(--md-orange-700)}.jupyter-wrapper .jp-DragIcon{margin-right:4px}.jupyter-wrapper .jp-icon-alt .jp-icon0[fill]{fill:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-alt .jp-icon1[fill]{fill:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-alt .jp-icon2[fill]{fill:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-alt .jp-icon3[fill]{fill:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-alt .jp-icon4[fill]{fill:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-alt .jp-icon0[stroke]{stroke:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-alt .jp-icon1[stroke]{stroke:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-alt .jp-icon2[stroke]{stroke:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-alt .jp-icon3[stroke]{stroke:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-alt .jp-icon4[stroke]{stroke:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent0[fill]{fill:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent1[fill]{fill:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent2[fill]{fill:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent3[fill]{fill:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent4[fill]{fill:var(--jp-inverse-layout-color4)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent0[stroke]{stroke:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent1[stroke]{stroke:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent2[stroke]{stroke:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent3[stroke]{stroke:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon-alt .jp-icon-accent4[stroke]{stroke:var(--jp-inverse-layout-color4)}.jupyter-wrapper .jp-icon-hoverShow:not(:hover) svg{display:none !important}.jupyter-wrapper .jp-icon-hover :hover .jp-icon0-hover[fill]{fill:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon1-hover[fill]{fill:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon2-hover[fill]{fill:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon3-hover[fill]{fill:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon4-hover[fill]{fill:var(--jp-inverse-layout-color4)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon0-hover[stroke]{stroke:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon1-hover[stroke]{stroke:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon2-hover[stroke]{stroke:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon3-hover[stroke]{stroke:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon4-hover[stroke]{stroke:var(--jp-inverse-layout-color4)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent0-hover[fill]{fill:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent1-hover[fill]{fill:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent2-hover[fill]{fill:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent3-hover[fill]{fill:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent4-hover[fill]{fill:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent0-hover[stroke]{stroke:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent1-hover[stroke]{stroke:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent2-hover[stroke]{stroke:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent3-hover[stroke]{stroke:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-accent4-hover[stroke]{stroke:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-none-hover[fill]{fill:none}.jupyter-wrapper .jp-icon-hover :hover .jp-icon-none-hover[stroke]{stroke:none}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon0-hover[fill]{fill:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon1-hover[fill]{fill:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon2-hover[fill]{fill:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon3-hover[fill]{fill:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon4-hover[fill]{fill:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon0-hover[stroke]{stroke:var(--jp-layout-color0)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon1-hover[stroke]{stroke:var(--jp-layout-color1)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon2-hover[stroke]{stroke:var(--jp-layout-color2)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon3-hover[stroke]{stroke:var(--jp-layout-color3)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon4-hover[stroke]{stroke:var(--jp-layout-color4)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent0-hover[fill]{fill:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent1-hover[fill]{fill:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent2-hover[fill]{fill:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent3-hover[fill]{fill:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent4-hover[fill]{fill:var(--jp-inverse-layout-color4)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent0-hover[stroke]{stroke:var(--jp-inverse-layout-color0)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent1-hover[stroke]{stroke:var(--jp-inverse-layout-color1)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent2-hover[stroke]{stroke:var(--jp-inverse-layout-color2)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent3-hover[stroke]{stroke:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-icon-hover.jp-icon-alt :hover .jp-icon-accent4-hover[stroke]{stroke:var(--jp-inverse-layout-color4)}.jupyter-wrapper :focus{outline:unset;outline-offset:unset;-moz-outline-radius:unset}.jupyter-wrapper .jp-Button{border-radius:var(--jp-border-radius);padding:0px 12px;font-size:var(--jp-ui-font-size1)}.jupyter-wrapper button.jp-Button.bp3-button.bp3-minimal:hover{background-color:var(--jp-layout-color2)}.jupyter-wrapper .jp-Button.minimal{color:unset !important}.jupyter-wrapper .jp-Button.jp-ToolbarButtonComponent{text-transform:none}.jupyter-wrapper .jp-InputGroup input{box-sizing:border-box;border-radius:0;background-color:rgba(0,0,0,0);color:var(--jp-ui-font-color0);box-shadow:inset 0 0 0 var(--jp-border-width) var(--jp-input-border-color)}.jupyter-wrapper .jp-InputGroup input:focus{box-shadow:inset 0 0 0 var(--jp-border-width) var(--jp-input-active-box-shadow-color),inset 0 0 0 3px var(--jp-input-active-box-shadow-color)}.jupyter-wrapper .jp-InputGroup input::placeholder,.jupyter-wrapper input::placeholder{color:var(--jp-ui-font-color3)}.jupyter-wrapper .jp-BPIcon{display:inline-block;vertical-align:middle;margin:auto}.jupyter-wrapper .bp3-icon.jp-BPIcon>svg:not([fill]){fill:var(--jp-inverse-layout-color3)}.jupyter-wrapper .jp-InputGroupAction{padding:6px}.jupyter-wrapper .jp-HTMLSelect.jp-DefaultStyle select{background-color:initial;border:none;border-radius:0;box-shadow:none;color:var(--jp-ui-font-color0);display:block;font-size:var(--jp-ui-font-size1);height:24px;line-height:14px;padding:0 25px 0 10px;text-align:left;-moz-appearance:none;-webkit-appearance:none}.jupyter-wrapper .jp-HTMLSelect.jp-DefaultStyle select:hover,.jupyter-wrapper .jp-HTMLSelect.jp-DefaultStyle select>option{background-color:var(--jp-layout-color2);color:var(--jp-ui-font-color0)}.jupyter-wrapper select{box-sizing:border-box}.jupyter-wrapper .jp-Collapse{display:flex;flex-direction:column;align-items:stretch;border-top:1px solid var(--jp-border-color2);border-bottom:1px solid var(--jp-border-color2)}.jupyter-wrapper .jp-Collapse-header{padding:1px 12px;color:var(--jp-ui-font-color1);background-color:var(--jp-layout-color1);font-size:var(--jp-ui-font-size2)}.jupyter-wrapper .jp-Collapse-header:hover{background-color:var(--jp-layout-color2)}.jupyter-wrapper .jp-Collapse-contents{padding:0px 12px 0px 12px;background-color:var(--jp-layout-color1);color:var(--jp-ui-font-color1);overflow:auto}.jupyter-wrapper :root{--jp-private-commandpalette-search-height: 28px}.jupyter-wrapper .lm-CommandPalette{padding-bottom:0px;color:var(--jp-ui-font-color1);background:var(--jp-layout-color1);font-size:var(--jp-ui-font-size1)}.jupyter-wrapper .lm-CommandPalette-search{padding:4px;background-color:var(--jp-layout-color1);z-index:2}.jupyter-wrapper .lm-CommandPalette-wrapper{overflow:overlay;padding:0px 9px;background-color:var(--jp-input-active-background);height:30px;box-shadow:inset 0 0 0 var(--jp-border-width) var(--jp-input-border-color)}.jupyter-wrapper .lm-CommandPalette.lm-mod-focused .lm-CommandPalette-wrapper{box-shadow:inset 0 0 0 1px var(--jp-input-active-box-shadow-color),inset 0 0 0 3px var(--jp-input-active-box-shadow-color)}.jupyter-wrapper .lm-CommandPalette-wrapper::after{content:\" \";color:#fff;background-color:var(--jp-brand-color1);position:absolute;top:4px;right:4px;height:30px;width:10px;padding:0px 10px;background-image:var(--jp-icon-search-white);background-size:20px;background-repeat:no-repeat;background-position:center}.jupyter-wrapper .lm-CommandPalette-input{background:rgba(0,0,0,0);width:calc(100% - 18px);float:left;border:none;outline:none;font-size:var(--jp-ui-font-size1);color:var(--jp-ui-font-color0);line-height:var(--jp-private-commandpalette-search-height)}.jupyter-wrapper .lm-CommandPalette-input::-webkit-input-placeholder,.jupyter-wrapper .lm-CommandPalette-input::-moz-placeholder,.jupyter-wrapper .lm-CommandPalette-input:-ms-input-placeholder{color:var(--jp-ui-font-color3);font-size:var(--jp-ui-font-size1)}.jupyter-wrapper .lm-CommandPalette-header:first-child{margin-top:0px}.jupyter-wrapper .lm-CommandPalette-header{border-bottom:solid var(--jp-border-width) var(--jp-border-color2);color:var(--jp-ui-font-color1);cursor:pointer;display:flex;font-size:var(--jp-ui-font-size0);font-weight:600;letter-spacing:1px;margin-top:8px;padding:8px 0 8px 12px;text-transform:uppercase}.jupyter-wrapper .lm-CommandPalette-header.lm-mod-active{background:var(--jp-layout-color2)}.jupyter-wrapper .lm-CommandPalette-header>mark{background-color:rgba(0,0,0,0);font-weight:bold;color:var(--jp-ui-font-color1)}.jupyter-wrapper .lm-CommandPalette-item{padding:4px 12px 4px 4px;color:var(--jp-ui-font-color1);font-size:var(--jp-ui-font-size1);font-weight:400;display:flex}.jupyter-wrapper .lm-CommandPalette-item.lm-mod-disabled{color:var(--jp-ui-font-color3)}.jupyter-wrapper .lm-CommandPalette-item.lm-mod-active{background:var(--jp-layout-color3)}.jupyter-wrapper .lm-CommandPalette-item.lm-mod-active:hover:not(.lm-mod-disabled){background:var(--jp-layout-color4)}.jupyter-wrapper .lm-CommandPalette-item:hover:not(.lm-mod-active):not(.lm-mod-disabled){background:var(--jp-layout-color2)}.jupyter-wrapper .lm-CommandPalette-itemContent{overflow:hidden}.jupyter-wrapper .lm-CommandPalette-itemLabel>mark{color:var(--jp-ui-font-color0);background-color:rgba(0,0,0,0);font-weight:bold}.jupyter-wrapper .lm-CommandPalette-item.lm-mod-disabled mark{color:var(--jp-ui-font-color3)}.jupyter-wrapper .lm-CommandPalette-item .lm-CommandPalette-itemIcon{margin:0 4px 0 0;position:relative;width:16px;top:2px;flex:0 0 auto}.jupyter-wrapper .lm-CommandPalette-item.lm-mod-disabled .lm-CommandPalette-itemIcon{opacity:.4}.jupyter-wrapper .lm-CommandPalette-item .lm-CommandPalette-itemShortcut{flex:0 0 auto}.jupyter-wrapper .lm-CommandPalette-itemCaption{display:none}.jupyter-wrapper .lm-CommandPalette-content{background-color:var(--jp-layout-color1)}.jupyter-wrapper .lm-CommandPalette-content:empty:after{content:\"No results\";margin:auto;margin-top:20px;width:100px;display:block;font-size:var(--jp-ui-font-size2);font-family:var(--jp-ui-font-family);font-weight:lighter}.jupyter-wrapper .lm-CommandPalette-emptyMessage{text-align:center;margin-top:24px;line-height:1.32;padding:0px 8px;color:var(--jp-content-font-color3)}.jupyter-wrapper .jp-Dialog{position:absolute;z-index:10000;display:flex;flex-direction:column;align-items:center;justify-content:center;top:0px;left:0px;margin:0;padding:0;width:100%;height:100%;background:var(--jp-dialog-background)}.jupyter-wrapper .jp-Dialog-content{display:flex;flex-direction:column;margin-left:auto;margin-right:auto;background:var(--jp-layout-color1);padding:24px;padding-bottom:12px;min-width:300px;min-height:150px;max-width:1000px;max-height:500px;box-sizing:border-box;box-shadow:var(--jp-elevation-z20);word-wrap:break-word;border-radius:var(--jp-border-radius);font-size:var(--jp-ui-font-size1);color:var(--jp-ui-font-color1)}.jupyter-wrapper .jp-Dialog-button{overflow:visible}.jupyter-wrapper button.jp-Dialog-button:focus{outline:1px solid var(--jp-brand-color1);outline-offset:4px;-moz-outline-radius:0px}.jupyter-wrapper button.jp-Dialog-button:focus::-moz-focus-inner{border:0}.jupyter-wrapper .jp-Dialog-header{flex:0 0 auto;padding-bottom:12px;font-size:var(--jp-ui-font-size3);font-weight:400;color:var(--jp-ui-font-color0)}.jupyter-wrapper .jp-Dialog-body{display:flex;flex-direction:column;flex:1 1 auto;font-size:var(--jp-ui-font-size1);background:var(--jp-layout-color1);overflow:auto}.jupyter-wrapper .jp-Dialog-footer{display:flex;flex-direction:row;justify-content:flex-end;flex:0 0 auto;margin-left:-12px;margin-right:-12px;padding:12px}.jupyter-wrapper .jp-Dialog-title{overflow:hidden;white-space:nowrap;text-overflow:ellipsis}.jupyter-wrapper .jp-Dialog-body>.jp-select-wrapper{width:100%}.jupyter-wrapper .jp-Dialog-body>button{padding:0px 16px}.jupyter-wrapper .jp-Dialog-body>label{line-height:1.4;color:var(--jp-ui-font-color0)}.jupyter-wrapper .jp-Dialog-button.jp-mod-styled:not(:last-child){margin-right:12px}.jupyter-wrapper .jp-HoverBox{position:fixed}.jupyter-wrapper .jp-HoverBox.jp-mod-outofview{display:none}.jupyter-wrapper .jp-IFrame{width:100%;height:100%}.jupyter-wrapper .jp-IFrame>iframe{border:none}.jupyter-wrapper body.lm-mod-override-cursor .jp-IFrame{position:relative}.jupyter-wrapper body.lm-mod-override-cursor .jp-IFrame:before{content:\"\";position:absolute;top:0;left:0;right:0;bottom:0;background:rgba(0,0,0,0)}.jupyter-wrapper .jp-MainAreaWidget>:focus{outline:none}.jupyter-wrapper :root{--md-red-50: #ffebee;--md-red-100: #ffcdd2;--md-red-200: #ef9a9a;--md-red-300: #e57373;--md-red-400: #ef5350;--md-red-500: #f44336;--md-red-600: #e53935;--md-red-700: #d32f2f;--md-red-800: #c62828;--md-red-900: #b71c1c;--md-red-A100: #ff8a80;--md-red-A200: #ff5252;--md-red-A400: #ff1744;--md-red-A700: #d50000;--md-pink-50: #fce4ec;--md-pink-100: #f8bbd0;--md-pink-200: #f48fb1;--md-pink-300: #f06292;--md-pink-400: #ec407a;--md-pink-500: #e91e63;--md-pink-600: #d81b60;--md-pink-700: #c2185b;--md-pink-800: #ad1457;--md-pink-900: #880e4f;--md-pink-A100: #ff80ab;--md-pink-A200: #ff4081;--md-pink-A400: #f50057;--md-pink-A700: #c51162;--md-purple-50: #f3e5f5;--md-purple-100: #e1bee7;--md-purple-200: #ce93d8;--md-purple-300: #ba68c8;--md-purple-400: #ab47bc;--md-purple-500: #9c27b0;--md-purple-600: #8e24aa;--md-purple-700: #7b1fa2;--md-purple-800: #6a1b9a;--md-purple-900: #4a148c;--md-purple-A100: #ea80fc;--md-purple-A200: #e040fb;--md-purple-A400: #d500f9;--md-purple-A700: #aa00ff;--md-deep-purple-50: #ede7f6;--md-deep-purple-100: #d1c4e9;--md-deep-purple-200: #b39ddb;--md-deep-purple-300: #9575cd;--md-deep-purple-400: #7e57c2;--md-deep-purple-500: #673ab7;--md-deep-purple-600: #5e35b1;--md-deep-purple-700: #512da8;--md-deep-purple-800: #4527a0;--md-deep-purple-900: #311b92;--md-deep-purple-A100: #b388ff;--md-deep-purple-A200: #7c4dff;--md-deep-purple-A400: #651fff;--md-deep-purple-A700: #6200ea;--md-indigo-50: #e8eaf6;--md-indigo-100: #c5cae9;--md-indigo-200: #9fa8da;--md-indigo-300: #7986cb;--md-indigo-400: #5c6bc0;--md-indigo-500: #3f51b5;--md-indigo-600: #3949ab;--md-indigo-700: #303f9f;--md-indigo-800: #283593;--md-indigo-900: #1a237e;--md-indigo-A100: #8c9eff;--md-indigo-A200: #536dfe;--md-indigo-A400: #3d5afe;--md-indigo-A700: #304ffe;--md-blue-50: #e3f2fd;--md-blue-100: #bbdefb;--md-blue-200: #90caf9;--md-blue-300: #64b5f6;--md-blue-400: #42a5f5;--md-blue-500: #2196f3;--md-blue-600: #1e88e5;--md-blue-700: #1976d2;--md-blue-800: #1565c0;--md-blue-900: #0d47a1;--md-blue-A100: #82b1ff;--md-blue-A200: #448aff;--md-blue-A400: #2979ff;--md-blue-A700: #2962ff;--md-light-blue-50: #e1f5fe;--md-light-blue-100: #b3e5fc;--md-light-blue-200: #81d4fa;--md-light-blue-300: #4fc3f7;--md-light-blue-400: #29b6f6;--md-light-blue-500: #03a9f4;--md-light-blue-600: #039be5;--md-light-blue-700: #0288d1;--md-light-blue-800: #0277bd;--md-light-blue-900: #01579b;--md-light-blue-A100: #80d8ff;--md-light-blue-A200: #40c4ff;--md-light-blue-A400: #00b0ff;--md-light-blue-A700: #0091ea;--md-cyan-50: #e0f7fa;--md-cyan-100: #b2ebf2;--md-cyan-200: #80deea;--md-cyan-300: #4dd0e1;--md-cyan-400: #26c6da;--md-cyan-500: #00bcd4;--md-cyan-600: #00acc1;--md-cyan-700: #0097a7;--md-cyan-800: #00838f;--md-cyan-900: #006064;--md-cyan-A100: #84ffff;--md-cyan-A200: #18ffff;--md-cyan-A400: #00e5ff;--md-cyan-A700: #00b8d4;--md-teal-50: #e0f2f1;--md-teal-100: #b2dfdb;--md-teal-200: #80cbc4;--md-teal-300: #4db6ac;--md-teal-400: #26a69a;--md-teal-500: #009688;--md-teal-600: #00897b;--md-teal-700: #00796b;--md-teal-800: #00695c;--md-teal-900: #004d40;--md-teal-A100: #a7ffeb;--md-teal-A200: #64ffda;--md-teal-A400: #1de9b6;--md-teal-A700: #00bfa5;--md-green-50: #e8f5e9;--md-green-100: #c8e6c9;--md-green-200: #a5d6a7;--md-green-300: #81c784;--md-green-400: #66bb6a;--md-green-500: #4caf50;--md-green-600: #43a047;--md-green-700: #388e3c;--md-green-800: #2e7d32;--md-green-900: #1b5e20;--md-green-A100: #b9f6ca;--md-green-A200: #69f0ae;--md-green-A400: #00e676;--md-green-A700: #00c853;--md-light-green-50: #f1f8e9;--md-light-green-100: #dcedc8;--md-light-green-200: #c5e1a5;--md-light-green-300: #aed581;--md-light-green-400: #9ccc65;--md-light-green-500: #8bc34a;--md-light-green-600: #7cb342;--md-light-green-700: #689f38;--md-light-green-800: #558b2f;--md-light-green-900: #33691e;--md-light-green-A100: #ccff90;--md-light-green-A200: #b2ff59;--md-light-green-A400: #76ff03;--md-light-green-A700: #64dd17;--md-lime-50: #f9fbe7;--md-lime-100: #f0f4c3;--md-lime-200: #e6ee9c;--md-lime-300: #dce775;--md-lime-400: #d4e157;--md-lime-500: #cddc39;--md-lime-600: #c0ca33;--md-lime-700: #afb42b;--md-lime-800: #9e9d24;--md-lime-900: #827717;--md-lime-A100: #f4ff81;--md-lime-A200: #eeff41;--md-lime-A400: #c6ff00;--md-lime-A700: #aeea00;--md-yellow-50: #fffde7;--md-yellow-100: #fff9c4;--md-yellow-200: #fff59d;--md-yellow-300: #fff176;--md-yellow-400: #ffee58;--md-yellow-500: #ffeb3b;--md-yellow-600: #fdd835;--md-yellow-700: #fbc02d;--md-yellow-800: #f9a825;--md-yellow-900: #f57f17;--md-yellow-A100: #ffff8d;--md-yellow-A200: #ffff00;--md-yellow-A400: #ffea00;--md-yellow-A700: #ffd600;--md-amber-50: #fff8e1;--md-amber-100: #ffecb3;--md-amber-200: #ffe082;--md-amber-300: #ffd54f;--md-amber-400: #ffca28;--md-amber-500: #ffc107;--md-amber-600: #ffb300;--md-amber-700: #ffa000;--md-amber-800: #ff8f00;--md-amber-900: #ff6f00;--md-amber-A100: #ffe57f;--md-amber-A200: #ffd740;--md-amber-A400: #ffc400;--md-amber-A700: #ffab00;--md-orange-50: #fff3e0;--md-orange-100: #ffe0b2;--md-orange-200: #ffcc80;--md-orange-300: #ffb74d;--md-orange-400: #ffa726;--md-orange-500: #ff9800;--md-orange-600: #fb8c00;--md-orange-700: #f57c00;--md-orange-800: #ef6c00;--md-orange-900: #e65100;--md-orange-A100: #ffd180;--md-orange-A200: #ffab40;--md-orange-A400: #ff9100;--md-orange-A700: #ff6d00;--md-deep-orange-50: #fbe9e7;--md-deep-orange-100: #ffccbc;--md-deep-orange-200: #ffab91;--md-deep-orange-300: #ff8a65;--md-deep-orange-400: #ff7043;--md-deep-orange-500: #ff5722;--md-deep-orange-600: #f4511e;--md-deep-orange-700: #e64a19;--md-deep-orange-800: #d84315;--md-deep-orange-900: #bf360c;--md-deep-orange-A100: #ff9e80;--md-deep-orange-A200: #ff6e40;--md-deep-orange-A400: #ff3d00;--md-deep-orange-A700: #dd2c00;--md-brown-50: #efebe9;--md-brown-100: #d7ccc8;--md-brown-200: #bcaaa4;--md-brown-300: #a1887f;--md-brown-400: #8d6e63;--md-brown-500: #795548;--md-brown-600: #6d4c41;--md-brown-700: #5d4037;--md-brown-800: #4e342e;--md-brown-900: #3e2723;--md-grey-50: #fafafa;--md-grey-100: #f5f5f5;--md-grey-200: #eeeeee;--md-grey-300: #e0e0e0;--md-grey-400: #bdbdbd;--md-grey-500: #9e9e9e;--md-grey-600: #757575;--md-grey-700: #616161;--md-grey-800: #424242;--md-grey-900: #212121;--md-blue-grey-50: #eceff1;--md-blue-grey-100: #cfd8dc;--md-blue-grey-200: #b0bec5;--md-blue-grey-300: #90a4ae;--md-blue-grey-400: #78909c;--md-blue-grey-500: #607d8b;--md-blue-grey-600: #546e7a;--md-blue-grey-700: #455a64;--md-blue-grey-800: #37474f;--md-blue-grey-900: #263238}.jupyter-wrapper .jp-Spinner{position:absolute;display:flex;justify-content:center;align-items:center;z-index:10;left:0;top:0;width:100%;height:100%;background:var(--jp-layout-color0);outline:none}.jupyter-wrapper .jp-SpinnerContent{font-size:10px;margin:50px auto;text-indent:-9999em;width:3em;height:3em;border-radius:50%;background:var(--jp-brand-color3);background:linear-gradient(to right, #f37626 10%, rgba(255, 255, 255, 0) 42%);position:relative;animation:load3 1s infinite linear,fadeIn 1s}.jupyter-wrapper .jp-SpinnerContent:before{width:50%;height:50%;background:#f37626;border-radius:100% 0 0 0;position:absolute;top:0;left:0;content:\"\"}.jupyter-wrapper .jp-SpinnerContent:after{background:var(--jp-layout-color0);width:75%;height:75%;border-radius:50%;content:\"\";margin:auto;position:absolute;top:0;left:0;bottom:0;right:0}@keyframes fadeIn{0%{opacity:0}100%{opacity:1}}@keyframes load3{0%{transform:rotate(0deg)}100%{transform:rotate(360deg)}}.jupyter-wrapper button.jp-mod-styled{font-size:var(--jp-ui-font-size1);color:var(--jp-ui-font-color0);border:none;box-sizing:border-box;text-align:center;line-height:32px;height:32px;padding:0px 12px;letter-spacing:.8px;outline:none;appearance:none;-webkit-appearance:none;-moz-appearance:none}.jupyter-wrapper input.jp-mod-styled{background:var(--jp-input-background);height:28px;box-sizing:border-box;border:var(--jp-border-width) solid var(--jp-border-color1);padding-left:7px;padding-right:7px;font-size:var(--jp-ui-font-size2);color:var(--jp-ui-font-color0);outline:none;appearance:none;-webkit-appearance:none;-moz-appearance:none}.jupyter-wrapper input.jp-mod-styled:focus{border:var(--jp-border-width) solid var(--md-blue-500);box-shadow:inset 0 0 4px var(--md-blue-300)}.jupyter-wrapper .jp-select-wrapper{display:flex;position:relative;flex-direction:column;padding:1px;background-color:var(--jp-layout-color1);height:28px;box-sizing:border-box;margin-bottom:12px}.jupyter-wrapper .jp-select-wrapper.jp-mod-focused select.jp-mod-styled{border:var(--jp-border-width) solid var(--jp-input-active-border-color);box-shadow:var(--jp-input-box-shadow);background-color:var(--jp-input-active-background)}.jupyter-wrapper select.jp-mod-styled:hover{background-color:var(--jp-layout-color1);cursor:pointer;color:var(--jp-ui-font-color0);background-color:var(--jp-input-hover-background);box-shadow:inset 0 0px 1px rgba(0,0,0,.5)}.jupyter-wrapper select.jp-mod-styled{flex:1 1 auto;height:32px;width:100%;font-size:var(--jp-ui-font-size2);background:var(--jp-input-background);color:var(--jp-ui-font-color0);padding:0 25px 0 8px;border:var(--jp-border-width) solid var(--jp-input-border-color);border-radius:0px;outline:none;appearance:none;-webkit-appearance:none;-moz-appearance:none}.jupyter-wrapper :root{--jp-private-toolbar-height: calc( 28px + var(--jp-border-width) )}.jupyter-wrapper .jp-Toolbar{color:var(--jp-ui-font-color1);flex:0 0 auto;display:flex;flex-direction:row;border-bottom:var(--jp-border-width) solid var(--jp-toolbar-border-color);box-shadow:var(--jp-toolbar-box-shadow);background:var(--jp-toolbar-background);min-height:var(--jp-toolbar-micro-height);padding:2px;z-index:1}.jupyter-wrapper .jp-Toolbar>.jp-Toolbar-item.jp-Toolbar-spacer{flex-grow:1;flex-shrink:1}.jupyter-wrapper .jp-Toolbar-item.jp-Toolbar-kernelStatus{display:inline-block;width:32px;background-repeat:no-repeat;background-position:center;background-size:16px}.jupyter-wrapper .jp-Toolbar>.jp-Toolbar-item{flex:0 0 auto;display:flex;padding-left:1px;padding-right:1px;font-size:var(--jp-ui-font-size1);line-height:var(--jp-private-toolbar-height);height:100%}.jupyter-wrapper div.jp-ToolbarButton{color:rgba(0,0,0,0);border:none;box-sizing:border-box;outline:none;appearance:none;-webkit-appearance:none;-moz-appearance:none;padding:0px;margin:0px}.jupyter-wrapper button.jp-ToolbarButtonComponent{background:var(--jp-layout-color1);border:none;box-sizing:border-box;outline:none;appearance:none;-webkit-appearance:none;-moz-appearance:none;padding:0px 6px;margin:0px;height:24px;border-radius:var(--jp-border-radius);display:flex;align-items:center;text-align:center;font-size:14px;min-width:unset;min-height:unset}.jupyter-wrapper button.jp-ToolbarButtonComponent:disabled{opacity:.4}.jupyter-wrapper button.jp-ToolbarButtonComponent span{padding:0px;flex:0 0 auto}.jupyter-wrapper button.jp-ToolbarButtonComponent .jp-ToolbarButtonComponent-label{font-size:var(--jp-ui-font-size1);line-height:100%;padding-left:2px;color:var(--jp-ui-font-color1)}.jupyter-wrapper body.p-mod-override-cursor *,.jupyter-wrapper body.lm-mod-override-cursor *{cursor:inherit !important}.jupyter-wrapper .jp-JSONEditor{display:flex;flex-direction:column;width:100%}.jupyter-wrapper .jp-JSONEditor-host{flex:1 1 auto;border:var(--jp-border-width) solid var(--jp-input-border-color);border-radius:0px;background:var(--jp-layout-color0);min-height:50px;padding:1px}.jupyter-wrapper .jp-JSONEditor.jp-mod-error .jp-JSONEditor-host{border-color:red;outline-color:red}.jupyter-wrapper .jp-JSONEditor-header{display:flex;flex:1 0 auto;padding:0 0 0 12px}.jupyter-wrapper .jp-JSONEditor-header label{flex:0 0 auto}.jupyter-wrapper .jp-JSONEditor-commitButton{height:16px;width:16px;background-size:18px;background-repeat:no-repeat;background-position:center}.jupyter-wrapper .jp-JSONEditor-host.jp-mod-focused{background-color:var(--jp-input-active-background);border:1px solid var(--jp-input-active-border-color);box-shadow:var(--jp-input-box-shadow)}.jupyter-wrapper .jp-Editor.jp-mod-dropTarget{border:var(--jp-border-width) solid var(--jp-input-active-border-color);box-shadow:var(--jp-input-box-shadow)}.jupyter-wrapper .CodeMirror{font-family:monospace;height:300px;color:#000;direction:ltr}.jupyter-wrapper .CodeMirror-lines{padding:4px 0}.jupyter-wrapper .CodeMirror pre.CodeMirror-line,.jupyter-wrapper .CodeMirror pre.CodeMirror-line-like{padding:0 4px}.jupyter-wrapper .CodeMirror-scrollbar-filler,.jupyter-wrapper .CodeMirror-gutter-filler{background-color:#fff}.jupyter-wrapper .CodeMirror-gutters{border-right:1px solid #ddd;background-color:#f7f7f7;white-space:nowrap}.jupyter-wrapper .CodeMirror-linenumber{padding:0 3px 0 5px;min-width:20px;text-align:right;color:#999;white-space:nowrap}.jupyter-wrapper .CodeMirror-guttermarker{color:#000}.jupyter-wrapper .CodeMirror-guttermarker-subtle{color:#999}.jupyter-wrapper .CodeMirror-cursor{border-left:1px solid #000;border-right:none;width:0}.jupyter-wrapper .CodeMirror div.CodeMirror-secondarycursor{border-left:1px solid silver}.jupyter-wrapper .cm-fat-cursor .CodeMirror-cursor{width:auto;border:0 !important;background:#7e7}.jupyter-wrapper .cm-fat-cursor div.CodeMirror-cursors{z-index:1}.jupyter-wrapper .cm-fat-cursor-mark{background-color:rgba(20,255,20,.5);-webkit-animation:blink 1.06s steps(1) infinite;-moz-animation:blink 1.06s steps(1) infinite;animation:blink 1.06s steps(1) infinite}.jupyter-wrapper .cm-animate-fat-cursor{width:auto;border:0;-webkit-animation:blink 1.06s steps(1) infinite;-moz-animation:blink 1.06s steps(1) infinite;animation:blink 1.06s steps(1) infinite;background-color:#7e7}@-moz-keyframes blink{50%{background-color:rgba(0,0,0,0)}}@-webkit-keyframes blink{50%{background-color:rgba(0,0,0,0)}}@keyframes blink{50%{background-color:rgba(0,0,0,0)}}.jupyter-wrapper .cm-tab{display:inline-block;text-decoration:inherit}.jupyter-wrapper .CodeMirror-rulers{position:absolute;left:0;right:0;top:-50px;bottom:0;overflow:hidden}.jupyter-wrapper .CodeMirror-ruler{border-left:1px solid #ccc;top:0;bottom:0;position:absolute}.jupyter-wrapper .cm-s-default .cm-header{color:blue}.jupyter-wrapper .cm-s-default .cm-quote{color:#090}.jupyter-wrapper .cm-negative{color:#d44}.jupyter-wrapper .cm-positive{color:#292}.jupyter-wrapper .cm-header,.jupyter-wrapper .cm-strong{font-weight:bold}.jupyter-wrapper .cm-em{font-style:italic}.jupyter-wrapper .cm-link{text-decoration:underline}.jupyter-wrapper .cm-strikethrough{text-decoration:line-through}.jupyter-wrapper .cm-s-default .cm-keyword{color:#708}.jupyter-wrapper .cm-s-default .cm-atom{color:#219}.jupyter-wrapper .cm-s-default .cm-number{color:#164}.jupyter-wrapper .cm-s-default .cm-def{color:blue}.jupyter-wrapper .cm-s-default .cm-variable-2{color:#05a}.jupyter-wrapper .cm-s-default .cm-variable-3,.jupyter-wrapper .cm-s-default .cm-type{color:#085}.jupyter-wrapper .cm-s-default .cm-comment{color:#a50}.jupyter-wrapper .cm-s-default .cm-string{color:#a11}.jupyter-wrapper .cm-s-default .cm-string-2{color:#f50}.jupyter-wrapper .cm-s-default .cm-meta{color:#555}.jupyter-wrapper .cm-s-default .cm-qualifier{color:#555}.jupyter-wrapper .cm-s-default .cm-builtin{color:#30a}.jupyter-wrapper .cm-s-default .cm-bracket{color:#997}.jupyter-wrapper .cm-s-default .cm-tag{color:#170}.jupyter-wrapper .cm-s-default .cm-attribute{color:#00c}.jupyter-wrapper .cm-s-default .cm-hr{color:#999}.jupyter-wrapper .cm-s-default .cm-link{color:#00c}.jupyter-wrapper .cm-s-default .cm-error{color:red}.jupyter-wrapper .cm-invalidchar{color:red}.jupyter-wrapper .CodeMirror-composing{border-bottom:2px solid}.jupyter-wrapper div.CodeMirror span.CodeMirror-matchingbracket{color:#0b0}.jupyter-wrapper div.CodeMirror span.CodeMirror-nonmatchingbracket{color:#a22}.jupyter-wrapper .CodeMirror-matchingtag{background:rgba(255,150,0,.3)}.jupyter-wrapper .CodeMirror-activeline-background{background:#e8f2ff}.jupyter-wrapper .CodeMirror{position:relative;overflow:hidden;background:#fff}.jupyter-wrapper .CodeMirror-scroll{overflow:scroll !important;margin-bottom:-30px;margin-right:-30px;padding-bottom:30px;height:100%;outline:none;position:relative}.jupyter-wrapper .CodeMirror-sizer{position:relative;border-right:30px solid rgba(0,0,0,0)}.jupyter-wrapper .CodeMirror-vscrollbar,.jupyter-wrapper .CodeMirror-hscrollbar,.jupyter-wrapper .CodeMirror-scrollbar-filler,.jupyter-wrapper .CodeMirror-gutter-filler{position:absolute;z-index:6;display:none}.jupyter-wrapper .CodeMirror-vscrollbar{right:0;top:0;overflow-x:hidden;overflow-y:scroll}.jupyter-wrapper .CodeMirror-hscrollbar{bottom:0;left:0;overflow-y:hidden;overflow-x:scroll}.jupyter-wrapper .CodeMirror-scrollbar-filler{right:0;bottom:0}.jupyter-wrapper .CodeMirror-gutter-filler{left:0;bottom:0}.jupyter-wrapper .CodeMirror-gutters{position:absolute;left:0;top:0;min-height:100%;z-index:3}.jupyter-wrapper .CodeMirror-gutter{white-space:normal;height:100%;display:inline-block;vertical-align:top;margin-bottom:-30px}.jupyter-wrapper .CodeMirror-gutter-wrapper{position:absolute;z-index:4;background:none !important;border:none !important}.jupyter-wrapper .CodeMirror-gutter-background{position:absolute;top:0;bottom:0;z-index:4}.jupyter-wrapper .CodeMirror-gutter-elt{position:absolute;cursor:default;z-index:4}.jupyter-wrapper .CodeMirror-gutter-wrapper ::selection{background-color:rgba(0,0,0,0)}.jupyter-wrapper .CodeMirror-gutter-wrapper ::-moz-selection{background-color:rgba(0,0,0,0)}.jupyter-wrapper .CodeMirror-lines{cursor:text;min-height:1px}.jupyter-wrapper .CodeMirror pre.CodeMirror-line,.jupyter-wrapper .CodeMirror pre.CodeMirror-line-like{-moz-border-radius:0;-webkit-border-radius:0;border-radius:0;border-width:0;background:rgba(0,0,0,0);font-family:inherit;font-size:inherit;margin:0;white-space:pre;word-wrap:normal;line-height:inherit;color:inherit;z-index:2;position:relative;overflow:visible;-webkit-tap-highlight-color:rgba(0,0,0,0);-webkit-font-variant-ligatures:contextual;font-variant-ligatures:contextual}.jupyter-wrapper .CodeMirror-wrap pre.CodeMirror-line,.jupyter-wrapper .CodeMirror-wrap pre.CodeMirror-line-like{word-wrap:break-word;white-space:pre-wrap;word-break:normal}.jupyter-wrapper .CodeMirror-linebackground{position:absolute;left:0;right:0;top:0;bottom:0;z-index:0}.jupyter-wrapper .CodeMirror-linewidget{position:relative;z-index:2;padding:.1px}.jupyter-wrapper .CodeMirror-rtl pre{direction:rtl}.jupyter-wrapper .CodeMirror-code{outline:none}.jupyter-wrapper .CodeMirror-scroll,.jupyter-wrapper .CodeMirror-sizer,.jupyter-wrapper .CodeMirror-gutter,.jupyter-wrapper .CodeMirror-gutters,.jupyter-wrapper .CodeMirror-linenumber{-moz-box-sizing:content-box;box-sizing:content-box}.jupyter-wrapper .CodeMirror-measure{position:absolute;width:100%;height:0;overflow:hidden;visibility:hidden}.jupyter-wrapper .CodeMirror-cursor{position:absolute;pointer-events:none}.jupyter-wrapper .CodeMirror-measure pre{position:static}.jupyter-wrapper div.CodeMirror-cursors{visibility:hidden;position:relative;z-index:3}.jupyter-wrapper div.CodeMirror-dragcursors{visibility:visible}.jupyter-wrapper .CodeMirror-focused div.CodeMirror-cursors{visibility:visible}.jupyter-wrapper .CodeMirror-selected{background:#d9d9d9}.jupyter-wrapper .CodeMirror-focused .CodeMirror-selected{background:#d7d4f0}.jupyter-wrapper .CodeMirror-crosshair{cursor:crosshair}.jupyter-wrapper .CodeMirror-line::selection,.jupyter-wrapper .CodeMirror-line>span::selection,.jupyter-wrapper .CodeMirror-line>span>span::selection{background:#d7d4f0}.jupyter-wrapper .CodeMirror-line::-moz-selection,.jupyter-wrapper .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .CodeMirror-line>span>span::-moz-selection{background:#d7d4f0}.jupyter-wrapper .cm-searching{background-color:#ffa;background-color:rgba(255,255,0,.4)}.jupyter-wrapper .cm-force-border{padding-right:.1px}@media print{.jupyter-wrapper .CodeMirror div.CodeMirror-cursors{visibility:hidden}}.jupyter-wrapper .cm-tab-wrap-hack:after{content:\"\"}.jupyter-wrapper span.CodeMirror-selectedtext{background:none}.jupyter-wrapper .CodeMirror-dialog{position:absolute;left:0;right:0;background:inherit;z-index:15;padding:.1em .8em;overflow:hidden;color:inherit}.jupyter-wrapper .CodeMirror-dialog-top{border-bottom:1px solid #eee;top:0}.jupyter-wrapper .CodeMirror-dialog-bottom{border-top:1px solid #eee;bottom:0}.jupyter-wrapper .CodeMirror-dialog input{border:none;outline:none;background:rgba(0,0,0,0);width:20em;color:inherit;font-family:monospace}.jupyter-wrapper .CodeMirror-dialog button{font-size:70%}.jupyter-wrapper .CodeMirror-foldmarker{color:blue;text-shadow:#b9f 1px 1px 2px,#b9f -1px -1px 2px,#b9f 1px -1px 2px,#b9f -1px 1px 2px;font-family:arial;line-height:.3;cursor:pointer}.jupyter-wrapper .CodeMirror-foldgutter{width:.7em}.jupyter-wrapper .CodeMirror-foldgutter-open,.jupyter-wrapper .CodeMirror-foldgutter-folded{cursor:pointer}.jupyter-wrapper .CodeMirror-foldgutter-open:after{content:\"\u25be\"}.jupyter-wrapper .CodeMirror-foldgutter-folded:after{content:\"\u25b8\"}.jupyter-wrapper .cm-s-material.CodeMirror{background-color:#263238;color:#eff}.jupyter-wrapper .cm-s-material .CodeMirror-gutters{background:#263238;color:#546e7a;border:none}.jupyter-wrapper .cm-s-material .CodeMirror-guttermarker,.jupyter-wrapper .cm-s-material .CodeMirror-guttermarker-subtle,.jupyter-wrapper .cm-s-material .CodeMirror-linenumber{color:#546e7a}.jupyter-wrapper .cm-s-material .CodeMirror-cursor{border-left:1px solid #fc0}.jupyter-wrapper .cm-s-material div.CodeMirror-selected{background:rgba(128,203,196,.2)}.jupyter-wrapper .cm-s-material.CodeMirror-focused div.CodeMirror-selected{background:rgba(128,203,196,.2)}.jupyter-wrapper .cm-s-material .CodeMirror-line::selection,.jupyter-wrapper .cm-s-material .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-material .CodeMirror-line>span>span::selection{background:rgba(128,203,196,.2)}.jupyter-wrapper .cm-s-material .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-material .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-material .CodeMirror-line>span>span::-moz-selection{background:rgba(128,203,196,.2)}.jupyter-wrapper .cm-s-material .CodeMirror-activeline-background{background:rgba(0,0,0,.5)}.jupyter-wrapper .cm-s-material .cm-keyword{color:#c792ea}.jupyter-wrapper .cm-s-material .cm-operator{color:#89ddff}.jupyter-wrapper .cm-s-material .cm-variable-2{color:#eff}.jupyter-wrapper .cm-s-material .cm-variable-3,.jupyter-wrapper .cm-s-material .cm-type{color:#f07178}.jupyter-wrapper .cm-s-material .cm-builtin{color:#ffcb6b}.jupyter-wrapper .cm-s-material .cm-atom{color:#f78c6c}.jupyter-wrapper .cm-s-material .cm-number{color:#ff5370}.jupyter-wrapper .cm-s-material .cm-def{color:#82aaff}.jupyter-wrapper .cm-s-material .cm-string{color:#c3e88d}.jupyter-wrapper .cm-s-material .cm-string-2{color:#f07178}.jupyter-wrapper .cm-s-material .cm-comment{color:#546e7a}.jupyter-wrapper .cm-s-material .cm-variable{color:#f07178}.jupyter-wrapper .cm-s-material .cm-tag{color:#ff5370}.jupyter-wrapper .cm-s-material .cm-meta{color:#ffcb6b}.jupyter-wrapper .cm-s-material .cm-attribute{color:#c792ea}.jupyter-wrapper .cm-s-material .cm-property{color:#c792ea}.jupyter-wrapper .cm-s-material .cm-qualifier{color:#decb6b}.jupyter-wrapper .cm-s-material .cm-variable-3,.jupyter-wrapper .cm-s-material .cm-type{color:#decb6b}.jupyter-wrapper .cm-s-material .cm-error{color:#fff;background-color:#ff5370}.jupyter-wrapper .cm-s-material .CodeMirror-matchingbracket{text-decoration:underline;color:#fff !important}.jupyter-wrapper .cm-s-zenburn .CodeMirror-gutters{background:#3f3f3f !important}.jupyter-wrapper .cm-s-zenburn .CodeMirror-foldgutter-open,.jupyter-wrapper .CodeMirror-foldgutter-folded{color:#999}.jupyter-wrapper .cm-s-zenburn .CodeMirror-cursor{border-left:1px solid #fff}.jupyter-wrapper .cm-s-zenburn{background-color:#3f3f3f;color:#dcdccc}.jupyter-wrapper .cm-s-zenburn span.cm-builtin{color:#dcdccc;font-weight:bold}.jupyter-wrapper .cm-s-zenburn span.cm-comment{color:#7f9f7f}.jupyter-wrapper .cm-s-zenburn span.cm-keyword{color:#f0dfaf;font-weight:bold}.jupyter-wrapper .cm-s-zenburn span.cm-atom{color:#bfebbf}.jupyter-wrapper .cm-s-zenburn span.cm-def{color:#dcdccc}.jupyter-wrapper .cm-s-zenburn span.cm-variable{color:#dfaf8f}.jupyter-wrapper .cm-s-zenburn span.cm-variable-2{color:#dcdccc}.jupyter-wrapper .cm-s-zenburn span.cm-string{color:#cc9393}.jupyter-wrapper .cm-s-zenburn span.cm-string-2{color:#cc9393}.jupyter-wrapper .cm-s-zenburn span.cm-number{color:#dcdccc}.jupyter-wrapper .cm-s-zenburn span.cm-tag{color:#93e0e3}.jupyter-wrapper .cm-s-zenburn span.cm-property{color:#dfaf8f}.jupyter-wrapper .cm-s-zenburn span.cm-attribute{color:#dfaf8f}.jupyter-wrapper .cm-s-zenburn span.cm-qualifier{color:#7cb8bb}.jupyter-wrapper .cm-s-zenburn span.cm-meta{color:#f0dfaf}.jupyter-wrapper .cm-s-zenburn span.cm-header{color:#f0efd0}.jupyter-wrapper .cm-s-zenburn span.cm-operator{color:#f0efd0}.jupyter-wrapper .cm-s-zenburn span.CodeMirror-matchingbracket{box-sizing:border-box;background:rgba(0,0,0,0);border-bottom:1px solid}.jupyter-wrapper .cm-s-zenburn span.CodeMirror-nonmatchingbracket{border-bottom:1px solid;background:none}.jupyter-wrapper .cm-s-zenburn .CodeMirror-activeline{background:#000}.jupyter-wrapper .cm-s-zenburn .CodeMirror-activeline-background{background:#000}.jupyter-wrapper .cm-s-zenburn div.CodeMirror-selected{background:#545454}.jupyter-wrapper .cm-s-zenburn .CodeMirror-focused div.CodeMirror-selected{background:#4f4f4f}.jupyter-wrapper .cm-s-abcdef.CodeMirror{background:#0f0f0f;color:#defdef}.jupyter-wrapper .cm-s-abcdef div.CodeMirror-selected{background:#515151}.jupyter-wrapper .cm-s-abcdef .CodeMirror-line::selection,.jupyter-wrapper .cm-s-abcdef .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-abcdef .CodeMirror-line>span>span::selection{background:rgba(56,56,56,.99)}.jupyter-wrapper .cm-s-abcdef .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-abcdef .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-abcdef .CodeMirror-line>span>span::-moz-selection{background:rgba(56,56,56,.99)}.jupyter-wrapper .cm-s-abcdef .CodeMirror-gutters{background:#555;border-right:2px solid #314151}.jupyter-wrapper .cm-s-abcdef .CodeMirror-guttermarker{color:#222}.jupyter-wrapper .cm-s-abcdef .CodeMirror-guttermarker-subtle{color:azure}.jupyter-wrapper .cm-s-abcdef .CodeMirror-linenumber{color:#fff}.jupyter-wrapper .cm-s-abcdef .CodeMirror-cursor{border-left:1px solid lime}.jupyter-wrapper .cm-s-abcdef span.cm-keyword{color:#b8860b;font-weight:bold}.jupyter-wrapper .cm-s-abcdef span.cm-atom{color:#77f}.jupyter-wrapper .cm-s-abcdef span.cm-number{color:violet}.jupyter-wrapper .cm-s-abcdef span.cm-def{color:#fffabc}.jupyter-wrapper .cm-s-abcdef span.cm-variable{color:#abcdef}.jupyter-wrapper .cm-s-abcdef span.cm-variable-2{color:#cacbcc}.jupyter-wrapper .cm-s-abcdef span.cm-variable-3,.jupyter-wrapper .cm-s-abcdef span.cm-type{color:#def}.jupyter-wrapper .cm-s-abcdef span.cm-property{color:#fedcba}.jupyter-wrapper .cm-s-abcdef span.cm-operator{color:#ff0}.jupyter-wrapper .cm-s-abcdef span.cm-comment{color:#7a7b7c;font-style:italic}.jupyter-wrapper .cm-s-abcdef span.cm-string{color:#2b4}.jupyter-wrapper .cm-s-abcdef span.cm-meta{color:#c9f}.jupyter-wrapper .cm-s-abcdef span.cm-qualifier{color:#fff700}.jupyter-wrapper .cm-s-abcdef span.cm-builtin{color:#30aabc}.jupyter-wrapper .cm-s-abcdef span.cm-bracket{color:#8a8a8a}.jupyter-wrapper .cm-s-abcdef span.cm-tag{color:#fd4}.jupyter-wrapper .cm-s-abcdef span.cm-attribute{color:#df0}.jupyter-wrapper .cm-s-abcdef span.cm-error{color:red}.jupyter-wrapper .cm-s-abcdef span.cm-header{color:#7fffd4;font-weight:bold}.jupyter-wrapper .cm-s-abcdef span.cm-link{color:#8a2be2}.jupyter-wrapper .cm-s-abcdef .CodeMirror-activeline-background{background:#314151}.jupyter-wrapper .cm-s-base16-light.CodeMirror{background:#f5f5f5;color:#202020}.jupyter-wrapper .cm-s-base16-light div.CodeMirror-selected{background:#e0e0e0}.jupyter-wrapper .cm-s-base16-light .CodeMirror-line::selection,.jupyter-wrapper .cm-s-base16-light .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-base16-light .CodeMirror-line>span>span::selection{background:#e0e0e0}.jupyter-wrapper .cm-s-base16-light .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-base16-light .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-base16-light .CodeMirror-line>span>span::-moz-selection{background:#e0e0e0}.jupyter-wrapper .cm-s-base16-light .CodeMirror-gutters{background:#f5f5f5;border-right:0px}.jupyter-wrapper .cm-s-base16-light .CodeMirror-guttermarker{color:#ac4142}.jupyter-wrapper .cm-s-base16-light .CodeMirror-guttermarker-subtle{color:#b0b0b0}.jupyter-wrapper .cm-s-base16-light .CodeMirror-linenumber{color:#b0b0b0}.jupyter-wrapper .cm-s-base16-light .CodeMirror-cursor{border-left:1px solid #505050}.jupyter-wrapper .cm-s-base16-light span.cm-comment{color:#8f5536}.jupyter-wrapper .cm-s-base16-light span.cm-atom{color:#aa759f}.jupyter-wrapper .cm-s-base16-light span.cm-number{color:#aa759f}.jupyter-wrapper .cm-s-base16-light span.cm-property,.jupyter-wrapper .cm-s-base16-light span.cm-attribute{color:#90a959}.jupyter-wrapper .cm-s-base16-light span.cm-keyword{color:#ac4142}.jupyter-wrapper .cm-s-base16-light span.cm-string{color:#f4bf75}.jupyter-wrapper .cm-s-base16-light span.cm-variable{color:#90a959}.jupyter-wrapper .cm-s-base16-light span.cm-variable-2{color:#6a9fb5}.jupyter-wrapper .cm-s-base16-light span.cm-def{color:#d28445}.jupyter-wrapper .cm-s-base16-light span.cm-bracket{color:#202020}.jupyter-wrapper .cm-s-base16-light span.cm-tag{color:#ac4142}.jupyter-wrapper .cm-s-base16-light span.cm-link{color:#aa759f}.jupyter-wrapper .cm-s-base16-light span.cm-error{background:#ac4142;color:#505050}.jupyter-wrapper .cm-s-base16-light .CodeMirror-activeline-background{background:#dddcdc}.jupyter-wrapper .cm-s-base16-light .CodeMirror-matchingbracket{color:#f5f5f5 !important;background-color:#6a9fb5 !important}.jupyter-wrapper .cm-s-base16-dark.CodeMirror{background:#151515;color:#e0e0e0}.jupyter-wrapper .cm-s-base16-dark div.CodeMirror-selected{background:#303030}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-line::selection,.jupyter-wrapper .cm-s-base16-dark .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-base16-dark .CodeMirror-line>span>span::selection{background:rgba(48,48,48,.99)}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-base16-dark .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-base16-dark .CodeMirror-line>span>span::-moz-selection{background:rgba(48,48,48,.99)}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-gutters{background:#151515;border-right:0px}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-guttermarker{color:#ac4142}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-guttermarker-subtle{color:#505050}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-linenumber{color:#505050}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-cursor{border-left:1px solid #b0b0b0}.jupyter-wrapper .cm-s-base16-dark span.cm-comment{color:#8f5536}.jupyter-wrapper .cm-s-base16-dark span.cm-atom{color:#aa759f}.jupyter-wrapper .cm-s-base16-dark span.cm-number{color:#aa759f}.jupyter-wrapper .cm-s-base16-dark span.cm-property,.jupyter-wrapper .cm-s-base16-dark span.cm-attribute{color:#90a959}.jupyter-wrapper .cm-s-base16-dark span.cm-keyword{color:#ac4142}.jupyter-wrapper .cm-s-base16-dark span.cm-string{color:#f4bf75}.jupyter-wrapper .cm-s-base16-dark span.cm-variable{color:#90a959}.jupyter-wrapper .cm-s-base16-dark span.cm-variable-2{color:#6a9fb5}.jupyter-wrapper .cm-s-base16-dark span.cm-def{color:#d28445}.jupyter-wrapper .cm-s-base16-dark span.cm-bracket{color:#e0e0e0}.jupyter-wrapper .cm-s-base16-dark span.cm-tag{color:#ac4142}.jupyter-wrapper .cm-s-base16-dark span.cm-link{color:#aa759f}.jupyter-wrapper .cm-s-base16-dark span.cm-error{background:#ac4142;color:#b0b0b0}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-activeline-background{background:#202020}.jupyter-wrapper .cm-s-base16-dark .CodeMirror-matchingbracket{text-decoration:underline;color:#fff !important}.jupyter-wrapper .cm-s-dracula.CodeMirror,.jupyter-wrapper .cm-s-dracula .CodeMirror-gutters{background-color:#282a36 !important;color:#f8f8f2 !important;border:none}.jupyter-wrapper .cm-s-dracula .CodeMirror-gutters{color:#282a36}.jupyter-wrapper .cm-s-dracula .CodeMirror-cursor{border-left:solid thin #f8f8f0}.jupyter-wrapper .cm-s-dracula .CodeMirror-linenumber{color:#6d8a88}.jupyter-wrapper .cm-s-dracula .CodeMirror-selected{background:rgba(255,255,255,.1)}.jupyter-wrapper .cm-s-dracula .CodeMirror-line::selection,.jupyter-wrapper .cm-s-dracula .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-dracula .CodeMirror-line>span>span::selection{background:rgba(255,255,255,.1)}.jupyter-wrapper .cm-s-dracula .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-dracula .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-dracula .CodeMirror-line>span>span::-moz-selection{background:rgba(255,255,255,.1)}.jupyter-wrapper .cm-s-dracula span.cm-comment{color:#6272a4}.jupyter-wrapper .cm-s-dracula span.cm-string,.jupyter-wrapper .cm-s-dracula span.cm-string-2{color:#f1fa8c}.jupyter-wrapper .cm-s-dracula span.cm-number{color:#bd93f9}.jupyter-wrapper .cm-s-dracula span.cm-variable{color:#50fa7b}.jupyter-wrapper .cm-s-dracula span.cm-variable-2{color:#fff}.jupyter-wrapper .cm-s-dracula span.cm-def{color:#50fa7b}.jupyter-wrapper .cm-s-dracula span.cm-operator{color:#ff79c6}.jupyter-wrapper .cm-s-dracula span.cm-keyword{color:#ff79c6}.jupyter-wrapper .cm-s-dracula span.cm-atom{color:#bd93f9}.jupyter-wrapper .cm-s-dracula span.cm-meta{color:#f8f8f2}.jupyter-wrapper .cm-s-dracula span.cm-tag{color:#ff79c6}.jupyter-wrapper .cm-s-dracula span.cm-attribute{color:#50fa7b}.jupyter-wrapper .cm-s-dracula span.cm-qualifier{color:#50fa7b}.jupyter-wrapper .cm-s-dracula span.cm-property{color:#66d9ef}.jupyter-wrapper .cm-s-dracula span.cm-builtin{color:#50fa7b}.jupyter-wrapper .cm-s-dracula span.cm-variable-3,.jupyter-wrapper .cm-s-dracula span.cm-type{color:#ffb86c}.jupyter-wrapper .cm-s-dracula .CodeMirror-activeline-background{background:rgba(255,255,255,.1)}.jupyter-wrapper .cm-s-dracula .CodeMirror-matchingbracket{text-decoration:underline;color:#fff !important}.jupyter-wrapper .cm-s-hopscotch.CodeMirror{background:#322931;color:#d5d3d5}.jupyter-wrapper .cm-s-hopscotch div.CodeMirror-selected{background:#433b42 !important}.jupyter-wrapper .cm-s-hopscotch .CodeMirror-gutters{background:#322931;border-right:0px}.jupyter-wrapper .cm-s-hopscotch .CodeMirror-linenumber{color:#797379}.jupyter-wrapper .cm-s-hopscotch .CodeMirror-cursor{border-left:1px solid #989498 !important}.jupyter-wrapper .cm-s-hopscotch span.cm-comment{color:#b33508}.jupyter-wrapper .cm-s-hopscotch span.cm-atom{color:#c85e7c}.jupyter-wrapper .cm-s-hopscotch span.cm-number{color:#c85e7c}.jupyter-wrapper .cm-s-hopscotch span.cm-property,.jupyter-wrapper .cm-s-hopscotch span.cm-attribute{color:#8fc13e}.jupyter-wrapper .cm-s-hopscotch span.cm-keyword{color:#dd464c}.jupyter-wrapper .cm-s-hopscotch span.cm-string{color:#fdcc59}.jupyter-wrapper .cm-s-hopscotch span.cm-variable{color:#8fc13e}.jupyter-wrapper .cm-s-hopscotch span.cm-variable-2{color:#1290bf}.jupyter-wrapper .cm-s-hopscotch span.cm-def{color:#fd8b19}.jupyter-wrapper .cm-s-hopscotch span.cm-error{background:#dd464c;color:#989498}.jupyter-wrapper .cm-s-hopscotch span.cm-bracket{color:#d5d3d5}.jupyter-wrapper .cm-s-hopscotch span.cm-tag{color:#dd464c}.jupyter-wrapper .cm-s-hopscotch span.cm-link{color:#c85e7c}.jupyter-wrapper .cm-s-hopscotch .CodeMirror-matchingbracket{text-decoration:underline;color:#fff !important}.jupyter-wrapper .cm-s-hopscotch .CodeMirror-activeline-background{background:#302020}.jupyter-wrapper .cm-s-mbo.CodeMirror{background:#2c2c2c;color:#ffffec}.jupyter-wrapper .cm-s-mbo div.CodeMirror-selected{background:#716c62}.jupyter-wrapper .cm-s-mbo .CodeMirror-line::selection,.jupyter-wrapper .cm-s-mbo .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-mbo .CodeMirror-line>span>span::selection{background:rgba(113,108,98,.99)}.jupyter-wrapper .cm-s-mbo .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-mbo .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-mbo .CodeMirror-line>span>span::-moz-selection{background:rgba(113,108,98,.99)}.jupyter-wrapper .cm-s-mbo .CodeMirror-gutters{background:#4e4e4e;border-right:0px}.jupyter-wrapper .cm-s-mbo .CodeMirror-guttermarker{color:#fff}.jupyter-wrapper .cm-s-mbo .CodeMirror-guttermarker-subtle{color:gray}.jupyter-wrapper .cm-s-mbo .CodeMirror-linenumber{color:#dadada}.jupyter-wrapper .cm-s-mbo .CodeMirror-cursor{border-left:1px solid #ffffec}.jupyter-wrapper .cm-s-mbo span.cm-comment{color:#95958a}.jupyter-wrapper .cm-s-mbo span.cm-atom{color:#00a8c6}.jupyter-wrapper .cm-s-mbo span.cm-number{color:#00a8c6}.jupyter-wrapper .cm-s-mbo span.cm-property,.jupyter-wrapper .cm-s-mbo span.cm-attribute{color:#9ddfe9}.jupyter-wrapper .cm-s-mbo span.cm-keyword{color:#ffb928}.jupyter-wrapper .cm-s-mbo span.cm-string{color:#ffcf6c}.jupyter-wrapper .cm-s-mbo span.cm-string.cm-property{color:#ffffec}.jupyter-wrapper .cm-s-mbo span.cm-variable{color:#ffffec}.jupyter-wrapper .cm-s-mbo span.cm-variable-2{color:#00a8c6}.jupyter-wrapper .cm-s-mbo span.cm-def{color:#ffffec}.jupyter-wrapper .cm-s-mbo span.cm-bracket{color:#fffffc;font-weight:bold}.jupyter-wrapper .cm-s-mbo span.cm-tag{color:#9ddfe9}.jupyter-wrapper .cm-s-mbo span.cm-link{color:#f54b07}.jupyter-wrapper .cm-s-mbo span.cm-error{border-bottom:#636363;color:#ffffec}.jupyter-wrapper .cm-s-mbo span.cm-qualifier{color:#ffffec}.jupyter-wrapper .cm-s-mbo .CodeMirror-activeline-background{background:#494b41}.jupyter-wrapper .cm-s-mbo .CodeMirror-matchingbracket{color:#ffb928 !important}.jupyter-wrapper .cm-s-mbo .CodeMirror-matchingtag{background:rgba(255,255,255,.37)}.jupyter-wrapper .cm-s-mdn-like.CodeMirror{color:#999;background-color:#fff}.jupyter-wrapper .cm-s-mdn-like div.CodeMirror-selected{background:#cfc}.jupyter-wrapper .cm-s-mdn-like .CodeMirror-line::selection,.jupyter-wrapper .cm-s-mdn-like .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-mdn-like .CodeMirror-line>span>span::selection{background:#cfc}.jupyter-wrapper .cm-s-mdn-like .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-mdn-like .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-mdn-like .CodeMirror-line>span>span::-moz-selection{background:#cfc}.jupyter-wrapper .cm-s-mdn-like .CodeMirror-gutters{background:#f8f8f8;border-left:6px solid rgba(0,83,159,.65);color:#333}.jupyter-wrapper .cm-s-mdn-like .CodeMirror-linenumber{color:#aaa;padding-left:8px}.jupyter-wrapper .cm-s-mdn-like .CodeMirror-cursor{border-left:2px solid #222}.jupyter-wrapper .cm-s-mdn-like .cm-keyword{color:#6262ff}.jupyter-wrapper .cm-s-mdn-like .cm-atom{color:#f90}.jupyter-wrapper .cm-s-mdn-like .cm-number{color:#ca7841}.jupyter-wrapper .cm-s-mdn-like .cm-def{color:#8da6ce}.jupyter-wrapper .cm-s-mdn-like span.cm-variable-2,.jupyter-wrapper .cm-s-mdn-like span.cm-tag{color:#690}.jupyter-wrapper .cm-s-mdn-like span.cm-variable-3,.jupyter-wrapper .cm-s-mdn-like span.cm-def,.jupyter-wrapper .cm-s-mdn-like span.cm-type{color:#07a}.jupyter-wrapper .cm-s-mdn-like .cm-variable{color:#07a}.jupyter-wrapper .cm-s-mdn-like .cm-property{color:#905}.jupyter-wrapper .cm-s-mdn-like .cm-qualifier{color:#690}.jupyter-wrapper .cm-s-mdn-like .cm-operator{color:#cda869}.jupyter-wrapper .cm-s-mdn-like .cm-comment{color:#777;font-weight:normal}.jupyter-wrapper .cm-s-mdn-like .cm-string{color:#07a;font-style:italic}.jupyter-wrapper .cm-s-mdn-like .cm-string-2{color:#bd6b18}.jupyter-wrapper .cm-s-mdn-like .cm-meta{color:#000}.jupyter-wrapper .cm-s-mdn-like .cm-builtin{color:#9b7536}.jupyter-wrapper .cm-s-mdn-like .cm-tag{color:#997643}.jupyter-wrapper .cm-s-mdn-like .cm-attribute{color:#d6bb6d}.jupyter-wrapper .cm-s-mdn-like .cm-header{color:#ff6400}.jupyter-wrapper .cm-s-mdn-like .cm-hr{color:#aeaeae}.jupyter-wrapper .cm-s-mdn-like .cm-link{color:#ad9361;font-style:italic;text-decoration:none}.jupyter-wrapper .cm-s-mdn-like .cm-error{border-bottom:1px solid red}.jupyter-wrapper div.cm-s-mdn-like .CodeMirror-activeline-background{background:#efefff}.jupyter-wrapper div.cm-s-mdn-like span.CodeMirror-matchingbracket{outline:1px solid gray;color:inherit}.jupyter-wrapper .cm-s-mdn-like.CodeMirror{background-image:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAFcAAAAyCAYAAAAp8UeFAAAHvklEQVR42s2b63bcNgyEQZCSHCdt2vd/0tWF7I+Q6XgMXiTtuvU5Pl57ZQKkKHzEAOtF5KeIJBGJ8uvL599FRFREZhFx8DeXv8trn68RuGaC8TRfo3SNp9dlDDHedyLyTUTeRWStXKPZrjtpZxaRw5hPqozRs1N8/enzIiQRWcCgy4MUA0f+XWliDhyL8Lfyvx7ei/Ae3iQFHyw7U/59pQVIMEEPEz0G7XiwdRjzSfC3UTtz9vchIntxvry5iMgfIhJoEflOz2CQr3F5h/HfeFe+GTdLaKcu9L8LTeQb/R/7GgbsfKedyNdoHsN31uRPWrfZ5wsj/NzzRQHuToIdU3ahwnsKPxXCjJITuOsi7XLc7SG/v5GdALs7wf8JjTFiB5+QvTEfRyGOfX3Lrx8wxyQi3sNq46O7QahQiCsRFgqddjBouVEHOKDgXAQHD9gJCr5sMKkEdjwsarG/ww3BMHBU7OBjXnzdyY7SfCxf5/z6ATccrwlKuwC/jhznnPF4CgVzhhVf4xp2EixcBActO75iZ8/fM9zAs2OMzKdslgXWJ9XG8PQoOAMA5fGcsvORgv0doBXyHrCwfLJAOwo71QLNkb8n2Pl6EWiR7OCibtkPaz4Kc/0NNAze2gju3zOwekALDaCFPI5vjPFmgGY5AZqyGEvH1x7QfIb8YtxMnA/b+QQ0aQDAwc6JMFg8CbQZ4qoYEEHbRwNojuK3EHwd7VALSgq+MNDKzfT58T8qdpADrgW0GmgcAS1lhzztJmkAzcPNOQbsWEALBDSlMKUG0Eq4CLAQWvEVQ9WU57gZJwZtgPO3r9oBTQ9WO8TjqXINx8R0EYpiZEUWOF3FxkbJkgU9B2f41YBrIj5ZfsQa0M5kTgiAAqM3ShXLgu8XMqcrQBvJ0CL5pnTsfMB13oB8athpAq2XOQmcGmoACCLydx7nToa23ATaSIY2ichfOdPTGxlasXMLaL0MLZAOwAKIM+y8CmicobGdCcbbK9DzN+yYGVoNNI5iUKTMyYOjPse4A8SM1MmcXgU0toOq1yO/v8FOxlASyc7TgeYaAMBJHcY1CcCwGI/TK4AmDbDyKYBBtFUkRwto8gygiQEaByFgJ00BH2M8JWwQS1nafDXQCidWyOI8AcjDCSjCLk8ngObuAm3JAHAdubAmOaK06V8MNEsKPJOhobSprwQa6gD7DclRQdqcwL4zxqgBrQcabUiBLclRDKAlWp+etPkBaNMA0AKlrHwTdEByZAA4GM+SNluSY6wAzcMNewxmgig5Ks0nkrSpBvSaQHMdKTBAnLojOdYyGpQ254602ZILPdTD1hdlggdIm74jbTp8vDwF5ZYUeLWGJpWsh6XNyXgcYwVoJQTEhhTYkxzZjiU5npU2TaB979TQehlaAVq4kaGpiPwwwLkYUuBbQwocyQTv1tA0+1UFWoJF3iv1oq+qoSk8EQdJmwHkziIF7oOZk14EGitibAdjLYYK78H5vZOhtWpoI0ATGHs0Q8OMb4Ey+2bU2UYztCtA0wFAs7TplGLRVQCcqaFdGSPCeTI1QNIC52iWNzof6Uib7xjEp07mNNoUYmVosVItHrHzRlLgBn9LFyRHaQCtVUMbtTNhoXWiTOO9k/V8BdAc1Oq0ArSQs6/5SU0hckNy9NnXqQY0PGYo5dWJ7nINaN6o958FWin27aBaWRka1r5myvLOAm0j30eBJqCxHLReVclxhxOEN2JfDWjxBtAC7MIH1fVaGdoOp4qJYDgKtKPSFNID2gSnGldrCqkFZ+5UeQXQBIRrSwocbdZYQT/2LwRahBPBXoHrB8nxaGROST62DKUbQOMMzZIC9abkuELfQzQALWTnDNAm8KHWFOJgJ5+SHIvTPcmx1xQyZRhNL5Qci689aXMEaN/uNIWkEwDAvFpOZmgsBaaGnbs1NPa1Jm32gBZAIh1pCtG7TSH4aE0y1uVY4uqoFPisGlpP2rSA5qTecWn5agK6BzSpgAyD+wFaqhnYoSZ1Vwr8CmlTQbrcO3ZaX0NAEyMbYaAlyquFoLKK3SPby9CeVUPThrSJmkCAE0CrKUQadi4DrdSlWhmah0YL9z9vClH59YGbHx1J8VZTyAjQepJjmXwAKTDQI3omc3p1U4gDUf6RfcdYfrUp5ClAi2J3Ba6UOXGo+K+bQrjjssitG2SJzshaLwMtXgRagUNpYYoVkMSBLM+9GGiJZMvduG6DRZ4qc04DMPtQQxOjEtACmhO7K1AbNbQDEggZyJwscFpAGwENhoBeUwh3bWolhe8BTYVKxQEWrSUn/uhcM5KhvUu/+eQu0Lzhi+VrK0PrZZNDQKs9cpYUuFYgMVpD4/NxenJTiMCNqdUEUf1qZWjppLT5qSkkUZbCwkbZMSuVnu80hfSkzRbQeqCZSAh6huR4VtoM2gHAlLf72smuWgE+VV7XpE25Ab2WFDgyhnSuKbs4GuGzCjR+tIoUuMFg3kgcWKLTwRqanJQ2W00hAsenfaApRC42hbCvK1SlE0HtE9BGgneJO+ELamitD1YjjOYnNYVcraGhtKkW0EqVVeDx733I2NH581k1NNxNLG0i0IJ8/NjVaOZ0tYZ2Vtr0Xv7tPV3hkWp9EFkgS/J0vosngTaSoaG06WHi+xObQkaAdlbanP8B2+2l0f90LmUAAAAASUVORK5CYII=)}.jupyter-wrapper .cm-s-seti.CodeMirror{background-color:#151718 !important;color:#cfd2d1 !important;border:none}.jupyter-wrapper .cm-s-seti .CodeMirror-gutters{color:#404b53;background-color:#0e1112;border:none}.jupyter-wrapper .cm-s-seti .CodeMirror-cursor{border-left:solid thin #f8f8f0}.jupyter-wrapper .cm-s-seti .CodeMirror-linenumber{color:#6d8a88}.jupyter-wrapper .cm-s-seti.CodeMirror-focused div.CodeMirror-selected{background:rgba(255,255,255,.1)}.jupyter-wrapper .cm-s-seti .CodeMirror-line::selection,.jupyter-wrapper .cm-s-seti .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-seti .CodeMirror-line>span>span::selection{background:rgba(255,255,255,.1)}.jupyter-wrapper .cm-s-seti .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-seti .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-seti .CodeMirror-line>span>span::-moz-selection{background:rgba(255,255,255,.1)}.jupyter-wrapper .cm-s-seti span.cm-comment{color:#41535b}.jupyter-wrapper .cm-s-seti span.cm-string,.jupyter-wrapper .cm-s-seti span.cm-string-2{color:#55b5db}.jupyter-wrapper .cm-s-seti span.cm-number{color:#cd3f45}.jupyter-wrapper .cm-s-seti span.cm-variable{color:#55b5db}.jupyter-wrapper .cm-s-seti span.cm-variable-2{color:#a074c4}.jupyter-wrapper .cm-s-seti span.cm-def{color:#55b5db}.jupyter-wrapper .cm-s-seti span.cm-keyword{color:#ff79c6}.jupyter-wrapper .cm-s-seti span.cm-operator{color:#9fca56}.jupyter-wrapper .cm-s-seti span.cm-keyword{color:#e6cd69}.jupyter-wrapper .cm-s-seti span.cm-atom{color:#cd3f45}.jupyter-wrapper .cm-s-seti span.cm-meta{color:#55b5db}.jupyter-wrapper .cm-s-seti span.cm-tag{color:#55b5db}.jupyter-wrapper .cm-s-seti span.cm-attribute{color:#9fca56}.jupyter-wrapper .cm-s-seti span.cm-qualifier{color:#9fca56}.jupyter-wrapper .cm-s-seti span.cm-property{color:#a074c4}.jupyter-wrapper .cm-s-seti span.cm-variable-3,.jupyter-wrapper .cm-s-seti span.cm-type{color:#9fca56}.jupyter-wrapper .cm-s-seti span.cm-builtin{color:#9fca56}.jupyter-wrapper .cm-s-seti .CodeMirror-activeline-background{background:#101213}.jupyter-wrapper .cm-s-seti .CodeMirror-matchingbracket{text-decoration:underline;color:#fff !important}.jupyter-wrapper .solarized.base03{color:#002b36}.jupyter-wrapper .solarized.base02{color:#073642}.jupyter-wrapper .solarized.base01{color:#586e75}.jupyter-wrapper .solarized.base00{color:#657b83}.jupyter-wrapper .solarized.base0{color:#839496}.jupyter-wrapper .solarized.base1{color:#93a1a1}.jupyter-wrapper .solarized.base2{color:#eee8d5}.jupyter-wrapper .solarized.base3{color:#fdf6e3}.jupyter-wrapper .solarized.solar-yellow{color:#b58900}.jupyter-wrapper .solarized.solar-orange{color:#cb4b16}.jupyter-wrapper .solarized.solar-red{color:#dc322f}.jupyter-wrapper .solarized.solar-magenta{color:#d33682}.jupyter-wrapper .solarized.solar-violet{color:#6c71c4}.jupyter-wrapper .solarized.solar-blue{color:#268bd2}.jupyter-wrapper .solarized.solar-cyan{color:#2aa198}.jupyter-wrapper .solarized.solar-green{color:#859900}.jupyter-wrapper .cm-s-solarized{line-height:1.45em;color-profile:sRGB;rendering-intent:auto}.jupyter-wrapper .cm-s-solarized.cm-s-dark{color:#839496;background-color:#002b36;text-shadow:#002b36 0 1px}.jupyter-wrapper .cm-s-solarized.cm-s-light{background-color:#fdf6e3;color:#657b83;text-shadow:#eee8d5 0 1px}.jupyter-wrapper .cm-s-solarized .CodeMirror-widget{text-shadow:none}.jupyter-wrapper .cm-s-solarized .cm-header{color:#586e75}.jupyter-wrapper .cm-s-solarized .cm-quote{color:#93a1a1}.jupyter-wrapper .cm-s-solarized .cm-keyword{color:#cb4b16}.jupyter-wrapper .cm-s-solarized .cm-atom{color:#d33682}.jupyter-wrapper .cm-s-solarized .cm-number{color:#d33682}.jupyter-wrapper .cm-s-solarized .cm-def{color:#2aa198}.jupyter-wrapper .cm-s-solarized .cm-variable{color:#839496}.jupyter-wrapper .cm-s-solarized .cm-variable-2{color:#b58900}.jupyter-wrapper .cm-s-solarized .cm-variable-3,.jupyter-wrapper .cm-s-solarized .cm-type{color:#6c71c4}.jupyter-wrapper .cm-s-solarized .cm-property{color:#2aa198}.jupyter-wrapper .cm-s-solarized .cm-operator{color:#6c71c4}.jupyter-wrapper .cm-s-solarized .cm-comment{color:#586e75;font-style:italic}.jupyter-wrapper .cm-s-solarized .cm-string{color:#859900}.jupyter-wrapper .cm-s-solarized .cm-string-2{color:#b58900}.jupyter-wrapper .cm-s-solarized .cm-meta{color:#859900}.jupyter-wrapper .cm-s-solarized .cm-qualifier{color:#b58900}.jupyter-wrapper .cm-s-solarized .cm-builtin{color:#d33682}.jupyter-wrapper .cm-s-solarized .cm-bracket{color:#cb4b16}.jupyter-wrapper .cm-s-solarized .CodeMirror-matchingbracket{color:#859900}.jupyter-wrapper .cm-s-solarized .CodeMirror-nonmatchingbracket{color:#dc322f}.jupyter-wrapper .cm-s-solarized .cm-tag{color:#93a1a1}.jupyter-wrapper .cm-s-solarized .cm-attribute{color:#2aa198}.jupyter-wrapper .cm-s-solarized .cm-hr{color:rgba(0,0,0,0);border-top:1px solid #586e75;display:block}.jupyter-wrapper .cm-s-solarized .cm-link{color:#93a1a1;cursor:pointer}.jupyter-wrapper .cm-s-solarized .cm-special{color:#6c71c4}.jupyter-wrapper .cm-s-solarized .cm-em{color:#999;text-decoration:underline;text-decoration-style:dotted}.jupyter-wrapper .cm-s-solarized .cm-error,.jupyter-wrapper .cm-s-solarized .cm-invalidchar{color:#586e75;border-bottom:1px dotted #dc322f}.jupyter-wrapper .cm-s-solarized.cm-s-dark div.CodeMirror-selected{background:#073642}.jupyter-wrapper .cm-s-solarized.cm-s-dark.CodeMirror ::selection{background:rgba(7,54,66,.99)}.jupyter-wrapper .cm-s-solarized.cm-s-dark .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-dark .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-dark .CodeMirror-line>span>span::-moz-selection{background:rgba(7,54,66,.99)}.jupyter-wrapper .cm-s-solarized.cm-s-light div.CodeMirror-selected{background:#eee8d5}.jupyter-wrapper .cm-s-solarized.cm-s-light .CodeMirror-line::selection,.jupyter-wrapper .cm-s-light .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-light .CodeMirror-line>span>span::selection{background:#eee8d5}.jupyter-wrapper .cm-s-solarized.cm-s-light .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-ligh .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-ligh .CodeMirror-line>span>span::-moz-selection{background:#eee8d5}.jupyter-wrapper .cm-s-solarized.CodeMirror{-moz-box-shadow:inset 7px 0 12px -6px #000;-webkit-box-shadow:inset 7px 0 12px -6px #000;box-shadow:inset 7px 0 12px -6px #000}.jupyter-wrapper .cm-s-solarized .CodeMirror-gutters{border-right:0}.jupyter-wrapper .cm-s-solarized.cm-s-dark .CodeMirror-gutters{background-color:#073642}.jupyter-wrapper .cm-s-solarized.cm-s-dark .CodeMirror-linenumber{color:#586e75;text-shadow:#021014 0 -1px}.jupyter-wrapper .cm-s-solarized.cm-s-light .CodeMirror-gutters{background-color:#eee8d5}.jupyter-wrapper .cm-s-solarized.cm-s-light .CodeMirror-linenumber{color:#839496}.jupyter-wrapper .cm-s-solarized .CodeMirror-linenumber{padding:0 5px}.jupyter-wrapper .cm-s-solarized .CodeMirror-guttermarker-subtle{color:#586e75}.jupyter-wrapper .cm-s-solarized.cm-s-dark .CodeMirror-guttermarker{color:#ddd}.jupyter-wrapper .cm-s-solarized.cm-s-light .CodeMirror-guttermarker{color:#cb4b16}.jupyter-wrapper .cm-s-solarized .CodeMirror-gutter .CodeMirror-gutter-text{color:#586e75}.jupyter-wrapper .cm-s-solarized .CodeMirror-cursor{border-left:1px solid #819090}.jupyter-wrapper .cm-s-solarized.cm-s-light.cm-fat-cursor .CodeMirror-cursor{background:#7e7}.jupyter-wrapper .cm-s-solarized.cm-s-light .cm-animate-fat-cursor{background-color:#7e7}.jupyter-wrapper .cm-s-solarized.cm-s-dark.cm-fat-cursor .CodeMirror-cursor{background:#586e75}.jupyter-wrapper .cm-s-solarized.cm-s-dark .cm-animate-fat-cursor{background-color:#586e75}.jupyter-wrapper .cm-s-solarized.cm-s-dark .CodeMirror-activeline-background{background:rgba(255,255,255,.06)}.jupyter-wrapper .cm-s-solarized.cm-s-light .CodeMirror-activeline-background{background:rgba(0,0,0,.06)}.jupyter-wrapper .cm-s-the-matrix.CodeMirror{background:#000;color:lime}.jupyter-wrapper .cm-s-the-matrix div.CodeMirror-selected{background:#2d2d2d}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-line::selection,.jupyter-wrapper .cm-s-the-matrix .CodeMirror-line>span::selection,.jupyter-wrapper .cm-s-the-matrix .CodeMirror-line>span>span::selection{background:rgba(45,45,45,.99)}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-line::-moz-selection,.jupyter-wrapper .cm-s-the-matrix .CodeMirror-line>span::-moz-selection,.jupyter-wrapper .cm-s-the-matrix .CodeMirror-line>span>span::-moz-selection{background:rgba(45,45,45,.99)}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-gutters{background:#060;border-right:2px solid lime}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-guttermarker{color:lime}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-guttermarker-subtle{color:#fff}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-linenumber{color:#fff}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-cursor{border-left:1px solid lime}.jupyter-wrapper .cm-s-the-matrix span.cm-keyword{color:#008803;font-weight:bold}.jupyter-wrapper .cm-s-the-matrix span.cm-atom{color:#3ff}.jupyter-wrapper .cm-s-the-matrix span.cm-number{color:#ffb94f}.jupyter-wrapper .cm-s-the-matrix span.cm-def{color:#99c}.jupyter-wrapper .cm-s-the-matrix span.cm-variable{color:#f6c}.jupyter-wrapper .cm-s-the-matrix span.cm-variable-2{color:#c6f}.jupyter-wrapper .cm-s-the-matrix span.cm-variable-3,.jupyter-wrapper .cm-s-the-matrix span.cm-type{color:#96f}.jupyter-wrapper .cm-s-the-matrix span.cm-property{color:#62ffa0}.jupyter-wrapper .cm-s-the-matrix span.cm-operator{color:#999}.jupyter-wrapper .cm-s-the-matrix span.cm-comment{color:#ccc}.jupyter-wrapper .cm-s-the-matrix span.cm-string{color:#39c}.jupyter-wrapper .cm-s-the-matrix span.cm-meta{color:#c9f}.jupyter-wrapper .cm-s-the-matrix span.cm-qualifier{color:#fff700}.jupyter-wrapper .cm-s-the-matrix span.cm-builtin{color:#30a}.jupyter-wrapper .cm-s-the-matrix span.cm-bracket{color:#cc7}.jupyter-wrapper .cm-s-the-matrix span.cm-tag{color:#ffbd40}.jupyter-wrapper .cm-s-the-matrix span.cm-attribute{color:#fff700}.jupyter-wrapper .cm-s-the-matrix span.cm-error{color:red}.jupyter-wrapper .cm-s-the-matrix .CodeMirror-activeline-background{background:#040}.jupyter-wrapper .cm-s-xq-light span.cm-keyword{line-height:1em;font-weight:bold;color:#5a5cad}.jupyter-wrapper .cm-s-xq-light span.cm-atom{color:#6c8cd5}.jupyter-wrapper .cm-s-xq-light span.cm-number{color:#164}.jupyter-wrapper .cm-s-xq-light span.cm-def{text-decoration:underline}.jupyter-wrapper .cm-s-xq-light span.cm-variable{color:#000}.jupyter-wrapper .cm-s-xq-light span.cm-variable-2{color:#000}.jupyter-wrapper .cm-s-xq-light span.cm-variable-3,.jupyter-wrapper .cm-s-xq-light span.cm-type{color:#000}.jupyter-wrapper .cm-s-xq-light span.cm-comment{color:#0080ff;font-style:italic}.jupyter-wrapper .cm-s-xq-light span.cm-string{color:red}.jupyter-wrapper .cm-s-xq-light span.cm-meta{color:#ff0}.jupyter-wrapper .cm-s-xq-light span.cm-qualifier{color:gray}.jupyter-wrapper .cm-s-xq-light span.cm-builtin{color:#7ea656}.jupyter-wrapper .cm-s-xq-light span.cm-bracket{color:#cc7}.jupyter-wrapper .cm-s-xq-light span.cm-tag{color:#3f7f7f}.jupyter-wrapper .cm-s-xq-light span.cm-attribute{color:#7f007f}.jupyter-wrapper .cm-s-xq-light span.cm-error{color:red}.jupyter-wrapper .cm-s-xq-light .CodeMirror-activeline-background{background:#e8f2ff}.jupyter-wrapper .cm-s-xq-light .CodeMirror-matchingbracket{outline:1px solid gray;color:#000 !important;background:#ff0}.jupyter-wrapper .CodeMirror{line-height:var(--jp-code-line-height);font-size:var(--jp-code-font-size);font-family:var(--jp-code-font-family);border:0;border-radius:0;height:auto}.jupyter-wrapper .CodeMirror pre{padding:0 var(--jp-code-padding)}.jupyter-wrapper .jp-CodeMirrorEditor[data-type=inline] .CodeMirror-dialog{background-color:var(--jp-layout-color0);color:var(--jp-content-font-color1)}.jupyter-wrapper .CodeMirror-lines{padding:var(--jp-code-padding) 0}.jupyter-wrapper .CodeMirror-linenumber{padding:0 8px}.jupyter-wrapper .jp-CodeMirrorEditor-static{margin:var(--jp-code-padding)}.jupyter-wrapper .jp-CodeMirrorEditor,.jupyter-wrapper .jp-CodeMirrorEditor-static{cursor:text}.jupyter-wrapper .jp-CodeMirrorEditor[data-type=inline] .CodeMirror-cursor{border-left:var(--jp-code-cursor-width0) solid var(--jp-editor-cursor-color)}@media screen and (min-width: 2138px)and (max-width: 4319px){.jupyter-wrapper .jp-CodeMirrorEditor[data-type=inline] .CodeMirror-cursor{border-left:var(--jp-code-cursor-width1) solid var(--jp-editor-cursor-color)}}@media screen and (min-width: 4320px){.jupyter-wrapper .jp-CodeMirrorEditor[data-type=inline] .CodeMirror-cursor{border-left:var(--jp-code-cursor-width2) solid var(--jp-editor-cursor-color)}}.jupyter-wrapper .CodeMirror.jp-mod-readOnly .CodeMirror-cursor{display:none}.jupyter-wrapper .CodeMirror-gutters{border-right:1px solid var(--jp-border-color2);background-color:var(--jp-layout-color0)}.jupyter-wrapper .jp-CollaboratorCursor{border-left:5px solid rgba(0,0,0,0);border-right:5px solid rgba(0,0,0,0);border-top:none;border-bottom:3px solid;background-clip:content-box;margin-left:-5px;margin-right:-5px}.jupyter-wrapper .CodeMirror-selectedtext.cm-searching{background-color:var(--jp-search-selected-match-background-color) !important;color:var(--jp-search-selected-match-color) !important}.jupyter-wrapper .cm-searching{background-color:var(--jp-search-unselected-match-background-color) !important;color:var(--jp-search-unselected-match-color) !important}.jupyter-wrapper .CodeMirror-focused .CodeMirror-selected{background-color:var(--jp-editor-selected-focused-background)}.jupyter-wrapper .CodeMirror-selected{background-color:var(--jp-editor-selected-background)}.jupyter-wrapper .jp-CollaboratorCursor-hover{position:absolute;z-index:1;transform:translateX(-50%);color:#fff;border-radius:3px;padding-left:4px;padding-right:4px;padding-top:1px;padding-bottom:1px;text-align:center;font-size:var(--jp-ui-font-size1);white-space:nowrap}.jupyter-wrapper .jp-CodeMirror-ruler{border-left:1px dashed var(--jp-border-color2)}.jupyter-wrapper .CodeMirror.cm-s-jupyter{background:var(--jp-layout-color0);color:var(--jp-content-font-color1)}.jupyter-wrapper .jp-CodeConsole .CodeMirror.cm-s-jupyter,.jupyter-wrapper .jp-Notebook .CodeMirror.cm-s-jupyter{background:rgba(0,0,0,0)}.jupyter-wrapper .cm-s-jupyter .CodeMirror-cursor{border-left:var(--jp-code-cursor-width0) solid var(--jp-editor-cursor-color)}.jupyter-wrapper .cm-s-jupyter span.cm-keyword{color:var(--jp-mirror-editor-keyword-color);font-weight:bold}.jupyter-wrapper .cm-s-jupyter span.cm-atom{color:var(--jp-mirror-editor-atom-color)}.jupyter-wrapper .cm-s-jupyter span.cm-number{color:var(--jp-mirror-editor-number-color)}.jupyter-wrapper .cm-s-jupyter span.cm-def{color:var(--jp-mirror-editor-def-color)}.jupyter-wrapper .cm-s-jupyter span.cm-variable{color:var(--jp-mirror-editor-variable-color)}.jupyter-wrapper .cm-s-jupyter span.cm-variable-2{color:var(--jp-mirror-editor-variable-2-color)}.jupyter-wrapper .cm-s-jupyter span.cm-variable-3{color:var(--jp-mirror-editor-variable-3-color)}.jupyter-wrapper .cm-s-jupyter span.cm-punctuation{color:var(--jp-mirror-editor-punctuation-color)}.jupyter-wrapper .cm-s-jupyter span.cm-property{color:var(--jp-mirror-editor-property-color)}.jupyter-wrapper .cm-s-jupyter span.cm-operator{color:var(--jp-mirror-editor-operator-color);font-weight:bold}.jupyter-wrapper .cm-s-jupyter span.cm-comment{color:var(--jp-mirror-editor-comment-color);font-style:italic}.jupyter-wrapper .cm-s-jupyter span.cm-string{color:var(--jp-mirror-editor-string-color)}.jupyter-wrapper .cm-s-jupyter span.cm-string-2{color:var(--jp-mirror-editor-string-2-color)}.jupyter-wrapper .cm-s-jupyter span.cm-meta{color:var(--jp-mirror-editor-meta-color)}.jupyter-wrapper .cm-s-jupyter span.cm-qualifier{color:var(--jp-mirror-editor-qualifier-color)}.jupyter-wrapper .cm-s-jupyter span.cm-builtin{color:var(--jp-mirror-editor-builtin-color)}.jupyter-wrapper .cm-s-jupyter span.cm-bracket{color:var(--jp-mirror-editor-bracket-color)}.jupyter-wrapper .cm-s-jupyter span.cm-tag{color:var(--jp-mirror-editor-tag-color)}.jupyter-wrapper .cm-s-jupyter span.cm-attribute{color:var(--jp-mirror-editor-attribute-color)}.jupyter-wrapper .cm-s-jupyter span.cm-header{color:var(--jp-mirror-editor-header-color)}.jupyter-wrapper .cm-s-jupyter span.cm-quote{color:var(--jp-mirror-editor-quote-color)}.jupyter-wrapper .cm-s-jupyter span.cm-link{color:var(--jp-mirror-editor-link-color)}.jupyter-wrapper .cm-s-jupyter span.cm-error{color:var(--jp-mirror-editor-error-color)}.jupyter-wrapper .cm-s-jupyter span.cm-hr{color:#999}.jupyter-wrapper .cm-s-jupyter span.cm-tab{background:url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAADAAAAAMCAYAAAAkuj5RAAAAAXNSR0IArs4c6QAAAGFJREFUSMft1LsRQFAQheHPowAKoACx3IgEKtaEHujDjORSgWTH/ZOdnZOcM/sgk/kFFWY0qV8foQwS4MKBCS3qR6ixBJvElOobYAtivseIE120FaowJPN75GMu8j/LfMwNjh4HUpwg4LUAAAAASUVORK5CYII=);background-position:right;background-repeat:no-repeat}.jupyter-wrapper .cm-s-jupyter .CodeMirror-activeline-background,.jupyter-wrapper .cm-s-jupyter .CodeMirror-gutter{background-color:var(--jp-layout-color2)}.jupyter-wrapper .jp-RenderedLatex{color:var(--jp-content-font-color1);font-size:var(--jp-content-font-size1);line-height:var(--jp-content-line-height)}.jupyter-wrapper .jp-OutputArea-output.jp-RenderedLatex{padding:var(--jp-code-padding);text-align:left}.jupyter-wrapper .jp-MimeDocument{outline:none}.jupyter-wrapper :root{--jp-private-filebrowser-button-height: 28px;--jp-private-filebrowser-button-width: 48px}.jupyter-wrapper .jp-FileBrowser{display:flex;flex-direction:column;color:var(--jp-ui-font-color1);background:var(--jp-layout-color1);font-size:var(--jp-ui-font-size1)}.jupyter-wrapper .jp-FileBrowser-toolbar.jp-Toolbar{border-bottom:none;height:auto;margin:var(--jp-toolbar-header-margin);box-shadow:none}.jupyter-wrapper .jp-BreadCrumbs{flex:0 0 auto;margin:4px 12px}.jupyter-wrapper .jp-BreadCrumbs-item{margin:0px 2px;padding:0px 2px;border-radius:var(--jp-border-radius);cursor:pointer}.jupyter-wrapper .jp-BreadCrumbs-item:hover{background-color:var(--jp-layout-color2)}.jupyter-wrapper .jp-BreadCrumbs-item:first-child{margin-left:0px}.jupyter-wrapper .jp-BreadCrumbs-item.jp-mod-dropTarget{background-color:var(--jp-brand-color2);opacity:.7}.jupyter-wrapper .jp-FileBrowser-toolbar.jp-Toolbar{padding:0px}.jupyter-wrapper .jp-FileBrowser-toolbar.jp-Toolbar{justify-content:space-evenly}.jupyter-wrapper .jp-FileBrowser-toolbar.jp-Toolbar .jp-Toolbar-item{flex:1}.jupyter-wrapper .jp-FileBrowser-toolbar.jp-Toolbar .jp-ToolbarButtonComponent{width:100%}.jupyter-wrapper .jp-DirListing{flex:1 1 auto;display:flex;flex-direction:column;outline:0}.jupyter-wrapper .jp-DirListing-header{flex:0 0 auto;display:flex;flex-direction:row;overflow:hidden;border-top:var(--jp-border-width) solid var(--jp-border-color2);border-bottom:var(--jp-border-width) solid var(--jp-border-color1);box-shadow:var(--jp-toolbar-box-shadow);z-index:2}.jupyter-wrapper .jp-DirListing-headerItem{padding:4px 12px 2px 12px;font-weight:500}.jupyter-wrapper .jp-DirListing-headerItem:hover{background:var(--jp-layout-color2)}.jupyter-wrapper .jp-DirListing-headerItem.jp-id-name{flex:1 0 84px}.jupyter-wrapper .jp-DirListing-headerItem.jp-id-modified{flex:0 0 112px;border-left:var(--jp-border-width) solid var(--jp-border-color2);text-align:right}.jupyter-wrapper .jp-DirListing-narrow .jp-id-modified,.jupyter-wrapper .jp-DirListing-narrow .jp-DirListing-itemModified{display:none}.jupyter-wrapper .jp-DirListing-headerItem.jp-mod-selected{font-weight:600}.jupyter-wrapper .jp-DirListing-content{flex:1 1 auto;margin:0;padding:0;list-style-type:none;overflow:auto;background-color:var(--jp-layout-color1)}.jupyter-wrapper .jp-DirListing.jp-mod-native-drop .jp-DirListing-content{outline:5px dashed rgba(128,128,128,.5);outline-offset:-10px;cursor:copy}.jupyter-wrapper .jp-DirListing-item{display:flex;flex-direction:row;padding:4px 12px;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .jp-DirListing-item.jp-mod-selected{color:#fff;background:var(--jp-brand-color1)}.jupyter-wrapper .jp-DirListing-item.jp-mod-dropTarget{background:var(--jp-brand-color3)}.jupyter-wrapper .jp-DirListing-item:hover:not(.jp-mod-selected){background:var(--jp-layout-color2)}.jupyter-wrapper .jp-DirListing-itemIcon{flex:0 0 20px;margin-right:4px}.jupyter-wrapper .jp-DirListing-itemText{flex:1 0 64px;white-space:nowrap;overflow:hidden;text-overflow:ellipsis;user-select:none}.jupyter-wrapper .jp-DirListing-itemModified{flex:0 0 125px;text-align:right}.jupyter-wrapper .jp-DirListing-editor{flex:1 0 64px;outline:none;border:none}.jupyter-wrapper .jp-DirListing-item.jp-mod-running .jp-DirListing-itemIcon:before{color:#32cd32;content:\"\u25cf\";font-size:8px;position:absolute;left:-8px}.jupyter-wrapper .jp-DirListing-item.lm-mod-drag-image,.jupyter-wrapper .jp-DirListing-item.jp-mod-selected.lm-mod-drag-image{font-size:var(--jp-ui-font-size1);padding-left:4px;margin-left:4px;width:160px;background-color:var(--jp-ui-inverse-font-color2);box-shadow:var(--jp-elevation-z2);border-radius:0px;color:var(--jp-ui-font-color1);transform:translateX(-40%) translateY(-58%)}.jupyter-wrapper .jp-DirListing-deadSpace{flex:1 1 auto;margin:0;padding:0;list-style-type:none;overflow:auto;background-color:var(--jp-layout-color1)}.jupyter-wrapper .jp-Document{min-width:120px;min-height:120px;outline:none}.jupyter-wrapper .jp-FileDialog.jp-mod-conflict input{color:red}.jupyter-wrapper .jp-FileDialog .jp-new-name-title{margin-top:12px}.jupyter-wrapper .jp-OutputArea{overflow-y:auto}.jupyter-wrapper .jp-OutputArea-child{display:flex;flex-direction:row}.jupyter-wrapper .jp-OutputPrompt{flex:0 0 var(--jp-cell-prompt-width);color:var(--jp-cell-outprompt-font-color);font-family:var(--jp-cell-prompt-font-family);padding:var(--jp-code-padding);letter-spacing:var(--jp-cell-prompt-letter-spacing);line-height:var(--jp-code-line-height);font-size:var(--jp-code-font-size);border:var(--jp-border-width) solid rgba(0,0,0,0);opacity:var(--jp-cell-prompt-opacity);text-align:right;white-space:nowrap;overflow:hidden;text-overflow:ellipsis;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .jp-OutputArea-output{height:auto;overflow:auto;user-select:text;-moz-user-select:text;-webkit-user-select:text;-ms-user-select:text}.jupyter-wrapper .jp-OutputArea-child .jp-OutputArea-output{flex-grow:1;flex-shrink:1}.jupyter-wrapper .jp-OutputArea-output.jp-mod-isolated{width:100%;display:block}.jupyter-wrapper body.lm-mod-override-cursor .jp-OutputArea-output.jp-mod-isolated{position:relative}.jupyter-wrapper body.lm-mod-override-cursor .jp-OutputArea-output.jp-mod-isolated:before{content:\"\";position:absolute;top:0;left:0;right:0;bottom:0;background:rgba(0,0,0,0)}.jupyter-wrapper .jp-OutputArea-output pre{border:none;margin:0px;padding:0px;overflow-x:auto;overflow-y:auto;word-break:break-all;word-wrap:break-word;white-space:pre-wrap}.jupyter-wrapper .jp-OutputArea-output.jp-RenderedHTMLCommon table{margin-left:0;margin-right:0}.jupyter-wrapper .jp-OutputArea-output dl,.jupyter-wrapper .jp-OutputArea-output dt,.jupyter-wrapper .jp-OutputArea-output dd{display:block}.jupyter-wrapper .jp-OutputArea-output dl{width:100%;overflow:hidden;padding:0;margin:0}.jupyter-wrapper .jp-OutputArea-output dt{font-weight:bold;float:left;width:20%;padding:0;margin:0}.jupyter-wrapper .jp-OutputArea-output dd{float:left;width:80%;padding:0;margin:0}.jupyter-wrapper .jp-OutputArea .jp-OutputArea .jp-OutputArea-prompt{display:none}.jupyter-wrapper .jp-OutputArea-output.jp-OutputArea-executeResult{margin-left:0px;flex:1 1 auto}.jupyter-wrapper .jp-OutputArea-executeResult.jp-RenderedText{padding-top:var(--jp-code-padding)}.jupyter-wrapper .jp-OutputArea-stdin{line-height:var(--jp-code-line-height);padding-top:var(--jp-code-padding);display:flex}.jupyter-wrapper .jp-Stdin-prompt{color:var(--jp-content-font-color0);padding-right:var(--jp-code-padding);vertical-align:baseline;flex:0 0 auto}.jupyter-wrapper .jp-Stdin-input{font-family:var(--jp-code-font-family);font-size:inherit;color:inherit;background-color:inherit;width:42%;min-width:200px;vertical-align:baseline;padding:0em .25em;margin:0em .25em;flex:0 0 70%}.jupyter-wrapper .jp-Stdin-input:focus{box-shadow:none}.jupyter-wrapper .jp-LinkedOutputView .jp-OutputArea{height:100%;display:block}.jupyter-wrapper .jp-LinkedOutputView .jp-OutputArea-output:only-child{height:100%}.jupyter-wrapper .jp-Collapser{flex:0 0 var(--jp-cell-collapser-width);padding:0px;margin:0px;border:none;outline:none;background:rgba(0,0,0,0);border-radius:var(--jp-border-radius);opacity:1}.jupyter-wrapper .jp-Collapser-child{display:block;width:100%;box-sizing:border-box;position:absolute;top:0px;bottom:0px}.jupyter-wrapper .jp-CellHeader,.jupyter-wrapper .jp-CellFooter{height:0px;width:100%;padding:0px;margin:0px;border:none;outline:none;background:rgba(0,0,0,0)}.jupyter-wrapper .jp-InputArea{display:flex;flex-direction:row}.jupyter-wrapper .jp-InputArea-editor{flex:1 1 auto}.jupyter-wrapper .jp-InputArea-editor{border:var(--jp-border-width) solid var(--jp-cell-editor-border-color);border-radius:0px;background:var(--jp-cell-editor-background)}.jupyter-wrapper .jp-InputPrompt{flex:0 0 var(--jp-cell-prompt-width);color:var(--jp-cell-inprompt-font-color);font-family:var(--jp-cell-prompt-font-family);padding:var(--jp-code-padding);letter-spacing:var(--jp-cell-prompt-letter-spacing);opacity:var(--jp-cell-prompt-opacity);line-height:var(--jp-code-line-height);font-size:var(--jp-code-font-size);border:var(--jp-border-width) solid rgba(0,0,0,0);opacity:var(--jp-cell-prompt-opacity);text-align:right;white-space:nowrap;overflow:hidden;text-overflow:ellipsis;-webkit-user-select:none;-moz-user-select:none;-ms-user-select:none;user-select:none}.jupyter-wrapper .jp-Placeholder{display:flex;flex-direction:row;flex:1 1 auto}.jupyter-wrapper .jp-Placeholder-prompt{box-sizing:border-box}.jupyter-wrapper .jp-Placeholder-content{flex:1 1 auto;border:none;background:rgba(0,0,0,0);height:20px;box-sizing:border-box}.jupyter-wrapper .jp-Placeholder-content .jp-MoreHorizIcon{width:32px;height:16px;border:1px solid rgba(0,0,0,0);border-radius:var(--jp-border-radius)}.jupyter-wrapper .jp-Placeholder-content .jp-MoreHorizIcon:hover{border:1px solid var(--jp-border-color1);box-shadow:0px 0px 2px 0px rgba(0,0,0,.25);background-color:var(--jp-layout-color0)}.jupyter-wrapper :root{--jp-private-cell-scrolling-output-offset: 5px}.jupyter-wrapper .jp-Cell{padding:var(--jp-cell-padding);margin:0px;border:none;outline:none;background:rgba(0,0,0,0)}.jupyter-wrapper .jp-Cell-inputWrapper,.jupyter-wrapper .jp-Cell-outputWrapper{display:flex;flex-direction:row;padding:0px;margin:0px;overflow:visible}.jupyter-wrapper .jp-Cell-inputArea,.jupyter-wrapper .jp-Cell-outputArea{flex:1 1 auto}.jupyter-wrapper .jp-Cell.jp-mod-noOutputs .jp-Cell-outputCollapser{border:none !important;background:rgba(0,0,0,0) !important}.jupyter-wrapper .jp-Cell:not(.jp-mod-noOutputs) .jp-Cell-outputCollapser{min-height:var(--jp-cell-collapser-min-height)}.jupyter-wrapper .jp-Cell:not(.jp-mod-noOutputs) .jp-Cell-outputWrapper{margin-top:5px}.jupyter-wrapper .jp-OutputArea-executeResult .jp-RenderedText.jp-OutputArea-output{padding-top:var(--jp-code-padding)}.jupyter-wrapper .jp-CodeCell.jp-mod-outputsScrolled .jp-Cell-outputArea{overflow-y:auto;max-height:200px;box-shadow:inset 0 0 6px 2px rgba(0,0,0,.3);margin-left:var(--jp-private-cell-scrolling-output-offset)}.jupyter-wrapper .jp-CodeCell.jp-mod-outputsScrolled .jp-OutputArea-prompt{flex:0 0 calc(var(--jp-cell-prompt-width) - var(--jp-private-cell-scrolling-output-offset))}.jupyter-wrapper .jp-MarkdownOutput{flex:1 1 auto;margin-top:0;margin-bottom:0;padding-left:var(--jp-code-padding)}.jupyter-wrapper .jp-MarkdownOutput.jp-RenderedHTMLCommon{overflow:auto}.jupyter-wrapper .jp-NotebookPanel-toolbar{padding:2px}.jupyter-wrapper .jp-Toolbar-item.jp-Notebook-toolbarCellType .jp-select-wrapper.jp-mod-focused{border:none;box-shadow:none}.jupyter-wrapper .jp-Notebook-toolbarCellTypeDropdown select{height:24px;font-size:var(--jp-ui-font-size1);line-height:14px;border-radius:0;display:block}.jupyter-wrapper .jp-Notebook-toolbarCellTypeDropdown span{top:5px !important}.jupyter-wrapper :root{--jp-private-notebook-dragImage-width: 304px;--jp-private-notebook-dragImage-height: 36px;--jp-private-notebook-selected-color: var(--md-blue-400);--jp-private-notebook-active-color: var(--md-green-400)}.jupyter-wrapper .jp-NotebookPanel{display:block;height:100%}.jupyter-wrapper .jp-NotebookPanel.jp-Document{min-width:240px;min-height:120px}.jupyter-wrapper .jp-Notebook{padding:var(--jp-notebook-padding);outline:none;overflow:auto;background:var(--jp-layout-color0)}.jupyter-wrapper .jp-Notebook.jp-mod-scrollPastEnd::after{display:block;content:\"\";min-height:var(--jp-notebook-scroll-padding)}.jupyter-wrapper .jp-Notebook .jp-Cell{overflow:visible}.jupyter-wrapper .jp-Notebook .jp-Cell .jp-InputPrompt{cursor:move}.jupyter-wrapper .jp-Notebook .jp-Cell:not(.jp-mod-active) .jp-InputPrompt{opacity:var(--jp-cell-prompt-not-active-opacity);color:var(--jp-cell-prompt-not-active-font-color)}.jupyter-wrapper .jp-Notebook .jp-Cell:not(.jp-mod-active) .jp-OutputPrompt{opacity:var(--jp-cell-prompt-not-active-opacity);color:var(--jp-cell-prompt-not-active-font-color)}.jupyter-wrapper .jp-Notebook .jp-Cell.jp-mod-active .jp-Collapser{background:var(--jp-brand-color1)}.jupyter-wrapper .jp-Notebook .jp-Cell .jp-Collapser:hover{box-shadow:var(--jp-elevation-z2);background:var(--jp-brand-color1);opacity:var(--jp-cell-collapser-not-active-hover-opacity)}.jupyter-wrapper .jp-Notebook .jp-Cell.jp-mod-active .jp-Collapser:hover{background:var(--jp-brand-color0);opacity:1}.jupyter-wrapper .jp-Notebook.jp-mod-commandMode .jp-Cell.jp-mod-selected{background:var(--jp-notebook-multiselected-color)}.jupyter-wrapper .jp-Notebook.jp-mod-commandMode .jp-Cell.jp-mod-active.jp-mod-selected:not(.jp-mod-multiSelected){background:rgba(0,0,0,0)}.jupyter-wrapper .jp-Notebook.jp-mod-editMode .jp-Cell.jp-mod-active .jp-InputArea-editor{border:var(--jp-border-width) solid var(--jp-cell-editor-active-border-color);box-shadow:var(--jp-input-box-shadow);background-color:var(--jp-cell-editor-active-background)}.jupyter-wrapper .jp-Notebook-cell.jp-mod-dropSource{opacity:.5}.jupyter-wrapper .jp-Notebook-cell.jp-mod-dropTarget,.jupyter-wrapper .jp-Notebook.jp-mod-commandMode .jp-Notebook-cell.jp-mod-active.jp-mod-selected.jp-mod-dropTarget{border-top-color:var(--jp-private-notebook-selected-color);border-top-style:solid;border-top-width:2px}.jupyter-wrapper .jp-dragImage{display:flex;flex-direction:row;width:var(--jp-private-notebook-dragImage-width);height:var(--jp-private-notebook-dragImage-height);border:var(--jp-border-width) solid var(--jp-cell-editor-border-color);background:var(--jp-cell-editor-background);overflow:visible}.jupyter-wrapper .jp-dragImage-singlePrompt{box-shadow:2px 2px 4px 0px rgba(0,0,0,.12)}.jupyter-wrapper .jp-dragImage .jp-dragImage-content{flex:1 1 auto;z-index:2;font-size:var(--jp-code-font-size);font-family:var(--jp-code-font-family);line-height:var(--jp-code-line-height);padding:var(--jp-code-padding);border:var(--jp-border-width) solid var(--jp-cell-editor-border-color);background:var(--jp-cell-editor-background-color);color:var(--jp-content-font-color3);text-align:left;margin:4px 4px 4px 0px}.jupyter-wrapper .jp-dragImage .jp-dragImage-prompt{flex:0 0 auto;min-width:36px;color:var(--jp-cell-inprompt-font-color);padding:var(--jp-code-padding);padding-left:12px;font-family:var(--jp-cell-prompt-font-family);letter-spacing:var(--jp-cell-prompt-letter-spacing);line-height:1.9;font-size:var(--jp-code-font-size);border:var(--jp-border-width) solid rgba(0,0,0,0)}.jupyter-wrapper .jp-dragImage-multipleBack{z-index:-1;position:absolute;height:32px;width:300px;top:8px;left:8px;background:var(--jp-layout-color2);border:var(--jp-border-width) solid var(--jp-input-border-color);box-shadow:2px 2px 4px 0px rgba(0,0,0,.12)}.jupyter-wrapper .jp-NotebookTools{display:block;min-width:var(--jp-sidebar-min-width);color:var(--jp-ui-font-color1);background:var(--jp-layout-color1);font-size:var(--jp-ui-font-size1);overflow:auto}.jupyter-wrapper .jp-NotebookTools-tool{padding:0px 12px 0 12px}.jupyter-wrapper .jp-ActiveCellTool{padding:12px;background-color:var(--jp-layout-color1);border-top:none !important}.jupyter-wrapper .jp-ActiveCellTool .jp-InputArea-prompt{flex:0 0 auto;padding-left:0px}.jupyter-wrapper .jp-ActiveCellTool .jp-InputArea-editor{flex:1 1 auto;background:var(--jp-cell-editor-background);border-color:var(--jp-cell-editor-border-color)}.jupyter-wrapper .jp-ActiveCellTool .jp-InputArea-editor .CodeMirror{background:rgba(0,0,0,0)}.jupyter-wrapper .jp-MetadataEditorTool{flex-direction:column;padding:12px 0px 12px 0px}.jupyter-wrapper .jp-RankedPanel>:not(:first-child){margin-top:12px}.jupyter-wrapper .jp-KeySelector select.jp-mod-styled{font-size:var(--jp-ui-font-size1);color:var(--jp-ui-font-color0);border:var(--jp-border-width) solid var(--jp-border-color1)}.jupyter-wrapper .jp-KeySelector label,.jupyter-wrapper .jp-MetadataEditorTool label{line-height:1.4}.jupyter-wrapper .jp-mod-presentationMode .jp-Notebook{--jp-content-font-size1: var(--jp-content-presentation-font-size1);--jp-code-font-size: var(--jp-code-presentation-font-size)}.jupyter-wrapper .jp-mod-presentationMode .jp-Notebook .jp-Cell .jp-InputPrompt,.jupyter-wrapper .jp-mod-presentationMode .jp-Notebook .jp-Cell .jp-OutputPrompt{flex:0 0 110px}.jupyter-wrapper table.dataframe{table-layout:auto !important}.jupyter-wrapper .md-typeset__scrollwrap{margin:0}.jupyter-wrapper .jp-MarkdownOutput{padding:0}.jupyter-wrapper h1 .anchor-link,.jupyter-wrapper h2 .anchor-link,.jupyter-wrapper h3 .anchor-link,.jupyter-wrapper h4 .anchor-link,.jupyter-wrapper h5 .anchor-link,.jupyter-wrapper h6 .anchor-link{display:none;margin-left:.5rem;color:var(--md-default-fg-color--lighter)}.jupyter-wrapper h1 .anchor-link:hover,.jupyter-wrapper h2 .anchor-link:hover,.jupyter-wrapper h3 .anchor-link:hover,.jupyter-wrapper h4 .anchor-link:hover,.jupyter-wrapper h5 .anchor-link:hover,.jupyter-wrapper h6 .anchor-link:hover{text-decoration:none;color:var(--md-accent-fg-color)}.jupyter-wrapper h1:hover .anchor-link,.jupyter-wrapper h2:hover .anchor-link,.jupyter-wrapper h3:hover .anchor-link,.jupyter-wrapper h4:hover .anchor-link,.jupyter-wrapper h5:hover .anchor-link,.jupyter-wrapper h6:hover .anchor-link{display:inline-block}.jupyter-wrapper .jp-InputArea{width:100%}.jupyter-wrapper .jp-Cell-inputArea{width:100%}.jupyter-wrapper .jp-RenderedHTMLCommon{width:100%}.jupyter-wrapper .jp-Cell-inputWrapper .jp-InputPrompt{display:none}.jupyter-wrapper .jp-CodeCell .jp-Cell-inputWrapper .jp-InputPrompt{display:block}.jupyter-wrapper .highlight pre{overflow:auto}.jupyter-wrapper .celltoolbar{border:none;background:#eee;border-radius:2px 2px 0px 0px;width:100%;height:29px;padding-right:4px;box-orient:horizontal;box-align:stretch;display:flex;flex-direction:row;align-items:stretch;box-pack:end;justify-content:flex-start;display:-webkit-flex}.jupyter-wrapper .celltoolbar .tags_button_container{display:flex}.jupyter-wrapper .celltoolbar .tags_button_container .tag-container{display:flex;flex-direction:row;flex-grow:1;overflow:hidden;position:relative}.jupyter-wrapper .celltoolbar .tags_button_container .tag-container .cell-tag{background-color:#fff;white-space:nowrap;margin:3px 4px;padding:0 4px;border-radius:1px;border:1px solid #ccc;box-shadow:none;width:inherit;font-size:11px;font-family:\"Roboto Mono\",SFMono-Regular,Consolas,Menlo,monospace;height:22px;display:inline-block}.jupyter-wrapper .jp-InputArea-editor{width:1px}.jupyter-wrapper .jp-InputPrompt{overflow:unset}.jupyter-wrapper .jp-OutputPrompt{overflow:unset}.jupyter-wrapper .jp-RenderedText{font-size:var(--jp-code-font-size)}.jupyter-wrapper .highlight-ipynb{overflow:auto}.jupyter-wrapper .highlight-ipynb pre{margin:0;padding:5px 10px}.jupyter-wrapper table{width:max-content}.jupyter-wrapper table.dataframe{margin-left:auto;margin-right:auto;border:none;border-collapse:collapse;border-spacing:0;color:#000;font-size:12px;table-layout:fixed}.jupyter-wrapper table.dataframe thead{border-bottom:1px solid #000;vertical-align:bottom}.jupyter-wrapper table.dataframe tr,.jupyter-wrapper table.dataframe th,.jupyter-wrapper table.dataframe td{text-align:right;vertical-align:middle;padding:.5em .5em;line-height:normal;white-space:normal;max-width:none;border:none}.jupyter-wrapper table.dataframe th{font-weight:bold}.jupyter-wrapper table.dataframe tbody tr:nth-child(odd){background:#f5f5f5}.jupyter-wrapper table.dataframe tbody tr:hover{background:rgba(66,165,245,.2)}.jupyter-wrapper *+table{margin-top:1em}.jupyter-wrapper .jp-InputArea-editor{position:relative}.jupyter-wrapper .zeroclipboard-container{position:absolute;top:-3px;right:0;z-index:1}.jupyter-wrapper .zeroclipboard-container clipboard-copy{-webkit-appearance:button;-moz-appearance:button;padding:7px 5px;font:11px system-ui,sans-serif;display:inline-block;cursor:default}.jupyter-wrapper .zeroclipboard-container .clipboard-copy-icon{padding:4px 4px 2px;color:#57606a;vertical-align:text-bottom}.jupyter-wrapper .clipboard-copy-txt{display:none}[data-md-color-scheme=slate] .clipboard-copy-icon{color:#fff !important}[data-md-color-scheme=slate] table.dataframe{color:#e9ebfc}[data-md-color-scheme=slate] table.dataframe thead{border-bottom:1px solid rgba(233,235,252,.12)}[data-md-color-scheme=slate] table.dataframe tbody tr:nth-child(odd){background:#222}[data-md-color-scheme=slate] table.dataframe tbody tr:hover{background:rgba(66,165,245,.2)}table{width:max-content} /*# sourceMappingURL=mkdocs-jupyter.css.map*/ init_mathjax = function() { if (window.MathJax) { // MathJax loaded MathJax.Hub.Config({ TeX: { equationNumbers: { autoNumber: \"AMS\", useLabelIds: true } }, tex2jax: { inlineMath: [ ['$','$'], [\"\\\\(\",\"\\\\)\"] ], displayMath: [ ['$$','$$'], [\"\\\\[\",\"\\\\]\"] ], processEscapes: true, processEnvironments: true }, displayAlign: 'center', CommonHTML: { linebreaks: { automatic: true } } }); MathJax.Hub.Queue([\"Typeset\", MathJax.Hub]); } } init_mathjax(); Expectile Regression \u00b6 Imports \u00b6 In [2]: Copied! from lightgbmlss.model import * from lightgbmlss.distributions.Expectile import * from lightgbmlss.datasets.data_loader import load_simulated_gaussian_data import plotnine from plotnine import * plotnine . options . figure_size = ( 20 , 10 ) from lightgbmlss.model import * from lightgbmlss.distributions.Expectile import * from lightgbmlss.datasets.data_loader import load_simulated_gaussian_data import plotnine from plotnine import * plotnine.options.figure_size = (20, 10) Data \u00b6 In [3]: Copied! # The data is a simulated Gaussian as follows, where x is the only true feature and all others are noise variables # loc = 10 # scale = 1 + 4*((0.3 < x) & (x < 0.5)) + 2*(x > 0.7) train , test = load_simulated_gaussian_data () X_train , y_train = train . filter ( regex = \"x\" ), train [ \"y\" ] . values X_test , y_test = test . filter ( regex = \"x\" ), test [ \"y\" ] . values dtrain = lgb . Dataset ( X_train , label = y_train ) # The data is a simulated Gaussian as follows, where x is the only true feature and all others are noise variables # loc = 10 # scale = 1 + 4*((0.3 < x) & (x < 0.5)) + 2*(x > 0.7) train, test = load_simulated_gaussian_data() X_train, y_train = train.filter(regex=\"x\"), train[\"y\"].values X_test, y_test = test.filter(regex=\"x\"), test[\"y\"].values dtrain = lgb.Dataset(X_train, label=y_train) Expectile Specification \u00b6 In [4]: Copied! lgblss = LightGBMLSS ( Expectile ( stabilization = \"None\" , # Options are \"None\", \"MAD\", \"L2\". expectiles = [ 0.05 , 0.95 ], # List of expectiles to be estimated, in increasing order. penalize_crossing = True # Whether to include a penalty term to discourage crossing of expectiles. ) ) lgblss = LightGBMLSS( Expectile(stabilization=\"None\", # Options are \"None\", \"MAD\", \"L2\". expectiles = [0.05, 0.95], # List of expectiles to be estimated, in increasing order. penalize_crossing = True # Whether to include a penalty term to discourage crossing of expectiles. ) ) Hyper-Parameter Optimization \u00b6 Any LightGBM hyperparameter can be tuned, where the structure of the parameter dictionary needs to be as follows: - Float/Int sample_type - {\"param_name\": [\"sample_type\", low, high, log]} - sample_type: str, Type of sampling, e.g., \"float\" or \"int\" - low: int, Lower endpoint of the range of suggested values - high: int, Upper endpoint of the range of suggested values - log: bool, Flag to sample the value from the log domain or not - Example: {\"eta\": \"float\", low=1e-5, high=1, log=True]} - Categorical sample_type - {\"param_name\": [\"sample_type\", [\"choice1\", \"choice2\", \"choice3\", \"...\"]]} - sample_type: str, Type of sampling, either \"categorical\" - choice1, choice2, choice3, ...: str, Possible choices for the parameter - Example: {\"boosting\": [\"categorical\", [\"gbdt\", \"dart\"]]} - For parameters without tunable choice (this is needed if tree_method = \"gpu_hist\" and gpu_id needs to be specified) - {\"param_name\": [\"none\", [value]]}, - param_name: str, Name of the parameter - value: int, Value of the parameter - Example: {\"gpu_id\": [\"none\", [0]]} In [5]: Copied! param_dict = { \"eta\" : [ \"float\" , { \"low\" : 1e-5 , \"high\" : 1 , \"log\" : True }], \"max_depth\" : [ \"int\" , { \"low\" : 1 , \"high\" : 10 , \"log\" : False }], \"num_leaves\" : [ \"int\" , { \"low\" : 255 , \"high\" : 255 , \"log\" : False }], # set to constant for this example \"min_data_in_leaf\" : [ \"int\" , { \"low\" : 20 , \"high\" : 20 , \"log\" : False }], # set to constant for this example \"min_gain_to_split\" : [ \"float\" , { \"low\" : 1e-8 , \"high\" : 40 , \"log\" : False }], \"min_sum_hessian_in_leaf\" : [ \"float\" , { \"low\" : 1e-8 , \"high\" : 500 , \"log\" : True }], \"subsample\" : [ \"float\" , { \"low\" : 0.2 , \"high\" : 1.0 , \"log\" : False }], \"feature_fraction\" : [ \"float\" , { \"low\" : 0.2 , \"high\" : 1.0 , \"log\" : False }], \"boosting\" : [ \"categorical\" , [ \"gbdt\" ]], } np . random . seed ( 123 ) opt_param = lgblss . hyper_opt ( param_dict , dtrain , num_boost_round = 100 , # Number of boosting iterations. nfold = 5 , # Number of cv-folds. early_stopping_rounds = 20 , # Number of early-stopping rounds max_minutes = 10 , # Time budget in minutes, i.e., stop study after the given number of minutes. n_trials = 30 , # The number of trials. If this argument is set to None, there is no limitation on the number of trials. silence = False , # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed = 123 , # Seed used to generate cv-folds. hp_seed = None # Seed for random number generator used in the Bayesian hyperparameter search. ) param_dict = { \"eta\": [\"float\", {\"low\": 1e-5, \"high\": 1, \"log\": True}], \"max_depth\": [\"int\", {\"low\": 1, \"high\": 10, \"log\": False}], \"num_leaves\": [\"int\", {\"low\": 255, \"high\": 255, \"log\": False}], # set to constant for this example \"min_data_in_leaf\": [\"int\", {\"low\": 20, \"high\": 20, \"log\": False}], # set to constant for this example \"min_gain_to_split\": [\"float\", {\"low\": 1e-8, \"high\": 40, \"log\": False}], \"min_sum_hessian_in_leaf\": [\"float\", {\"low\": 1e-8, \"high\": 500, \"log\": True}], \"subsample\": [\"float\", {\"low\": 0.2, \"high\": 1.0, \"log\": False}], \"feature_fraction\": [\"float\", {\"low\": 0.2, \"high\": 1.0, \"log\": False}], \"boosting\": [\"categorical\", [\"gbdt\"]], } np.random.seed(123) opt_param = lgblss.hyper_opt(param_dict, dtrain, num_boost_round=100, # Number of boosting iterations. nfold=5, # Number of cv-folds. early_stopping_rounds=20, # Number of early-stopping rounds max_minutes=10, # Time budget in minutes, i.e., stop study after the given number of minutes. n_trials=30, # The number of trials. If this argument is set to None, there is no limitation on the number of trials. silence=False, # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail. seed=123, # Seed used to generate cv-folds. hp_seed=None # Seed for random number generator used in the Bayesian hyperparameter search. ) [I 2023-08-11 12:21:09,469] A new study created in memory with name: LightGBMLSS Hyper-Parameter Optimization 0%| | 0/30 [00:000))return o;do o.push(new Date(+n));while(e(n,i),t(n),n