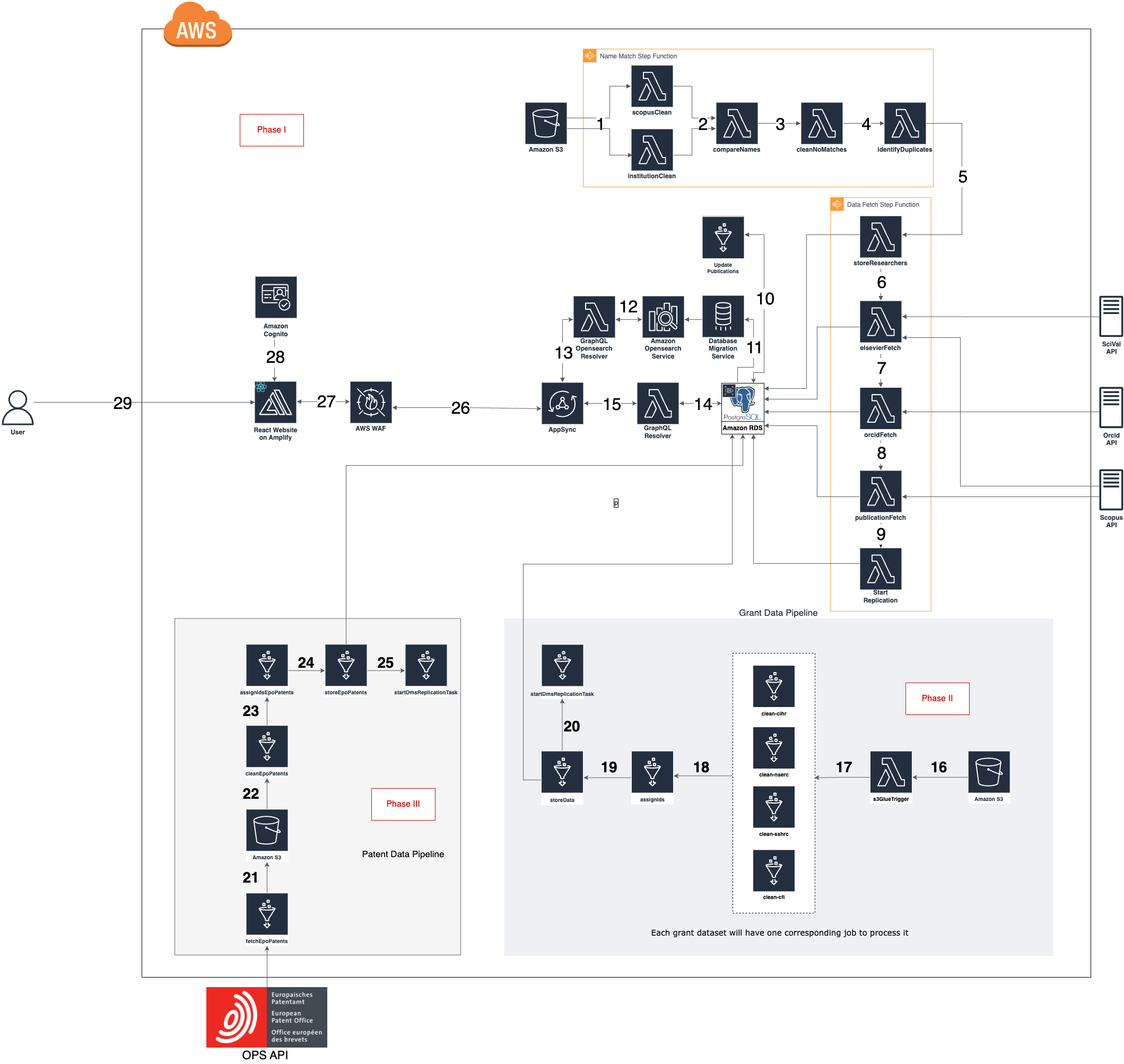
For AWS VPC Networking Details, see this document.
Architecture Diagram exported as XML file from draw.io can be found here.

Steps 1-9 are explored in more detail as part of the Data Pipeline Deep Dive
- Raw Scopus and Institution's HR data are fetched from an Amazon S3 bucket in the form of comma separated values (CSV) files. Both datasets are cleaned which involves standardizing the names present in both datasets. The results are then stored as CSV files in a new folder within the S3 bucket.
- The standardized names are compared in order to match Scopus Ids to Institution's HR data. This process uses a string metric called Jaro-Winkler distance in order to determine if two names are the same. The match that has the highest Jaro-Winkler distance is considered to be the closest match. If the Jaro-Winkler distance is above a certain threshold the match is considered final. If the match is below the threshold then the match requires further processing in step 3. If two or more potential matches have the same Jaro-Winkler Distance those matches are processed further in step 4.
- The matches that failed to meet the Jaro-Winkler distance threshold are further processed by comparing data obtained from Scopus to the Institution's HR data. First there is a comparison between the researchers department and subject area data from Scopus. Next there is a comparison between the researchers name and name variants present on Scopus.
- The researchers that have been matched to more than one Scopus Id are processed further by comparing Scopus subject area and name variant data against Institution's department and faculty data.
- Researchers whose Scopus Id’s were identified in steps 2-4 have their data stored in the Postgres database.
- For each Scopus Id in the database, metrics are fetched from the SciVal and Scopus APIs. Number of documents, number of citations, and ORCID Id are obtained from Scopus and a 5-year h-index is obtained from SciVal. This data is stored in the Postgres database.
- The number of filed patents listed on ORCID is fetched from the ORCID API and stored in the database
- Each researcher's publication data is fetched from the Scopus API and stored in the database. This data includes each publication’s title, associated keywords, author names and Scopus ids, journal title, and the number of times the publication has been cited.
- The start replication Lambda will start the DMS replication task to replicate data from the PostgreSQL database to the AWS Opensearch cluster to make the data searchable on the webapp.
- Every Saturday at midnight a Glue Job will be run to update the publications of the researchers in the database. It will update researcher’s h-indexes and number of publications. Update publications will also add newly published publications to the database and remove publications with no current Institution's researchers.
- Once per week the AWS DMS task will be run to replicate data from the PostgreSQL database to AWS opensearch. This makes the data searchable and keeps the searches up to date.
- When queried, the Lambda communicates with AWS OpenSearch and executes the search required.
- AWS Appsync triggers the OpenSearch Lambda and passes the correct variables needed to execute the query.
- When queried, Lambda connects to the RDS PostgreSQL database and gets the data requested by AppSync.
- AWS AppSync triggers the PostgreSQL Lambda and passes the correct variables needed to get the required data.
Step 16-20 are explored in more detail as part of the Grant Data Pipeline Deep Dive
- When files are uploaded to the S3 bucket, an Object upload event notification will be sent out to the Lambda function. The Function will filter the event received and in turns will invoke the correct Glue job. Some Glue jobs (clean-...-pythonshell, assign-ids-pythonshell) will create temporary subfolders and files in the same bucket, and the bucket will in turns create corresponding event notification to the Lambda function again, and again to invoke Glue jobs downstream of the pipeline, until the grant data is put in the PostgreSQL database.
- Raw grant data (currently CIHR, NSERC, SSHRC, CFI) are fetched from an Amazon S3 bucket in the form of comma separated values (CSV) files. The datasets are cleaned which involves standardizing the researcher names, modifying date encoding format, remove special characters. The researcher names are separated into First Name and Last Name for name matching in the next step. The results are stored in a temporary folder called clean in the same S3 bucket. A bucket event notification will be issued to the handling Lambda function to invoke the assign-ids-pythonshell job
- The standardized names are then compare with the researcher names that are already in the database. The name strings are compared using a string metric called Jaro-Winkler distance to see if the two names are similar enough to be considered belonging to the same person (see fuzzy string matching). If the Jaro-Winkler distance is above a certain threshold then it is a complete match, otherwise the name is ignored (not processed). For each complete match, it also include the researcher_id from our database associated with that person. The results are stored again in a temporary folder called ids-assigned in the same S3 bucket. A bucket event notification will be issued to the handling Lambda function to invoke the store-data-pythonshell
- This job will filtered out only the grant entries with an associated researcher id from earlier, and put the data into the PostgreSQL database. The pipeline is finished after this step.
- This job will start a Replication Task on Database Migration Service (DMS) to replicate the new grant data into AWS OpenSearch so that it is searchable on the web app.
Step 21-25 are explored in more detail as part of the Patent Data Pipeline Deep Dive
- This step fetches raw data from the API and stores it inside an S3 bucket as a CSV. This is achieved by making a GET request to the specific API endpoint that returns bibliographic data for patent publications. The query will retrieve all patent publications from the year 2001 up to the date on which the patent pipeline is invoked. Patent publication data includes both patent application documents (kind code A1, A2) and patent documents (kind code B1, B2, C) for both Canada (country code CA) and the United States (country code US).
- This step will get the raw data from S3 and perform the necessary cleaning steps. Data processing steps include: eliminating special characters, trimming white spaces, and modifying the date format. Additionally, inventors' names will be capitalized and split into first and last names for further processing downstream.
- With the first and last names separated, this step will match the names with the researcher names in the RDS PostgreSQL database. This process uses a string metric called Jaro-Winkler distance (see above) to determine if two names are the same. The match that has the highest Jaro-Winkler distance is considered to be the closest match:
- If the Jaro-Winkler distance is above a certain threshold, the match is considered final and the name will be assigned a unique ID associated with that researcher from the PostgreSQL database.
- After each CSV file has the IDs assigned, every First and Last name pair will be recombined into a single name.
- After each patent entry is name-matched, this step will insert the processed patent data into the RDS PostgreSQL under the patent_data table. Only patents with at least one matched researcher as an inventor will be inserted into the database.
- This step will start a data Replication Task on AWS Data Migration Service (DMS) to replicate the new patent data into AWS Opensearch Service. After this process is done, the data will be searchable on the front-end web app.

- All queries approved by AWS Web Application Firewall (WAF) are passed to AppSync.
- All queries are first sent to AWS WAF. This helps prevent malicious users from getting data or breaking the website with DDOS attacks.
- Users connect to the webpage, where access to AWS resources is done through authentication using AWS Cognito.
- Users navigate to the application in their web browser.
The goal of the update publications feature is to keep the database up to date when researchers publish new papers.
Update publications is run once a week at midnight (UTC time) on Saturday. To accomplish this, the following cron expression is used (0 0 ? * SAT *) (minute, hour, Day-of-month, Month, Day-of-week, Year). When the cron expression triggers, a Glue Job is invoked. When the Job is running, it runs a series of Python functions to update and add publications to the database.
When update publications is run, each researcher has their h-index value and last_updated value in the elsevier table updated. The last_updated value indicates to the user that a researcher’s data is up to date.
If a researcher has published a paper since the update publications function last ran, the following values will be changed in that researcher’s row in the researchers table: num_documents and keywords. Each newly published publication will be added to the publications table.

This function removes all the publications in the database that do not have an active Institution's researcher listed as an author. An active Institution's researcher is someone who has a row in the researchers table. Papers may get deleted because a researcher is removed from the researchers table or because a researcher's Scopus ID is changed.
This function queries the database for each researcher and sets the num_documents to a new value if required.
This function queries the database and Scopus to check if a researcher needs to be updated. If the researcher has less documents in the database than on Scopus the researcher must be updated and the code adds them to a list. This function also updates every researcher's h-index regardless of their number of documents changing. This is because their h-index can change even if they don’t publish a new paper.
This function fetches the publications of each researcher. There is a limitation with Scopus when you query for an author's publications. For each publication it will only show the first 100 authors on the publication, which can cause problems because Institution's authors on those publications might not be in the first 100 authors. So when the update publications function comes across a publication there are four possible options: The publication is not in the database and the publication has less than 100 authors. The publication is in the database and has less than 100 authors. The publication is not in the database and has more than 100 authors. The publication is in the database and has more than 100 authors.
Add the publication to the database, update any researchers num_documents who were a part of this publication and add to those researchers’ keywords with the keywords attached to this publication.
The code skips this publication because it is already in the database. Every author should have the keywords already and their num_documents should include this publication.
Check if the author which is being queried for in Scopus appears in the first 100 authors. If that author does not appear in the first 100, add that author to the array of author IDs and author names, then add the publication to the database and update any Institution authors’ keywords and num_documents.
Check if the publication has the queried author’s ID stored. If the author is already attached to the paper, skip this publication. If the author is not attached to the paper, add the current author to the publication, update the author’s keywords and increase their number of documents by one.
After all the researchers have been updated the update publications code triggers the AWS DMS replication task to start to replicate data from the PostgreSQL database to the opensearch cluster to make it searchable on the webapp and to keep the data up to date.