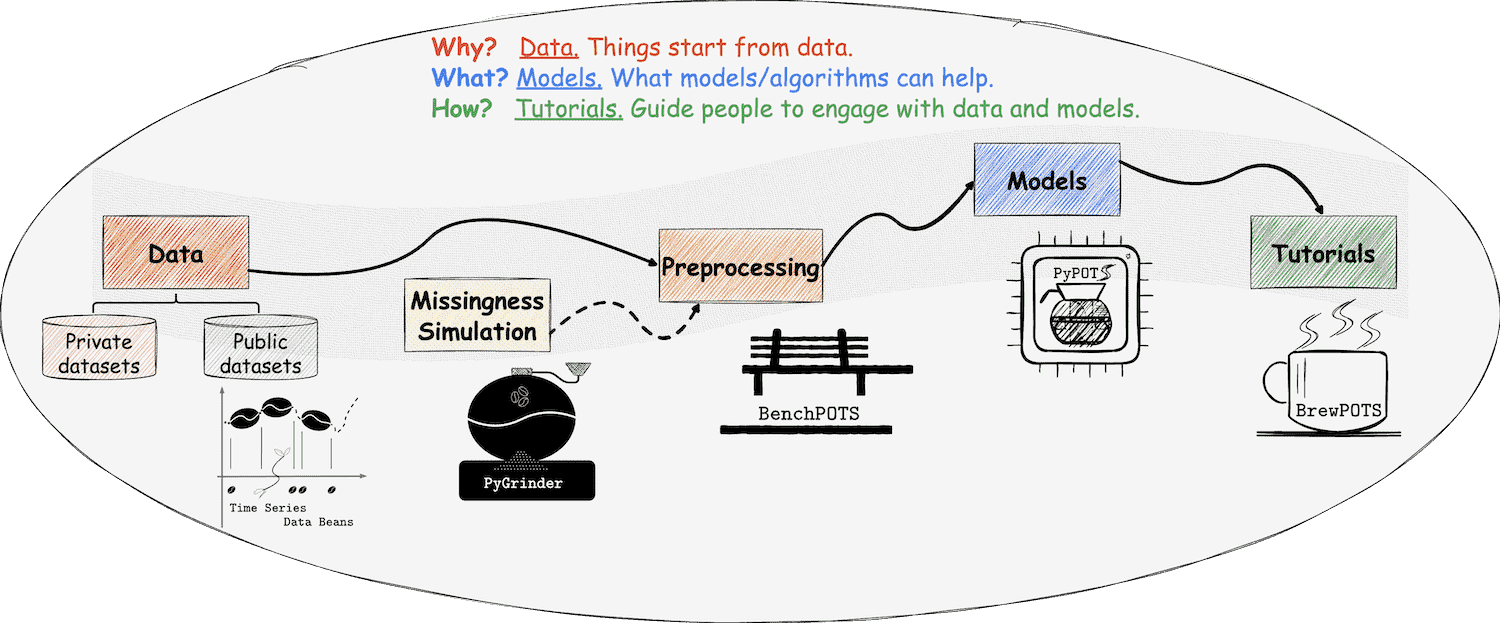
The tutorials help you brew Partially-Observed Time Series
The tutorials here are for PyPOTS users to quick start their practice, not for achieving the state-of-the-art performance. So we didn't fine tune the hyper-parameters of each models in the tutorials. You can tune the hyper-parameters by yourself to get better performance on the tutorial dataset PhysioNet-2012 or on your own datasets.
Enjoy it! ☕️ And have fun!
The paper introducing PyPOTS project is available on arXiv at this URL, and we are pursuing to publish it in prestigious academic venues, e.g. JMLR (track for Machine Learning Open Source Software). If the tutorials in BrewPOTS are helpful to your work, please cite PyPOTS project as below and 🌟star this repository to make others notice it. 🤗 Thank you!
@article{du2023PyPOTS,
title={{PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series}},
author={Wenjie Du},
year={2023},
eprint={2305.18811},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2305.18811},
doi={10.48550/arXiv.2305.18811},
}or
Wenjie Du. (2023). PyPOTS: a Python toolbox for data mining on Partially-Observed Time Series. arXiv, abs/2305.18811.https://arxiv.org/abs/2305.18811