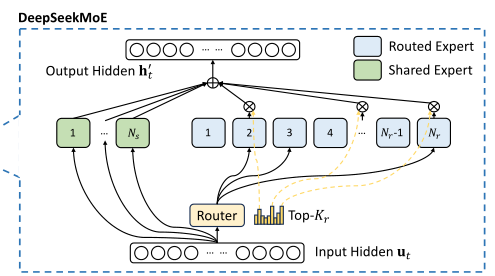
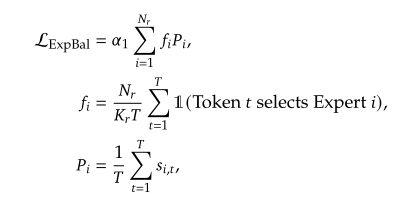
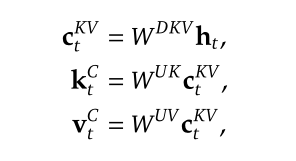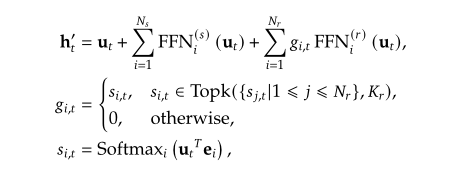-
-
公告
归路何方
+
+
公告
归路何方
目录
- 1. 计网实验期末考试常用指令
- 1.1. 配置NAT(关键)
- 1.2. VLAN:数据链路层
- 1.3. 三个数据链路层协议
- 1.4. OSPF协议
- 1.4.1. 配置Router ID
- 1.4.2. 启动OSPF
- 1.4.3. 显示OSPF调试信息
- 1.4.4. 配置回环地址(LoopBack)
- 1.4.5. 配置串口(Serial)
- 1.4.6. 配置OSPF Cost
- 1.4.7. 配置缺省路由
- 1.4.8. 查看OSPF LSDB(五类LSA如何查看)
- 1.4.9. 排查故障指令
- 1.4.10. 路由引入(重点中的重点)
- 1.4.11. tracert
- 1.4.12. OSPF的五种报文以及其交互过程
- 1.4.13. 路由器和交换机相连是某个网段相连,在这个网段下会选举路由器的接口作为DR,产生三类LSA;而两台路由器之间是点对点连接,无网段,无DR,BDR。
- 1.4.14. BDR和DR选举过程:
- 1.5. BGP实验
- 1.6. 复杂组网de坑
公告
归路何方
目录
- 1. 计网实验期末考试常用指令
- 1.1. 配置NAT(关键)
- 1.2. VLAN:数据链路层
- 1.3. 三个数据链路层协议
- 1.4. OSPF协议
- 1.4.1. 配置Router ID
- 1.4.2. 启动OSPF
- 1.4.3. 显示OSPF调试信息
- 1.4.4. 配置回环地址(LoopBack)
- 1.4.5. 配置串口(Serial)
- 1.4.6. 配置OSPF Cost
- 1.4.7. 配置缺省路由
- 1.4.8. 查看OSPF LSDB(五类LSA如何查看)
- 1.4.9. 排查故障指令
- 1.4.10. 路由引入(重点中的重点)
- 1.4.11. tracert
- 1.4.12. OSPF的五种报文以及其交互过程
- 1.4.13. 路由器和交换机相连是某个网段相连,在这个网段下会选举路由器的接口作为DR,产生三类LSA;而两台路由器之间是点对点连接,无网段,无DR,BDR。
- 1.4.14. BDR和DR选举过程:
- 1.5. BGP实验
- 1.6. 复杂组网de坑