-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy pathpython_ui
178 lines (160 loc) · 6.58 KB
/
python_ui
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
## Beyond Compare
Collected notes from: [Learn How to Quickly Create UIs in Python](https://towardsdatascience.com/learn-how-to-quickly-create-uis-in-python-a97ae1394d5).
<div style="text-align: right">Photo by Eftakher Alam on Unsplash</div>
### Motivation
Sometimes, however, your target audience is not technical enough.\\
They’d love to use your python scripts but only as long as they didn’t have to look at a single line of code.\\
They need a Uer Interface (UI) in such a case.\\
\* years ago, I used to code UIs using Java/Python/Matlab. They are good, but time-consuming in some cases. Some environments also provide graphical operations for UI design, which is essentially UI for UI designers :)
### The task
Design a UI to check if two files are identical, without mannually referecing to the Python scripts.\\
\* for file compare algorithms, pls check a previous post: [Beyond Compare](yongchaohuang/github.io/beyond_compare)\\
We essentially need a way to load up two files, and then choose the encryption we would like to use to do the file comparison.
## Python Libraries Available for UI usage
There are essentially 3 big Python UI libraries; Tkinter, wxPython and PyQT.
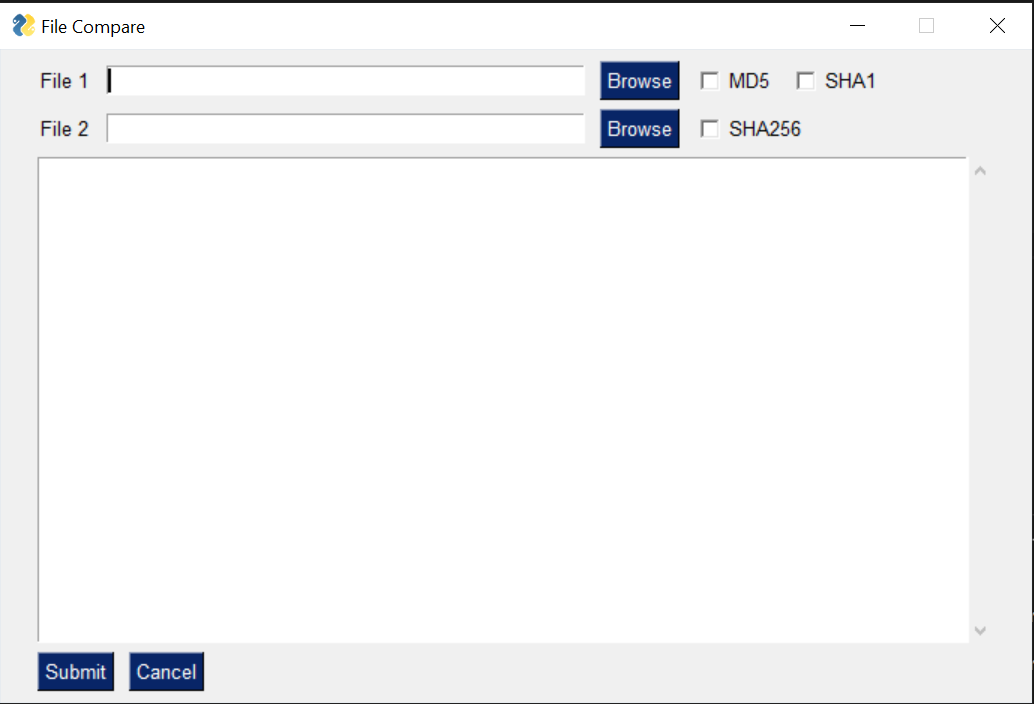
## Code the UI
To build that UI, we can use the following code:
```
import PySimpleGUI as sg
layout = [
[sg.Text('File 1'), sg.InputText(), sg.FileBrowse(),
sg.Checkbox('MD5'), sg.Checkbox('SHA1')
],
[sg.Text('File 2'), sg.InputText(), sg.FileBrowse(),
sg.Checkbox('SHA256')
],
[sg.Output(size=(88, 20))],
[sg.Submit(), sg.Cancel()]
]
window = sg.Window('File Compare', layout)
while True: # The Event Loop
event, values = window.read()
# print(event, values) #debug
if event in (None, 'Exit', 'Cancel'):
break
```
which results in:
### The Pythonic way
The original article introduces a Python-based approach to quickly compare two files, this is the focus of this note.
\\
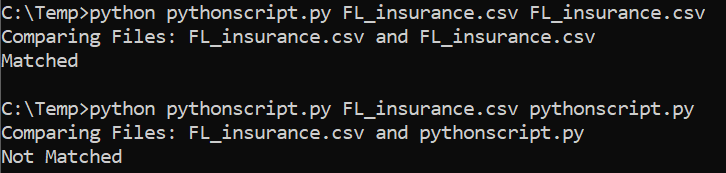
1. Check the integrity of data
* - MD5 Checksum: returns a hexadecimal number for the contents of a file.
```
import hashlib, sys
files = [sys.argv[1], sys.argv[2]] #these are the arguments we take
def md5(fname):
md5hash = hashlib.md5()
with open(fname) as handle: #opening the file one line at a time for memory considerations
for line in handle:
md5hash.update(line.encode('utf-8'))
return(md5hash.hexdigest())
print('Comparing Files:',files[0],'and',files[1])
if md5(files[0]) == md5(files[1]):
print('Matched')
else:
print('Not Matched')
```
Running above gives: \\

* - the SHA1 algorithm: another hexadecimal algorithm that converts file contents into a string.
```
import hashlib, sys
files = [sys.argv[1], sys.argv[2]] #these are the arguments we take
def sha1(fname):
sha1hash = hashlib.sha1()
with open(fname) as handle: #opening the file one line at a time for memory considerations
for line in handle:
sha1hash.update(line.encode('utf-8'))
return(sha1hash.hexdigest())
print('Comparing Files:',files[0],'and',files[1])
if sha1(files[0]) == sha1(files[1]):
print('Matched')
else:
print('Not Matched')
```
Running above gives: \\
2. Check data contents with SQL\\
Using a couple of Python libraries, we can import our files into an SQL database, and use the Except Operator to highlight any differences.\\
\* The only thing to note is that Except expects the data to be ordered; otherwise, it will highlight everything as a difference.
```
import sys, sqlite3, pandas as pd
files = [sys.argv[1], sys.argv[2]] #these are the arguments we take
conn = sqlite3.connect(':memory:') #we are spinning an SQL db in memory
cur = conn.cursor()
chunksize = 10000
i=0
for file in files:
i = i+1
for chunk in pd.read_csv(file, chunksize=chunksize): #load the file in chunks in case its too big
chunk.columns = chunk.columns.str.replace(' ', '_') #replacing spaces with underscores for column names
chunk.to_sql(name='file' + str(i), con=conn, if_exists='append')
print('Comparing', files[0], 'to', files[1]) #Compare if all data from File[0] are present in File[1]
cur.execute( '''SELECT * FROM File1
EXCEPT
SELECT * FROM File2''')
i=0
for row in cur:
print(row)
i=i+1
if i==0: print('No Differences')
print('Comparing', files[1], 'to', files[0]) #Compare if all data from File[1] are present in File[0]
cur.execute( '''SELECT * FROM File2
EXCEPT
SELECT * FROM File1''')
i=0
for row in cur:
print(row)
i=i+1
if i==0: print('No Differences')
cur.close()
```
Running above gives: \\

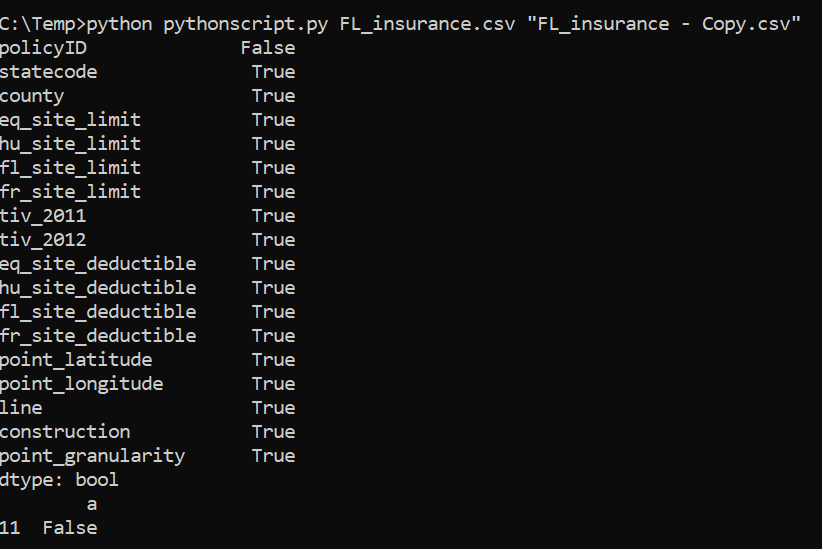
3. Check data contents with Pandas\\
\* prepare data in a dataframe
- Using the .equals() method
```
import sys, sqlite3, pandas as pd
files = [sys.argv[1], sys.argv[2]] #these are the arguments we take
df1 = pd.read_csv(files[0])
df2 = pd.read_csv(files[1])
df3 = df1.equals(df2)
print('Matches:', df3)
```
Running above gives: \\

- Using the .any()
```
import sys, sqlite3, pandas as pd
files = [sys.argv[1], sys.argv[2]] #these are the arguments we take
df1 = pd.read_csv(files[0])
df2 = pd.read_csv(files[1])
df3 = (df1 != df2).any(axis=None)
print('Differences in file:', df3)
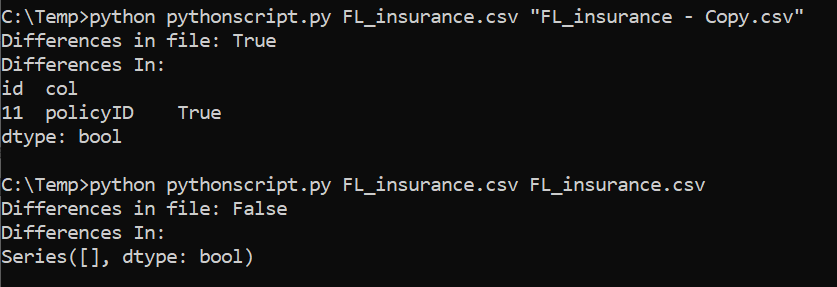
df3 = (df1 != df2).any(1)
ne_stacked = (df1 != df2).stack()
changed = ne_stacked[ne_stacked]
changed.index.names = ['id', 'col']
print('Differences In:')
print(changed)
```
Running above gives: \\
- Using the .Eq()
```
import sys, sqlite3, pandas as pd, numpy as np
files = [sys.argv[1], sys.argv[2]] #these are the arguments we take
df1 = pd.read_csv(files[0])
df2 = pd.read_csv(files[1])
df3 = df1.eq(df2)
print(df3.all())
#print(df3.all(axis=1))
df4 = df3.all(axis=1)
df4 = pd.DataFrame(df4, columns=['Columns'])
print(df4[df4['Columns']==False])
```
Running above gives: \\