本文仅为笔者为记录NeRF学习过程所编写,包括前置知识汇总、论文及代码解读。
NeRF,全称为神经辐射场(Neural Radiance Fields),是一种利用神经网络来表示和渲染复杂三维场景的方法。它能够从一组二维图片中学习出一个连续的三维函数,这个函数可以给出空间中任意位置和方向上的颜色和密度。通过体积渲染,NeRF可以从任意视角合成出逼真的图像,包括透明和半透明物体,以及复杂的光线传播效果。
要进行NeRF相关学习,绕不开一系列前置知识的掌握,涵盖计算机图形学、高等代数、计算机视觉以及深度学习相关知识。笔者的学习策略是用哪学哪,故本文也只记录NeRF相关知识。请在阅读前至少完成深度学习入门,起码对感知机和矩阵运算有一定掌握。
本章节内容主要是对NeRF在理论上进行拆解,罗列需要学习的前置知识以及在NeRF中的使用。本章节内容主要参考b站up主SY_007的NeRF教学视频。
学习之前,我们先要搞清楚渲染和反渲染是什么。3D模型可拆分为形状及外观,外观又涵盖material和lighting,经过渲染可得到不同视角的2D图像。
那么渲染是什么呢?事实上,渲染是计算机图形学中的一个过程,它涉及将三维场景转换为二维图像。这个过程通常包括几何变换、光照计算、纹理映射、着色等步骤,目的是生成视觉上令人信服的图像。在游戏、电影制作、建筑设计等领域,渲染是创建视觉内容的关键技术。
而想实现从图片中恢复出三维场景的信息,就需要用到反渲染技术(Inverse Rendering)。反渲染则是一个逆向过程,它尝试从已知的二维图像中恢复三维场景的信息。这通常涉及到估计场景的几何结构、材质属性、光照条件和相机参数。反渲染的目标是解决渲染方程的逆问题,即给定一个观察到的图像,推断出场景的可能配置。
在 NeRF(Neural Radiance Fields)技术中,反渲染的概念被用于从稀疏的输入视图出发,优化底层连续体积场景函数,从而实现新视角的合成。NeRF 通过训练一个深度神经网络来隐式地表示三维场景,并能够从这个隐式表示中渲染出高质量的新视角图像。
而在反渲染过程中,有三个关键因素,即怎样去表征形状,怎样去表征外观,如何渲染成图片。
常见的形状表征方式如下图所示:
不同的形状表征方式有着不同的表征难度、优化特点
对于外观表征,要表征出纹理材质以及光照阴影:
左图为材料及环境光照分开表征的外观表征方式,右图是NeRF中提到的辐射场的表征方式
下方是光线追踪(Ray Tracing),是一种在计算机图形学中用于生成二维图像的三维场景渲染技术。它模拟了光线如何在场景中传播,并与场景中的对象相互作用,从而产生逼真的视觉效果。
体渲染技术属于渲染技术的分支,目的是解决云/烟/果冻等非刚体[^1]物体的渲染建模,将物质抽象成一团飘忽不定的粒子群。当光线穿过时,光子[^2]会与粒子发生碰撞。二者的作用过程如下:
- 吸收:光子被粒子吸收
- 放射:粒子本身发光
- 外射光与内射光:可简单理解为其他物体反射来的光以及我们折射给其他物体的光
NeRF假设,物体是一团自发光的粒子,有密度和颜色。且外射光和内射光抵消,多个粒子被渲染成指定角度的图片。
在NeRF中,模型的输入其实是将物体进行稀疏表示[^3]的单个粒子的位姿。而模型的输出则是该粒子的密度和颜色。问题随之出现了,我们理解的模型输入输出还有数据集不应该是图片组成的吗?上文提到的粒子从何而来?粒子又怎么渲染成图片?
对于空间中的某一发光粒子,假设它的空间坐标是(x,y,z),发射光线穿过相机模型成为图片上的像素坐标(u,v),粒子的颜色即为像素的颜色。两个坐标之间的转换如下图所示:
具体数学公式的推导涉及世界坐标系与像素坐标的转换、齐次坐标与欧式坐标的转换,可以简单理解为world坐标系下的坐标乘相机内参矩阵与外参矩阵(即位姿)可实现w2c(world to camera),RT为旋转和平移矩阵。具体公式的推导可移步鲁鹏的三维重建课程第一节。
上述转换是已知粒子推图片的正向渲染过程。反之,在NeRF中,对于一张图片的某一个像素(u,v)的颜色,可以看作是沿某一条射线上的无数发光点的“和”。利用相机模型可以反推出射线,可以将这条射线表示为r(t)=o+td,O为原点射线,d为方向,t为距离,可取值0到+∞。对于一张H×W大小的图片,就有H×W条射线。那么怎么从像素点反推射线呢?请看下图,其中f为焦距:
上述内容其实就是前处理过程。我们已经可以回答上文提出的问题,图片用在哪?怎么得到粒子?事实上,我们会用图片和相机位姿来计算射线,从射线上采样粒子。训练时,我们可以从一张图片中取样1024个像素,得到1024条射线,每条射线上取样64个粒子,一共1024*64个粒子,这里取样的粒子也可以理解为深度学习中的batch,粒子以batch的形式输入模型,矩阵大小是[1024,64,3],其中3是x,y,z。后续会与计算得出的2D位姿一起作为5D向量输入模型,这一部分会在代码解读中详细解释。
在NeRF中,我们输入的是5D向量,得到的输出是关于粒子的密度和颜色的2D向量,那么之后又是怎么渲染成图片的呢?这就要提到NeRF中的后处理。
让我们先观察一下论文使用的神经网络模型。本论文用到的模型可进行如下概括:
-
模型的输入是5D向量,(x,y,z,θ,φ),也就是单个粒子的位姿
-
模型的输出是4D向量,(density,R,G,B),也就是该粒子的密度和颜色
-
模型的结构是8层的MLP
模型本身是比较简单的,可以看出NeRF的重点在于前后处理的过程,如将一张图片转化为5D向量,将4D向量转为2D图片,这也是论文关注的重点问题
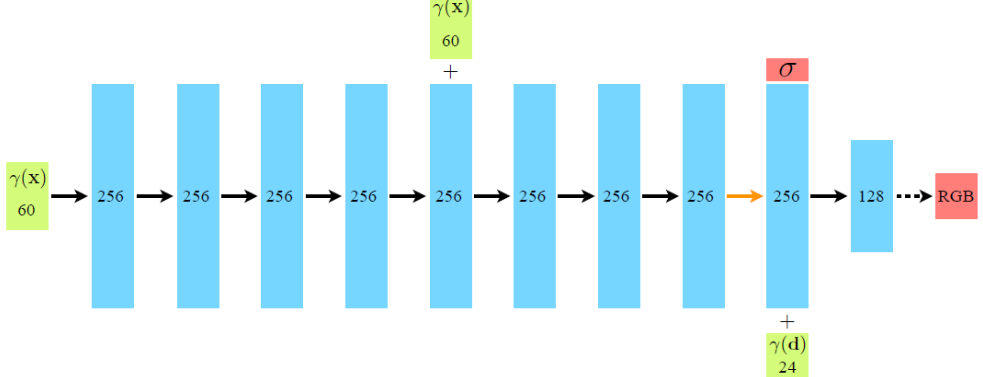
上面是NeRF中神经网络的结构,随之产生问题。前文提到NeRF的输入不是一个5D的向量,怎么图中会有一个60D和一个24D的向量作为输入呢?
事实上,在NeRF中,只输入简单的位置和视角的话,建模结果会丢失细节,缺乏高频信息[^4]。故论文引入了与transformer中相同的技术--位置编码。位置编码是一种将输入的三维空间坐标(例如,一个点在3D空间中的位置)编码为神经网络能够处理的高维向量的方法。这种编码方法使得神经网络能够学习到空间中不同位置的特征表示,进而用于渲染或重建3D场景。
具体来说,位置编码通过正弦和余弦函数的变换来引入高频信息。对于位置信息x(归一化到[-1, 1]区间),通常会选择一个编码的长度L(例如L=10),然后对每个维度的位置信息应用正弦和余弦函数的不同频率,生成一个编码向量。对于方向信息d,编码长度L可能会有所不同(例如L=4)。这样,位置编码帮助多层感知机(MLP)学习到更丰富的细节信息,从而提高NeRF的性能。
NeRF采用自监督[^5],GT(Ground Truth)即真实值,是图片某一像素的RGB。将该像素对应光线上的粒子颜色进行"求和",得到的粒子的颜色"和"则是该像素颜色的预测值,然后用这个预测值与真实像素颜色做MSE可以得到loss。那么粒子到底如何求"和"呢?
为了解决上述问题,我们要先引入一个数学公式来求出像素的颜色,它来自NeRF论文原文:
可以想象一个粒子的前面的粒子异常明亮,则后面的粒子颜色其实会被遮盖,故引入T(s)。T(s)是在s点之前,光线没有被阻碍的概率。σ(s)是在s点处,光线碰击粒子的概率密度(不透明度),C(s)是在s点处,粒子光的颜色。
T(s)的推导过程如下:
第一行公式的意思是,在射线上一点s处,其后方ds长度之后的点光线没有被阻碍的概率等于在s点没有被阻拦的概率乘以ds这一段没有被阻拦的概率,σ(s)的图像如下图所示。密度越大,被阻碍的概率就越大。故未被阻拦的概率是(1-σ(s)ds)。后续的计算则是基本的微积分计算,值得注意的是T(0)是在开始时被阻碍的概率,此时必然不会被阻碍故值为0。
值得注意的是上述公式是一个连续的积分,而计算机只能处理离散的数据,故我们需要离散化数据。将光线分为n个等间距区间,假设区间内密度和颜色固定,下图是与上述公式等价的公式。
现在,可以回答在Volume rendering 1中提出的问题,即如何把粒子渲染成新的图片。步骤如下:
-
分别计算出图片中每一个像素的颜色
-
计算该像素对应的光线和粒子
-
将这些粒子通过公式累加
-
得到该像素最终颜色
我们终于可以理清大概的脉络。已知模型输入其实是一个5D向量,网络可以得到粒子的位置,因为这些粒子是从我们对图片中每个像素所定义的射线上均匀采样得到,但此时我们并不知道粒子的颜色。对于每个采样点,使用NeRF的神经网络模型预测该点的颜色 C 和密度 σ,通过体渲染的方法,沿射线积分来计算最终的像素颜色。根据每个采样点的贡献(颜色乘以透明度),从射线的近端到远端逐步累积颜色,最终得到我们的预测值。
a图中粒子为黑色,代表此时粒子颜色未知。b图表明我们其实是用射线上的一排粒子来计算像素的颜色。
其实,我们并没有大功告成。一个新的问题是我们均匀采样的前提下,会有许多无效区域(空白区域和遮挡区域)被采集,我们更希望多采样有效区域。对无效区域不采样或者少采样。论文的解决方法是使用概率密度再次采样。
事实上,NeRF的网络模型由两个MLP组成,相当于把两个8层的MLP串联。把第一个叫做粗模型,均匀采样64个点。第二个模型叫细模型,根据第一个模型输出的概率密度函数再去采样更有价值的点,再进行后续的操作。换句话说,粗模型对于射线上每一段区间均匀采样,细模型在出现概率更大的区间上再采样128个点,并与之前的点加到一起,即每条光线采样192个粒子。
这个概率是怎么来的呢?先对每条射线上的粒子颜色前的权重做softmax,此时新的权重和为1,可看作pdf.随后生成它的cdf再去反函数,用均匀分布drand48()生成一个随机数r,得到的r就是符合pdf分布的随机数。
假如图片大小是400*400,那么分别采样64个点后细模型再采样128个点,输出的大小为[400 * 400 * 192,4]。再对这个4(RGB,σ)进行体渲染。
终于,我们从理论上把NeRF拆解完毕,核心内容主要是体渲染、位置编码、层级采样。来做一下简单总结:
-
前处理:
-
将图片中的每个像素,通过相机模型找到对应的射线
-
在每条射线上进行采样,得到64个粒子
-
对batch_size*64个粒子进行位置编码
-
位置坐标为63D和方向向量为27D
注意此处的数字63和27是前文提到的60和24加上最开始x,y,z
-
-
模型1:
-
8层MLP
-
输入为(bacth_size,64,63)和(bacth_size,64,27)
-
输出为(bacth_size,64,4)
-
-
后处理1:
-
计算模型1的输出,对射线进行二次采样
-
每条射线上共采样192个粒子
-
-
模型2:
-
输入为(bacth_size,192,63)和(bacth_size,192,27)
-
输出为(bacth_size,192,4)
-
-
后处理2:
- 将模型输出通过体渲染,转换为像素
以上就是NeRF大致的流程,用简单的话来总结:在NeRF实验中,我们拥有一系列图像,我们知道它们的像素坐标,我们需要把这些像素坐标映射为相机坐标系,再从相机坐标系映射到世界坐标系。于是我们得到了世界坐标下的粒子,把它们输入到NeRF网络中去,得到它们的不透明度和RGB值,利用体渲染公式可以把这些粒子映射回像素值,这就是预测值。把预测值与这个点的真值去做loss,从而优化网络。那么NeRF有什么缺点呢?首先是训练速度很慢,也只能表达静态场景。对光照处理一般,也没有泛化能力。
在解析代码前,笔者想详细记录Numpy相关知识,因为代码中含有大量的np数组操作。
np数组中,只会存放一种数据类型,整形or浮点型。只要有一个元素是浮点型,整个数组都是浮点型。整数和浮点数数组的相互转换,规范的方法是使用.astype()方法。
整数型数组如果计算过程中与浮点型元素运算,会共同改变为浮点型数组。如果是除法即使除整数也会改变为浮点型
n维数组会使用n层中括号表示。假设有一个数组它的形状是(D1, D2, D3),这意味着:
D1是第一层(最外层)括号中的元素数量。D2是第二层括号中的元素数量。D3是第三层括号中的元素数量。
这个数组的形状可以通过.shape属性来查看。不同维度的数组也可以相互转化,使用reshape方法可以改变数组的形状而不改变其数据。例如,将一个一维数组重塑为二维数组。
arr = np.arange(6) # 创建一个一维数组 [0, 1, 2, 3, 4, 5] arr_2d = arr.reshape((2, 3)) 将一个一维数组重塑为2x3的二维数组。若给定了其他维度的数值,剩下的维度可以填入-1自动计算。
可以使用 np.arange 创建递增数组array = np.arange(start, stop, step)。
-
arr1=np,random.random((2,5))生成0-1均匀分布的浮点型随机数组 -
arr2=np.random.randint(10,100,(1,15)) 生成形状是(1,15)范围是10-100的随机数组 -
arr3=np.random.normal(0,1,(2,3))服从0-1正态分布的随机数组
-
访问向量:arr1[3] arr1[-1]
-
访问矩阵:arr2[0,2] 第0行第2列 arr2[1,-2] 第一行倒数第二列
访问矩阵中逗号用于区分行列,其实逗号还有新功能且不会与行列区分混淆。会套两层中括号。
#向量的花式索引
arr1 = np.arrange(0,90,10)
[0 10 20 30 40 50 60 70 80]
print( arr1[ [0,2] ]) #区别于行列区分的一层中括号
#矩阵的花式索引
arr2 = np.arange(1,17).reshape(4,4)
print(arr2)
[[1 2 3 4]
[5 6 7 8]
[9101112]
[13141516]]
print(arr2 [ [0,1],[0,1]) # 第一个括号是行 第二个括号是列 这里表示取0行0列和1行1列
print(arr2 [ [0,1,2],[2,1,0])
[1 6]
[3 6 9]
- 向量切片:索引负责其指向区域的右侧一个单元格
arr1 = np.arange(10)
print(arr1)
print(arr1[1:4])#1到4之前
print(arr1[1:])#1到结尾
print(arr1[:4])#开头到4之前
print(arr1[ : :2])#从开头切到结尾 每2个元素切一次
print(arr1[1:-1:2])#切除一头一尾后,每2个元素采样一次
- 矩阵切片
arr2 = np.arange(1,21).reshape(4,5)
print(arr2)
print(arr2[1:3,1:-1]) #先切第一行到第三行前,然后切第一列到倒数第一列前
print(arr2[::3,::2])#跳跃采样
print(arr2[2,:])#提取第二行 == arr2[2]
print(arr2[:,3])#提取第二列 != arr2[3] 输出的是向量不是矩阵目的是节约空间
print(arr2[1:3,:])#提取第一至二行
提取行可以简写,列不可以。arr[1][2]是先提取第一行再提取该行第二个元素。
可以将提取列后输出的向量进行reshape(1,-1)来变成矩阵形式,再进行转置.T变为列矩阵,也可以直接reshape(-1,1)
Numpy的切片仅是原数组的视图,而不是真的创建了新变量。
本文选用的NeRF项目为基于pytorch的开源代码,框架图如下:

在上述框架图中,首先要从config_parse 中读取文件参数,在这个过程中可能会用到configargparse库,它是一个扩展了argparse库的库。所谓argument parse,是指命令行参数解析器。建议你先观看该视频。
该模块存放的是基本参数
def config_parser():
# 生成config.txt文件
parser.add_argument('--config', is_config_file=True,
help='config file path')
# 指定实验名称
parser.add_argument("--expname", type=str,
help='experiment name')
# 指定输出目录
parser.add_argument("--basedir", type=str, default='./logs/',
help='where to store ckpts and logs')
# 指定数据目录
parser.add_argument("--datadir", type=str, default='./data/llff/fern',
help='input data directory')
# training options
# 设置网络的深度,即网络的层数
parser.add_argument("--netdepth", type=int, default=8,
help='layers in network')
# 设置网络的宽度,即每一层神经元的个数
parser.add_argument("--netwidth", type=int, default=256,
help='channels per layer')
parser.add_argument("--netdepth_fine", type=int, default=8,
help='layers in fine network')
parser.add_argument("--netwidth_fine", type=int, default=256,
help='channels per layer in fine network')
# batch size,光束的数量
parser.add_argument("--N_rand", type=int, default=32*32*4,
help='batch size (number of random rays per gradient step)')
# 学习率
parser.add_argument("--lrate", type=float, default=5e-4,
help='learning rate')
# 指数学习率衰减
parser.add_argument("--lrate_decay", type=int, default=250,
help='exponential learning rate decay (in 1000 steps)')
# 并行处理的光线数量,如果溢出则减少
parser.add_argument("--chunk", type=int, default=1024*32,
help='number of rays processed in parallel, decrease if running out of memory')
# 并行发送的点数
parser.add_argument("--netchunk", type=int, default=1024*64,
help='number of pts sent through network in parallel, decrease if running out of memory')
# 一次只能从一张图片中获取随机光线
parser.add_argument("--no_batching", action='store_true',
help='only take random rays from 1 image at a time')
# 不要从保存的模型中加载权重
parser.add_argument("--no_reload", action='store_true',
help='do not reload weights from saved ckpt')
# 为粗网络重新加载特定权重
parser.add_argument("--ft_path", type=str, default=None,
help='specific weights npy file to reload for coarse network')
# rendering options
# 每条射线的粗样本数
parser.add_argument("--N_samples", type=int, default=64,
help='number of coarse samples per ray')
# 每条射线附加的细样本数
parser.add_argument("--N_importance", type=int, default=0,
help='number of additional fine samples per ray')
# 抖动
parser.add_argument("--perturb", type=float, default=1.,
help='set to 0. for no jitter, 1. for jitter')
parser.add_argument("--use_viewdirs", action='store_true',
help='use full 5D input instead of 3D')
# 默认位置编码
parser.add_argument("--i_embed", type=int, default=0,
help='set 0 for default positional encoding, -1 for none')
# 多分辨率
parser.add_argument("--multires", type=int, default=10,
help='log2 of max freq for positional encoding (3D location)')
# 2D方向的多分辨率
parser.add_argument("--multires_views", type=int, default=4,
help='log2 of max freq for positional encoding (2D direction)')
# 噪音方差
parser.add_argument("--raw_noise_std", type=float, default=0.,
help='std dev of noise added to regularize sigma_a output, 1e0 recommended')
# 不要优化,重新加载权重和渲染render_poses路径
parser.add_argument("--render_only", action='store_true',
help='do not optimize, reload weights and render out render_poses path')
# 渲染测试集而不是render_poses路径
parser.add_argument("--render_test", action='store_true',
help='render the test set instead of render_poses path')
# 下采样因子以加快渲染速度,设置为 4 或 8 用于快速预览
parser.add_argument("--render_factor", type=int, default=0,
help='downsampling factor to speed up renderi
ng, set 4 or 8 for fast preview')
# training options
parser.add_argument("--precrop_iters", type=int, default=0,
help='number of steps to train on central crops')
parser.add_argument("--precrop_frac", type=float,
default=.5, help='fraction of img taken for central crops')
# dataset options
parser.add_argument("--dataset_type", type=str, default='llff',
help='options: llff / blender / deepvoxels')
# # 将从测试/验证集中加载 1/N 图像,这对于像 deepvoxels 这样的大型数据集很有用
parser.add_argument("--testskip", type=int, default=8,
help='will load 1/N images from test/val sets, useful for large datasets like deepvoxels')
## deepvoxels flags
parser.add_argument("--shape", type=str, default='greek',
help='options : armchair / cube / greek / vase')
## blender flags
parser.add_argument("--white_bkgd", action='store_true',
help='set to render synthetic data on a white bkgd (always use for dvoxels)')
parser.add_argument("--half_res", action='store_true',
help='load blender synthetic data at 400x400 instead of 800x800')
## llff flags
# LLFF下采样因子
parser.add_argument("--factor", type=int, default=8,
help='downsample factor for LLFF images')
parser.add_argument("--no_ndc", action='store_true',
help='do not use normalized device coordinates (set for non-forward facing scenes)')
parser.add_argument("--lindisp", action='store_true',
help='sampling linearly in disparity rather than depth')
parser.add_argument("--spherify", action='store_true',
help='set for spherical 360 scenes')
parser.add_argument("--llffhold", type=int, default=8,
help='will take every 1/N images as LLFF test set, paper uses 8')
# logging/saving options
parser.add_argument("--i_print", type=int, default=100,
help='frequency of console printout and metric loggin')
parser.add_argument("--i_img", type=int, default=500,
help='frequency of tensorboard image logging')
parser.add_argument("--i_weights", type=int, default=10000,
help='frequency of weight ckpt saving')
parser.add_argument("--i_testset", type=int, default=50000,
help='frequency of testset saving')
parser.add_argument("--i_video", type=int, default=50000,
help='frequency of render_poses video saving')
注意第432行代码的文件名需要手动修改
设置完参数后,我们来看训练的部分。还记得理论部分的内容吗?我们输入的是5D向量,得到4D向量的输出(颜色和密度)。首先会有数据集类型的判定,我们使用的是llff格式。
def train():
parser = config_parser()
args = parser.parse_args()
# Load data
K = None #初始化一个k用来保存相机内参
if args.dataset_type == 'llff':
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75, spherify=args.spherify)
之后会调用load_llff_data函数来解析数据集,让我们观察来该函数的内部。
由于源码阅读困难,所以下文记录顺序可能比较混乱。笔者建议从下图掌握数据加载部分整体流程。

def load_llff_data(basedir, factor=8, recenter=True, bd_factor=.75, spherify=False, path_zflat=False):
poses, bds, imgs = _load_data(basedir, factor=factor) # factor=8 downsamples original imgs by 8x
print('Loaded', basedir, bds.min(), bds.max())
# Correct rotation matrix ordering and move variable dim to axis 0
'''
np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1)指的是进行矩阵变换,将poses每个通道的第0行的相反数和第1行互换位置;
紧接着用np.moveaxis(poses, -1, 0).astype(np.float32)将坐标轴的第-1轴换到第0轴;
得到的poses的shape为(20,3,5)
imgs同理,变换完的shape为(20,378,504,3)
bds的shape为(20,2)
'''
poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1)
poses = np.moveaxis(poses, -1, 0).astype(np.float32)
imgs = np.moveaxis(imgs, -1, 0).astype(np.float32)
images = imgs
bds = np.moveaxis(bds, -1, 0).astype(np.float32)
# Rescale if bd_factor is provided
# 深度边界和平移变换向量一同进行缩放
sc = 1. if bd_factor is None else 1./(bds.min() * bd_factor)
poses[:,:3,3] *= sc #第0到第2行,第3列的元素,即平移分量
bds *= sc
if recenter:
# 计算poses的均值,将所有pose做该均值的逆转换,即重新定义了世界坐标系,原点大致在被测物中心;
poses = recenter_poses(poses)
if spherify:
poses, render_poses, bds = spherify_poses(poses, bds)
else:
# 经过recenter pose均值逆变换处理后,旋转矩阵变为单位阵,平移矩阵变为0
'''[[ 1.0000000e+00 0.0000000e+00 0.0000000e+00 1.4901161e-09]
[ 0.0000000e+00 1.0000000e+00 -1.8730975e-09 -9.6857544e-09]
[-0.0000000e+00 1.8730975e-09 1.0000000e+00 0.0000000e+00]]
'''
c2w = poses_avg(poses)
print('recentered', c2w.shape)
print(c2w[:3,:4])
## Get spiral
# Get average pose
up = normalize(poses[:, :3, 1].sum(0))
# Find a reasonable "focus depth" for this dataset
close_depth, inf_depth = bds.min()*.9, bds.max()*5.
dt = .75
mean_dz = 1./(((1.-dt)/close_depth + dt/inf_depth))
# 定义新的焦距focal
focal = mean_dz
# Get radii for spiral path
shrink_factor = .8
zdelta = close_depth * .2
tt = poses[:,:3,3] # ptstocam(poses[:3,3,:].T, c2w).T
rads = np.percentile(np.abs(tt), 90, 0)
c2w_path = c2w
N_views = 120
N_rots = 2
if path_zflat:
# zloc = np.percentile(tt, 10, 0)[2]
zloc = -close_depth * .1
c2w_path[:3,3] = c2w_path[:3,3] + zloc * c2w_path[:3,2]
rads[2] = 0.
N_rots = 1
N_views/=2
# Generate poses for spiral path
# 生成用来渲染的螺旋路径的位姿,是一个list,有120个(N_views)元素,每个元素shape(3,5)
render_poses = render_path_spiral(c2w_path, up, rads, focal, zdelta, zrate=.5, rots=N_rots, N=N_views)
render_poses = np.array(render_poses).astype(np.float32)
c2w = poses_avg(poses)
print('Data:')
print(poses.shape, images.shape, bds.shape) # (20, 3, 5) (20, 378, 504, 3) (20, 2)
#区分训练集和测试集
dists = np.sum(np.square(c2w[:3,3] - poses[:,:3,3]), -1)
i_test = np.argmin(dists) # 距离最小值对应的下标,12
print('HOLDOUT view is', i_test)
images = images.astype(np.float32)
poses = poses.astype(np.float32)
return images, poses, bds, render_poses, i_test
该类首先调用了_load_data,来对原始图像进行八倍的下采样,该过程代码解析会在下文展示。
为什么读进poses_bounds.npy里的c2w矩阵之后,对c2w的旋转矩阵又做了一些列变换?
poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1)
上面的代码段的最后一行实际上是把旋转矩阵的第一列(X轴)和第二列(Y轴)互换,并且对第二列(Y轴)做了一个反向。这样做的目的是将LLFF的相机坐标系变成OpenGL/NeRF的相机坐标系(参考下图)。这些数组在水平方向(轴1)上合并,形成一个新的数组。合并后的数组将有N行3列,因为每个元素都是从原始数组中提取的单独的列。

poses = np.moveaxis(poses, -1, 0).astype(np.float32)
imgs = np.moveaxis(imgs, -1, 0).astype(np.float32)
bds = np.moveaxis(bds, -1, 0).astype(np.float32)
这是将batch维移到第一位。
if recenter: poses = recenter_poses(poses)
这句代码是将世界坐标系重中心化,目的是防止渲染时本来的世界坐标系下观察不到物体。让我们进入函数内部。变换后的世界坐标系的位置和朝向是所有相机视角的平均。
def recenter_poses(poses):
poses_ = poses+0 # clone数据而不改变数据本身
#创建了一个形状为 [1, 4] 的数组,包含一个齐次坐标表示的点 [0, 0, 0, 1]。这个点将用于构造一个单位矩阵的底部行。
bottom = np.reshape([0,0,0,1.], [1,4])
# 调用 poses_avg 函数计算所有位姿的平均变换矩阵 c2w。
c2w = poses_avg(poses)
c2w = np.concatenate([c2w[:3,:4], bottom], -2)
bottom = np.tile(np.reshape(bottom, [1,1,4]), [poses.shape[0],1,1])
poses = np.concatenate([poses[:,:3,:4], bottom], -2)
# 这行代码的目的是将每个位姿通过c2w的逆矩阵进行变换。具体来说,它将逆矩阵与位姿矩阵相乘,从而将位姿从世界坐标系变换回相机坐标系。
poses = np.linalg.inv(c2w) @ poses
poses_[:,:3,:4] = poses[:,:3,:4]
poses = poses_
return poses
view_matrix是一个构造相机矩阵的的函数,输入是相机的Z轴朝向、up轴的朝向(即相机平面朝上的方向Y)、以及相机中心。输出下图所示的camera-to-world (c2w)矩阵。因为Z轴朝向,Y轴朝向,和相机中心都已经给定,所以只需求X轴的方向即可。又由于X轴同时和Z轴和Y轴垂直,我们可以用Y轴与Z轴的叉乘得到X轴方向。

下面是load_llff.py里关于view_matrix()的定义,看起来复杂一些。其实就是比刚刚的描述比多了一步:在用Y轴与Z轴叉乘得到X轴后,再次用Z轴与X轴叉乘得到新的Y轴。为什么这么做呢?这是因为传入的up(Y)轴是通过一些计算得到的,不一定和Z轴垂直,所以多这么一步。
# load_llff.py
def viewmatrix(z, up, pos):
vec2 = normalize(z)
vec1_avg = up
vec0 = normalize(np.cross(vec1_avg, vec2))
vec1 = normalize(np.cross(vec2, vec0))
# 这行代码使用 np.stack 函数将 vec0、vec1 和 vec2 这三个归一化的向量以及位置向量 pos 按列堆叠起来,形成一个4x4的矩阵 m。这个矩阵就是视图矩阵,其中前三列分别代表局部坐标系下的x、y、z轴方向,最后一列是位置向量。
m = np.stack([vec0, vec1, vec2, pos], 1)
return m
这个函数其实很简单,顾名思义就是多个相机的平均位姿(包括位置和朝向)。输入是多个相机的位姿。
-
第一步对多个相机的中心进行求均值得到center。
-
第二步对所有相机的Z轴求平均得到vec2向量(方向向量相加其实等效于平均方向向量)。
-
第三步对所有的相机的Y轴求平均得到up向量。
-
最后将vec2, up, 和center输入到刚刚介绍的viewmatrix()函数就可以得到平均的相机位姿了。 def poses_avg(poses):
hwf = poses[0, :3, -1:] # 这一行代表宽高和焦距 # 这行代码计算 poses 中所有位姿的平移向量(第3列)的平均值。mean(0) 表示沿着第一个维度(即位姿的索引)求平均,得到一个平均的平移向量 center。 center = poses[:, :3, 3].mean(0) # 首先,这行代码沿着第一个维度求所有位姿的第3行(z轴)的和。然后,调用 normalize 函数对这个向量进行归一化处理,得到单位向量 vec2。 vec2 = normalize(poses[:, :3, 2].sum(0)) up = poses[:, :3, 1].sum(0) c2w = np.concatenate([viewmatrix(vec2, up, center), hwf], 1) return c2w
这个函数写的有点复杂,它和模型训练没有关系,主要是用来生成一个相机轨迹用于新视角的合成。需要知道这个函数它是想生成一段螺旋式的相机轨迹,相机绕着一个轴旋转,其中相机始终注视着一个焦点,相机的up轴保持不变。简单说一下上面的代码:
首先是一个for循环,每一迭代生成一个新的相机位置。c是当前迭代的相机在世界坐标系的位置,np.dot(c2w[:3,:4], np.array([0,0,-focal, 1.])是焦点在世界坐标系的位置,z是相机z轴在世界坐标系的朝向。接着使用介绍的viewmatrix(z, up, c)构造当前相机的矩阵。
def render_path_spiral(c2w, up, rads, focal, zdelta, zrate, rots, N):
#c2w:世界到相机的变换矩阵。
#up:向上向量。
#rads:螺旋路径的径向范围。
#focal:相机的焦距。
#zdelta:沿z轴的偏移量。
#zrate:z轴变化速率。
#rots:螺旋的旋转次数。
#N:生成的位姿数量
render_poses = []
rads = np.array(list(rads) + [1.])
hwf = c2w[:,4:5]
for theta in np.linspace(0., 2. * np.pi * rots, N+1)[:-1]:
c = np.dot(c2w[:3,:4], np.array([np.cos(theta), -np.sin(theta), -np.sin(theta*zrate), 1.]) * rads)
z = normalize(c - np.dot(c2w[:3,:4], np.array([0,0,-focal, 1.])))
render_poses.append(np.concatenate([viewmatrix(z, up, c), hwf], 1))
return render_poses
下面这个图可视化了 render_path_spiral()生成的轨迹:

spherify_poses()函数用于"球面化"相机分布并返回一个环绕的相机轨迹用于新视角合成。这两种类函数都不做赘述。
在该类中,我们首先要对输入的原始数据(Colmap)进行处理,让我们先回顾下相机模型的知识。首先要知道,在OpenCV/COLMAP的相机坐标系里相机朝向+z轴,在LLFF/NeRF的相机坐标系中里相机朝向-z轴。注意这里假设矩阵是列矩阵(column-major matrix),变换矩阵左乘坐标向量实现坐标变换(这也是OpenCV/OpenGL/NeRF里使用的形式)。

相机外参的逆矩阵被称为camera-to-world (c2w)矩阵,这个概念在理论部分有提到,其作用是把相机坐标系的点变换到世界坐标系。

c2w矩阵是一个4x4的矩阵,左上角3x3是旋转矩阵R,右上角的3x1向量是平移向量T。有时写的时候可以忽略最后一行[0,0,0,1]。
其实c2w矩阵的值直接描述了相机坐标系的朝向和原点:

旋转矩阵的第一列到第三列分别表示了相机坐标系的X, Y, Z轴在世界坐标系下对应的方向;平移向量表示的是相机原点在世界坐标系的对应位置
刚刚回顾了相机的外参,现在简单回顾一下相机的内参。
相机的内参矩阵将相机坐标系下的3D坐标映射到2D的图像平面,这里以针孔相机(Pinhole camera)为例介绍相机的内参矩阵K:

内参矩阵K包含4个值,其中fx和fy是相机的水平和垂直焦距(对于理想的针孔相机,fx=fy)。焦距的物理含义是相机中心到成像平面的距离,长度以像素为单位。cx和cy是图像原点相对于相机光心的水平和垂直偏移量。cx,cy有时候可以用图像宽和高的1/2近似:
# NeRF run_nerf.py有这么一段构造K的代码
if K is None:
K = np.array([
[focal, 0, 0.5*W],
[0, focal, 0.5*H],
[0, 0, 1]
])
那么如何获得相机内参呢?这里分合成数据集和真实数据集两种情况。
-
对于合成数据集,我们需要通过指定相机参数来渲染图像,所以得到图像的时候已经知道对应的相机参数,比如像NeRF用到的Blender Lego数据集。
-
对于真实场景,比如我们用手机拍摄了一组图像,怎么获得相机位姿?目前常用的方法是利用运动恢复结构(structure-from-motion, SFM)技术估计几个相机间的相对位姿。这个技术比较成熟了,现在学术界里用的比较多的开源软件包是COLMAP: https://colmap.github.io/。输入多张图像,COLMAP可以估计出相机的内参和外参(也就是sparse model)。
使用COLMAP得到相机参数后只需要转成NeRF可以读取的格式即可以用于模型训练了。那这里面需要做什么操作?这就是该类的主要内容。
怎么实现COLMAP到LLFF数据格式?其实很简单,imgs2poses.py这个文件就干了两件事。
- 第一件事是调用colmap软件估计相机的参数,在sparse/0/文件夹下生成一些二进制文件:cameras.bin, images.bin, points3D.bin, project.ini。
- 第二件事是读取上一步得到的二进制文件,保存成一个poses_bounds.npy文件。

上述代码是load_llff_data中的,上述操作实际上就是把相机坐标系轴的朝向进行了变换:X和Y轴调换,Z轴取反
Colmap生成的poses_bounds.npy文件中到底是什么呢?load_llff.py会直接读取poses_bounds.npy文件获得相机参数。poses_bounds.npy是一个Nx17的矩阵,其中N是图像的数量,即每一张图像有17个参数。其中前面15个参数可以重排成3x5的矩阵形式:

poses_bounds.npy的前15维参数。左边3x3矩阵是c2w的旋转矩阵,第四列是c2w的平移向量,第五列分别是图像的高H、宽W和相机的焦距f
最后两个参数用于表示场景的范围Bounds (bds),是该相机视角下场景点离相机中心最近(near)和最远(far)的距离,所以near/far肯定是大于0的。
- 这两个值是怎么得到的?是在imgs2poses.py中,计算colmap重建的3D稀疏点在各个相机视角下最近和最远的距离得到的。
- 这两个值有什么用?之前提到体素渲染需要在一条射线上采样3D点,这就需要一个采样区间,而near和far就是定义了采样区间的最近点和最远点。贴近场景边界的near/far可以使采样点分布更加密集,从而有效地提升收敛速度和渲染质量。

那我们正好可以看下_load_data是怎么对数据进行下采样并输出poses和bds的。注意注释中写到poses是提取了npy文件中的前十五列,一个(20,15)的array作为poses,后两列作为bds。
再往后看定义了一个变量img0.img0是20张图像中的第一张图像的路径名称——IMG_4026.JPG。这几行代码的解释如下:
-
img0变量通过列表推导式构建了一个图像文件路径的列表。这个列表推导式首先遍历basedir目录下的images文件夹中的所有文件。然后,它检查每个文件的扩展名是否以JPG、jpg或png结尾,这意味着它只关心JPEG或PNG格式的图像文件。最后,它使用os.path.join函数将basedir目录和文件名拼接成一个完整的文件路径,并选择排序后的列表中的第一个文件路径赋值给img0。 -
sh变量通过调用imageio.imread(img0)函数读取img0指定的图像文件,并获取图像的尺寸。imageio.imread函数是imageio库中的一个函数,用于读取图像文件并返回一个表示图像数据的数组。在这个例子中,返回的数组尺寸是(3024, 4032, 3),表示图像的高度是 3024 像素,宽度是 4032 像素,并且有3个颜色通道(红、绿、蓝)。 -
sfx变量是一个空字符串,它用于存储图像下采样(缩小尺寸)后生成的新图像文件的后缀。在这段代码中,它被初始化为空字符串,但在后面的条件判断中可能会被赋予新的值,以表示图像已经经过了下采样处理。
接下来,判断是否有下采样的相关参数,如果有,则对图像进行下采样。负责下采样的类是minify类,可在下文找到。首先检查是否提供了缩放因子 factor。如果提供了则直接minify,如果提供了height或weight也可计算出factor,如果不需要下采样则factor为1。
随后判断是否存在下采样的路径,如果没有打印信息。并将下采样图片进行排序,存到imgfiles这个list中。用poses的最后一个维度(也就是图片数量)检查姿势数量和图像文件数量是否匹配,如果不匹配则打印错误信息并返回。
再然后的代码目的是获取处理后的图像shape。sh=(378,504,3)=(3024/8, 4032/8, 3),并讲HWF放在他们在poses中的位置。若不需要加载图片即可返回。若需加载图片后续会把归一化后的图片信息放在imgs中返回。
# _load_data将图片下采样后输出imgs,并且输出数据集的位姿参数poses和深度范围bds
def _load_data(basedir, factor=None, width=None, height=None, load_imgs=True):
# 用load读取'./data/nerf_llff_data/fern/poses_bounds.npy'文件
poses_arr = np.load(os.path.join(basedir, 'poses_bounds.npy'))
poses = poses_arr[:, :-2].reshape([-1, 3, 5]).transpose([1,2,0])
'''
.npy文件是一个shape为(20,17),dtype为float64的array,20代表数据集的个数(一共有20张图片),17代表位姿参数。
poses_arr[:, :-2]代表取前15列,为一个(20,15)的array,
reshape([-1, 3, 5])代表将(20,15)的array转换为(20,3,5)的array,也就是把15列的一维数据变为3*5的二维数据。
transpose([1,2,0])则是将array的坐标系调换顺序,0换到2, 1、2换到0、1,shape变为(3,5,20);
最后poses输出的是一个(3,5,20)的array
'''
bds = poses_arr[:, -2:].transpose([1,0])
'''
poses_arr[:, -2:].transpose([1,0])则是先提取poses_arr的后两列数据(20,2),然后将0,1坐标系对调,得到(2,20)shape的array:bds
bds指的是bounds深度范围
'''
# img0是20张图像中的第一张图像的路径名称,'./data/nerf_llff_data/fern\\images\\IMG_4026.JPG'
img0 = [os.path.join(basedir, 'images', f) for f in sorted(os.listdir(os.path.join(basedir, 'images'))) \
if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')][0]
#这行代码使用 imageio 库的 imread 函数来读取图像文件 img0,然后获取该图像的尺寸信息,存储在变量 sh 中。
sh = imageio.imread(img0).shape # 读取图片大小为(3024, 4032, 3)
sfx = ''
# 判断是否有下采样的相关参数,如果有,则对图像进行下采样
if factor is not None:
sfx = '_{}'.format(factor) # sfx='_8'
_minify(basedir, factors=[factor])
factor = factor
elif height is not None:
factor = sh[0] / float(height)
width = int(sh[1] / factor)
_minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
elif width is not None:
factor = sh[1] / float(width)
height = int(sh[0] / factor)
_minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
else:
factor = 1
# 判断是否存在下采样的路径'./data/nerf_llff_data/fern\\images_8'
imgdir = os.path.join(basedir, 'images' + sfx)
if not os.path.exists(imgdir):
print( imgdir, 'does not exist, returning' )
return
# 判断pose数量与图像个数是否一致,
imgfiles = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir)) if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')] # 将下采样图片进行排序,存到imgfiles这个list中
if poses.shape[-1] != len(imgfiles):
print( 'Mismatch between imgs {} and poses {} !!!!'.format(len(imgfiles), poses.shape[-1]) )
return
# 获取处理后的图像shape,sh=(378,504,3)=(3024/8, 4032/8, 3)
sh = imageio.imread(imgfiles[0]).shape
poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1])
poses[2, 4, :] = poses[2, 4, :] * 1./factor
'''
sh[:2]存的是前两个数据,也就是图片单通道的大小(378,504);
np.array(sh[:2]).reshape([2, 1])将其先array化后reshape为2*1的大小:array([[378],[504]])
poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1])则表示将poses中3*5矩阵的前两行的第5列存放height=378,width=504;
poses[2, 4, :]则表示第三行第5列的存放图像的分辨率f,更新f的值最后为3261/8=407.56579161
另外,3*5矩阵的前3行3列为旋转变换矩阵,第4列为平移变换矩阵,第5列为h、w、f;
'''
if not load_imgs:
return poses, bds
def imread(f):
if f.endswith('png'):
return imageio.imread(f, ignoregamma=True)
else:
return imageio.imread(f)
# 读取所有图像数据并把值缩小到0-1之间,imgs存储所有图片信息,大小为(378,504,3,20)
# 当访问 NumPy 数组时,... 允许你指定除了当前维度之外的所有维度。
imgs = imgs = [imread(f)[...,:3]/255. for f in imgfiles]
imgs = np.stack(imgs, -1)
print('Loaded image data', imgs.shape, poses[:,-1,0]) # poses[:,-1,0]的值为array([378. , 504. , 407.56579161])
return poses, bds, imgs
该类功能是对根据参数对图片进行下采样[^6]。
def _minify(basedir, factors=[], resolutions=[]):
needtoload = False
# 按照下采样倍数
for r in factors:
# 判断本地是否已经存有下采样factors的图像
imgdir = os.path.join(basedir, 'images_{}'.format(r))
if not os.path.exists(imgdir):
needtoload = True
# 按照分辨率下采样
for r in resolutions:
# 判断本地是否已经存有对应具体分辨率的图像
imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0]))
if not os.path.exists(imgdir):
needtoload = True
# 如果有直接退出
if not needtoload:
return
# 如果没有需要重新加载
# 汇制命令语句(操作系统自带此功能)
from subprocess import check_output
# 获取原始图片的路径
imgdir = os.path.join(basedir, 'images')
# 获取所有图片地址,并排除其他非图像文件
# 这段代码的作用是:对于 imgs 列表中的每个元素 f,检查它是否以列表 ['JPG', 'jpg', 'png', 'jpeg', 'PNG'] 中的任何一个扩展名结尾。如果是,any 函数将返回 True,外层列表推导式将 f 包含在结果列表中。
imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))]
imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])]
imgdir_orig = imgdir.replace("\\", "/")
# 获得执行py文件当前所在目录
# os.getcwd() 是一个函数,它属于 os 模块,用于获取当前工作目录(Current Working Directory)的路径。
wd = os.getcwd()
for r in factors + resolutions:
# 下采样的倍数 int类型
# isinstance() 是 Python 中的一个内置函数,用于检查一个对象是否是一个已知的类型 isinstance(object, classinfo)
if isinstance(r, int):
# 保存新尺寸图像的文件夹
name = 'images_{}'.format(r)
# resize的大小
resizearg = '{}%'.format(100./r)
# 指定分辨率 list类型
else:
name = 'images_{}x{}'.format(r[1], r[0])
resizearg = '{}x{}'.format(r[1], r[0])
# 新尺寸图像的保存路径
imgdir = os.path.join(basedir, name).replace("\\", "/")
if os.path.exists(imgdir):
continue
print('Minifying', r, basedir)
# 创建新尺寸图像的保存文件夹
os.makedirs(imgdir)
# 将原始图片拷贝到指定新尺寸图像的保存文件夹下
check_output('cp {}/* {}'.format(imgdir_orig, imgdir), shell=True)
# 获取图片的数据格式
ext = imgs[0].split('.')[-1]
# 绘制执行命令语句
# mogrify 是 ImageMagick 软件包中的一个命令行工具,用于对图像文件进行各种转换操作。使用 -format 选项,可以将图像转换为不同的格式。例如,mogrify -format jpg *.png 将所有 .png 图像转换为 .jpg 格式。使用 -resize 选项后跟所需的宽度和高度,可以调整图像的大小。例如,mogrify -resize 50% *.jpg 将当前目录下所有 .jpg 图片的大小调整为原来的 50%。
args = ' '.join(['magick ', 'mogrify', '-resize', resizearg, '-format', 'png', '*.{}'.format(ext)])
# 切换到新尺寸图像的保存路径
os.chdir(imgdir)
# 对新尺寸图像的保存路径中的原始图片进行resize,并用png格式保存
check_output(args, shell=True)
# 切回当前执行py文件所在目录 os:是 Python 的标准库之一,提供了许多与操作系统交互的功能。chdir:是 os 模块中的一个函数,代表 "change directory"(改变目录)
os.chdir(wd)
# 因为新尺寸图像的保存路径下除了png格式的新尺寸图像,还有原始尺寸图像需要删除,要是原始图像也是png格式则直接覆盖
if ext != 'png':
#'rm {}/*.{}' 是一个字符串模板,用于构建一个删除特定文件扩展名文件的命令
check_output('rm {}/*.{}'.format(imgdir, ext), shell=True)
print('Removed duplicates')
print('Done')
我们终于完成了dataload的工作,下面进入网络的搭建环节。照例请参考图示顺序学习:


继续train的过程,在上文完成了load_llff_data这一行的工作。
hwf = poses[0,:3,-1]
poses = poses[:,:3,:4]
print('Loaded llff', images.shape, render_poses.shape, hwf, args.datadir)
# 如果i_test不是列表,这行代码将i_test包装在一个列表中。这确保了i_test总是一个列表,即使它最初是一个单一的索引值。这样做可以简化后续对i_test的处理,因为你可以总是假设它是一个列表。
if not isinstance(i_test, list):
i_test = [i_test]
# 用于指定在LLFF数据集中进行测试的图像的间隔。如果大于0,表示用户希望在训练过程中自动保留一些测试图像。
if args.llffhold > 0:
print('Auto LLFF holdout,', args.llffhold)
#这行代码使用NumPy库的arange函数来创建一个从0到images数组第一个维度的大小(即图像数量)的整数序列。
然后使用切片操作[::args.llffhold]来选择这个序列中每隔args.llffhold个元素的项。这样,i_test就会包含一个索引列表,这些索引对应的图像将被用作测试集。
例如,如果images.shape[0]是100,而args.llffhold是10,那么i_test将会是[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]。
i_test = np.arange(images.shape[0])[::args.llffhold]
# 这段代码是用于从图像数据集中划分训练集和验证集的索引
i_val = i_test
i_train = np.array([i for i in np.arange(int(images.shape[0])) if
(i not in i_test and i not in i_val)])
# 定义范围
print('DEFINING BOUNDS')
# no_ndc代表“不使用归一化设备坐标”(Non-normalized Device Coordinates)。
if args.no_ndc:
# 通过乘以0.9,代码确保near边界略小于场景中观测到的最小深度,从而为相机的近裁剪平面提供一个小的安全距离。far同理。
near = np.ndarray.min(bds) * .9
far = np.ndarray.max(bds) * 1.1
else:
near = 0.
far = 1.
print('NEAR FAR', near, far)
至此完成数据集加载的全部内容,之后再做一些准备工作即可输入到网络中。
# Cast intrinsics to right types
H, W, focal = hwf
# 将H和W转换为整数类型。因为图像的高度和宽度必须是整数。
H, W = int(H), int(W)
hwf = [H, W, focal]
if K is None:
K = np.array([
[focal, 0, 0.5*W],
[0, focal, 0.5*H],
[0, 0, 1]
if args.render_test:
render_poses = np.array(poses[i_test])
# Create log dir and copy the config file
basedir = args.basedir
expname = args.expname
# 使用os.makedirs创建一个以实验名称命名的目录,exist_ok=True参数表示如果目录已存在,不会抛出异常。
os.makedirs(os.path.join(basedir, expname), exist_ok=True)
f = os.path.join(basedir, expname, 'args.txt')
with open(f, 'w') as file:
# vars(args): 这个函数调用返回了一个字典,其中包含了对象args的所有属性和对应的值。sorted(vars(args)): sorted()函数对vars(args)返回的字典进行排序,返回一个包含字典键(即args的属性名)的列表,这些键按照字典序排序。
for arg in sorted(vars(args)):
# 这行代码的作用是遍历 args 对象的所有属性,并为每个属性获取其值
attr = getattr(args, arg)
file.write('{} = {}\n'.format(arg, attr))
if args.config is not None:
f = os.path.join(basedir, expname, 'config.txt')
# open(args.config, 'r'): 以读取模式('r')打开args.config指定的文件。这里假设args.config是一个字符串,表示配置文件的路径。
.read(): 读取打开文件的全部内容。
file.write(...): 将读取的内容写入到步骤3中打开的文件对象file中,即写入到config.txt文件。
with open(f, 'w') as file:
file.write(open(args.config, 'r').read())
准备工作完成,可以开始创建网络。
# Create nerf model
render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer = create_nerf(args)
# render_kwargs_train: 用于训练时渲染的参数字典。
render_kwargs_test: 用于测试时渲染的参数字典。
start: 一个用于跟踪训练进度的起始步骤值,可能是用于恢复训练或记录训练进度的。
grad_vars: 一个包含模型参数的列表,这些参数将接受梯度更新。
optimizer: 用于模型训练的优化器对象。
global_step = start
首先,该类会对输入数据进行位置编码(get_embedder),将输入的向量变成高维的表示。值得注意的是论文中对方向的表示是用方位角,但代码中不是这么体现的,我们发现输入的也是一个三维的向量。
def create_nerf(args):
"""Instantiate NeRF's MLP model.
"""
# 对x,y,z和方向信息都进行了位置编码,输入是x,y,z三维,输出是input_ch(input channels for views)=63维;如果use_viewdirs为真,则input_ch_views=27维;
embed_fn, input_ch = get_embedder(args.multires, args.i_embed)
input_ch_views = 0
embeddirs_fn = None
if args.use_viewdirs:
embeddirs_fn, input_ch_views = get_embedder(args.multires_views, args.i_embed)
# 输出的通道数
output_ch = 5 if args.N_importance > 0 else 4
skips = [4]
# 创建 NeRF 模型实例,配置网络深度 netdepth、网络宽度 netwidth、输入通道 input_ch、输出通道 output_ch、跳跃连接 skips、视图方向编码 input_ch_views 和 use_viewdirs。然后将模型移动到指定的设备(如GPU)上。
# 粗网络
model = NeRF(D=args.netdepth, W=args.netwidth,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
# model.parameters() 是一个方法,它返回模型中所有的参数。这些参数包括了模型中的权重(weights)、偏置(biases)以及其他可训练的参数。当你调用这个方法时,它会返回一个生成器,该生成器可以被用来迭代模型中的每个参数张量。
grad_vars = list(model.parameters()) # 梯度
model_fine = None
# args.N_importance 是一个参数,表示在体素渲染过程中除了基本采样点之外,额外进行的精细采样点的数量。如果 args.N_importance 大于0,说明需要进行额外的精细采样。
if args.N_importance > 0:
# 细网络
model_fine = NeRF(D=args.netdepth_fine, W=args.netwidth_fine,
input_ch=input_ch, output_ch=output_ch, skips=skips,
input_ch_views=input_ch_views, use_viewdirs=args.use_viewdirs).to(device)
grad_vars += list(model_fine.parameters())
# 定义一个查询函数,network_query_fn 是一个使用 Python 匿名函数(lambda 函数)定义的函数,它将作为调用网络(network_fn)的查询接口。这个查询函数通常用于将输入数据传递给神经网络,并获取输出结果。在神经网络模型的训练和推理过程中,network_query_fn 作为一个轻量级的接口,可以方便地将数据传递给模型,并获取所需的输出。这种方式在处理复杂的数据流和模型调用时非常有用,尤其是在需要对模型的输入和输出进行精细控制的场景中。
network_query_fn = lambda inputs, viewdirs, network_fn : run_network(inputs,viewdirs,network_fn,embed_fn=embed_fn,embeddirs_fn=embeddirs_fn,netchunk=args.netchunk)
# Create optimizer 优化器
optimizer = torch.optim.Adam(params=grad_vars, lr=args.lrate, betas=(0.9, 0.999))
optimizer.param_groups[0]['capturable'] = True
start = 0
basedir = args.basedir
expname = args.expname
##########################
# Load checkpoints
# 加载已有模型参数 这个条件判断用于检查是否提供了一个特定的文件路径来加载预训练模型。
if args.ft_path is not None and args.ft_path!='None':
ckpts = [args.ft_path] #如果提供了 args.ft_path,则将其作为检查点列表的唯一元素。
# 这行代码在没有提供特定检查点路径的情况下,自动搜索给定目录(basedir 和 expname 指定)中的所有 .tar 文件,并将它们作为可能的检查点列表。
else:
ckpts = [os.path.join(basedir, expname, f) for f in sorted(os.listdir(os.path.join(basedir, expname))) if 'tar' in f]
print('Found ckpts', ckpts)
# 这个条件判断检查是否找到了检查点(列表不为空),并且没有设置 args.no_reload 为 True(意味着允许重新加载检查点)。
if len(ckpts) > 0 and not args.no_reload:
# 选择最新的检查点(列表中的最后一个元素)作为加载的检查点。
ckpt_path = ckpts[-1]
# 打印出将要重新加载的检查点路径。
print('Reloading from', ckpt_path)
# torch.load 是 PyTorch 中用于加载之前保存的模型或张量数据的函数。
ckpt = torch.load(ckpt_path)
# 从检查点中获取全局步骤(global_step),这通常是训练迭代的次数,用于记录训练进度。
start = ckpt['global_step']
# optimizer.load_state_dict(ckpt['optimizer_state_dict']) 从检查点中加载优化器的状态字典,并更新当前优化器的状态。state_dict:一个包含优化器状态的字典。这通常是通过调用 torch.save 保存的,并且可以从文件中加载。
optimizer.load_state_dict(ckpt['optimizer_state_dict'])
# Load model
model.load_state_dict(ckpt['network_fn_state_dict'])
if model_fine is not None:
# 如果存在细模型,则从检查点中加载精细模型的状态字典,并更新精细模型的参数。
model_fine.load_state_dict(ckpt['network_fine_state_dict'])
##########################
render_kwargs_train = {
'network_query_fn' : network_query_fn,
'perturb' : args.perturb,# 一个布尔值或小数,表示在采样时是否引入扰动(例如,通过在采样点之间进行随机采样)。这有助于改善渲染的稳定性和视觉效果。
'N_importance' : args.N_importance,
'network_fine' : model_fine,
'N_samples' : args.N_samples, #在每条射线上进行的采样点的总数
'network_fn' : model,
'use_viewdirs' : args.use_viewdirs,
'white_bkgd' : args.white_bkgd,
'raw_noise_std' : args.raw_noise_std,
}
# NDC only good for LLFF-style forward facing data
if args.dataset_type != 'llff' or args.no_ndc:
print('Not ndc!')
render_kwargs_train['ndc'] = False
render_kwargs_train['lindisp'] = args.lindisp
render_kwargs_test = {k : render_kwargs_train[k] for k in render_kwargs_train}
render_kwargs_test['perturb'] = False
render_kwargs_test['raw_noise_std'] = 0.
return render_kwargs_train, render_kwargs_test, start, grad_vars, optimizer
def get_embedder(multires, i=0):
if i == -1:
return nn.Identity(), 3
# kwargs是一个常用的缩写,代表 "keyword arguments"(关键字参数)。当你在函数定义中看到**kwargs时,它表示函数可以接受任意数量的命名参数,并将它们存储在一个字典中。
embed_kwargs = {
'include_input':True, #当设置为 True 时,原始输入将包含在嵌入输中。
'input_dims' : 3,#输入数据的维度,这里是3,表示三维空间
'max_freq_log2' : multires-1,
'num_freqs' : multires,
'log_sampling' : True, #是否使用对数采样,这通常用于频率的分布
'periodic_fns' : [torch.sin, torch.cos],
}#一个包含周期函数的列表,这里使用 torch.sin 和 torch.cos
# 为Embedder创建一个实例
embedder_obj = Embedder(**embed_kwargs)
# 在 lambda 函数体中,调用 eo.embed(x),这实际上是调用 Embedder 实例的 embed 方法,并将输入数据 x 传递给它。
embed = lambda x, eo=embedder_obj : eo.embed(x)
return embed, embedder_obj.out_dim
class Embedder:
def __init__(self, **kwargs):
# 将传入的参数保存在
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
# 初始化一个空列表 embed_fns,用于存储将要创建的嵌入函数
embed_fns = []
d = self.kwargs['input_dims']
out_dim = 0
if self.kwargs['include_input']:
embed_fns.append(lambda x : x) # 匿名函数 它接受一个参数 x 并直接返回它。这是一种恒等映射(identity function),它不改变输入的值。
out_dim += d
# 从 kwargs 中获取最大频率的对数值,并存储在变量 max_freq 中
max_freq = self.kwargs['max_freq_log2']
# 从 kwargs 中获取频率带的数量,并存储在变量 N_freqs
N_freqs = self.kwargs['num_freqs']
# 检查是否使用对数采样方式来生成频率带
if self.kwargs['log_sampling']:
# linspace 用于生成一个在指定范围内均匀分布的序列。start 和 end 是序列的起始和结束值。steps 是要生成的样本数量。
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2.**0., 2.**max_freq, steps=N_freqs)
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
位置编码请结合下图理解:
对输入的数据进行位置编码过后,我们可以正式建立NeRF网络。源码中将网络中的各层用nn.ModuleList放在列表中,nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W)是一个条件表达式,用于根据条件决定创建哪种类型的nn.Linear层。
- 如果当前层索引
i不在self.skips列表中(if i not in self.skips),则创建一个输入和输出通道数都是W的全连接层(nn.Linear(W, W))。这意味着这一层只处理前一层的输出,不涉及输入的空间坐标点。注意i从0开始。
- 如果当前层索引
i在self.skips列表中(else部分),则创建一个输入通道数为W + input_ch的全连接层,输出通道数为W(nn.Linear(W + input_ch, W))。这里的W + input_ch表示输入不仅包括前一层的输出(W个通道),还包括原始的空间坐标点(input_ch个通道,通常是3,对应于x, y, z坐标)。
请重点关注该类的forward部分,这定义了整个模型的结构。它接受一个输入张量x,使用 torch.split 将输入张量 x 按照指定的尺寸 -1(即最后一个维度)分割成两部分:input_pts 和 input_views。input_pts 包含空间坐标点,其通道数由 self.input_ch 决定;input_views 包含观察方向信息,其通道数由 self.input_ch_views 决定。接下来的for循环遍历self.pts_linears中的每个全连接层(线性变换),别忘了初始化隐藏状态h。"隐藏状态"(Hidden State)是指网络内部的表示,它不是输入也不是最终的输出,而是网络在处理输入数据时在各层之间传递的信息。
h = self.pts_linears[i](h):将隐藏状态h通过第i个全连接层进行变换。h = F.relu(h):对变换后的隐藏状态h应用ReLU激活函数,引入非线性。
如果当前层的索引i在跳跃连接(skip connections)的索引列表self.skips中,则执行以下操作:
h = torch.cat([input_pts, h], -1):将原始的空间坐标input_pts与当前的隐藏状态h沿最后一个维度进行拼接。这样做可以将输入的空间坐标信息直接传递到网络的深层,有助于梯度流动并保持空间结构信息。
再之后会判断是否需要观察方向信息,进行向前传播。整个流程请参考代码后的流程图。
终于我们设定好了NeRF的网络模型,可以回到Create_nerf中,实际的创建粗模型和细模型。
# Model
class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
"""
"""
super(NeRF, self).__init__()
self.D = D # 网络深度,8层
self.W = W # 每层通道数,256
self.input_ch = input_ch # 输入的通道数=3(x,y,z)
self.input_ch_views = input_ch_views # 方向信息的通道数=3
self.skips = skips # skip代表的是加入的信息的输入位置、层数;
self.use_viewdirs = use_viewdirs # 是否使用方向信息;
# 生成D层全连接层,并且在skip+1层加入input_pts;
# nn.ModuleList用于存储一个由多个 nn.Module 对象组成的列表。在神经网络中,ModuleList 主要用于管理多个网络层或模块,这些层或模块通常具有不同的参数,但在模型的前向传播或后向传播过程中需要统一处理。
# 列表的第一个元素是[nn.Linear(input_ch, W)],它表示第一个全连接层,输入通道数为input_ch(通常是3,对应于空间坐标x, y, z),输出通道数为W(比如256)。
# 接下来的元素是一个列表推导式,用于创建剩余的全连接层。这个列表推导式遍历从0到D-2(因为D是网络的深度,所以这里不包括最后一层。
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] + [nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)])
### Implementation according to the official code release (https://github.com/bmild/nerf/blob/master/run_nerf_helpers.py#L104-L105)
# 对view处理的网络层,27+256->128 // 是整数除法运算符
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
### Implementation according to the paper
# self.views_linears = nn.ModuleList(
# [nn.Linear(input_ch_views + W, W//2)] + [nn.Linear(W//2, W//2) for i in range(D//2)])
# 输出特征alpha(第8层)和RGB最后结果
# use_viewdirs 是一个布尔值,指示模型是否应该考虑观察方向信息。如果为 True,模型将使用额外的方向信息来改善渲染效果。
if use_viewdirs:
self.feature_linear = nn.Linear(W, W)
self.alpha_linear = nn.Linear(W, 1)
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
# 如果你想分割张量,使得每个分割块有不同的大小,你可以传递一个整数列表。split_tensors = torch.split(x, [3, 7], dim=0)这将返回一个元组,其中包含两个张量:第一个张量的形状为 (3, 5),第二个张量的形状为 (7, 5)。分割后,input_pts包含空间坐标信息,input_views包含观察方向信息。
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
# 将初始隐藏状态h设置为输入的空间坐标input_pts
h = input_pts
# enumerate(self.pts_linears) 会返回每个层的索引 i 和层本身 l
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
# 这个条件判断用来确定是否使用观察方向信息。
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs
那么在执行完Create_nerf之后,我们得到了些什么参数呢?
render_kwargs_train:训练阶段的渲染参数。render_kwargs_test:测试阶段的渲染参数。start:从哪个全局步骤开始训练或继续训练。grad_vars:模型的参数列表,用于优化器。optimizer:用于模型训练的优化器实例。
让我们继续train的过程。
首先将训练集和测试集中的bds参数更新,之后一段代码的目的是如果指定了-- render_only参数,程序将不进行训练,而是直接使用训练好的模型进行渲染。渲染的结果将保存为视频文件。如果指定了--render_test参数,程序将使用测试姿势进行渲染;否则,将使用默认的姿势。渲染完成后,会创建一个视频文件保存结果。
bds_dict = {
'near' : near,
'far' : far,
}
render_kwargs_train.update(bds_dict)
render_kwargs_test.update(bds_dict)
# Move testing data to GPU
render_poses = torch.Tensor(render_poses).to(device)
# Short circuit if only rendering out from trained model
if args.render_only:
print('RENDER ONLY')
# 在PyTorch中,torch.no_grad()是一个上下文管理器,用于临时禁用梯度计算。这意味着在这个上下文块内执行的所有操作都不会追踪梯度,也就是说,不会计算梯度信息,这通常用于模型的推理阶段,以减少内存使用和提高计算速度。
with torch.no_grad():
if args.render_test:
# render_test switches to test poses
images = images[i_test]
else:
# Default is smoother render_poses path
images = None
# 构造保存渲染结果的目录路径。
testsavedir = os.path.join(basedir, expname, 'renderonly_{}_{:06d}'.format('test' if args.render_test else 'path', start))
os.makedirs(testsavedir, exist_ok=True)
print('test poses shape', render_poses.shape)
# 调用render_path函数进行渲染,该函数可能接受多个参数,包括姿势、图像尺寸、相机内参、渲染块大小、测试渲染参数、真实图像、保存目录和渲染因子。
rgbs, _ = render_path(render_poses, hwf, K, args.chunk, render_kwargs_test, gt_imgs=images, savedir=testsavedir, render_factor=args.render_factor)
print('Done rendering', testsavedir)
imageio.mimwrite(os.path.join(testsavedir, 'video.mp4'), to8b(rgbs), fps=30, quality=8)
return
Train 3中调用render_path函数进行渲染,让我们进入函数内部。各参数含义如下:
ray_batch:包含射线信息的数组,如射线原点、方向、最小和最大距离等。network_fn:用于预测空间中每个点的RGB和密度的神经网络模型。network_query_fn:用于向network_fn发送查询的函数。N_samples:沿每条射线采样的次数。retraw:如果为True,则返回模型的原始预测。lindisp:如果为True,则沿逆深度线性采样。perturb:非零时,沿每条射线在时间上进行分层随机采样。N_importance:沿每条射线额外采样的次数,这些采样只传递给network_fine。network_fine:与network_fn规格相同的“精细”网络。white_bkgd:如果为True,假设背景为白色。raw_noise_std:原始噪声的标准差。verbose:如果为True,打印更多调试信息。pytest:用于测试目的的特殊标志。
def render_rays(ray_batch,
network_fn,
network_query_fn,
N_samples,
retraw=False,
lindisp=False,
perturb=0.,
N_importance=0,
network_fine=None,
white_bkgd=False,
raw_noise_std=0.,
verbose=False,
pytest=False):
"""Volumetric rendering.体素渲染
Args:
ray_batch: array of shape [batch_size, ...]. All information necessary
for sampling along a ray, including: ray origin, ray direction, min
dist, max dist, and unit-magnitude viewing direction.
用来view_ray采样的所有必需数据:ray原点、ray方向、最大最小距离、方向单位向量;
network_fn: function. Model for predicting RGB and density at each point
in space.
nerf网络,用来预测空间中每个点的RGB和不透明度的函数
network_query_fn: function used for passing queries to network_fn.
将查询传递给network_fn的函数
N_samples: int. Number of different times to sample along each ray.coarse采样点数
retraw: bool. If True, include model's raw, unprocessed predictions.是否压缩数据
lindisp: bool. If True, sample linearly in inverse depth rather than in depth.在深度图上面逆向线性采样;
perturb: float, 0 or 1. If non-zero, each ray is sampled at stratified
random points in time.扰动
N_importance: int. Number of additional times to sample along each ray.
These samples are only passed to network_fine.fine增加的精细采样点数;
network_fine: "fine" network with same spec as network_fn.
white_bkgd: bool. If True, assume a white background.
raw_noise_std: ...
verbose: bool. If True, print more debugging info.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray. Comes from fine model.
disp_map: [num_rays]. Disparity map. 1 / depth.
acc_map: [num_rays]. Accumulated opacity along each ray. Comes from fine model.
raw: [num_rays, num_samples, 4]. Raw predictions from model.
rgb0: See rgb_map. Output for coarse model.
disp0: See disp_map. Output for coarse model.
acc0: See acc_map. Output for coarse model.
z_std: [num_rays]. Standard deviation of distances along ray for each
sample.
"""
# 将数据提取出来
# 从ray_batch数组中获取射线的数量。提取射线的原点rays_o和方向rays_d。
N_rays = ray_batch.shape[0]
rays_o, rays_d = ray_batch[:,0:3], ray_batch[:,3:6] # [N_rays, 3] each
viewdirs = ray_batch[:,-3:] if ray_batch.shape[-1] > 8 else None
bounds = torch.reshape(ray_batch[...,6:8], [-1,1,2])
near, far = bounds[...,0], bounds[...,1] # [-1,1]
t_vals = torch.linspace(0., 1., steps=N_samples) # 0-1线性采样N_samples个值
if not lindisp:
z_vals = near * (1.-t_vals) + far * (t_vals)
else:
z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))
z_vals = z_vals.expand([N_rays, N_samples])
# 加入扰动
if perturb > 0.:
# get intervals between samples
mids = .5 * (z_vals[...,1:] + z_vals[...,:-1])
upper = torch.cat([mids, z_vals[...,-1:]], -1)
lower = torch.cat([z_vals[...,:1], mids], -1)
# stratified samples in those intervals
t_rand = torch.rand(z_vals.shape)
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
t_rand = np.random.rand(*list(z_vals.shape))
t_rand = torch.Tensor(t_rand)
z_vals = lower + (upper - lower) * t_rand
# 每个采样点的3D坐标,o+td
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples, 3],torch.Size([1024, 64, 3])
# raw = run_network(pts)
raw = network_query_fn(pts, viewdirs, network_fn) # 送进网络进行预测,前向传播;
# 体素渲染!将光束颜色合成图像上的点
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
# fine网络情况,再次计算上述步骤,只是采样点不同;
if N_importance > 0:
rgb_map_0, disp_map_0, acc_map_0 = rgb_map, disp_map, acc_map
z_vals_mid = .5 * (z_vals[...,1:] + z_vals[...,:-1])
z_samples = sample_pdf(z_vals_mid, weights[...,1:-1], N_importance, det=(perturb==0.), pytest=pytest)
z_samples = z_samples.detach()
z_vals, _ = torch.sort(torch.cat([z_vals, z_samples], -1), -1)
pts = rays_o[...,None,:] + rays_d[...,None,:] * z_vals[...,:,None] # [N_rays, N_samples + N_importance, 3]
run_fn = network_fn if network_fine is None else network_fine
# raw = run_network(pts, fn=run_fn)
raw = network_query_fn(pts, viewdirs, run_fn)
rgb_map, disp_map, acc_map, weights, depth_map = raw2outputs(raw, z_vals, rays_d, raw_noise_std, white_bkgd, pytest=pytest)
ret = {'rgb_map' : rgb_map, 'disp_map' : disp_map, 'acc_map' : acc_map}
if retraw:
ret['raw'] = raw
if N_importance > 0:
ret['rgb0'] = rgb_map_0
ret['disp0'] = disp_map_0
ret['acc0'] = acc_map_0
ret['z_std'] = torch.std(z_samples, dim=-1, unbiased=False) # [N_rays]
for k in ret:
if (torch.isnan(ret[k]).any() or torch.isinf(ret[k]).any()) and DEBUG:
print(f"! [Numerical Error] {k} contains nan or inf.")
return ret
ck(disps, 0)
return rgbs, disps
# 采样光线的数量
N_rand = args.N_rand
use_batching = not args.no_batching
if use_batching:
# For random ray batching
print('get rays')
rays = np.stack([get_rays_np(H, W, K, p) for p in poses[:,:3,:4]], 0) # [N, ro+rd, H, W, 3]
print('done, concats')
rays_rgb = np.concatenate([rays, images[:,None]], 1) # [N, ro+rd+rgb, H, W, 3]
rays_rgb = np.transpose(rays_rgb, [0,2,3,1,4]) # [N, H, W, ro+rd+rgb, 3]
rays_rgb = np.stack([rays_rgb[i] for i in i_train], 0) # train images only
rays_rgb = np.reshape(rays_rgb, [-1,3,3]) # [(N-1)*H*W, ro+rd+rgb, 3]
rays_rgb = rays_rgb.astype(np.float32)
print('shuffle rays')
np.random.shuffle(rays_rgb)
print('done')
i_batch = 0
我们看一下采样的射线是怎么构造的。给定一张图像的一个像素点,我们的目标是构造以相机中心为起始点,经过相机中心和像素点的射线。 还要清楚,NeRF中的点的xyz以及两个方位角都是针对世界坐标系而言的。相机在不同的位置下拍摄的内容不同,换成数学的语言即相机原点在世界坐标系下的位置不同,拍摄到的内容也不同。固定住相机,转动他的朝向,拍摄的内容也会不同。而相机的位置和角度就是相机的外参,也就是上文提到的4×4矩阵。
相同外参下的两个不同相机,拍摄也会不一样,因为相机的内参是不一样的。
相机成像满足下方公式。焦距实际上是很小的,一般以毫米为单位。而物距通常都是几米以上,故物距取倒数可以近似为0。所以像距与焦距是近似的,从而得出长焦镜头拍的物体比标准镜头大,短焦镜头中的物体会变小。所以焦距会影响成像。
首先,明确两件事:
- 一条射线包括一个起始点和一个方向,起点的话就是相机中心。对于射线方向,我们都知道两点确定一条直线,所以除了相机中心我们还需另一个点,而这个点就是成像平面的像素点。
- NeRF代码是在相机坐标系下构建射线,然后再通过camera-to-world (c2w)矩阵将射线变换到世界坐标系。
通过上述的讨论,我们第一步是是要先写出相机中心和像素点在相机坐标系的3D坐标。下面我们以OpenCV/Colmap的相机坐标系为例介绍。相机中心的坐标很明显就是[0,0,0]了。像素点的坐标可能复杂一点:首先3D像素点的x和y坐标是2D的图像坐标 (i, j)减去光心坐标 (cx,cy),然后z坐标其实就是焦距f (因为图像平面距离相机中心的距离就是焦距f)。
所以我们就可以得到射线的方向向量是:
因为是向量,我们可以把整个向量除以焦距f归一化z坐标,得到:
接着只需要用c2w矩阵把相机坐标系下的相机中心和射线方向变换到世界坐标系就搞定了。

# 获得光束的方法
def get_rays_np(H, W, K, c2w):
i, j = np.meshgrid(np.arange(W, dtype=np.float32), np.arange(H, dtype=np.float32), indexing='xy') # meshgrid函数将图像的坐标id分别取出存入i(列号)、j(行号),shape为(378,504)
# 2D点到3D点的映射计算,[x,y,z]=[(u-cx)/fx,-(-v-cy)/fx,-1]
# 在y和z轴均取相反数,因为nerf使用的坐标系x轴向右,y轴向上,z轴向外;
# dirs的大小为(378, 504, 3)
dirs = np.stack([(i-K[0][2])/K[0][0], -(j-K[1][2])/K[1][1], -np.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
# 将ray方向从相机坐标系转到世界坐标系,矩阵不变
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1) # dot product, equals to: [c2w.dot(dir) for dir in dirs]
# Translate camera frame's origin to the world frame. It is the origin of all rays.
# 相机原点在世界坐标系的坐标,同一个相机所有ray的起点;
rays_o = np.broadcast_to(c2w[:3,-1], np.shape(rays_d)) # [1024,3]
return rays_o, rays_d
rays_d
关于这里面有一个细节需要注意一下:为什么函数的第二行中dirs的y和z的方向值需要乘以负号,和我们刚刚推导的的不太一样呢?这是因为OpenCV/Colmap的相机坐标系里相机的Up/Y朝下, 相机光心朝向+Z轴,而NeRF/OpenGL相机坐标系里相机的Up/朝上,相机光心朝向-Z轴,所以这里代码在方向向量dir的第二和第三项乘了个负号。还记得下面这张图吗?

# Move training data to GPU
if use_batching:
images = torch.Tensor(images).to(device)
poses = torch.Tensor(poses).to(device)
if use_batching:
rays_rgb = torch.Tensor(rays_rgb).to(device)
N_iters = 200000 + 1
print('Begin')
print('TRAIN views are', i_train)
print('TEST views are', i_test)
print('VAL views are', i_val)
# Summary writers
# writer = SummaryWriter(os.path.join(basedir, 'summaries', expname))
start = start + 1
for i in trange(start, N_iters):
time0 = time.time()
# Sample random ray batch
if use_batching:
# Random over all images
batch = rays_rgb[i_batch:i_batch+N_rand] # [B, 2+1, 3*?]
batch = torch.transpose(batch, 0, 1)
batch_rays, target_s = batch[:2], batch[2]
i_batch += N_rand
if i_batch >= rays_rgb.shape[0]:
print("Shuffle data after an epoch!")
rand_idx = torch.randperm(rays_rgb.shape[0])
rays_rgb = rays_rgb[rand_idx]
i_batch = 0
else:
# Random from one image
img_i = np.random.choice(i_train)
target = images[img_i]
target = torch.Tensor(target).to(device)
pose = poses[img_i, :3,:4]
if N_rand is not None:
rays_o, rays_d = get_rays(H, W, K, torch.Tensor(pose)) # (H, W, 3), (H, W, 3)
if i < args.precrop_iters:
dH = int(H//2 * args.precrop_frac)
dW = int(W//2 * args.precrop_frac)
coords = torch.stack(
torch.meshgrid(
torch.linspace(H//2 - dH, H//2 + dH - 1, 2*dH),
torch.linspace(W//2 - dW, W//2 + dW - 1, 2*dW)
), -1)
if i == start:
print(f"[Config] Center cropping of size {2*dH} x {2*dW} is enabled until iter {args.precrop_iters}")
else:
coords = torch.stack(torch.meshgrid(torch.linspace(0, H-1, H), torch.linspace(0, W-1, W)), -1) # (H, W, 2)
coords = torch.reshape(coords, [-1,2]) # (H * W, 2)
select_inds = np.random.choice(coords.shape[0], size=[N_rand], replace=False) # (N_rand,)
select_coords = coords[select_inds].long() # (N_rand, 2)
rays_o = rays_o[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
rays_d = rays_d[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
batch_rays = torch.stack([rays_o, rays_d], 0)
target_s = target[select_coords[:, 0], select_coords[:, 1]] # (N_rand, 3)
##### Core optimization loop #####
rgb, disp, acc, extras = render(H, W, K, chunk=args.chunk, rays=batch_rays,
verbose=i < 10, retraw=True,
**render_kwargs_train)
optimizer.zero_grad()
img_loss = img2mse(rgb, target_s)
trans = extras['raw'][...,-1]
loss = img_loss
psnr = mse2psnr(img_loss)
if 'rgb0' in extras:
img_loss0 = img2mse(extras['rgb0'], target_s)
loss = loss + img_loss0
psnr0 = mse2psnr(img_loss0)
loss.backward()
optimizer.step()
def render(H, W, K, chunk=1024*32, rays=None, c2w=None, ndc=True,
near=0., far=1.,
use_viewdirs=False, c2w_staticcam=None,
**kwargs):
"""Render rays
Args:
H: int. Height of image in pixels.图像高度
W: int. Width of image in pixels.图像宽度
focal: float. Focal length of pinhole camera.针孔相机焦距
chunk: int. Maximum number of rays to process simultaneously. Used to
control maximum memory usage. Does not affect final results.同步处理的最大光线数
rays: array of shape [2, batch_size, 3]. Ray origin and direction for
each example in batch. 2表示每个batch的原点和方向;
c2w: array of shape [3, 4]. Camera-to-world transformation matrix.相机到世界的旋转矩阵
ndc: bool. If True, represent ray origin, direction in NDC coordinates.
near: float or array of shape [batch_size]. Nearest distance for a ray.
far: float or array of shape [batch_size]. Farthest distance for a ray.
use_viewdirs: bool. If True, use viewing direction of a point in space in model.
c2w_staticcam: array of shape [3, 4]. If not None, use this transformation matrix for
camera while using other c2w argument for viewing directions.
Returns:
rgb_map: [batch_size, 3]. Predicted RGB values for rays.预测的RGB图
disp_map: [batch_size]. Disparity map. Inverse of depth.视差图
acc_map: [batch_size]. Accumulated opacity (alpha) along a ray.深度图、不透明度、alpha
extras: dict with everything returned by render_rays().
"""
if c2w is not None:
# special case to render full image
rays_o, rays_d = get_rays(H, W, K, c2w)
else:
# use provided ray batch
rays_o, rays_d = rays
if use_viewdirs:
# provide ray directions as input
viewdirs = rays_d
if c2w_staticcam is not None:
# special case to visualize effect of viewdirs
rays_o, rays_d = get_rays(H, W, K, c2w_staticcam)
viewdirs = viewdirs / torch.norm(viewdirs, dim=-1, keepdim=True)
viewdirs = torch.reshape(viewdirs, [-1,3]).float()
sh = rays_d.shape # [..., 3]
if ndc:
# for forward facing scenes
rays_o, rays_d = ndc_rays(H, W, K[0][0], 1., rays_o, rays_d)
# Create ray batch
rays_o = torch.reshape(rays_o, [-1,3]).float() # torch.Size([1024, 3])
rays_d = torch.reshape(rays_d, [-1,3]).float() # torch.Size([1024, 3])
near, far = near * torch.ones_like(rays_d[...,:1]), far * torch.ones_like(rays_d[...,:1])
rays = torch.cat([rays_o, rays_d, near, far], -1) # torch.Size([1024, 8])
if use_viewdirs:
rays = torch.cat([rays, viewdirs], -1) # torch.Size([1024, 11])
# Render and reshape
all_ret = batchify_rays(rays, chunk, **kwargs)
for k in all_ret:
k_sh = list(sh[:-1]) + list(all_ret[k].shape[1:])
all_ret[k] = torch.reshape(all_ret[k], k_sh)
k_extract = ['rgb_map', 'disp_map', 'acc_map']
ret_list = [all_ret[k] for k in k_extract]
ret_dict = {k : all_ret[k] for k in all_ret if k not in k_extract}
return ret_list + [ret_dict]