diff --git a/README.md b/README.md
index ca4bb5ac7..ac469ab0e 100644
--- a/README.md
+++ b/README.md
@@ -21,7 +21,7 @@
| 特色系列课程[:arrow_heading_down:](#3) | 经典深度学习案例集[:arrow_heading_down:](#4) |
| 深度学习百问[:arrow_heading_down:](#2) | 面试宝典[:arrow_heading_down:](#6) |
-
+### **如果本项目对您有帮忙,欢迎点击页面右上方star,方便访问**
# 二、零基础实践深度学习
@@ -409,6 +409,7 @@
| **其他** | [足球比赛动作定位](https://github.com/PaddlePaddle/PaddleVideo/tree/application/FootballAction) | - |
| **其他** | [基于强化学习的飞行器仿真](https://github.com/PaddlePaddle/PARL/tree/develop/examples/tutorials/homework/lesson5/ddpg_quadrotor) | - |
| **其他** | [基于ERNIE-Gram实现语义匹配](https://aistudio.baidu.com/aistudio/projectdetail/2247755) | - |
+| **其他** | [基于PaddleDetection的PCB瑕疵检测](https://aistudio.baidu.com/aistudio/projectdetail/2240725) | - |
[返回快速跳转:arrow_heading_up:](#0)
diff --git a/docs/images/pretrain_model/Transformer/Transformer_architecture.png b/docs/images/pretrain_model/Transformer/Transformer_architecture.png
new file mode 100644
index 000000000..2badfdc32
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/Transformer_architecture.png differ
diff --git a/docs/images/pretrain_model/Transformer/decoder.png b/docs/images/pretrain_model/Transformer/decoder.png
new file mode 100644
index 000000000..c30affbe4
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/decoder.png differ
diff --git a/docs/images/pretrain_model/Transformer/encoder.png b/docs/images/pretrain_model/Transformer/encoder.png
new file mode 100644
index 000000000..e88509ae7
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/encoder.png differ
diff --git a/docs/images/pretrain_model/Transformer/feed_forward.png b/docs/images/pretrain_model/Transformer/feed_forward.png
new file mode 100644
index 000000000..42f572903
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/feed_forward.png differ
diff --git a/docs/images/pretrain_model/Transformer/input_embedding.png b/docs/images/pretrain_model/Transformer/input_embedding.png
new file mode 100644
index 000000000..cdefb0d34
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/input_embedding.png differ
diff --git a/docs/images/pretrain_model/Transformer/linear_softmax.png b/docs/images/pretrain_model/Transformer/linear_softmax.png
new file mode 100644
index 000000000..6bf7a043b
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/linear_softmax.png differ
diff --git a/docs/images/pretrain_model/Transformer/transformer.png b/docs/images/pretrain_model/Transformer/transformer.png
new file mode 100644
index 000000000..7ae508e36
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/transformer.png differ
diff --git a/docs/images/pretrain_model/Transformer/transformer_decoding_2.gif b/docs/images/pretrain_model/Transformer/transformer_decoding_2.gif
new file mode 100644
index 000000000..a2e8c589f
Binary files /dev/null and b/docs/images/pretrain_model/Transformer/transformer_decoding_2.gif differ
diff --git a/docs/tutorials/pretrain_model/ELMo.md b/docs/tutorials/pretrain_model/ELMo.md
index af357465a..04a6a2ce1 100644
--- a/docs/tutorials/pretrain_model/ELMo.md
+++ b/docs/tutorials/pretrain_model/ELMo.md
@@ -1,10 +1,17 @@
# ELMo
## 1.介绍
-Deep contextualized word representations获得了NAACL 2018的outstanding paper award,其方法有很大的启发意义。近几年来,预训练的word representation在NLP任务中表现出了很好的性能,已经是很多NLP任务不可或缺的一部分,论文作者认为一个好的word representation需要能建模以下两部分信息:单词的特征,如语义,语法;单词在不同语境下的变化,即一词多义。基于这样的动机,作者提出了ELMo模型,下面的章节会详细介绍ELMo。
+Deep contextualized word representations获得了NAACL 2018的outstanding paper award,其方法有很大的启发意义。近几年来,预训练的word representation在NLP任务中表现出了很好的性能,已经是很多NLP任务不可或缺的一部分,论文作者认为一个好的word representation需要能建模以下两部分信息:单词的特征,如语义,语法;单词在不同语境下的变化,即一词多义。基于这样的动机,作者提出了ELMo模型。ELMo能够训练出来每个词的embedding,可以作为上下文相关的词的向量。其他几个贡献:
+
++ 使用字符级别的CNN表示。由于单词级别考虑数据可能稀疏,出现OOV问题,拆成字符后稀疏性没有那么强了,刻画的会更好。
++ 训练了从左到右或从右到左的语言模型。用这个语言模型输出的结果,直接作为词的向量。
++ contextualized:这是一个语言模型,其双向LSTM产生的词向量会包含左侧上文信息和右侧下文信息,所以称之为contextualized
++ deep:句子中每个单词都能得到对应的三个Embedding: 最底层是单词的Word Embedding,往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。
+
+下面的章节会详细介绍ELMo。
### 1.1从Word Embedding到ELMo
-Word Embedding:词嵌入。最简单粗劣的理解就是:将词进行向量化表示,实体的抽象成了数学描述,就可以进行建模,应用到很多任务中。之前用语言模型做Word Embedding比较火的是word2vec和glove。使用Word2Vec或者Glove,通过做语言模型任务,就可以获得每个单词的Word Embedding,但是Word Embedding无法解决多义词的问题,同一个词在不同的上下文中表示不同的意思,但是在Word Embedding中一个词只有一个表示,这导致两种不同的上下文信息都会编码到相同的word embedding空间里去。如何根据句子上下文来进行单词的Word Embedding表示。ELMO提供了解决方案。
+Word Embedding:词嵌入。最简单的理解就是:将词进行向量化表示,实体的抽象成了数学描述,就可以进行建模,应用到很多任务中。之前用语言模型做Word Embedding比较火的是word2vec和glove。使用Word2Vec或者Glove,通过做语言模型任务,就可以获得每个单词的Word Embedding,但是Word Embedding无法解决多义词的问题,同一个词在不同的上下文中表示不同的意思,但是在Word Embedding中一个词只有一个表示,这导致两种不同的上下文信息都会编码到相同的word embedding空间里去。如何根据句子上下文来进行单词的Word Embedding表示。ELMO提供了解决方案。
我们有以下两个句子:
@@ -34,16 +41,17 @@ ELMO 基于语言模型的,确切的来说是一个 Bidirectional language mod
2. 第二步:送入双向LSTM模型中,即上图中的Lstm;
3. 第三步:将LSTM的输出$h_{k}$,与上下文矩阵$W'$相乘,再将该列向量经过Softmax归一化。其中,假定数据集有V个单词,$W'$是$|V|*m$的矩阵,$h_{k}$是$m*1$的列向量,于是最终结果是$|V|*1$的归一化后向量,即从输入单词得到的针对每个单词的概率。
-### 2.2 公式解析
-前向表示:
+### 2.2 双向语言模型
+
+假定一个序列有N个token,即$(t_{1},t_{2},...,t_{N})$,对于前向语言模型(forward LM),我们基于$(t_{1},..,t_{k-1})$来预测$t_{k}$,前向公式表示为:
$$p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{1},t_{2},...,t_{k-1})$$
-后向表示:
+向后语言模型(backword LM)与向前语言模型类似,除了计算的时候倒置输入序列,用后面的上下文预测前面的词:
$$p(t_{1},t_{2},...,t_{N})=\prod_{k=1}^{N}p(t_{k}|t_{k+1},t_{k+2},...,t_{N})$$
-Bi-LM训练过程中的目标就是最大化:
+一个双向语言模型包含前向和后向语言模型,训练的目标就是联合前向和后向的最大似然:
$$\sum_{k=1}^N (log p(t_{k}|t_{1},...,t_{k-1};\Theta_{x},\overrightarrow\Theta_{LSTM},\Theta_{s})+log p(t_{k}|t_{k+1},...,t_{N};\overleftarrow\Theta_{LSTM},\Theta_{s}))$$
@@ -51,7 +59,9 @@ $$\sum_{k=1}^N (log p(t_{k}|t_{1},...,t_{k-1};\Theta_{x},\overrightarrow\Theta_{
其中$\Theta_{x}$表示映射层的共享,表示第一步中,将单词映射为word embedding的共享,就是说同一个单词,映射为同一个word embedding。
-$\Theta_{s}$表示第三步中的上下文矩阵的参数,这个参数在前向和后向lstm中是相同的。
+$\Theta_{s}$表示第三步中的上下文矩阵的参数,这个参数在前向和后向LSTM中是相同的。
+
+### 2.3 ELMo
ELMo对于每个token $t_{k}$, 通过一个L层的biLM计算2L+1个表征(representations),这是输入第二阶段的初始值:
@@ -84,10 +94,12 @@ ELMo采用了典型的两阶段过程,第一个阶段是利用语言模型进
### 3.2第二阶段 接入下游NLP任务
-ELMO的第一阶段:预训练阶段。那么预训练好网络结构后,如何给下游任务使用呢?下图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X,我们可以先将句子X作为预训练好的ELMo网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。对于下图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。
-
+下图展示了下游任务的使用过程,比如我们的下游任务仍然是QA问题,此时对于问句X,我们可以先将句子X作为预训练好的ELMo网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,之后给予这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个。然后将整合后的这个Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。

+对于上图所示下游任务QA中的回答句子Y来说也是如此处理。因为ELMO给下游提供的是每个单词的特征形式,所以这一类预训练的方法被称为“Feature-based Pre-Training”。
+
+
最后,作者发现给ELMo模型增加一定数量的Dropout,在某些情况下给损失函数加入正则项$\lambda ||w||^2_{2}$,这等于给ELMo模型加了一个归纳偏置,使得权重接近BiLM所有层的平均权重。
## 4. ELMo使用步骤
@@ -99,7 +111,6 @@ ELMO的使用主要有三步:
3. 利用ELMo产生的word embedding来作为任务的输入,有时也可以即在输入时加入,也在输出时加入。
-
## 5. 优缺点
### 优点
diff --git a/docs/tutorials/pretrain_model/transformer.md b/docs/tutorials/pretrain_model/transformer.md
index 4d30212ec..29fb848c4 100644
--- a/docs/tutorials/pretrain_model/transformer.md
+++ b/docs/tutorials/pretrain_model/transformer.md
@@ -1,7 +1,14 @@
# Transformer
-Transformer改进了RNN被人诟病的训练慢的特点,利用self-attention可以实现快速并行。
-## Transformer直观认识
+## 1.介绍
+
+Transformer 网络架构架构由 Ashish Vaswani 等人在 Attention Is All You Need一文中提出,并用于机器翻译任务,和以往网络架构有所区别的是,该网络架构中,编码器和解码器没有采用 RNN 或 CNN 等网络架构,而是采用完全依赖于注意力机制的架构。网络架构如下所示:
+
+
+
+Transformer改进了RNN被人诟病的训练慢的特点,利用self-attention可以实现快速并行。下面的章节会详细介绍Transformer的各个组成部分。
+
+## 2.Transformer直观认识
Transformer主要由encoder和decoder两部分组成。在Transformer的论文中,encoder和decoder均由6个encoder layer和decoder layer组成,通常我们称之为encoder block。
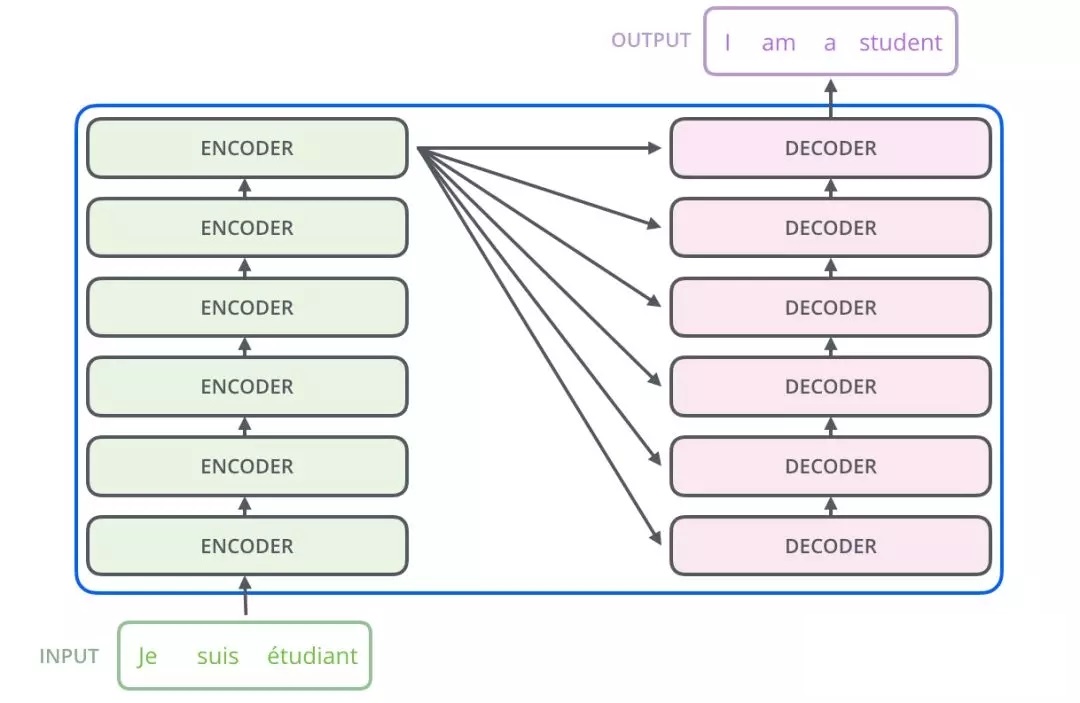 @@ -27,9 +34,66 @@ decoder也包含encoder提到的两层网络,但是在这两层中间还有一
@@ -27,9 +34,66 @@ decoder也包含encoder提到的两层网络,但是在这两层中间还有一
embedding和self-attention
+## 3. Transformer的结构
+Transformer的结构解析出来如下图表示,包括Input Embedding, Position Embedding, Encoder, Decoder。
+
+
+
+## 3.1 Embedding
+
+
+
+字向量与位置编码的公式表示如下:
+
+$$X=Embedding Lookup(X)+Position Encoding$$
+
+### 3.1.1 Input Embedding
+
+可以将Input Embedding看作是一个 lookup table,对于每个 word,进行 word embedding 就相当于一个lookup操作,查出一个对应结果。
+
+
+### 3.1.2 Position Encoding
+
+Transformer模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下
+
+$$PE(pos,2i)=sin(pos/10000^{2i}/d_{model})$$
+$$PE(pos,2i+1)=cos(pos/10000^{2i}/d_{model})$$
+
+其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码.
+
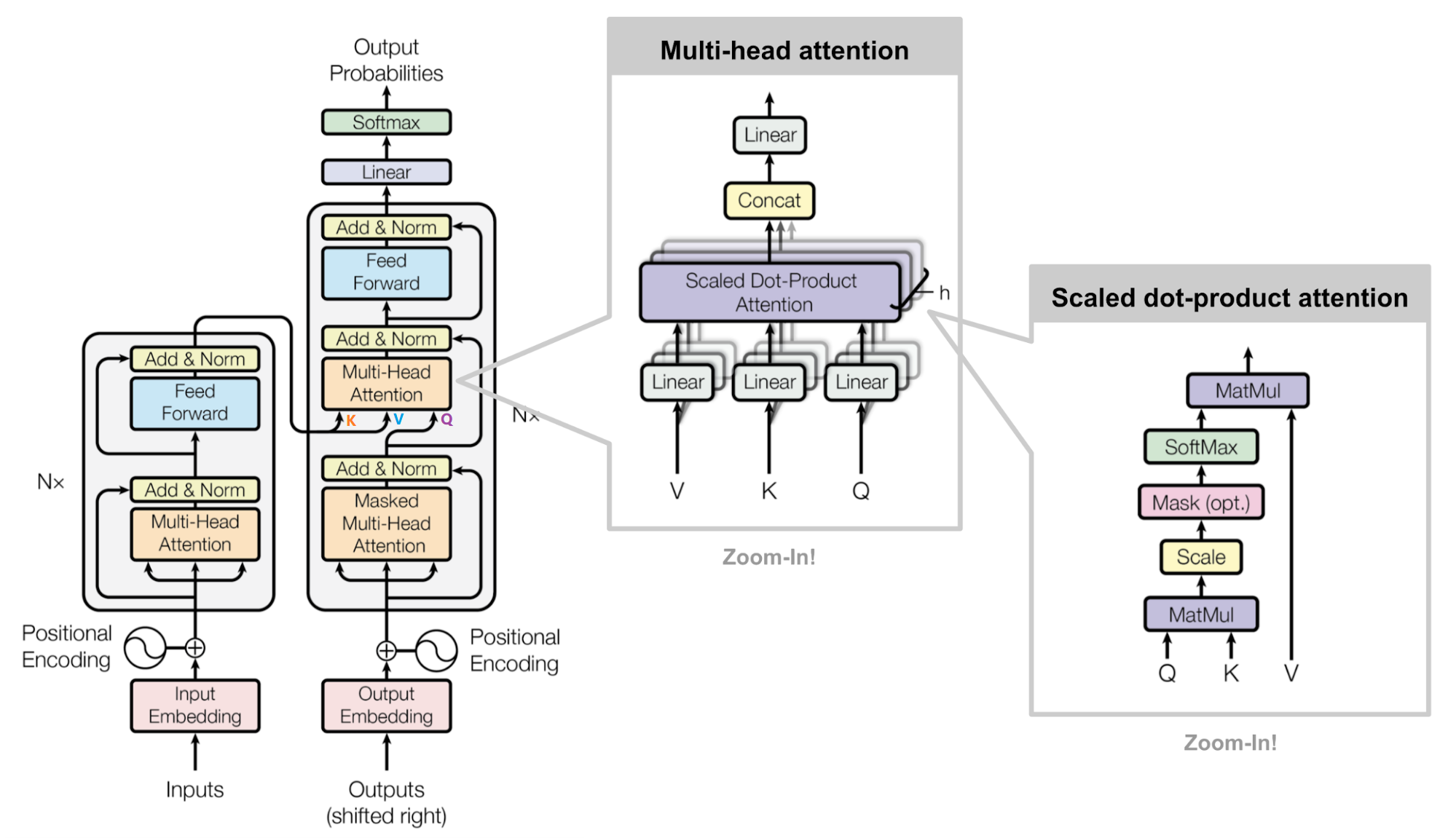
+## 3.2 Encoder
+
+
+
+用公式把一个Transformer Encoder block 的计算过程整理一下
+
++ 自注意力机制
+
+$$Q=XW_{Q}$$
+$$K=XW_{K}$$
+$$V=XW_{V}$$
+
+$$X_{attention}=selfAttention(Q,K,V)$$
+
++ self-attention 残差连接与 Layer Normalization
+
+
+$$X_{attention}=LayerNorm(X_{attention})$$
+
++ FeedForward,其实就是两层线性映射并用激活函数激活,比如说RELU
+
+$$X_{hidden}=Linear(RELU(Linear(X_{attention})))$$
+
++ FeedForward 残差连接与 Layer Normalization
+
+$$X_{hidden}=X_{attention}+X_{hidden}$$
+
+$$X_{hidden}=LayerNorm(X_{hidden})$$
+
+其中:$X_{hidden} \in R^{batch_size*seq_len*embed_dim}$
-## Self-attention
-- 首先,self-attention会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和embedding的维度一样,其值在反向传播的过程中会一直进行更新,得到的这三个向量的维度是64低于embedding维度的。
+### 3.2.1 自注意力机制
+- 首先,自注意力机制(self-attention)会计算出三个新的向量,在论文中,向量的维度是512维,我们把这三个向量分别称为Query、Key、Value,这三个向量是用embedding向量与一个矩阵相乘得到的结果,这个矩阵是随机初始化的,维度为(64,512)注意第二个维度需要和embedding的维度一样,其值在反向传播的过程中会一直进行更新,得到的这三个向量的维度是64低于embedding维度的。
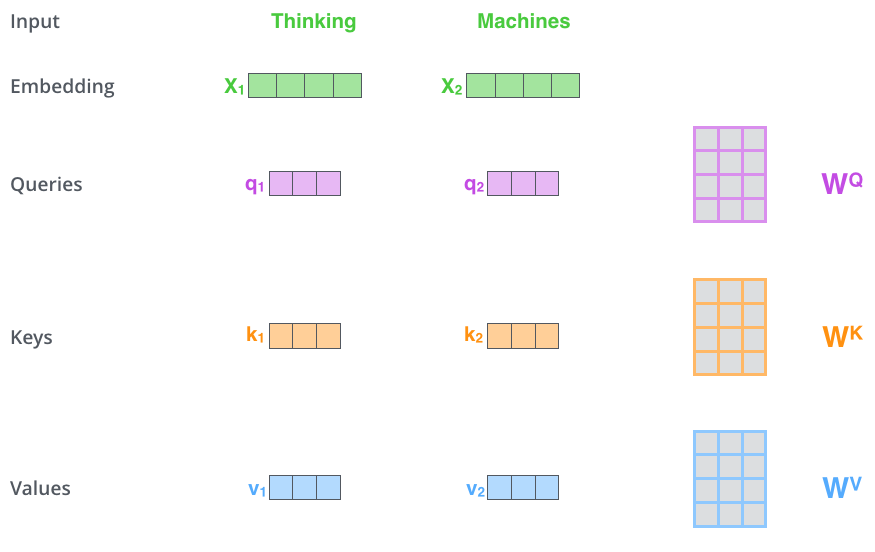
Query Key Value
@@ -60,7 +124,16 @@ decoder也包含encoder提到的两层网络,但是在这两层中间还有一
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。
-### Self-Attention 的时间复杂度的计算
+用公式表达如下:
+
+$$Q=XW_{Q}$$
+$$K=XW_{K}$$
+$$V=XW_{V}$$
+
+$$X_{attention}=selfAttention(Q,K,V)$$
+
+
+### 3.2.2 Self-Attention 复杂度
Self-Attention时间复杂度:$O(n^2 \cdot d)$ ,这里,n是序列的长度,d是embedding的维度。
@@ -74,7 +147,7 @@ softmax就是直接计算了,时间复杂度为: $O(n^2)$
因此,Self-Attention的时间复杂度是: $O(n^2 \cdot d)$
-## Multi-head Attention
+### 3.2.3 Multi-head Attention
不仅仅只初始化一组Q、K、V的矩阵,而是初始化多组,tranformer是使用了8组,所以最后得到的结果是8个矩阵。
@@ -87,7 +160,7 @@ multi-head注意力的全过程如下,首先输入句子,“Thinking Machine
multi-head attention总体结构
-### Multi-Head Attention的时间复杂度计算
+### 3.2.4 Multi-Head Attention复杂度
多头的实现不是循环的计算每个头,而是通过 transposes and reshapes,用矩阵乘法来完成的。
@@ -101,26 +174,24 @@ $$O(n^2 \cdot m \cdot a)=O(n^2 \cdot d)$$
-## Position Encoding
-
-Transformer模型中还缺少一种解释输入序列中单词顺序的方法。为了处理这个问题,transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。这个位置向量的具体计算方法有很多种,论文中的计算方法如下
+### 3.2.5 残差连接
+经过 self-attention 加权之后输出,也就是Attention(Q,K,V) ,然后把他们加起来做残差连接
-$$PE(pos,2i)=sin(pos/10000^{2i}/d_{model})$$
-$$PE(pos,2i+1)=cos(pos/10000^{2i}/d_{model})$$
+$$X_{hidden}=X_{embedding}+self Attention(Q,K,V)$$
-其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码.
+除了self-attention这里做残差连接外,feed forward那个地方也需要残差连接,公式类似:
+$$X_{hidden}=X_{feed_forward}+X_{hidden}$$
-## 残差连接和 Layer Normalization
-### 残差连接
-经过 self-attention 加权之后输出,也就是Attention(Q,K,V) ,然后把他们加起来做残差连接
+### 3.2.6 Layer Normalization
-$$X_{embedding}+self Attention(Q,K,V)$$
+Layer Normalization 的作用是把神经网络中隐藏层归一为标准正态分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用
+$$X_{hidden}=LayerNorm(X_{hidden})$$
-### Layer Normalization
+其中:$X_{hidden} \in R^{batch_size*seq_len*embed_dim}$
-Layer Normalization 的作用是把神经网络中隐藏层归一为标准正态分布,也就是独立同分布,以起到加快训练速度,加速收敛的作用
+LayerNorm的详细操作如下:
$$\mu_{L}=\dfrac{1}{m}\sum_{i=1}^{m}x_{i}$$
@@ -132,57 +203,60 @@ $$\delta^{2}=\dfrac{1}{m}\sum_{i=1}^{m}(x_{i}-\mu)^2$$
$$ LN(x_{i})=\alpha \dfrac{x_{i}-\mu_{L}}{\sqrt{\delta^{2}+\epsilon}}+\beta $$
然后用每一列的每一个元素减去这列的均值,再除以这列的标准差,从而得到归一化后的数值,加$\epsilon$是为了防止分母为0.此处一般初始化$\alpha$为全1,而$\beta$为全0.
-## Transformer Encoder 整体结构
-了解了 Encoder 的主要构成部分,下面我们用公式把一个 Encoder block 的计算过程整理一下
-1). 字向量与位置编码
-
-$$X=Embedding Lookup(X)+Position Encoding$$
-
-2). 自注意力机制
+### 3.2.7 Feed Forward
-$$Q=XW_{Q}$$
-$$K=XW_{K}$$
-$$V=XW_{V}$$
-$$X_{attention}=selfAttention(Q,K,V)$$
+
-3). self-attention 残差连接与 Layer Normalization
+将Multi-Head Attention得到的向量再投影到一个更大的空间(论文里将空间放大了4倍)在那个大空间里可以更方便地提取需要的信息(使用Relu激活函数),最后再投影回token向量原来的空间
-$$X_{attention}=X+X_{attention}$$
-$$X_{attention}=LayerNorm(X_{attention})$$
+$$FFN(x)=ReLU(W_{1}x+b_{1})W_{2}+b_{2}$$
-4). 下面进行 Encoder block 结构图中的第 4 部分,也就是 FeedForward,其实就是两层线性映射并用激活函数激活,比如说RELU
+借鉴SVM来理解:SVM对于比较复杂的问题通过将特征其投影到更高维的空间使得问题简单到一个超平面就能解决。这里token向量里的信息通过Feed Forward Layer被投影到更高维的空间,在高维空间里向量的各类信息彼此之间更容易区别。
-$$X_{hidden}=Linear(RELU(Linear(X_{attention})))$$
-5). FeedForward 残差连接与 Layer Normalization
-$$X_{hidden}=X_{attention}+X_{hidden}$$
-$$X_{hidden}=LayerNorm(X_{hidden})$$
-其中:$X_{hidden} \in R^{batch_size*seq_len*embed_dim}$
+## 3.3 Decoder
-## Transformer Decoder 整体结构
+
-和 Encoder 一样,上面三个部分的每一个部分,都有一个残差连接,后接一个 Layer Normalization。Decoder 的中间部件并不复杂,大部分在前面 Encoder 里我们已经介绍过了,但是 Decoder 由于其特殊的功能,因此在训练时会涉及到一些细节
+和 Encoder 一样,上面三个部分的每一个部分,都有一个残差连接,后接一个 Layer Normalization。Decoder 的中间部件并不复杂,大部分在前面 Encoder 里我们已经介绍过了,但是 Decoder 由于其特殊的功能,因此在训练时会涉及到一些细节,下面会介绍Decoder的Masked Self-Attention和Encoder-Decoder Attention两部分,其结构图如下图所示
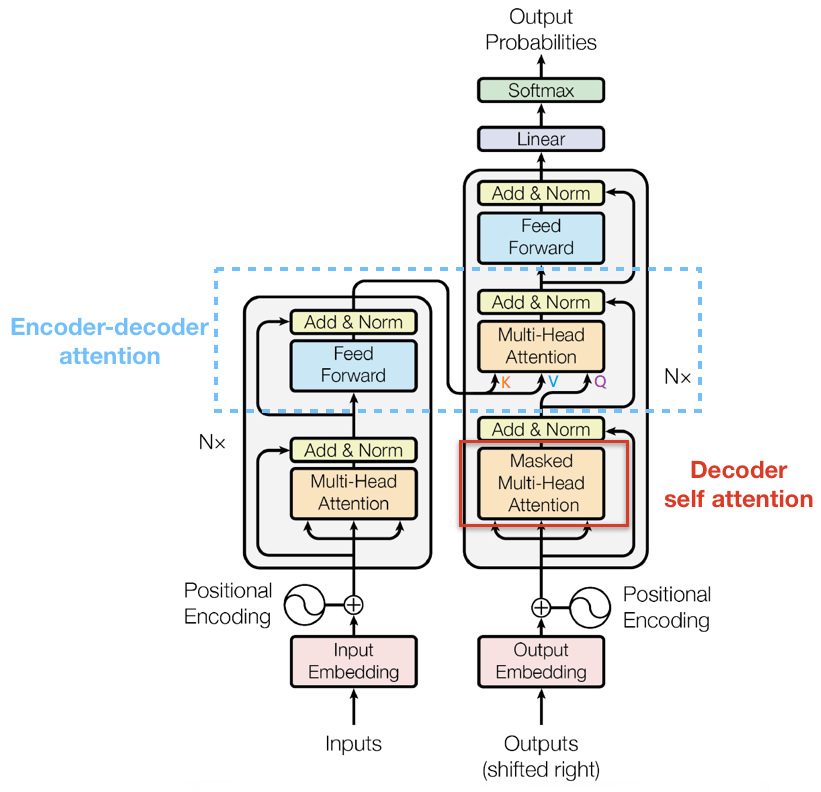
decoder self attention
-### Masked Self-Attention
+
+### 3.3.1 Masked Self-Attention
+
传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入因此在训练过程中输入t时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当t时刻运算结束了,才能看到t+1时刻的词。而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 都暴露在 Decoder 中,这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 Mask。
Mask 非常简单,首先生成一个下三角全 0,上三角全为负无穷的矩阵,然后将其与 Scaled Scores 相加即可,之后再做 softmax,就能将 -inf 变为 0,得到的这个矩阵即为每个字之间的权重。
-### Masked Encoder-Decoder Attention
+### 3.3.2 Masked Encoder-Decoder Attention
其实这一部分的计算流程和前面 Masked Self-Attention 很相似,结构也一摸一样,唯一不同的是这里的K,V为 Encoder 的输出,Q为 Decoder 中 Masked Self-Attention 的输出
Masked Encoder-Decoder Attention
-## Transformer的权重共享
+### 3.3.3 Decoder的解码
+
+下图展示了Decoder的解码过程,Decoder中的字符预测完之后,会当成输入预测下一个字符,知道遇见终止符号为止。
+
+
+
+## 3.4 Transformer的最后一层和Softmax
+
+线性层是一个简单的全连接的神经网络,它将解码器堆栈生成的向量投影到一个更大的向量,称为logits向量。如图linear的输出
+
+softmax层将这些分数转换为概率(全部为正值,总和为1.0)。选择概率最高的单元,并生成与其关联的单词作为此时间步的输出。如图softmax的输出。
+
+
+
+
+## 3.5 Transformer的权重共享
Transformer在两个地方进行了权重共享:
@@ -204,5 +278,12 @@ Embedding层可以说是通过onehot去取到对应的embedding向量,FC层可
通过这样的权重共享可以减少参数的数量,加快收敛。
+## 4 总结
+
+本文详细介绍了Transformer的细节,包括Encoder,Decoder部分,输出解码的部分,Transformer的共享机制等等。
+
+## 5. 参考文献
+[Attention Is All You Need](https://arxiv.org/abs/1706.03762)
+
diff --git a/examples/homework.md b/examples/homework.md
index 8a791cb2c..c37239da2 100644
--- a/examples/homework.md
+++ b/examples/homework.md
@@ -1,4 +1,4 @@
-【作业】
+【作业】123123
1. 使用CIFAR10数据集,基于EffNet网络实现图像分类。
2. 使用CIFAR10数据集,基于DarkNet网络实现图像分类。
3. 在眼疾识别数据集上训练SENet网络。
diff --git "a/examples/\344\275\234\344\270\232\346\217\220\344\272\244\350\257\246\346\203\205.md" "b/examples/\344\275\234\344\270\232\346\217\220\344\272\244\350\257\246\346\203\205.md"
index 54a0e0613..d9a50cf93 100644
--- "a/examples/\344\275\234\344\270\232\346\217\220\344\272\244\350\257\246\346\203\205.md"
+++ "b/examples/\344\275\234\344\270\232\346\217\220\344\272\244\350\257\246\346\203\205.md"
@@ -1,4 +1,4 @@
-# 作业内容
+# 作业内容123123
* 知识点原理编写题*5(共计50分)
diff --git "a/examples/\345\256\236\350\256\255\346\212\245\345\221\212.docx" "b/examples/\345\256\236\350\256\255\346\212\245\345\221\212.docx"
new file mode 100644
index 000000000..129b60dda
Binary files /dev/null and "b/examples/\345\256\236\350\256\255\346\212\245\345\221\212.docx" differ