对内容进行分类和归档
[TOC]
在说nginx前,先来看看什么是“惊群”?简单说来,多线程/多进程(linux下线程进程也没多大区别)等待同一个socket事件,当这个事件发生时,这些线程/进程被同时唤醒,就是惊群。可以想见,效率很低下,许多进程被内核重新调度唤醒,同时去响应这一个事件,当然只有一个进程能处理事件成功,其他的进程在处理该事件失败后重新休眠(也有其他选择)。这种性能浪费现象就是惊群。
简单了说,就是同一时刻只允许一个nginx worker在自己的epoll中处理监听句柄。它的负载均衡也很简单,当达到最大connection的7/8时,本worker不会去试图拿accept锁,也不会去处理新连接,这样其他nginx worker进程就更有机会去处理监听句柄,建立新连接了。而且,由于timeout的设定,使得没有拿到锁的worker进程,去拿锁的频繁更高。
https://blog.csdn.net/russell_tao/article/details/7204260
tcp socket:tcp socket通信方式,需要在nginx配置文件中填写php-fpm运行的ip地址和端口号。
location ~ \.php$ {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
}
unix socket:unix socket通信方式,需要在nginx配置文件中填写php-fpm运行的pid文件地址。
//service php-fpm start生成.sock文件
location ~ \.php$ {
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;;
fastcgi_pass unix:/var/run/php5-fpm.sock;
fastcgi_index index.php;
}
client_max_body_size 10M 设置上传文件大小限制
502 原因:php_fpm 配置文件错误,或者是接口请求有问题 503:机器维护或者暂时不可用 504:一般是NGINX配置有问题
通过观察,可以分析出大致的平滑重启过程为:
- master使用新配置 fork出n-1个worker及新master
- 新worker处理新情求,旧worker执行完退出
- master重新加载配置,期间使用新master接管服务
- master加载配置完毕,新master切换为worker工作模式 平滑重启完,master进程号并不会发生变化。
502 一般是fpm配置有问题。比如请求超时。max_children和request_terminate_timeout。max_children最大子进程数 超过了php-fpm 的最大响应数,就会出现502.netstat可以查看连接数。一个php-cgi消耗的内存在20M左右,php-cgi所占用的内存为20M*max_request数量。为单个请求的超时时间(request_terminate_timeout)。当数据库连接超时,或者大量请求超时的时候,会出现502.
504一般是NGINX配置有问题。Gateway Time-out。fastcgi_connect_timeout、fastcgi_send_timeout、fastcgi_read_timeout、fastcgi_buffer_size、fastcgi_buffers、fastcgi_busy_buffers_size、fastcgi_temp_file_write_size、fastcgi_intercept_errors。fgi缓冲区太小,会导致504. 或者是程序无故退出, 或者是程序执行太慢。 proxy_read_timeout 60 proxy_send_timeout 60
从网络角度,502已经与后端建立了连接,但超时;504与后端连接未建立,超时。
<?php
exec("sleep 5");
echo 'done';
会报502
[error] 29841#0: *1646 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 127.0.0.1, server: localhost, request: "GET /test.php HTTP/1.1", upstream: "fastcgi://127 .0.0.1:9001 ", host: "localhost" process_control_timeout 设置子进程接受主进程复用信号的超时时间 可以解决这个问题。如果不能保证平滑重启,就可以设定一下这个值。
max_requests意味着,子进程处理多少请求之后,就会关闭。因为子进程差不多都能同时打满,同时关闭,所以会出现502的问题。默认max_request为500个。可以修改这个参数。或者增加机器的内存,修改参数。
ip hash 根据ip进行hash可以解决session问题
upstream backserver {
ip_hash;
server 192.168.0.14:88;
server 192.168.0.15:80;
}
轮询(是默认的方式)
upstream backserver {
server 192.168.0.14;
server 192.168.0.15;
}
权重
upstream backserver {
server 192.168.0.14 weight=3;
server 192.168.0.15 weight=7;
}
fair 根据响应时间来进行分配,响应时间短的优先分配。
upstream backserver {
server server1;
server server2;
fair;
}
动态程序,将请求发送给php-fpm, fpm的master启动worker去执行phpcgi,然后将编译结果返回 fcgi执行原理
- Web Server启动时载入FastCGI进程管理器(IIS ISAPI或Apache Module)。
- FastCGI进程管理器自身初始化,启动多个CGI解释器进程(可见多个php-cgi)并等待来自Web Server的连接。
- 当客户端请求到达Web Server时,FastCGI进程管理器选择并连接到一个CGI解释器。Web server将CGI环境变量和标准输入发送到FastCGI子进程php-cgi。
- FastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web Server。当FastCGI子进程关闭连接时,请求便告处理完成。FastCGI子进程接着等待并处理来自FastCGI进程管理器(运行在Web Server中)的下一个连接。 而在CGI模式中,php-cgi在此便退出了。 在上述情况中,你可以想象CGI通常有多慢。每一个Web 请求PHP都必须重新解析php.ini、重新载入全部扩展并重初始化全部数据结构。使用FastCGI,所有这些都只在进程启动时发生一次。一个额外的好处是,持续数据库连接(Persistent database connection)可以工作。
FastCGI 与传统 CGI 模式的区别之一则是 Web 服务器不是直接执行 CGI 程序了,而是通过 Socket 与 FastCGI 响应器(FastCGI 进程管理器)进行交互,也正是由于 FastCGI 进程管理器是基于 Socket 通信的,所以也是分布式的,Web 服务器可以和 CGI 响应器服务器分开部署。Web 服务器需要将数据 CGI/1.1 的规范封装在遵循 FastCGI 协议包中发送给 FastCGI 响应器程序。
客户端访问 http://127.0.0.1:9003/cgi-bin/user?id=1 127.0.0.1 上监听 9003 端口的守护进程接受到该请求 通过解析 HTTP 头信息,得知是 GET 请求,并且请求的是 /cgi-bin/ 目录下的 user 文件。 将 uri 里的 id=1 通过存入 QUERY_STRING 环境变量。 Web 守护进程 fork 一个子进程,然后在子进程中执行 user 程序,通过环境变量获取到id。 执行完毕之后,将结果通过标准输出返回到子进程。 子进程将结果返回给客户端。
各位可以补充下,这个问题,应该是去看自己的硬件资源来决定。
lvs:重量级的四层负载软件,应该就是直接进行转发。
nginx:轻量级的四层负载软件,带缓存功能,正则表达式较灵活。可以进行限流,重定向吧。
reload --重新加载,reload会重新加载配置文件,Nginx服务不会中断。而且reload时会测试conf语法等,如果出错会rollback用上一次正确配置文件保持正常运行。
restart --重启(先stop后start),会重启Nginx服务。这个重启会造成服务一瞬间的中断,如果配置文件出错会导致服务启动失败,那就是更长时间的服务中断了。 所以,如果是线上的服务,修改的配置文件一定要备份。为了保证线上服务高可用,最好使用reload。
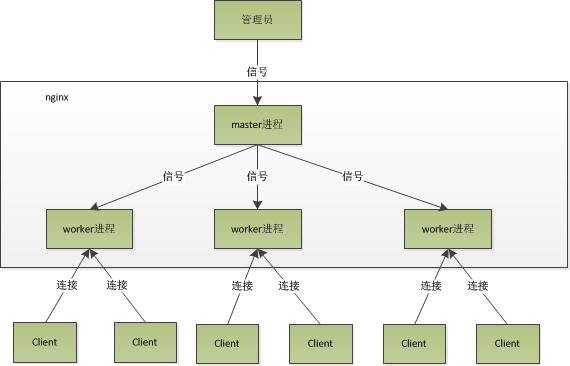
在nginx启动后,如果我们要操作nginx,要怎么做呢?从上文中我们可以看到,master来管理worker进程,所以我们只需要与master进程通信就行了。(所以每个worker不需要简单端口)
master进程会接收来自外界发来的信号,再根据信号做不同的事情。所以我们要控制nginx,只需要通过kill向master进程发送信号就行了。比如kill -HUP pid,则是告诉nginx,从容地重启nginx,我们一般用这个信号来重启nginx,或重新加载配置,因为是从容地重启,因此服务是不中断的。
master进程在接收到HUP信号后是怎么做的呢?首先master进程在接到信号后,会先重新加载配置文件,然后再启动新的worker进程,并向所有老的worker进程发送信号,告诉他们可以光荣退休了。新的worker在启动后,就开始接收新的请求,而老的worker在收到来自master的信号后,就不再接收新的请求,并且在当前进程中的所有未处理完的请求处理完成后,再退出。
当然,直接给master进程发送信号,这是比较老的操作方式,nginx在0.8版本之后,引入了一系列命令行参数,来方便我们管理。比如,./nginx -s reload,就是来重启nginx,./nginx -s stop,就是来停止nginx的运行。如何做到的呢?我们还是拿reload来说,我们看到,执行命令时,我们是启动一个新的nginx进程,而新的nginx进程在解析到reload参数后,就知道我们的目的是控制nginx来重新加载配置文件了,它会向master进程发送信号,然后接下来的动作,就和我们直接向master进程发送信号一样了。
**worker进程又是如何处理请求的呢?**我们前面有提到,worker进程之间是平等的,每个进程处理请求的机会也是一样的。
当我们提供80端口的http服务时,一个连接请求过来,每个进程都有可能处理这个连接,怎么做到的呢?首先,每个worker进程都是从master进程fork过来,在master进程里面,先建立好需要listen的socket(listenfd)之后,然后再fork出多个worker进程。所有worker进程的listenfd会在新连接到来时变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenfd读事件前抢accept_mutex,抢到互斥锁的那个进程注册listenfd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个连接之后,就开始读取请求、解析请求、处理请求,产生数据后,再返回给客户端,最后才断开连接,这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由worker进程来处理,而且只在一个worker进程中处理。[节选自PHP7内核剖析]
$host
$remote_addr
$http_cookie
$remote_port
$server_addr
$server_name
$server_port