![]()
Work in progress, without any warranty
Framework for station similarity classification.
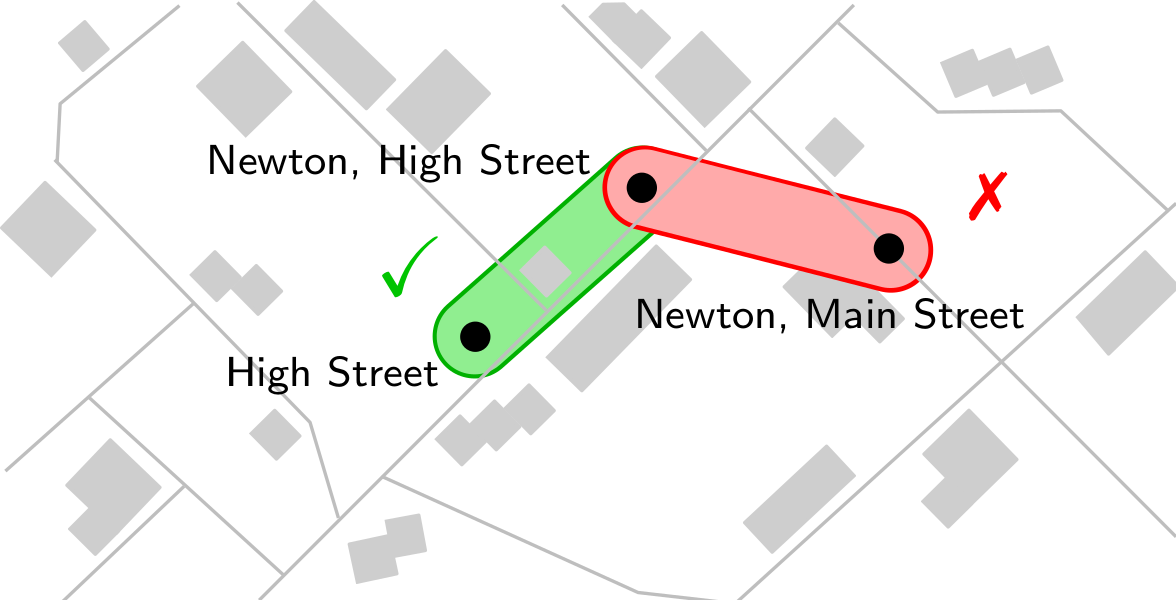
Three station identifiers for two stations in the fictional town of Newton, and some of their similarity relationships.
python3sklearnmatplotlibnumpyscipy
Fetch this repository:
$ git clone https://github.com/ad-freiburg/statsimi
$ cd statsimiCreate virtual environment
$ python3 -m venv venv
$ source venv/bin/activateBuild & Install
$ pip install .Build a classification model classify.mod for Germany (uses a random 20% of the input as training samples per default):
$ wget https://download.geofabrik.de/europe/germany-latest.osm.bz2
$ statsimi model --model_out classify.mod --train germany-latest.osm.bz2Write a fix file germany.fix for germany-latest.osm based on the previously build model (you can also download the model here):
$ statsimi fix --model classify.mod --fix_out germany.fix --test germany-latest.osm.bz2We provide some pre-trained models here.
statsimi can be used to train and output a reusable classification model, to start a classification HTTP server or to evaluate methods against some dataset.
The following basic commands are supported:
model(write a classification model for the given input data to a file)evaluate(test the given model or the given approach against a ground truth)fix(write a file with fix suggestions and error highlights for the input OSM data)pairs(write just the station pairs file from the input data)http(fire up a classification server for the given model and/or input data)
Instead of parsing the OSM data on each run, it is possible to generate the station pairs file once and use it instead of an OSM file:
$ statsimi pairs --test <input> --pairs_train_out <output>The pairs file is a tab separated file with the following fields: station1_id, station1_name, station1_lat, station1_lon, station2_id, station2_name, station2_lat, station2_lon, similar.
Example rows:
368 Freiburg, Bertoldsbrunnen 47.9947126 7.8500194 3903 Freiburg Bertoldsbrunnen 47.9951889 7.8501929 1
368 Freiburg, Bertoldsbrunnen 47.9947126 7.8500194 296 Freiburg ZOB Fernbus 47.9957201 7.8403324 0
$ statsimi model --train <train_input> -p <train_perc> --model_out <model_file> --method <method>where method may be one of those listed in statsimi --help.
Using a previously trained model, a classification HTTP server can be started like this:
$ statsimi http --model <model_file> --http_port <port>A GUI for playing around with the model will then be available at http://localhost:<port>.
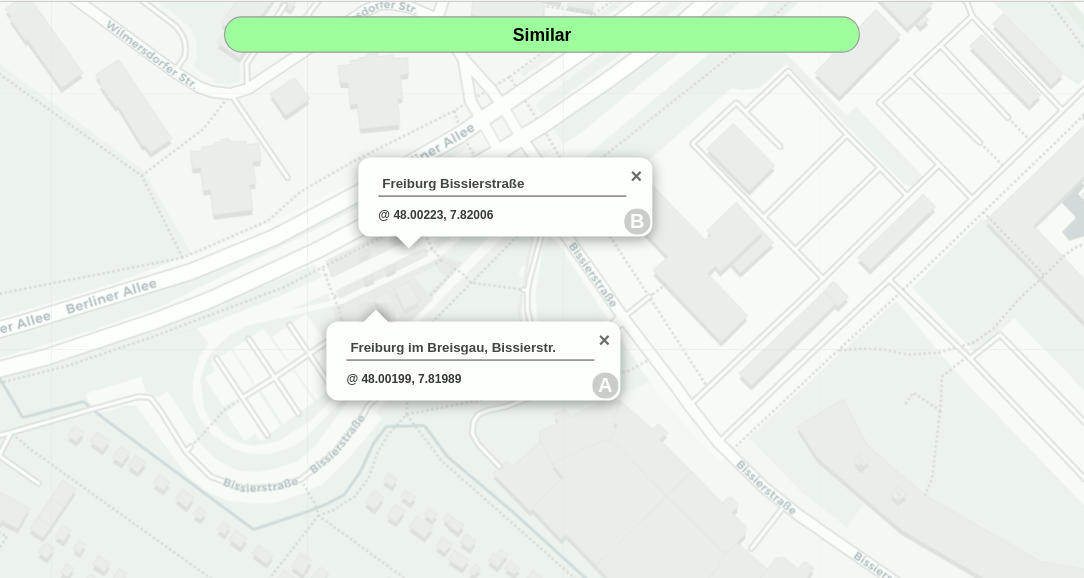
Classification server GUI
The API backend is at /api. A typical request then looks like this:
http://localhost:<port>/api?name1=Bertoldsbrunnen&lat1=47.995662&lon1=7.846041&name2=Freiburg,%20Bertoldsbrunnen&lat2=47.995321&lon2=7.846341
The answer will be
{"res": 1}if the two stations are similar, or
{"res": 0}if they are not similar.
To evaluate a model against a ground truth, use
$ statsimi evaluate --model <model_file> --test <osm_data>where <model_file> is a pre-trained model and <osm_data> is a OSM file (the ground truth data). statsimi will output precision, recall, F1 score, a confusion matrix and typical true positives, true negatives, false positives and false negatives.
You can also directly evaluate a method without building a model first:
$ statsimi evaluate --train <osm_data> --method=rf -p=0.2will train on 20% of <osm_data> and test the model against the remaining 80%.
To fix OSM data, use
$ statsimi fix --model <model_file> --test <osm_data> --fix_out <fix_file>where <model_file> is a pre-trained model and <osm_data> is an OSM file containing the data to be fixed. statsimi will analyze the input OSM data and output suggestions to stdout as well as into a file <fix_file> in a machine readable format (TODO: documentation of this format).
With a pre-trained model:
from statsimi.feature.model_builder import ModelBuilder
from statsimi.feature.feature_builder import FeatureBuilder
from statsimi.feature.stat_ident import StatIdent
mb = ModelBuilder()
model, ngram_idx, fbargs = mb.unpickle("model.lib")
fb = FeatureBuilder(ngram_idx = ngram_idx, topk = ngram_idx[2], **fbargs)
stat1 = StatIdent(name="Main Street", lat=51.52010, lon=-0.14270)
stat2 = StatIdent(name="High Street", lat=51.52035, lon=-0.14140)
res = model.predict(fb.get_feature_vec(stat1, stat2))
print(res)Without a pre-trained model:
from statsimi.feature.model_builder import ModelBuilder
from statsimi.feature.feature_builder import FeatureBuilder
from statsimi.feature.stat_ident import StatIdent
mb = ModelBuilder()
model, ngram_idx = mb.build(trainfiles=["britain-and-ireland-latest.osm.bz2"])
# re-use ngrams from model builder
fb = FeatureBuilder(ngram_idx = ngram_idx, topk = ngram_idx[2])
stat1 = StatIdent(name="Main Street", lat=51.52010, lon=-0.14270)
stat2 = StatIdent(name="High Street", lat=51.52035, lon=-0.14140)
res = model.predict(fb.get_feature_vec(stat1, stat2))
print(res)