Obtain and store data of top YouTube videos and compare average metrics to COVID-19 related videos.
Client demands for software that can obtain metrics of video engagement and performance in a certain time period. COVID-19 related videos should be identified through certain keywords/topics established in the video data obtained. These specific metrics are required for analysis:
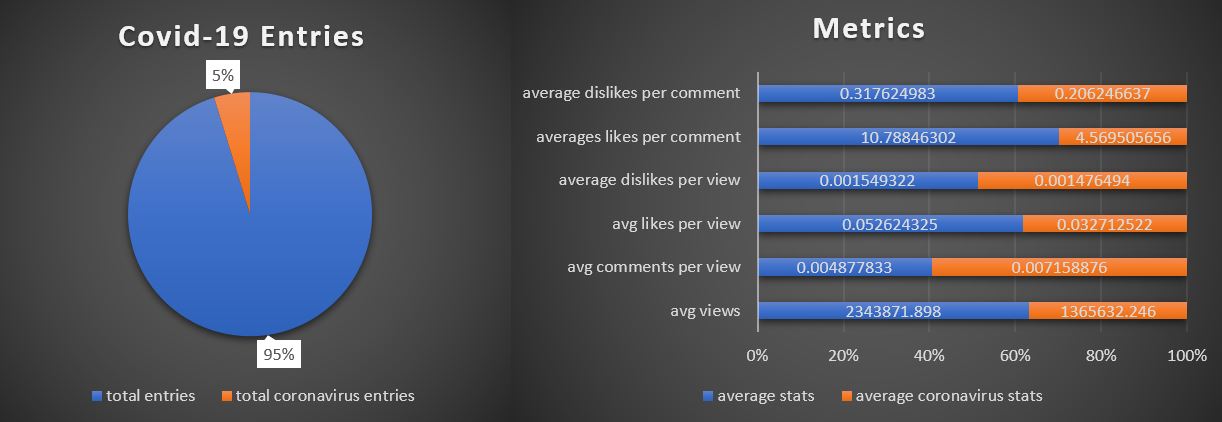
- Average views
- Average COVID-19 views
- Average comments per view
- Average COVID-19 comments per view
- Average likes/dislikes per view
- Average COVID019 likes/dislikes per view
Data should be exported in a format where an excel file can be used to illustrate trends. This practice is important as the data needs to be human-readable and used for futher analysis.
- Google APIs Client
pip install --upgrade google-api-python-clientpip install --upgrade google-auth-oauthlib google-auth-httplib2
Note: Download YOUR_CLIENT_SECRET_FILE.json and place in the directory, this is done following the api setup tutorial provided by Google.
- Run
grab_data.py. - Run
transform_data.py. - Run
analyse_data.py.
The goal of this project is to be able to visualise how videos with a title containing COVID-19/coronavirus perform against the other popular videos.
grab_data.py utilises YouTube v3 API. This script is designed to iterate through all possible pages that are returned by Google as to exhuast all data. The main directory for all data is simply called data however, the subdirectories are named after the day, month and year. This implementation allows for separation of data by a difference of a day - this script should be ran every day to harvest more data.
transform_data.py is designed to iterate through each subdirectory that contains the data. This script then transforms the data into a format (list of dictionaries) that is easily programmable. The list is then saved as a pickle file in the respective subdirectory, this storage allows for other usage.
analyse_data.py reads the generated pickle files and creates a list of videos. This list then iterated through to obtain desired statistics for further calculations. This script considers the title and tags as a source of identifying COVID-19 related videos, some channels use descriptions and tags with unrelated information however, this can be used to notice if applying a COVID-19 tag in a video would increase views and such. Originally, the script only considered the title but too few videos were placed on the popular video list that were related to the subject. If the title contains the virus then the video will be almost always COVID-19 related. Due to the nature of the API, with the intention of obtaining data every day the script has to be able capable of dealing with duplicates. For this reason this script now iterates through titles, notices duplicates and generates a new list of videos with no duplicates and updated statistics for each. Finally, the script exports a CSV files with useful metrics that can be visualised.
The original metrics measured against views but later through development it was decided that comparing engangement (comments, likes and dislikes) together seemed more conclusive. However, engagement per view is still considered.
These illustrations were generated with data obtained between the 18th of July and 19th of August.