- drives itself, with little or no human intervention
- different levels of authonomy
- Camera
- used for classification, segmentation, and localization.
- problem w/ night time, and extreme conditions like fog, heavy rain.
- LiDAR (Light Detection And Ranging,)
- uses lasers or light to measure the distance of the nearby objects.
- adds depth (3D perception), point cloud
- works at night or in dark, still fail when there’s noise from rain or fog.
- RADAR (Radio detection and ranging)
- use radio waves (instead of lasers), so they work in any conditions
- sense the distance from reflection,
- very noisy (needs clean up (thresholding, FFT)), lower spatial resolution, interference w/ other radio systems
- point cloud
- Audio
- Perception
- Perception
objects,
Raw sensor (lidar, camera, etc) data (image, point cloud)-> world understanding
- Object detection (traffic lights, pedestrians, road signs, walkways, parking spots, lanes, etc), traffic light state detection, etc
- Localization
- calculate position and orientation of the vehicle as it navigates (Visual Odometry (VO)).
- Deep learning used to improve the performance of VO, and to classify objects.
- Examples: PoseNet and VLocNet++, use point data to estimate the 3D position and orientation.
- ....
-
Behavior prediction
- predict future trajectory of agents
-
Planning: decision making and generate trajectory
-
Controller: generate control commands: accelerate, break, steer left or right
-
Note: latency: orders of millisecond for some tasks, and order of 10 msec's for others
-
2D Object detection:
- Two-stage detectors: using Region Proposal Network (RPN) to learn RoI for potential objects + bounding box predictions (using RoI pooling): (R-CNN, Fast R-CNN, Faster R-CNN, Mask-RCNN (also does segmentation)
- used to outperform until focal loss
- One-stage: skip proposal generation; directly produce obj BB: YOLO, SSD, RetinaNet
- computationally appealing (real time)
- Transformer based:
- Detection Transformer (DETR): End-to-End Object Detection with Transformers
- uses a transformer encoder-decoder architecture, backbone CNN as the encoder and a transformer-based decoder.
- input image -> CNN -> feature map -> decoder -> final object queries, corresponding class labels and bounding boxes.
- handles varying no. of objects in an image, as it does not rely on a fixed set of object proposals.
- More
- TrackFormer: Multi-Object Tracking with Transformers
- on top of DETR
- Detection Transformer (DETR): End-to-End Object Detection with Transformers
- NMS:
- Two-stage detectors: using Region Proposal Network (RPN) to learn RoI for potential objects + bounding box predictions (using RoI pooling): (R-CNN, Fast R-CNN, Faster R-CNN, Mask-RCNN (also does segmentation)
-
3D Object detection:
- from point cloud data, ideas transferred from 2D detection
- Examples:
- 3D convolutions on voxelized point cloud
- 2D convolutions on BEV
- heavy computation
-
Object tracking:
- use probabilistic methods such as EKF
- use ML based models
- use/fine-tune pre-trained CNNs for feature extraction -> do tracking with correlation or regression.
- use DL based tracking algorithm, such as SORT (Simple Online and Realtime Tracking) or DeepSORT
-
Semantic segmentation
- pixel-wise classification of image (each pixel assigned a class)
-
Instance segmentation
- combine obj detection + semantic segmatation -> classify pixels of each instance of an object
-
Main task: Motion forecasting/ trajectory prediction (future):
-
predict where each object will be in the future given multiple past frames
-
Examples:
- use RNN/LSTM for prediction
-
Input from perception + HDMap
-
Options:
- top-view representation: input -> CNN -> ..
- vectorized: context map
- graph representation: GNN
-
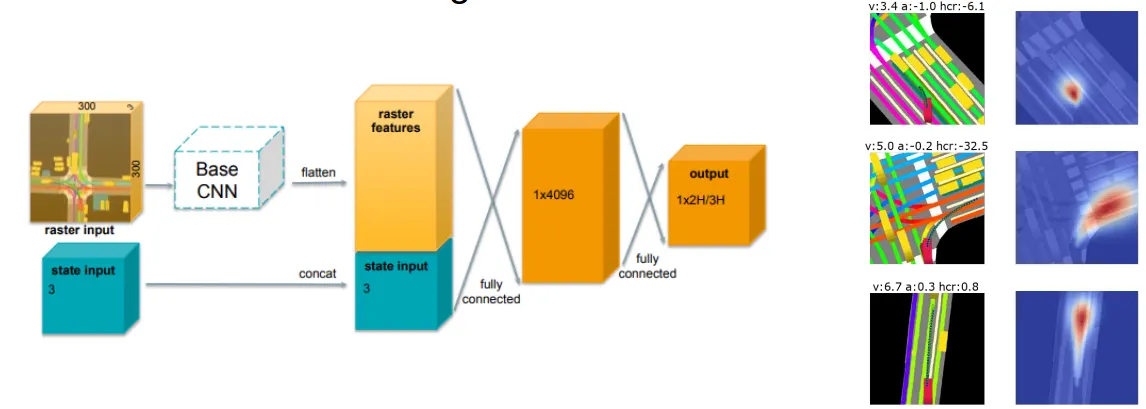
Render a bird eye view image on a single RGB image
- one option for history: also render on single image
- another option: use feature extractor (CNN) for each frame then use LSTM to get temporal info
- Input: BEV image + (v, a, a_v)
- Out: (x, y, std)
-
also possible to use LSTM networks to generate waypoints in the trajectory sequentially.
-
Challenge: Multimodality (distribution of different modes) - future uncertain
-
Decision making and generate trajectory
-
input: route (from A to B), context map, prediction for nearby agents
-
proposal: what are possible options for the plan (mathematical methods vs imitation learning) - predict what is optimal
- Hierarchical RL can be used
- high level planner: yield, stop, turn left/right, lane following, etc)
- low level planner: execute commands
- motion validation: check e.g. collision, red light, etc -> reject + ranking
-
- Fast& Furious (Uber):
- Tasks: Detection, tracking, short term (e.g. 1 sec) motion forecasting
- create BEV from point cloud data:
- quantize 3D → 3D voxel grid (binary for occupation) → height>channel(3rd dimension) in RGB + time as 4th dimension → Single stage detector similar to SSD
- deal with temporal dimension in two ways:
- early fusion (aggregate temporal info at the very first layer)
- late fusion (gradually merge the temporal info: allows the model to capture high-level motion features.)
- use multiple predefined boxes for each feature map location (similar to SSD)
- two branches after the feature map:
- binary classification (P (being a vehicle) for each pre-allocated box)
- predict (regress) the BB over the current frame as well as n − 1 frames into the future → size and heading
- IntentNet: learning to predict intent from raw sensor data (Uber)
- Fuse BEV generated from the point cloud + HDMap info to do detection, intention prediction, and trajectory prediction.
- I: Voxelized LiDAR in BEV, Rasterized HDMap
- O: detected objects, trajectory, 8-class intention (keep lane, turn left, etc)
- Fast& Furious (Uber):
-
- ChauffeurNet (Waymo)
- prediction and planning using single NN using Imitation Learning (IL)
- More info here
- ChauffeurNet (Waymo)
-
- Learning to drive in a day (wayve.ai)
- RL to train a driving policy to follow a lane from scratch in less than 20 minutes!
- Without any HDMap and hand-written rules!
- Learning to Drive Like a Human
- Imitation learning + RL
- used some auxiliary tasks like segmentation, depth estimation, and optical flow estimation to learn a better representation of the scene and use it to train the policy.
- Learning to drive in a day (wayve.ai)
Design an ML system to detect if a pedestrian is going to do jaywalking.
-
Jaywalking: a pedestrian crossing a street where there is no crosswalk or intersection.
-
Goal: develop an ML system that can accurately predict if a pedestrian is going to do jaywalking over a short time horizon (e.g. 1 sec) in real-time.
-
Pedestrian action prediction is harder than vehicle: future behavior depends on other factors such as body pose, activity, etc.
-
ML Objective
- binary classification (predict if a pedestrian is going to do jaywalking or not in the next T seconds.)
-
Discuss data sources and availability.
- Object detection
- Precision
- calculated based on IOU threshold
- AP: avg. across various IOU thresholds
- mAP: mean of AP over C classes
- Precision
- jaywalking detection:
- Precision, Recall, F1
- Manual intervention
- Simulation Errors
- historical log (scene recording) w/ expert driver
- input to our system and compare the decisions with the expert driver
- Visual Understanding System
- Camera: Object detection (pedestrian, drivable region?) + tracking
- [Optional] Camera + object detection: Activity recognition
- Radar: 3D Object detection (skip)
- Behavior prediction system
- Trajectory estimation
- require motion history
- Ml based approach (classification)
- Input:
- Vision: local context: seq. of ped's cropped image (last k frames) + global context (semantically segmented images over last k frames)
- Non-vision: Ped's trajectory (as BBs, last k frames) + context map + context(location, age group, etc)
- Input:
- Trajectory estimation
-
Data collection and annotation:
- Collect datasets of pedestrian behavior, including both jaywalking and non-jaywalking behavior. This data can be obtained through public video footage or by recording video footage ourselves.
- Collect a diverse dataset of video clips or image sequences from various locations, including urban and suburban areas, with different pedestrian behaviors, traffic conditions, and lighting conditions.
- Annotate the data by marking pedestrians, their positions, and whether they are jaywalking or not. This can be done by drawing bounding boxes around pedestrians and labeling them accordingly (initially human labelers eventually auto-labeler system)
- Targeted data collection:
- in later iterations, we check cases where driver had to intervene when pedestrian jaywalking, check performance on last 20 frames, and ask labelers to label those and add to the dataset (examples need to be seen)
-
Labeling:
- each video frame annotated with BB + pose info of the ped + activity tags (walking, standing, crossing, looking, etc) + attributes of pedestrian (age, gender, location, ets),
- each video is annotated weather conditions and time of day.
-
Data preprocessing:
- Split the dataset into training, validation, and test sets.
- Normalize and resize the images to maintain consistency in input data.
- Apply data augmentation techniques (e.g., rotation, flipping, brightness adjustments) to increase the dataset's size and improve model generalization.
- enhance or augment the data with GANs
-
Data augmentation
-
relevant features from the video footage, such as the pedestrian's position, speed, and direction of movement.
-
We can also use computer vision techniques to extract features like the presence of a crosswalk, traffic lights, or other relevant environmental cues.
-
features from frames: fc6 features by Faster R-CNN object detector at each BB (4096T vector)
- assume: we can query cropped images of last T (e.g. 5) frames of detected pedestrians from built-in object detector and tracking system
-
features from cropped frames: activity recognition
-
context map : traffic signs, street width, etc
-
ped's history (seq. of BB info) + current info (BB + pose info (openPose) + activity + local context) + global context (context map) + context(location, age group, etc) -> JW/NJW classifier
- other features that can be fused: ped's pose, BB, semantic segmentation maps (semantic masks for relevant objects), road geometry, surrounding people, interaction with other agents
Model selection and architecture:
Assume built-in object detector and tracker. If not,
- Object detection: Use a pre-trained object detection model like Faster R-CNN, YOLO, or SSD to identify and localize pedestrians in the video frames.
- Object tracking:
- use EKF based method or ML based method (SORT or DeepSORT)
- Activity recognition:
- 3D CNN, or CNN + RNN(GRU) (chose this to fit the rest of the architecture)
(Output of object detection and tracking can be converted into rasterized image for each actor -> Base CNN )
-
Encoders:
- Visual Encoder: vision content (last k frames) -> CNN base encoders + RNN for temporal info(GRU) [Another option is to use 3D CNNs]
- CNN base encoder -> another RNN for activity recognition
- Non-vision encoder: for temporal content use GRU
- Visual Encoder: vision content (last k frames) -> CNN base encoders + RNN for temporal info(GRU) [Another option is to use 3D CNNs]
-
Fusion strategies:
- early fusion
- late fusion
- hierarchical fusion
-
Jaywalking clf: Design a custom clf layer to classify detected pedestrians as jaywalking or not.
- Example: RF, or a FC layer
-
we can do ablation study for selection of the fusion architecture + visual and non-visual encoders Another example:


Model training and evaluation: a. Train model(s) using the annotated dataset,
- loss functions for object detection (MSE, BCE, IoU)
- jaywalking classification tasks (BCE).
b. Regularly evaluate the model on the validation set to monitor performance and avoid overfitting. Adjust hyperparameters, such as learning rate and batch size, if necessary.
c. Once the model converges, evaluate its performance on the test set, using relevant metrics like precision, recall, F1 score, and Intersection over Union (IoU).
Transfer learning for object detection (use powerful feature detectors from pre-trained models)
- for fine tuning e.g. use 500 videos each 5-10 seconds, 30fps
-
SDV on the road: will receive real-time images -> ...
-
Model optimization: Optimize the model for real-time deployment by using techniques such as model pruning, quantization, and TensorRT optimization.
Deployment: Deploy the trained model on edge devices or servers equipped with cameras to monitor real-time video feeds (e.g. traffic camera system) and detect jaywalking instances. Integrate the system with existing traffic infrastructure, such as traffic signals and surveillance systems.
Continuous improvement: Regularly update the model with new data and retrain it to improve its performance and adapt to changing pedestrian behaviors and environmental conditions.
- Other points:
- Occlusion detection
- hallucinated agent
- when visual signal is imprecise
- poor lighting conditions
- Occlusion detection