Nesse projeto, foi elaborada uma solução end-to-end, abrangendo desde a etapa de scrapy e captura dos dados até a visualização final. Realizou-se a captura e o tratamento das informações, seguido pela estruturação no banco de dados. A etapa de agrupamento dos dados para a construção dos gráficos foi crucial para a compreensão e apresentação de insights.
A última e principal etapa analisou o impacto da relação entre os dados de IMC e câncer, bem como o Potencial de Prevenção. Esse tipo de trabalho é fundamental para orientar tomadas de decisão e a eficiência dos gestores e governantes. O projeto poderia evoluir para um servidor público com dashboards contendo filtros e gráficos de mapas em uma segunda versão.
git init
git add .
git commit -m 'criação do projeto'
git remote add origin git@github.com:anselmomendes/International-Agency-for-Research-on-Cancer.gitselect a.continent,
a.cancer,
a.country,
a.paf_obs_m as male_att,
a.paf_obs_f as famele_att,
a.paf_obs_both as both_att,
p.paf_obs_m as male_prev,
p.paf_obs_f as famele_prev,
p.paf_obs_both as both_prev,
p.paf_obs_m * a.paf_obs_m as male_diff,
p.paf_obs_f * a.paf_obs_f as famele_diff,
p.paf_obs_both * a.paf_obs_both as both_diff
from attributable a
left join preventable p on a.country = p.country and a.cancer = p.cancer
O site apresentava uma area de download dos dados, porem a combinação de arquivos necessários para a aquisição dos dados não é eficiente em vista que o problema pode escalar
10 (opções de cancer) * 3 (opções de sexo) * 6 (opções de continentes) * 2 (opções de bases) = 360 arquivos.
Criação do script jupyter de web scraping para download de dados foi feito para aquisição dos dados de forma automatica.

A saida dos dados na figura abaixo referente ao primeiro item do desafio mostra as informações sobre pais, continente, sexo e tipo do cancer.

Para uma melhor esperiencia foi criado um do projeto na ferramenta no streamlit.

Foi elaborado gráficos para analise de dados da média de casos de cancer entre o sexo masculino e feminino, comparado as caracteristicas por tipo de cancer, continente. E o rank dos paises com maior indice do mundo.
Lista dos gráficos elaborados
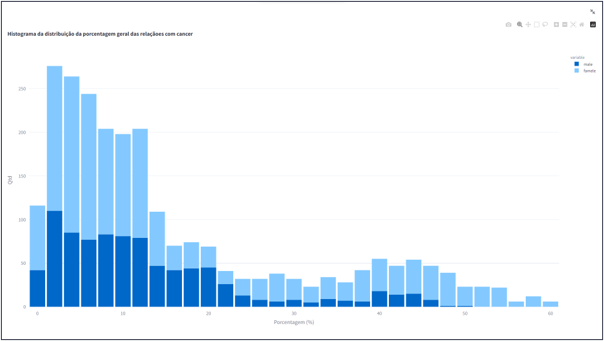
- Histograma da distribuição da porcentagem geral das relaçãoes com cancer
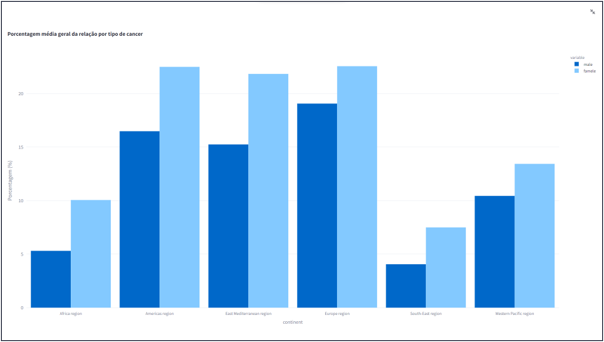
- Porcentagem média geral da relação por continente
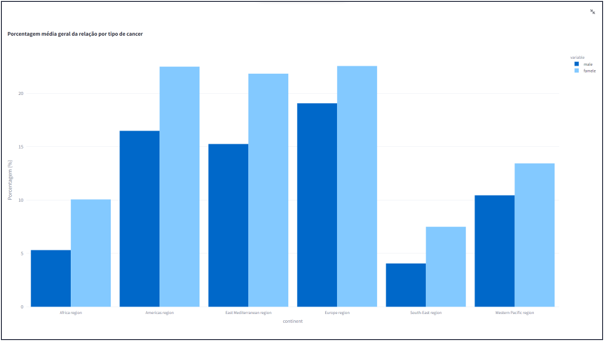
- Porcentagem média geral da relação por tipo de cancer
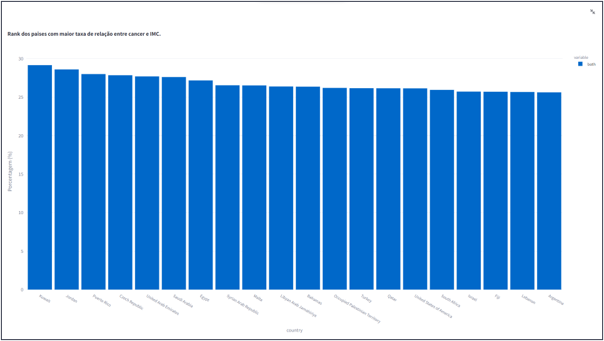
- Rank dos paises com maior taxa de relação entre cancer e IMC
{kind=link}
{kind=link}
{kind=link}
{kind=link}
3 - Faça uma comparação entre o cenário fração de casos de câncer em 2012 atribuíveis ao excesso de Índice de Massa Corporal (IMC) em países da América do Sul com o cenário previnível.

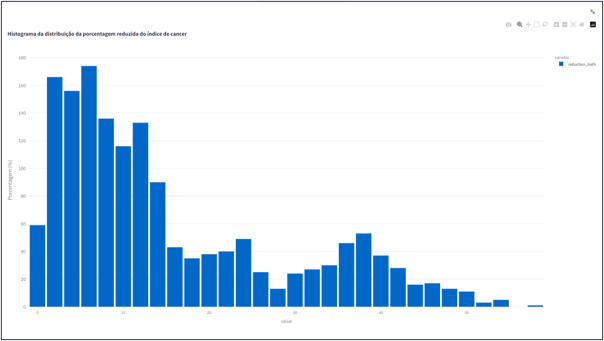
Fazendo o gruzamento dos dados dos casos de cancer que tiveram relação com o IMC e os dados da porcentagem de casos que poderiam ter sido evitados caso o indice do IMC tivesse se mantido. Foi gerado uma serie de gráficos apresentado os principais impactos na redução desses indices, agrupando por tipo de cancer e região.
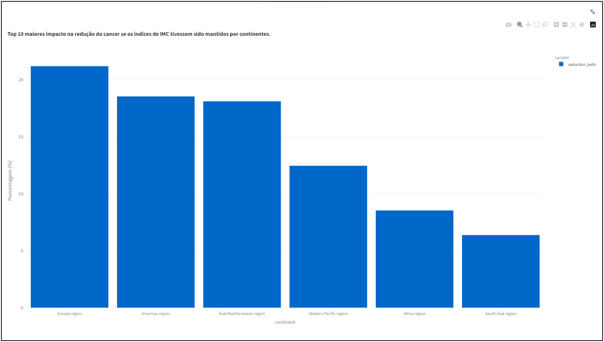
Foi possivel observar que as regiões que esse indice poderia ter sido evitado foram continentes onde ouve um grande aumento no IMC dos seus habitantes, relacionado ao IDH desses paises.
Lista dos gráficos elaborados
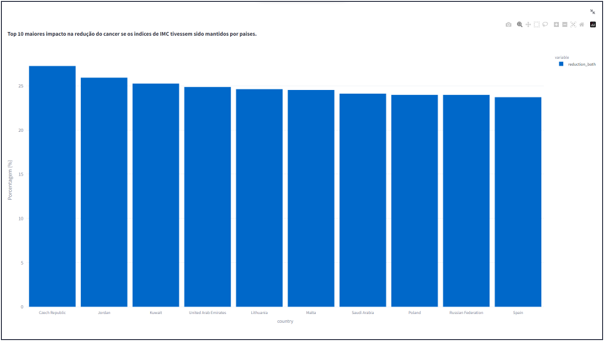
- Top 10 maiores impacto na redução do cancer se os indices de IMC tivessem sido mantidos por paises.
- Top 10 maiores impacto na redução do cancer se os indices de IMC tivessem sido mantidos por continentes.
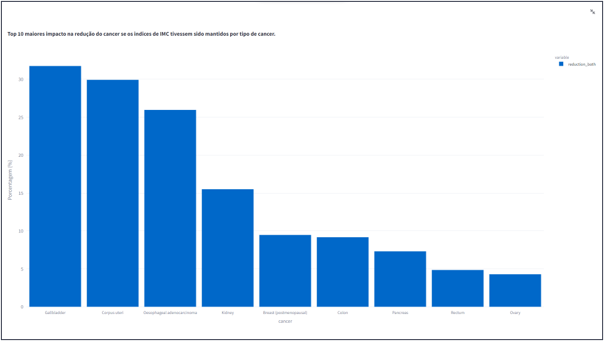
- Top 10 maiores impacto na redução do cancer se os indices de IMC tivessem sido mantidos por tipo de cancer.
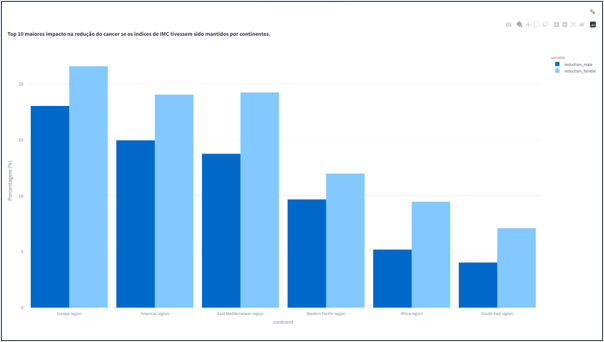
- Top 10 maiores impacto na redução do cancer se os indices de IMC tivessem sido mantidos por continentes.
- Histograma da distribuição da porcentagem reduzida do índice de cancer
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
O resultado da saída do estudo se deu em comparar os dados do item 3 com os paises das americas com a media mundial.

- Com os gráficos abaixo, podemos inferir que os casos de câncer na América do Sul estão acima da média mundial em relação a todos os tipos de câncer.
- O impacto, caso mantivéssemos os índices de IMC, seria maior na América do Sul do que em relação à média mundial.