This project provides scripting to enable users to easily begin capturing the traffic in their existing AWS cloud infrastructure using Arkime. It is a Python CLI which uses the AWS Cloud Development Kit (CDK) to provide orchestration and the CloudFormation Templates based on inputs.
The CDK is used to perform infrastructure specification, setup, management, and teardown. You can learn more about infrastructure-as-code using the CDK here.
Watch Chris's demo to learn more and see the project in action.
- Background
- Quick Start Guide
- Architecture and Design
- How to Run the AWS All-in-One CLI
- How to shell into the ECS containers
- Setting Up Demo Traffic Generation
- Account Limits, Scaling, and Other Concerns
- Troubleshooting
- Generally useful NPM/CDK commands
- Contribute
- Maintainers
- License
Deploying Arkime in AWS is a complex task. There are many resources that need to be created and configured. This project aims to provide a simple Python CLI that can handle this complexity to allow you to create and manage Arkime clusters as easily as on-prem.
- Install the prerequisites
aws iam create-service-linked-role --aws-service-name es.amazonaws.com(see Setting up your Arkime Cluster)./manage_arkime.py --region REGION cluster-create --name CLUSTER_NAME(seemanage_arkime.py cluster-create --helpfor important options)./manage_arkime.py --region REGION vpc-add --cluster-name CLUSTER_NAME --vpc-id VPC_IDto add the vpc to the cluster./manage_arkime.py --region REGION get-login-details --name CLUSTER_NAMEto see login details and viewer URL- Update the files in the
config-CLUSTER_NAME-ACCOUNT_ID-REGIONdirectory with viewer/capture configuration changes ./manage_arkime.py --region REGION config-update --cluster-name CLUSTER_NAMEto update running config
See the detailed instructions below for more information on how to run the AWS AIO CLI.
This tool provides a Python CLI which the user can interact with to manage the Arkime installation(s) in their account. The Python CLI wraps a CDK App. The CLI provides orchestration; the CDK App provides the CloudFormation Templates based on inputs from the CLI and performs CloudFormation create/update/destroy operations. State about the user's deployed Arkime Clusters is stored in the user's AWS Account using the AWS Systems Manager Parameter Store. The capture itself is performed by using VPC Traffic Mirroring to mirror traffic to/from the elastic network interfaces in the user's VPC through a Gateway Load Balancer and into another VPC (the Capture VPC), created by the CLI, in the user's account. The Arkime Capture Nodes live in the Capture VPC.
When a VPC is added to a Cluster with the vpc-add command, we attempt to set up monitoring for all network interfaces in the target VPC. After initial this setup, we listen for changes in the VPC using AWS EventBridge and attempt to automatically create/destroy mirroring accordingly. This should enable the user's fleet to scale naturally while still having its traffic captured/monitored by Arkime. We currently provide automated, on-going monitoring of the following resource types:
- EC2 Instances
- EC2 Autoscaling Groups
- ECS-on-EC2 Container Instances
- Fargate Tasks
Resources of those types should have capture configured for them when they are brought online and taken offline.
Figure 1: Current high level design of the Arkime AWS All-in-One Project
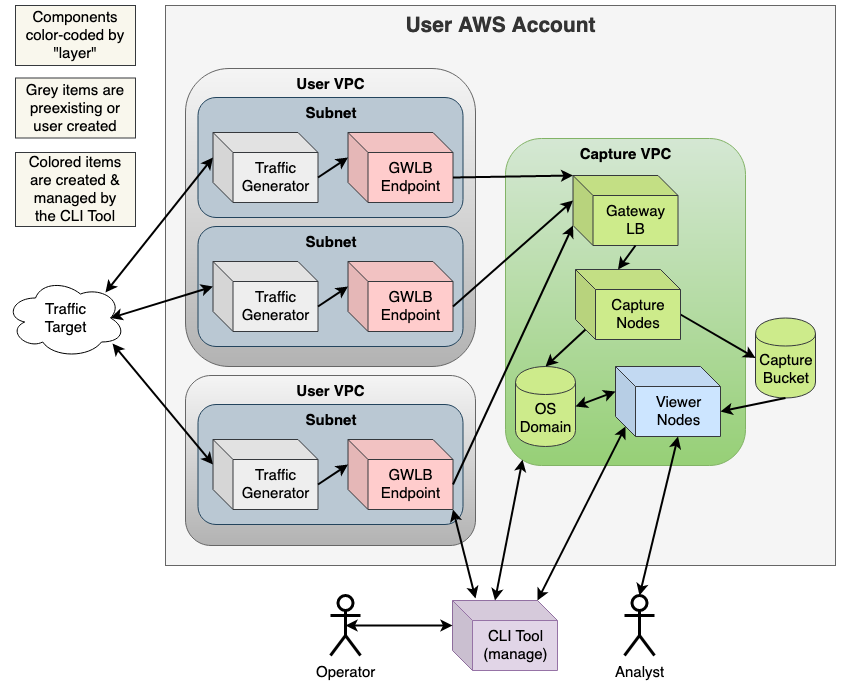
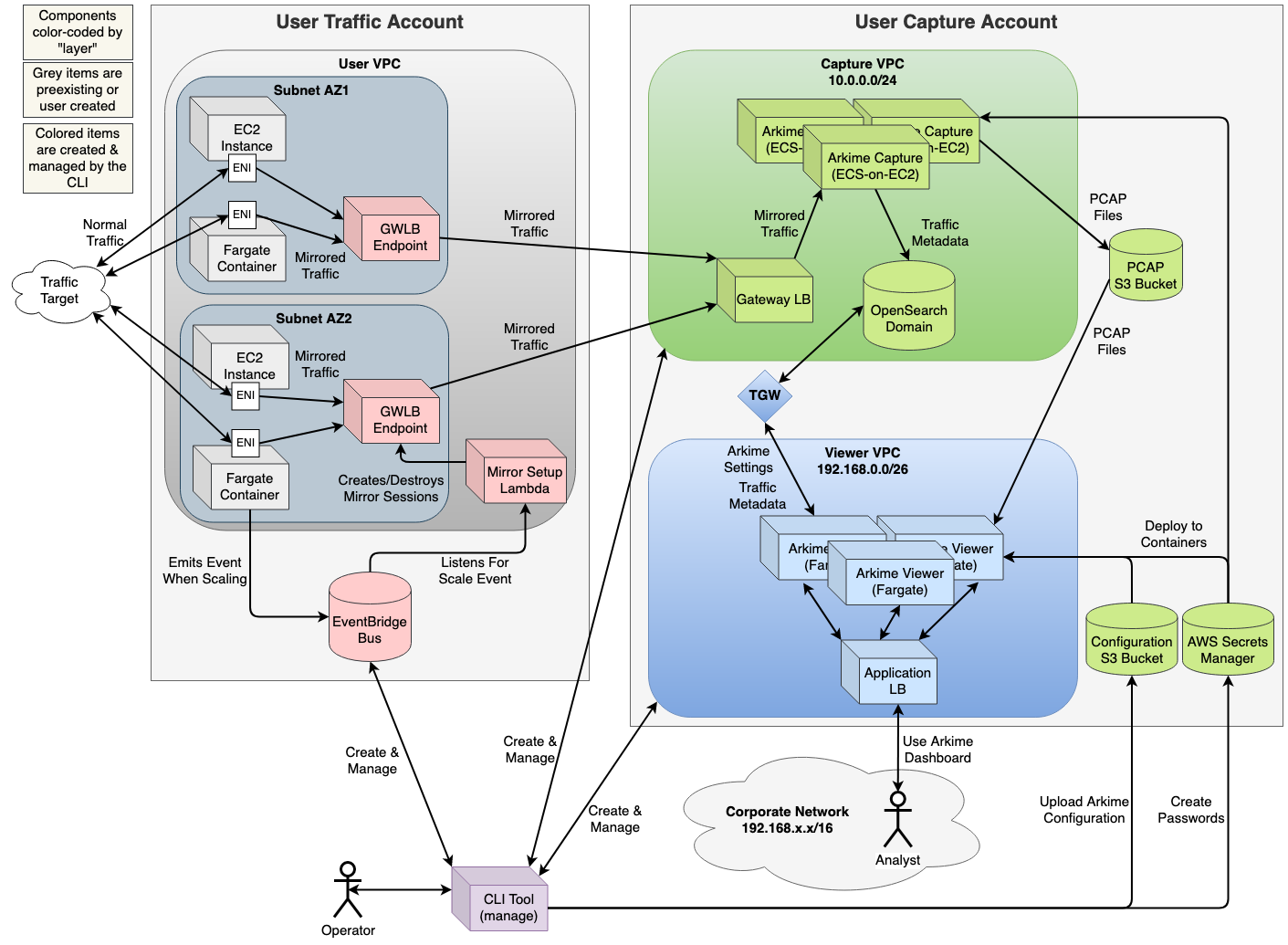
Figure 2: Current detailed design of the Arkime AWS All-in-One Project w/ all features in use
- REQUIRED: A copy of the aws-aio repo
- REQUIRED: A properly installed/configured copy of Node 18 (see instructions here)
- REQUIRED: A properly installed/configured copy of Python 3.9+ and venv (see instructions here)
- REQUIRED: A properly installed/configured copy of Docker (instructions vary by platform/organization)
- REQUIRED: A properly installed/configured copy of the CDK CLI (see instructions here)
- REQUIRED: Valid, accessible AWS Credentials (see instructions here and here)
- HIGHLY RECOMMENDED: A properly installed/configured copy of the AWS CLI (see instructions here)
Why each of these needed:
- Node is required to work with the CDK (our CDK Apps are written in TypeScript)
- The Management CLI is written in Python, so Python is needed to run it
- Docker is required to transform our local Dockerfiles into images to be uploaded/deployed into the AWS Account by the CDK
- The CDK CLI is how we deploy/manage the underlying AWS CloudFormation Stacks that encapsulate the Arkime AWS Resoruces; the Management CLI wraps this
- The AWS CLI is recommended (but not strictly required) as a way to set up your AWS Credentials and default region, etc. The CDK CLI needs these to be configured, but technically you can configure these manually without using the AWS CLI (see the CDK setup guide for details)
NOTE: By default, the CDK CLI will use the AWS Region specified as default in your AWS Configuration file; you can set this using the aws configure command. It will also use the AWS Account your credentials are associated with.
The project uses a Python Virtual Environment to manage dependencies. You can learn more about venv and Python Virtual Environments here. This ensures that when you run the CLI, it's using an instance of Python with all the correct dependencies installed rather than your system version of Python. To set up your Python Virtual Environment, run the following commands in the repo's root directory:
python3 -m venv .venv
source .venv/bin/activate
(cd manage_arkime ; pip install -r requirements.txt)
If the Virtual Environment is set up correclty, you should see the name of your environment prefixed in your terminal's prompt headers. The commands above name the Virtual Environment .venv, which you can see in this example terminal prompt:
(.venv) chelma@3c22fba4e266 aws-aio %
As mentioned in the prequisites intro, you need AWS Credentials in order to run the Arkime AWS AIO CLI. The CLI needs the credentials to gather information about your AWS Account, store/update/read state, and perform CloudFormation deployments. It is advised to run the CLI with Admin-level permissions in the account. This is both necessary and reflects the fact that the CloudFormation operations manipulate IAM Resources in the account.
The Arkime AIO CLI pulls credentials from the same places as the AWS CLI, so you should be able to set up your credentials in the standard way. You can easily check what AWS Identity is in your keyring using the AWS CLI:
aws sts get-caller-identity
NOTE: If you haven't already, be sure to install the prerequisite software, be in your Python Virtual Environment, and have the required AWS Credentials.
You can deploy the Arkime Cluster into your AWS account like so:
./manage_arkime.py cluster-create --name MyCluster
NOTE: You must perform a manual action in your AWS Account in order for this deployment to succeed. Specifically you must create an IAM Service Linked Role for AWS OpenSearch to be able to manage the OpenSearch Domain. This is very easy to do with the AWS CLI, and only needs to be done once per AWS Account:
aws iam create-service-linked-role --aws-service-name es.amazonaws.com
You can see your created cluster and the VPCs it is currently monitoring using the clusters-list command, like so:
./manage_arkime.py clusters-list
By default, you will be given the minimum-size Capture Cluster. You can provision a Cluster that will serve your expected usage using a set of optional command-line parameters, which will ensure the EC2 Capture Nodes and OpenSearch Domain are suitably provisioned (plus a little extra for safety):
./manage_arkime.py cluster-create --name MyCluster --expected-traffic 0.01 --spi-days 30 --replicas 1
Once you have an Arkime Cluster, you can begin capturing traffic in a target VPC using the vpc-add command, like so:
./manage_arkime.py vpc-add --cluster-name MyCluster --vpc-id vpc-123456789
If you need your Capture and/or Viewer Nodes to live in a particular IP space, the CLI provides two optional parameters for create-cluster to achieve this: --capture-cidr and --viewer-cidr.
./manage_arkime.py cluster-create --name MyCluster --capture-cidr 192.168.0.0/26 --viewer-cidr 10.0.0.0/26
NOTE: You can only set these during the initial creation of the Cluster, as changing them would require tearing down the entire Cluster.
When you specify the --capture-cidr parameter, it uses your preferred CIDR for the VPC containing the Cluster's components. The CLI does some basic checks to see if your required compute capacity will fit in the IP space you indicated.
The --viewer-cidr is a bit more complex, but allows you to ensure that the IPs your Arkime Dashboard is available on are taken from a specific range. When you specify this parameter, the CLI will split the Viewer Nodes into their own VPC that's connected to the OpenSearch Domain in the Capture VPC using a Transit Gateway. The CLI checks to see your Viewer Nodes will fit in the specified CIDR, but will also make sure that your Viewer CIDR doesn't overlap with your Capture CIDR to prevent IP-space collisions between the two connected VPCs. This parameter is handy if you need to peer this VPC into your other networks and want to limit the number of IPs taken up. Typically, there will be many more IPs required by the Capture components (the Capture Nodes, the OpenSearch Domain) than the Viewer Nodes.
You can capture/monitor traffic in a VPC living in a different account you control, with a few additional steps. We need to "register" the cross-account link in both the Cluster and VPC accounts, and make sure we're using AWS Credentials associated with the account we're currently performing operations against. State about the Cluster lives in the Cluster account; state about the VPC lives in the VPC account; cross-account IAM access roles are used to enable the CLI to orchestrate the setup/teardown of resources. Cross-account roles are not required during runtime, just during management create/update/destroy operations with the CLI.
The process is as follows. You can use an existing cluster, but we'll show the full process for completeness.
We start by making sure we have an Arkime Cluster provisioned, using AWS Credentials associated with the account the Cluster will live in (XXXXXXXXXXXX). In this example, we'll assume that we have an AWS Credential profile ClusterAccount that contains these creds.
./manage_arkime.py --profile ClusterAccount cluster-create --name MyCluster
Next, we register the cross-account association in the Cluster account, using the Cluster account's AWS Credentials, to the VPC in the VPC account (YYYYYYYYYYYY). This command will spit out the details you need to perform the cross-account association in the VPC account:
./manage_arkime.py --profile ClusterAccount cluster-register-vpc --cluster-name MyCluster3 --vpc-account-id YYYYYYYYYYYY --vpc-id vpc-08d5c92356da0ccb4
.
.
.
2023-08-22 12:41:58 - Cross-account association details:
{
"clusterAccount": "XXXXXXXXXXXX",
"clusterName": "MyCluster3",
"roleName": "arkime_MyCluster3_vpc-08d5c92356da0ccb4",
"vpcAccount": "YYYYYYYYYYYY",
"vpcId": "vpc-08d5c92356da0ccb4",
"vpceServiceId": "vpce-svc-0bf7f421d6596c8cb"
}
2023-08-22 12:41:58 - CLI Command to register the Cluster with the VPC in the VPC Account:
./manage_arkime.py vpc-register-cluster --cluster-account-id XXXXXXXXXXXX --cluster-name MyCluster3 --cross-account-role arkime_MyCluster3_vpc-08d5c92356da0ccb4 --vpc-account-id YYYYYYYYYYYY --vpc-id vpc-08d5c92356da0ccb4 --vpce-service-id vpce-svc-0bf7f421d6596c8cb
We then need to switch to our VPC account's credentials; we'll assume there're stored in the AWS Credential profile VpcAccount. We can use the pre-canned command spit out by cluster-register-vpc, being sure to update it to specify the new profile. This registers the association in the VPC account as well:
./manage_arkime.py --profile VpcAccount vpc-register-cluster --cluster-account-id XXXXXXXXXXXX --cluster-name MyCluster3 --cross-account-role arkime_MyCluster3_vpc-08d5c92356da0ccb4 --vpc-account-id YYYYYYYYYYYY --vpc-id vpc-08d5c92356da0ccb4 --vpce-service-id vpce-svc-0bf7f421d6596c8cb
After that, we can run vpc-add as normal, but being sure to use creds for the VPC account:
/manage_arkime.py --profile VpcAccount vpc-add --cluster-name MyCluster3 --vpc-id vpc-08d5c92356da0ccb4
Traffic should begin showing up from your cross-account VPC as usual, with no further effort.
As with setup, we need to perform some additional steps to tear down a cross-account VPC capture. Basically, we just perform the reverse of what we did while setting things up; just be careful to use the correct credentials (the CLI should remind you if you use the wrong ones).
./manage_arkime.py --profile VpcAccount vpc-remove --cluster-name MyCluster3 --vpc-id vpc-08d5c92356da0ccb4
./manage_arkime.py --profile VpcAccount vpc-deregister-cluster --cluster-name MyCluster3 --vpc-id vpc-08d5c92356da0ccb4
./manage_arkime.py --profile ClusterAccount cluster-deregister-vpc --cluster-name MyCluster3 --vpc-id vpc-08d5c92356da0ccb4
You can log into your Viewer Dashboard using credentials from the get-login-details command, which will provide the URL, username, and password of the Arkime Cluster.
./manage_arkime.py get-login-details --name MyCluster
NOTE: By default, we set up HTTPS using a self-signed certificate which your browser will give you a warning about when you visit the dashboard URL. In *most* situations, you can just acknowledge the risk and click through. However, if you're using Chrome on Mac OS you might not be allowed to click through (see here). In that case, you'll need to click on the browser window so it's in focus and type the exact phrase thisisunsafe and it will let you through.
We deploy default configuration for the Arkime Capture and Viewer processes that work "out of the box". However, you can customize the configuration for those processes - and add custom behavior to your Capture and Viewer Nodes.
As part of running cluster-create, the CLI will create a new, cluster-specific directory at the root of this repo on-disk that contains the configuration/scripts that will be deployed into your containers (currently at: ./config-YourClusterName-AccountNum-AwsRegion). This directory contains two sub directories which contain all the scripts/configuration that are copied onto the Capture (./config-YourClusterName-AccountNum-AwsRegion/capture/) and Viewer (./config-YourClusterName-AccountNum-AwsRegion/viewer/) Nodes as part of their startup process. By default, these directories will just contain the aforementioned "default configuration", but you're free to edit the files there or even add new ones. Any files in the ./config-YourClusterName-AccountNum-AwsRegion/capture/ will end copied to your Capture Nodes; any files in the ./config-YourClusterName/viewer/ will end copied to your Viewer Nodes.
chelma@3c22fba4e266 aws-aio % tree config-YourClusterName-111111111111-us-east-2
config-YourClusterName-111111111111-us-east-2
├── capture
│ ├── config.ini
│ ├── default.rules
│ └── initialize_arkime.sh
├── viewer
│ ├── config.ini
│ └── initialize_arkime.sh
To help understand how this process works (and how to leverage the system to your benefit), here's an overview of how this currently works:
- During
cluster-create, we turn thecapture/andviewer/config directories into archives and stick them in AWS S3. - When ECS starts the Capture and Viewer Nodes, it invokes the
run_*_node.shscripts embedded in their Docker Image - The
run_*_node.shscript invokes thebootstrap_config.shscript, also embedded in their Docker Image, which pulls the configuration tarball from S3 and unpacks it onto disk - The
run_*_node.shscript invokes theinitialize_arkime.shscript, which is one of the files in yourcapture/andviewer/config directories locally, and sent to the container via the tarball in S3. By default, it performs some final initialization to make the pre-canned behavior "go". You can modify this script to perform any steps you'd like, and stick any new files you need in the container in thecapture/andviewer/config directories. - The
run_*_node.shscript starts the Arkime Capture/Viewer process
After running cluster-create and uploading the initial configuration, you'll need to use the config-update CLI call to deploy changed configuration to your Capture/Viewer Nodes. This is to improve deployment safety by providing a clearer rollback path in the event the new configuration doesn't work out as expected.
config-update will take a look at the local configuration and compare it what is currently deployed on your Nodes. If the local configuration is different, it will be archived, sent to S3, and your ECS Containers recycled to pull down the new configuration. If we see that Containers with the new configuration fail to start up correctly, we automatically revert to the previously deployed configuration.
You can list the details of the currently (and previously) deployed configuration using the config-list command:
./manage_arkime.py config-list --cluster-name MyCluster --viewer --deployed
To see the clusters you currently have deployed, you can use the clusters-list CLI command. This will return a list of clusters and their associated details like so:
[
{
"cluster_name": "MyCluster",
"opensearch_domain": "arkimedomain872-1nzuztrqm7dl",
"configuration_capture": {
"aws_aio_version": "1",
"config_version": "7",
"md5_version": "64295265159ac577cf741bb4d1966fcc",
"source_version": "v0.1.1-10-g3487548",
"time_utc": "2023-07-27 18:26:23"
},
"configuration_viewer": {
"aws_aio_version": "1",
"config_version": "1",
"md5_version": "be13e172a6440fcd6a7e73c8ae41457b",
"source_version": "v0.1.1-7-g9c2d7ca",
"time_utc": "2023-07-24 17:04:25"
},
"monitored_vpcs": [
{
"vpc_id": "vpc-008d258d7c536384b",
"vni": "15"
}
]
}
]
An explanation of the returned fields is as follows:
- cluster_name: The name of your Arkime Cluster
- opensearch_domain: The name of your Arkime Cluster's OpenSearch Domain
- configuration_capture: The details of your Capture Nodes' deployed configuration
- aws_aio_version: A version number used to track backwards compatibility within the AWS AIO project
- config_version: An integer that's incremented every time new Arkime Configuration is deployed (e.g. whenever you run
config-updatewith new configuration). Used to keep track of which configuration archive in S3 is deployed to your ECS Containers. - md5_version: The md5 hash of the deployed Arkime Configuration archive. Used to find changes in configuration.
- source_version: A version tracker for the AWS AIO CLI source code running on the client machine.
- time_utc: A UTC timestamp for when the Arkime Configuration archive deployed to your Nodes was created.
- configuration_viewer: The details of your Viewer Nodes' deployed configuration
- monitored_vpcs: The VPCs your Arkime Cluster is currently monitoring
- vpc_id: The AWS VPC ID of the VPC being monitored
- vni: The Virtual Network Identifier (VNI) assigned to this VPC within Arkime. Makes it possible to uniquely identify traffic from each VPC being monitored.
You can destroy the Arkime Cluster in your AWS account by first turning off traffic capture for all VPCs:
./manage_arkime.py vpc-remove --cluster-name MyCluster --vpc-id vpc-123456789
and then terminating the Arkime Cluster:
./manage_arkime.py cluster-destroy --name MyCluster
By default, this will tear down the Capture/Viewer Nodes and leave the OpenSearch Domain and Capture Bucket intact. Consequently, it will also leave a number of CloudFormation stacks in place as well.
If you want to tear down EVERYTHING and are willing to blow away all your data, you can use the "nuke" option:
./manage_arkime.py cluster-destroy --name MyCluster --destroy-everything
It's possible to create interactive terminal sessions inside the ECS Docker containers deployed into your account. The official documentation/blog posts are a bit confusing, so we explain the process here. The ECS tasks we spin up have all been pre-configured on the server-side to enable this, so what you need to do is the stuff on the client-side (e.g. your laptop). This process involves using the ECS Exec capability to perform a remote Docker Exec, and works even if your Tasks are running in private subnets. You can learn way more in this (verbose/confusing) blog post.
First, you need a recent version of the AWS CLI that has the required commands. You can install/update your installation with the instructions here.
Second, you need to install the Session Manager Plugin for the AWS CLI using the instructions here.
Finally, you can create an interactive session using the AWS CLI. You'll need to know the ECS Cluster ID and the Task ID, which you can find either using the AWS CLI or the AWS Console.
aws ecs execute-command --cluster <your cluster ID> --container CaptureContainer --task <your task id> --interactive --command "/bin/bash"
This demo uses Docker containers to generate traffic (./docker-traffic-gen). The containers are simple Ubuntu boxes that continuously curl a selection of Alexa Top 20 websites. You can run the container locally like so:
cd ./docker-traffic-gen
# To build the docker container
npm run build
# To run the docker container
npm run start
# To stop the docker container
npm run stop
You can deploy copies of this container to your AWS Account like so. First, set up your Python virtual environment:
python3 -m venv .venv
source .venv/bin/activate
(cd manage_arkime ; pip install -r requirements.txt)
Next, pull in the Node dependencies required for the CDK:
npm ci
Finally, invoke the management CLI. It will use your default AWS Credentials and Region unless you specify otherwise (see ./manage_arkime.py --help).
./manage_arkime.py demo-traffic-deploy
You can tear down the demo stacks using an additional command:
./manage_arkime.py demo-traffic-deploy
In general, it should be assumed that this setup is intended for "light to medium usage". In other words, don't expect to pour massive amounts of data through it. The wording here is intentionally vague to encourage the reader to assess for themselves whether it will scale for their use-case. Ideally, load testing will be performed on the setup to give a bit more specifity here but that is not guaranteed.
Here are some scaling things that you'll want to consider:
- The compute/memory capacity of individual Capture Nodes
- The maximum scaling limit of the Capture Nodes ECS Service as well as the scaling conditions
- The number of availability zones the setup launches in, and whether specific zones are required
- The max throughput of a single Gateway Load Balancer Endpoint is 100 Gbps, and we provision one per User subnet
- The max number of CIDR ranges a User VPC can have is 4, due to the hard cap on Traffic Mirroring Filter Rules
Here are some account limits you'll want to watch out for:
- Number of EIPs per region is small, and we spin up several for each Arkime Cluster
- There's a max of 10,000 Traffic Mirroring Sessions. We use one per traffic source.
- There's a max of 10,000 Standard SSM Parameters per account/region. We use at least one for each User ENI, several for each Subnet in a User VPC, and several for each User VPC and Cluster.
The AWS AIO project contains many components that must operate together, and these components have embedded assumptions of how the other components will behave. We use a concept called the "AWS AIO Version" to determine whether the various components of the solution should be able to operate together successfully.
Most importantly, the version of the CLI currently installed must be compatible with the version of the Arkime Cluster it is operating against. If the CLI and Arkime Cluster are both on the same AWS AIO major version (e.g. v7.x.x), then they should be interoperable. If they are not on the same major version, then it is possible (or even likely) that performing CLI operations against the Arkime Cluster is unsafe and should be avoided. To help protect deployed Arkime Clusters, the CLI compares the AWS AIO version of the CLI and the Arkime Cluster before sensitive operations and aborts if there is a detected mismatch, or it can't figure out if there is one (which itself is likely a sign of a mismatch).
In the event you discover your installed CLI is not compatible with your Arkime Cluster, you should check out the latest version of the CLI whose major version matches the AWS AIO version of your Arkime Cluster. You can find the version of your installed CLI using git tags like so:
git describe --tags
You can retrieve a listing of CLI versions using git tags as well:
git ls-remote --tags git@github.com:arkime/aws-aio.git
If the CLI detects a version mismatch, it should inform you of the AWS AIO version of the Arkime Cluster you tried to operate against. However, you can also find the AWS AIO version of deployed Arkime Clusters in your account/region using the clusters-list command:
./manage_arkime.py clusters-list
Once you determine the correct major version to you with your Arkime Cluster, you can then check out the latest minor/patch version using git and operate against your Arkime Cluster as planned:
git checkout v2.2.0
This error is caused by having a mismatch between the Node packages aws-cdk (the CLI) and aws-cdk-lib (the CDK library), which can occaisionally result if one package is upgraded without the other package package. You'll see an error message like the following in the manage_arkime.log file:
2024-01-05 18:36:27.743662 - core.shell_interactions - This CDK CLI is not compatible with the CDK library used by your application. Please upgrade the CLI to the latest version.
2024-01-05 18:36:27.743906 - core.shell_interactions - (Cloud assembly schema version mismatch: Maximum schema version supported is 30.0.0, but found 36.0.0)
2024-01-05 18:36:27.890073 - cdk_interactions.cdk_client - Deployment failed
In that case, it can be solved by upgrading the versions of those packages using the command:
npm install aws-cdk && npm install aws-cdk-lib
I can also be caused by using the wrong version of Node. Currently the CDK expects Node 18 and using Node 20 (the latest) can cause issues. You can ensure you're using Node 18 by using nvm:
nvm install 18
nvm use 18
node --version
If you encounter this issue, please cut the Arkime AWS AIO team a bug report so we can address it for everyone.
npm run buildcompile typescript to jsnpm run watchwatch for changes and compilenpm run testperform the jest unit testscdk deploydeploy this stack to your default AWS account/regioncdk diffcompare deployed stack with current statecdk synthemits the synthesized CloudFormation template
Please refer to the CONTRIBUTING.md file for information about how to get involved. We welcome issues, feature requests, pull requests, and documentation updates in GitHub. For questions about using and troubleshooting Arkime AWS AIO please use the Slack channels.
The best way to reach us is on Slack. Please request an invitation to join the Arkime Slack workspace here.
This project is licensed under the terms of the Apache 2.0 open source license. Please refer to LICENSE for the full terms.