Auto Tagger with TensorRT implementation
This is meant to work with similing wolfs trained booru taggers
- wd-v1-4-moat-tagger-v2
- wd-v1-4-vit-tagger-v2
- wd-v1-4-swinv2-tagger-v2
- wd-v1-4-convnext-tagger-v2
- wd-v1-4-convnextv2-tagger-v2
Inferences can be made with the models in tensorflow, but inference can be much faster using TensorRT if you have an nvidia GPU.
explantion of how to convert these models are here https://github.com/bdiaz29/ConvertTagger2TensorRT however it is very important that the enviroment for conversation and inference be seperate, since newer versions of tensorflow do not have gpu support for windows past 2.10.
explantion of the parameters of autotagger.oy
"--image_dir" :the directory of the images to apply captions to
"--include_characters" :whether to include tags involving characters or not
'--tag_threshold': the threshold of wether to pass a tag or not
'--model_path' : the directory for the tagger model, will be a folder for WD tensorflow models and a file for TensorRT models
"--exclude_tags" : the tags you dont want to be applied to the captions even if they are above threshold
"--append_tags" : the tags you want to be applied to the front of the captions.
"--use_tensorrt" : set this flag if you intent to use tensorRT
There is also a gui for ease of use

git clone https://github.com/bdiaz29/autotagger
pip install -r requirements.txt
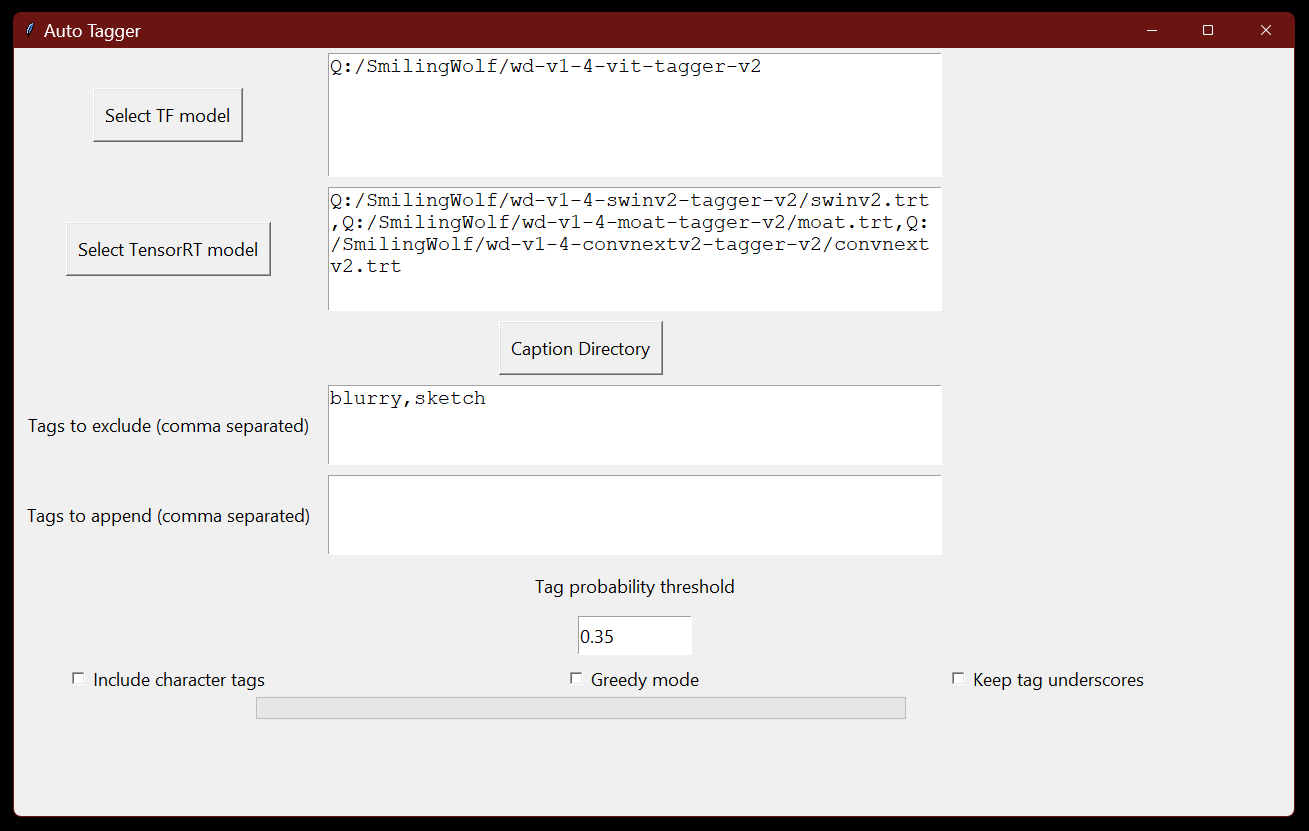
You can pass one or more taggers at the same time and get the combined probability of all the models using one of the following modes:
Mean (Default mode): all the probabilities above the threshold are combined together and the mean value is used. Theoretically, it should reduce the chances of one model predicting false positives and false negatives since the classification is going to be distributed.
Greedy: all the tags with probabilities above the threshold predicted by all the models will be used. Theoretically, it should reduce the chances of one model predicting false negatives, but will increase the chances for false positives. Use this mode if you plan to curate your dataset manually.
Remove underscores (Default mode)
Keep underscores (Default mode)