Interesting new features added to this project will be documented here reverse chronologically. This is not a change log.
There was a bug in Orientation ever since March 29th, 2015 when I had the
brilliant idea of allow existing scopes to Article.text_search so that it
could search on a sub-set of records like Fresh articles.
The problem is that Orientation almost always default to showing "current"
articles (which are not archived) and this Article.current scope does some
extra work... like ordering articles by their outdated_at, updated_at, or
created_at timestamps.
And this is usually fine. Unless we're talking about an array of articles that were sorted by the full-text search Postgres engine. In that case, you really don't care what the order of the existing scope was — only the subset is useful.
This was the hard lesson in this bug fix. Search scopes were a useful feature that inadvertently caused a regression which took a full two years to resolve. I apologize for not heeding the failing test that arose when I made this change. For once, the false negative was truly a negative.
The silver lining is that now your Orientation searches will be weighed properly
with matches on the title of the article prioritized slighting over matches
on the content of the article (which tend to be noisier matches).
People leave, and when they do it's always odd to see a broken Google avatar of them endorsing an article.
This shouldn't affect the endorsement and subscription counts. So an article can still benefit from old endorsements and subscriptions to increase its perceived value. Although this may not make sense in the long term, since by definition inactive users aren't there to see if they should still be endorsing an article.
Orientation now runs Rails 5.1. You can find the release notes for this version of Rails here: http://edgeguides.rubyonrails.org/5_1_release_notes.html#transactional-tests-with-multiple-connections
And the upgrade guide here: http://edgeguides.rubyonrails.org/upgrading_ruby_on_rails.html#upgrading-from-rails-5-0-to-rails-5-1
This should be a fairly smooth upgrade since I haven't opted to move to Webpack yet. Our JavaScript doesn't really warrant that and I'm not really excited about adding so many new dependencies without using a front-end framework.
This gem is now deprecated since Heroku now offers free Let's Encrypt SSL with all of their paid dynos. A paid account was required to setup the SSL certificate with the previous method so it's technically much more simple now.
Go to your Heroku app settings, update your DNS to point to their SSL endpoint and you're good to go.
You can find instructions on how to set that up here: https://blog.heroku.com/ssl-is-now-included-on-all-paid-dynos
Since I observe some issues with memory allocation on Heroku deploys of Orientation I investigated to find that we had two web servers in the Gemfile: Puma and Unicorn. Unicorn was set up back when Heroku recommended it over Webrick years ago. Now they recommend and maintain Puma instead, so we're switching to it. This will allow us to have more control (AFAIK) over the initial memory usage on single Puma worker, and use Puma's preload_app feature with Copy on Write to avoid re-allocating memory for subsequently forked worker processes.
I am not an ops genius, so please take this with a grain of salt and open a Pull Request if you think this makes no sense.
While the auto-completed full-text search worked fine with search queries, any time the input field was emptied, a 500 error was triggered. This didn't cause any visible errors but prevented the list of all articles to being brought back. This is now solved.
Additionally, an issue that previously didn't occur started causing the the index.js.erb view used to render search results with XHR requests to fail because it included the HTML layout used on normal views. Disabling the layout solved the issue.
Finally a race condition in the live search feature was mitigated by ignoring search queries of less than 3 characters since Postgres full-text can't produce a meaningful result with fewer than 3 characters. Queries of 0 characters are still sent so that the list can be reset when users remove their search query.
The search input delay was increased for 0.2 seconds to 0.4 seconds to reduce the possibility of race conditions (one search query coming back before one that was sent earlier, thus messing up the results). This will reduce the apparent responsiveness of the search but improve the user experience by avoiding the occasional glitch were all results would disappear.
Although I've rewritten the history of this document to avoid confusion, what was previously referred to as "rotten" articles is now "outdated". Please see commit 9f609603f7f9b9df7e34a8205ae6e67e3c62e1a4 for a detailed explanation of the reasoning behind this change which does introduce two migrations with column name changes, so I recommend placing Orientation in maintenance mode while you run these migrations to avoid database issues during the upgrade.
The "Fresh" and "Rotten" buttons on the article page have been renamed to "Mark Fresh" and "Mark Rotten" with useful tooltips to clarify their purpose further for people not familiar with Orientation.
You have to admit that self-documenting action buttons make a lot of sense, no?
While it's still possible to see the full date and time when article was first created and later updated, the date is now displayed in a long ordinal format.
So instead of: February 17, 2017 16:46, it now displays: February 17th, 2017.
Time is rarely critical but it's still possible to see the exact time an article
was created at or edited at by hovering on the date. This will display the
UTC timestamp: 2017-02-17 16:46:38 UTC.
As a testament to slow iterative progress, the articles.visits column that
was introduced in March 2015 is now used to display a simple anonymous count of
how many times an article was viewed or visited.
But since I wanted to establish a more meaningful connection between readers
and articles, we now have a user-specific Article::View concept that is
stored in a separate database table with a relationship between a single article
and user. This means we can now also display a precise count of unique readers
for a given article.

Down the line it should also enable us to display when a given user first read a specific article, when they last read it (most recently), and how many times they viewed the article.
You can now use tab-completion (in Chrome) to access Orientation search more quickly.

To avoid giving equal weight to archived articles in tag lists, we now separate the derelict articles from their fresher peers.
Now if you run bin/update on your local fork of Orientation, it will
add or use an upstream remote to rebase the latest changes on the
orientation/orientation repo. I tend to treat master as a
production-ready so please don't be horrified.
Deterministic resolution of transitive dependencies, faster installation of front-end packages. What's not to like? For now I've only included yarn as an npm module but soon we'll forgo npm entirely since yarn can be installed as a standalone.
Great contribution from @thewheat that now allows you to add a new tag that starts with the same initial letter as an existing tag. This used to be extremely frustrating.

I can't believe it took me so long to finally get this done. Unless you have your own paid SSL certificate set up, it's been quite difficult in the past to protect your Orientation installation with SSL. Now it should be much easier thanks to the most excellent letsencrypt-rails-heroku gem.
I've used this gem on two different projects so far and it's been a breeze to use compared to manually using Let's Encrypt's recommended CertBot command line interface.
I've added some documentation to .env.example on which variables are
needed but you can read their excellent documentation to protect your
Orientation.
One caveat for now, since it's tricky for me to enable Rails' force_ssl
without causing issues to people who don't have SSL set up, it's likely that
I'll add a new configuration variable to optionally enable force_ssl very
soon.
I can't believe it's been a whole year since the last major new feature, I've certainly been working on some cool stuff, but this has been perhaps the longest standing issue with Orientation: searching things easily.
I've replaced the search library we were using with one that allows us to be a lot more specific with regards to the weighing of results. Article titles are now weighed higher in search than article content. We now also display exactly what the full-text search engine matched on when you type keywords so you can know why an article came back in the search results.

Previously, even when a guide article was archived or marked as outdated, it would still show up on the homepage. Now we'll hide those guides.
I noticed a few weeks ago that private emails from people trying out
try.orientation.io were being displayed. That was problematic because people
testing out the site didn't agree to have their email shared. So I added a new
option that can be triggered with user.update(private_email: true). It's
stored inside of a native Postgres JSON column called preferences to which
we'll eventually add more user-specific settings (without need for new columns).
There's also a rake make_all_emails_private which can run this command for all
existing users. I will not be making private emails a default for now but will
likely add a new Orientation configuration option to have email privacy be a
default or not so that public-facing Orientation installations don't leak
private email information from people authenticating with their private Gmail
accounts.

Whenever someone reported an article as outdated, there used to be no way to know who that person was. Now rot reporter is logged and when the contributors to the article are notified, they are told who reported the rot. Here's why:
- it makes things more human, it's not just a game of whack-a-mole to find articles and mark them as outdated
- it allows for conversations to happen between the reporter and the article contributors
- if notifications are turned off it allows a reader or contributor of the article to reach out to the rot reporter in order to refresh the article
This update requires a manual update to your Mandrill templates for [Article Endorsement Notification](https://github.com/orientation/orientation/blob/maste
r/doc/MANDRILL.md#article-outdated-update) and Article Outdated Update](https://github.com/orientation/orientation/blob/master/doc/MANDRILL.md
#article-outdated-update)
It took me way too long to add these to the project but I'm glad they're finally there. Please take a look at them if you plan to contribute to Orientation at any point:
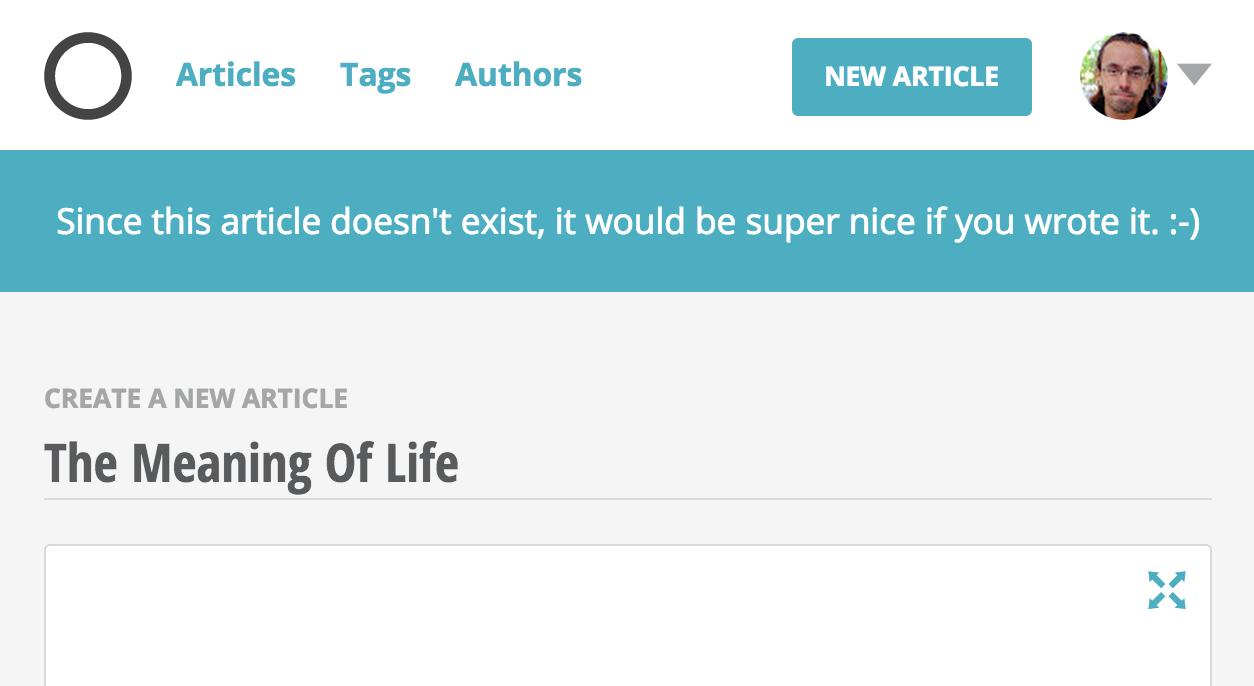
This one has also been on the wishlist for a while. It's very common while
building a Guide to create links to articles that don't exist yet. That was made
much easier yesterday with relative Markdown links ([[Title]] expands to
[Title](/articles/title)) and color-coded article existence checking (links to
non-existent articles show up in red).
Today this flow gets even better since you can now click those red links to non- existent articles and Orientation will present you with a new article form containing the URL slug converted in a title.
After a few weeks trying to make fuzzy search (on title and content) work, it's now clear that this approach won't work, so we switched back to advanced_search on the article title field only. This makes for a more intuitive search flow since it's far more common to search for something based on the article title (although tags should be added to that soon).
The sad part is that if the title doesn't contain the term you're looking for, now you're out of luck with search. I hope for now that the Guides feature makes up for that but I haven't given up hope on finding an even better way to make basic/advanced search cohabitate better with content-focused fuzzy search (full- text).
This is a feature I'm really happy to introduce because it really should have been here since the beginning.
It's now possible to link to any article using either the article title or its URL slug. Say you have an article titled "Onboarding", you can write the following Markdown and the proper link will automatically be expanded once the article you're editing is saved.
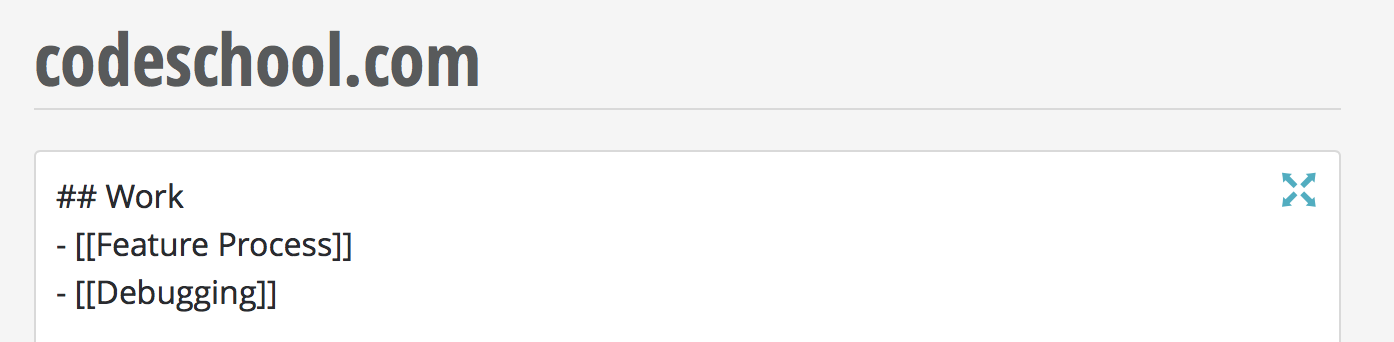
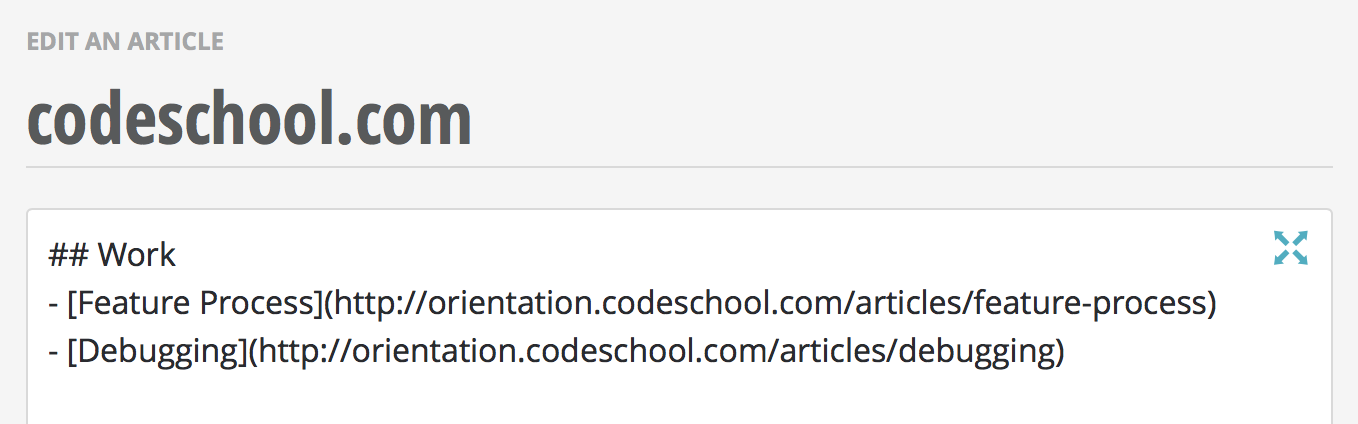
Now when you link to an article title, slug or URL that doesn't exist on Orientation you will see the color of the link change to red to indicate that an article is missing.

Thanks to Bruno Miranda, it's now possible to display only the authorized Google
Apps domain set in the ORIENTATION_EMAIL_WHITELIST environment variable in the
Google sign in page.
This way instead of listing all the Google accounts a user has, only the one authorized to sign into Orientation will be displayed. This should reduce confusion among first-time users of Orientation and prevent failed sign in attempts.
Thanks to Brandon Mathis it's now possible to use GitHub-style emojis in Orientation articles.
This is a fix I should have worked on much earlier as tags and articles always generated a heap of N+1 queries for no good reason when we fetched article or tag counts. I highly recommend merging in master into your forks at fe85cf0135c2ce02600034405de3ae167fc35373 or later to benefit from this significant reduction in queries on guide and article index pages.
This is less exciting but worth mentioning, Mark Oleson also contributed a useful little PR to update the Uglifier version which had been vulnerable for a little while. Another great reason to merge master into your forks and deploy to production quickly.
I took way to long to react on this but Michael Friis contributed a nifty patch to fix recurring issues when the Heroku button because our app.json manifest was too tightly coupled to specific Heroku add-on plans.
After upgrading RSpec I finally decided to take a much needed second look in order to figure out why search was behaving so poorly (it basically did not work at all). I realized I was wholly misusing the wonderful textactular gem that allows us to do full-text searching without anything fancy like Solr or Elastic Search.
And guess, what? It works. Search will now fuzzy (partial-match) search on article titles and their entire content. This is a very big deal because Orientation was predicated on the promise of instant search to reduce the cognitive load of having to browse for something you don't understand.
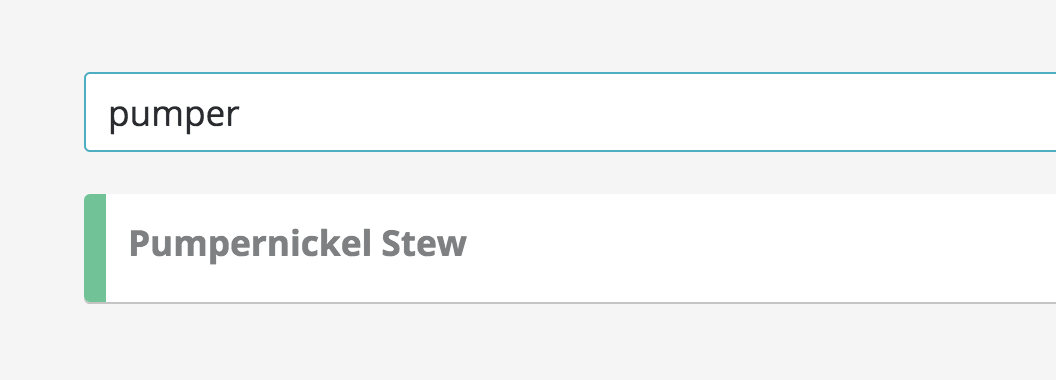
Now're finally back in the land where if you have the word "Pumpernickel"
anywhere within any article, a simple search for pumper will bring up all the
articles that contain any word which contains that — for example pumpernickel.
Additionally, I've fixed an issue where the articles listed on filtered articles pages (fresh, stale, popular) did not reappear after the search form was re- submitted with no query or if the currently typed query was removed. This makes the filtered article pages much more friendly they now behave once again like a proper "filtered search" page.
I'm so very sorry to anyone who invested time in Orientation since it was open- sourced. This is a bug I had meant to fix for literal years and for reasons I can't explain away, had never managed to.
Installing Orientation from scratch turned out to be a pain (even fore me) because S3's access policies are a huge pain and I couldn't even figure out how to make a properly segregated Orientation demo account on AWS without pulling hair.
Even without an avatar uploader, we still grab the avatar URL from Google OAuth if the person has one, so it seemed unjustifiable to depend on such a painful to setup service for a featuer that is trivial at best.
One thing that we'll have to address is default images for people who don't have one, but that shouldn't be too hard.
For now it's only on titles since there seems to be something wrong on the full- text indexing of the article content column, but it's better than what we used to have for sure.
If we ever enable full-text fuzzy search on article content again, we'll try to have search results return a preview of the line of content that matched the search keywords otherwise it's going to be very difficult for users to tell which search result is going to answer their question because they'll only see the title — which may not contain any of the search keywords they entered.
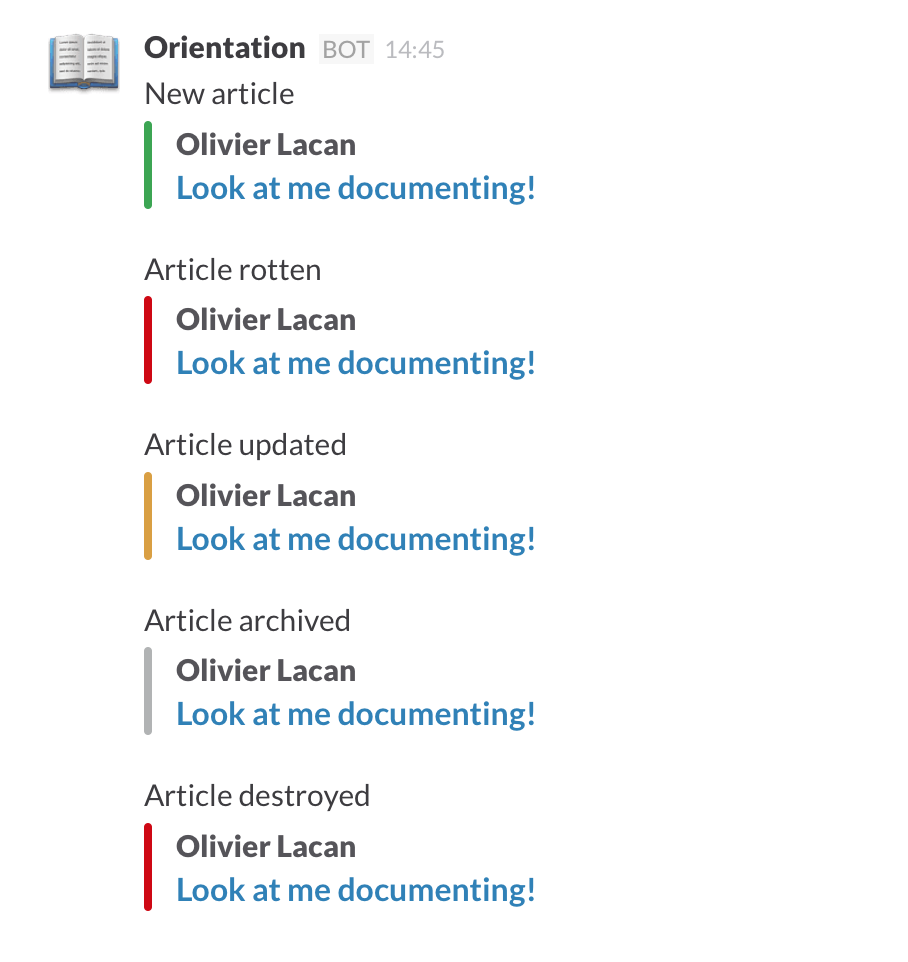
In a mad dash of excitement, I've added Slack notifications (via a webhook
configurable using the SLACK_WEBHOOK_URL you can find in
.env.example). This is clearly an experimental and untested
feature but I really wanted to play with it, so there you go.

Each article state now has its own "state" page to easily find Fresh, Stale, or Outdated articles.
There's also two additional "states": Archived and Popular. Archived articles are excluded from search so it's good to be able to find them somewhere if they need to be referenced (or deleted). Popular articles are ordered by endorsements first, subscriptions, and a brand new visits counter third.
Hovering over each filter button displays a definition of each state, which should help with discoverability.

There was no way to see who "cares" about what article (wants to be notified when the article is updated) so this Subscriptions page should do the trick. It also gives a good overview of how well-connected to the knowledge assembled inside Orientation your team is.

Speaking of caring, endorsements are a way for people to appreciate the documentation efforts of others and increase the authority of an article, so it's also interesting to have a page displaying recent endorsements.
I realize as I'm typing this that I may need to paginate this for active teams otherwise those two new pages are going to get slow fast. Oh well.
Previously stale articles included outdated articles as well. I've decided to segregate these two scopes/states from now on because articles in these two categories require very different levels of attention from readers and editors.
This is an invisible feature for now (aside from the Popular Articles page which will be impacted by it) but I've just added a simple visits counter on articles. It's automatically incremented any time the show page for an article is loaded. I might consider making more user-specific stats in the future to help you find articles you've consulted a lot but this is a good first step.

On the article index page or even on article "state" pages (Fresh, Outdated, etc.) it was hard to know how many articles were being shown compared to each other "state". Now, the article count for the current scope is dynamically displayed in the search field.