The topic of the project, initially was: Real-time monocular depth estimation for low-resources embedded devices, but due to incompatibilities between ARM 32-bit and the major libraries/framework to make inference, I had to slightly change the topic of the project.
Now the title is: MonoDeRT: A novel light-weight Real-Time architecture for Monocular Depth Estimation.
The project aims to design a model architecture for Real-Time Monocular Depth Estimation for low-resources embedded devices (i.e. Raspberry Pi Zero: 512 MB of RAM and 1GHz, single-core CPU). The task is hard due to the unusual resources constraints, so to pursue it I'll use optimization techniques learned during lectures and through some recent papers that explores the paradigm ranging from Micro-Controller Units (MCUs) to Embedded devices. Moreover there are some architectures that tries to decrease latency by cropping some output layers at inference, this is really helpful in order to achieve the real-time performances (i.e. >= 30 FPS) on such devices. For the data I'm going to use, I'll try various datasets: DIODE, NYU Depth and KITTI Depth.
The project aims to design a model architecture for Real-Time Monocular Depth Estimation that is lightweight. In particulare I'll leverage the smoothness of the bicubic interpolation in order to make accurate, fast and smooth predictions. This is an ill-posed task that is hard due to the lightweight and fast inference constraints, so to pursue it I'll use optimization techniques learned during lectures and through some recent papers that explores the paradigm ranging from Micro-Controller Units (MCUs) to Embedded devices. Moreover there are some architectures that tries to decrease latency by cropping some output layers at inference, this is really helpful in order to achieve the real-time performances (i.e. >= 30 FPS) on such devices. For the data I'm going to use, NYU Depth V2 (a subsample of 50.000 samples against 408.000).
The novel model called MonoDeRT (that stands for: Monocular Depth Estimation Real-Time) is a pyramidal encoder-decoder model with residual connections, that leverage the bicubic interpolation in both upsampling and downsampling. Follows its graphical representation
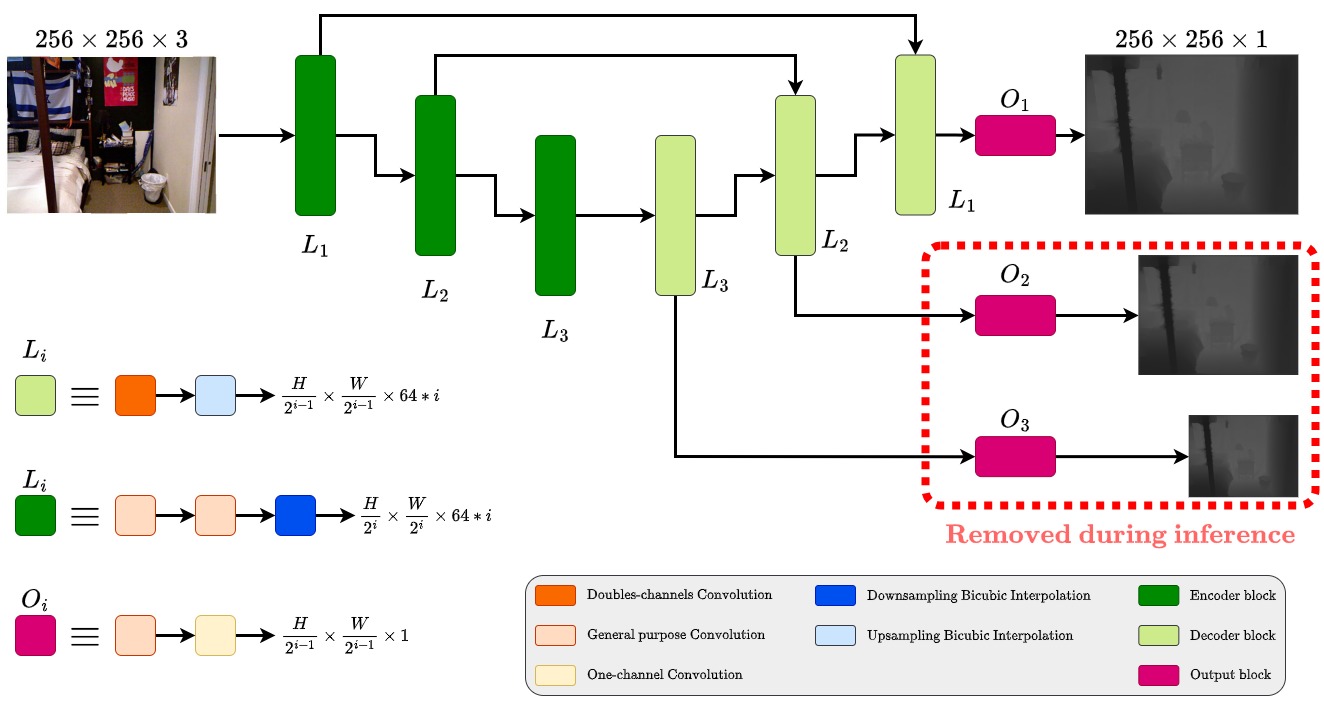
keypoints of MonoDeRT:
- each convolutional layer won't touch in any way the height and width of the input image, it will change only the number of channels
- to save parameters, upsampling and downsampling it's getting performed using bicubic interpolation
- to save FPS during inference and maintaining an high level of customization of the weights update pipeline during training, the first and the second decoder blocks produces output only during training.
I've used for both up- and down-sampling the bicubic interpolation so to be compact. In downsampling using bicubic/bilinear/nearest interpolation changes on the so called: "subpixel accuracy", but since we are in the pixel domain, this won't affect the training.

Moreover, I could use a gaussian blurr before the interpolation technique, so to reduce the aliasing effect; but since:
- we need real-time performances, so to enhance rapid processing I am tolerating lower quality
- the high-frequency contents are not really frequent for the NYUv2 dataset
- we have convolutional layers that can learn to enhance some pattern of the image, so the absence of a low-pass filter before the image won't affect too much the learning proess
hence, I've decided to avoid using gaussian blurr before downsampling using bicubic interpolation.
In order to show you how the model behave in training mode, follows a batch of predictions made during training (so against train dataset):
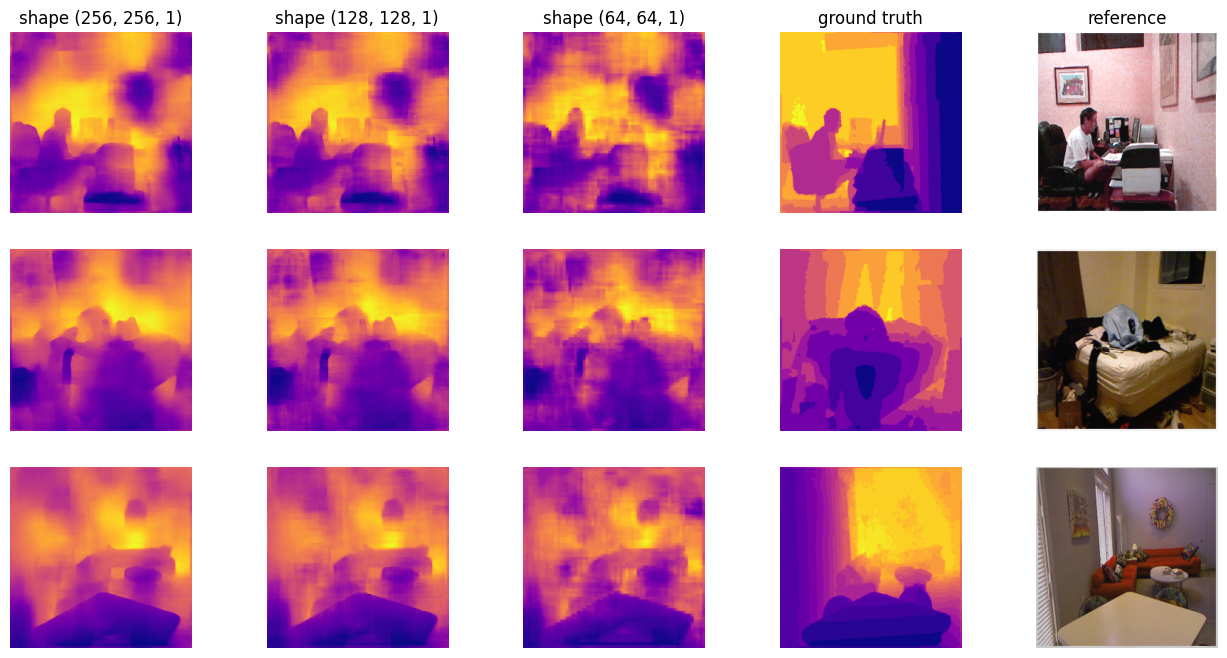
While, as we said, in evaluation mode we have only the last decoder that outputs predictions; follows some results

Every checkpoint is available in google drive at this link. If you need to download one of them, place it in a folder named checkpoints in the root, so you can easily use it without changing the code.
-
[OPTIONAL STEP] First of all, you need to convert the torch model to a ONNX model using the following command
python model_to_onnx.py [--ckpt <checkpoint_name>]
--ckptis an optional parameter; the checkpoint name, is the one without the extension.ckpt. If do not specify anything, the default loaded checkpoint is the last one:mde60_kaggle.ckpt(i.e., the last one).
After executing this command, you'll obtain in the root folder a file namedmodel.onnx, this will be the model used to make inference. Please be sure that you have downloaded the right checkpoint and placed it in thecheckpointsfolder.
NOTE: A file
model.onnxis already available in the root, so if you do not need to load a specific checkpoint, you can skip the first step.
-
Execute the script that tests the model with the currently mounted camera, you need to use the following command
python cam_online_or_mean_onnx.py [--online <True/False> --fps_verbose <True/False>]
where
--onlineis by defaultTrue, this helps in performance but maintaining a constant sampling rate that is defined a priori, otherwise we obtain a video that is sampled at right FPS, but with lower performances.
While--fps_verboseis by defaultFalseworks only for online mode abd it display FPS in command line.