diff --git a/docs/user-guide/cost-visibility/README.md b/docs/user-guide/cost-visibility/README.md
new file mode 100644
index 000000000..1fef48c7c
--- /dev/null
+++ b/docs/user-guide/cost-visibility/README.md
@@ -0,0 +1,12 @@
+# Cost Visibility
+## Introduction [](https://devtron.ai/pricing)
+
+Cost Visibility in Devtron provides a unified view of your Kubernetes infrastructure costs within the Devtron dashboard. It eliminates the need to switch between cloud provider billing consoles by integrating cost insights directly into your DevOps workflow.
+
+
+
+You can view and analyze costs across multiple scopes such as Clusters, Projects, Environments, Applications, and Infrastructure Resources. Devtron automatically tracks the spend on CPU, Memory, Storage, GPU, and Network, giving you a clear picture of how resources are utilized and what contributes most to your total cost.
+
+The dashboard highlights recommended costs and potential savings, helping you identify underutilized resources and opportunities for optimization.
+
+You can choose your preferred currency to view all cost data consistently across different time periods, such as daily, monthly, quarterly, or custom ranges. This helps you move seamlessly from a high-level overview to a granular analysis of costs within a specific category.
diff --git a/docs/user-guide/cost-visibility/configurations.md b/docs/user-guide/cost-visibility/configurations.md
new file mode 100644
index 000000000..1eaef1ea6
--- /dev/null
+++ b/docs/user-guide/cost-visibility/configurations.md
@@ -0,0 +1,311 @@
+# Configurations
+
+The **Configurations** page lets you manage configurations for Cost Visibility in Devtron. You can:
+
+ * Set the default currency for all cost-related data.
+ * Enable or disable cost tracking for your connected clusters.
+
+---
+
+## Currency (Default)
+
+You can select your preferred currency as default.
+
+---
+
+## Enable Cost Tracking
+
+To enable cost visibility for a cluster, follow the below steps:
+
+1. Choose your preferred cluster, and click on **Off/Enabled**. An **Edit Cluster** modal window will open.
+
+2. Enable the toggle next to **Enable cost tracking**.
+
+3. Select the cloud provider in which you have created your cluster.
+
+4. Based on the cloud provider you need to do the following configurations:
+
+{% tabs %}
+
+{% tab title="GCP" %}
+
+### Enable Cost Visibility for GCP
+
+To enable cost visibility for Google Cloud in Devtron, you need to generate an API key and use it to connect Devtron with your GCP account.
+
+1. Generate the API key using standard [Google Cloud API key documentation](https://cloud.google.com/docs/authentication/api-keys#gcloud).
+
+2. Now go back to the **Edit cluster** modal window, and enter the API key in the **Cloud Provider API Key** field.
+
+{% hint style="info" %}
+If you face any issues while enabling or configuring the **Cost Visibility** module, reach out to [Devtron Support Team](mailto:enterprise@devtron.ai) for assistance.
+{% endhint %}
+
+{% endtab %}
+
+{% tab title="Azure" %}
+
+### Enable Cost Visibility for Azure
+
+To enable cost visibility for your Azure clusters in Devtron, you need to allow Devtron to access your billing data securely. This requires two steps:
+ 1. Create a custom role in Azure with billing access.
+ 2. Create a service principal (an identity) that Devtron can use to fetch cost details.
+
+ ### Step 1: Creating Custom Role
+
+ 1. Open a text editor and copy the following JSON:
+
+ ```json
+{
+ "Name": "OpenCostRole",
+ "IsCustom": true,
+ "Description": "Rate Card query role",
+ "Actions": [
+ "Microsoft.Compute/virtualMachines/vmSizes/read",
+ "Microsoft.Resources/subscriptions/locations/read",
+ "Microsoft.Resources/providers/read",
+ "Microsoft.ContainerService/containerServices/read",
+ "Microsoft.Commerce/RateCard/read"
+ ],
+ "AssignableScopes": [
+ "/subscriptions/YOUR_SUBSCRIPTION_ID"
+ ]
+}
+ ```
+
+2. Replace `YOUR_SUBSCRIPTION_ID` with your actual subscription ID.
+
+3. Save the file as `myrole.json`.
+
+4. Run the following command in your terminal:
+
+```bash
+az role definition create --verbose --role-definition @myrole.json
+```
+
+This creates a role called `OpenCostRole` with just enough access to read pricing information.
+
+### Step 2: Create a Service Principal
+
+1. Run the command below, again replacing `YOUR_SUBSCRIPTION_ID` with your subscription ID:
+
+```bash
+az ad sp create-for-rbac \
+ --name "OpenCostAccess" \
+ --role "OpenCostRole" \
+ --scope "/subscriptions/YOUR_SUBSCRIPTION_ID" \
+ --output json
+```
+
+2. You’ll get an output like this:
+
+```json
+{
+ "appId": "1d9b1532-abe4-4e08-b172-adfa5384da1",
+ "displayName": "OpenCostAccess",
+ "password": "3DZ8Q~KOE.WgdmmRkBHg3dF1rfrpFhSPk.Hnb4-",
+ "tenant": "aee9b2ed-7ecc-4cb2-bfed-60d71c0e957"
+}
+```
+
+3. Note this information as you need to enter this in Devtron.
+
+### Step 3: Enter Details in Devtron
+
+Now go back to the **Edit cluster** modal window, and fill the following fields:
+
+| **Field** | **Value to Provide** |
+|---------------------|---------------------------------|
+| Subscription ID | Your Azure subscription ID |
+| App ID | Value of `appId` from the output |
+| Display Name | Value of `displayName` from the output|
+| Password | Value of `password` from the output |
+| Tenant | Value of `tenant` from the output |
+| Billing Account | Optional (fill if available) |
+| Offer ID | Optional (fill if available) |
+
+{% hint style="info" %}
+If you face any issues while enabling or configuring the **Cost Visibility** module, reach out to [Devtron Support Team](mailto:enterprise@devtron.ai) for assistance.
+{% endhint %}
+
+{% endtab %}
+
+{% tab title="AWS" %}
+
+### Enable Cost Visibility for AWS
+
+If you have spot node instances in your AWS cluster, then only you need to do the below additional configurations for your AWS cluster, else you can skip the below configurations
+
+### Step 1: Set up a Spot Instance Data Feed
+
+1. Create an S3 bucket
+
+2. Assign full access permissions to the AWS Spot Data Feed service
+
+```json
+{
+ "Version": "2012-10-17",
+ "Statement": [
+ {
+ "Effect": "Allow",
+ "Principal": {
+ "Service": "spot.amazonaws.com"
+ },
+ "Action": "*",
+ "Resource": "arn:aws:s3:::devtron-spot-feed/*"
+ },
+ {
+ "Effect": "Allow",
+ "Principal": {
+ "Service": "spot.amazonaws.com"
+ },
+ "Action": "*",
+ "Resource": "arn:aws:s3:::devtron-spot-feed"
+ }
+ ]
+}
+```
+
+3. Run the following command to subscribe to the data feed using the AWS CLI
+
+```bash
+aws ec2 create-spot-datafeed-subscription \
+ --bucket devtron-spot-feed --prefix cost
+```
+{% hint style="warning" %}
+### Note
+You can subscribe to the Spot Data Feed for only one S3 bucket at a time. Running the command again updates the feed to the latest bucket.{% endhint %}
+
+
+### Step 2: Create an IAM Role or Use Access Keys
+
+You can connect Devtron to AWS cost data using either of the following methods:
+
+#### IAM Role (Recommended)
+
+Create a Web Identity IAM role for your EKS/EC2 cluster with permissions to access the Spot Data Feed bucket. Attach the following policy (replace CHANGE-ME with your bucket name)
+
+```json
+{
+ "Version": "2012-10-17",
+ "Statement": [
+ {
+ "Action": [
+ "s3:ListAllMyBuckets",
+ "s3:ListBucket",
+ "s3:Get*"
+ ],
+ "Resource": [
+ "arn:aws:s3:::CHANGE-ME",
+ "arn:aws:s3:::CHANGE-ME/*"
+ ],
+ "Effect": "Allow"
+ }
+ ]
+}
+
+```
+
+#### Access Keys (Alternative)
+
+Provide an Access Key and Secret Key with permissions `s3:ListBucket` and `s3:GetObject` for the Spot Data Feed bucket.
+
+### Step 3: Configure in Devtron
+
+Now go back to the **Edit cluster** modal window, and fill the following fields:
+
+| **Field** | **Description** |
+|-----------------------|---------------------------------------------------------------------------------|
+| Spot Data Bucket | Name of the S3 bucket storing Spot Instance Data Feed |
+| Spot Data Region | AWS region of the Spot Data Feed |
+| Spot Data Prefix | Prefix (if any) used for the Spot Data Feed |
+| Project ID | Your AWS Account ID |
+| Access Key | (Optional) AWS Access Key with S3 read permissions |
+| Secret Access Key | (Optional) AWS Secret Access Key with S3 read permissions |
+| IAM Role | (Recommended) IAM role ARN assigned to the EKS/EC2 cluster for bucket access |
+
+{% endtab %}
+
+{% endtabs %}
+
+5. Enter Prometheus endpoint of your cluster. Refer [Fetching Prometheus Endpoint](#fetching-prometheus-endpoint) to learn more.
+
+{% hint style="warning" %}
+Prometheus endpoint should be publicly exposed for the cost visibility to work.
+{% endhint %}
+
+6. Click **Save**, cost visibility will be enabled for the cluster.
+
+{% hint style="warning"%}
+### Note
+After enabling cost visibility, you will see your cluster information after 1 hour in cost visibility module.
+{% endhint %}
+
+### Fetching Prometheus Endpoint
+
+{% hint style="warning" %}
+### Note
+Ensure [GitOps](../global-configurations/gitops.md) is configured before deploying Prometheus. If not, Prometheus will default to being deployed via Helm.
+{% endhint %}
+
+#### Installing Prometheus
+
+1. Go to the **Chart Store** and search for `prometheus`. Use the Prometheus community's `kube-prometheus-stack` chart to deploy Prometheus.
+
+ 
+
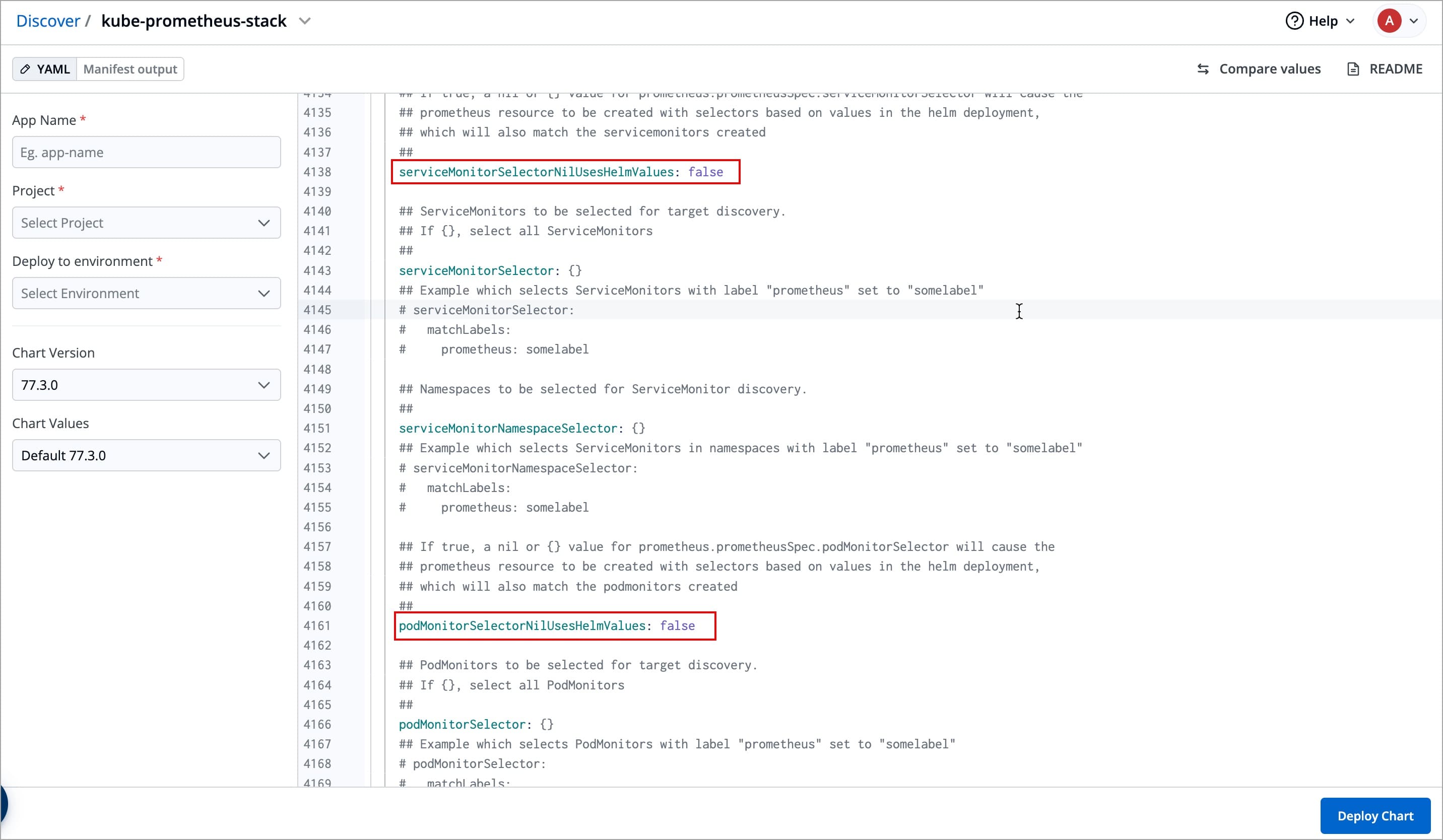
+2. After selecting the chart, configure these values as needed before deployment.
+
+ ```yaml
+ kube-state-metrics:
+ metricLabelsAllowlist:
+ - pods=[*]
+ ```
+
+
+
+ ```yaml
+ serviceMonitorSelectorNilUsesHelmValues: false
+ podMonitorSelectorNilUsesHelmValues: false
+ ```
+
+
+
+ Search for the above parameters, and update them as shown (or customize as needed).
+
+ 
+
+ 
+
+3. Enable `upgradeJob` parameter to install CRDs:
+
+ Since Helm does not automatically apply CRDs, you need to enable the `upgradeJob` parameter in the Helm chart to ensure CRDs are applied before deploying Prometheus.
+
+ In the Prometheus Helm chart settings, locate the `upgradeJob` parameter and set it to `true` if it is `false`.
+
+ 
+
+4. After enabling the parameter, click **Deploy Chart**.
+
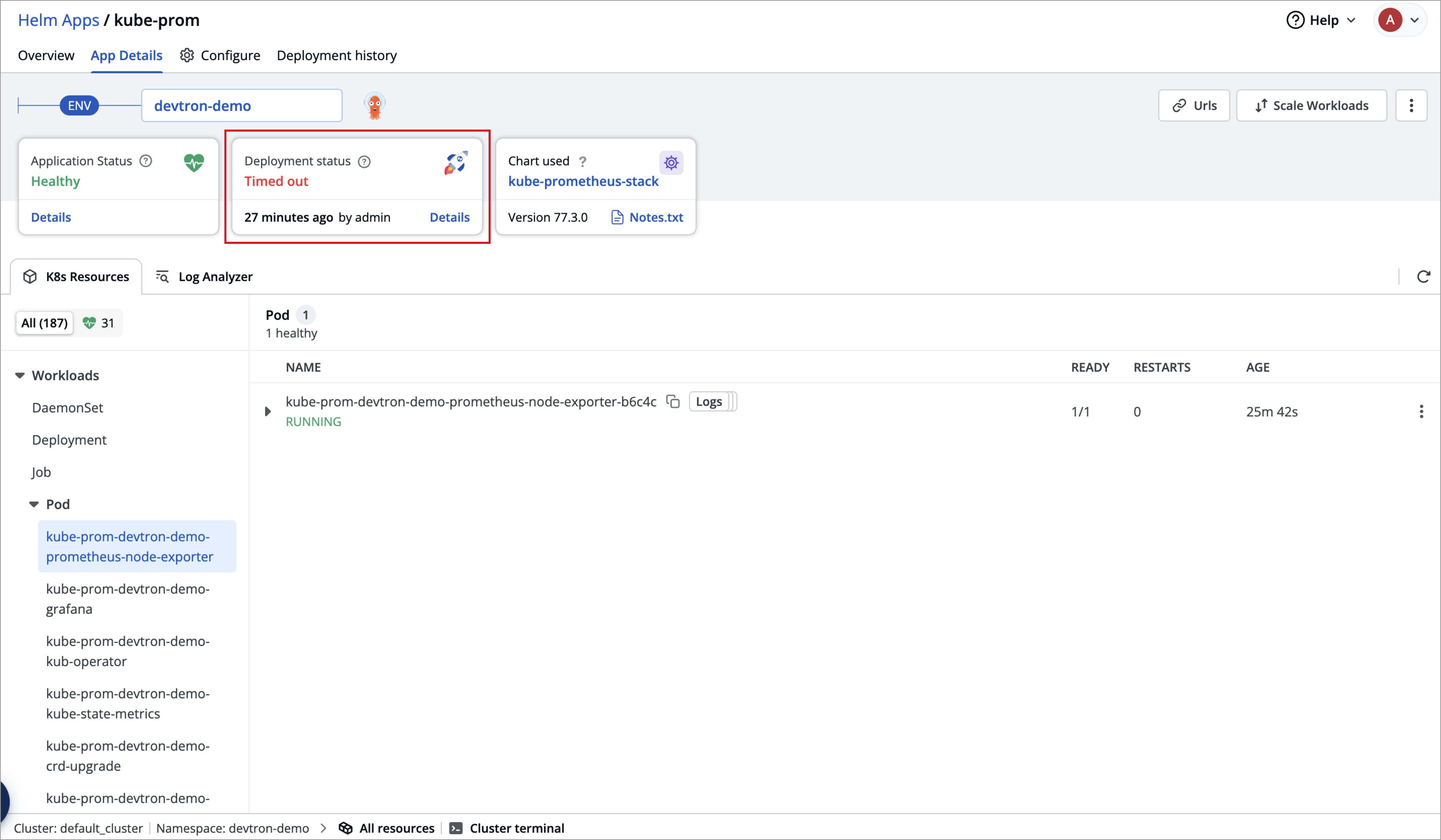
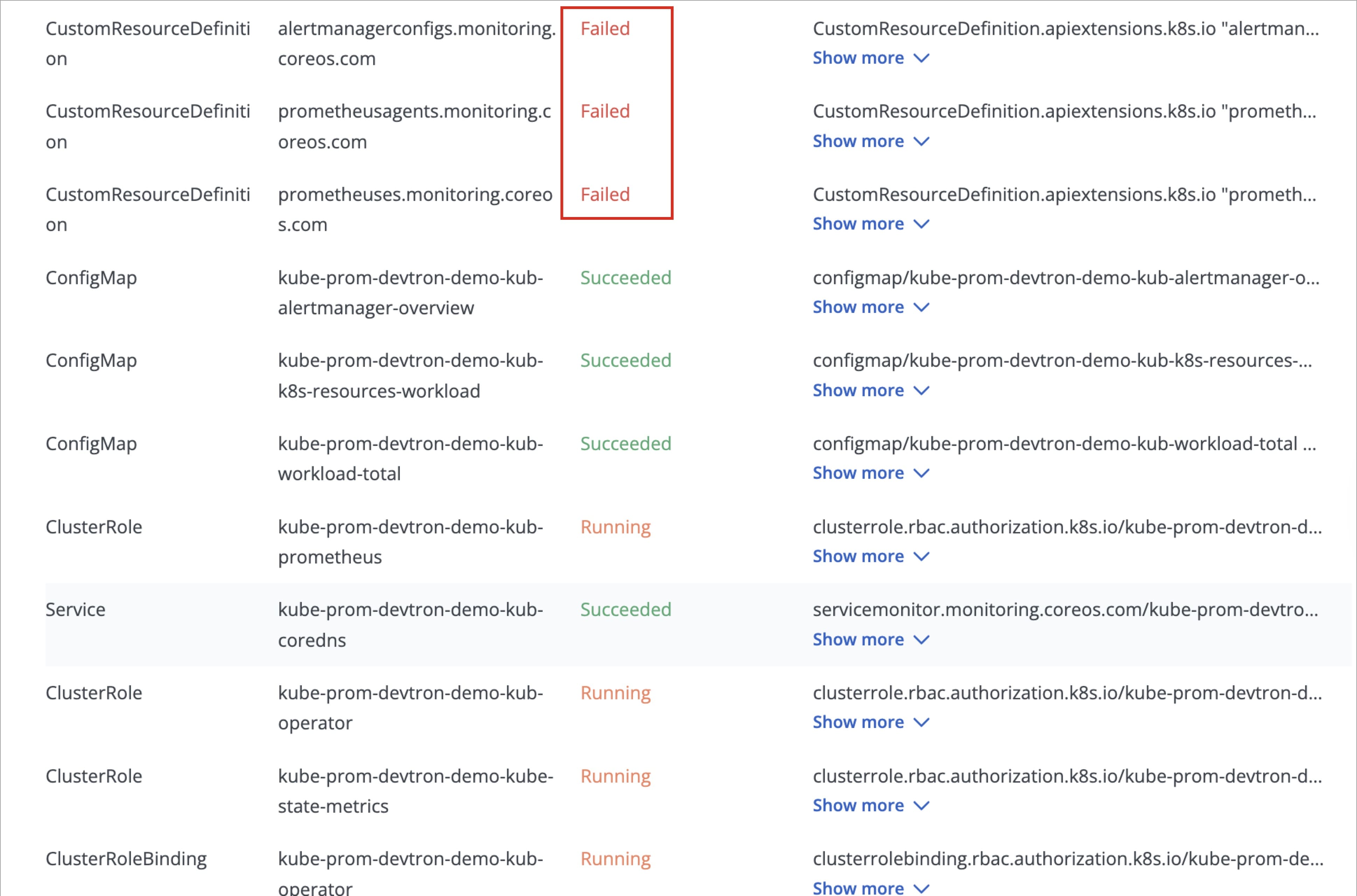
+{% hint style="warning" %}
+### Common Pitfall: Prometheus Deployment Timeout due to Failed CRDs
+
+While deploying `kube-prometheus-stack` chart, the deployment status may show as **Timed out**, and some CustomResourceDefinitions (CRDs) may appear as **Failed**.
+
+
+
+
+
+**This behavior is expected and do not require any action from you.**
+
+This occurs because certain Prometheus CRDs are large in size, which can lead to temporary sync issues during deployment, but, this does not impact the functionality of the Prometheus components.
+
+ArgoCD handles such cases automatically and the `kube-prometheus-stack` will continue to function as expected.
+
+{% endhint %}
+
+5. After the chart deployed successfully, you need to make the Prometheus endpoint exposed publicly.
+
+{% hint style="info" %}
+If you face any issues while enabling or configuring the **Cost Visibility** module, please contact the [Devtron Support Team](mailto:enterprise@devtron.ai) for assistance.
+{% endhint %}
diff --git a/docs/user-guide/cost-visibility/cost-breakdown.md b/docs/user-guide/cost-visibility/cost-breakdown.md
new file mode 100644
index 000000000..d951f1f27
--- /dev/null
+++ b/docs/user-guide/cost-visibility/cost-breakdown.md
@@ -0,0 +1,218 @@
+# Cost Breakdown
+
+## Introduction [](https://devtron.ai/pricing)
+
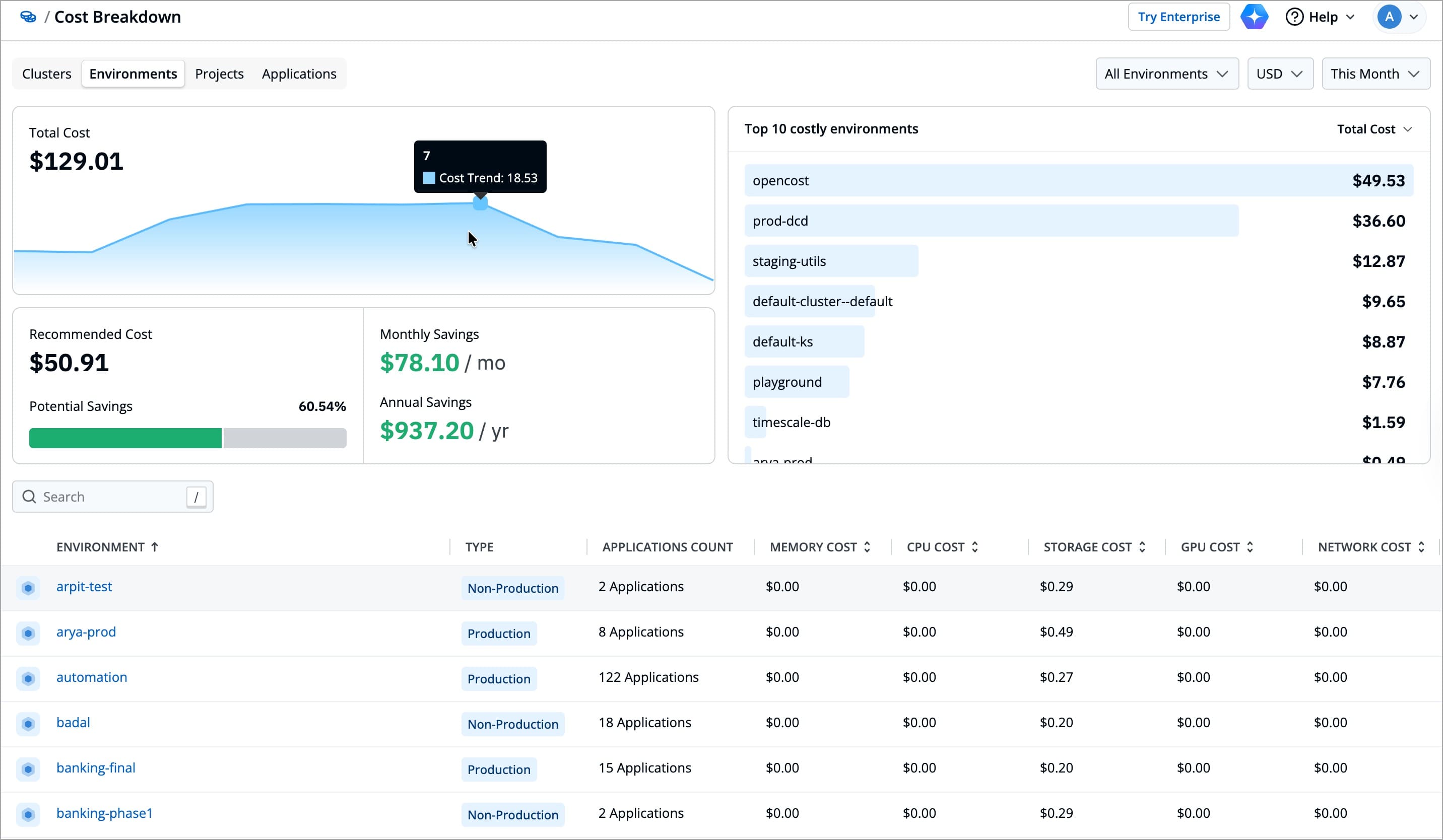
+While the **Overview** section gives you a quick summary of overall spending, the **Cost Breakdown** page lets you analyze deeper into where those costs come from. It helps you analyze costs within a selected category (**Clusters**, **Applications**, **Environments**, or **Projects**), for a specific time range.
+
+
+
+ You can apply filters in the top-right corner to adjust the view. Selecting the right filters helps you to focus on the most relevant cost information for your preferred analysis.
+
+For example, you might want to analyze your most recent infrastructure spend across production clusters. In that case, you can set the Clusters Scope filter to `Production` and select a Time Range of Last 30 Days. This will give you a focused view of active workloads and recent spending trends, without including cost from other clusters.
+
+{% hint style="success" %}
+
+### Use Case
+Imagine your team is reviewing this month’s cloud spends and wants to focus only on production clusters. You open the Cost Breakdown page, set the **Clusters Scope** to `Production`, choose your preferred Currency, and adjust the Time Range to Last 30 Days. Instantly, the data updates to show just the relevant costs, providing you a clear picture of active environments and helps you spot any unusual spending patterns. With these quick filters, your team can focus on costs within the defined scope, ensuring the analysis stays relevant to your current objective.
+
+{% endhint %}
+
+| Filter | Description |
+|------------------|-----------------------------------------------------------------------------|
+| **Cluster Scope** | Choose whether to view costs across all clusters or environments, or limit the view to only production or non-production clusters or environments |
+| **Currency** | Displays all cost values in the currency of your choice. |
+| **Time Range** | Defines the time range for data displayed |
+
+---
+
+## Inspecting Different Categories
+
+For the chosen category type (**Clusters**, **Applications**, **Environments**, or **Projects**), it shows the following:
+
+For example, if you select the Clusters category, you can view the total cost across all clusters, the recommended cost based on actual usage, and the potential savings if resources were optimized. This gives you a quick, high-level view of how efficiently each cluster is utilizing its allocated resources.
+
+{% hint style="success" %}
+
+### Use Case
+Imagine your team is analyzing monthly infrastructure expenses for multiple clusters. You notice that the **Total Cost** for one cluster is significantly higher than the others. When you check the **Recommended Cost**, it’s much lower, showing that this cluster is over-provisioned. The Potential Savings metric confirms this, showing how much of your current spend could be reduced by aligning resource allocation with actual usage. With this insight, your team adjusts resource requests to improve overall cost efficiency without impacting performance. By the next billing cycle, costs come down, while the performance remains stable.
+
+{% endhint %}
+
+| Field | Description |
+|:--------------------------- |:----------------------------------------------------------------------------|
+| **Total Cost** | The actual spend for the selected category type (e.g., all clusters). |
+| **Recommended Cost** | The estimated cost calculated from actual resource usage instead of allocated capacity|
+| **Potential Savings** | The amount which you could have saved, for the selected time period|
+| **Estimated cost reduction**| The percentage of your current spend that could be saved, for the selected time period |
+| **Top 10 Costly Resources** | A ranked list of 10 highest cost resources of the selected category|
+
+You will also find a complete list of all the resources for the selected category at the bottom, helping you identify where most of your spending is concentrated.
+
+For example, if you’re viewing the Cluster category, the list displays each cluster along with its CPU, Memory, Storage, GPU, and Network costs. You can quickly compare clusters and identify which ones have higher spend or greater potential savings.
+
+{% hint style="success" %}
+
+### Use Case
+Suppose you’re reviewing costs within the Clusters category. As you go through the list, you notice one cluster’s **Total Cost** is higher than others. You look across its row and notice that both Memory Cost and Storage (PV) Cost are also on the higher side. The **Potential Savings** column then shows a clear opportunity to optimize usage within that cluster. With this focused view, you get a clear understanding of where your resources are being used most and which clusters might need attention, all from a single, organized view. You can then check the detailed view for those clusters to investigate further.
+
+{% endhint %}
+
+
+Each row in the list shows the following for the specific resource of the selected category:
+
+| Field | Available For Categories | Description |
+|:-----------------------|:--------------------------------|:-------------------------------------------------------------------- |
+| **Provider** | Clusters | Shows the cloud provider or infrastructure source for each cluster |
+| **Type** | Clusters, Environments | Shows whether each cluster or environment is **Production** or **Non-Production** |
+| **Applications Count** | Environments, Projects | Shows the number of applications linked to each environment or project |
+| **Environments** | Applications | Shows the number of environments where each application is deployed |
+| **Memory Cost** | All categories | Shows the cost of memory usage for each resource in the selected category |
+| **CPU Cost** | All categories | Shows the cost of CPU usage for each resource in the selected category |
+| **Storage (PV) Cost** | All categories | Shows the cost of persistent volume (storage) usage for each resource in the selected category |
+| **GPU Cost** | All categories | Shows the cost of GPU usage for each resource in the selected category |
+| **Network Cost** | All categories | Shows the cost of network usage for each resource in the selected category |
+| **Total Cost** | All categories | Shows the total cost of each resource |
+| **Potential Savings** | All categories | Shows the cost and percentage of your current spend that could be saved for each resource |
+
+{% embed url="https://app.supademo.com/demo/cmgaokrt93iuk2nomat2gyz7c" %}
+
+### Inspecting Specific Resource
+
+Clicking on any resource in the Cost Breakdown list opens its detailed cost breakdown view. Based on the category you will see the following:
+
+For example, after identifying a high cost Cluster in the previous section, you can click on that cluster to open its detailed breakdown. In the detailed breakdown view of the cluster, you can see which Namespaces and Applications contribute most to its total cost, and how resource types (like CPU, Memory, and Storage) are distributed.
+
+{% hint style=“success” %}
+
+### Use Case
+
+Continuing from the earlier scenario, you open the detailed cost breakdown for the cluster that showed unusually high costs. In the **Top 10 Costly Namespaces** section, one namespace clearly dominates the cost chart. You then look at the Cost Breakdown by Resource Kind graph, where it becomes evident that most of this cost comes from CPU usage.
+
+Investigating further, you discover that a few workloads in that namespace have been consistently running above their requested CPU limits. This explains the cost spike you noticed earlier. With this insight, your team can adjust resource requests and limits for those workloads to optimize cluster performance and reduce unnecessary costs.
+
+{% endhint %}
+
+| Field |Available For Categories | Description |
+|:-----------------|:-------------|:----|
+| **Total Cost** | All categories | Shows the overall cost for the selected resource, along with a cost trend graph for the chosen time range |
+| **CPU** | All categories | Shows the total spend on CPU resources, along with the potential savings |
+| **Memory** | All categories | Shows the total cost for memory resources, along with the potential savings |
+| **Storage**| All categories | Shows the total cost for persistent volume (storage), along with potential savings |
+| **GPU** | All categories | Shows the total cost for GPU resources, along with potential savings |
+|**Top 10 costly namespace**|Cluster| A ranked list of 10 highest cost namespaces within a specific cluster|
+|**Top 10 costly application**|Environments & Projects|A ranked list of 10 highest cost application within a specific environment or project|
+|**Top 10 costly deployment**|Applications|A ranked list of 10 highest cost deployments within a specific application|
+|**Cost Breakdown by Namespace**|Clusters|Shows the distribution of costs across namespaces within the selected cluster. - Each bar represents a namespace, segmented by CPU, Memory, GPU, Storage, and Network costs
- Helps identify which namespaces are responsible for most cost inside a cluster
|
+|**Cost Breakdown by Application**|Clusters, Projects, & Environments|Shows the cost distribution across applications in the selected category - Each bar represents an application, segmented by CPU, Memory, GPU, Storage, and Network costs
|
+|**Cost Breakdown by Resource kind**|All categories|Shows the costs broken down by Kubernetes resource types (e.g., Pod, Deployment, StatefulSet, Job, DaemonSet, Rollout, Container). - Each bar represents a resource kind, segmented by CPU, Memory, GPU, Storage, and Network costs
|
+|**Cost Breakdown by Deployment**|Applications|Shows the distribution of costs across deployments within the selected application - Each bar represents a deployment, segmented by CPU, Memory, GPU, Storage, and Network costs
|
+
+{% embed url="https://app.supademo.com/demo/cmgga3snk6u0a2nomqwfntj11" %}
+
+### Custom Views
+
+**Custom Views** allows you to define your own filtered view of cluster costs. Instead of looking at costs for the entire cluster, you can create a focused view based on propagated tags (for example, filter by team, environment, or application tag).
+
+{% hint style="warning" %}
+### Note
+This feature is available only under the Clusters category.
+{% endhint %}
+
+
+For example, if your production workloads are labeled with `environment=production`, you can create a custom view to track cost of production workloads only.
+By creating a custom view with:
+
+**Key**: `environment`
+**Operator** : `:`
+**Value** : `production`
+
+This helps you quickly analyze how much your production workloads are costing without manually filtering every time. As long as your workloads have the right labels, Devtron automatically groups and updates the data in your custom view, giving you a consistent and focused view of your use case.
+
+{% hint style=“success” %}
+
+### Use Case
+
+Imagine your organization runs workloads for multiple teams, frontend, backend, and logistics, all within the same cluster. Each team’s workloads have propagated tags (labels) (for example, workloads of logistic team have `team=logistics` propagated tag).
+
+Your team often needs to check the monthly cloud spend for the logistics workloads, instead of applying filters for workloads every time, you create a custom view once using that label.
+
+Now, whenever you open Cost Visibility, you simply select the “Logistics Team View” from the sidebar to instantly see total cost, usage patterns, and potential savings specific to that team because the workloads are already labeled, the data stays accurate, and your analysis remains consistent, saving time and effort each time you review costs.
+
+{% endhint %}
+
+{% hint style="warning" %}
+### Note
+Custom Views are dependent on propagated tags (labels). If tags are not mentioned and propagated in the workloads, some resources may not appear in the view. Ensure that you have added and propagated tags for the workloads you want to include in the custom view.
+{% endhint %}
+
+#### Creating a Custom View
+
+To create a custom view:
+
+1. Go to **Cost Visibility** → **Cost Breakdown** → **Cluster**.
+
+2. In the sidebar, click `+` icon next to **Custom Views**.
+
+3. Enter a **Name** and an optional **Description** for your view.
+
+4. Enter one or more label-based filters using **Key**, **Operator**, and **Value**.
+
+5. Click Apply Changes.
+
+Once applied, a Custom View works just like any other category breakdown in Cost Visibility.
+
+#### Filters
+
+| **Field** | **Description** |
+|--------------|---------------------------------------------------------------------------------|
+| **Key** | The label key applied to your Kubernetes resources (for example, `app`, `team`). |
+| **Operator** | Defines the comparison logic between the key and value. |
+| **Value** | The label value to match against (for example, `logistics`, `prod`). |
+
+#### Operators
+
+| **Operator** | **Meaning** | **Example** |
+|--------------|--------------------------|--------------------------------------------|
+| `:` | Equals to | `app : frontend` → selects resources where `app=frontend`. |
+| `!:` | Not Equals To | `team !: dev` → excludes resources with `team=dev`. |
+| `~:` | Contains | `name ~: api` → selects resources where label contains `api`. |
+| `!~` | Not Contains | `app !~: test` → excludes resources where label contains `test`. |
+| `<~` | Contains Prefix | `env <~: prod` → selects resources where label starts with `prod`. |
+| `!<~` | Not Contains Prefix | `env !<~: staging` → excludes resources where label starts with `staging`. |
+
+---
+
+## FAQs
+
+
+1. Why does Cost Visibility show data for some clusters but not others?
+
+Cost data appears only for clusters where **Cost Visibility** is enabled.
+If a cluster doesn’t show cost insights, verify that the **Cost Visibility** module is active for that cluster.
+
+Refer [Configurations](./configurations.md) to learn more.
+
+
+
+2. What does **Connection Failed** mean in Cluster Health Status?
+
+**Connection Failed** means Devtron could not reach the cluster’s API server or retrieve data from it.
+This can happen due to:
+* Network or firewall restrictions
+* Expired or invalid Kubernetes credentials
+* Misconfigured cluster agent
+
+Try revalidating credentials or redeploying the Devtron agent to restore connectivity.
+
+
+
+3. Why does a cluster show **Not Detected** under Autoscaler in Node Counts?
+
+This means Devtron couldn’t identify any predefined autoscaling configuration, it can be a custom autoscaler.
+
+
+
+4. How often is the infrastructure data updated?
+
+Infrastructure data (including metrics, cost, and health status) is refreshed automatically every hour.
+
\ No newline at end of file
diff --git a/docs/user-guide/cost-visibility/overview-cost-visibility.md b/docs/user-guide/cost-visibility/overview-cost-visibility.md
new file mode 100644
index 000000000..719ca225f
--- /dev/null
+++ b/docs/user-guide/cost-visibility/overview-cost-visibility.md
@@ -0,0 +1,243 @@
+# Overview
+
+## Introduction [](https://devtron.ai/pricing)
+
+The **Overview** page provides a summary of infrastructure costs across your Applications, Clusters, Environments, Projects, and Infra Components in Devtron. It highlights overall spend, resource-level distribution, and opportunities for optimization (Potential Savings).
+
+At the top, you can choose your preferred currency time and time duration to set the context for your usage costs. This makes sure all costs on the **Overview** page are displayed in the correct currency and time range.
+
+
+
+Cost Overview has the following sections:
+
+1. [At a Glance](#at-a-glance)
+2. [Potential Savings](#potential-savings)
+3. [Track Performance](#track-performance)
+4. [Actions and Insights](#actions-and-insights)
+
+### How is cost calculated?
+
+Devtron calculates and updates cost data **every hour** based on the resource usage metrics collected from **Prometheus**.
+
+Prometheus gathers real-time data for **CPU**, **Memory**, **GPU**, **Storage (PV)**, and **Network** from your connected clusters.
+Devtron then processes this data every hour to display accurate and up-to-date cost insights across your infrastructure.
+
+{% hint style="info" %}
+### Note
+Cost Visibility is currently supported **only for Devtron and Helm applications**.
+It is **not available** for applications deployed externally through **Argo CD** or **Flux**.
+{% endhint %}
+
+---
+
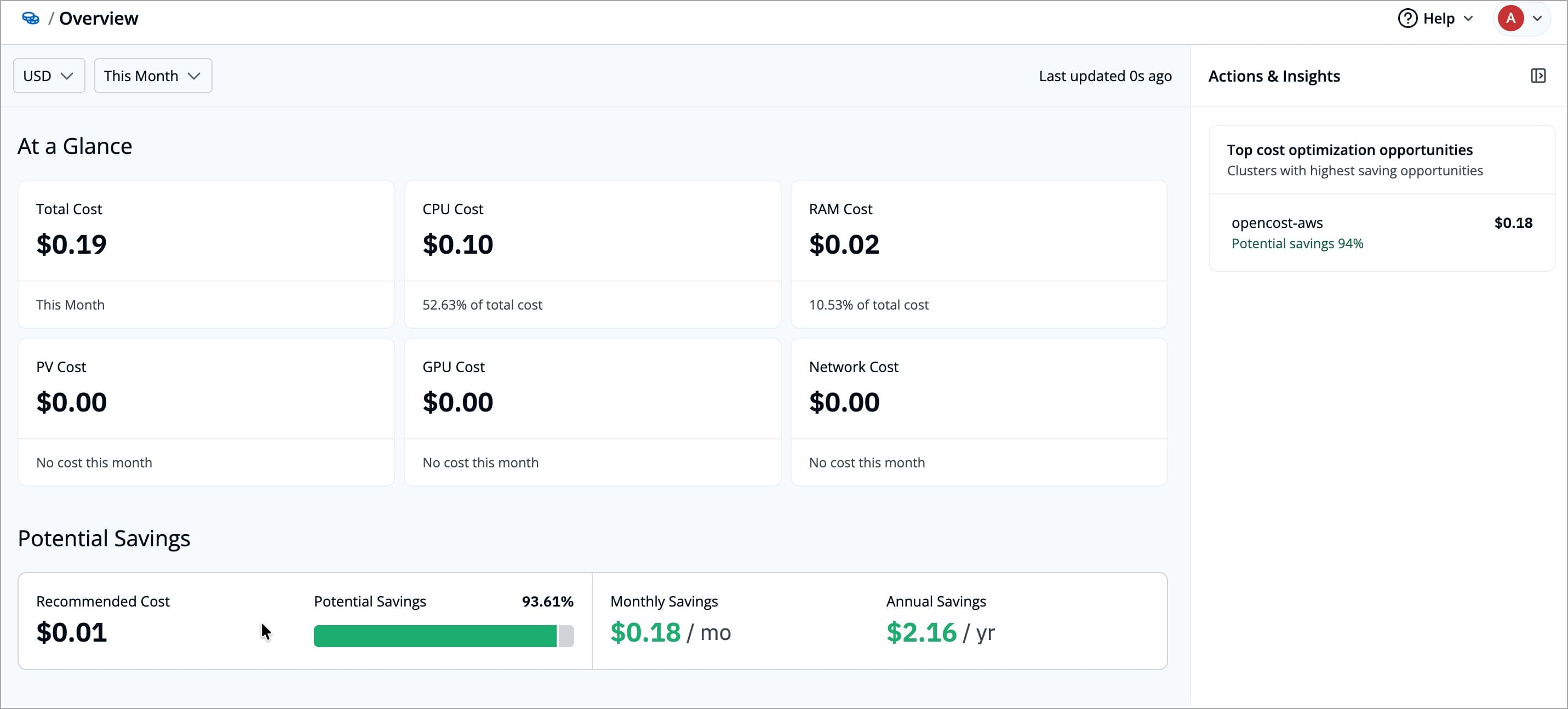
+## At a Glance
+
+The **At a Glance** summarizes the total cost for the selected period and breaks it down by resource type. Each card shows the cost, its share of the total, and a usage trend graph.
+
+{% embed url="https://app.supademo.com/demo/cmg7svcus10om2nommllm1nu2" %}
+
+| Card | Description |
+|:---------------- |:------------------------------------------------------------------------------------------------ |
+| **Total Cost** | Shows the overall infrastructure cost for the selected time period, and the cost-trend graph for the selected period of time |
+| **CPU Cost** | Shows the cost of CPU resources, their percentage contribution to the total cost, and the cost-trend graph for the selected period of time |
+| **RAM Cost** | Shows the cost of memory resources, their percentage contribution to the total cost, and the cost-trend graph for the selected period of time |
+| **PV Cost** | Shows the cost of persistent volume (storage), its percentage contribution to the total cost, and the cost-trend graph for the selected period of time |
+| **GPU Cost** | Shows the cost of GPU resources, their percentage contribution to the total cost, and the cost-trend graph for the selected period of time |
+| **Network Cost** | Shows the cost of network usage, its percentage contribution to the total cost, and the cost-trend graph for the selected period of time |
+
+{% hint style="success" %}
+### Tip
+Network cost refers to the expenses associated with **data transfer**, including communication between **pods, nodes, and external services** within or across clusters. Refer to [AWS guide on network cost](https://aws.amazon.com/premiumsupport/knowledge-center/eks-cluster-networking-costs/) to learn more.
+{% endhint %}
+
+## Potential Savings
+
+The **Potential Savings** section estimates how much cost can be saved by comparing the resources you have provisioned with the resources you have actually used. It also shows the percentage of current spend that could be saved.
+
+{% embed url="https://app.supademo.com/demo/cmg7qkb510x8w2nomc6d29rir" %}
+
+| Field | Description |
+|:---------------------- |:------------------------------------------------------------------------------------------------ |
+| **Recommended Cost** | The estimated cost calculated from actual resource usage instead of allocated capacity |
+| **Potential Savings** | The amount which you could have saved, for the selected time period|
+| **Estimated cost reduction** | The percentage of your current spend that could be saved, for the selected time period |
+
+
+
+## Track Performance
+
+The **Track Performance** section helps you understand costs in more detail by breaking them down across different views and time ranges. It includes two charts, **Cost Breakdown** and **Cost Trend**.
+
+### Cost Breakdown Bar Chart
+
+The **Cost Breakdown** Bar Chart helps you see how costs are distributed across different infrastructure components for the selected time period.
+
+{% embed url="https://app.supademo.com/demo/cmgaj0aid3d8l2nomb611rpbl" %}
+
+Each bar represents one [Application](../../reference/glossary.md#devtron-apps), [Cluster](../../reference/glossary.md#cluster), [Environment](../../reference/glossary.md#environment), or [Project](../global-configurations/projects.md), and the colored segments in the bar show the share of different resource types. This makes it easy to compare categories and see which resources are contributing most to their total cost.
+
+#### Color Schema
+
+| Resource Type | Color Used in Chart |
+|:--------------------- |:---------------------|
+| **CPU Cost** | LimeGreen |
+| **Memory Cost** | SkyBlue |
+| **Storage (PV) Cost** | AquaTeal |
+| **GPU Cost** | Magenta |
+| **Network Cost** | GoldenYellow |
+
+#### Filters
+
+| Filters | What It Shows |
+|:-----------------|:--------------|
+| **Application** | Each bar represents an application (Devtron App or Helm App), segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+| **Cluster** | Each bar represents a cluster, segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+| **Environment** | Each bar represents an environment, segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+| **Project** | Each bar represents a project, segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+
+#### Sorting Criteria
+
+| Sorting Option | Description |
+|:-------------------|:------------|
+| **Cost: High to Low** | Shows the highest cost items first |
+| **Cost: Low to High** | Shows the lowest cost items first |
+| **A to Z** | Sorts items alphabetically |
+| **Z to A** | Sorts items in reverse alphabetical order |
+
+#### Time Range Filters
+
+| Options | Description |
+|:-----------|:--------------|
+| **Last 24 hours** | Shows cost for the last 24 hours |
+| **Last 7 days** | Shows cost for last 7 days |
+| **Last 30 days**| Shows cost for the last 30 days |
+| **last 90 days** | Shows cost for the last 90 days |
+
+### Cost Trend Line Chart
+
+The **Cost Trend** line chart helps you understand, how your total and individual resource usage costs change over time. It helps you analyze spending patterns and identify which resources contribute most to your overall cost.
+
+{% embed url="https://app.supademo.com/demo/cmh343wdi09qkcdwp0vw8ncaw" %}
+
+Each colored line represents a specific infrastructure component, CPU, Memory, Storage, Network, or GPU, while the Total line combines all costs. Hovering over any point on the graph displays the exact cost breakdown for that day.
+
+You can change the time range (for example, Last 7 Days, Last 30 Days, or Last 90 Days) to view trends for a specific period.
+
+#### Time Range
+
+| Options | Description |
+|:-----------|:--------------|
+| **Last 24 hours** | Shows cost for the last 24 hours |
+| **Last 7 days** | Shows cost for last 7 days |
+| **Last 30 days**| Shows cost for the last 30 days |
+| **last 90 days** | Shows cost for the last 90 days |
+
+#### Color Schema
+
+| Resource Type | Color Used in Chart |
+|:--------------------- |:---------------------|
+| **CPU Cost** | LimeGreen |
+| **Memory Cost** | SkyBlue |
+| **Storage (PV) Cost** | AquaTeal |
+| **GPU Cost** | Magenta |
+| **Network Cost** | GoldenYellow |
+
+### Most Cost Efficient
+
+The **Most Cost Efficient** section helps you identify which resources are utilizing costs most effectively across different scopes, such as Cluster, Application, Environment, or Project.
+
+{% embed url="https://app.supademo.com/demo/cmh344vs309sicdwphlwbua6e" %}
+
+Each row in the list displays
+
+| **Field** | **Description** |
+|------------|-----------------|
+| **Name** | The name of the selected category (for example, a project, application, cluster, or environment)|
+| **Total Cost** | The total cost incurred by that category within the selected time range |
+| **Cost Efficiency (%)** | Indicates how efficiently the resource utilizes its allocated cost compared to others. Higher values represent better cost efficiency |
+
+You can use the dropdown menus to customize your view:
+
+| **Filter** | **Description** |
+|-------------|-----------------|
+| **Scope Selector** | Lets you choose whether to view cost efficiency by **Cluster**, **Application**, **Environment**, or **Project**. |
+| **Time Range** | Allows you to select the time range, **Last 24 Hours**, **Last 7 Days**, **Last 30 Days**, or **Last 90 Days**. |
+
+
+### Most Expensive
+
+The **Most Expensive** section highlights the clusters, applications, environments, or projects that contribute the highest costs over a selected time range. This helps you quickly identify where your infrastructure expenses are concentrated and which components may require optimization.
+
+{% embed url="https://app.supademo.com/demo/cmh34ohno0au7cdwpoz8p8bgg" %}
+
+Each row in the list displays:
+
+| **Field** | **Description** |
+|------------|-----------------|
+| **Name** | The name of the selected category, such as a **Cluster**, **Application**, **Environment**, or **Project** |
+| **Cost Type** | The selected cost type, such as **CPU**, **Memory**, **Storage**, **GPU**, **Network**, or **Total Cost** |
+| **Total Cost** | The total cost incurred by that category for the chosen cost type within the specified time period |
+
+You can customize the view using the following filters:
+
+| **Filter** | **Description** |
+|-------------|-----------------|
+| **Scope Selector** | Lets you choose for which category (**Cluster**, **Application**, **Environment**, or **Project**), you want to view the most expensive resources |
+| **Time Range** | Allows you to choose the time period for cost evaluation, **Last 24 Hours**, **Last 7 Days**, **Last 30 Days**, or **Last 90 Days**. |
+| **Cost Type** | Enables you to filter costs by specific categories such as **CPU Cost**, **Memory Cost**, **Storage Cost**, **GPU Cost**, **Network Cost**, or **Total Cost**. |
+
+## Actions and Insights
+
+The **Actions & Insights** section highlights where you can achieve the highest cost savings. It shows the categories with the largest cost saving opportunities, based on the difference between allocated resources and your actual usage.
+
+{% embed url="https://app.supademo.com/demo/cmgj316cr0x93krn9l7g4uo7a" %}
+
+It also shows the cost visibility status, which displays the number of clusters where cost visibility is enabled, failed, in progress, or not enabled. This helps you understand for which clusters cost data is currently being tracked and if you want you can enable/disable cost tracking for the cluster by clicking on **Go to configurations** button. Refer [configurations](./configurations.md) to learn more.
+
+Each category in the **Top saving opportunities** will show
+
+| Field | Description |
+|:-----------------------|:------------|
+| **Name** | The name of the category (for example, a cluster, application, or environment) with the largest savings opportunities |
+| **Potential Savings (%)** | The percentage of your current spend that could be saved, for the selected time range |
+| **Estimated Savings** | The estimated cost you could save in that category, based on the difference between provisioned and used resources, for the selected time range|
+
+Clicking on any item in this list takes you to its detailed Cost Breakdown page. Refer [Cost Breakdown](./cost-breakdown.md) to learn more.
+
+---
+
+## FAQs
+
+
+1. Why am I not seeing cost data on the Overview page?
+
+Cost Visibility is only supported for **Devtron** and **Helm** applications.
+If you’re only using **Argo CD** or **Flux** apps, their cost data won’t appear.
+Also, ensure that **Cost Visibility** is enabled for your cluster, refer [Configurations](./configurations.md) to learn more.
+
+
+
+2. What should I do if the graphs look empty or incomplete?
+
+This usually happens when cost tracking is not enabled for certain clusters or when there’s no activity in the selected time range.
+Try expanding the time range.
+
+
+
+3. Can I compare costs across different clusters or applications?
+
+Yes. The **Cost Breakdown**, let you compare spend across **Clusters**, **Applications**, **Environments**, or **Projects**.
+You can also use filters and sorting options to focus on a specific scope or resource type.
+
+
+
+4. What does Potential Savings mean in simple terms?
+
+It shows how much you could save if your resources were right-sized, i.e, it’s the difference between what you’ve **allocated** and what you actually **use**.
+
+
+
+5. How often is the cost data updated?
+
+Cost data is refreshed **automatically every hour**, based on the latest metrics from Prometheus.
+
\ No newline at end of file
diff --git a/docs/user-guide/creating-application/application-overview.md b/docs/user-guide/creating-application/application-overview.md
new file mode 100644
index 000000000..3706d3537
--- /dev/null
+++ b/docs/user-guide/creating-application/application-overview.md
@@ -0,0 +1,263 @@
+# Application Overview
+
+## Introduction
+
+The **Application Overview** page in Devtron gives you a complete view of your Devtron Applications. It includes information about your projects, applications, environments, and pipelines, all in a single view.
+
+It helps you understand how your applications are organized, how your workflows are performing, thus, giving you better visibility and control in a single pane of view.
+
+
+
+The **Application Overview** page contains the following sections:
+
+1. [At a Glance](#at-a-glance)
+2. [Workflow Overview](#workflow-overview)
+3. [Triggers & Build Time](#triggers--build-time)
+4. [Most & Least Triggered Pipelines](#most--least-triggered-pipelines)
+5. [Cost Visibility](#cost-visibility)
+6. [Best Practices](#best-practices)
+
+---
+
+## At a Glance
+
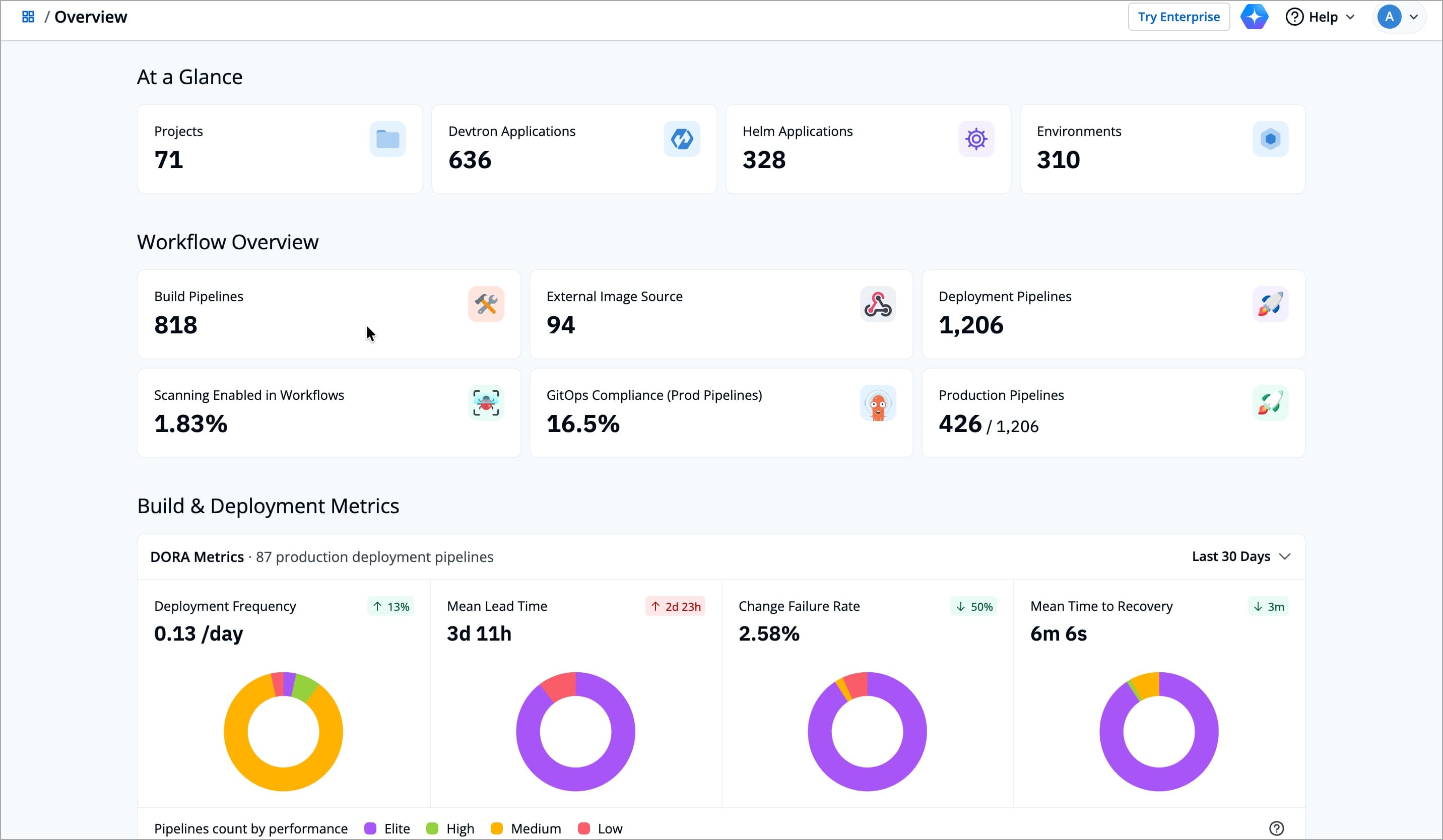
+The **At a Glance** section displays the total count of Projects, Devtron Applications, Helm Applications, and Environments, giving you an instant view of your overall applications in Devtron.
+
+{% embed url="https://app.supademo.com/demo/cmgoybsk909t912sxbkjaixtr" %}
+
+| **Card** | **Description** |
+|------------------------|----------------|
+| **Projects** | Total number of projects in Devtron |
+| **Devtron Applications** | Total number of Devtron applications across all the clusters |
+| **Helm Applications** | Total number of Helm applications across all the clusters|
+| **Environments** | Total number of Environments in Devtron across all the clusters|
+
+---
+
+## Workflow Overview
+
+The **Workflow Overview** section displays how your CI/CD workflows are functioning in Devtron. It displays important metrics such as the number of build and deployment pipelines, external image sources, and production pipelines. It also shows how many pipelines follow GitOps best practices and have image scanning enabled.
+
+{% embed url="https://app.supademo.com/demo/cmgvkilsc4rpcyzgyfz27ywut" %}
+
+| **Card** | **Description** |
+|-----------|-----------------|
+| **Build Pipelines** | Shows the total number of build pipelines configured in your Devtron |
+| **Deployment Pipelines** | Shows the total number of deployment pipelines across all applications|
+| **External Image Sources** | Shows the total number of build pipelines which uses external image source |
+| **Scanning Enabled in Workflows** | Shows the percentage of workflows that have scanning enabled for images |
+| **GitOps Compliance (Prod Pipelines)** | Shows how many production pipelines are configured using GitOps for configuration consistency|
+| **Production Pipelines** | Shows the total number of production pipelines defined within your Devtron|
+
+### Build & Deployment Metrics
+
+The **Build & Deployment Metrics** section helps you assess how efficiently your teams deliver software using Devtron pipelines. It uses the industry standard DORA metrics to measure delivery performance and reliability across production deployment pipelines.
+
+{% embed url="https://app.supademo.com/demo/cmgvm5zcy4scyyzgykhpfbjwn" %}
+
+You can track four key metrics over a selected time range (for example, the last 30 days).
+
+| **Metric** | **Description** |
+|-------------|-----------------|
+| **Deployment Frequency** |Shows how often your deployment pipelines push new releases to production |
+| **Mean Lead Time** | Shows the average time it takes for a code change to move from commit to production. It helps you understand how quickly your team can deliver new features or fixes|
+| **Change Failure Rate** | Indicates the percentage of deployments that result in a failure or rollback. It helps you measure release stability and identify where improvements can reduce disruptions|
+| **Mean Time to Recovery (MTTR)** | Measures how long it takes to recover from a failed deployment. It helps you assess how effectively your team can respond to and fix issues when they occur|
+| **Pipelines Count by Performance** | Categorizes pipelines into **Elite**, **High**, **Medium**, and **Low** performance based on DORA metrics. Helps identify which pipelines are performing well and which may need improvement |
+
+Each DORA metric in Devtron uses color-coded categories to represent pipeline performance levels. These colors help you quickly interpret how your production deployment pipelines are performing, from **Elite** (best-performing) to **Low** (needs attention).
+
+The meaning for each color vary slightly across different metrics, reflecting how delivery speed, stability, and recovery time are measured in real-world DevOps performance. The table below summarizes what each color means for every DORA metric in Devtron.
+
+| **Metric** | **Color** | **Category** | **Description** | **Range / Criteria** |
+|-------------|------------|---------------|------------------|-----------------------|
+| **Deployment Frequency** | 🟪 **Elite** | Top performing pipelines | Deployed more than once per day | > 1 per day |
+| | 🟩 **High** | High-performing pipelines | Deployed between once per day and once per week | 1 per day – 1 per week |
+| | 🟨 **Medium** | Moderately active pipelines | Deployed between once per week and once per month | 1 per week – 1 per month |
+| | 🟥 **Low** | Infrequently deployed pipelines | Deployed between once per month and once per 6 months | 1 per month – 1 per 6 months |
+| **Mean Lead Time** | 🟪 **Elite** | Top performing pipelines | Mean lead time is less than 1 day | < 1 day |
+| | 🟩 **High** | High-performing pipelines | Mean lead time is between 1 day and 1 week | 1 day – 1 week |
+| | 🟨 **Medium** | Moderately efficient pipelines | Mean lead time is between 1 week and 1 month | 1 week – 1 month |
+| | 🟥 **Low** | Slow pipelines | Mean lead time is between 1 day and 6 months | 1 day – 6 months |
+| **Change Failure Rate** | 🟪 **Elite** | Top performing pipelines | Change failure rate is between 0–15% | 0–15% |
+| | 🟩 **High** | High-performing pipelines | Change failure rate is between 16–30% | 16–30% |
+| | 🟨 **Medium** | Moderately stable pipelines | Change failure rate is between 31–45% | 31–45% |
+| | 🟥 **Low** | Unstable pipelines | Change failure rate is between 46–60% | 46–60% |
+| **Mean Time to Recovery (MTTR)** | 🟪 **Elite** | Top performing pipelines | Mean time to recovery is less than 1 hour | < 1 hour |
+| | 🟩 **High** | High-performing pipelines | Mean time to recovery is between 1 hour and 1 day | 1 hour – 1 day |
+| | 🟨 **Medium** | Moderately resilient pipelines | Mean time to recovery is between 1 day and 1 week | 1 day – 1 week |
+| | 🟥 **Low** | Slow recovery pipelines | Mean time to recovery is more than 1 week | > 1 week |
+
+{% hint style=“success” %}
+
+### Use Case
+
+Suppose your DevOps team is reviewing delivery performance for the last month. You notice that while Deployment Frequency has increased, the Mean Lead Time has also gone up. This suggests that more deployments are happening, but each one is taking longer to reach production. By comparing the Change Failure Rate and Mean Time to Recovery, your team can identify whether the delay is due to testing, approvals, or rollback handling. With these insights, you can fine-tune your workflow or automation to achieve faster and more reliable releases.
+
+{% endhint %}
+
+---
+
+## Triggers & Build Time
+
+The **Triggers & Build Time** section provides a detailed view of your build and deployment activities in Devtron. It helps you understand how frequently builds and deployments are triggered, how long they take, and how successful they are over time.
+
+{% embed url="https://app.supademo.com/demo/cmgvmh7mo4stnyzgyvk9dr2g7" %}
+
+At the top, you will see three key indicators:
+
+| **Field** | **Description** |
+|------------|----------------|
+| **Total Build Triggers** | The total number of builds triggered across all pipelines within the selected time period. |
+| **Average Build Time** | The average time taken for a build to complete successfully. |
+| **Total Deployment Triggers** | The total number of deployments triggered during the selected time period. |
+
+Below each indicator, you will also find a corresponding graph that visualizes its trend over selected period of time. You can adjust the **Time Range** in the top-right corner of the graph to analyze workflow trends over different periods.
+
+| Option | Description |
+|:----------------|:-------------|
+| **Today** | Shows build and deployment activity for the current day |
+| **This Week** | Displays data from the current week (Monday-Sunday) |
+| **Last Week** | Displays data from the previous week for comparison |
+| **This Month** | Aggregates data for the ongoing month |
+| **Last Month** | Shows activity from the previous month to help you analyze changes month-over-month|
+| **This Quarter**| Groups workflow data by the current quarter (**April-June**, **July-September**, **October-December**, or **Jan-March**) |
+
+### Build Triggers Graph
+
+This graph displays how build triggers change over time.
+* **Blue line** - Total build triggers
+* **Green line** - Successful builds
+* **Red line** - Failed builds
+
+Hover over any point on the graph to view daily build statistics, including total, successful, and failed builds. This helps you identify trends in build frequency and stability.
+
+### Deployment Triggers Graph
+
+This graph tracks how often deployments are triggered and how many of them succeed or fail.
+
+* **Blue line** - Total deployments triggered
+* **Green line** - Successful deployments
+* **Red line** - Failed deployments
+
+Hover over a specific date to see deployment counts and outcomes, helping you understand deployment frequency and reliability trends.
+
+
+### Average Build Time Graph
+
+This graph shows how the average build duration varies during the selected time range.
+
+* The **blue line** represents the average build time per day (in minutes).
+* The **dotted line** shows the overall average for the selected period.
+
+It helps you identify days when build duration increased significantly, signaling potential issues like resource bottlenecks or slower build steps.
+
+{% hint style="success" %}
+### Use Case
+
+Suppose your team wants to analyze why release cycles slowed down this month.
+You open the **Triggers & Build Time** section and notice that build triggers spiked on October 10, with several failed builds. Deployment triggers show a similar peak on October 8, where 73 deployments ran, and 18 failed. Meanwhile, the Average Build Time graph shows a sudden rise on October 3, where builds took three times longer than usual.
+
+With these insights, your team can connect the dots between build failures, longer build durations, and delayed deployments, helping you take timely corrective action to keep releases smooth and predictable.
+{% endhint %}
+
+---
+
+## Most & Least Triggered Pipelines
+
+This section shows the build and deployment pipelines that were triggered the most and the least within the selected time range.
+It helps you identify which pipelines are most active and where fewer executions might indicate inactive or underused workflows.
+
+{% embed url="https://app.supademo.com/demo/cmgvn5zsw4t45yzgychnu2lfv" %}
+
+The section provides two tabs, **Build Pipelines** and **Deployment Pipelines**, each displaying a bar chart that ranks pipelines based on how frequently they were triggered during the selected time range.
+
+| **Tab** | **Description** |
+|:---------|:----------------|
+| **Build Pipelines** | Displays the most and least triggered build pipelines based on their total build trigger count. Each bar represents a single pipeline, and its length indicates how often the pipeline was triggered. |
+| **Deployment Pipelines** | Displays the most and least triggered deployment pipelines based on their total deployment trigger count. Each bar represents a single deployment pipeline, and its length indicates the number of deployment triggers during the selected time range. |
+
+### Sorting and Filters
+
+| **Control** | **Description** |
+|:--------------|:----------------|
+| **Time Range** | Allows you to choose a time range such as **Today**, **This Week**, **This Month**, **Last Month**, or **This Quarter** to analyze pipeline activity during that period. |
+| **Sorting Order** | Lets you sort the list **High to Low** or **Low to High** based on trigger count, helping you focus on the busiest or least used pipelines. |
+
+---
+
+## Cost Visibility [](https://devtron.ai/pricing)
+
+{% hint style="info" %}
+This section provides a quick overview of cost insights within the **Application Overview** dashboard.
+For a more detailed breakdown of cost and usage across clusters, see the full [Cost Visibility](../cost-visibility/README.md)
+{% endhint %}
+
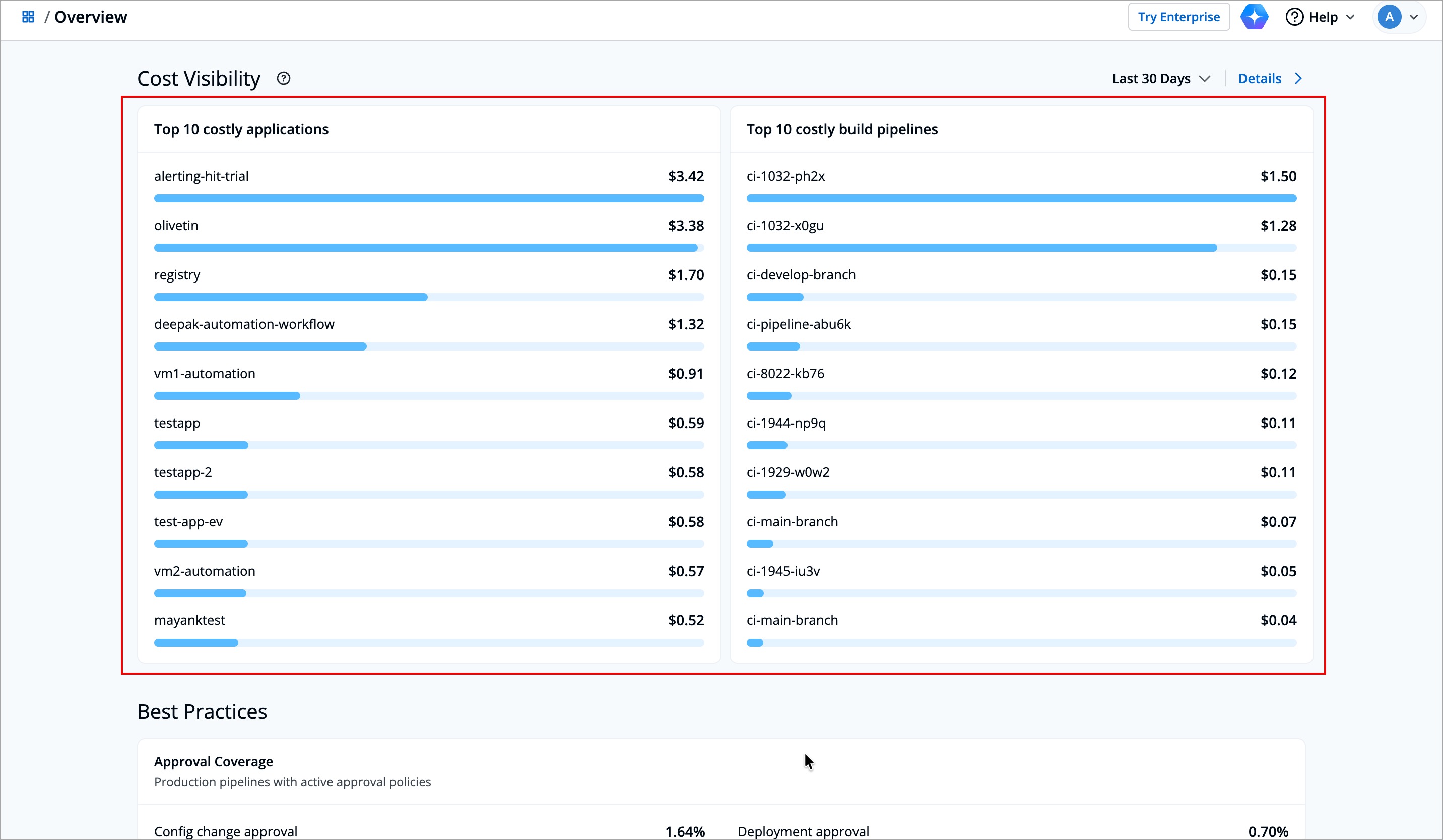
+The **Cost Visibility** section provides a comparison of costs across your applications and build pipelines within Devtron.
+
+
+
+It shows:
+
+ * **Top 10 Costly Applications** - It shows which deployed applications consume the most resources (such as CPU, memory, or storage) across your clusters.
+
+ * **Top 10 Costly Build Pipelines** - It shows the list of build pipelines that have the highest cost during image builds.
+
+You can use the time range filter (Last 24 Hours, Last 7 Days, Last 30 Days, or Last 90 Days) to select the preferred time range.
+
+{% hint style="warning" %}
+
+### Note
+If a cluster does not have cost tracking enabled, its data will not appear in this section.
+Enable the **Cost Visibility** module for those clusters to view accurate cost insights. Refer [Cost Visibility Configurations](../cost-visibility/configurations.md) to learn more.
+{% endhint %}
+
+---
+
+## Best Practices [](https://devtron.ai/pricing)
+
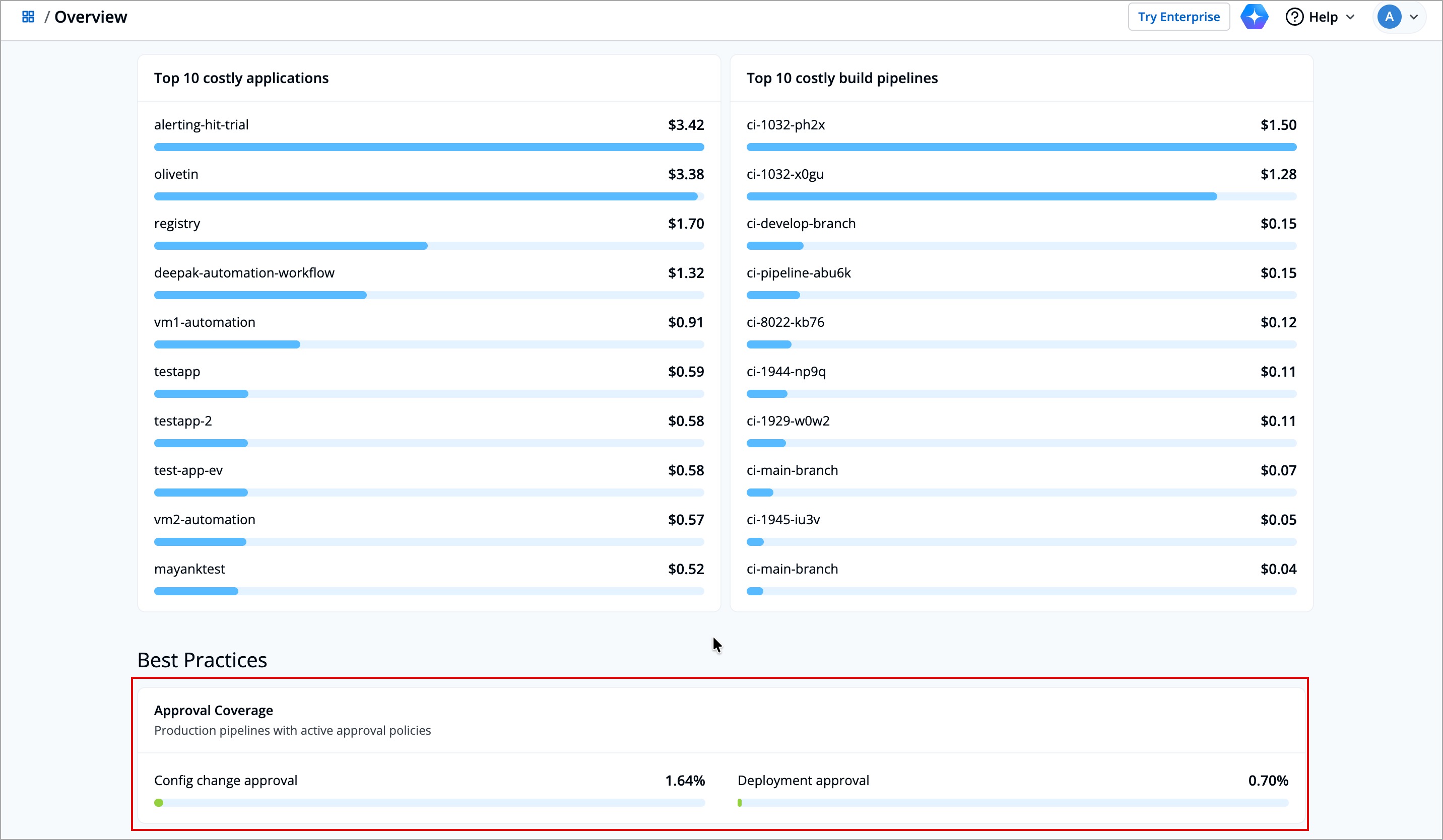
+The **Best Practices** section helps shows you the percentage of production pipelines for which you have enabled approval policies. It gives you a quick view of how many pipelines have checks in place before important configuration changes or deployments go live.
+
+
+
+These insights help you ensure that the right governance controls are followed, reducing risks from unreviewed or accidental changes.
+
+| **Field** | **Description** |
+|:-----------|:----------------|
+| **Config Change Approval** | Indicates the percentage of pipelines that require approval before applying configuration changes|
+| **Deployment Approval** | Indicates the percentage of pipelines that require approval before executing a deployment |
+
+## FAQs
+
+
+1. Why do the counts of Devtron and Helm applications differ from what I see in my dashboards?
+
+The counts displayed in the application overview across **all connected clusters**, which are reachable. If some applications are missing, verify that, the clusters where they are deployed are reachable.
+
+Disconnected clusters or standalone Helm releases won’t appear until Devtron syncs them.
+
+If still you cannot see your applications, contact [Devtron Support](mailto:enterprise@devtron.ai) for assistant.
+
+
+
+2. Why do my triggers or build time graphs look empty?
+
+Graphs may appear blank if:
+* No builds or deployments were triggered during the selected **Time Range**
+* Pipelines were recently created and have no activity yet
+Try expanding the time filter (for example, from **This Week** to **Last 30 Days**) or verifying pipeline execution history.
+
+
+
+3. Why do I see cost data for some applications but not others?
+
+Cost data appears only for applications deployed in clusters where **Cost Visibility** is enabled.
+If a cluster doesn’t have cost visibility enabled, its data won’t appear.
+You can enable it under **Cost Visibility** → **Configurations** to start tracking cost for those applications. Refer [Configurations](../cost-visibility/configurations.md) to learn more.
+
+
+
+4. How frequently are these metrics updated?
+
+Metrics on the **Application Overview** page are refreshed automatically every hour.
+
\ No newline at end of file
diff --git a/docs/user-guide/creating-application/infrastructure-overview.md b/docs/user-guide/creating-application/infrastructure-overview.md
new file mode 100644
index 000000000..32a5d7f49
--- /dev/null
+++ b/docs/user-guide/creating-application/infrastructure-overview.md
@@ -0,0 +1,242 @@
+# Infrastructure Overview
+
+## Introduction
+
+The **Infrastructure Overview** page provides a centralized view of your Kubernetes infrastructure across all connected clusters. It displays cluster health, resource capacity, node distribution, and version details in a single dashboard.
+
+It contains the following sections:
+
+1. [At a Glance](#at-a-glance)
+2. [Cluster & Nodes](#cluster--nodes)
+3. [Cost Visibility](#cost-visibility)
+4. [Actions & Insights](#actions-and-insights)
+
+---
+
+## At a Glance
+
+The **At a Glance** section helps you quickly understand the overall state of your connected clusters and available resources. It helps you understand your current infrastructure capacity and connectivity status at a single glance.
+
+{% embed url="https://app.supademo.com/demo/cmh0e4sh81naf6nxtlvrh3kwy" %}
+
+| **Card** | **Description** |
+|:----------|:----------------|
+| **Reachable Clusters** | Shows the number of clusters that are currently reachable out of the total clusters connected to Devtron |
+| **Total CPU Capacity** | Displays the total CPU capacity across all reachable clusters, giving you an overview of your available compute power|
+| **Total Memory Capacity** | Displays the total memory capacity across all reachable clusters, helping you keep track of your memory resources |
+
+
+{% hint style=“info” %}
+If some clusters don’t appear, they might be temporarily unreachable. You can verify their status under Cluster Configuration.
+{% endhint %}
+
+---
+
+## Cluster & Nodes
+
+The **Cluster & Nodes** section helps you monitor the health and stability of your connected clusters and nodes. It gives you visibility into cluster connectivity, node errors, and scheduling readiness, allowing you to quickly spot and resolve any infrastructure level issues before they affect workloads.
+
+{% embed url="https://app.supademo.com/demo/cmh0eklkn1npo6nxta30w3fnb" %}
+
+| **Card** | **Description** |
+|:----------|:----------------|
+| **Cluster Health Status** | Displays the number of clusters which are healthy. A healthy cluster indicates active connectivity, while **Connection Failed** highlights clusters that are currently unreachable|
+| **Node Errors** | Shows whether any node-level issues exist. If you see **No node errors**, all nodes are operating normally |
+| **Node Scheduling** | Displays the percentage of nodes currently available for scheduling workloads. **Schedulable** nodes are ready to accept pods|
+
+{% hint style="info" %}
+If you notice connection failures or scheduling issues, verify your cluster connectivity and node configurations under **Cluster Management**.
+{% endhint %}
+
+### Cluster Counts
+
+The **Cluster Counts** section gives you visibility into how your clusters are distributed across different cloud providers and Kubernetes versions. It helps you identify where most of your clusters are hosted and which versions are actively running in your infrastructure.
+
+{% embed url="https://app.supademo.com/demo/cmh0f2cp21nuo6nxt0u0xu6ab" %}
+
+There are two views available:
+
+| **Tab** | **Description** |
+|:---------|:----------------|
+| **By Providers** | Displays the total number of clusters grouped by cloud providers such as **GCP**, **AWS**, **Azure**, or Unknown. This helps you understand your cloud distribution and dependency. |
+| **By Cluster Versions** | Displays the number of clusters based on their Kubernetes version. This helps you track version diversity and identify clusters that may require upgrades for consistency and security. |
+
+{% hint style="info" %}
+You can sort the data **High to Low** or **Low to High** to quickly identify the most used cloud provider or the most common Kubernetes version in your setup.
+{% endhint %}
+
+### Cluster Capacity & Resource Allocation
+
+The **Cluster Capacity & Resource Allocation** section provides a detailed view of how CPU and Memory resources are distributed and utilized across all connected clusters. It helps you assess infrastructure efficiency, monitor resource limits, and identify clusters that may be underutilized or over committed.
+
+{% embed url="https://app.supademo.com/demo/cmh1t50wh0e6rnitlu546ellj" %}
+
+| **Field** | **Description** |
+|:-----------|:----------------|
+| **Cluster Name** | Lists all clusters connected to Devtron. You can click on a cluster name to view its detailed resource usage |
+| **CPU** | Displays the total CPU capacity, along with utilization, requests, and limits for each cluster. This helps you track compute usage and detect over-provisioning |
+| **Memory** | Displays the total memory capacity, along with utilization, requests, and limits for each cluster. It helps you ensure workloads are balanced, and resource allocation is efficient |
+
+You can sort the data by:
+* **Cluster Name** (A to Z or Z to A)
+* **Utilization** (High to Low or Low to High)
+
+{% hint style="info" %}
+### Note
+If a cluster shows zero utilization or capacity, it may be inactive or disconnected. Verify its status under **Cluster Configuration**.
+{% endhint %}
+
+---
+
+## Node Counts
+
+The **Node Counts** section helps you visualize how nodes are distributed across clusters and autoscaling modes.
+It provides a quick overview of your cluster node density and helps identify environments with higher or lower capacity.
+
+{% embed url="https://app.supademo.com/demo/cmh1te7ck0ei9nitl41zpx5mg" %}
+
+| **Tab** | **Description** |
+|:----------|:----------------|
+| **By Cluster** | This graph displays the total number of nodes within each cluster. Each bar shows the number of clusters within a specific cluster. This view helps you assess how evenly nodes are distributed and whether specific clusters may be over or under-provisioned |
+| **By Autoscaler** | Groups nodes based on their autoscaling configuration (for example, **GKE Automode** or **Not Detected**). Each bar shows the number of nodes within the autoscaling configuration|
+
+You can sort the chart data using the dropdown in the top-right corner:
+* **High to Low** or **Low to High**, to focus on clusters with the most or fewest nodes.
+
+### Troubleshooting Autoscaler Detection
+
+Devtron currently supports autoscaler detection for the following autoscalers: **EKS Auto Mode**, **Karpenter**, **CAST AI**, and **GKE Autopilot**.
+If your cluster uses any other autoscaler, it will be categorized as **Not Detected** under the **By Autoscaler** view.
+
+Devtron identifies supported autoscalers using the following Kubernetes node labels:
+
+```bash
+# EKS Auto Mode label
+
+LabelEKSComputeType = "eks.amazonaws.com/compute-type"
+LabelEKSComputeAuto = "auto"
+
+# Karpenter label
+
+LabelKarpenterInitialized = "karpenter.sh/initialized"
+LabelKarpenterTrue = "true"
+
+# Cast AI label
+
+LabelCastAIManagedBy = "provisioner.cast.ai/managed-by"
+LabelCastAIValue = "cast.ai"
+
+# GKE label
+
+LabelGKEProvisioning = "cloud.google.com/gke-provisioning"
+LabelGKEAutoPilot = "spot"
+
+```
+
+{% hint style="success" %}
+### Need support for another autoscaler?
+
+[Submit a feature request on GitHub](https://github.com/devtron-labs/devtron/issues). Our team regularly reviews community requests, and your feedback helps us prioritize new integrations in upcoming releases.
+
+{% endhint %}
+
+### Cost Visibility [](https://devtron.ai/pricing)
+
+The Cost Breakdown chart helps you see how costs are distributed across different infrastructure components for the selected time period.
+
+Each bar represents one Application, Cluster, Environment, or Project, and the colored segments in the bar show the share of different resource types. This makes it easy to compare categories and see which resources are contributing most to their total cost.
+
+{% embed url="https://app.supademo.com/demo/cmh1u1s3o0fbmnitleo58pcg3" %}
+
+| Resource Type | Color Used in Chart |
+|:--------------------- |:---------------------|
+| **CPU Cost** | LimeGreen |
+| **Memory Cost** | SkyBlue |
+| **Storage (PV) Cost** | AquaTeal |
+| **GPU Cost** | Magenta |
+| **Network Cost** | GoldenYellow |
+
+#### Filters
+
+| Filters | What It Shows |
+|:-----------------|:--------------|
+| **Application** | Each bar represents an application, segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+| **Cluster** | Each bar represents a cluster, segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+| **Environment** | Each bar represents an environment, segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+| **Project** | Each bar represents a project, segmented by CPU, Memory, Storage (PV), GPU, and Network costs |
+
+#### Sorting Criteria
+
+| Sorting Option | Description |
+|:-------------------|:------------|
+| **Cost: High to Low** | Shows the highest cost items first |
+| **Cost: Low to High** | Shows the lowest cost items first |
+| **A to Z** | Sorts items alphabetically |
+| **Z to A** | Sorts items in reverse alphabetical order |
+
+---
+
+## Actions and Insights
+
+The **Actions & Insights** section highlights where you can achieve the highest cost savings. It shows the categories with the largest cost saving opportunities, based on the difference between allocated resources and your actual usage.
+
+{% embed url="https://app.supademo.com/demo/cmh1u9uss0fvjnitlk1tn4lv0" %}
+
+It also shows, which version of Kubernetes your cluster is running, and you can also check the compatibility of the cluster to upgrade to the latest Kubernetes version. You can click **Show All** to expand and view additional clusters that are not immediately visible in the list.
+
+Each item in the **Top saving opportunities** will show
+
+| Field | Description |
+|:-----------------------|:------------|
+| **Name** | The name of the category (for example, a cluster, application, or environment) with the largest savings opportunities |
+| **Potential Savings (%)** | The percentage of your current spend that could be saved, for the selected time range |
+| **Estimated Savings** | The estimated cost you could save in that category, based on the difference between provisioned and used resources, for the selected time range|
+
+Clicking on any item in this list takes you to its detailed Cost Breakdown page. Refer [Cost Breakdown](../cost-visibility/cost-breakdown.md) to learn more.
+
+### Checking Upgrade Compatibility
+
+1. To check upgrade capability, go to **Infrastructure Management** → **Overview**.
+
+2. Under **Check cluster update compatibility**, hover over the cluster you want to check compatibility for and click the search button.
+
+3. A pop-up modal will appear, select the target version, and click scan cluster.
+
+4. A page will open, with the summary of all the API-endpoints that are compatible for upgrading. You can also check **Deprecated Fields** (Against current API version), **Resources with no PDB**, **Resources with 0 Disruption PDB**
+
+---
+
+## FAQs
+
+
+1. Why does Cost Visibility show data for some clusters but not others?
+
+Cost data appears only for clusters where **Cost Visibility** is enabled.
+If a cluster doesn’t show cost insights, verify that the **Cost Visibility** module is active for that cluster.
+
+Refer [Configurations](../cost-visibility/configurations.md) to learn more.
+
+
+
+2. What does **Connection Failed** mean in Cluster Health Status?
+
+**Connection Failed** means Devtron could not reach the cluster’s API server or retrieve data from it.
+This can happen due to:
+* Network or firewall restrictions
+* Expired or invalid Kubernetes credentials
+* Misconfigured cluster agent
+
+Try revalidating credentials or redeploying the Devtron agent to restore connectivity.
+
+
+
+3. Why does a cluster show **Not Detected** under Autoscaler in Node Counts?
+
+This means Devtron couldn’t identify any predefined autoscaling configuration, it can be a custom autoscaler.
+
+
+
+4. How often is the infrastructure data updated?
+
+Infrastructure data (including metrics, cost, and health status) is refreshed automatically every hour.
+
\ No newline at end of file