| title | datePublished | cuid | slug | canonical | cover | tags |
|---|---|---|---|---|---|---|
Workaround with OpenAI's token limit with Langchain |
Wed Oct 16 2024 05:21:04 GMT+0000 (Coordinated Universal Time) |
cm2bfc69c000409jsg14i02im |
workaround-with-openais-token-limit-with-langchain |
ai, llm, tuning-llm |
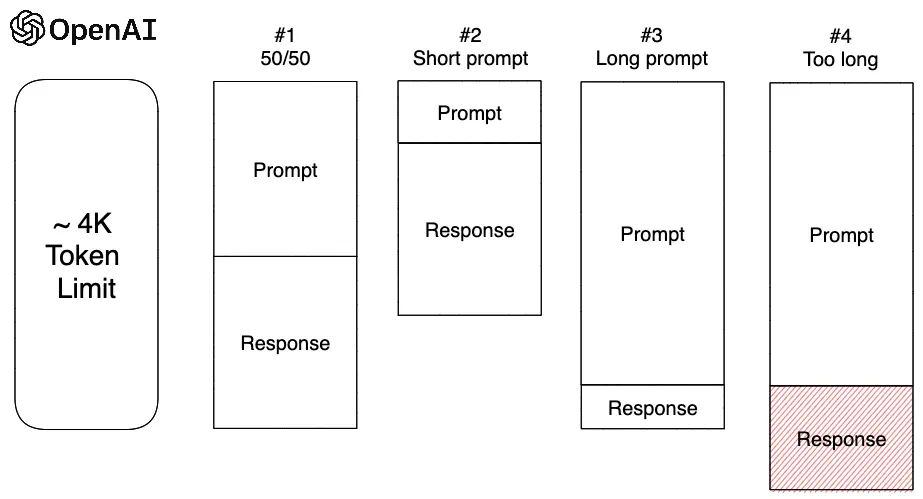
Tuning OpenAI's ChatGPT comes as a very finicky problem as we don't have access to the model and other forms of tuning GPT are very limited. Not to mention that OpenAI has a token limit, as of time of writing, of ~4,000 tokens (with each token being ~1.2 words). This limit is applied on both the prompt and response of the answer.
Langchain is a framework for developing applications powered by language models. It provides support for several main modules such as Models, Prompts, Memory, Indexes, Chains and Agents. LangChain believes that the most powerful and differentiated applications will not only call out to a language model via an API but will also be data-aware and allow a language model to interact with its environment.
A few strategies that Langchain uses, and that we can also create and customize, to get around the ~4,000 token limit are:
Essentially, if you can stuff your resource or document within the 4K token limit, you'll be able to get a valid and full response back. Most simplest method and usually only works for short documents or resources.

For documents or prompts that are over the limit, you can use map-reduce to split the document or prompt into smaller sections or summaries to consolidate as a summary that can fit into the 4K token limit. Map reduce is a paradigm where you map, shuffle, and reduce to fit as useful data to the model.
This is good for larger documents and due to how its designed with map-reduce, it can also be parallelized. On the other hand, this creates quite a few API calls and is prone to loss of information as we are contexting the summary as opposed to the original document.

The idea of refining is that you send multiple prompts to OpenAI's ChatGPT to refine its context prior to composing a final summary that will then be used to prime the conversation for the response.
You get much more accurate data this way. In contrast, this also means a ton more independent API calls to OpenAI.

Map-rerank essentially splits documents into prompts which are rated for their response or answer. These ratings are collected chunk-wise and whichever answer gets the highest rank or score will be considered the final response.
This is very convenient for single-answer questions as well as very well-sectioned documents that have manageable chunks of information. The drawback to this method is that we cannot combine information between these chunks, meaning any shared context between them is lost when map-reranking them.

These are some of the strategies that Langchain uses in their document loaders to get around the ~4K token limit on OpenAI. A lot of these strategies refer to existing programming paradigms we face with distributed data every day, and unsurprisingly have a great impact on systems that have end-to-end data restrictions, such as ChatGPT. In most cases, almost all these strategies will call the OpenAI API quite a few times in order to get distinct and accurate answers, which may pull up large costs over time.