+ Module for computing digitally reconstructed radiographs
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
DRR
+
DRR is a PyTorch module that compues differentiable digitally reconstructed radiographs. The viewing angle for the DRR (known generally in computer graphics as the camera pose) is parameterized by the following parameters:
+
+
SDR : Source-to-Detector radius (half of the source-to-detector distance)
+
\(\mathbf R \in \mathrm{SO}(3)\) : a rotation
+
\(\mathbf t \in \mathbb R^3\) : a translation
+
+
+
+
+
+
+
+Tip
+
+
+
+
DiffDRR can take a rotation parameterized in any of the following forms to move the detector plane:
+
+
axis_angle
+
euler_angles (note: also need to specify the convention for the Euler angles)
(bx, by, bz) are translational parameters and (alpha, beta, gamma) are rotational parameters. The rotational parameters are detailed in Spherical Coordiantes Tutorial.
PyTorch module that computes differentiable digitally reconstructed radiographs.
+
+
+
+
+
+
+
+
+
+
+
Type
+
Default
+
Details
+
+
+
+
+
volume
+
np.ndarray
+
+
CT volume
+
+
+
spacing
+
np.ndarray
+
+
Dimensions of voxels in the CT volume
+
+
+
sdr
+
float
+
+
Source-to-detector radius for the C-arm (half of the source-to-detector distance)
+
+
+
height
+
int
+
+
Height of the rendered DRR
+
+
+
delx
+
float
+
+
X-axis pixel size
+
+
+
width
+
int | None
+
None
+
+
+
+
dely
+
float | None
+
None
+
Y-axis pixel size (if not provided, set to delx)
+
+
+
x0
+
float
+
0.0
+
Principal point X-offset
+
+
+
y0
+
float
+
0.0
+
Principal point Y-offset
+
+
+
p_subsample
+
float | None
+
None
+
Proportion of pixels to randomly subsample
+
+
+
reshape
+
bool
+
True
+
Return DRR with shape (b, 1, h, w)
+
+
+
reverse_x_axis
+
bool
+
False
+
If pose includes reflection (in E(3) not SE(3)), reverse x-axis
+
+
+
patch_size
+
int | None
+
None
+
+
+
+
bone_attenuation_multiplier
+
float
+
1.0
+
Contrast ratio of bone to soft tissue
+
+
+
+
The forward pass of the DRR module generated DRRs from the input CT volume. The pose parameters (i.e., viewing angles) from which the DRRs are generated are passed to the forward call.
Generate DRR with rotational and translational parameters.
+
+
+
+
+
+
+
+
+
+
+
Type
+
Default
+
Details
+
+
+
+
+
rotation
+
torch.Tensor
+
+
+
+
+
translation
+
torch.Tensor
+
+
+
+
+
parameterization
+
str
+
+
+
+
+
convention
+
str
+
None
+
+
+
+
pose
+
Transform3d
+
None
+
If you have a preformed pose, can pass it directly
+
+
+
bone_attenuation_multiplier
+
float
+
None
+
Contrast ratio of bone to soft tissue
+
+
+
+
+
+
+
Registration
+
The Registration module uses the DRR module to perform differentiable 2D-to-3D registration. Initial guesses for the pose parameters are as stored as nn.Parameters of the module. This allows the pose parameters to be optimized with any PyTorch optimizer. Furthermore, this design choice allows DRR to be used purely as a differentiable renderer.
DRRs are generated by modeling the geometry of an idealized projectional radiography system. Let \(\mathbf s \in \mathbb R^3\) be the X-ray source and \(\mathbf p \in \mathbb R^3\) be a target pixel on the detector plane. Then, \(R(\alpha) = \mathbf s + \alpha (\mathbf p - \mathbf s)\) is a ray that originates from \(\mathbf s\) (\(\alpha=0\)), passes through the imaged volume, and hits the detector plane at \(\mathbf p\) (\(\alpha=1\)). The total energy attenuation experienced by the X-ray at the time it reaches pixel \(\mathbf p\) is given by the following line integral:
+
\[\begin{equation}
+ E(R) = \|\mathbf p - \mathbf s\|_2 \int_0^1 \mathbf V \left( \mathbf s + \alpha (\mathbf p - \mathbf s) \right) \, \mathrm d\alpha \,,
+\end{equation}\]
+
where \(\mathbf V : \mathbb R^3 \mapsto \mathbb R\) is the imaged volume. The term \(\|\mathbf p - \mathbf s\|_2\) endows the unit-free \(\mathrm d \alpha\) with the physical unit of length. For DRR synthesis, \(\mathbf V\) is approximated by a discrete 3D CT volume, and Eq. (1) becomes
+
\[\begin{equation}
+ E(R) = \|\mathbf p - \mathbf s\|_2 \sum_{m=1}^{M-1} (\alpha_{m+1} - \alpha_m) \mathbf V \left[ \mathbf s + \frac{\alpha_{m+1} + \alpha_m}{2} (\mathbf p - \mathbf s) \right] \,,
+\end{equation}\]
+
where \(\alpha_m\) parameterizes the locations where ray \(R\) intersects one of the orthogonal planes comprising the CT volume, and \(M\) is the number of such intersections.
+
+
+
+
+
+
+Note
+
+
+
+
Note that this model does not account for patterns of reflection and scattering that are present in real X-ray systems. While these simplifications preclude synthesis of realistic X-rays, the model in Eq. (2) has been widely and successfully used in slice-to-volume registration.
An auto-differentiable implementation of the raycasting algorithm known as Siddon’s method.
+
Siddon’s method provides a parametric method to identify the plane intersections \(\{\alpha_m\}_{m=1}^M\). Let \(\Delta X\) be the CT voxel size in the \(x\)-direction and \(b_x\) be the location of the \(0\)-th plane in this direction. Then the intersection of ray \(R\) with the \(i\)-th plane in the \(x\)-direction is given by \[\begin{equation}
+ \label{eqn:x-intersect}
+ \alpha_x(i) = \frac{b_x + i \Delta X - \mathbf s_x}{\mathbf p_x - \mathbf s_x} ,
+\end{equation}\] with analogous expressions for \(\alpha_y(\cdot)\) and \(\alpha_z(\cdot)\).
+
We can use Eq. (3) to compute the values \(\mathbf \alpha_x\) for all the intersections between \(R\) and the planes in the \(x\)-direction: \[\begin{equation*}
+ \mathbf\alpha_x = \{ \alpha_x(i_{\min}), \dots, \alpha_x(i_{\max}) \} ,
+\end{equation*}\] where \(i_{\min}\) and \(i_{\max}\) denote the first and last intersections of \(R\) with the \(x\)-direction planes.
+
Defining \(\mathbf\alpha_y\) and \(\mathbf\alpha_z\) analogously, we construct the array \[\begin{equation}
+ \label{eqn:alphas}
+ \mathbf\alpha = \mathrm{sort}(\mathbf\alpha_x, \mathbf\alpha_y, \mathbf\alpha_z) ,
+\end{equation}\] which contains \(M\) values of \(\alpha\) parameterizing the intersections between \(R\) and the orthogonal \(x\)-, \(y\)-, and \(z\)-directional planes. We substitute values in the sorted set \(\mathbf\alpha\) into Eq. (2) to evaluate \(E(R)\), which corresponds to the intensity of pixel \(\mathbf p\) in the synthesized DRR.
Implementations to convert rotation_10d (Peretroukhin et al., 2021) and quaternion_adjugate (Hanson and Hanson, 2022) parameterizations of SO(3) to quaternions. These can then be turned into rotation matrices by PyTorch3D.
Convert a 10-vector in the quaternion adjugate, a symmetric matrix whose eigenvector corresponding to the eigenvalue of maximum modulus is the (unnormalized) quaternion. Uses a fast method to solve for the eigenvector without explicity computing the eigendecomposition.
df is a pandas.DataFrame with columns ["alpha", "beta", "gamma", "bx", "by", "bz"]. Each row in df is an iteration of optimization with the updated values for that timestep.
+
+
+
+
3D Visualization
+
Uses pyvista and trame to interactively visualize DRR geometry in 3D.
For a given pose (not batched), turn the camera and detector into a mesh. Additionally, render the DRR for the pose. Convert into a texture that can be applied to the detector mesh.
Auto-differentiable DRR synthesis and optimization in PyTorch
+
+
+
DiffDRR is a PyTorch-based digitally reconstructed radiograph (DRR) generator that provides
+
+
Auto-differentiable X-ray rendering
+
GPU-accelerated DRR synthesis
+
A pure Python implementation
+
+
Most importantly, DiffDRR implements DRR rendering as a PyTorch module, making it interoperable with deep learning pipelines.
+
Below is a comparison of DiffDRR to a real X-ray (X-rays and CTs from the DeepFluoro dataset):
+
+
+
+DiffDRR rendered from the same camera pose as a real X-ray.
+
+
+
+
Install
+
To install DiffDRR from PyPI:
+
pip install diffdrr
+
DiffDRR also requires PyTorch3D to specify the pose of the C-arm. This also us the ability to use multiple parameterizations of SO(3) when constructing camera poses! For most users,
+
conda install pytorch3d -c pytorch3d
+
should work perfectly well. Otherwise, see PyTorch3D’s installation guide.
+
+
+
Usage
+
The following minimal example specifies the geometry of the projectional radiograph imaging system and traces rays through a CT volume:
+
+
import matplotlib.pyplot as plt
+import torch
+
+from diffdrr.data import load_example_ct
+from diffdrr.drr import DRR
+from diffdrr.visualization import plot_drr
+
+# Read in the volume and get the isocenter
+volume, spacing = load_example_ct()
+bx, by, bz = torch.tensor(volume.shape) * torch.tensor(spacing) /2
+
+# Initialize the DRR module for generating synthetic X-rays
+device ="cuda"if torch.cuda.is_available() else"cpu"
+drr = DRR(
+ volume, # The CT volume as a numpy array
+ spacing, # Voxel dimensions of the CT
+ sdr=300.0, # Source-to-detector radius (half of the source-to-detector distance)
+ height=200, # Height of the DRR (if width is not seperately provided, the generated image is square)
+ delx=4.0, # Pixel spacing (in mm)
+).to(device)
+
+# Set the camera pose with rotation (yaw, pitch, roll) and translation (x, y, z)
+rotation = torch.tensor([[torch.pi, 0.0, torch.pi /2]], device=device)
+translation = torch.tensor([[bx, by, bz]], device=device)
+
+# 📸 Also note that DiffDRR can take many representations of SO(3) 📸
+# For example, quaternions, rotation matrix, axis-angle, etc...
+img = drr(rotation, translation, parameterization="euler_angles", convention="ZYX")
+plot_drr(img, ticks=False)
+plt.show()
+
+
+
+
+
On a single NVIDIA RTX 2080 Ti GPU, producing such an image takes
+
+
+
+
33.3 ms ± 6.78 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
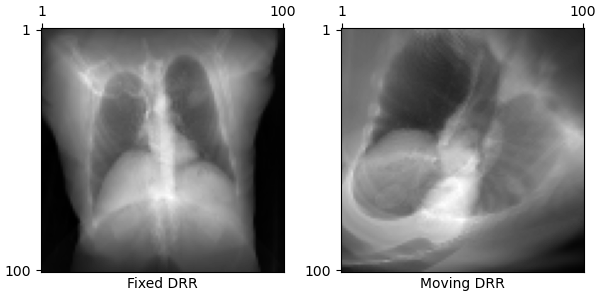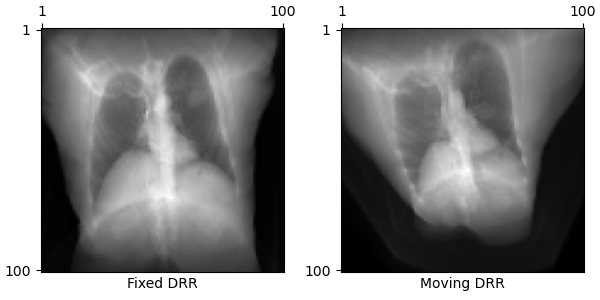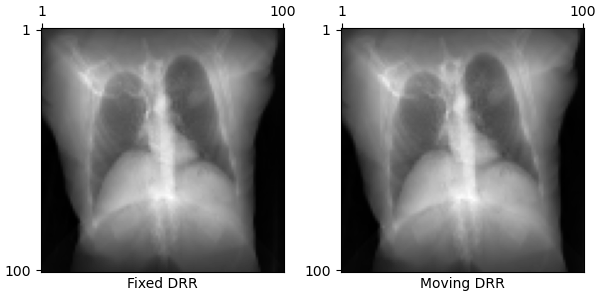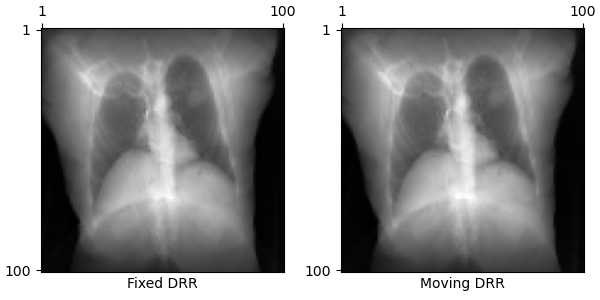
We demonstrate the utility of our auto-differentiable DRR generator by solving the 2D/3D registration problem with gradient-based optimization. Here, we generate two DRRs:
+
+
A fixed DRR from a set of ground truth parameters
+
A moving DRR from randomly initialized parameters
+
+
To solve the registration problem, we use gradient descent to maximize an image loss similarity metric between the two DRRs. This produces optimization runs like this:
DiffDRR reformulates Siddon’s method,1 the canonical algorithm for calculating the radiologic path of an X-ray through a volume, as a series of vectorized tensor operations. This version of the algorithm is easily implemented in tensor algebra libraries like PyTorch to achieve a fast auto-differentiable DRR generator.
DiffDRR is implemented as a custom PyTorch module.
+
All raytracing operations have been formulated in a vectorized function, enabling use of PyTorch’s GPU support and autograd. This also means that DRR generation is available as a layer in deep learning frameworks.
+
+
+
+
+
+
+Tip
+
+
+
+
Rotations can be parameterized with numerous conventions (not just Euler angles). See diffdrr.DRR for more details.
+
+
+
+
# Read in the volume and get the isocenter
+volume, spacing = load_example_ct()
+bx, by, bz = torch.tensor(volume.shape) * torch.tensor(spacing) /2
+
+# Initialize the DRR module for generating synthetic X-rays
+device = torch.device("cuda"if torch.cuda.is_available() else"cpu")
+drr = DRR(
+ volume, # The CT volume as a numpy array
+ spacing, # Voxel dimensions of the CT
+ sdr=300.0, # Source-to-detector radius (half of the source-to-detector distance)
+ height=200, # Height of the DRR (if width is not seperately provided, the generated image is square)
+ delx=4.0, # Pixel spacing (in mm)
+).to(device)
+
+# Set the camera pose with rotations (yaw, pitch, roll) and translations (x, y, z)
+rotations = torch.tensor([[torch.pi, 0.0, torch.pi /2]], device=device)
+translations = torch.tensor([[bx, by, bz]], device=device)
+img = drr(rotations, translations, parameterization="euler_angles", convention="ZYX")
+plot_drr(img, ticks=False)
+plt.show()
+
+
+
+
+
We demonstrate the speed of DiffDRR by timing repeated DRR synthesis. Timing results are on a single NVIDIA RTX 2080 Ti GPU.
+
+
+
+
33.8 ms ± 427 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
+
+
+
+
Sparse rendering
+
You can also render random sparse subsets of the pixels in a DRR.
+
+
+
+
+
+
+Tip
+
+
+
+
Sparse DRR rendering can be useful in registration and reconstruction tasks when coupled with a pixel-wise loss, such as MSE.
+
+
+
+
# Make the DRR with 10% of the pixels
+drr = DRR(
+ volume,
+ spacing,
+ sdr=300.0,
+ height=200,
+ delx=4.0,
+ p_subsample=0.1, # Set the proportion of pixels that should be rendered
+ reshape=True, # Map rendered pixels back to their location in true space,
+# Useful for plotting, but can be disabled if using MSE as a loss function
+).to(device)
+
+# Make the DRR
+img = drr(rotations, translations, parameterization="euler_angles", convention="ZYX")
+plot_drr(img, ticks=False)
+plt.show()
+
+
+
+
+
+
+
+
8.56 ms ± 661 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
+
+
+
+
+
+
Batched DRR synthesis
+
The tensors for rotations are expected to be of the size [batch_size, c], where c is the number of components needed to represent the rotation (3, 4, 6, 10). The tensors for translations are expected to be of the size [batch_size, 3].
CT scans are easily segmented using Hounsfield units. We can use this to identify which voxels are air, soft tissue, or bone. By up or downweighting voxels corresponding to bones, we can change the contrast of generated DRRs.
# Load a DICOM and extract voxel information
+example_ct_path =str(Path(getfile(DRR)).parent /"data/cxr") +"/"
+volume, materials, spacing = load_dicom(example_ct_path)
+
+# Make volume conventions same as DiffDR
+preprocess =lambda x: np.rot90(x, -1)[:, ::-1]
+volume = preprocess(volume)
+for key, value in materials.items():
+ materials[key] = preprocess(value)
+
+# Use the center of the volume as the "world" coordinates. The origin is the (0, 0, 0) index of the volume in the world frame.
+vol_center = (np.array(volume.shape) -1) /2* spacing
+origin = geo.point(-vol_center[0], -vol_center[1], -vol_center[2])
+
+# Create the volume object with segmentation
+patient = Volume.from_parameters(
+ data=volume,
+ materials=materials,
+ origin=origin,
+ spacing=spacing,
+ anatomical_coordinate_system="LPS",
+)
+patient.orient_patient(head_first=True, supine=True)
+
+
Using downloaded and verified file: /home/vivekg/datasets/DeepDRR_DATA/model_segmentation.pth.tar
+
+
+
+
# defines the C-Arm device, which is a convenience class for positioning the Camera.
+# isocenter=volume.center_in_world
+carm = MobileCArm(
+ isocenter=patient.center_in_world,
+ rotate_camera_left=False,
+ source_to_detector_distance=SDR *2,
+ source_to_isocenter_vertical_distance=SDR,
+ pixel_size=P,
+ sensor_height=256,
+ sensor_width=256,
+ min_alpha=-720,
+ max_alpha=720,
+ min_beta=-720,
+ max_beta=720,
+)
+
+
+def test_phantom_deepdrr(alpha, beta, gamma):
+with Projector(
+ volume=patient,
+ carm=carm,
+ ) as projector:
+ carm.move_to(
+ alpha=np.rad2deg(alpha),
+ beta=np.rad2deg(np.pi /2- beta),
+ gamma=np.rad2deg(-gamma),
+ degrees=True,
+ )
+ img = (
+ projector()
+ ) # The first run doesn't use updated parameters, for some reason?
+ img = projector()[:, ::-1].copy()
+return img
+
+
+
+
\ No newline at end of file
diff --git a/tutorials/metamorphasis_files/figure-html/cell-7-output-1.png b/tutorials/metamorphasis_files/figure-html/cell-7-output-1.png
new file mode 100644
index 000000000..1f1b9aa5e
Binary files /dev/null and b/tutorials/metamorphasis_files/figure-html/cell-7-output-1.png differ
diff --git a/tutorials/metamorphasis_files/figure-html/cell-7-output-2.png b/tutorials/metamorphasis_files/figure-html/cell-7-output-2.png
new file mode 100644
index 000000000..4cc6b768d
Binary files /dev/null and b/tutorials/metamorphasis_files/figure-html/cell-7-output-2.png differ
diff --git a/tutorials/metamorphasis_files/figure-html/cell-7-output-3.png b/tutorials/metamorphasis_files/figure-html/cell-7-output-3.png
new file mode 100644
index 000000000..95bca2e84
Binary files /dev/null and b/tutorials/metamorphasis_files/figure-html/cell-7-output-3.png differ
diff --git a/tutorials/metamorphasis_files/figure-html/cell-7-output-4.png b/tutorials/metamorphasis_files/figure-html/cell-7-output-4.png
new file mode 100644
index 000000000..3e13b9a29
Binary files /dev/null and b/tutorials/metamorphasis_files/figure-html/cell-7-output-4.png differ
diff --git a/tutorials/metamorphasis_files/figure-html/cell-7-output-5.png b/tutorials/metamorphasis_files/figure-html/cell-7-output-5.png
new file mode 100644
index 000000000..d02f62716
Binary files /dev/null and b/tutorials/metamorphasis_files/figure-html/cell-7-output-5.png differ
diff --git a/tutorials/metrics.html b/tutorials/metrics.html
new file mode 100644
index 000000000..31d9de56a
--- /dev/null
+++ b/tutorials/metrics.html
@@ -0,0 +1,724 @@
+
+
+
+
+
+
+
+
+
+
+diffdrr - Registration loss landscapes
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Registration loss landscapes
+
+
+
+
+ Visualization shows registration loss functions are locally convex
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
We visualize the loss landscape by simulating a synthetic registration problem. To do this, we start by simulating a DRR from a known angle, which will serve as the target for registration.
Next, we create a function that measures the normalized cross-correlation between the target DRR and a moving DRR, simulated by some perturbation from the true parameters of the target DRR.
Finally, we can simulate hundreds of moving DRRs and measure their cross correlation with the target. Plotting the cross correlation versus the perturbation from the true DRR parameters allows us to visualize the loss landscape for the six pose parameters. From this visualization, we see that the loss landscape is convex in this neighborhood (±15 mm and ±180 degrees).