Before we start, let's see how to interact with the AWS API from your local machine using the AWS CLI (Command Line Interface). This will allow you to manage AWS resources and services programmatically, in addition to using the AWS Management Console.
-
Follow AWS's official docs to install AWS cli on your Ubuntu machine.
-
Once installed, verify your installation by
aws --version, and make sureaws-cliversion2.*was installed! -
You will then need to create credentials in the IAM service and configure them on your local machine before running CLI commands to interact with AWS services.
- Use your AWS account ID or account alias, your IAM username, and your password to sign in to the IAM console.
- In the navigation bar on the upper right, choose your username, and then choose Security credentials.
- In the Access keys section, choose Create access key. If you already have two access keys, this button is deactivated and you must delete an access key before you can create a new one.
- On the Access key best practices & alternatives page, choose your use case to learn about additional options which can help you avoid creating a long-term access key. If you determine that your use case still requires an access key, choose Other and then choose Next.
- Set a description tag value for the access key. This adds a tag key-value pair to your IAM user. This can help you identify and rotate access keys later. The tag key is set to the access key id. The tag value is set to the access key description that you specify. When you are finished, choose Create access key.
- On the Retrieve access keys page, choose either Show to reveal the value of your user's secret access key, or Download .csv file. This is your only opportunity to save your secret access key. After you've saved your secret access key in a secure location, choose Done.
-
Open a new terminal session on your local machine, and type
aws configure. Enter the access key id and the access secret key. You can also provide the default region you are working on, and the default output format (json). -
Test your credentials by executing
aws sts get-caller-identity. This command returns details about your AWS user, which indicats a successful communication with API cli.
In this tutorial you'll provision an EC2 instance that will be used to deploy your monitoring stack (Grafana, InfluxDB and availability agent) containers.
Then we'll discuss some common real-life practices for applications deployed in instances.
We want to create an Ubuntu EC2 instance while utilizing User Data to install Docker at launch time. So you don't need to install it manually.
-
Open the Amazon EC2 console at https://console.aws.amazon.com/ec2/.
-
From the EC2 console dashboard, in the Launch instance box, choose Launch instance, and then choose Launch instance from the options that appear.
-
Under Name and tags, for Name, enter a descriptive name for your instance (e.g.
john-monitoring). -
Under Application and OS Images (Amazon Machine Image), do the following:
- Choose Quick Start, and then choose Ubuntu.
-
Under Instance type, from the Instance type list, you can select the hardware configuration for your instance. Choose the
t2.microinstance type, which is selected by default. In Regions wheret2.microis unavailable, you can use at3.microinstance. -
Under Key pair (login), choose your key-pair or create new key pair if needed.
-
Under Network setting, click the Edit button and choose your VPC.
-
Keep the default selections for the other configuration settings for your instance.
-
The User data field is located in the Advanced details section of the launch instance wizard. Enter the below shell script in the User data field, and then complete the instance launch procedure.
In the example script below, the script installs the Docker engine:
#!/bin/bash apt-get update apt-get install ca-certificates curl -y install -m 0755 -d /etc/apt/keyrings curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc chmod a+r /etc/apt/keyrings/docker.asc # Add the repository to Apt sources: echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | tee /etc/apt/sources.list.d/docker.list > /dev/null apt-get update # Install docker apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin -y usermod -aG docker ubuntu
By default, user data scripts run only during the boot cycle when you first launch or start an instance (not restart). User data must start with the sha-band (e.g.
#!/bin/bash) characters. Scripts entered as user data are run as therootuser, so do not use thesudocommand in the script. -
Review a summary of your instance configuration in the Summary panel, and when you're ready, choose Launch instance.
-
Connect to your instance and make sure Docker was installed properly by
docker info.
If you want to debug your User Data script, see the output logs in /var/log/cloud-init-output.log.
Let's deploy the monitoring stack to monitor the availability of your EC2 instances where the Netflix service is deployed.
-
In your instance, pull and run the Grafana and InfluxDB containers in the background.
-
Open Grafana's port in the instance's Security Group, visit the server and configure InfluxDB as a data source.
-
On the host machine, create a
hostsfile and specify the private IP of the EC2 instances you want to monitor (the instance running your Netflix app). -
Launch the availability agent container, while mounting the
hostsfile, as follows:docker run --name availability_agent -v $(pwd)/hosts:<hosts-path-within-container> <availability-agent-img-name>
You have to enable
pingcommunication (overICMPprotocol) between the availability agent container to the EC2 instances running the Netflix app. If needed, modify your Security Groups accordingly. -
When everything was set up, make sure you can see the availability test results in Grafana.
Edit your instance's User Data script to run the monitoring stack containers at launch time.
Let's say you found that your micro instance is over-utilized (the instance type is too small).
If this is the case, you can resize your instance by changing its instance type.
-
Select your instance and choose Instance state, Stop instance. When prompted for confirmation, choose **Stop **. It can take a few minutes for the instance to stop.
-
With the instance still selected, choose Actions, Instance settings, Change instance type. This option is grayed out if the instance state is not stopped.
-
On the Change instance type page, do the following:
- For Instance type, select the
smallinstance type. - Choose Apply to accept the new settings.
- For Instance type, select the
-
To start the instance, select the instance and choose Instance state, Start instance. It can take a few minutes for the instance to enter the running state.
-
Do the monitoring stack containers up and running when the instance starts? they should be...
Relying on a certain instance is risky, because your instance can be damaged from many reasons. E.g. disk failure, OS error, cyberattack, lost SSH keys, accidental termination etc...
"If I lost this instance, my system will experience downtime and data loss" - if this sentence is true in your service, something in your design is probably wrong. EC2 instances should be treated as ephemeral.
Implementing robust Disaster Recovery practices ensures resilience and continuity in the cace of unexpected failures.
"My system will recover quickly even if my instance was damaged" - This statement should be true. There are many approaches to achieve that.
As a first (and not-so-good) try, let's back up your instance by creating an AMI.
- In the EC2 navigation pane, choose Instances.
- Select the instance from which to create the AMI, and then choose Actions, Image and templates, Create image.
- On the Create image page, specify the following information:
- For No reboot:
- If the Enable check box for No reboot is cleared, when EC2 creates the new AMI, it reboots the instance so that it can take snapshots of the attached volumes while data is at rest, in order to ensure a consistent state.
- If the Enable check box for No reboot is selected, when EC2 creates the new AMI, it does not shut down and reboot the instance. This option doesn't guarantee the file system integrity of the created image.
- For No reboot:
Try to create a new instances based on your AMI. Was the monitoring stack recovered properly?
The approach of backing up data using AMI has some disadvantageous:
- The AMI includes the entire OS state, installed applications, and data. A lot of redundant data is also backed up.
- Since the monitoring stack consists of multiple containers, you can't manage backup up each container independently.
Let's try much better approach. Now you'll create a dedicated EBS encrypted volume for the InfluxDB container, and make InfluxDB writing its data into the dedicated volume.
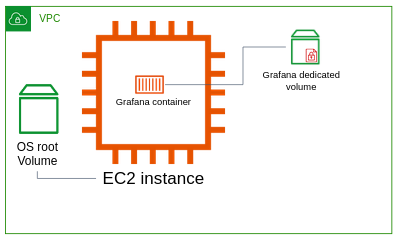
- In KMS, create encryption key. Make sure your IAM user can administer this key and delete it.
- In EC2 the navigation pane, choose Volumes.
- . Choose Create volume.
- For Volume type, choose the type of volume to create,
SSD gp3. For more information, see Amazon EBS volume types. - For Size, enter the size of the volume,
5GiB. - For Availability Zone, choose the Availability Zone in which to create the volume. A volume can be attached only to an instance that is in the same Availability Zone.
- For Snapshot ID, keep the default value (Don't create volume from a snapshot).
- Under Encryption, select the Encrypt this volume option and choose the encrypted keys you've just created in KMS.
- Assign custom tags to the volume, in the Tags section, choose Add tag, and then enter a tag key and value pair.
- Choose Create volume.
Note
The volume is ready for use when the Volume state is available. - To use the volume, attach it to your instance.
- Connect to your instance, format and mount the attached volume to
/influxdatadir. - Stop the running InfluxDB container, and re-run it while mounting the dir where Influx stores its data into
/influxdata.
In KMS page, disable your encryption key. What happened to the data in your instance? Stop the machine and start it again. What happened?
A tag is a label that you assign to an AWS resource. Tags enable you to categorize your AWS resources in different ways, for example, by purpose, owner, or environment.
Each tag consists of a key and an optional value, both of which you define.
- Tags can help you to restrict access to resource for different users group.
- Tag can help you manage resources billing per project/environment.
- In the navigation pane, select your instance.
- Choose the Tags tab.
- Choose Manage tags, and then choose Add new tag. Enter the key and value for the tag, as follows:
Env=dev- indicating the environment this instance belongs to.System=true- indicate that the app deployed in this instance are for internal system usage (Grafana, InfluxDB, availability agent).
- Choose Add new tag again for each additional tag to add. When you are finished adding tags, choose Save.
Repeat the process of attaching an external volume to the instance for the Grafana container.
Try to migrate the monitoring containers stack to another instance.
- Create a new instance
- Detach the dedicated InfluxDB and Grafana volumes from the old instance, attach and mount them to the new instance.
- In the new instance, run the containers while mounting the dedicated volumes into the designated dir in each container.
Create a volume snapshot policy that backing up your volumes every day.
Follow:
https://docs.aws.amazon.com/ebs/latest/userguide/snapshot-ami-policy.html#create-snap-policy
Suppose you run out of storage space on one of your volumes.
You decide to add 1GB to your volume.
To do this, first you create a snapshot (this is a good practice!), and then you increase the size of the data volume.
-
Create a snapshot of the data volume, in case you need to roll back your changes.
-
In the Amazon EC2 console, in the navigation pane, choose Instances, and select your instance.
-
On the Storage tab, under Block devices select the Volume ID of the data volume.
-
On the Volumes detail page, choose Actions, and Create snapshot.
-
Under Description, enter a meaningful description.
-
Choose Create snapshot.
-
-
To increase the data volume size, in the navigation pane, choose Instances, and select your instance.
-
Under the Storage tab, select the Volume ID of your data volume.
-
Select the check box for your Volume ID, choose Actions, and then Modify volume.
-
The Modify volume screen displays the volume ID and the volume’s current configuration, including type, size, input/output operations per second (IOPS), and throughput. In this tutorial you double the size of the data volume.
-
For Volume type, do not change value.
-
For Size, add 1GB.
-
For IOPS, do not change value.
-
For Throughput, do not change value.
-
-
Choose Modify, and when prompted for confirmation choose Modify again. Note
You must wait at least six hours and ensure the volume is in thein-useoravailablestate before you can modify the volume again.
Once the data volume enters the optimizing state, you should extend the file system.
- Use
awscli to list all instances tagged byEnv=dev. - Create a simple
.pyfile to stop all instances that were tagged byEnv=dev. Here is a good starting point:import boto3 # install it by `pip install boto3` ec2 = boto3.client('ec2', region_name='<your-region-code>') ec2.describe_instances(......)
Use AWS Cost Calculator to calculate the monthly price for the below spec:
- Region
us-east-1. - A 24/7 running
t3.micro, Linux instance. 8GBof SSD gp3 EBS.50GBof data transferred into the instance.600GBof data transferred from the instance to S3.230GBof data transfer out of the instance to customers around the world.8TBof data transferred from the instance to other instances in the same AZ.1TBof data transferred from the instance to another region.
Work with a friend on the same region.
Use the iperf tool to measure network performance between two EC2 instances.
You'll measure the bandwidth and latency of the connection using the iperf output.
- Install
iperfon both you and your friend machine:
sudo apt-get update
sudo apt-get install iperf3- Some of you should run the server:
iperf3 -s- The other participant should run the client:
iperf3 -c <SERVER_IP>Make sure the appropriate ports are opened.