A Workload is an application running on Kubernetes. Whether your workload is a single Docker container, or several containers that work together (e.g. HA mongo cluster), on Kubernetes you run it inside a set of Pods.
In this tutorial we will cover the following workloads:
- Pod
- ReplicaSet
- Deployment
Note
Official docs reference.
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. A Pod is a group of one or more containers (usually one), with shared storage and network resources, and a specification for how to run the containers.
The following is an example of a Pod which consists of a container running the nginx image.
# k8s/pod-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
project: ABC
env: prod
spec:
containers:
- name: server
image: nginx:1.26.0To create the Pod shown above, run the following command (the above content can be found in k8s/pod-demo.yaml):
kubectl apply -f k8s/pod-demo.yamlWhen a Pod gets created, the new Pod is scheduled to run on a Node in your cluster. The Pod remains on that node until somthing happens - the Pod finishes execution, the Pod is deleted, the Pod is evicted for lack of resources, or the node fails.
The labels attached to the pod can be used to list or describe it.
Labels are key/value pairs that are attached to objects such as Pods. Labels are intended to be used to specify identifying attributes of objects that are meaningful and relevant to users, as well as organizing a subsets of objects. Read here about labeling best practice.
$ kubectl get pods -l env=prod
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 14s
$ kubectl describe pods nginx
Name: nginx
Namespace: default
Priority: 0
Service Account: default
Node: minikube/192.168.49.2
Start Time: Sun, 24 Sep 2023 16:34:48 +0000
Labels: project=ABC
env=prod
Annotations: <none>
Status: Running
IP: 10.244.0.87
IPs:
IP: 10.244.0.87
Containers:
server:
Container ID: docker://b93064757aa593c7be63edbb4796cdb468ccf1f5d527f0872e7adc7692127f7c
Image: nginx:0.0.1
Image ID: docker-pullable://nginx:1.26.0@sha256:53d0416f79e3d4ba8d2092d7c48880375e3398f6e086996aa12b2e68d0a04976
Port: <none>
Host Port: <none>
State: Running
Started: Sun, 24 Sep 2023 16:34:49 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-lw7mq (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-lw7mq:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 21m default-scheduler Successfully assigned default/nginx to minikube
Normal Pulled 21m kubelet Container image "nginx:1.26.0" already present on machine
Normal Created 21m kubelet Created container server
Normal Started 21m kubelet Started container serverIn the above output we can see a detailed description of the pod. Reviewing all the presented information can be overwhelmed, but here are a few important notes:
- In you don't specify in which namespace to create the Pod object, the
defaultnamespace is used. - Each Pod is assigned a unique IP address.
- Pod events can help you debug your pod state.
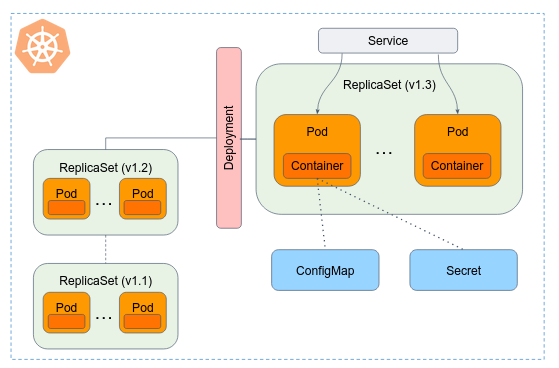
Usually you don't need to create Pods directly. Each Pod is meant to run a single instance of a given application. If you want to scale your application horizontally, you should replicate the Pod in different nodes. Replicated Pods are usually created and managed as a group by a Workload Resource.
Workload resources create and manage multiple Pods for you, with many added benefits. They handle replication and rollout and automatic healing in case of Pod failure. For example, if a Node fails, a workload resource notices that Pods on that Node have stopped working and creates a replacement Pod.
Available workload resources are:
- Deployment (and, indirectly, ReplicaSet), the most common way to run an stateless applications on your cluster.
- A StatefulSet lets you run Pods connected to a persistent storage.
- A DaemonSet lets you run single Pod on each Node of your cluster.
- You can use a Job (or a CronJob) to define tasks that (periodically) run to completion and then stop.
Note: Workload resources don't run containers directly, the only object in Kubernetes that does so is the Pod. All other workload resources only manage Pods. For that reason, workload resources are also known as Controllers. In Kubernetes, controllers are control loops that watch the state of your Pods, then make or request changes where needed. Each controller tries to move the current state closer to the desired state.
In this tutorial we will focus on Deployment and ReplicaSet.
A ReplicaSet's purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods.
Here is an example of ReplicaSet:
# k8s/replicaset-demo.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-rs
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: server
image: nginx:1.26.0In this example:
- The
.spec.templatefield contains a PodTemplates. PodTemplates are specifications for creating Pods. As you can see it's very similar toPodYAML described in the previous section. We can also notice that pods created from this template hold a label with keyappand valuenginx. - The ReplicaSet creates three replicated Pods, indicated by the
.spec.replicasfield. - The
.spec.selector.matchLabelsfield defines how the created ReplicaSet finds which Pods to manage (remember that ReplicaSet is a controller that manage Pods). In this case, the ReplicaSet will manage all Pods that match the labelapp: nginx, corresponding to the label we gave in the Pod template.
Let's apply this ReplicaSet in the cluster.
kubectl apply -f k8s/replicaset-demo.yamlYou can then get the current ReplicaSets deployed:
kubectl get rsYou can also check for the Pods brought up as part of the ReplicaSet:
kubectl get pods -l app=nginxLet's play with your ReplicaSet:
- Delete one of the pods owned by the ReplicaSet. What happened?
- A ReplicaSet can be easily scaled up or down by simply updating the
.spec.replicasfield. Try it out... - Create a Pod (separately to the ReplicaSet) in the cluster, with the same label key and value as you gave in the PodTemplate. What happened? Why?
- Try to update the image version in the YAML manifest (e.g. to
nginx:1.27.0or any other available version), and performkubectl applywith the updated YAML file. What happened? Why?
Delete your ReplicaSet before moving on to the next section:
kubectl delete replicaset nginx-rsWe started our tutorial with a bare Pod, then moved to work with a ReplicaSet. However, this is not good enough. For example, as you've probability noticed, Replicaset does not automatically update containers when image version is updates.
A Deployment is a higher-level concept that manages ReplicaSets and provides declarative updates to Pods along with a lot of other useful features. In most cases, ReplicaSet is not being used directly. Kubernetes' docs recommending using Deployments instead of directly using ReplicaSets.
The following is an example of a Deployment:
# k8s/deployment-demo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: server
image: nginx:1.26.0Apply it to your cluster, to see the Deployment rollout status, run kubectl rollout status deployment/nginx.
Under the hood, the Deployment object created a ReplicaSet (rs) for you:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-75675f5897 3 3 3 18sA Deployment's rollout is triggered if and only if the Deployment's Pod template (that is, .spec.template) is changed.
Let's update the nginx Pods to use the nginx:1.27.0 image instead of the nginx:1.26.0 image.
In the Deployment YAML manifest, edit the .spec.template.spec.containers[0].image value, and apply again.
Run kubectl get rs to see that the Deployment updated the Pods by creating a new ReplicaSet and scaling it up to 3 replicas, as well as scaling down the old ReplicaSet to 0 replicas.
This actually means that the Deployment manipulate ReplicaSet objects for you.
This process is known as RollingUpdate.
$ kubectl describe deployments nginx
Name: nginx
Namespace: default
CreationTimestamp: Thu, 28 Sep 2023 20:10:41 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision: 2
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
server:
Image: nginx:1.27.0
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: nginx-976d85c7c (0/0 replicas created)
NewReplicaSet: nginx-599c84db5d (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 76s deployment-controller Scaled up replica set nginx-976d85c7c to 3
Normal ScalingReplicaSet 30s deployment-controller Scaled up replica set nginx-599c84db5d to 1
Normal ScalingReplicaSet 28s deployment-controller Scaled down replica set nginx-976d85c7c to 2 from 3
Normal ScalingReplicaSet 28s deployment-controller Scaled up replica set nginx-599c84db5d to 2 from 1
Normal ScalingReplicaSet 26s deployment-controller Scaled down replica set nginx-976d85c7c to 1 from 2
Normal ScalingReplicaSet 25s deployment-controller Scaled up replica set nginx-599c84db5d to 3 from 2
Normal ScalingReplicaSet 23s deployment-controller Scaled down replica set nginx-976d85c7c to 0 from 1If you look at the above Deployment closely, you will see that it first creates a new Pod, then deletes an old Pod, and creates another new one. It does not kill old Pods until a sufficient number of new Pods have come up, and does not create new Pods until a sufficient number of old Pods have been killed.
Deployment ensures that only a certain number of Pods are down while they are being updated. By default, it ensures that at least 75% of the desired number of Pods are up (25% max unavailable).
Deployment also ensures that only a certain number of Pods are created above the desired number of Pods. By default, it ensures that at most 125% of the desired number of Pods are up (25% max surge).
When you updated the Deployment, it created a new ReplicaSet (nginx-599c84db5d) and scaled it up to 1 and waited for it to come up.
Then it scaled down the old ReplicaSet to 2 and scaled up the new ReplicaSet to 2 so that at least 3 Pods were available and at most 4 Pods were created at all times.
It then continued scaling up and down the new and the old ReplicaSet, with the same rolling update strategy.
Finally, you'll have 3 available replicas in the new ReplicaSet, and the old ReplicaSet is scaled down to 0.
Important
During a RollingUpdate, new versions of an application are gradually rolled out while old versions are gradually scaled down. This means that for a brief period, both the old and new versions of the application may be running concurrently in the cluster. this simultaneous running of multiple versions can potentially lead to compatibility issues. For example, if the new version of the application introduces changes to the data schema or format that are incompatible with the old version, it can lead to issues when both versions are accessing the same data store concurrently.
A Deployment enters various states during its lifecycle. It can be progressing while rolling out a new ReplicaSet, it can be complete while the Deployment scaled up its newest ReplicaSet, or it can fail to progress.
Sometimes, your Deployment may get stuck trying to deploy its newest ReplicaSet without ever completing. This could happen due to various reasons, for example, insufficient resources (CPU or RAM), or image pull errors.
The Deployment will try to reach its desire state for 10 minutes (this value can be changed in .spec.progressDeadlineSeconds), after that, the Deployment will indicate (in the Deployment status) that the Deployment progress has stalled.
Let's play with your deployment:
- Scale up and down your deployment
- Try to update the Deployment to the image
nginx:1.27.665. What happened? How did you resolve?
Every Pod in a cluster gets its own unique cluster-wide IP address, and Pods can communicate with all other pods on any other node.
But using Pods IP is not practical. If you use a Deployment to run your app, that Deployment can create and destroy Pods dynamically. From one moment to the next, you don't know how many of those Pods are working and healthy; you might not even know what those healthy Pods are named. Kubernetes Pods are created and destroyed to match the desired state of your cluster. Pods are ephemeral resources (you should not expect that an individual Pod is reliable and durable).
Enter Services.
The Service is an abstraction to help you expose groups of Pods over a network. Each Service object defines a logical set of Endpoints (usually these endpoints are Pods) along with a policy about how to make those pods accessible.
The set of Pods targeted by a Service is usually determined by a selector that you define.
Here is an example for Service exposing port 8080 for all Pods in the cluster labelled by the app: nginx key and value (this was the Pod label in the nginx Deployment):
# k8s/service-demo.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 8080
targetPort: 80Apply the above Service, and describe the created object:
$ kubectl apply -f k8s/service-demo.yaml
service/nginx-service created
$ kubectl describe svc nginx-service
Name: nginx-service
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.220.135
IPs: 10.100.220.135
Port: <unset> 8080/TCP
TargetPort: 80/TCP
Endpoints: 10.244.0.48:80,10.244.0.51:80,10.244.0.58:80 + 1 more...
Session Affinity: None
Events: <none>Endpoints are the set of Pods IP that the Service is routing traffic to.
The controller for that Service continuously scans for Pods that match this selector.
You should now be able to communicate with the nginx-service Service on 10.100.220.135:8080 (change the IP to your service IP) from any node in your cluster.
The above created service can be used only for consumption inside your cluster.
The kube-proxy (running in every node) ensures that connections to the service's IP are properly routed (or load balanced) to the correct pods that belong to the service.
Kubernetes is shipped with an internal DNS server, called CoreDNS, for resolving addresses and service discovery within the cluster.
The CoreDNS server is running as a Pod in the kube-system namespace.
It watches the Kubernetes API for new Services and creates a set of DNS records for each one.
Instead of accessing your service by its IP address, you can simply use the Service name as the domain name:
curl nginx-service:8080Kubernetes Service types allow you to specify what kind of Service you want. Here is some of the main types:
ClusterIP(the default type) - Exposes the Service on a cluster-internal IP, allow usage only from within the cluster.NodePort- Exposes the Service on each Node's IP at a static port.LoadBalancer- Exposes the Service externally using an external load balancer (e.g. AWS Application Load Balancer). This type requires integration between your Kubernetes cluster to a cloud provider.
Kubernetes Secrets are a way to securely store and manage sensitive information such as passwords, API keys, or certificates in the cluster. Secrets can be created independently of the Pods that use them, so there is less risk of the Secret (and its data) being exposed during the workflow of creating, viewing, and editing Pods.
Secrets can be mounted as files or exposed as environment variables within Pods.
Suppose you have to provide some basic authentication information to your nginx service:
- Username
nginx-username - Password
39528$vdg7Jb.
Create the Secret object using the kubectl create secret command:
kubectl create secret generic nginx-creds --from-literal='username=admin' --from-literal='password=39528$vdg7Jb'The created Secret is an Opaque type secret.
It is used to store an arbitrary user-defined data.
Kubernetes support other types of secrets for different usages.
$ kubectl get secret nginx-creds
NAME TYPE DATA AGE
nginx-creds Opaque 2 2m6sThe below example provides the secret data as environment variables to the running container:
# k8s/deployment-demo-secret-env-var.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: server
image: nginx:1.26.0
env:
- name: NGINX_WORKER_PROCESSES
value: "2"
- name: NG_USERNAME
valueFrom:
secretKeyRef:
name: nginx-creds
key: username
- name: NG_PASSWORD
valueFrom:
secretKeyRef:
name: nginx-creds
key: passwordIn your shell, display the content of NG_USERNAME and NG_PASSWORD container environment variable:
$ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-55df5dcf48-6xbgx 1/1 Running 1 (91m ago) 19h
$ kubectl exec -it nginx-55df5dcf48-6xbgx -- /bin/sh
root@nginx-55df5dcf48-6xbgx:/# echo $NG_USERNAME
admin
root@nginx-55df5dcf48-6xbgx:/# echo $NG_PASSWORD
39528$vdg7JbNote
You can also create secret from YAML manifests similarly to other k8s objects.
To do so, the data has to be encoded in Base64:
$ echo -n 'admin' | base64
YWRtaW4=
$ echo -n '39528$vdg7Jb' | base64
Mzk1MjgkdmRnN0piApply the below manifest by: kubectl apply -f k8s/secret-demo.yaml:
# k8s/secret-demo.yaml
apiVersion: v1
kind: Secret
metadata:
name: nginx-creds
type: Opaque
data:
username: YWRtaW4=
password: Mzk1MjgkdmRnN0piRead here for more information on how to provide secrets to containers.
ConfigMap is a mechanism for storing non-sensitive configuration data in key-value pairs. ConfigMaps provide a convenient way to manage and inject configuration settings into applications, allowing for easy configuration changes without modifying the application's container image or restarting the Pod.
We continue with our nginx service as an example.
Let's say you want to change the default nginx configuration server (located under /etc/nginx/conf.d/default.conf).
Two approaches can be taken here:
- Build a new Docker image with your own config file, while using the
nginx:1.26.0image as a base image in a Dockerfile. - Use the original
nginx:1.26.0image, and mount a/etc/nginx/conf.d/directory into the container file system, with your own config.
The first approach introduced the overhead of build and maintaining a Docker image, only because a single file has to be changed in the pre-built image. The seconds approach can be easily achieved using a ConfigMap.
# k8s/configmap-demo.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-conf
data:
# this known as "file-like" keys. In YAML, the "|" coming after the key allows to have multi-line values
default.conf: |
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://netflix-movie-catalog-service:8080;
}
} After applying the ConfigMap, let's update our Deployment accordingly:
# k8s/deployment-demo-configmap-mount.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: server
image: nginx:1.26.0
env:
- name: NGINX_WORKER_PROCESSES
value: "2"
- name: NG_USERNAME
valueFrom:
secretKeyRef:
name: nginx-creds
key: username
- name: NG_PASSWORD
valueFrom:
secretKeyRef:
name: nginx-creds
key: password
volumeMounts:
- name: nginx-configurations
mountPath: /etc/nginx/conf.d/
volumes:
- name: nginx-configurations
configMap:
name: nginx-confConnect to your nginx container and make sure the files has been mounted properly.
Similarly to Secrets, ConfigMap can also be consumed as environment variables.
Note: To be done in the order of appearance.
Create a Deployment for the 2048 game. You can either push the image you've built in the previous exercise to an ECR and use it, or use an existed image from DockerHub (the container listens on port 80).
Expose the Deployment with a Service listening on port 8080.
Visit the app locally using kubectl port-forward command. E.g.:
kubectl port-forward service/YOUR_SERVICE_NAME 8080:8080In this exercise you deploy the NetflixMovieCatalog and the NetflixFrontend apps.
- If haven't done yet, clone both repos locally, build Docker image out of them and push to either DockerHub or ECR to a public repos.
- Create the following
Deployments and the correspondingServices for them:netflix-movie-catalog- listens on port8080, running in 2 replicas.netflix-frontend- listens on port3000. In order for the app to fetch movies data, should be provided with an environment variable namedMOVIE_CATALOG_SERVICEwhich is the address of thenetflix-movie-catalogservice.
- Visit the app locally using
kubectl port-forwardcommand. E.g.:
kubectl port-forward service/YOUR_NETFLIX_FRONTEND_SERVICE_NAME 3000:3000Open your web browser and enter http://localhost:3000.
You should see the Netflix app with movies info and thumbnails.
In this exercise, you will integrate Redis into your Netflix service to cache users session data. Storing user session data on the server side is useful because it allows to keep sensitive information away from the client, reducing the risk of tampering. Additionally, it allows for better scalability and consistency, as session data can be centrally managed in a Redis database, and quickly accessed by different instances of the NetflixFrontend service.
- Deploy a redis as a
Deployment(together with the correspondingService) in your cluster. The container is listening on port6379. - The NetflixFrontend app should be provided with an environment variable called
REDIS_URLto start storing session data in your redis deployment (e.g.my-redis:6379).
In this exercise you deploy a Grafana server with Redis integration that present information about your Redis database.
- Create a grafana Deployment based on
grafana/grafanadocker image, as follows:
- The Deployment should set the following environment variables:
GF_AUTH_BASIC_ENABLEDwith a value equals totrue.GF_SECURITY_ADMIN_USERandGF_SECURITY_ADMIN_PASSWORDvariables to be read from dedicated Secret object that you'll create with corresponding username and password (to your choice).GF_INSTALL_PLUGINSwith the valueredis-datasource. This variable pass the plugins you want to install when the container is being launched.
- Visit the server (you can forward it using the
kubectl port-forwardcommand). - Configure the Redis datasource as described here.
- In the Redis data source page, click on the Dashboards tab, and import the
Redisdashboard. Take a look on the imported dashboard. - Now, instead of configuring the Redis datasource manually, configure it "as code" using a
ConfigMap:-
Create a
ConfigMapas follows:apiVersion: v1 kind: ConfigMap metadata: name: grafana-datasources data: datasources.yaml: |- { "apiVersion": 1, "datasources": [ { "version": 2, "name": "Redis", "type": "redis-datasource", "url": "<my-redis-service-url>", "isDefault": true } ] }
Change
<my-redis-service-url>to your redis service URL. -
Mount the configmap into
/etc/grafana/provisioning/datasourcesdirectory within the container. The Grafana server read all.yamlfiles in this dir and applies the data sources configurations. -
Make sure the datasource is configured on a clean Grafana deployment.
-
In this tutorial you will deploy an InfluxDB together with a CronJob to monitor the availability of the NetflixFrontend app.
- Deploy an InfluxDB instance:
- Deployed using a
Deploymentand a correspondingService. - USe the
influxdb:1.8.10image version. - Define the
INFLUXDB_ADMIN_USERandINFLUXDB_ADMIN_PASSWORDenv vars to be read from aSecretobject. - Define the
INFLUXDB_HTTP_AUTH_ENABLEDenv var to be equal totrue.
- Deployed using a
Let's now deploy a periodical job in the cluster that simple uses curl to test the availability of the NetflixFrontend service.
To to so, you'll use CronJob. To understand CronJob, let's introduce Job.
The Job workload is a way to reliably run "jobs" is the cluster, i.e. to run a Pod(s) until a successful completion. The Job object will continue to retry execution of the Pods until pods successfully complete (it will start a new Pod if the Pod fails or deleted).
When a Job completes, the Pods are usually not deleted. Keeping them around allows you to view the logs of completed pods to check for errors, warnings, or other diagnostic output. The job object also remains after it is completed so that you can view its status.
A CronJob creates Jobs on a repeating schedule.
- Based on the following example from k8s official docs, create a
CronJobobject that simplecurlorwgetthe NetflixFrontend service's home page, and fails when the status code is other than200. The CronJob should be running every 1 minute and stores the results data in the InfluxDB.