Update for librosa 0.7 #7
Comments
|
Thanks, I will re-ran the benchmark asap. Can't wait to have a fast audio loading in librosa 👍
I just updated the table, I oversaw the seek support. |
|
Great, thanks! As an aside, we also have some helpers for metadata (duration, samplerate). The same conditions apply there -- sndfile by default, backing out to audioread if necessary. So I would expect it to product a somewhat jagged set of plots. |
|
sorry for the delay, I am about to also add tf 2 and tf.io support and will reran the benchmark once for all of these. |
|
@bmcfee #8 is almost finished. Took quite some time to get things right for tensorflow-io. Anyway, concerning librosa, it looks as you predicted:
any idea why the soundfile backend is even faster than using soundfile directly - aka. is there anything I could optimize? python_audio_loading_benchmark/loaders.py Lines 59 to 61 in d71fbe6 |
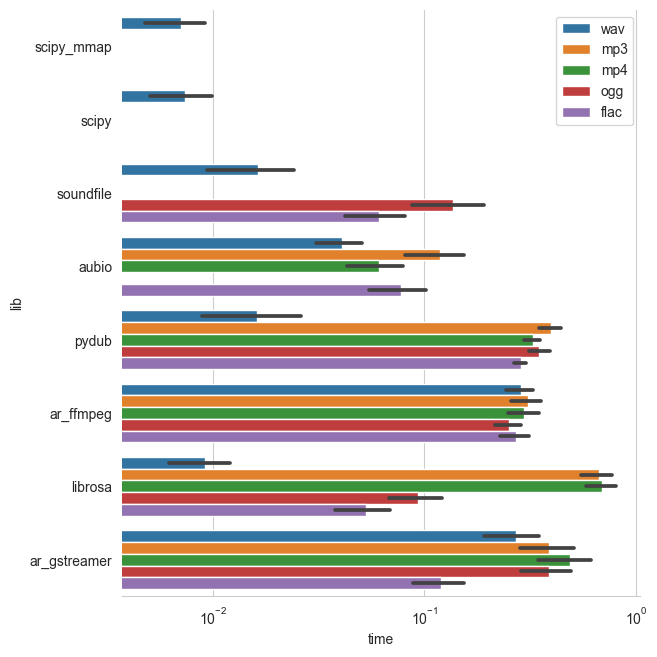
It shouldn't be faster, but it looks like the differences are within the error bars. (Viz suggestion: use dots/swarms instead of bar plots.) Probably this is down to cache effects and general system load fluctuations. If I understand correctly, it looks like you're implementing your own benchmark code by calling python_audio_loading_benchmark/benchmark_np.py Lines 85 to 91 in d71fbe6 I guess the point here is to average over a bunch of file loads to get a sense of the average behavior, but I think you could do a little bit better by using the |
Leaving a marker here that the benchmarks should rerun on librosa 0.7.0 (and probably include version numbers more generally).
Quick summary of changes:
As an aside, we always had API support for excerpts and seeking. It wasn't terribly efficient because audioread didn't support that universally, but it should be almost no overhead relative to soundfile now. The only additional overhead would be downmixing or resample-on-load, but those shouldn't be included in the benchmarks anyway.
The text was updated successfully, but these errors were encountered: