From e696a68485364c1ab95273881c51a1f49798bd2c Mon Sep 17 00:00:00 2001
From: imbant <13634731015@sina.cn>
Date: Tue, 14 Jan 2025 16:38:05 +0800
Subject: [PATCH] =?UTF-8?q?=E7=AC=AC=E4=BA=8C=E7=AB=A0=E5=88=9D=E7=A8=BF?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../_drafts/lsp3\350\215\211\347\250\277.md" | 43 +++++
source/_posts/LSP1.md | 8 +-
source/_posts/LSP2.md | 158 +++++++++++++++---
3 files changed, 181 insertions(+), 28 deletions(-)
create mode 100644 "source/_drafts/lsp3\350\215\211\347\250\277.md"
diff --git "a/source/_drafts/lsp3\350\215\211\347\250\277.md" "b/source/_drafts/lsp3\350\215\211\347\250\277.md"
new file mode 100644
index 00000000..1bfd1f81
--- /dev/null
+++ "b/source/_drafts/lsp3\350\215\211\347\250\277.md"
@@ -0,0 +1,43 @@
+如果想入门 LSP,查官方文档是必不可少的:microsoft.github.io
+
+但是语言服务非常重交互,只靠文字描述是很单薄的,初学者只看干巴巴的接口定义肯定会头晕,不知道这些接口都能干什么。不过也不怪 LSP 官方,毕竟只负责设计协议,具体的实现还得靠客户端(各大代码编辑器)。
+
+这时候就推荐 VS Code 的这篇文档了,列出了插件 API 和 LSP 的对应关系,毕竟和 LSP 一样都是微软家的,很多概念和术语都相通:code.visualstudio.com
+
+文档里详细列出了 VS Code 支持的语言特性,并且都配上了动图和聊胜于无的文字说明。要说为什么是聊胜于无,还是因为交互太重了,各个功能需要多写 demo 去体验,意会。
+
+从学习和方便调试的角度,可以尝试先用 VS Code API 实现一些功能,翻翻 API 的文档,然后再换成 LSP 实现,两者的文档交叉比对,能更好的体会“设计”和“实现”的差异,更好的理解 LSP。
+
+---
+
+在 VS Code 中的语言服务插件,指的是能给一种语言提供高亮、补全、诊断,悬浮提示,查看定义等等功能的插件。
+
+实现这些功能有两种方式。
+一种是在插件进程内,调用 vscode 这个 npm 包的 API。插件是一个 node 进程,也是 Electron 进程(具体是主进程,还是渲染进程,还不确定)的子进程。
+另一种是再新开一个进程,作为语言服务器,和插件(客户端)通过 LSP(Language Server Protocol) 通信。
+
+是的,这些功能都是插件作者一行一行的代码写出来的。在开发插件之前,我完全没有料到在编辑器里 console 后输一个点,要经历这么复杂的代码后,才会弹出 log,warn 和 error。
+
+两种方案有什么区别?
+vscode API。文档全面,教程详细。可以快速实现小功能。适合快速实现轻量化语言服务,例如 json,markdown 甚至 css 这种非编程语言。或者快速验证想法。
+缺点是只能使用 js(ts) 实现,而且业务功能和插件底层在一个进程会导致性能问题,不适合计算密集型的功能。提供语言服务和编译器的区别之一就是需要处理用户输入,要求写完代码后能快速更新语法树,然后基于语法树提供语言服务。例如给一个 1000 行的 js 代码生成 AST,然后提供语义高亮。这时候插件更新慢了,插件和 vs code 的通信就会慢,提供语言服务的速度也会慢。
+
+语言服务器。实现语言没有限制。与 vs code 解耦,只要是实现了 LSP 的客户端都可以通信,服务更多的编辑器。并且可以起多个进程(多个实例),一起给客户端服务,解放客户端进程的算力,客户端只需要转发其他进程算出来的数据给 vs code 即可。
+缺点是 LSP 有一定上手门槛,需要额外处理进程通信,架构复杂后,调试和开发都没那么轻便了。如果你还是用 node,微软官方提供了 vscode-languageserver 这个 npm 包,但是我都用它写完语义高亮、悬浮提示这些功能了,还是不知道这个包应该怎么用。比起 vs code API,它的文档太少了,示例代码也很少,相关讨论也很少,最要命的是 ChatGPT 也不太懂这个包怎么用,看来是能训练的资料确实太少了…
+
+文档缺失倒逼我去翻 GitHub,推荐一下 Volar.js 的源码,用 node 实现,实现的功能都很丰富,我就是抄它的配置,才做出语义高亮的…
+
+---
+
+插件进程主要的功能应该是和 VS Code 主体通信。就像 Electron 主进程一样,应该避免执行很重的任务。VS Code 通知插件,现在需要一个自动补全的列表,虽然插件可以返回一个 promise 异步处理,但如果等太久,VS Code 就不要这个结果了(不提供补全)。这也是 VS Code 的用户交互指南之一,插件不能影响 UI 响应速度
+
+---
+
+插件本体、语言服务器、代码编辑器这三者分别是什么关系?
+插件本体就是个转发层,代码编辑器是真正发请求的,语言服务器是真正处理请求的。
+他们在三个进程,分别是 VS Code 的 extension host 进程、VS Code 的渲染进程、语言服务器进程。后两者通过 LSP 通信,前两者通过 Electron IPC 通信(TODO: 存疑)。
+
+---
+
+拿自动补全举例,在 console 后输入一个点,这时候语法结构是不完整的,有错的,怎么根据不完整的语法结构和当前光标的位置,推断出当前上下文适用哪些补全,是很难的。
+现在理解尤雨溪为什么资助 Volar 作者全职开发这个插件了,它就是 DX 的基础之一,没有这种插件,开发者写 .vue 文件就和白纸写代码一样,是完全写不了的
diff --git a/source/_posts/LSP1.md b/source/_posts/LSP1.md
index 4addf503..d3dbfb9f 100644
--- a/source/_posts/LSP1.md
+++ b/source/_posts/LSP1.md
@@ -1,5 +1,5 @@
---
-title: LSP 与 VS Code 插件开发 第一章
+title: LSP 与 VS Code 插件开发(一)语言服务器架构
date: 2024-8-24
tags: [LSP, VS Code, 语言服务器]
---
@@ -84,9 +84,9 @@ Vue 插件做了哪些事情,才让你的编程体验变得如此美好呢?
- 查看启动性能:VS Code 指令 `Show Running Extensions` 可以列出插件的启动时间,也有 Profile 能力,用来查看运行缓慢的插件。
- 二分法检查问题:当 VS Code 用起来总是有问题,还有个[二分查找法](https://code.visualstudio.com/blogs/2021/02/16/extension-bisect)功能,用来关闭一半的插件,看看问题是否解决。持续二分,直到找到问题插件。
-#### 相关文档
+
## 语言服务器 —— 服务任何代码编辑器
@@ -133,4 +133,4 @@ Vue 插件做了哪些事情,才让你的编程体验变得如此美好呢?
我在播客 [`Web Worker`](https://www.xiaoyuzhoufm.com/episode/66a1197533ddcbb53cd7a063) 上和几位 Vue 生态的大佬、团队成员们聊过 Vue 插件,欢迎收听。
-我也会在[即刻](https://okjk.co/OUqto1)分享语言服务器相关的开发心得,计划将它们整理成系列文章,欢迎关注。
\ No newline at end of file
+我也会在[即刻](https://okjk.co/OUqto1)分享语言服务器相关的开发心得,计划将它们整理成系列文章,欢迎关注。
diff --git a/source/_posts/LSP2.md b/source/_posts/LSP2.md
index 872df6c4..24759b35 100644
--- a/source/_posts/LSP2.md
+++ b/source/_posts/LSP2.md
@@ -1,14 +1,14 @@
---
-title: LSP 与 VS Code 插件开发 第二章
+title: LSP 与 VS Code 插件开发(二)语义构建
date: 2024-12-31
tags: [LSP, VS Code, 语言服务器]
---
上一章我们讲到,语言服务器的输入是源码,而输出是结构化的数据。代码编辑器(客户端)某个位置显示什么颜色,鼠标悬浮到某个位置提示什么信息,都由客户端向语言服务器请求,获取数据后,渲染到用户界面。
-因此语言服务器需要编译源码,构建语义模型,以为客户端提供*智能编程服务*。
+因此语言服务器需要编译源码,构建语义模型,为客户端提供*智能编程服务*。
-所谓的 `编译` 是怎么回事?它和更常见的编译器是什么关系?本章会和大学里的编译原理知识有些关系,但保证比课本上的更有趣、更好玩!
+所谓的 `编译` 是怎么回事?它和编译器是什么关系?本章会和大学里的编译原理知识有些关系,但保证比课本上的更有趣、更好玩!
## 语言服务器与编译器的关系
@@ -18,9 +18,9 @@ tags: [LSP, VS Code, 语言服务器]
### 前端相似
具体各流程的作用就不赘述了,大学课本里那些长篇大论介绍 LL(1) 文法过于乏味。
-我们基本可以把编译器的工作分为`前端`、(`中端`)、`后端`几个流程,先说结论,编译器和语言服务器在编译的过程中,`前端`的过程是非常相似的。也就是 `词法分析`、`语法分析`、`语义分析` 几个阶段。
+我们基本可以把编译器的工作分为`前端`、(`中端`)、`后端`几个流程,事实上,编译器和语言服务器在编译的过程中,`前端`的过程是非常相似的。也就是 `词法分析`、`语法分析`、`语义分析` 几个阶段。
-通过这三个阶段,从源码中获取语义信息后,语言服务器等待客户端请求,为编程体验服务,而编译器则是继续中端、后端,为生成目标代码服务。在这之后,两种做的事情就大相径庭了。
+通过这三个阶段,从源码中获取语义信息后,语言服务器等待客户端请求,为编程体验服务,而编译器则是继续中端、后端,为生成目标产物服务。在这之后,两种做的事情就大相径庭了。
换句话说,对于 `console.log` 这一行代码,两者都经历了这样的阶段:
@@ -36,11 +36,11 @@ tags: [LSP, VS Code, 语言服务器]
接下来,有了语义信息后,语言服务器就可以:
1. 前 7 个字母涂成红色;后三个字母涂成蓝色 `console.log` -> console.log
-2. 鼠标悬停到后三个字母的位置,提示 `Prints to stdout with newline. `
+2. 鼠标悬停到后三个字母的位置,提示 `Prints to stdout with newline.`
3. 调用此函数时,校验实际参数的数量、类型是否与函数签名相符、返回值类型是否正确
4. ...
-而这些都是编译器无法做到的事情。
+而这些都是和编译器完全无关的事情。

@@ -58,6 +58,8 @@ tags: [LSP, VS Code, 语言服务器]
总的来说,编译器面向运行时一次性执行,要求最终正确性和可执行性,而语言服务器在用户编码时持续服务,要求及时性和友好性。
+这里可以看到,语言服务器的工作和运行时是无关的。换句话说,使用记事本写的 Hello World,经过编译器编译后,同样可以执行,而语言服务器提供的只是更好的编码体验。
+
### 使用同一种语言构建
上一章提到,语言服务器与编译器往往是同一种编程语言构建的程序。现在你应该更理解了,在编译原理前端,两者的逻辑高度相似,往后才开始异化。使用同一种语言,甚至在同一个工程中,能最大的复用代码,减少维护成本。这也是促成语言服务器架构的原因之一。
@@ -67,9 +69,9 @@ tags: [LSP, VS Code, 语言服务器]
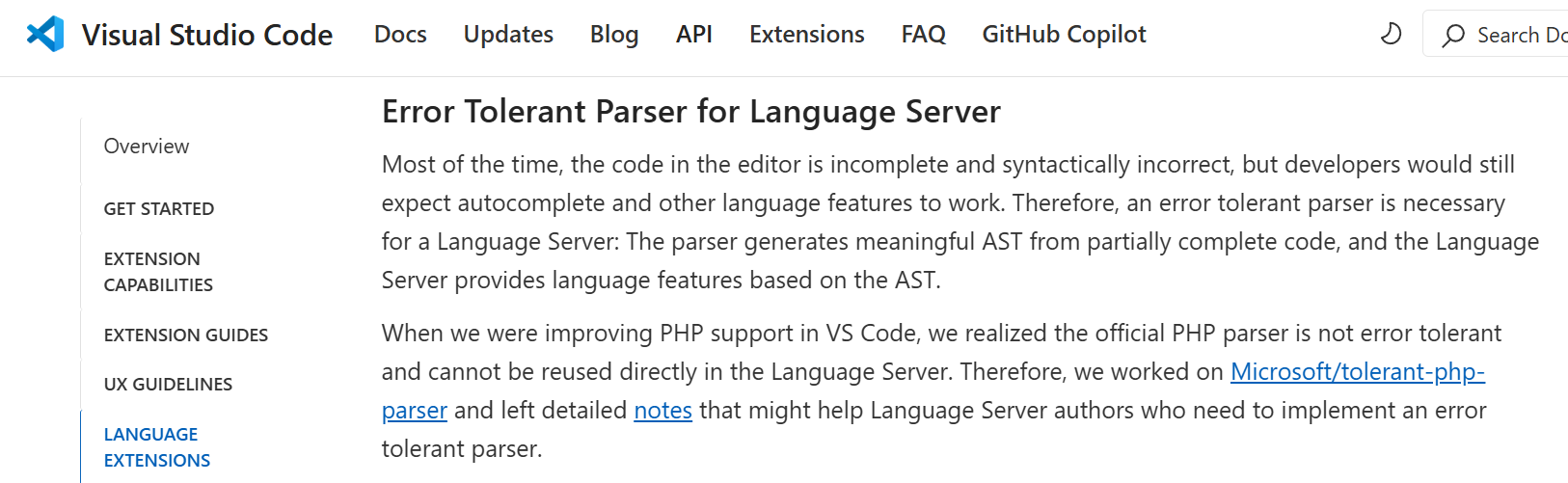
-## 语法错误与语义错误
+## 深入理解语法分析与语义分析
-刚才提到了语法分析和语义分析,这里从诊断的角度再详细说明下。
+刚才提到了语法分析和语义分析,这里再举几个例子详细说明下。
### 十六进制颜色字面量
@@ -93,11 +95,43 @@ tags: [LSP, VS Code, 语言服务器]
#ffffffffffffffffff
```
+### 类型推导和显式类型声明
+
+再举一个变量定义的例子
+
+```go
+var a = 5
+```
+
+`a` 的值是 `5`,类型是`整数`。这里没有显式的声明 `a` 的类型,因此是通过等号右边的表达式的类型推导出来的。
+右值是一个字面量,从词法分析可以通过正则匹配之类的方法得知它是一个 token,比如叫 `INT_DIGIT`。接着语法分析时,得知 `INT_DIGIT` 就是一个普通的字面量表达式。然后语义分析时,就知道一个整数字面量表达式的类型是`整数`,这是编程语言运行时就定义好的,无需额外的语法声明的(`typeof 5 == "int"`)。
+与之对应的,如果给 a 加了显式的类型声明:
+
+```go
+var a int = 5
+```
+
+那么语法上就是通过等号左边的 `int` token,在语义上查找符号表得知是`整数`类型。接着和右值类型比较,发现是一致的,这样就通过了类型检查。
+
+不论是类型推导或者显示声明类型,`a` 的类型都是基于词法分析后根据语法结构决定的。前者是分析了字面量值 `5` 的语义,为`整数`;后者是分析了类型符号 `int` 的语义,同样是`整数`。这两个过程都是基于语法分析,判断语义。
+
### 语法错误更为严重
-语法错误的影响更严重,例如少了半个括号,会影响后续也许是整个文件的代码的作用域。相比来说,语义错误更易于容错,蝴蝶效应较小。
+语法错误的影响更严重,例如少了半个括号,会影响后续也许是整个文件的代码的作用域。相比来说,语义错误更可控,能尽量避免蝴蝶效应。
+
+例如这样的 Go 代码,`bar` 是一个键为 `int`,值为 `string` 的字典。
+
+
+
+现在有两个典型的语义错误,分别在第 11 行,尝试用整数字面量赋值给 `string` 类型;和 13 行,尝试将 `string` 值赋值给 `int` 类型。
+
+现在我们制造一个语法错误,删掉第 9 行的一个右括号 `]`,这显然是一个简单的编码失误,但语言服务器不干了,没有正确的语法支持,很难继续构建语义,第 11 行、第 13 行的红色波浪线也消失了。
+
+
+
+一个简单的语法错误,导致了整个文件的语义分析失败,这是语法错误的严重性。而且报出的错误信息也只能基于语法,和代码改动毫无关系,这简直是新手的噩梦。
-
+> 顺便提一句,其实有经验的开发者一眼就能看出问题所在,但而基于编译原理的解析程序则难以做到这一点。我认为这也许会是大语言模型的一个应用场景,结合代码编辑器,帮助代码初学者快速定位语法错误。
### 语法错误更快出现
@@ -107,24 +141,100 @@ tags: [LSP, VS Code, 语言服务器]
例如,有些编程语言里支持“严格模式”,用来增强类型检查、避免隐式错误等。它在语法上可能就是一行字符串字面量或者魔法注释,例如 `"use strict"` 或者 `// @ts-check`。它们自身没有语法错误,但是会影响后续成千上万行代码的语义分析,带来数个语义错误。
----
+这里有一个提高语言服务器性能的方法:
+将语言服务器拆分成两个,一个面向语法,一个面向语义。
+语法服务器很轻量,只负责词法分析、语法分析,有语法错误时立即反馈诊断。另外也可以提供一些完全基于语法的,和语义无关的小功能,例如
+[显示颜色](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.18/specification/#textDocument_documentColor)。
+语义服务器更重,负责全部的语义构建和服务。
+将语法诊断和其他小功能从语义服务器中剥离,可以降低语义服务器的开销,也能让轻量的功能更快的反馈给用户。
+
+Vue 的[语言服务器](https://marketplace.visualstudio.com/items?itemName=Vue.volar)就是这么做的。
+
+## 语义模型
+
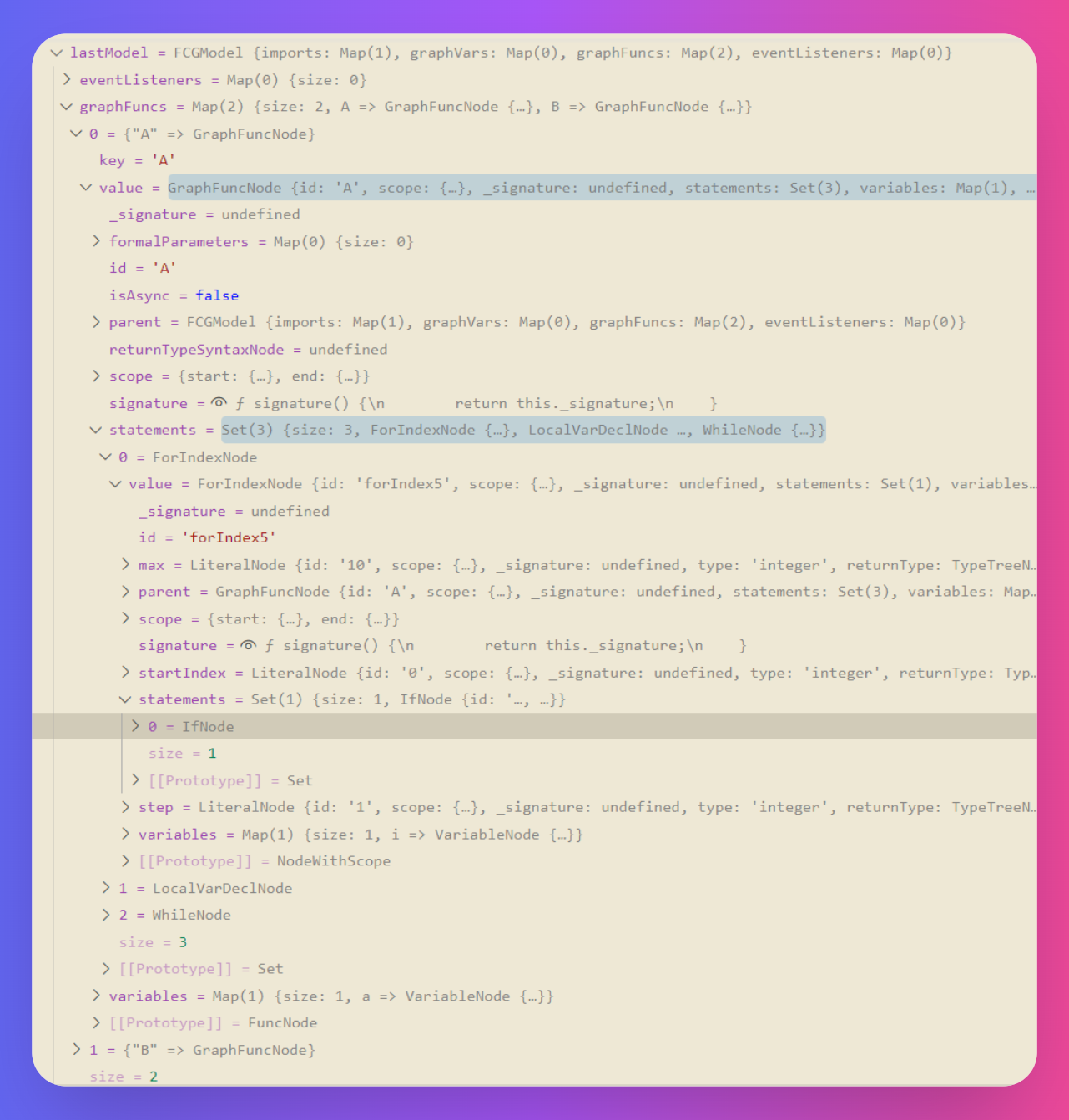
+这里展示一下我做的基于 Node 的语言服务器,编译这段代码后得到的语义模型
+
+```go
+graph test {
+ func A() {
+ for i = 0, 10, 1 {
+ if true {
+ LogInfo(i)
+ }
+ }
+ var a = 1
+ while true {
+ a++
+ }
+ }
+
+ func B() {
+
+ }
+}
+```
+
+
+
+这是一门自研的 DSL 语言,其具体的语义就不做讨论了,但可以看到,在 Node 内存中,我的语义模型是一个大的对象,`graph`、`func`、`for`、`if`、`while` 关键字分别开辟了新的作用域,它们层层嵌套,形成一颗树结构。
+既然是树结构,深度优先遍历算法就是可行的。第 4 行的 `if` 语句,要从根节点开始经过 `root` -> `func A` -> `for` -> `if` 几个语法节点,才能访问的到。
+鼠标移动到第 5 行的 `LogInfo` 上,就要经过上述的深度优先搜索,根据鼠标位置的行列号,一层一层查找语义模型,得知此位置的语义是一个函数名,悬浮提示出函数签名,按 F12 还能跳转到函数声明的地方。
+这个在树结构上层层查找的过程,有点类似语法分析中由上至下的递归下降分析法,从非终结符开始,递归展开,直到终结符;或者反过来,从终结符开始,递归折叠,直到非终结符。但两者还是有本质区别的,语法分析是为了构建语法树,而语义分析是基于语法树,构建语义模型。只不过从实现上,我的语义模型也是一个树结构的,毕竟是基于语法,两者的树结构也是相似的。
-草稿
+### shadow 机制
+
+有了这个形象的树形结构,我们就可以从新的角度理解编程语言中的 `shadow` 机制。
+`shadow` 机制通常指在当前作用域和外层作用域中,同名变量的优先级问题。
+
+```go
+func A() {
+ var foo = 0
+ while (true) {
+ var foo = 1
+ if true {
+ var foo = 2
+
+ foo += 10
+ }
+ }
+}
+```
+
+第 8 行的 `foo` 变量最终的值会是 12,也就是改变了第 6 行的 `foo`,即使外层还有两个同名变量。
+在语义分析阶段,第 8 行是一个加法赋值语句,右值是 10,左值是一个符号 x。为了找到这个符号的语义,语言服务器会就近当前位置的语义模型的作用域开始寻找,也就是 `if` 开辟的作用域中,发现符号表中有一个 `foo`,它的语义是 `int` 类型的变量。这样,第 8 行的 `foo` 符号就是一个变量的语义了,也许会变成 variable 的蓝色;而它的定义位置,根据符号表,得知在第 6 行,按 F12 跳转到定义,光标就会跳转到第 6 行。
+另外,得知第 8 行 `foo` 的语义后,还会做一系列的语义检查,常见的编程语言可能会检查:
+
+1. `foo` 是可写的局部变量,可以被赋值
+2. `foo` 是个整数,可以做加法赋值
+3. 右值是个整数字面量,和左值的类型相同,可以赋值
+4. ...
+
+`shadow` 机制对于自动补全也有积极意义:在 if 代码块中,输入 `fo`,语言服务器应该仅列出一个 `foo` 变量,忽略外层的两个。让我们给最外层的 `foo` 改名叫 `foo001`
+
+```go
+func A() {
+ var foo001 = 0
+ while (true) {
+ var foo = 1
+ if true {
+ var foo = 2
+
+ foo += 10
+ }
+ }
+}
+```
-## Volar、Vue 和 Astro
+这时候就会补全 if 中的 `foo` 和外层的 `foo001`,而不会再出现 while 中的 `foo`。
-## 如何调试 ts 语言服务器
+
-- 打开 log
-- TODO: 见语雀
+## 总结
-## 编译:从文本到结构化数据
+现在,我们明白了语言服务器想要提供智能编程服务,首先需要编译,构建语义模型,这个过程和编译器前端很相似。有了语义模型基础,语言服务器要做的就是接收客户端请求,返回数据。两者通信的过程中,使用的协议就是 LSP(语言服务器协议)。它定义了哪些智能编程能力,通信的具体内容是什么?我们下一章继续。
-- 词法分析、语法分析工具
-- 语义分析
-- 从语义转为智能编程
+## 更多资料
-## LSP 实践
+我在播客 [`Web Worker`](https://www.xiaoyuzhoufm.com/episode/66a1197533ddcbb53cd7a063) 上和几位 Vue 生态的大佬、团队成员们聊过 Vue 插件,欢迎收听。
-- 如何读 LSP 文档
-- 具体的智能编程功能的实现和踩坑
+我也会在[即刻](https://okjk.co/OUqto1)分享语言服务器相关的开发心得,计划将它们整理成系列文章,欢迎关注。