| outline |
|---|
deep |
In the Commercialization chapter of the Open-source Annual Report for the past two years, the underlying drivers of successful commercialization of open-source software, possible commercialization paths for open-source software companies, decision making criteria of investors in open-source projects, and case studies are presented. Last year, combined with some trends and changes in the market environment at that time, we discussed the drivers, challenges and realization paths for domestic open-source projects to explore the process of globalizationand commercial development, which triggered a lively discussion among many open-source buddies.
In 2022-2023, the field of AI has seen an explosion of pre-trained large language model (LLM) technology, which has sparked widespread interest across society and is predicted to continue to deepen its impact on life and work in the future. It is not difficult to find that in this wave of AI technology iteration, the open-source ecosystem has also played a essential role in promoting the development of technology, and there are many open-source models as well as open-source projects actively seeking commercialization. However, there are numerous differences between open-source models and traditional open-source software. In such an era, the commercial development of AI open-source projects and open-source models has become a topic worthy of in-depth research and discussion.
The security and controllability of open-source projects, including open-source software and open-source models, is one of the key considerations for business users in the commercialization process. Combined with the current technology trends, the analysis of the security of open-source software, the controllability of open-source models, and open-source commercial licenses are topics of interest.
Capital is an important participant in promoting the development of open-source markets. For investment institutions, when judging an open-source project, they will often consider the following points:In the product development stage, the focus should be on whether the team has the ownership and control of the code, and whether it has international competitiveness; in the community operation stage, the main point is to see whether the operating ability is strong enough; in the commercialization stage, the market matching ability and the maturity of the business model will become the main focus.
As the first organization in the field to focus on open-source and continue to work on it, Yunqi Partners has successfully identified and invested in open-source companies such as PingCAP, Zilliz, Jina AI, RisingWave Lab, TabbyML, etc., and continues to participate in the construction of the open-source ecosystem.
In order to further enrich the content of the report, this year we are honored to jointly organize a series of closed-door discussion Meetup with Open-source Society. We had a deep discussion on the development of open-source commercialization related to the development of AI Infrastructure, the development of open-source LLMs, together with industry guests including Microsoft, Google, Apple, Meta, Huawei, Baidu and other domestic and international manufacturers, Stanford University, Shanghai Jiao Tong University, China University of Science and Technology, UCSD and other universities and research institutes, as well as a large number of domestic and international front-line entrepreneurs open-source open-source LLMSome of the key insightsare included in this report.
This chapter is written by the investment team of Yunqi Partners, the topics discussed this year focusing oncutting-edge trends and technology, together with some outlookand prediction.We combined industry participants experience and opinions to put forward our views, if there are inconsiderate or different ideas, further discussion is highly welcomed.
Key elements include:
Open source ecosystem for rapid AI growth
Open source security challenges
Capital market situation for open source projects
The development of pre-trained LLM has been groundbreaking over the past few years, and they have become a major landmark in the field of AI. These models, not only are growing in scale, but also have made huge leaps in their intelligent processing capabilities. From the complexity of the language processing to the finesse of image processing, and the depth of advanced data analysis, these models demonstrate unprecedented capability and precision. Especially in the field of Natural Language Processing (NLP), pre-trained LLM, such as the GPT series, have been able to simulate complex human languages by learning a large amount of textual data for high-quality text generation, translation and comprehension. These models not only show significant improvements in expression fluency, but also show an increasing ability to understand context and capture subtle linguistic differences.
In addition, these LLMs perform extremely well in complex data analysis. They are capable of extracting meaningful patterns and correlations from huge data sets to support a wide range of fields such as scientific research, financial analysis, and market forecasting. It is worth noting that the development of these models is not limited to their own enhancements. As they are popularized and applied, they are driving technological advances across the industry and society as a whole, facilitating the creation of new applications such as intelligent assistants, automated writing tools, advanced diagnostic systems, etc. Their development opens up more new development directions for incoming AI applications and research, indicating a new round of technological innovation.
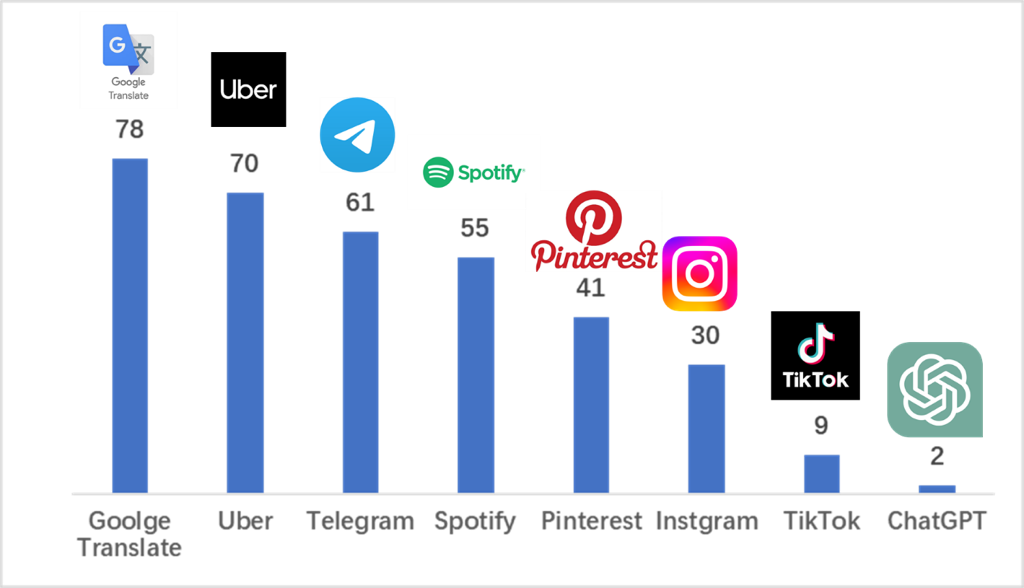
Enthusiasm for AI among public users is surging rapidly. Number of ChatGPT users reached 100 million in just 2 months, compared to TikTok's 9-month-record. This is not only a huge commercial success, but also a major milestone in the history of AI technology development.
 |
|---|
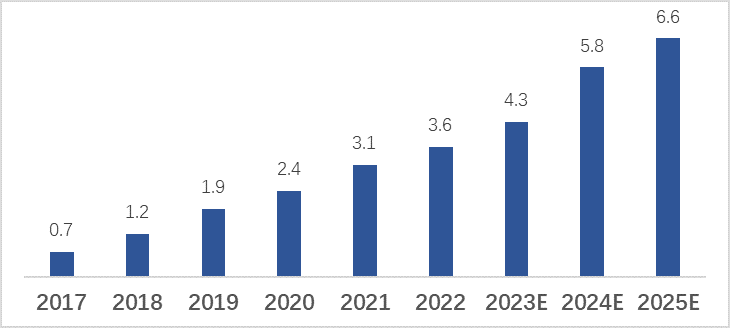
Along with the growing AI popularity, the global AI market size is also growing rapidly. According to Deloitte, it will grow at a CAGR of 23% during 2017-2022, and is expected to reach seven trillion dollars in 2025.
 |
|---|
The power of the open-source ecosystem has played an essential role in making such great strides in pre-trained models. This includes not only research from academia but also support from industry. Under the joint efforts of the open-source ecosystem, the performance of the open-source-based LLM is rapidly developing and gradually rivaling that of closed-source.
The power of open source from academia has contributed significantly to the evolution of AI technology
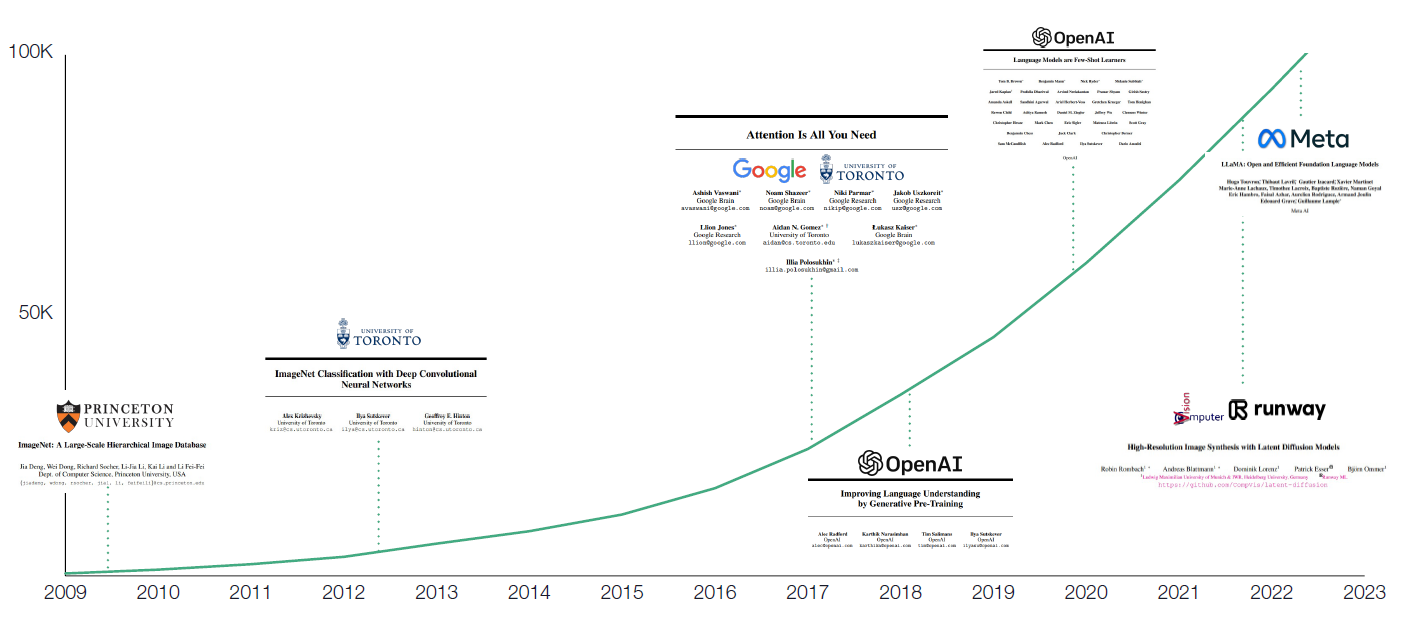
Since Princeton University published ImageNET in 2009, a significant paper in computer vision, there has been a gradual increase in the number of papers related to AI machine learning. Over the years, researchers have proposed many open-source algorithms. By 2017, the number of papers on AI machine learning on Arxiv had reached over 25,000. The "Attention Is All You Need" paper was published that same year, introducing the open-source Transformer model. The publication of this paper led to a concentrated surge in research and papers on LLM. As a result, from 2017 to 2023, the number of Arxiv papers related to LLM surged to over 100,000. This surge also considerably accelerated the open-source development of related models and laid the theoretical foundation for the subsequent explosion of LLM technology.
 |
|---|
:::info Expert Review Willem Ning JIANG:This insight is quite exciting, and academic open-source plays a very important role. :::
The industry's open source power fuels rapid development of LLM
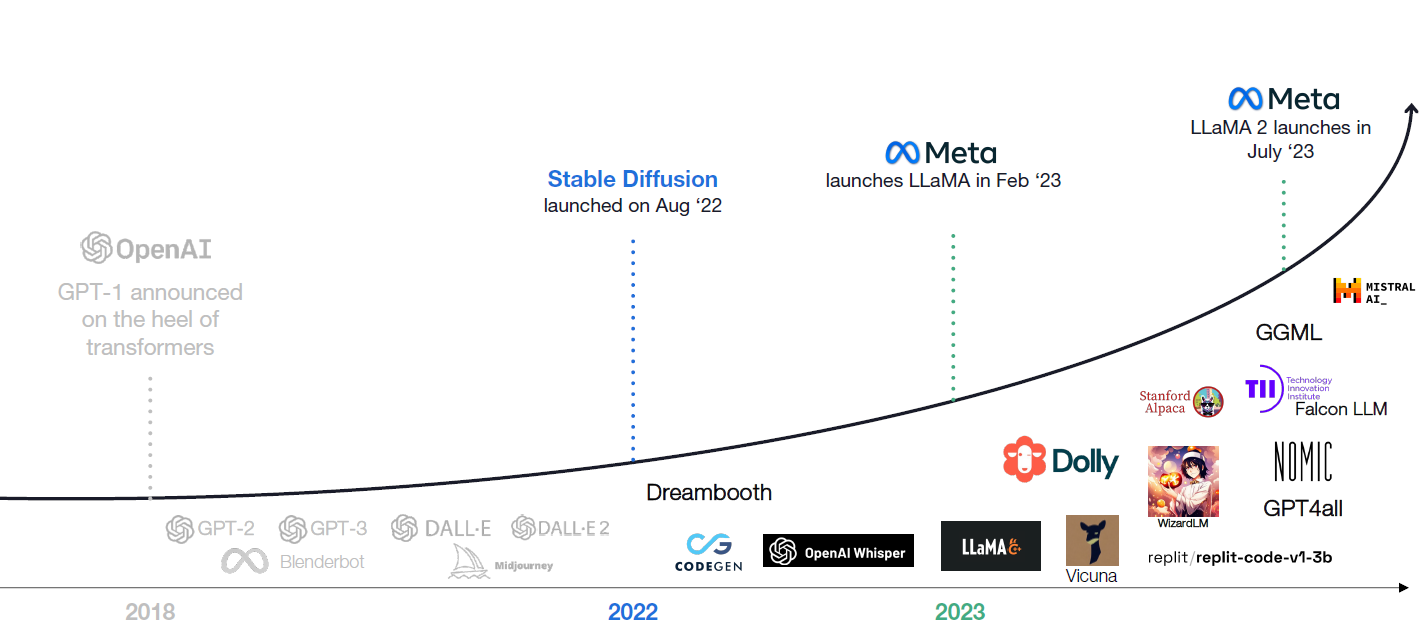
With the ChatGPT LLM popularity, more and more technicians are devoted to the research and development of LLMs. In addition to closed-source products, many great open-source LLMs are also leading the industry. Stable Diffusion in 2022, with its powerful graphical capabilities and community strength, quickly caught up with Midjourney, a famous closed-source graphical model, and has already taken the lead in some aspects; the robust capabilities of open-source large language models, represented by Meta LLaMA 2, have made Google researchers reflect that "we don't have a moat, and neither does OpenAI"; and there are also emerging open-source leaders in various fields, such as Dolly, Falcon, etc. With its powerful community resources and cheaper cost of use, Open-source LLM quickly gained many business and individual users, acting as an indispensable force in the development of LLM.
 |
|---|
Performance of open-source LLMs is rapidly catching up with closed-source
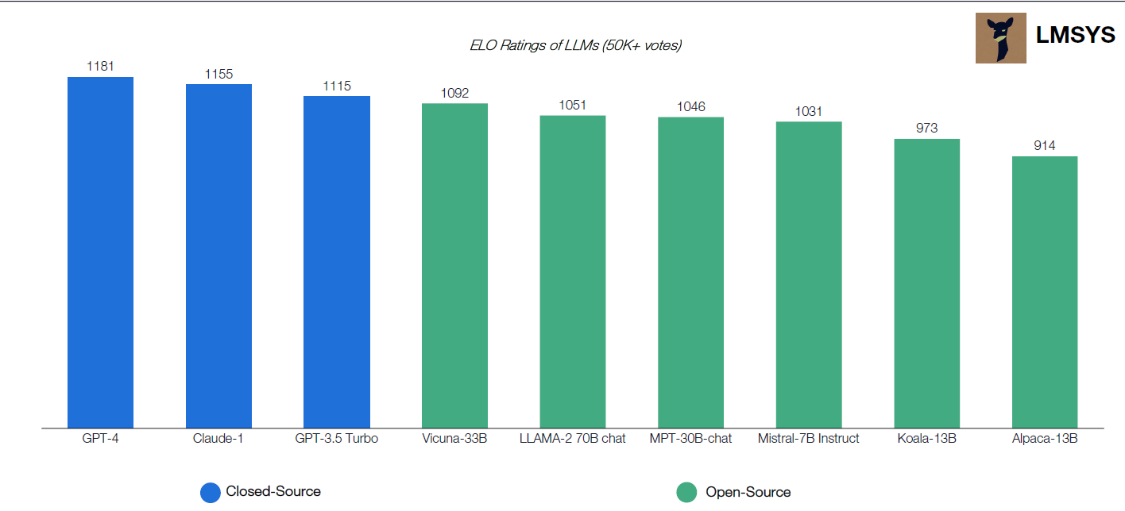
Closed-source LLM represented by OpenAI ChatGPT4 started earlier, and the number of parameters and various performance metrics showed a tendency to outperform open-source models in the early stage. However, open-source models have a strong community and technical support, resulting in rapid performance growth. The most mature version of ChatGPT4 scored 1,181, while Llama 2, an open-source LLM launched less than four months ago, scored 1,051, with a difference of only 11%. It's worth noting that the rankings 4-9 are all open-source LLMs, indicating that the growth in open-source LLM performance is not an isolated case but an industry trend. Open-source LLMs are highly cost-effective due to their low usage costs and smaller performance gap compared to closed-source LLMs, which makes them attractive to increasing numbers of business and individual users. Please see the more detailed discussion of costs later.
Benefiting from the open nature of open-source models, users can easily fine-tune LLMs to fit different vertical application scenarios. Fine-tuned LLMs are more industry-specific than general-purpose LLMs, which is an advantage that closed-source models cannot provide.
 |
|---|
Figure 2.5 ELO ratings of LLMs based on user feedback
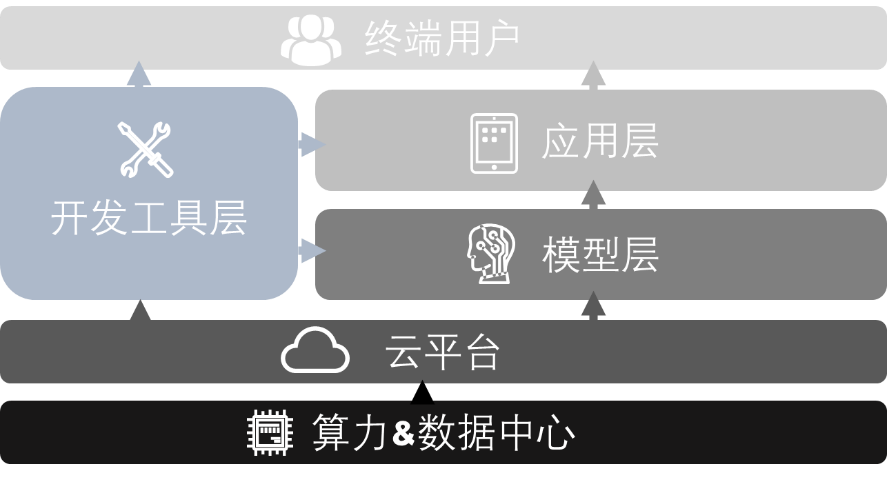
The technical architecture of the LLM is divided into three main layers, as shown in the figure below. Open source has made significant contributions to the model layer, the developer tools layer, and the application layer. Each layer has its unique function and importance, and together, they form the complete architecture of the large-scale model technology. The subsequent sections (2.2, 2.3, 2.4) will discuss each layer in detail.
 |
|---|
- Model layer
The model layer is the foundation of the entire architecture, including the core algorithms and computational frameworks that make up the LLM, typical models such as GPT and Diffusion are the core of generative AI. This layer involves model training, including pre-processing of large amounts of data, feature extraction, model optimization and parameter tuning. The key to the model layer is efficient algorithm design and large-scale data processing capabilities.
- Development tools layer
The development tools layer provides the necessary tools and platforms to support the development and deployment of LLM, including various machine learning frameworks (e.g., TensorFlow, PyTorch) and APIs that simplify the process of building, training, and testing models. The development tools layer may also include cloud services and computing resources that support model training and deployment. In addition, this layer is responsible for version control, testing, maintenance, and updating of the model.
- Application layer
The application layer mainly considers how to access the LLM capabilities in real applications. This layer integrates models into specific business scenarios, such as intelligent assistants, automated customer service, personalized recommendation systems, etc. The key to the application layer is translating complex models into user-friendly, efficient, and valuable applications while ensuring good performance and scalability.
These three layers are interdependent and constitute the complete architecture of the LLM technology; from the basic construction of the model to the realization of specific applications, each layer plays an important role. The corresponding open-source content for each of the three layers is discussed in detail next.
Saving the number of developers and centralizing R&D capabilities
The development of AI models requires technical expertise, and there is a shortage of related talent in China. Open-source technology can promote the development of advanced AI functionality and alleviate pressure on SMEs. Open-source Language Models lower the entry barrier and save development time, enabling more researchers to access advanced AI technologies directly.
Based on efficient pre-trained models, developers can directly innovate and improve in a targeted way rather than being distracted from building the infrastructure. This concentration on innovation rather than infrastructure has greatly contributed to rapid technological advances and the expansion of applications. At the same time, sharing open-source models facilitates the dissemination of knowledge and technology, providing a platform for developers worldwide to learn and collaborate, which plays a crucial role in driving overall progress across the industry.
Saving computational power and avoiding reinventing the wheels
As the performance of the LLM continues to grow, so does its number of parameters, which has jumped 1,000 times in the past five years. According to estimates, ChatGPT chip demand reaches more than 30,000 NVIDIA A100 GPUs, corresponding to an initial investment of about 800 million U.S. dollars, with daily electricity costs of $50,000. The computational requirements for training are becoming more and more costly, so reinventing wheels over and over again is a massive waste of resources. Coupled with the U.S. ban on NVIDIA's A100/H100 supply to mainland China, it's becoming increasingly difficult for domestic companies to train on LLMs. The open-source pre-trained LLM has become a perfect choice, which can solve the current dilemma so that more companies can leverage LLMs for secondary development.
Four steps are required for LLM training:pre-training, supervised fine-tuning, reward modeling, and reinforcement learning. The computational time for pre-training occupies more than 99% of the entire training cycle. Thus, the open-source model can help developers of LLM platforms directly skip the steps, with 99% of the cost of investing limited funds and time in fine-tuning steps, which is a significant help to most application layer developers. Many SMEs need model service providers to customize models for them. The open-source ecosystem can save a lot of costs for the secondary development of LLMs and thus can give birth to many startups.
 |
|---|
Open source allows for exploration of a wider range of technological possibilities
Whether the world-shattering Transformer model is the optimal solution is still unanswered, and whether the next best thing is an RNN (Recurrent Neural Network) is still in question. However, due to the open-source ecology, developers can try on different branches of the AI family cohesive with various new development forces, ensuring the diversity of technological development. Therefore, the human exploration of the LLM will be unrestricted to the local optimal solution and will promote the possibility of continuous development of AI technology in all directions.
Open source models significantly reduce costs for model users
Deploying an open-source model initially requires some investment, but as usage increases, it exhibits scale economy, and the cost of usage is more controllable compared to closed-source. If you have a usage scenario where the average daily request frequency has an upper limit, then directly invoking the API is less expensive. However, if you have a higher request frequency, deploying the open-source model is less costly, so you should choose the appropriate method based on your actual usage.
 |
|---|
Comparison of directly calling OpenAI's API and deploying Flan UL2 model on public cloud as an example:
According to the latest data from OpenAI's official website, using ChatGPT4 model, the input is $0.03 / 1000 tokens and the output is $0.06 / 1000 tokens. Considering the relationship between input and output and assuming an average cost of $0.04 / 1000 tokens, each token is about 3/4 of an English word, and the number of tokens in a request is equal to the prompt word + the output tokens. Assuming a block of text is 500 words, or about 670 tokens, the cost of a block of text is 670 x 0.004/1000 = $0.00268.
Suppose the open-source model is deployed on the AWS cloud, taking the Flan UL2 model with 20 billion parameters, as mentioned in the related tutorial published by AWS, as an example. In that case, the cost consists of three parts:
- Fixed cost of deploying models as endpoints using AWS SageMaker is about $5-6 per hour or $150 per day
- Connecting SageMaker endpoints to AWS Lambda: Assume responses are returned to users in 5s, using 128MB of memory. The price per request is: 5000 x 0.0000000021 (unit price per millisecond for 128MB) = $0.00001
- Open this Lambda function as an API via API Gateway. The Gateway costs about $1 / 1 million requests or $0.000001 per request.
Based on the above data, it can be calculated that the total cost of the two is equal when the number of requests is 56,200 in a day. When the number of requests reaches 100,000 per day, the cost of using ChatGPT4 is about $268, while the cost of the open-source big model is $151; when the number of requests reaches 1,000,000 per day, the cost of using ChatGPT4 is about $2,680, while the cost of the open-source big model is $161. It can be found that the cost savings of the open-source big model are significant as the request volume increases.
Open source improves the explanability and transparency of models and lowers the barrier to technology adoption
Open-source models are more accessible for evaluation than closed models. Open-source models provide access to their pre-training results, and some even disclose their training datasets, model architectures, and more, making it easier for researchers and users to conduct in-depth analyses of the LLMs and comprehend their strengths and weaknesses. Scientists and developers worldwide can review, evaluate, explore, and understand each other's underlying principles, improving security, reliability, explanability, and trust. Sharing knowledge widely is crucial to promote technological progress and also helps to reduce the possibility of technology misuse. Closed-source models can only be evaluated through performance tests, essentially a "black box." It is hard to measure the strengths and weaknesses, applicability scenarios, and other factors of the closed-source models, and their explanability and transparency are considerably lower than that of open-source models.
Closed-source models can face the risk of being questioned for their originality. Users cannot be sure that closed-source models are genuinely original, leading to concerns about copyright and sustainability issues. On the other hand, open-source models are more convincing to users because the code is available to validate their originality. According to Hugging Face technician comments, open-source models like Llama2, which have published details of training data, methods, labeling, and so on, are more transparent than the black box of closed-source LLMs. With transparency in the articles and the code, users know what's in there when they use it.
Higher explainability and transparency are conducive to enhancing users' trust, especially business users, in the LLMs.
Business users can realize specific needs with open source base models
Business users have multiple types of specific needs, such as:industry-specific fine-tuning, local deployment to ensure privacy, and so on.
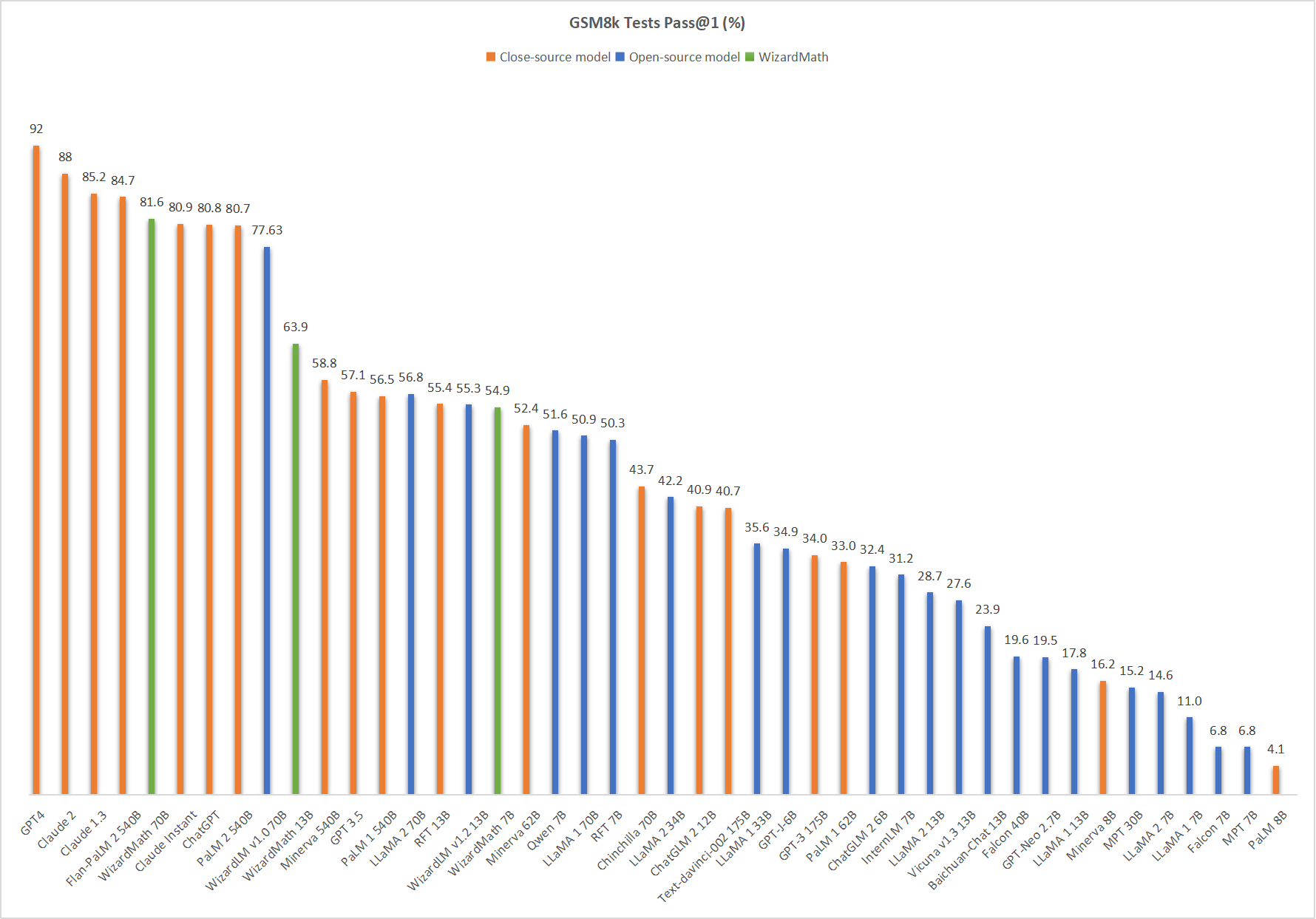
As the amount of LLM parameters continues to increase, the training cost continues to rise. There are better solutions than simply growing the LLM parameters to improve performance. On the contrary, fine-tuning for a specific problem can quickly improve the performance of LLM targeting to achieve better results with less effort. For example, WizardMath, an open-source LLM of mathematics fine-tuned by Microsoft based on LLaMA2, has only 70 billion parameters, but after testing on the GSM8k dataset, the mathematical ability of WizardMath directly beats that of several LLMs such as ChatGPT, Claude Instant 1, PaLM 2-540B, and so on, which fully shows the critical role of fine-tuning in improving the professional problem-solving ability of LLMs, which is also a significant advantage of the open-source LLM.
 |
|---|
Many business users have incredibly high data privacy requirements, and the ability to deploy open-source LLMs locally greatly protects business privacy. When clients call closed-source LLMs, the closed-source models always run on the servers of companies such as OpenAI. Clients can only send their data remotely to the servers of the LLM providers, which is very unfavorable to privacy protection. Enterprises in China also face related compliance issues. While the open-source LLM can be locally deployed, all the data is processed within the company owning the data, even allowing offline processing, significantly protecting the clients' data security.
Open source model facilitates long-lasting customer experience
FCreating a reliable dataset for enterprises is crucial to keeping up with the constant changes in open-source models. Open-source models can be customized to fit an enterprise's specific needs, but this requires a high-quality dataset. By investing in a dataset, enterprises can fine-tune multiple models and avoid constantly replacing them with newer versions, which saves money in the long run, as the dataset does not need to be updated continuously. Enterprises can leverage the model's capabilities without incurring significant costs.
Open-source models are updated quickly to meet the changing needs of users. The power of R&D in the open-source community quickly fills the shortcomings of open-source LLMs. LLaMA2 itself lacks a Chinese corpus, leading to unsatisfactory Chinese comprehension; however, only the day after LLaMA2 was made available, the first open-source Chinese LLaMA2 model, "Chinese LLaMA27B", appeared in the community and could be downloaded and run. Adequate community power support can meet the different needs of users. In contrast, closed-source companies usually need help to take care of the distinct needs of various types of users comprehensively.
Open source helps to capture market opportunities
Open-source models are more accessible to users and can expand the market quickly due to their low barrier to entry. Stable Diffusion, an open-source image generation model, has become an essential competitor to MidJourney, a closed-source model, because of its large developer community and diverse application scenarios. Although not as good as MidJourney in some ways, Stable Diffusion has captured a significant share of the image generation market with its open-source and free features, making it one of the most popular image generation models. Its success has also brought widespread attention and investment to the companies after it, RunwayML and Stability AI.
Open source facilitates large model companies to quickly seize ecological resources
The low threshold and easy accessibility of open-source models will also help the models quickly capture relevant ecological resources. StableDiffusion is an open-source project that has received positive responses and support from many freelance developers worldwide. Many enthusiastic programmers were actively involved in building the easy-to-use graphical user interface (GUI). Many LoRA modules have been developed to provide Stable Diffusion with features such as accelerated generating, more vivid images, etc. According to the official website of Stable Diffusion, one month after the release of Stable Diffusion 2.0, four of the top ten apps in the Apple App Store are AI painting apps based on Stable Diffusion. A thriving ecosystem has become the solid foundation of Stable Diffusion.
At the time of the original release of the open-source LLM LlaMA2, there were 5,600 projects on GitHub containing the "LLaMA" keyword and 4,100 projects containing the "GPT4" keyword. After two weeks, the LLaMA-related ecosystem has grown significantly, with 6,200 related projects compared to 4,400 "GPT4"-related projects. For LLM companies, ecosystem means markets, technological power, and inexhaustible driver for growth. With lower barriers, open source can grab ecological resources faster than closed-source models. Therefore, open-source LLM companies should seize this advantage, strengthen communication with community developers, and provide them with sufficient support to promote the rapid development of relevant ecosystems.
Open source facilitates large model vendors to pry the market and gain business alliances
After LLaMA2 was commercially open-sourced, Meta quickly cooperated with Microsoft and Qualcomm. As the major shareholder of OpenAI, Microsoft chose to collaborate with open-source vendor Meta, which means that open-source has become a force to be reckoned with. For future collaboration, Meta stated that users of Microsoft Azure cloud service will be able to fine-tune the deployment of Llama2 directly on the cloud. Microsoft disclosed that Llama2 has been optimized for Windows and can run directly on Windows locally.
The collaboration between the two companies highlights that open-source LLMs and cloud vendors have a natural cooperation foundation. Not coincidentally, there is a similar trend in domestic open-source LLM vendors: Baidu's ERNIE and Ali's Qwen are both open-source LLMs. Although users usually do not pay for using open-source LLMs, they need to pay for the computational power using Baidu Cloud and Ali Cloud as computational platforms.
Meta's partnership with Qualcomm also signals its expansion into the mobile sector. Due to its broad audience, open-source LLMs can be deployed locally. With other advantages, mobile phones have become the future of convenient use of LLMs of a vital carrier. This also attracts mobile phone chip manufacturers to collaborate with open-source model vendors.
In summary, the open-source LLM, with its broad reach, facilitates the company behind it to find partners and pry into the market.
Open source can mobilize a wide range of communities and bring together diverse development forces
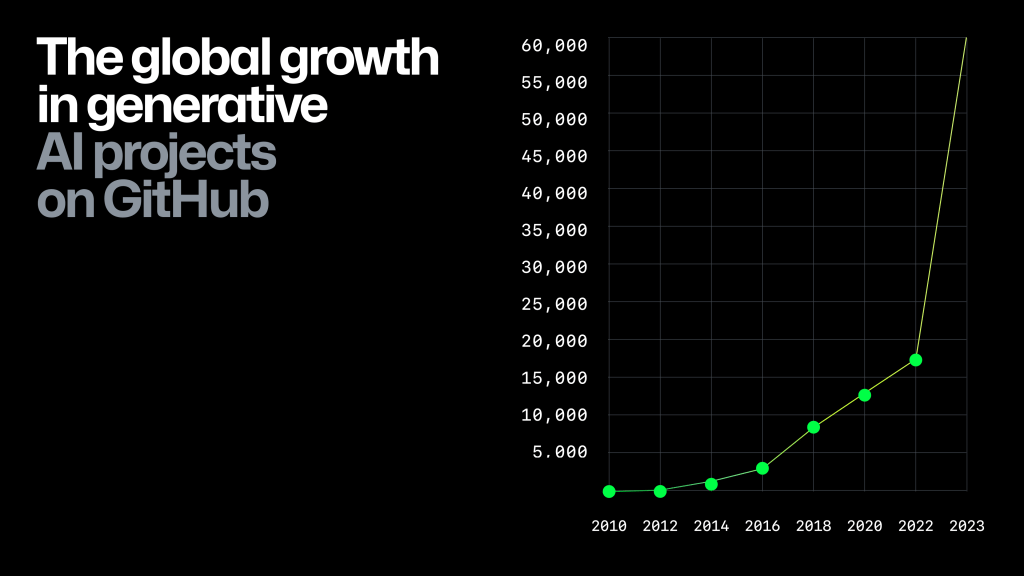
The power of the community has always been an essential strength of open source. As shown in the figure below, the generative AI projects on GitHub have realized rapid growth in 2022, soaring from 17,000 to 60,000. The rapidly growing community can not only quickly provide a large amount of technical feedback for open-source LLM developers but also fully enhance the end reach of open-source LLMs and fine-tune the application of open-source models to various vertical domains to bring more users to the LLMs.
 |
|---|
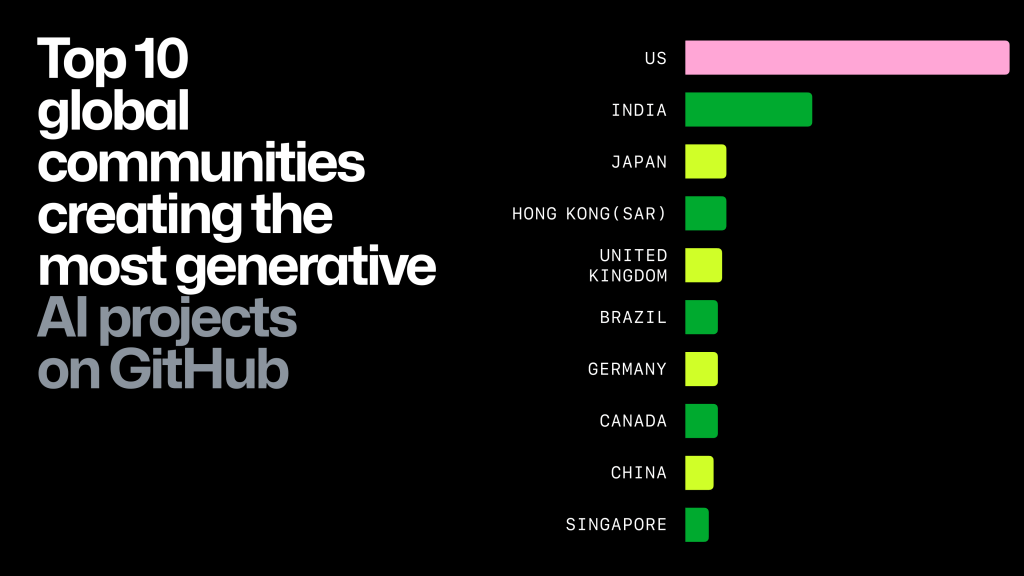
Open-source language models (LLMs) are built with contributions from developers worldwide from different cultures, regions, and technical backgrounds. This is in contrast to closed-source models. The graph below shows that contributors from various countries, including China, India, Japan, Brazil, and others, have made significant contributions to the open-source community for generative AI and the United States. By including contributions from developers worldwide, the open-source LLM can be adapted to suit different regions' customs, languages, industries, and other usage habits. This will make the open-source LLM more versatile and appealing to a broader audience.
 |
|---|
Domestic open source base LLM is booming, keeping pace with global leaders
Based on the domestic ecosystem of tech companies, the country's open-source pre-trained foundation LLMs are also booming, keeping pace with global leaders.
In June, Tsinghua ChatGLM was upgraded to the second generation, which took the "top spot" in the Chinese circle (Chinese C-Eval list), and ChatGLM3 launched in October not only has a performance comparable to that of GPT-4V at the multimodal level, but also is the first LLM product with code interaction capability in China ( Code Interpreter.)
In October, the Aquila LLM series has been fully upgraded to Aquila2, and Aquila2-34B with 34 billion parameters have been added. At that time, in 22 evaluation benchmarks in four dimensions, namely, code generation, examination, comprehension, reasoning, and language, Aquila2-34B strongly dominated the top 1 of several lists.
On November 6, the LLM startup company Zero One Everything, led by Dr. Kai-Fu Lee, officially open-sourced and released its first pre-trained LLM, Yi-34B, which has achieved amazing results in a number of leaderboards, including Hugging Face's Open LLM Leaderboard.
In December, Qwen-72B, a model with 72 billion parameters from AliCloud's Tongyi Qianwen, topped the Open LLM Leaderboard of Hugging Face, the world's largest modeling community, by overpowering domestic and international open-source LLM models such as Llama 2.
Domestic open-source pre-trained base LLMs are far more numerous than the above; the booming open-source pre-trained base LLM ecology is exciting, and it includes academic institutions, Internet giants, and some excellent startups. At the end of the report, the statistics of startups and models with open-sourced LLMs are summarized.
Currently, we are in the era of rapid development of open-source LLM technology, a field that, while promising, also faces significant business model exploration challenges. Based on exchanges with practitioners and case studies, this paragraph attempts to summarize some of the directions of commercialization exploration at this stage.
Provision of support services
With the emergence of more and more basic open-source technologies, the complexity and professionalism of the software have increased dramatically, and the user's demand for software stability has increased simultaneously, requiring professional technical support. At this time, the emergence of Redhat as a representative of the enterprise began to try to achieve commercialization of the operation based on open-source software, the main business model for the "Support Services" model, for the use of open-source software customers to provide paid technical support and consulting services.The overall complexity and specialization of the current foundation model is high, and the user needs professional technical support as well.
In the LLM space, Zhipu AI's business model is more similar to Redhat. It provides enterprises with local private deployment services of ChatGLM, a self-developed LLM, providing efficient data processing, model training and deployment services.Provide Wisdom Spectrum LLM files and related toolkits, users can train their own fine-tuned model and deploy reasoning services, on top of which Wisdom Spectrum will provide technical support and consulting related to the deployment of the application, updates of primary model. With this solution, companies can achieve complete control of data and run their models securely.
 |
|---|
Provision of cloud hosting services
Cloud growth has continued to exceed expectations since the development of cloud computing technology.The growing need for flexible and scalable infrastructure is driving IT organizations' cloud spending and increasing cloud penetration worldwide. Against this technological backdrop, there is a growing demand from users to reduce software O&M costs. Cloud hosting services are SaaS that enable customers to skip on-premise deployment and host software as a service directly on a cloud platform. By subscribing to SaaS services,clients can turn high upfront capital expenditures into small recurring expenditures, and relieve O&M pressure to a large extent. Some of the more successful open-source software companies include Databricks, HashiCorp, and others.
In the field of LLMs, Zhipu AI directly provides standard API products based on ChatGLM, so that customers can quickly build their own proprietary LLM applications, pricing according to the number of tokens of text actually processed by the model. The service is suitable for scenarios that require high level of knowledge, reasoning ability and creativity, such as advertisement copywriting, novel writing, knowledge-based writing, code generation, etc. The pricing is:0.005 yuan / thousand tokens.
At the same time, Zhipu AI also provides API interfaces for super-simulated LLMs (supporting character-based role-playing, extended multi-round memory, and individualized character dialogues) and vector LLMs (vectorizing the input text information so as to combine with vector databases, provide external knowledge bases for LLMs, and improve the accuracy of LLM inference).
Hugging Face also offers a cloud-hosted business model. The Hugging Face platform hosts a large number of open-source models and also offers a cloud-based solution, the Hugging Face Inference API, which allows users to easily deploy and run these models in the cloud via an API.This model combines the accessibility of an open-source model with the convenience of cloud hosting, allowing users to use it on demand without having to set up and manage a large infrastructure on their own.
 |
|---|
Development of commercial applications based on a foundation model
Based on the base model to charge fees, refers to part of the open-source vendor's own base model is free open source, but the vendor based on the base model and developed a series of commercial applications, and for commercial applications to charge for the model, typical cases, such as Tongyi Qianwen.
AliCloud has developed eight applications based on its open-source base model Tongyi Qianqi:Tongyi Tingwu (speech recognition), Tongyi Xiaomei (to improve customer service efficiency), Tongyi Zhiwen (text comprehension), Tongyi Stardust (personalized roles), Tongyi Spirit Codes (to assist in programming), Tongyi Faerui (legal industry), Tongyi Renxin (pharmaceutical industry), and Tongyi Diaojin (financial industry).Each of these applications has a corresponding enterprise-level payment model. Also some of the apps include a individual-level payment model , such as Tongyi Tingwu. It mainly provides voice-to-text related services such as meeting minutes, and its charges are mainly calculated based on the length of the audio.
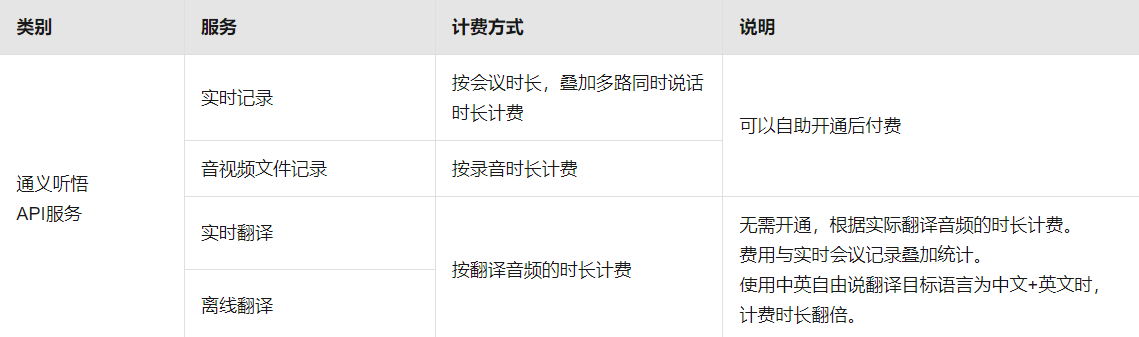 |
|---|
Model-as-a-Service business model
The lowest level of Model as a Service (abbreviated to:MaaS) means to take the model as an important production element, design products and technologies around the model life cycle, and provide a wide variety of products and technologies starting from the development of the model, including data processing, feature engineering, training and tuning of the model, and services for the model.
AliCloud initiated the "ModelScope Community" as the advocate of MaaS. In order to realize MaaS, AliCloud has made preparations in two aspects:One is to provide a model repository, which collects models, provides high-quality data, and can also be tuned for business scenarios. Model usage and computational need to be combined in order to provide a quick experience of the model so that a wide range of developers can quickly experience the effects of the model without having to coding. The second is to provide abstract interfaces or API interfaces so that developers can do secondary development for the model. In the face of specific application scenarios, providing fewer samples or zero samples, it is easy for developers to carry out secondary optimization of the model, which really allows the model to be applied to different scenarios.
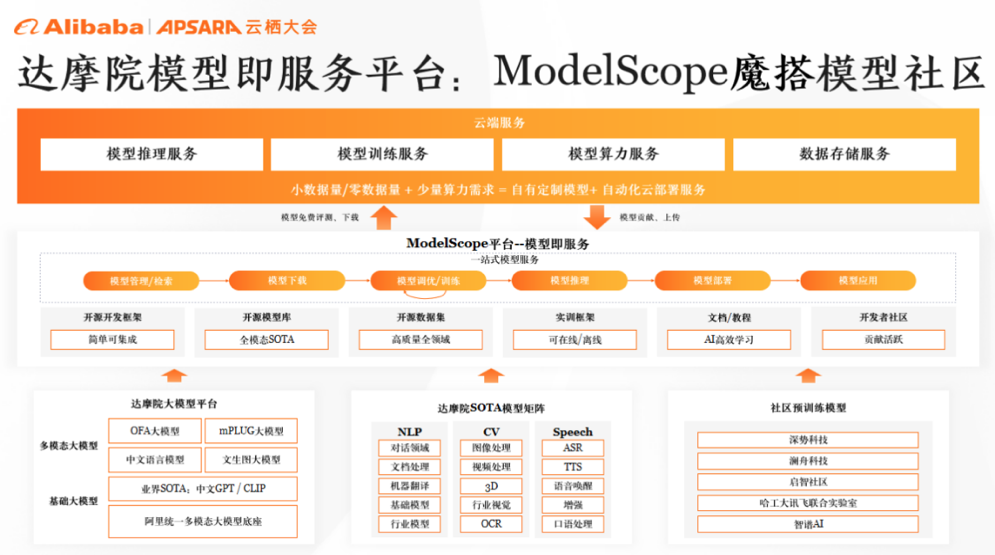 |
|---|
LLM business models need to be explored and experimented with
Currently, the business path of open-source LLM companies has not yet been validated by the market, so a large number of companies are actively exploring different business models without sticking to a single pricing strategy. However, so far, no effective business model has been found to cover their high development and operating and maintenance costs, thus making their economic sustainability questionable.This situation reflects, to some extent, the nature of this emerging industry:While technological breakthroughs have been made, the question of how to translate these technologies into economic benefits remains an open one.
However, it is worth noting that despite such challenges, the rise and development of open-source LLMs still marks the birth of a new industry. This industry has its own unique value and potential, offering unprecedented technical support and innovation possibilities for a wide range of industries. In this process, all participants (including research institutions, enterprises, developers and users) are actively exploring and trying to find a model that can balance technological innovation and economic returns.
This exploration is not an overnight process; it takes time, experimentation, and a deep understanding of market and technology trends. We are likely to see a variety of innovative business models emerge, such as technical support services, cloud hosting, MaaS, etc. as mentioned above. Although the current business models for these open-source LLMs are not yet mature, it is this kind of exploration and experimentation that will drive the entire LLM field forward and ultimately find a business path to sustainable growth with profitable returns.
The Develop Tools layer is an important link in the chain of AI LLM development. As shown in the figure below, the development tools layer plays the role of the top and bottom, linking the middle layer:
For taking on computational resources, the development tool layer plays a PaaS-like role.Cloud-based platforms help LLM developers more easily deploy computational, development environments, invoke, and allocate resources, allowing them to focus on the logic and functionality of model development and realize their own innovations.
For linking pre-trained models, the development tool layer provides a series of tools to accelerate the development of the model layer, including dataset cleaning and labeling tools.
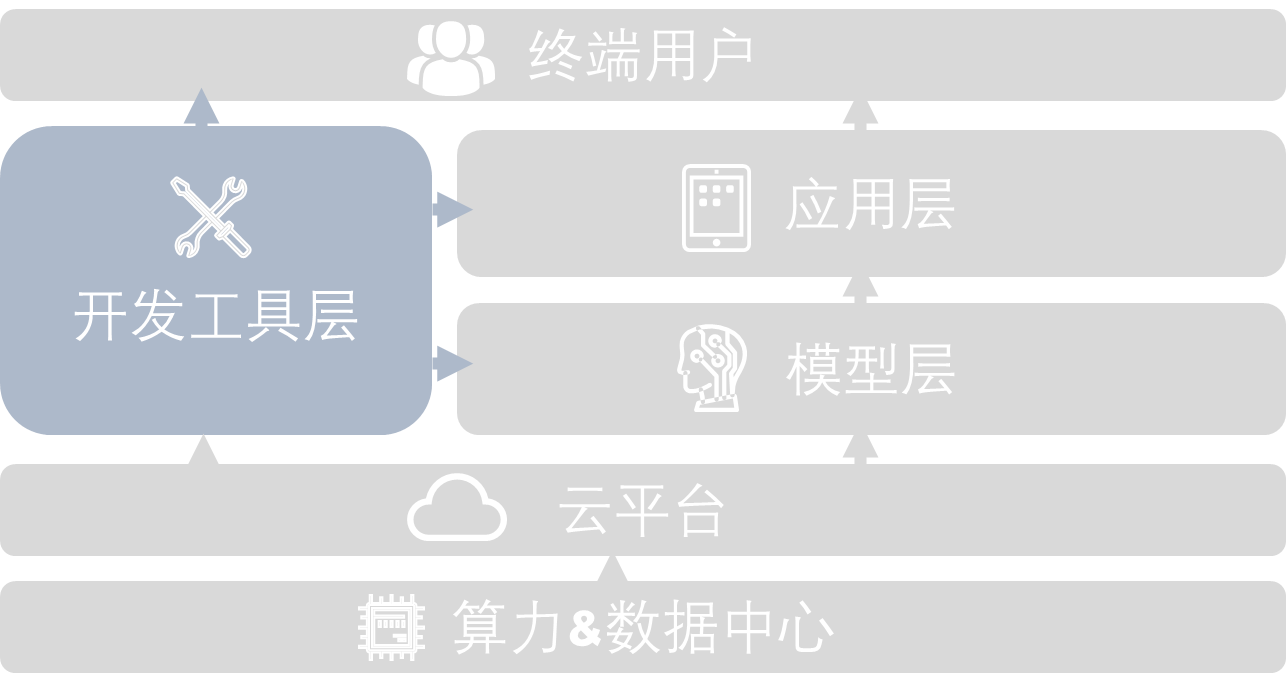 |
|---|
To promote the development of AI applications, the developer tools layer plays an essential role in helping enterprises and individual developers to develop and deploy their final products. For enterprise developers, developer tools help to realize the deployment of LLMs in the industry, as well as the monitoring of the model to ensure the regular operation of the enterprise model. Other related functions include model evaluation, database inference, and supplementation of the model running process. For individual developers, developer tools help them simplify deployment steps and reduce development costs, inspiring the creation of more fine-tuned models for specific functions, such as Autotrain by Hugging Face, which allows developers to fine-tune open-source models based on private data with just a few mouse clicks. At the same time, the developer tools also help to establish the connection between the end-user and the LLM APP and even the deployment of the LLM on the end-user's device.
With the increasing maturity and advancement of development tools, more and more developers are venturing into development related to LLMs. These tools not only improve development efficiency but also lower the barrier to entry, enabling more innovative-thinking talent to participate in the field. From data processing and model training to performance optimization, these tools provide comprehensive support for developers. As a result, we have witnessed the birth of a diverse and active LLM development community with some cutting-edge projects and innovative applications.
 |
|---|
LLM development tools are blossoming, covering everything from data preparation and model construction to performance tuning, and they continue to push the frontiers of AI technology. Some tools focus on data annotation and cleaning so that developers can more easily obtain high-quality data; some tools are committed to improving the efficiency of fine-tuning so that the LLM is more in line with the customization needs; there are also tools responsible for the operation of the LLM monitoring, to provide timely feedback to the developers, users. These diverse tools promote technological innovation and provide developers with more choices, together building a vibrant and creative ecosystem for LLM development. There is no shortage of great open-source projects that greatly benefit both users and open-source companies.
 |
|---|
Supply-side benefits
Open-source developer tools are conducive to polishing and upgrading the product in different scenarios, which contributes to its rapid maturity. One of the main advantages of open-source developer tools is that they provide an extensive testing and application environment. Because open-source tools are freely available for use and modification by a variety of users and organizations, they are often applied and tested in diverse real-world scenarios and are thus "battle-tested. "This extensive use and feedback helps the product identify and fix potential defects more quickly while facilitating the development of new features and improvements to existing ones. Especially for startups,this is the fastest and most cost-effective way to get product feedback, promote product improvement, and help quickly bring more mature commercialized products to market.
Open-source developer tools underlying products with high user stickiness are conducive to rapidly spreading the market. As mentioned earlier, developer tools contain many indispensable components of the LLM development process. Once developers become accustomed to specific tools, they tend to use them consistently because changing tools means relearning and adapting to the new tool's features and usage. Therefore, these products naturally have high user stickiness.

The chart shows the net revenue retention rate for major SaaS products, which reflects the retention rate of regular customers, their ability to keep paying, and their loyalty to the product. Developer product stickiness is generally higher than the median, with Snowflake at the top of the list at 174% and Hashicorp, Gitlab, and Confluent at over 120%.
As you can see, with such high stickiness, the faster the customer acquisition rate, the higher future revenues will be. When these tools are available as open source, they can be more quickly and widely adopted because open source lowers the barrier to trying and adopting new tools. This rapid market expansion is critical to building brand awareness and a user base.
Demand-side benefits
Open-source developer tools reduce the cost for SMEs to enter the LLM market, making it easier for them to focus more on application layer development. For SMEs, entering the market to develop large-scale models and complex systems often requires significant technical investment and financial support. Open-source developer tools lower this barrier because they are usually free or less expensive overall and contain many proven features and components. SMEs can utilize these resources to develop and test their products without creating all the essential elements from scratch. In this way, they can focus more resources and energy on application-level innovations and solutions for specific business needs rather than spend much time and money building the underlying technology. This reduces the cost of entry and speeds up product development, enabling SMEs to compete more effectively with larger firms.
Due to the ecological effect of open-source development tools, their technology iterations usually outpace closed-source tools. In such an open-source ecosystem, the latest research results from the lab can be quickly integrated and shared, and such a mechanism ensures the rapid updating and dissemination of technology. Active participation in the open-source community facilitates the rapid exchange of innovative ideas and technologies, making the latest development tools and technological achievements accessible and usable by many developers. The strength of this open-source culture is that it is open and collaborative, providing developers with a quick and easy way to access and utilize state-of-the-art tools. It not only accelerates the development of technology but also offers individual developers or small teams the opportunity to compete with large corporations, promoting the healthy development and innovation of the entire technology sector.
Making developer tools open source requires technical support to maintain a stable community ecosystem
Open-source development tools rely on the support and maintenance provided by the community and partners. This is essential to ensure the stability and reliability of the tool. For example, the success of an open-source database management system depends not only on its functionality but also on the community's ability to respond to user-reported problems and provide fixes promptly. At the same time, market feedback from partners and users in the ecosystem is critical to optimizing open-source development tools. If an open-source code analysis tool is widely used in an enterprise environment, the feedback from those enterprise users will directly influence the future direction of the tool. This feedback helps developers understand which features are most popular and which need improvement to tailor the tool to market needs.
Open source developer tools need to complement the strengths of cloud vendors to expand market reach and user base
The developer tools themselves are to be deployed based on the platform provided by the cloud vendor, whose strength lies in its specialization and technical strength. In contrast, the cloud vendor's advantage lies in delivering the just-needed computational platform and its broader user base. The two collaborate on developer tools, and developers can leverage cloud vendors to offer better computational power deals to attract more users while benefiting from the cloud vendors' own sales channels to gain more substantial end-to-end reach. This virtuous cycle helps to extend open-source development tools to a broader user base. This increases the tool's visibility and provides more opportunities for its practical application and improvement. More users means more feedback, which promotes continuous tool optimization and adaptation to changing market needs.
MongoDB, for example, started its cloud transformation early by launching Atlas, a SaaS service. Even though Atlas accounted for only 1% of total revenue when MongoDB went public in 2017, when MongoDB had already built all of its systems based on the Open Core model, MongoDB still spent a lot of resources on building SaaS-related products and marketing systems. Since then, Atlas's revenue has increased at a compound annual growth rate of more than 40%.In contrast, its competitor, CouchBase, has relied too heavily on its traditional model and has spent a lot of effort on mobile platform support services. This slow-growing market has dragged the company into a quagmire.SaaS service-based product systems are essential for developer tools vendors today and must emphasize cooperation with cloud vendors.
 |
|---|
Establishing an ecology conducive to building open source industry standards
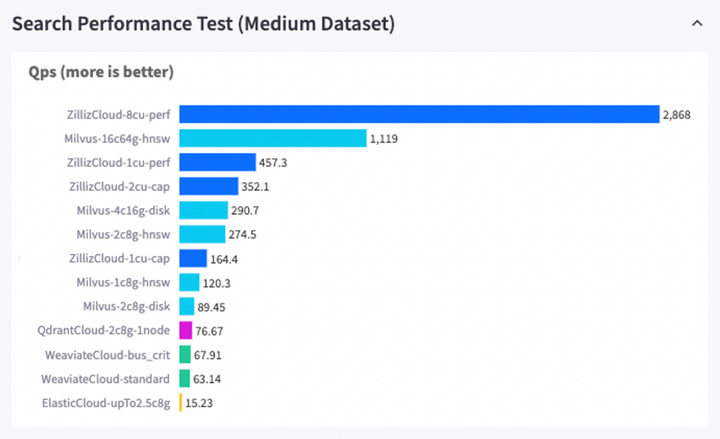
Developer tools, as the underlying tool layer, are decisive for the principle architecture of the upper model development. Collaboration with partners such as cloud vendors, open-source model vendors, and others helps to build consensus and establish industry standards, which is critical to ensure interoperability, compatibility, and consistency of user experience with development tools. Standardization reduces compatibility issues and enables easier integration and use of different products and services. For example, MongoDB leverages the community to form the industry standard for NoSQL RDMS. This active community not only brought high-quality, low-cost licenses to the early commercial versions of MongoDB but also served as the basis for the later Atlas (managed service). Based on the collaboration of the open-source community, Milvus launched Vector DB Bench (which can measure the performance of vector databases through the measurement of key metrics, allowing vector databases to maximize their potential), thus gradually establishing an industry standard for vector databases, and facilitating the selection of vector databases tailored to the needs of users.
 |
|---|
The commercialization dimension of AI developer tools can draw on traditional software developer tools; the overall commercialization is still in the early stage of exploration; based on the research and analysis of open-source developer tools that have attempted commercialization, we found that there are currently following commercial paths:
Cloud Hosting Managed Service - Consumption-Based Pricingg
With the popularity of cloud computing, more and more developer tools have defaulted to serving users directly through hosted resources on the cloud. Such hosting services on the cloud can reduce the user's threshold for use but also directly provide the latest and most professional product services; in the absence of data, security, and privacy concerns, it is a good commercialization option for open-source AI developer tools projects.
Under the business model of hosting services on the cloud, more and more projects are choosing Consumption-Based Pricing (CBP) with different product offerings; the pricing unit can be computational resources, data volume, number of requests, etc.
AutoTrain by Hugging Face is a platform that automatically selects suitable models and fine-tunes them based on a user-supplied dataset. It has selectable model categories, including text categorization, text regression, entity recognition, summarization, question answering, translation, and tables. AutoTrain provides non-researchers with the ability to train high-performance NLP models and deploy them at scale quickly and efficiently. AutoTrain's pricing rules are not disclosed; rather, an estimated fee is charged before training based on the amount of training data and model variants.
Scale AI focuses on data annotation products with a simple pricing model that starts at 2 cents per image and 6 cents per annotation for Scale image, 13 cents per frame and 3 cents per annotation for Scale Video, 5 cents per task and 3 cents per annotation for Scale Text, and 7 cents per annotation for Scale Document Al. Scale Text starts at 5 cents per task and 3 cents per entry; Scale Document begins at 2 cents per task and 7 cents per entry. In addition, there are enterprise-specific charging options based on the amount of data and services for specific enterprise-level projects.
Cloud Hosting Managed Service - tiered subscription pricing
Some development tool layer projects also use Cloud Hosting Managed Services but offer subscription services yearly or monthly.
 |
|---|
The subscription business model allows different tiers to balance cost and price according to users' needs and willingness to pay. The company Dify.ai, pictured above, for example, has tiered pricing for different volumes of users: There is a free version for individual users, but given the cost overhead, there are many limitations set; for professional individual developers and small teams, there are fewer limitations for a lower price, but there is still an upper limit on usage; and for medium-sized teams, there is a higher price for a relatively complete service.
However, Cloud Hosting Managed Services, whether per-volume pricing or tiered subscriptions, can only offer standardized product services, and the data needs to flow to the public cloud. Some large enterprises still need to privatize and customize such a business model.
Private Cloud / Dedicated cloud / Customized Deployment
While more and more projects are utilizing services hosted directly on the cloud, hosted services on the cloud are no longer an option when larger enterprises need to have more private, customized requirements.
Usually, with such a business model, the program also offers different options to the users. The Bring Your Own Cloud (BYOC) model is prevalent in North America, while the On-Premise scenario is better suited for more data-compliance-sensitive scenarios.
The commercialization of open source projects at the development tool level often provides a variety of options, including the above three business models. This can be interpreted as the diversity and complexity of customer demand at this level. In exploring business models, various projects are also attempting to synchronize different paths. The future direction of development is worthy of long-term sustained attention.
Zilliz is a next-generation data processing and analytics platform for AI that provides the underlying technology for application-oriented enterprises. Zilliz developed Mega, a GPU-accelerated AI data middleware solution, which includes MegaETL for data ETL, MegaWise for database, MegaLearning for model training in the Hadoop ecosystem, and Milvus for feature vector retrieval. These systems can meet the traditional scenarios and needs of accelerated data ETL, accelerated data warehousing, and accelerated data analytics, as well as emerging AI application scenarios.
 |
|---|
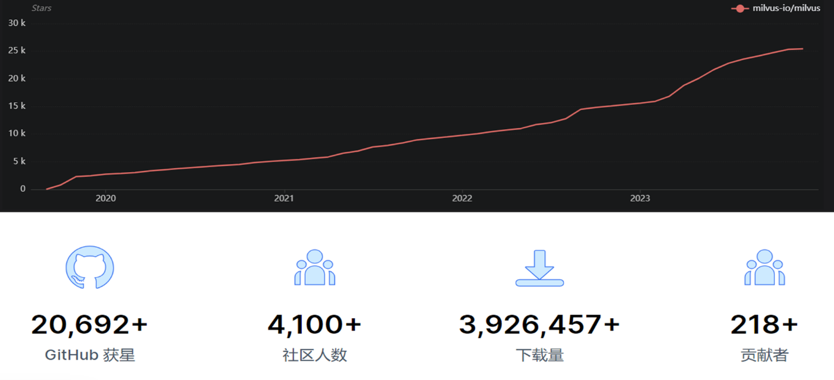
Zilliz's success represents a GPU-based giant data accelerator that provides an effective solution to organizations' growing data analytics needs. Zilliz's core project, the vector similarity search engine Milvus, is the world's first GPU-accelerated massive feature vector matching and retrieval engine. Relying on GPU acceleration, Milvus provides high-speed feature vector matching and multi-dimensional data joint query (joint query of features, labels, images, videos, text, and speech) and supports automatic database sharding and multi-replicas, which can interface with AI models such as TensorFlow, PyTorch, and MxNet, enabling second-level queries for billions of feature vectors. Milvus was open-sourced on GitHub in October 2019, and the number of Stars continues to grow at a high rate, reaching 25k+ in December 2023, with a developer community of over 200 contributors and 4000 + users. In the capital market, Zilliz received $43 million in Series B, the most significant single Series B financing for open-source infrastructure software worldwide. This indicates that investment institutions are optimistic about Zilliz's potential for future development.
 |
|---|
Zilliz's main product is the Vector Database, a key piece of developer tools. It is a database system specialized in storing, indexing, and querying embedded vectors. This allows LLMs to store and read knowledge bases more efficiently and fine-tune models at a much lower cost. It will also play an important role in the evolution of AI-native applications.
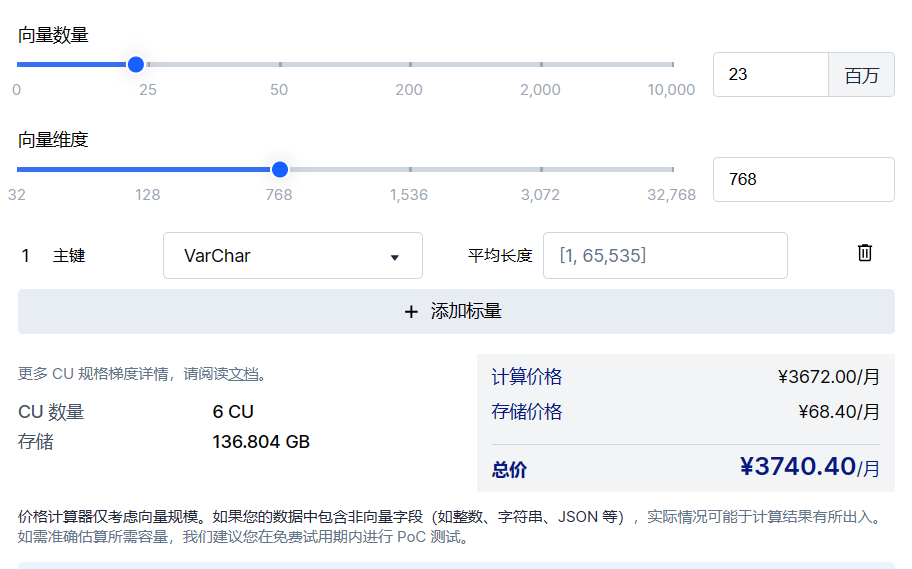
Zilliz is commercialized as Zilliz Cloud, with a monthly subscription business model. It is deployed in the form of SaaS, and determines the monthly subscription fee based on the number of vectors, vector dimensions, computational unit (CU) type, and average data length. Zilliz also offers a PaaS-based proprietary deployment service for scenarios with a high focus on data privacy and compliance, which is based on customized pricing.
 |
|---|
The development of application-layer AI is like a blossoming landscape, showing a spectacular picture of technological diversity and application breadth. Nowadays, the influence of application layer AI is expanding, some of them are oriented to consumer users, providing services covering all aspects of daily life, such as entertainment, socialization, music, personal health assistant, etc.; at the same time, they also play an important role in more specialized business fields, such as market analysis, legal processing, intelligent design, etc. These applications demonstrate the depth and breadth of AI technology, which not only improves efficiency and convenience, but also promotes innovation and technological advancement to a great extent.
 |
|---|
A large number of open-source application layer products have also been born, which are mostly based on LLMs and fine-tuned with industry-specific datasets. Application layer tools customized for the industry offer better performance than the generic LLMs, and the open-source nature helps bueiness and consumer users using these applications to further customize their development to better fit the needs.
Open-source tools at the application layer facilitate integration across disciplines and industries. For example, industries such as medicine, finance, education, and retail are utilizing open-source AI tools to solve industry-specific problems, driving the adoption of the technology across all sectors. Open-source tools encourage experimentation and innovation due to low cost and low risk. Developers are free to experiment with new ideas and technologies, and this spirit of experimentation has greatly contributed to the application layer boom.
 |
|---|
Open-source application layer products have a low threshold for use and are more easily accepted by users
Application layer open-source tools are less expensive and more in line with the low willingness of domestic enterprises to pay. According toiResearch, domestic enterprises are not professional enough in their internal management processes, have low recognition of the value of software, and are more willing to pay for manpower. Manufacturers need to curve to indoctrinate companies, give them a reprieve from accepting the product, and gradually unleash the demand side. Based on the above background, open-source tools meet the needs of these markets with their low-cost features, making organizations more willing to try and adopt these tools. For domestic companies with limited budgets, low cost is a significant advantage. Low- or no-cost features allow these organizations to access and use advanced technology tools without additional financial burden.
At the same time the low-cost nature of open-source tools encourages companies to make long-term investments. Firms can build and expand their technology infrastructure over time without taking on significant financial risk. With the deepening of the enterprise's understanding of open-source products and the deepening of the degree of dependence, open-source products can gradually consider providing value-added services content, so as to achieve the purpose of long-term customer acquisition.
At the same time open-source products are conducive to achieve seamless integration with other systems to enhance the user experience. A distinguishing feature of open-source application layer products is that they are often highly flexible and customizable. Allows users to modify and adapt to their specific needs. This means that open-source products can be customized to better fit existing systems and workflows for seamless integration with other systems. Many open-source projects follow industry standards, which helps ensure compatibility between different systems and components. Standardization promotes interoperability between different software products and simplifies the integration process, thereby improving the overall user experience. Open-source communities are typically made up of developers and users from around the world who work together to improve products and provide support. This collaborative spirit not only fosters continuous improvement of the product, but also provides a resource for solving problems that may be encountered during the integration process.
Open-source application layer products can receive contributions from the community to facilitate technology iteration and broaden the application scenarios
Application layer open-source can receive strong support from community development forces. As the application scenarios are more diverse and decentralized, the needs of different sub-scenarios are more differentiated, and the expertise of contributors to the corresponding scenarios is more demanding. Stable Diffusion (SD) is an open-source text-to-image application that, with the power of the community, has been rapidly catching up in terms of performance since its release and in some ways surpassing the closed-source text-to-image application Midjourney. While there are some inconveniences when using Stable Diffusion, users have access to hundreds of LoRAs, fine-tuning settings, and text embeds from the community. For example, users of Stable Diffusion found it to be limited in its ability to process hand images. In response, the community reacted quickly and within the next few weeks a LoRA fix was developed specifically for the hand image issue. This timely and professional feedback from the community greatly contributes to the rapid advancement and improvement of application layer open-source tools.
Open-source products, due to a lower barrier to use, may be adopted by users from different industries and backgrounds in a variety of environments and contexts as soon as they are released. These application scenarios may go far beyond the developer's initial design and imagination. When products are used in these diverse scenarios, they may reveal new potential or needs, revealing previously unnoticed usage scenarios. This can provide product developers with valuable insights into how their products are performing in real-world use and potential room for improvement. Faced with these newly discovered usage scenarios, developers have the opportunity to innovate and improve.They can add new features, optimize existing features, or redesign products to better meet these needs based on actual user experience in different environments. The iteration based on real-world use cases, is a key driver for the continued progress of open-source products.
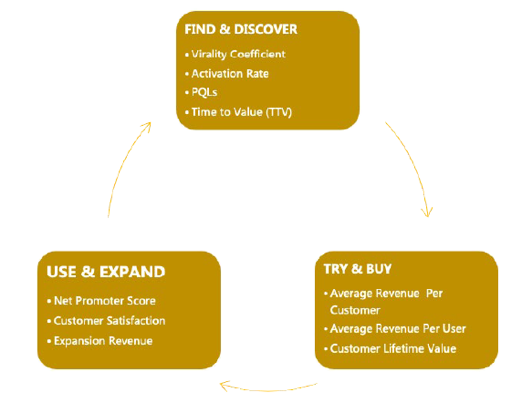
Application layer open-source products have Product-Led Growth (PLG) model features that can drive paid conversions
The PLG model focuses on customer acquisition through a bottom-up sales model, where the product is at the center of the entire sales process. The PLG model's growth flywheel has three main phases:Acquisition, Conversion, and Retention. In all three phases, open-source has advantages that distinguish it from traditional business models.
In the customer acquisition phase, the open-source operating model reduces the cost of customer acquisition and makes the customer acquisition process more targeted. The interactions between developers and the community-based collaboration brought about by platforms such as GitHub accelerate the spread of customer acquisition. The initial customer orientation of open-source products is usually participants in the open-source community, often developers or IT staff in the organization. By nurturing these quality prospects, you also have a "mass base". Communities help open up the boundaries of the enterprise and make word-of-mouth spreading of good open-source projects and products possible. Users spontaneously download and use it in order to solve their own problems and pain points. At this point, open-source software products are not just used as a way to solve user problems through functionality, but can also be a vehicle to help organizations spread and grow. In the long run, it will be possible to reduce the cost of customer acquisition for your organization, allowing for more and more automated customer acquisition and lowering expenses on the sales side.
At the conversion stage, open-source software tends to have a higher paid conversion rate compared to traditional commercial software. On the one hand, when the user has used the free version of the software, as long as the software's functions can well meet the user's needs, it can be converted into a paid conversion at the speed of a shorter cycle, and make it a long-term user. On the other hand, companies can conduct targeted conversion follow-up and up-selling by observing users' behavior with the free version of the software, for example, by providing the sales team with a list of customers who have exceeded their usage limits and are ready to pay. In addition to traditional sales conversions, conversions can also be made through self-service buying paths (Self-service selling), which largely reduces the cost of sales.
In the retention phase, open-source software allows users to avoid the risk of vendor lock-in, making them willing to engage in long-term use. Based on the same open-source project, there may be multiple vendors downstream that offer software with similar functionality, and the choice of vendor can be changed at a relatively small cost, so users can be confident in their choice of software for the long term. On the contrary, when a customer uses a closed-source product, if he/she wants to switch to another software after a period of time, he/she needs to redeploy hardware, data, etc., resulting in a significant transfer cost. Thus when users choose to use closed-source software, they may abandon their continued use of the software because the software's later development does not meet their needs or the cost of transferring it is too high.
 |
|---|
Internet giants and startups working together
There are opportunities for both Internet giants and startups to participate and compete in the LLM application layer open-source market. This is due to several factors:1) The lowered technology barrier. The open-source of the modeling layer and developer tools layer lowers the threshold of technology acquisition and application. Instead of having to develop complex LLM algorithms from scratch, startups can utilize open-source models and tools to develop solutions that meet specific needs. 2) Cost-effectiveness. Open-source models often do not require costly licenses or API fees, which is especially beneficial for SMEs with relatively limited capital. 3) Innovation and flexibility. Startups are often able to adapt more quickly to market changes and innovate for specific market segments or application scenarios.
At present, the Internet giants are mainly based on the LLM, on which they extend a series of vertical applications. For example, Ali's Tongyi Qianwen recently released Tongyi Qianwen 2.0 and derived eight applications based on it:Tongyi Tingwu (speech recognition), Tongyi Xiaomei (improving customer service efficiency), Tongyi Zhiwen (understanding text), Tongyi Stardust (personalized roles), Tongyi Lingyi (assisted programming), Tongyi Faryi (legal industry), Tongyi Renshen (pharmaceutical industry), and Tongyi Dijin (financial industry).
Startups mainly choose a certain niche industry for deep cultivation, such as Lanboat Technology's self-developed LLM focusing on marketing, finance, cultural creativity and other scenarios; XrayGPT focusing on medical radiology image analysis; Finchat focusing on financial field models, etc. Yunqi Partners has supported two open-source application layer startups this year, TabbyML, a tool to aid programming, and Realchar, an AI personal assistant that allows for real-time customization, both of which have quickly amassed a large number of users on Github.
Competitive landscapes in Business-end and Consumer-end are different
Significant differences in the competitive landscape between the business-end and consumer-end of the open-source market for LLM application layers:
- To-Business Markets:Enterprise-oriented applications are typically focused on improving efficiency, reducing costs, and enhancing decision-making capabilities. In this area, open-source LLMs can be used to automate processes, data analytics, customer service optimization, and more. The competition here focuses more on the practicality of the technology and the ability to customize it.
- To-Consumer Markets:Consumer-oriented applications are more focused on user experience, interactivity and ease of use. This includes personalized recommendations, virtual assistants, entertainment and social media apps, and more. Competition in the consumer market is more about innovative user interfaces and new features that appeal to users.
Large number of sub-scenarios still belong to the blue ocean market, no obvious lead
As technology evolves, market demand for AI applications becomes more segmented.For example, in industries such as healthcare, law, finance, and education, each field has its own unique needs and challenges. These market segments offer a great deal of opportunity, but also require targeted solutions.There are a number of relevant applications emerging in each of these areas, but most are at the start-up stage and have yet to produce a headline application. And because there are so many segments of the industry, there is not much competition, making it a better opportunity to get in. In these blue ocean markets, no clear market leader has yet formed due to the novelty and constant evolution of the market. This provides opportunities for new entrants and innovators to capture market share through unique solutions or innovative business models.
Expect innovative applications to emerge based on the new capabilities of LLMs
Although significant progress has been made in LLM technology, its deep integration and innovative application in specific application areas is still in its infancy. This means that there is plenty of room to explore and implement new ways of applying it in many sub-scenarios.With the rapid development of large-scale AI models, we are ushering in a new era of potential and innovation. These models will not only optimize and improve existing technology applications, but more importantly, they will be pioneers in leading completely new markets and application areas. In a future full of unknowns and surprises, we can look forward to the emergence of a huge variety of powerful new applications that will be integrated into our daily lives in unprecedented ways. These emerging markets and applications will open a window into never-before-seen possibilities for far-reaching social and cultural change. They will stimulate human creativity and imagination, pushing us to break through existing technological boundaries and explore a wider world.
In this dynamic and innovative era, we will witness the seamless integration of technology into our daily lives and experience the convenience and efficiency that comes with intelligence. The synergy between humans and machines will open up new modes of cooperation and innovation, leading us to a smarter, more efficient, and more personalized future. It's a time of great anticipation, with every step of technological advancement building a more exciting, rich and diverse world for us. In this new era, we will witness and create unprecedented miracles together, and explore together the infinite possibilities of the common development of science and technology and mankind.
2.5.1 Technology is evolving at a rapid pace and open-source projects need to be continuously iterated to remain competitive
In the field of artificial intelligence and LLMs, technology is evolving at an extremely fast pace with new algorithms, data processing techniques, optimization methods, and computational architectures continue to emerge. For open-source projects, this means that constant updates and upgrades are needed to keep the technology current and effective. This need for continuous updating is a challenge in terms of resources and time.For open-source projects, especially those with relatively limited financial and human resources, it can be challenging to keep up with this rapid pace of technology iteration. This means that not only do they have to race against the clock, but they also face stiff competition from commercial companies and other open-source projects. If a project is not kept up to date to reflect the latest technological advances, it can quickly become obsolete and thus lose the interest and support of users and community members.
In the face of well-funded companies from some tech giants such as OpenAI and Ali, some of the LLMs that small and medium-sized companies have spent a lot of money on developing could be quickly surpassed, leading to a serious funding gap. A "burn-in" strategy is possible for large vendors that small and medium-sized companies can't afford, which could potentially discourage the current 100-flower LLM market and reduce its diversity.
The original intention of open-source LLMs was to allow more users to access and use LLMs, but in the process of using them, disputes often arise over code attribution, licenses, and many other issues. Since LLM open-source is a relatively new concept, the relevant legal and regulatory system is not perfect, and many of them also involve cross-border issues, there is no clear definition of the boundary about whether LLM is plagiarized or borrowed. The recent Zero One Everything issue regarding LLaMA's "Shell Controversy" has generated a lot of attention. At the heart of the disagreement, but not the final judgment, is the difficulty of defining the scope of plagiarism / borrowing.
Some argue that Zero One Everything's software uses Llama's source code without attributing it, making it appear that they developed that part of the content themselves, and is indeed suspected of violating the right of attribution, i.e., suspected of plagiarism. However, there is also the view that the structural design of the Zero One Everything LLM is based on a mature structure that draws on the publicly available results of the industry's top level. Since the development of the LLM technology is still at a very early stage, keeping the structure consistent with the industry's mainstream will be more conducive to the overall adaptation and future iteration. Meanwhile the Zero One Everything team has done a lot of work on understanding models and training, and is also continuing to explore breakthroughs in the nature of the structural level of models.
This identification becomes even more complex in a context where LLMing technologies are still in their infancy and laws and regulations are not yet perfect. We should recognize that, with the continuous evolution of technology and the improvement of the legal system, how to balance the protection of innovation and the promotion of cooperation will be a process that needs to be continuously explored and improved.Ultimately, this is not only a legal and technical issue, but also an ethical and moral issue that concerns the healthy development of the entire industry.
In the process of building and iterating large-scale AI models, participants in the eco-community face a notable challenge:Due to the complexity of model training, it is often difficult for them to contribute directly to the development of the models. These LLMs, such as Llama or other advanced machine learning models, typically require highly specialized technical knowledge and resources, including large-scale data-processing capabilities, deep algorithmic understanding, and expensive hardware resources.For ordinary community members, these demands are often beyond their means.
As a result, while community members may be enthusiastic and willing to participate, they are limited in their ability to substantially iterate on the model. This lack of expertise means that even the most active community members may only be able to play a role in relatively peripheral areas such as model application, feedback collection, or elementary debugging. This limitation not only affects the extent to which the community contributes to the development of the model, but may also lead to a weakened sense of community involvement and belonging during the model development process. Finding appropriate ways to enable a wider range of community participants to contribute their wisdom and efforts effectively is therefore an important topic in the development of the LLM.
One of the main advantages of open-source software is that it reduces the initial cost to the user. Enterprises can acquire and use open-source LLMs without paying expensive license fees. This is especially attractive to small businesses or startups with limited budgets, as they can utilize advanced technology without a significant financial burden. While open-source software saves money in the initial phase, they can come with higher update costs over the long run.
Open-source projects are often known for their speed of innovation and community-driven dynamism, which drives technology to progress and evolve. However, as technology rapidly updates and iterates, the cost of maintaining and upgrading existing systems increases. Such costs include not only direct financial inputs, such as hardware upgrades or the purchase of new services, but also indirect costs, such as training staff to adapt to new technologies and the time and labor involved in migrating existing systems to newer versions. Especially for long-term projects, it becomes especially challenging to keep up with the latest open-source technologies. Every major update or technology transition can involve complex adaptation efforts and compatibility testing that require significant human and technical resources. In addition, frequent updates may lead to system stability and security issues, increasing potential operational risks.
Therefore, while open-source technologies offer great advantages in terms of innovation and flexibility, organizations and developers must carefully consider the update costs associated with adopting and maintaining these technologies, and how to find a balance between continuous innovation and cost-effectiveness.
Although open-source LLMs currently face numerous challenges, such as the rapid development of technology iterations, the risk of plagiarism, the limitations of community contributions, and the increased cost of maintenance, their future remains promising.Open-source LLMs have shown great potential to drive technological innovation, facilitate knowledge sharing, and accelerate R&D processes. In order to realize these potentials and overcome current challenges, a concerted effort by all parties from different fields and backgrounds is required!
Security is an important factor in determining whether an open-source product can be successfully commercialized. Business users usually need to conduct a comprehensive security assessment of the products they use to ensure that the overall business is secure and controllable, which includes cyber-attack security, data security, and commercial license controllability.
According to Synopsys, by the end of 2022, 84% of repository contain at least one known open-source vulnerability, 48% contain high-risk vulnerabilities, and 34% of respondents also said they had experienced "an attack launched using a known vulnerability in open-source software in the past 12 months. Open-source security is an issue that requires a great deal of attention, and it greatly affects customer trust in open-source software, as well as whether the large open-source ecosystem can be stabilized in the future. Only by ensuring security, open-source software can go farther on the road to commercialization.
 |
|---|
Open-source software plays a key role in driving technological innovation and facilitating knowledge sharing, but they are also inherently at risk of security vulnerabilities. The root causes of these security vulnerabilities usually lie in open-source code management and maintenance issues, such as programming errors, lack of continuous security reviews, and lagging application of updates and patches. Particularly where programs are not active enough or lack effective regulation, these vulnerabilities may go unrecognized or unfixed for long periods of time. Historically, several serious security incidents have occurred due to security vulnerabilities in open-source software, resulting in sensitive data breaches and financial losses.
In April 2014, a major security vulnerability in the widely used open-source component OpenSSL, known as Heartbleed, emerged. This vulnerability has existed since the May 2012 release and allows an attacker to obtain data containing certificate private keys, usernames, passwords, email addresses, and other sensitive information. Because this vulnerability went undetected for nearly two years, its impact was extremely widespread and almost impossible to accurately measure. Again, in December 2021, another widely used open-source component, Apache Log4j2, was found to have a serious remote code execution vulnerability called Log4Shell. This vulnerability quickly spread globally due to the high performance and low exploitation barrier of Apache Log4j2, affecting a number of well-known companies and service platforms, including Steam, Twitter, Amazon, and others.
Open source software is inherently more vulnerable
According to the results of "2022 QiAnXin QAX Open-source Project Inspection Program", the overall defect density of open-source software is 21.06/thousand lines, and the density of high-risk defects is 1.29/thousand lines. The number of defect densities and high-risk defect densities has been increasing for three consecutive years, with an accelerating trend. The overall detection rate of the ten categories of typical defects in open-source software was 72.3%, while this figure was only 56.3% two years ago. There is a rapid increase in the detection rate of open-source software, suggesting the security issue of the software itself is quite serious.
 |
|---|
In terms of the absolute number of open-source software flaws and vulnerabilities, according to data from QiAnXin (QAX), by the end of 2022, 57,610 vulnerabilities related to open-source software will be included in the public vulnerability database, and 7,682 new vulnerabilities will be added in 2022, an incremental increase of about 15%, which is a worrisome situation.
:::info Expert Review Yu Jie:The security of open-source software urgently needs to be given sufficient attention, and it is clear that the strength of individual communities alone is not enough to deal with it. How to build an effective systems and regimes to comprehensively protect the security of open-source software has become a major issue that cannot be avoided with its rapid development. :::
Open-source projects with too low or too high levels of activity are more likely to have security risks
Open-source software that is too inactive and updated too infrequently will result in vulnerabilities not being fixed in a timely manner, thus increasing the risk exposure of the software; if it is too active and updated too quickly, it will also result in users not being able to update accordingly in a timely manner, which puts more pressure on security operations and maintenance.
According to the data of QAX, if the open-source projects that have not been updated for more than a year are regarded as inactive projects, the number of inactive open-source projects in the mainstream open-source software package system will be 3,967,204 in 2022, accounting for 72.1%, while this ratio was 69.9% and 61.6% in 2021 and 2020, respectively, which indicates that the overall motivation of the open-source authors to maintain the software has decreased, which is not favorable to the long-term development of the security of the open-source software ecosystem.
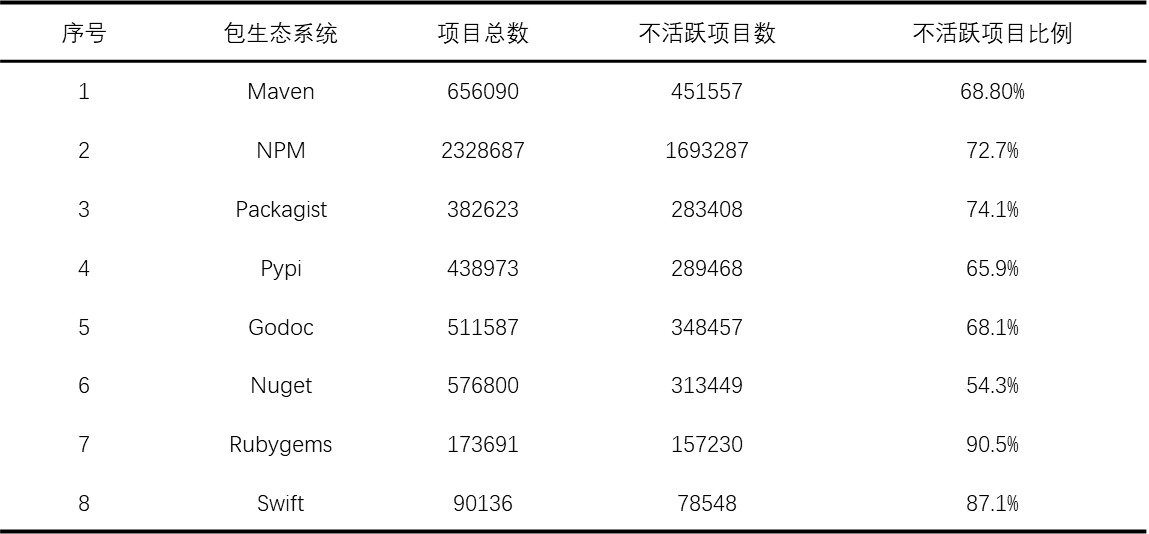 |
|---|
Against the backdrop of generally low activity, there are also some open-source software that are overly active, again putting a lot of security O&M pressure on users. According to QAX, there will be 22,403 open-source projects with more than 100 versions in the mainstream open-source package ecosystem in 2022, compared to 19,265 and 13,411 in 2021 and 2020, respectively.
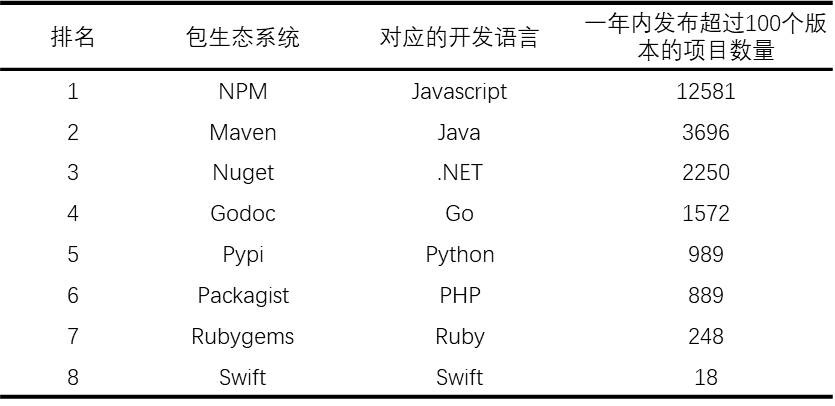 |
|---|
Too little or too much activity poses a high security risk to users of the open-source ecosystem, and a balance is urgently needed to ensure the healthy and sustainable development of open-source software. A more scientific version management and release mechanism is needed to ensure that updates respond to security and functionality needs in a timely manner without disturbing users too frequently. For projects with insufficient activity, their activity can be enhanced by increasing community participation and providing incentives. For projects with frequent updates, more attention should be paid to communicating with users, providing clear update logs and support guidelines to help users better understand and adapt to these changes.
At the same time, users should also be encouraged to actively participate in the feedback and contribution of the open-source project to form a positive interaction. Users' actual experience and feedback are important references for adjusting the update pace and optimizing software functions. By establishing a healthy user-developer interaction mechanism, we can effectively balance the activity and update frequency to ensure the safety and usability of the software.
Some users are using software that is outdated or with version usage being disorganized
According to QAX , many software projects use very outdated versions of open-source software, even versions released 30 years ago, with many vulnerabilities and very high risk exposure. One of the earliest software is IJG JPEG 6 released in 1995, which is still used by many projects. Older versions often come with older vulnerabilities, and there are still very old open-source vulnerabilities in some software projects. The oldest vulnerability is from 2002, 21 years ago, and is still used by 11 projects.
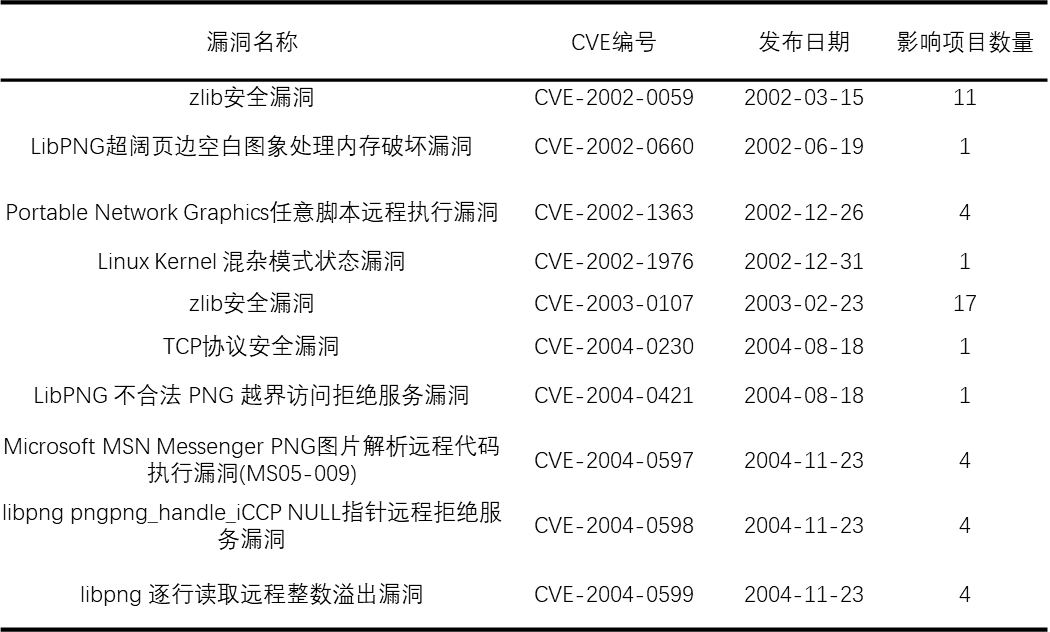 |
|---|
There is a lot of confusion over the use of versions of open-source software, not all of which are up-to-date. For example, there are 181 versions of Spring Framework in use. The use of earlier versions can lead to a large number of vulnerabilities that have been fixed in newer versions can still be exploited maliciously, thus posing a significant security risk.
Regular security audits and code checks
A clear audit process needs to be defined that includes a comprehensive review of the overall architecture, codebase, and dependencies of the software. These audits can be performed by assembling specialized security teams or utilizing third-party security services. These teams or service providers should have an in-depth understanding of open-source software.
Regular code review meetings are also held to encourage team members to review each other's code, which not only helps identify potential security issues, but also improves the team's programming skills and code quality. Audits and code review should be an continuous process, constantly monitoring and updating the code base in response to newly discovered vulnerabilities and security threats.
Using the SCA (Software Component Analysis) tool
Software Component Analysis (SCA) is a methodology for managing the security of open-source components, enabling development teams to quickly track and analyze the open-source components used in their projects. SCA tools identify all relevant components and supporting libraries, as well as direct and indirect dependencies between them. In addition, they can check software licenses, identify deprecated dependencies, and discover potential vulnerabilities and threats. A SCA scan produces a software bill of materials (SBOM) that contains a complete list of the project's software assets.
With the widespread use of open-source components in software development, SCA is emerging as a key component of application security, although the concept itself is not new. The number of SCA tools has grown with its importance. In modern software development practices, including DevSecOps, SCA not only needs to provide ease of use for developers, but also needs to guide and direct developers safely throughout the software development lifecycle (SDLC).
When using SCA for open-source security, the following points should be considered:
- Adopt developer-friendly SCA tools: Developers are often busy writing and optimizing code, and they need tools that promote efficient thinking and rapid iteration. Unfriendly SCA tools can slow down the development process. An easy-to-use SCA tool simplifies setup and operation. Such tools should integrate easily with existing development workflows and tools, and should be implemented early in the software development life cycle (SDLC). It is important that developers understand the importance of SCA and incorporate its security checking process into their daily work to minimize code rewrites due to security issues.
- Integrate SCA into the CI/CD process: Using SCA tools does not mean that they will interfere with the development, testing, and production processes. Instead, organizations should integrate SCA scanning into Continuous Integration/Continuous Deployment (CI/CD) processes so that vulnerabilities can be identified and remediated as a functional part of the software development and build process. This approach also helps developers make code security part of their daily workflow.
- Effective Use of Reports and Software Bills of Materials: Many organizations, including the U.S. Federal Government, require a software bill of materials (SBOM) when purchasing software. Providing a detailed SBOM means that organizations recognize the importance of keeping track of every component within an application. Clear security scanning and remediation reports are also critical, as they provide detailed information about an organization's security practices and the number of vulnerabilities remediated, demonstrating a commitment to and actual action on software security.
Enhancing education and training
Conduct regular security awareness training for developers to increase their knowledge of security threats and best security practices, including educating them on identifying common security vulnerabilities and attack tactics. Use hands-on simulation exercises and workshops to allow developers to learn how to handle security incidents in a secure environment. These exercises can include vulnerability mining, code remediation, and security testing.
Given the rapid changes in the security landscape, encourage developers to continuously learn and update their knowledge, including by participating in online courses, seminars and industry conferences. Create a platform, such as an internal forum or regular meetings, for developers to share their knowledge and experience in security to foster learning and collaboration among teams.
3.2.1 Open source licenses are a constraint on users of open source resources, with a wide range of categories
An open-source license is a binding for open-source resources (including, but not limited to, software, code, and web users). Based on the open-source license, the user gets the right to use, modify and share the open-source resources. If the software is not licensed, it means that the copyright is retained and the user can only view the source code and not use it. Therefore, an open-source license is essentially a legal permit that protects project contributors and users of open-source resources, ensures that contributors can open-source the resources they own in the way they want to, and also ensures that users can use the resources in a reasonable and legal way to avoid being caught in intellectual property disputes, which greatly contributes to the prosperity of the open-source community.
Open-source licenses are divided into three overall categories based on how restrictive the license is:Permissive, Weak Copyleft, Strong Copyleft
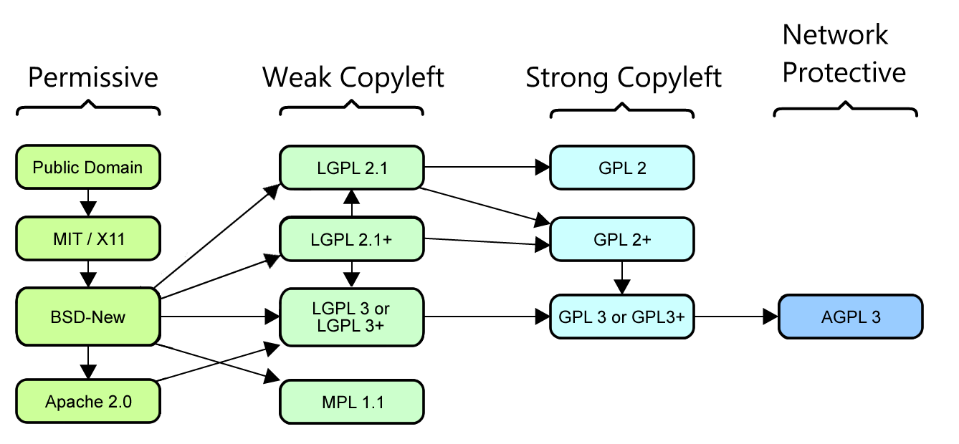 |
|---|
The Permissive category is the most flexible category of licenses, including BSD, MIT, Apache, ISC, etc., which provide extremely permissive licensing conditions that allow people to freely use, modify, copy, and distribute the software. They equally support the use of software for commercial or non-commercial purposes.The only requirement is that the appropriate license text and copyright information be included in each copy of the software.
The Weak Copyleft category is a more restrictive license than the Permissive category, including LGPL, MPL, etc., which requires that any changes made to the code be released under the same license. Also, the modified code must contain the license and copyright information of the original code. However, they do not mandate that the entire project be released under the same license.
The Strong Copyleft category is an even more restrictive type of license, including GPL, AGPL, CPL, etc. This type of license states that the entire project must be released under the same license, including those cases where only a portion of the software is used. In addition, these licenses require that all modified versions of the code be publicly released.
Under these broad categories, specific licenses and license families will have unique restrictions, permissions, and specific differences in additional parameters, and the overall logical relationship of licenses is organized as follows:
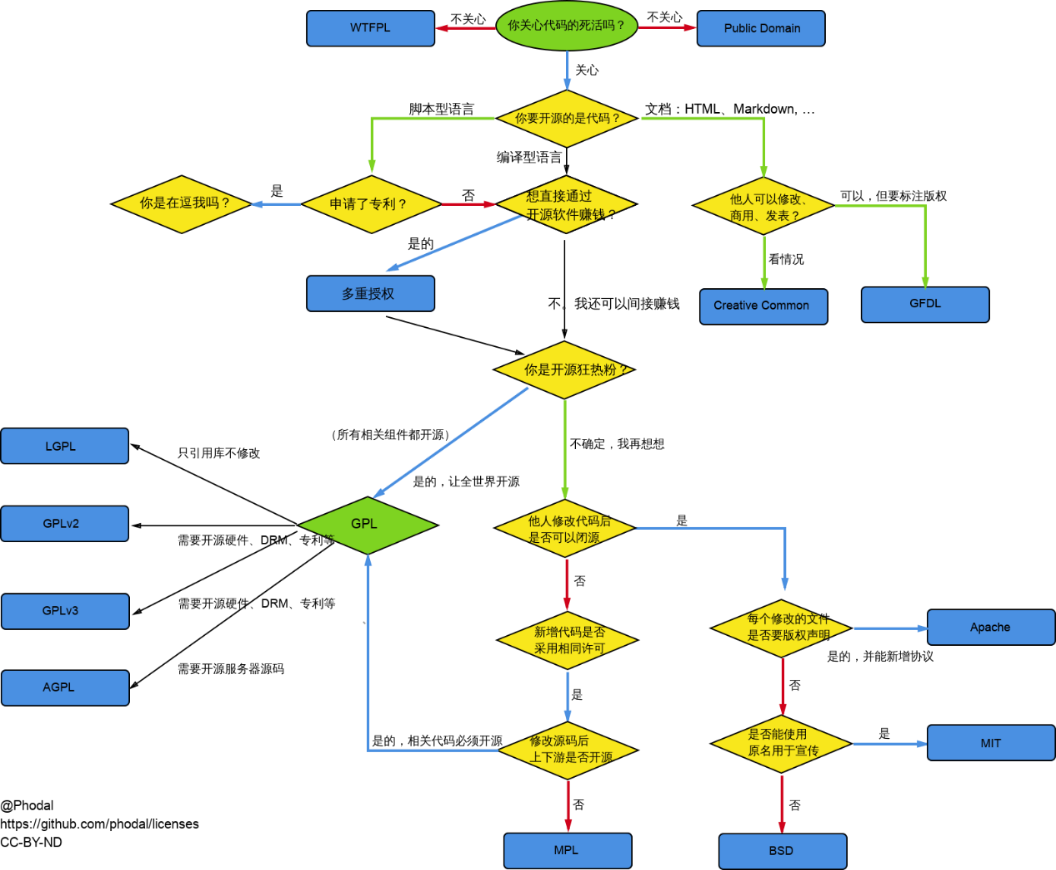 |
|---|
Kaiyuanshe provides an open-source license filter, which provides good help to understand the best license options faster and better, and is highly recommended for readers who need it:https://kaiyuanshe.cn/tool/license-filter
Open source license infringement
"Open-source license infringement" is the use of open-source software without complying with the terms and conditions of the open-source license associated with the software, thereby violating the legal constraints imposed by the license. Such behavior can lead to a host of legal and ethical problems. While open-source software is freely available to the public for use and modification, such use and modification is still subject to certain limitations, which are specified by the corresponding open-source license.
Specific instances include, but are not limited to, the following:
Ignoring Copyright Notices and Attribution:Many open-source licenses require that original copyright notices and author attributions be retained when copying, distributing, or modifying software. Ignoring this requirement, such as removing the original author's copyright information or failing to properly attribute the work, is considered an infringement.
Non-availability of Source Code:Some licenses, such as the GPL (General Public License), require that the source code be made available along with the distribution of the software. If a piece of software based on such a license is distributed without the source code being made available at the same time, this also constitutes infringement.
Restrictive Use:Some licenses have restrictions on the scenarios in which the software can be used. For example, certain licenses may prohibit the use of the software in certain types of business activities. Violation of these restrictive covenants is also a tort.
Violating Conditions for Distribution and Re-licensing:Copyleft open-source licenses such as the GPL requires that any modifications and derivative works based on GPL-licensed software must also be released under the GPL license. Violations of this rule, such as privatizing GPL code or distributing derivative works under non-GPL licenses, constitute copyright infringement.
Violation of Specific Terms:In addition to the common scenarios described above, there are specific license terms that may be violated under certain circumstances. This depends on the specific requirements of the particular license.
License Reciprocity Requirement Leads to Expanded Scope of Open Source Copyright Problems
The so-called "reciprocity requirement" of an open-source license, i.e., whether a derivative work follows the license of the original work, refers to the fact that the terms and conditions of an open-source license tend to continue to apply during the process of open sourcing the software, which includes copying, modifying, manipulating, redistributing, and displaying. The permissions and limitations of such licenses can extend vertically to derivative works and modified versions based on the original software development, and even horizontally affect other parts of the software developed based on such open-source software.
Of the many open-source licenses, the GPL has the strongest reciprocity requirements and the most lawsuits associated with it. The main reason for this is:Any derivative software based on GPL code modifications needs to be open source. If a piece of software contains GPL code, even if it is only a portion, the software as a whole is usually required to be open-source (unless it meets the terms of a specific exception). Failure to open-source portions of proprietary software affected by the GPL may result in infringement by the user in violation of the obligations of the GPL license. Moreover, the GPL is extremely complex, containing 17 terms. It has more stringent requirements for users, and once these requirements are violated, the user's license agreement is terminated and continued use of GPL-licensed open-source software may constitute copyright infringement.
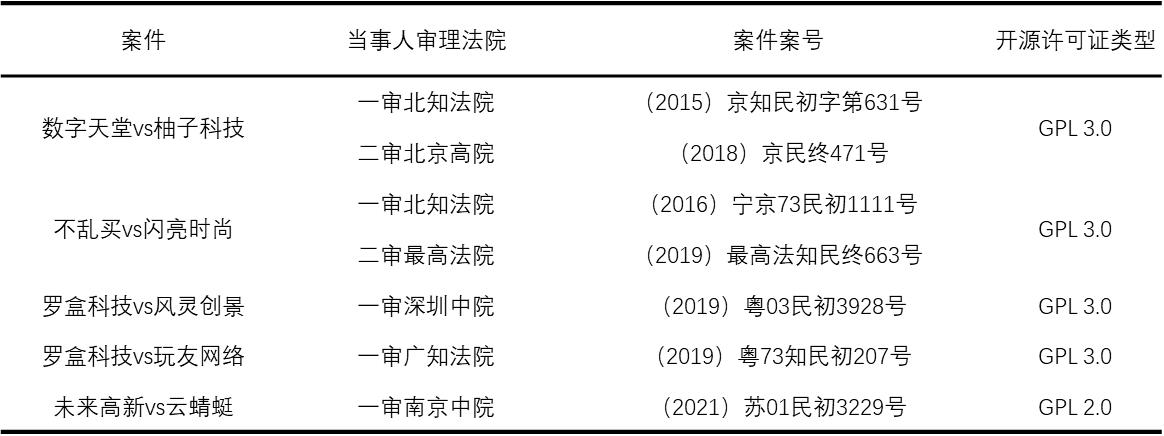 |
|---|
Infringement of open source licenses may lead to serious consequences
Once an open-source license is characterized as an infringement, the loss to the defendant company or individual is far more than just compensation payment, but also includes a series of issues such as reputation and partnership:
Lawsuits and Fines:In 2017, Versata Software sued Ameriprise Financial for violating Versata's patents. While this is not a pure case of open-source license infringement, it involves software licensing and copyright issues. The case eventually ended in a settlement, but the legal fees and time costs involved were prohibitive.
Enforcing Compliance with License Requirements:A famous case is the 2015 VMware vs. Hellwig case. Hellwig, a Linux kernel developer, accused VMware of using GPL-based Linux code in its ESXi products without following the open-source requirements of the GPL license. Although the court did not ultimately rule in Hellwig's favor, the case sparked a broader discussion about GPL license obligations and derivative works.
Reputational Damage:Red Hat filed a lawsuit against Speakeasy, Inc. in 2004 for allegedly failing to comply with the requirements of the GPL license. Despite the settlement of the case, Speakeasy's reputation has suffered, especially in the open-source community.
Business Impact:Cisco was sued by the Free Software Foundation (FSF) in 2008 for violating the GPL license for its Linksys products. Cisco ultimately agreed to comply with the GPL license and pay an undisclosed amount as a donation. The lawsuit led Cisco to reconsider its open-source strategy for its products.
Partnership Damage:a company is found to be in violation of an open-source license, its business partners may reevaluate their relationship with the company, especially if the collaborative project involves open-source software.
As open-source LLMs are still evolving and iterating, two highly influential open-source LLMs of the year:Llama2 and Falcon, have both been questioned as to whether or not they are truly "open source" due to tweaks to the terms of their open-source licenses. Both do not use commercially available licenses, but rather their own "LLAMA 2 COMMUNITY LICENSE AGREEMENT" and "TII Falcon LLM License", respectively; and both impose additional restrictions on their commercial use. Both have additional restrictions on their commercial use.
Difference in open source licenses for LLaMA2
Much of the discussion of Llama2's violation of open-source guidelines comes from its more unique terms:
- The Llama2 open-source model may not be used in products or service platforms with monthly active MAUs greater than 700 million, unless approved and licensed by Meta;
- The Llama2 open-source model may not be used in any manner that violates applicable laws or regulations, including trade compliance laws. Also not applicable to use in languages other than English;
- Other LLMs (not including Llama2 or its derivatives)
The Open Source Initiative (OSI) has published ten definitions of open source, which are currently recognized internationally, and the Llama2 protocol conflicts with two of them
- Non-Discrimination Against Individuals or Groups:The Llama License prevents enterprise users with more than 700 million monthly users from obtaining licenses directly through this License.
- Non-Discrimination Against Fields:The license shall not restrict anyone from using the program in a particular field. The Llama License prohibits the use of Llama2 outputs to improve other AI LLMs, which would be a restriction on the domain of use. Llama2's language restrictions also lead to limitations in the use of Chinese language domains.
Difference in open source licenses for Falcon
The TII Falcon LLM License makes some key changes from the Apache License. The Apache License is a popular open-source license that is friendly to commercial use and allows users to distribute or sell their modified code as an open-source or commercial product after meeting certain conditions.
Falcon's license is similar to the Apache License in that it also provides broad permissions to use, modify, and distribute the licensed work, and requires that the license text be included in the distribution and properly attributed, in addition to a disclaimer of limitations of liability and warranties.
However, the TII Falcon LLM License introduces additional commercial use terms that require commercial applications to pay a 10% license fee on annual revenues in excess of $1 million. It also places additional restrictions on the manner in which the work may be published or distributed, such as emphasizing the need for attribution to "Falcon LLM technology from the Technology Innovation Institute."
The purpose of open-source for LLMs of open-source is different from that of traditional open-source software
In the case of Llama2, for example, the license is essentially a guiding framework for organizations that intend to develop and deploy AI systems while adhering to Meta's established specifications and standards. The purpose of this framework is to ensure that these organizations meet specific rules and standards set by Meta when developing and deploying AI technologies. Such an approach helps Meta manage the scope and manner in which its AI technology is applied, thereby safeguarding its business interests and brand image.
The Llama2 license may constitute a compliance requirement that must be adhered to for those who plan to conduct AI development on the Meta platform. This means that these organizations must follow Meta's specific specifications and requirements when using Meta-provided tools and resources to develop and deploy AI models. In doing so, these companies may need to apply to Meta for the appropriate licenses, of which the Llama2 license is a part.
Document the use of open source components
When the enterprise or individual user's software reaches a certain size, the burden of managing the included open-source components becomes heavier, which leads to infringement problems due to the inability to manage them in a timely manner. According to Synopsys, 89% of the codebase contains open-source code that has been out of date for at least four years, and 88% of the codebase contains components that have been inactive for the past 2 years and contain components that are not the latest version. In many cases, developers may have completely forgotten which open-source components have been used and are unable to react in a timely manner when licenses for those open-source components are updated, leading to infringement issues. Therefore, it becomes very necessary to manage open-source components in a reasonable way.
Developers can manually or automatically maintain a detailed dependency list of all used open-source components and their version information in the project's documentation. For example, in many programming languages, dependencies can be tracked using files such as requirements.txt (Python), package.json (Node.js), and so on.
Create an internal document or knowledge base that records all relevant information about the open-source components used, including their origin, license information, and how they are used, and regularly check their licenses for updates. Track in detail in the documentation which open-source components are used, and add comments in the corresponding places in the code to indicate this. Add the corresponding license website to the document to check it regularly and find out the changes of the license terms in time. Also document in your programming how you have complied with valid license conditions.
For larger volumes of development work, manually recorded text may not be able to meet the project requirements, at this time you can use related tools, such as code component analysis (SCA) software. These tools automatically identify and document the open-source components used in a project. They are usually able to provide detailed reports that include component license information, versions, and possible security vulnerabilities.
Cautious use of supplementary coding tools
Intelligent programming assistants such as ChatGPT and GitHub Copilot provide programming advice and code snippets by analyzing a large number of codebases and documentation. While these tools are extremely valuable in improving programming efficiency, there are several key points to consider when using the code they generate to avoid potential open-source license infringement issues:
-
License Issues with Source Code:Assistive programming software may generate suggestions based on code in its training datasets. These training datasets may contain code from different open-source projects that may have various license requirements. Usually supplementary programming results do not index the corresponding licenses, and copyright issues may be involved if the generated code snippets are too close to the original code and are copied directly by the user.
-
Attribution of Responsibility:When using code generated by an intelligent programming assistant, it needs to be clear that the ultimate responsibility lies with the user. This means that the developer is responsible for the legality and suitability of the generated code. As a result, developers conduct regular code reviews, especially for sections generated using assisted programming, to ensure that they do not violate the terms of any open-source license.
Adequate code audits during mergers and acquisitions
An adequate code audit during the M&A process is essential, especially to avoid infringement issues involving open-source licenses. M&A activities usually involve a thorough evaluation of the target company's assets, of which technology assets, especially software assets, occupy an important place. The following issues need to be highlighted in M&A audits:
- Identifying Open-source Components:An important task of a code audit is to identify all open-source components used in the target company's products. This includes open-source libraries and frameworks that are used directly, as well as open-source software that is indirectly relied upon. Understanding these components and their versions is critical to assessing the associated license requirements.
- Reviewing License Compliance:After confirming an open-source component, its corresponding license needs to be reviewed. This includes determining the types, limitations and obligations of these licenses. In particular, note that some licenses may have specific restrictions on commercial use or require disclosure of modified source code.
- Assessing Risks and Responsibilities:During the audit, the legal and financial risks that may arise from non-compliance with open-source licenses should be assessed. This includes potential infringement lawsuits, fines, or the need to refactor parts of the product that rely on specific open-source components.
- Post-Integration Compliance Strategies:After an M&A is completed, there needs to be a clear plan for integrating the target company's codebase and ensuring continued compliance with all relevant open-source license requirements. This may involve implementing new code management and compliance monitoring processes throughout the organization.
- Professional Legal Advice:Because open-source licenses can be very complex, obtaining professional legal advice is critical. A professional attorney can help correctly interpret the terms of the license and provide advice on how to handle potential license conflicts.
With the popularity of LLMs, in addition to the LLM license issues mentioned above, more AI safety and control issues have gradually entered people's view. Since the technology is relatively new and there is no clear definition and specification, this paragraph lists the topics of greater concern to the relevant practitioners at the moment based on desk research, in the hope of triggering readers' thinking, and welcomes discussion and feedback.
Unlike traditional data security, since a large part of the output results of AI LLMs depends on the training dataset, issues such as the quality of the dataset and whether the dataset contains malicious data are particularly important for AI LLMs, especially open-source LLMs, because many of the datasets of the open-source LLMs provide data internally by the enterprise, and the cleansing, monitoring, and compliance can't be done as professionally as those of the professional closed-source LLM vendors.
Improper handling of the training dataset triggers a range of biases
Data bias occurs when certain elements in a data set are overemphasized or underrepresented. When training AI or machine learning models based on such biased data, it can lead to biased, unfair and inaccurate results.
- Selective Bias:Some facial recognition systems, trained primarily on white images, have relatively low accuracy in recognizing faces of different races;
- Exclusionary Bias:This bias usually occurs at the data preprocessing stage, and if the data is based on stereotypes or false assumptions, then the results will be biased regardless of which algorithm is used;
- Observer Bias:Researchers may consciously or unconsciously bring their personal views into a research project, which can influence the results;
- Racial Bias:Racial bias occurs when a dataset is biased toward a particular group;
- Measurement Bias:This bias occurs when the data used for training does not match the data in the real world, or when incorrect measurements distort the data.
These biases, when used maliciously, can lead to outputs that are significantly politically or racially biased, or data errors that can significantly affect the performance and credibility of the larger model.
Training data sources should be taken into account when choosing a LLM of an open-source base
Many of the LLM training data sources are obtained directly from the Internet via crawler tools, where discriminatory, hateful and offensive speech and information is prevalent. In practice, people read, comment, like and spread negative messages far more than positive ones. As a result, human-generated information sources have long been in a more chaotic and unhealthy state. LLMs in this environment may contribute to the spread of racial discrimination and disinformation by being influenced by such data.
Once the data source at the base of the LLM is contaminated, even if the enterprise itself is fine-tuned to use a perfect data source, it can lead to significant bias in the final output. Therefore, when choosing a LLM for the base, users should not only consider the performance of the LLM, but should also take the source of the training data into consideration. The focus should be on LLMs that select annotated datasets from multiple sources in a responsible manner, while considering bias minimization as a factor to focus on throughout the model building process and even after deployment.
The problem of LLM hallucinations can lead to serious consequences
There is an unresolved problem with current LLMs - hallucinations. According to the Sail Lab at HIT (Harbin Institute of Technology), hallucination refers to "text generation tasks in which unfaithful or meaningless text is sometimes produced. "While hallucinatory texts are unfaithful and meaningless, they are often so readable due to the powerful context generation capabilities of the LLM that the reader is led to believe that they are based on the provided context, even though it is actually very difficult to find or verify that such a context actually exists. This phenomenon is similar to mental hallucinations that are difficult to distinguish from other "real" perceptions, and it is also difficult to capture hallucinatory texts at a glance.
There are many types of illusions and they are still emerging as the use of LLMs expands. The main types of common hallucinations are the following:
- Logic Errors:The LLM makes logical errors in its reasoning, which results in outputs that seem reasonable but don't stand up to scrutiny;
- Fabricated Facts:The database of the LLM itself does not support its answer to this question, but since the LLM cannot define its own boundaries, it will confidently assert facts that simply do not exist;
- Data-Driven Bias:As mentioned in the previous section, due to the prevalence of certain data, the output of the model may be biased in certain directions, leading to erroneous results.
False outputs due to LLM hallucinations may cause harm to some users who are convinced by them. On May 16, 2023, the World Health Organization issued a statement of caution on the use of AI LLM tools. They noted that while these tools facilitate access to health information and may enhance the efficiency of diagnosis, particularly in resource-poor areas, their use requires a rigorous assessment of potential risks. The World Health Organization further emphasized that rushing into the use of inadequately tested systems could lead to mistakes by healthcare professionals, harm to patients and reduced trust in AI technologies, which could undermine or delay the potential long-term benefits and applications of such technologies globally.
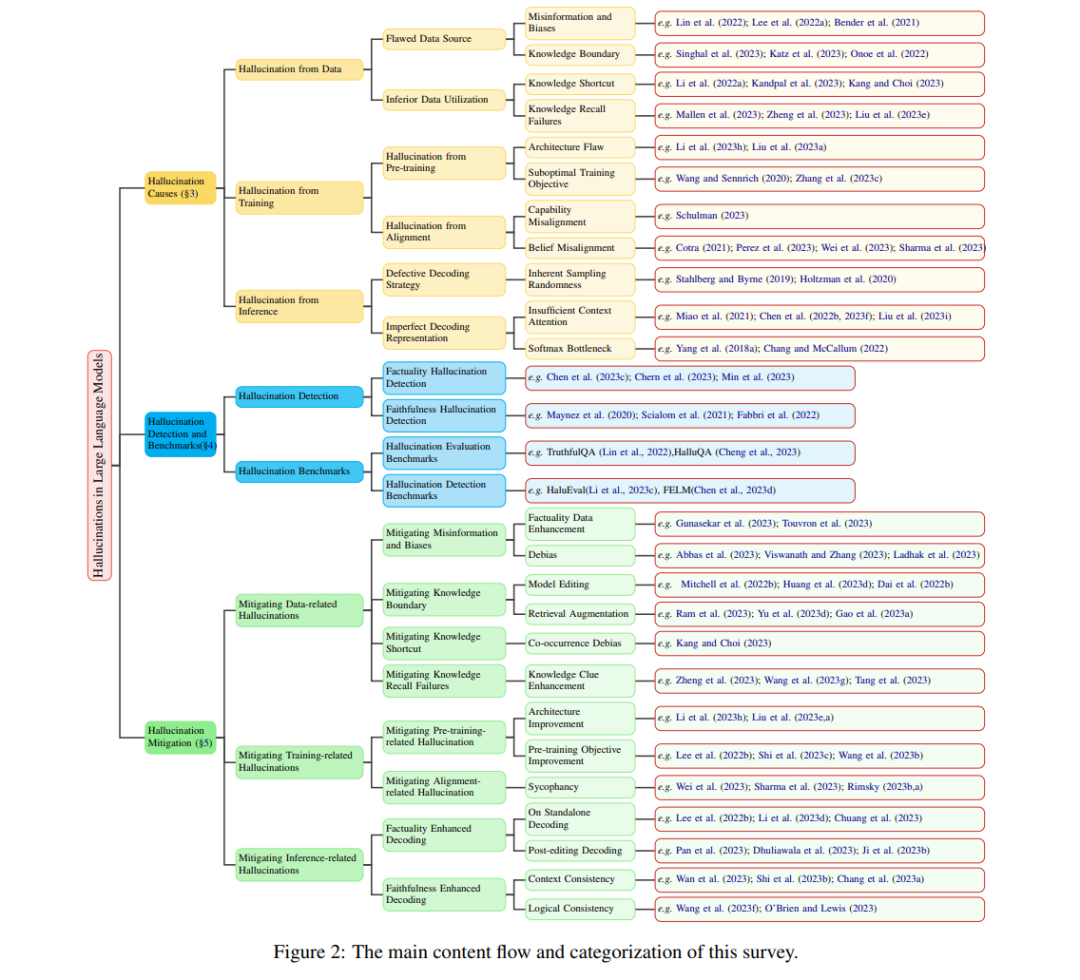 |
|---|
Since there is not yet a clear accountability entity for LLMs, and even more so for open-source LLMs, in the event of serious consequences, it will be very difficult for users who have suffered losses to defend their rights and their losses to be mitigated. Currently there are 2 pressing issues to be addressed in this regard:
- How LLMs hallucinations can be better addressed - technical aspects
- How to define more clearly who is responsible for LLMs - legal aspects
Outputs from LLMs may output content that violates ethical laws
At present, some LLMs lack content filtering mechanisms, resulting in output content that violates domestic laws and regulations, public order and morals, mainly containing the following situations:
-
Copyright Issues:LLMs may generate content that contains or resembles copyrighted material. For example, the model may create text that is similar to pre-existing literary works, song lyrics, movie scripts, and so on.Such a generation may violate the rights of the original author or copyright holder, leading to legal disputes;
-
Territorial legislation:Different countries and regions have their own unique legal systems. For example, certain countries have stricter censorship of Internet content, such as explicit bans on politically sensitive content, religious messages or specific expressions on gender issues. When the LLM runs in these regions, the generated content must comply with local laws. For example, when someone asked an LLM "how to cook wild giant salamander", the model answered "braise it" and even provided detailed steps. Such answers may mislead the questioner. As a matter of fact, wild giant salamander are Class II protected animals and should not be captured, killed or eaten.
-
Defamation and Misinformation:If model-generated content contains false accusations or defamatory statements about individuals or organizations, legal action may result. This places high demands on ensuring the accuracy and legitimacy of the content.
In order to ensure compliance with various legal requirements, organizations using LLMs may need to put in place regulatory mechanisms, such as auditing generated content to ensure that it does not violate any legal requirements. Especially for open-source models used by enterprises, they are relatively more leniently scrutinized for content output, and enterprises need to pay extra attention to related issues to prevent getting into legal disputes and incurring losses. Here again, it can be summarized in 2 questions:
- How to Enhance Information Filtering Mechanisms for LLMs - Technical Aspects
- How to define whether LLM output content is infringing and illegal - legal aspects
LLMs may exacerbate social divide
The Secretary General of the Digital Economy Committee of the Beijing Computer Society has said:The potential security issues of LLMs are of particular concern for those who lack critical thinking and analytical skills, and who are not well-informed about paid knowledge and healthcare services. With the dramatic increase in the number of Internet users and the widespread use of mobile devices, such as cell phones, low-education and low-income populations are increasingly relying on these avenues for medical, educational, and daily life advice. However, large-scale generative language models may exacerbate discriminatory portrayals and social biases against these marginalized groups, deepen social divisions, increase the harm of misleading, malicious information, and raise the risk of disclosure and misuse of individuals' real information.
The use of LLMs is like a double-edged sword; on the one hand, it can reintegrate network resources and improve the efficiency of information collection; on the other hand, it may exacerbate information barriers due to problems such as hallucinations and lead to the misinformation of many populations with scarce information sources. There are 2 issues that need to be addressed at this point:
- Enhancing public education that LLMs are not a panacea and need to be viewed with caution - Social communication aspect
- How to ensure the quality of LLM training datasets and reduce their bias - technical aspect
Since 2023, volatility in global financial markets has increased due to growing interest rates, challenging economic conditions, geopolitical conflicts, and concerns about the stability of the international financial system, which has led to a bleak picture for the global VC capital markets. According to KPMG, global venture capital activity has declined for seven consecutive quarters through Q3 2023 (see Figure 4.1).
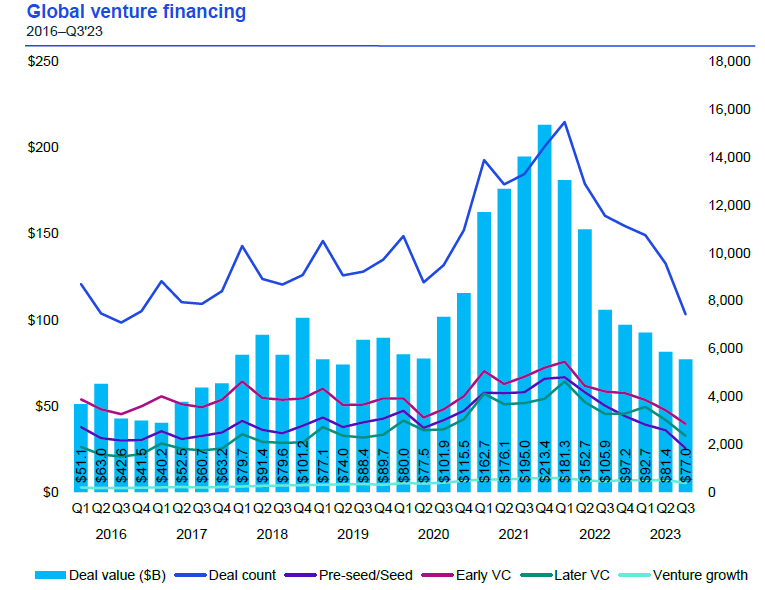 |
|---|
Against the backdrop of a declining equity market, fund managers have generally reduced their allocations to private equity assets to maintain portfolio proportions; at the same time, due to the high volatility of venture capital and the uncertainty of the future global economic situation, the scale of venture capital fundraising in 2023 will drop significantly compared with that of previous years. Compared to an average of more than $250 billion annually over the past five years (2018-2022), venture capital commitments as of 2023Q3 amounted to just $116 billion (according to KPMG). Overlaying the trend of seven consecutive quarters of declining venture capital activity, fundraising will shrink significantly in 2023Q4 and for the full year.
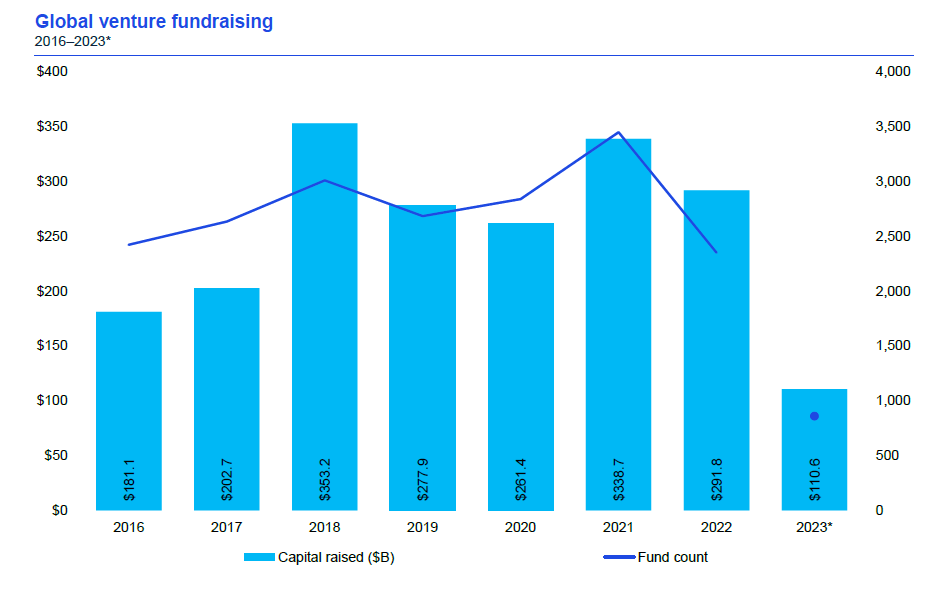 |
|---|
At the valuation level, investor caution is also growing. Compared to 2021 and 2022, the proportion of premium financing has decreased by about 10%, and the proportion of par and discount financing has risen by about 5%, which creates an obstacle to the exit of early-stage capital.
 |
|---|
However, against the backdrop of an overall bleak environment, AIGC-related financings have been in the global spotlight, with a significant increase in the size of related financings. In North America, the largest number of AI-related companies will be unicorns in 2023, including AI agent startup Imbue, AI + biotech company TrueBinding, generative AI company Runway, and natural language processing company Cohere; in Europe, despite the overall slowdown in funding, AI companies have been particularly strong, with a large number of startups receiving funding, such as French AI platform company Poolside; in Asia, investor interest in AI is also rising, but national regulators are also increasing the regulation of generative AI. In Europe, despite the overall funding slowdown, AI companies are doing particularly well, with a large number of startups receiving funding, such as French AI platform company Poolside; and while investor interest in AI in Asia continues to grow, so too does regulatory oversight of generative AI by national regulators.
It is expected that along with the rapid iteration of AI technology, the concepts of LLM and AI Agent continue to be hot, the investment and financing related to the AI field will be less affected by the contraction of the scale of global venture capital investment.
The growth of commercial open-source companies has been remarkable in recent years, with the combined market capitalization of these companies growing rapidly from $10 billion to surpass the $500 billion mark. This significant growth not only demonstrates the huge potential of open-source technology in the commercial sector, but also reflects the high level of investor recognition and trust in the open-source model. According to OSS Capital, the market capitalization of commercial open-source companies is expected to reach a staggering $3 trillion in the future.
The open-source business sector has shown solid growth over the past four years. Over 400 startups raised approximately 700 rounds totaling $29 billion during this period.Specifically, annual financing increases from $270 million in 2020 to $12.5 billion in 2023, a compound annual growth rate of 255%.
Although the size of the financing showed a downward trend in 2022, this trend was mitigated in 2023. Beginning in February 2023, financing begins to pick up gradually. In the first 11 months of 2023, total funding has already surpassed the amount raised in all of 2022. However, volatility in the scale of financing increased throughout the year, influenced by geopolitical conflicts and the post-epidemic economic recovery. Financing peaked at around $2 billion or so in March, May and September, and was below average in June and August.
Even in the lowest funding month of 2023, $386 million in monthly funding exceeded the highest monthly funding in 2021 and even surpassed the total funding for all of 2020 ($272 million). This trend reflects the capital market's continued interest in and recognition of open-source business. This apparent trend of growth in funding shows the growing interest and confidence of the capital markets in open-source business. Investors value not only the innovative potential and technological advantages of open-source models, but also their sustainability in the marketplace and long-term growth potential.
 |
|---|
Analyzing from the perspective of financing scale of each round, the capital prefers medium-term financing such as B, C, D, and so on. This reflects the characteristics of commercial open-source companies:In the early stage, the technical details are still unclear, and the business model is not clear; however, when they gradually cross the start-up stage, commercial open-source companies will explode with stronger growth momentum, attracting more capital; in the later stage when the business model is gradually matured and the open-source product becomes well-known and generates stable cash flow, the need for financing will be reduced.
 |
|---|
A total of 328 commercial open-source companies have received more than $10 million in funding over the past four years. Of these, the main concentration was in the US$10-50 million range, with a total of 210 rounds, or 64% of all rounds, in the US$10-20 million and US$20-50 million ranges. There were 49 rounds of $50-100 million and 46 rounds of $100-200 million, accounting for 29% of all rounds. A total of 23 companies received more than $200 million in funding, with two of them even receiving more than $500 million in a single round.
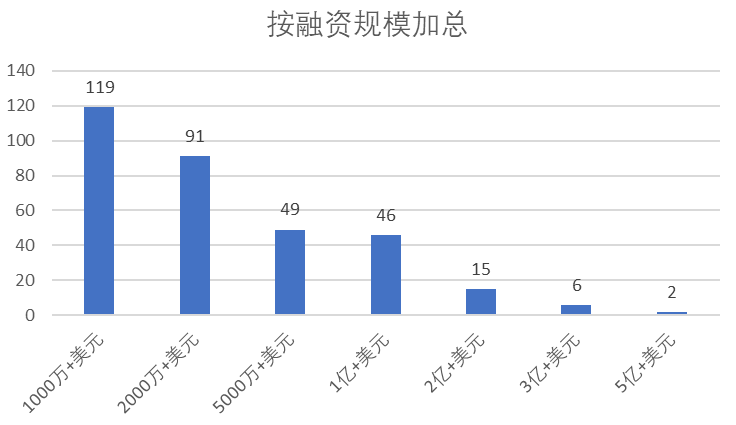 |
|---|
The number and size of newly established funds declined, but the overall trend is gradually improving
In the first half of 2023, 3,930 new funds were launched in the (PE/VC) market, down 12% from 4,456 new funds launched in the same period last year. During this period, new fund launches totaled $364.2 billion, a decrease of 3% year-over-year. Despite the decline in size and volume compared to last year, the second quarter performed better than the first quarter, with an overall improving trend:Specifically, new fund launches in the first quarter amounted to $161.4 billion, a decline of nearly 20% year-on-year, while the second quarter recorded $202.8 billion, an increase of 16% year-on-year.
 |
|---|
Increase in the size of RMB funds and a significant decrease in the size of foreign currency funds
In the first half of 2023, the number of new RMB funds launched was 3,840, a decrease of 13% compared to the same period last year. The total size of RMB funds reached US$339.5 billion, a 13% increase compared to the same period last year. The size of foreign currency funds was $24.7 billion, a significant decline of 67% from the previous year. Despite the increase in the number of foreign currency funds in 2023, their impact on the total size is small as most are small funds.
This trend indicates that the domestic equity investment market prefers the more conservative investment style of RMB funds:and requires a higher degree of stability in the portfolio companies. For open-source business startups in China, simply following the market buzz is no longer enough to attract investment. Technological strength and long-term growth potential become key factors in assessing whether to make further investments.
 |
|---|
 |
|---|
Economic recovery falls short of expectations and decline in overall investment volume and size
Against the macro backdrop of unstable roots of economic recovery, slowdown in overall demand, and instability in external markets, the total number of investments in the H1 equity market in 2023 will be 3,750, a year-on-year decline of 31%; the total amount of investment supplied will be USD56.9 billion, a decline of 6% compared to the same period last year. Compared to the financing side where the size of newly established funds declined by 3%, a stronger contraction has been shown on the investment side, which further illustrates the cautious sentiment of investors, which is consistent with the trend shown by international markets.
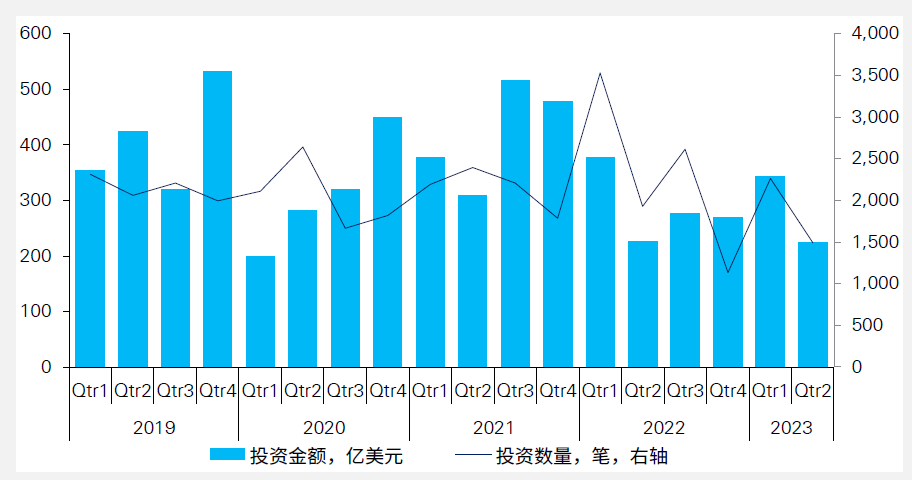 |
|---|
Open-source industry is gradually improving in all aspects of the ecosystem and is steadily growing
At present, the domestic open-source industry is experiencing the development pattern of both top-level design and industrial progress, talent reserve and technological innovation, making progress together in all aspects from laws and regulations, policy support, competition selection, and all links of the industry chain.
In terms of laws and regulations, Zhang Guofeng, deputy director of the Institute of Artificial Intelligence and Change Management at the University of International Business and Economics in Shanghai and secretary general of the Shanghai Open-source Information Technology Association on November 2, 2023, said at the media communication meeting of the 2023 Open-source Industry Ecological Conference that Shanghai's open-source industry planning and policies are in the process of being drafted and pushed forward, and that Shanghai must seize the historic opportunity to actively participate in digital governance and digital public goods international cooperation (news from The Paper); in terms of policy support, at the 2023 Global Open-source Technology Summit (GOTC), the Shanghai open-source industry service platform was officially announced to start:Shanghai Pudong Software Park signed a contract with the Linux Foundation Asia-Pacific to officially land the Linux Foundation Asia-Pacific Open-source Community Service Center, and signed a strategic cooperation agreement with OSChina to build the Shanghai open-source ecological (News from Wen Hui Bao). In terms of competition selection, China has already had a series of open-source competitions such as "China Software Open-source Innovation Competition" and "OpenHarmony Competition Training Camp", which have attracted students from Shanghai Jiaotong University, Fudan University and other domestic universities to participate in the competitions, and a large number of innovative highlights have emerged from the competitions, fully reflecting the momentum and great potential of the flourishing co-construction of the open-source ecosystem. A large number of innovative highlights emerged in the competition, fully reflecting the good momentum and great potential of the open-source ecological construction.
All segments of the open-source chain are thriving. In the field of artificial intelligence, numerous companies have open-sourced base LLMs, including Alibaba open-sourcing Tongyi Qianwen, High-Flyer Quant open-sourcing DeepSeek, and more. Startups in Baichuan Intelligence, Zhipu AI, Zero One Everything and so on have respectively released a variety of LLMs of their own training base, it is worth mentioning that these companies are favored by the capital market, respectively, in this year, one or more high-value financing. In the developer tools layer, a number of startups that are already deep in the game are joined by new players and there are already products that are trying to go global. In the foreseeable future, there are also opportunities for open-source AI applications to usher in more opportunities at the application layer.
In the area of underlying operating systems, large companies are promoting the localization of operating systems, including the Anolis OS open-source community developed by Alibaba and the openEuler community supported by the OpenAtom Open-Source Foundation. These large enterprises also have notable open-source project layouts in a number of key areas, including cloud native, big data, artificial intelligence, and front-end technologies. For example, ant-design, Ant Group's enterprise UI design tool, PaddlePaddle, Baidu's deep learning platform, and Apache Echarts, a data visualization charting library, all have a wide reach and large user base in the GitHub community.
In the big data and database industry, a number of startups are actively strategizing in response to the large and diverse data generated by domestic and international markets, as well as the growing demand for data processing. For example, PingCAP launched TiDB, a distributed relational database, and TiKV, a distributed key-value database; TDengine, a time-series database; and ShardingSphere, a distributed database middleware from SphereEx. With the development of AI technology, innovative products have emerged in the AI field, such as Zilliz's vector database developed for AI applications and Jina.ai's neural search engine, which enables searches across all types of content.
 |
|---|
ModelScope has become the first portal for domestic open source LLMs, marking the gradual growth of China's open-source AI community construction
ModelScope Community is an AI modeling community launched by Ali Dharma Institute in collaboration with the Open-source Development Committee of China Computer Federation (CCF), aiming to build a next-generation open-source model-as-a-service sharing platform, and strive to lower the threshold of AI applications. Since its launch, it has expanded rapidly:The community now has over 2,300 models, over 2.8 million developers, and over 100 million model downloads. Baichuan Intelligence, Wisdom Spectrum AI, Shanghai Artificial Intelligence Laboratory, IDEA Research Institute and other leading LLMing organizations use ModelScope as their open-source model debut platform.
The ModelScope community upholds the concept of "Model as a Service" and treats AI models as an important element of production, providing services around the model lifecycle, from model pre-training to secondary tuning and finally to model deployment. Compared to the foreign community Hugging Face, ModelScope pays more attention to domestic needs, provides a large number of Chinese models, and promotes the application of relevant AI scenes in China.
 |
|---|
The establishment and rapid development of the ModelScope community has set a benchmark for China's open-source community culture, which is conducive to further promoting the spread of open-source culture in China, attracting more creative, open-source spirit of technology creators, technology users to join, and promoting the further prosperity of China's open-source cause.
The market heat maintained in 2023, with several large investments taking place and some startups raising multiple rounds of funding in a year, reflecting the high level of investor interest. Open Source China is an open-source community platform company, including nearly 100,000 world-renowned open-source projects, under the banner of open-source community Landscape and Japan's old open-source community OSDN, and also owns the code hosting platform Gitee, which is the leading code hosting service platform in China, and has obtained a 775 million yuan of strategic financing in the B+ round; SelectDB develops and promotes open-source real-time data warehouse Apache Doris, and provides technical support and commercial services for Apache Doris users, and has obtained a new round of several hundred million yuan of financing so far. Flywheel Technology, which develops and promotes the open-source real-time data warehouse Apache Doris and provides technical support and commercial services for Apache Doris users, has obtained a new round of financing of hundreds of millions of yuan, and the total financing scale has reached nearly 1 billion yuan up to now; Lanboat Technology, which provides a new generation of cognitive intelligence platform based on NLP technology, has completed the investment of the Pre-A+ round, and the total financing scale has reached hundreds of millions of yuan in less than a year.
At present, the development of China's open-source ecosystem is still at an early stage, and the financing events in 2023 will mainly focus on round B and before, involving artificial intelligence, open-source communities, data warehouses and LLMing platforms, and other fields, with vast market opportunities.
Table 4.1 Investment and Financing of Domestic Open Source Software Startups (slide to right to view full content) (Github statistics as of December 7, 2023)| Company | Open source project | Corporate operations | Latest round of financing round | ** Amount of latest round of financing** | Time of latest round of financing | GitHub Star | GitHub Fork |
|---|---|---|---|---|---|---|---|
| Tributary Technologies | Apache APISIX | Microservices API Gateway | A + round | Millions of dollars. | June 2021 | 10.8k | 2k |
| Moby Dick Open Source | Apache DolphinScheduler | Cloud-Native DataOps Platform | Pre-A round | tens of millions of dollars | July 2022 | 9.4k | 3.5k |
| Flywheel Technologies | Apache Doris | Cloud Native Real-Time Warehouse | Pre-A round | several hundred million dollars | June 2023 | 6.5k | 1.9k |
| Even Tech | Apache HAWQ | Hadoop SQL Analysis Engine | B + round | Nearly $200 million | August 2021 | 672 | 324 |
| Tianmou Technology | Apache IoTDB | Time Series Database System | angel round (finance) | nearly a billion dollars | June 2022 | 2.8k | 750 |
| Short step information technology | Apache Kylin | Big Data online analytical processing engine | D round | $70 million. | April 2021 | 3.4k | 1.5k |
| StreamNative | Apache Pulsar | distributed message queue | A + round | - | 2023 | 12k | 3.2k |
| SphereEx | Apache ShardingSphere | Distributed Database Pluggable Ecology | Pre-A round | Nearly $10 million | January 2022 | 17.7k | 6.1k |
| Antoine Mound (AutoMQ) | automq-for-rocketmq automq-for-kafka | Streaming storage software and message queues | Angel rounds + | Tens of millions of RMB | November 2023 | 195 | 34 |
| Smart Spectrum AI | ChatGLM | Large Prophecy Model | B++++ | RMB 1.2 billion | September 2023 | 36.3k | 4.9k |
| Luchen Technology | Colossal-AI | High-Performance Enterprise AI Solutions | angel round (finance) | $6 million | September 2022 | 6.8k | 637 |
| Chatopera | cskefu | Multi-Channel Intelligent Customer Service System | angel round (finance) | millions of dollars | August 2018 | 2.2k | 742 |
| Digital Change Technology | Databend | cloud warehouse (computing) | angel round (finance) | Millions of dollars. | August 2021 | 4.8k | 500 |
| Dify.AI | Dify | LLMOps platform | fund | undisclosed | 44986 | 11.8k | 1596 |
| Image Cloud Technology | EMQX | MQTT Message Middleware | B round | 150 million | December 2020 | 10.8k | 1.9k |
| TensorChord | Envd | MLOps | seed round | Millions of dollars. | November 2022 | 1.3k | 102 |
| Stoneware Technology | FydeOS | Chromium-based operating systems | Pre-A round | tens of millions of dollars | February 2022 | 1.5k | 192 |
| Generalized intelligence | GAAS | Autonomous UAV flight program | * | undisclosed | October 2018 | 1.7k | 411 |
| GeekCode | Geekcode.cloud | cloud development environment | seed round | Millions of RMB | April 2022 | 42 | 2 |
| Gitee | git | Git Code Hosting | B + round | 775 million | July 2023 | - | * |
| Polar Fox | GitLab | DevOps Tooling Platform | A++ round | tens of millions of dollars | September 2022 | - | * |
| White Sea Technology | IDP | AI Data Development Platform | seed round | tens of millions of dollars | December 2021 | 17 | 3 |
| Ella Yunko | illa-builder | Low-code development platform | angel round (finance) | Millions of dollars. | September 2022 | 2.3k | 126 |
| Gina Technology | Jina | A multimodal neural network search framework | Series A | $30 million | November 2021 | 16.8k | 2k |
| Juicedata | JuiceFS | distributed file system (DFS) | angel round (finance) | millions of dollars | October 2018 | 7.1k | 605 |
| Harmonic Cloud Technology | Kingdling | Container Cloud Products and Solutions | B + round | over one hundred million dollars | January 2022 | 270 | 56 |
| Fly to Cloud | JumpServer | Cloud & DevOps | D + Wheel | 100 million | April 2022 | 19.5k | 4.8k |
| Talent Cloud Technology | Kubernetes | Container Cloud Platform | Mergers and Acquisitions - Bytes | undisclosed | July 2020 | 94.1k | 34.5k |
| Zeto Technology | Kunlun | distributed database | angel round (finance) | tens of millions of dollars | August 2021 | 112 | 15 |
| Deepness Technology | LinuxDeepin | Linux operating system | B round | tens of millions of dollars | April 2015 | 413 | 70 |
| Matrix origin | Matrixone | data intelligence | angel + round | Tens of millions of dollars | October 2021 | 1.3k | 212 |
| Mission Technologies | Mengzi | macrolanguage model | Pre-A+ round | several hundred million yuan (RMB) | March 2023 | 530 | 61 |
| Zilliz | milvus | vector search engine | B + round | $60 million. | August 2022 | 14.4k | 1.9k |
| Euronet | Nebula | distributed graph database | Pre-A + round | Nearly $10 million | November 2020 | 8.3k | 926 |
| PLEASURE NUMBER TECHNOLOGY | NebulaGraph | distributed graph database | Series A | Tens of millions of dollars | September 2022 | 9.7k | 1.1k |
| First class technology | oneflow | Deep Learning Framework | Mergers and Acquisitions - Meituan | - | 2023 | 4.1k | 478 |
| Facial Intelligence | OpenBMB | Large model applications | seed round | undisclosed | August 2021 | 359 | 49 |
| EasyJet Travel Cloud | OpenStack | IaaS | Round E | undisclosed | July 2021 | 4.6k | 1.6k |
| Original Language Technology | PrimiHub | privacy calculations | Angel rounds + | multi-million dollar | October 2022 | 263 | 60 |
| Good Rain Technology | Rainbond | Cloud Operating System for Enterprise Applications | Pre-A round | millions of dollars | August 2016 | 3.6k | 664 |
| Quick use of cloud computing | QuickTable | Code-free data modeling tools | * | undisclosed | August 2021 | 7 | 3 |
| Rayside Technology | RT-Thread | Internet of Things Operating System | - | undisclosed | January 2020 | 7.6k | 4.2k |
| Giant Sequoia Database | SequoiaDB | Distributed relational database | D round | several hundred million dollars | October 2020 | 305 | 115 |
| Borderless Technology | Shifu | IoT Software Development Framework | Series A | undisclosed | June 2022 | 205 | 21 |
| Dingshi Vertical | StarRocks | MPP Analytical Database | B round | undisclosed | January 2022 | 3.6k | 793 |
| Stone Atomic Technology | StoneDB | Real-time HTAP database | angel round (finance) | tens of millions of dollars | February 2022 | 639 | 100 |
| TabbyML | TabbyML | Open Source AI Programming Assistant | seed round | undisclosed | 45108 | 13.9k | 515 |
| Taiji graphic | Taichi | Digital content creation infrastructure | Series A | $50 million | February 2022 | 21.7k | 2.1k |
| Titanium-platinum data | Tapdata | Real-time data service platform | Pre-A + round | Tens of millions of dollars | July 2021 | 223 | 52 |
| Throughout data | TDengine | Time-Series Spatial Big Data Engine | B round | $47 million | May 2021 | 20.1k | 4.6k |
| PingCAP | TiDB | distributed database | Round E | undisclosed | July 2021 | 32.9k | 5.3k |
| Digital Paradise | uni-app | A Unified Front-End Framework with Vue Syntax | B + round | undisclosed | September 2018 | 37.4k | 3.4k |
| LINGO TECHNOLOGY | Vanus | Large Model Middleware | seed round | Millions of dollars. | 45108 | 2.2k | 110 |
| Future speed | Xorbits | Distributed Data Science Computing Framework | angel round (finance) | Millions of dollars. | 44958 | 933 | 58 |
| Levi Software | Zabbix | IT operations management | Series A | undisclosed | November 2022 | 2.6k | 766 |
| KodeRover | Zadig | Cloud Native Software Delivery Cloud | Pre-A round | tens of millions of dollars | August 2021 | 1.8k | 636 |
| EasySoft Tianchuang | zentaopms | Agile Project Management | Series A | tens of millions of dollars | October 2021 | 946 | 275 |
| Cloud Axis Information | ZStack | IaaS | * | undisclosed | March 2021 | 1.2k | 380 |
Table 4.2 Investment and Financing of Domestic Open-source LLMing Startups (slide to right to view full content) (Hugging Face statistics as of December 7, 2023)
| Company | Latest financing round | Date of last financing | Recent financing volume | Model Introduction | model name | likes | download |
|---|---|---|---|---|---|---|---|
| 百川智能 | A 轮 | 2023-10-17 00:00:00 | 3 亿美元 | 在知识问答、文本创作领域表现突出 | Baichuan-7B | 795 | 102k |
| Baichuan-13B-Chat | 612 | 8.29k | |||||
| Baichuan2-13B-Chat | 321 | 133k | |||||
| 智谱 AI | B+++++ 轮 | 2023-09-19 00:00:00 | 12 亿人民币 | 多模态理解、工具调用、代码解释、逻辑推理 | ChatGLM-6B | 2.67k | 56.8k |
| ChatGLM2-6B | 1.91k | 97.7k | |||||
| ChatGLM3-6B | 501 | 104k | |||||
| 元语智能 | 出资设立 | 2022-11-24 00:00:00 | — | 功能型对话大模型 | ChatYuan-large-v2 | 171 | 669 |
| ChatYuan-large-v1 | 108 | 120 | |||||
| ChatYuan-7B | 9 | 3 | |||||
| 面壁智能 | 天使轮 | 2023-04-14 00:00:00 | 数千万人民币 | 大语言模型,包括包括文字填空、文本生成、问答 | cpm-bee-10b | 158 | 19 |
| cpm-ant-10b | 22 | 12.6k | |||||
| cpm-bee-1b | 12 | 7 | |||||
| 澜舟科技 | Pre-A + 轮 | 2023-03-14 00:00:00 | 数亿人民币 | 处理多语言、多模态数据,文本理解、文本生成 | mengzi-t5-base | 41 | 1.42k |
| mengzi-bert-base | 32 | 1.46k | |||||
| mengzi-t5-base-mt | 17 | 44 | |||||
| 虎博科技 | A 轮 | 2019-03-01 00:00:00 | 3300 万美元 | 多语言任务大模型,覆盖生成、开放问答、编程、画图、翻译、头脑风暴等 15 大类能力 | tigerbot-70b-chat-v2 | 40 | 1.68k |
| tigerbot-180b-research | 33 | 12 | |||||
| tigerbot-70b-base-v1 | 15 | 3.25k | |||||
| 深势科技 | C 轮 | 2023-08-18 00:00:00 | 超 7 亿人民币 | 高精度蛋白质结构预测模型 | Uni-Fold-Data | — | 6 |
| 三维分子预训练模型 | Uni-Mol-Data | — | 3 | ||||
| 元象 XVERSE | A + 轮 | 2022-03-11 00:00:00 | 1.2 亿美元 | 大语言模型,具备认知、规划、推理和记忆能力 | XVERSE-13B | 117 | 42 |
| XVERSE-13B-Chat | 42 | 412 | |||||
| XVERSE-65B | 35 | 6.18k | |||||
| 零一万物 | 天使轮 | 2023-11-06 00:00:00 | — | 通用型 LLM,其次是图像、语音、视频等多模态能力。 | Yi-34B | 1.07k | 109k |
| Yi-6B | 303 | 26.7k | |||||
| Yi-34B-200K | 107 | 4.55k |