前言:
对于企业内部使用,通常可以通过直接登录ChatGPT或者调用API的方式处理企业日常业务,比如自动回复、客户支持、前台咨询、文书处理、数据或特征提取、代码辅助编写或办公软件代码和公式编写等,特别是经过微调后,借助ChatGPT强大的语言总结能力,往往能达到普通真实员工水平。但在国内,企业内部使用ChaGPT或调用API这类方式通常受限于注册账号、VPN、数据安全、隐私和政策等问题,实现起来不仅有一定难度也存在风险。特别是对于数据安全和数据保密有着严格要求的企业,如国企单位,直接通过VPN使用ChatGPT基本上是禁区。
因此这里主要探讨两种方法,第一种是无需通过代理而可以直接使用的方法,第二种是将开源模型直接部署到本地,前者可以访问强大的ChatGPT或GPT4,但数据安全性无法保证;后者数据可以留在本地,但部署开源模型除了需要自己拥有算力外,这些模型本身与ChatGPT的能力还存在一定差距,尽管如此,优点还是很明显的,特别是对于数据敏感行业,可以保证数据的绝对安全,并且,还可以经过微调来执行不同的任务。当然,这里提及的方法由于作者的能力有限,可能具有一定的局限性,期待后面有大神能继续补充。
ChatGPT的Web应用可以在Github搜索,找到合适的开源项目后进行部署,推荐以下两种方式,部署后无需通过代理即可访问。
-
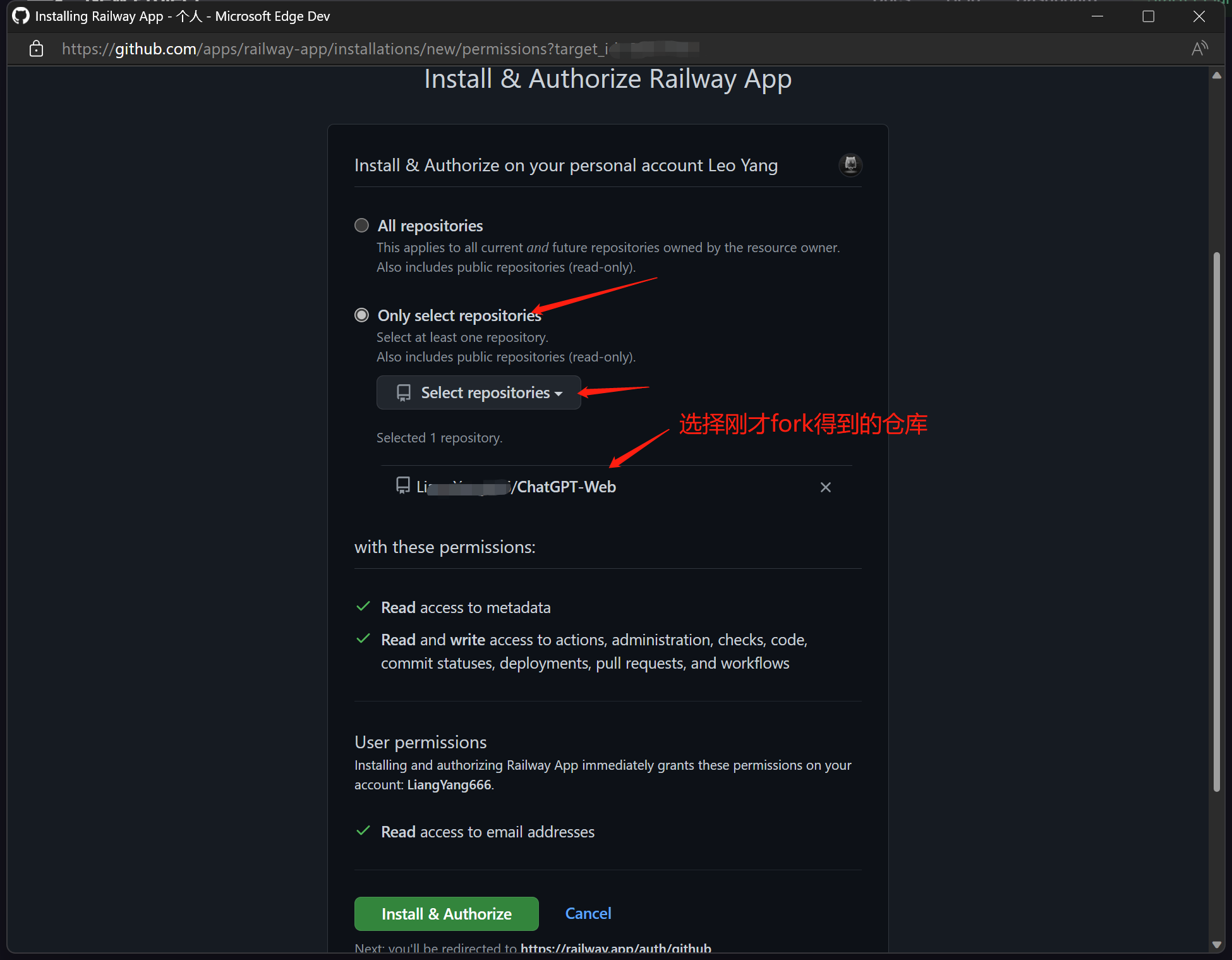
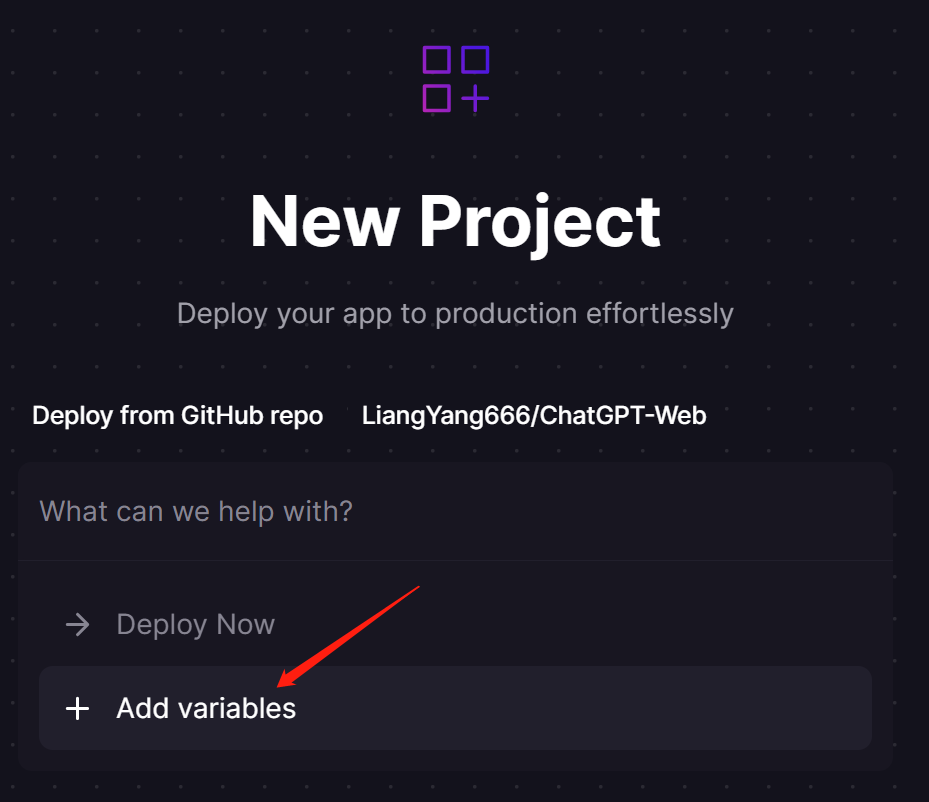
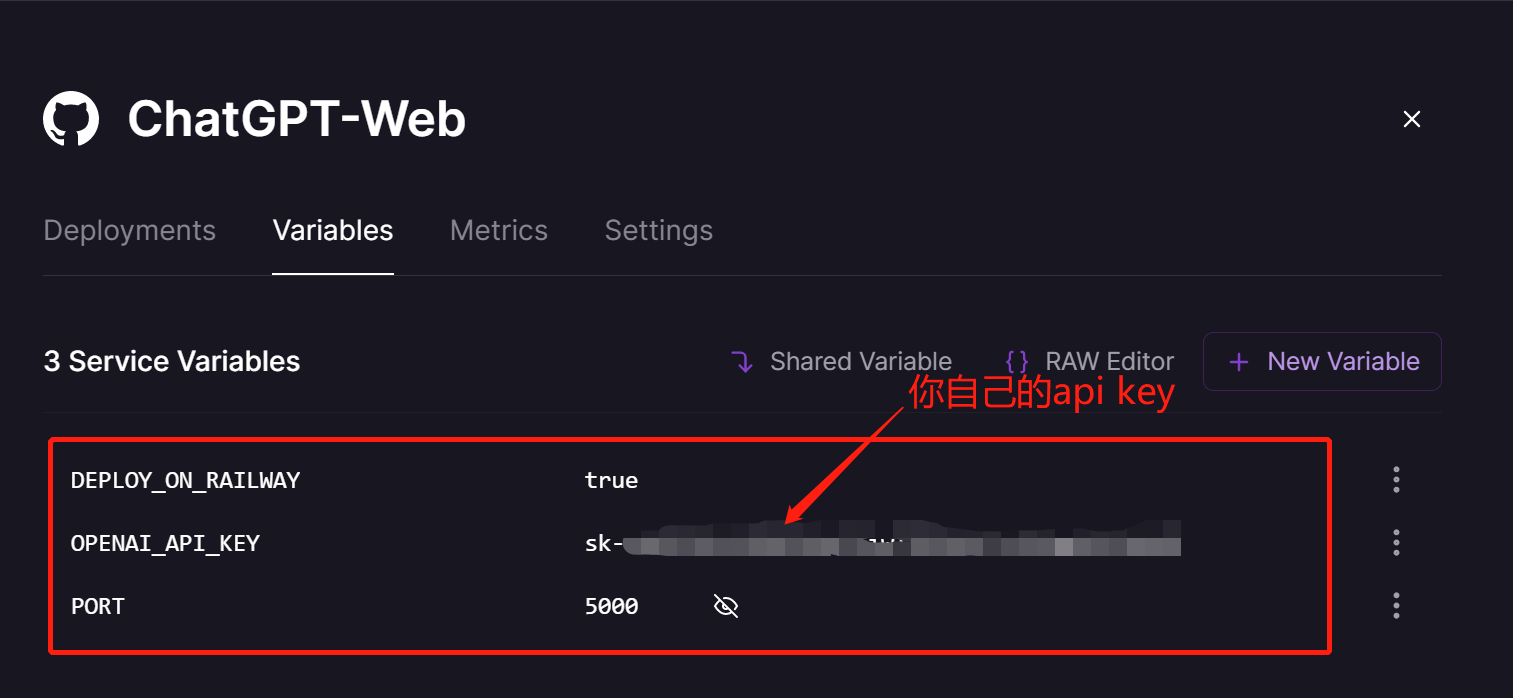
1.2当你在Github上找到合适你的ChatGPT Flask Web应用(推荐https://github.com/LiangYang666/ChatGPT-Web), 首先将代码fork到你的Github中,点击右侧Deploy on Railway,然后选择Deploy from GitHub repo,再选择Configure GitHub App,将会弹出新的窗口,在该窗口中选择Only select repositories,然后到下拉列表中选择刚才fork到你账号的仓库。
-20230514234600584.(null))
-20230514234600089.(null))
-20230514234600608.(null))
-20230514234559963.(null))
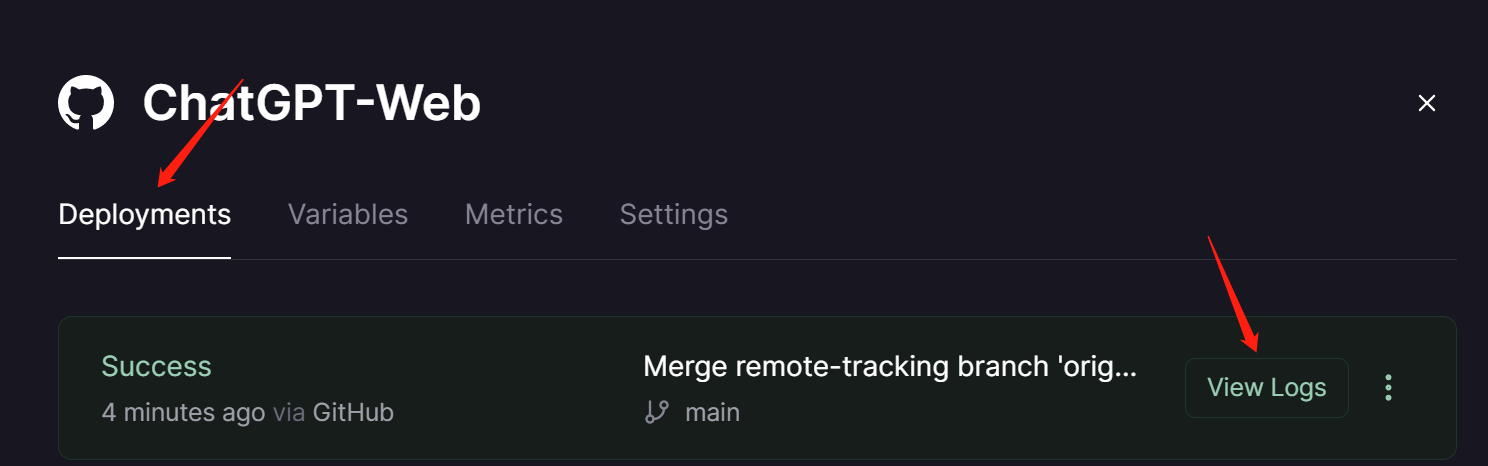
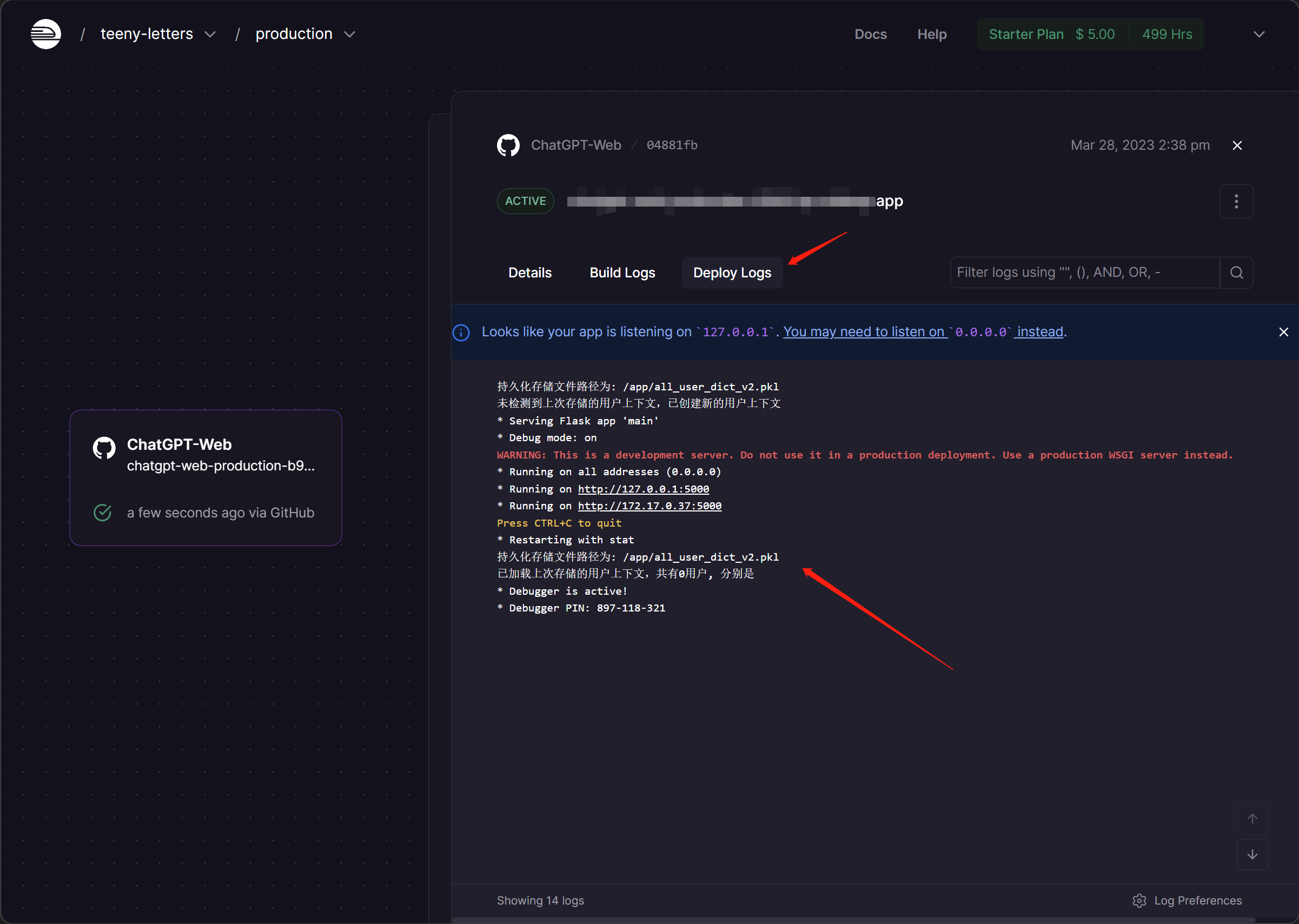
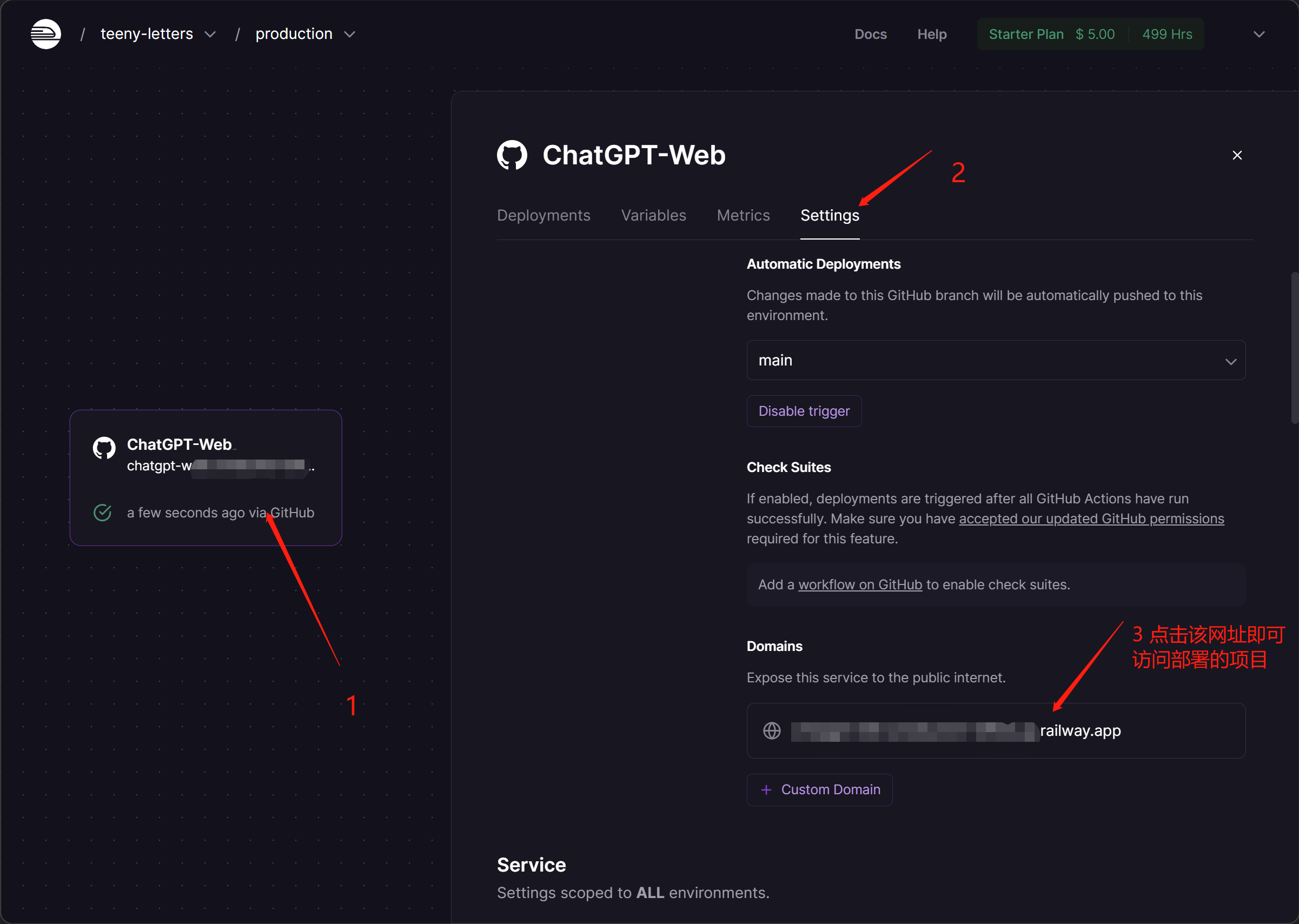
- 修改变量后会自动部署,可点击Deployments查看,还可以点击查看日志
-20230514234600107.(null))
-20230514234600769.(null))
-20230514234600793.(null))
- 完成部署后,任何网络环境下只要输入url即可访问
- 关于更新,当源仓库更新时,只需要将fork下来的仓库同步更新,railway将会自动部署更新的代码
**注意:**Railway是云容器提供商,你能够使用它部署你的应用,并使用url链接随时随地访问你的应用,Railway使用前提是你的GitHub账号满180天,绑定并验证后每月送5美元和500小时的使用时长,大概21天,即如果你的使用是不间断的,则这种方式存在不足。
Pythonanywhere可以提供Flask Web应用免费部署,速度会受到限制,如果是有规模应用的需求,则需要付费购买服务。
- 首先,访问 https://www.pythonanywhere.com/ 并注册一个免费账户。完成注册并登录后,进入 PythonAnywhere 的控制面板。
- 在控制面板的 "Web" 选项卡下,点击 "Add a new web app" 按钮。在弹出的窗口中,选择一个子域名,然后点击 "Next",如果有自己的域名也可以使用。
-20230514234600335.(null))
- 在下一个页面,选择 "Flask"。接下来,选择Python 版本(一般选择Python 3.8)。系统将自动创建一个新的 Flask 应用。
-20230514234600219.(null))
- 在 "Web" 选项卡中找到 "Code" 部分。包含一个 "Source code" 的文件夹,里面有一个名为 "mysite" 的子文件夹。点击 "Go to Directory" 按钮进入该文件夹。
- 在 "mysite" 文件夹中,删除现有的 "flask_app.py" 文件,然后使用 "Upload a file" 按钮上自己的 Flask 应用。并将Flask 应用的主文件名改为 "flask_app.py",PythonAnywhere 默认会寻找这个文件作为应用的入口。
-20230514234600401.(null))
- 在 "Web" 选项卡下,向下滚动到 "Code" 部分,点击 "Go to Directory" 按钮进入 "mysite" 文件夹。然后点击 "Open Bash console here" 按钮。在打开的终端中,运行以下命令来安装应用所需的依赖:
-20230514234600477.(null))
-
在 "Web" 选项卡下,向上滚动到页面顶部,点击 "Reload" 按钮。重启Web 应用并应用所有更改。
-
在 "Web" 选项卡下方的 "Your web apps are running at" 部分,可以看到应用的 URL。即成功部署在线。
-
如果免费版本不能满足需求,则需付费进行升级:
-20230514234600790.(null))
以我自己为例,我在ChatGPT的帮助下,编写了一个Flask应用,部署在pythonanywhere上,主要目的是让一些无法科学上网的同事使用,我设置了不同的工具来代替自由问答,工具的类型以便利工作为主,相比自由问答,这种方式即可以规避一些内容风险,也节省api消耗费用。一开始我在pythonanywhere使用免费版本,后来用的人多了,我就升级成付费账号。这些经验供参考。
-20230514234600717.(null))
-20230514234600796.(null))
-20230514234600901.(null))
本地部署LLM,推荐清华大学团队的开源项目ChatGLM,同时结合Github上的大佬开发的langchain+ChatGLM-6B基于本地知识的ChatGLM,可以实现模型的本地离线部署。有了这个前提,对数据安全有严格要求的企业可以通过这种方式,加上后期的微调或训练来建立服务企业内部的LLM。值得注意的是,ChatGLM如果商用,需要付费。ChatGLM-6B 模型有多个版本,最低显存需求为6G. ,下面的教程以https://github.com/imClumsyPanda/langchain-ChatGLM这个开源项目为基础:
-20230514234600875.(null))
-20230514234601250.(null))
- 通过CMD将项目Clone到本地
在本地建立文件夹,然后运行CMD,输入指令Git Clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
-20230514234601060.(null))
- 检查你的显卡CUDA版本
如果低于版本11则登录这个网址https://developer.nvidia.com/cuda-downloads下载更新版本,注意不要直接下载最新版本,下载11.8,即11的最新版本即可。链接https://developer.nvidia.com/cuda-11-8-0-download-archive
-20230514234601204.(null))
提示:在终端运行nividia-smi命令,可以查看显卡信息以及GPU的使用情况
- 使用 pip 安装依赖:pip install -r requirements.txt,其中 transformers 库版本推荐为 4.27.1,但理论上不低于 4.23.1 即可。这一步完成后,确保torch、torchaudio、torchvision与cuda版本正确安装。通过pip list检查:
-20230514234601008.(null))
- 从 Hugging Face Hub 下载模型到本地,需要先安装Git LFS(git-lfs.github.com ),然后运行git clone https://huggingface.co/THUDM/chatglm-6b
将模型下载到本地之后,将configs/model_config.py代码中的 THUDM/chatglm-6b 替换为你本地的 chatglm-6b 文件夹的路径,即可从本地加载模型。
- 安装 Gradio:pip install gradio,然后运行python webui.py:程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
-20230514234601055.(null))
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 部署成功后,可选择
LLM对话与知识库问答模式进行对话,支持流式对话;可手动调节保留对话历史长度、匹配知识库文段数量,可根据显存大小自行调节; - 添加
配置知识库功能,支持选择已有知识库或新建知识库,并可向知识库中新增上传文件/文件夹,使用文件上传组件选择好文件后点击上传文件并加载知识库,会将所选上传文档数据加载至知识库中,并基于更新后知识库进行问答,支持 md、pdf、docx、txt 文件格式;
补充:更多的设置请查看github源项目,另外本地部署微调部分请其他大佬继续完善,谢谢。