![]()
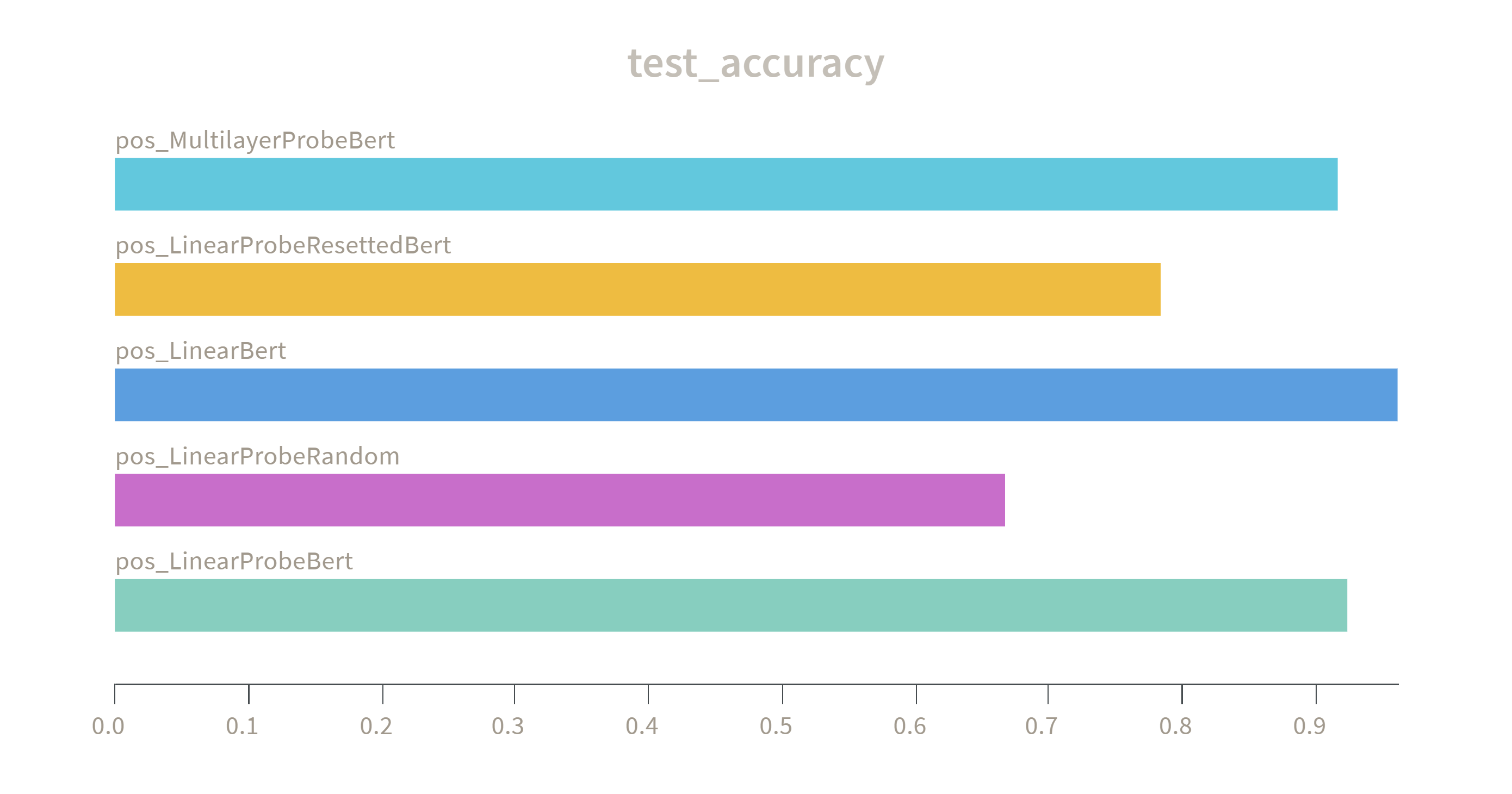
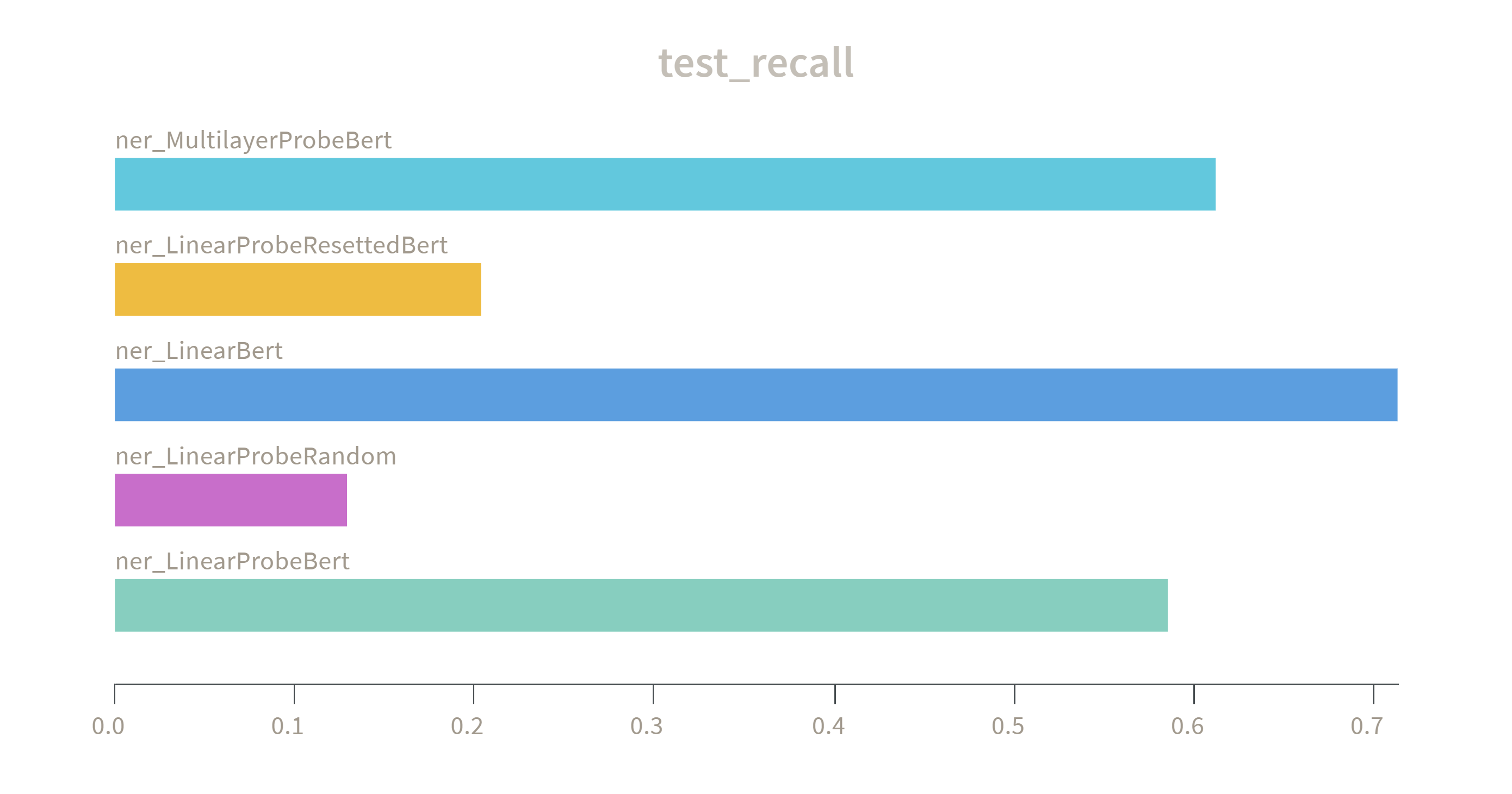
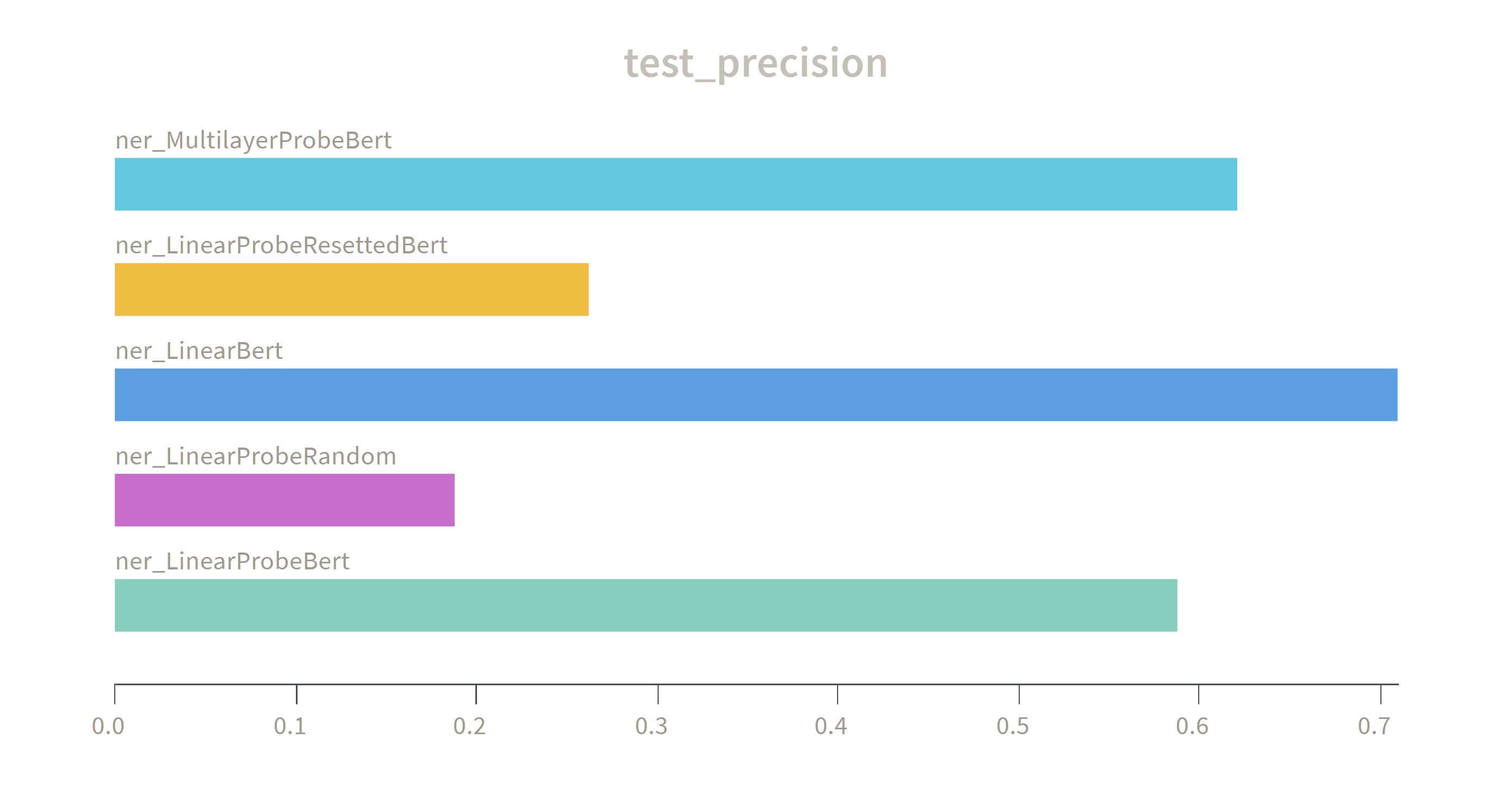
Aims to ascertain what linguistic information is captured by Bert encoded representations
Assuming Linux / Git Bash
- Clone the repo
git clone https://github.com/JlKmn/ProbingPretrainedLM.git && cd ProbingPretrainedLM - Create virtualenv
python -m venv env - Activate virtualenv
source env/bin/activate - Install requirements
pip install -r requirements.txt - Log into wandb
wandb login - Start training
python run.py --model 1 --dataset pos --epochs 5
| Epochs | Batch size | Loss rate |
|---|---|---|
| 50 | 64 | 0.01 |
The LinearBert model is an exception and was trained with an initial loss rate of 0.0001