| title | description | image |
|---|---|---|
AI art prompt guide: How to retrain YOLOv7 model with your own dataset? |
In this tutorial you will learn how to fine-tune YOLOv7 model with your own dataset in. |
By the end of this tutorial you will be able to retrain YOLOv7 model with your custom dataset and make simple prediction on your own image.
The first thing you will need to do is uploading your dataset to your Google Drive. I will use BCCD Dataset from Roboflow website, but you can use whatever data you want, but remember that it must be in a format suitable for YOLO. This article will tell you how labels should look like in YOLO format.
🔑 Important note. Remember to include information about the path to data folders in the configuration file of your data. In my case, the file structure looks like this (you can check it under the 📁 icon in the left bar).
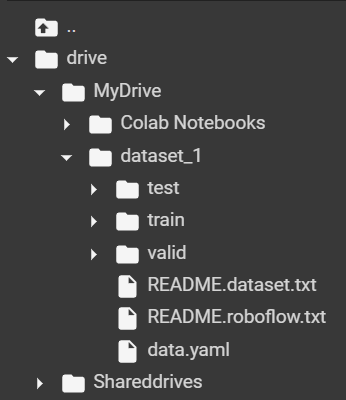
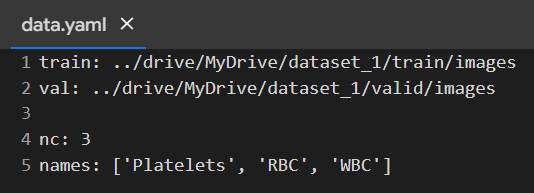
And the configuration file (data.yaml) looks like this:
Then let's go to Google Colab and create a new notebook. Of course, to speed up the training process we will change the runtime type to GPU. To do this go to 'Runtime' tab, then 'Change runtime type' and in 'Hardware accelerator' option select 'GPU' and save it.
After preparing the environment, we can start coding!
So let's start by connecting out Google Drive:
from google.colab import drive
drive.mount('/content/drive')Then we have to clone YOLOv7 repository
!git clone https://github.com/WongKinYiu/yolov7.gitLet's go to cloned directory
cd yolov7And install depedencies
!pip install -r requirements.txtNow I will download one version of YOLOv7 model. I will use YOLOv7-tiny model, but you can use any model you want. Here you can find the model list
!wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7-tiny.ptAfter downloading the model, we can start training! You can feel free to adjust the parameters below. I will use these. Remember that if you change the model type (or any other thing, like data path), you must successively change its name later in this tutorial.
!python train.py --workers 8 --device 0 --batch-size 32 --data ../drive/MyDrive/dataset_1/data.yaml --img 416 416 --cfg cfg/training/yolov7-tiny.yaml --weights 'yolov7-tiny.pt' --name yolov7-tiny --hyp data/hyp.scratch.custom.yaml --epochs 40After this step we can try to make test prediction. I will you one image from valid set. You can try to use any image you want. Just change path in --source argument.
!python detect.py --weight runs/train/yolov7-tiny/weights/best.pt --conf 0.35 --img-size 416 --source ../drive/MyDrive/dataset_1/valid/images/BloodImage_00000_jpg.rf.67c4a4312251eaa52b6ea2f2edf4855b.jpgNow let's run all cells and wait for results! The training process can take a long time depending on on the parameters you have given and the amount and size of your data.
The model will print the metrics in real time, so you can keep track of the model's performance. It is also possible to connect an experiment tracking tool - W&B - which will return the entire training report of the model.
And there is a result of test detection. Let's see it and judge for yourself if you would be satisfied after just 18 minutes of training!

{kind=link}
The YOLOv7 is a great model that increases our capabilities, and is also easy to use and has great performance. It will not be difficult to create applications that use this model and quickly achieve success. I look forward to the next models that have pushed our development forward!
I hope you had fun using YOLOv7 as well.
Stay tuned for future tutorials!
Thank you! - Jakub Misiło, Data Science Intern in New Native