|
| 1 | +gdscrapeR: scrape Glassdoor company reviews in R |
| 2 | +================ |
| 3 | + |
| 4 | +ABOUT |
| 5 | +----- |
| 6 | + |
| 7 | +**gdscrapeR** is an R package that scrapes company reviews from Glassdoor using a single function: `get_reviews`. It returns a data frame structure for holding the text data, which can be further prepped for text analytics learning projects. |
| 8 | + |
| 9 | +INSTALL & LOAD |
| 10 | +-------------- |
| 11 | + |
| 12 | +The latest version from GitHub: |
| 13 | + |
| 14 | +``` r |
| 15 | +install.packages("devtools") |
| 16 | +devtools::install_github("mguideng/gdscrapeR") |
| 17 | + |
| 18 | +library(gdscrapeR) |
| 19 | +``` |
| 20 | + |
| 21 | +USAGE |
| 22 | +----- |
| 23 | + |
| 24 | +#### Example |
| 25 | + |
| 26 | +The URL to scrape the awesome **SpaceX** company will be: [www.glassdoor.com/Reviews/SpaceX-Reviews-E40371.htm](https://www.glassdoor.com/Reviews/SpaceX-Reviews-E40371.htm). |
| 27 | + |
| 28 | +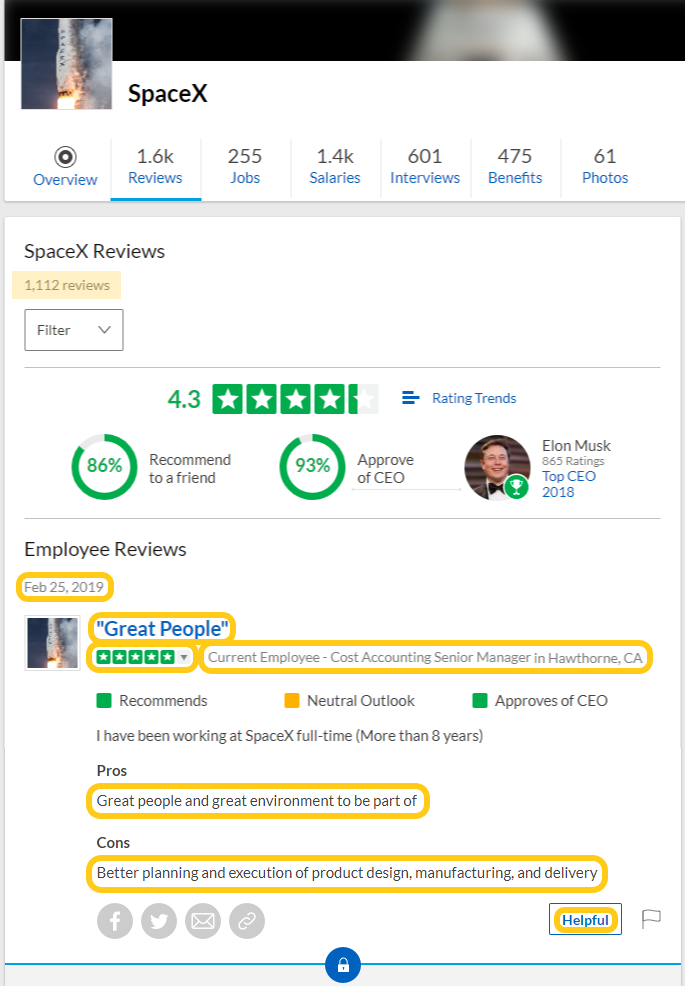 |
| 29 | + |
| 30 | +#### Function |
| 31 | + |
| 32 | +Pass the company number through the `get_reviews` function. The company number is a string representing a company's unique ID number. Identified by navigating to a company's Glassdoor reviews web page and reviewing the URL for characters between "Reviews-" and ".htm" (usually starts with an "E" and followed by digits). |
| 33 | + |
| 34 | +``` r |
| 35 | +# Create data frame of: Date, Summary, Rating, Title, Pros, Cons, Helpful |
| 36 | +df <- get_reviews(companyNum = "E40371") |
| 37 | +``` |
| 38 | + |
| 39 | +This will scrape the following variables: |
| 40 | + |
| 41 | +- Date - of when review was posted |
| 42 | +- Summary - e.g., "Great People" |
| 43 | +- Rating - star rating between 1.0 and 5.0 |
| 44 | +- Title - e.g., "Current Employee - Manager in Hawthorne, CA" |
| 45 | +- Pros - upsides of the workplace |
| 46 | +- Cons - downsides of the workplace |
| 47 | +- Helpful - count marked as being helpful, if any |
| 48 | +- (and other info related to the source link) |
| 49 | + |
| 50 | +PREP FOR TEXT ANALYTICS |
| 51 | +----------------------- |
| 52 | + |
| 53 | +#### RegEx |
| 54 | + |
| 55 | +Use regular expressions to clean and extract additional variables: |
| 56 | + |
| 57 | +- Primary Key (uniquely identify rows 1 to N reviewers, sorted from first to last by date) |
| 58 | +- Year (from Date) |
| 59 | +- Location (e.g., Hawthorne CA) |
| 60 | +- Position (e.g., Manager) |
| 61 | +- Status (current or former employee) |
| 62 | + |
| 63 | +``` r |
| 64 | +# Packages |
| 65 | +library(stringr) # pattern matching functions |
| 66 | + |
| 67 | +# Add: PriKey |
| 68 | +df$rev.pk <- as.numeric(rownames(df)) |
| 69 | + |
| 70 | +# Extract: Year, Position, Location, Status |
| 71 | +df$rev.year <- as.numeric(sub(".*, ","", df$rev.date)) |
| 72 | + |
| 73 | +df$rev.pos <- sub(".* Employee - ", "", df$rev.title) |
| 74 | +df$rev.pos <- sub(" in .*", "", df$rev.pos) |
| 75 | + |
| 76 | +df$rev.loc <- sub(".*\\ in ", "", df$rev.title) |
| 77 | +df$rev.loc <- ifelse(df$rev.loc %in% |
| 78 | + (grep("Former Employee|Current Employee", df$rev.loc, value = T)), |
| 79 | + "Not Given", df$rev.loc) |
| 80 | + |
| 81 | +df$rev.stat <- str_extract(df$rev.title, ".* Employee -") |
| 82 | +df$rev.stat <- sub(" Employee -", "", df$rev.stat) |
| 83 | + |
| 84 | +# Clean: Pros, Cons, Helpful |
| 85 | +df$rev.pros <- gsub("&", "&", df$rev.pros) |
| 86 | +df$rev.cons <- gsub("&", "&", df$rev.cons) |
| 87 | +df$rev.helpf <- as.numeric(gsub("\\D", "", df$rev.helpf)) |
| 88 | + |
| 89 | +# Export to csv |
| 90 | +write.csv(df, "df-results.csv", row.names = F) |
| 91 | +``` |
| 92 | + |
| 93 | +#### Result |
| 94 | + |
| 95 | +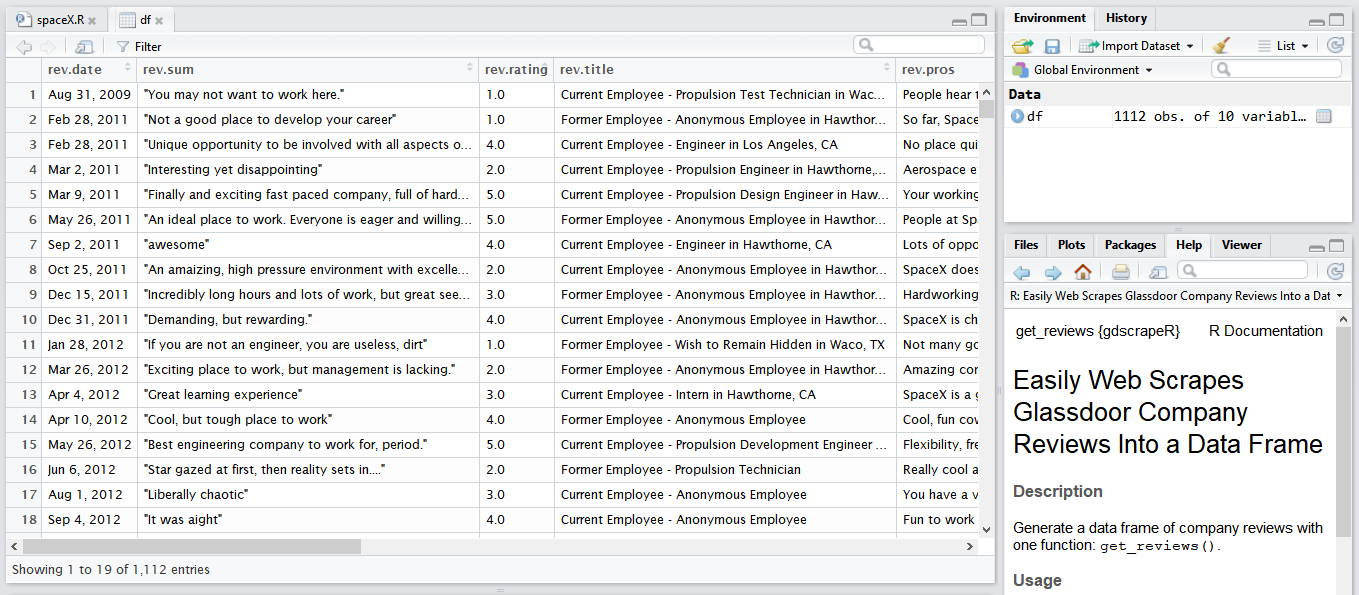 |
| 96 | + |
| 97 | +#### Exploration ideas |
| 98 | + |
| 99 | +`gdscrapeR` is for learning purposes only. Analyze the unstructured text, extract relevant information, and transform it into useful insights. |
| 100 | + |
| 101 | +- Apply Natural Language Processing (NLP) methods to show what is being written about the most. |
| 102 | +- Sentiment analysis by categorizing the text data to determine whether a review is considered positive, negative, or neutral as a way of deriving the emotions and attitudes of employees. Here's a sample project: ["Text Mining Company Reviews (in R) - Case of MBB Consulting"](https://mguideng.github.io/2018-07-16-text-mining-glassdoor-big3/). |
| 103 | +- Create a metrics profile for a company to track how star rating distributions are changing over time. |
| 104 | +- The ["Text Mining with R" book](https://www.tidytextmining.com/) by Julia Silge and David Robinson is highly recommended for further ideas. |
| 105 | + |
| 106 | +**If you find this package useful, feel free to star :star: it. Thanks for visiting :heart: .** |
| 107 | + |
| 108 | +NOTES |
| 109 | +----- |
| 110 | + |
| 111 | +- Uses the `rvest` and `purrr` packages to make it easy to scrape company reviews into a data frame. |
| 112 | +- Site will change often. Errors due to CSS selector changes are shown as some variation of *"Error in 1:maxResults : argument of length 0"* or *"Error in data.frame(), : arguments imply differing number of rows: 0, 1"*. |
| 113 | + - Try it again later. |
| 114 | + - It's straightforward to work around them if you know R and how `rvest` and `purrr` work. Copy the `get_reviews` function code and paste it into an R script that you can modify to update the selector(s) in the meantime. For more on this, see the demo write-up: ["It's Harvesting Season - Scraping Ripe Data"](https://mguideng.github.io/2018-08-01-rvesting-glassdoor/). |
| 115 | +- Be polite. |
| 116 | + - A system sleeper is built in so there will be delays to slow down the scraper (expect ~1 minute for every 100 reviews). |
| 117 | + - Also, saving the dataframe to avoid redundant scraping sessions is suggested. |
| 118 | +- To contact maintainer: Maria Guideng `[imlearningthethings at gmail]`. |
0 commit comments