#LARM (Locality Aware Roofline Model)
The ever growing complexity of high performance computing systems imposes significant challenges to exploit as much as possible their computational and communication resources. Recently, the Cache-aware Roofline Model has gained popularity due to its simplicity modeling multi-cores with complex memory hierarchy, characterizing applications' bottlenecks, and quantifying achieved or remaining improvements. With this project, we push this model a step further to model NUMA and heterogeneous memories with a handy tool.
The repository contains the material to build the benchmark tool, the library to collect roofline metrics of your application, and finally a script to present the results.
The tool is able to benchmark several types of micro-operations: mul, add, fma, mad, load, load_nt, store, store_nt, 2ld1st, copy, explained later.
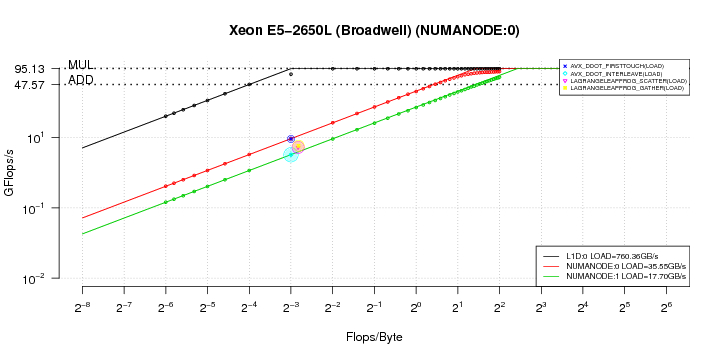
This plot shows load instruction rooflines (lines) and validation kernels (points) hitting the measured bandwidth. Additionnally, some application monitored with the librfsampling of the project are represented on the chart modeling a single memory location of the system. This output was obtained with the plot script: plot_roofs.R
plot_roofs.R -i joe0.roofs -d kernels.roofs -b 'L1d:0|load,L1d:0|2LD1ST,NUMANode:0|load,NUMANode:1|load,NUMANode:0|2LD1ST,NUMANode:1|2LD1ST' -f 'load|ddot,load|lagrange' -v -t "Xeon E5-2650L (Broadwell)"
###Set Up
git clone https://github.com/NicolasDenoyelle/LARM-Locality-Aware-Roofline-Model-.git
cd LARM-Locality-Aware-Roofline-Model-/src
make
Several options can be set in Makefile
-
LAST=repeat the benchmark to make it last LAST milliseconds. Making longer benchmarks can give more stable results. -
N_SAMPLES=Number of sample to take for each memory benchmark. The samples have an increasing size, and size bounds are automatically found according to memory sizes. -
PAPI=noChange to yes to compile librfsampling with PAPI support. This library allows model some applications part in the roofline chart. The library is compiled by default without PAPI and flop and byte count must be set by the wise user. With the PAPI support flop and byte count is retrieved with hardware counters. -
OMP_FLAG=Change to your compiler openmp flag to enable parallel benchmark.
###Requirements
- This soft requires a recent enough hwloc library to be installed (ABI 2.0).
- The library using hardware counters uses PAPI.
- For now, it only works with intel processors but one can implement the interface MSC.h with other architectures code.
- A gcc compiler on the machine running the validation benchmarks (
roofline -v). Validation micro benchmarks are built, compiled and run on the fly during plateform evaluation. - R to use the plot script.
Generally speaking, if you want to get relevant results on such benchmarks, you have to assert that options like turbo-boost are disabled and the cpu frequency is set. Therefore, it is required to inform the tool about the frequency set by exporting the variable CPU_FREQ (The frequency of your CPU in Hertz)
export CPU_FREQ=2100000000
Here you are ready to play
###Usage
-
Display usage:
./roofline -h -
Running plateform benchmark:
./roofline -
Running benchmark with validation
./roofline -v
Validation consists in writing a list of load/store operations, interleaved with mul/add operations for several arithmetic intensities.
-
Run benchmark for precise types of micro operation:
./roofline -t "fma|load|store"- fma: use fuse multiply add instructions for fpeak benchmarks (if architecture is capable of it)
- mul: use multiply instructions for fpeak benchmarks.
- add: use addition instructions for fpeak benchmarks.
- mad: use interleaved additions/multiply instructions for fpeak benchmarks.
- load: use load instructions for bandwidth benchmarks.
- store: use store instructions for bandwidth benchmarks.
- 2ld1st: Interleave one store each two loads. On some architectures, there are two load channels on L1 cache and one store channel that can be used simulateously. Using those simultaneously may yields better bandwidth.
- load_nt: use streaming load instructions for bandwidth benchmarks. The streaming instructions gives usually better memory bandwidth above caches because they bypass caches. It does not make much sense to use them for caches though you can. In case you see better results with streaming instructions instead of regular instructions on caches, they are rather due to measures variation than better hardware efficiency.
- store_nt: use streaming store instructions for bandwidth benchmarks.
-
plot help:
./utils/plot_roofs.R -h -
plot output:
./utils/plot_roofs.R -i input
###Library The library librfsampling defines a small set of C functions to project code samples in the model.
####Library Requirements
- To compile the librfsampling library with PAPI support, you have to install the PAPI library.
- The hardware counters work only on broadwell processors with FP_ARITH counters. Older processor from Intel have no existing or accurate flops counter.
- If you compile the library without PAPI support, you will have to set flop and byte count manually. This requires a deep understanding of the model arithmetic intensity.
####Library Setup
- In order to use the library you have to copy the compiled file
librfsampling.soin a directory pointed out byLD_LIBRARY_PATHvariable or by your compiler linker flag (-Lpath/to/librfsampling.so). - You also have to copy the file
sampling.hin a directory pointed out byC_INCLUDE_PATHor by your compiler header flag (-Ipath/to/sampling.h). - The library is very lightweight and all the functions can be found in the header sampling.h
- Compile your code using the library with
-lrfsamplingflag.
####Library example
#include <omp.h>
#include <sampling.h>
roofline_sampling_init("my_CARM_result.roofs", TYPE_LOAD, ROOFLINE_NUMA);
#pragma omp parallel
{
void * sample = roofline_sampling_start(0, hypothetic_flop_count, hypothetic_byte_count);
...
/* The code to evaluate */
...
roofline_sampling_stop (sample, "my_test_code");
}
roofline_sampling_fini();
Then plot the results of "my_CARM_result.roofs" in a handsome chart !