From 9b3b039cb9f9a7628580db4463d6d41a2770e119 Mon Sep 17 00:00:00 2001
From: o5-null <1517808818@qq.com>
Date: Thu, 16 Feb 2023 01:19:22 +0800
Subject: [PATCH] =?UTF-8?q?=E9=87=8D=E6=9E=84=E4=BA=86=E5=89=8D=E7=AB=AF?=
=?UTF-8?q?=E5=92=8Clofter=E4=B8=93=E7=94=A8=E7=9A=84=E4=B8=8B=E8=BD=BD?=
=?UTF-8?q?=E5=BC=95=E6=93=8E?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.gitignore | 7 +
README.md | 30 ++-
core.py | 116 +++++++++++-
loftersaver_130_GUI.py | 348 ++++++++++++++++++++++++++++++++++
"\345\244\207\346\263\250.md" | 5 +
5 files changed, 478 insertions(+), 28 deletions(-)
create mode 100644 .gitignore
create mode 100644 loftersaver_130_GUI.py
create mode 100644 "\345\244\207\346\263\250.md"
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..799f045
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,7 @@
+__pycache__
+*.json
+*.html
+*.obj
+build
+dist
+__pycache__
diff --git a/README.md b/README.md
index f5fef16..9711012 100644
--- a/README.md
+++ b/README.md
@@ -2,26 +2,20 @@
本软件是为了解决lofter批量下载问题而设计的
使用纯python编写
## 软件特性
-1.使用readability解析引擎驱动,对于网站正文提取无需手动进行适配,支持几乎所有互联网网页
-2.使用remi实现webui,具有良好跨平台性
+1.反编译了lofter客户端,直接使用api获取内容,速度极快
+2.使用pywebio实现webui,具有良好跨平台性
3.网页本地化保存支持良好,离线保存网页与原网页基本毫无区别
-4.使用aria实现图片高并发下载,速度极快,支持下载原图
-5.支持批量下载,可解析作者、tag、标签等
-6.可导入css样式表自定义webui样式
+4.支持批量下载,可解析作者、tag、标签等
+5.可导入css样式表自定义webui样式
6.(未实现)下载完成可转换成电子书格式
## 软件使用
1.下载软件
-2安装aria
-3.根据实际情况启动服务器版或桌面版
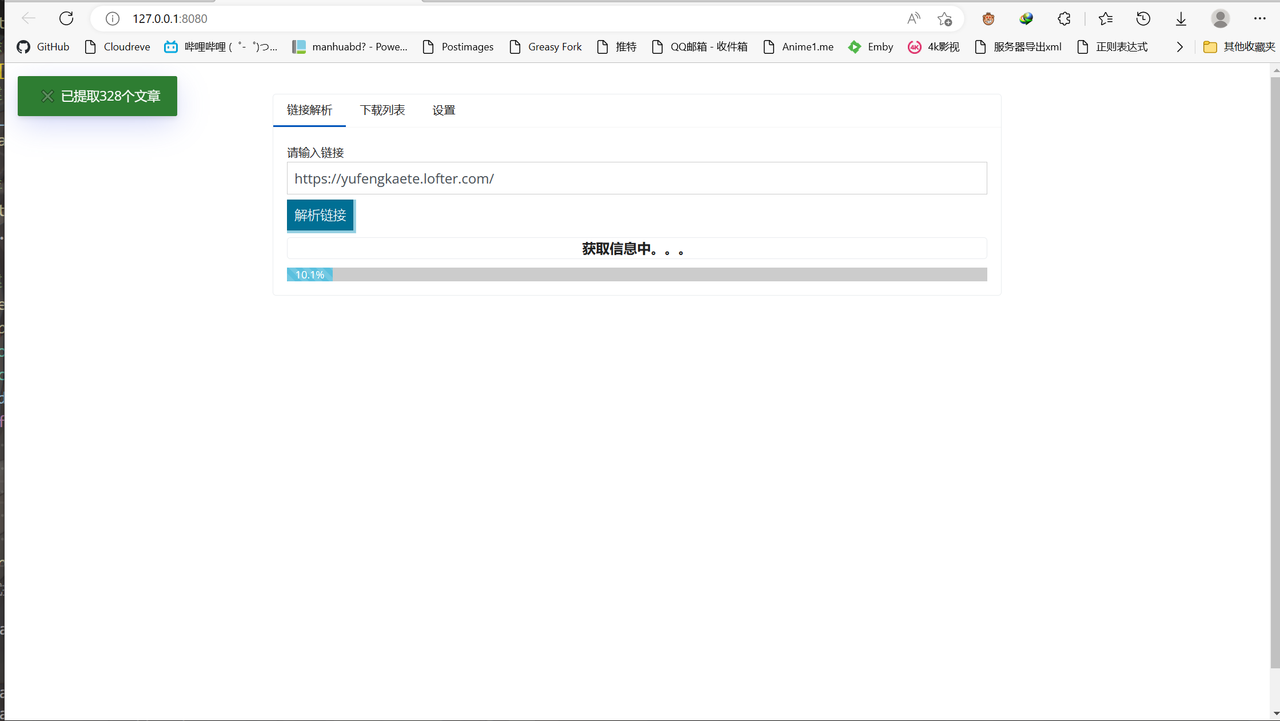
-4.输入解析地址,按**解析链接**按钮开始解析
-
-
-ps:软件解析过程中不会有加载进度条,请耐心等待,加载完成下载列表会显示
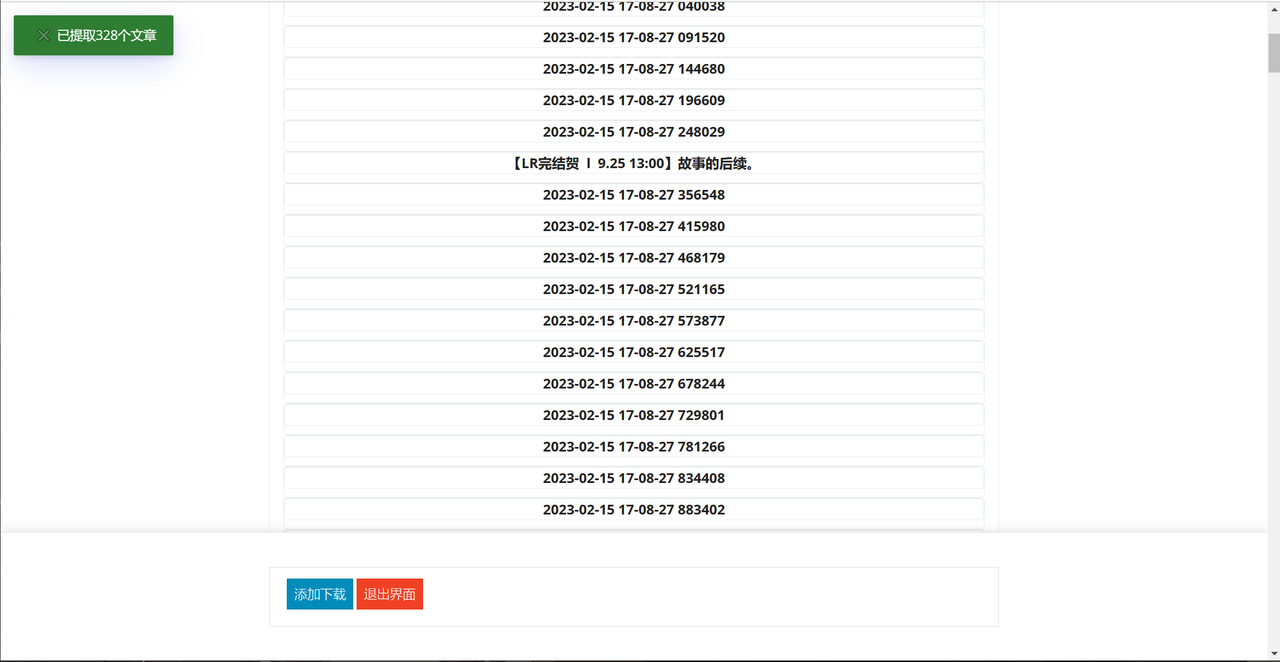
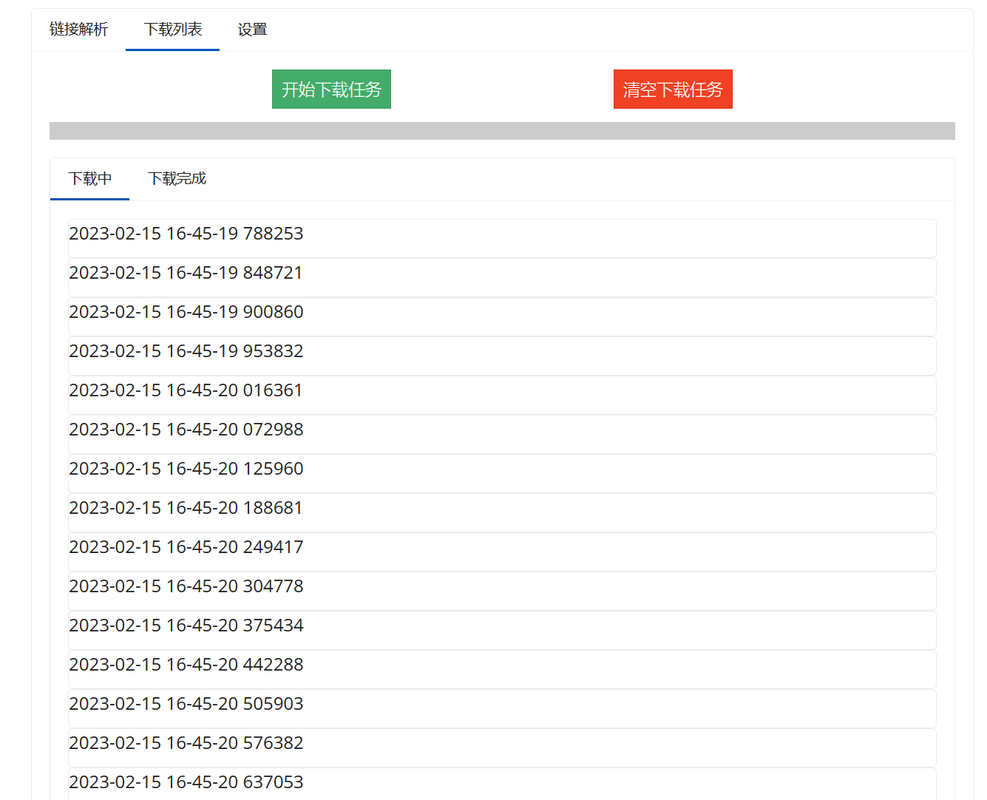
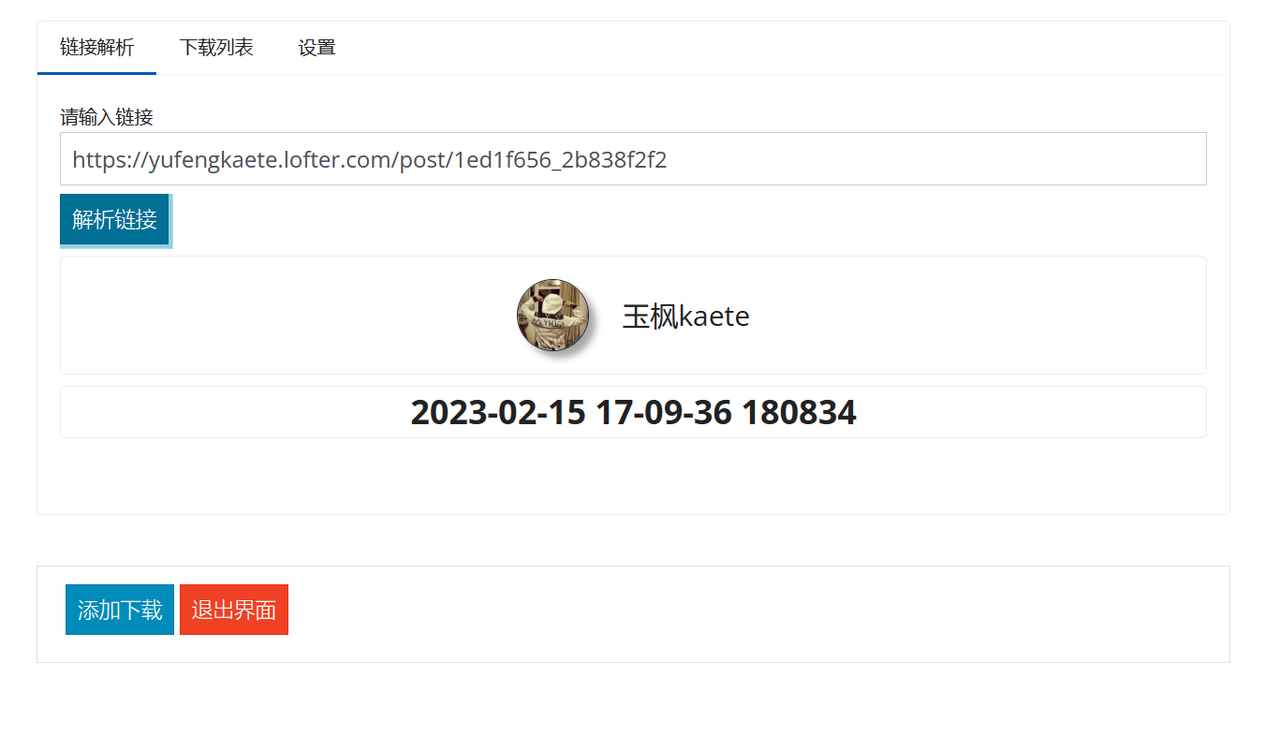
-## 软件使用情况展示
-
-
-
-#### 下载文件展示
-
-
+[](https://postimg.cc/jCqVpZ7C)
+[](https://postimg.cc/kVNZZbMx)
+[](https://postimg.cc/PN5c3Jgw)
+[](https://postimg.cc/qhMm5D5T)
+[](https://postimg.cc/BtRgTv4s)
+
+
+
### 当前版本为dev内测版,有问题请向开发者询问 qq1517808818
diff --git a/core.py b/core.py
index e968724..1c3a11d 100644
--- a/core.py
+++ b/core.py
@@ -2,12 +2,17 @@
from readability import Document
from bs4 import BeautifulSoup
from tqdm import tqdm
+import wget
+import unicodedata#标准编码库
from pathlib import Path
import re
import os
+
+from datetime import datetime
import time
import json
+import pickle#数据持久化
brower = requests.Session() #创建浏览器
@@ -19,6 +24,8 @@
}
api_url = 'http://url2api.applinzi.com/' # URL2Article API地址,使用体验版或购买独享资源
+api_headers = {'User-Agent': 'LOFTER-Android 7.3.4 (PRA-AL00X; Android 8.0.0; null) WIFI'}
+api_cookies = {'Cookie': 'usertrack=dZPgEWPiVMNF6YfwJEIHAg==; NEWTOKEN=ZGUyN2NjOTE1YzE2ZmIwOTM0ZGU5MTIwYjJkZjBhNDJkMDI3YTliNGE4M2ZhMjkxYmY3ODZkN2VkNWRhZTBkNDE1Y2NkNDg4ZDUyMDAzZWNmNWUyMjgwNWY5NTQ2MGZm; NTESwebSI=DFD9B345542ECECF843D7DC7D99313F2.lofter-tomcat-docker-lftpro-3-avkys-cd6be-774f69457-rggg6-8080'}
#get
def gets(url):
@@ -30,6 +37,24 @@ def gets(url):
if response.status_code == 404:
print('网址不存在')
return 'null'
+ print(response.status_code)
+ print(url+'访问出错')
+ time.sleep(1)
+ gets(url)
+ except:
+ print(url+'访问崩溃,请检查网络')
+ time.sleep(1)
+ gets(url)
+
+def api_post(url):
+ try:
+ #cj = {i.split("=")[0]:i.split("=")[1] for i in api_cookies.split(";")}
+ response = brower.post(url=url,headers=api_headers,cookies=api_cookies,timeout=5)
+ if response.status_code == 200:
+ return response
+ if response.status_code == 404:
+ print('网址不存在')
+ return 'null'
print(response)
print(url+'访问出错')
time.sleep(1)
@@ -41,10 +66,11 @@ def gets(url):
#清洗文件名
def clean_name(strs):
- strs = re.sub(r'/:<>?/\^|@& ', "",strs)
+ strs = unicodedata.normalize('NFKD',strs)
+ strs = re.sub(r'/<>?/\^|@& ', "",strs)
strs = strs.replace('@','')
strs = strs.replace('&','')
- strs = strs.replace(' ','_')
+ strs = strs.replace(':',':')
# 去除不可见字符
return strs
@@ -62,14 +88,42 @@ def dic(info):
#获取与修改下载列表
def downlist(set='null'):
if set == 'null':
- if os.path.exists('downlist.json'):
- with open('downlist.json','r') as f:
- list = json.load(f)
+ if os.path.exists('downlist.obj') and os.path.getsize('downlist.obj') > 0:
+ with open('downlist.obj','rb') as f:
+ list = pickle.load(f)
return list
+ else :
+ with open('downlist.obj','wb') as f:
+ pickle.dump([],f)
return []
else:
- with open('downlist.json','w') as f:
- json.dump(set,f)
+ with open('downlist.obj','wb') as f:
+ pickle.dump(set,f)
+
+#获取与修改完成列表
+def finlist(set='null'):
+ if set == 'null':
+ if os.path.exists('finlist.obj') and os.path.getsize('finlist.obj') > 0:
+ with open('finlist.obj','rb') as f:
+ list = pickle.load(f)
+ return list
+ else :
+ with open('finlist.obj','wb') as f:
+ pickle.dump([],f)
+ return []
+ else:
+ with open('finlist.obj','wb') as f:
+ pickle.dump(set,f)
+
+#删除下载任务
+def del_downlist(info):
+ old_downlist = downlist()
+ new_downlist = []
+ for a in old_downlist:#查找一致id的内容并排除
+ if a['targetblogid'] != info['targetblogid'] or a['postid'] != info['postid']:
+ new_downlist.append(a)
+ downlist(new_downlist)#重新写入下载列表
+ return
def get_set():
with open('set.json','r') as f:
@@ -140,7 +194,7 @@ def down_img(img,save_dir):
with open(Path(save_dir+'/url.txt'),'w') as f:
f.write(sep.join(img))
for url in tqdm(img,desc='图片下载中:',unit='img'):
- os.system('wget -N -nv '+url+' -P '+save_dir)
+ wget.download(url,save_dir)
#os.system('aria2c --quiet true -j 10 --continue=true --dir="'+str(Path(save_dir))+'" -i "'+str(Path(save_dir+'/url.txt'))+'"')
return
@@ -196,6 +250,47 @@ def lofter_info(data):
print(info['title'])
return info
+#lofter客户端api解析引擎
+def lofter_api(targetblogid:int,postid:int) -> dict:
+ """
+ 输入targetblogid,blogid
+ 调用安卓客户端oldapi
+
+ status = api状态
+ msg = 状态信息
+ title = 文章标题
+ writer name = 作者名
+ writer img = 作者头图
+ info = 文章内容
+ img = 图片链接
+ """
+
+ json_answer = api_post('https://api.lofter.com/oldapi/post/detail.api?product=lofter-android-7.3.4&targetblogid='+str(targetblogid)+'&supportposttypes=1,2,3,4,5,6&offset=0&postdigestnew=1&postid='+str(postid)+'&blogId='+str(targetblogid)+'&checkpwd=1&needgetpoststat=1').json()
+ info = {}
+ info['targetblogid'] = targetblogid
+ info['postid'] = postid
+ info['status'] = json_answer['meta']['status']#api状态
+ info['msg'] = json_answer['meta']['msg']#状态信息
+ try:#某些特殊玩意根本没有标题参数
+ info['title'] = json_answer['response']['posts'][0]['post']['title']#文章标题
+ except:
+ info['title'] = datetime.utcnow().strftime('%Y-%m-%d %H-%M-%S %f')
+ if info['title'] == '':
+ info['title'] = datetime.utcnow().strftime('%Y-%m-%d %H-%M-%S %f')
+ info['writer'] = {}
+ info['writer']['name'] = json_answer['response']['posts'][0]['post']['blogInfo']['blogNickName']#作者名
+ info['writer']['img'] = json_answer['response']['posts'][0]['post']['blogInfo']['bigAvaImg']#作者头图
+ info['info'] = json_answer['response']['posts'][0]['post']['content']#文章内容
+ info['type'] = json_answer['response']['posts'][0]['post']['type']#文章类型 1为文档 2为含有图片 3为音乐(?
+ info['img'] = []
+ if info['type'] == 2:
+ for a in json.loads(json_answer['response']['posts'][0]['post']['photoLinks']):#图片链接
+ info['img'].append(a['raw'])
+ #os.makedirs(Path('bug'),exist_ok=True)#创建临时文件夹
+ #save_json(str(Path('bug/'+str(targetblogid)+'_'+str(postid)+'.json')),json_answer)
+ #print('出现错误')
+ return info
+
#提取页面文章列表
def lofter_post_list(url):
page = 0
@@ -221,7 +316,7 @@ def lofter_post_list(url):
print('共提取'+str(len(post))+'个文章')
return post
-def lofter_down(data,local_dir):
+def down(data,local_dir):
text = clean_1(data['html']) #清洗文本
#检查是否有有效文本信息
test = text['txt'].replace('\n','')
@@ -278,4 +373,5 @@ def lofter_down(data,local_dir):
save_txt(Path(save_dir+'/index.txt'),data['txt'])
print('索引链接创建完成')
print('本地化完成')
- return
\ No newline at end of file
+ return
+
diff --git a/loftersaver_130_GUI.py b/loftersaver_130_GUI.py
new file mode 100644
index 0000000..7a0edea
--- /dev/null
+++ b/loftersaver_130_GUI.py
@@ -0,0 +1,348 @@
+from pathlib import Path
+import os
+from datetime import datetime
+import time
+import sys
+import re
+import requests
+
+import threading #多进程库
+from tqdm import tqdm
+import pywebio as io
+out = io.output
+ioin = io.input
+pin = io.pin
+
+import core#导入核心
+
+# 初始化
+local_time = time.strftime("%y/%m/%d", time.localtime())
+if not Path('set.json').exists():
+ local_dir = str(Path(str(Path.cwd().resolve())+'/Download'))
+ set = {}
+ set['download'] = local_dir
+ core.save_set(set)
+if Path('set.json').exists():
+ set = core.get_set()
+
+#开始下载任务
+def start_download():
+ list = core.downlist()#获取下载列表
+ while len(list) != 0:#当下载任务不为0时
+ lofter_info_down(list[0],set['download'])#下载任务
+ time.sleep(0.3)
+ core.del_downlist(list[0])#删除下载完成的任务
+
+ #添加到下载完成列表
+ fin = core.finlist()
+ fin.append(list[0])
+ core.finlist(fin)
+
+ #刷新下载进度条
+ value = len(fin) / len(list)
+ out.set_processbar('down_process',value)
+ list = core.downlist()#刷新下载任务
+ out.toast('下载任务已清空', position='center', color='success', duration=0)#显示完成通知
+ show_down_list()
+ show_fin_list()
+ return
+
+#显示下载列表
+def show_down_list():
+ """
+ 处理下载列表并显示
+ """
+ #加载任务列表
+ data_list = core.downlist()#获取需要下载的列表
+ if len(data_list) == 0:#如果列表为空则等待
+ time.sleep(1)
+ show_down_list()
+ show_list = []
+ #初始化
+ for list_one in data_list:#遍历创建下载列表
+ a = out.put_row([
+ out.put_text(list_one['title']),#TODO 创建标题
+ #out.put_button('暂停',onclick=lambda:core.patch_pause_task(list_one['control_name']),color='warning'),#暂停按钮
+ ]).style('border: 1px solid #e9ecef;border-radius: .25rem')
+ # 创建显示
+ show_list.append(a)
+ #显示列表
+ with out.use_scope('down_work',clear=True):#清除域
+ out.put_column(show_list)
+
+ #刷新状态
+ while 1==1:
+ time.sleep(1)#等待1秒
+ #如果下载列表更新
+ if data_list != core.downlist():#如果现在维护的和存储的不一样
+ show_down_list()
+
+#显示下载列表
+def show_fin_list():
+ """
+ 处理下载列表并显示
+ """
+ #加载任务列表
+ data_list = core.finlist()#获取需要下载的列表
+ if len(data_list) == 0:#如果列表为空则等待
+ time.sleep(1)
+ show_fin_list()
+ show_list = []
+ #初始化
+ for list_one in data_list:#遍历创建下载列表
+ a = out.put_row([
+ out.put_text(list_one['title']),#TODO 创建标题
+ #out.put_button('暂停',onclick=lambda:core.patch_pause_task(list_one['control_name']),color='warning'),#暂停按钮
+ ]).style('border: 1px solid #e9ecef;border-radius: .25rem')
+ # 创建显示
+ show_list.append(a)
+ #显示列表
+ with out.use_scope('down_fin',clear=True):#清除域
+ out.put_column(show_list)
+
+ #刷新状态
+ while 1==1:
+ time.sleep(1)#等待1秒
+ #如果下载列表更新
+ if data_list != core.finlist():#如果现在维护的和存储的不一样
+ show_fin_list()
+
+#下载内容
+def lofter_info_down(info,local_dir):
+ text = info['info'] #清洗文本
+ #获取txt格式
+ txt = text.replace('','\n')#doc.summary()为提取的网页正文但包含html控制符,这一步是替换换行符
+ txt = re.sub(r']*>', '', txt) #这一步是去掉<****>内的内容
+ #获取html格式
+ html = text.replace('\n','')#去除换行符
+ print('数据分析完毕')
+ #去除错误编码
+ info['title'] = core.clean_name(info['title'])
+ #创建根文件夹
+ save_dir =str(Path(str(local_dir)+'/'+core.clean_name(info['title'])).resolve())
+ os.makedirs(save_dir,exist_ok=True)
+
+ #保存元数据为json以便调用
+ print('保存元数据')
+ core.save_json(Path(save_dir+'/entry.json'),info)
+
+ #创建下载
+ if len(info['img']) != 0:
+ print('启动媒体数据本地化')
+ os.makedirs(Path(save_dir+'/img'),exist_ok=True)#创建图片文件夹
+ core.down_img(info['img'],Path(save_dir+'/img'))
+ down_name = os.listdir(Path(save_dir+'/img'))
+ for change_name in down_name:
+ if 'img%2F' in change_name:
+ #捕获错误段
+ true_name = change_name.split('%2F')[-1]
+ #true_name = true_name[3:]
+ os.rename(Path(save_dir+'/img/'+change_name),Path(save_dir+'/img/'+true_name))
+ print('媒体文件下载完毕')
+
+ #html本地化
+ # 截取图片文件名
+ img_list = []
+ for url in info['img']:
+ img_name = url.split('/').pop()
+ img_list.append(img_name)
+ img_html = ''
+ for local_img in img_list:#创建图片html代码
+ img_html += ' '
+ #创建index.html
+ if html != 'null':
+ html = ''+info['title']+''+img_html+html#添加标题和头标识
+ core.save_txt(Path(save_dir+'/index.html'),html)
+ if txt != 'null':#保存纯文本
+ core.save_txt(Path(save_dir+'/index.txt'),txt)
+ print('索引链接创建完成')
+ print('本地化完成')
+
+ core.del_downlist(info)#删除下载任务
+ return
+
+#提取页面文章列表
+def lofter_post_list(url):
+ page = 0
+ post = []
+ while 1==1:
+ page += 1
+ if page == 1:
+ post_url = url
+ else:
+ post_url = url+'?page='+str(page)
+ data = core.gets(post_url)
+ if data == 'null':
+ return 'null'
+ kk = re.compile('"(https://.*?\.lofter\.com/post/.*?_.*?)"')
+ post_list = kk.findall(data)
+ print('正在解析第'+str(page)+'页')
+ out.toast('正在解析第'+str(page)+'页',position='left', color='info', duration=1)#弹出提示
+ post_list = core.dic(post_list)
+ if len(core.dic(post + post_list)) - len(post) == 0:
+ break
+ post = core.dic(post + post_list)
+ print('本页提取'+str(len(post_list))+'个文章')
+ print('已提取'+str(len(post))+'个文章')
+ out.toast('已提取'+str(len(post))+'个文章',position='left', color='info', duration=1)#弹出提示
+ print('共提取'+str(len(post))+'个文章')
+ out.toast('已提取'+str(len(post))+'个文章',position='left', color='success', duration=0)#弹出提示
+ return post
+
+#显示文档信息
+def lofter_print(info):
+ #清除旧显示内容
+ out.clear('info')
+ with out.use_scope('info'):#进入视频信息域
+ with out.use_scope('up_info'):#切换到up信息域
+ face = requests.get(info['writer']['img']).content#缓存图片
+ out.put_row([
+ None,
+ out.put_image(face,height='50px').style('margin-top: 1rem;margin-bottom: 1rem;border:1px solid;border-radius:50%;box-shadow: 5px 5px 5px #A9A9A9'),
+ None,
+ out.put_column([
+ None,
+ out.put_text(info['writer']['name']).style('font-size:1.25em;line-height: 0'),
+ ],size='1fr 1fr'),
+ None
+ ],size='1fr 50px 25px auto 1fr').style('border: 1px solid #e9ecef;border-radius: .25rem')#限制up头像大小
+ info_title = out.put_text(info['title']).style('border: 1px solid #e9ecef;border-radius: .25rem;font-size:1.5em;font-weight:bold;text-align:center')#标题
+ out.put_column([info_title],size='auto 10px auto 10px auto').style('margin-top: 0.5rem;margin-bottom: 0.5rem')#设置为垂直排布
+ control_buttom = ioin.actions(buttons=[{'label':'添加下载','value':'0'},{'label':'退出界面','value':'2','color':'danger'}])#创建按键
+ if control_buttom == '0':#如果选择下载被勾选部分
+ downlist = core.downlist()#获取下载列表
+ downlist.append(info)#添加任务至下载列表
+ core.downlist(downlist)#写入下载列表
+ elif control_buttom == '1':#如果选择退出
+ return 'out'
+
+#显示批量信息
+def lofter_list_print(list:list):
+ #清除旧显示内容
+ out.clear('info')
+ with out.use_scope('info'):#进入视频信息域
+ #显示信息获取进度
+ out.put_text('获取信息中。。。').style('border: 1px solid #e9ecef;border-radius: .25rem;font-size:1em;font-weight:bold;text-align:center')#TODO 创建标题
+ out.put_processbar('get_api')#进度条
+ a = 0
+ info_list = []
+ for url in list:
+ a += 1
+ print(url)
+ answer = lofter_down(url)#申请数据
+ out.set_processbar('get_api',a / len(list))#刷新进度条
+ info_list.append(answer)
+ #遍历创建标题列表
+ show_list = []
+ for list_one in info_list:#遍历创建下载列表
+ a = out.put_row([
+ out.put_text(list_one['title']).style('border: 1px solid #e9ecef;border-radius: .25rem;font-size:1em;font-weight:bold;text-align:center')#标题
+ ]).style('border: 1px solid #e9ecef;border-radius: .25rem')
+ # 创建显示
+ show_list.append(a)
+ out.put_column(show_list).style('margin-top: 0.5rem;margin-bottom: 0.5rem')#设置为垂直排布
+ control_buttom = ioin.actions(buttons=[{'label':'添加下载','value':'0'},{'label':'退出界面','value':'2','color':'danger'}])#创建按键
+ if control_buttom == '0':#如果选择下载被勾选部分
+ downlist = core.downlist()#获取下载列表
+ downlist = downlist + info_list#添加任务至下载列表
+ core.downlist(downlist)#写入下载列表
+ return
+ elif control_buttom == '1':#如果选择退出
+ return 'out'
+
+#lofter处理下载
+def lofter_down(url):
+ #格式化链接
+ print(url)
+ id = re.findall('/post/(.*?_.*)',url)[0]
+ id = id.split('_')
+ targetblogid = int(id[0],16)
+ blogid = int(id[1],16)
+ #发送请求
+ print('tar '+str(targetblogid))
+ print('bl '+str(blogid))
+ answer = core.lofter_api(targetblogid,blogid)
+ if answer['status'] != 200:#如果返回不正常
+ #弹出错误弹窗
+ out.toast(answer['msg'],color='error',duration='0')#弹出错误弹窗
+ return
+ return answer
+
+
+
+#启动解析
+def start_url():
+ url = pin.pin['url_input']#获取输入
+ if 'lofter' in url:#如果为lofter地址
+ if '/post/' not in url:#尝试批量获取
+ list = lofter_post_list(url)
+ lofter_list_print(list)#显示列表
+ #清除旧显示内容
+ out.clear('info')
+ return
+ answer = lofter_down(url)
+ #显示内容
+ lofter_print(answer)
+ #清除旧显示内容
+ out.clear('info')
+ return
+
+
+#主函数
+def main():#主函数
+ print('主函数启动')
+ #初始化
+ out.scroll_to('main','top')
+ out.clear('main')
+ #创建横向标签栏
+ scope_url = out.put_scope('url')#创建url域
+ scope_set = out.put_scope('set')#创建set域
+ scope_down = out.put_scope('down')#创建down域
+ out.put_tabs([{'title':'链接解析','content':scope_url},{'title':'下载列表','content':scope_down},{'title':'设置','content':scope_set}])#创建
+
+
+ #创建url输入框
+ with out.use_scope('url'):#进入域
+ pin.put_input('url_input',label='请输入链接',type='text')#限制类型为url,使用check_input_url检查内容
+ out.put_button(label='解析链接',onclick=start_url).style('width: 100%')#创建按键
+ out.put_scope('info')
+
+ #创建下载列表
+ with out.use_scope('down'):
+ scope_down_work = out.put_scope('down_work')
+ scope_down_fin = out.put_scope('down_fin')
+ start_download_buttom = out.put_button('开始下载任务',onclick=start_download,color='success')#开始下载任务
+ del_download_buttom = out.put_button('清空下载任务',onclick=lambda:core.downlist([]),color='danger')#开始下载任务
+ out.put_row([None,start_download_buttom,None,del_download_buttom,None],size='1fr auto 1fr auto 1fr')#设置横向排布
+ out.put_processbar('down_process')#设置下载进度条
+ out.put_tabs([{'title':'下载中','content':scope_down_work},{'title':'下载完成','content':scope_down_fin}])#创建横向标签栏
+
+ #创建设置
+ with out.use_scope('set'):#进入域
+ pass
+
+ #启动副进程
+ if not show_down_list_core.is_alive():
+ print('启动下载任务管理')
+ io.session.register_thread(show_down_list_core)
+ show_down_list_core.daemon = True#设为守护进程
+ show_down_list_core.start()
+ if not show_fin_list_core.is_alive():
+ print('启动完成任务管理')
+ io.session.register_thread(show_fin_list_core)
+ show_fin_list_core.daemon = True#设为守护进程
+ show_fin_list_core.start()
+
+
+
+# gui创建
+#主函数
+print('LofterSaver 1.3 Dev')
+print('Power by python')
+print('Made in Mr.G')
+print('程序初始化。。。。')
+show_down_list_core = threading.Thread(target=show_down_list)#下载列表
+show_fin_list_core = threading.Thread(target=show_fin_list)#完成列表
+io.config(title='Jithon 2.0 Beta',description='基于python的webui实现',theme='yeti')
+print('主程序启动,如未自动跳转请打开http://127.0.0.1:8080')
+io.start_server(main,host='127.0.0.1',port=8080,debug=True,cdn=False,auto_open_webbrowser=True)
\ No newline at end of file
diff --git "a/\345\244\207\346\263\250.md" "b/\345\244\207\346\263\250.md"
new file mode 100644
index 0000000..ebba8e9
--- /dev/null
+++ "b/\345\244\207\346\263\250.md"
@@ -0,0 +1,5 @@
+lofter post id生成规律
+https://fushengjin705.lofter.com/post/309911ab_1cc44ecf1
+309911ab为16进制 转换完成为 815337899 targetblogid blogid(oldapi) blogid(api1.1) 此参数为作者id
+1cc44ecf1为16进制 转换完成为 7722036465 postid(oldapi) 此参数猜测为作品id
+collectionid(api1.1) 来源暂且不明
\ No newline at end of file
'
+ #创建index.html
+ if html != 'null':
+ html = ''+info['title']+''+img_html+html#添加标题和头标识
+ core.save_txt(Path(save_dir+'/index.html'),html)
+ if txt != 'null':#保存纯文本
+ core.save_txt(Path(save_dir+'/index.txt'),txt)
+ print('索引链接创建完成')
+ print('本地化完成')
+
+ core.del_downlist(info)#删除下载任务
+ return
+
+#提取页面文章列表
+def lofter_post_list(url):
+ page = 0
+ post = []
+ while 1==1:
+ page += 1
+ if page == 1:
+ post_url = url
+ else:
+ post_url = url+'?page='+str(page)
+ data = core.gets(post_url)
+ if data == 'null':
+ return 'null'
+ kk = re.compile('"(https://.*?\.lofter\.com/post/.*?_.*?)"')
+ post_list = kk.findall(data)
+ print('正在解析第'+str(page)+'页')
+ out.toast('正在解析第'+str(page)+'页',position='left', color='info', duration=1)#弹出提示
+ post_list = core.dic(post_list)
+ if len(core.dic(post + post_list)) - len(post) == 0:
+ break
+ post = core.dic(post + post_list)
+ print('本页提取'+str(len(post_list))+'个文章')
+ print('已提取'+str(len(post))+'个文章')
+ out.toast('已提取'+str(len(post))+'个文章',position='left', color='info', duration=1)#弹出提示
+ print('共提取'+str(len(post))+'个文章')
+ out.toast('已提取'+str(len(post))+'个文章',position='left', color='success', duration=0)#弹出提示
+ return post
+
+#显示文档信息
+def lofter_print(info):
+ #清除旧显示内容
+ out.clear('info')
+ with out.use_scope('info'):#进入视频信息域
+ with out.use_scope('up_info'):#切换到up信息域
+ face = requests.get(info['writer']['img']).content#缓存图片
+ out.put_row([
+ None,
+ out.put_image(face,height='50px').style('margin-top: 1rem;margin-bottom: 1rem;border:1px solid;border-radius:50%;box-shadow: 5px 5px 5px #A9A9A9'),
+ None,
+ out.put_column([
+ None,
+ out.put_text(info['writer']['name']).style('font-size:1.25em;line-height: 0'),
+ ],size='1fr 1fr'),
+ None
+ ],size='1fr 50px 25px auto 1fr').style('border: 1px solid #e9ecef;border-radius: .25rem')#限制up头像大小
+ info_title = out.put_text(info['title']).style('border: 1px solid #e9ecef;border-radius: .25rem;font-size:1.5em;font-weight:bold;text-align:center')#标题
+ out.put_column([info_title],size='auto 10px auto 10px auto').style('margin-top: 0.5rem;margin-bottom: 0.5rem')#设置为垂直排布
+ control_buttom = ioin.actions(buttons=[{'label':'添加下载','value':'0'},{'label':'退出界面','value':'2','color':'danger'}])#创建按键
+ if control_buttom == '0':#如果选择下载被勾选部分
+ downlist = core.downlist()#获取下载列表
+ downlist.append(info)#添加任务至下载列表
+ core.downlist(downlist)#写入下载列表
+ elif control_buttom == '1':#如果选择退出
+ return 'out'
+
+#显示批量信息
+def lofter_list_print(list:list):
+ #清除旧显示内容
+ out.clear('info')
+ with out.use_scope('info'):#进入视频信息域
+ #显示信息获取进度
+ out.put_text('获取信息中。。。').style('border: 1px solid #e9ecef;border-radius: .25rem;font-size:1em;font-weight:bold;text-align:center')#TODO 创建标题
+ out.put_processbar('get_api')#进度条
+ a = 0
+ info_list = []
+ for url in list:
+ a += 1
+ print(url)
+ answer = lofter_down(url)#申请数据
+ out.set_processbar('get_api',a / len(list))#刷新进度条
+ info_list.append(answer)
+ #遍历创建标题列表
+ show_list = []
+ for list_one in info_list:#遍历创建下载列表
+ a = out.put_row([
+ out.put_text(list_one['title']).style('border: 1px solid #e9ecef;border-radius: .25rem;font-size:1em;font-weight:bold;text-align:center')#标题
+ ]).style('border: 1px solid #e9ecef;border-radius: .25rem')
+ # 创建显示
+ show_list.append(a)
+ out.put_column(show_list).style('margin-top: 0.5rem;margin-bottom: 0.5rem')#设置为垂直排布
+ control_buttom = ioin.actions(buttons=[{'label':'添加下载','value':'0'},{'label':'退出界面','value':'2','color':'danger'}])#创建按键
+ if control_buttom == '0':#如果选择下载被勾选部分
+ downlist = core.downlist()#获取下载列表
+ downlist = downlist + info_list#添加任务至下载列表
+ core.downlist(downlist)#写入下载列表
+ return
+ elif control_buttom == '1':#如果选择退出
+ return 'out'
+
+#lofter处理下载
+def lofter_down(url):
+ #格式化链接
+ print(url)
+ id = re.findall('/post/(.*?_.*)',url)[0]
+ id = id.split('_')
+ targetblogid = int(id[0],16)
+ blogid = int(id[1],16)
+ #发送请求
+ print('tar '+str(targetblogid))
+ print('bl '+str(blogid))
+ answer = core.lofter_api(targetblogid,blogid)
+ if answer['status'] != 200:#如果返回不正常
+ #弹出错误弹窗
+ out.toast(answer['msg'],color='error',duration='0')#弹出错误弹窗
+ return
+ return answer
+
+
+
+#启动解析
+def start_url():
+ url = pin.pin['url_input']#获取输入
+ if 'lofter' in url:#如果为lofter地址
+ if '/post/' not in url:#尝试批量获取
+ list = lofter_post_list(url)
+ lofter_list_print(list)#显示列表
+ #清除旧显示内容
+ out.clear('info')
+ return
+ answer = lofter_down(url)
+ #显示内容
+ lofter_print(answer)
+ #清除旧显示内容
+ out.clear('info')
+ return
+
+
+#主函数
+def main():#主函数
+ print('主函数启动')
+ #初始化
+ out.scroll_to('main','top')
+ out.clear('main')
+ #创建横向标签栏
+ scope_url = out.put_scope('url')#创建url域
+ scope_set = out.put_scope('set')#创建set域
+ scope_down = out.put_scope('down')#创建down域
+ out.put_tabs([{'title':'链接解析','content':scope_url},{'title':'下载列表','content':scope_down},{'title':'设置','content':scope_set}])#创建
+
+
+ #创建url输入框
+ with out.use_scope('url'):#进入域
+ pin.put_input('url_input',label='请输入链接',type='text')#限制类型为url,使用check_input_url检查内容
+ out.put_button(label='解析链接',onclick=start_url).style('width: 100%')#创建按键
+ out.put_scope('info')
+
+ #创建下载列表
+ with out.use_scope('down'):
+ scope_down_work = out.put_scope('down_work')
+ scope_down_fin = out.put_scope('down_fin')
+ start_download_buttom = out.put_button('开始下载任务',onclick=start_download,color='success')#开始下载任务
+ del_download_buttom = out.put_button('清空下载任务',onclick=lambda:core.downlist([]),color='danger')#开始下载任务
+ out.put_row([None,start_download_buttom,None,del_download_buttom,None],size='1fr auto 1fr auto 1fr')#设置横向排布
+ out.put_processbar('down_process')#设置下载进度条
+ out.put_tabs([{'title':'下载中','content':scope_down_work},{'title':'下载完成','content':scope_down_fin}])#创建横向标签栏
+
+ #创建设置
+ with out.use_scope('set'):#进入域
+ pass
+
+ #启动副进程
+ if not show_down_list_core.is_alive():
+ print('启动下载任务管理')
+ io.session.register_thread(show_down_list_core)
+ show_down_list_core.daemon = True#设为守护进程
+ show_down_list_core.start()
+ if not show_fin_list_core.is_alive():
+ print('启动完成任务管理')
+ io.session.register_thread(show_fin_list_core)
+ show_fin_list_core.daemon = True#设为守护进程
+ show_fin_list_core.start()
+
+
+
+# gui创建
+#主函数
+print('LofterSaver 1.3 Dev')
+print('Power by python')
+print('Made in Mr.G')
+print('程序初始化。。。。')
+show_down_list_core = threading.Thread(target=show_down_list)#下载列表
+show_fin_list_core = threading.Thread(target=show_fin_list)#完成列表
+io.config(title='Jithon 2.0 Beta',description='基于python的webui实现',theme='yeti')
+print('主程序启动,如未自动跳转请打开http://127.0.0.1:8080')
+io.start_server(main,host='127.0.0.1',port=8080,debug=True,cdn=False,auto_open_webbrowser=True)
\ No newline at end of file
diff --git "a/\345\244\207\346\263\250.md" "b/\345\244\207\346\263\250.md"
new file mode 100644
index 0000000..ebba8e9
--- /dev/null
+++ "b/\345\244\207\346\263\250.md"
@@ -0,0 +1,5 @@
+lofter post id生成规律
+https://fushengjin705.lofter.com/post/309911ab_1cc44ecf1
+309911ab为16进制 转换完成为 815337899 targetblogid blogid(oldapi) blogid(api1.1) 此参数为作者id
+1cc44ecf1为16进制 转换完成为 7722036465 postid(oldapi) 此参数猜测为作品id
+collectionid(api1.1) 来源暂且不明
\ No newline at end of file